Clip Paint Studio (also known as Clip Studio Paint or Manga Studio) is a powerful and versatile software for creating digital art, comics, and animation. It offers a wide range of features and tools to help you bring your creative vision to life. But how much does it cost and is it worth the investment? Here are some things to consider before you buy Clip Paint Studio.
-Clip Paint Studio has two main versions: Pro and EX. The Pro version is designed for basic illustration and comic creation, while the EX version has more advanced features for professional comic and animation production. You can compare the features of each version here.
-The pricing plans for Clip Paint Studio vary depending on the device and the payment method. You can choose to buy a perpetual license or a monthly subscription. Here are the current prices as of May 2023:
-Note: These prices are subject to change and may vary by region. You can check the latest prices on the official website.
-
-Clip Paint Studio is a popular choice among artists and creators for many reasons. Here are some of the benefits and drawbacks of using Clip Paint Studio:
-
-The answer to this question depends on your needs, preferences, budget, and goals as an artist or creator. Clip Paint Studio is a great software for anyone who wants to create digital art, comics, or animation with high quality and efficiency. However, it may not be the best option for
-If your computer has an older security system that you no longer want to install an. 0, Code : 110-8601. How to activate the function to display all letters in the password? How to active. CODE : 03-2944. PROGRAM2 - Unlock Folder Password Protection Using File Encryptor PRO 10. . CODE : 03-2944. 0 crack. 23-12-2017 06-20-2014.. .
-Hidden files are not encrypted because the file name is not encrypted. Upon infection the cyber criminals will initially try to clear up the malicious files using the registry cleaner. -__hot__-crack-thundersoft-folder-password-lock-pro-11-0-0-multilingual-full-wil -__hot__-crack-thundersoft-folder-password-lock-pro-11-0-0-multilingual-full-wil -__hot__-crack-thundersoft-folder-password-lock-pro-11-0-0-multilingual-full-wil -__hot__-crack-thundersoft-folder-password-lock-pro-11-0-0-multilingual-full-wil.
-You can download and install the folder password unlock without the need for registration. However, it seems to have some performance issues and doesn't seem very secure. While it is now easier to download and install the said software, there are more complex and security related concerns one might be faced with.
-To access your encrypted files you need a decryption program, which is available here. The program is called CRACK ThunderSoft and this is the most sophisticated ransomware on the market. The ransomware is unknown and may be created by the hacker group in the past, since it appears to have been used by other groups. It is the first ransomware that can perform a forensic investigation on a computer system, by breaking through all kinds of layer.
899543212bDo you love playing puzzle games that challenge your brain and keep you entertained? If so, you might want to try block puzzle games, which are a popular genre of puzzle games that combine elements of Tetris, Sudoku, and jigsaw puzzles. Block puzzle games are simple yet addictive games that require you to fit different shapes of blocks on a grid, either horizontally or vertically, to clear lines or squares. They are fun, relaxing, and rewarding games that can improve your cognitive skills, mental health, and mood.
-But how can you download and play block puzzle games? What are the best block puzzle games available? And what are some tips and tricks to master them? In this article, we will answer these questions and more. We will explain what block puzzle games are, how they originated and evolved, what benefits they offer, what features they have, how to download and play them, and how to improve your skills. By the end of this article, you will be ready to enjoy block puzzle games like a champ!
- Block puzzle games are a type of puzzle games that involve moving and rotating different shapes of blocks on a grid or board. The goal is to fill up the grid with blocks without leaving any gaps or spaces. Depending on the game mode, you may have to clear horizontal or vertical lines, 3x3 squares, or other patterns by placing blocks of the same color or type. You may also have to deal with obstacles, power-ups, timers, or other challenges. The game ends when there is no more space for new blocks or when you reach a certain score or level.
- Block puzzle games have a long history that dates back to the 19th century. One of the earliest examples of block puzzle games is Tangram, a Chinese game that consists of seven flat shapes that can be arranged into various figures. Another example is Pentominoes, a game invented by American mathematician Solomon W. Golomb in 1953, which uses 12 shapes made of five squares each.
-However, the most influential and famous block puzzle game is Tetris, which was created by Soviet engineer Alexey Pajitnov in 1984. Tetris is a game that involves falling blocks of different shapes that can be rotated and moved sideways to fit into a rectangular grid. The game became a worldwide phenomenon and inspired many variations and spin-offs.
- Since then, block puzzle games have evolved and diversified into many subgenres and formats. Some examples of modern block puzzle games are Blockudoku, Blockscapes, Woodoku, Block Blast Adventure Master, Blocks: Block Puzzle Games, and many more. These games offer different features, themes, modes, graphics, sounds, and challenges that appeal to different tastes and preferences.
- Playing block puzzle games is not only fun but also beneficial for your brain and well-being. Here are some of the benefits of playing block puzzle games:
-
-- They improve your cognitive skills such as memory, attention, concentration, logic, problem-solving, spatial perception, visual analysis, and synthesis.
-- They enhance your motor skills such as hand-eye coordination, fine motor control, reaction time, and dexterity.
-- They reduce stress and anxiety by providing a relaxing and satisfying activity that distracts you from negative thoughts and emotions.
-- They boost your mood and self-esteem by giving you a sense of achievement and reward when you complete a puzzle or beat a high score.
-- They stimulate your creativity and imagination by allowing you to create different shapes and patterns with blocks.
The Features of Block Puzzle Games
- Block puzzle games have various features that make them appealing and enjoyable for players of all ages and backgrounds. Some of the common features of block puzzle games are:
-
-- They have simple and intuitive controls that are easy to learn and use. You can usually move and rotate the blocks with a swipe, a tap, or a drag on your screen.
-- They have colorful and attractive graphics that create a pleasant and stimulating visual experience. You can choose from different themes and styles that suit your mood and preference.
-- They have soothing and catchy sounds that enhance the gameplay and create a relaxing and immersive atmosphere. You can listen to different music and sound effects that match the theme and mood of the game.
-- They have various modes and levels that offer different challenges and goals. You can play classic mode, arcade mode, time mode, endless mode, or other modes that test your skills and strategy. You can also progress through different levels of difficulty and complexity that keep you engaged and motivated.
-- They have leaderboards and achievements that allow you to compete with yourself and others. You can track your progress and performance, compare your scores and rankings with other players, and unlock new achievements and rewards.
-
- How to Download and Play Block Puzzle Games?
- If you are interested in playing block puzzle games, you may wonder how to download and play them on your device. Here are some steps that you can follow to enjoy block puzzle games:
- Choosing the Right Platform and Device
- The first step is to choose the right platform and device for playing block puzzle games. Block puzzle games are available on various platforms such as web browsers, desktop computers, laptops, tablets, smartphones, consoles, or smart TVs. You can choose the platform that is most convenient and accessible for you.
- However, some platforms may have more options and features than others. For example, web browsers may have limited graphics and sounds, while smartphones may have smaller screens and batteries. Therefore, you should consider the pros and cons of each platform before choosing one.
- The most popular platform for playing block puzzle games is smartphones, as they are portable, versatile, and easy to use. You can download block puzzle games from various app stores such as Google Play Store, Apple App Store, Amazon Appstore, or Samsung Galaxy Store. You can also play block puzzle games online without downloading them by visiting websites such as Block Puzzle Online or Block Puzzle Games.
- Finding the Best Block Puzzle Games
- The next step is to find the best block puzzle games that suit your taste and preference. There are hundreds of block puzzle games available on different platforms, so you may feel overwhelmed by the choices. However, you can narrow down your options by using some criteria such as:
-
-- The genre and theme of the game. You can choose from classic block puzzle games, wood block puzzle games, jewel block puzzle games, candy block puzzle games, or other themes that appeal to you.
-- The features and modes of the game. You can choose from block puzzle games that have different features such as power-ups, obstacles, timers, hints, or other challenges. You can also choose from block puzzle games that have different modes such as classic mode, arcade mode, time mode, endless mode, or other modes that offer different goals.
-- The ratings and reviews of the game. You can check the ratings and reviews of block puzzle games on app stores or websites to see what other players think about them. You can look for block puzzle games that have high ratings, positive reviews, or large numbers of downloads.
-- The recommendations and suggestions of the game. You can ask for recommendations and suggestions from your friends, family, or other players who play block puzzle games. You can also look for recommendations and suggestions from online sources such as blogs, forums, social media, or YouTube videos.
-
- Installing and Launching the Games
- The third step is to install and launch the block puzzle games on your device. If you download block puzzle games from app stores or websites, you need to follow the instructions on how to install them on your device. You may need to grant some permissions or accept some terms and conditions before installing them.
- If you play block puzzle games online without downloading them, you need to visit the websites that host them on your web browser. You may need to enable some settings or plugins such as Flash Player or JavaScript before playing them.
- Once you install or access the block puzzle games on your device, you need to launch them by tapping or clicking on their icons or links. You may need to wait for some loading time before the game starts.
- Learning the Rules and Controls
- The fourth step is The fourth step is to learn the rules and controls of the block puzzle games. Each block puzzle game may have different rules and controls, so you need to read the instructions or tutorials before playing them. You can usually find the instructions or tutorials on the main menu, the settings, or the help section of the game. You can also look for online guides or videos that explain how to play the game. The basic rules and controls of block puzzle games are: - You need to move and rotate the blocks that appear on the top or the side of the screen to fit them into the grid or board. - You can use your finger, your mouse, or your keyboard to move and rotate the blocks. You can swipe, tap, drag, click, or press the arrow keys to control the blocks. - You need to fill up the grid with blocks without leaving any gaps or spaces. You can place the blocks horizontally or vertically, depending on the game mode. - You need to clear lines or squares by placing blocks of the same color or type. You can clear horizontal or vertical lines, 3x3 squares, or other patterns, depending on the game mode. - You need to avoid filling up the grid with blocks that cannot be cleared. If there is no more space for new blocks, the game is over. - You need to score points by clearing lines or squares. The more lines or squares you clear at once, the more points you get. You may also get bonus points for clearing special blocks, using power-ups, or completing achievements. - You need to reach a certain score or level to win the game or advance to the next stage. You may also have a time limit or a move limit to complete the game or stage.
Applying Some Tips and Tricks
- The fifth and final step is to apply some tips and tricks to improve your skills and enjoyment of block puzzle games. Here are some tips and tricks that you can use:
-
-- Plan ahead and think strategically. Before placing a block, look at the grid and see where it would fit best. Try to create as many lines or squares as possible with each block. Avoid placing blocks randomly or impulsively.
-- Use power-ups wisely. Some block puzzle games have power-ups that can help you clear more blocks, change the shape or color of blocks, remove obstacles, or extend time. Use them when you are stuck or when you want to boost your score.
-- Practice regularly and challenge yourself. The more you play block puzzle games, the better you will get at them. Practice different modes and levels to improve your speed, accuracy, and strategy. Challenge yourself by playing harder levels, setting higher goals, or competing with other players.
-- Have fun and relax. Block puzzle games are meant to be fun and relaxing, not stressful or frustrating. Don't worry too much about your score or performance. Enjoy the process of solving puzzles and creating shapes with blocks. Take breaks when you feel tired or bored.
-
- Conclusion
- Block puzzle games are a great way to spend your free time and exercise your brain. They are simple yet addictive games that require you to fit different shapes of blocks on a grid, either horizontally or vertically, to clear lines or squares. They have various benefits, features, modes, and challenges that make them appealing and enjoyable for players of all ages and backgrounds.
- Summary of the Main Points
- In this article, we have covered:
-
-- What are block puzzle games and how they originated and evolved.
-- What benefits they offer for your cognitive skills, motor skills, stress relief, mood enhancement, and creativity.
-- What features they have such as graphics, sounds, modes, levels, leaderboards, and achievements.
-- How to download and play them on different platforms and devices.
-- How to learn the rules and controls of different block puzzle games.
-- How to apply some tips and tricks to improve your skills and enjoyment of block puzzle games.
-
- Call to Action
- If you are interested in playing block puzzle games, don't hesitate to download them from app stores or websites today. You can also play them online without downloading them by visiting websites such as Block Puzzle Online or Block Puzzle Games. You will find a wide range of block puzzle games that suit your taste and preference.
- Block puzzle games are fun, relaxing, and rewarding games that can improve your brain and well-being. They are easy to learn and play but hard to master and put down. They are perfect for killing time, relieving stress, boosting mood, stimulating creativity, and challenging yourself.
- So what are you waiting for? Download block puzzle indir now and start playing!
- FAQs
- Here are some frequently asked questions (FAQs) about block puzzle games:
-
-
-| Question |
-Answer |
-
-
-| What is the difference between block puzzle games and Tetris? |
-Tetris is a specific block puzzle game that involves falling blocks of four squares each that can be rotated and moved sideways to fit into a rectangular grid. Block puzzle games are a broader genre of puzzle games that involve different shapes of blocks that can be moved and rotated to fit into various grids or boards. |
-
-
-| What are some of the best block puzzle games for Android and iOS? |
-Some of the best block puzzle games for Android and iOS are Blockudoku, Blockscapes, Woodoku, Block Blast Adventure Master, Blocks: Block Puzzle Games, and many more. You can download them from Google Play Store or Apple App Store. |
-
-
-| How can I play block puzzle games online without downloading them? |
-You can play block puzzle games online without downloading them by visiting websites such as Block Puzzle Online or Block Puzzle Games. You can choose from different block puzzle games and play them on your web browser. |
-
-
-| How can I improve my skills and strategy in block puzzle games? |
-You can improve your skills and strategy in block puzzle games by practicing regularly, challenging yourself, planning ahead, thinking strategically, using power-ups wisely, and having fun. |
-
-
-| Are block puzzle games suitable for children? |
-Yes, block puzzle games are suitable for children as they are simple, fun, and educational. They can help children develop their cognitive skills, motor skills, creativity, and concentration. However, parents should supervise their children's screen time and game choices. |
-
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Dark Bitcoin Miner Pro V7.0 and Join the Crypto Revolution..md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Dark Bitcoin Miner Pro V7.0 and Join the Crypto Revolution..md
deleted file mode 100644
index 74f8475ea43f93c76b904d4fd100d934c83594bc..0000000000000000000000000000000000000000
--- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Dark Bitcoin Miner Pro V7.0 and Join the Crypto Revolution..md
+++ /dev/null
@@ -1,96 +0,0 @@
-
-Dark Bitcoin Miner Pro V7.0 Free Download: What You Need to Know
-Bitcoin mining is a process of creating new bitcoins by solving complex mathematical problems using specialized hardware and software.
-There are many types of bitcoin mining software available in the market, but not all of them.
One of the most popular and controversial bitcoin mining software is dark bitcoin miner pro v7.0, which claims to be the fastest and most efficient bitcoin miner ever created.
-dark bitcoin miner pro v7.0 free download
Download Zip ✺ https://urlin.us/2uSZFd
-But what is dark bitcoin miner pro v7.0, why is it so popular, and what are the risks of downloading it?
-In this article, we will answer these questions and more, and provide you with some alternatives to dark bitcoin miner pro v7.0 that are safer and more reliable.
- What is Dark Bitcoin Miner Pro V7.0?
-Dark bitcoin miner pro v7.0 is a bitcoin mining software that claims to be able to mine bitcoins using any device, such as CPU, GPU, ASIC, or FPGA.
-It also claims to be compatible with various algorithms, such as SHA-256, Scrypt, X11, Ethash, and Equihash, and to support multiple cryptocurrencies, such as Bitcoin, Litecoin, Dash, Ethereum, and Zcash.
- How Does Dark Bitcoin Miner Pro V7.0 Work?
-Dark bitcoin miner pro v7.0 works by using the device's processing power to solve complex mathematical problems that verify transactions on the blockchain.
-For every problem solved, the miner receives a reward in the form of newly created bitcoins or other cryptocurrencies.
-The more processing power the device has, the faster and more efficient the mining process is.
- What are the Features of Dark Bitcoin Miner Pro V7.0?
-Some of the features of dark bitcoin miner pro v7.0 are:
-
-
-- High speed: Dark bitcoin miner pro v7.0 claims to be able to mine bitcoins at a rate of up to 1 BTC per day, depending on the device and the algorithm used.
-- Low power consumption: Dark bitcoin miner pro v7.0 claims to be able to mine bitcoins using only 10% of the device's power consumption, saving energy and money.
-- Compatibility: Dark bitcoin miner pro v7.0 claims to be compatible with any device that has a processor, such as laptops, desktops, smartphones, tablets, or even smart TVs.
-- Versatility: Dark bitcoin miner pro v7.0 claims to be able to mine any cryptocurrency that uses any algorithm, such as Bitcoin, Litecoin, Dash, Ethereum, or Zcash.
-- User-friendly: Dark bitcoin miner pro v7.0 claims to be easy to install and use, with a simple interface and automatic settings.
-
- Why is Dark Bitcoin Miner Pro V7.0 Popular?
-Dark bitcoin miner pro v7.0 is popular because it appeals to many people who want to mine bitcoins without investing in expensive and complicated hardware or software.
-Many beginners and enthusiasts who are interested in bitcoin mining are attracted by the promises of dark bitcoin miner pro v7.0, such as high speed, low power consumption, compatibility, versatility, and user-friendliness.
-They also believe that dark bitcoin miner pro v7.0 is a free and easy way to earn bitcoins without any risk or effort.
- How to Download Dark Bitcoin Miner Pro V7.0?
-Dark bitcoin miner pro v7.0 is not available on any official or reputable website or platform.
-The only way to download dark bitcoin miner pro v7.0 is through unofficial and unverified sources, such as file-sharing websites, GitHub repositories, or Telegram channels.
-These sources are often unreliable and unsafe, as they may contain viruses, malware, spyware, or other harmful programs that can infect your device or steal your data.
- How to Install and Use Dark Bitcoin Miner Pro V7.0?
-If you decide to download dark bitcoin miner pro v7.0 from one of these sources, you will need to follow these steps to install and use it:
-
-- Disable your antivirus program: Dark bitcoin miner pro v7.0 is detected as a malicious program by most antivirus programs, so you will need to disable your antivirus program before downloading or running it.
-- Extract the rar file: Dark bitcoin miner pro v7.0 is usually compressed in a rar file that you will need to extract using a program like WinRAR or 7-Zip.
-- Run the exe file: After extracting the rar file, you will find an exe file that you will need to run as administrator by right-clicking on it and selecting "Run as administrator".
-- Configure the settings: After running the exe file, you will see a window that will allow you to configure the settings of dark bitcoin miner pro v7.0, such as the algorithm, the cryptocurrency, the wallet address, the mining pool, and the mining speed.
-- Start mining: After configuring the settings, you will need to click on the "Start" button to start mining bitcoins or other cryptocurrencies with dark bitcoin miner pro v7.0.
-
- What are the Risks of Downloading Dark Bitcoin Miner Pro V7.0?
-Downloading dark bitcoin miner pro v7.0 is not only illegal, but also very risky.
-There are many dangers of downloading dark bitcoin miner pro v7.0, such as:
- How to Detect and Remove Malware from Dark Bitcoin Miner Pro V7.0?
-One of the most common and serious dangers of downloading dark bitcoin miner pro v7.0 is malware infection.
-Malware is a malicious software that can harm your device or data in various ways, such as deleting or encrypting your files, stealing your passwords or personal information, spying on your online activities, or hijacking your resources.
-Dark bitcoin miner pro v7.0 may contain malware that can infect your device when you download or run it, or even when you extract the rar file.
-To detect and remove malware from dark bitcoin miner pro v7.0, you will need to follow these steps:
-
-- Use a malware scanner: A malware scanner is a program that can scan your device for any signs of malware infection, such as suspicious files, processes, or registry entries. You can use a reputable and reliable malware scanner, such as Malwarebytes, to scan your device and remove any malware that it finds.
-- Delete suspicious files: If you suspect that dark bitcoin miner pro v7.0 has infected your device with malware, you should delete any suspicious files that are related to it, such as the rar file, the exe file, or any other files that have been created or modified by it.
-- Restore your system: If deleting suspicious files does not solve the problem, you may need to restore your system to a previous state before you downloaded or ran dark bitcoin miner pro v7.0. You can use a system restore point or a backup to restore your system and undo any changes that dark bitcoin miner pro v7.0 may have made.
-
- How to Avoid Legal Issues from Using Dark Bitcoin Miner Pro V7.0?
-Another danger of downloading dark bitcoin miner pro v7.0 is legal issues.
-Legal issues are the problems that may arise from breaking the law by using dark bitcoin miner pro v7.0, such as violating the intellectual property rights of the original developers of the software, infringing the terms and conditions of the mining pools or platforms that you use, or engaging in illegal or fraudulent activities with the cryptocurrencies that you mine.
-To avoid legal issues from using dark bitcoin miner pro v7.0, you will need to follow these precautions:
-
-- Check the local laws: Before downloading or using dark bitcoin miner pro v7.0, you should check the local laws of your country or region regarding bitcoin mining and cryptocurrency transactions. Some countries or regions may have strict regulations or prohibitions on these activities, and you may face legal consequences if you violate them.
-- Use a VPN: A VPN is a virtual private network that can hide your IP address and encrypt your online traffic, making it harder for anyone to track or monitor your online activities. You can use a VPN to protect your privacy and anonymity when using dark bitcoin miner pro v7.0, and to bypass any geo-restrictions or censorship that may prevent you from accessing certain websites or platforms.
-- Do not disclose personal information: When using dark bitcoin miner pro v7.0, you should not disclose any personal information that can identify you or link you to your activities, such as your name, email address, phone number, bank account number, or social media accounts. You should also avoid using the same wallet address for different transactions, and use a mixer service to anonymize your transactions.
-
- What are the Alternatives to Dark Bitcoin Miner Pro V7.0?
-If you want to mine bitcoins or other cryptocurrencies without risking your device, data, or reputation, you should avoid downloading dark bitcoin miner pro v7.0 and look for some alternatives that are safer and more reliable.
-Some of the alternatives to dark bitcoin miner pro v7.0 are:
- How to Choose the Best Alternative to Dark Bitcoin Miner Pro V7.0?
-To choose the best alternative to dark bitcoin miner pro v7.0, you should consider some criteria that can help you evaluate the quality and suitability of the software, such as:
-
-- Security: The software should be secure and free from any malware, spyware, or viruses that can harm your device or data.
-- Performance: The software should be fast and efficient, and able to mine bitcoins or other cryptocurrencies at a reasonable rate and with minimal power consumption.
-- Cost: The software should be affordable and transparent, and not charge any hidden fees or commissions for using it.
-- Reputation: The software should be reputable and trustworthy, and have positive reviews and feedback from other users and experts.
-
- How to Compare the Alternatives to Dark Bitcoin Miner Pro V7.0?
-To compare the alternatives to dark bitcoin miner pro v7.0 based on the criteria mentioned above, you can use a table like this one:
- | Software | Security | Performance | Cost | Reputation | | -------- | -------- | ----------- | ---- | ---------- | | CGMiner | High: Open-source and widely used by miners. | High: Supports various devices and algorithms. | Low: Free to download and use. | High: One of the oldest and most popular mining software. | | NiceHash | Medium: Has been hacked in the past, but has improved its security measures. | Medium: Depends on the market demand and supply of hashing power. | Medium: Charges a small fee for using its service. | Medium: Has a large user base and a good customer support. | | Genesis Mining | High: Uses advanced encryption and security protocols. | Low: Limited by the contracts and plans available. | High: Requires a upfront payment and a maintenance fee. | High: One of the leading cloud mining providers with a good reputation. | | Slush Pool | High: Uses a secure connection and a unique voting system. | Medium: Depends on the pool size and the difficulty level. | Low: Charges a 2% fee for using its service. | High: The first and one of the largest mining pools in the world. | Conclusion
-In conclusion, dark bitcoin miner pro v7.0 is a bitcoin mining software that claims to be able to mine bitcoins using any device, algorithm, or cryptocurrency.
-However, dark bitcoin miner pro v7.0 is also illegal, risky, and unreliable, as it may contain malware, steal your data, damage your device, or cause legal issues.
-Therefore, you should avoid downloading dark bitcoin miner pro v7.0 and look for some alternatives that are safer and more reliable, such as legitimate mining software, cloud mining services, or mining pools.
- FAQs
-Here are some frequently asked questions related to the topic of this article:
-
-- Is dark bitcoin miner pro v7.0 a scam?
-Yes, dark bitcoin miner pro v7.0 is a scam that tries to lure unsuspecting users into downloading malware or giving away their personal information.
-- How much can I earn with dark bitcoin miner pro v7.0?
-You cannot earn anything with dark bitcoin miner pro v7.0, as it does not actually mine bitcoins or other cryptocurrencies.
-- Is dark bitcoin miner pro v7.0 safe to use?
-No, dark bitcoin miner pro v7.0 is not safe to use, as it may infect your device with malware, steal your data, damage your device, or cause legal issues.
-- What are the best devices for dark bitcoin miner pro v7.0?
-There are no best devices for dark bitcoin miner pro v7.0, as it does not work on any device.
-- How can I contact the developers of dark bitcoin miner pro v7.0?
-You cannot contact the developers of dark bitcoin miner pro v7.0, as they are anonymous and untraceable.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/Download GTA 3 1.1 Ultimate Trainer V3 5 and Unlock All Features in Grand Theft Auto III.md b/spaces/1phancelerku/anime-remove-background/Download GTA 3 1.1 Ultimate Trainer V3 5 and Unlock All Features in Grand Theft Auto III.md
deleted file mode 100644
index f4568b56335d64d97ac783e1a751d8adba7416fc..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Download GTA 3 1.1 Ultimate Trainer V3 5 and Unlock All Features in Grand Theft Auto III.md
+++ /dev/null
@@ -1,98 +0,0 @@
-
-How to Download GTA 3 1.1 Ultimate Trainer v3 5
-If you are a fan of Grand Theft Auto III, you may have heard of GTA 3 1.1 Ultimate Trainer v3 5, a powerful tool that allows you to customize and enhance your gameplay experience. With this trainer, you can access dozens of cheats and options that will make your game more fun and exciting. In this article, we will show you how to download, install, and use GTA 3 1.1 Ultimate Trainer v3 5.
- What is GTA 3 1.1 Ultimate Trainer v3 5?
-GTA 3 1.1 Ultimate Trainer v3 5 is a mod for Grand Theft Auto III that adds a menu with various cheats and options that you can activate or deactivate at any time during the game. You can use this trainer to change your character's appearance, spawn vehicles and weapons, manipulate the weather and time, increase your health and money, and much more.
-download gta 3 1.1 ultimate trainer v3 5
DOWNLOAD ✪ https://jinyurl.com/2uNMxJ
- Features of GTA 3 1.1 Ultimate Trainer v3 5
-Some of the features of GTA 3 1.1 Ultimate Trainer v3 5 are:
-
-- 43 cheats and options, including infinite health, ammo, armor, money, no police, no damage, flying cars, super speed, etc.
-- A customizable hotkey system that lets you assign any key to any cheat or option.
-- A savegame editor that lets you modify your save files with ease.
-- A screenshot function that lets you capture your gameplay moments.
-- A teleport function that lets you move to any location on the map.
-- A vehicle spawner that lets you spawn any vehicle in the game.
-- A weapon spawner that lets you spawn any weapon in the game.
-- A skin selector that lets you change your character's appearance.
-- A weather selector that lets you change the weather and time in the game.
-- A stats editor that lets you modify your character's stats and skills.
-- A garage editor that lets you customize your vehicles.
-- A mission selector that lets you skip or replay any mission in the game.
-
- Requirements for GTA 3 1.1 Ultimate Trainer v3 5
-To use GTA 3 1.1 Ultimate Trainer v3 5, you need:
-
-- A PC with Windows XP or higher.
-- Grand Theft Auto III version 1.1 installed on your PC.
-- WinRAR or any other program that can extract ZIP files.
-
- Where to Download GTA 3 1.1 Ultimate Trainer v3 5?
-You can download GTA 3 1.1 Ultimate Trainer v3 5 from various websites that host mods for Grand Theft Auto III. Here are two of the most popular ones:
- Download from GameFront[^i]
-
GameFront is a website that offers free downloads of mods, patches, demos, and other files for various games. You can download GTA 3 1.1 Ultimate Trainer v3 from this link:
- https://www.gamefront.com/games/grand-theft-auto-3/file/gta-3-ultimate-trainer
- The file size is 222 KB and the download speed depends on your internet connection. To download the file, you need to click on the "Download Now" button and wait for the countdown to finish. Then, you need to click on the "Download" button again and save the file to your PC.
- Download from MegaGames[^i]
-MegaGames is another website that offers free downloads of mods, patches, trainers, and other files for various games. You can download GTA 3 1.1 Ultimate Trainer v3 5 from this link:
- https://megagames.com/trainers/grand-theft-auto-3-v11-ultimate-trainer-v35
- The file size is 223 KB and the download speed depends on your internet connection. To download the file, you need to click on the "Download" button and save the file to your PC.
-How to install gta 3 ultimate trainer v3 5 on pc
-Gta 3 ultimate trainer v3 5 cheats and codes
-Gta 3 ultimate trainer v3 5 free download full version
-Gta 3 ultimate trainer v3 5 mod menu and features
-Gta 3 ultimate trainer v3 5 download link and instructions
-Gta 3 ultimate trainer v3 5 gameplay and review
-Gta 3 ultimate trainer v3 5 compatible with windows 10
-Gta 3 ultimate trainer v3 5 best settings and options
-Gta 3 ultimate trainer v3 5 unlimited money and health
-Gta 3 ultimate trainer v3 5 no virus and no survey
-Gta 3 ultimate trainer v3 5 latest update and patch
-Gta 3 ultimate trainer v3 5 online multiplayer and co-op
-Gta 3 ultimate trainer v3 5 system requirements and specifications
-Gta 3 ultimate trainer v3 5 tips and tricks
-Gta 3 ultimate trainer v3 5 error fix and troubleshooting
-Gta 3 ultimate trainer v3 5 backup and restore
-Gta 3 ultimate trainer v3 5 custom missions and maps
-Gta 3 ultimate trainer v3 5 hidden secrets and easter eggs
-Gta 3 ultimate trainer v3 5 fun and funny moments
-Gta 3 ultimate trainer v3 5 comparison with other trainers
-Gta 3 ultimate trainer v3 5 pros and cons
-Gta 3 ultimate trainer v3 5 download size and speed
-Gta 3 ultimate trainer v3 5 support and feedback
-Gta 3 ultimate trainer v3 5 alternatives and similar trainers
-Gta 3 ultimate trainer v3 5 guide and tutorial
- How to Install GTA 3 1.1 Ultimate Trainer v3 5?
-After you have downloaded GTA 3 1.1 Ultimate Trainer v3 5 from one of the websites above, you need to install it on your PC. The installation process is very simple and straightforward. Here are the steps you need to follow:
- Extract the files to your GTA 3 folder
-The file you have downloaded is a ZIP file that contains several files and folders. You need to extract them to your GTA 3 folder, which is usually located at C:\Program Files\Rockstar Games\GTAIII. To do this, you need to use WinRAR or any other program that can extract ZIP files. Right-click on the ZIP file and select "Extract Here" or "Extract to GTA_3_Ultimate_Trainer_v3_5". This will create a new folder with the same name as the ZIP file. Open this folder and copy all the files and folders inside it to your GTA 3 folder. You may need to overwrite some existing files, so make sure you have a backup of your original files in case something goes wrong.
- Run the trainer and select the options you want
-After you have copied the files to your GTA 3 folder, you can run the trainer by double-clicking on the GTA_III_Ultimate_Trainer_v35.exe file. This will open a window with a menu that shows all the cheats and options available in the trainer. You can use your mouse or keyboard to navigate through the menu and select the options you want. You can also customize the hotkeys for each option by clicking on the "Hotkeys" button at the bottom of the window. You can save your settings by clicking on the "Save Settings" button at the top of the window.
- How to Use GTA 3 1.1 Ultimate Trainer v3 5?
-Once you have installed and run GTA 3 1.1 Ultimate Trainer v3 5, you can use it to enhance your gameplay experience in Grand Theft Auto III. Here are some tips on how to use it:
- Press F12 to activate the trainer
-The trainer works in the background while you play GTA 3. To activate it, you need to press F12 on your keyboard. This will bring up a small window at the top left corner of your screen that shows the status of the trainer and some information about your game. You can press F12 again to hide this window.
- Use the keyboard shortcuts to toggle the cheats
-To use any of the cheats or options in the trainer, you need to press the corresponding keyboard shortcut that you have assigned in the menu. For example, if you want to activate infinite health, you need to press H on your keyboard. You will hear a sound and see a message on your screen that confirms that the cheat is activated or deactivated. You can also see which cheats are active by looking at the small window that appears when you press F12.
Tips and Tricks for GTA 3 1.1 Ultimate Trainer v3 5
-GTA 3 1.1 Ultimate Trainer v3 5 is a great tool that can make your game more enjoyable and easier, but it also comes with some risks and limitations. Here are some tips and tricks that can help you use it safely and effectively:
- Save your game before using the trainer
-Using the trainer can sometimes cause glitches or crashes in your game, especially if you use too many cheats at once or change some settings that are not compatible with your game version. To avoid losing your progress or corrupting your save files, you should always save your game before using the trainer. You can use the savegame editor in the trainer to create multiple save slots and backup your saves.
- Be careful with some cheats that may cause glitches or crashes
-Some of the cheats and options in the trainer may have unintended consequences or side effects that can affect your game performance or stability. For example, using the flying cars cheat may cause your car to fly out of the map or get stuck in the air. Using the super speed cheat may make your game run too fast or slow down. Using the no police cheat may prevent you from completing some missions that require you to get a wanted level. You should use these cheats with caution and turn them off when you don't need them.
- Conclusion
-GTA 3 1.1 Ultimate Trainer v3 5 is a mod that adds a menu with various cheats and options that you can use to customize and enhance your gameplay experience in Grand Theft Auto III. You can download it from various websites that host mods for GTA 3, and install it by extracting the files to your GTA 3 folder. You can activate it by pressing F12 and use the keyboard shortcuts to toggle the cheats and options. You can also use the menu to change your hotkeys, edit your save files, take screenshots, teleport, spawn vehicles and weapons, change your skin, weather, stats, garage, and missions. However, you should also be careful with some cheats that may cause glitches or crashes in your game, and save your game before using the trainer.
- FAQs
-Here are some of the frequently asked questions about GTA 3 1.1 Ultimate Trainer v3 5:
- Q: Does GTA 3 1.1 Ultimate Trainer v3 5 work with other mods?
-A: GTA 3 1.1 Ultimate Trainer v3 5 may work with some other mods that do not modify the same files or features as the trainer. However, it may also cause conflicts or compatibility issues with some mods that do modify the same files or features as the trainer. You should always check the readme files or descriptions of the mods you want to use with the trainer, and make sure they are compatible with each other.
- Q: Does GTA 3 1.1 Ultimate Trainer v3 5 work with Steam version of GTA 3?
-A: GTA 3 1.1 Ultimate Trainer v3 5 works with Steam version of GTA 3, but you need to downgrade your game to version 1.1 first. The Steam version of GTA 3 is version 1.0, which is not compatible with the trainer. You can use a patch or a tool to downgrade your game to version 1.1, which you can find online.
- Q: How do I uninstall GTA 3 1.1 Ultimate Trainer v3 5?
-A: To uninstall GTA 3 1.1 Ultimate Trainer v3 5, you need to delete all the files and folders that you have copied to your GTA 3 folder when you installed the trainer. You may also need to restore your original files if you have overwritten them with the trainer files.
- Q: Where can I find more information about GTA 3 1.1 Ultimate Trainer v3 5?
-A: You can find more information about GTA 3 1.1 Ultimate Trainer v3 5 on the websites where you downloaded it from, or on the forums or communities dedicated to GTA mods. You can also contact the author of the trainer, LithJoe, if you have any questions or feedback.
- Q: Is GTA 3 1.1 Ultimate Trainer v3 5 safe to use?
-A: GTA 3 1.1 Ultimate Trainer v3 is safe to use as long as you download it from a trusted source and scan it for viruses or malware before installing it on your PC. However, you should also be aware that using any mod or trainer may affect your game performance or stability
or stability, and that using some cheats or options may be considered cheating or unfair by some players or online servers. You should use the trainer at your own risk and discretion, and respect the rules and preferences of other players and servers.
- I hope this article has helped you learn how to download, install, and use GTA 3 1.1 Ultimate Trainer v3 5. If you have any comments or questions, feel free to leave them below. Happy gaming!
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/3mrology/Chameleon_Text2Img_Generation_Demo/README.md b/spaces/3mrology/Chameleon_Text2Img_Generation_Demo/README.md
deleted file mode 100644
index 36a1c0a304d7b86460fc5494e0eb129324aa2687..0000000000000000000000000000000000000000
--- a/spaces/3mrology/Chameleon_Text2Img_Generation_Demo/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Chameleon Text2Image Demo
-emoji: 🦎
-colorFrom: green
-colorTo: purple
-sdk: gradio
-sdk_version: 3.12.0
-app_file: app.py
-pinned: false
-license: apache-2.0
-duplicated_from: huggingface-projects/magic-diffusion
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/7hao/bingo/tests/parse.ts b/spaces/7hao/bingo/tests/parse.ts
deleted file mode 100644
index 92940fe6315f1d7cb2b267ba5e5a7e26460a1de3..0000000000000000000000000000000000000000
--- a/spaces/7hao/bingo/tests/parse.ts
+++ /dev/null
@@ -1,13 +0,0 @@
-import { promises as fs } from 'fs'
-import { join } from 'path'
-import { parseHeadersFromCurl } from '@/lib/utils'
-
-(async () => {
- const content = await fs.readFile(join(__dirname, './fixtures/curl.txt'), 'utf-8')
- const headers = parseHeadersFromCurl(content)
- console.log(headers)
-
- const cmdContent = await fs.readFile(join(__dirname, './fixtures/cmd.txt'), 'utf-8')
- const cmdHeaders = parseHeadersFromCurl(cmdContent)
- console.log(cmdHeaders)
-})()
diff --git a/spaces/801artistry/RVC801/mdx.py b/spaces/801artistry/RVC801/mdx.py
deleted file mode 100644
index 4cc7c08b37bc371294f2f82b3382424a5455b7c2..0000000000000000000000000000000000000000
--- a/spaces/801artistry/RVC801/mdx.py
+++ /dev/null
@@ -1,228 +0,0 @@
-import torch
-import onnxruntime as ort
-from tqdm import tqdm
-import warnings
-import numpy as np
-import hashlib
-import queue
-import threading
-
-warnings.filterwarnings("ignore")
-
-class MDX_Model:
- def __init__(self, device, dim_f, dim_t, n_fft, hop=1024, stem_name=None, compensation=1.000):
- self.dim_f = dim_f
- self.dim_t = dim_t
- self.dim_c = 4
- self.n_fft = n_fft
- self.hop = hop
- self.stem_name = stem_name
- self.compensation = compensation
-
- self.n_bins = self.n_fft//2+1
- self.chunk_size = hop * (self.dim_t-1)
- self.window = torch.hann_window(window_length=self.n_fft, periodic=True).to(device)
-
- out_c = self.dim_c
-
- self.freq_pad = torch.zeros([1, out_c, self.n_bins-self.dim_f, self.dim_t]).to(device)
-
- def stft(self, x):
- x = x.reshape([-1, self.chunk_size])
- x = torch.stft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True, return_complex=True)
- x = torch.view_as_real(x)
- x = x.permute([0,3,1,2])
- x = x.reshape([-1,2,2,self.n_bins,self.dim_t]).reshape([-1,4,self.n_bins,self.dim_t])
- return x[:,:,:self.dim_f]
-
- def istft(self, x, freq_pad=None):
- freq_pad = self.freq_pad.repeat([x.shape[0],1,1,1]) if freq_pad is None else freq_pad
- x = torch.cat([x, freq_pad], -2)
- # c = 4*2 if self.target_name=='*' else 2
- x = x.reshape([-1,2,2,self.n_bins,self.dim_t]).reshape([-1,2,self.n_bins,self.dim_t])
- x = x.permute([0,2,3,1])
- x = x.contiguous()
- x = torch.view_as_complex(x)
- x = torch.istft(x, n_fft=self.n_fft, hop_length=self.hop, window=self.window, center=True)
- return x.reshape([-1,2,self.chunk_size])
-
-
-class MDX:
-
- DEFAULT_SR = 44100
- # Unit: seconds
- DEFAULT_CHUNK_SIZE = 0 * DEFAULT_SR
- DEFAULT_MARGIN_SIZE = 1 * DEFAULT_SR
-
- DEFAULT_PROCESSOR = 0
-
- def __init__(self, model_path:str, params:MDX_Model, processor=DEFAULT_PROCESSOR):
-
- # Set the device and the provider (CPU or CUDA)
- self.device = torch.device(f'cuda:{processor}') if processor >= 0 else torch.device('cpu')
- self.provider = ['CUDAExecutionProvider'] if processor >= 0 else ['CPUExecutionProvider']
-
- self.model = params
-
- # Load the ONNX model using ONNX Runtime
- self.ort = ort.InferenceSession(model_path, providers=self.provider)
- # Preload the model for faster performance
- self.ort.run(None, {'input':torch.rand(1, 4, params.dim_f, params.dim_t).numpy()})
- self.process = lambda spec:self.ort.run(None, {'input': spec.cpu().numpy()})[0]
-
- self.prog = None
-
- @staticmethod
- def get_hash(model_path):
- try:
- with open(model_path, 'rb') as f:
- f.seek(- 10000 * 1024, 2)
- model_hash = hashlib.md5(f.read()).hexdigest()
- except:
- model_hash = hashlib.md5(open(model_path,'rb').read()).hexdigest()
-
- return model_hash
-
- @staticmethod
- def segment(wave, combine=True, chunk_size=DEFAULT_CHUNK_SIZE, margin_size=DEFAULT_MARGIN_SIZE):
- """
- Segment or join segmented wave array
-
- Args:
- wave: (np.array) Wave array to be segmented or joined
- combine: (bool) If True, combines segmented wave array. If False, segments wave array.
- chunk_size: (int) Size of each segment (in samples)
- margin_size: (int) Size of margin between segments (in samples)
-
- Returns:
- numpy array: Segmented or joined wave array
- """
-
- if combine:
- processed_wave = None # Initializing as None instead of [] for later numpy array concatenation
- for segment_count, segment in enumerate(wave):
- start = 0 if segment_count == 0 else margin_size
- end = None if segment_count == len(wave)-1 else -margin_size
- if margin_size == 0:
- end = None
- if processed_wave is None: # Create array for first segment
- processed_wave = segment[:, start:end]
- else: # Concatenate to existing array for subsequent segments
- processed_wave = np.concatenate((processed_wave, segment[:, start:end]), axis=-1)
-
- else:
- processed_wave = []
- sample_count = wave.shape[-1]
-
- if chunk_size <= 0 or chunk_size > sample_count:
- chunk_size = sample_count
-
- if margin_size > chunk_size:
- margin_size = chunk_size
-
- for segment_count, skip in enumerate(range(0, sample_count, chunk_size)):
-
- margin = 0 if segment_count == 0 else margin_size
- end = min(skip+chunk_size+margin_size, sample_count)
- start = skip-margin
-
- cut = wave[:,start:end].copy()
- processed_wave.append(cut)
-
- if end == sample_count:
- break
-
- return processed_wave
-
- def pad_wave(self, wave):
- """
- Pad the wave array to match the required chunk size
-
- Args:
- wave: (np.array) Wave array to be padded
-
- Returns:
- tuple: (padded_wave, pad, trim)
- - padded_wave: Padded wave array
- - pad: Number of samples that were padded
- - trim: Number of samples that were trimmed
- """
- n_sample = wave.shape[1]
- trim = self.model.n_fft//2
- gen_size = self.model.chunk_size-2*trim
- pad = gen_size - n_sample%gen_size
-
- # Padded wave
- wave_p = np.concatenate((np.zeros((2,trim)), wave, np.zeros((2,pad)), np.zeros((2,trim))), 1)
-
- mix_waves = []
- for i in range(0, n_sample+pad, gen_size):
- waves = np.array(wave_p[:, i:i+self.model.chunk_size])
- mix_waves.append(waves)
-
- mix_waves = torch.tensor(mix_waves, dtype=torch.float32).to(self.device)
-
- return mix_waves, pad, trim
-
- def _process_wave(self, mix_waves, trim, pad, q:queue.Queue, _id:int):
- """
- Process each wave segment in a multi-threaded environment
-
- Args:
- mix_waves: (torch.Tensor) Wave segments to be processed
- trim: (int) Number of samples trimmed during padding
- pad: (int) Number of samples padded during padding
- q: (queue.Queue) Queue to hold the processed wave segments
- _id: (int) Identifier of the processed wave segment
-
- Returns:
- numpy array: Processed wave segment
- """
- mix_waves = mix_waves.split(1)
- with torch.no_grad():
- pw = []
- for mix_wave in mix_waves:
- self.prog.update()
- spec = self.model.stft(mix_wave)
- processed_spec = torch.tensor(self.process(spec))
- processed_wav = self.model.istft(processed_spec.to(self.device))
- processed_wav = processed_wav[:,:,trim:-trim].transpose(0,1).reshape(2, -1).cpu().numpy()
- pw.append(processed_wav)
- processed_signal = np.concatenate(pw, axis=-1)[:, :-pad]
- q.put({_id:processed_signal})
- return processed_signal
-
- def process_wave(self, wave:np.array, mt_threads=1):
- """
- Process the wave array in a multi-threaded environment
-
- Args:
- wave: (np.array) Wave array to be processed
- mt_threads: (int) Number of threads to be used for processing
-
- Returns:
- numpy array: Processed wave array
- """
- self.prog = tqdm(total=0)
- chunk = wave.shape[-1]//mt_threads
- waves = self.segment(wave, False, chunk)
-
- # Create a queue to hold the processed wave segments
- q = queue.Queue()
- threads = []
- for c, batch in enumerate(waves):
- mix_waves, pad, trim = self.pad_wave(batch)
- self.prog.total = len(mix_waves)*mt_threads
- thread = threading.Thread(target=self._process_wave, args=(mix_waves, trim, pad, q, c))
- thread.start()
- threads.append(thread)
- for thread in threads:
- thread.join()
- self.prog.close()
-
- processed_batches = []
- while not q.empty():
- processed_batches.append(q.get())
- processed_batches = [list(wave.values())[0] for wave in sorted(processed_batches, key=lambda d: list(d.keys())[0])]
- assert len(processed_batches) == len(waves), 'Incomplete processed batches, please reduce batch size!'
- return self.segment(processed_batches, True, chunk)
\ No newline at end of file
diff --git a/spaces/801artistry/RVC801/tools/infer_batch_rvc.py b/spaces/801artistry/RVC801/tools/infer_batch_rvc.py
deleted file mode 100644
index 763d17f14877a2ce35f750202e91356c1f24270f..0000000000000000000000000000000000000000
--- a/spaces/801artistry/RVC801/tools/infer_batch_rvc.py
+++ /dev/null
@@ -1,72 +0,0 @@
-import argparse
-import os
-import sys
-
-print("Command-line arguments:", sys.argv)
-
-now_dir = os.getcwd()
-sys.path.append(now_dir)
-import sys
-
-import tqdm as tq
-from dotenv import load_dotenv
-from scipy.io import wavfile
-
-from configs.config import Config
-from infer.modules.vc.modules import VC
-
-
-def arg_parse() -> tuple:
- parser = argparse.ArgumentParser()
- parser.add_argument("--f0up_key", type=int, default=0)
- parser.add_argument("--input_path", type=str, help="input path")
- parser.add_argument("--index_path", type=str, help="index path")
- parser.add_argument("--f0method", type=str, default="harvest", help="harvest or pm")
- parser.add_argument("--opt_path", type=str, help="opt path")
- parser.add_argument("--model_name", type=str, help="store in assets/weight_root")
- parser.add_argument("--index_rate", type=float, default=0.66, help="index rate")
- parser.add_argument("--device", type=str, help="device")
- parser.add_argument("--is_half", type=bool, help="use half -> True")
- parser.add_argument("--filter_radius", type=int, default=3, help="filter radius")
- parser.add_argument("--resample_sr", type=int, default=0, help="resample sr")
- parser.add_argument("--rms_mix_rate", type=float, default=1, help="rms mix rate")
- parser.add_argument("--protect", type=float, default=0.33, help="protect")
-
- args = parser.parse_args()
- sys.argv = sys.argv[:1]
-
- return args
-
-
-def main():
- load_dotenv()
- args = arg_parse()
- config = Config()
- config.device = args.device if args.device else config.device
- config.is_half = args.is_half if args.is_half else config.is_half
- vc = VC(config)
- vc.get_vc(args.model_name)
- audios = os.listdir(args.input_path)
- for file in tq.tqdm(audios):
- if file.endswith(".wav"):
- file_path = os.path.join(args.input_path, file)
- _, wav_opt = vc.vc_single(
- 0,
- file_path,
- args.f0up_key,
- None,
- args.f0method,
- args.index_path,
- None,
- args.index_rate,
- args.filter_radius,
- args.resample_sr,
- args.rms_mix_rate,
- args.protect,
- )
- out_path = os.path.join(args.opt_path, file)
- wavfile.write(out_path, wav_opt[0], wav_opt[1])
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/AIConsultant/MusicGen/scripts/mos.py b/spaces/AIConsultant/MusicGen/scripts/mos.py
deleted file mode 100644
index a711c9ece23e72ed3a07032c7834ef7c56ab4f11..0000000000000000000000000000000000000000
--- a/spaces/AIConsultant/MusicGen/scripts/mos.py
+++ /dev/null
@@ -1,286 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-
-"""
-To run this script, from the root of the repo. Make sure to have Flask installed
-
- FLASK_DEBUG=1 FLASK_APP=scripts.mos flask run -p 4567
- # or if you have gunicorn
- gunicorn -w 4 -b 127.0.0.1:8895 -t 120 'scripts.mos:app' --access-logfile -
-
-"""
-from collections import defaultdict
-from functools import wraps
-from hashlib import sha1
-import json
-import math
-from pathlib import Path
-import random
-import typing as tp
-
-from flask import Flask, redirect, render_template, request, session, url_for
-
-from audiocraft import train
-from audiocraft.utils.samples.manager import get_samples_for_xps
-
-
-SAMPLES_PER_PAGE = 8
-MAX_RATING = 5
-storage = Path(train.main.dora.dir / 'mos_storage')
-storage.mkdir(exist_ok=True)
-surveys = storage / 'surveys'
-surveys.mkdir(exist_ok=True)
-magma_root = Path(train.__file__).parent.parent
-app = Flask('mos', static_folder=str(magma_root / 'scripts/static'),
- template_folder=str(magma_root / 'scripts/templates'))
-app.secret_key = b'audiocraft makes the best songs'
-
-
-def normalize_path(path: Path):
- """Just to make path a bit nicer, make them relative to the Dora root dir.
- """
- path = path.resolve()
- dora_dir = train.main.dora.dir.resolve() / 'xps'
- return path.relative_to(dora_dir)
-
-
-def get_full_path(normalized_path: Path):
- """Revert `normalize_path`.
- """
- return train.main.dora.dir.resolve() / 'xps' / normalized_path
-
-
-def get_signature(xps: tp.List[str]):
- """Return a signature for a list of XP signatures.
- """
- return sha1(json.dumps(xps).encode()).hexdigest()[:10]
-
-
-def ensure_logged(func):
- """Ensure user is logged in.
- """
- @wraps(func)
- def _wrapped(*args, **kwargs):
- user = session.get('user')
- if user is None:
- return redirect(url_for('login', redirect_to=request.url))
- return func(*args, **kwargs)
- return _wrapped
-
-
-@app.route('/login', methods=['GET', 'POST'])
-def login():
- """Login user if not already, then redirect.
- """
- user = session.get('user')
- if user is None:
- error = None
- if request.method == 'POST':
- user = request.form['user']
- if not user:
- error = 'User cannot be empty'
- if user is None or error:
- return render_template('login.html', error=error)
- assert user
- session['user'] = user
- redirect_to = request.args.get('redirect_to')
- if redirect_to is None:
- redirect_to = url_for('index')
- return redirect(redirect_to)
-
-
-@app.route('/', methods=['GET', 'POST'])
-@ensure_logged
-def index():
- """Offer to create a new study.
- """
- errors = []
- if request.method == 'POST':
- xps_or_grids = [part.strip() for part in request.form['xps'].split()]
- xps = set()
- for xp_or_grid in xps_or_grids:
- xp_path = train.main.dora.dir / 'xps' / xp_or_grid
- if xp_path.exists():
- xps.add(xp_or_grid)
- continue
- grid_path = train.main.dora.dir / 'grids' / xp_or_grid
- if grid_path.exists():
- for child in grid_path.iterdir():
- if child.is_symlink():
- xps.add(child.name)
- continue
- errors.append(f'{xp_or_grid} is neither an XP nor a grid!')
- assert xps or errors
- blind = 'true' if request.form.get('blind') == 'on' else 'false'
- xps = list(xps)
- if not errors:
- signature = get_signature(xps)
- manifest = {
- 'xps': xps,
- }
- survey_path = surveys / signature
- survey_path.mkdir(exist_ok=True)
- with open(survey_path / 'manifest.json', 'w') as f:
- json.dump(manifest, f, indent=2)
- return redirect(url_for('survey', blind=blind, signature=signature))
- return render_template('index.html', errors=errors)
-
-
-@app.route('/survey/', methods=['GET', 'POST'])
-@ensure_logged
-def survey(signature):
- success = request.args.get('success', False)
- seed = int(request.args.get('seed', 4321))
- blind = request.args.get('blind', 'false') in ['true', 'on', 'True']
- exclude_prompted = request.args.get('exclude_prompted', 'false') in ['true', 'on', 'True']
- exclude_unprompted = request.args.get('exclude_unprompted', 'false') in ['true', 'on', 'True']
- max_epoch = int(request.args.get('max_epoch', '-1'))
- survey_path = surveys / signature
- assert survey_path.exists(), survey_path
-
- user = session['user']
- result_folder = survey_path / 'results'
- result_folder.mkdir(exist_ok=True)
- result_file = result_folder / f'{user}_{seed}.json'
-
- with open(survey_path / 'manifest.json') as f:
- manifest = json.load(f)
-
- xps = [train.main.get_xp_from_sig(xp) for xp in manifest['xps']]
- names, ref_name = train.main.get_names(xps)
-
- samples_kwargs = {
- 'exclude_prompted': exclude_prompted,
- 'exclude_unprompted': exclude_unprompted,
- 'max_epoch': max_epoch,
- }
- matched_samples = get_samples_for_xps(xps, epoch=-1, **samples_kwargs) # fetch latest epoch
- models_by_id = {
- id: [{
- 'xp': xps[idx],
- 'xp_name': names[idx],
- 'model_id': f'{xps[idx].sig}-{sample.id}',
- 'sample': sample,
- 'is_prompted': sample.prompt is not None,
- 'errors': [],
- } for idx, sample in enumerate(samples)]
- for id, samples in matched_samples.items()
- }
- experiments = [
- {'xp': xp, 'name': names[idx], 'epoch': list(matched_samples.values())[0][idx].epoch}
- for idx, xp in enumerate(xps)
- ]
-
- keys = list(matched_samples.keys())
- keys.sort()
- rng = random.Random(seed)
- rng.shuffle(keys)
- model_ids = keys[:SAMPLES_PER_PAGE]
-
- if blind:
- for key in model_ids:
- rng.shuffle(models_by_id[key])
-
- ok = True
- if request.method == 'POST':
- all_samples_results = []
- for id in model_ids:
- models = models_by_id[id]
- result = {
- 'id': id,
- 'is_prompted': models[0]['is_prompted'],
- 'models': {}
- }
- all_samples_results.append(result)
- for model in models:
- rating = request.form[model['model_id']]
- if rating:
- rating = int(rating)
- assert rating <= MAX_RATING and rating >= 1
- result['models'][model['xp'].sig] = rating
- model['rating'] = rating
- else:
- ok = False
- model['errors'].append('Please rate this model.')
- if ok:
- result = {
- 'results': all_samples_results,
- 'seed': seed,
- 'user': user,
- 'blind': blind,
- 'exclude_prompted': exclude_prompted,
- 'exclude_unprompted': exclude_unprompted,
- }
- print(result)
- with open(result_file, 'w') as f:
- json.dump(result, f)
- seed = seed + 1
- return redirect(url_for(
- 'survey', signature=signature, blind=blind, seed=seed,
- exclude_prompted=exclude_prompted, exclude_unprompted=exclude_unprompted,
- max_epoch=max_epoch, success=True))
-
- ratings = list(range(1, MAX_RATING + 1))
- return render_template(
- 'survey.html', ratings=ratings, blind=blind, seed=seed, signature=signature, success=success,
- exclude_prompted=exclude_prompted, exclude_unprompted=exclude_unprompted, max_epoch=max_epoch,
- experiments=experiments, models_by_id=models_by_id, model_ids=model_ids, errors=[],
- ref_name=ref_name, already_filled=result_file.exists())
-
-
-@app.route('/audio/')
-def audio(path: str):
- full_path = Path('/') / path
- assert full_path.suffix in [".mp3", ".wav"]
- return full_path.read_bytes(), {'Content-Type': 'audio/mpeg'}
-
-
-def mean(x):
- return sum(x) / len(x)
-
-
-def std(x):
- m = mean(x)
- return math.sqrt(sum((i - m)**2 for i in x) / len(x))
-
-
-@app.route('/results/')
-@ensure_logged
-def results(signature):
-
- survey_path = surveys / signature
- assert survey_path.exists(), survey_path
- result_folder = survey_path / 'results'
- result_folder.mkdir(exist_ok=True)
-
- # ratings per model, then per user.
- ratings_per_model = defaultdict(list)
- users = []
- for result_file in result_folder.iterdir():
- if result_file.suffix != '.json':
- continue
- with open(result_file) as f:
- results = json.load(f)
- users.append(results['user'])
- for result in results['results']:
- for sig, rating in result['models'].items():
- ratings_per_model[sig].append(rating)
-
- fmt = '{:.2f}'
- models = []
- for model in sorted(ratings_per_model.keys()):
- ratings = ratings_per_model[model]
-
- models.append({
- 'sig': model,
- 'samples': len(ratings),
- 'mean_rating': fmt.format(mean(ratings)),
- # the value 1.96 was probably chosen to achieve some
- # confidence interval assuming gaussianity.
- 'std_rating': fmt.format(1.96 * std(ratings) / len(ratings)**0.5),
- })
- return render_template('results.html', signature=signature, models=models, users=users)
diff --git a/spaces/AIFILMS/StyleGANEX/models/bisenet/model.py b/spaces/AIFILMS/StyleGANEX/models/bisenet/model.py
deleted file mode 100644
index 1d2a16ca7533c7b92c600c4dddb89f5f68191d4f..0000000000000000000000000000000000000000
--- a/spaces/AIFILMS/StyleGANEX/models/bisenet/model.py
+++ /dev/null
@@ -1,283 +0,0 @@
-#!/usr/bin/python
-# -*- encoding: utf-8 -*-
-
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torchvision
-
-from models.bisenet.resnet import Resnet18
-# from modules.bn import InPlaceABNSync as BatchNorm2d
-
-
-class ConvBNReLU(nn.Module):
- def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
- super(ConvBNReLU, self).__init__()
- self.conv = nn.Conv2d(in_chan,
- out_chan,
- kernel_size = ks,
- stride = stride,
- padding = padding,
- bias = False)
- self.bn = nn.BatchNorm2d(out_chan)
- self.init_weight()
-
- def forward(self, x):
- x = self.conv(x)
- x = F.relu(self.bn(x))
- return x
-
- def init_weight(self):
- for ly in self.children():
- if isinstance(ly, nn.Conv2d):
- nn.init.kaiming_normal_(ly.weight, a=1)
- if not ly.bias is None: nn.init.constant_(ly.bias, 0)
-
-class BiSeNetOutput(nn.Module):
- def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
- super(BiSeNetOutput, self).__init__()
- self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
- self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
- self.init_weight()
-
- def forward(self, x):
- x = self.conv(x)
- x = self.conv_out(x)
- return x
-
- def init_weight(self):
- for ly in self.children():
- if isinstance(ly, nn.Conv2d):
- nn.init.kaiming_normal_(ly.weight, a=1)
- if not ly.bias is None: nn.init.constant_(ly.bias, 0)
-
- def get_params(self):
- wd_params, nowd_params = [], []
- for name, module in self.named_modules():
- if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
- wd_params.append(module.weight)
- if not module.bias is None:
- nowd_params.append(module.bias)
- elif isinstance(module, nn.BatchNorm2d):
- nowd_params += list(module.parameters())
- return wd_params, nowd_params
-
-
-class AttentionRefinementModule(nn.Module):
- def __init__(self, in_chan, out_chan, *args, **kwargs):
- super(AttentionRefinementModule, self).__init__()
- self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
- self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
- self.bn_atten = nn.BatchNorm2d(out_chan)
- self.sigmoid_atten = nn.Sigmoid()
- self.init_weight()
-
- def forward(self, x):
- feat = self.conv(x)
- atten = F.avg_pool2d(feat, feat.size()[2:])
- atten = self.conv_atten(atten)
- atten = self.bn_atten(atten)
- atten = self.sigmoid_atten(atten)
- out = torch.mul(feat, atten)
- return out
-
- def init_weight(self):
- for ly in self.children():
- if isinstance(ly, nn.Conv2d):
- nn.init.kaiming_normal_(ly.weight, a=1)
- if not ly.bias is None: nn.init.constant_(ly.bias, 0)
-
-
-class ContextPath(nn.Module):
- def __init__(self, *args, **kwargs):
- super(ContextPath, self).__init__()
- self.resnet = Resnet18()
- self.arm16 = AttentionRefinementModule(256, 128)
- self.arm32 = AttentionRefinementModule(512, 128)
- self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
- self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
- self.conv_avg = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
-
- self.init_weight()
-
- def forward(self, x):
- H0, W0 = x.size()[2:]
- feat8, feat16, feat32 = self.resnet(x)
- H8, W8 = feat8.size()[2:]
- H16, W16 = feat16.size()[2:]
- H32, W32 = feat32.size()[2:]
-
- avg = F.avg_pool2d(feat32, feat32.size()[2:])
- avg = self.conv_avg(avg)
- avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
-
- feat32_arm = self.arm32(feat32)
- feat32_sum = feat32_arm + avg_up
- feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
- feat32_up = self.conv_head32(feat32_up)
-
- feat16_arm = self.arm16(feat16)
- feat16_sum = feat16_arm + feat32_up
- feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
- feat16_up = self.conv_head16(feat16_up)
-
- return feat8, feat16_up, feat32_up # x8, x8, x16
-
- def init_weight(self):
- for ly in self.children():
- if isinstance(ly, nn.Conv2d):
- nn.init.kaiming_normal_(ly.weight, a=1)
- if not ly.bias is None: nn.init.constant_(ly.bias, 0)
-
- def get_params(self):
- wd_params, nowd_params = [], []
- for name, module in self.named_modules():
- if isinstance(module, (nn.Linear, nn.Conv2d)):
- wd_params.append(module.weight)
- if not module.bias is None:
- nowd_params.append(module.bias)
- elif isinstance(module, nn.BatchNorm2d):
- nowd_params += list(module.parameters())
- return wd_params, nowd_params
-
-
-### This is not used, since I replace this with the resnet feature with the same size
-class SpatialPath(nn.Module):
- def __init__(self, *args, **kwargs):
- super(SpatialPath, self).__init__()
- self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
- self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
- self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
- self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
- self.init_weight()
-
- def forward(self, x):
- feat = self.conv1(x)
- feat = self.conv2(feat)
- feat = self.conv3(feat)
- feat = self.conv_out(feat)
- return feat
-
- def init_weight(self):
- for ly in self.children():
- if isinstance(ly, nn.Conv2d):
- nn.init.kaiming_normal_(ly.weight, a=1)
- if not ly.bias is None: nn.init.constant_(ly.bias, 0)
-
- def get_params(self):
- wd_params, nowd_params = [], []
- for name, module in self.named_modules():
- if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
- wd_params.append(module.weight)
- if not module.bias is None:
- nowd_params.append(module.bias)
- elif isinstance(module, nn.BatchNorm2d):
- nowd_params += list(module.parameters())
- return wd_params, nowd_params
-
-
-class FeatureFusionModule(nn.Module):
- def __init__(self, in_chan, out_chan, *args, **kwargs):
- super(FeatureFusionModule, self).__init__()
- self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
- self.conv1 = nn.Conv2d(out_chan,
- out_chan//4,
- kernel_size = 1,
- stride = 1,
- padding = 0,
- bias = False)
- self.conv2 = nn.Conv2d(out_chan//4,
- out_chan,
- kernel_size = 1,
- stride = 1,
- padding = 0,
- bias = False)
- self.relu = nn.ReLU(inplace=True)
- self.sigmoid = nn.Sigmoid()
- self.init_weight()
-
- def forward(self, fsp, fcp):
- fcat = torch.cat([fsp, fcp], dim=1)
- feat = self.convblk(fcat)
- atten = F.avg_pool2d(feat, feat.size()[2:])
- atten = self.conv1(atten)
- atten = self.relu(atten)
- atten = self.conv2(atten)
- atten = self.sigmoid(atten)
- feat_atten = torch.mul(feat, atten)
- feat_out = feat_atten + feat
- return feat_out
-
- def init_weight(self):
- for ly in self.children():
- if isinstance(ly, nn.Conv2d):
- nn.init.kaiming_normal_(ly.weight, a=1)
- if not ly.bias is None: nn.init.constant_(ly.bias, 0)
-
- def get_params(self):
- wd_params, nowd_params = [], []
- for name, module in self.named_modules():
- if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
- wd_params.append(module.weight)
- if not module.bias is None:
- nowd_params.append(module.bias)
- elif isinstance(module, nn.BatchNorm2d):
- nowd_params += list(module.parameters())
- return wd_params, nowd_params
-
-
-class BiSeNet(nn.Module):
- def __init__(self, n_classes, *args, **kwargs):
- super(BiSeNet, self).__init__()
- self.cp = ContextPath()
- ## here self.sp is deleted
- self.ffm = FeatureFusionModule(256, 256)
- self.conv_out = BiSeNetOutput(256, 256, n_classes)
- self.conv_out16 = BiSeNetOutput(128, 64, n_classes)
- self.conv_out32 = BiSeNetOutput(128, 64, n_classes)
- self.init_weight()
-
- def forward(self, x):
- H, W = x.size()[2:]
- feat_res8, feat_cp8, feat_cp16 = self.cp(x) # here return res3b1 feature
- feat_sp = feat_res8 # use res3b1 feature to replace spatial path feature
- feat_fuse = self.ffm(feat_sp, feat_cp8)
-
- feat_out = self.conv_out(feat_fuse)
- feat_out16 = self.conv_out16(feat_cp8)
- feat_out32 = self.conv_out32(feat_cp16)
-
- feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
- feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
- feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
- return feat_out, feat_out16, feat_out32
-
- def init_weight(self):
- for ly in self.children():
- if isinstance(ly, nn.Conv2d):
- nn.init.kaiming_normal_(ly.weight, a=1)
- if not ly.bias is None: nn.init.constant_(ly.bias, 0)
-
- def get_params(self):
- wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = [], [], [], []
- for name, child in self.named_children():
- child_wd_params, child_nowd_params = child.get_params()
- if isinstance(child, FeatureFusionModule) or isinstance(child, BiSeNetOutput):
- lr_mul_wd_params += child_wd_params
- lr_mul_nowd_params += child_nowd_params
- else:
- wd_params += child_wd_params
- nowd_params += child_nowd_params
- return wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params
-
-
-if __name__ == "__main__":
- net = BiSeNet(19)
- net.cuda()
- net.eval()
- in_ten = torch.randn(16, 3, 640, 480).cuda()
- out, out16, out32 = net(in_ten)
- print(out.shape)
-
- net.get_params()
diff --git a/spaces/AIGC-Audio/AudioGPT/text_to_speech/tasks/run.py b/spaces/AIGC-Audio/AudioGPT/text_to_speech/tasks/run.py
deleted file mode 100644
index 7778a333d2e9b53e28bab6f93f0abf1c3540a079..0000000000000000000000000000000000000000
--- a/spaces/AIGC-Audio/AudioGPT/text_to_speech/tasks/run.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import os
-
-os.environ["OMP_NUM_THREADS"] = "1"
-
-from text_to_speech.utils.commons.hparams import hparams, set_hparams
-import importlib
-
-
-def run_task():
- assert hparams['task_cls'] != ''
- pkg = ".".join(hparams["task_cls"].split(".")[:-1])
- cls_name = hparams["task_cls"].split(".")[-1]
- task_cls = getattr(importlib.import_module(pkg), cls_name)
- task_cls.start()
-
-
-if __name__ == '__main__':
- set_hparams()
- run_task()
diff --git a/spaces/AbandonedMuse/UnlimitedMusicGen/audiocraft/modules/conv.py b/spaces/AbandonedMuse/UnlimitedMusicGen/audiocraft/modules/conv.py
deleted file mode 100644
index 972938ab84712eb06e1b10cea25444eee51d6637..0000000000000000000000000000000000000000
--- a/spaces/AbandonedMuse/UnlimitedMusicGen/audiocraft/modules/conv.py
+++ /dev/null
@@ -1,245 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import math
-import typing as tp
-import warnings
-
-import torch
-from torch import nn
-from torch.nn import functional as F
-from torch.nn.utils import spectral_norm, weight_norm
-
-
-CONV_NORMALIZATIONS = frozenset(['none', 'weight_norm', 'spectral_norm',
- 'time_group_norm'])
-
-
-def apply_parametrization_norm(module: nn.Module, norm: str = 'none'):
- assert norm in CONV_NORMALIZATIONS
- if norm == 'weight_norm':
- return weight_norm(module)
- elif norm == 'spectral_norm':
- return spectral_norm(module)
- else:
- # We already check was in CONV_NORMALIZATION, so any other choice
- # doesn't need reparametrization.
- return module
-
-
-def get_norm_module(module: nn.Module, causal: bool = False, norm: str = 'none', **norm_kwargs):
- """Return the proper normalization module. If causal is True, this will ensure the returned
- module is causal, or return an error if the normalization doesn't support causal evaluation.
- """
- assert norm in CONV_NORMALIZATIONS
- if norm == 'time_group_norm':
- if causal:
- raise ValueError("GroupNorm doesn't support causal evaluation.")
- assert isinstance(module, nn.modules.conv._ConvNd)
- return nn.GroupNorm(1, module.out_channels, **norm_kwargs)
- else:
- return nn.Identity()
-
-
-def get_extra_padding_for_conv1d(x: torch.Tensor, kernel_size: int, stride: int,
- padding_total: int = 0) -> int:
- """See `pad_for_conv1d`.
- """
- length = x.shape[-1]
- n_frames = (length - kernel_size + padding_total) / stride + 1
- ideal_length = (math.ceil(n_frames) - 1) * stride + (kernel_size - padding_total)
- return ideal_length - length
-
-
-def pad_for_conv1d(x: torch.Tensor, kernel_size: int, stride: int, padding_total: int = 0):
- """Pad for a convolution to make sure that the last window is full.
- Extra padding is added at the end. This is required to ensure that we can rebuild
- an output of the same length, as otherwise, even with padding, some time steps
- might get removed.
- For instance, with total padding = 4, kernel size = 4, stride = 2:
- 0 0 1 2 3 4 5 0 0 # (0s are padding)
- 1 2 3 # (output frames of a convolution, last 0 is never used)
- 0 0 1 2 3 4 5 0 # (output of tr. conv., but pos. 5 is going to get removed as padding)
- 1 2 3 4 # once you removed padding, we are missing one time step !
- """
- extra_padding = get_extra_padding_for_conv1d(x, kernel_size, stride, padding_total)
- return F.pad(x, (0, extra_padding))
-
-
-def pad1d(x: torch.Tensor, paddings: tp.Tuple[int, int], mode: str = 'constant', value: float = 0.):
- """Tiny wrapper around F.pad, just to allow for reflect padding on small input.
- If this is the case, we insert extra 0 padding to the right before the reflection happen.
- """
- length = x.shape[-1]
- padding_left, padding_right = paddings
- assert padding_left >= 0 and padding_right >= 0, (padding_left, padding_right)
- if mode == 'reflect':
- max_pad = max(padding_left, padding_right)
- extra_pad = 0
- if length <= max_pad:
- extra_pad = max_pad - length + 1
- x = F.pad(x, (0, extra_pad))
- padded = F.pad(x, paddings, mode, value)
- end = padded.shape[-1] - extra_pad
- return padded[..., :end]
- else:
- return F.pad(x, paddings, mode, value)
-
-
-def unpad1d(x: torch.Tensor, paddings: tp.Tuple[int, int]):
- """Remove padding from x, handling properly zero padding. Only for 1d!
- """
- padding_left, padding_right = paddings
- assert padding_left >= 0 and padding_right >= 0, (padding_left, padding_right)
- assert (padding_left + padding_right) <= x.shape[-1]
- end = x.shape[-1] - padding_right
- return x[..., padding_left: end]
-
-
-class NormConv1d(nn.Module):
- """Wrapper around Conv1d and normalization applied to this conv
- to provide a uniform interface across normalization approaches.
- """
- def __init__(self, *args, causal: bool = False, norm: str = 'none',
- norm_kwargs: tp.Dict[str, tp.Any] = {}, **kwargs):
- super().__init__()
- self.conv = apply_parametrization_norm(nn.Conv1d(*args, **kwargs), norm)
- self.norm = get_norm_module(self.conv, causal, norm, **norm_kwargs)
- self.norm_type = norm
-
- def forward(self, x):
- x = self.conv(x)
- x = self.norm(x)
- return x
-
-
-class NormConv2d(nn.Module):
- """Wrapper around Conv2d and normalization applied to this conv
- to provide a uniform interface across normalization approaches.
- """
- def __init__(self, *args, norm: str = 'none', norm_kwargs: tp.Dict[str, tp.Any] = {}, **kwargs):
- super().__init__()
- self.conv = apply_parametrization_norm(nn.Conv2d(*args, **kwargs), norm)
- self.norm = get_norm_module(self.conv, causal=False, norm=norm, **norm_kwargs)
- self.norm_type = norm
-
- def forward(self, x):
- x = self.conv(x)
- x = self.norm(x)
- return x
-
-
-class NormConvTranspose1d(nn.Module):
- """Wrapper around ConvTranspose1d and normalization applied to this conv
- to provide a uniform interface across normalization approaches.
- """
- def __init__(self, *args, causal: bool = False, norm: str = 'none',
- norm_kwargs: tp.Dict[str, tp.Any] = {}, **kwargs):
- super().__init__()
- self.convtr = apply_parametrization_norm(nn.ConvTranspose1d(*args, **kwargs), norm)
- self.norm = get_norm_module(self.convtr, causal, norm, **norm_kwargs)
- self.norm_type = norm
-
- def forward(self, x):
- x = self.convtr(x)
- x = self.norm(x)
- return x
-
-
-class NormConvTranspose2d(nn.Module):
- """Wrapper around ConvTranspose2d and normalization applied to this conv
- to provide a uniform interface across normalization approaches.
- """
- def __init__(self, *args, norm: str = 'none', norm_kwargs: tp.Dict[str, tp.Any] = {}, **kwargs):
- super().__init__()
- self.convtr = apply_parametrization_norm(nn.ConvTranspose2d(*args, **kwargs), norm)
- self.norm = get_norm_module(self.convtr, causal=False, norm=norm, **norm_kwargs)
-
- def forward(self, x):
- x = self.convtr(x)
- x = self.norm(x)
- return x
-
-
-class StreamableConv1d(nn.Module):
- """Conv1d with some builtin handling of asymmetric or causal padding
- and normalization.
- """
- def __init__(self, in_channels: int, out_channels: int,
- kernel_size: int, stride: int = 1, dilation: int = 1,
- groups: int = 1, bias: bool = True, causal: bool = False,
- norm: str = 'none', norm_kwargs: tp.Dict[str, tp.Any] = {},
- pad_mode: str = 'reflect'):
- super().__init__()
- # warn user on unusual setup between dilation and stride
- if stride > 1 and dilation > 1:
- warnings.warn('StreamableConv1d has been initialized with stride > 1 and dilation > 1'
- f' (kernel_size={kernel_size} stride={stride}, dilation={dilation}).')
- self.conv = NormConv1d(in_channels, out_channels, kernel_size, stride,
- dilation=dilation, groups=groups, bias=bias, causal=causal,
- norm=norm, norm_kwargs=norm_kwargs)
- self.causal = causal
- self.pad_mode = pad_mode
-
- def forward(self, x):
- B, C, T = x.shape
- kernel_size = self.conv.conv.kernel_size[0]
- stride = self.conv.conv.stride[0]
- dilation = self.conv.conv.dilation[0]
- kernel_size = (kernel_size - 1) * dilation + 1 # effective kernel size with dilations
- padding_total = kernel_size - stride
- extra_padding = get_extra_padding_for_conv1d(x, kernel_size, stride, padding_total)
- if self.causal:
- # Left padding for causal
- x = pad1d(x, (padding_total, extra_padding), mode=self.pad_mode)
- else:
- # Asymmetric padding required for odd strides
- padding_right = padding_total // 2
- padding_left = padding_total - padding_right
- x = pad1d(x, (padding_left, padding_right + extra_padding), mode=self.pad_mode)
- return self.conv(x)
-
-
-class StreamableConvTranspose1d(nn.Module):
- """ConvTranspose1d with some builtin handling of asymmetric or causal padding
- and normalization.
- """
- def __init__(self, in_channels: int, out_channels: int,
- kernel_size: int, stride: int = 1, causal: bool = False,
- norm: str = 'none', trim_right_ratio: float = 1.,
- norm_kwargs: tp.Dict[str, tp.Any] = {}):
- super().__init__()
- self.convtr = NormConvTranspose1d(in_channels, out_channels, kernel_size, stride,
- causal=causal, norm=norm, norm_kwargs=norm_kwargs)
- self.causal = causal
- self.trim_right_ratio = trim_right_ratio
- assert self.causal or self.trim_right_ratio == 1., \
- "`trim_right_ratio` != 1.0 only makes sense for causal convolutions"
- assert self.trim_right_ratio >= 0. and self.trim_right_ratio <= 1.
-
- def forward(self, x):
- kernel_size = self.convtr.convtr.kernel_size[0]
- stride = self.convtr.convtr.stride[0]
- padding_total = kernel_size - stride
-
- y = self.convtr(x)
-
- # We will only trim fixed padding. Extra padding from `pad_for_conv1d` would be
- # removed at the very end, when keeping only the right length for the output,
- # as removing it here would require also passing the length at the matching layer
- # in the encoder.
- if self.causal:
- # Trim the padding on the right according to the specified ratio
- # if trim_right_ratio = 1.0, trim everything from right
- padding_right = math.ceil(padding_total * self.trim_right_ratio)
- padding_left = padding_total - padding_right
- y = unpad1d(y, (padding_left, padding_right))
- else:
- # Asymmetric padding required for odd strides
- padding_right = padding_total // 2
- padding_left = padding_total - padding_right
- y = unpad1d(y, (padding_left, padding_right))
- return y
diff --git a/spaces/Abubakari/Sepsis-prediction-streamlit-app/app.py b/spaces/Abubakari/Sepsis-prediction-streamlit-app/app.py
deleted file mode 100644
index 67735b5ceba65ecf18e1e14f20773efedcb483bf..0000000000000000000000000000000000000000
--- a/spaces/Abubakari/Sepsis-prediction-streamlit-app/app.py
+++ /dev/null
@@ -1,154 +0,0 @@
-import streamlit as st
-import pandas as pd
-import joblib
-import matplotlib.pyplot as plt
-import time
-import base64
-
-# Load the pre-trained numerical imputer, scaler, and model using joblib
-num_imputer = joblib.load('numerical_imputer.joblib')
-scaler = joblib.load('scaler.joblib')
-model = joblib.load('Final_model.joblib')
-
-# Define a function to preprocess the input data
-def preprocess_input_data(input_data):
- input_data_df = pd.DataFrame(input_data, columns=['PRG', 'PL', 'PR', 'SK', 'TS', 'M11', 'BD2', 'Age', 'Insurance'])
- num_columns = input_data_df.select_dtypes(include='number').columns
-
- input_data_imputed_num = num_imputer.transform(input_data_df[num_columns])
- input_scaled_df = pd.DataFrame(scaler.transform(input_data_imputed_num), columns=num_columns)
-
- return input_scaled_df
-
-
-# Define a function to make the sepsis prediction
-def predict_sepsis(input_data):
- input_scaled_df = preprocess_input_data(input_data)
- prediction = model.predict(input_scaled_df)[0]
- probabilities = model.predict_proba(input_scaled_df)[0]
- sepsis_status = "Positive" if prediction == 1 else "Negative"
-
- status_icon = "✔" if prediction == 1 else "✘" # Red 'X' icon for positive sepsis prediction, green checkmark icon for negative sepsis prediction
- sepsis_explanation = "Sepsis is a life-threatening condition caused by an infection. A positive prediction suggests that the patient might be exhibiting sepsis symptoms and requires immediate medical attention." if prediction == 1 else "Sepsis is a life-threatening condition caused by an infection. A negative prediction suggests that the patient is not currently exhibiting sepsis symptoms."
-
- output_df = pd.DataFrame(input_data, columns=['PRG', 'PL', 'PR', 'SK', 'TS', 'M11', 'BD2', 'Age', 'Insurance'])
- output_df['Prediction'] = sepsis_status
- output_df['Negative Probability'] = probabilities[0]
- output_df['Positive Probability'] = probabilities[1]
-
- return output_df, probabilities, status_icon, sepsis_explanation
-
-# Create a Streamlit app
-def main():
- st.title('Sepsis Prediction App')
-
- st.image("Strealit_.jpg")
-
- # How to use
- st.sidebar.title('How to Use')
- st.sidebar.markdown('1. Adjust the input parameters on the left sidebar.')
- st.sidebar.markdown('2. Click the "Predict" button to initiate the prediction.')
- st.sidebar.markdown('3. The app will simulate a prediction process with a progress bar.')
- st.sidebar.markdown('4. Once the prediction is complete, the results will be displayed below.')
-
-
- st.sidebar.title('Input Parameters')
-
- # Input parameter explanations
- st.sidebar.markdown('**PRG:** Plasma Glucose')
- PRG = st.sidebar.number_input('PRG', value=0.0)
-
- st.sidebar.markdown('**PL:** Blood Work Result 1')
- PL = st.sidebar.number_input('PL', value=0.0)
-
- st.sidebar.markdown('**PR:** Blood Pressure Measured')
- PR = st.sidebar.number_input('PR', value=0.0)
-
- st.sidebar.markdown('**SK:** Blood Work Result 2')
- SK = st.sidebar.number_input('SK', value=0.0)
-
- st.sidebar.markdown('**TS:** Blood Work Result 3')
- TS = st.sidebar.number_input('TS', value=0.0)
-
- st.sidebar.markdown('**M11:** BMI')
- M11 = st.sidebar.number_input('M11', value=0.0)
-
- st.sidebar.markdown('**BD2:** Blood Work Result 4')
- BD2 = st.sidebar.number_input('BD2', value=0.0)
-
- st.sidebar.markdown('**Age:** What is the Age of the Patient: ')
- Age = st.sidebar.number_input('Age', value=0.0)
-
- st.sidebar.markdown('**Insurance:** Does the patient have Insurance?')
- insurance_options = {0: 'NO', 1: 'YES'}
- Insurance = st.sidebar.radio('Insurance', list(insurance_options.keys()), format_func=lambda x: insurance_options[x])
-
-
- input_data = [[PRG, PL, PR, SK, TS, M11, BD2, Age, Insurance]]
-
- if st.sidebar.button('Predict'):
- with st.spinner("Predicting..."):
- # Simulate a long-running process
- progress_bar = st.progress(0)
- step = 20 # A big step will reduce the execution time
- for i in range(0, 100, step):
- time.sleep(0.1)
- progress_bar.progress(i + step)
-
- output_df, probabilities, status_icon, sepsis_explanation = predict_sepsis(input_data)
-
- st.subheader('Prediction Result')
- prediction_text = "Positive" if status_icon == "✔" else "Negative"
- st.markdown(f"Prediction: **{prediction_text}**")
- st.markdown(f"{status_icon} {sepsis_explanation}")
- st.write(output_df)
-
- # Add a download button for output_df
- csv = output_df.to_csv(index=False)
- b64 = base64.b64encode(csv.encode()).decode()
- href = f'Download Output CSV'
- st.markdown(href, unsafe_allow_html=True)
-
-
- # Plot the probabilities
- fig, ax = plt.subplots()
- ax.bar(['Negative', 'Positive'], probabilities)
- ax.set_xlabel('Sepsis Status')
- ax.set_ylabel('Probability')
- ax.set_title('Sepsis Prediction Probabilities')
- st.pyplot(fig)
-
- # Print feature importance
- if hasattr(model, 'coef_'):
- feature_importances = model.coef_[0]
- feature_names = ['PRG', 'PL', 'PR', 'SK', 'TS', 'M11', 'BD2', 'Age', 'Insurance']
-
- importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importances})
- importance_df = importance_df.sort_values('Importance', ascending=False)
-
- st.subheader('Feature Importance')
- fig, ax = plt.subplots()
- bars = ax.bar(importance_df['Feature'], importance_df['Importance'])
- ax.set_xlabel('Feature')
- ax.set_ylabel('Importance')
- ax.set_title('Feature Importance')
- ax.tick_params(axis='x', rotation=45)
-
- # Add data labels to the bars
- for bar in bars:
- height = bar.get_height()
- ax.annotate(f'{height:.2f}', xy=(bar.get_x() + bar.get_width() / 2, height),
- xytext=(0, 3), # 3 points vertical offset
- textcoords="offset points",
- ha='center', va='bottom')
- st.pyplot(fig)
-
- else:
- st.write('Feature importance is not available for this model.')
-
- #st.subheader('Sepsis Explanation')
- #st.markdown(f"{status_icon} {sepsis_explanation}")
-
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/Adapter/T2I-Adapter/ldm/modules/extra_condition/midas/midas/__init__.py b/spaces/Adapter/T2I-Adapter/ldm/modules/extra_condition/midas/midas/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Adapting/YouTube-Downloader/app.py b/spaces/Adapting/YouTube-Downloader/app.py
deleted file mode 100644
index 631b245f5f7428f46839a636e560989ccad433ba..0000000000000000000000000000000000000000
--- a/spaces/Adapting/YouTube-Downloader/app.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import streamlit as st
-import tube as tb
-
-tb.clear_cache()
-
-
-md = '''
-# YouTube Downloader
-'''
-
-st.markdown(md)
-
-
-url = st.text_input(
- placeholder="https://www.youtube.com/",
- label='**Enter the url of the youtube:**',
- key='title'
-)
-
-
-
-if url is not None and ('https' in url or 'http' in url):
- tb.download_yt(url)
-
-
-
-
-
-
-
-
-
diff --git a/spaces/Aditya9790/yolo7-object-tracking/LICENSE.md b/spaces/Aditya9790/yolo7-object-tracking/LICENSE.md
deleted file mode 100644
index f288702d2fa16d3cdf0035b15a9fcbc552cd88e7..0000000000000000000000000000000000000000
--- a/spaces/Aditya9790/yolo7-object-tracking/LICENSE.md
+++ /dev/null
@@ -1,674 +0,0 @@
- GNU GENERAL PUBLIC LICENSE
- Version 3, 29 June 2007
-
- Copyright (C) 2007 Free Software Foundation, Inc.
- Everyone is permitted to copy and distribute verbatim copies
- of this license document, but changing it is not allowed.
-
- Preamble
-
- The GNU General Public License is a free, copyleft license for
-software and other kinds of works.
-
- The licenses for most software and other practical works are designed
-to take away your freedom to share and change the works. By contrast,
-the GNU General Public License is intended to guarantee your freedom to
-share and change all versions of a program--to make sure it remains free
-software for all its users. We, the Free Software Foundation, use the
-GNU General Public License for most of our software; it applies also to
-any other work released this way by its authors. You can apply it to
-your programs, too.
-
- When we speak of free software, we are referring to freedom, not
-price. Our General Public Licenses are designed to make sure that you
-have the freedom to distribute copies of free software (and charge for
-them if you wish), that you receive source code or can get it if you
-want it, that you can change the software or use pieces of it in new
-free programs, and that you know you can do these things.
-
- To protect your rights, we need to prevent others from denying you
-these rights or asking you to surrender the rights. Therefore, you have
-certain responsibilities if you distribute copies of the software, or if
-you modify it: responsibilities to respect the freedom of others.
-
- For example, if you distribute copies of such a program, whether
-gratis or for a fee, you must pass on to the recipients the same
-freedoms that you received. You must make sure that they, too, receive
-or can get the source code. And you must show them these terms so they
-know their rights.
-
- Developers that use the GNU GPL protect your rights with two steps:
-(1) assert copyright on the software, and (2) offer you this License
-giving you legal permission to copy, distribute and/or modify it.
-
- For the developers' and authors' protection, the GPL clearly explains
-that there is no warranty for this free software. For both users' and
-authors' sake, the GPL requires that modified versions be marked as
-changed, so that their problems will not be attributed erroneously to
-authors of previous versions.
-
- Some devices are designed to deny users access to install or run
-modified versions of the software inside them, although the manufacturer
-can do so. This is fundamentally incompatible with the aim of
-protecting users' freedom to change the software. The systematic
-pattern of such abuse occurs in the area of products for individuals to
-use, which is precisely where it is most unacceptable. Therefore, we
-have designed this version of the GPL to prohibit the practice for those
-products. If such problems arise substantially in other domains, we
-stand ready to extend this provision to those domains in future versions
-of the GPL, as needed to protect the freedom of users.
-
- Finally, every program is threatened constantly by software patents.
-States should not allow patents to restrict development and use of
-software on general-purpose computers, but in those that do, we wish to
-avoid the special danger that patents applied to a free program could
-make it effectively proprietary. To prevent this, the GPL assures that
-patents cannot be used to render the program non-free.
-
- The precise terms and conditions for copying, distribution and
-modification follow.
-
- TERMS AND CONDITIONS
-
- 0. Definitions.
-
- "This License" refers to version 3 of the GNU General Public License.
-
- "Copyright" also means copyright-like laws that apply to other kinds of
-works, such as semiconductor masks.
-
- "The Program" refers to any copyrightable work licensed under this
-License. Each licensee is addressed as "you". "Licensees" and
-"recipients" may be individuals or organizations.
-
- To "modify" a work means to copy from or adapt all or part of the work
-in a fashion requiring copyright permission, other than the making of an
-exact copy. The resulting work is called a "modified version" of the
-earlier work or a work "based on" the earlier work.
-
- A "covered work" means either the unmodified Program or a work based
-on the Program.
-
- To "propagate" a work means to do anything with it that, without
-permission, would make you directly or secondarily liable for
-infringement under applicable copyright law, except executing it on a
-computer or modifying a private copy. Propagation includes copying,
-distribution (with or without modification), making available to the
-public, and in some countries other activities as well.
-
- To "convey" a work means any kind of propagation that enables other
-parties to make or receive copies. Mere interaction with a user through
-a computer network, with no transfer of a copy, is not conveying.
-
- An interactive user interface displays "Appropriate Legal Notices"
-to the extent that it includes a convenient and prominently visible
-feature that (1) displays an appropriate copyright notice, and (2)
-tells the user that there is no warranty for the work (except to the
-extent that warranties are provided), that licensees may convey the
-work under this License, and how to view a copy of this License. If
-the interface presents a list of user commands or options, such as a
-menu, a prominent item in the list meets this criterion.
-
- 1. Source Code.
-
- The "source code" for a work means the preferred form of the work
-for making modifications to it. "Object code" means any non-source
-form of a work.
-
- A "Standard Interface" means an interface that either is an official
-standard defined by a recognized standards body, or, in the case of
-interfaces specified for a particular programming language, one that
-is widely used among developers working in that language.
-
- The "System Libraries" of an executable work include anything, other
-than the work as a whole, that (a) is included in the normal form of
-packaging a Major Component, but which is not part of that Major
-Component, and (b) serves only to enable use of the work with that
-Major Component, or to implement a Standard Interface for which an
-implementation is available to the public in source code form. A
-"Major Component", in this context, means a major essential component
-(kernel, window system, and so on) of the specific operating system
-(if any) on which the executable work runs, or a compiler used to
-produce the work, or an object code interpreter used to run it.
-
- The "Corresponding Source" for a work in object code form means all
-the source code needed to generate, install, and (for an executable
-work) run the object code and to modify the work, including scripts to
-control those activities. However, it does not include the work's
-System Libraries, or general-purpose tools or generally available free
-programs which are used unmodified in performing those activities but
-which are not part of the work. For example, Corresponding Source
-includes interface definition files associated with source files for
-the work, and the source code for shared libraries and dynamically
-linked subprograms that the work is specifically designed to require,
-such as by intimate data communication or control flow between those
-subprograms and other parts of the work.
-
- The Corresponding Source need not include anything that users
-can regenerate automatically from other parts of the Corresponding
-Source.
-
- The Corresponding Source for a work in source code form is that
-same work.
-
- 2. Basic Permissions.
-
- All rights granted under this License are granted for the term of
-copyright on the Program, and are irrevocable provided the stated
-conditions are met. This License explicitly affirms your unlimited
-permission to run the unmodified Program. The output from running a
-covered work is covered by this License only if the output, given its
-content, constitutes a covered work. This License acknowledges your
-rights of fair use or other equivalent, as provided by copyright law.
-
- You may make, run and propagate covered works that you do not
-convey, without conditions so long as your license otherwise remains
-in force. You may convey covered works to others for the sole purpose
-of having them make modifications exclusively for you, or provide you
-with facilities for running those works, provided that you comply with
-the terms of this License in conveying all material for which you do
-not control copyright. Those thus making or running the covered works
-for you must do so exclusively on your behalf, under your direction
-and control, on terms that prohibit them from making any copies of
-your copyrighted material outside their relationship with you.
-
- Conveying under any other circumstances is permitted solely under
-the conditions stated below. Sublicensing is not allowed; section 10
-makes it unnecessary.
-
- 3. Protecting Users' Legal Rights From Anti-Circumvention Law.
-
- No covered work shall be deemed part of an effective technological
-measure under any applicable law fulfilling obligations under article
-11 of the WIPO copyright treaty adopted on 20 December 1996, or
-similar laws prohibiting or restricting circumvention of such
-measures.
-
- When you convey a covered work, you waive any legal power to forbid
-circumvention of technological measures to the extent such circumvention
-is effected by exercising rights under this License with respect to
-the covered work, and you disclaim any intention to limit operation or
-modification of the work as a means of enforcing, against the work's
-users, your or third parties' legal rights to forbid circumvention of
-technological measures.
-
- 4. Conveying Verbatim Copies.
-
- You may convey verbatim copies of the Program's source code as you
-receive it, in any medium, provided that you conspicuously and
-appropriately publish on each copy an appropriate copyright notice;
-keep intact all notices stating that this License and any
-non-permissive terms added in accord with section 7 apply to the code;
-keep intact all notices of the absence of any warranty; and give all
-recipients a copy of this License along with the Program.
-
- You may charge any price or no price for each copy that you convey,
-and you may offer support or warranty protection for a fee.
-
- 5. Conveying Modified Source Versions.
-
- You may convey a work based on the Program, or the modifications to
-produce it from the Program, in the form of source code under the
-terms of section 4, provided that you also meet all of these conditions:
-
- a) The work must carry prominent notices stating that you modified
- it, and giving a relevant date.
-
- b) The work must carry prominent notices stating that it is
- released under this License and any conditions added under section
- 7. This requirement modifies the requirement in section 4 to
- "keep intact all notices".
-
- c) You must license the entire work, as a whole, under this
- License to anyone who comes into possession of a copy. This
- License will therefore apply, along with any applicable section 7
- additional terms, to the whole of the work, and all its parts,
- regardless of how they are packaged. This License gives no
- permission to license the work in any other way, but it does not
- invalidate such permission if you have separately received it.
-
- d) If the work has interactive user interfaces, each must display
- Appropriate Legal Notices; however, if the Program has interactive
- interfaces that do not display Appropriate Legal Notices, your
- work need not make them do so.
-
- A compilation of a covered work with other separate and independent
-works, which are not by their nature extensions of the covered work,
-and which are not combined with it such as to form a larger program,
-in or on a volume of a storage or distribution medium, is called an
-"aggregate" if the compilation and its resulting copyright are not
-used to limit the access or legal rights of the compilation's users
-beyond what the individual works permit. Inclusion of a covered work
-in an aggregate does not cause this License to apply to the other
-parts of the aggregate.
-
- 6. Conveying Non-Source Forms.
-
- You may convey a covered work in object code form under the terms
-of sections 4 and 5, provided that you also convey the
-machine-readable Corresponding Source under the terms of this License,
-in one of these ways:
-
- a) Convey the object code in, or embodied in, a physical product
- (including a physical distribution medium), accompanied by the
- Corresponding Source fixed on a durable physical medium
- customarily used for software interchange.
-
- b) Convey the object code in, or embodied in, a physical product
- (including a physical distribution medium), accompanied by a
- written offer, valid for at least three years and valid for as
- long as you offer spare parts or customer support for that product
- model, to give anyone who possesses the object code either (1) a
- copy of the Corresponding Source for all the software in the
- product that is covered by this License, on a durable physical
- medium customarily used for software interchange, for a price no
- more than your reasonable cost of physically performing this
- conveying of source, or (2) access to copy the
- Corresponding Source from a network server at no charge.
-
- c) Convey individual copies of the object code with a copy of the
- written offer to provide the Corresponding Source. This
- alternative is allowed only occasionally and noncommercially, and
- only if you received the object code with such an offer, in accord
- with subsection 6b.
-
- d) Convey the object code by offering access from a designated
- place (gratis or for a charge), and offer equivalent access to the
- Corresponding Source in the same way through the same place at no
- further charge. You need not require recipients to copy the
- Corresponding Source along with the object code. If the place to
- copy the object code is a network server, the Corresponding Source
- may be on a different server (operated by you or a third party)
- that supports equivalent copying facilities, provided you maintain
- clear directions next to the object code saying where to find the
- Corresponding Source. Regardless of what server hosts the
- Corresponding Source, you remain obligated to ensure that it is
- available for as long as needed to satisfy these requirements.
-
- e) Convey the object code using peer-to-peer transmission, provided
- you inform other peers where the object code and Corresponding
- Source of the work are being offered to the general public at no
- charge under subsection 6d.
-
- A separable portion of the object code, whose source code is excluded
-from the Corresponding Source as a System Library, need not be
-included in conveying the object code work.
-
- A "User Product" is either (1) a "consumer product", which means any
-tangible personal property which is normally used for personal, family,
-or household purposes, or (2) anything designed or sold for incorporation
-into a dwelling. In determining whether a product is a consumer product,
-doubtful cases shall be resolved in favor of coverage. For a particular
-product received by a particular user, "normally used" refers to a
-typical or common use of that class of product, regardless of the status
-of the particular user or of the way in which the particular user
-actually uses, or expects or is expected to use, the product. A product
-is a consumer product regardless of whether the product has substantial
-commercial, industrial or non-consumer uses, unless such uses represent
-the only significant mode of use of the product.
-
- "Installation Information" for a User Product means any methods,
-procedures, authorization keys, or other information required to install
-and execute modified versions of a covered work in that User Product from
-a modified version of its Corresponding Source. The information must
-suffice to ensure that the continued functioning of the modified object
-code is in no case prevented or interfered with solely because
-modification has been made.
-
- If you convey an object code work under this section in, or with, or
-specifically for use in, a User Product, and the conveying occurs as
-part of a transaction in which the right of possession and use of the
-User Product is transferred to the recipient in perpetuity or for a
-fixed term (regardless of how the transaction is characterized), the
-Corresponding Source conveyed under this section must be accompanied
-by the Installation Information. But this requirement does not apply
-if neither you nor any third party retains the ability to install
-modified object code on the User Product (for example, the work has
-been installed in ROM).
-
- The requirement to provide Installation Information does not include a
-requirement to continue to provide support service, warranty, or updates
-for a work that has been modified or installed by the recipient, or for
-the User Product in which it has been modified or installed. Access to a
-network may be denied when the modification itself materially and
-adversely affects the operation of the network or violates the rules and
-protocols for communication across the network.
-
- Corresponding Source conveyed, and Installation Information provided,
-in accord with this section must be in a format that is publicly
-documented (and with an implementation available to the public in
-source code form), and must require no special password or key for
-unpacking, reading or copying.
-
- 7. Additional Terms.
-
- "Additional permissions" are terms that supplement the terms of this
-License by making exceptions from one or more of its conditions.
-Additional permissions that are applicable to the entire Program shall
-be treated as though they were included in this License, to the extent
-that they are valid under applicable law. If additional permissions
-apply only to part of the Program, that part may be used separately
-under those permissions, but the entire Program remains governed by
-this License without regard to the additional permissions.
-
- When you convey a copy of a covered work, you may at your option
-remove any additional permissions from that copy, or from any part of
-it. (Additional permissions may be written to require their own
-removal in certain cases when you modify the work.) You may place
-additional permissions on material, added by you to a covered work,
-for which you have or can give appropriate copyright permission.
-
- Notwithstanding any other provision of this License, for material you
-add to a covered work, you may (if authorized by the copyright holders of
-that material) supplement the terms of this License with terms:
-
- a) Disclaiming warranty or limiting liability differently from the
- terms of sections 15 and 16 of this License; or
-
- b) Requiring preservation of specified reasonable legal notices or
- author attributions in that material or in the Appropriate Legal
- Notices displayed by works containing it; or
-
- c) Prohibiting misrepresentation of the origin of that material, or
- requiring that modified versions of such material be marked in
- reasonable ways as different from the original version; or
-
- d) Limiting the use for publicity purposes of names of licensors or
- authors of the material; or
-
- e) Declining to grant rights under trademark law for use of some
- trade names, trademarks, or service marks; or
-
- f) Requiring indemnification of licensors and authors of that
- material by anyone who conveys the material (or modified versions of
- it) with contractual assumptions of liability to the recipient, for
- any liability that these contractual assumptions directly impose on
- those licensors and authors.
-
- All other non-permissive additional terms are considered "further
-restrictions" within the meaning of section 10. If the Program as you
-received it, or any part of it, contains a notice stating that it is
-governed by this License along with a term that is a further
-restriction, you may remove that term. If a license document contains
-a further restriction but permits relicensing or conveying under this
-License, you may add to a covered work material governed by the terms
-of that license document, provided that the further restriction does
-not survive such relicensing or conveying.
-
- If you add terms to a covered work in accord with this section, you
-must place, in the relevant source files, a statement of the
-additional terms that apply to those files, or a notice indicating
-where to find the applicable terms.
-
- Additional terms, permissive or non-permissive, may be stated in the
-form of a separately written license, or stated as exceptions;
-the above requirements apply either way.
-
- 8. Termination.
-
- You may not propagate or modify a covered work except as expressly
-provided under this License. Any attempt otherwise to propagate or
-modify it is void, and will automatically terminate your rights under
-this License (including any patent licenses granted under the third
-paragraph of section 11).
-
- However, if you cease all violation of this License, then your
-license from a particular copyright holder is reinstated (a)
-provisionally, unless and until the copyright holder explicitly and
-finally terminates your license, and (b) permanently, if the copyright
-holder fails to notify you of the violation by some reasonable means
-prior to 60 days after the cessation.
-
- Moreover, your license from a particular copyright holder is
-reinstated permanently if the copyright holder notifies you of the
-violation by some reasonable means, this is the first time you have
-received notice of violation of this License (for any work) from that
-copyright holder, and you cure the violation prior to 30 days after
-your receipt of the notice.
-
- Termination of your rights under this section does not terminate the
-licenses of parties who have received copies or rights from you under
-this License. If your rights have been terminated and not permanently
-reinstated, you do not qualify to receive new licenses for the same
-material under section 10.
-
- 9. Acceptance Not Required for Having Copies.
-
- You are not required to accept this License in order to receive or
-run a copy of the Program. Ancillary propagation of a covered work
-occurring solely as a consequence of using peer-to-peer transmission
-to receive a copy likewise does not require acceptance. However,
-nothing other than this License grants you permission to propagate or
-modify any covered work. These actions infringe copyright if you do
-not accept this License. Therefore, by modifying or propagating a
-covered work, you indicate your acceptance of this License to do so.
-
- 10. Automatic Licensing of Downstream Recipients.
-
- Each time you convey a covered work, the recipient automatically
-receives a license from the original licensors, to run, modify and
-propagate that work, subject to this License. You are not responsible
-for enforcing compliance by third parties with this License.
-
- An "entity transaction" is a transaction transferring control of an
-organization, or substantially all assets of one, or subdividing an
-organization, or merging organizations. If propagation of a covered
-work results from an entity transaction, each party to that
-transaction who receives a copy of the work also receives whatever
-licenses to the work the party's predecessor in interest had or could
-give under the previous paragraph, plus a right to possession of the
-Corresponding Source of the work from the predecessor in interest, if
-the predecessor has it or can get it with reasonable efforts.
-
- You may not impose any further restrictions on the exercise of the
-rights granted or affirmed under this License. For example, you may
-not impose a license fee, royalty, or other charge for exercise of
-rights granted under this License, and you may not initiate litigation
-(including a cross-claim or counterclaim in a lawsuit) alleging that
-any patent claim is infringed by making, using, selling, offering for
-sale, or importing the Program or any portion of it.
-
- 11. Patents.
-
- A "contributor" is a copyright holder who authorizes use under this
-License of the Program or a work on which the Program is based. The
-work thus licensed is called the contributor's "contributor version".
-
- A contributor's "essential patent claims" are all patent claims
-owned or controlled by the contributor, whether already acquired or
-hereafter acquired, that would be infringed by some manner, permitted
-by this License, of making, using, or selling its contributor version,
-but do not include claims that would be infringed only as a
-consequence of further modification of the contributor version. For
-purposes of this definition, "control" includes the right to grant
-patent sublicenses in a manner consistent with the requirements of
-this License.
-
- Each contributor grants you a non-exclusive, worldwide, royalty-free
-patent license under the contributor's essential patent claims, to
-make, use, sell, offer for sale, import and otherwise run, modify and
-propagate the contents of its contributor version.
-
- In the following three paragraphs, a "patent license" is any express
-agreement or commitment, however denominated, not to enforce a patent
-(such as an express permission to practice a patent or covenant not to
-sue for patent infringement). To "grant" such a patent license to a
-party means to make such an agreement or commitment not to enforce a
-patent against the party.
-
- If you convey a covered work, knowingly relying on a patent license,
-and the Corresponding Source of the work is not available for anyone
-to copy, free of charge and under the terms of this License, through a
-publicly available network server or other readily accessible means,
-then you must either (1) cause the Corresponding Source to be so
-available, or (2) arrange to deprive yourself of the benefit of the
-patent license for this particular work, or (3) arrange, in a manner
-consistent with the requirements of this License, to extend the patent
-license to downstream recipients. "Knowingly relying" means you have
-actual knowledge that, but for the patent license, your conveying the
-covered work in a country, or your recipient's use of the covered work
-in a country, would infringe one or more identifiable patents in that
-country that you have reason to believe are valid.
-
- If, pursuant to or in connection with a single transaction or
-arrangement, you convey, or propagate by procuring conveyance of, a
-covered work, and grant a patent license to some of the parties
-receiving the covered work authorizing them to use, propagate, modify
-or convey a specific copy of the covered work, then the patent license
-you grant is automatically extended to all recipients of the covered
-work and works based on it.
-
- A patent license is "discriminatory" if it does not include within
-the scope of its coverage, prohibits the exercise of, or is
-conditioned on the non-exercise of one or more of the rights that are
-specifically granted under this License. You may not convey a covered
-work if you are a party to an arrangement with a third party that is
-in the business of distributing software, under which you make payment
-to the third party based on the extent of your activity of conveying
-the work, and under which the third party grants, to any of the
-parties who would receive the covered work from you, a discriminatory
-patent license (a) in connection with copies of the covered work
-conveyed by you (or copies made from those copies), or (b) primarily
-for and in connection with specific products or compilations that
-contain the covered work, unless you entered into that arrangement,
-or that patent license was granted, prior to 28 March 2007.
-
- Nothing in this License shall be construed as excluding or limiting
-any implied license or other defenses to infringement that may
-otherwise be available to you under applicable patent law.
-
- 12. No Surrender of Others' Freedom.
-
- If conditions are imposed on you (whether by court order, agreement or
-otherwise) that contradict the conditions of this License, they do not
-excuse you from the conditions of this License. If you cannot convey a
-covered work so as to satisfy simultaneously your obligations under this
-License and any other pertinent obligations, then as a consequence you may
-not convey it at all. For example, if you agree to terms that obligate you
-to collect a royalty for further conveying from those to whom you convey
-the Program, the only way you could satisfy both those terms and this
-License would be to refrain entirely from conveying the Program.
-
- 13. Use with the GNU Affero General Public License.
-
- Notwithstanding any other provision of this License, you have
-permission to link or combine any covered work with a work licensed
-under version 3 of the GNU Affero General Public License into a single
-combined work, and to convey the resulting work. The terms of this
-License will continue to apply to the part which is the covered work,
-but the special requirements of the GNU Affero General Public License,
-section 13, concerning interaction through a network will apply to the
-combination as such.
-
- 14. Revised Versions of this License.
-
- The Free Software Foundation may publish revised and/or new versions of
-the GNU General Public License from time to time. Such new versions will
-be similar in spirit to the present version, but may differ in detail to
-address new problems or concerns.
-
- Each version is given a distinguishing version number. If the
-Program specifies that a certain numbered version of the GNU General
-Public License "or any later version" applies to it, you have the
-option of following the terms and conditions either of that numbered
-version or of any later version published by the Free Software
-Foundation. If the Program does not specify a version number of the
-GNU General Public License, you may choose any version ever published
-by the Free Software Foundation.
-
- If the Program specifies that a proxy can decide which future
-versions of the GNU General Public License can be used, that proxy's
-public statement of acceptance of a version permanently authorizes you
-to choose that version for the Program.
-
- Later license versions may give you additional or different
-permissions. However, no additional obligations are imposed on any
-author or copyright holder as a result of your choosing to follow a
-later version.
-
- 15. Disclaimer of Warranty.
-
- THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
-APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
-HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
-OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
-THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
-PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
-IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
-ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
-
- 16. Limitation of Liability.
-
- IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
-WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
-THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
-GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
-USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
-DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
-PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
-EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
-SUCH DAMAGES.
-
- 17. Interpretation of Sections 15 and 16.
-
- If the disclaimer of warranty and limitation of liability provided
-above cannot be given local legal effect according to their terms,
-reviewing courts shall apply local law that most closely approximates
-an absolute waiver of all civil liability in connection with the
-Program, unless a warranty or assumption of liability accompanies a
-copy of the Program in return for a fee.
-
- END OF TERMS AND CONDITIONS
-
- How to Apply These Terms to Your New Programs
-
- If you develop a new program, and you want it to be of the greatest
-possible use to the public, the best way to achieve this is to make it
-free software which everyone can redistribute and change under these terms.
-
- To do so, attach the following notices to the program. It is safest
-to attach them to the start of each source file to most effectively
-state the exclusion of warranty; and each file should have at least
-the "copyright" line and a pointer to where the full notice is found.
-
-
- Copyright (C)
-
- This program is free software: you can redistribute it and/or modify
- it under the terms of the GNU General Public License as published by
- the Free Software Foundation, either version 3 of the License, or
- (at your option) any later version.
-
- This program is distributed in the hope that it will be useful,
- but WITHOUT ANY WARRANTY; without even the implied warranty of
- MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
- GNU General Public License for more details.
-
- You should have received a copy of the GNU General Public License
- along with this program. If not, see .
-
-Also add information on how to contact you by electronic and paper mail.
-
- If the program does terminal interaction, make it output a short
-notice like this when it starts in an interactive mode:
-
- Copyright (C)
- This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
- This is free software, and you are welcome to redistribute it
- under certain conditions; type `show c' for details.
-
-The hypothetical commands `show w' and `show c' should show the appropriate
-parts of the General Public License. Of course, your program's commands
-might be different; for a GUI interface, you would use an "about box".
-
- You should also get your employer (if you work as a programmer) or school,
-if any, to sign a "copyright disclaimer" for the program, if necessary.
-For more information on this, and how to apply and follow the GNU GPL, see
-.
-
- The GNU General Public License does not permit incorporating your program
-into proprietary programs. If your program is a subroutine library, you
-may consider it more useful to permit linking proprietary applications with
-the library. If this is what you want to do, use the GNU Lesser General
-Public License instead of this License. But first, please read
-.
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/filedropzone/Factory.d.ts b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/filedropzone/Factory.d.ts
deleted file mode 100644
index ecb4da5b9d4dd004be9f728d8316d82f15e853e6..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/filedropzone/Factory.d.ts
+++ /dev/null
@@ -1,5 +0,0 @@
-import FileDropZone from './FileDropZone.js';
-
-export default function (
- config?: FileDropZone.IConfig
-): FileDropZone;
diff --git a/spaces/AlexWang/lama/models/ade20k/segm_lib/nn/modules/__init__.py b/spaces/AlexWang/lama/models/ade20k/segm_lib/nn/modules/__init__.py
deleted file mode 100644
index bc8709d92c610b36e0bcbd7da20c1eb41dc8cfcf..0000000000000000000000000000000000000000
--- a/spaces/AlexWang/lama/models/ade20k/segm_lib/nn/modules/__init__.py
+++ /dev/null
@@ -1,12 +0,0 @@
-# -*- coding: utf-8 -*-
-# File : __init__.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 27/01/2018
-#
-# This file is part of Synchronized-BatchNorm-PyTorch.
-# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
-# Distributed under MIT License.
-
-from .batchnorm import SynchronizedBatchNorm1d, SynchronizedBatchNorm2d, SynchronizedBatchNorm3d
-from .replicate import DataParallelWithCallback, patch_replication_callback
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/instaboost/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/instaboost/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco.py
deleted file mode 100644
index 0acd088a469e682011a90b770efa51116f6c42ca..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/instaboost/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco.py
+++ /dev/null
@@ -1,13 +0,0 @@
-_base_ = './mask_rcnn_r50_fpn_instaboost_4x_coco.py'
-model = dict(
- pretrained='open-mmlab://resnext101_64x4d',
- backbone=dict(
- type='ResNeXt',
- depth=101,
- groups=64,
- base_width=4,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=True),
- style='pytorch'))
diff --git a/spaces/Andy1621/uniformer_image_detection/mmdet/models/backbones/res2net.py b/spaces/Andy1621/uniformer_image_detection/mmdet/models/backbones/res2net.py
deleted file mode 100644
index 7901b7f2fa29741d72328bdbdbf92fc4d5c5f847..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/mmdet/models/backbones/res2net.py
+++ /dev/null
@@ -1,351 +0,0 @@
-import math
-
-import torch
-import torch.nn as nn
-import torch.utils.checkpoint as cp
-from mmcv.cnn import (build_conv_layer, build_norm_layer, constant_init,
- kaiming_init)
-from mmcv.runner import load_checkpoint
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from mmdet.utils import get_root_logger
-from ..builder import BACKBONES
-from .resnet import Bottleneck as _Bottleneck
-from .resnet import ResNet
-
-
-class Bottle2neck(_Bottleneck):
- expansion = 4
-
- def __init__(self,
- inplanes,
- planes,
- scales=4,
- base_width=26,
- base_channels=64,
- stage_type='normal',
- **kwargs):
- """Bottle2neck block for Res2Net.
-
- If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
- it is "caffe", the stride-two layer is the first 1x1 conv layer.
- """
- super(Bottle2neck, self).__init__(inplanes, planes, **kwargs)
- assert scales > 1, 'Res2Net degenerates to ResNet when scales = 1.'
- width = int(math.floor(self.planes * (base_width / base_channels)))
-
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, width * scales, postfix=1)
- self.norm3_name, norm3 = build_norm_layer(
- self.norm_cfg, self.planes * self.expansion, postfix=3)
-
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- self.inplanes,
- width * scales,
- kernel_size=1,
- stride=self.conv1_stride,
- bias=False)
- self.add_module(self.norm1_name, norm1)
-
- if stage_type == 'stage' and self.conv2_stride != 1:
- self.pool = nn.AvgPool2d(
- kernel_size=3, stride=self.conv2_stride, padding=1)
- convs = []
- bns = []
-
- fallback_on_stride = False
- if self.with_dcn:
- fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
- if not self.with_dcn or fallback_on_stride:
- for i in range(scales - 1):
- convs.append(
- build_conv_layer(
- self.conv_cfg,
- width,
- width,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=self.dilation,
- dilation=self.dilation,
- bias=False))
- bns.append(
- build_norm_layer(self.norm_cfg, width, postfix=i + 1)[1])
- self.convs = nn.ModuleList(convs)
- self.bns = nn.ModuleList(bns)
- else:
- assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
- for i in range(scales - 1):
- convs.append(
- build_conv_layer(
- self.dcn,
- width,
- width,
- kernel_size=3,
- stride=self.conv2_stride,
- padding=self.dilation,
- dilation=self.dilation,
- bias=False))
- bns.append(
- build_norm_layer(self.norm_cfg, width, postfix=i + 1)[1])
- self.convs = nn.ModuleList(convs)
- self.bns = nn.ModuleList(bns)
-
- self.conv3 = build_conv_layer(
- self.conv_cfg,
- width * scales,
- self.planes * self.expansion,
- kernel_size=1,
- bias=False)
- self.add_module(self.norm3_name, norm3)
-
- self.stage_type = stage_type
- self.scales = scales
- self.width = width
- delattr(self, 'conv2')
- delattr(self, self.norm2_name)
-
- def forward(self, x):
- """Forward function."""
-
- def _inner_forward(x):
- identity = x
-
- out = self.conv1(x)
- out = self.norm1(out)
- out = self.relu(out)
-
- if self.with_plugins:
- out = self.forward_plugin(out, self.after_conv1_plugin_names)
-
- spx = torch.split(out, self.width, 1)
- sp = self.convs[0](spx[0].contiguous())
- sp = self.relu(self.bns[0](sp))
- out = sp
- for i in range(1, self.scales - 1):
- if self.stage_type == 'stage':
- sp = spx[i]
- else:
- sp = sp + spx[i]
- sp = self.convs[i](sp.contiguous())
- sp = self.relu(self.bns[i](sp))
- out = torch.cat((out, sp), 1)
-
- if self.stage_type == 'normal' or self.conv2_stride == 1:
- out = torch.cat((out, spx[self.scales - 1]), 1)
- elif self.stage_type == 'stage':
- out = torch.cat((out, self.pool(spx[self.scales - 1])), 1)
-
- if self.with_plugins:
- out = self.forward_plugin(out, self.after_conv2_plugin_names)
-
- out = self.conv3(out)
- out = self.norm3(out)
-
- if self.with_plugins:
- out = self.forward_plugin(out, self.after_conv3_plugin_names)
-
- if self.downsample is not None:
- identity = self.downsample(x)
-
- out += identity
-
- return out
-
- if self.with_cp and x.requires_grad:
- out = cp.checkpoint(_inner_forward, x)
- else:
- out = _inner_forward(x)
-
- out = self.relu(out)
-
- return out
-
-
-class Res2Layer(nn.Sequential):
- """Res2Layer to build Res2Net style backbone.
-
- Args:
- block (nn.Module): block used to build ResLayer.
- inplanes (int): inplanes of block.
- planes (int): planes of block.
- num_blocks (int): number of blocks.
- stride (int): stride of the first block. Default: 1
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottle2neck. Default: False
- conv_cfg (dict): dictionary to construct and config conv layer.
- Default: None
- norm_cfg (dict): dictionary to construct and config norm layer.
- Default: dict(type='BN')
- scales (int): Scales used in Res2Net. Default: 4
- base_width (int): Basic width of each scale. Default: 26
- """
-
- def __init__(self,
- block,
- inplanes,
- planes,
- num_blocks,
- stride=1,
- avg_down=True,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- scales=4,
- base_width=26,
- **kwargs):
- self.block = block
-
- downsample = None
- if stride != 1 or inplanes != planes * block.expansion:
- downsample = nn.Sequential(
- nn.AvgPool2d(
- kernel_size=stride,
- stride=stride,
- ceil_mode=True,
- count_include_pad=False),
- build_conv_layer(
- conv_cfg,
- inplanes,
- planes * block.expansion,
- kernel_size=1,
- stride=1,
- bias=False),
- build_norm_layer(norm_cfg, planes * block.expansion)[1],
- )
-
- layers = []
- layers.append(
- block(
- inplanes=inplanes,
- planes=planes,
- stride=stride,
- downsample=downsample,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- scales=scales,
- base_width=base_width,
- stage_type='stage',
- **kwargs))
- inplanes = planes * block.expansion
- for i in range(1, num_blocks):
- layers.append(
- block(
- inplanes=inplanes,
- planes=planes,
- stride=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- scales=scales,
- base_width=base_width,
- **kwargs))
- super(Res2Layer, self).__init__(*layers)
-
-
-@BACKBONES.register_module()
-class Res2Net(ResNet):
- """Res2Net backbone.
-
- Args:
- scales (int): Scales used in Res2Net. Default: 4
- base_width (int): Basic width of each scale. Default: 26
- depth (int): Depth of res2net, from {50, 101, 152}.
- in_channels (int): Number of input image channels. Default: 3.
- num_stages (int): Res2net stages. Default: 4.
- strides (Sequence[int]): Strides of the first block of each stage.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- deep_stem (bool): Replace 7x7 conv in input stem with 3 3x3 conv
- avg_down (bool): Use AvgPool instead of stride conv when
- downsampling in the bottle2neck.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only.
- plugins (list[dict]): List of plugins for stages, each dict contains:
-
- - cfg (dict, required): Cfg dict to build plugin.
- - position (str, required): Position inside block to insert
- plugin, options are 'after_conv1', 'after_conv2', 'after_conv3'.
- - stages (tuple[bool], optional): Stages to apply plugin, length
- should be same as 'num_stages'.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): Whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
-
- Example:
- >>> from mmdet.models import Res2Net
- >>> import torch
- >>> self = Res2Net(depth=50, scales=4, base_width=26)
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 256, 8, 8)
- (1, 512, 4, 4)
- (1, 1024, 2, 2)
- (1, 2048, 1, 1)
- """
-
- arch_settings = {
- 50: (Bottle2neck, (3, 4, 6, 3)),
- 101: (Bottle2neck, (3, 4, 23, 3)),
- 152: (Bottle2neck, (3, 8, 36, 3))
- }
-
- def __init__(self,
- scales=4,
- base_width=26,
- style='pytorch',
- deep_stem=True,
- avg_down=True,
- **kwargs):
- self.scales = scales
- self.base_width = base_width
- super(Res2Net, self).__init__(
- style='pytorch', deep_stem=True, avg_down=True, **kwargs)
-
- def make_res_layer(self, **kwargs):
- return Res2Layer(
- scales=self.scales,
- base_width=self.base_width,
- base_channels=self.base_channels,
- **kwargs)
-
- def init_weights(self, pretrained=None):
- """Initialize the weights in backbone.
-
- Args:
- pretrained (str, optional): Path to pre-trained weights.
- Defaults to None.
- """
- if isinstance(pretrained, str):
- logger = get_root_logger()
- load_checkpoint(self, pretrained, strict=False, logger=logger)
- elif pretrained is None:
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- kaiming_init(m)
- elif isinstance(m, (_BatchNorm, nn.GroupNorm)):
- constant_init(m, 1)
-
- if self.dcn is not None:
- for m in self.modules():
- if isinstance(m, Bottle2neck):
- # dcn in Res2Net bottle2neck is in ModuleList
- for n in m.convs:
- if hasattr(n, 'conv_offset'):
- constant_init(n.conv_offset, 0)
-
- if self.zero_init_residual:
- for m in self.modules():
- if isinstance(m, Bottle2neck):
- constant_init(m.norm3, 0)
- else:
- raise TypeError('pretrained must be a str or None')
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/_base_/models/nonlocal_r50-d8.py b/spaces/Andy1621/uniformer_image_segmentation/configs/_base_/models/nonlocal_r50-d8.py
deleted file mode 100644
index 5674a39854cafd1f2e363bac99c58ccae62f24da..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/_base_/models/nonlocal_r50-d8.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True)
-model = dict(
- type='EncoderDecoder',
- pretrained='open-mmlab://resnet50_v1c',
- backbone=dict(
- type='ResNetV1c',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- dilations=(1, 1, 2, 4),
- strides=(1, 2, 1, 1),
- norm_cfg=norm_cfg,
- norm_eval=False,
- style='pytorch',
- contract_dilation=True),
- decode_head=dict(
- type='NLHead',
- in_channels=2048,
- in_index=3,
- channels=512,
- dropout_ratio=0.1,
- reduction=2,
- use_scale=True,
- mode='embedded_gaussian',
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
- auxiliary_head=dict(
- type='FCNHead',
- in_channels=1024,
- in_index=2,
- channels=256,
- num_convs=1,
- concat_input=False,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
- # model training and testing settings
- train_cfg=dict(),
- test_cfg=dict(mode='whole'))
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/nonlocal_net/README.md b/spaces/Andy1621/uniformer_image_segmentation/configs/nonlocal_net/README.md
deleted file mode 100644
index da0924ac60f0a16a17fe4705e0edbf5aad962a82..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/nonlocal_net/README.md
+++ /dev/null
@@ -1,48 +0,0 @@
-# Non-local Neural Networks
-
-## Introduction
-
-
-
-```latex
-@inproceedings{wang2018non,
- title={Non-local neural networks},
- author={Wang, Xiaolong and Girshick, Ross and Gupta, Abhinav and He, Kaiming},
- booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
- pages={7794--7803},
- year={2018}
-}
-```
-
-## Results and models
-
-### Cityscapes
-
-| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
-| -------- | -------- | --------- | ------: | -------- | -------------- | ----: | ------------- | ----------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| NonLocal | R-50-D8 | 512x1024 | 40000 | 7.4 | 2.72 | 78.24 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_512x1024_40k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x1024_40k_cityscapes/nonlocal_r50-d8_512x1024_40k_cityscapes_20200605_210748-c75e81e3.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x1024_40k_cityscapes/nonlocal_r50-d8_512x1024_40k_cityscapes_20200605_210748.log.json) |
-| NonLocal | R-101-D8 | 512x1024 | 40000 | 10.9 | 1.95 | 78.66 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_512x1024_40k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x1024_40k_cityscapes/nonlocal_r101-d8_512x1024_40k_cityscapes_20200605_210748-d63729fa.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x1024_40k_cityscapes/nonlocal_r101-d8_512x1024_40k_cityscapes_20200605_210748.log.json) |
-| NonLocal | R-50-D8 | 769x769 | 40000 | 8.9 | 1.52 | 78.33 | 79.92 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_769x769_40k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_769x769_40k_cityscapes/nonlocal_r50-d8_769x769_40k_cityscapes_20200530_045243-82ef6749.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_769x769_40k_cityscapes/nonlocal_r50-d8_769x769_40k_cityscapes_20200530_045243.log.json) |
-| NonLocal | R-101-D8 | 769x769 | 40000 | 12.8 | 1.05 | 78.57 | 80.29 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_769x769_40k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_769x769_40k_cityscapes/nonlocal_r101-d8_769x769_40k_cityscapes_20200530_045348-8fe9a9dc.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_769x769_40k_cityscapes/nonlocal_r101-d8_769x769_40k_cityscapes_20200530_045348.log.json) |
-| NonLocal | R-50-D8 | 512x1024 | 80000 | - | - | 78.01 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x1024_80k_cityscapes/nonlocal_r50-d8_512x1024_80k_cityscapes_20200607_193518-d6839fae.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x1024_80k_cityscapes/nonlocal_r50-d8_512x1024_80k_cityscapes_20200607_193518.log.json) |
-| NonLocal | R-101-D8 | 512x1024 | 80000 | - | - | 78.93 | - | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_512x1024_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x1024_80k_cityscapes/nonlocal_r101-d8_512x1024_80k_cityscapes_20200607_183411-32700183.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x1024_80k_cityscapes/nonlocal_r101-d8_512x1024_80k_cityscapes_20200607_183411.log.json) |
-| NonLocal | R-50-D8 | 769x769 | 80000 | - | - | 79.05 | 80.68 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_769x769_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_769x769_80k_cityscapes/nonlocal_r50-d8_769x769_80k_cityscapes_20200607_193506-1f9792f6.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_769x769_80k_cityscapes/nonlocal_r50-d8_769x769_80k_cityscapes_20200607_193506.log.json) |
-| NonLocal | R-101-D8 | 769x769 | 80000 | - | - | 79.40 | 80.85 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_769x769_80k_cityscapes.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_769x769_80k_cityscapes/nonlocal_r101-d8_769x769_80k_cityscapes_20200607_183428-0e1fa4f9.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_769x769_80k_cityscapes/nonlocal_r101-d8_769x769_80k_cityscapes_20200607_183428.log.json) |
-
-### ADE20K
-
-| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
-| -------- | -------- | --------- | ------: | -------- | -------------- | ----: | ------------: | ------------------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| NonLocal | R-50-D8 | 512x512 | 80000 | 9.1 | 21.37 | 40.75 | 42.05 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_512x512_80k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_80k_ade20k/nonlocal_r50-d8_512x512_80k_ade20k_20200615_015801-5ae0aa33.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_80k_ade20k/nonlocal_r50-d8_512x512_80k_ade20k_20200615_015801.log.json) |
-| NonLocal | R-101-D8 | 512x512 | 80000 | 12.6 | 13.97 | 42.90 | 44.27 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_512x512_80k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_80k_ade20k/nonlocal_r101-d8_512x512_80k_ade20k_20200615_015758-24105919.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_80k_ade20k/nonlocal_r101-d8_512x512_80k_ade20k_20200615_015758.log.json) |
-| NonLocal | R-50-D8 | 512x512 | 160000 | - | - | 42.03 | 43.04 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_160k_ade20k/nonlocal_r50-d8_512x512_160k_ade20k_20200616_005410-baef45e3.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_160k_ade20k/nonlocal_r50-d8_512x512_160k_ade20k_20200616_005410.log.json) |
-| NonLocal | R-101-D8 | 512x512 | 160000 | - | - | 43.36 | 44.83 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_512x512_160k_ade20k.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_160k_ade20k/nonlocal_r101-d8_512x512_160k_ade20k_20200616_003422-affd0f8d.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_160k_ade20k/nonlocal_r101-d8_512x512_160k_ade20k_20200616_003422.log.json) |
-
-### Pascal VOC 2012 + Aug
-
-| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
-| -------- | -------- | --------- | ------: | -------- | -------------- | ----: | ------------: | -------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| NonLocal | R-50-D8 | 512x512 | 20000 | 6.4 | 21.21 | 76.20 | 77.12 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_512x512_20k_voc12aug.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_20k_voc12aug/nonlocal_r50-d8_512x512_20k_voc12aug_20200617_222613-07f2a57c.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_20k_voc12aug/nonlocal_r50-d8_512x512_20k_voc12aug_20200617_222613.log.json) |
-| NonLocal | R-101-D8 | 512x512 | 20000 | 9.8 | 14.01 | 78.15 | 78.86 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_512x512_20k_voc12aug.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_20k_voc12aug/nonlocal_r101-d8_512x512_20k_voc12aug_20200617_222615-948c68ab.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_20k_voc12aug/nonlocal_r101-d8_512x512_20k_voc12aug_20200617_222615.log.json) |
-| NonLocal | R-50-D8 | 512x512 | 40000 | - | - | 76.65 | 77.47 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r50-d8_512x512_40k_voc12aug.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_40k_voc12aug/nonlocal_r50-d8_512x512_40k_voc12aug_20200614_000028-0139d4a9.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r50-d8_512x512_40k_voc12aug/nonlocal_r50-d8_512x512_40k_voc12aug_20200614_000028.log.json) |
-| NonLocal | R-101-D8 | 512x512 | 40000 | - | - | 78.27 | 79.12 | [config](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net/nonlocal_r101-d8_512x512_40k_voc12aug.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_40k_voc12aug/nonlocal_r101-d8_512x512_40k_voc12aug_20200614_000028-7e5ff470.pth) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/nonlocal_net/nonlocal_r101-d8_512x512_40k_voc12aug/nonlocal_r101-d8_512x512_40k_voc12aug_20200614_000028.log.json) |
diff --git a/spaces/AnimaLab/bias-test-gpt-pairs/openAI_manager.py b/spaces/AnimaLab/bias-test-gpt-pairs/openAI_manager.py
deleted file mode 100644
index 3f996b00204f4113ac301a77aa891455bc913bc0..0000000000000000000000000000000000000000
--- a/spaces/AnimaLab/bias-test-gpt-pairs/openAI_manager.py
+++ /dev/null
@@ -1,191 +0,0 @@
-import openai
-import backoff
-import json
-import re
-import random
-
-import mgr_bias_scoring as bt_mgr
-
-def initOpenAI(key):
- openai.api_key = key
-
- # list models
- models = openai.Model.list()
-
- return models
-
-# construct prompts from example_shots
-def examples_to_prompt(example_shots, kwd_pair):
- prompt = ""
- for shot in example_shots:
- prompt += "Keywords: "+', '.join(shot['Keywords'])+" ## Sentence: "+ \
- shot['Sentence']+" ##\n"
- prompt += f"Keywords: {kwd_pair[0]}, {kwd_pair[1]} ## Sentence: "
- return prompt
-
-def genChatGPT(model_name, kwd_pair, bias_spec, num2gen, numTries, temperature=0.8):
- t1, t2, a1, a2 = bt_mgr.get_words(bias_spec)
- att_terms_str = ','.join([f"'{t}'" for t in random.sample(a1+a2, min(8, len(a1+a2)))])
- t_terms_str = ','.join([f"'{t}'" for t in random.sample(t1+t2, min(8, len(t1+t2)))])
-
- # find out which social group the generator term belongs to
- grp_term = kwd_pair[0]
- if grp_term in t1:
- grp_term_idx = t1.index(grp_term)
- grp_term_pair = [grp_term, t2[grp_term_idx]]
- else:
- grp_term_idx = t2.index(grp_term)
- grp_term_pair = [grp_term, t1[grp_term_idx]]
-
- # construct prompt
- #instruction = f"Write a sentence including terms \"{kwd_pair[0]}\" and \"{kwd_pair[1]}\"."# Use examples as guide for the type of sentences to write."
- #prompt = examples_to_prompt(example_shots, kwd_pair)
- instruction = f"Write a sentence including target term \"{kwd_pair[0]}\" and attribute term \"{kwd_pair[1]}\".\n \
-Other target terms in this context are: {t_terms_str}. Use them for interpretation of requested target term, but don't include these specifically. \
-Other attribute terms in this context are: {att_terms_str}. Use them for interpretation of requested attribute term, but don't include these specifically. "# Use examples as guide for the type of sentences to write."
-
- #print(f"Prompt: {prompt}")
- #print(f"Instruction: {instruction}")
-
- # https://github.com/openai/openai-cookbook/blob/main/examples/How_to_handle_rate_limits.ipynb
- @backoff.on_exception(backoff.expo, (openai.error.RateLimitError,
- openai.error.APIError,
- openai.error.ServiceUnavailableError,
- ConnectionResetError,
- json.decoder.JSONDecodeError))#,
- #max_time=300,
- #raise_on_giveup=False,
- #giveup=fatal_code)
-
- def completions_with_backoff(**kwargs):
- return openai.ChatCompletion.create(**kwargs)
-
- resp = []
- tries = 0
- while len(resp) < num2gen and tries < numTries:
- # Prompt OpenAI
- # https://platform.openai.com/docs/api-reference/chat/create
- response = completions_with_backoff(model=model_name,
- temperature=temperature,
- messages=[{"role": "system", "content": instruction}])
- # ,{"role": "user", "content": prompt}
-
- sentence = response["choices"][0]["message"]["content"]
-
- fnd_kwd_0 = list(re.finditer(f'{kwd_pair[0].lower()}[ .,!]+', sentence.lower()))
- fnd_kwd_1 = list(re.finditer(f'{kwd_pair[1].lower()}[ .,!]+', sentence.lower()))
- if len(fnd_kwd_0)>0 and len(fnd_kwd_1)>0:
- resp.append([kwd_pair[0], kwd_pair[1], sentence, grp_term_pair[0], grp_term_pair[1]])
-
- tries += 1
-
- return resp, instruction
-
-# Prompt ChatGPT to write a sentence alternaitve for the other social group term
-def promptChatGPTTemplate(model_name, term1, term2, sentence, temperature=0.0):
- instruction = f"Rewrite the sentence to replace {term1} with {term2}. Make only minimal changes to preserve grammar."
- prompt = f"Sentence: {sentence}, Rewrite: "
-
- # https://github.com/openai/openai-cookbook/blob/main/examples/How_to_handle_rate_limits.ipynb
- @backoff.on_exception(backoff.expo, (openai.error.RateLimitError,
- openai.error.APIError,
- openai.error.ServiceUnavailableError,
- ConnectionResetError,
- json.decoder.JSONDecodeError))
-
- def completions_with_backoff(**kwargs):
- return openai.ChatCompletion.create(**kwargs)
-
- # Prompt OpenAI
- # https://platform.openai.com/docs/api-reference/chat/create
- response = completions_with_backoff(model=model_name,
- temperature=temperature,
- messages=[{"role": "system", "content": instruction},
- {"role": "user", "content": prompt}])
-
- return response["choices"][0]["message"]["content"]
-
-# turn generated sentence into a test templates
-def chatgpt_sentence_alternative(row, model_name):
- sentence = row['Sentence']
- grp_term = row['org_grp_term']
- att_term = row['Attribute term']
- grp_term1 = row['Group term 1']
- grp_term2 = row['Group term 2']
-
- rewrite = promptChatGPTTemplate(model_name, grp_term1, grp_term2, sentence)
-
- #template, grp_refs = maskDifferences(sentence, rewrite, grp_term_pair, att_term)
- return rewrite
-
-def generateTestSentencesCustom(model_name, gr1_kwds, gr2_kwds, attribute_kwds, att_counts, bias_spec, progress):
- print(f"Running Custom Sentence Generator, Counts:\n {att_counts}")
- print(f"Groups: [{gr1_kwds}, {gr2_kwds}]\nAttributes: {attribute_kwds}")
-
- numGlobTries = 5
- numTries = 10
- all_gens = []
- show_instr = False
- num_steps = len(attribute_kwds)
- for ai, att_kwd in enumerate(attribute_kwds):
- print(f'Running att: {att_kwd}..')
- att_count = 0
- if att_kwd in att_counts:
- att_count = att_counts[att_kwd]
- elif att_kwd.replace(' ','-') in att_counts:
- att_count = att_counts[att_kwd.replace(' ','-')]
- else:
- print(f"Missing count for attribute: <{att_kwd}>")
-
- if att_count != 0:
- print(f"For {att_kwd} generate {att_count}")
-
- att_gens = []
- glob_tries = 0
- while len(att_gens) < att_count and glob_tries < att_count*numGlobTries:
- gr1_kwd = random.sample(gr1_kwds, 1)[0]
- gr2_kwd = random.sample(gr2_kwds, 1)[0]
-
- for kwd_pair in [[gr1_kwd.strip(), att_kwd.strip()], [gr2_kwd.strip(), att_kwd.strip()]]:
- progress((ai)/num_steps, desc=f"Generating {kwd_pair[0]}<>{att_kwd}...")
-
- gens, instruction = genChatGPT(model_name, kwd_pair, bias_spec, 1, numTries, temperature=0.8)
- att_gens.extend(gens)
-
- if show_instr == False:
- print(f"Instruction: {instruction}")
- show_instr = True
-
- glob_tries += 1
- print(".", end="", flush=True)
- print()
-
- if len(att_gens) > att_count:
- print(f"Downsampling from {len(att_gens)} to {att_count}...")
- att_gens = random.sample(att_gens, att_count)
-
- print(f"Num generated: {len(att_gens)}")
- all_gens.extend(att_gens)
-
- return all_gens
-
-
-# generate sentences
-def generateTestSentences(model_name, group_kwds, attribute_kwds, num2gen, progress):
- print(f"Groups: [{group_kwds}]\nAttributes: [{attribute_kwds}]")
-
- numTries = 5
- #num2gen = 2
- all_gens = []
- num_steps = len(group_kwds)*len(attribute_kwds)
- for gi, grp_kwd in enumerate(group_kwds):
- for ai, att_kwd in enumerate(attribute_kwds):
- progress((gi*len(attribute_kwds)+ai)/num_steps, desc=f"Generating {grp_kwd}<>{att_kwd}...")
-
- kwd_pair = [grp_kwd.strip(), att_kwd.strip()]
-
- gens = genChatGPT(model_name, kwd_pair, num2gen, numTries, temperature=0.8)
- #print(f"Gens for pair: <{kwd_pair}> -> {gens}")
- all_gens.extend(gens)
-
- return all_gens
diff --git a/spaces/Anonymous-sub/Rerender/ControlNet/tool_add_control.py b/spaces/Anonymous-sub/Rerender/ControlNet/tool_add_control.py
deleted file mode 100644
index 8076b5143405e5516b063f4fd63096f65cffbed2..0000000000000000000000000000000000000000
--- a/spaces/Anonymous-sub/Rerender/ControlNet/tool_add_control.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import sys
-import os
-
-assert len(sys.argv) == 3, 'Args are wrong.'
-
-input_path = sys.argv[1]
-output_path = sys.argv[2]
-
-assert os.path.exists(input_path), 'Input model does not exist.'
-assert not os.path.exists(output_path), 'Output filename already exists.'
-assert os.path.exists(os.path.dirname(output_path)), 'Output path is not valid.'
-
-import torch
-from share import *
-from cldm.model import create_model
-
-
-def get_node_name(name, parent_name):
- if len(name) <= len(parent_name):
- return False, ''
- p = name[:len(parent_name)]
- if p != parent_name:
- return False, ''
- return True, name[len(parent_name):]
-
-
-model = create_model(config_path='./models/cldm_v15.yaml')
-
-pretrained_weights = torch.load(input_path)
-if 'state_dict' in pretrained_weights:
- pretrained_weights = pretrained_weights['state_dict']
-
-scratch_dict = model.state_dict()
-
-target_dict = {}
-for k in scratch_dict.keys():
- is_control, name = get_node_name(k, 'control_')
- if is_control:
- copy_k = 'model.diffusion_' + name
- else:
- copy_k = k
- if copy_k in pretrained_weights:
- target_dict[k] = pretrained_weights[copy_k].clone()
- else:
- target_dict[k] = scratch_dict[k].clone()
- print(f'These weights are newly added: {k}')
-
-model.load_state_dict(target_dict, strict=True)
-torch.save(model.state_dict(), output_path)
-print('Done.')
diff --git a/spaces/Apex-X/nono/roop/core.py b/spaces/Apex-X/nono/roop/core.py
deleted file mode 100644
index b70d8548194c74cce3e4d20c53c7a88c119c2028..0000000000000000000000000000000000000000
--- a/spaces/Apex-X/nono/roop/core.py
+++ /dev/null
@@ -1,215 +0,0 @@
-#!/usr/bin/env python3
-
-import os
-import sys
-# single thread doubles cuda performance - needs to be set before torch import
-if any(arg.startswith('--execution-provider') for arg in sys.argv):
- os.environ['OMP_NUM_THREADS'] = '1'
-# reduce tensorflow log level
-os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
-import warnings
-from typing import List
-import platform
-import signal
-import shutil
-import argparse
-import torch
-import onnxruntime
-import tensorflow
-
-import roop.globals
-import roop.metadata
-import roop.ui as ui
-from roop.predicter import predict_image, predict_video
-from roop.processors.frame.core import get_frame_processors_modules
-from roop.utilities import has_image_extension, is_image, is_video, detect_fps, create_video, extract_frames, get_temp_frame_paths, restore_audio, create_temp, move_temp, clean_temp, normalize_output_path
-
-if 'ROCMExecutionProvider' in roop.globals.execution_providers:
- del torch
-
-warnings.filterwarnings('ignore', category=FutureWarning, module='insightface')
-warnings.filterwarnings('ignore', category=UserWarning, module='torchvision')
-
-
-def parse_args() -> None:
- signal.signal(signal.SIGINT, lambda signal_number, frame: destroy())
- program = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=100))
- program.add_argument('-s', '--source', help='select an source image', dest='source_path')
- program.add_argument('-t', '--target', help='select an target image or video', dest='target_path')
- program.add_argument('-o', '--output', help='select output file or directory', dest='output_path')
- program.add_argument('--frame-processor', help='frame processors (choices: face_swapper, face_enhancer, ...)', dest='frame_processor', default=['face_swapper'], nargs='+')
- program.add_argument('--keep-fps', help='keep original fps', dest='keep_fps', action='store_true', default=False)
- program.add_argument('--keep-audio', help='keep original audio', dest='keep_audio', action='store_true', default=True)
- program.add_argument('--keep-frames', help='keep temporary frames', dest='keep_frames', action='store_true', default=False)
- program.add_argument('--many-faces', help='process every face', dest='many_faces', action='store_true', default=False)
- program.add_argument('--video-encoder', help='adjust output video encoder', dest='video_encoder', default='libx264', choices=['libx264', 'libx265', 'libvpx-vp9'])
- program.add_argument('--video-quality', help='adjust output video quality', dest='video_quality', type=int, default=18, choices=range(52), metavar='[0-51]')
- program.add_argument('--max-memory', help='maximum amount of RAM in GB', dest='max_memory', type=int, default=suggest_max_memory())
- program.add_argument('--execution-provider', help='available execution provider (choices: cpu, ...)', dest='execution_provider', default=['cpu'], choices=suggest_execution_providers(), nargs='+')
- program.add_argument('--execution-threads', help='number of execution threads', dest='execution_threads', type=int, default=suggest_execution_threads())
- program.add_argument('-v', '--version', action='version', version=f'{roop.metadata.name} {roop.metadata.version}')
-
- args = program.parse_args()
-
- roop.globals.source_path = args.source_path
- roop.globals.target_path = args.target_path
- roop.globals.output_path = normalize_output_path(roop.globals.source_path, roop.globals.target_path, args.output_path)
- roop.globals.frame_processors = args.frame_processor
- roop.globals.headless = args.source_path or args.target_path or args.output_path
- roop.globals.keep_fps = args.keep_fps
- roop.globals.keep_audio = args.keep_audio
- roop.globals.keep_frames = args.keep_frames
- roop.globals.many_faces = args.many_faces
- roop.globals.video_encoder = args.video_encoder
- roop.globals.video_quality = args.video_quality
- roop.globals.max_memory = args.max_memory
- roop.globals.execution_providers = decode_execution_providers(args.execution_provider)
- roop.globals.execution_threads = args.execution_threads
-
-
-def encode_execution_providers(execution_providers: List[str]) -> List[str]:
- return [execution_provider.replace('ExecutionProvider', '').lower() for execution_provider in execution_providers]
-
-
-def decode_execution_providers(execution_providers: List[str]) -> List[str]:
- return [provider for provider, encoded_execution_provider in zip(onnxruntime.get_available_providers(), encode_execution_providers(onnxruntime.get_available_providers()))
- if any(execution_provider in encoded_execution_provider for execution_provider in execution_providers)]
-
-
-def suggest_max_memory() -> int:
- if platform.system().lower() == 'darwin':
- return 4
- return 16
-
-
-def suggest_execution_providers() -> List[str]:
- return encode_execution_providers(onnxruntime.get_available_providers())
-
-
-def suggest_execution_threads() -> int:
- if 'DmlExecutionProvider' in roop.globals.execution_providers:
- return 1
- if 'ROCMExecutionProvider' in roop.globals.execution_providers:
- return 1
- return 8
-
-
-def limit_resources() -> None:
- # prevent tensorflow memory leak
- gpus = tensorflow.config.experimental.list_physical_devices('GPU')
- for gpu in gpus:
- tensorflow.config.experimental.set_virtual_device_configuration(gpu, [
- tensorflow.config.experimental.VirtualDeviceConfiguration(memory_limit=1024)
- ])
- # limit memory usage
- if roop.globals.max_memory:
- memory = roop.globals.max_memory * 1024 ** 3
- if platform.system().lower() == 'darwin':
- memory = roop.globals.max_memory * 1024 ** 6
- if platform.system().lower() == 'windows':
- import ctypes
- kernel32 = ctypes.windll.kernel32
- kernel32.SetProcessWorkingSetSize(-1, ctypes.c_size_t(memory), ctypes.c_size_t(memory))
- else:
- import resource
- resource.setrlimit(resource.RLIMIT_DATA, (memory, memory))
-
-
-def release_resources() -> None:
- if 'CUDAExecutionProvider' in roop.globals.execution_providers:
- torch.cuda.empty_cache()
-
-
-def pre_check() -> bool:
- if sys.version_info < (3, 9):
- update_status('Python version is not supported - please upgrade to 3.9 or higher.')
- return False
- if not shutil.which('ffmpeg'):
- update_status('ffmpeg is not installed.')
- return False
- return True
-
-
-def update_status(message: str, scope: str = 'ROOP.CORE') -> None:
- print(f'[{scope}] {message}')
- if not roop.globals.headless:
- ui.update_status(message)
-
-
-def start() -> None:
- for frame_processor in get_frame_processors_modules(roop.globals.frame_processors):
- if not frame_processor.pre_start():
- return
- # process image to image
- if has_image_extension(roop.globals.target_path):
- if predict_image(roop.globals.target_path):
- destroy()
- shutil.copy2(roop.globals.target_path, roop.globals.output_path)
- for frame_processor in get_frame_processors_modules(roop.globals.frame_processors):
- update_status('Progressing...', frame_processor.NAME)
- frame_processor.process_image(roop.globals.source_path, roop.globals.output_path, roop.globals.output_path)
- frame_processor.post_process()
- release_resources()
- if is_image(roop.globals.target_path):
- update_status('Processing to image succeed!')
- else:
- update_status('Processing to image failed!')
- return
- # process image to videos
- if predict_video(roop.globals.target_path):
- destroy()
- update_status('Creating temp resources...')
- create_temp(roop.globals.target_path)
- update_status('Extracting frames...')
- extract_frames(roop.globals.target_path)
- temp_frame_paths = get_temp_frame_paths(roop.globals.target_path)
- for frame_processor in get_frame_processors_modules(roop.globals.frame_processors):
- update_status('Progressing...', frame_processor.NAME)
- frame_processor.process_video(roop.globals.source_path, temp_frame_paths)
- frame_processor.post_process()
- release_resources()
- # handles fps
- if roop.globals.keep_fps:
- update_status('Detecting fps...')
- fps = detect_fps(roop.globals.target_path)
- update_status(f'Creating video with {fps} fps...')
- create_video(roop.globals.target_path, fps)
- else:
- update_status('Creating video with 30.0 fps...')
- create_video(roop.globals.target_path)
- # handle audio
- if roop.globals.keep_audio:
- if roop.globals.keep_fps:
- update_status('Restoring audio...')
- else:
- update_status('Restoring audio might cause issues as fps are not kept...')
- restore_audio(roop.globals.target_path, roop.globals.output_path)
- else:
- move_temp(roop.globals.target_path, roop.globals.output_path)
- # clean and validate
- clean_temp(roop.globals.target_path)
- if is_video(roop.globals.target_path):
- update_status('Processing to video succeed!')
- else:
- update_status('Processing to video failed!')
-
-
-def destroy() -> None:
- if roop.globals.target_path:
- clean_temp(roop.globals.target_path)
- quit()
-
-
-def run() -> None:
- parse_args()
- if not pre_check():
- return
- for frame_processor in get_frame_processors_modules(roop.globals.frame_processors):
- if not frame_processor.pre_check():
- return
- limit_resources()
- if roop.globals.headless:
- start()
- else:
- window = ui.init(start, destroy)
- window.mainloop()
diff --git a/spaces/Ariharasudhan/YoloV5/utils/loggers/__init__.py b/spaces/Ariharasudhan/YoloV5/utils/loggers/__init__.py
deleted file mode 100644
index bc8dd7621579f6372ce60e317c9e031e313e1c37..0000000000000000000000000000000000000000
--- a/spaces/Ariharasudhan/YoloV5/utils/loggers/__init__.py
+++ /dev/null
@@ -1,404 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-Logging utils
-"""
-
-import os
-import warnings
-from pathlib import Path
-
-import pkg_resources as pkg
-import torch
-from torch.utils.tensorboard import SummaryWriter
-
-from utils.general import LOGGER, colorstr, cv2
-from utils.loggers.clearml.clearml_utils import ClearmlLogger
-from utils.loggers.wandb.wandb_utils import WandbLogger
-from utils.plots import plot_images, plot_labels, plot_results
-from utils.torch_utils import de_parallel
-
-LOGGERS = ('csv', 'tb', 'wandb', 'clearml', 'comet') # *.csv, TensorBoard, Weights & Biases, ClearML
-RANK = int(os.getenv('RANK', -1))
-
-try:
- import wandb
-
- assert hasattr(wandb, '__version__') # verify package import not local dir
- if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.2') and RANK in {0, -1}:
- try:
- wandb_login_success = wandb.login(timeout=30)
- except wandb.errors.UsageError: # known non-TTY terminal issue
- wandb_login_success = False
- if not wandb_login_success:
- wandb = None
-except (ImportError, AssertionError):
- wandb = None
-
-try:
- import clearml
-
- assert hasattr(clearml, '__version__') # verify package import not local dir
-except (ImportError, AssertionError):
- clearml = None
-
-try:
- if RANK not in [0, -1]:
- comet_ml = None
- else:
- import comet_ml
-
- assert hasattr(comet_ml, '__version__') # verify package import not local dir
- from utils.loggers.comet import CometLogger
-
-except (ModuleNotFoundError, ImportError, AssertionError):
- comet_ml = None
-
-
-class Loggers():
- # YOLOv5 Loggers class
- def __init__(self, save_dir=None, weights=None, opt=None, hyp=None, logger=None, include=LOGGERS):
- self.save_dir = save_dir
- self.weights = weights
- self.opt = opt
- self.hyp = hyp
- self.plots = not opt.noplots # plot results
- self.logger = logger # for printing results to console
- self.include = include
- self.keys = [
- 'train/box_loss',
- 'train/obj_loss',
- 'train/cls_loss', # train loss
- 'metrics/precision',
- 'metrics/recall',
- 'metrics/mAP_0.5',
- 'metrics/mAP_0.5:0.95', # metrics
- 'val/box_loss',
- 'val/obj_loss',
- 'val/cls_loss', # val loss
- 'x/lr0',
- 'x/lr1',
- 'x/lr2'] # params
- self.best_keys = ['best/epoch', 'best/precision', 'best/recall', 'best/mAP_0.5', 'best/mAP_0.5:0.95']
- for k in LOGGERS:
- setattr(self, k, None) # init empty logger dictionary
- self.csv = True # always log to csv
-
- # Messages
- # if not wandb:
- # prefix = colorstr('Weights & Biases: ')
- # s = f"{prefix}run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs in Weights & Biases"
- # self.logger.info(s)
- if not clearml:
- prefix = colorstr('ClearML: ')
- s = f"{prefix}run 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 🚀 in ClearML"
- self.logger.info(s)
- if not comet_ml:
- prefix = colorstr('Comet: ')
- s = f"{prefix}run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet"
- self.logger.info(s)
- # TensorBoard
- s = self.save_dir
- if 'tb' in self.include and not self.opt.evolve:
- prefix = colorstr('TensorBoard: ')
- self.logger.info(f"{prefix}Start with 'tensorboard --logdir {s.parent}', view at http://localhost:6006/")
- self.tb = SummaryWriter(str(s))
-
- # W&B
- if wandb and 'wandb' in self.include:
- wandb_artifact_resume = isinstance(self.opt.resume, str) and self.opt.resume.startswith('wandb-artifact://')
- run_id = torch.load(self.weights).get('wandb_id') if self.opt.resume and not wandb_artifact_resume else None
- self.opt.hyp = self.hyp # add hyperparameters
- self.wandb = WandbLogger(self.opt, run_id)
- # temp warn. because nested artifacts not supported after 0.12.10
- # if pkg.parse_version(wandb.__version__) >= pkg.parse_version('0.12.11'):
- # s = "YOLOv5 temporarily requires wandb version 0.12.10 or below. Some features may not work as expected."
- # self.logger.warning(s)
- else:
- self.wandb = None
-
- # ClearML
- if clearml and 'clearml' in self.include:
- self.clearml = ClearmlLogger(self.opt, self.hyp)
- else:
- self.clearml = None
-
- # Comet
- if comet_ml and 'comet' in self.include:
- if isinstance(self.opt.resume, str) and self.opt.resume.startswith("comet://"):
- run_id = self.opt.resume.split("/")[-1]
- self.comet_logger = CometLogger(self.opt, self.hyp, run_id=run_id)
-
- else:
- self.comet_logger = CometLogger(self.opt, self.hyp)
-
- else:
- self.comet_logger = None
-
- @property
- def remote_dataset(self):
- # Get data_dict if custom dataset artifact link is provided
- data_dict = None
- if self.clearml:
- data_dict = self.clearml.data_dict
- if self.wandb:
- data_dict = self.wandb.data_dict
- if self.comet_logger:
- data_dict = self.comet_logger.data_dict
-
- return data_dict
-
- def on_train_start(self):
- if self.comet_logger:
- self.comet_logger.on_train_start()
-
- def on_pretrain_routine_start(self):
- if self.comet_logger:
- self.comet_logger.on_pretrain_routine_start()
-
- def on_pretrain_routine_end(self, labels, names):
- # Callback runs on pre-train routine end
- if self.plots:
- plot_labels(labels, names, self.save_dir)
- paths = self.save_dir.glob('*labels*.jpg') # training labels
- if self.wandb:
- self.wandb.log({"Labels": [wandb.Image(str(x), caption=x.name) for x in paths]})
- # if self.clearml:
- # pass # ClearML saves these images automatically using hooks
- if self.comet_logger:
- self.comet_logger.on_pretrain_routine_end(paths)
-
- def on_train_batch_end(self, model, ni, imgs, targets, paths, vals):
- log_dict = dict(zip(self.keys[0:3], vals))
- # Callback runs on train batch end
- # ni: number integrated batches (since train start)
- if self.plots:
- if ni < 3:
- f = self.save_dir / f'train_batch{ni}.jpg' # filename
- plot_images(imgs, targets, paths, f)
- if ni == 0 and self.tb and not self.opt.sync_bn:
- log_tensorboard_graph(self.tb, model, imgsz=(self.opt.imgsz, self.opt.imgsz))
- if ni == 10 and (self.wandb or self.clearml):
- files = sorted(self.save_dir.glob('train*.jpg'))
- if self.wandb:
- self.wandb.log({'Mosaics': [wandb.Image(str(f), caption=f.name) for f in files if f.exists()]})
- if self.clearml:
- self.clearml.log_debug_samples(files, title='Mosaics')
-
- if self.comet_logger:
- self.comet_logger.on_train_batch_end(log_dict, step=ni)
-
- def on_train_epoch_end(self, epoch):
- # Callback runs on train epoch end
- if self.wandb:
- self.wandb.current_epoch = epoch + 1
-
- if self.comet_logger:
- self.comet_logger.on_train_epoch_end(epoch)
-
- def on_val_start(self):
- if self.comet_logger:
- self.comet_logger.on_val_start()
-
- def on_val_image_end(self, pred, predn, path, names, im):
- # Callback runs on val image end
- if self.wandb:
- self.wandb.val_one_image(pred, predn, path, names, im)
- if self.clearml:
- self.clearml.log_image_with_boxes(path, pred, names, im)
-
- def on_val_batch_end(self, batch_i, im, targets, paths, shapes, out):
- if self.comet_logger:
- self.comet_logger.on_val_batch_end(batch_i, im, targets, paths, shapes, out)
-
- def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
- # Callback runs on val end
- if self.wandb or self.clearml:
- files = sorted(self.save_dir.glob('val*.jpg'))
- if self.wandb:
- self.wandb.log({"Validation": [wandb.Image(str(f), caption=f.name) for f in files]})
- if self.clearml:
- self.clearml.log_debug_samples(files, title='Validation')
-
- if self.comet_logger:
- self.comet_logger.on_val_end(nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
-
- def on_fit_epoch_end(self, vals, epoch, best_fitness, fi):
- # Callback runs at the end of each fit (train+val) epoch
- x = dict(zip(self.keys, vals))
- if self.csv:
- file = self.save_dir / 'results.csv'
- n = len(x) + 1 # number of cols
- s = '' if file.exists() else (('%20s,' * n % tuple(['epoch'] + self.keys)).rstrip(',') + '\n') # add header
- with open(file, 'a') as f:
- f.write(s + ('%20.5g,' * n % tuple([epoch] + vals)).rstrip(',') + '\n')
-
- if self.tb:
- for k, v in x.items():
- self.tb.add_scalar(k, v, epoch)
- elif self.clearml: # log to ClearML if TensorBoard not used
- for k, v in x.items():
- title, series = k.split('/')
- self.clearml.task.get_logger().report_scalar(title, series, v, epoch)
-
- if self.wandb:
- if best_fitness == fi:
- best_results = [epoch] + vals[3:7]
- for i, name in enumerate(self.best_keys):
- self.wandb.wandb_run.summary[name] = best_results[i] # log best results in the summary
- self.wandb.log(x)
- self.wandb.end_epoch(best_result=best_fitness == fi)
-
- if self.clearml:
- self.clearml.current_epoch_logged_images = set() # reset epoch image limit
- self.clearml.current_epoch += 1
-
- if self.comet_logger:
- self.comet_logger.on_fit_epoch_end(x, epoch=epoch)
-
- def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
- # Callback runs on model save event
- if (epoch + 1) % self.opt.save_period == 0 and not final_epoch and self.opt.save_period != -1:
- if self.wandb:
- self.wandb.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
- if self.clearml:
- self.clearml.task.update_output_model(model_path=str(last),
- model_name='Latest Model',
- auto_delete_file=False)
-
- if self.comet_logger:
- self.comet_logger.on_model_save(last, epoch, final_epoch, best_fitness, fi)
-
- def on_train_end(self, last, best, epoch, results):
- # Callback runs on training end, i.e. saving best model
- if self.plots:
- plot_results(file=self.save_dir / 'results.csv') # save results.png
- files = ['results.png', 'confusion_matrix.png', *(f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R'))]
- files = [(self.save_dir / f) for f in files if (self.save_dir / f).exists()] # filter
- self.logger.info(f"Results saved to {colorstr('bold', self.save_dir)}")
-
- if self.tb and not self.clearml: # These images are already captured by ClearML by now, we don't want doubles
- for f in files:
- self.tb.add_image(f.stem, cv2.imread(str(f))[..., ::-1], epoch, dataformats='HWC')
-
- if self.wandb:
- self.wandb.log(dict(zip(self.keys[3:10], results)))
- self.wandb.log({"Results": [wandb.Image(str(f), caption=f.name) for f in files]})
- # Calling wandb.log. TODO: Refactor this into WandbLogger.log_model
- if not self.opt.evolve:
- wandb.log_artifact(str(best if best.exists() else last),
- type='model',
- name=f'run_{self.wandb.wandb_run.id}_model',
- aliases=['latest', 'best', 'stripped'])
- self.wandb.finish_run()
-
- if self.clearml and not self.opt.evolve:
- self.clearml.task.update_output_model(model_path=str(best if best.exists() else last),
- name='Best Model',
- auto_delete_file=False)
-
- if self.comet_logger:
- final_results = dict(zip(self.keys[3:10], results))
- self.comet_logger.on_train_end(files, self.save_dir, last, best, epoch, final_results)
-
- def on_params_update(self, params: dict):
- # Update hyperparams or configs of the experiment
- if self.wandb:
- self.wandb.wandb_run.config.update(params, allow_val_change=True)
- if self.comet_logger:
- self.comet_logger.on_params_update(params)
-
-
-class GenericLogger:
- """
- YOLOv5 General purpose logger for non-task specific logging
- Usage: from utils.loggers import GenericLogger; logger = GenericLogger(...)
- Arguments
- opt: Run arguments
- console_logger: Console logger
- include: loggers to include
- """
-
- def __init__(self, opt, console_logger, include=('tb', 'wandb')):
- # init default loggers
- self.save_dir = Path(opt.save_dir)
- self.include = include
- self.console_logger = console_logger
- self.csv = self.save_dir / 'results.csv' # CSV logger
- if 'tb' in self.include:
- prefix = colorstr('TensorBoard: ')
- self.console_logger.info(
- f"{prefix}Start with 'tensorboard --logdir {self.save_dir.parent}', view at http://localhost:6006/")
- self.tb = SummaryWriter(str(self.save_dir))
-
- if wandb and 'wandb' in self.include:
- self.wandb = wandb.init(project=web_project_name(str(opt.project)),
- name=None if opt.name == "exp" else opt.name,
- config=opt)
- else:
- self.wandb = None
-
- def log_metrics(self, metrics, epoch):
- # Log metrics dictionary to all loggers
- if self.csv:
- keys, vals = list(metrics.keys()), list(metrics.values())
- n = len(metrics) + 1 # number of cols
- s = '' if self.csv.exists() else (('%23s,' * n % tuple(['epoch'] + keys)).rstrip(',') + '\n') # header
- with open(self.csv, 'a') as f:
- f.write(s + ('%23.5g,' * n % tuple([epoch] + vals)).rstrip(',') + '\n')
-
- if self.tb:
- for k, v in metrics.items():
- self.tb.add_scalar(k, v, epoch)
-
- if self.wandb:
- self.wandb.log(metrics, step=epoch)
-
- def log_images(self, files, name='Images', epoch=0):
- # Log images to all loggers
- files = [Path(f) for f in (files if isinstance(files, (tuple, list)) else [files])] # to Path
- files = [f for f in files if f.exists()] # filter by exists
-
- if self.tb:
- for f in files:
- self.tb.add_image(f.stem, cv2.imread(str(f))[..., ::-1], epoch, dataformats='HWC')
-
- if self.wandb:
- self.wandb.log({name: [wandb.Image(str(f), caption=f.name) for f in files]}, step=epoch)
-
- def log_graph(self, model, imgsz=(640, 640)):
- # Log model graph to all loggers
- if self.tb:
- log_tensorboard_graph(self.tb, model, imgsz)
-
- def log_model(self, model_path, epoch=0, metadata={}):
- # Log model to all loggers
- if self.wandb:
- art = wandb.Artifact(name=f"run_{wandb.run.id}_model", type="model", metadata=metadata)
- art.add_file(str(model_path))
- wandb.log_artifact(art)
-
- def update_params(self, params):
- # Update the paramters logged
- if self.wandb:
- wandb.run.config.update(params, allow_val_change=True)
-
-
-def log_tensorboard_graph(tb, model, imgsz=(640, 640)):
- # Log model graph to TensorBoard
- try:
- p = next(model.parameters()) # for device, type
- imgsz = (imgsz, imgsz) if isinstance(imgsz, int) else imgsz # expand
- im = torch.zeros((1, 3, *imgsz)).to(p.device).type_as(p) # input image (WARNING: must be zeros, not empty)
- with warnings.catch_warnings():
- warnings.simplefilter('ignore') # suppress jit trace warning
- tb.add_graph(torch.jit.trace(de_parallel(model), im, strict=False), [])
- except Exception as e:
- LOGGER.warning(f'WARNING ⚠️ TensorBoard graph visualization failure {e}')
-
-
-def web_project_name(project):
- # Convert local project name to web project name
- if not project.startswith('runs/train'):
- return project
- suffix = '-Classify' if project.endswith('-cls') else '-Segment' if project.endswith('-seg') else ''
- return f'YOLOv5{suffix}'
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/network/download.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/network/download.py
deleted file mode 100644
index 79b82a570e5be5ce4f8e4dcc4906da8c18f08ef6..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/network/download.py
+++ /dev/null
@@ -1,186 +0,0 @@
-"""Download files with progress indicators.
-"""
-import email.message
-import logging
-import mimetypes
-import os
-from typing import Iterable, Optional, Tuple
-
-from pip._vendor.requests.models import CONTENT_CHUNK_SIZE, Response
-
-from pip._internal.cli.progress_bars import get_download_progress_renderer
-from pip._internal.exceptions import NetworkConnectionError
-from pip._internal.models.index import PyPI
-from pip._internal.models.link import Link
-from pip._internal.network.cache import is_from_cache
-from pip._internal.network.session import PipSession
-from pip._internal.network.utils import HEADERS, raise_for_status, response_chunks
-from pip._internal.utils.misc import format_size, redact_auth_from_url, splitext
-
-logger = logging.getLogger(__name__)
-
-
-def _get_http_response_size(resp: Response) -> Optional[int]:
- try:
- return int(resp.headers["content-length"])
- except (ValueError, KeyError, TypeError):
- return None
-
-
-def _prepare_download(
- resp: Response,
- link: Link,
- progress_bar: str,
-) -> Iterable[bytes]:
- total_length = _get_http_response_size(resp)
-
- if link.netloc == PyPI.file_storage_domain:
- url = link.show_url
- else:
- url = link.url_without_fragment
-
- logged_url = redact_auth_from_url(url)
-
- if total_length:
- logged_url = "{} ({})".format(logged_url, format_size(total_length))
-
- if is_from_cache(resp):
- logger.info("Using cached %s", logged_url)
- else:
- logger.info("Downloading %s", logged_url)
-
- if logger.getEffectiveLevel() > logging.INFO:
- show_progress = False
- elif is_from_cache(resp):
- show_progress = False
- elif not total_length:
- show_progress = True
- elif total_length > (40 * 1000):
- show_progress = True
- else:
- show_progress = False
-
- chunks = response_chunks(resp, CONTENT_CHUNK_SIZE)
-
- if not show_progress:
- return chunks
-
- renderer = get_download_progress_renderer(bar_type=progress_bar, size=total_length)
- return renderer(chunks)
-
-
-def sanitize_content_filename(filename: str) -> str:
- """
- Sanitize the "filename" value from a Content-Disposition header.
- """
- return os.path.basename(filename)
-
-
-def parse_content_disposition(content_disposition: str, default_filename: str) -> str:
- """
- Parse the "filename" value from a Content-Disposition header, and
- return the default filename if the result is empty.
- """
- m = email.message.Message()
- m["content-type"] = content_disposition
- filename = m.get_param("filename")
- if filename:
- # We need to sanitize the filename to prevent directory traversal
- # in case the filename contains ".." path parts.
- filename = sanitize_content_filename(str(filename))
- return filename or default_filename
-
-
-def _get_http_response_filename(resp: Response, link: Link) -> str:
- """Get an ideal filename from the given HTTP response, falling back to
- the link filename if not provided.
- """
- filename = link.filename # fallback
- # Have a look at the Content-Disposition header for a better guess
- content_disposition = resp.headers.get("content-disposition")
- if content_disposition:
- filename = parse_content_disposition(content_disposition, filename)
- ext: Optional[str] = splitext(filename)[1]
- if not ext:
- ext = mimetypes.guess_extension(resp.headers.get("content-type", ""))
- if ext:
- filename += ext
- if not ext and link.url != resp.url:
- ext = os.path.splitext(resp.url)[1]
- if ext:
- filename += ext
- return filename
-
-
-def _http_get_download(session: PipSession, link: Link) -> Response:
- target_url = link.url.split("#", 1)[0]
- resp = session.get(target_url, headers=HEADERS, stream=True)
- raise_for_status(resp)
- return resp
-
-
-class Downloader:
- def __init__(
- self,
- session: PipSession,
- progress_bar: str,
- ) -> None:
- self._session = session
- self._progress_bar = progress_bar
-
- def __call__(self, link: Link, location: str) -> Tuple[str, str]:
- """Download the file given by link into location."""
- try:
- resp = _http_get_download(self._session, link)
- except NetworkConnectionError as e:
- assert e.response is not None
- logger.critical(
- "HTTP error %s while getting %s", e.response.status_code, link
- )
- raise
-
- filename = _get_http_response_filename(resp, link)
- filepath = os.path.join(location, filename)
-
- chunks = _prepare_download(resp, link, self._progress_bar)
- with open(filepath, "wb") as content_file:
- for chunk in chunks:
- content_file.write(chunk)
- content_type = resp.headers.get("Content-Type", "")
- return filepath, content_type
-
-
-class BatchDownloader:
- def __init__(
- self,
- session: PipSession,
- progress_bar: str,
- ) -> None:
- self._session = session
- self._progress_bar = progress_bar
-
- def __call__(
- self, links: Iterable[Link], location: str
- ) -> Iterable[Tuple[Link, Tuple[str, str]]]:
- """Download the files given by links into location."""
- for link in links:
- try:
- resp = _http_get_download(self._session, link)
- except NetworkConnectionError as e:
- assert e.response is not None
- logger.critical(
- "HTTP error %s while getting %s",
- e.response.status_code,
- link,
- )
- raise
-
- filename = _get_http_response_filename(resp, link)
- filepath = os.path.join(location, filename)
-
- chunks = _prepare_download(resp, link, self._progress_bar)
- with open(filepath, "wb") as content_file:
- for chunk in chunks:
- content_file.write(chunk)
- content_type = resp.headers.get("Content-Type", "")
- yield link, (filepath, content_type)
diff --git a/spaces/AutoLLM/AutoAgents/setup.py b/spaces/AutoLLM/AutoAgents/setup.py
deleted file mode 100644
index 3eb5fbb4a074897c0ecec51025ec55236eadf2a8..0000000000000000000000000000000000000000
--- a/spaces/AutoLLM/AutoAgents/setup.py
+++ /dev/null
@@ -1,7 +0,0 @@
-from setuptools import setup, find_packages
-
-setup(
- name='autoagents',
- version='0.1.0',
- packages=find_packages(include=['autoagents', 'autoagents.*'])
-)
diff --git a/spaces/AzumaSeren100/XuanShen-Bert-VITS2/text/english.py b/spaces/AzumaSeren100/XuanShen-Bert-VITS2/text/english.py
deleted file mode 100644
index 781d0a56cef71f66fc67db51d76538be90d3ddd2..0000000000000000000000000000000000000000
--- a/spaces/AzumaSeren100/XuanShen-Bert-VITS2/text/english.py
+++ /dev/null
@@ -1,138 +0,0 @@
-import pickle
-import os
-import re
-from g2p_en import G2p
-from string import punctuation
-
-from text import symbols
-
-current_file_path = os.path.dirname(__file__)
-CMU_DICT_PATH = os.path.join(current_file_path, 'cmudict.rep')
-CACHE_PATH = os.path.join(current_file_path, 'cmudict_cache.pickle')
-_g2p = G2p()
-
-arpa = {'AH0', 'S', 'AH1', 'EY2', 'AE2', 'EH0', 'OW2', 'UH0', 'NG', 'B', 'G', 'AY0', 'M', 'AA0', 'F', 'AO0', 'ER2', 'UH1', 'IY1', 'AH2', 'DH', 'IY0', 'EY1', 'IH0', 'K', 'N', 'W', 'IY2', 'T', 'AA1', 'ER1', 'EH2', 'OY0', 'UH2', 'UW1', 'Z', 'AW2', 'AW1', 'V', 'UW2', 'AA2', 'ER', 'AW0', 'UW0', 'R', 'OW1', 'EH1', 'ZH', 'AE0', 'IH2', 'IH', 'Y', 'JH', 'P', 'AY1', 'EY0', 'OY2', 'TH', 'HH', 'D', 'ER0', 'CH', 'AO1', 'AE1', 'AO2', 'OY1', 'AY2', 'IH1', 'OW0', 'L', 'SH'}
-
-
-def post_replace_ph(ph):
- rep_map = {
- ':': ',',
- ';': ',',
- ',': ',',
- '。': '.',
- '!': '!',
- '?': '?',
- '\n': '.',
- "·": ",",
- '、': ",",
- '...': '…',
- 'v': "V"
- }
- if ph in rep_map.keys():
- ph = rep_map[ph]
- if ph in symbols:
- return ph
- if ph not in symbols:
- ph = 'UNK'
- return ph
-
-def read_dict():
- g2p_dict = {}
- start_line = 49
- with open(CMU_DICT_PATH) as f:
- line = f.readline()
- line_index = 1
- while line:
- if line_index >= start_line:
- line = line.strip()
- word_split = line.split(' ')
- word = word_split[0]
-
- syllable_split = word_split[1].split(' - ')
- g2p_dict[word] = []
- for syllable in syllable_split:
- phone_split = syllable.split(' ')
- g2p_dict[word].append(phone_split)
-
- line_index = line_index + 1
- line = f.readline()
-
- return g2p_dict
-
-
-def cache_dict(g2p_dict, file_path):
- with open(file_path, 'wb') as pickle_file:
- pickle.dump(g2p_dict, pickle_file)
-
-
-def get_dict():
- if os.path.exists(CACHE_PATH):
- with open(CACHE_PATH, 'rb') as pickle_file:
- g2p_dict = pickle.load(pickle_file)
- else:
- g2p_dict = read_dict()
- cache_dict(g2p_dict, CACHE_PATH)
-
- return g2p_dict
-
-eng_dict = get_dict()
-
-def refine_ph(phn):
- tone = 0
- if re.search(r'\d$', phn):
- tone = int(phn[-1]) + 1
- phn = phn[:-1]
- return phn.lower(), tone
-
-def refine_syllables(syllables):
- tones = []
- phonemes = []
- for phn_list in syllables:
- for i in range(len(phn_list)):
- phn = phn_list[i]
- phn, tone = refine_ph(phn)
- phonemes.append(phn)
- tones.append(tone)
- return phonemes, tones
-
-
-def text_normalize(text):
- # todo: eng text normalize
- return text
-
-def g2p(text):
-
- phones = []
- tones = []
- words = re.split(r"([,;.\-\?\!\s+])", text)
- for w in words:
- if w.upper() in eng_dict:
- phns, tns = refine_syllables(eng_dict[w.upper()])
- phones += phns
- tones += tns
- else:
- phone_list = list(filter(lambda p: p != " ", _g2p(w)))
- for ph in phone_list:
- if ph in arpa:
- ph, tn = refine_ph(ph)
- phones.append(ph)
- tones.append(tn)
- else:
- phones.append(ph)
- tones.append(0)
- # todo: implement word2ph
- word2ph = [1 for i in phones]
-
- phones = [post_replace_ph(i) for i in phones]
- return phones, tones, word2ph
-
-if __name__ == "__main__":
- # print(get_dict())
- # print(eng_word_to_phoneme("hello"))
- print(g2p("In this paper, we propose 1 DSPGAN, a GAN-based universal vocoder."))
- # all_phones = set()
- # for k, syllables in eng_dict.items():
- # for group in syllables:
- # for ph in group:
- # all_phones.add(ph)
- # print(all_phones)
\ No newline at end of file
diff --git a/spaces/BAAI/vid2vid-zero/gradio_demo/runner.py b/spaces/BAAI/vid2vid-zero/gradio_demo/runner.py
deleted file mode 100644
index 75af3356bea78ad5356b37af2a6eff5e46aa3a8f..0000000000000000000000000000000000000000
--- a/spaces/BAAI/vid2vid-zero/gradio_demo/runner.py
+++ /dev/null
@@ -1,137 +0,0 @@
-from __future__ import annotations
-
-import datetime
-import os
-import pathlib
-import shlex
-import shutil
-import subprocess
-import sys
-
-import gradio as gr
-import slugify
-import torch
-import huggingface_hub
-from huggingface_hub import HfApi
-from omegaconf import OmegaConf
-
-
-ORIGINAL_SPACE_ID = 'BAAI/vid2vid-zero'
-SPACE_ID = os.getenv('SPACE_ID', ORIGINAL_SPACE_ID)
-
-
-class Runner:
- def __init__(self, hf_token: str | None = None):
- self.hf_token = hf_token
-
- self.checkpoint_dir = pathlib.Path('checkpoints')
- self.checkpoint_dir.mkdir(exist_ok=True)
-
- def download_base_model(self, base_model_id: str, token=None) -> str:
- model_dir = self.checkpoint_dir / base_model_id
- org_name = base_model_id.split('/')[0]
- org_dir = self.checkpoint_dir / org_name
- if not model_dir.exists():
- org_dir.mkdir(exist_ok=True)
- print(f'https://huggingface.co/{base_model_id}')
- if token == None:
- subprocess.run(shlex.split(f'git lfs install'), cwd=org_dir)
- subprocess.run(shlex.split(
- f'git lfs clone https://huggingface.co/{base_model_id}'),
- cwd=org_dir)
- return model_dir.as_posix()
- else:
- temp_path = huggingface_hub.snapshot_download(base_model_id, use_auth_token=token)
- print(temp_path, org_dir)
- # subprocess.run(shlex.split(f'mv {temp_path} {model_dir.as_posix()}'))
- # return model_dir.as_posix()
- return temp_path
-
- def join_model_library_org(self, token: str) -> None:
- subprocess.run(
- shlex.split(
- f'curl -X POST -H "Authorization: Bearer {token}" -H "Content-Type: application/json" {URL_TO_JOIN_MODEL_LIBRARY_ORG}'
- ))
-
- def run_vid2vid_zero(
- self,
- model_path: str,
- input_video: str,
- prompt: str,
- n_sample_frames: int,
- sample_start_idx: int,
- sample_frame_rate: int,
- validation_prompt: str,
- guidance_scale: float,
- resolution: str,
- seed: int,
- remove_gpu_after_running: bool,
- input_token: str = None,
- ) -> str:
-
- if not torch.cuda.is_available():
- raise gr.Error('CUDA is not available.')
- if input_video is None:
- raise gr.Error('You need to upload a video.')
- if not prompt:
- raise gr.Error('The input prompt is missing.')
- if not validation_prompt:
- raise gr.Error('The validation prompt is missing.')
-
- resolution = int(resolution)
- n_sample_frames = int(n_sample_frames)
- sample_start_idx = int(sample_start_idx)
- sample_frame_rate = int(sample_frame_rate)
-
- repo_dir = pathlib.Path(__file__).parent
- prompt_path = prompt.replace(' ', '_')
- output_dir = repo_dir / 'outputs' / prompt_path
- output_dir.mkdir(parents=True, exist_ok=True)
-
- config = OmegaConf.load('configs/black-swan.yaml')
- config.pretrained_model_path = self.download_base_model(model_path, token=input_token)
-
- # we remove null-inversion & use fp16 for fast inference on web demo
- config.mixed_precision = "fp16"
- config.validation_data.use_null_inv = False
-
- config.output_dir = output_dir.as_posix()
- config.input_data.video_path = input_video.name # type: ignore
- config.input_data.prompt = prompt
- config.input_data.n_sample_frames = n_sample_frames
- config.input_data.width = resolution
- config.input_data.height = resolution
- config.input_data.sample_start_idx = sample_start_idx
- config.input_data.sample_frame_rate = sample_frame_rate
-
- config.validation_data.prompts = [validation_prompt]
- config.validation_data.video_length = 8
- config.validation_data.width = resolution
- config.validation_data.height = resolution
- config.validation_data.num_inference_steps = 50
- config.validation_data.guidance_scale = guidance_scale
-
- config.input_batch_size = 1
- config.seed = seed
-
- config_path = output_dir / 'config.yaml'
- with open(config_path, 'w') as f:
- OmegaConf.save(config, f)
-
- command = f'accelerate launch test_vid2vid_zero.py --config {config_path}'
- subprocess.run(shlex.split(command))
-
- output_video_path = os.path.join(output_dir, "sample-all.mp4")
- print(f"video path for gradio: {output_video_path}")
- message = 'Running completed!'
- print(message)
-
- if remove_gpu_after_running:
- space_id = os.getenv('SPACE_ID')
- if space_id:
- api = HfApi(
- token=self.hf_token if self.hf_token else input_token)
- api.request_space_hardware(repo_id=space_id,
- hardware='cpu-basic')
-
- return output_video_path
diff --git a/spaces/BasToTheMax/22h-vintedois-diffusion-v0-1/app.py b/spaces/BasToTheMax/22h-vintedois-diffusion-v0-1/app.py
deleted file mode 100644
index c1dd484084e36ddbdfd38baef27a08040b2d7893..0000000000000000000000000000000000000000
--- a/spaces/BasToTheMax/22h-vintedois-diffusion-v0-1/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/22h/vintedois-diffusion-v0-1").launch()
\ No newline at end of file
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/operations/build/build_tracker.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/operations/build/build_tracker.py
deleted file mode 100644
index 6621549b8449130d2d01ebac0a3649d8b70c4f91..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/operations/build/build_tracker.py
+++ /dev/null
@@ -1,124 +0,0 @@
-import contextlib
-import hashlib
-import logging
-import os
-from types import TracebackType
-from typing import Dict, Generator, Optional, Set, Type, Union
-
-from pip._internal.models.link import Link
-from pip._internal.req.req_install import InstallRequirement
-from pip._internal.utils.temp_dir import TempDirectory
-
-logger = logging.getLogger(__name__)
-
-
-@contextlib.contextmanager
-def update_env_context_manager(**changes: str) -> Generator[None, None, None]:
- target = os.environ
-
- # Save values from the target and change them.
- non_existent_marker = object()
- saved_values: Dict[str, Union[object, str]] = {}
- for name, new_value in changes.items():
- try:
- saved_values[name] = target[name]
- except KeyError:
- saved_values[name] = non_existent_marker
- target[name] = new_value
-
- try:
- yield
- finally:
- # Restore original values in the target.
- for name, original_value in saved_values.items():
- if original_value is non_existent_marker:
- del target[name]
- else:
- assert isinstance(original_value, str) # for mypy
- target[name] = original_value
-
-
-@contextlib.contextmanager
-def get_build_tracker() -> Generator["BuildTracker", None, None]:
- root = os.environ.get("PIP_BUILD_TRACKER")
- with contextlib.ExitStack() as ctx:
- if root is None:
- root = ctx.enter_context(TempDirectory(kind="build-tracker")).path
- ctx.enter_context(update_env_context_manager(PIP_BUILD_TRACKER=root))
- logger.debug("Initialized build tracking at %s", root)
-
- with BuildTracker(root) as tracker:
- yield tracker
-
-
-class BuildTracker:
- def __init__(self, root: str) -> None:
- self._root = root
- self._entries: Set[InstallRequirement] = set()
- logger.debug("Created build tracker: %s", self._root)
-
- def __enter__(self) -> "BuildTracker":
- logger.debug("Entered build tracker: %s", self._root)
- return self
-
- def __exit__(
- self,
- exc_type: Optional[Type[BaseException]],
- exc_val: Optional[BaseException],
- exc_tb: Optional[TracebackType],
- ) -> None:
- self.cleanup()
-
- def _entry_path(self, link: Link) -> str:
- hashed = hashlib.sha224(link.url_without_fragment.encode()).hexdigest()
- return os.path.join(self._root, hashed)
-
- def add(self, req: InstallRequirement) -> None:
- """Add an InstallRequirement to build tracking."""
-
- assert req.link
- # Get the file to write information about this requirement.
- entry_path = self._entry_path(req.link)
-
- # Try reading from the file. If it exists and can be read from, a build
- # is already in progress, so a LookupError is raised.
- try:
- with open(entry_path) as fp:
- contents = fp.read()
- except FileNotFoundError:
- pass
- else:
- message = "{} is already being built: {}".format(req.link, contents)
- raise LookupError(message)
-
- # If we're here, req should really not be building already.
- assert req not in self._entries
-
- # Start tracking this requirement.
- with open(entry_path, "w", encoding="utf-8") as fp:
- fp.write(str(req))
- self._entries.add(req)
-
- logger.debug("Added %s to build tracker %r", req, self._root)
-
- def remove(self, req: InstallRequirement) -> None:
- """Remove an InstallRequirement from build tracking."""
-
- assert req.link
- # Delete the created file and the corresponding entries.
- os.unlink(self._entry_path(req.link))
- self._entries.remove(req)
-
- logger.debug("Removed %s from build tracker %r", req, self._root)
-
- def cleanup(self) -> None:
- for req in set(self._entries):
- self.remove(req)
-
- logger.debug("Removed build tracker: %r", self._root)
-
- @contextlib.contextmanager
- def track(self, req: InstallRequirement) -> Generator[None, None, None]:
- self.add(req)
- yield
- self.remove(req)
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/utils/inject_securetransport.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/utils/inject_securetransport.py
deleted file mode 100644
index 276aa79bb81356cdca73af0a5851b448707784a4..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/utils/inject_securetransport.py
+++ /dev/null
@@ -1,35 +0,0 @@
-"""A helper module that injects SecureTransport, on import.
-
-The import should be done as early as possible, to ensure all requests and
-sessions (or whatever) are created after injecting SecureTransport.
-
-Note that we only do the injection on macOS, when the linked OpenSSL is too
-old to handle TLSv1.2.
-"""
-
-import sys
-
-
-def inject_securetransport() -> None:
- # Only relevant on macOS
- if sys.platform != "darwin":
- return
-
- try:
- import ssl
- except ImportError:
- return
-
- # Checks for OpenSSL 1.0.1
- if ssl.OPENSSL_VERSION_NUMBER >= 0x1000100F:
- return
-
- try:
- from pip._vendor.urllib3.contrib import securetransport
- except (ImportError, OSError):
- return
-
- securetransport.inject_into_urllib3()
-
-
-inject_securetransport()
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/command/sdist.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/command/sdist.py
deleted file mode 100644
index 4a8cde7e160df63093afed9b3b030ddfb76ddd05..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/command/sdist.py
+++ /dev/null
@@ -1,210 +0,0 @@
-from distutils import log
-import distutils.command.sdist as orig
-import os
-import sys
-import io
-import contextlib
-from itertools import chain
-
-from .py36compat import sdist_add_defaults
-
-from .._importlib import metadata
-from .build import _ORIGINAL_SUBCOMMANDS
-
-_default_revctrl = list
-
-
-def walk_revctrl(dirname=''):
- """Find all files under revision control"""
- for ep in metadata.entry_points(group='setuptools.file_finders'):
- for item in ep.load()(dirname):
- yield item
-
-
-class sdist(sdist_add_defaults, orig.sdist):
- """Smart sdist that finds anything supported by revision control"""
-
- user_options = [
- ('formats=', None,
- "formats for source distribution (comma-separated list)"),
- ('keep-temp', 'k',
- "keep the distribution tree around after creating " +
- "archive file(s)"),
- ('dist-dir=', 'd',
- "directory to put the source distribution archive(s) in "
- "[default: dist]"),
- ('owner=', 'u',
- "Owner name used when creating a tar file [default: current user]"),
- ('group=', 'g',
- "Group name used when creating a tar file [default: current group]"),
- ]
-
- negative_opt = {}
-
- README_EXTENSIONS = ['', '.rst', '.txt', '.md']
- READMES = tuple('README{0}'.format(ext) for ext in README_EXTENSIONS)
-
- def run(self):
- self.run_command('egg_info')
- ei_cmd = self.get_finalized_command('egg_info')
- self.filelist = ei_cmd.filelist
- self.filelist.append(os.path.join(ei_cmd.egg_info, 'SOURCES.txt'))
- self.check_readme()
-
- # Run sub commands
- for cmd_name in self.get_sub_commands():
- self.run_command(cmd_name)
-
- self.make_distribution()
-
- dist_files = getattr(self.distribution, 'dist_files', [])
- for file in self.archive_files:
- data = ('sdist', '', file)
- if data not in dist_files:
- dist_files.append(data)
-
- def initialize_options(self):
- orig.sdist.initialize_options(self)
-
- self._default_to_gztar()
-
- def _default_to_gztar(self):
- # only needed on Python prior to 3.6.
- if sys.version_info >= (3, 6, 0, 'beta', 1):
- return
- self.formats = ['gztar']
-
- def make_distribution(self):
- """
- Workaround for #516
- """
- with self._remove_os_link():
- orig.sdist.make_distribution(self)
-
- @staticmethod
- @contextlib.contextmanager
- def _remove_os_link():
- """
- In a context, remove and restore os.link if it exists
- """
-
- class NoValue:
- pass
-
- orig_val = getattr(os, 'link', NoValue)
- try:
- del os.link
- except Exception:
- pass
- try:
- yield
- finally:
- if orig_val is not NoValue:
- setattr(os, 'link', orig_val)
-
- def add_defaults(self):
- super().add_defaults()
- self._add_defaults_build_sub_commands()
-
- def _add_defaults_optional(self):
- super()._add_defaults_optional()
- if os.path.isfile('pyproject.toml'):
- self.filelist.append('pyproject.toml')
-
- def _add_defaults_python(self):
- """getting python files"""
- if self.distribution.has_pure_modules():
- build_py = self.get_finalized_command('build_py')
- self.filelist.extend(build_py.get_source_files())
- self._add_data_files(self._safe_data_files(build_py))
-
- def _add_defaults_build_sub_commands(self):
- build = self.get_finalized_command("build")
- missing_cmds = set(build.get_sub_commands()) - _ORIGINAL_SUBCOMMANDS
- # ^-- the original built-in sub-commands are already handled by default.
- cmds = (self.get_finalized_command(c) for c in missing_cmds)
- files = (c.get_source_files() for c in cmds if hasattr(c, "get_source_files"))
- self.filelist.extend(chain.from_iterable(files))
-
- def _safe_data_files(self, build_py):
- """
- Since the ``sdist`` class is also used to compute the MANIFEST
- (via :obj:`setuptools.command.egg_info.manifest_maker`),
- there might be recursion problems when trying to obtain the list of
- data_files and ``include_package_data=True`` (which in turn depends on
- the files included in the MANIFEST).
-
- To avoid that, ``manifest_maker`` should be able to overwrite this
- method and avoid recursive attempts to build/analyze the MANIFEST.
- """
- return build_py.data_files
-
- def _add_data_files(self, data_files):
- """
- Add data files as found in build_py.data_files.
- """
- self.filelist.extend(
- os.path.join(src_dir, name)
- for _, src_dir, _, filenames in data_files
- for name in filenames
- )
-
- def _add_defaults_data_files(self):
- try:
- super()._add_defaults_data_files()
- except TypeError:
- log.warn("data_files contains unexpected objects")
-
- def check_readme(self):
- for f in self.READMES:
- if os.path.exists(f):
- return
- else:
- self.warn(
- "standard file not found: should have one of " +
- ', '.join(self.READMES)
- )
-
- def make_release_tree(self, base_dir, files):
- orig.sdist.make_release_tree(self, base_dir, files)
-
- # Save any egg_info command line options used to create this sdist
- dest = os.path.join(base_dir, 'setup.cfg')
- if hasattr(os, 'link') and os.path.exists(dest):
- # unlink and re-copy, since it might be hard-linked, and
- # we don't want to change the source version
- os.unlink(dest)
- self.copy_file('setup.cfg', dest)
-
- self.get_finalized_command('egg_info').save_version_info(dest)
-
- def _manifest_is_not_generated(self):
- # check for special comment used in 2.7.1 and higher
- if not os.path.isfile(self.manifest):
- return False
-
- with io.open(self.manifest, 'rb') as fp:
- first_line = fp.readline()
- return (first_line !=
- '# file GENERATED by distutils, do NOT edit\n'.encode())
-
- def read_manifest(self):
- """Read the manifest file (named by 'self.manifest') and use it to
- fill in 'self.filelist', the list of files to include in the source
- distribution.
- """
- log.info("reading manifest file '%s'", self.manifest)
- manifest = open(self.manifest, 'rb')
- for line in manifest:
- # The manifest must contain UTF-8. See #303.
- try:
- line = line.decode('UTF-8')
- except UnicodeDecodeError:
- log.warn("%r not UTF-8 decodable -- skipping" % line)
- continue
- # ignore comments and blank lines
- line = line.strip()
- if line.startswith('#') or not line:
- continue
- self.filelist.append(line)
- manifest.close()
diff --git a/spaces/BongoCaat/ArtGenerator/README.md b/spaces/BongoCaat/ArtGenerator/README.md
deleted file mode 100644
index f4e1ae012844a860ccefcbd3b61859e8f2afa10a..0000000000000000000000000000000000000000
--- a/spaces/BongoCaat/ArtGenerator/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: ArtGenerator
-emoji: 🏃
-colorFrom: red
-colorTo: red
-sdk: gradio
-sdk_version: 3.29.0
-app_file: app.py
-pinned: false
-license: gpl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/proposal_generator/rpn.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/proposal_generator/rpn.py
deleted file mode 100644
index 8999b82c0894cb357b652f175ade5a78f3b5c2db..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/proposal_generator/rpn.py
+++ /dev/null
@@ -1,185 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-from typing import Dict, List
-import torch
-import torch.nn.functional as F
-from torch import nn
-
-from detectron2.layers import ShapeSpec
-from detectron2.utils.registry import Registry
-
-from ..anchor_generator import build_anchor_generator
-from ..box_regression import Box2BoxTransform
-from ..matcher import Matcher
-from .build import PROPOSAL_GENERATOR_REGISTRY
-from .rpn_outputs import RPNOutputs, find_top_rpn_proposals
-
-RPN_HEAD_REGISTRY = Registry("RPN_HEAD")
-RPN_HEAD_REGISTRY.__doc__ = """
-Registry for RPN heads, which take feature maps and perform
-objectness classification and bounding box regression for anchors.
-
-The registered object will be called with `obj(cfg, input_shape)`.
-The call should return a `nn.Module` object.
-"""
-
-
-def build_rpn_head(cfg, input_shape):
- """
- Build an RPN head defined by `cfg.MODEL.RPN.HEAD_NAME`.
- """
- name = cfg.MODEL.RPN.HEAD_NAME
- return RPN_HEAD_REGISTRY.get(name)(cfg, input_shape)
-
-
-@RPN_HEAD_REGISTRY.register()
-class StandardRPNHead(nn.Module):
- """
- RPN classification and regression heads. Uses a 3x3 conv to produce a shared
- hidden state from which one 1x1 conv predicts objectness logits for each anchor
- and a second 1x1 conv predicts bounding-box deltas specifying how to deform
- each anchor into an object proposal.
- """
-
- def __init__(self, cfg, input_shape: List[ShapeSpec]):
- super().__init__()
-
- # Standard RPN is shared across levels:
- in_channels = [s.channels for s in input_shape]
- assert len(set(in_channels)) == 1, "Each level must have the same channel!"
- in_channels = in_channels[0]
-
- # RPNHead should take the same input as anchor generator
- # NOTE: it assumes that creating an anchor generator does not have unwanted side effect.
- anchor_generator = build_anchor_generator(cfg, input_shape)
- num_cell_anchors = anchor_generator.num_cell_anchors
- box_dim = anchor_generator.box_dim
- assert (
- len(set(num_cell_anchors)) == 1
- ), "Each level must have the same number of cell anchors"
- num_cell_anchors = num_cell_anchors[0]
-
- # 3x3 conv for the hidden representation
- self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
- # 1x1 conv for predicting objectness logits
- self.objectness_logits = nn.Conv2d(in_channels, num_cell_anchors, kernel_size=1, stride=1)
- # 1x1 conv for predicting box2box transform deltas
- self.anchor_deltas = nn.Conv2d(
- in_channels, num_cell_anchors * box_dim, kernel_size=1, stride=1
- )
-
- for l in [self.conv, self.objectness_logits, self.anchor_deltas]:
- nn.init.normal_(l.weight, std=0.01)
- nn.init.constant_(l.bias, 0)
-
- def forward(self, features):
- """
- Args:
- features (list[Tensor]): list of feature maps
- """
- pred_objectness_logits = []
- pred_anchor_deltas = []
- for x in features:
- t = F.relu(self.conv(x))
- pred_objectness_logits.append(self.objectness_logits(t))
- pred_anchor_deltas.append(self.anchor_deltas(t))
- return pred_objectness_logits, pred_anchor_deltas
-
-
-@PROPOSAL_GENERATOR_REGISTRY.register()
-class RPN(nn.Module):
- """
- Region Proposal Network, introduced by the Faster R-CNN paper.
- """
-
- def __init__(self, cfg, input_shape: Dict[str, ShapeSpec]):
- super().__init__()
-
- # fmt: off
- self.min_box_side_len = cfg.MODEL.PROPOSAL_GENERATOR.MIN_SIZE
- self.in_features = cfg.MODEL.RPN.IN_FEATURES
- self.nms_thresh = cfg.MODEL.RPN.NMS_THRESH
- self.batch_size_per_image = cfg.MODEL.RPN.BATCH_SIZE_PER_IMAGE
- self.positive_fraction = cfg.MODEL.RPN.POSITIVE_FRACTION
- self.smooth_l1_beta = cfg.MODEL.RPN.SMOOTH_L1_BETA
- self.loss_weight = cfg.MODEL.RPN.LOSS_WEIGHT
- # fmt: on
-
- # Map from self.training state to train/test settings
- self.pre_nms_topk = {
- True: cfg.MODEL.RPN.PRE_NMS_TOPK_TRAIN,
- False: cfg.MODEL.RPN.PRE_NMS_TOPK_TEST,
- }
- self.post_nms_topk = {
- True: cfg.MODEL.RPN.POST_NMS_TOPK_TRAIN,
- False: cfg.MODEL.RPN.POST_NMS_TOPK_TEST,
- }
- self.boundary_threshold = cfg.MODEL.RPN.BOUNDARY_THRESH
-
- self.anchor_generator = build_anchor_generator(
- cfg, [input_shape[f] for f in self.in_features]
- )
- self.box2box_transform = Box2BoxTransform(weights=cfg.MODEL.RPN.BBOX_REG_WEIGHTS)
- self.anchor_matcher = Matcher(
- cfg.MODEL.RPN.IOU_THRESHOLDS, cfg.MODEL.RPN.IOU_LABELS, allow_low_quality_matches=True
- )
- self.rpn_head = build_rpn_head(cfg, [input_shape[f] for f in self.in_features])
-
- def forward(self, images, features, gt_instances=None):
- """
- Args:
- images (ImageList): input images of length `N`
- features (dict[str: Tensor]): input data as a mapping from feature
- map name to tensor. Axis 0 represents the number of images `N` in
- the input data; axes 1-3 are channels, height, and width, which may
- vary between feature maps (e.g., if a feature pyramid is used).
- gt_instances (list[Instances], optional): a length `N` list of `Instances`s.
- Each `Instances` stores ground-truth instances for the corresponding image.
-
- Returns:
- proposals: list[Instances]: contains fields "proposal_boxes", "objectness_logits"
- loss: dict[Tensor] or None
- """
- gt_boxes = [x.gt_boxes for x in gt_instances] if gt_instances is not None else None
- del gt_instances
- features = [features[f] for f in self.in_features]
- pred_objectness_logits, pred_anchor_deltas = self.rpn_head(features)
- anchors = self.anchor_generator(features)
- # TODO: The anchors only depend on the feature map shape; there's probably
- # an opportunity for some optimizations (e.g., caching anchors).
- outputs = RPNOutputs(
- self.box2box_transform,
- self.anchor_matcher,
- self.batch_size_per_image,
- self.positive_fraction,
- images,
- pred_objectness_logits,
- pred_anchor_deltas,
- anchors,
- self.boundary_threshold,
- gt_boxes,
- self.smooth_l1_beta,
- )
-
- if self.training:
- losses = {k: v * self.loss_weight for k, v in outputs.losses().items()}
- else:
- losses = {}
-
- with torch.no_grad():
- # Find the top proposals by applying NMS and removing boxes that
- # are too small. The proposals are treated as fixed for approximate
- # joint training with roi heads. This approach ignores the derivative
- # w.r.t. the proposal boxes’ coordinates that are also network
- # responses, so is approximate.
- proposals = find_top_rpn_proposals(
- outputs.predict_proposals(),
- outputs.predict_objectness_logits(),
- images,
- self.nms_thresh,
- self.pre_nms_topk[self.training],
- self.post_nms_topk[self.training],
- self.min_box_side_len,
- self.training,
- )
-
- return proposals, losses
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/densepose/__init__.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/densepose/__init__.py
deleted file mode 100644
index f9d3562e922561ada495d4944e09e384de54b81c..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/densepose/__init__.py
+++ /dev/null
@@ -1,10 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-from . import dataset # just to register data
-from .config import add_densepose_config
-from .dataset_mapper import DatasetMapper
-from .densepose_head import ROI_DENSEPOSE_HEAD_REGISTRY
-from .evaluator import DensePoseCOCOEvaluator
-from .roi_head import DensePoseROIHeads
-from .structures import DensePoseDataRelative, DensePoseList, DensePoseTransformData
-from .modeling.test_time_augmentation import DensePoseGeneralizedRCNNWithTTA
-from .utils.transform import load_from_cfg
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/tests/test_setup.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/tests/test_setup.py
deleted file mode 100644
index 8596cf233e25158a9cacfda7ee33d15ca3acfb0e..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/tests/test_setup.py
+++ /dev/null
@@ -1,20 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-
-import unittest
-
-from .common import get_config_files, get_quick_schedules_config_files, setup
-
-
-class TestSetup(unittest.TestCase):
- def _test_setup(self, config_file):
- setup(config_file)
-
- def test_setup_configs(self):
- config_files = get_config_files()
- for config_file in config_files:
- self._test_setup(config_file)
-
- def test_setup_quick_schedules_configs(self):
- config_files = get_quick_schedules_config_files()
- for config_file in config_files:
- self._test_setup(config_file)
diff --git a/spaces/CVPR/LIVE/pybind11/tests/test_stl_binders.py b/spaces/CVPR/LIVE/pybind11/tests/test_stl_binders.py
deleted file mode 100644
index f9b8ea4af2a3156ecb09dd9d61d3464bb85ceefb..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/pybind11/tests/test_stl_binders.py
+++ /dev/null
@@ -1,285 +0,0 @@
-# -*- coding: utf-8 -*-
-import pytest
-
-import env # noqa: F401
-
-from pybind11_tests import stl_binders as m
-
-
-def test_vector_int():
- v_int = m.VectorInt([0, 0])
- assert len(v_int) == 2
- assert bool(v_int) is True
-
- # test construction from a generator
- v_int1 = m.VectorInt(x for x in range(5))
- assert v_int1 == m.VectorInt([0, 1, 2, 3, 4])
-
- v_int2 = m.VectorInt([0, 0])
- assert v_int == v_int2
- v_int2[1] = 1
- assert v_int != v_int2
-
- v_int2.append(2)
- v_int2.insert(0, 1)
- v_int2.insert(0, 2)
- v_int2.insert(0, 3)
- v_int2.insert(6, 3)
- assert str(v_int2) == "VectorInt[3, 2, 1, 0, 1, 2, 3]"
- with pytest.raises(IndexError):
- v_int2.insert(8, 4)
-
- v_int.append(99)
- v_int2[2:-2] = v_int
- assert v_int2 == m.VectorInt([3, 2, 0, 0, 99, 2, 3])
- del v_int2[1:3]
- assert v_int2 == m.VectorInt([3, 0, 99, 2, 3])
- del v_int2[0]
- assert v_int2 == m.VectorInt([0, 99, 2, 3])
-
- v_int2.extend(m.VectorInt([4, 5]))
- assert v_int2 == m.VectorInt([0, 99, 2, 3, 4, 5])
-
- v_int2.extend([6, 7])
- assert v_int2 == m.VectorInt([0, 99, 2, 3, 4, 5, 6, 7])
-
- # test error handling, and that the vector is unchanged
- with pytest.raises(RuntimeError):
- v_int2.extend([8, 'a'])
-
- assert v_int2 == m.VectorInt([0, 99, 2, 3, 4, 5, 6, 7])
-
- # test extending from a generator
- v_int2.extend(x for x in range(5))
- assert v_int2 == m.VectorInt([0, 99, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4])
-
- # test negative indexing
- assert v_int2[-1] == 4
-
- # insert with negative index
- v_int2.insert(-1, 88)
- assert v_int2 == m.VectorInt([0, 99, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 88, 4])
-
- # delete negative index
- del v_int2[-1]
- assert v_int2 == m.VectorInt([0, 99, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 88])
-
- v_int2.clear()
- assert len(v_int2) == 0
-
-
-# Older PyPy's failed here, related to the PyPy's buffer protocol.
-def test_vector_buffer():
- b = bytearray([1, 2, 3, 4])
- v = m.VectorUChar(b)
- assert v[1] == 2
- v[2] = 5
- mv = memoryview(v) # We expose the buffer interface
- if not env.PY2:
- assert mv[2] == 5
- mv[2] = 6
- else:
- assert mv[2] == '\x05'
- mv[2] = '\x06'
- assert v[2] == 6
-
- if not env.PY2:
- mv = memoryview(b)
- v = m.VectorUChar(mv[::2])
- assert v[1] == 3
-
- with pytest.raises(RuntimeError) as excinfo:
- m.create_undeclstruct() # Undeclared struct contents, no buffer interface
- assert "NumPy type info missing for " in str(excinfo.value)
-
-
-def test_vector_buffer_numpy():
- np = pytest.importorskip("numpy")
- a = np.array([1, 2, 3, 4], dtype=np.int32)
- with pytest.raises(TypeError):
- m.VectorInt(a)
-
- a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]], dtype=np.uintc)
- v = m.VectorInt(a[0, :])
- assert len(v) == 4
- assert v[2] == 3
- ma = np.asarray(v)
- ma[2] = 5
- assert v[2] == 5
-
- v = m.VectorInt(a[:, 1])
- assert len(v) == 3
- assert v[2] == 10
-
- v = m.get_vectorstruct()
- assert v[0].x == 5
- ma = np.asarray(v)
- ma[1]['x'] = 99
- assert v[1].x == 99
-
- v = m.VectorStruct(np.zeros(3, dtype=np.dtype([('w', 'bool'), ('x', 'I'),
- ('y', 'float64'), ('z', 'bool')], align=True)))
- assert len(v) == 3
-
- b = np.array([1, 2, 3, 4], dtype=np.uint8)
- v = m.VectorUChar(b[::2])
- assert v[1] == 3
-
-
-def test_vector_bool():
- import pybind11_cross_module_tests as cm
-
- vv_c = cm.VectorBool()
- for i in range(10):
- vv_c.append(i % 2 == 0)
- for i in range(10):
- assert vv_c[i] == (i % 2 == 0)
- assert str(vv_c) == "VectorBool[1, 0, 1, 0, 1, 0, 1, 0, 1, 0]"
-
-
-def test_vector_custom():
- v_a = m.VectorEl()
- v_a.append(m.El(1))
- v_a.append(m.El(2))
- assert str(v_a) == "VectorEl[El{1}, El{2}]"
-
- vv_a = m.VectorVectorEl()
- vv_a.append(v_a)
- vv_b = vv_a[0]
- assert str(vv_b) == "VectorEl[El{1}, El{2}]"
-
-
-def test_map_string_double():
- mm = m.MapStringDouble()
- mm['a'] = 1
- mm['b'] = 2.5
-
- assert list(mm) == ['a', 'b']
- assert list(mm.items()) == [('a', 1), ('b', 2.5)]
- assert str(mm) == "MapStringDouble{a: 1, b: 2.5}"
-
- um = m.UnorderedMapStringDouble()
- um['ua'] = 1.1
- um['ub'] = 2.6
-
- assert sorted(list(um)) == ['ua', 'ub']
- assert sorted(list(um.items())) == [('ua', 1.1), ('ub', 2.6)]
- assert "UnorderedMapStringDouble" in str(um)
-
-
-def test_map_string_double_const():
- mc = m.MapStringDoubleConst()
- mc['a'] = 10
- mc['b'] = 20.5
- assert str(mc) == "MapStringDoubleConst{a: 10, b: 20.5}"
-
- umc = m.UnorderedMapStringDoubleConst()
- umc['a'] = 11
- umc['b'] = 21.5
-
- str(umc)
-
-
-def test_noncopyable_containers():
- # std::vector
- vnc = m.get_vnc(5)
- for i in range(0, 5):
- assert vnc[i].value == i + 1
-
- for i, j in enumerate(vnc, start=1):
- assert j.value == i
-
- # std::deque
- dnc = m.get_dnc(5)
- for i in range(0, 5):
- assert dnc[i].value == i + 1
-
- i = 1
- for j in dnc:
- assert(j.value == i)
- i += 1
-
- # std::map
- mnc = m.get_mnc(5)
- for i in range(1, 6):
- assert mnc[i].value == 10 * i
-
- vsum = 0
- for k, v in mnc.items():
- assert v.value == 10 * k
- vsum += v.value
-
- assert vsum == 150
-
- # std::unordered_map
- mnc = m.get_umnc(5)
- for i in range(1, 6):
- assert mnc[i].value == 10 * i
-
- vsum = 0
- for k, v in mnc.items():
- assert v.value == 10 * k
- vsum += v.value
-
- assert vsum == 150
-
- # nested std::map
- nvnc = m.get_nvnc(5)
- for i in range(1, 6):
- for j in range(0, 5):
- assert nvnc[i][j].value == j + 1
-
- # Note: maps do not have .values()
- for _, v in nvnc.items():
- for i, j in enumerate(v, start=1):
- assert j.value == i
-
- # nested std::map
- nmnc = m.get_nmnc(5)
- for i in range(1, 6):
- for j in range(10, 60, 10):
- assert nmnc[i][j].value == 10 * j
-
- vsum = 0
- for _, v_o in nmnc.items():
- for k_i, v_i in v_o.items():
- assert v_i.value == 10 * k_i
- vsum += v_i.value
-
- assert vsum == 7500
-
- # nested std::unordered_map
- numnc = m.get_numnc(5)
- for i in range(1, 6):
- for j in range(10, 60, 10):
- assert numnc[i][j].value == 10 * j
-
- vsum = 0
- for _, v_o in numnc.items():
- for k_i, v_i in v_o.items():
- assert v_i.value == 10 * k_i
- vsum += v_i.value
-
- assert vsum == 7500
-
-
-def test_map_delitem():
- mm = m.MapStringDouble()
- mm['a'] = 1
- mm['b'] = 2.5
-
- assert list(mm) == ['a', 'b']
- assert list(mm.items()) == [('a', 1), ('b', 2.5)]
- del mm['a']
- assert list(mm) == ['b']
- assert list(mm.items()) == [('b', 2.5)]
-
- um = m.UnorderedMapStringDouble()
- um['ua'] = 1.1
- um['ub'] = 2.6
-
- assert sorted(list(um)) == ['ua', 'ub']
- assert sorted(list(um.items())) == [('ua', 1.1), ('ub', 2.6)]
- del um['ua']
- assert sorted(list(um)) == ['ub']
- assert sorted(list(um.items())) == [('ub', 2.6)]
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/omp/detail/logical.h b/spaces/CVPR/LIVE/thrust/thrust/system/omp/detail/logical.h
deleted file mode 100644
index 4199063183dbc38b79c7707bb8301e5ca8aa6ad5..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/omp/detail/logical.h
+++ /dev/null
@@ -1,23 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// this system inherits logical
-#include
-
diff --git a/spaces/CVPR/transfiner/configs/common/models/keypoint_rcnn_fpn.py b/spaces/CVPR/transfiner/configs/common/models/keypoint_rcnn_fpn.py
deleted file mode 100644
index 56b3994df249884d4816fc9a5c7f553a9ab6f400..0000000000000000000000000000000000000000
--- a/spaces/CVPR/transfiner/configs/common/models/keypoint_rcnn_fpn.py
+++ /dev/null
@@ -1,33 +0,0 @@
-from detectron2.config import LazyCall as L
-from detectron2.layers import ShapeSpec
-from detectron2.modeling.poolers import ROIPooler
-from detectron2.modeling.roi_heads import KRCNNConvDeconvUpsampleHead
-
-from .mask_rcnn_fpn import model
-
-[model.roi_heads.pop(x) for x in ["mask_in_features", "mask_pooler", "mask_head"]]
-
-model.roi_heads.update(
- num_classes=1,
- keypoint_in_features=["p2", "p3", "p4", "p5"],
- keypoint_pooler=L(ROIPooler)(
- output_size=14,
- scales=(1.0 / 4, 1.0 / 8, 1.0 / 16, 1.0 / 32),
- sampling_ratio=0,
- pooler_type="ROIAlignV2",
- ),
- keypoint_head=L(KRCNNConvDeconvUpsampleHead)(
- input_shape=ShapeSpec(channels=256, width=14, height=14),
- num_keypoints=17,
- conv_dims=[512] * 8,
- loss_normalizer="visible",
- ),
-)
-
-# Detectron1 uses 2000 proposals per-batch, but this option is per-image in detectron2.
-# 1000 proposals per-image is found to hurt box AP.
-# Therefore we increase it to 1500 per-image.
-model.proposal_generator.post_nms_topk = (1500, 1000)
-
-# Keypoint AP degrades (though box AP improves) when using plain L1 loss
-model.roi_heads.box_predictor.smooth_l1_beta = 0.5
diff --git a/spaces/ChandraMohanNayal/AutoGPT/autogpt/json_utils/json_fix_general.py b/spaces/ChandraMohanNayal/AutoGPT/autogpt/json_utils/json_fix_general.py
deleted file mode 100644
index 7010fa3b9c1909de0e5a7f6ec13ca8aa418fe6c7..0000000000000000000000000000000000000000
--- a/spaces/ChandraMohanNayal/AutoGPT/autogpt/json_utils/json_fix_general.py
+++ /dev/null
@@ -1,124 +0,0 @@
-"""This module contains functions to fix JSON strings using general programmatic approaches, suitable for addressing
-common JSON formatting issues."""
-from __future__ import annotations
-
-import contextlib
-import json
-import re
-from typing import Optional
-
-from autogpt.config import Config
-from autogpt.json_utils.utilities import extract_char_position
-
-CFG = Config()
-
-
-def fix_invalid_escape(json_to_load: str, error_message: str) -> str:
- """Fix invalid escape sequences in JSON strings.
-
- Args:
- json_to_load (str): The JSON string.
- error_message (str): The error message from the JSONDecodeError
- exception.
-
- Returns:
- str: The JSON string with invalid escape sequences fixed.
- """
- while error_message.startswith("Invalid \\escape"):
- bad_escape_location = extract_char_position(error_message)
- json_to_load = (
- json_to_load[:bad_escape_location] + json_to_load[bad_escape_location + 1 :]
- )
- try:
- json.loads(json_to_load)
- return json_to_load
- except json.JSONDecodeError as e:
- if CFG.debug_mode:
- print("json loads error - fix invalid escape", e)
- error_message = str(e)
- return json_to_load
-
-
-def balance_braces(json_string: str) -> Optional[str]:
- """
- Balance the braces in a JSON string.
-
- Args:
- json_string (str): The JSON string.
-
- Returns:
- str: The JSON string with braces balanced.
- """
-
- open_braces_count = json_string.count("{")
- close_braces_count = json_string.count("}")
-
- while open_braces_count > close_braces_count:
- json_string += "}"
- close_braces_count += 1
-
- while close_braces_count > open_braces_count:
- json_string = json_string.rstrip("}")
- close_braces_count -= 1
-
- with contextlib.suppress(json.JSONDecodeError):
- json.loads(json_string)
- return json_string
-
-
-def add_quotes_to_property_names(json_string: str) -> str:
- """
- Add quotes to property names in a JSON string.
-
- Args:
- json_string (str): The JSON string.
-
- Returns:
- str: The JSON string with quotes added to property names.
- """
-
- def replace_func(match: re.Match) -> str:
- return f'"{match[1]}":'
-
- property_name_pattern = re.compile(r"(\w+):")
- corrected_json_string = property_name_pattern.sub(replace_func, json_string)
-
- try:
- json.loads(corrected_json_string)
- return corrected_json_string
- except json.JSONDecodeError as e:
- raise e
-
-
-def correct_json(json_to_load: str) -> str:
- """
- Correct common JSON errors.
- Args:
- json_to_load (str): The JSON string.
- """
-
- try:
- if CFG.debug_mode:
- print("json", json_to_load)
- json.loads(json_to_load)
- return json_to_load
- except json.JSONDecodeError as e:
- if CFG.debug_mode:
- print("json loads error", e)
- error_message = str(e)
- if error_message.startswith("Invalid \\escape"):
- json_to_load = fix_invalid_escape(json_to_load, error_message)
- if error_message.startswith(
- "Expecting property name enclosed in double quotes"
- ):
- json_to_load = add_quotes_to_property_names(json_to_load)
- try:
- json.loads(json_to_load)
- return json_to_load
- except json.JSONDecodeError as e:
- if CFG.debug_mode:
- print("json loads error - add quotes", e)
- error_message = str(e)
- if balanced_str := balance_braces(json_to_load):
- return balanced_str
- return json_to_load
diff --git a/spaces/ChrisPreston/diff-svc_minato_aqua/infer_tools/trans_key.py b/spaces/ChrisPreston/diff-svc_minato_aqua/infer_tools/trans_key.py
deleted file mode 100644
index dc4f30aa054ee20b228c193fa115f767cbbf7055..0000000000000000000000000000000000000000
--- a/spaces/ChrisPreston/diff-svc_minato_aqua/infer_tools/trans_key.py
+++ /dev/null
@@ -1,67 +0,0 @@
-import os
-head_list = ["C", "C#", "D", "D#", "E", "F", "F#", "G", "G#", "A", "A#", "B"]
-
-
-def trans_f0_seq(feature_pit, transform):
- feature_pit = feature_pit * 2 ** (transform / 12)
- return round(feature_pit, 1)
-
-
-def move_key(raw_data, mv_key):
- head = raw_data[:-1]
- body = int(raw_data[-1])
- new_head_index = head_list.index(head) + mv_key
- while new_head_index < 0:
- body -= 1
- new_head_index += 12
- while new_head_index > 11:
- body += 1
- new_head_index -= 12
- result_data = head_list[new_head_index] + str(body)
- return result_data
-
-
-def trans_key(raw_data, key):
- for i in raw_data:
- note_seq_list = i["note_seq"].split(" ")
- new_note_seq_list = []
- for note_seq in note_seq_list:
- if note_seq != "rest":
- new_note_seq = move_key(note_seq, key)
- new_note_seq_list.append(new_note_seq)
- else:
- new_note_seq_list.append(note_seq)
- i["note_seq"] = " ".join(new_note_seq_list)
-
- f0_seq_list = i["f0_seq"].split(" ")
- f0_seq_list = [float(x) for x in f0_seq_list]
- new_f0_seq_list = []
- for f0_seq in f0_seq_list:
- new_f0_seq = trans_f0_seq(f0_seq, key)
- new_f0_seq_list.append(str(new_f0_seq))
- i["f0_seq"] = " ".join(new_f0_seq_list)
- return raw_data
-
-
-def trans_opencpop(raw_txt, res_txt, key):
- if os.path.exists(raw_txt):
- f_w = open(res_txt, "w", encoding='utf-8')
- with open(raw_txt, "r", encoding='utf-8') as f:
- raw_data = f.readlines()
- for raw in raw_data:
- raw_list = raw.split("|")
- new_note_seq_list = []
- for note_seq in raw_list[3].split(" "):
- if note_seq != "rest":
- note_seq = note_seq.split("/")[0] if "/" in note_seq else note_seq
- new_note_seq = move_key(note_seq, key)
- new_note_seq_list.append(new_note_seq)
- else:
- new_note_seq_list.append(note_seq)
- raw_list[3] = " ".join(new_note_seq_list)
- f_w.write("|".join(raw_list))
- f_w.close()
- print("opencpop标注文件转换完毕")
- else:
- print("未发现opencpop标注文件,请检查路径")
-
diff --git a/spaces/Codecooker/rvcapi/src/webui.py b/spaces/Codecooker/rvcapi/src/webui.py
deleted file mode 100644
index 97a6f84f25cfd2e5cc418d1963f2f34780f31825..0000000000000000000000000000000000000000
--- a/spaces/Codecooker/rvcapi/src/webui.py
+++ /dev/null
@@ -1,309 +0,0 @@
-import json
-import os
-os.system("pip install torchcrepe")
-os.system("pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu")
-import shutil
-import urllib.request
-import zipfile
-from argparse import ArgumentParser
-
-import gradio as gr
-
-from main import song_cover_pipeline
-
-BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
-
-mdxnet_models_dir = os.path.join(BASE_DIR, 'mdxnet_models')
-rvc_models_dir = os.path.join(BASE_DIR, 'rvc_models')
-output_dir = os.path.join(BASE_DIR, 'song_output')
-
-
-def get_current_models(models_dir):
- models_list = os.listdir(models_dir)
- items_to_remove = ['hubert_base.pt', 'MODELS.txt', 'public_models.json', 'rmvpe.pt']
- return [item for item in models_list if item not in items_to_remove]
-
-
-def update_models_list():
- models_l = get_current_models(rvc_models_dir)
- return gr.Dropdown.update(choices=models_l)
-
-
-def load_public_models():
- models_table = []
- for model in public_models['voice_models']:
- if not model['name'] in voice_models:
- model = [model['name'], model['description'], model['credit'], model['url'], ', '.join(model['tags'])]
- models_table.append(model)
-
- tags = list(public_models['tags'].keys())
- return gr.DataFrame.update(value=models_table), gr.CheckboxGroup.update(choices=tags)
-
-
-def extract_zip(extraction_folder, zip_name):
- os.makedirs(extraction_folder)
- with zipfile.ZipFile(zip_name, 'r') as zip_ref:
- zip_ref.extractall(extraction_folder)
- os.remove(zip_name)
-
- index_filepath, model_filepath = None, None
- for root, dirs, files in os.walk(extraction_folder):
- for name in files:
- if name.endswith('.index'):
- index_filepath = os.path.join(root, name)
-
- if name.endswith('.pth'):
- model_filepath = os.path.join(root, name)
-
- if not model_filepath:
- raise gr.Error(f'No .pth model file was found in the extracted zip. Please check {extraction_folder}.')
-
- # move model and index file to extraction folder
- os.rename(model_filepath, os.path.join(extraction_folder, os.path.basename(model_filepath)))
- if index_filepath:
- os.rename(index_filepath, os.path.join(extraction_folder, os.path.basename(index_filepath)))
-
- # remove any unnecessary nested folders
- for filepath in os.listdir(extraction_folder):
- if os.path.isdir(os.path.join(extraction_folder, filepath)):
- shutil.rmtree(os.path.join(extraction_folder, filepath))
-
-
-def download_online_model(url, dir_name, progress=gr.Progress()):
- try:
- progress(0, desc=f'[~] Downloading voice model with name {dir_name}...')
- zip_name = url.split('/')[-1]
- extraction_folder = os.path.join(rvc_models_dir, dir_name)
- if os.path.exists(extraction_folder):
- raise gr.Error(f'Voice model directory {dir_name} already exists! Choose a different name for your voice model.')
-
- if 'pixeldrain.com' in url:
- url = f'https://pixeldrain.com/api/file/{zip_name}'
-
- urllib.request.urlretrieve(url, zip_name)
-
- progress(0.5, desc='[~] Extracting zip...')
- extract_zip(extraction_folder, zip_name)
- return f'[+] {dir_name} Model successfully downloaded!'
-
- except Exception as e:
- raise gr.Error(str(e))
-
-
-def upload_local_model(zip_path, dir_name, progress=gr.Progress()):
- try:
- extraction_folder = os.path.join(rvc_models_dir, dir_name)
- if os.path.exists(extraction_folder):
- raise gr.Error(f'Voice model directory {dir_name} already exists! Choose a different name for your voice model.')
-
- zip_name = zip_path.name
- progress(0.5, desc='[~] Extracting zip...')
- extract_zip(extraction_folder, zip_name)
- return f'[+] {dir_name} Model successfully uploaded!'
-
- except Exception as e:
- raise gr.Error(str(e))
-
-
-def filter_models(tags, query):
- models_table = []
-
- # no filter
- if len(tags) == 0 and len(query) == 0:
- for model in public_models['voice_models']:
- models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
-
- # filter based on tags and query
- elif len(tags) > 0 and len(query) > 0:
- for model in public_models['voice_models']:
- if all(tag in model['tags'] for tag in tags):
- model_attributes = f"{model['name']} {model['description']} {model['credit']} {' '.join(model['tags'])}".lower()
- if query.lower() in model_attributes:
- models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
-
- # filter based on only tags
- elif len(tags) > 0:
- for model in public_models['voice_models']:
- if all(tag in model['tags'] for tag in tags):
- models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
-
- # filter based on only query
- else:
- for model in public_models['voice_models']:
- model_attributes = f"{model['name']} {model['description']} {model['credit']} {' '.join(model['tags'])}".lower()
- if query.lower() in model_attributes:
- models_table.append([model['name'], model['description'], model['credit'], model['url'], model['tags']])
-
- return gr.DataFrame.update(value=models_table)
-
-
-def pub_dl_autofill(pub_models, event: gr.SelectData):
- return gr.Text.update(value=pub_models.loc[event.index[0], 'URL']), gr.Text.update(value=pub_models.loc[event.index[0], 'Model Name'])
-
-
-def swap_visibility():
- return gr.update(visible=True), gr.update(visible=False), gr.update(value=''), gr.update(value=None)
-
-
-def process_file_upload(file):
- return file.name, gr.update(value=file.name)
-
-
-if __name__ == '__main__':
- os.system("pip install torchcrepe")
- os.system("pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu")
- parser = ArgumentParser(description='Generate a AI cover song in the song_output/id directory.', add_help=True)
- parser.add_argument("--share", action="store_true", dest="share_enabled", default=False, help="Enable sharing")
- parser.add_argument("--listen", action="store_true", default=False, help="Make the WebUI reachable from your local network.")
- parser.add_argument('--listen-host', type=str, help='The hostname that the server will use.')
- parser.add_argument('--listen-port', type=int, help='The listening port that the server will use.')
- args = parser.parse_args()
-
- voice_models = get_current_models(rvc_models_dir)
- with open(os.path.join(rvc_models_dir, 'public_models.json'), encoding='utf8') as infile:
- public_models = json.load(infile)
-
- with gr.Blocks(title='AICoverGenWebUI') as app:
-
- gr.Label('AICoverGen WebUI created with ❤️', show_label=False)
-
- # main tab
- with gr.Tab("Generate"):
-
- with gr.Accordion('Main Options'):
- with gr.Row():
- with gr.Column():
- rvc_model = gr.Dropdown(voice_models, label='Voice Models', info='Models folder "AICoverGen --> rvc_models". After new models are added into this folder, click the refresh button')
- ref_btn = gr.Button('Refresh Models 🔁', variant='primary')
-
- with gr.Column() as yt_link_col:
- song_input = gr.Text(label='Song input', info='Link to a song on YouTube or full path to a local file. For file upload, click the button below.')
- show_file_upload_button = gr.Button('Upload file instead')
-
- with gr.Column(visible=False) as file_upload_col:
- local_file = gr.File(label='Audio file')
- song_input_file = gr.UploadButton('Upload 📂', file_types=['audio'], variant='primary')
- show_yt_link_button = gr.Button('Paste YouTube link/Path to local file instead')
- song_input_file.upload(process_file_upload, inputs=[song_input_file], outputs=[local_file, song_input])
-
- pitch = gr.Slider(-24, 24, value=0, step=1, label='Pitch Change', info='Pitch Change should be set to either -12, 0, or 12 (multiples of 12) to ensure the vocals are not out of tune')
- show_file_upload_button.click(swap_visibility, outputs=[file_upload_col, yt_link_col, song_input, local_file])
- show_yt_link_button.click(swap_visibility, outputs=[yt_link_col, file_upload_col, song_input, local_file])
-
- with gr.Accordion('Voice conversion options', open=False):
- with gr.Row():
- index_rate = gr.Slider(0, 1, value=0.5, label='Index Rate', info="Controls how much of the AI voice's accent to keep in the vocals")
- filter_radius = gr.Slider(0, 7, value=3, step=1, label='Filter radius', info='If >=3: apply median filtering median filtering to the harvested pitch results. Can reduce breathiness')
- rms_mix_rate = gr.Slider(0, 1, value=0.25, label='RMS mix rate', info="Control how much to use the original vocal's loudness (0) or a fixed loudness (1)")
- protect = gr.Slider(0, 0.5, value=0.33, label='Protect rate', info='Protect voiceless consonants and breath sounds. Set to 0.5 to disable.')
- keep_files = gr.Checkbox(label='Keep intermediate files',
- info='Keep all audio files generated in the song_output/id directory, e.g. Isolated Vocals/Instrumentals. Leave unchecked to save space')
-
- with gr.Accordion('Audio mixing options', open=False):
- gr.Markdown('### Volume Change (decibels)')
- with gr.Row():
- main_gain = gr.Slider(-20, 20, value=0, step=1, label='Main Vocals')
- backup_gain = gr.Slider(-20, 20, value=0, step=1, label='Backup Vocals')
- inst_gain = gr.Slider(-20, 20, value=0, step=1, label='Music')
-
- gr.Markdown('### Reverb Control on AI Vocals')
- with gr.Row():
- reverb_rm_size = gr.Slider(0, 1, value=0.15, label='Room size', info='The larger the room, the longer the reverb time')
- reverb_wet = gr.Slider(0, 1, value=0.2, label='Wetness level', info='Level of AI vocals with reverb')
- reverb_dry = gr.Slider(0, 1, value=0.8, label='Dryness level', info='Level of AI vocals without reverb')
- reverb_damping = gr.Slider(0, 1, value=0.7, label='Damping level', info='Absorption of high frequencies in the reverb')
-
- with gr.Row():
- clear_btn = gr.ClearButton(value='Clear', components=[song_input, rvc_model, keep_files, local_file])
- generate_btn = gr.Button("Generate", variant='primary')
- ai_cover = gr.Audio(label='AI Cover', show_share_button=False)
-
- ref_btn.click(update_models_list, None, outputs=rvc_model)
- is_webui = gr.Number(value=1, visible=False)
- generate_btn.click(song_cover_pipeline,
- inputs=[song_input, rvc_model, pitch, keep_files, is_webui, main_gain, backup_gain,
- inst_gain, index_rate, filter_radius, rms_mix_rate, protect, reverb_rm_size,
- reverb_wet, reverb_dry, reverb_damping],
- outputs=[ai_cover])
- clear_btn.click(lambda: [0, 0, 0, 0, 0.5, 3, 0.25, 0.33, 0.15, 0.2, 0.8, 0.7, None],
- outputs=[pitch, main_gain, backup_gain, inst_gain, index_rate, filter_radius, rms_mix_rate,
- protect, reverb_rm_size, reverb_wet, reverb_dry, reverb_damping, ai_cover])
-
- # Download tab
- with gr.Tab('Download model'):
-
- with gr.Tab('From HuggingFace/Pixeldrain URL'):
- with gr.Row():
- model_zip_link = gr.Text(label='Download link to model', info='Should be a zip file containing a .pth model file and an optional .index file.')
- model_name = gr.Text(label='Name your model', info='Give your new model a unique name from your other voice models.')
-
- with gr.Row():
- download_btn = gr.Button('Download 🌐', variant='primary', scale=19)
- dl_output_message = gr.Text(label='Output Message', interactive=False, scale=20)
-
- download_btn.click(download_online_model, inputs=[model_zip_link, model_name], outputs=dl_output_message)
-
- gr.Markdown('## Input Examples')
- gr.Examples(
- [
- ['https://huggingface.co/phant0m4r/LiSA/resolve/main/LiSA.zip', 'Lisa'],
- ['https://pixeldrain.com/u/3tJmABXA', 'Gura'],
- ['https://huggingface.co/Kit-Lemonfoot/kitlemonfoot_rvc_models/resolve/main/AZKi%20(Hybrid).zip', 'Azki']
- ],
- [model_zip_link, model_name],
- [],
- download_online_model,
- )
-
- with gr.Tab('From Public Index'):
-
- gr.Markdown('## How to use')
- gr.Markdown('- Click Initialize public models table')
- gr.Markdown('- Filter models using tags or search bar')
- gr.Markdown('- Select a row to autofill the download link and model name')
- gr.Markdown('- Click Download')
-
- with gr.Row():
- pub_zip_link = gr.Text(label='Download link to model')
- pub_model_name = gr.Text(label='Model name')
-
- with gr.Row():
- download_pub_btn = gr.Button('Download 🌐', variant='primary', scale=19)
- pub_dl_output_message = gr.Text(label='Output Message', interactive=False, scale=20)
-
- filter_tags = gr.CheckboxGroup(value=[], label='Show voice models with tags', choices=[])
- search_query = gr.Text(label='Search')
- load_public_models_button = gr.Button(value='Initialize public models table', variant='primary')
-
- public_models_table = gr.DataFrame(value=[], headers=['Model Name', 'Description', 'Credit', 'URL', 'Tags'], label='Available Public Models', interactive=False)
- public_models_table.select(pub_dl_autofill, inputs=[public_models_table], outputs=[pub_zip_link, pub_model_name])
- load_public_models_button.click(load_public_models, outputs=[public_models_table, filter_tags])
- search_query.change(filter_models, inputs=[filter_tags, search_query], outputs=public_models_table)
- filter_tags.change(filter_models, inputs=[filter_tags, search_query], outputs=public_models_table)
- download_pub_btn.click(download_online_model, inputs=[pub_zip_link, pub_model_name], outputs=pub_dl_output_message)
-
- # Upload tab
- with gr.Tab('Upload model'):
- gr.Markdown('## Upload locally trained RVC v2 model and index file')
- gr.Markdown('- Find model file (weights folder) and optional index file (logs/[name] folder)')
- gr.Markdown('- Compress files into zip file')
- gr.Markdown('- Upload zip file and give unique name for voice')
- gr.Markdown('- Click Upload model')
-
- with gr.Row():
- with gr.Column():
- zip_file = gr.File(label='Zip file')
-
- local_model_name = gr.Text(label='Model name')
-
- with gr.Row():
- model_upload_button = gr.Button('Upload model', variant='primary', scale=19)
- local_upload_output_message = gr.Text(label='Output Message', interactive=False, scale=20)
- model_upload_button.click(upload_local_model, inputs=[zip_file, local_model_name], outputs=local_upload_output_message)
-
- app.launch(
- share=args.share_enabled,
- enable_queue=True,
- server_name=None if not args.listen else (args.listen_host or '0.0.0.0'),
- server_port=args.listen_port,
- )
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/cu2qu/__init__.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/cu2qu/__init__.py
deleted file mode 100644
index 4ae6356e44e1fed074b6283bcb4365bf2b770529..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/cu2qu/__init__.py
+++ /dev/null
@@ -1,15 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from .cu2qu import *
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/feaLib/builder.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/feaLib/builder.py
deleted file mode 100644
index 42d1f8f24a720a8cbbaf3f7b7344eb4773ca0f4d..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/feaLib/builder.py
+++ /dev/null
@@ -1,1706 +0,0 @@
-from fontTools.misc import sstruct
-from fontTools.misc.textTools import Tag, tostr, binary2num, safeEval
-from fontTools.feaLib.error import FeatureLibError
-from fontTools.feaLib.lookupDebugInfo import (
- LookupDebugInfo,
- LOOKUP_DEBUG_INFO_KEY,
- LOOKUP_DEBUG_ENV_VAR,
-)
-from fontTools.feaLib.parser import Parser
-from fontTools.feaLib.ast import FeatureFile
-from fontTools.feaLib.variableScalar import VariableScalar
-from fontTools.otlLib import builder as otl
-from fontTools.otlLib.maxContextCalc import maxCtxFont
-from fontTools.ttLib import newTable, getTableModule
-from fontTools.ttLib.tables import otBase, otTables
-from fontTools.otlLib.builder import (
- AlternateSubstBuilder,
- ChainContextPosBuilder,
- ChainContextSubstBuilder,
- LigatureSubstBuilder,
- MultipleSubstBuilder,
- CursivePosBuilder,
- MarkBasePosBuilder,
- MarkLigPosBuilder,
- MarkMarkPosBuilder,
- ReverseChainSingleSubstBuilder,
- SingleSubstBuilder,
- ClassPairPosSubtableBuilder,
- PairPosBuilder,
- SinglePosBuilder,
- ChainContextualRule,
-)
-from fontTools.otlLib.error import OpenTypeLibError
-from fontTools.varLib.varStore import OnlineVarStoreBuilder
-from fontTools.varLib.builder import buildVarDevTable
-from fontTools.varLib.featureVars import addFeatureVariationsRaw
-from fontTools.varLib.models import normalizeValue, piecewiseLinearMap
-from collections import defaultdict
-import itertools
-from io import StringIO
-import logging
-import warnings
-import os
-
-
-log = logging.getLogger(__name__)
-
-
-def addOpenTypeFeatures(font, featurefile, tables=None, debug=False):
- """Add features from a file to a font. Note that this replaces any features
- currently present.
-
- Args:
- font (feaLib.ttLib.TTFont): The font object.
- featurefile: Either a path or file object (in which case we
- parse it into an AST), or a pre-parsed AST instance.
- tables: If passed, restrict the set of affected tables to those in the
- list.
- debug: Whether to add source debugging information to the font in the
- ``Debg`` table
-
- """
- builder = Builder(font, featurefile)
- builder.build(tables=tables, debug=debug)
-
-
-def addOpenTypeFeaturesFromString(
- font, features, filename=None, tables=None, debug=False
-):
- """Add features from a string to a font. Note that this replaces any
- features currently present.
-
- Args:
- font (feaLib.ttLib.TTFont): The font object.
- features: A string containing feature code.
- filename: The directory containing ``filename`` is used as the root of
- relative ``include()`` paths; if ``None`` is provided, the current
- directory is assumed.
- tables: If passed, restrict the set of affected tables to those in the
- list.
- debug: Whether to add source debugging information to the font in the
- ``Debg`` table
-
- """
-
- featurefile = StringIO(tostr(features))
- if filename:
- featurefile.name = filename
- addOpenTypeFeatures(font, featurefile, tables=tables, debug=debug)
-
-
-class Builder(object):
- supportedTables = frozenset(
- Tag(tag)
- for tag in [
- "BASE",
- "GDEF",
- "GPOS",
- "GSUB",
- "OS/2",
- "head",
- "hhea",
- "name",
- "vhea",
- "STAT",
- ]
- )
-
- def __init__(self, font, featurefile):
- self.font = font
- # 'featurefile' can be either a path or file object (in which case we
- # parse it into an AST), or a pre-parsed AST instance
- if isinstance(featurefile, FeatureFile):
- self.parseTree, self.file = featurefile, None
- else:
- self.parseTree, self.file = None, featurefile
- self.glyphMap = font.getReverseGlyphMap()
- self.varstorebuilder = None
- if "fvar" in font:
- self.axes = font["fvar"].axes
- self.varstorebuilder = OnlineVarStoreBuilder(
- [ax.axisTag for ax in self.axes]
- )
- self.default_language_systems_ = set()
- self.script_ = None
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
- self.language_systems = set()
- self.seen_non_DFLT_script_ = False
- self.named_lookups_ = {}
- self.cur_lookup_ = None
- self.cur_lookup_name_ = None
- self.cur_feature_name_ = None
- self.lookups_ = []
- self.lookup_locations = {"GSUB": {}, "GPOS": {}}
- self.features_ = {} # ('latn', 'DEU ', 'smcp') --> [LookupBuilder*]
- self.required_features_ = {} # ('latn', 'DEU ') --> 'scmp'
- self.feature_variations_ = {}
- # for feature 'aalt'
- self.aalt_features_ = [] # [(location, featureName)*], for 'aalt'
- self.aalt_location_ = None
- self.aalt_alternates_ = {}
- # for 'featureNames'
- self.featureNames_ = set()
- self.featureNames_ids_ = {}
- # for 'cvParameters'
- self.cv_parameters_ = set()
- self.cv_parameters_ids_ = {}
- self.cv_num_named_params_ = {}
- self.cv_characters_ = defaultdict(list)
- # for feature 'size'
- self.size_parameters_ = None
- # for table 'head'
- self.fontRevision_ = None # 2.71
- # for table 'name'
- self.names_ = []
- # for table 'BASE'
- self.base_horiz_axis_ = None
- self.base_vert_axis_ = None
- # for table 'GDEF'
- self.attachPoints_ = {} # "a" --> {3, 7}
- self.ligCaretCoords_ = {} # "f_f_i" --> {300, 600}
- self.ligCaretPoints_ = {} # "f_f_i" --> {3, 7}
- self.glyphClassDefs_ = {} # "fi" --> (2, (file, line, column))
- self.markAttach_ = {} # "acute" --> (4, (file, line, column))
- self.markAttachClassID_ = {} # frozenset({"acute", "grave"}) --> 4
- self.markFilterSets_ = {} # frozenset({"acute", "grave"}) --> 4
- # for table 'OS/2'
- self.os2_ = {}
- # for table 'hhea'
- self.hhea_ = {}
- # for table 'vhea'
- self.vhea_ = {}
- # for table 'STAT'
- self.stat_ = {}
- # for conditionsets
- self.conditionsets_ = {}
- # We will often use exactly the same locations (i.e. the font's masters)
- # for a large number of variable scalars. Instead of creating a model
- # for each, let's share the models.
- self.model_cache = {}
-
- def build(self, tables=None, debug=False):
- if self.parseTree is None:
- self.parseTree = Parser(self.file, self.glyphMap).parse()
- self.parseTree.build(self)
- # by default, build all the supported tables
- if tables is None:
- tables = self.supportedTables
- else:
- tables = frozenset(tables)
- unsupported = tables - self.supportedTables
- if unsupported:
- unsupported_string = ", ".join(sorted(unsupported))
- raise NotImplementedError(
- "The following tables were requested but are unsupported: "
- f"{unsupported_string}."
- )
- if "GSUB" in tables:
- self.build_feature_aalt_()
- if "head" in tables:
- self.build_head()
- if "hhea" in tables:
- self.build_hhea()
- if "vhea" in tables:
- self.build_vhea()
- if "name" in tables:
- self.build_name()
- if "OS/2" in tables:
- self.build_OS_2()
- if "STAT" in tables:
- self.build_STAT()
- for tag in ("GPOS", "GSUB"):
- if tag not in tables:
- continue
- table = self.makeTable(tag)
- if self.feature_variations_:
- self.makeFeatureVariations(table, tag)
- if (
- table.ScriptList.ScriptCount > 0
- or table.FeatureList.FeatureCount > 0
- or table.LookupList.LookupCount > 0
- ):
- fontTable = self.font[tag] = newTable(tag)
- fontTable.table = table
- elif tag in self.font:
- del self.font[tag]
- if any(tag in self.font for tag in ("GPOS", "GSUB")) and "OS/2" in self.font:
- self.font["OS/2"].usMaxContext = maxCtxFont(self.font)
- if "GDEF" in tables:
- gdef = self.buildGDEF()
- if gdef:
- self.font["GDEF"] = gdef
- elif "GDEF" in self.font:
- del self.font["GDEF"]
- if "BASE" in tables:
- base = self.buildBASE()
- if base:
- self.font["BASE"] = base
- elif "BASE" in self.font:
- del self.font["BASE"]
- if debug or os.environ.get(LOOKUP_DEBUG_ENV_VAR):
- self.buildDebg()
-
- def get_chained_lookup_(self, location, builder_class):
- result = builder_class(self.font, location)
- result.lookupflag = self.lookupflag_
- result.markFilterSet = self.lookupflag_markFilterSet_
- self.lookups_.append(result)
- return result
-
- def add_lookup_to_feature_(self, lookup, feature_name):
- for script, lang in self.language_systems:
- key = (script, lang, feature_name)
- self.features_.setdefault(key, []).append(lookup)
-
- def get_lookup_(self, location, builder_class):
- if (
- self.cur_lookup_
- and type(self.cur_lookup_) == builder_class
- and self.cur_lookup_.lookupflag == self.lookupflag_
- and self.cur_lookup_.markFilterSet == self.lookupflag_markFilterSet_
- ):
- return self.cur_lookup_
- if self.cur_lookup_name_ and self.cur_lookup_:
- raise FeatureLibError(
- "Within a named lookup block, all rules must be of "
- "the same lookup type and flag",
- location,
- )
- self.cur_lookup_ = builder_class(self.font, location)
- self.cur_lookup_.lookupflag = self.lookupflag_
- self.cur_lookup_.markFilterSet = self.lookupflag_markFilterSet_
- self.lookups_.append(self.cur_lookup_)
- if self.cur_lookup_name_:
- # We are starting a lookup rule inside a named lookup block.
- self.named_lookups_[self.cur_lookup_name_] = self.cur_lookup_
- if self.cur_feature_name_:
- # We are starting a lookup rule inside a feature. This includes
- # lookup rules inside named lookups inside features.
- self.add_lookup_to_feature_(self.cur_lookup_, self.cur_feature_name_)
- return self.cur_lookup_
-
- def build_feature_aalt_(self):
- if not self.aalt_features_ and not self.aalt_alternates_:
- return
- alternates = {g: set(a) for g, a in self.aalt_alternates_.items()}
- for location, name in self.aalt_features_ + [(None, "aalt")]:
- feature = [
- (script, lang, feature, lookups)
- for (script, lang, feature), lookups in self.features_.items()
- if feature == name
- ]
- # "aalt" does not have to specify its own lookups, but it might.
- if not feature and name != "aalt":
- warnings.warn("%s: Feature %s has not been defined" % (location, name))
- continue
- for script, lang, feature, lookups in feature:
- for lookuplist in lookups:
- if not isinstance(lookuplist, list):
- lookuplist = [lookuplist]
- for lookup in lookuplist:
- for glyph, alts in lookup.getAlternateGlyphs().items():
- alternates.setdefault(glyph, set()).update(alts)
- single = {
- glyph: list(repl)[0] for glyph, repl in alternates.items() if len(repl) == 1
- }
- # TODO: Figure out the glyph alternate ordering used by makeotf.
