So, how can you download and install 8 Ball Pool Hile 2022 Apk on your device? It's very easy. Just follow these simple steps:
--
-
- Click on the link below to download the apk file of 8 Ball Pool Hile 2022 Apk. -
- Go to your device settings and enable the option to install apps from unknown sources. -
- Locate the downloaded apk file and tap on it to start the installation process. -
- Follow the instructions on the screen and wait for the installation to complete. -
- Launch the game and enjoy! -
Download 8 Ball Pool Hile 2022 Apk Here
-8 ball pool hileli apk indir 2022
-8 ball pool hile nasıl yapılır 2022
-8 ball pool hile mod apk son sürüm
-8 ball pool hile apk dayı
-8 ball pool hile apk android oyun club
-8 ball pool hile apk para hilesi
-8 ball pool hile apk sınırsız para
-8 ball pool hile apk güncel
-8 ball pool hile apk hızlı vuruş
-8 ball pool hile apk uzun çubuk
-8 ball pool hile apk mega mod
-8 ball pool hile apk anti ban
-8 ball pool hile apk online
-8 ball pool hile apk vip
-8 ball pool hile apk elmas hilesi
-8 ball pool hile apk level atlama
-8 ball pool hile apk tüm masalar açık
-8 ball pool hile apk tüm toplar açık
-8 ball pool hile apk tüm kıyafetler açık
-8 ball pool hile apk tüm sopalar açık
-8 ball pool hile apk tüm ödüller açık
-8 ball pool hile apk tüm turnuvalar açık
-8 ball pool hile apk tüm özellikler açık
-8 ball pool hile apk tüm modlar açık
-8 ball pool hile apk tüm skinler açık
-8 ball pool hile apk bedava indir
-8 ball pool hile apk ücretsiz indir
-8 ball pool hile apk full indir
-8 ball pool hile apk linkli indir
-8 ball pool hile apk direk indir
-8 ball pool hile apk kolay indir
-8 ball pool hile apk güvenli indir
-8 ball pool hile apk virüssüz indir
-8 ball pool hile apk reklamsız indir
-8 ball pool hile apk kurulumu nasıl yapılır
-8 ball pool hile apk kullanımı nasıl yapılır
-8 ball pool hile apk yorumları nasıl yapılır
-8 ball pool hile apk puanları nasıl yapılır
-8 ball pool hile apk güncelleme nasıl yapılır
-8 ball pool hile apk silme nasıl yapılır
-8 ball pool hilesi nasıl indirilir ve kurulur 2022
-8 ball pool hack mod menu download for android
-how to get unlimited coins and cash in 8 ball pool
-best tricks and tips for playing 8 ball pool
-how to win every game in 8 ball pool
-how to unlock all cues and tables in 8 ball pool
-how to play with friends in 8 ball pool
-how to get free spins and scratchers in 8 ball pool
How to Play 8 Ball Pool with 8 Ball Pool Hile 2022 Apk
-Now that you have installed 8 Ball Pool Hile 2022 Apk, you are ready to play and win every game. But how do you play 8 Ball Pool with this cheat? Well, it's very similar to playing the original game, but with some extra features and options. Here are some tips and tricks to help you play better:
-How to choose your game mode and table
-When you launch the game, you will see four different game modes: Play 1 on 1, Play with Friends, Play in Tournaments, and Practice Offline. You can choose any mode you want, depending on your preference and skill level. You can also choose from different tables, ranging from London to Venice, each with different entry fees and rewards.
-With 8 Ball Pool Hile 2022 Apk, you don't have to worry about losing your coins or cash, because you have unlimited amounts of them. You can also unlock all the tables for free, without having to level up or pay anything. Just tap on the table you want to play on and start the game.
-How to rack the balls and break effectively
-After choosing your game mode and table, you will see the balls arranged in a triangle on the table. This is called the rack. The player who breaks the rack is called the breaker. The breaker is decided randomly or by a coin toss. The breaker has to hit the cue ball with the cue stick and make contact with any ball in the rack. The goal is to spread the balls across the table and pocket one or more balls.
-With 8 Ball Pool Hile 2022 Apk, you can use extended guidelines and aim assist to help you break better. These features show you the trajectory and angle of your shots, as well as the possible outcomes of your shots. You can also enable auto-win mode or instant win option, which will automatically make you win the game after breaking, regardless of what happens next.
-How to use the cue stick and spin the cue ball
-The cue stick is the tool that you use to hit the cue ball. The cue ball is the white ball that you control with your cue stick. You can adjust the power and direction of your shots by dragging your finger on the screen. You can also apply spin to the cue ball by tapping on the spin icon on the bottom left corner of the screen. Spin can affect how the cue ball moves after hitting another ball or a cushion.
-With 8 Ball Pool Hile 2022 Apk, you can customize your cue stick and pool table with different designs and colors. You can also unlock exclusive cues that have better stats and abilities, such as more power, accuracy, spin, and time. You can also use unlimited cues without having to recharge them.
-How to pocket your balls and win the game
-The objective of 8 Ball Pool is to pocket all your balls (either solids or stripes) before your opponent does, and then pocket the black 8 ball in a designated pocket. You have to call your shots before making them, by tapping on the pocket where you want to send your ball. If you pocket a ball of your type, you get another turn. If you miss or foul (such as hitting your opponent's ball first, or not hitting any ball at all), your turn ends and your opponent gets a chance.
- the game after pocketing any ball, regardless of the rules or the outcome. -Tips and Tricks for Using 8 Ball Pool Hile 2022 Apk
-Now that you know how to play 8 Ball Pool with 8 Ball Pool Hile 2022 Apk, you might be wondering how to make the most of this cheat. Here are some tips and tricks that will help you enjoy the game more and improve your skills:
-How to customize your cue and pool table
-One of the fun aspects of 8 Ball Pool is that you can customize your cue and pool table with different styles and themes. You can choose from hundreds of cues and tables, each with different looks and features. You can also create your own cue and table by mixing and matching different parts and colors.
-With 8 Ball Pool Hile 2022 Apk, you can unlock all the cues and tables for free, without having to spend any coins or cash. You can also access exclusive cues and tables that are not available in the original game, such as the VIP cue, the Galaxy cue, and the Halloween table. You can change your cue and table anytime you want, by tapping on the gear icon on the top right corner of the screen.
-How to earn more coins and cash
-Coins and cash are the main currencies in 8 Ball Pool. You need coins to enter matches, buy cues, and upgrade your skills. You need cash to buy premium items, such as surprise boxes, scratch cards, and chat packs. You can earn coins and cash by winning matches, completing missions, watching ads, spinning the wheel, and opening chests.
-With 8 Ball Pool Hile 2022 Apk, you don't have to worry about earning coins and cash, because you have unlimited amounts of them. You can also use them to buy anything you want in the game, without any restrictions or limitations. You can also use them to tip your opponents or send gifts to your friends.
-How to unlock exclusive items and cues
-Another way to spice up your 8 Ball Pool experience is to unlock exclusive items and cues that are not available in the regular game. These items and cues have special designs, effects, and abilities that make them stand out from the rest. Some examples of these items and cues are:
-| Item/Cue | -Description | -
|---|---|
| The King Cue | -A golden cue that has a crown on its tip. It has high stats and a royal aura. | -
| The Firestorm Cue | -A fiery cue that has flames on its shaft. It has high power and a burning effect. | -
| The Ice Cue | -A frosty cue that has ice crystals on its butt. It has high spin and a freezing effect. | -
| The Dragon Cue | -A mythical cue that has a dragon head on its tip. It has high accuracy and a dragon breath effect. | -
| The Legendary Cue Collection | -A collection of 20 cues that have unique designs and abilities. They also have a chance to recharge themselves after every shot. | -
| The VIP Cue Collection | -A collection of 10 cues that are only available for VIP members. They have high stats and a VIP badge. | -
| The Surprise Box | -A box that contains a random item or cue. It can be opened with cash or keys. | -
| The Scratch Card | -A card that can be scratched to reveal a prize. It can be bought with cash or earned by playing matches. | -
| A pack of chat messages that can be used to communicate with other players. It can be bought with cash or earned by playing matches. | -
With 8 Ball Pool Hile 2022 Apk, you can unlock all these items and cues for free, without having to spend any coins, cash, or keys. You can also access them anytime you want, by tapping on the shop icon on the top left corner of the screen.
-How to challenge your friends and other players online
-One of the best features of 8 Ball Pool is that you can play with your friends and other players online, in real-time. You can challenge anyone you want, from anywhere in the world, and show off your skills and style. You can also chat with your opponents, send them emojis, and tip them coins.
-With 8 Ball Pool Hile 2022 Apk, you can challenge anyone you want, without any restrictions or limitations. You can also use extended guidelines and aim assist to help you win every match easily. You can also enable auto-win mode or instant win option, which will automatically make you win the game after making any shot, regardless of the rules or the outcome.
-How to avoid getting banned or detected by Miniclip
-The only downside of using 8 Ball Pool Hile 2022 Apk is that you might get banned or detected by Miniclip, the developer of the original game. Miniclip has a strict policy against cheating and hacking, and they use various methods to detect and ban users who use cheats or hacks. If you get banned or detected, you might lose your account, your progress, and your items.
-However, with 8 Ball Pool Hile 2022 Apk, you don't have to worry about getting banned or detected, because this cheat has a built-in anti-cheat detection and ban protection system. This system prevents Miniclip from detecting your cheat usage and banning your account. It also hides your IP address and encrypts your data, making it impossible for Miniclip to trace your identity or location.
-Conclusion
-In conclusion, 8 Ball Pool Hile 2022 Apk is the best cheat for 8 Ball Pool that you can find online. It gives you unlimited access to all the features and resources of the game, such as coins, cash, cues, tables, items, and modes. It also gives you extra features and options, such as extended guidelines, aim assist, auto-win mode, instant win option, anti-cheat detection, and ban protection. It is easy to download and install, safe and virus-free, compatible with any device or platform, and free of charge.
-If you love playing 8 Ball Pool and want to have more fun and excitement in your pool games, then you should definitely try out 8 Ball Pool Hile 2022 Apk. You will not regret it. You will enjoy the game more than ever before, and you will become a pool master in no time.
-So what are you waiting for? Download 8 Ball Pool Hile 2022 Apk now and start playing like a pro!
-Download 8 Ball Pool Hile 2022 Apk Here
-FAQs
-What is the difference between 8 Ball Pool Hile 2022 Apk and other cheats?
-8 Ball Pool Hile 2022 Apk is different from other cheats because it is a modified version of the original game that gives you unlimited access to all the features and resources of the game. Other cheats are usually external tools or apps that require you to run them separately from the game or inject them into the game. These cheats are more risky and less effective than 8 Ball Pool Hile 2022 Apk.
-Is 8 Ball Pool Hile 2022 Apk safe and virus-free?
-8 Ball Pool Hile 2022 Apk is safe and virus-free because it is developed by a team of professional programmers who have tested it thoroughly before releasing it to the public. It does not contain any malware or spyware that could harm your device or steal your personal information. It also does not require any permissions or access to your device's functions or data.
-Can I use 8 Ball Pool Hile 2022 Apk on any device or platform?
-8 Ball Pool Hile 2022 Apk can be used on any device or platform that supports Android applications. You can use it on your smartphone, tablet, laptop, or desktop, as long as they have an Android operating system. You can also use it on other platforms, such as iOS, Windows, or Mac, by using an Android emulator, such as BlueStacks or Nox Player.
-Do I need to root or jailbreak my device to use 8 Ball Pool Hile 2022 Apk?
-No, you do not need to root or jailbreak your device to use 8 Ball Pool Hile 2022 Apk. This cheat does not require any modifications or alterations to your device's system or firmware. It works perfectly fine on any device, regardless of its root or jailbreak status.
-How can I contact the developers of 8 Ball Pool Hile 2022 Apk if I have any questions or issues?
-If you have any questions or issues regarding 8 Ball Pool Hile 2022 Apk, you can contact the developers of this cheat by visiting their official website or social media pages. You can also leave a comment or a review on the download page of this cheat. The developers are very responsive and helpful, and they will try to solve your problems as soon as possible.
197e85843d-
-
\ No newline at end of file diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Dawn Awakening The Ultimate Guide to Surviving the Post-Apocalyptic World.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Dawn Awakening The Ultimate Guide to Surviving the Post-Apocalyptic World.md deleted file mode 100644 index 5e1562a27a47d5f021b5670e0740523b3f93d041..0000000000000000000000000000000000000000 --- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Dawn Awakening The Ultimate Guide to Surviving the Post-Apocalyptic World.md +++ /dev/null @@ -1,124 +0,0 @@ -
-
What is Dawn Awakening and Why is it Important?
-Dawn awakening is a practice of waking up naturally with the sunrise, without the use of an alarm clock or other artificial means. It is a way of aligning our sleep cycle with the natural rhythm of light and darkness, which has many benefits for our physical and mental health.
-dawn awakening
Download ⚹⚹⚹ https://urlin.us/2uT2Px
-
Some of the benefits of dawn awakening are:
--
-
- Improved sleep quality: Waking up with the light signals our brain to stop producing melatonin, the hormone that regulates sleep. This helps us feel more refreshed and alert in the morning. -
- Enhanced mood: Exposure to natural light in the morning boosts our serotonin levels, the neurotransmitter that regulates mood, happiness, and well-being. -
- Reduced stress: Waking up gradually and peacefully reduces the cortisol levels, the hormone that triggers stress, anxiety, and inflammation. -
- Better immunity: Waking up with the sun strengthens our immune system by stimulating the production of natural killer cells, which fight infections and diseases. -
- Increased energy: Waking up with the light increases our metabolism and blood circulation, which provide us with more energy throughout the day. -
How to practice dawn awakening:
-Practicing dawn awakening is not as difficult as it may seem. Here are some tips and techniques to help you wake up naturally with the sunrise:
--
-
- Go to bed early: The first step to wake up early is to go to bed early. Aim for at least seven to eight hours of sleep per night, and avoid caffeine, alcohol, and screens before bedtime. -
- Use curtains or blinds: If you live in an area where there is too much artificial light at night, use curtains or blinds to block it out. This will help you fall asleep faster and deeper. -
- Open your windows: If possible, open your windows before you go to bed or when you wake up. This will allow fresh air and natural light to enter your room, which will help you wake up more easily. -
- Avoid snoozing: When you wake up with the light, resist the temptation to snooze or go back to sleep. Snoozing disrupts your sleep cycle and makes you feel more groggy and tired. -
- Have a morning routine: Having a morning routine can motivate you to get out of bed and start your day. You can do some stretching, meditation, journaling, or anything that makes you feel good. -
The Science Behind Dawn Awakening
-Dawn awakening is not only a spiritual practice but also a scientific one. There is a lot of research that supports the benefits of waking up with the sun for our health and well-being.
-dawn awakening game
-dawn awakening tencent
-dawn awakening release date
-dawn awakening apk
-dawn awakening android
-dawn awakening ios
-dawn awakening download
-dawn awakening gameplay
-dawn awakening beta
-dawn awakening bluestacks
-dawn awakening open world survival
-dawn awakening zombie survival game
-dawn awakening unreal engine 4
-dawn awakening pre register
-dawn awakening official website
-dawn awakening english version
-dawn awakening system requirements
-dawn awakening trailer
-dawn awakening review
-dawn awakening reddit
-dawn awakening discord
-dawn awakening wiki
-dawn awakening mod apk
-dawn awakening cheats
-dawn awakening tips and tricks
-dawn awakening best weapons
-dawn awakening best skills
-dawn awakening best class
-dawn awakening character creation
-dawn awakening crafting guide
-dawn awakening base building
-dawn awakening coop mode
-dawn awakening multiplayer mode
-dawn awakening pvp mode
-dawn awakening online mode
-dawn awakening offline mode
-dawn awakening emulator
-dawn awakening pc version
-dawn awakening mac version
-dawn awakening windows version
-dawn awakening linux version
-dawn awakening steam version
-dawn awakening google play store
-dawn awakening app store
-dawn awakening facebook page
-dawn awakening youtube channel
-dawn awakening twitter account
-dawn awakening instagram account
-dawn awakening tiktok account
The main reason why dawn awakening works is because it affects our circadian rhythm, which is our internal clock that regulates our sleep-wake cycle. Our circadian rhythm is influenced by external cues, such as light and temperature, which tell us when to sleep and when to wake up.
-Light is the most powerful cue for our circadian rhythm. When we are exposed to natural light in the morning, it activates a part of our brain called the suprachiasmatic nucleus (SCN), which sends signals to other parts of our body to regulate our hormones, metabolism, temperature, and mood.
-
However, when we are exposed to artificial light at night, such as from screens, lamps, or streetlights, it confuses our circadian rhythm and disrupts our sleep quality. Artificial light suppresses the production of melatonin, which makes it harder for us to fall asleep and stay asleep. It also affects our serotonin levels, which can lead to depression, anxiety, and mood disorders.
-One way to overcome the negative effects of artificial light is to use dawn simulation devices, which are special lamps that mimic the natural sunrise in your bedroom. These devices gradually increase the brightness and color temperature of the light in the morning, which helps you wake up more naturally and comfortably.
-Dawn simulation devices have been shown to have many advantages over conventional alarm clocks, such as:
--
-
- Improving sleep quality and duration: Studies have found that dawn simulation devices can improve the quality and duration of sleep by reducing the number of awakenings and increasing the amount of deep sleep. -
- Enhancing mood and cognitive performance: Studies have also found that dawn simulation devices can enhance mood and cognitive performance by increasing alertness, attention, memory, and executive function. -
- Reducing seasonal affective disorder (SAD): Studies have also found that dawn simulation devices can reduce the symptoms of seasonal affective disorder (SAD), which is a type of depression that occurs during the winter months due to lack of sunlight. -
The Spiritual Meaning of Dawn Awakening
-Dawn awakening is not only a scientific practice but also a spiritual one. Waking up with the sun can help us connect with nature and the divine, and inspire us to live more creatively, gratefully, and optimistically.
-Waking up with the sun can help us connect with nature and the divine by:
--
-
- Aligning ourselves with the natural cycle of life: Waking up with the sun reminds us that we are part of nature and that we follow the same cycle of birth, growth, decay, and death. It helps us appreciate the beauty and wonder of creation and feel more in harmony with ourselves and the world. -
- Acknowledging the presence and power of a higher force: Waking up with the sun also reminds us that there is a higher force that governs the universe and that we are not alone. It helps us feel more humble, grateful, and trusting in the divine plan and guidance. -
Waking up with the sun can also inspire us to live more creatively, gratefully, and optimistically by:
--
-
- Stimulating our imagination and expression: Waking up with the sun can stimulate our imagination and expression by exposing us to different colors, shapes, sounds, and sensations. It can help us see things from a fresh perspective and express ourselves more authentically and artistically. -
- Cultivating our gratitude and appreciation: Waking up with the sun can also cultivate our gratitude and appreciation by making us aware of the gifts and opportunities that each day brings. It can help us focus on what we have rather than what we lack, and on what we can do rather than what we can't. -
- Fostering our optimism and hope: Waking up with the sun can also foster our optimism and hope by showing us that every day is a new beginning and a chance to start over. It can help us overcome our fears and challenges, and embrace our dreams and possibilities. -
The Challenges and Solutions of Dawn Awakening
-Dawn awakening is a rewarding practice but it also comes with some challenges. Some of the obstacles that may prevent us from waking up with the sun are:
--
-
- The modern lifestyle: Our modern lifestyle is often incompatible with dawn awakening. We tend to stay up late, work long hours, use artificial light, consume stimulants, and live in noisy environments. These factors interfere with our natural sleep cycle and make it harder for us to wake up early. -
- The different seasons: The different seasons also affect our ability to wake up with the sun. In winter, the days are shorter and darker, which makes it harder for us to get enough light exposure in the morning. In summer, the days are longer and brighter, which makes it harder for us to fall asleep at night. -
- The different climates: The different climates also influence our sleep-wake cycle. In hot climates, we may feel more uncomfortable sleeping at night due to high temperatures and humidity. In cold climates, we may feel more reluctant to get out of bed in the morning due to low temperatures and frost. -
- The different time zones: The different time zones also pose a challenge for dawn awakening. When we travel across different time zones, we may experience jet lag, which is a disruption of our circadian rhythm
caused by the mismatch between our internal clock and the external time. This can make us feel tired, irritable, and confused.
-How to overcome the challenges of dawn awakening:
-Despite these challenges, there are some solutions that can help us practice dawn awakening more easily and consistently. Here are some suggestions:
--
-
- Adjust your schedule: The best way to overcome the modern lifestyle is to adjust your schedule to fit your natural sleep cycle. Try to go to bed and wake up at the same time every day, and avoid activities that can disrupt your sleep, such as working, watching TV, or using your phone at night. -
- Use light therapy: The best way to overcome the different seasons is to use light therapy, which is a treatment that involves exposing yourself to artificial light that mimics the natural sunlight. You can use a light therapy device in the morning to help you wake up, or in the evening to help you fall asleep. -
- Use temperature regulation: The best way to overcome the different climates is to use temperature regulation, which is a method that involves adjusting the temperature of your bedroom and your body to optimize your sleep quality. You can use a fan, an air conditioner, a heater, or a humidifier to create a comfortable sleeping environment. You can also use a warm or cold shower, a hot or cold drink, or a heating pad or ice pack to regulate your body temperature. -
- Use melatonin supplements: The best way to overcome the different time zones is to use melatonin supplements, which are pills that contain the hormone that regulates sleep. You can take melatonin before you travel to help you adjust to the new time zone, or after you arrive to help you fall asleep. -
Conclusion
-Dawn awakening is a practice that can improve our health, happiness, and spirituality. By waking up naturally with the sunrise, we can align ourselves with the natural rhythm of life, connect with nature and the divine, and inspire ourselves to live more creatively, gratefully, and optimistically.
-Dawn awakening is not without its challenges, but they can be overcome with some adjustments and techniques. By following some simple tips and using some helpful tools, we can make dawn awakening a part of our daily routine and enjoy its benefits.
-If you are interested in learning more about dawn awakening and how to practice it, here are some resources and recommendations for further reading:
--
-
- The Miracle Morning: The Not-So-Obvious Secret Guaranteed to Transform Your Life (Before 8AM) by Hal Elrod: A book that teaches you how to create a morning routine that will transform your life. -
- The 5 AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: A book that shows you how to wake up early and achieve your goals. -
- Sunrise Alarm Clocks: The Best Way To Wake Up In 2023 by Sleep Advisor: An article that reviews the best dawn simulation devices on the market. -
- How To Wake Up Early And Enjoy It by Zen Habits: A blog post that offers some practical tips and advice on how to wake up early and enjoy it. -
- How To Wake Up At Dawn To Witness The Most Beautiful Sunrise by Travel + Leisure: A guide that tells you how to find the best spots and times to watch the sunrise around the world. -
-
-
\ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/APKPure The Ultimate App Store for Android Users.md b/spaces/1phancelerku/anime-remove-background/APKPure The Ultimate App Store for Android Users.md deleted file mode 100644 index 5ae70003a437f61698720cc95f59893e3cf06fe2..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/APKPure The Ultimate App Store for Android Users.md +++ /dev/null @@ -1,130 +0,0 @@ - -What is Apukpure and why you should use it
-If you are an Android user, you might have heard of Apukpure, an alternative app store that allows you to download all sorts of applications that you can't find in Google Play Store. But what is Apukpure exactly and what makes it different from other app stores? In this article, we will answer these questions and show you how to use Apukpure to download apps and games on your Android device.
-apukpure
DOWNLOAD ===> https://jinyurl.com/2uNMK2
-What is Apukpure?
-Apukpure is an online platform that provides APK files for Android users. APK files are the installation packages for Android applications, similar to EXE files for Windows. By downloading APK files from Apukpure, you can install apps and games that are not available in your country, region, or device. You can also access older versions of apps and games that have been removed or updated in Google Play Store.
-How does Apukpure work?
-Apukpure works by scanning and verifying the APK files from various sources on the internet. It then uploads them to its own servers and provides a download link for users. Apukpure also has an app that you can install on your Android device, which acts as a browser and downloader for the APK files. You can use the app to search, download, and install apps and games from Apukpure.
-What are the benefits of Apukpure?
-There are many benefits of using Apukpure, such as:
--
-
- You can access apps and games that are not available in Google Play Store due to geo-restrictions, compatibility issues, or censorship. -
- You can download apps and games faster and easier than using Google Play Store. -
- You can update apps and games without waiting for Google Play Store to release them. -
- You can downgrade apps and games to older versions if you don't like the new updates. -
- You can discover new and interesting apps and games that are not featured in Google Play Store. -
How to download and install Apukpure on your Android device
-To use Apukpure, you need to download and install its app on your Android device. Here are the steps to do so:
-Step 1: Enable unknown sources
-Before you can install any APK file on your Android device, you need to enable unknown sources in your settings. This will allow you to install apps from sources other than Google Play Store. To enable unknown sources, follow these steps:
-APKPure app download for Android
-
-APKPure apk file free download
-APKPure alternative app store
-APKPure games download
-APKPure app store review
-APKPure for PC Windows
-APKPure mod apk download
-APKPure app not working
-APKPure vs Aptoide
-APKPure app update
-APKPure app install
-APKPure app lock
-APKPure app manager
-APKPure app backup
-APKPure app uninstaller
-APKPure app downloader
-APKPure app categories
-APKPure app ratings
-APKPure app recommendations
-APKPure app search
-APKPure app history
-APKPure app settings
-APKPure app notifications
-APKPure app permissions
-APKPure app security
-APKPure app size
-APKPure app speed
-APKPure app language
-APKPure app region
-APKPure app support
-APKPure app feedback
-APKPure app features
-APKPure app benefits
-APKPure app disadvantages
-APKPure app pros and cons
-APKPure app comparison
-APKPure app alternatives
-APKPure app competitors
-APKPure app advantages
-APKPure app disadvantages-
-
- Go to your device's settings. -
- Tap on security or privacy. -
- Find and toggle on unknown sources or allow installation from unknown sources. -
Step 2: Download the Apukpure APK file
-Next, you need to download the Apukpure APK file from its official website. To do so, follow these steps:
--
-
- Open your browser and go to https://www.malavida.com/en/soft/apkpure/android/ -
- Tap on the green download button. -
- Wait for the download to finish. -
Step 3: Install the Apukpure app
-Finally, you need to install the Apukpure app on your device. To do so, follow these steps:
--
-
- Locate the Apukpure APK file in your downloads folder or notification bar. -
- Tap on the file to open it. -
- Tap on install and wait for the installation to complete. -
- Tap on open to launch the Apukpure app. -
How to use Apukpure to download apps and games
-Now that you have installed the Apukpure app, you can use it to download apps and games on your device. Here are the steps to do so:
-Step 1: Open the Apukpure app
-Open the Apukpure app from your app drawer or home screen. You will see a simple and user-friendly interface with various categories and tabs. You can browse the featured, popular, new, and updated apps and games on the home page. You can also use the menu button on the top left corner to access more options and settings.
-Step 2: Search for the app or game you want
-If you have a specific app or game in mind, you can use the search bar on the top right corner to find it. Just type in the name of the app or game and tap on the magnifying glass icon. You will see a list of results that match your query. You can also filter the results by category, rating, price, size, and more.
-Step 3: Download and install the app or game
-Once you have found the app or game you want, tap on it to open its details page. You will see a brief description, screenshots, ratings, reviews, and more information about the app or game. You will also see a green download button at the bottom of the page. Tap on it to start downloading the APK file. You will see a progress bar and a notification on your screen. When the download is finished, tap on install to install the app or game on your device. You can then open it from your app drawer or home screen.
-How to update apps and games with Apukpure
-One of the advantages of using Apukpure is that you can update apps and games without waiting for Google Play Store to release them. Here are the steps to do so:
-Step 1: Check for updates in the Apukpure app
-To check for updates, open the Apukpure app and tap on the menu button on the top left corner. Then tap on update. You will see a list of apps and games that have new versions available. You can also tap on check all to scan all your installed apps and games for updates.
-Step 2: Download and install the updates
-To download and install the updates, tap on update all or select the apps and games you want to update individually. Then tap on download. You will see a progress bar and a notification on your screen. When the download is finished, tap on install to install the updates on your device. You can then open them from your app drawer or home screen.
-Conclusion
-In conclusion, Apukpure is an alternative app store that allows you to download apps and games that are not available in Google Play Store. It also lets you update apps and games faster and easier than using Google Play Store. To use Apukpure, you need to download and install its app on your Android device. Then you can use it to search, download, and install apps and games from its platform.
-We hope this article has helped you understand what is Apukpure and how to use it. If you have any questions or feedback, please feel free to leave a comment below.
-Frequently Asked Questions
--
-
- Is Apukpure safe? -
- Is Apukpure legal? -
- Here are some more FAQs to complete the article:
-
-
-
- How to uninstall Apukpure? -
- Go to your device's settings. -
- Tap on apps or applications. -
- Find and tap on Apukpure. -
- Tap on uninstall and confirm. -
- How to contact Apukpure? -
- Email: support@apkpure.com -
- Facebook: https://www.facebook.com/apkpure -
- Twitter: https://twitter.com/apkpure -
- What are some alternatives to Apukpure? -
- Aptoide: A decentralized app store that allows users to create and manage their own app stores. -
- Uptodown: A multi-platform app store that offers apps and games for Android, Windows, Mac, Linux, and more. -
- APKMirror: A website that hosts APK files for popular apps and games that are updated frequently. -
- A new map with a city, a desert, and a highway. -
- A new garage with more space and options for car customization. -
- A new car wash system that lets you clean your car and earn money. -
- A new police mode that lets you chase or be chased by the cops. -
- A new chat system that lets you send emojis and stickers to other players. -
- A new radio system that lets you listen to music from your device or online stations. -
- A new weather system that changes the climate and the lighting of the map. -
- A new traffic system that adds more cars and pedestrians to the map. -
- A new damage system that shows the effects of collisions and accidents on your car. -
- A new physics system that makes the car handling more realistic and responsive. -
- Go to [Android Oyun Club] and search for Car Parking Multiplayer. -
- Click on the download button and wait for the file to be downloaded. -
- Open the file manager on your device and locate the downloaded file. -
- Tap on the file and allow the installation of unknown sources if prompted. -
- Wait for the installation to be completed and launch the game. -
- It is free to download and play. -
- It is realistic and fun to play. -
- It has a lot of cars, challenges, and modes to choose from. -
- It has a multiplayer open world mode where you can interact with other players. -
- It has a car customization feature where you can make your car unique. -
- It has a new version with new features and improvements. -
- Use different types of fences to separate different habitats and zones. -
- Use paths to connect different habitats and attractions. -
- Use signs to guide your visitors and staff. -
- Use plants, rocks, water features, etc. to decorate your habitats and park. -
- Use statues, fountains, benches, lamps, etc. to add more charm and beauty to your park. -
- Use roller coasters, ferris wheels, carousels, etc. to add more fun and excitement to your park. -
- Use food stalls, drink stands, restrooms, souvenir shops, etc. to provide services and amenities to your visitors. -
- Use a table to compare the pros and cons of different types of fences, paths, signs, plants, rocks, water features, statues, fountains, benches, lamps, roller coasters, ferris wheels, carousels, food stalls, drink stands, restrooms, souvenir shops, etc. -
- Es gratis para descargar y usar. -
- Tiene una gran colección de programas de anime en calidad HD. - -
- Tiene múltiples fuentes y servidores para cada espectáculo de anime. -
- Tiene una interfaz fácil de usar y ajustes personalizables. -
- Tiene actualizaciones regulares y correcciones de errores. -
- No está disponible en Google Play Store. -
- Puede contener algunos anuncios y ventanas emergentes. -
- Puede que no funcione en algunos dispositivos o regiones. -
- Puede tener algunos errores o fallos ocasionalmente. -
- Es Anime Negro APK seguro de usar? -
- Es Anime Negro APK legal de usar? - -
- ¿Cómo puedo actualizar Anime negro APK? -
- ¿Cómo puedo solicitar un espectáculo de anime que no está disponible en Anime Black APK? -
- ¿Cómo puedo apoyar Anime negro APK? -
- Final Destination 4 is also known as The Final Destination because it was initially intended to be the last film of the franchise. However, due to its commercial success, a fifth film was made in 2011. -
- Final Destination 4 is the first film of the franchise to be shot in 3D and the second one to be directed by David R. Ellis, who also directed Final Destination 2. -
- Final Destination 4 has the shortest runtime of all the films in the franchise, with only 82 minutes. -
- Final Destination 4 has the highest body count of all the films in the franchise, with 52 deaths. -
- Final Destination 4 features several references and homages to previous films in the franchise, such as the number 180, which is associated with death's design; the song "Dust in the Wind" by Kansas, which plays during several death scenes; and the character of William Bludworth (Tony Todd), who appears as a voice on a phone. -
- Final Destination (2000): The first movie introduces the concept of death's design and follows a group of teenagers who survive a plane explosion after one of them has a premonition. -
- Final Destination 2 (2003): The second movie expands the scope of death's design and follows a group of strangers who survive a highway pile-up after one of them has a premonition. -
- Final Destination 3 (2006): The third movie adds the element of photographs that foreshadow the deaths and follows a group of high school students who survive a roller coaster derailment after one of them has a premonition. -
- Final Destination 4 (2009): The fourth movie is the first one to be shot in 3D and follows a group of friends who survive a car race crash after one of them has a premonition. -
- Final Destination 5 (2011): The fifth movie introduces the concept of kill or be killed and follows a group of co-workers who survive a bridge collapse after one of them has a premonition. -
- Choose a torrent site that you trust and search for the movie that you want to download. For example, you can search for Final Destination 5 full movie in Hindi. -
- Find the torrent link that matches your preferences in terms of quality, size, and language. For example, you can choose a torrent link that offers Final Destination 5 full movie in Hindi in 1080p BluRay quality. -
- Click on the torrent link and open it with your torrent client. For example, you can use uTorrent to download Final Destination 5 full movie in Hindi. -
- Select the destination folder and start downloading the movie. -
- Bigger screen: You can enjoy the game's graphics and details more on a larger screen. You can also see more of your surroundings and have a wider view of your creations. -
- Better controls: You can use your keyboard and mouse to control the game more easily and precisely. You can also customize your key mappings and adjust your sensitivity settings according to your preferences. -
- Improved performance: You can run the game faster and smoother on your PC without any lag or glitches. You can also avoid draining your battery or overheating your device. -
- Q: Is Craftsman: Building Craft free to play? -
- A: Yes, Craftsman: Building Craft is a free-to-play game that you can download from Google Play Store or play online on now.gg. However, the game may contain ads or in-app purchases that require real money. -
- Q: Is Craftsman: Building Craft safe to play? -
- A: Yes, Craftsman: Building Craft is a safe game to play as long as you download it from a trusted source like Google Play Store or now.gg. You should also avoid clicking on any suspicious links or ads that may appear in the game or on the website. -
- Q: Can I play Craftsman: Building Craft offline? -
- A: Yes, you can play Craftsman: Building Craft offline if you download it on your device using an Android emulator like BlueStacks or MEmu. However, you will not be able to access some features like multiplayer mode or cloud save when you are offline. -
- Q: Can I play Craftsman: Building Craft with my friends? -
- A: Yes, you can play Craftsman: Building Craft with your friends online if you have an internet connection and a Google account. You can join other players online and chat with them, share your creations, and explore their worlds. -
- Q: How can I contact the developer of Craftsman: Building Craft? -
- A: You can contact the developer of Craftsman: Building Craft by sending an email to craftsmanbuildingcraft@gmail.com. You can also visit their Facebook page at https://www.facebook.com/Craftsman-Building-Craft-102056921581674/. -
- Steam: This is the most popular and widely used platform for PC gaming. It has over 30,000 games in its library, including Geometry Dash World. It also has a large and active community of players and creators. You can access Steam from your web browser or download its launcher for your PC. -
- Epic Games: This is another popular platform for PC gaming. It has over 500 games in its library, including Geometry Dash World. It also offers free games every week and exclusive deals on some titles. You can access Epic Games from your web browser or download its launcher for your PC. -
- GOG: This is a platform that focuses on DRM-free games for PC gaming. It has over 3,000 games in its library, including Geometry Dash World. It also offers classic games, indie games, and curated collections. You can access GOG from your web browser or download its launcher for your PC. -
- Practice mode is your friend. Use it to learn the patterns and timings of each level. -
- Collect stars, orbs, diamonds, keys, and coins to unlock new icons, colors, trails, effects, and secrets. -
- Use the level editor to create your own levels and share them online with other players. -
- Play online levels created by the community for more variety and challenge. -
- Have fun and don't give up! -
- OS: Windows XP/Vista/7/8/10 -
- Processor: 2 GHz -
- Memory: 512 MB RAM -
- Graphics: OpenGL 2.0 support -
- Storage: 100 MB available space -
- Is Raft Survival: Ocean Nomad Multiplayer Mod APK safe to download and install? -
- Is Raft Survival: Ocean Nomad Multiplayer Mod APK compatible with my device? -
- Can I play Raft Survival: Ocean Nomad Multiplayer Mod APK offline? -
- Can I play Raft Survival: Ocean Nomad Multiplayer Mod APK with my friends? -
- How can I update Raft Survival: Ocean Nomad Multiplayer Mod APK? -
- Find a reliable and safe Rubik's cube solver 3x3 mod apk online. There are many websites that offer such apps, but some of them may contain viruses or malware that can harm your device. You should always check the reviews and ratings of the app before downloading it. One of the best websites to find a Rubik's cube solver 3x3 mod apk is [Grubiks](^1^), which offers a fast, easy, and free online Rubik’s Cube Solver. -
- Download the Rubik's cube solver 3x3 mod apk file from the website. The file size may vary depending on the app, but it should not take too long to download. You may need to enable the option to install apps from unknown sources on your device settings. -
- Install the Rubik's cube solver 3x3 mod apk file on your device. You may need to grant some permissions to the app, such as access to your camera and storage. Follow the instructions on the screen and wait for the installation to complete. -
- Open the Rubik's cube solver 3x3 mod apk app on your device. You should see a camera view that allows you to scan your cube. Make sure that your cube is well-lit and that all the stickers are visible. You may need to adjust the angle and distance of your device to get a clear scan. -
- Scan your cube by following the app's instructions. You may need to scan each face of your cube separately or scan the whole cube at once, depending on the app. The app will analyze your cube and generate a solution for you. -
- Solve your cube by following the app's instructions. The app will show you the steps to solve your cube, either as text, images, or animations. You can follow the instructions on your screen and turn your cube accordingly until it is solved. You can also pause, resume, or restart the solution at any time. -
- Improve your cube recognition and finger speed. Cube recognition is the ability to identify the colors and patterns of your cube quickly and accurately. Finger speed is the ability to turn your cube fast and smoothly. You can improve both by practicing with different cubes, using a timer, and doing drills and exercises. -
- Learn and memorize the algorithms for solving a Rubik's cube. Algorithms are sequences of moves that change the position or orientation of some pieces of your cube without affecting others. There are many algorithms for solving a Rubik's cube, but you only need to know a few basic ones to solve any scramble. You can learn and memorize them by using mnemonics, flashcards, or apps. -
- Practice and challenge yourself with different scrambles and modes. Scrambles are random configurations of your cube that you need to solve. Modes are variations of solving methods that have different rules or goals. You can practice and challenge yourself by using online generators, apps, or books that provide different scrambles and modes for you to try. -
- Is Oreo TV APK safe and legal? -
- Oreo TV APK is safe and legal as long as you use it for personal and non-commercial purposes. However, some of the content on this app may be copyrighted or geo-restricted, so you should use a VPN service to avoid any legal issues. -
- Does Oreo TV APK require any registration or subscription? -
- No, Oreo TV APK does not require any registration or subscription. You can use it for free without creating an account or providing any personal information. -
- Does Oreo TV APK support Chromecast or other casting devices? -
- Yes, Oreo TV APK supports Chromecast and other casting devices. You can cast the content from your Android device to your TV screen using a compatible device. -
- Does Oreo TV APK have any ads or malware? -
- No, Oreo TV APK does not have any ads or malware. It is a clean and safe app that does not interfere with your user experience or device performance. -
- How can I update Oreo TV APK to the latest version? -
- You can update Oreo TV APK to the latest version by following the same steps as downloading and installing it. You can also check for updates within the app settings and download them from there. -
- Torrent sites: Torrent sites are platforms that allow users to share files using peer-to-peer technology. You can find many torrent files for Darr The Mall 2 in DVDRip quality on sites like The Pirate Bay, 1337x, or RARBG. However, downloading from torrent sites is illegal in many countries and can expose you to malware, viruses, or legal issues. You should always use a VPN (virtual private network) to protect your identity and data when using torrent sites. -
- Streaming sites: Streaming sites are websites that host video files and allow users to watch them online. You can find many streaming links for Darr The Mall 2 in DVDRip quality on sites like Putlocker, Fmovies, or Gomovies. However, streaming from these sites is also illegal in many countries and can expose you to pop-up ads, redirects, or phishing scams. You should always use an ad-blocker and a VPN when using streaming sites. -
- Legal platforms: Legal platforms are services that offer movies and shows for a fee or a subscription. You can find many legal platforms that have Darr The Mall 2 in DVDRip quality or better on sites like Amazon Prime Video, Netflix, or Hotstar. However, these platforms may not be available in your region or may require a payment method that you don't have. You should always check the availability and pricing of these platforms before signing up. -
- Click on this link to download Epubor Ultimate Converter 3.0.9.222 Key. -
- Extract the zip file and run the setup.exe file to install Epubor Ultimate Converter 3.0.9.222 on your PC. -
- Copy the key file from the key folder and paste it into the installation directory of Epubor Ultimate Converter 3.0.9.222. -
- Run Epubor Ultimate Converter 3.0.9.222 and enter the key from the key.txt file to activate it. -
- Enjoy Epubor Ultimate Converter 3.0.9.222 Key on your PC. -
- It can convert any eBook format to EPUB, MOBI, PDF, AZW3, TXT, and other formats that can be read on any device or app. -
- It can remove DRM from eBooks purchased from Kindle, Google Play, Kobo, Barnes & Noble, and other platforms. -
- It can edit the metadata of eBooks, such as title, author, cover, introduction, etc. -
- It can batch convert and remove DRM from multiple eBooks at once. -
- It can automatically detect the device or app connected to your PC and load the eBooks accordingly. -
- It can sync with different eBook libraries, such as Kindle for PC/Mac, Adobe Digital Editions, Calibre, etc. -
- It has a user-friendly interface that makes it easy to use. -
- Launch Epubor Ultimate Converter 3.0.9.222 from your desktop or start menu. -
- Select the source library from the left sidebar where your eBooks are stored. -
- Select the eBooks that you want to convert or remove DRM from. -
- Select the output format from the bottom right corner that you want to convert your eBooks to. -
- Click on "Convert" button at the bottom right corner to start the conversion or DRM removal process. -
- Find your converted or DRM-free eBooks in the output folder or click on "Output Folder" button at the bottom right corner to open it. -
- Is Epubor Ultimate Converter 3.0.9.222 Key safe to use? -
- Epubor Ultimate Converter 3.0.9.222 Key is safe to use as long as you download it from a trusted source and use it for legal purposes. However, you should always be careful when downloading and using eBooks from unknown sources, as they may contain viruses or malware. -
- Is Epubor Ultimate Converter 3.0.9.222 Key legal to use? -
- Epubor Ultimate Converter 3.0.9.222 Key is legal to use as a tool to convert and remove DRM from eBooks that you own or have the right to use. However, using Epubor Ultimate Converter 3.0.9.222 Key to convert and remove DRM from eBooks that you do not own or have the right to use is illegal and unethical. We do not condone or support eBook piracy in any way. -
- Does Epubor Ultimate Converter 3.0.9.222 Key work on Mac or Linux? -
- Epubor Ultimate Converter 3.0.9.222 Key is only compatible with Windows PC at the moment. However, Epubor also offers other products that can work on Mac or Linux, such as Epubor All DRM Removal for Mac or Epubor eBook Converter for Linux. -
- What are the system requirements for Epubor Ultimate Converter 3.0.9.222 Key? -
- The system requirements for Epubor Ultimate Converter 3.0.9.222 Key are as follows: -
- Operating System: Windows XP/Vista/7/8/10 -
- Processor: 1 GHz or higher -
- RAM: 512 MB or higher -
- Disk Space: 100 MB or higher -
- Internet Connection: Required for activation and updates -
- How can I contact Epubor for support or feedback? -
- If you have any questions, problems, suggestions, or feedback about Epubor Ultimate Converter 3.0.9.222 Key or any other Epubor products, you can contact Epubor via email at support@epubor.com or via live chat on their website at https://www.epubor.com/. -
- It supports a wide range of eBook formats and platforms, including EPUB, MOBI, PDF, AZW3, TXT, Kindle, Google Play, Kobo, Barnes & Noble, and more. -
- It can convert and remove DRM from eBooks with high speed and quality, without any loss of data or formatting. -
- It has a user-friendly interface that makes it easy to use for anyone, regardless of their technical skills or experience. -
- It has a built-in metadata editor that allows you to edit the title, author, cover, introduction, and other information of your eBooks. -
- It has a sync feature that automatically detects the device or app connected to your PC and loads the eBooks accordingly. -
- It has a free trial version that lets you try it before you buy it. -
- It has a giveaway program that offers free license keys for lucky winners every month. -
- It has a professional and responsive customer support team that can help you with any issues or questions you may have. -
- ' - self.article += 'Author/Dev: Duc Haba, 2022. ' - self.article += '
- https://linkedin.com/in/duchaba ' - self.article += '
- The training dataset is from the Data Scientist at Department of Health ' - self.article += 'and Social Care London, England, United Kingdom. ' - self.article += '
- https://www.kaggle.com/datasets/amandam1/120-dog-breeds-breed-classification ' - self.article += '
- "120 Dog Breeds on Hugging Face" on LinkedIn, ' - self.article += 'on Medium. ' - self.article += '
- F1-Score, Precision, and Recall -- Take the output from method sklearn.metrics.classification_report(), import to Pandas Data Fame, sorted, and graph it. ' - self.article += '
 '
- self.article += '
'
- self.article += '- Jupyter Notebook, Python, Pandas, Matplotlib, Sklearn ' - self.article += '
- Fast.ai, PyTorch ' - self.article += '
- GNU GPL 3.0, https://www.gnu.org/licenses/gpl-3.0.txt ' - self.article += '
- Getting free credit: Some hackers may try to manipulate the balance or validity of the Korek Telecom card to get more credit or extend the expiration date. -
- Bypassing restrictions: Some hackers may try to unlock the Korek Telecom card to use it with other devices or networks, or to access blocked or restricted services or websites. -
- Accessing other networks: Some hackers may try to clone the Korek Telecom card to use it with other SIM cards or networks, or to impersonate the original owner. -
- Nmap: A network scanner that can discover hosts, ports, services, and vulnerabilities on a network. -
- Metasploit: A framework that can exploit vulnerabilities and deliver payloads on a target system. -
- Wireshark: A packet analyzer that can capture and inspect network traffic. -
- Hydra: A password cracker that can perform brute-force attacks on various protocols and services. -
- Legal action: You may be sued or prosecuted by Korek Telecom or the authorities for violating the terms and conditions of the service provider and the laws of the country. You may face fines, imprisonment, or both. -
- Account suspension: You may lose your Korek Telecom card and account permanently if you are caught hacking or tampering with them. You may also lose your credit, contacts, and other data. -
- Malware infection: You may expose your device and network to malware, viruses, spyware, or ransomware if you use untrusted tools or applications to hack Korek Telecom card. These malicious programs may damage your device, steal your information, or lock your files. -
- Data breach: You may compromise your privacy and security if you hack Korek Telecom card. You may reveal your personal and account information, such as your phone number, balance, tariff plan, and contacts to hackers or third parties. You may also expose yourself to identity theft, fraud, or blackmail. -
- Use a PIN code: You should set a PIN code for your Korek Telecom card to prevent unauthorized access or use. You should also change your PIN code regularly and avoid using easy or obvious codes. -
- Keep it safe: You should keep your Korek Telecom card in a secure place and avoid losing or misplacing it. You should also avoid lending or sharing your Korek Telecom card with others. -
- Monitor your account: You should check your balance and activity regularly and report any suspicious or unusual transactions or charges to Korek Telecom. You should also update your account information and preferences periodically. -
- Avoid phishing: You should be careful of phishing emails, calls, or messages that claim to be from Korek Telecom or other entities and ask for your personal or account information. You should never click on unknown links or attachments or provide any information without verifying the source. -
- Switching plans: You can switch to a different tariff plan that suits your needs and budget better. You can choose from various plans that offer different rates, bundles, and features. -
- Using offers: You can use the various offers and promotions that Korek Telecom provides to its customers. You can get discounts, bonuses, rewards, or free services by using certain codes, vouchers, or scratch cards. -
- Recharging online: You can recharge your Korek Telecom card online using different methods, such as credit cards, bank transfers, or e-wallets. You can also get some benefits, such as extra credit, cashback, or coupons by recharging online. -
- Referring friends: You can refer your friends and family to join Korek Telecom and get some benefits, such as free credit, minutes, or data. You can also earn points and rewards by participating in the Korek Loyalty Program. -
- Phone: You can call 411 from your Korek Telecom phone or 0750 444 0411 from any other phone to speak to a customer service representative. -
- Email: You can send an email to info@korektel.com with your name, phone number, and inquiry. -
- Website: You can visit www.korektel.com and use the online chat or contact form to get in touch with Korek Telecom. -
- Social media: You can follow Korek Telecom on Facebook, Twitter, Instagram, or YouTube and send them a message or comment. -
- Store: You can visit any of the Korek Telecom stores or outlets across Iraq and get assistance from the staff. -
- Wide coverage: Korek Telecom card allows you to enjoy the widest and most reliable network coverage in Iraq, with more than 4,000 sites and 95% population coverage. -
- High quality: Korek Telecom card enables you to experience the best voice and data quality, with clear sound, fast speed, and low latency. -
- Low cost: Korek Telecom card offers you the most competitive and affordable rates and tariffs, with no hidden fees or charges. -
- Flexible options: Korek Telecom card gives you the freedom and flexibility to choose from various options and services, such as prepaid or postpaid, local or international, voice or data, and more. -
- Value-added services: Korek Telecom card provides you with many value-added services and features, such as caller ID, call waiting, call forwarding, voicemail, SMS, MMS, internet, roaming, and more. -
- Insert your Korek Telecom card into your phone and turn it on. -
- Dial *212*1# to register your phone number. -
- Dial *212*2*1# to set your preferred language (Arabic or English). -
- Dial *212*2*2# to check your SIM card number. -
- Dial *212*3# to check your balance and validity. -
- Dial *212*4# to recharge your account using a scratch card or voucher. -
- They offer free delivery within Sumqayit and a small fee for other regions of Azerbaijan. -
- They have a wide range of car tires from different brands and sizes, so you can find the perfect match for your car. -
- They have a team of experienced and certified technicians who can install and maintain your car tires with care and precision. -
- They have a customer loyalty program that rewards you with discounts and bonuses for every purchase you make. -
- They have a customer service team that is available 24/7 to answer your questions and assist you with your orders. -
- They have a social media presence on Facebook and Instagram where you can follow their updates, promotions, and tips. -
- Visit their website: www.4carx.az -
- Call their phone number: +994 50 555 55 55 -
- Email them: info@4carx.az -
- Follow them on Facebook: www.facebook.com/4carx.az -
- Follow them on Instagram: www.instagram.com/4carx.az -
- Visit their workshop: Sumqayit şəhəri, Səməd Vurğun küçəsi 8A -
- What are the payment methods accepted by 4carx.az?
You can pay online using your credit card or cash on delivery. You can also pay at their workshop when you get your car tires installed.
- - How long does it take to deliver the car tires?
It depends on your location and the availability of the car tires. Usually, it takes one to two days to deliver the car tires within Sumqayit and three to five days for other regions of Azerbaijan.
- - How much does it cost to install the car tires?
The installation cost is included in the price of the car tires. You don't have to pay extra for the installation service.
- - How often should I change my car tires?
It depends on several factors, such as the type, quality, and usage of your car tires, the road and weather conditions, and your driving habits. Generally, you should change your car tires every 40,000 to 50,000 kilometers or every four to five years, whichever comes first. You should also check your car tires regularly for signs of wear and tear, such as cracks, bulges, cuts, punctures, or low tread depth.
- - What are the benefits of buying car tires online?
Buying car tires online has many benefits, such as convenience, variety, affordability, and security. You can shop for car tires anytime and anywhere, compare different brands and prices, save money and time, and avoid scams and frauds. You can also read customer reviews and ratings, get expert advice and tips, and track your order status and delivery.
- - Fast and easy downloads: You can download any app or game from APKPure with just one tap. No need to sign up or log in. You can also pause and resume your downloads at any time. -
- Safe and secure downloads: All the apps and games on APKPure are verified by MD5 hash algorithm to ensure that they are safe and virus-free. You can also scan the downloaded files with your own antivirus software before installing them. -
- Small size downloads: Unlike Google Play Store, which downloads the full package of an app or game, APKPure only downloads the parts that are needed for your device. This saves you storage space and data usage. -
- No ads or pop-ups: APKPure does not show any annoying ads or pop-ups on its website or app. You can enjoy a clean and smooth user experience. -
- Offline mode: You can use APKPure even when you are offline. You can browse and install the apps and games that you have downloaded before without an internet connection. -
- Multi-language support: APKPure supports over 40 languages, including English, Spanish, French, German, Chinese, Japanese, Korean, Arabic, Hindi, and more. You can easily switch between different languages in the app settings. -
- App community and feedback: APKPure has a large and active community of app users and developers. You can join the discussion forums, leave comments, ratings, and reviews, and share your feedback and suggestions with others. -
- New and trending apps and games: APKPure keeps you updated with the latest and hottest apps and games in the market. You can discover new and exciting apps and games every day on APKPure. -
- Customizable app experience: APKPure allows you to customize your app experience according to your preferences. You can change the theme, font size, notifications, and more in the app settings. -
- Go to APKPure's official website on your device's browser. -
- Tap on the Download APK button at the top of the homepage. This will start downloading the APK file of APKPure on your device. -
- Once the download is complete, tap on the downloaded file to open it. You may need to enable Unknown Sources in your device's settings to allow the installation of apps from sources other than Google Play Store. -
- Follow the on-screen instructions to install APKPure on your device. It may take a few seconds to complete the installation. -
- Once the installation is done, you will see the APKPure icon on your device's home screen or app drawer. Tap on it to launch APKPure. -
- Launch APKPure on your device. You will see a list of recommended apps and games on the homepage. You can also use the Search function at the top of the screen to find any app or game you want. -
- Tap on the app or game you want to download or update. You will see a detailed page with information such as description, screenshots, ratings, reviews, version history, etc. -
- If you want to download the app or game for the first time, tap on the Install button at the bottom of the screen. This will start downloading the app or game on your device. -
- If you want to update an existing app or game on your device, tap on the Update button at the bottom of the screen. This will start downloading the latest version of the app or game on your device. -
- Once the download is complete, tap on the downloaded file to open it. Follow the on-screen instructions to install or update the app or game on your device. -
- You can also check for updates for all your apps and games at once by tapping on the Updates tab at the bottom of the screen. You will see a list of apps and games that have new versions available. You can tap on the Update All button to update them all at once, or tap on the individual Update buttons to update them one by one. -
- Launch APKPure on your device. Tap on the Menu icon at the top left corner of the screen. Then tap on the Settings option. -
- In the Settings menu, tap on the Location option. You will see a list of countries and regions that you can choose from. -
- Select the country or region that you want to access. For example, if you want to access Japanese apps and games, select Japan from the list. -
- Tap on the Save button at the top right corner of the screen. This will change your location settings in APKPure. -
- Go back to the homepage of APKPure. You will see a list of recommended apps and games based on your selected location. You can also use the Search function to find any app or game you want. -
- Tap on the app or game you want to download or update. Follow the same steps as before to download or update it on your device. -
- Launch APKPure on your device. Tap on the Menu icon at the top left corner of the screen. Then tap on the Modded Games option. -
- You will see a list of modded games that are available on APKPure. You can also use the Search function to find any modded game you want. -
- Tap on the modded game you want to download or update. You will see a detailed page with information such as description, screenshots, ratings, reviews, mod features, etc. -
- If you want to download the modded game for the first time, tap on the Install button at the bottom of the screen. This will start downloading the modded game on your device. -
- If you want to update an existing modded game on your device, tap on the Update button at the bottom of the screen. This will start downloading the latest version of the modded game on your device. -
- Once the download is complete, tap on the downloaded file to open it. Follow the on-screen instructions to install or update the modded game on your device. -
- Launch APKPure on your device. Tap on the Menu icon at the top left corner of the screen. Then tap on the Backup & Restore option. -
- You will see a list of apps and games that are installed on your device. You can select the ones that you want to backup by tapping on the checkbox next to them. -
- Tap on the Backup button at the bottom of the screen. This will start backing up your selected apps and games on your device's storage. -
- Once the backup is complete, you will see a message saying Backup Successful. You can tap on the View Backup button to see the backup files in your device's storage. -
- If you want to restore your apps and games from a backup, tap on the Restore button at the bottom of the screen. You will see a list of backup files that are available on your device's storage. You can select the ones that you want to restore by tapping on the checkbox next to them. -
- Tap on the Restore button at the bottom of the screen. This will start restoring your selected apps and games on your device. -
- Once the restore is complete, you will see a message saying Restore Successful. You can tap on the View Restored button to see the restored apps and games on your device. -
- Launch APKPure on your device. Tap on the Menu icon at the top left corner of the screen. Then tap on the App Manager option. -
- You will see a list of apps that are installed on your device. You can select the ones that you want to manage by tapping on them. -
- On the app page, you will see various options to manage your app permissions and settings, such as: -
- Permissions: You can view and modify the permissions that the app has access to, such as camera, microphone, contacts, location, etc. You can grant or revoke any permission by tapping on the toggle switch next to it. -
- Clear Cache: You can clear the cache data of the app, which may take up storage space and slow down your device. You can tap on the Clear Cache button to delete the cache data of the app. -
- Uninstall: You can uninstall the app from your device, which may free up storage space and improve your device performance. You can tap on the Uninstall button to remove the app from your device. -
- More Options: You can access more options to manage your app settings, such as force stop, disable, enable, move to SD card, etc. You can tap on the More Options button to see the available options for the app. -
- You can also sort and filter your apps by various criteria, such as name, size, date, etc. You can tap on the Sort & Filter button at the top right corner of the screen to see the available options. -
- Launch APKPure on your device. Tap on the app or game that you want to comment, rate, review, or discuss. You will see a detailed page with information such as description, screenshots, ratings, reviews, version history, etc. -
- If you want to comment on the app or game, tap on the Comments tab at the bottom of the screen. You will see a list of comments from other users. You can also write your own comment by tapping on the Add Comment button at the bottom of the screen. -
- If you want to rate or review the app or game, tap on the Ratings & Reviews tab at the bottom of the screen. You will see a list of ratings and reviews from other users. You can also write your own rating or review by tapping on the Add Rating & Review button at the bottom of the screen. -
- If you want to discuss the app or game with other users or developers, tap on the Forums tab at the bottom of the screen. You will see a list of topics and posts from other users and developers. You can also create your own topic or post by tapping on the Add Topic or Add Post button at the bottom of the screen. -
- Launch APKPure on your device. Tap on the Discover tab at the bottom of the screen. You will see a list of various ways to discover new and trending apps and games on APKPure, such as: -
- Editors' Picks: You can see a curated list of apps and games that are hand-picked by APKPure's editors for their quality, popularity, or uniqueness. -
- Top Charts: You can see a ranked list of apps and games that are most downloaded, updated, rated, or reviewed by APKPure's users. -
- Collections: You can see a themed list of apps and games that are grouped by categories, genres, interests, or occasions. -
- New Releases: You can see a fresh list of apps and games that are newly released or updated on APKPure. -
- Trending Now: You can see a dynamic list of apps and games that are currently hot or viral on APKPure. -
- Similar Apps & Games: You can see a personalized list of apps and games that are similar to the ones you have installed or viewed on APKPure. -
- Tap on any of the options to see more details. You will see a list of apps and games that match your selected option. You can also use the Filter & Sort button at the top right corner of the screen to refine your results by various criteria, such as name, size, date, rating, etc. -
- Tap on any app or game that interests you. You will see a detailed page with information such as description, screenshots, ratings, reviews, version history, etc. You can also download or update it by following the same steps as before. -
- Launch APKPure on your device. Tap on the Me tab at the bottom of the screen. Then tap on the Settings option. -
- In the Settings menu, you will see various options to customize your app experience, such as: -
- Theme: You can choose between light or dark theme for your app appearance. -
- Font Size: You can adjust the font size for your app text. -
- Notifications: You can enable or disable notifications for various events, such as downloads, updates, comments, ratings, reviews, etc. -
- Data Usage: You can limit your data usage for downloads by setting a maximum file size or using Wi-Fi only. -
- Language: You can change your app language from over 40 languages available. -
- About Us: You can view information about APKPure's team, version, website, email, social media, etc. -
- Feedback & Help: You can send feedback or report issues to APKPure's , Twitter, Instagram, YouTube, etc. You can also send them a message or comment on their posts. They will respond to you as soon as possible. -
- Feedback & Help: You can send feedback or report issues to APKPure's customer service team via the app itself. You can do that by tapping on the Me tab at the bottom of the screen, then tapping on the Settings option, then tapping on the Feedback & Help option. You can fill out the form with your query or problem and attach screenshots if needed. They will reply to you as soon as possible. -
- Newsletter: You can sign up for APKPure's newsletter and get the latest news and updates delivered to your email inbox. You can do that by going to APKPure's official website and entering your email address in the Subscribe box at the bottom of the homepage. You can also unsubscribe at any time by clicking on the Unsubscribe link in the newsletter. -
- Blog: You can read APKPure's blog and get the latest news and updates about APKPure's features, updates, promotions, etc. You can do that by going to APKPure's official blog and browsing through the posts. You can also comment on the posts and share your feedback and opinions. -
- Social media: You can follow APKPure on various social media platforms, such as Facebook, Twitter, Instagram, YouTube, etc. and get the latest news and updates about APKPure's features, updates, promotions, etc. You can also interact with them and other users by liking, commenting, sharing, or messaging them. -
- Q: Is APKPure safe and legal? -
- A: Yes, APKPure is safe and legal. All the apps and games on APKPure are verified by MD5 hash algorithm to ensure that they are safe and virus-free. You can also scan the downloaded files with your own antivirus software before installing them. APKPure does not host any illegal or pirated content on its website or app. However, you should be careful when downloading or installing modded apps and games, as they may contain malware or violate the terms of service of the original app or game developer. -
- Q: Is APKPure free? -
- A: Yes, APKPure is free. You can download and install any app or game from APKPure without paying any fees or charges. However, some apps or games may require in-app purchases or subscriptions to access their full features or content. -
- Q: Does APKPure require root access? -
- A: No, APKPure does not require root access. You can use APKPure on any Android device without rooting or modifying it in any way. However , some modded apps or games may require root access to install or run them properly. You should only root your device if you know what you are doing and at your own risk. -
- Q: Does APKPure work on iOS devices? -
- A: No, APKPure does not work on iOS devices. APKPure only supports Android devices and APK files, which are not compatible with iOS devices and IPA files. However, you can use APKPure on your PC or Mac with an Android emulator, such as BlueStacks, NoxPlayer, etc. -
- Q: What is the difference between APKPure and Google Play Store? -
- A: APKPure and Google Play Store are both online services that allow you to download and install Android apps and games. However, there are some differences between them, such as: -
- APKPure allows you to download and install apps and games that are not available in your country or region, while Google Play Store may restrict or block them. -
- APKPure allows you to update your apps and games without using Google Play Store, while Google Play Store may require you to use it for updates. -
- APKPure only downloads the parts that are needed for your device, while Google Play Store downloads the full package of an app or game. -
- APKPure does not show any ads or pop-ups, while Google Play Store may show them. -
- APKPure has a larger and more diverse collection of apps and games, including modded apps and games, while Google Play Store may have a smaller and more limited collection. -
- Find a reliable source for downloading car make up mod apk. You can search online or use one of the links provided in this article. -
- Select the app that you want to download and click on the download button. -
- Wait for the download to finish and then open the file. -
- Allow the installation of unknown sources if prompted by your device. -
- Follow the instructions on the screen to complete the installation. -
- Launch the app and enjoy customizing your car. -
- Select a car model that you want to customize from the app's library. You can choose from hundreds of different cars from various brands and countries. -
- Tap on the feature that you want to change. You can swipe left or right to see more options. -
- Pick a color or a design that you like from the palette or the gallery. You can also use the slider or the color picker tool to adjust the hue, saturation, brightness, and contrast. -
- Apply the changes and see how they look on your car. You can zoom in or out or rotate your view to see different
How to add stickers, decals, logos, and other accessories to your car
-To add some extra flair and personality to your car, you can use stickers, decals, logos, and other accessories. You can use the following steps to do so:
--
-
- Tap on the accessory icon on the bottom of the screen. You can choose from various categories, such as flags, flames, skulls, stars, and more. -
- Select the accessory that you want to add to your car. You can resize, rotate, move, or delete it as you wish. -
- Place the accessory on the desired spot on your car. You can also adjust the opacity and the blending mode to make it look more realistic. -
- Repeat the process for any other accessories that you want to add. You can also use the layer tool to arrange the order of the accessories. -
- Apply the changes and admire your car's new look. -
How to save and share your car make up creations with others
-After you have customized your car to your liking, you might want to save and share it with others. You can use the following steps to do so:
--
-
- Tap on the save icon on the top right corner of the screen. You can choose to save your creation as an image or a project file. -
- Select a name and a location for your file. You can also add a description or a tag if you want. -
- Tap on the share icon on the top right corner of the screen. You can choose to share your creation via social media, email, or other apps. -
- Select the platform or the app that you want to use. You can also add a caption or a message if you want. -
- Send or post your creation and wait for the feedback from your friends or other users. -
What are the best car make up mod apk apps?
-There are many car make up mod apk apps available on the market, but not all of them are equally good. Some of them might have more features, better graphics, or easier interface than others. Here are some of the best car make up mod apk apps that you can try:
-3DTuning: The most realistic and comprehensive car make up app
-If you are looking for a car make up app that offers realistic and detailed graphics, then 3DTuning is the app for you. This app has over 1000 cars from 80 manufacturers and over 1000 parts and accessories to choose from. You can customize every aspect of your car, from the exterior to the interior, and even the engine and suspension. You can also view your car in different environments and lighting conditions. You can download 3DTuning from here.
-FormaCar: The most social and interactive car make up app
-If you are looking for a car make up app that allows you to interact with other users and join a community of car lovers, then FormaCar is the app for you. This app lets you create your own profile and showcase your creations to other users. You can also browse, like, comment, and follow other users' creations. You can also join clubs, participate in contests, and chat with other users. You can download FormaCar from here.
-Tuning Car Racing: The most fun and exciting car make up app
-If you are looking for a car make up app that combines customization with gaming, then Tuning Car Racing is the app for you. This app lets you customize your car and then use it in racing games against other players or AI opponents. You can also upgrade your car's performance and unlock new cars and parts as you progress. You can download Tuning Car Racing from here.
-Conclusion
-Car make up mod apk is a great way to customize your car with your smartphone. You can change various features of your car, such as the color, wheels, bumper, headlights, stickers, decals, logos, and more. You can also save and share your creations with others or use them in games. There are many car make up mod apk apps available on the market, but some of the best ones are 3DTuning, FormaCar, and Tuning Car Racing. So what are you waiting for? Download one of these apps today and start making your car look awesome!
-Frequently Asked Questions
--
-
- What is car make up mod apk?
-Car make up mod apk is a term that refers to modified applications that allow you to customize your car with your smartphone.
- - How to download and install car make up mod apk?
-To download and install car make up mod apk, you need to find a reliable source, select the app that you want, download the file, allow the installation of unknown sources, follow the instructions, and launch the app.
- - How to use car make up mod apk?
-To use car make up mod apk, you need to select a car model that you want to customize, tap on the feature that you want to change, pick a color or a design that you like, apply the changes, and repeat the process for any other features or accessories that you want to add. You can also save and share your creations with others or use them in games.
- - What are the best car make up mod apk apps?
-Some of the best car make up mod apk apps are 3DTuning, FormaCar, and Tuning Car Racing. These apps offer realistic and detailed graphics, social and interactive features, and fun and exciting gaming modes.
- - Is car make up mod apk safe and legal?
-Car make up mod apk is generally safe and legal as long as you download it from a trusted source and use it for personal and non-commercial purposes. However, you should always be careful about the permissions and data that the app requires and avoid any malicious or illegal activities.
-
-
-
\ No newline at end of file diff --git a/spaces/fatiXbelha/sd/Download NEW STATE MOBILE and Join the Extreme Battle Royale Action on a 4x4 Desert Map.md b/spaces/fatiXbelha/sd/Download NEW STATE MOBILE and Join the Extreme Battle Royale Action on a 4x4 Desert Map.md deleted file mode 100644 index ea75a6e42c7bbbbd092e7409b160b339c031f41b..0000000000000000000000000000000000000000 --- a/spaces/fatiXbelha/sd/Download NEW STATE MOBILE and Join the Extreme Battle Royale Action on a 4x4 Desert Map.md +++ /dev/null @@ -1,159 +0,0 @@ -
-Download Game New State Mobile: The Ultimate Guide
-If you are a fan of battle royale games, you might have heard of New State Mobile, the latest game from PUBG Studios, the company behind the popular PlayerUnknown's Battlegrounds (PUBG). But what is New State Mobile, and how can you download it on your mobile device? In this article, we will answer these questions and more, as we guide you through everything you need to know about New State Mobile, including its features, gameplay, and tips and tricks. Let's get started!
-download game new state mobile
Download ✸✸✸ https://urllie.com/2uNG8o
-What is New State Mobile?
-New State Mobile is a new battle royale game that takes place in the year 2051, decades after the original PUBG. In this dystopian future, new factions emerge in an anarchic world, and the survival game evolves into a new battleground. As a player, you will dive into expansive maps, search for weapons, vehicles, and consumables, and fight for survival in an ever-shrinking play area. You will also experience new mechanics such as dodging, drone calls, and support requests, as well as new vehicles and weapons that are only available in New State Mobile.
-A new battle royale game from PUBG Studios
-New State Mobile is developed by PUBG Studios, the same company that created PUBG, one of the most popular and influential battle royale games of all time. PUBG Studios has years of experience and expertise in developing realistic and immersive battle royale games, and they have applied their knowledge and skills to create New State Mobile. New State Mobile is not a sequel or a spin-off of PUBG, but rather a new game that expands the PUBG universe and offers a fresh and unique experience to players.
-Features and gameplay of New State Mobile
-New State Mobile has many features and gameplay elements that make it stand out from other battle royale games. Here are some of them:
--
-
- New mode Bounty Royale: This is a new mode that allows you to earn rewards by hunting down specific targets or by surviving as long as possible. You can also use special items such as bounties, decoys, traps, and shields to gain an edge over your enemies. -
- New map Lagna: This is a 4x4 desert map that offers dynamic and tactical gameplay with limited cover. You can use the various ridge heights to set up your attack or defense, or use the sandstorms to conceal your movements. -
- Akinta: This is a fast-paced mode that takes place in a 4x4 map with a playzone that starts shrinking as soon as the match begins. You will have to loot quickly and fight aggressively to survive in this mode. -
- Round Deathmatch: This is a best-of-seven, 4 vs 4 deathmatch series that tests your skills and teamwork. You will have to eliminate the opposing team or survive till the end of each round to win. -
- Survivor Pass: This is a feature that allows you to earn rewards by completing missions and leveling up your pass. You can also unlock exclusive skins, emotes, outfits, and more by purchasing the premium pass. -
- Various events: These are limited-time events that offer different challenges and rewards to players. You can participate in these events to earn coins, crates, skins, vouchers, and more. -
How to download New State Mobile on Android and iOS devices
-New
New State Mobile is available for both Android and iOS devices, and you can download it for free from the Google Play Store or the App Store. However, you will need a compatible device that meets the minimum requirements to run the game smoothly. Here are the minimum requirements for each platform:
--
-- -Platform -Minimum Requirements -- -Android -OS: Android 6.0 or higher -
RAM: 2 GB or higher
CPU: Snapdragon 625 or higher
GPU: Adreno 506 or higher
Storage: 3 GB or more- -iOS -OS: iOS 11.0 or higher -
Device: iPhone 6s or higher
Storage: 3 GB or moreTo download New State Mobile on your device, follow these steps:
--
-
- Go to the Google Play Store or the App Store and search for New State Mobile. -
- Tap on the Install button and wait for the game to download and install on your device. -
- Launch the game and accept the terms and conditions. -
- Create your account and choose your nickname. -
- Select your region and server. -
- Enjoy the game! -
Why should you play New State Mobile?
-New State Mobile is not just another battle royale game. It is a game that offers a new and exciting experience that will keep you hooked for hours. Here are some of the reasons why you should play New State Mobile:
-How to download game new state mobile on android
-
-Download game new state mobile apk
-Download game new state mobile for ios
-Download game new state mobile for pc
-Download game new state mobile mod apk
-Download game new state mobile latest version
-Download game new state mobile obb file
-Download game new state mobile beta
-Download game new state mobile from play store
-Download game new state mobile from app store
-Download game new state mobile offline
-Download game new state mobile update
-Download game new state mobile hack
-Download game new state mobile cheats
-Download game new state mobile free fire
-Download game new state mobile pubg
-Download game new state mobile krafton
-Download game new state mobile review
-Download game new state mobile gameplay
-Download game new state mobile trailer
-Download game new state mobile tips and tricks
-Download game new state mobile system requirements
-Download game new state mobile size
-Download game new state mobile graphics settings
-Download game new state mobile best guns
-Download game new state mobile best settings
-Download game new state mobile best characters
-Download game new state mobile best vehicles
-Download game new state mobile best skins
-Download game new state mobile best maps
-Download game new state mobile best modes
-Download game new state mobile best strategies
-Download game new state mobile best teams
-Download game new state mobile best players
-Download game new state mobile ranking system
-Download game new state mobile rewards system
-Download game new state mobile events system
-Download game new state mobile patch notes
-Download game new state mobile news and updates
-Download game new state mobile community and forums
-Download game new state mobile support and feedback
-Download game new state mobile bugs and issues
-Download game new state mobile guides and tutorials
-Download game new state mobile videos and streams
-Download game new state mobile wallpapers and themes
-Download game new state mobile memes and jokes
-Download game new state mobile fan art and cosplay
-Download game new state mobile merchandise and accessories
-Download game new state mobile contests and giveawaysNext-generation graphics and performance
-New State Mobile uses Unreal Engine 4, one of the most advanced game engines in the world, to deliver stunning graphics and realistic physics. You will be amazed by the detailed textures, lighting, shadows, reflections, and animations that make the game look like a console or PC game. You will also enjoy smooth and responsive gameplay with minimal lag and loading times, thanks to the optimization and customization options that let you adjust the graphics settings according to your device and preference.
-Dynamic and strategic combat
-New State Mobile offers a variety of combat options that allow you to fight in different ways and situations. You can use the new mechanics such as dodging, drone calls, and support requests to gain an edge over your enemies. You can also use different weapons and attachments that suit your playstyle and strategy. You can choose from assault rifles, sniper rifles, shotguns, SMGs, pistols, melee weapons, grenades, and more. You can also customize your weapons with scopes, silencers, magazines, stocks, grips, skins, and more.
-Expansive and immersive map
-New State Mobile features a large and diverse map that offers a variety of terrains, locations, and landmarks. You can explore urban areas, rural areas, industrial zones, military bases, deserts, forests, mountains, lakes, rivers, bridges, tunnels, and more. You can also interact with the environment by breaking windows, doors, fences, walls, vehicles, and more. You can also use vehicles such as cars, bikes, trucks, boats, helicopters, and more to travel faster and escape danger.
-Customizable weapons and vehicles
-New State Mobile allows you to customize your weapons and vehicles with different parts and skins that change their appearance and performance. You can find these parts and skins in crates or buy them with coins or vouchers. You can also upgrade your parts and skins with materials that enhance their stats. You can also create your own unique weapons and vehicles by combining different parts and skins in the workshop.
-Tips and tricks for New State Mobile
-If you want to improve your skills and win more matches in New State Mobile, you will need some tips and tricks that will help you survive and thrive in the game. Here are some of them:
-Choose your landing spot wisely
-The first thing you need to do when you start a match is to choose where to land on the map. This is a crucial decision that can determine your chances of survival and victory. You should consider several factors when choosing your landing spot, such as:
--
-
- The distance from the plane's path: The closer you are to the plane's path, the faster you will land on the ground. However, this also means that more players will land near you, which increases the risk of early combat. -
- The loot quality: The loot quality varies depending on the location. Some locations have more loot than others, but they also attract more players. You should balance between finding enough loot for yourself and avoiding too much competition. -
- The circle The circle position: The circle is the play area that shrinks over time, forcing players to move closer to each other. You should try to land near the center of the circle, or at least within its range, to avoid being caught outside and taking damage from the blue zone. -
- The vehicle availability: Vehicles are useful for traveling faster and escaping danger, but they also make noise and attract attention. You should look for locations that have vehicle spawns nearby, but not too close to your landing spot. -
You can use the map to scout the locations and plan your landing spot before you jump off the plane. You can also mark your landing spot with a pin and communicate with your teammates if you are playing in a squad.
-Loot and equip the best gear
-Once you land on the ground, you should look for loot as soon as possible. Loot includes weapons, attachments, armor, helmets, backpacks, consumables, and other items that can help you survive and fight. You should prioritize finding a weapon and some ammo first, then look for other items that can improve your defense and utility. You should also loot quickly and efficiently, by using the quick pick-up button or the auto pick-up feature that automatically loots items for you based on your preferences.
-You should also equip the best gear that you can find or create. You should aim to have at least a level 2 armor and helmet, a level 2 or 3 backpack, and a variety of weapons and attachments that suit your playstyle and strategy. You should also upgrade your gear with materials that you can find or buy in the game. You can use the inventory menu to manage your gear and switch between different loadouts.
-Use the environment to your advantage
-New State Mobile has a dynamic and interactive environment that can affect your gameplay in various ways. You should use the environment to your advantage by doing the following:
--
-
- Use cover and concealment: Cover is anything that can protect you from enemy fire, such as walls, rocks, trees, vehicles, etc. Concealment is anything that can hide you from enemy sight, such as bushes, grass, smoke, etc. You should use cover and concealment to avoid being exposed and vulnerable to enemy attacks. -
- Use height and angles: Height and angles can give you a better view and position over your enemies. You should use height and angles to spot enemies, snipe them from afar, or flank them from behind. You can use buildings, hills, bridges, towers, etc. to gain height and angles. -
- Use sound and vision: Sound and vision are important for detecting enemies and their movements. You should use sound and vision to locate enemies, track their direction, and anticipate their actions. You can use headphones, sound settings, mini-map, compass, indicators, etc. to enhance your sound and vision. -
- Use weather and time: Weather and time can change the atmosphere and visibility of the game. You should use weather and time to adapt your strategy and tactics accordingly. You can use weather and time to create diversions, ambushes, stealth attacks, etc. -
Communicate and cooperate with your teammates
-If you are playing in a squad mode with other players, you will need to communicate and cooperate with your teammates to increase your chances of survival and victory. You should communicate and cooperate with your teammates by doing the following:
--
-
- Use voice chat or text chat: Voice chat or text chat are the main ways of communicating with your teammates in the game. You should use voice chat or text chat to share information, coordinate actions, ask for help, give commands, etc. You can also use quick chat or gestures to communicate with preset messages or expressions. -
- Use markers or pings: Markers or pings are visual aids that can help you communicate with your teammates without using voice or text chat. You can use markers or pings to mark locations, enemies, items, vehicles, etc. on the map or on the screen. -
- Use roles or strategies: Roles or strategies are predefined plans that can help you cooperate with your teammates more effectively. You can use roles or strategies to assign tasks, responsibilities , and goals for your team. You can also use roles or strategies to adapt to different situations and challenges in the game. -
- Use teamwork and synergy: Teamwork and synergy are the keys to success in a squad mode. You should use teamwork and synergy to support, protect, and assist your teammates in any way possible. You should also use teamwork and synergy to combine your skills, abilities, and resources to create a stronger and more effective team. -
Survive till the end and claim victory
-The ultimate goal of New State Mobile is to survive till the end and claim victory. You should do everything you can to achieve this goal by doing the following:
--
-
- Stay in the circle: The circle is the play area that shrinks over time, forcing players to move closer to each other. You should stay in the circle as much as possible, or at least within its range, to avoid being caught outside and taking damage from the blue zone. You should also pay attention to the circle timer, direction, and speed, and plan your movements accordingly. -
- Avoid unnecessary fights: Fights are inevitable in a battle royale game, but not all fights are worth taking. You should avoid unnecessary fights that can expose you to danger, waste your resources, or distract you from your objective. You should only engage in fights that are necessary, advantageous, or unavoidable. -
- Play smart and safe: Playing smart and safe means using your brain and common sense to make the best decisions in the game. You should play smart and safe by observing your surroundings, analyzing your situation, choosing your actions, and anticipating the consequences. You should also play smart and safe by avoiding risks, mistakes, or traps that can cost you your life. -
- Be ready for anything: Anything can happen in a battle royale game, and you should be ready for anything that comes your way. You should be ready for anything by being prepared, flexible, and adaptable. You should also be ready for anything by being alert, aware, and responsive. -
By following these tips and tricks, you will increase your chances of surviving till the end and claiming victory in New State Mobile.
-Conclusion
-New State Mobile is a new battle royale game that offers a new and exciting experience to players. It has next-generation graphics and performance, dynamic and strategic combat, expansive and immersive map, customizable weapons and vehicles, and various modes and events. It also has a simple and easy way to download it on Android and iOS devices. If you are looking for a new and fun game to play on your mobile device, you should definitely try New State Mobile. You will not regret it!
-FAQs
-Here are some of the frequently asked questions about New State Mobile:
--
-
- Is New State Mobile free to play? -
- Is New State Mobile related to PUBG? -
- Is New State Mobile cross-platform? -
- How can I play with my friends in New State Mobile? -
- How can I contact the customer service of New State Mobile? -
Yes, New State Mobile is free to play. However, it also has optional in-game purchases that can enhance your gameplay or appearance.
-New State Mobile is developed by PUBG Studios, the same company that created PUBG. However, New State Mobile is not a sequel or a spin-off of PUBG, but rather a new game that expands the PUBG universe and offers a fresh and unique experience to players.
-No, New State Mobile is not cross-platform. It is only available for Android and iOS devices.
-You can play with your friends in New State Mobile by inviting them to join your squad or clan. You can also add them as friends or send them messages in the game.
-You can contact the customer service of New State Mobile by using the in-game feedback system or by visiting their official website or social media channels.
-
-
-
\ No newline at end of file diff --git a/spaces/fatimahhussain/workoutwizard/pages/plank.py b/spaces/fatimahhussain/workoutwizard/pages/plank.py deleted file mode 100644 index 936158dc6ce82b486b179c2c60ffdfb4605fa1b6..0000000000000000000000000000000000000000 --- a/spaces/fatimahhussain/workoutwizard/pages/plank.py +++ /dev/null @@ -1,108 +0,0 @@ -import logging -import queue -from pathlib import Path -from typing import List, NamedTuple -import mediapipe as mp -import av -import cv2 -import numpy as np -import streamlit as st -from streamlit_webrtc import WebRtcMode, webrtc_streamer - -from sample_utils.turn import get_ice_servers - - -# st.set_page_config(page_title="Plank Exercise") - -mp_face_detection = mp.solutions.face_detection -mp_drawing = mp.solutions.drawing_utils - -def calculate_angle(a, b, c): - a = np.array(a) - b = np.array(b) - c = np.array(c) - - radians = np.arctan2(c[1]-b[1], c[0]-b[0]) - np.arctan2(a[1]-b[1], a[0]-b[0]) - angle = np.abs(radians*180.0/np.pi) - - if angle > 180.0: - angle = 360 - angle - - return angle - - - -def video_frame_callback(frame: av.VideoFrame) -> av.VideoFrame: - image = frame.to_ndarray(format="rgb24") - # image = image[:,::-1,:] - image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) - mp_drawing = mp.solutions.drawing_utils - mp_pose = mp.solutions.pose - - with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose1: - results = pose1.process(image) #previously image_rgb -# results2 = pose2.process(image2) - - if results.pose_landmarks: - landmarks1 = results.pose_landmarks.landmark - ankle1 = [int(landmarks1[mp_pose.PoseLandmark.LEFT_ANKLE.value].x * image.shape[1]), - int(landmarks1[mp_pose.PoseLandmark.LEFT_ANKLE.value].y * image.shape[0])] - knee1 = [int(landmarks1[mp_pose.PoseLandmark.LEFT_KNEE.value].x * image.shape[1]), - int(landmarks1[mp_pose.PoseLandmark.LEFT_KNEE.value].y * image.shape[0])] - hip1 = [int(landmarks1[mp_pose.PoseLandmark.LEFT_HIP.value].x * image.shape[1]), - int(landmarks1[mp_pose.PoseLandmark.LEFT_HIP.value].y * image.shape[0])] - shoulder1 = [int(landmarks1[mp_pose.PoseLandmark.LEFT_SHOULDER.value].x * image.shape[1]), - int(landmarks1[mp_pose.PoseLandmark.LEFT_SHOULDER.value].y * image.shape[0])] - - - angle1 = calculate_angle(shoulder1, hip1, knee1) - cv2.putText(image, f'Angle: {round(angle1, 2)}', (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2) - cv2.circle(image, tuple(shoulder1), 10, (255, 255, 255), -1) - cv2.circle(image, tuple(hip1), 10, (255, 255, 255), -1) - cv2.circle(image, tuple(knee1), 10, (255, 255, 255), -1) - - if 150 <= abs(angle1): - cv2.putText(image, 'YES', (50, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2) - else: - cv2.putText(image, 'INCORRECT FORM', (50, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 1) - - - return av.VideoFrame.from_ndarray(image, format="bgr24") - - - -def main(): - st.title("Plank Exercise") - - with st.sidebar: - st.caption("This is for a plank. It will track the RIGHT side of your body, so please make sure that you are in full view on your webcam. ") - st.caption("Please reference the video if you're confused!") - - - - # st.caption("This is for bicep curls. It will track your LEFT arm, so please position yourself at a slight angle (note: the camera is also flipped). See image below") - # st.caption("Your ENTIRE body needs to be in the webcam screen") - # st.caption("Slow and steady wins the race!") - - # stframe = st.empty() - webrtc_streamer( - key="object-detection", - mode= WebRtcMode.SENDRECV, - rtc_configuration={ - "iceServers": get_ice_servers(), - "iceTransportPolicy": "relay", - }, - video_frame_callback=video_frame_callback, - media_stream_constraints={"video": True, "audio": False}, - async_processing=True, - ) - - # st_player("bicepcurl.mp4", playing=True, muted=True) - st.video("videos/plank.mp4") - - -if __name__ == '__main__': - main() - - - \ No newline at end of file diff --git "a/spaces/fb700/chatglm-fitness-RLHF/crazy_functions/\350\247\243\346\236\220JupyterNotebook.py" "b/spaces/fb700/chatglm-fitness-RLHF/crazy_functions/\350\247\243\346\236\220JupyterNotebook.py" deleted file mode 100644 index b4bcd56109b42d3023f24eade7c0cd5671d3c5a4..0000000000000000000000000000000000000000 --- "a/spaces/fb700/chatglm-fitness-RLHF/crazy_functions/\350\247\243\346\236\220JupyterNotebook.py" +++ /dev/null @@ -1,146 +0,0 @@ -from toolbox import update_ui -from toolbox import CatchException, report_execption, write_results_to_file -fast_debug = True - - -class PaperFileGroup(): - def __init__(self): - self.file_paths = [] - self.file_contents = [] - self.sp_file_contents = [] - self.sp_file_index = [] - self.sp_file_tag = [] - - # count_token - from request_llm.bridge_all import model_info - enc = model_info["gpt-3.5-turbo"]['tokenizer'] - def get_token_num(txt): return len( - enc.encode(txt, disallowed_special=())) - self.get_token_num = get_token_num - - def run_file_split(self, max_token_limit=1900): - """ - 将长文本分离开来 - """ - for index, file_content in enumerate(self.file_contents): - if self.get_token_num(file_content) < max_token_limit: - self.sp_file_contents.append(file_content) - self.sp_file_index.append(index) - self.sp_file_tag.append(self.file_paths[index]) - else: - from .crazy_utils import breakdown_txt_to_satisfy_token_limit_for_pdf - segments = breakdown_txt_to_satisfy_token_limit_for_pdf( - file_content, self.get_token_num, max_token_limit) - for j, segment in enumerate(segments): - self.sp_file_contents.append(segment) - self.sp_file_index.append(index) - self.sp_file_tag.append( - self.file_paths[index] + f".part-{j}.txt") - - - -def parseNotebook(filename, enable_markdown=1): - import json - - CodeBlocks = [] - with open(filename, 'r', encoding='utf-8', errors='replace') as f: - notebook = json.load(f) - for cell in notebook['cells']: - if cell['cell_type'] == 'code' and cell['source']: - # remove blank lines - cell['source'] = [line for line in cell['source'] if line.strip() - != ''] - CodeBlocks.append("".join(cell['source'])) - elif enable_markdown and cell['cell_type'] == 'markdown' and cell['source']: - cell['source'] = [line for line in cell['source'] if line.strip() - != ''] - CodeBlocks.append("Markdown:"+"".join(cell['source'])) - - Code = "" - for idx, code in enumerate(CodeBlocks): - Code += f"This is {idx+1}th code block: \n" - Code += code+"\n" - - return Code - - -def ipynb解释(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt): - from .crazy_utils import request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency - - if ("advanced_arg" in plugin_kwargs) and (plugin_kwargs["advanced_arg"] == ""): plugin_kwargs.pop("advanced_arg") - enable_markdown = plugin_kwargs.get("advanced_arg", "1") - try: - enable_markdown = int(enable_markdown) - except ValueError: - enable_markdown = 1 - - pfg = PaperFileGroup() - - for fp in file_manifest: - file_content = parseNotebook(fp, enable_markdown=enable_markdown) - pfg.file_paths.append(fp) - pfg.file_contents.append(file_content) - - # <-------- 拆分过长的IPynb文件 ----------> - pfg.run_file_split(max_token_limit=1024) - n_split = len(pfg.sp_file_contents) - - inputs_array = [r"This is a Jupyter Notebook file, tell me about Each Block in Chinese. Focus Just On Code." + - r"If a block starts with `Markdown` which means it's a markdown block in ipynbipynb. " + - r"Start a new line for a block and block num use Chinese." + - f"\n\n{frag}" for frag in pfg.sp_file_contents] - inputs_show_user_array = [f"{f}的分析如下" for f in pfg.sp_file_tag] - sys_prompt_array = ["You are a professional programmer."] * n_split - - gpt_response_collection = yield from request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency( - inputs_array=inputs_array, - inputs_show_user_array=inputs_show_user_array, - llm_kwargs=llm_kwargs, - chatbot=chatbot, - history_array=[[""] for _ in range(n_split)], - sys_prompt_array=sys_prompt_array, - # max_workers=5, # OpenAI所允许的最大并行过载 - scroller_max_len=80 - ) - - # <-------- 整理结果,退出 ----------> - block_result = " \n".join(gpt_response_collection) - chatbot.append(("解析的结果如下", block_result)) - history.extend(["解析的结果如下", block_result]) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - - # <-------- 写入文件,退出 ----------> - res = write_results_to_file(history) - chatbot.append(("完成了吗?", res)) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - -@CatchException -def 解析ipynb文件(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port): - chatbot.append([ - "函数插件功能?", - "对IPynb文件进行解析。Contributor: codycjy."]) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - - history = [] # 清空历史 - import glob - import os - if os.path.exists(txt): - project_folder = txt - else: - if txt == "": - txt = '空空如也的输入栏' - report_execption(chatbot, history, - a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - if txt.endswith('.ipynb'): - file_manifest = [txt] - else: - file_manifest = [f for f in glob.glob( - f'{project_folder}/**/*.ipynb', recursive=True)] - if len(file_manifest) == 0: - report_execption(chatbot, history, - a=f"解析项目: {txt}", b=f"找不到任何.ipynb文件: {txt}") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - yield from ipynb解释(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, ) diff --git a/spaces/fclong/summary/fengshen/examples/zen2_finetune/ner_zen2_base_msra.sh b/spaces/fclong/summary/fengshen/examples/zen2_finetune/ner_zen2_base_msra.sh deleted file mode 100644 index 397c3ea6adc3d9f275389509aa41d0e4050b3c14..0000000000000000000000000000000000000000 --- a/spaces/fclong/summary/fengshen/examples/zen2_finetune/ner_zen2_base_msra.sh +++ /dev/null @@ -1,91 +0,0 @@ -#!/bin/bash -#SBATCH --job-name=zen2_base_msra # create a short name for your job -#SBATCH --nodes=1 # node count -#SBATCH --ntasks=1 # total number of tasks across all nodes -#SBATCH --cpus-per-task=30 # cpu-cores per task (>1 if multi-threaded tasks) -#SBATCH --gres=gpu:1 # number of gpus per node -#SBATCH --mail-type=ALL # send email when job begins, ends or failed etc. -#SBATCH -o /cognitive_comp/ganruyi/experiments/ner_finetune/zen2_base_msra/%x-%j.log # output and error file name (%x=job name, %j=job id) - - -# export CUDA_VISIBLE_DEVICES='2' -export TORCH_EXTENSIONS_DIR=/cognitive_comp/ganruyi/tmp/torch_extendsions - -MODEL_NAME=zen2_base - -TASK=msra - -ZERO_STAGE=1 -STRATEGY=deepspeed_stage_${ZERO_STAGE} - -ROOT_DIR=/cognitive_comp/ganruyi/experiments/ner_finetune/${MODEL_NAME}_${TASK} -if [ ! -d ${ROOT_DIR} ];then - mkdir -p ${ROOT_DIR} - echo ${ROOT_DIR} created!!!!!!!!!!!!!! -else - echo ${ROOT_DIR} exist!!!!!!!!!!!!!!! -fi - -DATA_DIR=/cognitive_comp/lujunyu/data_zh/NER_Aligned/MSRA/ -PRETRAINED_MODEL_PATH=/cognitive_comp/ganruyi/hf_models/zen/zh_zen_base_2.0 - -CHECKPOINT_PATH=${ROOT_DIR}/ckpt/ -OUTPUT_PATH=${ROOT_DIR}/predict.json - -DATA_ARGS="\ - --data_dir $DATA_DIR \ - --train_data train_dev.char.bmes \ - --valid_data test.char.bmes \ - --test_data test.char.bmes \ - --train_batchsize 32 \ - --valid_batchsize 16 \ - --max_seq_length 256 \ - --task_name msra \ - " - -MODEL_ARGS="\ - --learning_rate 3e-5 \ - --weight_decay 0.1 \ - --warmup_ratio 0.01 \ - --markup bioes \ - --middle_prefix M- \ - " - -MODEL_CHECKPOINT_ARGS="\ - --monitor val_f1 \ - --save_top_k 3 \ - --mode max \ - --every_n_train_steps 800 \ - --save_weights_only True \ - --dirpath $CHECKPOINT_PATH \ - --filename model-{epoch:02d}-{val_f1:.4f} \ - " - -TRAINER_ARGS="\ - --max_epochs 30 \ - --gpus 1 \ - --check_val_every_n_epoch 1 \ - --val_check_interval 800 \ - --default_root_dir $ROOT_DIR \ - " - - -options=" \ - --pretrained_model_path $PRETRAINED_MODEL_PATH \ - --vocab_file $PRETRAINED_MODEL_PATH/vocab.txt \ - --do_lower_case \ - --output_save_path $OUTPUT_PATH \ - $DATA_ARGS \ - $MODEL_ARGS \ - $MODEL_CHECKPOINT_ARGS \ - $TRAINER_ARGS \ -" -SCRIPT_PATH=/cognitive_comp/ganruyi/Fengshenbang-LM/fengshen/examples/zen2_finetune/fengshen_token_level_ft_task.py -/home/ganruyi/anaconda3/bin/python $SCRIPT_PATH $options - -# SINGULARITY_PATH=/cognitive_comp/ganruyi/pytorch21_06_py3_docker_image_v2.sif -# python3 $SCRIPT_PATH $options -# source activate base -# singularity exec --nv -B /cognitive_comp/:/cognitive_comp/ $SINGULARITY_PATH /home/ganruyi/anaconda3/bin/python $SCRIPT_PATH $options -# /home/ganruyi/anaconda3/bin/python $SCRIPT_PATH $options - diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Angry Birds Classic for Android - Download APK and Play Offline.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Angry Birds Classic for Android - Download APK and Play Offline.md deleted file mode 100644 index af481f01d38959be1cf9c6f9f290824466647119..0000000000000000000000000000000000000000 --- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Angry Birds Classic for Android - Download APK and Play Offline.md +++ /dev/null @@ -1,220 +0,0 @@ - -How to Download and Play Angry Birds Classic on Android
-Angry Birds Classic is one of the most popular mobile games of all time. It has been downloaded over 100 million times on Google Play Store alone, and has received countless awards and positive reviews from critics and players alike. If you are looking for a fun, addictive, and challenging game that will keep you entertained for hours, you should definitely try out Angry Birds Classic on your Android device.
-Introduction
-In this article, we will show you how to download and play Angry Birds Classic on Android. We will cover the following topics:
-angry birds classic apk download android
Download Zip > https://gohhs.com/2uPq4D
--
-
- What is Angry Birds Classic and why is it popular? -
- What are the main features and gameplay of Angry Birds Classic? -
- How to download Angry Birds Classic apk file from Google Play Store or other sources? -
What is Angry Birds Classic and why is it popular?
-Angry Birds Classic is a puzzle game that was released by Rovio Entertainment in 2009. The game features a flock of angry birds who are trying to get back their eggs from a group of greedy pigs who stole them. The game involves using a slingshot to launch the birds at various structures made of wood, stone, glass, and other materials, where the pigs are hiding. The goal is to destroy all the pigs and their defenses in each level using as few birds as possible.
-Angry Birds Classic is popular because it has a simple yet addictive gameplay that appeals to players of all ages and backgrounds. The game also has a colorful and cartoonish graphics style, a catchy and humorous sound design, and a variety of levels, episodes, birds, pigs, power-ups, and other elements that keep the game fresh and exciting. The game also has a social aspect, as players can compete against each other in the Mighty League mode, where they can earn trophies, coins, and bragging rights.
-What are the main features and gameplay of Angry Birds Classic?
-Angry Birds Classic has many features that make it a fun and satisfying game to play. Some of these features are:
--
-
- Fun and satisfying slingshot gameplay. The game uses a simple yet intuitive control scheme that involves dragging your finger on the screen to aim the slingshot, releasing it to launch the bird, and tapping again to activate its special power. The game also has a realistic physics engine that simulates the effects of gravity, friction, collision, explosion, etc., making the game more challenging and rewarding - Diverse and delightful birds and pigs. The game features a variety of birds and pigs, each with their own personality, appearance, and ability. For example, the red bird is the basic bird that can deal moderate damage, the yellow bird can speed up and pierce through materials, the black bird can explode and cause massive destruction, the green bird can boomerang back and hit targets from behind, and so on. The pigs also have different types, such as the helmet pig, the mustache pig, the king pig, etc., each with their own level of durability and difficulty. - Challenging and creative levels and episodes. The game has hundreds of levels and episodes, each with a different theme, setting, and objective. For example, the first episode is called "Poached Eggs", where the birds discover that their eggs have been stolen by the pigs. The second episode is called "Mighty Hoax", where the pigs use cardboard cutouts of their own kind to trick the birds. The third episode is called "Danger Above", where the birds chase the pigs in the sky using balloons and planes. The levels also have different layouts, obstacles, hazards, and hidden items that require strategy and skill to overcome. - Exciting and rewarding power-ups and boosters. The game also has various power-ups and boosters that can help the players in their quest to defeat the pigs. For example, the Mighty Eagle is a powerful bird that can be summoned once per hour to destroy all the pigs in a level. The power-ups include the Sling Scope, which shows the trajectory of the bird before launching it; the King Sling, which increases the speed and power of the bird; the Birdquake, which shakes the ground and causes the structures to collapse; and the Super Seeds, which enlarges the bird and makes it more destructive. - Competitive and social Mighty League mode. The game also has a Mighty League mode, where players can compete against other players from around the world in daily tournaments. The players can earn trophies, coins, and feathers by completing levels and ranking higher on the leaderboards. The players can also chat with each other, send gifts, and challenge their friends in friendly matches.
How to Download Angry Birds Classic apk file from Google Play Store or other sources?
-Downloading Angry Birds Classic apk file is easy and fast. There are two main ways to do it: from Google Play Store or from other sources.
-How to Download Angry Birds Classic apk file from Google Play Store?
-The easiest way to download Angry Birds Classic apk file is from Google Play Store, which is the official app store for Android devices. Here are the steps to do it:
--
-
- Open Google Play Store on your Android device. -
- Search for "Angry Birds Classic" in the search bar. -
- Select "Angry Birds Classic" from the list of results. -
- Tap on "Install" button to start downloading Angry Birds Classic apk file. -
- Wait for the download to finish and then tap on "Open" button to launch Angry Birds Classic on your Android device. -
You can also download Angry Birds Classic apk file from Google Play Store using your web browser on your computer or other devices. Here are the steps to do it:
--
-
- Open your web browser and go to https://play.google.com/store/apps/details?id=com.rovio.angrybirds. -
- Click on "Install" button to start downloading Angry Birds Classic apk file. -
- Select your Android device from the list of devices that are connected to your Google account. -
- Wait for the download to finish and then open Angry Birds Classic on your Android device. -
How to Download Angry Birds Classic apk file from other sources?
-If you cannot access Google Play Store or prefer to download Angry Birds Classic apk file from other sources, you can also do that. However, you need to be careful when downloading Angry Birds Classic apk file from other sources, as some of them may contain viruses, malware, or other harmful content that can damage your device or compromise your privacy. Here are some tips to download Angry Birds Classic apk file from other sources safely:
-angry birds classic game free download for android
-
-angry birds classic apk mod unlimited money
-angry birds classic apk latest version
-angry birds classic apk old version
-angry birds classic apk offline
-angry birds classic apk pure
-angry birds classic apk mirror
-angry birds classic apk revdl
-angry birds classic apk uptodown
-angry birds classic apk hack
-angry birds classic apk android 1
-angry birds classic apk android 2.3.6
-angry birds classic apk android 4.0.4
-angry birds classic apk android 4.4.2
-angry birds classic apk android 5.1.1
-angry birds classic apk android 6.0
-angry birds classic apk android 7.0
-angry birds classic apk android 8.0
-angry birds classic apk android 9.0
-angry birds classic apk android 10
-angry birds classic apk android 11
-angry birds classic download for android phone
-angry birds classic download for android tablet
-angry birds classic download for android tv
-angry birds classic download for android mobile
-angry birds classic download for android free
-angry birds classic download for android full version
-angry birds classic download for android without ads
-angry birds classic download for android no internet
-angry birds classic download for android play store
-how to download angry birds classic on android
-how to install angry birds classic on android
-how to play angry birds classic on android
-how to update angry birds classic on android
-how to uninstall angry birds classic on android
-how to get angry birds classic on android
-how to hack angry birds classic on android
-how to restore purchases on angry birds classic android
-how to transfer progress in angry birds classic android
-how to unlock all levels in angry birds classic android
-best site to download angry birds classic for android
-best way to download angry birds classic for android
-best alternative to download angry birds classic for android
-best tips and tricks for playing angry birds classic on android
-best cheats and codes for playing angry birds classic on android-
-
- Only download Angry Birds Classic apk file from trusted and reputable sources, such as official websites of Rovio Entertainment or other well-known app stores. -
- Avoid downloading Angry Birds Classic apk file from unknown or suspicious sources, such as pop-up ads, spam emails, or unverified links. -
- Check the reviews, ratings, comments, and feedback of other users who have downloaded Angry Birds Classic apk file from the same source before you download it. -
- Scan the Angry Birds Classic apk file with a reliable antivirus or anti-malware software before you install it on your device. -
- Backup your data and settings before you install Angry Birds Classic apk file on your device, in case something goes wrong or you need to uninstall it later. -
Here are the steps to download Angry Birds Classic apk file from other sources:
--
-
- Find a trusted and reputable source that offers Angry Birds Classic apk file for download. -
- Click on the download link or button to start downloading Angry Birds Classic apk file. -
- Save the Angry Birds Classic apk file to a location that you can easily access on your device, such as your downloads folder or your SD card. -
- Scan the Angry Birds Classic apk file with your antivirus or anti-malware software to make sure it is safe and clean. -
- Open the Angry Birds Classic apk file on your device and follow the instructions to install it. -
How to Install Angry Birds Classic apk file on Android
-Installing Angry Birds Classic apk file on Android is also easy and fast. However, you need to make sure that your device meets the requirements and that you have enabled the unknown sources option for apk file installation. Here are the details and steps to install Angry Birds Classic apk file on Android:
-What are the requirements and steps to install Angry Birds Classic apk file on Android devices?