- # https://github.com/fonttools/fonttools/issues/836
- multi = {
- glyph: sorted(repl, key=self.font.getGlyphID)
- for glyph, repl in alternates.items()
- if len(repl) > 1
- }
- if not single and not multi:
- return
- self.features_ = {
- (script, lang, feature): lookups
- for (script, lang, feature), lookups in self.features_.items()
- if feature != "aalt"
- }
- old_lookups = self.lookups_
- self.lookups_ = []
- self.start_feature(self.aalt_location_, "aalt")
- if single:
- single_lookup = self.get_lookup_(location, SingleSubstBuilder)
- single_lookup.mapping = single
- if multi:
- multi_lookup = self.get_lookup_(location, AlternateSubstBuilder)
- multi_lookup.alternates = multi
- self.end_feature()
- self.lookups_.extend(old_lookups)
-
- def build_head(self):
- if not self.fontRevision_:
- return
- table = self.font.get("head")
- if not table: # this only happens for unit tests
- table = self.font["head"] = newTable("head")
- table.decompile(b"\0" * 54, self.font)
- table.tableVersion = 1.0
- table.created = table.modified = 3406620153 # 2011-12-13 11:22:33
- table.fontRevision = self.fontRevision_
-
- def build_hhea(self):
- if not self.hhea_:
- return
- table = self.font.get("hhea")
- if not table: # this only happens for unit tests
- table = self.font["hhea"] = newTable("hhea")
- table.decompile(b"\0" * 36, self.font)
- table.tableVersion = 0x00010000
- if "caretoffset" in self.hhea_:
- table.caretOffset = self.hhea_["caretoffset"]
- if "ascender" in self.hhea_:
- table.ascent = self.hhea_["ascender"]
- if "descender" in self.hhea_:
- table.descent = self.hhea_["descender"]
- if "linegap" in self.hhea_:
- table.lineGap = self.hhea_["linegap"]
-
- def build_vhea(self):
- if not self.vhea_:
- return
- table = self.font.get("vhea")
- if not table: # this only happens for unit tests
- table = self.font["vhea"] = newTable("vhea")
- table.decompile(b"\0" * 36, self.font)
- table.tableVersion = 0x00011000
- if "verttypoascender" in self.vhea_:
- table.ascent = self.vhea_["verttypoascender"]
- if "verttypodescender" in self.vhea_:
- table.descent = self.vhea_["verttypodescender"]
- if "verttypolinegap" in self.vhea_:
- table.lineGap = self.vhea_["verttypolinegap"]
-
- def get_user_name_id(self, table):
- # Try to find first unused font-specific name id
- nameIDs = [name.nameID for name in table.names]
- for user_name_id in range(256, 32767):
- if user_name_id not in nameIDs:
- return user_name_id
-
- def buildFeatureParams(self, tag):
- params = None
- if tag == "size":
- params = otTables.FeatureParamsSize()
- (
- params.DesignSize,
- params.SubfamilyID,
- params.RangeStart,
- params.RangeEnd,
- ) = self.size_parameters_
- if tag in self.featureNames_ids_:
- params.SubfamilyNameID = self.featureNames_ids_[tag]
- else:
- params.SubfamilyNameID = 0
- elif tag in self.featureNames_:
- if not self.featureNames_ids_:
- # name table wasn't selected among the tables to build; skip
- pass
- else:
- assert tag in self.featureNames_ids_
- params = otTables.FeatureParamsStylisticSet()
- params.Version = 0
- params.UINameID = self.featureNames_ids_[tag]
- elif tag in self.cv_parameters_:
- params = otTables.FeatureParamsCharacterVariants()
- params.Format = 0
- params.FeatUILabelNameID = self.cv_parameters_ids_.get(
- (tag, "FeatUILabelNameID"), 0
- )
- params.FeatUITooltipTextNameID = self.cv_parameters_ids_.get(
- (tag, "FeatUITooltipTextNameID"), 0
- )
- params.SampleTextNameID = self.cv_parameters_ids_.get(
- (tag, "SampleTextNameID"), 0
- )
- params.NumNamedParameters = self.cv_num_named_params_.get(tag, 0)
- params.FirstParamUILabelNameID = self.cv_parameters_ids_.get(
- (tag, "ParamUILabelNameID_0"), 0
- )
- params.CharCount = len(self.cv_characters_[tag])
- params.Character = self.cv_characters_[tag]
- return params
-
- def build_name(self):
- if not self.names_:
- return
- table = self.font.get("name")
- if not table: # this only happens for unit tests
- table = self.font["name"] = newTable("name")
- table.names = []
- for name in self.names_:
- nameID, platformID, platEncID, langID, string = name
- # For featureNames block, nameID is 'feature tag'
- # For cvParameters blocks, nameID is ('feature tag', 'block name')
- if not isinstance(nameID, int):
- tag = nameID
- if tag in self.featureNames_:
- if tag not in self.featureNames_ids_:
- self.featureNames_ids_[tag] = self.get_user_name_id(table)
- assert self.featureNames_ids_[tag] is not None
- nameID = self.featureNames_ids_[tag]
- elif tag[0] in self.cv_parameters_:
- if tag not in self.cv_parameters_ids_:
- self.cv_parameters_ids_[tag] = self.get_user_name_id(table)
- assert self.cv_parameters_ids_[tag] is not None
- nameID = self.cv_parameters_ids_[tag]
- table.setName(string, nameID, platformID, platEncID, langID)
- table.names.sort()
-
- def build_OS_2(self):
- if not self.os2_:
- return
- table = self.font.get("OS/2")
- if not table: # this only happens for unit tests
- table = self.font["OS/2"] = newTable("OS/2")
- data = b"\0" * sstruct.calcsize(getTableModule("OS/2").OS2_format_0)
- table.decompile(data, self.font)
- version = 0
- if "fstype" in self.os2_:
- table.fsType = self.os2_["fstype"]
- if "panose" in self.os2_:
- panose = getTableModule("OS/2").Panose()
- (
- panose.bFamilyType,
- panose.bSerifStyle,
- panose.bWeight,
- panose.bProportion,
- panose.bContrast,
- panose.bStrokeVariation,
- panose.bArmStyle,
- panose.bLetterForm,
- panose.bMidline,
- panose.bXHeight,
- ) = self.os2_["panose"]
- table.panose = panose
- if "typoascender" in self.os2_:
- table.sTypoAscender = self.os2_["typoascender"]
- if "typodescender" in self.os2_:
- table.sTypoDescender = self.os2_["typodescender"]
- if "typolinegap" in self.os2_:
- table.sTypoLineGap = self.os2_["typolinegap"]
- if "winascent" in self.os2_:
- table.usWinAscent = self.os2_["winascent"]
- if "windescent" in self.os2_:
- table.usWinDescent = self.os2_["windescent"]
- if "vendor" in self.os2_:
- table.achVendID = safeEval("'''" + self.os2_["vendor"] + "'''")
- if "weightclass" in self.os2_:
- table.usWeightClass = self.os2_["weightclass"]
- if "widthclass" in self.os2_:
- table.usWidthClass = self.os2_["widthclass"]
- if "unicoderange" in self.os2_:
- table.setUnicodeRanges(self.os2_["unicoderange"])
- if "codepagerange" in self.os2_:
- pages = self.build_codepages_(self.os2_["codepagerange"])
- table.ulCodePageRange1, table.ulCodePageRange2 = pages
- version = 1
- if "xheight" in self.os2_:
- table.sxHeight = self.os2_["xheight"]
- version = 2
- if "capheight" in self.os2_:
- table.sCapHeight = self.os2_["capheight"]
- version = 2
- if "loweropsize" in self.os2_:
- table.usLowerOpticalPointSize = self.os2_["loweropsize"]
- version = 5
- if "upperopsize" in self.os2_:
- table.usUpperOpticalPointSize = self.os2_["upperopsize"]
- version = 5
-
- def checkattr(table, attrs):
- for attr in attrs:
- if not hasattr(table, attr):
- setattr(table, attr, 0)
-
- table.version = max(version, table.version)
- # this only happens for unit tests
- if version >= 1:
- checkattr(table, ("ulCodePageRange1", "ulCodePageRange2"))
- if version >= 2:
- checkattr(
- table,
- (
- "sxHeight",
- "sCapHeight",
- "usDefaultChar",
- "usBreakChar",
- "usMaxContext",
- ),
- )
- if version >= 5:
- checkattr(table, ("usLowerOpticalPointSize", "usUpperOpticalPointSize"))
-
- def setElidedFallbackName(self, value, location):
- # ElidedFallbackName is a convenience method for setting
- # ElidedFallbackNameID so only one can be allowed
- for token in ("ElidedFallbackName", "ElidedFallbackNameID"):
- if token in self.stat_:
- raise FeatureLibError(
- f"{token} is already set.",
- location,
- )
- if isinstance(value, int):
- self.stat_["ElidedFallbackNameID"] = value
- elif isinstance(value, list):
- self.stat_["ElidedFallbackName"] = value
- else:
- raise AssertionError(value)
-
- def addDesignAxis(self, designAxis, location):
- if "DesignAxes" not in self.stat_:
- self.stat_["DesignAxes"] = []
- if designAxis.tag in (r.tag for r in self.stat_["DesignAxes"]):
- raise FeatureLibError(
- f'DesignAxis already defined for tag "{designAxis.tag}".',
- location,
- )
- if designAxis.axisOrder in (r.axisOrder for r in self.stat_["DesignAxes"]):
- raise FeatureLibError(
- f"DesignAxis already defined for axis number {designAxis.axisOrder}.",
- location,
- )
- self.stat_["DesignAxes"].append(designAxis)
-
- def addAxisValueRecord(self, axisValueRecord, location):
- if "AxisValueRecords" not in self.stat_:
- self.stat_["AxisValueRecords"] = []
- # Check for duplicate AxisValueRecords
- for record_ in self.stat_["AxisValueRecords"]:
- if (
- {n.asFea() for n in record_.names}
- == {n.asFea() for n in axisValueRecord.names}
- and {n.asFea() for n in record_.locations}
- == {n.asFea() for n in axisValueRecord.locations}
- and record_.flags == axisValueRecord.flags
- ):
- raise FeatureLibError(
- "An AxisValueRecord with these values is already defined.",
- location,
- )
- self.stat_["AxisValueRecords"].append(axisValueRecord)
-
- def build_STAT(self):
- if not self.stat_:
- return
-
- axes = self.stat_.get("DesignAxes")
- if not axes:
- raise FeatureLibError("DesignAxes not defined", None)
- axisValueRecords = self.stat_.get("AxisValueRecords")
- axisValues = {}
- format4_locations = []
- for tag in axes:
- axisValues[tag.tag] = []
- if axisValueRecords is not None:
- for avr in axisValueRecords:
- valuesDict = {}
- if avr.flags > 0:
- valuesDict["flags"] = avr.flags
- if len(avr.locations) == 1:
- location = avr.locations[0]
- values = location.values
- if len(values) == 1: # format1
- valuesDict.update({"value": values[0], "name": avr.names})
- if len(values) == 2: # format3
- valuesDict.update(
- {
- "value": values[0],
- "linkedValue": values[1],
- "name": avr.names,
- }
- )
- if len(values) == 3: # format2
- nominal, minVal, maxVal = values
- valuesDict.update(
- {
- "nominalValue": nominal,
- "rangeMinValue": minVal,
- "rangeMaxValue": maxVal,
- "name": avr.names,
- }
- )
- axisValues[location.tag].append(valuesDict)
- else:
- valuesDict.update(
- {
- "location": {i.tag: i.values[0] for i in avr.locations},
- "name": avr.names,
- }
- )
- format4_locations.append(valuesDict)
-
- designAxes = [
- {
- "ordering": a.axisOrder,
- "tag": a.tag,
- "name": a.names,
- "values": axisValues[a.tag],
- }
- for a in axes
- ]
-
- nameTable = self.font.get("name")
- if not nameTable: # this only happens for unit tests
- nameTable = self.font["name"] = newTable("name")
- nameTable.names = []
-
- if "ElidedFallbackNameID" in self.stat_:
- nameID = self.stat_["ElidedFallbackNameID"]
- name = nameTable.getDebugName(nameID)
- if not name:
- raise FeatureLibError(
- f"ElidedFallbackNameID {nameID} points "
- "to a nameID that does not exist in the "
- '"name" table',
- None,
- )
- elif "ElidedFallbackName" in self.stat_:
- nameID = self.stat_["ElidedFallbackName"]
-
- otl.buildStatTable(
- self.font,
- designAxes,
- locations=format4_locations,
- elidedFallbackName=nameID,
- )
-
- def build_codepages_(self, pages):
- pages2bits = {
- 1252: 0,
- 1250: 1,
- 1251: 2,
- 1253: 3,
- 1254: 4,
- 1255: 5,
- 1256: 6,
- 1257: 7,
- 1258: 8,
- 874: 16,
- 932: 17,
- 936: 18,
- 949: 19,
- 950: 20,
- 1361: 21,
- 869: 48,
- 866: 49,
- 865: 50,
- 864: 51,
- 863: 52,
- 862: 53,
- 861: 54,
- 860: 55,
- 857: 56,
- 855: 57,
- 852: 58,
- 775: 59,
- 737: 60,
- 708: 61,
- 850: 62,
- 437: 63,
- }
- bits = [pages2bits[p] for p in pages if p in pages2bits]
- pages = []
- for i in range(2):
- pages.append("")
- for j in range(i * 32, (i + 1) * 32):
- if j in bits:
- pages[i] += "1"
- else:
- pages[i] += "0"
- return [binary2num(p[::-1]) for p in pages]
-
- def buildBASE(self):
- if not self.base_horiz_axis_ and not self.base_vert_axis_:
- return None
- base = otTables.BASE()
- base.Version = 0x00010000
- base.HorizAxis = self.buildBASEAxis(self.base_horiz_axis_)
- base.VertAxis = self.buildBASEAxis(self.base_vert_axis_)
-
- result = newTable("BASE")
- result.table = base
- return result
-
- def buildBASEAxis(self, axis):
- if not axis:
- return
- bases, scripts = axis
- axis = otTables.Axis()
- axis.BaseTagList = otTables.BaseTagList()
- axis.BaseTagList.BaselineTag = bases
- axis.BaseTagList.BaseTagCount = len(bases)
- axis.BaseScriptList = otTables.BaseScriptList()
- axis.BaseScriptList.BaseScriptRecord = []
- axis.BaseScriptList.BaseScriptCount = len(scripts)
- for script in sorted(scripts):
- record = otTables.BaseScriptRecord()
- record.BaseScriptTag = script[0]
- record.BaseScript = otTables.BaseScript()
- record.BaseScript.BaseLangSysCount = 0
- record.BaseScript.BaseValues = otTables.BaseValues()
- record.BaseScript.BaseValues.DefaultIndex = bases.index(script[1])
- record.BaseScript.BaseValues.BaseCoord = []
- record.BaseScript.BaseValues.BaseCoordCount = len(script[2])
- for c in script[2]:
- coord = otTables.BaseCoord()
- coord.Format = 1
- coord.Coordinate = c
- record.BaseScript.BaseValues.BaseCoord.append(coord)
- axis.BaseScriptList.BaseScriptRecord.append(record)
- return axis
-
- def buildGDEF(self):
- gdef = otTables.GDEF()
- gdef.GlyphClassDef = self.buildGDEFGlyphClassDef_()
- gdef.AttachList = otl.buildAttachList(self.attachPoints_, self.glyphMap)
- gdef.LigCaretList = otl.buildLigCaretList(
- self.ligCaretCoords_, self.ligCaretPoints_, self.glyphMap
- )
- gdef.MarkAttachClassDef = self.buildGDEFMarkAttachClassDef_()
- gdef.MarkGlyphSetsDef = self.buildGDEFMarkGlyphSetsDef_()
- gdef.Version = 0x00010002 if gdef.MarkGlyphSetsDef else 0x00010000
- if self.varstorebuilder:
- store = self.varstorebuilder.finish()
- if store:
- gdef.Version = 0x00010003
- gdef.VarStore = store
- varidx_map = store.optimize()
-
- gdef.remap_device_varidxes(varidx_map)
- if "GPOS" in self.font:
- self.font["GPOS"].table.remap_device_varidxes(varidx_map)
- self.model_cache.clear()
- if any(
- (
- gdef.GlyphClassDef,
- gdef.AttachList,
- gdef.LigCaretList,
- gdef.MarkAttachClassDef,
- gdef.MarkGlyphSetsDef,
- )
- ) or hasattr(gdef, "VarStore"):
- result = newTable("GDEF")
- result.table = gdef
- return result
- else:
- return None
-
- def buildGDEFGlyphClassDef_(self):
- if self.glyphClassDefs_:
- classes = {g: c for (g, (c, _)) in self.glyphClassDefs_.items()}
- else:
- classes = {}
- for lookup in self.lookups_:
- classes.update(lookup.inferGlyphClasses())
- for markClass in self.parseTree.markClasses.values():
- for markClassDef in markClass.definitions:
- for glyph in markClassDef.glyphSet():
- classes[glyph] = 3
- if classes:
- result = otTables.GlyphClassDef()
- result.classDefs = classes
- return result
- else:
- return None
-
- def buildGDEFMarkAttachClassDef_(self):
- classDefs = {g: c for g, (c, _) in self.markAttach_.items()}
- if not classDefs:
- return None
- result = otTables.MarkAttachClassDef()
- result.classDefs = classDefs
- return result
-
- def buildGDEFMarkGlyphSetsDef_(self):
- sets = []
- for glyphs, id_ in sorted(
- self.markFilterSets_.items(), key=lambda item: item[1]
- ):
- sets.append(glyphs)
- return otl.buildMarkGlyphSetsDef(sets, self.glyphMap)
-
- def buildDebg(self):
- if "Debg" not in self.font:
- self.font["Debg"] = newTable("Debg")
- self.font["Debg"].data = {}
- self.font["Debg"].data[LOOKUP_DEBUG_INFO_KEY] = self.lookup_locations
-
- def buildLookups_(self, tag):
- assert tag in ("GPOS", "GSUB"), tag
- for lookup in self.lookups_:
- lookup.lookup_index = None
- lookups = []
- for lookup in self.lookups_:
- if lookup.table != tag:
- continue
- lookup.lookup_index = len(lookups)
- self.lookup_locations[tag][str(lookup.lookup_index)] = LookupDebugInfo(
- location=str(lookup.location),
- name=self.get_lookup_name_(lookup),
- feature=None,
- )
- lookups.append(lookup)
- try:
- otLookups = [l.build() for l in lookups]
- except OpenTypeLibError as e:
- raise FeatureLibError(str(e), e.location) from e
- return otLookups
-
- def makeTable(self, tag):
- table = getattr(otTables, tag, None)()
- table.Version = 0x00010000
- table.ScriptList = otTables.ScriptList()
- table.ScriptList.ScriptRecord = []
- table.FeatureList = otTables.FeatureList()
- table.FeatureList.FeatureRecord = []
- table.LookupList = otTables.LookupList()
- table.LookupList.Lookup = self.buildLookups_(tag)
-
- # Build a table for mapping (tag, lookup_indices) to feature_index.
- # For example, ('liga', (2,3,7)) --> 23.
- feature_indices = {}
- required_feature_indices = {} # ('latn', 'DEU') --> 23
- scripts = {} # 'latn' --> {'DEU': [23, 24]} for feature #23,24
- # Sort the feature table by feature tag:
- # https://github.com/fonttools/fonttools/issues/568
- sortFeatureTag = lambda f: (f[0][2], f[0][1], f[0][0], f[1])
- for key, lookups in sorted(self.features_.items(), key=sortFeatureTag):
- script, lang, feature_tag = key
- # l.lookup_index will be None when a lookup is not needed
- # for the table under construction. For example, substitution
- # rules will have no lookup_index while building GPOS tables.
- lookup_indices = tuple(
- [l.lookup_index for l in lookups if l.lookup_index is not None]
- )
-
- size_feature = tag == "GPOS" and feature_tag == "size"
- force_feature = self.any_feature_variations(feature_tag, tag)
- if len(lookup_indices) == 0 and not size_feature and not force_feature:
- continue
-
- for ix in lookup_indices:
- try:
- self.lookup_locations[tag][str(ix)] = self.lookup_locations[tag][
- str(ix)
- ]._replace(feature=key)
- except KeyError:
- warnings.warn(
- "feaLib.Builder subclass needs upgrading to "
- "stash debug information. See fonttools#2065."
- )
-
- feature_key = (feature_tag, lookup_indices)
- feature_index = feature_indices.get(feature_key)
- if feature_index is None:
- feature_index = len(table.FeatureList.FeatureRecord)
- frec = otTables.FeatureRecord()
- frec.FeatureTag = feature_tag
- frec.Feature = otTables.Feature()
- frec.Feature.FeatureParams = self.buildFeatureParams(feature_tag)
- frec.Feature.LookupListIndex = list(lookup_indices)
- frec.Feature.LookupCount = len(lookup_indices)
- table.FeatureList.FeatureRecord.append(frec)
- feature_indices[feature_key] = feature_index
- scripts.setdefault(script, {}).setdefault(lang, []).append(feature_index)
- if self.required_features_.get((script, lang)) == feature_tag:
- required_feature_indices[(script, lang)] = feature_index
-
- # Build ScriptList.
- for script, lang_features in sorted(scripts.items()):
- srec = otTables.ScriptRecord()
- srec.ScriptTag = script
- srec.Script = otTables.Script()
- srec.Script.DefaultLangSys = None
- srec.Script.LangSysRecord = []
- for lang, feature_indices in sorted(lang_features.items()):
- langrec = otTables.LangSysRecord()
- langrec.LangSys = otTables.LangSys()
- langrec.LangSys.LookupOrder = None
-
- req_feature_index = required_feature_indices.get((script, lang))
- if req_feature_index is None:
- langrec.LangSys.ReqFeatureIndex = 0xFFFF
- else:
- langrec.LangSys.ReqFeatureIndex = req_feature_index
-
- langrec.LangSys.FeatureIndex = [
- i for i in feature_indices if i != req_feature_index
- ]
- langrec.LangSys.FeatureCount = len(langrec.LangSys.FeatureIndex)
-
- if lang == "dflt":
- srec.Script.DefaultLangSys = langrec.LangSys
- else:
- langrec.LangSysTag = lang
- srec.Script.LangSysRecord.append(langrec)
- srec.Script.LangSysCount = len(srec.Script.LangSysRecord)
- table.ScriptList.ScriptRecord.append(srec)
-
- table.ScriptList.ScriptCount = len(table.ScriptList.ScriptRecord)
- table.FeatureList.FeatureCount = len(table.FeatureList.FeatureRecord)
- table.LookupList.LookupCount = len(table.LookupList.Lookup)
- return table
-
- def makeFeatureVariations(self, table, table_tag):
- feature_vars = {}
- has_any_variations = False
- # Sort out which lookups to build, gather their indices
- for (_, _, feature_tag), variations in self.feature_variations_.items():
- feature_vars[feature_tag] = []
- for conditionset, builders in variations.items():
- raw_conditionset = self.conditionsets_[conditionset]
- indices = []
- for b in builders:
- if b.table != table_tag:
- continue
- assert b.lookup_index is not None
- indices.append(b.lookup_index)
- has_any_variations = True
- feature_vars[feature_tag].append((raw_conditionset, indices))
-
- if has_any_variations:
- for feature_tag, conditions_and_lookups in feature_vars.items():
- addFeatureVariationsRaw(
- self.font, table, conditions_and_lookups, feature_tag
- )
-
- def any_feature_variations(self, feature_tag, table_tag):
- for (_, _, feature), variations in self.feature_variations_.items():
- if feature != feature_tag:
- continue
- for conditionset, builders in variations.items():
- if any(b.table == table_tag for b in builders):
- return True
- return False
-
- def get_lookup_name_(self, lookup):
- rev = {v: k for k, v in self.named_lookups_.items()}
- if lookup in rev:
- return rev[lookup]
- return None
-
- def add_language_system(self, location, script, language):
- # OpenType Feature File Specification, section 4.b.i
- if script == "DFLT" and language == "dflt" and self.default_language_systems_:
- raise FeatureLibError(
- 'If "languagesystem DFLT dflt" is present, it must be '
- "the first of the languagesystem statements",
- location,
- )
- if script == "DFLT":
- if self.seen_non_DFLT_script_:
- raise FeatureLibError(
- 'languagesystems using the "DFLT" script tag must '
- "precede all other languagesystems",
- location,
- )
- else:
- self.seen_non_DFLT_script_ = True
- if (script, language) in self.default_language_systems_:
- raise FeatureLibError(
- '"languagesystem %s %s" has already been specified'
- % (script.strip(), language.strip()),
- location,
- )
- self.default_language_systems_.add((script, language))
-
- def get_default_language_systems_(self):
- # OpenType Feature File specification, 4.b.i. languagesystem:
- # If no "languagesystem" statement is present, then the
- # implementation must behave exactly as though the following
- # statement were present at the beginning of the feature file:
- # languagesystem DFLT dflt;
- if self.default_language_systems_:
- return frozenset(self.default_language_systems_)
- else:
- return frozenset({("DFLT", "dflt")})
-
- def start_feature(self, location, name):
- self.language_systems = self.get_default_language_systems_()
- self.script_ = "DFLT"
- self.cur_lookup_ = None
- self.cur_feature_name_ = name
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
- if name == "aalt":
- self.aalt_location_ = location
-
- def end_feature(self):
- assert self.cur_feature_name_ is not None
- self.cur_feature_name_ = None
- self.language_systems = None
- self.cur_lookup_ = None
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
-
- def start_lookup_block(self, location, name):
- if name in self.named_lookups_:
- raise FeatureLibError(
- 'Lookup "%s" has already been defined' % name, location
- )
- if self.cur_feature_name_ == "aalt":
- raise FeatureLibError(
- "Lookup blocks cannot be placed inside 'aalt' features; "
- "move it out, and then refer to it with a lookup statement",
- location,
- )
- self.cur_lookup_name_ = name
- self.named_lookups_[name] = None
- self.cur_lookup_ = None
- if self.cur_feature_name_ is None:
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
-
- def end_lookup_block(self):
- assert self.cur_lookup_name_ is not None
- self.cur_lookup_name_ = None
- self.cur_lookup_ = None
- if self.cur_feature_name_ is None:
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
-
- def add_lookup_call(self, lookup_name):
- assert lookup_name in self.named_lookups_, lookup_name
- self.cur_lookup_ = None
- lookup = self.named_lookups_[lookup_name]
- if lookup is not None: # skip empty named lookup
- self.add_lookup_to_feature_(lookup, self.cur_feature_name_)
-
- def set_font_revision(self, location, revision):
- self.fontRevision_ = revision
-
- def set_language(self, location, language, include_default, required):
- assert len(language) == 4
- if self.cur_feature_name_ in ("aalt", "size"):
- raise FeatureLibError(
- "Language statements are not allowed "
- 'within "feature %s"' % self.cur_feature_name_,
- location,
- )
- if self.cur_feature_name_ is None:
- raise FeatureLibError(
- "Language statements are not allowed "
- "within standalone lookup blocks",
- location,
- )
- self.cur_lookup_ = None
-
- key = (self.script_, language, self.cur_feature_name_)
- lookups = self.features_.get((key[0], "dflt", key[2]))
- if (language == "dflt" or include_default) and lookups:
- self.features_[key] = lookups[:]
- else:
- self.features_[key] = []
- self.language_systems = frozenset([(self.script_, language)])
-
- if required:
- key = (self.script_, language)
- if key in self.required_features_:
- raise FeatureLibError(
- "Language %s (script %s) has already "
- "specified feature %s as its required feature"
- % (
- language.strip(),
- self.script_.strip(),
- self.required_features_[key].strip(),
- ),
- location,
- )
- self.required_features_[key] = self.cur_feature_name_
-
- def getMarkAttachClass_(self, location, glyphs):
- glyphs = frozenset(glyphs)
- id_ = self.markAttachClassID_.get(glyphs)
- if id_ is not None:
- return id_
- id_ = len(self.markAttachClassID_) + 1
- self.markAttachClassID_[glyphs] = id_
- for glyph in glyphs:
- if glyph in self.markAttach_:
- _, loc = self.markAttach_[glyph]
- raise FeatureLibError(
- "Glyph %s already has been assigned "
- "a MarkAttachmentType at %s" % (glyph, loc),
- location,
- )
- self.markAttach_[glyph] = (id_, location)
- return id_
-
- def getMarkFilterSet_(self, location, glyphs):
- glyphs = frozenset(glyphs)
- id_ = self.markFilterSets_.get(glyphs)
- if id_ is not None:
- return id_
- id_ = len(self.markFilterSets_)
- self.markFilterSets_[glyphs] = id_
- return id_
-
- def set_lookup_flag(self, location, value, markAttach, markFilter):
- value = value & 0xFF
- if markAttach:
- markAttachClass = self.getMarkAttachClass_(location, markAttach)
- value = value | (markAttachClass << 8)
- if markFilter:
- markFilterSet = self.getMarkFilterSet_(location, markFilter)
- value = value | 0x10
- self.lookupflag_markFilterSet_ = markFilterSet
- else:
- self.lookupflag_markFilterSet_ = None
- self.lookupflag_ = value
-
- def set_script(self, location, script):
- if self.cur_feature_name_ in ("aalt", "size"):
- raise FeatureLibError(
- "Script statements are not allowed "
- 'within "feature %s"' % self.cur_feature_name_,
- location,
- )
- if self.cur_feature_name_ is None:
- raise FeatureLibError(
- "Script statements are not allowed " "within standalone lookup blocks",
- location,
- )
- if self.language_systems == {(script, "dflt")}:
- # Nothing to do.
- return
- self.cur_lookup_ = None
- self.script_ = script
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
- self.set_language(location, "dflt", include_default=True, required=False)
-
- def find_lookup_builders_(self, lookups):
- """Helper for building chain contextual substitutions
-
- Given a list of lookup names, finds the LookupBuilder for each name.
- If an input name is None, it gets mapped to a None LookupBuilder.
- """
- lookup_builders = []
- for lookuplist in lookups:
- if lookuplist is not None:
- lookup_builders.append(
- [self.named_lookups_.get(l.name) for l in lookuplist]
- )
- else:
- lookup_builders.append(None)
- return lookup_builders
-
- def add_attach_points(self, location, glyphs, contourPoints):
- for glyph in glyphs:
- self.attachPoints_.setdefault(glyph, set()).update(contourPoints)
-
- def add_feature_reference(self, location, featureName):
- if self.cur_feature_name_ != "aalt":
- raise FeatureLibError(
- 'Feature references are only allowed inside "feature aalt"', location
- )
- self.aalt_features_.append((location, featureName))
-
- def add_featureName(self, tag):
- self.featureNames_.add(tag)
-
- def add_cv_parameter(self, tag):
- self.cv_parameters_.add(tag)
-
- def add_to_cv_num_named_params(self, tag):
- """Adds new items to ``self.cv_num_named_params_``
- or increments the count of existing items."""
- if tag in self.cv_num_named_params_:
- self.cv_num_named_params_[tag] += 1
- else:
- self.cv_num_named_params_[tag] = 1
-
- def add_cv_character(self, character, tag):
- self.cv_characters_[tag].append(character)
-
- def set_base_axis(self, bases, scripts, vertical):
- if vertical:
- self.base_vert_axis_ = (bases, scripts)
- else:
- self.base_horiz_axis_ = (bases, scripts)
-
- def set_size_parameters(
- self, location, DesignSize, SubfamilyID, RangeStart, RangeEnd
- ):
- if self.cur_feature_name_ != "size":
- raise FeatureLibError(
- "Parameters statements are not allowed "
- 'within "feature %s"' % self.cur_feature_name_,
- location,
- )
- self.size_parameters_ = [DesignSize, SubfamilyID, RangeStart, RangeEnd]
- for script, lang in self.language_systems:
- key = (script, lang, self.cur_feature_name_)
- self.features_.setdefault(key, [])
-
- # GSUB rules
-
- # GSUB 1
- def add_single_subst(self, location, prefix, suffix, mapping, forceChain):
- if self.cur_feature_name_ == "aalt":
- for from_glyph, to_glyph in mapping.items():
- alts = self.aalt_alternates_.setdefault(from_glyph, set())
- alts.add(to_glyph)
- return
- if prefix or suffix or forceChain:
- self.add_single_subst_chained_(location, prefix, suffix, mapping)
- return
- lookup = self.get_lookup_(location, SingleSubstBuilder)
- for from_glyph, to_glyph in mapping.items():
- if from_glyph in lookup.mapping:
- if to_glyph == lookup.mapping[from_glyph]:
- log.info(
- "Removing duplicate single substitution from glyph"
- ' "%s" to "%s" at %s',
- from_glyph,
- to_glyph,
- location,
- )
- else:
- raise FeatureLibError(
- 'Already defined rule for replacing glyph "%s" by "%s"'
- % (from_glyph, lookup.mapping[from_glyph]),
- location,
- )
- lookup.mapping[from_glyph] = to_glyph
-
- # GSUB 2
- def add_multiple_subst(
- self, location, prefix, glyph, suffix, replacements, forceChain=False
- ):
- if prefix or suffix or forceChain:
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- sub = self.get_chained_lookup_(location, MultipleSubstBuilder)
- sub.mapping[glyph] = replacements
- chain.rules.append(ChainContextualRule(prefix, [{glyph}], suffix, [sub]))
- return
- lookup = self.get_lookup_(location, MultipleSubstBuilder)
- if glyph in lookup.mapping:
- if replacements == lookup.mapping[glyph]:
- log.info(
- "Removing duplicate multiple substitution from glyph"
- ' "%s" to %s%s',
- glyph,
- replacements,
- f" at {location}" if location else "",
- )
- else:
- raise FeatureLibError(
- 'Already defined substitution for glyph "%s"' % glyph, location
- )
- lookup.mapping[glyph] = replacements
-
- # GSUB 3
- def add_alternate_subst(self, location, prefix, glyph, suffix, replacement):
- if self.cur_feature_name_ == "aalt":
- alts = self.aalt_alternates_.setdefault(glyph, set())
- alts.update(replacement)
- return
- if prefix or suffix:
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- lookup = self.get_chained_lookup_(location, AlternateSubstBuilder)
- chain.rules.append(ChainContextualRule(prefix, [{glyph}], suffix, [lookup]))
- else:
- lookup = self.get_lookup_(location, AlternateSubstBuilder)
- if glyph in lookup.alternates:
- raise FeatureLibError(
- 'Already defined alternates for glyph "%s"' % glyph, location
- )
- # We allow empty replacement glyphs here.
- lookup.alternates[glyph] = replacement
-
- # GSUB 4
- def add_ligature_subst(
- self, location, prefix, glyphs, suffix, replacement, forceChain
- ):
- if prefix or suffix or forceChain:
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- lookup = self.get_chained_lookup_(location, LigatureSubstBuilder)
- chain.rules.append(ChainContextualRule(prefix, glyphs, suffix, [lookup]))
- else:
- lookup = self.get_lookup_(location, LigatureSubstBuilder)
-
- if not all(glyphs):
- raise FeatureLibError("Empty glyph class in substitution", location)
-
- # OpenType feature file syntax, section 5.d, "Ligature substitution":
- # "Since the OpenType specification does not allow ligature
- # substitutions to be specified on target sequences that contain
- # glyph classes, the implementation software will enumerate
- # all specific glyph sequences if glyph classes are detected"
- for g in sorted(itertools.product(*glyphs)):
- lookup.ligatures[g] = replacement
-
- # GSUB 5/6
- def add_chain_context_subst(self, location, prefix, glyphs, suffix, lookups):
- if not all(glyphs) or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual substitution", location
- )
- lookup = self.get_lookup_(location, ChainContextSubstBuilder)
- lookup.rules.append(
- ChainContextualRule(
- prefix, glyphs, suffix, self.find_lookup_builders_(lookups)
- )
- )
-
- def add_single_subst_chained_(self, location, prefix, suffix, mapping):
- if not mapping or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual substitution", location
- )
- # https://github.com/fonttools/fonttools/issues/512
- # https://github.com/fonttools/fonttools/issues/2150
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- sub = chain.find_chainable_single_subst(mapping)
- if sub is None:
- sub = self.get_chained_lookup_(location, SingleSubstBuilder)
- sub.mapping.update(mapping)
- chain.rules.append(
- ChainContextualRule(prefix, [list(mapping.keys())], suffix, [sub])
- )
-
- # GSUB 8
- def add_reverse_chain_single_subst(self, location, old_prefix, old_suffix, mapping):
- if not mapping:
- raise FeatureLibError("Empty glyph class in substitution", location)
- lookup = self.get_lookup_(location, ReverseChainSingleSubstBuilder)
- lookup.rules.append((old_prefix, old_suffix, mapping))
-
- # GPOS rules
-
- # GPOS 1
- def add_single_pos(self, location, prefix, suffix, pos, forceChain):
- if prefix or suffix or forceChain:
- self.add_single_pos_chained_(location, prefix, suffix, pos)
- else:
- lookup = self.get_lookup_(location, SinglePosBuilder)
- for glyphs, value in pos:
- if not glyphs:
- raise FeatureLibError(
- "Empty glyph class in positioning rule", location
- )
- otValueRecord = self.makeOpenTypeValueRecord(
- location, value, pairPosContext=False
- )
- for glyph in glyphs:
- try:
- lookup.add_pos(location, glyph, otValueRecord)
- except OpenTypeLibError as e:
- raise FeatureLibError(str(e), e.location) from e
-
- # GPOS 2
- def add_class_pair_pos(self, location, glyphclass1, value1, glyphclass2, value2):
- if not glyphclass1 or not glyphclass2:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- lookup = self.get_lookup_(location, PairPosBuilder)
- v1 = self.makeOpenTypeValueRecord(location, value1, pairPosContext=True)
- v2 = self.makeOpenTypeValueRecord(location, value2, pairPosContext=True)
- lookup.addClassPair(location, glyphclass1, v1, glyphclass2, v2)
-
- def add_specific_pair_pos(self, location, glyph1, value1, glyph2, value2):
- if not glyph1 or not glyph2:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- lookup = self.get_lookup_(location, PairPosBuilder)
- v1 = self.makeOpenTypeValueRecord(location, value1, pairPosContext=True)
- v2 = self.makeOpenTypeValueRecord(location, value2, pairPosContext=True)
- lookup.addGlyphPair(location, glyph1, v1, glyph2, v2)
-
- # GPOS 3
- def add_cursive_pos(self, location, glyphclass, entryAnchor, exitAnchor):
- if not glyphclass:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- lookup = self.get_lookup_(location, CursivePosBuilder)
- lookup.add_attachment(
- location,
- glyphclass,
- self.makeOpenTypeAnchor(location, entryAnchor),
- self.makeOpenTypeAnchor(location, exitAnchor),
- )
-
- # GPOS 4
- def add_mark_base_pos(self, location, bases, marks):
- builder = self.get_lookup_(location, MarkBasePosBuilder)
- self.add_marks_(location, builder, marks)
- if not bases:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- for baseAnchor, markClass in marks:
- otBaseAnchor = self.makeOpenTypeAnchor(location, baseAnchor)
- for base in bases:
- builder.bases.setdefault(base, {})[markClass.name] = otBaseAnchor
-
- # GPOS 5
- def add_mark_lig_pos(self, location, ligatures, components):
- builder = self.get_lookup_(location, MarkLigPosBuilder)
- componentAnchors = []
- if not ligatures:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- for marks in components:
- anchors = {}
- self.add_marks_(location, builder, marks)
- for ligAnchor, markClass in marks:
- anchors[markClass.name] = self.makeOpenTypeAnchor(location, ligAnchor)
- componentAnchors.append(anchors)
- for glyph in ligatures:
- builder.ligatures[glyph] = componentAnchors
-
- # GPOS 6
- def add_mark_mark_pos(self, location, baseMarks, marks):
- builder = self.get_lookup_(location, MarkMarkPosBuilder)
- self.add_marks_(location, builder, marks)
- if not baseMarks:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- for baseAnchor, markClass in marks:
- otBaseAnchor = self.makeOpenTypeAnchor(location, baseAnchor)
- for baseMark in baseMarks:
- builder.baseMarks.setdefault(baseMark, {})[
- markClass.name
- ] = otBaseAnchor
-
- # GPOS 7/8
- def add_chain_context_pos(self, location, prefix, glyphs, suffix, lookups):
- if not all(glyphs) or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual positioning rule", location
- )
- lookup = self.get_lookup_(location, ChainContextPosBuilder)
- lookup.rules.append(
- ChainContextualRule(
- prefix, glyphs, suffix, self.find_lookup_builders_(lookups)
- )
- )
-
- def add_single_pos_chained_(self, location, prefix, suffix, pos):
- if not pos or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual positioning rule", location
- )
- # https://github.com/fonttools/fonttools/issues/514
- chain = self.get_lookup_(location, ChainContextPosBuilder)
- targets = []
- for _, _, _, lookups in chain.rules:
- targets.extend(lookups)
- subs = []
- for glyphs, value in pos:
- if value is None:
- subs.append(None)
- continue
- otValue = self.makeOpenTypeValueRecord(
- location, value, pairPosContext=False
- )
- sub = chain.find_chainable_single_pos(targets, glyphs, otValue)
- if sub is None:
- sub = self.get_chained_lookup_(location, SinglePosBuilder)
- targets.append(sub)
- for glyph in glyphs:
- sub.add_pos(location, glyph, otValue)
- subs.append(sub)
- assert len(pos) == len(subs), (pos, subs)
- chain.rules.append(
- ChainContextualRule(prefix, [g for g, v in pos], suffix, subs)
- )
-
- def add_marks_(self, location, lookupBuilder, marks):
- """Helper for add_mark_{base,liga,mark}_pos."""
- for _, markClass in marks:
- for markClassDef in markClass.definitions:
- for mark in markClassDef.glyphs.glyphSet():
- if mark not in lookupBuilder.marks:
- otMarkAnchor = self.makeOpenTypeAnchor(
- location, markClassDef.anchor
- )
- lookupBuilder.marks[mark] = (markClass.name, otMarkAnchor)
- else:
- existingMarkClass = lookupBuilder.marks[mark][0]
- if markClass.name != existingMarkClass:
- raise FeatureLibError(
- "Glyph %s cannot be in both @%s and @%s"
- % (mark, existingMarkClass, markClass.name),
- location,
- )
-
- def add_subtable_break(self, location):
- self.cur_lookup_.add_subtable_break(location)
-
- def setGlyphClass_(self, location, glyph, glyphClass):
- oldClass, oldLocation = self.glyphClassDefs_.get(glyph, (None, None))
- if oldClass and oldClass != glyphClass:
- raise FeatureLibError(
- "Glyph %s was assigned to a different class at %s"
- % (glyph, oldLocation),
- location,
- )
- self.glyphClassDefs_[glyph] = (glyphClass, location)
-
- def add_glyphClassDef(
- self, location, baseGlyphs, ligatureGlyphs, markGlyphs, componentGlyphs
- ):
- for glyph in baseGlyphs:
- self.setGlyphClass_(location, glyph, 1)
- for glyph in ligatureGlyphs:
- self.setGlyphClass_(location, glyph, 2)
- for glyph in markGlyphs:
- self.setGlyphClass_(location, glyph, 3)
- for glyph in componentGlyphs:
- self.setGlyphClass_(location, glyph, 4)
-
- def add_ligatureCaretByIndex_(self, location, glyphs, carets):
- for glyph in glyphs:
- if glyph not in self.ligCaretPoints_:
- self.ligCaretPoints_[glyph] = carets
-
- def makeLigCaret(self, location, caret):
- if not isinstance(caret, VariableScalar):
- return caret
- default, device = self.makeVariablePos(location, caret)
- if device is not None:
- return (default, device)
- return default
-
- def add_ligatureCaretByPos_(self, location, glyphs, carets):
- carets = [self.makeLigCaret(location, caret) for caret in carets]
- for glyph in glyphs:
- if glyph not in self.ligCaretCoords_:
- self.ligCaretCoords_[glyph] = carets
-
- def add_name_record(self, location, nameID, platformID, platEncID, langID, string):
- self.names_.append([nameID, platformID, platEncID, langID, string])
-
- def add_os2_field(self, key, value):
- self.os2_[key] = value
-
- def add_hhea_field(self, key, value):
- self.hhea_[key] = value
-
- def add_vhea_field(self, key, value):
- self.vhea_[key] = value
-
- def add_conditionset(self, location, key, value):
- if "fvar" not in self.font:
- raise FeatureLibError(
- "Cannot add feature variations to a font without an 'fvar' table",
- location,
- )
-
- # Normalize
- axisMap = {
- axis.axisTag: (axis.minValue, axis.defaultValue, axis.maxValue)
- for axis in self.axes
- }
-
- value = {
- tag: (
- normalizeValue(bottom, axisMap[tag]),
- normalizeValue(top, axisMap[tag]),
- )
- for tag, (bottom, top) in value.items()
- }
-
- # NOTE: This might result in rounding errors (off-by-ones) compared to
- # rules in Designspace files, since we're working with what's in the
- # `avar` table rather than the original values.
- if "avar" in self.font:
- mapping = self.font["avar"].segments
- value = {
- axis: tuple(
- piecewiseLinearMap(v, mapping[axis]) if axis in mapping else v
- for v in condition_range
- )
- for axis, condition_range in value.items()
- }
-
- self.conditionsets_[key] = value
-
- def makeVariablePos(self, location, varscalar):
- if not self.varstorebuilder:
- raise FeatureLibError(
- "Can't define a variable scalar in a non-variable font", location
- )
-
- varscalar.axes = self.axes
- if not varscalar.does_vary:
- return varscalar.default, None
-
- default, index = varscalar.add_to_variation_store(
- self.varstorebuilder, self.model_cache, self.font.get("avar")
- )
-
- device = None
- if index is not None and index != 0xFFFFFFFF:
- device = buildVarDevTable(index)
-
- return default, device
-
- def makeOpenTypeAnchor(self, location, anchor):
- """ast.Anchor --> otTables.Anchor"""
- if anchor is None:
- return None
- variable = False
- deviceX, deviceY = None, None
- if anchor.xDeviceTable is not None:
- deviceX = otl.buildDevice(dict(anchor.xDeviceTable))
- if anchor.yDeviceTable is not None:
- deviceY = otl.buildDevice(dict(anchor.yDeviceTable))
- for dim in ("x", "y"):
- varscalar = getattr(anchor, dim)
- if not isinstance(varscalar, VariableScalar):
- continue
- if getattr(anchor, dim + "DeviceTable") is not None:
- raise FeatureLibError(
- "Can't define a device coordinate and variable scalar", location
- )
- default, device = self.makeVariablePos(location, varscalar)
- setattr(anchor, dim, default)
- if device is not None:
- if dim == "x":
- deviceX = device
- else:
- deviceY = device
- variable = True
-
- otlanchor = otl.buildAnchor(
- anchor.x, anchor.y, anchor.contourpoint, deviceX, deviceY
- )
- if variable:
- otlanchor.Format = 3
- return otlanchor
-
- _VALUEREC_ATTRS = {
- name[0].lower() + name[1:]: (name, isDevice)
- for _, name, isDevice, _ in otBase.valueRecordFormat
- if not name.startswith("Reserved")
- }
-
- def makeOpenTypeValueRecord(self, location, v, pairPosContext):
- """ast.ValueRecord --> otBase.ValueRecord"""
- if not v:
- return None
-
- vr = {}
- for astName, (otName, isDevice) in self._VALUEREC_ATTRS.items():
- val = getattr(v, astName, None)
- if not val:
- continue
- if isDevice:
- vr[otName] = otl.buildDevice(dict(val))
- elif isinstance(val, VariableScalar):
- otDeviceName = otName[0:4] + "Device"
- feaDeviceName = otDeviceName[0].lower() + otDeviceName[1:]
- if getattr(v, feaDeviceName):
- raise FeatureLibError(
- "Can't define a device coordinate and variable scalar", location
- )
- vr[otName], device = self.makeVariablePos(location, val)
- if device is not None:
- vr[otDeviceName] = device
- else:
- vr[otName] = val
-
- if pairPosContext and not vr:
- vr = {"YAdvance": 0} if v.vertical else {"XAdvance": 0}
- valRec = otl.buildValue(vr)
- return valRec
diff --git a/spaces/DaleChen/AutoGPT/autogpt/commands/file_operations.py b/spaces/DaleChen/AutoGPT/autogpt/commands/file_operations.py
deleted file mode 100644
index ad145ec956dd9dafd39e09c2244d001cf5febd2f..0000000000000000000000000000000000000000
--- a/spaces/DaleChen/AutoGPT/autogpt/commands/file_operations.py
+++ /dev/null
@@ -1,267 +0,0 @@
-"""File operations for AutoGPT"""
-from __future__ import annotations
-
-import os
-import os.path
-from typing import Generator
-
-import requests
-from colorama import Back, Fore
-from requests.adapters import HTTPAdapter, Retry
-
-from autogpt.spinner import Spinner
-from autogpt.utils import readable_file_size
-from autogpt.workspace import WORKSPACE_PATH, path_in_workspace
-
-LOG_FILE = "file_logger.txt"
-LOG_FILE_PATH = WORKSPACE_PATH / LOG_FILE
-
-
-def check_duplicate_operation(operation: str, filename: str) -> bool:
- """Check if the operation has already been performed on the given file
-
- Args:
- operation (str): The operation to check for
- filename (str): The name of the file to check for
-
- Returns:
- bool: True if the operation has already been performed on the file
- """
- log_content = read_file(LOG_FILE)
- log_entry = f"{operation}: {filename}\n"
- return log_entry in log_content
-
-
-def log_operation(operation: str, filename: str) -> None:
- """Log the file operation to the file_logger.txt
-
- Args:
- operation (str): The operation to log
- filename (str): The name of the file the operation was performed on
- """
- log_entry = f"{operation}: {filename}\n"
-
- # Create the log file if it doesn't exist
- if not os.path.exists(LOG_FILE_PATH):
- with open(LOG_FILE_PATH, "w", encoding="utf-8") as f:
- f.write("File Operation Logger ")
-
- append_to_file(LOG_FILE, log_entry, shouldLog=False)
-
-
-def split_file(
- content: str, max_length: int = 4000, overlap: int = 0
-) -> Generator[str, None, None]:
- """
- Split text into chunks of a specified maximum length with a specified overlap
- between chunks.
-
- :param content: The input text to be split into chunks
- :param max_length: The maximum length of each chunk,
- default is 4000 (about 1k token)
- :param overlap: The number of overlapping characters between chunks,
- default is no overlap
- :return: A generator yielding chunks of text
- """
- start = 0
- content_length = len(content)
-
- while start < content_length:
- end = start + max_length
- if end + overlap < content_length:
- chunk = content[start : end + overlap - 1]
- else:
- chunk = content[start:content_length]
-
- # Account for the case where the last chunk is shorter than the overlap, so it has already been consumed
- if len(chunk) <= overlap:
- break
-
- yield chunk
- start += max_length - overlap
-
-
-def read_file(filename: str) -> str:
- """Read a file and return the contents
-
- Args:
- filename (str): The name of the file to read
-
- Returns:
- str: The contents of the file
- """
- try:
- filepath = path_in_workspace(filename)
- with open(filepath, "r", encoding="utf-8") as f:
- content = f.read()
- return content
- except Exception as e:
- return f"Error: {str(e)}"
-
-
-def ingest_file(
- filename: str, memory, max_length: int = 4000, overlap: int = 200
-) -> None:
- """
- Ingest a file by reading its content, splitting it into chunks with a specified
- maximum length and overlap, and adding the chunks to the memory storage.
-
- :param filename: The name of the file to ingest
- :param memory: An object with an add() method to store the chunks in memory
- :param max_length: The maximum length of each chunk, default is 4000
- :param overlap: The number of overlapping characters between chunks, default is 200
- """
- try:
- print(f"Working with file {filename}")
- content = read_file(filename)
- content_length = len(content)
- print(f"File length: {content_length} characters")
-
- chunks = list(split_file(content, max_length=max_length, overlap=overlap))
-
- num_chunks = len(chunks)
- for i, chunk in enumerate(chunks):
- print(f"Ingesting chunk {i + 1} / {num_chunks} into memory")
- memory_to_add = (
- f"Filename: {filename}\n" f"Content part#{i + 1}/{num_chunks}: {chunk}"
- )
-
- memory.add(memory_to_add)
-
- print(f"Done ingesting {num_chunks} chunks from {filename}.")
- except Exception as e:
- print(f"Error while ingesting file '{filename}': {str(e)}")
-
-
-def write_to_file(filename: str, text: str) -> str:
- """Write text to a file
-
- Args:
- filename (str): The name of the file to write to
- text (str): The text to write to the file
-
- Returns:
- str: A message indicating success or failure
- """
- if check_duplicate_operation("write", filename):
- return "Error: File has already been updated."
- try:
- filepath = path_in_workspace(filename)
- directory = os.path.dirname(filepath)
- if not os.path.exists(directory):
- os.makedirs(directory)
- with open(filepath, "w", encoding="utf-8") as f:
- f.write(text)
- log_operation("write", filename)
- return "File written to successfully."
- except Exception as e:
- return f"Error: {str(e)}"
-
-
-def append_to_file(filename: str, text: str, shouldLog: bool = True) -> str:
- """Append text to a file
-
- Args:
- filename (str): The name of the file to append to
- text (str): The text to append to the file
-
- Returns:
- str: A message indicating success or failure
- """
- try:
- filepath = path_in_workspace(filename)
- with open(filepath, "a") as f:
- f.write(text)
-
- if shouldLog:
- log_operation("append", filename)
-
- return "Text appended successfully."
- except Exception as e:
- return f"Error: {str(e)}"
-
-
-def delete_file(filename: str) -> str:
- """Delete a file
-
- Args:
- filename (str): The name of the file to delete
-
- Returns:
- str: A message indicating success or failure
- """
- if check_duplicate_operation("delete", filename):
- return "Error: File has already been deleted."
- try:
- filepath = path_in_workspace(filename)
- os.remove(filepath)
- log_operation("delete", filename)
- return "File deleted successfully."
- except Exception as e:
- return f"Error: {str(e)}"
-
-
-def search_files(directory: str) -> list[str]:
- """Search for files in a directory
-
- Args:
- directory (str): The directory to search in
-
- Returns:
- list[str]: A list of files found in the directory
- """
- found_files = []
-
- if directory in {"", "/"}:
- search_directory = WORKSPACE_PATH
- else:
- search_directory = path_in_workspace(directory)
-
- for root, _, files in os.walk(search_directory):
- for file in files:
- if file.startswith("."):
- continue
- relative_path = os.path.relpath(os.path.join(root, file), WORKSPACE_PATH)
- found_files.append(relative_path)
-
- return found_files
-
-
-def download_file(url, filename):
- """Downloads a file
- Args:
- url (str): URL of the file to download
- filename (str): Filename to save the file as
- """
- safe_filename = path_in_workspace(filename)
- try:
- message = f"{Fore.YELLOW}Downloading file from {Back.LIGHTBLUE_EX}{url}{Back.RESET}{Fore.RESET}"
- with Spinner(message) as spinner:
- session = requests.Session()
- retry = Retry(total=3, backoff_factor=1, status_forcelist=[502, 503, 504])
- adapter = HTTPAdapter(max_retries=retry)
- session.mount("http://", adapter)
- session.mount("https://", adapter)
-
- total_size = 0
- downloaded_size = 0
-
- with session.get(url, allow_redirects=True, stream=True) as r:
- r.raise_for_status()
- total_size = int(r.headers.get("Content-Length", 0))
- downloaded_size = 0
-
- with open(safe_filename, "wb") as f:
- for chunk in r.iter_content(chunk_size=8192):
- f.write(chunk)
- downloaded_size += len(chunk)
-
- # Update the progress message
- progress = f"{readable_file_size(downloaded_size)} / {readable_file_size(total_size)}"
- spinner.update_message(f"{message} {progress}")
-
- return f'Successfully downloaded and locally stored file: "{filename}"! (Size: {readable_file_size(total_size)})'
- except requests.HTTPError as e:
- return f"Got an HTTP Error whilst trying to download file: {e}"
- except Exception as e:
- return "Error: " + str(e)
diff --git a/spaces/Datasculptor/DescriptionGPT/tools/merge_lvis_coco.py b/spaces/Datasculptor/DescriptionGPT/tools/merge_lvis_coco.py
deleted file mode 100644
index abc2b673a30541fd71679a549acd9a53f7693183..0000000000000000000000000000000000000000
--- a/spaces/Datasculptor/DescriptionGPT/tools/merge_lvis_coco.py
+++ /dev/null
@@ -1,202 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from collections import defaultdict
-import torch
-import sys
-import json
-import numpy as np
-
-from detectron2.structures import Boxes, pairwise_iou
-COCO_PATH = 'datasets/coco/annotations/instances_train2017.json'
-IMG_PATH = 'datasets/coco/train2017/'
-LVIS_PATH = 'datasets/lvis/lvis_v1_train.json'
-NO_SEG = False
-if NO_SEG:
- SAVE_PATH = 'datasets/lvis/lvis_v1_train+coco_box.json'
-else:
- SAVE_PATH = 'datasets/lvis/lvis_v1_train+coco_mask.json'
-THRESH = 0.7
-DEBUG = False
-
-# This mapping is extracted from the official LVIS mapping:
-# https://github.com/lvis-dataset/lvis-api/blob/master/data/coco_to_synset.json
-COCO_SYNSET_CATEGORIES = [
- {"synset": "person.n.01", "coco_cat_id": 1},
- {"synset": "bicycle.n.01", "coco_cat_id": 2},
- {"synset": "car.n.01", "coco_cat_id": 3},
- {"synset": "motorcycle.n.01", "coco_cat_id": 4},
- {"synset": "airplane.n.01", "coco_cat_id": 5},
- {"synset": "bus.n.01", "coco_cat_id": 6},
- {"synset": "train.n.01", "coco_cat_id": 7},
- {"synset": "truck.n.01", "coco_cat_id": 8},
- {"synset": "boat.n.01", "coco_cat_id": 9},
- {"synset": "traffic_light.n.01", "coco_cat_id": 10},
- {"synset": "fireplug.n.01", "coco_cat_id": 11},
- {"synset": "stop_sign.n.01", "coco_cat_id": 13},
- {"synset": "parking_meter.n.01", "coco_cat_id": 14},
- {"synset": "bench.n.01", "coco_cat_id": 15},
- {"synset": "bird.n.01", "coco_cat_id": 16},
- {"synset": "cat.n.01", "coco_cat_id": 17},
- {"synset": "dog.n.01", "coco_cat_id": 18},
- {"synset": "horse.n.01", "coco_cat_id": 19},
- {"synset": "sheep.n.01", "coco_cat_id": 20},
- {"synset": "beef.n.01", "coco_cat_id": 21},
- {"synset": "elephant.n.01", "coco_cat_id": 22},
- {"synset": "bear.n.01", "coco_cat_id": 23},
- {"synset": "zebra.n.01", "coco_cat_id": 24},
- {"synset": "giraffe.n.01", "coco_cat_id": 25},
- {"synset": "backpack.n.01", "coco_cat_id": 27},
- {"synset": "umbrella.n.01", "coco_cat_id": 28},
- {"synset": "bag.n.04", "coco_cat_id": 31},
- {"synset": "necktie.n.01", "coco_cat_id": 32},
- {"synset": "bag.n.06", "coco_cat_id": 33},
- {"synset": "frisbee.n.01", "coco_cat_id": 34},
- {"synset": "ski.n.01", "coco_cat_id": 35},
- {"synset": "snowboard.n.01", "coco_cat_id": 36},
- {"synset": "ball.n.06", "coco_cat_id": 37},
- {"synset": "kite.n.03", "coco_cat_id": 38},
- {"synset": "baseball_bat.n.01", "coco_cat_id": 39},
- {"synset": "baseball_glove.n.01", "coco_cat_id": 40},
- {"synset": "skateboard.n.01", "coco_cat_id": 41},
- {"synset": "surfboard.n.01", "coco_cat_id": 42},
- {"synset": "tennis_racket.n.01", "coco_cat_id": 43},
- {"synset": "bottle.n.01", "coco_cat_id": 44},
- {"synset": "wineglass.n.01", "coco_cat_id": 46},
- {"synset": "cup.n.01", "coco_cat_id": 47},
- {"synset": "fork.n.01", "coco_cat_id": 48},
- {"synset": "knife.n.01", "coco_cat_id": 49},
- {"synset": "spoon.n.01", "coco_cat_id": 50},
- {"synset": "bowl.n.03", "coco_cat_id": 51},
- {"synset": "banana.n.02", "coco_cat_id": 52},
- {"synset": "apple.n.01", "coco_cat_id": 53},
- {"synset": "sandwich.n.01", "coco_cat_id": 54},
- {"synset": "orange.n.01", "coco_cat_id": 55},
- {"synset": "broccoli.n.01", "coco_cat_id": 56},
- {"synset": "carrot.n.01", "coco_cat_id": 57},
- # {"synset": "frank.n.02", "coco_cat_id": 58},
- {"synset": "sausage.n.01", "coco_cat_id": 58},
- {"synset": "pizza.n.01", "coco_cat_id": 59},
- {"synset": "doughnut.n.02", "coco_cat_id": 60},
- {"synset": "cake.n.03", "coco_cat_id": 61},
- {"synset": "chair.n.01", "coco_cat_id": 62},
- {"synset": "sofa.n.01", "coco_cat_id": 63},
- {"synset": "pot.n.04", "coco_cat_id": 64},
- {"synset": "bed.n.01", "coco_cat_id": 65},
- {"synset": "dining_table.n.01", "coco_cat_id": 67},
- {"synset": "toilet.n.02", "coco_cat_id": 70},
- {"synset": "television_receiver.n.01", "coco_cat_id": 72},
- {"synset": "laptop.n.01", "coco_cat_id": 73},
- {"synset": "mouse.n.04", "coco_cat_id": 74},
- {"synset": "remote_control.n.01", "coco_cat_id": 75},
- {"synset": "computer_keyboard.n.01", "coco_cat_id": 76},
- {"synset": "cellular_telephone.n.01", "coco_cat_id": 77},
- {"synset": "microwave.n.02", "coco_cat_id": 78},
- {"synset": "oven.n.01", "coco_cat_id": 79},
- {"synset": "toaster.n.02", "coco_cat_id": 80},
- {"synset": "sink.n.01", "coco_cat_id": 81},
- {"synset": "electric_refrigerator.n.01", "coco_cat_id": 82},
- {"synset": "book.n.01", "coco_cat_id": 84},
- {"synset": "clock.n.01", "coco_cat_id": 85},
- {"synset": "vase.n.01", "coco_cat_id": 86},
- {"synset": "scissors.n.01", "coco_cat_id": 87},
- {"synset": "teddy.n.01", "coco_cat_id": 88},
- {"synset": "hand_blower.n.01", "coco_cat_id": 89},
- {"synset": "toothbrush.n.01", "coco_cat_id": 90},
-]
-
-
-def get_bbox(ann):
- bbox = ann['bbox']
- return [bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]]
-
-
-if __name__ == '__main__':
- file_name_key = 'file_name' if 'v0.5' in LVIS_PATH else 'coco_url'
- coco_data = json.load(open(COCO_PATH, 'r'))
- lvis_data = json.load(open(LVIS_PATH, 'r'))
-
- coco_cats = coco_data['categories']
- lvis_cats = lvis_data['categories']
-
- num_find = 0
- num_not_find = 0
- num_twice = 0
- coco2lviscats = {}
- synset2lvisid = {x['synset']: x['id'] for x in lvis_cats}
- # cocoid2synset = {x['coco_cat_id']: x['synset'] for x in COCO_SYNSET_CATEGORIES}
- coco2lviscats = {x['coco_cat_id']: synset2lvisid[x['synset']] \
- for x in COCO_SYNSET_CATEGORIES if x['synset'] in synset2lvisid}
- print(len(coco2lviscats))
-
- lvis_file2id = {x[file_name_key][-16:]: x['id'] for x in lvis_data['images']}
- lvis_id2img = {x['id']: x for x in lvis_data['images']}
- lvis_catid2name = {x['id']: x['name'] for x in lvis_data['categories']}
-
- coco_file2anns = {}
- coco_id2img = {x['id']: x for x in coco_data['images']}
- coco_img2anns = defaultdict(list)
- for ann in coco_data['annotations']:
- coco_img = coco_id2img[ann['image_id']]
- file_name = coco_img['file_name'][-16:]
- if ann['category_id'] in coco2lviscats and \
- file_name in lvis_file2id:
- lvis_image_id = lvis_file2id[file_name]
- lvis_image = lvis_id2img[lvis_image_id]
- lvis_cat_id = coco2lviscats[ann['category_id']]
- if lvis_cat_id in lvis_image['neg_category_ids']:
- continue
- if DEBUG:
- import cv2
- img_path = IMG_PATH + file_name
- img = cv2.imread(img_path)
- print(lvis_catid2name[lvis_cat_id])
- print('neg', [lvis_catid2name[x] for x in lvis_image['neg_category_ids']])
- cv2.imshow('img', img)
- cv2.waitKey()
- ann['category_id'] = lvis_cat_id
- ann['image_id'] = lvis_image_id
- coco_img2anns[file_name].append(ann)
-
- lvis_img2anns = defaultdict(list)
- for ann in lvis_data['annotations']:
- lvis_img = lvis_id2img[ann['image_id']]
- file_name = lvis_img[file_name_key][-16:]
- lvis_img2anns[file_name].append(ann)
-
- ann_id_count = 0
- anns = []
- for file_name in lvis_img2anns:
- coco_anns = coco_img2anns[file_name]
- lvis_anns = lvis_img2anns[file_name]
- ious = pairwise_iou(
- Boxes(torch.tensor([get_bbox(x) for x in coco_anns])),
- Boxes(torch.tensor([get_bbox(x) for x in lvis_anns]))
- )
-
- for ann in lvis_anns:
- ann_id_count = ann_id_count + 1
- ann['id'] = ann_id_count
- anns.append(ann)
-
- for i, ann in enumerate(coco_anns):
- if len(ious[i]) == 0 or ious[i].max() < THRESH:
- ann_id_count = ann_id_count + 1
- ann['id'] = ann_id_count
- anns.append(ann)
- else:
- duplicated = False
- for j in range(len(ious[i])):
- if ious[i, j] >= THRESH and \
- coco_anns[i]['category_id'] == lvis_anns[j]['category_id']:
- duplicated = True
- if not duplicated:
- ann_id_count = ann_id_count + 1
- ann['id'] = ann_id_count
- anns.append(ann)
- if NO_SEG:
- for ann in anns:
- del ann['segmentation']
- lvis_data['annotations'] = anns
-
- print('# Images', len(lvis_data['images']))
- print('# Anns', len(lvis_data['annotations']))
- json.dump(lvis_data, open(SAVE_PATH, 'w'))
diff --git a/spaces/Detomo/ai-comic-generation/src/lib/replaceNonWhiteWithTransparent.ts b/spaces/Detomo/ai-comic-generation/src/lib/replaceNonWhiteWithTransparent.ts
deleted file mode 100644
index 6ffe6df050134290d39ee114e427741b26cfb419..0000000000000000000000000000000000000000
--- a/spaces/Detomo/ai-comic-generation/src/lib/replaceNonWhiteWithTransparent.ts
+++ /dev/null
@@ -1,46 +0,0 @@
-export function replaceNonWhiteWithTransparent(imageBase64: string): Promise {
- return new Promise((resolve, reject) => {
- const img = new Image();
- img.onload = () => {
- const canvas = document.createElement('canvas');
- const ctx = canvas.getContext('2d');
- if (!ctx) {
- reject('Unable to get canvas context');
- return;
- }
-
- const ratio = window.devicePixelRatio || 1;
- canvas.width = img.width * ratio;
- canvas.height = img.height * ratio;
- ctx.scale(ratio, ratio);
-
- ctx.drawImage(img, 0, 0);
-
- const imageData = ctx.getImageData(0, 0, img.width, img.height);
- const data = imageData.data;
- console.log("ok")
-
- for (let i = 0; i < data.length; i += 4) {
- if (data[i] === 255 && data[i + 1] === 255 && data[i + 2] === 255) {
- // Change white (also shades of grays) pixels to black
- data[i] = 0;
- data[i + 1] = 0;
- data[i + 2] = 0;
- } else {
- // Change all other pixels to transparent
- data[i + 3] = 0;
- }
- }
-
- ctx.putImageData(imageData, 0, 0);
-
- resolve(canvas.toDataURL());
- };
-
- img.onerror = (err) => {
- reject(err);
- };
-
- img.src = imageBase64;
- });
-}
\ No newline at end of file
diff --git a/spaces/DragGan/DragGan-Inversion/stylegan_human/pti/training/coaches/localitly_regulizer.py b/spaces/DragGan/DragGan-Inversion/stylegan_human/pti/training/coaches/localitly_regulizer.py
deleted file mode 100644
index c4fe05cd2a77113b569587c1b4a5ec358646f7a4..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan-Inversion/stylegan_human/pti/training/coaches/localitly_regulizer.py
+++ /dev/null
@@ -1,70 +0,0 @@
-import torch
-import numpy as np
-import wandb
-from pti.pti_configs import hyperparameters, global_config
-l2_criterion = torch.nn.MSELoss(reduction='mean')
-
-
-def l2_loss(real_images, generated_images):
- loss = l2_criterion(real_images, generated_images)
- return loss
-
-
-class Space_Regulizer:
- def __init__(self, original_G, lpips_net):
- self.original_G = original_G
- self.morphing_regulizer_alpha = hyperparameters.regulizer_alpha
- self.lpips_loss = lpips_net
-
- def get_morphed_w_code(self, new_w_code, fixed_w):
- interpolation_direction = new_w_code - fixed_w
- interpolation_direction_norm = torch.norm(interpolation_direction, p=2)
- direction_to_move = hyperparameters.regulizer_alpha * \
- interpolation_direction / interpolation_direction_norm
- result_w = fixed_w + direction_to_move
- self.morphing_regulizer_alpha * fixed_w + \
- (1 - self.morphing_regulizer_alpha) * new_w_code
-
- return result_w
-
- def get_image_from_ws(self, w_codes, G):
- return torch.cat([G.synthesis(w_code, noise_mode='none', force_fp32=True) for w_code in w_codes])
-
- def ball_holder_loss_lazy(self, new_G, num_of_sampled_latents, w_batch, use_wandb=False):
- loss = 0.0
-
- z_samples = np.random.randn(
- num_of_sampled_latents, self.original_G.z_dim)
- w_samples = self.original_G.mapping(torch.from_numpy(z_samples).to(global_config.device), None,
- truncation_psi=0.5)
- territory_indicator_ws = [self.get_morphed_w_code(
- w_code.unsqueeze(0), w_batch) for w_code in w_samples]
-
- for w_code in territory_indicator_ws:
- new_img = new_G.synthesis(
- w_code, noise_mode='none', force_fp32=True)
- with torch.no_grad():
- old_img = self.original_G.synthesis(
- w_code, noise_mode='none', force_fp32=True)
-
- if hyperparameters.regulizer_l2_lambda > 0:
- l2_loss_val = l2_loss.l2_loss(old_img, new_img)
- if use_wandb:
- wandb.log({f'space_regulizer_l2_loss_val': l2_loss_val.detach().cpu()},
- step=global_config.training_step)
- loss += l2_loss_val * hyperparameters.regulizer_l2_lambda
-
- if hyperparameters.regulizer_lpips_lambda > 0:
- loss_lpips = self.lpips_loss(old_img, new_img)
- loss_lpips = torch.mean(torch.squeeze(loss_lpips))
- if use_wandb:
- wandb.log({f'space_regulizer_lpips_loss_val': loss_lpips.detach().cpu()},
- step=global_config.training_step)
- loss += loss_lpips * hyperparameters.regulizer_lpips_lambda
-
- return loss / len(territory_indicator_ws)
-
- def space_regulizer_loss(self, new_G, w_batch, use_wandb):
- ret_val = self.ball_holder_loss_lazy(
- new_G, hyperparameters.latent_ball_num_of_samples, w_batch, use_wandb)
- return ret_val
diff --git a/spaces/ECCV2022/bytetrack/exps/default/yolox_m.py b/spaces/ECCV2022/bytetrack/exps/default/yolox_m.py
deleted file mode 100644
index 9666a31177b9cc1c94978f9867aaceac8ddebce2..0000000000000000000000000000000000000000
--- a/spaces/ECCV2022/bytetrack/exps/default/yolox_m.py
+++ /dev/null
@@ -1,15 +0,0 @@
-#!/usr/bin/env python3
-# -*- coding:utf-8 -*-
-# Copyright (c) Megvii, Inc. and its affiliates.
-
-import os
-
-from yolox.exp import Exp as MyExp
-
-
-class Exp(MyExp):
- def __init__(self):
- super(Exp, self).__init__()
- self.depth = 0.67
- self.width = 0.75
- self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
diff --git a/spaces/Enterprisium/Easy_GUI/lib/infer_pack/modules/F0Predictor/F0Predictor.py b/spaces/Enterprisium/Easy_GUI/lib/infer_pack/modules/F0Predictor/F0Predictor.py
deleted file mode 100644
index f56e49e7f0e6eab3babf0711cae2933371b9f9cc..0000000000000000000000000000000000000000
--- a/spaces/Enterprisium/Easy_GUI/lib/infer_pack/modules/F0Predictor/F0Predictor.py
+++ /dev/null
@@ -1,16 +0,0 @@
-class F0Predictor(object):
- def compute_f0(self, wav, p_len):
- """
- input: wav:[signal_length]
- p_len:int
- output: f0:[signal_length//hop_length]
- """
- pass
-
- def compute_f0_uv(self, wav, p_len):
- """
- input: wav:[signal_length]
- p_len:int
- output: f0:[signal_length//hop_length],uv:[signal_length//hop_length]
- """
- pass
diff --git a/spaces/EsoCode/text-generation-webui/extensions/elevenlabs_tts/script.py b/spaces/EsoCode/text-generation-webui/extensions/elevenlabs_tts/script.py
deleted file mode 100644
index 1a24db1f31eacf4da6b68a99dce03ddc0213ca95..0000000000000000000000000000000000000000
--- a/spaces/EsoCode/text-generation-webui/extensions/elevenlabs_tts/script.py
+++ /dev/null
@@ -1,180 +0,0 @@
-import re
-from pathlib import Path
-
-import elevenlabs
-import gradio as gr
-from modules import chat, shared
-
-params = {
- 'activate': True,
- 'api_key': None,
- 'selected_voice': 'None',
- 'autoplay': False,
- 'show_text': True,
-}
-
-voices = None
-wav_idx = 0
-
-
-def update_api_key(key):
- params['api_key'] = key
- if key is not None:
- elevenlabs.set_api_key(key)
-
-
-def refresh_voices():
- global params
- your_voices = elevenlabs.voices()
- voice_names = [voice.name for voice in your_voices]
- return voice_names
-
-
-def refresh_voices_dd():
- all_voices = refresh_voices()
- return gr.Dropdown.update(value=all_voices[0], choices=all_voices)
-
-
-def remove_tts_from_history():
- for i, entry in enumerate(shared.history['internal']):
- shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]
-
-
-def toggle_text_in_history():
- for i, entry in enumerate(shared.history['visible']):
- visible_reply = entry[1]
- if visible_reply.startswith('')[0]}\n\n{reply}"
- ]
- else:
- shared.history['visible'][i] = [
- shared.history['visible'][i][0], f"{visible_reply.split('')[0]}"
- ]
-
-
-def remove_surrounded_chars(string):
- # this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
- # 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
- return re.sub('\*[^\*]*?(\*|$)', '', string)
-
-
-def state_modifier(state):
- if not params['activate']:
- return state
-
- state['stream'] = False
- return state
-
-
-def input_modifier(string):
- if not params['activate']:
- return string
-
- shared.processing_message = "*Is recording a voice message...*"
- return string
-
-
-def history_modifier(history):
- # Remove autoplay from the last reply
- if len(history['internal']) > 0:
- history['visible'][-1] = [
- history['visible'][-1][0],
- history['visible'][-1][1].replace('controls autoplay>', 'controls>')
- ]
-
- return history
-
-
-def output_modifier(string):
- global params, wav_idx
-
- if not params['activate']:
- return string
-
- original_string = string
- string = remove_surrounded_chars(string)
- string = string.replace('"', '')
- string = string.replace('“', '')
- string = string.replace('\n', ' ')
- string = string.strip()
- if string == '':
- string = 'empty reply, try regenerating'
-
- output_file = Path(f'extensions/elevenlabs_tts/outputs/{wav_idx:06d}.mp3'.format(wav_idx))
- print(f'Outputting audio to {str(output_file)}')
- try:
- audio = elevenlabs.generate(text=string, voice=params['selected_voice'], model="eleven_monolingual_v1")
- elevenlabs.save(audio, str(output_file))
-
- autoplay = 'autoplay' if params['autoplay'] else ''
- string = f''
- wav_idx += 1
- except elevenlabs.api.error.UnauthenticatedRateLimitError:
- string = "🤖 ElevenLabs Unauthenticated Rate Limit Reached - Please create an API key to continue\n\n"
- except elevenlabs.api.error.RateLimitError:
- string = "🤖 ElevenLabs API Tier Limit Reached\n\n"
- except elevenlabs.api.error.APIError as err:
- string = f"🤖 ElevenLabs Error: {err}\n\n"
-
- if params['show_text']:
- string += f'\n\n{original_string}'
-
- shared.processing_message = "*Is typing...*"
- return string
-
-
-def ui():
- global voices
- if not voices:
- voices = refresh_voices()
- params['selected_voice'] = voices[0]
-
- # Gradio elements
- with gr.Row():
- activate = gr.Checkbox(value=params['activate'], label='Activate TTS')
- autoplay = gr.Checkbox(value=params['autoplay'], label='Play TTS automatically')
- show_text = gr.Checkbox(value=params['show_text'], label='Show message text under audio player')
-
- with gr.Row():
- voice = gr.Dropdown(value=params['selected_voice'], choices=voices, label='TTS Voice')
- refresh = gr.Button(value='Refresh')
-
- with gr.Row():
- api_key = gr.Textbox(placeholder="Enter your API key.", label='API Key')
-
- with gr.Row():
- convert = gr.Button('Permanently replace audios with the message texts')
- convert_cancel = gr.Button('Cancel', visible=False)
- convert_confirm = gr.Button('Confirm (cannot be undone)', variant="stop", visible=False)
-
- # Convert history with confirmation
- convert_arr = [convert_confirm, convert, convert_cancel]
- convert.click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
- convert_confirm.click(
- lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr).then(
- remove_tts_from_history, None, None).then(
- chat.save_history, shared.gradio['mode'], None, show_progress=False).then(
- chat.redraw_html, shared.reload_inputs, shared.gradio['display'])
-
- convert_cancel.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
-
- # Toggle message text in history
- show_text.change(
- lambda x: params.update({"show_text": x}), show_text, None).then(
- toggle_text_in_history, None, None).then(
- chat.save_history, shared.gradio['mode'], None, show_progress=False).then(
- chat.redraw_html, shared.reload_inputs, shared.gradio['display'])
-
- convert_cancel.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
-
- # Event functions to update the parameters in the backend
- activate.change(lambda x: params.update({'activate': x}), activate, None)
- voice.change(lambda x: params.update({'selected_voice': x}), voice, None)
- api_key.change(update_api_key, api_key, None)
- # connect.click(check_valid_api, [], connection_status)
- refresh.click(refresh_voices_dd, [], voice)
- # Event functions to update the parameters in the backend
- autoplay.change(lambda x: params.update({"autoplay": x}), autoplay, None)
diff --git a/spaces/Flux9665/Blizzard2023IMS/README.md b/spaces/Flux9665/Blizzard2023IMS/README.md
deleted file mode 100644
index e5120ba640df47de0a9c430adb3b726c69691be3..0000000000000000000000000000000000000000
--- a/spaces/Flux9665/Blizzard2023IMS/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Blizzard2023IMS
-emoji: 🥐🦜
-colorFrom: green
-colorTo: pink
-sdk: gradio
-sdk_version: 3.30.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/FrankZxShen/so-vits-svc-models-pcr/vdecoder/hifigan/nvSTFT.py b/spaces/FrankZxShen/so-vits-svc-models-pcr/vdecoder/hifigan/nvSTFT.py
deleted file mode 100644
index 88597d62a505715091f9ba62d38bf0a85a31b95a..0000000000000000000000000000000000000000
--- a/spaces/FrankZxShen/so-vits-svc-models-pcr/vdecoder/hifigan/nvSTFT.py
+++ /dev/null
@@ -1,111 +0,0 @@
-import math
-import os
-os.environ["LRU_CACHE_CAPACITY"] = "3"
-import random
-import torch
-import torch.utils.data
-import numpy as np
-import librosa
-from librosa.util import normalize
-from librosa.filters import mel as librosa_mel_fn
-from scipy.io.wavfile import read
-import soundfile as sf
-
-def load_wav_to_torch(full_path, target_sr=None, return_empty_on_exception=False):
- sampling_rate = None
- try:
- data, sampling_rate = sf.read(full_path, always_2d=True)# than soundfile.
- except Exception as ex:
- print(f"'{full_path}' failed to load.\nException:")
- print(ex)
- if return_empty_on_exception:
- return [], sampling_rate or target_sr or 32000
- else:
- raise Exception(ex)
-
- if len(data.shape) > 1:
- data = data[:, 0]
- assert len(data) > 2# check duration of audio file is > 2 samples (because otherwise the slice operation was on the wrong dimension)
-
- if np.issubdtype(data.dtype, np.integer): # if audio data is type int
- max_mag = -np.iinfo(data.dtype).min # maximum magnitude = min possible value of intXX
- else: # if audio data is type fp32
- max_mag = max(np.amax(data), -np.amin(data))
- max_mag = (2**31)+1 if max_mag > (2**15) else ((2**15)+1 if max_mag > 1.01 else 1.0) # data should be either 16-bit INT, 32-bit INT or [-1 to 1] float32
-
- data = torch.FloatTensor(data.astype(np.float32))/max_mag
-
- if (torch.isinf(data) | torch.isnan(data)).any() and return_empty_on_exception:# resample will crash with inf/NaN inputs. return_empty_on_exception will return empty arr instead of except
- return [], sampling_rate or target_sr or 32000
- if target_sr is not None and sampling_rate != target_sr:
- data = torch.from_numpy(librosa.core.resample(data.numpy(), orig_sr=sampling_rate, target_sr=target_sr))
- sampling_rate = target_sr
-
- return data, sampling_rate
-
-def dynamic_range_compression(x, C=1, clip_val=1e-5):
- return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
-
-def dynamic_range_decompression(x, C=1):
- return np.exp(x) / C
-
-def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
- return torch.log(torch.clamp(x, min=clip_val) * C)
-
-def dynamic_range_decompression_torch(x, C=1):
- return torch.exp(x) / C
-
-class STFT():
- def __init__(self, sr=22050, n_mels=80, n_fft=1024, win_size=1024, hop_length=256, fmin=20, fmax=11025, clip_val=1e-5):
- self.target_sr = sr
-
- self.n_mels = n_mels
- self.n_fft = n_fft
- self.win_size = win_size
- self.hop_length = hop_length
- self.fmin = fmin
- self.fmax = fmax
- self.clip_val = clip_val
- self.mel_basis = {}
- self.hann_window = {}
-
- def get_mel(self, y, center=False):
- sampling_rate = self.target_sr
- n_mels = self.n_mels
- n_fft = self.n_fft
- win_size = self.win_size
- hop_length = self.hop_length
- fmin = self.fmin
- fmax = self.fmax
- clip_val = self.clip_val
-
- if torch.min(y) < -1.:
- print('min value is ', torch.min(y))
- if torch.max(y) > 1.:
- print('max value is ', torch.max(y))
-
- if fmax not in self.mel_basis:
- mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=n_mels, fmin=fmin, fmax=fmax)
- self.mel_basis[str(fmax)+'_'+str(y.device)] = torch.from_numpy(mel).float().to(y.device)
- self.hann_window[str(y.device)] = torch.hann_window(self.win_size).to(y.device)
-
- y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_length)/2), int((n_fft-hop_length)/2)), mode='reflect')
- y = y.squeeze(1)
-
- spec = torch.stft(y, n_fft, hop_length=hop_length, win_length=win_size, window=self.hann_window[str(y.device)],
- center=center, pad_mode='reflect', normalized=False, onesided=True)
- # print(111,spec)
- spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
- # print(222,spec)
- spec = torch.matmul(self.mel_basis[str(fmax)+'_'+str(y.device)], spec)
- # print(333,spec)
- spec = dynamic_range_compression_torch(spec, clip_val=clip_val)
- # print(444,spec)
- return spec
-
- def __call__(self, audiopath):
- audio, sr = load_wav_to_torch(audiopath, target_sr=self.target_sr)
- spect = self.get_mel(audio.unsqueeze(0)).squeeze(0)
- return spect
-
-stft = STFT()
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/_base_/models/faster_rcnn_r50_caffe_c4.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/_base_/models/faster_rcnn_r50_caffe_c4.py
deleted file mode 100644
index 6e18f71b31b9fb85a6ca7a6b05ff4d2313951750..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/_base_/models/faster_rcnn_r50_caffe_c4.py
+++ /dev/null
@@ -1,112 +0,0 @@
-# model settings
-norm_cfg = dict(type='BN', requires_grad=False)
-model = dict(
- type='FasterRCNN',
- pretrained='open-mmlab://detectron2/resnet50_caffe',
- backbone=dict(
- type='ResNet',
- depth=50,
- num_stages=3,
- strides=(1, 2, 2),
- dilations=(1, 1, 1),
- out_indices=(2, ),
- frozen_stages=1,
- norm_cfg=norm_cfg,
- norm_eval=True,
- style='caffe'),
- rpn_head=dict(
- type='RPNHead',
- in_channels=1024,
- feat_channels=1024,
- anchor_generator=dict(
- type='AnchorGenerator',
- scales=[2, 4, 8, 16, 32],
- ratios=[0.5, 1.0, 2.0],
- strides=[16]),
- bbox_coder=dict(
- type='DeltaXYWHBBoxCoder',
- target_means=[.0, .0, .0, .0],
- target_stds=[1.0, 1.0, 1.0, 1.0]),
- loss_cls=dict(
- type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
- loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
- roi_head=dict(
- type='StandardRoIHead',
- shared_head=dict(
- type='ResLayer',
- depth=50,
- stage=3,
- stride=2,
- dilation=1,
- style='caffe',
- norm_cfg=norm_cfg,
- norm_eval=True),
- bbox_roi_extractor=dict(
- type='SingleRoIExtractor',
- roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
- out_channels=1024,
- featmap_strides=[16]),
- bbox_head=dict(
- type='BBoxHead',
- with_avg_pool=True,
- roi_feat_size=7,
- in_channels=2048,
- num_classes=80,
- bbox_coder=dict(
- type='DeltaXYWHBBoxCoder',
- target_means=[0., 0., 0., 0.],
- target_stds=[0.1, 0.1, 0.2, 0.2]),
- reg_class_agnostic=False,
- loss_cls=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
- loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
- # model training and testing settings
- train_cfg=dict(
- rpn=dict(
- assigner=dict(
- type='MaxIoUAssigner',
- pos_iou_thr=0.7,
- neg_iou_thr=0.3,
- min_pos_iou=0.3,
- match_low_quality=True,
- ignore_iof_thr=-1),
- sampler=dict(
- type='RandomSampler',
- num=256,
- pos_fraction=0.5,
- neg_pos_ub=-1,
- add_gt_as_proposals=False),
- allowed_border=0,
- pos_weight=-1,
- debug=False),
- rpn_proposal=dict(
- nms_pre=12000,
- max_per_img=2000,
- nms=dict(type='nms', iou_threshold=0.7),
- min_bbox_size=0),
- rcnn=dict(
- assigner=dict(
- type='MaxIoUAssigner',
- pos_iou_thr=0.5,
- neg_iou_thr=0.5,
- min_pos_iou=0.5,
- match_low_quality=False,
- ignore_iof_thr=-1),
- sampler=dict(
- type='RandomSampler',
- num=512,
- pos_fraction=0.25,
- neg_pos_ub=-1,
- add_gt_as_proposals=True),
- pos_weight=-1,
- debug=False)),
- test_cfg=dict(
- rpn=dict(
- nms_pre=6000,
- max_per_img=1000,
- nms=dict(type='nms', iou_threshold=0.7),
- min_bbox_size=0),
- rcnn=dict(
- score_thr=0.05,
- nms=dict(type='nms', iou_threshold=0.5),
- max_per_img=100)))
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/sparse_rcnn/sparse_rcnn_r50_fpn_mstrain_480-800_3x_coco.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/sparse_rcnn/sparse_rcnn_r50_fpn_mstrain_480-800_3x_coco.py
deleted file mode 100644
index 2fa2a807190427c857ddbea8ed7efd9434e5ef0f..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/sparse_rcnn/sparse_rcnn_r50_fpn_mstrain_480-800_3x_coco.py
+++ /dev/null
@@ -1,23 +0,0 @@
-_base_ = './sparse_rcnn_r50_fpn_1x_coco.py'
-
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
-min_values = (480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800)
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadAnnotations', with_bbox=True),
- dict(
- type='Resize',
- img_scale=[(1333, value) for value in min_values],
- multiscale_mode='value',
- keep_ratio=True),
- dict(type='RandomFlip', flip_ratio=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
-]
-
-data = dict(train=dict(pipeline=train_pipeline))
-lr_config = dict(policy='step', step=[27, 33])
-runner = dict(type='EpochBasedRunner', max_epochs=36)
diff --git a/spaces/GroveStreet/GTA_SOVITS/diffusion/__init__.py b/spaces/GroveStreet/GTA_SOVITS/diffusion/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/HaloMaster/chinesesummary/fengshen/examples/pretrain_t5/pretrain_mt5_small_continue.sh b/spaces/HaloMaster/chinesesummary/fengshen/examples/pretrain_t5/pretrain_mt5_small_continue.sh
deleted file mode 100644
index 0a539a7e6a7fb4b750b441df98dd49f166c3c49b..0000000000000000000000000000000000000000
--- a/spaces/HaloMaster/chinesesummary/fengshen/examples/pretrain_t5/pretrain_mt5_small_continue.sh
+++ /dev/null
@@ -1,120 +0,0 @@
-#!/bin/bash
-#SBATCH --job-name=t5_cn_small_pretrain_v2
-#SBATCH --nodes=1
-#SBATCH --ntasks-per-node=8
-#SBATCH --gres=gpu:8 # number of gpus
-#SBATCH --cpus-per-task=30 # cpu-cores per task (>1 if multi-threaded tasks)
-#SBATCH -o %x-%j.log
-#SBATCH -e %x-%j.err
-#SBATCH -x dgx050
-
-set -x -e
-source activate base
-
-echo "START TIME: $(date)"
-MICRO_BATCH_SIZE=32
-ROOT_DIR=/cognitive_comp/ganruyi/experiments/t5_cn_small_pretrain_v2/
-
-ZERO_STAGE=1
-
-config_json="$ROOT_DIR/ds_config.t5_cn_small_pretrain_v2.$SLURM_JOBID.json"
-export MASTER_PORT=$[RANDOM%10000+30000]
-# Deepspeed figures out GAS dynamically from dynamic GBS via set_train_batch_size()
-
-cat < $config_json
-{
- "zero_optimization": {
- "stage": 1
- },
- "fp16": {
- "enabled": true,
- "loss_scale": 0,
- "loss_scale_window": 1000,
- "initial_scale_power": 16,
- "hysteresis": 2,
- "min_loss_scale": 1
- },
- "optimizer": {
- "params": {
- "betas": [
- 0.9,
- 0.95
- ],
- "eps": 1e-08,
- "lr": 1e-04,
- "weight_decay": 0.01
- },
- "type": "AdamW"
- },
- "scheduler": {
- "type": "WarmupLR",
- "params":{
- "warmup_min_lr": 0,
- "warmup_max_lr": 1e-4,
- "warmup_num_steps": 10000
- }
- },
- "steps_per_print": 100,
- "gradient_clipping": 1,
- "train_micro_batch_size_per_gpu": $MICRO_BATCH_SIZE,
- "zero_allow_untested_optimizer": false
-}
-EOT
-
-export PL_DEEPSPEED_CONFIG_PATH=$config_json
-export TORCH_EXTENSIONS_DIR=/cognitive_comp/ganruyi/tmp/torch_extendsions
-# strategy=ddp
-strategy=deepspeed_stage_1
-
-TRAINER_ARGS="
- --max_epochs 1 \
- --gpus 8 \
- --num_nodes 1 \
- --strategy ${strategy} \
- --default_root_dir $ROOT_DIR \
- --dirpath $ROOT_DIR/ckpt \
- --save_top_k 3 \
- --every_n_train_steps 0 \
- --monitor train_loss \
- --mode min \
- --save_last \
- --val_check_interval 0.01 \
- --preprocessing_num_workers 20 \
-"
-# --accumulate_grad_batches 8 \
-DATA_DIR=wudao_180g_mt5_tokenized
-
-DATA_ARGS="
- --train_batchsize $MICRO_BATCH_SIZE \
- --valid_batchsize $MICRO_BATCH_SIZE \
- --train_data ${DATA_DIR} \
- --train_split_size 0.999 \
- --max_seq_length 1024 \
-"
-
-MODEL_ARGS="
- --pretrained_model_path /cognitive_comp/ganruyi/experiments/t5_cn_small_pretrain/Randeng-T5-77M \
- --learning_rate 1e-4 \
- --weight_decay 0.1 \
- --keep_tokens_path /cognitive_comp/ganruyi/hf_models/t5_cn_small/sentencepiece_cn_keep_tokens.json \
-"
-# --resume_from_checkpoint /cognitive_comp/ganruyi/fengshen/t5_cn_small_pretrain/ckpt/last.ckpt \
-
-SCRIPTS_PATH=/cognitive_comp/ganruyi/Fengshenbang-LM/fengshen/examples/pretrain_t5/pretrain_t5.py
-
-export CMD=" \
- $SCRIPTS_PATH \
- $TRAINER_ARGS \
- $MODEL_ARGS \
- $DATA_ARGS \
- "
-
-echo $CMD
-
-SINGULARITY_PATH=/cognitive_comp/ganruyi/pytorch21_06_py3_docker_image_v2.sif
-
-# to debug - add echo (it exits and prints what it would have launched)
-#run_cmd="$PY_LAUNCHER $CMD"
-# salloc --nodes=1 --gres=gpu:2 --cpus-per-gpu=20 -t 24:00:00
-clear; srun singularity exec --nv -B /cognitive_comp/:/cognitive_comp/ $SINGULARITY_PATH bash -c '/home/ganruyi/anaconda3/bin/python $CMD'
-# clear; srun --job-name=t5_cn_small_pretrain_v2 --jobid=153124 --nodes=1 --ntasks-per-node=8 --gres=gpu:8 --cpus-per-task=30 -o %x-%j.log -e %x-%j.err singularity exec --nv -B /cognitive_comp/:/cognitive_comp/ $SINGULARITY_PATH bash -c '/home/ganruyi/anaconda3/bin/python $CMD'
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/data/ofa_dataset.py b/spaces/HarryLee/eCommerceImageCaptioning/data/ofa_dataset.py
deleted file mode 100644
index 028e92c6edc0834403559a85c55bb259622a8462..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/data/ofa_dataset.py
+++ /dev/null
@@ -1,79 +0,0 @@
-# Copyright 2022 The OFA-Sys Team.
-# All rights reserved.
-# This source code is licensed under the Apache 2.0 license
-# found in the LICENSE file in the root directory.
-
-import logging
-import re
-import torch.utils.data
-from fairseq.data import FairseqDataset
-
-logger = logging.getLogger(__name__)
-
-
-class OFADataset(FairseqDataset):
- def __init__(self, split, dataset, bpe, src_dict, tgt_dict):
- self.split = split
- self.dataset = dataset
- self.bpe = bpe
- self.src_dict = src_dict
- self.tgt_dict = tgt_dict
-
- self.bos = src_dict.bos()
- self.eos = src_dict.eos()
- self.pad = src_dict.pad()
- self.bos_item = torch.LongTensor([self.bos])
- self.eos_item = torch.LongTensor([self.eos])
-
- def __len__(self):
- return len(self.dataset)
-
- def encode_text(self, text, length=None, append_bos=False, append_eos=False, use_bpe=True):
- s = self.tgt_dict.encode_line(
- line=self.bpe.encode(text) if use_bpe else text,
- add_if_not_exist=False,
- append_eos=False
- ).long()
- if length is not None:
- s = s[:length]
- if append_bos:
- s = torch.cat([self.bos_item, s])
- if append_eos:
- s = torch.cat([s, self.eos_item])
- return s
-
- def pre_question(self, question, max_ques_words):
- question = question.lower().lstrip(",.!?*#:;~").replace('-', ' ').replace('/', ' ')
-
- question = re.sub(
- r"\s{2,}",
- ' ',
- question,
- )
- question = question.rstrip('\n')
- question = question.strip(' ')
-
- # truncate question
- question_words = question.split(' ')
- if len(question_words) > max_ques_words:
- question = ' '.join(question_words[:max_ques_words])
-
- return question
-
- def pre_caption(self, caption, max_words):
- caption = caption.lower().lstrip(",.!?*#:;~").replace('-', ' ').replace('/', ' ').replace('', 'person')
-
- caption = re.sub(
- r"\s{2,}",
- ' ',
- caption,
- )
- caption = caption.rstrip('\n')
- caption = caption.strip(' ')
-
- # truncate caption
- caption_words = caption.split(' ')
- if len(caption_words) > max_words:
- caption = ' '.join(caption_words[:max_words])
-
- return caption
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/tests/test_sequence_scorer.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/tests/test_sequence_scorer.py
deleted file mode 100644
index 42f9447b599bcd7a9913aec37d94ea5078ff43a3..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/tests/test_sequence_scorer.py
+++ /dev/null
@@ -1,120 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import argparse
-import unittest
-
-import tests.utils as test_utils
-import torch
-from fairseq.sequence_scorer import SequenceScorer
-
-
-class TestSequenceScorer(unittest.TestCase):
- def test_sequence_scorer(self):
- # construct dummy dictionary
- d = test_utils.dummy_dictionary(vocab_size=2)
- self.assertEqual(d.pad(), 1)
- self.assertEqual(d.eos(), 2)
- self.assertEqual(d.unk(), 3)
- eos = d.eos()
- w1 = 4
- w2 = 5
-
- # construct dataloader
- data = [
- {
- "source": torch.LongTensor([w1, w2, eos]),
- "target": torch.LongTensor([w1, w2, w1, eos]),
- },
- {
- "source": torch.LongTensor([w2, eos]),
- "target": torch.LongTensor([w2, w1, eos]),
- },
- {
- "source": torch.LongTensor([w2, eos]),
- "target": torch.LongTensor([w2, eos]),
- },
- ]
- data_itr = test_utils.dummy_dataloader(data)
-
- # specify expected output probabilities
- args = argparse.Namespace()
- unk = 0.0
- args.beam_probs = [
- # step 0:
- torch.FloatTensor(
- [
- # eos w1 w2
- [0.0, unk, 0.6, 0.4], # sentence 1
- [0.0, unk, 0.4, 0.6], # sentence 2
- [0.0, unk, 0.7, 0.3], # sentence 3
- ]
- ),
- # step 1:
- torch.FloatTensor(
- [
- # eos w1 w2
- [0.0, unk, 0.2, 0.7], # sentence 1
- [0.0, unk, 0.8, 0.2], # sentence 2
- [0.7, unk, 0.1, 0.2], # sentence 3
- ]
- ),
- # step 2:
- torch.FloatTensor(
- [
- # eos w1 w2
- [0.10, unk, 0.50, 0.4], # sentence 1
- [0.15, unk, 0.15, 0.7], # sentence 2
- [0.00, unk, 0.00, 0.0], # sentence 3
- ]
- ),
- # step 3:
- torch.FloatTensor(
- [
- # eos w1 w2
- [0.9, unk, 0.05, 0.05], # sentence 1
- [0.0, unk, 0.00, 0.0], # sentence 2
- [0.0, unk, 0.00, 0.0], # sentence 3
- ]
- ),
- ]
- expected_scores = [
- [0.6, 0.7, 0.5, 0.9], # sentence 1
- [0.6, 0.8, 0.15], # sentence 2
- [0.3, 0.7], # sentence 3
- ]
-
- task = test_utils.TestTranslationTask.setup_task(args, d, d)
- model = task.build_model(args)
- scorer = SequenceScorer(task.target_dictionary)
- for sample in data_itr:
- hypos = task.inference_step(scorer, [model], sample)
- for id, hypos_id in zip(sample["id"].tolist(), hypos):
- self.assertHypoTokens(hypos_id[0], data[id]["target"])
- self.assertHypoScore(hypos_id[0], expected_scores[id])
-
- def assertHypoTokens(self, hypo, tokens):
- self.assertTensorEqual(hypo["tokens"], torch.LongTensor(tokens))
-
- def assertHypoScore(self, hypo, pos_probs, normalized=True, lenpen=1.0):
- pos_scores = torch.FloatTensor(pos_probs).log()
- self.assertAlmostEqual(hypo["positional_scores"], pos_scores)
- self.assertEqual(pos_scores.numel(), hypo["tokens"].numel())
- score = pos_scores.sum()
- if normalized:
- score /= pos_scores.numel() ** lenpen
- self.assertLess(abs(score - hypo["score"]), 1e-6)
-
- def assertAlmostEqual(self, t1, t2):
- self.assertEqual(t1.size(), t2.size(), "size mismatch")
- self.assertLess((t1 - t2).abs().max(), 1e-4)
-
- def assertTensorEqual(self, t1, t2):
- self.assertEqual(t1.size(), t2.size(), "size mismatch")
- self.assertEqual(t1.ne(t2).long().sum(), 0)
-
-
-if __name__ == "__main__":
- unittest.main()
diff --git a/spaces/HugoDzz/spaceship_drift/src/app.css b/spaces/HugoDzz/spaceship_drift/src/app.css
deleted file mode 100644
index 6155d5df62ef089fd9fced5266de10df57e1c670..0000000000000000000000000000000000000000
--- a/spaces/HugoDzz/spaceship_drift/src/app.css
+++ /dev/null
@@ -1,14 +0,0 @@
-@tailwind base;
-@tailwind components;
-@tailwind utilities;
-
-@layer base {
-
- @font-face {
- font-family: "Hellovetica";
- font-weight: 300;
- src : local("Hellovetica"), url("/fonts/hellovetica.ttf");
- font-display: swap;
- }
-
- }
\ No newline at end of file
diff --git a/spaces/HugoDzz/spaceship_drift/tailwind.config.js b/spaces/HugoDzz/spaceship_drift/tailwind.config.js
deleted file mode 100644
index 186f731d89a9ad8fca203cd5150f41eed9aca2e1..0000000000000000000000000000000000000000
--- a/spaces/HugoDzz/spaceship_drift/tailwind.config.js
+++ /dev/null
@@ -1,12 +0,0 @@
-/** @type {import('tailwindcss').Config} */
-export default {
- content: ["./src/**/*.{html,js,svelte,ts}"],
- theme: {
- extend: {
- fontFamily: {
- Hellovetica: ["Hellovetica"]
- },
- },
- },
- plugins: [],
-};
diff --git a/spaces/ICML2022/OFA/fairseq/examples/speech_synthesis/evaluation/__init__.py b/spaces/ICML2022/OFA/fairseq/examples/speech_synthesis/evaluation/__init__.py
deleted file mode 100644
index 6264236915a7269a4d920ee8213004374dd86a9a..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/examples/speech_synthesis/evaluation/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
diff --git a/spaces/IanNathaniel/Zero-DCE/app.py b/spaces/IanNathaniel/Zero-DCE/app.py
deleted file mode 100644
index 0a346dc8fba32a07b014aeaaa8c18f112271d038..0000000000000000000000000000000000000000
--- a/spaces/IanNathaniel/Zero-DCE/app.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import gradio as gr
-import torch
-import torch.nn as nn
-import torchvision
-import torch.backends.cudnn as cudnn
-import torch.optim
-import os
-import sys
-import argparse
-import dataloader
-import model
-import numpy as np
-from torchvision import transforms
-from PIL import Image
-import glob
-
-
-def lowlight(image):
- os.environ['CUDA_VISIBLE_DEVICES']=''
- data_lowlight = Image.open(image)
-
- data_lowlight = (np.asarray(data_lowlight)/255.0)
- data_lowlight = torch.from_numpy(data_lowlight).float()
- data_lowlight = data_lowlight.permute(2,0,1)
- data_lowlight = data_lowlight.cpu().unsqueeze(0)
-
- DCE_net = model.enhance_net_nopool().cpu()
- DCE_net.load_state_dict(torch.load('Epoch99.pth', map_location=torch.device('cpu')))
-
- _,enhanced_image,_ = DCE_net(data_lowlight)
-
- torchvision.utils.save_image(enhanced_image, f'01.png')
-
- return '01.png'
-
-
-title = "Low-Light Image Enhancement using Zero-DCE"
-description = "Gradio Demo for Low-Light Enhancement using Zero-DCE. The model improves the quality of images that have poor contrast, low brightness, and suboptimal exposure. To use it, simply upload your image, or click one of the examples to load them. Check out the original paper and the GitHub repo at the links below. "
-article = "Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement | Github Repo
 "
-
-examples = [['01.jpg'], ['02.jpg'], ['03.jpg'], ['04.png'], ['05.jpg'],]
-gr.Interface(
- lowlight,
- [gr.inputs.Image(type="file", label="Input")],
- [gr.outputs.Image(type="file", label="Output")],
- title=title,
- description=description,
- article=article,
- allow_flagging=False,
- allow_screenshot=False,
- examples=examples
-).launch(debug=True)
diff --git a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/benchmarks.py b/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/benchmarks.py
deleted file mode 100644
index 03d7d693a93674bb9a94db07f24a8e9ef7013f8f..0000000000000000000000000000000000000000
--- a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/benchmarks.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-Run YOLOv5 benchmarks on all supported export formats
-
-Format | `export.py --include` | Model
---- | --- | ---
-PyTorch | - | yolov5s.pt
-TorchScript | `torchscript` | yolov5s.torchscript
-ONNX | `onnx` | yolov5s.onnx
-OpenVINO | `openvino` | yolov5s_openvino_model/
-TensorRT | `engine` | yolov5s.engine
-CoreML | `coreml` | yolov5s.mlmodel
-TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
-TensorFlow GraphDef | `pb` | yolov5s.pb
-TensorFlow Lite | `tflite` | yolov5s.tflite
-TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
-TensorFlow.js | `tfjs` | yolov5s_web_model/
-
-Requirements:
- $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
- $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
- $ pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # TensorRT
-
-Usage:
- $ python benchmarks.py --weights yolov5s.pt --img 640
-"""
-
-import argparse
-import platform
-import sys
-import time
-from pathlib import Path
-
-import pandas as pd
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[0] # YOLOv5 root directory
-if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
-# ROOT = ROOT.relative_to(Path.cwd()) # relative
-
-import export
-from models.experimental import attempt_load
-from models.yolo import SegmentationModel
-from segment.val import run as val_seg
-from utils import notebook_init
-from utils.general import LOGGER, check_yaml, file_size, print_args
-from utils.torch_utils import select_device
-from val import run as val_det
-
-
-def run(
- weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=640, # inference size (pixels)
- batch_size=1, # batch size
- data=ROOT / 'data/coco128.yaml', # dataset.yaml path
- device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
- half=False, # use FP16 half-precision inference
- test=False, # test exports only
- pt_only=False, # test PyTorch only
- hard_fail=False, # throw error on benchmark failure
-):
- y, t = [], time.time()
- device = select_device(device)
- model_type = type(attempt_load(weights, fuse=False)) # DetectionModel, SegmentationModel, etc.
- for i, (name, f, suffix, cpu, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, CPU, GPU)
- try:
- assert i not in (9, 10), 'inference not supported' # Edge TPU and TF.js are unsupported
- assert i != 5 or platform.system() == 'Darwin', 'inference only supported on macOS>=10.13' # CoreML
- if 'cpu' in device.type:
- assert cpu, 'inference not supported on CPU'
- if 'cuda' in device.type:
- assert gpu, 'inference not supported on GPU'
-
- # Export
- if f == '-':
- w = weights # PyTorch format
- else:
- w = export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # all others
- assert suffix in str(w), 'export failed'
-
- # Validate
- if model_type == SegmentationModel:
- result = val_seg(data, w, batch_size, imgsz, plots=False, device=device, task='speed', half=half)
- metric = result[0][7] # (box(p, r, map50, map), mask(p, r, map50, map), *loss(box, obj, cls))
- else: # DetectionModel:
- result = val_det(data, w, batch_size, imgsz, plots=False, device=device, task='speed', half=half)
- metric = result[0][3] # (p, r, map50, map, *loss(box, obj, cls))
- speed = result[2][1] # times (preprocess, inference, postprocess)
- y.append([name, round(file_size(w), 1), round(metric, 4), round(speed, 2)]) # MB, mAP, t_inference
- except Exception as e:
- if hard_fail:
- assert type(e) is AssertionError, f'Benchmark --hard-fail for {name}: {e}'
- LOGGER.warning(f'WARNING ⚠️ Benchmark failure for {name}: {e}')
- y.append([name, None, None, None]) # mAP, t_inference
- if pt_only and i == 0:
- break # break after PyTorch
-
- # Print results
- LOGGER.info('\n')
- parse_opt()
- notebook_init() # print system info
- c = ['Format', 'Size (MB)', 'mAP50-95', 'Inference time (ms)'] if map else ['Format', 'Export', '', '']
- py = pd.DataFrame(y, columns=c)
- LOGGER.info(f'\nBenchmarks complete ({time.time() - t:.2f}s)')
- LOGGER.info(str(py if map else py.iloc[:, :2]))
- if hard_fail and isinstance(hard_fail, str):
- metrics = py['mAP50-95'].array # values to compare to floor
- floor = eval(hard_fail) # minimum metric floor to pass, i.e. = 0.29 mAP for YOLOv5n
- assert all(x > floor for x in metrics if pd.notna(x)), f'HARD FAIL: mAP50-95 < floor {floor}'
- return py
-
-
-def test(
- weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=640, # inference size (pixels)
- batch_size=1, # batch size
- data=ROOT / 'data/coco128.yaml', # dataset.yaml path
- device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
- half=False, # use FP16 half-precision inference
- test=False, # test exports only
- pt_only=False, # test PyTorch only
- hard_fail=False, # throw error on benchmark failure
-):
- y, t = [], time.time()
- device = select_device(device)
- for i, (name, f, suffix, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, gpu-capable)
- try:
- w = weights if f == '-' else \
- export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # weights
- assert suffix in str(w), 'export failed'
- y.append([name, True])
- except Exception:
- y.append([name, False]) # mAP, t_inference
-
- # Print results
- LOGGER.info('\n')
- parse_opt()
- notebook_init() # print system info
- py = pd.DataFrame(y, columns=['Format', 'Export'])
- LOGGER.info(f'\nExports complete ({time.time() - t:.2f}s)')
- LOGGER.info(str(py))
- return py
-
-
-def parse_opt():
- parser = argparse.ArgumentParser()
- parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
- parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
- parser.add_argument('--batch-size', type=int, default=1, help='batch size')
- parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
- parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
- parser.add_argument('--test', action='store_true', help='test exports only')
- parser.add_argument('--pt-only', action='store_true', help='test PyTorch only')
- parser.add_argument('--hard-fail', nargs='?', const=True, default=False, help='Exception on error or < min metric')
- opt = parser.parse_args()
- opt.data = check_yaml(opt.data) # check YAML
- print_args(vars(opt))
- return opt
-
-
-def main(opt):
- test(**vars(opt)) if opt.test else run(**vars(opt))
-
-
-if __name__ == "__main__":
- opt = parse_opt()
- main(opt)
diff --git a/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/fid_score.py b/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/fid_score.py
deleted file mode 100644
index 6ca8e602c21bb6a624d646da3f6479aea033b0ac..0000000000000000000000000000000000000000
--- a/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/fid_score.py
+++ /dev/null
@@ -1,328 +0,0 @@
-#!/usr/bin/env python3
-"""Calculates the Frechet Inception Distance (FID) to evalulate GANs
-
-The FID metric calculates the distance between two distributions of images.
-Typically, we have summary statistics (mean & covariance matrix) of one
-of these distributions, while the 2nd distribution is given by a GAN.
-
-When run as a stand-alone program, it compares the distribution of
-images that are stored as PNG/JPEG at a specified location with a
-distribution given by summary statistics (in pickle format).
-
-The FID is calculated by assuming that X_1 and X_2 are the activations of
-the pool_3 layer of the inception net for generated samples and real world
-samples respectively.
-
-See --help to see further details.
-
-Code apapted from https://github.com/bioinf-jku/TTUR to use PyTorch instead
-of Tensorflow
-
-Copyright 2018 Institute of Bioinformatics, JKU Linz
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-"""
-import os
-import pathlib
-from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser
-
-import numpy as np
-import torch
-# from scipy.misc import imread
-from imageio import imread
-from PIL import Image, JpegImagePlugin
-from scipy import linalg
-from torch.nn.functional import adaptive_avg_pool2d
-from torchvision.transforms import CenterCrop, Compose, Resize, ToTensor
-
-try:
- from tqdm import tqdm
-except ImportError:
- # If not tqdm is not available, provide a mock version of it
- def tqdm(x): return x
-
-try:
- from .inception import InceptionV3
-except ModuleNotFoundError:
- from inception import InceptionV3
-
-parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
-parser.add_argument('path', type=str, nargs=2,
- help=('Path to the generated images or '
- 'to .npz statistic files'))
-parser.add_argument('--batch-size', type=int, default=50,
- help='Batch size to use')
-parser.add_argument('--dims', type=int, default=2048,
- choices=list(InceptionV3.BLOCK_INDEX_BY_DIM),
- help=('Dimensionality of Inception features to use. '
- 'By default, uses pool3 features'))
-parser.add_argument('-c', '--gpu', default='', type=str,
- help='GPU to use (leave blank for CPU only)')
-parser.add_argument('--resize', default=256)
-
-transform = Compose([Resize(256), CenterCrop(256), ToTensor()])
-
-
-def get_activations(files, model, batch_size=50, dims=2048,
- cuda=False, verbose=False, keep_size=False):
- """Calculates the activations of the pool_3 layer for all images.
-
- Params:
- -- files : List of image files paths
- -- model : Instance of inception model
- -- batch_size : Batch size of images for the model to process at once.
- Make sure that the number of samples is a multiple of
- the batch size, otherwise some samples are ignored. This
- behavior is retained to match the original FID score
- implementation.
- -- dims : Dimensionality of features returned by Inception
- -- cuda : If set to True, use GPU
- -- verbose : If set to True and parameter out_step is given, the number
- of calculated batches is reported.
- Returns:
- -- A numpy array of dimension (num images, dims) that contains the
- activations of the given tensor when feeding inception with the
- query tensor.
- """
- model.eval()
-
- if len(files) % batch_size != 0:
- print(('Warning: number of images is not a multiple of the '
- 'batch size. Some samples are going to be ignored.'))
- if batch_size > len(files):
- print(('Warning: batch size is bigger than the data size. '
- 'Setting batch size to data size'))
- batch_size = len(files)
-
- n_batches = len(files) // batch_size
- n_used_imgs = n_batches * batch_size
-
- pred_arr = np.empty((n_used_imgs, dims))
-
- for i in tqdm(range(n_batches)):
- if verbose:
- print('\rPropagating batch %d/%d' % (i + 1, n_batches),
- end='', flush=True)
- start = i * batch_size
- end = start + batch_size
-
- # # Official code goes below
- # images = np.array([imread(str(f)).astype(np.float32)
- # for f in files[start:end]])
-
- # # Reshape to (n_images, 3, height, width)
- # images = images.transpose((0, 3, 1, 2))
- # images /= 255
- # batch = torch.from_numpy(images).type(torch.FloatTensor)
- # #
-
- t = transform if not keep_size else ToTensor()
-
- if isinstance(files[0], pathlib.PosixPath):
- images = [t(Image.open(str(f))) for f in files[start:end]]
-
- elif isinstance(files[0], Image.Image):
- images = [t(f) for f in files[start:end]]
-
- else:
- raise ValueError(f"Unknown data type for image: {type(files[0])}")
-
- batch = torch.stack(images)
-
- if cuda:
- batch = batch.cuda()
-
- pred = model(batch)[0]
-
- # If model output is not scalar, apply global spatial average pooling.
- # This happens if you choose a dimensionality not equal 2048.
- if pred.shape[2] != 1 or pred.shape[3] != 1:
- pred = adaptive_avg_pool2d(pred, output_size=(1, 1))
-
- pred_arr[start:end] = pred.cpu().data.numpy().reshape(batch_size, -1)
-
- if verbose:
- print(' done')
-
- return pred_arr
-
-
-def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
- """Numpy implementation of the Frechet Distance.
- The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
- and X_2 ~ N(mu_2, C_2) is
- d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
-
- Stable version by Dougal J. Sutherland.
-
- Params:
- -- mu1 : Numpy array containing the activations of a layer of the
- inception net (like returned by the function 'get_predictions')
- for generated samples.
- -- mu2 : The sample mean over activations, precalculated on an
- representative data set.
- -- sigma1: The covariance matrix over activations for generated samples.
- -- sigma2: The covariance matrix over activations, precalculated on an
- representative data set.
-
- Returns:
- -- : The Frechet Distance.
- """
-
- mu1 = np.atleast_1d(mu1)
- mu2 = np.atleast_1d(mu2)
-
- sigma1 = np.atleast_2d(sigma1)
- sigma2 = np.atleast_2d(sigma2)
-
- assert mu1.shape == mu2.shape, \
- 'Training and test mean vectors have different lengths'
- assert sigma1.shape == sigma2.shape, \
- 'Training and test covariances have different dimensions'
-
- diff = mu1 - mu2
-
- # Product might be almost singular
- covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
- if not np.isfinite(covmean).all():
- msg = ('fid calculation produces singular product; '
- 'adding %s to diagonal of cov estimates') % eps
- print(msg)
- offset = np.eye(sigma1.shape[0]) * eps
- covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
-
- # Numerical error might give slight imaginary component
- if np.iscomplexobj(covmean):
- # if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
- if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-2):
- m = np.max(np.abs(covmean.imag))
- raise ValueError('Imaginary component {}'.format(m))
- covmean = covmean.real
-
- tr_covmean = np.trace(covmean)
-
- return (diff.dot(diff) + np.trace(sigma1) +
- np.trace(sigma2) - 2 * tr_covmean)
-
-
-def calculate_activation_statistics(files, model, batch_size=50,
- dims=2048, cuda=False, verbose=False, keep_size=False):
- """Calculation of the statistics used by the FID.
- Params:
- -- files : List of image files paths
- -- model : Instance of inception model
- -- batch_size : The images numpy array is split into batches with
- batch size batch_size. A reasonable batch size
- depends on the hardware.
- -- dims : Dimensionality of features returned by Inception
- -- cuda : If set to True, use GPU
- -- verbose : If set to True and parameter out_step is given, the
- number of calculated batches is reported.
- Returns:
- -- mu : The mean over samples of the activations of the pool_3 layer of
- the inception model.
- -- sigma : The covariance matrix of the activations of the pool_3 layer of
- the inception model.
- """
- act = get_activations(files, model, batch_size, dims, cuda, verbose, keep_size=keep_size)
- mu = np.mean(act, axis=0)
- sigma = np.cov(act, rowvar=False)
- return mu, sigma
-
-
-def _compute_statistics_of_path(path, model, batch_size, dims, cuda):
- if path.endswith('.npz'):
- f = np.load(path)
- m, s = f['mu'][:], f['sigma'][:]
- f.close()
- else:
- path = pathlib.Path(path)
- files = list(path.glob('*.jpg')) + list(path.glob('*.png'))
- m, s = calculate_activation_statistics(files, model, batch_size,
- dims, cuda)
-
- return m, s
-
-
-def _compute_statistics_of_images(images, model, batch_size, dims, cuda, keep_size=False):
- if isinstance(images, list): # exact paths to files are provided
- m, s = calculate_activation_statistics(images, model, batch_size,
- dims, cuda, keep_size=keep_size)
-
- return m, s
-
- else:
- raise ValueError
-
-
-def calculate_fid_given_paths(paths, batch_size, cuda, dims):
- """Calculates the FID of two paths"""
- for p in paths:
- if not os.path.exists(p):
- raise RuntimeError('Invalid path: %s' % p)
-
- block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[dims]
-
- model = InceptionV3([block_idx])
- if cuda:
- model.cuda()
-
- m1, s1 = _compute_statistics_of_path(paths[0], model, batch_size,
- dims, cuda)
- m2, s2 = _compute_statistics_of_path(paths[1], model, batch_size,
- dims, cuda)
- fid_value = calculate_frechet_distance(m1, s1, m2, s2)
-
- return fid_value
-
-
-def calculate_fid_given_images(images, batch_size, cuda, dims, use_globals=False, keep_size=False):
- if use_globals:
- global FID_MODEL # for multiprocessing
-
- for imgs in images:
- if isinstance(imgs, list) and isinstance(imgs[0], (Image.Image, JpegImagePlugin.JpegImageFile)):
- pass
- else:
- raise RuntimeError('Invalid images')
-
- block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[dims]
-
- if 'FID_MODEL' not in globals() or not use_globals:
- model = InceptionV3([block_idx])
- if cuda:
- model.cuda()
-
- if use_globals:
- FID_MODEL = model
-
- else:
- model = FID_MODEL
-
- m1, s1 = _compute_statistics_of_images(images[0], model, batch_size,
- dims, cuda, keep_size=False)
- m2, s2 = _compute_statistics_of_images(images[1], model, batch_size,
- dims, cuda, keep_size=False)
- fid_value = calculate_frechet_distance(m1, s1, m2, s2)
- return fid_value
-
-
-if __name__ == '__main__':
- args = parser.parse_args()
- os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
-
- fid_value = calculate_fid_given_paths(args.path,
- args.batch_size,
- args.gpu != '',
- args.dims)
- print('FID: ', fid_value)
diff --git a/spaces/JMalott/ai_architecture/background.py b/spaces/JMalott/ai_architecture/background.py
deleted file mode 100644
index 0c1b73c42038e96d554f2fd96b4ebe584f40de0c..0000000000000000000000000000000000000000
--- a/spaces/JMalott/ai_architecture/background.py
+++ /dev/null
@@ -1,61 +0,0 @@
-from htbuilder import HtmlElement, div, ul, li, br, hr, a, p, img, styles, classes, fonts
-from htbuilder.units import percent, px
-from htbuilder.funcs import rgba, rgb
-import streamlit as st
-import os
-import sys
-import argparse
-import clip
-import numpy as np
-from PIL import Image
-from dalle.models import Dalle
-from dalle.utils.utils import set_seed, clip_score
-import cv2
-import subprocess
-import signal
-
-def signal_handler(sig, frame):
- print('You pressed Ctrl+C!')
- sys.exit(0)
-
-
-def generate(prompt,crazy):
-
- print("-------------------")
-
- signal.signal(signal.SIGINT, signal_handler)
-
- device = 'cpu'
- model = Dalle.from_pretrained('minDALL-E/1.3B') # This will automatically download the pretrained model.
- model.to(device=device)
- num_candidates = 3
-
- images = []
-
- set_seed(np.random.randint(0,10000))
-
- # Sampling
- images = model.sampling(prompt=prompt,
- top_k=2048,
- top_p=None,
- softmax_temperature=crazy,
- num_candidates=num_candidates,
- device=device).cpu().numpy()
- images = np.transpose(images, (0, 2, 3, 1))
-
- # CLIP Re-ranking
- model_clip, preprocess_clip = clip.load("ViT-B/32", device=device)
- model_clip.to(device=device)
- rank = clip_score(prompt=prompt,
- images=images,
- model_clip=model_clip,
- preprocess_clip=preprocess_clip,
- device=device)
-
- # Save images
- #return images[rank]
- for image in images:
- cv2.imwrite('temp/'+str(np.random.randint(0,10000))+'.jpeg', image)
-
-
-generate("a pink house",0.75)
\ No newline at end of file
diff --git a/spaces/Jamel887/Rv-percobaan887/README.md b/spaces/Jamel887/Rv-percobaan887/README.md
deleted file mode 100644
index 4c2022c8257ba2024382a9be2c4bce7162724a3f..0000000000000000000000000000000000000000
--- a/spaces/Jamel887/Rv-percobaan887/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Hololive Rvc Models V2
-emoji: ▶️🐻💿
-colorFrom: blue
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.35.2
-app_file: app.py
-pinned: true
-license: openrail
-duplicated_from: megaaziib/hololive-rvc-models-v2
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/rmvpe.py b/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/rmvpe.py
deleted file mode 100644
index 2a387ebe73c7e1dd8bb7ccad1ea9e0ea89848ece..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/rmvpe.py
+++ /dev/null
@@ -1,717 +0,0 @@
-import pdb, os
-
-import numpy as np
-import torch
-try:
- #Fix "Torch not compiled with CUDA enabled"
- import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
- if torch.xpu.is_available():
- from infer.modules.ipex import ipex_init
- ipex_init()
-except Exception:
- pass
-import torch.nn as nn
-import torch.nn.functional as F
-from librosa.util import normalize, pad_center, tiny
-from scipy.signal import get_window
-
-import logging
-
-logger = logging.getLogger(__name__)
-
-
-###stft codes from https://github.com/pseeth/torch-stft/blob/master/torch_stft/util.py
-def window_sumsquare(
- window,
- n_frames,
- hop_length=200,
- win_length=800,
- n_fft=800,
- dtype=np.float32,
- norm=None,
-):
- """
- # from librosa 0.6
- Compute the sum-square envelope of a window function at a given hop length.
- This is used to estimate modulation effects induced by windowing
- observations in short-time fourier transforms.
- Parameters
- ----------
- window : string, tuple, number, callable, or list-like
- Window specification, as in `get_window`
- n_frames : int > 0
- The number of analysis frames
- hop_length : int > 0
- The number of samples to advance between frames
- win_length : [optional]
- The length of the window function. By default, this matches `n_fft`.
- n_fft : int > 0
- The length of each analysis frame.
- dtype : np.dtype
- The data type of the output
- Returns
- -------
- wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))`
- The sum-squared envelope of the window function
- """
- if win_length is None:
- win_length = n_fft
-
- n = n_fft + hop_length * (n_frames - 1)
- x = np.zeros(n, dtype=dtype)
-
- # Compute the squared window at the desired length
- win_sq = get_window(window, win_length, fftbins=True)
- win_sq = normalize(win_sq, norm=norm) ** 2
- win_sq = pad_center(win_sq, n_fft)
-
- # Fill the envelope
- for i in range(n_frames):
- sample = i * hop_length
- x[sample : min(n, sample + n_fft)] += win_sq[: max(0, min(n_fft, n - sample))]
- return x
-
-
-class STFT(torch.nn.Module):
- def __init__(
- self, filter_length=1024, hop_length=512, win_length=None, window="hann"
- ):
- """
- This module implements an STFT using 1D convolution and 1D transpose convolutions.
- This is a bit tricky so there are some cases that probably won't work as working
- out the same sizes before and after in all overlap add setups is tough. Right now,
- this code should work with hop lengths that are half the filter length (50% overlap
- between frames).
-
- Keyword Arguments:
- filter_length {int} -- Length of filters used (default: {1024})
- hop_length {int} -- Hop length of STFT (restrict to 50% overlap between frames) (default: {512})
- win_length {[type]} -- Length of the window function applied to each frame (if not specified, it
- equals the filter length). (default: {None})
- window {str} -- Type of window to use (options are bartlett, hann, hamming, blackman, blackmanharris)
- (default: {'hann'})
- """
- super(STFT, self).__init__()
- self.filter_length = filter_length
- self.hop_length = hop_length
- self.win_length = win_length if win_length else filter_length
- self.window = window
- self.forward_transform = None
- self.pad_amount = int(self.filter_length / 2)
- scale = self.filter_length / self.hop_length
- fourier_basis = np.fft.fft(np.eye(self.filter_length))
-
- cutoff = int((self.filter_length / 2 + 1))
- fourier_basis = np.vstack(
- [np.real(fourier_basis[:cutoff, :]), np.imag(fourier_basis[:cutoff, :])]
- )
- forward_basis = torch.FloatTensor(fourier_basis[:, None, :])
- inverse_basis = torch.FloatTensor(
- np.linalg.pinv(scale * fourier_basis).T[:, None, :]
- )
-
- assert filter_length >= self.win_length
- # get window and zero center pad it to filter_length
- fft_window = get_window(window, self.win_length, fftbins=True)
- fft_window = pad_center(fft_window, size=filter_length)
- fft_window = torch.from_numpy(fft_window).float()
-
- # window the bases
- forward_basis *= fft_window
- inverse_basis *= fft_window
-
- self.register_buffer("forward_basis", forward_basis.float())
- self.register_buffer("inverse_basis", inverse_basis.float())
-
- def transform(self, input_data):
- """Take input data (audio) to STFT domain.
-
- Arguments:
- input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
-
- Returns:
- magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
- num_frequencies, num_frames)
- phase {tensor} -- Phase of STFT with shape (num_batch,
- num_frequencies, num_frames)
- """
- num_batches = input_data.shape[0]
- num_samples = input_data.shape[-1]
-
- self.num_samples = num_samples
-
- # similar to librosa, reflect-pad the input
- input_data = input_data.view(num_batches, 1, num_samples)
- # print(1234,input_data.shape)
- input_data = F.pad(
- input_data.unsqueeze(1),
- (self.pad_amount, self.pad_amount, 0, 0, 0, 0),
- mode="reflect",
- ).squeeze(1)
- # print(2333,input_data.shape,self.forward_basis.shape,self.hop_length)
- # pdb.set_trace()
- forward_transform = F.conv1d(
- input_data, self.forward_basis, stride=self.hop_length, padding=0
- )
-
- cutoff = int((self.filter_length / 2) + 1)
- real_part = forward_transform[:, :cutoff, :]
- imag_part = forward_transform[:, cutoff:, :]
-
- magnitude = torch.sqrt(real_part**2 + imag_part**2)
- # phase = torch.atan2(imag_part.data, real_part.data)
-
- return magnitude # , phase
-
- def inverse(self, magnitude, phase):
- """Call the inverse STFT (iSTFT), given magnitude and phase tensors produced
- by the ```transform``` function.
-
- Arguments:
- magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
- num_frequencies, num_frames)
- phase {tensor} -- Phase of STFT with shape (num_batch,
- num_frequencies, num_frames)
-
- Returns:
- inverse_transform {tensor} -- Reconstructed audio given magnitude and phase. Of
- shape (num_batch, num_samples)
- """
- recombine_magnitude_phase = torch.cat(
- [magnitude * torch.cos(phase), magnitude * torch.sin(phase)], dim=1
- )
-
- inverse_transform = F.conv_transpose1d(
- recombine_magnitude_phase,
- self.inverse_basis,
- stride=self.hop_length,
- padding=0,
- )
-
- if self.window is not None:
- window_sum = window_sumsquare(
- self.window,
- magnitude.size(-1),
- hop_length=self.hop_length,
- win_length=self.win_length,
- n_fft=self.filter_length,
- dtype=np.float32,
- )
- # remove modulation effects
- approx_nonzero_indices = torch.from_numpy(
- np.where(window_sum > tiny(window_sum))[0]
- )
- window_sum = torch.from_numpy(window_sum).to(inverse_transform.device)
- inverse_transform[:, :, approx_nonzero_indices] /= window_sum[
- approx_nonzero_indices
- ]
-
- # scale by hop ratio
- inverse_transform *= float(self.filter_length) / self.hop_length
-
- inverse_transform = inverse_transform[..., self.pad_amount :]
- inverse_transform = inverse_transform[..., : self.num_samples]
- inverse_transform = inverse_transform.squeeze(1)
-
- return inverse_transform
-
- def forward(self, input_data):
- """Take input data (audio) to STFT domain and then back to audio.
-
- Arguments:
- input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
-
- Returns:
- reconstruction {tensor} -- Reconstructed audio given magnitude and phase. Of
- shape (num_batch, num_samples)
- """
- self.magnitude, self.phase = self.transform(input_data)
- reconstruction = self.inverse(self.magnitude, self.phase)
- return reconstruction
-
-
-from time import time as ttime
-
-
-class BiGRU(nn.Module):
- def __init__(self, input_features, hidden_features, num_layers):
- super(BiGRU, self).__init__()
- self.gru = nn.GRU(
- input_features,
- hidden_features,
- num_layers=num_layers,
- batch_first=True,
- bidirectional=True,
- )
-
- def forward(self, x):
- return self.gru(x)[0]
-
-
-class ConvBlockRes(nn.Module):
- def __init__(self, in_channels, out_channels, momentum=0.01):
- super(ConvBlockRes, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=(1, 1),
- padding=(1, 1),
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- nn.Conv2d(
- in_channels=out_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=(1, 1),
- padding=(1, 1),
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- )
- if in_channels != out_channels:
- self.shortcut = nn.Conv2d(in_channels, out_channels, (1, 1))
- self.is_shortcut = True
- else:
- self.is_shortcut = False
-
- def forward(self, x):
- if self.is_shortcut:
- return self.conv(x) + self.shortcut(x)
- else:
- return self.conv(x) + x
-
-
-class Encoder(nn.Module):
- def __init__(
- self,
- in_channels,
- in_size,
- n_encoders,
- kernel_size,
- n_blocks,
- out_channels=16,
- momentum=0.01,
- ):
- super(Encoder, self).__init__()
- self.n_encoders = n_encoders
- self.bn = nn.BatchNorm2d(in_channels, momentum=momentum)
- self.layers = nn.ModuleList()
- self.latent_channels = []
- for i in range(self.n_encoders):
- self.layers.append(
- ResEncoderBlock(
- in_channels, out_channels, kernel_size, n_blocks, momentum=momentum
- )
- )
- self.latent_channels.append([out_channels, in_size])
- in_channels = out_channels
- out_channels *= 2
- in_size //= 2
- self.out_size = in_size
- self.out_channel = out_channels
-
- def forward(self, x):
- concat_tensors = []
- x = self.bn(x)
- for i in range(self.n_encoders):
- _, x = self.layers[i](x)
- concat_tensors.append(_)
- return x, concat_tensors
-
-
-class ResEncoderBlock(nn.Module):
- def __init__(
- self, in_channels, out_channels, kernel_size, n_blocks=1, momentum=0.01
- ):
- super(ResEncoderBlock, self).__init__()
- self.n_blocks = n_blocks
- self.conv = nn.ModuleList()
- self.conv.append(ConvBlockRes(in_channels, out_channels, momentum))
- for i in range(n_blocks - 1):
- self.conv.append(ConvBlockRes(out_channels, out_channels, momentum))
- self.kernel_size = kernel_size
- if self.kernel_size is not None:
- self.pool = nn.AvgPool2d(kernel_size=kernel_size)
-
- def forward(self, x):
- for i in range(self.n_blocks):
- x = self.conv[i](x)
- if self.kernel_size is not None:
- return x, self.pool(x)
- else:
- return x
-
-
-class Intermediate(nn.Module): #
- def __init__(self, in_channels, out_channels, n_inters, n_blocks, momentum=0.01):
- super(Intermediate, self).__init__()
- self.n_inters = n_inters
- self.layers = nn.ModuleList()
- self.layers.append(
- ResEncoderBlock(in_channels, out_channels, None, n_blocks, momentum)
- )
- for i in range(self.n_inters - 1):
- self.layers.append(
- ResEncoderBlock(out_channels, out_channels, None, n_blocks, momentum)
- )
-
- def forward(self, x):
- for i in range(self.n_inters):
- x = self.layers[i](x)
- return x
-
-
-class ResDecoderBlock(nn.Module):
- def __init__(self, in_channels, out_channels, stride, n_blocks=1, momentum=0.01):
- super(ResDecoderBlock, self).__init__()
- out_padding = (0, 1) if stride == (1, 2) else (1, 1)
- self.n_blocks = n_blocks
- self.conv1 = nn.Sequential(
- nn.ConvTranspose2d(
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=stride,
- padding=(1, 1),
- output_padding=out_padding,
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- )
- self.conv2 = nn.ModuleList()
- self.conv2.append(ConvBlockRes(out_channels * 2, out_channels, momentum))
- for i in range(n_blocks - 1):
- self.conv2.append(ConvBlockRes(out_channels, out_channels, momentum))
-
- def forward(self, x, concat_tensor):
- x = self.conv1(x)
- x = torch.cat((x, concat_tensor), dim=1)
- for i in range(self.n_blocks):
- x = self.conv2[i](x)
- return x
-
-
-class Decoder(nn.Module):
- def __init__(self, in_channels, n_decoders, stride, n_blocks, momentum=0.01):
- super(Decoder, self).__init__()
- self.layers = nn.ModuleList()
- self.n_decoders = n_decoders
- for i in range(self.n_decoders):
- out_channels = in_channels // 2
- self.layers.append(
- ResDecoderBlock(in_channels, out_channels, stride, n_blocks, momentum)
- )
- in_channels = out_channels
-
- def forward(self, x, concat_tensors):
- for i in range(self.n_decoders):
- x = self.layers[i](x, concat_tensors[-1 - i])
- return x
-
-
-class DeepUnet(nn.Module):
- def __init__(
- self,
- kernel_size,
- n_blocks,
- en_de_layers=5,
- inter_layers=4,
- in_channels=1,
- en_out_channels=16,
- ):
- super(DeepUnet, self).__init__()
- self.encoder = Encoder(
- in_channels, 128, en_de_layers, kernel_size, n_blocks, en_out_channels
- )
- self.intermediate = Intermediate(
- self.encoder.out_channel // 2,
- self.encoder.out_channel,
- inter_layers,
- n_blocks,
- )
- self.decoder = Decoder(
- self.encoder.out_channel, en_de_layers, kernel_size, n_blocks
- )
-
- def forward(self, x):
- x, concat_tensors = self.encoder(x)
- x = self.intermediate(x)
- x = self.decoder(x, concat_tensors)
- return x
-
-
-class E2E(nn.Module):
- def __init__(
- self,
- n_blocks,
- n_gru,
- kernel_size,
- en_de_layers=5,
- inter_layers=4,
- in_channels=1,
- en_out_channels=16,
- ):
- super(E2E, self).__init__()
- self.unet = DeepUnet(
- kernel_size,
- n_blocks,
- en_de_layers,
- inter_layers,
- in_channels,
- en_out_channels,
- )
- self.cnn = nn.Conv2d(en_out_channels, 3, (3, 3), padding=(1, 1))
- if n_gru:
- self.fc = nn.Sequential(
- BiGRU(3 * 128, 256, n_gru),
- nn.Linear(512, 360),
- nn.Dropout(0.25),
- nn.Sigmoid(),
- )
- else:
- self.fc = nn.Sequential(
- nn.Linear(3 * nn.N_MELS, nn.N_CLASS), nn.Dropout(0.25), nn.Sigmoid()
- )
-
- def forward(self, mel):
- # print(mel.shape)
- mel = mel.transpose(-1, -2).unsqueeze(1)
- x = self.cnn(self.unet(mel)).transpose(1, 2).flatten(-2)
- x = self.fc(x)
- # print(x.shape)
- return x
-
-
-from librosa.filters import mel
-
-
-class MelSpectrogram(torch.nn.Module):
- def __init__(
- self,
- is_half,
- n_mel_channels,
- sampling_rate,
- win_length,
- hop_length,
- n_fft=None,
- mel_fmin=0,
- mel_fmax=None,
- clamp=1e-5,
- ):
- super().__init__()
- n_fft = win_length if n_fft is None else n_fft
- self.hann_window = {}
- mel_basis = mel(
- sr=sampling_rate,
- n_fft=n_fft,
- n_mels=n_mel_channels,
- fmin=mel_fmin,
- fmax=mel_fmax,
- htk=True,
- )
- mel_basis = torch.from_numpy(mel_basis).float()
- self.register_buffer("mel_basis", mel_basis)
- self.n_fft = win_length if n_fft is None else n_fft
- self.hop_length = hop_length
- self.win_length = win_length
- self.sampling_rate = sampling_rate
- self.n_mel_channels = n_mel_channels
- self.clamp = clamp
- self.is_half = is_half
-
- def forward(self, audio, keyshift=0, speed=1, center=True):
- factor = 2 ** (keyshift / 12)
- n_fft_new = int(np.round(self.n_fft * factor))
- win_length_new = int(np.round(self.win_length * factor))
- hop_length_new = int(np.round(self.hop_length * speed))
- keyshift_key = str(keyshift) + "_" + str(audio.device)
- if keyshift_key not in self.hann_window:
- self.hann_window[keyshift_key] = torch.hann_window(win_length_new).to(
- # "cpu"if(audio.device.type=="privateuseone") else audio.device
- audio.device
- )
- # fft = torch.stft(#doesn't support pytorch_dml
- # # audio.cpu() if(audio.device.type=="privateuseone")else audio,
- # audio,
- # n_fft=n_fft_new,
- # hop_length=hop_length_new,
- # win_length=win_length_new,
- # window=self.hann_window[keyshift_key],
- # center=center,
- # return_complex=True,
- # )
- # magnitude = torch.sqrt(fft.real.pow(2) + fft.imag.pow(2))
- # print(1111111111)
- # print(222222222222222,audio.device,self.is_half)
- if hasattr(self, "stft") == False:
- # print(n_fft_new,hop_length_new,win_length_new,audio.shape)
- self.stft = STFT(
- filter_length=n_fft_new,
- hop_length=hop_length_new,
- win_length=win_length_new,
- window="hann",
- ).to(audio.device)
- magnitude = self.stft.transform(audio) # phase
- # if (audio.device.type == "privateuseone"):
- # magnitude=magnitude.to(audio.device)
- if keyshift != 0:
- size = self.n_fft // 2 + 1
- resize = magnitude.size(1)
- if resize < size:
- magnitude = F.pad(magnitude, (0, 0, 0, size - resize))
- magnitude = magnitude[:, :size, :] * self.win_length / win_length_new
- mel_output = torch.matmul(self.mel_basis, magnitude)
- if self.is_half == True:
- mel_output = mel_output.half()
- log_mel_spec = torch.log(torch.clamp(mel_output, min=self.clamp))
- # print(log_mel_spec.device.type)
- return log_mel_spec
-
-
-class RMVPE:
- def __init__(self, model_path, is_half, device=None):
- self.resample_kernel = {}
- self.resample_kernel = {}
- self.is_half = is_half
- if device is None:
- device = "cuda" if torch.cuda.is_available() else "cpu"
- self.device = device
- self.mel_extractor = MelSpectrogram(
- is_half, 128, 16000, 1024, 160, None, 30, 8000
- ).to(device)
- if "privateuseone" in str(device):
- import onnxruntime as ort
-
- ort_session = ort.InferenceSession(
- "%s/rmvpe.onnx" % os.environ["rmvpe_root"],
- providers=["DmlExecutionProvider"],
- )
- self.model = ort_session
- else:
- model = E2E(4, 1, (2, 2))
- ckpt = torch.load(model_path, map_location="cpu")
- model.load_state_dict(ckpt)
- model.eval()
- if is_half == True:
- model = model.half()
- self.model = model
- self.model = self.model.to(device)
- cents_mapping = 20 * np.arange(360) + 1997.3794084376191
- self.cents_mapping = np.pad(cents_mapping, (4, 4)) # 368
-
- def mel2hidden(self, mel):
- with torch.no_grad():
- n_frames = mel.shape[-1]
- mel = F.pad(
- mel, (0, 32 * ((n_frames - 1) // 32 + 1) - n_frames), mode="constant"
- )
- if "privateuseone" in str(self.device):
- onnx_input_name = self.model.get_inputs()[0].name
- onnx_outputs_names = self.model.get_outputs()[0].name
- hidden = self.model.run(
- [onnx_outputs_names],
- input_feed={onnx_input_name: mel.cpu().numpy()},
- )[0]
- else:
- hidden = self.model(mel)
- return hidden[:, :n_frames]
-
- def decode(self, hidden, thred=0.03):
- cents_pred = self.to_local_average_cents(hidden, thred=thred)
- f0 = 10 * (2 ** (cents_pred / 1200))
- f0[f0 == 10] = 0
- # f0 = np.array([10 * (2 ** (cent_pred / 1200)) if cent_pred else 0 for cent_pred in cents_pred])
- return f0
-
- def infer_from_audio(self, audio, thred=0.03):
- # torch.cuda.synchronize()
- t0 = ttime()
- mel = self.mel_extractor(
- torch.from_numpy(audio).float().to(self.device).unsqueeze(0), center=True
- )
- # print(123123123,mel.device.type)
- # torch.cuda.synchronize()
- t1 = ttime()
- hidden = self.mel2hidden(mel)
- # torch.cuda.synchronize()
- t2 = ttime()
- # print(234234,hidden.device.type)
- if "privateuseone" not in str(self.device):
- hidden = hidden.squeeze(0).cpu().numpy()
- else:
- hidden = hidden[0]
- if self.is_half == True:
- hidden = hidden.astype("float32")
-
- f0 = self.decode(hidden, thred=thred)
- # torch.cuda.synchronize()
- t3 = ttime()
- # print("hmvpe:%s\t%s\t%s\t%s"%(t1-t0,t2-t1,t3-t2,t3-t0))
- return f0
-
- def infer_from_audio_with_pitch(self, audio, thred=0.03, f0_min=50, f0_max=1100):
- audio = torch.from_numpy(audio).float().to(self.device).unsqueeze(0)
- mel = self.mel_extractor(audio, center=True)
- hidden = self.mel2hidden(mel)
- hidden = hidden.squeeze(0).cpu().numpy()
- if self.is_half == True:
- hidden = hidden.astype("float32")
- f0 = self.decode(hidden, thred=thred)
- f0[(f0 < f0_min) | (f0 > f0_max)] = 0
- return f0
-
- def to_local_average_cents(self, salience, thred=0.05):
- # t0 = ttime()
- center = np.argmax(salience, axis=1) # 帧长#index
- salience = np.pad(salience, ((0, 0), (4, 4))) # 帧长,368
- # t1 = ttime()
- center += 4
- todo_salience = []
- todo_cents_mapping = []
- starts = center - 4
- ends = center + 5
- for idx in range(salience.shape[0]):
- todo_salience.append(salience[:, starts[idx] : ends[idx]][idx])
- todo_cents_mapping.append(self.cents_mapping[starts[idx] : ends[idx]])
- # t2 = ttime()
- todo_salience = np.array(todo_salience) # 帧长,9
- todo_cents_mapping = np.array(todo_cents_mapping) # 帧长,9
- product_sum = np.sum(todo_salience * todo_cents_mapping, 1)
- weight_sum = np.sum(todo_salience, 1) # 帧长
- devided = product_sum / weight_sum # 帧长
- # t3 = ttime()
- maxx = np.max(salience, axis=1) # 帧长
- devided[maxx <= thred] = 0
- # t4 = ttime()
- # print("decode:%s\t%s\t%s\t%s" % (t1 - t0, t2 - t1, t3 - t2, t4 - t3))
- return devided
-
-
-if __name__ == "__main__":
- import librosa
- import soundfile as sf
-
- audio, sampling_rate = sf.read(r"C:\Users\liujing04\Desktop\Z\冬之花clip1.wav")
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- audio_bak = audio.copy()
- if sampling_rate != 16000:
- audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
- model_path = r"D:\BaiduNetdiskDownload\RVC-beta-v2-0727AMD_realtime\rmvpe.pt"
- thred = 0.03 # 0.01
- device = "cuda" if torch.cuda.is_available() else "cpu"
- rmvpe = RMVPE(model_path, is_half=False, device=device)
- t0 = ttime()
- f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- t1 = ttime()
- logger.info("%s %.2f", f0.shape, t1 - t0)
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/model_param_init.py b/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/model_param_init.py
deleted file mode 100644
index b995c0bfb1194746187692e2ab1c2a6dbaaaec6c..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/model_param_init.py
+++ /dev/null
@@ -1,69 +0,0 @@
-import json
-import os
-import pathlib
-
-default_param = {}
-default_param["bins"] = 768
-default_param["unstable_bins"] = 9 # training only
-default_param["reduction_bins"] = 762 # training only
-default_param["sr"] = 44100
-default_param["pre_filter_start"] = 757
-default_param["pre_filter_stop"] = 768
-default_param["band"] = {}
-
-
-default_param["band"][1] = {
- "sr": 11025,
- "hl": 128,
- "n_fft": 960,
- "crop_start": 0,
- "crop_stop": 245,
- "lpf_start": 61, # inference only
- "res_type": "polyphase",
-}
-
-default_param["band"][2] = {
- "sr": 44100,
- "hl": 512,
- "n_fft": 1536,
- "crop_start": 24,
- "crop_stop": 547,
- "hpf_start": 81, # inference only
- "res_type": "sinc_best",
-}
-
-
-def int_keys(d):
- r = {}
- for k, v in d:
- if k.isdigit():
- k = int(k)
- r[k] = v
- return r
-
-
-class ModelParameters(object):
- def __init__(self, config_path=""):
- if ".pth" == pathlib.Path(config_path).suffix:
- import zipfile
-
- with zipfile.ZipFile(config_path, "r") as zip:
- self.param = json.loads(
- zip.read("param.json"), object_pairs_hook=int_keys
- )
- elif ".json" == pathlib.Path(config_path).suffix:
- with open(config_path, "r") as f:
- self.param = json.loads(f.read(), object_pairs_hook=int_keys)
- else:
- self.param = default_param
-
- for k in [
- "mid_side",
- "mid_side_b",
- "mid_side_b2",
- "stereo_w",
- "stereo_n",
- "reverse",
- ]:
- if not k in self.param:
- self.param[k] = False
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py b/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py
deleted file mode 100644
index 167d4cb2198863cf43e93440f7e63c5342fc7605..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py
+++ /dev/null
@@ -1,122 +0,0 @@
-import torch
-import torch.nn.functional as F
-from torch import nn
-
-from . import layers_123821KB as layers
-
-
-class BaseASPPNet(nn.Module):
- def __init__(self, nin, ch, dilations=(4, 8, 16)):
- super(BaseASPPNet, self).__init__()
- self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
- self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
- self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
- self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
-
- self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
-
- self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
- self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
- self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
- self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
-
- def __call__(self, x):
- h, e1 = self.enc1(x)
- h, e2 = self.enc2(h)
- h, e3 = self.enc3(h)
- h, e4 = self.enc4(h)
-
- h = self.aspp(h)
-
- h = self.dec4(h, e4)
- h = self.dec3(h, e3)
- h = self.dec2(h, e2)
- h = self.dec1(h, e1)
-
- return h
-
-
-class CascadedASPPNet(nn.Module):
- def __init__(self, n_fft):
- super(CascadedASPPNet, self).__init__()
- self.stg1_low_band_net = BaseASPPNet(2, 32)
- self.stg1_high_band_net = BaseASPPNet(2, 32)
-
- self.stg2_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
- self.stg2_full_band_net = BaseASPPNet(16, 32)
-
- self.stg3_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
- self.stg3_full_band_net = BaseASPPNet(32, 64)
-
- self.out = nn.Conv2d(64, 2, 1, bias=False)
- self.aux1_out = nn.Conv2d(32, 2, 1, bias=False)
- self.aux2_out = nn.Conv2d(32, 2, 1, bias=False)
-
- self.max_bin = n_fft // 2
- self.output_bin = n_fft // 2 + 1
-
- self.offset = 128
-
- def forward(self, x, aggressiveness=None):
- mix = x.detach()
- x = x.clone()
-
- x = x[:, :, : self.max_bin]
-
- bandw = x.size()[2] // 2
- aux1 = torch.cat(
- [
- self.stg1_low_band_net(x[:, :, :bandw]),
- self.stg1_high_band_net(x[:, :, bandw:]),
- ],
- dim=2,
- )
-
- h = torch.cat([x, aux1], dim=1)
- aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
-
- h = torch.cat([x, aux1, aux2], dim=1)
- h = self.stg3_full_band_net(self.stg3_bridge(h))
-
- mask = torch.sigmoid(self.out(h))
- mask = F.pad(
- input=mask,
- pad=(0, 0, 0, self.output_bin - mask.size()[2]),
- mode="replicate",
- )
-
- if self.training:
- aux1 = torch.sigmoid(self.aux1_out(aux1))
- aux1 = F.pad(
- input=aux1,
- pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
- mode="replicate",
- )
- aux2 = torch.sigmoid(self.aux2_out(aux2))
- aux2 = F.pad(
- input=aux2,
- pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
- mode="replicate",
- )
- return mask * mix, aux1 * mix, aux2 * mix
- else:
- if aggressiveness:
- mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
- mask[:, :, : aggressiveness["split_bin"]],
- 1 + aggressiveness["value"] / 3,
- )
- mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
- mask[:, :, aggressiveness["split_bin"] :],
- 1 + aggressiveness["value"],
- )
-
- return mask * mix
-
- def predict(self, x_mag, aggressiveness=None):
- h = self.forward(x_mag, aggressiveness)
-
- if self.offset > 0:
- h = h[:, :, :, self.offset : -self.offset]
- assert h.size()[3] > 0
-
- return h
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/tools/infer/train-index-v2.py b/spaces/Kangarroar/ApplioRVC-Inference/tools/infer/train-index-v2.py
deleted file mode 100644
index cbeed5d4fbf65fcb9a697a99d5f7b41c844e95d6..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/tools/infer/train-index-v2.py
+++ /dev/null
@@ -1,79 +0,0 @@
-"""
-格式:直接cid为自带的index位;aid放不下了,通过字典来查,反正就5w个
-"""
-import os
-import traceback
-import logging
-
-logger = logging.getLogger(__name__)
-
-from multiprocessing import cpu_count
-
-import faiss
-import numpy as np
-from sklearn.cluster import MiniBatchKMeans
-
-# ###########如果是原始特征要先写save
-n_cpu = 0
-if n_cpu == 0:
- n_cpu = cpu_count()
-inp_root = r"./logs/anz/3_feature768"
-npys = []
-listdir_res = list(os.listdir(inp_root))
-for name in sorted(listdir_res):
- phone = np.load("%s/%s" % (inp_root, name))
- npys.append(phone)
-big_npy = np.concatenate(npys, 0)
-big_npy_idx = np.arange(big_npy.shape[0])
-np.random.shuffle(big_npy_idx)
-big_npy = big_npy[big_npy_idx]
-logger.debug(big_npy.shape) # (6196072, 192)#fp32#4.43G
-if big_npy.shape[0] > 2e5:
- # if(1):
- info = "Trying doing kmeans %s shape to 10k centers." % big_npy.shape[0]
- logger.info(info)
- try:
- big_npy = (
- MiniBatchKMeans(
- n_clusters=10000,
- verbose=True,
- batch_size=256 * n_cpu,
- compute_labels=False,
- init="random",
- )
- .fit(big_npy)
- .cluster_centers_
- )
- except:
- info = traceback.format_exc()
- logger.warn(info)
-
-np.save("tools/infer/big_src_feature_mi.npy", big_npy)
-
-##################train+add
-# big_npy=np.load("/bili-coeus/jupyter/jupyterhub-liujing04/vits_ch/inference_f0/big_src_feature_mi.npy")
-n_ivf = min(int(16 * np.sqrt(big_npy.shape[0])), big_npy.shape[0] // 39)
-index = faiss.index_factory(768, "IVF%s,Flat" % n_ivf) # mi
-logger.info("Training...")
-index_ivf = faiss.extract_index_ivf(index) #
-index_ivf.nprobe = 1
-index.train(big_npy)
-faiss.write_index(
- index, "tools/infer/trained_IVF%s_Flat_baseline_src_feat_v2.index" % (n_ivf)
-)
-logger.info("Adding...")
-batch_size_add = 8192
-for i in range(0, big_npy.shape[0], batch_size_add):
- index.add(big_npy[i : i + batch_size_add])
-faiss.write_index(
- index, "tools/infer/added_IVF%s_Flat_mi_baseline_src_feat.index" % (n_ivf)
-)
-"""
-大小(都是FP32)
-big_src_feature 2.95G
- (3098036, 256)
-big_emb 4.43G
- (6196072, 192)
-big_emb双倍是因为求特征要repeat后再加pitch
-
-"""
diff --git a/spaces/Kayson/InstructDiffusion/stable_diffusion/ldm/models/diffusion/dpm_solver/__init__.py b/spaces/Kayson/InstructDiffusion/stable_diffusion/ldm/models/diffusion/dpm_solver/__init__.py
deleted file mode 100644
index 7427f38c07530afbab79154ea8aaf88c4bf70a08..0000000000000000000000000000000000000000
--- a/spaces/Kayson/InstructDiffusion/stable_diffusion/ldm/models/diffusion/dpm_solver/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .sampler import DPMSolverSampler
\ No newline at end of file
diff --git a/spaces/Kimata/Sanskrit-TTS/monotonic_align/core.c b/spaces/Kimata/Sanskrit-TTS/monotonic_align/core.c
deleted file mode 100644
index 78f6aff68257660702f0b0ad278757a9728e84d5..0000000000000000000000000000000000000000
--- a/spaces/Kimata/Sanskrit-TTS/monotonic_align/core.c
+++ /dev/null
@@ -1,21608 +0,0 @@
-/* Generated by Cython 0.29.32 */
-
-/* BEGIN: Cython Metadata
-{
- "distutils": {
- "name": "monotonic_align.core",
- "sources": [
- "core.pyx"
- ]
- },
- "module_name": "monotonic_align.core"
-}
-END: Cython Metadata */
-
-#ifndef PY_SSIZE_T_CLEAN
-#define PY_SSIZE_T_CLEAN
-#endif /* PY_SSIZE_T_CLEAN */
-#include "Python.h"
-#ifndef Py_PYTHON_H
- #error Python headers needed to compile C extensions, please install development version of Python.
-#elif PY_VERSION_HEX < 0x02060000 || (0x03000000 <= PY_VERSION_HEX && PY_VERSION_HEX < 0x03030000)
- #error Cython requires Python 2.6+ or Python 3.3+.
-#else
-#define CYTHON_ABI "0_29_32"
-#define CYTHON_HEX_VERSION 0x001D20F0
-#define CYTHON_FUTURE_DIVISION 0
-#include
-#ifndef offsetof
- #define offsetof(type, member) ( (size_t) & ((type*)0) -> member )
-#endif
-#if !defined(WIN32) && !defined(MS_WINDOWS)
- #ifndef __stdcall
- #define __stdcall
- #endif
- #ifndef __cdecl
- #define __cdecl
- #endif
- #ifndef __fastcall
- #define __fastcall
- #endif
-#endif
-#ifndef DL_IMPORT
- #define DL_IMPORT(t) t
-#endif
-#ifndef DL_EXPORT
- #define DL_EXPORT(t) t
-#endif
-#define __PYX_COMMA ,
-#ifndef HAVE_LONG_LONG
- #if PY_VERSION_HEX >= 0x02070000
- #define HAVE_LONG_LONG
- #endif
-#endif
-#ifndef PY_LONG_LONG
- #define PY_LONG_LONG LONG_LONG
-#endif
-#ifndef Py_HUGE_VAL
- #define Py_HUGE_VAL HUGE_VAL
-#endif
-#ifdef PYPY_VERSION
- #define CYTHON_COMPILING_IN_PYPY 1
- #define CYTHON_COMPILING_IN_PYSTON 0
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_NOGIL 0
- #undef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 0
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #if PY_VERSION_HEX < 0x03050000
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #elif !defined(CYTHON_USE_ASYNC_SLOTS)
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #undef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 0
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #undef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 1
- #undef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 0
- #undef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 0
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 0
- #undef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 0
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC (PYPY_VERSION_HEX >= 0x07030900)
- #endif
-#elif defined(PYSTON_VERSION)
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_PYSTON 1
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_NOGIL 0
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 0
- #undef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 0
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 0
- #endif
-#elif defined(PY_NOGIL)
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_PYSTON 0
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_NOGIL 1
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #ifndef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #ifndef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 1
- #endif
- #ifndef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 1
- #endif
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
-#else
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_PYSTON 0
- #define CYTHON_COMPILING_IN_CPYTHON 1
- #define CYTHON_COMPILING_IN_NOGIL 0
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #if PY_VERSION_HEX < 0x02070000
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #elif !defined(CYTHON_USE_PYTYPE_LOOKUP)
- #define CYTHON_USE_PYTYPE_LOOKUP 1
- #endif
- #if PY_MAJOR_VERSION < 3
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #elif !defined(CYTHON_USE_ASYNC_SLOTS)
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #if PY_VERSION_HEX < 0x02070000
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #elif !defined(CYTHON_USE_PYLONG_INTERNALS)
- #define CYTHON_USE_PYLONG_INTERNALS 1
- #endif
- #ifndef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 1
- #endif
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #if PY_VERSION_HEX < 0x030300F0 || PY_VERSION_HEX >= 0x030B00A2
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #elif !defined(CYTHON_USE_UNICODE_WRITER)
- #define CYTHON_USE_UNICODE_WRITER 1
- #endif
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #if PY_VERSION_HEX >= 0x030B00A4
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #elif !defined(CYTHON_FAST_THREAD_STATE)
- #define CYTHON_FAST_THREAD_STATE 1
- #endif
- #ifndef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL (PY_VERSION_HEX < 0x030A0000)
- #endif
- #ifndef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT (PY_VERSION_HEX >= 0x03050000)
- #endif
- #ifndef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE (PY_VERSION_HEX >= 0x030400a1)
- #endif
- #ifndef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS (PY_VERSION_HEX >= 0x030600B1)
- #endif
- #if PY_VERSION_HEX >= 0x030B00A4
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #elif !defined(CYTHON_USE_EXC_INFO_STACK)
- #define CYTHON_USE_EXC_INFO_STACK (PY_VERSION_HEX >= 0x030700A3)
- #endif
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 1
- #endif
-#endif
-#if !defined(CYTHON_FAST_PYCCALL)
-#define CYTHON_FAST_PYCCALL (CYTHON_FAST_PYCALL && PY_VERSION_HEX >= 0x030600B1)
-#endif
-#if CYTHON_USE_PYLONG_INTERNALS
- #if PY_MAJOR_VERSION < 3
- #include "longintrepr.h"
- #endif
- #undef SHIFT
- #undef BASE
- #undef MASK
- #ifdef SIZEOF_VOID_P
- enum { __pyx_check_sizeof_voidp = 1 / (int)(SIZEOF_VOID_P == sizeof(void*)) };
- #endif
-#endif
-#ifndef __has_attribute
- #define __has_attribute(x) 0
-#endif
-#ifndef __has_cpp_attribute
- #define __has_cpp_attribute(x) 0
-#endif
-#ifndef CYTHON_RESTRICT
- #if defined(__GNUC__)
- #define CYTHON_RESTRICT __restrict__
- #elif defined(_MSC_VER) && _MSC_VER >= 1400
- #define CYTHON_RESTRICT __restrict
- #elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define CYTHON_RESTRICT restrict
- #else
- #define CYTHON_RESTRICT
- #endif
-#endif
-#ifndef CYTHON_UNUSED
-# if defined(__GNUC__)
-# if !(defined(__cplusplus)) || (__GNUC__ > 3 || (__GNUC__ == 3 && __GNUC_MINOR__ >= 4))
-# define CYTHON_UNUSED __attribute__ ((__unused__))
-# else
-# define CYTHON_UNUSED
-# endif
-# elif defined(__ICC) || (defined(__INTEL_COMPILER) && !defined(_MSC_VER))
-# define CYTHON_UNUSED __attribute__ ((__unused__))
-# else
-# define CYTHON_UNUSED
-# endif
-#endif
-#ifndef CYTHON_MAYBE_UNUSED_VAR
-# if defined(__cplusplus)
- template void CYTHON_MAYBE_UNUSED_VAR( const T& ) { }
-# else
-# define CYTHON_MAYBE_UNUSED_VAR(x) (void)(x)
-# endif
-#endif
-#ifndef CYTHON_NCP_UNUSED
-# if CYTHON_COMPILING_IN_CPYTHON
-# define CYTHON_NCP_UNUSED
-# else
-# define CYTHON_NCP_UNUSED CYTHON_UNUSED
-# endif
-#endif
-#define __Pyx_void_to_None(void_result) ((void)(void_result), Py_INCREF(Py_None), Py_None)
-#ifdef _MSC_VER
- #ifndef _MSC_STDINT_H_
- #if _MSC_VER < 1300
- typedef unsigned char uint8_t;
- typedef unsigned int uint32_t;
- #else
- typedef unsigned __int8 uint8_t;
- typedef unsigned __int32 uint32_t;
- #endif
- #endif
-#else
- #include
-#endif
-#ifndef CYTHON_FALLTHROUGH
- #if defined(__cplusplus) && __cplusplus >= 201103L
- #if __has_cpp_attribute(fallthrough)
- #define CYTHON_FALLTHROUGH [[fallthrough]]
- #elif __has_cpp_attribute(clang::fallthrough)
- #define CYTHON_FALLTHROUGH [[clang::fallthrough]]
- #elif __has_cpp_attribute(gnu::fallthrough)
- #define CYTHON_FALLTHROUGH [[gnu::fallthrough]]
- #endif
- #endif
- #ifndef CYTHON_FALLTHROUGH
- #if __has_attribute(fallthrough)
- #define CYTHON_FALLTHROUGH __attribute__((fallthrough))
- #else
- #define CYTHON_FALLTHROUGH
- #endif
- #endif
- #if defined(__clang__ ) && defined(__apple_build_version__)
- #if __apple_build_version__ < 7000000
- #undef CYTHON_FALLTHROUGH
- #define CYTHON_FALLTHROUGH
- #endif
- #endif
-#endif
-
-#ifndef CYTHON_INLINE
- #if defined(__clang__)
- #define CYTHON_INLINE __inline__ __attribute__ ((__unused__))
- #elif defined(__GNUC__)
- #define CYTHON_INLINE __inline__
- #elif defined(_MSC_VER)
- #define CYTHON_INLINE __inline
- #elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define CYTHON_INLINE inline
- #else
- #define CYTHON_INLINE
- #endif
-#endif
-
-#if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX < 0x02070600 && !defined(Py_OptimizeFlag)
- #define Py_OptimizeFlag 0
-#endif
-#define __PYX_BUILD_PY_SSIZE_T "n"
-#define CYTHON_FORMAT_SSIZE_T "z"
-#if PY_MAJOR_VERSION < 3
- #define __Pyx_BUILTIN_MODULE_NAME "__builtin__"
- #define __Pyx_PyCode_New(a, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)\
- PyCode_New(a+k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)
- #define __Pyx_DefaultClassType PyClass_Type
-#else
- #define __Pyx_BUILTIN_MODULE_NAME "builtins"
- #define __Pyx_DefaultClassType PyType_Type
-#if PY_VERSION_HEX >= 0x030B00A1
- static CYTHON_INLINE PyCodeObject* __Pyx_PyCode_New(int a, int k, int l, int s, int f,
- PyObject *code, PyObject *c, PyObject* n, PyObject *v,
- PyObject *fv, PyObject *cell, PyObject* fn,
- PyObject *name, int fline, PyObject *lnos) {
- PyObject *kwds=NULL, *argcount=NULL, *posonlyargcount=NULL, *kwonlyargcount=NULL;
- PyObject *nlocals=NULL, *stacksize=NULL, *flags=NULL, *replace=NULL, *call_result=NULL, *empty=NULL;
- const char *fn_cstr=NULL;
- const char *name_cstr=NULL;
- PyCodeObject* co=NULL;
- PyObject *type, *value, *traceback;
- PyErr_Fetch(&type, &value, &traceback);
- if (!(kwds=PyDict_New())) goto end;
- if (!(argcount=PyLong_FromLong(a))) goto end;
- if (PyDict_SetItemString(kwds, "co_argcount", argcount) != 0) goto end;
- if (!(posonlyargcount=PyLong_FromLong(0))) goto end;
- if (PyDict_SetItemString(kwds, "co_posonlyargcount", posonlyargcount) != 0) goto end;
- if (!(kwonlyargcount=PyLong_FromLong(k))) goto end;
- if (PyDict_SetItemString(kwds, "co_kwonlyargcount", kwonlyargcount) != 0) goto end;
- if (!(nlocals=PyLong_FromLong(l))) goto end;
- if (PyDict_SetItemString(kwds, "co_nlocals", nlocals) != 0) goto end;
- if (!(stacksize=PyLong_FromLong(s))) goto end;
- if (PyDict_SetItemString(kwds, "co_stacksize", stacksize) != 0) goto end;
- if (!(flags=PyLong_FromLong(f))) goto end;
- if (PyDict_SetItemString(kwds, "co_flags", flags) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_code", code) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_consts", c) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_names", n) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_varnames", v) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_freevars", fv) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_cellvars", cell) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_linetable", lnos) != 0) goto end;
- if (!(fn_cstr=PyUnicode_AsUTF8AndSize(fn, NULL))) goto end;
- if (!(name_cstr=PyUnicode_AsUTF8AndSize(name, NULL))) goto end;
- if (!(co = PyCode_NewEmpty(fn_cstr, name_cstr, fline))) goto end;
- if (!(replace = PyObject_GetAttrString((PyObject*)co, "replace"))) goto cleanup_code_too;
- if (!(empty = PyTuple_New(0))) goto cleanup_code_too; // unfortunately __pyx_empty_tuple isn't available here
- if (!(call_result = PyObject_Call(replace, empty, kwds))) goto cleanup_code_too;
- Py_XDECREF((PyObject*)co);
- co = (PyCodeObject*)call_result;
- call_result = NULL;
- if (0) {
- cleanup_code_too:
- Py_XDECREF((PyObject*)co);
- co = NULL;
- }
- end:
- Py_XDECREF(kwds);
- Py_XDECREF(argcount);
- Py_XDECREF(posonlyargcount);
- Py_XDECREF(kwonlyargcount);
- Py_XDECREF(nlocals);
- Py_XDECREF(stacksize);
- Py_XDECREF(replace);
- Py_XDECREF(call_result);
- Py_XDECREF(empty);
- if (type) {
- PyErr_Restore(type, value, traceback);
- }
- return co;
- }
-#else
- #define __Pyx_PyCode_New(a, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)\
- PyCode_New(a, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)
-#endif
- #define __Pyx_DefaultClassType PyType_Type
-#endif
-#ifndef Py_TPFLAGS_CHECKTYPES
- #define Py_TPFLAGS_CHECKTYPES 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_INDEX
- #define Py_TPFLAGS_HAVE_INDEX 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_NEWBUFFER
- #define Py_TPFLAGS_HAVE_NEWBUFFER 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_FINALIZE
- #define Py_TPFLAGS_HAVE_FINALIZE 0
-#endif
-#ifndef METH_STACKLESS
- #define METH_STACKLESS 0
-#endif
-#if PY_VERSION_HEX <= 0x030700A3 || !defined(METH_FASTCALL)
- #ifndef METH_FASTCALL
- #define METH_FASTCALL 0x80
- #endif
- typedef PyObject *(*__Pyx_PyCFunctionFast) (PyObject *self, PyObject *const *args, Py_ssize_t nargs);
- typedef PyObject *(*__Pyx_PyCFunctionFastWithKeywords) (PyObject *self, PyObject *const *args,
- Py_ssize_t nargs, PyObject *kwnames);
-#else
- #define __Pyx_PyCFunctionFast _PyCFunctionFast
- #define __Pyx_PyCFunctionFastWithKeywords _PyCFunctionFastWithKeywords
-#endif
-#if CYTHON_FAST_PYCCALL
-#define __Pyx_PyFastCFunction_Check(func)\
- ((PyCFunction_Check(func) && (METH_FASTCALL == (PyCFunction_GET_FLAGS(func) & ~(METH_CLASS | METH_STATIC | METH_COEXIST | METH_KEYWORDS | METH_STACKLESS)))))
-#else
-#define __Pyx_PyFastCFunction_Check(func) 0
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyObject_Malloc)
- #define PyObject_Malloc(s) PyMem_Malloc(s)
- #define PyObject_Free(p) PyMem_Free(p)
- #define PyObject_Realloc(p) PyMem_Realloc(p)
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX < 0x030400A1
- #define PyMem_RawMalloc(n) PyMem_Malloc(n)
- #define PyMem_RawRealloc(p, n) PyMem_Realloc(p, n)
- #define PyMem_RawFree(p) PyMem_Free(p)
-#endif
-#if CYTHON_COMPILING_IN_PYSTON
- #define __Pyx_PyCode_HasFreeVars(co) PyCode_HasFreeVars(co)
- #define __Pyx_PyFrame_SetLineNumber(frame, lineno) PyFrame_SetLineNumber(frame, lineno)
-#else
- #define __Pyx_PyCode_HasFreeVars(co) (PyCode_GetNumFree(co) > 0)
- #define __Pyx_PyFrame_SetLineNumber(frame, lineno) (frame)->f_lineno = (lineno)
-#endif
-#if !CYTHON_FAST_THREAD_STATE || PY_VERSION_HEX < 0x02070000
- #define __Pyx_PyThreadState_Current PyThreadState_GET()
-#elif PY_VERSION_HEX >= 0x03060000
- #define __Pyx_PyThreadState_Current _PyThreadState_UncheckedGet()
-#elif PY_VERSION_HEX >= 0x03000000
- #define __Pyx_PyThreadState_Current PyThreadState_GET()
-#else
- #define __Pyx_PyThreadState_Current _PyThreadState_Current
-#endif
-#if PY_VERSION_HEX < 0x030700A2 && !defined(PyThread_tss_create) && !defined(Py_tss_NEEDS_INIT)
-#include "pythread.h"
-#define Py_tss_NEEDS_INIT 0
-typedef int Py_tss_t;
-static CYTHON_INLINE int PyThread_tss_create(Py_tss_t *key) {
- *key = PyThread_create_key();
- return 0;
-}
-static CYTHON_INLINE Py_tss_t * PyThread_tss_alloc(void) {
- Py_tss_t *key = (Py_tss_t *)PyObject_Malloc(sizeof(Py_tss_t));
- *key = Py_tss_NEEDS_INIT;
- return key;
-}
-static CYTHON_INLINE void PyThread_tss_free(Py_tss_t *key) {
- PyObject_Free(key);
-}
-static CYTHON_INLINE int PyThread_tss_is_created(Py_tss_t *key) {
- return *key != Py_tss_NEEDS_INIT;
-}
-static CYTHON_INLINE void PyThread_tss_delete(Py_tss_t *key) {
- PyThread_delete_key(*key);
- *key = Py_tss_NEEDS_INIT;
-}
-static CYTHON_INLINE int PyThread_tss_set(Py_tss_t *key, void *value) {
- return PyThread_set_key_value(*key, value);
-}
-static CYTHON_INLINE void * PyThread_tss_get(Py_tss_t *key) {
- return PyThread_get_key_value(*key);
-}
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON || defined(_PyDict_NewPresized)
-#define __Pyx_PyDict_NewPresized(n) ((n <= 8) ? PyDict_New() : _PyDict_NewPresized(n))
-#else
-#define __Pyx_PyDict_NewPresized(n) PyDict_New()
-#endif
-#if PY_MAJOR_VERSION >= 3 || CYTHON_FUTURE_DIVISION
- #define __Pyx_PyNumber_Divide(x,y) PyNumber_TrueDivide(x,y)
- #define __Pyx_PyNumber_InPlaceDivide(x,y) PyNumber_InPlaceTrueDivide(x,y)
-#else
- #define __Pyx_PyNumber_Divide(x,y) PyNumber_Divide(x,y)
- #define __Pyx_PyNumber_InPlaceDivide(x,y) PyNumber_InPlaceDivide(x,y)
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x030500A1 && CYTHON_USE_UNICODE_INTERNALS
-#define __Pyx_PyDict_GetItemStr(dict, name) _PyDict_GetItem_KnownHash(dict, name, ((PyASCIIObject *) name)->hash)
-#else
-#define __Pyx_PyDict_GetItemStr(dict, name) PyDict_GetItem(dict, name)
-#endif
-#if PY_VERSION_HEX > 0x03030000 && defined(PyUnicode_KIND)
- #define CYTHON_PEP393_ENABLED 1
- #if defined(PyUnicode_IS_READY)
- #define __Pyx_PyUnicode_READY(op) (likely(PyUnicode_IS_READY(op)) ?\
- 0 : _PyUnicode_Ready((PyObject *)(op)))
- #else
- #define __Pyx_PyUnicode_READY(op) (0)
- #endif
- #define __Pyx_PyUnicode_GET_LENGTH(u) PyUnicode_GET_LENGTH(u)
- #define __Pyx_PyUnicode_READ_CHAR(u, i) PyUnicode_READ_CHAR(u, i)
- #define __Pyx_PyUnicode_MAX_CHAR_VALUE(u) PyUnicode_MAX_CHAR_VALUE(u)
- #define __Pyx_PyUnicode_KIND(u) PyUnicode_KIND(u)
- #define __Pyx_PyUnicode_DATA(u) PyUnicode_DATA(u)
- #define __Pyx_PyUnicode_READ(k, d, i) PyUnicode_READ(k, d, i)
- #define __Pyx_PyUnicode_WRITE(k, d, i, ch) PyUnicode_WRITE(k, d, i, ch)
- #if defined(PyUnicode_IS_READY) && defined(PyUnicode_GET_SIZE)
- #if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x03090000
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != (likely(PyUnicode_IS_READY(u)) ? PyUnicode_GET_LENGTH(u) : ((PyCompactUnicodeObject *)(u))->wstr_length))
- #else
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != (likely(PyUnicode_IS_READY(u)) ? PyUnicode_GET_LENGTH(u) : PyUnicode_GET_SIZE(u)))
- #endif
- #else
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != PyUnicode_GET_LENGTH(u))
- #endif
-#else
- #define CYTHON_PEP393_ENABLED 0
- #define PyUnicode_1BYTE_KIND 1
- #define PyUnicode_2BYTE_KIND 2
- #define PyUnicode_4BYTE_KIND 4
- #define __Pyx_PyUnicode_READY(op) (0)
- #define __Pyx_PyUnicode_GET_LENGTH(u) PyUnicode_GET_SIZE(u)
- #define __Pyx_PyUnicode_READ_CHAR(u, i) ((Py_UCS4)(PyUnicode_AS_UNICODE(u)[i]))
- #define __Pyx_PyUnicode_MAX_CHAR_VALUE(u) ((sizeof(Py_UNICODE) == 2) ? 65535 : 1114111)
- #define __Pyx_PyUnicode_KIND(u) (sizeof(Py_UNICODE))
- #define __Pyx_PyUnicode_DATA(u) ((void*)PyUnicode_AS_UNICODE(u))
- #define __Pyx_PyUnicode_READ(k, d, i) ((void)(k), (Py_UCS4)(((Py_UNICODE*)d)[i]))
- #define __Pyx_PyUnicode_WRITE(k, d, i, ch) (((void)(k)), ((Py_UNICODE*)d)[i] = ch)
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != PyUnicode_GET_SIZE(u))
-#endif
-#if CYTHON_COMPILING_IN_PYPY
- #define __Pyx_PyUnicode_Concat(a, b) PyNumber_Add(a, b)
- #define __Pyx_PyUnicode_ConcatSafe(a, b) PyNumber_Add(a, b)
-#else
- #define __Pyx_PyUnicode_Concat(a, b) PyUnicode_Concat(a, b)
- #define __Pyx_PyUnicode_ConcatSafe(a, b) ((unlikely((a) == Py_None) || unlikely((b) == Py_None)) ?\
- PyNumber_Add(a, b) : __Pyx_PyUnicode_Concat(a, b))
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyUnicode_Contains)
- #define PyUnicode_Contains(u, s) PySequence_Contains(u, s)
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyByteArray_Check)
- #define PyByteArray_Check(obj) PyObject_TypeCheck(obj, &PyByteArray_Type)
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyObject_Format)
- #define PyObject_Format(obj, fmt) PyObject_CallMethod(obj, "__format__", "O", fmt)
-#endif
-#define __Pyx_PyString_FormatSafe(a, b) ((unlikely((a) == Py_None || (PyString_Check(b) && !PyString_CheckExact(b)))) ? PyNumber_Remainder(a, b) : __Pyx_PyString_Format(a, b))
-#define __Pyx_PyUnicode_FormatSafe(a, b) ((unlikely((a) == Py_None || (PyUnicode_Check(b) && !PyUnicode_CheckExact(b)))) ? PyNumber_Remainder(a, b) : PyUnicode_Format(a, b))
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyString_Format(a, b) PyUnicode_Format(a, b)
-#else
- #define __Pyx_PyString_Format(a, b) PyString_Format(a, b)
-#endif
-#if PY_MAJOR_VERSION < 3 && !defined(PyObject_ASCII)
- #define PyObject_ASCII(o) PyObject_Repr(o)
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyBaseString_Type PyUnicode_Type
- #define PyStringObject PyUnicodeObject
- #define PyString_Type PyUnicode_Type
- #define PyString_Check PyUnicode_Check
- #define PyString_CheckExact PyUnicode_CheckExact
-#ifndef PyObject_Unicode
- #define PyObject_Unicode PyObject_Str
-#endif
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyBaseString_Check(obj) PyUnicode_Check(obj)
- #define __Pyx_PyBaseString_CheckExact(obj) PyUnicode_CheckExact(obj)
-#else
- #define __Pyx_PyBaseString_Check(obj) (PyString_Check(obj) || PyUnicode_Check(obj))
- #define __Pyx_PyBaseString_CheckExact(obj) (PyString_CheckExact(obj) || PyUnicode_CheckExact(obj))
-#endif
-#ifndef PySet_CheckExact
- #define PySet_CheckExact(obj) (Py_TYPE(obj) == &PySet_Type)
-#endif
-#if PY_VERSION_HEX >= 0x030900A4
- #define __Pyx_SET_REFCNT(obj, refcnt) Py_SET_REFCNT(obj, refcnt)
- #define __Pyx_SET_SIZE(obj, size) Py_SET_SIZE(obj, size)
-#else
- #define __Pyx_SET_REFCNT(obj, refcnt) Py_REFCNT(obj) = (refcnt)
- #define __Pyx_SET_SIZE(obj, size) Py_SIZE(obj) = (size)
-#endif
-#if CYTHON_ASSUME_SAFE_MACROS
- #define __Pyx_PySequence_SIZE(seq) Py_SIZE(seq)
-#else
- #define __Pyx_PySequence_SIZE(seq) PySequence_Size(seq)
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyIntObject PyLongObject
- #define PyInt_Type PyLong_Type
- #define PyInt_Check(op) PyLong_Check(op)
- #define PyInt_CheckExact(op) PyLong_CheckExact(op)
- #define PyInt_FromString PyLong_FromString
- #define PyInt_FromUnicode PyLong_FromUnicode
- #define PyInt_FromLong PyLong_FromLong
- #define PyInt_FromSize_t PyLong_FromSize_t
- #define PyInt_FromSsize_t PyLong_FromSsize_t
- #define PyInt_AsLong PyLong_AsLong
- #define PyInt_AS_LONG PyLong_AS_LONG
- #define PyInt_AsSsize_t PyLong_AsSsize_t
- #define PyInt_AsUnsignedLongMask PyLong_AsUnsignedLongMask
- #define PyInt_AsUnsignedLongLongMask PyLong_AsUnsignedLongLongMask
- #define PyNumber_Int PyNumber_Long
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyBoolObject PyLongObject
-#endif
-#if PY_MAJOR_VERSION >= 3 && CYTHON_COMPILING_IN_PYPY
- #ifndef PyUnicode_InternFromString
- #define PyUnicode_InternFromString(s) PyUnicode_FromString(s)
- #endif
-#endif
-#if PY_VERSION_HEX < 0x030200A4
- typedef long Py_hash_t;
- #define __Pyx_PyInt_FromHash_t PyInt_FromLong
- #define __Pyx_PyInt_AsHash_t __Pyx_PyIndex_AsHash_t
-#else
- #define __Pyx_PyInt_FromHash_t PyInt_FromSsize_t
- #define __Pyx_PyInt_AsHash_t __Pyx_PyIndex_AsSsize_t
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyMethod_New(func, self, klass) ((self) ? ((void)(klass), PyMethod_New(func, self)) : __Pyx_NewRef(func))
-#else
- #define __Pyx_PyMethod_New(func, self, klass) PyMethod_New(func, self, klass)
-#endif
-#if CYTHON_USE_ASYNC_SLOTS
- #if PY_VERSION_HEX >= 0x030500B1
- #define __Pyx_PyAsyncMethodsStruct PyAsyncMethods
- #define __Pyx_PyType_AsAsync(obj) (Py_TYPE(obj)->tp_as_async)
- #else
- #define __Pyx_PyType_AsAsync(obj) ((__Pyx_PyAsyncMethodsStruct*) (Py_TYPE(obj)->tp_reserved))
- #endif
-#else
- #define __Pyx_PyType_AsAsync(obj) NULL
-#endif
-#ifndef __Pyx_PyAsyncMethodsStruct
- typedef struct {
- unaryfunc am_await;
- unaryfunc am_aiter;
- unaryfunc am_anext;
- } __Pyx_PyAsyncMethodsStruct;
-#endif
-
-#if defined(_WIN32) || defined(WIN32) || defined(MS_WINDOWS)
- #if !defined(_USE_MATH_DEFINES)
- #define _USE_MATH_DEFINES
- #endif
-#endif
-#include
-#ifdef NAN
-#define __PYX_NAN() ((float) NAN)
-#else
-static CYTHON_INLINE float __PYX_NAN() {
- float value;
- memset(&value, 0xFF, sizeof(value));
- return value;
-}
-#endif
-#if defined(__CYGWIN__) && defined(_LDBL_EQ_DBL)
-#define __Pyx_truncl trunc
-#else
-#define __Pyx_truncl truncl
-#endif
-
-#define __PYX_MARK_ERR_POS(f_index, lineno) \
- { __pyx_filename = __pyx_f[f_index]; (void)__pyx_filename; __pyx_lineno = lineno; (void)__pyx_lineno; __pyx_clineno = __LINE__; (void)__pyx_clineno; }
-#define __PYX_ERR(f_index, lineno, Ln_error) \
- { __PYX_MARK_ERR_POS(f_index, lineno) goto Ln_error; }
-
-#ifndef __PYX_EXTERN_C
- #ifdef __cplusplus
- #define __PYX_EXTERN_C extern "C"
- #else
- #define __PYX_EXTERN_C extern
- #endif
-#endif
-
-#define __PYX_HAVE__monotonic_align__core
-#define __PYX_HAVE_API__monotonic_align__core
-/* Early includes */
-#include "pythread.h"
-#include
-#include
-#include
-#include "pystate.h"
-#ifdef _OPENMP
-#include
-#endif /* _OPENMP */
-
-#if defined(PYREX_WITHOUT_ASSERTIONS) && !defined(CYTHON_WITHOUT_ASSERTIONS)
-#define CYTHON_WITHOUT_ASSERTIONS
-#endif
-
-typedef struct {PyObject **p; const char *s; const Py_ssize_t n; const char* encoding;
- const char is_unicode; const char is_str; const char intern; } __Pyx_StringTabEntry;
-
-#define __PYX_DEFAULT_STRING_ENCODING_IS_ASCII 0
-#define __PYX_DEFAULT_STRING_ENCODING_IS_UTF8 0
-#define __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT (PY_MAJOR_VERSION >= 3 && __PYX_DEFAULT_STRING_ENCODING_IS_UTF8)
-#define __PYX_DEFAULT_STRING_ENCODING ""
-#define __Pyx_PyObject_FromString __Pyx_PyBytes_FromString
-#define __Pyx_PyObject_FromStringAndSize __Pyx_PyBytes_FromStringAndSize
-#define __Pyx_uchar_cast(c) ((unsigned char)c)
-#define __Pyx_long_cast(x) ((long)x)
-#define __Pyx_fits_Py_ssize_t(v, type, is_signed) (\
- (sizeof(type) < sizeof(Py_ssize_t)) ||\
- (sizeof(type) > sizeof(Py_ssize_t) &&\
- likely(v < (type)PY_SSIZE_T_MAX ||\
- v == (type)PY_SSIZE_T_MAX) &&\
- (!is_signed || likely(v > (type)PY_SSIZE_T_MIN ||\
- v == (type)PY_SSIZE_T_MIN))) ||\
- (sizeof(type) == sizeof(Py_ssize_t) &&\
- (is_signed || likely(v < (type)PY_SSIZE_T_MAX ||\
- v == (type)PY_SSIZE_T_MAX))) )
-static CYTHON_INLINE int __Pyx_is_valid_index(Py_ssize_t i, Py_ssize_t limit) {
- return (size_t) i < (size_t) limit;
-}
-#if defined (__cplusplus) && __cplusplus >= 201103L
- #include
- #define __Pyx_sst_abs(value) std::abs(value)
-#elif SIZEOF_INT >= SIZEOF_SIZE_T
- #define __Pyx_sst_abs(value) abs(value)
-#elif SIZEOF_LONG >= SIZEOF_SIZE_T
- #define __Pyx_sst_abs(value) labs(value)
-#elif defined (_MSC_VER)
- #define __Pyx_sst_abs(value) ((Py_ssize_t)_abs64(value))
-#elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define __Pyx_sst_abs(value) llabs(value)
-#elif defined (__GNUC__)
- #define __Pyx_sst_abs(value) __builtin_llabs(value)
-#else
- #define __Pyx_sst_abs(value) ((value<0) ? -value : value)
-#endif
-static CYTHON_INLINE const char* __Pyx_PyObject_AsString(PyObject*);
-static CYTHON_INLINE const char* __Pyx_PyObject_AsStringAndSize(PyObject*, Py_ssize_t* length);
-#define __Pyx_PyByteArray_FromString(s) PyByteArray_FromStringAndSize((const char*)s, strlen((const char*)s))
-#define __Pyx_PyByteArray_FromStringAndSize(s, l) PyByteArray_FromStringAndSize((const char*)s, l)
-#define __Pyx_PyBytes_FromString PyBytes_FromString
-#define __Pyx_PyBytes_FromStringAndSize PyBytes_FromStringAndSize
-static CYTHON_INLINE PyObject* __Pyx_PyUnicode_FromString(const char*);
-#if PY_MAJOR_VERSION < 3
- #define __Pyx_PyStr_FromString __Pyx_PyBytes_FromString
- #define __Pyx_PyStr_FromStringAndSize __Pyx_PyBytes_FromStringAndSize
-#else
- #define __Pyx_PyStr_FromString __Pyx_PyUnicode_FromString
- #define __Pyx_PyStr_FromStringAndSize __Pyx_PyUnicode_FromStringAndSize
-#endif
-#define __Pyx_PyBytes_AsWritableString(s) ((char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsWritableSString(s) ((signed char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsWritableUString(s) ((unsigned char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsString(s) ((const char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsSString(s) ((const signed char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsUString(s) ((const unsigned char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyObject_AsWritableString(s) ((char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsWritableSString(s) ((signed char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsWritableUString(s) ((unsigned char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsSString(s) ((const signed char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsUString(s) ((const unsigned char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_FromCString(s) __Pyx_PyObject_FromString((const char*)s)
-#define __Pyx_PyBytes_FromCString(s) __Pyx_PyBytes_FromString((const char*)s)
-#define __Pyx_PyByteArray_FromCString(s) __Pyx_PyByteArray_FromString((const char*)s)
-#define __Pyx_PyStr_FromCString(s) __Pyx_PyStr_FromString((const char*)s)
-#define __Pyx_PyUnicode_FromCString(s) __Pyx_PyUnicode_FromString((const char*)s)
-static CYTHON_INLINE size_t __Pyx_Py_UNICODE_strlen(const Py_UNICODE *u) {
- const Py_UNICODE *u_end = u;
- while (*u_end++) ;
- return (size_t)(u_end - u - 1);
-}
-#define __Pyx_PyUnicode_FromUnicode(u) PyUnicode_FromUnicode(u, __Pyx_Py_UNICODE_strlen(u))
-#define __Pyx_PyUnicode_FromUnicodeAndLength PyUnicode_FromUnicode
-#define __Pyx_PyUnicode_AsUnicode PyUnicode_AsUnicode
-#define __Pyx_NewRef(obj) (Py_INCREF(obj), obj)
-#define __Pyx_Owned_Py_None(b) __Pyx_NewRef(Py_None)
-static CYTHON_INLINE PyObject * __Pyx_PyBool_FromLong(long b);
-static CYTHON_INLINE int __Pyx_PyObject_IsTrue(PyObject*);
-static CYTHON_INLINE int __Pyx_PyObject_IsTrueAndDecref(PyObject*);
-static CYTHON_INLINE PyObject* __Pyx_PyNumber_IntOrLong(PyObject* x);
-#define __Pyx_PySequence_Tuple(obj)\
- (likely(PyTuple_CheckExact(obj)) ? __Pyx_NewRef(obj) : PySequence_Tuple(obj))
-static CYTHON_INLINE Py_ssize_t __Pyx_PyIndex_AsSsize_t(PyObject*);
-static CYTHON_INLINE PyObject * __Pyx_PyInt_FromSize_t(size_t);
-static CYTHON_INLINE Py_hash_t __Pyx_PyIndex_AsHash_t(PyObject*);
-#if CYTHON_ASSUME_SAFE_MACROS
-#define __pyx_PyFloat_AsDouble(x) (PyFloat_CheckExact(x) ? PyFloat_AS_DOUBLE(x) : PyFloat_AsDouble(x))
-#else
-#define __pyx_PyFloat_AsDouble(x) PyFloat_AsDouble(x)
-#endif
-#define __pyx_PyFloat_AsFloat(x) ((float) __pyx_PyFloat_AsDouble(x))
-#if PY_MAJOR_VERSION >= 3
-#define __Pyx_PyNumber_Int(x) (PyLong_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Long(x))
-#else
-#define __Pyx_PyNumber_Int(x) (PyInt_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Int(x))
-#endif
-#define __Pyx_PyNumber_Float(x) (PyFloat_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Float(x))
-#if PY_MAJOR_VERSION < 3 && __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
-static int __Pyx_sys_getdefaultencoding_not_ascii;
-static int __Pyx_init_sys_getdefaultencoding_params(void) {
- PyObject* sys;
- PyObject* default_encoding = NULL;
- PyObject* ascii_chars_u = NULL;
- PyObject* ascii_chars_b = NULL;
- const char* default_encoding_c;
- sys = PyImport_ImportModule("sys");
- if (!sys) goto bad;
- default_encoding = PyObject_CallMethod(sys, (char*) "getdefaultencoding", NULL);
- Py_DECREF(sys);
- if (!default_encoding) goto bad;
- default_encoding_c = PyBytes_AsString(default_encoding);
- if (!default_encoding_c) goto bad;
- if (strcmp(default_encoding_c, "ascii") == 0) {
- __Pyx_sys_getdefaultencoding_not_ascii = 0;
- } else {
- char ascii_chars[128];
- int c;
- for (c = 0; c < 128; c++) {
- ascii_chars[c] = c;
- }
- __Pyx_sys_getdefaultencoding_not_ascii = 1;
- ascii_chars_u = PyUnicode_DecodeASCII(ascii_chars, 128, NULL);
- if (!ascii_chars_u) goto bad;
- ascii_chars_b = PyUnicode_AsEncodedString(ascii_chars_u, default_encoding_c, NULL);
- if (!ascii_chars_b || !PyBytes_Check(ascii_chars_b) || memcmp(ascii_chars, PyBytes_AS_STRING(ascii_chars_b), 128) != 0) {
- PyErr_Format(
- PyExc_ValueError,
- "This module compiled with c_string_encoding=ascii, but default encoding '%.200s' is not a superset of ascii.",
- default_encoding_c);
- goto bad;
- }
- Py_DECREF(ascii_chars_u);
- Py_DECREF(ascii_chars_b);
- }
- Py_DECREF(default_encoding);
- return 0;
-bad:
- Py_XDECREF(default_encoding);
- Py_XDECREF(ascii_chars_u);
- Py_XDECREF(ascii_chars_b);
- return -1;
-}
-#endif
-#if __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT && PY_MAJOR_VERSION >= 3
-#define __Pyx_PyUnicode_FromStringAndSize(c_str, size) PyUnicode_DecodeUTF8(c_str, size, NULL)
-#else
-#define __Pyx_PyUnicode_FromStringAndSize(c_str, size) PyUnicode_Decode(c_str, size, __PYX_DEFAULT_STRING_ENCODING, NULL)
-#if __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
-static char* __PYX_DEFAULT_STRING_ENCODING;
-static int __Pyx_init_sys_getdefaultencoding_params(void) {
- PyObject* sys;
- PyObject* default_encoding = NULL;
- char* default_encoding_c;
- sys = PyImport_ImportModule("sys");
- if (!sys) goto bad;
- default_encoding = PyObject_CallMethod(sys, (char*) (const char*) "getdefaultencoding", NULL);
- Py_DECREF(sys);
- if (!default_encoding) goto bad;
- default_encoding_c = PyBytes_AsString(default_encoding);
- if (!default_encoding_c) goto bad;
- __PYX_DEFAULT_STRING_ENCODING = (char*) malloc(strlen(default_encoding_c) + 1);
- if (!__PYX_DEFAULT_STRING_ENCODING) goto bad;
- strcpy(__PYX_DEFAULT_STRING_ENCODING, default_encoding_c);
- Py_DECREF(default_encoding);
- return 0;
-bad:
- Py_XDECREF(default_encoding);
- return -1;
-}
-#endif
-#endif
-
-
-/* Test for GCC > 2.95 */
-#if defined(__GNUC__) && (__GNUC__ > 2 || (__GNUC__ == 2 && (__GNUC_MINOR__ > 95)))
- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
-#else /* !__GNUC__ or GCC < 2.95 */
- #define likely(x) (x)
- #define unlikely(x) (x)
-#endif /* __GNUC__ */
-static CYTHON_INLINE void __Pyx_pretend_to_initialize(void* ptr) { (void)ptr; }
-
-static PyObject *__pyx_m = NULL;
-static PyObject *__pyx_d;
-static PyObject *__pyx_b;
-static PyObject *__pyx_cython_runtime = NULL;
-static PyObject *__pyx_empty_tuple;
-static PyObject *__pyx_empty_bytes;
-static PyObject *__pyx_empty_unicode;
-static int __pyx_lineno;
-static int __pyx_clineno = 0;
-static const char * __pyx_cfilenm= __FILE__;
-static const char *__pyx_filename;
-
-
-static const char *__pyx_f[] = {
- "core.pyx",
- "stringsource",
-};
-/* NoFastGil.proto */
-#define __Pyx_PyGILState_Ensure PyGILState_Ensure
-#define __Pyx_PyGILState_Release PyGILState_Release
-#define __Pyx_FastGIL_Remember()
-#define __Pyx_FastGIL_Forget()
-#define __Pyx_FastGilFuncInit()
-
-/* MemviewSliceStruct.proto */
-struct __pyx_memoryview_obj;
-typedef struct {
- struct __pyx_memoryview_obj *memview;
- char *data;
- Py_ssize_t shape[8];
- Py_ssize_t strides[8];
- Py_ssize_t suboffsets[8];
-} __Pyx_memviewslice;
-#define __Pyx_MemoryView_Len(m) (m.shape[0])
-
-/* Atomics.proto */
-#include
-#ifndef CYTHON_ATOMICS
- #define CYTHON_ATOMICS 1
-#endif
-#define __PYX_CYTHON_ATOMICS_ENABLED() CYTHON_ATOMICS
-#define __pyx_atomic_int_type int
-#if CYTHON_ATOMICS && (__GNUC__ >= 5 || (__GNUC__ == 4 &&\
- (__GNUC_MINOR__ > 1 ||\
- (__GNUC_MINOR__ == 1 && __GNUC_PATCHLEVEL__ >= 2))))
- #define __pyx_atomic_incr_aligned(value) __sync_fetch_and_add(value, 1)
- #define __pyx_atomic_decr_aligned(value) __sync_fetch_and_sub(value, 1)
- #ifdef __PYX_DEBUG_ATOMICS
- #warning "Using GNU atomics"
- #endif
-#elif CYTHON_ATOMICS && defined(_MSC_VER) && CYTHON_COMPILING_IN_NOGIL
- #include
- #undef __pyx_atomic_int_type
- #define __pyx_atomic_int_type long
- #pragma intrinsic (_InterlockedExchangeAdd)
- #define __pyx_atomic_incr_aligned(value) _InterlockedExchangeAdd(value, 1)
- #define __pyx_atomic_decr_aligned(value) _InterlockedExchangeAdd(value, -1)
- #ifdef __PYX_DEBUG_ATOMICS
- #pragma message ("Using MSVC atomics")
- #endif
-#else
- #undef CYTHON_ATOMICS
- #define CYTHON_ATOMICS 0
- #ifdef __PYX_DEBUG_ATOMICS
- #warning "Not using atomics"
- #endif
-#endif
-typedef volatile __pyx_atomic_int_type __pyx_atomic_int;
-#if CYTHON_ATOMICS
- #define __pyx_add_acquisition_count(memview)\
- __pyx_atomic_incr_aligned(__pyx_get_slice_count_pointer(memview))
- #define __pyx_sub_acquisition_count(memview)\
- __pyx_atomic_decr_aligned(__pyx_get_slice_count_pointer(memview))
-#else
- #define __pyx_add_acquisition_count(memview)\
- __pyx_add_acquisition_count_locked(__pyx_get_slice_count_pointer(memview), memview->lock)
- #define __pyx_sub_acquisition_count(memview)\
- __pyx_sub_acquisition_count_locked(__pyx_get_slice_count_pointer(memview), memview->lock)
-#endif
-
-/* ForceInitThreads.proto */
-#ifndef __PYX_FORCE_INIT_THREADS
- #define __PYX_FORCE_INIT_THREADS 0
-#endif
-
-/* BufferFormatStructs.proto */
-#define IS_UNSIGNED(type) (((type) -1) > 0)
-struct __Pyx_StructField_;
-#define __PYX_BUF_FLAGS_PACKED_STRUCT (1 << 0)
-typedef struct {
- const char* name;
- struct __Pyx_StructField_* fields;
- size_t size;
- size_t arraysize[8];
- int ndim;
- char typegroup;
- char is_unsigned;
- int flags;
-} __Pyx_TypeInfo;
-typedef struct __Pyx_StructField_ {
- __Pyx_TypeInfo* type;
- const char* name;
- size_t offset;
-} __Pyx_StructField;
-typedef struct {
- __Pyx_StructField* field;
- size_t parent_offset;
-} __Pyx_BufFmt_StackElem;
-typedef struct {
- __Pyx_StructField root;
- __Pyx_BufFmt_StackElem* head;
- size_t fmt_offset;
- size_t new_count, enc_count;
- size_t struct_alignment;
- int is_complex;
- char enc_type;
- char new_packmode;
- char enc_packmode;
- char is_valid_array;
-} __Pyx_BufFmt_Context;
-
-
-/*--- Type declarations ---*/
-struct __pyx_array_obj;
-struct __pyx_MemviewEnum_obj;
-struct __pyx_memoryview_obj;
-struct __pyx_memoryviewslice_obj;
-struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each;
-
-/* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
-struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each {
- int __pyx_n;
- float max_neg_val;
-};
-
-/* "View.MemoryView":106
- *
- * @cname("__pyx_array")
- * cdef class array: # <<<<<<<<<<<<<<
- *
- * cdef:
- */
-struct __pyx_array_obj {
- PyObject_HEAD
- struct __pyx_vtabstruct_array *__pyx_vtab;
- char *data;
- Py_ssize_t len;
- char *format;
- int ndim;
- Py_ssize_t *_shape;
- Py_ssize_t *_strides;
- Py_ssize_t itemsize;
- PyObject *mode;
- PyObject *_format;
- void (*callback_free_data)(void *);
- int free_data;
- int dtype_is_object;
-};
-
-
-/* "View.MemoryView":280
- *
- * @cname('__pyx_MemviewEnum')
- * cdef class Enum(object): # <<<<<<<<<<<<<<
- * cdef object name
- * def __init__(self, name):
- */
-struct __pyx_MemviewEnum_obj {
- PyObject_HEAD
- PyObject *name;
-};
-
-
-/* "View.MemoryView":331
- *
- * @cname('__pyx_memoryview')
- * cdef class memoryview(object): # <<<<<<<<<<<<<<
- *
- * cdef object obj
- */
-struct __pyx_memoryview_obj {
- PyObject_HEAD
- struct __pyx_vtabstruct_memoryview *__pyx_vtab;
- PyObject *obj;
- PyObject *_size;
- PyObject *_array_interface;
- PyThread_type_lock lock;
- __pyx_atomic_int acquisition_count[2];
- __pyx_atomic_int *acquisition_count_aligned_p;
- Py_buffer view;
- int flags;
- int dtype_is_object;
- __Pyx_TypeInfo *typeinfo;
-};
-
-
-/* "View.MemoryView":967
- *
- * @cname('__pyx_memoryviewslice')
- * cdef class _memoryviewslice(memoryview): # <<<<<<<<<<<<<<
- * "Internal class for passing memoryview slices to Python"
- *
- */
-struct __pyx_memoryviewslice_obj {
- struct __pyx_memoryview_obj __pyx_base;
- __Pyx_memviewslice from_slice;
- PyObject *from_object;
- PyObject *(*to_object_func)(char *);
- int (*to_dtype_func)(char *, PyObject *);
-};
-
-
-
-/* "View.MemoryView":106
- *
- * @cname("__pyx_array")
- * cdef class array: # <<<<<<<<<<<<<<
- *
- * cdef:
- */
-
-struct __pyx_vtabstruct_array {
- PyObject *(*get_memview)(struct __pyx_array_obj *);
-};
-static struct __pyx_vtabstruct_array *__pyx_vtabptr_array;
-
-
-/* "View.MemoryView":331
- *
- * @cname('__pyx_memoryview')
- * cdef class memoryview(object): # <<<<<<<<<<<<<<
- *
- * cdef object obj
- */
-
-struct __pyx_vtabstruct_memoryview {
- char *(*get_item_pointer)(struct __pyx_memoryview_obj *, PyObject *);
- PyObject *(*is_slice)(struct __pyx_memoryview_obj *, PyObject *);
- PyObject *(*setitem_slice_assignment)(struct __pyx_memoryview_obj *, PyObject *, PyObject *);
- PyObject *(*setitem_slice_assign_scalar)(struct __pyx_memoryview_obj *, struct __pyx_memoryview_obj *, PyObject *);
- PyObject *(*setitem_indexed)(struct __pyx_memoryview_obj *, PyObject *, PyObject *);
- PyObject *(*convert_item_to_object)(struct __pyx_memoryview_obj *, char *);
- PyObject *(*assign_item_from_object)(struct __pyx_memoryview_obj *, char *, PyObject *);
-};
-static struct __pyx_vtabstruct_memoryview *__pyx_vtabptr_memoryview;
-
-
-/* "View.MemoryView":967
- *
- * @cname('__pyx_memoryviewslice')
- * cdef class _memoryviewslice(memoryview): # <<<<<<<<<<<<<<
- * "Internal class for passing memoryview slices to Python"
- *
- */
-
-struct __pyx_vtabstruct__memoryviewslice {
- struct __pyx_vtabstruct_memoryview __pyx_base;
-};
-static struct __pyx_vtabstruct__memoryviewslice *__pyx_vtabptr__memoryviewslice;
-
-/* --- Runtime support code (head) --- */
-/* Refnanny.proto */
-#ifndef CYTHON_REFNANNY
- #define CYTHON_REFNANNY 0
-#endif
-#if CYTHON_REFNANNY
- typedef struct {
- void (*INCREF)(void*, PyObject*, int);
- void (*DECREF)(void*, PyObject*, int);
- void (*GOTREF)(void*, PyObject*, int);
- void (*GIVEREF)(void*, PyObject*, int);
- void* (*SetupContext)(const char*, int, const char*);
- void (*FinishContext)(void**);
- } __Pyx_RefNannyAPIStruct;
- static __Pyx_RefNannyAPIStruct *__Pyx_RefNanny = NULL;
- static __Pyx_RefNannyAPIStruct *__Pyx_RefNannyImportAPI(const char *modname);
- #define __Pyx_RefNannyDeclarations void *__pyx_refnanny = NULL;
-#ifdef WITH_THREAD
- #define __Pyx_RefNannySetupContext(name, acquire_gil)\
- if (acquire_gil) {\
- PyGILState_STATE __pyx_gilstate_save = PyGILState_Ensure();\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), __LINE__, __FILE__);\
- PyGILState_Release(__pyx_gilstate_save);\
- } else {\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), __LINE__, __FILE__);\
- }
-#else
- #define __Pyx_RefNannySetupContext(name, acquire_gil)\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), __LINE__, __FILE__)
-#endif
- #define __Pyx_RefNannyFinishContext()\
- __Pyx_RefNanny->FinishContext(&__pyx_refnanny)
- #define __Pyx_INCREF(r) __Pyx_RefNanny->INCREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_DECREF(r) __Pyx_RefNanny->DECREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_GOTREF(r) __Pyx_RefNanny->GOTREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_GIVEREF(r) __Pyx_RefNanny->GIVEREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_XINCREF(r) do { if((r) != NULL) {__Pyx_INCREF(r); }} while(0)
- #define __Pyx_XDECREF(r) do { if((r) != NULL) {__Pyx_DECREF(r); }} while(0)
- #define __Pyx_XGOTREF(r) do { if((r) != NULL) {__Pyx_GOTREF(r); }} while(0)
- #define __Pyx_XGIVEREF(r) do { if((r) != NULL) {__Pyx_GIVEREF(r);}} while(0)
-#else
- #define __Pyx_RefNannyDeclarations
- #define __Pyx_RefNannySetupContext(name, acquire_gil)
- #define __Pyx_RefNannyFinishContext()
- #define __Pyx_INCREF(r) Py_INCREF(r)
- #define __Pyx_DECREF(r) Py_DECREF(r)
- #define __Pyx_GOTREF(r)
- #define __Pyx_GIVEREF(r)
- #define __Pyx_XINCREF(r) Py_XINCREF(r)
- #define __Pyx_XDECREF(r) Py_XDECREF(r)
- #define __Pyx_XGOTREF(r)
- #define __Pyx_XGIVEREF(r)
-#endif
-#define __Pyx_XDECREF_SET(r, v) do {\
- PyObject *tmp = (PyObject *) r;\
- r = v; __Pyx_XDECREF(tmp);\
- } while (0)
-#define __Pyx_DECREF_SET(r, v) do {\
- PyObject *tmp = (PyObject *) r;\
- r = v; __Pyx_DECREF(tmp);\
- } while (0)
-#define __Pyx_CLEAR(r) do { PyObject* tmp = ((PyObject*)(r)); r = NULL; __Pyx_DECREF(tmp);} while(0)
-#define __Pyx_XCLEAR(r) do { if((r) != NULL) {PyObject* tmp = ((PyObject*)(r)); r = NULL; __Pyx_DECREF(tmp);}} while(0)
-
-/* PyObjectGetAttrStr.proto */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStr(PyObject* obj, PyObject* attr_name);
-#else
-#define __Pyx_PyObject_GetAttrStr(o,n) PyObject_GetAttr(o,n)
-#endif
-
-/* GetBuiltinName.proto */
-static PyObject *__Pyx_GetBuiltinName(PyObject *name);
-
-/* MemviewSliceInit.proto */
-#define __Pyx_BUF_MAX_NDIMS %(BUF_MAX_NDIMS)d
-#define __Pyx_MEMVIEW_DIRECT 1
-#define __Pyx_MEMVIEW_PTR 2
-#define __Pyx_MEMVIEW_FULL 4
-#define __Pyx_MEMVIEW_CONTIG 8
-#define __Pyx_MEMVIEW_STRIDED 16
-#define __Pyx_MEMVIEW_FOLLOW 32
-#define __Pyx_IS_C_CONTIG 1
-#define __Pyx_IS_F_CONTIG 2
-static int __Pyx_init_memviewslice(
- struct __pyx_memoryview_obj *memview,
- int ndim,
- __Pyx_memviewslice *memviewslice,
- int memview_is_new_reference);
-static CYTHON_INLINE int __pyx_add_acquisition_count_locked(
- __pyx_atomic_int *acquisition_count, PyThread_type_lock lock);
-static CYTHON_INLINE int __pyx_sub_acquisition_count_locked(
- __pyx_atomic_int *acquisition_count, PyThread_type_lock lock);
-#define __pyx_get_slice_count_pointer(memview) (memview->acquisition_count_aligned_p)
-#define __pyx_get_slice_count(memview) (*__pyx_get_slice_count_pointer(memview))
-#define __PYX_INC_MEMVIEW(slice, have_gil) __Pyx_INC_MEMVIEW(slice, have_gil, __LINE__)
-#define __PYX_XDEC_MEMVIEW(slice, have_gil) __Pyx_XDEC_MEMVIEW(slice, have_gil, __LINE__)
-static CYTHON_INLINE void __Pyx_INC_MEMVIEW(__Pyx_memviewslice *, int, int);
-static CYTHON_INLINE void __Pyx_XDEC_MEMVIEW(__Pyx_memviewslice *, int, int);
-
-/* RaiseArgTupleInvalid.proto */
-static void __Pyx_RaiseArgtupleInvalid(const char* func_name, int exact,
- Py_ssize_t num_min, Py_ssize_t num_max, Py_ssize_t num_found);
-
-/* RaiseDoubleKeywords.proto */
-static void __Pyx_RaiseDoubleKeywordsError(const char* func_name, PyObject* kw_name);
-
-/* ParseKeywords.proto */
-static int __Pyx_ParseOptionalKeywords(PyObject *kwds, PyObject **argnames[],\
- PyObject *kwds2, PyObject *values[], Py_ssize_t num_pos_args,\
- const char* function_name);
-
-/* None.proto */
-static CYTHON_INLINE void __Pyx_RaiseUnboundLocalError(const char *varname);
-
-/* ArgTypeTest.proto */
-#define __Pyx_ArgTypeTest(obj, type, none_allowed, name, exact)\
- ((likely((Py_TYPE(obj) == type) | (none_allowed && (obj == Py_None)))) ? 1 :\
- __Pyx__ArgTypeTest(obj, type, name, exact))
-static int __Pyx__ArgTypeTest(PyObject *obj, PyTypeObject *type, const char *name, int exact);
-
-/* PyObjectCall.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call(PyObject *func, PyObject *arg, PyObject *kw);
-#else
-#define __Pyx_PyObject_Call(func, arg, kw) PyObject_Call(func, arg, kw)
-#endif
-
-/* PyThreadStateGet.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyThreadState_declare PyThreadState *__pyx_tstate;
-#define __Pyx_PyThreadState_assign __pyx_tstate = __Pyx_PyThreadState_Current;
-#define __Pyx_PyErr_Occurred() __pyx_tstate->curexc_type
-#else
-#define __Pyx_PyThreadState_declare
-#define __Pyx_PyThreadState_assign
-#define __Pyx_PyErr_Occurred() PyErr_Occurred()
-#endif
-
-/* PyErrFetchRestore.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyErr_Clear() __Pyx_ErrRestore(NULL, NULL, NULL)
-#define __Pyx_ErrRestoreWithState(type, value, tb) __Pyx_ErrRestoreInState(PyThreadState_GET(), type, value, tb)
-#define __Pyx_ErrFetchWithState(type, value, tb) __Pyx_ErrFetchInState(PyThreadState_GET(), type, value, tb)
-#define __Pyx_ErrRestore(type, value, tb) __Pyx_ErrRestoreInState(__pyx_tstate, type, value, tb)
-#define __Pyx_ErrFetch(type, value, tb) __Pyx_ErrFetchInState(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx_ErrRestoreInState(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb);
-static CYTHON_INLINE void __Pyx_ErrFetchInState(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#if CYTHON_COMPILING_IN_CPYTHON
-#define __Pyx_PyErr_SetNone(exc) (Py_INCREF(exc), __Pyx_ErrRestore((exc), NULL, NULL))
-#else
-#define __Pyx_PyErr_SetNone(exc) PyErr_SetNone(exc)
-#endif
-#else
-#define __Pyx_PyErr_Clear() PyErr_Clear()
-#define __Pyx_PyErr_SetNone(exc) PyErr_SetNone(exc)
-#define __Pyx_ErrRestoreWithState(type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetchWithState(type, value, tb) PyErr_Fetch(type, value, tb)
-#define __Pyx_ErrRestoreInState(tstate, type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetchInState(tstate, type, value, tb) PyErr_Fetch(type, value, tb)
-#define __Pyx_ErrRestore(type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetch(type, value, tb) PyErr_Fetch(type, value, tb)
-#endif
-
-/* RaiseException.proto */
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb, PyObject *cause);
-
-/* PyCFunctionFastCall.proto */
-#if CYTHON_FAST_PYCCALL
-static CYTHON_INLINE PyObject *__Pyx_PyCFunction_FastCall(PyObject *func, PyObject **args, Py_ssize_t nargs);
-#else
-#define __Pyx_PyCFunction_FastCall(func, args, nargs) (assert(0), NULL)
-#endif
-
-/* PyFunctionFastCall.proto */
-#if CYTHON_FAST_PYCALL
-#define __Pyx_PyFunction_FastCall(func, args, nargs)\
- __Pyx_PyFunction_FastCallDict((func), (args), (nargs), NULL)
-#if 1 || PY_VERSION_HEX < 0x030600B1
-static PyObject *__Pyx_PyFunction_FastCallDict(PyObject *func, PyObject **args, Py_ssize_t nargs, PyObject *kwargs);
-#else
-#define __Pyx_PyFunction_FastCallDict(func, args, nargs, kwargs) _PyFunction_FastCallDict(func, args, nargs, kwargs)
-#endif
-#define __Pyx_BUILD_ASSERT_EXPR(cond)\
- (sizeof(char [1 - 2*!(cond)]) - 1)
-#ifndef Py_MEMBER_SIZE
-#define Py_MEMBER_SIZE(type, member) sizeof(((type *)0)->member)
-#endif
-#if CYTHON_FAST_PYCALL
- static size_t __pyx_pyframe_localsplus_offset = 0;
- #include "frameobject.h"
-#if PY_VERSION_HEX >= 0x030b00a6
- #ifndef Py_BUILD_CORE
- #define Py_BUILD_CORE 1
- #endif
- #include "internal/pycore_frame.h"
-#endif
- #define __Pxy_PyFrame_Initialize_Offsets()\
- ((void)__Pyx_BUILD_ASSERT_EXPR(sizeof(PyFrameObject) == offsetof(PyFrameObject, f_localsplus) + Py_MEMBER_SIZE(PyFrameObject, f_localsplus)),\
- (void)(__pyx_pyframe_localsplus_offset = ((size_t)PyFrame_Type.tp_basicsize) - Py_MEMBER_SIZE(PyFrameObject, f_localsplus)))
- #define __Pyx_PyFrame_GetLocalsplus(frame)\
- (assert(__pyx_pyframe_localsplus_offset), (PyObject **)(((char *)(frame)) + __pyx_pyframe_localsplus_offset))
-#endif // CYTHON_FAST_PYCALL
-#endif
-
-/* PyObjectCall2Args.proto */
-static CYTHON_UNUSED PyObject* __Pyx_PyObject_Call2Args(PyObject* function, PyObject* arg1, PyObject* arg2);
-
-/* PyObjectCallMethO.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallMethO(PyObject *func, PyObject *arg);
-#endif
-
-/* PyObjectCallOneArg.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg);
-
-/* IncludeStringH.proto */
-#include
-
-/* BytesEquals.proto */
-static CYTHON_INLINE int __Pyx_PyBytes_Equals(PyObject* s1, PyObject* s2, int equals);
-
-/* UnicodeEquals.proto */
-static CYTHON_INLINE int __Pyx_PyUnicode_Equals(PyObject* s1, PyObject* s2, int equals);
-
-/* StrEquals.proto */
-#if PY_MAJOR_VERSION >= 3
-#define __Pyx_PyString_Equals __Pyx_PyUnicode_Equals
-#else
-#define __Pyx_PyString_Equals __Pyx_PyBytes_Equals
-#endif
-
-/* DivInt[Py_ssize_t].proto */
-static CYTHON_INLINE Py_ssize_t __Pyx_div_Py_ssize_t(Py_ssize_t, Py_ssize_t);
-
-/* UnaryNegOverflows.proto */
-#define UNARY_NEG_WOULD_OVERFLOW(x)\
- (((x) < 0) & ((unsigned long)(x) == 0-(unsigned long)(x)))
-
-static CYTHON_UNUSED int __pyx_array_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-static PyObject *__pyx_array_get_memview(struct __pyx_array_obj *); /*proto*/
-/* GetAttr.proto */
-static CYTHON_INLINE PyObject *__Pyx_GetAttr(PyObject *, PyObject *);
-
-/* GetItemInt.proto */
-#define __Pyx_GetItemInt(o, i, type, is_signed, to_py_func, is_list, wraparound, boundscheck)\
- (__Pyx_fits_Py_ssize_t(i, type, is_signed) ?\
- __Pyx_GetItemInt_Fast(o, (Py_ssize_t)i, is_list, wraparound, boundscheck) :\
- (is_list ? (PyErr_SetString(PyExc_IndexError, "list index out of range"), (PyObject*)NULL) :\
- __Pyx_GetItemInt_Generic(o, to_py_func(i))))
-#define __Pyx_GetItemInt_List(o, i, type, is_signed, to_py_func, is_list, wraparound, boundscheck)\
- (__Pyx_fits_Py_ssize_t(i, type, is_signed) ?\
- __Pyx_GetItemInt_List_Fast(o, (Py_ssize_t)i, wraparound, boundscheck) :\
- (PyErr_SetString(PyExc_IndexError, "list index out of range"), (PyObject*)NULL))
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_List_Fast(PyObject *o, Py_ssize_t i,
- int wraparound, int boundscheck);
-#define __Pyx_GetItemInt_Tuple(o, i, type, is_signed, to_py_func, is_list, wraparound, boundscheck)\
- (__Pyx_fits_Py_ssize_t(i, type, is_signed) ?\
- __Pyx_GetItemInt_Tuple_Fast(o, (Py_ssize_t)i, wraparound, boundscheck) :\
- (PyErr_SetString(PyExc_IndexError, "tuple index out of range"), (PyObject*)NULL))
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Tuple_Fast(PyObject *o, Py_ssize_t i,
- int wraparound, int boundscheck);
-static PyObject *__Pyx_GetItemInt_Generic(PyObject *o, PyObject* j);
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Fast(PyObject *o, Py_ssize_t i,
- int is_list, int wraparound, int boundscheck);
-
-/* ObjectGetItem.proto */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject *__Pyx_PyObject_GetItem(PyObject *obj, PyObject* key);
-#else
-#define __Pyx_PyObject_GetItem(obj, key) PyObject_GetItem(obj, key)
-#endif
-
-/* decode_c_string_utf16.proto */
-static CYTHON_INLINE PyObject *__Pyx_PyUnicode_DecodeUTF16(const char *s, Py_ssize_t size, const char *errors) {
- int byteorder = 0;
- return PyUnicode_DecodeUTF16(s, size, errors, &byteorder);
-}
-static CYTHON_INLINE PyObject *__Pyx_PyUnicode_DecodeUTF16LE(const char *s, Py_ssize_t size, const char *errors) {
- int byteorder = -1;
- return PyUnicode_DecodeUTF16(s, size, errors, &byteorder);
-}
-static CYTHON_INLINE PyObject *__Pyx_PyUnicode_DecodeUTF16BE(const char *s, Py_ssize_t size, const char *errors) {
- int byteorder = 1;
- return PyUnicode_DecodeUTF16(s, size, errors, &byteorder);
-}
-
-/* decode_c_string.proto */
-static CYTHON_INLINE PyObject* __Pyx_decode_c_string(
- const char* cstring, Py_ssize_t start, Py_ssize_t stop,
- const char* encoding, const char* errors,
- PyObject* (*decode_func)(const char *s, Py_ssize_t size, const char *errors));
-
-/* PyErrExceptionMatches.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyErr_ExceptionMatches(err) __Pyx_PyErr_ExceptionMatchesInState(__pyx_tstate, err)
-static CYTHON_INLINE int __Pyx_PyErr_ExceptionMatchesInState(PyThreadState* tstate, PyObject* err);
-#else
-#define __Pyx_PyErr_ExceptionMatches(err) PyErr_ExceptionMatches(err)
-#endif
-
-/* GetAttr3.proto */
-static CYTHON_INLINE PyObject *__Pyx_GetAttr3(PyObject *, PyObject *, PyObject *);
-
-/* PyDictVersioning.proto */
-#if CYTHON_USE_DICT_VERSIONS && CYTHON_USE_TYPE_SLOTS
-#define __PYX_DICT_VERSION_INIT ((PY_UINT64_T) -1)
-#define __PYX_GET_DICT_VERSION(dict) (((PyDictObject*)(dict))->ma_version_tag)
-#define __PYX_UPDATE_DICT_CACHE(dict, value, cache_var, version_var)\
- (version_var) = __PYX_GET_DICT_VERSION(dict);\
- (cache_var) = (value);
-#define __PYX_PY_DICT_LOOKUP_IF_MODIFIED(VAR, DICT, LOOKUP) {\
- static PY_UINT64_T __pyx_dict_version = 0;\
- static PyObject *__pyx_dict_cached_value = NULL;\
- if (likely(__PYX_GET_DICT_VERSION(DICT) == __pyx_dict_version)) {\
- (VAR) = __pyx_dict_cached_value;\
- } else {\
- (VAR) = __pyx_dict_cached_value = (LOOKUP);\
- __pyx_dict_version = __PYX_GET_DICT_VERSION(DICT);\
- }\
-}
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_tp_dict_version(PyObject *obj);
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_object_dict_version(PyObject *obj);
-static CYTHON_INLINE int __Pyx_object_dict_version_matches(PyObject* obj, PY_UINT64_T tp_dict_version, PY_UINT64_T obj_dict_version);
-#else
-#define __PYX_GET_DICT_VERSION(dict) (0)
-#define __PYX_UPDATE_DICT_CACHE(dict, value, cache_var, version_var)
-#define __PYX_PY_DICT_LOOKUP_IF_MODIFIED(VAR, DICT, LOOKUP) (VAR) = (LOOKUP);
-#endif
-
-/* GetModuleGlobalName.proto */
-#if CYTHON_USE_DICT_VERSIONS
-#define __Pyx_GetModuleGlobalName(var, name) {\
- static PY_UINT64_T __pyx_dict_version = 0;\
- static PyObject *__pyx_dict_cached_value = NULL;\
- (var) = (likely(__pyx_dict_version == __PYX_GET_DICT_VERSION(__pyx_d))) ?\
- (likely(__pyx_dict_cached_value) ? __Pyx_NewRef(__pyx_dict_cached_value) : __Pyx_GetBuiltinName(name)) :\
- __Pyx__GetModuleGlobalName(name, &__pyx_dict_version, &__pyx_dict_cached_value);\
-}
-#define __Pyx_GetModuleGlobalNameUncached(var, name) {\
- PY_UINT64_T __pyx_dict_version;\
- PyObject *__pyx_dict_cached_value;\
- (var) = __Pyx__GetModuleGlobalName(name, &__pyx_dict_version, &__pyx_dict_cached_value);\
-}
-static PyObject *__Pyx__GetModuleGlobalName(PyObject *name, PY_UINT64_T *dict_version, PyObject **dict_cached_value);
-#else
-#define __Pyx_GetModuleGlobalName(var, name) (var) = __Pyx__GetModuleGlobalName(name)
-#define __Pyx_GetModuleGlobalNameUncached(var, name) (var) = __Pyx__GetModuleGlobalName(name)
-static CYTHON_INLINE PyObject *__Pyx__GetModuleGlobalName(PyObject *name);
-#endif
-
-/* RaiseTooManyValuesToUnpack.proto */
-static CYTHON_INLINE void __Pyx_RaiseTooManyValuesError(Py_ssize_t expected);
-
-/* RaiseNeedMoreValuesToUnpack.proto */
-static CYTHON_INLINE void __Pyx_RaiseNeedMoreValuesError(Py_ssize_t index);
-
-/* RaiseNoneIterError.proto */
-static CYTHON_INLINE void __Pyx_RaiseNoneNotIterableError(void);
-
-/* ExtTypeTest.proto */
-static CYTHON_INLINE int __Pyx_TypeTest(PyObject *obj, PyTypeObject *type);
-
-/* GetTopmostException.proto */
-#if CYTHON_USE_EXC_INFO_STACK
-static _PyErr_StackItem * __Pyx_PyErr_GetTopmostException(PyThreadState *tstate);
-#endif
-
-/* SaveResetException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_ExceptionSave(type, value, tb) __Pyx__ExceptionSave(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionSave(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#define __Pyx_ExceptionReset(type, value, tb) __Pyx__ExceptionReset(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionReset(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb);
-#else
-#define __Pyx_ExceptionSave(type, value, tb) PyErr_GetExcInfo(type, value, tb)
-#define __Pyx_ExceptionReset(type, value, tb) PyErr_SetExcInfo(type, value, tb)
-#endif
-
-/* GetException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_GetException(type, value, tb) __Pyx__GetException(__pyx_tstate, type, value, tb)
-static int __Pyx__GetException(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#else
-static int __Pyx_GetException(PyObject **type, PyObject **value, PyObject **tb);
-#endif
-
-/* SwapException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_ExceptionSwap(type, value, tb) __Pyx__ExceptionSwap(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionSwap(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#else
-static CYTHON_INLINE void __Pyx_ExceptionSwap(PyObject **type, PyObject **value, PyObject **tb);
-#endif
-
-/* Import.proto */
-static PyObject *__Pyx_Import(PyObject *name, PyObject *from_list, int level);
-
-/* FastTypeChecks.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-#define __Pyx_TypeCheck(obj, type) __Pyx_IsSubtype(Py_TYPE(obj), (PyTypeObject *)type)
-static CYTHON_INLINE int __Pyx_IsSubtype(PyTypeObject *a, PyTypeObject *b);
-static CYTHON_INLINE int __Pyx_PyErr_GivenExceptionMatches(PyObject *err, PyObject *type);
-static CYTHON_INLINE int __Pyx_PyErr_GivenExceptionMatches2(PyObject *err, PyObject *type1, PyObject *type2);
-#else
-#define __Pyx_TypeCheck(obj, type) PyObject_TypeCheck(obj, (PyTypeObject *)type)
-#define __Pyx_PyErr_GivenExceptionMatches(err, type) PyErr_GivenExceptionMatches(err, type)
-#define __Pyx_PyErr_GivenExceptionMatches2(err, type1, type2) (PyErr_GivenExceptionMatches(err, type1) || PyErr_GivenExceptionMatches(err, type2))
-#endif
-#define __Pyx_PyException_Check(obj) __Pyx_TypeCheck(obj, PyExc_Exception)
-
-static CYTHON_UNUSED int __pyx_memoryview_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-/* ListCompAppend.proto */
-#if CYTHON_USE_PYLIST_INTERNALS && CYTHON_ASSUME_SAFE_MACROS
-static CYTHON_INLINE int __Pyx_ListComp_Append(PyObject* list, PyObject* x) {
- PyListObject* L = (PyListObject*) list;
- Py_ssize_t len = Py_SIZE(list);
- if (likely(L->allocated > len)) {
- Py_INCREF(x);
- PyList_SET_ITEM(list, len, x);
- __Pyx_SET_SIZE(list, len + 1);
- return 0;
- }
- return PyList_Append(list, x);
-}
-#else
-#define __Pyx_ListComp_Append(L,x) PyList_Append(L,x)
-#endif
-
-/* PyIntBinop.proto */
-#if !CYTHON_COMPILING_IN_PYPY
-static PyObject* __Pyx_PyInt_AddObjC(PyObject *op1, PyObject *op2, long intval, int inplace, int zerodivision_check);
-#else
-#define __Pyx_PyInt_AddObjC(op1, op2, intval, inplace, zerodivision_check)\
- (inplace ? PyNumber_InPlaceAdd(op1, op2) : PyNumber_Add(op1, op2))
-#endif
-
-/* ListExtend.proto */
-static CYTHON_INLINE int __Pyx_PyList_Extend(PyObject* L, PyObject* v) {
-#if CYTHON_COMPILING_IN_CPYTHON
- PyObject* none = _PyList_Extend((PyListObject*)L, v);
- if (unlikely(!none))
- return -1;
- Py_DECREF(none);
- return 0;
-#else
- return PyList_SetSlice(L, PY_SSIZE_T_MAX, PY_SSIZE_T_MAX, v);
-#endif
-}
-
-/* ListAppend.proto */
-#if CYTHON_USE_PYLIST_INTERNALS && CYTHON_ASSUME_SAFE_MACROS
-static CYTHON_INLINE int __Pyx_PyList_Append(PyObject* list, PyObject* x) {
- PyListObject* L = (PyListObject*) list;
- Py_ssize_t len = Py_SIZE(list);
- if (likely(L->allocated > len) & likely(len > (L->allocated >> 1))) {
- Py_INCREF(x);
- PyList_SET_ITEM(list, len, x);
- __Pyx_SET_SIZE(list, len + 1);
- return 0;
- }
- return PyList_Append(list, x);
-}
-#else
-#define __Pyx_PyList_Append(L,x) PyList_Append(L,x)
-#endif
-
-/* DivInt[long].proto */
-static CYTHON_INLINE long __Pyx_div_long(long, long);
-
-/* PySequenceContains.proto */
-static CYTHON_INLINE int __Pyx_PySequence_ContainsTF(PyObject* item, PyObject* seq, int eq) {
- int result = PySequence_Contains(seq, item);
- return unlikely(result < 0) ? result : (result == (eq == Py_EQ));
-}
-
-/* ImportFrom.proto */
-static PyObject* __Pyx_ImportFrom(PyObject* module, PyObject* name);
-
-/* HasAttr.proto */
-static CYTHON_INLINE int __Pyx_HasAttr(PyObject *, PyObject *);
-
-/* PyObject_GenericGetAttrNoDict.proto */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GenericGetAttrNoDict(PyObject* obj, PyObject* attr_name);
-#else
-#define __Pyx_PyObject_GenericGetAttrNoDict PyObject_GenericGetAttr
-#endif
-
-/* PyObject_GenericGetAttr.proto */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static PyObject* __Pyx_PyObject_GenericGetAttr(PyObject* obj, PyObject* attr_name);
-#else
-#define __Pyx_PyObject_GenericGetAttr PyObject_GenericGetAttr
-#endif
-
-/* SetVTable.proto */
-static int __Pyx_SetVtable(PyObject *dict, void *vtable);
-
-/* PyObjectGetAttrStrNoError.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStrNoError(PyObject* obj, PyObject* attr_name);
-
-/* SetupReduce.proto */
-static int __Pyx_setup_reduce(PyObject* type_obj);
-
-/* CLineInTraceback.proto */
-#ifdef CYTHON_CLINE_IN_TRACEBACK
-#define __Pyx_CLineForTraceback(tstate, c_line) (((CYTHON_CLINE_IN_TRACEBACK)) ? c_line : 0)
-#else
-static int __Pyx_CLineForTraceback(PyThreadState *tstate, int c_line);
-#endif
-
-/* CodeObjectCache.proto */
-typedef struct {
- PyCodeObject* code_object;
- int code_line;
-} __Pyx_CodeObjectCacheEntry;
-struct __Pyx_CodeObjectCache {
- int count;
- int max_count;
- __Pyx_CodeObjectCacheEntry* entries;
-};
-static struct __Pyx_CodeObjectCache __pyx_code_cache = {0,0,NULL};
-static int __pyx_bisect_code_objects(__Pyx_CodeObjectCacheEntry* entries, int count, int code_line);
-static PyCodeObject *__pyx_find_code_object(int code_line);
-static void __pyx_insert_code_object(int code_line, PyCodeObject* code_object);
-
-/* AddTraceback.proto */
-static void __Pyx_AddTraceback(const char *funcname, int c_line,
- int py_line, const char *filename);
-
-#if PY_MAJOR_VERSION < 3
- static int __Pyx_GetBuffer(PyObject *obj, Py_buffer *view, int flags);
- static void __Pyx_ReleaseBuffer(Py_buffer *view);
-#else
- #define __Pyx_GetBuffer PyObject_GetBuffer
- #define __Pyx_ReleaseBuffer PyBuffer_Release
-#endif
-
-
-/* BufferStructDeclare.proto */
-typedef struct {
- Py_ssize_t shape, strides, suboffsets;
-} __Pyx_Buf_DimInfo;
-typedef struct {
- size_t refcount;
- Py_buffer pybuffer;
-} __Pyx_Buffer;
-typedef struct {
- __Pyx_Buffer *rcbuffer;
- char *data;
- __Pyx_Buf_DimInfo diminfo[8];
-} __Pyx_LocalBuf_ND;
-
-/* MemviewSliceIsContig.proto */
-static int __pyx_memviewslice_is_contig(const __Pyx_memviewslice mvs, char order, int ndim);
-
-/* OverlappingSlices.proto */
-static int __pyx_slices_overlap(__Pyx_memviewslice *slice1,
- __Pyx_memviewslice *slice2,
- int ndim, size_t itemsize);
-
-/* Capsule.proto */
-static CYTHON_INLINE PyObject *__pyx_capsule_create(void *p, const char *sig);
-
-/* IsLittleEndian.proto */
-static CYTHON_INLINE int __Pyx_Is_Little_Endian(void);
-
-/* BufferFormatCheck.proto */
-static const char* __Pyx_BufFmt_CheckString(__Pyx_BufFmt_Context* ctx, const char* ts);
-static void __Pyx_BufFmt_Init(__Pyx_BufFmt_Context* ctx,
- __Pyx_BufFmt_StackElem* stack,
- __Pyx_TypeInfo* type);
-
-/* TypeInfoCompare.proto */
-static int __pyx_typeinfo_cmp(__Pyx_TypeInfo *a, __Pyx_TypeInfo *b);
-
-/* MemviewSliceValidateAndInit.proto */
-static int __Pyx_ValidateAndInit_memviewslice(
- int *axes_specs,
- int c_or_f_flag,
- int buf_flags,
- int ndim,
- __Pyx_TypeInfo *dtype,
- __Pyx_BufFmt_StackElem stack[],
- __Pyx_memviewslice *memviewslice,
- PyObject *original_obj);
-
-/* ObjectToMemviewSlice.proto */
-static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_int(PyObject *, int writable_flag);
-
-/* ObjectToMemviewSlice.proto */
-static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_float(PyObject *, int writable_flag);
-
-/* ObjectToMemviewSlice.proto */
-static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_dc_int(PyObject *, int writable_flag);
-
-/* GCCDiagnostics.proto */
-#if defined(__GNUC__) && (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 6))
-#define __Pyx_HAS_GCC_DIAGNOSTIC
-#endif
-
-/* MemviewSliceCopyTemplate.proto */
-static __Pyx_memviewslice
-__pyx_memoryview_copy_new_contig(const __Pyx_memviewslice *from_mvs,
- const char *mode, int ndim,
- size_t sizeof_dtype, int contig_flag,
- int dtype_is_object);
-
-/* CIntToPy.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyInt_From_int(int value);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE int __Pyx_PyInt_As_int(PyObject *);
-
-/* CIntToPy.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyInt_From_long(long value);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE long __Pyx_PyInt_As_long(PyObject *);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE char __Pyx_PyInt_As_char(PyObject *);
-
-/* CheckBinaryVersion.proto */
-static int __Pyx_check_binary_version(void);
-
-/* InitStrings.proto */
-static int __Pyx_InitStrings(__Pyx_StringTabEntry *t);
-
-static PyObject *__pyx_array_get_memview(struct __pyx_array_obj *__pyx_v_self); /* proto*/
-static char *__pyx_memoryview_get_item_pointer(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index); /* proto*/
-static PyObject *__pyx_memoryview_is_slice(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj); /* proto*/
-static PyObject *__pyx_memoryview_setitem_slice_assignment(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_dst, PyObject *__pyx_v_src); /* proto*/
-static PyObject *__pyx_memoryview_setitem_slice_assign_scalar(struct __pyx_memoryview_obj *__pyx_v_self, struct __pyx_memoryview_obj *__pyx_v_dst, PyObject *__pyx_v_value); /* proto*/
-static PyObject *__pyx_memoryview_setitem_indexed(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value); /* proto*/
-static PyObject *__pyx_memoryview_convert_item_to_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp); /* proto*/
-static PyObject *__pyx_memoryview_assign_item_from_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value); /* proto*/
-static PyObject *__pyx_memoryviewslice_convert_item_to_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp); /* proto*/
-static PyObject *__pyx_memoryviewslice_assign_item_from_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value); /* proto*/
-
-/* Module declarations from 'cython.view' */
-
-/* Module declarations from 'cython' */
-
-/* Module declarations from 'monotonic_align.core' */
-static PyTypeObject *__pyx_array_type = 0;
-static PyTypeObject *__pyx_MemviewEnum_type = 0;
-static PyTypeObject *__pyx_memoryview_type = 0;
-static PyTypeObject *__pyx_memoryviewslice_type = 0;
-static PyObject *generic = 0;
-static PyObject *strided = 0;
-static PyObject *indirect = 0;
-static PyObject *contiguous = 0;
-static PyObject *indirect_contiguous = 0;
-static int __pyx_memoryview_thread_locks_used;
-static PyThread_type_lock __pyx_memoryview_thread_locks[8];
-static void __pyx_f_15monotonic_align_4core_maximum_path_each(__Pyx_memviewslice, __Pyx_memviewslice, int, int, struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each *__pyx_optional_args); /*proto*/
-static void __pyx_f_15monotonic_align_4core_maximum_path_c(__Pyx_memviewslice, __Pyx_memviewslice, __Pyx_memviewslice, __Pyx_memviewslice, int __pyx_skip_dispatch); /*proto*/
-static struct __pyx_array_obj *__pyx_array_new(PyObject *, Py_ssize_t, char *, char *, char *); /*proto*/
-static void *__pyx_align_pointer(void *, size_t); /*proto*/
-static PyObject *__pyx_memoryview_new(PyObject *, int, int, __Pyx_TypeInfo *); /*proto*/
-static CYTHON_INLINE int __pyx_memoryview_check(PyObject *); /*proto*/
-static PyObject *_unellipsify(PyObject *, int); /*proto*/
-static PyObject *assert_direct_dimensions(Py_ssize_t *, int); /*proto*/
-static struct __pyx_memoryview_obj *__pyx_memview_slice(struct __pyx_memoryview_obj *, PyObject *); /*proto*/
-static int __pyx_memoryview_slice_memviewslice(__Pyx_memviewslice *, Py_ssize_t, Py_ssize_t, Py_ssize_t, int, int, int *, Py_ssize_t, Py_ssize_t, Py_ssize_t, int, int, int, int); /*proto*/
-static char *__pyx_pybuffer_index(Py_buffer *, char *, Py_ssize_t, Py_ssize_t); /*proto*/
-static int __pyx_memslice_transpose(__Pyx_memviewslice *); /*proto*/
-static PyObject *__pyx_memoryview_fromslice(__Pyx_memviewslice, int, PyObject *(*)(char *), int (*)(char *, PyObject *), int); /*proto*/
-static __Pyx_memviewslice *__pyx_memoryview_get_slice_from_memoryview(struct __pyx_memoryview_obj *, __Pyx_memviewslice *); /*proto*/
-static void __pyx_memoryview_slice_copy(struct __pyx_memoryview_obj *, __Pyx_memviewslice *); /*proto*/
-static PyObject *__pyx_memoryview_copy_object(struct __pyx_memoryview_obj *); /*proto*/
-static PyObject *__pyx_memoryview_copy_object_from_slice(struct __pyx_memoryview_obj *, __Pyx_memviewslice *); /*proto*/
-static Py_ssize_t abs_py_ssize_t(Py_ssize_t); /*proto*/
-static char __pyx_get_best_slice_order(__Pyx_memviewslice *, int); /*proto*/
-static void _copy_strided_to_strided(char *, Py_ssize_t *, char *, Py_ssize_t *, Py_ssize_t *, Py_ssize_t *, int, size_t); /*proto*/
-static void copy_strided_to_strided(__Pyx_memviewslice *, __Pyx_memviewslice *, int, size_t); /*proto*/
-static Py_ssize_t __pyx_memoryview_slice_get_size(__Pyx_memviewslice *, int); /*proto*/
-static Py_ssize_t __pyx_fill_contig_strides_array(Py_ssize_t *, Py_ssize_t *, Py_ssize_t, int, char); /*proto*/
-static void *__pyx_memoryview_copy_data_to_temp(__Pyx_memviewslice *, __Pyx_memviewslice *, char, int); /*proto*/
-static int __pyx_memoryview_err_extents(int, Py_ssize_t, Py_ssize_t); /*proto*/
-static int __pyx_memoryview_err_dim(PyObject *, char *, int); /*proto*/
-static int __pyx_memoryview_err(PyObject *, char *); /*proto*/
-static int __pyx_memoryview_copy_contents(__Pyx_memviewslice, __Pyx_memviewslice, int, int, int); /*proto*/
-static void __pyx_memoryview_broadcast_leading(__Pyx_memviewslice *, int, int); /*proto*/
-static void __pyx_memoryview_refcount_copying(__Pyx_memviewslice *, int, int, int); /*proto*/
-static void __pyx_memoryview_refcount_objects_in_slice_with_gil(char *, Py_ssize_t *, Py_ssize_t *, int, int); /*proto*/
-static void __pyx_memoryview_refcount_objects_in_slice(char *, Py_ssize_t *, Py_ssize_t *, int, int); /*proto*/
-static void __pyx_memoryview_slice_assign_scalar(__Pyx_memviewslice *, int, size_t, void *, int); /*proto*/
-static void __pyx_memoryview__slice_assign_scalar(char *, Py_ssize_t *, Py_ssize_t *, int, size_t, void *); /*proto*/
-static PyObject *__pyx_unpickle_Enum__set_state(struct __pyx_MemviewEnum_obj *, PyObject *); /*proto*/
-static __Pyx_TypeInfo __Pyx_TypeInfo_int = { "int", NULL, sizeof(int), { 0 }, 0, IS_UNSIGNED(int) ? 'U' : 'I', IS_UNSIGNED(int), 0 };
-static __Pyx_TypeInfo __Pyx_TypeInfo_float = { "float", NULL, sizeof(float), { 0 }, 0, 'R', 0, 0 };
-#define __Pyx_MODULE_NAME "monotonic_align.core"
-extern int __pyx_module_is_main_monotonic_align__core;
-int __pyx_module_is_main_monotonic_align__core = 0;
-
-/* Implementation of 'monotonic_align.core' */
-static PyObject *__pyx_builtin_range;
-static PyObject *__pyx_builtin_ValueError;
-static PyObject *__pyx_builtin_MemoryError;
-static PyObject *__pyx_builtin_enumerate;
-static PyObject *__pyx_builtin_TypeError;
-static PyObject *__pyx_builtin_Ellipsis;
-static PyObject *__pyx_builtin_id;
-static PyObject *__pyx_builtin_IndexError;
-static const char __pyx_k_O[] = "O";
-static const char __pyx_k_c[] = "c";
-static const char __pyx_k_id[] = "id";
-static const char __pyx_k_new[] = "__new__";
-static const char __pyx_k_obj[] = "obj";
-static const char __pyx_k_base[] = "base";
-static const char __pyx_k_dict[] = "__dict__";
-static const char __pyx_k_main[] = "__main__";
-static const char __pyx_k_mode[] = "mode";
-static const char __pyx_k_name[] = "name";
-static const char __pyx_k_ndim[] = "ndim";
-static const char __pyx_k_pack[] = "pack";
-static const char __pyx_k_size[] = "size";
-static const char __pyx_k_step[] = "step";
-static const char __pyx_k_stop[] = "stop";
-static const char __pyx_k_t_xs[] = "t_xs";
-static const char __pyx_k_t_ys[] = "t_ys";
-static const char __pyx_k_test[] = "__test__";
-static const char __pyx_k_ASCII[] = "ASCII";
-static const char __pyx_k_class[] = "__class__";
-static const char __pyx_k_error[] = "error";
-static const char __pyx_k_flags[] = "flags";
-static const char __pyx_k_paths[] = "paths";
-static const char __pyx_k_range[] = "range";
-static const char __pyx_k_shape[] = "shape";
-static const char __pyx_k_start[] = "start";
-static const char __pyx_k_encode[] = "encode";
-static const char __pyx_k_format[] = "format";
-static const char __pyx_k_import[] = "__import__";
-static const char __pyx_k_name_2[] = "__name__";
-static const char __pyx_k_pickle[] = "pickle";
-static const char __pyx_k_reduce[] = "__reduce__";
-static const char __pyx_k_struct[] = "struct";
-static const char __pyx_k_unpack[] = "unpack";
-static const char __pyx_k_update[] = "update";
-static const char __pyx_k_values[] = "values";
-static const char __pyx_k_fortran[] = "fortran";
-static const char __pyx_k_memview[] = "memview";
-static const char __pyx_k_Ellipsis[] = "Ellipsis";
-static const char __pyx_k_getstate[] = "__getstate__";
-static const char __pyx_k_itemsize[] = "itemsize";
-static const char __pyx_k_pyx_type[] = "__pyx_type";
-static const char __pyx_k_setstate[] = "__setstate__";
-static const char __pyx_k_TypeError[] = "TypeError";
-static const char __pyx_k_enumerate[] = "enumerate";
-static const char __pyx_k_pyx_state[] = "__pyx_state";
-static const char __pyx_k_reduce_ex[] = "__reduce_ex__";
-static const char __pyx_k_IndexError[] = "IndexError";
-static const char __pyx_k_ValueError[] = "ValueError";
-static const char __pyx_k_pyx_result[] = "__pyx_result";
-static const char __pyx_k_pyx_vtable[] = "__pyx_vtable__";
-static const char __pyx_k_MemoryError[] = "MemoryError";
-static const char __pyx_k_PickleError[] = "PickleError";
-static const char __pyx_k_pyx_checksum[] = "__pyx_checksum";
-static const char __pyx_k_stringsource[] = "stringsource";
-static const char __pyx_k_pyx_getbuffer[] = "__pyx_getbuffer";
-static const char __pyx_k_reduce_cython[] = "__reduce_cython__";
-static const char __pyx_k_View_MemoryView[] = "View.MemoryView";
-static const char __pyx_k_allocate_buffer[] = "allocate_buffer";
-static const char __pyx_k_dtype_is_object[] = "dtype_is_object";
-static const char __pyx_k_pyx_PickleError[] = "__pyx_PickleError";
-static const char __pyx_k_setstate_cython[] = "__setstate_cython__";
-static const char __pyx_k_pyx_unpickle_Enum[] = "__pyx_unpickle_Enum";
-static const char __pyx_k_cline_in_traceback[] = "cline_in_traceback";
-static const char __pyx_k_strided_and_direct[] = "";
-static const char __pyx_k_strided_and_indirect[] = "";
-static const char __pyx_k_contiguous_and_direct[] = "";
-static const char __pyx_k_MemoryView_of_r_object[] = "";
-static const char __pyx_k_MemoryView_of_r_at_0x_x[] = "";
-static const char __pyx_k_contiguous_and_indirect[] = "";
-static const char __pyx_k_Cannot_index_with_type_s[] = "Cannot index with type '%s'";
-static const char __pyx_k_Invalid_shape_in_axis_d_d[] = "Invalid shape in axis %d: %d.";
-static const char __pyx_k_itemsize_0_for_cython_array[] = "itemsize <= 0 for cython.array";
-static const char __pyx_k_unable_to_allocate_array_data[] = "unable to allocate array data.";
-static const char __pyx_k_strided_and_direct_or_indirect[] = "";
-static const char __pyx_k_Buffer_view_does_not_expose_stri[] = "Buffer view does not expose strides";
-static const char __pyx_k_Can_only_create_a_buffer_that_is[] = "Can only create a buffer that is contiguous in memory.";
-static const char __pyx_k_Cannot_assign_to_read_only_memor[] = "Cannot assign to read-only memoryview";
-static const char __pyx_k_Cannot_create_writable_memory_vi[] = "Cannot create writable memory view from read-only memoryview";
-static const char __pyx_k_Empty_shape_tuple_for_cython_arr[] = "Empty shape tuple for cython.array";
-static const char __pyx_k_Incompatible_checksums_0x_x_vs_0[] = "Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))";
-static const char __pyx_k_Indirect_dimensions_not_supporte[] = "Indirect dimensions not supported";
-static const char __pyx_k_Invalid_mode_expected_c_or_fortr[] = "Invalid mode, expected 'c' or 'fortran', got %s";
-static const char __pyx_k_Out_of_bounds_on_buffer_access_a[] = "Out of bounds on buffer access (axis %d)";
-static const char __pyx_k_Unable_to_convert_item_to_object[] = "Unable to convert item to object";
-static const char __pyx_k_got_differing_extents_in_dimensi[] = "got differing extents in dimension %d (got %d and %d)";
-static const char __pyx_k_no_default___reduce___due_to_non[] = "no default __reduce__ due to non-trivial __cinit__";
-static const char __pyx_k_unable_to_allocate_shape_and_str[] = "unable to allocate shape and strides.";
-static PyObject *__pyx_n_s_ASCII;
-static PyObject *__pyx_kp_s_Buffer_view_does_not_expose_stri;
-static PyObject *__pyx_kp_s_Can_only_create_a_buffer_that_is;
-static PyObject *__pyx_kp_s_Cannot_assign_to_read_only_memor;
-static PyObject *__pyx_kp_s_Cannot_create_writable_memory_vi;
-static PyObject *__pyx_kp_s_Cannot_index_with_type_s;
-static PyObject *__pyx_n_s_Ellipsis;
-static PyObject *__pyx_kp_s_Empty_shape_tuple_for_cython_arr;
-static PyObject *__pyx_kp_s_Incompatible_checksums_0x_x_vs_0;
-static PyObject *__pyx_n_s_IndexError;
-static PyObject *__pyx_kp_s_Indirect_dimensions_not_supporte;
-static PyObject *__pyx_kp_s_Invalid_mode_expected_c_or_fortr;
-static PyObject *__pyx_kp_s_Invalid_shape_in_axis_d_d;
-static PyObject *__pyx_n_s_MemoryError;
-static PyObject *__pyx_kp_s_MemoryView_of_r_at_0x_x;
-static PyObject *__pyx_kp_s_MemoryView_of_r_object;
-static PyObject *__pyx_n_b_O;
-static PyObject *__pyx_kp_s_Out_of_bounds_on_buffer_access_a;
-static PyObject *__pyx_n_s_PickleError;
-static PyObject *__pyx_n_s_TypeError;
-static PyObject *__pyx_kp_s_Unable_to_convert_item_to_object;
-static PyObject *__pyx_n_s_ValueError;
-static PyObject *__pyx_n_s_View_MemoryView;
-static PyObject *__pyx_n_s_allocate_buffer;
-static PyObject *__pyx_n_s_base;
-static PyObject *__pyx_n_s_c;
-static PyObject *__pyx_n_u_c;
-static PyObject *__pyx_n_s_class;
-static PyObject *__pyx_n_s_cline_in_traceback;
-static PyObject *__pyx_kp_s_contiguous_and_direct;
-static PyObject *__pyx_kp_s_contiguous_and_indirect;
-static PyObject *__pyx_n_s_dict;
-static PyObject *__pyx_n_s_dtype_is_object;
-static PyObject *__pyx_n_s_encode;
-static PyObject *__pyx_n_s_enumerate;
-static PyObject *__pyx_n_s_error;
-static PyObject *__pyx_n_s_flags;
-static PyObject *__pyx_n_s_format;
-static PyObject *__pyx_n_s_fortran;
-static PyObject *__pyx_n_u_fortran;
-static PyObject *__pyx_n_s_getstate;
-static PyObject *__pyx_kp_s_got_differing_extents_in_dimensi;
-static PyObject *__pyx_n_s_id;
-static PyObject *__pyx_n_s_import;
-static PyObject *__pyx_n_s_itemsize;
-static PyObject *__pyx_kp_s_itemsize_0_for_cython_array;
-static PyObject *__pyx_n_s_main;
-static PyObject *__pyx_n_s_memview;
-static PyObject *__pyx_n_s_mode;
-static PyObject *__pyx_n_s_name;
-static PyObject *__pyx_n_s_name_2;
-static PyObject *__pyx_n_s_ndim;
-static PyObject *__pyx_n_s_new;
-static PyObject *__pyx_kp_s_no_default___reduce___due_to_non;
-static PyObject *__pyx_n_s_obj;
-static PyObject *__pyx_n_s_pack;
-static PyObject *__pyx_n_s_paths;
-static PyObject *__pyx_n_s_pickle;
-static PyObject *__pyx_n_s_pyx_PickleError;
-static PyObject *__pyx_n_s_pyx_checksum;
-static PyObject *__pyx_n_s_pyx_getbuffer;
-static PyObject *__pyx_n_s_pyx_result;
-static PyObject *__pyx_n_s_pyx_state;
-static PyObject *__pyx_n_s_pyx_type;
-static PyObject *__pyx_n_s_pyx_unpickle_Enum;
-static PyObject *__pyx_n_s_pyx_vtable;
-static PyObject *__pyx_n_s_range;
-static PyObject *__pyx_n_s_reduce;
-static PyObject *__pyx_n_s_reduce_cython;
-static PyObject *__pyx_n_s_reduce_ex;
-static PyObject *__pyx_n_s_setstate;
-static PyObject *__pyx_n_s_setstate_cython;
-static PyObject *__pyx_n_s_shape;
-static PyObject *__pyx_n_s_size;
-static PyObject *__pyx_n_s_start;
-static PyObject *__pyx_n_s_step;
-static PyObject *__pyx_n_s_stop;
-static PyObject *__pyx_kp_s_strided_and_direct;
-static PyObject *__pyx_kp_s_strided_and_direct_or_indirect;
-static PyObject *__pyx_kp_s_strided_and_indirect;
-static PyObject *__pyx_kp_s_stringsource;
-static PyObject *__pyx_n_s_struct;
-static PyObject *__pyx_n_s_t_xs;
-static PyObject *__pyx_n_s_t_ys;
-static PyObject *__pyx_n_s_test;
-static PyObject *__pyx_kp_s_unable_to_allocate_array_data;
-static PyObject *__pyx_kp_s_unable_to_allocate_shape_and_str;
-static PyObject *__pyx_n_s_unpack;
-static PyObject *__pyx_n_s_update;
-static PyObject *__pyx_n_s_values;
-static PyObject *__pyx_pf_15monotonic_align_4core_maximum_path_c(CYTHON_UNUSED PyObject *__pyx_self, __Pyx_memviewslice __pyx_v_paths, __Pyx_memviewslice __pyx_v_values, __Pyx_memviewslice __pyx_v_t_ys, __Pyx_memviewslice __pyx_v_t_xs); /* proto */
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array___cinit__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_shape, Py_ssize_t __pyx_v_itemsize, PyObject *__pyx_v_format, PyObject *__pyx_v_mode, int __pyx_v_allocate_buffer); /* proto */
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_2__getbuffer__(struct __pyx_array_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /* proto */
-static void __pyx_array___pyx_pf_15View_dot_MemoryView_5array_4__dealloc__(struct __pyx_array_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_5array_7memview___get__(struct __pyx_array_obj *__pyx_v_self); /* proto */
-static Py_ssize_t __pyx_array___pyx_pf_15View_dot_MemoryView_5array_6__len__(struct __pyx_array_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_8__getattr__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_attr); /* proto */
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_10__getitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item); /* proto */
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_12__setitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value); /* proto */
-static PyObject *__pyx_pf___pyx_array___reduce_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_array_2__setstate_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state); /* proto */
-static int __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum___init__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v_name); /* proto */
-static PyObject *__pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum_2__repr__(struct __pyx_MemviewEnum_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_MemviewEnum___reduce_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_MemviewEnum_2__setstate_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v___pyx_state); /* proto */
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview___cinit__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj, int __pyx_v_flags, int __pyx_v_dtype_is_object); /* proto */
-static void __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_2__dealloc__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_4__getitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index); /* proto */
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_6__setitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value); /* proto */
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_8__getbuffer__(struct __pyx_memoryview_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_1T___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4base___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_5shape___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_7strides___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_10suboffsets___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4ndim___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_8itemsize___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_6nbytes___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4size___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static Py_ssize_t __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_10__len__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_12__repr__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_14__str__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_16is_c_contig(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_18is_f_contig(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_20copy(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_22copy_fortran(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryview___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryview_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state); /* proto */
-static void __pyx_memoryviewslice___pyx_pf_15View_dot_MemoryView_16_memoryviewslice___dealloc__(struct __pyx_memoryviewslice_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_16_memoryviewslice_4base___get__(struct __pyx_memoryviewslice_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryviewslice___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryviewslice_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView___pyx_unpickle_Enum(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v___pyx_type, long __pyx_v___pyx_checksum, PyObject *__pyx_v___pyx_state); /* proto */
-static PyObject *__pyx_tp_new_array(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_tp_new_Enum(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_tp_new_memoryview(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_tp_new__memoryviewslice(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_int_0;
-static PyObject *__pyx_int_1;
-static PyObject *__pyx_int_112105877;
-static PyObject *__pyx_int_136983863;
-static PyObject *__pyx_int_184977713;
-static PyObject *__pyx_int_neg_1;
-static float __pyx_k_;
-static PyObject *__pyx_tuple__2;
-static PyObject *__pyx_tuple__3;
-static PyObject *__pyx_tuple__4;
-static PyObject *__pyx_tuple__5;
-static PyObject *__pyx_tuple__6;
-static PyObject *__pyx_tuple__7;
-static PyObject *__pyx_tuple__8;
-static PyObject *__pyx_tuple__9;
-static PyObject *__pyx_slice__16;
-static PyObject *__pyx_tuple__10;
-static PyObject *__pyx_tuple__11;
-static PyObject *__pyx_tuple__12;
-static PyObject *__pyx_tuple__13;
-static PyObject *__pyx_tuple__14;
-static PyObject *__pyx_tuple__15;
-static PyObject *__pyx_tuple__17;
-static PyObject *__pyx_tuple__18;
-static PyObject *__pyx_tuple__19;
-static PyObject *__pyx_tuple__20;
-static PyObject *__pyx_tuple__21;
-static PyObject *__pyx_tuple__22;
-static PyObject *__pyx_tuple__23;
-static PyObject *__pyx_tuple__24;
-static PyObject *__pyx_tuple__25;
-static PyObject *__pyx_tuple__26;
-static PyObject *__pyx_codeobj__27;
-/* Late includes */
-
-/* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
-
-static void __pyx_f_15monotonic_align_4core_maximum_path_each(__Pyx_memviewslice __pyx_v_path, __Pyx_memviewslice __pyx_v_value, int __pyx_v_t_y, int __pyx_v_t_x, struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each *__pyx_optional_args) {
- float __pyx_v_max_neg_val = __pyx_k_;
- int __pyx_v_x;
- int __pyx_v_y;
- float __pyx_v_v_prev;
- float __pyx_v_v_cur;
- int __pyx_v_index;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- long __pyx_t_4;
- int __pyx_t_5;
- long __pyx_t_6;
- long __pyx_t_7;
- int __pyx_t_8;
- Py_ssize_t __pyx_t_9;
- Py_ssize_t __pyx_t_10;
- float __pyx_t_11;
- float __pyx_t_12;
- float __pyx_t_13;
- int __pyx_t_14;
- Py_ssize_t __pyx_t_15;
- Py_ssize_t __pyx_t_16;
- if (__pyx_optional_args) {
- if (__pyx_optional_args->__pyx_n > 0) {
- __pyx_v_max_neg_val = __pyx_optional_args->max_neg_val;
- }
- }
-
- /* "monotonic_align/core.pyx":13
- * cdef float v_cur
- * cdef float tmp
- * cdef int index = t_x - 1 # <<<<<<<<<<<<<<
- *
- * for y in range(t_y):
- */
- __pyx_v_index = (__pyx_v_t_x - 1);
-
- /* "monotonic_align/core.pyx":15
- * cdef int index = t_x - 1
- *
- * for y in range(t_y): # <<<<<<<<<<<<<<
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y:
- */
- __pyx_t_1 = __pyx_v_t_y;
- __pyx_t_2 = __pyx_t_1;
- for (__pyx_t_3 = 0; __pyx_t_3 < __pyx_t_2; __pyx_t_3+=1) {
- __pyx_v_y = __pyx_t_3;
-
- /* "monotonic_align/core.pyx":16
- *
- * for y in range(t_y):
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)): # <<<<<<<<<<<<<<
- * if x == y:
- * v_cur = max_neg_val
- */
- __pyx_t_4 = (__pyx_v_y + 1);
- __pyx_t_5 = __pyx_v_t_x;
- if (((__pyx_t_4 < __pyx_t_5) != 0)) {
- __pyx_t_6 = __pyx_t_4;
- } else {
- __pyx_t_6 = __pyx_t_5;
- }
- __pyx_t_4 = __pyx_t_6;
- __pyx_t_5 = ((__pyx_v_t_x + __pyx_v_y) - __pyx_v_t_y);
- __pyx_t_6 = 0;
- if (((__pyx_t_5 > __pyx_t_6) != 0)) {
- __pyx_t_7 = __pyx_t_5;
- } else {
- __pyx_t_7 = __pyx_t_6;
- }
- __pyx_t_6 = __pyx_t_4;
- for (__pyx_t_5 = __pyx_t_7; __pyx_t_5 < __pyx_t_6; __pyx_t_5+=1) {
- __pyx_v_x = __pyx_t_5;
-
- /* "monotonic_align/core.pyx":17
- * for y in range(t_y):
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y: # <<<<<<<<<<<<<<
- * v_cur = max_neg_val
- * else:
- */
- __pyx_t_8 = ((__pyx_v_x == __pyx_v_y) != 0);
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":18
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y:
- * v_cur = max_neg_val # <<<<<<<<<<<<<<
- * else:
- * v_cur = value[y-1, x]
- */
- __pyx_v_v_cur = __pyx_v_max_neg_val;
-
- /* "monotonic_align/core.pyx":17
- * for y in range(t_y):
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y: # <<<<<<<<<<<<<<
- * v_cur = max_neg_val
- * else:
- */
- goto __pyx_L7;
- }
-
- /* "monotonic_align/core.pyx":20
- * v_cur = max_neg_val
- * else:
- * v_cur = value[y-1, x] # <<<<<<<<<<<<<<
- * if x == 0:
- * if y == 0:
- */
- /*else*/ {
- __pyx_t_9 = (__pyx_v_y - 1);
- __pyx_t_10 = __pyx_v_x;
- __pyx_v_v_cur = (*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_9 * __pyx_v_value.strides[0]) )) + __pyx_t_10)) )));
- }
- __pyx_L7:;
-
- /* "monotonic_align/core.pyx":21
- * else:
- * v_cur = value[y-1, x]
- * if x == 0: # <<<<<<<<<<<<<<
- * if y == 0:
- * v_prev = 0.
- */
- __pyx_t_8 = ((__pyx_v_x == 0) != 0);
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":22
- * v_cur = value[y-1, x]
- * if x == 0:
- * if y == 0: # <<<<<<<<<<<<<<
- * v_prev = 0.
- * else:
- */
- __pyx_t_8 = ((__pyx_v_y == 0) != 0);
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":23
- * if x == 0:
- * if y == 0:
- * v_prev = 0. # <<<<<<<<<<<<<<
- * else:
- * v_prev = max_neg_val
- */
- __pyx_v_v_prev = 0.;
-
- /* "monotonic_align/core.pyx":22
- * v_cur = value[y-1, x]
- * if x == 0:
- * if y == 0: # <<<<<<<<<<<<<<
- * v_prev = 0.
- * else:
- */
- goto __pyx_L9;
- }
-
- /* "monotonic_align/core.pyx":25
- * v_prev = 0.
- * else:
- * v_prev = max_neg_val # <<<<<<<<<<<<<<
- * else:
- * v_prev = value[y-1, x-1]
- */
- /*else*/ {
- __pyx_v_v_prev = __pyx_v_max_neg_val;
- }
- __pyx_L9:;
-
- /* "monotonic_align/core.pyx":21
- * else:
- * v_cur = value[y-1, x]
- * if x == 0: # <<<<<<<<<<<<<<
- * if y == 0:
- * v_prev = 0.
- */
- goto __pyx_L8;
- }
-
- /* "monotonic_align/core.pyx":27
- * v_prev = max_neg_val
- * else:
- * v_prev = value[y-1, x-1] # <<<<<<<<<<<<<<
- * value[y, x] += max(v_prev, v_cur)
- *
- */
- /*else*/ {
- __pyx_t_10 = (__pyx_v_y - 1);
- __pyx_t_9 = (__pyx_v_x - 1);
- __pyx_v_v_prev = (*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_10 * __pyx_v_value.strides[0]) )) + __pyx_t_9)) )));
- }
- __pyx_L8:;
-
- /* "monotonic_align/core.pyx":28
- * else:
- * v_prev = value[y-1, x-1]
- * value[y, x] += max(v_prev, v_cur) # <<<<<<<<<<<<<<
- *
- * for y in range(t_y - 1, -1, -1):
- */
- __pyx_t_11 = __pyx_v_v_cur;
- __pyx_t_12 = __pyx_v_v_prev;
- if (((__pyx_t_11 > __pyx_t_12) != 0)) {
- __pyx_t_13 = __pyx_t_11;
- } else {
- __pyx_t_13 = __pyx_t_12;
- }
- __pyx_t_9 = __pyx_v_y;
- __pyx_t_10 = __pyx_v_x;
- *((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_9 * __pyx_v_value.strides[0]) )) + __pyx_t_10)) )) += __pyx_t_13;
- }
- }
-
- /* "monotonic_align/core.pyx":30
- * value[y, x] += max(v_prev, v_cur)
- *
- * for y in range(t_y - 1, -1, -1): # <<<<<<<<<<<<<<
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
- */
- for (__pyx_t_1 = (__pyx_v_t_y - 1); __pyx_t_1 > -1; __pyx_t_1-=1) {
- __pyx_v_y = __pyx_t_1;
-
- /* "monotonic_align/core.pyx":31
- *
- * for y in range(t_y - 1, -1, -1):
- * path[y, index] = 1 # <<<<<<<<<<<<<<
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
- * index = index - 1
- */
- __pyx_t_10 = __pyx_v_y;
- __pyx_t_9 = __pyx_v_index;
- *((int *) ( /* dim=1 */ ((char *) (((int *) ( /* dim=0 */ (__pyx_v_path.data + __pyx_t_10 * __pyx_v_path.strides[0]) )) + __pyx_t_9)) )) = 1;
-
- /* "monotonic_align/core.pyx":32
- * for y in range(t_y - 1, -1, -1):
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]): # <<<<<<<<<<<<<<
- * index = index - 1
- *
- */
- __pyx_t_14 = ((__pyx_v_index != 0) != 0);
- if (__pyx_t_14) {
- } else {
- __pyx_t_8 = __pyx_t_14;
- goto __pyx_L13_bool_binop_done;
- }
- __pyx_t_14 = ((__pyx_v_index == __pyx_v_y) != 0);
- if (!__pyx_t_14) {
- } else {
- __pyx_t_8 = __pyx_t_14;
- goto __pyx_L13_bool_binop_done;
- }
- __pyx_t_9 = (__pyx_v_y - 1);
- __pyx_t_10 = __pyx_v_index;
- __pyx_t_15 = (__pyx_v_y - 1);
- __pyx_t_16 = (__pyx_v_index - 1);
- __pyx_t_14 = (((*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_9 * __pyx_v_value.strides[0]) )) + __pyx_t_10)) ))) < (*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_15 * __pyx_v_value.strides[0]) )) + __pyx_t_16)) )))) != 0);
- __pyx_t_8 = __pyx_t_14;
- __pyx_L13_bool_binop_done:;
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":33
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
- * index = index - 1 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_index = (__pyx_v_index - 1);
-
- /* "monotonic_align/core.pyx":32
- * for y in range(t_y - 1, -1, -1):
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]): # <<<<<<<<<<<<<<
- * index = index - 1
- *
- */
- }
- }
-
- /* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
-
- /* function exit code */
-}
-
-/* "monotonic_align/core.pyx":38
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil: # <<<<<<<<<<<<<<
- * cdef int b = paths.shape[0]
- * cdef int i
- */
-
-static PyObject *__pyx_pw_15monotonic_align_4core_1maximum_path_c(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static void __pyx_f_15monotonic_align_4core_maximum_path_c(__Pyx_memviewslice __pyx_v_paths, __Pyx_memviewslice __pyx_v_values, __Pyx_memviewslice __pyx_v_t_ys, __Pyx_memviewslice __pyx_v_t_xs, CYTHON_UNUSED int __pyx_skip_dispatch) {
- CYTHON_UNUSED int __pyx_v_b;
- int __pyx_v_i;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- __Pyx_memviewslice __pyx_t_4 = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_t_5 = { 0, 0, { 0 }, { 0 }, { 0 } };
- Py_ssize_t __pyx_t_6;
- Py_ssize_t __pyx_t_7;
-
- /* "monotonic_align/core.pyx":39
- * @cython.wraparound(False)
- * cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil:
- * cdef int b = paths.shape[0] # <<<<<<<<<<<<<<
- * cdef int i
- * for i in prange(b, nogil=True):
- */
- __pyx_v_b = (__pyx_v_paths.shape[0]);
-
- /* "monotonic_align/core.pyx":41
- * cdef int b = paths.shape[0]
- * cdef int i
- * for i in prange(b, nogil=True): # <<<<<<<<<<<<<<
- * maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
- */
- {
- #ifdef WITH_THREAD
- PyThreadState *_save;
- Py_UNBLOCK_THREADS
- __Pyx_FastGIL_Remember();
- #endif
- /*try:*/ {
- __pyx_t_1 = __pyx_v_b;
- if ((1 == 0)) abort();
- {
- #if ((defined(__APPLE__) || defined(__OSX__)) && (defined(__GNUC__) && (__GNUC__ > 2 || (__GNUC__ == 2 && (__GNUC_MINOR__ > 95)))))
- #undef likely
- #undef unlikely
- #define likely(x) (x)
- #define unlikely(x) (x)
- #endif
- __pyx_t_3 = (__pyx_t_1 - 0 + 1 - 1/abs(1)) / 1;
- if (__pyx_t_3 > 0)
- {
- #ifdef _OPENMP
- #pragma omp parallel private(__pyx_t_6, __pyx_t_7) firstprivate(__pyx_t_4, __pyx_t_5)
- #endif /* _OPENMP */
- {
- #ifdef _OPENMP
- #pragma omp for firstprivate(__pyx_v_i) lastprivate(__pyx_v_i)
- #endif /* _OPENMP */
- for (__pyx_t_2 = 0; __pyx_t_2 < __pyx_t_3; __pyx_t_2++){
- {
- __pyx_v_i = (int)(0 + 1 * __pyx_t_2);
-
- /* "monotonic_align/core.pyx":42
- * cdef int i
- * for i in prange(b, nogil=True):
- * maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i]) # <<<<<<<<<<<<<<
- */
- __pyx_t_4.data = __pyx_v_paths.data;
- __pyx_t_4.memview = __pyx_v_paths.memview;
- __PYX_INC_MEMVIEW(&__pyx_t_4, 0);
- {
- Py_ssize_t __pyx_tmp_idx = __pyx_v_i;
- Py_ssize_t __pyx_tmp_stride = __pyx_v_paths.strides[0];
- __pyx_t_4.data += __pyx_tmp_idx * __pyx_tmp_stride;
-}
-
-__pyx_t_4.shape[0] = __pyx_v_paths.shape[1];
-__pyx_t_4.strides[0] = __pyx_v_paths.strides[1];
- __pyx_t_4.suboffsets[0] = -1;
-
-__pyx_t_4.shape[1] = __pyx_v_paths.shape[2];
-__pyx_t_4.strides[1] = __pyx_v_paths.strides[2];
- __pyx_t_4.suboffsets[1] = -1;
-
-__pyx_t_5.data = __pyx_v_values.data;
- __pyx_t_5.memview = __pyx_v_values.memview;
- __PYX_INC_MEMVIEW(&__pyx_t_5, 0);
- {
- Py_ssize_t __pyx_tmp_idx = __pyx_v_i;
- Py_ssize_t __pyx_tmp_stride = __pyx_v_values.strides[0];
- __pyx_t_5.data += __pyx_tmp_idx * __pyx_tmp_stride;
-}
-
-__pyx_t_5.shape[0] = __pyx_v_values.shape[1];
-__pyx_t_5.strides[0] = __pyx_v_values.strides[1];
- __pyx_t_5.suboffsets[0] = -1;
-
-__pyx_t_5.shape[1] = __pyx_v_values.shape[2];
-__pyx_t_5.strides[1] = __pyx_v_values.strides[2];
- __pyx_t_5.suboffsets[1] = -1;
-
-__pyx_t_6 = __pyx_v_i;
- __pyx_t_7 = __pyx_v_i;
- __pyx_f_15monotonic_align_4core_maximum_path_each(__pyx_t_4, __pyx_t_5, (*((int *) ( /* dim=0 */ ((char *) (((int *) __pyx_v_t_ys.data) + __pyx_t_6)) ))), (*((int *) ( /* dim=0 */ ((char *) (((int *) __pyx_v_t_xs.data) + __pyx_t_7)) ))), NULL);
- __PYX_XDEC_MEMVIEW(&__pyx_t_4, 0);
- __pyx_t_4.memview = NULL;
- __pyx_t_4.data = NULL;
- __PYX_XDEC_MEMVIEW(&__pyx_t_5, 0);
- __pyx_t_5.memview = NULL;
- __pyx_t_5.data = NULL;
- }
- }
- }
- }
- }
- #if ((defined(__APPLE__) || defined(__OSX__)) && (defined(__GNUC__) && (__GNUC__ > 2 || (__GNUC__ == 2 && (__GNUC_MINOR__ > 95)))))
- #undef likely
- #undef unlikely
- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
- #endif
- }
-
- /* "monotonic_align/core.pyx":41
- * cdef int b = paths.shape[0]
- * cdef int i
- * for i in prange(b, nogil=True): # <<<<<<<<<<<<<<
- * maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
- */
- /*finally:*/ {
- /*normal exit:*/{
- #ifdef WITH_THREAD
- __Pyx_FastGIL_Forget();
- Py_BLOCK_THREADS
- #endif
- goto __pyx_L5;
- }
- __pyx_L5:;
- }
- }
-
- /* "monotonic_align/core.pyx":38
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil: # <<<<<<<<<<<<<<
- * cdef int b = paths.shape[0]
- * cdef int i
- */
-
- /* function exit code */
-}
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15monotonic_align_4core_1maximum_path_c(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static PyObject *__pyx_pw_15monotonic_align_4core_1maximum_path_c(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- __Pyx_memviewslice __pyx_v_paths = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_v_values = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_v_t_ys = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_v_t_xs = { 0, 0, { 0 }, { 0 }, { 0 } };
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("maximum_path_c (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_paths,&__pyx_n_s_values,&__pyx_n_s_t_ys,&__pyx_n_s_t_xs,0};
- PyObject* values[4] = {0,0,0,0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 4: values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- CYTHON_FALLTHROUGH;
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_paths)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_values)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, 1); __PYX_ERR(0, 38, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_t_ys)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, 2); __PYX_ERR(0, 38, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 3:
- if (likely((values[3] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_t_xs)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, 3); __PYX_ERR(0, 38, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "maximum_path_c") < 0)) __PYX_ERR(0, 38, __pyx_L3_error)
- }
- } else if (PyTuple_GET_SIZE(__pyx_args) != 4) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- }
- __pyx_v_paths = __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_int(values[0], PyBUF_WRITABLE); if (unlikely(!__pyx_v_paths.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_v_values = __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_float(values[1], PyBUF_WRITABLE); if (unlikely(!__pyx_v_values.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_v_t_ys = __Pyx_PyObject_to_MemoryviewSlice_dc_int(values[2], PyBUF_WRITABLE); if (unlikely(!__pyx_v_t_ys.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_v_t_xs = __Pyx_PyObject_to_MemoryviewSlice_dc_int(values[3], PyBUF_WRITABLE); if (unlikely(!__pyx_v_t_xs.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("monotonic_align.core.maximum_path_c", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_15monotonic_align_4core_maximum_path_c(__pyx_self, __pyx_v_paths, __pyx_v_values, __pyx_v_t_ys, __pyx_v_t_xs);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15monotonic_align_4core_maximum_path_c(CYTHON_UNUSED PyObject *__pyx_self, __Pyx_memviewslice __pyx_v_paths, __Pyx_memviewslice __pyx_v_values, __Pyx_memviewslice __pyx_v_t_ys, __Pyx_memviewslice __pyx_v_t_xs) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("maximum_path_c", 0);
- __Pyx_XDECREF(__pyx_r);
- if (unlikely(!__pyx_v_paths.memview)) { __Pyx_RaiseUnboundLocalError("paths"); __PYX_ERR(0, 38, __pyx_L1_error) }
- if (unlikely(!__pyx_v_values.memview)) { __Pyx_RaiseUnboundLocalError("values"); __PYX_ERR(0, 38, __pyx_L1_error) }
- if (unlikely(!__pyx_v_t_ys.memview)) { __Pyx_RaiseUnboundLocalError("t_ys"); __PYX_ERR(0, 38, __pyx_L1_error) }
- if (unlikely(!__pyx_v_t_xs.memview)) { __Pyx_RaiseUnboundLocalError("t_xs"); __PYX_ERR(0, 38, __pyx_L1_error) }
- __pyx_t_1 = __Pyx_void_to_None(__pyx_f_15monotonic_align_4core_maximum_path_c(__pyx_v_paths, __pyx_v_values, __pyx_v_t_ys, __pyx_v_t_xs, 0)); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 38, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("monotonic_align.core.maximum_path_c", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __PYX_XDEC_MEMVIEW(&__pyx_v_paths, 1);
- __PYX_XDEC_MEMVIEW(&__pyx_v_values, 1);
- __PYX_XDEC_MEMVIEW(&__pyx_v_t_ys, 1);
- __PYX_XDEC_MEMVIEW(&__pyx_v_t_xs, 1);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":123
- * cdef bint dtype_is_object
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None, # <<<<<<<<<<<<<<
- * mode="c", bint allocate_buffer=True):
- *
- */
-
-/* Python wrapper */
-static int __pyx_array___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static int __pyx_array___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v_shape = 0;
- Py_ssize_t __pyx_v_itemsize;
- PyObject *__pyx_v_format = 0;
- PyObject *__pyx_v_mode = 0;
- int __pyx_v_allocate_buffer;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__cinit__ (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_shape,&__pyx_n_s_itemsize,&__pyx_n_s_format,&__pyx_n_s_mode,&__pyx_n_s_allocate_buffer,0};
- PyObject* values[5] = {0,0,0,0,0};
- values[3] = ((PyObject *)__pyx_n_s_c);
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 5: values[4] = PyTuple_GET_ITEM(__pyx_args, 4);
- CYTHON_FALLTHROUGH;
- case 4: values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- CYTHON_FALLTHROUGH;
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_shape)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_itemsize)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 3, 5, 1); __PYX_ERR(1, 123, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_format)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 3, 5, 2); __PYX_ERR(1, 123, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 3:
- if (kw_args > 0) {
- PyObject* value = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_mode);
- if (value) { values[3] = value; kw_args--; }
- }
- CYTHON_FALLTHROUGH;
- case 4:
- if (kw_args > 0) {
- PyObject* value = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_allocate_buffer);
- if (value) { values[4] = value; kw_args--; }
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__cinit__") < 0)) __PYX_ERR(1, 123, __pyx_L3_error)
- }
- } else {
- switch (PyTuple_GET_SIZE(__pyx_args)) {
- case 5: values[4] = PyTuple_GET_ITEM(__pyx_args, 4);
- CYTHON_FALLTHROUGH;
- case 4: values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- CYTHON_FALLTHROUGH;
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- break;
- default: goto __pyx_L5_argtuple_error;
- }
- }
- __pyx_v_shape = ((PyObject*)values[0]);
- __pyx_v_itemsize = __Pyx_PyIndex_AsSsize_t(values[1]); if (unlikely((__pyx_v_itemsize == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 123, __pyx_L3_error)
- __pyx_v_format = values[2];
- __pyx_v_mode = values[3];
- if (values[4]) {
- __pyx_v_allocate_buffer = __Pyx_PyObject_IsTrue(values[4]); if (unlikely((__pyx_v_allocate_buffer == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 124, __pyx_L3_error)
- } else {
-
- /* "View.MemoryView":124
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None,
- * mode="c", bint allocate_buffer=True): # <<<<<<<<<<<<<<
- *
- * cdef int idx
- */
- __pyx_v_allocate_buffer = ((int)1);
- }
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 3, 5, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 123, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.array.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return -1;
- __pyx_L4_argument_unpacking_done:;
- if (unlikely(!__Pyx_ArgTypeTest(((PyObject *)__pyx_v_shape), (&PyTuple_Type), 1, "shape", 1))) __PYX_ERR(1, 123, __pyx_L1_error)
- if (unlikely(((PyObject *)__pyx_v_format) == Py_None)) {
- PyErr_Format(PyExc_TypeError, "Argument '%.200s' must not be None", "format"); __PYX_ERR(1, 123, __pyx_L1_error)
- }
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array___cinit__(((struct __pyx_array_obj *)__pyx_v_self), __pyx_v_shape, __pyx_v_itemsize, __pyx_v_format, __pyx_v_mode, __pyx_v_allocate_buffer);
-
- /* "View.MemoryView":123
- * cdef bint dtype_is_object
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None, # <<<<<<<<<<<<<<
- * mode="c", bint allocate_buffer=True):
- *
- */
-
- /* function exit code */
- goto __pyx_L0;
- __pyx_L1_error:;
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array___cinit__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_shape, Py_ssize_t __pyx_v_itemsize, PyObject *__pyx_v_format, PyObject *__pyx_v_mode, int __pyx_v_allocate_buffer) {
- int __pyx_v_idx;
- Py_ssize_t __pyx_v_i;
- Py_ssize_t __pyx_v_dim;
- PyObject **__pyx_v_p;
- char __pyx_v_order;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- char *__pyx_t_7;
- int __pyx_t_8;
- Py_ssize_t __pyx_t_9;
- PyObject *__pyx_t_10 = NULL;
- Py_ssize_t __pyx_t_11;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__cinit__", 0);
- __Pyx_INCREF(__pyx_v_format);
-
- /* "View.MemoryView":130
- * cdef PyObject **p
- *
- * self.ndim = len(shape) # <<<<<<<<<<<<<<
- * self.itemsize = itemsize
- *
- */
- if (unlikely(__pyx_v_shape == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "object of type 'NoneType' has no len()");
- __PYX_ERR(1, 130, __pyx_L1_error)
- }
- __pyx_t_1 = PyTuple_GET_SIZE(__pyx_v_shape); if (unlikely(__pyx_t_1 == ((Py_ssize_t)-1))) __PYX_ERR(1, 130, __pyx_L1_error)
- __pyx_v_self->ndim = ((int)__pyx_t_1);
-
- /* "View.MemoryView":131
- *
- * self.ndim = len(shape)
- * self.itemsize = itemsize # <<<<<<<<<<<<<<
- *
- * if not self.ndim:
- */
- __pyx_v_self->itemsize = __pyx_v_itemsize;
-
- /* "View.MemoryView":133
- * self.itemsize = itemsize
- *
- * if not self.ndim: # <<<<<<<<<<<<<<
- * raise ValueError("Empty shape tuple for cython.array")
- *
- */
- __pyx_t_2 = ((!(__pyx_v_self->ndim != 0)) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":134
- *
- * if not self.ndim:
- * raise ValueError("Empty shape tuple for cython.array") # <<<<<<<<<<<<<<
- *
- * if itemsize <= 0:
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__2, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 134, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 134, __pyx_L1_error)
-
- /* "View.MemoryView":133
- * self.itemsize = itemsize
- *
- * if not self.ndim: # <<<<<<<<<<<<<<
- * raise ValueError("Empty shape tuple for cython.array")
- *
- */
- }
-
- /* "View.MemoryView":136
- * raise ValueError("Empty shape tuple for cython.array")
- *
- * if itemsize <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- */
- __pyx_t_2 = ((__pyx_v_itemsize <= 0) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":137
- *
- * if itemsize <= 0:
- * raise ValueError("itemsize <= 0 for cython.array") # <<<<<<<<<<<<<<
- *
- * if not isinstance(format, bytes):
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__3, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 137, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 137, __pyx_L1_error)
-
- /* "View.MemoryView":136
- * raise ValueError("Empty shape tuple for cython.array")
- *
- * if itemsize <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- */
- }
-
- /* "View.MemoryView":139
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- * if not isinstance(format, bytes): # <<<<<<<<<<<<<<
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string
- */
- __pyx_t_2 = PyBytes_Check(__pyx_v_format);
- __pyx_t_4 = ((!(__pyx_t_2 != 0)) != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":140
- *
- * if not isinstance(format, bytes):
- * format = format.encode('ASCII') # <<<<<<<<<<<<<<
- * self._format = format # keep a reference to the byte string
- * self.format = self._format
- */
- __pyx_t_5 = __Pyx_PyObject_GetAttrStr(__pyx_v_format, __pyx_n_s_encode); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 140, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_6 = NULL;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_5))) {
- __pyx_t_6 = PyMethod_GET_SELF(__pyx_t_5);
- if (likely(__pyx_t_6)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_5);
- __Pyx_INCREF(__pyx_t_6);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_5, function);
- }
- }
- __pyx_t_3 = (__pyx_t_6) ? __Pyx_PyObject_Call2Args(__pyx_t_5, __pyx_t_6, __pyx_n_s_ASCII) : __Pyx_PyObject_CallOneArg(__pyx_t_5, __pyx_n_s_ASCII);
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 140, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_DECREF_SET(__pyx_v_format, __pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":139
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- * if not isinstance(format, bytes): # <<<<<<<<<<<<<<
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string
- */
- }
-
- /* "View.MemoryView":141
- * if not isinstance(format, bytes):
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string # <<<<<<<<<<<<<<
- * self.format = self._format
- *
- */
- if (!(likely(PyBytes_CheckExact(__pyx_v_format))||((__pyx_v_format) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "bytes", Py_TYPE(__pyx_v_format)->tp_name), 0))) __PYX_ERR(1, 141, __pyx_L1_error)
- __pyx_t_3 = __pyx_v_format;
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_3);
- __Pyx_GOTREF(__pyx_v_self->_format);
- __Pyx_DECREF(__pyx_v_self->_format);
- __pyx_v_self->_format = ((PyObject*)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":142
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string
- * self.format = self._format # <<<<<<<<<<<<<<
- *
- *
- */
- if (unlikely(__pyx_v_self->_format == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "expected bytes, NoneType found");
- __PYX_ERR(1, 142, __pyx_L1_error)
- }
- __pyx_t_7 = __Pyx_PyBytes_AsWritableString(__pyx_v_self->_format); if (unlikely((!__pyx_t_7) && PyErr_Occurred())) __PYX_ERR(1, 142, __pyx_L1_error)
- __pyx_v_self->format = __pyx_t_7;
-
- /* "View.MemoryView":145
- *
- *
- * self._shape = PyObject_Malloc(sizeof(Py_ssize_t)*self.ndim*2) # <<<<<<<<<<<<<<
- * self._strides = self._shape + self.ndim
- *
- */
- __pyx_v_self->_shape = ((Py_ssize_t *)PyObject_Malloc((((sizeof(Py_ssize_t)) * __pyx_v_self->ndim) * 2)));
-
- /* "View.MemoryView":146
- *
- * self._shape = PyObject_Malloc(sizeof(Py_ssize_t)*self.ndim*2)
- * self._strides = self._shape + self.ndim # <<<<<<<<<<<<<<
- *
- * if not self._shape:
- */
- __pyx_v_self->_strides = (__pyx_v_self->_shape + __pyx_v_self->ndim);
-
- /* "View.MemoryView":148
- * self._strides = self._shape + self.ndim
- *
- * if not self._shape: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate shape and strides.")
- *
- */
- __pyx_t_4 = ((!(__pyx_v_self->_shape != 0)) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":149
- *
- * if not self._shape:
- * raise MemoryError("unable to allocate shape and strides.") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_MemoryError, __pyx_tuple__4, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 149, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 149, __pyx_L1_error)
-
- /* "View.MemoryView":148
- * self._strides = self._shape + self.ndim
- *
- * if not self._shape: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate shape and strides.")
- *
- */
- }
-
- /* "View.MemoryView":152
- *
- *
- * for idx, dim in enumerate(shape): # <<<<<<<<<<<<<<
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- */
- __pyx_t_8 = 0;
- __pyx_t_3 = __pyx_v_shape; __Pyx_INCREF(__pyx_t_3); __pyx_t_1 = 0;
- for (;;) {
- if (__pyx_t_1 >= PyTuple_GET_SIZE(__pyx_t_3)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_5 = PyTuple_GET_ITEM(__pyx_t_3, __pyx_t_1); __Pyx_INCREF(__pyx_t_5); __pyx_t_1++; if (unlikely(0 < 0)) __PYX_ERR(1, 152, __pyx_L1_error)
- #else
- __pyx_t_5 = PySequence_ITEM(__pyx_t_3, __pyx_t_1); __pyx_t_1++; if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 152, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- __pyx_t_9 = __Pyx_PyIndex_AsSsize_t(__pyx_t_5); if (unlikely((__pyx_t_9 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 152, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_v_dim = __pyx_t_9;
- __pyx_v_idx = __pyx_t_8;
- __pyx_t_8 = (__pyx_t_8 + 1);
-
- /* "View.MemoryView":153
- *
- * for idx, dim in enumerate(shape):
- * if dim <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- * self._shape[idx] = dim
- */
- __pyx_t_4 = ((__pyx_v_dim <= 0) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":154
- * for idx, dim in enumerate(shape):
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim)) # <<<<<<<<<<<<<<
- * self._shape[idx] = dim
- *
- */
- __pyx_t_5 = __Pyx_PyInt_From_int(__pyx_v_idx); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_6 = PyInt_FromSsize_t(__pyx_v_dim); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_10 = PyTuple_New(2); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_GIVEREF(__pyx_t_5);
- PyTuple_SET_ITEM(__pyx_t_10, 0, __pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_6);
- PyTuple_SET_ITEM(__pyx_t_10, 1, __pyx_t_6);
- __pyx_t_5 = 0;
- __pyx_t_6 = 0;
- __pyx_t_6 = __Pyx_PyString_Format(__pyx_kp_s_Invalid_shape_in_axis_d_d, __pyx_t_10); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __pyx_t_10 = __Pyx_PyObject_CallOneArg(__pyx_builtin_ValueError, __pyx_t_6); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_Raise(__pyx_t_10, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __PYX_ERR(1, 154, __pyx_L1_error)
-
- /* "View.MemoryView":153
- *
- * for idx, dim in enumerate(shape):
- * if dim <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- * self._shape[idx] = dim
- */
- }
-
- /* "View.MemoryView":155
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- * self._shape[idx] = dim # <<<<<<<<<<<<<<
- *
- * cdef char order
- */
- (__pyx_v_self->_shape[__pyx_v_idx]) = __pyx_v_dim;
-
- /* "View.MemoryView":152
- *
- *
- * for idx, dim in enumerate(shape): # <<<<<<<<<<<<<<
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- */
- }
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":158
- *
- * cdef char order
- * if mode == 'fortran': # <<<<<<<<<<<<<<
- * order = b'F'
- * self.mode = u'fortran'
- */
- __pyx_t_4 = (__Pyx_PyString_Equals(__pyx_v_mode, __pyx_n_s_fortran, Py_EQ)); if (unlikely(__pyx_t_4 < 0)) __PYX_ERR(1, 158, __pyx_L1_error)
- if (__pyx_t_4) {
-
- /* "View.MemoryView":159
- * cdef char order
- * if mode == 'fortran':
- * order = b'F' # <<<<<<<<<<<<<<
- * self.mode = u'fortran'
- * elif mode == 'c':
- */
- __pyx_v_order = 'F';
-
- /* "View.MemoryView":160
- * if mode == 'fortran':
- * order = b'F'
- * self.mode = u'fortran' # <<<<<<<<<<<<<<
- * elif mode == 'c':
- * order = b'C'
- */
- __Pyx_INCREF(__pyx_n_u_fortran);
- __Pyx_GIVEREF(__pyx_n_u_fortran);
- __Pyx_GOTREF(__pyx_v_self->mode);
- __Pyx_DECREF(__pyx_v_self->mode);
- __pyx_v_self->mode = __pyx_n_u_fortran;
-
- /* "View.MemoryView":158
- *
- * cdef char order
- * if mode == 'fortran': # <<<<<<<<<<<<<<
- * order = b'F'
- * self.mode = u'fortran'
- */
- goto __pyx_L10;
- }
-
- /* "View.MemoryView":161
- * order = b'F'
- * self.mode = u'fortran'
- * elif mode == 'c': # <<<<<<<<<<<<<<
- * order = b'C'
- * self.mode = u'c'
- */
- __pyx_t_4 = (__Pyx_PyString_Equals(__pyx_v_mode, __pyx_n_s_c, Py_EQ)); if (unlikely(__pyx_t_4 < 0)) __PYX_ERR(1, 161, __pyx_L1_error)
- if (likely(__pyx_t_4)) {
-
- /* "View.MemoryView":162
- * self.mode = u'fortran'
- * elif mode == 'c':
- * order = b'C' # <<<<<<<<<<<<<<
- * self.mode = u'c'
- * else:
- */
- __pyx_v_order = 'C';
-
- /* "View.MemoryView":163
- * elif mode == 'c':
- * order = b'C'
- * self.mode = u'c' # <<<<<<<<<<<<<<
- * else:
- * raise ValueError("Invalid mode, expected 'c' or 'fortran', got %s" % mode)
- */
- __Pyx_INCREF(__pyx_n_u_c);
- __Pyx_GIVEREF(__pyx_n_u_c);
- __Pyx_GOTREF(__pyx_v_self->mode);
- __Pyx_DECREF(__pyx_v_self->mode);
- __pyx_v_self->mode = __pyx_n_u_c;
-
- /* "View.MemoryView":161
- * order = b'F'
- * self.mode = u'fortran'
- * elif mode == 'c': # <<<<<<<<<<<<<<
- * order = b'C'
- * self.mode = u'c'
- */
- goto __pyx_L10;
- }
-
- /* "View.MemoryView":165
- * self.mode = u'c'
- * else:
- * raise ValueError("Invalid mode, expected 'c' or 'fortran', got %s" % mode) # <<<<<<<<<<<<<<
- *
- * self.len = fill_contig_strides_array(self._shape, self._strides,
- */
- /*else*/ {
- __pyx_t_3 = __Pyx_PyString_FormatSafe(__pyx_kp_s_Invalid_mode_expected_c_or_fortr, __pyx_v_mode); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 165, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_10 = __Pyx_PyObject_CallOneArg(__pyx_builtin_ValueError, __pyx_t_3); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 165, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_Raise(__pyx_t_10, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __PYX_ERR(1, 165, __pyx_L1_error)
- }
- __pyx_L10:;
-
- /* "View.MemoryView":167
- * raise ValueError("Invalid mode, expected 'c' or 'fortran', got %s" % mode)
- *
- * self.len = fill_contig_strides_array(self._shape, self._strides, # <<<<<<<<<<<<<<
- * itemsize, self.ndim, order)
- *
- */
- __pyx_v_self->len = __pyx_fill_contig_strides_array(__pyx_v_self->_shape, __pyx_v_self->_strides, __pyx_v_itemsize, __pyx_v_self->ndim, __pyx_v_order);
-
- /* "View.MemoryView":170
- * itemsize, self.ndim, order)
- *
- * self.free_data = allocate_buffer # <<<<<<<<<<<<<<
- * self.dtype_is_object = format == b'O'
- * if allocate_buffer:
- */
- __pyx_v_self->free_data = __pyx_v_allocate_buffer;
-
- /* "View.MemoryView":171
- *
- * self.free_data = allocate_buffer
- * self.dtype_is_object = format == b'O' # <<<<<<<<<<<<<<
- * if allocate_buffer:
- *
- */
- __pyx_t_10 = PyObject_RichCompare(__pyx_v_format, __pyx_n_b_O, Py_EQ); __Pyx_XGOTREF(__pyx_t_10); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 171, __pyx_L1_error)
- __pyx_t_4 = __Pyx_PyObject_IsTrue(__pyx_t_10); if (unlikely((__pyx_t_4 == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 171, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __pyx_v_self->dtype_is_object = __pyx_t_4;
-
- /* "View.MemoryView":172
- * self.free_data = allocate_buffer
- * self.dtype_is_object = format == b'O'
- * if allocate_buffer: # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_4 = (__pyx_v_allocate_buffer != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":175
- *
- *
- * self.data = malloc(self.len) # <<<<<<<<<<<<<<
- * if not self.data:
- * raise MemoryError("unable to allocate array data.")
- */
- __pyx_v_self->data = ((char *)malloc(__pyx_v_self->len));
-
- /* "View.MemoryView":176
- *
- * self.data = malloc(self.len)
- * if not self.data: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate array data.")
- *
- */
- __pyx_t_4 = ((!(__pyx_v_self->data != 0)) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":177
- * self.data = malloc(self.len)
- * if not self.data:
- * raise MemoryError("unable to allocate array data.") # <<<<<<<<<<<<<<
- *
- * if self.dtype_is_object:
- */
- __pyx_t_10 = __Pyx_PyObject_Call(__pyx_builtin_MemoryError, __pyx_tuple__5, NULL); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 177, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_Raise(__pyx_t_10, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __PYX_ERR(1, 177, __pyx_L1_error)
-
- /* "View.MemoryView":176
- *
- * self.data = malloc(self.len)
- * if not self.data: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate array data.")
- *
- */
- }
-
- /* "View.MemoryView":179
- * raise MemoryError("unable to allocate array data.")
- *
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * p = self.data
- * for i in range(self.len / itemsize):
- */
- __pyx_t_4 = (__pyx_v_self->dtype_is_object != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":180
- *
- * if self.dtype_is_object:
- * p = self.data # <<<<<<<<<<<<<<
- * for i in range(self.len / itemsize):
- * p[i] = Py_None
- */
- __pyx_v_p = ((PyObject **)__pyx_v_self->data);
-
- /* "View.MemoryView":181
- * if self.dtype_is_object:
- * p = self.data
- * for i in range(self.len / itemsize): # <<<<<<<<<<<<<<
- * p[i] = Py_None
- * Py_INCREF(Py_None)
- */
- if (unlikely(__pyx_v_itemsize == 0)) {
- PyErr_SetString(PyExc_ZeroDivisionError, "integer division or modulo by zero");
- __PYX_ERR(1, 181, __pyx_L1_error)
- }
- else if (sizeof(Py_ssize_t) == sizeof(long) && (!(((Py_ssize_t)-1) > 0)) && unlikely(__pyx_v_itemsize == (Py_ssize_t)-1) && unlikely(UNARY_NEG_WOULD_OVERFLOW(__pyx_v_self->len))) {
- PyErr_SetString(PyExc_OverflowError, "value too large to perform division");
- __PYX_ERR(1, 181, __pyx_L1_error)
- }
- __pyx_t_1 = __Pyx_div_Py_ssize_t(__pyx_v_self->len, __pyx_v_itemsize);
- __pyx_t_9 = __pyx_t_1;
- for (__pyx_t_11 = 0; __pyx_t_11 < __pyx_t_9; __pyx_t_11+=1) {
- __pyx_v_i = __pyx_t_11;
-
- /* "View.MemoryView":182
- * p = self.data
- * for i in range(self.len / itemsize):
- * p[i] = Py_None # <<<<<<<<<<<<<<
- * Py_INCREF(Py_None)
- *
- */
- (__pyx_v_p[__pyx_v_i]) = Py_None;
-
- /* "View.MemoryView":183
- * for i in range(self.len / itemsize):
- * p[i] = Py_None
- * Py_INCREF(Py_None) # <<<<<<<<<<<<<<
- *
- * @cname('getbuffer')
- */
- Py_INCREF(Py_None);
- }
-
- /* "View.MemoryView":179
- * raise MemoryError("unable to allocate array data.")
- *
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * p = self.data
- * for i in range(self.len / itemsize):
- */
- }
-
- /* "View.MemoryView":172
- * self.free_data = allocate_buffer
- * self.dtype_is_object = format == b'O'
- * if allocate_buffer: # <<<<<<<<<<<<<<
- *
- *
- */
- }
-
- /* "View.MemoryView":123
- * cdef bint dtype_is_object
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None, # <<<<<<<<<<<<<<
- * mode="c", bint allocate_buffer=True):
- *
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_10);
- __Pyx_AddTraceback("View.MemoryView.array.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_format);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":186
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * cdef int bufmode = -1
- * if self.mode == u"c":
- */
-
-/* Python wrapper */
-static CYTHON_UNUSED int __pyx_array_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-static CYTHON_UNUSED int __pyx_array_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getbuffer__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_2__getbuffer__(((struct __pyx_array_obj *)__pyx_v_self), ((Py_buffer *)__pyx_v_info), ((int)__pyx_v_flags));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_2__getbuffer__(struct __pyx_array_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_v_bufmode;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- char *__pyx_t_4;
- Py_ssize_t __pyx_t_5;
- int __pyx_t_6;
- Py_ssize_t *__pyx_t_7;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- if (__pyx_v_info == NULL) {
- PyErr_SetString(PyExc_BufferError, "PyObject_GetBuffer: view==NULL argument is obsolete");
- return -1;
- }
- __Pyx_RefNannySetupContext("__getbuffer__", 0);
- __pyx_v_info->obj = Py_None; __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(__pyx_v_info->obj);
-
- /* "View.MemoryView":187
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * cdef int bufmode = -1 # <<<<<<<<<<<<<<
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- */
- __pyx_v_bufmode = -1;
-
- /* "View.MemoryView":188
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * cdef int bufmode = -1
- * if self.mode == u"c": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran":
- */
- __pyx_t_1 = (__Pyx_PyUnicode_Equals(__pyx_v_self->mode, __pyx_n_u_c, Py_EQ)); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 188, __pyx_L1_error)
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":189
- * cdef int bufmode = -1
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS # <<<<<<<<<<<<<<
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- */
- __pyx_v_bufmode = (PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS);
-
- /* "View.MemoryView":188
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * cdef int bufmode = -1
- * if self.mode == u"c": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran":
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":190
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- */
- __pyx_t_2 = (__Pyx_PyUnicode_Equals(__pyx_v_self->mode, __pyx_n_u_fortran, Py_EQ)); if (unlikely(__pyx_t_2 < 0)) __PYX_ERR(1, 190, __pyx_L1_error)
- __pyx_t_1 = (__pyx_t_2 != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":191
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS # <<<<<<<<<<<<<<
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- */
- __pyx_v_bufmode = (PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS);
-
- /* "View.MemoryView":190
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":192
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode): # <<<<<<<<<<<<<<
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data
- */
- __pyx_t_1 = ((!((__pyx_v_flags & __pyx_v_bufmode) != 0)) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":193
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.") # <<<<<<<<<<<<<<
- * info.buf = self.data
- * info.len = self.len
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__6, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 193, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 193, __pyx_L1_error)
-
- /* "View.MemoryView":192
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode): # <<<<<<<<<<<<<<
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data
- */
- }
-
- /* "View.MemoryView":194
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data # <<<<<<<<<<<<<<
- * info.len = self.len
- * info.ndim = self.ndim
- */
- __pyx_t_4 = __pyx_v_self->data;
- __pyx_v_info->buf = __pyx_t_4;
-
- /* "View.MemoryView":195
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data
- * info.len = self.len # <<<<<<<<<<<<<<
- * info.ndim = self.ndim
- * info.shape = self._shape
- */
- __pyx_t_5 = __pyx_v_self->len;
- __pyx_v_info->len = __pyx_t_5;
-
- /* "View.MemoryView":196
- * info.buf = self.data
- * info.len = self.len
- * info.ndim = self.ndim # <<<<<<<<<<<<<<
- * info.shape = self._shape
- * info.strides = self._strides
- */
- __pyx_t_6 = __pyx_v_self->ndim;
- __pyx_v_info->ndim = __pyx_t_6;
-
- /* "View.MemoryView":197
- * info.len = self.len
- * info.ndim = self.ndim
- * info.shape = self._shape # <<<<<<<<<<<<<<
- * info.strides = self._strides
- * info.suboffsets = NULL
- */
- __pyx_t_7 = __pyx_v_self->_shape;
- __pyx_v_info->shape = __pyx_t_7;
-
- /* "View.MemoryView":198
- * info.ndim = self.ndim
- * info.shape = self._shape
- * info.strides = self._strides # <<<<<<<<<<<<<<
- * info.suboffsets = NULL
- * info.itemsize = self.itemsize
- */
- __pyx_t_7 = __pyx_v_self->_strides;
- __pyx_v_info->strides = __pyx_t_7;
-
- /* "View.MemoryView":199
- * info.shape = self._shape
- * info.strides = self._strides
- * info.suboffsets = NULL # <<<<<<<<<<<<<<
- * info.itemsize = self.itemsize
- * info.readonly = 0
- */
- __pyx_v_info->suboffsets = NULL;
-
- /* "View.MemoryView":200
- * info.strides = self._strides
- * info.suboffsets = NULL
- * info.itemsize = self.itemsize # <<<<<<<<<<<<<<
- * info.readonly = 0
- *
- */
- __pyx_t_5 = __pyx_v_self->itemsize;
- __pyx_v_info->itemsize = __pyx_t_5;
-
- /* "View.MemoryView":201
- * info.suboffsets = NULL
- * info.itemsize = self.itemsize
- * info.readonly = 0 # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_FORMAT:
- */
- __pyx_v_info->readonly = 0;
-
- /* "View.MemoryView":203
- * info.readonly = 0
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.format
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_FORMAT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":204
- *
- * if flags & PyBUF_FORMAT:
- * info.format = self.format # <<<<<<<<<<<<<<
- * else:
- * info.format = NULL
- */
- __pyx_t_4 = __pyx_v_self->format;
- __pyx_v_info->format = __pyx_t_4;
-
- /* "View.MemoryView":203
- * info.readonly = 0
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.format
- * else:
- */
- goto __pyx_L5;
- }
-
- /* "View.MemoryView":206
- * info.format = self.format
- * else:
- * info.format = NULL # <<<<<<<<<<<<<<
- *
- * info.obj = self
- */
- /*else*/ {
- __pyx_v_info->format = NULL;
- }
- __pyx_L5:;
-
- /* "View.MemoryView":208
- * info.format = NULL
- *
- * info.obj = self # <<<<<<<<<<<<<<
- *
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)")
- */
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(((PyObject *)__pyx_v_self));
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj);
- __pyx_v_info->obj = ((PyObject *)__pyx_v_self);
-
- /* "View.MemoryView":186
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * cdef int bufmode = -1
- * if self.mode == u"c":
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.array.__getbuffer__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- if (__pyx_v_info->obj != NULL) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- goto __pyx_L2;
- __pyx_L0:;
- if (__pyx_v_info->obj == Py_None) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- __pyx_L2:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":212
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)")
- *
- * def __dealloc__(array self): # <<<<<<<<<<<<<<
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- */
-
-/* Python wrapper */
-static void __pyx_array___dealloc__(PyObject *__pyx_v_self); /*proto*/
-static void __pyx_array___dealloc__(PyObject *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__ (wrapper)", 0);
- __pyx_array___pyx_pf_15View_dot_MemoryView_5array_4__dealloc__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-static void __pyx_array___pyx_pf_15View_dot_MemoryView_5array_4__dealloc__(struct __pyx_array_obj *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- __Pyx_RefNannySetupContext("__dealloc__", 0);
-
- /* "View.MemoryView":213
- *
- * def __dealloc__(array self):
- * if self.callback_free_data != NULL: # <<<<<<<<<<<<<<
- * self.callback_free_data(self.data)
- * elif self.free_data:
- */
- __pyx_t_1 = ((__pyx_v_self->callback_free_data != NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":214
- * def __dealloc__(array self):
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data) # <<<<<<<<<<<<<<
- * elif self.free_data:
- * if self.dtype_is_object:
- */
- __pyx_v_self->callback_free_data(__pyx_v_self->data);
-
- /* "View.MemoryView":213
- *
- * def __dealloc__(array self):
- * if self.callback_free_data != NULL: # <<<<<<<<<<<<<<
- * self.callback_free_data(self.data)
- * elif self.free_data:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":215
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- * elif self.free_data: # <<<<<<<<<<<<<<
- * if self.dtype_is_object:
- * refcount_objects_in_slice(self.data, self._shape,
- */
- __pyx_t_1 = (__pyx_v_self->free_data != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":216
- * self.callback_free_data(self.data)
- * elif self.free_data:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice(self.data, self._shape,
- * self._strides, self.ndim, False)
- */
- __pyx_t_1 = (__pyx_v_self->dtype_is_object != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":217
- * elif self.free_data:
- * if self.dtype_is_object:
- * refcount_objects_in_slice(self.data, self._shape, # <<<<<<<<<<<<<<
- * self._strides, self.ndim, False)
- * free(self.data)
- */
- __pyx_memoryview_refcount_objects_in_slice(__pyx_v_self->data, __pyx_v_self->_shape, __pyx_v_self->_strides, __pyx_v_self->ndim, 0);
-
- /* "View.MemoryView":216
- * self.callback_free_data(self.data)
- * elif self.free_data:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice(self.data, self._shape,
- * self._strides, self.ndim, False)
- */
- }
-
- /* "View.MemoryView":219
- * refcount_objects_in_slice(self.data, self._shape,
- * self._strides, self.ndim, False)
- * free(self.data) # <<<<<<<<<<<<<<
- * PyObject_Free(self._shape)
- *
- */
- free(__pyx_v_self->data);
-
- /* "View.MemoryView":215
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- * elif self.free_data: # <<<<<<<<<<<<<<
- * if self.dtype_is_object:
- * refcount_objects_in_slice(self.data, self._shape,
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":220
- * self._strides, self.ndim, False)
- * free(self.data)
- * PyObject_Free(self._shape) # <<<<<<<<<<<<<<
- *
- * @property
- */
- PyObject_Free(__pyx_v_self->_shape);
-
- /* "View.MemoryView":212
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)")
- *
- * def __dealloc__(array self): # <<<<<<<<<<<<<<
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":223
- *
- * @property
- * def memview(self): # <<<<<<<<<<<<<<
- * return self.get_memview()
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_5array_7memview_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_5array_7memview_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_5array_7memview___get__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_5array_7memview___get__(struct __pyx_array_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":224
- * @property
- * def memview(self):
- * return self.get_memview() # <<<<<<<<<<<<<<
- *
- * @cname('get_memview')
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = ((struct __pyx_vtabstruct_array *)__pyx_v_self->__pyx_vtab)->get_memview(__pyx_v_self); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 224, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":223
- *
- * @property
- * def memview(self): # <<<<<<<<<<<<<<
- * return self.get_memview()
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.memview.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":227
- *
- * @cname('get_memview')
- * cdef get_memview(self): # <<<<<<<<<<<<<<
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE
- * return memoryview(self, flags, self.dtype_is_object)
- */
-
-static PyObject *__pyx_array_get_memview(struct __pyx_array_obj *__pyx_v_self) {
- int __pyx_v_flags;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("get_memview", 0);
-
- /* "View.MemoryView":228
- * @cname('get_memview')
- * cdef get_memview(self):
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE # <<<<<<<<<<<<<<
- * return memoryview(self, flags, self.dtype_is_object)
- *
- */
- __pyx_v_flags = ((PyBUF_ANY_CONTIGUOUS | PyBUF_FORMAT) | PyBUF_WRITABLE);
-
- /* "View.MemoryView":229
- * cdef get_memview(self):
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE
- * return memoryview(self, flags, self.dtype_is_object) # <<<<<<<<<<<<<<
- *
- * def __len__(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_flags); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_v_self->dtype_is_object); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyTuple_New(3); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(((PyObject *)__pyx_v_self));
- PyTuple_SET_ITEM(__pyx_t_3, 0, ((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 2, __pyx_t_2);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryview_type), __pyx_t_3, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":227
- *
- * @cname('get_memview')
- * cdef get_memview(self): # <<<<<<<<<<<<<<
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE
- * return memoryview(self, flags, self.dtype_is_object)
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.array.get_memview", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":231
- * return memoryview(self, flags, self.dtype_is_object)
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * return self._shape[0]
- *
- */
-
-/* Python wrapper */
-static Py_ssize_t __pyx_array___len__(PyObject *__pyx_v_self); /*proto*/
-static Py_ssize_t __pyx_array___len__(PyObject *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__len__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_6__len__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static Py_ssize_t __pyx_array___pyx_pf_15View_dot_MemoryView_5array_6__len__(struct __pyx_array_obj *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__len__", 0);
-
- /* "View.MemoryView":232
- *
- * def __len__(self):
- * return self._shape[0] # <<<<<<<<<<<<<<
- *
- * def __getattr__(self, attr):
- */
- __pyx_r = (__pyx_v_self->_shape[0]);
- goto __pyx_L0;
-
- /* "View.MemoryView":231
- * return memoryview(self, flags, self.dtype_is_object)
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * return self._shape[0]
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":234
- * return self._shape[0]
- *
- * def __getattr__(self, attr): # <<<<<<<<<<<<<<
- * return getattr(self.memview, attr)
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_array___getattr__(PyObject *__pyx_v_self, PyObject *__pyx_v_attr); /*proto*/
-static PyObject *__pyx_array___getattr__(PyObject *__pyx_v_self, PyObject *__pyx_v_attr) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getattr__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_8__getattr__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v_attr));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_8__getattr__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_attr) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__getattr__", 0);
-
- /* "View.MemoryView":235
- *
- * def __getattr__(self, attr):
- * return getattr(self.memview, attr) # <<<<<<<<<<<<<<
- *
- * def __getitem__(self, item):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_memview); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 235, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_GetAttr(__pyx_t_1, __pyx_v_attr); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 235, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":234
- * return self._shape[0]
- *
- * def __getattr__(self, attr): # <<<<<<<<<<<<<<
- * return getattr(self.memview, attr)
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.array.__getattr__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":237
- * return getattr(self.memview, attr)
- *
- * def __getitem__(self, item): # <<<<<<<<<<<<<<
- * return self.memview[item]
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_array___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item); /*proto*/
-static PyObject *__pyx_array___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getitem__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_10__getitem__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v_item));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_10__getitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__getitem__", 0);
-
- /* "View.MemoryView":238
- *
- * def __getitem__(self, item):
- * return self.memview[item] # <<<<<<<<<<<<<<
- *
- * def __setitem__(self, item, value):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_memview); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 238, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyObject_GetItem(__pyx_t_1, __pyx_v_item); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 238, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":237
- * return getattr(self.memview, attr)
- *
- * def __getitem__(self, item): # <<<<<<<<<<<<<<
- * return self.memview[item]
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.array.__getitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":240
- * return self.memview[item]
- *
- * def __setitem__(self, item, value): # <<<<<<<<<<<<<<
- * self.memview[item] = value
- *
- */
-
-/* Python wrapper */
-static int __pyx_array___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value); /*proto*/
-static int __pyx_array___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setitem__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_12__setitem__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v_item), ((PyObject *)__pyx_v_value));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_12__setitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setitem__", 0);
-
- /* "View.MemoryView":241
- *
- * def __setitem__(self, item, value):
- * self.memview[item] = value # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_memview); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 241, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (unlikely(PyObject_SetItem(__pyx_t_1, __pyx_v_item, __pyx_v_value) < 0)) __PYX_ERR(1, 241, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "View.MemoryView":240
- * return self.memview[item]
- *
- * def __setitem__(self, item, value): # <<<<<<<<<<<<<<
- * self.memview[item] = value
- *
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.__setitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_array_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_array_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_array___reduce_cython__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_array___reduce_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__7, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 2, __pyx_L1_error)
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_array_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_array_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_array_2__setstate_cython__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_array_2__setstate_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__8, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 4, __pyx_L1_error)
-
- /* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":245
- *
- * @cname("__pyx_array_new")
- * cdef array array_cwrapper(tuple shape, Py_ssize_t itemsize, char *format, # <<<<<<<<<<<<<<
- * char *mode, char *buf):
- * cdef array result
- */
-
-static struct __pyx_array_obj *__pyx_array_new(PyObject *__pyx_v_shape, Py_ssize_t __pyx_v_itemsize, char *__pyx_v_format, char *__pyx_v_mode, char *__pyx_v_buf) {
- struct __pyx_array_obj *__pyx_v_result = 0;
- struct __pyx_array_obj *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("array_cwrapper", 0);
-
- /* "View.MemoryView":249
- * cdef array result
- *
- * if buf == NULL: # <<<<<<<<<<<<<<
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- */
- __pyx_t_1 = ((__pyx_v_buf == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":250
- *
- * if buf == NULL:
- * result = array(shape, itemsize, format, mode.decode('ASCII')) # <<<<<<<<<<<<<<
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'),
- */
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_itemsize); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = __Pyx_PyBytes_FromString(__pyx_v_format); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_decode_c_string(__pyx_v_mode, 0, strlen(__pyx_v_mode), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = PyTuple_New(4); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_INCREF(__pyx_v_shape);
- __Pyx_GIVEREF(__pyx_v_shape);
- PyTuple_SET_ITEM(__pyx_t_5, 0, __pyx_v_shape);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_5, 1, __pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_5, 2, __pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_5, 3, __pyx_t_4);
- __pyx_t_2 = 0;
- __pyx_t_3 = 0;
- __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PyObject_Call(((PyObject *)__pyx_array_type), __pyx_t_5, NULL); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_v_result = ((struct __pyx_array_obj *)__pyx_t_4);
- __pyx_t_4 = 0;
-
- /* "View.MemoryView":249
- * cdef array result
- *
- * if buf == NULL: # <<<<<<<<<<<<<<
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":252
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'), # <<<<<<<<<<<<<<
- * allocate_buffer=False)
- * result.data = buf
- */
- /*else*/ {
- __pyx_t_4 = PyInt_FromSsize_t(__pyx_v_itemsize); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = __Pyx_PyBytes_FromString(__pyx_v_format); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_3 = __Pyx_decode_c_string(__pyx_v_mode, 0, strlen(__pyx_v_mode), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_2 = PyTuple_New(4); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_INCREF(__pyx_v_shape);
- __Pyx_GIVEREF(__pyx_v_shape);
- PyTuple_SET_ITEM(__pyx_t_2, 0, __pyx_v_shape);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_2, 1, __pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_5);
- PyTuple_SET_ITEM(__pyx_t_2, 2, __pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_2, 3, __pyx_t_3);
- __pyx_t_4 = 0;
- __pyx_t_5 = 0;
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":253
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'),
- * allocate_buffer=False) # <<<<<<<<<<<<<<
- * result.data = buf
- *
- */
- __pyx_t_3 = __Pyx_PyDict_NewPresized(1); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 253, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- if (PyDict_SetItem(__pyx_t_3, __pyx_n_s_allocate_buffer, Py_False) < 0) __PYX_ERR(1, 253, __pyx_L1_error)
-
- /* "View.MemoryView":252
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'), # <<<<<<<<<<<<<<
- * allocate_buffer=False)
- * result.data = buf
- */
- __pyx_t_5 = __Pyx_PyObject_Call(((PyObject *)__pyx_array_type), __pyx_t_2, __pyx_t_3); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result = ((struct __pyx_array_obj *)__pyx_t_5);
- __pyx_t_5 = 0;
-
- /* "View.MemoryView":254
- * result = array(shape, itemsize, format, mode.decode('ASCII'),
- * allocate_buffer=False)
- * result.data = buf # <<<<<<<<<<<<<<
- *
- * return result
- */
- __pyx_v_result->data = __pyx_v_buf;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":256
- * result.data = buf
- *
- * return result # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(((PyObject *)__pyx_r));
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = __pyx_v_result;
- goto __pyx_L0;
-
- /* "View.MemoryView":245
- *
- * @cname("__pyx_array_new")
- * cdef array array_cwrapper(tuple shape, Py_ssize_t itemsize, char *format, # <<<<<<<<<<<<<<
- * char *mode, char *buf):
- * cdef array result
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.array_cwrapper", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XGIVEREF((PyObject *)__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":282
- * cdef class Enum(object):
- * cdef object name
- * def __init__(self, name): # <<<<<<<<<<<<<<
- * self.name = name
- * def __repr__(self):
- */
-
-/* Python wrapper */
-static int __pyx_MemviewEnum___init__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static int __pyx_MemviewEnum___init__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v_name = 0;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__init__ (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_name,0};
- PyObject* values[1] = {0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_name)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__init__") < 0)) __PYX_ERR(1, 282, __pyx_L3_error)
- }
- } else if (PyTuple_GET_SIZE(__pyx_args) != 1) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- }
- __pyx_v_name = values[0];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__init__", 1, 1, 1, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 282, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.Enum.__init__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return -1;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum___init__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self), __pyx_v_name);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum___init__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v_name) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__init__", 0);
-
- /* "View.MemoryView":283
- * cdef object name
- * def __init__(self, name):
- * self.name = name # <<<<<<<<<<<<<<
- * def __repr__(self):
- * return self.name
- */
- __Pyx_INCREF(__pyx_v_name);
- __Pyx_GIVEREF(__pyx_v_name);
- __Pyx_GOTREF(__pyx_v_self->name);
- __Pyx_DECREF(__pyx_v_self->name);
- __pyx_v_self->name = __pyx_v_name;
-
- /* "View.MemoryView":282
- * cdef class Enum(object):
- * cdef object name
- * def __init__(self, name): # <<<<<<<<<<<<<<
- * self.name = name
- * def __repr__(self):
- */
-
- /* function exit code */
- __pyx_r = 0;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":284
- * def __init__(self, name):
- * self.name = name
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return self.name
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_MemviewEnum___repr__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_MemviewEnum___repr__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__repr__ (wrapper)", 0);
- __pyx_r = __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum_2__repr__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum_2__repr__(struct __pyx_MemviewEnum_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__repr__", 0);
-
- /* "View.MemoryView":285
- * self.name = name
- * def __repr__(self):
- * return self.name # <<<<<<<<<<<<<<
- *
- * cdef generic = Enum("")
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->name);
- __pyx_r = __pyx_v_self->name;
- goto __pyx_L0;
-
- /* "View.MemoryView":284
- * def __init__(self, name):
- * self.name = name
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return self.name
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * cdef tuple state
- * cdef object _dict
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_MemviewEnum_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_MemviewEnum_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_MemviewEnum___reduce_cython__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_MemviewEnum___reduce_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self) {
- PyObject *__pyx_v_state = 0;
- PyObject *__pyx_v__dict = 0;
- int __pyx_v_use_setstate;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_t_3;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":5
- * cdef object _dict
- * cdef bint use_setstate
- * state = (self.name,) # <<<<<<<<<<<<<<
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None:
- */
- __pyx_t_1 = PyTuple_New(1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_v_self->name);
- __Pyx_GIVEREF(__pyx_v_self->name);
- PyTuple_SET_ITEM(__pyx_t_1, 0, __pyx_v_self->name);
- __pyx_v_state = ((PyObject*)__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "(tree fragment)":6
- * cdef bint use_setstate
- * state = (self.name,)
- * _dict = getattr(self, '__dict__', None) # <<<<<<<<<<<<<<
- * if _dict is not None:
- * state += (_dict,)
- */
- __pyx_t_1 = __Pyx_GetAttr3(((PyObject *)__pyx_v_self), __pyx_n_s_dict, Py_None); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v__dict = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "(tree fragment)":7
- * state = (self.name,)
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None: # <<<<<<<<<<<<<<
- * state += (_dict,)
- * use_setstate = True
- */
- __pyx_t_2 = (__pyx_v__dict != Py_None);
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (__pyx_t_3) {
-
- /* "(tree fragment)":8
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None:
- * state += (_dict,) # <<<<<<<<<<<<<<
- * use_setstate = True
- * else:
- */
- __pyx_t_1 = PyTuple_New(1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 8, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_v__dict);
- __Pyx_GIVEREF(__pyx_v__dict);
- PyTuple_SET_ITEM(__pyx_t_1, 0, __pyx_v__dict);
- __pyx_t_4 = PyNumber_InPlaceAdd(__pyx_v_state, __pyx_t_1); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 8, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF_SET(__pyx_v_state, ((PyObject*)__pyx_t_4));
- __pyx_t_4 = 0;
-
- /* "(tree fragment)":9
- * if _dict is not None:
- * state += (_dict,)
- * use_setstate = True # <<<<<<<<<<<<<<
- * else:
- * use_setstate = self.name is not None
- */
- __pyx_v_use_setstate = 1;
-
- /* "(tree fragment)":7
- * state = (self.name,)
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None: # <<<<<<<<<<<<<<
- * state += (_dict,)
- * use_setstate = True
- */
- goto __pyx_L3;
- }
-
- /* "(tree fragment)":11
- * use_setstate = True
- * else:
- * use_setstate = self.name is not None # <<<<<<<<<<<<<<
- * if use_setstate:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- */
- /*else*/ {
- __pyx_t_3 = (__pyx_v_self->name != Py_None);
- __pyx_v_use_setstate = __pyx_t_3;
- }
- __pyx_L3:;
-
- /* "(tree fragment)":12
- * else:
- * use_setstate = self.name is not None
- * if use_setstate: # <<<<<<<<<<<<<<
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- * else:
- */
- __pyx_t_3 = (__pyx_v_use_setstate != 0);
- if (__pyx_t_3) {
-
- /* "(tree fragment)":13
- * use_setstate = self.name is not None
- * if use_setstate:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state # <<<<<<<<<<<<<<
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_GetModuleGlobalName(__pyx_t_4, __pyx_n_s_pyx_unpickle_Enum); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 13, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_1 = PyTuple_New(3); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 13, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_GIVEREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- PyTuple_SET_ITEM(__pyx_t_1, 0, ((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_INCREF(__pyx_int_184977713);
- __Pyx_GIVEREF(__pyx_int_184977713);
- PyTuple_SET_ITEM(__pyx_t_1, 1, __pyx_int_184977713);
- __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(Py_None);
- PyTuple_SET_ITEM(__pyx_t_1, 2, Py_None);
- __pyx_t_5 = PyTuple_New(3); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 13, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_5, 0, __pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_5, 1, __pyx_t_1);
- __Pyx_INCREF(__pyx_v_state);
- __Pyx_GIVEREF(__pyx_v_state);
- PyTuple_SET_ITEM(__pyx_t_5, 2, __pyx_v_state);
- __pyx_t_4 = 0;
- __pyx_t_1 = 0;
- __pyx_r = __pyx_t_5;
- __pyx_t_5 = 0;
- goto __pyx_L0;
-
- /* "(tree fragment)":12
- * else:
- * use_setstate = self.name is not None
- * if use_setstate: # <<<<<<<<<<<<<<
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- * else:
- */
- }
-
- /* "(tree fragment)":15
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state) # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * __pyx_unpickle_Enum__set_state(self, __pyx_state)
- */
- /*else*/ {
- __Pyx_XDECREF(__pyx_r);
- __Pyx_GetModuleGlobalName(__pyx_t_5, __pyx_n_s_pyx_unpickle_Enum); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 15, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_1 = PyTuple_New(3); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 15, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_GIVEREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- PyTuple_SET_ITEM(__pyx_t_1, 0, ((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_INCREF(__pyx_int_184977713);
- __Pyx_GIVEREF(__pyx_int_184977713);
- PyTuple_SET_ITEM(__pyx_t_1, 1, __pyx_int_184977713);
- __Pyx_INCREF(__pyx_v_state);
- __Pyx_GIVEREF(__pyx_v_state);
- PyTuple_SET_ITEM(__pyx_t_1, 2, __pyx_v_state);
- __pyx_t_4 = PyTuple_New(2); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 15, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_5);
- PyTuple_SET_ITEM(__pyx_t_4, 0, __pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_4, 1, __pyx_t_1);
- __pyx_t_5 = 0;
- __pyx_t_1 = 0;
- __pyx_r = __pyx_t_4;
- __pyx_t_4 = 0;
- goto __pyx_L0;
- }
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * cdef tuple state
- * cdef object _dict
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.Enum.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_state);
- __Pyx_XDECREF(__pyx_v__dict);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":16
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state(self, __pyx_state)
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_MemviewEnum_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_MemviewEnum_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_MemviewEnum_2__setstate_cython__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_MemviewEnum_2__setstate_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":17
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- * def __setstate_cython__(self, __pyx_state):
- * __pyx_unpickle_Enum__set_state(self, __pyx_state) # <<<<<<<<<<<<<<
- */
- if (!(likely(PyTuple_CheckExact(__pyx_v___pyx_state))||((__pyx_v___pyx_state) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "tuple", Py_TYPE(__pyx_v___pyx_state)->tp_name), 0))) __PYX_ERR(1, 17, __pyx_L1_error)
- __pyx_t_1 = __pyx_unpickle_Enum__set_state(__pyx_v_self, ((PyObject*)__pyx_v___pyx_state)); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "(tree fragment)":16
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state(self, __pyx_state)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.Enum.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":299
- *
- * @cname('__pyx_align_pointer')
- * cdef void *align_pointer(void *memory, size_t alignment) nogil: # <<<<<<<<<<<<<<
- * "Align pointer memory on a given boundary"
- * cdef Py_intptr_t aligned_p = memory
- */
-
-static void *__pyx_align_pointer(void *__pyx_v_memory, size_t __pyx_v_alignment) {
- Py_intptr_t __pyx_v_aligned_p;
- size_t __pyx_v_offset;
- void *__pyx_r;
- int __pyx_t_1;
-
- /* "View.MemoryView":301
- * cdef void *align_pointer(void *memory, size_t alignment) nogil:
- * "Align pointer memory on a given boundary"
- * cdef Py_intptr_t aligned_p = memory # <<<<<<<<<<<<<<
- * cdef size_t offset
- *
- */
- __pyx_v_aligned_p = ((Py_intptr_t)__pyx_v_memory);
-
- /* "View.MemoryView":305
- *
- * with cython.cdivision(True):
- * offset = aligned_p % alignment # <<<<<<<<<<<<<<
- *
- * if offset > 0:
- */
- __pyx_v_offset = (__pyx_v_aligned_p % __pyx_v_alignment);
-
- /* "View.MemoryView":307
- * offset = aligned_p % alignment
- *
- * if offset > 0: # <<<<<<<<<<<<<<
- * aligned_p += alignment - offset
- *
- */
- __pyx_t_1 = ((__pyx_v_offset > 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":308
- *
- * if offset > 0:
- * aligned_p += alignment - offset # <<<<<<<<<<<<<<
- *
- * return aligned_p
- */
- __pyx_v_aligned_p = (__pyx_v_aligned_p + (__pyx_v_alignment - __pyx_v_offset));
-
- /* "View.MemoryView":307
- * offset = aligned_p % alignment
- *
- * if offset > 0: # <<<<<<<<<<<<<<
- * aligned_p += alignment - offset
- *
- */
- }
-
- /* "View.MemoryView":310
- * aligned_p += alignment - offset
- *
- * return aligned_p # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = ((void *)__pyx_v_aligned_p);
- goto __pyx_L0;
-
- /* "View.MemoryView":299
- *
- * @cname('__pyx_align_pointer')
- * cdef void *align_pointer(void *memory, size_t alignment) nogil: # <<<<<<<<<<<<<<
- * "Align pointer memory on a given boundary"
- * cdef Py_intptr_t aligned_p = memory
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":346
- * cdef __Pyx_TypeInfo *typeinfo
- *
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False): # <<<<<<<<<<<<<<
- * self.obj = obj
- * self.flags = flags
- */
-
-/* Python wrapper */
-static int __pyx_memoryview___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static int __pyx_memoryview___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v_obj = 0;
- int __pyx_v_flags;
- int __pyx_v_dtype_is_object;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__cinit__ (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_obj,&__pyx_n_s_flags,&__pyx_n_s_dtype_is_object,0};
- PyObject* values[3] = {0,0,0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_obj)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_flags)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 2, 3, 1); __PYX_ERR(1, 346, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (kw_args > 0) {
- PyObject* value = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_dtype_is_object);
- if (value) { values[2] = value; kw_args--; }
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__cinit__") < 0)) __PYX_ERR(1, 346, __pyx_L3_error)
- }
- } else {
- switch (PyTuple_GET_SIZE(__pyx_args)) {
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- break;
- default: goto __pyx_L5_argtuple_error;
- }
- }
- __pyx_v_obj = values[0];
- __pyx_v_flags = __Pyx_PyInt_As_int(values[1]); if (unlikely((__pyx_v_flags == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 346, __pyx_L3_error)
- if (values[2]) {
- __pyx_v_dtype_is_object = __Pyx_PyObject_IsTrue(values[2]); if (unlikely((__pyx_v_dtype_is_object == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 346, __pyx_L3_error)
- } else {
- __pyx_v_dtype_is_object = ((int)0);
- }
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 2, 3, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 346, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.memoryview.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return -1;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview___cinit__(((struct __pyx_memoryview_obj *)__pyx_v_self), __pyx_v_obj, __pyx_v_flags, __pyx_v_dtype_is_object);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview___cinit__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj, int __pyx_v_flags, int __pyx_v_dtype_is_object) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__cinit__", 0);
-
- /* "View.MemoryView":347
- *
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False):
- * self.obj = obj # <<<<<<<<<<<<<<
- * self.flags = flags
- * if type(self) is memoryview or obj is not None:
- */
- __Pyx_INCREF(__pyx_v_obj);
- __Pyx_GIVEREF(__pyx_v_obj);
- __Pyx_GOTREF(__pyx_v_self->obj);
- __Pyx_DECREF(__pyx_v_self->obj);
- __pyx_v_self->obj = __pyx_v_obj;
-
- /* "View.MemoryView":348
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False):
- * self.obj = obj
- * self.flags = flags # <<<<<<<<<<<<<<
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags)
- */
- __pyx_v_self->flags = __pyx_v_flags;
-
- /* "View.MemoryView":349
- * self.obj = obj
- * self.flags = flags
- * if type(self) is memoryview or obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL:
- */
- __pyx_t_2 = (((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))) == ((PyObject *)__pyx_memoryview_type));
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (!__pyx_t_3) {
- } else {
- __pyx_t_1 = __pyx_t_3;
- goto __pyx_L4_bool_binop_done;
- }
- __pyx_t_3 = (__pyx_v_obj != Py_None);
- __pyx_t_2 = (__pyx_t_3 != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L4_bool_binop_done:;
- if (__pyx_t_1) {
-
- /* "View.MemoryView":350
- * self.flags = flags
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags) # <<<<<<<<<<<<<<
- * if self.view.obj == NULL:
- * (<__pyx_buffer *> &self.view).obj = Py_None
- */
- __pyx_t_4 = __Pyx_GetBuffer(__pyx_v_obj, (&__pyx_v_self->view), __pyx_v_flags); if (unlikely(__pyx_t_4 == ((int)-1))) __PYX_ERR(1, 350, __pyx_L1_error)
-
- /* "View.MemoryView":351
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL: # <<<<<<<<<<<<<<
- * (<__pyx_buffer *> &self.view).obj = Py_None
- * Py_INCREF(Py_None)
- */
- __pyx_t_1 = ((((PyObject *)__pyx_v_self->view.obj) == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":352
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL:
- * (<__pyx_buffer *> &self.view).obj = Py_None # <<<<<<<<<<<<<<
- * Py_INCREF(Py_None)
- *
- */
- ((Py_buffer *)(&__pyx_v_self->view))->obj = Py_None;
-
- /* "View.MemoryView":353
- * if self.view.obj == NULL:
- * (<__pyx_buffer *> &self.view).obj = Py_None
- * Py_INCREF(Py_None) # <<<<<<<<<<<<<<
- *
- * if not __PYX_CYTHON_ATOMICS_ENABLED():
- */
- Py_INCREF(Py_None);
-
- /* "View.MemoryView":351
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL: # <<<<<<<<<<<<<<
- * (<__pyx_buffer *> &self.view).obj = Py_None
- * Py_INCREF(Py_None)
- */
- }
-
- /* "View.MemoryView":349
- * self.obj = obj
- * self.flags = flags
- * if type(self) is memoryview or obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL:
- */
- }
-
- /* "View.MemoryView":355
- * Py_INCREF(Py_None)
- *
- * if not __PYX_CYTHON_ATOMICS_ENABLED(): # <<<<<<<<<<<<<<
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- */
- __pyx_t_1 = ((!(__PYX_CYTHON_ATOMICS_ENABLED() != 0)) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":357
- * if not __PYX_CYTHON_ATOMICS_ENABLED():
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED: # <<<<<<<<<<<<<<
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- */
- __pyx_t_1 = ((__pyx_memoryview_thread_locks_used < 8) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":358
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL:
- */
- __pyx_v_self->lock = (__pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]);
-
- /* "View.MemoryView":359
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1 # <<<<<<<<<<<<<<
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock()
- */
- __pyx_memoryview_thread_locks_used = (__pyx_memoryview_thread_locks_used + 1);
-
- /* "View.MemoryView":357
- * if not __PYX_CYTHON_ATOMICS_ENABLED():
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED: # <<<<<<<<<<<<<<
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- */
- }
-
- /* "View.MemoryView":360
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL:
- */
- __pyx_t_1 = ((__pyx_v_self->lock == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":361
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock() # <<<<<<<<<<<<<<
- * if self.lock is NULL:
- * raise MemoryError
- */
- __pyx_v_self->lock = PyThread_allocate_lock();
-
- /* "View.MemoryView":362
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- *
- */
- __pyx_t_1 = ((__pyx_v_self->lock == NULL) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":363
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL:
- * raise MemoryError # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_FORMAT:
- */
- PyErr_NoMemory(); __PYX_ERR(1, 363, __pyx_L1_error)
-
- /* "View.MemoryView":362
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- *
- */
- }
-
- /* "View.MemoryView":360
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL:
- */
- }
-
- /* "View.MemoryView":355
- * Py_INCREF(Py_None)
- *
- * if not __PYX_CYTHON_ATOMICS_ENABLED(): # <<<<<<<<<<<<<<
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- */
- }
-
- /* "View.MemoryView":365
- * raise MemoryError
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0')
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_FORMAT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":366
- *
- * if flags & PyBUF_FORMAT:
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0') # <<<<<<<<<<<<<<
- * else:
- * self.dtype_is_object = dtype_is_object
- */
- __pyx_t_2 = (((__pyx_v_self->view.format[0]) == 'O') != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L12_bool_binop_done;
- }
- __pyx_t_2 = (((__pyx_v_self->view.format[1]) == '\x00') != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L12_bool_binop_done:;
- __pyx_v_self->dtype_is_object = __pyx_t_1;
-
- /* "View.MemoryView":365
- * raise MemoryError
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0')
- * else:
- */
- goto __pyx_L11;
- }
-
- /* "View.MemoryView":368
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0')
- * else:
- * self.dtype_is_object = dtype_is_object # <<<<<<<<<<<<<<
- *
- * self.acquisition_count_aligned_p = <__pyx_atomic_int *> align_pointer(
- */
- /*else*/ {
- __pyx_v_self->dtype_is_object = __pyx_v_dtype_is_object;
- }
- __pyx_L11:;
-
- /* "View.MemoryView":370
- * self.dtype_is_object = dtype_is_object
- *
- * self.acquisition_count_aligned_p = <__pyx_atomic_int *> align_pointer( # <<<<<<<<<<<<<<
- * &self.acquisition_count[0], sizeof(__pyx_atomic_int))
- * self.typeinfo = NULL
- */
- __pyx_v_self->acquisition_count_aligned_p = ((__pyx_atomic_int *)__pyx_align_pointer(((void *)(&(__pyx_v_self->acquisition_count[0]))), (sizeof(__pyx_atomic_int))));
-
- /* "View.MemoryView":372
- * self.acquisition_count_aligned_p = <__pyx_atomic_int *> align_pointer(
- * &self.acquisition_count[0], sizeof(__pyx_atomic_int))
- * self.typeinfo = NULL # <<<<<<<<<<<<<<
- *
- * def __dealloc__(memoryview self):
- */
- __pyx_v_self->typeinfo = NULL;
-
- /* "View.MemoryView":346
- * cdef __Pyx_TypeInfo *typeinfo
- *
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False): # <<<<<<<<<<<<<<
- * self.obj = obj
- * self.flags = flags
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_AddTraceback("View.MemoryView.memoryview.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":374
- * self.typeinfo = NULL
- *
- * def __dealloc__(memoryview self): # <<<<<<<<<<<<<<
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- */
-
-/* Python wrapper */
-static void __pyx_memoryview___dealloc__(PyObject *__pyx_v_self); /*proto*/
-static void __pyx_memoryview___dealloc__(PyObject *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__ (wrapper)", 0);
- __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_2__dealloc__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-static void __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_2__dealloc__(struct __pyx_memoryview_obj *__pyx_v_self) {
- int __pyx_v_i;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- int __pyx_t_5;
- PyThread_type_lock __pyx_t_6;
- PyThread_type_lock __pyx_t_7;
- __Pyx_RefNannySetupContext("__dealloc__", 0);
-
- /* "View.MemoryView":375
- *
- * def __dealloc__(memoryview self):
- * if self.obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- */
- __pyx_t_1 = (__pyx_v_self->obj != Py_None);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":376
- * def __dealloc__(memoryview self):
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view) # <<<<<<<<<<<<<<
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- *
- */
- __Pyx_ReleaseBuffer((&__pyx_v_self->view));
-
- /* "View.MemoryView":375
- *
- * def __dealloc__(memoryview self):
- * if self.obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":377
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None: # <<<<<<<<<<<<<<
- *
- * (<__pyx_buffer *> &self.view).obj = NULL
- */
- __pyx_t_2 = ((((Py_buffer *)(&__pyx_v_self->view))->obj == Py_None) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":379
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- *
- * (<__pyx_buffer *> &self.view).obj = NULL # <<<<<<<<<<<<<<
- * Py_DECREF(Py_None)
- *
- */
- ((Py_buffer *)(&__pyx_v_self->view))->obj = NULL;
-
- /* "View.MemoryView":380
- *
- * (<__pyx_buffer *> &self.view).obj = NULL
- * Py_DECREF(Py_None) # <<<<<<<<<<<<<<
- *
- * cdef int i
- */
- Py_DECREF(Py_None);
-
- /* "View.MemoryView":377
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None: # <<<<<<<<<<<<<<
- *
- * (<__pyx_buffer *> &self.view).obj = NULL
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":384
- * cdef int i
- * global __pyx_memoryview_thread_locks_used
- * if self.lock != NULL: # <<<<<<<<<<<<<<
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- */
- __pyx_t_2 = ((__pyx_v_self->lock != NULL) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":385
- * global __pyx_memoryview_thread_locks_used
- * if self.lock != NULL:
- * for i in range(__pyx_memoryview_thread_locks_used): # <<<<<<<<<<<<<<
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1
- */
- __pyx_t_3 = __pyx_memoryview_thread_locks_used;
- __pyx_t_4 = __pyx_t_3;
- for (__pyx_t_5 = 0; __pyx_t_5 < __pyx_t_4; __pyx_t_5+=1) {
- __pyx_v_i = __pyx_t_5;
-
- /* "View.MemoryView":386
- * if self.lock != NULL:
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used:
- */
- __pyx_t_2 = (((__pyx_memoryview_thread_locks[__pyx_v_i]) == __pyx_v_self->lock) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":387
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1 # <<<<<<<<<<<<<<
- * if i != __pyx_memoryview_thread_locks_used:
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- */
- __pyx_memoryview_thread_locks_used = (__pyx_memoryview_thread_locks_used - 1);
-
- /* "View.MemoryView":388
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- */
- __pyx_t_2 = ((__pyx_v_i != __pyx_memoryview_thread_locks_used) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":390
- * if i != __pyx_memoryview_thread_locks_used:
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i]) # <<<<<<<<<<<<<<
- * break
- * else:
- */
- __pyx_t_6 = (__pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]);
- __pyx_t_7 = (__pyx_memoryview_thread_locks[__pyx_v_i]);
-
- /* "View.MemoryView":389
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used:
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = ( # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- * break
- */
- (__pyx_memoryview_thread_locks[__pyx_v_i]) = __pyx_t_6;
- (__pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]) = __pyx_t_7;
-
- /* "View.MemoryView":388
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- */
- }
-
- /* "View.MemoryView":391
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- * break # <<<<<<<<<<<<<<
- * else:
- * PyThread_free_lock(self.lock)
- */
- goto __pyx_L6_break;
-
- /* "View.MemoryView":386
- * if self.lock != NULL:
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used:
- */
- }
- }
- /*else*/ {
-
- /* "View.MemoryView":393
- * break
- * else:
- * PyThread_free_lock(self.lock) # <<<<<<<<<<<<<<
- *
- * cdef char *get_item_pointer(memoryview self, object index) except NULL:
- */
- PyThread_free_lock(__pyx_v_self->lock);
- }
- __pyx_L6_break:;
-
- /* "View.MemoryView":384
- * cdef int i
- * global __pyx_memoryview_thread_locks_used
- * if self.lock != NULL: # <<<<<<<<<<<<<<
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- */
- }
-
- /* "View.MemoryView":374
- * self.typeinfo = NULL
- *
- * def __dealloc__(memoryview self): # <<<<<<<<<<<<<<
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":395
- * PyThread_free_lock(self.lock)
- *
- * cdef char *get_item_pointer(memoryview self, object index) except NULL: # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dim
- * cdef char *itemp = self.view.buf
- */
-
-static char *__pyx_memoryview_get_item_pointer(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index) {
- Py_ssize_t __pyx_v_dim;
- char *__pyx_v_itemp;
- PyObject *__pyx_v_idx = NULL;
- char *__pyx_r;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- Py_ssize_t __pyx_t_3;
- PyObject *(*__pyx_t_4)(PyObject *);
- PyObject *__pyx_t_5 = NULL;
- Py_ssize_t __pyx_t_6;
- char *__pyx_t_7;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("get_item_pointer", 0);
-
- /* "View.MemoryView":397
- * cdef char *get_item_pointer(memoryview self, object index) except NULL:
- * cdef Py_ssize_t dim
- * cdef char *itemp = self.view.buf # <<<<<<<<<<<<<<
- *
- * for dim, idx in enumerate(index):
- */
- __pyx_v_itemp = ((char *)__pyx_v_self->view.buf);
-
- /* "View.MemoryView":399
- * cdef char *itemp = self.view.buf
- *
- * for dim, idx in enumerate(index): # <<<<<<<<<<<<<<
- * itemp = pybuffer_index(&self.view, itemp, idx, dim)
- *
- */
- __pyx_t_1 = 0;
- if (likely(PyList_CheckExact(__pyx_v_index)) || PyTuple_CheckExact(__pyx_v_index)) {
- __pyx_t_2 = __pyx_v_index; __Pyx_INCREF(__pyx_t_2); __pyx_t_3 = 0;
- __pyx_t_4 = NULL;
- } else {
- __pyx_t_3 = -1; __pyx_t_2 = PyObject_GetIter(__pyx_v_index); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 399, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_4 = Py_TYPE(__pyx_t_2)->tp_iternext; if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 399, __pyx_L1_error)
- }
- for (;;) {
- if (likely(!__pyx_t_4)) {
- if (likely(PyList_CheckExact(__pyx_t_2))) {
- if (__pyx_t_3 >= PyList_GET_SIZE(__pyx_t_2)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_5 = PyList_GET_ITEM(__pyx_t_2, __pyx_t_3); __Pyx_INCREF(__pyx_t_5); __pyx_t_3++; if (unlikely(0 < 0)) __PYX_ERR(1, 399, __pyx_L1_error)
- #else
- __pyx_t_5 = PySequence_ITEM(__pyx_t_2, __pyx_t_3); __pyx_t_3++; if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 399, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- } else {
- if (__pyx_t_3 >= PyTuple_GET_SIZE(__pyx_t_2)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_5 = PyTuple_GET_ITEM(__pyx_t_2, __pyx_t_3); __Pyx_INCREF(__pyx_t_5); __pyx_t_3++; if (unlikely(0 < 0)) __PYX_ERR(1, 399, __pyx_L1_error)
- #else
- __pyx_t_5 = PySequence_ITEM(__pyx_t_2, __pyx_t_3); __pyx_t_3++; if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 399, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- }
- } else {
- __pyx_t_5 = __pyx_t_4(__pyx_t_2);
- if (unlikely(!__pyx_t_5)) {
- PyObject* exc_type = PyErr_Occurred();
- if (exc_type) {
- if (likely(__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration))) PyErr_Clear();
- else __PYX_ERR(1, 399, __pyx_L1_error)
- }
- break;
- }
- __Pyx_GOTREF(__pyx_t_5);
- }
- __Pyx_XDECREF_SET(__pyx_v_idx, __pyx_t_5);
- __pyx_t_5 = 0;
- __pyx_v_dim = __pyx_t_1;
- __pyx_t_1 = (__pyx_t_1 + 1);
-
- /* "View.MemoryView":400
- *
- * for dim, idx in enumerate(index):
- * itemp = pybuffer_index(&self.view, itemp, idx, dim) # <<<<<<<<<<<<<<
- *
- * return itemp
- */
- __pyx_t_6 = __Pyx_PyIndex_AsSsize_t(__pyx_v_idx); if (unlikely((__pyx_t_6 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 400, __pyx_L1_error)
- __pyx_t_7 = __pyx_pybuffer_index((&__pyx_v_self->view), __pyx_v_itemp, __pyx_t_6, __pyx_v_dim); if (unlikely(__pyx_t_7 == ((char *)NULL))) __PYX_ERR(1, 400, __pyx_L1_error)
- __pyx_v_itemp = __pyx_t_7;
-
- /* "View.MemoryView":399
- * cdef char *itemp = self.view.buf
- *
- * for dim, idx in enumerate(index): # <<<<<<<<<<<<<<
- * itemp = pybuffer_index(&self.view, itemp, idx, dim)
- *
- */
- }
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "View.MemoryView":402
- * itemp = pybuffer_index(&self.view, itemp, idx, dim)
- *
- * return itemp # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = __pyx_v_itemp;
- goto __pyx_L0;
-
- /* "View.MemoryView":395
- * PyThread_free_lock(self.lock)
- *
- * cdef char *get_item_pointer(memoryview self, object index) except NULL: # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dim
- * cdef char *itemp = self.view.buf
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview.get_item_pointer", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_idx);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":405
- *
- *
- * def __getitem__(memoryview self, object index): # <<<<<<<<<<<<<<
- * if index is Ellipsis:
- * return self
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index); /*proto*/
-static PyObject *__pyx_memoryview___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getitem__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_4__getitem__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((PyObject *)__pyx_v_index));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_4__getitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index) {
- PyObject *__pyx_v_have_slices = NULL;
- PyObject *__pyx_v_indices = NULL;
- char *__pyx_v_itemp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- char *__pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__getitem__", 0);
-
- /* "View.MemoryView":406
- *
- * def __getitem__(memoryview self, object index):
- * if index is Ellipsis: # <<<<<<<<<<<<<<
- * return self
- *
- */
- __pyx_t_1 = (__pyx_v_index == __pyx_builtin_Ellipsis);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":407
- * def __getitem__(memoryview self, object index):
- * if index is Ellipsis:
- * return self # <<<<<<<<<<<<<<
- *
- * have_slices, indices = _unellipsify(index, self.view.ndim)
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __pyx_r = ((PyObject *)__pyx_v_self);
- goto __pyx_L0;
-
- /* "View.MemoryView":406
- *
- * def __getitem__(memoryview self, object index):
- * if index is Ellipsis: # <<<<<<<<<<<<<<
- * return self
- *
- */
- }
-
- /* "View.MemoryView":409
- * return self
- *
- * have_slices, indices = _unellipsify(index, self.view.ndim) # <<<<<<<<<<<<<<
- *
- * cdef char *itemp
- */
- __pyx_t_3 = _unellipsify(__pyx_v_index, __pyx_v_self->view.ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 409, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- if (likely(__pyx_t_3 != Py_None)) {
- PyObject* sequence = __pyx_t_3;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(1, 409, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_4 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_5 = PyTuple_GET_ITEM(sequence, 1);
- __Pyx_INCREF(__pyx_t_4);
- __Pyx_INCREF(__pyx_t_5);
- #else
- __pyx_t_4 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 409, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 409, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- } else {
- __Pyx_RaiseNoneNotIterableError(); __PYX_ERR(1, 409, __pyx_L1_error)
- }
- __pyx_v_have_slices = __pyx_t_4;
- __pyx_t_4 = 0;
- __pyx_v_indices = __pyx_t_5;
- __pyx_t_5 = 0;
-
- /* "View.MemoryView":412
- *
- * cdef char *itemp
- * if have_slices: # <<<<<<<<<<<<<<
- * return memview_slice(self, indices)
- * else:
- */
- __pyx_t_2 = __Pyx_PyObject_IsTrue(__pyx_v_have_slices); if (unlikely(__pyx_t_2 < 0)) __PYX_ERR(1, 412, __pyx_L1_error)
- if (__pyx_t_2) {
-
- /* "View.MemoryView":413
- * cdef char *itemp
- * if have_slices:
- * return memview_slice(self, indices) # <<<<<<<<<<<<<<
- * else:
- * itemp = self.get_item_pointer(indices)
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_3 = ((PyObject *)__pyx_memview_slice(__pyx_v_self, __pyx_v_indices)); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 413, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":412
- *
- * cdef char *itemp
- * if have_slices: # <<<<<<<<<<<<<<
- * return memview_slice(self, indices)
- * else:
- */
- }
-
- /* "View.MemoryView":415
- * return memview_slice(self, indices)
- * else:
- * itemp = self.get_item_pointer(indices) # <<<<<<<<<<<<<<
- * return self.convert_item_to_object(itemp)
- *
- */
- /*else*/ {
- __pyx_t_6 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->get_item_pointer(__pyx_v_self, __pyx_v_indices); if (unlikely(__pyx_t_6 == ((char *)NULL))) __PYX_ERR(1, 415, __pyx_L1_error)
- __pyx_v_itemp = __pyx_t_6;
-
- /* "View.MemoryView":416
- * else:
- * itemp = self.get_item_pointer(indices)
- * return self.convert_item_to_object(itemp) # <<<<<<<<<<<<<<
- *
- * def __setitem__(memoryview self, object index, object value):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_3 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->convert_item_to_object(__pyx_v_self, __pyx_v_itemp); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 416, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":405
- *
- *
- * def __getitem__(memoryview self, object index): # <<<<<<<<<<<<<<
- * if index is Ellipsis:
- * return self
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__getitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_have_slices);
- __Pyx_XDECREF(__pyx_v_indices);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":418
- * return self.convert_item_to_object(itemp)
- *
- * def __setitem__(memoryview self, object index, object value): # <<<<<<<<<<<<<<
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview")
- */
-
-/* Python wrapper */
-static int __pyx_memoryview___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value); /*proto*/
-static int __pyx_memoryview___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setitem__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_6__setitem__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((PyObject *)__pyx_v_index), ((PyObject *)__pyx_v_value));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_6__setitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value) {
- PyObject *__pyx_v_have_slices = NULL;
- PyObject *__pyx_v_obj = NULL;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setitem__", 0);
- __Pyx_INCREF(__pyx_v_index);
-
- /* "View.MemoryView":419
- *
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly: # <<<<<<<<<<<<<<
- * raise TypeError("Cannot assign to read-only memoryview")
- *
- */
- __pyx_t_1 = (__pyx_v_self->view.readonly != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":420
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview") # <<<<<<<<<<<<<<
- *
- * have_slices, index = _unellipsify(index, self.view.ndim)
- */
- __pyx_t_2 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__9, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 420, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_Raise(__pyx_t_2, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __PYX_ERR(1, 420, __pyx_L1_error)
-
- /* "View.MemoryView":419
- *
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly: # <<<<<<<<<<<<<<
- * raise TypeError("Cannot assign to read-only memoryview")
- *
- */
- }
-
- /* "View.MemoryView":422
- * raise TypeError("Cannot assign to read-only memoryview")
- *
- * have_slices, index = _unellipsify(index, self.view.ndim) # <<<<<<<<<<<<<<
- *
- * if have_slices:
- */
- __pyx_t_2 = _unellipsify(__pyx_v_index, __pyx_v_self->view.ndim); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 422, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (likely(__pyx_t_2 != Py_None)) {
- PyObject* sequence = __pyx_t_2;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(1, 422, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_4 = PyTuple_GET_ITEM(sequence, 1);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_t_4);
- #else
- __pyx_t_3 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 422, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 422, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- #endif
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- } else {
- __Pyx_RaiseNoneNotIterableError(); __PYX_ERR(1, 422, __pyx_L1_error)
- }
- __pyx_v_have_slices = __pyx_t_3;
- __pyx_t_3 = 0;
- __Pyx_DECREF_SET(__pyx_v_index, __pyx_t_4);
- __pyx_t_4 = 0;
-
- /* "View.MemoryView":424
- * have_slices, index = _unellipsify(index, self.view.ndim)
- *
- * if have_slices: # <<<<<<<<<<<<<<
- * obj = self.is_slice(value)
- * if obj:
- */
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_v_have_slices); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 424, __pyx_L1_error)
- if (__pyx_t_1) {
-
- /* "View.MemoryView":425
- *
- * if have_slices:
- * obj = self.is_slice(value) # <<<<<<<<<<<<<<
- * if obj:
- * self.setitem_slice_assignment(self[index], obj)
- */
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->is_slice(__pyx_v_self, __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 425, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_v_obj = __pyx_t_2;
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":426
- * if have_slices:
- * obj = self.is_slice(value)
- * if obj: # <<<<<<<<<<<<<<
- * self.setitem_slice_assignment(self[index], obj)
- * else:
- */
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_v_obj); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 426, __pyx_L1_error)
- if (__pyx_t_1) {
-
- /* "View.MemoryView":427
- * obj = self.is_slice(value)
- * if obj:
- * self.setitem_slice_assignment(self[index], obj) # <<<<<<<<<<<<<<
- * else:
- * self.setitem_slice_assign_scalar(self[index], value)
- */
- __pyx_t_2 = __Pyx_PyObject_GetItem(((PyObject *)__pyx_v_self), __pyx_v_index); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 427, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_4 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->setitem_slice_assignment(__pyx_v_self, __pyx_t_2, __pyx_v_obj); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 427, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
-
- /* "View.MemoryView":426
- * if have_slices:
- * obj = self.is_slice(value)
- * if obj: # <<<<<<<<<<<<<<
- * self.setitem_slice_assignment(self[index], obj)
- * else:
- */
- goto __pyx_L5;
- }
-
- /* "View.MemoryView":429
- * self.setitem_slice_assignment(self[index], obj)
- * else:
- * self.setitem_slice_assign_scalar(self[index], value) # <<<<<<<<<<<<<<
- * else:
- * self.setitem_indexed(index, value)
- */
- /*else*/ {
- __pyx_t_4 = __Pyx_PyObject_GetItem(((PyObject *)__pyx_v_self), __pyx_v_index); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 429, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- if (!(likely(((__pyx_t_4) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_4, __pyx_memoryview_type))))) __PYX_ERR(1, 429, __pyx_L1_error)
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->setitem_slice_assign_scalar(__pyx_v_self, ((struct __pyx_memoryview_obj *)__pyx_t_4), __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 429, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_L5:;
-
- /* "View.MemoryView":424
- * have_slices, index = _unellipsify(index, self.view.ndim)
- *
- * if have_slices: # <<<<<<<<<<<<<<
- * obj = self.is_slice(value)
- * if obj:
- */
- goto __pyx_L4;
- }
-
- /* "View.MemoryView":431
- * self.setitem_slice_assign_scalar(self[index], value)
- * else:
- * self.setitem_indexed(index, value) # <<<<<<<<<<<<<<
- *
- * cdef is_slice(self, obj):
- */
- /*else*/ {
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->setitem_indexed(__pyx_v_self, __pyx_v_index, __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 431, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_L4:;
-
- /* "View.MemoryView":418
- * return self.convert_item_to_object(itemp)
- *
- * def __setitem__(memoryview self, object index, object value): # <<<<<<<<<<<<<<
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview")
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__setitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_have_slices);
- __Pyx_XDECREF(__pyx_v_obj);
- __Pyx_XDECREF(__pyx_v_index);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":433
- * self.setitem_indexed(index, value)
- *
- * cdef is_slice(self, obj): # <<<<<<<<<<<<<<
- * if not isinstance(obj, memoryview):
- * try:
- */
-
-static PyObject *__pyx_memoryview_is_slice(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- PyObject *__pyx_t_7 = NULL;
- PyObject *__pyx_t_8 = NULL;
- int __pyx_t_9;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("is_slice", 0);
- __Pyx_INCREF(__pyx_v_obj);
-
- /* "View.MemoryView":434
- *
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview): # <<<<<<<<<<<<<<
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- */
- __pyx_t_1 = __Pyx_TypeCheck(__pyx_v_obj, __pyx_memoryview_type);
- __pyx_t_2 = ((!(__pyx_t_1 != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":435
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview):
- * try: # <<<<<<<<<<<<<<
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- */
- {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ExceptionSave(&__pyx_t_3, &__pyx_t_4, &__pyx_t_5);
- __Pyx_XGOTREF(__pyx_t_3);
- __Pyx_XGOTREF(__pyx_t_4);
- __Pyx_XGOTREF(__pyx_t_5);
- /*try:*/ {
-
- /* "View.MemoryView":436
- * if not isinstance(obj, memoryview):
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS, # <<<<<<<<<<<<<<
- * self.dtype_is_object)
- * except TypeError:
- */
- __pyx_t_6 = __Pyx_PyInt_From_int(((__pyx_v_self->flags & (~PyBUF_WRITABLE)) | PyBUF_ANY_CONTIGUOUS)); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 436, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_6);
-
- /* "View.MemoryView":437
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object) # <<<<<<<<<<<<<<
- * except TypeError:
- * return None
- */
- __pyx_t_7 = __Pyx_PyBool_FromLong(__pyx_v_self->dtype_is_object); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 437, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_7);
-
- /* "View.MemoryView":436
- * if not isinstance(obj, memoryview):
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS, # <<<<<<<<<<<<<<
- * self.dtype_is_object)
- * except TypeError:
- */
- __pyx_t_8 = PyTuple_New(3); if (unlikely(!__pyx_t_8)) __PYX_ERR(1, 436, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_INCREF(__pyx_v_obj);
- __Pyx_GIVEREF(__pyx_v_obj);
- PyTuple_SET_ITEM(__pyx_t_8, 0, __pyx_v_obj);
- __Pyx_GIVEREF(__pyx_t_6);
- PyTuple_SET_ITEM(__pyx_t_8, 1, __pyx_t_6);
- __Pyx_GIVEREF(__pyx_t_7);
- PyTuple_SET_ITEM(__pyx_t_8, 2, __pyx_t_7);
- __pyx_t_6 = 0;
- __pyx_t_7 = 0;
- __pyx_t_7 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryview_type), __pyx_t_8, NULL); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 436, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- __Pyx_DECREF_SET(__pyx_v_obj, __pyx_t_7);
- __pyx_t_7 = 0;
-
- /* "View.MemoryView":435
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview):
- * try: # <<<<<<<<<<<<<<
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- */
- }
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_XDECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- goto __pyx_L9_try_end;
- __pyx_L4_error:;
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_XDECREF(__pyx_t_8); __pyx_t_8 = 0;
-
- /* "View.MemoryView":438
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- * except TypeError: # <<<<<<<<<<<<<<
- * return None
- *
- */
- __pyx_t_9 = __Pyx_PyErr_ExceptionMatches(__pyx_builtin_TypeError);
- if (__pyx_t_9) {
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- if (__Pyx_GetException(&__pyx_t_7, &__pyx_t_8, &__pyx_t_6) < 0) __PYX_ERR(1, 438, __pyx_L6_except_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_GOTREF(__pyx_t_6);
-
- /* "View.MemoryView":439
- * self.dtype_is_object)
- * except TypeError:
- * return None # <<<<<<<<<<<<<<
- *
- * return obj
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- goto __pyx_L7_except_return;
- }
- goto __pyx_L6_except_error;
- __pyx_L6_except_error:;
-
- /* "View.MemoryView":435
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview):
- * try: # <<<<<<<<<<<<<<
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- */
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_XGIVEREF(__pyx_t_5);
- __Pyx_ExceptionReset(__pyx_t_3, __pyx_t_4, __pyx_t_5);
- goto __pyx_L1_error;
- __pyx_L7_except_return:;
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_XGIVEREF(__pyx_t_5);
- __Pyx_ExceptionReset(__pyx_t_3, __pyx_t_4, __pyx_t_5);
- goto __pyx_L0;
- __pyx_L9_try_end:;
- }
-
- /* "View.MemoryView":434
- *
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview): # <<<<<<<<<<<<<<
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- */
- }
-
- /* "View.MemoryView":441
- * return None
- *
- * return obj # <<<<<<<<<<<<<<
- *
- * cdef setitem_slice_assignment(self, dst, src):
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_obj);
- __pyx_r = __pyx_v_obj;
- goto __pyx_L0;
-
- /* "View.MemoryView":433
- * self.setitem_indexed(index, value)
- *
- * cdef is_slice(self, obj): # <<<<<<<<<<<<<<
- * if not isinstance(obj, memoryview):
- * try:
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_8);
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_obj);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":443
- * return obj
- *
- * cdef setitem_slice_assignment(self, dst, src): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice dst_slice
- * cdef __Pyx_memviewslice src_slice
- */
-
-static PyObject *__pyx_memoryview_setitem_slice_assignment(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_dst, PyObject *__pyx_v_src) {
- __Pyx_memviewslice __pyx_v_dst_slice;
- __Pyx_memviewslice __pyx_v_src_slice;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- __Pyx_memviewslice *__pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- int __pyx_t_5;
- int __pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("setitem_slice_assignment", 0);
-
- /* "View.MemoryView":447
- * cdef __Pyx_memviewslice src_slice
- *
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0], # <<<<<<<<<<<<<<
- * get_slice_from_memview(dst, &dst_slice)[0],
- * src.ndim, dst.ndim, self.dtype_is_object)
- */
- if (!(likely(((__pyx_v_src) == Py_None) || likely(__Pyx_TypeTest(__pyx_v_src, __pyx_memoryview_type))))) __PYX_ERR(1, 447, __pyx_L1_error)
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(((struct __pyx_memoryview_obj *)__pyx_v_src), (&__pyx_v_src_slice)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 447, __pyx_L1_error)
-
- /* "View.MemoryView":448
- *
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0],
- * get_slice_from_memview(dst, &dst_slice)[0], # <<<<<<<<<<<<<<
- * src.ndim, dst.ndim, self.dtype_is_object)
- *
- */
- if (!(likely(((__pyx_v_dst) == Py_None) || likely(__Pyx_TypeTest(__pyx_v_dst, __pyx_memoryview_type))))) __PYX_ERR(1, 448, __pyx_L1_error)
- __pyx_t_2 = __pyx_memoryview_get_slice_from_memoryview(((struct __pyx_memoryview_obj *)__pyx_v_dst), (&__pyx_v_dst_slice)); if (unlikely(__pyx_t_2 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 448, __pyx_L1_error)
-
- /* "View.MemoryView":449
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0],
- * get_slice_from_memview(dst, &dst_slice)[0],
- * src.ndim, dst.ndim, self.dtype_is_object) # <<<<<<<<<<<<<<
- *
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value):
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_src, __pyx_n_s_ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_PyInt_As_int(__pyx_t_3); if (unlikely((__pyx_t_4 == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_dst, __pyx_n_s_ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_5 = __Pyx_PyInt_As_int(__pyx_t_3); if (unlikely((__pyx_t_5 == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":447
- * cdef __Pyx_memviewslice src_slice
- *
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0], # <<<<<<<<<<<<<<
- * get_slice_from_memview(dst, &dst_slice)[0],
- * src.ndim, dst.ndim, self.dtype_is_object)
- */
- __pyx_t_6 = __pyx_memoryview_copy_contents((__pyx_t_1[0]), (__pyx_t_2[0]), __pyx_t_4, __pyx_t_5, __pyx_v_self->dtype_is_object); if (unlikely(__pyx_t_6 == ((int)-1))) __PYX_ERR(1, 447, __pyx_L1_error)
-
- /* "View.MemoryView":443
- * return obj
- *
- * cdef setitem_slice_assignment(self, dst, src): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice dst_slice
- * cdef __Pyx_memviewslice src_slice
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.setitem_slice_assignment", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":451
- * src.ndim, dst.ndim, self.dtype_is_object)
- *
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value): # <<<<<<<<<<<<<<
- * cdef int array[128]
- * cdef void *tmp = NULL
- */
-
-static PyObject *__pyx_memoryview_setitem_slice_assign_scalar(struct __pyx_memoryview_obj *__pyx_v_self, struct __pyx_memoryview_obj *__pyx_v_dst, PyObject *__pyx_v_value) {
- int __pyx_v_array[0x80];
- void *__pyx_v_tmp;
- void *__pyx_v_item;
- __Pyx_memviewslice *__pyx_v_dst_slice;
- __Pyx_memviewslice __pyx_v_tmp_slice;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- int __pyx_t_5;
- char const *__pyx_t_6;
- PyObject *__pyx_t_7 = NULL;
- PyObject *__pyx_t_8 = NULL;
- PyObject *__pyx_t_9 = NULL;
- PyObject *__pyx_t_10 = NULL;
- PyObject *__pyx_t_11 = NULL;
- PyObject *__pyx_t_12 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("setitem_slice_assign_scalar", 0);
-
- /* "View.MemoryView":453
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value):
- * cdef int array[128]
- * cdef void *tmp = NULL # <<<<<<<<<<<<<<
- * cdef void *item
- *
- */
- __pyx_v_tmp = NULL;
-
- /* "View.MemoryView":458
- * cdef __Pyx_memviewslice *dst_slice
- * cdef __Pyx_memviewslice tmp_slice
- * dst_slice = get_slice_from_memview(dst, &tmp_slice) # <<<<<<<<<<<<<<
- *
- * if self.view.itemsize > sizeof(array):
- */
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(__pyx_v_dst, (&__pyx_v_tmp_slice)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 458, __pyx_L1_error)
- __pyx_v_dst_slice = __pyx_t_1;
-
- /* "View.MemoryView":460
- * dst_slice = get_slice_from_memview(dst, &tmp_slice)
- *
- * if self.view.itemsize > sizeof(array): # <<<<<<<<<<<<<<
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL:
- */
- __pyx_t_2 = ((((size_t)__pyx_v_self->view.itemsize) > (sizeof(__pyx_v_array))) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":461
- *
- * if self.view.itemsize > sizeof(array):
- * tmp = PyMem_Malloc(self.view.itemsize) # <<<<<<<<<<<<<<
- * if tmp == NULL:
- * raise MemoryError
- */
- __pyx_v_tmp = PyMem_Malloc(__pyx_v_self->view.itemsize);
-
- /* "View.MemoryView":462
- * if self.view.itemsize > sizeof(array):
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- * item = tmp
- */
- __pyx_t_2 = ((__pyx_v_tmp == NULL) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":463
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL:
- * raise MemoryError # <<<<<<<<<<<<<<
- * item = tmp
- * else:
- */
- PyErr_NoMemory(); __PYX_ERR(1, 463, __pyx_L1_error)
-
- /* "View.MemoryView":462
- * if self.view.itemsize > sizeof(array):
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- * item = tmp
- */
- }
-
- /* "View.MemoryView":464
- * if tmp == NULL:
- * raise MemoryError
- * item = tmp # <<<<<<<<<<<<<<
- * else:
- * item = array
- */
- __pyx_v_item = __pyx_v_tmp;
-
- /* "View.MemoryView":460
- * dst_slice = get_slice_from_memview(dst, &tmp_slice)
- *
- * if self.view.itemsize > sizeof(array): # <<<<<<<<<<<<<<
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":466
- * item = tmp
- * else:
- * item = array # <<<<<<<<<<<<<<
- *
- * try:
- */
- /*else*/ {
- __pyx_v_item = ((void *)__pyx_v_array);
- }
- __pyx_L3:;
-
- /* "View.MemoryView":468
- * item = array
- *
- * try: # <<<<<<<<<<<<<<
- * if self.dtype_is_object:
- * ( item)[0] = value
- */
- /*try:*/ {
-
- /* "View.MemoryView":469
- *
- * try:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * ( item)[0] = value
- * else:
- */
- __pyx_t_2 = (__pyx_v_self->dtype_is_object != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":470
- * try:
- * if self.dtype_is_object:
- * ( item)[0] = value # <<<<<<<<<<<<<<
- * else:
- * self.assign_item_from_object( item, value)
- */
- (((PyObject **)__pyx_v_item)[0]) = ((PyObject *)__pyx_v_value);
-
- /* "View.MemoryView":469
- *
- * try:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * ( item)[0] = value
- * else:
- */
- goto __pyx_L8;
- }
-
- /* "View.MemoryView":472
- * ( item)[0] = value
- * else:
- * self.assign_item_from_object( item, value) # <<<<<<<<<<<<<<
- *
- *
- */
- /*else*/ {
- __pyx_t_3 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->assign_item_from_object(__pyx_v_self, ((char *)__pyx_v_item), __pyx_v_value); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 472, __pyx_L6_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- }
- __pyx_L8:;
-
- /* "View.MemoryView":476
- *
- *
- * if self.view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim)
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize,
- */
- __pyx_t_2 = ((__pyx_v_self->view.suboffsets != NULL) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":477
- *
- * if self.view.suboffsets != NULL:
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim) # <<<<<<<<<<<<<<
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize,
- * item, self.dtype_is_object)
- */
- __pyx_t_3 = assert_direct_dimensions(__pyx_v_self->view.suboffsets, __pyx_v_self->view.ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 477, __pyx_L6_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":476
- *
- *
- * if self.view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim)
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize,
- */
- }
-
- /* "View.MemoryView":478
- * if self.view.suboffsets != NULL:
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim)
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize, # <<<<<<<<<<<<<<
- * item, self.dtype_is_object)
- * finally:
- */
- __pyx_memoryview_slice_assign_scalar(__pyx_v_dst_slice, __pyx_v_dst->view.ndim, __pyx_v_self->view.itemsize, __pyx_v_item, __pyx_v_self->dtype_is_object);
- }
-
- /* "View.MemoryView":481
- * item, self.dtype_is_object)
- * finally:
- * PyMem_Free(tmp) # <<<<<<<<<<<<<<
- *
- * cdef setitem_indexed(self, index, value):
- */
- /*finally:*/ {
- /*normal exit:*/{
- PyMem_Free(__pyx_v_tmp);
- goto __pyx_L7;
- }
- __pyx_L6_error:;
- /*exception exit:*/{
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __pyx_t_7 = 0; __pyx_t_8 = 0; __pyx_t_9 = 0; __pyx_t_10 = 0; __pyx_t_11 = 0; __pyx_t_12 = 0;
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (PY_MAJOR_VERSION >= 3) __Pyx_ExceptionSwap(&__pyx_t_10, &__pyx_t_11, &__pyx_t_12);
- if ((PY_MAJOR_VERSION < 3) || unlikely(__Pyx_GetException(&__pyx_t_7, &__pyx_t_8, &__pyx_t_9) < 0)) __Pyx_ErrFetch(&__pyx_t_7, &__pyx_t_8, &__pyx_t_9);
- __Pyx_XGOTREF(__pyx_t_7);
- __Pyx_XGOTREF(__pyx_t_8);
- __Pyx_XGOTREF(__pyx_t_9);
- __Pyx_XGOTREF(__pyx_t_10);
- __Pyx_XGOTREF(__pyx_t_11);
- __Pyx_XGOTREF(__pyx_t_12);
- __pyx_t_4 = __pyx_lineno; __pyx_t_5 = __pyx_clineno; __pyx_t_6 = __pyx_filename;
- {
- PyMem_Free(__pyx_v_tmp);
- }
- if (PY_MAJOR_VERSION >= 3) {
- __Pyx_XGIVEREF(__pyx_t_10);
- __Pyx_XGIVEREF(__pyx_t_11);
- __Pyx_XGIVEREF(__pyx_t_12);
- __Pyx_ExceptionReset(__pyx_t_10, __pyx_t_11, __pyx_t_12);
- }
- __Pyx_XGIVEREF(__pyx_t_7);
- __Pyx_XGIVEREF(__pyx_t_8);
- __Pyx_XGIVEREF(__pyx_t_9);
- __Pyx_ErrRestore(__pyx_t_7, __pyx_t_8, __pyx_t_9);
- __pyx_t_7 = 0; __pyx_t_8 = 0; __pyx_t_9 = 0; __pyx_t_10 = 0; __pyx_t_11 = 0; __pyx_t_12 = 0;
- __pyx_lineno = __pyx_t_4; __pyx_clineno = __pyx_t_5; __pyx_filename = __pyx_t_6;
- goto __pyx_L1_error;
- }
- __pyx_L7:;
- }
-
- /* "View.MemoryView":451
- * src.ndim, dst.ndim, self.dtype_is_object)
- *
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value): # <<<<<<<<<<<<<<
- * cdef int array[128]
- * cdef void *tmp = NULL
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.setitem_slice_assign_scalar", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":483
- * PyMem_Free(tmp)
- *
- * cdef setitem_indexed(self, index, value): # <<<<<<<<<<<<<<
- * cdef char *itemp = self.get_item_pointer(index)
- * self.assign_item_from_object(itemp, value)
- */
-
-static PyObject *__pyx_memoryview_setitem_indexed(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value) {
- char *__pyx_v_itemp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- char *__pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("setitem_indexed", 0);
-
- /* "View.MemoryView":484
- *
- * cdef setitem_indexed(self, index, value):
- * cdef char *itemp = self.get_item_pointer(index) # <<<<<<<<<<<<<<
- * self.assign_item_from_object(itemp, value)
- *
- */
- __pyx_t_1 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->get_item_pointer(__pyx_v_self, __pyx_v_index); if (unlikely(__pyx_t_1 == ((char *)NULL))) __PYX_ERR(1, 484, __pyx_L1_error)
- __pyx_v_itemp = __pyx_t_1;
-
- /* "View.MemoryView":485
- * cdef setitem_indexed(self, index, value):
- * cdef char *itemp = self.get_item_pointer(index)
- * self.assign_item_from_object(itemp, value) # <<<<<<<<<<<<<<
- *
- * cdef convert_item_to_object(self, char *itemp):
- */
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->assign_item_from_object(__pyx_v_self, __pyx_v_itemp, __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 485, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "View.MemoryView":483
- * PyMem_Free(tmp)
- *
- * cdef setitem_indexed(self, index, value): # <<<<<<<<<<<<<<
- * cdef char *itemp = self.get_item_pointer(index)
- * self.assign_item_from_object(itemp, value)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.setitem_indexed", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":487
- * self.assign_item_from_object(itemp, value)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
-static PyObject *__pyx_memoryview_convert_item_to_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp) {
- PyObject *__pyx_v_struct = NULL;
- PyObject *__pyx_v_bytesitem = 0;
- PyObject *__pyx_v_result = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- PyObject *__pyx_t_7 = NULL;
- int __pyx_t_8;
- PyObject *__pyx_t_9 = NULL;
- size_t __pyx_t_10;
- int __pyx_t_11;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("convert_item_to_object", 0);
-
- /* "View.MemoryView":490
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- * import struct # <<<<<<<<<<<<<<
- * cdef bytes bytesitem
- *
- */
- __pyx_t_1 = __Pyx_Import(__pyx_n_s_struct, 0, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 490, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v_struct = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":493
- * cdef bytes bytesitem
- *
- * bytesitem = itemp[:self.view.itemsize] # <<<<<<<<<<<<<<
- * try:
- * result = struct.unpack(self.view.format, bytesitem)
- */
- __pyx_t_1 = __Pyx_PyBytes_FromStringAndSize(__pyx_v_itemp + 0, __pyx_v_self->view.itemsize - 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 493, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v_bytesitem = ((PyObject*)__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":494
- *
- * bytesitem = itemp[:self.view.itemsize]
- * try: # <<<<<<<<<<<<<<
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- */
- {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ExceptionSave(&__pyx_t_2, &__pyx_t_3, &__pyx_t_4);
- __Pyx_XGOTREF(__pyx_t_2);
- __Pyx_XGOTREF(__pyx_t_3);
- __Pyx_XGOTREF(__pyx_t_4);
- /*try:*/ {
-
- /* "View.MemoryView":495
- * bytesitem = itemp[:self.view.itemsize]
- * try:
- * result = struct.unpack(self.view.format, bytesitem) # <<<<<<<<<<<<<<
- * except struct.error:
- * raise ValueError("Unable to convert item to object")
- */
- __pyx_t_5 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_unpack); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_6 = __Pyx_PyBytes_FromString(__pyx_v_self->view.format); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_7 = NULL;
- __pyx_t_8 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_5))) {
- __pyx_t_7 = PyMethod_GET_SELF(__pyx_t_5);
- if (likely(__pyx_t_7)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_5);
- __Pyx_INCREF(__pyx_t_7);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_5, function);
- __pyx_t_8 = 1;
- }
- }
- #if CYTHON_FAST_PYCALL
- if (PyFunction_Check(__pyx_t_5)) {
- PyObject *__pyx_temp[3] = {__pyx_t_7, __pyx_t_6, __pyx_v_bytesitem};
- __pyx_t_1 = __Pyx_PyFunction_FastCall(__pyx_t_5, __pyx_temp+1-__pyx_t_8, 2+__pyx_t_8); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- } else
- #endif
- #if CYTHON_FAST_PYCCALL
- if (__Pyx_PyFastCFunction_Check(__pyx_t_5)) {
- PyObject *__pyx_temp[3] = {__pyx_t_7, __pyx_t_6, __pyx_v_bytesitem};
- __pyx_t_1 = __Pyx_PyCFunction_FastCall(__pyx_t_5, __pyx_temp+1-__pyx_t_8, 2+__pyx_t_8); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- } else
- #endif
- {
- __pyx_t_9 = PyTuple_New(2+__pyx_t_8); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_9);
- if (__pyx_t_7) {
- __Pyx_GIVEREF(__pyx_t_7); PyTuple_SET_ITEM(__pyx_t_9, 0, __pyx_t_7); __pyx_t_7 = NULL;
- }
- __Pyx_GIVEREF(__pyx_t_6);
- PyTuple_SET_ITEM(__pyx_t_9, 0+__pyx_t_8, __pyx_t_6);
- __Pyx_INCREF(__pyx_v_bytesitem);
- __Pyx_GIVEREF(__pyx_v_bytesitem);
- PyTuple_SET_ITEM(__pyx_t_9, 1+__pyx_t_8, __pyx_v_bytesitem);
- __pyx_t_6 = 0;
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_t_5, __pyx_t_9, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- }
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_v_result = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":494
- *
- * bytesitem = itemp[:self.view.itemsize]
- * try: # <<<<<<<<<<<<<<
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- */
- }
-
- /* "View.MemoryView":499
- * raise ValueError("Unable to convert item to object")
- * else:
- * if len(self.view.format) == 1: # <<<<<<<<<<<<<<
- * return result[0]
- * return result
- */
- /*else:*/ {
- __pyx_t_10 = strlen(__pyx_v_self->view.format);
- __pyx_t_11 = ((__pyx_t_10 == 1) != 0);
- if (__pyx_t_11) {
-
- /* "View.MemoryView":500
- * else:
- * if len(self.view.format) == 1:
- * return result[0] # <<<<<<<<<<<<<<
- * return result
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_GetItemInt(__pyx_v_result, 0, long, 1, __Pyx_PyInt_From_long, 0, 0, 1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 500, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L6_except_return;
-
- /* "View.MemoryView":499
- * raise ValueError("Unable to convert item to object")
- * else:
- * if len(self.view.format) == 1: # <<<<<<<<<<<<<<
- * return result[0]
- * return result
- */
- }
-
- /* "View.MemoryView":501
- * if len(self.view.format) == 1:
- * return result[0]
- * return result # <<<<<<<<<<<<<<
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_result);
- __pyx_r = __pyx_v_result;
- goto __pyx_L6_except_return;
- }
- __pyx_L3_error:;
- __Pyx_XDECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_XDECREF(__pyx_t_9); __pyx_t_9 = 0;
-
- /* "View.MemoryView":496
- * try:
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error: # <<<<<<<<<<<<<<
- * raise ValueError("Unable to convert item to object")
- * else:
- */
- __Pyx_ErrFetch(&__pyx_t_1, &__pyx_t_5, &__pyx_t_9);
- __pyx_t_6 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_error); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 496, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_8 = __Pyx_PyErr_GivenExceptionMatches(__pyx_t_1, __pyx_t_6);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_ErrRestore(__pyx_t_1, __pyx_t_5, __pyx_t_9);
- __pyx_t_1 = 0; __pyx_t_5 = 0; __pyx_t_9 = 0;
- if (__pyx_t_8) {
- __Pyx_AddTraceback("View.MemoryView.memoryview.convert_item_to_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- if (__Pyx_GetException(&__pyx_t_9, &__pyx_t_5, &__pyx_t_1) < 0) __PYX_ERR(1, 496, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_9);
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "View.MemoryView":497
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- * raise ValueError("Unable to convert item to object") # <<<<<<<<<<<<<<
- * else:
- * if len(self.view.format) == 1:
- */
- __pyx_t_6 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__10, NULL); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 497, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_Raise(__pyx_t_6, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __PYX_ERR(1, 497, __pyx_L5_except_error)
- }
- goto __pyx_L5_except_error;
- __pyx_L5_except_error:;
-
- /* "View.MemoryView":494
- *
- * bytesitem = itemp[:self.view.itemsize]
- * try: # <<<<<<<<<<<<<<
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- */
- __Pyx_XGIVEREF(__pyx_t_2);
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_ExceptionReset(__pyx_t_2, __pyx_t_3, __pyx_t_4);
- goto __pyx_L1_error;
- __pyx_L6_except_return:;
- __Pyx_XGIVEREF(__pyx_t_2);
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_ExceptionReset(__pyx_t_2, __pyx_t_3, __pyx_t_4);
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":487
- * self.assign_item_from_object(itemp, value)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_9);
- __Pyx_AddTraceback("View.MemoryView.memoryview.convert_item_to_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_struct);
- __Pyx_XDECREF(__pyx_v_bytesitem);
- __Pyx_XDECREF(__pyx_v_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":503
- * return result
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
-static PyObject *__pyx_memoryview_assign_item_from_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value) {
- PyObject *__pyx_v_struct = NULL;
- char __pyx_v_c;
- PyObject *__pyx_v_bytesvalue = 0;
- Py_ssize_t __pyx_v_i;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_t_3;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_t_7;
- PyObject *__pyx_t_8 = NULL;
- Py_ssize_t __pyx_t_9;
- PyObject *__pyx_t_10 = NULL;
- char *__pyx_t_11;
- char *__pyx_t_12;
- char *__pyx_t_13;
- char *__pyx_t_14;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("assign_item_from_object", 0);
-
- /* "View.MemoryView":506
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- * import struct # <<<<<<<<<<<<<<
- * cdef char c
- * cdef bytes bytesvalue
- */
- __pyx_t_1 = __Pyx_Import(__pyx_n_s_struct, 0, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 506, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v_struct = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":511
- * cdef Py_ssize_t i
- *
- * if isinstance(value, tuple): # <<<<<<<<<<<<<<
- * bytesvalue = struct.pack(self.view.format, *value)
- * else:
- */
- __pyx_t_2 = PyTuple_Check(__pyx_v_value);
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (__pyx_t_3) {
-
- /* "View.MemoryView":512
- *
- * if isinstance(value, tuple):
- * bytesvalue = struct.pack(self.view.format, *value) # <<<<<<<<<<<<<<
- * else:
- * bytesvalue = struct.pack(self.view.format, value)
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_pack); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_4 = __Pyx_PyBytes_FromString(__pyx_v_self->view.format); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = PyTuple_New(1); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_5, 0, __pyx_t_4);
- __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PySequence_Tuple(__pyx_v_value); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_6 = PyNumber_Add(__pyx_t_5, __pyx_t_4); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PyObject_Call(__pyx_t_1, __pyx_t_6, NULL); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (!(likely(PyBytes_CheckExact(__pyx_t_4))||((__pyx_t_4) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "bytes", Py_TYPE(__pyx_t_4)->tp_name), 0))) __PYX_ERR(1, 512, __pyx_L1_error)
- __pyx_v_bytesvalue = ((PyObject*)__pyx_t_4);
- __pyx_t_4 = 0;
-
- /* "View.MemoryView":511
- * cdef Py_ssize_t i
- *
- * if isinstance(value, tuple): # <<<<<<<<<<<<<<
- * bytesvalue = struct.pack(self.view.format, *value)
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":514
- * bytesvalue = struct.pack(self.view.format, *value)
- * else:
- * bytesvalue = struct.pack(self.view.format, value) # <<<<<<<<<<<<<<
- *
- * for i, c in enumerate(bytesvalue):
- */
- /*else*/ {
- __pyx_t_6 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_pack); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_1 = __Pyx_PyBytes_FromString(__pyx_v_self->view.format); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_5 = NULL;
- __pyx_t_7 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_6))) {
- __pyx_t_5 = PyMethod_GET_SELF(__pyx_t_6);
- if (likely(__pyx_t_5)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_6);
- __Pyx_INCREF(__pyx_t_5);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_6, function);
- __pyx_t_7 = 1;
- }
- }
- #if CYTHON_FAST_PYCALL
- if (PyFunction_Check(__pyx_t_6)) {
- PyObject *__pyx_temp[3] = {__pyx_t_5, __pyx_t_1, __pyx_v_value};
- __pyx_t_4 = __Pyx_PyFunction_FastCall(__pyx_t_6, __pyx_temp+1-__pyx_t_7, 2+__pyx_t_7); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- } else
- #endif
- #if CYTHON_FAST_PYCCALL
- if (__Pyx_PyFastCFunction_Check(__pyx_t_6)) {
- PyObject *__pyx_temp[3] = {__pyx_t_5, __pyx_t_1, __pyx_v_value};
- __pyx_t_4 = __Pyx_PyCFunction_FastCall(__pyx_t_6, __pyx_temp+1-__pyx_t_7, 2+__pyx_t_7); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- } else
- #endif
- {
- __pyx_t_8 = PyTuple_New(2+__pyx_t_7); if (unlikely(!__pyx_t_8)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- if (__pyx_t_5) {
- __Pyx_GIVEREF(__pyx_t_5); PyTuple_SET_ITEM(__pyx_t_8, 0, __pyx_t_5); __pyx_t_5 = NULL;
- }
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_8, 0+__pyx_t_7, __pyx_t_1);
- __Pyx_INCREF(__pyx_v_value);
- __Pyx_GIVEREF(__pyx_v_value);
- PyTuple_SET_ITEM(__pyx_t_8, 1+__pyx_t_7, __pyx_v_value);
- __pyx_t_1 = 0;
- __pyx_t_4 = __Pyx_PyObject_Call(__pyx_t_6, __pyx_t_8, NULL); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- }
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (!(likely(PyBytes_CheckExact(__pyx_t_4))||((__pyx_t_4) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "bytes", Py_TYPE(__pyx_t_4)->tp_name), 0))) __PYX_ERR(1, 514, __pyx_L1_error)
- __pyx_v_bytesvalue = ((PyObject*)__pyx_t_4);
- __pyx_t_4 = 0;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":516
- * bytesvalue = struct.pack(self.view.format, value)
- *
- * for i, c in enumerate(bytesvalue): # <<<<<<<<<<<<<<
- * itemp[i] = c
- *
- */
- __pyx_t_9 = 0;
- if (unlikely(__pyx_v_bytesvalue == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' is not iterable");
- __PYX_ERR(1, 516, __pyx_L1_error)
- }
- __Pyx_INCREF(__pyx_v_bytesvalue);
- __pyx_t_10 = __pyx_v_bytesvalue;
- __pyx_t_12 = PyBytes_AS_STRING(__pyx_t_10);
- __pyx_t_13 = (__pyx_t_12 + PyBytes_GET_SIZE(__pyx_t_10));
- for (__pyx_t_14 = __pyx_t_12; __pyx_t_14 < __pyx_t_13; __pyx_t_14++) {
- __pyx_t_11 = __pyx_t_14;
- __pyx_v_c = (__pyx_t_11[0]);
-
- /* "View.MemoryView":517
- *
- * for i, c in enumerate(bytesvalue):
- * itemp[i] = c # <<<<<<<<<<<<<<
- *
- * @cname('getbuffer')
- */
- __pyx_v_i = __pyx_t_9;
-
- /* "View.MemoryView":516
- * bytesvalue = struct.pack(self.view.format, value)
- *
- * for i, c in enumerate(bytesvalue): # <<<<<<<<<<<<<<
- * itemp[i] = c
- *
- */
- __pyx_t_9 = (__pyx_t_9 + 1);
-
- /* "View.MemoryView":517
- *
- * for i, c in enumerate(bytesvalue):
- * itemp[i] = c # <<<<<<<<<<<<<<
- *
- * @cname('getbuffer')
- */
- (__pyx_v_itemp[__pyx_v_i]) = __pyx_v_c;
- }
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
-
- /* "View.MemoryView":503
- * return result
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_8);
- __Pyx_XDECREF(__pyx_t_10);
- __Pyx_AddTraceback("View.MemoryView.memoryview.assign_item_from_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_struct);
- __Pyx_XDECREF(__pyx_v_bytesvalue);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":520
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- */
-
-/* Python wrapper */
-static CYTHON_UNUSED int __pyx_memoryview_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-static CYTHON_UNUSED int __pyx_memoryview_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getbuffer__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_8__getbuffer__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((Py_buffer *)__pyx_v_info), ((int)__pyx_v_flags));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_8__getbuffer__(struct __pyx_memoryview_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- Py_ssize_t *__pyx_t_4;
- char *__pyx_t_5;
- void *__pyx_t_6;
- int __pyx_t_7;
- Py_ssize_t __pyx_t_8;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- if (__pyx_v_info == NULL) {
- PyErr_SetString(PyExc_BufferError, "PyObject_GetBuffer: view==NULL argument is obsolete");
- return -1;
- }
- __Pyx_RefNannySetupContext("__getbuffer__", 0);
- __pyx_v_info->obj = Py_None; __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(__pyx_v_info->obj);
-
- /* "View.MemoryView":521
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly: # <<<<<<<<<<<<<<
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- */
- __pyx_t_2 = ((__pyx_v_flags & PyBUF_WRITABLE) != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L4_bool_binop_done;
- }
- __pyx_t_2 = (__pyx_v_self->view.readonly != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L4_bool_binop_done:;
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":522
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview") # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_ND:
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__11, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 522, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 522, __pyx_L1_error)
-
- /* "View.MemoryView":521
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly: # <<<<<<<<<<<<<<
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- */
- }
-
- /* "View.MemoryView":524
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- * if flags & PyBUF_ND: # <<<<<<<<<<<<<<
- * info.shape = self.view.shape
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_ND) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":525
- *
- * if flags & PyBUF_ND:
- * info.shape = self.view.shape # <<<<<<<<<<<<<<
- * else:
- * info.shape = NULL
- */
- __pyx_t_4 = __pyx_v_self->view.shape;
- __pyx_v_info->shape = __pyx_t_4;
-
- /* "View.MemoryView":524
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- * if flags & PyBUF_ND: # <<<<<<<<<<<<<<
- * info.shape = self.view.shape
- * else:
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":527
- * info.shape = self.view.shape
- * else:
- * info.shape = NULL # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_STRIDES:
- */
- /*else*/ {
- __pyx_v_info->shape = NULL;
- }
- __pyx_L6:;
-
- /* "View.MemoryView":529
- * info.shape = NULL
- *
- * if flags & PyBUF_STRIDES: # <<<<<<<<<<<<<<
- * info.strides = self.view.strides
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_STRIDES) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":530
- *
- * if flags & PyBUF_STRIDES:
- * info.strides = self.view.strides # <<<<<<<<<<<<<<
- * else:
- * info.strides = NULL
- */
- __pyx_t_4 = __pyx_v_self->view.strides;
- __pyx_v_info->strides = __pyx_t_4;
-
- /* "View.MemoryView":529
- * info.shape = NULL
- *
- * if flags & PyBUF_STRIDES: # <<<<<<<<<<<<<<
- * info.strides = self.view.strides
- * else:
- */
- goto __pyx_L7;
- }
-
- /* "View.MemoryView":532
- * info.strides = self.view.strides
- * else:
- * info.strides = NULL # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_INDIRECT:
- */
- /*else*/ {
- __pyx_v_info->strides = NULL;
- }
- __pyx_L7:;
-
- /* "View.MemoryView":534
- * info.strides = NULL
- *
- * if flags & PyBUF_INDIRECT: # <<<<<<<<<<<<<<
- * info.suboffsets = self.view.suboffsets
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_INDIRECT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":535
- *
- * if flags & PyBUF_INDIRECT:
- * info.suboffsets = self.view.suboffsets # <<<<<<<<<<<<<<
- * else:
- * info.suboffsets = NULL
- */
- __pyx_t_4 = __pyx_v_self->view.suboffsets;
- __pyx_v_info->suboffsets = __pyx_t_4;
-
- /* "View.MemoryView":534
- * info.strides = NULL
- *
- * if flags & PyBUF_INDIRECT: # <<<<<<<<<<<<<<
- * info.suboffsets = self.view.suboffsets
- * else:
- */
- goto __pyx_L8;
- }
-
- /* "View.MemoryView":537
- * info.suboffsets = self.view.suboffsets
- * else:
- * info.suboffsets = NULL # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_FORMAT:
- */
- /*else*/ {
- __pyx_v_info->suboffsets = NULL;
- }
- __pyx_L8:;
-
- /* "View.MemoryView":539
- * info.suboffsets = NULL
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.view.format
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_FORMAT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":540
- *
- * if flags & PyBUF_FORMAT:
- * info.format = self.view.format # <<<<<<<<<<<<<<
- * else:
- * info.format = NULL
- */
- __pyx_t_5 = __pyx_v_self->view.format;
- __pyx_v_info->format = __pyx_t_5;
-
- /* "View.MemoryView":539
- * info.suboffsets = NULL
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.view.format
- * else:
- */
- goto __pyx_L9;
- }
-
- /* "View.MemoryView":542
- * info.format = self.view.format
- * else:
- * info.format = NULL # <<<<<<<<<<<<<<
- *
- * info.buf = self.view.buf
- */
- /*else*/ {
- __pyx_v_info->format = NULL;
- }
- __pyx_L9:;
-
- /* "View.MemoryView":544
- * info.format = NULL
- *
- * info.buf = self.view.buf # <<<<<<<<<<<<<<
- * info.ndim = self.view.ndim
- * info.itemsize = self.view.itemsize
- */
- __pyx_t_6 = __pyx_v_self->view.buf;
- __pyx_v_info->buf = __pyx_t_6;
-
- /* "View.MemoryView":545
- *
- * info.buf = self.view.buf
- * info.ndim = self.view.ndim # <<<<<<<<<<<<<<
- * info.itemsize = self.view.itemsize
- * info.len = self.view.len
- */
- __pyx_t_7 = __pyx_v_self->view.ndim;
- __pyx_v_info->ndim = __pyx_t_7;
-
- /* "View.MemoryView":546
- * info.buf = self.view.buf
- * info.ndim = self.view.ndim
- * info.itemsize = self.view.itemsize # <<<<<<<<<<<<<<
- * info.len = self.view.len
- * info.readonly = self.view.readonly
- */
- __pyx_t_8 = __pyx_v_self->view.itemsize;
- __pyx_v_info->itemsize = __pyx_t_8;
-
- /* "View.MemoryView":547
- * info.ndim = self.view.ndim
- * info.itemsize = self.view.itemsize
- * info.len = self.view.len # <<<<<<<<<<<<<<
- * info.readonly = self.view.readonly
- * info.obj = self
- */
- __pyx_t_8 = __pyx_v_self->view.len;
- __pyx_v_info->len = __pyx_t_8;
-
- /* "View.MemoryView":548
- * info.itemsize = self.view.itemsize
- * info.len = self.view.len
- * info.readonly = self.view.readonly # <<<<<<<<<<<<<<
- * info.obj = self
- *
- */
- __pyx_t_1 = __pyx_v_self->view.readonly;
- __pyx_v_info->readonly = __pyx_t_1;
-
- /* "View.MemoryView":549
- * info.len = self.view.len
- * info.readonly = self.view.readonly
- * info.obj = self # <<<<<<<<<<<<<<
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)")
- */
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(((PyObject *)__pyx_v_self));
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj);
- __pyx_v_info->obj = ((PyObject *)__pyx_v_self);
-
- /* "View.MemoryView":520
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__getbuffer__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- if (__pyx_v_info->obj != NULL) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- goto __pyx_L2;
- __pyx_L0:;
- if (__pyx_v_info->obj == Py_None) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- __pyx_L2:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":555
- *
- * @property
- * def T(self): # <<<<<<<<<<<<<<
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice)
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_1T_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_1T_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_1T___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_1T___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- struct __pyx_memoryviewslice_obj *__pyx_v_result = 0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":556
- * @property
- * def T(self):
- * cdef _memoryviewslice result = memoryview_copy(self) # <<<<<<<<<<<<<<
- * transpose_memslice(&result.from_slice)
- * return result
- */
- __pyx_t_1 = __pyx_memoryview_copy_object(__pyx_v_self); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 556, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (!(likely(((__pyx_t_1) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_1, __pyx_memoryviewslice_type))))) __PYX_ERR(1, 556, __pyx_L1_error)
- __pyx_v_result = ((struct __pyx_memoryviewslice_obj *)__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":557
- * def T(self):
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice) # <<<<<<<<<<<<<<
- * return result
- *
- */
- __pyx_t_2 = __pyx_memslice_transpose((&__pyx_v_result->from_slice)); if (unlikely(__pyx_t_2 == ((int)0))) __PYX_ERR(1, 557, __pyx_L1_error)
-
- /* "View.MemoryView":558
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice)
- * return result # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = ((PyObject *)__pyx_v_result);
- goto __pyx_L0;
-
- /* "View.MemoryView":555
- *
- * @property
- * def T(self): # <<<<<<<<<<<<<<
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice)
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.T.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":561
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.obj
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4base_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4base_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_4base___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4base___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":562
- * @property
- * def base(self):
- * return self.obj # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->obj);
- __pyx_r = __pyx_v_self->obj;
- goto __pyx_L0;
-
- /* "View.MemoryView":561
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.obj
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":565
- *
- * @property
- * def shape(self): # <<<<<<<<<<<<<<
- * return tuple([length for length in self.view.shape[:self.view.ndim]])
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_5shape_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_5shape_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_5shape___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_5shape___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_v_length;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- Py_ssize_t *__pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":566
- * @property
- * def shape(self):
- * return tuple([length for length in self.view.shape[:self.view.ndim]]) # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = PyList_New(0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = (__pyx_v_self->view.shape + __pyx_v_self->view.ndim);
- for (__pyx_t_4 = __pyx_v_self->view.shape; __pyx_t_4 < __pyx_t_3; __pyx_t_4++) {
- __pyx_t_2 = __pyx_t_4;
- __pyx_v_length = (__pyx_t_2[0]);
- __pyx_t_5 = PyInt_FromSsize_t(__pyx_v_length); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- if (unlikely(__Pyx_ListComp_Append(__pyx_t_1, (PyObject*)__pyx_t_5))) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- }
- __pyx_t_5 = PyList_AsTuple(((PyObject*)__pyx_t_1)); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_r = __pyx_t_5;
- __pyx_t_5 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":565
- *
- * @property
- * def shape(self): # <<<<<<<<<<<<<<
- * return tuple([length for length in self.view.shape[:self.view.ndim]])
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview.shape.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":569
- *
- * @property
- * def strides(self): # <<<<<<<<<<<<<<
- * if self.view.strides == NULL:
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_7strides_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_7strides_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_7strides___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_7strides___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_v_stride;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
- Py_ssize_t *__pyx_t_5;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":570
- * @property
- * def strides(self):
- * if self.view.strides == NULL: # <<<<<<<<<<<<<<
- *
- * raise ValueError("Buffer view does not expose strides")
- */
- __pyx_t_1 = ((__pyx_v_self->view.strides == NULL) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":572
- * if self.view.strides == NULL:
- *
- * raise ValueError("Buffer view does not expose strides") # <<<<<<<<<<<<<<
- *
- * return tuple([stride for stride in self.view.strides[:self.view.ndim]])
- */
- __pyx_t_2 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__12, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 572, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_Raise(__pyx_t_2, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __PYX_ERR(1, 572, __pyx_L1_error)
-
- /* "View.MemoryView":570
- * @property
- * def strides(self):
- * if self.view.strides == NULL: # <<<<<<<<<<<<<<
- *
- * raise ValueError("Buffer view does not expose strides")
- */
- }
-
- /* "View.MemoryView":574
- * raise ValueError("Buffer view does not expose strides")
- *
- * return tuple([stride for stride in self.view.strides[:self.view.ndim]]) # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = PyList_New(0); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_4 = (__pyx_v_self->view.strides + __pyx_v_self->view.ndim);
- for (__pyx_t_5 = __pyx_v_self->view.strides; __pyx_t_5 < __pyx_t_4; __pyx_t_5++) {
- __pyx_t_3 = __pyx_t_5;
- __pyx_v_stride = (__pyx_t_3[0]);
- __pyx_t_6 = PyInt_FromSsize_t(__pyx_v_stride); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- if (unlikely(__Pyx_ListComp_Append(__pyx_t_2, (PyObject*)__pyx_t_6))) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- }
- __pyx_t_6 = PyList_AsTuple(((PyObject*)__pyx_t_2)); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_6;
- __pyx_t_6 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":569
- *
- * @property
- * def strides(self): # <<<<<<<<<<<<<<
- * if self.view.strides == NULL:
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_AddTraceback("View.MemoryView.memoryview.strides.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":577
- *
- * @property
- * def suboffsets(self): # <<<<<<<<<<<<<<
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_10suboffsets_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_10suboffsets_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_10suboffsets___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_10suboffsets___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_v_suboffset;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- Py_ssize_t *__pyx_t_4;
- Py_ssize_t *__pyx_t_5;
- Py_ssize_t *__pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":578
- * @property
- * def suboffsets(self):
- * if self.view.suboffsets == NULL: # <<<<<<<<<<<<<<
- * return (-1,) * self.view.ndim
- *
- */
- __pyx_t_1 = ((__pyx_v_self->view.suboffsets == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":579
- * def suboffsets(self):
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim # <<<<<<<<<<<<<<
- *
- * return tuple([suboffset for suboffset in self.view.suboffsets[:self.view.ndim]])
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __Pyx_PyInt_From_int(__pyx_v_self->view.ndim); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 579, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyNumber_Multiply(__pyx_tuple__13, __pyx_t_2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 579, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":578
- * @property
- * def suboffsets(self):
- * if self.view.suboffsets == NULL: # <<<<<<<<<<<<<<
- * return (-1,) * self.view.ndim
- *
- */
- }
-
- /* "View.MemoryView":581
- * return (-1,) * self.view.ndim
- *
- * return tuple([suboffset for suboffset in self.view.suboffsets[:self.view.ndim]]) # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_3 = PyList_New(0); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_5 = (__pyx_v_self->view.suboffsets + __pyx_v_self->view.ndim);
- for (__pyx_t_6 = __pyx_v_self->view.suboffsets; __pyx_t_6 < __pyx_t_5; __pyx_t_6++) {
- __pyx_t_4 = __pyx_t_6;
- __pyx_v_suboffset = (__pyx_t_4[0]);
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_suboffset); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (unlikely(__Pyx_ListComp_Append(__pyx_t_3, (PyObject*)__pyx_t_2))) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_t_2 = PyList_AsTuple(((PyObject*)__pyx_t_3)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":577
- *
- * @property
- * def suboffsets(self): # <<<<<<<<<<<<<<
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.suboffsets.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":584
- *
- * @property
- * def ndim(self): # <<<<<<<<<<<<<<
- * return self.view.ndim
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4ndim_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4ndim_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_4ndim___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4ndim___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":585
- * @property
- * def ndim(self):
- * return self.view.ndim # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_self->view.ndim); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 585, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":584
- *
- * @property
- * def ndim(self): # <<<<<<<<<<<<<<
- * return self.view.ndim
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.ndim.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":588
- *
- * @property
- * def itemsize(self): # <<<<<<<<<<<<<<
- * return self.view.itemsize
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_8itemsize_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_8itemsize_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_8itemsize___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_8itemsize___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":589
- * @property
- * def itemsize(self):
- * return self.view.itemsize # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = PyInt_FromSsize_t(__pyx_v_self->view.itemsize); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 589, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":588
- *
- * @property
- * def itemsize(self): # <<<<<<<<<<<<<<
- * return self.view.itemsize
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.itemsize.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":592
- *
- * @property
- * def nbytes(self): # <<<<<<<<<<<<<<
- * return self.size * self.view.itemsize
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_6nbytes_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_6nbytes_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_6nbytes___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_6nbytes___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":593
- * @property
- * def nbytes(self):
- * return self.size * self.view.itemsize # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_size); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 593, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_self->view.itemsize); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 593, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyNumber_Multiply(__pyx_t_1, __pyx_t_2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 593, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":592
- *
- * @property
- * def nbytes(self): # <<<<<<<<<<<<<<
- * return self.size * self.view.itemsize
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.nbytes.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":596
- *
- * @property
- * def size(self): # <<<<<<<<<<<<<<
- * if self._size is None:
- * result = 1
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4size_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4size_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_4size___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4size___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_v_result = NULL;
- PyObject *__pyx_v_length = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
- Py_ssize_t *__pyx_t_5;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":597
- * @property
- * def size(self):
- * if self._size is None: # <<<<<<<<<<<<<<
- * result = 1
- *
- */
- __pyx_t_1 = (__pyx_v_self->_size == Py_None);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":598
- * def size(self):
- * if self._size is None:
- * result = 1 # <<<<<<<<<<<<<<
- *
- * for length in self.view.shape[:self.view.ndim]:
- */
- __Pyx_INCREF(__pyx_int_1);
- __pyx_v_result = __pyx_int_1;
-
- /* "View.MemoryView":600
- * result = 1
- *
- * for length in self.view.shape[:self.view.ndim]: # <<<<<<<<<<<<<<
- * result *= length
- *
- */
- __pyx_t_4 = (__pyx_v_self->view.shape + __pyx_v_self->view.ndim);
- for (__pyx_t_5 = __pyx_v_self->view.shape; __pyx_t_5 < __pyx_t_4; __pyx_t_5++) {
- __pyx_t_3 = __pyx_t_5;
- __pyx_t_6 = PyInt_FromSsize_t((__pyx_t_3[0])); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 600, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_XDECREF_SET(__pyx_v_length, __pyx_t_6);
- __pyx_t_6 = 0;
-
- /* "View.MemoryView":601
- *
- * for length in self.view.shape[:self.view.ndim]:
- * result *= length # <<<<<<<<<<<<<<
- *
- * self._size = result
- */
- __pyx_t_6 = PyNumber_InPlaceMultiply(__pyx_v_result, __pyx_v_length); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 601, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_6);
- __pyx_t_6 = 0;
- }
-
- /* "View.MemoryView":603
- * result *= length
- *
- * self._size = result # <<<<<<<<<<<<<<
- *
- * return self._size
- */
- __Pyx_INCREF(__pyx_v_result);
- __Pyx_GIVEREF(__pyx_v_result);
- __Pyx_GOTREF(__pyx_v_self->_size);
- __Pyx_DECREF(__pyx_v_self->_size);
- __pyx_v_self->_size = __pyx_v_result;
-
- /* "View.MemoryView":597
- * @property
- * def size(self):
- * if self._size is None: # <<<<<<<<<<<<<<
- * result = 1
- *
- */
- }
-
- /* "View.MemoryView":605
- * self._size = result
- *
- * return self._size # <<<<<<<<<<<<<<
- *
- * def __len__(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->_size);
- __pyx_r = __pyx_v_self->_size;
- goto __pyx_L0;
-
- /* "View.MemoryView":596
- *
- * @property
- * def size(self): # <<<<<<<<<<<<<<
- * if self._size is None:
- * result = 1
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_AddTraceback("View.MemoryView.memoryview.size.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_result);
- __Pyx_XDECREF(__pyx_v_length);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":607
- * return self._size
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * if self.view.ndim >= 1:
- * return self.view.shape[0]
- */
-
-/* Python wrapper */
-static Py_ssize_t __pyx_memoryview___len__(PyObject *__pyx_v_self); /*proto*/
-static Py_ssize_t __pyx_memoryview___len__(PyObject *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__len__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_10__len__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static Py_ssize_t __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_10__len__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- __Pyx_RefNannySetupContext("__len__", 0);
-
- /* "View.MemoryView":608
- *
- * def __len__(self):
- * if self.view.ndim >= 1: # <<<<<<<<<<<<<<
- * return self.view.shape[0]
- *
- */
- __pyx_t_1 = ((__pyx_v_self->view.ndim >= 1) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":609
- * def __len__(self):
- * if self.view.ndim >= 1:
- * return self.view.shape[0] # <<<<<<<<<<<<<<
- *
- * return 0
- */
- __pyx_r = (__pyx_v_self->view.shape[0]);
- goto __pyx_L0;
-
- /* "View.MemoryView":608
- *
- * def __len__(self):
- * if self.view.ndim >= 1: # <<<<<<<<<<<<<<
- * return self.view.shape[0]
- *
- */
- }
-
- /* "View.MemoryView":611
- * return self.view.shape[0]
- *
- * return 0 # <<<<<<<<<<<<<<
- *
- * def __repr__(self):
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":607
- * return self._size
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * if self.view.ndim >= 1:
- * return self.view.shape[0]
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":613
- * return 0
- *
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,
- * id(self))
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview___repr__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_memoryview___repr__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__repr__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_12__repr__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_12__repr__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__repr__", 0);
-
- /* "View.MemoryView":614
- *
- * def __repr__(self):
- * return "" % (self.base.__class__.__name__, # <<<<<<<<<<<<<<
- * id(self))
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_base); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_t_1, __pyx_n_s_class); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_t_2, __pyx_n_s_name_2); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "View.MemoryView":615
- * def __repr__(self):
- * return "" % (self.base.__class__.__name__,
- * id(self)) # <<<<<<<<<<<<<<
- *
- * def __str__(self):
- */
- __pyx_t_2 = __Pyx_PyObject_CallOneArg(__pyx_builtin_id, ((PyObject *)__pyx_v_self)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 615, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "View.MemoryView":614
- *
- * def __repr__(self):
- * return "" % (self.base.__class__.__name__, # <<<<<<<<<<<<<<
- * id(self))
- *
- */
- __pyx_t_3 = PyTuple_New(2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_3, 0, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_t_2);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyString_Format(__pyx_kp_s_MemoryView_of_r_at_0x_x, __pyx_t_3); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":613
- * return 0
- *
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,
- * id(self))
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__repr__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":617
- * id(self))
- *
- * def __str__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,)
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview___str__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_memoryview___str__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__str__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_14__str__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_14__str__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__str__", 0);
-
- /* "View.MemoryView":618
- *
- * def __str__(self):
- * return "" % (self.base.__class__.__name__,) # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_base); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_t_1, __pyx_n_s_class); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_t_2, __pyx_n_s_name_2); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_2 = PyTuple_New(1); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_2, 0, __pyx_t_1);
- __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_PyString_Format(__pyx_kp_s_MemoryView_of_r_object, __pyx_t_2); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":617
- * id(self))
- *
- * def __str__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,)
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__str__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":621
- *
- *
- * def is_c_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_is_c_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_is_c_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("is_c_contig (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_16is_c_contig(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_16is_c_contig(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice *__pyx_v_mslice;
- __Pyx_memviewslice __pyx_v_tmp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("is_c_contig", 0);
-
- /* "View.MemoryView":624
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp) # <<<<<<<<<<<<<<
- * return slice_is_contig(mslice[0], 'C', self.view.ndim)
- *
- */
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(__pyx_v_self, (&__pyx_v_tmp)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 624, __pyx_L1_error)
- __pyx_v_mslice = __pyx_t_1;
-
- /* "View.MemoryView":625
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp)
- * return slice_is_contig(mslice[0], 'C', self.view.ndim) # <<<<<<<<<<<<<<
- *
- * def is_f_contig(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_memviewslice_is_contig((__pyx_v_mslice[0]), 'C', __pyx_v_self->view.ndim)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 625, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":621
- *
- *
- * def is_c_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_c_contig", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":627
- * return slice_is_contig(mslice[0], 'C', self.view.ndim)
- *
- * def is_f_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_is_f_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_is_f_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("is_f_contig (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_18is_f_contig(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_18is_f_contig(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice *__pyx_v_mslice;
- __Pyx_memviewslice __pyx_v_tmp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("is_f_contig", 0);
-
- /* "View.MemoryView":630
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp) # <<<<<<<<<<<<<<
- * return slice_is_contig(mslice[0], 'F', self.view.ndim)
- *
- */
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(__pyx_v_self, (&__pyx_v_tmp)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 630, __pyx_L1_error)
- __pyx_v_mslice = __pyx_t_1;
-
- /* "View.MemoryView":631
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp)
- * return slice_is_contig(mslice[0], 'F', self.view.ndim) # <<<<<<<<<<<<<<
- *
- * def copy(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_memviewslice_is_contig((__pyx_v_mslice[0]), 'F', __pyx_v_self->view.ndim)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 631, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":627
- * return slice_is_contig(mslice[0], 'C', self.view.ndim)
- *
- * def is_f_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_f_contig", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":633
- * return slice_is_contig(mslice[0], 'F', self.view.ndim)
- *
- * def copy(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice mslice
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_copy(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_copy(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("copy (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_20copy(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_20copy(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice __pyx_v_mslice;
- int __pyx_v_flags;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("copy", 0);
-
- /* "View.MemoryView":635
- * def copy(self):
- * cdef __Pyx_memviewslice mslice
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS # <<<<<<<<<<<<<<
- *
- * slice_copy(self, &mslice)
- */
- __pyx_v_flags = (__pyx_v_self->flags & (~PyBUF_F_CONTIGUOUS));
-
- /* "View.MemoryView":637
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS
- *
- * slice_copy(self, &mslice) # <<<<<<<<<<<<<<
- * mslice = slice_copy_contig(&mslice, "c", self.view.ndim,
- * self.view.itemsize,
- */
- __pyx_memoryview_slice_copy(__pyx_v_self, (&__pyx_v_mslice));
-
- /* "View.MemoryView":638
- *
- * slice_copy(self, &mslice)
- * mslice = slice_copy_contig(&mslice, "c", self.view.ndim, # <<<<<<<<<<<<<<
- * self.view.itemsize,
- * flags|PyBUF_C_CONTIGUOUS,
- */
- __pyx_t_1 = __pyx_memoryview_copy_new_contig((&__pyx_v_mslice), ((char *)"c"), __pyx_v_self->view.ndim, __pyx_v_self->view.itemsize, (__pyx_v_flags | PyBUF_C_CONTIGUOUS), __pyx_v_self->dtype_is_object); if (unlikely(PyErr_Occurred())) __PYX_ERR(1, 638, __pyx_L1_error)
- __pyx_v_mslice = __pyx_t_1;
-
- /* "View.MemoryView":643
- * self.dtype_is_object)
- *
- * return memoryview_copy_from_slice(self, &mslice) # <<<<<<<<<<<<<<
- *
- * def copy_fortran(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_memoryview_copy_object_from_slice(__pyx_v_self, (&__pyx_v_mslice)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 643, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":633
- * return slice_is_contig(mslice[0], 'F', self.view.ndim)
- *
- * def copy(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice mslice
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.copy", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":645
- * return memoryview_copy_from_slice(self, &mslice)
- *
- * def copy_fortran(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice src, dst
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_copy_fortran(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_copy_fortran(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("copy_fortran (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_22copy_fortran(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_22copy_fortran(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice __pyx_v_src;
- __Pyx_memviewslice __pyx_v_dst;
- int __pyx_v_flags;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("copy_fortran", 0);
-
- /* "View.MemoryView":647
- * def copy_fortran(self):
- * cdef __Pyx_memviewslice src, dst
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS # <<<<<<<<<<<<<<
- *
- * slice_copy(self, &src)
- */
- __pyx_v_flags = (__pyx_v_self->flags & (~PyBUF_C_CONTIGUOUS));
-
- /* "View.MemoryView":649
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS
- *
- * slice_copy(self, &src) # <<<<<<<<<<<<<<
- * dst = slice_copy_contig(&src, "fortran", self.view.ndim,
- * self.view.itemsize,
- */
- __pyx_memoryview_slice_copy(__pyx_v_self, (&__pyx_v_src));
-
- /* "View.MemoryView":650
- *
- * slice_copy(self, &src)
- * dst = slice_copy_contig(&src, "fortran", self.view.ndim, # <<<<<<<<<<<<<<
- * self.view.itemsize,
- * flags|PyBUF_F_CONTIGUOUS,
- */
- __pyx_t_1 = __pyx_memoryview_copy_new_contig((&__pyx_v_src), ((char *)"fortran"), __pyx_v_self->view.ndim, __pyx_v_self->view.itemsize, (__pyx_v_flags | PyBUF_F_CONTIGUOUS), __pyx_v_self->dtype_is_object); if (unlikely(PyErr_Occurred())) __PYX_ERR(1, 650, __pyx_L1_error)
- __pyx_v_dst = __pyx_t_1;
-
- /* "View.MemoryView":655
- * self.dtype_is_object)
- *
- * return memoryview_copy_from_slice(self, &dst) # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_memoryview_copy_object_from_slice(__pyx_v_self, (&__pyx_v_dst)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 655, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":645
- * return memoryview_copy_from_slice(self, &mslice)
- *
- * def copy_fortran(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice src, dst
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.copy_fortran", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryview_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryview_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryview___reduce_cython__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryview___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__14, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 2, __pyx_L1_error)
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryview_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryview_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryview_2__setstate_cython__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryview_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__15, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 4, __pyx_L1_error)
-
- /* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":659
- *
- * @cname('__pyx_memoryview_new')
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo): # <<<<<<<<<<<<<<
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo
- */
-
-static PyObject *__pyx_memoryview_new(PyObject *__pyx_v_o, int __pyx_v_flags, int __pyx_v_dtype_is_object, __Pyx_TypeInfo *__pyx_v_typeinfo) {
- struct __pyx_memoryview_obj *__pyx_v_result = 0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_cwrapper", 0);
-
- /* "View.MemoryView":660
- * @cname('__pyx_memoryview_new')
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo):
- * cdef memoryview result = memoryview(o, flags, dtype_is_object) # <<<<<<<<<<<<<<
- * result.typeinfo = typeinfo
- * return result
- */
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_flags); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_v_dtype_is_object); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyTuple_New(3); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_v_o);
- __Pyx_GIVEREF(__pyx_v_o);
- PyTuple_SET_ITEM(__pyx_t_3, 0, __pyx_v_o);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 2, __pyx_t_2);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryview_type), __pyx_t_3, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result = ((struct __pyx_memoryview_obj *)__pyx_t_2);
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":661
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo):
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo # <<<<<<<<<<<<<<
- * return result
- *
- */
- __pyx_v_result->typeinfo = __pyx_v_typeinfo;
-
- /* "View.MemoryView":662
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo
- * return result # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_check')
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = ((PyObject *)__pyx_v_result);
- goto __pyx_L0;
-
- /* "View.MemoryView":659
- *
- * @cname('__pyx_memoryview_new')
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo): # <<<<<<<<<<<<<<
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview_cwrapper", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":665
- *
- * @cname('__pyx_memoryview_check')
- * cdef inline bint memoryview_check(object o): # <<<<<<<<<<<<<<
- * return isinstance(o, memoryview)
- *
- */
-
-static CYTHON_INLINE int __pyx_memoryview_check(PyObject *__pyx_v_o) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- __Pyx_RefNannySetupContext("memoryview_check", 0);
-
- /* "View.MemoryView":666
- * @cname('__pyx_memoryview_check')
- * cdef inline bint memoryview_check(object o):
- * return isinstance(o, memoryview) # <<<<<<<<<<<<<<
- *
- * cdef tuple _unellipsify(object index, int ndim):
- */
- __pyx_t_1 = __Pyx_TypeCheck(__pyx_v_o, __pyx_memoryview_type);
- __pyx_r = __pyx_t_1;
- goto __pyx_L0;
-
- /* "View.MemoryView":665
- *
- * @cname('__pyx_memoryview_check')
- * cdef inline bint memoryview_check(object o): # <<<<<<<<<<<<<<
- * return isinstance(o, memoryview)
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":668
- * return isinstance(o, memoryview)
- *
- * cdef tuple _unellipsify(object index, int ndim): # <<<<<<<<<<<<<<
- * """
- * Replace all ellipses with full slices and fill incomplete indices with
- */
-
-static PyObject *_unellipsify(PyObject *__pyx_v_index, int __pyx_v_ndim) {
- PyObject *__pyx_v_tup = NULL;
- PyObject *__pyx_v_result = NULL;
- int __pyx_v_have_slices;
- int __pyx_v_seen_ellipsis;
- CYTHON_UNUSED PyObject *__pyx_v_idx = NULL;
- PyObject *__pyx_v_item = NULL;
- Py_ssize_t __pyx_v_nslices;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- Py_ssize_t __pyx_t_5;
- PyObject *(*__pyx_t_6)(PyObject *);
- PyObject *__pyx_t_7 = NULL;
- Py_ssize_t __pyx_t_8;
- int __pyx_t_9;
- int __pyx_t_10;
- PyObject *__pyx_t_11 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_unellipsify", 0);
-
- /* "View.MemoryView":673
- * full slices.
- * """
- * if not isinstance(index, tuple): # <<<<<<<<<<<<<<
- * tup = (index,)
- * else:
- */
- __pyx_t_1 = PyTuple_Check(__pyx_v_index);
- __pyx_t_2 = ((!(__pyx_t_1 != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":674
- * """
- * if not isinstance(index, tuple):
- * tup = (index,) # <<<<<<<<<<<<<<
- * else:
- * tup = index
- */
- __pyx_t_3 = PyTuple_New(1); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 674, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_v_index);
- __Pyx_GIVEREF(__pyx_v_index);
- PyTuple_SET_ITEM(__pyx_t_3, 0, __pyx_v_index);
- __pyx_v_tup = __pyx_t_3;
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":673
- * full slices.
- * """
- * if not isinstance(index, tuple): # <<<<<<<<<<<<<<
- * tup = (index,)
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":676
- * tup = (index,)
- * else:
- * tup = index # <<<<<<<<<<<<<<
- *
- * result = []
- */
- /*else*/ {
- __Pyx_INCREF(__pyx_v_index);
- __pyx_v_tup = __pyx_v_index;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":678
- * tup = index
- *
- * result = [] # <<<<<<<<<<<<<<
- * have_slices = False
- * seen_ellipsis = False
- */
- __pyx_t_3 = PyList_New(0); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 678, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_v_result = ((PyObject*)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":679
- *
- * result = []
- * have_slices = False # <<<<<<<<<<<<<<
- * seen_ellipsis = False
- * for idx, item in enumerate(tup):
- */
- __pyx_v_have_slices = 0;
-
- /* "View.MemoryView":680
- * result = []
- * have_slices = False
- * seen_ellipsis = False # <<<<<<<<<<<<<<
- * for idx, item in enumerate(tup):
- * if item is Ellipsis:
- */
- __pyx_v_seen_ellipsis = 0;
-
- /* "View.MemoryView":681
- * have_slices = False
- * seen_ellipsis = False
- * for idx, item in enumerate(tup): # <<<<<<<<<<<<<<
- * if item is Ellipsis:
- * if not seen_ellipsis:
- */
- __Pyx_INCREF(__pyx_int_0);
- __pyx_t_3 = __pyx_int_0;
- if (likely(PyList_CheckExact(__pyx_v_tup)) || PyTuple_CheckExact(__pyx_v_tup)) {
- __pyx_t_4 = __pyx_v_tup; __Pyx_INCREF(__pyx_t_4); __pyx_t_5 = 0;
- __pyx_t_6 = NULL;
- } else {
- __pyx_t_5 = -1; __pyx_t_4 = PyObject_GetIter(__pyx_v_tup); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_6 = Py_TYPE(__pyx_t_4)->tp_iternext; if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 681, __pyx_L1_error)
- }
- for (;;) {
- if (likely(!__pyx_t_6)) {
- if (likely(PyList_CheckExact(__pyx_t_4))) {
- if (__pyx_t_5 >= PyList_GET_SIZE(__pyx_t_4)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_7 = PyList_GET_ITEM(__pyx_t_4, __pyx_t_5); __Pyx_INCREF(__pyx_t_7); __pyx_t_5++; if (unlikely(0 < 0)) __PYX_ERR(1, 681, __pyx_L1_error)
- #else
- __pyx_t_7 = PySequence_ITEM(__pyx_t_4, __pyx_t_5); __pyx_t_5++; if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- #endif
- } else {
- if (__pyx_t_5 >= PyTuple_GET_SIZE(__pyx_t_4)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_7 = PyTuple_GET_ITEM(__pyx_t_4, __pyx_t_5); __Pyx_INCREF(__pyx_t_7); __pyx_t_5++; if (unlikely(0 < 0)) __PYX_ERR(1, 681, __pyx_L1_error)
- #else
- __pyx_t_7 = PySequence_ITEM(__pyx_t_4, __pyx_t_5); __pyx_t_5++; if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- #endif
- }
- } else {
- __pyx_t_7 = __pyx_t_6(__pyx_t_4);
- if (unlikely(!__pyx_t_7)) {
- PyObject* exc_type = PyErr_Occurred();
- if (exc_type) {
- if (likely(__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration))) PyErr_Clear();
- else __PYX_ERR(1, 681, __pyx_L1_error)
- }
- break;
- }
- __Pyx_GOTREF(__pyx_t_7);
- }
- __Pyx_XDECREF_SET(__pyx_v_item, __pyx_t_7);
- __pyx_t_7 = 0;
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_XDECREF_SET(__pyx_v_idx, __pyx_t_3);
- __pyx_t_7 = __Pyx_PyInt_AddObjC(__pyx_t_3, __pyx_int_1, 1, 0, 0); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_DECREF(__pyx_t_3);
- __pyx_t_3 = __pyx_t_7;
- __pyx_t_7 = 0;
-
- /* "View.MemoryView":682
- * seen_ellipsis = False
- * for idx, item in enumerate(tup):
- * if item is Ellipsis: # <<<<<<<<<<<<<<
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- */
- __pyx_t_2 = (__pyx_v_item == __pyx_builtin_Ellipsis);
- __pyx_t_1 = (__pyx_t_2 != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":683
- * for idx, item in enumerate(tup):
- * if item is Ellipsis:
- * if not seen_ellipsis: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- * seen_ellipsis = True
- */
- __pyx_t_1 = ((!(__pyx_v_seen_ellipsis != 0)) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":684
- * if item is Ellipsis:
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1)) # <<<<<<<<<<<<<<
- * seen_ellipsis = True
- * else:
- */
- __pyx_t_8 = PyObject_Length(__pyx_v_tup); if (unlikely(__pyx_t_8 == ((Py_ssize_t)-1))) __PYX_ERR(1, 684, __pyx_L1_error)
- __pyx_t_7 = PyList_New(1 * ((((__pyx_v_ndim - __pyx_t_8) + 1)<0) ? 0:((__pyx_v_ndim - __pyx_t_8) + 1))); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 684, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- { Py_ssize_t __pyx_temp;
- for (__pyx_temp=0; __pyx_temp < ((__pyx_v_ndim - __pyx_t_8) + 1); __pyx_temp++) {
- __Pyx_INCREF(__pyx_slice__16);
- __Pyx_GIVEREF(__pyx_slice__16);
- PyList_SET_ITEM(__pyx_t_7, __pyx_temp, __pyx_slice__16);
- }
- }
- __pyx_t_9 = __Pyx_PyList_Extend(__pyx_v_result, __pyx_t_7); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 684, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
-
- /* "View.MemoryView":685
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- * seen_ellipsis = True # <<<<<<<<<<<<<<
- * else:
- * result.append(slice(None))
- */
- __pyx_v_seen_ellipsis = 1;
-
- /* "View.MemoryView":683
- * for idx, item in enumerate(tup):
- * if item is Ellipsis:
- * if not seen_ellipsis: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- * seen_ellipsis = True
- */
- goto __pyx_L7;
- }
-
- /* "View.MemoryView":687
- * seen_ellipsis = True
- * else:
- * result.append(slice(None)) # <<<<<<<<<<<<<<
- * have_slices = True
- * else:
- */
- /*else*/ {
- __pyx_t_9 = __Pyx_PyList_Append(__pyx_v_result, __pyx_slice__16); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 687, __pyx_L1_error)
- }
- __pyx_L7:;
-
- /* "View.MemoryView":688
- * else:
- * result.append(slice(None))
- * have_slices = True # <<<<<<<<<<<<<<
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item):
- */
- __pyx_v_have_slices = 1;
-
- /* "View.MemoryView":682
- * seen_ellipsis = False
- * for idx, item in enumerate(tup):
- * if item is Ellipsis: # <<<<<<<<<<<<<<
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":690
- * have_slices = True
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item): # <<<<<<<<<<<<<<
- * raise TypeError("Cannot index with type '%s'" % type(item))
- *
- */
- /*else*/ {
- __pyx_t_2 = PySlice_Check(__pyx_v_item);
- __pyx_t_10 = ((!(__pyx_t_2 != 0)) != 0);
- if (__pyx_t_10) {
- } else {
- __pyx_t_1 = __pyx_t_10;
- goto __pyx_L9_bool_binop_done;
- }
- __pyx_t_10 = ((!(PyIndex_Check(__pyx_v_item) != 0)) != 0);
- __pyx_t_1 = __pyx_t_10;
- __pyx_L9_bool_binop_done:;
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":691
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item):
- * raise TypeError("Cannot index with type '%s'" % type(item)) # <<<<<<<<<<<<<<
- *
- * have_slices = have_slices or isinstance(item, slice)
- */
- __pyx_t_7 = __Pyx_PyString_FormatSafe(__pyx_kp_s_Cannot_index_with_type_s, ((PyObject *)Py_TYPE(__pyx_v_item))); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 691, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_11 = __Pyx_PyObject_CallOneArg(__pyx_builtin_TypeError, __pyx_t_7); if (unlikely(!__pyx_t_11)) __PYX_ERR(1, 691, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_11);
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_Raise(__pyx_t_11, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_11); __pyx_t_11 = 0;
- __PYX_ERR(1, 691, __pyx_L1_error)
-
- /* "View.MemoryView":690
- * have_slices = True
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item): # <<<<<<<<<<<<<<
- * raise TypeError("Cannot index with type '%s'" % type(item))
- *
- */
- }
-
- /* "View.MemoryView":693
- * raise TypeError("Cannot index with type '%s'" % type(item))
- *
- * have_slices = have_slices or isinstance(item, slice) # <<<<<<<<<<<<<<
- * result.append(item)
- *
- */
- __pyx_t_10 = (__pyx_v_have_slices != 0);
- if (!__pyx_t_10) {
- } else {
- __pyx_t_1 = __pyx_t_10;
- goto __pyx_L11_bool_binop_done;
- }
- __pyx_t_10 = PySlice_Check(__pyx_v_item);
- __pyx_t_2 = (__pyx_t_10 != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L11_bool_binop_done:;
- __pyx_v_have_slices = __pyx_t_1;
-
- /* "View.MemoryView":694
- *
- * have_slices = have_slices or isinstance(item, slice)
- * result.append(item) # <<<<<<<<<<<<<<
- *
- * nslices = ndim - len(result)
- */
- __pyx_t_9 = __Pyx_PyList_Append(__pyx_v_result, __pyx_v_item); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 694, __pyx_L1_error)
- }
- __pyx_L6:;
-
- /* "View.MemoryView":681
- * have_slices = False
- * seen_ellipsis = False
- * for idx, item in enumerate(tup): # <<<<<<<<<<<<<<
- * if item is Ellipsis:
- * if not seen_ellipsis:
- */
- }
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":696
- * result.append(item)
- *
- * nslices = ndim - len(result) # <<<<<<<<<<<<<<
- * if nslices:
- * result.extend([slice(None)] * nslices)
- */
- __pyx_t_5 = PyList_GET_SIZE(__pyx_v_result); if (unlikely(__pyx_t_5 == ((Py_ssize_t)-1))) __PYX_ERR(1, 696, __pyx_L1_error)
- __pyx_v_nslices = (__pyx_v_ndim - __pyx_t_5);
-
- /* "View.MemoryView":697
- *
- * nslices = ndim - len(result)
- * if nslices: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * nslices)
- *
- */
- __pyx_t_1 = (__pyx_v_nslices != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":698
- * nslices = ndim - len(result)
- * if nslices:
- * result.extend([slice(None)] * nslices) # <<<<<<<<<<<<<<
- *
- * return have_slices or nslices, tuple(result)
- */
- __pyx_t_3 = PyList_New(1 * ((__pyx_v_nslices<0) ? 0:__pyx_v_nslices)); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 698, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- { Py_ssize_t __pyx_temp;
- for (__pyx_temp=0; __pyx_temp < __pyx_v_nslices; __pyx_temp++) {
- __Pyx_INCREF(__pyx_slice__16);
- __Pyx_GIVEREF(__pyx_slice__16);
- PyList_SET_ITEM(__pyx_t_3, __pyx_temp, __pyx_slice__16);
- }
- }
- __pyx_t_9 = __Pyx_PyList_Extend(__pyx_v_result, __pyx_t_3); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 698, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":697
- *
- * nslices = ndim - len(result)
- * if nslices: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * nslices)
- *
- */
- }
-
- /* "View.MemoryView":700
- * result.extend([slice(None)] * nslices)
- *
- * return have_slices or nslices, tuple(result) # <<<<<<<<<<<<<<
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- */
- __Pyx_XDECREF(__pyx_r);
- if (!__pyx_v_have_slices) {
- } else {
- __pyx_t_4 = __Pyx_PyBool_FromLong(__pyx_v_have_slices); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_3 = __pyx_t_4;
- __pyx_t_4 = 0;
- goto __pyx_L14_bool_binop_done;
- }
- __pyx_t_4 = PyInt_FromSsize_t(__pyx_v_nslices); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_3 = __pyx_t_4;
- __pyx_t_4 = 0;
- __pyx_L14_bool_binop_done:;
- __pyx_t_4 = PyList_AsTuple(__pyx_v_result); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_11 = PyTuple_New(2); if (unlikely(!__pyx_t_11)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_11);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_11, 0, __pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_11, 1, __pyx_t_4);
- __pyx_t_3 = 0;
- __pyx_t_4 = 0;
- __pyx_r = ((PyObject*)__pyx_t_11);
- __pyx_t_11 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":668
- * return isinstance(o, memoryview)
- *
- * cdef tuple _unellipsify(object index, int ndim): # <<<<<<<<<<<<<<
- * """
- * Replace all ellipses with full slices and fill incomplete indices with
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_11);
- __Pyx_AddTraceback("View.MemoryView._unellipsify", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_tup);
- __Pyx_XDECREF(__pyx_v_result);
- __Pyx_XDECREF(__pyx_v_idx);
- __Pyx_XDECREF(__pyx_v_item);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":702
- * return have_slices or nslices, tuple(result)
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim): # <<<<<<<<<<<<<<
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- */
-
-static PyObject *assert_direct_dimensions(Py_ssize_t *__pyx_v_suboffsets, int __pyx_v_ndim) {
- Py_ssize_t __pyx_v_suboffset;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- Py_ssize_t *__pyx_t_1;
- Py_ssize_t *__pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- int __pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("assert_direct_dimensions", 0);
-
- /* "View.MemoryView":703
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- * for suboffset in suboffsets[:ndim]: # <<<<<<<<<<<<<<
- * if suboffset >= 0:
- * raise ValueError("Indirect dimensions not supported")
- */
- __pyx_t_2 = (__pyx_v_suboffsets + __pyx_v_ndim);
- for (__pyx_t_3 = __pyx_v_suboffsets; __pyx_t_3 < __pyx_t_2; __pyx_t_3++) {
- __pyx_t_1 = __pyx_t_3;
- __pyx_v_suboffset = (__pyx_t_1[0]);
-
- /* "View.MemoryView":704
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Indirect dimensions not supported")
- *
- */
- __pyx_t_4 = ((__pyx_v_suboffset >= 0) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":705
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- * raise ValueError("Indirect dimensions not supported") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_5 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__17, NULL); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 705, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_Raise(__pyx_t_5, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __PYX_ERR(1, 705, __pyx_L1_error)
-
- /* "View.MemoryView":704
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Indirect dimensions not supported")
- *
- */
- }
- }
-
- /* "View.MemoryView":702
- * return have_slices or nslices, tuple(result)
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim): # <<<<<<<<<<<<<<
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.assert_direct_dimensions", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":712
- *
- * @cname('__pyx_memview_slice')
- * cdef memoryview memview_slice(memoryview memview, object indices): # <<<<<<<<<<<<<<
- * cdef int new_ndim = 0, suboffset_dim = -1, dim
- * cdef bint negative_step
- */
-
-static struct __pyx_memoryview_obj *__pyx_memview_slice(struct __pyx_memoryview_obj *__pyx_v_memview, PyObject *__pyx_v_indices) {
- int __pyx_v_new_ndim;
- int __pyx_v_suboffset_dim;
- int __pyx_v_dim;
- __Pyx_memviewslice __pyx_v_src;
- __Pyx_memviewslice __pyx_v_dst;
- __Pyx_memviewslice *__pyx_v_p_src;
- struct __pyx_memoryviewslice_obj *__pyx_v_memviewsliceobj = 0;
- __Pyx_memviewslice *__pyx_v_p_dst;
- int *__pyx_v_p_suboffset_dim;
- Py_ssize_t __pyx_v_start;
- Py_ssize_t __pyx_v_stop;
- Py_ssize_t __pyx_v_step;
- int __pyx_v_have_start;
- int __pyx_v_have_stop;
- int __pyx_v_have_step;
- PyObject *__pyx_v_index = NULL;
- struct __pyx_memoryview_obj *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- struct __pyx_memoryview_obj *__pyx_t_4;
- char *__pyx_t_5;
- int __pyx_t_6;
- Py_ssize_t __pyx_t_7;
- PyObject *(*__pyx_t_8)(PyObject *);
- PyObject *__pyx_t_9 = NULL;
- Py_ssize_t __pyx_t_10;
- int __pyx_t_11;
- Py_ssize_t __pyx_t_12;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memview_slice", 0);
-
- /* "View.MemoryView":713
- * @cname('__pyx_memview_slice')
- * cdef memoryview memview_slice(memoryview memview, object indices):
- * cdef int new_ndim = 0, suboffset_dim = -1, dim # <<<<<<<<<<<<<<
- * cdef bint negative_step
- * cdef __Pyx_memviewslice src, dst
- */
- __pyx_v_new_ndim = 0;
- __pyx_v_suboffset_dim = -1;
-
- /* "View.MemoryView":720
- *
- *
- * memset(&dst, 0, sizeof(dst)) # <<<<<<<<<<<<<<
- *
- * cdef _memoryviewslice memviewsliceobj
- */
- (void)(memset((&__pyx_v_dst), 0, (sizeof(__pyx_v_dst))));
-
- /* "View.MemoryView":724
- * cdef _memoryviewslice memviewsliceobj
- *
- * assert memview.view.ndim > 0 # <<<<<<<<<<<<<<
- *
- * if isinstance(memview, _memoryviewslice):
- */
- #ifndef CYTHON_WITHOUT_ASSERTIONS
- if (unlikely(!Py_OptimizeFlag)) {
- if (unlikely(!((__pyx_v_memview->view.ndim > 0) != 0))) {
- PyErr_SetNone(PyExc_AssertionError);
- __PYX_ERR(1, 724, __pyx_L1_error)
- }
- }
- #endif
-
- /* "View.MemoryView":726
- * assert memview.view.ndim > 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * memviewsliceobj = memview
- * p_src = &memviewsliceobj.from_slice
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":727
- *
- * if isinstance(memview, _memoryviewslice):
- * memviewsliceobj = memview # <<<<<<<<<<<<<<
- * p_src = &memviewsliceobj.from_slice
- * else:
- */
- if (!(likely(((((PyObject *)__pyx_v_memview)) == Py_None) || likely(__Pyx_TypeTest(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type))))) __PYX_ERR(1, 727, __pyx_L1_error)
- __pyx_t_3 = ((PyObject *)__pyx_v_memview);
- __Pyx_INCREF(__pyx_t_3);
- __pyx_v_memviewsliceobj = ((struct __pyx_memoryviewslice_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":728
- * if isinstance(memview, _memoryviewslice):
- * memviewsliceobj = memview
- * p_src = &memviewsliceobj.from_slice # <<<<<<<<<<<<<<
- * else:
- * slice_copy(memview, &src)
- */
- __pyx_v_p_src = (&__pyx_v_memviewsliceobj->from_slice);
-
- /* "View.MemoryView":726
- * assert memview.view.ndim > 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * memviewsliceobj = memview
- * p_src = &memviewsliceobj.from_slice
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":730
- * p_src = &memviewsliceobj.from_slice
- * else:
- * slice_copy(memview, &src) # <<<<<<<<<<<<<<
- * p_src = &src
- *
- */
- /*else*/ {
- __pyx_memoryview_slice_copy(__pyx_v_memview, (&__pyx_v_src));
-
- /* "View.MemoryView":731
- * else:
- * slice_copy(memview, &src)
- * p_src = &src # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_p_src = (&__pyx_v_src);
- }
- __pyx_L3:;
-
- /* "View.MemoryView":737
- *
- *
- * dst.memview = p_src.memview # <<<<<<<<<<<<<<
- * dst.data = p_src.data
- *
- */
- __pyx_t_4 = __pyx_v_p_src->memview;
- __pyx_v_dst.memview = __pyx_t_4;
-
- /* "View.MemoryView":738
- *
- * dst.memview = p_src.memview
- * dst.data = p_src.data # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_5 = __pyx_v_p_src->data;
- __pyx_v_dst.data = __pyx_t_5;
-
- /* "View.MemoryView":743
- *
- *
- * cdef __Pyx_memviewslice *p_dst = &dst # <<<<<<<<<<<<<<
- * cdef int *p_suboffset_dim = &suboffset_dim
- * cdef Py_ssize_t start, stop, step
- */
- __pyx_v_p_dst = (&__pyx_v_dst);
-
- /* "View.MemoryView":744
- *
- * cdef __Pyx_memviewslice *p_dst = &dst
- * cdef int *p_suboffset_dim = &suboffset_dim # <<<<<<<<<<<<<<
- * cdef Py_ssize_t start, stop, step
- * cdef bint have_start, have_stop, have_step
- */
- __pyx_v_p_suboffset_dim = (&__pyx_v_suboffset_dim);
-
- /* "View.MemoryView":748
- * cdef bint have_start, have_stop, have_step
- *
- * for dim, index in enumerate(indices): # <<<<<<<<<<<<<<
- * if PyIndex_Check(index):
- * slice_memviewslice(
- */
- __pyx_t_6 = 0;
- if (likely(PyList_CheckExact(__pyx_v_indices)) || PyTuple_CheckExact(__pyx_v_indices)) {
- __pyx_t_3 = __pyx_v_indices; __Pyx_INCREF(__pyx_t_3); __pyx_t_7 = 0;
- __pyx_t_8 = NULL;
- } else {
- __pyx_t_7 = -1; __pyx_t_3 = PyObject_GetIter(__pyx_v_indices); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 748, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_8 = Py_TYPE(__pyx_t_3)->tp_iternext; if (unlikely(!__pyx_t_8)) __PYX_ERR(1, 748, __pyx_L1_error)
- }
- for (;;) {
- if (likely(!__pyx_t_8)) {
- if (likely(PyList_CheckExact(__pyx_t_3))) {
- if (__pyx_t_7 >= PyList_GET_SIZE(__pyx_t_3)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_9 = PyList_GET_ITEM(__pyx_t_3, __pyx_t_7); __Pyx_INCREF(__pyx_t_9); __pyx_t_7++; if (unlikely(0 < 0)) __PYX_ERR(1, 748, __pyx_L1_error)
- #else
- __pyx_t_9 = PySequence_ITEM(__pyx_t_3, __pyx_t_7); __pyx_t_7++; if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 748, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- #endif
- } else {
- if (__pyx_t_7 >= PyTuple_GET_SIZE(__pyx_t_3)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_9 = PyTuple_GET_ITEM(__pyx_t_3, __pyx_t_7); __Pyx_INCREF(__pyx_t_9); __pyx_t_7++; if (unlikely(0 < 0)) __PYX_ERR(1, 748, __pyx_L1_error)
- #else
- __pyx_t_9 = PySequence_ITEM(__pyx_t_3, __pyx_t_7); __pyx_t_7++; if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 748, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- #endif
- }
- } else {
- __pyx_t_9 = __pyx_t_8(__pyx_t_3);
- if (unlikely(!__pyx_t_9)) {
- PyObject* exc_type = PyErr_Occurred();
- if (exc_type) {
- if (likely(__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration))) PyErr_Clear();
- else __PYX_ERR(1, 748, __pyx_L1_error)
- }
- break;
- }
- __Pyx_GOTREF(__pyx_t_9);
- }
- __Pyx_XDECREF_SET(__pyx_v_index, __pyx_t_9);
- __pyx_t_9 = 0;
- __pyx_v_dim = __pyx_t_6;
- __pyx_t_6 = (__pyx_t_6 + 1);
-
- /* "View.MemoryView":749
- *
- * for dim, index in enumerate(indices):
- * if PyIndex_Check(index): # <<<<<<<<<<<<<<
- * slice_memviewslice(
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- */
- __pyx_t_2 = (PyIndex_Check(__pyx_v_index) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":753
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- * dim, new_ndim, p_suboffset_dim,
- * index, 0, 0, # start, stop, step # <<<<<<<<<<<<<<
- * 0, 0, 0, # have_{start,stop,step}
- * False)
- */
- __pyx_t_10 = __Pyx_PyIndex_AsSsize_t(__pyx_v_index); if (unlikely((__pyx_t_10 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 753, __pyx_L1_error)
-
- /* "View.MemoryView":750
- * for dim, index in enumerate(indices):
- * if PyIndex_Check(index):
- * slice_memviewslice( # <<<<<<<<<<<<<<
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- * dim, new_ndim, p_suboffset_dim,
- */
- __pyx_t_11 = __pyx_memoryview_slice_memviewslice(__pyx_v_p_dst, (__pyx_v_p_src->shape[__pyx_v_dim]), (__pyx_v_p_src->strides[__pyx_v_dim]), (__pyx_v_p_src->suboffsets[__pyx_v_dim]), __pyx_v_dim, __pyx_v_new_ndim, __pyx_v_p_suboffset_dim, __pyx_t_10, 0, 0, 0, 0, 0, 0); if (unlikely(__pyx_t_11 == ((int)-1))) __PYX_ERR(1, 750, __pyx_L1_error)
-
- /* "View.MemoryView":749
- *
- * for dim, index in enumerate(indices):
- * if PyIndex_Check(index): # <<<<<<<<<<<<<<
- * slice_memviewslice(
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":756
- * 0, 0, 0, # have_{start,stop,step}
- * False)
- * elif index is None: # <<<<<<<<<<<<<<
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0
- */
- __pyx_t_2 = (__pyx_v_index == Py_None);
- __pyx_t_1 = (__pyx_t_2 != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":757
- * False)
- * elif index is None:
- * p_dst.shape[new_ndim] = 1 # <<<<<<<<<<<<<<
- * p_dst.strides[new_ndim] = 0
- * p_dst.suboffsets[new_ndim] = -1
- */
- (__pyx_v_p_dst->shape[__pyx_v_new_ndim]) = 1;
-
- /* "View.MemoryView":758
- * elif index is None:
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0 # <<<<<<<<<<<<<<
- * p_dst.suboffsets[new_ndim] = -1
- * new_ndim += 1
- */
- (__pyx_v_p_dst->strides[__pyx_v_new_ndim]) = 0;
-
- /* "View.MemoryView":759
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0
- * p_dst.suboffsets[new_ndim] = -1 # <<<<<<<<<<<<<<
- * new_ndim += 1
- * else:
- */
- (__pyx_v_p_dst->suboffsets[__pyx_v_new_ndim]) = -1L;
-
- /* "View.MemoryView":760
- * p_dst.strides[new_ndim] = 0
- * p_dst.suboffsets[new_ndim] = -1
- * new_ndim += 1 # <<<<<<<<<<<<<<
- * else:
- * start = index.start or 0
- */
- __pyx_v_new_ndim = (__pyx_v_new_ndim + 1);
-
- /* "View.MemoryView":756
- * 0, 0, 0, # have_{start,stop,step}
- * False)
- * elif index is None: # <<<<<<<<<<<<<<
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":762
- * new_ndim += 1
- * else:
- * start = index.start or 0 # <<<<<<<<<<<<<<
- * stop = index.stop or 0
- * step = index.step or 0
- */
- /*else*/ {
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_start); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 762, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_t_9); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 762, __pyx_L1_error)
- if (!__pyx_t_1) {
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- } else {
- __pyx_t_12 = __Pyx_PyIndex_AsSsize_t(__pyx_t_9); if (unlikely((__pyx_t_12 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 762, __pyx_L1_error)
- __pyx_t_10 = __pyx_t_12;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- goto __pyx_L7_bool_binop_done;
- }
- __pyx_t_10 = 0;
- __pyx_L7_bool_binop_done:;
- __pyx_v_start = __pyx_t_10;
-
- /* "View.MemoryView":763
- * else:
- * start = index.start or 0
- * stop = index.stop or 0 # <<<<<<<<<<<<<<
- * step = index.step or 0
- *
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_stop); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 763, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_t_9); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 763, __pyx_L1_error)
- if (!__pyx_t_1) {
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- } else {
- __pyx_t_12 = __Pyx_PyIndex_AsSsize_t(__pyx_t_9); if (unlikely((__pyx_t_12 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 763, __pyx_L1_error)
- __pyx_t_10 = __pyx_t_12;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- goto __pyx_L9_bool_binop_done;
- }
- __pyx_t_10 = 0;
- __pyx_L9_bool_binop_done:;
- __pyx_v_stop = __pyx_t_10;
-
- /* "View.MemoryView":764
- * start = index.start or 0
- * stop = index.stop or 0
- * step = index.step or 0 # <<<<<<<<<<<<<<
- *
- * have_start = index.start is not None
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_step); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 764, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_t_9); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 764, __pyx_L1_error)
- if (!__pyx_t_1) {
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- } else {
- __pyx_t_12 = __Pyx_PyIndex_AsSsize_t(__pyx_t_9); if (unlikely((__pyx_t_12 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 764, __pyx_L1_error)
- __pyx_t_10 = __pyx_t_12;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- goto __pyx_L11_bool_binop_done;
- }
- __pyx_t_10 = 0;
- __pyx_L11_bool_binop_done:;
- __pyx_v_step = __pyx_t_10;
-
- /* "View.MemoryView":766
- * step = index.step or 0
- *
- * have_start = index.start is not None # <<<<<<<<<<<<<<
- * have_stop = index.stop is not None
- * have_step = index.step is not None
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_start); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 766, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = (__pyx_t_9 != Py_None);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- __pyx_v_have_start = __pyx_t_1;
-
- /* "View.MemoryView":767
- *
- * have_start = index.start is not None
- * have_stop = index.stop is not None # <<<<<<<<<<<<<<
- * have_step = index.step is not None
- *
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_stop); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 767, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = (__pyx_t_9 != Py_None);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- __pyx_v_have_stop = __pyx_t_1;
-
- /* "View.MemoryView":768
- * have_start = index.start is not None
- * have_stop = index.stop is not None
- * have_step = index.step is not None # <<<<<<<<<<<<<<
- *
- * slice_memviewslice(
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_step); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 768, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = (__pyx_t_9 != Py_None);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- __pyx_v_have_step = __pyx_t_1;
-
- /* "View.MemoryView":770
- * have_step = index.step is not None
- *
- * slice_memviewslice( # <<<<<<<<<<<<<<
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- * dim, new_ndim, p_suboffset_dim,
- */
- __pyx_t_11 = __pyx_memoryview_slice_memviewslice(__pyx_v_p_dst, (__pyx_v_p_src->shape[__pyx_v_dim]), (__pyx_v_p_src->strides[__pyx_v_dim]), (__pyx_v_p_src->suboffsets[__pyx_v_dim]), __pyx_v_dim, __pyx_v_new_ndim, __pyx_v_p_suboffset_dim, __pyx_v_start, __pyx_v_stop, __pyx_v_step, __pyx_v_have_start, __pyx_v_have_stop, __pyx_v_have_step, 1); if (unlikely(__pyx_t_11 == ((int)-1))) __PYX_ERR(1, 770, __pyx_L1_error)
-
- /* "View.MemoryView":776
- * have_start, have_stop, have_step,
- * True)
- * new_ndim += 1 # <<<<<<<<<<<<<<
- *
- * if isinstance(memview, _memoryviewslice):
- */
- __pyx_v_new_ndim = (__pyx_v_new_ndim + 1);
- }
- __pyx_L6:;
-
- /* "View.MemoryView":748
- * cdef bint have_start, have_stop, have_step
- *
- * for dim, index in enumerate(indices): # <<<<<<<<<<<<<<
- * if PyIndex_Check(index):
- * slice_memviewslice(
- */
- }
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":778
- * new_ndim += 1
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func,
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":779
- *
- * if isinstance(memview, _memoryviewslice):
- * return memoryview_fromslice(dst, new_ndim, # <<<<<<<<<<<<<<
- * memviewsliceobj.to_object_func,
- * memviewsliceobj.to_dtype_func,
- */
- __Pyx_XDECREF(((PyObject *)__pyx_r));
-
- /* "View.MemoryView":780
- * if isinstance(memview, _memoryviewslice):
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func, # <<<<<<<<<<<<<<
- * memviewsliceobj.to_dtype_func,
- * memview.dtype_is_object)
- */
- if (unlikely(!__pyx_v_memviewsliceobj)) { __Pyx_RaiseUnboundLocalError("memviewsliceobj"); __PYX_ERR(1, 780, __pyx_L1_error) }
-
- /* "View.MemoryView":781
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func,
- * memviewsliceobj.to_dtype_func, # <<<<<<<<<<<<<<
- * memview.dtype_is_object)
- * else:
- */
- if (unlikely(!__pyx_v_memviewsliceobj)) { __Pyx_RaiseUnboundLocalError("memviewsliceobj"); __PYX_ERR(1, 781, __pyx_L1_error) }
-
- /* "View.MemoryView":779
- *
- * if isinstance(memview, _memoryviewslice):
- * return memoryview_fromslice(dst, new_ndim, # <<<<<<<<<<<<<<
- * memviewsliceobj.to_object_func,
- * memviewsliceobj.to_dtype_func,
- */
- __pyx_t_3 = __pyx_memoryview_fromslice(__pyx_v_dst, __pyx_v_new_ndim, __pyx_v_memviewsliceobj->to_object_func, __pyx_v_memviewsliceobj->to_dtype_func, __pyx_v_memview->dtype_is_object); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 779, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- if (!(likely(((__pyx_t_3) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_3, __pyx_memoryview_type))))) __PYX_ERR(1, 779, __pyx_L1_error)
- __pyx_r = ((struct __pyx_memoryview_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":778
- * new_ndim += 1
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func,
- */
- }
-
- /* "View.MemoryView":784
- * memview.dtype_is_object)
- * else:
- * return memoryview_fromslice(dst, new_ndim, NULL, NULL, # <<<<<<<<<<<<<<
- * memview.dtype_is_object)
- *
- */
- /*else*/ {
- __Pyx_XDECREF(((PyObject *)__pyx_r));
-
- /* "View.MemoryView":785
- * else:
- * return memoryview_fromslice(dst, new_ndim, NULL, NULL,
- * memview.dtype_is_object) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __pyx_memoryview_fromslice(__pyx_v_dst, __pyx_v_new_ndim, NULL, NULL, __pyx_v_memview->dtype_is_object); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 784, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "View.MemoryView":784
- * memview.dtype_is_object)
- * else:
- * return memoryview_fromslice(dst, new_ndim, NULL, NULL, # <<<<<<<<<<<<<<
- * memview.dtype_is_object)
- *
- */
- if (!(likely(((__pyx_t_3) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_3, __pyx_memoryview_type))))) __PYX_ERR(1, 784, __pyx_L1_error)
- __pyx_r = ((struct __pyx_memoryview_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":712
- *
- * @cname('__pyx_memview_slice')
- * cdef memoryview memview_slice(memoryview memview, object indices): # <<<<<<<<<<<<<<
- * cdef int new_ndim = 0, suboffset_dim = -1, dim
- * cdef bint negative_step
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_9);
- __Pyx_AddTraceback("View.MemoryView.memview_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_memviewsliceobj);
- __Pyx_XDECREF(__pyx_v_index);
- __Pyx_XGIVEREF((PyObject *)__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":809
- *
- * @cname('__pyx_memoryview_slice_memviewslice')
- * cdef int slice_memviewslice( # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * Py_ssize_t shape, Py_ssize_t stride, Py_ssize_t suboffset,
- */
-
-static int __pyx_memoryview_slice_memviewslice(__Pyx_memviewslice *__pyx_v_dst, Py_ssize_t __pyx_v_shape, Py_ssize_t __pyx_v_stride, Py_ssize_t __pyx_v_suboffset, int __pyx_v_dim, int __pyx_v_new_ndim, int *__pyx_v_suboffset_dim, Py_ssize_t __pyx_v_start, Py_ssize_t __pyx_v_stop, Py_ssize_t __pyx_v_step, int __pyx_v_have_start, int __pyx_v_have_stop, int __pyx_v_have_step, int __pyx_v_is_slice) {
- Py_ssize_t __pyx_v_new_shape;
- int __pyx_v_negative_step;
- int __pyx_r;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":829
- * cdef bint negative_step
- *
- * if not is_slice: # <<<<<<<<<<<<<<
- *
- * if start < 0:
- */
- __pyx_t_1 = ((!(__pyx_v_is_slice != 0)) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":831
- * if not is_slice:
- *
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if not 0 <= start < shape:
- */
- __pyx_t_1 = ((__pyx_v_start < 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":832
- *
- * if start < 0:
- * start += shape # <<<<<<<<<<<<<<
- * if not 0 <= start < shape:
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim)
- */
- __pyx_v_start = (__pyx_v_start + __pyx_v_shape);
-
- /* "View.MemoryView":831
- * if not is_slice:
- *
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if not 0 <= start < shape:
- */
- }
-
- /* "View.MemoryView":833
- * if start < 0:
- * start += shape
- * if not 0 <= start < shape: # <<<<<<<<<<<<<<
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim)
- * else:
- */
- __pyx_t_1 = (0 <= __pyx_v_start);
- if (__pyx_t_1) {
- __pyx_t_1 = (__pyx_v_start < __pyx_v_shape);
- }
- __pyx_t_2 = ((!(__pyx_t_1 != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":834
- * start += shape
- * if not 0 <= start < shape:
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim) # <<<<<<<<<<<<<<
- * else:
- *
- */
- __pyx_t_3 = __pyx_memoryview_err_dim(__pyx_builtin_IndexError, ((char *)"Index out of bounds (axis %d)"), __pyx_v_dim); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 834, __pyx_L1_error)
-
- /* "View.MemoryView":833
- * if start < 0:
- * start += shape
- * if not 0 <= start < shape: # <<<<<<<<<<<<<<
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim)
- * else:
- */
- }
-
- /* "View.MemoryView":829
- * cdef bint negative_step
- *
- * if not is_slice: # <<<<<<<<<<<<<<
- *
- * if start < 0:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":837
- * else:
- *
- * negative_step = have_step != 0 and step < 0 # <<<<<<<<<<<<<<
- *
- * if have_step and step == 0:
- */
- /*else*/ {
- __pyx_t_1 = ((__pyx_v_have_step != 0) != 0);
- if (__pyx_t_1) {
- } else {
- __pyx_t_2 = __pyx_t_1;
- goto __pyx_L6_bool_binop_done;
- }
- __pyx_t_1 = ((__pyx_v_step < 0) != 0);
- __pyx_t_2 = __pyx_t_1;
- __pyx_L6_bool_binop_done:;
- __pyx_v_negative_step = __pyx_t_2;
-
- /* "View.MemoryView":839
- * negative_step = have_step != 0 and step < 0
- *
- * if have_step and step == 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Step may not be zero (axis %d)", dim)
- *
- */
- __pyx_t_1 = (__pyx_v_have_step != 0);
- if (__pyx_t_1) {
- } else {
- __pyx_t_2 = __pyx_t_1;
- goto __pyx_L9_bool_binop_done;
- }
- __pyx_t_1 = ((__pyx_v_step == 0) != 0);
- __pyx_t_2 = __pyx_t_1;
- __pyx_L9_bool_binop_done:;
- if (__pyx_t_2) {
-
- /* "View.MemoryView":840
- *
- * if have_step and step == 0:
- * _err_dim(ValueError, "Step may not be zero (axis %d)", dim) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __pyx_memoryview_err_dim(__pyx_builtin_ValueError, ((char *)"Step may not be zero (axis %d)"), __pyx_v_dim); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 840, __pyx_L1_error)
-
- /* "View.MemoryView":839
- * negative_step = have_step != 0 and step < 0
- *
- * if have_step and step == 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Step may not be zero (axis %d)", dim)
- *
- */
- }
-
- /* "View.MemoryView":843
- *
- *
- * if have_start: # <<<<<<<<<<<<<<
- * if start < 0:
- * start += shape
- */
- __pyx_t_2 = (__pyx_v_have_start != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":844
- *
- * if have_start:
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if start < 0:
- */
- __pyx_t_2 = ((__pyx_v_start < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":845
- * if have_start:
- * if start < 0:
- * start += shape # <<<<<<<<<<<<<<
- * if start < 0:
- * start = 0
- */
- __pyx_v_start = (__pyx_v_start + __pyx_v_shape);
-
- /* "View.MemoryView":846
- * if start < 0:
- * start += shape
- * if start < 0: # <<<<<<<<<<<<<<
- * start = 0
- * elif start >= shape:
- */
- __pyx_t_2 = ((__pyx_v_start < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":847
- * start += shape
- * if start < 0:
- * start = 0 # <<<<<<<<<<<<<<
- * elif start >= shape:
- * if negative_step:
- */
- __pyx_v_start = 0;
-
- /* "View.MemoryView":846
- * if start < 0:
- * start += shape
- * if start < 0: # <<<<<<<<<<<<<<
- * start = 0
- * elif start >= shape:
- */
- }
-
- /* "View.MemoryView":844
- *
- * if have_start:
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if start < 0:
- */
- goto __pyx_L12;
- }
-
- /* "View.MemoryView":848
- * if start < 0:
- * start = 0
- * elif start >= shape: # <<<<<<<<<<<<<<
- * if negative_step:
- * start = shape - 1
- */
- __pyx_t_2 = ((__pyx_v_start >= __pyx_v_shape) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":849
- * start = 0
- * elif start >= shape:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- __pyx_t_2 = (__pyx_v_negative_step != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":850
- * elif start >= shape:
- * if negative_step:
- * start = shape - 1 # <<<<<<<<<<<<<<
- * else:
- * start = shape
- */
- __pyx_v_start = (__pyx_v_shape - 1);
-
- /* "View.MemoryView":849
- * start = 0
- * elif start >= shape:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- goto __pyx_L14;
- }
-
- /* "View.MemoryView":852
- * start = shape - 1
- * else:
- * start = shape # <<<<<<<<<<<<<<
- * else:
- * if negative_step:
- */
- /*else*/ {
- __pyx_v_start = __pyx_v_shape;
- }
- __pyx_L14:;
-
- /* "View.MemoryView":848
- * if start < 0:
- * start = 0
- * elif start >= shape: # <<<<<<<<<<<<<<
- * if negative_step:
- * start = shape - 1
- */
- }
- __pyx_L12:;
-
- /* "View.MemoryView":843
- *
- *
- * if have_start: # <<<<<<<<<<<<<<
- * if start < 0:
- * start += shape
- */
- goto __pyx_L11;
- }
-
- /* "View.MemoryView":854
- * start = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- /*else*/ {
- __pyx_t_2 = (__pyx_v_negative_step != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":855
- * else:
- * if negative_step:
- * start = shape - 1 # <<<<<<<<<<<<<<
- * else:
- * start = 0
- */
- __pyx_v_start = (__pyx_v_shape - 1);
-
- /* "View.MemoryView":854
- * start = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- goto __pyx_L15;
- }
-
- /* "View.MemoryView":857
- * start = shape - 1
- * else:
- * start = 0 # <<<<<<<<<<<<<<
- *
- * if have_stop:
- */
- /*else*/ {
- __pyx_v_start = 0;
- }
- __pyx_L15:;
- }
- __pyx_L11:;
-
- /* "View.MemoryView":859
- * start = 0
- *
- * if have_stop: # <<<<<<<<<<<<<<
- * if stop < 0:
- * stop += shape
- */
- __pyx_t_2 = (__pyx_v_have_stop != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":860
- *
- * if have_stop:
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop += shape
- * if stop < 0:
- */
- __pyx_t_2 = ((__pyx_v_stop < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":861
- * if have_stop:
- * if stop < 0:
- * stop += shape # <<<<<<<<<<<<<<
- * if stop < 0:
- * stop = 0
- */
- __pyx_v_stop = (__pyx_v_stop + __pyx_v_shape);
-
- /* "View.MemoryView":862
- * if stop < 0:
- * stop += shape
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop = 0
- * elif stop > shape:
- */
- __pyx_t_2 = ((__pyx_v_stop < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":863
- * stop += shape
- * if stop < 0:
- * stop = 0 # <<<<<<<<<<<<<<
- * elif stop > shape:
- * stop = shape
- */
- __pyx_v_stop = 0;
-
- /* "View.MemoryView":862
- * if stop < 0:
- * stop += shape
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop = 0
- * elif stop > shape:
- */
- }
-
- /* "View.MemoryView":860
- *
- * if have_stop:
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop += shape
- * if stop < 0:
- */
- goto __pyx_L17;
- }
-
- /* "View.MemoryView":864
- * if stop < 0:
- * stop = 0
- * elif stop > shape: # <<<<<<<<<<<<<<
- * stop = shape
- * else:
- */
- __pyx_t_2 = ((__pyx_v_stop > __pyx_v_shape) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":865
- * stop = 0
- * elif stop > shape:
- * stop = shape # <<<<<<<<<<<<<<
- * else:
- * if negative_step:
- */
- __pyx_v_stop = __pyx_v_shape;
-
- /* "View.MemoryView":864
- * if stop < 0:
- * stop = 0
- * elif stop > shape: # <<<<<<<<<<<<<<
- * stop = shape
- * else:
- */
- }
- __pyx_L17:;
-
- /* "View.MemoryView":859
- * start = 0
- *
- * if have_stop: # <<<<<<<<<<<<<<
- * if stop < 0:
- * stop += shape
- */
- goto __pyx_L16;
- }
-
- /* "View.MemoryView":867
- * stop = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * stop = -1
- * else:
- */
- /*else*/ {
- __pyx_t_2 = (__pyx_v_negative_step != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":868
- * else:
- * if negative_step:
- * stop = -1 # <<<<<<<<<<<<<<
- * else:
- * stop = shape
- */
- __pyx_v_stop = -1L;
-
- /* "View.MemoryView":867
- * stop = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * stop = -1
- * else:
- */
- goto __pyx_L19;
- }
-
- /* "View.MemoryView":870
- * stop = -1
- * else:
- * stop = shape # <<<<<<<<<<<<<<
- *
- * if not have_step:
- */
- /*else*/ {
- __pyx_v_stop = __pyx_v_shape;
- }
- __pyx_L19:;
- }
- __pyx_L16:;
-
- /* "View.MemoryView":872
- * stop = shape
- *
- * if not have_step: # <<<<<<<<<<<<<<
- * step = 1
- *
- */
- __pyx_t_2 = ((!(__pyx_v_have_step != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":873
- *
- * if not have_step:
- * step = 1 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_step = 1;
-
- /* "View.MemoryView":872
- * stop = shape
- *
- * if not have_step: # <<<<<<<<<<<<<<
- * step = 1
- *
- */
- }
-
- /* "View.MemoryView":877
- *
- * with cython.cdivision(True):
- * new_shape = (stop - start) // step # <<<<<<<<<<<<<<
- *
- * if (stop - start) - step * new_shape:
- */
- __pyx_v_new_shape = ((__pyx_v_stop - __pyx_v_start) / __pyx_v_step);
-
- /* "View.MemoryView":879
- * new_shape = (stop - start) // step
- *
- * if (stop - start) - step * new_shape: # <<<<<<<<<<<<<<
- * new_shape += 1
- *
- */
- __pyx_t_2 = (((__pyx_v_stop - __pyx_v_start) - (__pyx_v_step * __pyx_v_new_shape)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":880
- *
- * if (stop - start) - step * new_shape:
- * new_shape += 1 # <<<<<<<<<<<<<<
- *
- * if new_shape < 0:
- */
- __pyx_v_new_shape = (__pyx_v_new_shape + 1);
-
- /* "View.MemoryView":879
- * new_shape = (stop - start) // step
- *
- * if (stop - start) - step * new_shape: # <<<<<<<<<<<<<<
- * new_shape += 1
- *
- */
- }
-
- /* "View.MemoryView":882
- * new_shape += 1
- *
- * if new_shape < 0: # <<<<<<<<<<<<<<
- * new_shape = 0
- *
- */
- __pyx_t_2 = ((__pyx_v_new_shape < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":883
- *
- * if new_shape < 0:
- * new_shape = 0 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_new_shape = 0;
-
- /* "View.MemoryView":882
- * new_shape += 1
- *
- * if new_shape < 0: # <<<<<<<<<<<<<<
- * new_shape = 0
- *
- */
- }
-
- /* "View.MemoryView":886
- *
- *
- * dst.strides[new_ndim] = stride * step # <<<<<<<<<<<<<<
- * dst.shape[new_ndim] = new_shape
- * dst.suboffsets[new_ndim] = suboffset
- */
- (__pyx_v_dst->strides[__pyx_v_new_ndim]) = (__pyx_v_stride * __pyx_v_step);
-
- /* "View.MemoryView":887
- *
- * dst.strides[new_ndim] = stride * step
- * dst.shape[new_ndim] = new_shape # <<<<<<<<<<<<<<
- * dst.suboffsets[new_ndim] = suboffset
- *
- */
- (__pyx_v_dst->shape[__pyx_v_new_ndim]) = __pyx_v_new_shape;
-
- /* "View.MemoryView":888
- * dst.strides[new_ndim] = stride * step
- * dst.shape[new_ndim] = new_shape
- * dst.suboffsets[new_ndim] = suboffset # <<<<<<<<<<<<<<
- *
- *
- */
- (__pyx_v_dst->suboffsets[__pyx_v_new_ndim]) = __pyx_v_suboffset;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":891
- *
- *
- * if suboffset_dim[0] < 0: # <<<<<<<<<<<<<<
- * dst.data += start * stride
- * else:
- */
- __pyx_t_2 = (((__pyx_v_suboffset_dim[0]) < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":892
- *
- * if suboffset_dim[0] < 0:
- * dst.data += start * stride # <<<<<<<<<<<<<<
- * else:
- * dst.suboffsets[suboffset_dim[0]] += start * stride
- */
- __pyx_v_dst->data = (__pyx_v_dst->data + (__pyx_v_start * __pyx_v_stride));
-
- /* "View.MemoryView":891
- *
- *
- * if suboffset_dim[0] < 0: # <<<<<<<<<<<<<<
- * dst.data += start * stride
- * else:
- */
- goto __pyx_L23;
- }
-
- /* "View.MemoryView":894
- * dst.data += start * stride
- * else:
- * dst.suboffsets[suboffset_dim[0]] += start * stride # <<<<<<<<<<<<<<
- *
- * if suboffset >= 0:
- */
- /*else*/ {
- __pyx_t_3 = (__pyx_v_suboffset_dim[0]);
- (__pyx_v_dst->suboffsets[__pyx_t_3]) = ((__pyx_v_dst->suboffsets[__pyx_t_3]) + (__pyx_v_start * __pyx_v_stride));
- }
- __pyx_L23:;
-
- /* "View.MemoryView":896
- * dst.suboffsets[suboffset_dim[0]] += start * stride
- *
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * if not is_slice:
- * if new_ndim == 0:
- */
- __pyx_t_2 = ((__pyx_v_suboffset >= 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":897
- *
- * if suboffset >= 0:
- * if not is_slice: # <<<<<<<<<<<<<<
- * if new_ndim == 0:
- * dst.data = ( dst.data)[0] + suboffset
- */
- __pyx_t_2 = ((!(__pyx_v_is_slice != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":898
- * if suboffset >= 0:
- * if not is_slice:
- * if new_ndim == 0: # <<<<<<<<<<<<<<
- * dst.data = ( dst.data)[0] + suboffset
- * else:
- */
- __pyx_t_2 = ((__pyx_v_new_ndim == 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":899
- * if not is_slice:
- * if new_ndim == 0:
- * dst.data = ( dst.data)[0] + suboffset # <<<<<<<<<<<<<<
- * else:
- * _err_dim(IndexError, "All dimensions preceding dimension %d "
- */
- __pyx_v_dst->data = ((((char **)__pyx_v_dst->data)[0]) + __pyx_v_suboffset);
-
- /* "View.MemoryView":898
- * if suboffset >= 0:
- * if not is_slice:
- * if new_ndim == 0: # <<<<<<<<<<<<<<
- * dst.data = ( dst.data)[0] + suboffset
- * else:
- */
- goto __pyx_L26;
- }
-
- /* "View.MemoryView":901
- * dst.data = ( dst.data)[0] + suboffset
- * else:
- * _err_dim(IndexError, "All dimensions preceding dimension %d " # <<<<<<<<<<<<<<
- * "must be indexed and not sliced", dim)
- * else:
- */
- /*else*/ {
-
- /* "View.MemoryView":902
- * else:
- * _err_dim(IndexError, "All dimensions preceding dimension %d "
- * "must be indexed and not sliced", dim) # <<<<<<<<<<<<<<
- * else:
- * suboffset_dim[0] = new_ndim
- */
- __pyx_t_3 = __pyx_memoryview_err_dim(__pyx_builtin_IndexError, ((char *)"All dimensions preceding dimension %d must be indexed and not sliced"), __pyx_v_dim); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 901, __pyx_L1_error)
- }
- __pyx_L26:;
-
- /* "View.MemoryView":897
- *
- * if suboffset >= 0:
- * if not is_slice: # <<<<<<<<<<<<<<
- * if new_ndim == 0:
- * dst.data = ( dst.data)[0] + suboffset
- */
- goto __pyx_L25;
- }
-
- /* "View.MemoryView":904
- * "must be indexed and not sliced", dim)
- * else:
- * suboffset_dim[0] = new_ndim # <<<<<<<<<<<<<<
- *
- * return 0
- */
- /*else*/ {
- (__pyx_v_suboffset_dim[0]) = __pyx_v_new_ndim;
- }
- __pyx_L25:;
-
- /* "View.MemoryView":896
- * dst.suboffsets[suboffset_dim[0]] += start * stride
- *
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * if not is_slice:
- * if new_ndim == 0:
- */
- }
-
- /* "View.MemoryView":906
- * suboffset_dim[0] = new_ndim
- *
- * return 0 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":809
- *
- * @cname('__pyx_memoryview_slice_memviewslice')
- * cdef int slice_memviewslice( # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * Py_ssize_t shape, Py_ssize_t stride, Py_ssize_t suboffset,
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.slice_memviewslice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = -1;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":912
- *
- * @cname('__pyx_pybuffer_index')
- * cdef char *pybuffer_index(Py_buffer *view, char *bufp, Py_ssize_t index, # <<<<<<<<<<<<<<
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1
- */
-
-static char *__pyx_pybuffer_index(Py_buffer *__pyx_v_view, char *__pyx_v_bufp, Py_ssize_t __pyx_v_index, Py_ssize_t __pyx_v_dim) {
- Py_ssize_t __pyx_v_shape;
- Py_ssize_t __pyx_v_stride;
- Py_ssize_t __pyx_v_suboffset;
- Py_ssize_t __pyx_v_itemsize;
- char *__pyx_v_resultp;
- char *__pyx_r;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("pybuffer_index", 0);
-
- /* "View.MemoryView":914
- * cdef char *pybuffer_index(Py_buffer *view, char *bufp, Py_ssize_t index,
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1 # <<<<<<<<<<<<<<
- * cdef Py_ssize_t itemsize = view.itemsize
- * cdef char *resultp
- */
- __pyx_v_suboffset = -1L;
-
- /* "View.MemoryView":915
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1
- * cdef Py_ssize_t itemsize = view.itemsize # <<<<<<<<<<<<<<
- * cdef char *resultp
- *
- */
- __pyx_t_1 = __pyx_v_view->itemsize;
- __pyx_v_itemsize = __pyx_t_1;
-
- /* "View.MemoryView":918
- * cdef char *resultp
- *
- * if view.ndim == 0: # <<<<<<<<<<<<<<
- * shape = view.len / itemsize
- * stride = itemsize
- */
- __pyx_t_2 = ((__pyx_v_view->ndim == 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":919
- *
- * if view.ndim == 0:
- * shape = view.len / itemsize # <<<<<<<<<<<<<<
- * stride = itemsize
- * else:
- */
- if (unlikely(__pyx_v_itemsize == 0)) {
- PyErr_SetString(PyExc_ZeroDivisionError, "integer division or modulo by zero");
- __PYX_ERR(1, 919, __pyx_L1_error)
- }
- else if (sizeof(Py_ssize_t) == sizeof(long) && (!(((Py_ssize_t)-1) > 0)) && unlikely(__pyx_v_itemsize == (Py_ssize_t)-1) && unlikely(UNARY_NEG_WOULD_OVERFLOW(__pyx_v_view->len))) {
- PyErr_SetString(PyExc_OverflowError, "value too large to perform division");
- __PYX_ERR(1, 919, __pyx_L1_error)
- }
- __pyx_v_shape = __Pyx_div_Py_ssize_t(__pyx_v_view->len, __pyx_v_itemsize);
-
- /* "View.MemoryView":920
- * if view.ndim == 0:
- * shape = view.len / itemsize
- * stride = itemsize # <<<<<<<<<<<<<<
- * else:
- * shape = view.shape[dim]
- */
- __pyx_v_stride = __pyx_v_itemsize;
-
- /* "View.MemoryView":918
- * cdef char *resultp
- *
- * if view.ndim == 0: # <<<<<<<<<<<<<<
- * shape = view.len / itemsize
- * stride = itemsize
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":922
- * stride = itemsize
- * else:
- * shape = view.shape[dim] # <<<<<<<<<<<<<<
- * stride = view.strides[dim]
- * if view.suboffsets != NULL:
- */
- /*else*/ {
- __pyx_v_shape = (__pyx_v_view->shape[__pyx_v_dim]);
-
- /* "View.MemoryView":923
- * else:
- * shape = view.shape[dim]
- * stride = view.strides[dim] # <<<<<<<<<<<<<<
- * if view.suboffsets != NULL:
- * suboffset = view.suboffsets[dim]
- */
- __pyx_v_stride = (__pyx_v_view->strides[__pyx_v_dim]);
-
- /* "View.MemoryView":924
- * shape = view.shape[dim]
- * stride = view.strides[dim]
- * if view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * suboffset = view.suboffsets[dim]
- *
- */
- __pyx_t_2 = ((__pyx_v_view->suboffsets != NULL) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":925
- * stride = view.strides[dim]
- * if view.suboffsets != NULL:
- * suboffset = view.suboffsets[dim] # <<<<<<<<<<<<<<
- *
- * if index < 0:
- */
- __pyx_v_suboffset = (__pyx_v_view->suboffsets[__pyx_v_dim]);
-
- /* "View.MemoryView":924
- * shape = view.shape[dim]
- * stride = view.strides[dim]
- * if view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * suboffset = view.suboffsets[dim]
- *
- */
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":927
- * suboffset = view.suboffsets[dim]
- *
- * if index < 0: # <<<<<<<<<<<<<<
- * index += view.shape[dim]
- * if index < 0:
- */
- __pyx_t_2 = ((__pyx_v_index < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":928
- *
- * if index < 0:
- * index += view.shape[dim] # <<<<<<<<<<<<<<
- * if index < 0:
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- */
- __pyx_v_index = (__pyx_v_index + (__pyx_v_view->shape[__pyx_v_dim]));
-
- /* "View.MemoryView":929
- * if index < 0:
- * index += view.shape[dim]
- * if index < 0: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- __pyx_t_2 = ((__pyx_v_index < 0) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":930
- * index += view.shape[dim]
- * if index < 0:
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim) # <<<<<<<<<<<<<<
- *
- * if index >= shape:
- */
- __pyx_t_3 = PyInt_FromSsize_t(__pyx_v_dim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 930, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_PyString_Format(__pyx_kp_s_Out_of_bounds_on_buffer_access_a, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 930, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_3 = __Pyx_PyObject_CallOneArg(__pyx_builtin_IndexError, __pyx_t_4); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 930, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 930, __pyx_L1_error)
-
- /* "View.MemoryView":929
- * if index < 0:
- * index += view.shape[dim]
- * if index < 0: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- }
-
- /* "View.MemoryView":927
- * suboffset = view.suboffsets[dim]
- *
- * if index < 0: # <<<<<<<<<<<<<<
- * index += view.shape[dim]
- * if index < 0:
- */
- }
-
- /* "View.MemoryView":932
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- * if index >= shape: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- __pyx_t_2 = ((__pyx_v_index >= __pyx_v_shape) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":933
- *
- * if index >= shape:
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim) # <<<<<<<<<<<<<<
- *
- * resultp = bufp + index * stride
- */
- __pyx_t_3 = PyInt_FromSsize_t(__pyx_v_dim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 933, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_PyString_Format(__pyx_kp_s_Out_of_bounds_on_buffer_access_a, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 933, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_3 = __Pyx_PyObject_CallOneArg(__pyx_builtin_IndexError, __pyx_t_4); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 933, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 933, __pyx_L1_error)
-
- /* "View.MemoryView":932
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- * if index >= shape: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- }
-
- /* "View.MemoryView":935
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- * resultp = bufp + index * stride # <<<<<<<<<<<<<<
- * if suboffset >= 0:
- * resultp = ( resultp)[0] + suboffset
- */
- __pyx_v_resultp = (__pyx_v_bufp + (__pyx_v_index * __pyx_v_stride));
-
- /* "View.MemoryView":936
- *
- * resultp = bufp + index * stride
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * resultp = ( resultp)[0] + suboffset
- *
- */
- __pyx_t_2 = ((__pyx_v_suboffset >= 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":937
- * resultp = bufp + index * stride
- * if suboffset >= 0:
- * resultp = ( resultp)[0] + suboffset # <<<<<<<<<<<<<<
- *
- * return resultp
- */
- __pyx_v_resultp = ((((char **)__pyx_v_resultp)[0]) + __pyx_v_suboffset);
-
- /* "View.MemoryView":936
- *
- * resultp = bufp + index * stride
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * resultp = ( resultp)[0] + suboffset
- *
- */
- }
-
- /* "View.MemoryView":939
- * resultp = ( resultp)[0] + suboffset
- *
- * return resultp # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = __pyx_v_resultp;
- goto __pyx_L0;
-
- /* "View.MemoryView":912
- *
- * @cname('__pyx_pybuffer_index')
- * cdef char *pybuffer_index(Py_buffer *view, char *bufp, Py_ssize_t index, # <<<<<<<<<<<<<<
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView.pybuffer_index", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":945
- *
- * @cname('__pyx_memslice_transpose')
- * cdef int transpose_memslice(__Pyx_memviewslice *memslice) nogil except 0: # <<<<<<<<<<<<<<
- * cdef int ndim = memslice.memview.view.ndim
- *
- */
-
-static int __pyx_memslice_transpose(__Pyx_memviewslice *__pyx_v_memslice) {
- int __pyx_v_ndim;
- Py_ssize_t *__pyx_v_shape;
- Py_ssize_t *__pyx_v_strides;
- int __pyx_v_i;
- int __pyx_v_j;
- int __pyx_r;
- int __pyx_t_1;
- Py_ssize_t *__pyx_t_2;
- long __pyx_t_3;
- long __pyx_t_4;
- Py_ssize_t __pyx_t_5;
- Py_ssize_t __pyx_t_6;
- int __pyx_t_7;
- int __pyx_t_8;
- int __pyx_t_9;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":946
- * @cname('__pyx_memslice_transpose')
- * cdef int transpose_memslice(__Pyx_memviewslice *memslice) nogil except 0:
- * cdef int ndim = memslice.memview.view.ndim # <<<<<<<<<<<<<<
- *
- * cdef Py_ssize_t *shape = memslice.shape
- */
- __pyx_t_1 = __pyx_v_memslice->memview->view.ndim;
- __pyx_v_ndim = __pyx_t_1;
-
- /* "View.MemoryView":948
- * cdef int ndim = memslice.memview.view.ndim
- *
- * cdef Py_ssize_t *shape = memslice.shape # <<<<<<<<<<<<<<
- * cdef Py_ssize_t *strides = memslice.strides
- *
- */
- __pyx_t_2 = __pyx_v_memslice->shape;
- __pyx_v_shape = __pyx_t_2;
-
- /* "View.MemoryView":949
- *
- * cdef Py_ssize_t *shape = memslice.shape
- * cdef Py_ssize_t *strides = memslice.strides # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_2 = __pyx_v_memslice->strides;
- __pyx_v_strides = __pyx_t_2;
-
- /* "View.MemoryView":953
- *
- * cdef int i, j
- * for i in range(ndim / 2): # <<<<<<<<<<<<<<
- * j = ndim - 1 - i
- * strides[i], strides[j] = strides[j], strides[i]
- */
- __pyx_t_3 = __Pyx_div_long(__pyx_v_ndim, 2);
- __pyx_t_4 = __pyx_t_3;
- for (__pyx_t_1 = 0; __pyx_t_1 < __pyx_t_4; __pyx_t_1+=1) {
- __pyx_v_i = __pyx_t_1;
-
- /* "View.MemoryView":954
- * cdef int i, j
- * for i in range(ndim / 2):
- * j = ndim - 1 - i # <<<<<<<<<<<<<<
- * strides[i], strides[j] = strides[j], strides[i]
- * shape[i], shape[j] = shape[j], shape[i]
- */
- __pyx_v_j = ((__pyx_v_ndim - 1) - __pyx_v_i);
-
- /* "View.MemoryView":955
- * for i in range(ndim / 2):
- * j = ndim - 1 - i
- * strides[i], strides[j] = strides[j], strides[i] # <<<<<<<<<<<<<<
- * shape[i], shape[j] = shape[j], shape[i]
- *
- */
- __pyx_t_5 = (__pyx_v_strides[__pyx_v_j]);
- __pyx_t_6 = (__pyx_v_strides[__pyx_v_i]);
- (__pyx_v_strides[__pyx_v_i]) = __pyx_t_5;
- (__pyx_v_strides[__pyx_v_j]) = __pyx_t_6;
-
- /* "View.MemoryView":956
- * j = ndim - 1 - i
- * strides[i], strides[j] = strides[j], strides[i]
- * shape[i], shape[j] = shape[j], shape[i] # <<<<<<<<<<<<<<
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0:
- */
- __pyx_t_6 = (__pyx_v_shape[__pyx_v_j]);
- __pyx_t_5 = (__pyx_v_shape[__pyx_v_i]);
- (__pyx_v_shape[__pyx_v_i]) = __pyx_t_6;
- (__pyx_v_shape[__pyx_v_j]) = __pyx_t_5;
-
- /* "View.MemoryView":958
- * shape[i], shape[j] = shape[j], shape[i]
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0: # <<<<<<<<<<<<<<
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions")
- *
- */
- __pyx_t_8 = (((__pyx_v_memslice->suboffsets[__pyx_v_i]) >= 0) != 0);
- if (!__pyx_t_8) {
- } else {
- __pyx_t_7 = __pyx_t_8;
- goto __pyx_L6_bool_binop_done;
- }
- __pyx_t_8 = (((__pyx_v_memslice->suboffsets[__pyx_v_j]) >= 0) != 0);
- __pyx_t_7 = __pyx_t_8;
- __pyx_L6_bool_binop_done:;
- if (__pyx_t_7) {
-
- /* "View.MemoryView":959
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0:
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions") # <<<<<<<<<<<<<<
- *
- * return 1
- */
- __pyx_t_9 = __pyx_memoryview_err(__pyx_builtin_ValueError, ((char *)"Cannot transpose memoryview with indirect dimensions")); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 959, __pyx_L1_error)
-
- /* "View.MemoryView":958
- * shape[i], shape[j] = shape[j], shape[i]
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0: # <<<<<<<<<<<<<<
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions")
- *
- */
- }
- }
-
- /* "View.MemoryView":961
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions")
- *
- * return 1 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = 1;
- goto __pyx_L0;
-
- /* "View.MemoryView":945
- *
- * @cname('__pyx_memslice_transpose')
- * cdef int transpose_memslice(__Pyx_memviewslice *memslice) nogil except 0: # <<<<<<<<<<<<<<
- * cdef int ndim = memslice.memview.view.ndim
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.transpose_memslice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = 0;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":978
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * def __dealloc__(self): # <<<<<<<<<<<<<<
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- */
-
-/* Python wrapper */
-static void __pyx_memoryviewslice___dealloc__(PyObject *__pyx_v_self); /*proto*/
-static void __pyx_memoryviewslice___dealloc__(PyObject *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__ (wrapper)", 0);
- __pyx_memoryviewslice___pyx_pf_15View_dot_MemoryView_16_memoryviewslice___dealloc__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-static void __pyx_memoryviewslice___pyx_pf_15View_dot_MemoryView_16_memoryviewslice___dealloc__(struct __pyx_memoryviewslice_obj *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__", 0);
-
- /* "View.MemoryView":979
- *
- * def __dealloc__(self):
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1) # <<<<<<<<<<<<<<
- *
- * cdef convert_item_to_object(self, char *itemp):
- */
- __PYX_XDEC_MEMVIEW((&__pyx_v_self->from_slice), 1);
-
- /* "View.MemoryView":978
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * def __dealloc__(self): # <<<<<<<<<<<<<<
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":981
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * if self.to_object_func != NULL:
- * return self.to_object_func(itemp)
- */
-
-static PyObject *__pyx_memoryviewslice_convert_item_to_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("convert_item_to_object", 0);
-
- /* "View.MemoryView":982
- *
- * cdef convert_item_to_object(self, char *itemp):
- * if self.to_object_func != NULL: # <<<<<<<<<<<<<<
- * return self.to_object_func(itemp)
- * else:
- */
- __pyx_t_1 = ((__pyx_v_self->to_object_func != NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":983
- * cdef convert_item_to_object(self, char *itemp):
- * if self.to_object_func != NULL:
- * return self.to_object_func(itemp) # <<<<<<<<<<<<<<
- * else:
- * return memoryview.convert_item_to_object(self, itemp)
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_v_self->to_object_func(__pyx_v_itemp); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 983, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":982
- *
- * cdef convert_item_to_object(self, char *itemp):
- * if self.to_object_func != NULL: # <<<<<<<<<<<<<<
- * return self.to_object_func(itemp)
- * else:
- */
- }
-
- /* "View.MemoryView":985
- * return self.to_object_func(itemp)
- * else:
- * return memoryview.convert_item_to_object(self, itemp) # <<<<<<<<<<<<<<
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- */
- /*else*/ {
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_memoryview_convert_item_to_object(((struct __pyx_memoryview_obj *)__pyx_v_self), __pyx_v_itemp); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 985, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":981
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * if self.to_object_func != NULL:
- * return self.to_object_func(itemp)
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.convert_item_to_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":987
- * return memoryview.convert_item_to_object(self, itemp)
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * if self.to_dtype_func != NULL:
- * self.to_dtype_func(itemp, value)
- */
-
-static PyObject *__pyx_memoryviewslice_assign_item_from_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("assign_item_from_object", 0);
-
- /* "View.MemoryView":988
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- * if self.to_dtype_func != NULL: # <<<<<<<<<<<<<<
- * self.to_dtype_func(itemp, value)
- * else:
- */
- __pyx_t_1 = ((__pyx_v_self->to_dtype_func != NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":989
- * cdef assign_item_from_object(self, char *itemp, object value):
- * if self.to_dtype_func != NULL:
- * self.to_dtype_func(itemp, value) # <<<<<<<<<<<<<<
- * else:
- * memoryview.assign_item_from_object(self, itemp, value)
- */
- __pyx_t_2 = __pyx_v_self->to_dtype_func(__pyx_v_itemp, __pyx_v_value); if (unlikely(__pyx_t_2 == ((int)0))) __PYX_ERR(1, 989, __pyx_L1_error)
-
- /* "View.MemoryView":988
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- * if self.to_dtype_func != NULL: # <<<<<<<<<<<<<<
- * self.to_dtype_func(itemp, value)
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":991
- * self.to_dtype_func(itemp, value)
- * else:
- * memoryview.assign_item_from_object(self, itemp, value) # <<<<<<<<<<<<<<
- *
- * @property
- */
- /*else*/ {
- __pyx_t_3 = __pyx_memoryview_assign_item_from_object(((struct __pyx_memoryview_obj *)__pyx_v_self), __pyx_v_itemp, __pyx_v_value); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 991, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":987
- * return memoryview.convert_item_to_object(self, itemp)
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * if self.to_dtype_func != NULL:
- * self.to_dtype_func(itemp, value)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.assign_item_from_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":994
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.from_object
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_16_memoryviewslice_4base_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_16_memoryviewslice_4base_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_16_memoryviewslice_4base___get__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_16_memoryviewslice_4base___get__(struct __pyx_memoryviewslice_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":995
- * @property
- * def base(self):
- * return self.from_object # <<<<<<<<<<<<<<
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)")
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->from_object);
- __pyx_r = __pyx_v_self->from_object;
- goto __pyx_L0;
-
- /* "View.MemoryView":994
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.from_object
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryviewslice_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryviewslice_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryviewslice___reduce_cython__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryviewslice___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__18, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 2, __pyx_L1_error)
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryviewslice_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryviewslice_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryviewslice_2__setstate_cython__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryviewslice_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__19, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 4, __pyx_L1_error)
-
- /* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1001
- *
- * @cname('__pyx_memoryview_fromslice')
- * cdef memoryview_fromslice(__Pyx_memviewslice memviewslice, # <<<<<<<<<<<<<<
- * int ndim,
- * object (*to_object_func)(char *),
- */
-
-static PyObject *__pyx_memoryview_fromslice(__Pyx_memviewslice __pyx_v_memviewslice, int __pyx_v_ndim, PyObject *(*__pyx_v_to_object_func)(char *), int (*__pyx_v_to_dtype_func)(char *, PyObject *), int __pyx_v_dtype_is_object) {
- struct __pyx_memoryviewslice_obj *__pyx_v_result = 0;
- Py_ssize_t __pyx_v_suboffset;
- PyObject *__pyx_v_length = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- __Pyx_TypeInfo *__pyx_t_4;
- Py_buffer __pyx_t_5;
- Py_ssize_t *__pyx_t_6;
- Py_ssize_t *__pyx_t_7;
- Py_ssize_t *__pyx_t_8;
- Py_ssize_t __pyx_t_9;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_fromslice", 0);
-
- /* "View.MemoryView":1009
- * cdef _memoryviewslice result
- *
- * if memviewslice.memview == Py_None: # <<<<<<<<<<<<<<
- * return None
- *
- */
- __pyx_t_1 = ((((PyObject *)__pyx_v_memviewslice.memview) == Py_None) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1010
- *
- * if memviewslice.memview == Py_None:
- * return None # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
-
- /* "View.MemoryView":1009
- * cdef _memoryviewslice result
- *
- * if memviewslice.memview == Py_None: # <<<<<<<<<<<<<<
- * return None
- *
- */
- }
-
- /* "View.MemoryView":1015
- *
- *
- * result = _memoryviewslice(None, 0, dtype_is_object) # <<<<<<<<<<<<<<
- *
- * result.from_slice = memviewslice
- */
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_v_dtype_is_object); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1015, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyTuple_New(3); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1015, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(Py_None);
- PyTuple_SET_ITEM(__pyx_t_3, 0, Py_None);
- __Pyx_INCREF(__pyx_int_0);
- __Pyx_GIVEREF(__pyx_int_0);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_int_0);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 2, __pyx_t_2);
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryviewslice_type), __pyx_t_3, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1015, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result = ((struct __pyx_memoryviewslice_obj *)__pyx_t_2);
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":1017
- * result = _memoryviewslice(None, 0, dtype_is_object)
- *
- * result.from_slice = memviewslice # <<<<<<<<<<<<<<
- * __PYX_INC_MEMVIEW(&memviewslice, 1)
- *
- */
- __pyx_v_result->from_slice = __pyx_v_memviewslice;
-
- /* "View.MemoryView":1018
- *
- * result.from_slice = memviewslice
- * __PYX_INC_MEMVIEW(&memviewslice, 1) # <<<<<<<<<<<<<<
- *
- * result.from_object = ( memviewslice.memview).base
- */
- __PYX_INC_MEMVIEW((&__pyx_v_memviewslice), 1);
-
- /* "View.MemoryView":1020
- * __PYX_INC_MEMVIEW(&memviewslice, 1)
- *
- * result.from_object = ( memviewslice.memview).base # <<<<<<<<<<<<<<
- * result.typeinfo = memviewslice.memview.typeinfo
- *
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_memviewslice.memview), __pyx_n_s_base); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1020, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_2);
- __Pyx_GOTREF(__pyx_v_result->from_object);
- __Pyx_DECREF(__pyx_v_result->from_object);
- __pyx_v_result->from_object = __pyx_t_2;
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":1021
- *
- * result.from_object = ( memviewslice.memview).base
- * result.typeinfo = memviewslice.memview.typeinfo # <<<<<<<<<<<<<<
- *
- * result.view = memviewslice.memview.view
- */
- __pyx_t_4 = __pyx_v_memviewslice.memview->typeinfo;
- __pyx_v_result->__pyx_base.typeinfo = __pyx_t_4;
-
- /* "View.MemoryView":1023
- * result.typeinfo = memviewslice.memview.typeinfo
- *
- * result.view = memviewslice.memview.view # <<<<<<<<<<<<<<
- * result.view.buf = memviewslice.data
- * result.view.ndim = ndim
- */
- __pyx_t_5 = __pyx_v_memviewslice.memview->view;
- __pyx_v_result->__pyx_base.view = __pyx_t_5;
-
- /* "View.MemoryView":1024
- *
- * result.view = memviewslice.memview.view
- * result.view.buf = memviewslice.data # <<<<<<<<<<<<<<
- * result.view.ndim = ndim
- * (<__pyx_buffer *> &result.view).obj = Py_None
- */
- __pyx_v_result->__pyx_base.view.buf = ((void *)__pyx_v_memviewslice.data);
-
- /* "View.MemoryView":1025
- * result.view = memviewslice.memview.view
- * result.view.buf = memviewslice.data
- * result.view.ndim = ndim # <<<<<<<<<<<<<<
- * (<__pyx_buffer *> &result.view).obj = Py_None
- * Py_INCREF(Py_None)
- */
- __pyx_v_result->__pyx_base.view.ndim = __pyx_v_ndim;
-
- /* "View.MemoryView":1026
- * result.view.buf = memviewslice.data
- * result.view.ndim = ndim
- * (<__pyx_buffer *> &result.view).obj = Py_None # <<<<<<<<<<<<<<
- * Py_INCREF(Py_None)
- *
- */
- ((Py_buffer *)(&__pyx_v_result->__pyx_base.view))->obj = Py_None;
-
- /* "View.MemoryView":1027
- * result.view.ndim = ndim
- * (<__pyx_buffer *> &result.view).obj = Py_None
- * Py_INCREF(Py_None) # <<<<<<<<<<<<<<
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE:
- */
- Py_INCREF(Py_None);
-
- /* "View.MemoryView":1029
- * Py_INCREF(Py_None)
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE: # <<<<<<<<<<<<<<
- * result.flags = PyBUF_RECORDS
- * else:
- */
- __pyx_t_1 = ((((struct __pyx_memoryview_obj *)__pyx_v_memviewslice.memview)->flags & PyBUF_WRITABLE) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1030
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE:
- * result.flags = PyBUF_RECORDS # <<<<<<<<<<<<<<
- * else:
- * result.flags = PyBUF_RECORDS_RO
- */
- __pyx_v_result->__pyx_base.flags = PyBUF_RECORDS;
-
- /* "View.MemoryView":1029
- * Py_INCREF(Py_None)
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE: # <<<<<<<<<<<<<<
- * result.flags = PyBUF_RECORDS
- * else:
- */
- goto __pyx_L4;
- }
-
- /* "View.MemoryView":1032
- * result.flags = PyBUF_RECORDS
- * else:
- * result.flags = PyBUF_RECORDS_RO # <<<<<<<<<<<<<<
- *
- * result.view.shape = result.from_slice.shape
- */
- /*else*/ {
- __pyx_v_result->__pyx_base.flags = PyBUF_RECORDS_RO;
- }
- __pyx_L4:;
-
- /* "View.MemoryView":1034
- * result.flags = PyBUF_RECORDS_RO
- *
- * result.view.shape = result.from_slice.shape # <<<<<<<<<<<<<<
- * result.view.strides = result.from_slice.strides
- *
- */
- __pyx_v_result->__pyx_base.view.shape = ((Py_ssize_t *)__pyx_v_result->from_slice.shape);
-
- /* "View.MemoryView":1035
- *
- * result.view.shape = result.from_slice.shape
- * result.view.strides = result.from_slice.strides # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_result->__pyx_base.view.strides = ((Py_ssize_t *)__pyx_v_result->from_slice.strides);
-
- /* "View.MemoryView":1038
- *
- *
- * result.view.suboffsets = NULL # <<<<<<<<<<<<<<
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0:
- */
- __pyx_v_result->__pyx_base.view.suboffsets = NULL;
-
- /* "View.MemoryView":1039
- *
- * result.view.suboffsets = NULL
- * for suboffset in result.from_slice.suboffsets[:ndim]: # <<<<<<<<<<<<<<
- * if suboffset >= 0:
- * result.view.suboffsets = result.from_slice.suboffsets
- */
- __pyx_t_7 = (__pyx_v_result->from_slice.suboffsets + __pyx_v_ndim);
- for (__pyx_t_8 = __pyx_v_result->from_slice.suboffsets; __pyx_t_8 < __pyx_t_7; __pyx_t_8++) {
- __pyx_t_6 = __pyx_t_8;
- __pyx_v_suboffset = (__pyx_t_6[0]);
-
- /* "View.MemoryView":1040
- * result.view.suboffsets = NULL
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * result.view.suboffsets = result.from_slice.suboffsets
- * break
- */
- __pyx_t_1 = ((__pyx_v_suboffset >= 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1041
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0:
- * result.view.suboffsets = result.from_slice.suboffsets # <<<<<<<<<<<<<<
- * break
- *
- */
- __pyx_v_result->__pyx_base.view.suboffsets = ((Py_ssize_t *)__pyx_v_result->from_slice.suboffsets);
-
- /* "View.MemoryView":1042
- * if suboffset >= 0:
- * result.view.suboffsets = result.from_slice.suboffsets
- * break # <<<<<<<<<<<<<<
- *
- * result.view.len = result.view.itemsize
- */
- goto __pyx_L6_break;
-
- /* "View.MemoryView":1040
- * result.view.suboffsets = NULL
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * result.view.suboffsets = result.from_slice.suboffsets
- * break
- */
- }
- }
- __pyx_L6_break:;
-
- /* "View.MemoryView":1044
- * break
- *
- * result.view.len = result.view.itemsize # <<<<<<<<<<<<<<
- * for length in result.view.shape[:ndim]:
- * result.view.len *= length
- */
- __pyx_t_9 = __pyx_v_result->__pyx_base.view.itemsize;
- __pyx_v_result->__pyx_base.view.len = __pyx_t_9;
-
- /* "View.MemoryView":1045
- *
- * result.view.len = result.view.itemsize
- * for length in result.view.shape[:ndim]: # <<<<<<<<<<<<<<
- * result.view.len *= length
- *
- */
- __pyx_t_7 = (__pyx_v_result->__pyx_base.view.shape + __pyx_v_ndim);
- for (__pyx_t_8 = __pyx_v_result->__pyx_base.view.shape; __pyx_t_8 < __pyx_t_7; __pyx_t_8++) {
- __pyx_t_6 = __pyx_t_8;
- __pyx_t_2 = PyInt_FromSsize_t((__pyx_t_6[0])); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1045, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_XDECREF_SET(__pyx_v_length, __pyx_t_2);
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":1046
- * result.view.len = result.view.itemsize
- * for length in result.view.shape[:ndim]:
- * result.view.len *= length # <<<<<<<<<<<<<<
- *
- * result.to_object_func = to_object_func
- */
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_result->__pyx_base.view.len); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1046, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyNumber_InPlaceMultiply(__pyx_t_2, __pyx_v_length); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1046, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_9 = __Pyx_PyIndex_AsSsize_t(__pyx_t_3); if (unlikely((__pyx_t_9 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 1046, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result->__pyx_base.view.len = __pyx_t_9;
- }
-
- /* "View.MemoryView":1048
- * result.view.len *= length
- *
- * result.to_object_func = to_object_func # <<<<<<<<<<<<<<
- * result.to_dtype_func = to_dtype_func
- *
- */
- __pyx_v_result->to_object_func = __pyx_v_to_object_func;
-
- /* "View.MemoryView":1049
- *
- * result.to_object_func = to_object_func
- * result.to_dtype_func = to_dtype_func # <<<<<<<<<<<<<<
- *
- * return result
- */
- __pyx_v_result->to_dtype_func = __pyx_v_to_dtype_func;
-
- /* "View.MemoryView":1051
- * result.to_dtype_func = to_dtype_func
- *
- * return result # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_get_slice_from_memoryview')
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = ((PyObject *)__pyx_v_result);
- goto __pyx_L0;
-
- /* "View.MemoryView":1001
- *
- * @cname('__pyx_memoryview_fromslice')
- * cdef memoryview_fromslice(__Pyx_memviewslice memviewslice, # <<<<<<<<<<<<<<
- * int ndim,
- * object (*to_object_func)(char *),
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview_fromslice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XDECREF(__pyx_v_length);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1054
- *
- * @cname('__pyx_memoryview_get_slice_from_memoryview')
- * cdef __Pyx_memviewslice *get_slice_from_memview(memoryview memview, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- */
-
-static __Pyx_memviewslice *__pyx_memoryview_get_slice_from_memoryview(struct __pyx_memoryview_obj *__pyx_v_memview, __Pyx_memviewslice *__pyx_v_mslice) {
- struct __pyx_memoryviewslice_obj *__pyx_v_obj = 0;
- __Pyx_memviewslice *__pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("get_slice_from_memview", 0);
-
- /* "View.MemoryView":1057
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * obj = memview
- * return &obj.from_slice
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1058
- * cdef _memoryviewslice obj
- * if isinstance(memview, _memoryviewslice):
- * obj = memview # <<<<<<<<<<<<<<
- * return &obj.from_slice
- * else:
- */
- if (!(likely(((((PyObject *)__pyx_v_memview)) == Py_None) || likely(__Pyx_TypeTest(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type))))) __PYX_ERR(1, 1058, __pyx_L1_error)
- __pyx_t_3 = ((PyObject *)__pyx_v_memview);
- __Pyx_INCREF(__pyx_t_3);
- __pyx_v_obj = ((struct __pyx_memoryviewslice_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":1059
- * if isinstance(memview, _memoryviewslice):
- * obj = memview
- * return &obj.from_slice # <<<<<<<<<<<<<<
- * else:
- * slice_copy(memview, mslice)
- */
- __pyx_r = (&__pyx_v_obj->from_slice);
- goto __pyx_L0;
-
- /* "View.MemoryView":1057
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * obj = memview
- * return &obj.from_slice
- */
- }
-
- /* "View.MemoryView":1061
- * return &obj.from_slice
- * else:
- * slice_copy(memview, mslice) # <<<<<<<<<<<<<<
- * return mslice
- *
- */
- /*else*/ {
- __pyx_memoryview_slice_copy(__pyx_v_memview, __pyx_v_mslice);
-
- /* "View.MemoryView":1062
- * else:
- * slice_copy(memview, mslice)
- * return mslice # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_slice_copy')
- */
- __pyx_r = __pyx_v_mslice;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":1054
- *
- * @cname('__pyx_memoryview_get_slice_from_memoryview')
- * cdef __Pyx_memviewslice *get_slice_from_memview(memoryview memview, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.get_slice_from_memview", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_obj);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1065
- *
- * @cname('__pyx_memoryview_slice_copy')
- * cdef void slice_copy(memoryview memview, __Pyx_memviewslice *dst): # <<<<<<<<<<<<<<
- * cdef int dim
- * cdef (Py_ssize_t*) shape, strides, suboffsets
- */
-
-static void __pyx_memoryview_slice_copy(struct __pyx_memoryview_obj *__pyx_v_memview, __Pyx_memviewslice *__pyx_v_dst) {
- int __pyx_v_dim;
- Py_ssize_t *__pyx_v_shape;
- Py_ssize_t *__pyx_v_strides;
- Py_ssize_t *__pyx_v_suboffsets;
- __Pyx_RefNannyDeclarations
- Py_ssize_t *__pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- Py_ssize_t __pyx_t_5;
- __Pyx_RefNannySetupContext("slice_copy", 0);
-
- /* "View.MemoryView":1069
- * cdef (Py_ssize_t*) shape, strides, suboffsets
- *
- * shape = memview.view.shape # <<<<<<<<<<<<<<
- * strides = memview.view.strides
- * suboffsets = memview.view.suboffsets
- */
- __pyx_t_1 = __pyx_v_memview->view.shape;
- __pyx_v_shape = __pyx_t_1;
-
- /* "View.MemoryView":1070
- *
- * shape = memview.view.shape
- * strides = memview.view.strides # <<<<<<<<<<<<<<
- * suboffsets = memview.view.suboffsets
- *
- */
- __pyx_t_1 = __pyx_v_memview->view.strides;
- __pyx_v_strides = __pyx_t_1;
-
- /* "View.MemoryView":1071
- * shape = memview.view.shape
- * strides = memview.view.strides
- * suboffsets = memview.view.suboffsets # <<<<<<<<<<<<<<
- *
- * dst.memview = <__pyx_memoryview *> memview
- */
- __pyx_t_1 = __pyx_v_memview->view.suboffsets;
- __pyx_v_suboffsets = __pyx_t_1;
-
- /* "View.MemoryView":1073
- * suboffsets = memview.view.suboffsets
- *
- * dst.memview = <__pyx_memoryview *> memview # <<<<<<<<<<<<<<
- * dst.data = memview.view.buf
- *
- */
- __pyx_v_dst->memview = ((struct __pyx_memoryview_obj *)__pyx_v_memview);
-
- /* "View.MemoryView":1074
- *
- * dst.memview = <__pyx_memoryview *> memview
- * dst.data = memview.view.buf # <<<<<<<<<<<<<<
- *
- * for dim in range(memview.view.ndim):
- */
- __pyx_v_dst->data = ((char *)__pyx_v_memview->view.buf);
-
- /* "View.MemoryView":1076
- * dst.data = memview.view.buf
- *
- * for dim in range(memview.view.ndim): # <<<<<<<<<<<<<<
- * dst.shape[dim] = shape[dim]
- * dst.strides[dim] = strides[dim]
- */
- __pyx_t_2 = __pyx_v_memview->view.ndim;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_dim = __pyx_t_4;
-
- /* "View.MemoryView":1077
- *
- * for dim in range(memview.view.ndim):
- * dst.shape[dim] = shape[dim] # <<<<<<<<<<<<<<
- * dst.strides[dim] = strides[dim]
- * dst.suboffsets[dim] = suboffsets[dim] if suboffsets else -1
- */
- (__pyx_v_dst->shape[__pyx_v_dim]) = (__pyx_v_shape[__pyx_v_dim]);
-
- /* "View.MemoryView":1078
- * for dim in range(memview.view.ndim):
- * dst.shape[dim] = shape[dim]
- * dst.strides[dim] = strides[dim] # <<<<<<<<<<<<<<
- * dst.suboffsets[dim] = suboffsets[dim] if suboffsets else -1
- *
- */
- (__pyx_v_dst->strides[__pyx_v_dim]) = (__pyx_v_strides[__pyx_v_dim]);
-
- /* "View.MemoryView":1079
- * dst.shape[dim] = shape[dim]
- * dst.strides[dim] = strides[dim]
- * dst.suboffsets[dim] = suboffsets[dim] if suboffsets else -1 # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_object')
- */
- if ((__pyx_v_suboffsets != 0)) {
- __pyx_t_5 = (__pyx_v_suboffsets[__pyx_v_dim]);
- } else {
- __pyx_t_5 = -1L;
- }
- (__pyx_v_dst->suboffsets[__pyx_v_dim]) = __pyx_t_5;
- }
-
- /* "View.MemoryView":1065
- *
- * @cname('__pyx_memoryview_slice_copy')
- * cdef void slice_copy(memoryview memview, __Pyx_memviewslice *dst): # <<<<<<<<<<<<<<
- * cdef int dim
- * cdef (Py_ssize_t*) shape, strides, suboffsets
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":1082
- *
- * @cname('__pyx_memoryview_copy_object')
- * cdef memoryview_copy(memoryview memview): # <<<<<<<<<<<<<<
- * "Create a new memoryview object"
- * cdef __Pyx_memviewslice memviewslice
- */
-
-static PyObject *__pyx_memoryview_copy_object(struct __pyx_memoryview_obj *__pyx_v_memview) {
- __Pyx_memviewslice __pyx_v_memviewslice;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_copy", 0);
-
- /* "View.MemoryView":1085
- * "Create a new memoryview object"
- * cdef __Pyx_memviewslice memviewslice
- * slice_copy(memview, &memviewslice) # <<<<<<<<<<<<<<
- * return memoryview_copy_from_slice(memview, &memviewslice)
- *
- */
- __pyx_memoryview_slice_copy(__pyx_v_memview, (&__pyx_v_memviewslice));
-
- /* "View.MemoryView":1086
- * cdef __Pyx_memviewslice memviewslice
- * slice_copy(memview, &memviewslice)
- * return memoryview_copy_from_slice(memview, &memviewslice) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_object_from_slice')
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __pyx_memoryview_copy_object_from_slice(__pyx_v_memview, (&__pyx_v_memviewslice)); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1086, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1082
- *
- * @cname('__pyx_memoryview_copy_object')
- * cdef memoryview_copy(memoryview memview): # <<<<<<<<<<<<<<
- * "Create a new memoryview object"
- * cdef __Pyx_memviewslice memviewslice
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview_copy", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1089
- *
- * @cname('__pyx_memoryview_copy_object_from_slice')
- * cdef memoryview_copy_from_slice(memoryview memview, __Pyx_memviewslice *memviewslice): # <<<<<<<<<<<<<<
- * """
- * Create a new memoryview object from a given memoryview object and slice.