-The requirements and steps to install Angry Birds Classic apk file on Android devices are:
--
-
- Requirements: Your device must have Android 4.1 or higher version, at least 100 MB of free storage space, and a stable internet connection. -
- Steps: -
- Locate the Angry Birds Classic apk file that you have downloaded on your device. -
- Tap on the Angry Birds Classic apk file to open it. -
- You may see a warning message that says "For your security, your phone is not allowed to install unknown apps from this source". Tap on "Settings" to go to the security settings of your device. -
- Find and enable the option that says "Allow from this source" or "Unknown sources". This will allow you to install Angry Birds Classic apk file on your device. -
- Go back to the Angry Birds Classic apk file and tap on "Install" to start the installation process. -
- Wait for the installation to finish and then tap on "Done" or "Open" to launch Angry Birds Classic on your device. -
-
-
How to Troubleshoot Common Installation Issues and Errors for Angry Birds Classic apk file?
-Sometimes, you may encounter some issues or errors when installing Angry Birds Classic apk file on your device. These issues or errors may prevent you from installing or launching the game successfully. Here are some common issues or errors and how to fix them:
-Insufficient storage space
-This issue occurs when your device does not have enough free storage space to install Angry Birds Classic apk file. To fix this issue, you need to free up some storage space on your device by deleting some unwanted files, apps, photos, videos, etc. You can also use a cleaning app or a file manager app to help you with this task. Alternatively, you can move some files or apps to your SD card if your device supports it.
-Invalid or corrupted apk file
-This issue occurs when the Angry Birds Classic apk file that you have downloaded is not valid or corrupted. This may happen due to various reasons, such as incomplete download, interrupted download, virus infection, etc. To fix this issue, you need to delete the Angry Birds Classic apk file that you have downloaded and download it again from a trusted and reputable source. You can also use a different browser or a download manager app to help you with this task.
-App not installed
-This issue occurs when the installation process of Angry Birds Classic apk file fails or is interrupted for some reason. This may happen due to various reasons, such as incompatible device, low battery, insufficient permissions, etc. To fix this issue, you need to check the following things:
--
-
- Make sure your device meets the requirements and is compatible with Angry Birds Classic apk file. -
- Make sure your device has enough battery power and is not in power-saving mode. -
- Make sure you have enabled the unknown sources option and granted all the necessary permissions for Angry Birds Classic apk file installation. -
- Make sure you have closed all other apps and processes that may interfere with the installation process. -
- Make sure you have a stable internet connection and are not using a VPN or a proxy server. -
If none of these things work, you can try to restart your device and install Angry Birds Classic apk file again.
-How to Play Angry Birds Classic on Android
-Playing Angry Birds Classic on Android is fun and easy. Once you have installed Angry Birds Classic apk file on your device, you can launch and start the game by following these steps:
--
-
- Tap on the Angry Birds Classic icon on your home screen or app drawer to open the game. -
- You will see the main menu of the game, where you can choose from different options, such as Play, Mighty League, Settings, etc. -
- Tap on Play to start playing the game. You will see a map of different episodes and levels that you can play. You can swipe left or right to navigate through the map. -
- Tap on an episode that you want to play. You will see a list of levels that you can play in that episode. You can swipe up or down to navigate through the list. -
- Tap on a level that you want to play. You will see the gameplay screen of that level, where you can see the slingshot, the birds, the pigs, and their structures. -
- To play the level, you need to use the slingshot to launch the birds at the pigs and their structures. To do this, follow these steps: -
- Drag your finger on the screen to aim the slingshot. You will see a dotted line that shows the trajectory of the bird. -
- Release your finger to launch the bird. You will see the bird fly towards the pigs and their structures. -
- Tap on the screen again to activate the special power of the bird. Each bird has a different power that can help you destroy more pigs and structures. -
- Your goal is to destroy all the pigs and their structures in each level using as few birds as possible. You will earn stars based on how well you perform in each level. You will also earn coins that you can use to buy power-ups and boosters. -
- If you fail to destroy all the pigs in a level, you will lose a life and have to retry the level. You have five lives in total, which regenerate over time or can be refilled by watching ads or spending coins. -
- If you succeed in destroying all the pigs in a level, you will complete the level and unlock the next one. You will also see your score and rank for that level. -
-
-
Tips and Tricks for Angry Birds Classic on Android
Tips and Tricks for Angry Birds Classic on Android
-Angry Birds Classic is a game that requires skill, strategy, and luck to master. If you want to improve your performance and enjoy the game more, you can follow these tips and tricks:
-How to master the unique traits and abilities of each bird in Angry Birds Classic?
-Each bird in Angry Birds Classic has a unique trait and ability that can help you destroy more pigs and structures. You need to know how to use them effectively and wisely. Here are some examples:
--
-
- Red bird: The red bird is the basic bird that can deal moderate damage. It has no special power, but it can be useful for hitting targets directly or breaking weak materials. -
- Yellow bird: The yellow bird can speed up and pierce through materials. It has a special power that allows it to accelerate when you tap on the screen. You can use it to hit hard-to-reach targets or break through strong materials. -
- Black bird: The black bird can explode and cause massive destruction. It has a special power that allows it to detonate when you tap on the screen or when it hits something. You can use it to blow up large structures or groups of pigs. -
- Green bird: The green bird can boomerang back and hit targets from behind. It has a special power that allows it to change direction when you tap on the screen. You can use it to hit targets that are hidden or protected by other structures. -
- White bird: The white bird can drop an egg bomb and fly away. It has a special power that allows it to drop an egg when you tap on the screen. You can use it to hit targets below or behind the white bird. -
- Blue bird: The blue bird can split into three smaller birds and cover a wider area. It has a special power that allows it to split when you tap on the screen. You can use it to hit multiple targets or break glass materials. -
- Big red bird: The big red bird is a larger version of the red bird that can deal more damage. It has no special power, but it can be useful for hitting large targets or breaking heavy materials. -
How to plan your strategy and aim your shots in Angry Birds Classic?
-Aiming your shots in Angry Birds Classic is not only about accuracy, but also about strategy. You need to consider the following factors when aiming your shots:
--
-
- The type of bird: You need to choose the right bird for the right situation. For example, you may want to use the yellow bird to hit a target that is far away or behind a strong material, or you may want to use the black bird to blow up a large structure or a group of pigs. -
- The angle of the shot: You need to adjust the angle of the shot according to the trajectory of the bird and the gravity of the level. For example, you may want to aim higher or lower depending on how far or close the target is, or you may want to aim differently depending on whether the level is in space or underwater. -
- The timing of the shot: You need to time your shot according to the movement of the target and the activation of the special power. For example, you may want to wait for the right moment to launch the bird when the target is exposed or vulnerable, or you may want to tap on the screen at the right moment to activate the special power when it is most effective. -
How to find hidden golden eggs and unlock bonus levels in Angry Birds Classic?
-Angry Birds Classic has many hidden golden eggs that can unlock bonus levels with different themes and challenges. These golden eggs are usually hidden in secret locations or require certain actions to reveal them. Here are some examples of how to find some of them:
--
-
- In level 1-8: Tap on the treasure chest in the background to open it and reveal a golden egg. -
- In level 2-2: Break the beach ball in the foreground to reveal a golden egg. -
- In level 4-7: Zoom out and tap on the yellow balloon in the top right corner of the screen to pop it and reveal a golden egg. -
- In level 5-19: Launch a white bird backwards and drop an egg on top of the cliff behind the slingshot to reveal a golden egg. -
- In level 6-14: Launch a yellow bird at the bottom right corner of the screen and activate its power to break the wooden block and reveal a golden egg. -
- In level 8-15: Launch a black bird at the TNT box in the bottom left corner of the screen and detonate it to blow up the structure and reveal a golden egg. -
You can also find some golden eggs by tapping on certain objects or icons in the main menu or the episode selection screen. For example, you can tap on the sun in the main menu, the boomerang bird in the episode selection screen, or the Facebook icon in the settings menu to reveal some golden eggs.
-How to save your progress and sync your game across devices in Angry Birds Classic?
-Angry Birds Classic allows you to save your progress and sync your game across devices using your Rovio Account or your Facebook Account. This way, you can continue playing the game on different devices without losing your data or achievements. Here are the steps to do it:
--
-
- Using Rovio Account: -
- Create a Rovio Account by tapping on the Rovio icon in the main menu or the settings menu of the game. -
- Enter your email address and password and tap on "Create Account". -
- Verify your email address by clicking on the link that is sent to your email. -
- Login to your Rovio Account by tapping on the Rovio icon in the main menu or the settings menu of the game. -
- Select "Sync" to sync your game data with your Rovio Account. -
- To sync your game data on another device, login to your Rovio Account on that device and select "Sync". -
- Using Facebook Account: -
- Login to your Facebook Account by tapping on the Facebook icon in the main menu or the settings menu of the game. -
- Grant permission for Angry Birds Classic to access your Facebook information. -
- Select "Sync" to sync your game data with your Facebook Account. -
- To sync your game data on another device, login to your Facebook Account on that device and select "Sync". -
-
-
-
-
How to avoid ads, in-app purchases, and data charges in Angry Birds Classic?
-Angry Birds Classic is a free-to-play game that supports ads and in-app purchases. However, some players may find these features annoying or distracting. If you want to avoid ads, in-app purchases, and data charges in Angry Birds Classic, you can follow these tips:
--
-
- To avoid ads: You can turn off your internet connection or switch to airplane mode before launching Angry Birds Classic. This will prevent the game from showing any ads. However, this will also disable some features that require internet connection, such as Mighty League, power-ups, etc. -
- To avoid in-app purchases: You can disable in-app purchases by going to the settings of your device and turning off the option that allows apps to make purchases. This will prevent you from accidentally or intentionally buying any coins, power-ups, or other items in Angry Birds Classic. -
- To avoid data charges: You can use a Wi-Fi connection instead of a mobile data connection when playing Angry Birds Classic. This will reduce or eliminate any data charges that may occur due to downloading or updating Angry Birds Classic or its content. -
Conclusion
-Angry Birds Classic is a fun, addictive, and challenging game that will keep you entertained for hours. It has a simple yet satisfying slingshot gameplay, a diverse and delightful cast of birds and pigs, a challenging and creative set of levels and episodes, an exciting and rewarding set of power-ups and boosters, and a competitive and social Mighty League mode. You can download and play Angry Birds Classic on Android by following our guide above. We hope you enjoy playing Angry Birds Classic on Android as much as we do!
-FAQs
-Here are some common questions and answers about Angry Birds Classic on Android:
-Q: How many levels are there in Angry Birds Classic?
-A: There are over 800 levels in Angry Birds Classic, spread across 15 episodes. Each episode has a different theme, setting, and objective. You can unlock new episodes by completing previous ones or by finding hidden golden eggs.
-Q: How do I get more coins in Angry Birds Classic?
-A: Coins are the currency of Angry Birds Classic that you can use to buy power-ups and boosters. You can get more coins by completing levels, earning stars, ranking higher in the Mighty League, watching ads, or buying them with real money.
-Q: How do I use the Mighty Eagle in Angry Birds Classic?
-A: The Mighty Eagle is a powerful bird that can be summoned once per hour to destroy all the pigs in a level. You can use the Mighty Eagle by tapping on the eagle icon in the top left corner of the screen and then launching a can of sardines at the pigs. The Mighty Eagle will then swoop down and wipe out everything in its path. You can earn feathers by using the Mighty Eagle and achieving a certain percentage of destruction in each level.
-Q: How do I update Angry Birds Classic on Android?
-A: You can update Angry Birds Classic on Android by going to Google Play Store and tapping on the update button. You can also enable the auto-update option in the settings of Google Play Store to update Angry Birds Classic automatically whenever a new version is available. Updating Angry Birds Classic will give you access to new features, levels, episodes, bug fixes, and improvements.
-Q: Is Angry Birds Classic safe and secure to play on Android?
-A: Yes, Angry Birds Classic is safe and secure to play on Android. The game does not contain any viruses, malware, or other harmful content that can damage your device or compromise your privacy. The game also does not collect or share any personal or sensitive information from you or your device without your consent. The game only requires some permissions and access to your device's features, such as storage, internet, etc., to function properly and enhance your gaming experience.
401be4b1e0
-
-
\ No newline at end of file diff --git a/spaces/fffiloni/Pix2Pix-Video/app.py b/spaces/fffiloni/Pix2Pix-Video/app.py deleted file mode 100644 index aace586f6434819ddb6b66cd2dd34cfdcc71ebe5..0000000000000000000000000000000000000000 --- a/spaces/fffiloni/Pix2Pix-Video/app.py +++ /dev/null @@ -1,222 +0,0 @@ -import gradio as gr -import os -import cv2 -import numpy as np -from moviepy.editor import * -from share_btn import community_icon_html, loading_icon_html, share_js - -from diffusers import StableDiffusionInstructPix2PixPipeline -import torch -from PIL import Image, ImageOps -import time -import psutil -import math -import random - - -pipe = StableDiffusionInstructPix2PixPipeline.from_pretrained("timbrooks/instruct-pix2pix", torch_dtype=torch.float16, safety_checker=None) - -device = "GPU 🔥" if torch.cuda.is_available() else "CPU 🥶" - -if torch.cuda.is_available(): - pipe = pipe.to("cuda") - - -def pix2pix( - input_image: Image.Image, - instruction: str, - steps: int, - seed: int, - text_cfg_scale: float, - image_cfg_scale: float, - ): - - width, height = input_image.size - factor = 512 / max(width, height) - factor = math.ceil(min(width, height) * factor / 64) * 64 / min(width, height) - width = int((width * factor) // 64) * 64 - height = int((height * factor) // 64) * 64 - input_image = ImageOps.fit(input_image, (width, height), method=Image.Resampling.LANCZOS) - - if instruction == "": - return [input_image, seed] - - generator = torch.manual_seed(seed) - edited_image = pipe( - instruction, image=input_image, - guidance_scale=text_cfg_scale, image_guidance_scale=image_cfg_scale, - num_inference_steps=steps, generator=generator, - ).images[0] - print(f"EDITED: {edited_image}") - return edited_image - - - -def get_frames(video_in): - frames = [] - #resize the video - clip = VideoFileClip(video_in) - - #check fps - if clip.fps > 30: - print("vide rate is over 30, resetting to 30") - clip_resized = clip.resize(height=512) - clip_resized.write_videofile("video_resized.mp4", fps=30) - else: - print("video rate is OK") - clip_resized = clip.resize(height=512) - clip_resized.write_videofile("video_resized.mp4", fps=clip.fps) - - print("video resized to 512 height") - - # Opens the Video file with CV2 - cap= cv2.VideoCapture("video_resized.mp4") - - fps = cap.get(cv2.CAP_PROP_FPS) - print("video fps: " + str(fps)) - i=0 - while(cap.isOpened()): - ret, frame = cap.read() - if ret == False: - break - cv2.imwrite('kang'+str(i)+'.jpg',frame) - frames.append('kang'+str(i)+'.jpg') - i+=1 - - cap.release() - cv2.destroyAllWindows() - print("broke the video into frames") - - return frames, fps - - -def create_video(frames, fps): - print("building video result") - clip = ImageSequenceClip(frames, fps=fps) - clip.write_videofile("movie.mp4", fps=fps) - - return 'movie.mp4' - - -def infer(prompt,video_in, seed_in, trim_value): - print(prompt) - break_vid = get_frames(video_in) - - frames_list= break_vid[0] - fps = break_vid[1] - n_frame = int(trim_value*fps) - - if n_frame >= len(frames_list): - print("video is shorter than the cut value") - n_frame = len(frames_list) - - result_frames = [] - print("set stop frames to: " + str(n_frame)) - - for i in frames_list[0:int(n_frame)]: - pil_i = Image.open(i).convert("RGB") - - pix2pix_img = pix2pix(pil_i, prompt, 50, seed_in, 7.5, 1.5) - #print(pix2pix_img) - #image = Image.open(pix2pix_img) - #rgb_im = image.convert("RGB") - - # exporting the image - pix2pix_img.save(f"result_img-{i}.jpg") - result_frames.append(f"result_img-{i}.jpg") - print("frame " + i + "/" + str(n_frame) + ": done;") - - final_vid = create_video(result_frames, fps) - print("finished !") - - return final_vid, gr.Group.update(visible=True) - -title = """ ---""" - -article = """ - - ---- Pix2Pix Video -
-- Apply Instruct Pix2Pix Diffusion to a video -
--- -""" - -with gr.Blocks(css='style.css') as demo: - with gr.Column(elem_id="col-container"): - gr.HTML(title) - with gr.Row(): - with gr.Column(): - video_inp = gr.Video(label="Video source", source="upload", type="filepath", elem_id="input-vid") - prompt = gr.Textbox(label="Prompt", placeholder="enter prompt", show_label=False, elem_id="prompt-in") - with gr.Row(): - seed_inp = gr.Slider(label="Seed", minimum=0, maximum=2147483647, step=1, value=123456) - trim_in = gr.Slider(label="Cut video at (s)", minimun=1, maximum=5, step=1, value=1) - with gr.Column(): - video_out = gr.Video(label="Pix2pix video result", elem_id="video-output") - gr.HTML(""" -You may also like:
-- - - -- -- work with longer videos / skip the queue: - """, elem_id="duplicate-container") - submit_btn = gr.Button("Generate Pix2Pix video") - - with gr.Group(elem_id="share-btn-container", visible=False) as share_group: - community_icon = gr.HTML(community_icon_html) - loading_icon = gr.HTML(loading_icon_html) - share_button = gr.Button("Share to community", elem_id="share-btn") - - inputs = [prompt,video_inp,seed_inp, trim_in] - outputs = [video_out, share_group] - - #ex = gr.Examples( - # [ - # ["Make it a marble sculpture", "./examples/pexels-jill-burrow-7665249_512x512.mp4", 422112651, 4], - # ["Make it molten lava", "./examples/Ocean_Pexels_ 8953474_512x512.mp4", 43571876, 4] - # ], - # inputs=inputs, - # outputs=outputs, - # fn=infer, - # cache_examples=True, - #) - - gr.HTML(article) - - submit_btn.click(infer, inputs, outputs) - share_button.click(None, [], [], _js=share_js) - - - -demo.queue(max_size=12).launch() diff --git a/spaces/fffiloni/Video-Matting-Anything/GroundingDINO/README.md b/spaces/fffiloni/Video-Matting-Anything/GroundingDINO/README.md deleted file mode 100644 index b6610df03d409633e572ef49d67a445d35a63967..0000000000000000000000000000000000000000 --- a/spaces/fffiloni/Video-Matting-Anything/GroundingDINO/README.md +++ /dev/null @@ -1,163 +0,0 @@ -# Grounding DINO - ---- - -[](https://arxiv.org/abs/2303.05499) -[](https://youtu.be/wxWDt5UiwY8) -[](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-grounding-dino.ipynb) -[](https://youtu.be/cMa77r3YrDk) -[](https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo) - -[](https://paperswithcode.com/sota/zero-shot-object-detection-on-mscoco?p=grounding-dino-marrying-dino-with-grounded) \ -[](https://paperswithcode.com/sota/zero-shot-object-detection-on-odinw?p=grounding-dino-marrying-dino-with-grounded) \ -[](https://paperswithcode.com/sota/object-detection-on-coco-minival?p=grounding-dino-marrying-dino-with-grounded) \ -[](https://paperswithcode.com/sota/object-detection-on-coco?p=grounding-dino-marrying-dino-with-grounded) - - - -Official PyTorch implementation of [Grounding DINO](https://arxiv.org/abs/2303.05499), a stronger open-set object detector. Code is available now! - - -## Highlight - -- **Open-Set Detection.** Detect **everything** with language! -- **High Performancce.** COCO zero-shot **52.5 AP** (training without COCO data!). COCO fine-tune **63.0 AP**. -- **Flexible.** Collaboration with Stable Diffusion for Image Editting. - -## News -[2023/03/28] A YouTube [video](https://youtu.be/cMa77r3YrDk) about Grounding DINO and basic object detection prompt engineering. [[SkalskiP](https://github.com/SkalskiP)] \ -[2023/03/28] Add a [demo](https://huggingface.co/spaces/ShilongLiu/Grounding_DINO_demo) on Hugging Face Space! \ -[2023/03/27] Support CPU-only mode. Now the model can run on machines without GPUs.\ -[2023/03/25] A [demo](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/zero-shot-object-detection-with-grounding-dino.ipynb) for Grounding DINO is available at Colab. [[SkalskiP](https://github.com/SkalskiP)] \ -[2023/03/22] Code is available Now! - -
-- - - -## TODO - -- [x] Release inference code and demo. -- [x] Release checkpoints. -- [ ] Grounding DINO with Stable Diffusion and GLIGEN demos. -- [ ] Release training codes. - -## Install - -If you have a CUDA environment, please make sure the environment variable `CUDA_HOME` is set. It will be compiled under CPU-only mode if no CUDA available. - -```bash -pip install -e . -``` - -## Demo - -```bash -CUDA_VISIBLE_DEVICES=6 python demo/inference_on_a_image.py \ - -c /path/to/config \ - -p /path/to/checkpoint \ - -i .asset/cats.png \ - -o "outputs/0" \ - -t "cat ear." \ - [--cpu-only] # open it for cpu mode -``` -See the `demo/inference_on_a_image.py` for more details. - -**Web UI** - -We also provide a demo code to integrate Grounding DINO with Gradio Web UI. See the file `demo/gradio_app.py` for more details. - -## Checkpoints - - --Description -
- -
-- -
- -## Results - -- - - -- name -backbone -Data -box AP on COCO -Checkpoint -Config -- - -1 -GroundingDINO-T -Swin-T -O365,GoldG,Cap4M -48.4 (zero-shot) / 57.2 (fine-tune) -Github link | HF link -link --- --COCO Object Detection Results -
- --- -
--- --ODinW Object Detection Results -
- --- -
--- --Marrying Grounding DINO with Stable Diffusion for Image Editing -
- --- -## Model - -Includes: a text backbone, an image backbone, a feature enhancer, a language-guided query selection, and a cross-modality decoder. - - - - -## Acknowledgement - -Our model is related to [DINO](https://github.com/IDEA-Research/DINO) and [GLIP](https://github.com/microsoft/GLIP). Thanks for their great work! - -We also thank great previous work including DETR, Deformable DETR, SMCA, Conditional DETR, Anchor DETR, Dynamic DETR, DAB-DETR, DN-DETR, etc. More related work are available at [Awesome Detection Transformer](https://github.com/IDEACVR/awesome-detection-transformer). A new toolbox [detrex](https://github.com/IDEA-Research/detrex) is available as well. - -Thanks [Stable Diffusion](https://github.com/Stability-AI/StableDiffusion) and [GLIGEN](https://github.com/gligen/GLIGEN) for their awesome models. - - -## Citation - -If you find our work helpful for your research, please consider citing the following BibTeX entry. - -```bibtex -@inproceedings{ShilongLiu2023GroundingDM, - title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection}, - author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang}, - year={2023} -} -``` - - - - diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/test/quoteStyle.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/test/quoteStyle.js deleted file mode 100644 index ae4d734bff6c30bbabc11c4fb071e220a4cef02b..0000000000000000000000000000000000000000 --- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/test/quoteStyle.js +++ /dev/null @@ -1,17 +0,0 @@ -'use strict'; - -var inspect = require('../'); -var test = require('tape'); - -test('quoteStyle option', function (t) { - t['throws'](function () { inspect(null, { quoteStyle: false }); }, 'false is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: true }); }, 'true is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: '' }); }, '"" is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: {} }); }, '{} is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: [] }); }, '[] is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: 42 }); }, '42 is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: NaN }); }, 'NaN is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: function () {} }); }, 'a function is not a valid value'); - - t.end(); -}); diff --git a/spaces/flax-community/code-clippy-problem-solver/README.md b/spaces/flax-community/code-clippy-problem-solver/README.md deleted file mode 100644 index f524e35d161a39cce97100cc5c90549b9bf334b8..0000000000000000000000000000000000000000 --- a/spaces/flax-community/code-clippy-problem-solver/README.md +++ /dev/null @@ -1,33 +0,0 @@ ---- -title: Code Clippy Problem Solver -emoji: 💻 -colorFrom: blue -colorTo: green -sdk: streamlit -app_file: app.py -pinned: false ---- - -# Configuration - -`title`: _string_ -Display title for the Space - -`emoji`: _string_ -Space emoji (emoji-only character allowed) - -`colorFrom`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`colorTo`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`sdk`: _string_ -Can be either `gradio` or `streamlit` - -`app_file`: _string_ -Path to your main application file (which contains either `gradio` or `streamlit` Python code). -Path is relative to the root of the repository. - -`pinned`: _boolean_ -Whether the Space stays on top of your list. diff --git a/spaces/flax-community/spanish-gpt2/app.py b/spaces/flax-community/spanish-gpt2/app.py deleted file mode 100644 index bd2dd7627c217d1f0d26017c7002a6a35c9022eb..0000000000000000000000000000000000000000 --- a/spaces/flax-community/spanish-gpt2/app.py +++ /dev/null @@ -1,171 +0,0 @@ -import json -import random -import requests - -from mtranslate import translate -import streamlit as st - - -LOGO = "https://raw.githubusercontent.com/nlp-en-es/assets/main/logo.png" - -MODELS = { - "Model trained on OSCAR": { - "url": "https://api-inference.huggingface.co/models/flax-community/gpt-2-spanish" - }, - "Model trained on the Large Spanish Corpus": { - "url": "https://api-inference.huggingface.co/models/mrm8488/spanish-gpt2" - }, -} - -PROMPT_LIST = { - "Érase una vez...": ["Érase una vez "], - "¡Hola!": ["¡Hola! Me llamo "], - "¿Ser o no ser?": ["En mi opinión, 'ser' es "], -} - - -def query(payload, model_name): - data = json.dumps(payload) - print("model url:", MODELS[model_name]["url"]) - response = requests.request( - "POST", MODELS[model_name]["url"], headers={}, data=data - ) - return json.loads(response.content.decode("utf-8")) - - -def process( - text: str, model_name: str, max_len: int, temp: float, top_k: int, top_p: float -): - payload = { - "inputs": text, - "parameters": { - "max_new_tokens": max_len, - "top_k": top_k, - "top_p": top_p, - "temperature": temp, - "repetition_penalty": 2.0, - }, - "options": { - "use_cache": True, - }, - } - return query(payload, model_name) - - -# Page -st.set_page_config(page_title="Spanish GPT-2 Demo", page_icon=LOGO) -st.title("Spanish GPT-2") - - -# Sidebar -st.sidebar.image(LOGO) -st.sidebar.subheader("Configurable parameters") - -max_len = st.sidebar.number_input( - "Maximum length", - value=100, - help="The maximum length of the sequence to be generated.", -) - -temp = st.sidebar.slider( - "Temperature", - value=1.0, - min_value=0.1, - max_value=100.0, - help="The value used to module the next token probabilities.", -) - -top_k = st.sidebar.number_input( - "Top k", - value=10, - help="The number of highest probability vocabulary tokens to keep for top-k-filtering.", -) - -top_p = st.sidebar.number_input( - "Top p", - value=0.95, - help=" If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.", -) - -do_sample = st.sidebar.selectbox( - "Sampling?", - (True, False), - help="Whether or not to use sampling; use greedy decoding otherwise.", -) - - -# Body -st.markdown( - """ - Spanish GPT-2 models trained from scratch on two different datasets. One - model is trained on the Spanish portion of - [OSCAR](https://huggingface.co/datasets/viewer/?dataset=oscar) - and the other on the - [large_spanish_corpus](https://huggingface.co/datasets/viewer/?dataset=large_spanish_corpus) - aka BETO's corpus. - - The models are trained with Flax and using TPUs sponsored by Google since this is part of the - [Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) - organised by HuggingFace. - """ -) - -model_name = st.selectbox("Model", (list(MODELS.keys()))) - -ALL_PROMPTS = list(PROMPT_LIST.keys()) + ["Custom"] -prompt = st.selectbox("Prompt", ALL_PROMPTS, index=len(ALL_PROMPTS) - 1) -if prompt == "Custom": - prompt_box = "Enter your text here" -else: - prompt_box = random.choice(PROMPT_LIST[prompt]) - -text = st.text_area("Enter text", prompt_box) - -if st.button("Run"): - with st.spinner(text="Getting results..."): - st.subheader("Result") - print(f"maxlen:{max_len}, temp:{temp}, top_k:{top_k}, top_p:{top_p}") - result = process( - text=text, - model_name=model_name, - max_len=int(max_len), - temp=temp, - top_k=int(top_k), - top_p=float(top_p), - ) - print("result:", result) - if "error" in result: - if type(result["error"]) is str: - st.write(f'{result["error"]}.', end=" ") - if "estimated_time" in result: - st.write( - f'Please try again in about {result["estimated_time"]:.0f} seconds.' - ) - else: - if type(result["error"]) is list: - for error in result["error"]: - st.write(f"{error}") - else: - result = result[0]["generated_text"] - st.write(result.replace("\n", " \n")) - st.text("English translation") - st.write(translate(result, "en", "es").replace("\n", " \n")) - -st.markdown( - """ - ### Team members - - Manuel Romero ([mrm8488](https://huggingface.co/mrm8488)) - - María Grandury ([mariagrandury](https://huggingface.co/mariagrandury)) - - Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps)) - - Daniel Vera ([daveni](https://huggingface.co/daveni)) - - Sri Lakshmi ([srisweet](https://huggingface.co/srisweet)) - - José Posada ([jdposa](https://huggingface.co/jdposa)) - - Santiago Hincapie ([shpotes](https://huggingface.co/shpotes)) - - Jorge ([jorgealro](https://huggingface.co/jorgealro)) - - ### More information - You can find more information about these models in their cards: - - [Model trained on OSCAR](https://huggingface.co/models/flax-community/gpt-2-spanish) - - [Model trained on the Large Spanish Corpus](https://huggingface.co/mrm8488/spanish-gpt2) - """ -) diff --git a/spaces/freddyaboulton/3.1.4.9-all-demos/demos/live_with_vars/run.py b/spaces/freddyaboulton/3.1.4.9-all-demos/demos/live_with_vars/run.py deleted file mode 100644 index 70c39b36ccbfa1e1ad3239c4efadcdcb8fccbf14..0000000000000000000000000000000000000000 --- a/spaces/freddyaboulton/3.1.4.9-all-demos/demos/live_with_vars/run.py +++ /dev/null @@ -1,9 +0,0 @@ -import gradio as gr - -demo = gr.Interface( - lambda x, y: (x + y if y is not None else x, x + y if y is not None else x), - ["textbox", "state"], - ["textbox", "state"], live=True) - -if __name__ == "__main__": - demo.launch() diff --git a/spaces/fynn3003/image_to_text/app.py b/spaces/fynn3003/image_to_text/app.py deleted file mode 100644 index 07fc4f5710db0af94ab0d680a9de0ace80596475..0000000000000000000000000000000000000000 --- a/spaces/fynn3003/image_to_text/app.py +++ /dev/null @@ -1,34 +0,0 @@ -from transformers import VisionEncoderDecoderModel, ViTImageProcessor, AutoTokenizer -import torch -from PIL import Image -import gradio as gr -import numpy as np - -model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning") -feature_extractor = ViTImageProcessor.from_pretrained("nlpconnect/vit-gpt2-image-captioning") -tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning") - -device = torch.device("cuda" if torch.cuda.is_available() else "cpu") -model.to(device) - -max_length = 16 -num_beams = 4 -gen_kwargs = {"max_length": max_length, "num_beams": num_beams} - -def predict_step(image): - i_image = Image.fromarray(np.uint8(image)) - if i_image.mode != "RGB": - i_image = i_image.convert(mode="RGB") - pixel_values = feature_extractor(images=i_image, return_tensors="pt").pixel_values - pixel_values = pixel_values.to(device) - output_ids = model.generate(pixel_values, **gen_kwargs) - preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True) - preds = [pred.strip() for pred in preds] - return preds - -iface = gr.Interface(fn=predict_step, - inputs=gr.inputs.Image(shape=(224, 224)), - outputs=gr.outputs.Textbox(label="Generated Caption")) - -iface.launch() - diff --git a/spaces/gangviolence/giftmediscordnitro/app.py b/spaces/gangviolence/giftmediscordnitro/app.py deleted file mode 100644 index 3703e2db0009fea1686d779101b431c47248e5e9..0000000000000000000000000000000000000000 --- a/spaces/gangviolence/giftmediscordnitro/app.py +++ /dev/null @@ -1,7 +0,0 @@ -import gradio as gr - -def greet(name): - return "Hello " + name + "!!" - -iface = gr.Interface(fn=greet, inputs="text", outputs="text") -iface.launch() diff --git a/spaces/geekyrakshit/enhance-me/enhance_me/mirnet/models/mirnet_model.py b/spaces/geekyrakshit/enhance-me/enhance_me/mirnet/models/mirnet_model.py deleted file mode 100644 index 0a46b04e0fc03e7278056855a1e796c5bde33341..0000000000000000000000000000000000000000 --- a/spaces/geekyrakshit/enhance-me/enhance_me/mirnet/models/mirnet_model.py +++ /dev/null @@ -1,13 +0,0 @@ -from tensorflow.keras import layers, Input, Model - -from .recursive_residual_blocks import recursive_residual_group - - -def build_mirnet_model(num_rrg, num_mrb, channels): - input_tensor = Input(shape=[None, None, 3]) - x1 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(input_tensor) - for _ in range(num_rrg): - x1 = recursive_residual_group(x1, num_mrb, channels) - conv = layers.Conv2D(3, kernel_size=(3, 3), padding="same")(x1) - output_tensor = layers.Add()([input_tensor, conv]) - return Model(input_tensor, output_tensor) diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/ade.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/ade.py deleted file mode 100644 index 5913e43775ed4920b6934c855eb5a37c54218ebf..0000000000000000000000000000000000000000 --- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/ade.py +++ /dev/null @@ -1,84 +0,0 @@ -from .builder import DATASETS -from .custom import CustomDataset - - -@DATASETS.register_module() -class ADE20KDataset(CustomDataset): - """ADE20K dataset. - - In segmentation map annotation for ADE20K, 0 stands for background, which - is not included in 150 categories. ``reduce_zero_label`` is fixed to True. - The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is fixed to - '.png'. - """ - CLASSES = ( - 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ', - 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth', - 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car', - 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug', - 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe', - 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column', - 'signboard', 'chest of drawers', 'counter', 'sand', 'sink', - 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path', - 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door', - 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table', - 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove', - 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar', - 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower', - 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver', - 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister', - 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van', - 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything', - 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent', - 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank', - 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake', - 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce', - 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen', - 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass', - 'clock', 'flag') - - PALETTE = [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50], - [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255], - [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7], - [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82], - [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3], - [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255], - [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220], - [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224], - [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255], - [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7], - [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153], - [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255], - [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0], - [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255], - [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255], - [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255], - [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0], - [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0], - [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255], - [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255], - [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20], - [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255], - [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255], - [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255], - [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0], - [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0], - [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255], - [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112], - [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160], - [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163], - [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0], - [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0], - [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255], - [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204], - [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255], - [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255], - [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194], - [102, 255, 0], [92, 0, 255]] - - def __init__(self, **kwargs): - super(ADE20KDataset, self).__init__( - img_suffix='.jpg', - seg_map_suffix='.png', - reduce_zero_label=True, - **kwargs) diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/models/losses/dice_loss.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/models/losses/dice_loss.py deleted file mode 100644 index 27a77b962d7d8b3079c7d6cd9db52280c6fb4970..0000000000000000000000000000000000000000 --- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/models/losses/dice_loss.py +++ /dev/null @@ -1,119 +0,0 @@ -"""Modified from https://github.com/LikeLy-Journey/SegmenTron/blob/master/ -segmentron/solver/loss.py (Apache-2.0 License)""" -import torch -import torch.nn as nn -import torch.nn.functional as F - -from ..builder import LOSSES -from .utils import get_class_weight, weighted_loss - - -@weighted_loss -def dice_loss(pred, - target, - valid_mask, - smooth=1, - exponent=2, - class_weight=None, - ignore_index=255): - assert pred.shape[0] == target.shape[0] - total_loss = 0 - num_classes = pred.shape[1] - for i in range(num_classes): - if i != ignore_index: - dice_loss = binary_dice_loss( - pred[:, i], - target[..., i], - valid_mask=valid_mask, - smooth=smooth, - exponent=exponent) - if class_weight is not None: - dice_loss *= class_weight[i] - total_loss += dice_loss - return total_loss / num_classes - - -@weighted_loss -def binary_dice_loss(pred, target, valid_mask, smooth=1, exponent=2, **kwards): - assert pred.shape[0] == target.shape[0] - pred = pred.reshape(pred.shape[0], -1) - target = target.reshape(target.shape[0], -1) - valid_mask = valid_mask.reshape(valid_mask.shape[0], -1) - - num = torch.sum(torch.mul(pred, target) * valid_mask, dim=1) * 2 + smooth - den = torch.sum(pred.pow(exponent) + target.pow(exponent), dim=1) + smooth - - return 1 - num / den - - -@LOSSES.register_module() -class DiceLoss(nn.Module): - """DiceLoss. - - This loss is proposed in `V-Net: Fully Convolutional Neural Networks for - Volumetric Medical Image Segmentation
--- -## Model - -Includes: a text backbone, an image backbone, a feature enhancer, a language-guided query selection, and a cross-modality decoder. - - - - -## Acknowledgement - -Our model is related to [DINO](https://github.com/IDEA-Research/DINO) and [GLIP](https://github.com/microsoft/GLIP). Thanks for their great work! - -We also thank great previous work including DETR, Deformable DETR, SMCA, Conditional DETR, Anchor DETR, Dynamic DETR, DAB-DETR, DN-DETR, etc. More related work are available at [Awesome Detection Transformer](https://github.com/IDEACVR/awesome-detection-transformer). A new toolbox [detrex](https://github.com/IDEA-Research/detrex) is available as well. - -Thanks [Stable Diffusion](https://github.com/Stability-AI/StableDiffusion) and [GLIGEN](https://github.com/gligen/GLIGEN) for their awesome models. - - -## Citation - -If you find our work helpful for your research, please consider citing the following BibTeX entry. - -```bibtex -@inproceedings{ShilongLiu2023GroundingDM, - title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection}, - author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang}, - year={2023} -} -``` - - - - diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/test/quoteStyle.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/test/quoteStyle.js deleted file mode 100644 index ae4d734bff6c30bbabc11c4fb071e220a4cef02b..0000000000000000000000000000000000000000 --- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/object-inspect/test/quoteStyle.js +++ /dev/null @@ -1,17 +0,0 @@ -'use strict'; - -var inspect = require('../'); -var test = require('tape'); - -test('quoteStyle option', function (t) { - t['throws'](function () { inspect(null, { quoteStyle: false }); }, 'false is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: true }); }, 'true is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: '' }); }, '"" is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: {} }); }, '{} is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: [] }); }, '[] is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: 42 }); }, '42 is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: NaN }); }, 'NaN is not a valid value'); - t['throws'](function () { inspect(null, { quoteStyle: function () {} }); }, 'a function is not a valid value'); - - t.end(); -}); diff --git a/spaces/flax-community/code-clippy-problem-solver/README.md b/spaces/flax-community/code-clippy-problem-solver/README.md deleted file mode 100644 index f524e35d161a39cce97100cc5c90549b9bf334b8..0000000000000000000000000000000000000000 --- a/spaces/flax-community/code-clippy-problem-solver/README.md +++ /dev/null @@ -1,33 +0,0 @@ ---- -title: Code Clippy Problem Solver -emoji: 💻 -colorFrom: blue -colorTo: green -sdk: streamlit -app_file: app.py -pinned: false ---- - -# Configuration - -`title`: _string_ -Display title for the Space - -`emoji`: _string_ -Space emoji (emoji-only character allowed) - -`colorFrom`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`colorTo`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`sdk`: _string_ -Can be either `gradio` or `streamlit` - -`app_file`: _string_ -Path to your main application file (which contains either `gradio` or `streamlit` Python code). -Path is relative to the root of the repository. - -`pinned`: _boolean_ -Whether the Space stays on top of your list. diff --git a/spaces/flax-community/spanish-gpt2/app.py b/spaces/flax-community/spanish-gpt2/app.py deleted file mode 100644 index bd2dd7627c217d1f0d26017c7002a6a35c9022eb..0000000000000000000000000000000000000000 --- a/spaces/flax-community/spanish-gpt2/app.py +++ /dev/null @@ -1,171 +0,0 @@ -import json -import random -import requests - -from mtranslate import translate -import streamlit as st - - -LOGO = "https://raw.githubusercontent.com/nlp-en-es/assets/main/logo.png" - -MODELS = { - "Model trained on OSCAR": { - "url": "https://api-inference.huggingface.co/models/flax-community/gpt-2-spanish" - }, - "Model trained on the Large Spanish Corpus": { - "url": "https://api-inference.huggingface.co/models/mrm8488/spanish-gpt2" - }, -} - -PROMPT_LIST = { - "Érase una vez...": ["Érase una vez "], - "¡Hola!": ["¡Hola! Me llamo "], - "¿Ser o no ser?": ["En mi opinión, 'ser' es "], -} - - -def query(payload, model_name): - data = json.dumps(payload) - print("model url:", MODELS[model_name]["url"]) - response = requests.request( - "POST", MODELS[model_name]["url"], headers={}, data=data - ) - return json.loads(response.content.decode("utf-8")) - - -def process( - text: str, model_name: str, max_len: int, temp: float, top_k: int, top_p: float -): - payload = { - "inputs": text, - "parameters": { - "max_new_tokens": max_len, - "top_k": top_k, - "top_p": top_p, - "temperature": temp, - "repetition_penalty": 2.0, - }, - "options": { - "use_cache": True, - }, - } - return query(payload, model_name) - - -# Page -st.set_page_config(page_title="Spanish GPT-2 Demo", page_icon=LOGO) -st.title("Spanish GPT-2") - - -# Sidebar -st.sidebar.image(LOGO) -st.sidebar.subheader("Configurable parameters") - -max_len = st.sidebar.number_input( - "Maximum length", - value=100, - help="The maximum length of the sequence to be generated.", -) - -temp = st.sidebar.slider( - "Temperature", - value=1.0, - min_value=0.1, - max_value=100.0, - help="The value used to module the next token probabilities.", -) - -top_k = st.sidebar.number_input( - "Top k", - value=10, - help="The number of highest probability vocabulary tokens to keep for top-k-filtering.", -) - -top_p = st.sidebar.number_input( - "Top p", - value=0.95, - help=" If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.", -) - -do_sample = st.sidebar.selectbox( - "Sampling?", - (True, False), - help="Whether or not to use sampling; use greedy decoding otherwise.", -) - - -# Body -st.markdown( - """ - Spanish GPT-2 models trained from scratch on two different datasets. One - model is trained on the Spanish portion of - [OSCAR](https://huggingface.co/datasets/viewer/?dataset=oscar) - and the other on the - [large_spanish_corpus](https://huggingface.co/datasets/viewer/?dataset=large_spanish_corpus) - aka BETO's corpus. - - The models are trained with Flax and using TPUs sponsored by Google since this is part of the - [Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) - organised by HuggingFace. - """ -) - -model_name = st.selectbox("Model", (list(MODELS.keys()))) - -ALL_PROMPTS = list(PROMPT_LIST.keys()) + ["Custom"] -prompt = st.selectbox("Prompt", ALL_PROMPTS, index=len(ALL_PROMPTS) - 1) -if prompt == "Custom": - prompt_box = "Enter your text here" -else: - prompt_box = random.choice(PROMPT_LIST[prompt]) - -text = st.text_area("Enter text", prompt_box) - -if st.button("Run"): - with st.spinner(text="Getting results..."): - st.subheader("Result") - print(f"maxlen:{max_len}, temp:{temp}, top_k:{top_k}, top_p:{top_p}") - result = process( - text=text, - model_name=model_name, - max_len=int(max_len), - temp=temp, - top_k=int(top_k), - top_p=float(top_p), - ) - print("result:", result) - if "error" in result: - if type(result["error"]) is str: - st.write(f'{result["error"]}.', end=" ") - if "estimated_time" in result: - st.write( - f'Please try again in about {result["estimated_time"]:.0f} seconds.' - ) - else: - if type(result["error"]) is list: - for error in result["error"]: - st.write(f"{error}") - else: - result = result[0]["generated_text"] - st.write(result.replace("\n", " \n")) - st.text("English translation") - st.write(translate(result, "en", "es").replace("\n", " \n")) - -st.markdown( - """ - ### Team members - - Manuel Romero ([mrm8488](https://huggingface.co/mrm8488)) - - María Grandury ([mariagrandury](https://huggingface.co/mariagrandury)) - - Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps)) - - Daniel Vera ([daveni](https://huggingface.co/daveni)) - - Sri Lakshmi ([srisweet](https://huggingface.co/srisweet)) - - José Posada ([jdposa](https://huggingface.co/jdposa)) - - Santiago Hincapie ([shpotes](https://huggingface.co/shpotes)) - - Jorge ([jorgealro](https://huggingface.co/jorgealro)) - - ### More information - You can find more information about these models in their cards: - - [Model trained on OSCAR](https://huggingface.co/models/flax-community/gpt-2-spanish) - - [Model trained on the Large Spanish Corpus](https://huggingface.co/mrm8488/spanish-gpt2) - """ -) diff --git a/spaces/freddyaboulton/3.1.4.9-all-demos/demos/live_with_vars/run.py b/spaces/freddyaboulton/3.1.4.9-all-demos/demos/live_with_vars/run.py deleted file mode 100644 index 70c39b36ccbfa1e1ad3239c4efadcdcb8fccbf14..0000000000000000000000000000000000000000 --- a/spaces/freddyaboulton/3.1.4.9-all-demos/demos/live_with_vars/run.py +++ /dev/null @@ -1,9 +0,0 @@ -import gradio as gr - -demo = gr.Interface( - lambda x, y: (x + y if y is not None else x, x + y if y is not None else x), - ["textbox", "state"], - ["textbox", "state"], live=True) - -if __name__ == "__main__": - demo.launch() diff --git a/spaces/fynn3003/image_to_text/app.py b/spaces/fynn3003/image_to_text/app.py deleted file mode 100644 index 07fc4f5710db0af94ab0d680a9de0ace80596475..0000000000000000000000000000000000000000 --- a/spaces/fynn3003/image_to_text/app.py +++ /dev/null @@ -1,34 +0,0 @@ -from transformers import VisionEncoderDecoderModel, ViTImageProcessor, AutoTokenizer -import torch -from PIL import Image -import gradio as gr -import numpy as np - -model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning") -feature_extractor = ViTImageProcessor.from_pretrained("nlpconnect/vit-gpt2-image-captioning") -tokenizer = AutoTokenizer.from_pretrained("nlpconnect/vit-gpt2-image-captioning") - -device = torch.device("cuda" if torch.cuda.is_available() else "cpu") -model.to(device) - -max_length = 16 -num_beams = 4 -gen_kwargs = {"max_length": max_length, "num_beams": num_beams} - -def predict_step(image): - i_image = Image.fromarray(np.uint8(image)) - if i_image.mode != "RGB": - i_image = i_image.convert(mode="RGB") - pixel_values = feature_extractor(images=i_image, return_tensors="pt").pixel_values - pixel_values = pixel_values.to(device) - output_ids = model.generate(pixel_values, **gen_kwargs) - preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True) - preds = [pred.strip() for pred in preds] - return preds - -iface = gr.Interface(fn=predict_step, - inputs=gr.inputs.Image(shape=(224, 224)), - outputs=gr.outputs.Textbox(label="Generated Caption")) - -iface.launch() - diff --git a/spaces/gangviolence/giftmediscordnitro/app.py b/spaces/gangviolence/giftmediscordnitro/app.py deleted file mode 100644 index 3703e2db0009fea1686d779101b431c47248e5e9..0000000000000000000000000000000000000000 --- a/spaces/gangviolence/giftmediscordnitro/app.py +++ /dev/null @@ -1,7 +0,0 @@ -import gradio as gr - -def greet(name): - return "Hello " + name + "!!" - -iface = gr.Interface(fn=greet, inputs="text", outputs="text") -iface.launch() diff --git a/spaces/geekyrakshit/enhance-me/enhance_me/mirnet/models/mirnet_model.py b/spaces/geekyrakshit/enhance-me/enhance_me/mirnet/models/mirnet_model.py deleted file mode 100644 index 0a46b04e0fc03e7278056855a1e796c5bde33341..0000000000000000000000000000000000000000 --- a/spaces/geekyrakshit/enhance-me/enhance_me/mirnet/models/mirnet_model.py +++ /dev/null @@ -1,13 +0,0 @@ -from tensorflow.keras import layers, Input, Model - -from .recursive_residual_blocks import recursive_residual_group - - -def build_mirnet_model(num_rrg, num_mrb, channels): - input_tensor = Input(shape=[None, None, 3]) - x1 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(input_tensor) - for _ in range(num_rrg): - x1 = recursive_residual_group(x1, num_mrb, channels) - conv = layers.Conv2D(3, kernel_size=(3, 3), padding="same")(x1) - output_tensor = layers.Add()([input_tensor, conv]) - return Model(input_tensor, output_tensor) diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/ade.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/ade.py deleted file mode 100644 index 5913e43775ed4920b6934c855eb5a37c54218ebf..0000000000000000000000000000000000000000 --- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/ade.py +++ /dev/null @@ -1,84 +0,0 @@ -from .builder import DATASETS -from .custom import CustomDataset - - -@DATASETS.register_module() -class ADE20KDataset(CustomDataset): - """ADE20K dataset. - - In segmentation map annotation for ADE20K, 0 stands for background, which - is not included in 150 categories. ``reduce_zero_label`` is fixed to True. - The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is fixed to - '.png'. - """ - CLASSES = ( - 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ', - 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth', - 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car', - 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug', - 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe', - 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column', - 'signboard', 'chest of drawers', 'counter', 'sand', 'sink', - 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path', - 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door', - 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table', - 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove', - 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar', - 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower', - 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver', - 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister', - 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van', - 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything', - 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent', - 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank', - 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake', - 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce', - 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen', - 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass', - 'clock', 'flag') - - PALETTE = [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50], - [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255], - [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7], - [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82], - [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3], - [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255], - [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220], - [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224], - [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255], - [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7], - [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153], - [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255], - [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0], - [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255], - [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255], - [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255], - [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0], - [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0], - [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255], - [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255], - [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20], - [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255], - [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255], - [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255], - [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0], - [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0], - [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255], - [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112], - [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160], - [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163], - [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0], - [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0], - [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255], - [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204], - [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255], - [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255], - [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194], - [102, 255, 0], [92, 0, 255]] - - def __init__(self, **kwargs): - super(ADE20KDataset, self).__init__( - img_suffix='.jpg', - seg_map_suffix='.png', - reduce_zero_label=True, - **kwargs) diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/models/losses/dice_loss.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/models/losses/dice_loss.py deleted file mode 100644 index 27a77b962d7d8b3079c7d6cd9db52280c6fb4970..0000000000000000000000000000000000000000 --- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/models/losses/dice_loss.py +++ /dev/null @@ -1,119 +0,0 @@ -"""Modified from https://github.com/LikeLy-Journey/SegmenTron/blob/master/ -segmentron/solver/loss.py (Apache-2.0 License)""" -import torch -import torch.nn as nn -import torch.nn.functional as F - -from ..builder import LOSSES -from .utils import get_class_weight, weighted_loss - - -@weighted_loss -def dice_loss(pred, - target, - valid_mask, - smooth=1, - exponent=2, - class_weight=None, - ignore_index=255): - assert pred.shape[0] == target.shape[0] - total_loss = 0 - num_classes = pred.shape[1] - for i in range(num_classes): - if i != ignore_index: - dice_loss = binary_dice_loss( - pred[:, i], - target[..., i], - valid_mask=valid_mask, - smooth=smooth, - exponent=exponent) - if class_weight is not None: - dice_loss *= class_weight[i] - total_loss += dice_loss - return total_loss / num_classes - - -@weighted_loss -def binary_dice_loss(pred, target, valid_mask, smooth=1, exponent=2, **kwards): - assert pred.shape[0] == target.shape[0] - pred = pred.reshape(pred.shape[0], -1) - target = target.reshape(target.shape[0], -1) - valid_mask = valid_mask.reshape(valid_mask.shape[0], -1) - - num = torch.sum(torch.mul(pred, target) * valid_mask, dim=1) * 2 + smooth - den = torch.sum(pred.pow(exponent) + target.pow(exponent), dim=1) + smooth - - return 1 - num / den - - -@LOSSES.register_module() -class DiceLoss(nn.Module): - """DiceLoss. - - This loss is proposed in `V-Net: Fully Convolutional Neural Networks for - Volumetric Medical Image Segmentation-Marrying Grounding DINO with GLIGEN for more Detailed Image Editing -
- -
-Icoms Billing System Manual maria gratisi gundam
Download Zip ➡ https://urlgoal.com/2uyLCp
-
- aaccfb2cb3
-
-
- diff --git a/spaces/gradio/HuBERT/examples/backtranslation/prepare-de-monolingual.sh b/spaces/gradio/HuBERT/examples/backtranslation/prepare-de-monolingual.sh deleted file mode 100644 index 5e67b2b3bcf27d3436031453e796e58a0ae79ec4..0000000000000000000000000000000000000000 --- a/spaces/gradio/HuBERT/examples/backtranslation/prepare-de-monolingual.sh +++ /dev/null @@ -1,98 +0,0 @@ -#!/bin/bash - -SCRIPTS=mosesdecoder/scripts -TOKENIZER=$SCRIPTS/tokenizer/tokenizer.perl -NORM_PUNC=$SCRIPTS/tokenizer/normalize-punctuation.perl -REM_NON_PRINT_CHAR=$SCRIPTS/tokenizer/remove-non-printing-char.perl -BPEROOT=subword-nmt/subword_nmt - - -BPE_CODE=wmt18_en_de/code -SUBSAMPLE_SIZE=25000000 -LANG=de - - -OUTDIR=wmt18_${LANG}_mono -orig=orig -tmp=$OUTDIR/tmp -mkdir -p $OUTDIR $tmp - - -URLS=( - "http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2007.de.shuffled.gz" - "http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2008.de.shuffled.gz" - "http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2009.de.shuffled.gz" - "http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2010.de.shuffled.gz" - "http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2011.de.shuffled.gz" - "http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2012.de.shuffled.gz" - "http://www.statmt.org/wmt14/training-monolingual-news-crawl/news.2013.de.shuffled.gz" - "http://www.statmt.org/wmt15/training-monolingual-news-crawl-v2/news.2014.de.shuffled.v2.gz" - "http://data.statmt.org/wmt16/translation-task/news.2015.de.shuffled.gz" - "http://data.statmt.org/wmt17/translation-task/news.2016.de.shuffled.gz" - "http://data.statmt.org/wmt18/translation-task/news.2017.de.shuffled.deduped.gz" -) -FILES=( - "news.2007.de.shuffled.gz" - "news.2008.de.shuffled.gz" - "news.2009.de.shuffled.gz" - "news.2010.de.shuffled.gz" - "news.2011.de.shuffled.gz" - "news.2012.de.shuffled.gz" - "news.2013.de.shuffled.gz" - "news.2014.de.shuffled.v2.gz" - "news.2015.de.shuffled.gz" - "news.2016.de.shuffled.gz" - "news.2017.de.shuffled.deduped.gz" -) - - -cd $orig -for ((i=0;i<${#URLS[@]};++i)); do - file=${FILES[i]} - if [ -f $file ]; then - echo "$file already exists, skipping download" - else - url=${URLS[i]} - wget "$url" - fi -done -cd .. - - -if [ -f $tmp/monolingual.${SUBSAMPLE_SIZE}.${LANG} ]; then - echo "found monolingual sample, skipping shuffle/sample/tokenize" -else - gzip -c -d -k $(for FILE in "${FILES[@]}"; do echo $orig/$FILE; done) \ - | shuf -n $SUBSAMPLE_SIZE \ - | perl $NORM_PUNC $LANG \ - | perl $REM_NON_PRINT_CHAR \ - | perl $TOKENIZER -threads 8 -a -l $LANG \ - > $tmp/monolingual.${SUBSAMPLE_SIZE}.${LANG} -fi - - -if [ -f $tmp/bpe.monolingual.${SUBSAMPLE_SIZE}.${LANG} ]; then - echo "found BPE monolingual sample, skipping BPE step" -else - python $BPEROOT/apply_bpe.py -c $BPE_CODE \ - < $tmp/monolingual.${SUBSAMPLE_SIZE}.${LANG} \ - > $tmp/bpe.monolingual.${SUBSAMPLE_SIZE}.${LANG} -fi - - -if [ -f $tmp/bpe.monolingual.dedup.${SUBSAMPLE_SIZE}.${LANG} ]; then - echo "found deduplicated monolingual sample, skipping deduplication step" -else - python deduplicate_lines.py $tmp/bpe.monolingual.${SUBSAMPLE_SIZE}.${LANG} \ - > $tmp/bpe.monolingual.dedup.${SUBSAMPLE_SIZE}.${LANG} -fi - - -if [ -f $OUTDIR/bpe.monolingual.dedup.00.de ]; then - echo "found sharded data, skipping sharding step" -else - split --lines 1000000 --numeric-suffixes \ - --additional-suffix .${LANG} \ - $tmp/bpe.monolingual.dedup.${SUBSAMPLE_SIZE}.${LANG} \ - $OUTDIR/bpe.monolingual.dedup. -fi diff --git a/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/model/SurfaceClassifier.py b/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/model/SurfaceClassifier.py deleted file mode 100644 index af5afe4fdd4767f72549df258e5b67dea6ac671d..0000000000000000000000000000000000000000 --- a/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/model/SurfaceClassifier.py +++ /dev/null @@ -1,71 +0,0 @@ -import torch -import torch.nn as nn -import torch.nn.functional as F - - -class SurfaceClassifier(nn.Module): - def __init__(self, filter_channels, num_views=1, no_residual=True, last_op=None): - super(SurfaceClassifier, self).__init__() - - self.filters = [] - self.num_views = num_views - self.no_residual = no_residual - filter_channels = filter_channels - self.last_op = last_op - - if self.no_residual: - for l in range(0, len(filter_channels) - 1): - self.filters.append(nn.Conv1d( - filter_channels[l], - filter_channels[l + 1], - 1)) - self.add_module("conv%d" % l, self.filters[l]) - else: - for l in range(0, len(filter_channels) - 1): - if 0 != l: - self.filters.append( - nn.Conv1d( - filter_channels[l] + filter_channels[0], - filter_channels[l + 1], - 1)) - else: - self.filters.append(nn.Conv1d( - filter_channels[l], - filter_channels[l + 1], - 1)) - - self.add_module("conv%d" % l, self.filters[l]) - - def forward(self, feature): - ''' - - :param feature: list of [BxC_inxHxW] tensors of image features - :param xy: [Bx3xN] tensor of (x,y) coodinates in the image plane - :return: [BxC_outxN] tensor of features extracted at the coordinates - ''' - - y = feature - tmpy = feature - for i, f in enumerate(self.filters): - if self.no_residual: - y = self._modules['conv' + str(i)](y) - else: - y = self._modules['conv' + str(i)]( - y if i == 0 - else torch.cat([y, tmpy], 1) - ) - if i != len(self.filters) - 1: - y = F.leaky_relu(y) - - if self.num_views > 1 and i == len(self.filters) // 2: - y = y.view( - -1, self.num_views, y.shape[1], y.shape[2] - ).mean(dim=1) - tmpy = feature.view( - -1, self.num_views, feature.shape[1], feature.shape[2] - ).mean(dim=1) - - if self.last_op: - y = self.last_op(y) - - return y diff --git a/spaces/grisuji/min_dog_classifier/README.md b/spaces/grisuji/min_dog_classifier/README.md deleted file mode 100644 index 2e2c396f58b1cfb7dd80ea321faeba92be5f37c7..0000000000000000000000000000000000000000 --- a/spaces/grisuji/min_dog_classifier/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Min Dog Classifier -emoji: ⚡ -colorFrom: gray -colorTo: red -sdk: gradio -sdk_version: 3.29.0 -app_file: app.py -pinned: false -license: apache-2.0 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/guanghap/nob-hill-noir/README.md b/spaces/guanghap/nob-hill-noir/README.md deleted file mode 100644 index 23932b16b390aa10369f66f9f6c0738440ef83fa..0000000000000000000000000000000000000000 --- a/spaces/guanghap/nob-hill-noir/README.md +++ /dev/null @@ -1,11 +0,0 @@ ---- -title: Nob Hill Noir -emoji: 🐨 -colorFrom: red -colorTo: purple -sdk: static -pinned: false -license: apache-2.0 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/gulabpatel/GFP_GAN/tests/test_utils.py b/spaces/gulabpatel/GFP_GAN/tests/test_utils.py deleted file mode 100644 index a963b3269dea05f9b7ec6c3db016e9a579c92fc8..0000000000000000000000000000000000000000 --- a/spaces/gulabpatel/GFP_GAN/tests/test_utils.py +++ /dev/null @@ -1,43 +0,0 @@ -import cv2 -from facexlib.utils.face_restoration_helper import FaceRestoreHelper - -from gfpgan.archs.gfpganv1_arch import GFPGANv1 -from gfpgan.archs.gfpganv1_clean_arch import GFPGANv1Clean -from gfpgan.utils import GFPGANer - - -def test_gfpganer(): - # initialize with the clean model - restorer = GFPGANer( - model_path='experiments/pretrained_models/GFPGANCleanv1-NoCE-C2.pth', - upscale=2, - arch='clean', - channel_multiplier=2, - bg_upsampler=None) - # test attribute - assert isinstance(restorer.gfpgan, GFPGANv1Clean) - assert isinstance(restorer.face_helper, FaceRestoreHelper) - - # initialize with the original model - restorer = GFPGANer( - model_path='experiments/pretrained_models/GFPGANv1.pth', - upscale=2, - arch='original', - channel_multiplier=1, - bg_upsampler=None) - # test attribute - assert isinstance(restorer.gfpgan, GFPGANv1) - assert isinstance(restorer.face_helper, FaceRestoreHelper) - - # ------------------ test enhance ---------------- # - img = cv2.imread('tests/data/gt/00000000.png', cv2.IMREAD_COLOR) - result = restorer.enhance(img, has_aligned=False, paste_back=True) - assert result[0][0].shape == (512, 512, 3) - assert result[1][0].shape == (512, 512, 3) - assert result[2].shape == (1024, 1024, 3) - - # with has_aligned=True - result = restorer.enhance(img, has_aligned=True, paste_back=False) - assert result[0][0].shape == (512, 512, 3) - assert result[1][0].shape == (512, 512, 3) - assert result[2] is None diff --git a/spaces/gyrojeff/YuzuMarker.FontDetection/font_dataset/font.py b/spaces/gyrojeff/YuzuMarker.FontDetection/font_dataset/font.py deleted file mode 100644 index aa5035d8af791723b2889b157ace9d84932b44fa..0000000000000000000000000000000000000000 --- a/spaces/gyrojeff/YuzuMarker.FontDetection/font_dataset/font.py +++ /dev/null @@ -1,70 +0,0 @@ -import yaml -import os -from typing import Dict -import pickle - - -from .utils import get_files - - -__all__ = ["load_fonts", "DSFont"] - - -class DSFont: - def __init__(self, path, language): - self.path = path - self.language = language - - -def load_fonts(config_path="configs/font.yml"): - with open(config_path, "r", encoding="utf-8") as f: - config = yaml.safe_load(f) - - ds_config = config["dataset"] - ds_path = ds_config["path"] - - font_list = [] - - for spec in ds_config["specs"]: - for spec_path in spec["path"]: - spec_path = os.path.join(ds_path, spec_path) - spec_files = get_files(spec_path) - - if spec.keys().__contains__("rule"): - rule = eval(spec["rule"]) - else: - rule = None - - for file in spec_files: - if rule is not None and not rule(file): - print("skip: " + file) - continue - font_list.append(DSFont(str(file).replace("\\", "/"), spec["language"])) - - font_list.sort(key=lambda x: x.path) - - exclusion_list = ds_config["exclusion"] - exclusion_list = [os.path.join(ds_path, path) for path in exclusion_list] - - def exclusion_rule(font: DSFont): - for exclusion in exclusion_list: - if os.path.samefile(font.path, exclusion): - return True - return False - - return font_list, exclusion_rule - - -def load_font_with_exclusion( - config_path="configs/font.yml", cache_path="font_list_cache.bin" -) -> Dict: - if os.path.exists(cache_path): - return pickle.load(open(cache_path, "rb")) - font_list, exclusion_rule = load_fonts(config_path) - font_list = list(filter(lambda x: not exclusion_rule(x), font_list)) - font_list.sort(key=lambda x: x.path) - print("font count: " + str(len(font_list))) - ret = {font_list[i].path: i for i in range(len(font_list))} - with open(cache_path, "wb") as f: - pickle.dump(ret, f) - return ret diff --git a/spaces/h1r41/OpenBuddy-Gradio/app.py b/spaces/h1r41/OpenBuddy-Gradio/app.py deleted file mode 100644 index c4d574a5e8c6c27d9c402e3d05ba17e93c0098c9..0000000000000000000000000000000000000000 --- a/spaces/h1r41/OpenBuddy-Gradio/app.py +++ /dev/null @@ -1,43 +0,0 @@ -import os -import gradio as gr -from llama_cpp import Llama -from huggingface_hub import hf_hub_download - -# Hugging FaceのAPIトークンを設定 -os.environ["HUGGINGFACE_TOKEN"] = os.getenv("HUGGINGFACE_TOKEN") - -model_name_or_path = "TheBloke/OpenBuddy-Llama2-13B-v11.1-GGUF" -model_basename = "openbuddy-llama2-13b-v11.1.Q2_K.gguf" - -model_path = hf_hub_download(repo_id=model_name_or_path, filename=model_basename, revision="main") -llama = Llama(model_path) - -def predict(message, history): - messages = [] - for human_content, system_content in history: - message_human = { - "role": "user", - "content": human_content + "\n", - } - message_system = { - "role": "system", - "content": system_content + "\n", - } - messages.append(message_human) - messages.append(message_system) - message_human = { - "role": "user", - "content": message + "\n", - } - messages.append(message_human) - # Llamaでの回答を取得(ストリーミングオン) - streamer = llama.create_chat_completion(messages, stream=True) - - partial_message = "" - for msg in streamer: - message = msg['choices'][0]['delta'] - if 'content' in message: - partial_message += message['content'] - yield partial_message - -gr.ChatInterface(predict).launch(enable_queue=True) diff --git a/spaces/h2oai/h2ogpt-chatbot/src/gradio_utils/grclient.py b/spaces/h2oai/h2ogpt-chatbot/src/gradio_utils/grclient.py deleted file mode 100644 index 8346a61cad99d492f8a10de17851454488364b83..0000000000000000000000000000000000000000 --- a/spaces/h2oai/h2ogpt-chatbot/src/gradio_utils/grclient.py +++ /dev/null @@ -1,82 +0,0 @@ -import traceback -from typing import Callable -import os - -from gradio_client.client import Job - -os.environ['HF_HUB_DISABLE_TELEMETRY'] = '1' - -from gradio_client import Client - - -class GradioClient(Client): - """ - Parent class of gradio client - To handle automatically refreshing client if detect gradio server changed - """ - - def __init__(self, *args, **kwargs): - self.args = args - self.kwargs = kwargs - super().__init__(*args, **kwargs) - self.server_hash = self.get_server_hash() - - def get_server_hash(self): - """ - Get server hash using super without any refresh action triggered - Returns: git hash of gradio server - """ - return super().submit(api_name='/system_hash').result() - - def refresh_client_if_should(self): - # get current hash in order to update api_name -> fn_index map in case gradio server changed - # FIXME: Could add cli api as hash - server_hash = self.get_server_hash() - if self.server_hash != server_hash: - self.refresh_client() - self.server_hash = server_hash - else: - self.reset_session() - - def refresh_client(self): - """ - Ensure every client call is independent - Also ensure map between api_name and fn_index is updated in case server changed (e.g. restarted with new code) - Returns: - """ - # need session hash to be new every time, to avoid "generator already executing" - self.reset_session() - - client = Client(*self.args, **self.kwargs) - for k, v in client.__dict__.items(): - setattr(self, k, v) - - def submit( - self, - *args, - api_name: str | None = None, - fn_index: int | None = None, - result_callbacks: Callable | list[Callable] | None = None, - ) -> Job: - # Note predict calls submit - try: - self.refresh_client_if_should() - job = super().submit(*args, api_name=api_name, fn_index=fn_index) - except Exception as e: - print("Hit e=%s" % str(e), flush=True) - # force reconfig in case only that - self.refresh_client() - job = super().submit(*args, api_name=api_name, fn_index=fn_index) - - # see if immediately failed - e = job.future._exception - if e is not None: - print("GR job failed: %s %s" % (str(e), ''.join(traceback.format_tb(e.__traceback__))), flush=True) - # force reconfig in case only that - self.refresh_client() - job = super().submit(*args, api_name=api_name, fn_index=fn_index) - e2 = job.future._exception - if e2 is not None: - print("GR job failed again: %s\n%s" % (str(e2), ''.join(traceback.format_tb(e2.__traceback__))), flush=True) - - return job diff --git a/spaces/hahahafofo/ChatGLM-Chinese-Summary/utils/llm.py b/spaces/hahahafofo/ChatGLM-Chinese-Summary/utils/llm.py deleted file mode 100644 index c950bc92e74b431443bcd30e8f7b95b1863cd80e..0000000000000000000000000000000000000000 --- a/spaces/hahahafofo/ChatGLM-Chinese-Summary/utils/llm.py +++ /dev/null @@ -1,50 +0,0 @@ -from textgen import ChatGlmModel, LlamaModel -from loguru import logger - - -class LLM(object): - def __init__( - self, - gen_model_type: str = "chatglm", - gen_model_name_or_path: str = "THUDM/chatglm-6b-int4", - lora_model_name_or_path: str = None, - - ): - - self.model_type = gen_model_type - - if gen_model_type == "chatglm": - self.gen_model = ChatGlmModel( - gen_model_type, - gen_model_name_or_path, - lora_name=lora_model_name_or_path, - ) - elif gen_model_type == "llama": - - self.gen_model = LlamaModel( - gen_model_type, - gen_model_name_or_path, - lora_name=lora_model_name_or_path, - ) - - else: - raise ValueError('gen_model_type must be chatglm or llama.') - self.history = None - - def generate_answer(self, query_str, context_str, history=None, max_length=1024, prompt_template=None): - """Generate answer from query and context.""" - if self.model_type == "t5": - response = self.gen_model(query_str, max_length=max_length, do_sample=True)[0]['generated_text'] - return response, history - prompt = prompt_template.format(context_str=context_str, query_str=query_str) - response, out_history = self.gen_model.chat(prompt, history, max_length=max_length) - return response, out_history - - def chat(self, query_str, history=None, max_length=1024): - if self.model_type == "t5": - response = self.gen_model(query_str, max_length=max_length, do_sample=True)[0]['generated_text'] - logger.debug(response) - return response, history - - response, out_history = self.gen_model.chat(query_str, history, max_length=max_length) - return response, out_history diff --git a/spaces/hamacojr/CAT-Seg/cat_seg/test_time_augmentation.py b/spaces/hamacojr/CAT-Seg/cat_seg/test_time_augmentation.py deleted file mode 100644 index 8d250b6bb7792b54ddeaaab62cc6c170d74d3bb9..0000000000000000000000000000000000000000 --- a/spaces/hamacojr/CAT-Seg/cat_seg/test_time_augmentation.py +++ /dev/null @@ -1,113 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -import copy -from itertools import count - -import numpy as np -import torch -from fvcore.transforms import HFlipTransform -from torch import nn -from torch.nn.parallel import DistributedDataParallel - -from detectron2.data.detection_utils import read_image -from detectron2.modeling import DatasetMapperTTA - -__all__ = [ - "SemanticSegmentorWithTTA", -] - - -class SemanticSegmentorWithTTA(nn.Module): - """ - A SemanticSegmentor with test-time augmentation enabled. - Its :meth:`__call__` method has the same interface as :meth:`SemanticSegmentor.forward`. - """ - - def __init__(self, cfg, model, tta_mapper=None, batch_size=1): - """ - Args: - cfg (CfgNode): - model (SemanticSegmentor): a SemanticSegmentor to apply TTA on. - tta_mapper (callable): takes a dataset dict and returns a list of - augmented versions of the dataset dict. Defaults to - `DatasetMapperTTA(cfg)`. - batch_size (int): batch the augmented images into this batch size for inference. - """ - super().__init__() - if isinstance(model, DistributedDataParallel): - model = model.module - self.cfg = cfg.clone() - - self.model = model - - if tta_mapper is None: - tta_mapper = DatasetMapperTTA(cfg) - self.tta_mapper = tta_mapper - self.batch_size = batch_size - - def _batch_inference(self, batched_inputs): - """ - Execute inference on a list of inputs, - using batch size = self.batch_size, instead of the length of the list. - Inputs & outputs have the same format as :meth:`SemanticSegmentor.forward` - """ - outputs = [] - inputs = [] - for idx, input in zip(count(), batched_inputs): - inputs.append(input) - if len(inputs) == self.batch_size or idx == len(batched_inputs) - 1: - with torch.no_grad(): - outputs.extend(self.model(inputs)) - inputs = [] - return outputs - - def __call__(self, batched_inputs): - """ - Same input/output format as :meth:`SemanticSegmentor.forward` - """ - - def _maybe_read_image(dataset_dict): - ret = copy.copy(dataset_dict) - if "image" not in ret: - image = read_image(ret.pop("file_name"), self.model.input_format) - image = torch.from_numpy(np.ascontiguousarray(image.transpose(2, 0, 1))) # CHW - ret["image"] = image - if "height" not in ret and "width" not in ret: - ret["height"] = image.shape[1] - ret["width"] = image.shape[2] - return ret - - return [self._inference_one_image(_maybe_read_image(x)) for x in batched_inputs] - - def _inference_one_image(self, input): - """ - Args: - input (dict): one dataset dict with "image" field being a CHW tensor - Returns: - dict: one output dict - """ - augmented_inputs, tfms = self._get_augmented_inputs(input) - # 1: forward with all augmented images - outputs = self._batch_inference(augmented_inputs) - # Delete now useless variables to avoid being out of memory - del augmented_inputs - # 2: merge the results - # handle flip specially - new_outputs = [] - for output, tfm in zip(outputs, tfms): - if any(isinstance(t, HFlipTransform) for t in tfm.transforms): - new_outputs.append(output.pop("sem_seg").flip(dims=[2])) - else: - new_outputs.append(output.pop("sem_seg")) - del outputs - # to avoid OOM with torch.stack - final_predictions = new_outputs[0] - for i in range(1, len(new_outputs)): - final_predictions += new_outputs[i] - final_predictions = final_predictions / len(new_outputs) - del new_outputs - return {"sem_seg": final_predictions} - - def _get_augmented_inputs(self, input): - augmented_inputs = self.tta_mapper(input) - tfms = [x.pop("transforms") for x in augmented_inputs] - return augmented_inputs, tfms diff --git a/spaces/hamelcubsfan/AutoGPT/autogpt/speech/say.py b/spaces/hamelcubsfan/AutoGPT/autogpt/speech/say.py deleted file mode 100644 index 727983d12bf334205550a54bcd69a7a36824eda4..0000000000000000000000000000000000000000 --- a/spaces/hamelcubsfan/AutoGPT/autogpt/speech/say.py +++ /dev/null @@ -1,41 +0,0 @@ -""" Text to speech module """ -import threading -from threading import Semaphore - -from autogpt.config import Config -from autogpt.speech.brian import BrianSpeech -from autogpt.speech.eleven_labs import ElevenLabsSpeech -from autogpt.speech.gtts import GTTSVoice -from autogpt.speech.macos_tts import MacOSTTS - -CFG = Config() -DEFAULT_VOICE_ENGINE = GTTSVoice() -VOICE_ENGINE = None -if CFG.elevenlabs_api_key: - VOICE_ENGINE = ElevenLabsSpeech() -elif CFG.use_mac_os_tts == "True": - VOICE_ENGINE = MacOSTTS() -elif CFG.use_brian_tts == "True": - VOICE_ENGINE = BrianSpeech() -else: - VOICE_ENGINE = GTTSVoice() - - -QUEUE_SEMAPHORE = Semaphore( - 1 -) # The amount of sounds to queue before blocking the main thread - - -def say_text(text: str, voice_index: int = 0) -> None: - """Speak the given text using the given voice index""" - - def speak() -> None: - success = VOICE_ENGINE.say(text, voice_index) - if not success: - DEFAULT_VOICE_ENGINE.say(text) - - QUEUE_SEMAPHORE.release() - - QUEUE_SEMAPHORE.acquire(True) - thread = threading.Thread(target=speak) - thread.start() diff --git a/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/modeling/roi_heads/box_head/roi_box_predictors.py b/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/modeling/roi_heads/box_head/roi_box_predictors.py deleted file mode 100644 index e05fcbb1d7aec374414fd0552cb7f4d79bd63053..0000000000000000000000000000000000000000 --- a/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/modeling/roi_heads/box_head/roi_box_predictors.py +++ /dev/null @@ -1,62 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved. -from torch import nn - - -class FastRCNNPredictor(nn.Module): - def __init__(self, config, pretrained=None): - super(FastRCNNPredictor, self).__init__() - - stage_index = 4 - stage2_relative_factor = 2 ** (stage_index - 1) - res2_out_channels = config.MODEL.RESNETS.RES2_OUT_CHANNELS - num_inputs = res2_out_channels * stage2_relative_factor - - num_classes = config.MODEL.ROI_BOX_HEAD.NUM_CLASSES - self.avgpool = nn.AvgPool2d(kernel_size=7, stride=7) - self.cls_score = nn.Linear(num_inputs, num_classes) - self.bbox_pred = nn.Linear(num_inputs, num_classes * 4) - - nn.init.normal_(self.cls_score.weight, mean=0, std=0.01) - nn.init.constant_(self.cls_score.bias, 0) - - nn.init.normal_(self.bbox_pred.weight, mean=0, std=0.001) - nn.init.constant_(self.bbox_pred.bias, 0) - - def forward(self, x): - x = self.avgpool(x) - x = x.view(x.size(0), -1) - cls_logit = self.cls_score(x) - bbox_pred = self.bbox_pred(x) - return cls_logit, bbox_pred - - -class FPNPredictor(nn.Module): - def __init__(self, cfg): - super(FPNPredictor, self).__init__() - num_classes = cfg.MODEL.ROI_BOX_HEAD.NUM_CLASSES - representation_size = cfg.MODEL.ROI_BOX_HEAD.MLP_HEAD_DIM - - self.cls_score = nn.Linear(representation_size, num_classes) - self.bbox_pred = nn.Linear(representation_size, num_classes * 4) - - nn.init.normal_(self.cls_score.weight, std=0.01) - nn.init.normal_(self.bbox_pred.weight, std=0.001) - for l in [self.cls_score, self.bbox_pred]: - nn.init.constant_(l.bias, 0) - - def forward(self, x): - scores = self.cls_score(x) - bbox_deltas = self.bbox_pred(x) - - return scores, bbox_deltas - - -_ROI_BOX_PREDICTOR = { - "FastRCNNPredictor": FastRCNNPredictor, - "FPNPredictor": FPNPredictor, -} - - -def make_roi_box_predictor(cfg): - func = _ROI_BOX_PREDICTOR[cfg.MODEL.ROI_BOX_HEAD.PREDICTOR] - return func(cfg) diff --git a/spaces/hasibzunair/fifa-tryon-demo/options/test_options.py b/spaces/hasibzunair/fifa-tryon-demo/options/test_options.py deleted file mode 100644 index 88a50551a110f275ccd472cbc60e283e756ef638..0000000000000000000000000000000000000000 --- a/spaces/hasibzunair/fifa-tryon-demo/options/test_options.py +++ /dev/null @@ -1,31 +0,0 @@ -from .base_options import BaseOptions - - -class TestOptions(BaseOptions): - def initialize(self): - BaseOptions.initialize(self) - self.parser.add_argument( - '--ntest', type=int, default=float("inf"), help='# of test examples.') - self.parser.add_argument( - '--results_dir', type=str, default='./results/', help='saves results here.') - self.parser.add_argument( - '--aspect_ratio', type=float, default=1.0, help='aspect ratio of result images') - self.parser.add_argument( - '--phase', type=str, default='test', help='train, val, test, etc') - self.parser.add_argument('--which_epoch', type=str, default='latest', - help='which epoch to load? set to latest to use latest cached model') - self.parser.add_argument( - '--how_many', type=int, default=1000, help='how many test images to run') - self.parser.add_argument('--serial_batches', action='store_false', - help='if true, takes images in order to make batches, otherwise takes them randomly') - self.parser.add_argument('--cluster_path', type=str, default='features_clustered_010.npy', - help='the path for clustered results of encoded features') - self.parser.add_argument('--use_encoded_image', action='store_true', - help='if specified, encode the real image to get the feature map') - self.parser.add_argument( - "--export_onnx", type=str, help="export ONNX model to a given file") - self.parser.add_argument("--engine", type=str, - help="run serialized TRT engine") - self.parser.add_argument( - "--onnx", type=str, help="run ONNX model via TRT") - self.isTrain = False diff --git a/spaces/hca97/Mosquito-Detection/my_models/torch_hub_cache/yolov5/utils/flask_rest_api/README.md b/spaces/hca97/Mosquito-Detection/my_models/torch_hub_cache/yolov5/utils/flask_rest_api/README.md deleted file mode 100644 index a726acbd92043458311dd949cc09c0195cd35400..0000000000000000000000000000000000000000 --- a/spaces/hca97/Mosquito-Detection/my_models/torch_hub_cache/yolov5/utils/flask_rest_api/README.md +++ /dev/null @@ -1,73 +0,0 @@ -# Flask REST API - -[REST](https://en.wikipedia.org/wiki/Representational_state_transfer) [API](https://en.wikipedia.org/wiki/API)s are -commonly used to expose Machine Learning (ML) models to other services. This folder contains an example REST API -created using Flask to expose the YOLOv5s model from [PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5/). - -## Requirements - -[Flask](https://palletsprojects.com/p/flask/) is required. Install with: - -```shell -$ pip install Flask -``` - -## Run - -After Flask installation run: - -```shell -$ python3 restapi.py --port 5000 -``` - -Then use [curl](https://curl.se/) to perform a request: - -```shell -$ curl -X POST -F image=@zidane.jpg 'http://localhost:5000/v1/object-detection/yolov5s' -``` - -The model inference results are returned as a JSON response: - -```json -[ - { - "class": 0, - "confidence": 0.8900438547, - "height": 0.9318675399, - "name": "person", - "width": 0.3264600933, - "xcenter": 0.7438579798, - "ycenter": 0.5207948685 - }, - { - "class": 0, - "confidence": 0.8440024257, - "height": 0.7155083418, - "name": "person", - "width": 0.6546785235, - "xcenter": 0.427829951, - "ycenter": 0.6334488392 - }, - { - "class": 27, - "confidence": 0.3771208823, - "height": 0.3902671337, - "name": "tie", - "width": 0.0696444362, - "xcenter": 0.3675483763, - "ycenter": 0.7991207838 - }, - { - "class": 27, - "confidence": 0.3527112305, - "height": 0.1540903747, - "name": "tie", - "width": 0.0336618312, - "xcenter": 0.7814827561, - "ycenter": 0.5065554976 - } -] -``` - -An example python script to perform inference using [requests](https://docs.python-requests.org/en/master/) is given -in `example_request.py` diff --git a/spaces/hudsonhayes/PerformanceSummarisation/app.py b/spaces/hudsonhayes/PerformanceSummarisation/app.py deleted file mode 100644 index 3f3ef3ae4bfa834f329689f85d240a83e5be9581..0000000000000000000000000000000000000000 --- a/spaces/hudsonhayes/PerformanceSummarisation/app.py +++ /dev/null @@ -1,664 +0,0 @@ -import openai -import os -import pdfplumber -from langchain.chains.mapreduce import MapReduceChain -from langchain.text_splitter import CharacterTextSplitter -from langchain.chains.summarize import load_summarize_chain -from langchain.chat_models import ChatOpenAI -from langchain.document_loaders import UnstructuredFileLoader -from langchain.prompts import PromptTemplate -import logging -import json -from typing import List -import mimetypes -import validators -import requests -import tempfile -from bs4 import BeautifulSoup -from langchain.chains import create_extraction_chain -from GoogleNews import GoogleNews -import pandas as pd -import requests -import gradio as gr -import re -from langchain.document_loaders import WebBaseLoader -from langchain.chains.llm import LLMChain -from langchain.chains.combine_documents.stuff import StuffDocumentsChain -from transformers import pipeline -import plotly.express as px -import yfinance as yf -import pandas as pd -import nltk -from nltk.tokenize import sent_tokenize - -class KeyValueExtractor: - - def __init__(self): - - """ - Initialize the ContractSummarizer object. - Parameters: - pdf_file_path (str): The path to the input PDF file. - """ - self.model = "facebook/bart-large-mnli" - - def get_news(self,keyword): - - googlenews = GoogleNews(lang='en', region='US', period='1d', encode='utf-8') - googlenews.clear() - googlenews.search(keyword) - googlenews.get_page(2) - news_result = googlenews.result(sort=True) - news_data_df = pd.DataFrame.from_dict(news_result) - - news_data_df.info() - - # Display header of dataframe. - news_data_df.head() - - tot_news_link = [] - for index, headers in news_data_df.iterrows(): - news_link = str(headers['link']) - tot_news_link.append(news_link) - - return tot_news_link - - def url_format(self,urls): - - tot_url_links = [] - for url_text in urls: - # Define a regex pattern to match URLs starting with 'http' or 'https' - pattern = r'(https?://[^\s]+)' - - # Search for the URL in the text using the regex pattern - match = re.search(pattern, url_text) - - if match: - extracted_url = match.group(1) - tot_url_links.append(extracted_url) - - else: - print("No URL found in the given text.") - - return tot_url_links - - def clear_error_ulr(self,urls): - - error_url = [] - for url in urls: - if validators.url(url): - headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',} - r = requests.get(url,headers=headers) - if r.status_code != 200: - # raise ValueError("Check the url of your file; returned status code %s" % r.status_code) - print(f"Error fetching {url}:") - error_url.append(url) - continue - cleaned_list_url = [item for item in urls if item not in error_url] - return cleaned_list_url - - def get_each_link_summary(self,urls): - - each_link_summary = "" - - for url in urls: - loader = WebBaseLoader(url) - docs = loader.load() - text_splitter = CharacterTextSplitter.from_tiktoken_encoder( - chunk_size=3000, chunk_overlap=200 - ) - - # Split the documents into chunks - split_docs = text_splitter.split_documents(docs) - - # Prepare the prompt template for summarization - prompt_template = """Write a concise summary of the following: - {text} - CONCISE SUMMARY:""" - prompt = PromptTemplate.from_template(prompt_template) - - # Prepare the template for refining the summary with additional context - refine_template = ( - "Your job is to produce a final summary\n" - "We have provided an existing summary up to a certain point: {existing_answer}\n" - "We have the opportunity to refine the existing summary" - "(only if needed) with some more context below.\n" - "------------\n" - "{text}\n" - "------------\n" - "Given the new context, refine the original summary" - "If the context isn't useful, return the original summary." - ) - refine_prompt = PromptTemplate.from_template(refine_template) - - # Load the summarization chain using the ChatOpenAI language model - chain = load_summarize_chain( - llm = ChatOpenAI(temperature=0), - chain_type="refine", - question_prompt=prompt, - refine_prompt=refine_prompt, - return_intermediate_steps=True, - input_key="input_documents", - output_key="output_text", - ) - - # Generate the refined summary using the loaded summarization chain - result = chain({"input_documents": split_docs}, return_only_outputs=True) - print(result["output_text"]) - - # Return the refined summary - each_link_summary = each_link_summary + result["output_text"] - - return each_link_summary - - def save_text_to_file(self,each_link_summary) -> str: - - """ - Load the text from the saved file and split it into documents. - Returns: - List[str]: List of document texts. - """ - - # Get the path to the text file where the extracted text will be saved - file_path = "extracted_text.txt" - try: - with open(file_path, 'w') as file: - # Write the extracted text into the text file - file.write(each_link_summary) - # Return the file path of the saved text file - return file_path - except IOError as e: - # If an IOError occurs during the file saving process, log the error - logging.error(f"Error while saving text to file: {e}") - - def document_loader(self,file_path) -> List[str]: - - """ - Load the text from the saved file and split it into documents. - Returns: - List[str]: List of document texts. - """ - - # Initialize the UnstructuredFileLoader - loader = UnstructuredFileLoader(file_path, strategy="fast") - # Load the documents from the file - docs = loader.load() - - # Return the list of loaded document texts - return docs - - def document_text_spilliter(self,docs) -> List[str]: - - """ - Split documents into chunks for efficient processing. - Returns: - List[str]: List of split document chunks. - """ - - # Initialize the text splitter with specified chunk size and overlap - text_splitter = CharacterTextSplitter.from_tiktoken_encoder( - chunk_size=3000, chunk_overlap=200 - ) - - # Split the documents into chunks - split_docs = text_splitter.split_documents(docs) - - # Return the list of split document chunks - return split_docs - - def extract_key_value_pair_for_news(self,content) -> None: - - """ - Extract key-value pairs from the refined summary. - Prints the extracted key-value pairs. - """ - - try: - - # Use OpenAI's Completion API to analyze the text and extract key-value pairs - response = openai.Completion.create( - engine="text-davinci-003", # You can choose a different engine as well - temperature = 0, - prompt=f"Get maximum count meaningfull key value pairs. content in backticks.```{content}```.", - max_tokens=1000 # You can adjust the length of the response - ) - - # Extract and return the chatbot's reply - result = response['choices'][0]['text'].strip() - return result - except Exception as e: - # If an error occurs during the key-value extraction process, log the error - logging.error(f"Error while extracting key-value pairs: {e}") - print("Error:", e) - - def refine_summary(self,split_docs) -> str: - - """ - Refine the summary using the provided context. - Returns: - str: Refined summary. - """ - - # Prepare the prompt template for summarization - prompt_template = """Write a detalied broad abractive summary of the following: - {text} - CONCISE SUMMARY:""" - prompt = PromptTemplate.from_template(prompt_template) - - # Prepare the template for refining the summary with additional context - refine_template = ( - "Your job is to produce a final summary\n" - "We have provided an existing summary up to a certain point: {existing_answer}\n" - "We have the opportunity to refine the existing summary" - "(only if needed) with some more context below.\n" - "------------\n" - "{text}\n" - "------------\n" - "Given the new context, refine the original summary" - "If the context isn't useful, return the original summary." - ) - refine_prompt = PromptTemplate.from_template(refine_template) - - # Load the summarization chain using the ChatOpenAI language model - chain = load_summarize_chain( - llm = ChatOpenAI(temperature=0), - chain_type="refine", - question_prompt=prompt, - refine_prompt=refine_prompt, - return_intermediate_steps=True, - input_key="input_documents", - output_key="output_text", - ) - - # Generate the refined summary using the loaded summarization chain - result = chain({"input_documents": split_docs}, return_only_outputs=True) - - key_value_pair = self.extract_key_value_pair_for_news(result["output_text"]) - - # Return the refined summary - return result["output_text"],key_value_pair - - def analyze_sentiment_for_graph(self, text): - - pipe = pipeline("zero-shot-classification", model=self.model) - label=["Positive", "Negative", "Neutral"] - result = pipe(text, label) - sentiment_scores = { - result['labels'][0]: result['scores'][0], - result['labels'][1]: result['scores'][1], - result['labels'][2]: result['scores'][2] - } - return sentiment_scores - - def display_graph_for_news(self,text): - - sentiment_scores = self.analyze_sentiment_for_graph(text) - labels = sentiment_scores.keys() - scores = sentiment_scores.values() - fig = px.bar(x=scores, y=labels, orientation='h', color=labels, color_discrete_map={"Negative": "red", "Positive": "green", "Neutral": "gray"}) - fig.update_traces(texttemplate='%{x:.1%}', textposition='outside',textfont=dict(size=6)) - fig.update_layout(title="Sentiment Analysis",width=600) - - formatted_pairs = [] - for key, value in sentiment_scores.items(): - formatted_value = round(value, 2) # Round the value to two decimal places - formatted_pairs.append(f"{key} : {formatted_value}") - - result_string = '\t'.join(formatted_pairs) - - return fig - - def main_for_news(self,keyword): - - try: - urls = self.get_news(keyword) - tot_urls = self.url_format(urls) - clean_url = self.clear_error_ulr(tot_urls) - each_link_summary = self.get_each_link_summary(clean_url) - print("half") - file_path = self.save_text_to_file(each_link_summary) - docs = self.document_loader(file_path) - split_docs = self.document_text_spilliter(docs) - print("half1") - result_summary_for_news,key_value_pair_for_news = self.refine_summary(split_docs) - fig = self.display_graph_for_news(result_summary_for_news) - - return result_summary_for_news,key_value_pair_for_news,fig - except: - return "Sorry No URL Found!! Please Try Again","",None - - - def get_url(self,keyword): - - return f"https://finance.yahoo.com/quote/{keyword}?p={keyword}" - - def get_link_summary_for_finance(self,url): - - loader = WebBaseLoader(url) - docs = loader.load() - text_splitter = CharacterTextSplitter.from_tiktoken_encoder( - chunk_size=3000, chunk_overlap=200 - ) - - # Split the documents into chunks - split_docs = text_splitter.split_documents(docs) - - # Prepare the prompt template for summarization - prompt_template = """The give text is Finance Stock Details for one company i want to get values for - Previous Close : [value] - Open : [value] - Bid : [value] - Ask : [value] - Day's Range : [value] - 52 Week Range : [value] - Volume : [value] - Avg. Volume : [value] - Market Cap : [value] - Beta (5Y Monthly) : [value] - PE Ratio (TTM) : [value] - EPS (TTM) : [value] - Earnings Date : [value] - Forward Dividend & Yield : [value] - Ex-Dividend Date : [value] - 1y Target Est : [value] - these details form that and Write a abractive summary about those details: - Given Text: {text} - CONCISE SUMMARY:""" - prompt = PromptTemplate.from_template(prompt_template) - - # Prepare the template for refining the summary with additional context - refine_template = ( - "Your job is to produce a final summary\n" - "We have provided an existing summary up to a certain point: {existing_answer}\n" - "We have the opportunity to refine the existing summary" - "(only if needed) with some more context below.\n" - "------------\n" - "{text}\n" - "------------\n" - "Given the new context, refine the original summary" - "If the context isn't useful, return the original summary." - ) - refine_prompt = PromptTemplate.from_template(refine_template) - - # Load the summarization chain using the ChatOpenAI language model - chain = load_summarize_chain( - llm = ChatOpenAI(temperature=0), - chain_type="refine", - question_prompt=prompt, - refine_prompt=refine_prompt, - return_intermediate_steps=True, - input_key="input_documents", - output_key="output_text", - ) - - # Generate the refined summary using the loaded summarization chain - result = chain({"input_documents": split_docs}, return_only_outputs=True) - print(result["output_text"]) - - return result["output_text"] - - def one_day_summary_finance(self,content) -> None: - - # Use OpenAI's Completion API to analyze the text and extract key-value pairs - response = openai.Completion.create( - engine="text-davinci-003", # You can choose a different engine as well - temperature = 0, - prompt=f"i want detailed Summary from given finance details. i want information like what happen today comparing last day good or bad Bullish or Bearish like these details i want summary. content in backticks.```{content}```.", - max_tokens=1000 # You can adjust the length of the response - ) - - # Extract and return the chatbot's reply - result = response['choices'][0]['text'].strip() - print(result) - return result - - def extract_key_value_pair_for_finance(self,content) -> None: - - """ - Extract key-value pairs from the refined summary. - Prints the extracted key-value pairs. - """ - - try: - - # Use OpenAI's Completion API to analyze the text and extract key-value pairs - response = openai.Completion.create( - engine="text-davinci-003", # You can choose a different engine as well - temperature = 0, - prompt=f"Get maximum count meaningfull key value pairs. content in backticks.```{content}```.", - max_tokens=1000 # You can adjust the length of the response - ) - - # Extract and return the chatbot's reply - result = response['choices'][0]['text'].strip() - return result - except Exception as e: - # If an error occurs during the key-value extraction process, log the error - logging.error(f"Error while extracting key-value pairs: {e}") - print("Error:", e) - - def analyze_sentiment_for_graph_finance(self, text): - - pipe = pipeline("zero-shot-classification", model=self.model) - label=["Positive", "Negative", "Neutral"] - result = pipe(text, label) - sentiment_scores = { - result['labels'][0]: result['scores'][0], - result['labels'][1]: result['scores'][1], - result['labels'][2]: result['scores'][2] - } - return sentiment_scores - - def display_graph_for_finance(self,text): - - sentiment_scores = self.analyze_sentiment_for_graph_finance(text) - labels = sentiment_scores.keys() - scores = sentiment_scores.values() - fig = px.bar(x=scores, y=labels, orientation='h', color=labels, color_discrete_map={"Negative": "red", "Positive": "green", "Neutral": "gray"}) - fig.update_traces(texttemplate='%{x:.1%}', textposition='outside',textfont=dict(size=6)) - fig.update_layout(title="Sentiment Analysis",width=600) - - formatted_pairs = [] - for key, value in sentiment_scores.items(): - formatted_value = round(value, 2) # Round the value to two decimal places - formatted_pairs.append(f"{key} : {formatted_value}") - - result_string = '\t'.join(formatted_pairs) - - return fig - - def get_finance_data(self,symbol): - - # Define the stock symbol and date range - start_date = '2022-08-19' - end_date = '2023-08-19' - - # Fetch historical OHLC data using yfinance - data = yf.download(symbol, start=start_date, end=end_date) - - # Select only the OHLC columns - ohlc_data = data[['Open', 'High', 'Low', 'Close']] - - csv_path = "ohlc_data.csv" - # Save the OHLC data to a CSV file - ohlc_data.to_csv(csv_path) - return csv_path - - def csv_to_dataframe(self,csv_path): - - # Replace 'your_file.csv' with the actual path to your CSV file - csv_file_path = csv_path - # Read the CSV file into a DataFrame - df = pd.read_csv(csv_file_path) - # Now you can work with the 'df' DataFrame - return df # Display the first few rows of the DataFrame - - def save_dataframe_in_text_file(self,df): - - output_file_path = 'output.txt' - - # Convert the DataFrame to a text file - df.to_csv(output_file_path, sep='\t', index=False) - - return output_file_path - - def csv_loader(self,output_file_path): - - loader = UnstructuredFileLoader(output_file_path, strategy="fast") - docs = loader.load() - - return docs - - def document_text_spilliter_finance(self,docs): - - """ - Split documents into chunks for efficient processing. - Returns: - List[str]: List of split document chunks. - """ - - # Initialize the text splitter with specified chunk size and overlap - text_splitter = CharacterTextSplitter.from_tiktoken_encoder( - chunk_size=1000, chunk_overlap=200 - ) - - # Split the documents into chunks - split_docs = text_splitter.split_documents(docs) - - # Return the list of split document chunks - return split_docs - - def change_bullet_points(self,text): - - nltk.download('punkt') # Download the sentence tokenizer data (only need to run this once) - - # Example passage - passage = text - - # Tokenize the passage into sentences - sentences = sent_tokenize(passage) - bullet_string = "" - # Print the extracted sentences - for sentence in sentences: - bullet_string+="* "+sentence+"\n" - - return bullet_string - - def one_year_summary_for_finance(self,keyword): - - csv_path = self.get_finance_data(keyword) - df = self.csv_to_dataframe(csv_path) - output_file_path = self.save_dataframe_in_text_file(df) - docs = self.csv_loader(output_file_path) - split_docs = self.document_text_spilliter(docs) - - prompt_template = """Analyze the Financial Details and Write a abractive quick short summary how the company perform up and down,Bullish/Bearish of the following: - {text} - CONCISE SUMMARY:""" - prompt = PromptTemplate.from_template(prompt_template) - - # Prepare the template for refining the summary with additional context - refine_template = ( - "Your job is to produce a final summary\n" - "We have provided an existing summary up to a certain point: {existing_answer}\n" - "We have the opportunity to refine the existing summary" - "(only if needed) with some more context below.\n" - "------------\n" - "{text}\n" - "------------\n" - "Given the new context, refine the original summary" - "If the context isn't useful, return the original summary." - "10 line summary is enough" - ) - refine_prompt = PromptTemplate.from_template(refine_template) - - # Load the summarization chain using the ChatOpenAI language model - chain = load_summarize_chain( - llm = ChatOpenAI(temperature=0), - chain_type="refine", - question_prompt=prompt, - refine_prompt=refine_prompt, - return_intermediate_steps=True, - input_key="input_documents", - output_key="output_text", - ) - - # Generate the refined summary using the loaded summarization chain - result = chain({"input_documents": split_docs}, return_only_outputs=True) - one_year_perfomance_summary = self.change_bullet_points(result["output_text"]) - plot_for_year = self.display_graph_for_finance(one_year_perfomance_summary) - # Return the refined summary - return one_year_perfomance_summary, plot_for_year - - def main_for_finance_tool(self,keyword): - - - clean_url = self.get_url(keyword) - link_summary = self.get_link_summary_for_finance(clean_url) - clean_summary = self.one_day_summary_finance(link_summary) - key_value = self.extract_key_value_pair_for_finance(clean_summary) - sentiment_plot_for_one_day = self.display_graph_for_finance(clean_summary) - - return clean_summary, key_value, sentiment_plot_for_one_day - - def company_names(self,input_text): - words = input_text.split("-") - return words[1] - def clear(self,input_news,result_summary_for_news,key_value_pair_result_for_news,sentiment_plot): - input_news = None - result_summary_for_news = None - key_value_pair_result_for_news = None - sentiment_plot = None - return input_news,result_summary_for_news,key_value_pair_result_for_news,sentiment_plot - - def gradio_interface(self): - - with gr.Blocks(css="style.css",theme= 'karthikeyan-adople/hudsonhayes-gray') as app: - gr.HTML("""-

Company performance summarisation and sentiment analysis
- - """) - chatbot = gr.Chatbot(label='ChatYuan') - message = gr.Textbox() - state = gr.State() - message.submit(chatyuan_bot, inputs=[message, state], outputs=[chatbot, state]) - with gr.Row(): - clear_history = gr.Button("👋 清除历史对话 | Clear History") - clear = gr.Button('🧹 清除发送框 | Clear Input') - send = gr.Button("🚀 发送 | Send") - regenerate = gr.Button("🚀 重新生成本次结果 | regenerate") - - - regenerate.click(chatyuan_bot_regenerate, inputs=[message, state], outputs=[chatbot, state]) - send.click(chatyuan_bot, inputs=[message, state], outputs=[chatbot, state]) - clear.click(lambda: None, None, message, queue=False) - clear_history.click(fn=clear_session , inputs=[], outputs=[chatbot, state], queue=False) - - -def ChatYuan(api_key, text_prompt): - - cl = clueai.Client(api_key, - check_api_key=True) - # generate a prediction for a prompt - # 需要返回得分的话,指定return_likelihoods="GENERATION" - prediction = cl.generate(model_name='ChatYuan-large', prompt=text_prompt) - # print the predicted text - #print('prediction: {}'.format(prediction.generations[0].text)) - response = prediction.generations[0].text - if response == '': - response = "很抱歉,我无法回答这个问题" - - return response - -def chatyuan_bot_api(api_key, input, history): - history = history or [] - - if len(history) > 5: - history = history[-5:] - - context = "\n".join([f"用户:{input_text}\n小元:{answer_text}" for input_text, answer_text in history]) - #print(context) - - input_text = context + "\n用户:" + input + "\n小元:" - input_text = input_text.strip() - output_text = ChatYuan(api_key, input_text) - print("api".center(20, "=")) - print(f"api_key:{api_key}\n{input_text}\n{output_text}") - #print("="*20) - history.append((input, output_text)) - #print(history) - return history, history - - - -block = gr.Blocks() - -with block as demo_1: - gr.Markdown(""" - """) - api_key = gr.inputs.Textbox(label="请输入你的api-key(必填)", default="", type='password') - chatbot = gr.Chatbot(label='ChatYuan') - message = gr.Textbox() - state = gr.State() - message.submit(chatyuan_bot_api, inputs=[api_key,message, state], outputs=[chatbot, state]) - with gr.Row(): - clear_history = gr.Button("👋 清除历史对话 | Clear Context") - clear = gr.Button('🧹 清除发送框 | Clear Input') - send = gr.Button("🚀 发送 | Send") - - send.click(chatyuan_bot_api, inputs=[api_key,message, state], outputs=[chatbot, state],api_name='send') - clear.click(lambda: None, None, message, queue=False) - clear_history.click(fn=clear_session , inputs=[], outputs=[chatbot, state], queue=False) - -block = gr.Blocks() -with block as introduction: - gr.Markdown("""啥也没有 - """) - - -gui = gr.TabbedInterface(interface_list=[demo], tab_names=["开源模型"]) -gui.launch(quiet=True,show_api=True, share = False) \ No newline at end of file diff --git a/spaces/hylee/photo2cartoon/p2c/utils/utils.py b/spaces/hylee/photo2cartoon/p2c/utils/utils.py deleted file mode 100644 index 9ceb869662722da49ce843142ce150379b451819..0000000000000000000000000000000000000000 --- a/spaces/hylee/photo2cartoon/p2c/utils/utils.py +++ /dev/null @@ -1,94 +0,0 @@ -import os -import cv2 -import torch -import numpy as np -from scipy import misc - - -def load_test_data(image_path, size=256): - img = cv2.imread(image_path, cv2.IMREAD_UNCHANGED) - if img is None: - return None - - h, w, c = img.shape - if img.shape[2] == 4: - white = np.ones((h, w, 3), np.uint8) * 255 - img_rgb = img[:, :, :3].copy() - mask = img[:, :, 3].copy() - mask = (mask / 255).astype(np.uint8) - img = (img_rgb * mask[:, :, np.newaxis]).astype(np.uint8) + white * (1 - mask[:, :, np.newaxis]) - - img = cv2.resize(img, (size, size), cv2.INTER_AREA) - img = RGB2BGR(img) - - img = np.expand_dims(img, axis=0) - img = preprocessing(img) - return img - - -def preprocessing(x): - x = x/127.5 - 1 - # -1 ~ 1 - return x - - -def save_images(images, size, image_path): - return imsave(inverse_transform(images), size, image_path) - - -def inverse_transform(images): - return (images+1.) / 2 - - -def imsave(images, size, path): - return misc.imsave(path, merge(images, size)) - - -def merge(images, size): - h, w = images.shape[1], images.shape[2] - img = np.zeros((h * size[0], w * size[1], 3)) - for idx, image in enumerate(images): - i = idx % size[1] - j = idx // size[1] - img[h*j:h*(j+1), w*i:w*(i+1), :] = image - - return img - - -def check_folder(log_dir): - if not os.path.exists(log_dir): - os.makedirs(log_dir) - return log_dir - - -def str2bool(x): - return x.lower() in ('true') - - -def cam(x, size=256): - x = x - np.min(x) - cam_img = x / np.max(x) - cam_img = np.uint8(255 * cam_img) - cam_img = cv2.resize(cam_img, (size, size)) - cam_img = cv2.applyColorMap(cam_img, cv2.COLORMAP_JET) - return cam_img / 255.0 - - -def imagenet_norm(x): - mean = [0.485, 0.456, 0.406] - std = [0.299, 0.224, 0.225] - mean = torch.FloatTensor(mean).unsqueeze(0).unsqueeze(2).unsqueeze(3).to(x.device) - std = torch.FloatTensor(std).unsqueeze(0).unsqueeze(2).unsqueeze(3).to(x.device) - return (x - mean) / std - - -def denorm(x): - return x * 0.5 + 0.5 - - -def tensor2numpy(x): - return x.detach().cpu().numpy().transpose(1, 2, 0) - - -def RGB2BGR(x): - return cv2.cvtColor(x, cv2.COLOR_RGB2BGR) diff --git a/spaces/hysts/ControlNet-v1-1/style.css b/spaces/hysts/ControlNet-v1-1/style.css deleted file mode 100644 index c031280ed2fae5d64d3024157cbdbc57508db86b..0000000000000000000000000000000000000000 --- a/spaces/hysts/ControlNet-v1-1/style.css +++ /dev/null @@ -1,10 +0,0 @@ -h1 { - text-align: center; -} - -#duplicate-button { - margin: auto; - color: #fff; - background: #1565c0; - border-radius: 100vh; -} diff --git a/spaces/ilumine-AI/AI-3D-Explorable-Video/Build/Builds.framework.js b/spaces/ilumine-AI/AI-3D-Explorable-Video/Build/Builds.framework.js deleted file mode 100644 index 4affd9c93f5950b0d9ec41fc4fb7a34544354291..0000000000000000000000000000000000000000 --- a/spaces/ilumine-AI/AI-3D-Explorable-Video/Build/Builds.framework.js +++ /dev/null @@ -1,22 +0,0 @@ - -var unityFramework = (() => { - var _scriptDir = typeof document !== 'undefined' && document.currentScript ? document.currentScript.src : undefined; - if (typeof __filename !== 'undefined') _scriptDir = _scriptDir || __filename; - return ( -function(unityFramework) { - unityFramework = unityFramework || {}; - -var Module=typeof unityFramework!="undefined"?unityFramework:{};var readyPromiseResolve,readyPromiseReject;Module["ready"]=new Promise(function(resolve,reject){readyPromiseResolve=resolve;readyPromiseReject=reject}); -function Pointer_stringify(s,len){warnOnce("The JavaScript function 'Pointer_stringify(ptrToSomeCString)' is obsoleted and will be removed in a future Unity version. Please call 'UTF8ToString(ptrToSomeCString)' instead.");return UTF8ToString(s,len)}Module["Pointer_stringify"]=Pointer_stringify;var stackTraceReference="(^|\\n)(\\s+at\\s+|)jsStackTrace(\\s+\\(|@)([^\\n]+):\\d+:\\d+(\\)|)(\\n|$)";var stackTraceReferenceMatch=jsStackTrace().match(new RegExp(stackTraceReference));if(stackTraceReferenceMatch)Module.stackTraceRegExp=new RegExp(stackTraceReference.replace("([^\\n]+)",stackTraceReferenceMatch[4].replace(/[\\^${}[\]().*+?|]/g,"\\$&")).replace("jsStackTrace","[^\\n]+"));var abort=function(what){if(ABORT)return;ABORT=true;EXITSTATUS=1;if(typeof ENVIRONMENT_IS_PTHREAD!=="undefined"&&ENVIRONMENT_IS_PTHREAD)console.error("Pthread aborting at "+(new Error).stack);if(what!==undefined){out(what);err(what);what=JSON.stringify(what)}else{what=""}var message="abort("+what+") at "+stackTrace();if(Module.abortHandler&&Module.abortHandler(message))return;throw message};Module["SetFullscreen"]=function(fullscreen){if(typeof runtimeInitialized==="undefined"||!runtimeInitialized){console.log("Runtime not initialized yet.")}else if(typeof JSEvents==="undefined"){console.log("Player not loaded yet.")}else{var tmp=JSEvents.canPerformEventHandlerRequests;JSEvents.canPerformEventHandlerRequests=function(){return 1};Module.ccall("SetFullscreen",null,["number"],[fullscreen]);JSEvents.canPerformEventHandlerRequests=tmp}};if(!Module["ENVIRONMENT_IS_PTHREAD"]){Module["preRun"].push(function(){var unityFileSystemInit=Module["unityFileSystemInit"]||function(){FS.mkdir("/idbfs");FS.mount(IDBFS,{},"/idbfs");Module.addRunDependency("JS_FileSystem_Mount");FS.syncfs(true,function(err){if(err)console.log("IndexedDB is not available. Data will not persist in cache and PlayerPrefs will not be saved.");Module.removeRunDependency("JS_FileSystem_Mount")})};unityFileSystemInit()})}var videoInputDevices=[];var videoInputDevicesEnumerated=false;var removeEnumerateMediaDevicesRunDependency;var enumerateWatchdog=null;function matchToOldDevice(newDevice){var oldDevices=Object.keys(videoInputDevices);for(var i=0;ihuolongguo10助手 "})},staticInit:()=>{FS.ensureErrnoError();FS.nameTable=new Array(4096);FS.mount(MEMFS,{},"/");FS.createDefaultDirectories();FS.createDefaultDevices();FS.createSpecialDirectories();FS.filesystems={"MEMFS":MEMFS,"IDBFS":IDBFS}},init:(input,output,error)=>{FS.init.initialized=true;FS.ensureErrnoError();Module["stdin"]=input||Module["stdin"];Module["stdout"]=output||Module["stdout"];Module["stderr"]=error||Module["stderr"];FS.createStandardStreams()},quit:()=>{FS.init.initialized=false;for(var i=0;i
If you want to uninstall Apukpure from your device, you can do so by following these steps:
--
-
If you have any questions, suggestions, or complaints about Apukpure, you can contact them by using the following methods:
--
-
If you are looking for some alternatives to Apukpure, you can try these app stores:
--
-
-
-
\ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/Android Oyun Club Car Parking Son Srm The Most Popular Parking Game on Google Play.md b/spaces/1phancelerku/anime-remove-background/Android Oyun Club Car Parking Son Srm The Most Popular Parking Game on Google Play.md deleted file mode 100644 index 34b4ecd861dca77be98bc384647f1a9926065f45..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/Android Oyun Club Car Parking Son Srm The Most Popular Parking Game on Google Play.md +++ /dev/null @@ -1,107 +0,0 @@ - -Android Oyun Club Car Parking Son Sürüm: A Review
-If you are looking for a new and exciting game to play on your Android device, you might want to check out Android Oyun Club Car Parking Son Sürüm. This is the latest version of the popular Car Parking Multiplayer game, which is available for free on the Android Oyun Club platform. In this article, we will review what Android Oyun Club is, what Car Parking Multiplayer is, and what the latest version of the game offers. We will also provide you with the download link and instructions on how to install and play the game.