- */
-
-static PyObject *__pyx_memoryview_copy_object_from_slice(struct __pyx_memoryview_obj *__pyx_v_memview, __Pyx_memviewslice *__pyx_v_memviewslice) {
- PyObject *(*__pyx_v_to_object_func)(char *);
- int (*__pyx_v_to_dtype_func)(char *, PyObject *);
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *(*__pyx_t_3)(char *);
- int (*__pyx_t_4)(char *, PyObject *);
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_copy_from_slice", 0);
-
- /* "View.MemoryView":1096
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * to_object_func = (<_memoryviewslice> memview).to_object_func
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1097
- *
- * if isinstance(memview, _memoryviewslice):
- * to_object_func = (<_memoryviewslice> memview).to_object_func # <<<<<<<<<<<<<<
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- * else:
- */
- __pyx_t_3 = ((struct __pyx_memoryviewslice_obj *)__pyx_v_memview)->to_object_func;
- __pyx_v_to_object_func = __pyx_t_3;
-
- /* "View.MemoryView":1098
- * if isinstance(memview, _memoryviewslice):
- * to_object_func = (<_memoryviewslice> memview).to_object_func
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func # <<<<<<<<<<<<<<
- * else:
- * to_object_func = NULL
- */
- __pyx_t_4 = ((struct __pyx_memoryviewslice_obj *)__pyx_v_memview)->to_dtype_func;
- __pyx_v_to_dtype_func = __pyx_t_4;
-
- /* "View.MemoryView":1096
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * to_object_func = (<_memoryviewslice> memview).to_object_func
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1100
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- * else:
- * to_object_func = NULL # <<<<<<<<<<<<<<
- * to_dtype_func = NULL
- *
- */
- /*else*/ {
- __pyx_v_to_object_func = NULL;
-
- /* "View.MemoryView":1101
- * else:
- * to_object_func = NULL
- * to_dtype_func = NULL # <<<<<<<<<<<<<<
- *
- * return memoryview_fromslice(memviewslice[0], memview.view.ndim,
- */
- __pyx_v_to_dtype_func = NULL;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1103
- * to_dtype_func = NULL
- *
- * return memoryview_fromslice(memviewslice[0], memview.view.ndim, # <<<<<<<<<<<<<<
- * to_object_func, to_dtype_func,
- * memview.dtype_is_object)
- */
- __Pyx_XDECREF(__pyx_r);
-
- /* "View.MemoryView":1105
- * return memoryview_fromslice(memviewslice[0], memview.view.ndim,
- * to_object_func, to_dtype_func,
- * memview.dtype_is_object) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_5 = __pyx_memoryview_fromslice((__pyx_v_memviewslice[0]), __pyx_v_memview->view.ndim, __pyx_v_to_object_func, __pyx_v_to_dtype_func, __pyx_v_memview->dtype_is_object); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 1103, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_r = __pyx_t_5;
- __pyx_t_5 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1089
- *
- * @cname('__pyx_memoryview_copy_object_from_slice')
- * cdef memoryview_copy_from_slice(memoryview memview, __Pyx_memviewslice *memviewslice): # <<<<<<<<<<<<<<
- * """
- * Create a new memoryview object from a given memoryview object and slice.
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview_copy_from_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1111
- *
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil: # <<<<<<<<<<<<<<
- * if arg < 0:
- * return -arg
- */
-
-static Py_ssize_t abs_py_ssize_t(Py_ssize_t __pyx_v_arg) {
- Py_ssize_t __pyx_r;
- int __pyx_t_1;
-
- /* "View.MemoryView":1112
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil:
- * if arg < 0: # <<<<<<<<<<<<<<
- * return -arg
- * else:
- */
- __pyx_t_1 = ((__pyx_v_arg < 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1113
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil:
- * if arg < 0:
- * return -arg # <<<<<<<<<<<<<<
- * else:
- * return arg
- */
- __pyx_r = (-__pyx_v_arg);
- goto __pyx_L0;
-
- /* "View.MemoryView":1112
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil:
- * if arg < 0: # <<<<<<<<<<<<<<
- * return -arg
- * else:
- */
- }
-
- /* "View.MemoryView":1115
- * return -arg
- * else:
- * return arg # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_get_best_slice_order')
- */
- /*else*/ {
- __pyx_r = __pyx_v_arg;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":1111
- *
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil: # <<<<<<<<<<<<<<
- * if arg < 0:
- * return -arg
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1118
- *
- * @cname('__pyx_get_best_slice_order')
- * cdef char get_best_order(__Pyx_memviewslice *mslice, int ndim) nogil: # <<<<<<<<<<<<<<
- * """
- * Figure out the best memory access order for a given slice.
- */
-
-static char __pyx_get_best_slice_order(__Pyx_memviewslice *__pyx_v_mslice, int __pyx_v_ndim) {
- int __pyx_v_i;
- Py_ssize_t __pyx_v_c_stride;
- Py_ssize_t __pyx_v_f_stride;
- char __pyx_r;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
-
- /* "View.MemoryView":1123
- * """
- * cdef int i
- * cdef Py_ssize_t c_stride = 0 # <<<<<<<<<<<<<<
- * cdef Py_ssize_t f_stride = 0
- *
- */
- __pyx_v_c_stride = 0;
-
- /* "View.MemoryView":1124
- * cdef int i
- * cdef Py_ssize_t c_stride = 0
- * cdef Py_ssize_t f_stride = 0 # <<<<<<<<<<<<<<
- *
- * for i in range(ndim - 1, -1, -1):
- */
- __pyx_v_f_stride = 0;
-
- /* "View.MemoryView":1126
- * cdef Py_ssize_t f_stride = 0
- *
- * for i in range(ndim - 1, -1, -1): # <<<<<<<<<<<<<<
- * if mslice.shape[i] > 1:
- * c_stride = mslice.strides[i]
- */
- for (__pyx_t_1 = (__pyx_v_ndim - 1); __pyx_t_1 > -1; __pyx_t_1-=1) {
- __pyx_v_i = __pyx_t_1;
-
- /* "View.MemoryView":1127
- *
- * for i in range(ndim - 1, -1, -1):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * c_stride = mslice.strides[i]
- * break
- */
- __pyx_t_2 = (((__pyx_v_mslice->shape[__pyx_v_i]) > 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1128
- * for i in range(ndim - 1, -1, -1):
- * if mslice.shape[i] > 1:
- * c_stride = mslice.strides[i] # <<<<<<<<<<<<<<
- * break
- *
- */
- __pyx_v_c_stride = (__pyx_v_mslice->strides[__pyx_v_i]);
-
- /* "View.MemoryView":1129
- * if mslice.shape[i] > 1:
- * c_stride = mslice.strides[i]
- * break # <<<<<<<<<<<<<<
- *
- * for i in range(ndim):
- */
- goto __pyx_L4_break;
-
- /* "View.MemoryView":1127
- *
- * for i in range(ndim - 1, -1, -1):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * c_stride = mslice.strides[i]
- * break
- */
- }
- }
- __pyx_L4_break:;
-
- /* "View.MemoryView":1131
- * break
- *
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * if mslice.shape[i] > 1:
- * f_stride = mslice.strides[i]
- */
- __pyx_t_1 = __pyx_v_ndim;
- __pyx_t_3 = __pyx_t_1;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1132
- *
- * for i in range(ndim):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * f_stride = mslice.strides[i]
- * break
- */
- __pyx_t_2 = (((__pyx_v_mslice->shape[__pyx_v_i]) > 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1133
- * for i in range(ndim):
- * if mslice.shape[i] > 1:
- * f_stride = mslice.strides[i] # <<<<<<<<<<<<<<
- * break
- *
- */
- __pyx_v_f_stride = (__pyx_v_mslice->strides[__pyx_v_i]);
-
- /* "View.MemoryView":1134
- * if mslice.shape[i] > 1:
- * f_stride = mslice.strides[i]
- * break # <<<<<<<<<<<<<<
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride):
- */
- goto __pyx_L7_break;
-
- /* "View.MemoryView":1132
- *
- * for i in range(ndim):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * f_stride = mslice.strides[i]
- * break
- */
- }
- }
- __pyx_L7_break:;
-
- /* "View.MemoryView":1136
- * break
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride): # <<<<<<<<<<<<<<
- * return 'C'
- * else:
- */
- __pyx_t_2 = ((abs_py_ssize_t(__pyx_v_c_stride) <= abs_py_ssize_t(__pyx_v_f_stride)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1137
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride):
- * return 'C' # <<<<<<<<<<<<<<
- * else:
- * return 'F'
- */
- __pyx_r = 'C';
- goto __pyx_L0;
-
- /* "View.MemoryView":1136
- * break
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride): # <<<<<<<<<<<<<<
- * return 'C'
- * else:
- */
- }
-
- /* "View.MemoryView":1139
- * return 'C'
- * else:
- * return 'F' # <<<<<<<<<<<<<<
- *
- * @cython.cdivision(True)
- */
- /*else*/ {
- __pyx_r = 'F';
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":1118
- *
- * @cname('__pyx_get_best_slice_order')
- * cdef char get_best_order(__Pyx_memviewslice *mslice, int ndim) nogil: # <<<<<<<<<<<<<<
- * """
- * Figure out the best memory access order for a given slice.
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1142
- *
- * @cython.cdivision(True)
- * cdef void _copy_strided_to_strided(char *src_data, Py_ssize_t *src_strides, # <<<<<<<<<<<<<<
- * char *dst_data, Py_ssize_t *dst_strides,
- * Py_ssize_t *src_shape, Py_ssize_t *dst_shape,
- */
-
-static void _copy_strided_to_strided(char *__pyx_v_src_data, Py_ssize_t *__pyx_v_src_strides, char *__pyx_v_dst_data, Py_ssize_t *__pyx_v_dst_strides, Py_ssize_t *__pyx_v_src_shape, Py_ssize_t *__pyx_v_dst_shape, int __pyx_v_ndim, size_t __pyx_v_itemsize) {
- CYTHON_UNUSED Py_ssize_t __pyx_v_i;
- CYTHON_UNUSED Py_ssize_t __pyx_v_src_extent;
- Py_ssize_t __pyx_v_dst_extent;
- Py_ssize_t __pyx_v_src_stride;
- Py_ssize_t __pyx_v_dst_stride;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- Py_ssize_t __pyx_t_4;
- Py_ssize_t __pyx_t_5;
- Py_ssize_t __pyx_t_6;
-
- /* "View.MemoryView":1149
- *
- * cdef Py_ssize_t i
- * cdef Py_ssize_t src_extent = src_shape[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dst_extent = dst_shape[0]
- * cdef Py_ssize_t src_stride = src_strides[0]
- */
- __pyx_v_src_extent = (__pyx_v_src_shape[0]);
-
- /* "View.MemoryView":1150
- * cdef Py_ssize_t i
- * cdef Py_ssize_t src_extent = src_shape[0]
- * cdef Py_ssize_t dst_extent = dst_shape[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t src_stride = src_strides[0]
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- */
- __pyx_v_dst_extent = (__pyx_v_dst_shape[0]);
-
- /* "View.MemoryView":1151
- * cdef Py_ssize_t src_extent = src_shape[0]
- * cdef Py_ssize_t dst_extent = dst_shape[0]
- * cdef Py_ssize_t src_stride = src_strides[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- *
- */
- __pyx_v_src_stride = (__pyx_v_src_strides[0]);
-
- /* "View.MemoryView":1152
- * cdef Py_ssize_t dst_extent = dst_shape[0]
- * cdef Py_ssize_t src_stride = src_strides[0]
- * cdef Py_ssize_t dst_stride = dst_strides[0] # <<<<<<<<<<<<<<
- *
- * if ndim == 1:
- */
- __pyx_v_dst_stride = (__pyx_v_dst_strides[0]);
-
- /* "View.MemoryView":1154
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride):
- */
- __pyx_t_1 = ((__pyx_v_ndim == 1) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1155
- *
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and # <<<<<<<<<<<<<<
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- */
- __pyx_t_2 = ((__pyx_v_src_stride > 0) != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L5_bool_binop_done;
- }
- __pyx_t_2 = ((__pyx_v_dst_stride > 0) != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L5_bool_binop_done;
- }
-
- /* "View.MemoryView":1156
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride): # <<<<<<<<<<<<<<
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- * else:
- */
- __pyx_t_2 = (((size_t)__pyx_v_src_stride) == __pyx_v_itemsize);
- if (__pyx_t_2) {
- __pyx_t_2 = (__pyx_v_itemsize == ((size_t)__pyx_v_dst_stride));
- }
- __pyx_t_3 = (__pyx_t_2 != 0);
- __pyx_t_1 = __pyx_t_3;
- __pyx_L5_bool_binop_done:;
-
- /* "View.MemoryView":1155
- *
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and # <<<<<<<<<<<<<<
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- */
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1157
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent) # <<<<<<<<<<<<<<
- * else:
- * for i in range(dst_extent):
- */
- (void)(memcpy(__pyx_v_dst_data, __pyx_v_src_data, (__pyx_v_itemsize * __pyx_v_dst_extent)));
-
- /* "View.MemoryView":1155
- *
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and # <<<<<<<<<<<<<<
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- */
- goto __pyx_L4;
- }
-
- /* "View.MemoryView":1159
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- * else:
- * for i in range(dst_extent): # <<<<<<<<<<<<<<
- * memcpy(dst_data, src_data, itemsize)
- * src_data += src_stride
- */
- /*else*/ {
- __pyx_t_4 = __pyx_v_dst_extent;
- __pyx_t_5 = __pyx_t_4;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1160
- * else:
- * for i in range(dst_extent):
- * memcpy(dst_data, src_data, itemsize) # <<<<<<<<<<<<<<
- * src_data += src_stride
- * dst_data += dst_stride
- */
- (void)(memcpy(__pyx_v_dst_data, __pyx_v_src_data, __pyx_v_itemsize));
-
- /* "View.MemoryView":1161
- * for i in range(dst_extent):
- * memcpy(dst_data, src_data, itemsize)
- * src_data += src_stride # <<<<<<<<<<<<<<
- * dst_data += dst_stride
- * else:
- */
- __pyx_v_src_data = (__pyx_v_src_data + __pyx_v_src_stride);
-
- /* "View.MemoryView":1162
- * memcpy(dst_data, src_data, itemsize)
- * src_data += src_stride
- * dst_data += dst_stride # <<<<<<<<<<<<<<
- * else:
- * for i in range(dst_extent):
- */
- __pyx_v_dst_data = (__pyx_v_dst_data + __pyx_v_dst_stride);
- }
- }
- __pyx_L4:;
-
- /* "View.MemoryView":1154
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride):
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1164
- * dst_data += dst_stride
- * else:
- * for i in range(dst_extent): # <<<<<<<<<<<<<<
- * _copy_strided_to_strided(src_data, src_strides + 1,
- * dst_data, dst_strides + 1,
- */
- /*else*/ {
- __pyx_t_4 = __pyx_v_dst_extent;
- __pyx_t_5 = __pyx_t_4;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1165
- * else:
- * for i in range(dst_extent):
- * _copy_strided_to_strided(src_data, src_strides + 1, # <<<<<<<<<<<<<<
- * dst_data, dst_strides + 1,
- * src_shape + 1, dst_shape + 1,
- */
- _copy_strided_to_strided(__pyx_v_src_data, (__pyx_v_src_strides + 1), __pyx_v_dst_data, (__pyx_v_dst_strides + 1), (__pyx_v_src_shape + 1), (__pyx_v_dst_shape + 1), (__pyx_v_ndim - 1), __pyx_v_itemsize);
-
- /* "View.MemoryView":1169
- * src_shape + 1, dst_shape + 1,
- * ndim - 1, itemsize)
- * src_data += src_stride # <<<<<<<<<<<<<<
- * dst_data += dst_stride
- *
- */
- __pyx_v_src_data = (__pyx_v_src_data + __pyx_v_src_stride);
-
- /* "View.MemoryView":1170
- * ndim - 1, itemsize)
- * src_data += src_stride
- * dst_data += dst_stride # <<<<<<<<<<<<<<
- *
- * cdef void copy_strided_to_strided(__Pyx_memviewslice *src,
- */
- __pyx_v_dst_data = (__pyx_v_dst_data + __pyx_v_dst_stride);
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1142
- *
- * @cython.cdivision(True)
- * cdef void _copy_strided_to_strided(char *src_data, Py_ssize_t *src_strides, # <<<<<<<<<<<<<<
- * char *dst_data, Py_ssize_t *dst_strides,
- * Py_ssize_t *src_shape, Py_ssize_t *dst_shape,
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1172
- * dst_data += dst_stride
- *
- * cdef void copy_strided_to_strided(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * int ndim, size_t itemsize) nogil:
- */
-
-static void copy_strided_to_strided(__Pyx_memviewslice *__pyx_v_src, __Pyx_memviewslice *__pyx_v_dst, int __pyx_v_ndim, size_t __pyx_v_itemsize) {
-
- /* "View.MemoryView":1175
- * __Pyx_memviewslice *dst,
- * int ndim, size_t itemsize) nogil:
- * _copy_strided_to_strided(src.data, src.strides, dst.data, dst.strides, # <<<<<<<<<<<<<<
- * src.shape, dst.shape, ndim, itemsize)
- *
- */
- _copy_strided_to_strided(__pyx_v_src->data, __pyx_v_src->strides, __pyx_v_dst->data, __pyx_v_dst->strides, __pyx_v_src->shape, __pyx_v_dst->shape, __pyx_v_ndim, __pyx_v_itemsize);
-
- /* "View.MemoryView":1172
- * dst_data += dst_stride
- *
- * cdef void copy_strided_to_strided(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * int ndim, size_t itemsize) nogil:
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1179
- *
- * @cname('__pyx_memoryview_slice_get_size')
- * cdef Py_ssize_t slice_get_size(__Pyx_memviewslice *src, int ndim) nogil: # <<<<<<<<<<<<<<
- * "Return the size of the memory occupied by the slice in number of bytes"
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize
- */
-
-static Py_ssize_t __pyx_memoryview_slice_get_size(__Pyx_memviewslice *__pyx_v_src, int __pyx_v_ndim) {
- Py_ssize_t __pyx_v_shape;
- Py_ssize_t __pyx_v_size;
- Py_ssize_t __pyx_r;
- Py_ssize_t __pyx_t_1;
- Py_ssize_t *__pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
-
- /* "View.MemoryView":1181
- * cdef Py_ssize_t slice_get_size(__Pyx_memviewslice *src, int ndim) nogil:
- * "Return the size of the memory occupied by the slice in number of bytes"
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize # <<<<<<<<<<<<<<
- *
- * for shape in src.shape[:ndim]:
- */
- __pyx_t_1 = __pyx_v_src->memview->view.itemsize;
- __pyx_v_size = __pyx_t_1;
-
- /* "View.MemoryView":1183
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize
- *
- * for shape in src.shape[:ndim]: # <<<<<<<<<<<<<<
- * size *= shape
- *
- */
- __pyx_t_3 = (__pyx_v_src->shape + __pyx_v_ndim);
- for (__pyx_t_4 = __pyx_v_src->shape; __pyx_t_4 < __pyx_t_3; __pyx_t_4++) {
- __pyx_t_2 = __pyx_t_4;
- __pyx_v_shape = (__pyx_t_2[0]);
-
- /* "View.MemoryView":1184
- *
- * for shape in src.shape[:ndim]:
- * size *= shape # <<<<<<<<<<<<<<
- *
- * return size
- */
- __pyx_v_size = (__pyx_v_size * __pyx_v_shape);
- }
-
- /* "View.MemoryView":1186
- * size *= shape
- *
- * return size # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_fill_contig_strides_array')
- */
- __pyx_r = __pyx_v_size;
- goto __pyx_L0;
-
- /* "View.MemoryView":1179
- *
- * @cname('__pyx_memoryview_slice_get_size')
- * cdef Py_ssize_t slice_get_size(__Pyx_memviewslice *src, int ndim) nogil: # <<<<<<<<<<<<<<
- * "Return the size of the memory occupied by the slice in number of bytes"
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1189
- *
- * @cname('__pyx_fill_contig_strides_array')
- * cdef Py_ssize_t fill_contig_strides_array( # <<<<<<<<<<<<<<
- * Py_ssize_t *shape, Py_ssize_t *strides, Py_ssize_t stride,
- * int ndim, char order) nogil:
- */
-
-static Py_ssize_t __pyx_fill_contig_strides_array(Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, Py_ssize_t __pyx_v_stride, int __pyx_v_ndim, char __pyx_v_order) {
- int __pyx_v_idx;
- Py_ssize_t __pyx_r;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
-
- /* "View.MemoryView":1198
- * cdef int idx
- *
- * if order == 'F': # <<<<<<<<<<<<<<
- * for idx in range(ndim):
- * strides[idx] = stride
- */
- __pyx_t_1 = ((__pyx_v_order == 'F') != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1199
- *
- * if order == 'F':
- * for idx in range(ndim): # <<<<<<<<<<<<<<
- * strides[idx] = stride
- * stride *= shape[idx]
- */
- __pyx_t_2 = __pyx_v_ndim;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_idx = __pyx_t_4;
-
- /* "View.MemoryView":1200
- * if order == 'F':
- * for idx in range(ndim):
- * strides[idx] = stride # <<<<<<<<<<<<<<
- * stride *= shape[idx]
- * else:
- */
- (__pyx_v_strides[__pyx_v_idx]) = __pyx_v_stride;
-
- /* "View.MemoryView":1201
- * for idx in range(ndim):
- * strides[idx] = stride
- * stride *= shape[idx] # <<<<<<<<<<<<<<
- * else:
- * for idx in range(ndim - 1, -1, -1):
- */
- __pyx_v_stride = (__pyx_v_stride * (__pyx_v_shape[__pyx_v_idx]));
- }
-
- /* "View.MemoryView":1198
- * cdef int idx
- *
- * if order == 'F': # <<<<<<<<<<<<<<
- * for idx in range(ndim):
- * strides[idx] = stride
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1203
- * stride *= shape[idx]
- * else:
- * for idx in range(ndim - 1, -1, -1): # <<<<<<<<<<<<<<
- * strides[idx] = stride
- * stride *= shape[idx]
- */
- /*else*/ {
- for (__pyx_t_2 = (__pyx_v_ndim - 1); __pyx_t_2 > -1; __pyx_t_2-=1) {
- __pyx_v_idx = __pyx_t_2;
-
- /* "View.MemoryView":1204
- * else:
- * for idx in range(ndim - 1, -1, -1):
- * strides[idx] = stride # <<<<<<<<<<<<<<
- * stride *= shape[idx]
- *
- */
- (__pyx_v_strides[__pyx_v_idx]) = __pyx_v_stride;
-
- /* "View.MemoryView":1205
- * for idx in range(ndim - 1, -1, -1):
- * strides[idx] = stride
- * stride *= shape[idx] # <<<<<<<<<<<<<<
- *
- * return stride
- */
- __pyx_v_stride = (__pyx_v_stride * (__pyx_v_shape[__pyx_v_idx]));
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1207
- * stride *= shape[idx]
- *
- * return stride # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_data_to_temp')
- */
- __pyx_r = __pyx_v_stride;
- goto __pyx_L0;
-
- /* "View.MemoryView":1189
- *
- * @cname('__pyx_fill_contig_strides_array')
- * cdef Py_ssize_t fill_contig_strides_array( # <<<<<<<<<<<<<<
- * Py_ssize_t *shape, Py_ssize_t *strides, Py_ssize_t stride,
- * int ndim, char order) nogil:
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1210
- *
- * @cname('__pyx_memoryview_copy_data_to_temp')
- * cdef void *copy_data_to_temp(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *tmpslice,
- * char order,
- */
-
-static void *__pyx_memoryview_copy_data_to_temp(__Pyx_memviewslice *__pyx_v_src, __Pyx_memviewslice *__pyx_v_tmpslice, char __pyx_v_order, int __pyx_v_ndim) {
- int __pyx_v_i;
- void *__pyx_v_result;
- size_t __pyx_v_itemsize;
- size_t __pyx_v_size;
- void *__pyx_r;
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- struct __pyx_memoryview_obj *__pyx_t_4;
- int __pyx_t_5;
- int __pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":1221
- * cdef void *result
- *
- * cdef size_t itemsize = src.memview.view.itemsize # <<<<<<<<<<<<<<
- * cdef size_t size = slice_get_size(src, ndim)
- *
- */
- __pyx_t_1 = __pyx_v_src->memview->view.itemsize;
- __pyx_v_itemsize = __pyx_t_1;
-
- /* "View.MemoryView":1222
- *
- * cdef size_t itemsize = src.memview.view.itemsize
- * cdef size_t size = slice_get_size(src, ndim) # <<<<<<<<<<<<<<
- *
- * result = malloc(size)
- */
- __pyx_v_size = __pyx_memoryview_slice_get_size(__pyx_v_src, __pyx_v_ndim);
-
- /* "View.MemoryView":1224
- * cdef size_t size = slice_get_size(src, ndim)
- *
- * result = malloc(size) # <<<<<<<<<<<<<<
- * if not result:
- * _err(MemoryError, NULL)
- */
- __pyx_v_result = malloc(__pyx_v_size);
-
- /* "View.MemoryView":1225
- *
- * result = malloc(size)
- * if not result: # <<<<<<<<<<<<<<
- * _err(MemoryError, NULL)
- *
- */
- __pyx_t_2 = ((!(__pyx_v_result != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1226
- * result = malloc(size)
- * if not result:
- * _err(MemoryError, NULL) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __pyx_memoryview_err(__pyx_builtin_MemoryError, NULL); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 1226, __pyx_L1_error)
-
- /* "View.MemoryView":1225
- *
- * result = malloc(size)
- * if not result: # <<<<<<<<<<<<<<
- * _err(MemoryError, NULL)
- *
- */
- }
-
- /* "View.MemoryView":1229
- *
- *
- * tmpslice.data = result # <<<<<<<<<<<<<<
- * tmpslice.memview = src.memview
- * for i in range(ndim):
- */
- __pyx_v_tmpslice->data = ((char *)__pyx_v_result);
-
- /* "View.MemoryView":1230
- *
- * tmpslice.data = result
- * tmpslice.memview = src.memview # <<<<<<<<<<<<<<
- * for i in range(ndim):
- * tmpslice.shape[i] = src.shape[i]
- */
- __pyx_t_4 = __pyx_v_src->memview;
- __pyx_v_tmpslice->memview = __pyx_t_4;
-
- /* "View.MemoryView":1231
- * tmpslice.data = result
- * tmpslice.memview = src.memview
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * tmpslice.shape[i] = src.shape[i]
- * tmpslice.suboffsets[i] = -1
- */
- __pyx_t_3 = __pyx_v_ndim;
- __pyx_t_5 = __pyx_t_3;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1232
- * tmpslice.memview = src.memview
- * for i in range(ndim):
- * tmpslice.shape[i] = src.shape[i] # <<<<<<<<<<<<<<
- * tmpslice.suboffsets[i] = -1
- *
- */
- (__pyx_v_tmpslice->shape[__pyx_v_i]) = (__pyx_v_src->shape[__pyx_v_i]);
-
- /* "View.MemoryView":1233
- * for i in range(ndim):
- * tmpslice.shape[i] = src.shape[i]
- * tmpslice.suboffsets[i] = -1 # <<<<<<<<<<<<<<
- *
- * fill_contig_strides_array(&tmpslice.shape[0], &tmpslice.strides[0], itemsize,
- */
- (__pyx_v_tmpslice->suboffsets[__pyx_v_i]) = -1L;
- }
-
- /* "View.MemoryView":1235
- * tmpslice.suboffsets[i] = -1
- *
- * fill_contig_strides_array(&tmpslice.shape[0], &tmpslice.strides[0], itemsize, # <<<<<<<<<<<<<<
- * ndim, order)
- *
- */
- (void)(__pyx_fill_contig_strides_array((&(__pyx_v_tmpslice->shape[0])), (&(__pyx_v_tmpslice->strides[0])), __pyx_v_itemsize, __pyx_v_ndim, __pyx_v_order));
-
- /* "View.MemoryView":1239
- *
- *
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * if tmpslice.shape[i] == 1:
- * tmpslice.strides[i] = 0
- */
- __pyx_t_3 = __pyx_v_ndim;
- __pyx_t_5 = __pyx_t_3;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1240
- *
- * for i in range(ndim):
- * if tmpslice.shape[i] == 1: # <<<<<<<<<<<<<<
- * tmpslice.strides[i] = 0
- *
- */
- __pyx_t_2 = (((__pyx_v_tmpslice->shape[__pyx_v_i]) == 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1241
- * for i in range(ndim):
- * if tmpslice.shape[i] == 1:
- * tmpslice.strides[i] = 0 # <<<<<<<<<<<<<<
- *
- * if slice_is_contig(src[0], order, ndim):
- */
- (__pyx_v_tmpslice->strides[__pyx_v_i]) = 0;
-
- /* "View.MemoryView":1240
- *
- * for i in range(ndim):
- * if tmpslice.shape[i] == 1: # <<<<<<<<<<<<<<
- * tmpslice.strides[i] = 0
- *
- */
- }
- }
-
- /* "View.MemoryView":1243
- * tmpslice.strides[i] = 0
- *
- * if slice_is_contig(src[0], order, ndim): # <<<<<<<<<<<<<<
- * memcpy(result, src.data, size)
- * else:
- */
- __pyx_t_2 = (__pyx_memviewslice_is_contig((__pyx_v_src[0]), __pyx_v_order, __pyx_v_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1244
- *
- * if slice_is_contig(src[0], order, ndim):
- * memcpy(result, src.data, size) # <<<<<<<<<<<<<<
- * else:
- * copy_strided_to_strided(src, tmpslice, ndim, itemsize)
- */
- (void)(memcpy(__pyx_v_result, __pyx_v_src->data, __pyx_v_size));
-
- /* "View.MemoryView":1243
- * tmpslice.strides[i] = 0
- *
- * if slice_is_contig(src[0], order, ndim): # <<<<<<<<<<<<<<
- * memcpy(result, src.data, size)
- * else:
- */
- goto __pyx_L9;
- }
-
- /* "View.MemoryView":1246
- * memcpy(result, src.data, size)
- * else:
- * copy_strided_to_strided(src, tmpslice, ndim, itemsize) # <<<<<<<<<<<<<<
- *
- * return result
- */
- /*else*/ {
- copy_strided_to_strided(__pyx_v_src, __pyx_v_tmpslice, __pyx_v_ndim, __pyx_v_itemsize);
- }
- __pyx_L9:;
-
- /* "View.MemoryView":1248
- * copy_strided_to_strided(src, tmpslice, ndim, itemsize)
- *
- * return result # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = __pyx_v_result;
- goto __pyx_L0;
-
- /* "View.MemoryView":1210
- *
- * @cname('__pyx_memoryview_copy_data_to_temp')
- * cdef void *copy_data_to_temp(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *tmpslice,
- * char order,
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.copy_data_to_temp", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = NULL;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1253
- *
- * @cname('__pyx_memoryview_err_extents')
- * cdef int _err_extents(int i, Py_ssize_t extent1, # <<<<<<<<<<<<<<
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" %
- */
-
-static int __pyx_memoryview_err_extents(int __pyx_v_i, Py_ssize_t __pyx_v_extent1, Py_ssize_t __pyx_v_extent2) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("_err_extents", 0);
-
- /* "View.MemoryView":1256
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" %
- * (i, extent1, extent2)) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_err_dim')
- */
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_i); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_extent1); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyInt_FromSsize_t(__pyx_v_extent2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = PyTuple_New(3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_4, 0, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_4, 1, __pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_4, 2, __pyx_t_3);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":1255
- * cdef int _err_extents(int i, Py_ssize_t extent1,
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" % # <<<<<<<<<<<<<<
- * (i, extent1, extent2))
- *
- */
- __pyx_t_3 = __Pyx_PyString_Format(__pyx_kp_s_got_differing_extents_in_dimensi, __pyx_t_4); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1255, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PyObject_CallOneArg(__pyx_builtin_ValueError, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 1255, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_Raise(__pyx_t_4, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __PYX_ERR(1, 1255, __pyx_L1_error)
-
- /* "View.MemoryView":1253
- *
- * @cname('__pyx_memoryview_err_extents')
- * cdef int _err_extents(int i, Py_ssize_t extent1, # <<<<<<<<<<<<<<
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" %
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView._err_extents", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- return __pyx_r;
-}
-
-/* "View.MemoryView":1259
- *
- * @cname('__pyx_memoryview_err_dim')
- * cdef int _err_dim(object error, char *msg, int dim) except -1 with gil: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii') % dim)
- *
- */
-
-static int __pyx_memoryview_err_dim(PyObject *__pyx_v_error, char *__pyx_v_msg, int __pyx_v_dim) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("_err_dim", 0);
- __Pyx_INCREF(__pyx_v_error);
-
- /* "View.MemoryView":1260
- * @cname('__pyx_memoryview_err_dim')
- * cdef int _err_dim(object error, char *msg, int dim) except -1 with gil:
- * raise error(msg.decode('ascii') % dim) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_err')
- */
- __pyx_t_2 = __Pyx_decode_c_string(__pyx_v_msg, 0, strlen(__pyx_v_msg), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = __Pyx_PyInt_From_int(__pyx_v_dim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = PyUnicode_Format(__pyx_t_2, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_INCREF(__pyx_v_error);
- __pyx_t_3 = __pyx_v_error; __pyx_t_2 = NULL;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_3))) {
- __pyx_t_2 = PyMethod_GET_SELF(__pyx_t_3);
- if (likely(__pyx_t_2)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_3);
- __Pyx_INCREF(__pyx_t_2);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_3, function);
- }
- }
- __pyx_t_1 = (__pyx_t_2) ? __Pyx_PyObject_Call2Args(__pyx_t_3, __pyx_t_2, __pyx_t_4) : __Pyx_PyObject_CallOneArg(__pyx_t_3, __pyx_t_4);
- __Pyx_XDECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 1260, __pyx_L1_error)
-
- /* "View.MemoryView":1259
- *
- * @cname('__pyx_memoryview_err_dim')
- * cdef int _err_dim(object error, char *msg, int dim) except -1 with gil: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii') % dim)
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView._err_dim", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __Pyx_XDECREF(__pyx_v_error);
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- return __pyx_r;
-}
-
-/* "View.MemoryView":1263
- *
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil: # <<<<<<<<<<<<<<
- * if msg != NULL:
- * raise error(msg.decode('ascii'))
- */
-
-static int __pyx_memoryview_err(PyObject *__pyx_v_error, char *__pyx_v_msg) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("_err", 0);
- __Pyx_INCREF(__pyx_v_error);
-
- /* "View.MemoryView":1264
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil:
- * if msg != NULL: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii'))
- * else:
- */
- __pyx_t_1 = ((__pyx_v_msg != NULL) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":1265
- * cdef int _err(object error, char *msg) except -1 with gil:
- * if msg != NULL:
- * raise error(msg.decode('ascii')) # <<<<<<<<<<<<<<
- * else:
- * raise error
- */
- __pyx_t_3 = __Pyx_decode_c_string(__pyx_v_msg, 0, strlen(__pyx_v_msg), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1265, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_v_error);
- __pyx_t_4 = __pyx_v_error; __pyx_t_5 = NULL;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_4))) {
- __pyx_t_5 = PyMethod_GET_SELF(__pyx_t_4);
- if (likely(__pyx_t_5)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_4);
- __Pyx_INCREF(__pyx_t_5);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_4, function);
- }
- }
- __pyx_t_2 = (__pyx_t_5) ? __Pyx_PyObject_Call2Args(__pyx_t_4, __pyx_t_5, __pyx_t_3) : __Pyx_PyObject_CallOneArg(__pyx_t_4, __pyx_t_3);
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1265, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_Raise(__pyx_t_2, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __PYX_ERR(1, 1265, __pyx_L1_error)
-
- /* "View.MemoryView":1264
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil:
- * if msg != NULL: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii'))
- * else:
- */
- }
-
- /* "View.MemoryView":1267
- * raise error(msg.decode('ascii'))
- * else:
- * raise error # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_contents')
- */
- /*else*/ {
- __Pyx_Raise(__pyx_v_error, 0, 0, 0);
- __PYX_ERR(1, 1267, __pyx_L1_error)
- }
-
- /* "View.MemoryView":1263
- *
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil: # <<<<<<<<<<<<<<
- * if msg != NULL:
- * raise error(msg.decode('ascii'))
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView._err", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __Pyx_XDECREF(__pyx_v_error);
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- return __pyx_r;
-}
-
-/* "View.MemoryView":1270
- *
- * @cname('__pyx_memoryview_copy_contents')
- * cdef int memoryview_copy_contents(__Pyx_memviewslice src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice dst,
- * int src_ndim, int dst_ndim,
- */
-
-static int __pyx_memoryview_copy_contents(__Pyx_memviewslice __pyx_v_src, __Pyx_memviewslice __pyx_v_dst, int __pyx_v_src_ndim, int __pyx_v_dst_ndim, int __pyx_v_dtype_is_object) {
- void *__pyx_v_tmpdata;
- size_t __pyx_v_itemsize;
- int __pyx_v_i;
- char __pyx_v_order;
- int __pyx_v_broadcasting;
- int __pyx_v_direct_copy;
- __Pyx_memviewslice __pyx_v_tmp;
- int __pyx_v_ndim;
- int __pyx_r;
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- int __pyx_t_5;
- int __pyx_t_6;
- void *__pyx_t_7;
- int __pyx_t_8;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":1278
- * Check for overlapping memory and verify the shapes.
- * """
- * cdef void *tmpdata = NULL # <<<<<<<<<<<<<<
- * cdef size_t itemsize = src.memview.view.itemsize
- * cdef int i
- */
- __pyx_v_tmpdata = NULL;
-
- /* "View.MemoryView":1279
- * """
- * cdef void *tmpdata = NULL
- * cdef size_t itemsize = src.memview.view.itemsize # <<<<<<<<<<<<<<
- * cdef int i
- * cdef char order = get_best_order(&src, src_ndim)
- */
- __pyx_t_1 = __pyx_v_src.memview->view.itemsize;
- __pyx_v_itemsize = __pyx_t_1;
-
- /* "View.MemoryView":1281
- * cdef size_t itemsize = src.memview.view.itemsize
- * cdef int i
- * cdef char order = get_best_order(&src, src_ndim) # <<<<<<<<<<<<<<
- * cdef bint broadcasting = False
- * cdef bint direct_copy = False
- */
- __pyx_v_order = __pyx_get_best_slice_order((&__pyx_v_src), __pyx_v_src_ndim);
-
- /* "View.MemoryView":1282
- * cdef int i
- * cdef char order = get_best_order(&src, src_ndim)
- * cdef bint broadcasting = False # <<<<<<<<<<<<<<
- * cdef bint direct_copy = False
- * cdef __Pyx_memviewslice tmp
- */
- __pyx_v_broadcasting = 0;
-
- /* "View.MemoryView":1283
- * cdef char order = get_best_order(&src, src_ndim)
- * cdef bint broadcasting = False
- * cdef bint direct_copy = False # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice tmp
- *
- */
- __pyx_v_direct_copy = 0;
-
- /* "View.MemoryView":1286
- * cdef __Pyx_memviewslice tmp
- *
- * if src_ndim < dst_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim:
- */
- __pyx_t_2 = ((__pyx_v_src_ndim < __pyx_v_dst_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1287
- *
- * if src_ndim < dst_ndim:
- * broadcast_leading(&src, src_ndim, dst_ndim) # <<<<<<<<<<<<<<
- * elif dst_ndim < src_ndim:
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- */
- __pyx_memoryview_broadcast_leading((&__pyx_v_src), __pyx_v_src_ndim, __pyx_v_dst_ndim);
-
- /* "View.MemoryView":1286
- * cdef __Pyx_memviewslice tmp
- *
- * if src_ndim < dst_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1288
- * if src_ndim < dst_ndim:
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- *
- */
- __pyx_t_2 = ((__pyx_v_dst_ndim < __pyx_v_src_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1289
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim:
- * broadcast_leading(&dst, dst_ndim, src_ndim) # <<<<<<<<<<<<<<
- *
- * cdef int ndim = max(src_ndim, dst_ndim)
- */
- __pyx_memoryview_broadcast_leading((&__pyx_v_dst), __pyx_v_dst_ndim, __pyx_v_src_ndim);
-
- /* "View.MemoryView":1288
- * if src_ndim < dst_ndim:
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- *
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1291
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- *
- * cdef int ndim = max(src_ndim, dst_ndim) # <<<<<<<<<<<<<<
- *
- * for i in range(ndim):
- */
- __pyx_t_3 = __pyx_v_dst_ndim;
- __pyx_t_4 = __pyx_v_src_ndim;
- if (((__pyx_t_3 > __pyx_t_4) != 0)) {
- __pyx_t_5 = __pyx_t_3;
- } else {
- __pyx_t_5 = __pyx_t_4;
- }
- __pyx_v_ndim = __pyx_t_5;
-
- /* "View.MemoryView":1293
- * cdef int ndim = max(src_ndim, dst_ndim)
- *
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1:
- */
- __pyx_t_5 = __pyx_v_ndim;
- __pyx_t_3 = __pyx_t_5;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1294
- *
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]: # <<<<<<<<<<<<<<
- * if src.shape[i] == 1:
- * broadcasting = True
- */
- __pyx_t_2 = (((__pyx_v_src.shape[__pyx_v_i]) != (__pyx_v_dst.shape[__pyx_v_i])) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1295
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1: # <<<<<<<<<<<<<<
- * broadcasting = True
- * src.strides[i] = 0
- */
- __pyx_t_2 = (((__pyx_v_src.shape[__pyx_v_i]) == 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1296
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1:
- * broadcasting = True # <<<<<<<<<<<<<<
- * src.strides[i] = 0
- * else:
- */
- __pyx_v_broadcasting = 1;
-
- /* "View.MemoryView":1297
- * if src.shape[i] == 1:
- * broadcasting = True
- * src.strides[i] = 0 # <<<<<<<<<<<<<<
- * else:
- * _err_extents(i, dst.shape[i], src.shape[i])
- */
- (__pyx_v_src.strides[__pyx_v_i]) = 0;
-
- /* "View.MemoryView":1295
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1: # <<<<<<<<<<<<<<
- * broadcasting = True
- * src.strides[i] = 0
- */
- goto __pyx_L7;
- }
-
- /* "View.MemoryView":1299
- * src.strides[i] = 0
- * else:
- * _err_extents(i, dst.shape[i], src.shape[i]) # <<<<<<<<<<<<<<
- *
- * if src.suboffsets[i] >= 0:
- */
- /*else*/ {
- __pyx_t_6 = __pyx_memoryview_err_extents(__pyx_v_i, (__pyx_v_dst.shape[__pyx_v_i]), (__pyx_v_src.shape[__pyx_v_i])); if (unlikely(__pyx_t_6 == ((int)-1))) __PYX_ERR(1, 1299, __pyx_L1_error)
- }
- __pyx_L7:;
-
- /* "View.MemoryView":1294
- *
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]: # <<<<<<<<<<<<<<
- * if src.shape[i] == 1:
- * broadcasting = True
- */
- }
-
- /* "View.MemoryView":1301
- * _err_extents(i, dst.shape[i], src.shape[i])
- *
- * if src.suboffsets[i] >= 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- */
- __pyx_t_2 = (((__pyx_v_src.suboffsets[__pyx_v_i]) >= 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1302
- *
- * if src.suboffsets[i] >= 0:
- * _err_dim(ValueError, "Dimension %d is not direct", i) # <<<<<<<<<<<<<<
- *
- * if slices_overlap(&src, &dst, ndim, itemsize):
- */
- __pyx_t_6 = __pyx_memoryview_err_dim(__pyx_builtin_ValueError, ((char *)"Dimension %d is not direct"), __pyx_v_i); if (unlikely(__pyx_t_6 == ((int)-1))) __PYX_ERR(1, 1302, __pyx_L1_error)
-
- /* "View.MemoryView":1301
- * _err_extents(i, dst.shape[i], src.shape[i])
- *
- * if src.suboffsets[i] >= 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- */
- }
- }
-
- /* "View.MemoryView":1304
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- * if slices_overlap(&src, &dst, ndim, itemsize): # <<<<<<<<<<<<<<
- *
- * if not slice_is_contig(src, order, ndim):
- */
- __pyx_t_2 = (__pyx_slices_overlap((&__pyx_v_src), (&__pyx_v_dst), __pyx_v_ndim, __pyx_v_itemsize) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1306
- * if slices_overlap(&src, &dst, ndim, itemsize):
- *
- * if not slice_is_contig(src, order, ndim): # <<<<<<<<<<<<<<
- * order = get_best_order(&dst, ndim)
- *
- */
- __pyx_t_2 = ((!(__pyx_memviewslice_is_contig(__pyx_v_src, __pyx_v_order, __pyx_v_ndim) != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1307
- *
- * if not slice_is_contig(src, order, ndim):
- * order = get_best_order(&dst, ndim) # <<<<<<<<<<<<<<
- *
- * tmpdata = copy_data_to_temp(&src, &tmp, order, ndim)
- */
- __pyx_v_order = __pyx_get_best_slice_order((&__pyx_v_dst), __pyx_v_ndim);
-
- /* "View.MemoryView":1306
- * if slices_overlap(&src, &dst, ndim, itemsize):
- *
- * if not slice_is_contig(src, order, ndim): # <<<<<<<<<<<<<<
- * order = get_best_order(&dst, ndim)
- *
- */
- }
-
- /* "View.MemoryView":1309
- * order = get_best_order(&dst, ndim)
- *
- * tmpdata = copy_data_to_temp(&src, &tmp, order, ndim) # <<<<<<<<<<<<<<
- * src = tmp
- *
- */
- __pyx_t_7 = __pyx_memoryview_copy_data_to_temp((&__pyx_v_src), (&__pyx_v_tmp), __pyx_v_order, __pyx_v_ndim); if (unlikely(__pyx_t_7 == ((void *)NULL))) __PYX_ERR(1, 1309, __pyx_L1_error)
- __pyx_v_tmpdata = __pyx_t_7;
-
- /* "View.MemoryView":1310
- *
- * tmpdata = copy_data_to_temp(&src, &tmp, order, ndim)
- * src = tmp # <<<<<<<<<<<<<<
- *
- * if not broadcasting:
- */
- __pyx_v_src = __pyx_v_tmp;
-
- /* "View.MemoryView":1304
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- * if slices_overlap(&src, &dst, ndim, itemsize): # <<<<<<<<<<<<<<
- *
- * if not slice_is_contig(src, order, ndim):
- */
- }
-
- /* "View.MemoryView":1312
- * src = tmp
- *
- * if not broadcasting: # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_2 = ((!(__pyx_v_broadcasting != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1315
- *
- *
- * if slice_is_contig(src, 'C', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim):
- */
- __pyx_t_2 = (__pyx_memviewslice_is_contig(__pyx_v_src, 'C', __pyx_v_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1316
- *
- * if slice_is_contig(src, 'C', ndim):
- * direct_copy = slice_is_contig(dst, 'C', ndim) # <<<<<<<<<<<<<<
- * elif slice_is_contig(src, 'F', ndim):
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- */
- __pyx_v_direct_copy = __pyx_memviewslice_is_contig(__pyx_v_dst, 'C', __pyx_v_ndim);
-
- /* "View.MemoryView":1315
- *
- *
- * if slice_is_contig(src, 'C', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim):
- */
- goto __pyx_L12;
- }
-
- /* "View.MemoryView":1317
- * if slice_is_contig(src, 'C', ndim):
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- */
- __pyx_t_2 = (__pyx_memviewslice_is_contig(__pyx_v_src, 'F', __pyx_v_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1318
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim):
- * direct_copy = slice_is_contig(dst, 'F', ndim) # <<<<<<<<<<<<<<
- *
- * if direct_copy:
- */
- __pyx_v_direct_copy = __pyx_memviewslice_is_contig(__pyx_v_dst, 'F', __pyx_v_ndim);
-
- /* "View.MemoryView":1317
- * if slice_is_contig(src, 'C', ndim):
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- */
- }
- __pyx_L12:;
-
- /* "View.MemoryView":1320
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- * if direct_copy: # <<<<<<<<<<<<<<
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- */
- __pyx_t_2 = (__pyx_v_direct_copy != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1322
- * if direct_copy:
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False) # <<<<<<<<<<<<<<
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim))
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 0);
-
- /* "View.MemoryView":1323
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim)) # <<<<<<<<<<<<<<
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- * free(tmpdata)
- */
- (void)(memcpy(__pyx_v_dst.data, __pyx_v_src.data, __pyx_memoryview_slice_get_size((&__pyx_v_src), __pyx_v_ndim)));
-
- /* "View.MemoryView":1324
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim))
- * refcount_copying(&dst, dtype_is_object, ndim, True) # <<<<<<<<<<<<<<
- * free(tmpdata)
- * return 0
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 1);
-
- /* "View.MemoryView":1325
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim))
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- * free(tmpdata) # <<<<<<<<<<<<<<
- * return 0
- *
- */
- free(__pyx_v_tmpdata);
-
- /* "View.MemoryView":1326
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- * free(tmpdata)
- * return 0 # <<<<<<<<<<<<<<
- *
- * if order == 'F' == get_best_order(&dst, ndim):
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1320
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- * if direct_copy: # <<<<<<<<<<<<<<
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- */
- }
-
- /* "View.MemoryView":1312
- * src = tmp
- *
- * if not broadcasting: # <<<<<<<<<<<<<<
- *
- *
- */
- }
-
- /* "View.MemoryView":1328
- * return 0
- *
- * if order == 'F' == get_best_order(&dst, ndim): # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_2 = (__pyx_v_order == 'F');
- if (__pyx_t_2) {
- __pyx_t_2 = ('F' == __pyx_get_best_slice_order((&__pyx_v_dst), __pyx_v_ndim));
- }
- __pyx_t_8 = (__pyx_t_2 != 0);
- if (__pyx_t_8) {
-
- /* "View.MemoryView":1331
- *
- *
- * transpose_memslice(&src) # <<<<<<<<<<<<<<
- * transpose_memslice(&dst)
- *
- */
- __pyx_t_5 = __pyx_memslice_transpose((&__pyx_v_src)); if (unlikely(__pyx_t_5 == ((int)0))) __PYX_ERR(1, 1331, __pyx_L1_error)
-
- /* "View.MemoryView":1332
- *
- * transpose_memslice(&src)
- * transpose_memslice(&dst) # <<<<<<<<<<<<<<
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- */
- __pyx_t_5 = __pyx_memslice_transpose((&__pyx_v_dst)); if (unlikely(__pyx_t_5 == ((int)0))) __PYX_ERR(1, 1332, __pyx_L1_error)
-
- /* "View.MemoryView":1328
- * return 0
- *
- * if order == 'F' == get_best_order(&dst, ndim): # <<<<<<<<<<<<<<
- *
- *
- */
- }
-
- /* "View.MemoryView":1334
- * transpose_memslice(&dst)
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False) # <<<<<<<<<<<<<<
- * copy_strided_to_strided(&src, &dst, ndim, itemsize)
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 0);
-
- /* "View.MemoryView":1335
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * copy_strided_to_strided(&src, &dst, ndim, itemsize) # <<<<<<<<<<<<<<
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- *
- */
- copy_strided_to_strided((&__pyx_v_src), (&__pyx_v_dst), __pyx_v_ndim, __pyx_v_itemsize);
-
- /* "View.MemoryView":1336
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * copy_strided_to_strided(&src, &dst, ndim, itemsize)
- * refcount_copying(&dst, dtype_is_object, ndim, True) # <<<<<<<<<<<<<<
- *
- * free(tmpdata)
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 1);
-
- /* "View.MemoryView":1338
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- *
- * free(tmpdata) # <<<<<<<<<<<<<<
- * return 0
- *
- */
- free(__pyx_v_tmpdata);
-
- /* "View.MemoryView":1339
- *
- * free(tmpdata)
- * return 0 # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_broadcast_leading')
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1270
- *
- * @cname('__pyx_memoryview_copy_contents')
- * cdef int memoryview_copy_contents(__Pyx_memviewslice src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice dst,
- * int src_ndim, int dst_ndim,
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.memoryview_copy_contents", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = -1;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1342
- *
- * @cname('__pyx_memoryview_broadcast_leading')
- * cdef void broadcast_leading(__Pyx_memviewslice *mslice, # <<<<<<<<<<<<<<
- * int ndim,
- * int ndim_other) nogil:
- */
-
-static void __pyx_memoryview_broadcast_leading(__Pyx_memviewslice *__pyx_v_mslice, int __pyx_v_ndim, int __pyx_v_ndim_other) {
- int __pyx_v_i;
- int __pyx_v_offset;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
-
- /* "View.MemoryView":1346
- * int ndim_other) nogil:
- * cdef int i
- * cdef int offset = ndim_other - ndim # <<<<<<<<<<<<<<
- *
- * for i in range(ndim - 1, -1, -1):
- */
- __pyx_v_offset = (__pyx_v_ndim_other - __pyx_v_ndim);
-
- /* "View.MemoryView":1348
- * cdef int offset = ndim_other - ndim
- *
- * for i in range(ndim - 1, -1, -1): # <<<<<<<<<<<<<<
- * mslice.shape[i + offset] = mslice.shape[i]
- * mslice.strides[i + offset] = mslice.strides[i]
- */
- for (__pyx_t_1 = (__pyx_v_ndim - 1); __pyx_t_1 > -1; __pyx_t_1-=1) {
- __pyx_v_i = __pyx_t_1;
-
- /* "View.MemoryView":1349
- *
- * for i in range(ndim - 1, -1, -1):
- * mslice.shape[i + offset] = mslice.shape[i] # <<<<<<<<<<<<<<
- * mslice.strides[i + offset] = mslice.strides[i]
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i]
- */
- (__pyx_v_mslice->shape[(__pyx_v_i + __pyx_v_offset)]) = (__pyx_v_mslice->shape[__pyx_v_i]);
-
- /* "View.MemoryView":1350
- * for i in range(ndim - 1, -1, -1):
- * mslice.shape[i + offset] = mslice.shape[i]
- * mslice.strides[i + offset] = mslice.strides[i] # <<<<<<<<<<<<<<
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i]
- *
- */
- (__pyx_v_mslice->strides[(__pyx_v_i + __pyx_v_offset)]) = (__pyx_v_mslice->strides[__pyx_v_i]);
-
- /* "View.MemoryView":1351
- * mslice.shape[i + offset] = mslice.shape[i]
- * mslice.strides[i + offset] = mslice.strides[i]
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i] # <<<<<<<<<<<<<<
- *
- * for i in range(offset):
- */
- (__pyx_v_mslice->suboffsets[(__pyx_v_i + __pyx_v_offset)]) = (__pyx_v_mslice->suboffsets[__pyx_v_i]);
- }
-
- /* "View.MemoryView":1353
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i]
- *
- * for i in range(offset): # <<<<<<<<<<<<<<
- * mslice.shape[i] = 1
- * mslice.strides[i] = mslice.strides[0]
- */
- __pyx_t_1 = __pyx_v_offset;
- __pyx_t_2 = __pyx_t_1;
- for (__pyx_t_3 = 0; __pyx_t_3 < __pyx_t_2; __pyx_t_3+=1) {
- __pyx_v_i = __pyx_t_3;
-
- /* "View.MemoryView":1354
- *
- * for i in range(offset):
- * mslice.shape[i] = 1 # <<<<<<<<<<<<<<
- * mslice.strides[i] = mslice.strides[0]
- * mslice.suboffsets[i] = -1
- */
- (__pyx_v_mslice->shape[__pyx_v_i]) = 1;
-
- /* "View.MemoryView":1355
- * for i in range(offset):
- * mslice.shape[i] = 1
- * mslice.strides[i] = mslice.strides[0] # <<<<<<<<<<<<<<
- * mslice.suboffsets[i] = -1
- *
- */
- (__pyx_v_mslice->strides[__pyx_v_i]) = (__pyx_v_mslice->strides[0]);
-
- /* "View.MemoryView":1356
- * mslice.shape[i] = 1
- * mslice.strides[i] = mslice.strides[0]
- * mslice.suboffsets[i] = -1 # <<<<<<<<<<<<<<
- *
- *
- */
- (__pyx_v_mslice->suboffsets[__pyx_v_i]) = -1L;
- }
-
- /* "View.MemoryView":1342
- *
- * @cname('__pyx_memoryview_broadcast_leading')
- * cdef void broadcast_leading(__Pyx_memviewslice *mslice, # <<<<<<<<<<<<<<
- * int ndim,
- * int ndim_other) nogil:
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1364
- *
- * @cname('__pyx_memoryview_refcount_copying')
- * cdef void refcount_copying(__Pyx_memviewslice *dst, bint dtype_is_object, # <<<<<<<<<<<<<<
- * int ndim, bint inc) nogil:
- *
- */
-
-static void __pyx_memoryview_refcount_copying(__Pyx_memviewslice *__pyx_v_dst, int __pyx_v_dtype_is_object, int __pyx_v_ndim, int __pyx_v_inc) {
- int __pyx_t_1;
-
- /* "View.MemoryView":1368
- *
- *
- * if dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice_with_gil(dst.data, dst.shape,
- * dst.strides, ndim, inc)
- */
- __pyx_t_1 = (__pyx_v_dtype_is_object != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1369
- *
- * if dtype_is_object:
- * refcount_objects_in_slice_with_gil(dst.data, dst.shape, # <<<<<<<<<<<<<<
- * dst.strides, ndim, inc)
- *
- */
- __pyx_memoryview_refcount_objects_in_slice_with_gil(__pyx_v_dst->data, __pyx_v_dst->shape, __pyx_v_dst->strides, __pyx_v_ndim, __pyx_v_inc);
-
- /* "View.MemoryView":1368
- *
- *
- * if dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice_with_gil(dst.data, dst.shape,
- * dst.strides, ndim, inc)
- */
- }
-
- /* "View.MemoryView":1364
- *
- * @cname('__pyx_memoryview_refcount_copying')
- * cdef void refcount_copying(__Pyx_memviewslice *dst, bint dtype_is_object, # <<<<<<<<<<<<<<
- * int ndim, bint inc) nogil:
- *
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1373
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice_with_gil')
- * cdef void refcount_objects_in_slice_with_gil(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * bint inc) with gil:
- */
-
-static void __pyx_memoryview_refcount_objects_in_slice_with_gil(char *__pyx_v_data, Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, int __pyx_v_ndim, int __pyx_v_inc) {
- __Pyx_RefNannyDeclarations
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("refcount_objects_in_slice_with_gil", 0);
-
- /* "View.MemoryView":1376
- * Py_ssize_t *strides, int ndim,
- * bint inc) with gil:
- * refcount_objects_in_slice(data, shape, strides, ndim, inc) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice')
- */
- __pyx_memoryview_refcount_objects_in_slice(__pyx_v_data, __pyx_v_shape, __pyx_v_strides, __pyx_v_ndim, __pyx_v_inc);
-
- /* "View.MemoryView":1373
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice_with_gil')
- * cdef void refcount_objects_in_slice_with_gil(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * bint inc) with gil:
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
-}
-
-/* "View.MemoryView":1379
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice')
- * cdef void refcount_objects_in_slice(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim, bint inc):
- * cdef Py_ssize_t i
- */
-
-static void __pyx_memoryview_refcount_objects_in_slice(char *__pyx_v_data, Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, int __pyx_v_ndim, int __pyx_v_inc) {
- CYTHON_UNUSED Py_ssize_t __pyx_v_i;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- Py_ssize_t __pyx_t_2;
- Py_ssize_t __pyx_t_3;
- int __pyx_t_4;
- __Pyx_RefNannySetupContext("refcount_objects_in_slice", 0);
-
- /* "View.MemoryView":1383
- * cdef Py_ssize_t i
- *
- * for i in range(shape[0]): # <<<<<<<<<<<<<<
- * if ndim == 1:
- * if inc:
- */
- __pyx_t_1 = (__pyx_v_shape[0]);
- __pyx_t_2 = __pyx_t_1;
- for (__pyx_t_3 = 0; __pyx_t_3 < __pyx_t_2; __pyx_t_3+=1) {
- __pyx_v_i = __pyx_t_3;
-
- /* "View.MemoryView":1384
- *
- * for i in range(shape[0]):
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if inc:
- * Py_INCREF(( data)[0])
- */
- __pyx_t_4 = ((__pyx_v_ndim == 1) != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":1385
- * for i in range(shape[0]):
- * if ndim == 1:
- * if inc: # <<<<<<<<<<<<<<
- * Py_INCREF(( data)[0])
- * else:
- */
- __pyx_t_4 = (__pyx_v_inc != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":1386
- * if ndim == 1:
- * if inc:
- * Py_INCREF(( data)[0]) # <<<<<<<<<<<<<<
- * else:
- * Py_DECREF(( data)[0])
- */
- Py_INCREF((((PyObject **)__pyx_v_data)[0]));
-
- /* "View.MemoryView":1385
- * for i in range(shape[0]):
- * if ndim == 1:
- * if inc: # <<<<<<<<<<<<<<
- * Py_INCREF(( data)[0])
- * else:
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":1388
- * Py_INCREF(( data)[0])
- * else:
- * Py_DECREF(( data)[0]) # <<<<<<<<<<<<<<
- * else:
- * refcount_objects_in_slice(data, shape + 1, strides + 1,
- */
- /*else*/ {
- Py_DECREF((((PyObject **)__pyx_v_data)[0]));
- }
- __pyx_L6:;
-
- /* "View.MemoryView":1384
- *
- * for i in range(shape[0]):
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if inc:
- * Py_INCREF(( data)[0])
- */
- goto __pyx_L5;
- }
-
- /* "View.MemoryView":1390
- * Py_DECREF(( data)[0])
- * else:
- * refcount_objects_in_slice(data, shape + 1, strides + 1, # <<<<<<<<<<<<<<
- * ndim - 1, inc)
- *
- */
- /*else*/ {
-
- /* "View.MemoryView":1391
- * else:
- * refcount_objects_in_slice(data, shape + 1, strides + 1,
- * ndim - 1, inc) # <<<<<<<<<<<<<<
- *
- * data += strides[0]
- */
- __pyx_memoryview_refcount_objects_in_slice(__pyx_v_data, (__pyx_v_shape + 1), (__pyx_v_strides + 1), (__pyx_v_ndim - 1), __pyx_v_inc);
- }
- __pyx_L5:;
-
- /* "View.MemoryView":1393
- * ndim - 1, inc)
- *
- * data += strides[0] # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_data = (__pyx_v_data + (__pyx_v_strides[0]));
- }
-
- /* "View.MemoryView":1379
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice')
- * cdef void refcount_objects_in_slice(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim, bint inc):
- * cdef Py_ssize_t i
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":1399
- *
- * @cname('__pyx_memoryview_slice_assign_scalar')
- * cdef void slice_assign_scalar(__Pyx_memviewslice *dst, int ndim, # <<<<<<<<<<<<<<
- * size_t itemsize, void *item,
- * bint dtype_is_object) nogil:
- */
-
-static void __pyx_memoryview_slice_assign_scalar(__Pyx_memviewslice *__pyx_v_dst, int __pyx_v_ndim, size_t __pyx_v_itemsize, void *__pyx_v_item, int __pyx_v_dtype_is_object) {
-
- /* "View.MemoryView":1402
- * size_t itemsize, void *item,
- * bint dtype_is_object) nogil:
- * refcount_copying(dst, dtype_is_object, ndim, False) # <<<<<<<<<<<<<<
- * _slice_assign_scalar(dst.data, dst.shape, dst.strides, ndim,
- * itemsize, item)
- */
- __pyx_memoryview_refcount_copying(__pyx_v_dst, __pyx_v_dtype_is_object, __pyx_v_ndim, 0);
-
- /* "View.MemoryView":1403
- * bint dtype_is_object) nogil:
- * refcount_copying(dst, dtype_is_object, ndim, False)
- * _slice_assign_scalar(dst.data, dst.shape, dst.strides, ndim, # <<<<<<<<<<<<<<
- * itemsize, item)
- * refcount_copying(dst, dtype_is_object, ndim, True)
- */
- __pyx_memoryview__slice_assign_scalar(__pyx_v_dst->data, __pyx_v_dst->shape, __pyx_v_dst->strides, __pyx_v_ndim, __pyx_v_itemsize, __pyx_v_item);
-
- /* "View.MemoryView":1405
- * _slice_assign_scalar(dst.data, dst.shape, dst.strides, ndim,
- * itemsize, item)
- * refcount_copying(dst, dtype_is_object, ndim, True) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_memoryview_refcount_copying(__pyx_v_dst, __pyx_v_dtype_is_object, __pyx_v_ndim, 1);
-
- /* "View.MemoryView":1399
- *
- * @cname('__pyx_memoryview_slice_assign_scalar')
- * cdef void slice_assign_scalar(__Pyx_memviewslice *dst, int ndim, # <<<<<<<<<<<<<<
- * size_t itemsize, void *item,
- * bint dtype_is_object) nogil:
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1409
- *
- * @cname('__pyx_memoryview__slice_assign_scalar')
- * cdef void _slice_assign_scalar(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * size_t itemsize, void *item) nogil:
- */
-
-static void __pyx_memoryview__slice_assign_scalar(char *__pyx_v_data, Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, int __pyx_v_ndim, size_t __pyx_v_itemsize, void *__pyx_v_item) {
- CYTHON_UNUSED Py_ssize_t __pyx_v_i;
- Py_ssize_t __pyx_v_stride;
- Py_ssize_t __pyx_v_extent;
- int __pyx_t_1;
- Py_ssize_t __pyx_t_2;
- Py_ssize_t __pyx_t_3;
- Py_ssize_t __pyx_t_4;
-
- /* "View.MemoryView":1413
- * size_t itemsize, void *item) nogil:
- * cdef Py_ssize_t i
- * cdef Py_ssize_t stride = strides[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t extent = shape[0]
- *
- */
- __pyx_v_stride = (__pyx_v_strides[0]);
-
- /* "View.MemoryView":1414
- * cdef Py_ssize_t i
- * cdef Py_ssize_t stride = strides[0]
- * cdef Py_ssize_t extent = shape[0] # <<<<<<<<<<<<<<
- *
- * if ndim == 1:
- */
- __pyx_v_extent = (__pyx_v_shape[0]);
-
- /* "View.MemoryView":1416
- * cdef Py_ssize_t extent = shape[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * for i in range(extent):
- * memcpy(data, item, itemsize)
- */
- __pyx_t_1 = ((__pyx_v_ndim == 1) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1417
- *
- * if ndim == 1:
- * for i in range(extent): # <<<<<<<<<<<<<<
- * memcpy(data, item, itemsize)
- * data += stride
- */
- __pyx_t_2 = __pyx_v_extent;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1418
- * if ndim == 1:
- * for i in range(extent):
- * memcpy(data, item, itemsize) # <<<<<<<<<<<<<<
- * data += stride
- * else:
- */
- (void)(memcpy(__pyx_v_data, __pyx_v_item, __pyx_v_itemsize));
-
- /* "View.MemoryView":1419
- * for i in range(extent):
- * memcpy(data, item, itemsize)
- * data += stride # <<<<<<<<<<<<<<
- * else:
- * for i in range(extent):
- */
- __pyx_v_data = (__pyx_v_data + __pyx_v_stride);
- }
-
- /* "View.MemoryView":1416
- * cdef Py_ssize_t extent = shape[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * for i in range(extent):
- * memcpy(data, item, itemsize)
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1421
- * data += stride
- * else:
- * for i in range(extent): # <<<<<<<<<<<<<<
- * _slice_assign_scalar(data, shape + 1, strides + 1,
- * ndim - 1, itemsize, item)
- */
- /*else*/ {
- __pyx_t_2 = __pyx_v_extent;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1422
- * else:
- * for i in range(extent):
- * _slice_assign_scalar(data, shape + 1, strides + 1, # <<<<<<<<<<<<<<
- * ndim - 1, itemsize, item)
- * data += stride
- */
- __pyx_memoryview__slice_assign_scalar(__pyx_v_data, (__pyx_v_shape + 1), (__pyx_v_strides + 1), (__pyx_v_ndim - 1), __pyx_v_itemsize, __pyx_v_item);
-
- /* "View.MemoryView":1424
- * _slice_assign_scalar(data, shape + 1, strides + 1,
- * ndim - 1, itemsize, item)
- * data += stride # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_data = (__pyx_v_data + __pyx_v_stride);
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1409
- *
- * @cname('__pyx_memoryview__slice_assign_scalar')
- * cdef void _slice_assign_scalar(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * size_t itemsize, void *item) nogil:
- */
-
- /* function exit code */
-}
-
-/* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_1__pyx_unpickle_Enum(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static PyMethodDef __pyx_mdef_15View_dot_MemoryView_1__pyx_unpickle_Enum = {"__pyx_unpickle_Enum", (PyCFunction)(void*)(PyCFunctionWithKeywords)__pyx_pw_15View_dot_MemoryView_1__pyx_unpickle_Enum, METH_VARARGS|METH_KEYWORDS, 0};
-static PyObject *__pyx_pw_15View_dot_MemoryView_1__pyx_unpickle_Enum(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v___pyx_type = 0;
- long __pyx_v___pyx_checksum;
- PyObject *__pyx_v___pyx_state = 0;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__pyx_unpickle_Enum (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_pyx_type,&__pyx_n_s_pyx_checksum,&__pyx_n_s_pyx_state,0};
- PyObject* values[3] = {0,0,0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_pyx_type)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_pyx_checksum)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__pyx_unpickle_Enum", 1, 3, 3, 1); __PYX_ERR(1, 1, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_pyx_state)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__pyx_unpickle_Enum", 1, 3, 3, 2); __PYX_ERR(1, 1, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__pyx_unpickle_Enum") < 0)) __PYX_ERR(1, 1, __pyx_L3_error)
- }
- } else if (PyTuple_GET_SIZE(__pyx_args) != 3) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- }
- __pyx_v___pyx_type = values[0];
- __pyx_v___pyx_checksum = __Pyx_PyInt_As_long(values[1]); if (unlikely((__pyx_v___pyx_checksum == (long)-1) && PyErr_Occurred())) __PYX_ERR(1, 1, __pyx_L3_error)
- __pyx_v___pyx_state = values[2];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__pyx_unpickle_Enum", 1, 3, 3, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 1, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.__pyx_unpickle_Enum", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_15View_dot_MemoryView___pyx_unpickle_Enum(__pyx_self, __pyx_v___pyx_type, __pyx_v___pyx_checksum, __pyx_v___pyx_state);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView___pyx_unpickle_Enum(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v___pyx_type, long __pyx_v___pyx_checksum, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_v___pyx_PickleError = 0;
- PyObject *__pyx_v___pyx_result = 0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_t_3;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__pyx_unpickle_Enum", 0);
-
- /* "(tree fragment)":4
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995): # <<<<<<<<<<<<<<
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- */
- __pyx_t_1 = __Pyx_PyInt_From_long(__pyx_v___pyx_checksum); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = (__Pyx_PySequence_ContainsTF(__pyx_t_1, __pyx_tuple__20, Py_NE)); if (unlikely(__pyx_t_2 < 0)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (__pyx_t_3) {
-
- /* "(tree fragment)":5
- * cdef object __pyx_result
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995):
- * from pickle import PickleError as __pyx_PickleError # <<<<<<<<<<<<<<
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type)
- */
- __pyx_t_1 = PyList_New(1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_n_s_PickleError);
- __Pyx_GIVEREF(__pyx_n_s_PickleError);
- PyList_SET_ITEM(__pyx_t_1, 0, __pyx_n_s_PickleError);
- __pyx_t_4 = __Pyx_Import(__pyx_n_s_pickle, __pyx_t_1, 0); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_ImportFrom(__pyx_t_4, __pyx_n_s_PickleError); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_1);
- __pyx_v___pyx_PickleError = __pyx_t_1;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
-
- /* "(tree fragment)":6
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995):
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum) # <<<<<<<<<<<<<<
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None:
- */
- __pyx_t_1 = __Pyx_PyInt_From_long(__pyx_v___pyx_checksum); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_5 = __Pyx_PyString_Format(__pyx_kp_s_Incompatible_checksums_0x_x_vs_0, __pyx_t_1); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_INCREF(__pyx_v___pyx_PickleError);
- __pyx_t_1 = __pyx_v___pyx_PickleError; __pyx_t_6 = NULL;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_1))) {
- __pyx_t_6 = PyMethod_GET_SELF(__pyx_t_1);
- if (likely(__pyx_t_6)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_6);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_1, function);
- }
- }
- __pyx_t_4 = (__pyx_t_6) ? __Pyx_PyObject_Call2Args(__pyx_t_1, __pyx_t_6, __pyx_t_5) : __Pyx_PyObject_CallOneArg(__pyx_t_1, __pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_Raise(__pyx_t_4, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __PYX_ERR(1, 6, __pyx_L1_error)
-
- /* "(tree fragment)":4
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995): # <<<<<<<<<<<<<<
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- */
- }
-
- /* "(tree fragment)":7
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type) # <<<<<<<<<<<<<<
- * if __pyx_state is not None:
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_MemviewEnum_type), __pyx_n_s_new); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 7, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_5 = NULL;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_1))) {
- __pyx_t_5 = PyMethod_GET_SELF(__pyx_t_1);
- if (likely(__pyx_t_5)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_5);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_1, function);
- }
- }
- __pyx_t_4 = (__pyx_t_5) ? __Pyx_PyObject_Call2Args(__pyx_t_1, __pyx_t_5, __pyx_v___pyx_type) : __Pyx_PyObject_CallOneArg(__pyx_t_1, __pyx_v___pyx_type);
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 7, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_v___pyx_result = __pyx_t_4;
- __pyx_t_4 = 0;
-
- /* "(tree fragment)":8
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None: # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- */
- __pyx_t_3 = (__pyx_v___pyx_state != Py_None);
- __pyx_t_2 = (__pyx_t_3 != 0);
- if (__pyx_t_2) {
-
- /* "(tree fragment)":9
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None:
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state) # <<<<<<<<<<<<<<
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- */
- if (!(likely(PyTuple_CheckExact(__pyx_v___pyx_state))||((__pyx_v___pyx_state) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "tuple", Py_TYPE(__pyx_v___pyx_state)->tp_name), 0))) __PYX_ERR(1, 9, __pyx_L1_error)
- __pyx_t_4 = __pyx_unpickle_Enum__set_state(((struct __pyx_MemviewEnum_obj *)__pyx_v___pyx_result), ((PyObject*)__pyx_v___pyx_state)); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 9, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
-
- /* "(tree fragment)":8
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None: # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- */
- }
-
- /* "(tree fragment)":10
- * if __pyx_state is not None:
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result # <<<<<<<<<<<<<<
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0]
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v___pyx_result);
- __pyx_r = __pyx_v___pyx_result;
- goto __pyx_L0;
-
- /* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_AddTraceback("View.MemoryView.__pyx_unpickle_Enum", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v___pyx_PickleError);
- __Pyx_XDECREF(__pyx_v___pyx_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":11
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- */
-
-static PyObject *__pyx_unpickle_Enum__set_state(struct __pyx_MemviewEnum_obj *__pyx_v___pyx_result, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- Py_ssize_t __pyx_t_3;
- int __pyx_t_4;
- int __pyx_t_5;
- PyObject *__pyx_t_6 = NULL;
- PyObject *__pyx_t_7 = NULL;
- PyObject *__pyx_t_8 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__pyx_unpickle_Enum__set_state", 0);
-
- /* "(tree fragment)":12
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0] # <<<<<<<<<<<<<<
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- * __pyx_result.__dict__.update(__pyx_state[1])
- */
- if (unlikely(__pyx_v___pyx_state == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' object is not subscriptable");
- __PYX_ERR(1, 12, __pyx_L1_error)
- }
- __pyx_t_1 = __Pyx_GetItemInt_Tuple(__pyx_v___pyx_state, 0, long, 1, __Pyx_PyInt_From_long, 0, 0, 1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 12, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __Pyx_GOTREF(__pyx_v___pyx_result->name);
- __Pyx_DECREF(__pyx_v___pyx_result->name);
- __pyx_v___pyx_result->name = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "(tree fragment)":13
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'): # <<<<<<<<<<<<<<
- * __pyx_result.__dict__.update(__pyx_state[1])
- */
- if (unlikely(__pyx_v___pyx_state == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "object of type 'NoneType' has no len()");
- __PYX_ERR(1, 13, __pyx_L1_error)
- }
- __pyx_t_3 = PyTuple_GET_SIZE(__pyx_v___pyx_state); if (unlikely(__pyx_t_3 == ((Py_ssize_t)-1))) __PYX_ERR(1, 13, __pyx_L1_error)
- __pyx_t_4 = ((__pyx_t_3 > 1) != 0);
- if (__pyx_t_4) {
- } else {
- __pyx_t_2 = __pyx_t_4;
- goto __pyx_L4_bool_binop_done;
- }
- __pyx_t_4 = __Pyx_HasAttr(((PyObject *)__pyx_v___pyx_result), __pyx_n_s_dict); if (unlikely(__pyx_t_4 == ((int)-1))) __PYX_ERR(1, 13, __pyx_L1_error)
- __pyx_t_5 = (__pyx_t_4 != 0);
- __pyx_t_2 = __pyx_t_5;
- __pyx_L4_bool_binop_done:;
- if (__pyx_t_2) {
-
- /* "(tree fragment)":14
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- * __pyx_result.__dict__.update(__pyx_state[1]) # <<<<<<<<<<<<<<
- */
- __pyx_t_6 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v___pyx_result), __pyx_n_s_dict); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_7 = __Pyx_PyObject_GetAttrStr(__pyx_t_6, __pyx_n_s_update); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (unlikely(__pyx_v___pyx_state == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' object is not subscriptable");
- __PYX_ERR(1, 14, __pyx_L1_error)
- }
- __pyx_t_6 = __Pyx_GetItemInt_Tuple(__pyx_v___pyx_state, 1, long, 1, __Pyx_PyInt_From_long, 0, 0, 1); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_8 = NULL;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_7))) {
- __pyx_t_8 = PyMethod_GET_SELF(__pyx_t_7);
- if (likely(__pyx_t_8)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_7);
- __Pyx_INCREF(__pyx_t_8);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_7, function);
- }
- }
- __pyx_t_1 = (__pyx_t_8) ? __Pyx_PyObject_Call2Args(__pyx_t_7, __pyx_t_8, __pyx_t_6) : __Pyx_PyObject_CallOneArg(__pyx_t_7, __pyx_t_6);
- __Pyx_XDECREF(__pyx_t_8); __pyx_t_8 = 0;
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "(tree fragment)":13
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'): # <<<<<<<<<<<<<<
- * __pyx_result.__dict__.update(__pyx_state[1])
- */
- }
-
- /* "(tree fragment)":11
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_8);
- __Pyx_AddTraceback("View.MemoryView.__pyx_unpickle_Enum__set_state", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-static struct __pyx_vtabstruct_array __pyx_vtable_array;
-
-static PyObject *__pyx_tp_new_array(PyTypeObject *t, PyObject *a, PyObject *k) {
- struct __pyx_array_obj *p;
- PyObject *o;
- if (likely((t->tp_flags & Py_TPFLAGS_IS_ABSTRACT) == 0)) {
- o = (*t->tp_alloc)(t, 0);
- } else {
- o = (PyObject *) PyBaseObject_Type.tp_new(t, __pyx_empty_tuple, 0);
- }
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_array_obj *)o);
- p->__pyx_vtab = __pyx_vtabptr_array;
- p->mode = ((PyObject*)Py_None); Py_INCREF(Py_None);
- p->_format = ((PyObject*)Py_None); Py_INCREF(Py_None);
- if (unlikely(__pyx_array___cinit__(o, a, k) < 0)) goto bad;
- return o;
- bad:
- Py_DECREF(o); o = 0;
- return NULL;
-}
-
-static void __pyx_tp_dealloc_array(PyObject *o) {
- struct __pyx_array_obj *p = (struct __pyx_array_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && (!PyType_IS_GC(Py_TYPE(o)) || !_PyGC_FINALIZED(o))) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- {
- PyObject *etype, *eval, *etb;
- PyErr_Fetch(&etype, &eval, &etb);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) + 1);
- __pyx_array___dealloc__(o);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) - 1);
- PyErr_Restore(etype, eval, etb);
- }
- Py_CLEAR(p->mode);
- Py_CLEAR(p->_format);
- (*Py_TYPE(o)->tp_free)(o);
-}
-static PyObject *__pyx_sq_item_array(PyObject *o, Py_ssize_t i) {
- PyObject *r;
- PyObject *x = PyInt_FromSsize_t(i); if(!x) return 0;
- r = Py_TYPE(o)->tp_as_mapping->mp_subscript(o, x);
- Py_DECREF(x);
- return r;
-}
-
-static int __pyx_mp_ass_subscript_array(PyObject *o, PyObject *i, PyObject *v) {
- if (v) {
- return __pyx_array___setitem__(o, i, v);
- }
- else {
- PyErr_Format(PyExc_NotImplementedError,
- "Subscript deletion not supported by %.200s", Py_TYPE(o)->tp_name);
- return -1;
- }
-}
-
-static PyObject *__pyx_tp_getattro_array(PyObject *o, PyObject *n) {
- PyObject *v = __Pyx_PyObject_GenericGetAttr(o, n);
- if (!v && PyErr_ExceptionMatches(PyExc_AttributeError)) {
- PyErr_Clear();
- v = __pyx_array___getattr__(o, n);
- }
- return v;
-}
-
-static PyObject *__pyx_getprop___pyx_array_memview(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_5array_7memview_1__get__(o);
-}
-
-static PyMethodDef __pyx_methods_array[] = {
- {"__getattr__", (PyCFunction)__pyx_array___getattr__, METH_O|METH_COEXIST, 0},
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_array_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_array_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static struct PyGetSetDef __pyx_getsets_array[] = {
- {(char *)"memview", __pyx_getprop___pyx_array_memview, 0, (char *)0, 0},
- {0, 0, 0, 0, 0}
-};
-
-static PySequenceMethods __pyx_tp_as_sequence_array = {
- __pyx_array___len__, /*sq_length*/
- 0, /*sq_concat*/
- 0, /*sq_repeat*/
- __pyx_sq_item_array, /*sq_item*/
- 0, /*sq_slice*/
- 0, /*sq_ass_item*/
- 0, /*sq_ass_slice*/
- 0, /*sq_contains*/
- 0, /*sq_inplace_concat*/
- 0, /*sq_inplace_repeat*/
-};
-
-static PyMappingMethods __pyx_tp_as_mapping_array = {
- __pyx_array___len__, /*mp_length*/
- __pyx_array___getitem__, /*mp_subscript*/
- __pyx_mp_ass_subscript_array, /*mp_ass_subscript*/
-};
-
-static PyBufferProcs __pyx_tp_as_buffer_array = {
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getreadbuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getwritebuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getsegcount*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getcharbuffer*/
- #endif
- __pyx_array_getbuffer, /*bf_getbuffer*/
- 0, /*bf_releasebuffer*/
-};
-
-static PyTypeObject __pyx_type___pyx_array = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core.array", /*tp_name*/
- sizeof(struct __pyx_array_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc_array, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- 0, /*tp_repr*/
- 0, /*tp_as_number*/
- &__pyx_tp_as_sequence_array, /*tp_as_sequence*/
- &__pyx_tp_as_mapping_array, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- 0, /*tp_str*/
- __pyx_tp_getattro_array, /*tp_getattro*/
- 0, /*tp_setattro*/
- &__pyx_tp_as_buffer_array, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE, /*tp_flags*/
- 0, /*tp_doc*/
- 0, /*tp_traverse*/
- 0, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods_array, /*tp_methods*/
- 0, /*tp_members*/
- __pyx_getsets_array, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- 0, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new_array, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-
-static PyObject *__pyx_tp_new_Enum(PyTypeObject *t, CYTHON_UNUSED PyObject *a, CYTHON_UNUSED PyObject *k) {
- struct __pyx_MemviewEnum_obj *p;
- PyObject *o;
- if (likely((t->tp_flags & Py_TPFLAGS_IS_ABSTRACT) == 0)) {
- o = (*t->tp_alloc)(t, 0);
- } else {
- o = (PyObject *) PyBaseObject_Type.tp_new(t, __pyx_empty_tuple, 0);
- }
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_MemviewEnum_obj *)o);
- p->name = Py_None; Py_INCREF(Py_None);
- return o;
-}
-
-static void __pyx_tp_dealloc_Enum(PyObject *o) {
- struct __pyx_MemviewEnum_obj *p = (struct __pyx_MemviewEnum_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && !_PyGC_FINALIZED(o)) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- PyObject_GC_UnTrack(o);
- Py_CLEAR(p->name);
- (*Py_TYPE(o)->tp_free)(o);
-}
-
-static int __pyx_tp_traverse_Enum(PyObject *o, visitproc v, void *a) {
- int e;
- struct __pyx_MemviewEnum_obj *p = (struct __pyx_MemviewEnum_obj *)o;
- if (p->name) {
- e = (*v)(p->name, a); if (e) return e;
- }
- return 0;
-}
-
-static int __pyx_tp_clear_Enum(PyObject *o) {
- PyObject* tmp;
- struct __pyx_MemviewEnum_obj *p = (struct __pyx_MemviewEnum_obj *)o;
- tmp = ((PyObject*)p->name);
- p->name = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- return 0;
-}
-
-static PyMethodDef __pyx_methods_Enum[] = {
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_MemviewEnum_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_MemviewEnum_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static PyTypeObject __pyx_type___pyx_MemviewEnum = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core.Enum", /*tp_name*/
- sizeof(struct __pyx_MemviewEnum_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc_Enum, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- __pyx_MemviewEnum___repr__, /*tp_repr*/
- 0, /*tp_as_number*/
- 0, /*tp_as_sequence*/
- 0, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- 0, /*tp_str*/
- 0, /*tp_getattro*/
- 0, /*tp_setattro*/
- 0, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE|Py_TPFLAGS_HAVE_GC, /*tp_flags*/
- 0, /*tp_doc*/
- __pyx_tp_traverse_Enum, /*tp_traverse*/
- __pyx_tp_clear_Enum, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods_Enum, /*tp_methods*/
- 0, /*tp_members*/
- 0, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- __pyx_MemviewEnum___init__, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new_Enum, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-static struct __pyx_vtabstruct_memoryview __pyx_vtable_memoryview;
-
-static PyObject *__pyx_tp_new_memoryview(PyTypeObject *t, PyObject *a, PyObject *k) {
- struct __pyx_memoryview_obj *p;
- PyObject *o;
- if (likely((t->tp_flags & Py_TPFLAGS_IS_ABSTRACT) == 0)) {
- o = (*t->tp_alloc)(t, 0);
- } else {
- o = (PyObject *) PyBaseObject_Type.tp_new(t, __pyx_empty_tuple, 0);
- }
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_memoryview_obj *)o);
- p->__pyx_vtab = __pyx_vtabptr_memoryview;
- p->obj = Py_None; Py_INCREF(Py_None);
- p->_size = Py_None; Py_INCREF(Py_None);
- p->_array_interface = Py_None; Py_INCREF(Py_None);
- p->view.obj = NULL;
- if (unlikely(__pyx_memoryview___cinit__(o, a, k) < 0)) goto bad;
- return o;
- bad:
- Py_DECREF(o); o = 0;
- return NULL;
-}
-
-static void __pyx_tp_dealloc_memoryview(PyObject *o) {
- struct __pyx_memoryview_obj *p = (struct __pyx_memoryview_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && !_PyGC_FINALIZED(o)) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- PyObject_GC_UnTrack(o);
- {
- PyObject *etype, *eval, *etb;
- PyErr_Fetch(&etype, &eval, &etb);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) + 1);
- __pyx_memoryview___dealloc__(o);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) - 1);
- PyErr_Restore(etype, eval, etb);
- }
- Py_CLEAR(p->obj);
- Py_CLEAR(p->_size);
- Py_CLEAR(p->_array_interface);
- (*Py_TYPE(o)->tp_free)(o);
-}
-
-static int __pyx_tp_traverse_memoryview(PyObject *o, visitproc v, void *a) {
- int e;
- struct __pyx_memoryview_obj *p = (struct __pyx_memoryview_obj *)o;
- if (p->obj) {
- e = (*v)(p->obj, a); if (e) return e;
- }
- if (p->_size) {
- e = (*v)(p->_size, a); if (e) return e;
- }
- if (p->_array_interface) {
- e = (*v)(p->_array_interface, a); if (e) return e;
- }
- if (p->view.obj) {
- e = (*v)(p->view.obj, a); if (e) return e;
- }
- return 0;
-}
-
-static int __pyx_tp_clear_memoryview(PyObject *o) {
- PyObject* tmp;
- struct __pyx_memoryview_obj *p = (struct __pyx_memoryview_obj *)o;
- tmp = ((PyObject*)p->obj);
- p->obj = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- tmp = ((PyObject*)p->_size);
- p->_size = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- tmp = ((PyObject*)p->_array_interface);
- p->_array_interface = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- Py_CLEAR(p->view.obj);
- return 0;
-}
-static PyObject *__pyx_sq_item_memoryview(PyObject *o, Py_ssize_t i) {
- PyObject *r;
- PyObject *x = PyInt_FromSsize_t(i); if(!x) return 0;
- r = Py_TYPE(o)->tp_as_mapping->mp_subscript(o, x);
- Py_DECREF(x);
- return r;
-}
-
-static int __pyx_mp_ass_subscript_memoryview(PyObject *o, PyObject *i, PyObject *v) {
- if (v) {
- return __pyx_memoryview___setitem__(o, i, v);
- }
- else {
- PyErr_Format(PyExc_NotImplementedError,
- "Subscript deletion not supported by %.200s", Py_TYPE(o)->tp_name);
- return -1;
- }
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_T(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_1T_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_base(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_4base_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_shape(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_5shape_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_strides(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_7strides_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_suboffsets(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_10suboffsets_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_ndim(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_4ndim_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_itemsize(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_8itemsize_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_nbytes(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_6nbytes_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_size(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_4size_1__get__(o);
-}
-
-static PyMethodDef __pyx_methods_memoryview[] = {
- {"is_c_contig", (PyCFunction)__pyx_memoryview_is_c_contig, METH_NOARGS, 0},
- {"is_f_contig", (PyCFunction)__pyx_memoryview_is_f_contig, METH_NOARGS, 0},
- {"copy", (PyCFunction)__pyx_memoryview_copy, METH_NOARGS, 0},
- {"copy_fortran", (PyCFunction)__pyx_memoryview_copy_fortran, METH_NOARGS, 0},
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_memoryview_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_memoryview_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static struct PyGetSetDef __pyx_getsets_memoryview[] = {
- {(char *)"T", __pyx_getprop___pyx_memoryview_T, 0, (char *)0, 0},
- {(char *)"base", __pyx_getprop___pyx_memoryview_base, 0, (char *)0, 0},
- {(char *)"shape", __pyx_getprop___pyx_memoryview_shape, 0, (char *)0, 0},
- {(char *)"strides", __pyx_getprop___pyx_memoryview_strides, 0, (char *)0, 0},
- {(char *)"suboffsets", __pyx_getprop___pyx_memoryview_suboffsets, 0, (char *)0, 0},
- {(char *)"ndim", __pyx_getprop___pyx_memoryview_ndim, 0, (char *)0, 0},
- {(char *)"itemsize", __pyx_getprop___pyx_memoryview_itemsize, 0, (char *)0, 0},
- {(char *)"nbytes", __pyx_getprop___pyx_memoryview_nbytes, 0, (char *)0, 0},
- {(char *)"size", __pyx_getprop___pyx_memoryview_size, 0, (char *)0, 0},
- {0, 0, 0, 0, 0}
-};
-
-static PySequenceMethods __pyx_tp_as_sequence_memoryview = {
- __pyx_memoryview___len__, /*sq_length*/
- 0, /*sq_concat*/
- 0, /*sq_repeat*/
- __pyx_sq_item_memoryview, /*sq_item*/
- 0, /*sq_slice*/
- 0, /*sq_ass_item*/
- 0, /*sq_ass_slice*/
- 0, /*sq_contains*/
- 0, /*sq_inplace_concat*/
- 0, /*sq_inplace_repeat*/
-};
-
-static PyMappingMethods __pyx_tp_as_mapping_memoryview = {
- __pyx_memoryview___len__, /*mp_length*/
- __pyx_memoryview___getitem__, /*mp_subscript*/
- __pyx_mp_ass_subscript_memoryview, /*mp_ass_subscript*/
-};
-
-static PyBufferProcs __pyx_tp_as_buffer_memoryview = {
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getreadbuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getwritebuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getsegcount*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getcharbuffer*/
- #endif
- __pyx_memoryview_getbuffer, /*bf_getbuffer*/
- 0, /*bf_releasebuffer*/
-};
-
-static PyTypeObject __pyx_type___pyx_memoryview = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core.memoryview", /*tp_name*/
- sizeof(struct __pyx_memoryview_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc_memoryview, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- __pyx_memoryview___repr__, /*tp_repr*/
- 0, /*tp_as_number*/
- &__pyx_tp_as_sequence_memoryview, /*tp_as_sequence*/
- &__pyx_tp_as_mapping_memoryview, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- __pyx_memoryview___str__, /*tp_str*/
- 0, /*tp_getattro*/
- 0, /*tp_setattro*/
- &__pyx_tp_as_buffer_memoryview, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE|Py_TPFLAGS_HAVE_GC, /*tp_flags*/
- 0, /*tp_doc*/
- __pyx_tp_traverse_memoryview, /*tp_traverse*/
- __pyx_tp_clear_memoryview, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods_memoryview, /*tp_methods*/
- 0, /*tp_members*/
- __pyx_getsets_memoryview, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- 0, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new_memoryview, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-static struct __pyx_vtabstruct__memoryviewslice __pyx_vtable__memoryviewslice;
-
-static PyObject *__pyx_tp_new__memoryviewslice(PyTypeObject *t, PyObject *a, PyObject *k) {
- struct __pyx_memoryviewslice_obj *p;
- PyObject *o = __pyx_tp_new_memoryview(t, a, k);
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_memoryviewslice_obj *)o);
- p->__pyx_base.__pyx_vtab = (struct __pyx_vtabstruct_memoryview*)__pyx_vtabptr__memoryviewslice;
- p->from_object = Py_None; Py_INCREF(Py_None);
- p->from_slice.memview = NULL;
- return o;
-}
-
-static void __pyx_tp_dealloc__memoryviewslice(PyObject *o) {
- struct __pyx_memoryviewslice_obj *p = (struct __pyx_memoryviewslice_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && !_PyGC_FINALIZED(o)) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- PyObject_GC_UnTrack(o);
- {
- PyObject *etype, *eval, *etb;
- PyErr_Fetch(&etype, &eval, &etb);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) + 1);
- __pyx_memoryviewslice___dealloc__(o);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) - 1);
- PyErr_Restore(etype, eval, etb);
- }
- Py_CLEAR(p->from_object);
- PyObject_GC_Track(o);
- __pyx_tp_dealloc_memoryview(o);
-}
-
-static int __pyx_tp_traverse__memoryviewslice(PyObject *o, visitproc v, void *a) {
- int e;
- struct __pyx_memoryviewslice_obj *p = (struct __pyx_memoryviewslice_obj *)o;
- e = __pyx_tp_traverse_memoryview(o, v, a); if (e) return e;
- if (p->from_object) {
- e = (*v)(p->from_object, a); if (e) return e;
- }
- return 0;
-}
-
-static int __pyx_tp_clear__memoryviewslice(PyObject *o) {
- PyObject* tmp;
- struct __pyx_memoryviewslice_obj *p = (struct __pyx_memoryviewslice_obj *)o;
- __pyx_tp_clear_memoryview(o);
- tmp = ((PyObject*)p->from_object);
- p->from_object = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- __PYX_XDEC_MEMVIEW(&p->from_slice, 1);
- return 0;
-}
-
-static PyObject *__pyx_getprop___pyx_memoryviewslice_base(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_16_memoryviewslice_4base_1__get__(o);
-}
-
-static PyMethodDef __pyx_methods__memoryviewslice[] = {
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_memoryviewslice_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_memoryviewslice_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static struct PyGetSetDef __pyx_getsets__memoryviewslice[] = {
- {(char *)"base", __pyx_getprop___pyx_memoryviewslice_base, 0, (char *)0, 0},
- {0, 0, 0, 0, 0}
-};
-
-static PyTypeObject __pyx_type___pyx_memoryviewslice = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core._memoryviewslice", /*tp_name*/
- sizeof(struct __pyx_memoryviewslice_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc__memoryviewslice, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY
- __pyx_memoryview___repr__, /*tp_repr*/
- #else
- 0, /*tp_repr*/
- #endif
- 0, /*tp_as_number*/
- 0, /*tp_as_sequence*/
- 0, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- #if CYTHON_COMPILING_IN_PYPY
- __pyx_memoryview___str__, /*tp_str*/
- #else
- 0, /*tp_str*/
- #endif
- 0, /*tp_getattro*/
- 0, /*tp_setattro*/
- 0, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE|Py_TPFLAGS_HAVE_GC, /*tp_flags*/
- "Internal class for passing memoryview slices to Python", /*tp_doc*/
- __pyx_tp_traverse__memoryviewslice, /*tp_traverse*/
- __pyx_tp_clear__memoryviewslice, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods__memoryviewslice, /*tp_methods*/
- 0, /*tp_members*/
- __pyx_getsets__memoryviewslice, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- 0, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new__memoryviewslice, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-
-static PyMethodDef __pyx_methods[] = {
- {"maximum_path_c", (PyCFunction)(void*)(PyCFunctionWithKeywords)__pyx_pw_15monotonic_align_4core_1maximum_path_c, METH_VARARGS|METH_KEYWORDS, 0},
- {0, 0, 0, 0}
-};
-
-#if PY_MAJOR_VERSION >= 3
-#if CYTHON_PEP489_MULTI_PHASE_INIT
-static PyObject* __pyx_pymod_create(PyObject *spec, PyModuleDef *def); /*proto*/
-static int __pyx_pymod_exec_core(PyObject* module); /*proto*/
-static PyModuleDef_Slot __pyx_moduledef_slots[] = {
- {Py_mod_create, (void*)__pyx_pymod_create},
- {Py_mod_exec, (void*)__pyx_pymod_exec_core},
- {0, NULL}
-};
-#endif
-
-static struct PyModuleDef __pyx_moduledef = {
- PyModuleDef_HEAD_INIT,
- "core",
- 0, /* m_doc */
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- 0, /* m_size */
- #else
- -1, /* m_size */
- #endif
- __pyx_methods /* m_methods */,
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- __pyx_moduledef_slots, /* m_slots */
- #else
- NULL, /* m_reload */
- #endif
- NULL, /* m_traverse */
- NULL, /* m_clear */
- NULL /* m_free */
-};
-#endif
-#ifndef CYTHON_SMALL_CODE
-#if defined(__clang__)
- #define CYTHON_SMALL_CODE
-#elif defined(__GNUC__) && (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 3))
- #define CYTHON_SMALL_CODE __attribute__((cold))
-#else
- #define CYTHON_SMALL_CODE
-#endif
-#endif
-
-static __Pyx_StringTabEntry __pyx_string_tab[] = {
- {&__pyx_n_s_ASCII, __pyx_k_ASCII, sizeof(__pyx_k_ASCII), 0, 0, 1, 1},
- {&__pyx_kp_s_Buffer_view_does_not_expose_stri, __pyx_k_Buffer_view_does_not_expose_stri, sizeof(__pyx_k_Buffer_view_does_not_expose_stri), 0, 0, 1, 0},
- {&__pyx_kp_s_Can_only_create_a_buffer_that_is, __pyx_k_Can_only_create_a_buffer_that_is, sizeof(__pyx_k_Can_only_create_a_buffer_that_is), 0, 0, 1, 0},
- {&__pyx_kp_s_Cannot_assign_to_read_only_memor, __pyx_k_Cannot_assign_to_read_only_memor, sizeof(__pyx_k_Cannot_assign_to_read_only_memor), 0, 0, 1, 0},
- {&__pyx_kp_s_Cannot_create_writable_memory_vi, __pyx_k_Cannot_create_writable_memory_vi, sizeof(__pyx_k_Cannot_create_writable_memory_vi), 0, 0, 1, 0},
- {&__pyx_kp_s_Cannot_index_with_type_s, __pyx_k_Cannot_index_with_type_s, sizeof(__pyx_k_Cannot_index_with_type_s), 0, 0, 1, 0},
- {&__pyx_n_s_Ellipsis, __pyx_k_Ellipsis, sizeof(__pyx_k_Ellipsis), 0, 0, 1, 1},
- {&__pyx_kp_s_Empty_shape_tuple_for_cython_arr, __pyx_k_Empty_shape_tuple_for_cython_arr, sizeof(__pyx_k_Empty_shape_tuple_for_cython_arr), 0, 0, 1, 0},
- {&__pyx_kp_s_Incompatible_checksums_0x_x_vs_0, __pyx_k_Incompatible_checksums_0x_x_vs_0, sizeof(__pyx_k_Incompatible_checksums_0x_x_vs_0), 0, 0, 1, 0},
- {&__pyx_n_s_IndexError, __pyx_k_IndexError, sizeof(__pyx_k_IndexError), 0, 0, 1, 1},
- {&__pyx_kp_s_Indirect_dimensions_not_supporte, __pyx_k_Indirect_dimensions_not_supporte, sizeof(__pyx_k_Indirect_dimensions_not_supporte), 0, 0, 1, 0},
- {&__pyx_kp_s_Invalid_mode_expected_c_or_fortr, __pyx_k_Invalid_mode_expected_c_or_fortr, sizeof(__pyx_k_Invalid_mode_expected_c_or_fortr), 0, 0, 1, 0},
- {&__pyx_kp_s_Invalid_shape_in_axis_d_d, __pyx_k_Invalid_shape_in_axis_d_d, sizeof(__pyx_k_Invalid_shape_in_axis_d_d), 0, 0, 1, 0},
- {&__pyx_n_s_MemoryError, __pyx_k_MemoryError, sizeof(__pyx_k_MemoryError), 0, 0, 1, 1},
- {&__pyx_kp_s_MemoryView_of_r_at_0x_x, __pyx_k_MemoryView_of_r_at_0x_x, sizeof(__pyx_k_MemoryView_of_r_at_0x_x), 0, 0, 1, 0},
- {&__pyx_kp_s_MemoryView_of_r_object, __pyx_k_MemoryView_of_r_object, sizeof(__pyx_k_MemoryView_of_r_object), 0, 0, 1, 0},
- {&__pyx_n_b_O, __pyx_k_O, sizeof(__pyx_k_O), 0, 0, 0, 1},
- {&__pyx_kp_s_Out_of_bounds_on_buffer_access_a, __pyx_k_Out_of_bounds_on_buffer_access_a, sizeof(__pyx_k_Out_of_bounds_on_buffer_access_a), 0, 0, 1, 0},
- {&__pyx_n_s_PickleError, __pyx_k_PickleError, sizeof(__pyx_k_PickleError), 0, 0, 1, 1},
- {&__pyx_n_s_TypeError, __pyx_k_TypeError, sizeof(__pyx_k_TypeError), 0, 0, 1, 1},
- {&__pyx_kp_s_Unable_to_convert_item_to_object, __pyx_k_Unable_to_convert_item_to_object, sizeof(__pyx_k_Unable_to_convert_item_to_object), 0, 0, 1, 0},
- {&__pyx_n_s_ValueError, __pyx_k_ValueError, sizeof(__pyx_k_ValueError), 0, 0, 1, 1},
- {&__pyx_n_s_View_MemoryView, __pyx_k_View_MemoryView, sizeof(__pyx_k_View_MemoryView), 0, 0, 1, 1},
- {&__pyx_n_s_allocate_buffer, __pyx_k_allocate_buffer, sizeof(__pyx_k_allocate_buffer), 0, 0, 1, 1},
- {&__pyx_n_s_base, __pyx_k_base, sizeof(__pyx_k_base), 0, 0, 1, 1},
- {&__pyx_n_s_c, __pyx_k_c, sizeof(__pyx_k_c), 0, 0, 1, 1},
- {&__pyx_n_u_c, __pyx_k_c, sizeof(__pyx_k_c), 0, 1, 0, 1},
- {&__pyx_n_s_class, __pyx_k_class, sizeof(__pyx_k_class), 0, 0, 1, 1},
- {&__pyx_n_s_cline_in_traceback, __pyx_k_cline_in_traceback, sizeof(__pyx_k_cline_in_traceback), 0, 0, 1, 1},
- {&__pyx_kp_s_contiguous_and_direct, __pyx_k_contiguous_and_direct, sizeof(__pyx_k_contiguous_and_direct), 0, 0, 1, 0},
- {&__pyx_kp_s_contiguous_and_indirect, __pyx_k_contiguous_and_indirect, sizeof(__pyx_k_contiguous_and_indirect), 0, 0, 1, 0},
- {&__pyx_n_s_dict, __pyx_k_dict, sizeof(__pyx_k_dict), 0, 0, 1, 1},
- {&__pyx_n_s_dtype_is_object, __pyx_k_dtype_is_object, sizeof(__pyx_k_dtype_is_object), 0, 0, 1, 1},
- {&__pyx_n_s_encode, __pyx_k_encode, sizeof(__pyx_k_encode), 0, 0, 1, 1},
- {&__pyx_n_s_enumerate, __pyx_k_enumerate, sizeof(__pyx_k_enumerate), 0, 0, 1, 1},
- {&__pyx_n_s_error, __pyx_k_error, sizeof(__pyx_k_error), 0, 0, 1, 1},
- {&__pyx_n_s_flags, __pyx_k_flags, sizeof(__pyx_k_flags), 0, 0, 1, 1},
- {&__pyx_n_s_format, __pyx_k_format, sizeof(__pyx_k_format), 0, 0, 1, 1},
- {&__pyx_n_s_fortran, __pyx_k_fortran, sizeof(__pyx_k_fortran), 0, 0, 1, 1},
- {&__pyx_n_u_fortran, __pyx_k_fortran, sizeof(__pyx_k_fortran), 0, 1, 0, 1},
- {&__pyx_n_s_getstate, __pyx_k_getstate, sizeof(__pyx_k_getstate), 0, 0, 1, 1},
- {&__pyx_kp_s_got_differing_extents_in_dimensi, __pyx_k_got_differing_extents_in_dimensi, sizeof(__pyx_k_got_differing_extents_in_dimensi), 0, 0, 1, 0},
- {&__pyx_n_s_id, __pyx_k_id, sizeof(__pyx_k_id), 0, 0, 1, 1},
- {&__pyx_n_s_import, __pyx_k_import, sizeof(__pyx_k_import), 0, 0, 1, 1},
- {&__pyx_n_s_itemsize, __pyx_k_itemsize, sizeof(__pyx_k_itemsize), 0, 0, 1, 1},
- {&__pyx_kp_s_itemsize_0_for_cython_array, __pyx_k_itemsize_0_for_cython_array, sizeof(__pyx_k_itemsize_0_for_cython_array), 0, 0, 1, 0},
- {&__pyx_n_s_main, __pyx_k_main, sizeof(__pyx_k_main), 0, 0, 1, 1},
- {&__pyx_n_s_memview, __pyx_k_memview, sizeof(__pyx_k_memview), 0, 0, 1, 1},
- {&__pyx_n_s_mode, __pyx_k_mode, sizeof(__pyx_k_mode), 0, 0, 1, 1},
- {&__pyx_n_s_name, __pyx_k_name, sizeof(__pyx_k_name), 0, 0, 1, 1},
- {&__pyx_n_s_name_2, __pyx_k_name_2, sizeof(__pyx_k_name_2), 0, 0, 1, 1},
- {&__pyx_n_s_ndim, __pyx_k_ndim, sizeof(__pyx_k_ndim), 0, 0, 1, 1},
- {&__pyx_n_s_new, __pyx_k_new, sizeof(__pyx_k_new), 0, 0, 1, 1},
- {&__pyx_kp_s_no_default___reduce___due_to_non, __pyx_k_no_default___reduce___due_to_non, sizeof(__pyx_k_no_default___reduce___due_to_non), 0, 0, 1, 0},
- {&__pyx_n_s_obj, __pyx_k_obj, sizeof(__pyx_k_obj), 0, 0, 1, 1},
- {&__pyx_n_s_pack, __pyx_k_pack, sizeof(__pyx_k_pack), 0, 0, 1, 1},
- {&__pyx_n_s_paths, __pyx_k_paths, sizeof(__pyx_k_paths), 0, 0, 1, 1},
- {&__pyx_n_s_pickle, __pyx_k_pickle, sizeof(__pyx_k_pickle), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_PickleError, __pyx_k_pyx_PickleError, sizeof(__pyx_k_pyx_PickleError), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_checksum, __pyx_k_pyx_checksum, sizeof(__pyx_k_pyx_checksum), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_getbuffer, __pyx_k_pyx_getbuffer, sizeof(__pyx_k_pyx_getbuffer), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_result, __pyx_k_pyx_result, sizeof(__pyx_k_pyx_result), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_state, __pyx_k_pyx_state, sizeof(__pyx_k_pyx_state), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_type, __pyx_k_pyx_type, sizeof(__pyx_k_pyx_type), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_unpickle_Enum, __pyx_k_pyx_unpickle_Enum, sizeof(__pyx_k_pyx_unpickle_Enum), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_vtable, __pyx_k_pyx_vtable, sizeof(__pyx_k_pyx_vtable), 0, 0, 1, 1},
- {&__pyx_n_s_range, __pyx_k_range, sizeof(__pyx_k_range), 0, 0, 1, 1},
- {&__pyx_n_s_reduce, __pyx_k_reduce, sizeof(__pyx_k_reduce), 0, 0, 1, 1},
- {&__pyx_n_s_reduce_cython, __pyx_k_reduce_cython, sizeof(__pyx_k_reduce_cython), 0, 0, 1, 1},
- {&__pyx_n_s_reduce_ex, __pyx_k_reduce_ex, sizeof(__pyx_k_reduce_ex), 0, 0, 1, 1},
- {&__pyx_n_s_setstate, __pyx_k_setstate, sizeof(__pyx_k_setstate), 0, 0, 1, 1},
- {&__pyx_n_s_setstate_cython, __pyx_k_setstate_cython, sizeof(__pyx_k_setstate_cython), 0, 0, 1, 1},
- {&__pyx_n_s_shape, __pyx_k_shape, sizeof(__pyx_k_shape), 0, 0, 1, 1},
- {&__pyx_n_s_size, __pyx_k_size, sizeof(__pyx_k_size), 0, 0, 1, 1},
- {&__pyx_n_s_start, __pyx_k_start, sizeof(__pyx_k_start), 0, 0, 1, 1},
- {&__pyx_n_s_step, __pyx_k_step, sizeof(__pyx_k_step), 0, 0, 1, 1},
- {&__pyx_n_s_stop, __pyx_k_stop, sizeof(__pyx_k_stop), 0, 0, 1, 1},
- {&__pyx_kp_s_strided_and_direct, __pyx_k_strided_and_direct, sizeof(__pyx_k_strided_and_direct), 0, 0, 1, 0},
- {&__pyx_kp_s_strided_and_direct_or_indirect, __pyx_k_strided_and_direct_or_indirect, sizeof(__pyx_k_strided_and_direct_or_indirect), 0, 0, 1, 0},
- {&__pyx_kp_s_strided_and_indirect, __pyx_k_strided_and_indirect, sizeof(__pyx_k_strided_and_indirect), 0, 0, 1, 0},
- {&__pyx_kp_s_stringsource, __pyx_k_stringsource, sizeof(__pyx_k_stringsource), 0, 0, 1, 0},
- {&__pyx_n_s_struct, __pyx_k_struct, sizeof(__pyx_k_struct), 0, 0, 1, 1},
- {&__pyx_n_s_t_xs, __pyx_k_t_xs, sizeof(__pyx_k_t_xs), 0, 0, 1, 1},
- {&__pyx_n_s_t_ys, __pyx_k_t_ys, sizeof(__pyx_k_t_ys), 0, 0, 1, 1},
- {&__pyx_n_s_test, __pyx_k_test, sizeof(__pyx_k_test), 0, 0, 1, 1},
- {&__pyx_kp_s_unable_to_allocate_array_data, __pyx_k_unable_to_allocate_array_data, sizeof(__pyx_k_unable_to_allocate_array_data), 0, 0, 1, 0},
- {&__pyx_kp_s_unable_to_allocate_shape_and_str, __pyx_k_unable_to_allocate_shape_and_str, sizeof(__pyx_k_unable_to_allocate_shape_and_str), 0, 0, 1, 0},
- {&__pyx_n_s_unpack, __pyx_k_unpack, sizeof(__pyx_k_unpack), 0, 0, 1, 1},
- {&__pyx_n_s_update, __pyx_k_update, sizeof(__pyx_k_update), 0, 0, 1, 1},
- {&__pyx_n_s_values, __pyx_k_values, sizeof(__pyx_k_values), 0, 0, 1, 1},
- {0, 0, 0, 0, 0, 0, 0}
-};
-static CYTHON_SMALL_CODE int __Pyx_InitCachedBuiltins(void) {
- __pyx_builtin_range = __Pyx_GetBuiltinName(__pyx_n_s_range); if (!__pyx_builtin_range) __PYX_ERR(0, 15, __pyx_L1_error)
- __pyx_builtin_ValueError = __Pyx_GetBuiltinName(__pyx_n_s_ValueError); if (!__pyx_builtin_ValueError) __PYX_ERR(1, 134, __pyx_L1_error)
- __pyx_builtin_MemoryError = __Pyx_GetBuiltinName(__pyx_n_s_MemoryError); if (!__pyx_builtin_MemoryError) __PYX_ERR(1, 149, __pyx_L1_error)
- __pyx_builtin_enumerate = __Pyx_GetBuiltinName(__pyx_n_s_enumerate); if (!__pyx_builtin_enumerate) __PYX_ERR(1, 152, __pyx_L1_error)
- __pyx_builtin_TypeError = __Pyx_GetBuiltinName(__pyx_n_s_TypeError); if (!__pyx_builtin_TypeError) __PYX_ERR(1, 2, __pyx_L1_error)
- __pyx_builtin_Ellipsis = __Pyx_GetBuiltinName(__pyx_n_s_Ellipsis); if (!__pyx_builtin_Ellipsis) __PYX_ERR(1, 406, __pyx_L1_error)
- __pyx_builtin_id = __Pyx_GetBuiltinName(__pyx_n_s_id); if (!__pyx_builtin_id) __PYX_ERR(1, 615, __pyx_L1_error)
- __pyx_builtin_IndexError = __Pyx_GetBuiltinName(__pyx_n_s_IndexError); if (!__pyx_builtin_IndexError) __PYX_ERR(1, 834, __pyx_L1_error)
- return 0;
- __pyx_L1_error:;
- return -1;
-}
-
-static CYTHON_SMALL_CODE int __Pyx_InitCachedConstants(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_InitCachedConstants", 0);
-
- /* "View.MemoryView":134
- *
- * if not self.ndim:
- * raise ValueError("Empty shape tuple for cython.array") # <<<<<<<<<<<<<<
- *
- * if itemsize <= 0:
- */
- __pyx_tuple__2 = PyTuple_Pack(1, __pyx_kp_s_Empty_shape_tuple_for_cython_arr); if (unlikely(!__pyx_tuple__2)) __PYX_ERR(1, 134, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__2);
- __Pyx_GIVEREF(__pyx_tuple__2);
-
- /* "View.MemoryView":137
- *
- * if itemsize <= 0:
- * raise ValueError("itemsize <= 0 for cython.array") # <<<<<<<<<<<<<<
- *
- * if not isinstance(format, bytes):
- */
- __pyx_tuple__3 = PyTuple_Pack(1, __pyx_kp_s_itemsize_0_for_cython_array); if (unlikely(!__pyx_tuple__3)) __PYX_ERR(1, 137, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__3);
- __Pyx_GIVEREF(__pyx_tuple__3);
-
- /* "View.MemoryView":149
- *
- * if not self._shape:
- * raise MemoryError("unable to allocate shape and strides.") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__4 = PyTuple_Pack(1, __pyx_kp_s_unable_to_allocate_shape_and_str); if (unlikely(!__pyx_tuple__4)) __PYX_ERR(1, 149, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__4);
- __Pyx_GIVEREF(__pyx_tuple__4);
-
- /* "View.MemoryView":177
- * self.data = malloc(self.len)
- * if not self.data:
- * raise MemoryError("unable to allocate array data.") # <<<<<<<<<<<<<<
- *
- * if self.dtype_is_object:
- */
- __pyx_tuple__5 = PyTuple_Pack(1, __pyx_kp_s_unable_to_allocate_array_data); if (unlikely(!__pyx_tuple__5)) __PYX_ERR(1, 177, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__5);
- __Pyx_GIVEREF(__pyx_tuple__5);
-
- /* "View.MemoryView":193
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.") # <<<<<<<<<<<<<<
- * info.buf = self.data
- * info.len = self.len
- */
- __pyx_tuple__6 = PyTuple_Pack(1, __pyx_kp_s_Can_only_create_a_buffer_that_is); if (unlikely(!__pyx_tuple__6)) __PYX_ERR(1, 193, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__6);
- __Pyx_GIVEREF(__pyx_tuple__6);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_tuple__7 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__7)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__7);
- __Pyx_GIVEREF(__pyx_tuple__7);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_tuple__8 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__8)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__8);
- __Pyx_GIVEREF(__pyx_tuple__8);
-
- /* "View.MemoryView":420
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview") # <<<<<<<<<<<<<<
- *
- * have_slices, index = _unellipsify(index, self.view.ndim)
- */
- __pyx_tuple__9 = PyTuple_Pack(1, __pyx_kp_s_Cannot_assign_to_read_only_memor); if (unlikely(!__pyx_tuple__9)) __PYX_ERR(1, 420, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__9);
- __Pyx_GIVEREF(__pyx_tuple__9);
-
- /* "View.MemoryView":497
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- * raise ValueError("Unable to convert item to object") # <<<<<<<<<<<<<<
- * else:
- * if len(self.view.format) == 1:
- */
- __pyx_tuple__10 = PyTuple_Pack(1, __pyx_kp_s_Unable_to_convert_item_to_object); if (unlikely(!__pyx_tuple__10)) __PYX_ERR(1, 497, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__10);
- __Pyx_GIVEREF(__pyx_tuple__10);
-
- /* "View.MemoryView":522
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview") # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_ND:
- */
- __pyx_tuple__11 = PyTuple_Pack(1, __pyx_kp_s_Cannot_create_writable_memory_vi); if (unlikely(!__pyx_tuple__11)) __PYX_ERR(1, 522, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__11);
- __Pyx_GIVEREF(__pyx_tuple__11);
-
- /* "View.MemoryView":572
- * if self.view.strides == NULL:
- *
- * raise ValueError("Buffer view does not expose strides") # <<<<<<<<<<<<<<
- *
- * return tuple([stride for stride in self.view.strides[:self.view.ndim]])
- */
- __pyx_tuple__12 = PyTuple_Pack(1, __pyx_kp_s_Buffer_view_does_not_expose_stri); if (unlikely(!__pyx_tuple__12)) __PYX_ERR(1, 572, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__12);
- __Pyx_GIVEREF(__pyx_tuple__12);
-
- /* "View.MemoryView":579
- * def suboffsets(self):
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim # <<<<<<<<<<<<<<
- *
- * return tuple([suboffset for suboffset in self.view.suboffsets[:self.view.ndim]])
- */
- __pyx_tuple__13 = PyTuple_New(1); if (unlikely(!__pyx_tuple__13)) __PYX_ERR(1, 579, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__13);
- __Pyx_INCREF(__pyx_int_neg_1);
- __Pyx_GIVEREF(__pyx_int_neg_1);
- PyTuple_SET_ITEM(__pyx_tuple__13, 0, __pyx_int_neg_1);
- __Pyx_GIVEREF(__pyx_tuple__13);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_tuple__14 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__14)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__14);
- __Pyx_GIVEREF(__pyx_tuple__14);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_tuple__15 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__15)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__15);
- __Pyx_GIVEREF(__pyx_tuple__15);
-
- /* "View.MemoryView":684
- * if item is Ellipsis:
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1)) # <<<<<<<<<<<<<<
- * seen_ellipsis = True
- * else:
- */
- __pyx_slice__16 = PySlice_New(Py_None, Py_None, Py_None); if (unlikely(!__pyx_slice__16)) __PYX_ERR(1, 684, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_slice__16);
- __Pyx_GIVEREF(__pyx_slice__16);
-
- /* "View.MemoryView":705
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- * raise ValueError("Indirect dimensions not supported") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__17 = PyTuple_Pack(1, __pyx_kp_s_Indirect_dimensions_not_supporte); if (unlikely(!__pyx_tuple__17)) __PYX_ERR(1, 705, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__17);
- __Pyx_GIVEREF(__pyx_tuple__17);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_tuple__18 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__18)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__18);
- __Pyx_GIVEREF(__pyx_tuple__18);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_tuple__19 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__19)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__19);
- __Pyx_GIVEREF(__pyx_tuple__19);
- __pyx_tuple__20 = PyTuple_Pack(3, __pyx_int_184977713, __pyx_int_136983863, __pyx_int_112105877); if (unlikely(!__pyx_tuple__20)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__20);
- __Pyx_GIVEREF(__pyx_tuple__20);
-
- /* "View.MemoryView":287
- * return self.name
- *
- * cdef generic = Enum("") # <<<<<<<<<<<<<<
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("")
- */
- __pyx_tuple__21 = PyTuple_Pack(1, __pyx_kp_s_strided_and_direct_or_indirect); if (unlikely(!__pyx_tuple__21)) __PYX_ERR(1, 287, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__21);
- __Pyx_GIVEREF(__pyx_tuple__21);
-
- /* "View.MemoryView":288
- *
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default # <<<<<<<<<<<<<<
- * cdef indirect = Enum("")
- *
- */
- __pyx_tuple__22 = PyTuple_Pack(1, __pyx_kp_s_strided_and_direct); if (unlikely(!__pyx_tuple__22)) __PYX_ERR(1, 288, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__22);
- __Pyx_GIVEREF(__pyx_tuple__22);
-
- /* "View.MemoryView":289
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__23 = PyTuple_Pack(1, __pyx_kp_s_strided_and_indirect); if (unlikely(!__pyx_tuple__23)) __PYX_ERR(1, 289, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__23);
- __Pyx_GIVEREF(__pyx_tuple__23);
-
- /* "View.MemoryView":292
- *
- *
- * cdef contiguous = Enum("") # <<<<<<<<<<<<<<
- * cdef indirect_contiguous = Enum("")
- *
- */
- __pyx_tuple__24 = PyTuple_Pack(1, __pyx_kp_s_contiguous_and_direct); if (unlikely(!__pyx_tuple__24)) __PYX_ERR(1, 292, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__24);
- __Pyx_GIVEREF(__pyx_tuple__24);
-
- /* "View.MemoryView":293
- *
- * cdef contiguous = Enum("")
- * cdef indirect_contiguous = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__25 = PyTuple_Pack(1, __pyx_kp_s_contiguous_and_indirect); if (unlikely(!__pyx_tuple__25)) __PYX_ERR(1, 293, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__25);
- __Pyx_GIVEREF(__pyx_tuple__25);
-
- /* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
- __pyx_tuple__26 = PyTuple_Pack(5, __pyx_n_s_pyx_type, __pyx_n_s_pyx_checksum, __pyx_n_s_pyx_state, __pyx_n_s_pyx_PickleError, __pyx_n_s_pyx_result); if (unlikely(!__pyx_tuple__26)) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__26);
- __Pyx_GIVEREF(__pyx_tuple__26);
- __pyx_codeobj__27 = (PyObject*)__Pyx_PyCode_New(3, 0, 5, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__26, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_stringsource, __pyx_n_s_pyx_unpickle_Enum, 1, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__27)) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_RefNannyFinishContext();
- return 0;
- __pyx_L1_error:;
- __Pyx_RefNannyFinishContext();
- return -1;
-}
-
-static CYTHON_SMALL_CODE int __Pyx_InitGlobals(void) {
- /* InitThreads.init */
- #if defined(WITH_THREAD) && PY_VERSION_HEX < 0x030700F0
-PyEval_InitThreads();
-#endif
-
-if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 1, __pyx_L1_error)
-
- if (__Pyx_InitStrings(__pyx_string_tab) < 0) __PYX_ERR(0, 1, __pyx_L1_error);
- __pyx_int_0 = PyInt_FromLong(0); if (unlikely(!__pyx_int_0)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_1 = PyInt_FromLong(1); if (unlikely(!__pyx_int_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_112105877 = PyInt_FromLong(112105877L); if (unlikely(!__pyx_int_112105877)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_136983863 = PyInt_FromLong(136983863L); if (unlikely(!__pyx_int_136983863)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_184977713 = PyInt_FromLong(184977713L); if (unlikely(!__pyx_int_184977713)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_neg_1 = PyInt_FromLong(-1); if (unlikely(!__pyx_int_neg_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- return 0;
- __pyx_L1_error:;
- return -1;
-}
-
-static CYTHON_SMALL_CODE int __Pyx_modinit_global_init_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_variable_export_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_function_export_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_type_init_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_type_import_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_variable_import_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_function_import_code(void); /*proto*/
-
-static int __Pyx_modinit_global_init_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_global_init_code", 0);
- /*--- Global init code ---*/
- generic = Py_None; Py_INCREF(Py_None);
- strided = Py_None; Py_INCREF(Py_None);
- indirect = Py_None; Py_INCREF(Py_None);
- contiguous = Py_None; Py_INCREF(Py_None);
- indirect_contiguous = Py_None; Py_INCREF(Py_None);
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_variable_export_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_variable_export_code", 0);
- /*--- Variable export code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_function_export_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_function_export_code", 0);
- /*--- Function export code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_type_init_code(void) {
- __Pyx_RefNannyDeclarations
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__Pyx_modinit_type_init_code", 0);
- /*--- Type init code ---*/
- __pyx_vtabptr_array = &__pyx_vtable_array;
- __pyx_vtable_array.get_memview = (PyObject *(*)(struct __pyx_array_obj *))__pyx_array_get_memview;
- if (PyType_Ready(&__pyx_type___pyx_array) < 0) __PYX_ERR(1, 106, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_array.tp_print = 0;
- #endif
- if (__Pyx_SetVtable(__pyx_type___pyx_array.tp_dict, __pyx_vtabptr_array) < 0) __PYX_ERR(1, 106, __pyx_L1_error)
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_array) < 0) __PYX_ERR(1, 106, __pyx_L1_error)
- __pyx_array_type = &__pyx_type___pyx_array;
- if (PyType_Ready(&__pyx_type___pyx_MemviewEnum) < 0) __PYX_ERR(1, 280, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_MemviewEnum.tp_print = 0;
- #endif
- if ((CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP) && likely(!__pyx_type___pyx_MemviewEnum.tp_dictoffset && __pyx_type___pyx_MemviewEnum.tp_getattro == PyObject_GenericGetAttr)) {
- __pyx_type___pyx_MemviewEnum.tp_getattro = __Pyx_PyObject_GenericGetAttr;
- }
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_MemviewEnum) < 0) __PYX_ERR(1, 280, __pyx_L1_error)
- __pyx_MemviewEnum_type = &__pyx_type___pyx_MemviewEnum;
- __pyx_vtabptr_memoryview = &__pyx_vtable_memoryview;
- __pyx_vtable_memoryview.get_item_pointer = (char *(*)(struct __pyx_memoryview_obj *, PyObject *))__pyx_memoryview_get_item_pointer;
- __pyx_vtable_memoryview.is_slice = (PyObject *(*)(struct __pyx_memoryview_obj *, PyObject *))__pyx_memoryview_is_slice;
- __pyx_vtable_memoryview.setitem_slice_assignment = (PyObject *(*)(struct __pyx_memoryview_obj *, PyObject *, PyObject *))__pyx_memoryview_setitem_slice_assignment;
- __pyx_vtable_memoryview.setitem_slice_assign_scalar = (PyObject *(*)(struct __pyx_memoryview_obj *, struct __pyx_memoryview_obj *, PyObject *))__pyx_memoryview_setitem_slice_assign_scalar;
- __pyx_vtable_memoryview.setitem_indexed = (PyObject *(*)(struct __pyx_memoryview_obj *, PyObject *, PyObject *))__pyx_memoryview_setitem_indexed;
- __pyx_vtable_memoryview.convert_item_to_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *))__pyx_memoryview_convert_item_to_object;
- __pyx_vtable_memoryview.assign_item_from_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *, PyObject *))__pyx_memoryview_assign_item_from_object;
- if (PyType_Ready(&__pyx_type___pyx_memoryview) < 0) __PYX_ERR(1, 331, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_memoryview.tp_print = 0;
- #endif
- if ((CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP) && likely(!__pyx_type___pyx_memoryview.tp_dictoffset && __pyx_type___pyx_memoryview.tp_getattro == PyObject_GenericGetAttr)) {
- __pyx_type___pyx_memoryview.tp_getattro = __Pyx_PyObject_GenericGetAttr;
- }
- if (__Pyx_SetVtable(__pyx_type___pyx_memoryview.tp_dict, __pyx_vtabptr_memoryview) < 0) __PYX_ERR(1, 331, __pyx_L1_error)
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_memoryview) < 0) __PYX_ERR(1, 331, __pyx_L1_error)
- __pyx_memoryview_type = &__pyx_type___pyx_memoryview;
- __pyx_vtabptr__memoryviewslice = &__pyx_vtable__memoryviewslice;
- __pyx_vtable__memoryviewslice.__pyx_base = *__pyx_vtabptr_memoryview;
- __pyx_vtable__memoryviewslice.__pyx_base.convert_item_to_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *))__pyx_memoryviewslice_convert_item_to_object;
- __pyx_vtable__memoryviewslice.__pyx_base.assign_item_from_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *, PyObject *))__pyx_memoryviewslice_assign_item_from_object;
- __pyx_type___pyx_memoryviewslice.tp_base = __pyx_memoryview_type;
- if (PyType_Ready(&__pyx_type___pyx_memoryviewslice) < 0) __PYX_ERR(1, 967, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_memoryviewslice.tp_print = 0;
- #endif
- if ((CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP) && likely(!__pyx_type___pyx_memoryviewslice.tp_dictoffset && __pyx_type___pyx_memoryviewslice.tp_getattro == PyObject_GenericGetAttr)) {
- __pyx_type___pyx_memoryviewslice.tp_getattro = __Pyx_PyObject_GenericGetAttr;
- }
- if (__Pyx_SetVtable(__pyx_type___pyx_memoryviewslice.tp_dict, __pyx_vtabptr__memoryviewslice) < 0) __PYX_ERR(1, 967, __pyx_L1_error)
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_memoryviewslice) < 0) __PYX_ERR(1, 967, __pyx_L1_error)
- __pyx_memoryviewslice_type = &__pyx_type___pyx_memoryviewslice;
- __Pyx_RefNannyFinishContext();
- return 0;
- __pyx_L1_error:;
- __Pyx_RefNannyFinishContext();
- return -1;
-}
-
-static int __Pyx_modinit_type_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_type_import_code", 0);
- /*--- Type import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_variable_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_variable_import_code", 0);
- /*--- Variable import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_function_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_function_import_code", 0);
- /*--- Function import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-
-#ifndef CYTHON_NO_PYINIT_EXPORT
-#define __Pyx_PyMODINIT_FUNC PyMODINIT_FUNC
-#elif PY_MAJOR_VERSION < 3
-#ifdef __cplusplus
-#define __Pyx_PyMODINIT_FUNC extern "C" void
-#else
-#define __Pyx_PyMODINIT_FUNC void
-#endif
-#else
-#ifdef __cplusplus
-#define __Pyx_PyMODINIT_FUNC extern "C" PyObject *
-#else
-#define __Pyx_PyMODINIT_FUNC PyObject *
-#endif
-#endif
-
-
-#if PY_MAJOR_VERSION < 3
-__Pyx_PyMODINIT_FUNC initcore(void) CYTHON_SMALL_CODE; /*proto*/
-__Pyx_PyMODINIT_FUNC initcore(void)
-#else
-__Pyx_PyMODINIT_FUNC PyInit_core(void) CYTHON_SMALL_CODE; /*proto*/
-__Pyx_PyMODINIT_FUNC PyInit_core(void)
-#if CYTHON_PEP489_MULTI_PHASE_INIT
-{
- return PyModuleDef_Init(&__pyx_moduledef);
-}
-static CYTHON_SMALL_CODE int __Pyx_check_single_interpreter(void) {
- #if PY_VERSION_HEX >= 0x030700A1
- static PY_INT64_T main_interpreter_id = -1;
- PY_INT64_T current_id = PyInterpreterState_GetID(PyThreadState_Get()->interp);
- if (main_interpreter_id == -1) {
- main_interpreter_id = current_id;
- return (unlikely(current_id == -1)) ? -1 : 0;
- } else if (unlikely(main_interpreter_id != current_id))
- #else
- static PyInterpreterState *main_interpreter = NULL;
- PyInterpreterState *current_interpreter = PyThreadState_Get()->interp;
- if (!main_interpreter) {
- main_interpreter = current_interpreter;
- } else if (unlikely(main_interpreter != current_interpreter))
- #endif
- {
- PyErr_SetString(
- PyExc_ImportError,
- "Interpreter change detected - this module can only be loaded into one interpreter per process.");
- return -1;
- }
- return 0;
-}
-static CYTHON_SMALL_CODE int __Pyx_copy_spec_to_module(PyObject *spec, PyObject *moddict, const char* from_name, const char* to_name, int allow_none) {
- PyObject *value = PyObject_GetAttrString(spec, from_name);
- int result = 0;
- if (likely(value)) {
- if (allow_none || value != Py_None) {
- result = PyDict_SetItemString(moddict, to_name, value);
- }
- Py_DECREF(value);
- } else if (PyErr_ExceptionMatches(PyExc_AttributeError)) {
- PyErr_Clear();
- } else {
- result = -1;
- }
- return result;
-}
-static CYTHON_SMALL_CODE PyObject* __pyx_pymod_create(PyObject *spec, CYTHON_UNUSED PyModuleDef *def) {
- PyObject *module = NULL, *moddict, *modname;
- if (__Pyx_check_single_interpreter())
- return NULL;
- if (__pyx_m)
- return __Pyx_NewRef(__pyx_m);
- modname = PyObject_GetAttrString(spec, "name");
- if (unlikely(!modname)) goto bad;
- module = PyModule_NewObject(modname);
- Py_DECREF(modname);
- if (unlikely(!module)) goto bad;
- moddict = PyModule_GetDict(module);
- if (unlikely(!moddict)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "loader", "__loader__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "origin", "__file__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "parent", "__package__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "submodule_search_locations", "__path__", 0) < 0)) goto bad;
- return module;
-bad:
- Py_XDECREF(module);
- return NULL;
-}
-
-
-static CYTHON_SMALL_CODE int __pyx_pymod_exec_core(PyObject *__pyx_pyinit_module)
-#endif
-#endif
-{
- PyObject *__pyx_t_1 = NULL;
- static PyThread_type_lock __pyx_t_2[8];
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannyDeclarations
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- if (__pyx_m) {
- if (__pyx_m == __pyx_pyinit_module) return 0;
- PyErr_SetString(PyExc_RuntimeError, "Module 'core' has already been imported. Re-initialisation is not supported.");
- return -1;
- }
- #elif PY_MAJOR_VERSION >= 3
- if (__pyx_m) return __Pyx_NewRef(__pyx_m);
- #endif
- #if CYTHON_REFNANNY
-__Pyx_RefNanny = __Pyx_RefNannyImportAPI("refnanny");
-if (!__Pyx_RefNanny) {
- PyErr_Clear();
- __Pyx_RefNanny = __Pyx_RefNannyImportAPI("Cython.Runtime.refnanny");
- if (!__Pyx_RefNanny)
- Py_FatalError("failed to import 'refnanny' module");
-}
-#endif
- __Pyx_RefNannySetupContext("__Pyx_PyMODINIT_FUNC PyInit_core(void)", 0);
- if (__Pyx_check_binary_version() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #ifdef __Pxy_PyFrame_Initialize_Offsets
- __Pxy_PyFrame_Initialize_Offsets();
- #endif
- __pyx_empty_tuple = PyTuple_New(0); if (unlikely(!__pyx_empty_tuple)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_empty_bytes = PyBytes_FromStringAndSize("", 0); if (unlikely(!__pyx_empty_bytes)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_empty_unicode = PyUnicode_FromStringAndSize("", 0); if (unlikely(!__pyx_empty_unicode)) __PYX_ERR(0, 1, __pyx_L1_error)
- #ifdef __Pyx_CyFunction_USED
- if (__pyx_CyFunction_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_FusedFunction_USED
- if (__pyx_FusedFunction_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_Coroutine_USED
- if (__pyx_Coroutine_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_Generator_USED
- if (__pyx_Generator_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_AsyncGen_USED
- if (__pyx_AsyncGen_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_StopAsyncIteration_USED
- if (__pyx_StopAsyncIteration_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- /*--- Library function declarations ---*/
- /*--- Threads initialization code ---*/
- #if defined(WITH_THREAD) && PY_VERSION_HEX < 0x030700F0 && defined(__PYX_FORCE_INIT_THREADS) && __PYX_FORCE_INIT_THREADS
- PyEval_InitThreads();
- #endif
- /*--- Module creation code ---*/
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- __pyx_m = __pyx_pyinit_module;
- Py_INCREF(__pyx_m);
- #else
- #if PY_MAJOR_VERSION < 3
- __pyx_m = Py_InitModule4("core", __pyx_methods, 0, 0, PYTHON_API_VERSION); Py_XINCREF(__pyx_m);
- #else
- __pyx_m = PyModule_Create(&__pyx_moduledef);
- #endif
- if (unlikely(!__pyx_m)) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- __pyx_d = PyModule_GetDict(__pyx_m); if (unlikely(!__pyx_d)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_d);
- __pyx_b = PyImport_AddModule(__Pyx_BUILTIN_MODULE_NAME); if (unlikely(!__pyx_b)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_b);
- __pyx_cython_runtime = PyImport_AddModule((char *) "cython_runtime"); if (unlikely(!__pyx_cython_runtime)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_cython_runtime);
- if (PyObject_SetAttrString(__pyx_m, "__builtins__", __pyx_b) < 0) __PYX_ERR(0, 1, __pyx_L1_error);
- /*--- Initialize various global constants etc. ---*/
- if (__Pyx_InitGlobals() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #if PY_MAJOR_VERSION < 3 && (__PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT)
- if (__Pyx_init_sys_getdefaultencoding_params() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- if (__pyx_module_is_main_monotonic_align__core) {
- if (PyObject_SetAttr(__pyx_m, __pyx_n_s_name_2, __pyx_n_s_main) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- }
- #if PY_MAJOR_VERSION >= 3
- {
- PyObject *modules = PyImport_GetModuleDict(); if (unlikely(!modules)) __PYX_ERR(0, 1, __pyx_L1_error)
- if (!PyDict_GetItemString(modules, "monotonic_align.core")) {
- if (unlikely(PyDict_SetItemString(modules, "monotonic_align.core", __pyx_m) < 0)) __PYX_ERR(0, 1, __pyx_L1_error)
- }
- }
- #endif
- /*--- Builtin init code ---*/
- if (__Pyx_InitCachedBuiltins() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- /*--- Constants init code ---*/
- if (__Pyx_InitCachedConstants() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- /*--- Global type/function init code ---*/
- (void)__Pyx_modinit_global_init_code();
- (void)__Pyx_modinit_variable_export_code();
- (void)__Pyx_modinit_function_export_code();
- if (unlikely(__Pyx_modinit_type_init_code() < 0)) __PYX_ERR(0, 1, __pyx_L1_error)
- (void)__Pyx_modinit_type_import_code();
- (void)__Pyx_modinit_variable_import_code();
- (void)__Pyx_modinit_function_import_code();
- /*--- Execution code ---*/
- #if defined(__Pyx_Generator_USED) || defined(__Pyx_Coroutine_USED)
- if (__Pyx_patch_abc() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
-
- /* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
- __pyx_k_ = (-1e9);
-
- /* "monotonic_align/core.pyx":1
- * cimport cython # <<<<<<<<<<<<<<
- * from cython.parallel import prange
- *
- */
- __pyx_t_1 = __Pyx_PyDict_NewPresized(0); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_test, __pyx_t_1) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "View.MemoryView":210
- * info.obj = self
- *
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)") # <<<<<<<<<<<<<<
- *
- * def __dealloc__(array self):
- */
- __pyx_t_1 = __pyx_capsule_create(((void *)(&__pyx_array_getbuffer)), ((char *)"getbuffer(obj, view, flags)")); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 210, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem((PyObject *)__pyx_array_type->tp_dict, __pyx_n_s_pyx_getbuffer, __pyx_t_1) < 0) __PYX_ERR(1, 210, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- PyType_Modified(__pyx_array_type);
-
- /* "View.MemoryView":287
- * return self.name
- *
- * cdef generic = Enum("") # <<<<<<<<<<<<<<
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__21, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 287, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(generic);
- __Pyx_DECREF_SET(generic, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":288
- *
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default # <<<<<<<<<<<<<<
- * cdef indirect = Enum("")
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__22, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 288, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(strided);
- __Pyx_DECREF_SET(strided, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":289
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__23, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 289, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(indirect);
- __Pyx_DECREF_SET(indirect, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":292
- *
- *
- * cdef contiguous = Enum("") # <<<<<<<<<<<<<<
- * cdef indirect_contiguous = Enum("")
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__24, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 292, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(contiguous);
- __Pyx_DECREF_SET(contiguous, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":293
- *
- * cdef contiguous = Enum("")
- * cdef indirect_contiguous = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__25, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 293, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(indirect_contiguous);
- __Pyx_DECREF_SET(indirect_contiguous, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":317
- *
- * DEF THREAD_LOCKS_PREALLOCATED = 8
- * cdef int __pyx_memoryview_thread_locks_used = 0 # <<<<<<<<<<<<<<
- * cdef PyThread_type_lock[THREAD_LOCKS_PREALLOCATED] __pyx_memoryview_thread_locks = [
- * PyThread_allocate_lock(),
- */
- __pyx_memoryview_thread_locks_used = 0;
-
- /* "View.MemoryView":318
- * DEF THREAD_LOCKS_PREALLOCATED = 8
- * cdef int __pyx_memoryview_thread_locks_used = 0
- * cdef PyThread_type_lock[THREAD_LOCKS_PREALLOCATED] __pyx_memoryview_thread_locks = [ # <<<<<<<<<<<<<<
- * PyThread_allocate_lock(),
- * PyThread_allocate_lock(),
- */
- __pyx_t_2[0] = PyThread_allocate_lock();
- __pyx_t_2[1] = PyThread_allocate_lock();
- __pyx_t_2[2] = PyThread_allocate_lock();
- __pyx_t_2[3] = PyThread_allocate_lock();
- __pyx_t_2[4] = PyThread_allocate_lock();
- __pyx_t_2[5] = PyThread_allocate_lock();
- __pyx_t_2[6] = PyThread_allocate_lock();
- __pyx_t_2[7] = PyThread_allocate_lock();
- memcpy(&(__pyx_memoryview_thread_locks[0]), __pyx_t_2, sizeof(__pyx_memoryview_thread_locks[0]) * (8));
-
- /* "View.MemoryView":551
- * info.obj = self
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __pyx_capsule_create(((void *)(&__pyx_memoryview_getbuffer)), ((char *)"getbuffer(obj, view, flags)")); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 551, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem((PyObject *)__pyx_memoryview_type->tp_dict, __pyx_n_s_pyx_getbuffer, __pyx_t_1) < 0) __PYX_ERR(1, 551, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- PyType_Modified(__pyx_memoryview_type);
-
- /* "View.MemoryView":997
- * return self.from_object
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __pyx_capsule_create(((void *)(&__pyx_memoryview_getbuffer)), ((char *)"getbuffer(obj, view, flags)")); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 997, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem((PyObject *)__pyx_memoryviewslice_type->tp_dict, __pyx_n_s_pyx_getbuffer, __pyx_t_1) < 0) __PYX_ERR(1, 997, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- PyType_Modified(__pyx_memoryviewslice_type);
-
- /* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
- __pyx_t_1 = PyCFunction_NewEx(&__pyx_mdef_15View_dot_MemoryView_1__pyx_unpickle_Enum, NULL, __pyx_n_s_View_MemoryView); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_pyx_unpickle_Enum, __pyx_t_1) < 0) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "(tree fragment)":11
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- */
-
- /*--- Wrapped vars code ---*/
-
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- if (__pyx_m) {
- if (__pyx_d) {
- __Pyx_AddTraceback("init monotonic_align.core", __pyx_clineno, __pyx_lineno, __pyx_filename);
- }
- Py_CLEAR(__pyx_m);
- } else if (!PyErr_Occurred()) {
- PyErr_SetString(PyExc_ImportError, "init monotonic_align.core");
- }
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- return (__pyx_m != NULL) ? 0 : -1;
- #elif PY_MAJOR_VERSION >= 3
- return __pyx_m;
- #else
- return;
- #endif
-}
-
-/* --- Runtime support code --- */
-/* Refnanny */
-#if CYTHON_REFNANNY
-static __Pyx_RefNannyAPIStruct *__Pyx_RefNannyImportAPI(const char *modname) {
- PyObject *m = NULL, *p = NULL;
- void *r = NULL;
- m = PyImport_ImportModule(modname);
- if (!m) goto end;
- p = PyObject_GetAttrString(m, "RefNannyAPI");
- if (!p) goto end;
- r = PyLong_AsVoidPtr(p);
-end:
- Py_XDECREF(p);
- Py_XDECREF(m);
- return (__Pyx_RefNannyAPIStruct *)r;
-}
-#endif
-
-/* PyObjectGetAttrStr */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStr(PyObject* obj, PyObject* attr_name) {
- PyTypeObject* tp = Py_TYPE(obj);
- if (likely(tp->tp_getattro))
- return tp->tp_getattro(obj, attr_name);
-#if PY_MAJOR_VERSION < 3
- if (likely(tp->tp_getattr))
- return tp->tp_getattr(obj, PyString_AS_STRING(attr_name));
-#endif
- return PyObject_GetAttr(obj, attr_name);
-}
-#endif
-
-/* GetBuiltinName */
-static PyObject *__Pyx_GetBuiltinName(PyObject *name) {
- PyObject* result = __Pyx_PyObject_GetAttrStr(__pyx_b, name);
- if (unlikely(!result)) {
- PyErr_Format(PyExc_NameError,
-#if PY_MAJOR_VERSION >= 3
- "name '%U' is not defined", name);
-#else
- "name '%.200s' is not defined", PyString_AS_STRING(name));
-#endif
- }
- return result;
-}
-
-/* MemviewSliceInit */
-static int
-__Pyx_init_memviewslice(struct __pyx_memoryview_obj *memview,
- int ndim,
- __Pyx_memviewslice *memviewslice,
- int memview_is_new_reference)
-{
- __Pyx_RefNannyDeclarations
- int i, retval=-1;
- Py_buffer *buf = &memview->view;
- __Pyx_RefNannySetupContext("init_memviewslice", 0);
- if (unlikely(memviewslice->memview || memviewslice->data)) {
- PyErr_SetString(PyExc_ValueError,
- "memviewslice is already initialized!");
- goto fail;
- }
- if (buf->strides) {
- for (i = 0; i < ndim; i++) {
- memviewslice->strides[i] = buf->strides[i];
- }
- } else {
- Py_ssize_t stride = buf->itemsize;
- for (i = ndim - 1; i >= 0; i--) {
- memviewslice->strides[i] = stride;
- stride *= buf->shape[i];
- }
- }
- for (i = 0; i < ndim; i++) {
- memviewslice->shape[i] = buf->shape[i];
- if (buf->suboffsets) {
- memviewslice->suboffsets[i] = buf->suboffsets[i];
- } else {
- memviewslice->suboffsets[i] = -1;
- }
- }
- memviewslice->memview = memview;
- memviewslice->data = (char *)buf->buf;
- if (__pyx_add_acquisition_count(memview) == 0 && !memview_is_new_reference) {
- Py_INCREF(memview);
- }
- retval = 0;
- goto no_fail;
-fail:
- memviewslice->memview = 0;
- memviewslice->data = 0;
- retval = -1;
-no_fail:
- __Pyx_RefNannyFinishContext();
- return retval;
-}
-#ifndef Py_NO_RETURN
-#define Py_NO_RETURN
-#endif
-static void __pyx_fatalerror(const char *fmt, ...) Py_NO_RETURN {
- va_list vargs;
- char msg[200];
-#if PY_VERSION_HEX >= 0x030A0000 || defined(HAVE_STDARG_PROTOTYPES)
- va_start(vargs, fmt);
-#else
- va_start(vargs);
-#endif
- vsnprintf(msg, 200, fmt, vargs);
- va_end(vargs);
- Py_FatalError(msg);
-}
-static CYTHON_INLINE int
-__pyx_add_acquisition_count_locked(__pyx_atomic_int *acquisition_count,
- PyThread_type_lock lock)
-{
- int result;
- PyThread_acquire_lock(lock, 1);
- result = (*acquisition_count)++;
- PyThread_release_lock(lock);
- return result;
-}
-static CYTHON_INLINE int
-__pyx_sub_acquisition_count_locked(__pyx_atomic_int *acquisition_count,
- PyThread_type_lock lock)
-{
- int result;
- PyThread_acquire_lock(lock, 1);
- result = (*acquisition_count)--;
- PyThread_release_lock(lock);
- return result;
-}
-static CYTHON_INLINE void
-__Pyx_INC_MEMVIEW(__Pyx_memviewslice *memslice, int have_gil, int lineno)
-{
- int first_time;
- struct __pyx_memoryview_obj *memview = memslice->memview;
- if (unlikely(!memview || (PyObject *) memview == Py_None))
- return;
- if (unlikely(__pyx_get_slice_count(memview) < 0))
- __pyx_fatalerror("Acquisition count is %d (line %d)",
- __pyx_get_slice_count(memview), lineno);
- first_time = __pyx_add_acquisition_count(memview) == 0;
- if (unlikely(first_time)) {
- if (have_gil) {
- Py_INCREF((PyObject *) memview);
- } else {
- PyGILState_STATE _gilstate = PyGILState_Ensure();
- Py_INCREF((PyObject *) memview);
- PyGILState_Release(_gilstate);
- }
- }
-}
-static CYTHON_INLINE void __Pyx_XDEC_MEMVIEW(__Pyx_memviewslice *memslice,
- int have_gil, int lineno) {
- int last_time;
- struct __pyx_memoryview_obj *memview = memslice->memview;
- if (unlikely(!memview || (PyObject *) memview == Py_None)) {
- memslice->memview = NULL;
- return;
- }
- if (unlikely(__pyx_get_slice_count(memview) <= 0))
- __pyx_fatalerror("Acquisition count is %d (line %d)",
- __pyx_get_slice_count(memview), lineno);
- last_time = __pyx_sub_acquisition_count(memview) == 1;
- memslice->data = NULL;
- if (unlikely(last_time)) {
- if (have_gil) {
- Py_CLEAR(memslice->memview);
- } else {
- PyGILState_STATE _gilstate = PyGILState_Ensure();
- Py_CLEAR(memslice->memview);
- PyGILState_Release(_gilstate);
- }
- } else {
- memslice->memview = NULL;
- }
-}
-
-/* RaiseArgTupleInvalid */
-static void __Pyx_RaiseArgtupleInvalid(
- const char* func_name,
- int exact,
- Py_ssize_t num_min,
- Py_ssize_t num_max,
- Py_ssize_t num_found)
-{
- Py_ssize_t num_expected;
- const char *more_or_less;
- if (num_found < num_min) {
- num_expected = num_min;
- more_or_less = "at least";
- } else {
- num_expected = num_max;
- more_or_less = "at most";
- }
- if (exact) {
- more_or_less = "exactly";
- }
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes %.8s %" CYTHON_FORMAT_SSIZE_T "d positional argument%.1s (%" CYTHON_FORMAT_SSIZE_T "d given)",
- func_name, more_or_less, num_expected,
- (num_expected == 1) ? "" : "s", num_found);
-}
-
-/* RaiseDoubleKeywords */
-static void __Pyx_RaiseDoubleKeywordsError(
- const char* func_name,
- PyObject* kw_name)
-{
- PyErr_Format(PyExc_TypeError,
- #if PY_MAJOR_VERSION >= 3
- "%s() got multiple values for keyword argument '%U'", func_name, kw_name);
- #else
- "%s() got multiple values for keyword argument '%s'", func_name,
- PyString_AsString(kw_name));
- #endif
-}
-
-/* ParseKeywords */
-static int __Pyx_ParseOptionalKeywords(
- PyObject *kwds,
- PyObject **argnames[],
- PyObject *kwds2,
- PyObject *values[],
- Py_ssize_t num_pos_args,
- const char* function_name)
-{
- PyObject *key = 0, *value = 0;
- Py_ssize_t pos = 0;
- PyObject*** name;
- PyObject*** first_kw_arg = argnames + num_pos_args;
- while (PyDict_Next(kwds, &pos, &key, &value)) {
- name = first_kw_arg;
- while (*name && (**name != key)) name++;
- if (*name) {
- values[name-argnames] = value;
- continue;
- }
- name = first_kw_arg;
- #if PY_MAJOR_VERSION < 3
- if (likely(PyString_Check(key))) {
- while (*name) {
- if ((CYTHON_COMPILING_IN_PYPY || PyString_GET_SIZE(**name) == PyString_GET_SIZE(key))
- && _PyString_Eq(**name, key)) {
- values[name-argnames] = value;
- break;
- }
- name++;
- }
- if (*name) continue;
- else {
- PyObject*** argname = argnames;
- while (argname != first_kw_arg) {
- if ((**argname == key) || (
- (CYTHON_COMPILING_IN_PYPY || PyString_GET_SIZE(**argname) == PyString_GET_SIZE(key))
- && _PyString_Eq(**argname, key))) {
- goto arg_passed_twice;
- }
- argname++;
- }
- }
- } else
- #endif
- if (likely(PyUnicode_Check(key))) {
- while (*name) {
- int cmp = (**name == key) ? 0 :
- #if !CYTHON_COMPILING_IN_PYPY && PY_MAJOR_VERSION >= 3
- (__Pyx_PyUnicode_GET_LENGTH(**name) != __Pyx_PyUnicode_GET_LENGTH(key)) ? 1 :
- #endif
- PyUnicode_Compare(**name, key);
- if (cmp < 0 && unlikely(PyErr_Occurred())) goto bad;
- if (cmp == 0) {
- values[name-argnames] = value;
- break;
- }
- name++;
- }
- if (*name) continue;
- else {
- PyObject*** argname = argnames;
- while (argname != first_kw_arg) {
- int cmp = (**argname == key) ? 0 :
- #if !CYTHON_COMPILING_IN_PYPY && PY_MAJOR_VERSION >= 3
- (__Pyx_PyUnicode_GET_LENGTH(**argname) != __Pyx_PyUnicode_GET_LENGTH(key)) ? 1 :
- #endif
- PyUnicode_Compare(**argname, key);
- if (cmp < 0 && unlikely(PyErr_Occurred())) goto bad;
- if (cmp == 0) goto arg_passed_twice;
- argname++;
- }
- }
- } else
- goto invalid_keyword_type;
- if (kwds2) {
- if (unlikely(PyDict_SetItem(kwds2, key, value))) goto bad;
- } else {
- goto invalid_keyword;
- }
- }
- return 0;
-arg_passed_twice:
- __Pyx_RaiseDoubleKeywordsError(function_name, key);
- goto bad;
-invalid_keyword_type:
- PyErr_Format(PyExc_TypeError,
- "%.200s() keywords must be strings", function_name);
- goto bad;
-invalid_keyword:
- PyErr_Format(PyExc_TypeError,
- #if PY_MAJOR_VERSION < 3
- "%.200s() got an unexpected keyword argument '%.200s'",
- function_name, PyString_AsString(key));
- #else
- "%s() got an unexpected keyword argument '%U'",
- function_name, key);
- #endif
-bad:
- return -1;
-}
-
-/* None */
-static CYTHON_INLINE void __Pyx_RaiseUnboundLocalError(const char *varname) {
- PyErr_Format(PyExc_UnboundLocalError, "local variable '%s' referenced before assignment", varname);
-}
-
-/* ArgTypeTest */
-static int __Pyx__ArgTypeTest(PyObject *obj, PyTypeObject *type, const char *name, int exact)
-{
- if (unlikely(!type)) {
- PyErr_SetString(PyExc_SystemError, "Missing type object");
- return 0;
- }
- else if (exact) {
- #if PY_MAJOR_VERSION == 2
- if ((type == &PyBaseString_Type) && likely(__Pyx_PyBaseString_CheckExact(obj))) return 1;
- #endif
- }
- else {
- if (likely(__Pyx_TypeCheck(obj, type))) return 1;
- }
- PyErr_Format(PyExc_TypeError,
- "Argument '%.200s' has incorrect type (expected %.200s, got %.200s)",
- name, type->tp_name, Py_TYPE(obj)->tp_name);
- return 0;
-}
-
-/* PyObjectCall */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call(PyObject *func, PyObject *arg, PyObject *kw) {
- PyObject *result;
- ternaryfunc call = Py_TYPE(func)->tp_call;
- if (unlikely(!call))
- return PyObject_Call(func, arg, kw);
- if (unlikely(Py_EnterRecursiveCall((char*)" while calling a Python object")))
- return NULL;
- result = (*call)(func, arg, kw);
- Py_LeaveRecursiveCall();
- if (unlikely(!result) && unlikely(!PyErr_Occurred())) {
- PyErr_SetString(
- PyExc_SystemError,
- "NULL result without error in PyObject_Call");
- }
- return result;
-}
-#endif
-
-/* PyErrFetchRestore */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx_ErrRestoreInState(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- tmp_type = tstate->curexc_type;
- tmp_value = tstate->curexc_value;
- tmp_tb = tstate->curexc_traceback;
- tstate->curexc_type = type;
- tstate->curexc_value = value;
- tstate->curexc_traceback = tb;
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-}
-static CYTHON_INLINE void __Pyx_ErrFetchInState(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
- *type = tstate->curexc_type;
- *value = tstate->curexc_value;
- *tb = tstate->curexc_traceback;
- tstate->curexc_type = 0;
- tstate->curexc_value = 0;
- tstate->curexc_traceback = 0;
-}
-#endif
-
-/* RaiseException */
-#if PY_MAJOR_VERSION < 3
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb,
- CYTHON_UNUSED PyObject *cause) {
- __Pyx_PyThreadState_declare
- Py_XINCREF(type);
- if (!value || value == Py_None)
- value = NULL;
- else
- Py_INCREF(value);
- if (!tb || tb == Py_None)
- tb = NULL;
- else {
- Py_INCREF(tb);
- if (!PyTraceBack_Check(tb)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: arg 3 must be a traceback or None");
- goto raise_error;
- }
- }
- if (PyType_Check(type)) {
-#if CYTHON_COMPILING_IN_PYPY
- if (!value) {
- Py_INCREF(Py_None);
- value = Py_None;
- }
-#endif
- PyErr_NormalizeException(&type, &value, &tb);
- } else {
- if (value) {
- PyErr_SetString(PyExc_TypeError,
- "instance exception may not have a separate value");
- goto raise_error;
- }
- value = type;
- type = (PyObject*) Py_TYPE(type);
- Py_INCREF(type);
- if (!PyType_IsSubtype((PyTypeObject *)type, (PyTypeObject *)PyExc_BaseException)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: exception class must be a subclass of BaseException");
- goto raise_error;
- }
- }
- __Pyx_PyThreadState_assign
- __Pyx_ErrRestore(type, value, tb);
- return;
-raise_error:
- Py_XDECREF(value);
- Py_XDECREF(type);
- Py_XDECREF(tb);
- return;
-}
-#else
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb, PyObject *cause) {
- PyObject* owned_instance = NULL;
- if (tb == Py_None) {
- tb = 0;
- } else if (tb && !PyTraceBack_Check(tb)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: arg 3 must be a traceback or None");
- goto bad;
- }
- if (value == Py_None)
- value = 0;
- if (PyExceptionInstance_Check(type)) {
- if (value) {
- PyErr_SetString(PyExc_TypeError,
- "instance exception may not have a separate value");
- goto bad;
- }
- value = type;
- type = (PyObject*) Py_TYPE(value);
- } else if (PyExceptionClass_Check(type)) {
- PyObject *instance_class = NULL;
- if (value && PyExceptionInstance_Check(value)) {
- instance_class = (PyObject*) Py_TYPE(value);
- if (instance_class != type) {
- int is_subclass = PyObject_IsSubclass(instance_class, type);
- if (!is_subclass) {
- instance_class = NULL;
- } else if (unlikely(is_subclass == -1)) {
- goto bad;
- } else {
- type = instance_class;
- }
- }
- }
- if (!instance_class) {
- PyObject *args;
- if (!value)
- args = PyTuple_New(0);
- else if (PyTuple_Check(value)) {
- Py_INCREF(value);
- args = value;
- } else
- args = PyTuple_Pack(1, value);
- if (!args)
- goto bad;
- owned_instance = PyObject_Call(type, args, NULL);
- Py_DECREF(args);
- if (!owned_instance)
- goto bad;
- value = owned_instance;
- if (!PyExceptionInstance_Check(value)) {
- PyErr_Format(PyExc_TypeError,
- "calling %R should have returned an instance of "
- "BaseException, not %R",
- type, Py_TYPE(value));
- goto bad;
- }
- }
- } else {
- PyErr_SetString(PyExc_TypeError,
- "raise: exception class must be a subclass of BaseException");
- goto bad;
- }
- if (cause) {
- PyObject *fixed_cause;
- if (cause == Py_None) {
- fixed_cause = NULL;
- } else if (PyExceptionClass_Check(cause)) {
- fixed_cause = PyObject_CallObject(cause, NULL);
- if (fixed_cause == NULL)
- goto bad;
- } else if (PyExceptionInstance_Check(cause)) {
- fixed_cause = cause;
- Py_INCREF(fixed_cause);
- } else {
- PyErr_SetString(PyExc_TypeError,
- "exception causes must derive from "
- "BaseException");
- goto bad;
- }
- PyException_SetCause(value, fixed_cause);
- }
- PyErr_SetObject(type, value);
- if (tb) {
-#if CYTHON_COMPILING_IN_PYPY
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- PyErr_Fetch(&tmp_type, &tmp_value, &tmp_tb);
- Py_INCREF(tb);
- PyErr_Restore(tmp_type, tmp_value, tb);
- Py_XDECREF(tmp_tb);
-#else
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject* tmp_tb = tstate->curexc_traceback;
- if (tb != tmp_tb) {
- Py_INCREF(tb);
- tstate->curexc_traceback = tb;
- Py_XDECREF(tmp_tb);
- }
-#endif
- }
-bad:
- Py_XDECREF(owned_instance);
- return;
-}
-#endif
-
-/* PyCFunctionFastCall */
-#if CYTHON_FAST_PYCCALL
-static CYTHON_INLINE PyObject * __Pyx_PyCFunction_FastCall(PyObject *func_obj, PyObject **args, Py_ssize_t nargs) {
- PyCFunctionObject *func = (PyCFunctionObject*)func_obj;
- PyCFunction meth = PyCFunction_GET_FUNCTION(func);
- PyObject *self = PyCFunction_GET_SELF(func);
- int flags = PyCFunction_GET_FLAGS(func);
- assert(PyCFunction_Check(func));
- assert(METH_FASTCALL == (flags & ~(METH_CLASS | METH_STATIC | METH_COEXIST | METH_KEYWORDS | METH_STACKLESS)));
- assert(nargs >= 0);
- assert(nargs == 0 || args != NULL);
- /* _PyCFunction_FastCallDict() must not be called with an exception set,
- because it may clear it (directly or indirectly) and so the
- caller loses its exception */
- assert(!PyErr_Occurred());
- if ((PY_VERSION_HEX < 0x030700A0) || unlikely(flags & METH_KEYWORDS)) {
- return (*((__Pyx_PyCFunctionFastWithKeywords)(void*)meth)) (self, args, nargs, NULL);
- } else {
- return (*((__Pyx_PyCFunctionFast)(void*)meth)) (self, args, nargs);
- }
-}
-#endif
-
-/* PyFunctionFastCall */
-#if CYTHON_FAST_PYCALL
-static PyObject* __Pyx_PyFunction_FastCallNoKw(PyCodeObject *co, PyObject **args, Py_ssize_t na,
- PyObject *globals) {
- PyFrameObject *f;
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject **fastlocals;
- Py_ssize_t i;
- PyObject *result;
- assert(globals != NULL);
- /* XXX Perhaps we should create a specialized
- PyFrame_New() that doesn't take locals, but does
- take builtins without sanity checking them.
- */
- assert(tstate != NULL);
- f = PyFrame_New(tstate, co, globals, NULL);
- if (f == NULL) {
- return NULL;
- }
- fastlocals = __Pyx_PyFrame_GetLocalsplus(f);
- for (i = 0; i < na; i++) {
- Py_INCREF(*args);
- fastlocals[i] = *args++;
- }
- result = PyEval_EvalFrameEx(f,0);
- ++tstate->recursion_depth;
- Py_DECREF(f);
- --tstate->recursion_depth;
- return result;
-}
-#if 1 || PY_VERSION_HEX < 0x030600B1
-static PyObject *__Pyx_PyFunction_FastCallDict(PyObject *func, PyObject **args, Py_ssize_t nargs, PyObject *kwargs) {
- PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
- PyObject *globals = PyFunction_GET_GLOBALS(func);
- PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
- PyObject *closure;
-#if PY_MAJOR_VERSION >= 3
- PyObject *kwdefs;
-#endif
- PyObject *kwtuple, **k;
- PyObject **d;
- Py_ssize_t nd;
- Py_ssize_t nk;
- PyObject *result;
- assert(kwargs == NULL || PyDict_Check(kwargs));
- nk = kwargs ? PyDict_Size(kwargs) : 0;
- if (Py_EnterRecursiveCall((char*)" while calling a Python object")) {
- return NULL;
- }
- if (
-#if PY_MAJOR_VERSION >= 3
- co->co_kwonlyargcount == 0 &&
-#endif
- likely(kwargs == NULL || nk == 0) &&
- co->co_flags == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE)) {
- if (argdefs == NULL && co->co_argcount == nargs) {
- result = __Pyx_PyFunction_FastCallNoKw(co, args, nargs, globals);
- goto done;
- }
- else if (nargs == 0 && argdefs != NULL
- && co->co_argcount == Py_SIZE(argdefs)) {
- /* function called with no arguments, but all parameters have
- a default value: use default values as arguments .*/
- args = &PyTuple_GET_ITEM(argdefs, 0);
- result =__Pyx_PyFunction_FastCallNoKw(co, args, Py_SIZE(argdefs), globals);
- goto done;
- }
- }
- if (kwargs != NULL) {
- Py_ssize_t pos, i;
- kwtuple = PyTuple_New(2 * nk);
- if (kwtuple == NULL) {
- result = NULL;
- goto done;
- }
- k = &PyTuple_GET_ITEM(kwtuple, 0);
- pos = i = 0;
- while (PyDict_Next(kwargs, &pos, &k[i], &k[i+1])) {
- Py_INCREF(k[i]);
- Py_INCREF(k[i+1]);
- i += 2;
- }
- nk = i / 2;
- }
- else {
- kwtuple = NULL;
- k = NULL;
- }
- closure = PyFunction_GET_CLOSURE(func);
-#if PY_MAJOR_VERSION >= 3
- kwdefs = PyFunction_GET_KW_DEFAULTS(func);
-#endif
- if (argdefs != NULL) {
- d = &PyTuple_GET_ITEM(argdefs, 0);
- nd = Py_SIZE(argdefs);
- }
- else {
- d = NULL;
- nd = 0;
- }
-#if PY_MAJOR_VERSION >= 3
- result = PyEval_EvalCodeEx((PyObject*)co, globals, (PyObject *)NULL,
- args, (int)nargs,
- k, (int)nk,
- d, (int)nd, kwdefs, closure);
-#else
- result = PyEval_EvalCodeEx(co, globals, (PyObject *)NULL,
- args, (int)nargs,
- k, (int)nk,
- d, (int)nd, closure);
-#endif
- Py_XDECREF(kwtuple);
-done:
- Py_LeaveRecursiveCall();
- return result;
-}
-#endif
-#endif
-
-/* PyObjectCall2Args */
-static CYTHON_UNUSED PyObject* __Pyx_PyObject_Call2Args(PyObject* function, PyObject* arg1, PyObject* arg2) {
- PyObject *args, *result = NULL;
- #if CYTHON_FAST_PYCALL
- if (PyFunction_Check(function)) {
- PyObject *args[2] = {arg1, arg2};
- return __Pyx_PyFunction_FastCall(function, args, 2);
- }
- #endif
- #if CYTHON_FAST_PYCCALL
- if (__Pyx_PyFastCFunction_Check(function)) {
- PyObject *args[2] = {arg1, arg2};
- return __Pyx_PyCFunction_FastCall(function, args, 2);
- }
- #endif
- args = PyTuple_New(2);
- if (unlikely(!args)) goto done;
- Py_INCREF(arg1);
- PyTuple_SET_ITEM(args, 0, arg1);
- Py_INCREF(arg2);
- PyTuple_SET_ITEM(args, 1, arg2);
- Py_INCREF(function);
- result = __Pyx_PyObject_Call(function, args, NULL);
- Py_DECREF(args);
- Py_DECREF(function);
-done:
- return result;
-}
-
-/* PyObjectCallMethO */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallMethO(PyObject *func, PyObject *arg) {
- PyObject *self, *result;
- PyCFunction cfunc;
- cfunc = PyCFunction_GET_FUNCTION(func);
- self = PyCFunction_GET_SELF(func);
- if (unlikely(Py_EnterRecursiveCall((char*)" while calling a Python object")))
- return NULL;
- result = cfunc(self, arg);
- Py_LeaveRecursiveCall();
- if (unlikely(!result) && unlikely(!PyErr_Occurred())) {
- PyErr_SetString(
- PyExc_SystemError,
- "NULL result without error in PyObject_Call");
- }
- return result;
-}
-#endif
-
-/* PyObjectCallOneArg */
-#if CYTHON_COMPILING_IN_CPYTHON
-static PyObject* __Pyx__PyObject_CallOneArg(PyObject *func, PyObject *arg) {
- PyObject *result;
- PyObject *args = PyTuple_New(1);
- if (unlikely(!args)) return NULL;
- Py_INCREF(arg);
- PyTuple_SET_ITEM(args, 0, arg);
- result = __Pyx_PyObject_Call(func, args, NULL);
- Py_DECREF(args);
- return result;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg) {
-#if CYTHON_FAST_PYCALL
- if (PyFunction_Check(func)) {
- return __Pyx_PyFunction_FastCall(func, &arg, 1);
- }
-#endif
- if (likely(PyCFunction_Check(func))) {
- if (likely(PyCFunction_GET_FLAGS(func) & METH_O)) {
- return __Pyx_PyObject_CallMethO(func, arg);
-#if CYTHON_FAST_PYCCALL
- } else if (__Pyx_PyFastCFunction_Check(func)) {
- return __Pyx_PyCFunction_FastCall(func, &arg, 1);
-#endif
- }
- }
- return __Pyx__PyObject_CallOneArg(func, arg);
-}
-#else
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg) {
- PyObject *result;
- PyObject *args = PyTuple_Pack(1, arg);
- if (unlikely(!args)) return NULL;
- result = __Pyx_PyObject_Call(func, args, NULL);
- Py_DECREF(args);
- return result;
-}
-#endif
-
-/* BytesEquals */
-static CYTHON_INLINE int __Pyx_PyBytes_Equals(PyObject* s1, PyObject* s2, int equals) {
-#if CYTHON_COMPILING_IN_PYPY
- return PyObject_RichCompareBool(s1, s2, equals);
-#else
- if (s1 == s2) {
- return (equals == Py_EQ);
- } else if (PyBytes_CheckExact(s1) & PyBytes_CheckExact(s2)) {
- const char *ps1, *ps2;
- Py_ssize_t length = PyBytes_GET_SIZE(s1);
- if (length != PyBytes_GET_SIZE(s2))
- return (equals == Py_NE);
- ps1 = PyBytes_AS_STRING(s1);
- ps2 = PyBytes_AS_STRING(s2);
- if (ps1[0] != ps2[0]) {
- return (equals == Py_NE);
- } else if (length == 1) {
- return (equals == Py_EQ);
- } else {
- int result;
-#if CYTHON_USE_UNICODE_INTERNALS && (PY_VERSION_HEX < 0x030B0000)
- Py_hash_t hash1, hash2;
- hash1 = ((PyBytesObject*)s1)->ob_shash;
- hash2 = ((PyBytesObject*)s2)->ob_shash;
- if (hash1 != hash2 && hash1 != -1 && hash2 != -1) {
- return (equals == Py_NE);
- }
-#endif
- result = memcmp(ps1, ps2, (size_t)length);
- return (equals == Py_EQ) ? (result == 0) : (result != 0);
- }
- } else if ((s1 == Py_None) & PyBytes_CheckExact(s2)) {
- return (equals == Py_NE);
- } else if ((s2 == Py_None) & PyBytes_CheckExact(s1)) {
- return (equals == Py_NE);
- } else {
- int result;
- PyObject* py_result = PyObject_RichCompare(s1, s2, equals);
- if (!py_result)
- return -1;
- result = __Pyx_PyObject_IsTrue(py_result);
- Py_DECREF(py_result);
- return result;
- }
-#endif
-}
-
-/* UnicodeEquals */
-static CYTHON_INLINE int __Pyx_PyUnicode_Equals(PyObject* s1, PyObject* s2, int equals) {
-#if CYTHON_COMPILING_IN_PYPY
- return PyObject_RichCompareBool(s1, s2, equals);
-#else
-#if PY_MAJOR_VERSION < 3
- PyObject* owned_ref = NULL;
-#endif
- int s1_is_unicode, s2_is_unicode;
- if (s1 == s2) {
- goto return_eq;
- }
- s1_is_unicode = PyUnicode_CheckExact(s1);
- s2_is_unicode = PyUnicode_CheckExact(s2);
-#if PY_MAJOR_VERSION < 3
- if ((s1_is_unicode & (!s2_is_unicode)) && PyString_CheckExact(s2)) {
- owned_ref = PyUnicode_FromObject(s2);
- if (unlikely(!owned_ref))
- return -1;
- s2 = owned_ref;
- s2_is_unicode = 1;
- } else if ((s2_is_unicode & (!s1_is_unicode)) && PyString_CheckExact(s1)) {
- owned_ref = PyUnicode_FromObject(s1);
- if (unlikely(!owned_ref))
- return -1;
- s1 = owned_ref;
- s1_is_unicode = 1;
- } else if (((!s2_is_unicode) & (!s1_is_unicode))) {
- return __Pyx_PyBytes_Equals(s1, s2, equals);
- }
-#endif
- if (s1_is_unicode & s2_is_unicode) {
- Py_ssize_t length;
- int kind;
- void *data1, *data2;
- if (unlikely(__Pyx_PyUnicode_READY(s1) < 0) || unlikely(__Pyx_PyUnicode_READY(s2) < 0))
- return -1;
- length = __Pyx_PyUnicode_GET_LENGTH(s1);
- if (length != __Pyx_PyUnicode_GET_LENGTH(s2)) {
- goto return_ne;
- }
-#if CYTHON_USE_UNICODE_INTERNALS
- {
- Py_hash_t hash1, hash2;
- #if CYTHON_PEP393_ENABLED
- hash1 = ((PyASCIIObject*)s1)->hash;
- hash2 = ((PyASCIIObject*)s2)->hash;
- #else
- hash1 = ((PyUnicodeObject*)s1)->hash;
- hash2 = ((PyUnicodeObject*)s2)->hash;
- #endif
- if (hash1 != hash2 && hash1 != -1 && hash2 != -1) {
- goto return_ne;
- }
- }
-#endif
- kind = __Pyx_PyUnicode_KIND(s1);
- if (kind != __Pyx_PyUnicode_KIND(s2)) {
- goto return_ne;
- }
- data1 = __Pyx_PyUnicode_DATA(s1);
- data2 = __Pyx_PyUnicode_DATA(s2);
- if (__Pyx_PyUnicode_READ(kind, data1, 0) != __Pyx_PyUnicode_READ(kind, data2, 0)) {
- goto return_ne;
- } else if (length == 1) {
- goto return_eq;
- } else {
- int result = memcmp(data1, data2, (size_t)(length * kind));
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_EQ) ? (result == 0) : (result != 0);
- }
- } else if ((s1 == Py_None) & s2_is_unicode) {
- goto return_ne;
- } else if ((s2 == Py_None) & s1_is_unicode) {
- goto return_ne;
- } else {
- int result;
- PyObject* py_result = PyObject_RichCompare(s1, s2, equals);
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- if (!py_result)
- return -1;
- result = __Pyx_PyObject_IsTrue(py_result);
- Py_DECREF(py_result);
- return result;
- }
-return_eq:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_EQ);
-return_ne:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_NE);
-#endif
-}
-
-/* DivInt[Py_ssize_t] */
-static CYTHON_INLINE Py_ssize_t __Pyx_div_Py_ssize_t(Py_ssize_t a, Py_ssize_t b) {
- Py_ssize_t q = a / b;
- Py_ssize_t r = a - q*b;
- q -= ((r != 0) & ((r ^ b) < 0));
- return q;
-}
-
-/* GetAttr */
-static CYTHON_INLINE PyObject *__Pyx_GetAttr(PyObject *o, PyObject *n) {
-#if CYTHON_USE_TYPE_SLOTS
-#if PY_MAJOR_VERSION >= 3
- if (likely(PyUnicode_Check(n)))
-#else
- if (likely(PyString_Check(n)))
-#endif
- return __Pyx_PyObject_GetAttrStr(o, n);
-#endif
- return PyObject_GetAttr(o, n);
-}
-
-/* GetItemInt */
-static PyObject *__Pyx_GetItemInt_Generic(PyObject *o, PyObject* j) {
- PyObject *r;
- if (!j) return NULL;
- r = PyObject_GetItem(o, j);
- Py_DECREF(j);
- return r;
-}
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_List_Fast(PyObject *o, Py_ssize_t i,
- CYTHON_NCP_UNUSED int wraparound,
- CYTHON_NCP_UNUSED int boundscheck) {
-#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- Py_ssize_t wrapped_i = i;
- if (wraparound & unlikely(i < 0)) {
- wrapped_i += PyList_GET_SIZE(o);
- }
- if ((!boundscheck) || likely(__Pyx_is_valid_index(wrapped_i, PyList_GET_SIZE(o)))) {
- PyObject *r = PyList_GET_ITEM(o, wrapped_i);
- Py_INCREF(r);
- return r;
- }
- return __Pyx_GetItemInt_Generic(o, PyInt_FromSsize_t(i));
-#else
- return PySequence_GetItem(o, i);
-#endif
-}
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Tuple_Fast(PyObject *o, Py_ssize_t i,
- CYTHON_NCP_UNUSED int wraparound,
- CYTHON_NCP_UNUSED int boundscheck) {
-#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- Py_ssize_t wrapped_i = i;
- if (wraparound & unlikely(i < 0)) {
- wrapped_i += PyTuple_GET_SIZE(o);
- }
- if ((!boundscheck) || likely(__Pyx_is_valid_index(wrapped_i, PyTuple_GET_SIZE(o)))) {
- PyObject *r = PyTuple_GET_ITEM(o, wrapped_i);
- Py_INCREF(r);
- return r;
- }
- return __Pyx_GetItemInt_Generic(o, PyInt_FromSsize_t(i));
-#else
- return PySequence_GetItem(o, i);
-#endif
-}
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Fast(PyObject *o, Py_ssize_t i, int is_list,
- CYTHON_NCP_UNUSED int wraparound,
- CYTHON_NCP_UNUSED int boundscheck) {
-#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS && CYTHON_USE_TYPE_SLOTS
- if (is_list || PyList_CheckExact(o)) {
- Py_ssize_t n = ((!wraparound) | likely(i >= 0)) ? i : i + PyList_GET_SIZE(o);
- if ((!boundscheck) || (likely(__Pyx_is_valid_index(n, PyList_GET_SIZE(o))))) {
- PyObject *r = PyList_GET_ITEM(o, n);
- Py_INCREF(r);
- return r;
- }
- }
- else if (PyTuple_CheckExact(o)) {
- Py_ssize_t n = ((!wraparound) | likely(i >= 0)) ? i : i + PyTuple_GET_SIZE(o);
- if ((!boundscheck) || likely(__Pyx_is_valid_index(n, PyTuple_GET_SIZE(o)))) {
- PyObject *r = PyTuple_GET_ITEM(o, n);
- Py_INCREF(r);
- return r;
- }
- } else {
- PySequenceMethods *m = Py_TYPE(o)->tp_as_sequence;
- if (likely(m && m->sq_item)) {
- if (wraparound && unlikely(i < 0) && likely(m->sq_length)) {
- Py_ssize_t l = m->sq_length(o);
- if (likely(l >= 0)) {
- i += l;
- } else {
- if (!PyErr_ExceptionMatches(PyExc_OverflowError))
- return NULL;
- PyErr_Clear();
- }
- }
- return m->sq_item(o, i);
- }
- }
-#else
- if (is_list || PySequence_Check(o)) {
- return PySequence_GetItem(o, i);
- }
-#endif
- return __Pyx_GetItemInt_Generic(o, PyInt_FromSsize_t(i));
-}
-
-/* ObjectGetItem */
-#if CYTHON_USE_TYPE_SLOTS
-static PyObject *__Pyx_PyObject_GetIndex(PyObject *obj, PyObject* index) {
- PyObject *runerr;
- Py_ssize_t key_value;
- PySequenceMethods *m = Py_TYPE(obj)->tp_as_sequence;
- if (unlikely(!(m && m->sq_item))) {
- PyErr_Format(PyExc_TypeError, "'%.200s' object is not subscriptable", Py_TYPE(obj)->tp_name);
- return NULL;
- }
- key_value = __Pyx_PyIndex_AsSsize_t(index);
- if (likely(key_value != -1 || !(runerr = PyErr_Occurred()))) {
- return __Pyx_GetItemInt_Fast(obj, key_value, 0, 1, 1);
- }
- if (PyErr_GivenExceptionMatches(runerr, PyExc_OverflowError)) {
- PyErr_Clear();
- PyErr_Format(PyExc_IndexError, "cannot fit '%.200s' into an index-sized integer", Py_TYPE(index)->tp_name);
- }
- return NULL;
-}
-static PyObject *__Pyx_PyObject_GetItem(PyObject *obj, PyObject* key) {
- PyMappingMethods *m = Py_TYPE(obj)->tp_as_mapping;
- if (likely(m && m->mp_subscript)) {
- return m->mp_subscript(obj, key);
- }
- return __Pyx_PyObject_GetIndex(obj, key);
-}
-#endif
-
-/* decode_c_string */
-static CYTHON_INLINE PyObject* __Pyx_decode_c_string(
- const char* cstring, Py_ssize_t start, Py_ssize_t stop,
- const char* encoding, const char* errors,
- PyObject* (*decode_func)(const char *s, Py_ssize_t size, const char *errors)) {
- Py_ssize_t length;
- if (unlikely((start < 0) | (stop < 0))) {
- size_t slen = strlen(cstring);
- if (unlikely(slen > (size_t) PY_SSIZE_T_MAX)) {
- PyErr_SetString(PyExc_OverflowError,
- "c-string too long to convert to Python");
- return NULL;
- }
- length = (Py_ssize_t) slen;
- if (start < 0) {
- start += length;
- if (start < 0)
- start = 0;
- }
- if (stop < 0)
- stop += length;
- }
- if (unlikely(stop <= start))
- return __Pyx_NewRef(__pyx_empty_unicode);
- length = stop - start;
- cstring += start;
- if (decode_func) {
- return decode_func(cstring, length, errors);
- } else {
- return PyUnicode_Decode(cstring, length, encoding, errors);
- }
-}
-
-/* PyErrExceptionMatches */
-#if CYTHON_FAST_THREAD_STATE
-static int __Pyx_PyErr_ExceptionMatchesTuple(PyObject *exc_type, PyObject *tuple) {
- Py_ssize_t i, n;
- n = PyTuple_GET_SIZE(tuple);
-#if PY_MAJOR_VERSION >= 3
- for (i=0; icurexc_type;
- if (exc_type == err) return 1;
- if (unlikely(!exc_type)) return 0;
- if (unlikely(PyTuple_Check(err)))
- return __Pyx_PyErr_ExceptionMatchesTuple(exc_type, err);
- return __Pyx_PyErr_GivenExceptionMatches(exc_type, err);
-}
-#endif
-
-/* GetAttr3 */
-static PyObject *__Pyx_GetAttr3Default(PyObject *d) {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- if (unlikely(!__Pyx_PyErr_ExceptionMatches(PyExc_AttributeError)))
- return NULL;
- __Pyx_PyErr_Clear();
- Py_INCREF(d);
- return d;
-}
-static CYTHON_INLINE PyObject *__Pyx_GetAttr3(PyObject *o, PyObject *n, PyObject *d) {
- PyObject *r = __Pyx_GetAttr(o, n);
- return (likely(r)) ? r : __Pyx_GetAttr3Default(d);
-}
-
-/* PyDictVersioning */
-#if CYTHON_USE_DICT_VERSIONS && CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_tp_dict_version(PyObject *obj) {
- PyObject *dict = Py_TYPE(obj)->tp_dict;
- return likely(dict) ? __PYX_GET_DICT_VERSION(dict) : 0;
-}
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_object_dict_version(PyObject *obj) {
- PyObject **dictptr = NULL;
- Py_ssize_t offset = Py_TYPE(obj)->tp_dictoffset;
- if (offset) {
-#if CYTHON_COMPILING_IN_CPYTHON
- dictptr = (likely(offset > 0)) ? (PyObject **) ((char *)obj + offset) : _PyObject_GetDictPtr(obj);
-#else
- dictptr = _PyObject_GetDictPtr(obj);
-#endif
- }
- return (dictptr && *dictptr) ? __PYX_GET_DICT_VERSION(*dictptr) : 0;
-}
-static CYTHON_INLINE int __Pyx_object_dict_version_matches(PyObject* obj, PY_UINT64_T tp_dict_version, PY_UINT64_T obj_dict_version) {
- PyObject *dict = Py_TYPE(obj)->tp_dict;
- if (unlikely(!dict) || unlikely(tp_dict_version != __PYX_GET_DICT_VERSION(dict)))
- return 0;
- return obj_dict_version == __Pyx_get_object_dict_version(obj);
-}
-#endif
-
-/* GetModuleGlobalName */
-#if CYTHON_USE_DICT_VERSIONS
-static PyObject *__Pyx__GetModuleGlobalName(PyObject *name, PY_UINT64_T *dict_version, PyObject **dict_cached_value)
-#else
-static CYTHON_INLINE PyObject *__Pyx__GetModuleGlobalName(PyObject *name)
-#endif
-{
- PyObject *result;
-#if !CYTHON_AVOID_BORROWED_REFS
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x030500A1
- result = _PyDict_GetItem_KnownHash(__pyx_d, name, ((PyASCIIObject *) name)->hash);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- } else if (unlikely(PyErr_Occurred())) {
- return NULL;
- }
-#else
- result = PyDict_GetItem(__pyx_d, name);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- }
-#endif
-#else
- result = PyObject_GetItem(__pyx_d, name);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- }
- PyErr_Clear();
-#endif
- return __Pyx_GetBuiltinName(name);
-}
-
-/* RaiseTooManyValuesToUnpack */
-static CYTHON_INLINE void __Pyx_RaiseTooManyValuesError(Py_ssize_t expected) {
- PyErr_Format(PyExc_ValueError,
- "too many values to unpack (expected %" CYTHON_FORMAT_SSIZE_T "d)", expected);
-}
-
-/* RaiseNeedMoreValuesToUnpack */
-static CYTHON_INLINE void __Pyx_RaiseNeedMoreValuesError(Py_ssize_t index) {
- PyErr_Format(PyExc_ValueError,
- "need more than %" CYTHON_FORMAT_SSIZE_T "d value%.1s to unpack",
- index, (index == 1) ? "" : "s");
-}
-
-/* RaiseNoneIterError */
-static CYTHON_INLINE void __Pyx_RaiseNoneNotIterableError(void) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' object is not iterable");
-}
-
-/* ExtTypeTest */
-static CYTHON_INLINE int __Pyx_TypeTest(PyObject *obj, PyTypeObject *type) {
- if (unlikely(!type)) {
- PyErr_SetString(PyExc_SystemError, "Missing type object");
- return 0;
- }
- if (likely(__Pyx_TypeCheck(obj, type)))
- return 1;
- PyErr_Format(PyExc_TypeError, "Cannot convert %.200s to %.200s",
- Py_TYPE(obj)->tp_name, type->tp_name);
- return 0;
-}
-
-/* GetTopmostException */
-#if CYTHON_USE_EXC_INFO_STACK
-static _PyErr_StackItem *
-__Pyx_PyErr_GetTopmostException(PyThreadState *tstate)
-{
- _PyErr_StackItem *exc_info = tstate->exc_info;
- while ((exc_info->exc_type == NULL || exc_info->exc_type == Py_None) &&
- exc_info->previous_item != NULL)
- {
- exc_info = exc_info->previous_item;
- }
- return exc_info;
-}
-#endif
-
-/* SaveResetException */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx__ExceptionSave(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
- #if CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = __Pyx_PyErr_GetTopmostException(tstate);
- *type = exc_info->exc_type;
- *value = exc_info->exc_value;
- *tb = exc_info->exc_traceback;
- #else
- *type = tstate->exc_type;
- *value = tstate->exc_value;
- *tb = tstate->exc_traceback;
- #endif
- Py_XINCREF(*type);
- Py_XINCREF(*value);
- Py_XINCREF(*tb);
-}
-static CYTHON_INLINE void __Pyx__ExceptionReset(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- #if CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = tstate->exc_info;
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = type;
- exc_info->exc_value = value;
- exc_info->exc_traceback = tb;
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = type;
- tstate->exc_value = value;
- tstate->exc_traceback = tb;
- #endif
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-}
-#endif
-
-/* GetException */
-#if CYTHON_FAST_THREAD_STATE
-static int __Pyx__GetException(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb)
-#else
-static int __Pyx_GetException(PyObject **type, PyObject **value, PyObject **tb)
-#endif
-{
- PyObject *local_type, *local_value, *local_tb;
-#if CYTHON_FAST_THREAD_STATE
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- local_type = tstate->curexc_type;
- local_value = tstate->curexc_value;
- local_tb = tstate->curexc_traceback;
- tstate->curexc_type = 0;
- tstate->curexc_value = 0;
- tstate->curexc_traceback = 0;
-#else
- PyErr_Fetch(&local_type, &local_value, &local_tb);
-#endif
- PyErr_NormalizeException(&local_type, &local_value, &local_tb);
-#if CYTHON_FAST_THREAD_STATE
- if (unlikely(tstate->curexc_type))
-#else
- if (unlikely(PyErr_Occurred()))
-#endif
- goto bad;
- #if PY_MAJOR_VERSION >= 3
- if (local_tb) {
- if (unlikely(PyException_SetTraceback(local_value, local_tb) < 0))
- goto bad;
- }
- #endif
- Py_XINCREF(local_tb);
- Py_XINCREF(local_type);
- Py_XINCREF(local_value);
- *type = local_type;
- *value = local_value;
- *tb = local_tb;
-#if CYTHON_FAST_THREAD_STATE
- #if CYTHON_USE_EXC_INFO_STACK
- {
- _PyErr_StackItem *exc_info = tstate->exc_info;
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = local_type;
- exc_info->exc_value = local_value;
- exc_info->exc_traceback = local_tb;
- }
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = local_type;
- tstate->exc_value = local_value;
- tstate->exc_traceback = local_tb;
- #endif
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-#else
- PyErr_SetExcInfo(local_type, local_value, local_tb);
-#endif
- return 0;
-bad:
- *type = 0;
- *value = 0;
- *tb = 0;
- Py_XDECREF(local_type);
- Py_XDECREF(local_value);
- Py_XDECREF(local_tb);
- return -1;
-}
-
-/* SwapException */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx__ExceptionSwap(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- #if CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = tstate->exc_info;
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = *type;
- exc_info->exc_value = *value;
- exc_info->exc_traceback = *tb;
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = *type;
- tstate->exc_value = *value;
- tstate->exc_traceback = *tb;
- #endif
- *type = tmp_type;
- *value = tmp_value;
- *tb = tmp_tb;
-}
-#else
-static CYTHON_INLINE void __Pyx_ExceptionSwap(PyObject **type, PyObject **value, PyObject **tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- PyErr_GetExcInfo(&tmp_type, &tmp_value, &tmp_tb);
- PyErr_SetExcInfo(*type, *value, *tb);
- *type = tmp_type;
- *value = tmp_value;
- *tb = tmp_tb;
-}
-#endif
-
-/* Import */
-static PyObject *__Pyx_Import(PyObject *name, PyObject *from_list, int level) {
- PyObject *empty_list = 0;
- PyObject *module = 0;
- PyObject *global_dict = 0;
- PyObject *empty_dict = 0;
- PyObject *list;
- #if PY_MAJOR_VERSION < 3
- PyObject *py_import;
- py_import = __Pyx_PyObject_GetAttrStr(__pyx_b, __pyx_n_s_import);
- if (!py_import)
- goto bad;
- #endif
- if (from_list)
- list = from_list;
- else {
- empty_list = PyList_New(0);
- if (!empty_list)
- goto bad;
- list = empty_list;
- }
- global_dict = PyModule_GetDict(__pyx_m);
- if (!global_dict)
- goto bad;
- empty_dict = PyDict_New();
- if (!empty_dict)
- goto bad;
- {
- #if PY_MAJOR_VERSION >= 3
- if (level == -1) {
- if ((1) && (strchr(__Pyx_MODULE_NAME, '.'))) {
- module = PyImport_ImportModuleLevelObject(
- name, global_dict, empty_dict, list, 1);
- if (!module) {
- if (!PyErr_ExceptionMatches(PyExc_ImportError))
- goto bad;
- PyErr_Clear();
- }
- }
- level = 0;
- }
- #endif
- if (!module) {
- #if PY_MAJOR_VERSION < 3
- PyObject *py_level = PyInt_FromLong(level);
- if (!py_level)
- goto bad;
- module = PyObject_CallFunctionObjArgs(py_import,
- name, global_dict, empty_dict, list, py_level, (PyObject *)NULL);
- Py_DECREF(py_level);
- #else
- module = PyImport_ImportModuleLevelObject(
- name, global_dict, empty_dict, list, level);
- #endif
- }
- }
-bad:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(py_import);
- #endif
- Py_XDECREF(empty_list);
- Py_XDECREF(empty_dict);
- return module;
-}
-
-/* FastTypeChecks */
-#if CYTHON_COMPILING_IN_CPYTHON
-static int __Pyx_InBases(PyTypeObject *a, PyTypeObject *b) {
- while (a) {
- a = a->tp_base;
- if (a == b)
- return 1;
- }
- return b == &PyBaseObject_Type;
-}
-static CYTHON_INLINE int __Pyx_IsSubtype(PyTypeObject *a, PyTypeObject *b) {
- PyObject *mro;
- if (a == b) return 1;
- mro = a->tp_mro;
- if (likely(mro)) {
- Py_ssize_t i, n;
- n = PyTuple_GET_SIZE(mro);
- for (i = 0; i < n; i++) {
- if (PyTuple_GET_ITEM(mro, i) == (PyObject *)b)
- return 1;
- }
- return 0;
- }
- return __Pyx_InBases(a, b);
-}
-#if PY_MAJOR_VERSION == 2
-static int __Pyx_inner_PyErr_GivenExceptionMatches2(PyObject *err, PyObject* exc_type1, PyObject* exc_type2) {
- PyObject *exception, *value, *tb;
- int res;
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ErrFetch(&exception, &value, &tb);
- res = exc_type1 ? PyObject_IsSubclass(err, exc_type1) : 0;
- if (unlikely(res == -1)) {
- PyErr_WriteUnraisable(err);
- res = 0;
- }
- if (!res) {
- res = PyObject_IsSubclass(err, exc_type2);
- if (unlikely(res == -1)) {
- PyErr_WriteUnraisable(err);
- res = 0;
- }
- }
- __Pyx_ErrRestore(exception, value, tb);
- return res;
-}
-#else
-static CYTHON_INLINE int __Pyx_inner_PyErr_GivenExceptionMatches2(PyObject *err, PyObject* exc_type1, PyObject *exc_type2) {
- int res = exc_type1 ? __Pyx_IsSubtype((PyTypeObject*)err, (PyTypeObject*)exc_type1) : 0;
- if (!res) {
- res = __Pyx_IsSubtype((PyTypeObject*)err, (PyTypeObject*)exc_type2);
- }
- return res;
-}
-#endif
-static int __Pyx_PyErr_GivenExceptionMatchesTuple(PyObject *exc_type, PyObject *tuple) {
- Py_ssize_t i, n;
- assert(PyExceptionClass_Check(exc_type));
- n = PyTuple_GET_SIZE(tuple);
-#if PY_MAJOR_VERSION >= 3
- for (i=0; i= 0 || (x^b) >= 0))
- return PyInt_FromLong(x);
- return PyLong_Type.tp_as_number->nb_add(op1, op2);
- }
- #endif
- #if CYTHON_USE_PYLONG_INTERNALS
- if (likely(PyLong_CheckExact(op1))) {
- const long b = intval;
- long a, x;
-#ifdef HAVE_LONG_LONG
- const PY_LONG_LONG llb = intval;
- PY_LONG_LONG lla, llx;
-#endif
- const digit* digits = ((PyLongObject*)op1)->ob_digit;
- const Py_ssize_t size = Py_SIZE(op1);
- if (likely(__Pyx_sst_abs(size) <= 1)) {
- a = likely(size) ? digits[0] : 0;
- if (size == -1) a = -a;
- } else {
- switch (size) {
- case -2:
- if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- a = -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 2 * PyLong_SHIFT) {
- lla = -(PY_LONG_LONG) (((((unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- a = (long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 2 * PyLong_SHIFT) {
- lla = (PY_LONG_LONG) (((((unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case -3:
- if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- a = -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 3 * PyLong_SHIFT) {
- lla = -(PY_LONG_LONG) (((((((unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case 3:
- if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- a = (long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 3 * PyLong_SHIFT) {
- lla = (PY_LONG_LONG) (((((((unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case -4:
- if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- a = -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 4 * PyLong_SHIFT) {
- lla = -(PY_LONG_LONG) (((((((((unsigned PY_LONG_LONG)digits[3]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case 4:
- if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- a = (long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 4 * PyLong_SHIFT) {
- lla = (PY_LONG_LONG) (((((((((unsigned PY_LONG_LONG)digits[3]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- default: return PyLong_Type.tp_as_number->nb_add(op1, op2);
- }
- }
- x = a + b;
- return PyLong_FromLong(x);
-#ifdef HAVE_LONG_LONG
- long_long:
- llx = lla + llb;
- return PyLong_FromLongLong(llx);
-#endif
-
-
- }
- #endif
- if (PyFloat_CheckExact(op1)) {
- const long b = intval;
- double a = PyFloat_AS_DOUBLE(op1);
- double result;
- PyFPE_START_PROTECT("add", return NULL)
- result = ((double)a) + (double)b;
- PyFPE_END_PROTECT(result)
- return PyFloat_FromDouble(result);
- }
- return (inplace ? PyNumber_InPlaceAdd : PyNumber_Add)(op1, op2);
-}
-#endif
-
-/* DivInt[long] */
-static CYTHON_INLINE long __Pyx_div_long(long a, long b) {
- long q = a / b;
- long r = a - q*b;
- q -= ((r != 0) & ((r ^ b) < 0));
- return q;
-}
-
-/* ImportFrom */
-static PyObject* __Pyx_ImportFrom(PyObject* module, PyObject* name) {
- PyObject* value = __Pyx_PyObject_GetAttrStr(module, name);
- if (unlikely(!value) && PyErr_ExceptionMatches(PyExc_AttributeError)) {
- PyErr_Format(PyExc_ImportError,
- #if PY_MAJOR_VERSION < 3
- "cannot import name %.230s", PyString_AS_STRING(name));
- #else
- "cannot import name %S", name);
- #endif
- }
- return value;
-}
-
-/* HasAttr */
-static CYTHON_INLINE int __Pyx_HasAttr(PyObject *o, PyObject *n) {
- PyObject *r;
- if (unlikely(!__Pyx_PyBaseString_Check(n))) {
- PyErr_SetString(PyExc_TypeError,
- "hasattr(): attribute name must be string");
- return -1;
- }
- r = __Pyx_GetAttr(o, n);
- if (unlikely(!r)) {
- PyErr_Clear();
- return 0;
- } else {
- Py_DECREF(r);
- return 1;
- }
-}
-
-/* PyObject_GenericGetAttrNoDict */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static PyObject *__Pyx_RaiseGenericGetAttributeError(PyTypeObject *tp, PyObject *attr_name) {
- PyErr_Format(PyExc_AttributeError,
-#if PY_MAJOR_VERSION >= 3
- "'%.50s' object has no attribute '%U'",
- tp->tp_name, attr_name);
-#else
- "'%.50s' object has no attribute '%.400s'",
- tp->tp_name, PyString_AS_STRING(attr_name));
-#endif
- return NULL;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GenericGetAttrNoDict(PyObject* obj, PyObject* attr_name) {
- PyObject *descr;
- PyTypeObject *tp = Py_TYPE(obj);
- if (unlikely(!PyString_Check(attr_name))) {
- return PyObject_GenericGetAttr(obj, attr_name);
- }
- assert(!tp->tp_dictoffset);
- descr = _PyType_Lookup(tp, attr_name);
- if (unlikely(!descr)) {
- return __Pyx_RaiseGenericGetAttributeError(tp, attr_name);
- }
- Py_INCREF(descr);
- #if PY_MAJOR_VERSION < 3
- if (likely(PyType_HasFeature(Py_TYPE(descr), Py_TPFLAGS_HAVE_CLASS)))
- #endif
- {
- descrgetfunc f = Py_TYPE(descr)->tp_descr_get;
- if (unlikely(f)) {
- PyObject *res = f(descr, obj, (PyObject *)tp);
- Py_DECREF(descr);
- return res;
- }
- }
- return descr;
-}
-#endif
-
-/* PyObject_GenericGetAttr */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static PyObject* __Pyx_PyObject_GenericGetAttr(PyObject* obj, PyObject* attr_name) {
- if (unlikely(Py_TYPE(obj)->tp_dictoffset)) {
- return PyObject_GenericGetAttr(obj, attr_name);
- }
- return __Pyx_PyObject_GenericGetAttrNoDict(obj, attr_name);
-}
-#endif
-
-/* SetVTable */
-static int __Pyx_SetVtable(PyObject *dict, void *vtable) {
-#if PY_VERSION_HEX >= 0x02070000
- PyObject *ob = PyCapsule_New(vtable, 0, 0);
-#else
- PyObject *ob = PyCObject_FromVoidPtr(vtable, 0);
-#endif
- if (!ob)
- goto bad;
- if (PyDict_SetItem(dict, __pyx_n_s_pyx_vtable, ob) < 0)
- goto bad;
- Py_DECREF(ob);
- return 0;
-bad:
- Py_XDECREF(ob);
- return -1;
-}
-
-/* PyObjectGetAttrStrNoError */
-static void __Pyx_PyObject_GetAttrStr_ClearAttributeError(void) {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- if (likely(__Pyx_PyErr_ExceptionMatches(PyExc_AttributeError)))
- __Pyx_PyErr_Clear();
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStrNoError(PyObject* obj, PyObject* attr_name) {
- PyObject *result;
-#if CYTHON_COMPILING_IN_CPYTHON && CYTHON_USE_TYPE_SLOTS && PY_VERSION_HEX >= 0x030700B1
- PyTypeObject* tp = Py_TYPE(obj);
- if (likely(tp->tp_getattro == PyObject_GenericGetAttr)) {
- return _PyObject_GenericGetAttrWithDict(obj, attr_name, NULL, 1);
- }
-#endif
- result = __Pyx_PyObject_GetAttrStr(obj, attr_name);
- if (unlikely(!result)) {
- __Pyx_PyObject_GetAttrStr_ClearAttributeError();
- }
- return result;
-}
-
-/* SetupReduce */
-static int __Pyx_setup_reduce_is_named(PyObject* meth, PyObject* name) {
- int ret;
- PyObject *name_attr;
- name_attr = __Pyx_PyObject_GetAttrStr(meth, __pyx_n_s_name_2);
- if (likely(name_attr)) {
- ret = PyObject_RichCompareBool(name_attr, name, Py_EQ);
- } else {
- ret = -1;
- }
- if (unlikely(ret < 0)) {
- PyErr_Clear();
- ret = 0;
- }
- Py_XDECREF(name_attr);
- return ret;
-}
-static int __Pyx_setup_reduce(PyObject* type_obj) {
- int ret = 0;
- PyObject *object_reduce = NULL;
- PyObject *object_getstate = NULL;
- PyObject *object_reduce_ex = NULL;
- PyObject *reduce = NULL;
- PyObject *reduce_ex = NULL;
- PyObject *reduce_cython = NULL;
- PyObject *setstate = NULL;
- PyObject *setstate_cython = NULL;
- PyObject *getstate = NULL;
-#if CYTHON_USE_PYTYPE_LOOKUP
- getstate = _PyType_Lookup((PyTypeObject*)type_obj, __pyx_n_s_getstate);
-#else
- getstate = __Pyx_PyObject_GetAttrStrNoError(type_obj, __pyx_n_s_getstate);
- if (!getstate && PyErr_Occurred()) {
- goto __PYX_BAD;
- }
-#endif
- if (getstate) {
-#if CYTHON_USE_PYTYPE_LOOKUP
- object_getstate = _PyType_Lookup(&PyBaseObject_Type, __pyx_n_s_getstate);
-#else
- object_getstate = __Pyx_PyObject_GetAttrStrNoError((PyObject*)&PyBaseObject_Type, __pyx_n_s_getstate);
- if (!object_getstate && PyErr_Occurred()) {
- goto __PYX_BAD;
- }
-#endif
- if (object_getstate != getstate) {
- goto __PYX_GOOD;
- }
- }
-#if CYTHON_USE_PYTYPE_LOOKUP
- object_reduce_ex = _PyType_Lookup(&PyBaseObject_Type, __pyx_n_s_reduce_ex); if (!object_reduce_ex) goto __PYX_BAD;
-#else
- object_reduce_ex = __Pyx_PyObject_GetAttrStr((PyObject*)&PyBaseObject_Type, __pyx_n_s_reduce_ex); if (!object_reduce_ex) goto __PYX_BAD;
-#endif
- reduce_ex = __Pyx_PyObject_GetAttrStr(type_obj, __pyx_n_s_reduce_ex); if (unlikely(!reduce_ex)) goto __PYX_BAD;
- if (reduce_ex == object_reduce_ex) {
-#if CYTHON_USE_PYTYPE_LOOKUP
- object_reduce = _PyType_Lookup(&PyBaseObject_Type, __pyx_n_s_reduce); if (!object_reduce) goto __PYX_BAD;
-#else
- object_reduce = __Pyx_PyObject_GetAttrStr((PyObject*)&PyBaseObject_Type, __pyx_n_s_reduce); if (!object_reduce) goto __PYX_BAD;
-#endif
- reduce = __Pyx_PyObject_GetAttrStr(type_obj, __pyx_n_s_reduce); if (unlikely(!reduce)) goto __PYX_BAD;
- if (reduce == object_reduce || __Pyx_setup_reduce_is_named(reduce, __pyx_n_s_reduce_cython)) {
- reduce_cython = __Pyx_PyObject_GetAttrStrNoError(type_obj, __pyx_n_s_reduce_cython);
- if (likely(reduce_cython)) {
- ret = PyDict_SetItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_reduce, reduce_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- ret = PyDict_DelItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_reduce_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- } else if (reduce == object_reduce || PyErr_Occurred()) {
- goto __PYX_BAD;
- }
- setstate = __Pyx_PyObject_GetAttrStr(type_obj, __pyx_n_s_setstate);
- if (!setstate) PyErr_Clear();
- if (!setstate || __Pyx_setup_reduce_is_named(setstate, __pyx_n_s_setstate_cython)) {
- setstate_cython = __Pyx_PyObject_GetAttrStrNoError(type_obj, __pyx_n_s_setstate_cython);
- if (likely(setstate_cython)) {
- ret = PyDict_SetItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_setstate, setstate_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- ret = PyDict_DelItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_setstate_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- } else if (!setstate || PyErr_Occurred()) {
- goto __PYX_BAD;
- }
- }
- PyType_Modified((PyTypeObject*)type_obj);
- }
- }
- goto __PYX_GOOD;
-__PYX_BAD:
- if (!PyErr_Occurred())
- PyErr_Format(PyExc_RuntimeError, "Unable to initialize pickling for %s", ((PyTypeObject*)type_obj)->tp_name);
- ret = -1;
-__PYX_GOOD:
-#if !CYTHON_USE_PYTYPE_LOOKUP
- Py_XDECREF(object_reduce);
- Py_XDECREF(object_reduce_ex);
- Py_XDECREF(object_getstate);
- Py_XDECREF(getstate);
-#endif
- Py_XDECREF(reduce);
- Py_XDECREF(reduce_ex);
- Py_XDECREF(reduce_cython);
- Py_XDECREF(setstate);
- Py_XDECREF(setstate_cython);
- return ret;
-}
-
-/* CLineInTraceback */
-#ifndef CYTHON_CLINE_IN_TRACEBACK
-static int __Pyx_CLineForTraceback(CYTHON_NCP_UNUSED PyThreadState *tstate, int c_line) {
- PyObject *use_cline;
- PyObject *ptype, *pvalue, *ptraceback;
-#if CYTHON_COMPILING_IN_CPYTHON
- PyObject **cython_runtime_dict;
-#endif
- if (unlikely(!__pyx_cython_runtime)) {
- return c_line;
- }
- __Pyx_ErrFetchInState(tstate, &ptype, &pvalue, &ptraceback);
-#if CYTHON_COMPILING_IN_CPYTHON
- cython_runtime_dict = _PyObject_GetDictPtr(__pyx_cython_runtime);
- if (likely(cython_runtime_dict)) {
- __PYX_PY_DICT_LOOKUP_IF_MODIFIED(
- use_cline, *cython_runtime_dict,
- __Pyx_PyDict_GetItemStr(*cython_runtime_dict, __pyx_n_s_cline_in_traceback))
- } else
-#endif
- {
- PyObject *use_cline_obj = __Pyx_PyObject_GetAttrStr(__pyx_cython_runtime, __pyx_n_s_cline_in_traceback);
- if (use_cline_obj) {
- use_cline = PyObject_Not(use_cline_obj) ? Py_False : Py_True;
- Py_DECREF(use_cline_obj);
- } else {
- PyErr_Clear();
- use_cline = NULL;
- }
- }
- if (!use_cline) {
- c_line = 0;
- (void) PyObject_SetAttr(__pyx_cython_runtime, __pyx_n_s_cline_in_traceback, Py_False);
- }
- else if (use_cline == Py_False || (use_cline != Py_True && PyObject_Not(use_cline) != 0)) {
- c_line = 0;
- }
- __Pyx_ErrRestoreInState(tstate, ptype, pvalue, ptraceback);
- return c_line;
-}
-#endif
-
-/* CodeObjectCache */
-static int __pyx_bisect_code_objects(__Pyx_CodeObjectCacheEntry* entries, int count, int code_line) {
- int start = 0, mid = 0, end = count - 1;
- if (end >= 0 && code_line > entries[end].code_line) {
- return count;
- }
- while (start < end) {
- mid = start + (end - start) / 2;
- if (code_line < entries[mid].code_line) {
- end = mid;
- } else if (code_line > entries[mid].code_line) {
- start = mid + 1;
- } else {
- return mid;
- }
- }
- if (code_line <= entries[mid].code_line) {
- return mid;
- } else {
- return mid + 1;
- }
-}
-static PyCodeObject *__pyx_find_code_object(int code_line) {
- PyCodeObject* code_object;
- int pos;
- if (unlikely(!code_line) || unlikely(!__pyx_code_cache.entries)) {
- return NULL;
- }
- pos = __pyx_bisect_code_objects(__pyx_code_cache.entries, __pyx_code_cache.count, code_line);
- if (unlikely(pos >= __pyx_code_cache.count) || unlikely(__pyx_code_cache.entries[pos].code_line != code_line)) {
- return NULL;
- }
- code_object = __pyx_code_cache.entries[pos].code_object;
- Py_INCREF(code_object);
- return code_object;
-}
-static void __pyx_insert_code_object(int code_line, PyCodeObject* code_object) {
- int pos, i;
- __Pyx_CodeObjectCacheEntry* entries = __pyx_code_cache.entries;
- if (unlikely(!code_line)) {
- return;
- }
- if (unlikely(!entries)) {
- entries = (__Pyx_CodeObjectCacheEntry*)PyMem_Malloc(64*sizeof(__Pyx_CodeObjectCacheEntry));
- if (likely(entries)) {
- __pyx_code_cache.entries = entries;
- __pyx_code_cache.max_count = 64;
- __pyx_code_cache.count = 1;
- entries[0].code_line = code_line;
- entries[0].code_object = code_object;
- Py_INCREF(code_object);
- }
- return;
- }
- pos = __pyx_bisect_code_objects(__pyx_code_cache.entries, __pyx_code_cache.count, code_line);
- if ((pos < __pyx_code_cache.count) && unlikely(__pyx_code_cache.entries[pos].code_line == code_line)) {
- PyCodeObject* tmp = entries[pos].code_object;
- entries[pos].code_object = code_object;
- Py_DECREF(tmp);
- return;
- }
- if (__pyx_code_cache.count == __pyx_code_cache.max_count) {
- int new_max = __pyx_code_cache.max_count + 64;
- entries = (__Pyx_CodeObjectCacheEntry*)PyMem_Realloc(
- __pyx_code_cache.entries, ((size_t)new_max) * sizeof(__Pyx_CodeObjectCacheEntry));
- if (unlikely(!entries)) {
- return;
- }
- __pyx_code_cache.entries = entries;
- __pyx_code_cache.max_count = new_max;
- }
- for (i=__pyx_code_cache.count; i>pos; i--) {
- entries[i] = entries[i-1];
- }
- entries[pos].code_line = code_line;
- entries[pos].code_object = code_object;
- __pyx_code_cache.count++;
- Py_INCREF(code_object);
-}
-
-/* AddTraceback */
-#include "compile.h"
-#include "frameobject.h"
-#include "traceback.h"
-#if PY_VERSION_HEX >= 0x030b00a6
- #ifndef Py_BUILD_CORE
- #define Py_BUILD_CORE 1
- #endif
- #include "internal/pycore_frame.h"
-#endif
-static PyCodeObject* __Pyx_CreateCodeObjectForTraceback(
- const char *funcname, int c_line,
- int py_line, const char *filename) {
- PyCodeObject *py_code = NULL;
- PyObject *py_funcname = NULL;
- #if PY_MAJOR_VERSION < 3
- PyObject *py_srcfile = NULL;
- py_srcfile = PyString_FromString(filename);
- if (!py_srcfile) goto bad;
- #endif
- if (c_line) {
- #if PY_MAJOR_VERSION < 3
- py_funcname = PyString_FromFormat( "%s (%s:%d)", funcname, __pyx_cfilenm, c_line);
- if (!py_funcname) goto bad;
- #else
- py_funcname = PyUnicode_FromFormat( "%s (%s:%d)", funcname, __pyx_cfilenm, c_line);
- if (!py_funcname) goto bad;
- funcname = PyUnicode_AsUTF8(py_funcname);
- if (!funcname) goto bad;
- #endif
- }
- else {
- #if PY_MAJOR_VERSION < 3
- py_funcname = PyString_FromString(funcname);
- if (!py_funcname) goto bad;
- #endif
- }
- #if PY_MAJOR_VERSION < 3
- py_code = __Pyx_PyCode_New(
- 0,
- 0,
- 0,
- 0,
- 0,
- __pyx_empty_bytes, /*PyObject *code,*/
- __pyx_empty_tuple, /*PyObject *consts,*/
- __pyx_empty_tuple, /*PyObject *names,*/
- __pyx_empty_tuple, /*PyObject *varnames,*/
- __pyx_empty_tuple, /*PyObject *freevars,*/
- __pyx_empty_tuple, /*PyObject *cellvars,*/
- py_srcfile, /*PyObject *filename,*/
- py_funcname, /*PyObject *name,*/
- py_line,
- __pyx_empty_bytes /*PyObject *lnotab*/
- );
- Py_DECREF(py_srcfile);
- #else
- py_code = PyCode_NewEmpty(filename, funcname, py_line);
- #endif
- Py_XDECREF(py_funcname); // XDECREF since it's only set on Py3 if cline
- return py_code;
-bad:
- Py_XDECREF(py_funcname);
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(py_srcfile);
- #endif
- return NULL;
-}
-static void __Pyx_AddTraceback(const char *funcname, int c_line,
- int py_line, const char *filename) {
- PyCodeObject *py_code = 0;
- PyFrameObject *py_frame = 0;
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject *ptype, *pvalue, *ptraceback;
- if (c_line) {
- c_line = __Pyx_CLineForTraceback(tstate, c_line);
- }
- py_code = __pyx_find_code_object(c_line ? -c_line : py_line);
- if (!py_code) {
- __Pyx_ErrFetchInState(tstate, &ptype, &pvalue, &ptraceback);
- py_code = __Pyx_CreateCodeObjectForTraceback(
- funcname, c_line, py_line, filename);
- if (!py_code) {
- /* If the code object creation fails, then we should clear the
- fetched exception references and propagate the new exception */
- Py_XDECREF(ptype);
- Py_XDECREF(pvalue);
- Py_XDECREF(ptraceback);
- goto bad;
- }
- __Pyx_ErrRestoreInState(tstate, ptype, pvalue, ptraceback);
- __pyx_insert_code_object(c_line ? -c_line : py_line, py_code);
- }
- py_frame = PyFrame_New(
- tstate, /*PyThreadState *tstate,*/
- py_code, /*PyCodeObject *code,*/
- __pyx_d, /*PyObject *globals,*/
- 0 /*PyObject *locals*/
- );
- if (!py_frame) goto bad;
- __Pyx_PyFrame_SetLineNumber(py_frame, py_line);
- PyTraceBack_Here(py_frame);
-bad:
- Py_XDECREF(py_code);
- Py_XDECREF(py_frame);
-}
-
-#if PY_MAJOR_VERSION < 3
-static int __Pyx_GetBuffer(PyObject *obj, Py_buffer *view, int flags) {
- if (PyObject_CheckBuffer(obj)) return PyObject_GetBuffer(obj, view, flags);
- if (__Pyx_TypeCheck(obj, __pyx_array_type)) return __pyx_array_getbuffer(obj, view, flags);
- if (__Pyx_TypeCheck(obj, __pyx_memoryview_type)) return __pyx_memoryview_getbuffer(obj, view, flags);
- PyErr_Format(PyExc_TypeError, "'%.200s' does not have the buffer interface", Py_TYPE(obj)->tp_name);
- return -1;
-}
-static void __Pyx_ReleaseBuffer(Py_buffer *view) {
- PyObject *obj = view->obj;
- if (!obj) return;
- if (PyObject_CheckBuffer(obj)) {
- PyBuffer_Release(view);
- return;
- }
- if ((0)) {}
- view->obj = NULL;
- Py_DECREF(obj);
-}
-#endif
-
-
-/* MemviewSliceIsContig */
-static int
-__pyx_memviewslice_is_contig(const __Pyx_memviewslice mvs, char order, int ndim)
-{
- int i, index, step, start;
- Py_ssize_t itemsize = mvs.memview->view.itemsize;
- if (order == 'F') {
- step = 1;
- start = 0;
- } else {
- step = -1;
- start = ndim - 1;
- }
- for (i = 0; i < ndim; i++) {
- index = start + step * i;
- if (mvs.suboffsets[index] >= 0 || mvs.strides[index] != itemsize)
- return 0;
- itemsize *= mvs.shape[index];
- }
- return 1;
-}
-
-/* OverlappingSlices */
-static void
-__pyx_get_array_memory_extents(__Pyx_memviewslice *slice,
- void **out_start, void **out_end,
- int ndim, size_t itemsize)
-{
- char *start, *end;
- int i;
- start = end = slice->data;
- for (i = 0; i < ndim; i++) {
- Py_ssize_t stride = slice->strides[i];
- Py_ssize_t extent = slice->shape[i];
- if (extent == 0) {
- *out_start = *out_end = start;
- return;
- } else {
- if (stride > 0)
- end += stride * (extent - 1);
- else
- start += stride * (extent - 1);
- }
- }
- *out_start = start;
- *out_end = end + itemsize;
-}
-static int
-__pyx_slices_overlap(__Pyx_memviewslice *slice1,
- __Pyx_memviewslice *slice2,
- int ndim, size_t itemsize)
-{
- void *start1, *end1, *start2, *end2;
- __pyx_get_array_memory_extents(slice1, &start1, &end1, ndim, itemsize);
- __pyx_get_array_memory_extents(slice2, &start2, &end2, ndim, itemsize);
- return (start1 < end2) && (start2 < end1);
-}
-
-/* Capsule */
-static CYTHON_INLINE PyObject *
-__pyx_capsule_create(void *p, CYTHON_UNUSED const char *sig)
-{
- PyObject *cobj;
-#if PY_VERSION_HEX >= 0x02070000
- cobj = PyCapsule_New(p, sig, NULL);
-#else
- cobj = PyCObject_FromVoidPtr(p, NULL);
-#endif
- return cobj;
-}
-
-/* IsLittleEndian */
-static CYTHON_INLINE int __Pyx_Is_Little_Endian(void)
-{
- union {
- uint32_t u32;
- uint8_t u8[4];
- } S;
- S.u32 = 0x01020304;
- return S.u8[0] == 4;
-}
-
-/* BufferFormatCheck */
-static void __Pyx_BufFmt_Init(__Pyx_BufFmt_Context* ctx,
- __Pyx_BufFmt_StackElem* stack,
- __Pyx_TypeInfo* type) {
- stack[0].field = &ctx->root;
- stack[0].parent_offset = 0;
- ctx->root.type = type;
- ctx->root.name = "buffer dtype";
- ctx->root.offset = 0;
- ctx->head = stack;
- ctx->head->field = &ctx->root;
- ctx->fmt_offset = 0;
- ctx->head->parent_offset = 0;
- ctx->new_packmode = '@';
- ctx->enc_packmode = '@';
- ctx->new_count = 1;
- ctx->enc_count = 0;
- ctx->enc_type = 0;
- ctx->is_complex = 0;
- ctx->is_valid_array = 0;
- ctx->struct_alignment = 0;
- while (type->typegroup == 'S') {
- ++ctx->head;
- ctx->head->field = type->fields;
- ctx->head->parent_offset = 0;
- type = type->fields->type;
- }
-}
-static int __Pyx_BufFmt_ParseNumber(const char** ts) {
- int count;
- const char* t = *ts;
- if (*t < '0' || *t > '9') {
- return -1;
- } else {
- count = *t++ - '0';
- while (*t >= '0' && *t <= '9') {
- count *= 10;
- count += *t++ - '0';
- }
- }
- *ts = t;
- return count;
-}
-static int __Pyx_BufFmt_ExpectNumber(const char **ts) {
- int number = __Pyx_BufFmt_ParseNumber(ts);
- if (number == -1)
- PyErr_Format(PyExc_ValueError,\
- "Does not understand character buffer dtype format string ('%c')", **ts);
- return number;
-}
-static void __Pyx_BufFmt_RaiseUnexpectedChar(char ch) {
- PyErr_Format(PyExc_ValueError,
- "Unexpected format string character: '%c'", ch);
-}
-static const char* __Pyx_BufFmt_DescribeTypeChar(char ch, int is_complex) {
- switch (ch) {
- case '?': return "'bool'";
- case 'c': return "'char'";
- case 'b': return "'signed char'";
- case 'B': return "'unsigned char'";
- case 'h': return "'short'";
- case 'H': return "'unsigned short'";
- case 'i': return "'int'";
- case 'I': return "'unsigned int'";
- case 'l': return "'long'";
- case 'L': return "'unsigned long'";
- case 'q': return "'long long'";
- case 'Q': return "'unsigned long long'";
- case 'f': return (is_complex ? "'complex float'" : "'float'");
- case 'd': return (is_complex ? "'complex double'" : "'double'");
- case 'g': return (is_complex ? "'complex long double'" : "'long double'");
- case 'T': return "a struct";
- case 'O': return "Python object";
- case 'P': return "a pointer";
- case 's': case 'p': return "a string";
- case 0: return "end";
- default: return "unparseable format string";
- }
-}
-static size_t __Pyx_BufFmt_TypeCharToStandardSize(char ch, int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return 2;
- case 'i': case 'I': case 'l': case 'L': return 4;
- case 'q': case 'Q': return 8;
- case 'f': return (is_complex ? 8 : 4);
- case 'd': return (is_complex ? 16 : 8);
- case 'g': {
- PyErr_SetString(PyExc_ValueError, "Python does not define a standard format string size for long double ('g')..");
- return 0;
- }
- case 'O': case 'P': return sizeof(void*);
- default:
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
-}
-static size_t __Pyx_BufFmt_TypeCharToNativeSize(char ch, int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return sizeof(short);
- case 'i': case 'I': return sizeof(int);
- case 'l': case 'L': return sizeof(long);
- #ifdef HAVE_LONG_LONG
- case 'q': case 'Q': return sizeof(PY_LONG_LONG);
- #endif
- case 'f': return sizeof(float) * (is_complex ? 2 : 1);
- case 'd': return sizeof(double) * (is_complex ? 2 : 1);
- case 'g': return sizeof(long double) * (is_complex ? 2 : 1);
- case 'O': case 'P': return sizeof(void*);
- default: {
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
- }
-}
-typedef struct { char c; short x; } __Pyx_st_short;
-typedef struct { char c; int x; } __Pyx_st_int;
-typedef struct { char c; long x; } __Pyx_st_long;
-typedef struct { char c; float x; } __Pyx_st_float;
-typedef struct { char c; double x; } __Pyx_st_double;
-typedef struct { char c; long double x; } __Pyx_st_longdouble;
-typedef struct { char c; void *x; } __Pyx_st_void_p;
-#ifdef HAVE_LONG_LONG
-typedef struct { char c; PY_LONG_LONG x; } __Pyx_st_longlong;
-#endif
-static size_t __Pyx_BufFmt_TypeCharToAlignment(char ch, CYTHON_UNUSED int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return sizeof(__Pyx_st_short) - sizeof(short);
- case 'i': case 'I': return sizeof(__Pyx_st_int) - sizeof(int);
- case 'l': case 'L': return sizeof(__Pyx_st_long) - sizeof(long);
-#ifdef HAVE_LONG_LONG
- case 'q': case 'Q': return sizeof(__Pyx_st_longlong) - sizeof(PY_LONG_LONG);
-#endif
- case 'f': return sizeof(__Pyx_st_float) - sizeof(float);
- case 'd': return sizeof(__Pyx_st_double) - sizeof(double);
- case 'g': return sizeof(__Pyx_st_longdouble) - sizeof(long double);
- case 'P': case 'O': return sizeof(__Pyx_st_void_p) - sizeof(void*);
- default:
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
-}
-/* These are for computing the padding at the end of the struct to align
- on the first member of the struct. This will probably the same as above,
- but we don't have any guarantees.