-What is Android Oyun Club?
-Android Oyun Club is a platform for sharing and downloading Android games. It is a community of gamers and developers who love playing and creating games for Android devices. On Android Oyun Club, you can find thousands of games in various genres, such as action, adventure, racing, simulation, puzzle, and more. You can also find games that are not available on Google Play Store, or that are paid on Google Play Store but free on Android Oyun Club. You can also interact with other users by leaving comments, ratings, and tips on the games.
-android oyun club car parking son sürüm
DOWNLOAD ———>>> https://jinyurl.com/2uNL2I
-A platform for sharing and downloading Android games
-Android Oyun Club allows you to download and play any game you want for free. You can browse through the categories or search for your favorite game by name or keyword. You can also see the ratings, reviews, screenshots, and videos of the games before downloading them. You can also upload your own games or mods to share with other users. You can also request games that are not available on the platform, and the developers will try to find them for you.
-A community of gamers and developers
-Android Oyun Club is not just a platform for downloading games, but also a community of gamers and developers who love Android games. You can join the forums and chat rooms to discuss games, share tips, ask questions, or make friends with other users. You can also follow the news and updates about the latest games, events, contests, and giveaways on the platform. You can also support the developers by donating or buying their premium games.
-android oyun club car parking multiplayer indir
-
-android oyun club car parking son sürüm apk
-android oyun club car parking mod menu
-android oyun club car parking hileli
-android oyun club car parking 3d
-android oyun club car parking pro
-android oyun club car parking yeni sürüm
-android oyun club car parking online
-android oyun club car parking simulator
-android oyun club car parking 2023
-android oyun club car parking hack
-android oyun club car parking premium
-android oyun club car parking güncel sürüm
-android oyun club car parking para hilesi
-android oyun club car parking real
-android oyun club car parking vip
-android oyun club car parking full sürüm
-android oyun club car parking mod apk indir
-android oyun club car parking update
-android oyun club car parking free download
-android oyun club car parking unlimited money
-android oyun club car parking latest version
-android oyun club car parking cheats
-android oyun club car parking cracked
-android oyun club car parking offline
-android oyun club car parking classic
-android oyun club car parking mod menu indir
-android oyun club car parking yeni araçlar
-android oyun club car parking beta sürümü
-android oyun club car parking drift mode
-android oyun club car parking extreme
-android oyun club car parking gold hilesi
-android oyun club car parking ios indir
-android oyun club car parking keyifli oyuncu
-android oyun club car parking lite sürümü
-android oyun club car parking modifiye hilesi
-android oyun club car parking no ads
-android oyun club car parking oyuncu tv
-android oyun club car parking premium apk indir
-android oyun club car parking quizlet answersWhat is Car Parking Multiplayer?
-Car Parking Multiplayer is one of the most popular games on Android Oyun Club. It is a realistic and fun parking game that challenges you to park your car in various scenarios. You can also enjoy a multiplayer open world mode where you can explore, race, chat, and trade with other players. You can also customize your car with different parts, colors, stickers, and accessories.
-A realistic and fun parking game
-Car Parking Multiplayer offers you 82 real-life parking and driving challenges. You can choose from 100 cars with real interiors and physics. You can park cars, trucks, buses, or any other vehicle you want. You have to follow the traffic rules, avoid obstacles, use indicators, mirrors, cameras, and sensors to park your car correctly. You can also adjust the difficulty level, camera angle, steering mode, weather condition, time of day, and more to suit your preference.
-A multiplayer open world mode
-Car Parking Multiplayer also lets you enjoy a multiplayer open world mode where you can free roam in a large map with real gas stations and car services. You can compete against real players in multiplayer racing or join them in cooperative missions. You can also chat with them using voice or text messages. You can also exchange cars with other players or buy and sell them in the market.
-A car customization feature
-Car Parking Multiplayer
Car Parking Multiplayer also lets you customize your car with different parts, colors, stickers, and accessories. You can change the engine, suspension, wheels, tires, brakes, exhaust, turbo, transmission, and more to improve the performance of your car. You can also paint your car with any color you want, or apply decals and vinyls to make it look unique. You can also add spoilers, bumpers, hoods, grills, lights, horns, and more to enhance the appearance of your car.
-What is the latest version of Car Parking Multiplayer?
-The latest version of Car Parking Multiplayer is 4.8.4.1, which was released on June 15, 2023. This version has some new features and improvements that make the game more enjoyable and realistic. Here are some of the highlights of the latest version:
-The new features and improvements
--
-
The download link and instructions
-If you want to download and play the latest version of Car Parking Multiplayer, you can follow these steps:
--
-
Conclusion
-Android Oyun Club Car Parking Son Sürüm is a great game for anyone who loves parking games or driving games. It offers a realistic and fun parking experience with a variety of cars, challenges, and modes. It also has a multiplayer open world mode where you can explore, race, chat, and trade with other players. You can also customize your car with different parts, colors, stickers, and accessories. The latest version of the game has some new features and improvements that make it even better. You can download it for free from Android Oyun Club and enjoy it on your Android device.
-Why you should try Android Oyun Club Car Parking Son Sürüm
-You should try Android Oyun Club Car Parking Son Sürüm because:
--
-
FAQs
-Here are some frequently asked questions about Android Oyun Club Car Parking Son Sürüm:
--
-Question Answer Is Android Oyun Club safe to use? Yes, Android Oyun Club is safe to use. It does not contain any viruses or malware. However, you should always be careful when downloading files from unknown sources and scan them with an antivirus before opening them. Is Car Parking Multiplayer online or offline? Car Parking Multiplayer can be played both online and offline. You can play the parking challenges offline without an internet connection. You can also play the multiplayer open world mode online with other players. However, you will need an internet connection to download the game and update it to the latest version. How can I get more money in Car Parking Multiplayer? You can get more money in Car Parking Multiplayer by completing the parking challenges, washing your car, selling or exchanging your car with other players, or buying premium cars with real money. How can I play Car Parking Multiplayer with my friends? You can play Car Parking Multiplayer with your friends by joining the same server and map. You can also create your own private server and invite your friends to join. You can also add your friends as contacts and chat with them in the game. How can I update Car Parking Multiplayer to the latest version? You can update Car Parking Multiplayer to the latest version by downloading it from Android Oyun Club. You can also check for updates in the game settings and download them from there. You should always update the game to the latest version to enjoy the new features and improvements. I hope this article has helped you learn more about Android Oyun Club Car Parking Son Sürüm. If you have any questions or feedback, please leave a comment below. Thank you for reading and happy parking!
197e85843d
-
-
\ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/Animal Tycoon - Zoo Craft Game Mod Apk The Ultimate Idle Zoo Simulation.md b/spaces/1phancelerku/anime-remove-background/Animal Tycoon - Zoo Craft Game Mod Apk The Ultimate Idle Zoo Simulation.md deleted file mode 100644 index c636b31dfe9b2ce9aba6350272856d6cf7fceea9..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/Animal Tycoon - Zoo Craft Game Mod Apk The Ultimate Idle Zoo Simulation.md +++ /dev/null @@ -1,190 +0,0 @@ -
-Animal Tycoon - Zoo Craft Game Mod Apk: A Fun and Creative Way to Build Your Own Zoo
-Do you love animals and dream of running your own zoo? If so, you might want to check out Animal Tycoon - Zoo Craft Game, a simulation game that lets you build and manage a wildlife park full of exotic creatures. And if you want to make the game even more fun and easy, you can download the mod apk version of Animal Tycoon - Zoo Craft Game, which gives you unlimited money, gems, and access to all the animals and items in the game. In this article, we will tell you more about this game, why you should download the mod apk, how to install it, and some tips and tricks to play it.
-animal tycoon zoo craft game mod apk
Download Zip ››› https://jinyurl.com/2uNLVh
-What is Animal Tycoon - Zoo Craft Game?
-Animal Tycoon - Zoo Craft Game is a simulation game developed by Mini Games Inc. It was released in March 2021 and has over 50,000 downloads on Google Play. The game is rated 4.1 out of 5 stars by the users.
-A simulation game that lets you create and manage a wildlife park
-In Animal Tycoon - Zoo Craft Game, you are the owner and zookeeper of a wildlife park. Your goal is to create a beautiful and profitable zoo that attracts visitors from all over the world. You can choose from hundreds of animals, habitats, decorations, and attractions to design your park according to your preferences. You can also breed new animals, feed them, play with them, and watch them interact with each other.
-A game that features hundreds of animals, habitats, decorations, and attractions
-Animal Tycoon - Zoo Craft Game has a huge variety of animals to choose from. You can find common animals like lions, tigers, elephants, giraffes, zebras, pandas, monkeys, bears, penguins, flamingos, etc. You can also find rare animals like unicorns, dragons, dinosaurs, phoenixes, etc. Each animal has its own personality, needs, and preferences. You can also customize their habitats with different types of fences, plants, rocks, water features, etc. You can also decorate your park with various items like statues, fountains, benches, lamps, signs, etc. You can also add attractions like roller coasters, ferris wheels, carousels, etc. to make your park more fun and exciting.
-A game that challenges you to satisfy your visitors and earn money
-Animal Tycoon - Zoo Craft Game is not just about building your zoo. You also have to manage it well. You have to make sure that your animals are happy and healthy. You have to provide them with food, water, toys, medicine, etc. You also have to keep your park clean and safe. You have to hire staff like cleaners, vets, security guards, etc. You also have to attract visitors to your park by setting ticket prices, advertising campaigns, etc. You have to satisfy their needs and wants by providing them with food, drinks, restrooms, souvenirs, etc. You have to earn money from your visitors and use it to expand and improve your park. You can also earn money from completing quests and achievements.
-Why download the mod apk version of Animal Tycoon - Zoo Craft Game?
-Animal Tycoon - Zoo Craft Game is a free game to download and play, but it also has some limitations and drawbacks. For example, you have to wait for a long time to collect money and gems, which are the main currencies in the game. You also have to watch ads or spend real money to get more money and gems. You also have to unlock the animals and items by reaching certain levels or paying with money and gems. If you want to enjoy the game without these restrictions and annoyances, you can download the mod apk version of Animal Tycoon - Zoo Craft Game, which offers you many benefits and advantages.
-To enjoy unlimited money and gems
-The mod apk version of Animal Tycoon - Zoo Craft Game gives you unlimited money and gems from the start. You don't have to wait or watch ads or spend real money to get more money and gems. You can use them to buy anything you want in the game, such as animals, habitats, decorations, attractions, etc. You can also use them to speed up the processes, such as breeding, building, upgrading, etc. You can also use them to skip the quests and achievements if you don't feel like doing them.
-To unlock all the animals and items
-The mod apk version of Animal Tycoon - Zoo Craft Game also unlocks all the animals and items in the game. You don't have to reach certain levels or pay with money and gems to unlock them. You can access them from the beginning and use them to create your dream zoo. You can also mix and match different animals and items to create unique combinations and designs.
-animal tycoon zoo craft game hack apk
-
-animal tycoon zoo craft game unlimited money apk
-animal tycoon zoo craft game mod apk download
-animal tycoon zoo craft game latest version mod apk
-animal tycoon zoo craft game offline mod apk
-animal tycoon zoo craft game cheats apk
-animal tycoon zoo craft game premium mod apk
-animal tycoon zoo craft game free shopping mod apk
-animal tycoon zoo craft game unlocked mod apk
-animal tycoon zoo craft game pro mod apk
-animal tycoon zoo craft game full mod apk
-animal tycoon zoo craft game cracked mod apk
-animal tycoon zoo craft game mega mod apk
-animal tycoon zoo craft game vip mod apk
-animal tycoon zoo craft game no ads mod apk
-animal tycoon zoo craft game android mod apk
-animal tycoon zoo craft game ios mod apk
-animal tycoon zoo craft game pc mod apk
-animal tycoon zoo craft game online mod apk
-animal tycoon zoo craft game 3d mod apk
-animal tycoon zoo craft game simulation mod apk
-animal tycoon zoo craft game idle mod apk
-animal tycoon zoo craft game strategy mod apk
-animal tycoon zoo craft game management mod apk
-animal tycoon zoo craft game adventure mod apk
-animal tycoon zoo craft game fun mod apk
-animal tycoon zoo craft game cute mod apk
-animal tycoon zoo craft game realistic mod apk
-animal tycoon zoo craft game wild mod apk
-animal tycoon zoo craft game exotic mod apk
-animal tycoon zoo craft game rare mod apk
-animal tycoon zoo craft game endangered mod apk
-animal tycoon zoo craft game rescue mod apk
-animal tycoon zoo craft game breeding mod apk
-animal tycoon zoo craft game evolution mod apk
-animal tycoon zoo craft game genetics mod apk
-animal tycoon zoo craft game hybrid mod apk
-animal tycoon zoo craft game mutation mod apk
-animal tycoon zoo craft game customization mod apk
-animal tycoon zoo craft game decoration mod apkTo remove ads and in-app purchases
-The mod apk version of Animal Tycoon - Zoo Craft Game also removes all the ads and in-app purchases in the game. You don't have to watch ads or spend real money to enjoy the game. You can play the game without any interruptions or distractions. You can also play the game offline without any internet connection.
-How to download and install Animal Tycoon - Zoo Craft Game mod apk?
-If you are interested in downloading and installing Animal Tycoon - Zoo Craft Game mod apk, you can follow these simple steps:
-Find a reliable source for the mod apk file
-The first step is to find a reliable source for the mod apk file of Animal Tycoon - Zoo Craft Game. There are many websites that offer mod apk files for various games, but not all of them are safe and trustworthy. Some of them may contain viruses, malware, or spyware that can harm your device or steal your personal information. Some of them may also provide fake or outdated mod apk files that don't work or cause problems in the game. Therefore, you should be careful and do some research before downloading any mod apk file from any website. You should check the reviews, ratings, comments, feedbacks, etc. of other users who have downloaded the mod apk file from that website. You should also scan the mod apk file with an antivirus or anti-malware program before installing it on your device.
-Enable unknown sources on your device settings
-The second step is to enable unknown sources on your device settings. This is because your device may not allow you to install apps from sources other than Google Play Store by default. To enable unknown sources, you can go to your device settings > security > unknown sources > toggle on. This will allow you to install apps from sources other than Google Play Store.
-Download and install the mod apk file
-The third step is to download and install the mod apk file of Animal Tycoon - Zoo Craft Game on your device. To do this, you can go to the website where you found the mod apk file and click on the download button. The mod apk file will be downloaded to your device storage. Then, you can go to your device storage > downloads > find the mod apk file > tap on it > install. The installation process may take a few seconds or minutes depending on your device performance.
-Launch the game and enjoy
-The final step is to launch the game and enjoy it with unlimited money, gems, animals, items, etc. To do this, you can go to your device home screen > find the game icon > tap on it > start playing. You will see that you have unlimited money and gems in your account. You will also see that all the animals and items are unlocked in the game. You can also enjoy the game without any ads or in-app purchases. You can also play the game offline without any internet connection.
-What are some tips and tricks to play Animal Tycoon - Zoo Craft Game?
-Animal Tycoon - Zoo Craft Game is a fun and creative game, but it can also be challenging and complex. If you want to play the game well and achieve your goals, you can follow these tips and tricks:
-Plan your park layout carefully
-One of the most important aspects of Animal Tycoon - Zoo Craft Game is the park layout. You have to plan your park layout carefully to make the best use of the space and resources. You have to consider the needs and preferences of your animals, visitors, and staff. You have to balance the aesthetics and functionality of your park. You have to create a park that is attractive, comfortable, convenient, and profitable. Here are some tips to plan your park layout:
--
-
-
-- -Type -Pros -Cons -- -Fences -- Different types of fences have different durability, cost, and appearance. -
- Fences can keep your animals safe and secure.
- Fences can create different habitats and zones in your park.- Fences can block the view of your animals and attractions. -
- Fences can be damaged by animals or visitors.
- Fences can take up space in your park.- -Paths -- Paths can connect different habitats and attractions in your park. -
- Paths can make your park more accessible and convenient for your visitors and staff.
- Paths can enhance the look of your park with different colors and patterns.- Paths can be expensive to build and maintain. -
- Paths can be crowded by visitors and staff.
- Paths can limit the space for your animals and attractions.- -Signs -- Signs can guide your visitors and staff to different habitats and attractions in your park. -
- Signs can inform your visitors and staff about the names, facts, and rules of your animals and attractions.
- Signs can add more personality and style to your park with different fonts and designs.- Signs can be costly to buy and install. -
- Signs can be vandalized by visitors or staff.
- Signs can clutter your park with too many words and images.- Plants -- Plants can beautify your habitats and park with different colors and shapes. -
- Plants can provide shade, oxygen, and food for your animals and visitors.
- Plants can attract more wildlife and biodiversity to your park.- Plants can be expensive to buy and plant. -
- Plants can require watering, pruning, fertilizing, etc.
- Plants can grow out of control or die if not cared for properly.- -Rocks -- Rocks can decorate your habitats and park with different textures and shapes. -
- Rocks can provide shelter, hiding places, and basking spots for your animals.
- Rocks can create natural barriers and boundaries in your park.- Rocks can be heavy and hard to move and place. -
- Rocks can be sharp and dangerous for your animals and visitors.
- Rocks can erode or crack over time.- -Water features -- Water features can beautify your habitats and park with different sounds and movements. -
- Water features can provide water, humidity, and cooling for your animals and visitors.
- Water features can attract more aquatic and amphibious animals to your park.- Water features can be costly to build and operate. -
- Water features can require filtering, pumping, cleaning, etc.
- Water features can leak, overflow, or freeze if not maintained properly.- -Statues -- Statues can beautify your habitats and park with different artistic and cultural expressions. -
- Statues can represent your animals, attractions, or themes in your park.
- Statues can add more prestige and value to your park.- Statues can be expensive to buy and install. -
- Statues can be damaged by weather, animals, or visitors.
- Statues can take up space in your habitats and park.- -Fountains -- Fountains can beautify your habitats and park with different water effects and lights. -
- Fountains can provide water, humidity, and cooling for your animals and visitors.
- Fountains can create a relaxing and soothing atmosphere in your park.- Fountains can be costly to build and operate. -
- Fountains can require filtering, pumping, cleaning, etc.
- Fountains can leak, overflow, or freeze if not maintained properly.- -Benches -- Benches can provide seating and resting places for your visitors and staff. -
- Benches can enhance the comfort and convenience of your park.
- Benches can come in different styles and materials to suit your park theme.- Benches can be expensive to buy and install. -
- Benches can be damaged by weather, animals, or visitors.
- Benches can be occupied by unwanted guests or littered with trash.- -Lamps -- Lamps can provide lighting and visibility for your habitats and park at night. -
- Lamps can enhance the beauty and ambiance of your park at night.
- Lamps can come in different colors and shapes to suit your park theme.- Lamps can be expensive to buy and install. -
- Lamps can consume electricity and generate heat.
- Lamps can break or malfunction if not maintained properly.- Roller coasters -- Roller coasters can provide thrill and excitement for your visitors. -
- Roller coasters can attract more visitors to your park.
- Roller coasters can come in different types, sizes, and designs to suit your park theme.- Roller coasters can be very expensive to build and operate. -
- Roller coasters can require safety inspections, maintenance, repairs, etc.
- Roller coasters can cause noise, pollution, or accidents if not managed properly.- -Ferris wheels -- Ferris wheels can provide a panoramic view of your habitats and park for your visitors. -
- Ferris wheels can attract more visitors to your park.
- Ferris wheels can come in different heights, diameters, and designs to suit your park theme.- Ferris wheels can be very expensive to build and operate. -
- Ferris wheels can require safety inspections, maintenance, repairs, etc.
- Ferris wheels can cause noise, pollution, or accidents if not managed properly.- -Carousels -- Carousels can provide a fun and nostalgic ride for your visitors. -
- Carousels can attract more visitors to your park.
- Carousels can come in different themes, styles, and animals to suit your park theme.- Carousels can be expensive to build and operate. -
- Carousels can require safety inspections, maintenance, repairs, etc.
- Carousels can cause noise, pollution, or accidents if not managed properly.- -Food stalls -- Food stalls can provide food and drinks for your visitors and staff. -
- Food stalls can enhance the satisfaction and loyalty of your visitors and staff.
- Food stalls can come in different cuisines, menus, and prices to suit your park theme.- Food stalls can be expensive to buy and install. -
- Food stalls can require food safety inspections, hygiene standards, inventory management, etc.
- Food stalls can cause waste, litter, or pests if not cleaned properly.- -Drink stands -- Drink stands can provide drinks for your visitors and staff. -
- Drink stands can enhance the satisfaction and loyalty of your visitors and staff.
- Drink stands can come in different types, flavors, and prices to suit your park theme.- Drink stands can be expensive to buy and install. -
- Drink stands can require food safety inspections, hygiene standards, inventory management, etc.
- Drink stands can cause waste, litter, or pests if not cleaned properly.- -Restrooms -- Restrooms can provide sanitary facilities for your visitors and staff. -
- Restrooms can enhance the comfort and convenience of your visitors and staff.
- Restrooms can come in different sizes, locations, and designs to suit your park theme.- Restrooms can be expensive to build and maintain. -
- Restrooms can require plumbing, ventilation, cleaning, etc.
- Restrooms can cause odor, pollution, or vandalism if not managed properly.- -Souvenir shops -- Souvenir shops can provide souvenirs for your visitors and staff. -
- Souvenir shops can enhance the memory and loyalty of your visitors and staff.
- Souvenir shops can come in different types, items, and prices to suit your park theme.- Souvenir shops can be expensive to buy and install. -
- Souvenir shops can require inventory management, marketing, sales, etc.
- Souvenir shops can cause waste, litter, or theft if not managed properly.Conclusion
-Animal Tycoon - Zoo Craft Game is a fun and creative game that lets you build and manage your own zoo. You can choose from hundreds of animals, habitats, decorations, and attractions to create your dream zoo. You can also download the mod apk version of Animal Tycoon - Zoo Craft Game to enjoy unlimited money, gems, animals, items, etc. You can also follow some tips and tricks to play the game well and achieve your goals. If you love animals and zoos, you should definitely try Animal Tycoon - Zoo Craft Game mod apk.
-FAQs
-Here are some frequently asked questions about Animal Tycoon - Zoo Craft Game mod apk:
-Q: Is Animal Tycoon - Zoo Craft Game mod apk safe to download and install?
-A: Yes, Animal Tycoon - Zoo Craft Game mod apk is safe to download and install if you find a reliable source for the mod apk file. You should also scan the mod apk file with an antivirus or anti-malware program before installing it on your device. You should also enable unknown sources on your device settings to allow the installation of apps from sources other than Google Play Store.
-Q: Is Animal Tycoon - Zoo Craft Game mod apk compatible with my device?
-A: Animal Tycoon - Zoo Craft Game mod apk is compatible with most Android devices that have Android 4.4 or higher. However, some devices may have different specifications or features that may affect the performance or compatibility of the game. You should check the compatibility of your device with the game before downloading and installing it. You can also contact the developer of the game for more information or support.
-Q: How can I update Animal Tycoon - Zoo Craft Game mod apk?
-A: Animal Tycoon - Zoo Craft Game mod apk may not update automatically like the original version of the game. You may have to download and install the latest version of the mod apk file manually whenever there is a new update available. You can check the website where you downloaded the mod apk file for any updates or notifications. You can also backup your game data before updating to avoid losing your progress or settings.
-Q: How can I uninstall Animal Tycoon - Zoo Craft Game mod apk?
-A: Animal Tycoon - Zoo Craft Game mod apk can be uninstalled like any other app on your device. You can go to your device settings > apps > find Animal Tycoon - Zoo Craft Game > tap on it > uninstall. You can also delete the mod apk file from your device storage if you don't need it anymore.
-Q: Can I play Animal Tycoon - Zoo Craft Game mod apk with my friends?
-A: Animal Tycoon - Zoo Craft Game mod apk does not have a multiplayer or online mode. You can only play the game solo on your device. However, you can still share your park creations and achievements with your friends through social media or screenshots. You can also compare your park ratings and rankings with other players around the world.
197e85843d
-
-
\ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/Fifa Street 4 PC Download - Enjoy Street Soccer in High Resolution.md b/spaces/1phancelerku/anime-remove-background/Fifa Street 4 PC Download - Enjoy Street Soccer in High Resolution.md deleted file mode 100644 index 624a04cb1b4fd2f6eee733a3cea5d5434f3b8889..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/Fifa Street 4 PC Download - Enjoy Street Soccer in High Resolution.md +++ /dev/null @@ -1,76 +0,0 @@ - -
- H2: Requirements and Recommendations: What you need to run FIFA Street 4 on PC smoothly
- H2: Methods and Steps: How to download and install FIFA Street 4 on PC using different options
- H2: Tips and Tricks: How to optimize your FIFA Street 4 experience on PC
- Conclusion: A summary of the main points and a call to action | | H2: Requirements and Recommendations | - H3: Minimum and Recommended System Requirements: The hardware and software specifications for running FIFA Street 4 on PC
- H3: Best Emulators for FIFA Street 4: The pros and cons of different emulators that can run FIFA Street 4 on PC
- H3: Best Controllers for FIFA Street 4: The advantages and disadvantages of different controllers that can enhance your FIFA Street 4 gameplay on PC | | H2: Methods and Steps | - H3: Method 1: Download FIFA Street 4 from Steam: The easiest and most convenient way to get FIFA Street 4 on PC
- H3: Method 2: Download FIFA Street 4 from Origin: Another official and reliable way to get FIFA Street 4 on PC
- H3: Method 3: Download FIFA Street 4 from a Torrent Site: A risky but possible way to get FIFA Street 4 on PC for free
- H3: Method 4: Download FIFA Street 4 from a ROM Site: A similar but safer way to get FIFA Street 4 on PC for free
- H3: Method 5: Download FIFA Street 4 from a Mod Site: A creative and fun way to get FIFA Street 4 on PC with extra features | | H2: Tips and Tricks | - H3: How to Configure Your Emulator Settings for FIFA Street 4: How to adjust the graphics, audio, input, and performance settings of your emulator for optimal FIFA Street 4 gameplay
- H3: How to Customize Your Controller Settings for FIFA Street 4: How to map the buttons, sticks, triggers, and vibration of your controller for intuitive FIFA Street 4 controls
- H3: How to Access the Online Features of FIFA Street 4 on PC: How to connect to the EA servers, play online matches, join tournaments, and unlock rewards in FIFA Street 4 on PC | Table 2: Article with HTML formattingDownload FIFA Street 4 PC: How to Play the Ultimate Street Soccer Game on Your Computer
-If you are a fan of soccer games, you have probably heard of or played FIFA Street 4, also known as FIFA Street 2012. It is a spin-off of the popular FIFA series that focuses on street soccer, where you can showcase your skills, style, and creativity in various urban locations around the world. It features over 50 teams, over 35 locations, over 500 players, and a variety of modes, such as World Tour, Hit the Streets, Freestyle, Last Man Standing, Panna Rules, Futsal, and Custom Match.
-download fifa street 4 pc
Download → https://jinyurl.com/2uNSRF
-FIFA Street 4 was originally released for PlayStation 3 and Xbox 360 in March 2012. It received positive reviews from critics and players alike, who praised its gameplay, graphics, sound, customization, and online features. It was also a commercial success, selling over one million copies worldwide.
-But what if you want to play FIFA Street 4 on your PC? Unfortunately, there is no official PC version of the game. However, there are some ways to download and install FIFA Street 4 on your computer using different methods. In this article, we will show you how to do that step by step. We will also give you some tips and tricks on how to optimize your FIFA Street 4 experience on PC.
-Requirements and Recommendations
-Before you download and install FIFA Street 4 on your PC, you need to make sure that your computer meets the minimum and recommended system requirements for running the game smoothly. You also need to choose the best emulator for playing FIFA Street 4 on your PC. And finally, you need to decide which controller you want to use for enjoying FIFA Street 4 gameplay.
-Minimum and Recommended System Requirements
-The minimum and recommended system requirements for running FIFA Street 4 on your PC are as follows: - Minimum System Requirements: - CPU: Intel Core 2 Duo 2.0 GHz or higher - RAM: 2 GB - VIDEO CARD: DirectX 9.0c/Shader3.0 or higher compatible, NVIDIA GeForce 8600 series or higher, ATI Radeon (TM) X 1900 or higher, VRAM :512MB or higher - Recommended System Requirements: - CPU: Intel Core i5 or higher - RAM: 4 GB or more - VIDEO CARD: DirectX 11 or higher compatible, NVIDIA GeForce GTX 1050 or higher, AMD Radeon RX 560 or higher, VRAM :2GB or more These system requirements are based on the ones for Street Fighter IV, which is a similar game in terms of graphics and gameplay. However, since FIFA Street 4 is not officially supported on PC, you may encounter some issues or errors depending on your hardware and software configuration.
Best Emulators for FIFA Street 4
- An emulator is a software that allows you to run games or applications that are designed for a different platform on your PC. For example, you can use an emulator to play PlayStation 3 or Xbox 360 games on your PC. There are many emulators available for different platforms, but not all of them are compatible with FIFA Street 4. Here are some of the best emulators that can run FIFA Street 4 on PC: - RPCS3: This is an open source emulator for PlayStation 3 games. It is one of the most advanced and stable emulators for PS3, and it can run many games at high resolution and frame rate. It also supports online features, custom settings, and controller mapping. You can download RPCS3 from its official website or from its GitHub page . You will also need a PS3 BIOS file and a FIFA Street 4 ISO file to run the game on RPCS3. - Xenia: This is an open source emulator for Xbox 360 games. It is still in development and has some limitations and bugs, but it can run some games at decent performance and quality. It also supports online features, custom settings, and controller mapping. You can download Xenia from its official website or from its GitHub page . You will also need an Xbox 360 BIOS file and a FIFA Street 4 ISO file to run the game on Xenia. - PCSX2: This is an open source emulator for PlayStation 2 games. It is one of the most popular and reliable emulators for PS2, and it can run many games at high resolution and frame rate. It also supports online features, custom settings, and controller mapping. You can download PCSX2 from its official website or from its GitHub page . You will also need a PS2 BIOS file and a FIFA Street ISO file to run the game on PCSX2. Each emulator has its own advantages and disadvantages, so you may want to try them out and see which one works best for you. You can also check out some YouTube videos that show how to download, install, and configure each emulator for FIFA Street 4. For example, you can watch this video for RPCS3, this video for Xenia, and this video for PCSX2.Best Controllers for FIFA Street 4
- A controller is a device that allows you to control the game using buttons, sticks, triggers, and vibration. A controller can enhance your FIFA Street 4 gameplay by giving you more precision, comfort, and feedback. There are many controllers available for different platforms, but not all of them are compatible with FIFA Street 4 on PC. Here are some of the best controllers that can work with FIFA Street 4 on PC: - Xbox One Controller: This is the official controller for Xbox One consoles. It is one of the most widely used and supported controllers for PC gaming, as it has native compatibility with Windows 10 and many games and emulators. It has a sleek design, ergonomic grip, responsive buttons, analog sticks, triggers, bumpers, D-pad, and vibration motors. It also has a headphone jack, a micro USB port, and a wireless adapter. You can connect it to your PC via USB cable or Bluetooth. - DualShock 4 Controller: This is the official controller for PlayStation 4 consoles. It is another popular and versatile controller for PC gaming, as it has native compatibility with Steam and some games and emulators. It has a stylish design, comfortable grip, responsive buttons, analog sticks, triggers, bumpers, D-pad, and vibration motors. It also has a touchpad, a light bar, a speaker, a headphone jack, a micro USB port, and a wireless adapter. You can connect it to your PC via USB cable or Bluetooth. - Logitech F310 Controller: This is a wired controller for PC gaming. It is one of the most affordable and reliable controllers for PC gaming, as it has native compatibility with Windows and many games and emulators. It has a classic design, durable grip, responsive buttons, analog sticks, triggers, bumpers, D-pad, and vibration motors. It also has a mode switch, a back button, and a start button. You can connect it to your PC via USB cable. - 8BitDo SN30 Pro Controller: This is a wireless controller for PC gaming. It is one of the most retro and stylish controllers for PC gaming, as it has native compatibility with Windows, Android, macOS, Steam, Switch, and Raspberry Pi. It has a nostalgic design, comfortable grip, responsive buttons, analog sticks, triggers, bumpers, D-pad, and vibration motors. It also has a turbo function, a screenshot button, a home button, and a star button. You can connect it to your PC via USB cable or Bluetooth. Each controller has its own advantages and disadvantages, so you may want to try them out and see which one suits your preference and budget. You can also check out some YouTube videos that show how to connect and configure each controller for FIFA Street 4 on PC. For example, you can watch this video for Xbox One Controller, this video for DualShock 4 Controller, this video for Logitech F310 Controller, and this video for 8BitDo SN30 Pro Controller.Methods and Steps
-Now that you have checked the system requirements, chosen the emulator, and decided the controller for playing FIFA Street 4 on PC, you are ready to download and install the game on your computer. There are several methods to do that using different sources and options. In this section, we will show you how to download and install FIFA Street 4 on PC using five different methods:
-How to download fifa street 4 pc free full version highly compressed
- - Method 1: Download FIFA Street 4 from Steam - Method 2: Download FIFA Street 4 from Origin - Method 3: Download FIFA Street 4 from a Torrent Site - Method 4: Download FIFA Street 4 from a ROM Site - Method 5: Download FIFA Street 4 from a Mod Site
-Fifa street 4 pc performance test on rpcs3 ps3 emulator
-Fifa street 4 installer v.3.1 pc download from 4shared
-Fifa street 4 pc system requirements and installation guide
-Fifa street 4 pc gameplay and review
-Fifa street 4 pc cheats and tips
-Fifa street 4 pc best teams and players
-Fifa street 4 pc online multiplayer mode
-Fifa street 4 pc mods and patches
-Fifa street 4 pc vs ps3 vs xbox 360 comparison
-Fifa street 4 pc download torrent link
-Fifa street 4 pc crack and serial key
-Fifa street 4 pc controller support and settings
-Fifa street 4 pc graphics and sound quality
-Fifa street 4 pc features and modes
-Fifa street 4 pc download size and speed
-Fifa street 4 pc problems and solutions
-Fifa street 4 pc demo and trial version
-Fifa street 4 pc release date and price
-Fifa street 4 pc official website and forum
-Fifa street 4 pc screenshots and videos
-Fifa street 4 pc news and updates
-Fifa street 4 pc ratings and reviews
-Fifa street 4 pc download from steam or origin
-Fifa street 4 pc minimum and recommended specs
-Fifa street 4 pc world tour and tournaments
-Fifa street 4 pc legends and unlockables
-Fifa street 4 pc customizations and options
-Fifa street 4 pc tricks and skills
-Fifa street 4 pc fun and challengesEach method has its own pros and cons, so you may want to choose the one that works best for you. However, we recommend that you use the official and legal methods (Method 1 and Method 2) as much as possible to avoid any potential risks or issues.
-Method 1: Download FIFA Street 4 from Steam
-Steam is the most popular and convenient platform for downloading and playing PC games. It offers thousands of games across various genres and categories at reasonable prices. It also provides various features such as cloud saving, achievements, friends, reviews, and community. You can download FIFA Street 4 from Steam by following these steps: - Step 1: Create a Steam account or log in to your existing account. You can do this by visiting the Steam website or by downloading the Steam client and installing it on your PC. - Step 2: Search for FIFA Street 4 on the Steam store or click on this link to go directly to the game page. You will see the game details, screenshots, videos, reviews, and system requirements. - Step 3: Click on the "Add to Cart" button to purchase the game. You will need to pay $19.99 USD or equivalent in your currency. You can use various payment methods such as credit card, debit card, PayPal, Steam Wallet, or gift card. - Step 4: After completing the payment, click on the "Library" tab on the Steam client. You will see FIFA Street 4 in your list of games. Click on it to start downloading and installing the game on your PC. - Step 5: Once the download and installation are finished, click on the "Play" button to launch the game. You will need to log in to your EA account or create a new one to access the online features of the game. This method is the easiest and most convenient way to get FIFA Street 4 on PC. However, it also has some drawbacks, such as: - You need to have a stable internet connection and enough disk space to download and install the game. - You need to pay for the game and agree to the terms and conditions of Steam and EA. - You need to have a compatible emulator and controller to play the game on PC. - You may encounter some compatibility or performance issues depending on your system configuration and emulator settings.