- */
-typedef struct { short x; char c; } __Pyx_pad_short;
-typedef struct { int x; char c; } __Pyx_pad_int;
-typedef struct { long x; char c; } __Pyx_pad_long;
-typedef struct { float x; char c; } __Pyx_pad_float;
-typedef struct { double x; char c; } __Pyx_pad_double;
-typedef struct { long double x; char c; } __Pyx_pad_longdouble;
-typedef struct { void *x; char c; } __Pyx_pad_void_p;
-#ifdef HAVE_LONG_LONG
-typedef struct { PY_LONG_LONG x; char c; } __Pyx_pad_longlong;
-#endif
-static size_t __Pyx_BufFmt_TypeCharToPadding(char ch, CYTHON_UNUSED int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return sizeof(__Pyx_pad_short) - sizeof(short);
- case 'i': case 'I': return sizeof(__Pyx_pad_int) - sizeof(int);
- case 'l': case 'L': return sizeof(__Pyx_pad_long) - sizeof(long);
-#ifdef HAVE_LONG_LONG
- case 'q': case 'Q': return sizeof(__Pyx_pad_longlong) - sizeof(PY_LONG_LONG);
-#endif
- case 'f': return sizeof(__Pyx_pad_float) - sizeof(float);
- case 'd': return sizeof(__Pyx_pad_double) - sizeof(double);
- case 'g': return sizeof(__Pyx_pad_longdouble) - sizeof(long double);
- case 'P': case 'O': return sizeof(__Pyx_pad_void_p) - sizeof(void*);
- default:
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
-}
-static char __Pyx_BufFmt_TypeCharToGroup(char ch, int is_complex) {
- switch (ch) {
- case 'c':
- return 'H';
- case 'b': case 'h': case 'i':
- case 'l': case 'q': case 's': case 'p':
- return 'I';
- case '?': case 'B': case 'H': case 'I': case 'L': case 'Q':
- return 'U';
- case 'f': case 'd': case 'g':
- return (is_complex ? 'C' : 'R');
- case 'O':
- return 'O';
- case 'P':
- return 'P';
- default: {
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
- }
-}
-static void __Pyx_BufFmt_RaiseExpected(__Pyx_BufFmt_Context* ctx) {
- if (ctx->head == NULL || ctx->head->field == &ctx->root) {
- const char* expected;
- const char* quote;
- if (ctx->head == NULL) {
- expected = "end";
- quote = "";
- } else {
- expected = ctx->head->field->type->name;
- quote = "'";
- }
- PyErr_Format(PyExc_ValueError,
- "Buffer dtype mismatch, expected %s%s%s but got %s",
- quote, expected, quote,
- __Pyx_BufFmt_DescribeTypeChar(ctx->enc_type, ctx->is_complex));
- } else {
- __Pyx_StructField* field = ctx->head->field;
- __Pyx_StructField* parent = (ctx->head - 1)->field;
- PyErr_Format(PyExc_ValueError,
- "Buffer dtype mismatch, expected '%s' but got %s in '%s.%s'",
- field->type->name, __Pyx_BufFmt_DescribeTypeChar(ctx->enc_type, ctx->is_complex),
- parent->type->name, field->name);
- }
-}
-static int __Pyx_BufFmt_ProcessTypeChunk(__Pyx_BufFmt_Context* ctx) {
- char group;
- size_t size, offset, arraysize = 1;
- if (ctx->enc_type == 0) return 0;
- if (ctx->head->field->type->arraysize[0]) {
- int i, ndim = 0;
- if (ctx->enc_type == 's' || ctx->enc_type == 'p') {
- ctx->is_valid_array = ctx->head->field->type->ndim == 1;
- ndim = 1;
- if (ctx->enc_count != ctx->head->field->type->arraysize[0]) {
- PyErr_Format(PyExc_ValueError,
- "Expected a dimension of size %zu, got %zu",
- ctx->head->field->type->arraysize[0], ctx->enc_count);
- return -1;
- }
- }
- if (!ctx->is_valid_array) {
- PyErr_Format(PyExc_ValueError, "Expected %d dimensions, got %d",
- ctx->head->field->type->ndim, ndim);
- return -1;
- }
- for (i = 0; i < ctx->head->field->type->ndim; i++) {
- arraysize *= ctx->head->field->type->arraysize[i];
- }
- ctx->is_valid_array = 0;
- ctx->enc_count = 1;
- }
- group = __Pyx_BufFmt_TypeCharToGroup(ctx->enc_type, ctx->is_complex);
- do {
- __Pyx_StructField* field = ctx->head->field;
- __Pyx_TypeInfo* type = field->type;
- if (ctx->enc_packmode == '@' || ctx->enc_packmode == '^') {
- size = __Pyx_BufFmt_TypeCharToNativeSize(ctx->enc_type, ctx->is_complex);
- } else {
- size = __Pyx_BufFmt_TypeCharToStandardSize(ctx->enc_type, ctx->is_complex);
- }
- if (ctx->enc_packmode == '@') {
- size_t align_at = __Pyx_BufFmt_TypeCharToAlignment(ctx->enc_type, ctx->is_complex);
- size_t align_mod_offset;
- if (align_at == 0) return -1;
- align_mod_offset = ctx->fmt_offset % align_at;
- if (align_mod_offset > 0) ctx->fmt_offset += align_at - align_mod_offset;
- if (ctx->struct_alignment == 0)
- ctx->struct_alignment = __Pyx_BufFmt_TypeCharToPadding(ctx->enc_type,
- ctx->is_complex);
- }
- if (type->size != size || type->typegroup != group) {
- if (type->typegroup == 'C' && type->fields != NULL) {
- size_t parent_offset = ctx->head->parent_offset + field->offset;
- ++ctx->head;
- ctx->head->field = type->fields;
- ctx->head->parent_offset = parent_offset;
- continue;
- }
- if ((type->typegroup == 'H' || group == 'H') && type->size == size) {
- } else {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return -1;
- }
- }
- offset = ctx->head->parent_offset + field->offset;
- if (ctx->fmt_offset != offset) {
- PyErr_Format(PyExc_ValueError,
- "Buffer dtype mismatch; next field is at offset %" CYTHON_FORMAT_SSIZE_T "d but %" CYTHON_FORMAT_SSIZE_T "d expected",
- (Py_ssize_t)ctx->fmt_offset, (Py_ssize_t)offset);
- return -1;
- }
- ctx->fmt_offset += size;
- if (arraysize)
- ctx->fmt_offset += (arraysize - 1) * size;
- --ctx->enc_count;
- while (1) {
- if (field == &ctx->root) {
- ctx->head = NULL;
- if (ctx->enc_count != 0) {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return -1;
- }
- break;
- }
- ctx->head->field = ++field;
- if (field->type == NULL) {
- --ctx->head;
- field = ctx->head->field;
- continue;
- } else if (field->type->typegroup == 'S') {
- size_t parent_offset = ctx->head->parent_offset + field->offset;
- if (field->type->fields->type == NULL) continue;
- field = field->type->fields;
- ++ctx->head;
- ctx->head->field = field;
- ctx->head->parent_offset = parent_offset;
- break;
- } else {
- break;
- }
- }
- } while (ctx->enc_count);
- ctx->enc_type = 0;
- ctx->is_complex = 0;
- return 0;
-}
-static PyObject *
-__pyx_buffmt_parse_array(__Pyx_BufFmt_Context* ctx, const char** tsp)
-{
- const char *ts = *tsp;
- int i = 0, number, ndim;
- ++ts;
- if (ctx->new_count != 1) {
- PyErr_SetString(PyExc_ValueError,
- "Cannot handle repeated arrays in format string");
- return NULL;
- }
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ndim = ctx->head->field->type->ndim;
- while (*ts && *ts != ')') {
- switch (*ts) {
- case ' ': case '\f': case '\r': case '\n': case '\t': case '\v': continue;
- default: break;
- }
- number = __Pyx_BufFmt_ExpectNumber(&ts);
- if (number == -1) return NULL;
- if (i < ndim && (size_t) number != ctx->head->field->type->arraysize[i])
- return PyErr_Format(PyExc_ValueError,
- "Expected a dimension of size %zu, got %d",
- ctx->head->field->type->arraysize[i], number);
- if (*ts != ',' && *ts != ')')
- return PyErr_Format(PyExc_ValueError,
- "Expected a comma in format string, got '%c'", *ts);
- if (*ts == ',') ts++;
- i++;
- }
- if (i != ndim)
- return PyErr_Format(PyExc_ValueError, "Expected %d dimension(s), got %d",
- ctx->head->field->type->ndim, i);
- if (!*ts) {
- PyErr_SetString(PyExc_ValueError,
- "Unexpected end of format string, expected ')'");
- return NULL;
- }
- ctx->is_valid_array = 1;
- ctx->new_count = 1;
- *tsp = ++ts;
- return Py_None;
-}
-static const char* __Pyx_BufFmt_CheckString(__Pyx_BufFmt_Context* ctx, const char* ts) {
- int got_Z = 0;
- while (1) {
- switch(*ts) {
- case 0:
- if (ctx->enc_type != 0 && ctx->head == NULL) {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return NULL;
- }
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- if (ctx->head != NULL) {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return NULL;
- }
- return ts;
- case ' ':
- case '\r':
- case '\n':
- ++ts;
- break;
- case '<':
- if (!__Pyx_Is_Little_Endian()) {
- PyErr_SetString(PyExc_ValueError, "Little-endian buffer not supported on big-endian compiler");
- return NULL;
- }
- ctx->new_packmode = '=';
- ++ts;
- break;
- case '>':
- case '!':
- if (__Pyx_Is_Little_Endian()) {
- PyErr_SetString(PyExc_ValueError, "Big-endian buffer not supported on little-endian compiler");
- return NULL;
- }
- ctx->new_packmode = '=';
- ++ts;
- break;
- case '=':
- case '@':
- case '^':
- ctx->new_packmode = *ts++;
- break;
- case 'T':
- {
- const char* ts_after_sub;
- size_t i, struct_count = ctx->new_count;
- size_t struct_alignment = ctx->struct_alignment;
- ctx->new_count = 1;
- ++ts;
- if (*ts != '{') {
- PyErr_SetString(PyExc_ValueError, "Buffer acquisition: Expected '{' after 'T'");
- return NULL;
- }
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->enc_type = 0;
- ctx->enc_count = 0;
- ctx->struct_alignment = 0;
- ++ts;
- ts_after_sub = ts;
- for (i = 0; i != struct_count; ++i) {
- ts_after_sub = __Pyx_BufFmt_CheckString(ctx, ts);
- if (!ts_after_sub) return NULL;
- }
- ts = ts_after_sub;
- if (struct_alignment) ctx->struct_alignment = struct_alignment;
- }
- break;
- case '}':
- {
- size_t alignment = ctx->struct_alignment;
- ++ts;
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->enc_type = 0;
- if (alignment && ctx->fmt_offset % alignment) {
- ctx->fmt_offset += alignment - (ctx->fmt_offset % alignment);
- }
- }
- return ts;
- case 'x':
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->fmt_offset += ctx->new_count;
- ctx->new_count = 1;
- ctx->enc_count = 0;
- ctx->enc_type = 0;
- ctx->enc_packmode = ctx->new_packmode;
- ++ts;
- break;
- case 'Z':
- got_Z = 1;
- ++ts;
- if (*ts != 'f' && *ts != 'd' && *ts != 'g') {
- __Pyx_BufFmt_RaiseUnexpectedChar('Z');
- return NULL;
- }
- CYTHON_FALLTHROUGH;
- case '?': case 'c': case 'b': case 'B': case 'h': case 'H': case 'i': case 'I':
- case 'l': case 'L': case 'q': case 'Q':
- case 'f': case 'd': case 'g':
- case 'O': case 'p':
- if ((ctx->enc_type == *ts) && (got_Z == ctx->is_complex) &&
- (ctx->enc_packmode == ctx->new_packmode) && (!ctx->is_valid_array)) {
- ctx->enc_count += ctx->new_count;
- ctx->new_count = 1;
- got_Z = 0;
- ++ts;
- break;
- }
- CYTHON_FALLTHROUGH;
- case 's':
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->enc_count = ctx->new_count;
- ctx->enc_packmode = ctx->new_packmode;
- ctx->enc_type = *ts;
- ctx->is_complex = got_Z;
- ++ts;
- ctx->new_count = 1;
- got_Z = 0;
- break;
- case ':':
- ++ts;
- while(*ts != ':') ++ts;
- ++ts;
- break;
- case '(':
- if (!__pyx_buffmt_parse_array(ctx, &ts)) return NULL;
- break;
- default:
- {
- int number = __Pyx_BufFmt_ExpectNumber(&ts);
- if (number == -1) return NULL;
- ctx->new_count = (size_t)number;
- }
- }
- }
-}
-
-/* TypeInfoCompare */
- static int
-__pyx_typeinfo_cmp(__Pyx_TypeInfo *a, __Pyx_TypeInfo *b)
-{
- int i;
- if (!a || !b)
- return 0;
- if (a == b)
- return 1;
- if (a->size != b->size || a->typegroup != b->typegroup ||
- a->is_unsigned != b->is_unsigned || a->ndim != b->ndim) {
- if (a->typegroup == 'H' || b->typegroup == 'H') {
- return a->size == b->size;
- } else {
- return 0;
- }
- }
- if (a->ndim) {
- for (i = 0; i < a->ndim; i++)
- if (a->arraysize[i] != b->arraysize[i])
- return 0;
- }
- if (a->typegroup == 'S') {
- if (a->flags != b->flags)
- return 0;
- if (a->fields || b->fields) {
- if (!(a->fields && b->fields))
- return 0;
- for (i = 0; a->fields[i].type && b->fields[i].type; i++) {
- __Pyx_StructField *field_a = a->fields + i;
- __Pyx_StructField *field_b = b->fields + i;
- if (field_a->offset != field_b->offset ||
- !__pyx_typeinfo_cmp(field_a->type, field_b->type))
- return 0;
- }
- return !a->fields[i].type && !b->fields[i].type;
- }
- }
- return 1;
-}
-
-/* MemviewSliceValidateAndInit */
- static int
-__pyx_check_strides(Py_buffer *buf, int dim, int ndim, int spec)
-{
- if (buf->shape[dim] <= 1)
- return 1;
- if (buf->strides) {
- if (spec & __Pyx_MEMVIEW_CONTIG) {
- if (spec & (__Pyx_MEMVIEW_PTR|__Pyx_MEMVIEW_FULL)) {
- if (unlikely(buf->strides[dim] != sizeof(void *))) {
- PyErr_Format(PyExc_ValueError,
- "Buffer is not indirectly contiguous "
- "in dimension %d.", dim);
- goto fail;
- }
- } else if (unlikely(buf->strides[dim] != buf->itemsize)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer and memoryview are not contiguous "
- "in the same dimension.");
- goto fail;
- }
- }
- if (spec & __Pyx_MEMVIEW_FOLLOW) {
- Py_ssize_t stride = buf->strides[dim];
- if (stride < 0)
- stride = -stride;
- if (unlikely(stride < buf->itemsize)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer and memoryview are not contiguous "
- "in the same dimension.");
- goto fail;
- }
- }
- } else {
- if (unlikely(spec & __Pyx_MEMVIEW_CONTIG && dim != ndim - 1)) {
- PyErr_Format(PyExc_ValueError,
- "C-contiguous buffer is not contiguous in "
- "dimension %d", dim);
- goto fail;
- } else if (unlikely(spec & (__Pyx_MEMVIEW_PTR))) {
- PyErr_Format(PyExc_ValueError,
- "C-contiguous buffer is not indirect in "
- "dimension %d", dim);
- goto fail;
- } else if (unlikely(buf->suboffsets)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer exposes suboffsets but no strides");
- goto fail;
- }
- }
- return 1;
-fail:
- return 0;
-}
-static int
-__pyx_check_suboffsets(Py_buffer *buf, int dim, CYTHON_UNUSED int ndim, int spec)
-{
- if (spec & __Pyx_MEMVIEW_DIRECT) {
- if (unlikely(buf->suboffsets && buf->suboffsets[dim] >= 0)) {
- PyErr_Format(PyExc_ValueError,
- "Buffer not compatible with direct access "
- "in dimension %d.", dim);
- goto fail;
- }
- }
- if (spec & __Pyx_MEMVIEW_PTR) {
- if (unlikely(!buf->suboffsets || (buf->suboffsets[dim] < 0))) {
- PyErr_Format(PyExc_ValueError,
- "Buffer is not indirectly accessible "
- "in dimension %d.", dim);
- goto fail;
- }
- }
- return 1;
-fail:
- return 0;
-}
-static int
-__pyx_verify_contig(Py_buffer *buf, int ndim, int c_or_f_flag)
-{
- int i;
- if (c_or_f_flag & __Pyx_IS_F_CONTIG) {
- Py_ssize_t stride = 1;
- for (i = 0; i < ndim; i++) {
- if (unlikely(stride * buf->itemsize != buf->strides[i] && buf->shape[i] > 1)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer not fortran contiguous.");
- goto fail;
- }
- stride = stride * buf->shape[i];
- }
- } else if (c_or_f_flag & __Pyx_IS_C_CONTIG) {
- Py_ssize_t stride = 1;
- for (i = ndim - 1; i >- 1; i--) {
- if (unlikely(stride * buf->itemsize != buf->strides[i] && buf->shape[i] > 1)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer not C contiguous.");
- goto fail;
- }
- stride = stride * buf->shape[i];
- }
- }
- return 1;
-fail:
- return 0;
-}
-static int __Pyx_ValidateAndInit_memviewslice(
- int *axes_specs,
- int c_or_f_flag,
- int buf_flags,
- int ndim,
- __Pyx_TypeInfo *dtype,
- __Pyx_BufFmt_StackElem stack[],
- __Pyx_memviewslice *memviewslice,
- PyObject *original_obj)
-{
- struct __pyx_memoryview_obj *memview, *new_memview;
- __Pyx_RefNannyDeclarations
- Py_buffer *buf;
- int i, spec = 0, retval = -1;
- __Pyx_BufFmt_Context ctx;
- int from_memoryview = __pyx_memoryview_check(original_obj);
- __Pyx_RefNannySetupContext("ValidateAndInit_memviewslice", 0);
- if (from_memoryview && __pyx_typeinfo_cmp(dtype, ((struct __pyx_memoryview_obj *)
- original_obj)->typeinfo)) {
- memview = (struct __pyx_memoryview_obj *) original_obj;
- new_memview = NULL;
- } else {
- memview = (struct __pyx_memoryview_obj *) __pyx_memoryview_new(
- original_obj, buf_flags, 0, dtype);
- new_memview = memview;
- if (unlikely(!memview))
- goto fail;
- }
- buf = &memview->view;
- if (unlikely(buf->ndim != ndim)) {
- PyErr_Format(PyExc_ValueError,
- "Buffer has wrong number of dimensions (expected %d, got %d)",
- ndim, buf->ndim);
- goto fail;
- }
- if (new_memview) {
- __Pyx_BufFmt_Init(&ctx, stack, dtype);
- if (unlikely(!__Pyx_BufFmt_CheckString(&ctx, buf->format))) goto fail;
- }
- if (unlikely((unsigned) buf->itemsize != dtype->size)) {
- PyErr_Format(PyExc_ValueError,
- "Item size of buffer (%" CYTHON_FORMAT_SSIZE_T "u byte%s) "
- "does not match size of '%s' (%" CYTHON_FORMAT_SSIZE_T "u byte%s)",
- buf->itemsize,
- (buf->itemsize > 1) ? "s" : "",
- dtype->name,
- dtype->size,
- (dtype->size > 1) ? "s" : "");
- goto fail;
- }
- if (buf->len > 0) {
- for (i = 0; i < ndim; i++) {
- spec = axes_specs[i];
- if (unlikely(!__pyx_check_strides(buf, i, ndim, spec)))
- goto fail;
- if (unlikely(!__pyx_check_suboffsets(buf, i, ndim, spec)))
- goto fail;
- }
- if (unlikely(buf->strides && !__pyx_verify_contig(buf, ndim, c_or_f_flag)))
- goto fail;
- }
- if (unlikely(__Pyx_init_memviewslice(memview, ndim, memviewslice,
- new_memview != NULL) == -1)) {
- goto fail;
- }
- retval = 0;
- goto no_fail;
-fail:
- Py_XDECREF(new_memview);
- retval = -1;
-no_fail:
- __Pyx_RefNannyFinishContext();
- return retval;
-}
-
-/* ObjectToMemviewSlice */
- static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_int(PyObject *obj, int writable_flag) {
- __Pyx_memviewslice result = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_BufFmt_StackElem stack[1];
- int axes_specs[] = { (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_CONTIG) };
- int retcode;
- if (obj == Py_None) {
- result.memview = (struct __pyx_memoryview_obj *) Py_None;
- return result;
- }
- retcode = __Pyx_ValidateAndInit_memviewslice(axes_specs, __Pyx_IS_C_CONTIG,
- (PyBUF_C_CONTIGUOUS | PyBUF_FORMAT) | writable_flag, 3,
- &__Pyx_TypeInfo_int, stack,
- &result, obj);
- if (unlikely(retcode == -1))
- goto __pyx_fail;
- return result;
-__pyx_fail:
- result.memview = NULL;
- result.data = NULL;
- return result;
-}
-
-/* ObjectToMemviewSlice */
- static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_float(PyObject *obj, int writable_flag) {
- __Pyx_memviewslice result = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_BufFmt_StackElem stack[1];
- int axes_specs[] = { (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_CONTIG) };
- int retcode;
- if (obj == Py_None) {
- result.memview = (struct __pyx_memoryview_obj *) Py_None;
- return result;
- }
- retcode = __Pyx_ValidateAndInit_memviewslice(axes_specs, __Pyx_IS_C_CONTIG,
- (PyBUF_C_CONTIGUOUS | PyBUF_FORMAT) | writable_flag, 3,
- &__Pyx_TypeInfo_float, stack,
- &result, obj);
- if (unlikely(retcode == -1))
- goto __pyx_fail;
- return result;
-__pyx_fail:
- result.memview = NULL;
- result.data = NULL;
- return result;
-}
-
-/* ObjectToMemviewSlice */
- static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_dc_int(PyObject *obj, int writable_flag) {
- __Pyx_memviewslice result = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_BufFmt_StackElem stack[1];
- int axes_specs[] = { (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_CONTIG) };
- int retcode;
- if (obj == Py_None) {
- result.memview = (struct __pyx_memoryview_obj *) Py_None;
- return result;
- }
- retcode = __Pyx_ValidateAndInit_memviewslice(axes_specs, __Pyx_IS_C_CONTIG,
- (PyBUF_C_CONTIGUOUS | PyBUF_FORMAT) | writable_flag, 1,
- &__Pyx_TypeInfo_int, stack,
- &result, obj);
- if (unlikely(retcode == -1))
- goto __pyx_fail;
- return result;
-__pyx_fail:
- result.memview = NULL;
- result.data = NULL;
- return result;
-}
-
-/* CIntFromPyVerify */
- #define __PYX_VERIFY_RETURN_INT(target_type, func_type, func_value)\
- __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, 0)
-#define __PYX_VERIFY_RETURN_INT_EXC(target_type, func_type, func_value)\
- __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, 1)
-#define __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, exc)\
- {\
- func_type value = func_value;\
- if (sizeof(target_type) < sizeof(func_type)) {\
- if (unlikely(value != (func_type) (target_type) value)) {\
- func_type zero = 0;\
- if (exc && unlikely(value == (func_type)-1 && PyErr_Occurred()))\
- return (target_type) -1;\
- if (is_unsigned && unlikely(value < zero))\
- goto raise_neg_overflow;\
- else\
- goto raise_overflow;\
- }\
- }\
- return (target_type) value;\
- }
-
-/* MemviewSliceCopyTemplate */
- static __Pyx_memviewslice
-__pyx_memoryview_copy_new_contig(const __Pyx_memviewslice *from_mvs,
- const char *mode, int ndim,
- size_t sizeof_dtype, int contig_flag,
- int dtype_is_object)
-{
- __Pyx_RefNannyDeclarations
- int i;
- __Pyx_memviewslice new_mvs = { 0, 0, { 0 }, { 0 }, { 0 } };
- struct __pyx_memoryview_obj *from_memview = from_mvs->memview;
- Py_buffer *buf = &from_memview->view;
- PyObject *shape_tuple = NULL;
- PyObject *temp_int = NULL;
- struct __pyx_array_obj *array_obj = NULL;
- struct __pyx_memoryview_obj *memview_obj = NULL;
- __Pyx_RefNannySetupContext("__pyx_memoryview_copy_new_contig", 0);
- for (i = 0; i < ndim; i++) {
- if (unlikely(from_mvs->suboffsets[i] >= 0)) {
- PyErr_Format(PyExc_ValueError, "Cannot copy memoryview slice with "
- "indirect dimensions (axis %d)", i);
- goto fail;
- }
- }
- shape_tuple = PyTuple_New(ndim);
- if (unlikely(!shape_tuple)) {
- goto fail;
- }
- __Pyx_GOTREF(shape_tuple);
- for(i = 0; i < ndim; i++) {
- temp_int = PyInt_FromSsize_t(from_mvs->shape[i]);
- if(unlikely(!temp_int)) {
- goto fail;
- } else {
- PyTuple_SET_ITEM(shape_tuple, i, temp_int);
- temp_int = NULL;
- }
- }
- array_obj = __pyx_array_new(shape_tuple, sizeof_dtype, buf->format, (char *) mode, NULL);
- if (unlikely(!array_obj)) {
- goto fail;
- }
- __Pyx_GOTREF(array_obj);
- memview_obj = (struct __pyx_memoryview_obj *) __pyx_memoryview_new(
- (PyObject *) array_obj, contig_flag,
- dtype_is_object,
- from_mvs->memview->typeinfo);
- if (unlikely(!memview_obj))
- goto fail;
- if (unlikely(__Pyx_init_memviewslice(memview_obj, ndim, &new_mvs, 1) < 0))
- goto fail;
- if (unlikely(__pyx_memoryview_copy_contents(*from_mvs, new_mvs, ndim, ndim,
- dtype_is_object) < 0))
- goto fail;
- goto no_fail;
-fail:
- __Pyx_XDECREF(new_mvs.memview);
- new_mvs.memview = NULL;
- new_mvs.data = NULL;
-no_fail:
- __Pyx_XDECREF(shape_tuple);
- __Pyx_XDECREF(temp_int);
- __Pyx_XDECREF(array_obj);
- __Pyx_RefNannyFinishContext();
- return new_mvs;
-}
-
-/* CIntToPy */
- static CYTHON_INLINE PyObject* __Pyx_PyInt_From_int(int value) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const int neg_one = (int) -1, const_zero = (int) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
- if (is_unsigned) {
- if (sizeof(int) < sizeof(long)) {
- return PyInt_FromLong((long) value);
- } else if (sizeof(int) <= sizeof(unsigned long)) {
- return PyLong_FromUnsignedLong((unsigned long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(unsigned PY_LONG_LONG)) {
- return PyLong_FromUnsignedLongLong((unsigned PY_LONG_LONG) value);
-#endif
- }
- } else {
- if (sizeof(int) <= sizeof(long)) {
- return PyInt_FromLong((long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(PY_LONG_LONG)) {
- return PyLong_FromLongLong((PY_LONG_LONG) value);
-#endif
- }
- }
- {
- int one = 1; int little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&value;
- return _PyLong_FromByteArray(bytes, sizeof(int),
- little, !is_unsigned);
- }
-}
-
-/* CIntFromPy */
- static CYTHON_INLINE int __Pyx_PyInt_As_int(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const int neg_one = (int) -1, const_zero = (int) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if (sizeof(int) < sizeof(long)) {
- __PYX_VERIFY_RETURN_INT(int, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (int) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (int) 0;
- case 1: __PYX_VERIFY_RETURN_INT(int, digit, digits[0])
- case 2:
- if (8 * sizeof(int) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) >= 2 * PyLong_SHIFT) {
- return (int) (((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- case 3:
- if (8 * sizeof(int) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) >= 3 * PyLong_SHIFT) {
- return (int) (((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- case 4:
- if (8 * sizeof(int) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) >= 4 * PyLong_SHIFT) {
- return (int) (((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (int) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if (sizeof(int) <= sizeof(unsigned long)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(unsigned PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (int) 0;
- case -1: __PYX_VERIFY_RETURN_INT(int, sdigit, (sdigit) (-(sdigit)digits[0]))
- case 1: __PYX_VERIFY_RETURN_INT(int, digit, +digits[0])
- case -2:
- if (8 * sizeof(int) - 1 > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 2 * PyLong_SHIFT) {
- return (int) (((int)-1)*(((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 2:
- if (8 * sizeof(int) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 2 * PyLong_SHIFT) {
- return (int) ((((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case -3:
- if (8 * sizeof(int) - 1 > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 3 * PyLong_SHIFT) {
- return (int) (((int)-1)*(((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 3:
- if (8 * sizeof(int) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 3 * PyLong_SHIFT) {
- return (int) ((((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case -4:
- if (8 * sizeof(int) - 1 > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 4 * PyLong_SHIFT) {
- return (int) (((int)-1)*(((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 4:
- if (8 * sizeof(int) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 4 * PyLong_SHIFT) {
- return (int) ((((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- }
-#endif
- if (sizeof(int) <= sizeof(long)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
-#if CYTHON_COMPILING_IN_PYPY && !defined(_PyLong_AsByteArray)
- PyErr_SetString(PyExc_RuntimeError,
- "_PyLong_AsByteArray() not available in PyPy, cannot convert large numbers");
-#else
- int val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
- #if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
- #endif
- if (likely(v)) {
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- int ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
-#endif
- return (int) -1;
- }
- } else {
- int val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (int) -1;
- val = __Pyx_PyInt_As_int(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to int");
- return (int) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to int");
- return (int) -1;
-}
-
-/* CIntToPy */
- static CYTHON_INLINE PyObject* __Pyx_PyInt_From_long(long value) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const long neg_one = (long) -1, const_zero = (long) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
- if (is_unsigned) {
- if (sizeof(long) < sizeof(long)) {
- return PyInt_FromLong((long) value);
- } else if (sizeof(long) <= sizeof(unsigned long)) {
- return PyLong_FromUnsignedLong((unsigned long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(unsigned PY_LONG_LONG)) {
- return PyLong_FromUnsignedLongLong((unsigned PY_LONG_LONG) value);
-#endif
- }
- } else {
- if (sizeof(long) <= sizeof(long)) {
- return PyInt_FromLong((long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(PY_LONG_LONG)) {
- return PyLong_FromLongLong((PY_LONG_LONG) value);
-#endif
- }
- }
- {
- int one = 1; int little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&value;
- return _PyLong_FromByteArray(bytes, sizeof(long),
- little, !is_unsigned);
- }
-}
-
-/* CIntFromPy */
- static CYTHON_INLINE long __Pyx_PyInt_As_long(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const long neg_one = (long) -1, const_zero = (long) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if (sizeof(long) < sizeof(long)) {
- __PYX_VERIFY_RETURN_INT(long, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (long) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (long) 0;
- case 1: __PYX_VERIFY_RETURN_INT(long, digit, digits[0])
- case 2:
- if (8 * sizeof(long) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) >= 2 * PyLong_SHIFT) {
- return (long) (((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- case 3:
- if (8 * sizeof(long) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) >= 3 * PyLong_SHIFT) {
- return (long) (((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- case 4:
- if (8 * sizeof(long) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) >= 4 * PyLong_SHIFT) {
- return (long) (((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (long) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if (sizeof(long) <= sizeof(unsigned long)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(unsigned PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (long) 0;
- case -1: __PYX_VERIFY_RETURN_INT(long, sdigit, (sdigit) (-(sdigit)digits[0]))
- case 1: __PYX_VERIFY_RETURN_INT(long, digit, +digits[0])
- case -2:
- if (8 * sizeof(long) - 1 > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- return (long) (((long)-1)*(((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 2:
- if (8 * sizeof(long) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- return (long) ((((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case -3:
- if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- return (long) (((long)-1)*(((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 3:
- if (8 * sizeof(long) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- return (long) ((((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case -4:
- if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- return (long) (((long)-1)*(((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 4:
- if (8 * sizeof(long) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- return (long) ((((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- }
-#endif
- if (sizeof(long) <= sizeof(long)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
-#if CYTHON_COMPILING_IN_PYPY && !defined(_PyLong_AsByteArray)
- PyErr_SetString(PyExc_RuntimeError,
- "_PyLong_AsByteArray() not available in PyPy, cannot convert large numbers");
-#else
- long val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
- #if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
- #endif
- if (likely(v)) {
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- int ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
-#endif
- return (long) -1;
- }
- } else {
- long val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (long) -1;
- val = __Pyx_PyInt_As_long(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to long");
- return (long) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to long");
- return (long) -1;
-}
-
-/* CIntFromPy */
- static CYTHON_INLINE char __Pyx_PyInt_As_char(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const char neg_one = (char) -1, const_zero = (char) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if (sizeof(char) < sizeof(long)) {
- __PYX_VERIFY_RETURN_INT(char, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (char) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (char) 0;
- case 1: __PYX_VERIFY_RETURN_INT(char, digit, digits[0])
- case 2:
- if (8 * sizeof(char) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) >= 2 * PyLong_SHIFT) {
- return (char) (((((char)digits[1]) << PyLong_SHIFT) | (char)digits[0]));
- }
- }
- break;
- case 3:
- if (8 * sizeof(char) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) >= 3 * PyLong_SHIFT) {
- return (char) (((((((char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0]));
- }
- }
- break;
- case 4:
- if (8 * sizeof(char) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) >= 4 * PyLong_SHIFT) {
- return (char) (((((((((char)digits[3]) << PyLong_SHIFT) | (char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0]));
- }
- }
- break;
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (char) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if (sizeof(char) <= sizeof(unsigned long)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(char) <= sizeof(unsigned PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (char) 0;
- case -1: __PYX_VERIFY_RETURN_INT(char, sdigit, (sdigit) (-(sdigit)digits[0]))
- case 1: __PYX_VERIFY_RETURN_INT(char, digit, +digits[0])
- case -2:
- if (8 * sizeof(char) - 1 > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 2 * PyLong_SHIFT) {
- return (char) (((char)-1)*(((((char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case 2:
- if (8 * sizeof(char) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 2 * PyLong_SHIFT) {
- return (char) ((((((char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case -3:
- if (8 * sizeof(char) - 1 > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 3 * PyLong_SHIFT) {
- return (char) (((char)-1)*(((((((char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case 3:
- if (8 * sizeof(char) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 3 * PyLong_SHIFT) {
- return (char) ((((((((char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case -4:
- if (8 * sizeof(char) - 1 > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 4 * PyLong_SHIFT) {
- return (char) (((char)-1)*(((((((((char)digits[3]) << PyLong_SHIFT) | (char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case 4:
- if (8 * sizeof(char) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 4 * PyLong_SHIFT) {
- return (char) ((((((((((char)digits[3]) << PyLong_SHIFT) | (char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- }
-#endif
- if (sizeof(char) <= sizeof(long)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(char) <= sizeof(PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
-#if CYTHON_COMPILING_IN_PYPY && !defined(_PyLong_AsByteArray)
- PyErr_SetString(PyExc_RuntimeError,
- "_PyLong_AsByteArray() not available in PyPy, cannot convert large numbers");
-#else
- char val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
- #if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
- #endif
- if (likely(v)) {
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- int ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
-#endif
- return (char) -1;
- }
- } else {
- char val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (char) -1;
- val = __Pyx_PyInt_As_char(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to char");
- return (char) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to char");
- return (char) -1;
-}
-
-/* CheckBinaryVersion */
- static int __Pyx_check_binary_version(void) {
- char ctversion[5];
- int same=1, i, found_dot;
- const char* rt_from_call = Py_GetVersion();
- PyOS_snprintf(ctversion, 5, "%d.%d", PY_MAJOR_VERSION, PY_MINOR_VERSION);
- found_dot = 0;
- for (i = 0; i < 4; i++) {
- if (!ctversion[i]) {
- same = (rt_from_call[i] < '0' || rt_from_call[i] > '9');
- break;
- }
- if (rt_from_call[i] != ctversion[i]) {
- same = 0;
- break;
- }
- }
- if (!same) {
- char rtversion[5] = {'\0'};
- char message[200];
- for (i=0; i<4; ++i) {
- if (rt_from_call[i] == '.') {
- if (found_dot) break;
- found_dot = 1;
- } else if (rt_from_call[i] < '0' || rt_from_call[i] > '9') {
- break;
- }
- rtversion[i] = rt_from_call[i];
- }
- PyOS_snprintf(message, sizeof(message),
- "compiletime version %s of module '%.100s' "
- "does not match runtime version %s",
- ctversion, __Pyx_MODULE_NAME, rtversion);
- return PyErr_WarnEx(NULL, message, 1);
- }
- return 0;
-}
-
-/* InitStrings */
- static int __Pyx_InitStrings(__Pyx_StringTabEntry *t) {
- while (t->p) {
- #if PY_MAJOR_VERSION < 3
- if (t->is_unicode) {
- *t->p = PyUnicode_DecodeUTF8(t->s, t->n - 1, NULL);
- } else if (t->intern) {
- *t->p = PyString_InternFromString(t->s);
- } else {
- *t->p = PyString_FromStringAndSize(t->s, t->n - 1);
- }
- #else
- if (t->is_unicode | t->is_str) {
- if (t->intern) {
- *t->p = PyUnicode_InternFromString(t->s);
- } else if (t->encoding) {
- *t->p = PyUnicode_Decode(t->s, t->n - 1, t->encoding, NULL);
- } else {
- *t->p = PyUnicode_FromStringAndSize(t->s, t->n - 1);
- }
- } else {
- *t->p = PyBytes_FromStringAndSize(t->s, t->n - 1);
- }
- #endif
- if (!*t->p)
- return -1;
- if (PyObject_Hash(*t->p) == -1)
- return -1;
- ++t;
- }
- return 0;
-}
-
-static CYTHON_INLINE PyObject* __Pyx_PyUnicode_FromString(const char* c_str) {
- return __Pyx_PyUnicode_FromStringAndSize(c_str, (Py_ssize_t)strlen(c_str));
-}
-static CYTHON_INLINE const char* __Pyx_PyObject_AsString(PyObject* o) {
- Py_ssize_t ignore;
- return __Pyx_PyObject_AsStringAndSize(o, &ignore);
-}
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
-#if !CYTHON_PEP393_ENABLED
-static const char* __Pyx_PyUnicode_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
- char* defenc_c;
- PyObject* defenc = _PyUnicode_AsDefaultEncodedString(o, NULL);
- if (!defenc) return NULL;
- defenc_c = PyBytes_AS_STRING(defenc);
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- {
- char* end = defenc_c + PyBytes_GET_SIZE(defenc);
- char* c;
- for (c = defenc_c; c < end; c++) {
- if ((unsigned char) (*c) >= 128) {
- PyUnicode_AsASCIIString(o);
- return NULL;
- }
- }
- }
-#endif
- *length = PyBytes_GET_SIZE(defenc);
- return defenc_c;
-}
-#else
-static CYTHON_INLINE const char* __Pyx_PyUnicode_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
- if (unlikely(__Pyx_PyUnicode_READY(o) == -1)) return NULL;
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- if (likely(PyUnicode_IS_ASCII(o))) {
- *length = PyUnicode_GET_LENGTH(o);
- return PyUnicode_AsUTF8(o);
- } else {
- PyUnicode_AsASCIIString(o);
- return NULL;
- }
-#else
- return PyUnicode_AsUTF8AndSize(o, length);
-#endif
-}
-#endif
-#endif
-static CYTHON_INLINE const char* __Pyx_PyObject_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
- if (
-#if PY_MAJOR_VERSION < 3 && __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- __Pyx_sys_getdefaultencoding_not_ascii &&
-#endif
- PyUnicode_Check(o)) {
- return __Pyx_PyUnicode_AsStringAndSize(o, length);
- } else
-#endif
-#if (!CYTHON_COMPILING_IN_PYPY) || (defined(PyByteArray_AS_STRING) && defined(PyByteArray_GET_SIZE))
- if (PyByteArray_Check(o)) {
- *length = PyByteArray_GET_SIZE(o);
- return PyByteArray_AS_STRING(o);
- } else
-#endif
- {
- char* result;
- int r = PyBytes_AsStringAndSize(o, &result, length);
- if (unlikely(r < 0)) {
- return NULL;
- } else {
- return result;
- }
- }
-}
-static CYTHON_INLINE int __Pyx_PyObject_IsTrue(PyObject* x) {
- int is_true = x == Py_True;
- if (is_true | (x == Py_False) | (x == Py_None)) return is_true;
- else return PyObject_IsTrue(x);
-}
-static CYTHON_INLINE int __Pyx_PyObject_IsTrueAndDecref(PyObject* x) {
- int retval;
- if (unlikely(!x)) return -1;
- retval = __Pyx_PyObject_IsTrue(x);
- Py_DECREF(x);
- return retval;
-}
-static PyObject* __Pyx_PyNumber_IntOrLongWrongResultType(PyObject* result, const char* type_name) {
-#if PY_MAJOR_VERSION >= 3
- if (PyLong_Check(result)) {
- if (PyErr_WarnFormat(PyExc_DeprecationWarning, 1,
- "__int__ returned non-int (type %.200s). "
- "The ability to return an instance of a strict subclass of int "
- "is deprecated, and may be removed in a future version of Python.",
- Py_TYPE(result)->tp_name)) {
- Py_DECREF(result);
- return NULL;
- }
- return result;
- }
-#endif
- PyErr_Format(PyExc_TypeError,
- "__%.4s__ returned non-%.4s (type %.200s)",
- type_name, type_name, Py_TYPE(result)->tp_name);
- Py_DECREF(result);
- return NULL;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyNumber_IntOrLong(PyObject* x) {
-#if CYTHON_USE_TYPE_SLOTS
- PyNumberMethods *m;
-#endif
- const char *name = NULL;
- PyObject *res = NULL;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x) || PyLong_Check(x)))
-#else
- if (likely(PyLong_Check(x)))
-#endif
- return __Pyx_NewRef(x);
-#if CYTHON_USE_TYPE_SLOTS
- m = Py_TYPE(x)->tp_as_number;
- #if PY_MAJOR_VERSION < 3
- if (m && m->nb_int) {
- name = "int";
- res = m->nb_int(x);
- }
- else if (m && m->nb_long) {
- name = "long";
- res = m->nb_long(x);
- }
- #else
- if (likely(m && m->nb_int)) {
- name = "int";
- res = m->nb_int(x);
- }
- #endif
-#else
- if (!PyBytes_CheckExact(x) && !PyUnicode_CheckExact(x)) {
- res = PyNumber_Int(x);
- }
-#endif
- if (likely(res)) {
-#if PY_MAJOR_VERSION < 3
- if (unlikely(!PyInt_Check(res) && !PyLong_Check(res))) {
-#else
- if (unlikely(!PyLong_CheckExact(res))) {
-#endif
- return __Pyx_PyNumber_IntOrLongWrongResultType(res, name);
- }
- }
- else if (!PyErr_Occurred()) {
- PyErr_SetString(PyExc_TypeError,
- "an integer is required");
- }
- return res;
-}
-static CYTHON_INLINE Py_ssize_t __Pyx_PyIndex_AsSsize_t(PyObject* b) {
- Py_ssize_t ival;
- PyObject *x;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_CheckExact(b))) {
- if (sizeof(Py_ssize_t) >= sizeof(long))
- return PyInt_AS_LONG(b);
- else
- return PyInt_AsSsize_t(b);
- }
-#endif
- if (likely(PyLong_CheckExact(b))) {
- #if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)b)->ob_digit;
- const Py_ssize_t size = Py_SIZE(b);
- if (likely(__Pyx_sst_abs(size) <= 1)) {
- ival = likely(size) ? digits[0] : 0;
- if (size == -1) ival = -ival;
- return ival;
- } else {
- switch (size) {
- case 2:
- if (8 * sizeof(Py_ssize_t) > 2 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -2:
- if (8 * sizeof(Py_ssize_t) > 2 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case 3:
- if (8 * sizeof(Py_ssize_t) > 3 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((((size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -3:
- if (8 * sizeof(Py_ssize_t) > 3 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((((size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case 4:
- if (8 * sizeof(Py_ssize_t) > 4 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((((((size_t)digits[3]) << PyLong_SHIFT) | (size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -4:
- if (8 * sizeof(Py_ssize_t) > 4 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((((((size_t)digits[3]) << PyLong_SHIFT) | (size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- }
- }
- #endif
- return PyLong_AsSsize_t(b);
- }
- x = PyNumber_Index(b);
- if (!x) return -1;
- ival = PyInt_AsSsize_t(x);
- Py_DECREF(x);
- return ival;
-}
-static CYTHON_INLINE Py_hash_t __Pyx_PyIndex_AsHash_t(PyObject* o) {
- if (sizeof(Py_hash_t) == sizeof(Py_ssize_t)) {
- return (Py_hash_t) __Pyx_PyIndex_AsSsize_t(o);
-#if PY_MAJOR_VERSION < 3
- } else if (likely(PyInt_CheckExact(o))) {
- return PyInt_AS_LONG(o);
-#endif
- } else {
- Py_ssize_t ival;
- PyObject *x;
- x = PyNumber_Index(o);
- if (!x) return -1;
- ival = PyInt_AsLong(x);
- Py_DECREF(x);
- return ival;
- }
-}
-static CYTHON_INLINE PyObject * __Pyx_PyBool_FromLong(long b) {
- return b ? __Pyx_NewRef(Py_True) : __Pyx_NewRef(Py_False);
-}
-static CYTHON_INLINE PyObject * __Pyx_PyInt_FromSize_t(size_t ival) {
- return PyInt_FromSize_t(ival);
-}
-
-
-#endif /* Py_PYTHON_H */
diff --git a/spaces/Kvikontent/kviimager/app.py b/spaces/Kvikontent/kviimager/app.py
deleted file mode 100644
index 7aaf3e9e4b70717583f9d73f35307e64f404ccd0..0000000000000000000000000000000000000000
--- a/spaces/Kvikontent/kviimager/app.py
+++ /dev/null
@@ -1,725 +0,0 @@
-import gradio as gr
-from PIL import Image
-import requests
-from io import BytesIO
-import random
-import time
-
-def load_image(url):
- response = requests.get(url)
- image = Image.open(BytesIO(response.content))
- return image
-
-def generate_image(prompt):
- prompt = prompt.lower()
-
- time.sleep(random.randint(10, 20))
- faces = [
- "https://avatars.mds.yandex.net/i?id=f9676dc9c99572353c509d298a0b9f6571edca4e-10514707-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=e02f3f0a7cab6ae7eba3b1209ba9d56dcc24715a-7552414-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=aa883402ff70aa4c6d77441e3b2f3fb85483a047-5480663-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=30ae3f522a50aea82e7c61444656a259dbc106af-7823046-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=0ffd2b2d3d6927fdd824ce3af649bdc2827bc72c-10092505-images-thumbs&n=13"
- ]
-
- landscapes = [
- "https://avatars.mds.yandex.net/i?id=d817020d4f33ce8dd5f012ec14b46026230f7f38-4304379-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=0c44f37e0f3240a7f873ade37dbf77d87be8d3a0-9103996-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=54432591615e90e906f554b6deb6a33ae47e56b0-7551636-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=ef1792a7e82c70fb5a12c0b159c061b31c1c2461-9237918-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=e2639ee50941423c94aab655b416c8e1db84a015-9712020-images-thumbs&n=13",
- "https://img.freepik.com/free-photo/beautiful-shot-grassy-hills-covered-trees-near-mountains-dolomites-italy_181624-24400.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/mount-fuji-lake-kawaguchiko-sunrise-vintage_30824-49.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-mountains-landscape_23-2150787970.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/beautiful-view-caucasus-mountains_114963-19244.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/top-view-fir-tree-forest_181624-28786.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/misty-carpathian-mountain-landscape-with-fir-forest-tops-trees-sticking-out-fog_146671-18433.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-landscape-mother-nature_23-2148992397.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/hand-painted-sunset-mountain-trees-landscape_1048-19076.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- animal = [
- "https://avatars.mds.yandex.net/i?id=a1a7b590d43b39c427304b03c180802c-5714596-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=4da68929c18e73e06c2332018658f2f344f4e56e-8567697-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=c4000087b8d4c591d887a3d21f25a76738cb3d21-5880141-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=d507afc55fdbef5d6c51aa82acbf2d06211b79d8-7051980-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=52bfb5b4c8638c1c5feecf49797240d0e4128425-9181120-images-thumbs&n=13"
- ]
-
- car = [
- "https://avatars.mds.yandex.net/i?id=4b8a4a2285b409371e8b45060db83d522fd7e3a8-9624682-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=5583a40b92d72bbaacd0726f5b7504b5bb41ec4f-8264916-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=f2bf530d35b3eb1e4a50db12a3f6347fca90504a-9609067-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=fa0f8f3c6411a8122be313df6c8adcf7d389d3c6-7552082-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=93519c6b3adf47b03313c2a325eb51e75018eeaa-10332876-images-thumbs&n=13"
- ]
-
- food = [
- "https://avatars.mds.yandex.net/i?id=aa2854aebae7aad2c9c84f9ca556823076924800-6974903-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=c9b4d7e1c5991af6efdc61d3a3f5b91c7b5790b8-5229803-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=f4ba649ad0017b1a8ad1bdba4c0b523e-4290971-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=045887a75bb76213d556631a67a27ce7c9df7b81-9716553-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=4b8a4a2285b409371e8b45060db83d522fd7e3a8-9624682-images-thumbs&n=13"
- ]
-
- boat = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT7uC_XzpcX5FOfoPiKG-OR3O9-gTgRQ97t5dTW9kCtSKNRJ6Oz6J8fav5um1U&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRDzZkpmyutasQm5JmkcwFCJ964i1SaShl5uZ2JWVysTJ-USU-m2g4jnGCJ3A&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTIHj-QBEXroe_P-t8PVd7hVlA_XeQT2O9emiDb2dDODwOKU3GJM3XAo0BiLP8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRN_7Cg8g0GR0pHIsWlC6zucsVad6GJQeoxjZuCC6NtEYSi6iN3PD_oOqgMCs0&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQbO69SuDBUWRxPmSaMvY9tUzvN3CPDGy6Qy7Ws88jgNHXtLDMJAv9dTYPKYbo&s"
- ]
-
- logo = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSzDj5UHlSMn4JnM-LU1lDI5Gj8IyXoUGcPJFUW2L9g4ud_A2DEaCBVAlupLnE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQuEVbV_xtLzMDbVj9Hqfet_JoN7-L0uTflNS9szF9nxWWYtEiGrMnA4H_59EQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS9m3Ifv2-Gqjlq6q2YefVARxit9uQYXVvrFkCXhXF2xvFxQoY2iFUCjRPBwA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtS6eh12jeaQA5bVBKL-Vs2bbeUVE6i9i05-5qGjL6WyrSG-ipgR1x41DB49w&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRxVnmLkyBugPNPiUPbE91e8M6hNm8MprUyECSMO_FrJ49maB-1AYvVBeI10fI&s"
- ]
-
- eye = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRWYbVL4JZbaW2lRAFGhFw22TU2m1qpVjc8o7Z0PCGkOG3--FLJbwv_Errvwg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRaSR6_WMsGOAfItkCMiFxNgXKmAZVOhsAH0yI-0cuecvH8SnbJZIw2t2VfwQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQvJagN3MtIQPzKjextKbUHtF5Km_R5JXIPSq4LY8stLtCzrLHJhtCcXpiXpXo&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRLHok8H8zbsX5Oupg5DJBxLcp6Tm6LAg4S0gJ3o5lpbXYeNm5j36sWI8DX1Q&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT5a0d5jgLm6lOMHIFTC5NN0Bea6EItJJPo5mNa3oX5dwMf7dwDjoTW1SogTu0&s"
- ]
-
- beard = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTiJOMp_SLFTOUXZCz9ssycWmh5Sn2WpE0AfIfnVdpooNqnqDT0n_gcpyzeMA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRO4dmmQnmxAP3_0AUBH031bbk-YMWnQNMIhEUxz6LV4JdPZ5ic0B3WhnEpXw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQpzFdwz_l57Nkuz089OMl8rZiKvr6zVLeyMbaQOTEKRk2e7Hgwr2tkCIkwsQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSWFIOd5jPEVlc6hll0oyF3rbcOAWxAi8OF-BnCxAaCQBWWQDG_La69bmOm_g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTQO-zriw-KQA6JNr-Wg2vzlsd-JJBoAoDclFuEJ900j01XuMFpN0qB_QbJ5Hc&s"
- ]
-
- avatar = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQhoGkHKK-mUcbSGNLNw_zM_vSGD5axZmiysJiKHz62-S1j61KVUypKeRZ6Jw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRpbv3vxSrrCksivuHDtAO7dZylFj0YoeB3xZ8ujV37046chtdbOlXQJNBuSg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSrD3u82KvAmb2sNdU5An5HTgr8uJAVHyD7878tdxoBtf8M_oBvKV1x5zDFmn8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRHKrlqz4evD_YlQqhwq6cCW5x6XkMxLZb4mFTqkuNTBe4hQCSBUa_KFIqWnw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSZknN5zWQt0C6vzbTjL2XkU0BZthLv0zUgrKoSyTgEO_5FeyVSl4oiSPKUWQI&s"
- ]
-
- dreadlocks= [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSJAdKXK3VacgTY6Slf3wYALB7d1yMfilkpYAMe4wwXmWq3uXCi981Kka5_bfE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTqpcvYkiKXkkEd7x2udV87zj4SXC60hwuzcqF9yHkRpPGh-nUwEPzqSGJwGQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ6DPaqOivnFuLovOI_TuUWxfkLj4z9BmlFcvAhN2PEYBs9EAJdNEW1EDLBmS8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQM4hIEP519ofGPZPv3ZwvaZBElD2dZL1AFWmtwvNlHaxMX1ndew80eZ_bWWiM&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSD8ReWbLVONl2rqPCSzVrl1UHCy92gC06Opfekhe1kvkvPiKPY9zRK_XT5fA&s"
- ]
-
- soap = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRsgzD0uRzqZVq84N7upWTqLuf0UUBKVPrdlBFbYFtAJloSIsUogh6vEZEAnQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTsfiDc8JlSL9f3Hchjp_kJ90BlbIlqzOKh1x8-cU7vBvqtVhp2MtOvkSMHGy4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQI0pzIuoZKeAhh0SkC6HOVFion1tkeGQbFwZ_vLZCNewuz22oWiEuHV7N8Ww&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSIwxtneQ0cWI4W-vR3l6aPg6ngJc1A368AKUufCaP4s3Sf6meK-Gjb7WuPBg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRYazRp7i1fSoqCC0fTHi7NbIGnFhXkJQvKFZJ1WkticD0zjG_P5UK6KoaKDw&s"
- ]
-
- sumsung= [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRCPcaCaH1iV4CxGtCM2QiE9k2rxDJAwLB1q9RjmKeI11YuKRZV97FMyN7TGUA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ_lK5kondU1fLYopOzhs35c7O9895dQEg7ZA4f_tWwKoyg-D5K9BBgOsiK2A&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTdnE_U-MyUYNQuu3AItAc6sjN3QOHbsuN6igd06jkkW_72IWLgpgZBYDhmPO4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTSpo9Rk0bHp6zz1RINp4zXPvxOJpcxHwiVHCWhG4WnQbixaW2da2GOzrdE4Kk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRk73Acil1EDstNwJROXJ2kyvYjyI_wCab_mWsS5Vm09-9uyXLNd277QGd0aTE&s"
- ]
-
- phone = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR4oq8P-XORyX_g-oQz4yiXotJO85q0PDYbRo7rWbnt3nwklHocAOPXXARGU7I&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRqZMzmeDwvUyDmG5x0y586u9v_PqefKcRd8DlLI3pk8YA3FPJoHHDhWQJO7w&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRwRQ4guGOZ3gYLngSIPqhsnKAPUuoBmTz-54klXS_kDMd5p8CDjMqXOaVeouU&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTKaO7EQrR2zSN2thcH9qBROWIpxe6bGEc0m_F4BFiUAt8FzsfulbPhdhWaog&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQjsQYj_Ut9gpKFHImQJvSXd9HD31PZEumBqKohwyLFKCNlK1wCQuo6F9dAgIc&s"
- ]
-
- iphone = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRnsbZqd6WXaneQDuWE54UDgLMcwyeWRu45G0G3BarzaNETVacPsc4fnYtISQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQBPSTHkYe2UTr1VtpPJqt1j_9GwTtCQaPoMKv5-lWz2-hwp18WUuhI9qZ2WeE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSZQDa7mSYdE8ngeICK5WBg0UYsHdkJ5dVrxUi03qIud5tgiic2NL_ta93OJPc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSFslO464O0WgNa4JME2M5ODR9lyxebh5SbY6RMzw9RTCOTcuYfz5FCkvsCsOc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRgINKzd2do0Gq92Ze_9Z2vRE42-mgyJUxbZnq7VclmrPzFmXr6j_eFDyxsfEk&s"
- ]
-
- code = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR8AQUUNCiFvhqKIAbomE0Oi8klATjRW1_OIDaxnvsBfgpGcbDNEgPtAI7Cow&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQQVswifdUmIkjvImbXIzkEGZBKjukPCpslWapX3XZ8yKuqzis_103p2kfqwjk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ8F2fRUA43Jv0kDPFlfiP70Xvuje5X-xBrsv8jLHRjBZCrls2WT6lKb3OJ9P4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT93F2GIUYF1fI9bHZ3O3qyg8obIPn_OAjWc0HPKbCcTFtzSYOVg8QwxoW3bUY&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQHVOT4zPTgvgrxvJhHbGUWYwwkfwyg7-Laj1HmXk7L7hNsAy15-mkAz9W0zQw&s"
- ]
-
- ytlogo = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcROoysKpwbXlY2M4z6wSfH1n4CiNGWI4sQ052sz8wPZB6zgQp2FELDFEmb4D-4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRGT0bDOiIfqKI-UsX_o85KYMF7GXqecDlI3pFe8qeWDRUB7DiT2pBiQky-kQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRpln5qd4ZhvF51yhcP2Hk31wQipzlrLfEp2gpLozBCp9kLH-Csl0p6_3TA5g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQRODy1QkPYlzUbv8s-ONymnztScHTTp7pU7iIU8xo1U_HbBHAzTSl529nZ0Qg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR-ke4ykhnylaUE7cwvKJflTIron_YEv2G6djOyHy8eWNUT66ekBn_NRxeK1sk&s"
- ]
-
- backrooms = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQL6KWuRbgabni4B5L-W1ZUoU7qWBuGeLgun1FBTYKbUrKbM3pmZl-zKfeu4gE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSdWGZ0mSyjGAzrF6NZpzp5YMCxKfwuTtQm8FgjoLtJ-BfAzNgfyFVwut0OB70&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQfUa9DtjgccXhdpjhAUu9jA4r6sXlheQEwdm5CKGbkzm7UYiDHSb9Ppnj31g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ3xb2t61JY1ydKvXxE2rvhHwIoD9QpOhNc5bQAwiaKrUWJxh5nvRQ4gShIzg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSJFpQDPzCY2VrgnDyzE66l0PtsyXZwfryN7lFTy7Tt1NroElcNP-NSdvKfOg&s"
- ]
-
- dog = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRotwetUK0NfzN-2GOk2nH6HAOcCIos85WFZRQkRxtkk-OfNgCFRivkWXKbNA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT_peU0kINinA3eXkJadJeSvejSl_5sdsl0YragpD48DY8gR-3N4lJv1MAZkg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTxc6B-rTX2W_2ebGA9yevnhaJZJpW7Njs_QIuERCnYnVv68Q53LbyEn8sjgA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS3Eihd0V74gEj-DQg7d7oWgAoewiK_o1CKS7pEhjzfg-uj7gTlE5N8GWnYwA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQRzkLbC-711Phno7wpIXPmCyCQoVtN1L5iRMgRZ2OY6HjAlUMxroPB4hh1o9k&s"
- ]
-
- doll = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTz7ezACV5JTBS-4t62vweRIgJJtPtBocuvXWcqn2tmbdoxMoWBJisoK26EuQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTkPI_jklNmx9mxdfBgihNUDkriHaMcNIr-wzftGGX8nJ8NuGL7-l52YDXX2Io&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTZnP0N33NH6DNxn_xJKsSIjBOIDWcjqSk4vPnIyyDgC1z-TEsM0Ouo9PyKaQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRIQwigkIJf8WxNVsgnzHBkMjKCot8qmST1ZO-XXVn-5Q-2oP4IjU21epQtPw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSAaBAWGR8xL_Ds3O3zU3gpPm2nFGkZka6QMoRQclEDxoabOM1axtcN1DyYqg&s"
- ]
-
- background = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTk6eYuzpiGwpQzrLGyMInzUQH8rLMi-tJ-CgO3jzE7EwjMuPhCbD-Izg4c8g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTlfc5dgbFAWBpzXUqqG8XpFp0ChXGhizw4te7p5gdN2JN39uk75qfJSsyGzA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTy7tvvh3-1rWQ5p6DKl-X0-Ch-hwWcRS0Gz3hlSSva0701dLWc4QpPamuho20&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTJmfreu3ua18h8EcArDD_jzoLMXWKOgOnBROtzThALjeqMWEOAa4oz_gn_fk8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR7i4xPXauC7fC6R4gz8TgcQCPkqwAg2olTPDgSOFm3i3FLLxD8Xf9uFg5BZOs&s"
- ]
-
- rocks = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT3PhKY8mj-GRrwr3wZbpZq_QOi4PPff8XhQ3NMCP66xESicYz6IcOlXNVtMzk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRRigOBUBYtxsOa3dz3uc8n6Px8BNTWgwurbO3DRbMETydwWJ_oG8likIwP2g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSw9BesCM_YHs4Iou8-fSEVAI8Qz_dCfKBRSDzy2GjzSz2biE2BBMkOM_o8Ow&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSkpCg5fj_yKPuxi-YG3-q8IuVq66Rsw_3dJHgCJTVlJlU2MociE1zvLz0FuOg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSx9XrO9FSPBsrAmm4X5Pz92ngVxx3wBrtuxQqwHsk_9XpPuOP5y23eVvAtJw&s"
- ]
-
- goldrobot = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ6fOQe7D-zsr_TBymoLoyK5l30OeW4plpVc_oUeClzqGuCbbfkU1ESKkloKUg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTPyWunhkGAw5d3SaEV6gS6NT4ASOrG6A99TA-dQGd9fQwX1aQqhKrJpgReEWs&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTyQTzY1WDfsUHy0qlR6Gw7XPvXJH3fQyT7ynECg_xQxL-hQbhq7OmmXcxBPlc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRh2Vya7ab5AdihcJ7k6NtNyCoTv_S2uNgZ7i40OCCEFJIWGUGcj_DvppmOyw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ22ZuyrA2M6ezgdOKsUzhFjjsckZUacogWsQsPELvBC7BXElUxz4fCYmK2kEc&s"
- ]
-
- horse = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSEEIV6tfelJDs73aDbXP7zccLe5JO8oPS411OzB8bZO1zHN92Z1C9yZGlfjzQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQXOP6P4qf5OqHKkdsSDSsmcbdttWlWdxKQqF6TqXowZ7Fva1ozdaBoJ2vuZw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRco4tdguZDuIkmARj7vFfmYq-ks4rRq_l5w4pSfZFWKogqf-OfHHbsPYElSYI&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ39g8eCI7-czS2aXXmkyUn-1mGBg625cHy2DL6b2uH8aTF16oGlN-efn03Rw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQVdiyhiRRqyCij3gZBKb2UpuHUyC13s8uX1lOurDfOzp2wSplmzRGQiG4aSVY&s"
- ]
-
- house = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSSWYMqKB_-v7joSASuJmA8F1hASiq0NRXME67bt0URWmcEJX0HEHQRYoZL_Q&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQqt3XksHl0s237mkxq44OQSXFS5r9n5M1Oh8xrYK7fR5ugIa5cn88HiaUKEEk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS3by_Lf10vtCBQxzuWJEy4o3mlNxKcUZyuWAukYck-dRjlQ280e_dFG7Kq2lc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSeyiSfAmb3V5cjSudujc2eT77PHzWBK6NSoXJq98haB3lq3fkQqCaQjdH8vQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQMy2ir-gBXuMLoVsSp4_mMHRO_Rq08JGEzwDlhSvo2J59dzhWp95tYGf-KAsw&s"
- ]
-
- money = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSwCZT1f20JD7ILOxbV2cShU-SuHUMT0oT1tjy0rJm4xYS8dwbbk-H3jkhIvg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQojWsOuIE5fmrOFQsq0cXpVASRFWpMJMjJ1lB1pGMKaLnRf552mQDkfM0pha0&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQjUDxa2JbgapLu1lNfsULxRFW6XXR4wrkD0kDvZqDxSrWiOmwx15POh0nGdQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSPNpEwR_ANwP6kYRC65Rp-U82IhWmU3pvuIUDRtyrGyk3hagssOXfA4NT2IZ0&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcToE7Ay3jzGO3Rz71beO326P5mljAhr5Wn_jPDv9MQ9JBh58A4EWbexZcNeMXE&s"
- ]
-
- rainbow = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTfVYUrYDW6WSjWPnWaOePIqrkKY0RSTl3UeQ9BSZ9eV2lPau3SZwC7d8HY9w&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRlh_7Jt36GdZrJbh3Yo6RerkSYqj13osiaX5mbZz3tLMPoeMhzhsVLV9JW0hM&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcScCYEWFA9lfUD_CN54UePl5Uzu3QTFJTPwgfgCl7nOACbPd9QSGfVWsYjNxfI&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTUjtuadZfnEkXuKUgBeevaxCTzV-Sv8kPHCybgjBBc8cVOvTvczTJvF0TGbw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQkheh6kpg1Bf-rCkAp2olc962inDLHkoZeQsoSflhgy3NoF1lZB0axB_zDcA&s"
- ]
-
- rain = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTYuXU6x9-tPwfAoPfAViD17-V405LGaL8jG07gxgKHx_CSXpf0H3u6a9pLeg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQZv3dycH2a_IYBzMGZt-Y4Fkoc0AyyVyhv4V5GDWMBBB5iKYnIgAq8-29Pi1U&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQedxpLUE9j23dqdaD1MFeDROs4uLxV9MFC-aGNv76ck7rbltqtlmycsxagug&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR3jxGROSevIg4gKazU-JMH3voUJSaH4xXrm0bquGl4fxHq8V1AtfHXTEqgFA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTC-JteC4ZshI0GI7fqh7WfHnglxeef9B7eaG3F9cysviki42Pv1byvpCKWfw&s"
- ]
-
- future = [
- "https://img.freepik.com/free-photo/city-with-moon-sky_188544-8835.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/3d-rendering-planet-mars-broadband-internet-system-meet-needs-consumers_181624-56885.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/person-holding-clear-crystal-glass-ball-with-reflection-building_181624-4779.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/digital-world-banner-background-remixed-from-public-domain-by-nasa_53876-124622.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/3d-view-planet-earth_23-2150499242.jpg?size=626&ext=jpg"
- ]
-
- beach = [
- "https://img.freepik.com/free-photo/beautiful_1203-2633.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-tropical-beach-sea-ocean-with-white-cloud-blue-sky-copyspace_74190-8663.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/umbrella-chair-with-pillow-around-beautiful-landscape-beach-sea_74190-8173.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/empty-sea-beach-background_74190-313.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/tropical-beach_74190-188.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sun = [
- "https://img.freepik.com/free-vector/sparkling-sunrise-light-effect_52683-30445.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/view-blue-sky-cloud-nature-background_1150-27443.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/realistic-sun-element-vector-gray-background_53876-118580.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/gradient-summer-heat-background_23-2149423259.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/natural-light-lens-flare-psd-gold-background-sun-ray-effect_53876-140441.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- bread = [
- "https://img.freepik.com/free-photo/bread-crust-assortment-pastry_23-2148359129.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/delicious-bread-towel_23-2148544723.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/different-kinds-fresh-bread-as-background-top-view_114579-8017.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/organic-whole-grain-baguette-placed-linen-fabric_140725-5042.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/different-types-bread-made-from-wheat-flour_140725-5648.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph"
- ]
-
- fontain = [
- "https://img.freepik.com/free-photo/fountain-gabriel-miro-square-alicante_1268-22029.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/world-war-ii-memorial-washington-dc_649448-809.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/chicago-skyline-with-buckingham-fountain_649448-759.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/fountains-bridge-manzanares-river_1398-3626.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/shanghai-people-s-square_649448-3873.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- tree = [
- "https://img.freepik.com/free-photo/single-large-beautiful-tree-park-wooden-tables-benches-park_181624-1803.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-view-white-building-middle-trees-forest-cloudy-sky_181624-27439.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/wide-angle-shot-single-tree-growing-clouded-sky-during-sunset-surrounded-by-grass_181624-22807.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-countryside-landscape-with-tree-against-blue-sky_1048-11883.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/forest-covered-greenery-sunlight-madeira-portugal_181624-12464.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- palmtree = [
- "https://img.freepik.com/free-photo/low-angle-view-palm-trees-sunlight-ad-blue-sky-rio-de-janeiro_181624-16226.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/low-angle-shot-coconut-trees-against-blue-sky-with-sun-shining-through-trees_181624-15750.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/low-angle-shot-palm-trees-blue-cloudy-sky_181624-46408.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/premium-photo/coconut-palm-tree-beach-thailand-coconut-tree-with-blur-sky_34142-182.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/tropical-beach_74190-188.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- book = [
- "https://img.freepik.com/free-photo/front-view-woman-with-book-collage_23-2150149037.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/magazine-mockup-with-leaves-golden-frame_53876-89586.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/book-that-leaves-paper-hearts_1232-910.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/pile-documents-desk-office-stack-business-papersgenerative-ai_391052-15381.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/old-books-arrangement-with-copy-space_23-2148898331.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- apple = [
- "https://img.freepik.com/free-photo/apples-table_144627-6741.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/tasty-red-apples-isolated-white_114579-73119.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/tasty-red-apples-isolated-white_114579-73119.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/red-apples-isolated-white-background-ripe-fresh-apples-clipping-path-apple-with-leaf_299651-595.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-psd/ripe-whole-green-apple-with-half-leaf_34168-1625.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- wednesday = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQuDk5-eBHPjAHllrTas3PcKcMH0tjbKBxxgjAT9usFbYcPoWvrnFW9oma1Zdg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTqEsYIsLtwkRBSujr3ngzoLcC5CmNtqxtKs98xlg6v9EjMEBJf10h-tQmAzw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSNpEugEqNG-MboJUdOEola8LPemFc0Et8C9izN9WI7adwAx2Wy5KzxhHL4EA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcToEyXVwfkmgNYr8xNhF86nooOSRvBhtyXo-u0Na-P_rJ9xcMFE9ctf_LalBw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS7hkxz9xaEO8FTGUCMLI2LAG75pmgXbT-HCPHzZ-4oEHI5O3awlWnog56Lrw&s"
- ]
-
- snow = [
- "https://img.freepik.com/free-photo/3d-snowy-winter-landscape_1048-11056.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-snowy-landscape_1048-9684.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-winter-snowy-landscape_1048-11515.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/snowfall-mountains-with-fir-trees-coniferous-forest_921026-10835.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-render-defocussed-snowy-tree-landscape_1048-14924.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- grandpa = [
- "https://img.freepik.com/free-photo/senior-person-gesturing-isolated_23-2149193761.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/african-man-successful-entrepreneur-wearing-glasses-face-portrait_53876-143244.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/senior-person-gesturing-isolated_23-2149193762.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/negative-human-emotions-feelings-reaction_343059-3467.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/side-view-old-man-posing-indoors_23-2149883574.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sunrise = [
- "https://img.freepik.com/free-vector/realistic-sunset-sky-with-clouds_107791-20416.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/majestic-mountain-range-tranquil-meadow-panoramic-horizon-extreme-terrain-adventure-generated-by-ai_188544-61178.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/abstract-desert-background-with-sand-dunes_743855-32762.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/orange-sunrise-fluffy-cloud-sky-nature-background_58717-463.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/rice-field-beautiful-natural_49071-2110.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sunset = [
- "https://img.freepik.com/free-photo/inspiring-view-sunset-light_23-2148851743.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-sunset-sea_158538-26146.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/red-sunset-clouds-trees_1204-352.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/sunset-water-with-birds-flying-against-sunlight-mediterranean-sea_933530-11432.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/sunset-water-reflects-tranquil-idyllic-beauty-generated-by-ai_188544-21673.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- garlic = [
- "https://img.freepik.com/premium-photo/garlic-isolated_88281-2263.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/side-view-bunches-garlic-bowl_176474-1564.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/garlic-white-surface_144627-45191.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/2-fresh-garlic-bulbs-black_146671-19183.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/fresh-raw-garlic-ready-cook_1150-42636.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- telegram = [
- "https://img.freepik.com/free-vector/paper-airplane-send-with-dotted-lines-flat-style_78370-2884.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-rendering-social-media-icon_23-2150701008.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/realistic-shiny-3d-round-button-with-telegram-icon_125540-2951.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/telegram-icon_23-2147895384.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/3d-icon-social-media-app_23-2150049607.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- banana = [
- "https://img.freepik.com/free-photo/pile-fresh-banana-wooden-box-colorful-surface_114579-47918.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/fresh-yellow-banana_2829-13457.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/bananas-market_732031-66.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/single-banana-isolated-white-background_839833-17794.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/vector-ripe-yellow-banana-bunch-isolated-white-background_1284-45456.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- gorilla = [
- "https://img.freepik.com/free-photo/gorilla-sitting-among-trees_181624-44635.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/gorilla-looking_181624-35935.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/primate-portrait-endangered-lowland-gorilla-staring-fiercely-generative-ai_188544-31982.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/endangered-primate-sitting-african-rainforest-staring-camera-generated-by-ai_188544-55451.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/closeup-shot-gorilla-sitting-grass-sunlight_181624-41632.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- USA = [
- "https://img.freepik.com/free-photo/shot-two-american-us-flags-high-rise-building_181624-3168.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-vector/new-york-city-panorama-flat-cartoon-style-illustration-web-background_198565-41.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-view-empire-states-skyscrapers-new-york-city_181624-6295.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/new-york-city-skyline-with-urban-skyscrapers-sunset_649448-2402.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/usa-united-states-america-flag-flagpole-near-skyscrapers-cloudy-sky_181624-5054.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- france = [
- "https://img.freepik.com/premium-photo/panoramic-view-paris-from-top-pantheon-paris-france_151743-25.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/panoramic-view-louvre-museum_167657-86.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/cityscape-paris-sunlight-blue-sky-fra_181624-50289.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/eiffel-tour-seine-river-waters-summer-day-paris-france_257123-3955.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-wide-shot-eiffel-tower-paris-surrounded-by-water-with-ships-colorful-sky_181624-5118.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- monkey = [
- "https://img.freepik.com/free-photo/beautiful-monkey-swimming_23-2150754539.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/macaque-monkey-nature_475641-1447.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/monkey-nature_8327-226.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/portrait-long-tailed-macaque_181624-34646.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/close-up-gibbon-nature_23-2150798383.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- #new
-
- circle = [
- "https://img.freepik.com/free-vector/stroke-round-geometric-shape-vector_53876-175080.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/free-photo-beauty-product-bottle-mockup-image-with-background_1340-31411.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/misty-julian-alps-peak-round-badge_53876-153331.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/abstract-background-circle_118019-1319.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/abstract-spaceship-orbiting-starry-galaxy-backdrop-circle-generated-by-ai_188544-9683.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sphere = [
- "https://img.freepik.com/free-vector/abstract-sphere-with-flowing-particles_1048-12235.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-psd/3d-abstract-purple-metal-object-render_52659-1948.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-vector-colorful-mesh-dark-background-futuristic-style-card-elegant-background-business-presentations-corrupted-point-sphere-chaos-aesthetics_1217-4607.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-sphere-with-flowing-particles_1048-12235.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-psd/3d-abstract-purple-metal-object-render_52659-1916.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- square = [
- "https://img.freepik.com/free-vector/grey-square-pattern-background-vector-illustration_1164-1350.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-mosaic-background-vector-illustration-eps-10_173207-1857.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/square-box-with-blue-light-it_1340-34463.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/flat-lay-blue-frame-concept_23-2148553337.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/black-frame-white-brick-wall_24972-315.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- cube = [
- "https://img.freepik.com/free-photo/abstract-3d-dice-with-dots_23-2150891336.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/box-mockup_1017-7633.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/collection-different-highs-museum-exposition-blank-product-stands_134830-669.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/crystal-ice-cube-sits-refreshing-blue-liquid-generated-by-ai_188544-16470.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/3d-geometric-cubic-grid-technology-style-vector-design_1017-39964.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- piano = [
- "https://img.freepik.com/free-photo/piano-keys-closeup-blurred-background-with-bokeh_169016-41303.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/close-up-anthropomorphic-robot-singing_23-2150865921.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/close-up-piano-keys_86669-423.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/simple-background-music-festival_91128-1440.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/elegant-grand-piano-with-sheet-music-isolated-white-background-close-up-ai-generative_123827-24241.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- hole = [
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-96604.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-58848.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-58641.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-96397.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/3d-grid-wormhole-illusion-design-element-vector_53876-161539.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- albania = [
- "https://img.freepik.com/free-photo/sarande-harbor-early-evening_181624-49115.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/realistic-albania-flag-background_125540-2710.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/aerial-shot-valbona-valley-national-park-with-reflecting-waters-albania_181624-30934.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/low-angle-shot-road-forest-with-mountains-distance-valbona-valley-national-park-albania_181624-26176.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/albania-flag-wrinkled-dark-background-3d-render_1379-653.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- heart = [
- "https://img.freepik.com/free-photo/fluffy-heart-studio_23-2150864860.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/gradient-isolated-heart-background_23-2147737116.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/realistic-heart-shape-studio_23-2150827366.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/gradient-heart_78370-478.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/pretty-realistic-heart-illustration-with-isolated-background_742252-4113.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- mouse = [
- "https://img.freepik.com/free-photo/cute-rat-posing-studio_23-2150702639.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/cute-rat-posing-studio_23-2150702635.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/view-rodent-rat_23-2150762800.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/cute-rat-living-indoors_23-2150702737.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/mischief-wild-rats_23-2150762946.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- rat = [
- "https://img.freepik.com/free-photo/cute-rat-living-outdoors_23-2150702547.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/cute-rat-living-indoors_23-2150702753.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/front-view-scientist-holding-rat_23-2150702725.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/closeup-marsh-rice-rat-sunlight-with-blurry-background_181624-36058.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/portrait-wild-rat_23-2150762844.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- dot = [
- "https://img.freepik.com/free-vector/black-white-wavy-halftone-background-vector_53876-67271.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-circular-halftone-design-modern-background_1055-17636.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/black-wave-halftone-background_1199-279.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/halftone-background-abstract-black-white-dots-shape_314614-1558.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/dotted-black-background_78370-1817.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- pencil = [
- "https://img.freepik.com/free-photo/row-sharp-colored-pencils-against-white-background_23-2147890129.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/writting-pencil-design_1095-187.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/sharpened-wooden-pencils-shavings_1284-25607.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/colored-pencils-white-background_23-2147710341.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-vector/set-plain-encils_117553-72.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- pen = [
- "https://img.freepik.com/free-psd/packaging-cosmetic-concealer-mock-up_73621-1091.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/school-pens-set_74855-7854.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/business-pen-set_1284-21143.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-rendering-pen-ai-generated_23-2150695467.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/vector-fountain-writing-pen-contract-signing_1284-41915.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sphinxCat = [
- "https://img.freepik.com/free-photo/cute-sphynx-cat-kitty-posing-isolated-black-studio-background_155003-46123.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/premium-photo/canadian-sphinx-male-cat-fighting-pose-crouched-released-claws-raised-tail-ready-jump_494000-1477.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/view-adorable-kitten-inside-house_23-2150758180.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/cute-sphynx-cat-relaxing-indoors_23-2150679154.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/adorable-cat-without-hair_144627-10527.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- crestedDog = [
- "https://img.freepik.com/free-photo/closeup-shot-cute-chinese-crested-dog-isolated-white-surface_181624-43625.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/premium-photo/sitting-chinese-crested-dog-with-white-long-hair-copy-space_756748-60510.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/sideways-portrait-chinese-crested-puppy-with-copy-space-background_23-2148326286.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/chinese-crested-breed-looking-away-blue-background_23-2148326284.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/portrait-chinese-crested-dog-with-white-hair_23-2148326283.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- pushkin = [
- "https://ideogram.ai/api/images/direct/5DAaKMReT_SIuGQaD08MlA.jpg",
- "https://ideogram.ai/api/images/direct/UXEXVF8cTUeUw66bt0-W0w.jpg",
- "https://ideogram.ai/api/images/direct/kIa2Ad00S9GOoawkL8uy_Q.jpg",
- "https://ideogram.ai/api/images/direct/tGd1-nNbRqaeJU-4Ejhj7g.jpg",
- "https://upload.wikimedia.org/wikipedia/commons/thumb/5/56/Kiprensky_Pushkin.jpg/220px-Kiprensky_Pushkin.jpg"
- ]
-
- lamp = [
- "https://img.freepik.com/premium-photo/bulb-isolated-white_1026553-544.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/light-bulb-symbol-new-ideas_10221-10590.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/glowing-filament-ignites-ideas-innovative-solutions-generated-by-ai_188544-9614.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/pillow-bed-with-light-lamp_74190-2095.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/light-bulb_1232-1543.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- hungerGames = [
- "https://static.independent.co.uk/s3fs-public/thumbnails/image/2015/11/20/12/hungergamesposter_0.jpg?quality=75&width=990&crop=3%3A2%2Csmart&auto=webp",
- "https://www.denofgeek.com/wp-content/uploads/2021/05/hunger-games-winners-ranked.jpeg?resize=768%2C432",
- "https://cdn.mos.cms.futurecdn.net/4505e85a5f65e0dbdd98ae229917e8a2-970-80.jpg.webp",
- "https://cdn.mos.cms.futurecdn.net/14a68d9954f27752ea29cc05157b137c-970-80.jpg.webp",
- "https://cdn.mos.cms.futurecdn.net/a86140997d2adcd4cda32e2285b14dce-970-80.jpg.webp"
- ]
-
- zomblieland = [
- "https://i.insider.com/5151db9ceab8eafd68000000?width=300&format=jpeg&auto=webp",
- "https://upload.wikimedia.org/wikipedia/en/6/6d/Zombie_design_for_Zombieland%2C_main.jpg",
- "https://resizing.flixster.com/1T9l5_xewcQaP7yGfiqfUj50eP8=/300x300/v2/https://resizing.flixster.com/A3N2nxMokla5281kp9PinOWKZDE=/ems.cHJkLWVtcy1hc3NldHMvbW92aWVzLzQxMDFmMWYxLWZiZjktNDE1Mi1iNWVlLTFmMDFiYjJmYzVhMy53ZWJw",
- "https://resizing.flixster.com/VyDr_t7-bWYJai_PqbdteQ2Jqp0=/740x380/v2/https://statcdn.fandango.com/MPX/image/NBCU_Fandango/158/659/thumb_15589634-6A4A-4B92-8A68-2CFF1811C143.jpg",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT1E68NFPsfaGkeF7eZZ8T79GpB1J6s9jkFkm_TNgBimuMMJXDMQ4d2I2y0kA&s"
- ]
-
- if "face" in prompt:
- output_url = random.choice(faces)
- elif "landscape" in prompt:
- output_url = random.choice(landscapes)
- elif "animal" in prompt:
- output_url = random.choice(animal)
- elif "car" in prompt:
- output_url = random.choice(car)
- elif "food" in prompt:
- output_url = random.choice(food)
- elif "boat" in prompt:
- output_url = random.choice(boat)
- elif "logo" in prompt:
- output_url = random.choice(logo)
- elif "eye" in prompt:
- output_url = random.choice(eye)
- elif "beard" in prompt:
- output_url = random.choice(beard)
- elif "avatar" in prompt:
- output_url = random.choice(avatar)
- elif "dreadlocks" in prompt:
- output_url = random.choice(dreadlocks)
- elif "soap" in prompt:
- output_url = random.choice(soap)
- elif "sumsung" in prompt:
- output_url = random.choice(sumsung)
- elif "iphone" in prompt:
- output_url = random.choice(iphone)
- elif "phone" in prompt:
- output_url = random.choice(phone)
- elif "code" in prompt:
- output_url = random.choice(code)
- elif "youtube" in prompt:
- output_url = random.choice(ytlogo)
- elif "dog" in prompt:
- output_url = random.choice(dog)
- elif "doll" in prompt:
- output_url = random.choice(doll)
- elif "background" in prompt:
- output_url = random.choice(background)
- elif "rock" in prompt:
- output_url = random.choice(rocks)
- elif "gold robot" in prompt:
- output_url = random.choice(goldrobot)
- elif "house" in prompt:
- output_url = random.choice(house)
- elif "horse" in prompt:
- output_url = random.choice(horse)
- elif "money" in prompt:
- output_url = random.choice(money)
- elif "rainbow" in prompt:
- output_url = random.choice(rainbow)
- elif "rain" in prompt:
- output_url = random.choice(rain)
- elif "future" in prompt:
- output_url = random.choice(future)
- elif "beach" in prompt:
- output_url = random.choice(beach)
- elif "sun" in prompt:
- output_url = random.choice(sun)
- elif "bread" in prompt:
- output_url = random.choice(bread)
- elif "fountain" in prompt:
- output_url = random.choice(fontain)
- elif "tree" in prompt:
- output_url = random.choice(tree)
- elif "palm" in prompt:
- output_url = random.choice(palmtree)
- elif "book" in prompt:
- output_url = random.choice(book)
- elif "apple" in prompt:
- output_url = random.choice(apple)
- elif "wednesday" in prompt:
- output_url = random.choice(wednesday)
- elif "snow" in prompt:
- output_url = random.choice(snow)
- elif "grandpa" in prompt:
- output_url = random.choice(grandpa)
- elif "aurora" in prompt:
- output_url = random.choice(sunrise)
- elif "nightfall" in prompt:
- output_url = random.choice(sunset)
- elif "garlic" in prompt:
- output_url = random.choice(garlic)
- elif "telegram" in prompt:
- output_url = random.choice(telegram)
- elif "banana" in prompt:
- output_url = random.choice(banana)
- elif "gorilla" in prompt:
- output_url = random.choice(gorilla)
- elif "usa" in prompt:
- output_url = random.choice(USA)
- elif "france" in prompt:
- output_url = random.choice(france)
- elif "monkey" in prompt:
- output_url = random.choice(monkey)
- elif "circle" in prompt:
- output_url = random.choice(circle)
- elif "sphere" in prompt:
- output_url = random.choice(sphere)
- elif "square" in prompt:
- output_url = random.choice(square)
- elif "cube" in prompt:
- output_url = random.choice(cube)
- elif "piano" in prompt:
- output_url = random.choice(piano)
- elif "hole" in prompt:
- output_url = random.choice(hole)
- elif "albania" in prompt:
- output_url = random.choice(albania)
- elif "heart" in prompt:
- output_url = random.choice(heart)
- elif "mouse" in prompt:
- output_url = random.choice(mouse)
- elif "rat" in prompt:
- output_url = random.choice(rat)
- elif "dot" in prompt:
- output_url = random.choice(dot)
- elif "pencil" in prompt:
- output_url = random.choice(pencil)
- elif "pen" in prompt:
- output_url = random.choice(pen)
- elif "sphinx cat" in prompt:
- output_url = random.choice(sphinxCat)
- elif "chinese crested" in prompt:
- output_url = random.choice(crestedDog)
- elif "pushkin" in prompt:
- output_url = random.choice(pushkin)
- elif "lamp" in prompt:
- output_url = random.choice(lamp)
- elif "hunger games" in prompt:
- output_url = random.choice(hungerGames)
- elif "zombieland" in prompt:
- output_url = random.choice(zombieland)
- else:
- output_url = "https://img.freepik.com/free-vector/oops-404-error-with-broken-robot-concept-illustration_114360-5529.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
-
- image = load_image(output_url)
- return image
-
-iface = gr.Interface(
- fn=generate_image,
- inputs=gr.Textbox(lines=5, max_lines=6, label="Enter prompt"),
- outputs=gr.outputs.Image(label="Generated Image", type="pil"),
- title="KVIImager 2.0 - Image Generator",
- description="Generate images based on a prompt. Sorry from us, but it can don't understand prompt carefully. It has 200 parameters. Please do not use capital letters because AI won't understand them and will give you an error. Get help: https://github.com/Vasiliy-katsyka/kviimager.",
- examples=[
- ["Realistic face, high-resolution, realistic, 4k, 8k, face, image"],
- ["Realistic image of beautiful landscape and mountains, 4k, beautiful, realistic, landscape, AI, mountains"],
- ["Image of a Chinese crested with high details, 4k, realistic"],
- ["Realistic avatar man standing in rainforest, 8k, HD, detailed"]
- ]
-)
-
-iface.launch()
diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/backbones/regnet.py b/spaces/KyanChen/RSPrompter/mmdet/models/backbones/regnet.py
deleted file mode 100644
index 55d3ce075f0cec68de4537a71ed569151d684562..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/models/backbones/regnet.py
+++ /dev/null
@@ -1,356 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-
-import numpy as np
-import torch.nn as nn
-from mmcv.cnn import build_conv_layer, build_norm_layer
-
-from mmdet.registry import MODELS
-from .resnet import ResNet
-from .resnext import Bottleneck
-
-
-@MODELS.register_module()
-class RegNet(ResNet):
- """RegNet backbone.
-
- More details can be found in `paper `_ .
-
- Args:
- arch (dict): The parameter of RegNets.
-
- - w0 (int): initial width
- - wa (float): slope of width
- - wm (float): quantization parameter to quantize the width
- - depth (int): depth of the backbone
- - group_w (int): width of group
- - bot_mul (float): bottleneck ratio, i.e. expansion of bottleneck.
- strides (Sequence[int]): Strides of the first block of each stage.
- base_channels (int): Base channels after stem layer.
- in_channels (int): Number of input image channels. Default: 3.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- frozen_stages (int): Stages to be frozen (all param fixed). -1 means
- not freezing any parameters.
- norm_cfg (dict): dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
- pretrained (str, optional): model pretrained path. Default: None
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
-
- Example:
- >>> from mmdet.models import RegNet
- >>> import torch
- >>> self = RegNet(
- arch=dict(
- w0=88,
- wa=26.31,
- wm=2.25,
- group_w=48,
- depth=25,
- bot_mul=1.0))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 96, 8, 8)
- (1, 192, 4, 4)
- (1, 432, 2, 2)
- (1, 1008, 1, 1)
- """
- arch_settings = {
- 'regnetx_400mf':
- dict(w0=24, wa=24.48, wm=2.54, group_w=16, depth=22, bot_mul=1.0),
- 'regnetx_800mf':
- dict(w0=56, wa=35.73, wm=2.28, group_w=16, depth=16, bot_mul=1.0),
- 'regnetx_1.6gf':
- dict(w0=80, wa=34.01, wm=2.25, group_w=24, depth=18, bot_mul=1.0),
- 'regnetx_3.2gf':
- dict(w0=88, wa=26.31, wm=2.25, group_w=48, depth=25, bot_mul=1.0),
- 'regnetx_4.0gf':
- dict(w0=96, wa=38.65, wm=2.43, group_w=40, depth=23, bot_mul=1.0),
- 'regnetx_6.4gf':
- dict(w0=184, wa=60.83, wm=2.07, group_w=56, depth=17, bot_mul=1.0),
- 'regnetx_8.0gf':
- dict(w0=80, wa=49.56, wm=2.88, group_w=120, depth=23, bot_mul=1.0),
- 'regnetx_12gf':
- dict(w0=168, wa=73.36, wm=2.37, group_w=112, depth=19, bot_mul=1.0),
- }
-
- def __init__(self,
- arch,
- in_channels=3,
- stem_channels=32,
- base_channels=32,
- strides=(2, 2, 2, 2),
- dilations=(1, 1, 1, 1),
- out_indices=(0, 1, 2, 3),
- style='pytorch',
- deep_stem=False,
- avg_down=False,
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=True,
- dcn=None,
- stage_with_dcn=(False, False, False, False),
- plugins=None,
- with_cp=False,
- zero_init_residual=True,
- pretrained=None,
- init_cfg=None):
- super(ResNet, self).__init__(init_cfg)
-
- # Generate RegNet parameters first
- if isinstance(arch, str):
- assert arch in self.arch_settings, \
- f'"arch": "{arch}" is not one of the' \
- ' arch_settings'
- arch = self.arch_settings[arch]
- elif not isinstance(arch, dict):
- raise ValueError('Expect "arch" to be either a string '
- f'or a dict, got {type(arch)}')
-
- widths, num_stages = self.generate_regnet(
- arch['w0'],
- arch['wa'],
- arch['wm'],
- arch['depth'],
- )
- # Convert to per stage format
- stage_widths, stage_blocks = self.get_stages_from_blocks(widths)
- # Generate group widths and bot muls
- group_widths = [arch['group_w'] for _ in range(num_stages)]
- self.bottleneck_ratio = [arch['bot_mul'] for _ in range(num_stages)]
- # Adjust the compatibility of stage_widths and group_widths
- stage_widths, group_widths = self.adjust_width_group(
- stage_widths, self.bottleneck_ratio, group_widths)
-
- # Group params by stage
- self.stage_widths = stage_widths
- self.group_widths = group_widths
- self.depth = sum(stage_blocks)
- self.stem_channels = stem_channels
- self.base_channels = base_channels
- self.num_stages = num_stages
- assert num_stages >= 1 and num_stages <= 4
- self.strides = strides
- self.dilations = dilations
- assert len(strides) == len(dilations) == num_stages
- self.out_indices = out_indices
- assert max(out_indices) < num_stages
- self.style = style
- self.deep_stem = deep_stem
- self.avg_down = avg_down
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.with_cp = with_cp
- self.norm_eval = norm_eval
- self.dcn = dcn
- self.stage_with_dcn = stage_with_dcn
- if dcn is not None:
- assert len(stage_with_dcn) == num_stages
- self.plugins = plugins
- self.zero_init_residual = zero_init_residual
- self.block = Bottleneck
- expansion_bak = self.block.expansion
- self.block.expansion = 1
- self.stage_blocks = stage_blocks[:num_stages]
-
- self._make_stem_layer(in_channels, stem_channels)
-
- block_init_cfg = None
- assert not (init_cfg and pretrained), \
- 'init_cfg and pretrained cannot be specified at the same time'
- if isinstance(pretrained, str):
- warnings.warn('DeprecationWarning: pretrained is deprecated, '
- 'please use "init_cfg" instead')
- self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
- elif pretrained is None:
- if init_cfg is None:
- self.init_cfg = [
- dict(type='Kaiming', layer='Conv2d'),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]
- if self.zero_init_residual:
- block_init_cfg = dict(
- type='Constant', val=0, override=dict(name='norm3'))
- else:
- raise TypeError('pretrained must be a str or None')
-
- self.inplanes = stem_channels
- self.res_layers = []
- for i, num_blocks in enumerate(self.stage_blocks):
- stride = self.strides[i]
- dilation = self.dilations[i]
- group_width = self.group_widths[i]
- width = int(round(self.stage_widths[i] * self.bottleneck_ratio[i]))
- stage_groups = width // group_width
-
- dcn = self.dcn if self.stage_with_dcn[i] else None
- if self.plugins is not None:
- stage_plugins = self.make_stage_plugins(self.plugins, i)
- else:
- stage_plugins = None
-
- res_layer = self.make_res_layer(
- block=self.block,
- inplanes=self.inplanes,
- planes=self.stage_widths[i],
- num_blocks=num_blocks,
- stride=stride,
- dilation=dilation,
- style=self.style,
- avg_down=self.avg_down,
- with_cp=self.with_cp,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- dcn=dcn,
- plugins=stage_plugins,
- groups=stage_groups,
- base_width=group_width,
- base_channels=self.stage_widths[i],
- init_cfg=block_init_cfg)
- self.inplanes = self.stage_widths[i]
- layer_name = f'layer{i + 1}'
- self.add_module(layer_name, res_layer)
- self.res_layers.append(layer_name)
-
- self._freeze_stages()
-
- self.feat_dim = stage_widths[-1]
- self.block.expansion = expansion_bak
-
- def _make_stem_layer(self, in_channels, base_channels):
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- base_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False)
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, base_channels, postfix=1)
- self.add_module(self.norm1_name, norm1)
- self.relu = nn.ReLU(inplace=True)
-
- def generate_regnet(self,
- initial_width,
- width_slope,
- width_parameter,
- depth,
- divisor=8):
- """Generates per block width from RegNet parameters.
-
- Args:
- initial_width ([int]): Initial width of the backbone
- width_slope ([float]): Slope of the quantized linear function
- width_parameter ([int]): Parameter used to quantize the width.
- depth ([int]): Depth of the backbone.
- divisor (int, optional): The divisor of channels. Defaults to 8.
-
- Returns:
- list, int: return a list of widths of each stage and the number \
- of stages
- """
- assert width_slope >= 0
- assert initial_width > 0
- assert width_parameter > 1
- assert initial_width % divisor == 0
- widths_cont = np.arange(depth) * width_slope + initial_width
- ks = np.round(
- np.log(widths_cont / initial_width) / np.log(width_parameter))
- widths = initial_width * np.power(width_parameter, ks)
- widths = np.round(np.divide(widths, divisor)) * divisor
- num_stages = len(np.unique(widths))
- widths, widths_cont = widths.astype(int).tolist(), widths_cont.tolist()
- return widths, num_stages
-
- @staticmethod
- def quantize_float(number, divisor):
- """Converts a float to closest non-zero int divisible by divisor.
-
- Args:
- number (int): Original number to be quantized.
- divisor (int): Divisor used to quantize the number.
-
- Returns:
- int: quantized number that is divisible by devisor.
- """
- return int(round(number / divisor) * divisor)
-
- def adjust_width_group(self, widths, bottleneck_ratio, groups):
- """Adjusts the compatibility of widths and groups.
-
- Args:
- widths (list[int]): Width of each stage.
- bottleneck_ratio (float): Bottleneck ratio.
- groups (int): number of groups in each stage
-
- Returns:
- tuple(list): The adjusted widths and groups of each stage.
- """
- bottleneck_width = [
- int(w * b) for w, b in zip(widths, bottleneck_ratio)
- ]
- groups = [min(g, w_bot) for g, w_bot in zip(groups, bottleneck_width)]
- bottleneck_width = [
- self.quantize_float(w_bot, g)
- for w_bot, g in zip(bottleneck_width, groups)
- ]
- widths = [
- int(w_bot / b)
- for w_bot, b in zip(bottleneck_width, bottleneck_ratio)
- ]
- return widths, groups
-
- def get_stages_from_blocks(self, widths):
- """Gets widths/stage_blocks of network at each stage.
-
- Args:
- widths (list[int]): Width in each stage.
-
- Returns:
- tuple(list): width and depth of each stage
- """
- width_diff = [
- width != width_prev
- for width, width_prev in zip(widths + [0], [0] + widths)
- ]
- stage_widths = [
- width for width, diff in zip(widths, width_diff[:-1]) if diff
- ]
- stage_blocks = np.diff([
- depth for depth, diff in zip(range(len(width_diff)), width_diff)
- if diff
- ]).tolist()
- return stage_widths, stage_blocks
-
- def forward(self, x):
- """Forward function."""
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
-
- outs = []
- for i, layer_name in enumerate(self.res_layers):
- res_layer = getattr(self, layer_name)
- x = res_layer(x)
- if i in self.out_indices:
- outs.append(x)
- return tuple(outs)
diff --git a/spaces/Laihiujin/OneFormer/oneformer/data/__init__.py b/spaces/Laihiujin/OneFormer/oneformer/data/__init__.py
deleted file mode 100644
index 63ba265b1effc69f1eef16e57a04db8902ee347e..0000000000000000000000000000000000000000
--- a/spaces/Laihiujin/OneFormer/oneformer/data/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from . import datasets
diff --git a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/infer_cli.py b/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/infer_cli.py
deleted file mode 100644
index 113c57dd00d1dfa57dd914563b57770021d7dee6..0000000000000000000000000000000000000000
--- a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/infer_cli.py
+++ /dev/null
@@ -1,67 +0,0 @@
-import argparse
-import os
-import sys
-
-now_dir = os.getcwd()
-sys.path.append(now_dir)
-from dotenv import load_dotenv
-from scipy.io import wavfile
-
-from assets.configs.config import Config
-from lib.infer.modules.vc.modules import VC
-
-####
-# USAGE
-#
-# In your Terminal or CMD or whatever
-
-
-def arg_parse() -> tuple:
- parser = argparse.ArgumentParser()
- parser.add_argument("--f0up_key", type=int, default=0)
- parser.add_argument("--input_path", type=str, help="input path")
- parser.add_argument("--index_path", type=str, help="index path")
- parser.add_argument("--f0method", type=str, default="harvest", help="harvest or pm")
- parser.add_argument("--opt_path", type=str, help="opt path")
- parser.add_argument("--model_name", type=str, help="store in assets/weight_root")
- parser.add_argument("--index_rate", type=float, default=0.66, help="index rate")
- parser.add_argument("--device", type=str, help="device")
- parser.add_argument("--is_half", type=bool, help="use half -> True")
- parser.add_argument("--filter_radius", type=int, default=3, help="filter radius")
- parser.add_argument("--resample_sr", type=int, default=0, help="resample sr")
- parser.add_argument("--rms_mix_rate", type=float, default=1, help="rms mix rate")
- parser.add_argument("--protect", type=float, default=0.33, help="protect")
-
- args = parser.parse_args()
- sys.argv = sys.argv[:1]
-
- return args
-
-
-def main():
- load_dotenv()
- args = arg_parse()
- config = Config()
- config.device = args.device if args.device else config.device
- config.is_half = args.is_half if args.is_half else config.is_half
- vc = VC(config)
- vc.get_vc(args.model_name)
- _, wav_opt = vc.vc_single(
- 0,
- args.input_path,
- args.f0up_key,
- None,
- args.f0method,
- args.index_path,
- None,
- args.index_rate,
- args.filter_radius,
- args.resample_sr,
- args.rms_mix_rate,
- args.protect,
- )
- wavfile.write(args.opt_path, wav_opt[0], wav_opt[1])
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/LaynzKunz/RVC-Inference-webui-grado-colab-huggingafce/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py b/spaces/LaynzKunz/RVC-Inference-webui-grado-colab-huggingafce/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
deleted file mode 100644
index b412ba2814e114ca7bb00b6fd6ef217f63d788a3..0000000000000000000000000000000000000000
--- a/spaces/LaynzKunz/RVC-Inference-webui-grado-colab-huggingafce/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
+++ /dev/null
@@ -1,86 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import pyworld
-import numpy as np
-
-
-class HarvestF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def resize_f0(self, x, target_len):
- source = np.array(x)
- source[source < 0.001] = np.nan
- target = np.interp(
- np.arange(0, len(source) * target_len, len(source)) / target_len,
- np.arange(0, len(source)),
- source,
- )
- res = np.nan_to_num(target)
- return res
-
- def compute_f0(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.hop_length,
- f0_ceil=self.f0_max,
- f0_floor=self.f0_min,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.fs)
- return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
-
- def compute_f0_uv(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.sampling_rate,
- f0_floor=self.f0_min,
- f0_ceil=self.f0_max,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
- return self.interpolate_f0(self.resize_f0(f0, p_len))
diff --git a/spaces/Lbin123/Lbingo/src/components/chat-attachments.tsx b/spaces/Lbin123/Lbingo/src/components/chat-attachments.tsx
deleted file mode 100644
index ef43d4e262935d263b6099138c56f7daade5299d..0000000000000000000000000000000000000000
--- a/spaces/Lbin123/Lbingo/src/components/chat-attachments.tsx
+++ /dev/null
@@ -1,37 +0,0 @@
-import Image from 'next/image'
-import ClearIcon from '@/assets/images/clear.svg'
-import RefreshIcon from '@/assets/images/refresh.svg'
-import { FileItem } from '@/lib/bots/bing/types'
-import { cn } from '@/lib/utils'
-import { useBing } from '@/lib/hooks/use-bing'
-
-type ChatAttachmentsProps = Pick, 'attachmentList' | 'setAttachmentList' | 'uploadImage'>
-
-export function ChatAttachments({ attachmentList = [], setAttachmentList, uploadImage }: ChatAttachmentsProps) {
- return attachmentList.length ? (
-
"
-
-examples = [['01.jpg'], ['02.jpg'], ['03.jpg'], ['04.png'], ['05.jpg'],]
-gr.Interface(
- lowlight,
- [gr.inputs.Image(type="file", label="Input")],
- [gr.outputs.Image(type="file", label="Output")],
- title=title,
- description=description,
- article=article,
- allow_flagging=False,
- allow_screenshot=False,
- examples=examples
-).launch(debug=True)
diff --git a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/benchmarks.py b/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/benchmarks.py
deleted file mode 100644
index 03d7d693a93674bb9a94db07f24a8e9ef7013f8f..0000000000000000000000000000000000000000
--- a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/benchmarks.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-Run YOLOv5 benchmarks on all supported export formats
-
-Format | `export.py --include` | Model
---- | --- | ---
-PyTorch | - | yolov5s.pt
-TorchScript | `torchscript` | yolov5s.torchscript
-ONNX | `onnx` | yolov5s.onnx
-OpenVINO | `openvino` | yolov5s_openvino_model/
-TensorRT | `engine` | yolov5s.engine
-CoreML | `coreml` | yolov5s.mlmodel
-TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
-TensorFlow GraphDef | `pb` | yolov5s.pb
-TensorFlow Lite | `tflite` | yolov5s.tflite
-TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
-TensorFlow.js | `tfjs` | yolov5s_web_model/
-
-Requirements:
- $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
- $ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
- $ pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # TensorRT
-
-Usage:
- $ python benchmarks.py --weights yolov5s.pt --img 640
-"""
-
-import argparse
-import platform
-import sys
-import time
-from pathlib import Path
-
-import pandas as pd
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[0] # YOLOv5 root directory
-if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
-# ROOT = ROOT.relative_to(Path.cwd()) # relative
-
-import export
-from models.experimental import attempt_load
-from models.yolo import SegmentationModel
-from segment.val import run as val_seg
-from utils import notebook_init
-from utils.general import LOGGER, check_yaml, file_size, print_args
-from utils.torch_utils import select_device
-from val import run as val_det
-
-
-def run(
- weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=640, # inference size (pixels)
- batch_size=1, # batch size
- data=ROOT / 'data/coco128.yaml', # dataset.yaml path
- device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
- half=False, # use FP16 half-precision inference
- test=False, # test exports only
- pt_only=False, # test PyTorch only
- hard_fail=False, # throw error on benchmark failure
-):
- y, t = [], time.time()
- device = select_device(device)
- model_type = type(attempt_load(weights, fuse=False)) # DetectionModel, SegmentationModel, etc.
- for i, (name, f, suffix, cpu, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, CPU, GPU)
- try:
- assert i not in (9, 10), 'inference not supported' # Edge TPU and TF.js are unsupported
- assert i != 5 or platform.system() == 'Darwin', 'inference only supported on macOS>=10.13' # CoreML
- if 'cpu' in device.type:
- assert cpu, 'inference not supported on CPU'
- if 'cuda' in device.type:
- assert gpu, 'inference not supported on GPU'
-
- # Export
- if f == '-':
- w = weights # PyTorch format
- else:
- w = export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # all others
- assert suffix in str(w), 'export failed'
-
- # Validate
- if model_type == SegmentationModel:
- result = val_seg(data, w, batch_size, imgsz, plots=False, device=device, task='speed', half=half)
- metric = result[0][7] # (box(p, r, map50, map), mask(p, r, map50, map), *loss(box, obj, cls))
- else: # DetectionModel:
- result = val_det(data, w, batch_size, imgsz, plots=False, device=device, task='speed', half=half)
- metric = result[0][3] # (p, r, map50, map, *loss(box, obj, cls))
- speed = result[2][1] # times (preprocess, inference, postprocess)
- y.append([name, round(file_size(w), 1), round(metric, 4), round(speed, 2)]) # MB, mAP, t_inference
- except Exception as e:
- if hard_fail:
- assert type(e) is AssertionError, f'Benchmark --hard-fail for {name}: {e}'
- LOGGER.warning(f'WARNING ⚠️ Benchmark failure for {name}: {e}')
- y.append([name, None, None, None]) # mAP, t_inference
- if pt_only and i == 0:
- break # break after PyTorch
-
- # Print results
- LOGGER.info('\n')
- parse_opt()
- notebook_init() # print system info
- c = ['Format', 'Size (MB)', 'mAP50-95', 'Inference time (ms)'] if map else ['Format', 'Export', '', '']
- py = pd.DataFrame(y, columns=c)
- LOGGER.info(f'\nBenchmarks complete ({time.time() - t:.2f}s)')
- LOGGER.info(str(py if map else py.iloc[:, :2]))
- if hard_fail and isinstance(hard_fail, str):
- metrics = py['mAP50-95'].array # values to compare to floor
- floor = eval(hard_fail) # minimum metric floor to pass, i.e. = 0.29 mAP for YOLOv5n
- assert all(x > floor for x in metrics if pd.notna(x)), f'HARD FAIL: mAP50-95 < floor {floor}'
- return py
-
-
-def test(
- weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=640, # inference size (pixels)
- batch_size=1, # batch size
- data=ROOT / 'data/coco128.yaml', # dataset.yaml path
- device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
- half=False, # use FP16 half-precision inference
- test=False, # test exports only
- pt_only=False, # test PyTorch only
- hard_fail=False, # throw error on benchmark failure
-):
- y, t = [], time.time()
- device = select_device(device)
- for i, (name, f, suffix, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, gpu-capable)
- try:
- w = weights if f == '-' else \
- export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # weights
- assert suffix in str(w), 'export failed'
- y.append([name, True])
- except Exception:
- y.append([name, False]) # mAP, t_inference
-
- # Print results
- LOGGER.info('\n')
- parse_opt()
- notebook_init() # print system info
- py = pd.DataFrame(y, columns=['Format', 'Export'])
- LOGGER.info(f'\nExports complete ({time.time() - t:.2f}s)')
- LOGGER.info(str(py))
- return py
-
-
-def parse_opt():
- parser = argparse.ArgumentParser()
- parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
- parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
- parser.add_argument('--batch-size', type=int, default=1, help='batch size')
- parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
- parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
- parser.add_argument('--test', action='store_true', help='test exports only')
- parser.add_argument('--pt-only', action='store_true', help='test PyTorch only')
- parser.add_argument('--hard-fail', nargs='?', const=True, default=False, help='Exception on error or < min metric')
- opt = parser.parse_args()
- opt.data = check_yaml(opt.data) # check YAML
- print_args(vars(opt))
- return opt
-
-
-def main(opt):
- test(**vars(opt)) if opt.test else run(**vars(opt))
-
-
-if __name__ == "__main__":
- opt = parse_opt()
- main(opt)
diff --git a/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/fid_score.py b/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/fid_score.py
deleted file mode 100644
index 6ca8e602c21bb6a624d646da3f6479aea033b0ac..0000000000000000000000000000000000000000
--- a/spaces/InpaintAI/Inpaint-Anything/third_party/lama/saicinpainting/evaluation/losses/fid/fid_score.py
+++ /dev/null
@@ -1,328 +0,0 @@
-#!/usr/bin/env python3
-"""Calculates the Frechet Inception Distance (FID) to evalulate GANs
-
-The FID metric calculates the distance between two distributions of images.
-Typically, we have summary statistics (mean & covariance matrix) of one
-of these distributions, while the 2nd distribution is given by a GAN.
-
-When run as a stand-alone program, it compares the distribution of
-images that are stored as PNG/JPEG at a specified location with a
-distribution given by summary statistics (in pickle format).
-
-The FID is calculated by assuming that X_1 and X_2 are the activations of
-the pool_3 layer of the inception net for generated samples and real world
-samples respectively.
-
-See --help to see further details.
-
-Code apapted from https://github.com/bioinf-jku/TTUR to use PyTorch instead
-of Tensorflow
-
-Copyright 2018 Institute of Bioinformatics, JKU Linz
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-"""
-import os
-import pathlib
-from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser
-
-import numpy as np
-import torch
-# from scipy.misc import imread
-from imageio import imread
-from PIL import Image, JpegImagePlugin
-from scipy import linalg
-from torch.nn.functional import adaptive_avg_pool2d
-from torchvision.transforms import CenterCrop, Compose, Resize, ToTensor
-
-try:
- from tqdm import tqdm
-except ImportError:
- # If not tqdm is not available, provide a mock version of it
- def tqdm(x): return x
-
-try:
- from .inception import InceptionV3
-except ModuleNotFoundError:
- from inception import InceptionV3
-
-parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
-parser.add_argument('path', type=str, nargs=2,
- help=('Path to the generated images or '
- 'to .npz statistic files'))
-parser.add_argument('--batch-size', type=int, default=50,
- help='Batch size to use')
-parser.add_argument('--dims', type=int, default=2048,
- choices=list(InceptionV3.BLOCK_INDEX_BY_DIM),
- help=('Dimensionality of Inception features to use. '
- 'By default, uses pool3 features'))
-parser.add_argument('-c', '--gpu', default='', type=str,
- help='GPU to use (leave blank for CPU only)')
-parser.add_argument('--resize', default=256)
-
-transform = Compose([Resize(256), CenterCrop(256), ToTensor()])
-
-
-def get_activations(files, model, batch_size=50, dims=2048,
- cuda=False, verbose=False, keep_size=False):
- """Calculates the activations of the pool_3 layer for all images.
-
- Params:
- -- files : List of image files paths
- -- model : Instance of inception model
- -- batch_size : Batch size of images for the model to process at once.
- Make sure that the number of samples is a multiple of
- the batch size, otherwise some samples are ignored. This
- behavior is retained to match the original FID score
- implementation.
- -- dims : Dimensionality of features returned by Inception
- -- cuda : If set to True, use GPU
- -- verbose : If set to True and parameter out_step is given, the number
- of calculated batches is reported.
- Returns:
- -- A numpy array of dimension (num images, dims) that contains the
- activations of the given tensor when feeding inception with the
- query tensor.
- """
- model.eval()
-
- if len(files) % batch_size != 0:
- print(('Warning: number of images is not a multiple of the '
- 'batch size. Some samples are going to be ignored.'))
- if batch_size > len(files):
- print(('Warning: batch size is bigger than the data size. '
- 'Setting batch size to data size'))
- batch_size = len(files)
-
- n_batches = len(files) // batch_size
- n_used_imgs = n_batches * batch_size
-
- pred_arr = np.empty((n_used_imgs, dims))
-
- for i in tqdm(range(n_batches)):
- if verbose:
- print('\rPropagating batch %d/%d' % (i + 1, n_batches),
- end='', flush=True)
- start = i * batch_size
- end = start + batch_size
-
- # # Official code goes below
- # images = np.array([imread(str(f)).astype(np.float32)
- # for f in files[start:end]])
-
- # # Reshape to (n_images, 3, height, width)
- # images = images.transpose((0, 3, 1, 2))
- # images /= 255
- # batch = torch.from_numpy(images).type(torch.FloatTensor)
- # #
-
- t = transform if not keep_size else ToTensor()
-
- if isinstance(files[0], pathlib.PosixPath):
- images = [t(Image.open(str(f))) for f in files[start:end]]
-
- elif isinstance(files[0], Image.Image):
- images = [t(f) for f in files[start:end]]
-
- else:
- raise ValueError(f"Unknown data type for image: {type(files[0])}")
-
- batch = torch.stack(images)
-
- if cuda:
- batch = batch.cuda()
-
- pred = model(batch)[0]
-
- # If model output is not scalar, apply global spatial average pooling.
- # This happens if you choose a dimensionality not equal 2048.
- if pred.shape[2] != 1 or pred.shape[3] != 1:
- pred = adaptive_avg_pool2d(pred, output_size=(1, 1))
-
- pred_arr[start:end] = pred.cpu().data.numpy().reshape(batch_size, -1)
-
- if verbose:
- print(' done')
-
- return pred_arr
-
-
-def calculate_frechet_distance(mu1, sigma1, mu2, sigma2, eps=1e-6):
- """Numpy implementation of the Frechet Distance.
- The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
- and X_2 ~ N(mu_2, C_2) is
- d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
-
- Stable version by Dougal J. Sutherland.
-
- Params:
- -- mu1 : Numpy array containing the activations of a layer of the
- inception net (like returned by the function 'get_predictions')
- for generated samples.
- -- mu2 : The sample mean over activations, precalculated on an
- representative data set.
- -- sigma1: The covariance matrix over activations for generated samples.
- -- sigma2: The covariance matrix over activations, precalculated on an
- representative data set.
-
- Returns:
- -- : The Frechet Distance.
- """
-
- mu1 = np.atleast_1d(mu1)
- mu2 = np.atleast_1d(mu2)
-
- sigma1 = np.atleast_2d(sigma1)
- sigma2 = np.atleast_2d(sigma2)
-
- assert mu1.shape == mu2.shape, \
- 'Training and test mean vectors have different lengths'
- assert sigma1.shape == sigma2.shape, \
- 'Training and test covariances have different dimensions'
-
- diff = mu1 - mu2
-
- # Product might be almost singular
- covmean, _ = linalg.sqrtm(sigma1.dot(sigma2), disp=False)
- if not np.isfinite(covmean).all():
- msg = ('fid calculation produces singular product; '
- 'adding %s to diagonal of cov estimates') % eps
- print(msg)
- offset = np.eye(sigma1.shape[0]) * eps
- covmean = linalg.sqrtm((sigma1 + offset).dot(sigma2 + offset))
-
- # Numerical error might give slight imaginary component
- if np.iscomplexobj(covmean):
- # if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-3):
- if not np.allclose(np.diagonal(covmean).imag, 0, atol=1e-2):
- m = np.max(np.abs(covmean.imag))
- raise ValueError('Imaginary component {}'.format(m))
- covmean = covmean.real
-
- tr_covmean = np.trace(covmean)
-
- return (diff.dot(diff) + np.trace(sigma1) +
- np.trace(sigma2) - 2 * tr_covmean)
-
-
-def calculate_activation_statistics(files, model, batch_size=50,
- dims=2048, cuda=False, verbose=False, keep_size=False):
- """Calculation of the statistics used by the FID.
- Params:
- -- files : List of image files paths
- -- model : Instance of inception model
- -- batch_size : The images numpy array is split into batches with
- batch size batch_size. A reasonable batch size
- depends on the hardware.
- -- dims : Dimensionality of features returned by Inception
- -- cuda : If set to True, use GPU
- -- verbose : If set to True and parameter out_step is given, the
- number of calculated batches is reported.
- Returns:
- -- mu : The mean over samples of the activations of the pool_3 layer of
- the inception model.
- -- sigma : The covariance matrix of the activations of the pool_3 layer of
- the inception model.
- """
- act = get_activations(files, model, batch_size, dims, cuda, verbose, keep_size=keep_size)
- mu = np.mean(act, axis=0)
- sigma = np.cov(act, rowvar=False)
- return mu, sigma
-
-
-def _compute_statistics_of_path(path, model, batch_size, dims, cuda):
- if path.endswith('.npz'):
- f = np.load(path)
- m, s = f['mu'][:], f['sigma'][:]
- f.close()
- else:
- path = pathlib.Path(path)
- files = list(path.glob('*.jpg')) + list(path.glob('*.png'))
- m, s = calculate_activation_statistics(files, model, batch_size,
- dims, cuda)
-
- return m, s
-
-
-def _compute_statistics_of_images(images, model, batch_size, dims, cuda, keep_size=False):
- if isinstance(images, list): # exact paths to files are provided
- m, s = calculate_activation_statistics(images, model, batch_size,
- dims, cuda, keep_size=keep_size)
-
- return m, s
-
- else:
- raise ValueError
-
-
-def calculate_fid_given_paths(paths, batch_size, cuda, dims):
- """Calculates the FID of two paths"""
- for p in paths:
- if not os.path.exists(p):
- raise RuntimeError('Invalid path: %s' % p)
-
- block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[dims]
-
- model = InceptionV3([block_idx])
- if cuda:
- model.cuda()
-
- m1, s1 = _compute_statistics_of_path(paths[0], model, batch_size,
- dims, cuda)
- m2, s2 = _compute_statistics_of_path(paths[1], model, batch_size,
- dims, cuda)
- fid_value = calculate_frechet_distance(m1, s1, m2, s2)
-
- return fid_value
-
-
-def calculate_fid_given_images(images, batch_size, cuda, dims, use_globals=False, keep_size=False):
- if use_globals:
- global FID_MODEL # for multiprocessing
-
- for imgs in images:
- if isinstance(imgs, list) and isinstance(imgs[0], (Image.Image, JpegImagePlugin.JpegImageFile)):
- pass
- else:
- raise RuntimeError('Invalid images')
-
- block_idx = InceptionV3.BLOCK_INDEX_BY_DIM[dims]
-
- if 'FID_MODEL' not in globals() or not use_globals:
- model = InceptionV3([block_idx])
- if cuda:
- model.cuda()
-
- if use_globals:
- FID_MODEL = model
-
- else:
- model = FID_MODEL
-
- m1, s1 = _compute_statistics_of_images(images[0], model, batch_size,
- dims, cuda, keep_size=False)
- m2, s2 = _compute_statistics_of_images(images[1], model, batch_size,
- dims, cuda, keep_size=False)
- fid_value = calculate_frechet_distance(m1, s1, m2, s2)
- return fid_value
-
-
-if __name__ == '__main__':
- args = parser.parse_args()
- os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
-
- fid_value = calculate_fid_given_paths(args.path,
- args.batch_size,
- args.gpu != '',
- args.dims)
- print('FID: ', fid_value)
diff --git a/spaces/JMalott/ai_architecture/background.py b/spaces/JMalott/ai_architecture/background.py
deleted file mode 100644
index 0c1b73c42038e96d554f2fd96b4ebe584f40de0c..0000000000000000000000000000000000000000
--- a/spaces/JMalott/ai_architecture/background.py
+++ /dev/null
@@ -1,61 +0,0 @@
-from htbuilder import HtmlElement, div, ul, li, br, hr, a, p, img, styles, classes, fonts
-from htbuilder.units import percent, px
-from htbuilder.funcs import rgba, rgb
-import streamlit as st
-import os
-import sys
-import argparse
-import clip
-import numpy as np
-from PIL import Image
-from dalle.models import Dalle
-from dalle.utils.utils import set_seed, clip_score
-import cv2
-import subprocess
-import signal
-
-def signal_handler(sig, frame):
- print('You pressed Ctrl+C!')
- sys.exit(0)
-
-
-def generate(prompt,crazy):
-
- print("-------------------")
-
- signal.signal(signal.SIGINT, signal_handler)
-
- device = 'cpu'
- model = Dalle.from_pretrained('minDALL-E/1.3B') # This will automatically download the pretrained model.
- model.to(device=device)
- num_candidates = 3
-
- images = []
-
- set_seed(np.random.randint(0,10000))
-
- # Sampling
- images = model.sampling(prompt=prompt,
- top_k=2048,
- top_p=None,
- softmax_temperature=crazy,
- num_candidates=num_candidates,
- device=device).cpu().numpy()
- images = np.transpose(images, (0, 2, 3, 1))
-
- # CLIP Re-ranking
- model_clip, preprocess_clip = clip.load("ViT-B/32", device=device)
- model_clip.to(device=device)
- rank = clip_score(prompt=prompt,
- images=images,
- model_clip=model_clip,
- preprocess_clip=preprocess_clip,
- device=device)
-
- # Save images
- #return images[rank]
- for image in images:
- cv2.imwrite('temp/'+str(np.random.randint(0,10000))+'.jpeg', image)
-
-
-generate("a pink house",0.75)
\ No newline at end of file
diff --git a/spaces/Jamel887/Rv-percobaan887/README.md b/spaces/Jamel887/Rv-percobaan887/README.md
deleted file mode 100644
index 4c2022c8257ba2024382a9be2c4bce7162724a3f..0000000000000000000000000000000000000000
--- a/spaces/Jamel887/Rv-percobaan887/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Hololive Rvc Models V2
-emoji: ▶️🐻💿
-colorFrom: blue
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.35.2
-app_file: app.py
-pinned: true
-license: openrail
-duplicated_from: megaaziib/hololive-rvc-models-v2
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/rmvpe.py b/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/rmvpe.py
deleted file mode 100644
index 2a387ebe73c7e1dd8bb7ccad1ea9e0ea89848ece..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/rmvpe.py
+++ /dev/null
@@ -1,717 +0,0 @@
-import pdb, os
-
-import numpy as np
-import torch
-try:
- #Fix "Torch not compiled with CUDA enabled"
- import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
- if torch.xpu.is_available():
- from infer.modules.ipex import ipex_init
- ipex_init()
-except Exception:
- pass
-import torch.nn as nn
-import torch.nn.functional as F
-from librosa.util import normalize, pad_center, tiny
-from scipy.signal import get_window
-
-import logging
-
-logger = logging.getLogger(__name__)
-
-
-###stft codes from https://github.com/pseeth/torch-stft/blob/master/torch_stft/util.py
-def window_sumsquare(
- window,
- n_frames,
- hop_length=200,
- win_length=800,
- n_fft=800,
- dtype=np.float32,
- norm=None,
-):
- """
- # from librosa 0.6
- Compute the sum-square envelope of a window function at a given hop length.
- This is used to estimate modulation effects induced by windowing
- observations in short-time fourier transforms.
- Parameters
- ----------
- window : string, tuple, number, callable, or list-like
- Window specification, as in `get_window`
- n_frames : int > 0
- The number of analysis frames
- hop_length : int > 0
- The number of samples to advance between frames
- win_length : [optional]
- The length of the window function. By default, this matches `n_fft`.
- n_fft : int > 0
- The length of each analysis frame.
- dtype : np.dtype
- The data type of the output
- Returns
- -------
- wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))`
- The sum-squared envelope of the window function
- """
- if win_length is None:
- win_length = n_fft
-
- n = n_fft + hop_length * (n_frames - 1)
- x = np.zeros(n, dtype=dtype)
-
- # Compute the squared window at the desired length
- win_sq = get_window(window, win_length, fftbins=True)
- win_sq = normalize(win_sq, norm=norm) ** 2
- win_sq = pad_center(win_sq, n_fft)
-
- # Fill the envelope
- for i in range(n_frames):
- sample = i * hop_length
- x[sample : min(n, sample + n_fft)] += win_sq[: max(0, min(n_fft, n - sample))]
- return x
-
-
-class STFT(torch.nn.Module):
- def __init__(
- self, filter_length=1024, hop_length=512, win_length=None, window="hann"
- ):
- """
- This module implements an STFT using 1D convolution and 1D transpose convolutions.
- This is a bit tricky so there are some cases that probably won't work as working
- out the same sizes before and after in all overlap add setups is tough. Right now,
- this code should work with hop lengths that are half the filter length (50% overlap
- between frames).
-
- Keyword Arguments:
- filter_length {int} -- Length of filters used (default: {1024})
- hop_length {int} -- Hop length of STFT (restrict to 50% overlap between frames) (default: {512})
- win_length {[type]} -- Length of the window function applied to each frame (if not specified, it
- equals the filter length). (default: {None})
- window {str} -- Type of window to use (options are bartlett, hann, hamming, blackman, blackmanharris)
- (default: {'hann'})
- """
- super(STFT, self).__init__()
- self.filter_length = filter_length
- self.hop_length = hop_length
- self.win_length = win_length if win_length else filter_length
- self.window = window
- self.forward_transform = None
- self.pad_amount = int(self.filter_length / 2)
- scale = self.filter_length / self.hop_length
- fourier_basis = np.fft.fft(np.eye(self.filter_length))
-
- cutoff = int((self.filter_length / 2 + 1))
- fourier_basis = np.vstack(
- [np.real(fourier_basis[:cutoff, :]), np.imag(fourier_basis[:cutoff, :])]
- )
- forward_basis = torch.FloatTensor(fourier_basis[:, None, :])
- inverse_basis = torch.FloatTensor(
- np.linalg.pinv(scale * fourier_basis).T[:, None, :]
- )
-
- assert filter_length >= self.win_length
- # get window and zero center pad it to filter_length
- fft_window = get_window(window, self.win_length, fftbins=True)
- fft_window = pad_center(fft_window, size=filter_length)
- fft_window = torch.from_numpy(fft_window).float()
-
- # window the bases
- forward_basis *= fft_window
- inverse_basis *= fft_window
-
- self.register_buffer("forward_basis", forward_basis.float())
- self.register_buffer("inverse_basis", inverse_basis.float())
-
- def transform(self, input_data):
- """Take input data (audio) to STFT domain.
-
- Arguments:
- input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
-
- Returns:
- magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
- num_frequencies, num_frames)
- phase {tensor} -- Phase of STFT with shape (num_batch,
- num_frequencies, num_frames)
- """
- num_batches = input_data.shape[0]
- num_samples = input_data.shape[-1]
-
- self.num_samples = num_samples
-
- # similar to librosa, reflect-pad the input
- input_data = input_data.view(num_batches, 1, num_samples)
- # print(1234,input_data.shape)
- input_data = F.pad(
- input_data.unsqueeze(1),
- (self.pad_amount, self.pad_amount, 0, 0, 0, 0),
- mode="reflect",
- ).squeeze(1)
- # print(2333,input_data.shape,self.forward_basis.shape,self.hop_length)
- # pdb.set_trace()
- forward_transform = F.conv1d(
- input_data, self.forward_basis, stride=self.hop_length, padding=0
- )
-
- cutoff = int((self.filter_length / 2) + 1)
- real_part = forward_transform[:, :cutoff, :]
- imag_part = forward_transform[:, cutoff:, :]
-
- magnitude = torch.sqrt(real_part**2 + imag_part**2)
- # phase = torch.atan2(imag_part.data, real_part.data)
-
- return magnitude # , phase
-
- def inverse(self, magnitude, phase):
- """Call the inverse STFT (iSTFT), given magnitude and phase tensors produced
- by the ```transform``` function.
-
- Arguments:
- magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
- num_frequencies, num_frames)
- phase {tensor} -- Phase of STFT with shape (num_batch,
- num_frequencies, num_frames)
-
- Returns:
- inverse_transform {tensor} -- Reconstructed audio given magnitude and phase. Of
- shape (num_batch, num_samples)
- """
- recombine_magnitude_phase = torch.cat(
- [magnitude * torch.cos(phase), magnitude * torch.sin(phase)], dim=1
- )
-
- inverse_transform = F.conv_transpose1d(
- recombine_magnitude_phase,
- self.inverse_basis,
- stride=self.hop_length,
- padding=0,
- )
-
- if self.window is not None:
- window_sum = window_sumsquare(
- self.window,
- magnitude.size(-1),
- hop_length=self.hop_length,
- win_length=self.win_length,
- n_fft=self.filter_length,
- dtype=np.float32,
- )
- # remove modulation effects
- approx_nonzero_indices = torch.from_numpy(
- np.where(window_sum > tiny(window_sum))[0]
- )
- window_sum = torch.from_numpy(window_sum).to(inverse_transform.device)
- inverse_transform[:, :, approx_nonzero_indices] /= window_sum[
- approx_nonzero_indices
- ]
-
- # scale by hop ratio
- inverse_transform *= float(self.filter_length) / self.hop_length
-
- inverse_transform = inverse_transform[..., self.pad_amount :]
- inverse_transform = inverse_transform[..., : self.num_samples]
- inverse_transform = inverse_transform.squeeze(1)
-
- return inverse_transform
-
- def forward(self, input_data):
- """Take input data (audio) to STFT domain and then back to audio.
-
- Arguments:
- input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
-
- Returns:
- reconstruction {tensor} -- Reconstructed audio given magnitude and phase. Of
- shape (num_batch, num_samples)
- """
- self.magnitude, self.phase = self.transform(input_data)
- reconstruction = self.inverse(self.magnitude, self.phase)
- return reconstruction
-
-
-from time import time as ttime
-
-
-class BiGRU(nn.Module):
- def __init__(self, input_features, hidden_features, num_layers):
- super(BiGRU, self).__init__()
- self.gru = nn.GRU(
- input_features,
- hidden_features,
- num_layers=num_layers,
- batch_first=True,
- bidirectional=True,
- )
-
- def forward(self, x):
- return self.gru(x)[0]
-
-
-class ConvBlockRes(nn.Module):
- def __init__(self, in_channels, out_channels, momentum=0.01):
- super(ConvBlockRes, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=(1, 1),
- padding=(1, 1),
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- nn.Conv2d(
- in_channels=out_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=(1, 1),
- padding=(1, 1),
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- )
- if in_channels != out_channels:
- self.shortcut = nn.Conv2d(in_channels, out_channels, (1, 1))
- self.is_shortcut = True
- else:
- self.is_shortcut = False
-
- def forward(self, x):
- if self.is_shortcut:
- return self.conv(x) + self.shortcut(x)
- else:
- return self.conv(x) + x
-
-
-class Encoder(nn.Module):
- def __init__(
- self,
- in_channels,
- in_size,
- n_encoders,
- kernel_size,
- n_blocks,
- out_channels=16,
- momentum=0.01,
- ):
- super(Encoder, self).__init__()
- self.n_encoders = n_encoders
- self.bn = nn.BatchNorm2d(in_channels, momentum=momentum)
- self.layers = nn.ModuleList()
- self.latent_channels = []
- for i in range(self.n_encoders):
- self.layers.append(
- ResEncoderBlock(
- in_channels, out_channels, kernel_size, n_blocks, momentum=momentum
- )
- )
- self.latent_channels.append([out_channels, in_size])
- in_channels = out_channels
- out_channels *= 2
- in_size //= 2
- self.out_size = in_size
- self.out_channel = out_channels
-
- def forward(self, x):
- concat_tensors = []
- x = self.bn(x)
- for i in range(self.n_encoders):
- _, x = self.layers[i](x)
- concat_tensors.append(_)
- return x, concat_tensors
-
-
-class ResEncoderBlock(nn.Module):
- def __init__(
- self, in_channels, out_channels, kernel_size, n_blocks=1, momentum=0.01
- ):
- super(ResEncoderBlock, self).__init__()
- self.n_blocks = n_blocks
- self.conv = nn.ModuleList()
- self.conv.append(ConvBlockRes(in_channels, out_channels, momentum))
- for i in range(n_blocks - 1):
- self.conv.append(ConvBlockRes(out_channels, out_channels, momentum))
- self.kernel_size = kernel_size
- if self.kernel_size is not None:
- self.pool = nn.AvgPool2d(kernel_size=kernel_size)
-
- def forward(self, x):
- for i in range(self.n_blocks):
- x = self.conv[i](x)
- if self.kernel_size is not None:
- return x, self.pool(x)
- else:
- return x
-
-
-class Intermediate(nn.Module): #
- def __init__(self, in_channels, out_channels, n_inters, n_blocks, momentum=0.01):
- super(Intermediate, self).__init__()
- self.n_inters = n_inters
- self.layers = nn.ModuleList()
- self.layers.append(
- ResEncoderBlock(in_channels, out_channels, None, n_blocks, momentum)
- )
- for i in range(self.n_inters - 1):
- self.layers.append(
- ResEncoderBlock(out_channels, out_channels, None, n_blocks, momentum)
- )
-
- def forward(self, x):
- for i in range(self.n_inters):
- x = self.layers[i](x)
- return x
-
-
-class ResDecoderBlock(nn.Module):
- def __init__(self, in_channels, out_channels, stride, n_blocks=1, momentum=0.01):
- super(ResDecoderBlock, self).__init__()
- out_padding = (0, 1) if stride == (1, 2) else (1, 1)
- self.n_blocks = n_blocks
- self.conv1 = nn.Sequential(
- nn.ConvTranspose2d(
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=stride,
- padding=(1, 1),
- output_padding=out_padding,
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- )
- self.conv2 = nn.ModuleList()
- self.conv2.append(ConvBlockRes(out_channels * 2, out_channels, momentum))
- for i in range(n_blocks - 1):
- self.conv2.append(ConvBlockRes(out_channels, out_channels, momentum))
-
- def forward(self, x, concat_tensor):
- x = self.conv1(x)
- x = torch.cat((x, concat_tensor), dim=1)
- for i in range(self.n_blocks):
- x = self.conv2[i](x)
- return x
-
-
-class Decoder(nn.Module):
- def __init__(self, in_channels, n_decoders, stride, n_blocks, momentum=0.01):
- super(Decoder, self).__init__()
- self.layers = nn.ModuleList()
- self.n_decoders = n_decoders
- for i in range(self.n_decoders):
- out_channels = in_channels // 2
- self.layers.append(
- ResDecoderBlock(in_channels, out_channels, stride, n_blocks, momentum)
- )
- in_channels = out_channels
-
- def forward(self, x, concat_tensors):
- for i in range(self.n_decoders):
- x = self.layers[i](x, concat_tensors[-1 - i])
- return x
-
-
-class DeepUnet(nn.Module):
- def __init__(
- self,
- kernel_size,
- n_blocks,
- en_de_layers=5,
- inter_layers=4,
- in_channels=1,
- en_out_channels=16,
- ):
- super(DeepUnet, self).__init__()
- self.encoder = Encoder(
- in_channels, 128, en_de_layers, kernel_size, n_blocks, en_out_channels
- )
- self.intermediate = Intermediate(
- self.encoder.out_channel // 2,
- self.encoder.out_channel,
- inter_layers,
- n_blocks,
- )
- self.decoder = Decoder(
- self.encoder.out_channel, en_de_layers, kernel_size, n_blocks
- )
-
- def forward(self, x):
- x, concat_tensors = self.encoder(x)
- x = self.intermediate(x)
- x = self.decoder(x, concat_tensors)
- return x
-
-
-class E2E(nn.Module):
- def __init__(
- self,
- n_blocks,
- n_gru,
- kernel_size,
- en_de_layers=5,
- inter_layers=4,
- in_channels=1,
- en_out_channels=16,
- ):
- super(E2E, self).__init__()
- self.unet = DeepUnet(
- kernel_size,
- n_blocks,
- en_de_layers,
- inter_layers,
- in_channels,
- en_out_channels,
- )
- self.cnn = nn.Conv2d(en_out_channels, 3, (3, 3), padding=(1, 1))
- if n_gru:
- self.fc = nn.Sequential(
- BiGRU(3 * 128, 256, n_gru),
- nn.Linear(512, 360),
- nn.Dropout(0.25),
- nn.Sigmoid(),
- )
- else:
- self.fc = nn.Sequential(
- nn.Linear(3 * nn.N_MELS, nn.N_CLASS), nn.Dropout(0.25), nn.Sigmoid()
- )
-
- def forward(self, mel):
- # print(mel.shape)
- mel = mel.transpose(-1, -2).unsqueeze(1)
- x = self.cnn(self.unet(mel)).transpose(1, 2).flatten(-2)
- x = self.fc(x)
- # print(x.shape)
- return x
-
-
-from librosa.filters import mel
-
-
-class MelSpectrogram(torch.nn.Module):
- def __init__(
- self,
- is_half,
- n_mel_channels,
- sampling_rate,
- win_length,
- hop_length,
- n_fft=None,
- mel_fmin=0,
- mel_fmax=None,
- clamp=1e-5,
- ):
- super().__init__()
- n_fft = win_length if n_fft is None else n_fft
- self.hann_window = {}
- mel_basis = mel(
- sr=sampling_rate,
- n_fft=n_fft,
- n_mels=n_mel_channels,
- fmin=mel_fmin,
- fmax=mel_fmax,
- htk=True,
- )
- mel_basis = torch.from_numpy(mel_basis).float()
- self.register_buffer("mel_basis", mel_basis)
- self.n_fft = win_length if n_fft is None else n_fft
- self.hop_length = hop_length
- self.win_length = win_length
- self.sampling_rate = sampling_rate
- self.n_mel_channels = n_mel_channels
- self.clamp = clamp
- self.is_half = is_half
-
- def forward(self, audio, keyshift=0, speed=1, center=True):
- factor = 2 ** (keyshift / 12)
- n_fft_new = int(np.round(self.n_fft * factor))
- win_length_new = int(np.round(self.win_length * factor))
- hop_length_new = int(np.round(self.hop_length * speed))
- keyshift_key = str(keyshift) + "_" + str(audio.device)
- if keyshift_key not in self.hann_window:
- self.hann_window[keyshift_key] = torch.hann_window(win_length_new).to(
- # "cpu"if(audio.device.type=="privateuseone") else audio.device
- audio.device
- )
- # fft = torch.stft(#doesn't support pytorch_dml
- # # audio.cpu() if(audio.device.type=="privateuseone")else audio,
- # audio,
- # n_fft=n_fft_new,
- # hop_length=hop_length_new,
- # win_length=win_length_new,
- # window=self.hann_window[keyshift_key],
- # center=center,
- # return_complex=True,
- # )
- # magnitude = torch.sqrt(fft.real.pow(2) + fft.imag.pow(2))
- # print(1111111111)
- # print(222222222222222,audio.device,self.is_half)
- if hasattr(self, "stft") == False:
- # print(n_fft_new,hop_length_new,win_length_new,audio.shape)
- self.stft = STFT(
- filter_length=n_fft_new,
- hop_length=hop_length_new,
- win_length=win_length_new,
- window="hann",
- ).to(audio.device)
- magnitude = self.stft.transform(audio) # phase
- # if (audio.device.type == "privateuseone"):
- # magnitude=magnitude.to(audio.device)
- if keyshift != 0:
- size = self.n_fft // 2 + 1
- resize = magnitude.size(1)
- if resize < size:
- magnitude = F.pad(magnitude, (0, 0, 0, size - resize))
- magnitude = magnitude[:, :size, :] * self.win_length / win_length_new
- mel_output = torch.matmul(self.mel_basis, magnitude)
- if self.is_half == True:
- mel_output = mel_output.half()
- log_mel_spec = torch.log(torch.clamp(mel_output, min=self.clamp))
- # print(log_mel_spec.device.type)
- return log_mel_spec
-
-
-class RMVPE:
- def __init__(self, model_path, is_half, device=None):
- self.resample_kernel = {}
- self.resample_kernel = {}
- self.is_half = is_half
- if device is None:
- device = "cuda" if torch.cuda.is_available() else "cpu"
- self.device = device
- self.mel_extractor = MelSpectrogram(
- is_half, 128, 16000, 1024, 160, None, 30, 8000
- ).to(device)
- if "privateuseone" in str(device):
- import onnxruntime as ort
-
- ort_session = ort.InferenceSession(
- "%s/rmvpe.onnx" % os.environ["rmvpe_root"],
- providers=["DmlExecutionProvider"],
- )
- self.model = ort_session
- else:
- model = E2E(4, 1, (2, 2))
- ckpt = torch.load(model_path, map_location="cpu")
- model.load_state_dict(ckpt)
- model.eval()
- if is_half == True:
- model = model.half()
- self.model = model
- self.model = self.model.to(device)
- cents_mapping = 20 * np.arange(360) + 1997.3794084376191
- self.cents_mapping = np.pad(cents_mapping, (4, 4)) # 368
-
- def mel2hidden(self, mel):
- with torch.no_grad():
- n_frames = mel.shape[-1]
- mel = F.pad(
- mel, (0, 32 * ((n_frames - 1) // 32 + 1) - n_frames), mode="constant"
- )
- if "privateuseone" in str(self.device):
- onnx_input_name = self.model.get_inputs()[0].name
- onnx_outputs_names = self.model.get_outputs()[0].name
- hidden = self.model.run(
- [onnx_outputs_names],
- input_feed={onnx_input_name: mel.cpu().numpy()},
- )[0]
- else:
- hidden = self.model(mel)
- return hidden[:, :n_frames]
-
- def decode(self, hidden, thred=0.03):
- cents_pred = self.to_local_average_cents(hidden, thred=thred)
- f0 = 10 * (2 ** (cents_pred / 1200))
- f0[f0 == 10] = 0
- # f0 = np.array([10 * (2 ** (cent_pred / 1200)) if cent_pred else 0 for cent_pred in cents_pred])
- return f0
-
- def infer_from_audio(self, audio, thred=0.03):
- # torch.cuda.synchronize()
- t0 = ttime()
- mel = self.mel_extractor(
- torch.from_numpy(audio).float().to(self.device).unsqueeze(0), center=True
- )
- # print(123123123,mel.device.type)
- # torch.cuda.synchronize()
- t1 = ttime()
- hidden = self.mel2hidden(mel)
- # torch.cuda.synchronize()
- t2 = ttime()
- # print(234234,hidden.device.type)
- if "privateuseone" not in str(self.device):
- hidden = hidden.squeeze(0).cpu().numpy()
- else:
- hidden = hidden[0]
- if self.is_half == True:
- hidden = hidden.astype("float32")
-
- f0 = self.decode(hidden, thred=thred)
- # torch.cuda.synchronize()
- t3 = ttime()
- # print("hmvpe:%s\t%s\t%s\t%s"%(t1-t0,t2-t1,t3-t2,t3-t0))
- return f0
-
- def infer_from_audio_with_pitch(self, audio, thred=0.03, f0_min=50, f0_max=1100):
- audio = torch.from_numpy(audio).float().to(self.device).unsqueeze(0)
- mel = self.mel_extractor(audio, center=True)
- hidden = self.mel2hidden(mel)
- hidden = hidden.squeeze(0).cpu().numpy()
- if self.is_half == True:
- hidden = hidden.astype("float32")
- f0 = self.decode(hidden, thred=thred)
- f0[(f0 < f0_min) | (f0 > f0_max)] = 0
- return f0
-
- def to_local_average_cents(self, salience, thred=0.05):
- # t0 = ttime()
- center = np.argmax(salience, axis=1) # 帧长#index
- salience = np.pad(salience, ((0, 0), (4, 4))) # 帧长,368
- # t1 = ttime()
- center += 4
- todo_salience = []
- todo_cents_mapping = []
- starts = center - 4
- ends = center + 5
- for idx in range(salience.shape[0]):
- todo_salience.append(salience[:, starts[idx] : ends[idx]][idx])
- todo_cents_mapping.append(self.cents_mapping[starts[idx] : ends[idx]])
- # t2 = ttime()
- todo_salience = np.array(todo_salience) # 帧长,9
- todo_cents_mapping = np.array(todo_cents_mapping) # 帧长,9
- product_sum = np.sum(todo_salience * todo_cents_mapping, 1)
- weight_sum = np.sum(todo_salience, 1) # 帧长
- devided = product_sum / weight_sum # 帧长
- # t3 = ttime()
- maxx = np.max(salience, axis=1) # 帧长
- devided[maxx <= thred] = 0
- # t4 = ttime()
- # print("decode:%s\t%s\t%s\t%s" % (t1 - t0, t2 - t1, t3 - t2, t4 - t3))
- return devided
-
-
-if __name__ == "__main__":
- import librosa
- import soundfile as sf
-
- audio, sampling_rate = sf.read(r"C:\Users\liujing04\Desktop\Z\冬之花clip1.wav")
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- audio_bak = audio.copy()
- if sampling_rate != 16000:
- audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
- model_path = r"D:\BaiduNetdiskDownload\RVC-beta-v2-0727AMD_realtime\rmvpe.pt"
- thred = 0.03 # 0.01
- device = "cuda" if torch.cuda.is_available() else "cpu"
- rmvpe = RMVPE(model_path, is_half=False, device=device)
- t0 = ttime()
- f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- t1 = ttime()
- logger.info("%s %.2f", f0.shape, t1 - t0)
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/model_param_init.py b/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/model_param_init.py
deleted file mode 100644
index b995c0bfb1194746187692e2ab1c2a6dbaaaec6c..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/model_param_init.py
+++ /dev/null
@@ -1,69 +0,0 @@
-import json
-import os
-import pathlib
-
-default_param = {}
-default_param["bins"] = 768
-default_param["unstable_bins"] = 9 # training only
-default_param["reduction_bins"] = 762 # training only
-default_param["sr"] = 44100
-default_param["pre_filter_start"] = 757
-default_param["pre_filter_stop"] = 768
-default_param["band"] = {}
-
-
-default_param["band"][1] = {
- "sr": 11025,
- "hl": 128,
- "n_fft": 960,
- "crop_start": 0,
- "crop_stop": 245,
- "lpf_start": 61, # inference only
- "res_type": "polyphase",
-}
-
-default_param["band"][2] = {
- "sr": 44100,
- "hl": 512,
- "n_fft": 1536,
- "crop_start": 24,
- "crop_stop": 547,
- "hpf_start": 81, # inference only
- "res_type": "sinc_best",
-}
-
-
-def int_keys(d):
- r = {}
- for k, v in d:
- if k.isdigit():
- k = int(k)
- r[k] = v
- return r
-
-
-class ModelParameters(object):
- def __init__(self, config_path=""):
- if ".pth" == pathlib.Path(config_path).suffix:
- import zipfile
-
- with zipfile.ZipFile(config_path, "r") as zip:
- self.param = json.loads(
- zip.read("param.json"), object_pairs_hook=int_keys
- )
- elif ".json" == pathlib.Path(config_path).suffix:
- with open(config_path, "r") as f:
- self.param = json.loads(f.read(), object_pairs_hook=int_keys)
- else:
- self.param = default_param
-
- for k in [
- "mid_side",
- "mid_side_b",
- "mid_side_b2",
- "stereo_w",
- "stereo_n",
- "reverse",
- ]:
- if not k in self.param:
- self.param[k] = False
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py b/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py
deleted file mode 100644
index 167d4cb2198863cf43e93440f7e63c5342fc7605..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/infer/lib/uvr5_pack/lib_v5/nets_123812KB.py
+++ /dev/null
@@ -1,122 +0,0 @@
-import torch
-import torch.nn.functional as F
-from torch import nn
-
-from . import layers_123821KB as layers
-
-
-class BaseASPPNet(nn.Module):
- def __init__(self, nin, ch, dilations=(4, 8, 16)):
- super(BaseASPPNet, self).__init__()
- self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
- self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
- self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
- self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
-
- self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
-
- self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
- self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
- self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
- self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
-
- def __call__(self, x):
- h, e1 = self.enc1(x)
- h, e2 = self.enc2(h)
- h, e3 = self.enc3(h)
- h, e4 = self.enc4(h)
-
- h = self.aspp(h)
-
- h = self.dec4(h, e4)
- h = self.dec3(h, e3)
- h = self.dec2(h, e2)
- h = self.dec1(h, e1)
-
- return h
-
-
-class CascadedASPPNet(nn.Module):
- def __init__(self, n_fft):
- super(CascadedASPPNet, self).__init__()
- self.stg1_low_band_net = BaseASPPNet(2, 32)
- self.stg1_high_band_net = BaseASPPNet(2, 32)
-
- self.stg2_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
- self.stg2_full_band_net = BaseASPPNet(16, 32)
-
- self.stg3_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
- self.stg3_full_band_net = BaseASPPNet(32, 64)
-
- self.out = nn.Conv2d(64, 2, 1, bias=False)
- self.aux1_out = nn.Conv2d(32, 2, 1, bias=False)
- self.aux2_out = nn.Conv2d(32, 2, 1, bias=False)
-
- self.max_bin = n_fft // 2
- self.output_bin = n_fft // 2 + 1
-
- self.offset = 128
-
- def forward(self, x, aggressiveness=None):
- mix = x.detach()
- x = x.clone()
-
- x = x[:, :, : self.max_bin]
-
- bandw = x.size()[2] // 2
- aux1 = torch.cat(
- [
- self.stg1_low_band_net(x[:, :, :bandw]),
- self.stg1_high_band_net(x[:, :, bandw:]),
- ],
- dim=2,
- )
-
- h = torch.cat([x, aux1], dim=1)
- aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
-
- h = torch.cat([x, aux1, aux2], dim=1)
- h = self.stg3_full_band_net(self.stg3_bridge(h))
-
- mask = torch.sigmoid(self.out(h))
- mask = F.pad(
- input=mask,
- pad=(0, 0, 0, self.output_bin - mask.size()[2]),
- mode="replicate",
- )
-
- if self.training:
- aux1 = torch.sigmoid(self.aux1_out(aux1))
- aux1 = F.pad(
- input=aux1,
- pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
- mode="replicate",
- )
- aux2 = torch.sigmoid(self.aux2_out(aux2))
- aux2 = F.pad(
- input=aux2,
- pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
- mode="replicate",
- )
- return mask * mix, aux1 * mix, aux2 * mix
- else:
- if aggressiveness:
- mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
- mask[:, :, : aggressiveness["split_bin"]],
- 1 + aggressiveness["value"] / 3,
- )
- mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
- mask[:, :, aggressiveness["split_bin"] :],
- 1 + aggressiveness["value"],
- )
-
- return mask * mix
-
- def predict(self, x_mag, aggressiveness=None):
- h = self.forward(x_mag, aggressiveness)
-
- if self.offset > 0:
- h = h[:, :, :, self.offset : -self.offset]
- assert h.size()[3] > 0
-
- return h
diff --git a/spaces/Kangarroar/ApplioRVC-Inference/tools/infer/train-index-v2.py b/spaces/Kangarroar/ApplioRVC-Inference/tools/infer/train-index-v2.py
deleted file mode 100644
index cbeed5d4fbf65fcb9a697a99d5f7b41c844e95d6..0000000000000000000000000000000000000000
--- a/spaces/Kangarroar/ApplioRVC-Inference/tools/infer/train-index-v2.py
+++ /dev/null
@@ -1,79 +0,0 @@
-"""
-格式:直接cid为自带的index位;aid放不下了,通过字典来查,反正就5w个
-"""
-import os
-import traceback
-import logging
-
-logger = logging.getLogger(__name__)
-
-from multiprocessing import cpu_count
-
-import faiss
-import numpy as np
-from sklearn.cluster import MiniBatchKMeans
-
-# ###########如果是原始特征要先写save
-n_cpu = 0
-if n_cpu == 0:
- n_cpu = cpu_count()
-inp_root = r"./logs/anz/3_feature768"
-npys = []
-listdir_res = list(os.listdir(inp_root))
-for name in sorted(listdir_res):
- phone = np.load("%s/%s" % (inp_root, name))
- npys.append(phone)
-big_npy = np.concatenate(npys, 0)
-big_npy_idx = np.arange(big_npy.shape[0])
-np.random.shuffle(big_npy_idx)
-big_npy = big_npy[big_npy_idx]
-logger.debug(big_npy.shape) # (6196072, 192)#fp32#4.43G
-if big_npy.shape[0] > 2e5:
- # if(1):
- info = "Trying doing kmeans %s shape to 10k centers." % big_npy.shape[0]
- logger.info(info)
- try:
- big_npy = (
- MiniBatchKMeans(
- n_clusters=10000,
- verbose=True,
- batch_size=256 * n_cpu,
- compute_labels=False,
- init="random",
- )
- .fit(big_npy)
- .cluster_centers_
- )
- except:
- info = traceback.format_exc()
- logger.warn(info)
-
-np.save("tools/infer/big_src_feature_mi.npy", big_npy)
-
-##################train+add
-# big_npy=np.load("/bili-coeus/jupyter/jupyterhub-liujing04/vits_ch/inference_f0/big_src_feature_mi.npy")
-n_ivf = min(int(16 * np.sqrt(big_npy.shape[0])), big_npy.shape[0] // 39)
-index = faiss.index_factory(768, "IVF%s,Flat" % n_ivf) # mi
-logger.info("Training...")
-index_ivf = faiss.extract_index_ivf(index) #
-index_ivf.nprobe = 1
-index.train(big_npy)
-faiss.write_index(
- index, "tools/infer/trained_IVF%s_Flat_baseline_src_feat_v2.index" % (n_ivf)
-)
-logger.info("Adding...")
-batch_size_add = 8192
-for i in range(0, big_npy.shape[0], batch_size_add):
- index.add(big_npy[i : i + batch_size_add])
-faiss.write_index(
- index, "tools/infer/added_IVF%s_Flat_mi_baseline_src_feat.index" % (n_ivf)
-)
-"""
-大小(都是FP32)
-big_src_feature 2.95G
- (3098036, 256)
-big_emb 4.43G
- (6196072, 192)
-big_emb双倍是因为求特征要repeat后再加pitch
-
-"""
diff --git a/spaces/Kayson/InstructDiffusion/stable_diffusion/ldm/models/diffusion/dpm_solver/__init__.py b/spaces/Kayson/InstructDiffusion/stable_diffusion/ldm/models/diffusion/dpm_solver/__init__.py
deleted file mode 100644
index 7427f38c07530afbab79154ea8aaf88c4bf70a08..0000000000000000000000000000000000000000
--- a/spaces/Kayson/InstructDiffusion/stable_diffusion/ldm/models/diffusion/dpm_solver/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .sampler import DPMSolverSampler
\ No newline at end of file
diff --git a/spaces/Kimata/Sanskrit-TTS/monotonic_align/core.c b/spaces/Kimata/Sanskrit-TTS/monotonic_align/core.c
deleted file mode 100644
index 78f6aff68257660702f0b0ad278757a9728e84d5..0000000000000000000000000000000000000000
--- a/spaces/Kimata/Sanskrit-TTS/monotonic_align/core.c
+++ /dev/null
@@ -1,21608 +0,0 @@
-/* Generated by Cython 0.29.32 */
-
-/* BEGIN: Cython Metadata
-{
- "distutils": {
- "name": "monotonic_align.core",
- "sources": [
- "core.pyx"
- ]
- },
- "module_name": "monotonic_align.core"
-}
-END: Cython Metadata */
-
-#ifndef PY_SSIZE_T_CLEAN
-#define PY_SSIZE_T_CLEAN
-#endif /* PY_SSIZE_T_CLEAN */
-#include "Python.h"
-#ifndef Py_PYTHON_H
- #error Python headers needed to compile C extensions, please install development version of Python.
-#elif PY_VERSION_HEX < 0x02060000 || (0x03000000 <= PY_VERSION_HEX && PY_VERSION_HEX < 0x03030000)
- #error Cython requires Python 2.6+ or Python 3.3+.
-#else
-#define CYTHON_ABI "0_29_32"
-#define CYTHON_HEX_VERSION 0x001D20F0
-#define CYTHON_FUTURE_DIVISION 0
-#include
-#ifndef offsetof
- #define offsetof(type, member) ( (size_t) & ((type*)0) -> member )
-#endif
-#if !defined(WIN32) && !defined(MS_WINDOWS)
- #ifndef __stdcall
- #define __stdcall
- #endif
- #ifndef __cdecl
- #define __cdecl
- #endif
- #ifndef __fastcall
- #define __fastcall
- #endif
-#endif
-#ifndef DL_IMPORT
- #define DL_IMPORT(t) t
-#endif
-#ifndef DL_EXPORT
- #define DL_EXPORT(t) t
-#endif
-#define __PYX_COMMA ,
-#ifndef HAVE_LONG_LONG
- #if PY_VERSION_HEX >= 0x02070000
- #define HAVE_LONG_LONG
- #endif
-#endif
-#ifndef PY_LONG_LONG
- #define PY_LONG_LONG LONG_LONG
-#endif
-#ifndef Py_HUGE_VAL
- #define Py_HUGE_VAL HUGE_VAL
-#endif
-#ifdef PYPY_VERSION
- #define CYTHON_COMPILING_IN_PYPY 1
- #define CYTHON_COMPILING_IN_PYSTON 0
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_NOGIL 0
- #undef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 0
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #if PY_VERSION_HEX < 0x03050000
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #elif !defined(CYTHON_USE_ASYNC_SLOTS)
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #undef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 0
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #undef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 1
- #undef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 0
- #undef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 0
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 0
- #undef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 0
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC (PYPY_VERSION_HEX >= 0x07030900)
- #endif
-#elif defined(PYSTON_VERSION)
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_PYSTON 1
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_NOGIL 0
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #undef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 0
- #undef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 0
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 0
- #endif
-#elif defined(PY_NOGIL)
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_PYSTON 0
- #define CYTHON_COMPILING_IN_CPYTHON 0
- #define CYTHON_COMPILING_IN_NOGIL 1
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #ifndef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #undef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 0
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #undef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL 0
- #ifndef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT 1
- #endif
- #ifndef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE 1
- #endif
- #undef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS 0
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
-#else
- #define CYTHON_COMPILING_IN_PYPY 0
- #define CYTHON_COMPILING_IN_PYSTON 0
- #define CYTHON_COMPILING_IN_CPYTHON 1
- #define CYTHON_COMPILING_IN_NOGIL 0
- #ifndef CYTHON_USE_TYPE_SLOTS
- #define CYTHON_USE_TYPE_SLOTS 1
- #endif
- #if PY_VERSION_HEX < 0x02070000
- #undef CYTHON_USE_PYTYPE_LOOKUP
- #define CYTHON_USE_PYTYPE_LOOKUP 0
- #elif !defined(CYTHON_USE_PYTYPE_LOOKUP)
- #define CYTHON_USE_PYTYPE_LOOKUP 1
- #endif
- #if PY_MAJOR_VERSION < 3
- #undef CYTHON_USE_ASYNC_SLOTS
- #define CYTHON_USE_ASYNC_SLOTS 0
- #elif !defined(CYTHON_USE_ASYNC_SLOTS)
- #define CYTHON_USE_ASYNC_SLOTS 1
- #endif
- #if PY_VERSION_HEX < 0x02070000
- #undef CYTHON_USE_PYLONG_INTERNALS
- #define CYTHON_USE_PYLONG_INTERNALS 0
- #elif !defined(CYTHON_USE_PYLONG_INTERNALS)
- #define CYTHON_USE_PYLONG_INTERNALS 1
- #endif
- #ifndef CYTHON_USE_PYLIST_INTERNALS
- #define CYTHON_USE_PYLIST_INTERNALS 1
- #endif
- #ifndef CYTHON_USE_UNICODE_INTERNALS
- #define CYTHON_USE_UNICODE_INTERNALS 1
- #endif
- #if PY_VERSION_HEX < 0x030300F0 || PY_VERSION_HEX >= 0x030B00A2
- #undef CYTHON_USE_UNICODE_WRITER
- #define CYTHON_USE_UNICODE_WRITER 0
- #elif !defined(CYTHON_USE_UNICODE_WRITER)
- #define CYTHON_USE_UNICODE_WRITER 1
- #endif
- #ifndef CYTHON_AVOID_BORROWED_REFS
- #define CYTHON_AVOID_BORROWED_REFS 0
- #endif
- #ifndef CYTHON_ASSUME_SAFE_MACROS
- #define CYTHON_ASSUME_SAFE_MACROS 1
- #endif
- #ifndef CYTHON_UNPACK_METHODS
- #define CYTHON_UNPACK_METHODS 1
- #endif
- #if PY_VERSION_HEX >= 0x030B00A4
- #undef CYTHON_FAST_THREAD_STATE
- #define CYTHON_FAST_THREAD_STATE 0
- #elif !defined(CYTHON_FAST_THREAD_STATE)
- #define CYTHON_FAST_THREAD_STATE 1
- #endif
- #ifndef CYTHON_FAST_PYCALL
- #define CYTHON_FAST_PYCALL (PY_VERSION_HEX < 0x030A0000)
- #endif
- #ifndef CYTHON_PEP489_MULTI_PHASE_INIT
- #define CYTHON_PEP489_MULTI_PHASE_INIT (PY_VERSION_HEX >= 0x03050000)
- #endif
- #ifndef CYTHON_USE_TP_FINALIZE
- #define CYTHON_USE_TP_FINALIZE (PY_VERSION_HEX >= 0x030400a1)
- #endif
- #ifndef CYTHON_USE_DICT_VERSIONS
- #define CYTHON_USE_DICT_VERSIONS (PY_VERSION_HEX >= 0x030600B1)
- #endif
- #if PY_VERSION_HEX >= 0x030B00A4
- #undef CYTHON_USE_EXC_INFO_STACK
- #define CYTHON_USE_EXC_INFO_STACK 0
- #elif !defined(CYTHON_USE_EXC_INFO_STACK)
- #define CYTHON_USE_EXC_INFO_STACK (PY_VERSION_HEX >= 0x030700A3)
- #endif
- #ifndef CYTHON_UPDATE_DESCRIPTOR_DOC
- #define CYTHON_UPDATE_DESCRIPTOR_DOC 1
- #endif
-#endif
-#if !defined(CYTHON_FAST_PYCCALL)
-#define CYTHON_FAST_PYCCALL (CYTHON_FAST_PYCALL && PY_VERSION_HEX >= 0x030600B1)
-#endif
-#if CYTHON_USE_PYLONG_INTERNALS
- #if PY_MAJOR_VERSION < 3
- #include "longintrepr.h"
- #endif
- #undef SHIFT
- #undef BASE
- #undef MASK
- #ifdef SIZEOF_VOID_P
- enum { __pyx_check_sizeof_voidp = 1 / (int)(SIZEOF_VOID_P == sizeof(void*)) };
- #endif
-#endif
-#ifndef __has_attribute
- #define __has_attribute(x) 0
-#endif
-#ifndef __has_cpp_attribute
- #define __has_cpp_attribute(x) 0
-#endif
-#ifndef CYTHON_RESTRICT
- #if defined(__GNUC__)
- #define CYTHON_RESTRICT __restrict__
- #elif defined(_MSC_VER) && _MSC_VER >= 1400
- #define CYTHON_RESTRICT __restrict
- #elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define CYTHON_RESTRICT restrict
- #else
- #define CYTHON_RESTRICT
- #endif
-#endif
-#ifndef CYTHON_UNUSED
-# if defined(__GNUC__)
-# if !(defined(__cplusplus)) || (__GNUC__ > 3 || (__GNUC__ == 3 && __GNUC_MINOR__ >= 4))
-# define CYTHON_UNUSED __attribute__ ((__unused__))
-# else
-# define CYTHON_UNUSED
-# endif
-# elif defined(__ICC) || (defined(__INTEL_COMPILER) && !defined(_MSC_VER))
-# define CYTHON_UNUSED __attribute__ ((__unused__))
-# else
-# define CYTHON_UNUSED
-# endif
-#endif
-#ifndef CYTHON_MAYBE_UNUSED_VAR
-# if defined(__cplusplus)
- template void CYTHON_MAYBE_UNUSED_VAR( const T& ) { }
-# else
-# define CYTHON_MAYBE_UNUSED_VAR(x) (void)(x)
-# endif
-#endif
-#ifndef CYTHON_NCP_UNUSED
-# if CYTHON_COMPILING_IN_CPYTHON
-# define CYTHON_NCP_UNUSED
-# else
-# define CYTHON_NCP_UNUSED CYTHON_UNUSED
-# endif
-#endif
-#define __Pyx_void_to_None(void_result) ((void)(void_result), Py_INCREF(Py_None), Py_None)
-#ifdef _MSC_VER
- #ifndef _MSC_STDINT_H_
- #if _MSC_VER < 1300
- typedef unsigned char uint8_t;
- typedef unsigned int uint32_t;
- #else
- typedef unsigned __int8 uint8_t;
- typedef unsigned __int32 uint32_t;
- #endif
- #endif
-#else
- #include
-#endif
-#ifndef CYTHON_FALLTHROUGH
- #if defined(__cplusplus) && __cplusplus >= 201103L
- #if __has_cpp_attribute(fallthrough)
- #define CYTHON_FALLTHROUGH [[fallthrough]]
- #elif __has_cpp_attribute(clang::fallthrough)
- #define CYTHON_FALLTHROUGH [[clang::fallthrough]]
- #elif __has_cpp_attribute(gnu::fallthrough)
- #define CYTHON_FALLTHROUGH [[gnu::fallthrough]]
- #endif
- #endif
- #ifndef CYTHON_FALLTHROUGH
- #if __has_attribute(fallthrough)
- #define CYTHON_FALLTHROUGH __attribute__((fallthrough))
- #else
- #define CYTHON_FALLTHROUGH
- #endif
- #endif
- #if defined(__clang__ ) && defined(__apple_build_version__)
- #if __apple_build_version__ < 7000000
- #undef CYTHON_FALLTHROUGH
- #define CYTHON_FALLTHROUGH
- #endif
- #endif
-#endif
-
-#ifndef CYTHON_INLINE
- #if defined(__clang__)
- #define CYTHON_INLINE __inline__ __attribute__ ((__unused__))
- #elif defined(__GNUC__)
- #define CYTHON_INLINE __inline__
- #elif defined(_MSC_VER)
- #define CYTHON_INLINE __inline
- #elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define CYTHON_INLINE inline
- #else
- #define CYTHON_INLINE
- #endif
-#endif
-
-#if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX < 0x02070600 && !defined(Py_OptimizeFlag)
- #define Py_OptimizeFlag 0
-#endif
-#define __PYX_BUILD_PY_SSIZE_T "n"
-#define CYTHON_FORMAT_SSIZE_T "z"
-#if PY_MAJOR_VERSION < 3
- #define __Pyx_BUILTIN_MODULE_NAME "__builtin__"
- #define __Pyx_PyCode_New(a, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)\
- PyCode_New(a+k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)
- #define __Pyx_DefaultClassType PyClass_Type
-#else
- #define __Pyx_BUILTIN_MODULE_NAME "builtins"
- #define __Pyx_DefaultClassType PyType_Type
-#if PY_VERSION_HEX >= 0x030B00A1
- static CYTHON_INLINE PyCodeObject* __Pyx_PyCode_New(int a, int k, int l, int s, int f,
- PyObject *code, PyObject *c, PyObject* n, PyObject *v,
- PyObject *fv, PyObject *cell, PyObject* fn,
- PyObject *name, int fline, PyObject *lnos) {
- PyObject *kwds=NULL, *argcount=NULL, *posonlyargcount=NULL, *kwonlyargcount=NULL;
- PyObject *nlocals=NULL, *stacksize=NULL, *flags=NULL, *replace=NULL, *call_result=NULL, *empty=NULL;
- const char *fn_cstr=NULL;
- const char *name_cstr=NULL;
- PyCodeObject* co=NULL;
- PyObject *type, *value, *traceback;
- PyErr_Fetch(&type, &value, &traceback);
- if (!(kwds=PyDict_New())) goto end;
- if (!(argcount=PyLong_FromLong(a))) goto end;
- if (PyDict_SetItemString(kwds, "co_argcount", argcount) != 0) goto end;
- if (!(posonlyargcount=PyLong_FromLong(0))) goto end;
- if (PyDict_SetItemString(kwds, "co_posonlyargcount", posonlyargcount) != 0) goto end;
- if (!(kwonlyargcount=PyLong_FromLong(k))) goto end;
- if (PyDict_SetItemString(kwds, "co_kwonlyargcount", kwonlyargcount) != 0) goto end;
- if (!(nlocals=PyLong_FromLong(l))) goto end;
- if (PyDict_SetItemString(kwds, "co_nlocals", nlocals) != 0) goto end;
- if (!(stacksize=PyLong_FromLong(s))) goto end;
- if (PyDict_SetItemString(kwds, "co_stacksize", stacksize) != 0) goto end;
- if (!(flags=PyLong_FromLong(f))) goto end;
- if (PyDict_SetItemString(kwds, "co_flags", flags) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_code", code) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_consts", c) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_names", n) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_varnames", v) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_freevars", fv) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_cellvars", cell) != 0) goto end;
- if (PyDict_SetItemString(kwds, "co_linetable", lnos) != 0) goto end;
- if (!(fn_cstr=PyUnicode_AsUTF8AndSize(fn, NULL))) goto end;
- if (!(name_cstr=PyUnicode_AsUTF8AndSize(name, NULL))) goto end;
- if (!(co = PyCode_NewEmpty(fn_cstr, name_cstr, fline))) goto end;
- if (!(replace = PyObject_GetAttrString((PyObject*)co, "replace"))) goto cleanup_code_too;
- if (!(empty = PyTuple_New(0))) goto cleanup_code_too; // unfortunately __pyx_empty_tuple isn't available here
- if (!(call_result = PyObject_Call(replace, empty, kwds))) goto cleanup_code_too;
- Py_XDECREF((PyObject*)co);
- co = (PyCodeObject*)call_result;
- call_result = NULL;
- if (0) {
- cleanup_code_too:
- Py_XDECREF((PyObject*)co);
- co = NULL;
- }
- end:
- Py_XDECREF(kwds);
- Py_XDECREF(argcount);
- Py_XDECREF(posonlyargcount);
- Py_XDECREF(kwonlyargcount);
- Py_XDECREF(nlocals);
- Py_XDECREF(stacksize);
- Py_XDECREF(replace);
- Py_XDECREF(call_result);
- Py_XDECREF(empty);
- if (type) {
- PyErr_Restore(type, value, traceback);
- }
- return co;
- }
-#else
- #define __Pyx_PyCode_New(a, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)\
- PyCode_New(a, k, l, s, f, code, c, n, v, fv, cell, fn, name, fline, lnos)
-#endif
- #define __Pyx_DefaultClassType PyType_Type
-#endif
-#ifndef Py_TPFLAGS_CHECKTYPES
- #define Py_TPFLAGS_CHECKTYPES 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_INDEX
- #define Py_TPFLAGS_HAVE_INDEX 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_NEWBUFFER
- #define Py_TPFLAGS_HAVE_NEWBUFFER 0
-#endif
-#ifndef Py_TPFLAGS_HAVE_FINALIZE
- #define Py_TPFLAGS_HAVE_FINALIZE 0
-#endif
-#ifndef METH_STACKLESS
- #define METH_STACKLESS 0
-#endif
-#if PY_VERSION_HEX <= 0x030700A3 || !defined(METH_FASTCALL)
- #ifndef METH_FASTCALL
- #define METH_FASTCALL 0x80
- #endif
- typedef PyObject *(*__Pyx_PyCFunctionFast) (PyObject *self, PyObject *const *args, Py_ssize_t nargs);
- typedef PyObject *(*__Pyx_PyCFunctionFastWithKeywords) (PyObject *self, PyObject *const *args,
- Py_ssize_t nargs, PyObject *kwnames);
-#else
- #define __Pyx_PyCFunctionFast _PyCFunctionFast
- #define __Pyx_PyCFunctionFastWithKeywords _PyCFunctionFastWithKeywords
-#endif
-#if CYTHON_FAST_PYCCALL
-#define __Pyx_PyFastCFunction_Check(func)\
- ((PyCFunction_Check(func) && (METH_FASTCALL == (PyCFunction_GET_FLAGS(func) & ~(METH_CLASS | METH_STATIC | METH_COEXIST | METH_KEYWORDS | METH_STACKLESS)))))
-#else
-#define __Pyx_PyFastCFunction_Check(func) 0
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyObject_Malloc)
- #define PyObject_Malloc(s) PyMem_Malloc(s)
- #define PyObject_Free(p) PyMem_Free(p)
- #define PyObject_Realloc(p) PyMem_Realloc(p)
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX < 0x030400A1
- #define PyMem_RawMalloc(n) PyMem_Malloc(n)
- #define PyMem_RawRealloc(p, n) PyMem_Realloc(p, n)
- #define PyMem_RawFree(p) PyMem_Free(p)
-#endif
-#if CYTHON_COMPILING_IN_PYSTON
- #define __Pyx_PyCode_HasFreeVars(co) PyCode_HasFreeVars(co)
- #define __Pyx_PyFrame_SetLineNumber(frame, lineno) PyFrame_SetLineNumber(frame, lineno)
-#else
- #define __Pyx_PyCode_HasFreeVars(co) (PyCode_GetNumFree(co) > 0)
- #define __Pyx_PyFrame_SetLineNumber(frame, lineno) (frame)->f_lineno = (lineno)
-#endif
-#if !CYTHON_FAST_THREAD_STATE || PY_VERSION_HEX < 0x02070000
- #define __Pyx_PyThreadState_Current PyThreadState_GET()
-#elif PY_VERSION_HEX >= 0x03060000
- #define __Pyx_PyThreadState_Current _PyThreadState_UncheckedGet()
-#elif PY_VERSION_HEX >= 0x03000000
- #define __Pyx_PyThreadState_Current PyThreadState_GET()
-#else
- #define __Pyx_PyThreadState_Current _PyThreadState_Current
-#endif
-#if PY_VERSION_HEX < 0x030700A2 && !defined(PyThread_tss_create) && !defined(Py_tss_NEEDS_INIT)
-#include "pythread.h"
-#define Py_tss_NEEDS_INIT 0
-typedef int Py_tss_t;
-static CYTHON_INLINE int PyThread_tss_create(Py_tss_t *key) {
- *key = PyThread_create_key();
- return 0;
-}
-static CYTHON_INLINE Py_tss_t * PyThread_tss_alloc(void) {
- Py_tss_t *key = (Py_tss_t *)PyObject_Malloc(sizeof(Py_tss_t));
- *key = Py_tss_NEEDS_INIT;
- return key;
-}
-static CYTHON_INLINE void PyThread_tss_free(Py_tss_t *key) {
- PyObject_Free(key);
-}
-static CYTHON_INLINE int PyThread_tss_is_created(Py_tss_t *key) {
- return *key != Py_tss_NEEDS_INIT;
-}
-static CYTHON_INLINE void PyThread_tss_delete(Py_tss_t *key) {
- PyThread_delete_key(*key);
- *key = Py_tss_NEEDS_INIT;
-}
-static CYTHON_INLINE int PyThread_tss_set(Py_tss_t *key, void *value) {
- return PyThread_set_key_value(*key, value);
-}
-static CYTHON_INLINE void * PyThread_tss_get(Py_tss_t *key) {
- return PyThread_get_key_value(*key);
-}
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON || defined(_PyDict_NewPresized)
-#define __Pyx_PyDict_NewPresized(n) ((n <= 8) ? PyDict_New() : _PyDict_NewPresized(n))
-#else
-#define __Pyx_PyDict_NewPresized(n) PyDict_New()
-#endif
-#if PY_MAJOR_VERSION >= 3 || CYTHON_FUTURE_DIVISION
- #define __Pyx_PyNumber_Divide(x,y) PyNumber_TrueDivide(x,y)
- #define __Pyx_PyNumber_InPlaceDivide(x,y) PyNumber_InPlaceTrueDivide(x,y)
-#else
- #define __Pyx_PyNumber_Divide(x,y) PyNumber_Divide(x,y)
- #define __Pyx_PyNumber_InPlaceDivide(x,y) PyNumber_InPlaceDivide(x,y)
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x030500A1 && CYTHON_USE_UNICODE_INTERNALS
-#define __Pyx_PyDict_GetItemStr(dict, name) _PyDict_GetItem_KnownHash(dict, name, ((PyASCIIObject *) name)->hash)
-#else
-#define __Pyx_PyDict_GetItemStr(dict, name) PyDict_GetItem(dict, name)
-#endif
-#if PY_VERSION_HEX > 0x03030000 && defined(PyUnicode_KIND)
- #define CYTHON_PEP393_ENABLED 1
- #if defined(PyUnicode_IS_READY)
- #define __Pyx_PyUnicode_READY(op) (likely(PyUnicode_IS_READY(op)) ?\
- 0 : _PyUnicode_Ready((PyObject *)(op)))
- #else
- #define __Pyx_PyUnicode_READY(op) (0)
- #endif
- #define __Pyx_PyUnicode_GET_LENGTH(u) PyUnicode_GET_LENGTH(u)
- #define __Pyx_PyUnicode_READ_CHAR(u, i) PyUnicode_READ_CHAR(u, i)
- #define __Pyx_PyUnicode_MAX_CHAR_VALUE(u) PyUnicode_MAX_CHAR_VALUE(u)
- #define __Pyx_PyUnicode_KIND(u) PyUnicode_KIND(u)
- #define __Pyx_PyUnicode_DATA(u) PyUnicode_DATA(u)
- #define __Pyx_PyUnicode_READ(k, d, i) PyUnicode_READ(k, d, i)
- #define __Pyx_PyUnicode_WRITE(k, d, i, ch) PyUnicode_WRITE(k, d, i, ch)
- #if defined(PyUnicode_IS_READY) && defined(PyUnicode_GET_SIZE)
- #if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x03090000
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != (likely(PyUnicode_IS_READY(u)) ? PyUnicode_GET_LENGTH(u) : ((PyCompactUnicodeObject *)(u))->wstr_length))
- #else
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != (likely(PyUnicode_IS_READY(u)) ? PyUnicode_GET_LENGTH(u) : PyUnicode_GET_SIZE(u)))
- #endif
- #else
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != PyUnicode_GET_LENGTH(u))
- #endif
-#else
- #define CYTHON_PEP393_ENABLED 0
- #define PyUnicode_1BYTE_KIND 1
- #define PyUnicode_2BYTE_KIND 2
- #define PyUnicode_4BYTE_KIND 4
- #define __Pyx_PyUnicode_READY(op) (0)
- #define __Pyx_PyUnicode_GET_LENGTH(u) PyUnicode_GET_SIZE(u)
- #define __Pyx_PyUnicode_READ_CHAR(u, i) ((Py_UCS4)(PyUnicode_AS_UNICODE(u)[i]))
- #define __Pyx_PyUnicode_MAX_CHAR_VALUE(u) ((sizeof(Py_UNICODE) == 2) ? 65535 : 1114111)
- #define __Pyx_PyUnicode_KIND(u) (sizeof(Py_UNICODE))
- #define __Pyx_PyUnicode_DATA(u) ((void*)PyUnicode_AS_UNICODE(u))
- #define __Pyx_PyUnicode_READ(k, d, i) ((void)(k), (Py_UCS4)(((Py_UNICODE*)d)[i]))
- #define __Pyx_PyUnicode_WRITE(k, d, i, ch) (((void)(k)), ((Py_UNICODE*)d)[i] = ch)
- #define __Pyx_PyUnicode_IS_TRUE(u) (0 != PyUnicode_GET_SIZE(u))
-#endif
-#if CYTHON_COMPILING_IN_PYPY
- #define __Pyx_PyUnicode_Concat(a, b) PyNumber_Add(a, b)
- #define __Pyx_PyUnicode_ConcatSafe(a, b) PyNumber_Add(a, b)
-#else
- #define __Pyx_PyUnicode_Concat(a, b) PyUnicode_Concat(a, b)
- #define __Pyx_PyUnicode_ConcatSafe(a, b) ((unlikely((a) == Py_None) || unlikely((b) == Py_None)) ?\
- PyNumber_Add(a, b) : __Pyx_PyUnicode_Concat(a, b))
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyUnicode_Contains)
- #define PyUnicode_Contains(u, s) PySequence_Contains(u, s)
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyByteArray_Check)
- #define PyByteArray_Check(obj) PyObject_TypeCheck(obj, &PyByteArray_Type)
-#endif
-#if CYTHON_COMPILING_IN_PYPY && !defined(PyObject_Format)
- #define PyObject_Format(obj, fmt) PyObject_CallMethod(obj, "__format__", "O", fmt)
-#endif
-#define __Pyx_PyString_FormatSafe(a, b) ((unlikely((a) == Py_None || (PyString_Check(b) && !PyString_CheckExact(b)))) ? PyNumber_Remainder(a, b) : __Pyx_PyString_Format(a, b))
-#define __Pyx_PyUnicode_FormatSafe(a, b) ((unlikely((a) == Py_None || (PyUnicode_Check(b) && !PyUnicode_CheckExact(b)))) ? PyNumber_Remainder(a, b) : PyUnicode_Format(a, b))
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyString_Format(a, b) PyUnicode_Format(a, b)
-#else
- #define __Pyx_PyString_Format(a, b) PyString_Format(a, b)
-#endif
-#if PY_MAJOR_VERSION < 3 && !defined(PyObject_ASCII)
- #define PyObject_ASCII(o) PyObject_Repr(o)
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyBaseString_Type PyUnicode_Type
- #define PyStringObject PyUnicodeObject
- #define PyString_Type PyUnicode_Type
- #define PyString_Check PyUnicode_Check
- #define PyString_CheckExact PyUnicode_CheckExact
-#ifndef PyObject_Unicode
- #define PyObject_Unicode PyObject_Str
-#endif
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyBaseString_Check(obj) PyUnicode_Check(obj)
- #define __Pyx_PyBaseString_CheckExact(obj) PyUnicode_CheckExact(obj)
-#else
- #define __Pyx_PyBaseString_Check(obj) (PyString_Check(obj) || PyUnicode_Check(obj))
- #define __Pyx_PyBaseString_CheckExact(obj) (PyString_CheckExact(obj) || PyUnicode_CheckExact(obj))
-#endif
-#ifndef PySet_CheckExact
- #define PySet_CheckExact(obj) (Py_TYPE(obj) == &PySet_Type)
-#endif
-#if PY_VERSION_HEX >= 0x030900A4
- #define __Pyx_SET_REFCNT(obj, refcnt) Py_SET_REFCNT(obj, refcnt)
- #define __Pyx_SET_SIZE(obj, size) Py_SET_SIZE(obj, size)
-#else
- #define __Pyx_SET_REFCNT(obj, refcnt) Py_REFCNT(obj) = (refcnt)
- #define __Pyx_SET_SIZE(obj, size) Py_SIZE(obj) = (size)
-#endif
-#if CYTHON_ASSUME_SAFE_MACROS
- #define __Pyx_PySequence_SIZE(seq) Py_SIZE(seq)
-#else
- #define __Pyx_PySequence_SIZE(seq) PySequence_Size(seq)
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyIntObject PyLongObject
- #define PyInt_Type PyLong_Type
- #define PyInt_Check(op) PyLong_Check(op)
- #define PyInt_CheckExact(op) PyLong_CheckExact(op)
- #define PyInt_FromString PyLong_FromString
- #define PyInt_FromUnicode PyLong_FromUnicode
- #define PyInt_FromLong PyLong_FromLong
- #define PyInt_FromSize_t PyLong_FromSize_t
- #define PyInt_FromSsize_t PyLong_FromSsize_t
- #define PyInt_AsLong PyLong_AsLong
- #define PyInt_AS_LONG PyLong_AS_LONG
- #define PyInt_AsSsize_t PyLong_AsSsize_t
- #define PyInt_AsUnsignedLongMask PyLong_AsUnsignedLongMask
- #define PyInt_AsUnsignedLongLongMask PyLong_AsUnsignedLongLongMask
- #define PyNumber_Int PyNumber_Long
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define PyBoolObject PyLongObject
-#endif
-#if PY_MAJOR_VERSION >= 3 && CYTHON_COMPILING_IN_PYPY
- #ifndef PyUnicode_InternFromString
- #define PyUnicode_InternFromString(s) PyUnicode_FromString(s)
- #endif
-#endif
-#if PY_VERSION_HEX < 0x030200A4
- typedef long Py_hash_t;
- #define __Pyx_PyInt_FromHash_t PyInt_FromLong
- #define __Pyx_PyInt_AsHash_t __Pyx_PyIndex_AsHash_t
-#else
- #define __Pyx_PyInt_FromHash_t PyInt_FromSsize_t
- #define __Pyx_PyInt_AsHash_t __Pyx_PyIndex_AsSsize_t
-#endif
-#if PY_MAJOR_VERSION >= 3
- #define __Pyx_PyMethod_New(func, self, klass) ((self) ? ((void)(klass), PyMethod_New(func, self)) : __Pyx_NewRef(func))
-#else
- #define __Pyx_PyMethod_New(func, self, klass) PyMethod_New(func, self, klass)
-#endif
-#if CYTHON_USE_ASYNC_SLOTS
- #if PY_VERSION_HEX >= 0x030500B1
- #define __Pyx_PyAsyncMethodsStruct PyAsyncMethods
- #define __Pyx_PyType_AsAsync(obj) (Py_TYPE(obj)->tp_as_async)
- #else
- #define __Pyx_PyType_AsAsync(obj) ((__Pyx_PyAsyncMethodsStruct*) (Py_TYPE(obj)->tp_reserved))
- #endif
-#else
- #define __Pyx_PyType_AsAsync(obj) NULL
-#endif
-#ifndef __Pyx_PyAsyncMethodsStruct
- typedef struct {
- unaryfunc am_await;
- unaryfunc am_aiter;
- unaryfunc am_anext;
- } __Pyx_PyAsyncMethodsStruct;
-#endif
-
-#if defined(_WIN32) || defined(WIN32) || defined(MS_WINDOWS)
- #if !defined(_USE_MATH_DEFINES)
- #define _USE_MATH_DEFINES
- #endif
-#endif
-#include
-#ifdef NAN
-#define __PYX_NAN() ((float) NAN)
-#else
-static CYTHON_INLINE float __PYX_NAN() {
- float value;
- memset(&value, 0xFF, sizeof(value));
- return value;
-}
-#endif
-#if defined(__CYGWIN__) && defined(_LDBL_EQ_DBL)
-#define __Pyx_truncl trunc
-#else
-#define __Pyx_truncl truncl
-#endif
-
-#define __PYX_MARK_ERR_POS(f_index, lineno) \
- { __pyx_filename = __pyx_f[f_index]; (void)__pyx_filename; __pyx_lineno = lineno; (void)__pyx_lineno; __pyx_clineno = __LINE__; (void)__pyx_clineno; }
-#define __PYX_ERR(f_index, lineno, Ln_error) \
- { __PYX_MARK_ERR_POS(f_index, lineno) goto Ln_error; }
-
-#ifndef __PYX_EXTERN_C
- #ifdef __cplusplus
- #define __PYX_EXTERN_C extern "C"
- #else
- #define __PYX_EXTERN_C extern
- #endif
-#endif
-
-#define __PYX_HAVE__monotonic_align__core
-#define __PYX_HAVE_API__monotonic_align__core
-/* Early includes */
-#include "pythread.h"
-#include
-#include
-#include
-#include "pystate.h"
-#ifdef _OPENMP
-#include
-#endif /* _OPENMP */
-
-#if defined(PYREX_WITHOUT_ASSERTIONS) && !defined(CYTHON_WITHOUT_ASSERTIONS)
-#define CYTHON_WITHOUT_ASSERTIONS
-#endif
-
-typedef struct {PyObject **p; const char *s; const Py_ssize_t n; const char* encoding;
- const char is_unicode; const char is_str; const char intern; } __Pyx_StringTabEntry;
-
-#define __PYX_DEFAULT_STRING_ENCODING_IS_ASCII 0
-#define __PYX_DEFAULT_STRING_ENCODING_IS_UTF8 0
-#define __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT (PY_MAJOR_VERSION >= 3 && __PYX_DEFAULT_STRING_ENCODING_IS_UTF8)
-#define __PYX_DEFAULT_STRING_ENCODING ""
-#define __Pyx_PyObject_FromString __Pyx_PyBytes_FromString
-#define __Pyx_PyObject_FromStringAndSize __Pyx_PyBytes_FromStringAndSize
-#define __Pyx_uchar_cast(c) ((unsigned char)c)
-#define __Pyx_long_cast(x) ((long)x)
-#define __Pyx_fits_Py_ssize_t(v, type, is_signed) (\
- (sizeof(type) < sizeof(Py_ssize_t)) ||\
- (sizeof(type) > sizeof(Py_ssize_t) &&\
- likely(v < (type)PY_SSIZE_T_MAX ||\
- v == (type)PY_SSIZE_T_MAX) &&\
- (!is_signed || likely(v > (type)PY_SSIZE_T_MIN ||\
- v == (type)PY_SSIZE_T_MIN))) ||\
- (sizeof(type) == sizeof(Py_ssize_t) &&\
- (is_signed || likely(v < (type)PY_SSIZE_T_MAX ||\
- v == (type)PY_SSIZE_T_MAX))) )
-static CYTHON_INLINE int __Pyx_is_valid_index(Py_ssize_t i, Py_ssize_t limit) {
- return (size_t) i < (size_t) limit;
-}
-#if defined (__cplusplus) && __cplusplus >= 201103L
- #include
- #define __Pyx_sst_abs(value) std::abs(value)
-#elif SIZEOF_INT >= SIZEOF_SIZE_T
- #define __Pyx_sst_abs(value) abs(value)
-#elif SIZEOF_LONG >= SIZEOF_SIZE_T
- #define __Pyx_sst_abs(value) labs(value)
-#elif defined (_MSC_VER)
- #define __Pyx_sst_abs(value) ((Py_ssize_t)_abs64(value))
-#elif defined (__STDC_VERSION__) && __STDC_VERSION__ >= 199901L
- #define __Pyx_sst_abs(value) llabs(value)
-#elif defined (__GNUC__)
- #define __Pyx_sst_abs(value) __builtin_llabs(value)
-#else
- #define __Pyx_sst_abs(value) ((value<0) ? -value : value)
-#endif
-static CYTHON_INLINE const char* __Pyx_PyObject_AsString(PyObject*);
-static CYTHON_INLINE const char* __Pyx_PyObject_AsStringAndSize(PyObject*, Py_ssize_t* length);
-#define __Pyx_PyByteArray_FromString(s) PyByteArray_FromStringAndSize((const char*)s, strlen((const char*)s))
-#define __Pyx_PyByteArray_FromStringAndSize(s, l) PyByteArray_FromStringAndSize((const char*)s, l)
-#define __Pyx_PyBytes_FromString PyBytes_FromString
-#define __Pyx_PyBytes_FromStringAndSize PyBytes_FromStringAndSize
-static CYTHON_INLINE PyObject* __Pyx_PyUnicode_FromString(const char*);
-#if PY_MAJOR_VERSION < 3
- #define __Pyx_PyStr_FromString __Pyx_PyBytes_FromString
- #define __Pyx_PyStr_FromStringAndSize __Pyx_PyBytes_FromStringAndSize
-#else
- #define __Pyx_PyStr_FromString __Pyx_PyUnicode_FromString
- #define __Pyx_PyStr_FromStringAndSize __Pyx_PyUnicode_FromStringAndSize
-#endif
-#define __Pyx_PyBytes_AsWritableString(s) ((char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsWritableSString(s) ((signed char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsWritableUString(s) ((unsigned char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsString(s) ((const char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsSString(s) ((const signed char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyBytes_AsUString(s) ((const unsigned char*) PyBytes_AS_STRING(s))
-#define __Pyx_PyObject_AsWritableString(s) ((char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsWritableSString(s) ((signed char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsWritableUString(s) ((unsigned char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsSString(s) ((const signed char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_AsUString(s) ((const unsigned char*) __Pyx_PyObject_AsString(s))
-#define __Pyx_PyObject_FromCString(s) __Pyx_PyObject_FromString((const char*)s)
-#define __Pyx_PyBytes_FromCString(s) __Pyx_PyBytes_FromString((const char*)s)
-#define __Pyx_PyByteArray_FromCString(s) __Pyx_PyByteArray_FromString((const char*)s)
-#define __Pyx_PyStr_FromCString(s) __Pyx_PyStr_FromString((const char*)s)
-#define __Pyx_PyUnicode_FromCString(s) __Pyx_PyUnicode_FromString((const char*)s)
-static CYTHON_INLINE size_t __Pyx_Py_UNICODE_strlen(const Py_UNICODE *u) {
- const Py_UNICODE *u_end = u;
- while (*u_end++) ;
- return (size_t)(u_end - u - 1);
-}
-#define __Pyx_PyUnicode_FromUnicode(u) PyUnicode_FromUnicode(u, __Pyx_Py_UNICODE_strlen(u))
-#define __Pyx_PyUnicode_FromUnicodeAndLength PyUnicode_FromUnicode
-#define __Pyx_PyUnicode_AsUnicode PyUnicode_AsUnicode
-#define __Pyx_NewRef(obj) (Py_INCREF(obj), obj)
-#define __Pyx_Owned_Py_None(b) __Pyx_NewRef(Py_None)
-static CYTHON_INLINE PyObject * __Pyx_PyBool_FromLong(long b);
-static CYTHON_INLINE int __Pyx_PyObject_IsTrue(PyObject*);
-static CYTHON_INLINE int __Pyx_PyObject_IsTrueAndDecref(PyObject*);
-static CYTHON_INLINE PyObject* __Pyx_PyNumber_IntOrLong(PyObject* x);
-#define __Pyx_PySequence_Tuple(obj)\
- (likely(PyTuple_CheckExact(obj)) ? __Pyx_NewRef(obj) : PySequence_Tuple(obj))
-static CYTHON_INLINE Py_ssize_t __Pyx_PyIndex_AsSsize_t(PyObject*);
-static CYTHON_INLINE PyObject * __Pyx_PyInt_FromSize_t(size_t);
-static CYTHON_INLINE Py_hash_t __Pyx_PyIndex_AsHash_t(PyObject*);
-#if CYTHON_ASSUME_SAFE_MACROS
-#define __pyx_PyFloat_AsDouble(x) (PyFloat_CheckExact(x) ? PyFloat_AS_DOUBLE(x) : PyFloat_AsDouble(x))
-#else
-#define __pyx_PyFloat_AsDouble(x) PyFloat_AsDouble(x)
-#endif
-#define __pyx_PyFloat_AsFloat(x) ((float) __pyx_PyFloat_AsDouble(x))
-#if PY_MAJOR_VERSION >= 3
-#define __Pyx_PyNumber_Int(x) (PyLong_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Long(x))
-#else
-#define __Pyx_PyNumber_Int(x) (PyInt_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Int(x))
-#endif
-#define __Pyx_PyNumber_Float(x) (PyFloat_CheckExact(x) ? __Pyx_NewRef(x) : PyNumber_Float(x))
-#if PY_MAJOR_VERSION < 3 && __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
-static int __Pyx_sys_getdefaultencoding_not_ascii;
-static int __Pyx_init_sys_getdefaultencoding_params(void) {
- PyObject* sys;
- PyObject* default_encoding = NULL;
- PyObject* ascii_chars_u = NULL;
- PyObject* ascii_chars_b = NULL;
- const char* default_encoding_c;
- sys = PyImport_ImportModule("sys");
- if (!sys) goto bad;
- default_encoding = PyObject_CallMethod(sys, (char*) "getdefaultencoding", NULL);
- Py_DECREF(sys);
- if (!default_encoding) goto bad;
- default_encoding_c = PyBytes_AsString(default_encoding);
- if (!default_encoding_c) goto bad;
- if (strcmp(default_encoding_c, "ascii") == 0) {
- __Pyx_sys_getdefaultencoding_not_ascii = 0;
- } else {
- char ascii_chars[128];
- int c;
- for (c = 0; c < 128; c++) {
- ascii_chars[c] = c;
- }
- __Pyx_sys_getdefaultencoding_not_ascii = 1;
- ascii_chars_u = PyUnicode_DecodeASCII(ascii_chars, 128, NULL);
- if (!ascii_chars_u) goto bad;
- ascii_chars_b = PyUnicode_AsEncodedString(ascii_chars_u, default_encoding_c, NULL);
- if (!ascii_chars_b || !PyBytes_Check(ascii_chars_b) || memcmp(ascii_chars, PyBytes_AS_STRING(ascii_chars_b), 128) != 0) {
- PyErr_Format(
- PyExc_ValueError,
- "This module compiled with c_string_encoding=ascii, but default encoding '%.200s' is not a superset of ascii.",
- default_encoding_c);
- goto bad;
- }
- Py_DECREF(ascii_chars_u);
- Py_DECREF(ascii_chars_b);
- }
- Py_DECREF(default_encoding);
- return 0;
-bad:
- Py_XDECREF(default_encoding);
- Py_XDECREF(ascii_chars_u);
- Py_XDECREF(ascii_chars_b);
- return -1;
-}
-#endif
-#if __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT && PY_MAJOR_VERSION >= 3
-#define __Pyx_PyUnicode_FromStringAndSize(c_str, size) PyUnicode_DecodeUTF8(c_str, size, NULL)
-#else
-#define __Pyx_PyUnicode_FromStringAndSize(c_str, size) PyUnicode_Decode(c_str, size, __PYX_DEFAULT_STRING_ENCODING, NULL)
-#if __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
-static char* __PYX_DEFAULT_STRING_ENCODING;
-static int __Pyx_init_sys_getdefaultencoding_params(void) {
- PyObject* sys;
- PyObject* default_encoding = NULL;
- char* default_encoding_c;
- sys = PyImport_ImportModule("sys");
- if (!sys) goto bad;
- default_encoding = PyObject_CallMethod(sys, (char*) (const char*) "getdefaultencoding", NULL);
- Py_DECREF(sys);
- if (!default_encoding) goto bad;
- default_encoding_c = PyBytes_AsString(default_encoding);
- if (!default_encoding_c) goto bad;
- __PYX_DEFAULT_STRING_ENCODING = (char*) malloc(strlen(default_encoding_c) + 1);
- if (!__PYX_DEFAULT_STRING_ENCODING) goto bad;
- strcpy(__PYX_DEFAULT_STRING_ENCODING, default_encoding_c);
- Py_DECREF(default_encoding);
- return 0;
-bad:
- Py_XDECREF(default_encoding);
- return -1;
-}
-#endif
-#endif
-
-
-/* Test for GCC > 2.95 */
-#if defined(__GNUC__) && (__GNUC__ > 2 || (__GNUC__ == 2 && (__GNUC_MINOR__ > 95)))
- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
-#else /* !__GNUC__ or GCC < 2.95 */
- #define likely(x) (x)
- #define unlikely(x) (x)
-#endif /* __GNUC__ */
-static CYTHON_INLINE void __Pyx_pretend_to_initialize(void* ptr) { (void)ptr; }
-
-static PyObject *__pyx_m = NULL;
-static PyObject *__pyx_d;
-static PyObject *__pyx_b;
-static PyObject *__pyx_cython_runtime = NULL;
-static PyObject *__pyx_empty_tuple;
-static PyObject *__pyx_empty_bytes;
-static PyObject *__pyx_empty_unicode;
-static int __pyx_lineno;
-static int __pyx_clineno = 0;
-static const char * __pyx_cfilenm= __FILE__;
-static const char *__pyx_filename;
-
-
-static const char *__pyx_f[] = {
- "core.pyx",
- "stringsource",
-};
-/* NoFastGil.proto */
-#define __Pyx_PyGILState_Ensure PyGILState_Ensure
-#define __Pyx_PyGILState_Release PyGILState_Release
-#define __Pyx_FastGIL_Remember()
-#define __Pyx_FastGIL_Forget()
-#define __Pyx_FastGilFuncInit()
-
-/* MemviewSliceStruct.proto */
-struct __pyx_memoryview_obj;
-typedef struct {
- struct __pyx_memoryview_obj *memview;
- char *data;
- Py_ssize_t shape[8];
- Py_ssize_t strides[8];
- Py_ssize_t suboffsets[8];
-} __Pyx_memviewslice;
-#define __Pyx_MemoryView_Len(m) (m.shape[0])
-
-/* Atomics.proto */
-#include
-#ifndef CYTHON_ATOMICS
- #define CYTHON_ATOMICS 1
-#endif
-#define __PYX_CYTHON_ATOMICS_ENABLED() CYTHON_ATOMICS
-#define __pyx_atomic_int_type int
-#if CYTHON_ATOMICS && (__GNUC__ >= 5 || (__GNUC__ == 4 &&\
- (__GNUC_MINOR__ > 1 ||\
- (__GNUC_MINOR__ == 1 && __GNUC_PATCHLEVEL__ >= 2))))
- #define __pyx_atomic_incr_aligned(value) __sync_fetch_and_add(value, 1)
- #define __pyx_atomic_decr_aligned(value) __sync_fetch_and_sub(value, 1)
- #ifdef __PYX_DEBUG_ATOMICS
- #warning "Using GNU atomics"
- #endif
-#elif CYTHON_ATOMICS && defined(_MSC_VER) && CYTHON_COMPILING_IN_NOGIL
- #include
- #undef __pyx_atomic_int_type
- #define __pyx_atomic_int_type long
- #pragma intrinsic (_InterlockedExchangeAdd)
- #define __pyx_atomic_incr_aligned(value) _InterlockedExchangeAdd(value, 1)
- #define __pyx_atomic_decr_aligned(value) _InterlockedExchangeAdd(value, -1)
- #ifdef __PYX_DEBUG_ATOMICS
- #pragma message ("Using MSVC atomics")
- #endif
-#else
- #undef CYTHON_ATOMICS
- #define CYTHON_ATOMICS 0
- #ifdef __PYX_DEBUG_ATOMICS
- #warning "Not using atomics"
- #endif
-#endif
-typedef volatile __pyx_atomic_int_type __pyx_atomic_int;
-#if CYTHON_ATOMICS
- #define __pyx_add_acquisition_count(memview)\
- __pyx_atomic_incr_aligned(__pyx_get_slice_count_pointer(memview))
- #define __pyx_sub_acquisition_count(memview)\
- __pyx_atomic_decr_aligned(__pyx_get_slice_count_pointer(memview))
-#else
- #define __pyx_add_acquisition_count(memview)\
- __pyx_add_acquisition_count_locked(__pyx_get_slice_count_pointer(memview), memview->lock)
- #define __pyx_sub_acquisition_count(memview)\
- __pyx_sub_acquisition_count_locked(__pyx_get_slice_count_pointer(memview), memview->lock)
-#endif
-
-/* ForceInitThreads.proto */
-#ifndef __PYX_FORCE_INIT_THREADS
- #define __PYX_FORCE_INIT_THREADS 0
-#endif
-
-/* BufferFormatStructs.proto */
-#define IS_UNSIGNED(type) (((type) -1) > 0)
-struct __Pyx_StructField_;
-#define __PYX_BUF_FLAGS_PACKED_STRUCT (1 << 0)
-typedef struct {
- const char* name;
- struct __Pyx_StructField_* fields;
- size_t size;
- size_t arraysize[8];
- int ndim;
- char typegroup;
- char is_unsigned;
- int flags;
-} __Pyx_TypeInfo;
-typedef struct __Pyx_StructField_ {
- __Pyx_TypeInfo* type;
- const char* name;
- size_t offset;
-} __Pyx_StructField;
-typedef struct {
- __Pyx_StructField* field;
- size_t parent_offset;
-} __Pyx_BufFmt_StackElem;
-typedef struct {
- __Pyx_StructField root;
- __Pyx_BufFmt_StackElem* head;
- size_t fmt_offset;
- size_t new_count, enc_count;
- size_t struct_alignment;
- int is_complex;
- char enc_type;
- char new_packmode;
- char enc_packmode;
- char is_valid_array;
-} __Pyx_BufFmt_Context;
-
-
-/*--- Type declarations ---*/
-struct __pyx_array_obj;
-struct __pyx_MemviewEnum_obj;
-struct __pyx_memoryview_obj;
-struct __pyx_memoryviewslice_obj;
-struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each;
-
-/* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
-struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each {
- int __pyx_n;
- float max_neg_val;
-};
-
-/* "View.MemoryView":106
- *
- * @cname("__pyx_array")
- * cdef class array: # <<<<<<<<<<<<<<
- *
- * cdef:
- */
-struct __pyx_array_obj {
- PyObject_HEAD
- struct __pyx_vtabstruct_array *__pyx_vtab;
- char *data;
- Py_ssize_t len;
- char *format;
- int ndim;
- Py_ssize_t *_shape;
- Py_ssize_t *_strides;
- Py_ssize_t itemsize;
- PyObject *mode;
- PyObject *_format;
- void (*callback_free_data)(void *);
- int free_data;
- int dtype_is_object;
-};
-
-
-/* "View.MemoryView":280
- *
- * @cname('__pyx_MemviewEnum')
- * cdef class Enum(object): # <<<<<<<<<<<<<<
- * cdef object name
- * def __init__(self, name):
- */
-struct __pyx_MemviewEnum_obj {
- PyObject_HEAD
- PyObject *name;
-};
-
-
-/* "View.MemoryView":331
- *
- * @cname('__pyx_memoryview')
- * cdef class memoryview(object): # <<<<<<<<<<<<<<
- *
- * cdef object obj
- */
-struct __pyx_memoryview_obj {
- PyObject_HEAD
- struct __pyx_vtabstruct_memoryview *__pyx_vtab;
- PyObject *obj;
- PyObject *_size;
- PyObject *_array_interface;
- PyThread_type_lock lock;
- __pyx_atomic_int acquisition_count[2];
- __pyx_atomic_int *acquisition_count_aligned_p;
- Py_buffer view;
- int flags;
- int dtype_is_object;
- __Pyx_TypeInfo *typeinfo;
-};
-
-
-/* "View.MemoryView":967
- *
- * @cname('__pyx_memoryviewslice')
- * cdef class _memoryviewslice(memoryview): # <<<<<<<<<<<<<<
- * "Internal class for passing memoryview slices to Python"
- *
- */
-struct __pyx_memoryviewslice_obj {
- struct __pyx_memoryview_obj __pyx_base;
- __Pyx_memviewslice from_slice;
- PyObject *from_object;
- PyObject *(*to_object_func)(char *);
- int (*to_dtype_func)(char *, PyObject *);
-};
-
-
-
-/* "View.MemoryView":106
- *
- * @cname("__pyx_array")
- * cdef class array: # <<<<<<<<<<<<<<
- *
- * cdef:
- */
-
-struct __pyx_vtabstruct_array {
- PyObject *(*get_memview)(struct __pyx_array_obj *);
-};
-static struct __pyx_vtabstruct_array *__pyx_vtabptr_array;
-
-
-/* "View.MemoryView":331
- *
- * @cname('__pyx_memoryview')
- * cdef class memoryview(object): # <<<<<<<<<<<<<<
- *
- * cdef object obj
- */
-
-struct __pyx_vtabstruct_memoryview {
- char *(*get_item_pointer)(struct __pyx_memoryview_obj *, PyObject *);
- PyObject *(*is_slice)(struct __pyx_memoryview_obj *, PyObject *);
- PyObject *(*setitem_slice_assignment)(struct __pyx_memoryview_obj *, PyObject *, PyObject *);
- PyObject *(*setitem_slice_assign_scalar)(struct __pyx_memoryview_obj *, struct __pyx_memoryview_obj *, PyObject *);
- PyObject *(*setitem_indexed)(struct __pyx_memoryview_obj *, PyObject *, PyObject *);
- PyObject *(*convert_item_to_object)(struct __pyx_memoryview_obj *, char *);
- PyObject *(*assign_item_from_object)(struct __pyx_memoryview_obj *, char *, PyObject *);
-};
-static struct __pyx_vtabstruct_memoryview *__pyx_vtabptr_memoryview;
-
-
-/* "View.MemoryView":967
- *
- * @cname('__pyx_memoryviewslice')
- * cdef class _memoryviewslice(memoryview): # <<<<<<<<<<<<<<
- * "Internal class for passing memoryview slices to Python"
- *
- */
-
-struct __pyx_vtabstruct__memoryviewslice {
- struct __pyx_vtabstruct_memoryview __pyx_base;
-};
-static struct __pyx_vtabstruct__memoryviewslice *__pyx_vtabptr__memoryviewslice;
-
-/* --- Runtime support code (head) --- */
-/* Refnanny.proto */
-#ifndef CYTHON_REFNANNY
- #define CYTHON_REFNANNY 0
-#endif
-#if CYTHON_REFNANNY
- typedef struct {
- void (*INCREF)(void*, PyObject*, int);
- void (*DECREF)(void*, PyObject*, int);
- void (*GOTREF)(void*, PyObject*, int);
- void (*GIVEREF)(void*, PyObject*, int);
- void* (*SetupContext)(const char*, int, const char*);
- void (*FinishContext)(void**);
- } __Pyx_RefNannyAPIStruct;
- static __Pyx_RefNannyAPIStruct *__Pyx_RefNanny = NULL;
- static __Pyx_RefNannyAPIStruct *__Pyx_RefNannyImportAPI(const char *modname);
- #define __Pyx_RefNannyDeclarations void *__pyx_refnanny = NULL;
-#ifdef WITH_THREAD
- #define __Pyx_RefNannySetupContext(name, acquire_gil)\
- if (acquire_gil) {\
- PyGILState_STATE __pyx_gilstate_save = PyGILState_Ensure();\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), __LINE__, __FILE__);\
- PyGILState_Release(__pyx_gilstate_save);\
- } else {\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), __LINE__, __FILE__);\
- }
-#else
- #define __Pyx_RefNannySetupContext(name, acquire_gil)\
- __pyx_refnanny = __Pyx_RefNanny->SetupContext((name), __LINE__, __FILE__)
-#endif
- #define __Pyx_RefNannyFinishContext()\
- __Pyx_RefNanny->FinishContext(&__pyx_refnanny)
- #define __Pyx_INCREF(r) __Pyx_RefNanny->INCREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_DECREF(r) __Pyx_RefNanny->DECREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_GOTREF(r) __Pyx_RefNanny->GOTREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_GIVEREF(r) __Pyx_RefNanny->GIVEREF(__pyx_refnanny, (PyObject *)(r), __LINE__)
- #define __Pyx_XINCREF(r) do { if((r) != NULL) {__Pyx_INCREF(r); }} while(0)
- #define __Pyx_XDECREF(r) do { if((r) != NULL) {__Pyx_DECREF(r); }} while(0)
- #define __Pyx_XGOTREF(r) do { if((r) != NULL) {__Pyx_GOTREF(r); }} while(0)
- #define __Pyx_XGIVEREF(r) do { if((r) != NULL) {__Pyx_GIVEREF(r);}} while(0)
-#else
- #define __Pyx_RefNannyDeclarations
- #define __Pyx_RefNannySetupContext(name, acquire_gil)
- #define __Pyx_RefNannyFinishContext()
- #define __Pyx_INCREF(r) Py_INCREF(r)
- #define __Pyx_DECREF(r) Py_DECREF(r)
- #define __Pyx_GOTREF(r)
- #define __Pyx_GIVEREF(r)
- #define __Pyx_XINCREF(r) Py_XINCREF(r)
- #define __Pyx_XDECREF(r) Py_XDECREF(r)
- #define __Pyx_XGOTREF(r)
- #define __Pyx_XGIVEREF(r)
-#endif
-#define __Pyx_XDECREF_SET(r, v) do {\
- PyObject *tmp = (PyObject *) r;\
- r = v; __Pyx_XDECREF(tmp);\
- } while (0)
-#define __Pyx_DECREF_SET(r, v) do {\
- PyObject *tmp = (PyObject *) r;\
- r = v; __Pyx_DECREF(tmp);\
- } while (0)
-#define __Pyx_CLEAR(r) do { PyObject* tmp = ((PyObject*)(r)); r = NULL; __Pyx_DECREF(tmp);} while(0)
-#define __Pyx_XCLEAR(r) do { if((r) != NULL) {PyObject* tmp = ((PyObject*)(r)); r = NULL; __Pyx_DECREF(tmp);}} while(0)
-
-/* PyObjectGetAttrStr.proto */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStr(PyObject* obj, PyObject* attr_name);
-#else
-#define __Pyx_PyObject_GetAttrStr(o,n) PyObject_GetAttr(o,n)
-#endif
-
-/* GetBuiltinName.proto */
-static PyObject *__Pyx_GetBuiltinName(PyObject *name);
-
-/* MemviewSliceInit.proto */
-#define __Pyx_BUF_MAX_NDIMS %(BUF_MAX_NDIMS)d
-#define __Pyx_MEMVIEW_DIRECT 1
-#define __Pyx_MEMVIEW_PTR 2
-#define __Pyx_MEMVIEW_FULL 4
-#define __Pyx_MEMVIEW_CONTIG 8
-#define __Pyx_MEMVIEW_STRIDED 16
-#define __Pyx_MEMVIEW_FOLLOW 32
-#define __Pyx_IS_C_CONTIG 1
-#define __Pyx_IS_F_CONTIG 2
-static int __Pyx_init_memviewslice(
- struct __pyx_memoryview_obj *memview,
- int ndim,
- __Pyx_memviewslice *memviewslice,
- int memview_is_new_reference);
-static CYTHON_INLINE int __pyx_add_acquisition_count_locked(
- __pyx_atomic_int *acquisition_count, PyThread_type_lock lock);
-static CYTHON_INLINE int __pyx_sub_acquisition_count_locked(
- __pyx_atomic_int *acquisition_count, PyThread_type_lock lock);
-#define __pyx_get_slice_count_pointer(memview) (memview->acquisition_count_aligned_p)
-#define __pyx_get_slice_count(memview) (*__pyx_get_slice_count_pointer(memview))
-#define __PYX_INC_MEMVIEW(slice, have_gil) __Pyx_INC_MEMVIEW(slice, have_gil, __LINE__)
-#define __PYX_XDEC_MEMVIEW(slice, have_gil) __Pyx_XDEC_MEMVIEW(slice, have_gil, __LINE__)
-static CYTHON_INLINE void __Pyx_INC_MEMVIEW(__Pyx_memviewslice *, int, int);
-static CYTHON_INLINE void __Pyx_XDEC_MEMVIEW(__Pyx_memviewslice *, int, int);
-
-/* RaiseArgTupleInvalid.proto */
-static void __Pyx_RaiseArgtupleInvalid(const char* func_name, int exact,
- Py_ssize_t num_min, Py_ssize_t num_max, Py_ssize_t num_found);
-
-/* RaiseDoubleKeywords.proto */
-static void __Pyx_RaiseDoubleKeywordsError(const char* func_name, PyObject* kw_name);
-
-/* ParseKeywords.proto */
-static int __Pyx_ParseOptionalKeywords(PyObject *kwds, PyObject **argnames[],\
- PyObject *kwds2, PyObject *values[], Py_ssize_t num_pos_args,\
- const char* function_name);
-
-/* None.proto */
-static CYTHON_INLINE void __Pyx_RaiseUnboundLocalError(const char *varname);
-
-/* ArgTypeTest.proto */
-#define __Pyx_ArgTypeTest(obj, type, none_allowed, name, exact)\
- ((likely((Py_TYPE(obj) == type) | (none_allowed && (obj == Py_None)))) ? 1 :\
- __Pyx__ArgTypeTest(obj, type, name, exact))
-static int __Pyx__ArgTypeTest(PyObject *obj, PyTypeObject *type, const char *name, int exact);
-
-/* PyObjectCall.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call(PyObject *func, PyObject *arg, PyObject *kw);
-#else
-#define __Pyx_PyObject_Call(func, arg, kw) PyObject_Call(func, arg, kw)
-#endif
-
-/* PyThreadStateGet.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyThreadState_declare PyThreadState *__pyx_tstate;
-#define __Pyx_PyThreadState_assign __pyx_tstate = __Pyx_PyThreadState_Current;
-#define __Pyx_PyErr_Occurred() __pyx_tstate->curexc_type
-#else
-#define __Pyx_PyThreadState_declare
-#define __Pyx_PyThreadState_assign
-#define __Pyx_PyErr_Occurred() PyErr_Occurred()
-#endif
-
-/* PyErrFetchRestore.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyErr_Clear() __Pyx_ErrRestore(NULL, NULL, NULL)
-#define __Pyx_ErrRestoreWithState(type, value, tb) __Pyx_ErrRestoreInState(PyThreadState_GET(), type, value, tb)
-#define __Pyx_ErrFetchWithState(type, value, tb) __Pyx_ErrFetchInState(PyThreadState_GET(), type, value, tb)
-#define __Pyx_ErrRestore(type, value, tb) __Pyx_ErrRestoreInState(__pyx_tstate, type, value, tb)
-#define __Pyx_ErrFetch(type, value, tb) __Pyx_ErrFetchInState(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx_ErrRestoreInState(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb);
-static CYTHON_INLINE void __Pyx_ErrFetchInState(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#if CYTHON_COMPILING_IN_CPYTHON
-#define __Pyx_PyErr_SetNone(exc) (Py_INCREF(exc), __Pyx_ErrRestore((exc), NULL, NULL))
-#else
-#define __Pyx_PyErr_SetNone(exc) PyErr_SetNone(exc)
-#endif
-#else
-#define __Pyx_PyErr_Clear() PyErr_Clear()
-#define __Pyx_PyErr_SetNone(exc) PyErr_SetNone(exc)
-#define __Pyx_ErrRestoreWithState(type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetchWithState(type, value, tb) PyErr_Fetch(type, value, tb)
-#define __Pyx_ErrRestoreInState(tstate, type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetchInState(tstate, type, value, tb) PyErr_Fetch(type, value, tb)
-#define __Pyx_ErrRestore(type, value, tb) PyErr_Restore(type, value, tb)
-#define __Pyx_ErrFetch(type, value, tb) PyErr_Fetch(type, value, tb)
-#endif
-
-/* RaiseException.proto */
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb, PyObject *cause);
-
-/* PyCFunctionFastCall.proto */
-#if CYTHON_FAST_PYCCALL
-static CYTHON_INLINE PyObject *__Pyx_PyCFunction_FastCall(PyObject *func, PyObject **args, Py_ssize_t nargs);
-#else
-#define __Pyx_PyCFunction_FastCall(func, args, nargs) (assert(0), NULL)
-#endif
-
-/* PyFunctionFastCall.proto */
-#if CYTHON_FAST_PYCALL
-#define __Pyx_PyFunction_FastCall(func, args, nargs)\
- __Pyx_PyFunction_FastCallDict((func), (args), (nargs), NULL)
-#if 1 || PY_VERSION_HEX < 0x030600B1
-static PyObject *__Pyx_PyFunction_FastCallDict(PyObject *func, PyObject **args, Py_ssize_t nargs, PyObject *kwargs);
-#else
-#define __Pyx_PyFunction_FastCallDict(func, args, nargs, kwargs) _PyFunction_FastCallDict(func, args, nargs, kwargs)
-#endif
-#define __Pyx_BUILD_ASSERT_EXPR(cond)\
- (sizeof(char [1 - 2*!(cond)]) - 1)
-#ifndef Py_MEMBER_SIZE
-#define Py_MEMBER_SIZE(type, member) sizeof(((type *)0)->member)
-#endif
-#if CYTHON_FAST_PYCALL
- static size_t __pyx_pyframe_localsplus_offset = 0;
- #include "frameobject.h"
-#if PY_VERSION_HEX >= 0x030b00a6
- #ifndef Py_BUILD_CORE
- #define Py_BUILD_CORE 1
- #endif
- #include "internal/pycore_frame.h"
-#endif
- #define __Pxy_PyFrame_Initialize_Offsets()\
- ((void)__Pyx_BUILD_ASSERT_EXPR(sizeof(PyFrameObject) == offsetof(PyFrameObject, f_localsplus) + Py_MEMBER_SIZE(PyFrameObject, f_localsplus)),\
- (void)(__pyx_pyframe_localsplus_offset = ((size_t)PyFrame_Type.tp_basicsize) - Py_MEMBER_SIZE(PyFrameObject, f_localsplus)))
- #define __Pyx_PyFrame_GetLocalsplus(frame)\
- (assert(__pyx_pyframe_localsplus_offset), (PyObject **)(((char *)(frame)) + __pyx_pyframe_localsplus_offset))
-#endif // CYTHON_FAST_PYCALL
-#endif
-
-/* PyObjectCall2Args.proto */
-static CYTHON_UNUSED PyObject* __Pyx_PyObject_Call2Args(PyObject* function, PyObject* arg1, PyObject* arg2);
-
-/* PyObjectCallMethO.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallMethO(PyObject *func, PyObject *arg);
-#endif
-
-/* PyObjectCallOneArg.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg);
-
-/* IncludeStringH.proto */
-#include
-
-/* BytesEquals.proto */
-static CYTHON_INLINE int __Pyx_PyBytes_Equals(PyObject* s1, PyObject* s2, int equals);
-
-/* UnicodeEquals.proto */
-static CYTHON_INLINE int __Pyx_PyUnicode_Equals(PyObject* s1, PyObject* s2, int equals);
-
-/* StrEquals.proto */
-#if PY_MAJOR_VERSION >= 3
-#define __Pyx_PyString_Equals __Pyx_PyUnicode_Equals
-#else
-#define __Pyx_PyString_Equals __Pyx_PyBytes_Equals
-#endif
-
-/* DivInt[Py_ssize_t].proto */
-static CYTHON_INLINE Py_ssize_t __Pyx_div_Py_ssize_t(Py_ssize_t, Py_ssize_t);
-
-/* UnaryNegOverflows.proto */
-#define UNARY_NEG_WOULD_OVERFLOW(x)\
- (((x) < 0) & ((unsigned long)(x) == 0-(unsigned long)(x)))
-
-static CYTHON_UNUSED int __pyx_array_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-static PyObject *__pyx_array_get_memview(struct __pyx_array_obj *); /*proto*/
-/* GetAttr.proto */
-static CYTHON_INLINE PyObject *__Pyx_GetAttr(PyObject *, PyObject *);
-
-/* GetItemInt.proto */
-#define __Pyx_GetItemInt(o, i, type, is_signed, to_py_func, is_list, wraparound, boundscheck)\
- (__Pyx_fits_Py_ssize_t(i, type, is_signed) ?\
- __Pyx_GetItemInt_Fast(o, (Py_ssize_t)i, is_list, wraparound, boundscheck) :\
- (is_list ? (PyErr_SetString(PyExc_IndexError, "list index out of range"), (PyObject*)NULL) :\
- __Pyx_GetItemInt_Generic(o, to_py_func(i))))
-#define __Pyx_GetItemInt_List(o, i, type, is_signed, to_py_func, is_list, wraparound, boundscheck)\
- (__Pyx_fits_Py_ssize_t(i, type, is_signed) ?\
- __Pyx_GetItemInt_List_Fast(o, (Py_ssize_t)i, wraparound, boundscheck) :\
- (PyErr_SetString(PyExc_IndexError, "list index out of range"), (PyObject*)NULL))
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_List_Fast(PyObject *o, Py_ssize_t i,
- int wraparound, int boundscheck);
-#define __Pyx_GetItemInt_Tuple(o, i, type, is_signed, to_py_func, is_list, wraparound, boundscheck)\
- (__Pyx_fits_Py_ssize_t(i, type, is_signed) ?\
- __Pyx_GetItemInt_Tuple_Fast(o, (Py_ssize_t)i, wraparound, boundscheck) :\
- (PyErr_SetString(PyExc_IndexError, "tuple index out of range"), (PyObject*)NULL))
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Tuple_Fast(PyObject *o, Py_ssize_t i,
- int wraparound, int boundscheck);
-static PyObject *__Pyx_GetItemInt_Generic(PyObject *o, PyObject* j);
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Fast(PyObject *o, Py_ssize_t i,
- int is_list, int wraparound, int boundscheck);
-
-/* ObjectGetItem.proto */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject *__Pyx_PyObject_GetItem(PyObject *obj, PyObject* key);
-#else
-#define __Pyx_PyObject_GetItem(obj, key) PyObject_GetItem(obj, key)
-#endif
-
-/* decode_c_string_utf16.proto */
-static CYTHON_INLINE PyObject *__Pyx_PyUnicode_DecodeUTF16(const char *s, Py_ssize_t size, const char *errors) {
- int byteorder = 0;
- return PyUnicode_DecodeUTF16(s, size, errors, &byteorder);
-}
-static CYTHON_INLINE PyObject *__Pyx_PyUnicode_DecodeUTF16LE(const char *s, Py_ssize_t size, const char *errors) {
- int byteorder = -1;
- return PyUnicode_DecodeUTF16(s, size, errors, &byteorder);
-}
-static CYTHON_INLINE PyObject *__Pyx_PyUnicode_DecodeUTF16BE(const char *s, Py_ssize_t size, const char *errors) {
- int byteorder = 1;
- return PyUnicode_DecodeUTF16(s, size, errors, &byteorder);
-}
-
-/* decode_c_string.proto */
-static CYTHON_INLINE PyObject* __Pyx_decode_c_string(
- const char* cstring, Py_ssize_t start, Py_ssize_t stop,
- const char* encoding, const char* errors,
- PyObject* (*decode_func)(const char *s, Py_ssize_t size, const char *errors));
-
-/* PyErrExceptionMatches.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_PyErr_ExceptionMatches(err) __Pyx_PyErr_ExceptionMatchesInState(__pyx_tstate, err)
-static CYTHON_INLINE int __Pyx_PyErr_ExceptionMatchesInState(PyThreadState* tstate, PyObject* err);
-#else
-#define __Pyx_PyErr_ExceptionMatches(err) PyErr_ExceptionMatches(err)
-#endif
-
-/* GetAttr3.proto */
-static CYTHON_INLINE PyObject *__Pyx_GetAttr3(PyObject *, PyObject *, PyObject *);
-
-/* PyDictVersioning.proto */
-#if CYTHON_USE_DICT_VERSIONS && CYTHON_USE_TYPE_SLOTS
-#define __PYX_DICT_VERSION_INIT ((PY_UINT64_T) -1)
-#define __PYX_GET_DICT_VERSION(dict) (((PyDictObject*)(dict))->ma_version_tag)
-#define __PYX_UPDATE_DICT_CACHE(dict, value, cache_var, version_var)\
- (version_var) = __PYX_GET_DICT_VERSION(dict);\
- (cache_var) = (value);
-#define __PYX_PY_DICT_LOOKUP_IF_MODIFIED(VAR, DICT, LOOKUP) {\
- static PY_UINT64_T __pyx_dict_version = 0;\
- static PyObject *__pyx_dict_cached_value = NULL;\
- if (likely(__PYX_GET_DICT_VERSION(DICT) == __pyx_dict_version)) {\
- (VAR) = __pyx_dict_cached_value;\
- } else {\
- (VAR) = __pyx_dict_cached_value = (LOOKUP);\
- __pyx_dict_version = __PYX_GET_DICT_VERSION(DICT);\
- }\
-}
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_tp_dict_version(PyObject *obj);
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_object_dict_version(PyObject *obj);
-static CYTHON_INLINE int __Pyx_object_dict_version_matches(PyObject* obj, PY_UINT64_T tp_dict_version, PY_UINT64_T obj_dict_version);
-#else
-#define __PYX_GET_DICT_VERSION(dict) (0)
-#define __PYX_UPDATE_DICT_CACHE(dict, value, cache_var, version_var)
-#define __PYX_PY_DICT_LOOKUP_IF_MODIFIED(VAR, DICT, LOOKUP) (VAR) = (LOOKUP);
-#endif
-
-/* GetModuleGlobalName.proto */
-#if CYTHON_USE_DICT_VERSIONS
-#define __Pyx_GetModuleGlobalName(var, name) {\
- static PY_UINT64_T __pyx_dict_version = 0;\
- static PyObject *__pyx_dict_cached_value = NULL;\
- (var) = (likely(__pyx_dict_version == __PYX_GET_DICT_VERSION(__pyx_d))) ?\
- (likely(__pyx_dict_cached_value) ? __Pyx_NewRef(__pyx_dict_cached_value) : __Pyx_GetBuiltinName(name)) :\
- __Pyx__GetModuleGlobalName(name, &__pyx_dict_version, &__pyx_dict_cached_value);\
-}
-#define __Pyx_GetModuleGlobalNameUncached(var, name) {\
- PY_UINT64_T __pyx_dict_version;\
- PyObject *__pyx_dict_cached_value;\
- (var) = __Pyx__GetModuleGlobalName(name, &__pyx_dict_version, &__pyx_dict_cached_value);\
-}
-static PyObject *__Pyx__GetModuleGlobalName(PyObject *name, PY_UINT64_T *dict_version, PyObject **dict_cached_value);
-#else
-#define __Pyx_GetModuleGlobalName(var, name) (var) = __Pyx__GetModuleGlobalName(name)
-#define __Pyx_GetModuleGlobalNameUncached(var, name) (var) = __Pyx__GetModuleGlobalName(name)
-static CYTHON_INLINE PyObject *__Pyx__GetModuleGlobalName(PyObject *name);
-#endif
-
-/* RaiseTooManyValuesToUnpack.proto */
-static CYTHON_INLINE void __Pyx_RaiseTooManyValuesError(Py_ssize_t expected);
-
-/* RaiseNeedMoreValuesToUnpack.proto */
-static CYTHON_INLINE void __Pyx_RaiseNeedMoreValuesError(Py_ssize_t index);
-
-/* RaiseNoneIterError.proto */
-static CYTHON_INLINE void __Pyx_RaiseNoneNotIterableError(void);
-
-/* ExtTypeTest.proto */
-static CYTHON_INLINE int __Pyx_TypeTest(PyObject *obj, PyTypeObject *type);
-
-/* GetTopmostException.proto */
-#if CYTHON_USE_EXC_INFO_STACK
-static _PyErr_StackItem * __Pyx_PyErr_GetTopmostException(PyThreadState *tstate);
-#endif
-
-/* SaveResetException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_ExceptionSave(type, value, tb) __Pyx__ExceptionSave(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionSave(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#define __Pyx_ExceptionReset(type, value, tb) __Pyx__ExceptionReset(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionReset(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb);
-#else
-#define __Pyx_ExceptionSave(type, value, tb) PyErr_GetExcInfo(type, value, tb)
-#define __Pyx_ExceptionReset(type, value, tb) PyErr_SetExcInfo(type, value, tb)
-#endif
-
-/* GetException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_GetException(type, value, tb) __Pyx__GetException(__pyx_tstate, type, value, tb)
-static int __Pyx__GetException(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#else
-static int __Pyx_GetException(PyObject **type, PyObject **value, PyObject **tb);
-#endif
-
-/* SwapException.proto */
-#if CYTHON_FAST_THREAD_STATE
-#define __Pyx_ExceptionSwap(type, value, tb) __Pyx__ExceptionSwap(__pyx_tstate, type, value, tb)
-static CYTHON_INLINE void __Pyx__ExceptionSwap(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb);
-#else
-static CYTHON_INLINE void __Pyx_ExceptionSwap(PyObject **type, PyObject **value, PyObject **tb);
-#endif
-
-/* Import.proto */
-static PyObject *__Pyx_Import(PyObject *name, PyObject *from_list, int level);
-
-/* FastTypeChecks.proto */
-#if CYTHON_COMPILING_IN_CPYTHON
-#define __Pyx_TypeCheck(obj, type) __Pyx_IsSubtype(Py_TYPE(obj), (PyTypeObject *)type)
-static CYTHON_INLINE int __Pyx_IsSubtype(PyTypeObject *a, PyTypeObject *b);
-static CYTHON_INLINE int __Pyx_PyErr_GivenExceptionMatches(PyObject *err, PyObject *type);
-static CYTHON_INLINE int __Pyx_PyErr_GivenExceptionMatches2(PyObject *err, PyObject *type1, PyObject *type2);
-#else
-#define __Pyx_TypeCheck(obj, type) PyObject_TypeCheck(obj, (PyTypeObject *)type)
-#define __Pyx_PyErr_GivenExceptionMatches(err, type) PyErr_GivenExceptionMatches(err, type)
-#define __Pyx_PyErr_GivenExceptionMatches2(err, type1, type2) (PyErr_GivenExceptionMatches(err, type1) || PyErr_GivenExceptionMatches(err, type2))
-#endif
-#define __Pyx_PyException_Check(obj) __Pyx_TypeCheck(obj, PyExc_Exception)
-
-static CYTHON_UNUSED int __pyx_memoryview_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-/* ListCompAppend.proto */
-#if CYTHON_USE_PYLIST_INTERNALS && CYTHON_ASSUME_SAFE_MACROS
-static CYTHON_INLINE int __Pyx_ListComp_Append(PyObject* list, PyObject* x) {
- PyListObject* L = (PyListObject*) list;
- Py_ssize_t len = Py_SIZE(list);
- if (likely(L->allocated > len)) {
- Py_INCREF(x);
- PyList_SET_ITEM(list, len, x);
- __Pyx_SET_SIZE(list, len + 1);
- return 0;
- }
- return PyList_Append(list, x);
-}
-#else
-#define __Pyx_ListComp_Append(L,x) PyList_Append(L,x)
-#endif
-
-/* PyIntBinop.proto */
-#if !CYTHON_COMPILING_IN_PYPY
-static PyObject* __Pyx_PyInt_AddObjC(PyObject *op1, PyObject *op2, long intval, int inplace, int zerodivision_check);
-#else
-#define __Pyx_PyInt_AddObjC(op1, op2, intval, inplace, zerodivision_check)\
- (inplace ? PyNumber_InPlaceAdd(op1, op2) : PyNumber_Add(op1, op2))
-#endif
-
-/* ListExtend.proto */
-static CYTHON_INLINE int __Pyx_PyList_Extend(PyObject* L, PyObject* v) {
-#if CYTHON_COMPILING_IN_CPYTHON
- PyObject* none = _PyList_Extend((PyListObject*)L, v);
- if (unlikely(!none))
- return -1;
- Py_DECREF(none);
- return 0;
-#else
- return PyList_SetSlice(L, PY_SSIZE_T_MAX, PY_SSIZE_T_MAX, v);
-#endif
-}
-
-/* ListAppend.proto */
-#if CYTHON_USE_PYLIST_INTERNALS && CYTHON_ASSUME_SAFE_MACROS
-static CYTHON_INLINE int __Pyx_PyList_Append(PyObject* list, PyObject* x) {
- PyListObject* L = (PyListObject*) list;
- Py_ssize_t len = Py_SIZE(list);
- if (likely(L->allocated > len) & likely(len > (L->allocated >> 1))) {
- Py_INCREF(x);
- PyList_SET_ITEM(list, len, x);
- __Pyx_SET_SIZE(list, len + 1);
- return 0;
- }
- return PyList_Append(list, x);
-}
-#else
-#define __Pyx_PyList_Append(L,x) PyList_Append(L,x)
-#endif
-
-/* DivInt[long].proto */
-static CYTHON_INLINE long __Pyx_div_long(long, long);
-
-/* PySequenceContains.proto */
-static CYTHON_INLINE int __Pyx_PySequence_ContainsTF(PyObject* item, PyObject* seq, int eq) {
- int result = PySequence_Contains(seq, item);
- return unlikely(result < 0) ? result : (result == (eq == Py_EQ));
-}
-
-/* ImportFrom.proto */
-static PyObject* __Pyx_ImportFrom(PyObject* module, PyObject* name);
-
-/* HasAttr.proto */
-static CYTHON_INLINE int __Pyx_HasAttr(PyObject *, PyObject *);
-
-/* PyObject_GenericGetAttrNoDict.proto */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GenericGetAttrNoDict(PyObject* obj, PyObject* attr_name);
-#else
-#define __Pyx_PyObject_GenericGetAttrNoDict PyObject_GenericGetAttr
-#endif
-
-/* PyObject_GenericGetAttr.proto */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static PyObject* __Pyx_PyObject_GenericGetAttr(PyObject* obj, PyObject* attr_name);
-#else
-#define __Pyx_PyObject_GenericGetAttr PyObject_GenericGetAttr
-#endif
-
-/* SetVTable.proto */
-static int __Pyx_SetVtable(PyObject *dict, void *vtable);
-
-/* PyObjectGetAttrStrNoError.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStrNoError(PyObject* obj, PyObject* attr_name);
-
-/* SetupReduce.proto */
-static int __Pyx_setup_reduce(PyObject* type_obj);
-
-/* CLineInTraceback.proto */
-#ifdef CYTHON_CLINE_IN_TRACEBACK
-#define __Pyx_CLineForTraceback(tstate, c_line) (((CYTHON_CLINE_IN_TRACEBACK)) ? c_line : 0)
-#else
-static int __Pyx_CLineForTraceback(PyThreadState *tstate, int c_line);
-#endif
-
-/* CodeObjectCache.proto */
-typedef struct {
- PyCodeObject* code_object;
- int code_line;
-} __Pyx_CodeObjectCacheEntry;
-struct __Pyx_CodeObjectCache {
- int count;
- int max_count;
- __Pyx_CodeObjectCacheEntry* entries;
-};
-static struct __Pyx_CodeObjectCache __pyx_code_cache = {0,0,NULL};
-static int __pyx_bisect_code_objects(__Pyx_CodeObjectCacheEntry* entries, int count, int code_line);
-static PyCodeObject *__pyx_find_code_object(int code_line);
-static void __pyx_insert_code_object(int code_line, PyCodeObject* code_object);
-
-/* AddTraceback.proto */
-static void __Pyx_AddTraceback(const char *funcname, int c_line,
- int py_line, const char *filename);
-
-#if PY_MAJOR_VERSION < 3
- static int __Pyx_GetBuffer(PyObject *obj, Py_buffer *view, int flags);
- static void __Pyx_ReleaseBuffer(Py_buffer *view);
-#else
- #define __Pyx_GetBuffer PyObject_GetBuffer
- #define __Pyx_ReleaseBuffer PyBuffer_Release
-#endif
-
-
-/* BufferStructDeclare.proto */
-typedef struct {
- Py_ssize_t shape, strides, suboffsets;
-} __Pyx_Buf_DimInfo;
-typedef struct {
- size_t refcount;
- Py_buffer pybuffer;
-} __Pyx_Buffer;
-typedef struct {
- __Pyx_Buffer *rcbuffer;
- char *data;
- __Pyx_Buf_DimInfo diminfo[8];
-} __Pyx_LocalBuf_ND;
-
-/* MemviewSliceIsContig.proto */
-static int __pyx_memviewslice_is_contig(const __Pyx_memviewslice mvs, char order, int ndim);
-
-/* OverlappingSlices.proto */
-static int __pyx_slices_overlap(__Pyx_memviewslice *slice1,
- __Pyx_memviewslice *slice2,
- int ndim, size_t itemsize);
-
-/* Capsule.proto */
-static CYTHON_INLINE PyObject *__pyx_capsule_create(void *p, const char *sig);
-
-/* IsLittleEndian.proto */
-static CYTHON_INLINE int __Pyx_Is_Little_Endian(void);
-
-/* BufferFormatCheck.proto */
-static const char* __Pyx_BufFmt_CheckString(__Pyx_BufFmt_Context* ctx, const char* ts);
-static void __Pyx_BufFmt_Init(__Pyx_BufFmt_Context* ctx,
- __Pyx_BufFmt_StackElem* stack,
- __Pyx_TypeInfo* type);
-
-/* TypeInfoCompare.proto */
-static int __pyx_typeinfo_cmp(__Pyx_TypeInfo *a, __Pyx_TypeInfo *b);
-
-/* MemviewSliceValidateAndInit.proto */
-static int __Pyx_ValidateAndInit_memviewslice(
- int *axes_specs,
- int c_or_f_flag,
- int buf_flags,
- int ndim,
- __Pyx_TypeInfo *dtype,
- __Pyx_BufFmt_StackElem stack[],
- __Pyx_memviewslice *memviewslice,
- PyObject *original_obj);
-
-/* ObjectToMemviewSlice.proto */
-static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_int(PyObject *, int writable_flag);
-
-/* ObjectToMemviewSlice.proto */
-static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_float(PyObject *, int writable_flag);
-
-/* ObjectToMemviewSlice.proto */
-static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_dc_int(PyObject *, int writable_flag);
-
-/* GCCDiagnostics.proto */
-#if defined(__GNUC__) && (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 6))
-#define __Pyx_HAS_GCC_DIAGNOSTIC
-#endif
-
-/* MemviewSliceCopyTemplate.proto */
-static __Pyx_memviewslice
-__pyx_memoryview_copy_new_contig(const __Pyx_memviewslice *from_mvs,
- const char *mode, int ndim,
- size_t sizeof_dtype, int contig_flag,
- int dtype_is_object);
-
-/* CIntToPy.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyInt_From_int(int value);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE int __Pyx_PyInt_As_int(PyObject *);
-
-/* CIntToPy.proto */
-static CYTHON_INLINE PyObject* __Pyx_PyInt_From_long(long value);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE long __Pyx_PyInt_As_long(PyObject *);
-
-/* CIntFromPy.proto */
-static CYTHON_INLINE char __Pyx_PyInt_As_char(PyObject *);
-
-/* CheckBinaryVersion.proto */
-static int __Pyx_check_binary_version(void);
-
-/* InitStrings.proto */
-static int __Pyx_InitStrings(__Pyx_StringTabEntry *t);
-
-static PyObject *__pyx_array_get_memview(struct __pyx_array_obj *__pyx_v_self); /* proto*/
-static char *__pyx_memoryview_get_item_pointer(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index); /* proto*/
-static PyObject *__pyx_memoryview_is_slice(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj); /* proto*/
-static PyObject *__pyx_memoryview_setitem_slice_assignment(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_dst, PyObject *__pyx_v_src); /* proto*/
-static PyObject *__pyx_memoryview_setitem_slice_assign_scalar(struct __pyx_memoryview_obj *__pyx_v_self, struct __pyx_memoryview_obj *__pyx_v_dst, PyObject *__pyx_v_value); /* proto*/
-static PyObject *__pyx_memoryview_setitem_indexed(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value); /* proto*/
-static PyObject *__pyx_memoryview_convert_item_to_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp); /* proto*/
-static PyObject *__pyx_memoryview_assign_item_from_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value); /* proto*/
-static PyObject *__pyx_memoryviewslice_convert_item_to_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp); /* proto*/
-static PyObject *__pyx_memoryviewslice_assign_item_from_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value); /* proto*/
-
-/* Module declarations from 'cython.view' */
-
-/* Module declarations from 'cython' */
-
-/* Module declarations from 'monotonic_align.core' */
-static PyTypeObject *__pyx_array_type = 0;
-static PyTypeObject *__pyx_MemviewEnum_type = 0;
-static PyTypeObject *__pyx_memoryview_type = 0;
-static PyTypeObject *__pyx_memoryviewslice_type = 0;
-static PyObject *generic = 0;
-static PyObject *strided = 0;
-static PyObject *indirect = 0;
-static PyObject *contiguous = 0;
-static PyObject *indirect_contiguous = 0;
-static int __pyx_memoryview_thread_locks_used;
-static PyThread_type_lock __pyx_memoryview_thread_locks[8];
-static void __pyx_f_15monotonic_align_4core_maximum_path_each(__Pyx_memviewslice, __Pyx_memviewslice, int, int, struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each *__pyx_optional_args); /*proto*/
-static void __pyx_f_15monotonic_align_4core_maximum_path_c(__Pyx_memviewslice, __Pyx_memviewslice, __Pyx_memviewslice, __Pyx_memviewslice, int __pyx_skip_dispatch); /*proto*/
-static struct __pyx_array_obj *__pyx_array_new(PyObject *, Py_ssize_t, char *, char *, char *); /*proto*/
-static void *__pyx_align_pointer(void *, size_t); /*proto*/
-static PyObject *__pyx_memoryview_new(PyObject *, int, int, __Pyx_TypeInfo *); /*proto*/
-static CYTHON_INLINE int __pyx_memoryview_check(PyObject *); /*proto*/
-static PyObject *_unellipsify(PyObject *, int); /*proto*/
-static PyObject *assert_direct_dimensions(Py_ssize_t *, int); /*proto*/
-static struct __pyx_memoryview_obj *__pyx_memview_slice(struct __pyx_memoryview_obj *, PyObject *); /*proto*/
-static int __pyx_memoryview_slice_memviewslice(__Pyx_memviewslice *, Py_ssize_t, Py_ssize_t, Py_ssize_t, int, int, int *, Py_ssize_t, Py_ssize_t, Py_ssize_t, int, int, int, int); /*proto*/
-static char *__pyx_pybuffer_index(Py_buffer *, char *, Py_ssize_t, Py_ssize_t); /*proto*/
-static int __pyx_memslice_transpose(__Pyx_memviewslice *); /*proto*/
-static PyObject *__pyx_memoryview_fromslice(__Pyx_memviewslice, int, PyObject *(*)(char *), int (*)(char *, PyObject *), int); /*proto*/
-static __Pyx_memviewslice *__pyx_memoryview_get_slice_from_memoryview(struct __pyx_memoryview_obj *, __Pyx_memviewslice *); /*proto*/
-static void __pyx_memoryview_slice_copy(struct __pyx_memoryview_obj *, __Pyx_memviewslice *); /*proto*/
-static PyObject *__pyx_memoryview_copy_object(struct __pyx_memoryview_obj *); /*proto*/
-static PyObject *__pyx_memoryview_copy_object_from_slice(struct __pyx_memoryview_obj *, __Pyx_memviewslice *); /*proto*/
-static Py_ssize_t abs_py_ssize_t(Py_ssize_t); /*proto*/
-static char __pyx_get_best_slice_order(__Pyx_memviewslice *, int); /*proto*/
-static void _copy_strided_to_strided(char *, Py_ssize_t *, char *, Py_ssize_t *, Py_ssize_t *, Py_ssize_t *, int, size_t); /*proto*/
-static void copy_strided_to_strided(__Pyx_memviewslice *, __Pyx_memviewslice *, int, size_t); /*proto*/
-static Py_ssize_t __pyx_memoryview_slice_get_size(__Pyx_memviewslice *, int); /*proto*/
-static Py_ssize_t __pyx_fill_contig_strides_array(Py_ssize_t *, Py_ssize_t *, Py_ssize_t, int, char); /*proto*/
-static void *__pyx_memoryview_copy_data_to_temp(__Pyx_memviewslice *, __Pyx_memviewslice *, char, int); /*proto*/
-static int __pyx_memoryview_err_extents(int, Py_ssize_t, Py_ssize_t); /*proto*/
-static int __pyx_memoryview_err_dim(PyObject *, char *, int); /*proto*/
-static int __pyx_memoryview_err(PyObject *, char *); /*proto*/
-static int __pyx_memoryview_copy_contents(__Pyx_memviewslice, __Pyx_memviewslice, int, int, int); /*proto*/
-static void __pyx_memoryview_broadcast_leading(__Pyx_memviewslice *, int, int); /*proto*/
-static void __pyx_memoryview_refcount_copying(__Pyx_memviewslice *, int, int, int); /*proto*/
-static void __pyx_memoryview_refcount_objects_in_slice_with_gil(char *, Py_ssize_t *, Py_ssize_t *, int, int); /*proto*/
-static void __pyx_memoryview_refcount_objects_in_slice(char *, Py_ssize_t *, Py_ssize_t *, int, int); /*proto*/
-static void __pyx_memoryview_slice_assign_scalar(__Pyx_memviewslice *, int, size_t, void *, int); /*proto*/
-static void __pyx_memoryview__slice_assign_scalar(char *, Py_ssize_t *, Py_ssize_t *, int, size_t, void *); /*proto*/
-static PyObject *__pyx_unpickle_Enum__set_state(struct __pyx_MemviewEnum_obj *, PyObject *); /*proto*/
-static __Pyx_TypeInfo __Pyx_TypeInfo_int = { "int", NULL, sizeof(int), { 0 }, 0, IS_UNSIGNED(int) ? 'U' : 'I', IS_UNSIGNED(int), 0 };
-static __Pyx_TypeInfo __Pyx_TypeInfo_float = { "float", NULL, sizeof(float), { 0 }, 0, 'R', 0, 0 };
-#define __Pyx_MODULE_NAME "monotonic_align.core"
-extern int __pyx_module_is_main_monotonic_align__core;
-int __pyx_module_is_main_monotonic_align__core = 0;
-
-/* Implementation of 'monotonic_align.core' */
-static PyObject *__pyx_builtin_range;
-static PyObject *__pyx_builtin_ValueError;
-static PyObject *__pyx_builtin_MemoryError;
-static PyObject *__pyx_builtin_enumerate;
-static PyObject *__pyx_builtin_TypeError;
-static PyObject *__pyx_builtin_Ellipsis;
-static PyObject *__pyx_builtin_id;
-static PyObject *__pyx_builtin_IndexError;
-static const char __pyx_k_O[] = "O";
-static const char __pyx_k_c[] = "c";
-static const char __pyx_k_id[] = "id";
-static const char __pyx_k_new[] = "__new__";
-static const char __pyx_k_obj[] = "obj";
-static const char __pyx_k_base[] = "base";
-static const char __pyx_k_dict[] = "__dict__";
-static const char __pyx_k_main[] = "__main__";
-static const char __pyx_k_mode[] = "mode";
-static const char __pyx_k_name[] = "name";
-static const char __pyx_k_ndim[] = "ndim";
-static const char __pyx_k_pack[] = "pack";
-static const char __pyx_k_size[] = "size";
-static const char __pyx_k_step[] = "step";
-static const char __pyx_k_stop[] = "stop";
-static const char __pyx_k_t_xs[] = "t_xs";
-static const char __pyx_k_t_ys[] = "t_ys";
-static const char __pyx_k_test[] = "__test__";
-static const char __pyx_k_ASCII[] = "ASCII";
-static const char __pyx_k_class[] = "__class__";
-static const char __pyx_k_error[] = "error";
-static const char __pyx_k_flags[] = "flags";
-static const char __pyx_k_paths[] = "paths";
-static const char __pyx_k_range[] = "range";
-static const char __pyx_k_shape[] = "shape";
-static const char __pyx_k_start[] = "start";
-static const char __pyx_k_encode[] = "encode";
-static const char __pyx_k_format[] = "format";
-static const char __pyx_k_import[] = "__import__";
-static const char __pyx_k_name_2[] = "__name__";
-static const char __pyx_k_pickle[] = "pickle";
-static const char __pyx_k_reduce[] = "__reduce__";
-static const char __pyx_k_struct[] = "struct";
-static const char __pyx_k_unpack[] = "unpack";
-static const char __pyx_k_update[] = "update";
-static const char __pyx_k_values[] = "values";
-static const char __pyx_k_fortran[] = "fortran";
-static const char __pyx_k_memview[] = "memview";
-static const char __pyx_k_Ellipsis[] = "Ellipsis";
-static const char __pyx_k_getstate[] = "__getstate__";
-static const char __pyx_k_itemsize[] = "itemsize";
-static const char __pyx_k_pyx_type[] = "__pyx_type";
-static const char __pyx_k_setstate[] = "__setstate__";
-static const char __pyx_k_TypeError[] = "TypeError";
-static const char __pyx_k_enumerate[] = "enumerate";
-static const char __pyx_k_pyx_state[] = "__pyx_state";
-static const char __pyx_k_reduce_ex[] = "__reduce_ex__";
-static const char __pyx_k_IndexError[] = "IndexError";
-static const char __pyx_k_ValueError[] = "ValueError";
-static const char __pyx_k_pyx_result[] = "__pyx_result";
-static const char __pyx_k_pyx_vtable[] = "__pyx_vtable__";
-static const char __pyx_k_MemoryError[] = "MemoryError";
-static const char __pyx_k_PickleError[] = "PickleError";
-static const char __pyx_k_pyx_checksum[] = "__pyx_checksum";
-static const char __pyx_k_stringsource[] = "stringsource";
-static const char __pyx_k_pyx_getbuffer[] = "__pyx_getbuffer";
-static const char __pyx_k_reduce_cython[] = "__reduce_cython__";
-static const char __pyx_k_View_MemoryView[] = "View.MemoryView";
-static const char __pyx_k_allocate_buffer[] = "allocate_buffer";
-static const char __pyx_k_dtype_is_object[] = "dtype_is_object";
-static const char __pyx_k_pyx_PickleError[] = "__pyx_PickleError";
-static const char __pyx_k_setstate_cython[] = "__setstate_cython__";
-static const char __pyx_k_pyx_unpickle_Enum[] = "__pyx_unpickle_Enum";
-static const char __pyx_k_cline_in_traceback[] = "cline_in_traceback";
-static const char __pyx_k_strided_and_direct[] = "";
-static const char __pyx_k_strided_and_indirect[] = "";
-static const char __pyx_k_contiguous_and_direct[] = "";
-static const char __pyx_k_MemoryView_of_r_object[] = "";
-static const char __pyx_k_MemoryView_of_r_at_0x_x[] = "";
-static const char __pyx_k_contiguous_and_indirect[] = "";
-static const char __pyx_k_Cannot_index_with_type_s[] = "Cannot index with type '%s'";
-static const char __pyx_k_Invalid_shape_in_axis_d_d[] = "Invalid shape in axis %d: %d.";
-static const char __pyx_k_itemsize_0_for_cython_array[] = "itemsize <= 0 for cython.array";
-static const char __pyx_k_unable_to_allocate_array_data[] = "unable to allocate array data.";
-static const char __pyx_k_strided_and_direct_or_indirect[] = "";
-static const char __pyx_k_Buffer_view_does_not_expose_stri[] = "Buffer view does not expose strides";
-static const char __pyx_k_Can_only_create_a_buffer_that_is[] = "Can only create a buffer that is contiguous in memory.";
-static const char __pyx_k_Cannot_assign_to_read_only_memor[] = "Cannot assign to read-only memoryview";
-static const char __pyx_k_Cannot_create_writable_memory_vi[] = "Cannot create writable memory view from read-only memoryview";
-static const char __pyx_k_Empty_shape_tuple_for_cython_arr[] = "Empty shape tuple for cython.array";
-static const char __pyx_k_Incompatible_checksums_0x_x_vs_0[] = "Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))";
-static const char __pyx_k_Indirect_dimensions_not_supporte[] = "Indirect dimensions not supported";
-static const char __pyx_k_Invalid_mode_expected_c_or_fortr[] = "Invalid mode, expected 'c' or 'fortran', got %s";
-static const char __pyx_k_Out_of_bounds_on_buffer_access_a[] = "Out of bounds on buffer access (axis %d)";
-static const char __pyx_k_Unable_to_convert_item_to_object[] = "Unable to convert item to object";
-static const char __pyx_k_got_differing_extents_in_dimensi[] = "got differing extents in dimension %d (got %d and %d)";
-static const char __pyx_k_no_default___reduce___due_to_non[] = "no default __reduce__ due to non-trivial __cinit__";
-static const char __pyx_k_unable_to_allocate_shape_and_str[] = "unable to allocate shape and strides.";
-static PyObject *__pyx_n_s_ASCII;
-static PyObject *__pyx_kp_s_Buffer_view_does_not_expose_stri;
-static PyObject *__pyx_kp_s_Can_only_create_a_buffer_that_is;
-static PyObject *__pyx_kp_s_Cannot_assign_to_read_only_memor;
-static PyObject *__pyx_kp_s_Cannot_create_writable_memory_vi;
-static PyObject *__pyx_kp_s_Cannot_index_with_type_s;
-static PyObject *__pyx_n_s_Ellipsis;
-static PyObject *__pyx_kp_s_Empty_shape_tuple_for_cython_arr;
-static PyObject *__pyx_kp_s_Incompatible_checksums_0x_x_vs_0;
-static PyObject *__pyx_n_s_IndexError;
-static PyObject *__pyx_kp_s_Indirect_dimensions_not_supporte;
-static PyObject *__pyx_kp_s_Invalid_mode_expected_c_or_fortr;
-static PyObject *__pyx_kp_s_Invalid_shape_in_axis_d_d;
-static PyObject *__pyx_n_s_MemoryError;
-static PyObject *__pyx_kp_s_MemoryView_of_r_at_0x_x;
-static PyObject *__pyx_kp_s_MemoryView_of_r_object;
-static PyObject *__pyx_n_b_O;
-static PyObject *__pyx_kp_s_Out_of_bounds_on_buffer_access_a;
-static PyObject *__pyx_n_s_PickleError;
-static PyObject *__pyx_n_s_TypeError;
-static PyObject *__pyx_kp_s_Unable_to_convert_item_to_object;
-static PyObject *__pyx_n_s_ValueError;
-static PyObject *__pyx_n_s_View_MemoryView;
-static PyObject *__pyx_n_s_allocate_buffer;
-static PyObject *__pyx_n_s_base;
-static PyObject *__pyx_n_s_c;
-static PyObject *__pyx_n_u_c;
-static PyObject *__pyx_n_s_class;
-static PyObject *__pyx_n_s_cline_in_traceback;
-static PyObject *__pyx_kp_s_contiguous_and_direct;
-static PyObject *__pyx_kp_s_contiguous_and_indirect;
-static PyObject *__pyx_n_s_dict;
-static PyObject *__pyx_n_s_dtype_is_object;
-static PyObject *__pyx_n_s_encode;
-static PyObject *__pyx_n_s_enumerate;
-static PyObject *__pyx_n_s_error;
-static PyObject *__pyx_n_s_flags;
-static PyObject *__pyx_n_s_format;
-static PyObject *__pyx_n_s_fortran;
-static PyObject *__pyx_n_u_fortran;
-static PyObject *__pyx_n_s_getstate;
-static PyObject *__pyx_kp_s_got_differing_extents_in_dimensi;
-static PyObject *__pyx_n_s_id;
-static PyObject *__pyx_n_s_import;
-static PyObject *__pyx_n_s_itemsize;
-static PyObject *__pyx_kp_s_itemsize_0_for_cython_array;
-static PyObject *__pyx_n_s_main;
-static PyObject *__pyx_n_s_memview;
-static PyObject *__pyx_n_s_mode;
-static PyObject *__pyx_n_s_name;
-static PyObject *__pyx_n_s_name_2;
-static PyObject *__pyx_n_s_ndim;
-static PyObject *__pyx_n_s_new;
-static PyObject *__pyx_kp_s_no_default___reduce___due_to_non;
-static PyObject *__pyx_n_s_obj;
-static PyObject *__pyx_n_s_pack;
-static PyObject *__pyx_n_s_paths;
-static PyObject *__pyx_n_s_pickle;
-static PyObject *__pyx_n_s_pyx_PickleError;
-static PyObject *__pyx_n_s_pyx_checksum;
-static PyObject *__pyx_n_s_pyx_getbuffer;
-static PyObject *__pyx_n_s_pyx_result;
-static PyObject *__pyx_n_s_pyx_state;
-static PyObject *__pyx_n_s_pyx_type;
-static PyObject *__pyx_n_s_pyx_unpickle_Enum;
-static PyObject *__pyx_n_s_pyx_vtable;
-static PyObject *__pyx_n_s_range;
-static PyObject *__pyx_n_s_reduce;
-static PyObject *__pyx_n_s_reduce_cython;
-static PyObject *__pyx_n_s_reduce_ex;
-static PyObject *__pyx_n_s_setstate;
-static PyObject *__pyx_n_s_setstate_cython;
-static PyObject *__pyx_n_s_shape;
-static PyObject *__pyx_n_s_size;
-static PyObject *__pyx_n_s_start;
-static PyObject *__pyx_n_s_step;
-static PyObject *__pyx_n_s_stop;
-static PyObject *__pyx_kp_s_strided_and_direct;
-static PyObject *__pyx_kp_s_strided_and_direct_or_indirect;
-static PyObject *__pyx_kp_s_strided_and_indirect;
-static PyObject *__pyx_kp_s_stringsource;
-static PyObject *__pyx_n_s_struct;
-static PyObject *__pyx_n_s_t_xs;
-static PyObject *__pyx_n_s_t_ys;
-static PyObject *__pyx_n_s_test;
-static PyObject *__pyx_kp_s_unable_to_allocate_array_data;
-static PyObject *__pyx_kp_s_unable_to_allocate_shape_and_str;
-static PyObject *__pyx_n_s_unpack;
-static PyObject *__pyx_n_s_update;
-static PyObject *__pyx_n_s_values;
-static PyObject *__pyx_pf_15monotonic_align_4core_maximum_path_c(CYTHON_UNUSED PyObject *__pyx_self, __Pyx_memviewslice __pyx_v_paths, __Pyx_memviewslice __pyx_v_values, __Pyx_memviewslice __pyx_v_t_ys, __Pyx_memviewslice __pyx_v_t_xs); /* proto */
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array___cinit__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_shape, Py_ssize_t __pyx_v_itemsize, PyObject *__pyx_v_format, PyObject *__pyx_v_mode, int __pyx_v_allocate_buffer); /* proto */
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_2__getbuffer__(struct __pyx_array_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /* proto */
-static void __pyx_array___pyx_pf_15View_dot_MemoryView_5array_4__dealloc__(struct __pyx_array_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_5array_7memview___get__(struct __pyx_array_obj *__pyx_v_self); /* proto */
-static Py_ssize_t __pyx_array___pyx_pf_15View_dot_MemoryView_5array_6__len__(struct __pyx_array_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_8__getattr__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_attr); /* proto */
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_10__getitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item); /* proto */
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_12__setitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value); /* proto */
-static PyObject *__pyx_pf___pyx_array___reduce_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_array_2__setstate_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state); /* proto */
-static int __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum___init__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v_name); /* proto */
-static PyObject *__pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum_2__repr__(struct __pyx_MemviewEnum_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_MemviewEnum___reduce_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_MemviewEnum_2__setstate_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v___pyx_state); /* proto */
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview___cinit__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj, int __pyx_v_flags, int __pyx_v_dtype_is_object); /* proto */
-static void __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_2__dealloc__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_4__getitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index); /* proto */
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_6__setitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value); /* proto */
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_8__getbuffer__(struct __pyx_memoryview_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_1T___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4base___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_5shape___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_7strides___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_10suboffsets___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4ndim___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_8itemsize___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_6nbytes___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4size___get__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static Py_ssize_t __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_10__len__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_12__repr__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_14__str__(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_16is_c_contig(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_18is_f_contig(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_20copy(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_22copy_fortran(struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryview___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryview_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state); /* proto */
-static void __pyx_memoryviewslice___pyx_pf_15View_dot_MemoryView_16_memoryviewslice___dealloc__(struct __pyx_memoryviewslice_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView_16_memoryviewslice_4base___get__(struct __pyx_memoryviewslice_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryviewslice___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self); /* proto */
-static PyObject *__pyx_pf___pyx_memoryviewslice_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state); /* proto */
-static PyObject *__pyx_pf_15View_dot_MemoryView___pyx_unpickle_Enum(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v___pyx_type, long __pyx_v___pyx_checksum, PyObject *__pyx_v___pyx_state); /* proto */
-static PyObject *__pyx_tp_new_array(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_tp_new_Enum(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_tp_new_memoryview(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_tp_new__memoryviewslice(PyTypeObject *t, PyObject *a, PyObject *k); /*proto*/
-static PyObject *__pyx_int_0;
-static PyObject *__pyx_int_1;
-static PyObject *__pyx_int_112105877;
-static PyObject *__pyx_int_136983863;
-static PyObject *__pyx_int_184977713;
-static PyObject *__pyx_int_neg_1;
-static float __pyx_k_;
-static PyObject *__pyx_tuple__2;
-static PyObject *__pyx_tuple__3;
-static PyObject *__pyx_tuple__4;
-static PyObject *__pyx_tuple__5;
-static PyObject *__pyx_tuple__6;
-static PyObject *__pyx_tuple__7;
-static PyObject *__pyx_tuple__8;
-static PyObject *__pyx_tuple__9;
-static PyObject *__pyx_slice__16;
-static PyObject *__pyx_tuple__10;
-static PyObject *__pyx_tuple__11;
-static PyObject *__pyx_tuple__12;
-static PyObject *__pyx_tuple__13;
-static PyObject *__pyx_tuple__14;
-static PyObject *__pyx_tuple__15;
-static PyObject *__pyx_tuple__17;
-static PyObject *__pyx_tuple__18;
-static PyObject *__pyx_tuple__19;
-static PyObject *__pyx_tuple__20;
-static PyObject *__pyx_tuple__21;
-static PyObject *__pyx_tuple__22;
-static PyObject *__pyx_tuple__23;
-static PyObject *__pyx_tuple__24;
-static PyObject *__pyx_tuple__25;
-static PyObject *__pyx_tuple__26;
-static PyObject *__pyx_codeobj__27;
-/* Late includes */
-
-/* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
-
-static void __pyx_f_15monotonic_align_4core_maximum_path_each(__Pyx_memviewslice __pyx_v_path, __Pyx_memviewslice __pyx_v_value, int __pyx_v_t_y, int __pyx_v_t_x, struct __pyx_opt_args_15monotonic_align_4core_maximum_path_each *__pyx_optional_args) {
- float __pyx_v_max_neg_val = __pyx_k_;
- int __pyx_v_x;
- int __pyx_v_y;
- float __pyx_v_v_prev;
- float __pyx_v_v_cur;
- int __pyx_v_index;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- long __pyx_t_4;
- int __pyx_t_5;
- long __pyx_t_6;
- long __pyx_t_7;
- int __pyx_t_8;
- Py_ssize_t __pyx_t_9;
- Py_ssize_t __pyx_t_10;
- float __pyx_t_11;
- float __pyx_t_12;
- float __pyx_t_13;
- int __pyx_t_14;
- Py_ssize_t __pyx_t_15;
- Py_ssize_t __pyx_t_16;
- if (__pyx_optional_args) {
- if (__pyx_optional_args->__pyx_n > 0) {
- __pyx_v_max_neg_val = __pyx_optional_args->max_neg_val;
- }
- }
-
- /* "monotonic_align/core.pyx":13
- * cdef float v_cur
- * cdef float tmp
- * cdef int index = t_x - 1 # <<<<<<<<<<<<<<
- *
- * for y in range(t_y):
- */
- __pyx_v_index = (__pyx_v_t_x - 1);
-
- /* "monotonic_align/core.pyx":15
- * cdef int index = t_x - 1
- *
- * for y in range(t_y): # <<<<<<<<<<<<<<
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y:
- */
- __pyx_t_1 = __pyx_v_t_y;
- __pyx_t_2 = __pyx_t_1;
- for (__pyx_t_3 = 0; __pyx_t_3 < __pyx_t_2; __pyx_t_3+=1) {
- __pyx_v_y = __pyx_t_3;
-
- /* "monotonic_align/core.pyx":16
- *
- * for y in range(t_y):
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)): # <<<<<<<<<<<<<<
- * if x == y:
- * v_cur = max_neg_val
- */
- __pyx_t_4 = (__pyx_v_y + 1);
- __pyx_t_5 = __pyx_v_t_x;
- if (((__pyx_t_4 < __pyx_t_5) != 0)) {
- __pyx_t_6 = __pyx_t_4;
- } else {
- __pyx_t_6 = __pyx_t_5;
- }
- __pyx_t_4 = __pyx_t_6;
- __pyx_t_5 = ((__pyx_v_t_x + __pyx_v_y) - __pyx_v_t_y);
- __pyx_t_6 = 0;
- if (((__pyx_t_5 > __pyx_t_6) != 0)) {
- __pyx_t_7 = __pyx_t_5;
- } else {
- __pyx_t_7 = __pyx_t_6;
- }
- __pyx_t_6 = __pyx_t_4;
- for (__pyx_t_5 = __pyx_t_7; __pyx_t_5 < __pyx_t_6; __pyx_t_5+=1) {
- __pyx_v_x = __pyx_t_5;
-
- /* "monotonic_align/core.pyx":17
- * for y in range(t_y):
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y: # <<<<<<<<<<<<<<
- * v_cur = max_neg_val
- * else:
- */
- __pyx_t_8 = ((__pyx_v_x == __pyx_v_y) != 0);
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":18
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y:
- * v_cur = max_neg_val # <<<<<<<<<<<<<<
- * else:
- * v_cur = value[y-1, x]
- */
- __pyx_v_v_cur = __pyx_v_max_neg_val;
-
- /* "monotonic_align/core.pyx":17
- * for y in range(t_y):
- * for x in range(max(0, t_x + y - t_y), min(t_x, y + 1)):
- * if x == y: # <<<<<<<<<<<<<<
- * v_cur = max_neg_val
- * else:
- */
- goto __pyx_L7;
- }
-
- /* "monotonic_align/core.pyx":20
- * v_cur = max_neg_val
- * else:
- * v_cur = value[y-1, x] # <<<<<<<<<<<<<<
- * if x == 0:
- * if y == 0:
- */
- /*else*/ {
- __pyx_t_9 = (__pyx_v_y - 1);
- __pyx_t_10 = __pyx_v_x;
- __pyx_v_v_cur = (*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_9 * __pyx_v_value.strides[0]) )) + __pyx_t_10)) )));
- }
- __pyx_L7:;
-
- /* "monotonic_align/core.pyx":21
- * else:
- * v_cur = value[y-1, x]
- * if x == 0: # <<<<<<<<<<<<<<
- * if y == 0:
- * v_prev = 0.
- */
- __pyx_t_8 = ((__pyx_v_x == 0) != 0);
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":22
- * v_cur = value[y-1, x]
- * if x == 0:
- * if y == 0: # <<<<<<<<<<<<<<
- * v_prev = 0.
- * else:
- */
- __pyx_t_8 = ((__pyx_v_y == 0) != 0);
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":23
- * if x == 0:
- * if y == 0:
- * v_prev = 0. # <<<<<<<<<<<<<<
- * else:
- * v_prev = max_neg_val
- */
- __pyx_v_v_prev = 0.;
-
- /* "monotonic_align/core.pyx":22
- * v_cur = value[y-1, x]
- * if x == 0:
- * if y == 0: # <<<<<<<<<<<<<<
- * v_prev = 0.
- * else:
- */
- goto __pyx_L9;
- }
-
- /* "monotonic_align/core.pyx":25
- * v_prev = 0.
- * else:
- * v_prev = max_neg_val # <<<<<<<<<<<<<<
- * else:
- * v_prev = value[y-1, x-1]
- */
- /*else*/ {
- __pyx_v_v_prev = __pyx_v_max_neg_val;
- }
- __pyx_L9:;
-
- /* "monotonic_align/core.pyx":21
- * else:
- * v_cur = value[y-1, x]
- * if x == 0: # <<<<<<<<<<<<<<
- * if y == 0:
- * v_prev = 0.
- */
- goto __pyx_L8;
- }
-
- /* "monotonic_align/core.pyx":27
- * v_prev = max_neg_val
- * else:
- * v_prev = value[y-1, x-1] # <<<<<<<<<<<<<<
- * value[y, x] += max(v_prev, v_cur)
- *
- */
- /*else*/ {
- __pyx_t_10 = (__pyx_v_y - 1);
- __pyx_t_9 = (__pyx_v_x - 1);
- __pyx_v_v_prev = (*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_10 * __pyx_v_value.strides[0]) )) + __pyx_t_9)) )));
- }
- __pyx_L8:;
-
- /* "monotonic_align/core.pyx":28
- * else:
- * v_prev = value[y-1, x-1]
- * value[y, x] += max(v_prev, v_cur) # <<<<<<<<<<<<<<
- *
- * for y in range(t_y - 1, -1, -1):
- */
- __pyx_t_11 = __pyx_v_v_cur;
- __pyx_t_12 = __pyx_v_v_prev;
- if (((__pyx_t_11 > __pyx_t_12) != 0)) {
- __pyx_t_13 = __pyx_t_11;
- } else {
- __pyx_t_13 = __pyx_t_12;
- }
- __pyx_t_9 = __pyx_v_y;
- __pyx_t_10 = __pyx_v_x;
- *((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_9 * __pyx_v_value.strides[0]) )) + __pyx_t_10)) )) += __pyx_t_13;
- }
- }
-
- /* "monotonic_align/core.pyx":30
- * value[y, x] += max(v_prev, v_cur)
- *
- * for y in range(t_y - 1, -1, -1): # <<<<<<<<<<<<<<
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
- */
- for (__pyx_t_1 = (__pyx_v_t_y - 1); __pyx_t_1 > -1; __pyx_t_1-=1) {
- __pyx_v_y = __pyx_t_1;
-
- /* "monotonic_align/core.pyx":31
- *
- * for y in range(t_y - 1, -1, -1):
- * path[y, index] = 1 # <<<<<<<<<<<<<<
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
- * index = index - 1
- */
- __pyx_t_10 = __pyx_v_y;
- __pyx_t_9 = __pyx_v_index;
- *((int *) ( /* dim=1 */ ((char *) (((int *) ( /* dim=0 */ (__pyx_v_path.data + __pyx_t_10 * __pyx_v_path.strides[0]) )) + __pyx_t_9)) )) = 1;
-
- /* "monotonic_align/core.pyx":32
- * for y in range(t_y - 1, -1, -1):
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]): # <<<<<<<<<<<<<<
- * index = index - 1
- *
- */
- __pyx_t_14 = ((__pyx_v_index != 0) != 0);
- if (__pyx_t_14) {
- } else {
- __pyx_t_8 = __pyx_t_14;
- goto __pyx_L13_bool_binop_done;
- }
- __pyx_t_14 = ((__pyx_v_index == __pyx_v_y) != 0);
- if (!__pyx_t_14) {
- } else {
- __pyx_t_8 = __pyx_t_14;
- goto __pyx_L13_bool_binop_done;
- }
- __pyx_t_9 = (__pyx_v_y - 1);
- __pyx_t_10 = __pyx_v_index;
- __pyx_t_15 = (__pyx_v_y - 1);
- __pyx_t_16 = (__pyx_v_index - 1);
- __pyx_t_14 = (((*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_9 * __pyx_v_value.strides[0]) )) + __pyx_t_10)) ))) < (*((float *) ( /* dim=1 */ ((char *) (((float *) ( /* dim=0 */ (__pyx_v_value.data + __pyx_t_15 * __pyx_v_value.strides[0]) )) + __pyx_t_16)) )))) != 0);
- __pyx_t_8 = __pyx_t_14;
- __pyx_L13_bool_binop_done:;
- if (__pyx_t_8) {
-
- /* "monotonic_align/core.pyx":33
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]):
- * index = index - 1 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_index = (__pyx_v_index - 1);
-
- /* "monotonic_align/core.pyx":32
- * for y in range(t_y - 1, -1, -1):
- * path[y, index] = 1
- * if index != 0 and (index == y or value[y-1, index] < value[y-1, index-1]): # <<<<<<<<<<<<<<
- * index = index - 1
- *
- */
- }
- }
-
- /* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
-
- /* function exit code */
-}
-
-/* "monotonic_align/core.pyx":38
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil: # <<<<<<<<<<<<<<
- * cdef int b = paths.shape[0]
- * cdef int i
- */
-
-static PyObject *__pyx_pw_15monotonic_align_4core_1maximum_path_c(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static void __pyx_f_15monotonic_align_4core_maximum_path_c(__Pyx_memviewslice __pyx_v_paths, __Pyx_memviewslice __pyx_v_values, __Pyx_memviewslice __pyx_v_t_ys, __Pyx_memviewslice __pyx_v_t_xs, CYTHON_UNUSED int __pyx_skip_dispatch) {
- CYTHON_UNUSED int __pyx_v_b;
- int __pyx_v_i;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- __Pyx_memviewslice __pyx_t_4 = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_t_5 = { 0, 0, { 0 }, { 0 }, { 0 } };
- Py_ssize_t __pyx_t_6;
- Py_ssize_t __pyx_t_7;
-
- /* "monotonic_align/core.pyx":39
- * @cython.wraparound(False)
- * cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil:
- * cdef int b = paths.shape[0] # <<<<<<<<<<<<<<
- * cdef int i
- * for i in prange(b, nogil=True):
- */
- __pyx_v_b = (__pyx_v_paths.shape[0]);
-
- /* "monotonic_align/core.pyx":41
- * cdef int b = paths.shape[0]
- * cdef int i
- * for i in prange(b, nogil=True): # <<<<<<<<<<<<<<
- * maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
- */
- {
- #ifdef WITH_THREAD
- PyThreadState *_save;
- Py_UNBLOCK_THREADS
- __Pyx_FastGIL_Remember();
- #endif
- /*try:*/ {
- __pyx_t_1 = __pyx_v_b;
- if ((1 == 0)) abort();
- {
- #if ((defined(__APPLE__) || defined(__OSX__)) && (defined(__GNUC__) && (__GNUC__ > 2 || (__GNUC__ == 2 && (__GNUC_MINOR__ > 95)))))
- #undef likely
- #undef unlikely
- #define likely(x) (x)
- #define unlikely(x) (x)
- #endif
- __pyx_t_3 = (__pyx_t_1 - 0 + 1 - 1/abs(1)) / 1;
- if (__pyx_t_3 > 0)
- {
- #ifdef _OPENMP
- #pragma omp parallel private(__pyx_t_6, __pyx_t_7) firstprivate(__pyx_t_4, __pyx_t_5)
- #endif /* _OPENMP */
- {
- #ifdef _OPENMP
- #pragma omp for firstprivate(__pyx_v_i) lastprivate(__pyx_v_i)
- #endif /* _OPENMP */
- for (__pyx_t_2 = 0; __pyx_t_2 < __pyx_t_3; __pyx_t_2++){
- {
- __pyx_v_i = (int)(0 + 1 * __pyx_t_2);
-
- /* "monotonic_align/core.pyx":42
- * cdef int i
- * for i in prange(b, nogil=True):
- * maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i]) # <<<<<<<<<<<<<<
- */
- __pyx_t_4.data = __pyx_v_paths.data;
- __pyx_t_4.memview = __pyx_v_paths.memview;
- __PYX_INC_MEMVIEW(&__pyx_t_4, 0);
- {
- Py_ssize_t __pyx_tmp_idx = __pyx_v_i;
- Py_ssize_t __pyx_tmp_stride = __pyx_v_paths.strides[0];
- __pyx_t_4.data += __pyx_tmp_idx * __pyx_tmp_stride;
-}
-
-__pyx_t_4.shape[0] = __pyx_v_paths.shape[1];
-__pyx_t_4.strides[0] = __pyx_v_paths.strides[1];
- __pyx_t_4.suboffsets[0] = -1;
-
-__pyx_t_4.shape[1] = __pyx_v_paths.shape[2];
-__pyx_t_4.strides[1] = __pyx_v_paths.strides[2];
- __pyx_t_4.suboffsets[1] = -1;
-
-__pyx_t_5.data = __pyx_v_values.data;
- __pyx_t_5.memview = __pyx_v_values.memview;
- __PYX_INC_MEMVIEW(&__pyx_t_5, 0);
- {
- Py_ssize_t __pyx_tmp_idx = __pyx_v_i;
- Py_ssize_t __pyx_tmp_stride = __pyx_v_values.strides[0];
- __pyx_t_5.data += __pyx_tmp_idx * __pyx_tmp_stride;
-}
-
-__pyx_t_5.shape[0] = __pyx_v_values.shape[1];
-__pyx_t_5.strides[0] = __pyx_v_values.strides[1];
- __pyx_t_5.suboffsets[0] = -1;
-
-__pyx_t_5.shape[1] = __pyx_v_values.shape[2];
-__pyx_t_5.strides[1] = __pyx_v_values.strides[2];
- __pyx_t_5.suboffsets[1] = -1;
-
-__pyx_t_6 = __pyx_v_i;
- __pyx_t_7 = __pyx_v_i;
- __pyx_f_15monotonic_align_4core_maximum_path_each(__pyx_t_4, __pyx_t_5, (*((int *) ( /* dim=0 */ ((char *) (((int *) __pyx_v_t_ys.data) + __pyx_t_6)) ))), (*((int *) ( /* dim=0 */ ((char *) (((int *) __pyx_v_t_xs.data) + __pyx_t_7)) ))), NULL);
- __PYX_XDEC_MEMVIEW(&__pyx_t_4, 0);
- __pyx_t_4.memview = NULL;
- __pyx_t_4.data = NULL;
- __PYX_XDEC_MEMVIEW(&__pyx_t_5, 0);
- __pyx_t_5.memview = NULL;
- __pyx_t_5.data = NULL;
- }
- }
- }
- }
- }
- #if ((defined(__APPLE__) || defined(__OSX__)) && (defined(__GNUC__) && (__GNUC__ > 2 || (__GNUC__ == 2 && (__GNUC_MINOR__ > 95)))))
- #undef likely
- #undef unlikely
- #define likely(x) __builtin_expect(!!(x), 1)
- #define unlikely(x) __builtin_expect(!!(x), 0)
- #endif
- }
-
- /* "monotonic_align/core.pyx":41
- * cdef int b = paths.shape[0]
- * cdef int i
- * for i in prange(b, nogil=True): # <<<<<<<<<<<<<<
- * maximum_path_each(paths[i], values[i], t_ys[i], t_xs[i])
- */
- /*finally:*/ {
- /*normal exit:*/{
- #ifdef WITH_THREAD
- __Pyx_FastGIL_Forget();
- Py_BLOCK_THREADS
- #endif
- goto __pyx_L5;
- }
- __pyx_L5:;
- }
- }
-
- /* "monotonic_align/core.pyx":38
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cpdef void maximum_path_c(int[:,:,::1] paths, float[:,:,::1] values, int[::1] t_ys, int[::1] t_xs) nogil: # <<<<<<<<<<<<<<
- * cdef int b = paths.shape[0]
- * cdef int i
- */
-
- /* function exit code */
-}
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15monotonic_align_4core_1maximum_path_c(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static PyObject *__pyx_pw_15monotonic_align_4core_1maximum_path_c(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- __Pyx_memviewslice __pyx_v_paths = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_v_values = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_v_t_ys = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_memviewslice __pyx_v_t_xs = { 0, 0, { 0 }, { 0 }, { 0 } };
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("maximum_path_c (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_paths,&__pyx_n_s_values,&__pyx_n_s_t_ys,&__pyx_n_s_t_xs,0};
- PyObject* values[4] = {0,0,0,0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 4: values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- CYTHON_FALLTHROUGH;
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_paths)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_values)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, 1); __PYX_ERR(0, 38, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_t_ys)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, 2); __PYX_ERR(0, 38, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 3:
- if (likely((values[3] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_t_xs)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, 3); __PYX_ERR(0, 38, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "maximum_path_c") < 0)) __PYX_ERR(0, 38, __pyx_L3_error)
- }
- } else if (PyTuple_GET_SIZE(__pyx_args) != 4) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- }
- __pyx_v_paths = __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_int(values[0], PyBUF_WRITABLE); if (unlikely(!__pyx_v_paths.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_v_values = __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_float(values[1], PyBUF_WRITABLE); if (unlikely(!__pyx_v_values.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_v_t_ys = __Pyx_PyObject_to_MemoryviewSlice_dc_int(values[2], PyBUF_WRITABLE); if (unlikely(!__pyx_v_t_ys.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_v_t_xs = __Pyx_PyObject_to_MemoryviewSlice_dc_int(values[3], PyBUF_WRITABLE); if (unlikely(!__pyx_v_t_xs.memview)) __PYX_ERR(0, 38, __pyx_L3_error)
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("maximum_path_c", 1, 4, 4, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(0, 38, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("monotonic_align.core.maximum_path_c", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_15monotonic_align_4core_maximum_path_c(__pyx_self, __pyx_v_paths, __pyx_v_values, __pyx_v_t_ys, __pyx_v_t_xs);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15monotonic_align_4core_maximum_path_c(CYTHON_UNUSED PyObject *__pyx_self, __Pyx_memviewslice __pyx_v_paths, __Pyx_memviewslice __pyx_v_values, __Pyx_memviewslice __pyx_v_t_ys, __Pyx_memviewslice __pyx_v_t_xs) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("maximum_path_c", 0);
- __Pyx_XDECREF(__pyx_r);
- if (unlikely(!__pyx_v_paths.memview)) { __Pyx_RaiseUnboundLocalError("paths"); __PYX_ERR(0, 38, __pyx_L1_error) }
- if (unlikely(!__pyx_v_values.memview)) { __Pyx_RaiseUnboundLocalError("values"); __PYX_ERR(0, 38, __pyx_L1_error) }
- if (unlikely(!__pyx_v_t_ys.memview)) { __Pyx_RaiseUnboundLocalError("t_ys"); __PYX_ERR(0, 38, __pyx_L1_error) }
- if (unlikely(!__pyx_v_t_xs.memview)) { __Pyx_RaiseUnboundLocalError("t_xs"); __PYX_ERR(0, 38, __pyx_L1_error) }
- __pyx_t_1 = __Pyx_void_to_None(__pyx_f_15monotonic_align_4core_maximum_path_c(__pyx_v_paths, __pyx_v_values, __pyx_v_t_ys, __pyx_v_t_xs, 0)); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 38, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("monotonic_align.core.maximum_path_c", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __PYX_XDEC_MEMVIEW(&__pyx_v_paths, 1);
- __PYX_XDEC_MEMVIEW(&__pyx_v_values, 1);
- __PYX_XDEC_MEMVIEW(&__pyx_v_t_ys, 1);
- __PYX_XDEC_MEMVIEW(&__pyx_v_t_xs, 1);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":123
- * cdef bint dtype_is_object
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None, # <<<<<<<<<<<<<<
- * mode="c", bint allocate_buffer=True):
- *
- */
-
-/* Python wrapper */
-static int __pyx_array___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static int __pyx_array___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v_shape = 0;
- Py_ssize_t __pyx_v_itemsize;
- PyObject *__pyx_v_format = 0;
- PyObject *__pyx_v_mode = 0;
- int __pyx_v_allocate_buffer;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__cinit__ (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_shape,&__pyx_n_s_itemsize,&__pyx_n_s_format,&__pyx_n_s_mode,&__pyx_n_s_allocate_buffer,0};
- PyObject* values[5] = {0,0,0,0,0};
- values[3] = ((PyObject *)__pyx_n_s_c);
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 5: values[4] = PyTuple_GET_ITEM(__pyx_args, 4);
- CYTHON_FALLTHROUGH;
- case 4: values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- CYTHON_FALLTHROUGH;
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_shape)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_itemsize)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 3, 5, 1); __PYX_ERR(1, 123, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_format)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 3, 5, 2); __PYX_ERR(1, 123, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 3:
- if (kw_args > 0) {
- PyObject* value = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_mode);
- if (value) { values[3] = value; kw_args--; }
- }
- CYTHON_FALLTHROUGH;
- case 4:
- if (kw_args > 0) {
- PyObject* value = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_allocate_buffer);
- if (value) { values[4] = value; kw_args--; }
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__cinit__") < 0)) __PYX_ERR(1, 123, __pyx_L3_error)
- }
- } else {
- switch (PyTuple_GET_SIZE(__pyx_args)) {
- case 5: values[4] = PyTuple_GET_ITEM(__pyx_args, 4);
- CYTHON_FALLTHROUGH;
- case 4: values[3] = PyTuple_GET_ITEM(__pyx_args, 3);
- CYTHON_FALLTHROUGH;
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- break;
- default: goto __pyx_L5_argtuple_error;
- }
- }
- __pyx_v_shape = ((PyObject*)values[0]);
- __pyx_v_itemsize = __Pyx_PyIndex_AsSsize_t(values[1]); if (unlikely((__pyx_v_itemsize == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 123, __pyx_L3_error)
- __pyx_v_format = values[2];
- __pyx_v_mode = values[3];
- if (values[4]) {
- __pyx_v_allocate_buffer = __Pyx_PyObject_IsTrue(values[4]); if (unlikely((__pyx_v_allocate_buffer == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 124, __pyx_L3_error)
- } else {
-
- /* "View.MemoryView":124
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None,
- * mode="c", bint allocate_buffer=True): # <<<<<<<<<<<<<<
- *
- * cdef int idx
- */
- __pyx_v_allocate_buffer = ((int)1);
- }
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 3, 5, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 123, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.array.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return -1;
- __pyx_L4_argument_unpacking_done:;
- if (unlikely(!__Pyx_ArgTypeTest(((PyObject *)__pyx_v_shape), (&PyTuple_Type), 1, "shape", 1))) __PYX_ERR(1, 123, __pyx_L1_error)
- if (unlikely(((PyObject *)__pyx_v_format) == Py_None)) {
- PyErr_Format(PyExc_TypeError, "Argument '%.200s' must not be None", "format"); __PYX_ERR(1, 123, __pyx_L1_error)
- }
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array___cinit__(((struct __pyx_array_obj *)__pyx_v_self), __pyx_v_shape, __pyx_v_itemsize, __pyx_v_format, __pyx_v_mode, __pyx_v_allocate_buffer);
-
- /* "View.MemoryView":123
- * cdef bint dtype_is_object
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None, # <<<<<<<<<<<<<<
- * mode="c", bint allocate_buffer=True):
- *
- */
-
- /* function exit code */
- goto __pyx_L0;
- __pyx_L1_error:;
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array___cinit__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_shape, Py_ssize_t __pyx_v_itemsize, PyObject *__pyx_v_format, PyObject *__pyx_v_mode, int __pyx_v_allocate_buffer) {
- int __pyx_v_idx;
- Py_ssize_t __pyx_v_i;
- Py_ssize_t __pyx_v_dim;
- PyObject **__pyx_v_p;
- char __pyx_v_order;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- char *__pyx_t_7;
- int __pyx_t_8;
- Py_ssize_t __pyx_t_9;
- PyObject *__pyx_t_10 = NULL;
- Py_ssize_t __pyx_t_11;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__cinit__", 0);
- __Pyx_INCREF(__pyx_v_format);
-
- /* "View.MemoryView":130
- * cdef PyObject **p
- *
- * self.ndim = len(shape) # <<<<<<<<<<<<<<
- * self.itemsize = itemsize
- *
- */
- if (unlikely(__pyx_v_shape == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "object of type 'NoneType' has no len()");
- __PYX_ERR(1, 130, __pyx_L1_error)
- }
- __pyx_t_1 = PyTuple_GET_SIZE(__pyx_v_shape); if (unlikely(__pyx_t_1 == ((Py_ssize_t)-1))) __PYX_ERR(1, 130, __pyx_L1_error)
- __pyx_v_self->ndim = ((int)__pyx_t_1);
-
- /* "View.MemoryView":131
- *
- * self.ndim = len(shape)
- * self.itemsize = itemsize # <<<<<<<<<<<<<<
- *
- * if not self.ndim:
- */
- __pyx_v_self->itemsize = __pyx_v_itemsize;
-
- /* "View.MemoryView":133
- * self.itemsize = itemsize
- *
- * if not self.ndim: # <<<<<<<<<<<<<<
- * raise ValueError("Empty shape tuple for cython.array")
- *
- */
- __pyx_t_2 = ((!(__pyx_v_self->ndim != 0)) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":134
- *
- * if not self.ndim:
- * raise ValueError("Empty shape tuple for cython.array") # <<<<<<<<<<<<<<
- *
- * if itemsize <= 0:
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__2, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 134, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 134, __pyx_L1_error)
-
- /* "View.MemoryView":133
- * self.itemsize = itemsize
- *
- * if not self.ndim: # <<<<<<<<<<<<<<
- * raise ValueError("Empty shape tuple for cython.array")
- *
- */
- }
-
- /* "View.MemoryView":136
- * raise ValueError("Empty shape tuple for cython.array")
- *
- * if itemsize <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- */
- __pyx_t_2 = ((__pyx_v_itemsize <= 0) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":137
- *
- * if itemsize <= 0:
- * raise ValueError("itemsize <= 0 for cython.array") # <<<<<<<<<<<<<<
- *
- * if not isinstance(format, bytes):
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__3, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 137, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 137, __pyx_L1_error)
-
- /* "View.MemoryView":136
- * raise ValueError("Empty shape tuple for cython.array")
- *
- * if itemsize <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- */
- }
-
- /* "View.MemoryView":139
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- * if not isinstance(format, bytes): # <<<<<<<<<<<<<<
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string
- */
- __pyx_t_2 = PyBytes_Check(__pyx_v_format);
- __pyx_t_4 = ((!(__pyx_t_2 != 0)) != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":140
- *
- * if not isinstance(format, bytes):
- * format = format.encode('ASCII') # <<<<<<<<<<<<<<
- * self._format = format # keep a reference to the byte string
- * self.format = self._format
- */
- __pyx_t_5 = __Pyx_PyObject_GetAttrStr(__pyx_v_format, __pyx_n_s_encode); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 140, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_6 = NULL;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_5))) {
- __pyx_t_6 = PyMethod_GET_SELF(__pyx_t_5);
- if (likely(__pyx_t_6)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_5);
- __Pyx_INCREF(__pyx_t_6);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_5, function);
- }
- }
- __pyx_t_3 = (__pyx_t_6) ? __Pyx_PyObject_Call2Args(__pyx_t_5, __pyx_t_6, __pyx_n_s_ASCII) : __Pyx_PyObject_CallOneArg(__pyx_t_5, __pyx_n_s_ASCII);
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 140, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_DECREF_SET(__pyx_v_format, __pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":139
- * raise ValueError("itemsize <= 0 for cython.array")
- *
- * if not isinstance(format, bytes): # <<<<<<<<<<<<<<
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string
- */
- }
-
- /* "View.MemoryView":141
- * if not isinstance(format, bytes):
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string # <<<<<<<<<<<<<<
- * self.format = self._format
- *
- */
- if (!(likely(PyBytes_CheckExact(__pyx_v_format))||((__pyx_v_format) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "bytes", Py_TYPE(__pyx_v_format)->tp_name), 0))) __PYX_ERR(1, 141, __pyx_L1_error)
- __pyx_t_3 = __pyx_v_format;
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_3);
- __Pyx_GOTREF(__pyx_v_self->_format);
- __Pyx_DECREF(__pyx_v_self->_format);
- __pyx_v_self->_format = ((PyObject*)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":142
- * format = format.encode('ASCII')
- * self._format = format # keep a reference to the byte string
- * self.format = self._format # <<<<<<<<<<<<<<
- *
- *
- */
- if (unlikely(__pyx_v_self->_format == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "expected bytes, NoneType found");
- __PYX_ERR(1, 142, __pyx_L1_error)
- }
- __pyx_t_7 = __Pyx_PyBytes_AsWritableString(__pyx_v_self->_format); if (unlikely((!__pyx_t_7) && PyErr_Occurred())) __PYX_ERR(1, 142, __pyx_L1_error)
- __pyx_v_self->format = __pyx_t_7;
-
- /* "View.MemoryView":145
- *
- *
- * self._shape = PyObject_Malloc(sizeof(Py_ssize_t)*self.ndim*2) # <<<<<<<<<<<<<<
- * self._strides = self._shape + self.ndim
- *
- */
- __pyx_v_self->_shape = ((Py_ssize_t *)PyObject_Malloc((((sizeof(Py_ssize_t)) * __pyx_v_self->ndim) * 2)));
-
- /* "View.MemoryView":146
- *
- * self._shape = PyObject_Malloc(sizeof(Py_ssize_t)*self.ndim*2)
- * self._strides = self._shape + self.ndim # <<<<<<<<<<<<<<
- *
- * if not self._shape:
- */
- __pyx_v_self->_strides = (__pyx_v_self->_shape + __pyx_v_self->ndim);
-
- /* "View.MemoryView":148
- * self._strides = self._shape + self.ndim
- *
- * if not self._shape: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate shape and strides.")
- *
- */
- __pyx_t_4 = ((!(__pyx_v_self->_shape != 0)) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":149
- *
- * if not self._shape:
- * raise MemoryError("unable to allocate shape and strides.") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_MemoryError, __pyx_tuple__4, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 149, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 149, __pyx_L1_error)
-
- /* "View.MemoryView":148
- * self._strides = self._shape + self.ndim
- *
- * if not self._shape: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate shape and strides.")
- *
- */
- }
-
- /* "View.MemoryView":152
- *
- *
- * for idx, dim in enumerate(shape): # <<<<<<<<<<<<<<
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- */
- __pyx_t_8 = 0;
- __pyx_t_3 = __pyx_v_shape; __Pyx_INCREF(__pyx_t_3); __pyx_t_1 = 0;
- for (;;) {
- if (__pyx_t_1 >= PyTuple_GET_SIZE(__pyx_t_3)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_5 = PyTuple_GET_ITEM(__pyx_t_3, __pyx_t_1); __Pyx_INCREF(__pyx_t_5); __pyx_t_1++; if (unlikely(0 < 0)) __PYX_ERR(1, 152, __pyx_L1_error)
- #else
- __pyx_t_5 = PySequence_ITEM(__pyx_t_3, __pyx_t_1); __pyx_t_1++; if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 152, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- __pyx_t_9 = __Pyx_PyIndex_AsSsize_t(__pyx_t_5); if (unlikely((__pyx_t_9 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 152, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_v_dim = __pyx_t_9;
- __pyx_v_idx = __pyx_t_8;
- __pyx_t_8 = (__pyx_t_8 + 1);
-
- /* "View.MemoryView":153
- *
- * for idx, dim in enumerate(shape):
- * if dim <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- * self._shape[idx] = dim
- */
- __pyx_t_4 = ((__pyx_v_dim <= 0) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":154
- * for idx, dim in enumerate(shape):
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim)) # <<<<<<<<<<<<<<
- * self._shape[idx] = dim
- *
- */
- __pyx_t_5 = __Pyx_PyInt_From_int(__pyx_v_idx); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_6 = PyInt_FromSsize_t(__pyx_v_dim); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_10 = PyTuple_New(2); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_GIVEREF(__pyx_t_5);
- PyTuple_SET_ITEM(__pyx_t_10, 0, __pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_6);
- PyTuple_SET_ITEM(__pyx_t_10, 1, __pyx_t_6);
- __pyx_t_5 = 0;
- __pyx_t_6 = 0;
- __pyx_t_6 = __Pyx_PyString_Format(__pyx_kp_s_Invalid_shape_in_axis_d_d, __pyx_t_10); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __pyx_t_10 = __Pyx_PyObject_CallOneArg(__pyx_builtin_ValueError, __pyx_t_6); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 154, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_Raise(__pyx_t_10, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __PYX_ERR(1, 154, __pyx_L1_error)
-
- /* "View.MemoryView":153
- *
- * for idx, dim in enumerate(shape):
- * if dim <= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- * self._shape[idx] = dim
- */
- }
-
- /* "View.MemoryView":155
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- * self._shape[idx] = dim # <<<<<<<<<<<<<<
- *
- * cdef char order
- */
- (__pyx_v_self->_shape[__pyx_v_idx]) = __pyx_v_dim;
-
- /* "View.MemoryView":152
- *
- *
- * for idx, dim in enumerate(shape): # <<<<<<<<<<<<<<
- * if dim <= 0:
- * raise ValueError("Invalid shape in axis %d: %d." % (idx, dim))
- */
- }
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":158
- *
- * cdef char order
- * if mode == 'fortran': # <<<<<<<<<<<<<<
- * order = b'F'
- * self.mode = u'fortran'
- */
- __pyx_t_4 = (__Pyx_PyString_Equals(__pyx_v_mode, __pyx_n_s_fortran, Py_EQ)); if (unlikely(__pyx_t_4 < 0)) __PYX_ERR(1, 158, __pyx_L1_error)
- if (__pyx_t_4) {
-
- /* "View.MemoryView":159
- * cdef char order
- * if mode == 'fortran':
- * order = b'F' # <<<<<<<<<<<<<<
- * self.mode = u'fortran'
- * elif mode == 'c':
- */
- __pyx_v_order = 'F';
-
- /* "View.MemoryView":160
- * if mode == 'fortran':
- * order = b'F'
- * self.mode = u'fortran' # <<<<<<<<<<<<<<
- * elif mode == 'c':
- * order = b'C'
- */
- __Pyx_INCREF(__pyx_n_u_fortran);
- __Pyx_GIVEREF(__pyx_n_u_fortran);
- __Pyx_GOTREF(__pyx_v_self->mode);
- __Pyx_DECREF(__pyx_v_self->mode);
- __pyx_v_self->mode = __pyx_n_u_fortran;
-
- /* "View.MemoryView":158
- *
- * cdef char order
- * if mode == 'fortran': # <<<<<<<<<<<<<<
- * order = b'F'
- * self.mode = u'fortran'
- */
- goto __pyx_L10;
- }
-
- /* "View.MemoryView":161
- * order = b'F'
- * self.mode = u'fortran'
- * elif mode == 'c': # <<<<<<<<<<<<<<
- * order = b'C'
- * self.mode = u'c'
- */
- __pyx_t_4 = (__Pyx_PyString_Equals(__pyx_v_mode, __pyx_n_s_c, Py_EQ)); if (unlikely(__pyx_t_4 < 0)) __PYX_ERR(1, 161, __pyx_L1_error)
- if (likely(__pyx_t_4)) {
-
- /* "View.MemoryView":162
- * self.mode = u'fortran'
- * elif mode == 'c':
- * order = b'C' # <<<<<<<<<<<<<<
- * self.mode = u'c'
- * else:
- */
- __pyx_v_order = 'C';
-
- /* "View.MemoryView":163
- * elif mode == 'c':
- * order = b'C'
- * self.mode = u'c' # <<<<<<<<<<<<<<
- * else:
- * raise ValueError("Invalid mode, expected 'c' or 'fortran', got %s" % mode)
- */
- __Pyx_INCREF(__pyx_n_u_c);
- __Pyx_GIVEREF(__pyx_n_u_c);
- __Pyx_GOTREF(__pyx_v_self->mode);
- __Pyx_DECREF(__pyx_v_self->mode);
- __pyx_v_self->mode = __pyx_n_u_c;
-
- /* "View.MemoryView":161
- * order = b'F'
- * self.mode = u'fortran'
- * elif mode == 'c': # <<<<<<<<<<<<<<
- * order = b'C'
- * self.mode = u'c'
- */
- goto __pyx_L10;
- }
-
- /* "View.MemoryView":165
- * self.mode = u'c'
- * else:
- * raise ValueError("Invalid mode, expected 'c' or 'fortran', got %s" % mode) # <<<<<<<<<<<<<<
- *
- * self.len = fill_contig_strides_array(self._shape, self._strides,
- */
- /*else*/ {
- __pyx_t_3 = __Pyx_PyString_FormatSafe(__pyx_kp_s_Invalid_mode_expected_c_or_fortr, __pyx_v_mode); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 165, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_10 = __Pyx_PyObject_CallOneArg(__pyx_builtin_ValueError, __pyx_t_3); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 165, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_Raise(__pyx_t_10, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __PYX_ERR(1, 165, __pyx_L1_error)
- }
- __pyx_L10:;
-
- /* "View.MemoryView":167
- * raise ValueError("Invalid mode, expected 'c' or 'fortran', got %s" % mode)
- *
- * self.len = fill_contig_strides_array(self._shape, self._strides, # <<<<<<<<<<<<<<
- * itemsize, self.ndim, order)
- *
- */
- __pyx_v_self->len = __pyx_fill_contig_strides_array(__pyx_v_self->_shape, __pyx_v_self->_strides, __pyx_v_itemsize, __pyx_v_self->ndim, __pyx_v_order);
-
- /* "View.MemoryView":170
- * itemsize, self.ndim, order)
- *
- * self.free_data = allocate_buffer # <<<<<<<<<<<<<<
- * self.dtype_is_object = format == b'O'
- * if allocate_buffer:
- */
- __pyx_v_self->free_data = __pyx_v_allocate_buffer;
-
- /* "View.MemoryView":171
- *
- * self.free_data = allocate_buffer
- * self.dtype_is_object = format == b'O' # <<<<<<<<<<<<<<
- * if allocate_buffer:
- *
- */
- __pyx_t_10 = PyObject_RichCompare(__pyx_v_format, __pyx_n_b_O, Py_EQ); __Pyx_XGOTREF(__pyx_t_10); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 171, __pyx_L1_error)
- __pyx_t_4 = __Pyx_PyObject_IsTrue(__pyx_t_10); if (unlikely((__pyx_t_4 == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 171, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __pyx_v_self->dtype_is_object = __pyx_t_4;
-
- /* "View.MemoryView":172
- * self.free_data = allocate_buffer
- * self.dtype_is_object = format == b'O'
- * if allocate_buffer: # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_4 = (__pyx_v_allocate_buffer != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":175
- *
- *
- * self.data = malloc(self.len) # <<<<<<<<<<<<<<
- * if not self.data:
- * raise MemoryError("unable to allocate array data.")
- */
- __pyx_v_self->data = ((char *)malloc(__pyx_v_self->len));
-
- /* "View.MemoryView":176
- *
- * self.data = malloc(self.len)
- * if not self.data: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate array data.")
- *
- */
- __pyx_t_4 = ((!(__pyx_v_self->data != 0)) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":177
- * self.data = malloc(self.len)
- * if not self.data:
- * raise MemoryError("unable to allocate array data.") # <<<<<<<<<<<<<<
- *
- * if self.dtype_is_object:
- */
- __pyx_t_10 = __Pyx_PyObject_Call(__pyx_builtin_MemoryError, __pyx_tuple__5, NULL); if (unlikely(!__pyx_t_10)) __PYX_ERR(1, 177, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_10);
- __Pyx_Raise(__pyx_t_10, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
- __PYX_ERR(1, 177, __pyx_L1_error)
-
- /* "View.MemoryView":176
- *
- * self.data = malloc(self.len)
- * if not self.data: # <<<<<<<<<<<<<<
- * raise MemoryError("unable to allocate array data.")
- *
- */
- }
-
- /* "View.MemoryView":179
- * raise MemoryError("unable to allocate array data.")
- *
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * p = self.data
- * for i in range(self.len / itemsize):
- */
- __pyx_t_4 = (__pyx_v_self->dtype_is_object != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":180
- *
- * if self.dtype_is_object:
- * p = self.data # <<<<<<<<<<<<<<
- * for i in range(self.len / itemsize):
- * p[i] = Py_None
- */
- __pyx_v_p = ((PyObject **)__pyx_v_self->data);
-
- /* "View.MemoryView":181
- * if self.dtype_is_object:
- * p = self.data
- * for i in range(self.len / itemsize): # <<<<<<<<<<<<<<
- * p[i] = Py_None
- * Py_INCREF(Py_None)
- */
- if (unlikely(__pyx_v_itemsize == 0)) {
- PyErr_SetString(PyExc_ZeroDivisionError, "integer division or modulo by zero");
- __PYX_ERR(1, 181, __pyx_L1_error)
- }
- else if (sizeof(Py_ssize_t) == sizeof(long) && (!(((Py_ssize_t)-1) > 0)) && unlikely(__pyx_v_itemsize == (Py_ssize_t)-1) && unlikely(UNARY_NEG_WOULD_OVERFLOW(__pyx_v_self->len))) {
- PyErr_SetString(PyExc_OverflowError, "value too large to perform division");
- __PYX_ERR(1, 181, __pyx_L1_error)
- }
- __pyx_t_1 = __Pyx_div_Py_ssize_t(__pyx_v_self->len, __pyx_v_itemsize);
- __pyx_t_9 = __pyx_t_1;
- for (__pyx_t_11 = 0; __pyx_t_11 < __pyx_t_9; __pyx_t_11+=1) {
- __pyx_v_i = __pyx_t_11;
-
- /* "View.MemoryView":182
- * p = self.data
- * for i in range(self.len / itemsize):
- * p[i] = Py_None # <<<<<<<<<<<<<<
- * Py_INCREF(Py_None)
- *
- */
- (__pyx_v_p[__pyx_v_i]) = Py_None;
-
- /* "View.MemoryView":183
- * for i in range(self.len / itemsize):
- * p[i] = Py_None
- * Py_INCREF(Py_None) # <<<<<<<<<<<<<<
- *
- * @cname('getbuffer')
- */
- Py_INCREF(Py_None);
- }
-
- /* "View.MemoryView":179
- * raise MemoryError("unable to allocate array data.")
- *
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * p = self.data
- * for i in range(self.len / itemsize):
- */
- }
-
- /* "View.MemoryView":172
- * self.free_data = allocate_buffer
- * self.dtype_is_object = format == b'O'
- * if allocate_buffer: # <<<<<<<<<<<<<<
- *
- *
- */
- }
-
- /* "View.MemoryView":123
- * cdef bint dtype_is_object
- *
- * def __cinit__(array self, tuple shape, Py_ssize_t itemsize, format not None, # <<<<<<<<<<<<<<
- * mode="c", bint allocate_buffer=True):
- *
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_10);
- __Pyx_AddTraceback("View.MemoryView.array.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_format);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":186
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * cdef int bufmode = -1
- * if self.mode == u"c":
- */
-
-/* Python wrapper */
-static CYTHON_UNUSED int __pyx_array_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-static CYTHON_UNUSED int __pyx_array_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getbuffer__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_2__getbuffer__(((struct __pyx_array_obj *)__pyx_v_self), ((Py_buffer *)__pyx_v_info), ((int)__pyx_v_flags));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_2__getbuffer__(struct __pyx_array_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_v_bufmode;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- char *__pyx_t_4;
- Py_ssize_t __pyx_t_5;
- int __pyx_t_6;
- Py_ssize_t *__pyx_t_7;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- if (__pyx_v_info == NULL) {
- PyErr_SetString(PyExc_BufferError, "PyObject_GetBuffer: view==NULL argument is obsolete");
- return -1;
- }
- __Pyx_RefNannySetupContext("__getbuffer__", 0);
- __pyx_v_info->obj = Py_None; __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(__pyx_v_info->obj);
-
- /* "View.MemoryView":187
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * cdef int bufmode = -1 # <<<<<<<<<<<<<<
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- */
- __pyx_v_bufmode = -1;
-
- /* "View.MemoryView":188
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * cdef int bufmode = -1
- * if self.mode == u"c": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran":
- */
- __pyx_t_1 = (__Pyx_PyUnicode_Equals(__pyx_v_self->mode, __pyx_n_u_c, Py_EQ)); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 188, __pyx_L1_error)
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":189
- * cdef int bufmode = -1
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS # <<<<<<<<<<<<<<
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- */
- __pyx_v_bufmode = (PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS);
-
- /* "View.MemoryView":188
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * cdef int bufmode = -1
- * if self.mode == u"c": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran":
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":190
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- */
- __pyx_t_2 = (__Pyx_PyUnicode_Equals(__pyx_v_self->mode, __pyx_n_u_fortran, Py_EQ)); if (unlikely(__pyx_t_2 < 0)) __PYX_ERR(1, 190, __pyx_L1_error)
- __pyx_t_1 = (__pyx_t_2 != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":191
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS # <<<<<<<<<<<<<<
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- */
- __pyx_v_bufmode = (PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS);
-
- /* "View.MemoryView":190
- * if self.mode == u"c":
- * bufmode = PyBUF_C_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * elif self.mode == u"fortran": # <<<<<<<<<<<<<<
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":192
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode): # <<<<<<<<<<<<<<
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data
- */
- __pyx_t_1 = ((!((__pyx_v_flags & __pyx_v_bufmode) != 0)) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":193
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.") # <<<<<<<<<<<<<<
- * info.buf = self.data
- * info.len = self.len
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__6, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 193, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 193, __pyx_L1_error)
-
- /* "View.MemoryView":192
- * elif self.mode == u"fortran":
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode): # <<<<<<<<<<<<<<
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data
- */
- }
-
- /* "View.MemoryView":194
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data # <<<<<<<<<<<<<<
- * info.len = self.len
- * info.ndim = self.ndim
- */
- __pyx_t_4 = __pyx_v_self->data;
- __pyx_v_info->buf = __pyx_t_4;
-
- /* "View.MemoryView":195
- * raise ValueError("Can only create a buffer that is contiguous in memory.")
- * info.buf = self.data
- * info.len = self.len # <<<<<<<<<<<<<<
- * info.ndim = self.ndim
- * info.shape = self._shape
- */
- __pyx_t_5 = __pyx_v_self->len;
- __pyx_v_info->len = __pyx_t_5;
-
- /* "View.MemoryView":196
- * info.buf = self.data
- * info.len = self.len
- * info.ndim = self.ndim # <<<<<<<<<<<<<<
- * info.shape = self._shape
- * info.strides = self._strides
- */
- __pyx_t_6 = __pyx_v_self->ndim;
- __pyx_v_info->ndim = __pyx_t_6;
-
- /* "View.MemoryView":197
- * info.len = self.len
- * info.ndim = self.ndim
- * info.shape = self._shape # <<<<<<<<<<<<<<
- * info.strides = self._strides
- * info.suboffsets = NULL
- */
- __pyx_t_7 = __pyx_v_self->_shape;
- __pyx_v_info->shape = __pyx_t_7;
-
- /* "View.MemoryView":198
- * info.ndim = self.ndim
- * info.shape = self._shape
- * info.strides = self._strides # <<<<<<<<<<<<<<
- * info.suboffsets = NULL
- * info.itemsize = self.itemsize
- */
- __pyx_t_7 = __pyx_v_self->_strides;
- __pyx_v_info->strides = __pyx_t_7;
-
- /* "View.MemoryView":199
- * info.shape = self._shape
- * info.strides = self._strides
- * info.suboffsets = NULL # <<<<<<<<<<<<<<
- * info.itemsize = self.itemsize
- * info.readonly = 0
- */
- __pyx_v_info->suboffsets = NULL;
-
- /* "View.MemoryView":200
- * info.strides = self._strides
- * info.suboffsets = NULL
- * info.itemsize = self.itemsize # <<<<<<<<<<<<<<
- * info.readonly = 0
- *
- */
- __pyx_t_5 = __pyx_v_self->itemsize;
- __pyx_v_info->itemsize = __pyx_t_5;
-
- /* "View.MemoryView":201
- * info.suboffsets = NULL
- * info.itemsize = self.itemsize
- * info.readonly = 0 # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_FORMAT:
- */
- __pyx_v_info->readonly = 0;
-
- /* "View.MemoryView":203
- * info.readonly = 0
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.format
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_FORMAT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":204
- *
- * if flags & PyBUF_FORMAT:
- * info.format = self.format # <<<<<<<<<<<<<<
- * else:
- * info.format = NULL
- */
- __pyx_t_4 = __pyx_v_self->format;
- __pyx_v_info->format = __pyx_t_4;
-
- /* "View.MemoryView":203
- * info.readonly = 0
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.format
- * else:
- */
- goto __pyx_L5;
- }
-
- /* "View.MemoryView":206
- * info.format = self.format
- * else:
- * info.format = NULL # <<<<<<<<<<<<<<
- *
- * info.obj = self
- */
- /*else*/ {
- __pyx_v_info->format = NULL;
- }
- __pyx_L5:;
-
- /* "View.MemoryView":208
- * info.format = NULL
- *
- * info.obj = self # <<<<<<<<<<<<<<
- *
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)")
- */
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(((PyObject *)__pyx_v_self));
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj);
- __pyx_v_info->obj = ((PyObject *)__pyx_v_self);
-
- /* "View.MemoryView":186
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * cdef int bufmode = -1
- * if self.mode == u"c":
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.array.__getbuffer__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- if (__pyx_v_info->obj != NULL) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- goto __pyx_L2;
- __pyx_L0:;
- if (__pyx_v_info->obj == Py_None) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- __pyx_L2:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":212
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)")
- *
- * def __dealloc__(array self): # <<<<<<<<<<<<<<
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- */
-
-/* Python wrapper */
-static void __pyx_array___dealloc__(PyObject *__pyx_v_self); /*proto*/
-static void __pyx_array___dealloc__(PyObject *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__ (wrapper)", 0);
- __pyx_array___pyx_pf_15View_dot_MemoryView_5array_4__dealloc__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-static void __pyx_array___pyx_pf_15View_dot_MemoryView_5array_4__dealloc__(struct __pyx_array_obj *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- __Pyx_RefNannySetupContext("__dealloc__", 0);
-
- /* "View.MemoryView":213
- *
- * def __dealloc__(array self):
- * if self.callback_free_data != NULL: # <<<<<<<<<<<<<<
- * self.callback_free_data(self.data)
- * elif self.free_data:
- */
- __pyx_t_1 = ((__pyx_v_self->callback_free_data != NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":214
- * def __dealloc__(array self):
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data) # <<<<<<<<<<<<<<
- * elif self.free_data:
- * if self.dtype_is_object:
- */
- __pyx_v_self->callback_free_data(__pyx_v_self->data);
-
- /* "View.MemoryView":213
- *
- * def __dealloc__(array self):
- * if self.callback_free_data != NULL: # <<<<<<<<<<<<<<
- * self.callback_free_data(self.data)
- * elif self.free_data:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":215
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- * elif self.free_data: # <<<<<<<<<<<<<<
- * if self.dtype_is_object:
- * refcount_objects_in_slice(self.data, self._shape,
- */
- __pyx_t_1 = (__pyx_v_self->free_data != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":216
- * self.callback_free_data(self.data)
- * elif self.free_data:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice(self.data, self._shape,
- * self._strides, self.ndim, False)
- */
- __pyx_t_1 = (__pyx_v_self->dtype_is_object != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":217
- * elif self.free_data:
- * if self.dtype_is_object:
- * refcount_objects_in_slice(self.data, self._shape, # <<<<<<<<<<<<<<
- * self._strides, self.ndim, False)
- * free(self.data)
- */
- __pyx_memoryview_refcount_objects_in_slice(__pyx_v_self->data, __pyx_v_self->_shape, __pyx_v_self->_strides, __pyx_v_self->ndim, 0);
-
- /* "View.MemoryView":216
- * self.callback_free_data(self.data)
- * elif self.free_data:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice(self.data, self._shape,
- * self._strides, self.ndim, False)
- */
- }
-
- /* "View.MemoryView":219
- * refcount_objects_in_slice(self.data, self._shape,
- * self._strides, self.ndim, False)
- * free(self.data) # <<<<<<<<<<<<<<
- * PyObject_Free(self._shape)
- *
- */
- free(__pyx_v_self->data);
-
- /* "View.MemoryView":215
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- * elif self.free_data: # <<<<<<<<<<<<<<
- * if self.dtype_is_object:
- * refcount_objects_in_slice(self.data, self._shape,
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":220
- * self._strides, self.ndim, False)
- * free(self.data)
- * PyObject_Free(self._shape) # <<<<<<<<<<<<<<
- *
- * @property
- */
- PyObject_Free(__pyx_v_self->_shape);
-
- /* "View.MemoryView":212
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)")
- *
- * def __dealloc__(array self): # <<<<<<<<<<<<<<
- * if self.callback_free_data != NULL:
- * self.callback_free_data(self.data)
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":223
- *
- * @property
- * def memview(self): # <<<<<<<<<<<<<<
- * return self.get_memview()
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_5array_7memview_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_5array_7memview_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_5array_7memview___get__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_5array_7memview___get__(struct __pyx_array_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":224
- * @property
- * def memview(self):
- * return self.get_memview() # <<<<<<<<<<<<<<
- *
- * @cname('get_memview')
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = ((struct __pyx_vtabstruct_array *)__pyx_v_self->__pyx_vtab)->get_memview(__pyx_v_self); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 224, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":223
- *
- * @property
- * def memview(self): # <<<<<<<<<<<<<<
- * return self.get_memview()
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.memview.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":227
- *
- * @cname('get_memview')
- * cdef get_memview(self): # <<<<<<<<<<<<<<
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE
- * return memoryview(self, flags, self.dtype_is_object)
- */
-
-static PyObject *__pyx_array_get_memview(struct __pyx_array_obj *__pyx_v_self) {
- int __pyx_v_flags;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("get_memview", 0);
-
- /* "View.MemoryView":228
- * @cname('get_memview')
- * cdef get_memview(self):
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE # <<<<<<<<<<<<<<
- * return memoryview(self, flags, self.dtype_is_object)
- *
- */
- __pyx_v_flags = ((PyBUF_ANY_CONTIGUOUS | PyBUF_FORMAT) | PyBUF_WRITABLE);
-
- /* "View.MemoryView":229
- * cdef get_memview(self):
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE
- * return memoryview(self, flags, self.dtype_is_object) # <<<<<<<<<<<<<<
- *
- * def __len__(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_flags); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_v_self->dtype_is_object); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyTuple_New(3); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(((PyObject *)__pyx_v_self));
- PyTuple_SET_ITEM(__pyx_t_3, 0, ((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 2, __pyx_t_2);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryview_type), __pyx_t_3, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 229, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":227
- *
- * @cname('get_memview')
- * cdef get_memview(self): # <<<<<<<<<<<<<<
- * flags = PyBUF_ANY_CONTIGUOUS|PyBUF_FORMAT|PyBUF_WRITABLE
- * return memoryview(self, flags, self.dtype_is_object)
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.array.get_memview", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":231
- * return memoryview(self, flags, self.dtype_is_object)
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * return self._shape[0]
- *
- */
-
-/* Python wrapper */
-static Py_ssize_t __pyx_array___len__(PyObject *__pyx_v_self); /*proto*/
-static Py_ssize_t __pyx_array___len__(PyObject *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__len__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_6__len__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static Py_ssize_t __pyx_array___pyx_pf_15View_dot_MemoryView_5array_6__len__(struct __pyx_array_obj *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__len__", 0);
-
- /* "View.MemoryView":232
- *
- * def __len__(self):
- * return self._shape[0] # <<<<<<<<<<<<<<
- *
- * def __getattr__(self, attr):
- */
- __pyx_r = (__pyx_v_self->_shape[0]);
- goto __pyx_L0;
-
- /* "View.MemoryView":231
- * return memoryview(self, flags, self.dtype_is_object)
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * return self._shape[0]
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":234
- * return self._shape[0]
- *
- * def __getattr__(self, attr): # <<<<<<<<<<<<<<
- * return getattr(self.memview, attr)
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_array___getattr__(PyObject *__pyx_v_self, PyObject *__pyx_v_attr); /*proto*/
-static PyObject *__pyx_array___getattr__(PyObject *__pyx_v_self, PyObject *__pyx_v_attr) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getattr__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_8__getattr__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v_attr));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_8__getattr__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_attr) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__getattr__", 0);
-
- /* "View.MemoryView":235
- *
- * def __getattr__(self, attr):
- * return getattr(self.memview, attr) # <<<<<<<<<<<<<<
- *
- * def __getitem__(self, item):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_memview); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 235, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_GetAttr(__pyx_t_1, __pyx_v_attr); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 235, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":234
- * return self._shape[0]
- *
- * def __getattr__(self, attr): # <<<<<<<<<<<<<<
- * return getattr(self.memview, attr)
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.array.__getattr__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":237
- * return getattr(self.memview, attr)
- *
- * def __getitem__(self, item): # <<<<<<<<<<<<<<
- * return self.memview[item]
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_array___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item); /*proto*/
-static PyObject *__pyx_array___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getitem__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_10__getitem__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v_item));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_array___pyx_pf_15View_dot_MemoryView_5array_10__getitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__getitem__", 0);
-
- /* "View.MemoryView":238
- *
- * def __getitem__(self, item):
- * return self.memview[item] # <<<<<<<<<<<<<<
- *
- * def __setitem__(self, item, value):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_memview); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 238, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyObject_GetItem(__pyx_t_1, __pyx_v_item); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 238, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":237
- * return getattr(self.memview, attr)
- *
- * def __getitem__(self, item): # <<<<<<<<<<<<<<
- * return self.memview[item]
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.array.__getitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":240
- * return self.memview[item]
- *
- * def __setitem__(self, item, value): # <<<<<<<<<<<<<<
- * self.memview[item] = value
- *
- */
-
-/* Python wrapper */
-static int __pyx_array___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value); /*proto*/
-static int __pyx_array___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setitem__ (wrapper)", 0);
- __pyx_r = __pyx_array___pyx_pf_15View_dot_MemoryView_5array_12__setitem__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v_item), ((PyObject *)__pyx_v_value));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_array___pyx_pf_15View_dot_MemoryView_5array_12__setitem__(struct __pyx_array_obj *__pyx_v_self, PyObject *__pyx_v_item, PyObject *__pyx_v_value) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setitem__", 0);
-
- /* "View.MemoryView":241
- *
- * def __setitem__(self, item, value):
- * self.memview[item] = value # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_memview); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 241, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (unlikely(PyObject_SetItem(__pyx_t_1, __pyx_v_item, __pyx_v_value) < 0)) __PYX_ERR(1, 241, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "View.MemoryView":240
- * return self.memview[item]
- *
- * def __setitem__(self, item, value): # <<<<<<<<<<<<<<
- * self.memview[item] = value
- *
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.__setitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_array_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_array_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_array___reduce_cython__(((struct __pyx_array_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_array___reduce_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__7, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 2, __pyx_L1_error)
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_array_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_array_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_array_2__setstate_cython__(((struct __pyx_array_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_array_2__setstate_cython__(CYTHON_UNUSED struct __pyx_array_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__8, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 4, __pyx_L1_error)
-
- /* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.array.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":245
- *
- * @cname("__pyx_array_new")
- * cdef array array_cwrapper(tuple shape, Py_ssize_t itemsize, char *format, # <<<<<<<<<<<<<<
- * char *mode, char *buf):
- * cdef array result
- */
-
-static struct __pyx_array_obj *__pyx_array_new(PyObject *__pyx_v_shape, Py_ssize_t __pyx_v_itemsize, char *__pyx_v_format, char *__pyx_v_mode, char *__pyx_v_buf) {
- struct __pyx_array_obj *__pyx_v_result = 0;
- struct __pyx_array_obj *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("array_cwrapper", 0);
-
- /* "View.MemoryView":249
- * cdef array result
- *
- * if buf == NULL: # <<<<<<<<<<<<<<
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- */
- __pyx_t_1 = ((__pyx_v_buf == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":250
- *
- * if buf == NULL:
- * result = array(shape, itemsize, format, mode.decode('ASCII')) # <<<<<<<<<<<<<<
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'),
- */
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_itemsize); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = __Pyx_PyBytes_FromString(__pyx_v_format); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_decode_c_string(__pyx_v_mode, 0, strlen(__pyx_v_mode), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = PyTuple_New(4); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_INCREF(__pyx_v_shape);
- __Pyx_GIVEREF(__pyx_v_shape);
- PyTuple_SET_ITEM(__pyx_t_5, 0, __pyx_v_shape);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_5, 1, __pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_5, 2, __pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_5, 3, __pyx_t_4);
- __pyx_t_2 = 0;
- __pyx_t_3 = 0;
- __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PyObject_Call(((PyObject *)__pyx_array_type), __pyx_t_5, NULL); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 250, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_v_result = ((struct __pyx_array_obj *)__pyx_t_4);
- __pyx_t_4 = 0;
-
- /* "View.MemoryView":249
- * cdef array result
- *
- * if buf == NULL: # <<<<<<<<<<<<<<
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":252
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'), # <<<<<<<<<<<<<<
- * allocate_buffer=False)
- * result.data = buf
- */
- /*else*/ {
- __pyx_t_4 = PyInt_FromSsize_t(__pyx_v_itemsize); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = __Pyx_PyBytes_FromString(__pyx_v_format); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_3 = __Pyx_decode_c_string(__pyx_v_mode, 0, strlen(__pyx_v_mode), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_2 = PyTuple_New(4); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_INCREF(__pyx_v_shape);
- __Pyx_GIVEREF(__pyx_v_shape);
- PyTuple_SET_ITEM(__pyx_t_2, 0, __pyx_v_shape);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_2, 1, __pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_5);
- PyTuple_SET_ITEM(__pyx_t_2, 2, __pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_2, 3, __pyx_t_3);
- __pyx_t_4 = 0;
- __pyx_t_5 = 0;
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":253
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'),
- * allocate_buffer=False) # <<<<<<<<<<<<<<
- * result.data = buf
- *
- */
- __pyx_t_3 = __Pyx_PyDict_NewPresized(1); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 253, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- if (PyDict_SetItem(__pyx_t_3, __pyx_n_s_allocate_buffer, Py_False) < 0) __PYX_ERR(1, 253, __pyx_L1_error)
-
- /* "View.MemoryView":252
- * result = array(shape, itemsize, format, mode.decode('ASCII'))
- * else:
- * result = array(shape, itemsize, format, mode.decode('ASCII'), # <<<<<<<<<<<<<<
- * allocate_buffer=False)
- * result.data = buf
- */
- __pyx_t_5 = __Pyx_PyObject_Call(((PyObject *)__pyx_array_type), __pyx_t_2, __pyx_t_3); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 252, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result = ((struct __pyx_array_obj *)__pyx_t_5);
- __pyx_t_5 = 0;
-
- /* "View.MemoryView":254
- * result = array(shape, itemsize, format, mode.decode('ASCII'),
- * allocate_buffer=False)
- * result.data = buf # <<<<<<<<<<<<<<
- *
- * return result
- */
- __pyx_v_result->data = __pyx_v_buf;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":256
- * result.data = buf
- *
- * return result # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(((PyObject *)__pyx_r));
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = __pyx_v_result;
- goto __pyx_L0;
-
- /* "View.MemoryView":245
- *
- * @cname("__pyx_array_new")
- * cdef array array_cwrapper(tuple shape, Py_ssize_t itemsize, char *format, # <<<<<<<<<<<<<<
- * char *mode, char *buf):
- * cdef array result
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.array_cwrapper", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XGIVEREF((PyObject *)__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":282
- * cdef class Enum(object):
- * cdef object name
- * def __init__(self, name): # <<<<<<<<<<<<<<
- * self.name = name
- * def __repr__(self):
- */
-
-/* Python wrapper */
-static int __pyx_MemviewEnum___init__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static int __pyx_MemviewEnum___init__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v_name = 0;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__init__ (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_name,0};
- PyObject* values[1] = {0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_name)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__init__") < 0)) __PYX_ERR(1, 282, __pyx_L3_error)
- }
- } else if (PyTuple_GET_SIZE(__pyx_args) != 1) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- }
- __pyx_v_name = values[0];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__init__", 1, 1, 1, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 282, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.Enum.__init__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return -1;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum___init__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self), __pyx_v_name);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum___init__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v_name) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__init__", 0);
-
- /* "View.MemoryView":283
- * cdef object name
- * def __init__(self, name):
- * self.name = name # <<<<<<<<<<<<<<
- * def __repr__(self):
- * return self.name
- */
- __Pyx_INCREF(__pyx_v_name);
- __Pyx_GIVEREF(__pyx_v_name);
- __Pyx_GOTREF(__pyx_v_self->name);
- __Pyx_DECREF(__pyx_v_self->name);
- __pyx_v_self->name = __pyx_v_name;
-
- /* "View.MemoryView":282
- * cdef class Enum(object):
- * cdef object name
- * def __init__(self, name): # <<<<<<<<<<<<<<
- * self.name = name
- * def __repr__(self):
- */
-
- /* function exit code */
- __pyx_r = 0;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":284
- * def __init__(self, name):
- * self.name = name
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return self.name
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_MemviewEnum___repr__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_MemviewEnum___repr__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__repr__ (wrapper)", 0);
- __pyx_r = __pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum_2__repr__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_MemviewEnum___pyx_pf_15View_dot_MemoryView_4Enum_2__repr__(struct __pyx_MemviewEnum_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__repr__", 0);
-
- /* "View.MemoryView":285
- * self.name = name
- * def __repr__(self):
- * return self.name # <<<<<<<<<<<<<<
- *
- * cdef generic = Enum("")
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->name);
- __pyx_r = __pyx_v_self->name;
- goto __pyx_L0;
-
- /* "View.MemoryView":284
- * def __init__(self, name):
- * self.name = name
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return self.name
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * cdef tuple state
- * cdef object _dict
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_MemviewEnum_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_MemviewEnum_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_MemviewEnum___reduce_cython__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_MemviewEnum___reduce_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self) {
- PyObject *__pyx_v_state = 0;
- PyObject *__pyx_v__dict = 0;
- int __pyx_v_use_setstate;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_t_3;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":5
- * cdef object _dict
- * cdef bint use_setstate
- * state = (self.name,) # <<<<<<<<<<<<<<
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None:
- */
- __pyx_t_1 = PyTuple_New(1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_v_self->name);
- __Pyx_GIVEREF(__pyx_v_self->name);
- PyTuple_SET_ITEM(__pyx_t_1, 0, __pyx_v_self->name);
- __pyx_v_state = ((PyObject*)__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "(tree fragment)":6
- * cdef bint use_setstate
- * state = (self.name,)
- * _dict = getattr(self, '__dict__', None) # <<<<<<<<<<<<<<
- * if _dict is not None:
- * state += (_dict,)
- */
- __pyx_t_1 = __Pyx_GetAttr3(((PyObject *)__pyx_v_self), __pyx_n_s_dict, Py_None); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v__dict = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "(tree fragment)":7
- * state = (self.name,)
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None: # <<<<<<<<<<<<<<
- * state += (_dict,)
- * use_setstate = True
- */
- __pyx_t_2 = (__pyx_v__dict != Py_None);
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (__pyx_t_3) {
-
- /* "(tree fragment)":8
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None:
- * state += (_dict,) # <<<<<<<<<<<<<<
- * use_setstate = True
- * else:
- */
- __pyx_t_1 = PyTuple_New(1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 8, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_v__dict);
- __Pyx_GIVEREF(__pyx_v__dict);
- PyTuple_SET_ITEM(__pyx_t_1, 0, __pyx_v__dict);
- __pyx_t_4 = PyNumber_InPlaceAdd(__pyx_v_state, __pyx_t_1); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 8, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF_SET(__pyx_v_state, ((PyObject*)__pyx_t_4));
- __pyx_t_4 = 0;
-
- /* "(tree fragment)":9
- * if _dict is not None:
- * state += (_dict,)
- * use_setstate = True # <<<<<<<<<<<<<<
- * else:
- * use_setstate = self.name is not None
- */
- __pyx_v_use_setstate = 1;
-
- /* "(tree fragment)":7
- * state = (self.name,)
- * _dict = getattr(self, '__dict__', None)
- * if _dict is not None: # <<<<<<<<<<<<<<
- * state += (_dict,)
- * use_setstate = True
- */
- goto __pyx_L3;
- }
-
- /* "(tree fragment)":11
- * use_setstate = True
- * else:
- * use_setstate = self.name is not None # <<<<<<<<<<<<<<
- * if use_setstate:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- */
- /*else*/ {
- __pyx_t_3 = (__pyx_v_self->name != Py_None);
- __pyx_v_use_setstate = __pyx_t_3;
- }
- __pyx_L3:;
-
- /* "(tree fragment)":12
- * else:
- * use_setstate = self.name is not None
- * if use_setstate: # <<<<<<<<<<<<<<
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- * else:
- */
- __pyx_t_3 = (__pyx_v_use_setstate != 0);
- if (__pyx_t_3) {
-
- /* "(tree fragment)":13
- * use_setstate = self.name is not None
- * if use_setstate:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state # <<<<<<<<<<<<<<
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_GetModuleGlobalName(__pyx_t_4, __pyx_n_s_pyx_unpickle_Enum); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 13, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_1 = PyTuple_New(3); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 13, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_GIVEREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- PyTuple_SET_ITEM(__pyx_t_1, 0, ((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_INCREF(__pyx_int_184977713);
- __Pyx_GIVEREF(__pyx_int_184977713);
- PyTuple_SET_ITEM(__pyx_t_1, 1, __pyx_int_184977713);
- __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(Py_None);
- PyTuple_SET_ITEM(__pyx_t_1, 2, Py_None);
- __pyx_t_5 = PyTuple_New(3); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 13, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_5, 0, __pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_5, 1, __pyx_t_1);
- __Pyx_INCREF(__pyx_v_state);
- __Pyx_GIVEREF(__pyx_v_state);
- PyTuple_SET_ITEM(__pyx_t_5, 2, __pyx_v_state);
- __pyx_t_4 = 0;
- __pyx_t_1 = 0;
- __pyx_r = __pyx_t_5;
- __pyx_t_5 = 0;
- goto __pyx_L0;
-
- /* "(tree fragment)":12
- * else:
- * use_setstate = self.name is not None
- * if use_setstate: # <<<<<<<<<<<<<<
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- * else:
- */
- }
-
- /* "(tree fragment)":15
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, None), state
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state) # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * __pyx_unpickle_Enum__set_state(self, __pyx_state)
- */
- /*else*/ {
- __Pyx_XDECREF(__pyx_r);
- __Pyx_GetModuleGlobalName(__pyx_t_5, __pyx_n_s_pyx_unpickle_Enum); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 15, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_1 = PyTuple_New(3); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 15, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_GIVEREF(((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- PyTuple_SET_ITEM(__pyx_t_1, 0, ((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))));
- __Pyx_INCREF(__pyx_int_184977713);
- __Pyx_GIVEREF(__pyx_int_184977713);
- PyTuple_SET_ITEM(__pyx_t_1, 1, __pyx_int_184977713);
- __Pyx_INCREF(__pyx_v_state);
- __Pyx_GIVEREF(__pyx_v_state);
- PyTuple_SET_ITEM(__pyx_t_1, 2, __pyx_v_state);
- __pyx_t_4 = PyTuple_New(2); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 15, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_5);
- PyTuple_SET_ITEM(__pyx_t_4, 0, __pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_4, 1, __pyx_t_1);
- __pyx_t_5 = 0;
- __pyx_t_1 = 0;
- __pyx_r = __pyx_t_4;
- __pyx_t_4 = 0;
- goto __pyx_L0;
- }
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * cdef tuple state
- * cdef object _dict
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.Enum.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_state);
- __Pyx_XDECREF(__pyx_v__dict);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":16
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state(self, __pyx_state)
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_MemviewEnum_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_MemviewEnum_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_MemviewEnum_2__setstate_cython__(((struct __pyx_MemviewEnum_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_MemviewEnum_2__setstate_cython__(struct __pyx_MemviewEnum_obj *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":17
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- * def __setstate_cython__(self, __pyx_state):
- * __pyx_unpickle_Enum__set_state(self, __pyx_state) # <<<<<<<<<<<<<<
- */
- if (!(likely(PyTuple_CheckExact(__pyx_v___pyx_state))||((__pyx_v___pyx_state) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "tuple", Py_TYPE(__pyx_v___pyx_state)->tp_name), 0))) __PYX_ERR(1, 17, __pyx_L1_error)
- __pyx_t_1 = __pyx_unpickle_Enum__set_state(__pyx_v_self, ((PyObject*)__pyx_v___pyx_state)); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 17, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "(tree fragment)":16
- * else:
- * return __pyx_unpickle_Enum, (type(self), 0xb068931, state)
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state(self, __pyx_state)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.Enum.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":299
- *
- * @cname('__pyx_align_pointer')
- * cdef void *align_pointer(void *memory, size_t alignment) nogil: # <<<<<<<<<<<<<<
- * "Align pointer memory on a given boundary"
- * cdef Py_intptr_t aligned_p = memory
- */
-
-static void *__pyx_align_pointer(void *__pyx_v_memory, size_t __pyx_v_alignment) {
- Py_intptr_t __pyx_v_aligned_p;
- size_t __pyx_v_offset;
- void *__pyx_r;
- int __pyx_t_1;
-
- /* "View.MemoryView":301
- * cdef void *align_pointer(void *memory, size_t alignment) nogil:
- * "Align pointer memory on a given boundary"
- * cdef Py_intptr_t aligned_p = memory # <<<<<<<<<<<<<<
- * cdef size_t offset
- *
- */
- __pyx_v_aligned_p = ((Py_intptr_t)__pyx_v_memory);
-
- /* "View.MemoryView":305
- *
- * with cython.cdivision(True):
- * offset = aligned_p % alignment # <<<<<<<<<<<<<<
- *
- * if offset > 0:
- */
- __pyx_v_offset = (__pyx_v_aligned_p % __pyx_v_alignment);
-
- /* "View.MemoryView":307
- * offset = aligned_p % alignment
- *
- * if offset > 0: # <<<<<<<<<<<<<<
- * aligned_p += alignment - offset
- *
- */
- __pyx_t_1 = ((__pyx_v_offset > 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":308
- *
- * if offset > 0:
- * aligned_p += alignment - offset # <<<<<<<<<<<<<<
- *
- * return aligned_p
- */
- __pyx_v_aligned_p = (__pyx_v_aligned_p + (__pyx_v_alignment - __pyx_v_offset));
-
- /* "View.MemoryView":307
- * offset = aligned_p % alignment
- *
- * if offset > 0: # <<<<<<<<<<<<<<
- * aligned_p += alignment - offset
- *
- */
- }
-
- /* "View.MemoryView":310
- * aligned_p += alignment - offset
- *
- * return aligned_p # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = ((void *)__pyx_v_aligned_p);
- goto __pyx_L0;
-
- /* "View.MemoryView":299
- *
- * @cname('__pyx_align_pointer')
- * cdef void *align_pointer(void *memory, size_t alignment) nogil: # <<<<<<<<<<<<<<
- * "Align pointer memory on a given boundary"
- * cdef Py_intptr_t aligned_p = memory
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":346
- * cdef __Pyx_TypeInfo *typeinfo
- *
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False): # <<<<<<<<<<<<<<
- * self.obj = obj
- * self.flags = flags
- */
-
-/* Python wrapper */
-static int __pyx_memoryview___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static int __pyx_memoryview___cinit__(PyObject *__pyx_v_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v_obj = 0;
- int __pyx_v_flags;
- int __pyx_v_dtype_is_object;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__cinit__ (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_obj,&__pyx_n_s_flags,&__pyx_n_s_dtype_is_object,0};
- PyObject* values[3] = {0,0,0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_obj)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_flags)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 2, 3, 1); __PYX_ERR(1, 346, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (kw_args > 0) {
- PyObject* value = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_dtype_is_object);
- if (value) { values[2] = value; kw_args--; }
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__cinit__") < 0)) __PYX_ERR(1, 346, __pyx_L3_error)
- }
- } else {
- switch (PyTuple_GET_SIZE(__pyx_args)) {
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- break;
- default: goto __pyx_L5_argtuple_error;
- }
- }
- __pyx_v_obj = values[0];
- __pyx_v_flags = __Pyx_PyInt_As_int(values[1]); if (unlikely((__pyx_v_flags == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 346, __pyx_L3_error)
- if (values[2]) {
- __pyx_v_dtype_is_object = __Pyx_PyObject_IsTrue(values[2]); if (unlikely((__pyx_v_dtype_is_object == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 346, __pyx_L3_error)
- } else {
- __pyx_v_dtype_is_object = ((int)0);
- }
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__cinit__", 0, 2, 3, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 346, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.memoryview.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return -1;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview___cinit__(((struct __pyx_memoryview_obj *)__pyx_v_self), __pyx_v_obj, __pyx_v_flags, __pyx_v_dtype_is_object);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview___cinit__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj, int __pyx_v_flags, int __pyx_v_dtype_is_object) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__cinit__", 0);
-
- /* "View.MemoryView":347
- *
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False):
- * self.obj = obj # <<<<<<<<<<<<<<
- * self.flags = flags
- * if type(self) is memoryview or obj is not None:
- */
- __Pyx_INCREF(__pyx_v_obj);
- __Pyx_GIVEREF(__pyx_v_obj);
- __Pyx_GOTREF(__pyx_v_self->obj);
- __Pyx_DECREF(__pyx_v_self->obj);
- __pyx_v_self->obj = __pyx_v_obj;
-
- /* "View.MemoryView":348
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False):
- * self.obj = obj
- * self.flags = flags # <<<<<<<<<<<<<<
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags)
- */
- __pyx_v_self->flags = __pyx_v_flags;
-
- /* "View.MemoryView":349
- * self.obj = obj
- * self.flags = flags
- * if type(self) is memoryview or obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL:
- */
- __pyx_t_2 = (((PyObject *)Py_TYPE(((PyObject *)__pyx_v_self))) == ((PyObject *)__pyx_memoryview_type));
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (!__pyx_t_3) {
- } else {
- __pyx_t_1 = __pyx_t_3;
- goto __pyx_L4_bool_binop_done;
- }
- __pyx_t_3 = (__pyx_v_obj != Py_None);
- __pyx_t_2 = (__pyx_t_3 != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L4_bool_binop_done:;
- if (__pyx_t_1) {
-
- /* "View.MemoryView":350
- * self.flags = flags
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags) # <<<<<<<<<<<<<<
- * if self.view.obj == NULL:
- * (<__pyx_buffer *> &self.view).obj = Py_None
- */
- __pyx_t_4 = __Pyx_GetBuffer(__pyx_v_obj, (&__pyx_v_self->view), __pyx_v_flags); if (unlikely(__pyx_t_4 == ((int)-1))) __PYX_ERR(1, 350, __pyx_L1_error)
-
- /* "View.MemoryView":351
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL: # <<<<<<<<<<<<<<
- * (<__pyx_buffer *> &self.view).obj = Py_None
- * Py_INCREF(Py_None)
- */
- __pyx_t_1 = ((((PyObject *)__pyx_v_self->view.obj) == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":352
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL:
- * (<__pyx_buffer *> &self.view).obj = Py_None # <<<<<<<<<<<<<<
- * Py_INCREF(Py_None)
- *
- */
- ((Py_buffer *)(&__pyx_v_self->view))->obj = Py_None;
-
- /* "View.MemoryView":353
- * if self.view.obj == NULL:
- * (<__pyx_buffer *> &self.view).obj = Py_None
- * Py_INCREF(Py_None) # <<<<<<<<<<<<<<
- *
- * if not __PYX_CYTHON_ATOMICS_ENABLED():
- */
- Py_INCREF(Py_None);
-
- /* "View.MemoryView":351
- * if type(self) is memoryview or obj is not None:
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL: # <<<<<<<<<<<<<<
- * (<__pyx_buffer *> &self.view).obj = Py_None
- * Py_INCREF(Py_None)
- */
- }
-
- /* "View.MemoryView":349
- * self.obj = obj
- * self.flags = flags
- * if type(self) is memoryview or obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_GetBuffer(obj, &self.view, flags)
- * if self.view.obj == NULL:
- */
- }
-
- /* "View.MemoryView":355
- * Py_INCREF(Py_None)
- *
- * if not __PYX_CYTHON_ATOMICS_ENABLED(): # <<<<<<<<<<<<<<
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- */
- __pyx_t_1 = ((!(__PYX_CYTHON_ATOMICS_ENABLED() != 0)) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":357
- * if not __PYX_CYTHON_ATOMICS_ENABLED():
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED: # <<<<<<<<<<<<<<
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- */
- __pyx_t_1 = ((__pyx_memoryview_thread_locks_used < 8) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":358
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL:
- */
- __pyx_v_self->lock = (__pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]);
-
- /* "View.MemoryView":359
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1 # <<<<<<<<<<<<<<
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock()
- */
- __pyx_memoryview_thread_locks_used = (__pyx_memoryview_thread_locks_used + 1);
-
- /* "View.MemoryView":357
- * if not __PYX_CYTHON_ATOMICS_ENABLED():
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED: # <<<<<<<<<<<<<<
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- */
- }
-
- /* "View.MemoryView":360
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL:
- */
- __pyx_t_1 = ((__pyx_v_self->lock == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":361
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock() # <<<<<<<<<<<<<<
- * if self.lock is NULL:
- * raise MemoryError
- */
- __pyx_v_self->lock = PyThread_allocate_lock();
-
- /* "View.MemoryView":362
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- *
- */
- __pyx_t_1 = ((__pyx_v_self->lock == NULL) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":363
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL:
- * raise MemoryError # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_FORMAT:
- */
- PyErr_NoMemory(); __PYX_ERR(1, 363, __pyx_L1_error)
-
- /* "View.MemoryView":362
- * if self.lock is NULL:
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- *
- */
- }
-
- /* "View.MemoryView":360
- * self.lock = __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]
- * __pyx_memoryview_thread_locks_used += 1
- * if self.lock is NULL: # <<<<<<<<<<<<<<
- * self.lock = PyThread_allocate_lock()
- * if self.lock is NULL:
- */
- }
-
- /* "View.MemoryView":355
- * Py_INCREF(Py_None)
- *
- * if not __PYX_CYTHON_ATOMICS_ENABLED(): # <<<<<<<<<<<<<<
- * global __pyx_memoryview_thread_locks_used
- * if __pyx_memoryview_thread_locks_used < THREAD_LOCKS_PREALLOCATED:
- */
- }
-
- /* "View.MemoryView":365
- * raise MemoryError
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0')
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_FORMAT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":366
- *
- * if flags & PyBUF_FORMAT:
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0') # <<<<<<<<<<<<<<
- * else:
- * self.dtype_is_object = dtype_is_object
- */
- __pyx_t_2 = (((__pyx_v_self->view.format[0]) == 'O') != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L12_bool_binop_done;
- }
- __pyx_t_2 = (((__pyx_v_self->view.format[1]) == '\x00') != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L12_bool_binop_done:;
- __pyx_v_self->dtype_is_object = __pyx_t_1;
-
- /* "View.MemoryView":365
- * raise MemoryError
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0')
- * else:
- */
- goto __pyx_L11;
- }
-
- /* "View.MemoryView":368
- * self.dtype_is_object = (self.view.format[0] == b'O' and self.view.format[1] == b'\0')
- * else:
- * self.dtype_is_object = dtype_is_object # <<<<<<<<<<<<<<
- *
- * self.acquisition_count_aligned_p = <__pyx_atomic_int *> align_pointer(
- */
- /*else*/ {
- __pyx_v_self->dtype_is_object = __pyx_v_dtype_is_object;
- }
- __pyx_L11:;
-
- /* "View.MemoryView":370
- * self.dtype_is_object = dtype_is_object
- *
- * self.acquisition_count_aligned_p = <__pyx_atomic_int *> align_pointer( # <<<<<<<<<<<<<<
- * &self.acquisition_count[0], sizeof(__pyx_atomic_int))
- * self.typeinfo = NULL
- */
- __pyx_v_self->acquisition_count_aligned_p = ((__pyx_atomic_int *)__pyx_align_pointer(((void *)(&(__pyx_v_self->acquisition_count[0]))), (sizeof(__pyx_atomic_int))));
-
- /* "View.MemoryView":372
- * self.acquisition_count_aligned_p = <__pyx_atomic_int *> align_pointer(
- * &self.acquisition_count[0], sizeof(__pyx_atomic_int))
- * self.typeinfo = NULL # <<<<<<<<<<<<<<
- *
- * def __dealloc__(memoryview self):
- */
- __pyx_v_self->typeinfo = NULL;
-
- /* "View.MemoryView":346
- * cdef __Pyx_TypeInfo *typeinfo
- *
- * def __cinit__(memoryview self, object obj, int flags, bint dtype_is_object=False): # <<<<<<<<<<<<<<
- * self.obj = obj
- * self.flags = flags
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_AddTraceback("View.MemoryView.memoryview.__cinit__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":374
- * self.typeinfo = NULL
- *
- * def __dealloc__(memoryview self): # <<<<<<<<<<<<<<
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- */
-
-/* Python wrapper */
-static void __pyx_memoryview___dealloc__(PyObject *__pyx_v_self); /*proto*/
-static void __pyx_memoryview___dealloc__(PyObject *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__ (wrapper)", 0);
- __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_2__dealloc__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-static void __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_2__dealloc__(struct __pyx_memoryview_obj *__pyx_v_self) {
- int __pyx_v_i;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- int __pyx_t_5;
- PyThread_type_lock __pyx_t_6;
- PyThread_type_lock __pyx_t_7;
- __Pyx_RefNannySetupContext("__dealloc__", 0);
-
- /* "View.MemoryView":375
- *
- * def __dealloc__(memoryview self):
- * if self.obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- */
- __pyx_t_1 = (__pyx_v_self->obj != Py_None);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":376
- * def __dealloc__(memoryview self):
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view) # <<<<<<<<<<<<<<
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- *
- */
- __Pyx_ReleaseBuffer((&__pyx_v_self->view));
-
- /* "View.MemoryView":375
- *
- * def __dealloc__(memoryview self):
- * if self.obj is not None: # <<<<<<<<<<<<<<
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":377
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None: # <<<<<<<<<<<<<<
- *
- * (<__pyx_buffer *> &self.view).obj = NULL
- */
- __pyx_t_2 = ((((Py_buffer *)(&__pyx_v_self->view))->obj == Py_None) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":379
- * elif (<__pyx_buffer *> &self.view).obj == Py_None:
- *
- * (<__pyx_buffer *> &self.view).obj = NULL # <<<<<<<<<<<<<<
- * Py_DECREF(Py_None)
- *
- */
- ((Py_buffer *)(&__pyx_v_self->view))->obj = NULL;
-
- /* "View.MemoryView":380
- *
- * (<__pyx_buffer *> &self.view).obj = NULL
- * Py_DECREF(Py_None) # <<<<<<<<<<<<<<
- *
- * cdef int i
- */
- Py_DECREF(Py_None);
-
- /* "View.MemoryView":377
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- * elif (<__pyx_buffer *> &self.view).obj == Py_None: # <<<<<<<<<<<<<<
- *
- * (<__pyx_buffer *> &self.view).obj = NULL
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":384
- * cdef int i
- * global __pyx_memoryview_thread_locks_used
- * if self.lock != NULL: # <<<<<<<<<<<<<<
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- */
- __pyx_t_2 = ((__pyx_v_self->lock != NULL) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":385
- * global __pyx_memoryview_thread_locks_used
- * if self.lock != NULL:
- * for i in range(__pyx_memoryview_thread_locks_used): # <<<<<<<<<<<<<<
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1
- */
- __pyx_t_3 = __pyx_memoryview_thread_locks_used;
- __pyx_t_4 = __pyx_t_3;
- for (__pyx_t_5 = 0; __pyx_t_5 < __pyx_t_4; __pyx_t_5+=1) {
- __pyx_v_i = __pyx_t_5;
-
- /* "View.MemoryView":386
- * if self.lock != NULL:
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used:
- */
- __pyx_t_2 = (((__pyx_memoryview_thread_locks[__pyx_v_i]) == __pyx_v_self->lock) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":387
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1 # <<<<<<<<<<<<<<
- * if i != __pyx_memoryview_thread_locks_used:
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- */
- __pyx_memoryview_thread_locks_used = (__pyx_memoryview_thread_locks_used - 1);
-
- /* "View.MemoryView":388
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- */
- __pyx_t_2 = ((__pyx_v_i != __pyx_memoryview_thread_locks_used) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":390
- * if i != __pyx_memoryview_thread_locks_used:
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i]) # <<<<<<<<<<<<<<
- * break
- * else:
- */
- __pyx_t_6 = (__pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]);
- __pyx_t_7 = (__pyx_memoryview_thread_locks[__pyx_v_i]);
-
- /* "View.MemoryView":389
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used:
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = ( # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- * break
- */
- (__pyx_memoryview_thread_locks[__pyx_v_i]) = __pyx_t_6;
- (__pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used]) = __pyx_t_7;
-
- /* "View.MemoryView":388
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- */
- }
-
- /* "View.MemoryView":391
- * __pyx_memoryview_thread_locks[i], __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used] = (
- * __pyx_memoryview_thread_locks[__pyx_memoryview_thread_locks_used], __pyx_memoryview_thread_locks[i])
- * break # <<<<<<<<<<<<<<
- * else:
- * PyThread_free_lock(self.lock)
- */
- goto __pyx_L6_break;
-
- /* "View.MemoryView":386
- * if self.lock != NULL:
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock: # <<<<<<<<<<<<<<
- * __pyx_memoryview_thread_locks_used -= 1
- * if i != __pyx_memoryview_thread_locks_used:
- */
- }
- }
- /*else*/ {
-
- /* "View.MemoryView":393
- * break
- * else:
- * PyThread_free_lock(self.lock) # <<<<<<<<<<<<<<
- *
- * cdef char *get_item_pointer(memoryview self, object index) except NULL:
- */
- PyThread_free_lock(__pyx_v_self->lock);
- }
- __pyx_L6_break:;
-
- /* "View.MemoryView":384
- * cdef int i
- * global __pyx_memoryview_thread_locks_used
- * if self.lock != NULL: # <<<<<<<<<<<<<<
- * for i in range(__pyx_memoryview_thread_locks_used):
- * if __pyx_memoryview_thread_locks[i] is self.lock:
- */
- }
-
- /* "View.MemoryView":374
- * self.typeinfo = NULL
- *
- * def __dealloc__(memoryview self): # <<<<<<<<<<<<<<
- * if self.obj is not None:
- * __Pyx_ReleaseBuffer(&self.view)
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":395
- * PyThread_free_lock(self.lock)
- *
- * cdef char *get_item_pointer(memoryview self, object index) except NULL: # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dim
- * cdef char *itemp = self.view.buf
- */
-
-static char *__pyx_memoryview_get_item_pointer(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index) {
- Py_ssize_t __pyx_v_dim;
- char *__pyx_v_itemp;
- PyObject *__pyx_v_idx = NULL;
- char *__pyx_r;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- Py_ssize_t __pyx_t_3;
- PyObject *(*__pyx_t_4)(PyObject *);
- PyObject *__pyx_t_5 = NULL;
- Py_ssize_t __pyx_t_6;
- char *__pyx_t_7;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("get_item_pointer", 0);
-
- /* "View.MemoryView":397
- * cdef char *get_item_pointer(memoryview self, object index) except NULL:
- * cdef Py_ssize_t dim
- * cdef char *itemp = self.view.buf # <<<<<<<<<<<<<<
- *
- * for dim, idx in enumerate(index):
- */
- __pyx_v_itemp = ((char *)__pyx_v_self->view.buf);
-
- /* "View.MemoryView":399
- * cdef char *itemp = self.view.buf
- *
- * for dim, idx in enumerate(index): # <<<<<<<<<<<<<<
- * itemp = pybuffer_index(&self.view, itemp, idx, dim)
- *
- */
- __pyx_t_1 = 0;
- if (likely(PyList_CheckExact(__pyx_v_index)) || PyTuple_CheckExact(__pyx_v_index)) {
- __pyx_t_2 = __pyx_v_index; __Pyx_INCREF(__pyx_t_2); __pyx_t_3 = 0;
- __pyx_t_4 = NULL;
- } else {
- __pyx_t_3 = -1; __pyx_t_2 = PyObject_GetIter(__pyx_v_index); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 399, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_4 = Py_TYPE(__pyx_t_2)->tp_iternext; if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 399, __pyx_L1_error)
- }
- for (;;) {
- if (likely(!__pyx_t_4)) {
- if (likely(PyList_CheckExact(__pyx_t_2))) {
- if (__pyx_t_3 >= PyList_GET_SIZE(__pyx_t_2)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_5 = PyList_GET_ITEM(__pyx_t_2, __pyx_t_3); __Pyx_INCREF(__pyx_t_5); __pyx_t_3++; if (unlikely(0 < 0)) __PYX_ERR(1, 399, __pyx_L1_error)
- #else
- __pyx_t_5 = PySequence_ITEM(__pyx_t_2, __pyx_t_3); __pyx_t_3++; if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 399, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- } else {
- if (__pyx_t_3 >= PyTuple_GET_SIZE(__pyx_t_2)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_5 = PyTuple_GET_ITEM(__pyx_t_2, __pyx_t_3); __Pyx_INCREF(__pyx_t_5); __pyx_t_3++; if (unlikely(0 < 0)) __PYX_ERR(1, 399, __pyx_L1_error)
- #else
- __pyx_t_5 = PySequence_ITEM(__pyx_t_2, __pyx_t_3); __pyx_t_3++; if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 399, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- }
- } else {
- __pyx_t_5 = __pyx_t_4(__pyx_t_2);
- if (unlikely(!__pyx_t_5)) {
- PyObject* exc_type = PyErr_Occurred();
- if (exc_type) {
- if (likely(__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration))) PyErr_Clear();
- else __PYX_ERR(1, 399, __pyx_L1_error)
- }
- break;
- }
- __Pyx_GOTREF(__pyx_t_5);
- }
- __Pyx_XDECREF_SET(__pyx_v_idx, __pyx_t_5);
- __pyx_t_5 = 0;
- __pyx_v_dim = __pyx_t_1;
- __pyx_t_1 = (__pyx_t_1 + 1);
-
- /* "View.MemoryView":400
- *
- * for dim, idx in enumerate(index):
- * itemp = pybuffer_index(&self.view, itemp, idx, dim) # <<<<<<<<<<<<<<
- *
- * return itemp
- */
- __pyx_t_6 = __Pyx_PyIndex_AsSsize_t(__pyx_v_idx); if (unlikely((__pyx_t_6 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 400, __pyx_L1_error)
- __pyx_t_7 = __pyx_pybuffer_index((&__pyx_v_self->view), __pyx_v_itemp, __pyx_t_6, __pyx_v_dim); if (unlikely(__pyx_t_7 == ((char *)NULL))) __PYX_ERR(1, 400, __pyx_L1_error)
- __pyx_v_itemp = __pyx_t_7;
-
- /* "View.MemoryView":399
- * cdef char *itemp = self.view.buf
- *
- * for dim, idx in enumerate(index): # <<<<<<<<<<<<<<
- * itemp = pybuffer_index(&self.view, itemp, idx, dim)
- *
- */
- }
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "View.MemoryView":402
- * itemp = pybuffer_index(&self.view, itemp, idx, dim)
- *
- * return itemp # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = __pyx_v_itemp;
- goto __pyx_L0;
-
- /* "View.MemoryView":395
- * PyThread_free_lock(self.lock)
- *
- * cdef char *get_item_pointer(memoryview self, object index) except NULL: # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dim
- * cdef char *itemp = self.view.buf
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview.get_item_pointer", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_idx);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":405
- *
- *
- * def __getitem__(memoryview self, object index): # <<<<<<<<<<<<<<
- * if index is Ellipsis:
- * return self
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index); /*proto*/
-static PyObject *__pyx_memoryview___getitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getitem__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_4__getitem__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((PyObject *)__pyx_v_index));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_4__getitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index) {
- PyObject *__pyx_v_have_slices = NULL;
- PyObject *__pyx_v_indices = NULL;
- char *__pyx_v_itemp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- char *__pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__getitem__", 0);
-
- /* "View.MemoryView":406
- *
- * def __getitem__(memoryview self, object index):
- * if index is Ellipsis: # <<<<<<<<<<<<<<
- * return self
- *
- */
- __pyx_t_1 = (__pyx_v_index == __pyx_builtin_Ellipsis);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":407
- * def __getitem__(memoryview self, object index):
- * if index is Ellipsis:
- * return self # <<<<<<<<<<<<<<
- *
- * have_slices, indices = _unellipsify(index, self.view.ndim)
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __pyx_r = ((PyObject *)__pyx_v_self);
- goto __pyx_L0;
-
- /* "View.MemoryView":406
- *
- * def __getitem__(memoryview self, object index):
- * if index is Ellipsis: # <<<<<<<<<<<<<<
- * return self
- *
- */
- }
-
- /* "View.MemoryView":409
- * return self
- *
- * have_slices, indices = _unellipsify(index, self.view.ndim) # <<<<<<<<<<<<<<
- *
- * cdef char *itemp
- */
- __pyx_t_3 = _unellipsify(__pyx_v_index, __pyx_v_self->view.ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 409, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- if (likely(__pyx_t_3 != Py_None)) {
- PyObject* sequence = __pyx_t_3;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(1, 409, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_4 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_5 = PyTuple_GET_ITEM(sequence, 1);
- __Pyx_INCREF(__pyx_t_4);
- __Pyx_INCREF(__pyx_t_5);
- #else
- __pyx_t_4 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 409, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 409, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- #endif
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- } else {
- __Pyx_RaiseNoneNotIterableError(); __PYX_ERR(1, 409, __pyx_L1_error)
- }
- __pyx_v_have_slices = __pyx_t_4;
- __pyx_t_4 = 0;
- __pyx_v_indices = __pyx_t_5;
- __pyx_t_5 = 0;
-
- /* "View.MemoryView":412
- *
- * cdef char *itemp
- * if have_slices: # <<<<<<<<<<<<<<
- * return memview_slice(self, indices)
- * else:
- */
- __pyx_t_2 = __Pyx_PyObject_IsTrue(__pyx_v_have_slices); if (unlikely(__pyx_t_2 < 0)) __PYX_ERR(1, 412, __pyx_L1_error)
- if (__pyx_t_2) {
-
- /* "View.MemoryView":413
- * cdef char *itemp
- * if have_slices:
- * return memview_slice(self, indices) # <<<<<<<<<<<<<<
- * else:
- * itemp = self.get_item_pointer(indices)
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_3 = ((PyObject *)__pyx_memview_slice(__pyx_v_self, __pyx_v_indices)); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 413, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":412
- *
- * cdef char *itemp
- * if have_slices: # <<<<<<<<<<<<<<
- * return memview_slice(self, indices)
- * else:
- */
- }
-
- /* "View.MemoryView":415
- * return memview_slice(self, indices)
- * else:
- * itemp = self.get_item_pointer(indices) # <<<<<<<<<<<<<<
- * return self.convert_item_to_object(itemp)
- *
- */
- /*else*/ {
- __pyx_t_6 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->get_item_pointer(__pyx_v_self, __pyx_v_indices); if (unlikely(__pyx_t_6 == ((char *)NULL))) __PYX_ERR(1, 415, __pyx_L1_error)
- __pyx_v_itemp = __pyx_t_6;
-
- /* "View.MemoryView":416
- * else:
- * itemp = self.get_item_pointer(indices)
- * return self.convert_item_to_object(itemp) # <<<<<<<<<<<<<<
- *
- * def __setitem__(memoryview self, object index, object value):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_3 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->convert_item_to_object(__pyx_v_self, __pyx_v_itemp); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 416, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":405
- *
- *
- * def __getitem__(memoryview self, object index): # <<<<<<<<<<<<<<
- * if index is Ellipsis:
- * return self
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__getitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_have_slices);
- __Pyx_XDECREF(__pyx_v_indices);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":418
- * return self.convert_item_to_object(itemp)
- *
- * def __setitem__(memoryview self, object index, object value): # <<<<<<<<<<<<<<
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview")
- */
-
-/* Python wrapper */
-static int __pyx_memoryview___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value); /*proto*/
-static int __pyx_memoryview___setitem__(PyObject *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setitem__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_6__setitem__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((PyObject *)__pyx_v_index), ((PyObject *)__pyx_v_value));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_6__setitem__(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value) {
- PyObject *__pyx_v_have_slices = NULL;
- PyObject *__pyx_v_obj = NULL;
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setitem__", 0);
- __Pyx_INCREF(__pyx_v_index);
-
- /* "View.MemoryView":419
- *
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly: # <<<<<<<<<<<<<<
- * raise TypeError("Cannot assign to read-only memoryview")
- *
- */
- __pyx_t_1 = (__pyx_v_self->view.readonly != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":420
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview") # <<<<<<<<<<<<<<
- *
- * have_slices, index = _unellipsify(index, self.view.ndim)
- */
- __pyx_t_2 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__9, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 420, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_Raise(__pyx_t_2, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __PYX_ERR(1, 420, __pyx_L1_error)
-
- /* "View.MemoryView":419
- *
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly: # <<<<<<<<<<<<<<
- * raise TypeError("Cannot assign to read-only memoryview")
- *
- */
- }
-
- /* "View.MemoryView":422
- * raise TypeError("Cannot assign to read-only memoryview")
- *
- * have_slices, index = _unellipsify(index, self.view.ndim) # <<<<<<<<<<<<<<
- *
- * if have_slices:
- */
- __pyx_t_2 = _unellipsify(__pyx_v_index, __pyx_v_self->view.ndim); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 422, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (likely(__pyx_t_2 != Py_None)) {
- PyObject* sequence = __pyx_t_2;
- Py_ssize_t size = __Pyx_PySequence_SIZE(sequence);
- if (unlikely(size != 2)) {
- if (size > 2) __Pyx_RaiseTooManyValuesError(2);
- else if (size >= 0) __Pyx_RaiseNeedMoreValuesError(size);
- __PYX_ERR(1, 422, __pyx_L1_error)
- }
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_3 = PyTuple_GET_ITEM(sequence, 0);
- __pyx_t_4 = PyTuple_GET_ITEM(sequence, 1);
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_t_4);
- #else
- __pyx_t_3 = PySequence_ITEM(sequence, 0); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 422, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = PySequence_ITEM(sequence, 1); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 422, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- #endif
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- } else {
- __Pyx_RaiseNoneNotIterableError(); __PYX_ERR(1, 422, __pyx_L1_error)
- }
- __pyx_v_have_slices = __pyx_t_3;
- __pyx_t_3 = 0;
- __Pyx_DECREF_SET(__pyx_v_index, __pyx_t_4);
- __pyx_t_4 = 0;
-
- /* "View.MemoryView":424
- * have_slices, index = _unellipsify(index, self.view.ndim)
- *
- * if have_slices: # <<<<<<<<<<<<<<
- * obj = self.is_slice(value)
- * if obj:
- */
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_v_have_slices); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 424, __pyx_L1_error)
- if (__pyx_t_1) {
-
- /* "View.MemoryView":425
- *
- * if have_slices:
- * obj = self.is_slice(value) # <<<<<<<<<<<<<<
- * if obj:
- * self.setitem_slice_assignment(self[index], obj)
- */
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->is_slice(__pyx_v_self, __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 425, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_v_obj = __pyx_t_2;
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":426
- * if have_slices:
- * obj = self.is_slice(value)
- * if obj: # <<<<<<<<<<<<<<
- * self.setitem_slice_assignment(self[index], obj)
- * else:
- */
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_v_obj); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 426, __pyx_L1_error)
- if (__pyx_t_1) {
-
- /* "View.MemoryView":427
- * obj = self.is_slice(value)
- * if obj:
- * self.setitem_slice_assignment(self[index], obj) # <<<<<<<<<<<<<<
- * else:
- * self.setitem_slice_assign_scalar(self[index], value)
- */
- __pyx_t_2 = __Pyx_PyObject_GetItem(((PyObject *)__pyx_v_self), __pyx_v_index); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 427, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_4 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->setitem_slice_assignment(__pyx_v_self, __pyx_t_2, __pyx_v_obj); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 427, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
-
- /* "View.MemoryView":426
- * if have_slices:
- * obj = self.is_slice(value)
- * if obj: # <<<<<<<<<<<<<<
- * self.setitem_slice_assignment(self[index], obj)
- * else:
- */
- goto __pyx_L5;
- }
-
- /* "View.MemoryView":429
- * self.setitem_slice_assignment(self[index], obj)
- * else:
- * self.setitem_slice_assign_scalar(self[index], value) # <<<<<<<<<<<<<<
- * else:
- * self.setitem_indexed(index, value)
- */
- /*else*/ {
- __pyx_t_4 = __Pyx_PyObject_GetItem(((PyObject *)__pyx_v_self), __pyx_v_index); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 429, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- if (!(likely(((__pyx_t_4) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_4, __pyx_memoryview_type))))) __PYX_ERR(1, 429, __pyx_L1_error)
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->setitem_slice_assign_scalar(__pyx_v_self, ((struct __pyx_memoryview_obj *)__pyx_t_4), __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 429, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_L5:;
-
- /* "View.MemoryView":424
- * have_slices, index = _unellipsify(index, self.view.ndim)
- *
- * if have_slices: # <<<<<<<<<<<<<<
- * obj = self.is_slice(value)
- * if obj:
- */
- goto __pyx_L4;
- }
-
- /* "View.MemoryView":431
- * self.setitem_slice_assign_scalar(self[index], value)
- * else:
- * self.setitem_indexed(index, value) # <<<<<<<<<<<<<<
- *
- * cdef is_slice(self, obj):
- */
- /*else*/ {
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->setitem_indexed(__pyx_v_self, __pyx_v_index, __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 431, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_L4:;
-
- /* "View.MemoryView":418
- * return self.convert_item_to_object(itemp)
- *
- * def __setitem__(memoryview self, object index, object value): # <<<<<<<<<<<<<<
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview")
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__setitem__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_have_slices);
- __Pyx_XDECREF(__pyx_v_obj);
- __Pyx_XDECREF(__pyx_v_index);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":433
- * self.setitem_indexed(index, value)
- *
- * cdef is_slice(self, obj): # <<<<<<<<<<<<<<
- * if not isinstance(obj, memoryview):
- * try:
- */
-
-static PyObject *__pyx_memoryview_is_slice(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_obj) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- PyObject *__pyx_t_7 = NULL;
- PyObject *__pyx_t_8 = NULL;
- int __pyx_t_9;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("is_slice", 0);
- __Pyx_INCREF(__pyx_v_obj);
-
- /* "View.MemoryView":434
- *
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview): # <<<<<<<<<<<<<<
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- */
- __pyx_t_1 = __Pyx_TypeCheck(__pyx_v_obj, __pyx_memoryview_type);
- __pyx_t_2 = ((!(__pyx_t_1 != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":435
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview):
- * try: # <<<<<<<<<<<<<<
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- */
- {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ExceptionSave(&__pyx_t_3, &__pyx_t_4, &__pyx_t_5);
- __Pyx_XGOTREF(__pyx_t_3);
- __Pyx_XGOTREF(__pyx_t_4);
- __Pyx_XGOTREF(__pyx_t_5);
- /*try:*/ {
-
- /* "View.MemoryView":436
- * if not isinstance(obj, memoryview):
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS, # <<<<<<<<<<<<<<
- * self.dtype_is_object)
- * except TypeError:
- */
- __pyx_t_6 = __Pyx_PyInt_From_int(((__pyx_v_self->flags & (~PyBUF_WRITABLE)) | PyBUF_ANY_CONTIGUOUS)); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 436, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_6);
-
- /* "View.MemoryView":437
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object) # <<<<<<<<<<<<<<
- * except TypeError:
- * return None
- */
- __pyx_t_7 = __Pyx_PyBool_FromLong(__pyx_v_self->dtype_is_object); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 437, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_7);
-
- /* "View.MemoryView":436
- * if not isinstance(obj, memoryview):
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS, # <<<<<<<<<<<<<<
- * self.dtype_is_object)
- * except TypeError:
- */
- __pyx_t_8 = PyTuple_New(3); if (unlikely(!__pyx_t_8)) __PYX_ERR(1, 436, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_INCREF(__pyx_v_obj);
- __Pyx_GIVEREF(__pyx_v_obj);
- PyTuple_SET_ITEM(__pyx_t_8, 0, __pyx_v_obj);
- __Pyx_GIVEREF(__pyx_t_6);
- PyTuple_SET_ITEM(__pyx_t_8, 1, __pyx_t_6);
- __Pyx_GIVEREF(__pyx_t_7);
- PyTuple_SET_ITEM(__pyx_t_8, 2, __pyx_t_7);
- __pyx_t_6 = 0;
- __pyx_t_7 = 0;
- __pyx_t_7 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryview_type), __pyx_t_8, NULL); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 436, __pyx_L4_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- __Pyx_DECREF_SET(__pyx_v_obj, __pyx_t_7);
- __pyx_t_7 = 0;
-
- /* "View.MemoryView":435
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview):
- * try: # <<<<<<<<<<<<<<
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- */
- }
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_XDECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- goto __pyx_L9_try_end;
- __pyx_L4_error:;
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_XDECREF(__pyx_t_8); __pyx_t_8 = 0;
-
- /* "View.MemoryView":438
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- * except TypeError: # <<<<<<<<<<<<<<
- * return None
- *
- */
- __pyx_t_9 = __Pyx_PyErr_ExceptionMatches(__pyx_builtin_TypeError);
- if (__pyx_t_9) {
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- if (__Pyx_GetException(&__pyx_t_7, &__pyx_t_8, &__pyx_t_6) < 0) __PYX_ERR(1, 438, __pyx_L6_except_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_GOTREF(__pyx_t_8);
- __Pyx_GOTREF(__pyx_t_6);
-
- /* "View.MemoryView":439
- * self.dtype_is_object)
- * except TypeError:
- * return None # <<<<<<<<<<<<<<
- *
- * return obj
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- goto __pyx_L7_except_return;
- }
- goto __pyx_L6_except_error;
- __pyx_L6_except_error:;
-
- /* "View.MemoryView":435
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview):
- * try: # <<<<<<<<<<<<<<
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- * self.dtype_is_object)
- */
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_XGIVEREF(__pyx_t_5);
- __Pyx_ExceptionReset(__pyx_t_3, __pyx_t_4, __pyx_t_5);
- goto __pyx_L1_error;
- __pyx_L7_except_return:;
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_XGIVEREF(__pyx_t_5);
- __Pyx_ExceptionReset(__pyx_t_3, __pyx_t_4, __pyx_t_5);
- goto __pyx_L0;
- __pyx_L9_try_end:;
- }
-
- /* "View.MemoryView":434
- *
- * cdef is_slice(self, obj):
- * if not isinstance(obj, memoryview): # <<<<<<<<<<<<<<
- * try:
- * obj = memoryview(obj, self.flags & ~PyBUF_WRITABLE | PyBUF_ANY_CONTIGUOUS,
- */
- }
-
- /* "View.MemoryView":441
- * return None
- *
- * return obj # <<<<<<<<<<<<<<
- *
- * cdef setitem_slice_assignment(self, dst, src):
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_obj);
- __pyx_r = __pyx_v_obj;
- goto __pyx_L0;
-
- /* "View.MemoryView":433
- * self.setitem_indexed(index, value)
- *
- * cdef is_slice(self, obj): # <<<<<<<<<<<<<<
- * if not isinstance(obj, memoryview):
- * try:
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_8);
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_obj);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":443
- * return obj
- *
- * cdef setitem_slice_assignment(self, dst, src): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice dst_slice
- * cdef __Pyx_memviewslice src_slice
- */
-
-static PyObject *__pyx_memoryview_setitem_slice_assignment(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_dst, PyObject *__pyx_v_src) {
- __Pyx_memviewslice __pyx_v_dst_slice;
- __Pyx_memviewslice __pyx_v_src_slice;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- __Pyx_memviewslice *__pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- int __pyx_t_5;
- int __pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("setitem_slice_assignment", 0);
-
- /* "View.MemoryView":447
- * cdef __Pyx_memviewslice src_slice
- *
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0], # <<<<<<<<<<<<<<
- * get_slice_from_memview(dst, &dst_slice)[0],
- * src.ndim, dst.ndim, self.dtype_is_object)
- */
- if (!(likely(((__pyx_v_src) == Py_None) || likely(__Pyx_TypeTest(__pyx_v_src, __pyx_memoryview_type))))) __PYX_ERR(1, 447, __pyx_L1_error)
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(((struct __pyx_memoryview_obj *)__pyx_v_src), (&__pyx_v_src_slice)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 447, __pyx_L1_error)
-
- /* "View.MemoryView":448
- *
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0],
- * get_slice_from_memview(dst, &dst_slice)[0], # <<<<<<<<<<<<<<
- * src.ndim, dst.ndim, self.dtype_is_object)
- *
- */
- if (!(likely(((__pyx_v_dst) == Py_None) || likely(__Pyx_TypeTest(__pyx_v_dst, __pyx_memoryview_type))))) __PYX_ERR(1, 448, __pyx_L1_error)
- __pyx_t_2 = __pyx_memoryview_get_slice_from_memoryview(((struct __pyx_memoryview_obj *)__pyx_v_dst), (&__pyx_v_dst_slice)); if (unlikely(__pyx_t_2 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 448, __pyx_L1_error)
-
- /* "View.MemoryView":449
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0],
- * get_slice_from_memview(dst, &dst_slice)[0],
- * src.ndim, dst.ndim, self.dtype_is_object) # <<<<<<<<<<<<<<
- *
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value):
- */
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_src, __pyx_n_s_ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_PyInt_As_int(__pyx_t_3); if (unlikely((__pyx_t_4 == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_3 = __Pyx_PyObject_GetAttrStr(__pyx_v_dst, __pyx_n_s_ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_5 = __Pyx_PyInt_As_int(__pyx_t_3); if (unlikely((__pyx_t_5 == (int)-1) && PyErr_Occurred())) __PYX_ERR(1, 449, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":447
- * cdef __Pyx_memviewslice src_slice
- *
- * memoryview_copy_contents(get_slice_from_memview(src, &src_slice)[0], # <<<<<<<<<<<<<<
- * get_slice_from_memview(dst, &dst_slice)[0],
- * src.ndim, dst.ndim, self.dtype_is_object)
- */
- __pyx_t_6 = __pyx_memoryview_copy_contents((__pyx_t_1[0]), (__pyx_t_2[0]), __pyx_t_4, __pyx_t_5, __pyx_v_self->dtype_is_object); if (unlikely(__pyx_t_6 == ((int)-1))) __PYX_ERR(1, 447, __pyx_L1_error)
-
- /* "View.MemoryView":443
- * return obj
- *
- * cdef setitem_slice_assignment(self, dst, src): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice dst_slice
- * cdef __Pyx_memviewslice src_slice
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.setitem_slice_assignment", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":451
- * src.ndim, dst.ndim, self.dtype_is_object)
- *
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value): # <<<<<<<<<<<<<<
- * cdef int array[128]
- * cdef void *tmp = NULL
- */
-
-static PyObject *__pyx_memoryview_setitem_slice_assign_scalar(struct __pyx_memoryview_obj *__pyx_v_self, struct __pyx_memoryview_obj *__pyx_v_dst, PyObject *__pyx_v_value) {
- int __pyx_v_array[0x80];
- void *__pyx_v_tmp;
- void *__pyx_v_item;
- __Pyx_memviewslice *__pyx_v_dst_slice;
- __Pyx_memviewslice __pyx_v_tmp_slice;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_t_4;
- int __pyx_t_5;
- char const *__pyx_t_6;
- PyObject *__pyx_t_7 = NULL;
- PyObject *__pyx_t_8 = NULL;
- PyObject *__pyx_t_9 = NULL;
- PyObject *__pyx_t_10 = NULL;
- PyObject *__pyx_t_11 = NULL;
- PyObject *__pyx_t_12 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("setitem_slice_assign_scalar", 0);
-
- /* "View.MemoryView":453
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value):
- * cdef int array[128]
- * cdef void *tmp = NULL # <<<<<<<<<<<<<<
- * cdef void *item
- *
- */
- __pyx_v_tmp = NULL;
-
- /* "View.MemoryView":458
- * cdef __Pyx_memviewslice *dst_slice
- * cdef __Pyx_memviewslice tmp_slice
- * dst_slice = get_slice_from_memview(dst, &tmp_slice) # <<<<<<<<<<<<<<
- *
- * if self.view.itemsize > sizeof(array):
- */
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(__pyx_v_dst, (&__pyx_v_tmp_slice)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 458, __pyx_L1_error)
- __pyx_v_dst_slice = __pyx_t_1;
-
- /* "View.MemoryView":460
- * dst_slice = get_slice_from_memview(dst, &tmp_slice)
- *
- * if self.view.itemsize > sizeof(array): # <<<<<<<<<<<<<<
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL:
- */
- __pyx_t_2 = ((((size_t)__pyx_v_self->view.itemsize) > (sizeof(__pyx_v_array))) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":461
- *
- * if self.view.itemsize > sizeof(array):
- * tmp = PyMem_Malloc(self.view.itemsize) # <<<<<<<<<<<<<<
- * if tmp == NULL:
- * raise MemoryError
- */
- __pyx_v_tmp = PyMem_Malloc(__pyx_v_self->view.itemsize);
-
- /* "View.MemoryView":462
- * if self.view.itemsize > sizeof(array):
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- * item = tmp
- */
- __pyx_t_2 = ((__pyx_v_tmp == NULL) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":463
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL:
- * raise MemoryError # <<<<<<<<<<<<<<
- * item = tmp
- * else:
- */
- PyErr_NoMemory(); __PYX_ERR(1, 463, __pyx_L1_error)
-
- /* "View.MemoryView":462
- * if self.view.itemsize > sizeof(array):
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL: # <<<<<<<<<<<<<<
- * raise MemoryError
- * item = tmp
- */
- }
-
- /* "View.MemoryView":464
- * if tmp == NULL:
- * raise MemoryError
- * item = tmp # <<<<<<<<<<<<<<
- * else:
- * item = array
- */
- __pyx_v_item = __pyx_v_tmp;
-
- /* "View.MemoryView":460
- * dst_slice = get_slice_from_memview(dst, &tmp_slice)
- *
- * if self.view.itemsize > sizeof(array): # <<<<<<<<<<<<<<
- * tmp = PyMem_Malloc(self.view.itemsize)
- * if tmp == NULL:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":466
- * item = tmp
- * else:
- * item = array # <<<<<<<<<<<<<<
- *
- * try:
- */
- /*else*/ {
- __pyx_v_item = ((void *)__pyx_v_array);
- }
- __pyx_L3:;
-
- /* "View.MemoryView":468
- * item = array
- *
- * try: # <<<<<<<<<<<<<<
- * if self.dtype_is_object:
- * ( item)[0] = value
- */
- /*try:*/ {
-
- /* "View.MemoryView":469
- *
- * try:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * ( item)[0] = value
- * else:
- */
- __pyx_t_2 = (__pyx_v_self->dtype_is_object != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":470
- * try:
- * if self.dtype_is_object:
- * ( item)[0] = value # <<<<<<<<<<<<<<
- * else:
- * self.assign_item_from_object( item, value)
- */
- (((PyObject **)__pyx_v_item)[0]) = ((PyObject *)__pyx_v_value);
-
- /* "View.MemoryView":469
- *
- * try:
- * if self.dtype_is_object: # <<<<<<<<<<<<<<
- * ( item)[0] = value
- * else:
- */
- goto __pyx_L8;
- }
-
- /* "View.MemoryView":472
- * ( item)[0] = value
- * else:
- * self.assign_item_from_object( item, value) # <<<<<<<<<<<<<<
- *
- *
- */
- /*else*/ {
- __pyx_t_3 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->assign_item_from_object(__pyx_v_self, ((char *)__pyx_v_item), __pyx_v_value); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 472, __pyx_L6_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- }
- __pyx_L8:;
-
- /* "View.MemoryView":476
- *
- *
- * if self.view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim)
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize,
- */
- __pyx_t_2 = ((__pyx_v_self->view.suboffsets != NULL) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":477
- *
- * if self.view.suboffsets != NULL:
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim) # <<<<<<<<<<<<<<
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize,
- * item, self.dtype_is_object)
- */
- __pyx_t_3 = assert_direct_dimensions(__pyx_v_self->view.suboffsets, __pyx_v_self->view.ndim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 477, __pyx_L6_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":476
- *
- *
- * if self.view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim)
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize,
- */
- }
-
- /* "View.MemoryView":478
- * if self.view.suboffsets != NULL:
- * assert_direct_dimensions(self.view.suboffsets, self.view.ndim)
- * slice_assign_scalar(dst_slice, dst.view.ndim, self.view.itemsize, # <<<<<<<<<<<<<<
- * item, self.dtype_is_object)
- * finally:
- */
- __pyx_memoryview_slice_assign_scalar(__pyx_v_dst_slice, __pyx_v_dst->view.ndim, __pyx_v_self->view.itemsize, __pyx_v_item, __pyx_v_self->dtype_is_object);
- }
-
- /* "View.MemoryView":481
- * item, self.dtype_is_object)
- * finally:
- * PyMem_Free(tmp) # <<<<<<<<<<<<<<
- *
- * cdef setitem_indexed(self, index, value):
- */
- /*finally:*/ {
- /*normal exit:*/{
- PyMem_Free(__pyx_v_tmp);
- goto __pyx_L7;
- }
- __pyx_L6_error:;
- /*exception exit:*/{
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __pyx_t_7 = 0; __pyx_t_8 = 0; __pyx_t_9 = 0; __pyx_t_10 = 0; __pyx_t_11 = 0; __pyx_t_12 = 0;
- __Pyx_XDECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (PY_MAJOR_VERSION >= 3) __Pyx_ExceptionSwap(&__pyx_t_10, &__pyx_t_11, &__pyx_t_12);
- if ((PY_MAJOR_VERSION < 3) || unlikely(__Pyx_GetException(&__pyx_t_7, &__pyx_t_8, &__pyx_t_9) < 0)) __Pyx_ErrFetch(&__pyx_t_7, &__pyx_t_8, &__pyx_t_9);
- __Pyx_XGOTREF(__pyx_t_7);
- __Pyx_XGOTREF(__pyx_t_8);
- __Pyx_XGOTREF(__pyx_t_9);
- __Pyx_XGOTREF(__pyx_t_10);
- __Pyx_XGOTREF(__pyx_t_11);
- __Pyx_XGOTREF(__pyx_t_12);
- __pyx_t_4 = __pyx_lineno; __pyx_t_5 = __pyx_clineno; __pyx_t_6 = __pyx_filename;
- {
- PyMem_Free(__pyx_v_tmp);
- }
- if (PY_MAJOR_VERSION >= 3) {
- __Pyx_XGIVEREF(__pyx_t_10);
- __Pyx_XGIVEREF(__pyx_t_11);
- __Pyx_XGIVEREF(__pyx_t_12);
- __Pyx_ExceptionReset(__pyx_t_10, __pyx_t_11, __pyx_t_12);
- }
- __Pyx_XGIVEREF(__pyx_t_7);
- __Pyx_XGIVEREF(__pyx_t_8);
- __Pyx_XGIVEREF(__pyx_t_9);
- __Pyx_ErrRestore(__pyx_t_7, __pyx_t_8, __pyx_t_9);
- __pyx_t_7 = 0; __pyx_t_8 = 0; __pyx_t_9 = 0; __pyx_t_10 = 0; __pyx_t_11 = 0; __pyx_t_12 = 0;
- __pyx_lineno = __pyx_t_4; __pyx_clineno = __pyx_t_5; __pyx_filename = __pyx_t_6;
- goto __pyx_L1_error;
- }
- __pyx_L7:;
- }
-
- /* "View.MemoryView":451
- * src.ndim, dst.ndim, self.dtype_is_object)
- *
- * cdef setitem_slice_assign_scalar(self, memoryview dst, value): # <<<<<<<<<<<<<<
- * cdef int array[128]
- * cdef void *tmp = NULL
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.setitem_slice_assign_scalar", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":483
- * PyMem_Free(tmp)
- *
- * cdef setitem_indexed(self, index, value): # <<<<<<<<<<<<<<
- * cdef char *itemp = self.get_item_pointer(index)
- * self.assign_item_from_object(itemp, value)
- */
-
-static PyObject *__pyx_memoryview_setitem_indexed(struct __pyx_memoryview_obj *__pyx_v_self, PyObject *__pyx_v_index, PyObject *__pyx_v_value) {
- char *__pyx_v_itemp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- char *__pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("setitem_indexed", 0);
-
- /* "View.MemoryView":484
- *
- * cdef setitem_indexed(self, index, value):
- * cdef char *itemp = self.get_item_pointer(index) # <<<<<<<<<<<<<<
- * self.assign_item_from_object(itemp, value)
- *
- */
- __pyx_t_1 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->get_item_pointer(__pyx_v_self, __pyx_v_index); if (unlikely(__pyx_t_1 == ((char *)NULL))) __PYX_ERR(1, 484, __pyx_L1_error)
- __pyx_v_itemp = __pyx_t_1;
-
- /* "View.MemoryView":485
- * cdef setitem_indexed(self, index, value):
- * cdef char *itemp = self.get_item_pointer(index)
- * self.assign_item_from_object(itemp, value) # <<<<<<<<<<<<<<
- *
- * cdef convert_item_to_object(self, char *itemp):
- */
- __pyx_t_2 = ((struct __pyx_vtabstruct_memoryview *)__pyx_v_self->__pyx_vtab)->assign_item_from_object(__pyx_v_self, __pyx_v_itemp, __pyx_v_value); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 485, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "View.MemoryView":483
- * PyMem_Free(tmp)
- *
- * cdef setitem_indexed(self, index, value): # <<<<<<<<<<<<<<
- * cdef char *itemp = self.get_item_pointer(index)
- * self.assign_item_from_object(itemp, value)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.setitem_indexed", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":487
- * self.assign_item_from_object(itemp, value)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
-static PyObject *__pyx_memoryview_convert_item_to_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp) {
- PyObject *__pyx_v_struct = NULL;
- PyObject *__pyx_v_bytesitem = 0;
- PyObject *__pyx_v_result = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- PyObject *__pyx_t_7 = NULL;
- int __pyx_t_8;
- PyObject *__pyx_t_9 = NULL;
- size_t __pyx_t_10;
- int __pyx_t_11;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("convert_item_to_object", 0);
-
- /* "View.MemoryView":490
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- * import struct # <<<<<<<<<<<<<<
- * cdef bytes bytesitem
- *
- */
- __pyx_t_1 = __Pyx_Import(__pyx_n_s_struct, 0, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 490, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v_struct = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":493
- * cdef bytes bytesitem
- *
- * bytesitem = itemp[:self.view.itemsize] # <<<<<<<<<<<<<<
- * try:
- * result = struct.unpack(self.view.format, bytesitem)
- */
- __pyx_t_1 = __Pyx_PyBytes_FromStringAndSize(__pyx_v_itemp + 0, __pyx_v_self->view.itemsize - 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 493, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v_bytesitem = ((PyObject*)__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":494
- *
- * bytesitem = itemp[:self.view.itemsize]
- * try: # <<<<<<<<<<<<<<
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- */
- {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ExceptionSave(&__pyx_t_2, &__pyx_t_3, &__pyx_t_4);
- __Pyx_XGOTREF(__pyx_t_2);
- __Pyx_XGOTREF(__pyx_t_3);
- __Pyx_XGOTREF(__pyx_t_4);
- /*try:*/ {
-
- /* "View.MemoryView":495
- * bytesitem = itemp[:self.view.itemsize]
- * try:
- * result = struct.unpack(self.view.format, bytesitem) # <<<<<<<<<<<<<<
- * except struct.error:
- * raise ValueError("Unable to convert item to object")
- */
- __pyx_t_5 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_unpack); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_t_6 = __Pyx_PyBytes_FromString(__pyx_v_self->view.format); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_7 = NULL;
- __pyx_t_8 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_5))) {
- __pyx_t_7 = PyMethod_GET_SELF(__pyx_t_5);
- if (likely(__pyx_t_7)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_5);
- __Pyx_INCREF(__pyx_t_7);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_5, function);
- __pyx_t_8 = 1;
- }
- }
- #if CYTHON_FAST_PYCALL
- if (PyFunction_Check(__pyx_t_5)) {
- PyObject *__pyx_temp[3] = {__pyx_t_7, __pyx_t_6, __pyx_v_bytesitem};
- __pyx_t_1 = __Pyx_PyFunction_FastCall(__pyx_t_5, __pyx_temp+1-__pyx_t_8, 2+__pyx_t_8); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- } else
- #endif
- #if CYTHON_FAST_PYCCALL
- if (__Pyx_PyFastCFunction_Check(__pyx_t_5)) {
- PyObject *__pyx_temp[3] = {__pyx_t_7, __pyx_t_6, __pyx_v_bytesitem};
- __pyx_t_1 = __Pyx_PyCFunction_FastCall(__pyx_t_5, __pyx_temp+1-__pyx_t_8, 2+__pyx_t_8); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- } else
- #endif
- {
- __pyx_t_9 = PyTuple_New(2+__pyx_t_8); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_9);
- if (__pyx_t_7) {
- __Pyx_GIVEREF(__pyx_t_7); PyTuple_SET_ITEM(__pyx_t_9, 0, __pyx_t_7); __pyx_t_7 = NULL;
- }
- __Pyx_GIVEREF(__pyx_t_6);
- PyTuple_SET_ITEM(__pyx_t_9, 0+__pyx_t_8, __pyx_t_6);
- __Pyx_INCREF(__pyx_v_bytesitem);
- __Pyx_GIVEREF(__pyx_v_bytesitem);
- PyTuple_SET_ITEM(__pyx_t_9, 1+__pyx_t_8, __pyx_v_bytesitem);
- __pyx_t_6 = 0;
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_t_5, __pyx_t_9, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 495, __pyx_L3_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- }
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __pyx_v_result = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":494
- *
- * bytesitem = itemp[:self.view.itemsize]
- * try: # <<<<<<<<<<<<<<
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- */
- }
-
- /* "View.MemoryView":499
- * raise ValueError("Unable to convert item to object")
- * else:
- * if len(self.view.format) == 1: # <<<<<<<<<<<<<<
- * return result[0]
- * return result
- */
- /*else:*/ {
- __pyx_t_10 = strlen(__pyx_v_self->view.format);
- __pyx_t_11 = ((__pyx_t_10 == 1) != 0);
- if (__pyx_t_11) {
-
- /* "View.MemoryView":500
- * else:
- * if len(self.view.format) == 1:
- * return result[0] # <<<<<<<<<<<<<<
- * return result
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_GetItemInt(__pyx_v_result, 0, long, 1, __Pyx_PyInt_From_long, 0, 0, 1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 500, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L6_except_return;
-
- /* "View.MemoryView":499
- * raise ValueError("Unable to convert item to object")
- * else:
- * if len(self.view.format) == 1: # <<<<<<<<<<<<<<
- * return result[0]
- * return result
- */
- }
-
- /* "View.MemoryView":501
- * if len(self.view.format) == 1:
- * return result[0]
- * return result # <<<<<<<<<<<<<<
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_result);
- __pyx_r = __pyx_v_result;
- goto __pyx_L6_except_return;
- }
- __pyx_L3_error:;
- __Pyx_XDECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_XDECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_XDECREF(__pyx_t_9); __pyx_t_9 = 0;
-
- /* "View.MemoryView":496
- * try:
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error: # <<<<<<<<<<<<<<
- * raise ValueError("Unable to convert item to object")
- * else:
- */
- __Pyx_ErrFetch(&__pyx_t_1, &__pyx_t_5, &__pyx_t_9);
- __pyx_t_6 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_error); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 496, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_8 = __Pyx_PyErr_GivenExceptionMatches(__pyx_t_1, __pyx_t_6);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_ErrRestore(__pyx_t_1, __pyx_t_5, __pyx_t_9);
- __pyx_t_1 = 0; __pyx_t_5 = 0; __pyx_t_9 = 0;
- if (__pyx_t_8) {
- __Pyx_AddTraceback("View.MemoryView.memoryview.convert_item_to_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- if (__Pyx_GetException(&__pyx_t_9, &__pyx_t_5, &__pyx_t_1) < 0) __PYX_ERR(1, 496, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_9);
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_GOTREF(__pyx_t_1);
-
- /* "View.MemoryView":497
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- * raise ValueError("Unable to convert item to object") # <<<<<<<<<<<<<<
- * else:
- * if len(self.view.format) == 1:
- */
- __pyx_t_6 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__10, NULL); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 497, __pyx_L5_except_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_Raise(__pyx_t_6, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- __PYX_ERR(1, 497, __pyx_L5_except_error)
- }
- goto __pyx_L5_except_error;
- __pyx_L5_except_error:;
-
- /* "View.MemoryView":494
- *
- * bytesitem = itemp[:self.view.itemsize]
- * try: # <<<<<<<<<<<<<<
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- */
- __Pyx_XGIVEREF(__pyx_t_2);
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_ExceptionReset(__pyx_t_2, __pyx_t_3, __pyx_t_4);
- goto __pyx_L1_error;
- __pyx_L6_except_return:;
- __Pyx_XGIVEREF(__pyx_t_2);
- __Pyx_XGIVEREF(__pyx_t_3);
- __Pyx_XGIVEREF(__pyx_t_4);
- __Pyx_ExceptionReset(__pyx_t_2, __pyx_t_3, __pyx_t_4);
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":487
- * self.assign_item_from_object(itemp, value)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_9);
- __Pyx_AddTraceback("View.MemoryView.memoryview.convert_item_to_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_struct);
- __Pyx_XDECREF(__pyx_v_bytesitem);
- __Pyx_XDECREF(__pyx_v_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":503
- * return result
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
-static PyObject *__pyx_memoryview_assign_item_from_object(struct __pyx_memoryview_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value) {
- PyObject *__pyx_v_struct = NULL;
- char __pyx_v_c;
- PyObject *__pyx_v_bytesvalue = 0;
- Py_ssize_t __pyx_v_i;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_t_3;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_t_7;
- PyObject *__pyx_t_8 = NULL;
- Py_ssize_t __pyx_t_9;
- PyObject *__pyx_t_10 = NULL;
- char *__pyx_t_11;
- char *__pyx_t_12;
- char *__pyx_t_13;
- char *__pyx_t_14;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("assign_item_from_object", 0);
-
- /* "View.MemoryView":506
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- * import struct # <<<<<<<<<<<<<<
- * cdef char c
- * cdef bytes bytesvalue
- */
- __pyx_t_1 = __Pyx_Import(__pyx_n_s_struct, 0, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 506, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_v_struct = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":511
- * cdef Py_ssize_t i
- *
- * if isinstance(value, tuple): # <<<<<<<<<<<<<<
- * bytesvalue = struct.pack(self.view.format, *value)
- * else:
- */
- __pyx_t_2 = PyTuple_Check(__pyx_v_value);
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (__pyx_t_3) {
-
- /* "View.MemoryView":512
- *
- * if isinstance(value, tuple):
- * bytesvalue = struct.pack(self.view.format, *value) # <<<<<<<<<<<<<<
- * else:
- * bytesvalue = struct.pack(self.view.format, value)
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_pack); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_4 = __Pyx_PyBytes_FromString(__pyx_v_self->view.format); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_5 = PyTuple_New(1); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_5, 0, __pyx_t_4);
- __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PySequence_Tuple(__pyx_v_value); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_6 = PyNumber_Add(__pyx_t_5, __pyx_t_4); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PyObject_Call(__pyx_t_1, __pyx_t_6, NULL); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 512, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (!(likely(PyBytes_CheckExact(__pyx_t_4))||((__pyx_t_4) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "bytes", Py_TYPE(__pyx_t_4)->tp_name), 0))) __PYX_ERR(1, 512, __pyx_L1_error)
- __pyx_v_bytesvalue = ((PyObject*)__pyx_t_4);
- __pyx_t_4 = 0;
-
- /* "View.MemoryView":511
- * cdef Py_ssize_t i
- *
- * if isinstance(value, tuple): # <<<<<<<<<<<<<<
- * bytesvalue = struct.pack(self.view.format, *value)
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":514
- * bytesvalue = struct.pack(self.view.format, *value)
- * else:
- * bytesvalue = struct.pack(self.view.format, value) # <<<<<<<<<<<<<<
- *
- * for i, c in enumerate(bytesvalue):
- */
- /*else*/ {
- __pyx_t_6 = __Pyx_PyObject_GetAttrStr(__pyx_v_struct, __pyx_n_s_pack); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_1 = __Pyx_PyBytes_FromString(__pyx_v_self->view.format); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_5 = NULL;
- __pyx_t_7 = 0;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_6))) {
- __pyx_t_5 = PyMethod_GET_SELF(__pyx_t_6);
- if (likely(__pyx_t_5)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_6);
- __Pyx_INCREF(__pyx_t_5);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_6, function);
- __pyx_t_7 = 1;
- }
- }
- #if CYTHON_FAST_PYCALL
- if (PyFunction_Check(__pyx_t_6)) {
- PyObject *__pyx_temp[3] = {__pyx_t_5, __pyx_t_1, __pyx_v_value};
- __pyx_t_4 = __Pyx_PyFunction_FastCall(__pyx_t_6, __pyx_temp+1-__pyx_t_7, 2+__pyx_t_7); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- } else
- #endif
- #if CYTHON_FAST_PYCCALL
- if (__Pyx_PyFastCFunction_Check(__pyx_t_6)) {
- PyObject *__pyx_temp[3] = {__pyx_t_5, __pyx_t_1, __pyx_v_value};
- __pyx_t_4 = __Pyx_PyCFunction_FastCall(__pyx_t_6, __pyx_temp+1-__pyx_t_7, 2+__pyx_t_7); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- } else
- #endif
- {
- __pyx_t_8 = PyTuple_New(2+__pyx_t_7); if (unlikely(!__pyx_t_8)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_8);
- if (__pyx_t_5) {
- __Pyx_GIVEREF(__pyx_t_5); PyTuple_SET_ITEM(__pyx_t_8, 0, __pyx_t_5); __pyx_t_5 = NULL;
- }
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_8, 0+__pyx_t_7, __pyx_t_1);
- __Pyx_INCREF(__pyx_v_value);
- __Pyx_GIVEREF(__pyx_v_value);
- PyTuple_SET_ITEM(__pyx_t_8, 1+__pyx_t_7, __pyx_v_value);
- __pyx_t_1 = 0;
- __pyx_t_4 = __Pyx_PyObject_Call(__pyx_t_6, __pyx_t_8, NULL); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 514, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_8); __pyx_t_8 = 0;
- }
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (!(likely(PyBytes_CheckExact(__pyx_t_4))||((__pyx_t_4) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "bytes", Py_TYPE(__pyx_t_4)->tp_name), 0))) __PYX_ERR(1, 514, __pyx_L1_error)
- __pyx_v_bytesvalue = ((PyObject*)__pyx_t_4);
- __pyx_t_4 = 0;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":516
- * bytesvalue = struct.pack(self.view.format, value)
- *
- * for i, c in enumerate(bytesvalue): # <<<<<<<<<<<<<<
- * itemp[i] = c
- *
- */
- __pyx_t_9 = 0;
- if (unlikely(__pyx_v_bytesvalue == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' is not iterable");
- __PYX_ERR(1, 516, __pyx_L1_error)
- }
- __Pyx_INCREF(__pyx_v_bytesvalue);
- __pyx_t_10 = __pyx_v_bytesvalue;
- __pyx_t_12 = PyBytes_AS_STRING(__pyx_t_10);
- __pyx_t_13 = (__pyx_t_12 + PyBytes_GET_SIZE(__pyx_t_10));
- for (__pyx_t_14 = __pyx_t_12; __pyx_t_14 < __pyx_t_13; __pyx_t_14++) {
- __pyx_t_11 = __pyx_t_14;
- __pyx_v_c = (__pyx_t_11[0]);
-
- /* "View.MemoryView":517
- *
- * for i, c in enumerate(bytesvalue):
- * itemp[i] = c # <<<<<<<<<<<<<<
- *
- * @cname('getbuffer')
- */
- __pyx_v_i = __pyx_t_9;
-
- /* "View.MemoryView":516
- * bytesvalue = struct.pack(self.view.format, value)
- *
- * for i, c in enumerate(bytesvalue): # <<<<<<<<<<<<<<
- * itemp[i] = c
- *
- */
- __pyx_t_9 = (__pyx_t_9 + 1);
-
- /* "View.MemoryView":517
- *
- * for i, c in enumerate(bytesvalue):
- * itemp[i] = c # <<<<<<<<<<<<<<
- *
- * @cname('getbuffer')
- */
- (__pyx_v_itemp[__pyx_v_i]) = __pyx_v_c;
- }
- __Pyx_DECREF(__pyx_t_10); __pyx_t_10 = 0;
-
- /* "View.MemoryView":503
- * return result
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * """Only used if instantiated manually by the user, or if Cython doesn't
- * know how to convert the type"""
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_8);
- __Pyx_XDECREF(__pyx_t_10);
- __Pyx_AddTraceback("View.MemoryView.memoryview.assign_item_from_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_struct);
- __Pyx_XDECREF(__pyx_v_bytesvalue);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":520
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- */
-
-/* Python wrapper */
-static CYTHON_UNUSED int __pyx_memoryview_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags); /*proto*/
-static CYTHON_UNUSED int __pyx_memoryview_getbuffer(PyObject *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__getbuffer__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_8__getbuffer__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((Py_buffer *)__pyx_v_info), ((int)__pyx_v_flags));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static int __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_8__getbuffer__(struct __pyx_memoryview_obj *__pyx_v_self, Py_buffer *__pyx_v_info, int __pyx_v_flags) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- Py_ssize_t *__pyx_t_4;
- char *__pyx_t_5;
- void *__pyx_t_6;
- int __pyx_t_7;
- Py_ssize_t __pyx_t_8;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- if (__pyx_v_info == NULL) {
- PyErr_SetString(PyExc_BufferError, "PyObject_GetBuffer: view==NULL argument is obsolete");
- return -1;
- }
- __Pyx_RefNannySetupContext("__getbuffer__", 0);
- __pyx_v_info->obj = Py_None; __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(__pyx_v_info->obj);
-
- /* "View.MemoryView":521
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly: # <<<<<<<<<<<<<<
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- */
- __pyx_t_2 = ((__pyx_v_flags & PyBUF_WRITABLE) != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L4_bool_binop_done;
- }
- __pyx_t_2 = (__pyx_v_self->view.readonly != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L4_bool_binop_done:;
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":522
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview") # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_ND:
- */
- __pyx_t_3 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__11, NULL); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 522, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 522, __pyx_L1_error)
-
- /* "View.MemoryView":521
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly: # <<<<<<<<<<<<<<
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- */
- }
-
- /* "View.MemoryView":524
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- * if flags & PyBUF_ND: # <<<<<<<<<<<<<<
- * info.shape = self.view.shape
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_ND) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":525
- *
- * if flags & PyBUF_ND:
- * info.shape = self.view.shape # <<<<<<<<<<<<<<
- * else:
- * info.shape = NULL
- */
- __pyx_t_4 = __pyx_v_self->view.shape;
- __pyx_v_info->shape = __pyx_t_4;
-
- /* "View.MemoryView":524
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- *
- * if flags & PyBUF_ND: # <<<<<<<<<<<<<<
- * info.shape = self.view.shape
- * else:
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":527
- * info.shape = self.view.shape
- * else:
- * info.shape = NULL # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_STRIDES:
- */
- /*else*/ {
- __pyx_v_info->shape = NULL;
- }
- __pyx_L6:;
-
- /* "View.MemoryView":529
- * info.shape = NULL
- *
- * if flags & PyBUF_STRIDES: # <<<<<<<<<<<<<<
- * info.strides = self.view.strides
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_STRIDES) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":530
- *
- * if flags & PyBUF_STRIDES:
- * info.strides = self.view.strides # <<<<<<<<<<<<<<
- * else:
- * info.strides = NULL
- */
- __pyx_t_4 = __pyx_v_self->view.strides;
- __pyx_v_info->strides = __pyx_t_4;
-
- /* "View.MemoryView":529
- * info.shape = NULL
- *
- * if flags & PyBUF_STRIDES: # <<<<<<<<<<<<<<
- * info.strides = self.view.strides
- * else:
- */
- goto __pyx_L7;
- }
-
- /* "View.MemoryView":532
- * info.strides = self.view.strides
- * else:
- * info.strides = NULL # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_INDIRECT:
- */
- /*else*/ {
- __pyx_v_info->strides = NULL;
- }
- __pyx_L7:;
-
- /* "View.MemoryView":534
- * info.strides = NULL
- *
- * if flags & PyBUF_INDIRECT: # <<<<<<<<<<<<<<
- * info.suboffsets = self.view.suboffsets
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_INDIRECT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":535
- *
- * if flags & PyBUF_INDIRECT:
- * info.suboffsets = self.view.suboffsets # <<<<<<<<<<<<<<
- * else:
- * info.suboffsets = NULL
- */
- __pyx_t_4 = __pyx_v_self->view.suboffsets;
- __pyx_v_info->suboffsets = __pyx_t_4;
-
- /* "View.MemoryView":534
- * info.strides = NULL
- *
- * if flags & PyBUF_INDIRECT: # <<<<<<<<<<<<<<
- * info.suboffsets = self.view.suboffsets
- * else:
- */
- goto __pyx_L8;
- }
-
- /* "View.MemoryView":537
- * info.suboffsets = self.view.suboffsets
- * else:
- * info.suboffsets = NULL # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_FORMAT:
- */
- /*else*/ {
- __pyx_v_info->suboffsets = NULL;
- }
- __pyx_L8:;
-
- /* "View.MemoryView":539
- * info.suboffsets = NULL
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.view.format
- * else:
- */
- __pyx_t_1 = ((__pyx_v_flags & PyBUF_FORMAT) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":540
- *
- * if flags & PyBUF_FORMAT:
- * info.format = self.view.format # <<<<<<<<<<<<<<
- * else:
- * info.format = NULL
- */
- __pyx_t_5 = __pyx_v_self->view.format;
- __pyx_v_info->format = __pyx_t_5;
-
- /* "View.MemoryView":539
- * info.suboffsets = NULL
- *
- * if flags & PyBUF_FORMAT: # <<<<<<<<<<<<<<
- * info.format = self.view.format
- * else:
- */
- goto __pyx_L9;
- }
-
- /* "View.MemoryView":542
- * info.format = self.view.format
- * else:
- * info.format = NULL # <<<<<<<<<<<<<<
- *
- * info.buf = self.view.buf
- */
- /*else*/ {
- __pyx_v_info->format = NULL;
- }
- __pyx_L9:;
-
- /* "View.MemoryView":544
- * info.format = NULL
- *
- * info.buf = self.view.buf # <<<<<<<<<<<<<<
- * info.ndim = self.view.ndim
- * info.itemsize = self.view.itemsize
- */
- __pyx_t_6 = __pyx_v_self->view.buf;
- __pyx_v_info->buf = __pyx_t_6;
-
- /* "View.MemoryView":545
- *
- * info.buf = self.view.buf
- * info.ndim = self.view.ndim # <<<<<<<<<<<<<<
- * info.itemsize = self.view.itemsize
- * info.len = self.view.len
- */
- __pyx_t_7 = __pyx_v_self->view.ndim;
- __pyx_v_info->ndim = __pyx_t_7;
-
- /* "View.MemoryView":546
- * info.buf = self.view.buf
- * info.ndim = self.view.ndim
- * info.itemsize = self.view.itemsize # <<<<<<<<<<<<<<
- * info.len = self.view.len
- * info.readonly = self.view.readonly
- */
- __pyx_t_8 = __pyx_v_self->view.itemsize;
- __pyx_v_info->itemsize = __pyx_t_8;
-
- /* "View.MemoryView":547
- * info.ndim = self.view.ndim
- * info.itemsize = self.view.itemsize
- * info.len = self.view.len # <<<<<<<<<<<<<<
- * info.readonly = self.view.readonly
- * info.obj = self
- */
- __pyx_t_8 = __pyx_v_self->view.len;
- __pyx_v_info->len = __pyx_t_8;
-
- /* "View.MemoryView":548
- * info.itemsize = self.view.itemsize
- * info.len = self.view.len
- * info.readonly = self.view.readonly # <<<<<<<<<<<<<<
- * info.obj = self
- *
- */
- __pyx_t_1 = __pyx_v_self->view.readonly;
- __pyx_v_info->readonly = __pyx_t_1;
-
- /* "View.MemoryView":549
- * info.len = self.view.len
- * info.readonly = self.view.readonly
- * info.obj = self # <<<<<<<<<<<<<<
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)")
- */
- __Pyx_INCREF(((PyObject *)__pyx_v_self));
- __Pyx_GIVEREF(((PyObject *)__pyx_v_self));
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj);
- __pyx_v_info->obj = ((PyObject *)__pyx_v_self);
-
- /* "View.MemoryView":520
- *
- * @cname('getbuffer')
- * def __getbuffer__(self, Py_buffer *info, int flags): # <<<<<<<<<<<<<<
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview")
- */
-
- /* function exit code */
- __pyx_r = 0;
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__getbuffer__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- if (__pyx_v_info->obj != NULL) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- goto __pyx_L2;
- __pyx_L0:;
- if (__pyx_v_info->obj == Py_None) {
- __Pyx_GOTREF(__pyx_v_info->obj);
- __Pyx_DECREF(__pyx_v_info->obj); __pyx_v_info->obj = 0;
- }
- __pyx_L2:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":555
- *
- * @property
- * def T(self): # <<<<<<<<<<<<<<
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice)
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_1T_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_1T_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_1T___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_1T___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- struct __pyx_memoryviewslice_obj *__pyx_v_result = 0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":556
- * @property
- * def T(self):
- * cdef _memoryviewslice result = memoryview_copy(self) # <<<<<<<<<<<<<<
- * transpose_memslice(&result.from_slice)
- * return result
- */
- __pyx_t_1 = __pyx_memoryview_copy_object(__pyx_v_self); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 556, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (!(likely(((__pyx_t_1) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_1, __pyx_memoryviewslice_type))))) __PYX_ERR(1, 556, __pyx_L1_error)
- __pyx_v_result = ((struct __pyx_memoryviewslice_obj *)__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":557
- * def T(self):
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice) # <<<<<<<<<<<<<<
- * return result
- *
- */
- __pyx_t_2 = __pyx_memslice_transpose((&__pyx_v_result->from_slice)); if (unlikely(__pyx_t_2 == ((int)0))) __PYX_ERR(1, 557, __pyx_L1_error)
-
- /* "View.MemoryView":558
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice)
- * return result # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = ((PyObject *)__pyx_v_result);
- goto __pyx_L0;
-
- /* "View.MemoryView":555
- *
- * @property
- * def T(self): # <<<<<<<<<<<<<<
- * cdef _memoryviewslice result = memoryview_copy(self)
- * transpose_memslice(&result.from_slice)
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.T.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":561
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.obj
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4base_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4base_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_4base___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4base___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":562
- * @property
- * def base(self):
- * return self.obj # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->obj);
- __pyx_r = __pyx_v_self->obj;
- goto __pyx_L0;
-
- /* "View.MemoryView":561
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.obj
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":565
- *
- * @property
- * def shape(self): # <<<<<<<<<<<<<<
- * return tuple([length for length in self.view.shape[:self.view.ndim]])
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_5shape_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_5shape_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_5shape___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_5shape___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_v_length;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- Py_ssize_t *__pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":566
- * @property
- * def shape(self):
- * return tuple([length for length in self.view.shape[:self.view.ndim]]) # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = PyList_New(0); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_3 = (__pyx_v_self->view.shape + __pyx_v_self->view.ndim);
- for (__pyx_t_4 = __pyx_v_self->view.shape; __pyx_t_4 < __pyx_t_3; __pyx_t_4++) {
- __pyx_t_2 = __pyx_t_4;
- __pyx_v_length = (__pyx_t_2[0]);
- __pyx_t_5 = PyInt_FromSsize_t(__pyx_v_length); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- if (unlikely(__Pyx_ListComp_Append(__pyx_t_1, (PyObject*)__pyx_t_5))) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- }
- __pyx_t_5 = PyList_AsTuple(((PyObject*)__pyx_t_1)); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 566, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_r = __pyx_t_5;
- __pyx_t_5 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":565
- *
- * @property
- * def shape(self): # <<<<<<<<<<<<<<
- * return tuple([length for length in self.view.shape[:self.view.ndim]])
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview.shape.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":569
- *
- * @property
- * def strides(self): # <<<<<<<<<<<<<<
- * if self.view.strides == NULL:
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_7strides_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_7strides_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_7strides___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_7strides___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_v_stride;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
- Py_ssize_t *__pyx_t_5;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":570
- * @property
- * def strides(self):
- * if self.view.strides == NULL: # <<<<<<<<<<<<<<
- *
- * raise ValueError("Buffer view does not expose strides")
- */
- __pyx_t_1 = ((__pyx_v_self->view.strides == NULL) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":572
- * if self.view.strides == NULL:
- *
- * raise ValueError("Buffer view does not expose strides") # <<<<<<<<<<<<<<
- *
- * return tuple([stride for stride in self.view.strides[:self.view.ndim]])
- */
- __pyx_t_2 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__12, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 572, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_Raise(__pyx_t_2, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __PYX_ERR(1, 572, __pyx_L1_error)
-
- /* "View.MemoryView":570
- * @property
- * def strides(self):
- * if self.view.strides == NULL: # <<<<<<<<<<<<<<
- *
- * raise ValueError("Buffer view does not expose strides")
- */
- }
-
- /* "View.MemoryView":574
- * raise ValueError("Buffer view does not expose strides")
- *
- * return tuple([stride for stride in self.view.strides[:self.view.ndim]]) # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = PyList_New(0); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_4 = (__pyx_v_self->view.strides + __pyx_v_self->view.ndim);
- for (__pyx_t_5 = __pyx_v_self->view.strides; __pyx_t_5 < __pyx_t_4; __pyx_t_5++) {
- __pyx_t_3 = __pyx_t_5;
- __pyx_v_stride = (__pyx_t_3[0]);
- __pyx_t_6 = PyInt_FromSsize_t(__pyx_v_stride); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- if (unlikely(__Pyx_ListComp_Append(__pyx_t_2, (PyObject*)__pyx_t_6))) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- }
- __pyx_t_6 = PyList_AsTuple(((PyObject*)__pyx_t_2)); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 574, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_6;
- __pyx_t_6 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":569
- *
- * @property
- * def strides(self): # <<<<<<<<<<<<<<
- * if self.view.strides == NULL:
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_AddTraceback("View.MemoryView.memoryview.strides.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":577
- *
- * @property
- * def suboffsets(self): # <<<<<<<<<<<<<<
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_10suboffsets_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_10suboffsets_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_10suboffsets___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_10suboffsets___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_v_suboffset;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- Py_ssize_t *__pyx_t_4;
- Py_ssize_t *__pyx_t_5;
- Py_ssize_t *__pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":578
- * @property
- * def suboffsets(self):
- * if self.view.suboffsets == NULL: # <<<<<<<<<<<<<<
- * return (-1,) * self.view.ndim
- *
- */
- __pyx_t_1 = ((__pyx_v_self->view.suboffsets == NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":579
- * def suboffsets(self):
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim # <<<<<<<<<<<<<<
- *
- * return tuple([suboffset for suboffset in self.view.suboffsets[:self.view.ndim]])
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __Pyx_PyInt_From_int(__pyx_v_self->view.ndim); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 579, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyNumber_Multiply(__pyx_tuple__13, __pyx_t_2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 579, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":578
- * @property
- * def suboffsets(self):
- * if self.view.suboffsets == NULL: # <<<<<<<<<<<<<<
- * return (-1,) * self.view.ndim
- *
- */
- }
-
- /* "View.MemoryView":581
- * return (-1,) * self.view.ndim
- *
- * return tuple([suboffset for suboffset in self.view.suboffsets[:self.view.ndim]]) # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_3 = PyList_New(0); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_5 = (__pyx_v_self->view.suboffsets + __pyx_v_self->view.ndim);
- for (__pyx_t_6 = __pyx_v_self->view.suboffsets; __pyx_t_6 < __pyx_t_5; __pyx_t_6++) {
- __pyx_t_4 = __pyx_t_6;
- __pyx_v_suboffset = (__pyx_t_4[0]);
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_suboffset); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- if (unlikely(__Pyx_ListComp_Append(__pyx_t_3, (PyObject*)__pyx_t_2))) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- }
- __pyx_t_2 = PyList_AsTuple(((PyObject*)__pyx_t_3)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 581, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":577
- *
- * @property
- * def suboffsets(self): # <<<<<<<<<<<<<<
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.suboffsets.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":584
- *
- * @property
- * def ndim(self): # <<<<<<<<<<<<<<
- * return self.view.ndim
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4ndim_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4ndim_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_4ndim___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4ndim___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":585
- * @property
- * def ndim(self):
- * return self.view.ndim # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_self->view.ndim); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 585, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":584
- *
- * @property
- * def ndim(self): # <<<<<<<<<<<<<<
- * return self.view.ndim
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.ndim.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":588
- *
- * @property
- * def itemsize(self): # <<<<<<<<<<<<<<
- * return self.view.itemsize
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_8itemsize_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_8itemsize_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_8itemsize___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_8itemsize___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":589
- * @property
- * def itemsize(self):
- * return self.view.itemsize # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = PyInt_FromSsize_t(__pyx_v_self->view.itemsize); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 589, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":588
- *
- * @property
- * def itemsize(self): # <<<<<<<<<<<<<<
- * return self.view.itemsize
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.itemsize.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":592
- *
- * @property
- * def nbytes(self): # <<<<<<<<<<<<<<
- * return self.size * self.view.itemsize
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_6nbytes_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_6nbytes_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_6nbytes___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_6nbytes___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":593
- * @property
- * def nbytes(self):
- * return self.size * self.view.itemsize # <<<<<<<<<<<<<<
- *
- * @property
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_size); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 593, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_self->view.itemsize); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 593, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyNumber_Multiply(__pyx_t_1, __pyx_t_2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 593, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_3;
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":592
- *
- * @property
- * def nbytes(self): # <<<<<<<<<<<<<<
- * return self.size * self.view.itemsize
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.nbytes.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":596
- *
- * @property
- * def size(self): # <<<<<<<<<<<<<<
- * if self._size is None:
- * result = 1
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4size_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_10memoryview_4size_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_10memoryview_4size___get__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_10memoryview_4size___get__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_v_result = NULL;
- PyObject *__pyx_v_length = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
- Py_ssize_t *__pyx_t_5;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":597
- * @property
- * def size(self):
- * if self._size is None: # <<<<<<<<<<<<<<
- * result = 1
- *
- */
- __pyx_t_1 = (__pyx_v_self->_size == Py_None);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":598
- * def size(self):
- * if self._size is None:
- * result = 1 # <<<<<<<<<<<<<<
- *
- * for length in self.view.shape[:self.view.ndim]:
- */
- __Pyx_INCREF(__pyx_int_1);
- __pyx_v_result = __pyx_int_1;
-
- /* "View.MemoryView":600
- * result = 1
- *
- * for length in self.view.shape[:self.view.ndim]: # <<<<<<<<<<<<<<
- * result *= length
- *
- */
- __pyx_t_4 = (__pyx_v_self->view.shape + __pyx_v_self->view.ndim);
- for (__pyx_t_5 = __pyx_v_self->view.shape; __pyx_t_5 < __pyx_t_4; __pyx_t_5++) {
- __pyx_t_3 = __pyx_t_5;
- __pyx_t_6 = PyInt_FromSsize_t((__pyx_t_3[0])); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 600, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_XDECREF_SET(__pyx_v_length, __pyx_t_6);
- __pyx_t_6 = 0;
-
- /* "View.MemoryView":601
- *
- * for length in self.view.shape[:self.view.ndim]:
- * result *= length # <<<<<<<<<<<<<<
- *
- * self._size = result
- */
- __pyx_t_6 = PyNumber_InPlaceMultiply(__pyx_v_result, __pyx_v_length); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 601, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_6);
- __pyx_t_6 = 0;
- }
-
- /* "View.MemoryView":603
- * result *= length
- *
- * self._size = result # <<<<<<<<<<<<<<
- *
- * return self._size
- */
- __Pyx_INCREF(__pyx_v_result);
- __Pyx_GIVEREF(__pyx_v_result);
- __Pyx_GOTREF(__pyx_v_self->_size);
- __Pyx_DECREF(__pyx_v_self->_size);
- __pyx_v_self->_size = __pyx_v_result;
-
- /* "View.MemoryView":597
- * @property
- * def size(self):
- * if self._size is None: # <<<<<<<<<<<<<<
- * result = 1
- *
- */
- }
-
- /* "View.MemoryView":605
- * self._size = result
- *
- * return self._size # <<<<<<<<<<<<<<
- *
- * def __len__(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->_size);
- __pyx_r = __pyx_v_self->_size;
- goto __pyx_L0;
-
- /* "View.MemoryView":596
- *
- * @property
- * def size(self): # <<<<<<<<<<<<<<
- * if self._size is None:
- * result = 1
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_AddTraceback("View.MemoryView.memoryview.size.__get__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_result);
- __Pyx_XDECREF(__pyx_v_length);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":607
- * return self._size
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * if self.view.ndim >= 1:
- * return self.view.shape[0]
- */
-
-/* Python wrapper */
-static Py_ssize_t __pyx_memoryview___len__(PyObject *__pyx_v_self); /*proto*/
-static Py_ssize_t __pyx_memoryview___len__(PyObject *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__len__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_10__len__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static Py_ssize_t __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_10__len__(struct __pyx_memoryview_obj *__pyx_v_self) {
- Py_ssize_t __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- __Pyx_RefNannySetupContext("__len__", 0);
-
- /* "View.MemoryView":608
- *
- * def __len__(self):
- * if self.view.ndim >= 1: # <<<<<<<<<<<<<<
- * return self.view.shape[0]
- *
- */
- __pyx_t_1 = ((__pyx_v_self->view.ndim >= 1) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":609
- * def __len__(self):
- * if self.view.ndim >= 1:
- * return self.view.shape[0] # <<<<<<<<<<<<<<
- *
- * return 0
- */
- __pyx_r = (__pyx_v_self->view.shape[0]);
- goto __pyx_L0;
-
- /* "View.MemoryView":608
- *
- * def __len__(self):
- * if self.view.ndim >= 1: # <<<<<<<<<<<<<<
- * return self.view.shape[0]
- *
- */
- }
-
- /* "View.MemoryView":611
- * return self.view.shape[0]
- *
- * return 0 # <<<<<<<<<<<<<<
- *
- * def __repr__(self):
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":607
- * return self._size
- *
- * def __len__(self): # <<<<<<<<<<<<<<
- * if self.view.ndim >= 1:
- * return self.view.shape[0]
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":613
- * return 0
- *
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,
- * id(self))
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview___repr__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_memoryview___repr__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__repr__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_12__repr__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_12__repr__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__repr__", 0);
-
- /* "View.MemoryView":614
- *
- * def __repr__(self):
- * return "" % (self.base.__class__.__name__, # <<<<<<<<<<<<<<
- * id(self))
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_base); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_t_1, __pyx_n_s_class); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_t_2, __pyx_n_s_name_2); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
-
- /* "View.MemoryView":615
- * def __repr__(self):
- * return "" % (self.base.__class__.__name__,
- * id(self)) # <<<<<<<<<<<<<<
- *
- * def __str__(self):
- */
- __pyx_t_2 = __Pyx_PyObject_CallOneArg(__pyx_builtin_id, ((PyObject *)__pyx_v_self)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 615, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
-
- /* "View.MemoryView":614
- *
- * def __repr__(self):
- * return "" % (self.base.__class__.__name__, # <<<<<<<<<<<<<<
- * id(self))
- *
- */
- __pyx_t_3 = PyTuple_New(2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_3, 0, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_t_2);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyString_Format(__pyx_kp_s_MemoryView_of_r_at_0x_x, __pyx_t_3); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 614, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":613
- * return 0
- *
- * def __repr__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,
- * id(self))
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__repr__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":617
- * id(self))
- *
- * def __str__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,)
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview___str__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_memoryview___str__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__str__ (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_14__str__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_14__str__(struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__str__", 0);
-
- /* "View.MemoryView":618
- *
- * def __str__(self):
- * return "" % (self.base.__class__.__name__,) # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_self), __pyx_n_s_base); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(__pyx_t_1, __pyx_n_s_class); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(__pyx_t_2, __pyx_n_s_name_2); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_2 = PyTuple_New(1); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_2, 0, __pyx_t_1);
- __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_PyString_Format(__pyx_kp_s_MemoryView_of_r_object, __pyx_t_2); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 618, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":617
- * id(self))
- *
- * def __str__(self): # <<<<<<<<<<<<<<
- * return "" % (self.base.__class__.__name__,)
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__str__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":621
- *
- *
- * def is_c_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_is_c_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_is_c_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("is_c_contig (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_16is_c_contig(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_16is_c_contig(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice *__pyx_v_mslice;
- __Pyx_memviewslice __pyx_v_tmp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("is_c_contig", 0);
-
- /* "View.MemoryView":624
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp) # <<<<<<<<<<<<<<
- * return slice_is_contig(mslice[0], 'C', self.view.ndim)
- *
- */
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(__pyx_v_self, (&__pyx_v_tmp)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 624, __pyx_L1_error)
- __pyx_v_mslice = __pyx_t_1;
-
- /* "View.MemoryView":625
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp)
- * return slice_is_contig(mslice[0], 'C', self.view.ndim) # <<<<<<<<<<<<<<
- *
- * def is_f_contig(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_memviewslice_is_contig((__pyx_v_mslice[0]), 'C', __pyx_v_self->view.ndim)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 625, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":621
- *
- *
- * def is_c_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_c_contig", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":627
- * return slice_is_contig(mslice[0], 'C', self.view.ndim)
- *
- * def is_f_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_is_f_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_is_f_contig(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("is_f_contig (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_18is_f_contig(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_18is_f_contig(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice *__pyx_v_mslice;
- __Pyx_memviewslice __pyx_v_tmp;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice *__pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("is_f_contig", 0);
-
- /* "View.MemoryView":630
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp) # <<<<<<<<<<<<<<
- * return slice_is_contig(mslice[0], 'F', self.view.ndim)
- *
- */
- __pyx_t_1 = __pyx_memoryview_get_slice_from_memoryview(__pyx_v_self, (&__pyx_v_tmp)); if (unlikely(__pyx_t_1 == ((__Pyx_memviewslice *)NULL))) __PYX_ERR(1, 630, __pyx_L1_error)
- __pyx_v_mslice = __pyx_t_1;
-
- /* "View.MemoryView":631
- * cdef __Pyx_memviewslice tmp
- * mslice = get_slice_from_memview(self, &tmp)
- * return slice_is_contig(mslice[0], 'F', self.view.ndim) # <<<<<<<<<<<<<<
- *
- * def copy(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_memviewslice_is_contig((__pyx_v_mslice[0]), 'F', __pyx_v_self->view.ndim)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 631, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":627
- * return slice_is_contig(mslice[0], 'C', self.view.ndim)
- *
- * def is_f_contig(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice *mslice
- * cdef __Pyx_memviewslice tmp
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.is_f_contig", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":633
- * return slice_is_contig(mslice[0], 'F', self.view.ndim)
- *
- * def copy(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice mslice
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_copy(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_copy(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("copy (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_20copy(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_20copy(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice __pyx_v_mslice;
- int __pyx_v_flags;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("copy", 0);
-
- /* "View.MemoryView":635
- * def copy(self):
- * cdef __Pyx_memviewslice mslice
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS # <<<<<<<<<<<<<<
- *
- * slice_copy(self, &mslice)
- */
- __pyx_v_flags = (__pyx_v_self->flags & (~PyBUF_F_CONTIGUOUS));
-
- /* "View.MemoryView":637
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS
- *
- * slice_copy(self, &mslice) # <<<<<<<<<<<<<<
- * mslice = slice_copy_contig(&mslice, "c", self.view.ndim,
- * self.view.itemsize,
- */
- __pyx_memoryview_slice_copy(__pyx_v_self, (&__pyx_v_mslice));
-
- /* "View.MemoryView":638
- *
- * slice_copy(self, &mslice)
- * mslice = slice_copy_contig(&mslice, "c", self.view.ndim, # <<<<<<<<<<<<<<
- * self.view.itemsize,
- * flags|PyBUF_C_CONTIGUOUS,
- */
- __pyx_t_1 = __pyx_memoryview_copy_new_contig((&__pyx_v_mslice), ((char *)"c"), __pyx_v_self->view.ndim, __pyx_v_self->view.itemsize, (__pyx_v_flags | PyBUF_C_CONTIGUOUS), __pyx_v_self->dtype_is_object); if (unlikely(PyErr_Occurred())) __PYX_ERR(1, 638, __pyx_L1_error)
- __pyx_v_mslice = __pyx_t_1;
-
- /* "View.MemoryView":643
- * self.dtype_is_object)
- *
- * return memoryview_copy_from_slice(self, &mslice) # <<<<<<<<<<<<<<
- *
- * def copy_fortran(self):
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_memoryview_copy_object_from_slice(__pyx_v_self, (&__pyx_v_mslice)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 643, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":633
- * return slice_is_contig(mslice[0], 'F', self.view.ndim)
- *
- * def copy(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice mslice
- * cdef int flags = self.flags & ~PyBUF_F_CONTIGUOUS
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.copy", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":645
- * return memoryview_copy_from_slice(self, &mslice)
- *
- * def copy_fortran(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice src, dst
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS
- */
-
-/* Python wrapper */
-static PyObject *__pyx_memoryview_copy_fortran(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_memoryview_copy_fortran(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("copy_fortran (wrapper)", 0);
- __pyx_r = __pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_22copy_fortran(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_memoryview___pyx_pf_15View_dot_MemoryView_10memoryview_22copy_fortran(struct __pyx_memoryview_obj *__pyx_v_self) {
- __Pyx_memviewslice __pyx_v_src;
- __Pyx_memviewslice __pyx_v_dst;
- int __pyx_v_flags;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_memviewslice __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("copy_fortran", 0);
-
- /* "View.MemoryView":647
- * def copy_fortran(self):
- * cdef __Pyx_memviewslice src, dst
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS # <<<<<<<<<<<<<<
- *
- * slice_copy(self, &src)
- */
- __pyx_v_flags = (__pyx_v_self->flags & (~PyBUF_C_CONTIGUOUS));
-
- /* "View.MemoryView":649
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS
- *
- * slice_copy(self, &src) # <<<<<<<<<<<<<<
- * dst = slice_copy_contig(&src, "fortran", self.view.ndim,
- * self.view.itemsize,
- */
- __pyx_memoryview_slice_copy(__pyx_v_self, (&__pyx_v_src));
-
- /* "View.MemoryView":650
- *
- * slice_copy(self, &src)
- * dst = slice_copy_contig(&src, "fortran", self.view.ndim, # <<<<<<<<<<<<<<
- * self.view.itemsize,
- * flags|PyBUF_F_CONTIGUOUS,
- */
- __pyx_t_1 = __pyx_memoryview_copy_new_contig((&__pyx_v_src), ((char *)"fortran"), __pyx_v_self->view.ndim, __pyx_v_self->view.itemsize, (__pyx_v_flags | PyBUF_F_CONTIGUOUS), __pyx_v_self->dtype_is_object); if (unlikely(PyErr_Occurred())) __PYX_ERR(1, 650, __pyx_L1_error)
- __pyx_v_dst = __pyx_t_1;
-
- /* "View.MemoryView":655
- * self.dtype_is_object)
- *
- * return memoryview_copy_from_slice(self, &dst) # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_memoryview_copy_object_from_slice(__pyx_v_self, (&__pyx_v_dst)); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 655, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":645
- * return memoryview_copy_from_slice(self, &mslice)
- *
- * def copy_fortran(self): # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice src, dst
- * cdef int flags = self.flags & ~PyBUF_C_CONTIGUOUS
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView.memoryview.copy_fortran", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryview_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryview_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryview___reduce_cython__(((struct __pyx_memoryview_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryview___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__14, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 2, __pyx_L1_error)
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryview_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryview_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryview_2__setstate_cython__(((struct __pyx_memoryview_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryview_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryview_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__15, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 4, __pyx_L1_error)
-
- /* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":659
- *
- * @cname('__pyx_memoryview_new')
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo): # <<<<<<<<<<<<<<
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo
- */
-
-static PyObject *__pyx_memoryview_new(PyObject *__pyx_v_o, int __pyx_v_flags, int __pyx_v_dtype_is_object, __Pyx_TypeInfo *__pyx_v_typeinfo) {
- struct __pyx_memoryview_obj *__pyx_v_result = 0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_cwrapper", 0);
-
- /* "View.MemoryView":660
- * @cname('__pyx_memoryview_new')
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo):
- * cdef memoryview result = memoryview(o, flags, dtype_is_object) # <<<<<<<<<<<<<<
- * result.typeinfo = typeinfo
- * return result
- */
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_flags); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_v_dtype_is_object); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyTuple_New(3); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_v_o);
- __Pyx_GIVEREF(__pyx_v_o);
- PyTuple_SET_ITEM(__pyx_t_3, 0, __pyx_v_o);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 2, __pyx_t_2);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryview_type), __pyx_t_3, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 660, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result = ((struct __pyx_memoryview_obj *)__pyx_t_2);
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":661
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo):
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo # <<<<<<<<<<<<<<
- * return result
- *
- */
- __pyx_v_result->typeinfo = __pyx_v_typeinfo;
-
- /* "View.MemoryView":662
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo
- * return result # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_check')
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = ((PyObject *)__pyx_v_result);
- goto __pyx_L0;
-
- /* "View.MemoryView":659
- *
- * @cname('__pyx_memoryview_new')
- * cdef memoryview_cwrapper(object o, int flags, bint dtype_is_object, __Pyx_TypeInfo *typeinfo): # <<<<<<<<<<<<<<
- * cdef memoryview result = memoryview(o, flags, dtype_is_object)
- * result.typeinfo = typeinfo
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview_cwrapper", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":665
- *
- * @cname('__pyx_memoryview_check')
- * cdef inline bint memoryview_check(object o): # <<<<<<<<<<<<<<
- * return isinstance(o, memoryview)
- *
- */
-
-static CYTHON_INLINE int __pyx_memoryview_check(PyObject *__pyx_v_o) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- __Pyx_RefNannySetupContext("memoryview_check", 0);
-
- /* "View.MemoryView":666
- * @cname('__pyx_memoryview_check')
- * cdef inline bint memoryview_check(object o):
- * return isinstance(o, memoryview) # <<<<<<<<<<<<<<
- *
- * cdef tuple _unellipsify(object index, int ndim):
- */
- __pyx_t_1 = __Pyx_TypeCheck(__pyx_v_o, __pyx_memoryview_type);
- __pyx_r = __pyx_t_1;
- goto __pyx_L0;
-
- /* "View.MemoryView":665
- *
- * @cname('__pyx_memoryview_check')
- * cdef inline bint memoryview_check(object o): # <<<<<<<<<<<<<<
- * return isinstance(o, memoryview)
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":668
- * return isinstance(o, memoryview)
- *
- * cdef tuple _unellipsify(object index, int ndim): # <<<<<<<<<<<<<<
- * """
- * Replace all ellipses with full slices and fill incomplete indices with
- */
-
-static PyObject *_unellipsify(PyObject *__pyx_v_index, int __pyx_v_ndim) {
- PyObject *__pyx_v_tup = NULL;
- PyObject *__pyx_v_result = NULL;
- int __pyx_v_have_slices;
- int __pyx_v_seen_ellipsis;
- CYTHON_UNUSED PyObject *__pyx_v_idx = NULL;
- PyObject *__pyx_v_item = NULL;
- Py_ssize_t __pyx_v_nslices;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- Py_ssize_t __pyx_t_5;
- PyObject *(*__pyx_t_6)(PyObject *);
- PyObject *__pyx_t_7 = NULL;
- Py_ssize_t __pyx_t_8;
- int __pyx_t_9;
- int __pyx_t_10;
- PyObject *__pyx_t_11 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("_unellipsify", 0);
-
- /* "View.MemoryView":673
- * full slices.
- * """
- * if not isinstance(index, tuple): # <<<<<<<<<<<<<<
- * tup = (index,)
- * else:
- */
- __pyx_t_1 = PyTuple_Check(__pyx_v_index);
- __pyx_t_2 = ((!(__pyx_t_1 != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":674
- * """
- * if not isinstance(index, tuple):
- * tup = (index,) # <<<<<<<<<<<<<<
- * else:
- * tup = index
- */
- __pyx_t_3 = PyTuple_New(1); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 674, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_v_index);
- __Pyx_GIVEREF(__pyx_v_index);
- PyTuple_SET_ITEM(__pyx_t_3, 0, __pyx_v_index);
- __pyx_v_tup = __pyx_t_3;
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":673
- * full slices.
- * """
- * if not isinstance(index, tuple): # <<<<<<<<<<<<<<
- * tup = (index,)
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":676
- * tup = (index,)
- * else:
- * tup = index # <<<<<<<<<<<<<<
- *
- * result = []
- */
- /*else*/ {
- __Pyx_INCREF(__pyx_v_index);
- __pyx_v_tup = __pyx_v_index;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":678
- * tup = index
- *
- * result = [] # <<<<<<<<<<<<<<
- * have_slices = False
- * seen_ellipsis = False
- */
- __pyx_t_3 = PyList_New(0); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 678, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_v_result = ((PyObject*)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":679
- *
- * result = []
- * have_slices = False # <<<<<<<<<<<<<<
- * seen_ellipsis = False
- * for idx, item in enumerate(tup):
- */
- __pyx_v_have_slices = 0;
-
- /* "View.MemoryView":680
- * result = []
- * have_slices = False
- * seen_ellipsis = False # <<<<<<<<<<<<<<
- * for idx, item in enumerate(tup):
- * if item is Ellipsis:
- */
- __pyx_v_seen_ellipsis = 0;
-
- /* "View.MemoryView":681
- * have_slices = False
- * seen_ellipsis = False
- * for idx, item in enumerate(tup): # <<<<<<<<<<<<<<
- * if item is Ellipsis:
- * if not seen_ellipsis:
- */
- __Pyx_INCREF(__pyx_int_0);
- __pyx_t_3 = __pyx_int_0;
- if (likely(PyList_CheckExact(__pyx_v_tup)) || PyTuple_CheckExact(__pyx_v_tup)) {
- __pyx_t_4 = __pyx_v_tup; __Pyx_INCREF(__pyx_t_4); __pyx_t_5 = 0;
- __pyx_t_6 = NULL;
- } else {
- __pyx_t_5 = -1; __pyx_t_4 = PyObject_GetIter(__pyx_v_tup); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_6 = Py_TYPE(__pyx_t_4)->tp_iternext; if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 681, __pyx_L1_error)
- }
- for (;;) {
- if (likely(!__pyx_t_6)) {
- if (likely(PyList_CheckExact(__pyx_t_4))) {
- if (__pyx_t_5 >= PyList_GET_SIZE(__pyx_t_4)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_7 = PyList_GET_ITEM(__pyx_t_4, __pyx_t_5); __Pyx_INCREF(__pyx_t_7); __pyx_t_5++; if (unlikely(0 < 0)) __PYX_ERR(1, 681, __pyx_L1_error)
- #else
- __pyx_t_7 = PySequence_ITEM(__pyx_t_4, __pyx_t_5); __pyx_t_5++; if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- #endif
- } else {
- if (__pyx_t_5 >= PyTuple_GET_SIZE(__pyx_t_4)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_7 = PyTuple_GET_ITEM(__pyx_t_4, __pyx_t_5); __Pyx_INCREF(__pyx_t_7); __pyx_t_5++; if (unlikely(0 < 0)) __PYX_ERR(1, 681, __pyx_L1_error)
- #else
- __pyx_t_7 = PySequence_ITEM(__pyx_t_4, __pyx_t_5); __pyx_t_5++; if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- #endif
- }
- } else {
- __pyx_t_7 = __pyx_t_6(__pyx_t_4);
- if (unlikely(!__pyx_t_7)) {
- PyObject* exc_type = PyErr_Occurred();
- if (exc_type) {
- if (likely(__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration))) PyErr_Clear();
- else __PYX_ERR(1, 681, __pyx_L1_error)
- }
- break;
- }
- __Pyx_GOTREF(__pyx_t_7);
- }
- __Pyx_XDECREF_SET(__pyx_v_item, __pyx_t_7);
- __pyx_t_7 = 0;
- __Pyx_INCREF(__pyx_t_3);
- __Pyx_XDECREF_SET(__pyx_v_idx, __pyx_t_3);
- __pyx_t_7 = __Pyx_PyInt_AddObjC(__pyx_t_3, __pyx_int_1, 1, 0, 0); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 681, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_DECREF(__pyx_t_3);
- __pyx_t_3 = __pyx_t_7;
- __pyx_t_7 = 0;
-
- /* "View.MemoryView":682
- * seen_ellipsis = False
- * for idx, item in enumerate(tup):
- * if item is Ellipsis: # <<<<<<<<<<<<<<
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- */
- __pyx_t_2 = (__pyx_v_item == __pyx_builtin_Ellipsis);
- __pyx_t_1 = (__pyx_t_2 != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":683
- * for idx, item in enumerate(tup):
- * if item is Ellipsis:
- * if not seen_ellipsis: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- * seen_ellipsis = True
- */
- __pyx_t_1 = ((!(__pyx_v_seen_ellipsis != 0)) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":684
- * if item is Ellipsis:
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1)) # <<<<<<<<<<<<<<
- * seen_ellipsis = True
- * else:
- */
- __pyx_t_8 = PyObject_Length(__pyx_v_tup); if (unlikely(__pyx_t_8 == ((Py_ssize_t)-1))) __PYX_ERR(1, 684, __pyx_L1_error)
- __pyx_t_7 = PyList_New(1 * ((((__pyx_v_ndim - __pyx_t_8) + 1)<0) ? 0:((__pyx_v_ndim - __pyx_t_8) + 1))); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 684, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- { Py_ssize_t __pyx_temp;
- for (__pyx_temp=0; __pyx_temp < ((__pyx_v_ndim - __pyx_t_8) + 1); __pyx_temp++) {
- __Pyx_INCREF(__pyx_slice__16);
- __Pyx_GIVEREF(__pyx_slice__16);
- PyList_SET_ITEM(__pyx_t_7, __pyx_temp, __pyx_slice__16);
- }
- }
- __pyx_t_9 = __Pyx_PyList_Extend(__pyx_v_result, __pyx_t_7); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 684, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
-
- /* "View.MemoryView":685
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- * seen_ellipsis = True # <<<<<<<<<<<<<<
- * else:
- * result.append(slice(None))
- */
- __pyx_v_seen_ellipsis = 1;
-
- /* "View.MemoryView":683
- * for idx, item in enumerate(tup):
- * if item is Ellipsis:
- * if not seen_ellipsis: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- * seen_ellipsis = True
- */
- goto __pyx_L7;
- }
-
- /* "View.MemoryView":687
- * seen_ellipsis = True
- * else:
- * result.append(slice(None)) # <<<<<<<<<<<<<<
- * have_slices = True
- * else:
- */
- /*else*/ {
- __pyx_t_9 = __Pyx_PyList_Append(__pyx_v_result, __pyx_slice__16); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 687, __pyx_L1_error)
- }
- __pyx_L7:;
-
- /* "View.MemoryView":688
- * else:
- * result.append(slice(None))
- * have_slices = True # <<<<<<<<<<<<<<
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item):
- */
- __pyx_v_have_slices = 1;
-
- /* "View.MemoryView":682
- * seen_ellipsis = False
- * for idx, item in enumerate(tup):
- * if item is Ellipsis: # <<<<<<<<<<<<<<
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1))
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":690
- * have_slices = True
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item): # <<<<<<<<<<<<<<
- * raise TypeError("Cannot index with type '%s'" % type(item))
- *
- */
- /*else*/ {
- __pyx_t_2 = PySlice_Check(__pyx_v_item);
- __pyx_t_10 = ((!(__pyx_t_2 != 0)) != 0);
- if (__pyx_t_10) {
- } else {
- __pyx_t_1 = __pyx_t_10;
- goto __pyx_L9_bool_binop_done;
- }
- __pyx_t_10 = ((!(PyIndex_Check(__pyx_v_item) != 0)) != 0);
- __pyx_t_1 = __pyx_t_10;
- __pyx_L9_bool_binop_done:;
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":691
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item):
- * raise TypeError("Cannot index with type '%s'" % type(item)) # <<<<<<<<<<<<<<
- *
- * have_slices = have_slices or isinstance(item, slice)
- */
- __pyx_t_7 = __Pyx_PyString_FormatSafe(__pyx_kp_s_Cannot_index_with_type_s, ((PyObject *)Py_TYPE(__pyx_v_item))); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 691, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __pyx_t_11 = __Pyx_PyObject_CallOneArg(__pyx_builtin_TypeError, __pyx_t_7); if (unlikely(!__pyx_t_11)) __PYX_ERR(1, 691, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_11);
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_Raise(__pyx_t_11, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_11); __pyx_t_11 = 0;
- __PYX_ERR(1, 691, __pyx_L1_error)
-
- /* "View.MemoryView":690
- * have_slices = True
- * else:
- * if not isinstance(item, slice) and not PyIndex_Check(item): # <<<<<<<<<<<<<<
- * raise TypeError("Cannot index with type '%s'" % type(item))
- *
- */
- }
-
- /* "View.MemoryView":693
- * raise TypeError("Cannot index with type '%s'" % type(item))
- *
- * have_slices = have_slices or isinstance(item, slice) # <<<<<<<<<<<<<<
- * result.append(item)
- *
- */
- __pyx_t_10 = (__pyx_v_have_slices != 0);
- if (!__pyx_t_10) {
- } else {
- __pyx_t_1 = __pyx_t_10;
- goto __pyx_L11_bool_binop_done;
- }
- __pyx_t_10 = PySlice_Check(__pyx_v_item);
- __pyx_t_2 = (__pyx_t_10 != 0);
- __pyx_t_1 = __pyx_t_2;
- __pyx_L11_bool_binop_done:;
- __pyx_v_have_slices = __pyx_t_1;
-
- /* "View.MemoryView":694
- *
- * have_slices = have_slices or isinstance(item, slice)
- * result.append(item) # <<<<<<<<<<<<<<
- *
- * nslices = ndim - len(result)
- */
- __pyx_t_9 = __Pyx_PyList_Append(__pyx_v_result, __pyx_v_item); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 694, __pyx_L1_error)
- }
- __pyx_L6:;
-
- /* "View.MemoryView":681
- * have_slices = False
- * seen_ellipsis = False
- * for idx, item in enumerate(tup): # <<<<<<<<<<<<<<
- * if item is Ellipsis:
- * if not seen_ellipsis:
- */
- }
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":696
- * result.append(item)
- *
- * nslices = ndim - len(result) # <<<<<<<<<<<<<<
- * if nslices:
- * result.extend([slice(None)] * nslices)
- */
- __pyx_t_5 = PyList_GET_SIZE(__pyx_v_result); if (unlikely(__pyx_t_5 == ((Py_ssize_t)-1))) __PYX_ERR(1, 696, __pyx_L1_error)
- __pyx_v_nslices = (__pyx_v_ndim - __pyx_t_5);
-
- /* "View.MemoryView":697
- *
- * nslices = ndim - len(result)
- * if nslices: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * nslices)
- *
- */
- __pyx_t_1 = (__pyx_v_nslices != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":698
- * nslices = ndim - len(result)
- * if nslices:
- * result.extend([slice(None)] * nslices) # <<<<<<<<<<<<<<
- *
- * return have_slices or nslices, tuple(result)
- */
- __pyx_t_3 = PyList_New(1 * ((__pyx_v_nslices<0) ? 0:__pyx_v_nslices)); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 698, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- { Py_ssize_t __pyx_temp;
- for (__pyx_temp=0; __pyx_temp < __pyx_v_nslices; __pyx_temp++) {
- __Pyx_INCREF(__pyx_slice__16);
- __Pyx_GIVEREF(__pyx_slice__16);
- PyList_SET_ITEM(__pyx_t_3, __pyx_temp, __pyx_slice__16);
- }
- }
- __pyx_t_9 = __Pyx_PyList_Extend(__pyx_v_result, __pyx_t_3); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 698, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":697
- *
- * nslices = ndim - len(result)
- * if nslices: # <<<<<<<<<<<<<<
- * result.extend([slice(None)] * nslices)
- *
- */
- }
-
- /* "View.MemoryView":700
- * result.extend([slice(None)] * nslices)
- *
- * return have_slices or nslices, tuple(result) # <<<<<<<<<<<<<<
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- */
- __Pyx_XDECREF(__pyx_r);
- if (!__pyx_v_have_slices) {
- } else {
- __pyx_t_4 = __Pyx_PyBool_FromLong(__pyx_v_have_slices); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_3 = __pyx_t_4;
- __pyx_t_4 = 0;
- goto __pyx_L14_bool_binop_done;
- }
- __pyx_t_4 = PyInt_FromSsize_t(__pyx_v_nslices); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_3 = __pyx_t_4;
- __pyx_t_4 = 0;
- __pyx_L14_bool_binop_done:;
- __pyx_t_4 = PyList_AsTuple(__pyx_v_result); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __pyx_t_11 = PyTuple_New(2); if (unlikely(!__pyx_t_11)) __PYX_ERR(1, 700, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_11);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_11, 0, __pyx_t_3);
- __Pyx_GIVEREF(__pyx_t_4);
- PyTuple_SET_ITEM(__pyx_t_11, 1, __pyx_t_4);
- __pyx_t_3 = 0;
- __pyx_t_4 = 0;
- __pyx_r = ((PyObject*)__pyx_t_11);
- __pyx_t_11 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":668
- * return isinstance(o, memoryview)
- *
- * cdef tuple _unellipsify(object index, int ndim): # <<<<<<<<<<<<<<
- * """
- * Replace all ellipses with full slices and fill incomplete indices with
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_11);
- __Pyx_AddTraceback("View.MemoryView._unellipsify", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v_tup);
- __Pyx_XDECREF(__pyx_v_result);
- __Pyx_XDECREF(__pyx_v_idx);
- __Pyx_XDECREF(__pyx_v_item);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":702
- * return have_slices or nslices, tuple(result)
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim): # <<<<<<<<<<<<<<
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- */
-
-static PyObject *assert_direct_dimensions(Py_ssize_t *__pyx_v_suboffsets, int __pyx_v_ndim) {
- Py_ssize_t __pyx_v_suboffset;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- Py_ssize_t *__pyx_t_1;
- Py_ssize_t *__pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- int __pyx_t_4;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("assert_direct_dimensions", 0);
-
- /* "View.MemoryView":703
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- * for suboffset in suboffsets[:ndim]: # <<<<<<<<<<<<<<
- * if suboffset >= 0:
- * raise ValueError("Indirect dimensions not supported")
- */
- __pyx_t_2 = (__pyx_v_suboffsets + __pyx_v_ndim);
- for (__pyx_t_3 = __pyx_v_suboffsets; __pyx_t_3 < __pyx_t_2; __pyx_t_3++) {
- __pyx_t_1 = __pyx_t_3;
- __pyx_v_suboffset = (__pyx_t_1[0]);
-
- /* "View.MemoryView":704
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Indirect dimensions not supported")
- *
- */
- __pyx_t_4 = ((__pyx_v_suboffset >= 0) != 0);
- if (unlikely(__pyx_t_4)) {
-
- /* "View.MemoryView":705
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- * raise ValueError("Indirect dimensions not supported") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_5 = __Pyx_PyObject_Call(__pyx_builtin_ValueError, __pyx_tuple__17, NULL); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 705, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_Raise(__pyx_t_5, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- __PYX_ERR(1, 705, __pyx_L1_error)
-
- /* "View.MemoryView":704
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim):
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * raise ValueError("Indirect dimensions not supported")
- *
- */
- }
- }
-
- /* "View.MemoryView":702
- * return have_slices or nslices, tuple(result)
- *
- * cdef assert_direct_dimensions(Py_ssize_t *suboffsets, int ndim): # <<<<<<<<<<<<<<
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.assert_direct_dimensions", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":712
- *
- * @cname('__pyx_memview_slice')
- * cdef memoryview memview_slice(memoryview memview, object indices): # <<<<<<<<<<<<<<
- * cdef int new_ndim = 0, suboffset_dim = -1, dim
- * cdef bint negative_step
- */
-
-static struct __pyx_memoryview_obj *__pyx_memview_slice(struct __pyx_memoryview_obj *__pyx_v_memview, PyObject *__pyx_v_indices) {
- int __pyx_v_new_ndim;
- int __pyx_v_suboffset_dim;
- int __pyx_v_dim;
- __Pyx_memviewslice __pyx_v_src;
- __Pyx_memviewslice __pyx_v_dst;
- __Pyx_memviewslice *__pyx_v_p_src;
- struct __pyx_memoryviewslice_obj *__pyx_v_memviewsliceobj = 0;
- __Pyx_memviewslice *__pyx_v_p_dst;
- int *__pyx_v_p_suboffset_dim;
- Py_ssize_t __pyx_v_start;
- Py_ssize_t __pyx_v_stop;
- Py_ssize_t __pyx_v_step;
- int __pyx_v_have_start;
- int __pyx_v_have_stop;
- int __pyx_v_have_step;
- PyObject *__pyx_v_index = NULL;
- struct __pyx_memoryview_obj *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- struct __pyx_memoryview_obj *__pyx_t_4;
- char *__pyx_t_5;
- int __pyx_t_6;
- Py_ssize_t __pyx_t_7;
- PyObject *(*__pyx_t_8)(PyObject *);
- PyObject *__pyx_t_9 = NULL;
- Py_ssize_t __pyx_t_10;
- int __pyx_t_11;
- Py_ssize_t __pyx_t_12;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memview_slice", 0);
-
- /* "View.MemoryView":713
- * @cname('__pyx_memview_slice')
- * cdef memoryview memview_slice(memoryview memview, object indices):
- * cdef int new_ndim = 0, suboffset_dim = -1, dim # <<<<<<<<<<<<<<
- * cdef bint negative_step
- * cdef __Pyx_memviewslice src, dst
- */
- __pyx_v_new_ndim = 0;
- __pyx_v_suboffset_dim = -1;
-
- /* "View.MemoryView":720
- *
- *
- * memset(&dst, 0, sizeof(dst)) # <<<<<<<<<<<<<<
- *
- * cdef _memoryviewslice memviewsliceobj
- */
- (void)(memset((&__pyx_v_dst), 0, (sizeof(__pyx_v_dst))));
-
- /* "View.MemoryView":724
- * cdef _memoryviewslice memviewsliceobj
- *
- * assert memview.view.ndim > 0 # <<<<<<<<<<<<<<
- *
- * if isinstance(memview, _memoryviewslice):
- */
- #ifndef CYTHON_WITHOUT_ASSERTIONS
- if (unlikely(!Py_OptimizeFlag)) {
- if (unlikely(!((__pyx_v_memview->view.ndim > 0) != 0))) {
- PyErr_SetNone(PyExc_AssertionError);
- __PYX_ERR(1, 724, __pyx_L1_error)
- }
- }
- #endif
-
- /* "View.MemoryView":726
- * assert memview.view.ndim > 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * memviewsliceobj = memview
- * p_src = &memviewsliceobj.from_slice
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":727
- *
- * if isinstance(memview, _memoryviewslice):
- * memviewsliceobj = memview # <<<<<<<<<<<<<<
- * p_src = &memviewsliceobj.from_slice
- * else:
- */
- if (!(likely(((((PyObject *)__pyx_v_memview)) == Py_None) || likely(__Pyx_TypeTest(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type))))) __PYX_ERR(1, 727, __pyx_L1_error)
- __pyx_t_3 = ((PyObject *)__pyx_v_memview);
- __Pyx_INCREF(__pyx_t_3);
- __pyx_v_memviewsliceobj = ((struct __pyx_memoryviewslice_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":728
- * if isinstance(memview, _memoryviewslice):
- * memviewsliceobj = memview
- * p_src = &memviewsliceobj.from_slice # <<<<<<<<<<<<<<
- * else:
- * slice_copy(memview, &src)
- */
- __pyx_v_p_src = (&__pyx_v_memviewsliceobj->from_slice);
-
- /* "View.MemoryView":726
- * assert memview.view.ndim > 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * memviewsliceobj = memview
- * p_src = &memviewsliceobj.from_slice
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":730
- * p_src = &memviewsliceobj.from_slice
- * else:
- * slice_copy(memview, &src) # <<<<<<<<<<<<<<
- * p_src = &src
- *
- */
- /*else*/ {
- __pyx_memoryview_slice_copy(__pyx_v_memview, (&__pyx_v_src));
-
- /* "View.MemoryView":731
- * else:
- * slice_copy(memview, &src)
- * p_src = &src # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_p_src = (&__pyx_v_src);
- }
- __pyx_L3:;
-
- /* "View.MemoryView":737
- *
- *
- * dst.memview = p_src.memview # <<<<<<<<<<<<<<
- * dst.data = p_src.data
- *
- */
- __pyx_t_4 = __pyx_v_p_src->memview;
- __pyx_v_dst.memview = __pyx_t_4;
-
- /* "View.MemoryView":738
- *
- * dst.memview = p_src.memview
- * dst.data = p_src.data # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_5 = __pyx_v_p_src->data;
- __pyx_v_dst.data = __pyx_t_5;
-
- /* "View.MemoryView":743
- *
- *
- * cdef __Pyx_memviewslice *p_dst = &dst # <<<<<<<<<<<<<<
- * cdef int *p_suboffset_dim = &suboffset_dim
- * cdef Py_ssize_t start, stop, step
- */
- __pyx_v_p_dst = (&__pyx_v_dst);
-
- /* "View.MemoryView":744
- *
- * cdef __Pyx_memviewslice *p_dst = &dst
- * cdef int *p_suboffset_dim = &suboffset_dim # <<<<<<<<<<<<<<
- * cdef Py_ssize_t start, stop, step
- * cdef bint have_start, have_stop, have_step
- */
- __pyx_v_p_suboffset_dim = (&__pyx_v_suboffset_dim);
-
- /* "View.MemoryView":748
- * cdef bint have_start, have_stop, have_step
- *
- * for dim, index in enumerate(indices): # <<<<<<<<<<<<<<
- * if PyIndex_Check(index):
- * slice_memviewslice(
- */
- __pyx_t_6 = 0;
- if (likely(PyList_CheckExact(__pyx_v_indices)) || PyTuple_CheckExact(__pyx_v_indices)) {
- __pyx_t_3 = __pyx_v_indices; __Pyx_INCREF(__pyx_t_3); __pyx_t_7 = 0;
- __pyx_t_8 = NULL;
- } else {
- __pyx_t_7 = -1; __pyx_t_3 = PyObject_GetIter(__pyx_v_indices); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 748, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_8 = Py_TYPE(__pyx_t_3)->tp_iternext; if (unlikely(!__pyx_t_8)) __PYX_ERR(1, 748, __pyx_L1_error)
- }
- for (;;) {
- if (likely(!__pyx_t_8)) {
- if (likely(PyList_CheckExact(__pyx_t_3))) {
- if (__pyx_t_7 >= PyList_GET_SIZE(__pyx_t_3)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_9 = PyList_GET_ITEM(__pyx_t_3, __pyx_t_7); __Pyx_INCREF(__pyx_t_9); __pyx_t_7++; if (unlikely(0 < 0)) __PYX_ERR(1, 748, __pyx_L1_error)
- #else
- __pyx_t_9 = PySequence_ITEM(__pyx_t_3, __pyx_t_7); __pyx_t_7++; if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 748, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- #endif
- } else {
- if (__pyx_t_7 >= PyTuple_GET_SIZE(__pyx_t_3)) break;
- #if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- __pyx_t_9 = PyTuple_GET_ITEM(__pyx_t_3, __pyx_t_7); __Pyx_INCREF(__pyx_t_9); __pyx_t_7++; if (unlikely(0 < 0)) __PYX_ERR(1, 748, __pyx_L1_error)
- #else
- __pyx_t_9 = PySequence_ITEM(__pyx_t_3, __pyx_t_7); __pyx_t_7++; if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 748, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- #endif
- }
- } else {
- __pyx_t_9 = __pyx_t_8(__pyx_t_3);
- if (unlikely(!__pyx_t_9)) {
- PyObject* exc_type = PyErr_Occurred();
- if (exc_type) {
- if (likely(__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration))) PyErr_Clear();
- else __PYX_ERR(1, 748, __pyx_L1_error)
- }
- break;
- }
- __Pyx_GOTREF(__pyx_t_9);
- }
- __Pyx_XDECREF_SET(__pyx_v_index, __pyx_t_9);
- __pyx_t_9 = 0;
- __pyx_v_dim = __pyx_t_6;
- __pyx_t_6 = (__pyx_t_6 + 1);
-
- /* "View.MemoryView":749
- *
- * for dim, index in enumerate(indices):
- * if PyIndex_Check(index): # <<<<<<<<<<<<<<
- * slice_memviewslice(
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- */
- __pyx_t_2 = (PyIndex_Check(__pyx_v_index) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":753
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- * dim, new_ndim, p_suboffset_dim,
- * index, 0, 0, # start, stop, step # <<<<<<<<<<<<<<
- * 0, 0, 0, # have_{start,stop,step}
- * False)
- */
- __pyx_t_10 = __Pyx_PyIndex_AsSsize_t(__pyx_v_index); if (unlikely((__pyx_t_10 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 753, __pyx_L1_error)
-
- /* "View.MemoryView":750
- * for dim, index in enumerate(indices):
- * if PyIndex_Check(index):
- * slice_memviewslice( # <<<<<<<<<<<<<<
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- * dim, new_ndim, p_suboffset_dim,
- */
- __pyx_t_11 = __pyx_memoryview_slice_memviewslice(__pyx_v_p_dst, (__pyx_v_p_src->shape[__pyx_v_dim]), (__pyx_v_p_src->strides[__pyx_v_dim]), (__pyx_v_p_src->suboffsets[__pyx_v_dim]), __pyx_v_dim, __pyx_v_new_ndim, __pyx_v_p_suboffset_dim, __pyx_t_10, 0, 0, 0, 0, 0, 0); if (unlikely(__pyx_t_11 == ((int)-1))) __PYX_ERR(1, 750, __pyx_L1_error)
-
- /* "View.MemoryView":749
- *
- * for dim, index in enumerate(indices):
- * if PyIndex_Check(index): # <<<<<<<<<<<<<<
- * slice_memviewslice(
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":756
- * 0, 0, 0, # have_{start,stop,step}
- * False)
- * elif index is None: # <<<<<<<<<<<<<<
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0
- */
- __pyx_t_2 = (__pyx_v_index == Py_None);
- __pyx_t_1 = (__pyx_t_2 != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":757
- * False)
- * elif index is None:
- * p_dst.shape[new_ndim] = 1 # <<<<<<<<<<<<<<
- * p_dst.strides[new_ndim] = 0
- * p_dst.suboffsets[new_ndim] = -1
- */
- (__pyx_v_p_dst->shape[__pyx_v_new_ndim]) = 1;
-
- /* "View.MemoryView":758
- * elif index is None:
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0 # <<<<<<<<<<<<<<
- * p_dst.suboffsets[new_ndim] = -1
- * new_ndim += 1
- */
- (__pyx_v_p_dst->strides[__pyx_v_new_ndim]) = 0;
-
- /* "View.MemoryView":759
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0
- * p_dst.suboffsets[new_ndim] = -1 # <<<<<<<<<<<<<<
- * new_ndim += 1
- * else:
- */
- (__pyx_v_p_dst->suboffsets[__pyx_v_new_ndim]) = -1L;
-
- /* "View.MemoryView":760
- * p_dst.strides[new_ndim] = 0
- * p_dst.suboffsets[new_ndim] = -1
- * new_ndim += 1 # <<<<<<<<<<<<<<
- * else:
- * start = index.start or 0
- */
- __pyx_v_new_ndim = (__pyx_v_new_ndim + 1);
-
- /* "View.MemoryView":756
- * 0, 0, 0, # have_{start,stop,step}
- * False)
- * elif index is None: # <<<<<<<<<<<<<<
- * p_dst.shape[new_ndim] = 1
- * p_dst.strides[new_ndim] = 0
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":762
- * new_ndim += 1
- * else:
- * start = index.start or 0 # <<<<<<<<<<<<<<
- * stop = index.stop or 0
- * step = index.step or 0
- */
- /*else*/ {
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_start); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 762, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_t_9); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 762, __pyx_L1_error)
- if (!__pyx_t_1) {
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- } else {
- __pyx_t_12 = __Pyx_PyIndex_AsSsize_t(__pyx_t_9); if (unlikely((__pyx_t_12 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 762, __pyx_L1_error)
- __pyx_t_10 = __pyx_t_12;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- goto __pyx_L7_bool_binop_done;
- }
- __pyx_t_10 = 0;
- __pyx_L7_bool_binop_done:;
- __pyx_v_start = __pyx_t_10;
-
- /* "View.MemoryView":763
- * else:
- * start = index.start or 0
- * stop = index.stop or 0 # <<<<<<<<<<<<<<
- * step = index.step or 0
- *
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_stop); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 763, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_t_9); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 763, __pyx_L1_error)
- if (!__pyx_t_1) {
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- } else {
- __pyx_t_12 = __Pyx_PyIndex_AsSsize_t(__pyx_t_9); if (unlikely((__pyx_t_12 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 763, __pyx_L1_error)
- __pyx_t_10 = __pyx_t_12;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- goto __pyx_L9_bool_binop_done;
- }
- __pyx_t_10 = 0;
- __pyx_L9_bool_binop_done:;
- __pyx_v_stop = __pyx_t_10;
-
- /* "View.MemoryView":764
- * start = index.start or 0
- * stop = index.stop or 0
- * step = index.step or 0 # <<<<<<<<<<<<<<
- *
- * have_start = index.start is not None
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_step); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 764, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = __Pyx_PyObject_IsTrue(__pyx_t_9); if (unlikely(__pyx_t_1 < 0)) __PYX_ERR(1, 764, __pyx_L1_error)
- if (!__pyx_t_1) {
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- } else {
- __pyx_t_12 = __Pyx_PyIndex_AsSsize_t(__pyx_t_9); if (unlikely((__pyx_t_12 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 764, __pyx_L1_error)
- __pyx_t_10 = __pyx_t_12;
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- goto __pyx_L11_bool_binop_done;
- }
- __pyx_t_10 = 0;
- __pyx_L11_bool_binop_done:;
- __pyx_v_step = __pyx_t_10;
-
- /* "View.MemoryView":766
- * step = index.step or 0
- *
- * have_start = index.start is not None # <<<<<<<<<<<<<<
- * have_stop = index.stop is not None
- * have_step = index.step is not None
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_start); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 766, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = (__pyx_t_9 != Py_None);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- __pyx_v_have_start = __pyx_t_1;
-
- /* "View.MemoryView":767
- *
- * have_start = index.start is not None
- * have_stop = index.stop is not None # <<<<<<<<<<<<<<
- * have_step = index.step is not None
- *
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_stop); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 767, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = (__pyx_t_9 != Py_None);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- __pyx_v_have_stop = __pyx_t_1;
-
- /* "View.MemoryView":768
- * have_start = index.start is not None
- * have_stop = index.stop is not None
- * have_step = index.step is not None # <<<<<<<<<<<<<<
- *
- * slice_memviewslice(
- */
- __pyx_t_9 = __Pyx_PyObject_GetAttrStr(__pyx_v_index, __pyx_n_s_step); if (unlikely(!__pyx_t_9)) __PYX_ERR(1, 768, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_9);
- __pyx_t_1 = (__pyx_t_9 != Py_None);
- __Pyx_DECREF(__pyx_t_9); __pyx_t_9 = 0;
- __pyx_v_have_step = __pyx_t_1;
-
- /* "View.MemoryView":770
- * have_step = index.step is not None
- *
- * slice_memviewslice( # <<<<<<<<<<<<<<
- * p_dst, p_src.shape[dim], p_src.strides[dim], p_src.suboffsets[dim],
- * dim, new_ndim, p_suboffset_dim,
- */
- __pyx_t_11 = __pyx_memoryview_slice_memviewslice(__pyx_v_p_dst, (__pyx_v_p_src->shape[__pyx_v_dim]), (__pyx_v_p_src->strides[__pyx_v_dim]), (__pyx_v_p_src->suboffsets[__pyx_v_dim]), __pyx_v_dim, __pyx_v_new_ndim, __pyx_v_p_suboffset_dim, __pyx_v_start, __pyx_v_stop, __pyx_v_step, __pyx_v_have_start, __pyx_v_have_stop, __pyx_v_have_step, 1); if (unlikely(__pyx_t_11 == ((int)-1))) __PYX_ERR(1, 770, __pyx_L1_error)
-
- /* "View.MemoryView":776
- * have_start, have_stop, have_step,
- * True)
- * new_ndim += 1 # <<<<<<<<<<<<<<
- *
- * if isinstance(memview, _memoryviewslice):
- */
- __pyx_v_new_ndim = (__pyx_v_new_ndim + 1);
- }
- __pyx_L6:;
-
- /* "View.MemoryView":748
- * cdef bint have_start, have_stop, have_step
- *
- * for dim, index in enumerate(indices): # <<<<<<<<<<<<<<
- * if PyIndex_Check(index):
- * slice_memviewslice(
- */
- }
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
-
- /* "View.MemoryView":778
- * new_ndim += 1
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func,
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":779
- *
- * if isinstance(memview, _memoryviewslice):
- * return memoryview_fromslice(dst, new_ndim, # <<<<<<<<<<<<<<
- * memviewsliceobj.to_object_func,
- * memviewsliceobj.to_dtype_func,
- */
- __Pyx_XDECREF(((PyObject *)__pyx_r));
-
- /* "View.MemoryView":780
- * if isinstance(memview, _memoryviewslice):
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func, # <<<<<<<<<<<<<<
- * memviewsliceobj.to_dtype_func,
- * memview.dtype_is_object)
- */
- if (unlikely(!__pyx_v_memviewsliceobj)) { __Pyx_RaiseUnboundLocalError("memviewsliceobj"); __PYX_ERR(1, 780, __pyx_L1_error) }
-
- /* "View.MemoryView":781
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func,
- * memviewsliceobj.to_dtype_func, # <<<<<<<<<<<<<<
- * memview.dtype_is_object)
- * else:
- */
- if (unlikely(!__pyx_v_memviewsliceobj)) { __Pyx_RaiseUnboundLocalError("memviewsliceobj"); __PYX_ERR(1, 781, __pyx_L1_error) }
-
- /* "View.MemoryView":779
- *
- * if isinstance(memview, _memoryviewslice):
- * return memoryview_fromslice(dst, new_ndim, # <<<<<<<<<<<<<<
- * memviewsliceobj.to_object_func,
- * memviewsliceobj.to_dtype_func,
- */
- __pyx_t_3 = __pyx_memoryview_fromslice(__pyx_v_dst, __pyx_v_new_ndim, __pyx_v_memviewsliceobj->to_object_func, __pyx_v_memviewsliceobj->to_dtype_func, __pyx_v_memview->dtype_is_object); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 779, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- if (!(likely(((__pyx_t_3) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_3, __pyx_memoryview_type))))) __PYX_ERR(1, 779, __pyx_L1_error)
- __pyx_r = ((struct __pyx_memoryview_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":778
- * new_ndim += 1
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * return memoryview_fromslice(dst, new_ndim,
- * memviewsliceobj.to_object_func,
- */
- }
-
- /* "View.MemoryView":784
- * memview.dtype_is_object)
- * else:
- * return memoryview_fromslice(dst, new_ndim, NULL, NULL, # <<<<<<<<<<<<<<
- * memview.dtype_is_object)
- *
- */
- /*else*/ {
- __Pyx_XDECREF(((PyObject *)__pyx_r));
-
- /* "View.MemoryView":785
- * else:
- * return memoryview_fromslice(dst, new_ndim, NULL, NULL,
- * memview.dtype_is_object) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __pyx_memoryview_fromslice(__pyx_v_dst, __pyx_v_new_ndim, NULL, NULL, __pyx_v_memview->dtype_is_object); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 784, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
-
- /* "View.MemoryView":784
- * memview.dtype_is_object)
- * else:
- * return memoryview_fromslice(dst, new_ndim, NULL, NULL, # <<<<<<<<<<<<<<
- * memview.dtype_is_object)
- *
- */
- if (!(likely(((__pyx_t_3) == Py_None) || likely(__Pyx_TypeTest(__pyx_t_3, __pyx_memoryview_type))))) __PYX_ERR(1, 784, __pyx_L1_error)
- __pyx_r = ((struct __pyx_memoryview_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":712
- *
- * @cname('__pyx_memview_slice')
- * cdef memoryview memview_slice(memoryview memview, object indices): # <<<<<<<<<<<<<<
- * cdef int new_ndim = 0, suboffset_dim = -1, dim
- * cdef bint negative_step
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_9);
- __Pyx_AddTraceback("View.MemoryView.memview_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_memviewsliceobj);
- __Pyx_XDECREF(__pyx_v_index);
- __Pyx_XGIVEREF((PyObject *)__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":809
- *
- * @cname('__pyx_memoryview_slice_memviewslice')
- * cdef int slice_memviewslice( # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * Py_ssize_t shape, Py_ssize_t stride, Py_ssize_t suboffset,
- */
-
-static int __pyx_memoryview_slice_memviewslice(__Pyx_memviewslice *__pyx_v_dst, Py_ssize_t __pyx_v_shape, Py_ssize_t __pyx_v_stride, Py_ssize_t __pyx_v_suboffset, int __pyx_v_dim, int __pyx_v_new_ndim, int *__pyx_v_suboffset_dim, Py_ssize_t __pyx_v_start, Py_ssize_t __pyx_v_stop, Py_ssize_t __pyx_v_step, int __pyx_v_have_start, int __pyx_v_have_stop, int __pyx_v_have_step, int __pyx_v_is_slice) {
- Py_ssize_t __pyx_v_new_shape;
- int __pyx_v_negative_step;
- int __pyx_r;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":829
- * cdef bint negative_step
- *
- * if not is_slice: # <<<<<<<<<<<<<<
- *
- * if start < 0:
- */
- __pyx_t_1 = ((!(__pyx_v_is_slice != 0)) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":831
- * if not is_slice:
- *
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if not 0 <= start < shape:
- */
- __pyx_t_1 = ((__pyx_v_start < 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":832
- *
- * if start < 0:
- * start += shape # <<<<<<<<<<<<<<
- * if not 0 <= start < shape:
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim)
- */
- __pyx_v_start = (__pyx_v_start + __pyx_v_shape);
-
- /* "View.MemoryView":831
- * if not is_slice:
- *
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if not 0 <= start < shape:
- */
- }
-
- /* "View.MemoryView":833
- * if start < 0:
- * start += shape
- * if not 0 <= start < shape: # <<<<<<<<<<<<<<
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim)
- * else:
- */
- __pyx_t_1 = (0 <= __pyx_v_start);
- if (__pyx_t_1) {
- __pyx_t_1 = (__pyx_v_start < __pyx_v_shape);
- }
- __pyx_t_2 = ((!(__pyx_t_1 != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":834
- * start += shape
- * if not 0 <= start < shape:
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim) # <<<<<<<<<<<<<<
- * else:
- *
- */
- __pyx_t_3 = __pyx_memoryview_err_dim(__pyx_builtin_IndexError, ((char *)"Index out of bounds (axis %d)"), __pyx_v_dim); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 834, __pyx_L1_error)
-
- /* "View.MemoryView":833
- * if start < 0:
- * start += shape
- * if not 0 <= start < shape: # <<<<<<<<<<<<<<
- * _err_dim(IndexError, "Index out of bounds (axis %d)", dim)
- * else:
- */
- }
-
- /* "View.MemoryView":829
- * cdef bint negative_step
- *
- * if not is_slice: # <<<<<<<<<<<<<<
- *
- * if start < 0:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":837
- * else:
- *
- * negative_step = have_step != 0 and step < 0 # <<<<<<<<<<<<<<
- *
- * if have_step and step == 0:
- */
- /*else*/ {
- __pyx_t_1 = ((__pyx_v_have_step != 0) != 0);
- if (__pyx_t_1) {
- } else {
- __pyx_t_2 = __pyx_t_1;
- goto __pyx_L6_bool_binop_done;
- }
- __pyx_t_1 = ((__pyx_v_step < 0) != 0);
- __pyx_t_2 = __pyx_t_1;
- __pyx_L6_bool_binop_done:;
- __pyx_v_negative_step = __pyx_t_2;
-
- /* "View.MemoryView":839
- * negative_step = have_step != 0 and step < 0
- *
- * if have_step and step == 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Step may not be zero (axis %d)", dim)
- *
- */
- __pyx_t_1 = (__pyx_v_have_step != 0);
- if (__pyx_t_1) {
- } else {
- __pyx_t_2 = __pyx_t_1;
- goto __pyx_L9_bool_binop_done;
- }
- __pyx_t_1 = ((__pyx_v_step == 0) != 0);
- __pyx_t_2 = __pyx_t_1;
- __pyx_L9_bool_binop_done:;
- if (__pyx_t_2) {
-
- /* "View.MemoryView":840
- *
- * if have_step and step == 0:
- * _err_dim(ValueError, "Step may not be zero (axis %d)", dim) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __pyx_memoryview_err_dim(__pyx_builtin_ValueError, ((char *)"Step may not be zero (axis %d)"), __pyx_v_dim); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 840, __pyx_L1_error)
-
- /* "View.MemoryView":839
- * negative_step = have_step != 0 and step < 0
- *
- * if have_step and step == 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Step may not be zero (axis %d)", dim)
- *
- */
- }
-
- /* "View.MemoryView":843
- *
- *
- * if have_start: # <<<<<<<<<<<<<<
- * if start < 0:
- * start += shape
- */
- __pyx_t_2 = (__pyx_v_have_start != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":844
- *
- * if have_start:
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if start < 0:
- */
- __pyx_t_2 = ((__pyx_v_start < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":845
- * if have_start:
- * if start < 0:
- * start += shape # <<<<<<<<<<<<<<
- * if start < 0:
- * start = 0
- */
- __pyx_v_start = (__pyx_v_start + __pyx_v_shape);
-
- /* "View.MemoryView":846
- * if start < 0:
- * start += shape
- * if start < 0: # <<<<<<<<<<<<<<
- * start = 0
- * elif start >= shape:
- */
- __pyx_t_2 = ((__pyx_v_start < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":847
- * start += shape
- * if start < 0:
- * start = 0 # <<<<<<<<<<<<<<
- * elif start >= shape:
- * if negative_step:
- */
- __pyx_v_start = 0;
-
- /* "View.MemoryView":846
- * if start < 0:
- * start += shape
- * if start < 0: # <<<<<<<<<<<<<<
- * start = 0
- * elif start >= shape:
- */
- }
-
- /* "View.MemoryView":844
- *
- * if have_start:
- * if start < 0: # <<<<<<<<<<<<<<
- * start += shape
- * if start < 0:
- */
- goto __pyx_L12;
- }
-
- /* "View.MemoryView":848
- * if start < 0:
- * start = 0
- * elif start >= shape: # <<<<<<<<<<<<<<
- * if negative_step:
- * start = shape - 1
- */
- __pyx_t_2 = ((__pyx_v_start >= __pyx_v_shape) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":849
- * start = 0
- * elif start >= shape:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- __pyx_t_2 = (__pyx_v_negative_step != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":850
- * elif start >= shape:
- * if negative_step:
- * start = shape - 1 # <<<<<<<<<<<<<<
- * else:
- * start = shape
- */
- __pyx_v_start = (__pyx_v_shape - 1);
-
- /* "View.MemoryView":849
- * start = 0
- * elif start >= shape:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- goto __pyx_L14;
- }
-
- /* "View.MemoryView":852
- * start = shape - 1
- * else:
- * start = shape # <<<<<<<<<<<<<<
- * else:
- * if negative_step:
- */
- /*else*/ {
- __pyx_v_start = __pyx_v_shape;
- }
- __pyx_L14:;
-
- /* "View.MemoryView":848
- * if start < 0:
- * start = 0
- * elif start >= shape: # <<<<<<<<<<<<<<
- * if negative_step:
- * start = shape - 1
- */
- }
- __pyx_L12:;
-
- /* "View.MemoryView":843
- *
- *
- * if have_start: # <<<<<<<<<<<<<<
- * if start < 0:
- * start += shape
- */
- goto __pyx_L11;
- }
-
- /* "View.MemoryView":854
- * start = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- /*else*/ {
- __pyx_t_2 = (__pyx_v_negative_step != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":855
- * else:
- * if negative_step:
- * start = shape - 1 # <<<<<<<<<<<<<<
- * else:
- * start = 0
- */
- __pyx_v_start = (__pyx_v_shape - 1);
-
- /* "View.MemoryView":854
- * start = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * start = shape - 1
- * else:
- */
- goto __pyx_L15;
- }
-
- /* "View.MemoryView":857
- * start = shape - 1
- * else:
- * start = 0 # <<<<<<<<<<<<<<
- *
- * if have_stop:
- */
- /*else*/ {
- __pyx_v_start = 0;
- }
- __pyx_L15:;
- }
- __pyx_L11:;
-
- /* "View.MemoryView":859
- * start = 0
- *
- * if have_stop: # <<<<<<<<<<<<<<
- * if stop < 0:
- * stop += shape
- */
- __pyx_t_2 = (__pyx_v_have_stop != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":860
- *
- * if have_stop:
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop += shape
- * if stop < 0:
- */
- __pyx_t_2 = ((__pyx_v_stop < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":861
- * if have_stop:
- * if stop < 0:
- * stop += shape # <<<<<<<<<<<<<<
- * if stop < 0:
- * stop = 0
- */
- __pyx_v_stop = (__pyx_v_stop + __pyx_v_shape);
-
- /* "View.MemoryView":862
- * if stop < 0:
- * stop += shape
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop = 0
- * elif stop > shape:
- */
- __pyx_t_2 = ((__pyx_v_stop < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":863
- * stop += shape
- * if stop < 0:
- * stop = 0 # <<<<<<<<<<<<<<
- * elif stop > shape:
- * stop = shape
- */
- __pyx_v_stop = 0;
-
- /* "View.MemoryView":862
- * if stop < 0:
- * stop += shape
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop = 0
- * elif stop > shape:
- */
- }
-
- /* "View.MemoryView":860
- *
- * if have_stop:
- * if stop < 0: # <<<<<<<<<<<<<<
- * stop += shape
- * if stop < 0:
- */
- goto __pyx_L17;
- }
-
- /* "View.MemoryView":864
- * if stop < 0:
- * stop = 0
- * elif stop > shape: # <<<<<<<<<<<<<<
- * stop = shape
- * else:
- */
- __pyx_t_2 = ((__pyx_v_stop > __pyx_v_shape) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":865
- * stop = 0
- * elif stop > shape:
- * stop = shape # <<<<<<<<<<<<<<
- * else:
- * if negative_step:
- */
- __pyx_v_stop = __pyx_v_shape;
-
- /* "View.MemoryView":864
- * if stop < 0:
- * stop = 0
- * elif stop > shape: # <<<<<<<<<<<<<<
- * stop = shape
- * else:
- */
- }
- __pyx_L17:;
-
- /* "View.MemoryView":859
- * start = 0
- *
- * if have_stop: # <<<<<<<<<<<<<<
- * if stop < 0:
- * stop += shape
- */
- goto __pyx_L16;
- }
-
- /* "View.MemoryView":867
- * stop = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * stop = -1
- * else:
- */
- /*else*/ {
- __pyx_t_2 = (__pyx_v_negative_step != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":868
- * else:
- * if negative_step:
- * stop = -1 # <<<<<<<<<<<<<<
- * else:
- * stop = shape
- */
- __pyx_v_stop = -1L;
-
- /* "View.MemoryView":867
- * stop = shape
- * else:
- * if negative_step: # <<<<<<<<<<<<<<
- * stop = -1
- * else:
- */
- goto __pyx_L19;
- }
-
- /* "View.MemoryView":870
- * stop = -1
- * else:
- * stop = shape # <<<<<<<<<<<<<<
- *
- * if not have_step:
- */
- /*else*/ {
- __pyx_v_stop = __pyx_v_shape;
- }
- __pyx_L19:;
- }
- __pyx_L16:;
-
- /* "View.MemoryView":872
- * stop = shape
- *
- * if not have_step: # <<<<<<<<<<<<<<
- * step = 1
- *
- */
- __pyx_t_2 = ((!(__pyx_v_have_step != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":873
- *
- * if not have_step:
- * step = 1 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_step = 1;
-
- /* "View.MemoryView":872
- * stop = shape
- *
- * if not have_step: # <<<<<<<<<<<<<<
- * step = 1
- *
- */
- }
-
- /* "View.MemoryView":877
- *
- * with cython.cdivision(True):
- * new_shape = (stop - start) // step # <<<<<<<<<<<<<<
- *
- * if (stop - start) - step * new_shape:
- */
- __pyx_v_new_shape = ((__pyx_v_stop - __pyx_v_start) / __pyx_v_step);
-
- /* "View.MemoryView":879
- * new_shape = (stop - start) // step
- *
- * if (stop - start) - step * new_shape: # <<<<<<<<<<<<<<
- * new_shape += 1
- *
- */
- __pyx_t_2 = (((__pyx_v_stop - __pyx_v_start) - (__pyx_v_step * __pyx_v_new_shape)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":880
- *
- * if (stop - start) - step * new_shape:
- * new_shape += 1 # <<<<<<<<<<<<<<
- *
- * if new_shape < 0:
- */
- __pyx_v_new_shape = (__pyx_v_new_shape + 1);
-
- /* "View.MemoryView":879
- * new_shape = (stop - start) // step
- *
- * if (stop - start) - step * new_shape: # <<<<<<<<<<<<<<
- * new_shape += 1
- *
- */
- }
-
- /* "View.MemoryView":882
- * new_shape += 1
- *
- * if new_shape < 0: # <<<<<<<<<<<<<<
- * new_shape = 0
- *
- */
- __pyx_t_2 = ((__pyx_v_new_shape < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":883
- *
- * if new_shape < 0:
- * new_shape = 0 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_new_shape = 0;
-
- /* "View.MemoryView":882
- * new_shape += 1
- *
- * if new_shape < 0: # <<<<<<<<<<<<<<
- * new_shape = 0
- *
- */
- }
-
- /* "View.MemoryView":886
- *
- *
- * dst.strides[new_ndim] = stride * step # <<<<<<<<<<<<<<
- * dst.shape[new_ndim] = new_shape
- * dst.suboffsets[new_ndim] = suboffset
- */
- (__pyx_v_dst->strides[__pyx_v_new_ndim]) = (__pyx_v_stride * __pyx_v_step);
-
- /* "View.MemoryView":887
- *
- * dst.strides[new_ndim] = stride * step
- * dst.shape[new_ndim] = new_shape # <<<<<<<<<<<<<<
- * dst.suboffsets[new_ndim] = suboffset
- *
- */
- (__pyx_v_dst->shape[__pyx_v_new_ndim]) = __pyx_v_new_shape;
-
- /* "View.MemoryView":888
- * dst.strides[new_ndim] = stride * step
- * dst.shape[new_ndim] = new_shape
- * dst.suboffsets[new_ndim] = suboffset # <<<<<<<<<<<<<<
- *
- *
- */
- (__pyx_v_dst->suboffsets[__pyx_v_new_ndim]) = __pyx_v_suboffset;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":891
- *
- *
- * if suboffset_dim[0] < 0: # <<<<<<<<<<<<<<
- * dst.data += start * stride
- * else:
- */
- __pyx_t_2 = (((__pyx_v_suboffset_dim[0]) < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":892
- *
- * if suboffset_dim[0] < 0:
- * dst.data += start * stride # <<<<<<<<<<<<<<
- * else:
- * dst.suboffsets[suboffset_dim[0]] += start * stride
- */
- __pyx_v_dst->data = (__pyx_v_dst->data + (__pyx_v_start * __pyx_v_stride));
-
- /* "View.MemoryView":891
- *
- *
- * if suboffset_dim[0] < 0: # <<<<<<<<<<<<<<
- * dst.data += start * stride
- * else:
- */
- goto __pyx_L23;
- }
-
- /* "View.MemoryView":894
- * dst.data += start * stride
- * else:
- * dst.suboffsets[suboffset_dim[0]] += start * stride # <<<<<<<<<<<<<<
- *
- * if suboffset >= 0:
- */
- /*else*/ {
- __pyx_t_3 = (__pyx_v_suboffset_dim[0]);
- (__pyx_v_dst->suboffsets[__pyx_t_3]) = ((__pyx_v_dst->suboffsets[__pyx_t_3]) + (__pyx_v_start * __pyx_v_stride));
- }
- __pyx_L23:;
-
- /* "View.MemoryView":896
- * dst.suboffsets[suboffset_dim[0]] += start * stride
- *
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * if not is_slice:
- * if new_ndim == 0:
- */
- __pyx_t_2 = ((__pyx_v_suboffset >= 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":897
- *
- * if suboffset >= 0:
- * if not is_slice: # <<<<<<<<<<<<<<
- * if new_ndim == 0:
- * dst.data = ( dst.data)[0] + suboffset
- */
- __pyx_t_2 = ((!(__pyx_v_is_slice != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":898
- * if suboffset >= 0:
- * if not is_slice:
- * if new_ndim == 0: # <<<<<<<<<<<<<<
- * dst.data = ( dst.data)[0] + suboffset
- * else:
- */
- __pyx_t_2 = ((__pyx_v_new_ndim == 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":899
- * if not is_slice:
- * if new_ndim == 0:
- * dst.data = ( dst.data)[0] + suboffset # <<<<<<<<<<<<<<
- * else:
- * _err_dim(IndexError, "All dimensions preceding dimension %d "
- */
- __pyx_v_dst->data = ((((char **)__pyx_v_dst->data)[0]) + __pyx_v_suboffset);
-
- /* "View.MemoryView":898
- * if suboffset >= 0:
- * if not is_slice:
- * if new_ndim == 0: # <<<<<<<<<<<<<<
- * dst.data = ( dst.data)[0] + suboffset
- * else:
- */
- goto __pyx_L26;
- }
-
- /* "View.MemoryView":901
- * dst.data = ( dst.data)[0] + suboffset
- * else:
- * _err_dim(IndexError, "All dimensions preceding dimension %d " # <<<<<<<<<<<<<<
- * "must be indexed and not sliced", dim)
- * else:
- */
- /*else*/ {
-
- /* "View.MemoryView":902
- * else:
- * _err_dim(IndexError, "All dimensions preceding dimension %d "
- * "must be indexed and not sliced", dim) # <<<<<<<<<<<<<<
- * else:
- * suboffset_dim[0] = new_ndim
- */
- __pyx_t_3 = __pyx_memoryview_err_dim(__pyx_builtin_IndexError, ((char *)"All dimensions preceding dimension %d must be indexed and not sliced"), __pyx_v_dim); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 901, __pyx_L1_error)
- }
- __pyx_L26:;
-
- /* "View.MemoryView":897
- *
- * if suboffset >= 0:
- * if not is_slice: # <<<<<<<<<<<<<<
- * if new_ndim == 0:
- * dst.data = ( dst.data)[0] + suboffset
- */
- goto __pyx_L25;
- }
-
- /* "View.MemoryView":904
- * "must be indexed and not sliced", dim)
- * else:
- * suboffset_dim[0] = new_ndim # <<<<<<<<<<<<<<
- *
- * return 0
- */
- /*else*/ {
- (__pyx_v_suboffset_dim[0]) = __pyx_v_new_ndim;
- }
- __pyx_L25:;
-
- /* "View.MemoryView":896
- * dst.suboffsets[suboffset_dim[0]] += start * stride
- *
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * if not is_slice:
- * if new_ndim == 0:
- */
- }
-
- /* "View.MemoryView":906
- * suboffset_dim[0] = new_ndim
- *
- * return 0 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":809
- *
- * @cname('__pyx_memoryview_slice_memviewslice')
- * cdef int slice_memviewslice( # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * Py_ssize_t shape, Py_ssize_t stride, Py_ssize_t suboffset,
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.slice_memviewslice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = -1;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":912
- *
- * @cname('__pyx_pybuffer_index')
- * cdef char *pybuffer_index(Py_buffer *view, char *bufp, Py_ssize_t index, # <<<<<<<<<<<<<<
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1
- */
-
-static char *__pyx_pybuffer_index(Py_buffer *__pyx_v_view, char *__pyx_v_bufp, Py_ssize_t __pyx_v_index, Py_ssize_t __pyx_v_dim) {
- Py_ssize_t __pyx_v_shape;
- Py_ssize_t __pyx_v_stride;
- Py_ssize_t __pyx_v_suboffset;
- Py_ssize_t __pyx_v_itemsize;
- char *__pyx_v_resultp;
- char *__pyx_r;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("pybuffer_index", 0);
-
- /* "View.MemoryView":914
- * cdef char *pybuffer_index(Py_buffer *view, char *bufp, Py_ssize_t index,
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1 # <<<<<<<<<<<<<<
- * cdef Py_ssize_t itemsize = view.itemsize
- * cdef char *resultp
- */
- __pyx_v_suboffset = -1L;
-
- /* "View.MemoryView":915
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1
- * cdef Py_ssize_t itemsize = view.itemsize # <<<<<<<<<<<<<<
- * cdef char *resultp
- *
- */
- __pyx_t_1 = __pyx_v_view->itemsize;
- __pyx_v_itemsize = __pyx_t_1;
-
- /* "View.MemoryView":918
- * cdef char *resultp
- *
- * if view.ndim == 0: # <<<<<<<<<<<<<<
- * shape = view.len / itemsize
- * stride = itemsize
- */
- __pyx_t_2 = ((__pyx_v_view->ndim == 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":919
- *
- * if view.ndim == 0:
- * shape = view.len / itemsize # <<<<<<<<<<<<<<
- * stride = itemsize
- * else:
- */
- if (unlikely(__pyx_v_itemsize == 0)) {
- PyErr_SetString(PyExc_ZeroDivisionError, "integer division or modulo by zero");
- __PYX_ERR(1, 919, __pyx_L1_error)
- }
- else if (sizeof(Py_ssize_t) == sizeof(long) && (!(((Py_ssize_t)-1) > 0)) && unlikely(__pyx_v_itemsize == (Py_ssize_t)-1) && unlikely(UNARY_NEG_WOULD_OVERFLOW(__pyx_v_view->len))) {
- PyErr_SetString(PyExc_OverflowError, "value too large to perform division");
- __PYX_ERR(1, 919, __pyx_L1_error)
- }
- __pyx_v_shape = __Pyx_div_Py_ssize_t(__pyx_v_view->len, __pyx_v_itemsize);
-
- /* "View.MemoryView":920
- * if view.ndim == 0:
- * shape = view.len / itemsize
- * stride = itemsize # <<<<<<<<<<<<<<
- * else:
- * shape = view.shape[dim]
- */
- __pyx_v_stride = __pyx_v_itemsize;
-
- /* "View.MemoryView":918
- * cdef char *resultp
- *
- * if view.ndim == 0: # <<<<<<<<<<<<<<
- * shape = view.len / itemsize
- * stride = itemsize
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":922
- * stride = itemsize
- * else:
- * shape = view.shape[dim] # <<<<<<<<<<<<<<
- * stride = view.strides[dim]
- * if view.suboffsets != NULL:
- */
- /*else*/ {
- __pyx_v_shape = (__pyx_v_view->shape[__pyx_v_dim]);
-
- /* "View.MemoryView":923
- * else:
- * shape = view.shape[dim]
- * stride = view.strides[dim] # <<<<<<<<<<<<<<
- * if view.suboffsets != NULL:
- * suboffset = view.suboffsets[dim]
- */
- __pyx_v_stride = (__pyx_v_view->strides[__pyx_v_dim]);
-
- /* "View.MemoryView":924
- * shape = view.shape[dim]
- * stride = view.strides[dim]
- * if view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * suboffset = view.suboffsets[dim]
- *
- */
- __pyx_t_2 = ((__pyx_v_view->suboffsets != NULL) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":925
- * stride = view.strides[dim]
- * if view.suboffsets != NULL:
- * suboffset = view.suboffsets[dim] # <<<<<<<<<<<<<<
- *
- * if index < 0:
- */
- __pyx_v_suboffset = (__pyx_v_view->suboffsets[__pyx_v_dim]);
-
- /* "View.MemoryView":924
- * shape = view.shape[dim]
- * stride = view.strides[dim]
- * if view.suboffsets != NULL: # <<<<<<<<<<<<<<
- * suboffset = view.suboffsets[dim]
- *
- */
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":927
- * suboffset = view.suboffsets[dim]
- *
- * if index < 0: # <<<<<<<<<<<<<<
- * index += view.shape[dim]
- * if index < 0:
- */
- __pyx_t_2 = ((__pyx_v_index < 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":928
- *
- * if index < 0:
- * index += view.shape[dim] # <<<<<<<<<<<<<<
- * if index < 0:
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- */
- __pyx_v_index = (__pyx_v_index + (__pyx_v_view->shape[__pyx_v_dim]));
-
- /* "View.MemoryView":929
- * if index < 0:
- * index += view.shape[dim]
- * if index < 0: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- __pyx_t_2 = ((__pyx_v_index < 0) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":930
- * index += view.shape[dim]
- * if index < 0:
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim) # <<<<<<<<<<<<<<
- *
- * if index >= shape:
- */
- __pyx_t_3 = PyInt_FromSsize_t(__pyx_v_dim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 930, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_PyString_Format(__pyx_kp_s_Out_of_bounds_on_buffer_access_a, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 930, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_3 = __Pyx_PyObject_CallOneArg(__pyx_builtin_IndexError, __pyx_t_4); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 930, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 930, __pyx_L1_error)
-
- /* "View.MemoryView":929
- * if index < 0:
- * index += view.shape[dim]
- * if index < 0: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- }
-
- /* "View.MemoryView":927
- * suboffset = view.suboffsets[dim]
- *
- * if index < 0: # <<<<<<<<<<<<<<
- * index += view.shape[dim]
- * if index < 0:
- */
- }
-
- /* "View.MemoryView":932
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- * if index >= shape: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- __pyx_t_2 = ((__pyx_v_index >= __pyx_v_shape) != 0);
- if (unlikely(__pyx_t_2)) {
-
- /* "View.MemoryView":933
- *
- * if index >= shape:
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim) # <<<<<<<<<<<<<<
- *
- * resultp = bufp + index * stride
- */
- __pyx_t_3 = PyInt_FromSsize_t(__pyx_v_dim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 933, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = __Pyx_PyString_Format(__pyx_kp_s_Out_of_bounds_on_buffer_access_a, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 933, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_t_3 = __Pyx_PyObject_CallOneArg(__pyx_builtin_IndexError, __pyx_t_4); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 933, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_Raise(__pyx_t_3, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __PYX_ERR(1, 933, __pyx_L1_error)
-
- /* "View.MemoryView":932
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- * if index >= shape: # <<<<<<<<<<<<<<
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- */
- }
-
- /* "View.MemoryView":935
- * raise IndexError("Out of bounds on buffer access (axis %d)" % dim)
- *
- * resultp = bufp + index * stride # <<<<<<<<<<<<<<
- * if suboffset >= 0:
- * resultp = ( resultp)[0] + suboffset
- */
- __pyx_v_resultp = (__pyx_v_bufp + (__pyx_v_index * __pyx_v_stride));
-
- /* "View.MemoryView":936
- *
- * resultp = bufp + index * stride
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * resultp = ( resultp)[0] + suboffset
- *
- */
- __pyx_t_2 = ((__pyx_v_suboffset >= 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":937
- * resultp = bufp + index * stride
- * if suboffset >= 0:
- * resultp = ( resultp)[0] + suboffset # <<<<<<<<<<<<<<
- *
- * return resultp
- */
- __pyx_v_resultp = ((((char **)__pyx_v_resultp)[0]) + __pyx_v_suboffset);
-
- /* "View.MemoryView":936
- *
- * resultp = bufp + index * stride
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * resultp = ( resultp)[0] + suboffset
- *
- */
- }
-
- /* "View.MemoryView":939
- * resultp = ( resultp)[0] + suboffset
- *
- * return resultp # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = __pyx_v_resultp;
- goto __pyx_L0;
-
- /* "View.MemoryView":912
- *
- * @cname('__pyx_pybuffer_index')
- * cdef char *pybuffer_index(Py_buffer *view, char *bufp, Py_ssize_t index, # <<<<<<<<<<<<<<
- * Py_ssize_t dim) except NULL:
- * cdef Py_ssize_t shape, stride, suboffset = -1
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView.pybuffer_index", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":945
- *
- * @cname('__pyx_memslice_transpose')
- * cdef int transpose_memslice(__Pyx_memviewslice *memslice) nogil except 0: # <<<<<<<<<<<<<<
- * cdef int ndim = memslice.memview.view.ndim
- *
- */
-
-static int __pyx_memslice_transpose(__Pyx_memviewslice *__pyx_v_memslice) {
- int __pyx_v_ndim;
- Py_ssize_t *__pyx_v_shape;
- Py_ssize_t *__pyx_v_strides;
- int __pyx_v_i;
- int __pyx_v_j;
- int __pyx_r;
- int __pyx_t_1;
- Py_ssize_t *__pyx_t_2;
- long __pyx_t_3;
- long __pyx_t_4;
- Py_ssize_t __pyx_t_5;
- Py_ssize_t __pyx_t_6;
- int __pyx_t_7;
- int __pyx_t_8;
- int __pyx_t_9;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":946
- * @cname('__pyx_memslice_transpose')
- * cdef int transpose_memslice(__Pyx_memviewslice *memslice) nogil except 0:
- * cdef int ndim = memslice.memview.view.ndim # <<<<<<<<<<<<<<
- *
- * cdef Py_ssize_t *shape = memslice.shape
- */
- __pyx_t_1 = __pyx_v_memslice->memview->view.ndim;
- __pyx_v_ndim = __pyx_t_1;
-
- /* "View.MemoryView":948
- * cdef int ndim = memslice.memview.view.ndim
- *
- * cdef Py_ssize_t *shape = memslice.shape # <<<<<<<<<<<<<<
- * cdef Py_ssize_t *strides = memslice.strides
- *
- */
- __pyx_t_2 = __pyx_v_memslice->shape;
- __pyx_v_shape = __pyx_t_2;
-
- /* "View.MemoryView":949
- *
- * cdef Py_ssize_t *shape = memslice.shape
- * cdef Py_ssize_t *strides = memslice.strides # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_2 = __pyx_v_memslice->strides;
- __pyx_v_strides = __pyx_t_2;
-
- /* "View.MemoryView":953
- *
- * cdef int i, j
- * for i in range(ndim / 2): # <<<<<<<<<<<<<<
- * j = ndim - 1 - i
- * strides[i], strides[j] = strides[j], strides[i]
- */
- __pyx_t_3 = __Pyx_div_long(__pyx_v_ndim, 2);
- __pyx_t_4 = __pyx_t_3;
- for (__pyx_t_1 = 0; __pyx_t_1 < __pyx_t_4; __pyx_t_1+=1) {
- __pyx_v_i = __pyx_t_1;
-
- /* "View.MemoryView":954
- * cdef int i, j
- * for i in range(ndim / 2):
- * j = ndim - 1 - i # <<<<<<<<<<<<<<
- * strides[i], strides[j] = strides[j], strides[i]
- * shape[i], shape[j] = shape[j], shape[i]
- */
- __pyx_v_j = ((__pyx_v_ndim - 1) - __pyx_v_i);
-
- /* "View.MemoryView":955
- * for i in range(ndim / 2):
- * j = ndim - 1 - i
- * strides[i], strides[j] = strides[j], strides[i] # <<<<<<<<<<<<<<
- * shape[i], shape[j] = shape[j], shape[i]
- *
- */
- __pyx_t_5 = (__pyx_v_strides[__pyx_v_j]);
- __pyx_t_6 = (__pyx_v_strides[__pyx_v_i]);
- (__pyx_v_strides[__pyx_v_i]) = __pyx_t_5;
- (__pyx_v_strides[__pyx_v_j]) = __pyx_t_6;
-
- /* "View.MemoryView":956
- * j = ndim - 1 - i
- * strides[i], strides[j] = strides[j], strides[i]
- * shape[i], shape[j] = shape[j], shape[i] # <<<<<<<<<<<<<<
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0:
- */
- __pyx_t_6 = (__pyx_v_shape[__pyx_v_j]);
- __pyx_t_5 = (__pyx_v_shape[__pyx_v_i]);
- (__pyx_v_shape[__pyx_v_i]) = __pyx_t_6;
- (__pyx_v_shape[__pyx_v_j]) = __pyx_t_5;
-
- /* "View.MemoryView":958
- * shape[i], shape[j] = shape[j], shape[i]
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0: # <<<<<<<<<<<<<<
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions")
- *
- */
- __pyx_t_8 = (((__pyx_v_memslice->suboffsets[__pyx_v_i]) >= 0) != 0);
- if (!__pyx_t_8) {
- } else {
- __pyx_t_7 = __pyx_t_8;
- goto __pyx_L6_bool_binop_done;
- }
- __pyx_t_8 = (((__pyx_v_memslice->suboffsets[__pyx_v_j]) >= 0) != 0);
- __pyx_t_7 = __pyx_t_8;
- __pyx_L6_bool_binop_done:;
- if (__pyx_t_7) {
-
- /* "View.MemoryView":959
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0:
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions") # <<<<<<<<<<<<<<
- *
- * return 1
- */
- __pyx_t_9 = __pyx_memoryview_err(__pyx_builtin_ValueError, ((char *)"Cannot transpose memoryview with indirect dimensions")); if (unlikely(__pyx_t_9 == ((int)-1))) __PYX_ERR(1, 959, __pyx_L1_error)
-
- /* "View.MemoryView":958
- * shape[i], shape[j] = shape[j], shape[i]
- *
- * if memslice.suboffsets[i] >= 0 or memslice.suboffsets[j] >= 0: # <<<<<<<<<<<<<<
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions")
- *
- */
- }
- }
-
- /* "View.MemoryView":961
- * _err(ValueError, "Cannot transpose memoryview with indirect dimensions")
- *
- * return 1 # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = 1;
- goto __pyx_L0;
-
- /* "View.MemoryView":945
- *
- * @cname('__pyx_memslice_transpose')
- * cdef int transpose_memslice(__Pyx_memviewslice *memslice) nogil except 0: # <<<<<<<<<<<<<<
- * cdef int ndim = memslice.memview.view.ndim
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.transpose_memslice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = 0;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":978
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * def __dealloc__(self): # <<<<<<<<<<<<<<
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- */
-
-/* Python wrapper */
-static void __pyx_memoryviewslice___dealloc__(PyObject *__pyx_v_self); /*proto*/
-static void __pyx_memoryviewslice___dealloc__(PyObject *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__ (wrapper)", 0);
- __pyx_memoryviewslice___pyx_pf_15View_dot_MemoryView_16_memoryviewslice___dealloc__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-static void __pyx_memoryviewslice___pyx_pf_15View_dot_MemoryView_16_memoryviewslice___dealloc__(struct __pyx_memoryviewslice_obj *__pyx_v_self) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__dealloc__", 0);
-
- /* "View.MemoryView":979
- *
- * def __dealloc__(self):
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1) # <<<<<<<<<<<<<<
- *
- * cdef convert_item_to_object(self, char *itemp):
- */
- __PYX_XDEC_MEMVIEW((&__pyx_v_self->from_slice), 1);
-
- /* "View.MemoryView":978
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * def __dealloc__(self): # <<<<<<<<<<<<<<
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":981
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * if self.to_object_func != NULL:
- * return self.to_object_func(itemp)
- */
-
-static PyObject *__pyx_memoryviewslice_convert_item_to_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("convert_item_to_object", 0);
-
- /* "View.MemoryView":982
- *
- * cdef convert_item_to_object(self, char *itemp):
- * if self.to_object_func != NULL: # <<<<<<<<<<<<<<
- * return self.to_object_func(itemp)
- * else:
- */
- __pyx_t_1 = ((__pyx_v_self->to_object_func != NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":983
- * cdef convert_item_to_object(self, char *itemp):
- * if self.to_object_func != NULL:
- * return self.to_object_func(itemp) # <<<<<<<<<<<<<<
- * else:
- * return memoryview.convert_item_to_object(self, itemp)
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_v_self->to_object_func(__pyx_v_itemp); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 983, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":982
- *
- * cdef convert_item_to_object(self, char *itemp):
- * if self.to_object_func != NULL: # <<<<<<<<<<<<<<
- * return self.to_object_func(itemp)
- * else:
- */
- }
-
- /* "View.MemoryView":985
- * return self.to_object_func(itemp)
- * else:
- * return memoryview.convert_item_to_object(self, itemp) # <<<<<<<<<<<<<<
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- */
- /*else*/ {
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_2 = __pyx_memoryview_convert_item_to_object(((struct __pyx_memoryview_obj *)__pyx_v_self), __pyx_v_itemp); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 985, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_r = __pyx_t_2;
- __pyx_t_2 = 0;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":981
- * __PYX_XDEC_MEMVIEW(&self.from_slice, 1)
- *
- * cdef convert_item_to_object(self, char *itemp): # <<<<<<<<<<<<<<
- * if self.to_object_func != NULL:
- * return self.to_object_func(itemp)
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.convert_item_to_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":987
- * return memoryview.convert_item_to_object(self, itemp)
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * if self.to_dtype_func != NULL:
- * self.to_dtype_func(itemp, value)
- */
-
-static PyObject *__pyx_memoryviewslice_assign_item_from_object(struct __pyx_memoryviewslice_obj *__pyx_v_self, char *__pyx_v_itemp, PyObject *__pyx_v_value) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("assign_item_from_object", 0);
-
- /* "View.MemoryView":988
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- * if self.to_dtype_func != NULL: # <<<<<<<<<<<<<<
- * self.to_dtype_func(itemp, value)
- * else:
- */
- __pyx_t_1 = ((__pyx_v_self->to_dtype_func != NULL) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":989
- * cdef assign_item_from_object(self, char *itemp, object value):
- * if self.to_dtype_func != NULL:
- * self.to_dtype_func(itemp, value) # <<<<<<<<<<<<<<
- * else:
- * memoryview.assign_item_from_object(self, itemp, value)
- */
- __pyx_t_2 = __pyx_v_self->to_dtype_func(__pyx_v_itemp, __pyx_v_value); if (unlikely(__pyx_t_2 == ((int)0))) __PYX_ERR(1, 989, __pyx_L1_error)
-
- /* "View.MemoryView":988
- *
- * cdef assign_item_from_object(self, char *itemp, object value):
- * if self.to_dtype_func != NULL: # <<<<<<<<<<<<<<
- * self.to_dtype_func(itemp, value)
- * else:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":991
- * self.to_dtype_func(itemp, value)
- * else:
- * memoryview.assign_item_from_object(self, itemp, value) # <<<<<<<<<<<<<<
- *
- * @property
- */
- /*else*/ {
- __pyx_t_3 = __pyx_memoryview_assign_item_from_object(((struct __pyx_memoryview_obj *)__pyx_v_self), __pyx_v_itemp, __pyx_v_value); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 991, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":987
- * return memoryview.convert_item_to_object(self, itemp)
- *
- * cdef assign_item_from_object(self, char *itemp, object value): # <<<<<<<<<<<<<<
- * if self.to_dtype_func != NULL:
- * self.to_dtype_func(itemp, value)
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.assign_item_from_object", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":994
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.from_object
- *
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_16_memoryviewslice_4base_1__get__(PyObject *__pyx_v_self); /*proto*/
-static PyObject *__pyx_pw_15View_dot_MemoryView_16_memoryviewslice_4base_1__get__(PyObject *__pyx_v_self) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__ (wrapper)", 0);
- __pyx_r = __pyx_pf_15View_dot_MemoryView_16_memoryviewslice_4base___get__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView_16_memoryviewslice_4base___get__(struct __pyx_memoryviewslice_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__get__", 0);
-
- /* "View.MemoryView":995
- * @property
- * def base(self):
- * return self.from_object # <<<<<<<<<<<<<<
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)")
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v_self->from_object);
- __pyx_r = __pyx_v_self->from_object;
- goto __pyx_L0;
-
- /* "View.MemoryView":994
- *
- * @property
- * def base(self): # <<<<<<<<<<<<<<
- * return self.from_object
- *
- */
-
- /* function exit code */
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryviewslice_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryviewslice_1__reduce_cython__(PyObject *__pyx_v_self, CYTHON_UNUSED PyObject *unused) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__reduce_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryviewslice___reduce_cython__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryviewslice___reduce_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__reduce_cython__", 0);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__18, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 2, __pyx_L1_error)
-
- /* "(tree fragment)":1
- * def __reduce_cython__(self): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.__reduce_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw___pyx_memoryviewslice_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state); /*proto*/
-static PyObject *__pyx_pw___pyx_memoryviewslice_3__setstate_cython__(PyObject *__pyx_v_self, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__setstate_cython__ (wrapper)", 0);
- __pyx_r = __pyx_pf___pyx_memoryviewslice_2__setstate_cython__(((struct __pyx_memoryviewslice_obj *)__pyx_v_self), ((PyObject *)__pyx_v___pyx_state));
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf___pyx_memoryviewslice_2__setstate_cython__(CYTHON_UNUSED struct __pyx_memoryviewslice_obj *__pyx_v_self, CYTHON_UNUSED PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__setstate_cython__", 0);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_t_1 = __Pyx_PyObject_Call(__pyx_builtin_TypeError, __pyx_tuple__19, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 4, __pyx_L1_error)
-
- /* "(tree fragment)":3
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state): # <<<<<<<<<<<<<<
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView._memoryviewslice.__setstate_cython__", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1001
- *
- * @cname('__pyx_memoryview_fromslice')
- * cdef memoryview_fromslice(__Pyx_memviewslice memviewslice, # <<<<<<<<<<<<<<
- * int ndim,
- * object (*to_object_func)(char *),
- */
-
-static PyObject *__pyx_memoryview_fromslice(__Pyx_memviewslice __pyx_v_memviewslice, int __pyx_v_ndim, PyObject *(*__pyx_v_to_object_func)(char *), int (*__pyx_v_to_dtype_func)(char *, PyObject *), int __pyx_v_dtype_is_object) {
- struct __pyx_memoryviewslice_obj *__pyx_v_result = 0;
- Py_ssize_t __pyx_v_suboffset;
- PyObject *__pyx_v_length = NULL;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- __Pyx_TypeInfo *__pyx_t_4;
- Py_buffer __pyx_t_5;
- Py_ssize_t *__pyx_t_6;
- Py_ssize_t *__pyx_t_7;
- Py_ssize_t *__pyx_t_8;
- Py_ssize_t __pyx_t_9;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_fromslice", 0);
-
- /* "View.MemoryView":1009
- * cdef _memoryviewslice result
- *
- * if memviewslice.memview == Py_None: # <<<<<<<<<<<<<<
- * return None
- *
- */
- __pyx_t_1 = ((((PyObject *)__pyx_v_memviewslice.memview) == Py_None) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1010
- *
- * if memviewslice.memview == Py_None:
- * return None # <<<<<<<<<<<<<<
- *
- *
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
-
- /* "View.MemoryView":1009
- * cdef _memoryviewslice result
- *
- * if memviewslice.memview == Py_None: # <<<<<<<<<<<<<<
- * return None
- *
- */
- }
-
- /* "View.MemoryView":1015
- *
- *
- * result = _memoryviewslice(None, 0, dtype_is_object) # <<<<<<<<<<<<<<
- *
- * result.from_slice = memviewslice
- */
- __pyx_t_2 = __Pyx_PyBool_FromLong(__pyx_v_dtype_is_object); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1015, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyTuple_New(3); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1015, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(Py_None);
- __Pyx_GIVEREF(Py_None);
- PyTuple_SET_ITEM(__pyx_t_3, 0, Py_None);
- __Pyx_INCREF(__pyx_int_0);
- __Pyx_GIVEREF(__pyx_int_0);
- PyTuple_SET_ITEM(__pyx_t_3, 1, __pyx_int_0);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_3, 2, __pyx_t_2);
- __pyx_t_2 = 0;
- __pyx_t_2 = __Pyx_PyObject_Call(((PyObject *)__pyx_memoryviewslice_type), __pyx_t_3, NULL); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1015, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result = ((struct __pyx_memoryviewslice_obj *)__pyx_t_2);
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":1017
- * result = _memoryviewslice(None, 0, dtype_is_object)
- *
- * result.from_slice = memviewslice # <<<<<<<<<<<<<<
- * __PYX_INC_MEMVIEW(&memviewslice, 1)
- *
- */
- __pyx_v_result->from_slice = __pyx_v_memviewslice;
-
- /* "View.MemoryView":1018
- *
- * result.from_slice = memviewslice
- * __PYX_INC_MEMVIEW(&memviewslice, 1) # <<<<<<<<<<<<<<
- *
- * result.from_object = ( memviewslice.memview).base
- */
- __PYX_INC_MEMVIEW((&__pyx_v_memviewslice), 1);
-
- /* "View.MemoryView":1020
- * __PYX_INC_MEMVIEW(&memviewslice, 1)
- *
- * result.from_object = ( memviewslice.memview).base # <<<<<<<<<<<<<<
- * result.typeinfo = memviewslice.memview.typeinfo
- *
- */
- __pyx_t_2 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v_memviewslice.memview), __pyx_n_s_base); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1020, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_2);
- __Pyx_GOTREF(__pyx_v_result->from_object);
- __Pyx_DECREF(__pyx_v_result->from_object);
- __pyx_v_result->from_object = __pyx_t_2;
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":1021
- *
- * result.from_object = ( memviewslice.memview).base
- * result.typeinfo = memviewslice.memview.typeinfo # <<<<<<<<<<<<<<
- *
- * result.view = memviewslice.memview.view
- */
- __pyx_t_4 = __pyx_v_memviewslice.memview->typeinfo;
- __pyx_v_result->__pyx_base.typeinfo = __pyx_t_4;
-
- /* "View.MemoryView":1023
- * result.typeinfo = memviewslice.memview.typeinfo
- *
- * result.view = memviewslice.memview.view # <<<<<<<<<<<<<<
- * result.view.buf = memviewslice.data
- * result.view.ndim = ndim
- */
- __pyx_t_5 = __pyx_v_memviewslice.memview->view;
- __pyx_v_result->__pyx_base.view = __pyx_t_5;
-
- /* "View.MemoryView":1024
- *
- * result.view = memviewslice.memview.view
- * result.view.buf = memviewslice.data # <<<<<<<<<<<<<<
- * result.view.ndim = ndim
- * (<__pyx_buffer *> &result.view).obj = Py_None
- */
- __pyx_v_result->__pyx_base.view.buf = ((void *)__pyx_v_memviewslice.data);
-
- /* "View.MemoryView":1025
- * result.view = memviewslice.memview.view
- * result.view.buf = memviewslice.data
- * result.view.ndim = ndim # <<<<<<<<<<<<<<
- * (<__pyx_buffer *> &result.view).obj = Py_None
- * Py_INCREF(Py_None)
- */
- __pyx_v_result->__pyx_base.view.ndim = __pyx_v_ndim;
-
- /* "View.MemoryView":1026
- * result.view.buf = memviewslice.data
- * result.view.ndim = ndim
- * (<__pyx_buffer *> &result.view).obj = Py_None # <<<<<<<<<<<<<<
- * Py_INCREF(Py_None)
- *
- */
- ((Py_buffer *)(&__pyx_v_result->__pyx_base.view))->obj = Py_None;
-
- /* "View.MemoryView":1027
- * result.view.ndim = ndim
- * (<__pyx_buffer *> &result.view).obj = Py_None
- * Py_INCREF(Py_None) # <<<<<<<<<<<<<<
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE:
- */
- Py_INCREF(Py_None);
-
- /* "View.MemoryView":1029
- * Py_INCREF(Py_None)
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE: # <<<<<<<<<<<<<<
- * result.flags = PyBUF_RECORDS
- * else:
- */
- __pyx_t_1 = ((((struct __pyx_memoryview_obj *)__pyx_v_memviewslice.memview)->flags & PyBUF_WRITABLE) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1030
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE:
- * result.flags = PyBUF_RECORDS # <<<<<<<<<<<<<<
- * else:
- * result.flags = PyBUF_RECORDS_RO
- */
- __pyx_v_result->__pyx_base.flags = PyBUF_RECORDS;
-
- /* "View.MemoryView":1029
- * Py_INCREF(Py_None)
- *
- * if (memviewslice.memview).flags & PyBUF_WRITABLE: # <<<<<<<<<<<<<<
- * result.flags = PyBUF_RECORDS
- * else:
- */
- goto __pyx_L4;
- }
-
- /* "View.MemoryView":1032
- * result.flags = PyBUF_RECORDS
- * else:
- * result.flags = PyBUF_RECORDS_RO # <<<<<<<<<<<<<<
- *
- * result.view.shape = result.from_slice.shape
- */
- /*else*/ {
- __pyx_v_result->__pyx_base.flags = PyBUF_RECORDS_RO;
- }
- __pyx_L4:;
-
- /* "View.MemoryView":1034
- * result.flags = PyBUF_RECORDS_RO
- *
- * result.view.shape = result.from_slice.shape # <<<<<<<<<<<<<<
- * result.view.strides = result.from_slice.strides
- *
- */
- __pyx_v_result->__pyx_base.view.shape = ((Py_ssize_t *)__pyx_v_result->from_slice.shape);
-
- /* "View.MemoryView":1035
- *
- * result.view.shape = result.from_slice.shape
- * result.view.strides = result.from_slice.strides # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_result->__pyx_base.view.strides = ((Py_ssize_t *)__pyx_v_result->from_slice.strides);
-
- /* "View.MemoryView":1038
- *
- *
- * result.view.suboffsets = NULL # <<<<<<<<<<<<<<
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0:
- */
- __pyx_v_result->__pyx_base.view.suboffsets = NULL;
-
- /* "View.MemoryView":1039
- *
- * result.view.suboffsets = NULL
- * for suboffset in result.from_slice.suboffsets[:ndim]: # <<<<<<<<<<<<<<
- * if suboffset >= 0:
- * result.view.suboffsets = result.from_slice.suboffsets
- */
- __pyx_t_7 = (__pyx_v_result->from_slice.suboffsets + __pyx_v_ndim);
- for (__pyx_t_8 = __pyx_v_result->from_slice.suboffsets; __pyx_t_8 < __pyx_t_7; __pyx_t_8++) {
- __pyx_t_6 = __pyx_t_8;
- __pyx_v_suboffset = (__pyx_t_6[0]);
-
- /* "View.MemoryView":1040
- * result.view.suboffsets = NULL
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * result.view.suboffsets = result.from_slice.suboffsets
- * break
- */
- __pyx_t_1 = ((__pyx_v_suboffset >= 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1041
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0:
- * result.view.suboffsets = result.from_slice.suboffsets # <<<<<<<<<<<<<<
- * break
- *
- */
- __pyx_v_result->__pyx_base.view.suboffsets = ((Py_ssize_t *)__pyx_v_result->from_slice.suboffsets);
-
- /* "View.MemoryView":1042
- * if suboffset >= 0:
- * result.view.suboffsets = result.from_slice.suboffsets
- * break # <<<<<<<<<<<<<<
- *
- * result.view.len = result.view.itemsize
- */
- goto __pyx_L6_break;
-
- /* "View.MemoryView":1040
- * result.view.suboffsets = NULL
- * for suboffset in result.from_slice.suboffsets[:ndim]:
- * if suboffset >= 0: # <<<<<<<<<<<<<<
- * result.view.suboffsets = result.from_slice.suboffsets
- * break
- */
- }
- }
- __pyx_L6_break:;
-
- /* "View.MemoryView":1044
- * break
- *
- * result.view.len = result.view.itemsize # <<<<<<<<<<<<<<
- * for length in result.view.shape[:ndim]:
- * result.view.len *= length
- */
- __pyx_t_9 = __pyx_v_result->__pyx_base.view.itemsize;
- __pyx_v_result->__pyx_base.view.len = __pyx_t_9;
-
- /* "View.MemoryView":1045
- *
- * result.view.len = result.view.itemsize
- * for length in result.view.shape[:ndim]: # <<<<<<<<<<<<<<
- * result.view.len *= length
- *
- */
- __pyx_t_7 = (__pyx_v_result->__pyx_base.view.shape + __pyx_v_ndim);
- for (__pyx_t_8 = __pyx_v_result->__pyx_base.view.shape; __pyx_t_8 < __pyx_t_7; __pyx_t_8++) {
- __pyx_t_6 = __pyx_t_8;
- __pyx_t_2 = PyInt_FromSsize_t((__pyx_t_6[0])); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1045, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_XDECREF_SET(__pyx_v_length, __pyx_t_2);
- __pyx_t_2 = 0;
-
- /* "View.MemoryView":1046
- * result.view.len = result.view.itemsize
- * for length in result.view.shape[:ndim]:
- * result.view.len *= length # <<<<<<<<<<<<<<
- *
- * result.to_object_func = to_object_func
- */
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_result->__pyx_base.view.len); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1046, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyNumber_InPlaceMultiply(__pyx_t_2, __pyx_v_length); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1046, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __pyx_t_9 = __Pyx_PyIndex_AsSsize_t(__pyx_t_3); if (unlikely((__pyx_t_9 == (Py_ssize_t)-1) && PyErr_Occurred())) __PYX_ERR(1, 1046, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __pyx_v_result->__pyx_base.view.len = __pyx_t_9;
- }
-
- /* "View.MemoryView":1048
- * result.view.len *= length
- *
- * result.to_object_func = to_object_func # <<<<<<<<<<<<<<
- * result.to_dtype_func = to_dtype_func
- *
- */
- __pyx_v_result->to_object_func = __pyx_v_to_object_func;
-
- /* "View.MemoryView":1049
- *
- * result.to_object_func = to_object_func
- * result.to_dtype_func = to_dtype_func # <<<<<<<<<<<<<<
- *
- * return result
- */
- __pyx_v_result->to_dtype_func = __pyx_v_to_dtype_func;
-
- /* "View.MemoryView":1051
- * result.to_dtype_func = to_dtype_func
- *
- * return result # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_get_slice_from_memoryview')
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(((PyObject *)__pyx_v_result));
- __pyx_r = ((PyObject *)__pyx_v_result);
- goto __pyx_L0;
-
- /* "View.MemoryView":1001
- *
- * @cname('__pyx_memoryview_fromslice')
- * cdef memoryview_fromslice(__Pyx_memviewslice memviewslice, # <<<<<<<<<<<<<<
- * int ndim,
- * object (*to_object_func)(char *),
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.memoryview_fromslice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_result);
- __Pyx_XDECREF(__pyx_v_length);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1054
- *
- * @cname('__pyx_memoryview_get_slice_from_memoryview')
- * cdef __Pyx_memviewslice *get_slice_from_memview(memoryview memview, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- */
-
-static __Pyx_memviewslice *__pyx_memoryview_get_slice_from_memoryview(struct __pyx_memoryview_obj *__pyx_v_memview, __Pyx_memviewslice *__pyx_v_mslice) {
- struct __pyx_memoryviewslice_obj *__pyx_v_obj = 0;
- __Pyx_memviewslice *__pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *__pyx_t_3 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("get_slice_from_memview", 0);
-
- /* "View.MemoryView":1057
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * obj = memview
- * return &obj.from_slice
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1058
- * cdef _memoryviewslice obj
- * if isinstance(memview, _memoryviewslice):
- * obj = memview # <<<<<<<<<<<<<<
- * return &obj.from_slice
- * else:
- */
- if (!(likely(((((PyObject *)__pyx_v_memview)) == Py_None) || likely(__Pyx_TypeTest(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type))))) __PYX_ERR(1, 1058, __pyx_L1_error)
- __pyx_t_3 = ((PyObject *)__pyx_v_memview);
- __Pyx_INCREF(__pyx_t_3);
- __pyx_v_obj = ((struct __pyx_memoryviewslice_obj *)__pyx_t_3);
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":1059
- * if isinstance(memview, _memoryviewslice):
- * obj = memview
- * return &obj.from_slice # <<<<<<<<<<<<<<
- * else:
- * slice_copy(memview, mslice)
- */
- __pyx_r = (&__pyx_v_obj->from_slice);
- goto __pyx_L0;
-
- /* "View.MemoryView":1057
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * obj = memview
- * return &obj.from_slice
- */
- }
-
- /* "View.MemoryView":1061
- * return &obj.from_slice
- * else:
- * slice_copy(memview, mslice) # <<<<<<<<<<<<<<
- * return mslice
- *
- */
- /*else*/ {
- __pyx_memoryview_slice_copy(__pyx_v_memview, __pyx_v_mslice);
-
- /* "View.MemoryView":1062
- * else:
- * slice_copy(memview, mslice)
- * return mslice # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_slice_copy')
- */
- __pyx_r = __pyx_v_mslice;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":1054
- *
- * @cname('__pyx_memoryview_get_slice_from_memoryview')
- * cdef __Pyx_memviewslice *get_slice_from_memview(memoryview memview, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *mslice) except NULL:
- * cdef _memoryviewslice obj
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_AddTraceback("View.MemoryView.get_slice_from_memview", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF((PyObject *)__pyx_v_obj);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1065
- *
- * @cname('__pyx_memoryview_slice_copy')
- * cdef void slice_copy(memoryview memview, __Pyx_memviewslice *dst): # <<<<<<<<<<<<<<
- * cdef int dim
- * cdef (Py_ssize_t*) shape, strides, suboffsets
- */
-
-static void __pyx_memoryview_slice_copy(struct __pyx_memoryview_obj *__pyx_v_memview, __Pyx_memviewslice *__pyx_v_dst) {
- int __pyx_v_dim;
- Py_ssize_t *__pyx_v_shape;
- Py_ssize_t *__pyx_v_strides;
- Py_ssize_t *__pyx_v_suboffsets;
- __Pyx_RefNannyDeclarations
- Py_ssize_t *__pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- Py_ssize_t __pyx_t_5;
- __Pyx_RefNannySetupContext("slice_copy", 0);
-
- /* "View.MemoryView":1069
- * cdef (Py_ssize_t*) shape, strides, suboffsets
- *
- * shape = memview.view.shape # <<<<<<<<<<<<<<
- * strides = memview.view.strides
- * suboffsets = memview.view.suboffsets
- */
- __pyx_t_1 = __pyx_v_memview->view.shape;
- __pyx_v_shape = __pyx_t_1;
-
- /* "View.MemoryView":1070
- *
- * shape = memview.view.shape
- * strides = memview.view.strides # <<<<<<<<<<<<<<
- * suboffsets = memview.view.suboffsets
- *
- */
- __pyx_t_1 = __pyx_v_memview->view.strides;
- __pyx_v_strides = __pyx_t_1;
-
- /* "View.MemoryView":1071
- * shape = memview.view.shape
- * strides = memview.view.strides
- * suboffsets = memview.view.suboffsets # <<<<<<<<<<<<<<
- *
- * dst.memview = <__pyx_memoryview *> memview
- */
- __pyx_t_1 = __pyx_v_memview->view.suboffsets;
- __pyx_v_suboffsets = __pyx_t_1;
-
- /* "View.MemoryView":1073
- * suboffsets = memview.view.suboffsets
- *
- * dst.memview = <__pyx_memoryview *> memview # <<<<<<<<<<<<<<
- * dst.data = memview.view.buf
- *
- */
- __pyx_v_dst->memview = ((struct __pyx_memoryview_obj *)__pyx_v_memview);
-
- /* "View.MemoryView":1074
- *
- * dst.memview = <__pyx_memoryview *> memview
- * dst.data = memview.view.buf # <<<<<<<<<<<<<<
- *
- * for dim in range(memview.view.ndim):
- */
- __pyx_v_dst->data = ((char *)__pyx_v_memview->view.buf);
-
- /* "View.MemoryView":1076
- * dst.data = memview.view.buf
- *
- * for dim in range(memview.view.ndim): # <<<<<<<<<<<<<<
- * dst.shape[dim] = shape[dim]
- * dst.strides[dim] = strides[dim]
- */
- __pyx_t_2 = __pyx_v_memview->view.ndim;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_dim = __pyx_t_4;
-
- /* "View.MemoryView":1077
- *
- * for dim in range(memview.view.ndim):
- * dst.shape[dim] = shape[dim] # <<<<<<<<<<<<<<
- * dst.strides[dim] = strides[dim]
- * dst.suboffsets[dim] = suboffsets[dim] if suboffsets else -1
- */
- (__pyx_v_dst->shape[__pyx_v_dim]) = (__pyx_v_shape[__pyx_v_dim]);
-
- /* "View.MemoryView":1078
- * for dim in range(memview.view.ndim):
- * dst.shape[dim] = shape[dim]
- * dst.strides[dim] = strides[dim] # <<<<<<<<<<<<<<
- * dst.suboffsets[dim] = suboffsets[dim] if suboffsets else -1
- *
- */
- (__pyx_v_dst->strides[__pyx_v_dim]) = (__pyx_v_strides[__pyx_v_dim]);
-
- /* "View.MemoryView":1079
- * dst.shape[dim] = shape[dim]
- * dst.strides[dim] = strides[dim]
- * dst.suboffsets[dim] = suboffsets[dim] if suboffsets else -1 # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_object')
- */
- if ((__pyx_v_suboffsets != 0)) {
- __pyx_t_5 = (__pyx_v_suboffsets[__pyx_v_dim]);
- } else {
- __pyx_t_5 = -1L;
- }
- (__pyx_v_dst->suboffsets[__pyx_v_dim]) = __pyx_t_5;
- }
-
- /* "View.MemoryView":1065
- *
- * @cname('__pyx_memoryview_slice_copy')
- * cdef void slice_copy(memoryview memview, __Pyx_memviewslice *dst): # <<<<<<<<<<<<<<
- * cdef int dim
- * cdef (Py_ssize_t*) shape, strides, suboffsets
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":1082
- *
- * @cname('__pyx_memoryview_copy_object')
- * cdef memoryview_copy(memoryview memview): # <<<<<<<<<<<<<<
- * "Create a new memoryview object"
- * cdef __Pyx_memviewslice memviewslice
- */
-
-static PyObject *__pyx_memoryview_copy_object(struct __pyx_memoryview_obj *__pyx_v_memview) {
- __Pyx_memviewslice __pyx_v_memviewslice;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_copy", 0);
-
- /* "View.MemoryView":1085
- * "Create a new memoryview object"
- * cdef __Pyx_memviewslice memviewslice
- * slice_copy(memview, &memviewslice) # <<<<<<<<<<<<<<
- * return memoryview_copy_from_slice(memview, &memviewslice)
- *
- */
- __pyx_memoryview_slice_copy(__pyx_v_memview, (&__pyx_v_memviewslice));
-
- /* "View.MemoryView":1086
- * cdef __Pyx_memviewslice memviewslice
- * slice_copy(memview, &memviewslice)
- * return memoryview_copy_from_slice(memview, &memviewslice) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_object_from_slice')
- */
- __Pyx_XDECREF(__pyx_r);
- __pyx_t_1 = __pyx_memoryview_copy_object_from_slice(__pyx_v_memview, (&__pyx_v_memviewslice)); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1086, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_r = __pyx_t_1;
- __pyx_t_1 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1082
- *
- * @cname('__pyx_memoryview_copy_object')
- * cdef memoryview_copy(memoryview memview): # <<<<<<<<<<<<<<
- * "Create a new memoryview object"
- * cdef __Pyx_memviewslice memviewslice
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_AddTraceback("View.MemoryView.memoryview_copy", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1089
- *
- * @cname('__pyx_memoryview_copy_object_from_slice')
- * cdef memoryview_copy_from_slice(memoryview memview, __Pyx_memviewslice *memviewslice): # <<<<<<<<<<<<<<
- * """
- * Create a new memoryview object from a given memoryview object and slice.