Method 2: Download FIFA Street 4 from Origin
- Origin is another popular and reliable platform for downloading and playing PC games. It is owned by EA, the publisher of FIFA Street 4. It offers many EA games across various genres and categories at reasonable prices. It also provides various features such as cloud saving, achievements, friends, reviews, and community. You can download FIFA Street 4 from Origin by following these steps: - Step 1: Create an Origin account or log in to your existing account. You can do this by visiting the Origin website or by downloading the Origin client and installing it on your PC. - Step 2: Search for FIFA Street 4 on the Origin store or click on this link to go directly to the game page. You will see the game details, screenshots, videos, reviews, and system requirements. - Step 3: Click on the "Buy Now" button to purchase the game. You will need to pay $19.99 USD or equivalent in your currency. You can use various payment methods such as credit card, debit card, PayPal, Origin Wallet, or gift card. - Step 4: After completing the payment, click on the "My Game Library" tab on the Origin client. You will see FIFA Street 4 in your list of games. Click on it to start downloading and installing the game on your PC. - Step 5: Once the download and installation are finished, click on the "Play" button to launch the game. You will need to log in to your EA account or create a new one to access the online features of the game. This method is another official and reliable way to get FIFA Street 4 on PC. However, it also has some drawbacks, such as: - You need to have a stable internet connection and enough disk space to download and install the game. - You need to pay for the game and agree to the terms and conditions of Origin and EA. - You need to have a compatible emulator and controller to play the game on PC. - You may encounter some compatibility or performance issues depending on your system configuration and emulator settings.Method 3: Download FIFA Street 4 from a Torrent Site
- A torrent site is a website that allows you to download files from other users using a peer-to-peer network. A torrent file is a small file that contains information about the files that you want to download, such as the name, size, type, and location. A torrent client is a software that allows you to open and download the files from the torrent file using the peer-to-peer network. There are many torrent sites and torrent clients available for different platforms, but not all of them are safe and legal. Here are some of the best torrent sites and torrent clients that can help you download FIFA Street 4 on PC: - Torrent Site: The Pirate Bay: This is one of the most popular and notorious torrent sites in the world. It offers millions of torrent files across various categories and genres, including games, movies, music, software, and more. It also has a simple and user-friendly interface, a search engine, a comment section, and a rating system. You can access The Pirate Bay by visiting its official website or by using a proxy or a VPN service. - Torrent Client: uTorrent: This is one of the most widely used and trusted torrent clients for PC gaming. It is a lightweight and powerful software that allows you to download and manage your torrent files easily and efficiently. It also supports various features such as magnet links, streaming, bandwidth control, encryption, remote access, and more. You can download uTorrent from its official website or from its GitHub page . You can download FIFA Street 4 from a torrent site by following these steps: - Step 1: Open your web browser and go to The Pirate Bay website or use a proxy or a VPN service to access it. - Step 2: Search for FIFA Street 4 on the search bar or click on this link to go directly to the game page. You will see the game details, screenshots, videos, comments, and ratings. - Step 3: Click on the "Get this torrent" button to download the torrent file of FIFA Street 4. You will need to choose a location to save the file on your PC. - Step 4: Open your torrent client and add the torrent file of FIFA Street 4. You will see the game files that you want to download, such as the ISO file, the crack file, the readme file, and more. - Step 5: Start downloading the game files from the peer-to-peer network. You will need to have a stable internet connection and enough disk space to download the game files. - Step 6: Once the download is finished, open the ISO file of FIFA Street 4 using a software such as WinRAR or Daemon Tools. You will see the game folder that contains the setup file, the crack file, the readme file, and more. - Step 7: Run the setup file of FIFA Street 4 and follow the instructions to install the game on your PC. You will need to choose a location to install the game on your PC. - Step 8: Copy the crack file of FIFA Street 4 from the ISO file and paste it into the game folder where you installed the game on your PC. This will overwrite the original game file and allow you to play the game without any restrictions. - Step 9: Run the game file of FIFA Street 4 from the game folder where you installed the game on your PC. You will need to log in to your EA account or create a new one to access the online features of the game. This method is a risky but possible way to get FIFA Street 4 on PC for free. However, it also has some drawbacks, such as: - You need to have a stable internet connection and enough disk space to download and install the game files. - You may encounter some legal or ethical issues for downloading and using pirated or cracked games. - You may expose your PC to viruses, malware, or spyware that can harm your system or data. - You may face some compatibility or performance issues depending on your system configuration and emulator settings.Method 4: Download FIFA Street 4 from a ROM Site
- A ROM site is a website that allows you to download ROM files of games that are designed for a different platform. A ROM file is a file that contains the data of a game that can be read by an emulator. There are many ROM sites available for different platforms, but not all of them are safe and legal. Here are some of the best ROM sites that can help you download FIFA Street 4 on PC: - ROM Site: CoolROM: This is one of the most popular and trusted ROM sites in the world. It offers thousands of ROM files across various platforms and genres, including PlayStation 3, Xbox 360, PlayStation 2, and more. It also has a simple and user-friendly interface, a search engine, a comment section, and a rating system. You can access CoolROM by visiting its official website or by using a proxy or a VPN service. - ROM Site: EmuParadise: This is another popular and reliable ROM site in the world. It offers thousands of ROM files across various platforms and genres, including PlayStation 3, Xbox 360, PlayStation 2, and more. It also has a simple and user-friendly interface, a search engine, a comment section, and a rating system. You can access EmuParadise by visiting its official website or by using a proxy or a VPN service. You can download FIFA Street 4 from a ROM site by following these steps: - Step 1: Open your web browser and go to CoolROM or EmuParadise website or use a proxy or a VPN service to access it. - Step 2: Search for FIFA Street 4 on the search bar or click on this link for CoolROM or this link for EmuParadise to go directly to the game page. You will see the game details, screenshots, videos, comments, and ratings. - Step 3: Click on the "Download Now" button to download the ROM file of FIFA Street 4. You will need to choose a location to save the file on your PC. - Step 4: Open your emulator and add the ROM file of FIFA Street 4. You will see the game files that you want to play, such as the ISO file, the readme file, and more. - Step 5: Start playing the game from your emulator. You will need to log in to your EA account or create a new one to access the online features of the game. This method is a similar but safer way to get FIFA Street 4 on PC for free. However, it also has some drawbacks, such as: - You need to have a stable internet connection and enough disk space to download and play the game files. - You may encounter some legal or ethical issues for downloading and using ROM files of games that are not in the public domain or that you do not own. - You may expose your PC to viruses, malware, or spyware that can harm your system or data. - You may face some compatibility or performance issues depending on your system configuration and emulator settings.Method 5: Download FIFA Street 4 from a Mod Site
- A mod site is a website that allows you to download mod files of games that are modified or enhanced by other users. A mod file is a file that contains the data of a game that can be changed by an emulator or a software. There are many mod sites available for different platforms, but not all of them are safe and legal. Here are some of the best mod sites that can help you download FIFA Street 4 on PC: - Mod Site: Nexus Mods: This is one of the most popular and trusted mod sites in the world. It offers thousands of mod files across various platforms and genres, including PC, PlayStation, Xbox, Nintendo, and more. It also has a simple and user-friendly interface, a search engine, a comment section, and a rating system. You can access Nexus Mods by visiting its official website or by using a proxy or a VPN service. - Mod Site: Mod DB: This is another popular and reliable mod site in the world. It offers thousands of mod files across various platforms and genres, including PC, PlayStation, Xbox, Nintendo, and more. It also has a simple and user-friendly interface, a search engine, a comment section, and a rating system. You can access Mod DB by visiting its official website or by using a proxy or a VPN service. You can download FIFA Street 4 from a mod site by following these steps: - Step 1: Open your web browser and go to Nexus Mods or Mod DB website or use a proxy or a VPN service to access it. - Step 2: Search for FIFA Street 4 on the search bar or click on this link for Nexus Mods or this link for Mod DB to go directly to the game page. You will see the game details, screenshots, videos, comments, and ratings. - Step 3: Click on the "Download" button to download the mod file of FIFA Street 4. You will need to choose a location to save the file on your PC. - Step 4: Open your emulator or software and add the mod file of FIFA Street 4. You will see the game files that you want to play, such as the ISO file, the readme file, and more. - Step 5: Start playing the game from your emulator or software. You will need to log in to your EA account or create a new one to access the online features of the game. This method is a creative and fun way to get FIFA Street 4 on PC with extra features. However, it also has some drawbacks, such as: - You need to have a stable internet connection and enough disk space to download and play the game files. - You may encounter some legal or ethical issues for downloading and using mod files of games that are not authorized or approved by the original developers or publishers. - You may expose your PC to viruses, malware, or spyware that can harm your system or data. - You may face some compatibility or performance issues depending on your system configuration and emulator or software settings.Tips and Tricks
-Now that you have downloaded and installed FIFA Street 4 on your PC using one of the methods above, you are ready to enjoy the ultimate street soccer game on your computer. However, you may want to optimize your FIFA Street 4 experience on PC by adjusting some settings and customizing some features. In this section, we will give you some tips and tricks on how to do that:
- - How to Configure Your Emulator Settings for FIFA Street 4 - How to Customize Your Controller Settings for FIFA Street 4 - How to Access the Online Features of FIFA Street 4 on PCHow to Configure Your Emulator Settings for FIFA Street 4
-An emulator is a software that allows you to run games or applications that are designed for a different platform on your PC. For example, you can use an emulator to play PlayStation 3 or Xbox 360 games on your PC. However, an emulator may not run the game perfectly by default, and you may need to configure some settings to improve the graphics, audio, input, and performance of the game. Here are some steps on how to configure your emulator settings for FIFA Street 4:
- - Step 1: Open your emulator and go to the settings menu. You will see different options and tabs for various settings, such as graphics, audio, input, and performance. - Step 2: Adjust the graphics settings according to your preference and system capability. You can change the resolution, aspect ratio, frame rate, anti-aliasing, texture filtering, shaders, and more. You can also enable or disable fullscreen mode, vsync, and windowed mode. The higher the graphics settings, the better the game will look, but the more demanding it will be on your system. - Step 3: Adjust the audio settings according to your preference and system capability. You can change the volume, output device, sample rate, latency, and more. You can also enable or disable sound effects, music, voice, and subtitles. The higher the audio settings, the better the game will sound, but the more demanding it will be on your system. - Step 4: Adjust the input settings according to your preference and controller type. You can map the buttons, sticks, triggers, and vibration of your controller to match the game controls. You can also enable or disable analog mode, dead zone, sensitivity, and rumble. The more accurate the input settings, the better the game will respond, but the more complex it will be to set up. - Step 5: Adjust the performance settings according to your preference and system capability. You can change the emulation speed, CPU mode, GPU mode, cache size, and more. You can also enable or disable hacks, cheats, patches, and logs. The higher the performance settings, the faster the game will run, but the more unstable it will be on your system. You can also use some presets or profiles that are already configured for FIFA Street 4 by other users or developers. You can find them on the emulator website, forum, or wiki. You can also save your own settings and load them later.How to Customize Your Controller Settings for FIFA Street 4
-A controller is a device that allows you to control the game using buttons, sticks, triggers, and vibration. A controller can enhance your FIFA Street 4 gameplay by giving you more precision, comfort, and feedback. However, a controller may not work well with the game by default, and you may need to customize some settings to improve the mapping, sensitivity, and vibration of the controller. Here are some steps on how to customize your controller settings for FIFA Street 4:
- - Step 1: Open your emulator and go to the input menu. You will see different options and tabs for various input devices, such as keyboard, mouse, joystick, gamepad, and more. - Step 2: Choose the input device that you want to use for playing FIFA Street 4. You can use a keyboard and mouse, but we recommend using a controller for better gameplay. - Step 3: Configure the mapping of your controller according to your preference and game controls. You can assign the buttons, sticks, triggers, and vibration of your controller to match the actions, movements, skills, and feedback of the game. You can also enable or disable analog mode, dead zone, sensitivity, and rumble. - Step 4: Test your controller settings by playing a practice match or a tutorial in FIFA Street 4. You can check if the controller works properly and if you are comfortable with the settings. You can also adjust the settings as you play until you find the best configuration for you. - Step 5: Save your controller settings and load them later. You can also use some presets or profiles that are already configured for FIFA Street 4 by other users or developers. You can find them on the emulator website, forum, or wiki.How to Access the Online Features of FIFA Street 4 on PC
-One of the best features of FIFA Street 4 is its online mode, where you can connect to the EA servers, play online matches, join tournaments, and unlock rewards. However, accessing the online features of FIFA Street 4 on PC may not be easy or possible depending on your method and emulator. Here are some tips on how to access the online features of FIFA Street 4 on PC:
- - Tip 1: Use an official and legal method (Method 1 or Method 2) to download and install FIFA Street 4 on PC. This will ensure that you have a valid copy of the game and that you can log in to your EA account without any issues. - Tip 2: Use a compatible and stable emulator (RPCS3 or Xenia) to play FIFA Street 4 on PC. This will ensure that you can run the game smoothly and that you can connect to the EA servers without any errors. - Tip 3: Use a reliable and secure internet connection to play FIFA Street 4 on PC. This will ensure that you can play online matches without any lag or disconnection. - Tip 4: Use a VPN service to play FIFA Street 4 on PC. This will ensure that you can bypass any regional or network restrictions that may prevent you from accessing the online features of the game. - Tip 5: Use a mod file or a patch file to play FIFA Street 4 on PC. This will ensure that you can unlock some extra features or fix some bugs that may affect the online mode of the game.Conclusion
-FIFA Street 4 is one of the best soccer games ever made. It offers a unique and exciting street soccer experience that showcases your skills, style, and creativity in various urban locations around the world. It features over 50 teams, over 35 locations, over 500 players, and a variety of modes, such as World Tour, Hit the Streets, Freestyle, Last Man Standing, Panna Rules, Futsal, and Custom Match.
-However, if you want to play FIFA Street 4 on your PC, you may face some challenges, as there is no official PC version of the game. But don't worry, we have got you covered. In this article, we have shown you how to download and install FIFA Street 4 on PC using five different methods:
- - Method 1: Download FIFA Street 4 from Steam - Method 2: Download FIFA Street 4 from Origin - Method 3: Download FIFA Street 4 from a Torrent Site - Method 4: Download FIFA Street 4 from a ROM Site - Method 5: Download FIFA Street 4 from a Mod SiteWe have also given you some tips and tricks on how to optimize your FIFA Street 4 experience on PC by configuring your emulator settings, customizing your controller settings, and accessing the online features of the game.
-We hope that this article has helped you to play FIFA Street 4 on PC and enjoy the ultimate street soccer game on your computer. If you have any questions or feedback, please feel free to leave a comment below. And if you liked this article, please share it with your friends and family who are also fans of soccer games.
-FAQs
-Here are some of the frequently asked questions about FIFA Street 4 on PC:
-Q: Is FIFA Street 4 available for PC?
-A: No, FIFA Street 4 is not officially available for PC. It was only released for PlayStation 3 and Xbox 360 in March 2012. However, you can use some methods and emulators to play FIFA Street 4 on PC.
-Q: What is the best method to download and install FIFA Street 4 on PC?
-A: The best method to download and install FIFA Street 4 on PC depends on your preference and situation. However, we recommend that you use the official and legal methods (Method 1 and Method 2) as much as possible to avoid any potential risks or issues.
-Q: What is the best emulator to play FIFA Street 4 on PC?
-A: The best emulator to play FIFA Street 4 on PC depends on your system configuration and performance. However, we recommend that you use RPCS3 or Xenia as they are the most compatible and stable emulators for PlayStation 3 and Xbox 360 games.
-Q: What is the best controller to play FIFA Street 4 on PC?
-A: The best controller to play FIFA Street 4 on PC depends on your preference and budget. However, we recommend that you use Xbox One Controller or DualShock 4 Controller as they are the most widely used and supported controllers for PC gaming.
-Q: How can I access the online features of FIFA Street 4 on PC?
-A: You can access the online features of FIFA Street 4 on PC by using an official and legal method (Method 1 or Method 2) to download and install the game, using a compatible and stable emulator (RPCS3 or Xenia) to play the game, using a reliable and secure internet connection to connect to the EA servers, using a VPN service to bypass any regional or network restrictions, and using a mod file or a patch file to unlock some extra features or fix some bugs.
401be4b1e0
-
-
\ No newline at end of file diff --git a/spaces/3B-Group/ConvRe-Leaderboard/app.py b/spaces/3B-Group/ConvRe-Leaderboard/app.py deleted file mode 100644 index 4016501d624e0225c6fe4d30053b6bb9e0206456..0000000000000000000000000000000000000000 --- a/spaces/3B-Group/ConvRe-Leaderboard/app.py +++ /dev/null @@ -1,237 +0,0 @@ -import gradio as gr -import pandas as pd - -from src.css_html import custom_css -from src.utils import ( - AutoEvalColumn, - fields, - make_clickable_names, - make_plot_data -) -from src.demo import ( - generate, - random_examples, - return_ground_truth, -) - - -DEFAULT_SYSTEM_PROMPT = "You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.\n\nIf a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information." -MAX_MAX_NEW_TOKENS = 1024 -DEFAULT_MAX_NEW_TOKENS = 512 - - -df = pd.read_csv("data/eval_board.csv") - -COLS = [c.name for c in fields(AutoEvalColumn)] -TYPES = [c.type for c in fields(AutoEvalColumn)] -COLS_LITE = [c.name for c in fields(AutoEvalColumn) if c.displayed_by_default and not c.hidden] -TYPES_LITE = [c.type for c in fields(AutoEvalColumn) if c.displayed_by_default and not c.hidden] - - -def add_new_eval( - model: str, - re2text_easy_precision: str, - re2text_hard_precision: str, - text2re_easy_precision: str, - text2re_hard_precision: str, - links: str, -): - print("adding new eval") - - eval_entry = { - "model": model, - "re2text_easy": re2text_easy_precision, - "re2text_hard": re2text_hard_precision, - "text2re_easy": text2re_easy_precision, - "text2re_hard": text2re_hard_precision, - "link": links - } - - - -def select_columns(df, columns): - always_here_cols = [ - AutoEvalColumn.model.name - ] - # We use COLS to maintain sorting - filtered_df = df[ - always_here_cols + [c for c in COLS if c in df.columns and c in columns] - ] - return filtered_df - - -df["pure_name"] = df['Models'] -df = make_clickable_names(df) -demo = gr.Blocks(css=custom_css) - -with demo: - with gr.Row(): - gr.Markdown( - """-- -""", - elem_classes="markdown-text", - ) - - gr.Markdown("""🤖**ConvRe**🤯 is the benchmark proposed in our EMNLP 2023 main conference paper: [An Investigation of LLMs’ Inefficacy in Understanding Converse Relations](https://arxiv.org/abs/2310.05163). -It aims to evaluate LLMs' ability on understanding converse relations. -Converse relation is defined as the opposite of semantic relation while keeping the surface form of the triple unchanged. -For example, the triple `(x, has part, y)` is interpreted as "x has a part called y" in normal relation, while "y has a part called x" in converse relation 🔁. - -The experiments in our paper suggested that LLMs often resort to shortcut learning (or superficial correlations) and still face challenges on our 🤖ConvRe🤯 benchmark even for powerful models like GPT-4. - """, elem_classes="markdown-text") - - with gr.Tabs(elem_classes="tab-buttons") as tabs: - with gr.TabItem("🔢 Data", id=0): - with gr.Accordion("➡️ See All Columns", open=False): - shown_columns = gr.CheckboxGroup( - choices=[ - c for c in COLS if c not in [AutoEvalColumn.model.name] - ], - value=[ - c for c in COLS_LITE if c not in [AutoEvalColumn.model.name] - ], - label="", - elem_id="column-select", - interactive=True - ) - leaderboard_df_re2text = gr.components.Dataframe( - value=df[ - [ - AutoEvalColumn.model.name, - ] + shown_columns.value - ], - headers=[ - AutoEvalColumn.model.name, - ] + shown_columns.value, - datatype=TYPES, - elem_id="leaderboard-table", - interactive=False, - ) - - hidden_leaderboard_df_re2text = gr.components.DataFrame( - value=df, - headers=COLS, - datatype=["str" for _ in range(len(COLS))], - visible=False, - ) - - shown_columns.change( - select_columns, - [hidden_leaderboard_df_re2text, shown_columns], - leaderboard_df_re2text - ) - - with gr.TabItem("📊 Plot", id=1): - with gr.Row(): - with gr.Column(): - gr.LinePlot( - make_plot_data(df, task="Re2Text"), - x="Setting", - y="Accuracy", - color="Symbol", - title="Re2Text", - y_lim=[0, 100], - x_label_angle=0, - height=400, - width=500, - ) - - with gr.Column(): - gr.LinePlot( - make_plot_data(df, task="Text2Re"), - x="Setting", - y="Accuracy", - color="Symbol", - title="Text2Re", - y_lim=[0, 100], - x_label_angle=0, - height=400, - width=500, - ) - - with gr.TabItem("Submit results 🚀", id=3): - gr.Markdown("""🤖 ConvRe 🤯 Leaderboard
--- -""") - - with gr.Column(): - gr.Markdown( - """Comming Soon ❤️
-\ -🤖ConvRe🤯 Demo (Llama-2-Chat-7B🦙)
\ - """, - elem_classes="markdown-text", - ) - - output_box = gr.Textbox(lines=10, max_lines=10, label="Llama-2-Chat-7B Answer", interactive=False) - - input_box = gr.Textbox(lines=12, max_lines=12, label="User Input") - - ground_truth_display = gr.Textbox("", lines=1, max_lines=1, label="😊Correct Answer😊", interactive=False) - - with gr.Column(): - - - with gr.Accordion("Additional Inputs", open=False): - sys_prompt = gr.Textbox(label="System prompt", value=DEFAULT_SYSTEM_PROMPT, lines=6) - - max_new_tokens=gr.Slider( - label="Max new tokens", - minimum=1, - maximum=MAX_MAX_NEW_TOKENS, - step=1, - value=DEFAULT_MAX_NEW_TOKENS, - ) - - temperature = gr.Slider( - label="Temperature", - minimum=0.1, - maximum=4.0, - step=0.1, - value=0.1, - ) - - - with gr.Row(): - re2text_easy_btn = gr.Button("Random Re2Text Easy Example 😄") - re2text_easy_btn.click( - fn=random_examples, - inputs=gr.Text("re2text-easy", visible=False), - outputs = input_box, - ) - - re2text_hard_btn = gr.Button("Random Re2Text Hard Example 🤯") - re2text_hard_btn.click( - fn=random_examples, - inputs=gr.Text("re2text-hard", visible=False), - outputs=input_box, - ) - - text2re_easy_btn = gr.Button("Random Text2Re Easy Example 😄") - text2re_easy_btn.click( - fn=random_examples, - inputs=gr.Text("text2re-easy", visible=False), - outputs = input_box, - ) - - text2re_hard_btn = gr.Button("Random Text2Re Hard Example 🤯") - text2re_hard_btn.click( - fn=random_examples, - inputs=gr.Text("text2re-hard", visible=False), - outputs = input_box, - ) - - with gr.Row(): - gr.ClearButton([input_box, output_box]) - submit_btn = gr.Button("Submit🏃") - submit_btn.click(generate, inputs=[input_box, sys_prompt, temperature, max_new_tokens], outputs=[output_box]) - - answer_btn = gr.Button("Answer🤔") - answer_btn.click(return_ground_truth, inputs=[], outputs=[ground_truth_display]) - - -demo.queue(max_size=32).launch(enable_queue=True) \ No newline at end of file diff --git a/spaces/44ov41za8i/FreeVC/speaker_encoder/data_objects/speaker_verification_dataset.py b/spaces/44ov41za8i/FreeVC/speaker_encoder/data_objects/speaker_verification_dataset.py deleted file mode 100644 index cecd8ed8ac100b80d5087fa47f22f92c84fea032..0000000000000000000000000000000000000000 --- a/spaces/44ov41za8i/FreeVC/speaker_encoder/data_objects/speaker_verification_dataset.py +++ /dev/null @@ -1,56 +0,0 @@ -from speaker_encoder.data_objects.random_cycler import RandomCycler -from speaker_encoder.data_objects.speaker_batch import SpeakerBatch -from speaker_encoder.data_objects.speaker import Speaker -from speaker_encoder.params_data import partials_n_frames -from torch.utils.data import Dataset, DataLoader -from pathlib import Path - -# TODO: improve with a pool of speakers for data efficiency - -class SpeakerVerificationDataset(Dataset): - def __init__(self, datasets_root: Path): - self.root = datasets_root - speaker_dirs = [f for f in self.root.glob("*") if f.is_dir()] - if len(speaker_dirs) == 0: - raise Exception("No speakers found. Make sure you are pointing to the directory " - "containing all preprocessed speaker directories.") - self.speakers = [Speaker(speaker_dir) for speaker_dir in speaker_dirs] - self.speaker_cycler = RandomCycler(self.speakers) - - def __len__(self): - return int(1e10) - - def __getitem__(self, index): - return next(self.speaker_cycler) - - def get_logs(self): - log_string = "" - for log_fpath in self.root.glob("*.txt"): - with log_fpath.open("r") as log_file: - log_string += "".join(log_file.readlines()) - return log_string - - -class SpeakerVerificationDataLoader(DataLoader): - def __init__(self, dataset, speakers_per_batch, utterances_per_speaker, sampler=None, - batch_sampler=None, num_workers=0, pin_memory=False, timeout=0, - worker_init_fn=None): - self.utterances_per_speaker = utterances_per_speaker - - super().__init__( - dataset=dataset, - batch_size=speakers_per_batch, - shuffle=False, - sampler=sampler, - batch_sampler=batch_sampler, - num_workers=num_workers, - collate_fn=self.collate, - pin_memory=pin_memory, - drop_last=False, - timeout=timeout, - worker_init_fn=worker_init_fn - ) - - def collate(self, speakers): - return SpeakerBatch(speakers, self.utterances_per_speaker, partials_n_frames) - \ No newline at end of file diff --git a/spaces/801artistry/RVC801/LazyImport.py b/spaces/801artistry/RVC801/LazyImport.py deleted file mode 100644 index 5bdb05ddd5a546a43adba7274b4c3465bb77f2f5..0000000000000000000000000000000000000000 --- a/spaces/801artistry/RVC801/LazyImport.py +++ /dev/null @@ -1,13 +0,0 @@ -from importlib.util import find_spec, LazyLoader, module_from_spec -from sys import modules - -def lazyload(name): - if name in modules: - return modules[name] - else: - spec = find_spec(name) - loader = LazyLoader(spec.loader) - module = module_from_spec(spec) - modules[name] = module - loader.exec_module(module) - return module \ No newline at end of file diff --git a/spaces/AI-Hobbyist/Hoyo-RVC/docs/faq.md b/spaces/AI-Hobbyist/Hoyo-RVC/docs/faq.md deleted file mode 100644 index 74eff82d9e4f96f50ad0aed628c253d08e16a426..0000000000000000000000000000000000000000 --- a/spaces/AI-Hobbyist/Hoyo-RVC/docs/faq.md +++ /dev/null @@ -1,89 +0,0 @@ -## Q1:ffmpeg error/utf8 error. - -大概率不是ffmpeg问题,而是音频路径问题;
-ffmpeg读取路径带空格、()等特殊符号,可能出现ffmpeg error;训练集音频带中文路径,在写入filelist.txt的时候可能出现utf8 error;
- -## Q2:一键训练结束没有索引 - -显示"Training is done. The program is closed."则模型训练成功,后续紧邻的报错是假的;
- -一键训练结束完成没有added开头的索引文件,可能是因为训练集太大卡住了添加索引的步骤;已通过批处理add索引解决内存add索引对内存需求过大的问题。临时可尝试再次点击"训练索引"按钮。
- -## Q3:训练结束推理没看到训练集的音色 -点刷新音色再看看,如果还没有看看训练有没有报错,控制台和webui的截图,logs/实验名下的log,都可以发给开发者看看。
- -## Q4:如何分享模型 - rvc_root/logs/实验名 下面存储的pth不是用来分享模型用来推理的,而是为了存储实验状态供复现,以及继续训练用的。用来分享的模型应该是weights文件夹下大小为60+MB的pth文件;
- 后续将把weights/exp_name.pth和logs/exp_name/added_xxx.index合并打包成weights/exp_name.zip省去填写index的步骤,那么zip文件用来分享,不要分享pth文件,除非是想换机器继续训练;
- 如果你把logs文件夹下的几百MB的pth文件复制/分享到weights文件夹下强行用于推理,可能会出现f0,tgt_sr等各种key不存在的报错。你需要用ckpt选项卡最下面,手工或自动(本地logs下如果能找到相关信息则会自动)选择是否携带音高、目标音频采样率的选项后进行ckpt小模型提取(输入路径填G开头的那个),提取完在weights文件夹下会出现60+MB的pth文件,刷新音色后可以选择使用。
- -## Q5:Connection Error. -也许你关闭了控制台(黑色窗口)。
- -## Q6:WebUI弹出Expecting value: line 1 column 1 (char 0). -请关闭系统局域网代理/全局代理。
- -这个不仅是客户端的代理,也包括服务端的代理(例如你使用autodl设置了http_proxy和https_proxy学术加速,使用时也需要unset关掉)
- -## Q7:不用WebUI如何通过命令训练推理 -训练脚本:
-可先跑通WebUI,消息窗内会显示数据集处理和训练用命令行;
- -推理脚本:
-https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
- -例子:
- -runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
- -f0up_key=sys.argv[1]
-input_path=sys.argv[2]
-index_path=sys.argv[3]
-f0method=sys.argv[4]#harvest or pm
-opt_path=sys.argv[5]
-model_path=sys.argv[6]
-index_rate=float(sys.argv[7])
-device=sys.argv[8]
-is_half=bool(sys.argv[9])
- -## Q8:Cuda error/Cuda out of memory. -小概率是cuda配置问题、设备不支持;大概率是显存不够(out of memory);
- -训练的话缩小batch size(如果缩小到1还不够只能更换显卡训练),推理的话酌情缩小config.py结尾的x_pad,x_query,x_center,x_max。4G以下显存(例如1060(3G)和各种2G显卡)可以直接放弃,4G显存显卡还有救。
- -## Q9:total_epoch调多少比较好 - -如果训练集音质差底噪大,20~30足够了,调太高,底模音质无法带高你的低音质训练集
-如果训练集音质高底噪低时长多,可以调高,200是ok的(训练速度很快,既然你有条件准备高音质训练集,显卡想必条件也不错,肯定不在乎多一些训练时间)
- -## Q10:需要多少训练集时长 - 推荐10min至50min
- 保证音质高底噪低的情况下,如果有个人特色的音色统一,则多多益善
- 高水平的训练集(精简+音色有特色),5min至10min也是ok的,仓库作者本人就经常这么玩
- 也有人拿1min至2min的数据来训练并且训练成功的,但是成功经验是其他人不可复现的,不太具备参考价值。这要求训练集音色特色非常明显(比如说高频气声较明显的萝莉少女音),且音质高;
- 1min以下时长数据目前没见有人尝试(成功)过。不建议进行这种鬼畜行为。
- -## Q11:index rate干嘛用的,怎么调(科普) - 如果底模和推理源的音质高于训练集的音质,他们可以带高推理结果的音质,但代价可能是音色往底模/推理源的音色靠,这种现象叫做"音色泄露";
- index rate用来削减/解决音色泄露问题。调到1,则理论上不存在推理源的音色泄露问题,但音质更倾向于训练集。如果训练集音质比推理源低,则index rate调高可能降低音质。调到0,则不具备利用检索混合来保护训练集音色的效果;
- 如果训练集优质时长多,可调高total_epoch,此时模型本身不太会引用推理源和底模的音色,很少存在"音色泄露"问题,此时index_rate不重要,你甚至可以不建立/分享index索引文件。
- -## Q11:推理怎么选gpu -config.py文件里device cuda:后面选择卡号;
-卡号和显卡的映射关系,在训练选项卡的显卡信息栏里能看到。
- -## Q12:如何推理训练中间保存的pth -通过ckpt选项卡最下面提取小模型。
- - -## Q13:如何中断和继续训练 -现阶段只能关闭WebUI控制台双击go-web.bat重启程序。网页参数也要刷新重新填写;
-继续训练:相同网页参数点训练模型,就会接着上次的checkpoint继续训练。
- -## Q14:训练时出现文件页面/内存error -进程开太多了,内存炸了。你可能可以通过如下方式解决
-1、"提取音高和处理数据使用的CPU进程数" 酌情拉低;
-2、训练集音频手工切一下,不要太长。
- - - diff --git a/spaces/AIFILMS/generate_human_motion/pyrender/tests/unit/test_meshes.py b/spaces/AIFILMS/generate_human_motion/pyrender/tests/unit/test_meshes.py deleted file mode 100644 index 7070b01171c97069fa013c6eba8eee217017f08e..0000000000000000000000000000000000000000 --- a/spaces/AIFILMS/generate_human_motion/pyrender/tests/unit/test_meshes.py +++ /dev/null @@ -1,133 +0,0 @@ -import numpy as np -import pytest -import trimesh - -from pyrender import (Mesh, Primitive) - - -def test_meshes(): - - with pytest.raises(TypeError): - x = Mesh() - with pytest.raises(TypeError): - x = Primitive() - with pytest.raises(ValueError): - x = Primitive([], mode=10) - - # Basics - x = Mesh([]) - assert x.name is None - assert x.is_visible - assert x.weights is None - - x.name = 'str' - - # From Trimesh - x = Mesh.from_trimesh(trimesh.creation.box()) - assert isinstance(x, Mesh) - assert len(x.primitives) == 1 - assert x.is_visible - assert np.allclose(x.bounds, np.array([ - [-0.5, -0.5, -0.5], - [0.5, 0.5, 0.5] - ])) - assert np.allclose(x.centroid, np.zeros(3)) - assert np.allclose(x.extents, np.ones(3)) - assert np.allclose(x.scale, np.sqrt(3)) - assert not x.is_transparent - - # Test some primitive functions - x = x.primitives[0] - with pytest.raises(ValueError): - x.normals = np.zeros(10) - with pytest.raises(ValueError): - x.tangents = np.zeros(10) - with pytest.raises(ValueError): - x.texcoord_0 = np.zeros(10) - with pytest.raises(ValueError): - x.texcoord_1 = np.zeros(10) - with pytest.raises(TypeError): - x.material = np.zeros(10) - assert x.targets is None - assert np.allclose(x.bounds, np.array([ - [-0.5, -0.5, -0.5], - [0.5, 0.5, 0.5] - ])) - assert np.allclose(x.centroid, np.zeros(3)) - assert np.allclose(x.extents, np.ones(3)) - assert np.allclose(x.scale, np.sqrt(3)) - x.material.baseColorFactor = np.array([0.0, 0.0, 0.0, 0.0]) - assert x.is_transparent - - # From two trimeshes - x = Mesh.from_trimesh([trimesh.creation.box(), - trimesh.creation.cylinder(radius=0.1, height=2.0)], - smooth=False) - assert isinstance(x, Mesh) - assert len(x.primitives) == 2 - assert x.is_visible - assert np.allclose(x.bounds, np.array([ - [-0.5, -0.5, -1.0], - [0.5, 0.5, 1.0] - ])) - assert np.allclose(x.centroid, np.zeros(3)) - assert np.allclose(x.extents, [1.0, 1.0, 2.0]) - assert np.allclose(x.scale, np.sqrt(6)) - assert not x.is_transparent - - # From bad data - with pytest.raises(TypeError): - x = Mesh.from_trimesh(None) - - # With instancing - poses = np.tile(np.eye(4), (5,1,1)) - poses[:,0,3] = np.array([0,1,2,3,4]) - x = Mesh.from_trimesh(trimesh.creation.box(), poses=poses) - assert np.allclose(x.bounds, np.array([ - [-0.5, -0.5, -0.5], - [4.5, 0.5, 0.5] - ])) - poses = np.eye(4) - x = Mesh.from_trimesh(trimesh.creation.box(), poses=poses) - poses = np.eye(3) - with pytest.raises(ValueError): - x = Mesh.from_trimesh(trimesh.creation.box(), poses=poses) - - # From textured meshes - fm = trimesh.load('tests/data/fuze.obj') - x = Mesh.from_trimesh(fm) - assert isinstance(x, Mesh) - assert len(x.primitives) == 1 - assert x.is_visible - assert not x.is_transparent - assert x.primitives[0].material.baseColorTexture is not None - - x = Mesh.from_trimesh(fm, smooth=False) - fm.visual = fm.visual.to_color() - fm.visual.face_colors = np.array([1.0, 0.0, 0.0, 1.0]) - x = Mesh.from_trimesh(fm, smooth=False) - with pytest.raises(ValueError): - x = Mesh.from_trimesh(fm, smooth=True) - - fm.visual.vertex_colors = np.array([1.0, 0.0, 0.0, 0.5]) - x = Mesh.from_trimesh(fm, smooth=False) - x = Mesh.from_trimesh(fm, smooth=True) - assert x.primitives[0].color_0 is not None - assert x.is_transparent - - bm = trimesh.load('tests/data/WaterBottle.glb').dump()[0] - x = Mesh.from_trimesh(bm) - assert x.primitives[0].material.baseColorTexture is not None - assert x.primitives[0].material.emissiveTexture is not None - assert x.primitives[0].material.metallicRoughnessTexture is not None - - # From point cloud - x = Mesh.from_points(fm.vertices) - -# def test_duck(): -# bm = trimesh.load('tests/data/Duck.glb').dump()[0] -# x = Mesh.from_trimesh(bm) -# assert x.primitives[0].material.baseColorTexture is not None -# pixel = x.primitives[0].material.baseColorTexture.source[100, 100] -# yellowish = np.array([1.0, 0.7411765, 0.0, 1.0]) -# assert np.allclose(pixel, yellowish) diff --git a/spaces/Abhay1210/prompt-generator_V1/app.py b/spaces/Abhay1210/prompt-generator_V1/app.py deleted file mode 100644 index 736b3892146a2e0b94d03891a7d2d1edec33791a..0000000000000000000000000000000000000000 --- a/spaces/Abhay1210/prompt-generator_V1/app.py +++ /dev/null @@ -1,18 +0,0 @@ -from transformers import AutoTokenizer, AutoModelForSeq2SeqLM -import gradio as gr - -tokenizer = AutoTokenizer.from_pretrained("merve/chatgpt-prompts-bart-long") -model = AutoModelForSeq2SeqLM.from_pretrained("merve/chatgpt-prompts-bart-long", from_tf=True) - -def generate(prompt): - - batch = tokenizer(prompt, return_tensors="pt") - generated_ids = model.generate(batch["input_ids"], max_new_tokens=150) - output = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) - return output[0] - -input_component = gr.Textbox(label = "Input a persona, e.g. photographer", value = "photographer") -output_component = gr.Textbox(label = "Prompt") -examples = [["photographer"], ["Linux Admin"]] -description = "This app generates ChatGPT prompts, it's based on a BART model trained on [this dataset](https://huggingface.co/datasets/fka/awesome-chatgpt-prompts). Simply enter a persona that you want the prompt to be generated based on." -gr.Interface(generate, inputs = input_component, outputs=output_component, examples=examples, title = "👨 ChatGPT Prompt Generator 👨", description=description).launch() diff --git a/spaces/Abubakari/Sales_Prediction/app.py b/spaces/Abubakari/Sales_Prediction/app.py deleted file mode 100644 index c1cd67695b9c1cb2ef73fdd5f48006cd0f608f52..0000000000000000000000000000000000000000 --- a/spaces/Abubakari/Sales_Prediction/app.py +++ /dev/null @@ -1,166 +0,0 @@ -import pandas as pd -import streamlit as st -import numpy as np -from matplotlib import pyplot as plt -import pickle -import sklearn -import joblib -from PIL import Image -import base64 - - -num_imputer = joblib.load('numerical_imputer.joblib') -cat_imputer = joblib.load('categorical_imputer.joblib') -encoder = joblib.load('encoder.joblib') -scaler = joblib.load('scaler.joblib') -dt_model = joblib.load('Final_model.joblib') - -# Add a title and subtitle -st.write("Sales Prediction App
{download_csv()}', - unsafe_allow_html=True -) diff --git a/spaces/Adr740/SmartHadithFR/app.py b/spaces/Adr740/SmartHadithFR/app.py deleted file mode 100644 index 058d9f011669de121ece41a138f2a99de76696ce..0000000000000000000000000000000000000000 --- a/spaces/Adr740/SmartHadithFR/app.py +++ /dev/null @@ -1,41 +0,0 @@ - -import gradio as gr -from functools import partial -from get_similar_hadiths import search_hadiths -import pandas as pd - -title = "Smart Hadith (Version Française) -> [English version here](https://huggingface.co/spaces/Adr740/Hadith_AI_Explorer)" -desc = "Bienvenue dans Smart Hadith. Smart Hadith est un outil de recherche sémantique de hadith utilisant l'intelligence artificelle. Contact suggestions/questions: [hdthaiexplorer@gmail.com](mailto:hdthaiexplorer@gmail.com)" - -# "This is a tool that helps you find quickly relevant hadiths on a topic or a problem you have. Just type in plain English what you are looking for in the box below.\n\n" -warning = "\n\n**AVERTISSEMENT (seulement environ 3000 hadiths sont présents)**\nCET OUTIL EST DESTINÉ À DES FINS DE RÉFÉRENCE AFIN DE FACILITER LA RECHERCHE SUR LES HADITHS (PAROLES ET ACTES PROPHÉTIQUES), IL N'EST PAS DESTINÉ À ÊTRE UTILISÉ COMME OUTIL DE GUIDANCE OU DANS TOUT AUTRE BUT. LES UTILISATEURS SONT RESPONSABLES DE CONDUIRE LEURS PROPRES RECHERCHES ET DE DEMANDER DES CONSEILS AUX SAVANTS RELIGIEUX.\nVEUILLEZ NOTER QUE LE CONTENU AFFICHÉ PAR CET OUTIL N'EST PAS GARANTI COMME ÉTANT PRÉCIS, COMPLET OU À JOUR, ET N'EST PAS DESTINÉ À ÊTRE UTILISÉ COMME SOURCE RELIGIEUSE UNIQUE.\nLES DÉVELOPPEURS DE CET OUTIL NE SERONT PAS TENUS RESPONSABLES DE TOUTE DÉCISION OU UTILISATION FAITE PAR LES UTILISATEURS DE CET OUTIL." -disclaimer = "\n## DISCLAIMER\n\nTHIS TOOL IS INTENDED FOR REFERENCE PURPOSES ONLY AND IS NOT INTENDED TO BE TAKEN AS RELIGIOUS ADVICE. THE HADITHS DISPLAYED BY THIS TOOL ARE NOT INTENDED TO BE USED AS A SOLE SOURCE OF RELIGIOUS GUIDANCE. USERS ARE RESPONSIBLE FOR CONDUCTING THEIR OWN RESEARCH AND SEEKING GUIDANCE FROM RELIGIOUS SCHOLARS.\n\nPLEASE NOTE THAT THE CONTENT DISPLAYED BY THIS TOOL IS NOT GUARANTEED TO BE ACCURATE, COMPLETE, OR UP-TO-DATE.\n\nTHE DEVELOPERS OF THIS TOOL WILL NOT BE HELD RESPONSIBLE FOR ANY DECISIONS MADE BY THE USERS OF THIS TOOL THAT ARE BASED ON THE CONTENT DISPLAYED BY THIS TOOL.\n\nHadiths gathered from this repository: https:\/\/www.kaggle.com\/datasets\/fahd09\/hadith-dataset" -def iter_grid(n_rows, n_cols): - for _ in range(n_rows): - with gr.Row(): - for _ in range(n_cols): - with gr.Column(): - yield -with gr.Blocks(title=title) as demo: - gr.Markdown(f"## {title}") - gr.Markdown(desc+warning) - # gr.Markdown(warning) - with gr.Row(): - with gr.Column(scale=4): - text_area = gr.Textbox(placeholder="Écrivez ici... Exemple: 'Hadiths sur le bon comportement et la nourriture'", lines=3, label="Décrivez avec vos mots ce que vous recherchez (mot-clé, sujet etc...)") - with gr.Column(scale=1): - number_to_display = gr.Number(value=10,label = "Nombre de hadiths à afficher") - submit_button = gr.Button(value="Trouver des hadiths") - pass - - fn = partial(search_hadiths) - - with gr.Accordion("Tous les résultats:"): - ll = gr.Markdown("Vide") - - - submit_button.click(fn=fn, inputs=[text_area,number_to_display], outputs=[ll]) - - - -demo.launch( enable_queue=True,max_threads=40) \ No newline at end of file diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/gridsizer/ResolveChildrenWidth.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/gridsizer/ResolveChildrenWidth.js deleted file mode 100644 index 77e4f6b28113ac390185701f6a1782fb4331494e..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/gridsizer/ResolveChildrenWidth.js +++ /dev/null @@ -1,16 +0,0 @@ -var ResolveChildrenWidth = function (parentWidth) { - // Resolve width of sizer children - var child, childWidth; - var colWidth; - for (var i in this.sizerChildren) { - child = this.sizerChildren[i]; - if (child && child.isRexSizer && !child.ignoreLayout) { - colWidth = this.getColumnWidth(parseInt(i) % this.columnCount); - childWidth = this.getExpandedChildWidth(child, colWidth); - childWidth = child.resolveWidth(childWidth); - child.resolveChildrenWidth(childWidth); - } - } -} - -export default ResolveChildrenWidth; \ No newline at end of file diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/press/Press.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/press/Press.js deleted file mode 100644 index 1cf74edb5aaef00b93bb199769cc55fe86df1e84..0000000000000000000000000000000000000000 --- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/press/Press.js +++ /dev/null @@ -1,2 +0,0 @@ -import { Press } from '../../../plugins/gestures.js'; -export default Press; \ No newline at end of file diff --git a/spaces/Ajay07pandey/Netfilx_Movie_Recommendation_System/README.md b/spaces/Ajay07pandey/Netfilx_Movie_Recommendation_System/README.md deleted file mode 100644 index 1f8339747ca190a8c30f6034293943a3a056ee10..0000000000000000000000000000000000000000 --- a/spaces/Ajay07pandey/Netfilx_Movie_Recommendation_System/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Netfilx Movie Recommendation System -emoji: 👀 -colorFrom: pink -colorTo: blue -sdk: streamlit -sdk_version: 1.27.2 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Alycer/VITS-Umamusume-voice-synthesizer/utils.py b/spaces/Alycer/VITS-Umamusume-voice-synthesizer/utils.py deleted file mode 100644 index 9794e0fc3463a5e8fad05c037cce64683059a6d3..0000000000000000000000000000000000000000 --- a/spaces/Alycer/VITS-Umamusume-voice-synthesizer/utils.py +++ /dev/null @@ -1,226 +0,0 @@ -import os -import glob -import sys -import argparse -import logging -import json -import subprocess -import numpy as np -from scipy.io.wavfile import read -import torch - -MATPLOTLIB_FLAG = False - -logging.basicConfig(stream=sys.stdout, level=logging.ERROR) -logger = logging - - -def load_checkpoint(checkpoint_path, model, optimizer=None): - assert os.path.isfile(checkpoint_path) - checkpoint_dict = torch.load(checkpoint_path, map_location='cpu') - iteration = checkpoint_dict['iteration'] - learning_rate = checkpoint_dict['learning_rate'] - if optimizer is not None: - optimizer.load_state_dict(checkpoint_dict['optimizer']) - saved_state_dict = checkpoint_dict['model'] - if hasattr(model, 'module'): - state_dict = model.module.state_dict() - else: - state_dict = model.state_dict() - new_state_dict = {} - for k, v in state_dict.items(): - try: - new_state_dict[k] = saved_state_dict[k] - except: - logger.info("%s is not in the checkpoint" % k) - new_state_dict[k] = v - if hasattr(model, 'module'): - model.module.load_state_dict(new_state_dict) - else: - model.load_state_dict(new_state_dict) - logger.info("Loaded checkpoint '{}' (iteration {})".format( - checkpoint_path, iteration)) - return model, optimizer, learning_rate, iteration - - -def plot_spectrogram_to_numpy(spectrogram): - global MATPLOTLIB_FLAG - if not MATPLOTLIB_FLAG: - import matplotlib - matplotlib.use("Agg") - MATPLOTLIB_FLAG = True - mpl_logger = logging.getLogger('matplotlib') - mpl_logger.setLevel(logging.WARNING) - import matplotlib.pylab as plt - import numpy as np - - fig, ax = plt.subplots(figsize=(10, 2)) - im = ax.imshow(spectrogram, aspect="auto", origin="lower", - interpolation='none') - plt.colorbar(im, ax=ax) - plt.xlabel("Frames") - plt.ylabel("Channels") - plt.tight_layout() - - fig.canvas.draw() - data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,)) - plt.close() - return data - - -def plot_alignment_to_numpy(alignment, info=None): - global MATPLOTLIB_FLAG - if not MATPLOTLIB_FLAG: - import matplotlib - matplotlib.use("Agg") - MATPLOTLIB_FLAG = True - mpl_logger = logging.getLogger('matplotlib') - mpl_logger.setLevel(logging.WARNING) - import matplotlib.pylab as plt - import numpy as np - - fig, ax = plt.subplots(figsize=(6, 4)) - im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower', - interpolation='none') - fig.colorbar(im, ax=ax) - xlabel = 'Decoder timestep' - if info is not None: - xlabel += '\n\n' + info - plt.xlabel(xlabel) - plt.ylabel('Encoder timestep') - plt.tight_layout() - - fig.canvas.draw() - data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,)) - plt.close() - return data - - -def load_wav_to_torch(full_path): - sampling_rate, data = read(full_path) - return torch.FloatTensor(data.astype(np.float32)), sampling_rate - - -def load_filepaths_and_text(filename, split="|"): - with open(filename, encoding='utf-8') as f: - filepaths_and_text = [line.strip().split(split) for line in f] - return filepaths_and_text - - -def get_hparams(init=True): - parser = argparse.ArgumentParser() - parser.add_argument('-c', '--config', type=str, default="./configs/base.json", - help='JSON file for configuration') - parser.add_argument('-m', '--model', type=str, required=True, - help='Model name') - - args = parser.parse_args() - model_dir = os.path.join("./logs", args.model) - - if not os.path.exists(model_dir): - os.makedirs(model_dir) - - config_path = args.config - config_save_path = os.path.join(model_dir, "config.json") - if init: - with open(config_path, "r") as f: - data = f.read() - with open(config_save_path, "w") as f: - f.write(data) - else: - with open(config_save_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams = HParams(**config) - hparams.model_dir = model_dir - return hparams - - -def get_hparams_from_dir(model_dir): - config_save_path = os.path.join(model_dir, "config.json") - with open(config_save_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams = HParams(**config) - hparams.model_dir = model_dir - return hparams - - -def get_hparams_from_file(config_path): - with open(config_path, "r", encoding="utf-8") as f: - data = f.read() - config = json.loads(data) - - hparams = HParams(**config) - return hparams - - -def check_git_hash(model_dir): - source_dir = os.path.dirname(os.path.realpath(__file__)) - if not os.path.exists(os.path.join(source_dir, ".git")): - logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format( - source_dir - )) - return - - cur_hash = subprocess.getoutput("git rev-parse HEAD") - - path = os.path.join(model_dir, "githash") - if os.path.exists(path): - saved_hash = open(path).read() - if saved_hash != cur_hash: - logger.warn("git hash values are different. {}(saved) != {}(current)".format( - saved_hash[:8], cur_hash[:8])) - else: - open(path, "w").write(cur_hash) - - -def get_logger(model_dir, filename="train.log"): - global logger - logger = logging.getLogger(os.path.basename(model_dir)) - logger.setLevel(logging.DEBUG) - - formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s") - if not os.path.exists(model_dir): - os.makedirs(model_dir) - h = logging.FileHandler(os.path.join(model_dir, filename)) - h.setLevel(logging.DEBUG) - h.setFormatter(formatter) - logger.addHandler(h) - return logger - - -class HParams(): - def __init__(self, **kwargs): - for k, v in kwargs.items(): - if type(v) == dict: - v = HParams(**v) - self[k] = v - - def keys(self): - return self.__dict__.keys() - - def items(self): - return self.__dict__.items() - - def values(self): - return self.__dict__.values() - - def __len__(self): - return len(self.__dict__) - - def __getitem__(self, key): - return getattr(self, key) - - def __setitem__(self, key, value): - return setattr(self, key, value) - - def __contains__(self, key): - return key in self.__dict__ - - def __repr__(self): - return self.__dict__.