- */
-
-static PyObject *__pyx_memoryview_copy_object_from_slice(struct __pyx_memoryview_obj *__pyx_v_memview, __Pyx_memviewslice *__pyx_v_memviewslice) {
- PyObject *(*__pyx_v_to_object_func)(char *);
- int (*__pyx_v_to_dtype_func)(char *, PyObject *);
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- int __pyx_t_2;
- PyObject *(*__pyx_t_3)(char *);
- int (*__pyx_t_4)(char *, PyObject *);
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("memoryview_copy_from_slice", 0);
-
- /* "View.MemoryView":1096
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * to_object_func = (<_memoryviewslice> memview).to_object_func
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- */
- __pyx_t_1 = __Pyx_TypeCheck(((PyObject *)__pyx_v_memview), __pyx_memoryviewslice_type);
- __pyx_t_2 = (__pyx_t_1 != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1097
- *
- * if isinstance(memview, _memoryviewslice):
- * to_object_func = (<_memoryviewslice> memview).to_object_func # <<<<<<<<<<<<<<
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- * else:
- */
- __pyx_t_3 = ((struct __pyx_memoryviewslice_obj *)__pyx_v_memview)->to_object_func;
- __pyx_v_to_object_func = __pyx_t_3;
-
- /* "View.MemoryView":1098
- * if isinstance(memview, _memoryviewslice):
- * to_object_func = (<_memoryviewslice> memview).to_object_func
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func # <<<<<<<<<<<<<<
- * else:
- * to_object_func = NULL
- */
- __pyx_t_4 = ((struct __pyx_memoryviewslice_obj *)__pyx_v_memview)->to_dtype_func;
- __pyx_v_to_dtype_func = __pyx_t_4;
-
- /* "View.MemoryView":1096
- * cdef int (*to_dtype_func)(char *, object) except 0
- *
- * if isinstance(memview, _memoryviewslice): # <<<<<<<<<<<<<<
- * to_object_func = (<_memoryviewslice> memview).to_object_func
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1100
- * to_dtype_func = (<_memoryviewslice> memview).to_dtype_func
- * else:
- * to_object_func = NULL # <<<<<<<<<<<<<<
- * to_dtype_func = NULL
- *
- */
- /*else*/ {
- __pyx_v_to_object_func = NULL;
-
- /* "View.MemoryView":1101
- * else:
- * to_object_func = NULL
- * to_dtype_func = NULL # <<<<<<<<<<<<<<
- *
- * return memoryview_fromslice(memviewslice[0], memview.view.ndim,
- */
- __pyx_v_to_dtype_func = NULL;
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1103
- * to_dtype_func = NULL
- *
- * return memoryview_fromslice(memviewslice[0], memview.view.ndim, # <<<<<<<<<<<<<<
- * to_object_func, to_dtype_func,
- * memview.dtype_is_object)
- */
- __Pyx_XDECREF(__pyx_r);
-
- /* "View.MemoryView":1105
- * return memoryview_fromslice(memviewslice[0], memview.view.ndim,
- * to_object_func, to_dtype_func,
- * memview.dtype_is_object) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_5 = __pyx_memoryview_fromslice((__pyx_v_memviewslice[0]), __pyx_v_memview->view.ndim, __pyx_v_to_object_func, __pyx_v_to_dtype_func, __pyx_v_memview->dtype_is_object); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 1103, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __pyx_r = __pyx_t_5;
- __pyx_t_5 = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1089
- *
- * @cname('__pyx_memoryview_copy_object_from_slice')
- * cdef memoryview_copy_from_slice(memoryview memview, __Pyx_memviewslice *memviewslice): # <<<<<<<<<<<<<<
- * """
- * Create a new memoryview object from a given memoryview object and slice.
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView.memoryview_copy_from_slice", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "View.MemoryView":1111
- *
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil: # <<<<<<<<<<<<<<
- * if arg < 0:
- * return -arg
- */
-
-static Py_ssize_t abs_py_ssize_t(Py_ssize_t __pyx_v_arg) {
- Py_ssize_t __pyx_r;
- int __pyx_t_1;
-
- /* "View.MemoryView":1112
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil:
- * if arg < 0: # <<<<<<<<<<<<<<
- * return -arg
- * else:
- */
- __pyx_t_1 = ((__pyx_v_arg < 0) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1113
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil:
- * if arg < 0:
- * return -arg # <<<<<<<<<<<<<<
- * else:
- * return arg
- */
- __pyx_r = (-__pyx_v_arg);
- goto __pyx_L0;
-
- /* "View.MemoryView":1112
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil:
- * if arg < 0: # <<<<<<<<<<<<<<
- * return -arg
- * else:
- */
- }
-
- /* "View.MemoryView":1115
- * return -arg
- * else:
- * return arg # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_get_best_slice_order')
- */
- /*else*/ {
- __pyx_r = __pyx_v_arg;
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":1111
- *
- *
- * cdef Py_ssize_t abs_py_ssize_t(Py_ssize_t arg) nogil: # <<<<<<<<<<<<<<
- * if arg < 0:
- * return -arg
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1118
- *
- * @cname('__pyx_get_best_slice_order')
- * cdef char get_best_order(__Pyx_memviewslice *mslice, int ndim) nogil: # <<<<<<<<<<<<<<
- * """
- * Figure out the best memory access order for a given slice.
- */
-
-static char __pyx_get_best_slice_order(__Pyx_memviewslice *__pyx_v_mslice, int __pyx_v_ndim) {
- int __pyx_v_i;
- Py_ssize_t __pyx_v_c_stride;
- Py_ssize_t __pyx_v_f_stride;
- char __pyx_r;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
-
- /* "View.MemoryView":1123
- * """
- * cdef int i
- * cdef Py_ssize_t c_stride = 0 # <<<<<<<<<<<<<<
- * cdef Py_ssize_t f_stride = 0
- *
- */
- __pyx_v_c_stride = 0;
-
- /* "View.MemoryView":1124
- * cdef int i
- * cdef Py_ssize_t c_stride = 0
- * cdef Py_ssize_t f_stride = 0 # <<<<<<<<<<<<<<
- *
- * for i in range(ndim - 1, -1, -1):
- */
- __pyx_v_f_stride = 0;
-
- /* "View.MemoryView":1126
- * cdef Py_ssize_t f_stride = 0
- *
- * for i in range(ndim - 1, -1, -1): # <<<<<<<<<<<<<<
- * if mslice.shape[i] > 1:
- * c_stride = mslice.strides[i]
- */
- for (__pyx_t_1 = (__pyx_v_ndim - 1); __pyx_t_1 > -1; __pyx_t_1-=1) {
- __pyx_v_i = __pyx_t_1;
-
- /* "View.MemoryView":1127
- *
- * for i in range(ndim - 1, -1, -1):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * c_stride = mslice.strides[i]
- * break
- */
- __pyx_t_2 = (((__pyx_v_mslice->shape[__pyx_v_i]) > 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1128
- * for i in range(ndim - 1, -1, -1):
- * if mslice.shape[i] > 1:
- * c_stride = mslice.strides[i] # <<<<<<<<<<<<<<
- * break
- *
- */
- __pyx_v_c_stride = (__pyx_v_mslice->strides[__pyx_v_i]);
-
- /* "View.MemoryView":1129
- * if mslice.shape[i] > 1:
- * c_stride = mslice.strides[i]
- * break # <<<<<<<<<<<<<<
- *
- * for i in range(ndim):
- */
- goto __pyx_L4_break;
-
- /* "View.MemoryView":1127
- *
- * for i in range(ndim - 1, -1, -1):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * c_stride = mslice.strides[i]
- * break
- */
- }
- }
- __pyx_L4_break:;
-
- /* "View.MemoryView":1131
- * break
- *
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * if mslice.shape[i] > 1:
- * f_stride = mslice.strides[i]
- */
- __pyx_t_1 = __pyx_v_ndim;
- __pyx_t_3 = __pyx_t_1;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1132
- *
- * for i in range(ndim):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * f_stride = mslice.strides[i]
- * break
- */
- __pyx_t_2 = (((__pyx_v_mslice->shape[__pyx_v_i]) > 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1133
- * for i in range(ndim):
- * if mslice.shape[i] > 1:
- * f_stride = mslice.strides[i] # <<<<<<<<<<<<<<
- * break
- *
- */
- __pyx_v_f_stride = (__pyx_v_mslice->strides[__pyx_v_i]);
-
- /* "View.MemoryView":1134
- * if mslice.shape[i] > 1:
- * f_stride = mslice.strides[i]
- * break # <<<<<<<<<<<<<<
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride):
- */
- goto __pyx_L7_break;
-
- /* "View.MemoryView":1132
- *
- * for i in range(ndim):
- * if mslice.shape[i] > 1: # <<<<<<<<<<<<<<
- * f_stride = mslice.strides[i]
- * break
- */
- }
- }
- __pyx_L7_break:;
-
- /* "View.MemoryView":1136
- * break
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride): # <<<<<<<<<<<<<<
- * return 'C'
- * else:
- */
- __pyx_t_2 = ((abs_py_ssize_t(__pyx_v_c_stride) <= abs_py_ssize_t(__pyx_v_f_stride)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1137
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride):
- * return 'C' # <<<<<<<<<<<<<<
- * else:
- * return 'F'
- */
- __pyx_r = 'C';
- goto __pyx_L0;
-
- /* "View.MemoryView":1136
- * break
- *
- * if abs_py_ssize_t(c_stride) <= abs_py_ssize_t(f_stride): # <<<<<<<<<<<<<<
- * return 'C'
- * else:
- */
- }
-
- /* "View.MemoryView":1139
- * return 'C'
- * else:
- * return 'F' # <<<<<<<<<<<<<<
- *
- * @cython.cdivision(True)
- */
- /*else*/ {
- __pyx_r = 'F';
- goto __pyx_L0;
- }
-
- /* "View.MemoryView":1118
- *
- * @cname('__pyx_get_best_slice_order')
- * cdef char get_best_order(__Pyx_memviewslice *mslice, int ndim) nogil: # <<<<<<<<<<<<<<
- * """
- * Figure out the best memory access order for a given slice.
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1142
- *
- * @cython.cdivision(True)
- * cdef void _copy_strided_to_strided(char *src_data, Py_ssize_t *src_strides, # <<<<<<<<<<<<<<
- * char *dst_data, Py_ssize_t *dst_strides,
- * Py_ssize_t *src_shape, Py_ssize_t *dst_shape,
- */
-
-static void _copy_strided_to_strided(char *__pyx_v_src_data, Py_ssize_t *__pyx_v_src_strides, char *__pyx_v_dst_data, Py_ssize_t *__pyx_v_dst_strides, Py_ssize_t *__pyx_v_src_shape, Py_ssize_t *__pyx_v_dst_shape, int __pyx_v_ndim, size_t __pyx_v_itemsize) {
- CYTHON_UNUSED Py_ssize_t __pyx_v_i;
- CYTHON_UNUSED Py_ssize_t __pyx_v_src_extent;
- Py_ssize_t __pyx_v_dst_extent;
- Py_ssize_t __pyx_v_src_stride;
- Py_ssize_t __pyx_v_dst_stride;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- Py_ssize_t __pyx_t_4;
- Py_ssize_t __pyx_t_5;
- Py_ssize_t __pyx_t_6;
-
- /* "View.MemoryView":1149
- *
- * cdef Py_ssize_t i
- * cdef Py_ssize_t src_extent = src_shape[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dst_extent = dst_shape[0]
- * cdef Py_ssize_t src_stride = src_strides[0]
- */
- __pyx_v_src_extent = (__pyx_v_src_shape[0]);
-
- /* "View.MemoryView":1150
- * cdef Py_ssize_t i
- * cdef Py_ssize_t src_extent = src_shape[0]
- * cdef Py_ssize_t dst_extent = dst_shape[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t src_stride = src_strides[0]
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- */
- __pyx_v_dst_extent = (__pyx_v_dst_shape[0]);
-
- /* "View.MemoryView":1151
- * cdef Py_ssize_t src_extent = src_shape[0]
- * cdef Py_ssize_t dst_extent = dst_shape[0]
- * cdef Py_ssize_t src_stride = src_strides[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- *
- */
- __pyx_v_src_stride = (__pyx_v_src_strides[0]);
-
- /* "View.MemoryView":1152
- * cdef Py_ssize_t dst_extent = dst_shape[0]
- * cdef Py_ssize_t src_stride = src_strides[0]
- * cdef Py_ssize_t dst_stride = dst_strides[0] # <<<<<<<<<<<<<<
- *
- * if ndim == 1:
- */
- __pyx_v_dst_stride = (__pyx_v_dst_strides[0]);
-
- /* "View.MemoryView":1154
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride):
- */
- __pyx_t_1 = ((__pyx_v_ndim == 1) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1155
- *
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and # <<<<<<<<<<<<<<
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- */
- __pyx_t_2 = ((__pyx_v_src_stride > 0) != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L5_bool_binop_done;
- }
- __pyx_t_2 = ((__pyx_v_dst_stride > 0) != 0);
- if (__pyx_t_2) {
- } else {
- __pyx_t_1 = __pyx_t_2;
- goto __pyx_L5_bool_binop_done;
- }
-
- /* "View.MemoryView":1156
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride): # <<<<<<<<<<<<<<
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- * else:
- */
- __pyx_t_2 = (((size_t)__pyx_v_src_stride) == __pyx_v_itemsize);
- if (__pyx_t_2) {
- __pyx_t_2 = (__pyx_v_itemsize == ((size_t)__pyx_v_dst_stride));
- }
- __pyx_t_3 = (__pyx_t_2 != 0);
- __pyx_t_1 = __pyx_t_3;
- __pyx_L5_bool_binop_done:;
-
- /* "View.MemoryView":1155
- *
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and # <<<<<<<<<<<<<<
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- */
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1157
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent) # <<<<<<<<<<<<<<
- * else:
- * for i in range(dst_extent):
- */
- (void)(memcpy(__pyx_v_dst_data, __pyx_v_src_data, (__pyx_v_itemsize * __pyx_v_dst_extent)));
-
- /* "View.MemoryView":1155
- *
- * if ndim == 1:
- * if (src_stride > 0 and dst_stride > 0 and # <<<<<<<<<<<<<<
- * src_stride == itemsize == dst_stride):
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- */
- goto __pyx_L4;
- }
-
- /* "View.MemoryView":1159
- * memcpy(dst_data, src_data, itemsize * dst_extent)
- * else:
- * for i in range(dst_extent): # <<<<<<<<<<<<<<
- * memcpy(dst_data, src_data, itemsize)
- * src_data += src_stride
- */
- /*else*/ {
- __pyx_t_4 = __pyx_v_dst_extent;
- __pyx_t_5 = __pyx_t_4;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1160
- * else:
- * for i in range(dst_extent):
- * memcpy(dst_data, src_data, itemsize) # <<<<<<<<<<<<<<
- * src_data += src_stride
- * dst_data += dst_stride
- */
- (void)(memcpy(__pyx_v_dst_data, __pyx_v_src_data, __pyx_v_itemsize));
-
- /* "View.MemoryView":1161
- * for i in range(dst_extent):
- * memcpy(dst_data, src_data, itemsize)
- * src_data += src_stride # <<<<<<<<<<<<<<
- * dst_data += dst_stride
- * else:
- */
- __pyx_v_src_data = (__pyx_v_src_data + __pyx_v_src_stride);
-
- /* "View.MemoryView":1162
- * memcpy(dst_data, src_data, itemsize)
- * src_data += src_stride
- * dst_data += dst_stride # <<<<<<<<<<<<<<
- * else:
- * for i in range(dst_extent):
- */
- __pyx_v_dst_data = (__pyx_v_dst_data + __pyx_v_dst_stride);
- }
- }
- __pyx_L4:;
-
- /* "View.MemoryView":1154
- * cdef Py_ssize_t dst_stride = dst_strides[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if (src_stride > 0 and dst_stride > 0 and
- * src_stride == itemsize == dst_stride):
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1164
- * dst_data += dst_stride
- * else:
- * for i in range(dst_extent): # <<<<<<<<<<<<<<
- * _copy_strided_to_strided(src_data, src_strides + 1,
- * dst_data, dst_strides + 1,
- */
- /*else*/ {
- __pyx_t_4 = __pyx_v_dst_extent;
- __pyx_t_5 = __pyx_t_4;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1165
- * else:
- * for i in range(dst_extent):
- * _copy_strided_to_strided(src_data, src_strides + 1, # <<<<<<<<<<<<<<
- * dst_data, dst_strides + 1,
- * src_shape + 1, dst_shape + 1,
- */
- _copy_strided_to_strided(__pyx_v_src_data, (__pyx_v_src_strides + 1), __pyx_v_dst_data, (__pyx_v_dst_strides + 1), (__pyx_v_src_shape + 1), (__pyx_v_dst_shape + 1), (__pyx_v_ndim - 1), __pyx_v_itemsize);
-
- /* "View.MemoryView":1169
- * src_shape + 1, dst_shape + 1,
- * ndim - 1, itemsize)
- * src_data += src_stride # <<<<<<<<<<<<<<
- * dst_data += dst_stride
- *
- */
- __pyx_v_src_data = (__pyx_v_src_data + __pyx_v_src_stride);
-
- /* "View.MemoryView":1170
- * ndim - 1, itemsize)
- * src_data += src_stride
- * dst_data += dst_stride # <<<<<<<<<<<<<<
- *
- * cdef void copy_strided_to_strided(__Pyx_memviewslice *src,
- */
- __pyx_v_dst_data = (__pyx_v_dst_data + __pyx_v_dst_stride);
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1142
- *
- * @cython.cdivision(True)
- * cdef void _copy_strided_to_strided(char *src_data, Py_ssize_t *src_strides, # <<<<<<<<<<<<<<
- * char *dst_data, Py_ssize_t *dst_strides,
- * Py_ssize_t *src_shape, Py_ssize_t *dst_shape,
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1172
- * dst_data += dst_stride
- *
- * cdef void copy_strided_to_strided(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * int ndim, size_t itemsize) nogil:
- */
-
-static void copy_strided_to_strided(__Pyx_memviewslice *__pyx_v_src, __Pyx_memviewslice *__pyx_v_dst, int __pyx_v_ndim, size_t __pyx_v_itemsize) {
-
- /* "View.MemoryView":1175
- * __Pyx_memviewslice *dst,
- * int ndim, size_t itemsize) nogil:
- * _copy_strided_to_strided(src.data, src.strides, dst.data, dst.strides, # <<<<<<<<<<<<<<
- * src.shape, dst.shape, ndim, itemsize)
- *
- */
- _copy_strided_to_strided(__pyx_v_src->data, __pyx_v_src->strides, __pyx_v_dst->data, __pyx_v_dst->strides, __pyx_v_src->shape, __pyx_v_dst->shape, __pyx_v_ndim, __pyx_v_itemsize);
-
- /* "View.MemoryView":1172
- * dst_data += dst_stride
- *
- * cdef void copy_strided_to_strided(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *dst,
- * int ndim, size_t itemsize) nogil:
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1179
- *
- * @cname('__pyx_memoryview_slice_get_size')
- * cdef Py_ssize_t slice_get_size(__Pyx_memviewslice *src, int ndim) nogil: # <<<<<<<<<<<<<<
- * "Return the size of the memory occupied by the slice in number of bytes"
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize
- */
-
-static Py_ssize_t __pyx_memoryview_slice_get_size(__Pyx_memviewslice *__pyx_v_src, int __pyx_v_ndim) {
- Py_ssize_t __pyx_v_shape;
- Py_ssize_t __pyx_v_size;
- Py_ssize_t __pyx_r;
- Py_ssize_t __pyx_t_1;
- Py_ssize_t *__pyx_t_2;
- Py_ssize_t *__pyx_t_3;
- Py_ssize_t *__pyx_t_4;
-
- /* "View.MemoryView":1181
- * cdef Py_ssize_t slice_get_size(__Pyx_memviewslice *src, int ndim) nogil:
- * "Return the size of the memory occupied by the slice in number of bytes"
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize # <<<<<<<<<<<<<<
- *
- * for shape in src.shape[:ndim]:
- */
- __pyx_t_1 = __pyx_v_src->memview->view.itemsize;
- __pyx_v_size = __pyx_t_1;
-
- /* "View.MemoryView":1183
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize
- *
- * for shape in src.shape[:ndim]: # <<<<<<<<<<<<<<
- * size *= shape
- *
- */
- __pyx_t_3 = (__pyx_v_src->shape + __pyx_v_ndim);
- for (__pyx_t_4 = __pyx_v_src->shape; __pyx_t_4 < __pyx_t_3; __pyx_t_4++) {
- __pyx_t_2 = __pyx_t_4;
- __pyx_v_shape = (__pyx_t_2[0]);
-
- /* "View.MemoryView":1184
- *
- * for shape in src.shape[:ndim]:
- * size *= shape # <<<<<<<<<<<<<<
- *
- * return size
- */
- __pyx_v_size = (__pyx_v_size * __pyx_v_shape);
- }
-
- /* "View.MemoryView":1186
- * size *= shape
- *
- * return size # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_fill_contig_strides_array')
- */
- __pyx_r = __pyx_v_size;
- goto __pyx_L0;
-
- /* "View.MemoryView":1179
- *
- * @cname('__pyx_memoryview_slice_get_size')
- * cdef Py_ssize_t slice_get_size(__Pyx_memviewslice *src, int ndim) nogil: # <<<<<<<<<<<<<<
- * "Return the size of the memory occupied by the slice in number of bytes"
- * cdef Py_ssize_t shape, size = src.memview.view.itemsize
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1189
- *
- * @cname('__pyx_fill_contig_strides_array')
- * cdef Py_ssize_t fill_contig_strides_array( # <<<<<<<<<<<<<<
- * Py_ssize_t *shape, Py_ssize_t *strides, Py_ssize_t stride,
- * int ndim, char order) nogil:
- */
-
-static Py_ssize_t __pyx_fill_contig_strides_array(Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, Py_ssize_t __pyx_v_stride, int __pyx_v_ndim, char __pyx_v_order) {
- int __pyx_v_idx;
- Py_ssize_t __pyx_r;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
-
- /* "View.MemoryView":1198
- * cdef int idx
- *
- * if order == 'F': # <<<<<<<<<<<<<<
- * for idx in range(ndim):
- * strides[idx] = stride
- */
- __pyx_t_1 = ((__pyx_v_order == 'F') != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1199
- *
- * if order == 'F':
- * for idx in range(ndim): # <<<<<<<<<<<<<<
- * strides[idx] = stride
- * stride *= shape[idx]
- */
- __pyx_t_2 = __pyx_v_ndim;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_idx = __pyx_t_4;
-
- /* "View.MemoryView":1200
- * if order == 'F':
- * for idx in range(ndim):
- * strides[idx] = stride # <<<<<<<<<<<<<<
- * stride *= shape[idx]
- * else:
- */
- (__pyx_v_strides[__pyx_v_idx]) = __pyx_v_stride;
-
- /* "View.MemoryView":1201
- * for idx in range(ndim):
- * strides[idx] = stride
- * stride *= shape[idx] # <<<<<<<<<<<<<<
- * else:
- * for idx in range(ndim - 1, -1, -1):
- */
- __pyx_v_stride = (__pyx_v_stride * (__pyx_v_shape[__pyx_v_idx]));
- }
-
- /* "View.MemoryView":1198
- * cdef int idx
- *
- * if order == 'F': # <<<<<<<<<<<<<<
- * for idx in range(ndim):
- * strides[idx] = stride
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1203
- * stride *= shape[idx]
- * else:
- * for idx in range(ndim - 1, -1, -1): # <<<<<<<<<<<<<<
- * strides[idx] = stride
- * stride *= shape[idx]
- */
- /*else*/ {
- for (__pyx_t_2 = (__pyx_v_ndim - 1); __pyx_t_2 > -1; __pyx_t_2-=1) {
- __pyx_v_idx = __pyx_t_2;
-
- /* "View.MemoryView":1204
- * else:
- * for idx in range(ndim - 1, -1, -1):
- * strides[idx] = stride # <<<<<<<<<<<<<<
- * stride *= shape[idx]
- *
- */
- (__pyx_v_strides[__pyx_v_idx]) = __pyx_v_stride;
-
- /* "View.MemoryView":1205
- * for idx in range(ndim - 1, -1, -1):
- * strides[idx] = stride
- * stride *= shape[idx] # <<<<<<<<<<<<<<
- *
- * return stride
- */
- __pyx_v_stride = (__pyx_v_stride * (__pyx_v_shape[__pyx_v_idx]));
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1207
- * stride *= shape[idx]
- *
- * return stride # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_data_to_temp')
- */
- __pyx_r = __pyx_v_stride;
- goto __pyx_L0;
-
- /* "View.MemoryView":1189
- *
- * @cname('__pyx_fill_contig_strides_array')
- * cdef Py_ssize_t fill_contig_strides_array( # <<<<<<<<<<<<<<
- * Py_ssize_t *shape, Py_ssize_t *strides, Py_ssize_t stride,
- * int ndim, char order) nogil:
- */
-
- /* function exit code */
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1210
- *
- * @cname('__pyx_memoryview_copy_data_to_temp')
- * cdef void *copy_data_to_temp(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *tmpslice,
- * char order,
- */
-
-static void *__pyx_memoryview_copy_data_to_temp(__Pyx_memviewslice *__pyx_v_src, __Pyx_memviewslice *__pyx_v_tmpslice, char __pyx_v_order, int __pyx_v_ndim) {
- int __pyx_v_i;
- void *__pyx_v_result;
- size_t __pyx_v_itemsize;
- size_t __pyx_v_size;
- void *__pyx_r;
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- struct __pyx_memoryview_obj *__pyx_t_4;
- int __pyx_t_5;
- int __pyx_t_6;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":1221
- * cdef void *result
- *
- * cdef size_t itemsize = src.memview.view.itemsize # <<<<<<<<<<<<<<
- * cdef size_t size = slice_get_size(src, ndim)
- *
- */
- __pyx_t_1 = __pyx_v_src->memview->view.itemsize;
- __pyx_v_itemsize = __pyx_t_1;
-
- /* "View.MemoryView":1222
- *
- * cdef size_t itemsize = src.memview.view.itemsize
- * cdef size_t size = slice_get_size(src, ndim) # <<<<<<<<<<<<<<
- *
- * result = malloc(size)
- */
- __pyx_v_size = __pyx_memoryview_slice_get_size(__pyx_v_src, __pyx_v_ndim);
-
- /* "View.MemoryView":1224
- * cdef size_t size = slice_get_size(src, ndim)
- *
- * result = malloc(size) # <<<<<<<<<<<<<<
- * if not result:
- * _err(MemoryError, NULL)
- */
- __pyx_v_result = malloc(__pyx_v_size);
-
- /* "View.MemoryView":1225
- *
- * result = malloc(size)
- * if not result: # <<<<<<<<<<<<<<
- * _err(MemoryError, NULL)
- *
- */
- __pyx_t_2 = ((!(__pyx_v_result != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1226
- * result = malloc(size)
- * if not result:
- * _err(MemoryError, NULL) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_3 = __pyx_memoryview_err(__pyx_builtin_MemoryError, NULL); if (unlikely(__pyx_t_3 == ((int)-1))) __PYX_ERR(1, 1226, __pyx_L1_error)
-
- /* "View.MemoryView":1225
- *
- * result = malloc(size)
- * if not result: # <<<<<<<<<<<<<<
- * _err(MemoryError, NULL)
- *
- */
- }
-
- /* "View.MemoryView":1229
- *
- *
- * tmpslice.data = result # <<<<<<<<<<<<<<
- * tmpslice.memview = src.memview
- * for i in range(ndim):
- */
- __pyx_v_tmpslice->data = ((char *)__pyx_v_result);
-
- /* "View.MemoryView":1230
- *
- * tmpslice.data = result
- * tmpslice.memview = src.memview # <<<<<<<<<<<<<<
- * for i in range(ndim):
- * tmpslice.shape[i] = src.shape[i]
- */
- __pyx_t_4 = __pyx_v_src->memview;
- __pyx_v_tmpslice->memview = __pyx_t_4;
-
- /* "View.MemoryView":1231
- * tmpslice.data = result
- * tmpslice.memview = src.memview
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * tmpslice.shape[i] = src.shape[i]
- * tmpslice.suboffsets[i] = -1
- */
- __pyx_t_3 = __pyx_v_ndim;
- __pyx_t_5 = __pyx_t_3;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1232
- * tmpslice.memview = src.memview
- * for i in range(ndim):
- * tmpslice.shape[i] = src.shape[i] # <<<<<<<<<<<<<<
- * tmpslice.suboffsets[i] = -1
- *
- */
- (__pyx_v_tmpslice->shape[__pyx_v_i]) = (__pyx_v_src->shape[__pyx_v_i]);
-
- /* "View.MemoryView":1233
- * for i in range(ndim):
- * tmpslice.shape[i] = src.shape[i]
- * tmpslice.suboffsets[i] = -1 # <<<<<<<<<<<<<<
- *
- * fill_contig_strides_array(&tmpslice.shape[0], &tmpslice.strides[0], itemsize,
- */
- (__pyx_v_tmpslice->suboffsets[__pyx_v_i]) = -1L;
- }
-
- /* "View.MemoryView":1235
- * tmpslice.suboffsets[i] = -1
- *
- * fill_contig_strides_array(&tmpslice.shape[0], &tmpslice.strides[0], itemsize, # <<<<<<<<<<<<<<
- * ndim, order)
- *
- */
- (void)(__pyx_fill_contig_strides_array((&(__pyx_v_tmpslice->shape[0])), (&(__pyx_v_tmpslice->strides[0])), __pyx_v_itemsize, __pyx_v_ndim, __pyx_v_order));
-
- /* "View.MemoryView":1239
- *
- *
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * if tmpslice.shape[i] == 1:
- * tmpslice.strides[i] = 0
- */
- __pyx_t_3 = __pyx_v_ndim;
- __pyx_t_5 = __pyx_t_3;
- for (__pyx_t_6 = 0; __pyx_t_6 < __pyx_t_5; __pyx_t_6+=1) {
- __pyx_v_i = __pyx_t_6;
-
- /* "View.MemoryView":1240
- *
- * for i in range(ndim):
- * if tmpslice.shape[i] == 1: # <<<<<<<<<<<<<<
- * tmpslice.strides[i] = 0
- *
- */
- __pyx_t_2 = (((__pyx_v_tmpslice->shape[__pyx_v_i]) == 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1241
- * for i in range(ndim):
- * if tmpslice.shape[i] == 1:
- * tmpslice.strides[i] = 0 # <<<<<<<<<<<<<<
- *
- * if slice_is_contig(src[0], order, ndim):
- */
- (__pyx_v_tmpslice->strides[__pyx_v_i]) = 0;
-
- /* "View.MemoryView":1240
- *
- * for i in range(ndim):
- * if tmpslice.shape[i] == 1: # <<<<<<<<<<<<<<
- * tmpslice.strides[i] = 0
- *
- */
- }
- }
-
- /* "View.MemoryView":1243
- * tmpslice.strides[i] = 0
- *
- * if slice_is_contig(src[0], order, ndim): # <<<<<<<<<<<<<<
- * memcpy(result, src.data, size)
- * else:
- */
- __pyx_t_2 = (__pyx_memviewslice_is_contig((__pyx_v_src[0]), __pyx_v_order, __pyx_v_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1244
- *
- * if slice_is_contig(src[0], order, ndim):
- * memcpy(result, src.data, size) # <<<<<<<<<<<<<<
- * else:
- * copy_strided_to_strided(src, tmpslice, ndim, itemsize)
- */
- (void)(memcpy(__pyx_v_result, __pyx_v_src->data, __pyx_v_size));
-
- /* "View.MemoryView":1243
- * tmpslice.strides[i] = 0
- *
- * if slice_is_contig(src[0], order, ndim): # <<<<<<<<<<<<<<
- * memcpy(result, src.data, size)
- * else:
- */
- goto __pyx_L9;
- }
-
- /* "View.MemoryView":1246
- * memcpy(result, src.data, size)
- * else:
- * copy_strided_to_strided(src, tmpslice, ndim, itemsize) # <<<<<<<<<<<<<<
- *
- * return result
- */
- /*else*/ {
- copy_strided_to_strided(__pyx_v_src, __pyx_v_tmpslice, __pyx_v_ndim, __pyx_v_itemsize);
- }
- __pyx_L9:;
-
- /* "View.MemoryView":1248
- * copy_strided_to_strided(src, tmpslice, ndim, itemsize)
- *
- * return result # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_r = __pyx_v_result;
- goto __pyx_L0;
-
- /* "View.MemoryView":1210
- *
- * @cname('__pyx_memoryview_copy_data_to_temp')
- * cdef void *copy_data_to_temp(__Pyx_memviewslice *src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice *tmpslice,
- * char order,
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.copy_data_to_temp", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = NULL;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1253
- *
- * @cname('__pyx_memoryview_err_extents')
- * cdef int _err_extents(int i, Py_ssize_t extent1, # <<<<<<<<<<<<<<
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" %
- */
-
-static int __pyx_memoryview_err_extents(int __pyx_v_i, Py_ssize_t __pyx_v_extent1, Py_ssize_t __pyx_v_extent2) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("_err_extents", 0);
-
- /* "View.MemoryView":1256
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" %
- * (i, extent1, extent2)) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_err_dim')
- */
- __pyx_t_1 = __Pyx_PyInt_From_int(__pyx_v_i); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = PyInt_FromSsize_t(__pyx_v_extent1); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = PyInt_FromSsize_t(__pyx_v_extent2); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = PyTuple_New(3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 1256, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_GIVEREF(__pyx_t_1);
- PyTuple_SET_ITEM(__pyx_t_4, 0, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_2);
- PyTuple_SET_ITEM(__pyx_t_4, 1, __pyx_t_2);
- __Pyx_GIVEREF(__pyx_t_3);
- PyTuple_SET_ITEM(__pyx_t_4, 2, __pyx_t_3);
- __pyx_t_1 = 0;
- __pyx_t_2 = 0;
- __pyx_t_3 = 0;
-
- /* "View.MemoryView":1255
- * cdef int _err_extents(int i, Py_ssize_t extent1,
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" % # <<<<<<<<<<<<<<
- * (i, extent1, extent2))
- *
- */
- __pyx_t_3 = __Pyx_PyString_Format(__pyx_kp_s_got_differing_extents_in_dimensi, __pyx_t_4); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1255, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __pyx_t_4 = __Pyx_PyObject_CallOneArg(__pyx_builtin_ValueError, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 1255, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_Raise(__pyx_t_4, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __PYX_ERR(1, 1255, __pyx_L1_error)
-
- /* "View.MemoryView":1253
- *
- * @cname('__pyx_memoryview_err_extents')
- * cdef int _err_extents(int i, Py_ssize_t extent1, # <<<<<<<<<<<<<<
- * Py_ssize_t extent2) except -1 with gil:
- * raise ValueError("got differing extents in dimension %d (got %d and %d)" %
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView._err_extents", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- return __pyx_r;
-}
-
-/* "View.MemoryView":1259
- *
- * @cname('__pyx_memoryview_err_dim')
- * cdef int _err_dim(object error, char *msg, int dim) except -1 with gil: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii') % dim)
- *
- */
-
-static int __pyx_memoryview_err_dim(PyObject *__pyx_v_error, char *__pyx_v_msg, int __pyx_v_dim) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("_err_dim", 0);
- __Pyx_INCREF(__pyx_v_error);
-
- /* "View.MemoryView":1260
- * @cname('__pyx_memoryview_err_dim')
- * cdef int _err_dim(object error, char *msg, int dim) except -1 with gil:
- * raise error(msg.decode('ascii') % dim) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_err')
- */
- __pyx_t_2 = __Pyx_decode_c_string(__pyx_v_msg, 0, strlen(__pyx_v_msg), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __pyx_t_3 = __Pyx_PyInt_From_int(__pyx_v_dim); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __pyx_t_4 = PyUnicode_Format(__pyx_t_2, __pyx_t_3); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_INCREF(__pyx_v_error);
- __pyx_t_3 = __pyx_v_error; __pyx_t_2 = NULL;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_3))) {
- __pyx_t_2 = PyMethod_GET_SELF(__pyx_t_3);
- if (likely(__pyx_t_2)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_3);
- __Pyx_INCREF(__pyx_t_2);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_3, function);
- }
- }
- __pyx_t_1 = (__pyx_t_2) ? __Pyx_PyObject_Call2Args(__pyx_t_3, __pyx_t_2, __pyx_t_4) : __Pyx_PyObject_CallOneArg(__pyx_t_3, __pyx_t_4);
- __Pyx_XDECREF(__pyx_t_2); __pyx_t_2 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1260, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- __Pyx_Raise(__pyx_t_1, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __PYX_ERR(1, 1260, __pyx_L1_error)
-
- /* "View.MemoryView":1259
- *
- * @cname('__pyx_memoryview_err_dim')
- * cdef int _err_dim(object error, char *msg, int dim) except -1 with gil: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii') % dim)
- *
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_AddTraceback("View.MemoryView._err_dim", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __Pyx_XDECREF(__pyx_v_error);
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- return __pyx_r;
-}
-
-/* "View.MemoryView":1263
- *
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil: # <<<<<<<<<<<<<<
- * if msg != NULL:
- * raise error(msg.decode('ascii'))
- */
-
-static int __pyx_memoryview_err(PyObject *__pyx_v_error, char *__pyx_v_msg) {
- int __pyx_r;
- __Pyx_RefNannyDeclarations
- int __pyx_t_1;
- PyObject *__pyx_t_2 = NULL;
- PyObject *__pyx_t_3 = NULL;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("_err", 0);
- __Pyx_INCREF(__pyx_v_error);
-
- /* "View.MemoryView":1264
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil:
- * if msg != NULL: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii'))
- * else:
- */
- __pyx_t_1 = ((__pyx_v_msg != NULL) != 0);
- if (unlikely(__pyx_t_1)) {
-
- /* "View.MemoryView":1265
- * cdef int _err(object error, char *msg) except -1 with gil:
- * if msg != NULL:
- * raise error(msg.decode('ascii')) # <<<<<<<<<<<<<<
- * else:
- * raise error
- */
- __pyx_t_3 = __Pyx_decode_c_string(__pyx_v_msg, 0, strlen(__pyx_v_msg), NULL, NULL, PyUnicode_DecodeASCII); if (unlikely(!__pyx_t_3)) __PYX_ERR(1, 1265, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_3);
- __Pyx_INCREF(__pyx_v_error);
- __pyx_t_4 = __pyx_v_error; __pyx_t_5 = NULL;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_4))) {
- __pyx_t_5 = PyMethod_GET_SELF(__pyx_t_4);
- if (likely(__pyx_t_5)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_4);
- __Pyx_INCREF(__pyx_t_5);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_4, function);
- }
- }
- __pyx_t_2 = (__pyx_t_5) ? __Pyx_PyObject_Call2Args(__pyx_t_4, __pyx_t_5, __pyx_t_3) : __Pyx_PyObject_CallOneArg(__pyx_t_4, __pyx_t_3);
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- __Pyx_DECREF(__pyx_t_3); __pyx_t_3 = 0;
- if (unlikely(!__pyx_t_2)) __PYX_ERR(1, 1265, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_2);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __Pyx_Raise(__pyx_t_2, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;
- __PYX_ERR(1, 1265, __pyx_L1_error)
-
- /* "View.MemoryView":1264
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil:
- * if msg != NULL: # <<<<<<<<<<<<<<
- * raise error(msg.decode('ascii'))
- * else:
- */
- }
-
- /* "View.MemoryView":1267
- * raise error(msg.decode('ascii'))
- * else:
- * raise error # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_copy_contents')
- */
- /*else*/ {
- __Pyx_Raise(__pyx_v_error, 0, 0, 0);
- __PYX_ERR(1, 1267, __pyx_L1_error)
- }
-
- /* "View.MemoryView":1263
- *
- * @cname('__pyx_memoryview_err')
- * cdef int _err(object error, char *msg) except -1 with gil: # <<<<<<<<<<<<<<
- * if msg != NULL:
- * raise error(msg.decode('ascii'))
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_2);
- __Pyx_XDECREF(__pyx_t_3);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_AddTraceback("View.MemoryView._err", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = -1;
- __Pyx_XDECREF(__pyx_v_error);
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- return __pyx_r;
-}
-
-/* "View.MemoryView":1270
- *
- * @cname('__pyx_memoryview_copy_contents')
- * cdef int memoryview_copy_contents(__Pyx_memviewslice src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice dst,
- * int src_ndim, int dst_ndim,
- */
-
-static int __pyx_memoryview_copy_contents(__Pyx_memviewslice __pyx_v_src, __Pyx_memviewslice __pyx_v_dst, int __pyx_v_src_ndim, int __pyx_v_dst_ndim, int __pyx_v_dtype_is_object) {
- void *__pyx_v_tmpdata;
- size_t __pyx_v_itemsize;
- int __pyx_v_i;
- char __pyx_v_order;
- int __pyx_v_broadcasting;
- int __pyx_v_direct_copy;
- __Pyx_memviewslice __pyx_v_tmp;
- int __pyx_v_ndim;
- int __pyx_r;
- Py_ssize_t __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
- int __pyx_t_4;
- int __pyx_t_5;
- int __pyx_t_6;
- void *__pyx_t_7;
- int __pyx_t_8;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
-
- /* "View.MemoryView":1278
- * Check for overlapping memory and verify the shapes.
- * """
- * cdef void *tmpdata = NULL # <<<<<<<<<<<<<<
- * cdef size_t itemsize = src.memview.view.itemsize
- * cdef int i
- */
- __pyx_v_tmpdata = NULL;
-
- /* "View.MemoryView":1279
- * """
- * cdef void *tmpdata = NULL
- * cdef size_t itemsize = src.memview.view.itemsize # <<<<<<<<<<<<<<
- * cdef int i
- * cdef char order = get_best_order(&src, src_ndim)
- */
- __pyx_t_1 = __pyx_v_src.memview->view.itemsize;
- __pyx_v_itemsize = __pyx_t_1;
-
- /* "View.MemoryView":1281
- * cdef size_t itemsize = src.memview.view.itemsize
- * cdef int i
- * cdef char order = get_best_order(&src, src_ndim) # <<<<<<<<<<<<<<
- * cdef bint broadcasting = False
- * cdef bint direct_copy = False
- */
- __pyx_v_order = __pyx_get_best_slice_order((&__pyx_v_src), __pyx_v_src_ndim);
-
- /* "View.MemoryView":1282
- * cdef int i
- * cdef char order = get_best_order(&src, src_ndim)
- * cdef bint broadcasting = False # <<<<<<<<<<<<<<
- * cdef bint direct_copy = False
- * cdef __Pyx_memviewslice tmp
- */
- __pyx_v_broadcasting = 0;
-
- /* "View.MemoryView":1283
- * cdef char order = get_best_order(&src, src_ndim)
- * cdef bint broadcasting = False
- * cdef bint direct_copy = False # <<<<<<<<<<<<<<
- * cdef __Pyx_memviewslice tmp
- *
- */
- __pyx_v_direct_copy = 0;
-
- /* "View.MemoryView":1286
- * cdef __Pyx_memviewslice tmp
- *
- * if src_ndim < dst_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim:
- */
- __pyx_t_2 = ((__pyx_v_src_ndim < __pyx_v_dst_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1287
- *
- * if src_ndim < dst_ndim:
- * broadcast_leading(&src, src_ndim, dst_ndim) # <<<<<<<<<<<<<<
- * elif dst_ndim < src_ndim:
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- */
- __pyx_memoryview_broadcast_leading((&__pyx_v_src), __pyx_v_src_ndim, __pyx_v_dst_ndim);
-
- /* "View.MemoryView":1286
- * cdef __Pyx_memviewslice tmp
- *
- * if src_ndim < dst_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim:
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1288
- * if src_ndim < dst_ndim:
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- *
- */
- __pyx_t_2 = ((__pyx_v_dst_ndim < __pyx_v_src_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1289
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim:
- * broadcast_leading(&dst, dst_ndim, src_ndim) # <<<<<<<<<<<<<<
- *
- * cdef int ndim = max(src_ndim, dst_ndim)
- */
- __pyx_memoryview_broadcast_leading((&__pyx_v_dst), __pyx_v_dst_ndim, __pyx_v_src_ndim);
-
- /* "View.MemoryView":1288
- * if src_ndim < dst_ndim:
- * broadcast_leading(&src, src_ndim, dst_ndim)
- * elif dst_ndim < src_ndim: # <<<<<<<<<<<<<<
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- *
- */
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1291
- * broadcast_leading(&dst, dst_ndim, src_ndim)
- *
- * cdef int ndim = max(src_ndim, dst_ndim) # <<<<<<<<<<<<<<
- *
- * for i in range(ndim):
- */
- __pyx_t_3 = __pyx_v_dst_ndim;
- __pyx_t_4 = __pyx_v_src_ndim;
- if (((__pyx_t_3 > __pyx_t_4) != 0)) {
- __pyx_t_5 = __pyx_t_3;
- } else {
- __pyx_t_5 = __pyx_t_4;
- }
- __pyx_v_ndim = __pyx_t_5;
-
- /* "View.MemoryView":1293
- * cdef int ndim = max(src_ndim, dst_ndim)
- *
- * for i in range(ndim): # <<<<<<<<<<<<<<
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1:
- */
- __pyx_t_5 = __pyx_v_ndim;
- __pyx_t_3 = __pyx_t_5;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1294
- *
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]: # <<<<<<<<<<<<<<
- * if src.shape[i] == 1:
- * broadcasting = True
- */
- __pyx_t_2 = (((__pyx_v_src.shape[__pyx_v_i]) != (__pyx_v_dst.shape[__pyx_v_i])) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1295
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1: # <<<<<<<<<<<<<<
- * broadcasting = True
- * src.strides[i] = 0
- */
- __pyx_t_2 = (((__pyx_v_src.shape[__pyx_v_i]) == 1) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1296
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1:
- * broadcasting = True # <<<<<<<<<<<<<<
- * src.strides[i] = 0
- * else:
- */
- __pyx_v_broadcasting = 1;
-
- /* "View.MemoryView":1297
- * if src.shape[i] == 1:
- * broadcasting = True
- * src.strides[i] = 0 # <<<<<<<<<<<<<<
- * else:
- * _err_extents(i, dst.shape[i], src.shape[i])
- */
- (__pyx_v_src.strides[__pyx_v_i]) = 0;
-
- /* "View.MemoryView":1295
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]:
- * if src.shape[i] == 1: # <<<<<<<<<<<<<<
- * broadcasting = True
- * src.strides[i] = 0
- */
- goto __pyx_L7;
- }
-
- /* "View.MemoryView":1299
- * src.strides[i] = 0
- * else:
- * _err_extents(i, dst.shape[i], src.shape[i]) # <<<<<<<<<<<<<<
- *
- * if src.suboffsets[i] >= 0:
- */
- /*else*/ {
- __pyx_t_6 = __pyx_memoryview_err_extents(__pyx_v_i, (__pyx_v_dst.shape[__pyx_v_i]), (__pyx_v_src.shape[__pyx_v_i])); if (unlikely(__pyx_t_6 == ((int)-1))) __PYX_ERR(1, 1299, __pyx_L1_error)
- }
- __pyx_L7:;
-
- /* "View.MemoryView":1294
- *
- * for i in range(ndim):
- * if src.shape[i] != dst.shape[i]: # <<<<<<<<<<<<<<
- * if src.shape[i] == 1:
- * broadcasting = True
- */
- }
-
- /* "View.MemoryView":1301
- * _err_extents(i, dst.shape[i], src.shape[i])
- *
- * if src.suboffsets[i] >= 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- */
- __pyx_t_2 = (((__pyx_v_src.suboffsets[__pyx_v_i]) >= 0) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1302
- *
- * if src.suboffsets[i] >= 0:
- * _err_dim(ValueError, "Dimension %d is not direct", i) # <<<<<<<<<<<<<<
- *
- * if slices_overlap(&src, &dst, ndim, itemsize):
- */
- __pyx_t_6 = __pyx_memoryview_err_dim(__pyx_builtin_ValueError, ((char *)"Dimension %d is not direct"), __pyx_v_i); if (unlikely(__pyx_t_6 == ((int)-1))) __PYX_ERR(1, 1302, __pyx_L1_error)
-
- /* "View.MemoryView":1301
- * _err_extents(i, dst.shape[i], src.shape[i])
- *
- * if src.suboffsets[i] >= 0: # <<<<<<<<<<<<<<
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- */
- }
- }
-
- /* "View.MemoryView":1304
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- * if slices_overlap(&src, &dst, ndim, itemsize): # <<<<<<<<<<<<<<
- *
- * if not slice_is_contig(src, order, ndim):
- */
- __pyx_t_2 = (__pyx_slices_overlap((&__pyx_v_src), (&__pyx_v_dst), __pyx_v_ndim, __pyx_v_itemsize) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1306
- * if slices_overlap(&src, &dst, ndim, itemsize):
- *
- * if not slice_is_contig(src, order, ndim): # <<<<<<<<<<<<<<
- * order = get_best_order(&dst, ndim)
- *
- */
- __pyx_t_2 = ((!(__pyx_memviewslice_is_contig(__pyx_v_src, __pyx_v_order, __pyx_v_ndim) != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1307
- *
- * if not slice_is_contig(src, order, ndim):
- * order = get_best_order(&dst, ndim) # <<<<<<<<<<<<<<
- *
- * tmpdata = copy_data_to_temp(&src, &tmp, order, ndim)
- */
- __pyx_v_order = __pyx_get_best_slice_order((&__pyx_v_dst), __pyx_v_ndim);
-
- /* "View.MemoryView":1306
- * if slices_overlap(&src, &dst, ndim, itemsize):
- *
- * if not slice_is_contig(src, order, ndim): # <<<<<<<<<<<<<<
- * order = get_best_order(&dst, ndim)
- *
- */
- }
-
- /* "View.MemoryView":1309
- * order = get_best_order(&dst, ndim)
- *
- * tmpdata = copy_data_to_temp(&src, &tmp, order, ndim) # <<<<<<<<<<<<<<
- * src = tmp
- *
- */
- __pyx_t_7 = __pyx_memoryview_copy_data_to_temp((&__pyx_v_src), (&__pyx_v_tmp), __pyx_v_order, __pyx_v_ndim); if (unlikely(__pyx_t_7 == ((void *)NULL))) __PYX_ERR(1, 1309, __pyx_L1_error)
- __pyx_v_tmpdata = __pyx_t_7;
-
- /* "View.MemoryView":1310
- *
- * tmpdata = copy_data_to_temp(&src, &tmp, order, ndim)
- * src = tmp # <<<<<<<<<<<<<<
- *
- * if not broadcasting:
- */
- __pyx_v_src = __pyx_v_tmp;
-
- /* "View.MemoryView":1304
- * _err_dim(ValueError, "Dimension %d is not direct", i)
- *
- * if slices_overlap(&src, &dst, ndim, itemsize): # <<<<<<<<<<<<<<
- *
- * if not slice_is_contig(src, order, ndim):
- */
- }
-
- /* "View.MemoryView":1312
- * src = tmp
- *
- * if not broadcasting: # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_2 = ((!(__pyx_v_broadcasting != 0)) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1315
- *
- *
- * if slice_is_contig(src, 'C', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim):
- */
- __pyx_t_2 = (__pyx_memviewslice_is_contig(__pyx_v_src, 'C', __pyx_v_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1316
- *
- * if slice_is_contig(src, 'C', ndim):
- * direct_copy = slice_is_contig(dst, 'C', ndim) # <<<<<<<<<<<<<<
- * elif slice_is_contig(src, 'F', ndim):
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- */
- __pyx_v_direct_copy = __pyx_memviewslice_is_contig(__pyx_v_dst, 'C', __pyx_v_ndim);
-
- /* "View.MemoryView":1315
- *
- *
- * if slice_is_contig(src, 'C', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim):
- */
- goto __pyx_L12;
- }
-
- /* "View.MemoryView":1317
- * if slice_is_contig(src, 'C', ndim):
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- */
- __pyx_t_2 = (__pyx_memviewslice_is_contig(__pyx_v_src, 'F', __pyx_v_ndim) != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1318
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim):
- * direct_copy = slice_is_contig(dst, 'F', ndim) # <<<<<<<<<<<<<<
- *
- * if direct_copy:
- */
- __pyx_v_direct_copy = __pyx_memviewslice_is_contig(__pyx_v_dst, 'F', __pyx_v_ndim);
-
- /* "View.MemoryView":1317
- * if slice_is_contig(src, 'C', ndim):
- * direct_copy = slice_is_contig(dst, 'C', ndim)
- * elif slice_is_contig(src, 'F', ndim): # <<<<<<<<<<<<<<
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- */
- }
- __pyx_L12:;
-
- /* "View.MemoryView":1320
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- * if direct_copy: # <<<<<<<<<<<<<<
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- */
- __pyx_t_2 = (__pyx_v_direct_copy != 0);
- if (__pyx_t_2) {
-
- /* "View.MemoryView":1322
- * if direct_copy:
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False) # <<<<<<<<<<<<<<
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim))
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 0);
-
- /* "View.MemoryView":1323
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim)) # <<<<<<<<<<<<<<
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- * free(tmpdata)
- */
- (void)(memcpy(__pyx_v_dst.data, __pyx_v_src.data, __pyx_memoryview_slice_get_size((&__pyx_v_src), __pyx_v_ndim)));
-
- /* "View.MemoryView":1324
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim))
- * refcount_copying(&dst, dtype_is_object, ndim, True) # <<<<<<<<<<<<<<
- * free(tmpdata)
- * return 0
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 1);
-
- /* "View.MemoryView":1325
- * memcpy(dst.data, src.data, slice_get_size(&src, ndim))
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- * free(tmpdata) # <<<<<<<<<<<<<<
- * return 0
- *
- */
- free(__pyx_v_tmpdata);
-
- /* "View.MemoryView":1326
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- * free(tmpdata)
- * return 0 # <<<<<<<<<<<<<<
- *
- * if order == 'F' == get_best_order(&dst, ndim):
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1320
- * direct_copy = slice_is_contig(dst, 'F', ndim)
- *
- * if direct_copy: # <<<<<<<<<<<<<<
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- */
- }
-
- /* "View.MemoryView":1312
- * src = tmp
- *
- * if not broadcasting: # <<<<<<<<<<<<<<
- *
- *
- */
- }
-
- /* "View.MemoryView":1328
- * return 0
- *
- * if order == 'F' == get_best_order(&dst, ndim): # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_2 = (__pyx_v_order == 'F');
- if (__pyx_t_2) {
- __pyx_t_2 = ('F' == __pyx_get_best_slice_order((&__pyx_v_dst), __pyx_v_ndim));
- }
- __pyx_t_8 = (__pyx_t_2 != 0);
- if (__pyx_t_8) {
-
- /* "View.MemoryView":1331
- *
- *
- * transpose_memslice(&src) # <<<<<<<<<<<<<<
- * transpose_memslice(&dst)
- *
- */
- __pyx_t_5 = __pyx_memslice_transpose((&__pyx_v_src)); if (unlikely(__pyx_t_5 == ((int)0))) __PYX_ERR(1, 1331, __pyx_L1_error)
-
- /* "View.MemoryView":1332
- *
- * transpose_memslice(&src)
- * transpose_memslice(&dst) # <<<<<<<<<<<<<<
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- */
- __pyx_t_5 = __pyx_memslice_transpose((&__pyx_v_dst)); if (unlikely(__pyx_t_5 == ((int)0))) __PYX_ERR(1, 1332, __pyx_L1_error)
-
- /* "View.MemoryView":1328
- * return 0
- *
- * if order == 'F' == get_best_order(&dst, ndim): # <<<<<<<<<<<<<<
- *
- *
- */
- }
-
- /* "View.MemoryView":1334
- * transpose_memslice(&dst)
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False) # <<<<<<<<<<<<<<
- * copy_strided_to_strided(&src, &dst, ndim, itemsize)
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 0);
-
- /* "View.MemoryView":1335
- *
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * copy_strided_to_strided(&src, &dst, ndim, itemsize) # <<<<<<<<<<<<<<
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- *
- */
- copy_strided_to_strided((&__pyx_v_src), (&__pyx_v_dst), __pyx_v_ndim, __pyx_v_itemsize);
-
- /* "View.MemoryView":1336
- * refcount_copying(&dst, dtype_is_object, ndim, False)
- * copy_strided_to_strided(&src, &dst, ndim, itemsize)
- * refcount_copying(&dst, dtype_is_object, ndim, True) # <<<<<<<<<<<<<<
- *
- * free(tmpdata)
- */
- __pyx_memoryview_refcount_copying((&__pyx_v_dst), __pyx_v_dtype_is_object, __pyx_v_ndim, 1);
-
- /* "View.MemoryView":1338
- * refcount_copying(&dst, dtype_is_object, ndim, True)
- *
- * free(tmpdata) # <<<<<<<<<<<<<<
- * return 0
- *
- */
- free(__pyx_v_tmpdata);
-
- /* "View.MemoryView":1339
- *
- * free(tmpdata)
- * return 0 # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_broadcast_leading')
- */
- __pyx_r = 0;
- goto __pyx_L0;
-
- /* "View.MemoryView":1270
- *
- * @cname('__pyx_memoryview_copy_contents')
- * cdef int memoryview_copy_contents(__Pyx_memviewslice src, # <<<<<<<<<<<<<<
- * __Pyx_memviewslice dst,
- * int src_ndim, int dst_ndim,
- */
-
- /* function exit code */
- __pyx_L1_error:;
- {
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_AddTraceback("View.MemoryView.memoryview_copy_contents", __pyx_clineno, __pyx_lineno, __pyx_filename);
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
- }
- __pyx_r = -1;
- __pyx_L0:;
- return __pyx_r;
-}
-
-/* "View.MemoryView":1342
- *
- * @cname('__pyx_memoryview_broadcast_leading')
- * cdef void broadcast_leading(__Pyx_memviewslice *mslice, # <<<<<<<<<<<<<<
- * int ndim,
- * int ndim_other) nogil:
- */
-
-static void __pyx_memoryview_broadcast_leading(__Pyx_memviewslice *__pyx_v_mslice, int __pyx_v_ndim, int __pyx_v_ndim_other) {
- int __pyx_v_i;
- int __pyx_v_offset;
- int __pyx_t_1;
- int __pyx_t_2;
- int __pyx_t_3;
-
- /* "View.MemoryView":1346
- * int ndim_other) nogil:
- * cdef int i
- * cdef int offset = ndim_other - ndim # <<<<<<<<<<<<<<
- *
- * for i in range(ndim - 1, -1, -1):
- */
- __pyx_v_offset = (__pyx_v_ndim_other - __pyx_v_ndim);
-
- /* "View.MemoryView":1348
- * cdef int offset = ndim_other - ndim
- *
- * for i in range(ndim - 1, -1, -1): # <<<<<<<<<<<<<<
- * mslice.shape[i + offset] = mslice.shape[i]
- * mslice.strides[i + offset] = mslice.strides[i]
- */
- for (__pyx_t_1 = (__pyx_v_ndim - 1); __pyx_t_1 > -1; __pyx_t_1-=1) {
- __pyx_v_i = __pyx_t_1;
-
- /* "View.MemoryView":1349
- *
- * for i in range(ndim - 1, -1, -1):
- * mslice.shape[i + offset] = mslice.shape[i] # <<<<<<<<<<<<<<
- * mslice.strides[i + offset] = mslice.strides[i]
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i]
- */
- (__pyx_v_mslice->shape[(__pyx_v_i + __pyx_v_offset)]) = (__pyx_v_mslice->shape[__pyx_v_i]);
-
- /* "View.MemoryView":1350
- * for i in range(ndim - 1, -1, -1):
- * mslice.shape[i + offset] = mslice.shape[i]
- * mslice.strides[i + offset] = mslice.strides[i] # <<<<<<<<<<<<<<
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i]
- *
- */
- (__pyx_v_mslice->strides[(__pyx_v_i + __pyx_v_offset)]) = (__pyx_v_mslice->strides[__pyx_v_i]);
-
- /* "View.MemoryView":1351
- * mslice.shape[i + offset] = mslice.shape[i]
- * mslice.strides[i + offset] = mslice.strides[i]
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i] # <<<<<<<<<<<<<<
- *
- * for i in range(offset):
- */
- (__pyx_v_mslice->suboffsets[(__pyx_v_i + __pyx_v_offset)]) = (__pyx_v_mslice->suboffsets[__pyx_v_i]);
- }
-
- /* "View.MemoryView":1353
- * mslice.suboffsets[i + offset] = mslice.suboffsets[i]
- *
- * for i in range(offset): # <<<<<<<<<<<<<<
- * mslice.shape[i] = 1
- * mslice.strides[i] = mslice.strides[0]
- */
- __pyx_t_1 = __pyx_v_offset;
- __pyx_t_2 = __pyx_t_1;
- for (__pyx_t_3 = 0; __pyx_t_3 < __pyx_t_2; __pyx_t_3+=1) {
- __pyx_v_i = __pyx_t_3;
-
- /* "View.MemoryView":1354
- *
- * for i in range(offset):
- * mslice.shape[i] = 1 # <<<<<<<<<<<<<<
- * mslice.strides[i] = mslice.strides[0]
- * mslice.suboffsets[i] = -1
- */
- (__pyx_v_mslice->shape[__pyx_v_i]) = 1;
-
- /* "View.MemoryView":1355
- * for i in range(offset):
- * mslice.shape[i] = 1
- * mslice.strides[i] = mslice.strides[0] # <<<<<<<<<<<<<<
- * mslice.suboffsets[i] = -1
- *
- */
- (__pyx_v_mslice->strides[__pyx_v_i]) = (__pyx_v_mslice->strides[0]);
-
- /* "View.MemoryView":1356
- * mslice.shape[i] = 1
- * mslice.strides[i] = mslice.strides[0]
- * mslice.suboffsets[i] = -1 # <<<<<<<<<<<<<<
- *
- *
- */
- (__pyx_v_mslice->suboffsets[__pyx_v_i]) = -1L;
- }
-
- /* "View.MemoryView":1342
- *
- * @cname('__pyx_memoryview_broadcast_leading')
- * cdef void broadcast_leading(__Pyx_memviewslice *mslice, # <<<<<<<<<<<<<<
- * int ndim,
- * int ndim_other) nogil:
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1364
- *
- * @cname('__pyx_memoryview_refcount_copying')
- * cdef void refcount_copying(__Pyx_memviewslice *dst, bint dtype_is_object, # <<<<<<<<<<<<<<
- * int ndim, bint inc) nogil:
- *
- */
-
-static void __pyx_memoryview_refcount_copying(__Pyx_memviewslice *__pyx_v_dst, int __pyx_v_dtype_is_object, int __pyx_v_ndim, int __pyx_v_inc) {
- int __pyx_t_1;
-
- /* "View.MemoryView":1368
- *
- *
- * if dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice_with_gil(dst.data, dst.shape,
- * dst.strides, ndim, inc)
- */
- __pyx_t_1 = (__pyx_v_dtype_is_object != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1369
- *
- * if dtype_is_object:
- * refcount_objects_in_slice_with_gil(dst.data, dst.shape, # <<<<<<<<<<<<<<
- * dst.strides, ndim, inc)
- *
- */
- __pyx_memoryview_refcount_objects_in_slice_with_gil(__pyx_v_dst->data, __pyx_v_dst->shape, __pyx_v_dst->strides, __pyx_v_ndim, __pyx_v_inc);
-
- /* "View.MemoryView":1368
- *
- *
- * if dtype_is_object: # <<<<<<<<<<<<<<
- * refcount_objects_in_slice_with_gil(dst.data, dst.shape,
- * dst.strides, ndim, inc)
- */
- }
-
- /* "View.MemoryView":1364
- *
- * @cname('__pyx_memoryview_refcount_copying')
- * cdef void refcount_copying(__Pyx_memviewslice *dst, bint dtype_is_object, # <<<<<<<<<<<<<<
- * int ndim, bint inc) nogil:
- *
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1373
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice_with_gil')
- * cdef void refcount_objects_in_slice_with_gil(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * bint inc) with gil:
- */
-
-static void __pyx_memoryview_refcount_objects_in_slice_with_gil(char *__pyx_v_data, Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, int __pyx_v_ndim, int __pyx_v_inc) {
- __Pyx_RefNannyDeclarations
- #ifdef WITH_THREAD
- PyGILState_STATE __pyx_gilstate_save = __Pyx_PyGILState_Ensure();
- #endif
- __Pyx_RefNannySetupContext("refcount_objects_in_slice_with_gil", 0);
-
- /* "View.MemoryView":1376
- * Py_ssize_t *strides, int ndim,
- * bint inc) with gil:
- * refcount_objects_in_slice(data, shape, strides, ndim, inc) # <<<<<<<<<<<<<<
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice')
- */
- __pyx_memoryview_refcount_objects_in_slice(__pyx_v_data, __pyx_v_shape, __pyx_v_strides, __pyx_v_ndim, __pyx_v_inc);
-
- /* "View.MemoryView":1373
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice_with_gil')
- * cdef void refcount_objects_in_slice_with_gil(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * bint inc) with gil:
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- #ifdef WITH_THREAD
- __Pyx_PyGILState_Release(__pyx_gilstate_save);
- #endif
-}
-
-/* "View.MemoryView":1379
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice')
- * cdef void refcount_objects_in_slice(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim, bint inc):
- * cdef Py_ssize_t i
- */
-
-static void __pyx_memoryview_refcount_objects_in_slice(char *__pyx_v_data, Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, int __pyx_v_ndim, int __pyx_v_inc) {
- CYTHON_UNUSED Py_ssize_t __pyx_v_i;
- __Pyx_RefNannyDeclarations
- Py_ssize_t __pyx_t_1;
- Py_ssize_t __pyx_t_2;
- Py_ssize_t __pyx_t_3;
- int __pyx_t_4;
- __Pyx_RefNannySetupContext("refcount_objects_in_slice", 0);
-
- /* "View.MemoryView":1383
- * cdef Py_ssize_t i
- *
- * for i in range(shape[0]): # <<<<<<<<<<<<<<
- * if ndim == 1:
- * if inc:
- */
- __pyx_t_1 = (__pyx_v_shape[0]);
- __pyx_t_2 = __pyx_t_1;
- for (__pyx_t_3 = 0; __pyx_t_3 < __pyx_t_2; __pyx_t_3+=1) {
- __pyx_v_i = __pyx_t_3;
-
- /* "View.MemoryView":1384
- *
- * for i in range(shape[0]):
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if inc:
- * Py_INCREF(( data)[0])
- */
- __pyx_t_4 = ((__pyx_v_ndim == 1) != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":1385
- * for i in range(shape[0]):
- * if ndim == 1:
- * if inc: # <<<<<<<<<<<<<<
- * Py_INCREF(( data)[0])
- * else:
- */
- __pyx_t_4 = (__pyx_v_inc != 0);
- if (__pyx_t_4) {
-
- /* "View.MemoryView":1386
- * if ndim == 1:
- * if inc:
- * Py_INCREF(( data)[0]) # <<<<<<<<<<<<<<
- * else:
- * Py_DECREF(( data)[0])
- */
- Py_INCREF((((PyObject **)__pyx_v_data)[0]));
-
- /* "View.MemoryView":1385
- * for i in range(shape[0]):
- * if ndim == 1:
- * if inc: # <<<<<<<<<<<<<<
- * Py_INCREF(( data)[0])
- * else:
- */
- goto __pyx_L6;
- }
-
- /* "View.MemoryView":1388
- * Py_INCREF(( data)[0])
- * else:
- * Py_DECREF(( data)[0]) # <<<<<<<<<<<<<<
- * else:
- * refcount_objects_in_slice(data, shape + 1, strides + 1,
- */
- /*else*/ {
- Py_DECREF((((PyObject **)__pyx_v_data)[0]));
- }
- __pyx_L6:;
-
- /* "View.MemoryView":1384
- *
- * for i in range(shape[0]):
- * if ndim == 1: # <<<<<<<<<<<<<<
- * if inc:
- * Py_INCREF(( data)[0])
- */
- goto __pyx_L5;
- }
-
- /* "View.MemoryView":1390
- * Py_DECREF(( data)[0])
- * else:
- * refcount_objects_in_slice(data, shape + 1, strides + 1, # <<<<<<<<<<<<<<
- * ndim - 1, inc)
- *
- */
- /*else*/ {
-
- /* "View.MemoryView":1391
- * else:
- * refcount_objects_in_slice(data, shape + 1, strides + 1,
- * ndim - 1, inc) # <<<<<<<<<<<<<<
- *
- * data += strides[0]
- */
- __pyx_memoryview_refcount_objects_in_slice(__pyx_v_data, (__pyx_v_shape + 1), (__pyx_v_strides + 1), (__pyx_v_ndim - 1), __pyx_v_inc);
- }
- __pyx_L5:;
-
- /* "View.MemoryView":1393
- * ndim - 1, inc)
- *
- * data += strides[0] # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_data = (__pyx_v_data + (__pyx_v_strides[0]));
- }
-
- /* "View.MemoryView":1379
- *
- * @cname('__pyx_memoryview_refcount_objects_in_slice')
- * cdef void refcount_objects_in_slice(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim, bint inc):
- * cdef Py_ssize_t i
- */
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
-}
-
-/* "View.MemoryView":1399
- *
- * @cname('__pyx_memoryview_slice_assign_scalar')
- * cdef void slice_assign_scalar(__Pyx_memviewslice *dst, int ndim, # <<<<<<<<<<<<<<
- * size_t itemsize, void *item,
- * bint dtype_is_object) nogil:
- */
-
-static void __pyx_memoryview_slice_assign_scalar(__Pyx_memviewslice *__pyx_v_dst, int __pyx_v_ndim, size_t __pyx_v_itemsize, void *__pyx_v_item, int __pyx_v_dtype_is_object) {
-
- /* "View.MemoryView":1402
- * size_t itemsize, void *item,
- * bint dtype_is_object) nogil:
- * refcount_copying(dst, dtype_is_object, ndim, False) # <<<<<<<<<<<<<<
- * _slice_assign_scalar(dst.data, dst.shape, dst.strides, ndim,
- * itemsize, item)
- */
- __pyx_memoryview_refcount_copying(__pyx_v_dst, __pyx_v_dtype_is_object, __pyx_v_ndim, 0);
-
- /* "View.MemoryView":1403
- * bint dtype_is_object) nogil:
- * refcount_copying(dst, dtype_is_object, ndim, False)
- * _slice_assign_scalar(dst.data, dst.shape, dst.strides, ndim, # <<<<<<<<<<<<<<
- * itemsize, item)
- * refcount_copying(dst, dtype_is_object, ndim, True)
- */
- __pyx_memoryview__slice_assign_scalar(__pyx_v_dst->data, __pyx_v_dst->shape, __pyx_v_dst->strides, __pyx_v_ndim, __pyx_v_itemsize, __pyx_v_item);
-
- /* "View.MemoryView":1405
- * _slice_assign_scalar(dst.data, dst.shape, dst.strides, ndim,
- * itemsize, item)
- * refcount_copying(dst, dtype_is_object, ndim, True) # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_memoryview_refcount_copying(__pyx_v_dst, __pyx_v_dtype_is_object, __pyx_v_ndim, 1);
-
- /* "View.MemoryView":1399
- *
- * @cname('__pyx_memoryview_slice_assign_scalar')
- * cdef void slice_assign_scalar(__Pyx_memviewslice *dst, int ndim, # <<<<<<<<<<<<<<
- * size_t itemsize, void *item,
- * bint dtype_is_object) nogil:
- */
-
- /* function exit code */
-}
-
-/* "View.MemoryView":1409
- *
- * @cname('__pyx_memoryview__slice_assign_scalar')
- * cdef void _slice_assign_scalar(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * size_t itemsize, void *item) nogil:
- */
-
-static void __pyx_memoryview__slice_assign_scalar(char *__pyx_v_data, Py_ssize_t *__pyx_v_shape, Py_ssize_t *__pyx_v_strides, int __pyx_v_ndim, size_t __pyx_v_itemsize, void *__pyx_v_item) {
- CYTHON_UNUSED Py_ssize_t __pyx_v_i;
- Py_ssize_t __pyx_v_stride;
- Py_ssize_t __pyx_v_extent;
- int __pyx_t_1;
- Py_ssize_t __pyx_t_2;
- Py_ssize_t __pyx_t_3;
- Py_ssize_t __pyx_t_4;
-
- /* "View.MemoryView":1413
- * size_t itemsize, void *item) nogil:
- * cdef Py_ssize_t i
- * cdef Py_ssize_t stride = strides[0] # <<<<<<<<<<<<<<
- * cdef Py_ssize_t extent = shape[0]
- *
- */
- __pyx_v_stride = (__pyx_v_strides[0]);
-
- /* "View.MemoryView":1414
- * cdef Py_ssize_t i
- * cdef Py_ssize_t stride = strides[0]
- * cdef Py_ssize_t extent = shape[0] # <<<<<<<<<<<<<<
- *
- * if ndim == 1:
- */
- __pyx_v_extent = (__pyx_v_shape[0]);
-
- /* "View.MemoryView":1416
- * cdef Py_ssize_t extent = shape[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * for i in range(extent):
- * memcpy(data, item, itemsize)
- */
- __pyx_t_1 = ((__pyx_v_ndim == 1) != 0);
- if (__pyx_t_1) {
-
- /* "View.MemoryView":1417
- *
- * if ndim == 1:
- * for i in range(extent): # <<<<<<<<<<<<<<
- * memcpy(data, item, itemsize)
- * data += stride
- */
- __pyx_t_2 = __pyx_v_extent;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1418
- * if ndim == 1:
- * for i in range(extent):
- * memcpy(data, item, itemsize) # <<<<<<<<<<<<<<
- * data += stride
- * else:
- */
- (void)(memcpy(__pyx_v_data, __pyx_v_item, __pyx_v_itemsize));
-
- /* "View.MemoryView":1419
- * for i in range(extent):
- * memcpy(data, item, itemsize)
- * data += stride # <<<<<<<<<<<<<<
- * else:
- * for i in range(extent):
- */
- __pyx_v_data = (__pyx_v_data + __pyx_v_stride);
- }
-
- /* "View.MemoryView":1416
- * cdef Py_ssize_t extent = shape[0]
- *
- * if ndim == 1: # <<<<<<<<<<<<<<
- * for i in range(extent):
- * memcpy(data, item, itemsize)
- */
- goto __pyx_L3;
- }
-
- /* "View.MemoryView":1421
- * data += stride
- * else:
- * for i in range(extent): # <<<<<<<<<<<<<<
- * _slice_assign_scalar(data, shape + 1, strides + 1,
- * ndim - 1, itemsize, item)
- */
- /*else*/ {
- __pyx_t_2 = __pyx_v_extent;
- __pyx_t_3 = __pyx_t_2;
- for (__pyx_t_4 = 0; __pyx_t_4 < __pyx_t_3; __pyx_t_4+=1) {
- __pyx_v_i = __pyx_t_4;
-
- /* "View.MemoryView":1422
- * else:
- * for i in range(extent):
- * _slice_assign_scalar(data, shape + 1, strides + 1, # <<<<<<<<<<<<<<
- * ndim - 1, itemsize, item)
- * data += stride
- */
- __pyx_memoryview__slice_assign_scalar(__pyx_v_data, (__pyx_v_shape + 1), (__pyx_v_strides + 1), (__pyx_v_ndim - 1), __pyx_v_itemsize, __pyx_v_item);
-
- /* "View.MemoryView":1424
- * _slice_assign_scalar(data, shape + 1, strides + 1,
- * ndim - 1, itemsize, item)
- * data += stride # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_v_data = (__pyx_v_data + __pyx_v_stride);
- }
- }
- __pyx_L3:;
-
- /* "View.MemoryView":1409
- *
- * @cname('__pyx_memoryview__slice_assign_scalar')
- * cdef void _slice_assign_scalar(char *data, Py_ssize_t *shape, # <<<<<<<<<<<<<<
- * Py_ssize_t *strides, int ndim,
- * size_t itemsize, void *item) nogil:
- */
-
- /* function exit code */
-}
-
-/* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
-
-/* Python wrapper */
-static PyObject *__pyx_pw_15View_dot_MemoryView_1__pyx_unpickle_Enum(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
-static PyMethodDef __pyx_mdef_15View_dot_MemoryView_1__pyx_unpickle_Enum = {"__pyx_unpickle_Enum", (PyCFunction)(void*)(PyCFunctionWithKeywords)__pyx_pw_15View_dot_MemoryView_1__pyx_unpickle_Enum, METH_VARARGS|METH_KEYWORDS, 0};
-static PyObject *__pyx_pw_15View_dot_MemoryView_1__pyx_unpickle_Enum(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
- PyObject *__pyx_v___pyx_type = 0;
- long __pyx_v___pyx_checksum;
- PyObject *__pyx_v___pyx_state = 0;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- PyObject *__pyx_r = 0;
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__pyx_unpickle_Enum (wrapper)", 0);
- {
- static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_pyx_type,&__pyx_n_s_pyx_checksum,&__pyx_n_s_pyx_state,0};
- PyObject* values[3] = {0,0,0};
- if (unlikely(__pyx_kwds)) {
- Py_ssize_t kw_args;
- const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
- switch (pos_args) {
- case 3: values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- CYTHON_FALLTHROUGH;
- case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- CYTHON_FALLTHROUGH;
- case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- CYTHON_FALLTHROUGH;
- case 0: break;
- default: goto __pyx_L5_argtuple_error;
- }
- kw_args = PyDict_Size(__pyx_kwds);
- switch (pos_args) {
- case 0:
- if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_pyx_type)) != 0)) kw_args--;
- else goto __pyx_L5_argtuple_error;
- CYTHON_FALLTHROUGH;
- case 1:
- if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_pyx_checksum)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__pyx_unpickle_Enum", 1, 3, 3, 1); __PYX_ERR(1, 1, __pyx_L3_error)
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (likely((values[2] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_pyx_state)) != 0)) kw_args--;
- else {
- __Pyx_RaiseArgtupleInvalid("__pyx_unpickle_Enum", 1, 3, 3, 2); __PYX_ERR(1, 1, __pyx_L3_error)
- }
- }
- if (unlikely(kw_args > 0)) {
- if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "__pyx_unpickle_Enum") < 0)) __PYX_ERR(1, 1, __pyx_L3_error)
- }
- } else if (PyTuple_GET_SIZE(__pyx_args) != 3) {
- goto __pyx_L5_argtuple_error;
- } else {
- values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
- values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
- values[2] = PyTuple_GET_ITEM(__pyx_args, 2);
- }
- __pyx_v___pyx_type = values[0];
- __pyx_v___pyx_checksum = __Pyx_PyInt_As_long(values[1]); if (unlikely((__pyx_v___pyx_checksum == (long)-1) && PyErr_Occurred())) __PYX_ERR(1, 1, __pyx_L3_error)
- __pyx_v___pyx_state = values[2];
- }
- goto __pyx_L4_argument_unpacking_done;
- __pyx_L5_argtuple_error:;
- __Pyx_RaiseArgtupleInvalid("__pyx_unpickle_Enum", 1, 3, 3, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(1, 1, __pyx_L3_error)
- __pyx_L3_error:;
- __Pyx_AddTraceback("View.MemoryView.__pyx_unpickle_Enum", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __Pyx_RefNannyFinishContext();
- return NULL;
- __pyx_L4_argument_unpacking_done:;
- __pyx_r = __pyx_pf_15View_dot_MemoryView___pyx_unpickle_Enum(__pyx_self, __pyx_v___pyx_type, __pyx_v___pyx_checksum, __pyx_v___pyx_state);
-
- /* function exit code */
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-static PyObject *__pyx_pf_15View_dot_MemoryView___pyx_unpickle_Enum(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v___pyx_type, long __pyx_v___pyx_checksum, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_v___pyx_PickleError = 0;
- PyObject *__pyx_v___pyx_result = 0;
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- int __pyx_t_3;
- PyObject *__pyx_t_4 = NULL;
- PyObject *__pyx_t_5 = NULL;
- PyObject *__pyx_t_6 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__pyx_unpickle_Enum", 0);
-
- /* "(tree fragment)":4
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995): # <<<<<<<<<<<<<<
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- */
- __pyx_t_1 = __Pyx_PyInt_From_long(__pyx_v___pyx_checksum); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_2 = (__Pyx_PySequence_ContainsTF(__pyx_t_1, __pyx_tuple__20, Py_NE)); if (unlikely(__pyx_t_2 < 0)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_3 = (__pyx_t_2 != 0);
- if (__pyx_t_3) {
-
- /* "(tree fragment)":5
- * cdef object __pyx_result
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995):
- * from pickle import PickleError as __pyx_PickleError # <<<<<<<<<<<<<<
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type)
- */
- __pyx_t_1 = PyList_New(1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_n_s_PickleError);
- __Pyx_GIVEREF(__pyx_n_s_PickleError);
- PyList_SET_ITEM(__pyx_t_1, 0, __pyx_n_s_PickleError);
- __pyx_t_4 = __Pyx_Import(__pyx_n_s_pickle, __pyx_t_1, 0); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_t_1 = __Pyx_ImportFrom(__pyx_t_4, __pyx_n_s_PickleError); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 5, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_1);
- __pyx_v___pyx_PickleError = __pyx_t_1;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
-
- /* "(tree fragment)":6
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995):
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum) # <<<<<<<<<<<<<<
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None:
- */
- __pyx_t_1 = __Pyx_PyInt_From_long(__pyx_v___pyx_checksum); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_5 = __Pyx_PyString_Format(__pyx_kp_s_Incompatible_checksums_0x_x_vs_0, __pyx_t_1); if (unlikely(!__pyx_t_5)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_5);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_INCREF(__pyx_v___pyx_PickleError);
- __pyx_t_1 = __pyx_v___pyx_PickleError; __pyx_t_6 = NULL;
- if (CYTHON_UNPACK_METHODS && unlikely(PyMethod_Check(__pyx_t_1))) {
- __pyx_t_6 = PyMethod_GET_SELF(__pyx_t_1);
- if (likely(__pyx_t_6)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_6);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_1, function);
- }
- }
- __pyx_t_4 = (__pyx_t_6) ? __Pyx_PyObject_Call2Args(__pyx_t_1, __pyx_t_6, __pyx_t_5) : __Pyx_PyObject_CallOneArg(__pyx_t_1, __pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
- __Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
- if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 6, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __Pyx_Raise(__pyx_t_4, 0, 0, 0);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
- __PYX_ERR(1, 6, __pyx_L1_error)
-
- /* "(tree fragment)":4
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- * if __pyx_checksum not in (0xb068931, 0x82a3537, 0x6ae9995): # <<<<<<<<<<<<<<
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- */
- }
-
- /* "(tree fragment)":7
- * from pickle import PickleError as __pyx_PickleError
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type) # <<<<<<<<<<<<<<
- * if __pyx_state is not None:
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- */
- __pyx_t_1 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_MemviewEnum_type), __pyx_n_s_new); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 7, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __pyx_t_5 = NULL;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_1))) {
- __pyx_t_5 = PyMethod_GET_SELF(__pyx_t_1);
- if (likely(__pyx_t_5)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_1);
- __Pyx_INCREF(__pyx_t_5);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_1, function);
- }
- }
- __pyx_t_4 = (__pyx_t_5) ? __Pyx_PyObject_Call2Args(__pyx_t_1, __pyx_t_5, __pyx_v___pyx_type) : __Pyx_PyObject_CallOneArg(__pyx_t_1, __pyx_v___pyx_type);
- __Pyx_XDECREF(__pyx_t_5); __pyx_t_5 = 0;
- if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 7, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- __pyx_v___pyx_result = __pyx_t_4;
- __pyx_t_4 = 0;
-
- /* "(tree fragment)":8
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None: # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- */
- __pyx_t_3 = (__pyx_v___pyx_state != Py_None);
- __pyx_t_2 = (__pyx_t_3 != 0);
- if (__pyx_t_2) {
-
- /* "(tree fragment)":9
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None:
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state) # <<<<<<<<<<<<<<
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- */
- if (!(likely(PyTuple_CheckExact(__pyx_v___pyx_state))||((__pyx_v___pyx_state) == Py_None)||(PyErr_Format(PyExc_TypeError, "Expected %.16s, got %.200s", "tuple", Py_TYPE(__pyx_v___pyx_state)->tp_name), 0))) __PYX_ERR(1, 9, __pyx_L1_error)
- __pyx_t_4 = __pyx_unpickle_Enum__set_state(((struct __pyx_MemviewEnum_obj *)__pyx_v___pyx_result), ((PyObject*)__pyx_v___pyx_state)); if (unlikely(!__pyx_t_4)) __PYX_ERR(1, 9, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_4);
- __Pyx_DECREF(__pyx_t_4); __pyx_t_4 = 0;
-
- /* "(tree fragment)":8
- * raise __pyx_PickleError("Incompatible checksums (0x%x vs (0xb068931, 0x82a3537, 0x6ae9995) = (name))" % __pyx_checksum)
- * __pyx_result = Enum.__new__(__pyx_type)
- * if __pyx_state is not None: # <<<<<<<<<<<<<<
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- */
- }
-
- /* "(tree fragment)":10
- * if __pyx_state is not None:
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result # <<<<<<<<<<<<<<
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0]
- */
- __Pyx_XDECREF(__pyx_r);
- __Pyx_INCREF(__pyx_v___pyx_result);
- __pyx_r = __pyx_v___pyx_result;
- goto __pyx_L0;
-
- /* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
-
- /* function exit code */
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_4);
- __Pyx_XDECREF(__pyx_t_5);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_AddTraceback("View.MemoryView.__pyx_unpickle_Enum", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = NULL;
- __pyx_L0:;
- __Pyx_XDECREF(__pyx_v___pyx_PickleError);
- __Pyx_XDECREF(__pyx_v___pyx_result);
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-
-/* "(tree fragment)":11
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- */
-
-static PyObject *__pyx_unpickle_Enum__set_state(struct __pyx_MemviewEnum_obj *__pyx_v___pyx_result, PyObject *__pyx_v___pyx_state) {
- PyObject *__pyx_r = NULL;
- __Pyx_RefNannyDeclarations
- PyObject *__pyx_t_1 = NULL;
- int __pyx_t_2;
- Py_ssize_t __pyx_t_3;
- int __pyx_t_4;
- int __pyx_t_5;
- PyObject *__pyx_t_6 = NULL;
- PyObject *__pyx_t_7 = NULL;
- PyObject *__pyx_t_8 = NULL;
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__pyx_unpickle_Enum__set_state", 0);
-
- /* "(tree fragment)":12
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0] # <<<<<<<<<<<<<<
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- * __pyx_result.__dict__.update(__pyx_state[1])
- */
- if (unlikely(__pyx_v___pyx_state == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' object is not subscriptable");
- __PYX_ERR(1, 12, __pyx_L1_error)
- }
- __pyx_t_1 = __Pyx_GetItemInt_Tuple(__pyx_v___pyx_state, 0, long, 1, __Pyx_PyInt_From_long, 0, 0, 1); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 12, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __Pyx_GOTREF(__pyx_v___pyx_result->name);
- __Pyx_DECREF(__pyx_v___pyx_result->name);
- __pyx_v___pyx_result->name = __pyx_t_1;
- __pyx_t_1 = 0;
-
- /* "(tree fragment)":13
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'): # <<<<<<<<<<<<<<
- * __pyx_result.__dict__.update(__pyx_state[1])
- */
- if (unlikely(__pyx_v___pyx_state == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "object of type 'NoneType' has no len()");
- __PYX_ERR(1, 13, __pyx_L1_error)
- }
- __pyx_t_3 = PyTuple_GET_SIZE(__pyx_v___pyx_state); if (unlikely(__pyx_t_3 == ((Py_ssize_t)-1))) __PYX_ERR(1, 13, __pyx_L1_error)
- __pyx_t_4 = ((__pyx_t_3 > 1) != 0);
- if (__pyx_t_4) {
- } else {
- __pyx_t_2 = __pyx_t_4;
- goto __pyx_L4_bool_binop_done;
- }
- __pyx_t_4 = __Pyx_HasAttr(((PyObject *)__pyx_v___pyx_result), __pyx_n_s_dict); if (unlikely(__pyx_t_4 == ((int)-1))) __PYX_ERR(1, 13, __pyx_L1_error)
- __pyx_t_5 = (__pyx_t_4 != 0);
- __pyx_t_2 = __pyx_t_5;
- __pyx_L4_bool_binop_done:;
- if (__pyx_t_2) {
-
- /* "(tree fragment)":14
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- * __pyx_result.__dict__.update(__pyx_state[1]) # <<<<<<<<<<<<<<
- */
- __pyx_t_6 = __Pyx_PyObject_GetAttrStr(((PyObject *)__pyx_v___pyx_result), __pyx_n_s_dict); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_7 = __Pyx_PyObject_GetAttrStr(__pyx_t_6, __pyx_n_s_update); if (unlikely(!__pyx_t_7)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_7);
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (unlikely(__pyx_v___pyx_state == Py_None)) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' object is not subscriptable");
- __PYX_ERR(1, 14, __pyx_L1_error)
- }
- __pyx_t_6 = __Pyx_GetItemInt_Tuple(__pyx_v___pyx_state, 1, long, 1, __Pyx_PyInt_From_long, 0, 0, 1); if (unlikely(!__pyx_t_6)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_6);
- __pyx_t_8 = NULL;
- if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_7))) {
- __pyx_t_8 = PyMethod_GET_SELF(__pyx_t_7);
- if (likely(__pyx_t_8)) {
- PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_7);
- __Pyx_INCREF(__pyx_t_8);
- __Pyx_INCREF(function);
- __Pyx_DECREF_SET(__pyx_t_7, function);
- }
- }
- __pyx_t_1 = (__pyx_t_8) ? __Pyx_PyObject_Call2Args(__pyx_t_7, __pyx_t_8, __pyx_t_6) : __Pyx_PyObject_CallOneArg(__pyx_t_7, __pyx_t_6);
- __Pyx_XDECREF(__pyx_t_8); __pyx_t_8 = 0;
- __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0;
- if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 14, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_DECREF(__pyx_t_7); __pyx_t_7 = 0;
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "(tree fragment)":13
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state):
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'): # <<<<<<<<<<<<<<
- * __pyx_result.__dict__.update(__pyx_state[1])
- */
- }
-
- /* "(tree fragment)":11
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- */
-
- /* function exit code */
- __pyx_r = Py_None; __Pyx_INCREF(Py_None);
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- __Pyx_XDECREF(__pyx_t_6);
- __Pyx_XDECREF(__pyx_t_7);
- __Pyx_XDECREF(__pyx_t_8);
- __Pyx_AddTraceback("View.MemoryView.__pyx_unpickle_Enum__set_state", __pyx_clineno, __pyx_lineno, __pyx_filename);
- __pyx_r = 0;
- __pyx_L0:;
- __Pyx_XGIVEREF(__pyx_r);
- __Pyx_RefNannyFinishContext();
- return __pyx_r;
-}
-static struct __pyx_vtabstruct_array __pyx_vtable_array;
-
-static PyObject *__pyx_tp_new_array(PyTypeObject *t, PyObject *a, PyObject *k) {
- struct __pyx_array_obj *p;
- PyObject *o;
- if (likely((t->tp_flags & Py_TPFLAGS_IS_ABSTRACT) == 0)) {
- o = (*t->tp_alloc)(t, 0);
- } else {
- o = (PyObject *) PyBaseObject_Type.tp_new(t, __pyx_empty_tuple, 0);
- }
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_array_obj *)o);
- p->__pyx_vtab = __pyx_vtabptr_array;
- p->mode = ((PyObject*)Py_None); Py_INCREF(Py_None);
- p->_format = ((PyObject*)Py_None); Py_INCREF(Py_None);
- if (unlikely(__pyx_array___cinit__(o, a, k) < 0)) goto bad;
- return o;
- bad:
- Py_DECREF(o); o = 0;
- return NULL;
-}
-
-static void __pyx_tp_dealloc_array(PyObject *o) {
- struct __pyx_array_obj *p = (struct __pyx_array_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && (!PyType_IS_GC(Py_TYPE(o)) || !_PyGC_FINALIZED(o))) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- {
- PyObject *etype, *eval, *etb;
- PyErr_Fetch(&etype, &eval, &etb);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) + 1);
- __pyx_array___dealloc__(o);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) - 1);
- PyErr_Restore(etype, eval, etb);
- }
- Py_CLEAR(p->mode);
- Py_CLEAR(p->_format);
- (*Py_TYPE(o)->tp_free)(o);
-}
-static PyObject *__pyx_sq_item_array(PyObject *o, Py_ssize_t i) {
- PyObject *r;
- PyObject *x = PyInt_FromSsize_t(i); if(!x) return 0;
- r = Py_TYPE(o)->tp_as_mapping->mp_subscript(o, x);
- Py_DECREF(x);
- return r;
-}
-
-static int __pyx_mp_ass_subscript_array(PyObject *o, PyObject *i, PyObject *v) {
- if (v) {
- return __pyx_array___setitem__(o, i, v);
- }
- else {
- PyErr_Format(PyExc_NotImplementedError,
- "Subscript deletion not supported by %.200s", Py_TYPE(o)->tp_name);
- return -1;
- }
-}
-
-static PyObject *__pyx_tp_getattro_array(PyObject *o, PyObject *n) {
- PyObject *v = __Pyx_PyObject_GenericGetAttr(o, n);
- if (!v && PyErr_ExceptionMatches(PyExc_AttributeError)) {
- PyErr_Clear();
- v = __pyx_array___getattr__(o, n);
- }
- return v;
-}
-
-static PyObject *__pyx_getprop___pyx_array_memview(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_5array_7memview_1__get__(o);
-}
-
-static PyMethodDef __pyx_methods_array[] = {
- {"__getattr__", (PyCFunction)__pyx_array___getattr__, METH_O|METH_COEXIST, 0},
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_array_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_array_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static struct PyGetSetDef __pyx_getsets_array[] = {
- {(char *)"memview", __pyx_getprop___pyx_array_memview, 0, (char *)0, 0},
- {0, 0, 0, 0, 0}
-};
-
-static PySequenceMethods __pyx_tp_as_sequence_array = {
- __pyx_array___len__, /*sq_length*/
- 0, /*sq_concat*/
- 0, /*sq_repeat*/
- __pyx_sq_item_array, /*sq_item*/
- 0, /*sq_slice*/
- 0, /*sq_ass_item*/
- 0, /*sq_ass_slice*/
- 0, /*sq_contains*/
- 0, /*sq_inplace_concat*/
- 0, /*sq_inplace_repeat*/
-};
-
-static PyMappingMethods __pyx_tp_as_mapping_array = {
- __pyx_array___len__, /*mp_length*/
- __pyx_array___getitem__, /*mp_subscript*/
- __pyx_mp_ass_subscript_array, /*mp_ass_subscript*/
-};
-
-static PyBufferProcs __pyx_tp_as_buffer_array = {
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getreadbuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getwritebuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getsegcount*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getcharbuffer*/
- #endif
- __pyx_array_getbuffer, /*bf_getbuffer*/
- 0, /*bf_releasebuffer*/
-};
-
-static PyTypeObject __pyx_type___pyx_array = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core.array", /*tp_name*/
- sizeof(struct __pyx_array_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc_array, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- 0, /*tp_repr*/
- 0, /*tp_as_number*/
- &__pyx_tp_as_sequence_array, /*tp_as_sequence*/
- &__pyx_tp_as_mapping_array, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- 0, /*tp_str*/
- __pyx_tp_getattro_array, /*tp_getattro*/
- 0, /*tp_setattro*/
- &__pyx_tp_as_buffer_array, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE, /*tp_flags*/
- 0, /*tp_doc*/
- 0, /*tp_traverse*/
- 0, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods_array, /*tp_methods*/
- 0, /*tp_members*/
- __pyx_getsets_array, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- 0, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new_array, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-
-static PyObject *__pyx_tp_new_Enum(PyTypeObject *t, CYTHON_UNUSED PyObject *a, CYTHON_UNUSED PyObject *k) {
- struct __pyx_MemviewEnum_obj *p;
- PyObject *o;
- if (likely((t->tp_flags & Py_TPFLAGS_IS_ABSTRACT) == 0)) {
- o = (*t->tp_alloc)(t, 0);
- } else {
- o = (PyObject *) PyBaseObject_Type.tp_new(t, __pyx_empty_tuple, 0);
- }
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_MemviewEnum_obj *)o);
- p->name = Py_None; Py_INCREF(Py_None);
- return o;
-}
-
-static void __pyx_tp_dealloc_Enum(PyObject *o) {
- struct __pyx_MemviewEnum_obj *p = (struct __pyx_MemviewEnum_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && !_PyGC_FINALIZED(o)) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- PyObject_GC_UnTrack(o);
- Py_CLEAR(p->name);
- (*Py_TYPE(o)->tp_free)(o);
-}
-
-static int __pyx_tp_traverse_Enum(PyObject *o, visitproc v, void *a) {
- int e;
- struct __pyx_MemviewEnum_obj *p = (struct __pyx_MemviewEnum_obj *)o;
- if (p->name) {
- e = (*v)(p->name, a); if (e) return e;
- }
- return 0;
-}
-
-static int __pyx_tp_clear_Enum(PyObject *o) {
- PyObject* tmp;
- struct __pyx_MemviewEnum_obj *p = (struct __pyx_MemviewEnum_obj *)o;
- tmp = ((PyObject*)p->name);
- p->name = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- return 0;
-}
-
-static PyMethodDef __pyx_methods_Enum[] = {
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_MemviewEnum_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_MemviewEnum_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static PyTypeObject __pyx_type___pyx_MemviewEnum = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core.Enum", /*tp_name*/
- sizeof(struct __pyx_MemviewEnum_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc_Enum, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- __pyx_MemviewEnum___repr__, /*tp_repr*/
- 0, /*tp_as_number*/
- 0, /*tp_as_sequence*/
- 0, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- 0, /*tp_str*/
- 0, /*tp_getattro*/
- 0, /*tp_setattro*/
- 0, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE|Py_TPFLAGS_HAVE_GC, /*tp_flags*/
- 0, /*tp_doc*/
- __pyx_tp_traverse_Enum, /*tp_traverse*/
- __pyx_tp_clear_Enum, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods_Enum, /*tp_methods*/
- 0, /*tp_members*/
- 0, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- __pyx_MemviewEnum___init__, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new_Enum, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-static struct __pyx_vtabstruct_memoryview __pyx_vtable_memoryview;
-
-static PyObject *__pyx_tp_new_memoryview(PyTypeObject *t, PyObject *a, PyObject *k) {
- struct __pyx_memoryview_obj *p;
- PyObject *o;
- if (likely((t->tp_flags & Py_TPFLAGS_IS_ABSTRACT) == 0)) {
- o = (*t->tp_alloc)(t, 0);
- } else {
- o = (PyObject *) PyBaseObject_Type.tp_new(t, __pyx_empty_tuple, 0);
- }
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_memoryview_obj *)o);
- p->__pyx_vtab = __pyx_vtabptr_memoryview;
- p->obj = Py_None; Py_INCREF(Py_None);
- p->_size = Py_None; Py_INCREF(Py_None);
- p->_array_interface = Py_None; Py_INCREF(Py_None);
- p->view.obj = NULL;
- if (unlikely(__pyx_memoryview___cinit__(o, a, k) < 0)) goto bad;
- return o;
- bad:
- Py_DECREF(o); o = 0;
- return NULL;
-}
-
-static void __pyx_tp_dealloc_memoryview(PyObject *o) {
- struct __pyx_memoryview_obj *p = (struct __pyx_memoryview_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && !_PyGC_FINALIZED(o)) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- PyObject_GC_UnTrack(o);
- {
- PyObject *etype, *eval, *etb;
- PyErr_Fetch(&etype, &eval, &etb);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) + 1);
- __pyx_memoryview___dealloc__(o);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) - 1);
- PyErr_Restore(etype, eval, etb);
- }
- Py_CLEAR(p->obj);
- Py_CLEAR(p->_size);
- Py_CLEAR(p->_array_interface);
- (*Py_TYPE(o)->tp_free)(o);
-}
-
-static int __pyx_tp_traverse_memoryview(PyObject *o, visitproc v, void *a) {
- int e;
- struct __pyx_memoryview_obj *p = (struct __pyx_memoryview_obj *)o;
- if (p->obj) {
- e = (*v)(p->obj, a); if (e) return e;
- }
- if (p->_size) {
- e = (*v)(p->_size, a); if (e) return e;
- }
- if (p->_array_interface) {
- e = (*v)(p->_array_interface, a); if (e) return e;
- }
- if (p->view.obj) {
- e = (*v)(p->view.obj, a); if (e) return e;
- }
- return 0;
-}
-
-static int __pyx_tp_clear_memoryview(PyObject *o) {
- PyObject* tmp;
- struct __pyx_memoryview_obj *p = (struct __pyx_memoryview_obj *)o;
- tmp = ((PyObject*)p->obj);
- p->obj = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- tmp = ((PyObject*)p->_size);
- p->_size = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- tmp = ((PyObject*)p->_array_interface);
- p->_array_interface = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- Py_CLEAR(p->view.obj);
- return 0;
-}
-static PyObject *__pyx_sq_item_memoryview(PyObject *o, Py_ssize_t i) {
- PyObject *r;
- PyObject *x = PyInt_FromSsize_t(i); if(!x) return 0;
- r = Py_TYPE(o)->tp_as_mapping->mp_subscript(o, x);
- Py_DECREF(x);
- return r;
-}
-
-static int __pyx_mp_ass_subscript_memoryview(PyObject *o, PyObject *i, PyObject *v) {
- if (v) {
- return __pyx_memoryview___setitem__(o, i, v);
- }
- else {
- PyErr_Format(PyExc_NotImplementedError,
- "Subscript deletion not supported by %.200s", Py_TYPE(o)->tp_name);
- return -1;
- }
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_T(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_1T_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_base(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_4base_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_shape(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_5shape_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_strides(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_7strides_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_suboffsets(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_10suboffsets_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_ndim(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_4ndim_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_itemsize(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_8itemsize_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_nbytes(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_6nbytes_1__get__(o);
-}
-
-static PyObject *__pyx_getprop___pyx_memoryview_size(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_10memoryview_4size_1__get__(o);
-}
-
-static PyMethodDef __pyx_methods_memoryview[] = {
- {"is_c_contig", (PyCFunction)__pyx_memoryview_is_c_contig, METH_NOARGS, 0},
- {"is_f_contig", (PyCFunction)__pyx_memoryview_is_f_contig, METH_NOARGS, 0},
- {"copy", (PyCFunction)__pyx_memoryview_copy, METH_NOARGS, 0},
- {"copy_fortran", (PyCFunction)__pyx_memoryview_copy_fortran, METH_NOARGS, 0},
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_memoryview_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_memoryview_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static struct PyGetSetDef __pyx_getsets_memoryview[] = {
- {(char *)"T", __pyx_getprop___pyx_memoryview_T, 0, (char *)0, 0},
- {(char *)"base", __pyx_getprop___pyx_memoryview_base, 0, (char *)0, 0},
- {(char *)"shape", __pyx_getprop___pyx_memoryview_shape, 0, (char *)0, 0},
- {(char *)"strides", __pyx_getprop___pyx_memoryview_strides, 0, (char *)0, 0},
- {(char *)"suboffsets", __pyx_getprop___pyx_memoryview_suboffsets, 0, (char *)0, 0},
- {(char *)"ndim", __pyx_getprop___pyx_memoryview_ndim, 0, (char *)0, 0},
- {(char *)"itemsize", __pyx_getprop___pyx_memoryview_itemsize, 0, (char *)0, 0},
- {(char *)"nbytes", __pyx_getprop___pyx_memoryview_nbytes, 0, (char *)0, 0},
- {(char *)"size", __pyx_getprop___pyx_memoryview_size, 0, (char *)0, 0},
- {0, 0, 0, 0, 0}
-};
-
-static PySequenceMethods __pyx_tp_as_sequence_memoryview = {
- __pyx_memoryview___len__, /*sq_length*/
- 0, /*sq_concat*/
- 0, /*sq_repeat*/
- __pyx_sq_item_memoryview, /*sq_item*/
- 0, /*sq_slice*/
- 0, /*sq_ass_item*/
- 0, /*sq_ass_slice*/
- 0, /*sq_contains*/
- 0, /*sq_inplace_concat*/
- 0, /*sq_inplace_repeat*/
-};
-
-static PyMappingMethods __pyx_tp_as_mapping_memoryview = {
- __pyx_memoryview___len__, /*mp_length*/
- __pyx_memoryview___getitem__, /*mp_subscript*/
- __pyx_mp_ass_subscript_memoryview, /*mp_ass_subscript*/
-};
-
-static PyBufferProcs __pyx_tp_as_buffer_memoryview = {
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getreadbuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getwritebuffer*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getsegcount*/
- #endif
- #if PY_MAJOR_VERSION < 3
- 0, /*bf_getcharbuffer*/
- #endif
- __pyx_memoryview_getbuffer, /*bf_getbuffer*/
- 0, /*bf_releasebuffer*/
-};
-
-static PyTypeObject __pyx_type___pyx_memoryview = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core.memoryview", /*tp_name*/
- sizeof(struct __pyx_memoryview_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc_memoryview, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- __pyx_memoryview___repr__, /*tp_repr*/
- 0, /*tp_as_number*/
- &__pyx_tp_as_sequence_memoryview, /*tp_as_sequence*/
- &__pyx_tp_as_mapping_memoryview, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- __pyx_memoryview___str__, /*tp_str*/
- 0, /*tp_getattro*/
- 0, /*tp_setattro*/
- &__pyx_tp_as_buffer_memoryview, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE|Py_TPFLAGS_HAVE_GC, /*tp_flags*/
- 0, /*tp_doc*/
- __pyx_tp_traverse_memoryview, /*tp_traverse*/
- __pyx_tp_clear_memoryview, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods_memoryview, /*tp_methods*/
- 0, /*tp_members*/
- __pyx_getsets_memoryview, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- 0, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new_memoryview, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-static struct __pyx_vtabstruct__memoryviewslice __pyx_vtable__memoryviewslice;
-
-static PyObject *__pyx_tp_new__memoryviewslice(PyTypeObject *t, PyObject *a, PyObject *k) {
- struct __pyx_memoryviewslice_obj *p;
- PyObject *o = __pyx_tp_new_memoryview(t, a, k);
- if (unlikely(!o)) return 0;
- p = ((struct __pyx_memoryviewslice_obj *)o);
- p->__pyx_base.__pyx_vtab = (struct __pyx_vtabstruct_memoryview*)__pyx_vtabptr__memoryviewslice;
- p->from_object = Py_None; Py_INCREF(Py_None);
- p->from_slice.memview = NULL;
- return o;
-}
-
-static void __pyx_tp_dealloc__memoryviewslice(PyObject *o) {
- struct __pyx_memoryviewslice_obj *p = (struct __pyx_memoryviewslice_obj *)o;
- #if CYTHON_USE_TP_FINALIZE
- if (unlikely(PyType_HasFeature(Py_TYPE(o), Py_TPFLAGS_HAVE_FINALIZE) && Py_TYPE(o)->tp_finalize) && !_PyGC_FINALIZED(o)) {
- if (PyObject_CallFinalizerFromDealloc(o)) return;
- }
- #endif
- PyObject_GC_UnTrack(o);
- {
- PyObject *etype, *eval, *etb;
- PyErr_Fetch(&etype, &eval, &etb);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) + 1);
- __pyx_memoryviewslice___dealloc__(o);
- __Pyx_SET_REFCNT(o, Py_REFCNT(o) - 1);
- PyErr_Restore(etype, eval, etb);
- }
- Py_CLEAR(p->from_object);
- PyObject_GC_Track(o);
- __pyx_tp_dealloc_memoryview(o);
-}
-
-static int __pyx_tp_traverse__memoryviewslice(PyObject *o, visitproc v, void *a) {
- int e;
- struct __pyx_memoryviewslice_obj *p = (struct __pyx_memoryviewslice_obj *)o;
- e = __pyx_tp_traverse_memoryview(o, v, a); if (e) return e;
- if (p->from_object) {
- e = (*v)(p->from_object, a); if (e) return e;
- }
- return 0;
-}
-
-static int __pyx_tp_clear__memoryviewslice(PyObject *o) {
- PyObject* tmp;
- struct __pyx_memoryviewslice_obj *p = (struct __pyx_memoryviewslice_obj *)o;
- __pyx_tp_clear_memoryview(o);
- tmp = ((PyObject*)p->from_object);
- p->from_object = Py_None; Py_INCREF(Py_None);
- Py_XDECREF(tmp);
- __PYX_XDEC_MEMVIEW(&p->from_slice, 1);
- return 0;
-}
-
-static PyObject *__pyx_getprop___pyx_memoryviewslice_base(PyObject *o, CYTHON_UNUSED void *x) {
- return __pyx_pw_15View_dot_MemoryView_16_memoryviewslice_4base_1__get__(o);
-}
-
-static PyMethodDef __pyx_methods__memoryviewslice[] = {
- {"__reduce_cython__", (PyCFunction)__pyx_pw___pyx_memoryviewslice_1__reduce_cython__, METH_NOARGS, 0},
- {"__setstate_cython__", (PyCFunction)__pyx_pw___pyx_memoryviewslice_3__setstate_cython__, METH_O, 0},
- {0, 0, 0, 0}
-};
-
-static struct PyGetSetDef __pyx_getsets__memoryviewslice[] = {
- {(char *)"base", __pyx_getprop___pyx_memoryviewslice_base, 0, (char *)0, 0},
- {0, 0, 0, 0, 0}
-};
-
-static PyTypeObject __pyx_type___pyx_memoryviewslice = {
- PyVarObject_HEAD_INIT(0, 0)
- "monotonic_align.core._memoryviewslice", /*tp_name*/
- sizeof(struct __pyx_memoryviewslice_obj), /*tp_basicsize*/
- 0, /*tp_itemsize*/
- __pyx_tp_dealloc__memoryviewslice, /*tp_dealloc*/
- #if PY_VERSION_HEX < 0x030800b4
- 0, /*tp_print*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4
- 0, /*tp_vectorcall_offset*/
- #endif
- 0, /*tp_getattr*/
- 0, /*tp_setattr*/
- #if PY_MAJOR_VERSION < 3
- 0, /*tp_compare*/
- #endif
- #if PY_MAJOR_VERSION >= 3
- 0, /*tp_as_async*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY
- __pyx_memoryview___repr__, /*tp_repr*/
- #else
- 0, /*tp_repr*/
- #endif
- 0, /*tp_as_number*/
- 0, /*tp_as_sequence*/
- 0, /*tp_as_mapping*/
- 0, /*tp_hash*/
- 0, /*tp_call*/
- #if CYTHON_COMPILING_IN_PYPY
- __pyx_memoryview___str__, /*tp_str*/
- #else
- 0, /*tp_str*/
- #endif
- 0, /*tp_getattro*/
- 0, /*tp_setattro*/
- 0, /*tp_as_buffer*/
- Py_TPFLAGS_DEFAULT|Py_TPFLAGS_HAVE_VERSION_TAG|Py_TPFLAGS_CHECKTYPES|Py_TPFLAGS_HAVE_NEWBUFFER|Py_TPFLAGS_BASETYPE|Py_TPFLAGS_HAVE_GC, /*tp_flags*/
- "Internal class for passing memoryview slices to Python", /*tp_doc*/
- __pyx_tp_traverse__memoryviewslice, /*tp_traverse*/
- __pyx_tp_clear__memoryviewslice, /*tp_clear*/
- 0, /*tp_richcompare*/
- 0, /*tp_weaklistoffset*/
- 0, /*tp_iter*/
- 0, /*tp_iternext*/
- __pyx_methods__memoryviewslice, /*tp_methods*/
- 0, /*tp_members*/
- __pyx_getsets__memoryviewslice, /*tp_getset*/
- 0, /*tp_base*/
- 0, /*tp_dict*/
- 0, /*tp_descr_get*/
- 0, /*tp_descr_set*/
- 0, /*tp_dictoffset*/
- 0, /*tp_init*/
- 0, /*tp_alloc*/
- __pyx_tp_new__memoryviewslice, /*tp_new*/
- 0, /*tp_free*/
- 0, /*tp_is_gc*/
- 0, /*tp_bases*/
- 0, /*tp_mro*/
- 0, /*tp_cache*/
- 0, /*tp_subclasses*/
- 0, /*tp_weaklist*/
- 0, /*tp_del*/
- 0, /*tp_version_tag*/
- #if PY_VERSION_HEX >= 0x030400a1
- 0, /*tp_finalize*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b1 && (!CYTHON_COMPILING_IN_PYPY || PYPY_VERSION_NUM >= 0x07030800)
- 0, /*tp_vectorcall*/
- #endif
- #if PY_VERSION_HEX >= 0x030800b4 && PY_VERSION_HEX < 0x03090000
- 0, /*tp_print*/
- #endif
- #if CYTHON_COMPILING_IN_PYPY && PY_VERSION_HEX >= 0x03090000
- 0, /*tp_pypy_flags*/
- #endif
-};
-
-static PyMethodDef __pyx_methods[] = {
- {"maximum_path_c", (PyCFunction)(void*)(PyCFunctionWithKeywords)__pyx_pw_15monotonic_align_4core_1maximum_path_c, METH_VARARGS|METH_KEYWORDS, 0},
- {0, 0, 0, 0}
-};
-
-#if PY_MAJOR_VERSION >= 3
-#if CYTHON_PEP489_MULTI_PHASE_INIT
-static PyObject* __pyx_pymod_create(PyObject *spec, PyModuleDef *def); /*proto*/
-static int __pyx_pymod_exec_core(PyObject* module); /*proto*/
-static PyModuleDef_Slot __pyx_moduledef_slots[] = {
- {Py_mod_create, (void*)__pyx_pymod_create},
- {Py_mod_exec, (void*)__pyx_pymod_exec_core},
- {0, NULL}
-};
-#endif
-
-static struct PyModuleDef __pyx_moduledef = {
- PyModuleDef_HEAD_INIT,
- "core",
- 0, /* m_doc */
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- 0, /* m_size */
- #else
- -1, /* m_size */
- #endif
- __pyx_methods /* m_methods */,
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- __pyx_moduledef_slots, /* m_slots */
- #else
- NULL, /* m_reload */
- #endif
- NULL, /* m_traverse */
- NULL, /* m_clear */
- NULL /* m_free */
-};
-#endif
-#ifndef CYTHON_SMALL_CODE
-#if defined(__clang__)
- #define CYTHON_SMALL_CODE
-#elif defined(__GNUC__) && (__GNUC__ > 4 || (__GNUC__ == 4 && __GNUC_MINOR__ >= 3))
- #define CYTHON_SMALL_CODE __attribute__((cold))
-#else
- #define CYTHON_SMALL_CODE
-#endif
-#endif
-
-static __Pyx_StringTabEntry __pyx_string_tab[] = {
- {&__pyx_n_s_ASCII, __pyx_k_ASCII, sizeof(__pyx_k_ASCII), 0, 0, 1, 1},
- {&__pyx_kp_s_Buffer_view_does_not_expose_stri, __pyx_k_Buffer_view_does_not_expose_stri, sizeof(__pyx_k_Buffer_view_does_not_expose_stri), 0, 0, 1, 0},
- {&__pyx_kp_s_Can_only_create_a_buffer_that_is, __pyx_k_Can_only_create_a_buffer_that_is, sizeof(__pyx_k_Can_only_create_a_buffer_that_is), 0, 0, 1, 0},
- {&__pyx_kp_s_Cannot_assign_to_read_only_memor, __pyx_k_Cannot_assign_to_read_only_memor, sizeof(__pyx_k_Cannot_assign_to_read_only_memor), 0, 0, 1, 0},
- {&__pyx_kp_s_Cannot_create_writable_memory_vi, __pyx_k_Cannot_create_writable_memory_vi, sizeof(__pyx_k_Cannot_create_writable_memory_vi), 0, 0, 1, 0},
- {&__pyx_kp_s_Cannot_index_with_type_s, __pyx_k_Cannot_index_with_type_s, sizeof(__pyx_k_Cannot_index_with_type_s), 0, 0, 1, 0},
- {&__pyx_n_s_Ellipsis, __pyx_k_Ellipsis, sizeof(__pyx_k_Ellipsis), 0, 0, 1, 1},
- {&__pyx_kp_s_Empty_shape_tuple_for_cython_arr, __pyx_k_Empty_shape_tuple_for_cython_arr, sizeof(__pyx_k_Empty_shape_tuple_for_cython_arr), 0, 0, 1, 0},
- {&__pyx_kp_s_Incompatible_checksums_0x_x_vs_0, __pyx_k_Incompatible_checksums_0x_x_vs_0, sizeof(__pyx_k_Incompatible_checksums_0x_x_vs_0), 0, 0, 1, 0},
- {&__pyx_n_s_IndexError, __pyx_k_IndexError, sizeof(__pyx_k_IndexError), 0, 0, 1, 1},
- {&__pyx_kp_s_Indirect_dimensions_not_supporte, __pyx_k_Indirect_dimensions_not_supporte, sizeof(__pyx_k_Indirect_dimensions_not_supporte), 0, 0, 1, 0},
- {&__pyx_kp_s_Invalid_mode_expected_c_or_fortr, __pyx_k_Invalid_mode_expected_c_or_fortr, sizeof(__pyx_k_Invalid_mode_expected_c_or_fortr), 0, 0, 1, 0},
- {&__pyx_kp_s_Invalid_shape_in_axis_d_d, __pyx_k_Invalid_shape_in_axis_d_d, sizeof(__pyx_k_Invalid_shape_in_axis_d_d), 0, 0, 1, 0},
- {&__pyx_n_s_MemoryError, __pyx_k_MemoryError, sizeof(__pyx_k_MemoryError), 0, 0, 1, 1},
- {&__pyx_kp_s_MemoryView_of_r_at_0x_x, __pyx_k_MemoryView_of_r_at_0x_x, sizeof(__pyx_k_MemoryView_of_r_at_0x_x), 0, 0, 1, 0},
- {&__pyx_kp_s_MemoryView_of_r_object, __pyx_k_MemoryView_of_r_object, sizeof(__pyx_k_MemoryView_of_r_object), 0, 0, 1, 0},
- {&__pyx_n_b_O, __pyx_k_O, sizeof(__pyx_k_O), 0, 0, 0, 1},
- {&__pyx_kp_s_Out_of_bounds_on_buffer_access_a, __pyx_k_Out_of_bounds_on_buffer_access_a, sizeof(__pyx_k_Out_of_bounds_on_buffer_access_a), 0, 0, 1, 0},
- {&__pyx_n_s_PickleError, __pyx_k_PickleError, sizeof(__pyx_k_PickleError), 0, 0, 1, 1},
- {&__pyx_n_s_TypeError, __pyx_k_TypeError, sizeof(__pyx_k_TypeError), 0, 0, 1, 1},
- {&__pyx_kp_s_Unable_to_convert_item_to_object, __pyx_k_Unable_to_convert_item_to_object, sizeof(__pyx_k_Unable_to_convert_item_to_object), 0, 0, 1, 0},
- {&__pyx_n_s_ValueError, __pyx_k_ValueError, sizeof(__pyx_k_ValueError), 0, 0, 1, 1},
- {&__pyx_n_s_View_MemoryView, __pyx_k_View_MemoryView, sizeof(__pyx_k_View_MemoryView), 0, 0, 1, 1},
- {&__pyx_n_s_allocate_buffer, __pyx_k_allocate_buffer, sizeof(__pyx_k_allocate_buffer), 0, 0, 1, 1},
- {&__pyx_n_s_base, __pyx_k_base, sizeof(__pyx_k_base), 0, 0, 1, 1},
- {&__pyx_n_s_c, __pyx_k_c, sizeof(__pyx_k_c), 0, 0, 1, 1},
- {&__pyx_n_u_c, __pyx_k_c, sizeof(__pyx_k_c), 0, 1, 0, 1},
- {&__pyx_n_s_class, __pyx_k_class, sizeof(__pyx_k_class), 0, 0, 1, 1},
- {&__pyx_n_s_cline_in_traceback, __pyx_k_cline_in_traceback, sizeof(__pyx_k_cline_in_traceback), 0, 0, 1, 1},
- {&__pyx_kp_s_contiguous_and_direct, __pyx_k_contiguous_and_direct, sizeof(__pyx_k_contiguous_and_direct), 0, 0, 1, 0},
- {&__pyx_kp_s_contiguous_and_indirect, __pyx_k_contiguous_and_indirect, sizeof(__pyx_k_contiguous_and_indirect), 0, 0, 1, 0},
- {&__pyx_n_s_dict, __pyx_k_dict, sizeof(__pyx_k_dict), 0, 0, 1, 1},
- {&__pyx_n_s_dtype_is_object, __pyx_k_dtype_is_object, sizeof(__pyx_k_dtype_is_object), 0, 0, 1, 1},
- {&__pyx_n_s_encode, __pyx_k_encode, sizeof(__pyx_k_encode), 0, 0, 1, 1},
- {&__pyx_n_s_enumerate, __pyx_k_enumerate, sizeof(__pyx_k_enumerate), 0, 0, 1, 1},
- {&__pyx_n_s_error, __pyx_k_error, sizeof(__pyx_k_error), 0, 0, 1, 1},
- {&__pyx_n_s_flags, __pyx_k_flags, sizeof(__pyx_k_flags), 0, 0, 1, 1},
- {&__pyx_n_s_format, __pyx_k_format, sizeof(__pyx_k_format), 0, 0, 1, 1},
- {&__pyx_n_s_fortran, __pyx_k_fortran, sizeof(__pyx_k_fortran), 0, 0, 1, 1},
- {&__pyx_n_u_fortran, __pyx_k_fortran, sizeof(__pyx_k_fortran), 0, 1, 0, 1},
- {&__pyx_n_s_getstate, __pyx_k_getstate, sizeof(__pyx_k_getstate), 0, 0, 1, 1},
- {&__pyx_kp_s_got_differing_extents_in_dimensi, __pyx_k_got_differing_extents_in_dimensi, sizeof(__pyx_k_got_differing_extents_in_dimensi), 0, 0, 1, 0},
- {&__pyx_n_s_id, __pyx_k_id, sizeof(__pyx_k_id), 0, 0, 1, 1},
- {&__pyx_n_s_import, __pyx_k_import, sizeof(__pyx_k_import), 0, 0, 1, 1},
- {&__pyx_n_s_itemsize, __pyx_k_itemsize, sizeof(__pyx_k_itemsize), 0, 0, 1, 1},
- {&__pyx_kp_s_itemsize_0_for_cython_array, __pyx_k_itemsize_0_for_cython_array, sizeof(__pyx_k_itemsize_0_for_cython_array), 0, 0, 1, 0},
- {&__pyx_n_s_main, __pyx_k_main, sizeof(__pyx_k_main), 0, 0, 1, 1},
- {&__pyx_n_s_memview, __pyx_k_memview, sizeof(__pyx_k_memview), 0, 0, 1, 1},
- {&__pyx_n_s_mode, __pyx_k_mode, sizeof(__pyx_k_mode), 0, 0, 1, 1},
- {&__pyx_n_s_name, __pyx_k_name, sizeof(__pyx_k_name), 0, 0, 1, 1},
- {&__pyx_n_s_name_2, __pyx_k_name_2, sizeof(__pyx_k_name_2), 0, 0, 1, 1},
- {&__pyx_n_s_ndim, __pyx_k_ndim, sizeof(__pyx_k_ndim), 0, 0, 1, 1},
- {&__pyx_n_s_new, __pyx_k_new, sizeof(__pyx_k_new), 0, 0, 1, 1},
- {&__pyx_kp_s_no_default___reduce___due_to_non, __pyx_k_no_default___reduce___due_to_non, sizeof(__pyx_k_no_default___reduce___due_to_non), 0, 0, 1, 0},
- {&__pyx_n_s_obj, __pyx_k_obj, sizeof(__pyx_k_obj), 0, 0, 1, 1},
- {&__pyx_n_s_pack, __pyx_k_pack, sizeof(__pyx_k_pack), 0, 0, 1, 1},
- {&__pyx_n_s_paths, __pyx_k_paths, sizeof(__pyx_k_paths), 0, 0, 1, 1},
- {&__pyx_n_s_pickle, __pyx_k_pickle, sizeof(__pyx_k_pickle), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_PickleError, __pyx_k_pyx_PickleError, sizeof(__pyx_k_pyx_PickleError), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_checksum, __pyx_k_pyx_checksum, sizeof(__pyx_k_pyx_checksum), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_getbuffer, __pyx_k_pyx_getbuffer, sizeof(__pyx_k_pyx_getbuffer), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_result, __pyx_k_pyx_result, sizeof(__pyx_k_pyx_result), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_state, __pyx_k_pyx_state, sizeof(__pyx_k_pyx_state), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_type, __pyx_k_pyx_type, sizeof(__pyx_k_pyx_type), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_unpickle_Enum, __pyx_k_pyx_unpickle_Enum, sizeof(__pyx_k_pyx_unpickle_Enum), 0, 0, 1, 1},
- {&__pyx_n_s_pyx_vtable, __pyx_k_pyx_vtable, sizeof(__pyx_k_pyx_vtable), 0, 0, 1, 1},
- {&__pyx_n_s_range, __pyx_k_range, sizeof(__pyx_k_range), 0, 0, 1, 1},
- {&__pyx_n_s_reduce, __pyx_k_reduce, sizeof(__pyx_k_reduce), 0, 0, 1, 1},
- {&__pyx_n_s_reduce_cython, __pyx_k_reduce_cython, sizeof(__pyx_k_reduce_cython), 0, 0, 1, 1},
- {&__pyx_n_s_reduce_ex, __pyx_k_reduce_ex, sizeof(__pyx_k_reduce_ex), 0, 0, 1, 1},
- {&__pyx_n_s_setstate, __pyx_k_setstate, sizeof(__pyx_k_setstate), 0, 0, 1, 1},
- {&__pyx_n_s_setstate_cython, __pyx_k_setstate_cython, sizeof(__pyx_k_setstate_cython), 0, 0, 1, 1},
- {&__pyx_n_s_shape, __pyx_k_shape, sizeof(__pyx_k_shape), 0, 0, 1, 1},
- {&__pyx_n_s_size, __pyx_k_size, sizeof(__pyx_k_size), 0, 0, 1, 1},
- {&__pyx_n_s_start, __pyx_k_start, sizeof(__pyx_k_start), 0, 0, 1, 1},
- {&__pyx_n_s_step, __pyx_k_step, sizeof(__pyx_k_step), 0, 0, 1, 1},
- {&__pyx_n_s_stop, __pyx_k_stop, sizeof(__pyx_k_stop), 0, 0, 1, 1},
- {&__pyx_kp_s_strided_and_direct, __pyx_k_strided_and_direct, sizeof(__pyx_k_strided_and_direct), 0, 0, 1, 0},
- {&__pyx_kp_s_strided_and_direct_or_indirect, __pyx_k_strided_and_direct_or_indirect, sizeof(__pyx_k_strided_and_direct_or_indirect), 0, 0, 1, 0},
- {&__pyx_kp_s_strided_and_indirect, __pyx_k_strided_and_indirect, sizeof(__pyx_k_strided_and_indirect), 0, 0, 1, 0},
- {&__pyx_kp_s_stringsource, __pyx_k_stringsource, sizeof(__pyx_k_stringsource), 0, 0, 1, 0},
- {&__pyx_n_s_struct, __pyx_k_struct, sizeof(__pyx_k_struct), 0, 0, 1, 1},
- {&__pyx_n_s_t_xs, __pyx_k_t_xs, sizeof(__pyx_k_t_xs), 0, 0, 1, 1},
- {&__pyx_n_s_t_ys, __pyx_k_t_ys, sizeof(__pyx_k_t_ys), 0, 0, 1, 1},
- {&__pyx_n_s_test, __pyx_k_test, sizeof(__pyx_k_test), 0, 0, 1, 1},
- {&__pyx_kp_s_unable_to_allocate_array_data, __pyx_k_unable_to_allocate_array_data, sizeof(__pyx_k_unable_to_allocate_array_data), 0, 0, 1, 0},
- {&__pyx_kp_s_unable_to_allocate_shape_and_str, __pyx_k_unable_to_allocate_shape_and_str, sizeof(__pyx_k_unable_to_allocate_shape_and_str), 0, 0, 1, 0},
- {&__pyx_n_s_unpack, __pyx_k_unpack, sizeof(__pyx_k_unpack), 0, 0, 1, 1},
- {&__pyx_n_s_update, __pyx_k_update, sizeof(__pyx_k_update), 0, 0, 1, 1},
- {&__pyx_n_s_values, __pyx_k_values, sizeof(__pyx_k_values), 0, 0, 1, 1},
- {0, 0, 0, 0, 0, 0, 0}
-};
-static CYTHON_SMALL_CODE int __Pyx_InitCachedBuiltins(void) {
- __pyx_builtin_range = __Pyx_GetBuiltinName(__pyx_n_s_range); if (!__pyx_builtin_range) __PYX_ERR(0, 15, __pyx_L1_error)
- __pyx_builtin_ValueError = __Pyx_GetBuiltinName(__pyx_n_s_ValueError); if (!__pyx_builtin_ValueError) __PYX_ERR(1, 134, __pyx_L1_error)
- __pyx_builtin_MemoryError = __Pyx_GetBuiltinName(__pyx_n_s_MemoryError); if (!__pyx_builtin_MemoryError) __PYX_ERR(1, 149, __pyx_L1_error)
- __pyx_builtin_enumerate = __Pyx_GetBuiltinName(__pyx_n_s_enumerate); if (!__pyx_builtin_enumerate) __PYX_ERR(1, 152, __pyx_L1_error)
- __pyx_builtin_TypeError = __Pyx_GetBuiltinName(__pyx_n_s_TypeError); if (!__pyx_builtin_TypeError) __PYX_ERR(1, 2, __pyx_L1_error)
- __pyx_builtin_Ellipsis = __Pyx_GetBuiltinName(__pyx_n_s_Ellipsis); if (!__pyx_builtin_Ellipsis) __PYX_ERR(1, 406, __pyx_L1_error)
- __pyx_builtin_id = __Pyx_GetBuiltinName(__pyx_n_s_id); if (!__pyx_builtin_id) __PYX_ERR(1, 615, __pyx_L1_error)
- __pyx_builtin_IndexError = __Pyx_GetBuiltinName(__pyx_n_s_IndexError); if (!__pyx_builtin_IndexError) __PYX_ERR(1, 834, __pyx_L1_error)
- return 0;
- __pyx_L1_error:;
- return -1;
-}
-
-static CYTHON_SMALL_CODE int __Pyx_InitCachedConstants(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_InitCachedConstants", 0);
-
- /* "View.MemoryView":134
- *
- * if not self.ndim:
- * raise ValueError("Empty shape tuple for cython.array") # <<<<<<<<<<<<<<
- *
- * if itemsize <= 0:
- */
- __pyx_tuple__2 = PyTuple_Pack(1, __pyx_kp_s_Empty_shape_tuple_for_cython_arr); if (unlikely(!__pyx_tuple__2)) __PYX_ERR(1, 134, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__2);
- __Pyx_GIVEREF(__pyx_tuple__2);
-
- /* "View.MemoryView":137
- *
- * if itemsize <= 0:
- * raise ValueError("itemsize <= 0 for cython.array") # <<<<<<<<<<<<<<
- *
- * if not isinstance(format, bytes):
- */
- __pyx_tuple__3 = PyTuple_Pack(1, __pyx_kp_s_itemsize_0_for_cython_array); if (unlikely(!__pyx_tuple__3)) __PYX_ERR(1, 137, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__3);
- __Pyx_GIVEREF(__pyx_tuple__3);
-
- /* "View.MemoryView":149
- *
- * if not self._shape:
- * raise MemoryError("unable to allocate shape and strides.") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__4 = PyTuple_Pack(1, __pyx_kp_s_unable_to_allocate_shape_and_str); if (unlikely(!__pyx_tuple__4)) __PYX_ERR(1, 149, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__4);
- __Pyx_GIVEREF(__pyx_tuple__4);
-
- /* "View.MemoryView":177
- * self.data = malloc(self.len)
- * if not self.data:
- * raise MemoryError("unable to allocate array data.") # <<<<<<<<<<<<<<
- *
- * if self.dtype_is_object:
- */
- __pyx_tuple__5 = PyTuple_Pack(1, __pyx_kp_s_unable_to_allocate_array_data); if (unlikely(!__pyx_tuple__5)) __PYX_ERR(1, 177, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__5);
- __Pyx_GIVEREF(__pyx_tuple__5);
-
- /* "View.MemoryView":193
- * bufmode = PyBUF_F_CONTIGUOUS | PyBUF_ANY_CONTIGUOUS
- * if not (flags & bufmode):
- * raise ValueError("Can only create a buffer that is contiguous in memory.") # <<<<<<<<<<<<<<
- * info.buf = self.data
- * info.len = self.len
- */
- __pyx_tuple__6 = PyTuple_Pack(1, __pyx_kp_s_Can_only_create_a_buffer_that_is); if (unlikely(!__pyx_tuple__6)) __PYX_ERR(1, 193, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__6);
- __Pyx_GIVEREF(__pyx_tuple__6);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_tuple__7 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__7)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__7);
- __Pyx_GIVEREF(__pyx_tuple__7);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_tuple__8 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__8)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__8);
- __Pyx_GIVEREF(__pyx_tuple__8);
-
- /* "View.MemoryView":420
- * def __setitem__(memoryview self, object index, object value):
- * if self.view.readonly:
- * raise TypeError("Cannot assign to read-only memoryview") # <<<<<<<<<<<<<<
- *
- * have_slices, index = _unellipsify(index, self.view.ndim)
- */
- __pyx_tuple__9 = PyTuple_Pack(1, __pyx_kp_s_Cannot_assign_to_read_only_memor); if (unlikely(!__pyx_tuple__9)) __PYX_ERR(1, 420, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__9);
- __Pyx_GIVEREF(__pyx_tuple__9);
-
- /* "View.MemoryView":497
- * result = struct.unpack(self.view.format, bytesitem)
- * except struct.error:
- * raise ValueError("Unable to convert item to object") # <<<<<<<<<<<<<<
- * else:
- * if len(self.view.format) == 1:
- */
- __pyx_tuple__10 = PyTuple_Pack(1, __pyx_kp_s_Unable_to_convert_item_to_object); if (unlikely(!__pyx_tuple__10)) __PYX_ERR(1, 497, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__10);
- __Pyx_GIVEREF(__pyx_tuple__10);
-
- /* "View.MemoryView":522
- * def __getbuffer__(self, Py_buffer *info, int flags):
- * if flags & PyBUF_WRITABLE and self.view.readonly:
- * raise ValueError("Cannot create writable memory view from read-only memoryview") # <<<<<<<<<<<<<<
- *
- * if flags & PyBUF_ND:
- */
- __pyx_tuple__11 = PyTuple_Pack(1, __pyx_kp_s_Cannot_create_writable_memory_vi); if (unlikely(!__pyx_tuple__11)) __PYX_ERR(1, 522, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__11);
- __Pyx_GIVEREF(__pyx_tuple__11);
-
- /* "View.MemoryView":572
- * if self.view.strides == NULL:
- *
- * raise ValueError("Buffer view does not expose strides") # <<<<<<<<<<<<<<
- *
- * return tuple([stride for stride in self.view.strides[:self.view.ndim]])
- */
- __pyx_tuple__12 = PyTuple_Pack(1, __pyx_kp_s_Buffer_view_does_not_expose_stri); if (unlikely(!__pyx_tuple__12)) __PYX_ERR(1, 572, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__12);
- __Pyx_GIVEREF(__pyx_tuple__12);
-
- /* "View.MemoryView":579
- * def suboffsets(self):
- * if self.view.suboffsets == NULL:
- * return (-1,) * self.view.ndim # <<<<<<<<<<<<<<
- *
- * return tuple([suboffset for suboffset in self.view.suboffsets[:self.view.ndim]])
- */
- __pyx_tuple__13 = PyTuple_New(1); if (unlikely(!__pyx_tuple__13)) __PYX_ERR(1, 579, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__13);
- __Pyx_INCREF(__pyx_int_neg_1);
- __Pyx_GIVEREF(__pyx_int_neg_1);
- PyTuple_SET_ITEM(__pyx_tuple__13, 0, __pyx_int_neg_1);
- __Pyx_GIVEREF(__pyx_tuple__13);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_tuple__14 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__14)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__14);
- __Pyx_GIVEREF(__pyx_tuple__14);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_tuple__15 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__15)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__15);
- __Pyx_GIVEREF(__pyx_tuple__15);
-
- /* "View.MemoryView":684
- * if item is Ellipsis:
- * if not seen_ellipsis:
- * result.extend([slice(None)] * (ndim - len(tup) + 1)) # <<<<<<<<<<<<<<
- * seen_ellipsis = True
- * else:
- */
- __pyx_slice__16 = PySlice_New(Py_None, Py_None, Py_None); if (unlikely(!__pyx_slice__16)) __PYX_ERR(1, 684, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_slice__16);
- __Pyx_GIVEREF(__pyx_slice__16);
-
- /* "View.MemoryView":705
- * for suboffset in suboffsets[:ndim]:
- * if suboffset >= 0:
- * raise ValueError("Indirect dimensions not supported") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__17 = PyTuple_Pack(1, __pyx_kp_s_Indirect_dimensions_not_supporte); if (unlikely(!__pyx_tuple__17)) __PYX_ERR(1, 705, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__17);
- __Pyx_GIVEREF(__pyx_tuple__17);
-
- /* "(tree fragment)":2
- * def __reduce_cython__(self):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- */
- __pyx_tuple__18 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__18)) __PYX_ERR(1, 2, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__18);
- __Pyx_GIVEREF(__pyx_tuple__18);
-
- /* "(tree fragment)":4
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__")
- * def __setstate_cython__(self, __pyx_state):
- * raise TypeError("no default __reduce__ due to non-trivial __cinit__") # <<<<<<<<<<<<<<
- */
- __pyx_tuple__19 = PyTuple_Pack(1, __pyx_kp_s_no_default___reduce___due_to_non); if (unlikely(!__pyx_tuple__19)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__19);
- __Pyx_GIVEREF(__pyx_tuple__19);
- __pyx_tuple__20 = PyTuple_Pack(3, __pyx_int_184977713, __pyx_int_136983863, __pyx_int_112105877); if (unlikely(!__pyx_tuple__20)) __PYX_ERR(1, 4, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__20);
- __Pyx_GIVEREF(__pyx_tuple__20);
-
- /* "View.MemoryView":287
- * return self.name
- *
- * cdef generic = Enum("") # <<<<<<<<<<<<<<
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("")
- */
- __pyx_tuple__21 = PyTuple_Pack(1, __pyx_kp_s_strided_and_direct_or_indirect); if (unlikely(!__pyx_tuple__21)) __PYX_ERR(1, 287, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__21);
- __Pyx_GIVEREF(__pyx_tuple__21);
-
- /* "View.MemoryView":288
- *
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default # <<<<<<<<<<<<<<
- * cdef indirect = Enum("")
- *
- */
- __pyx_tuple__22 = PyTuple_Pack(1, __pyx_kp_s_strided_and_direct); if (unlikely(!__pyx_tuple__22)) __PYX_ERR(1, 288, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__22);
- __Pyx_GIVEREF(__pyx_tuple__22);
-
- /* "View.MemoryView":289
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__23 = PyTuple_Pack(1, __pyx_kp_s_strided_and_indirect); if (unlikely(!__pyx_tuple__23)) __PYX_ERR(1, 289, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__23);
- __Pyx_GIVEREF(__pyx_tuple__23);
-
- /* "View.MemoryView":292
- *
- *
- * cdef contiguous = Enum("") # <<<<<<<<<<<<<<
- * cdef indirect_contiguous = Enum("")
- *
- */
- __pyx_tuple__24 = PyTuple_Pack(1, __pyx_kp_s_contiguous_and_direct); if (unlikely(!__pyx_tuple__24)) __PYX_ERR(1, 292, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__24);
- __Pyx_GIVEREF(__pyx_tuple__24);
-
- /* "View.MemoryView":293
- *
- * cdef contiguous = Enum("")
- * cdef indirect_contiguous = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_tuple__25 = PyTuple_Pack(1, __pyx_kp_s_contiguous_and_indirect); if (unlikely(!__pyx_tuple__25)) __PYX_ERR(1, 293, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__25);
- __Pyx_GIVEREF(__pyx_tuple__25);
-
- /* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
- __pyx_tuple__26 = PyTuple_Pack(5, __pyx_n_s_pyx_type, __pyx_n_s_pyx_checksum, __pyx_n_s_pyx_state, __pyx_n_s_pyx_PickleError, __pyx_n_s_pyx_result); if (unlikely(!__pyx_tuple__26)) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_tuple__26);
- __Pyx_GIVEREF(__pyx_tuple__26);
- __pyx_codeobj__27 = (PyObject*)__Pyx_PyCode_New(3, 0, 5, 0, CO_OPTIMIZED|CO_NEWLOCALS, __pyx_empty_bytes, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_tuple__26, __pyx_empty_tuple, __pyx_empty_tuple, __pyx_kp_s_stringsource, __pyx_n_s_pyx_unpickle_Enum, 1, __pyx_empty_bytes); if (unlikely(!__pyx_codeobj__27)) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_RefNannyFinishContext();
- return 0;
- __pyx_L1_error:;
- __Pyx_RefNannyFinishContext();
- return -1;
-}
-
-static CYTHON_SMALL_CODE int __Pyx_InitGlobals(void) {
- /* InitThreads.init */
- #if defined(WITH_THREAD) && PY_VERSION_HEX < 0x030700F0
-PyEval_InitThreads();
-#endif
-
-if (unlikely(PyErr_Occurred())) __PYX_ERR(0, 1, __pyx_L1_error)
-
- if (__Pyx_InitStrings(__pyx_string_tab) < 0) __PYX_ERR(0, 1, __pyx_L1_error);
- __pyx_int_0 = PyInt_FromLong(0); if (unlikely(!__pyx_int_0)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_1 = PyInt_FromLong(1); if (unlikely(!__pyx_int_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_112105877 = PyInt_FromLong(112105877L); if (unlikely(!__pyx_int_112105877)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_136983863 = PyInt_FromLong(136983863L); if (unlikely(!__pyx_int_136983863)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_184977713 = PyInt_FromLong(184977713L); if (unlikely(!__pyx_int_184977713)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_int_neg_1 = PyInt_FromLong(-1); if (unlikely(!__pyx_int_neg_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- return 0;
- __pyx_L1_error:;
- return -1;
-}
-
-static CYTHON_SMALL_CODE int __Pyx_modinit_global_init_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_variable_export_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_function_export_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_type_init_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_type_import_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_variable_import_code(void); /*proto*/
-static CYTHON_SMALL_CODE int __Pyx_modinit_function_import_code(void); /*proto*/
-
-static int __Pyx_modinit_global_init_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_global_init_code", 0);
- /*--- Global init code ---*/
- generic = Py_None; Py_INCREF(Py_None);
- strided = Py_None; Py_INCREF(Py_None);
- indirect = Py_None; Py_INCREF(Py_None);
- contiguous = Py_None; Py_INCREF(Py_None);
- indirect_contiguous = Py_None; Py_INCREF(Py_None);
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_variable_export_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_variable_export_code", 0);
- /*--- Variable export code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_function_export_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_function_export_code", 0);
- /*--- Function export code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_type_init_code(void) {
- __Pyx_RefNannyDeclarations
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannySetupContext("__Pyx_modinit_type_init_code", 0);
- /*--- Type init code ---*/
- __pyx_vtabptr_array = &__pyx_vtable_array;
- __pyx_vtable_array.get_memview = (PyObject *(*)(struct __pyx_array_obj *))__pyx_array_get_memview;
- if (PyType_Ready(&__pyx_type___pyx_array) < 0) __PYX_ERR(1, 106, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_array.tp_print = 0;
- #endif
- if (__Pyx_SetVtable(__pyx_type___pyx_array.tp_dict, __pyx_vtabptr_array) < 0) __PYX_ERR(1, 106, __pyx_L1_error)
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_array) < 0) __PYX_ERR(1, 106, __pyx_L1_error)
- __pyx_array_type = &__pyx_type___pyx_array;
- if (PyType_Ready(&__pyx_type___pyx_MemviewEnum) < 0) __PYX_ERR(1, 280, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_MemviewEnum.tp_print = 0;
- #endif
- if ((CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP) && likely(!__pyx_type___pyx_MemviewEnum.tp_dictoffset && __pyx_type___pyx_MemviewEnum.tp_getattro == PyObject_GenericGetAttr)) {
- __pyx_type___pyx_MemviewEnum.tp_getattro = __Pyx_PyObject_GenericGetAttr;
- }
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_MemviewEnum) < 0) __PYX_ERR(1, 280, __pyx_L1_error)
- __pyx_MemviewEnum_type = &__pyx_type___pyx_MemviewEnum;
- __pyx_vtabptr_memoryview = &__pyx_vtable_memoryview;
- __pyx_vtable_memoryview.get_item_pointer = (char *(*)(struct __pyx_memoryview_obj *, PyObject *))__pyx_memoryview_get_item_pointer;
- __pyx_vtable_memoryview.is_slice = (PyObject *(*)(struct __pyx_memoryview_obj *, PyObject *))__pyx_memoryview_is_slice;
- __pyx_vtable_memoryview.setitem_slice_assignment = (PyObject *(*)(struct __pyx_memoryview_obj *, PyObject *, PyObject *))__pyx_memoryview_setitem_slice_assignment;
- __pyx_vtable_memoryview.setitem_slice_assign_scalar = (PyObject *(*)(struct __pyx_memoryview_obj *, struct __pyx_memoryview_obj *, PyObject *))__pyx_memoryview_setitem_slice_assign_scalar;
- __pyx_vtable_memoryview.setitem_indexed = (PyObject *(*)(struct __pyx_memoryview_obj *, PyObject *, PyObject *))__pyx_memoryview_setitem_indexed;
- __pyx_vtable_memoryview.convert_item_to_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *))__pyx_memoryview_convert_item_to_object;
- __pyx_vtable_memoryview.assign_item_from_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *, PyObject *))__pyx_memoryview_assign_item_from_object;
- if (PyType_Ready(&__pyx_type___pyx_memoryview) < 0) __PYX_ERR(1, 331, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_memoryview.tp_print = 0;
- #endif
- if ((CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP) && likely(!__pyx_type___pyx_memoryview.tp_dictoffset && __pyx_type___pyx_memoryview.tp_getattro == PyObject_GenericGetAttr)) {
- __pyx_type___pyx_memoryview.tp_getattro = __Pyx_PyObject_GenericGetAttr;
- }
- if (__Pyx_SetVtable(__pyx_type___pyx_memoryview.tp_dict, __pyx_vtabptr_memoryview) < 0) __PYX_ERR(1, 331, __pyx_L1_error)
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_memoryview) < 0) __PYX_ERR(1, 331, __pyx_L1_error)
- __pyx_memoryview_type = &__pyx_type___pyx_memoryview;
- __pyx_vtabptr__memoryviewslice = &__pyx_vtable__memoryviewslice;
- __pyx_vtable__memoryviewslice.__pyx_base = *__pyx_vtabptr_memoryview;
- __pyx_vtable__memoryviewslice.__pyx_base.convert_item_to_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *))__pyx_memoryviewslice_convert_item_to_object;
- __pyx_vtable__memoryviewslice.__pyx_base.assign_item_from_object = (PyObject *(*)(struct __pyx_memoryview_obj *, char *, PyObject *))__pyx_memoryviewslice_assign_item_from_object;
- __pyx_type___pyx_memoryviewslice.tp_base = __pyx_memoryview_type;
- if (PyType_Ready(&__pyx_type___pyx_memoryviewslice) < 0) __PYX_ERR(1, 967, __pyx_L1_error)
- #if PY_VERSION_HEX < 0x030800B1
- __pyx_type___pyx_memoryviewslice.tp_print = 0;
- #endif
- if ((CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP) && likely(!__pyx_type___pyx_memoryviewslice.tp_dictoffset && __pyx_type___pyx_memoryviewslice.tp_getattro == PyObject_GenericGetAttr)) {
- __pyx_type___pyx_memoryviewslice.tp_getattro = __Pyx_PyObject_GenericGetAttr;
- }
- if (__Pyx_SetVtable(__pyx_type___pyx_memoryviewslice.tp_dict, __pyx_vtabptr__memoryviewslice) < 0) __PYX_ERR(1, 967, __pyx_L1_error)
- if (__Pyx_setup_reduce((PyObject*)&__pyx_type___pyx_memoryviewslice) < 0) __PYX_ERR(1, 967, __pyx_L1_error)
- __pyx_memoryviewslice_type = &__pyx_type___pyx_memoryviewslice;
- __Pyx_RefNannyFinishContext();
- return 0;
- __pyx_L1_error:;
- __Pyx_RefNannyFinishContext();
- return -1;
-}
-
-static int __Pyx_modinit_type_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_type_import_code", 0);
- /*--- Type import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_variable_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_variable_import_code", 0);
- /*--- Variable import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-static int __Pyx_modinit_function_import_code(void) {
- __Pyx_RefNannyDeclarations
- __Pyx_RefNannySetupContext("__Pyx_modinit_function_import_code", 0);
- /*--- Function import code ---*/
- __Pyx_RefNannyFinishContext();
- return 0;
-}
-
-
-#ifndef CYTHON_NO_PYINIT_EXPORT
-#define __Pyx_PyMODINIT_FUNC PyMODINIT_FUNC
-#elif PY_MAJOR_VERSION < 3
-#ifdef __cplusplus
-#define __Pyx_PyMODINIT_FUNC extern "C" void
-#else
-#define __Pyx_PyMODINIT_FUNC void
-#endif
-#else
-#ifdef __cplusplus
-#define __Pyx_PyMODINIT_FUNC extern "C" PyObject *
-#else
-#define __Pyx_PyMODINIT_FUNC PyObject *
-#endif
-#endif
-
-
-#if PY_MAJOR_VERSION < 3
-__Pyx_PyMODINIT_FUNC initcore(void) CYTHON_SMALL_CODE; /*proto*/
-__Pyx_PyMODINIT_FUNC initcore(void)
-#else
-__Pyx_PyMODINIT_FUNC PyInit_core(void) CYTHON_SMALL_CODE; /*proto*/
-__Pyx_PyMODINIT_FUNC PyInit_core(void)
-#if CYTHON_PEP489_MULTI_PHASE_INIT
-{
- return PyModuleDef_Init(&__pyx_moduledef);
-}
-static CYTHON_SMALL_CODE int __Pyx_check_single_interpreter(void) {
- #if PY_VERSION_HEX >= 0x030700A1
- static PY_INT64_T main_interpreter_id = -1;
- PY_INT64_T current_id = PyInterpreterState_GetID(PyThreadState_Get()->interp);
- if (main_interpreter_id == -1) {
- main_interpreter_id = current_id;
- return (unlikely(current_id == -1)) ? -1 : 0;
- } else if (unlikely(main_interpreter_id != current_id))
- #else
- static PyInterpreterState *main_interpreter = NULL;
- PyInterpreterState *current_interpreter = PyThreadState_Get()->interp;
- if (!main_interpreter) {
- main_interpreter = current_interpreter;
- } else if (unlikely(main_interpreter != current_interpreter))
- #endif
- {
- PyErr_SetString(
- PyExc_ImportError,
- "Interpreter change detected - this module can only be loaded into one interpreter per process.");
- return -1;
- }
- return 0;
-}
-static CYTHON_SMALL_CODE int __Pyx_copy_spec_to_module(PyObject *spec, PyObject *moddict, const char* from_name, const char* to_name, int allow_none) {
- PyObject *value = PyObject_GetAttrString(spec, from_name);
- int result = 0;
- if (likely(value)) {
- if (allow_none || value != Py_None) {
- result = PyDict_SetItemString(moddict, to_name, value);
- }
- Py_DECREF(value);
- } else if (PyErr_ExceptionMatches(PyExc_AttributeError)) {
- PyErr_Clear();
- } else {
- result = -1;
- }
- return result;
-}
-static CYTHON_SMALL_CODE PyObject* __pyx_pymod_create(PyObject *spec, CYTHON_UNUSED PyModuleDef *def) {
- PyObject *module = NULL, *moddict, *modname;
- if (__Pyx_check_single_interpreter())
- return NULL;
- if (__pyx_m)
- return __Pyx_NewRef(__pyx_m);
- modname = PyObject_GetAttrString(spec, "name");
- if (unlikely(!modname)) goto bad;
- module = PyModule_NewObject(modname);
- Py_DECREF(modname);
- if (unlikely(!module)) goto bad;
- moddict = PyModule_GetDict(module);
- if (unlikely(!moddict)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "loader", "__loader__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "origin", "__file__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "parent", "__package__", 1) < 0)) goto bad;
- if (unlikely(__Pyx_copy_spec_to_module(spec, moddict, "submodule_search_locations", "__path__", 0) < 0)) goto bad;
- return module;
-bad:
- Py_XDECREF(module);
- return NULL;
-}
-
-
-static CYTHON_SMALL_CODE int __pyx_pymod_exec_core(PyObject *__pyx_pyinit_module)
-#endif
-#endif
-{
- PyObject *__pyx_t_1 = NULL;
- static PyThread_type_lock __pyx_t_2[8];
- int __pyx_lineno = 0;
- const char *__pyx_filename = NULL;
- int __pyx_clineno = 0;
- __Pyx_RefNannyDeclarations
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- if (__pyx_m) {
- if (__pyx_m == __pyx_pyinit_module) return 0;
- PyErr_SetString(PyExc_RuntimeError, "Module 'core' has already been imported. Re-initialisation is not supported.");
- return -1;
- }
- #elif PY_MAJOR_VERSION >= 3
- if (__pyx_m) return __Pyx_NewRef(__pyx_m);
- #endif
- #if CYTHON_REFNANNY
-__Pyx_RefNanny = __Pyx_RefNannyImportAPI("refnanny");
-if (!__Pyx_RefNanny) {
- PyErr_Clear();
- __Pyx_RefNanny = __Pyx_RefNannyImportAPI("Cython.Runtime.refnanny");
- if (!__Pyx_RefNanny)
- Py_FatalError("failed to import 'refnanny' module");
-}
-#endif
- __Pyx_RefNannySetupContext("__Pyx_PyMODINIT_FUNC PyInit_core(void)", 0);
- if (__Pyx_check_binary_version() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #ifdef __Pxy_PyFrame_Initialize_Offsets
- __Pxy_PyFrame_Initialize_Offsets();
- #endif
- __pyx_empty_tuple = PyTuple_New(0); if (unlikely(!__pyx_empty_tuple)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_empty_bytes = PyBytes_FromStringAndSize("", 0); if (unlikely(!__pyx_empty_bytes)) __PYX_ERR(0, 1, __pyx_L1_error)
- __pyx_empty_unicode = PyUnicode_FromStringAndSize("", 0); if (unlikely(!__pyx_empty_unicode)) __PYX_ERR(0, 1, __pyx_L1_error)
- #ifdef __Pyx_CyFunction_USED
- if (__pyx_CyFunction_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_FusedFunction_USED
- if (__pyx_FusedFunction_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_Coroutine_USED
- if (__pyx_Coroutine_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_Generator_USED
- if (__pyx_Generator_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_AsyncGen_USED
- if (__pyx_AsyncGen_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- #ifdef __Pyx_StopAsyncIteration_USED
- if (__pyx_StopAsyncIteration_init() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- /*--- Library function declarations ---*/
- /*--- Threads initialization code ---*/
- #if defined(WITH_THREAD) && PY_VERSION_HEX < 0x030700F0 && defined(__PYX_FORCE_INIT_THREADS) && __PYX_FORCE_INIT_THREADS
- PyEval_InitThreads();
- #endif
- /*--- Module creation code ---*/
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- __pyx_m = __pyx_pyinit_module;
- Py_INCREF(__pyx_m);
- #else
- #if PY_MAJOR_VERSION < 3
- __pyx_m = Py_InitModule4("core", __pyx_methods, 0, 0, PYTHON_API_VERSION); Py_XINCREF(__pyx_m);
- #else
- __pyx_m = PyModule_Create(&__pyx_moduledef);
- #endif
- if (unlikely(!__pyx_m)) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- __pyx_d = PyModule_GetDict(__pyx_m); if (unlikely(!__pyx_d)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_d);
- __pyx_b = PyImport_AddModule(__Pyx_BUILTIN_MODULE_NAME); if (unlikely(!__pyx_b)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_b);
- __pyx_cython_runtime = PyImport_AddModule((char *) "cython_runtime"); if (unlikely(!__pyx_cython_runtime)) __PYX_ERR(0, 1, __pyx_L1_error)
- Py_INCREF(__pyx_cython_runtime);
- if (PyObject_SetAttrString(__pyx_m, "__builtins__", __pyx_b) < 0) __PYX_ERR(0, 1, __pyx_L1_error);
- /*--- Initialize various global constants etc. ---*/
- if (__Pyx_InitGlobals() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #if PY_MAJOR_VERSION < 3 && (__PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT)
- if (__Pyx_init_sys_getdefaultencoding_params() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
- if (__pyx_module_is_main_monotonic_align__core) {
- if (PyObject_SetAttr(__pyx_m, __pyx_n_s_name_2, __pyx_n_s_main) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- }
- #if PY_MAJOR_VERSION >= 3
- {
- PyObject *modules = PyImport_GetModuleDict(); if (unlikely(!modules)) __PYX_ERR(0, 1, __pyx_L1_error)
- if (!PyDict_GetItemString(modules, "monotonic_align.core")) {
- if (unlikely(PyDict_SetItemString(modules, "monotonic_align.core", __pyx_m) < 0)) __PYX_ERR(0, 1, __pyx_L1_error)
- }
- }
- #endif
- /*--- Builtin init code ---*/
- if (__Pyx_InitCachedBuiltins() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- /*--- Constants init code ---*/
- if (__Pyx_InitCachedConstants() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- /*--- Global type/function init code ---*/
- (void)__Pyx_modinit_global_init_code();
- (void)__Pyx_modinit_variable_export_code();
- (void)__Pyx_modinit_function_export_code();
- if (unlikely(__Pyx_modinit_type_init_code() < 0)) __PYX_ERR(0, 1, __pyx_L1_error)
- (void)__Pyx_modinit_type_import_code();
- (void)__Pyx_modinit_variable_import_code();
- (void)__Pyx_modinit_function_import_code();
- /*--- Execution code ---*/
- #if defined(__Pyx_Generator_USED) || defined(__Pyx_Coroutine_USED)
- if (__Pyx_patch_abc() < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- #endif
-
- /* "monotonic_align/core.pyx":7
- * @cython.boundscheck(False)
- * @cython.wraparound(False)
- * cdef void maximum_path_each(int[:,::1] path, float[:,::1] value, int t_y, int t_x, float max_neg_val=-1e9) nogil: # <<<<<<<<<<<<<<
- * cdef int x
- * cdef int y
- */
- __pyx_k_ = (-1e9);
-
- /* "monotonic_align/core.pyx":1
- * cimport cython # <<<<<<<<<<<<<<
- * from cython.parallel import prange
- *
- */
- __pyx_t_1 = __Pyx_PyDict_NewPresized(0); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_test, __pyx_t_1) < 0) __PYX_ERR(0, 1, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "View.MemoryView":210
- * info.obj = self
- *
- * __pyx_getbuffer = capsule( &__pyx_array_getbuffer, "getbuffer(obj, view, flags)") # <<<<<<<<<<<<<<
- *
- * def __dealloc__(array self):
- */
- __pyx_t_1 = __pyx_capsule_create(((void *)(&__pyx_array_getbuffer)), ((char *)"getbuffer(obj, view, flags)")); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 210, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem((PyObject *)__pyx_array_type->tp_dict, __pyx_n_s_pyx_getbuffer, __pyx_t_1) < 0) __PYX_ERR(1, 210, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- PyType_Modified(__pyx_array_type);
-
- /* "View.MemoryView":287
- * return self.name
- *
- * cdef generic = Enum("") # <<<<<<<<<<<<<<
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("")
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__21, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 287, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(generic);
- __Pyx_DECREF_SET(generic, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":288
- *
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default # <<<<<<<<<<<<<<
- * cdef indirect = Enum("")
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__22, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 288, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(strided);
- __Pyx_DECREF_SET(strided, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":289
- * cdef generic = Enum("")
- * cdef strided = Enum("") # default
- * cdef indirect = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__23, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 289, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(indirect);
- __Pyx_DECREF_SET(indirect, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":292
- *
- *
- * cdef contiguous = Enum("") # <<<<<<<<<<<<<<
- * cdef indirect_contiguous = Enum("")
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__24, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 292, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(contiguous);
- __Pyx_DECREF_SET(contiguous, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":293
- *
- * cdef contiguous = Enum("")
- * cdef indirect_contiguous = Enum("") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __Pyx_PyObject_Call(((PyObject *)__pyx_MemviewEnum_type), __pyx_tuple__25, NULL); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 293, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- __Pyx_XGOTREF(indirect_contiguous);
- __Pyx_DECREF_SET(indirect_contiguous, __pyx_t_1);
- __Pyx_GIVEREF(__pyx_t_1);
- __pyx_t_1 = 0;
-
- /* "View.MemoryView":317
- *
- * DEF THREAD_LOCKS_PREALLOCATED = 8
- * cdef int __pyx_memoryview_thread_locks_used = 0 # <<<<<<<<<<<<<<
- * cdef PyThread_type_lock[THREAD_LOCKS_PREALLOCATED] __pyx_memoryview_thread_locks = [
- * PyThread_allocate_lock(),
- */
- __pyx_memoryview_thread_locks_used = 0;
-
- /* "View.MemoryView":318
- * DEF THREAD_LOCKS_PREALLOCATED = 8
- * cdef int __pyx_memoryview_thread_locks_used = 0
- * cdef PyThread_type_lock[THREAD_LOCKS_PREALLOCATED] __pyx_memoryview_thread_locks = [ # <<<<<<<<<<<<<<
- * PyThread_allocate_lock(),
- * PyThread_allocate_lock(),
- */
- __pyx_t_2[0] = PyThread_allocate_lock();
- __pyx_t_2[1] = PyThread_allocate_lock();
- __pyx_t_2[2] = PyThread_allocate_lock();
- __pyx_t_2[3] = PyThread_allocate_lock();
- __pyx_t_2[4] = PyThread_allocate_lock();
- __pyx_t_2[5] = PyThread_allocate_lock();
- __pyx_t_2[6] = PyThread_allocate_lock();
- __pyx_t_2[7] = PyThread_allocate_lock();
- memcpy(&(__pyx_memoryview_thread_locks[0]), __pyx_t_2, sizeof(__pyx_memoryview_thread_locks[0]) * (8));
-
- /* "View.MemoryView":551
- * info.obj = self
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __pyx_capsule_create(((void *)(&__pyx_memoryview_getbuffer)), ((char *)"getbuffer(obj, view, flags)")); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 551, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem((PyObject *)__pyx_memoryview_type->tp_dict, __pyx_n_s_pyx_getbuffer, __pyx_t_1) < 0) __PYX_ERR(1, 551, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- PyType_Modified(__pyx_memoryview_type);
-
- /* "View.MemoryView":997
- * return self.from_object
- *
- * __pyx_getbuffer = capsule( &__pyx_memoryview_getbuffer, "getbuffer(obj, view, flags)") # <<<<<<<<<<<<<<
- *
- *
- */
- __pyx_t_1 = __pyx_capsule_create(((void *)(&__pyx_memoryview_getbuffer)), ((char *)"getbuffer(obj, view, flags)")); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 997, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem((PyObject *)__pyx_memoryviewslice_type->tp_dict, __pyx_n_s_pyx_getbuffer, __pyx_t_1) < 0) __PYX_ERR(1, 997, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
- PyType_Modified(__pyx_memoryviewslice_type);
-
- /* "(tree fragment)":1
- * def __pyx_unpickle_Enum(__pyx_type, long __pyx_checksum, __pyx_state): # <<<<<<<<<<<<<<
- * cdef object __pyx_PickleError
- * cdef object __pyx_result
- */
- __pyx_t_1 = PyCFunction_NewEx(&__pyx_mdef_15View_dot_MemoryView_1__pyx_unpickle_Enum, NULL, __pyx_n_s_View_MemoryView); if (unlikely(!__pyx_t_1)) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_GOTREF(__pyx_t_1);
- if (PyDict_SetItem(__pyx_d, __pyx_n_s_pyx_unpickle_Enum, __pyx_t_1) < 0) __PYX_ERR(1, 1, __pyx_L1_error)
- __Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
-
- /* "(tree fragment)":11
- * __pyx_unpickle_Enum__set_state( __pyx_result, __pyx_state)
- * return __pyx_result
- * cdef __pyx_unpickle_Enum__set_state(Enum __pyx_result, tuple __pyx_state): # <<<<<<<<<<<<<<
- * __pyx_result.name = __pyx_state[0]
- * if len(__pyx_state) > 1 and hasattr(__pyx_result, '__dict__'):
- */
-
- /*--- Wrapped vars code ---*/
-
- goto __pyx_L0;
- __pyx_L1_error:;
- __Pyx_XDECREF(__pyx_t_1);
- if (__pyx_m) {
- if (__pyx_d) {
- __Pyx_AddTraceback("init monotonic_align.core", __pyx_clineno, __pyx_lineno, __pyx_filename);
- }
- Py_CLEAR(__pyx_m);
- } else if (!PyErr_Occurred()) {
- PyErr_SetString(PyExc_ImportError, "init monotonic_align.core");
- }
- __pyx_L0:;
- __Pyx_RefNannyFinishContext();
- #if CYTHON_PEP489_MULTI_PHASE_INIT
- return (__pyx_m != NULL) ? 0 : -1;
- #elif PY_MAJOR_VERSION >= 3
- return __pyx_m;
- #else
- return;
- #endif
-}
-
-/* --- Runtime support code --- */
-/* Refnanny */
-#if CYTHON_REFNANNY
-static __Pyx_RefNannyAPIStruct *__Pyx_RefNannyImportAPI(const char *modname) {
- PyObject *m = NULL, *p = NULL;
- void *r = NULL;
- m = PyImport_ImportModule(modname);
- if (!m) goto end;
- p = PyObject_GetAttrString(m, "RefNannyAPI");
- if (!p) goto end;
- r = PyLong_AsVoidPtr(p);
-end:
- Py_XDECREF(p);
- Py_XDECREF(m);
- return (__Pyx_RefNannyAPIStruct *)r;
-}
-#endif
-
-/* PyObjectGetAttrStr */
-#if CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStr(PyObject* obj, PyObject* attr_name) {
- PyTypeObject* tp = Py_TYPE(obj);
- if (likely(tp->tp_getattro))
- return tp->tp_getattro(obj, attr_name);
-#if PY_MAJOR_VERSION < 3
- if (likely(tp->tp_getattr))
- return tp->tp_getattr(obj, PyString_AS_STRING(attr_name));
-#endif
- return PyObject_GetAttr(obj, attr_name);
-}
-#endif
-
-/* GetBuiltinName */
-static PyObject *__Pyx_GetBuiltinName(PyObject *name) {
- PyObject* result = __Pyx_PyObject_GetAttrStr(__pyx_b, name);
- if (unlikely(!result)) {
- PyErr_Format(PyExc_NameError,
-#if PY_MAJOR_VERSION >= 3
- "name '%U' is not defined", name);
-#else
- "name '%.200s' is not defined", PyString_AS_STRING(name));
-#endif
- }
- return result;
-}
-
-/* MemviewSliceInit */
-static int
-__Pyx_init_memviewslice(struct __pyx_memoryview_obj *memview,
- int ndim,
- __Pyx_memviewslice *memviewslice,
- int memview_is_new_reference)
-{
- __Pyx_RefNannyDeclarations
- int i, retval=-1;
- Py_buffer *buf = &memview->view;
- __Pyx_RefNannySetupContext("init_memviewslice", 0);
- if (unlikely(memviewslice->memview || memviewslice->data)) {
- PyErr_SetString(PyExc_ValueError,
- "memviewslice is already initialized!");
- goto fail;
- }
- if (buf->strides) {
- for (i = 0; i < ndim; i++) {
- memviewslice->strides[i] = buf->strides[i];
- }
- } else {
- Py_ssize_t stride = buf->itemsize;
- for (i = ndim - 1; i >= 0; i--) {
- memviewslice->strides[i] = stride;
- stride *= buf->shape[i];
- }
- }
- for (i = 0; i < ndim; i++) {
- memviewslice->shape[i] = buf->shape[i];
- if (buf->suboffsets) {
- memviewslice->suboffsets[i] = buf->suboffsets[i];
- } else {
- memviewslice->suboffsets[i] = -1;
- }
- }
- memviewslice->memview = memview;
- memviewslice->data = (char *)buf->buf;
- if (__pyx_add_acquisition_count(memview) == 0 && !memview_is_new_reference) {
- Py_INCREF(memview);
- }
- retval = 0;
- goto no_fail;
-fail:
- memviewslice->memview = 0;
- memviewslice->data = 0;
- retval = -1;
-no_fail:
- __Pyx_RefNannyFinishContext();
- return retval;
-}
-#ifndef Py_NO_RETURN
-#define Py_NO_RETURN
-#endif
-static void __pyx_fatalerror(const char *fmt, ...) Py_NO_RETURN {
- va_list vargs;
- char msg[200];
-#if PY_VERSION_HEX >= 0x030A0000 || defined(HAVE_STDARG_PROTOTYPES)
- va_start(vargs, fmt);
-#else
- va_start(vargs);
-#endif
- vsnprintf(msg, 200, fmt, vargs);
- va_end(vargs);
- Py_FatalError(msg);
-}
-static CYTHON_INLINE int
-__pyx_add_acquisition_count_locked(__pyx_atomic_int *acquisition_count,
- PyThread_type_lock lock)
-{
- int result;
- PyThread_acquire_lock(lock, 1);
- result = (*acquisition_count)++;
- PyThread_release_lock(lock);
- return result;
-}
-static CYTHON_INLINE int
-__pyx_sub_acquisition_count_locked(__pyx_atomic_int *acquisition_count,
- PyThread_type_lock lock)
-{
- int result;
- PyThread_acquire_lock(lock, 1);
- result = (*acquisition_count)--;
- PyThread_release_lock(lock);
- return result;
-}
-static CYTHON_INLINE void
-__Pyx_INC_MEMVIEW(__Pyx_memviewslice *memslice, int have_gil, int lineno)
-{
- int first_time;
- struct __pyx_memoryview_obj *memview = memslice->memview;
- if (unlikely(!memview || (PyObject *) memview == Py_None))
- return;
- if (unlikely(__pyx_get_slice_count(memview) < 0))
- __pyx_fatalerror("Acquisition count is %d (line %d)",
- __pyx_get_slice_count(memview), lineno);
- first_time = __pyx_add_acquisition_count(memview) == 0;
- if (unlikely(first_time)) {
- if (have_gil) {
- Py_INCREF((PyObject *) memview);
- } else {
- PyGILState_STATE _gilstate = PyGILState_Ensure();
- Py_INCREF((PyObject *) memview);
- PyGILState_Release(_gilstate);
- }
- }
-}
-static CYTHON_INLINE void __Pyx_XDEC_MEMVIEW(__Pyx_memviewslice *memslice,
- int have_gil, int lineno) {
- int last_time;
- struct __pyx_memoryview_obj *memview = memslice->memview;
- if (unlikely(!memview || (PyObject *) memview == Py_None)) {
- memslice->memview = NULL;
- return;
- }
- if (unlikely(__pyx_get_slice_count(memview) <= 0))
- __pyx_fatalerror("Acquisition count is %d (line %d)",
- __pyx_get_slice_count(memview), lineno);
- last_time = __pyx_sub_acquisition_count(memview) == 1;
- memslice->data = NULL;
- if (unlikely(last_time)) {
- if (have_gil) {
- Py_CLEAR(memslice->memview);
- } else {
- PyGILState_STATE _gilstate = PyGILState_Ensure();
- Py_CLEAR(memslice->memview);
- PyGILState_Release(_gilstate);
- }
- } else {
- memslice->memview = NULL;
- }
-}
-
-/* RaiseArgTupleInvalid */
-static void __Pyx_RaiseArgtupleInvalid(
- const char* func_name,
- int exact,
- Py_ssize_t num_min,
- Py_ssize_t num_max,
- Py_ssize_t num_found)
-{
- Py_ssize_t num_expected;
- const char *more_or_less;
- if (num_found < num_min) {
- num_expected = num_min;
- more_or_less = "at least";
- } else {
- num_expected = num_max;
- more_or_less = "at most";
- }
- if (exact) {
- more_or_less = "exactly";
- }
- PyErr_Format(PyExc_TypeError,
- "%.200s() takes %.8s %" CYTHON_FORMAT_SSIZE_T "d positional argument%.1s (%" CYTHON_FORMAT_SSIZE_T "d given)",
- func_name, more_or_less, num_expected,
- (num_expected == 1) ? "" : "s", num_found);
-}
-
-/* RaiseDoubleKeywords */
-static void __Pyx_RaiseDoubleKeywordsError(
- const char* func_name,
- PyObject* kw_name)
-{
- PyErr_Format(PyExc_TypeError,
- #if PY_MAJOR_VERSION >= 3
- "%s() got multiple values for keyword argument '%U'", func_name, kw_name);
- #else
- "%s() got multiple values for keyword argument '%s'", func_name,
- PyString_AsString(kw_name));
- #endif
-}
-
-/* ParseKeywords */
-static int __Pyx_ParseOptionalKeywords(
- PyObject *kwds,
- PyObject **argnames[],
- PyObject *kwds2,
- PyObject *values[],
- Py_ssize_t num_pos_args,
- const char* function_name)
-{
- PyObject *key = 0, *value = 0;
- Py_ssize_t pos = 0;
- PyObject*** name;
- PyObject*** first_kw_arg = argnames + num_pos_args;
- while (PyDict_Next(kwds, &pos, &key, &value)) {
- name = first_kw_arg;
- while (*name && (**name != key)) name++;
- if (*name) {
- values[name-argnames] = value;
- continue;
- }
- name = first_kw_arg;
- #if PY_MAJOR_VERSION < 3
- if (likely(PyString_Check(key))) {
- while (*name) {
- if ((CYTHON_COMPILING_IN_PYPY || PyString_GET_SIZE(**name) == PyString_GET_SIZE(key))
- && _PyString_Eq(**name, key)) {
- values[name-argnames] = value;
- break;
- }
- name++;
- }
- if (*name) continue;
- else {
- PyObject*** argname = argnames;
- while (argname != first_kw_arg) {
- if ((**argname == key) || (
- (CYTHON_COMPILING_IN_PYPY || PyString_GET_SIZE(**argname) == PyString_GET_SIZE(key))
- && _PyString_Eq(**argname, key))) {
- goto arg_passed_twice;
- }
- argname++;
- }
- }
- } else
- #endif
- if (likely(PyUnicode_Check(key))) {
- while (*name) {
- int cmp = (**name == key) ? 0 :
- #if !CYTHON_COMPILING_IN_PYPY && PY_MAJOR_VERSION >= 3
- (__Pyx_PyUnicode_GET_LENGTH(**name) != __Pyx_PyUnicode_GET_LENGTH(key)) ? 1 :
- #endif
- PyUnicode_Compare(**name, key);
- if (cmp < 0 && unlikely(PyErr_Occurred())) goto bad;
- if (cmp == 0) {
- values[name-argnames] = value;
- break;
- }
- name++;
- }
- if (*name) continue;
- else {
- PyObject*** argname = argnames;
- while (argname != first_kw_arg) {
- int cmp = (**argname == key) ? 0 :
- #if !CYTHON_COMPILING_IN_PYPY && PY_MAJOR_VERSION >= 3
- (__Pyx_PyUnicode_GET_LENGTH(**argname) != __Pyx_PyUnicode_GET_LENGTH(key)) ? 1 :
- #endif
- PyUnicode_Compare(**argname, key);
- if (cmp < 0 && unlikely(PyErr_Occurred())) goto bad;
- if (cmp == 0) goto arg_passed_twice;
- argname++;
- }
- }
- } else
- goto invalid_keyword_type;
- if (kwds2) {
- if (unlikely(PyDict_SetItem(kwds2, key, value))) goto bad;
- } else {
- goto invalid_keyword;
- }
- }
- return 0;
-arg_passed_twice:
- __Pyx_RaiseDoubleKeywordsError(function_name, key);
- goto bad;
-invalid_keyword_type:
- PyErr_Format(PyExc_TypeError,
- "%.200s() keywords must be strings", function_name);
- goto bad;
-invalid_keyword:
- PyErr_Format(PyExc_TypeError,
- #if PY_MAJOR_VERSION < 3
- "%.200s() got an unexpected keyword argument '%.200s'",
- function_name, PyString_AsString(key));
- #else
- "%s() got an unexpected keyword argument '%U'",
- function_name, key);
- #endif
-bad:
- return -1;
-}
-
-/* None */
-static CYTHON_INLINE void __Pyx_RaiseUnboundLocalError(const char *varname) {
- PyErr_Format(PyExc_UnboundLocalError, "local variable '%s' referenced before assignment", varname);
-}
-
-/* ArgTypeTest */
-static int __Pyx__ArgTypeTest(PyObject *obj, PyTypeObject *type, const char *name, int exact)
-{
- if (unlikely(!type)) {
- PyErr_SetString(PyExc_SystemError, "Missing type object");
- return 0;
- }
- else if (exact) {
- #if PY_MAJOR_VERSION == 2
- if ((type == &PyBaseString_Type) && likely(__Pyx_PyBaseString_CheckExact(obj))) return 1;
- #endif
- }
- else {
- if (likely(__Pyx_TypeCheck(obj, type))) return 1;
- }
- PyErr_Format(PyExc_TypeError,
- "Argument '%.200s' has incorrect type (expected %.200s, got %.200s)",
- name, type->tp_name, Py_TYPE(obj)->tp_name);
- return 0;
-}
-
-/* PyObjectCall */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_Call(PyObject *func, PyObject *arg, PyObject *kw) {
- PyObject *result;
- ternaryfunc call = Py_TYPE(func)->tp_call;
- if (unlikely(!call))
- return PyObject_Call(func, arg, kw);
- if (unlikely(Py_EnterRecursiveCall((char*)" while calling a Python object")))
- return NULL;
- result = (*call)(func, arg, kw);
- Py_LeaveRecursiveCall();
- if (unlikely(!result) && unlikely(!PyErr_Occurred())) {
- PyErr_SetString(
- PyExc_SystemError,
- "NULL result without error in PyObject_Call");
- }
- return result;
-}
-#endif
-
-/* PyErrFetchRestore */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx_ErrRestoreInState(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- tmp_type = tstate->curexc_type;
- tmp_value = tstate->curexc_value;
- tmp_tb = tstate->curexc_traceback;
- tstate->curexc_type = type;
- tstate->curexc_value = value;
- tstate->curexc_traceback = tb;
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-}
-static CYTHON_INLINE void __Pyx_ErrFetchInState(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
- *type = tstate->curexc_type;
- *value = tstate->curexc_value;
- *tb = tstate->curexc_traceback;
- tstate->curexc_type = 0;
- tstate->curexc_value = 0;
- tstate->curexc_traceback = 0;
-}
-#endif
-
-/* RaiseException */
-#if PY_MAJOR_VERSION < 3
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb,
- CYTHON_UNUSED PyObject *cause) {
- __Pyx_PyThreadState_declare
- Py_XINCREF(type);
- if (!value || value == Py_None)
- value = NULL;
- else
- Py_INCREF(value);
- if (!tb || tb == Py_None)
- tb = NULL;
- else {
- Py_INCREF(tb);
- if (!PyTraceBack_Check(tb)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: arg 3 must be a traceback or None");
- goto raise_error;
- }
- }
- if (PyType_Check(type)) {
-#if CYTHON_COMPILING_IN_PYPY
- if (!value) {
- Py_INCREF(Py_None);
- value = Py_None;
- }
-#endif
- PyErr_NormalizeException(&type, &value, &tb);
- } else {
- if (value) {
- PyErr_SetString(PyExc_TypeError,
- "instance exception may not have a separate value");
- goto raise_error;
- }
- value = type;
- type = (PyObject*) Py_TYPE(type);
- Py_INCREF(type);
- if (!PyType_IsSubtype((PyTypeObject *)type, (PyTypeObject *)PyExc_BaseException)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: exception class must be a subclass of BaseException");
- goto raise_error;
- }
- }
- __Pyx_PyThreadState_assign
- __Pyx_ErrRestore(type, value, tb);
- return;
-raise_error:
- Py_XDECREF(value);
- Py_XDECREF(type);
- Py_XDECREF(tb);
- return;
-}
-#else
-static void __Pyx_Raise(PyObject *type, PyObject *value, PyObject *tb, PyObject *cause) {
- PyObject* owned_instance = NULL;
- if (tb == Py_None) {
- tb = 0;
- } else if (tb && !PyTraceBack_Check(tb)) {
- PyErr_SetString(PyExc_TypeError,
- "raise: arg 3 must be a traceback or None");
- goto bad;
- }
- if (value == Py_None)
- value = 0;
- if (PyExceptionInstance_Check(type)) {
- if (value) {
- PyErr_SetString(PyExc_TypeError,
- "instance exception may not have a separate value");
- goto bad;
- }
- value = type;
- type = (PyObject*) Py_TYPE(value);
- } else if (PyExceptionClass_Check(type)) {
- PyObject *instance_class = NULL;
- if (value && PyExceptionInstance_Check(value)) {
- instance_class = (PyObject*) Py_TYPE(value);
- if (instance_class != type) {
- int is_subclass = PyObject_IsSubclass(instance_class, type);
- if (!is_subclass) {
- instance_class = NULL;
- } else if (unlikely(is_subclass == -1)) {
- goto bad;
- } else {
- type = instance_class;
- }
- }
- }
- if (!instance_class) {
- PyObject *args;
- if (!value)
- args = PyTuple_New(0);
- else if (PyTuple_Check(value)) {
- Py_INCREF(value);
- args = value;
- } else
- args = PyTuple_Pack(1, value);
- if (!args)
- goto bad;
- owned_instance = PyObject_Call(type, args, NULL);
- Py_DECREF(args);
- if (!owned_instance)
- goto bad;
- value = owned_instance;
- if (!PyExceptionInstance_Check(value)) {
- PyErr_Format(PyExc_TypeError,
- "calling %R should have returned an instance of "
- "BaseException, not %R",
- type, Py_TYPE(value));
- goto bad;
- }
- }
- } else {
- PyErr_SetString(PyExc_TypeError,
- "raise: exception class must be a subclass of BaseException");
- goto bad;
- }
- if (cause) {
- PyObject *fixed_cause;
- if (cause == Py_None) {
- fixed_cause = NULL;
- } else if (PyExceptionClass_Check(cause)) {
- fixed_cause = PyObject_CallObject(cause, NULL);
- if (fixed_cause == NULL)
- goto bad;
- } else if (PyExceptionInstance_Check(cause)) {
- fixed_cause = cause;
- Py_INCREF(fixed_cause);
- } else {
- PyErr_SetString(PyExc_TypeError,
- "exception causes must derive from "
- "BaseException");
- goto bad;
- }
- PyException_SetCause(value, fixed_cause);
- }
- PyErr_SetObject(type, value);
- if (tb) {
-#if CYTHON_COMPILING_IN_PYPY
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- PyErr_Fetch(&tmp_type, &tmp_value, &tmp_tb);
- Py_INCREF(tb);
- PyErr_Restore(tmp_type, tmp_value, tb);
- Py_XDECREF(tmp_tb);
-#else
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject* tmp_tb = tstate->curexc_traceback;
- if (tb != tmp_tb) {
- Py_INCREF(tb);
- tstate->curexc_traceback = tb;
- Py_XDECREF(tmp_tb);
- }
-#endif
- }
-bad:
- Py_XDECREF(owned_instance);
- return;
-}
-#endif
-
-/* PyCFunctionFastCall */
-#if CYTHON_FAST_PYCCALL
-static CYTHON_INLINE PyObject * __Pyx_PyCFunction_FastCall(PyObject *func_obj, PyObject **args, Py_ssize_t nargs) {
- PyCFunctionObject *func = (PyCFunctionObject*)func_obj;
- PyCFunction meth = PyCFunction_GET_FUNCTION(func);
- PyObject *self = PyCFunction_GET_SELF(func);
- int flags = PyCFunction_GET_FLAGS(func);
- assert(PyCFunction_Check(func));
- assert(METH_FASTCALL == (flags & ~(METH_CLASS | METH_STATIC | METH_COEXIST | METH_KEYWORDS | METH_STACKLESS)));
- assert(nargs >= 0);
- assert(nargs == 0 || args != NULL);
- /* _PyCFunction_FastCallDict() must not be called with an exception set,
- because it may clear it (directly or indirectly) and so the
- caller loses its exception */
- assert(!PyErr_Occurred());
- if ((PY_VERSION_HEX < 0x030700A0) || unlikely(flags & METH_KEYWORDS)) {
- return (*((__Pyx_PyCFunctionFastWithKeywords)(void*)meth)) (self, args, nargs, NULL);
- } else {
- return (*((__Pyx_PyCFunctionFast)(void*)meth)) (self, args, nargs);
- }
-}
-#endif
-
-/* PyFunctionFastCall */
-#if CYTHON_FAST_PYCALL
-static PyObject* __Pyx_PyFunction_FastCallNoKw(PyCodeObject *co, PyObject **args, Py_ssize_t na,
- PyObject *globals) {
- PyFrameObject *f;
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject **fastlocals;
- Py_ssize_t i;
- PyObject *result;
- assert(globals != NULL);
- /* XXX Perhaps we should create a specialized
- PyFrame_New() that doesn't take locals, but does
- take builtins without sanity checking them.