__repr__() \ No newline at end of file diff --git a/spaces/Amon1/ChatGPTForAcadamic/crazy_functions/test_project/cpp/cppipc/waiter.h b/spaces/Amon1/ChatGPTForAcadamic/crazy_functions/test_project/cpp/cppipc/waiter.h deleted file mode 100644 index ee45fe3517be95ac1688a3e3540189edeb0d860c..0000000000000000000000000000000000000000 --- a/spaces/Amon1/ChatGPTForAcadamic/crazy_functions/test_project/cpp/cppipc/waiter.h +++ /dev/null @@ -1,83 +0,0 @@ -#pragma once - -#include-#include -#include -#include - -#include "libipc/def.h" -#include "libipc/mutex.h" -#include "libipc/condition.h" -#include "libipc/platform/detail.h" - -namespace ipc { -namespace detail { - -class waiter { - ipc::sync::condition cond_; - ipc::sync::mutex lock_; - std::atomic quit_ {false}; - -public: - static void init(); - - waiter() = default; - waiter(char const *name) { - open(name); - } - - ~waiter() { - close(); - } - - bool valid() const noexcept { - return cond_.valid() && lock_.valid(); - } - - bool open(char const *name) noexcept { - quit_.store(false, std::memory_order_relaxed); - if (!cond_.open((std::string{"_waiter_cond_"} + name).c_str())) { - return false; - } - if (!lock_.open((std::string{"_waiter_lock_"} + name).c_str())) { - cond_.close(); - return false; - } - return valid(); - } - - void close() noexcept { - cond_.close(); - lock_.close(); - } - - template - bool wait_if(F &&pred, std::uint64_t tm = ipc::invalid_value) noexcept { - IPC_UNUSED_ std::lock_guard (pred)(); - }()) { - if (!cond_.wait(lock_, tm)) return false; - } - return true; - } - - bool notify() noexcept { - std::lock_guard .""" - - usage = """ - %prog [options] """ - ignore_require_venv = True - - def add_options(self) -> None: - self.cmd_opts.add_option( - "-i", - "--index", - dest="index", - metavar="URL", - default=PyPI.pypi_url, - help="Base URL of Python Package Index (default %default)", - ) - - self.parser.insert_option_group(0, self.cmd_opts) - - def run(self, options: Values, args: List[str]) -> int: - if not args: - raise CommandError("Missing required argument (search query).") - query = args - pypi_hits = self.search(query, options) - hits = transform_hits(pypi_hits) - - terminal_width = None - if sys.stdout.isatty(): - terminal_width = shutil.get_terminal_size()[0] - - print_results(hits, terminal_width=terminal_width) - if pypi_hits: - return SUCCESS - return NO_MATCHES_FOUND - - def search(self, query: List[str], options: Values) -> List[Dict[str, str]]: - index_url = options.index - - session = self.get_default_session(options) - - transport = PipXmlrpcTransport(index_url, session) - pypi = xmlrpc.client.ServerProxy(index_url, transport) - try: - hits = pypi.search({"name": query, "summary": query}, "or") - except xmlrpc.client.Fault as fault: - message = "XMLRPC request failed [code: {code}]\n{string}".format( - code=fault.faultCode, - string=fault.faultString, - ) - raise CommandError(message) - assert isinstance(hits, list) - return hits - - -def transform_hits(hits: List[Dict[str, str]]) -> List["TransformedHit"]: - """ - The list from pypi is really a list of versions. We want a list of - packages with the list of versions stored inline. This converts the - list from pypi into one we can use. - """ - packages: Dict[str, "TransformedHit"] = OrderedDict() - for hit in hits: - name = hit["name"] - summary = hit["summary"] - version = hit["version"] - - if name not in packages.keys(): - packages[name] = { - "name": name, - "summary": summary, - "versions": [version], - } - else: - packages[name]["versions"].append(version) - - # if this is the highest version, replace summary and score - if version == highest_version(packages[name]["versions"]): - packages[name]["summary"] = summary - - return list(packages.values()) - - -def print_dist_installation_info(name: str, latest: str) -> None: - env = get_default_environment() - dist = env.get_distribution(name) - if dist is not None: - with indent_log(): - if dist.version == latest: - write_output("INSTALLED: %s (latest)", dist.version) - else: - write_output("INSTALLED: %s", dist.version) - if parse_version(latest).pre: - write_output( - "LATEST: %s (pre-release; install" - " with `pip install --pre`)", - latest, - ) - else: - write_output("LATEST: %s", latest) - - -def print_results( - hits: List["TransformedHit"], - name_column_width: Optional[int] = None, - terminal_width: Optional[int] = None, -) -> None: - if not hits: - return - if name_column_width is None: - name_column_width = ( - max( - [ - len(hit["name"]) + len(highest_version(hit.get("versions", ["-"]))) - for hit in hits - ] - ) - + 4 - ) - - for hit in hits: - name = hit["name"] - summary = hit["summary"] or "" - latest = highest_version(hit.get("versions", ["-"])) - if terminal_width is not None: - target_width = terminal_width - name_column_width - 5 - if target_width > 10: - # wrap and indent summary to fit terminal - summary_lines = textwrap.wrap(summary, target_width) - summary = ("\n" + " " * (name_column_width + 3)).join(summary_lines) - - name_latest = f"{name} ({latest})" - line = f"{name_latest:{name_column_width}} - {summary}" - try: - write_output(line) - print_dist_installation_info(name, latest) - except UnicodeEncodeError: - pass - - -def highest_version(versions: List[str]) -> str: - return max(versions, key=parse_version) diff --git a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/engine/hooks.py b/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/engine/hooks.py deleted file mode 100644 index 52c321f979726b8aa89ba34874bc6729a75b70b4..0000000000000000000000000000000000000000 --- a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/engine/hooks.py +++ /dev/null @@ -1,686 +0,0 @@ -# -*- coding: utf-8 -*- -# Copyright (c) Facebook, Inc. and its affiliates. - -import datetime -import itertools -import logging -import math -import operator -import os -import tempfile -import time -import warnings -from collections import Counter -import torch -from fvcore.common.checkpoint import Checkpointer -from fvcore.common.checkpoint import PeriodicCheckpointer as _PeriodicCheckpointer -from fvcore.common.param_scheduler import ParamScheduler -from fvcore.common.timer import Timer -from fvcore.nn.precise_bn import get_bn_modules, update_bn_stats - -import detectron2.utils.comm as comm -from detectron2.evaluation.testing import flatten_results_dict -from detectron2.solver import LRMultiplier -from detectron2.utils.events import EventStorage, EventWriter -from detectron2.utils.file_io import PathManager - -from .train_loop import HookBase - -__all__ = [ - "CallbackHook", - "IterationTimer", - "PeriodicWriter", - "PeriodicCheckpointer", - "BestCheckpointer", - "LRScheduler", - "AutogradProfiler", - "EvalHook", - "PreciseBN", - "TorchProfiler", - "TorchMemoryStats", -] - - -""" -Implement some common hooks. -""" - - -class CallbackHook(HookBase): - """ - Create a hook using callback functions provided by the user. - """ - - def __init__(self, *, before_train=None, after_train=None, before_step=None, after_step=None): - """ - Each argument is a function that takes one argument: the trainer. - """ - self._before_train = before_train - self._before_step = before_step - self._after_step = after_step - self._after_train = after_train - - def before_train(self): - if self._before_train: - self._before_train(self.trainer) - - def after_train(self): - if self._after_train: - self._after_train(self.trainer) - # The functions may be closures that hold reference to the trainer - # Therefore, delete them to avoid circular reference. - del self._before_train, self._after_train - del self._before_step, self._after_step - - def before_step(self): - if self._before_step: - self._before_step(self.trainer) - - def after_step(self): - if self._after_step: - self._after_step(self.trainer) - - -class IterationTimer(HookBase): - """ - Track the time spent for each iteration (each run_step call in the trainer). - Print a summary in the end of training. - - This hook uses the time between the call to its :meth:`before_step` - and :meth:`after_step` methods. - Under the convention that :meth:`before_step` of all hooks should only - take negligible amount of time, the :class:`IterationTimer` hook should be - placed at the beginning of the list of hooks to obtain accurate timing. - """ - - def __init__(self, warmup_iter=3): - """ - Args: - warmup_iter (int): the number of iterations at the beginning to exclude - from timing. - """ - self._warmup_iter = warmup_iter - self._step_timer = Timer() - self._start_time = time.perf_counter() - self._total_timer = Timer() - - def before_train(self): - self._start_time = time.perf_counter() - self._total_timer.reset() - self._total_timer.pause() - - def after_train(self): - logger = logging.getLogger(__name__) - total_time = time.perf_counter() - self._start_time - total_time_minus_hooks = self._total_timer.seconds() - hook_time = total_time - total_time_minus_hooks - - num_iter = self.trainer.storage.iter + 1 - self.trainer.start_iter - self._warmup_iter - - if num_iter > 0 and total_time_minus_hooks > 0: - # Speed is meaningful only after warmup - # NOTE this format is parsed by grep in some scripts - logger.info( - "Overall training speed: {} iterations in {} ({:.4f} s / it)".format( - num_iter, - str(datetime.timedelta(seconds=int(total_time_minus_hooks))), - total_time_minus_hooks / num_iter, - ) - ) - - logger.info( - "Total training time: {} ({} on hooks)".format( - str(datetime.timedelta(seconds=int(total_time))), - str(datetime.timedelta(seconds=int(hook_time))), - ) - ) - - def before_step(self): - self._step_timer.reset() - self._total_timer.resume() - - def after_step(self): - # +1 because we're in after_step, the current step is done - # but not yet counted - iter_done = self.trainer.storage.iter - self.trainer.start_iter + 1 - if iter_done >= self._warmup_iter: - sec = self._step_timer.seconds() - self.trainer.storage.put_scalars(time=sec) - else: - self._start_time = time.perf_counter() - self._total_timer.reset() - - self._total_timer.pause() - - -class PeriodicWriter(HookBase): - """ - Write events to EventStorage (by calling ``writer.write()``) periodically. - - It is executed every ``period`` iterations and after the last iteration. - Note that ``period`` does not affect how data is smoothed by each writer. - """ - - def __init__(self, writers, period=20): - """ - Args: - writers (list[EventWriter]): a list of EventWriter objects - period (int): - """ - self._writers = writers - for w in writers: - assert isinstance(w, EventWriter), w - self._period = period - - def after_step(self): - if (self.trainer.iter + 1) % self._period == 0 or ( - self.trainer.iter == self.trainer.max_iter - 1 - ): - for writer in self._writers: - writer.write() - - def after_train(self): - for writer in self._writers: - # If any new data is found (e.g. produced by other after_train), - # write them before closing - writer.write() - writer.close() - - -class PeriodicCheckpointer(_PeriodicCheckpointer, HookBase): - """ - Same as :class:`detectron2.checkpoint.PeriodicCheckpointer`, but as a hook. - - Note that when used as a hook, - it is unable to save additional data other than what's defined - by the given `checkpointer`. - - It is executed every ``period`` iterations and after the last iteration. - """ - - def before_train(self): - self.max_iter = self.trainer.max_iter - - def after_step(self): - # No way to use **kwargs - self.step(self.trainer.iter) - - -class BestCheckpointer(HookBase): - """ - Checkpoints best weights based off given metric. - - This hook should be used in conjunction to and executed after the hook - that produces the metric, e.g. `EvalHook`. - """ - - def __init__( - self, - eval_period: int, - checkpointer: Checkpointer, - val_metric: str, - mode: str = "max", - file_prefix: str = "model_best", - ) -> None: - """ - Args: - eval_period (int): the period `EvalHook` is set to run. - checkpointer: the checkpointer object used to save checkpoints. - val_metric (str): validation metric to track for best checkpoint, e.g. "bbox/AP50" - mode (str): one of {'max', 'min'}. controls whether the chosen val metric should be - maximized or minimized, e.g. for "bbox/AP50" it should be "max" - file_prefix (str): the prefix of checkpoint's filename, defaults to "model_best" - """ - self._logger = logging.getLogger(__name__) - self._period = eval_period - self._val_metric = val_metric - assert mode in [ - "max", - "min", - ], f'Mode "{mode}" to `BestCheckpointer` is unknown. It should be one of {"max", "min"}.' - if mode == "max": - self._compare = operator.gt - else: - self._compare = operator.lt - self._checkpointer = checkpointer - self._file_prefix = file_prefix - self.best_metric = None - self.best_iter = None - - def _update_best(self, val, iteration): - if math.isnan(val) or math.isinf(val): - return False - self.best_metric = val - self.best_iter = iteration - return True - - def _best_checking(self): - metric_tuple = self.trainer.storage.latest().get(self._val_metric) - if metric_tuple is None: - self._logger.warning( - f"Given val metric {self._val_metric} does not seem to be computed/stored." - "Will not be checkpointing based on it." - ) - return - else: - latest_metric, metric_iter = metric_tuple - - if self.best_metric is None: - if self._update_best(latest_metric, metric_iter): - additional_state = {"iteration": metric_iter} - self._checkpointer.save(f"{self._file_prefix}", **additional_state) - self._logger.info( - f"Saved first model at {self.best_metric:0.5f} @ {self.best_iter} steps" - ) - elif self._compare(latest_metric, self.best_metric): - additional_state = {"iteration": metric_iter} - self._checkpointer.save(f"{self._file_prefix}", **additional_state) - self._logger.info( - f"Saved best model as latest eval score for {self._val_metric} is " - f"{latest_metric:0.5f}, better than last best score " - f"{self.best_metric:0.5f} @ iteration {self.best_iter}." - ) - self._update_best(latest_metric, metric_iter) - else: - self._logger.info( - f"Not saving as latest eval score for {self._val_metric} is {latest_metric:0.5f}, " - f"not better than best score {self.best_metric:0.5f} @ iteration {self.best_iter}." - ) - - def after_step(self): - # same conditions as `EvalHook` - next_iter = self.trainer.iter + 1 - if ( - self._period > 0 - and next_iter % self._period == 0 - and next_iter != self.trainer.max_iter - ): - self._best_checking() - - def after_train(self): - # same conditions as `EvalHook` - if self.trainer.iter + 1 >= self.trainer.max_iter: - self._best_checking() - - -class LRScheduler(HookBase): - """ - A hook which executes a torch builtin LR scheduler and summarizes the LR. - It is executed after every iteration. - """ - - def __init__(self, optimizer=None, scheduler=None): - """ - Args: - optimizer (torch.optim.Optimizer): - scheduler (torch.optim.LRScheduler or fvcore.common.param_scheduler.ParamScheduler): - if a :class:`ParamScheduler` object, it defines the multiplier over the base LR - in the optimizer. - - If any argument is not given, will try to obtain it from the trainer. - """ - self._optimizer = optimizer - self._scheduler = scheduler - - def before_train(self): - self._optimizer = self._optimizer or self.trainer.optimizer - if isinstance(self.scheduler, ParamScheduler): - self._scheduler = LRMultiplier( - self._optimizer, - self.scheduler, - self.trainer.max_iter, - last_iter=self.trainer.iter - 1, - ) - self._best_param_group_id = LRScheduler.get_best_param_group_id(self._optimizer) - - @staticmethod - def get_best_param_group_id(optimizer): - # NOTE: some heuristics on what LR to summarize - # summarize the param group with most parameters - largest_group = max(len(g["params"]) for g in optimizer.param_groups) - - if largest_group == 1: - # If all groups have one parameter, - # then find the most common initial LR, and use it for summary - lr_count = Counter([g["lr"] for g in optimizer.param_groups]) - lr = lr_count.most_common()[0][0] - for i, g in enumerate(optimizer.param_groups): - if g["lr"] == lr: - return i - else: - for i, g in enumerate(optimizer.param_groups): - if len(g["params"]) == largest_group: - return i - - def after_step(self): - lr = self._optimizer.param_groups[self._best_param_group_id]["lr"] - self.trainer.storage.put_scalar("lr", lr, smoothing_hint=False) - self.scheduler.step() - - @property - def scheduler(self): - return self._scheduler or self.trainer.scheduler - - def state_dict(self): - if isinstance(self.scheduler, torch.optim.lr_scheduler._LRScheduler): - return self.scheduler.state_dict() - return {} - - def load_state_dict(self, state_dict): - if isinstance(self.scheduler, torch.optim.lr_scheduler._LRScheduler): - logger = logging.getLogger(__name__) - logger.info("Loading scheduler from state_dict ...") - self.scheduler.load_state_dict(state_dict) - - -class TorchProfiler(HookBase): - """ - A hook which runs `torch.profiler.profile`. - - Examples: - :: - hooks.TorchProfiler( - lambda trainer: 10 < trainer.iter < 20, self.cfg.OUTPUT_DIR - ) - - The above example will run the profiler for iteration 10~20 and dump - results to ``OUTPUT_DIR``. We did not profile the first few iterations - because they are typically slower than the rest. - The result files can be loaded in the ``chrome://tracing`` page in chrome browser, - and the tensorboard visualizations can be visualized using - ``tensorboard --logdir OUTPUT_DIR/log`` - """ - - def __init__(self, enable_predicate, output_dir, *, activities=None, save_tensorboard=True): - """ - Args: - enable_predicate (callable[trainer -> bool]): a function which takes a trainer, - and returns whether to enable the profiler. - It will be called once every step, and can be used to select which steps to profile. - output_dir (str): the output directory to dump tracing files. - activities (iterable): same as in `torch.profiler.profile`. - save_tensorboard (bool): whether to save tensorboard visualizations at (output_dir)/log/ - """ - self._enable_predicate = enable_predicate - self._activities = activities - self._output_dir = output_dir - self._save_tensorboard = save_tensorboard - - def before_step(self): - if self._enable_predicate(self.trainer): - if self._save_tensorboard: - on_trace_ready = torch.profiler.tensorboard_trace_handler( - os.path.join( - self._output_dir, - "log", - "profiler-tensorboard-iter{}".format(self.trainer.iter), - ), - f"worker{comm.get_rank()}", - ) - else: - on_trace_ready = None - self._profiler = torch.profiler.profile( - activities=self._activities, - on_trace_ready=on_trace_ready, - record_shapes=True, - profile_memory=True, - with_stack=True, - with_flops=True, - ) - self._profiler.__enter__() - else: - self._profiler = None - - def after_step(self): - if self._profiler is None: - return - self._profiler.__exit__(None, None, None) - if not self._save_tensorboard: - PathManager.mkdirs(self._output_dir) - out_file = os.path.join( - self._output_dir, "profiler-trace-iter{}.json".format(self.trainer.iter) - ) - if "://" not in out_file: - self._profiler.export_chrome_trace(out_file) - else: - # Support non-posix filesystems - with tempfile.TemporaryDirectory(prefix="detectron2_profiler") as d: - tmp_file = os.path.join(d, "tmp.json") - self._profiler.export_chrome_trace(tmp_file) - with open(tmp_file) as f: - content = f.read() - with PathManager.open(out_file, "w") as f: - f.write(content) - - -class AutogradProfiler(TorchProfiler): - """ - A hook which runs `torch.autograd.profiler.profile`. - - Examples: - :: - hooks.AutogradProfiler( - lambda trainer: 10 < trainer.iter < 20, self.cfg.OUTPUT_DIR - ) - - The above example will run the profiler for iteration 10~20 and dump - results to ``OUTPUT_DIR``. We did not profile the first few iterations - because they are typically slower than the rest. - The result files can be loaded in the ``chrome://tracing`` page in chrome browser. - - Note: - When used together with NCCL on older version of GPUs, - autograd profiler may cause deadlock because it unnecessarily allocates - memory on every device it sees. The memory management calls, if - interleaved with NCCL calls, lead to deadlock on GPUs that do not - support ``cudaLaunchCooperativeKernelMultiDevice``. - """ - - def __init__(self, enable_predicate, output_dir, *, use_cuda=True): - """ - Args: - enable_predicate (callable[trainer -> bool]): a function which takes a trainer, - and returns whether to enable the profiler. - It will be called once every step, and can be used to select which steps to profile. - output_dir (str): the output directory to dump tracing files. - use_cuda (bool): same as in `torch.autograd.profiler.profile`. - """ - warnings.warn("AutogradProfiler has been deprecated in favor of TorchProfiler.") - self._enable_predicate = enable_predicate - self._use_cuda = use_cuda - self._output_dir = output_dir - - def before_step(self): - if self._enable_predicate(self.trainer): - self._profiler = torch.autograd.profiler.profile(use_cuda=self._use_cuda) - self._profiler.__enter__() - else: - self._profiler = None - - -class EvalHook(HookBase): - """ - Run an evaluation function periodically, and at the end of training. - - It is executed every ``eval_period`` iterations and after the last iteration. - """ - - def __init__(self, eval_period, eval_function): - """ - Args: - eval_period (int): the period to run `eval_function`. Set to 0 to - not evaluate periodically (but still after the last iteration). - eval_function (callable): a function which takes no arguments, and - returns a nested dict of evaluation metrics. - - Note: - This hook must be enabled in all or none workers. - If you would like only certain workers to perform evaluation, - give other workers a no-op function (`eval_function=lambda: None`). - """ - self._period = eval_period - self._func = eval_function - - def _do_eval(self): - results = self._func() - - if results: - assert isinstance( - results, dict - ), "Eval function must return a dict. Got {} instead.".format(results) - - flattened_results = flatten_results_dict(results) - for k, v in flattened_results.items(): - try: - v = float(v) - except Exception as e: - raise ValueError( - "[EvalHook] eval_function should return a nested dict of float. " - "Got '{}: {}' instead.".format(k, v) - ) from e - self.trainer.storage.put_scalars(**flattened_results, smoothing_hint=False) - - # Evaluation may take different time among workers. - # A barrier make them start the next iteration together. - comm.synchronize() - - def after_step(self): - next_iter = self.trainer.iter + 1 - if self._period > 0 and next_iter % self._period == 0: - # do the last eval in after_train - if next_iter != self.trainer.max_iter: - self._do_eval() - - def after_train(self): - # This condition is to prevent the eval from running after a failed training - if self.trainer.iter + 1 >= self.trainer.max_iter: - self._do_eval() - # func is likely a closure that holds reference to the trainer - # therefore we clean it to avoid circular reference in the end - del self._func - - -class PreciseBN(HookBase): - """ - The standard implementation of BatchNorm uses EMA in inference, which is - sometimes suboptimal. - This class computes the true average of statistics rather than the moving average, - and put true averages to every BN layer in the given model. - - It is executed every ``period`` iterations and after the last iteration. - """ - - def __init__(self, period, model, data_loader, num_iter): - """ - Args: - period (int): the period this hook is run, or 0 to not run during training. - The hook will always run in the end of training. - model (nn.Module): a module whose all BN layers in training mode will be - updated by precise BN. - Note that user is responsible for ensuring the BN layers to be - updated are in training mode when this hook is triggered. - data_loader (iterable): it will produce data to be run by `model(data)`. - num_iter (int): number of iterations used to compute the precise - statistics. - """ - self._logger = logging.getLogger(__name__) - if len(get_bn_modules(model)) == 0: - self._logger.info( - "PreciseBN is disabled because model does not contain BN layers in training mode." - ) - self._disabled = True - return - - self._model = model - self._data_loader = data_loader - self._num_iter = num_iter - self._period = period - self._disabled = False - - self._data_iter = None - - def after_step(self): - next_iter = self.trainer.iter + 1 - is_final = next_iter == self.trainer.max_iter - if is_final or (self._period > 0 and next_iter % self._period == 0): - self.update_stats() - - def update_stats(self): - """ - Update the model with precise statistics. Users can manually call this method. - """ - if self._disabled: - return - - if self._data_iter is None: - self._data_iter = iter(self._data_loader) - - def data_loader(): - for num_iter in itertools.count(1): - if num_iter % 100 == 0: - self._logger.info( - "Running precise-BN ... {}/{} iterations.".format(num_iter, self._num_iter) - ) - # This way we can reuse the same iterator - yield next(self._data_iter) - - with EventStorage(): # capture events in a new storage to discard them - self._logger.info( - "Running precise-BN for {} iterations... ".format(self._num_iter) - + "Note that this could produce different statistics every time." - ) - update_bn_stats(self._model, data_loader(), self._num_iter) - - -class TorchMemoryStats(HookBase): - """ - Writes pytorch's cuda memory statistics periodically. - """ - - def __init__(self, period=20, max_runs=10): - """ - Args: - period (int): Output stats each 'period' iterations - max_runs (int): Stop the logging after 'max_runs' - """ - - self._logger = logging.getLogger(__name__) - self._period = period - self._max_runs = max_runs - self._runs = 0 - - def after_step(self): - if self._runs > self._max_runs: - return - - if (self.trainer.iter + 1) % self._period == 0 or ( - self.trainer.iter == self.trainer.max_iter - 1 - ): - if torch.cuda.is_available(): - max_reserved_mb = torch.cuda.max_memory_reserved() / 1024.0 / 1024.0 - reserved_mb = torch.cuda.memory_reserved() / 1024.0 / 1024.0 - max_allocated_mb = torch.cuda.max_memory_allocated() / 1024.0 / 1024.0 - allocated_mb = torch.cuda.memory_allocated() / 1024.0 / 1024.0 - - self._logger.info( - ( - " iter: {} " - " max_reserved_mem: {:.0f}MB " - " reserved_mem: {:.0f}MB " - " max_allocated_mem: {:.0f}MB " - " allocated_mem: {:.0f}MB " - ).format( - self.trainer.iter, - max_reserved_mb, - reserved_mb, - max_allocated_mb, - allocated_mb, - ) - ) - - self._runs += 1 - if self._runs == self._max_runs: - mem_summary = torch.cuda.memory_summary() - self._logger.info("\n" + mem_summary) - - torch.cuda.reset_peak_memory_stats() diff --git a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/evaluation/pascal_voc_evaluation.py b/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/evaluation/pascal_voc_evaluation.py deleted file mode 100644 index 1d1abcde2f87bb5f103e73cb364aaabbecb6e619..0000000000000000000000000000000000000000 --- a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/evaluation/pascal_voc_evaluation.py +++ /dev/null @@ -1,300 +0,0 @@ -# -*- coding: utf-8 -*- -# Copyright (c) Facebook, Inc. and its affiliates. - -import logging -import numpy as np -import os -import tempfile -import xml.etree.ElementTree as ET -from collections import OrderedDict, defaultdict -from functools import lru_cache -import torch - -from detectron2.data import MetadataCatalog -from detectron2.utils import comm -from detectron2.utils.file_io import PathManager - -from .evaluator import DatasetEvaluator - - -class PascalVOCDetectionEvaluator(DatasetEvaluator): - """ - Evaluate Pascal VOC style AP for Pascal VOC dataset. - It contains a synchronization, therefore has to be called from all ranks. - - Note that the concept of AP can be implemented in different ways and may not - produce identical results. This class mimics the implementation of the official - Pascal VOC Matlab API, and should produce similar but not identical results to the - official API. - """ - - def __init__(self, dataset_name): - """ - Args: - dataset_name (str): name of the dataset, e.g., "voc_2007_test" - """ - self._dataset_name = dataset_name - meta = MetadataCatalog.get(dataset_name) - - # Too many tiny files, download all to local for speed. - annotation_dir_local = PathManager.get_local_path( - os.path.join(meta.dirname, "Annotations/") - ) - self._anno_file_template = os.path.join(annotation_dir_local, "{}.xml") - self._image_set_path = os.path.join(meta.dirname, "ImageSets", "Main", meta.split + ".txt") - self._class_names = meta.thing_classes - assert meta.year in [2007, 2012], meta.year - self._is_2007 = meta.year == 2007 - self._cpu_device = torch.device("cpu") - self._logger = logging.getLogger(__name__) - - def reset(self): - self._predictions = defaultdict(list) # class name -> list of prediction strings - - def process(self, inputs, outputs): - for input, output in zip(inputs, outputs): - image_id = input["image_id"] - instances = output["instances"].to(self._cpu_device) - boxes = instances.pred_boxes.tensor.numpy() - scores = instances.scores.tolist() - classes = instances.pred_classes.tolist() - for box, score, cls in zip(boxes, scores, classes): - xmin, ymin, xmax, ymax = box - # The inverse of data loading logic in `datasets/pascal_voc.py` - xmin += 1 - ymin += 1 - self._predictions[cls].append( - f"{image_id} {score:.3f} {xmin:.1f} {ymin:.1f} {xmax:.1f} {ymax:.1f}" - ) - - def evaluate(self): - """ - Returns: - dict: has a key "segm", whose value is a dict of "AP", "AP50", and "AP75". - """ - all_predictions = comm.gather(self._predictions, dst=0) - if not comm.is_main_process(): - return - predictions = defaultdict(list) - for predictions_per_rank in all_predictions: - for clsid, lines in predictions_per_rank.items(): - predictions[clsid].extend(lines) - del all_predictions - - self._logger.info( - "Evaluating {} using {} metric. " - "Note that results do not use the official Matlab API.".format( - self._dataset_name, 2007 if self._is_2007 else 2012 - ) - ) - - with tempfile.TemporaryDirectory(prefix="pascal_voc_eval_") as dirname: - res_file_template = os.path.join(dirname, "{}.txt") - - aps = defaultdict(list) # iou -> ap per class - for cls_id, cls_name in enumerate(self._class_names): - lines = predictions.get(cls_id, [""]) - - with open(res_file_template.format(cls_name), "w") as f: - f.write("\n".join(lines)) - - for thresh in range(50, 100, 5): - rec, prec, ap = voc_eval( - res_file_template, - self._anno_file_template, - self._image_set_path, - cls_name, - ovthresh=thresh / 100.0, - use_07_metric=self._is_2007, - ) - aps[thresh].append(ap * 100) - - ret = OrderedDict() - mAP = {iou: np.mean(x) for iou, x in aps.items()} - ret["bbox"] = {"AP": np.mean(list(mAP.values())), "AP50": mAP[50], "AP75": mAP[75]} - return ret - - -############################################################################## -# -# Below code is modified from -# https://github.com/rbgirshick/py-faster-rcnn/blob/master/lib/datasets/voc_eval.py -# -------------------------------------------------------- -# Fast/er R-CNN -# Licensed under The MIT License [see LICENSE for details] -# Written by Bharath Hariharan -# -------------------------------------------------------- - -"""Python implementation of the PASCAL VOC devkit's AP evaluation code.""" - - -@lru_cache(maxsize=None) -def parse_rec(filename): - """Parse a PASCAL VOC xml file.""" - with PathManager.open(filename) as f: - tree = ET.parse(f) - objects = [] - for obj in tree.findall("object"): - obj_struct = {} - obj_struct["name"] = obj.find("name").text - obj_struct["pose"] = obj.find("pose").text - obj_struct["truncated"] = int(obj.find("truncated").text) - obj_struct["difficult"] = int(obj.find("difficult").text) - bbox = obj.find("bndbox") - obj_struct["bbox"] = [ - int(bbox.find("xmin").text), - int(bbox.find("ymin").text), - int(bbox.find("xmax").text), - int(bbox.find("ymax").text), - ] - objects.append(obj_struct) - - return objects - - -def voc_ap(rec, prec, use_07_metric=False): - """Compute VOC AP given precision and recall. If use_07_metric is true, uses - the VOC 07 11-point method (default:False). - """ - if use_07_metric: - # 11 point metric - ap = 0.0 - for t in np.arange(0.0, 1.1, 0.1): - if np.sum(rec >= t) == 0: - p = 0 - else: - p = np.max(prec[rec >= t]) - ap = ap + p / 11.0 - else: - # correct AP calculation - # first append sentinel values at the end - mrec = np.concatenate(([0.0], rec, [1.0])) - mpre = np.concatenate(([0.0], prec, [0.0])) - - # compute the precision envelope - for i in range(mpre.size - 1, 0, -1): - mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) - - # to calculate area under PR curve, look for points - # where X axis (recall) changes value - i = np.where(mrec[1:] != mrec[:-1])[0] - - # and sum (\Delta recall) * prec - ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) - return ap - - -def voc_eval(detpath, annopath, imagesetfile, classname, ovthresh=0.5, use_07_metric=False): - """rec, prec, ap = voc_eval(detpath, - annopath, - imagesetfile, - classname, - [ovthresh], - [use_07_metric]) - - Top level function that does the PASCAL VOC evaluation. - - detpath: Path to detections - detpath.format(classname) should produce the detection results file. - annopath: Path to annotations - annopath.format(imagename) should be the xml annotations file. - imagesetfile: Text file containing the list of images, one image per line. - classname: Category name (duh) - [ovthresh]: Overlap threshold (default = 0.5) - [use_07_metric]: Whether to use VOC07's 11 point AP computation - (default False) - """ - # assumes detections are in detpath.format(classname) - # assumes annotations are in annopath.format(imagename) - # assumes imagesetfile is a text file with each line an image name - - # first load gt - # read list of images - with PathManager.open(imagesetfile, "r") as f: - lines = f.readlines() - imagenames = [x.strip() for x in lines] - - # load annots - recs = {} - for imagename in imagenames: - recs[imagename] = parse_rec(annopath.format(imagename)) - - # extract gt objects for this class - class_recs = {} - npos = 0 - for imagename in imagenames: - R = [obj for obj in recs[imagename] if obj["name"] == classname] - bbox = np.array([x["bbox"] for x in R]) - difficult = np.array([x["difficult"] for x in R]).astype(np.bool) - # difficult = np.array([False for x in R]).astype(np.bool) # treat all "difficult" as GT - det = [False] * len(R) - npos = npos + sum(~difficult) - class_recs[imagename] = {"bbox": bbox, "difficult": difficult, "det": det} - - # read dets - detfile = detpath.format(classname) - with open(detfile, "r") as f: - lines = f.readlines() - - splitlines = [x.strip().split(" ") for x in lines] - image_ids = [x[0] for x in splitlines] - confidence = np.array([float(x[1]) for x in splitlines]) - BB = np.array([[float(z) for z in x[2:]] for x in splitlines]).reshape(-1, 4) - - # sort by confidence - sorted_ind = np.argsort(-confidence) - BB = BB[sorted_ind, :] - image_ids = [image_ids[x] for x in sorted_ind] - - # go down dets and mark TPs and FPs - nd = len(image_ids) - tp = np.zeros(nd) - fp = np.zeros(nd) - for d in range(nd): - R = class_recs[image_ids[d]] - bb = BB[d, :].astype(float) - ovmax = -np.inf - BBGT = R["bbox"].astype(float) - - if BBGT.size > 0: - # compute overlaps - # intersection - ixmin = np.maximum(BBGT[:, 0], bb[0]) - iymin = np.maximum(BBGT[:, 1], bb[1]) - ixmax = np.minimum(BBGT[:, 2], bb[2]) - iymax = np.minimum(BBGT[:, 3], bb[3]) - iw = np.maximum(ixmax - ixmin + 1.0, 0.0) - ih = np.maximum(iymax - iymin + 1.0, 0.0) - inters = iw * ih - - # union - uni = ( - (bb[2] - bb[0] + 1.0) * (bb[3] - bb[1] + 1.0) - + (BBGT[:, 2] - BBGT[:, 0] + 1.0) * (BBGT[:, 3] - BBGT[:, 1] + 1.0) - - inters - ) - - overlaps = inters / uni - ovmax = np.max(overlaps) - jmax = np.argmax(overlaps) - - if ovmax > ovthresh: - if not R["difficult"][jmax]: - if not R["det"][jmax]: - tp[d] = 1.0 - R["det"][jmax] = 1 - else: - fp[d] = 1.0 - else: - fp[d] = 1.0 - - # compute precision recall - fp = np.cumsum(fp) - tp = np.cumsum(tp) - rec = tp / float(npos) - # avoid divide by zero in case the first detection matches a difficult - # ground truth - prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps) - ap = voc_ap(rec, prec, use_07_metric) - - return rec, prec, ap diff --git a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/docs/tutorials/datasets.md b/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/docs/tutorials/datasets.md deleted file mode 100644 index 91103f64264aa6f3059611c5fe06ecd65bcb986f..0000000000000000000000000000000000000000 --- a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/docs/tutorials/datasets.md +++ /dev/null @@ -1,290 +0,0 @@ -# Use Custom Datasets - -This document explains how the dataset APIs -([DatasetCatalog](../modules/data.html#detectron2.data.DatasetCatalog), [MetadataCatalog](../modules/data.html#detectron2.data.MetadataCatalog)) -work, and how to use them to add custom datasets. - -Datasets that have builtin support in detectron2 are listed in [builtin datasets](builtin_datasets.md). -If you want to use a custom dataset while also reusing detectron2's data loaders, -you will need to: - -1. __Register__ your dataset (i.e., tell detectron2 how to obtain your dataset). -2. Optionally, __register metadata__ for your dataset. - -Next, we explain the above two concepts in detail. - -The [Colab tutorial](https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5) -has a live example of how to register and train on a dataset of custom formats. - -### Register a Dataset - -To let detectron2 know how to obtain a dataset named "my_dataset", users need to implement -a function that returns the items in your dataset and then tell detectron2 about this -function: -```python -def my_dataset_function(): - ... - return list[dict] in the following format - -from detectron2.data import DatasetCatalog -DatasetCatalog.register("my_dataset", my_dataset_function) -# later, to access the data: -data: List[Dict] = DatasetCatalog.get("my_dataset") -``` - -Here, the snippet associates a dataset named "my_dataset" with a function that returns the data. -The function must return the same data (with same order) if called multiple times. -The registration stays effective until the process exits. - -The function can do arbitrary things and should return the data in `list[dict]`, each dict in either -of the following formats: -1. Detectron2's standard dataset dict, described below. This will make it work with many other builtin - features in detectron2, so it's recommended to use it when it's sufficient. -2. Any custom format. You can also return arbitrary dicts in your own format, - such as adding extra keys for new tasks. - Then you will need to handle them properly downstream as well. - See below for more details. - -#### Standard Dataset Dicts - -For standard tasks -(instance detection, instance/semantic/panoptic segmentation, keypoint detection), -we load the original dataset into `list[dict]` with a specification similar to COCO's annotations. -This is our standard representation for a dataset. - -Each dict contains information about one image. -The dict may have the following fields, -and the required fields vary based on what the dataloader or the task needs (see more below). - -```eval_rst -.. list-table:: - :header-rows: 1 - - * - Task - - Fields - * - Common - - file_name, height, width, image_id - - * - Instance detection/segmentation - - annotations - - * - Semantic segmentation - - sem_seg_file_name - - * - Panoptic segmentation - - pan_seg_file_name, segments_info -``` - -+ `file_name`: the full path to the image file. -+ `height`, `width`: integer. The shape of the image. -+ `image_id` (str or int): a unique id that identifies this image. Required by many - evaluators to identify the images, but a dataset may use it for different purposes. -+ `annotations` (list[dict]): Required by __instance detection/segmentation or keypoint detection__ tasks. - Each dict corresponds to annotations of one instance in this image, and - may contain the following keys: - + `bbox` (list[float], required): list of 4 numbers representing the bounding box of the instance. - + `bbox_mode` (int, required): the format of bbox. It must be a member of - [structures.BoxMode](../modules/structures.html#detectron2.structures.BoxMode). - Currently supports: `BoxMode.XYXY_ABS`, `BoxMode.XYWH_ABS`. - + `category_id` (int, required): an integer in the range [0, num_categories-1] representing the category label. - The value num_categories is reserved to represent the "background" category, if applicable. - + `segmentation` (list[list[float]] or dict): the segmentation mask of the instance. - + If `list[list[float]]`, it represents a list of polygons, one for each connected component - of the object. Each `list[float]` is one simple polygon in the format of `[x1, y1, ..., xn, yn]` (n≥3). - The Xs and Ys are absolute coordinates in unit of pixels. - + If `dict`, it represents the per-pixel segmentation mask in COCO's compressed RLE format. - The dict should have keys "size" and "counts". You can convert a uint8 segmentation mask of 0s and - 1s into such dict by `pycocotools.mask.encode(np.asarray(mask, order="F"))`. - `cfg.INPUT.MASK_FORMAT` must be set to `bitmask` if using the default data loader with such format. - + `keypoints` (list[float]): in the format of [x1, y1, v1,..., xn, yn, vn]. - v[i] means the [visibility](http://cocodataset.org/#format-data) of this keypoint. - `n` must be equal to the number of keypoint categories. - The Xs and Ys are absolute real-value coordinates in range [0, W or H]. - - (Note that the keypoint coordinates in COCO format are integers in range [0, W-1 or H-1], which is different - from our standard format. Detectron2 adds 0.5 to COCO keypoint coordinates to convert them from discrete - pixel indices to floating point coordinates.) - + `iscrowd`: 0 (default) or 1. Whether this instance is labeled as COCO's "crowd - region". Don't include this field if you don't know what it means. - - If `annotations` is an empty list, it means the image is labeled to have no objects. - Such images will by default be removed from training, - but can be included using `DATALOADER.FILTER_EMPTY_ANNOTATIONS`. - -+ `sem_seg_file_name` (str): - The full path to the semantic segmentation ground truth file. - It should be a grayscale image whose pixel values are integer labels. -+ `pan_seg_file_name` (str): - The full path to panoptic segmentation ground truth file. - It should be an RGB image whose pixel values are integer ids encoded using the - [panopticapi.utils.id2rgb](https://github.com/cocodataset/panopticapi/) function. - The ids are defined by `segments_info`. - If an id does not appear in `segments_info`, the pixel is considered unlabeled - and is usually ignored in training & evaluation. -+ `segments_info` (list[dict]): defines the meaning of each id in panoptic segmentation ground truth. - Each dict has the following keys: - + `id` (int): integer that appears in the ground truth image. - + `category_id` (int): an integer in the range [0, num_categories-1] representing the category label. - + `iscrowd`: 0 (default) or 1. Whether this instance is labeled as COCO's "crowd region". - - -```eval_rst - -.. note:: - - The PanopticFPN model does not use the panoptic segmentation - format defined here, but a combination of both instance segmentation and semantic segmentation data - format. See :doc:`builtin_datasets` for instructions on COCO. - -``` - -Fast R-CNN (with pre-computed proposals) models are rarely used today. -To train a Fast R-CNN, the following extra keys are needed: - -+ `proposal_boxes` (array): 2D numpy array with shape (K, 4) representing K precomputed proposal boxes for this image. -+ `proposal_objectness_logits` (array): numpy array with shape (K, ), which corresponds to the objectness - logits of proposals in 'proposal_boxes'. -+ `proposal_bbox_mode` (int): the format of the precomputed proposal bbox. - It must be a member of - [structures.BoxMode](../modules/structures.html#detectron2.structures.BoxMode). - Default is `BoxMode.XYXY_ABS`. - - - -#### Custom Dataset Dicts for New Tasks - -In the `list[dict]` that your dataset function returns, the dictionary can also have __arbitrary custom data__. -This will be useful for a new task that needs extra information not covered -by the standard dataset dicts. In this case, you need to make sure the downstream code can handle your data -correctly. Usually this requires writing a new `mapper` for the dataloader (see [Use Custom Dataloaders](./data_loading.md)). - -When designing a custom format, note that all dicts are stored in memory -(sometimes serialized and with multiple copies). -To save memory, each dict is meant to contain __small__ but sufficient information -about each sample, such as file names and annotations. -Loading full samples typically happens in the data loader. - -For attributes shared among the entire dataset, use `Metadata` (see below). -To avoid extra memory, do not save such information inside each sample. - -### "Metadata" for Datasets - -Each dataset is associated with some metadata, accessible through -`MetadataCatalog.get(dataset_name).some_metadata`. -Metadata is a key-value mapping that contains information that's shared among -the entire dataset, and usually is used to interpret what's in the dataset, e.g., -names of classes, colors of classes, root of files, etc. -This information will be useful for augmentation, evaluation, visualization, logging, etc. -The structure of metadata depends on what is needed from the corresponding downstream code. - -If you register a new dataset through `DatasetCatalog.register`, -you may also want to add its corresponding metadata through -`MetadataCatalog.get(dataset_name).some_key = some_value`, to enable any features that need the metadata. -You can do it like this (using the metadata key "thing_classes" as an example): - -```python -from detectron2.data import MetadataCatalog -MetadataCatalog.get("my_dataset").thing_classes = ["person", "dog"] -``` - -Here is a list of metadata keys that are used by builtin features in detectron2. -If you add your own dataset without these metadata, some features may be -unavailable to you: - -* `thing_classes` (list[str]): Used by all instance detection/segmentation tasks. - A list of names for each instance/thing category. - If you load a COCO format dataset, it will be automatically set by the function `load_coco_json`. - -* `thing_colors` (list[tuple(r, g, b)]): Pre-defined color (in [0, 255]) for each thing category. - Used for visualization. If not given, random colors will be used. - -* `stuff_classes` (list[str]): Used by semantic and panoptic segmentation tasks. - A list of names for each stuff category. - -* `stuff_colors` (list[tuple(r, g, b)]): Pre-defined color (in [0, 255]) for each stuff category. - Used for visualization. If not given, random colors are used. - -* `ignore_label` (int): Used by semantic and panoptic segmentation tasks. Pixels in ground-truth - annotations with this category label should be ignored in evaluation. Typically these are "unlabeled" - pixels. - -* `keypoint_names` (list[str]): Used by keypoint detection. A list of names for each keypoint. - -* `keypoint_flip_map` (list[tuple[str]]): Used by keypoint detection. A list of pairs of names, - where each pair are the two keypoints that should be flipped if the image is - flipped horizontally during augmentation. -* `keypoint_connection_rules`: list[tuple(str, str, (r, g, b))]. Each tuple specifies a pair of keypoints - that are connected and the color (in [0, 255]) to use for the line between them when visualized. - -Some additional metadata that are specific to the evaluation of certain datasets (e.g. COCO): - -* `thing_dataset_id_to_contiguous_id` (dict[int->int]): Used by all instance detection/segmentation tasks in the COCO format. - A mapping from instance class ids in the dataset to contiguous ids in range [0, #class). - Will be automatically set by the function `load_coco_json`. - -* `stuff_dataset_id_to_contiguous_id` (dict[int->int]): Used when generating prediction json files for - semantic/panoptic segmentation. - A mapping from semantic segmentation class ids in the dataset - to contiguous ids in [0, num_categories). It is useful for evaluation only. - -* `json_file`: The COCO annotation json file. Used by COCO evaluation for COCO-format datasets. -* `panoptic_root`, `panoptic_json`: Used by COCO-format panoptic evaluation. -* `evaluator_type`: Used by the builtin main training script to select - evaluator. Don't use it in a new training script. - You can just provide the [DatasetEvaluator](../modules/evaluation.html#detectron2.evaluation.DatasetEvaluator) - for your dataset directly in your main script. - -```eval_rst -.. note:: - - In recognition, sometimes we use the term "thing" for instance-level tasks, - and "stuff" for semantic segmentation tasks. - Both are used in panoptic segmentation tasks. - For background on the concept of "thing" and "stuff", see - `On Seeing Stuff: The Perception of Materials by Humans and Machines -
-Descargar Anime Negro APK: La aplicación definitiva para los fans de anime
-Si eres un amante del anime, probablemente sabes lo difícil que puede ser encontrar una buena aplicación para ver tus programas favoritos en tu dispositivo Android. Hay muchas aplicaciones por ahí, pero la mayoría de ellos son de baja calidad, poco fiable, o lleno de anuncios. Es por eso que usted necesita para descargar Anime Negro APK, la aplicación definitiva para los fans del anime.
-descargar anime negro apk
Download Zip ⭐ https://bltlly.com/2v6K4k
-¿Qué es Anime negro APK?
-Anime Negro APK es una aplicación para Android que le permite ver y descargar miles de episodios de anime de varios géneros y categorías. Puede disfrutar viendo anime en calidad HD, con transmisión rápida y reproducción suave. También puedes descargar episodios de anime para verlos sin conexión, para que puedas verlos en cualquier momento y en cualquier lugar.
-Características del anime negro APK
-Anime Negro APK tiene muchas características que lo convierten en una de las mejores aplicaciones para los amantes del anime. Aquí están algunos de ellos:
-Ver miles de episodios de anime en calidad HD
-Anime Negro APK tiene una enorme biblioteca de espectáculos de anime, desde los últimos lanzamientos a los clásicos. Puedes encontrar anime de diferentes géneros, como acción, comedia, romance, terror, ciencia ficción, fantasía y más. También puede buscar anime por nombre, género o popularidad. Puede ver anime en calidad HD, con sonido claro y subtítulos. También puede ajustar la calidad del vídeo según su velocidad de Internet y el uso de datos.
-Descargar episodios de anime para ver sin conexión
-Si desea ver anime sin conexión a Internet, puede descargar episodios de anime para ver sin conexión. Puede elegir la calidad de descarga y la ubicación en su dispositivo. También puede administrar sus descargas y eliminarlas cuando haya terminado de verlas.
-Acceso a múltiples fuentes y servidores
- -Personaliza la configuración y las preferencias de tu app
-Anime Negro APK le permite personalizar la configuración de la aplicación y las preferencias de acuerdo a su gusto. Puede cambiar el tema de la aplicación, el idioma, el tamaño de la fuente, la configuración de notificaciones y más. También puede activar o desactivar anuncios, reproducción automática, descarga automática y otras funciones.
- -Cómo descargar e instalar Anime Negro APK?
-Descargar e instalar Anime Black APK es muy fácil y simple. Solo tienes que seguir estos pasos:
-Paso 1: Habilitar fuentes desconocidas en su dispositivo
-Dado que Anime Negro APK no está disponible en el Google Play Store, es necesario habilitar fuentes desconocidas en su dispositivo para instalarlo. Para hacer esto, vaya a la configuración del dispositivo > seguridad > fuentes desconocidas > habilitar.
-Paso 2: Descargar el archivo APK de una fuente de confianza
-Puede descargar el archivo APK de una fuente de confianza como [ANIME NEGRO APK (Android App) - تنزيل مجاني - APKCombo]( 1 ). Asegúrate de descargar la última versión de la aplicación.
-Paso 3: Instalar el archivo APK en su dispositivo
-Una vez que haya descargado el archivo APK, localizarlo en su dispositivo y toque en él para instalarlo. Siga las instrucciones en la pantalla para completar la instalación.
-Paso 4: Inicie la aplicación y disfrute viendo anime
-Después de instalar la aplicación, se puede iniciar y empezar a ver anime. Puede navegar a través de las categorías de la aplicación, o utilizar la función de búsqueda para encontrar su anime favorito. También puede agregar anime a su lista de favoritos, o ver los últimos episodios de la página principal de la aplicación. También puede consultar las secciones de actualizaciones, noticias y comentarios de la aplicación para obtener más información y soporte.
-Pros y contras de anime negro APK
-Como cualquier otra aplicación, Anime Negro APK tiene sus pros y contras. Aquí están algunos de ellos:
-Pros
--
-
Contras
--
-
Conclusión
-Anime Negro APK es una gran aplicación para los fans del anime que quieren ver y descargar sus programas favoritos en sus dispositivos Android. Tiene muchas características que lo convierten en una de las mejores aplicaciones para los amantes del anime. Es fácil de descargar e instalar, y es de uso gratuito. Sin embargo, también tiene algunos inconvenientes que debe tener en cuenta antes de usarlo. En general, Anime Negro APK es una aplicación imprescindible para cualquier fan del anime que quiere disfrutar viendo anime en cualquier momento y en cualquier lugar.
-Si usted tiene alguna pregunta o comentario acerca de Anime Negro APK, puede dejar un comentario a continuación o póngase en contacto con el desarrollador de la aplicación. También puede compartir este artículo con sus amigos que también están en el anime. Gracias por leer!
-Preguntas frecuentes
-Aquí están algunas de las preguntas más comunes que la gente pregunta acerca de Anime Negro APK:
--
-
Anime Negro APK es seguro de usar, siempre y cuando se descarga de una fuente de confianza, tales como [ANIME NEGRO APK (Android App) - تنزيل مجاني - APKCombo]. Sin embargo, siempre debe tener cuidado al descargar e instalar cualquier aplicación de fuentes desconocidas, ya que pueden contener virus o malware que pueden dañar su dispositivo. También debe escanear el archivo APK con una aplicación antivirus antes de instalarlo.
-Anime Negro APK tiene actualizaciones regulares que corrigen errores y añadir nuevas características. Puedes buscar actualizaciones en el menú de configuración de la aplicación, o visitar el sitio web oficial de la aplicación o las páginas de redes sociales para obtener más información. También puede descargar la última versión de la aplicación de [ANIME NEGRO APK (Android App) - Cuando hay una nueva actualización disponible.
-Anime Negro APK tiene una sección de comentarios donde se puede solicitar un espectáculo de anime que no está disponible en la aplicación. También puede ponerse en contacto con el desarrollador de la aplicación a través de correo electrónico o plataformas de redes sociales y sugerir un anime que desea ver o descargar. Sin embargo, no hay garantía de que su solicitud se cumplirá, ya que depende de la disponibilidad y compatibilidad de la serie de anime con la aplicación.
-Anime Negro APK es una aplicación gratuita que no cobra ninguna cuota o suscripciones por sus servicios. Sin embargo, si desea apoyar el desarrollo y mantenimiento de la aplicación, puede hacerlo mediante una donación a través de PayPal o Patreon, o mediante la compra de funciones premium como el modo sin anuncios o descargas ilimitadas. También puedes dar soporte a la aplicación calificándola, revisándola, compartiéndola o dándole feedback.