- */
- assert(tstate != NULL);
- f = PyFrame_New(tstate, co, globals, NULL);
- if (f == NULL) {
- return NULL;
- }
- fastlocals = __Pyx_PyFrame_GetLocalsplus(f);
- for (i = 0; i < na; i++) {
- Py_INCREF(*args);
- fastlocals[i] = *args++;
- }
- result = PyEval_EvalFrameEx(f,0);
- ++tstate->recursion_depth;
- Py_DECREF(f);
- --tstate->recursion_depth;
- return result;
-}
-#if 1 || PY_VERSION_HEX < 0x030600B1
-static PyObject *__Pyx_PyFunction_FastCallDict(PyObject *func, PyObject **args, Py_ssize_t nargs, PyObject *kwargs) {
- PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
- PyObject *globals = PyFunction_GET_GLOBALS(func);
- PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
- PyObject *closure;
-#if PY_MAJOR_VERSION >= 3
- PyObject *kwdefs;
-#endif
- PyObject *kwtuple, **k;
- PyObject **d;
- Py_ssize_t nd;
- Py_ssize_t nk;
- PyObject *result;
- assert(kwargs == NULL || PyDict_Check(kwargs));
- nk = kwargs ? PyDict_Size(kwargs) : 0;
- if (Py_EnterRecursiveCall((char*)" while calling a Python object")) {
- return NULL;
- }
- if (
-#if PY_MAJOR_VERSION >= 3
- co->co_kwonlyargcount == 0 &&
-#endif
- likely(kwargs == NULL || nk == 0) &&
- co->co_flags == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE)) {
- if (argdefs == NULL && co->co_argcount == nargs) {
- result = __Pyx_PyFunction_FastCallNoKw(co, args, nargs, globals);
- goto done;
- }
- else if (nargs == 0 && argdefs != NULL
- && co->co_argcount == Py_SIZE(argdefs)) {
- /* function called with no arguments, but all parameters have
- a default value: use default values as arguments .*/
- args = &PyTuple_GET_ITEM(argdefs, 0);
- result =__Pyx_PyFunction_FastCallNoKw(co, args, Py_SIZE(argdefs), globals);
- goto done;
- }
- }
- if (kwargs != NULL) {
- Py_ssize_t pos, i;
- kwtuple = PyTuple_New(2 * nk);
- if (kwtuple == NULL) {
- result = NULL;
- goto done;
- }
- k = &PyTuple_GET_ITEM(kwtuple, 0);
- pos = i = 0;
- while (PyDict_Next(kwargs, &pos, &k[i], &k[i+1])) {
- Py_INCREF(k[i]);
- Py_INCREF(k[i+1]);
- i += 2;
- }
- nk = i / 2;
- }
- else {
- kwtuple = NULL;
- k = NULL;
- }
- closure = PyFunction_GET_CLOSURE(func);
-#if PY_MAJOR_VERSION >= 3
- kwdefs = PyFunction_GET_KW_DEFAULTS(func);
-#endif
- if (argdefs != NULL) {
- d = &PyTuple_GET_ITEM(argdefs, 0);
- nd = Py_SIZE(argdefs);
- }
- else {
- d = NULL;
- nd = 0;
- }
-#if PY_MAJOR_VERSION >= 3
- result = PyEval_EvalCodeEx((PyObject*)co, globals, (PyObject *)NULL,
- args, (int)nargs,
- k, (int)nk,
- d, (int)nd, kwdefs, closure);
-#else
- result = PyEval_EvalCodeEx(co, globals, (PyObject *)NULL,
- args, (int)nargs,
- k, (int)nk,
- d, (int)nd, closure);
-#endif
- Py_XDECREF(kwtuple);
-done:
- Py_LeaveRecursiveCall();
- return result;
-}
-#endif
-#endif
-
-/* PyObjectCall2Args */
-static CYTHON_UNUSED PyObject* __Pyx_PyObject_Call2Args(PyObject* function, PyObject* arg1, PyObject* arg2) {
- PyObject *args, *result = NULL;
- #if CYTHON_FAST_PYCALL
- if (PyFunction_Check(function)) {
- PyObject *args[2] = {arg1, arg2};
- return __Pyx_PyFunction_FastCall(function, args, 2);
- }
- #endif
- #if CYTHON_FAST_PYCCALL
- if (__Pyx_PyFastCFunction_Check(function)) {
- PyObject *args[2] = {arg1, arg2};
- return __Pyx_PyCFunction_FastCall(function, args, 2);
- }
- #endif
- args = PyTuple_New(2);
- if (unlikely(!args)) goto done;
- Py_INCREF(arg1);
- PyTuple_SET_ITEM(args, 0, arg1);
- Py_INCREF(arg2);
- PyTuple_SET_ITEM(args, 1, arg2);
- Py_INCREF(function);
- result = __Pyx_PyObject_Call(function, args, NULL);
- Py_DECREF(args);
- Py_DECREF(function);
-done:
- return result;
-}
-
-/* PyObjectCallMethO */
-#if CYTHON_COMPILING_IN_CPYTHON
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallMethO(PyObject *func, PyObject *arg) {
- PyObject *self, *result;
- PyCFunction cfunc;
- cfunc = PyCFunction_GET_FUNCTION(func);
- self = PyCFunction_GET_SELF(func);
- if (unlikely(Py_EnterRecursiveCall((char*)" while calling a Python object")))
- return NULL;
- result = cfunc(self, arg);
- Py_LeaveRecursiveCall();
- if (unlikely(!result) && unlikely(!PyErr_Occurred())) {
- PyErr_SetString(
- PyExc_SystemError,
- "NULL result without error in PyObject_Call");
- }
- return result;
-}
-#endif
-
-/* PyObjectCallOneArg */
-#if CYTHON_COMPILING_IN_CPYTHON
-static PyObject* __Pyx__PyObject_CallOneArg(PyObject *func, PyObject *arg) {
- PyObject *result;
- PyObject *args = PyTuple_New(1);
- if (unlikely(!args)) return NULL;
- Py_INCREF(arg);
- PyTuple_SET_ITEM(args, 0, arg);
- result = __Pyx_PyObject_Call(func, args, NULL);
- Py_DECREF(args);
- return result;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg) {
-#if CYTHON_FAST_PYCALL
- if (PyFunction_Check(func)) {
- return __Pyx_PyFunction_FastCall(func, &arg, 1);
- }
-#endif
- if (likely(PyCFunction_Check(func))) {
- if (likely(PyCFunction_GET_FLAGS(func) & METH_O)) {
- return __Pyx_PyObject_CallMethO(func, arg);
-#if CYTHON_FAST_PYCCALL
- } else if (__Pyx_PyFastCFunction_Check(func)) {
- return __Pyx_PyCFunction_FastCall(func, &arg, 1);
-#endif
- }
- }
- return __Pyx__PyObject_CallOneArg(func, arg);
-}
-#else
-static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg) {
- PyObject *result;
- PyObject *args = PyTuple_Pack(1, arg);
- if (unlikely(!args)) return NULL;
- result = __Pyx_PyObject_Call(func, args, NULL);
- Py_DECREF(args);
- return result;
-}
-#endif
-
-/* BytesEquals */
-static CYTHON_INLINE int __Pyx_PyBytes_Equals(PyObject* s1, PyObject* s2, int equals) {
-#if CYTHON_COMPILING_IN_PYPY
- return PyObject_RichCompareBool(s1, s2, equals);
-#else
- if (s1 == s2) {
- return (equals == Py_EQ);
- } else if (PyBytes_CheckExact(s1) & PyBytes_CheckExact(s2)) {
- const char *ps1, *ps2;
- Py_ssize_t length = PyBytes_GET_SIZE(s1);
- if (length != PyBytes_GET_SIZE(s2))
- return (equals == Py_NE);
- ps1 = PyBytes_AS_STRING(s1);
- ps2 = PyBytes_AS_STRING(s2);
- if (ps1[0] != ps2[0]) {
- return (equals == Py_NE);
- } else if (length == 1) {
- return (equals == Py_EQ);
- } else {
- int result;
-#if CYTHON_USE_UNICODE_INTERNALS && (PY_VERSION_HEX < 0x030B0000)
- Py_hash_t hash1, hash2;
- hash1 = ((PyBytesObject*)s1)->ob_shash;
- hash2 = ((PyBytesObject*)s2)->ob_shash;
- if (hash1 != hash2 && hash1 != -1 && hash2 != -1) {
- return (equals == Py_NE);
- }
-#endif
- result = memcmp(ps1, ps2, (size_t)length);
- return (equals == Py_EQ) ? (result == 0) : (result != 0);
- }
- } else if ((s1 == Py_None) & PyBytes_CheckExact(s2)) {
- return (equals == Py_NE);
- } else if ((s2 == Py_None) & PyBytes_CheckExact(s1)) {
- return (equals == Py_NE);
- } else {
- int result;
- PyObject* py_result = PyObject_RichCompare(s1, s2, equals);
- if (!py_result)
- return -1;
- result = __Pyx_PyObject_IsTrue(py_result);
- Py_DECREF(py_result);
- return result;
- }
-#endif
-}
-
-/* UnicodeEquals */
-static CYTHON_INLINE int __Pyx_PyUnicode_Equals(PyObject* s1, PyObject* s2, int equals) {
-#if CYTHON_COMPILING_IN_PYPY
- return PyObject_RichCompareBool(s1, s2, equals);
-#else
-#if PY_MAJOR_VERSION < 3
- PyObject* owned_ref = NULL;
-#endif
- int s1_is_unicode, s2_is_unicode;
- if (s1 == s2) {
- goto return_eq;
- }
- s1_is_unicode = PyUnicode_CheckExact(s1);
- s2_is_unicode = PyUnicode_CheckExact(s2);
-#if PY_MAJOR_VERSION < 3
- if ((s1_is_unicode & (!s2_is_unicode)) && PyString_CheckExact(s2)) {
- owned_ref = PyUnicode_FromObject(s2);
- if (unlikely(!owned_ref))
- return -1;
- s2 = owned_ref;
- s2_is_unicode = 1;
- } else if ((s2_is_unicode & (!s1_is_unicode)) && PyString_CheckExact(s1)) {
- owned_ref = PyUnicode_FromObject(s1);
- if (unlikely(!owned_ref))
- return -1;
- s1 = owned_ref;
- s1_is_unicode = 1;
- } else if (((!s2_is_unicode) & (!s1_is_unicode))) {
- return __Pyx_PyBytes_Equals(s1, s2, equals);
- }
-#endif
- if (s1_is_unicode & s2_is_unicode) {
- Py_ssize_t length;
- int kind;
- void *data1, *data2;
- if (unlikely(__Pyx_PyUnicode_READY(s1) < 0) || unlikely(__Pyx_PyUnicode_READY(s2) < 0))
- return -1;
- length = __Pyx_PyUnicode_GET_LENGTH(s1);
- if (length != __Pyx_PyUnicode_GET_LENGTH(s2)) {
- goto return_ne;
- }
-#if CYTHON_USE_UNICODE_INTERNALS
- {
- Py_hash_t hash1, hash2;
- #if CYTHON_PEP393_ENABLED
- hash1 = ((PyASCIIObject*)s1)->hash;
- hash2 = ((PyASCIIObject*)s2)->hash;
- #else
- hash1 = ((PyUnicodeObject*)s1)->hash;
- hash2 = ((PyUnicodeObject*)s2)->hash;
- #endif
- if (hash1 != hash2 && hash1 != -1 && hash2 != -1) {
- goto return_ne;
- }
- }
-#endif
- kind = __Pyx_PyUnicode_KIND(s1);
- if (kind != __Pyx_PyUnicode_KIND(s2)) {
- goto return_ne;
- }
- data1 = __Pyx_PyUnicode_DATA(s1);
- data2 = __Pyx_PyUnicode_DATA(s2);
- if (__Pyx_PyUnicode_READ(kind, data1, 0) != __Pyx_PyUnicode_READ(kind, data2, 0)) {
- goto return_ne;
- } else if (length == 1) {
- goto return_eq;
- } else {
- int result = memcmp(data1, data2, (size_t)(length * kind));
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_EQ) ? (result == 0) : (result != 0);
- }
- } else if ((s1 == Py_None) & s2_is_unicode) {
- goto return_ne;
- } else if ((s2 == Py_None) & s1_is_unicode) {
- goto return_ne;
- } else {
- int result;
- PyObject* py_result = PyObject_RichCompare(s1, s2, equals);
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- if (!py_result)
- return -1;
- result = __Pyx_PyObject_IsTrue(py_result);
- Py_DECREF(py_result);
- return result;
- }
-return_eq:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_EQ);
-return_ne:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(owned_ref);
- #endif
- return (equals == Py_NE);
-#endif
-}
-
-/* DivInt[Py_ssize_t] */
-static CYTHON_INLINE Py_ssize_t __Pyx_div_Py_ssize_t(Py_ssize_t a, Py_ssize_t b) {
- Py_ssize_t q = a / b;
- Py_ssize_t r = a - q*b;
- q -= ((r != 0) & ((r ^ b) < 0));
- return q;
-}
-
-/* GetAttr */
-static CYTHON_INLINE PyObject *__Pyx_GetAttr(PyObject *o, PyObject *n) {
-#if CYTHON_USE_TYPE_SLOTS
-#if PY_MAJOR_VERSION >= 3
- if (likely(PyUnicode_Check(n)))
-#else
- if (likely(PyString_Check(n)))
-#endif
- return __Pyx_PyObject_GetAttrStr(o, n);
-#endif
- return PyObject_GetAttr(o, n);
-}
-
-/* GetItemInt */
-static PyObject *__Pyx_GetItemInt_Generic(PyObject *o, PyObject* j) {
- PyObject *r;
- if (!j) return NULL;
- r = PyObject_GetItem(o, j);
- Py_DECREF(j);
- return r;
-}
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_List_Fast(PyObject *o, Py_ssize_t i,
- CYTHON_NCP_UNUSED int wraparound,
- CYTHON_NCP_UNUSED int boundscheck) {
-#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- Py_ssize_t wrapped_i = i;
- if (wraparound & unlikely(i < 0)) {
- wrapped_i += PyList_GET_SIZE(o);
- }
- if ((!boundscheck) || likely(__Pyx_is_valid_index(wrapped_i, PyList_GET_SIZE(o)))) {
- PyObject *r = PyList_GET_ITEM(o, wrapped_i);
- Py_INCREF(r);
- return r;
- }
- return __Pyx_GetItemInt_Generic(o, PyInt_FromSsize_t(i));
-#else
- return PySequence_GetItem(o, i);
-#endif
-}
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Tuple_Fast(PyObject *o, Py_ssize_t i,
- CYTHON_NCP_UNUSED int wraparound,
- CYTHON_NCP_UNUSED int boundscheck) {
-#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
- Py_ssize_t wrapped_i = i;
- if (wraparound & unlikely(i < 0)) {
- wrapped_i += PyTuple_GET_SIZE(o);
- }
- if ((!boundscheck) || likely(__Pyx_is_valid_index(wrapped_i, PyTuple_GET_SIZE(o)))) {
- PyObject *r = PyTuple_GET_ITEM(o, wrapped_i);
- Py_INCREF(r);
- return r;
- }
- return __Pyx_GetItemInt_Generic(o, PyInt_FromSsize_t(i));
-#else
- return PySequence_GetItem(o, i);
-#endif
-}
-static CYTHON_INLINE PyObject *__Pyx_GetItemInt_Fast(PyObject *o, Py_ssize_t i, int is_list,
- CYTHON_NCP_UNUSED int wraparound,
- CYTHON_NCP_UNUSED int boundscheck) {
-#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS && CYTHON_USE_TYPE_SLOTS
- if (is_list || PyList_CheckExact(o)) {
- Py_ssize_t n = ((!wraparound) | likely(i >= 0)) ? i : i + PyList_GET_SIZE(o);
- if ((!boundscheck) || (likely(__Pyx_is_valid_index(n, PyList_GET_SIZE(o))))) {
- PyObject *r = PyList_GET_ITEM(o, n);
- Py_INCREF(r);
- return r;
- }
- }
- else if (PyTuple_CheckExact(o)) {
- Py_ssize_t n = ((!wraparound) | likely(i >= 0)) ? i : i + PyTuple_GET_SIZE(o);
- if ((!boundscheck) || likely(__Pyx_is_valid_index(n, PyTuple_GET_SIZE(o)))) {
- PyObject *r = PyTuple_GET_ITEM(o, n);
- Py_INCREF(r);
- return r;
- }
- } else {
- PySequenceMethods *m = Py_TYPE(o)->tp_as_sequence;
- if (likely(m && m->sq_item)) {
- if (wraparound && unlikely(i < 0) && likely(m->sq_length)) {
- Py_ssize_t l = m->sq_length(o);
- if (likely(l >= 0)) {
- i += l;
- } else {
- if (!PyErr_ExceptionMatches(PyExc_OverflowError))
- return NULL;
- PyErr_Clear();
- }
- }
- return m->sq_item(o, i);
- }
- }
-#else
- if (is_list || PySequence_Check(o)) {
- return PySequence_GetItem(o, i);
- }
-#endif
- return __Pyx_GetItemInt_Generic(o, PyInt_FromSsize_t(i));
-}
-
-/* ObjectGetItem */
-#if CYTHON_USE_TYPE_SLOTS
-static PyObject *__Pyx_PyObject_GetIndex(PyObject *obj, PyObject* index) {
- PyObject *runerr;
- Py_ssize_t key_value;
- PySequenceMethods *m = Py_TYPE(obj)->tp_as_sequence;
- if (unlikely(!(m && m->sq_item))) {
- PyErr_Format(PyExc_TypeError, "'%.200s' object is not subscriptable", Py_TYPE(obj)->tp_name);
- return NULL;
- }
- key_value = __Pyx_PyIndex_AsSsize_t(index);
- if (likely(key_value != -1 || !(runerr = PyErr_Occurred()))) {
- return __Pyx_GetItemInt_Fast(obj, key_value, 0, 1, 1);
- }
- if (PyErr_GivenExceptionMatches(runerr, PyExc_OverflowError)) {
- PyErr_Clear();
- PyErr_Format(PyExc_IndexError, "cannot fit '%.200s' into an index-sized integer", Py_TYPE(index)->tp_name);
- }
- return NULL;
-}
-static PyObject *__Pyx_PyObject_GetItem(PyObject *obj, PyObject* key) {
- PyMappingMethods *m = Py_TYPE(obj)->tp_as_mapping;
- if (likely(m && m->mp_subscript)) {
- return m->mp_subscript(obj, key);
- }
- return __Pyx_PyObject_GetIndex(obj, key);
-}
-#endif
-
-/* decode_c_string */
-static CYTHON_INLINE PyObject* __Pyx_decode_c_string(
- const char* cstring, Py_ssize_t start, Py_ssize_t stop,
- const char* encoding, const char* errors,
- PyObject* (*decode_func)(const char *s, Py_ssize_t size, const char *errors)) {
- Py_ssize_t length;
- if (unlikely((start < 0) | (stop < 0))) {
- size_t slen = strlen(cstring);
- if (unlikely(slen > (size_t) PY_SSIZE_T_MAX)) {
- PyErr_SetString(PyExc_OverflowError,
- "c-string too long to convert to Python");
- return NULL;
- }
- length = (Py_ssize_t) slen;
- if (start < 0) {
- start += length;
- if (start < 0)
- start = 0;
- }
- if (stop < 0)
- stop += length;
- }
- if (unlikely(stop <= start))
- return __Pyx_NewRef(__pyx_empty_unicode);
- length = stop - start;
- cstring += start;
- if (decode_func) {
- return decode_func(cstring, length, errors);
- } else {
- return PyUnicode_Decode(cstring, length, encoding, errors);
- }
-}
-
-/* PyErrExceptionMatches */
-#if CYTHON_FAST_THREAD_STATE
-static int __Pyx_PyErr_ExceptionMatchesTuple(PyObject *exc_type, PyObject *tuple) {
- Py_ssize_t i, n;
- n = PyTuple_GET_SIZE(tuple);
-#if PY_MAJOR_VERSION >= 3
- for (i=0; icurexc_type;
- if (exc_type == err) return 1;
- if (unlikely(!exc_type)) return 0;
- if (unlikely(PyTuple_Check(err)))
- return __Pyx_PyErr_ExceptionMatchesTuple(exc_type, err);
- return __Pyx_PyErr_GivenExceptionMatches(exc_type, err);
-}
-#endif
-
-/* GetAttr3 */
-static PyObject *__Pyx_GetAttr3Default(PyObject *d) {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- if (unlikely(!__Pyx_PyErr_ExceptionMatches(PyExc_AttributeError)))
- return NULL;
- __Pyx_PyErr_Clear();
- Py_INCREF(d);
- return d;
-}
-static CYTHON_INLINE PyObject *__Pyx_GetAttr3(PyObject *o, PyObject *n, PyObject *d) {
- PyObject *r = __Pyx_GetAttr(o, n);
- return (likely(r)) ? r : __Pyx_GetAttr3Default(d);
-}
-
-/* PyDictVersioning */
-#if CYTHON_USE_DICT_VERSIONS && CYTHON_USE_TYPE_SLOTS
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_tp_dict_version(PyObject *obj) {
- PyObject *dict = Py_TYPE(obj)->tp_dict;
- return likely(dict) ? __PYX_GET_DICT_VERSION(dict) : 0;
-}
-static CYTHON_INLINE PY_UINT64_T __Pyx_get_object_dict_version(PyObject *obj) {
- PyObject **dictptr = NULL;
- Py_ssize_t offset = Py_TYPE(obj)->tp_dictoffset;
- if (offset) {
-#if CYTHON_COMPILING_IN_CPYTHON
- dictptr = (likely(offset > 0)) ? (PyObject **) ((char *)obj + offset) : _PyObject_GetDictPtr(obj);
-#else
- dictptr = _PyObject_GetDictPtr(obj);
-#endif
- }
- return (dictptr && *dictptr) ? __PYX_GET_DICT_VERSION(*dictptr) : 0;
-}
-static CYTHON_INLINE int __Pyx_object_dict_version_matches(PyObject* obj, PY_UINT64_T tp_dict_version, PY_UINT64_T obj_dict_version) {
- PyObject *dict = Py_TYPE(obj)->tp_dict;
- if (unlikely(!dict) || unlikely(tp_dict_version != __PYX_GET_DICT_VERSION(dict)))
- return 0;
- return obj_dict_version == __Pyx_get_object_dict_version(obj);
-}
-#endif
-
-/* GetModuleGlobalName */
-#if CYTHON_USE_DICT_VERSIONS
-static PyObject *__Pyx__GetModuleGlobalName(PyObject *name, PY_UINT64_T *dict_version, PyObject **dict_cached_value)
-#else
-static CYTHON_INLINE PyObject *__Pyx__GetModuleGlobalName(PyObject *name)
-#endif
-{
- PyObject *result;
-#if !CYTHON_AVOID_BORROWED_REFS
-#if CYTHON_COMPILING_IN_CPYTHON && PY_VERSION_HEX >= 0x030500A1
- result = _PyDict_GetItem_KnownHash(__pyx_d, name, ((PyASCIIObject *) name)->hash);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- } else if (unlikely(PyErr_Occurred())) {
- return NULL;
- }
-#else
- result = PyDict_GetItem(__pyx_d, name);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- }
-#endif
-#else
- result = PyObject_GetItem(__pyx_d, name);
- __PYX_UPDATE_DICT_CACHE(__pyx_d, result, *dict_cached_value, *dict_version)
- if (likely(result)) {
- return __Pyx_NewRef(result);
- }
- PyErr_Clear();
-#endif
- return __Pyx_GetBuiltinName(name);
-}
-
-/* RaiseTooManyValuesToUnpack */
-static CYTHON_INLINE void __Pyx_RaiseTooManyValuesError(Py_ssize_t expected) {
- PyErr_Format(PyExc_ValueError,
- "too many values to unpack (expected %" CYTHON_FORMAT_SSIZE_T "d)", expected);
-}
-
-/* RaiseNeedMoreValuesToUnpack */
-static CYTHON_INLINE void __Pyx_RaiseNeedMoreValuesError(Py_ssize_t index) {
- PyErr_Format(PyExc_ValueError,
- "need more than %" CYTHON_FORMAT_SSIZE_T "d value%.1s to unpack",
- index, (index == 1) ? "" : "s");
-}
-
-/* RaiseNoneIterError */
-static CYTHON_INLINE void __Pyx_RaiseNoneNotIterableError(void) {
- PyErr_SetString(PyExc_TypeError, "'NoneType' object is not iterable");
-}
-
-/* ExtTypeTest */
-static CYTHON_INLINE int __Pyx_TypeTest(PyObject *obj, PyTypeObject *type) {
- if (unlikely(!type)) {
- PyErr_SetString(PyExc_SystemError, "Missing type object");
- return 0;
- }
- if (likely(__Pyx_TypeCheck(obj, type)))
- return 1;
- PyErr_Format(PyExc_TypeError, "Cannot convert %.200s to %.200s",
- Py_TYPE(obj)->tp_name, type->tp_name);
- return 0;
-}
-
-/* GetTopmostException */
-#if CYTHON_USE_EXC_INFO_STACK
-static _PyErr_StackItem *
-__Pyx_PyErr_GetTopmostException(PyThreadState *tstate)
-{
- _PyErr_StackItem *exc_info = tstate->exc_info;
- while ((exc_info->exc_type == NULL || exc_info->exc_type == Py_None) &&
- exc_info->previous_item != NULL)
- {
- exc_info = exc_info->previous_item;
- }
- return exc_info;
-}
-#endif
-
-/* SaveResetException */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx__ExceptionSave(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
- #if CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = __Pyx_PyErr_GetTopmostException(tstate);
- *type = exc_info->exc_type;
- *value = exc_info->exc_value;
- *tb = exc_info->exc_traceback;
- #else
- *type = tstate->exc_type;
- *value = tstate->exc_value;
- *tb = tstate->exc_traceback;
- #endif
- Py_XINCREF(*type);
- Py_XINCREF(*value);
- Py_XINCREF(*tb);
-}
-static CYTHON_INLINE void __Pyx__ExceptionReset(PyThreadState *tstate, PyObject *type, PyObject *value, PyObject *tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- #if CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = tstate->exc_info;
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = type;
- exc_info->exc_value = value;
- exc_info->exc_traceback = tb;
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = type;
- tstate->exc_value = value;
- tstate->exc_traceback = tb;
- #endif
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-}
-#endif
-
-/* GetException */
-#if CYTHON_FAST_THREAD_STATE
-static int __Pyx__GetException(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb)
-#else
-static int __Pyx_GetException(PyObject **type, PyObject **value, PyObject **tb)
-#endif
-{
- PyObject *local_type, *local_value, *local_tb;
-#if CYTHON_FAST_THREAD_STATE
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- local_type = tstate->curexc_type;
- local_value = tstate->curexc_value;
- local_tb = tstate->curexc_traceback;
- tstate->curexc_type = 0;
- tstate->curexc_value = 0;
- tstate->curexc_traceback = 0;
-#else
- PyErr_Fetch(&local_type, &local_value, &local_tb);
-#endif
- PyErr_NormalizeException(&local_type, &local_value, &local_tb);
-#if CYTHON_FAST_THREAD_STATE
- if (unlikely(tstate->curexc_type))
-#else
- if (unlikely(PyErr_Occurred()))
-#endif
- goto bad;
- #if PY_MAJOR_VERSION >= 3
- if (local_tb) {
- if (unlikely(PyException_SetTraceback(local_value, local_tb) < 0))
- goto bad;
- }
- #endif
- Py_XINCREF(local_tb);
- Py_XINCREF(local_type);
- Py_XINCREF(local_value);
- *type = local_type;
- *value = local_value;
- *tb = local_tb;
-#if CYTHON_FAST_THREAD_STATE
- #if CYTHON_USE_EXC_INFO_STACK
- {
- _PyErr_StackItem *exc_info = tstate->exc_info;
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = local_type;
- exc_info->exc_value = local_value;
- exc_info->exc_traceback = local_tb;
- }
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = local_type;
- tstate->exc_value = local_value;
- tstate->exc_traceback = local_tb;
- #endif
- Py_XDECREF(tmp_type);
- Py_XDECREF(tmp_value);
- Py_XDECREF(tmp_tb);
-#else
- PyErr_SetExcInfo(local_type, local_value, local_tb);
-#endif
- return 0;
-bad:
- *type = 0;
- *value = 0;
- *tb = 0;
- Py_XDECREF(local_type);
- Py_XDECREF(local_value);
- Py_XDECREF(local_tb);
- return -1;
-}
-
-/* SwapException */
-#if CYTHON_FAST_THREAD_STATE
-static CYTHON_INLINE void __Pyx__ExceptionSwap(PyThreadState *tstate, PyObject **type, PyObject **value, PyObject **tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- #if CYTHON_USE_EXC_INFO_STACK
- _PyErr_StackItem *exc_info = tstate->exc_info;
- tmp_type = exc_info->exc_type;
- tmp_value = exc_info->exc_value;
- tmp_tb = exc_info->exc_traceback;
- exc_info->exc_type = *type;
- exc_info->exc_value = *value;
- exc_info->exc_traceback = *tb;
- #else
- tmp_type = tstate->exc_type;
- tmp_value = tstate->exc_value;
- tmp_tb = tstate->exc_traceback;
- tstate->exc_type = *type;
- tstate->exc_value = *value;
- tstate->exc_traceback = *tb;
- #endif
- *type = tmp_type;
- *value = tmp_value;
- *tb = tmp_tb;
-}
-#else
-static CYTHON_INLINE void __Pyx_ExceptionSwap(PyObject **type, PyObject **value, PyObject **tb) {
- PyObject *tmp_type, *tmp_value, *tmp_tb;
- PyErr_GetExcInfo(&tmp_type, &tmp_value, &tmp_tb);
- PyErr_SetExcInfo(*type, *value, *tb);
- *type = tmp_type;
- *value = tmp_value;
- *tb = tmp_tb;
-}
-#endif
-
-/* Import */
-static PyObject *__Pyx_Import(PyObject *name, PyObject *from_list, int level) {
- PyObject *empty_list = 0;
- PyObject *module = 0;
- PyObject *global_dict = 0;
- PyObject *empty_dict = 0;
- PyObject *list;
- #if PY_MAJOR_VERSION < 3
- PyObject *py_import;
- py_import = __Pyx_PyObject_GetAttrStr(__pyx_b, __pyx_n_s_import);
- if (!py_import)
- goto bad;
- #endif
- if (from_list)
- list = from_list;
- else {
- empty_list = PyList_New(0);
- if (!empty_list)
- goto bad;
- list = empty_list;
- }
- global_dict = PyModule_GetDict(__pyx_m);
- if (!global_dict)
- goto bad;
- empty_dict = PyDict_New();
- if (!empty_dict)
- goto bad;
- {
- #if PY_MAJOR_VERSION >= 3
- if (level == -1) {
- if ((1) && (strchr(__Pyx_MODULE_NAME, '.'))) {
- module = PyImport_ImportModuleLevelObject(
- name, global_dict, empty_dict, list, 1);
- if (!module) {
- if (!PyErr_ExceptionMatches(PyExc_ImportError))
- goto bad;
- PyErr_Clear();
- }
- }
- level = 0;
- }
- #endif
- if (!module) {
- #if PY_MAJOR_VERSION < 3
- PyObject *py_level = PyInt_FromLong(level);
- if (!py_level)
- goto bad;
- module = PyObject_CallFunctionObjArgs(py_import,
- name, global_dict, empty_dict, list, py_level, (PyObject *)NULL);
- Py_DECREF(py_level);
- #else
- module = PyImport_ImportModuleLevelObject(
- name, global_dict, empty_dict, list, level);
- #endif
- }
- }
-bad:
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(py_import);
- #endif
- Py_XDECREF(empty_list);
- Py_XDECREF(empty_dict);
- return module;
-}
-
-/* FastTypeChecks */
-#if CYTHON_COMPILING_IN_CPYTHON
-static int __Pyx_InBases(PyTypeObject *a, PyTypeObject *b) {
- while (a) {
- a = a->tp_base;
- if (a == b)
- return 1;
- }
- return b == &PyBaseObject_Type;
-}
-static CYTHON_INLINE int __Pyx_IsSubtype(PyTypeObject *a, PyTypeObject *b) {
- PyObject *mro;
- if (a == b) return 1;
- mro = a->tp_mro;
- if (likely(mro)) {
- Py_ssize_t i, n;
- n = PyTuple_GET_SIZE(mro);
- for (i = 0; i < n; i++) {
- if (PyTuple_GET_ITEM(mro, i) == (PyObject *)b)
- return 1;
- }
- return 0;
- }
- return __Pyx_InBases(a, b);
-}
-#if PY_MAJOR_VERSION == 2
-static int __Pyx_inner_PyErr_GivenExceptionMatches2(PyObject *err, PyObject* exc_type1, PyObject* exc_type2) {
- PyObject *exception, *value, *tb;
- int res;
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- __Pyx_ErrFetch(&exception, &value, &tb);
- res = exc_type1 ? PyObject_IsSubclass(err, exc_type1) : 0;
- if (unlikely(res == -1)) {
- PyErr_WriteUnraisable(err);
- res = 0;
- }
- if (!res) {
- res = PyObject_IsSubclass(err, exc_type2);
- if (unlikely(res == -1)) {
- PyErr_WriteUnraisable(err);
- res = 0;
- }
- }
- __Pyx_ErrRestore(exception, value, tb);
- return res;
-}
-#else
-static CYTHON_INLINE int __Pyx_inner_PyErr_GivenExceptionMatches2(PyObject *err, PyObject* exc_type1, PyObject *exc_type2) {
- int res = exc_type1 ? __Pyx_IsSubtype((PyTypeObject*)err, (PyTypeObject*)exc_type1) : 0;
- if (!res) {
- res = __Pyx_IsSubtype((PyTypeObject*)err, (PyTypeObject*)exc_type2);
- }
- return res;
-}
-#endif
-static int __Pyx_PyErr_GivenExceptionMatchesTuple(PyObject *exc_type, PyObject *tuple) {
- Py_ssize_t i, n;
- assert(PyExceptionClass_Check(exc_type));
- n = PyTuple_GET_SIZE(tuple);
-#if PY_MAJOR_VERSION >= 3
- for (i=0; i= 0 || (x^b) >= 0))
- return PyInt_FromLong(x);
- return PyLong_Type.tp_as_number->nb_add(op1, op2);
- }
- #endif
- #if CYTHON_USE_PYLONG_INTERNALS
- if (likely(PyLong_CheckExact(op1))) {
- const long b = intval;
- long a, x;
-#ifdef HAVE_LONG_LONG
- const PY_LONG_LONG llb = intval;
- PY_LONG_LONG lla, llx;
-#endif
- const digit* digits = ((PyLongObject*)op1)->ob_digit;
- const Py_ssize_t size = Py_SIZE(op1);
- if (likely(__Pyx_sst_abs(size) <= 1)) {
- a = likely(size) ? digits[0] : 0;
- if (size == -1) a = -a;
- } else {
- switch (size) {
- case -2:
- if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- a = -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 2 * PyLong_SHIFT) {
- lla = -(PY_LONG_LONG) (((((unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case 2:
- if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- a = (long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 2 * PyLong_SHIFT) {
- lla = (PY_LONG_LONG) (((((unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case -3:
- if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- a = -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 3 * PyLong_SHIFT) {
- lla = -(PY_LONG_LONG) (((((((unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case 3:
- if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- a = (long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 3 * PyLong_SHIFT) {
- lla = (PY_LONG_LONG) (((((((unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case -4:
- if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- a = -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 4 * PyLong_SHIFT) {
- lla = -(PY_LONG_LONG) (((((((((unsigned PY_LONG_LONG)digits[3]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- case 4:
- if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- a = (long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0]));
- break;
-#ifdef HAVE_LONG_LONG
- } else if (8 * sizeof(PY_LONG_LONG) - 1 > 4 * PyLong_SHIFT) {
- lla = (PY_LONG_LONG) (((((((((unsigned PY_LONG_LONG)digits[3]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[2]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[1]) << PyLong_SHIFT) | (unsigned PY_LONG_LONG)digits[0]));
- goto long_long;
-#endif
- }
- CYTHON_FALLTHROUGH;
- default: return PyLong_Type.tp_as_number->nb_add(op1, op2);
- }
- }
- x = a + b;
- return PyLong_FromLong(x);
-#ifdef HAVE_LONG_LONG
- long_long:
- llx = lla + llb;
- return PyLong_FromLongLong(llx);
-#endif
-
-
- }
- #endif
- if (PyFloat_CheckExact(op1)) {
- const long b = intval;
- double a = PyFloat_AS_DOUBLE(op1);
- double result;
- PyFPE_START_PROTECT("add", return NULL)
- result = ((double)a) + (double)b;
- PyFPE_END_PROTECT(result)
- return PyFloat_FromDouble(result);
- }
- return (inplace ? PyNumber_InPlaceAdd : PyNumber_Add)(op1, op2);
-}
-#endif
-
-/* DivInt[long] */
-static CYTHON_INLINE long __Pyx_div_long(long a, long b) {
- long q = a / b;
- long r = a - q*b;
- q -= ((r != 0) & ((r ^ b) < 0));
- return q;
-}
-
-/* ImportFrom */
-static PyObject* __Pyx_ImportFrom(PyObject* module, PyObject* name) {
- PyObject* value = __Pyx_PyObject_GetAttrStr(module, name);
- if (unlikely(!value) && PyErr_ExceptionMatches(PyExc_AttributeError)) {
- PyErr_Format(PyExc_ImportError,
- #if PY_MAJOR_VERSION < 3
- "cannot import name %.230s", PyString_AS_STRING(name));
- #else
- "cannot import name %S", name);
- #endif
- }
- return value;
-}
-
-/* HasAttr */
-static CYTHON_INLINE int __Pyx_HasAttr(PyObject *o, PyObject *n) {
- PyObject *r;
- if (unlikely(!__Pyx_PyBaseString_Check(n))) {
- PyErr_SetString(PyExc_TypeError,
- "hasattr(): attribute name must be string");
- return -1;
- }
- r = __Pyx_GetAttr(o, n);
- if (unlikely(!r)) {
- PyErr_Clear();
- return 0;
- } else {
- Py_DECREF(r);
- return 1;
- }
-}
-
-/* PyObject_GenericGetAttrNoDict */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static PyObject *__Pyx_RaiseGenericGetAttributeError(PyTypeObject *tp, PyObject *attr_name) {
- PyErr_Format(PyExc_AttributeError,
-#if PY_MAJOR_VERSION >= 3
- "'%.50s' object has no attribute '%U'",
- tp->tp_name, attr_name);
-#else
- "'%.50s' object has no attribute '%.400s'",
- tp->tp_name, PyString_AS_STRING(attr_name));
-#endif
- return NULL;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GenericGetAttrNoDict(PyObject* obj, PyObject* attr_name) {
- PyObject *descr;
- PyTypeObject *tp = Py_TYPE(obj);
- if (unlikely(!PyString_Check(attr_name))) {
- return PyObject_GenericGetAttr(obj, attr_name);
- }
- assert(!tp->tp_dictoffset);
- descr = _PyType_Lookup(tp, attr_name);
- if (unlikely(!descr)) {
- return __Pyx_RaiseGenericGetAttributeError(tp, attr_name);
- }
- Py_INCREF(descr);
- #if PY_MAJOR_VERSION < 3
- if (likely(PyType_HasFeature(Py_TYPE(descr), Py_TPFLAGS_HAVE_CLASS)))
- #endif
- {
- descrgetfunc f = Py_TYPE(descr)->tp_descr_get;
- if (unlikely(f)) {
- PyObject *res = f(descr, obj, (PyObject *)tp);
- Py_DECREF(descr);
- return res;
- }
- }
- return descr;
-}
-#endif
-
-/* PyObject_GenericGetAttr */
-#if CYTHON_USE_TYPE_SLOTS && CYTHON_USE_PYTYPE_LOOKUP && PY_VERSION_HEX < 0x03070000
-static PyObject* __Pyx_PyObject_GenericGetAttr(PyObject* obj, PyObject* attr_name) {
- if (unlikely(Py_TYPE(obj)->tp_dictoffset)) {
- return PyObject_GenericGetAttr(obj, attr_name);
- }
- return __Pyx_PyObject_GenericGetAttrNoDict(obj, attr_name);
-}
-#endif
-
-/* SetVTable */
-static int __Pyx_SetVtable(PyObject *dict, void *vtable) {
-#if PY_VERSION_HEX >= 0x02070000
- PyObject *ob = PyCapsule_New(vtable, 0, 0);
-#else
- PyObject *ob = PyCObject_FromVoidPtr(vtable, 0);
-#endif
- if (!ob)
- goto bad;
- if (PyDict_SetItem(dict, __pyx_n_s_pyx_vtable, ob) < 0)
- goto bad;
- Py_DECREF(ob);
- return 0;
-bad:
- Py_XDECREF(ob);
- return -1;
-}
-
-/* PyObjectGetAttrStrNoError */
-static void __Pyx_PyObject_GetAttrStr_ClearAttributeError(void) {
- __Pyx_PyThreadState_declare
- __Pyx_PyThreadState_assign
- if (likely(__Pyx_PyErr_ExceptionMatches(PyExc_AttributeError)))
- __Pyx_PyErr_Clear();
-}
-static CYTHON_INLINE PyObject* __Pyx_PyObject_GetAttrStrNoError(PyObject* obj, PyObject* attr_name) {
- PyObject *result;
-#if CYTHON_COMPILING_IN_CPYTHON && CYTHON_USE_TYPE_SLOTS && PY_VERSION_HEX >= 0x030700B1
- PyTypeObject* tp = Py_TYPE(obj);
- if (likely(tp->tp_getattro == PyObject_GenericGetAttr)) {
- return _PyObject_GenericGetAttrWithDict(obj, attr_name, NULL, 1);
- }
-#endif
- result = __Pyx_PyObject_GetAttrStr(obj, attr_name);
- if (unlikely(!result)) {
- __Pyx_PyObject_GetAttrStr_ClearAttributeError();
- }
- return result;
-}
-
-/* SetupReduce */
-static int __Pyx_setup_reduce_is_named(PyObject* meth, PyObject* name) {
- int ret;
- PyObject *name_attr;
- name_attr = __Pyx_PyObject_GetAttrStr(meth, __pyx_n_s_name_2);
- if (likely(name_attr)) {
- ret = PyObject_RichCompareBool(name_attr, name, Py_EQ);
- } else {
- ret = -1;
- }
- if (unlikely(ret < 0)) {
- PyErr_Clear();
- ret = 0;
- }
- Py_XDECREF(name_attr);
- return ret;
-}
-static int __Pyx_setup_reduce(PyObject* type_obj) {
- int ret = 0;
- PyObject *object_reduce = NULL;
- PyObject *object_getstate = NULL;
- PyObject *object_reduce_ex = NULL;
- PyObject *reduce = NULL;
- PyObject *reduce_ex = NULL;
- PyObject *reduce_cython = NULL;
- PyObject *setstate = NULL;
- PyObject *setstate_cython = NULL;
- PyObject *getstate = NULL;
-#if CYTHON_USE_PYTYPE_LOOKUP
- getstate = _PyType_Lookup((PyTypeObject*)type_obj, __pyx_n_s_getstate);
-#else
- getstate = __Pyx_PyObject_GetAttrStrNoError(type_obj, __pyx_n_s_getstate);
- if (!getstate && PyErr_Occurred()) {
- goto __PYX_BAD;
- }
-#endif
- if (getstate) {
-#if CYTHON_USE_PYTYPE_LOOKUP
- object_getstate = _PyType_Lookup(&PyBaseObject_Type, __pyx_n_s_getstate);
-#else
- object_getstate = __Pyx_PyObject_GetAttrStrNoError((PyObject*)&PyBaseObject_Type, __pyx_n_s_getstate);
- if (!object_getstate && PyErr_Occurred()) {
- goto __PYX_BAD;
- }
-#endif
- if (object_getstate != getstate) {
- goto __PYX_GOOD;
- }
- }
-#if CYTHON_USE_PYTYPE_LOOKUP
- object_reduce_ex = _PyType_Lookup(&PyBaseObject_Type, __pyx_n_s_reduce_ex); if (!object_reduce_ex) goto __PYX_BAD;
-#else
- object_reduce_ex = __Pyx_PyObject_GetAttrStr((PyObject*)&PyBaseObject_Type, __pyx_n_s_reduce_ex); if (!object_reduce_ex) goto __PYX_BAD;
-#endif
- reduce_ex = __Pyx_PyObject_GetAttrStr(type_obj, __pyx_n_s_reduce_ex); if (unlikely(!reduce_ex)) goto __PYX_BAD;
- if (reduce_ex == object_reduce_ex) {
-#if CYTHON_USE_PYTYPE_LOOKUP
- object_reduce = _PyType_Lookup(&PyBaseObject_Type, __pyx_n_s_reduce); if (!object_reduce) goto __PYX_BAD;
-#else
- object_reduce = __Pyx_PyObject_GetAttrStr((PyObject*)&PyBaseObject_Type, __pyx_n_s_reduce); if (!object_reduce) goto __PYX_BAD;
-#endif
- reduce = __Pyx_PyObject_GetAttrStr(type_obj, __pyx_n_s_reduce); if (unlikely(!reduce)) goto __PYX_BAD;
- if (reduce == object_reduce || __Pyx_setup_reduce_is_named(reduce, __pyx_n_s_reduce_cython)) {
- reduce_cython = __Pyx_PyObject_GetAttrStrNoError(type_obj, __pyx_n_s_reduce_cython);
- if (likely(reduce_cython)) {
- ret = PyDict_SetItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_reduce, reduce_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- ret = PyDict_DelItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_reduce_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- } else if (reduce == object_reduce || PyErr_Occurred()) {
- goto __PYX_BAD;
- }
- setstate = __Pyx_PyObject_GetAttrStr(type_obj, __pyx_n_s_setstate);
- if (!setstate) PyErr_Clear();
- if (!setstate || __Pyx_setup_reduce_is_named(setstate, __pyx_n_s_setstate_cython)) {
- setstate_cython = __Pyx_PyObject_GetAttrStrNoError(type_obj, __pyx_n_s_setstate_cython);
- if (likely(setstate_cython)) {
- ret = PyDict_SetItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_setstate, setstate_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- ret = PyDict_DelItem(((PyTypeObject*)type_obj)->tp_dict, __pyx_n_s_setstate_cython); if (unlikely(ret < 0)) goto __PYX_BAD;
- } else if (!setstate || PyErr_Occurred()) {
- goto __PYX_BAD;
- }
- }
- PyType_Modified((PyTypeObject*)type_obj);
- }
- }
- goto __PYX_GOOD;
-__PYX_BAD:
- if (!PyErr_Occurred())
- PyErr_Format(PyExc_RuntimeError, "Unable to initialize pickling for %s", ((PyTypeObject*)type_obj)->tp_name);
- ret = -1;
-__PYX_GOOD:
-#if !CYTHON_USE_PYTYPE_LOOKUP
- Py_XDECREF(object_reduce);
- Py_XDECREF(object_reduce_ex);
- Py_XDECREF(object_getstate);
- Py_XDECREF(getstate);
-#endif
- Py_XDECREF(reduce);
- Py_XDECREF(reduce_ex);
- Py_XDECREF(reduce_cython);
- Py_XDECREF(setstate);
- Py_XDECREF(setstate_cython);
- return ret;
-}
-
-/* CLineInTraceback */
-#ifndef CYTHON_CLINE_IN_TRACEBACK
-static int __Pyx_CLineForTraceback(CYTHON_NCP_UNUSED PyThreadState *tstate, int c_line) {
- PyObject *use_cline;
- PyObject *ptype, *pvalue, *ptraceback;
-#if CYTHON_COMPILING_IN_CPYTHON
- PyObject **cython_runtime_dict;
-#endif
- if (unlikely(!__pyx_cython_runtime)) {
- return c_line;
- }
- __Pyx_ErrFetchInState(tstate, &ptype, &pvalue, &ptraceback);
-#if CYTHON_COMPILING_IN_CPYTHON
- cython_runtime_dict = _PyObject_GetDictPtr(__pyx_cython_runtime);
- if (likely(cython_runtime_dict)) {
- __PYX_PY_DICT_LOOKUP_IF_MODIFIED(
- use_cline, *cython_runtime_dict,
- __Pyx_PyDict_GetItemStr(*cython_runtime_dict, __pyx_n_s_cline_in_traceback))
- } else
-#endif
- {
- PyObject *use_cline_obj = __Pyx_PyObject_GetAttrStr(__pyx_cython_runtime, __pyx_n_s_cline_in_traceback);
- if (use_cline_obj) {
- use_cline = PyObject_Not(use_cline_obj) ? Py_False : Py_True;
- Py_DECREF(use_cline_obj);
- } else {
- PyErr_Clear();
- use_cline = NULL;
- }
- }
- if (!use_cline) {
- c_line = 0;
- (void) PyObject_SetAttr(__pyx_cython_runtime, __pyx_n_s_cline_in_traceback, Py_False);
- }
- else if (use_cline == Py_False || (use_cline != Py_True && PyObject_Not(use_cline) != 0)) {
- c_line = 0;
- }
- __Pyx_ErrRestoreInState(tstate, ptype, pvalue, ptraceback);
- return c_line;
-}
-#endif
-
-/* CodeObjectCache */
-static int __pyx_bisect_code_objects(__Pyx_CodeObjectCacheEntry* entries, int count, int code_line) {
- int start = 0, mid = 0, end = count - 1;
- if (end >= 0 && code_line > entries[end].code_line) {
- return count;
- }
- while (start < end) {
- mid = start + (end - start) / 2;
- if (code_line < entries[mid].code_line) {
- end = mid;
- } else if (code_line > entries[mid].code_line) {
- start = mid + 1;
- } else {
- return mid;
- }
- }
- if (code_line <= entries[mid].code_line) {
- return mid;
- } else {
- return mid + 1;
- }
-}
-static PyCodeObject *__pyx_find_code_object(int code_line) {
- PyCodeObject* code_object;
- int pos;
- if (unlikely(!code_line) || unlikely(!__pyx_code_cache.entries)) {
- return NULL;
- }
- pos = __pyx_bisect_code_objects(__pyx_code_cache.entries, __pyx_code_cache.count, code_line);
- if (unlikely(pos >= __pyx_code_cache.count) || unlikely(__pyx_code_cache.entries[pos].code_line != code_line)) {
- return NULL;
- }
- code_object = __pyx_code_cache.entries[pos].code_object;
- Py_INCREF(code_object);
- return code_object;
-}
-static void __pyx_insert_code_object(int code_line, PyCodeObject* code_object) {
- int pos, i;
- __Pyx_CodeObjectCacheEntry* entries = __pyx_code_cache.entries;
- if (unlikely(!code_line)) {
- return;
- }
- if (unlikely(!entries)) {
- entries = (__Pyx_CodeObjectCacheEntry*)PyMem_Malloc(64*sizeof(__Pyx_CodeObjectCacheEntry));
- if (likely(entries)) {
- __pyx_code_cache.entries = entries;
- __pyx_code_cache.max_count = 64;
- __pyx_code_cache.count = 1;
- entries[0].code_line = code_line;
- entries[0].code_object = code_object;
- Py_INCREF(code_object);
- }
- return;
- }
- pos = __pyx_bisect_code_objects(__pyx_code_cache.entries, __pyx_code_cache.count, code_line);
- if ((pos < __pyx_code_cache.count) && unlikely(__pyx_code_cache.entries[pos].code_line == code_line)) {
- PyCodeObject* tmp = entries[pos].code_object;
- entries[pos].code_object = code_object;
- Py_DECREF(tmp);
- return;
- }
- if (__pyx_code_cache.count == __pyx_code_cache.max_count) {
- int new_max = __pyx_code_cache.max_count + 64;
- entries = (__Pyx_CodeObjectCacheEntry*)PyMem_Realloc(
- __pyx_code_cache.entries, ((size_t)new_max) * sizeof(__Pyx_CodeObjectCacheEntry));
- if (unlikely(!entries)) {
- return;
- }
- __pyx_code_cache.entries = entries;
- __pyx_code_cache.max_count = new_max;
- }
- for (i=__pyx_code_cache.count; i>pos; i--) {
- entries[i] = entries[i-1];
- }
- entries[pos].code_line = code_line;
- entries[pos].code_object = code_object;
- __pyx_code_cache.count++;
- Py_INCREF(code_object);
-}
-
-/* AddTraceback */
-#include "compile.h"
-#include "frameobject.h"
-#include "traceback.h"
-#if PY_VERSION_HEX >= 0x030b00a6
- #ifndef Py_BUILD_CORE
- #define Py_BUILD_CORE 1
- #endif
- #include "internal/pycore_frame.h"
-#endif
-static PyCodeObject* __Pyx_CreateCodeObjectForTraceback(
- const char *funcname, int c_line,
- int py_line, const char *filename) {
- PyCodeObject *py_code = NULL;
- PyObject *py_funcname = NULL;
- #if PY_MAJOR_VERSION < 3
- PyObject *py_srcfile = NULL;
- py_srcfile = PyString_FromString(filename);
- if (!py_srcfile) goto bad;
- #endif
- if (c_line) {
- #if PY_MAJOR_VERSION < 3
- py_funcname = PyString_FromFormat( "%s (%s:%d)", funcname, __pyx_cfilenm, c_line);
- if (!py_funcname) goto bad;
- #else
- py_funcname = PyUnicode_FromFormat( "%s (%s:%d)", funcname, __pyx_cfilenm, c_line);
- if (!py_funcname) goto bad;
- funcname = PyUnicode_AsUTF8(py_funcname);
- if (!funcname) goto bad;
- #endif
- }
- else {
- #if PY_MAJOR_VERSION < 3
- py_funcname = PyString_FromString(funcname);
- if (!py_funcname) goto bad;
- #endif
- }
- #if PY_MAJOR_VERSION < 3
- py_code = __Pyx_PyCode_New(
- 0,
- 0,
- 0,
- 0,
- 0,
- __pyx_empty_bytes, /*PyObject *code,*/
- __pyx_empty_tuple, /*PyObject *consts,*/
- __pyx_empty_tuple, /*PyObject *names,*/
- __pyx_empty_tuple, /*PyObject *varnames,*/
- __pyx_empty_tuple, /*PyObject *freevars,*/
- __pyx_empty_tuple, /*PyObject *cellvars,*/
- py_srcfile, /*PyObject *filename,*/
- py_funcname, /*PyObject *name,*/
- py_line,
- __pyx_empty_bytes /*PyObject *lnotab*/
- );
- Py_DECREF(py_srcfile);
- #else
- py_code = PyCode_NewEmpty(filename, funcname, py_line);
- #endif
- Py_XDECREF(py_funcname); // XDECREF since it's only set on Py3 if cline
- return py_code;
-bad:
- Py_XDECREF(py_funcname);
- #if PY_MAJOR_VERSION < 3
- Py_XDECREF(py_srcfile);
- #endif
- return NULL;
-}
-static void __Pyx_AddTraceback(const char *funcname, int c_line,
- int py_line, const char *filename) {
- PyCodeObject *py_code = 0;
- PyFrameObject *py_frame = 0;
- PyThreadState *tstate = __Pyx_PyThreadState_Current;
- PyObject *ptype, *pvalue, *ptraceback;
- if (c_line) {
- c_line = __Pyx_CLineForTraceback(tstate, c_line);
- }
- py_code = __pyx_find_code_object(c_line ? -c_line : py_line);
- if (!py_code) {
- __Pyx_ErrFetchInState(tstate, &ptype, &pvalue, &ptraceback);
- py_code = __Pyx_CreateCodeObjectForTraceback(
- funcname, c_line, py_line, filename);
- if (!py_code) {
- /* If the code object creation fails, then we should clear the
- fetched exception references and propagate the new exception */
- Py_XDECREF(ptype);
- Py_XDECREF(pvalue);
- Py_XDECREF(ptraceback);
- goto bad;
- }
- __Pyx_ErrRestoreInState(tstate, ptype, pvalue, ptraceback);
- __pyx_insert_code_object(c_line ? -c_line : py_line, py_code);
- }
- py_frame = PyFrame_New(
- tstate, /*PyThreadState *tstate,*/
- py_code, /*PyCodeObject *code,*/
- __pyx_d, /*PyObject *globals,*/
- 0 /*PyObject *locals*/
- );
- if (!py_frame) goto bad;
- __Pyx_PyFrame_SetLineNumber(py_frame, py_line);
- PyTraceBack_Here(py_frame);
-bad:
- Py_XDECREF(py_code);
- Py_XDECREF(py_frame);
-}
-
-#if PY_MAJOR_VERSION < 3
-static int __Pyx_GetBuffer(PyObject *obj, Py_buffer *view, int flags) {
- if (PyObject_CheckBuffer(obj)) return PyObject_GetBuffer(obj, view, flags);
- if (__Pyx_TypeCheck(obj, __pyx_array_type)) return __pyx_array_getbuffer(obj, view, flags);
- if (__Pyx_TypeCheck(obj, __pyx_memoryview_type)) return __pyx_memoryview_getbuffer(obj, view, flags);
- PyErr_Format(PyExc_TypeError, "'%.200s' does not have the buffer interface", Py_TYPE(obj)->tp_name);
- return -1;
-}
-static void __Pyx_ReleaseBuffer(Py_buffer *view) {
- PyObject *obj = view->obj;
- if (!obj) return;
- if (PyObject_CheckBuffer(obj)) {
- PyBuffer_Release(view);
- return;
- }
- if ((0)) {}
- view->obj = NULL;
- Py_DECREF(obj);
-}
-#endif
-
-
-/* MemviewSliceIsContig */
-static int
-__pyx_memviewslice_is_contig(const __Pyx_memviewslice mvs, char order, int ndim)
-{
- int i, index, step, start;
- Py_ssize_t itemsize = mvs.memview->view.itemsize;
- if (order == 'F') {
- step = 1;
- start = 0;
- } else {
- step = -1;
- start = ndim - 1;
- }
- for (i = 0; i < ndim; i++) {
- index = start + step * i;
- if (mvs.suboffsets[index] >= 0 || mvs.strides[index] != itemsize)
- return 0;
- itemsize *= mvs.shape[index];
- }
- return 1;
-}
-
-/* OverlappingSlices */
-static void
-__pyx_get_array_memory_extents(__Pyx_memviewslice *slice,
- void **out_start, void **out_end,
- int ndim, size_t itemsize)
-{
- char *start, *end;
- int i;
- start = end = slice->data;
- for (i = 0; i < ndim; i++) {
- Py_ssize_t stride = slice->strides[i];
- Py_ssize_t extent = slice->shape[i];
- if (extent == 0) {
- *out_start = *out_end = start;
- return;
- } else {
- if (stride > 0)
- end += stride * (extent - 1);
- else
- start += stride * (extent - 1);
- }
- }
- *out_start = start;
- *out_end = end + itemsize;
-}
-static int
-__pyx_slices_overlap(__Pyx_memviewslice *slice1,
- __Pyx_memviewslice *slice2,
- int ndim, size_t itemsize)
-{
- void *start1, *end1, *start2, *end2;
- __pyx_get_array_memory_extents(slice1, &start1, &end1, ndim, itemsize);
- __pyx_get_array_memory_extents(slice2, &start2, &end2, ndim, itemsize);
- return (start1 < end2) && (start2 < end1);
-}
-
-/* Capsule */
-static CYTHON_INLINE PyObject *
-__pyx_capsule_create(void *p, CYTHON_UNUSED const char *sig)
-{
- PyObject *cobj;
-#if PY_VERSION_HEX >= 0x02070000
- cobj = PyCapsule_New(p, sig, NULL);
-#else
- cobj = PyCObject_FromVoidPtr(p, NULL);
-#endif
- return cobj;
-}
-
-/* IsLittleEndian */
-static CYTHON_INLINE int __Pyx_Is_Little_Endian(void)
-{
- union {
- uint32_t u32;
- uint8_t u8[4];
- } S;
- S.u32 = 0x01020304;
- return S.u8[0] == 4;
-}
-
-/* BufferFormatCheck */
-static void __Pyx_BufFmt_Init(__Pyx_BufFmt_Context* ctx,
- __Pyx_BufFmt_StackElem* stack,
- __Pyx_TypeInfo* type) {
- stack[0].field = &ctx->root;
- stack[0].parent_offset = 0;
- ctx->root.type = type;
- ctx->root.name = "buffer dtype";
- ctx->root.offset = 0;
- ctx->head = stack;
- ctx->head->field = &ctx->root;
- ctx->fmt_offset = 0;
- ctx->head->parent_offset = 0;
- ctx->new_packmode = '@';
- ctx->enc_packmode = '@';
- ctx->new_count = 1;
- ctx->enc_count = 0;
- ctx->enc_type = 0;
- ctx->is_complex = 0;
- ctx->is_valid_array = 0;
- ctx->struct_alignment = 0;
- while (type->typegroup == 'S') {
- ++ctx->head;
- ctx->head->field = type->fields;
- ctx->head->parent_offset = 0;
- type = type->fields->type;
- }
-}
-static int __Pyx_BufFmt_ParseNumber(const char** ts) {
- int count;
- const char* t = *ts;
- if (*t < '0' || *t > '9') {
- return -1;
- } else {
- count = *t++ - '0';
- while (*t >= '0' && *t <= '9') {
- count *= 10;
- count += *t++ - '0';
- }
- }
- *ts = t;
- return count;
-}
-static int __Pyx_BufFmt_ExpectNumber(const char **ts) {
- int number = __Pyx_BufFmt_ParseNumber(ts);
- if (number == -1)
- PyErr_Format(PyExc_ValueError,\
- "Does not understand character buffer dtype format string ('%c')", **ts);
- return number;
-}
-static void __Pyx_BufFmt_RaiseUnexpectedChar(char ch) {
- PyErr_Format(PyExc_ValueError,
- "Unexpected format string character: '%c'", ch);
-}
-static const char* __Pyx_BufFmt_DescribeTypeChar(char ch, int is_complex) {
- switch (ch) {
- case '?': return "'bool'";
- case 'c': return "'char'";
- case 'b': return "'signed char'";
- case 'B': return "'unsigned char'";
- case 'h': return "'short'";
- case 'H': return "'unsigned short'";
- case 'i': return "'int'";
- case 'I': return "'unsigned int'";
- case 'l': return "'long'";
- case 'L': return "'unsigned long'";
- case 'q': return "'long long'";
- case 'Q': return "'unsigned long long'";
- case 'f': return (is_complex ? "'complex float'" : "'float'");
- case 'd': return (is_complex ? "'complex double'" : "'double'");
- case 'g': return (is_complex ? "'complex long double'" : "'long double'");
- case 'T': return "a struct";
- case 'O': return "Python object";
- case 'P': return "a pointer";
- case 's': case 'p': return "a string";
- case 0: return "end";
- default: return "unparseable format string";
- }
-}
-static size_t __Pyx_BufFmt_TypeCharToStandardSize(char ch, int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return 2;
- case 'i': case 'I': case 'l': case 'L': return 4;
- case 'q': case 'Q': return 8;
- case 'f': return (is_complex ? 8 : 4);
- case 'd': return (is_complex ? 16 : 8);
- case 'g': {
- PyErr_SetString(PyExc_ValueError, "Python does not define a standard format string size for long double ('g')..");
- return 0;
- }
- case 'O': case 'P': return sizeof(void*);
- default:
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
-}
-static size_t __Pyx_BufFmt_TypeCharToNativeSize(char ch, int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return sizeof(short);
- case 'i': case 'I': return sizeof(int);
- case 'l': case 'L': return sizeof(long);
- #ifdef HAVE_LONG_LONG
- case 'q': case 'Q': return sizeof(PY_LONG_LONG);
- #endif
- case 'f': return sizeof(float) * (is_complex ? 2 : 1);
- case 'd': return sizeof(double) * (is_complex ? 2 : 1);
- case 'g': return sizeof(long double) * (is_complex ? 2 : 1);
- case 'O': case 'P': return sizeof(void*);
- default: {
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
- }
-}
-typedef struct { char c; short x; } __Pyx_st_short;
-typedef struct { char c; int x; } __Pyx_st_int;
-typedef struct { char c; long x; } __Pyx_st_long;
-typedef struct { char c; float x; } __Pyx_st_float;
-typedef struct { char c; double x; } __Pyx_st_double;
-typedef struct { char c; long double x; } __Pyx_st_longdouble;
-typedef struct { char c; void *x; } __Pyx_st_void_p;
-#ifdef HAVE_LONG_LONG
-typedef struct { char c; PY_LONG_LONG x; } __Pyx_st_longlong;
-#endif
-static size_t __Pyx_BufFmt_TypeCharToAlignment(char ch, CYTHON_UNUSED int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return sizeof(__Pyx_st_short) - sizeof(short);
- case 'i': case 'I': return sizeof(__Pyx_st_int) - sizeof(int);
- case 'l': case 'L': return sizeof(__Pyx_st_long) - sizeof(long);
-#ifdef HAVE_LONG_LONG
- case 'q': case 'Q': return sizeof(__Pyx_st_longlong) - sizeof(PY_LONG_LONG);
-#endif
- case 'f': return sizeof(__Pyx_st_float) - sizeof(float);
- case 'd': return sizeof(__Pyx_st_double) - sizeof(double);
- case 'g': return sizeof(__Pyx_st_longdouble) - sizeof(long double);
- case 'P': case 'O': return sizeof(__Pyx_st_void_p) - sizeof(void*);
- default:
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
-}
-/* These are for computing the padding at the end of the struct to align
- on the first member of the struct. This will probably the same as above,
- but we don't have any guarantees.
- */
-typedef struct { short x; char c; } __Pyx_pad_short;
-typedef struct { int x; char c; } __Pyx_pad_int;
-typedef struct { long x; char c; } __Pyx_pad_long;
-typedef struct { float x; char c; } __Pyx_pad_float;
-typedef struct { double x; char c; } __Pyx_pad_double;
-typedef struct { long double x; char c; } __Pyx_pad_longdouble;
-typedef struct { void *x; char c; } __Pyx_pad_void_p;
-#ifdef HAVE_LONG_LONG
-typedef struct { PY_LONG_LONG x; char c; } __Pyx_pad_longlong;
-#endif
-static size_t __Pyx_BufFmt_TypeCharToPadding(char ch, CYTHON_UNUSED int is_complex) {
- switch (ch) {
- case '?': case 'c': case 'b': case 'B': case 's': case 'p': return 1;
- case 'h': case 'H': return sizeof(__Pyx_pad_short) - sizeof(short);
- case 'i': case 'I': return sizeof(__Pyx_pad_int) - sizeof(int);
- case 'l': case 'L': return sizeof(__Pyx_pad_long) - sizeof(long);
-#ifdef HAVE_LONG_LONG
- case 'q': case 'Q': return sizeof(__Pyx_pad_longlong) - sizeof(PY_LONG_LONG);
-#endif
- case 'f': return sizeof(__Pyx_pad_float) - sizeof(float);
- case 'd': return sizeof(__Pyx_pad_double) - sizeof(double);
- case 'g': return sizeof(__Pyx_pad_longdouble) - sizeof(long double);
- case 'P': case 'O': return sizeof(__Pyx_pad_void_p) - sizeof(void*);
- default:
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
-}
-static char __Pyx_BufFmt_TypeCharToGroup(char ch, int is_complex) {
- switch (ch) {
- case 'c':
- return 'H';
- case 'b': case 'h': case 'i':
- case 'l': case 'q': case 's': case 'p':
- return 'I';
- case '?': case 'B': case 'H': case 'I': case 'L': case 'Q':
- return 'U';
- case 'f': case 'd': case 'g':
- return (is_complex ? 'C' : 'R');
- case 'O':
- return 'O';
- case 'P':
- return 'P';
- default: {
- __Pyx_BufFmt_RaiseUnexpectedChar(ch);
- return 0;
- }
- }
-}
-static void __Pyx_BufFmt_RaiseExpected(__Pyx_BufFmt_Context* ctx) {
- if (ctx->head == NULL || ctx->head->field == &ctx->root) {
- const char* expected;
- const char* quote;
- if (ctx->head == NULL) {
- expected = "end";
- quote = "";
- } else {
- expected = ctx->head->field->type->name;
- quote = "'";
- }
- PyErr_Format(PyExc_ValueError,
- "Buffer dtype mismatch, expected %s%s%s but got %s",
- quote, expected, quote,
- __Pyx_BufFmt_DescribeTypeChar(ctx->enc_type, ctx->is_complex));
- } else {
- __Pyx_StructField* field = ctx->head->field;
- __Pyx_StructField* parent = (ctx->head - 1)->field;
- PyErr_Format(PyExc_ValueError,
- "Buffer dtype mismatch, expected '%s' but got %s in '%s.%s'",
- field->type->name, __Pyx_BufFmt_DescribeTypeChar(ctx->enc_type, ctx->is_complex),
- parent->type->name, field->name);
- }
-}
-static int __Pyx_BufFmt_ProcessTypeChunk(__Pyx_BufFmt_Context* ctx) {
- char group;
- size_t size, offset, arraysize = 1;
- if (ctx->enc_type == 0) return 0;
- if (ctx->head->field->type->arraysize[0]) {
- int i, ndim = 0;
- if (ctx->enc_type == 's' || ctx->enc_type == 'p') {
- ctx->is_valid_array = ctx->head->field->type->ndim == 1;
- ndim = 1;
- if (ctx->enc_count != ctx->head->field->type->arraysize[0]) {
- PyErr_Format(PyExc_ValueError,
- "Expected a dimension of size %zu, got %zu",
- ctx->head->field->type->arraysize[0], ctx->enc_count);
- return -1;
- }
- }
- if (!ctx->is_valid_array) {
- PyErr_Format(PyExc_ValueError, "Expected %d dimensions, got %d",
- ctx->head->field->type->ndim, ndim);
- return -1;
- }
- for (i = 0; i < ctx->head->field->type->ndim; i++) {
- arraysize *= ctx->head->field->type->arraysize[i];
- }
- ctx->is_valid_array = 0;
- ctx->enc_count = 1;
- }
- group = __Pyx_BufFmt_TypeCharToGroup(ctx->enc_type, ctx->is_complex);
- do {
- __Pyx_StructField* field = ctx->head->field;
- __Pyx_TypeInfo* type = field->type;
- if (ctx->enc_packmode == '@' || ctx->enc_packmode == '^') {
- size = __Pyx_BufFmt_TypeCharToNativeSize(ctx->enc_type, ctx->is_complex);
- } else {
- size = __Pyx_BufFmt_TypeCharToStandardSize(ctx->enc_type, ctx->is_complex);
- }
- if (ctx->enc_packmode == '@') {
- size_t align_at = __Pyx_BufFmt_TypeCharToAlignment(ctx->enc_type, ctx->is_complex);
- size_t align_mod_offset;
- if (align_at == 0) return -1;
- align_mod_offset = ctx->fmt_offset % align_at;
- if (align_mod_offset > 0) ctx->fmt_offset += align_at - align_mod_offset;
- if (ctx->struct_alignment == 0)
- ctx->struct_alignment = __Pyx_BufFmt_TypeCharToPadding(ctx->enc_type,
- ctx->is_complex);
- }
- if (type->size != size || type->typegroup != group) {
- if (type->typegroup == 'C' && type->fields != NULL) {
- size_t parent_offset = ctx->head->parent_offset + field->offset;
- ++ctx->head;
- ctx->head->field = type->fields;
- ctx->head->parent_offset = parent_offset;
- continue;
- }
- if ((type->typegroup == 'H' || group == 'H') && type->size == size) {
- } else {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return -1;
- }
- }
- offset = ctx->head->parent_offset + field->offset;
- if (ctx->fmt_offset != offset) {
- PyErr_Format(PyExc_ValueError,
- "Buffer dtype mismatch; next field is at offset %" CYTHON_FORMAT_SSIZE_T "d but %" CYTHON_FORMAT_SSIZE_T "d expected",
- (Py_ssize_t)ctx->fmt_offset, (Py_ssize_t)offset);
- return -1;
- }
- ctx->fmt_offset += size;
- if (arraysize)
- ctx->fmt_offset += (arraysize - 1) * size;
- --ctx->enc_count;
- while (1) {
- if (field == &ctx->root) {
- ctx->head = NULL;
- if (ctx->enc_count != 0) {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return -1;
- }
- break;
- }
- ctx->head->field = ++field;
- if (field->type == NULL) {
- --ctx->head;
- field = ctx->head->field;
- continue;
- } else if (field->type->typegroup == 'S') {
- size_t parent_offset = ctx->head->parent_offset + field->offset;
- if (field->type->fields->type == NULL) continue;
- field = field->type->fields;
- ++ctx->head;
- ctx->head->field = field;
- ctx->head->parent_offset = parent_offset;
- break;
- } else {
- break;
- }
- }
- } while (ctx->enc_count);
- ctx->enc_type = 0;
- ctx->is_complex = 0;
- return 0;
-}
-static PyObject *
-__pyx_buffmt_parse_array(__Pyx_BufFmt_Context* ctx, const char** tsp)
-{
- const char *ts = *tsp;
- int i = 0, number, ndim;
- ++ts;
- if (ctx->new_count != 1) {
- PyErr_SetString(PyExc_ValueError,
- "Cannot handle repeated arrays in format string");
- return NULL;
- }
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ndim = ctx->head->field->type->ndim;
- while (*ts && *ts != ')') {
- switch (*ts) {
- case ' ': case '\f': case '\r': case '\n': case '\t': case '\v': continue;
- default: break;
- }
- number = __Pyx_BufFmt_ExpectNumber(&ts);
- if (number == -1) return NULL;
- if (i < ndim && (size_t) number != ctx->head->field->type->arraysize[i])
- return PyErr_Format(PyExc_ValueError,
- "Expected a dimension of size %zu, got %d",
- ctx->head->field->type->arraysize[i], number);
- if (*ts != ',' && *ts != ')')
- return PyErr_Format(PyExc_ValueError,
- "Expected a comma in format string, got '%c'", *ts);
- if (*ts == ',') ts++;
- i++;
- }
- if (i != ndim)
- return PyErr_Format(PyExc_ValueError, "Expected %d dimension(s), got %d",
- ctx->head->field->type->ndim, i);
- if (!*ts) {
- PyErr_SetString(PyExc_ValueError,
- "Unexpected end of format string, expected ')'");
- return NULL;
- }
- ctx->is_valid_array = 1;
- ctx->new_count = 1;
- *tsp = ++ts;
- return Py_None;
-}
-static const char* __Pyx_BufFmt_CheckString(__Pyx_BufFmt_Context* ctx, const char* ts) {
- int got_Z = 0;
- while (1) {
- switch(*ts) {
- case 0:
- if (ctx->enc_type != 0 && ctx->head == NULL) {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return NULL;
- }
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- if (ctx->head != NULL) {
- __Pyx_BufFmt_RaiseExpected(ctx);
- return NULL;
- }
- return ts;
- case ' ':
- case '\r':
- case '\n':
- ++ts;
- break;
- case '<':
- if (!__Pyx_Is_Little_Endian()) {
- PyErr_SetString(PyExc_ValueError, "Little-endian buffer not supported on big-endian compiler");
- return NULL;
- }
- ctx->new_packmode = '=';
- ++ts;
- break;
- case '>':
- case '!':
- if (__Pyx_Is_Little_Endian()) {
- PyErr_SetString(PyExc_ValueError, "Big-endian buffer not supported on little-endian compiler");
- return NULL;
- }
- ctx->new_packmode = '=';
- ++ts;
- break;
- case '=':
- case '@':
- case '^':
- ctx->new_packmode = *ts++;
- break;
- case 'T':
- {
- const char* ts_after_sub;
- size_t i, struct_count = ctx->new_count;
- size_t struct_alignment = ctx->struct_alignment;
- ctx->new_count = 1;
- ++ts;
- if (*ts != '{') {
- PyErr_SetString(PyExc_ValueError, "Buffer acquisition: Expected '{' after 'T'");
- return NULL;
- }
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->enc_type = 0;
- ctx->enc_count = 0;
- ctx->struct_alignment = 0;
- ++ts;
- ts_after_sub = ts;
- for (i = 0; i != struct_count; ++i) {
- ts_after_sub = __Pyx_BufFmt_CheckString(ctx, ts);
- if (!ts_after_sub) return NULL;
- }
- ts = ts_after_sub;
- if (struct_alignment) ctx->struct_alignment = struct_alignment;
- }
- break;
- case '}':
- {
- size_t alignment = ctx->struct_alignment;
- ++ts;
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->enc_type = 0;
- if (alignment && ctx->fmt_offset % alignment) {
- ctx->fmt_offset += alignment - (ctx->fmt_offset % alignment);
- }
- }
- return ts;
- case 'x':
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->fmt_offset += ctx->new_count;
- ctx->new_count = 1;
- ctx->enc_count = 0;
- ctx->enc_type = 0;
- ctx->enc_packmode = ctx->new_packmode;
- ++ts;
- break;
- case 'Z':
- got_Z = 1;
- ++ts;
- if (*ts != 'f' && *ts != 'd' && *ts != 'g') {
- __Pyx_BufFmt_RaiseUnexpectedChar('Z');
- return NULL;
- }
- CYTHON_FALLTHROUGH;
- case '?': case 'c': case 'b': case 'B': case 'h': case 'H': case 'i': case 'I':
- case 'l': case 'L': case 'q': case 'Q':
- case 'f': case 'd': case 'g':
- case 'O': case 'p':
- if ((ctx->enc_type == *ts) && (got_Z == ctx->is_complex) &&
- (ctx->enc_packmode == ctx->new_packmode) && (!ctx->is_valid_array)) {
- ctx->enc_count += ctx->new_count;
- ctx->new_count = 1;
- got_Z = 0;
- ++ts;
- break;
- }
- CYTHON_FALLTHROUGH;
- case 's':
- if (__Pyx_BufFmt_ProcessTypeChunk(ctx) == -1) return NULL;
- ctx->enc_count = ctx->new_count;
- ctx->enc_packmode = ctx->new_packmode;
- ctx->enc_type = *ts;
- ctx->is_complex = got_Z;
- ++ts;
- ctx->new_count = 1;
- got_Z = 0;
- break;
- case ':':
- ++ts;
- while(*ts != ':') ++ts;
- ++ts;
- break;
- case '(':
- if (!__pyx_buffmt_parse_array(ctx, &ts)) return NULL;
- break;
- default:
- {
- int number = __Pyx_BufFmt_ExpectNumber(&ts);
- if (number == -1) return NULL;
- ctx->new_count = (size_t)number;
- }
- }
- }
-}
-
-/* TypeInfoCompare */
- static int
-__pyx_typeinfo_cmp(__Pyx_TypeInfo *a, __Pyx_TypeInfo *b)
-{
- int i;
- if (!a || !b)
- return 0;
- if (a == b)
- return 1;
- if (a->size != b->size || a->typegroup != b->typegroup ||
- a->is_unsigned != b->is_unsigned || a->ndim != b->ndim) {
- if (a->typegroup == 'H' || b->typegroup == 'H') {
- return a->size == b->size;
- } else {
- return 0;
- }
- }
- if (a->ndim) {
- for (i = 0; i < a->ndim; i++)
- if (a->arraysize[i] != b->arraysize[i])
- return 0;
- }
- if (a->typegroup == 'S') {
- if (a->flags != b->flags)
- return 0;
- if (a->fields || b->fields) {
- if (!(a->fields && b->fields))
- return 0;
- for (i = 0; a->fields[i].type && b->fields[i].type; i++) {
- __Pyx_StructField *field_a = a->fields + i;
- __Pyx_StructField *field_b = b->fields + i;
- if (field_a->offset != field_b->offset ||
- !__pyx_typeinfo_cmp(field_a->type, field_b->type))
- return 0;
- }
- return !a->fields[i].type && !b->fields[i].type;
- }
- }
- return 1;
-}
-
-/* MemviewSliceValidateAndInit */
- static int
-__pyx_check_strides(Py_buffer *buf, int dim, int ndim, int spec)
-{
- if (buf->shape[dim] <= 1)
- return 1;
- if (buf->strides) {
- if (spec & __Pyx_MEMVIEW_CONTIG) {
- if (spec & (__Pyx_MEMVIEW_PTR|__Pyx_MEMVIEW_FULL)) {
- if (unlikely(buf->strides[dim] != sizeof(void *))) {
- PyErr_Format(PyExc_ValueError,
- "Buffer is not indirectly contiguous "
- "in dimension %d.", dim);
- goto fail;
- }
- } else if (unlikely(buf->strides[dim] != buf->itemsize)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer and memoryview are not contiguous "
- "in the same dimension.");
- goto fail;
- }
- }
- if (spec & __Pyx_MEMVIEW_FOLLOW) {
- Py_ssize_t stride = buf->strides[dim];
- if (stride < 0)
- stride = -stride;
- if (unlikely(stride < buf->itemsize)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer and memoryview are not contiguous "
- "in the same dimension.");
- goto fail;
- }
- }
- } else {
- if (unlikely(spec & __Pyx_MEMVIEW_CONTIG && dim != ndim - 1)) {
- PyErr_Format(PyExc_ValueError,
- "C-contiguous buffer is not contiguous in "
- "dimension %d", dim);
- goto fail;
- } else if (unlikely(spec & (__Pyx_MEMVIEW_PTR))) {
- PyErr_Format(PyExc_ValueError,
- "C-contiguous buffer is not indirect in "
- "dimension %d", dim);
- goto fail;
- } else if (unlikely(buf->suboffsets)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer exposes suboffsets but no strides");
- goto fail;
- }
- }
- return 1;
-fail:
- return 0;
-}
-static int
-__pyx_check_suboffsets(Py_buffer *buf, int dim, CYTHON_UNUSED int ndim, int spec)
-{
- if (spec & __Pyx_MEMVIEW_DIRECT) {
- if (unlikely(buf->suboffsets && buf->suboffsets[dim] >= 0)) {
- PyErr_Format(PyExc_ValueError,
- "Buffer not compatible with direct access "
- "in dimension %d.", dim);
- goto fail;
- }
- }
- if (spec & __Pyx_MEMVIEW_PTR) {
- if (unlikely(!buf->suboffsets || (buf->suboffsets[dim] < 0))) {
- PyErr_Format(PyExc_ValueError,
- "Buffer is not indirectly accessible "
- "in dimension %d.", dim);
- goto fail;
- }
- }
- return 1;
-fail:
- return 0;
-}
-static int
-__pyx_verify_contig(Py_buffer *buf, int ndim, int c_or_f_flag)
-{
- int i;
- if (c_or_f_flag & __Pyx_IS_F_CONTIG) {
- Py_ssize_t stride = 1;
- for (i = 0; i < ndim; i++) {
- if (unlikely(stride * buf->itemsize != buf->strides[i] && buf->shape[i] > 1)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer not fortran contiguous.");
- goto fail;
- }
- stride = stride * buf->shape[i];
- }
- } else if (c_or_f_flag & __Pyx_IS_C_CONTIG) {
- Py_ssize_t stride = 1;
- for (i = ndim - 1; i >- 1; i--) {
- if (unlikely(stride * buf->itemsize != buf->strides[i] && buf->shape[i] > 1)) {
- PyErr_SetString(PyExc_ValueError,
- "Buffer not C contiguous.");
- goto fail;
- }
- stride = stride * buf->shape[i];
- }
- }
- return 1;
-fail:
- return 0;
-}
-static int __Pyx_ValidateAndInit_memviewslice(
- int *axes_specs,
- int c_or_f_flag,
- int buf_flags,
- int ndim,
- __Pyx_TypeInfo *dtype,
- __Pyx_BufFmt_StackElem stack[],
- __Pyx_memviewslice *memviewslice,
- PyObject *original_obj)
-{
- struct __pyx_memoryview_obj *memview, *new_memview;
- __Pyx_RefNannyDeclarations
- Py_buffer *buf;
- int i, spec = 0, retval = -1;
- __Pyx_BufFmt_Context ctx;
- int from_memoryview = __pyx_memoryview_check(original_obj);
- __Pyx_RefNannySetupContext("ValidateAndInit_memviewslice", 0);
- if (from_memoryview && __pyx_typeinfo_cmp(dtype, ((struct __pyx_memoryview_obj *)
- original_obj)->typeinfo)) {
- memview = (struct __pyx_memoryview_obj *) original_obj;
- new_memview = NULL;
- } else {
- memview = (struct __pyx_memoryview_obj *) __pyx_memoryview_new(
- original_obj, buf_flags, 0, dtype);
- new_memview = memview;
- if (unlikely(!memview))
- goto fail;
- }
- buf = &memview->view;
- if (unlikely(buf->ndim != ndim)) {
- PyErr_Format(PyExc_ValueError,
- "Buffer has wrong number of dimensions (expected %d, got %d)",
- ndim, buf->ndim);
- goto fail;
- }
- if (new_memview) {
- __Pyx_BufFmt_Init(&ctx, stack, dtype);
- if (unlikely(!__Pyx_BufFmt_CheckString(&ctx, buf->format))) goto fail;
- }
- if (unlikely((unsigned) buf->itemsize != dtype->size)) {
- PyErr_Format(PyExc_ValueError,
- "Item size of buffer (%" CYTHON_FORMAT_SSIZE_T "u byte%s) "
- "does not match size of '%s' (%" CYTHON_FORMAT_SSIZE_T "u byte%s)",
- buf->itemsize,
- (buf->itemsize > 1) ? "s" : "",
- dtype->name,
- dtype->size,
- (dtype->size > 1) ? "s" : "");
- goto fail;
- }
- if (buf->len > 0) {
- for (i = 0; i < ndim; i++) {
- spec = axes_specs[i];
- if (unlikely(!__pyx_check_strides(buf, i, ndim, spec)))
- goto fail;
- if (unlikely(!__pyx_check_suboffsets(buf, i, ndim, spec)))
- goto fail;
- }
- if (unlikely(buf->strides && !__pyx_verify_contig(buf, ndim, c_or_f_flag)))
- goto fail;
- }
- if (unlikely(__Pyx_init_memviewslice(memview, ndim, memviewslice,
- new_memview != NULL) == -1)) {
- goto fail;
- }
- retval = 0;
- goto no_fail;
-fail:
- Py_XDECREF(new_memview);
- retval = -1;
-no_fail:
- __Pyx_RefNannyFinishContext();
- return retval;
-}
-
-/* ObjectToMemviewSlice */
- static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_int(PyObject *obj, int writable_flag) {
- __Pyx_memviewslice result = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_BufFmt_StackElem stack[1];
- int axes_specs[] = { (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_CONTIG) };
- int retcode;
- if (obj == Py_None) {
- result.memview = (struct __pyx_memoryview_obj *) Py_None;
- return result;
- }
- retcode = __Pyx_ValidateAndInit_memviewslice(axes_specs, __Pyx_IS_C_CONTIG,
- (PyBUF_C_CONTIGUOUS | PyBUF_FORMAT) | writable_flag, 3,
- &__Pyx_TypeInfo_int, stack,
- &result, obj);
- if (unlikely(retcode == -1))
- goto __pyx_fail;
- return result;
-__pyx_fail:
- result.memview = NULL;
- result.data = NULL;
- return result;
-}
-
-/* ObjectToMemviewSlice */
- static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_d_d_dc_float(PyObject *obj, int writable_flag) {
- __Pyx_memviewslice result = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_BufFmt_StackElem stack[1];
- int axes_specs[] = { (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_FOLLOW), (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_CONTIG) };
- int retcode;
- if (obj == Py_None) {
- result.memview = (struct __pyx_memoryview_obj *) Py_None;
- return result;
- }
- retcode = __Pyx_ValidateAndInit_memviewslice(axes_specs, __Pyx_IS_C_CONTIG,
- (PyBUF_C_CONTIGUOUS | PyBUF_FORMAT) | writable_flag, 3,
- &__Pyx_TypeInfo_float, stack,
- &result, obj);
- if (unlikely(retcode == -1))
- goto __pyx_fail;
- return result;
-__pyx_fail:
- result.memview = NULL;
- result.data = NULL;
- return result;
-}
-
-/* ObjectToMemviewSlice */
- static CYTHON_INLINE __Pyx_memviewslice __Pyx_PyObject_to_MemoryviewSlice_dc_int(PyObject *obj, int writable_flag) {
- __Pyx_memviewslice result = { 0, 0, { 0 }, { 0 }, { 0 } };
- __Pyx_BufFmt_StackElem stack[1];
- int axes_specs[] = { (__Pyx_MEMVIEW_DIRECT | __Pyx_MEMVIEW_CONTIG) };
- int retcode;
- if (obj == Py_None) {
- result.memview = (struct __pyx_memoryview_obj *) Py_None;
- return result;
- }
- retcode = __Pyx_ValidateAndInit_memviewslice(axes_specs, __Pyx_IS_C_CONTIG,
- (PyBUF_C_CONTIGUOUS | PyBUF_FORMAT) | writable_flag, 1,
- &__Pyx_TypeInfo_int, stack,
- &result, obj);
- if (unlikely(retcode == -1))
- goto __pyx_fail;
- return result;
-__pyx_fail:
- result.memview = NULL;
- result.data = NULL;
- return result;
-}
-
-/* CIntFromPyVerify */
- #define __PYX_VERIFY_RETURN_INT(target_type, func_type, func_value)\
- __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, 0)
-#define __PYX_VERIFY_RETURN_INT_EXC(target_type, func_type, func_value)\
- __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, 1)
-#define __PYX__VERIFY_RETURN_INT(target_type, func_type, func_value, exc)\
- {\
- func_type value = func_value;\
- if (sizeof(target_type) < sizeof(func_type)) {\
- if (unlikely(value != (func_type) (target_type) value)) {\
- func_type zero = 0;\
- if (exc && unlikely(value == (func_type)-1 && PyErr_Occurred()))\
- return (target_type) -1;\
- if (is_unsigned && unlikely(value < zero))\
- goto raise_neg_overflow;\
- else\
- goto raise_overflow;\
- }\
- }\
- return (target_type) value;\
- }
-
-/* MemviewSliceCopyTemplate */
- static __Pyx_memviewslice
-__pyx_memoryview_copy_new_contig(const __Pyx_memviewslice *from_mvs,
- const char *mode, int ndim,
- size_t sizeof_dtype, int contig_flag,
- int dtype_is_object)
-{
- __Pyx_RefNannyDeclarations
- int i;
- __Pyx_memviewslice new_mvs = { 0, 0, { 0 }, { 0 }, { 0 } };
- struct __pyx_memoryview_obj *from_memview = from_mvs->memview;
- Py_buffer *buf = &from_memview->view;
- PyObject *shape_tuple = NULL;
- PyObject *temp_int = NULL;
- struct __pyx_array_obj *array_obj = NULL;
- struct __pyx_memoryview_obj *memview_obj = NULL;
- __Pyx_RefNannySetupContext("__pyx_memoryview_copy_new_contig", 0);
- for (i = 0; i < ndim; i++) {
- if (unlikely(from_mvs->suboffsets[i] >= 0)) {
- PyErr_Format(PyExc_ValueError, "Cannot copy memoryview slice with "
- "indirect dimensions (axis %d)", i);
- goto fail;
- }
- }
- shape_tuple = PyTuple_New(ndim);
- if (unlikely(!shape_tuple)) {
- goto fail;
- }
- __Pyx_GOTREF(shape_tuple);
- for(i = 0; i < ndim; i++) {
- temp_int = PyInt_FromSsize_t(from_mvs->shape[i]);
- if(unlikely(!temp_int)) {
- goto fail;
- } else {
- PyTuple_SET_ITEM(shape_tuple, i, temp_int);
- temp_int = NULL;
- }
- }
- array_obj = __pyx_array_new(shape_tuple, sizeof_dtype, buf->format, (char *) mode, NULL);
- if (unlikely(!array_obj)) {
- goto fail;
- }
- __Pyx_GOTREF(array_obj);
- memview_obj = (struct __pyx_memoryview_obj *) __pyx_memoryview_new(
- (PyObject *) array_obj, contig_flag,
- dtype_is_object,
- from_mvs->memview->typeinfo);
- if (unlikely(!memview_obj))
- goto fail;
- if (unlikely(__Pyx_init_memviewslice(memview_obj, ndim, &new_mvs, 1) < 0))
- goto fail;
- if (unlikely(__pyx_memoryview_copy_contents(*from_mvs, new_mvs, ndim, ndim,
- dtype_is_object) < 0))
- goto fail;
- goto no_fail;
-fail:
- __Pyx_XDECREF(new_mvs.memview);
- new_mvs.memview = NULL;
- new_mvs.data = NULL;
-no_fail:
- __Pyx_XDECREF(shape_tuple);
- __Pyx_XDECREF(temp_int);
- __Pyx_XDECREF(array_obj);
- __Pyx_RefNannyFinishContext();
- return new_mvs;
-}
-
-/* CIntToPy */
- static CYTHON_INLINE PyObject* __Pyx_PyInt_From_int(int value) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const int neg_one = (int) -1, const_zero = (int) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
- if (is_unsigned) {
- if (sizeof(int) < sizeof(long)) {
- return PyInt_FromLong((long) value);
- } else if (sizeof(int) <= sizeof(unsigned long)) {
- return PyLong_FromUnsignedLong((unsigned long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(unsigned PY_LONG_LONG)) {
- return PyLong_FromUnsignedLongLong((unsigned PY_LONG_LONG) value);
-#endif
- }
- } else {
- if (sizeof(int) <= sizeof(long)) {
- return PyInt_FromLong((long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(PY_LONG_LONG)) {
- return PyLong_FromLongLong((PY_LONG_LONG) value);
-#endif
- }
- }
- {
- int one = 1; int little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&value;
- return _PyLong_FromByteArray(bytes, sizeof(int),
- little, !is_unsigned);
- }
-}
-
-/* CIntFromPy */
- static CYTHON_INLINE int __Pyx_PyInt_As_int(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const int neg_one = (int) -1, const_zero = (int) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if (sizeof(int) < sizeof(long)) {
- __PYX_VERIFY_RETURN_INT(int, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (int) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (int) 0;
- case 1: __PYX_VERIFY_RETURN_INT(int, digit, digits[0])
- case 2:
- if (8 * sizeof(int) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) >= 2 * PyLong_SHIFT) {
- return (int) (((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- case 3:
- if (8 * sizeof(int) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) >= 3 * PyLong_SHIFT) {
- return (int) (((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- case 4:
- if (8 * sizeof(int) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) >= 4 * PyLong_SHIFT) {
- return (int) (((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0]));
- }
- }
- break;
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (int) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if (sizeof(int) <= sizeof(unsigned long)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(unsigned PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (int) 0;
- case -1: __PYX_VERIFY_RETURN_INT(int, sdigit, (sdigit) (-(sdigit)digits[0]))
- case 1: __PYX_VERIFY_RETURN_INT(int, digit, +digits[0])
- case -2:
- if (8 * sizeof(int) - 1 > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 2 * PyLong_SHIFT) {
- return (int) (((int)-1)*(((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 2:
- if (8 * sizeof(int) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 2 * PyLong_SHIFT) {
- return (int) ((((((int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case -3:
- if (8 * sizeof(int) - 1 > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 3 * PyLong_SHIFT) {
- return (int) (((int)-1)*(((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 3:
- if (8 * sizeof(int) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 3 * PyLong_SHIFT) {
- return (int) ((((((((int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case -4:
- if (8 * sizeof(int) - 1 > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 4 * PyLong_SHIFT) {
- return (int) (((int)-1)*(((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- case 4:
- if (8 * sizeof(int) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(int, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(int) - 1 > 4 * PyLong_SHIFT) {
- return (int) ((((((((((int)digits[3]) << PyLong_SHIFT) | (int)digits[2]) << PyLong_SHIFT) | (int)digits[1]) << PyLong_SHIFT) | (int)digits[0])));
- }
- }
- break;
- }
-#endif
- if (sizeof(int) <= sizeof(long)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(int) <= sizeof(PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(int, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
-#if CYTHON_COMPILING_IN_PYPY && !defined(_PyLong_AsByteArray)
- PyErr_SetString(PyExc_RuntimeError,
- "_PyLong_AsByteArray() not available in PyPy, cannot convert large numbers");
-#else
- int val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
- #if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
- #endif
- if (likely(v)) {
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- int ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
-#endif
- return (int) -1;
- }
- } else {
- int val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (int) -1;
- val = __Pyx_PyInt_As_int(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to int");
- return (int) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to int");
- return (int) -1;
-}
-
-/* CIntToPy */
- static CYTHON_INLINE PyObject* __Pyx_PyInt_From_long(long value) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const long neg_one = (long) -1, const_zero = (long) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
- if (is_unsigned) {
- if (sizeof(long) < sizeof(long)) {
- return PyInt_FromLong((long) value);
- } else if (sizeof(long) <= sizeof(unsigned long)) {
- return PyLong_FromUnsignedLong((unsigned long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(unsigned PY_LONG_LONG)) {
- return PyLong_FromUnsignedLongLong((unsigned PY_LONG_LONG) value);
-#endif
- }
- } else {
- if (sizeof(long) <= sizeof(long)) {
- return PyInt_FromLong((long) value);
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(PY_LONG_LONG)) {
- return PyLong_FromLongLong((PY_LONG_LONG) value);
-#endif
- }
- }
- {
- int one = 1; int little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&value;
- return _PyLong_FromByteArray(bytes, sizeof(long),
- little, !is_unsigned);
- }
-}
-
-/* CIntFromPy */
- static CYTHON_INLINE long __Pyx_PyInt_As_long(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const long neg_one = (long) -1, const_zero = (long) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if (sizeof(long) < sizeof(long)) {
- __PYX_VERIFY_RETURN_INT(long, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (long) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (long) 0;
- case 1: __PYX_VERIFY_RETURN_INT(long, digit, digits[0])
- case 2:
- if (8 * sizeof(long) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) >= 2 * PyLong_SHIFT) {
- return (long) (((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- case 3:
- if (8 * sizeof(long) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) >= 3 * PyLong_SHIFT) {
- return (long) (((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- case 4:
- if (8 * sizeof(long) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) >= 4 * PyLong_SHIFT) {
- return (long) (((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0]));
- }
- }
- break;
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (long) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if (sizeof(long) <= sizeof(unsigned long)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(unsigned PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (long) 0;
- case -1: __PYX_VERIFY_RETURN_INT(long, sdigit, (sdigit) (-(sdigit)digits[0]))
- case 1: __PYX_VERIFY_RETURN_INT(long, digit, +digits[0])
- case -2:
- if (8 * sizeof(long) - 1 > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- return (long) (((long)-1)*(((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 2:
- if (8 * sizeof(long) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- return (long) ((((((long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case -3:
- if (8 * sizeof(long) - 1 > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- return (long) (((long)-1)*(((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 3:
- if (8 * sizeof(long) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- return (long) ((((((((long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case -4:
- if (8 * sizeof(long) - 1 > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- return (long) (((long)-1)*(((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- case 4:
- if (8 * sizeof(long) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(long, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(long) - 1 > 4 * PyLong_SHIFT) {
- return (long) ((((((((((long)digits[3]) << PyLong_SHIFT) | (long)digits[2]) << PyLong_SHIFT) | (long)digits[1]) << PyLong_SHIFT) | (long)digits[0])));
- }
- }
- break;
- }
-#endif
- if (sizeof(long) <= sizeof(long)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(long) <= sizeof(PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(long, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
-#if CYTHON_COMPILING_IN_PYPY && !defined(_PyLong_AsByteArray)
- PyErr_SetString(PyExc_RuntimeError,
- "_PyLong_AsByteArray() not available in PyPy, cannot convert large numbers");
-#else
- long val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
- #if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
- #endif
- if (likely(v)) {
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- int ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
-#endif
- return (long) -1;
- }
- } else {
- long val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (long) -1;
- val = __Pyx_PyInt_As_long(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to long");
- return (long) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to long");
- return (long) -1;
-}
-
-/* CIntFromPy */
- static CYTHON_INLINE char __Pyx_PyInt_As_char(PyObject *x) {
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic push
-#pragma GCC diagnostic ignored "-Wconversion"
-#endif
- const char neg_one = (char) -1, const_zero = (char) 0;
-#ifdef __Pyx_HAS_GCC_DIAGNOSTIC
-#pragma GCC diagnostic pop
-#endif
- const int is_unsigned = neg_one > const_zero;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x))) {
- if (sizeof(char) < sizeof(long)) {
- __PYX_VERIFY_RETURN_INT(char, long, PyInt_AS_LONG(x))
- } else {
- long val = PyInt_AS_LONG(x);
- if (is_unsigned && unlikely(val < 0)) {
- goto raise_neg_overflow;
- }
- return (char) val;
- }
- } else
-#endif
- if (likely(PyLong_Check(x))) {
- if (is_unsigned) {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (char) 0;
- case 1: __PYX_VERIFY_RETURN_INT(char, digit, digits[0])
- case 2:
- if (8 * sizeof(char) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) >= 2 * PyLong_SHIFT) {
- return (char) (((((char)digits[1]) << PyLong_SHIFT) | (char)digits[0]));
- }
- }
- break;
- case 3:
- if (8 * sizeof(char) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) >= 3 * PyLong_SHIFT) {
- return (char) (((((((char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0]));
- }
- }
- break;
- case 4:
- if (8 * sizeof(char) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) >= 4 * PyLong_SHIFT) {
- return (char) (((((((((char)digits[3]) << PyLong_SHIFT) | (char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0]));
- }
- }
- break;
- }
-#endif
-#if CYTHON_COMPILING_IN_CPYTHON
- if (unlikely(Py_SIZE(x) < 0)) {
- goto raise_neg_overflow;
- }
-#else
- {
- int result = PyObject_RichCompareBool(x, Py_False, Py_LT);
- if (unlikely(result < 0))
- return (char) -1;
- if (unlikely(result == 1))
- goto raise_neg_overflow;
- }
-#endif
- if (sizeof(char) <= sizeof(unsigned long)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, unsigned long, PyLong_AsUnsignedLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(char) <= sizeof(unsigned PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, unsigned PY_LONG_LONG, PyLong_AsUnsignedLongLong(x))
-#endif
- }
- } else {
-#if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)x)->ob_digit;
- switch (Py_SIZE(x)) {
- case 0: return (char) 0;
- case -1: __PYX_VERIFY_RETURN_INT(char, sdigit, (sdigit) (-(sdigit)digits[0]))
- case 1: __PYX_VERIFY_RETURN_INT(char, digit, +digits[0])
- case -2:
- if (8 * sizeof(char) - 1 > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, long, -(long) (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 2 * PyLong_SHIFT) {
- return (char) (((char)-1)*(((((char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case 2:
- if (8 * sizeof(char) > 1 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 2 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 2 * PyLong_SHIFT) {
- return (char) ((((((char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case -3:
- if (8 * sizeof(char) - 1 > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, long, -(long) (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 3 * PyLong_SHIFT) {
- return (char) (((char)-1)*(((((((char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case 3:
- if (8 * sizeof(char) > 2 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 3 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 3 * PyLong_SHIFT) {
- return (char) ((((((((char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case -4:
- if (8 * sizeof(char) - 1 > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, long, -(long) (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 4 * PyLong_SHIFT) {
- return (char) (((char)-1)*(((((((((char)digits[3]) << PyLong_SHIFT) | (char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- case 4:
- if (8 * sizeof(char) > 3 * PyLong_SHIFT) {
- if (8 * sizeof(unsigned long) > 4 * PyLong_SHIFT) {
- __PYX_VERIFY_RETURN_INT(char, unsigned long, (((((((((unsigned long)digits[3]) << PyLong_SHIFT) | (unsigned long)digits[2]) << PyLong_SHIFT) | (unsigned long)digits[1]) << PyLong_SHIFT) | (unsigned long)digits[0])))
- } else if (8 * sizeof(char) - 1 > 4 * PyLong_SHIFT) {
- return (char) ((((((((((char)digits[3]) << PyLong_SHIFT) | (char)digits[2]) << PyLong_SHIFT) | (char)digits[1]) << PyLong_SHIFT) | (char)digits[0])));
- }
- }
- break;
- }
-#endif
- if (sizeof(char) <= sizeof(long)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, long, PyLong_AsLong(x))
-#ifdef HAVE_LONG_LONG
- } else if (sizeof(char) <= sizeof(PY_LONG_LONG)) {
- __PYX_VERIFY_RETURN_INT_EXC(char, PY_LONG_LONG, PyLong_AsLongLong(x))
-#endif
- }
- }
- {
-#if CYTHON_COMPILING_IN_PYPY && !defined(_PyLong_AsByteArray)
- PyErr_SetString(PyExc_RuntimeError,
- "_PyLong_AsByteArray() not available in PyPy, cannot convert large numbers");
-#else
- char val;
- PyObject *v = __Pyx_PyNumber_IntOrLong(x);
- #if PY_MAJOR_VERSION < 3
- if (likely(v) && !PyLong_Check(v)) {
- PyObject *tmp = v;
- v = PyNumber_Long(tmp);
- Py_DECREF(tmp);
- }
- #endif
- if (likely(v)) {
- int one = 1; int is_little = (int)*(unsigned char *)&one;
- unsigned char *bytes = (unsigned char *)&val;
- int ret = _PyLong_AsByteArray((PyLongObject *)v,
- bytes, sizeof(val),
- is_little, !is_unsigned);
- Py_DECREF(v);
- if (likely(!ret))
- return val;
- }
-#endif
- return (char) -1;
- }
- } else {
- char val;
- PyObject *tmp = __Pyx_PyNumber_IntOrLong(x);
- if (!tmp) return (char) -1;
- val = __Pyx_PyInt_As_char(tmp);
- Py_DECREF(tmp);
- return val;
- }
-raise_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "value too large to convert to char");
- return (char) -1;
-raise_neg_overflow:
- PyErr_SetString(PyExc_OverflowError,
- "can't convert negative value to char");
- return (char) -1;
-}
-
-/* CheckBinaryVersion */
- static int __Pyx_check_binary_version(void) {
- char ctversion[5];
- int same=1, i, found_dot;
- const char* rt_from_call = Py_GetVersion();
- PyOS_snprintf(ctversion, 5, "%d.%d", PY_MAJOR_VERSION, PY_MINOR_VERSION);
- found_dot = 0;
- for (i = 0; i < 4; i++) {
- if (!ctversion[i]) {
- same = (rt_from_call[i] < '0' || rt_from_call[i] > '9');
- break;
- }
- if (rt_from_call[i] != ctversion[i]) {
- same = 0;
- break;
- }
- }
- if (!same) {
- char rtversion[5] = {'\0'};
- char message[200];
- for (i=0; i<4; ++i) {
- if (rt_from_call[i] == '.') {
- if (found_dot) break;
- found_dot = 1;
- } else if (rt_from_call[i] < '0' || rt_from_call[i] > '9') {
- break;
- }
- rtversion[i] = rt_from_call[i];
- }
- PyOS_snprintf(message, sizeof(message),
- "compiletime version %s of module '%.100s' "
- "does not match runtime version %s",
- ctversion, __Pyx_MODULE_NAME, rtversion);
- return PyErr_WarnEx(NULL, message, 1);
- }
- return 0;
-}
-
-/* InitStrings */
- static int __Pyx_InitStrings(__Pyx_StringTabEntry *t) {
- while (t->p) {
- #if PY_MAJOR_VERSION < 3
- if (t->is_unicode) {
- *t->p = PyUnicode_DecodeUTF8(t->s, t->n - 1, NULL);
- } else if (t->intern) {
- *t->p = PyString_InternFromString(t->s);
- } else {
- *t->p = PyString_FromStringAndSize(t->s, t->n - 1);
- }
- #else
- if (t->is_unicode | t->is_str) {
- if (t->intern) {
- *t->p = PyUnicode_InternFromString(t->s);
- } else if (t->encoding) {
- *t->p = PyUnicode_Decode(t->s, t->n - 1, t->encoding, NULL);
- } else {
- *t->p = PyUnicode_FromStringAndSize(t->s, t->n - 1);
- }
- } else {
- *t->p = PyBytes_FromStringAndSize(t->s, t->n - 1);
- }
- #endif
- if (!*t->p)
- return -1;
- if (PyObject_Hash(*t->p) == -1)
- return -1;
- ++t;
- }
- return 0;
-}
-
-static CYTHON_INLINE PyObject* __Pyx_PyUnicode_FromString(const char* c_str) {
- return __Pyx_PyUnicode_FromStringAndSize(c_str, (Py_ssize_t)strlen(c_str));
-}
-static CYTHON_INLINE const char* __Pyx_PyObject_AsString(PyObject* o) {
- Py_ssize_t ignore;
- return __Pyx_PyObject_AsStringAndSize(o, &ignore);
-}
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
-#if !CYTHON_PEP393_ENABLED
-static const char* __Pyx_PyUnicode_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
- char* defenc_c;
- PyObject* defenc = _PyUnicode_AsDefaultEncodedString(o, NULL);
- if (!defenc) return NULL;
- defenc_c = PyBytes_AS_STRING(defenc);
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- {
- char* end = defenc_c + PyBytes_GET_SIZE(defenc);
- char* c;
- for (c = defenc_c; c < end; c++) {
- if ((unsigned char) (*c) >= 128) {
- PyUnicode_AsASCIIString(o);
- return NULL;
- }
- }
- }
-#endif
- *length = PyBytes_GET_SIZE(defenc);
- return defenc_c;
-}
-#else
-static CYTHON_INLINE const char* __Pyx_PyUnicode_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
- if (unlikely(__Pyx_PyUnicode_READY(o) == -1)) return NULL;
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- if (likely(PyUnicode_IS_ASCII(o))) {
- *length = PyUnicode_GET_LENGTH(o);
- return PyUnicode_AsUTF8(o);
- } else {
- PyUnicode_AsASCIIString(o);
- return NULL;
- }
-#else
- return PyUnicode_AsUTF8AndSize(o, length);
-#endif
-}
-#endif
-#endif
-static CYTHON_INLINE const char* __Pyx_PyObject_AsStringAndSize(PyObject* o, Py_ssize_t *length) {
-#if __PYX_DEFAULT_STRING_ENCODING_IS_ASCII || __PYX_DEFAULT_STRING_ENCODING_IS_DEFAULT
- if (
-#if PY_MAJOR_VERSION < 3 && __PYX_DEFAULT_STRING_ENCODING_IS_ASCII
- __Pyx_sys_getdefaultencoding_not_ascii &&
-#endif
- PyUnicode_Check(o)) {
- return __Pyx_PyUnicode_AsStringAndSize(o, length);
- } else
-#endif
-#if (!CYTHON_COMPILING_IN_PYPY) || (defined(PyByteArray_AS_STRING) && defined(PyByteArray_GET_SIZE))
- if (PyByteArray_Check(o)) {
- *length = PyByteArray_GET_SIZE(o);
- return PyByteArray_AS_STRING(o);
- } else
-#endif
- {
- char* result;
- int r = PyBytes_AsStringAndSize(o, &result, length);
- if (unlikely(r < 0)) {
- return NULL;
- } else {
- return result;
- }
- }
-}
-static CYTHON_INLINE int __Pyx_PyObject_IsTrue(PyObject* x) {
- int is_true = x == Py_True;
- if (is_true | (x == Py_False) | (x == Py_None)) return is_true;
- else return PyObject_IsTrue(x);
-}
-static CYTHON_INLINE int __Pyx_PyObject_IsTrueAndDecref(PyObject* x) {
- int retval;
- if (unlikely(!x)) return -1;
- retval = __Pyx_PyObject_IsTrue(x);
- Py_DECREF(x);
- return retval;
-}
-static PyObject* __Pyx_PyNumber_IntOrLongWrongResultType(PyObject* result, const char* type_name) {
-#if PY_MAJOR_VERSION >= 3
- if (PyLong_Check(result)) {
- if (PyErr_WarnFormat(PyExc_DeprecationWarning, 1,
- "__int__ returned non-int (type %.200s). "
- "The ability to return an instance of a strict subclass of int "
- "is deprecated, and may be removed in a future version of Python.",
- Py_TYPE(result)->tp_name)) {
- Py_DECREF(result);
- return NULL;
- }
- return result;
- }
-#endif
- PyErr_Format(PyExc_TypeError,
- "__%.4s__ returned non-%.4s (type %.200s)",
- type_name, type_name, Py_TYPE(result)->tp_name);
- Py_DECREF(result);
- return NULL;
-}
-static CYTHON_INLINE PyObject* __Pyx_PyNumber_IntOrLong(PyObject* x) {
-#if CYTHON_USE_TYPE_SLOTS
- PyNumberMethods *m;
-#endif
- const char *name = NULL;
- PyObject *res = NULL;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_Check(x) || PyLong_Check(x)))
-#else
- if (likely(PyLong_Check(x)))
-#endif
- return __Pyx_NewRef(x);
-#if CYTHON_USE_TYPE_SLOTS
- m = Py_TYPE(x)->tp_as_number;
- #if PY_MAJOR_VERSION < 3
- if (m && m->nb_int) {
- name = "int";
- res = m->nb_int(x);
- }
- else if (m && m->nb_long) {
- name = "long";
- res = m->nb_long(x);
- }
- #else
- if (likely(m && m->nb_int)) {
- name = "int";
- res = m->nb_int(x);
- }
- #endif
-#else
- if (!PyBytes_CheckExact(x) && !PyUnicode_CheckExact(x)) {
- res = PyNumber_Int(x);
- }
-#endif
- if (likely(res)) {
-#if PY_MAJOR_VERSION < 3
- if (unlikely(!PyInt_Check(res) && !PyLong_Check(res))) {
-#else
- if (unlikely(!PyLong_CheckExact(res))) {
-#endif
- return __Pyx_PyNumber_IntOrLongWrongResultType(res, name);
- }
- }
- else if (!PyErr_Occurred()) {
- PyErr_SetString(PyExc_TypeError,
- "an integer is required");
- }
- return res;
-}
-static CYTHON_INLINE Py_ssize_t __Pyx_PyIndex_AsSsize_t(PyObject* b) {
- Py_ssize_t ival;
- PyObject *x;
-#if PY_MAJOR_VERSION < 3
- if (likely(PyInt_CheckExact(b))) {
- if (sizeof(Py_ssize_t) >= sizeof(long))
- return PyInt_AS_LONG(b);
- else
- return PyInt_AsSsize_t(b);
- }
-#endif
- if (likely(PyLong_CheckExact(b))) {
- #if CYTHON_USE_PYLONG_INTERNALS
- const digit* digits = ((PyLongObject*)b)->ob_digit;
- const Py_ssize_t size = Py_SIZE(b);
- if (likely(__Pyx_sst_abs(size) <= 1)) {
- ival = likely(size) ? digits[0] : 0;
- if (size == -1) ival = -ival;
- return ival;
- } else {
- switch (size) {
- case 2:
- if (8 * sizeof(Py_ssize_t) > 2 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -2:
- if (8 * sizeof(Py_ssize_t) > 2 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case 3:
- if (8 * sizeof(Py_ssize_t) > 3 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((((size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -3:
- if (8 * sizeof(Py_ssize_t) > 3 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((((size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case 4:
- if (8 * sizeof(Py_ssize_t) > 4 * PyLong_SHIFT) {
- return (Py_ssize_t) (((((((((size_t)digits[3]) << PyLong_SHIFT) | (size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- case -4:
- if (8 * sizeof(Py_ssize_t) > 4 * PyLong_SHIFT) {
- return -(Py_ssize_t) (((((((((size_t)digits[3]) << PyLong_SHIFT) | (size_t)digits[2]) << PyLong_SHIFT) | (size_t)digits[1]) << PyLong_SHIFT) | (size_t)digits[0]));
- }
- break;
- }
- }
- #endif
- return PyLong_AsSsize_t(b);
- }
- x = PyNumber_Index(b);
- if (!x) return -1;
- ival = PyInt_AsSsize_t(x);
- Py_DECREF(x);
- return ival;
-}
-static CYTHON_INLINE Py_hash_t __Pyx_PyIndex_AsHash_t(PyObject* o) {
- if (sizeof(Py_hash_t) == sizeof(Py_ssize_t)) {
- return (Py_hash_t) __Pyx_PyIndex_AsSsize_t(o);
-#if PY_MAJOR_VERSION < 3
- } else if (likely(PyInt_CheckExact(o))) {
- return PyInt_AS_LONG(o);
-#endif
- } else {
- Py_ssize_t ival;
- PyObject *x;
- x = PyNumber_Index(o);
- if (!x) return -1;
- ival = PyInt_AsLong(x);
- Py_DECREF(x);
- return ival;
- }
-}
-static CYTHON_INLINE PyObject * __Pyx_PyBool_FromLong(long b) {
- return b ? __Pyx_NewRef(Py_True) : __Pyx_NewRef(Py_False);
-}
-static CYTHON_INLINE PyObject * __Pyx_PyInt_FromSize_t(size_t ival) {
- return PyInt_FromSize_t(ival);
-}
-
-
-#endif /* Py_PYTHON_H */
diff --git a/spaces/Kvikontent/kviimager/app.py b/spaces/Kvikontent/kviimager/app.py
deleted file mode 100644
index 7aaf3e9e4b70717583f9d73f35307e64f404ccd0..0000000000000000000000000000000000000000
--- a/spaces/Kvikontent/kviimager/app.py
+++ /dev/null
@@ -1,725 +0,0 @@
-import gradio as gr
-from PIL import Image
-import requests
-from io import BytesIO
-import random
-import time
-
-def load_image(url):
- response = requests.get(url)
- image = Image.open(BytesIO(response.content))
- return image
-
-def generate_image(prompt):
- prompt = prompt.lower()
-
- time.sleep(random.randint(10, 20))
- faces = [
- "https://avatars.mds.yandex.net/i?id=f9676dc9c99572353c509d298a0b9f6571edca4e-10514707-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=e02f3f0a7cab6ae7eba3b1209ba9d56dcc24715a-7552414-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=aa883402ff70aa4c6d77441e3b2f3fb85483a047-5480663-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=30ae3f522a50aea82e7c61444656a259dbc106af-7823046-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=0ffd2b2d3d6927fdd824ce3af649bdc2827bc72c-10092505-images-thumbs&n=13"
- ]
-
- landscapes = [
- "https://avatars.mds.yandex.net/i?id=d817020d4f33ce8dd5f012ec14b46026230f7f38-4304379-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=0c44f37e0f3240a7f873ade37dbf77d87be8d3a0-9103996-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=54432591615e90e906f554b6deb6a33ae47e56b0-7551636-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=ef1792a7e82c70fb5a12c0b159c061b31c1c2461-9237918-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=e2639ee50941423c94aab655b416c8e1db84a015-9712020-images-thumbs&n=13",
- "https://img.freepik.com/free-photo/beautiful-shot-grassy-hills-covered-trees-near-mountains-dolomites-italy_181624-24400.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/mount-fuji-lake-kawaguchiko-sunrise-vintage_30824-49.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-mountains-landscape_23-2150787970.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/beautiful-view-caucasus-mountains_114963-19244.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/top-view-fir-tree-forest_181624-28786.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/misty-carpathian-mountain-landscape-with-fir-forest-tops-trees-sticking-out-fog_146671-18433.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-landscape-mother-nature_23-2148992397.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/hand-painted-sunset-mountain-trees-landscape_1048-19076.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- animal = [
- "https://avatars.mds.yandex.net/i?id=a1a7b590d43b39c427304b03c180802c-5714596-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=4da68929c18e73e06c2332018658f2f344f4e56e-8567697-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=c4000087b8d4c591d887a3d21f25a76738cb3d21-5880141-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=d507afc55fdbef5d6c51aa82acbf2d06211b79d8-7051980-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=52bfb5b4c8638c1c5feecf49797240d0e4128425-9181120-images-thumbs&n=13"
- ]
-
- car = [
- "https://avatars.mds.yandex.net/i?id=4b8a4a2285b409371e8b45060db83d522fd7e3a8-9624682-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=5583a40b92d72bbaacd0726f5b7504b5bb41ec4f-8264916-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=f2bf530d35b3eb1e4a50db12a3f6347fca90504a-9609067-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=fa0f8f3c6411a8122be313df6c8adcf7d389d3c6-7552082-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=93519c6b3adf47b03313c2a325eb51e75018eeaa-10332876-images-thumbs&n=13"
- ]
-
- food = [
- "https://avatars.mds.yandex.net/i?id=aa2854aebae7aad2c9c84f9ca556823076924800-6974903-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=c9b4d7e1c5991af6efdc61d3a3f5b91c7b5790b8-5229803-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=f4ba649ad0017b1a8ad1bdba4c0b523e-4290971-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=045887a75bb76213d556631a67a27ce7c9df7b81-9716553-images-thumbs&n=13",
- "https://avatars.mds.yandex.net/i?id=4b8a4a2285b409371e8b45060db83d522fd7e3a8-9624682-images-thumbs&n=13"
- ]
-
- boat = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT7uC_XzpcX5FOfoPiKG-OR3O9-gTgRQ97t5dTW9kCtSKNRJ6Oz6J8fav5um1U&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRDzZkpmyutasQm5JmkcwFCJ964i1SaShl5uZ2JWVysTJ-USU-m2g4jnGCJ3A&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTIHj-QBEXroe_P-t8PVd7hVlA_XeQT2O9emiDb2dDODwOKU3GJM3XAo0BiLP8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRN_7Cg8g0GR0pHIsWlC6zucsVad6GJQeoxjZuCC6NtEYSi6iN3PD_oOqgMCs0&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQbO69SuDBUWRxPmSaMvY9tUzvN3CPDGy6Qy7Ws88jgNHXtLDMJAv9dTYPKYbo&s"
- ]
-
- logo = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSzDj5UHlSMn4JnM-LU1lDI5Gj8IyXoUGcPJFUW2L9g4ud_A2DEaCBVAlupLnE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQuEVbV_xtLzMDbVj9Hqfet_JoN7-L0uTflNS9szF9nxWWYtEiGrMnA4H_59EQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS9m3Ifv2-Gqjlq6q2YefVARxit9uQYXVvrFkCXhXF2xvFxQoY2iFUCjRPBwA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQtS6eh12jeaQA5bVBKL-Vs2bbeUVE6i9i05-5qGjL6WyrSG-ipgR1x41DB49w&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRxVnmLkyBugPNPiUPbE91e8M6hNm8MprUyECSMO_FrJ49maB-1AYvVBeI10fI&s"
- ]
-
- eye = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRWYbVL4JZbaW2lRAFGhFw22TU2m1qpVjc8o7Z0PCGkOG3--FLJbwv_Errvwg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRaSR6_WMsGOAfItkCMiFxNgXKmAZVOhsAH0yI-0cuecvH8SnbJZIw2t2VfwQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQvJagN3MtIQPzKjextKbUHtF5Km_R5JXIPSq4LY8stLtCzrLHJhtCcXpiXpXo&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRLHok8H8zbsX5Oupg5DJBxLcp6Tm6LAg4S0gJ3o5lpbXYeNm5j36sWI8DX1Q&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT5a0d5jgLm6lOMHIFTC5NN0Bea6EItJJPo5mNa3oX5dwMf7dwDjoTW1SogTu0&s"
- ]
-
- beard = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTiJOMp_SLFTOUXZCz9ssycWmh5Sn2WpE0AfIfnVdpooNqnqDT0n_gcpyzeMA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRO4dmmQnmxAP3_0AUBH031bbk-YMWnQNMIhEUxz6LV4JdPZ5ic0B3WhnEpXw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQpzFdwz_l57Nkuz089OMl8rZiKvr6zVLeyMbaQOTEKRk2e7Hgwr2tkCIkwsQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSWFIOd5jPEVlc6hll0oyF3rbcOAWxAi8OF-BnCxAaCQBWWQDG_La69bmOm_g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTQO-zriw-KQA6JNr-Wg2vzlsd-JJBoAoDclFuEJ900j01XuMFpN0qB_QbJ5Hc&s"
- ]
-
- avatar = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQhoGkHKK-mUcbSGNLNw_zM_vSGD5axZmiysJiKHz62-S1j61KVUypKeRZ6Jw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRpbv3vxSrrCksivuHDtAO7dZylFj0YoeB3xZ8ujV37046chtdbOlXQJNBuSg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSrD3u82KvAmb2sNdU5An5HTgr8uJAVHyD7878tdxoBtf8M_oBvKV1x5zDFmn8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRHKrlqz4evD_YlQqhwq6cCW5x6XkMxLZb4mFTqkuNTBe4hQCSBUa_KFIqWnw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSZknN5zWQt0C6vzbTjL2XkU0BZthLv0zUgrKoSyTgEO_5FeyVSl4oiSPKUWQI&s"
- ]
-
- dreadlocks= [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSJAdKXK3VacgTY6Slf3wYALB7d1yMfilkpYAMe4wwXmWq3uXCi981Kka5_bfE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTqpcvYkiKXkkEd7x2udV87zj4SXC60hwuzcqF9yHkRpPGh-nUwEPzqSGJwGQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ6DPaqOivnFuLovOI_TuUWxfkLj4z9BmlFcvAhN2PEYBs9EAJdNEW1EDLBmS8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQM4hIEP519ofGPZPv3ZwvaZBElD2dZL1AFWmtwvNlHaxMX1ndew80eZ_bWWiM&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSD8ReWbLVONl2rqPCSzVrl1UHCy92gC06Opfekhe1kvkvPiKPY9zRK_XT5fA&s"
- ]
-
- soap = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRsgzD0uRzqZVq84N7upWTqLuf0UUBKVPrdlBFbYFtAJloSIsUogh6vEZEAnQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTsfiDc8JlSL9f3Hchjp_kJ90BlbIlqzOKh1x8-cU7vBvqtVhp2MtOvkSMHGy4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQI0pzIuoZKeAhh0SkC6HOVFion1tkeGQbFwZ_vLZCNewuz22oWiEuHV7N8Ww&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSIwxtneQ0cWI4W-vR3l6aPg6ngJc1A368AKUufCaP4s3Sf6meK-Gjb7WuPBg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRYazRp7i1fSoqCC0fTHi7NbIGnFhXkJQvKFZJ1WkticD0zjG_P5UK6KoaKDw&s"
- ]
-
- sumsung= [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRCPcaCaH1iV4CxGtCM2QiE9k2rxDJAwLB1q9RjmKeI11YuKRZV97FMyN7TGUA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ_lK5kondU1fLYopOzhs35c7O9895dQEg7ZA4f_tWwKoyg-D5K9BBgOsiK2A&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTdnE_U-MyUYNQuu3AItAc6sjN3QOHbsuN6igd06jkkW_72IWLgpgZBYDhmPO4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTSpo9Rk0bHp6zz1RINp4zXPvxOJpcxHwiVHCWhG4WnQbixaW2da2GOzrdE4Kk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRk73Acil1EDstNwJROXJ2kyvYjyI_wCab_mWsS5Vm09-9uyXLNd277QGd0aTE&s"
- ]
-
- phone = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR4oq8P-XORyX_g-oQz4yiXotJO85q0PDYbRo7rWbnt3nwklHocAOPXXARGU7I&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRqZMzmeDwvUyDmG5x0y586u9v_PqefKcRd8DlLI3pk8YA3FPJoHHDhWQJO7w&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRwRQ4guGOZ3gYLngSIPqhsnKAPUuoBmTz-54klXS_kDMd5p8CDjMqXOaVeouU&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTKaO7EQrR2zSN2thcH9qBROWIpxe6bGEc0m_F4BFiUAt8FzsfulbPhdhWaog&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQjsQYj_Ut9gpKFHImQJvSXd9HD31PZEumBqKohwyLFKCNlK1wCQuo6F9dAgIc&s"
- ]
-
- iphone = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRnsbZqd6WXaneQDuWE54UDgLMcwyeWRu45G0G3BarzaNETVacPsc4fnYtISQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQBPSTHkYe2UTr1VtpPJqt1j_9GwTtCQaPoMKv5-lWz2-hwp18WUuhI9qZ2WeE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSZQDa7mSYdE8ngeICK5WBg0UYsHdkJ5dVrxUi03qIud5tgiic2NL_ta93OJPc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSFslO464O0WgNa4JME2M5ODR9lyxebh5SbY6RMzw9RTCOTcuYfz5FCkvsCsOc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRgINKzd2do0Gq92Ze_9Z2vRE42-mgyJUxbZnq7VclmrPzFmXr6j_eFDyxsfEk&s"
- ]
-
- code = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR8AQUUNCiFvhqKIAbomE0Oi8klATjRW1_OIDaxnvsBfgpGcbDNEgPtAI7Cow&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQQVswifdUmIkjvImbXIzkEGZBKjukPCpslWapX3XZ8yKuqzis_103p2kfqwjk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ8F2fRUA43Jv0kDPFlfiP70Xvuje5X-xBrsv8jLHRjBZCrls2WT6lKb3OJ9P4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT93F2GIUYF1fI9bHZ3O3qyg8obIPn_OAjWc0HPKbCcTFtzSYOVg8QwxoW3bUY&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQHVOT4zPTgvgrxvJhHbGUWYwwkfwyg7-Laj1HmXk7L7hNsAy15-mkAz9W0zQw&s"
- ]
-
- ytlogo = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcROoysKpwbXlY2M4z6wSfH1n4CiNGWI4sQ052sz8wPZB6zgQp2FELDFEmb4D-4&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRGT0bDOiIfqKI-UsX_o85KYMF7GXqecDlI3pFe8qeWDRUB7DiT2pBiQky-kQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRpln5qd4ZhvF51yhcP2Hk31wQipzlrLfEp2gpLozBCp9kLH-Csl0p6_3TA5g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQRODy1QkPYlzUbv8s-ONymnztScHTTp7pU7iIU8xo1U_HbBHAzTSl529nZ0Qg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR-ke4ykhnylaUE7cwvKJflTIron_YEv2G6djOyHy8eWNUT66ekBn_NRxeK1sk&s"
- ]
-
- backrooms = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQL6KWuRbgabni4B5L-W1ZUoU7qWBuGeLgun1FBTYKbUrKbM3pmZl-zKfeu4gE&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSdWGZ0mSyjGAzrF6NZpzp5YMCxKfwuTtQm8FgjoLtJ-BfAzNgfyFVwut0OB70&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQfUa9DtjgccXhdpjhAUu9jA4r6sXlheQEwdm5CKGbkzm7UYiDHSb9Ppnj31g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ3xb2t61JY1ydKvXxE2rvhHwIoD9QpOhNc5bQAwiaKrUWJxh5nvRQ4gShIzg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSJFpQDPzCY2VrgnDyzE66l0PtsyXZwfryN7lFTy7Tt1NroElcNP-NSdvKfOg&s"
- ]
-
- dog = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRotwetUK0NfzN-2GOk2nH6HAOcCIos85WFZRQkRxtkk-OfNgCFRivkWXKbNA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT_peU0kINinA3eXkJadJeSvejSl_5sdsl0YragpD48DY8gR-3N4lJv1MAZkg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTxc6B-rTX2W_2ebGA9yevnhaJZJpW7Njs_QIuERCnYnVv68Q53LbyEn8sjgA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS3Eihd0V74gEj-DQg7d7oWgAoewiK_o1CKS7pEhjzfg-uj7gTlE5N8GWnYwA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQRzkLbC-711Phno7wpIXPmCyCQoVtN1L5iRMgRZ2OY6HjAlUMxroPB4hh1o9k&s"
- ]
-
- doll = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTz7ezACV5JTBS-4t62vweRIgJJtPtBocuvXWcqn2tmbdoxMoWBJisoK26EuQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTkPI_jklNmx9mxdfBgihNUDkriHaMcNIr-wzftGGX8nJ8NuGL7-l52YDXX2Io&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTZnP0N33NH6DNxn_xJKsSIjBOIDWcjqSk4vPnIyyDgC1z-TEsM0Ouo9PyKaQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRIQwigkIJf8WxNVsgnzHBkMjKCot8qmST1ZO-XXVn-5Q-2oP4IjU21epQtPw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSAaBAWGR8xL_Ds3O3zU3gpPm2nFGkZka6QMoRQclEDxoabOM1axtcN1DyYqg&s"
- ]
-
- background = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTk6eYuzpiGwpQzrLGyMInzUQH8rLMi-tJ-CgO3jzE7EwjMuPhCbD-Izg4c8g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTlfc5dgbFAWBpzXUqqG8XpFp0ChXGhizw4te7p5gdN2JN39uk75qfJSsyGzA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTy7tvvh3-1rWQ5p6DKl-X0-Ch-hwWcRS0Gz3hlSSva0701dLWc4QpPamuho20&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTJmfreu3ua18h8EcArDD_jzoLMXWKOgOnBROtzThALjeqMWEOAa4oz_gn_fk8&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR7i4xPXauC7fC6R4gz8TgcQCPkqwAg2olTPDgSOFm3i3FLLxD8Xf9uFg5BZOs&s"
- ]
-
- rocks = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT3PhKY8mj-GRrwr3wZbpZq_QOi4PPff8XhQ3NMCP66xESicYz6IcOlXNVtMzk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRRigOBUBYtxsOa3dz3uc8n6Px8BNTWgwurbO3DRbMETydwWJ_oG8likIwP2g&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSw9BesCM_YHs4Iou8-fSEVAI8Qz_dCfKBRSDzy2GjzSz2biE2BBMkOM_o8Ow&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSkpCg5fj_yKPuxi-YG3-q8IuVq66Rsw_3dJHgCJTVlJlU2MociE1zvLz0FuOg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSx9XrO9FSPBsrAmm4X5Pz92ngVxx3wBrtuxQqwHsk_9XpPuOP5y23eVvAtJw&s"
- ]
-
- goldrobot = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ6fOQe7D-zsr_TBymoLoyK5l30OeW4plpVc_oUeClzqGuCbbfkU1ESKkloKUg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTPyWunhkGAw5d3SaEV6gS6NT4ASOrG6A99TA-dQGd9fQwX1aQqhKrJpgReEWs&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTyQTzY1WDfsUHy0qlR6Gw7XPvXJH3fQyT7ynECg_xQxL-hQbhq7OmmXcxBPlc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRh2Vya7ab5AdihcJ7k6NtNyCoTv_S2uNgZ7i40OCCEFJIWGUGcj_DvppmOyw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ22ZuyrA2M6ezgdOKsUzhFjjsckZUacogWsQsPELvBC7BXElUxz4fCYmK2kEc&s"
- ]
-
- horse = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSEEIV6tfelJDs73aDbXP7zccLe5JO8oPS411OzB8bZO1zHN92Z1C9yZGlfjzQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQXOP6P4qf5OqHKkdsSDSsmcbdttWlWdxKQqF6TqXowZ7Fva1ozdaBoJ2vuZw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRco4tdguZDuIkmARj7vFfmYq-ks4rRq_l5w4pSfZFWKogqf-OfHHbsPYElSYI&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQ39g8eCI7-czS2aXXmkyUn-1mGBg625cHy2DL6b2uH8aTF16oGlN-efn03Rw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQVdiyhiRRqyCij3gZBKb2UpuHUyC13s8uX1lOurDfOzp2wSplmzRGQiG4aSVY&s"
- ]
-
- house = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSSWYMqKB_-v7joSASuJmA8F1hASiq0NRXME67bt0URWmcEJX0HEHQRYoZL_Q&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQqt3XksHl0s237mkxq44OQSXFS5r9n5M1Oh8xrYK7fR5ugIa5cn88HiaUKEEk&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS3by_Lf10vtCBQxzuWJEy4o3mlNxKcUZyuWAukYck-dRjlQ280e_dFG7Kq2lc&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSeyiSfAmb3V5cjSudujc2eT77PHzWBK6NSoXJq98haB3lq3fkQqCaQjdH8vQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQMy2ir-gBXuMLoVsSp4_mMHRO_Rq08JGEzwDlhSvo2J59dzhWp95tYGf-KAsw&s"
- ]
-
- money = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSwCZT1f20JD7ILOxbV2cShU-SuHUMT0oT1tjy0rJm4xYS8dwbbk-H3jkhIvg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQojWsOuIE5fmrOFQsq0cXpVASRFWpMJMjJ1lB1pGMKaLnRf552mQDkfM0pha0&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQjUDxa2JbgapLu1lNfsULxRFW6XXR4wrkD0kDvZqDxSrWiOmwx15POh0nGdQ&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSPNpEwR_ANwP6kYRC65Rp-U82IhWmU3pvuIUDRtyrGyk3hagssOXfA4NT2IZ0&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcToE7Ay3jzGO3Rz71beO326P5mljAhr5Wn_jPDv9MQ9JBh58A4EWbexZcNeMXE&s"
- ]
-
- rainbow = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTfVYUrYDW6WSjWPnWaOePIqrkKY0RSTl3UeQ9BSZ9eV2lPau3SZwC7d8HY9w&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcRlh_7Jt36GdZrJbh3Yo6RerkSYqj13osiaX5mbZz3tLMPoeMhzhsVLV9JW0hM&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcScCYEWFA9lfUD_CN54UePl5Uzu3QTFJTPwgfgCl7nOACbPd9QSGfVWsYjNxfI&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTUjtuadZfnEkXuKUgBeevaxCTzV-Sv8kPHCybgjBBc8cVOvTvczTJvF0TGbw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQkheh6kpg1Bf-rCkAp2olc962inDLHkoZeQsoSflhgy3NoF1lZB0axB_zDcA&s"
- ]
-
- rain = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTYuXU6x9-tPwfAoPfAViD17-V405LGaL8jG07gxgKHx_CSXpf0H3u6a9pLeg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQZv3dycH2a_IYBzMGZt-Y4Fkoc0AyyVyhv4V5GDWMBBB5iKYnIgAq8-29Pi1U&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQedxpLUE9j23dqdaD1MFeDROs4uLxV9MFC-aGNv76ck7rbltqtlmycsxagug&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR3jxGROSevIg4gKazU-JMH3voUJSaH4xXrm0bquGl4fxHq8V1AtfHXTEqgFA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTC-JteC4ZshI0GI7fqh7WfHnglxeef9B7eaG3F9cysviki42Pv1byvpCKWfw&s"
- ]
-
- future = [
- "https://img.freepik.com/free-photo/city-with-moon-sky_188544-8835.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/3d-rendering-planet-mars-broadband-internet-system-meet-needs-consumers_181624-56885.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/person-holding-clear-crystal-glass-ball-with-reflection-building_181624-4779.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/digital-world-banner-background-remixed-from-public-domain-by-nasa_53876-124622.jpg?size=626&ext=jpg",
- "https://img.freepik.com/free-photo/3d-view-planet-earth_23-2150499242.jpg?size=626&ext=jpg"
- ]
-
- beach = [
- "https://img.freepik.com/free-photo/beautiful_1203-2633.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-tropical-beach-sea-ocean-with-white-cloud-blue-sky-copyspace_74190-8663.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/umbrella-chair-with-pillow-around-beautiful-landscape-beach-sea_74190-8173.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/empty-sea-beach-background_74190-313.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/tropical-beach_74190-188.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sun = [
- "https://img.freepik.com/free-vector/sparkling-sunrise-light-effect_52683-30445.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/view-blue-sky-cloud-nature-background_1150-27443.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/realistic-sun-element-vector-gray-background_53876-118580.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/gradient-summer-heat-background_23-2149423259.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/natural-light-lens-flare-psd-gold-background-sun-ray-effect_53876-140441.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- bread = [
- "https://img.freepik.com/free-photo/bread-crust-assortment-pastry_23-2148359129.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/delicious-bread-towel_23-2148544723.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/different-kinds-fresh-bread-as-background-top-view_114579-8017.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/organic-whole-grain-baguette-placed-linen-fabric_140725-5042.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/different-types-bread-made-from-wheat-flour_140725-5648.jpg?size=626&ext=jpg&ga=GA1.2.1708812069.1697374121&semt=sph"
- ]
-
- fontain = [
- "https://img.freepik.com/free-photo/fountain-gabriel-miro-square-alicante_1268-22029.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/world-war-ii-memorial-washington-dc_649448-809.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/chicago-skyline-with-buckingham-fountain_649448-759.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/fountains-bridge-manzanares-river_1398-3626.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/shanghai-people-s-square_649448-3873.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- tree = [
- "https://img.freepik.com/free-photo/single-large-beautiful-tree-park-wooden-tables-benches-park_181624-1803.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-view-white-building-middle-trees-forest-cloudy-sky_181624-27439.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/wide-angle-shot-single-tree-growing-clouded-sky-during-sunset-surrounded-by-grass_181624-22807.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-countryside-landscape-with-tree-against-blue-sky_1048-11883.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/forest-covered-greenery-sunlight-madeira-portugal_181624-12464.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- palmtree = [
- "https://img.freepik.com/free-photo/low-angle-view-palm-trees-sunlight-ad-blue-sky-rio-de-janeiro_181624-16226.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/low-angle-shot-coconut-trees-against-blue-sky-with-sun-shining-through-trees_181624-15750.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/low-angle-shot-palm-trees-blue-cloudy-sky_181624-46408.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/premium-photo/coconut-palm-tree-beach-thailand-coconut-tree-with-blur-sky_34142-182.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/tropical-beach_74190-188.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- book = [
- "https://img.freepik.com/free-photo/front-view-woman-with-book-collage_23-2150149037.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/magazine-mockup-with-leaves-golden-frame_53876-89586.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/book-that-leaves-paper-hearts_1232-910.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/pile-documents-desk-office-stack-business-papersgenerative-ai_391052-15381.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/old-books-arrangement-with-copy-space_23-2148898331.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- apple = [
- "https://img.freepik.com/free-photo/apples-table_144627-6741.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/tasty-red-apples-isolated-white_114579-73119.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/tasty-red-apples-isolated-white_114579-73119.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/red-apples-isolated-white-background-ripe-fresh-apples-clipping-path-apple-with-leaf_299651-595.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-psd/ripe-whole-green-apple-with-half-leaf_34168-1625.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- wednesday = [
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQuDk5-eBHPjAHllrTas3PcKcMH0tjbKBxxgjAT9usFbYcPoWvrnFW9oma1Zdg&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTqEsYIsLtwkRBSujr3ngzoLcC5CmNtqxtKs98xlg6v9EjMEBJf10h-tQmAzw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSNpEugEqNG-MboJUdOEola8LPemFc0Et8C9izN9WI7adwAx2Wy5KzxhHL4EA&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcToEyXVwfkmgNYr8xNhF86nooOSRvBhtyXo-u0Na-P_rJ9xcMFE9ctf_LalBw&s",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS7hkxz9xaEO8FTGUCMLI2LAG75pmgXbT-HCPHzZ-4oEHI5O3awlWnog56Lrw&s"
- ]
-
- snow = [
- "https://img.freepik.com/free-photo/3d-snowy-winter-landscape_1048-11056.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-snowy-landscape_1048-9684.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-winter-snowy-landscape_1048-11515.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/snowfall-mountains-with-fir-trees-coniferous-forest_921026-10835.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-render-defocussed-snowy-tree-landscape_1048-14924.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- grandpa = [
- "https://img.freepik.com/free-photo/senior-person-gesturing-isolated_23-2149193761.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/african-man-successful-entrepreneur-wearing-glasses-face-portrait_53876-143244.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/senior-person-gesturing-isolated_23-2149193762.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/negative-human-emotions-feelings-reaction_343059-3467.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/side-view-old-man-posing-indoors_23-2149883574.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sunrise = [
- "https://img.freepik.com/free-vector/realistic-sunset-sky-with-clouds_107791-20416.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/majestic-mountain-range-tranquil-meadow-panoramic-horizon-extreme-terrain-adventure-generated-by-ai_188544-61178.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/abstract-desert-background-with-sand-dunes_743855-32762.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/orange-sunrise-fluffy-cloud-sky-nature-background_58717-463.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/rice-field-beautiful-natural_49071-2110.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sunset = [
- "https://img.freepik.com/free-photo/inspiring-view-sunset-light_23-2148851743.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-sunset-sea_158538-26146.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/red-sunset-clouds-trees_1204-352.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/sunset-water-with-birds-flying-against-sunlight-mediterranean-sea_933530-11432.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/sunset-water-reflects-tranquil-idyllic-beauty-generated-by-ai_188544-21673.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- garlic = [
- "https://img.freepik.com/premium-photo/garlic-isolated_88281-2263.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/side-view-bunches-garlic-bowl_176474-1564.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/garlic-white-surface_144627-45191.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/2-fresh-garlic-bulbs-black_146671-19183.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/fresh-raw-garlic-ready-cook_1150-42636.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- telegram = [
- "https://img.freepik.com/free-vector/paper-airplane-send-with-dotted-lines-flat-style_78370-2884.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-rendering-social-media-icon_23-2150701008.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/realistic-shiny-3d-round-button-with-telegram-icon_125540-2951.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/telegram-icon_23-2147895384.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-psd/3d-icon-social-media-app_23-2150049607.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- banana = [
- "https://img.freepik.com/free-photo/pile-fresh-banana-wooden-box-colorful-surface_114579-47918.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/fresh-yellow-banana_2829-13457.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/bananas-market_732031-66.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/single-banana-isolated-white-background_839833-17794.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/vector-ripe-yellow-banana-bunch-isolated-white-background_1284-45456.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- gorilla = [
- "https://img.freepik.com/free-photo/gorilla-sitting-among-trees_181624-44635.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/gorilla-looking_181624-35935.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/primate-portrait-endangered-lowland-gorilla-staring-fiercely-generative-ai_188544-31982.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/endangered-primate-sitting-african-rainforest-staring-camera-generated-by-ai_188544-55451.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/closeup-shot-gorilla-sitting-grass-sunlight_181624-41632.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- USA = [
- "https://img.freepik.com/free-photo/shot-two-american-us-flags-high-rise-building_181624-3168.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-vector/new-york-city-panorama-flat-cartoon-style-illustration-web-background_198565-41.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-view-empire-states-skyscrapers-new-york-city_181624-6295.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/new-york-city-skyline-with-urban-skyscrapers-sunset_649448-2402.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/usa-united-states-america-flag-flagpole-near-skyscrapers-cloudy-sky_181624-5054.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- france = [
- "https://img.freepik.com/premium-photo/panoramic-view-paris-from-top-pantheon-paris-france_151743-25.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/panoramic-view-louvre-museum_167657-86.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/cityscape-paris-sunlight-blue-sky-fra_181624-50289.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/eiffel-tour-seine-river-waters-summer-day-paris-france_257123-3955.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/beautiful-wide-shot-eiffel-tower-paris-surrounded-by-water-with-ships-colorful-sky_181624-5118.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- monkey = [
- "https://img.freepik.com/free-photo/beautiful-monkey-swimming_23-2150754539.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/macaque-monkey-nature_475641-1447.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/monkey-nature_8327-226.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/portrait-long-tailed-macaque_181624-34646.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/close-up-gibbon-nature_23-2150798383.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- #new
-
- circle = [
- "https://img.freepik.com/free-vector/stroke-round-geometric-shape-vector_53876-175080.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/free-photo-beauty-product-bottle-mockup-image-with-background_1340-31411.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/misty-julian-alps-peak-round-badge_53876-153331.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/abstract-background-circle_118019-1319.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/abstract-spaceship-orbiting-starry-galaxy-backdrop-circle-generated-by-ai_188544-9683.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sphere = [
- "https://img.freepik.com/free-vector/abstract-sphere-with-flowing-particles_1048-12235.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-psd/3d-abstract-purple-metal-object-render_52659-1948.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-vector-colorful-mesh-dark-background-futuristic-style-card-elegant-background-business-presentations-corrupted-point-sphere-chaos-aesthetics_1217-4607.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-sphere-with-flowing-particles_1048-12235.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-psd/3d-abstract-purple-metal-object-render_52659-1916.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- square = [
- "https://img.freepik.com/free-vector/grey-square-pattern-background-vector-illustration_1164-1350.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-mosaic-background-vector-illustration-eps-10_173207-1857.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/square-box-with-blue-light-it_1340-34463.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/flat-lay-blue-frame-concept_23-2148553337.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/black-frame-white-brick-wall_24972-315.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- cube = [
- "https://img.freepik.com/free-photo/abstract-3d-dice-with-dots_23-2150891336.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/box-mockup_1017-7633.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/collection-different-highs-museum-exposition-blank-product-stands_134830-669.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/crystal-ice-cube-sits-refreshing-blue-liquid-generated-by-ai_188544-16470.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/3d-geometric-cubic-grid-technology-style-vector-design_1017-39964.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- piano = [
- "https://img.freepik.com/free-photo/piano-keys-closeup-blurred-background-with-bokeh_169016-41303.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/close-up-anthropomorphic-robot-singing_23-2150865921.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/close-up-piano-keys_86669-423.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/simple-background-music-festival_91128-1440.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/elegant-grand-piano-with-sheet-music-isolated-white-background-close-up-ai-generative_123827-24241.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- hole = [
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-96604.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-58848.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-58641.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/black-hole-digital-black-hole-space-illustration_950002-96397.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/3d-grid-wormhole-illusion-design-element-vector_53876-161539.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- albania = [
- "https://img.freepik.com/free-photo/sarande-harbor-early-evening_181624-49115.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/realistic-albania-flag-background_125540-2710.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/aerial-shot-valbona-valley-national-park-with-reflecting-waters-albania_181624-30934.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/low-angle-shot-road-forest-with-mountains-distance-valbona-valley-national-park-albania_181624-26176.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/albania-flag-wrinkled-dark-background-3d-render_1379-653.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- heart = [
- "https://img.freepik.com/free-photo/fluffy-heart-studio_23-2150864860.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/gradient-isolated-heart-background_23-2147737116.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/realistic-heart-shape-studio_23-2150827366.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/gradient-heart_78370-478.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/pretty-realistic-heart-illustration-with-isolated-background_742252-4113.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- mouse = [
- "https://img.freepik.com/free-photo/cute-rat-posing-studio_23-2150702639.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/cute-rat-posing-studio_23-2150702635.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/view-rodent-rat_23-2150762800.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/cute-rat-living-indoors_23-2150702737.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/mischief-wild-rats_23-2150762946.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- rat = [
- "https://img.freepik.com/free-photo/cute-rat-living-outdoors_23-2150702547.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/cute-rat-living-indoors_23-2150702753.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/front-view-scientist-holding-rat_23-2150702725.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/closeup-marsh-rice-rat-sunlight-with-blurry-background_181624-36058.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/portrait-wild-rat_23-2150762844.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- dot = [
- "https://img.freepik.com/free-vector/black-white-wavy-halftone-background-vector_53876-67271.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/abstract-circular-halftone-design-modern-background_1055-17636.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/black-wave-halftone-background_1199-279.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/halftone-background-abstract-black-white-dots-shape_314614-1558.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/dotted-black-background_78370-1817.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- pencil = [
- "https://img.freepik.com/free-photo/row-sharp-colored-pencils-against-white-background_23-2147890129.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/writting-pencil-design_1095-187.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/sharpened-wooden-pencils-shavings_1284-25607.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/colored-pencils-white-background_23-2147710341.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-vector/set-plain-encils_117553-72.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- pen = [
- "https://img.freepik.com/free-psd/packaging-cosmetic-concealer-mock-up_73621-1091.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/school-pens-set_74855-7854.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/business-pen-set_1284-21143.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/3d-rendering-pen-ai-generated_23-2150695467.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-vector/vector-fountain-writing-pen-contract-signing_1284-41915.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- sphinxCat = [
- "https://img.freepik.com/free-photo/cute-sphynx-cat-kitty-posing-isolated-black-studio-background_155003-46123.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/premium-photo/canadian-sphinx-male-cat-fighting-pose-crouched-released-claws-raised-tail-ready-jump_494000-1477.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/view-adorable-kitten-inside-house_23-2150758180.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/cute-sphynx-cat-relaxing-indoors_23-2150679154.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/adorable-cat-without-hair_144627-10527.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- crestedDog = [
- "https://img.freepik.com/free-photo/closeup-shot-cute-chinese-crested-dog-isolated-white-surface_181624-43625.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/premium-photo/sitting-chinese-crested-dog-with-white-long-hair-copy-space_756748-60510.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/sideways-portrait-chinese-crested-puppy-with-copy-space-background_23-2148326286.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/chinese-crested-breed-looking-away-blue-background_23-2148326284.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais",
- "https://img.freepik.com/free-photo/portrait-chinese-crested-dog-with-white-hair_23-2148326283.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
- ]
-
- pushkin = [
- "https://ideogram.ai/api/images/direct/5DAaKMReT_SIuGQaD08MlA.jpg",
- "https://ideogram.ai/api/images/direct/UXEXVF8cTUeUw66bt0-W0w.jpg",
- "https://ideogram.ai/api/images/direct/kIa2Ad00S9GOoawkL8uy_Q.jpg",
- "https://ideogram.ai/api/images/direct/tGd1-nNbRqaeJU-4Ejhj7g.jpg",
- "https://upload.wikimedia.org/wikipedia/commons/thumb/5/56/Kiprensky_Pushkin.jpg/220px-Kiprensky_Pushkin.jpg"
- ]
-
- lamp = [
- "https://img.freepik.com/premium-photo/bulb-isolated-white_1026553-544.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/premium-photo/light-bulb-symbol-new-ideas_10221-10590.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/glowing-filament-ignites-ideas-innovative-solutions-generated-by-ai_188544-9614.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/pillow-bed-with-light-lamp_74190-2095.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph",
- "https://img.freepik.com/free-photo/light-bulb_1232-1543.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=sph"
- ]
-
- hungerGames = [
- "https://static.independent.co.uk/s3fs-public/thumbnails/image/2015/11/20/12/hungergamesposter_0.jpg?quality=75&width=990&crop=3%3A2%2Csmart&auto=webp",
- "https://www.denofgeek.com/wp-content/uploads/2021/05/hunger-games-winners-ranked.jpeg?resize=768%2C432",
- "https://cdn.mos.cms.futurecdn.net/4505e85a5f65e0dbdd98ae229917e8a2-970-80.jpg.webp",
- "https://cdn.mos.cms.futurecdn.net/14a68d9954f27752ea29cc05157b137c-970-80.jpg.webp",
- "https://cdn.mos.cms.futurecdn.net/a86140997d2adcd4cda32e2285b14dce-970-80.jpg.webp"
- ]
-
- zomblieland = [
- "https://i.insider.com/5151db9ceab8eafd68000000?width=300&format=jpeg&auto=webp",
- "https://upload.wikimedia.org/wikipedia/en/6/6d/Zombie_design_for_Zombieland%2C_main.jpg",
- "https://resizing.flixster.com/1T9l5_xewcQaP7yGfiqfUj50eP8=/300x300/v2/https://resizing.flixster.com/A3N2nxMokla5281kp9PinOWKZDE=/ems.cHJkLWVtcy1hc3NldHMvbW92aWVzLzQxMDFmMWYxLWZiZjktNDE1Mi1iNWVlLTFmMDFiYjJmYzVhMy53ZWJw",
- "https://resizing.flixster.com/VyDr_t7-bWYJai_PqbdteQ2Jqp0=/740x380/v2/https://statcdn.fandango.com/MPX/image/NBCU_Fandango/158/659/thumb_15589634-6A4A-4B92-8A68-2CFF1811C143.jpg",
- "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcT1E68NFPsfaGkeF7eZZ8T79GpB1J6s9jkFkm_TNgBimuMMJXDMQ4d2I2y0kA&s"
- ]
-
- if "face" in prompt:
- output_url = random.choice(faces)
- elif "landscape" in prompt:
- output_url = random.choice(landscapes)
- elif "animal" in prompt:
- output_url = random.choice(animal)
- elif "car" in prompt:
- output_url = random.choice(car)
- elif "food" in prompt:
- output_url = random.choice(food)
- elif "boat" in prompt:
- output_url = random.choice(boat)
- elif "logo" in prompt:
- output_url = random.choice(logo)
- elif "eye" in prompt:
- output_url = random.choice(eye)
- elif "beard" in prompt:
- output_url = random.choice(beard)
- elif "avatar" in prompt:
- output_url = random.choice(avatar)
- elif "dreadlocks" in prompt:
- output_url = random.choice(dreadlocks)
- elif "soap" in prompt:
- output_url = random.choice(soap)
- elif "sumsung" in prompt:
- output_url = random.choice(sumsung)
- elif "iphone" in prompt:
- output_url = random.choice(iphone)
- elif "phone" in prompt:
- output_url = random.choice(phone)
- elif "code" in prompt:
- output_url = random.choice(code)
- elif "youtube" in prompt:
- output_url = random.choice(ytlogo)
- elif "dog" in prompt:
- output_url = random.choice(dog)
- elif "doll" in prompt:
- output_url = random.choice(doll)
- elif "background" in prompt:
- output_url = random.choice(background)
- elif "rock" in prompt:
- output_url = random.choice(rocks)
- elif "gold robot" in prompt:
- output_url = random.choice(goldrobot)
- elif "house" in prompt:
- output_url = random.choice(house)
- elif "horse" in prompt:
- output_url = random.choice(horse)
- elif "money" in prompt:
- output_url = random.choice(money)
- elif "rainbow" in prompt:
- output_url = random.choice(rainbow)
- elif "rain" in prompt:
- output_url = random.choice(rain)
- elif "future" in prompt:
- output_url = random.choice(future)
- elif "beach" in prompt:
- output_url = random.choice(beach)
- elif "sun" in prompt:
- output_url = random.choice(sun)
- elif "bread" in prompt:
- output_url = random.choice(bread)
- elif "fountain" in prompt:
- output_url = random.choice(fontain)
- elif "tree" in prompt:
- output_url = random.choice(tree)
- elif "palm" in prompt:
- output_url = random.choice(palmtree)
- elif "book" in prompt:
- output_url = random.choice(book)
- elif "apple" in prompt:
- output_url = random.choice(apple)
- elif "wednesday" in prompt:
- output_url = random.choice(wednesday)
- elif "snow" in prompt:
- output_url = random.choice(snow)
- elif "grandpa" in prompt:
- output_url = random.choice(grandpa)
- elif "aurora" in prompt:
- output_url = random.choice(sunrise)
- elif "nightfall" in prompt:
- output_url = random.choice(sunset)
- elif "garlic" in prompt:
- output_url = random.choice(garlic)
- elif "telegram" in prompt:
- output_url = random.choice(telegram)
- elif "banana" in prompt:
- output_url = random.choice(banana)
- elif "gorilla" in prompt:
- output_url = random.choice(gorilla)
- elif "usa" in prompt:
- output_url = random.choice(USA)
- elif "france" in prompt:
- output_url = random.choice(france)
- elif "monkey" in prompt:
- output_url = random.choice(monkey)
- elif "circle" in prompt:
- output_url = random.choice(circle)
- elif "sphere" in prompt:
- output_url = random.choice(sphere)
- elif "square" in prompt:
- output_url = random.choice(square)
- elif "cube" in prompt:
- output_url = random.choice(cube)
- elif "piano" in prompt:
- output_url = random.choice(piano)
- elif "hole" in prompt:
- output_url = random.choice(hole)
- elif "albania" in prompt:
- output_url = random.choice(albania)
- elif "heart" in prompt:
- output_url = random.choice(heart)
- elif "mouse" in prompt:
- output_url = random.choice(mouse)
- elif "rat" in prompt:
- output_url = random.choice(rat)
- elif "dot" in prompt:
- output_url = random.choice(dot)
- elif "pencil" in prompt:
- output_url = random.choice(pencil)
- elif "pen" in prompt:
- output_url = random.choice(pen)
- elif "sphinx cat" in prompt:
- output_url = random.choice(sphinxCat)
- elif "chinese crested" in prompt:
- output_url = random.choice(crestedDog)
- elif "pushkin" in prompt:
- output_url = random.choice(pushkin)
- elif "lamp" in prompt:
- output_url = random.choice(lamp)
- elif "hunger games" in prompt:
- output_url = random.choice(hungerGames)
- elif "zombieland" in prompt:
- output_url = random.choice(zombieland)
- else:
- output_url = "https://img.freepik.com/free-vector/oops-404-error-with-broken-robot-concept-illustration_114360-5529.jpg?size=626&ext=jpg&ga=GA1.1.1708812069.1697374121&semt=ais"
-
- image = load_image(output_url)
- return image
-
-iface = gr.Interface(
- fn=generate_image,
- inputs=gr.Textbox(lines=5, max_lines=6, label="Enter prompt"),
- outputs=gr.outputs.Image(label="Generated Image", type="pil"),
- title="KVIImager 2.0 - Image Generator",
- description="Generate images based on a prompt. Sorry from us, but it can don't understand prompt carefully. It has 200 parameters. Please do not use capital letters because AI won't understand them and will give you an error. Get help: https://github.com/Vasiliy-katsyka/kviimager.",
- examples=[
- ["Realistic face, high-resolution, realistic, 4k, 8k, face, image"],
- ["Realistic image of beautiful landscape and mountains, 4k, beautiful, realistic, landscape, AI, mountains"],
- ["Image of a Chinese crested with high details, 4k, realistic"],
- ["Realistic avatar man standing in rainforest, 8k, HD, detailed"]
- ]
-)
-
-iface.launch()
diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/backbones/regnet.py b/spaces/KyanChen/RSPrompter/mmdet/models/backbones/regnet.py
deleted file mode 100644
index 55d3ce075f0cec68de4537a71ed569151d684562..0000000000000000000000000000000000000000
--- a/spaces/KyanChen/RSPrompter/mmdet/models/backbones/regnet.py
+++ /dev/null
@@ -1,356 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-
-import numpy as np
-import torch.nn as nn
-from mmcv.cnn import build_conv_layer, build_norm_layer
-
-from mmdet.registry import MODELS
-from .resnet import ResNet
-from .resnext import Bottleneck
-
-
-@MODELS.register_module()
-class RegNet(ResNet):
- """RegNet backbone.
-
- More details can be found in `paper `_ .
-
- Args:
- arch (dict): The parameter of RegNets.
-
- - w0 (int): initial width
- - wa (float): slope of width
- - wm (float): quantization parameter to quantize the width
- - depth (int): depth of the backbone
- - group_w (int): width of group
- - bot_mul (float): bottleneck ratio, i.e. expansion of bottleneck.
- strides (Sequence[int]): Strides of the first block of each stage.
- base_channels (int): Base channels after stem layer.
- in_channels (int): Number of input image channels. Default: 3.
- dilations (Sequence[int]): Dilation of each stage.
- out_indices (Sequence[int]): Output from which stages.
- style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
- layer is the 3x3 conv layer, otherwise the stride-two layer is
- the first 1x1 conv layer.
- frozen_stages (int): Stages to be frozen (all param fixed). -1 means
- not freezing any parameters.
- norm_cfg (dict): dictionary to construct and config norm layer.
- norm_eval (bool): Whether to set norm layers to eval mode, namely,
- freeze running stats (mean and var). Note: Effect on Batch Norm
- and its variants only.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed.
- zero_init_residual (bool): whether to use zero init for last norm layer
- in resblocks to let them behave as identity.
- pretrained (str, optional): model pretrained path. Default: None
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Default: None
-
- Example:
- >>> from mmdet.models import RegNet
- >>> import torch
- >>> self = RegNet(
- arch=dict(
- w0=88,
- wa=26.31,
- wm=2.25,
- group_w=48,
- depth=25,
- bot_mul=1.0))
- >>> self.eval()
- >>> inputs = torch.rand(1, 3, 32, 32)
- >>> level_outputs = self.forward(inputs)
- >>> for level_out in level_outputs:
- ... print(tuple(level_out.shape))
- (1, 96, 8, 8)
- (1, 192, 4, 4)
- (1, 432, 2, 2)
- (1, 1008, 1, 1)
- """
- arch_settings = {
- 'regnetx_400mf':
- dict(w0=24, wa=24.48, wm=2.54, group_w=16, depth=22, bot_mul=1.0),
- 'regnetx_800mf':
- dict(w0=56, wa=35.73, wm=2.28, group_w=16, depth=16, bot_mul=1.0),
- 'regnetx_1.6gf':
- dict(w0=80, wa=34.01, wm=2.25, group_w=24, depth=18, bot_mul=1.0),
- 'regnetx_3.2gf':
- dict(w0=88, wa=26.31, wm=2.25, group_w=48, depth=25, bot_mul=1.0),
- 'regnetx_4.0gf':
- dict(w0=96, wa=38.65, wm=2.43, group_w=40, depth=23, bot_mul=1.0),
- 'regnetx_6.4gf':
- dict(w0=184, wa=60.83, wm=2.07, group_w=56, depth=17, bot_mul=1.0),
- 'regnetx_8.0gf':
- dict(w0=80, wa=49.56, wm=2.88, group_w=120, depth=23, bot_mul=1.0),
- 'regnetx_12gf':
- dict(w0=168, wa=73.36, wm=2.37, group_w=112, depth=19, bot_mul=1.0),
- }
-
- def __init__(self,
- arch,
- in_channels=3,
- stem_channels=32,
- base_channels=32,
- strides=(2, 2, 2, 2),
- dilations=(1, 1, 1, 1),
- out_indices=(0, 1, 2, 3),
- style='pytorch',
- deep_stem=False,
- avg_down=False,
- frozen_stages=-1,
- conv_cfg=None,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=True,
- dcn=None,
- stage_with_dcn=(False, False, False, False),
- plugins=None,
- with_cp=False,
- zero_init_residual=True,
- pretrained=None,
- init_cfg=None):
- super(ResNet, self).__init__(init_cfg)
-
- # Generate RegNet parameters first
- if isinstance(arch, str):
- assert arch in self.arch_settings, \
- f'"arch": "{arch}" is not one of the' \
- ' arch_settings'
- arch = self.arch_settings[arch]
- elif not isinstance(arch, dict):
- raise ValueError('Expect "arch" to be either a string '
- f'or a dict, got {type(arch)}')
-
- widths, num_stages = self.generate_regnet(
- arch['w0'],
- arch['wa'],
- arch['wm'],
- arch['depth'],
- )
- # Convert to per stage format
- stage_widths, stage_blocks = self.get_stages_from_blocks(widths)
- # Generate group widths and bot muls
- group_widths = [arch['group_w'] for _ in range(num_stages)]
- self.bottleneck_ratio = [arch['bot_mul'] for _ in range(num_stages)]
- # Adjust the compatibility of stage_widths and group_widths
- stage_widths, group_widths = self.adjust_width_group(
- stage_widths, self.bottleneck_ratio, group_widths)
-
- # Group params by stage
- self.stage_widths = stage_widths
- self.group_widths = group_widths
- self.depth = sum(stage_blocks)
- self.stem_channels = stem_channels
- self.base_channels = base_channels
- self.num_stages = num_stages
- assert num_stages >= 1 and num_stages <= 4
- self.strides = strides
- self.dilations = dilations
- assert len(strides) == len(dilations) == num_stages
- self.out_indices = out_indices
- assert max(out_indices) < num_stages
- self.style = style
- self.deep_stem = deep_stem
- self.avg_down = avg_down
- self.frozen_stages = frozen_stages
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- self.with_cp = with_cp
- self.norm_eval = norm_eval
- self.dcn = dcn
- self.stage_with_dcn = stage_with_dcn
- if dcn is not None:
- assert len(stage_with_dcn) == num_stages
- self.plugins = plugins
- self.zero_init_residual = zero_init_residual
- self.block = Bottleneck
- expansion_bak = self.block.expansion
- self.block.expansion = 1
- self.stage_blocks = stage_blocks[:num_stages]
-
- self._make_stem_layer(in_channels, stem_channels)
-
- block_init_cfg = None
- assert not (init_cfg and pretrained), \
- 'init_cfg and pretrained cannot be specified at the same time'
- if isinstance(pretrained, str):
- warnings.warn('DeprecationWarning: pretrained is deprecated, '
- 'please use "init_cfg" instead')
- self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
- elif pretrained is None:
- if init_cfg is None:
- self.init_cfg = [
- dict(type='Kaiming', layer='Conv2d'),
- dict(
- type='Constant',
- val=1,
- layer=['_BatchNorm', 'GroupNorm'])
- ]
- if self.zero_init_residual:
- block_init_cfg = dict(
- type='Constant', val=0, override=dict(name='norm3'))
- else:
- raise TypeError('pretrained must be a str or None')
-
- self.inplanes = stem_channels
- self.res_layers = []
- for i, num_blocks in enumerate(self.stage_blocks):
- stride = self.strides[i]
- dilation = self.dilations[i]
- group_width = self.group_widths[i]
- width = int(round(self.stage_widths[i] * self.bottleneck_ratio[i]))
- stage_groups = width // group_width
-
- dcn = self.dcn if self.stage_with_dcn[i] else None
- if self.plugins is not None:
- stage_plugins = self.make_stage_plugins(self.plugins, i)
- else:
- stage_plugins = None
-
- res_layer = self.make_res_layer(
- block=self.block,
- inplanes=self.inplanes,
- planes=self.stage_widths[i],
- num_blocks=num_blocks,
- stride=stride,
- dilation=dilation,
- style=self.style,
- avg_down=self.avg_down,
- with_cp=self.with_cp,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- dcn=dcn,
- plugins=stage_plugins,
- groups=stage_groups,
- base_width=group_width,
- base_channels=self.stage_widths[i],
- init_cfg=block_init_cfg)
- self.inplanes = self.stage_widths[i]
- layer_name = f'layer{i + 1}'
- self.add_module(layer_name, res_layer)
- self.res_layers.append(layer_name)
-
- self._freeze_stages()
-
- self.feat_dim = stage_widths[-1]
- self.block.expansion = expansion_bak
-
- def _make_stem_layer(self, in_channels, base_channels):
- self.conv1 = build_conv_layer(
- self.conv_cfg,
- in_channels,
- base_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False)
- self.norm1_name, norm1 = build_norm_layer(
- self.norm_cfg, base_channels, postfix=1)
- self.add_module(self.norm1_name, norm1)
- self.relu = nn.ReLU(inplace=True)
-
- def generate_regnet(self,
- initial_width,
- width_slope,
- width_parameter,
- depth,
- divisor=8):
- """Generates per block width from RegNet parameters.
-
- Args:
- initial_width ([int]): Initial width of the backbone
- width_slope ([float]): Slope of the quantized linear function
- width_parameter ([int]): Parameter used to quantize the width.
- depth ([int]): Depth of the backbone.
- divisor (int, optional): The divisor of channels. Defaults to 8.
-
- Returns:
- list, int: return a list of widths of each stage and the number \
- of stages
- """
- assert width_slope >= 0
- assert initial_width > 0
- assert width_parameter > 1
- assert initial_width % divisor == 0
- widths_cont = np.arange(depth) * width_slope + initial_width
- ks = np.round(
- np.log(widths_cont / initial_width) / np.log(width_parameter))
- widths = initial_width * np.power(width_parameter, ks)
- widths = np.round(np.divide(widths, divisor)) * divisor
- num_stages = len(np.unique(widths))
- widths, widths_cont = widths.astype(int).tolist(), widths_cont.tolist()
- return widths, num_stages
-
- @staticmethod
- def quantize_float(number, divisor):
- """Converts a float to closest non-zero int divisible by divisor.
-
- Args:
- number (int): Original number to be quantized.
- divisor (int): Divisor used to quantize the number.
-
- Returns:
- int: quantized number that is divisible by devisor.
- """
- return int(round(number / divisor) * divisor)
-
- def adjust_width_group(self, widths, bottleneck_ratio, groups):
- """Adjusts the compatibility of widths and groups.
-
- Args:
- widths (list[int]): Width of each stage.
- bottleneck_ratio (float): Bottleneck ratio.
- groups (int): number of groups in each stage
-
- Returns:
- tuple(list): The adjusted widths and groups of each stage.
- """
- bottleneck_width = [
- int(w * b) for w, b in zip(widths, bottleneck_ratio)
- ]
- groups = [min(g, w_bot) for g, w_bot in zip(groups, bottleneck_width)]
- bottleneck_width = [
- self.quantize_float(w_bot, g)
- for w_bot, g in zip(bottleneck_width, groups)
- ]
- widths = [
- int(w_bot / b)
- for w_bot, b in zip(bottleneck_width, bottleneck_ratio)
- ]
- return widths, groups
-
- def get_stages_from_blocks(self, widths):
- """Gets widths/stage_blocks of network at each stage.
-
- Args:
- widths (list[int]): Width in each stage.
-
- Returns:
- tuple(list): width and depth of each stage
- """
- width_diff = [
- width != width_prev
- for width, width_prev in zip(widths + [0], [0] + widths)
- ]
- stage_widths = [
- width for width, diff in zip(widths, width_diff[:-1]) if diff
- ]
- stage_blocks = np.diff([
- depth for depth, diff in zip(range(len(width_diff)), width_diff)
- if diff
- ]).tolist()
- return stage_widths, stage_blocks
-
- def forward(self, x):
- """Forward function."""
- x = self.conv1(x)
- x = self.norm1(x)
- x = self.relu(x)
-
- outs = []
- for i, layer_name in enumerate(self.res_layers):
- res_layer = getattr(self, layer_name)
- x = res_layer(x)
- if i in self.out_indices:
- outs.append(x)
- return tuple(outs)
diff --git a/spaces/Laihiujin/OneFormer/oneformer/data/__init__.py b/spaces/Laihiujin/OneFormer/oneformer/data/__init__.py
deleted file mode 100644
index 63ba265b1effc69f1eef16e57a04db8902ee347e..0000000000000000000000000000000000000000
--- a/spaces/Laihiujin/OneFormer/oneformer/data/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from . import datasets
diff --git a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/infer_cli.py b/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/infer_cli.py
deleted file mode 100644
index 113c57dd00d1dfa57dd914563b57770021d7dee6..0000000000000000000000000000000000000000
--- a/spaces/LaynzKunz/Aesthetic_RVC_Inference_HF/lib/tools/infer_cli.py
+++ /dev/null
@@ -1,67 +0,0 @@
-import argparse
-import os
-import sys
-
-now_dir = os.getcwd()
-sys.path.append(now_dir)
-from dotenv import load_dotenv
-from scipy.io import wavfile
-
-from assets.configs.config import Config
-from lib.infer.modules.vc.modules import VC
-
-####
-# USAGE
-#
-# In your Terminal or CMD or whatever
-
-
-def arg_parse() -> tuple:
- parser = argparse.ArgumentParser()
- parser.add_argument("--f0up_key", type=int, default=0)
- parser.add_argument("--input_path", type=str, help="input path")
- parser.add_argument("--index_path", type=str, help="index path")
- parser.add_argument("--f0method", type=str, default="harvest", help="harvest or pm")
- parser.add_argument("--opt_path", type=str, help="opt path")
- parser.add_argument("--model_name", type=str, help="store in assets/weight_root")
- parser.add_argument("--index_rate", type=float, default=0.66, help="index rate")
- parser.add_argument("--device", type=str, help="device")
- parser.add_argument("--is_half", type=bool, help="use half -> True")
- parser.add_argument("--filter_radius", type=int, default=3, help="filter radius")
- parser.add_argument("--resample_sr", type=int, default=0, help="resample sr")
- parser.add_argument("--rms_mix_rate", type=float, default=1, help="rms mix rate")
- parser.add_argument("--protect", type=float, default=0.33, help="protect")
-
- args = parser.parse_args()
- sys.argv = sys.argv[:1]
-
- return args
-
-
-def main():
- load_dotenv()
- args = arg_parse()
- config = Config()
- config.device = args.device if args.device else config.device
- config.is_half = args.is_half if args.is_half else config.is_half
- vc = VC(config)
- vc.get_vc(args.model_name)
- _, wav_opt = vc.vc_single(
- 0,
- args.input_path,
- args.f0up_key,
- None,
- args.f0method,
- args.index_path,
- None,
- args.index_rate,
- args.filter_radius,
- args.resample_sr,
- args.rms_mix_rate,
- args.protect,
- )
- wavfile.write(args.opt_path, wav_opt[0], wav_opt[1])
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/LaynzKunz/RVC-Inference-webui-grado-colab-huggingafce/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py b/spaces/LaynzKunz/RVC-Inference-webui-grado-colab-huggingafce/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
deleted file mode 100644
index b412ba2814e114ca7bb00b6fd6ef217f63d788a3..0000000000000000000000000000000000000000
--- a/spaces/LaynzKunz/RVC-Inference-webui-grado-colab-huggingafce/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
+++ /dev/null
@@ -1,86 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import pyworld
-import numpy as np
-
-
-class HarvestF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def resize_f0(self, x, target_len):
- source = np.array(x)
- source[source < 0.001] = np.nan
- target = np.interp(
- np.arange(0, len(source) * target_len, len(source)) / target_len,
- np.arange(0, len(source)),
- source,
- )
- res = np.nan_to_num(target)
- return res
-
- def compute_f0(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.hop_length,
- f0_ceil=self.f0_max,
- f0_floor=self.f0_min,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.fs)
- return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
-
- def compute_f0_uv(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.sampling_rate,
- f0_floor=self.f0_min,
- f0_ceil=self.f0_max,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
- return self.interpolate_f0(self.resize_f0(f0, p_len))
diff --git a/spaces/Lbin123/Lbingo/src/components/chat-attachments.tsx b/spaces/Lbin123/Lbingo/src/components/chat-attachments.tsx
deleted file mode 100644
index ef43d4e262935d263b6099138c56f7daade5299d..0000000000000000000000000000000000000000
--- a/spaces/Lbin123/Lbingo/src/components/chat-attachments.tsx
+++ /dev/null
@@ -1,37 +0,0 @@
-import Image from 'next/image'
-import ClearIcon from '@/assets/images/clear.svg'
-import RefreshIcon from '@/assets/images/refresh.svg'
-import { FileItem } from '@/lib/bots/bing/types'
-import { cn } from '@/lib/utils'
-import { useBing } from '@/lib/hooks/use-bing'
-
-type ChatAttachmentsProps = Pick, 'attachmentList' | 'setAttachmentList' | 'uploadImage'>
-
-export function ChatAttachments({ attachmentList = [], setAttachmentList, uploadImage }: ChatAttachmentsProps) {
- return attachmentList.length ? (
-
- {attachmentList.map(file => (
-
- {file.status === 'loading' && (
-
)
- }
- {file.status !== 'error' && (
-
-

-
)
- }
- {file.status === 'error' && (
-
- uploadImage(file.url)} />
-
- )}
-
-
- ))}
-
-
-
-
- FairDiffusion Demo
-
-
-
- FairDiffusion is the latest strategy to introduce fairness after the deployment of generative text-to-image models
- This unofficial demo is based on the Github Implementation.
-
-
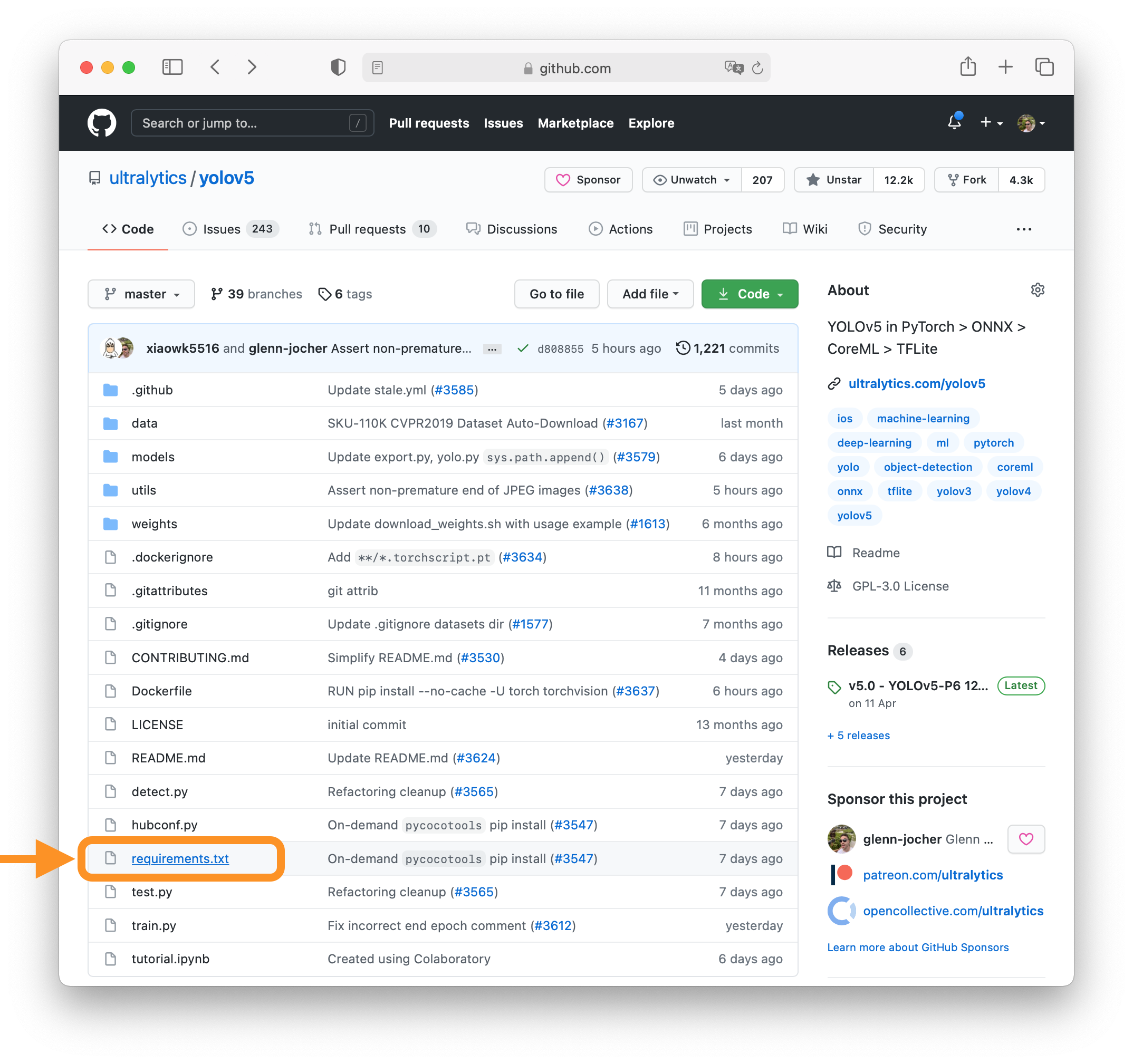
-
-### 2. Click 'Edit this file'
-
-The button is in the top-right corner.
-
-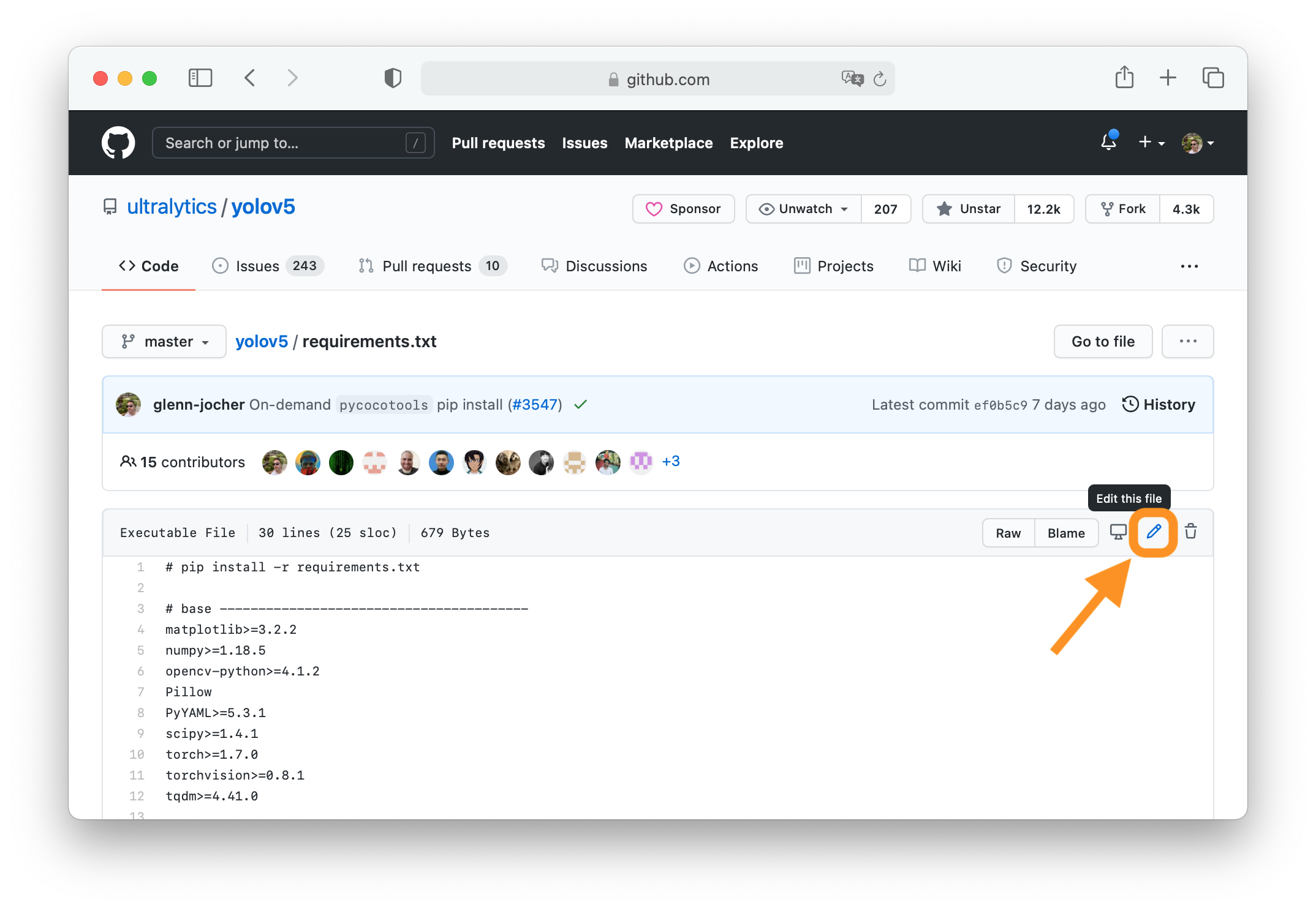
-
-### 3. Make Changes
-
-Change the `matplotlib` version from `3.2.2` to `3.3`.
-
-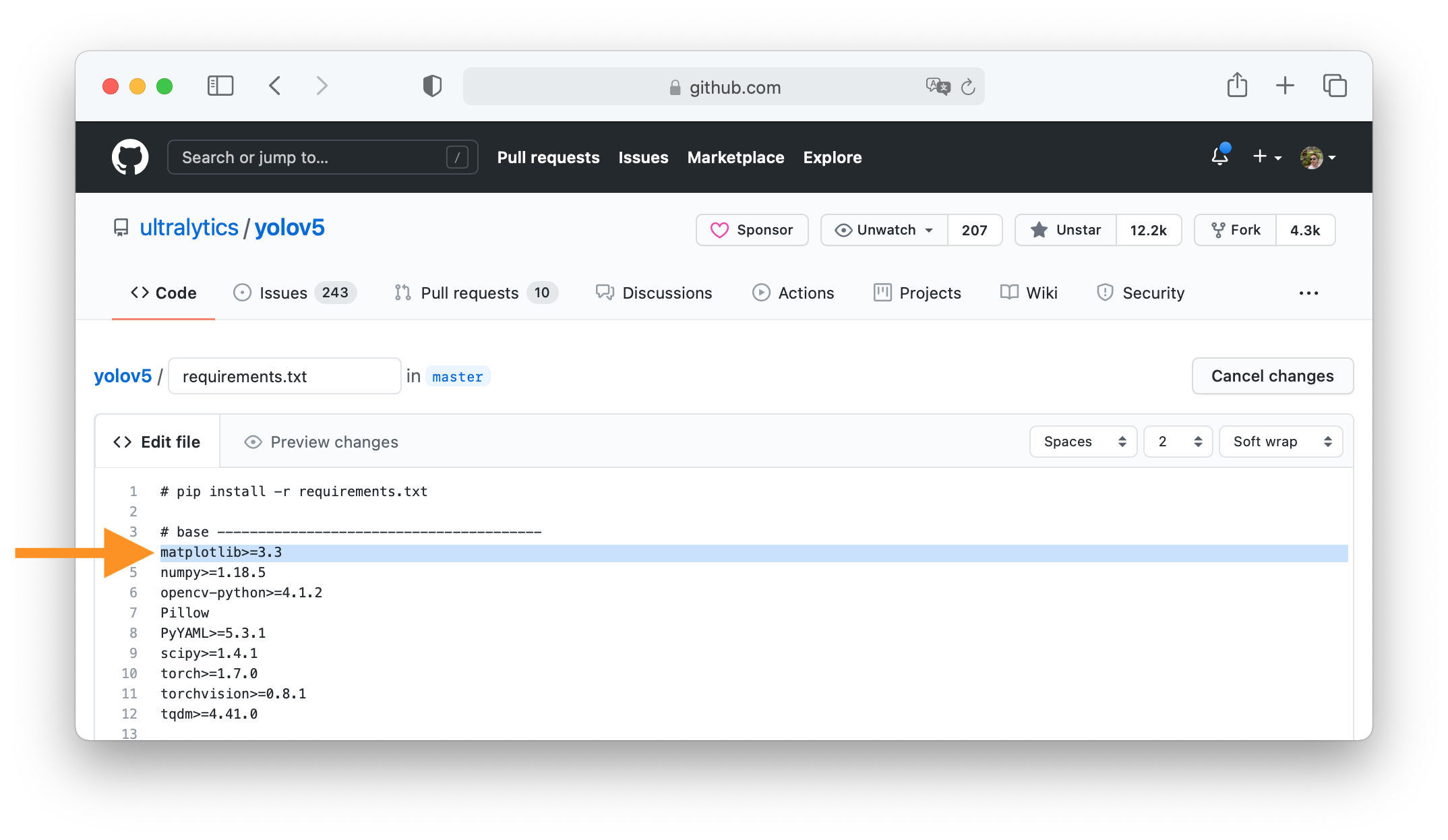
-
-### 4. Preview Changes and Submit PR
-
-Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch**
-for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose
-changes** button. All done, your PR is now submitted to YOLOv5 for review and approval 😃!
-
-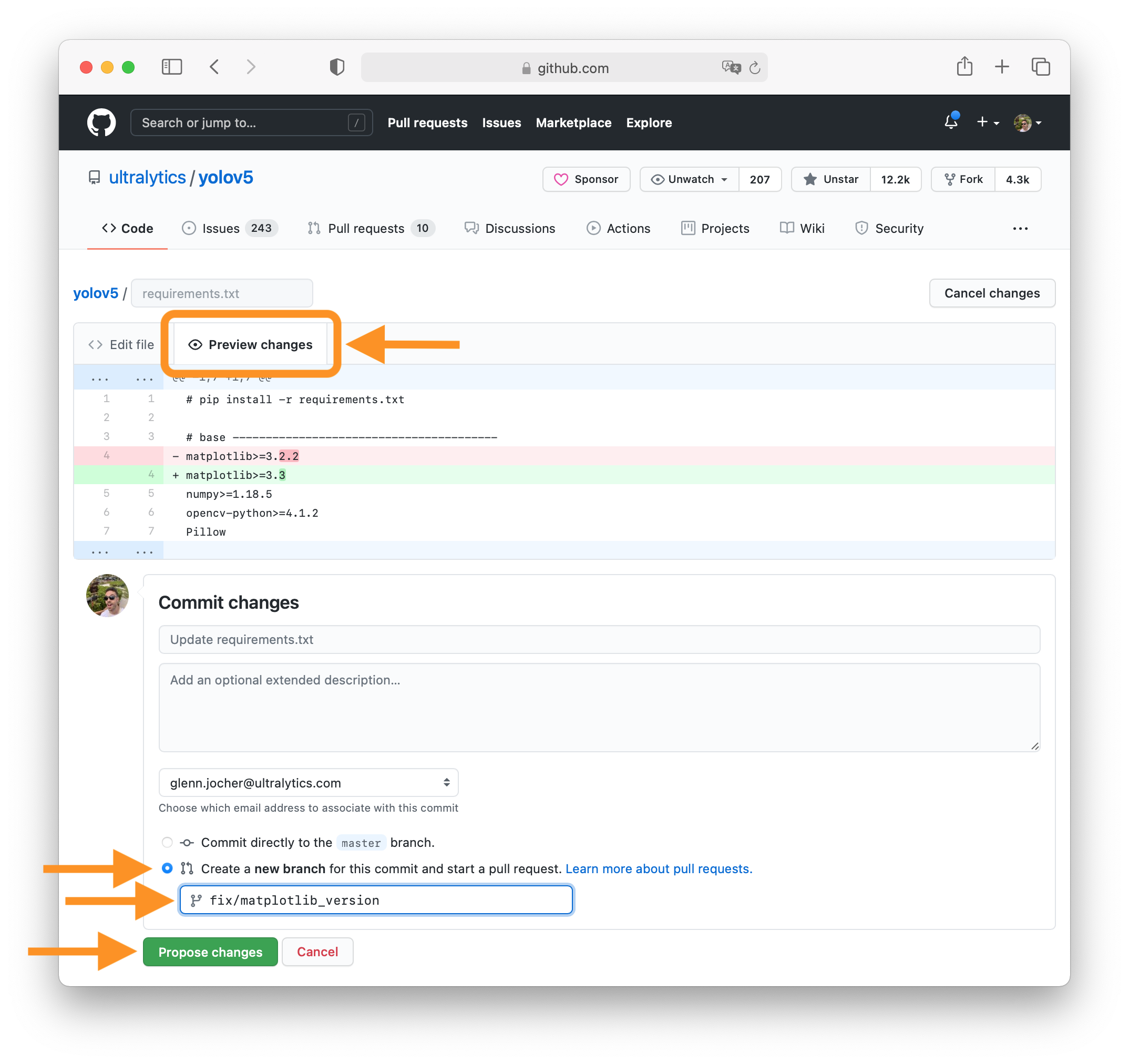
-
-### PR recommendations
-
-To allow your work to be integrated as seamlessly as possible, we advise you to:
-
-- ✅ Verify your PR is **up-to-date** with `ultralytics/yolov5` `master` branch. If your PR is behind you can update
- your code by clicking the 'Update branch' button or by running `git pull` and `git merge master` locally.
-
-
-
-- ✅ Verify all YOLOv5 Continuous Integration (CI) **checks are passing**.
-
-
-
-- ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase
- but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
-
-## Submitting a Bug Report 🐛
-
-If you spot a problem with YOLOv5 please submit a Bug Report!
-
-For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few
-short guidelines below to help users provide what we need to get started.
-
-When asking a question, people will be better able to provide help if you provide **code** that they can easily
-understand and use to **reproduce** the problem. This is referred to by community members as creating
-a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/). Your code that reproduces
-the problem should be:
-
-- ✅ **Minimal** – Use as little code as possible that still produces the same problem
-- ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
-- ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
-
-In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code
-should be:
-
-- ✅ **Current** – Verify that your code is up-to-date with the current
- GitHub [master](https://github.com/ultralytics/yolov5/tree/master), and if necessary `git pull` or `git clone` a new
- copy to ensure your problem has not already been resolved by previous commits.
-- ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this
- repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
-
-If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛
-**Bug Report** [template](https://github.com/ultralytics/yolov5/issues/new/choose) and provide
-a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us better
-understand and diagnose your problem.
-
-## License
-
-By contributing, you agree that your contributions will be licensed under
-the [AGPL-3.0 license](https://choosealicense.com/licenses/agpl-3.0/)
diff --git a/spaces/XzJosh/Azuma-Bert-VITS2/mel_processing.py b/spaces/XzJosh/Azuma-Bert-VITS2/mel_processing.py
deleted file mode 100644
index 50435ecf88ef4fb6c1d47f3e6edd04c3ea7d3e80..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/Azuma-Bert-VITS2/mel_processing.py
+++ /dev/null
@@ -1,112 +0,0 @@
-import math
-import os
-import random
-import torch
-from torch import nn
-import torch.nn.functional as F
-import torch.utils.data
-import numpy as np
-import librosa
-import librosa.util as librosa_util
-from librosa.util import normalize, pad_center, tiny
-from scipy.signal import get_window
-from scipy.io.wavfile import read
-from librosa.filters import mel as librosa_mel_fn
-
-MAX_WAV_VALUE = 32768.0
-
-
-def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
- """
- PARAMS
- ------
- C: compression factor
- """
- return torch.log(torch.clamp(x, min=clip_val) * C)
-
-
-def dynamic_range_decompression_torch(x, C=1):
- """
- PARAMS
- ------
- C: compression factor used to compress
- """
- return torch.exp(x) / C
-
-
-def spectral_normalize_torch(magnitudes):
- output = dynamic_range_compression_torch(magnitudes)
- return output
-
-
-def spectral_de_normalize_torch(magnitudes):
- output = dynamic_range_decompression_torch(magnitudes)
- return output
-
-
-mel_basis = {}
-hann_window = {}
-
-
-def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
- if torch.min(y) < -1.:
- print('min value is ', torch.min(y))
- if torch.max(y) > 1.:
- print('max value is ', torch.max(y))
-
- global hann_window
- dtype_device = str(y.dtype) + '_' + str(y.device)
- wnsize_dtype_device = str(win_size) + '_' + dtype_device
- if wnsize_dtype_device not in hann_window:
- hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
-
- y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
- y = y.squeeze(1)
-
- spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
- center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
-
- spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
- return spec
-
-
-def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
- global mel_basis
- dtype_device = str(spec.dtype) + '_' + str(spec.device)
- fmax_dtype_device = str(fmax) + '_' + dtype_device
- if fmax_dtype_device not in mel_basis:
- mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
- mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device)
- spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
- spec = spectral_normalize_torch(spec)
- return spec
-
-
-def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False):
- if torch.min(y) < -1.:
- print('min value is ', torch.min(y))
- if torch.max(y) > 1.:
- print('max value is ', torch.max(y))
-
- global mel_basis, hann_window
- dtype_device = str(y.dtype) + '_' + str(y.device)
- fmax_dtype_device = str(fmax) + '_' + dtype_device
- wnsize_dtype_device = str(win_size) + '_' + dtype_device
- if fmax_dtype_device not in mel_basis:
- mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
- mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device)
- if wnsize_dtype_device not in hann_window:
- hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
-
- y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
- y = y.squeeze(1)
-
- spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
- center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
-
- spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
-
- spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
- spec = spectral_normalize_torch(spec)
-
- return spec
diff --git a/spaces/YaeMiko2005/Yae_Miko_voice_jp/app.py b/spaces/YaeMiko2005/Yae_Miko_voice_jp/app.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Yiqin/ChatVID/model/vision/grit_src/third_party/CenterNet2/detectron2/data/datasets/register_coco.py b/spaces/Yiqin/ChatVID/model/vision/grit_src/third_party/CenterNet2/detectron2/data/datasets/register_coco.py
deleted file mode 100644
index e564438d5bf016bcdbb65b4bbdc215d79f579f8a..0000000000000000000000000000000000000000
--- a/spaces/Yiqin/ChatVID/model/vision/grit_src/third_party/CenterNet2/detectron2/data/datasets/register_coco.py
+++ /dev/null
@@ -1,3 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from .coco import register_coco_instances # noqa
-from .coco_panoptic import register_coco_panoptic_separated # noqa
diff --git a/spaces/YuhangDeng123/Whisper-online/app.py b/spaces/YuhangDeng123/Whisper-online/app.py
deleted file mode 100644
index 631a5c38b75e4d2fb89c415ad7275a0686b9f4ef..0000000000000000000000000000000000000000
--- a/spaces/YuhangDeng123/Whisper-online/app.py
+++ /dev/null
@@ -1,23 +0,0 @@
-from transformers import pipeline
-import gradio as gr
-import time
-
-pipe= pipeline(model="YuhangDeng123/whisper-small-hi")
-
-def transcribe(audio, state=""):
- text = pipe(audio)["text"]
- state += text + " "
- return state, state
-
-gr.Interface(
- title="Whisper-Small Online Cantonese Recognition",
- fn=transcribe,
- inputs=[
- gr.Audio(source="microphone", type="filepath", streaming=True),
- "state"
- ],
- outputs=[
- "textbox",
- "state"
- ],
- live=True).launch()
\ No newline at end of file
diff --git a/spaces/Yunshansongbai/SVC-Nahida/modules/losses.py b/spaces/Yunshansongbai/SVC-Nahida/modules/losses.py
deleted file mode 100644
index 93f9523df3e326825c9130b5bbcced39c4a5be3f..0000000000000000000000000000000000000000
--- a/spaces/Yunshansongbai/SVC-Nahida/modules/losses.py
+++ /dev/null
@@ -1,61 +0,0 @@
-import paddle
-from paddle.nn import functional as F
-
-import modules.commons as commons
-
-
-def feature_loss(fmap_r, fmap_g):
- loss = 0
- for dr, dg in zip(fmap_r, fmap_g):
- for rl, gl in zip(dr, dg):
- rl = rl.astype('float32').detach()
- gl = gl.astype('float32')
- loss += paddle.mean(paddle.abs(rl - gl))
-
- return loss * 2
-
-
-def discriminator_loss(disc_real_outputs, disc_generated_outputs):
- loss = 0
- r_losses = []
- g_losses = []
- for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
- dr = dr.astype('float32')
- dg = dg.astype('float32')
- r_loss = paddle.mean((1-dr)**2)
- g_loss = paddle.mean(dg**2)
- loss += (r_loss + g_loss)
- r_losses.append(r_loss.item())
- g_losses.append(g_loss.item())
-
- return loss, r_losses, g_losses
-
-
-def generator_loss(disc_outputs):
- loss = 0
- gen_losses = []
- for dg in disc_outputs:
- dg = dg.astype('float32')
- l = paddle.mean((1-dg)**2)
- gen_losses.append(l)
- loss += l
-
- return loss, gen_losses
-
-
-def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
- """
- z_p, logs_q: [b, h, t_t]
- m_p, logs_p: [b, h, t_t]
- """
- z_p = z_p.astype('float32')
- logs_q = logs_q.astype('float32')
- m_p = m_p.astype('float32')
- logs_p = logs_p.astype('float32')
- z_mask = z_mask.astype('float32')
- #print(logs_p)
- kl = logs_p - logs_q - 0.5
- kl += 0.5 * ((z_p - m_p)**2) * paddle.exp(-2. * logs_p)
- kl = paddle.sum(kl * z_mask)
- l = kl / paddle.sum(z_mask)
- return l
diff --git a/spaces/ZenXir/FreeVC/speaker_encoder/compute_embed.py b/spaces/ZenXir/FreeVC/speaker_encoder/compute_embed.py
deleted file mode 100644
index 2fee33db0168f40efc42145c06fa62016e3e008e..0000000000000000000000000000000000000000
--- a/spaces/ZenXir/FreeVC/speaker_encoder/compute_embed.py
+++ /dev/null
@@ -1,40 +0,0 @@
-from speaker_encoder import inference as encoder
-from multiprocessing.pool import Pool
-from functools import partial
-from pathlib import Path
-# from utils import logmmse
-# from tqdm import tqdm
-# import numpy as np
-# import librosa
-
-
-def embed_utterance(fpaths, encoder_model_fpath):
- if not encoder.is_loaded():
- encoder.load_model(encoder_model_fpath)
-
- # Compute the speaker embedding of the utterance
- wav_fpath, embed_fpath = fpaths
- wav = np.load(wav_fpath)
- wav = encoder.preprocess_wav(wav)
- embed = encoder.embed_utterance(wav)
- np.save(embed_fpath, embed, allow_pickle=False)
-
-
-def create_embeddings(outdir_root: Path, wav_dir: Path, encoder_model_fpath: Path, n_processes: int):
-
- wav_dir = outdir_root.joinpath("audio")
- metadata_fpath = synthesizer_root.joinpath("train.txt")
- assert wav_dir.exists() and metadata_fpath.exists()
- embed_dir = synthesizer_root.joinpath("embeds")
- embed_dir.mkdir(exist_ok=True)
-
- # Gather the input wave filepath and the target output embed filepath
- with metadata_fpath.open("r") as metadata_file:
- metadata = [line.split("|") for line in metadata_file]
- fpaths = [(wav_dir.joinpath(m[0]), embed_dir.joinpath(m[2])) for m in metadata]
-
- # TODO: improve on the multiprocessing, it's terrible. Disk I/O is the bottleneck here.
- # Embed the utterances in separate threads
- func = partial(embed_utterance, encoder_model_fpath=encoder_model_fpath)
- job = Pool(n_processes).imap(func, fpaths)
- list(tqdm(job, "Embedding", len(fpaths), unit="utterances"))
\ No newline at end of file
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/losses/focal_loss.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/losses/focal_loss.py
deleted file mode 100644
index 493907c6984d532175e0351daf2eafe4b9ff0256..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/losses/focal_loss.py
+++ /dev/null
@@ -1,181 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.ops import sigmoid_focal_loss as _sigmoid_focal_loss
-
-from ..builder import LOSSES
-from .utils import weight_reduce_loss
-
-
-# This method is only for debugging
-def py_sigmoid_focal_loss(pred,
- target,
- weight=None,
- gamma=2.0,
- alpha=0.25,
- reduction='mean',
- avg_factor=None):
- """PyTorch version of `Focal Loss `_.
-
- Args:
- pred (torch.Tensor): The prediction with shape (N, C), C is the
- number of classes
- target (torch.Tensor): The learning label of the prediction.
- weight (torch.Tensor, optional): Sample-wise loss weight.
- gamma (float, optional): The gamma for calculating the modulating
- factor. Defaults to 2.0.
- alpha (float, optional): A balanced form for Focal Loss.
- Defaults to 0.25.
- reduction (str, optional): The method used to reduce the loss into
- a scalar. Defaults to 'mean'.
- avg_factor (int, optional): Average factor that is used to average
- the loss. Defaults to None.
- """
- pred_sigmoid = pred.sigmoid()
- target = target.type_as(pred)
- pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
- focal_weight = (alpha * target + (1 - alpha) *
- (1 - target)) * pt.pow(gamma)
- loss = F.binary_cross_entropy_with_logits(
- pred, target, reduction='none') * focal_weight
- if weight is not None:
- if weight.shape != loss.shape:
- if weight.size(0) == loss.size(0):
- # For most cases, weight is of shape (num_priors, ),
- # which means it does not have the second axis num_class
- weight = weight.view(-1, 1)
- else:
- # Sometimes, weight per anchor per class is also needed. e.g.
- # in FSAF. But it may be flattened of shape
- # (num_priors x num_class, ), while loss is still of shape
- # (num_priors, num_class).
- assert weight.numel() == loss.numel()
- weight = weight.view(loss.size(0), -1)
- assert weight.ndim == loss.ndim
- loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
- return loss
-
-
-def sigmoid_focal_loss(pred,
- target,
- weight=None,
- gamma=2.0,
- alpha=0.25,
- reduction='mean',
- avg_factor=None):
- r"""A warpper of cuda version `Focal Loss
- `_.
-
- Args:
- pred (torch.Tensor): The prediction with shape (N, C), C is the number
- of classes.
- target (torch.Tensor): The learning label of the prediction.
- weight (torch.Tensor, optional): Sample-wise loss weight.
- gamma (float, optional): The gamma for calculating the modulating
- factor. Defaults to 2.0.
- alpha (float, optional): A balanced form for Focal Loss.
- Defaults to 0.25.
- reduction (str, optional): The method used to reduce the loss into
- a scalar. Defaults to 'mean'. Options are "none", "mean" and "sum".
- avg_factor (int, optional): Average factor that is used to average
- the loss. Defaults to None.
- """
- # Function.apply does not accept keyword arguments, so the decorator
- # "weighted_loss" is not applicable
- loss = _sigmoid_focal_loss(pred.contiguous(), target, gamma, alpha, None,
- 'none')
- if weight is not None:
- if weight.shape != loss.shape:
- if weight.size(0) == loss.size(0):
- # For most cases, weight is of shape (num_priors, ),
- # which means it does not have the second axis num_class
- weight = weight.view(-1, 1)
- else:
- # Sometimes, weight per anchor per class is also needed. e.g.
- # in FSAF. But it may be flattened of shape
- # (num_priors x num_class, ), while loss is still of shape
- # (num_priors, num_class).
- assert weight.numel() == loss.numel()
- weight = weight.view(loss.size(0), -1)
- assert weight.ndim == loss.ndim
- loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
- return loss
-
-
-@LOSSES.register_module()
-class FocalLoss(nn.Module):
-
- def __init__(self,
- use_sigmoid=True,
- gamma=2.0,
- alpha=0.25,
- reduction='mean',
- loss_weight=1.0):
- """`Focal Loss `_
-
- Args:
- use_sigmoid (bool, optional): Whether to the prediction is
- used for sigmoid or softmax. Defaults to True.
- gamma (float, optional): The gamma for calculating the modulating
- factor. Defaults to 2.0.
- alpha (float, optional): A balanced form for Focal Loss.
- Defaults to 0.25.
- reduction (str, optional): The method used to reduce the loss into
- a scalar. Defaults to 'mean'. Options are "none", "mean" and
- "sum".
- loss_weight (float, optional): Weight of loss. Defaults to 1.0.
- """
- super(FocalLoss, self).__init__()
- assert use_sigmoid is True, 'Only sigmoid focal loss supported now.'
- self.use_sigmoid = use_sigmoid
- self.gamma = gamma
- self.alpha = alpha
- self.reduction = reduction
- self.loss_weight = loss_weight
-
- def forward(self,
- pred,
- target,
- weight=None,
- avg_factor=None,
- reduction_override=None):
- """Forward function.
-
- Args:
- pred (torch.Tensor): The prediction.
- target (torch.Tensor): The learning label of the prediction.
- weight (torch.Tensor, optional): The weight of loss for each
- prediction. Defaults to None.
- avg_factor (int, optional): Average factor that is used to average
- the loss. Defaults to None.
- reduction_override (str, optional): The reduction method used to
- override the original reduction method of the loss.
- Options are "none", "mean" and "sum".
-
- Returns:
- torch.Tensor: The calculated loss
- """
- assert reduction_override in (None, 'none', 'mean', 'sum')
- reduction = (
- reduction_override if reduction_override else self.reduction)
- if self.use_sigmoid:
- if torch.cuda.is_available() and pred.is_cuda:
- calculate_loss_func = sigmoid_focal_loss
- else:
- num_classes = pred.size(1)
- target = F.one_hot(target, num_classes=num_classes + 1)
- target = target[:, :num_classes]
- calculate_loss_func = py_sigmoid_focal_loss
-
- loss_cls = self.loss_weight * calculate_loss_func(
- pred,
- target,
- weight,
- gamma=self.gamma,
- alpha=self.alpha,
- reduction=reduction,
- avg_factor=avg_factor)
-
- else:
- raise NotImplementedError
- return loss_cls
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/configs/_base_/models/emanet_r50-d8.py b/spaces/abhishek/sketch-to-image/annotator/uniformer_base/configs/_base_/models/emanet_r50-d8.py
deleted file mode 100644
index 26adcd430926de0862204a71d345f2543167f27b..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/configs/_base_/models/emanet_r50-d8.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True)
-model = dict(
- type='EncoderDecoder',
- pretrained='open-mmlab://resnet50_v1c',
- backbone=dict(
- type='ResNetV1c',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- dilations=(1, 1, 2, 4),
- strides=(1, 2, 1, 1),
- norm_cfg=norm_cfg,
- norm_eval=False,
- style='pytorch',
- contract_dilation=True),
- decode_head=dict(
- type='EMAHead',
- in_channels=2048,
- in_index=3,
- channels=256,
- ema_channels=512,
- num_bases=64,
- num_stages=3,
- momentum=0.1,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
- auxiliary_head=dict(
- type='FCNHead',
- in_channels=1024,
- in_index=2,
- channels=256,
- num_convs=1,
- concat_input=False,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
- # model training and testing settings
- train_cfg=dict(),
- test_cfg=dict(mode='whole'))
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmseg/models/decode_heads/enc_head.py b/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmseg/models/decode_heads/enc_head.py
deleted file mode 100644
index d7c6b8ed6a72cf402802c828f27a3de321cc52a0..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmseg/models/decode_heads/enc_head.py
+++ /dev/null
@@ -1,199 +0,0 @@
-'''
- * Copyright (c) 2023 Salesforce, Inc.
- * All rights reserved.
- * SPDX-License-Identifier: Apache License 2.0
- * For full license text, see LICENSE.txt file in the repo root or http://www.apache.org/licenses/
- * By Can Qin
- * Modified from ControlNet repo: https://github.com/lllyasviel/ControlNet
- * Copyright (c) 2023 Lvmin Zhang and Maneesh Agrawala
- * Modified from MMCV repo: From https://github.com/open-mmlab/mmcv
- * Copyright (c) OpenMMLab. All rights reserved.
-'''
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from annotator.uniformer.mmcv.cnn import ConvModule, build_norm_layer
-
-from annotator.uniformer.mmseg.ops import Encoding, resize
-from ..builder import HEADS, build_loss
-from .decode_head import BaseDecodeHead
-
-
-class EncModule(nn.Module):
- """Encoding Module used in EncNet.
-
- Args:
- in_channels (int): Input channels.
- num_codes (int): Number of code words.
- conv_cfg (dict|None): Config of conv layers.
- norm_cfg (dict|None): Config of norm layers.
- act_cfg (dict): Config of activation layers.
- """
-
- def __init__(self, in_channels, num_codes, conv_cfg, norm_cfg, act_cfg):
- super(EncModule, self).__init__()
- self.encoding_project = ConvModule(
- in_channels,
- in_channels,
- 1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- # TODO: resolve this hack
- # change to 1d
- if norm_cfg is not None:
- encoding_norm_cfg = norm_cfg.copy()
- if encoding_norm_cfg['type'] in ['BN', 'IN']:
- encoding_norm_cfg['type'] += '1d'
- else:
- encoding_norm_cfg['type'] = encoding_norm_cfg['type'].replace(
- '2d', '1d')
- else:
- # fallback to BN1d
- encoding_norm_cfg = dict(type='BN1d')
- self.encoding = nn.Sequential(
- Encoding(channels=in_channels, num_codes=num_codes),
- build_norm_layer(encoding_norm_cfg, num_codes)[1],
- nn.ReLU(inplace=True))
- self.fc = nn.Sequential(
- nn.Linear(in_channels, in_channels), nn.Sigmoid())
-
- def forward(self, x):
- """Forward function."""
- encoding_projection = self.encoding_project(x)
- encoding_feat = self.encoding(encoding_projection).mean(dim=1)
- batch_size, channels, _, _ = x.size()
- gamma = self.fc(encoding_feat)
- y = gamma.view(batch_size, channels, 1, 1)
- output = F.relu_(x + x * y)
- return encoding_feat, output
-
-
-@HEADS.register_module()
-class EncHead(BaseDecodeHead):
- """Context Encoding for Semantic Segmentation.
-
- This head is the implementation of `EncNet
- `_.
-
- Args:
- num_codes (int): Number of code words. Default: 32.
- use_se_loss (bool): Whether use Semantic Encoding Loss (SE-loss) to
- regularize the training. Default: True.
- add_lateral (bool): Whether use lateral connection to fuse features.
- Default: False.
- loss_se_decode (dict): Config of decode loss.
- Default: dict(type='CrossEntropyLoss', use_sigmoid=True).
- """
-
- def __init__(self,
- num_codes=32,
- use_se_loss=True,
- add_lateral=False,
- loss_se_decode=dict(
- type='CrossEntropyLoss',
- use_sigmoid=True,
- loss_weight=0.2),
- **kwargs):
- super(EncHead, self).__init__(
- input_transform='multiple_select', **kwargs)
- self.use_se_loss = use_se_loss
- self.add_lateral = add_lateral
- self.num_codes = num_codes
- self.bottleneck = ConvModule(
- self.in_channels[-1],
- self.channels,
- 3,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- if add_lateral:
- self.lateral_convs = nn.ModuleList()
- for in_channels in self.in_channels[:-1]: # skip the last one
- self.lateral_convs.append(
- ConvModule(
- in_channels,
- self.channels,
- 1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg))
- self.fusion = ConvModule(
- len(self.in_channels) * self.channels,
- self.channels,
- 3,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- self.enc_module = EncModule(
- self.channels,
- num_codes=num_codes,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg,
- act_cfg=self.act_cfg)
- if self.use_se_loss:
- self.loss_se_decode = build_loss(loss_se_decode)
- self.se_layer = nn.Linear(self.channels, self.num_classes)
-
- def forward(self, inputs):
- """Forward function."""
- inputs = self._transform_inputs(inputs)
- feat = self.bottleneck(inputs[-1])
- if self.add_lateral:
- laterals = [
- resize(
- lateral_conv(inputs[i]),
- size=feat.shape[2:],
- mode='bilinear',
- align_corners=self.align_corners)
- for i, lateral_conv in enumerate(self.lateral_convs)
- ]
- feat = self.fusion(torch.cat([feat, *laterals], 1))
- encode_feat, output = self.enc_module(feat)
- output = self.cls_seg(output)
- if self.use_se_loss:
- se_output = self.se_layer(encode_feat)
- return output, se_output
- else:
- return output
-
- def forward_test(self, inputs, img_metas, test_cfg):
- """Forward function for testing, ignore se_loss."""
- if self.use_se_loss:
- return self.forward(inputs)[0]
- else:
- return self.forward(inputs)
-
- @staticmethod
- def _convert_to_onehot_labels(seg_label, num_classes):
- """Convert segmentation label to onehot.
-
- Args:
- seg_label (Tensor): Segmentation label of shape (N, H, W).
- num_classes (int): Number of classes.
-
- Returns:
- Tensor: Onehot labels of shape (N, num_classes).
- """
-
- batch_size = seg_label.size(0)
- onehot_labels = seg_label.new_zeros((batch_size, num_classes))
- for i in range(batch_size):
- hist = seg_label[i].float().histc(
- bins=num_classes, min=0, max=num_classes - 1)
- onehot_labels[i] = hist > 0
- return onehot_labels
-
- def losses(self, seg_logit, seg_label):
- """Compute segmentation and semantic encoding loss."""
- seg_logit, se_seg_logit = seg_logit
- loss = dict()
- loss.update(super(EncHead, self).losses(seg_logit, seg_label))
- se_loss = self.loss_se_decode(
- se_seg_logit,
- self._convert_to_onehot_labels(seg_label, self.num_classes))
- loss['loss_se'] = se_loss
- return loss
diff --git a/spaces/aijack/hair/README.md b/spaces/aijack/hair/README.md
deleted file mode 100644
index b4bbe8194cee06b6940c3c06a9f2f68dc9eef552..0000000000000000000000000000000000000000
--- a/spaces/aijack/hair/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Hair
-emoji: 📈
-colorFrom: red
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.19.1
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/akhaliq/PaintTransformer/train/models/base_model.py b/spaces/akhaliq/PaintTransformer/train/models/base_model.py
deleted file mode 100644
index a75506f05817df8b86e0eee5c450d10158ecee0d..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/PaintTransformer/train/models/base_model.py
+++ /dev/null
@@ -1,230 +0,0 @@
-import os
-import torch
-from collections import OrderedDict
-from abc import ABC, abstractmethod
-from . import networks
-
-
-class BaseModel(ABC):
- """This class is an abstract base class (ABC) for models.
- To create a subclass, you need to implement the following five functions:
- -- <__init__>: initialize the class; first call BaseModel.__init__(self, opt).
- -- : unpack data from dataset and apply preprocessing.
- -- : produce intermediate results.
- -- : calculate losses, gradients, and update network weights.
- -- : (optionally) add model-specific options and set default options.
- """
-
- def __init__(self, opt):
- """Initialize the BaseModel class.
-
- Parameters:
- opt (Option class)-- stores all the experiment flags; needs to be a subclass of BaseOptions
-
- When creating your custom class, you need to implement your own initialization.
- In this function, you should first call
- Then, you need to define four lists:
- -- self.loss_names (str list): specify the training losses that you want to plot and save.
- -- self.model_names (str list): define networks used in our training.
- -- self.visual_names (str list): specify the images that you want to display and save.
- -- self.optimizers (optimizer list): define and initialize optimizers. You can define one optimizer for each network. If two networks are updated at the same time, you can use itertools.chain to group them. See cycle_gan_model.py for an example.
- """
- self.opt = opt
- self.gpu_ids = opt.gpu_ids
- self.isTrain = opt.isTrain
- self.device = torch.device('cuda:{}'.format(self.gpu_ids[0])) if self.gpu_ids else torch.device('cpu') # get device name: CPU or GPU
- self.save_dir = os.path.join(opt.checkpoints_dir, opt.name) # save all the checkpoints to save_dir
- if opt.preprocess != 'scale_width': # with [scale_width], input images might have different sizes, which hurts the performance of cudnn.benchmark.
- torch.backends.cudnn.benchmark = True
- self.loss_names = []
- self.model_names = []
- self.visual_names = []
- self.optimizers = []
- self.image_paths = []
- self.metric = 0 # used for learning rate policy 'plateau'
-
- @staticmethod
- def modify_commandline_options(parser, is_train):
- """Add new model-specific options, and rewrite default values for existing options.
-
- Parameters:
- parser -- original option parser
- is_train (bool) -- whether training phase or test phase. You can use this flag to add training-specific or test-specific options.
-
- Returns:
- the modified parser.
- """
- return parser
-
- @abstractmethod
- def set_input(self, input):
- """Unpack input data from the dataloader and perform necessary pre-processing steps.
-
- Parameters:
- input (dict): includes the data itself and its metadata information.
- """
- pass
-
- @abstractmethod
- def forward(self):
- """Run forward pass; called by both functions and ."""
- pass
-
- @abstractmethod
- def optimize_parameters(self):
- """Calculate losses, gradients, and update network weights; called in every training iteration"""
- pass
-
- def setup(self, opt):
- """Load and print networks; create schedulers
-
- Parameters:
- opt (Option class) -- stores all the experiment flags; needs to be a subclass of BaseOptions
- """
- if self.isTrain:
- self.schedulers = [networks.get_scheduler(optimizer, opt) for optimizer in self.optimizers]
- if not self.isTrain or opt.continue_train:
- load_suffix = 'iter_%d' % opt.load_iter if opt.load_iter > 0 else opt.epoch
- self.load_networks(load_suffix)
- self.print_networks(opt.verbose)
-
- def eval(self):
- """Make models eval mode during test time"""
- for name in self.model_names:
- if isinstance(name, str):
- net = getattr(self, 'net_' + name)
- net.eval()
-
- def test(self):
- """Forward function used in test time.
-
- This function wraps function in no_grad() so we don't save intermediate steps for backprop
- It also calls to produce additional visualization results
- """
- with torch.no_grad():
- self.forward()
- self.compute_visuals()
-
- def compute_visuals(self):
- """Calculate additional output images for visdom and HTML visualization"""
- pass
-
- def get_image_paths(self):
- """ Return image paths that are used to load current data"""
- return self.image_paths
-
- def update_learning_rate(self):
- """Update learning rates for all the networks; called at the end of every epoch"""
- old_lr = self.optimizers[0].param_groups[0]['lr']
- for scheduler in self.schedulers:
- if self.opt.lr_policy == 'plateau':
- scheduler.step(self.metric)
- else:
- scheduler.step()
-
- lr = self.optimizers[0].param_groups[0]['lr']
- print('learning rate %.7f -> %.7f' % (old_lr, lr))
-
- def get_current_visuals(self):
- """Return visualization images. train.py will display these images with visdom, and save the images to a HTML"""
- visual_ret = OrderedDict()
- for name in self.visual_names:
- if isinstance(name, str):
- visual_ret[name] = getattr(self, name)
- return visual_ret
-
- def get_current_losses(self):
- """Return traning losses / errors. train.py will print out these errors on console, and save them to a file"""
- errors_ret = OrderedDict()
- for name in self.loss_names:
- if isinstance(name, str):
- errors_ret[name] = float(getattr(self, 'loss_' + name)) # float(...) works for both scalar tensor and float number
- return errors_ret
-
- def save_networks(self, epoch):
- """Save all the networks to the disk.
-
- Parameters:
- epoch (int) -- current epoch; used in the file name '%s_net_%s.pth' % (epoch, name)
- """
- for name in self.model_names:
- if isinstance(name, str):
- save_filename = '%s_net_%s.pth' % (epoch, name)
- save_path = os.path.join(self.save_dir, save_filename)
- net = getattr(self, 'net_' + name)
-
- if len(self.gpu_ids) > 0 and torch.cuda.is_available():
- torch.save(net.module.cpu().state_dict(), save_path)
- net.cuda(self.gpu_ids[0])
- else:
- torch.save(net.cpu().state_dict(), save_path)
-
- def __patch_instance_norm_state_dict(self, state_dict, module, keys, i=0):
- """Fix InstanceNorm checkpoints incompatibility (prior to 0.4)"""
- key = keys[i]
- if i + 1 == len(keys): # at the end, pointing to a parameter/buffer
- if module.__class__.__name__.startswith('InstanceNorm') and \
- (key == 'running_mean' or key == 'running_var'):
- if getattr(module, key) is None:
- state_dict.pop('.'.join(keys))
- if module.__class__.__name__.startswith('InstanceNorm') and \
- (key == 'num_batches_tracked'):
- state_dict.pop('.'.join(keys))
- else:
- self.__patch_instance_norm_state_dict(state_dict, getattr(module, key), keys, i + 1)
-
- def load_networks(self, epoch):
- """Load all the networks from the disk.
-
- Parameters:
- epoch (int) -- current epoch; used in the file name '%s_net_%s.pth' % (epoch, name)
- """
- for name in self.model_names:
- if isinstance(name, str):
- load_filename = '%s_net_%s.pth' % (epoch, name)
- load_path = os.path.join(self.save_dir, load_filename)
- net = getattr(self, 'net_' + name)
- if isinstance(net, torch.nn.DataParallel):
- net = net.module
- print('loading the model from %s' % load_path)
- # if you are using PyTorch newer than 0.4 (e.g., built from
- # GitHub source), you can remove str() on self.device
- state_dict = torch.load(load_path, map_location=str(self.device))
- if hasattr(state_dict, '_metadata'):
- del state_dict._metadata
-
- # patch InstanceNorm checkpoints prior to 0.4
- for key in list(state_dict.keys()): # need to copy keys here because we mutate in loop
- self.__patch_instance_norm_state_dict(state_dict, net, key.split('.'))
- net.load_state_dict(state_dict)
-
- def print_networks(self, verbose):
- """Print the total number of parameters in the network and (if verbose) network architecture
-
- Parameters:
- verbose (bool) -- if verbose: print the network architecture
- """
- print('---------- Networks initialized -------------')
- for name in self.model_names:
- if isinstance(name, str):
- net = getattr(self, 'net_' + name)
- num_params = 0
- for param in net.parameters():
- num_params += param.numel()
- if verbose:
- print(net)
- print('[Network %s] Total number of parameters : %.3f M' % (name, num_params / 1e6))
- print('-----------------------------------------------')
-
- def set_requires_grad(self, nets, requires_grad=False):
- """Set requies_grad=Fasle for all the networks to avoid unnecessary computations
- Parameters:
- nets (network list) -- a list of networks
- requires_grad (bool) -- whether the networks require gradients or not
- """
- if not isinstance(nets, list):
- nets = [nets]
- for net in nets:
- if net is not None:
- for param in net.parameters():
- param.requires_grad = requires_grad
diff --git a/spaces/akhaliq/kogpt/README.md b/spaces/akhaliq/kogpt/README.md
deleted file mode 100644
index fa4808990c35c0959cba0e7f116f749e2786a995..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/kogpt/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Kogpt
-emoji: 🌍
-colorFrom: red
-colorTo: gray
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/utils/misc.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/utils/misc.py
deleted file mode 100644
index 0bf9e99af5238a37aef81159521a8c97da27a375..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/utils/misc.py
+++ /dev/null
@@ -1,653 +0,0 @@
-# The following comment should be removed at some point in the future.
-# mypy: strict-optional=False
-
-import contextlib
-import errno
-import getpass
-import hashlib
-import io
-import logging
-import os
-import posixpath
-import shutil
-import stat
-import sys
-import urllib.parse
-from io import StringIO
-from itertools import filterfalse, tee, zip_longest
-from types import TracebackType
-from typing import (
- Any,
- BinaryIO,
- Callable,
- ContextManager,
- Iterable,
- Iterator,
- List,
- Optional,
- TextIO,
- Tuple,
- Type,
- TypeVar,
- cast,
-)
-
-from pip._vendor.tenacity import retry, stop_after_delay, wait_fixed
-
-from pip import __version__
-from pip._internal.exceptions import CommandError
-from pip._internal.locations import get_major_minor_version
-from pip._internal.utils.compat import WINDOWS
-from pip._internal.utils.virtualenv import running_under_virtualenv
-
-__all__ = [
- "rmtree",
- "display_path",
- "backup_dir",
- "ask",
- "splitext",
- "format_size",
- "is_installable_dir",
- "normalize_path",
- "renames",
- "get_prog",
- "captured_stdout",
- "ensure_dir",
- "remove_auth_from_url",
-]
-
-
-logger = logging.getLogger(__name__)
-
-T = TypeVar("T")
-ExcInfo = Tuple[Type[BaseException], BaseException, TracebackType]
-VersionInfo = Tuple[int, int, int]
-NetlocTuple = Tuple[str, Tuple[Optional[str], Optional[str]]]
-
-
-def get_pip_version() -> str:
- pip_pkg_dir = os.path.join(os.path.dirname(__file__), "..", "..")
- pip_pkg_dir = os.path.abspath(pip_pkg_dir)
-
- return "pip {} from {} (python {})".format(
- __version__,
- pip_pkg_dir,
- get_major_minor_version(),
- )
-
-
-def normalize_version_info(py_version_info: Tuple[int, ...]) -> Tuple[int, int, int]:
- """
- Convert a tuple of ints representing a Python version to one of length
- three.
-
- :param py_version_info: a tuple of ints representing a Python version,
- or None to specify no version. The tuple can have any length.
-
- :return: a tuple of length three if `py_version_info` is non-None.
- Otherwise, return `py_version_info` unchanged (i.e. None).
- """
- if len(py_version_info) < 3:
- py_version_info += (3 - len(py_version_info)) * (0,)
- elif len(py_version_info) > 3:
- py_version_info = py_version_info[:3]
-
- return cast("VersionInfo", py_version_info)
-
-
-def ensure_dir(path: str) -> None:
- """os.path.makedirs without EEXIST."""
- try:
- os.makedirs(path)
- except OSError as e:
- # Windows can raise spurious ENOTEMPTY errors. See #6426.
- if e.errno != errno.EEXIST and e.errno != errno.ENOTEMPTY:
- raise
-
-
-def get_prog() -> str:
- try:
- prog = os.path.basename(sys.argv[0])
- if prog in ("__main__.py", "-c"):
- return f"{sys.executable} -m pip"
- else:
- return prog
- except (AttributeError, TypeError, IndexError):
- pass
- return "pip"
-
-
-# Retry every half second for up to 3 seconds
-# Tenacity raises RetryError by default, explicitly raise the original exception
-@retry(reraise=True, stop=stop_after_delay(3), wait=wait_fixed(0.5))
-def rmtree(dir: str, ignore_errors: bool = False) -> None:
- shutil.rmtree(dir, ignore_errors=ignore_errors, onerror=rmtree_errorhandler)
-
-
-def rmtree_errorhandler(func: Callable[..., Any], path: str, exc_info: ExcInfo) -> None:
- """On Windows, the files in .svn are read-only, so when rmtree() tries to
- remove them, an exception is thrown. We catch that here, remove the
- read-only attribute, and hopefully continue without problems."""
- try:
- has_attr_readonly = not (os.stat(path).st_mode & stat.S_IWRITE)
- except OSError:
- # it's equivalent to os.path.exists
- return
-
- if has_attr_readonly:
- # convert to read/write
- os.chmod(path, stat.S_IWRITE)
- # use the original function to repeat the operation
- func(path)
- return
- else:
- raise
-
-
-def display_path(path: str) -> str:
- """Gives the display value for a given path, making it relative to cwd
- if possible."""
- path = os.path.normcase(os.path.abspath(path))
- if path.startswith(os.getcwd() + os.path.sep):
- path = "." + path[len(os.getcwd()) :]
- return path
-
-
-def backup_dir(dir: str, ext: str = ".bak") -> str:
- """Figure out the name of a directory to back up the given dir to
- (adding .bak, .bak2, etc)"""
- n = 1
- extension = ext
- while os.path.exists(dir + extension):
- n += 1
- extension = ext + str(n)
- return dir + extension
-
-
-def ask_path_exists(message: str, options: Iterable[str]) -> str:
- for action in os.environ.get("PIP_EXISTS_ACTION", "").split():
- if action in options:
- return action
- return ask(message, options)
-
-
-def _check_no_input(message: str) -> None:
- """Raise an error if no input is allowed."""
- if os.environ.get("PIP_NO_INPUT"):
- raise Exception(
- f"No input was expected ($PIP_NO_INPUT set); question: {message}"
- )
-
-
-def ask(message: str, options: Iterable[str]) -> str:
- """Ask the message interactively, with the given possible responses"""
- while 1:
- _check_no_input(message)
- response = input(message)
- response = response.strip().lower()
- if response not in options:
- print(
- "Your response ({!r}) was not one of the expected responses: "
- "{}".format(response, ", ".join(options))
- )
- else:
- return response
-
-
-def ask_input(message: str) -> str:
- """Ask for input interactively."""
- _check_no_input(message)
- return input(message)
-
-
-def ask_password(message: str) -> str:
- """Ask for a password interactively."""
- _check_no_input(message)
- return getpass.getpass(message)
-
-
-def strtobool(val: str) -> int:
- """Convert a string representation of truth to true (1) or false (0).
-
- True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values
- are 'n', 'no', 'f', 'false', 'off', and '0'. Raises ValueError if
- 'val' is anything else.
- """
- val = val.lower()
- if val in ("y", "yes", "t", "true", "on", "1"):
- return 1
- elif val in ("n", "no", "f", "false", "off", "0"):
- return 0
- else:
- raise ValueError(f"invalid truth value {val!r}")
-
-
-def format_size(bytes: float) -> str:
- if bytes > 1000 * 1000:
- return "{:.1f} MB".format(bytes / 1000.0 / 1000)
- elif bytes > 10 * 1000:
- return "{} kB".format(int(bytes / 1000))
- elif bytes > 1000:
- return "{:.1f} kB".format(bytes / 1000.0)
- else:
- return "{} bytes".format(int(bytes))
-
-
-def tabulate(rows: Iterable[Iterable[Any]]) -> Tuple[List[str], List[int]]:
- """Return a list of formatted rows and a list of column sizes.
-
- For example::
-
- >>> tabulate([['foobar', 2000], [0xdeadbeef]])
- (['foobar 2000', '3735928559'], [10, 4])
- """
- rows = [tuple(map(str, row)) for row in rows]
- sizes = [max(map(len, col)) for col in zip_longest(*rows, fillvalue="")]
- table = [" ".join(map(str.ljust, row, sizes)).rstrip() for row in rows]
- return table, sizes
-
-
-def is_installable_dir(path: str) -> bool:
- """Is path is a directory containing pyproject.toml or setup.py?
-
- If pyproject.toml exists, this is a PEP 517 project. Otherwise we look for
- a legacy setuptools layout by identifying setup.py. We don't check for the
- setup.cfg because using it without setup.py is only available for PEP 517
- projects, which are already covered by the pyproject.toml check.
- """
- if not os.path.isdir(path):
- return False
- if os.path.isfile(os.path.join(path, "pyproject.toml")):
- return True
- if os.path.isfile(os.path.join(path, "setup.py")):
- return True
- return False
-
-
-def read_chunks(file: BinaryIO, size: int = io.DEFAULT_BUFFER_SIZE) -> Iterator[bytes]:
- """Yield pieces of data from a file-like object until EOF."""
- while True:
- chunk = file.read(size)
- if not chunk:
- break
- yield chunk
-
-
-def normalize_path(path: str, resolve_symlinks: bool = True) -> str:
- """
- Convert a path to its canonical, case-normalized, absolute version.
-
- """
- path = os.path.expanduser(path)
- if resolve_symlinks:
- path = os.path.realpath(path)
- else:
- path = os.path.abspath(path)
- return os.path.normcase(path)
-
-
-def splitext(path: str) -> Tuple[str, str]:
- """Like os.path.splitext, but take off .tar too"""
- base, ext = posixpath.splitext(path)
- if base.lower().endswith(".tar"):
- ext = base[-4:] + ext
- base = base[:-4]
- return base, ext
-
-
-def renames(old: str, new: str) -> None:
- """Like os.renames(), but handles renaming across devices."""
- # Implementation borrowed from os.renames().
- head, tail = os.path.split(new)
- if head and tail and not os.path.exists(head):
- os.makedirs(head)
-
- shutil.move(old, new)
-
- head, tail = os.path.split(old)
- if head and tail:
- try:
- os.removedirs(head)
- except OSError:
- pass
-
-
-def is_local(path: str) -> bool:
- """
- Return True if this is a path pip is allowed to modify.
-
- If we're in a virtualenv, sys.prefix points to the virtualenv's
- prefix; only sys.prefix is considered local.
-
- If we're not in a virtualenv, in general we can modify anything.
- However, if the OS vendor has configured distutils to install
- somewhere other than sys.prefix (which could be a subdirectory of
- sys.prefix, e.g. /usr/local), we consider sys.prefix itself nonlocal
- and the domain of the OS vendor. (In other words, everything _other
- than_ sys.prefix is considered local.)
-
- Caution: this function assumes the head of path has been normalized
- with normalize_path.
- """
-
- path = normalize_path(path)
- # Hard-coded becouse PyPy uses a different sys.prefix on Debian
- prefix = '/usr'
-
- if running_under_virtualenv():
- return path.startswith(normalize_path(sys.prefix))
- else:
- from pip._internal.locations import get_scheme
- from pip._internal.models.scheme import SCHEME_KEYS
- if path.startswith(prefix):
- scheme = get_scheme("")
- for key in SCHEME_KEYS:
- local_path = getattr(scheme, key)
- if path.startswith(normalize_path(local_path)):
- return True
- return False
- else:
- return True
-
-
-def write_output(msg: Any, *args: Any) -> None:
- logger.info(msg, *args)
-
-
-class StreamWrapper(StringIO):
- orig_stream: TextIO = None
-
- @classmethod
- def from_stream(cls, orig_stream: TextIO) -> "StreamWrapper":
- cls.orig_stream = orig_stream
- return cls()
-
- # compileall.compile_dir() needs stdout.encoding to print to stdout
- # https://github.com/python/mypy/issues/4125
- @property
- def encoding(self): # type: ignore
- return self.orig_stream.encoding
-
-
-@contextlib.contextmanager
-def captured_output(stream_name: str) -> Iterator[StreamWrapper]:
- """Return a context manager used by captured_stdout/stdin/stderr
- that temporarily replaces the sys stream *stream_name* with a StringIO.
-
- Taken from Lib/support/__init__.py in the CPython repo.
- """
- orig_stdout = getattr(sys, stream_name)
- setattr(sys, stream_name, StreamWrapper.from_stream(orig_stdout))
- try:
- yield getattr(sys, stream_name)
- finally:
- setattr(sys, stream_name, orig_stdout)
-
-
-def captured_stdout() -> ContextManager[StreamWrapper]:
- """Capture the output of sys.stdout:
-
- with captured_stdout() as stdout:
- print('hello')
- self.assertEqual(stdout.getvalue(), 'hello\n')
-
- Taken from Lib/support/__init__.py in the CPython repo.
- """
- return captured_output("stdout")
-
-
-def captured_stderr() -> ContextManager[StreamWrapper]:
- """
- See captured_stdout().
- """
- return captured_output("stderr")
-
-
-# Simulates an enum
-def enum(*sequential: Any, **named: Any) -> Type[Any]:
- enums = dict(zip(sequential, range(len(sequential))), **named)
- reverse = {value: key for key, value in enums.items()}
- enums["reverse_mapping"] = reverse
- return type("Enum", (), enums)
-
-
-def build_netloc(host: str, port: Optional[int]) -> str:
- """
- Build a netloc from a host-port pair
- """
- if port is None:
- return host
- if ":" in host:
- # Only wrap host with square brackets when it is IPv6
- host = f"[{host}]"
- return f"{host}:{port}"
-
-
-def build_url_from_netloc(netloc: str, scheme: str = "https") -> str:
- """
- Build a full URL from a netloc.
- """
- if netloc.count(":") >= 2 and "@" not in netloc and "[" not in netloc:
- # It must be a bare IPv6 address, so wrap it with brackets.
- netloc = f"[{netloc}]"
- return f"{scheme}://{netloc}"
-
-
-def parse_netloc(netloc: str) -> Tuple[str, Optional[int]]:
- """
- Return the host-port pair from a netloc.
- """
- url = build_url_from_netloc(netloc)
- parsed = urllib.parse.urlparse(url)
- return parsed.hostname, parsed.port
-
-
-def split_auth_from_netloc(netloc: str) -> NetlocTuple:
- """
- Parse out and remove the auth information from a netloc.
-
- Returns: (netloc, (username, password)).
- """
- if "@" not in netloc:
- return netloc, (None, None)
-
- # Split from the right because that's how urllib.parse.urlsplit()
- # behaves if more than one @ is present (which can be checked using
- # the password attribute of urlsplit()'s return value).
- auth, netloc = netloc.rsplit("@", 1)
- pw: Optional[str] = None
- if ":" in auth:
- # Split from the left because that's how urllib.parse.urlsplit()
- # behaves if more than one : is present (which again can be checked
- # using the password attribute of the return value)
- user, pw = auth.split(":", 1)
- else:
- user, pw = auth, None
-
- user = urllib.parse.unquote(user)
- if pw is not None:
- pw = urllib.parse.unquote(pw)
-
- return netloc, (user, pw)
-
-
-def redact_netloc(netloc: str) -> str:
- """
- Replace the sensitive data in a netloc with "****", if it exists.
-
- For example:
- - "user:pass@example.com" returns "user:****@example.com"
- - "accesstoken@example.com" returns "****@example.com"
- """
- netloc, (user, password) = split_auth_from_netloc(netloc)
- if user is None:
- return netloc
- if password is None:
- user = "****"
- password = ""
- else:
- user = urllib.parse.quote(user)
- password = ":****"
- return "{user}{password}@{netloc}".format(
- user=user, password=password, netloc=netloc
- )
-
-
-def _transform_url(
- url: str, transform_netloc: Callable[[str], Tuple[Any, ...]]
-) -> Tuple[str, NetlocTuple]:
- """Transform and replace netloc in a url.
-
- transform_netloc is a function taking the netloc and returning a
- tuple. The first element of this tuple is the new netloc. The
- entire tuple is returned.
-
- Returns a tuple containing the transformed url as item 0 and the
- original tuple returned by transform_netloc as item 1.
- """
- purl = urllib.parse.urlsplit(url)
- netloc_tuple = transform_netloc(purl.netloc)
- # stripped url
- url_pieces = (purl.scheme, netloc_tuple[0], purl.path, purl.query, purl.fragment)
- surl = urllib.parse.urlunsplit(url_pieces)
- return surl, cast("NetlocTuple", netloc_tuple)
-
-
-def _get_netloc(netloc: str) -> NetlocTuple:
- return split_auth_from_netloc(netloc)
-
-
-def _redact_netloc(netloc: str) -> Tuple[str]:
- return (redact_netloc(netloc),)
-
-
-def split_auth_netloc_from_url(url: str) -> Tuple[str, str, Tuple[str, str]]:
- """
- Parse a url into separate netloc, auth, and url with no auth.
-
- Returns: (url_without_auth, netloc, (username, password))
- """
- url_without_auth, (netloc, auth) = _transform_url(url, _get_netloc)
- return url_without_auth, netloc, auth
-
-
-def remove_auth_from_url(url: str) -> str:
- """Return a copy of url with 'username:password@' removed."""
- # username/pass params are passed to subversion through flags
- # and are not recognized in the url.
- return _transform_url(url, _get_netloc)[0]
-
-
-def redact_auth_from_url(url: str) -> str:
- """Replace the password in a given url with ****."""
- return _transform_url(url, _redact_netloc)[0]
-
-
-class HiddenText:
- def __init__(self, secret: str, redacted: str) -> None:
- self.secret = secret
- self.redacted = redacted
-
- def __repr__(self) -> str:
- return "".format(str(self))
-
- def __str__(self) -> str:
- return self.redacted
-
- # This is useful for testing.
- def __eq__(self, other: Any) -> bool:
- if type(self) != type(other):
- return False
-
- # The string being used for redaction doesn't also have to match,
- # just the raw, original string.
- return self.secret == other.secret
-
-
-def hide_value(value: str) -> HiddenText:
- return HiddenText(value, redacted="****")
-
-
-def hide_url(url: str) -> HiddenText:
- redacted = redact_auth_from_url(url)
- return HiddenText(url, redacted=redacted)
-
-
-def protect_pip_from_modification_on_windows(modifying_pip: bool) -> None:
- """Protection of pip.exe from modification on Windows
-
- On Windows, any operation modifying pip should be run as:
- python -m pip ...
- """
- pip_names = [
- "pip.exe",
- "pip{}.exe".format(sys.version_info[0]),
- "pip{}.{}.exe".format(*sys.version_info[:2]),
- ]
-
- # See https://github.com/pypa/pip/issues/1299 for more discussion
- should_show_use_python_msg = (
- modifying_pip and WINDOWS and os.path.basename(sys.argv[0]) in pip_names
- )
-
- if should_show_use_python_msg:
- new_command = [sys.executable, "-m", "pip"] + sys.argv[1:]
- raise CommandError(
- "To modify pip, please run the following command:\n{}".format(
- " ".join(new_command)
- )
- )
-
-
-def is_console_interactive() -> bool:
- """Is this console interactive?"""
- return sys.stdin is not None and sys.stdin.isatty()
-
-
-def hash_file(path: str, blocksize: int = 1 << 20) -> Tuple[Any, int]:
- """Return (hash, length) for path using hashlib.sha256()"""
-
- h = hashlib.sha256()
- length = 0
- with open(path, "rb") as f:
- for block in read_chunks(f, size=blocksize):
- length += len(block)
- h.update(block)
- return h, length
-
-
-def is_wheel_installed() -> bool:
- """
- Return whether the wheel package is installed.
- """
- try:
- import wheel # noqa: F401
- except ImportError:
- return False
-
- return True
-
-
-def pairwise(iterable: Iterable[Any]) -> Iterator[Tuple[Any, Any]]:
- """
- Return paired elements.
-
- For example:
- s -> (s0, s1), (s2, s3), (s4, s5), ...
- """
- iterable = iter(iterable)
- return zip_longest(iterable, iterable)
-
-
-def partition(
- pred: Callable[[T], bool],
- iterable: Iterable[T],
-) -> Tuple[Iterable[T], Iterable[T]]:
- """
- Use a predicate to partition entries into false entries and true entries,
- like
-
- partition(is_odd, range(10)) --> 0 2 4 6 8 and 1 3 5 7 9
- """
- t1, t2 = tee(iterable)
- return filterfalse(pred, t1), filter(pred, t2)
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/formatters/img.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/formatters/img.py
deleted file mode 100644
index 978559237a6273266399514500268fa45f39d89b..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/formatters/img.py
+++ /dev/null
@@ -1,641 +0,0 @@
-"""
- pygments.formatters.img
- ~~~~~~~~~~~~~~~~~~~~~~~
-
- Formatter for Pixmap output.
-
- :copyright: Copyright 2006-2021 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-import os
-import sys
-
-from pip._vendor.pygments.formatter import Formatter
-from pip._vendor.pygments.util import get_bool_opt, get_int_opt, get_list_opt, \
- get_choice_opt
-
-import subprocess
-
-# Import this carefully
-try:
- from PIL import Image, ImageDraw, ImageFont
- pil_available = True
-except ImportError:
- pil_available = False
-
-try:
- import _winreg
-except ImportError:
- try:
- import winreg as _winreg
- except ImportError:
- _winreg = None
-
-__all__ = ['ImageFormatter', 'GifImageFormatter', 'JpgImageFormatter',
- 'BmpImageFormatter']
-
-
-# For some unknown reason every font calls it something different
-STYLES = {
- 'NORMAL': ['', 'Roman', 'Book', 'Normal', 'Regular', 'Medium'],
- 'ITALIC': ['Oblique', 'Italic'],
- 'BOLD': ['Bold'],
- 'BOLDITALIC': ['Bold Oblique', 'Bold Italic'],
-}
-
-# A sane default for modern systems
-DEFAULT_FONT_NAME_NIX = 'DejaVu Sans Mono'
-DEFAULT_FONT_NAME_WIN = 'Courier New'
-DEFAULT_FONT_NAME_MAC = 'Menlo'
-
-
-class PilNotAvailable(ImportError):
- """When Python imaging library is not available"""
-
-
-class FontNotFound(Exception):
- """When there are no usable fonts specified"""
-
-
-class FontManager:
- """
- Manages a set of fonts: normal, italic, bold, etc...
- """
-
- def __init__(self, font_name, font_size=14):
- self.font_name = font_name
- self.font_size = font_size
- self.fonts = {}
- self.encoding = None
- if sys.platform.startswith('win'):
- if not font_name:
- self.font_name = DEFAULT_FONT_NAME_WIN
- self._create_win()
- elif sys.platform.startswith('darwin'):
- if not font_name:
- self.font_name = DEFAULT_FONT_NAME_MAC
- self._create_mac()
- else:
- if not font_name:
- self.font_name = DEFAULT_FONT_NAME_NIX
- self._create_nix()
-
- def _get_nix_font_path(self, name, style):
- proc = subprocess.Popen(['fc-list', "%s:style=%s" % (name, style), 'file'],
- stdout=subprocess.PIPE, stderr=None)
- stdout, _ = proc.communicate()
- if proc.returncode == 0:
- lines = stdout.splitlines()
- for line in lines:
- if line.startswith(b'Fontconfig warning:'):
- continue
- path = line.decode().strip().strip(':')
- if path:
- return path
- return None
-
- def _create_nix(self):
- for name in STYLES['NORMAL']:
- path = self._get_nix_font_path(self.font_name, name)
- if path is not None:
- self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
- break
- else:
- raise FontNotFound('No usable fonts named: "%s"' %
- self.font_name)
- for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
- for stylename in STYLES[style]:
- path = self._get_nix_font_path(self.font_name, stylename)
- if path is not None:
- self.fonts[style] = ImageFont.truetype(path, self.font_size)
- break
- else:
- if style == 'BOLDITALIC':
- self.fonts[style] = self.fonts['BOLD']
- else:
- self.fonts[style] = self.fonts['NORMAL']
-
- def _get_mac_font_path(self, font_map, name, style):
- return font_map.get((name + ' ' + style).strip().lower())
-
- def _create_mac(self):
- font_map = {}
- for font_dir in (os.path.join(os.getenv("HOME"), 'Library/Fonts/'),
- '/Library/Fonts/', '/System/Library/Fonts/'):
- font_map.update(
- (os.path.splitext(f)[0].lower(), os.path.join(font_dir, f))
- for f in os.listdir(font_dir)
- if f.lower().endswith(('ttf', 'ttc')))
-
- for name in STYLES['NORMAL']:
- path = self._get_mac_font_path(font_map, self.font_name, name)
- if path is not None:
- self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
- break
- else:
- raise FontNotFound('No usable fonts named: "%s"' %
- self.font_name)
- for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
- for stylename in STYLES[style]:
- path = self._get_mac_font_path(font_map, self.font_name, stylename)
- if path is not None:
- self.fonts[style] = ImageFont.truetype(path, self.font_size)
- break
- else:
- if style == 'BOLDITALIC':
- self.fonts[style] = self.fonts['BOLD']
- else:
- self.fonts[style] = self.fonts['NORMAL']
-
- def _lookup_win(self, key, basename, styles, fail=False):
- for suffix in ('', ' (TrueType)'):
- for style in styles:
- try:
- valname = '%s%s%s' % (basename, style and ' '+style, suffix)
- val, _ = _winreg.QueryValueEx(key, valname)
- return val
- except OSError:
- continue
- else:
- if fail:
- raise FontNotFound('Font %s (%s) not found in registry' %
- (basename, styles[0]))
- return None
-
- def _create_win(self):
- lookuperror = None
- keynames = [ (_winreg.HKEY_CURRENT_USER, r'Software\Microsoft\Windows NT\CurrentVersion\Fonts'),
- (_winreg.HKEY_CURRENT_USER, r'Software\Microsoft\Windows\CurrentVersion\Fonts'),
- (_winreg.HKEY_LOCAL_MACHINE, r'Software\Microsoft\Windows NT\CurrentVersion\Fonts'),
- (_winreg.HKEY_LOCAL_MACHINE, r'Software\Microsoft\Windows\CurrentVersion\Fonts') ]
- for keyname in keynames:
- try:
- key = _winreg.OpenKey(*keyname)
- try:
- path = self._lookup_win(key, self.font_name, STYLES['NORMAL'], True)
- self.fonts['NORMAL'] = ImageFont.truetype(path, self.font_size)
- for style in ('ITALIC', 'BOLD', 'BOLDITALIC'):
- path = self._lookup_win(key, self.font_name, STYLES[style])
- if path:
- self.fonts[style] = ImageFont.truetype(path, self.font_size)
- else:
- if style == 'BOLDITALIC':
- self.fonts[style] = self.fonts['BOLD']
- else:
- self.fonts[style] = self.fonts['NORMAL']
- return
- except FontNotFound as err:
- lookuperror = err
- finally:
- _winreg.CloseKey(key)
- except OSError:
- pass
- else:
- # If we get here, we checked all registry keys and had no luck
- # We can be in one of two situations now:
- # * All key lookups failed. In this case lookuperror is None and we
- # will raise a generic error
- # * At least one lookup failed with a FontNotFound error. In this
- # case, we will raise that as a more specific error
- if lookuperror:
- raise lookuperror
- raise FontNotFound('Can\'t open Windows font registry key')
-
- def get_char_size(self):
- """
- Get the character size.
- """
- return self.fonts['NORMAL'].getsize('M')
-
- def get_text_size(self, text):
- """
- Get the text size(width, height).
- """
- return self.fonts['NORMAL'].getsize(text)
-
- def get_font(self, bold, oblique):
- """
- Get the font based on bold and italic flags.
- """
- if bold and oblique:
- return self.fonts['BOLDITALIC']
- elif bold:
- return self.fonts['BOLD']
- elif oblique:
- return self.fonts['ITALIC']
- else:
- return self.fonts['NORMAL']
-
-
-class ImageFormatter(Formatter):
- """
- Create a PNG image from source code. This uses the Python Imaging Library to
- generate a pixmap from the source code.
-
- .. versionadded:: 0.10
-
- Additional options accepted:
-
- `image_format`
- An image format to output to that is recognised by PIL, these include:
-
- * "PNG" (default)
- * "JPEG"
- * "BMP"
- * "GIF"
-
- `line_pad`
- The extra spacing (in pixels) between each line of text.
-
- Default: 2
-
- `font_name`
- The font name to be used as the base font from which others, such as
- bold and italic fonts will be generated. This really should be a
- monospace font to look sane.
-
- Default: "Courier New" on Windows, "Menlo" on Mac OS, and
- "DejaVu Sans Mono" on \\*nix
-
- `font_size`
- The font size in points to be used.
-
- Default: 14
-
- `image_pad`
- The padding, in pixels to be used at each edge of the resulting image.
-
- Default: 10
-
- `line_numbers`
- Whether line numbers should be shown: True/False
-
- Default: True
-
- `line_number_start`
- The line number of the first line.
-
- Default: 1
-
- `line_number_step`
- The step used when printing line numbers.
-
- Default: 1
-
- `line_number_bg`
- The background colour (in "#123456" format) of the line number bar, or
- None to use the style background color.
-
- Default: "#eed"
-
- `line_number_fg`
- The text color of the line numbers (in "#123456"-like format).
-
- Default: "#886"
-
- `line_number_chars`
- The number of columns of line numbers allowable in the line number
- margin.
-
- Default: 2
-
- `line_number_bold`
- Whether line numbers will be bold: True/False
-
- Default: False
-
- `line_number_italic`
- Whether line numbers will be italicized: True/False
-
- Default: False
-
- `line_number_separator`
- Whether a line will be drawn between the line number area and the
- source code area: True/False
-
- Default: True
-
- `line_number_pad`
- The horizontal padding (in pixels) between the line number margin, and
- the source code area.
-
- Default: 6
-
- `hl_lines`
- Specify a list of lines to be highlighted.
-
- .. versionadded:: 1.2
-
- Default: empty list
-
- `hl_color`
- Specify the color for highlighting lines.
-
- .. versionadded:: 1.2
-
- Default: highlight color of the selected style
- """
-
- # Required by the pygments mapper
- name = 'img'
- aliases = ['img', 'IMG', 'png']
- filenames = ['*.png']
-
- unicodeoutput = False
-
- default_image_format = 'png'
-
- def __init__(self, **options):
- """
- See the class docstring for explanation of options.
- """
- if not pil_available:
- raise PilNotAvailable(
- 'Python Imaging Library is required for this formatter')
- Formatter.__init__(self, **options)
- self.encoding = 'latin1' # let pygments.format() do the right thing
- # Read the style
- self.styles = dict(self.style)
- if self.style.background_color is None:
- self.background_color = '#fff'
- else:
- self.background_color = self.style.background_color
- # Image options
- self.image_format = get_choice_opt(
- options, 'image_format', ['png', 'jpeg', 'gif', 'bmp'],
- self.default_image_format, normcase=True)
- self.image_pad = get_int_opt(options, 'image_pad', 10)
- self.line_pad = get_int_opt(options, 'line_pad', 2)
- # The fonts
- fontsize = get_int_opt(options, 'font_size', 14)
- self.fonts = FontManager(options.get('font_name', ''), fontsize)
- self.fontw, self.fonth = self.fonts.get_char_size()
- # Line number options
- self.line_number_fg = options.get('line_number_fg', '#886')
- self.line_number_bg = options.get('line_number_bg', '#eed')
- self.line_number_chars = get_int_opt(options,
- 'line_number_chars', 2)
- self.line_number_bold = get_bool_opt(options,
- 'line_number_bold', False)
- self.line_number_italic = get_bool_opt(options,
- 'line_number_italic', False)
- self.line_number_pad = get_int_opt(options, 'line_number_pad', 6)
- self.line_numbers = get_bool_opt(options, 'line_numbers', True)
- self.line_number_separator = get_bool_opt(options,
- 'line_number_separator', True)
- self.line_number_step = get_int_opt(options, 'line_number_step', 1)
- self.line_number_start = get_int_opt(options, 'line_number_start', 1)
- if self.line_numbers:
- self.line_number_width = (self.fontw * self.line_number_chars +
- self.line_number_pad * 2)
- else:
- self.line_number_width = 0
- self.hl_lines = []
- hl_lines_str = get_list_opt(options, 'hl_lines', [])
- for line in hl_lines_str:
- try:
- self.hl_lines.append(int(line))
- except ValueError:
- pass
- self.hl_color = options.get('hl_color',
- self.style.highlight_color) or '#f90'
- self.drawables = []
-
- def get_style_defs(self, arg=''):
- raise NotImplementedError('The -S option is meaningless for the image '
- 'formatter. Use -O style= instead.')
-
- def _get_line_height(self):
- """
- Get the height of a line.
- """
- return self.fonth + self.line_pad
-
- def _get_line_y(self, lineno):
- """
- Get the Y coordinate of a line number.
- """
- return lineno * self._get_line_height() + self.image_pad
-
- def _get_char_width(self):
- """
- Get the width of a character.
- """
- return self.fontw
-
- def _get_char_x(self, linelength):
- """
- Get the X coordinate of a character position.
- """
- return linelength + self.image_pad + self.line_number_width
-
- def _get_text_pos(self, linelength, lineno):
- """
- Get the actual position for a character and line position.
- """
- return self._get_char_x(linelength), self._get_line_y(lineno)
-
- def _get_linenumber_pos(self, lineno):
- """
- Get the actual position for the start of a line number.
- """
- return (self.image_pad, self._get_line_y(lineno))
-
- def _get_text_color(self, style):
- """
- Get the correct color for the token from the style.
- """
- if style['color'] is not None:
- fill = '#' + style['color']
- else:
- fill = '#000'
- return fill
-
- def _get_text_bg_color(self, style):
- """
- Get the correct background color for the token from the style.
- """
- if style['bgcolor'] is not None:
- bg_color = '#' + style['bgcolor']
- else:
- bg_color = None
- return bg_color
-
- def _get_style_font(self, style):
- """
- Get the correct font for the style.
- """
- return self.fonts.get_font(style['bold'], style['italic'])
-
- def _get_image_size(self, maxlinelength, maxlineno):
- """
- Get the required image size.
- """
- return (self._get_char_x(maxlinelength) + self.image_pad,
- self._get_line_y(maxlineno + 0) + self.image_pad)
-
- def _draw_linenumber(self, posno, lineno):
- """
- Remember a line number drawable to paint later.
- """
- self._draw_text(
- self._get_linenumber_pos(posno),
- str(lineno).rjust(self.line_number_chars),
- font=self.fonts.get_font(self.line_number_bold,
- self.line_number_italic),
- text_fg=self.line_number_fg,
- text_bg=None,
- )
-
- def _draw_text(self, pos, text, font, text_fg, text_bg):
- """
- Remember a single drawable tuple to paint later.
- """
- self.drawables.append((pos, text, font, text_fg, text_bg))
-
- def _create_drawables(self, tokensource):
- """
- Create drawables for the token content.
- """
- lineno = charno = maxcharno = 0
- maxlinelength = linelength = 0
- for ttype, value in tokensource:
- while ttype not in self.styles:
- ttype = ttype.parent
- style = self.styles[ttype]
- # TODO: make sure tab expansion happens earlier in the chain. It
- # really ought to be done on the input, as to do it right here is
- # quite complex.
- value = value.expandtabs(4)
- lines = value.splitlines(True)
- # print lines
- for i, line in enumerate(lines):
- temp = line.rstrip('\n')
- if temp:
- self._draw_text(
- self._get_text_pos(linelength, lineno),
- temp,
- font = self._get_style_font(style),
- text_fg = self._get_text_color(style),
- text_bg = self._get_text_bg_color(style),
- )
- temp_width, temp_hight = self.fonts.get_text_size(temp)
- linelength += temp_width
- maxlinelength = max(maxlinelength, linelength)
- charno += len(temp)
- maxcharno = max(maxcharno, charno)
- if line.endswith('\n'):
- # add a line for each extra line in the value
- linelength = 0
- charno = 0
- lineno += 1
- self.maxlinelength = maxlinelength
- self.maxcharno = maxcharno
- self.maxlineno = lineno
-
- def _draw_line_numbers(self):
- """
- Create drawables for the line numbers.
- """
- if not self.line_numbers:
- return
- for p in range(self.maxlineno):
- n = p + self.line_number_start
- if (n % self.line_number_step) == 0:
- self._draw_linenumber(p, n)
-
- def _paint_line_number_bg(self, im):
- """
- Paint the line number background on the image.
- """
- if not self.line_numbers:
- return
- if self.line_number_fg is None:
- return
- draw = ImageDraw.Draw(im)
- recth = im.size[-1]
- rectw = self.image_pad + self.line_number_width - self.line_number_pad
- draw.rectangle([(0, 0), (rectw, recth)],
- fill=self.line_number_bg)
- if self.line_number_separator:
- draw.line([(rectw, 0), (rectw, recth)], fill=self.line_number_fg)
- del draw
-
- def format(self, tokensource, outfile):
- """
- Format ``tokensource``, an iterable of ``(tokentype, tokenstring)``
- tuples and write it into ``outfile``.
-
- This implementation calculates where it should draw each token on the
- pixmap, then calculates the required pixmap size and draws the items.
- """
- self._create_drawables(tokensource)
- self._draw_line_numbers()
- im = Image.new(
- 'RGB',
- self._get_image_size(self.maxlinelength, self.maxlineno),
- self.background_color
- )
- self._paint_line_number_bg(im)
- draw = ImageDraw.Draw(im)
- # Highlight
- if self.hl_lines:
- x = self.image_pad + self.line_number_width - self.line_number_pad + 1
- recth = self._get_line_height()
- rectw = im.size[0] - x
- for linenumber in self.hl_lines:
- y = self._get_line_y(linenumber - 1)
- draw.rectangle([(x, y), (x + rectw, y + recth)],
- fill=self.hl_color)
- for pos, value, font, text_fg, text_bg in self.drawables:
- if text_bg:
- text_size = draw.textsize(text=value, font=font)
- draw.rectangle([pos[0], pos[1], pos[0] + text_size[0], pos[1] + text_size[1]], fill=text_bg)
- draw.text(pos, value, font=font, fill=text_fg)
- im.save(outfile, self.image_format.upper())
-
-
-# Add one formatter per format, so that the "-f gif" option gives the correct result
-# when used in pygmentize.
-
-class GifImageFormatter(ImageFormatter):
- """
- Create a GIF image from source code. This uses the Python Imaging Library to
- generate a pixmap from the source code.
-
- .. versionadded:: 1.0
- """
-
- name = 'img_gif'
- aliases = ['gif']
- filenames = ['*.gif']
- default_image_format = 'gif'
-
-
-class JpgImageFormatter(ImageFormatter):
- """
- Create a JPEG image from source code. This uses the Python Imaging Library to
- generate a pixmap from the source code.
-
- .. versionadded:: 1.0
- """
-
- name = 'img_jpg'
- aliases = ['jpg', 'jpeg']
- filenames = ['*.jpg']
- default_image_format = 'jpeg'
-
-
-class BmpImageFormatter(ImageFormatter):
- """
- Create a bitmap image from source code. This uses the Python Imaging Library to
- generate a pixmap from the source code.
-
- .. versionadded:: 1.0
- """
-
- name = 'img_bmp'
- aliases = ['bmp', 'bitmap']
- filenames = ['*.bmp']
- default_image_format = 'bmp'
diff --git a/spaces/ali-ghamdan/gfp-Gans/tests/test_stylegan2_clean_arch.py b/spaces/ali-ghamdan/gfp-Gans/tests/test_stylegan2_clean_arch.py
deleted file mode 100644
index 78bb920e73ce28cfec9ea89a4339cc5b87981b47..0000000000000000000000000000000000000000
--- a/spaces/ali-ghamdan/gfp-Gans/tests/test_stylegan2_clean_arch.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import torch
-
-from gfpgan.archs.stylegan2_clean_arch import StyleGAN2GeneratorClean
-
-
-def test_stylegan2generatorclean():
- """Test arch: StyleGAN2GeneratorClean."""
-
- # model init and forward (gpu)
- if torch.cuda.is_available():
- net = StyleGAN2GeneratorClean(
- out_size=32, num_style_feat=512, num_mlp=8, channel_multiplier=1, narrow=0.5).cuda().eval()
- style = torch.rand((1, 512), dtype=torch.float32).cuda()
- output = net([style], input_is_latent=False)
- assert output[0].shape == (1, 3, 32, 32)
- assert output[1] is None
-
- # -------------------- with return_latents ----------------------- #
- output = net([style], input_is_latent=True, return_latents=True)
- assert output[0].shape == (1, 3, 32, 32)
- assert len(output[1]) == 1
- # check latent
- assert output[1][0].shape == (8, 512)
-
- # -------------------- with randomize_noise = False ----------------------- #
- output = net([style], randomize_noise=False)
- assert output[0].shape == (1, 3, 32, 32)
- assert output[1] is None
-
- # -------------------- with truncation = 0.5 and mixing----------------------- #
- output = net([style, style], truncation=0.5, truncation_latent=style)
- assert output[0].shape == (1, 3, 32, 32)
- assert output[1] is None
-
- # ------------------ test make_noise ----------------------- #
- out = net.make_noise()
- assert len(out) == 7
- assert out[0].shape == (1, 1, 4, 4)
- assert out[1].shape == (1, 1, 8, 8)
- assert out[2].shape == (1, 1, 8, 8)
- assert out[3].shape == (1, 1, 16, 16)
- assert out[4].shape == (1, 1, 16, 16)
- assert out[5].shape == (1, 1, 32, 32)
- assert out[6].shape == (1, 1, 32, 32)
-
- # ------------------ test get_latent ----------------------- #
- out = net.get_latent(style)
- assert out.shape == (1, 512)
-
- # ------------------ test mean_latent ----------------------- #
- out = net.mean_latent(2)
- assert out.shape == (1, 512)
diff --git a/spaces/allknowingroger/Image-Models-Test149/app.py b/spaces/allknowingroger/Image-Models-Test149/app.py
deleted file mode 100644
index 77522ffc536c474245fe273cc4de9986fc306122..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test149/app.py
+++ /dev/null
@@ -1,144 +0,0 @@
-import gradio as gr
-# import os
-# import sys
-# from pathlib import Path
-import time
-
-models =[
- "DavideTHU/lora-trained-xl",
- "Kalyani03/mountain-valley-with-greenary-and-a-parrot",
- "DSP-31/volley-ball-rgv",
- "datascientistjohn/sdxl-self",
- "harikeshava1223/art-khk",
- "digiplay/CleanLinearMix_nsfw",
- "smjain/kishor",
- "Yntec/BeenYou",
- "mussso/lora-trained-xl",
-]
-
-
-model_functions = {}
-model_idx = 1
-for model_path in models:
- try:
- model_functions[model_idx] = gr.Interface.load(f"models/{model_path}", live=False, preprocess=True, postprocess=False)
- except Exception as error:
- def the_fn(txt):
- return None
- model_functions[model_idx] = gr.Interface(fn=the_fn, inputs=["text"], outputs=["image"])
- model_idx+=1
-
-
-def send_it_idx(idx):
- def send_it_fn(prompt):
- output = (model_functions.get(str(idx)) or model_functions.get(str(1)))(prompt)
- return output
- return send_it_fn
-
-def get_prompts(prompt_text):
- return prompt_text
-
-def clear_it(val):
- if int(val) != 0:
- val = 0
- else:
- val = 0
- pass
- return val
-
-def all_task_end(cnt,t_stamp):
- to = t_stamp + 60
- et = time.time()
- if et > to and t_stamp != 0:
- d = gr.update(value=0)
- tog = gr.update(value=1)
- #print(f'to: {to} et: {et}')
- else:
- if cnt != 0:
- d = gr.update(value=et)
- else:
- d = gr.update(value=0)
- tog = gr.update(value=0)
- #print (f'passing: to: {to} et: {et}')
- pass
- return d, tog
-
-def all_task_start():
- print("\n\n\n\n\n\n\n")
- t = time.gmtime()
- t_stamp = time.time()
- current_time = time.strftime("%H:%M:%S", t)
- return gr.update(value=t_stamp), gr.update(value=t_stamp), gr.update(value=0)
-
-def clear_fn():
- nn = len(models)
- return tuple([None, *[None for _ in range(nn)]])
-
-
-
-with gr.Blocks(title="SD Models") as my_interface:
- with gr.Column(scale=12):
- # with gr.Row():
- # gr.Markdown("""- Primary prompt: 你想画的内容(英文单词,如 a cat, 加英文逗号效果更好;点 Improve 按钮进行完善)\n- Real prompt: 完善后的提示词,出现后再点右边的 Run 按钮开始运行""")
- with gr.Row():
- with gr.Row(scale=6):
- primary_prompt=gr.Textbox(label="Prompt", value="")
- # real_prompt=gr.Textbox(label="Real prompt")
- with gr.Row(scale=6):
- # improve_prompts_btn=gr.Button("Improve")
- with gr.Row():
- run=gr.Button("Run",variant="primary")
- clear_btn=gr.Button("Clear")
- with gr.Row():
- sd_outputs = {}
- model_idx = 1
- for model_path in models:
- with gr.Column(scale=3, min_width=320):
- with gr.Box():
- sd_outputs[model_idx] = gr.Image(label=model_path)
- pass
- model_idx += 1
- pass
- pass
-
- with gr.Row(visible=False):
- start_box=gr.Number(interactive=False)
- end_box=gr.Number(interactive=False)
- tog_box=gr.Textbox(value=0,interactive=False)
-
- start_box.change(
- all_task_end,
- [start_box, end_box],
- [start_box, tog_box],
- every=1,
- show_progress=False)
-
- primary_prompt.submit(all_task_start, None, [start_box, end_box, tog_box])
- run.click(all_task_start, None, [start_box, end_box, tog_box])
- runs_dict = {}
- model_idx = 1
- for model_path in models:
- runs_dict[model_idx] = run.click(model_functions[model_idx], inputs=[primary_prompt], outputs=[sd_outputs[model_idx]])
- model_idx += 1
- pass
- pass
-
- # improve_prompts_btn_clicked=improve_prompts_btn.click(
- # get_prompts,
- # inputs=[primary_prompt],
- # outputs=[primary_prompt],
- # cancels=list(runs_dict.values()))
- clear_btn.click(
- clear_fn,
- None,
- [primary_prompt, *list(sd_outputs.values())],
- cancels=[*list(runs_dict.values())])
- tog_box.change(
- clear_it,
- tog_box,
- tog_box,
- cancels=[*list(runs_dict.values())])
-
-my_interface.queue(concurrency_count=600, status_update_rate=1)
-my_interface.launch(inline=True, show_api=False)
-
\ No newline at end of file
diff --git a/spaces/allknowingroger/Image-Models-Test73/README.md b/spaces/allknowingroger/Image-Models-Test73/README.md
deleted file mode 100644
index 4eea031a1072cb9ea2f1b0d15d427500eb6dd65e..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test73/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: More Image Models
-emoji: 😻
-colorFrom: red
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: true
-duplicated_from: allknowingroger/Image-Models-Test72
----
-
-
\ No newline at end of file
diff --git a/spaces/almakedon/faster-whisper-webui/src/modelCache.py b/spaces/almakedon/faster-whisper-webui/src/modelCache.py
deleted file mode 100644
index 680a4b386fc37e17ed2353e72d04a646ece2c4a6..0000000000000000000000000000000000000000
--- a/spaces/almakedon/faster-whisper-webui/src/modelCache.py
+++ /dev/null
@@ -1,17 +0,0 @@
-class ModelCache:
- def __init__(self):
- self._cache = dict()
-
- def get(self, model_key: str, model_factory):
- result = self._cache.get(model_key)
-
- if result is None:
- result = model_factory()
- self._cache[model_key] = result
- return result
-
- def clear(self):
- self._cache.clear()
-
-# A global cache of models. This is mainly used by the daemon processes to avoid loading the same model multiple times.
-GLOBAL_MODEL_CACHE = ModelCache()
\ No newline at end of file
diff --git a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/pa_win_wasapi.c b/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/pa_win_wasapi.c
deleted file mode 100644
index c76f302e68c8b35c5f3fa598a438e4c5a28497f1..0000000000000000000000000000000000000000
--- a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/pa_win_wasapi.c
+++ /dev/null
@@ -1,6534 +0,0 @@
-/*
- * Portable Audio I/O Library WASAPI implementation
- * Copyright (c) 2006-2010 David Viens
- * Copyright (c) 2010-2019 Dmitry Kostjuchenko
- *
- * Based on the Open Source API proposed by Ross Bencina
- * Copyright (c) 1999-2019 Ross Bencina, Phil Burk
- *
- * Permission is hereby granted, free of charge, to any person obtaining
- * a copy of this software and associated documentation files
- * (the "Software"), to deal in the Software without restriction,
- * including without limitation the rights to use, copy, modify, merge,
- * publish, distribute, sublicense, and/or sell copies of the Software,
- * and to permit persons to whom the Software is furnished to do so,
- * subject to the following conditions:
- *
- * The above copyright notice and this permission notice shall be
- * included in all copies or substantial portions of the Software.
- *
- * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
- * EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
- * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
- * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR
- * ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF
- * CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
- * WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
- */
-
-/*
- * The text above constitutes the entire PortAudio license; however,
- * the PortAudio community also makes the following non-binding requests:
- *
- * Any person wishing to distribute modifications to the Software is
- * requested to send the modifications to the original developer so that
- * they can be incorporated into the canonical version. It is also
- * requested that these non-binding requests be included along with the
- * license above.
- */
-
-/** @file
- @ingroup hostapi_src
- @brief WASAPI implementation of support for a host API.
- @note pa_wasapi currently requires minimum VC 2005, and the latest Vista SDK
-*/
-
-#include
-#include
-#include
-#include
-
-// Max device count (if defined) causes max constant device count in the device list that
-// enables PaWasapi_UpdateDeviceList() API and makes it possible to update WASAPI list dynamically
-#ifndef PA_WASAPI_MAX_CONST_DEVICE_COUNT
- #define PA_WASAPI_MAX_CONST_DEVICE_COUNT 0 // Force basic behavior by defining 0 if not defined by user
-#endif
-
-// Fallback from Event to the Polling method in case if latency is higher than 21.33ms, as it allows to use
-// 100% of CPU inside the PA's callback.
-// Note: Some USB DAC drivers are buggy when Polling method is forced in Exclusive mode, audio output becomes
-// unstable with a lot of interruptions, therefore this define is optional. The default behavior is to
-// not change the Event mode to Polling and use the mode which user provided.
-//#define PA_WASAPI_FORCE_POLL_IF_LARGE_BUFFER
-
-//! Poll mode time slots logging.
-//#define PA_WASAPI_LOG_TIME_SLOTS
-
-// WinRT
-#if defined(WINAPI_FAMILY) && (WINAPI_FAMILY == WINAPI_FAMILY_APP)
- #define PA_WINRT
- #define INITGUID
-#endif
-
-// WASAPI
-// using adjustments for MinGW build from @mgeier/MXE
-// https://github.com/mxe/mxe/commit/f4bbc45682f021948bdaefd9fd476e2a04c4740f
-#include // must be before other Wasapi headers
-#if defined(_MSC_VER) && (_MSC_VER >= 1400) || defined(__MINGW64_VERSION_MAJOR)
- #include
- #define COBJMACROS
- #include
- #include
- #define INITGUID // Avoid additional linkage of static libs, excessive code will be optimized out by the compiler
-#ifndef _MSC_VER
- #include
-#endif
- #include
- #include
- #include // Used to get IKsJackDescription interface
- #undef INITGUID
-// Visual Studio 2010 does not support the inline keyword
-#if (_MSC_VER <= 1600)
- #define inline _inline
-#endif
-#endif
-#ifndef __MWERKS__
- #include
- #include
-#endif
-#ifndef PA_WINRT
- #include
-#endif
-
-#include "pa_util.h"
-#include "pa_allocation.h"
-#include "pa_hostapi.h"
-#include "pa_stream.h"
-#include "pa_cpuload.h"
-#include "pa_process.h"
-#include "pa_win_wasapi.h"
-#include "pa_debugprint.h"
-#include "pa_ringbuffer.h"
-#include "pa_win_coinitialize.h"
-
-#if !defined(NTDDI_VERSION) || (defined(__GNUC__) && (__GNUC__ <= 6) && !defined(__MINGW64__))
-
- #undef WINVER
- #undef _WIN32_WINNT
- #define WINVER 0x0600 // VISTA
- #define _WIN32_WINNT WINVER
-
- #ifndef WINAPI
- #define WINAPI __stdcall
- #endif
-
- #ifndef __unaligned
- #define __unaligned
- #endif
-
- #ifndef __C89_NAMELESS
- #define __C89_NAMELESS
- #endif
-
- #ifndef _AVRT_ //<< fix MinGW dummy compile by defining missing type: AVRT_PRIORITY
- typedef enum _AVRT_PRIORITY
- {
- AVRT_PRIORITY_LOW = -1,
- AVRT_PRIORITY_NORMAL,
- AVRT_PRIORITY_HIGH,
- AVRT_PRIORITY_CRITICAL
- } AVRT_PRIORITY, *PAVRT_PRIORITY;
- #endif
-
- #include // << for IID/CLSID
- #include
- #include
-
- #ifndef __LPCGUID_DEFINED__
- #define __LPCGUID_DEFINED__
- typedef const GUID *LPCGUID;
- #endif
- typedef GUID IID;
- typedef GUID CLSID;
-
- #ifndef PROPERTYKEY_DEFINED
- #define PROPERTYKEY_DEFINED
- typedef struct _tagpropertykey
- {
- GUID fmtid;
- DWORD pid;
- } PROPERTYKEY;
- #endif
-
- #ifdef __midl_proxy
- #define __MIDL_CONST
- #else
- #define __MIDL_CONST const
- #endif
-
- #ifdef WIN64
- #include
- #define FASTCALL
- #include