-
-
-
\ No newline at end of file diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/command/install_scripts.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/command/install_scripts.py deleted file mode 100644 index f09bd644207e5c5a891d3605cb6aff4f00d70c8a..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/command/install_scripts.py +++ /dev/null @@ -1,61 +0,0 @@ -"""distutils.command.install_scripts - -Implements the Distutils 'install_scripts' command, for installing -Python scripts.""" - -# contributed by Bastian Kleineidam - -import os -from distutils.core import Command -from distutils import log -from stat import ST_MODE - - -class install_scripts(Command): - - description = "install scripts (Python or otherwise)" - - user_options = [ - ('install-dir=', 'd', "directory to install scripts to"), - ('build-dir=', 'b', "build directory (where to install from)"), - ('force', 'f', "force installation (overwrite existing files)"), - ('skip-build', None, "skip the build steps"), - ] - - boolean_options = ['force', 'skip-build'] - - def initialize_options(self): - self.install_dir = None - self.force = 0 - self.build_dir = None - self.skip_build = None - - def finalize_options(self): - self.set_undefined_options('build', ('build_scripts', 'build_dir')) - self.set_undefined_options( - 'install', - ('install_scripts', 'install_dir'), - ('force', 'force'), - ('skip_build', 'skip_build'), - ) - - def run(self): - if not self.skip_build: - self.run_command('build_scripts') - self.outfiles = self.copy_tree(self.build_dir, self.install_dir) - if os.name == 'posix': - # Set the executable bits (owner, group, and world) on - # all the scripts we just installed. - for file in self.get_outputs(): - if self.dry_run: - log.info("changing mode of %s", file) - else: - mode = ((os.stat(file)[ST_MODE]) | 0o555) & 0o7777 - log.info("changing mode of %s to %o", file, mode) - os.chmod(file, mode) - - def get_inputs(self): - return self.distribution.scripts or [] - - def get_outputs(self): - return self.outfiles or [] diff --git a/spaces/Boadiwaa/Recipes/openai/util.py b/spaces/Boadiwaa/Recipes/openai/util.py deleted file mode 100644 index becd7d14db63d7671b570cd2e9778b91ca96bce2..0000000000000000000000000000000000000000 --- a/spaces/Boadiwaa/Recipes/openai/util.py +++ /dev/null @@ -1,185 +0,0 @@ -import logging -import os -import re -import sys -from enum import Enum -from typing import Optional - -import openai - -OPENAI_LOG = os.environ.get("OPENAI_LOG") - -logger = logging.getLogger("openai") - -__all__ = [ - "log_info", - "log_debug", - "log_warn", - "logfmt", -] - -api_key_to_header = ( - lambda api, key: {"Authorization": f"Bearer {key}"} - if api == ApiType.OPEN_AI - else {"api-key": f"{key}"} -) - - -class ApiType(Enum): - AZURE = 1 - OPEN_AI = 2 - - @staticmethod - def from_str(label): - if label.lower() == "azure": - return ApiType.AZURE - elif label.lower() in ("open_ai", "openai"): - return ApiType.OPEN_AI - else: - raise openai.error.InvalidAPIType( - "The API type provided in invalid. Please select one of the supported API types: 'azure', 'open_ai'" - ) - - -def _console_log_level(): - if openai.log in ["debug", "info"]: - return openai.log - elif OPENAI_LOG in ["debug", "info"]: - return OPENAI_LOG - else: - return None - - -def log_debug(message, **params): - msg = logfmt(dict(message=message, **params)) - if _console_log_level() == "debug": - print(msg, file=sys.stderr) - logger.debug(msg) - - -def log_info(message, **params): - msg = logfmt(dict(message=message, **params)) - if _console_log_level() in ["debug", "info"]: - print(msg, file=sys.stderr) - logger.info(msg) - - -def log_warn(message, **params): - msg = logfmt(dict(message=message, **params)) - print(msg, file=sys.stderr) - logger.warn(msg) - - -def logfmt(props): - def fmt(key, val): - # Handle case where val is a bytes or bytesarray - if hasattr(val, "decode"): - val = val.decode("utf-8") - # Check if val is already a string to avoid re-encoding into ascii. - if not isinstance(val, str): - val = str(val) - if re.search(r"\s", val): - val = repr(val) - # key should already be a string - if re.search(r"\s", key): - key = repr(key) - return "{key}={val}".format(key=key, val=val) - - return " ".join([fmt(key, val) for key, val in sorted(props.items())]) - - -def get_object_classes(): - # This is here to avoid a circular dependency - from openai.object_classes import OBJECT_CLASSES - - return OBJECT_CLASSES - - -def convert_to_openai_object( - resp, - api_key=None, - api_version=None, - organization=None, - engine=None, - plain_old_data=False, -): - # If we get a OpenAIResponse, we'll want to return a OpenAIObject. - - response_ms: Optional[int] = None - if isinstance(resp, openai.openai_response.OpenAIResponse): - organization = resp.organization - response_ms = resp.response_ms - resp = resp.data - - if plain_old_data: - return resp - elif isinstance(resp, list): - return [ - convert_to_openai_object( - i, api_key, api_version, organization, engine=engine - ) - for i in resp - ] - elif isinstance(resp, dict) and not isinstance( - resp, openai.openai_object.OpenAIObject - ): - resp = resp.copy() - klass_name = resp.get("object") - if isinstance(klass_name, str): - klass = get_object_classes().get( - klass_name, openai.openai_object.OpenAIObject - ) - else: - klass = openai.openai_object.OpenAIObject - - return klass.construct_from( - resp, - api_key=api_key, - api_version=api_version, - organization=organization, - response_ms=response_ms, - engine=engine, - ) - else: - return resp - - -def convert_to_dict(obj): - """Converts a OpenAIObject back to a regular dict. - - Nested OpenAIObjects are also converted back to regular dicts. - - :param obj: The OpenAIObject to convert. - - :returns: The OpenAIObject as a dict. - """ - if isinstance(obj, list): - return [convert_to_dict(i) for i in obj] - # This works by virtue of the fact that OpenAIObjects _are_ dicts. The dict - # comprehension returns a regular dict and recursively applies the - # conversion to each value. - elif isinstance(obj, dict): - return {k: convert_to_dict(v) for k, v in obj.items()} - else: - return obj - - -def merge_dicts(x, y): - z = x.copy() - z.update(y) - return z - - -def default_api_key() -> str: - if openai.api_key_path: - with open(openai.api_key_path, "rt") as k: - api_key = k.read().strip() - if not api_key.startswith("sk-"): - raise ValueError(f"Malformed API key in {openai.api_key_path}.") - return api_key - elif openai.api_key is not None: - return openai.api_key - else: - raise openai.error.AuthenticationError( - "No API key provided. You can set your API key in code using 'openai.api_key =', or you can set the environment variable OPENAI_API_KEY= ). If your API key is stored in a file, you can point the openai module at it with 'openai.api_key_path = '. You can generate API keys in the OpenAI web interface. See https://onboard.openai.com for details, or email support@openai.com if you have any questions." - ) diff --git a/spaces/CVPR/LIVE/thrust/thrust/detail/swap.h b/spaces/CVPR/LIVE/thrust/thrust/detail/swap.h deleted file mode 100644 index 96783c762bd9c2ebae3ca5318fe04f15457c545f..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/detail/swap.h +++ /dev/null @@ -1,36 +0,0 @@ -/* - * Copyright 2008-2013 NVIDIA Corporation - * - * Licensed under the Apache License, Version 2.0 (the "License"); - * you may not use this file except in compliance with the License. - * You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * - * Unless required by applicable law or agreed to in writing, software - * distributed under the License is distributed on an "AS IS" BASIS, - * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - * See the License for the specific language governing permissions and - * limitations under the License. - */ - - -#pragma once - -#include - -namespace thrust -{ - -__thrust_exec_check_disable__ -template -__host__ __device__ -inline void swap(Assignable1 &a, Assignable2 &b) -{ - Assignable1 temp = a; - a = b; - b = temp; -} // end swap() - -} // end namespace thrust - diff --git a/spaces/CVPR/LIVE/thrust/thrust/iterator/detail/zip_iterator_base.h b/spaces/CVPR/LIVE/thrust/thrust/iterator/detail/zip_iterator_base.h deleted file mode 100644 index b1603aed4d209bbe3d8b8f211857c250b0bb7c3e..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/iterator/detail/zip_iterator_base.h +++ /dev/null @@ -1,405 +0,0 @@ -/* - * Copyright 2008-2013 NVIDIA Corporation - * - * Licensed under the Apache License, Version 2.0 (the "License"); - * you may not use this file except in compliance with the License. - * You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * - * Unless required by applicable law or agreed to in writing, software - * distributed under the License is distributed on an "AS IS" BASIS, - * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - * See the License for the specific language governing permissions and - * limitations under the License. - */ - -#pragma once - -#include -#include -#include -#include -#include -#include -#include -#include -#include -#include -#include - -namespace thrust -{ - -// forward declare zip_iterator for zip_iterator_base -template class zip_iterator; - -namespace detail -{ - - -// Functors to be used with tuple algorithms -// -template -class advance_iterator -{ -public: - inline __host__ __device__ - advance_iterator(DiffType step) : m_step(step) {} - - __thrust_exec_check_disable__ - template - inline __host__ __device__ - void operator()(Iterator& it) const - { thrust::advance(it, m_step); } - -private: - DiffType m_step; -}; // end advance_iterator - - -struct increment_iterator -{ - __thrust_exec_check_disable__ - template - inline __host__ __device__ - void operator()(Iterator& it) - { ++it; } -}; // end increment_iterator - - -struct decrement_iterator -{ - __thrust_exec_check_disable__ - template - inline __host__ __device__ - void operator()(Iterator& it) - { --it; } -}; // end decrement_iterator - - -struct dereference_iterator -{ - template - struct apply - { - typedef typename - iterator_traits ::reference - type; - }; // end apply - - // XXX silence warnings of the form "calling a __host__ function from a __host__ __device__ function is not allowed - __thrust_exec_check_disable__ - template - __host__ __device__ - typename apply ::type operator()(Iterator const& it) - { - return *it; - } -}; // end dereference_iterator - - -// The namespace tuple_impl_specific provides two meta- -// algorithms and two algorithms for tuples. -namespace tuple_impl_specific -{ - -// define apply1 for tuple_meta_transform_impl -template - struct apply1 - : UnaryMetaFunctionClass::template apply -{ -}; // end apply1 - - -// define apply2 for tuple_meta_accumulate_impl -template - struct apply2 - : UnaryMetaFunctionClass::template apply - struct tuple_meta_accumulate; - -template< - typename Tuple - , class BinaryMetaFun - , typename StartType -> - struct tuple_meta_accumulate_impl -{ - typedef typename apply2< - BinaryMetaFun - , typename Tuple::head_type - , typename tuple_meta_accumulate< - typename Tuple::tail_type - , BinaryMetaFun - , StartType - >::type - >::type type; -}; - - -template< - typename Tuple - , class BinaryMetaFun - , typename StartType -> -struct tuple_meta_accumulate - : thrust::detail::eval_if< - thrust::detail::is_same - , tuple_meta_accumulate_impl< - Tuple - , BinaryMetaFun - , StartType - > - > // end eval_if -{ -}; // end tuple_meta_accumulate - - -// transform algorithm for tuples. The template parameter Fun -// must be a unary functor which is also a unary metafunction -// class that computes its return type based on its argument -// type. For example: -// -// struct to_ptr -// { -// template -// struct apply -// { -// typedef Arg* type; -// } -// -// template -// Arg* operator()(Arg x); -// }; - - - -// for_each algorithm for tuples. -template -inline __host__ __device__ -Fun tuple_for_each(thrust::null_type, Fun f) -{ - return f; -} // end tuple_for_each() - - -template -inline __host__ __device__ -Fun tuple_for_each(Tuple& t, Fun f) -{ - f( t.get_head() ); - return tuple_for_each(t.get_tail(), f); -} // end tuple_for_each() - - -// Equality of tuples. NOTE: "==" for tuples currently (7/2003) -// has problems under some compilers, so I just do my own. -// No point in bringing in a bunch of #ifdefs here. This is -// going to go away with the next tuple implementation anyway. -// -__host__ __device__ -inline bool tuple_equal(thrust::null_type, thrust::null_type) -{ return true; } - - -template -__host__ __device__ -bool tuple_equal(Tuple1 const& t1, Tuple2 const& t2) -{ - return t1.get_head() == t2.get_head() && - tuple_equal(t1.get_tail(), t2.get_tail()); -} // end tuple_equal() - -} // end end tuple_impl_specific - - -// Metafunction to obtain the type of the tuple whose element types -// are the value_types of an iterator tupel. -// -template - struct tuple_of_value_types - : tuple_meta_transform< - IteratorTuple, - iterator_value - > -{ -}; // end tuple_of_value_types - - -struct minimum_category_lambda -{ - template - struct apply : minimum_category -struct minimum_traversal_category_in_iterator_tuple -{ - typedef typename tuple_meta_transform< - IteratorTuple - , thrust::iterator_traversal - >::type tuple_of_traversal_tags; - - typedef typename tuple_impl_specific::tuple_meta_accumulate< - tuple_of_traversal_tags - , minimum_category_lambda - , thrust::random_access_traversal_tag - >::type type; -}; - - -struct minimum_system_lambda -{ - template - struct apply : minimum_system -struct minimum_system_in_iterator_tuple -{ - typedef typename thrust::detail::tuple_meta_transform< - IteratorTuple, - thrust::iterator_system - >::type tuple_of_system_tags; - - typedef typename tuple_impl_specific::tuple_meta_accumulate< - tuple_of_system_tags, - minimum_system_lambda, - thrust::any_system_tag - >::type type; -}; - -namespace zip_iterator_base_ns -{ - - -template - struct tuple_elements_helper - : eval_if< - (i < tuple_size ::value), - tuple_element - struct tuple_elements -{ - typedef typename tuple_elements_helper<0,Tuple>::type T0; - typedef typename tuple_elements_helper<1,Tuple>::type T1; - typedef typename tuple_elements_helper<2,Tuple>::type T2; - typedef typename tuple_elements_helper<3,Tuple>::type T3; - typedef typename tuple_elements_helper<4,Tuple>::type T4; - typedef typename tuple_elements_helper<5,Tuple>::type T5; - typedef typename tuple_elements_helper<6,Tuple>::type T6; - typedef typename tuple_elements_helper<7,Tuple>::type T7; - typedef typename tuple_elements_helper<8,Tuple>::type T8; - typedef typename tuple_elements_helper<9,Tuple>::type T9; -}; - - -template - struct tuple_of_iterator_references -{ - // get a thrust::tuple of the iterators' references - typedef typename tuple_meta_transform< - IteratorTuple, - iterator_reference - >::type tuple_of_references; - - // get at the individual tuple element types by name - typedef tuple_elements elements; - - // map thrust::tuple to tuple_of_iterator_references - typedef thrust::detail::tuple_of_iterator_references< - typename elements::T0, - typename elements::T1, - typename elements::T2, - typename elements::T3, - typename elements::T4, - typename elements::T5, - typename elements::T6, - typename elements::T7, - typename elements::T8, - typename elements::T9 - > type; -}; - - -} // end zip_iterator_base_ns - -/////////////////////////////////////////////////////////////////// -// -// Class zip_iterator_base -// -// Builds and exposes the iterator facade type from which the zip -// iterator will be derived. -// -template - struct zip_iterator_base -{ - //private: - // reference type is the type of the tuple obtained from the - // iterators' reference types. - typedef typename zip_iterator_base_ns::tuple_of_iterator_references ::type reference; - - // Boost's Value type is the same as reference type. - //typedef reference value_type; - typedef typename tuple_of_value_types ::type value_type; - - // Difference type is the first iterator's difference type - typedef typename thrust::iterator_traits< - typename thrust::tuple_element<0, IteratorTuple>::type - >::difference_type difference_type; - - // Iterator system is the minimum system tag in the - // iterator tuple - typedef typename - minimum_system_in_iterator_tuple ::type system; - - // Traversal category is the minimum traversal category in the - // iterator tuple - typedef typename - minimum_traversal_category_in_iterator_tuple ::type traversal_category; - - public: - - // The iterator facade type from which the zip iterator will - // be derived. - typedef thrust::iterator_facade< - zip_iterator , - value_type, - system, - traversal_category, - reference, - difference_type - > type; -}; // end zip_iterator_base - -} // end detail - -} // end thrust - - diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/cpp/detail/malloc_and_free.h b/spaces/CVPR/LIVE/thrust/thrust/system/cpp/detail/malloc_and_free.h deleted file mode 100644 index b1ad7a7341bf701b7f333033059c18b98096c2d7..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/system/cpp/detail/malloc_and_free.h +++ /dev/null @@ -1,23 +0,0 @@ -/* - * Copyright 2008-2013 NVIDIA Corporation - * - * Licensed under the Apache License, Version 2.0 (the "License"); - * you may not use this file except in compliance with the License. - * You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * - * Unless required by applicable law or agreed to in writing, software - * distributed under the License is distributed on an "AS IS" BASIS, - * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - * See the License for the specific language governing permissions and - * limitations under the License. - */ - -#pragma once - -#include - -// this system inherits malloc & free -#include - diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/uninitialized_copy.h b/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/uninitialized_copy.h deleted file mode 100644 index 8d916e33ba2a09662839b0ef97277c5e1a671adb..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/system/cuda/detail/uninitialized_copy.h +++ /dev/null @@ -1,116 +0,0 @@ -/****************************************************************************** - * Copyright (c) 2016, NVIDIA CORPORATION. All rights reserved. - * - * Redistribution and use in source and binary forms, with or without - * modification, are permitted provided that the following conditions are met: - * * Redistributions of source code must retain the above copyright - * notice, this list of conditions and the following disclaimer. - * * Redistributions in binary form must reproduce the above copyright - * notice, this list of conditions and the following disclaimer in the - * documentation and/or other materials provided with the distribution. - * * Neither the name of the NVIDIA CORPORATION nor the - * names of its contributors may be used to endorse or promote products - * derived from this software without specific prior written permission. - * - * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" - * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE - * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE - * ARE DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY - * DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES - * (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; - * LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND - * ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT - * (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS - * SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. - * - ******************************************************************************/ -#pragma once - - -#if THRUST_DEVICE_COMPILER == THRUST_DEVICE_COMPILER_NVCC -#include -#include -#include -#include -#include - -namespace thrust -{ - -namespace cuda_cub { - -namespace __uninitialized_copy { - - template - struct functor - { - InputIt input; - OutputIt output; - - typedef typename iterator_traits ::value_type InputType; - typedef typename iterator_traits ::value_type OutputType; - - THRUST_FUNCTION - functor(InputIt input_, OutputIt output_) - : input(input_), output(output_) {} - - template - void THRUST_DEVICE_FUNCTION operator()(Size idx) - { - InputType const &in = raw_reference_cast(input[idx]); - OutputType & out = raw_reference_cast(output[idx]); - -#if defined(__CUDA__) && defined(__clang__) - // XXX unsafe, but clang is seemngly unable to call in-place new - out = in; -#else - ::new (static_cast (&out)) OutputType(in); -#endif - } - }; // struct functor - -} // namespace __uninitialized_copy - -template -OutputIt __host__ __device__ -uninitialized_copy_n(execution_policy &policy, - InputIt first, - Size count, - OutputIt result) -{ - typedef __uninitialized_copy::functor -OutputIt __host__ __device__ -uninitialized_copy(execution_policy & policy, - InputIt first, - InputIt last, - OutputIt result) -{ - return cuda_cub::uninitialized_copy_n(policy, - first, - thrust::distance(first, last), - result); -} - -} // namespace cuda_ - -} // end namespace thrust -#endif diff --git a/spaces/CVPR/WALT/mmdet/datasets/custom.py b/spaces/CVPR/WALT/mmdet/datasets/custom.py deleted file mode 100644 index 356f01ede6456312920b6fe8fa618258d8898075..0000000000000000000000000000000000000000 --- a/spaces/CVPR/WALT/mmdet/datasets/custom.py +++ /dev/null @@ -1,334 +0,0 @@ -import os.path as osp -import warnings -from collections import OrderedDict - -import mmcv -import numpy as np -from mmcv.utils import print_log -from torch.utils.data import Dataset - -from mmdet.core import eval_map, eval_recalls -from .builder import DATASETS -from .pipelines import Compose - - -@DATASETS.register_module() -class CustomDataset(Dataset): - """Custom dataset for detection. - - The annotation format is shown as follows. The `ann` field is optional for - testing. - - .. code-block:: none - - [ - { - 'filename': 'a.jpg', - 'width': 1280, - 'height': 720, - 'ann': { - 'bboxes': (n, 4) in (x1, y1, x2, y2) order. - 'labels': (n, ), - 'bboxes_ignore': (k, 4), (optional field) - 'labels_ignore': (k, 4) (optional field) - } - }, - ... - ] - - Args: - ann_file (str): Annotation file path. - pipeline (list[dict]): Processing pipeline. - classes (str | Sequence[str], optional): Specify classes to load. - If is None, ``cls.CLASSES`` will be used. Default: None. - data_root (str, optional): Data root for ``ann_file``, - ``img_prefix``, ``seg_prefix``, ``proposal_file`` if specified. - test_mode (bool, optional): If set True, annotation will not be loaded. - filter_empty_gt (bool, optional): If set true, images without bounding - boxes of the dataset's classes will be filtered out. This option - only works when `test_mode=False`, i.e., we never filter images - during tests. - """ - - CLASSES = None - - def __init__(self, - ann_file, - pipeline, - classes=None, - data_root=None, - img_prefix='', - seg_prefix=None, - proposal_file=None, - test_mode=False, - filter_empty_gt=True): - self.ann_file = ann_file - self.data_root = data_root - self.img_prefix = img_prefix - self.seg_prefix = seg_prefix - self.proposal_file = proposal_file - self.test_mode = test_mode - self.filter_empty_gt = filter_empty_gt - self.CLASSES = self.get_classes(classes) - - # join paths if data_root is specified - if self.data_root is not None: - if not osp.isabs(self.ann_file): - self.ann_file = osp.join(self.data_root, self.ann_file) - if not (self.img_prefix is None or osp.isabs(self.img_prefix)): - self.img_prefix = osp.join(self.data_root, self.img_prefix) - if not (self.seg_prefix is None or osp.isabs(self.seg_prefix)): - self.seg_prefix = osp.join(self.data_root, self.seg_prefix) - if not (self.proposal_file is None - or osp.isabs(self.proposal_file)): - self.proposal_file = osp.join(self.data_root, - self.proposal_file) - # load annotations (and proposals) - self.data_infos = self.load_annotations(self.ann_file) - - if self.proposal_file is not None: - self.proposals = self.load_proposals(self.proposal_file) - else: - self.proposals = None - - # filter images too small and containing no annotations - if not test_mode: - valid_inds = self._filter_imgs() - self.data_infos = [self.data_infos[i] for i in valid_inds] - if self.proposals is not None: - self.proposals = [self.proposals[i] for i in valid_inds] - # set group flag for the sampler - self._set_group_flag() - - # processing pipeline - self.pipeline = Compose(pipeline) - - def __len__(self): - """Total number of samples of data.""" - return len(self.data_infos) - - def load_annotations(self, ann_file): - """Load annotation from annotation file.""" - return mmcv.load(ann_file) - - def load_proposals(self, proposal_file): - """Load proposal from proposal file.""" - return mmcv.load(proposal_file) - - def get_ann_info(self, idx): - """Get annotation by index. - - Args: - idx (int): Index of data. - - Returns: - dict: Annotation info of specified index. - """ - - return self.data_infos[idx]['ann'] - - def get_cat_ids(self, idx): - """Get category ids by index. - - Args: - idx (int): Index of data. - - Returns: - list[int]: All categories in the image of specified index. - """ - - return self.data_infos[idx]['ann']['labels'].astype(np.int).tolist() - - def pre_pipeline(self, results): - """Prepare results dict for pipeline.""" - results['img_prefix'] = self.img_prefix - results['seg_prefix'] = self.seg_prefix - results['proposal_file'] = self.proposal_file - results['bbox_fields'] = [] - results['mask_fields'] = [] - results['seg_fields'] = [] - - def _filter_imgs(self, min_size=32): - """Filter images too small.""" - if self.filter_empty_gt: - warnings.warn( - 'CustomDataset does not support filtering empty gt images.') - valid_inds = [] - for i, img_info in enumerate(self.data_infos): - if min(img_info['width'], img_info['height']) >= min_size: - valid_inds.append(i) - return valid_inds - - def _set_group_flag(self): - """Set flag according to image aspect ratio. - - Images with aspect ratio greater than 1 will be set as group 1, - otherwise group 0. - """ - self.flag = np.zeros(len(self), dtype=np.uint8) - for i in range(len(self)): - img_info = self.data_infos[i] - if img_info['width'] / img_info['height'] > 1: - self.flag[i] = 1 - - def _rand_another(self, idx): - """Get another random index from the same group as the given index.""" - pool = np.where(self.flag == self.flag[idx])[0] - return np.random.choice(pool) - - def __getitem__(self, idx): - """Get training/test data after pipeline. - - Args: - idx (int): Index of data. - - Returns: - dict: Training/test data (with annotation if `test_mode` is set \ - True). - """ - - if self.test_mode: - while 1: - try: - return self.prepare_test_img(idx) - except: - idx = idx+1 - #return self.prepare_test_img(idx+1) - - #return self.prepare_test_img(idx) - while True: - try: - data = self.prepare_train_img(idx) - except: - data = self.prepare_train_img(idx-1) - - if data is None: - idx = self._rand_another(idx) - continue - return data - - def prepare_train_img(self, idx): - """Get training data and annotations after pipeline. - - Args: - idx (int): Index of data. - - Returns: - dict: Training data and annotation after pipeline with new keys \ - introduced by pipeline. - """ - - img_info = self.data_infos[idx] - ann_info = self.get_ann_info(idx) - results = dict(img_info=img_info, ann_info=ann_info) - if self.proposals is not None: - results['proposals'] = self.proposals[idx] - self.pre_pipeline(results) - return self.pipeline(results) - - def prepare_test_img(self, idx): - """Get testing data after pipeline. - - Args: - idx (int): Index of data. - - Returns: - dict: Testing data after pipeline with new keys introduced by \ - pipeline. - """ - - img_info = self.data_infos[idx] - results = dict(img_info=img_info) - if self.proposals is not None: - results['proposals'] = self.proposals[idx] - self.pre_pipeline(results) - return self.pipeline(results) - - @classmethod - def get_classes(cls, classes=None): - """Get class names of current dataset. - - Args: - classes (Sequence[str] | str | None): If classes is None, use - default CLASSES defined by builtin dataset. If classes is a - string, take it as a file name. The file contains the name of - classes where each line contains one class name. If classes is - a tuple or list, override the CLASSES defined by the dataset. - - Returns: - tuple[str] or list[str]: Names of categories of the dataset. - """ - if classes is None: - return cls.CLASSES - - if isinstance(classes, str): - # take it as a file path - class_names = mmcv.list_from_file(classes) - elif isinstance(classes, (tuple, list)): - class_names = classes - else: - raise ValueError(f'Unsupported type {type(classes)} of classes.') - - return class_names - - def format_results(self, results, **kwargs): - """Place holder to format result to dataset specific output.""" - - def evaluate(self, - results, - metric='mAP', - logger=None, - proposal_nums=(100, 300, 1000), - iou_thr=0.5, - scale_ranges=None): - """Evaluate the dataset. - - Args: - results (list): Testing results of the dataset. - metric (str | list[str]): Metrics to be evaluated. - logger (logging.Logger | None | str): Logger used for printing - related information during evaluation. Default: None. - proposal_nums (Sequence[int]): Proposal number used for evaluating - recalls, such as recall@100, recall@1000. - Default: (100, 300, 1000). - iou_thr (float | list[float]): IoU threshold. Default: 0.5. - scale_ranges (list[tuple] | None): Scale ranges for evaluating mAP. - Default: None. - """ - - if not isinstance(metric, str): - assert len(metric) == 1 - metric = metric[0] - allowed_metrics = ['mAP', 'recall'] - if metric not in allowed_metrics: - raise KeyError(f'metric {metric} is not supported') - annotations = [self.get_ann_info(i) for i in range(len(self))] - eval_results = OrderedDict() - iou_thrs = [iou_thr] if isinstance(iou_thr, float) else iou_thr - if metric == 'mAP': - assert isinstance(iou_thrs, list) - mean_aps = [] - for iou_thr in iou_thrs: - print_log(f'\n{"-" * 15}iou_thr: {iou_thr}{"-" * 15}') - mean_ap, _ = eval_map( - results, - annotations, - scale_ranges=scale_ranges, - iou_thr=iou_thr, - dataset=self.CLASSES, - logger=logger) - mean_aps.append(mean_ap) - eval_results[f'AP{int(iou_thr * 100):02d}'] = round(mean_ap, 3) - eval_results['mAP'] = sum(mean_aps) / len(mean_aps) - elif metric == 'recall': - gt_bboxes = [ann['bboxes'] for ann in annotations] - recalls = eval_recalls( - gt_bboxes, results, proposal_nums, iou_thr, logger=logger) - for i, num in enumerate(proposal_nums): - for j, iou in enumerate(iou_thrs): - eval_results[f'recall@{num}@{iou}'] = recalls[i, j] - if recalls.shape[1] > 1: - ar = recalls.mean(axis=1) - for i, num in enumerate(proposal_nums): - eval_results[f'AR@{num}'] = ar[i] - return eval_results diff --git a/spaces/Chaitanya01/InvestingPlatform/notifier.py b/spaces/Chaitanya01/InvestingPlatform/notifier.py deleted file mode 100644 index 3d691e9a1abb2ac354eec22068e0e2b2a0581593..0000000000000000000000000000000000000000 --- a/spaces/Chaitanya01/InvestingPlatform/notifier.py +++ /dev/null @@ -1,40 +0,0 @@ -import threading -from config import * -import requests -import slack -import json -from datetime import datetime -import time -arr = [] -def symbol_info(req_params, i): - global arr - url = "https://api.binance.com/api/v3/ticker/24hr" - val = requests.get(url,params = req_params) - try: - data = json.loads(val.text) - - x = arr[i] - try: - if float(data["priceChangePercent"])>=x: - client = slack.WebClient(token = SLACK_TOKEN) - client.chat_postMessage(channel = "#bot_alerts", - text = f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')} {data['symbol']} 24Hchange={float(data['priceChangePercent'])}% new benchmark {x+5}%") - arr[i] = arr[i] + 5 - except: - pass - except: - print("Could not connect") - -for i in range(len(crypto_symbols)): - arr.append(20) - -while True: - for i in range(len(crypto_symbols)): - today = datetime.now() - if today.hour + today.minute + today.second == 0: - for i in range(len(crypto_symbols)): - arr[i] = 20 - req_params = dict(symbol = crypto_symbols[i] + "USDT") - thread = threading.Thread(target = symbol_info, args = (req_params,i,)) - thread.start() - time.sleep(15) diff --git a/spaces/CikeyQI/Yunzai/Yunzai/plugins/system/friend.js b/spaces/CikeyQI/Yunzai/Yunzai/plugins/system/friend.js deleted file mode 100644 index ce3c17b40efbf828ac9cea4589bea90795583c73..0000000000000000000000000000000000000000 --- a/spaces/CikeyQI/Yunzai/Yunzai/plugins/system/friend.js +++ /dev/null @@ -1,22 +0,0 @@ -import cfg from '../../lib/config/config.js' -import common from '../../lib/common/common.js' - -export class friend extends plugin { - constructor () { - super({ - name: 'autoFriend', - dsc: '自动同意好友', - event: 'request.friend' - }) - } - - async accept() { - if (this.e.sub_type == 'add' || this.e.sub_type == 'single') { - if (cfg.other.autoFriend == 1) { - logger.mark(`[自动同意][添加好友] ${this.e.user_id}`) - await common.sleep(2000) - this.e.approve(true) - } - } - } -} \ No newline at end of file diff --git a/spaces/Codecooker/rvcapi/src/infer_pack/commons.py b/spaces/Codecooker/rvcapi/src/infer_pack/commons.py deleted file mode 100644 index 54470986f37825b35d90d7efa7437d1c26b87215..0000000000000000000000000000000000000000 --- a/spaces/Codecooker/rvcapi/src/infer_pack/commons.py +++ /dev/null @@ -1,166 +0,0 @@ -import math -import numpy as np -import torch -from torch import nn -from torch.nn import functional as F - - -def init_weights(m, mean=0.0, std=0.01): - classname = m.__class__.__name__ - if classname.find("Conv") != -1: - m.weight.data.normal_(mean, std) - - -def get_padding(kernel_size, dilation=1): - return int((kernel_size * dilation - dilation) / 2) - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def kl_divergence(m_p, logs_p, m_q, logs_q): - """KL(P||Q)""" - kl = (logs_q - logs_p) - 0.5 - kl += ( - 0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q) - ) - return kl - - -def rand_gumbel(shape): - """Sample from the Gumbel distribution, protect from overflows.""" - uniform_samples = torch.rand(shape) * 0.99998 + 0.00001 - return -torch.log(-torch.log(uniform_samples)) - - -def rand_gumbel_like(x): - g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device) - return g - - -def slice_segments(x, ids_str, segment_size=4): - ret = torch.zeros_like(x[:, :, :segment_size]) - for i in range(x.size(0)): - idx_str = ids_str[i] - idx_end = idx_str + segment_size - ret[i] = x[i, :, idx_str:idx_end] - return ret - - -def slice_segments2(x, ids_str, segment_size=4): - ret = torch.zeros_like(x[:, :segment_size]) - for i in range(x.size(0)): - idx_str = ids_str[i] - idx_end = idx_str + segment_size - ret[i] = x[i, idx_str:idx_end] - return ret - - -def rand_slice_segments(x, x_lengths=None, segment_size=4): - b, d, t = x.size() - if x_lengths is None: - x_lengths = t - ids_str_max = x_lengths - segment_size + 1 - ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long) - ret = slice_segments(x, ids_str, segment_size) - return ret, ids_str - - -def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4): - position = torch.arange(length, dtype=torch.float) - num_timescales = channels // 2 - log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / ( - num_timescales - 1 - ) - inv_timescales = min_timescale * torch.exp( - torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment - ) - scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1) - signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0) - signal = F.pad(signal, [0, 0, 0, channels % 2]) - signal = signal.view(1, channels, length) - return signal - - -def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return x + signal.to(dtype=x.dtype, device=x.device) - - -def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis) - - -def subsequent_mask(length): - mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0) - return mask - - -@torch.jit.script -def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels): - n_channels_int = n_channels[0] - in_act = input_a + input_b - t_act = torch.tanh(in_act[:, :n_channels_int, :]) - s_act = torch.sigmoid(in_act[:, n_channels_int:, :]) - acts = t_act * s_act - return acts - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def shift_1d(x): - x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1] - return x - - -def sequence_mask(length, max_length=None): - if max_length is None: - max_length = length.max() - x = torch.arange(max_length, dtype=length.dtype, device=length.device) - return x.unsqueeze(0) < length.unsqueeze(1) - - -def generate_path(duration, mask): - """ - duration: [b, 1, t_x] - mask: [b, 1, t_y, t_x] - """ - device = duration.device - - b, _, t_y, t_x = mask.shape - cum_duration = torch.cumsum(duration, -1) - - cum_duration_flat = cum_duration.view(b * t_x) - path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype) - path = path.view(b, t_x, t_y) - path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1] - path = path.unsqueeze(1).transpose(2, 3) * mask - return path - - -def clip_grad_value_(parameters, clip_value, norm_type=2): - if isinstance(parameters, torch.Tensor): - parameters = [parameters] - parameters = list(filter(lambda p: p.grad is not None, parameters)) - norm_type = float(norm_type) - if clip_value is not None: - clip_value = float(clip_value) - - total_norm = 0 - for p in parameters: - param_norm = p.grad.data.norm(norm_type) - total_norm += param_norm.item() ** norm_type - if clip_value is not None: - p.grad.data.clamp_(min=-clip_value, max=clip_value) - total_norm = total_norm ** (1.0 / norm_type) - return total_norm diff --git a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/modeling/roi_heads/boundary_head/roi_boundary_predictors.py b/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/modeling/roi_heads/boundary_head/roi_boundary_predictors.py deleted file mode 100644 index 9727592b5ca4d6280a4c017d5501f40f6a0d16d5..0000000000000000000000000000000000000000 --- a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/modeling/roi_heads/boundary_head/roi_boundary_predictors.py +++ /dev/null @@ -1,78 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved. -import torch -from torch import nn -from torch.nn import functional as F - -from maskrcnn_benchmark.layers import Conv2d -from maskrcnn_benchmark.layers import ConvTranspose2d - -from maskrcnn_benchmark import layers - -class BOUNDARYRCNNC4Predictor(nn.Module): - def __init__(self, cfg): - super(BOUNDARYRCNNC4Predictor, self).__init__() - dim_reduced = cfg.MODEL.ROI_BOUNDARY_HEAD.CONV_LAYERS[-1] - self.resol = cfg.MODEL.ROI_BOUNDARY_HEAD.RESOLUTION # 56 - - if cfg.MODEL.ROI_HEADS.USE_FPN: - num_inputs = dim_reduced - else: - stage_index = 4 - stage2_relative_factor = 2 ** (stage_index - 1) - res2_out_channels = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS #256 - num_inputs = res2_out_channels * stage2_relative_factor - - self.bo_input_xy = Conv2d(num_inputs, num_inputs, 1, 1, 0) - nn.init.kaiming_normal_(self.bo_input_xy.weight, - mode='fan_out', nonlinearity='relu') - nn.init.constant_(self.bo_input_xy.bias, 0) - - self.conv5_bo_xy = ConvTranspose2d(num_inputs, dim_reduced, 2, 2, 0) - nn.init.kaiming_normal_(self.conv5_bo_xy.weight, - mode='fan_out', nonlinearity='relu') - nn.init.constant_(self.conv5_bo_xy.bias, 0) - - self.bo_input_1_1 = Conv2d(dim_reduced, dim_reduced, 1, 1, 0) - nn.init.kaiming_normal_(self.bo_input_1_1.weight, - mode='fan_out', nonlinearity='relu') - nn.init.constant_(self.bo_input_1_1.bias, 0) - - self.bo_input_2_1 = Conv2d(dim_reduced, dim_reduced, 1, 1, 0) - nn.init.kaiming_normal_(self.bo_input_2_1.weight, - mode='fan_out', nonlinearity='relu') - nn.init.constant_(self.bo_input_2_1.bias, 0) - - self.conv5_bo_x = Conv2d(dim_reduced, 1, (3, 1), 1, (1,0)) # H W - nn.init.kaiming_normal_(self.conv5_bo_x.weight, - mode='fan_out', nonlinearity='relu') # 'relu' - nn.init.constant_(self.conv5_bo_x.bias, 0) - - self.conv5_bo_y = Conv2d(dim_reduced, 1, (1, 3), 1, (0,1)) # H W - nn.init.kaiming_normal_(self.conv5_bo_y.weight, - mode='fan_out', nonlinearity='relu') - nn.init.constant_(self.conv5_bo_y.bias, 0) - self.up_scale=2 - - - def forward(self, ft): - ft = self.bo_input_xy(ft) - ft_2x = self.conv5_bo_xy(ft) - - ft_2x = layers.interpolate(ft_2x, size = (48,48), mode='bilinear', align_corners=True) - - x = self.bo_input_1_1(ft_2x) - y = self.bo_input_2_1(ft_2x) - - x = self.conv5_bo_x(x) - y = self.conv5_bo_y(y) - - return x, y - - - -_ROI_KE_PREDICTOR = {"BoundaryRCNNC4Predictor": BOUNDARYRCNNC4Predictor} - - -def make_roi_boundary_predictor(cfg): - func = _ROI_KE_PREDICTOR[cfg.MODEL.ROI_BOUNDARY_HEAD.PREDICTOR] - return func(cfg) diff --git a/spaces/DHEIVER/Kidney_Image_Classifier/README.md b/spaces/DHEIVER/Kidney_Image_Classifier/README.md deleted file mode 100644 index 3431572d70b55040ed838e932804d8784cf9df8f..0000000000000000000000000000000000000000 --- a/spaces/DHEIVER/Kidney_Image_Classifier/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Kidney Disease Classification CT Scan -emoji: 🏢 -colorFrom: indigo -colorTo: green -sdk: gradio -sdk_version: 3.17.0 -app_file: app.py -pinned: false -duplicated_from: ahmedxeno/kidney_disease_classification_CT_scan ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-390bcf9f.js b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-390bcf9f.js deleted file mode 100644 index eaa2c0d41ad677012f6b49b3e086e84e92e0db5f..0000000000000000000000000000000000000000 --- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-390bcf9f.js +++ /dev/null @@ -1,2 +0,0 @@ -import{S as v,e as g,s as d,a9 as r,N as q,K as o,as as h,U as f,p as b,ab as w,ac as R,ad as j,z as C,v as S,A as z}from"./index-1d65707a.js";function A(i){let e,_,s;const u=i[6].default,a=r(u,i,i[5],null);return{c(){e=q("div"),a&&a.c(),o(e,"id",i[1]),o(e,"class",_=h(i[2].join(" "))+" svelte-15lo0d8"),f(e,"compact",i[4]==="compact"),f(e,"panel",i[4]==="panel"),f(e,"unequal-height",i[0]===!1),f(e,"stretch",i[0]),f(e,"hide",!i[3])},m(l,t){b(l,e,t),a&&a.m(e,null),s=!0},p(l,[t]){a&&a.p&&(!s||t&32)&&w(a,u,l,l[5],s?j(u,l[5],t,null):R(l[5]),null),(!s||t&2)&&o(e,"id",l[1]),(!s||t&4&&_!==(_=h(l[2].join(" "))+" svelte-15lo0d8"))&&o(e,"class",_),(!s||t&20)&&f(e,"compact",l[4]==="compact"),(!s||t&20)&&f(e,"panel",l[4]==="panel"),(!s||t&5)&&f(e,"unequal-height",l[0]===!1),(!s||t&5)&&f(e,"stretch",l[0]),(!s||t&12)&&f(e,"hide",!l[3])},i(l){s||(C(a,l),s=!0)},o(l){S(a,l),s=!1},d(l){l&&z(e),a&&a.d(l)}}}function K(i,e,_){let{$$slots:s={},$$scope:u}=e,{equal_height:a=!0}=e,{elem_id:l}=e,{elem_classes:t=[]}=e,{visible:m=!0}=e,{variant:c="default"}=e;return i.$$set=n=>{"equal_height"in n&&_(0,a=n.equal_height),"elem_id"in n&&_(1,l=n.elem_id),"elem_classes"in n&&_(2,t=n.elem_classes),"visible"in n&&_(3,m=n.visible),"variant"in n&&_(4,c=n.variant),"$$scope"in n&&_(5,u=n.$$scope)},[a,l,t,m,c,u,s]}class N extends v{constructor(e){super(),g(this,e,K,A,d,{equal_height:0,elem_id:1,elem_classes:2,visible:3,variant:4})}}const k=N,B=["static"];export{k as Component,B as modes}; -//# sourceMappingURL=index-390bcf9f.js.map diff --git a/spaces/DaFujaTyping/hf-Chat-ui/src/routes/settings/+page.server.ts b/spaces/DaFujaTyping/hf-Chat-ui/src/routes/settings/+page.server.ts deleted file mode 100644 index 315d474f5f893140ed8a2948f50087f6c1f6dc09..0000000000000000000000000000000000000000 --- a/spaces/DaFujaTyping/hf-Chat-ui/src/routes/settings/+page.server.ts +++ /dev/null @@ -1,45 +0,0 @@ -import { base } from "$app/paths"; -import { collections } from "$lib/server/database"; -import { redirect } from "@sveltejs/kit"; -import { z } from "zod"; -import { defaultModel, models } from "$lib/server/models"; -import { validateModel } from "$lib/utils/models.js"; - -export const actions = { - default: async function ({ request, locals }) { - const formData = await request.formData(); - - const { ethicsModalAccepted, ...settings } = z - .object({ - shareConversationsWithModelAuthors: z.boolean({ coerce: true }).default(true), - ethicsModalAccepted: z.boolean({ coerce: true }).optional(), - activeModel: validateModel(models), - }) - .parse({ - shareConversationsWithModelAuthors: formData.get("shareConversationsWithModelAuthors"), - ethicsModalAccepted: formData.get("ethicsModalAccepted"), - activeModel: formData.get("activeModel") ?? defaultModel.id, - }); - - await collections.settings.updateOne( - { - sessionId: locals.sessionId, - }, - { - $set: { - ...settings, - ...(ethicsModalAccepted && { ethicsModalAcceptedAt: new Date() }), - updatedAt: new Date(), - }, - $setOnInsert: { - createdAt: new Date(), - }, - }, - { - upsert: true, - } - ); - - throw redirect(303, request.headers.get("referer") || base || "/"); - }, -}; diff --git a/spaces/DanLeBossDeESGI/Musica/README.md b/spaces/DanLeBossDeESGI/Musica/README.md deleted file mode 100644 index 6357123bb119a1f427dd178f11881f2d174b8aa1..0000000000000000000000000000000000000000 --- a/spaces/DanLeBossDeESGI/Musica/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Musica -emoji: 😻 -colorFrom: gray -colorTo: red -sdk: streamlit -sdk_version: 1.26.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Detomo/ai-avatar-backend/helpers/blendshapeNames.js b/spaces/Detomo/ai-avatar-backend/helpers/blendshapeNames.js deleted file mode 100644 index 96432a4e821cf0ee4838bc25aae66d46bc253cb6..0000000000000000000000000000000000000000 --- a/spaces/Detomo/ai-avatar-backend/helpers/blendshapeNames.js +++ /dev/null @@ -1,55 +0,0 @@ -module.exports = ["eyeBlinkLeft", -"eyeLookDownLeft", -"eyeLookInLeft", -"eyeLookOutLeft", -"eyeLookUpLeft", -"eyeSquintLeft", -"eyeWideLeft", -"eyeBlinkRight", -"eyeLookDownRight", -"eyeLookInRight", -"eyeLookOutRight", -"eyeLookUpRight", -"eyeSquintRight", -"eyeWideRight", -"jawForward", -"jawLeft", -"jawRight", -"jawOpen", -"mouthClose", -"mouthFunnel", -"mouthPucker", -"mouthLeft", -"mouthRight", -"mouthSmileLeft", -"mouthSmileRight", -"mouthFrownLeft", -"mouthFrownRight", -"mouthDimpleLeft", -"mouthDimpleRight", -"mouthStretchLeft", -"mouthStretchRight", -"mouthRollLower", -"mouthRollUpper", -"mouthShrugLower", -"mouthShrugUpper", -"mouthPressLeft", -"mouthPressRight", -"mouthLowerDownLeft", -"mouthLowerDownRight", -"mouthUpperUpLeft", -"mouthUpperUpRight", -"browDownLeft", -"browDownRight", -"browInnerUp", -"browOuterUpLeft", -"browOuterUpRight", -"cheekPuff", -"cheekSquintLeft", -"cheekSquintRight", -"noseSneerLeft", -"noseSneerRight", -"tongueOut", -"headRoll", -"leftEyeRoll", -"rightEyeRoll"] \ No newline at end of file diff --git a/spaces/DragGan/DragGan-Inversion/torch_utils/ops/filtered_lrelu.py b/spaces/DragGan/DragGan-Inversion/torch_utils/ops/filtered_lrelu.py deleted file mode 100644 index 1a77f7e7a0ed0e951435cf6c7171d1baac8cf834..0000000000000000000000000000000000000000 --- a/spaces/DragGan/DragGan-Inversion/torch_utils/ops/filtered_lrelu.py +++ /dev/null @@ -1,307 +0,0 @@ -# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved. -# -# NVIDIA CORPORATION and its licensors retain all intellectual property -# and proprietary rights in and to this software, related documentation -# and any modifications thereto. Any use, reproduction, disclosure or -# distribution of this software and related documentation without an express -# license agreement from NVIDIA CORPORATION is strictly prohibited. - -import os -import numpy as np -import torch -import warnings - -from .. import custom_ops -from .. import misc -from . import upfirdn2d -from . import bias_act - -# ---------------------------------------------------------------------------- - -_plugin = None - - -def _init(): - global _plugin - if _plugin is None: - _plugin = custom_ops.get_plugin( - module_name='filtered_lrelu_plugin', - sources=['filtered_lrelu.cpp', 'filtered_lrelu_wr.cu', - 'filtered_lrelu_rd.cu', 'filtered_lrelu_ns.cu'], - headers=['filtered_lrelu.h', 'filtered_lrelu.cu'], - source_dir=os.path.dirname(__file__), - extra_cuda_cflags=['--use_fast_math', - '--allow-unsupported-compiler'], - ) - return True - - -def _get_filter_size(f): - if f is None: - return 1, 1 - assert isinstance(f, torch.Tensor) - assert 1 <= f.ndim <= 2 - return f.shape[-1], f.shape[0] # width, height - - -def _parse_padding(padding): - if isinstance(padding, int): - padding = [padding, padding] - assert isinstance(padding, (list, tuple)) - assert all(isinstance(x, (int, np.integer)) for x in padding) - padding = [int(x) for x in padding] - if len(padding) == 2: - px, py = padding - padding = [px, px, py, py] - px0, px1, py0, py1 = padding - return px0, px1, py0, py1 - -# ---------------------------------------------------------------------------- - - -def filtered_lrelu(x, fu=None, fd=None, b=None, up=1, down=1, padding=0, gain=np.sqrt(2), slope=0.2, clamp=None, flip_filter=False, impl='cuda'): - r"""Filtered leaky ReLU for a batch of 2D images. - - Performs the following sequence of operations for each channel: - - 1. Add channel-specific bias if provided (`b`). - - 2. Upsample the image by inserting N-1 zeros after each pixel (`up`). - - 3. Pad the image with the specified number of zeros on each side (`padding`). - Negative padding corresponds to cropping the image. - - 4. Convolve the image with the specified upsampling FIR filter (`fu`), shrinking it - so that the footprint of all output pixels lies within the input image. - - 5. Multiply each value by the provided gain factor (`gain`). - - 6. Apply leaky ReLU activation function to each value. - - 7. Clamp each value between -clamp and +clamp, if `clamp` parameter is provided. - - 8. Convolve the image with the specified downsampling FIR filter (`fd`), shrinking - it so that the footprint of all output pixels lies within the input image. - - 9. Downsample the image by keeping every Nth pixel (`down`). - - The fused op is considerably more efficient than performing the same calculation - using standard PyTorch ops. It supports gradients of arbitrary order. - - Args: - x: Float32/float16/float64 input tensor of the shape - `[batch_size, num_channels, in_height, in_width]`. - fu: Float32 upsampling FIR filter of the shape - `[filter_height, filter_width]` (non-separable), - `[filter_taps]` (separable), or - `None` (identity). - fd: Float32 downsampling FIR filter of the shape - `[filter_height, filter_width]` (non-separable), - `[filter_taps]` (separable), or - `None` (identity). - b: Bias vector, or `None` to disable. Must be a 1D tensor of the same type - as `x`. The length of vector must must match the channel dimension of `x`. - up: Integer upsampling factor (default: 1). - down: Integer downsampling factor. (default: 1). - padding: Padding with respect to the upsampled image. Can be a single number - or a list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]` - (default: 0). - gain: Overall scaling factor for signal magnitude (default: sqrt(2)). - slope: Slope on the negative side of leaky ReLU (default: 0.2). - clamp: Maximum magnitude for leaky ReLU output (default: None). - flip_filter: False = convolution, True = correlation (default: False). - impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`). - - Returns: - Tensor of the shape `[batch_size, num_channels, out_height, out_width]`. - """ - assert isinstance(x, torch.Tensor) - assert impl in ['ref', 'cuda'] - if impl == 'cuda' and x.device.type == 'cuda' and _init(): - return _filtered_lrelu_cuda(up=up, down=down, padding=padding, gain=gain, slope=slope, clamp=clamp, flip_filter=flip_filter).apply(x, fu, fd, b, None, 0, 0) - return _filtered_lrelu_ref(x, fu=fu, fd=fd, b=b, up=up, down=down, padding=padding, gain=gain, slope=slope, clamp=clamp, flip_filter=flip_filter) - -# ---------------------------------------------------------------------------- - - -@misc.profiled_function -def _filtered_lrelu_ref(x, fu=None, fd=None, b=None, up=1, down=1, padding=0, gain=np.sqrt(2), slope=0.2, clamp=None, flip_filter=False): - """Slow and memory-inefficient reference implementation of `filtered_lrelu()` using - existing `upfirdn2n()` and `bias_act()` ops. - """ - assert isinstance(x, torch.Tensor) and x.ndim == 4 - fu_w, fu_h = _get_filter_size(fu) - fd_w, fd_h = _get_filter_size(fd) - if b is not None: - assert isinstance(b, torch.Tensor) and b.dtype == x.dtype - misc.assert_shape(b, [x.shape[1]]) - assert isinstance(up, int) and up >= 1 - assert isinstance(down, int) and down >= 1 - px0, px1, py0, py1 = _parse_padding(padding) - assert gain == float(gain) and gain > 0 - assert slope == float(slope) and slope >= 0 - assert clamp is None or (clamp == float(clamp) and clamp >= 0) - - # Calculate output size. - batch_size, channels, in_h, in_w = x.shape - in_dtype = x.dtype - out_w = (in_w * up + (px0 + px1) - (fu_w - 1) - - (fd_w - 1) + (down - 1)) // down - out_h = (in_h * up + (py0 + py1) - (fu_h - 1) - - (fd_h - 1) + (down - 1)) // down - - # Compute using existing ops. - x = bias_act.bias_act(x=x, b=b) # Apply bias. - # Upsample. - x = upfirdn2d.upfirdn2d(x=x, f=fu, up=up, padding=[ - px0, px1, py0, py1], gain=up**2, flip_filter=flip_filter) - # Bias, leaky ReLU, clamp. - x = bias_act.bias_act(x=x, act='lrelu', alpha=slope, - gain=gain, clamp=clamp) - # Downsample. - x = upfirdn2d.upfirdn2d(x=x, f=fd, down=down, flip_filter=flip_filter) - - # Check output shape & dtype. - misc.assert_shape(x, [batch_size, channels, out_h, out_w]) - assert x.dtype == in_dtype - return x - -# ---------------------------------------------------------------------------- - - -_filtered_lrelu_cuda_cache = dict() - - -def _filtered_lrelu_cuda(up=1, down=1, padding=0, gain=np.sqrt(2), slope=0.2, clamp=None, flip_filter=False): - """Fast CUDA implementation of `filtered_lrelu()` using custom ops. - """ - assert isinstance(up, int) and up >= 1 - assert isinstance(down, int) and down >= 1 - px0, px1, py0, py1 = _parse_padding(padding) - assert gain == float(gain) and gain > 0 - gain = float(gain) - assert slope == float(slope) and slope >= 0 - slope = float(slope) - assert clamp is None or (clamp == float(clamp) and clamp >= 0) - clamp = float(clamp if clamp is not None else 'inf') - - # Lookup from cache. - key = (up, down, px0, px1, py0, py1, gain, slope, clamp, flip_filter) - if key in _filtered_lrelu_cuda_cache: - return _filtered_lrelu_cuda_cache[key] - - # Forward op. - class FilteredLReluCuda(torch.autograd.Function): - @staticmethod - def forward(ctx, x, fu, fd, b, si, sx, sy): # pylint: disable=arguments-differ - assert isinstance(x, torch.Tensor) and x.ndim == 4 - - # Replace empty up/downsample kernels with full 1x1 kernels (faster than separable). - if fu is None: - fu = torch.ones([1, 1], dtype=torch.float32, device=x.device) - if fd is None: - fd = torch.ones([1, 1], dtype=torch.float32, device=x.device) - assert 1 <= fu.ndim <= 2 - assert 1 <= fd.ndim <= 2 - - # Replace separable 1x1 kernels with full 1x1 kernels when scale factor is 1. - if up == 1 and fu.ndim == 1 and fu.shape[0] == 1: - fu = fu.square()[None] - if down == 1 and fd.ndim == 1 and fd.shape[0] == 1: - fd = fd.square()[None] - - # Missing sign input tensor. - if si is None: - si = torch.empty([0]) - - # Missing bias tensor. - if b is None: - b = torch.zeros([x.shape[1]], dtype=x.dtype, device=x.device) - - # Construct internal sign tensor only if gradients are needed. - write_signs = (si.numel() == 0) and ( - x.requires_grad or b.requires_grad) - - # Warn if input storage strides are not in decreasing order due to e.g. channels-last layout. - strides = [x.stride(i) for i in range(x.ndim) if x.size(i) > 1] - if any(a < b for a, b in zip(strides[:-1], strides[1:])): - warnings.warn( - "low-performance memory layout detected in filtered_lrelu input", RuntimeWarning) - - # Call C++/Cuda plugin if datatype is supported. - if x.dtype in [torch.float16, torch.float32]: - if torch.cuda.current_stream(x.device) != torch.cuda.default_stream(x.device): - warnings.warn( - "filtered_lrelu called with non-default cuda stream but concurrent execution is not supported", RuntimeWarning) - y, so, return_code = _plugin.filtered_lrelu( - x, fu, fd, b, si, up, down, px0, px1, py0, py1, sx, sy, gain, slope, clamp, flip_filter, write_signs) - else: - return_code = -1 - - # No Cuda kernel found? Fall back to generic implementation. Still more memory efficient than the reference implementation because - # only the bit-packed sign tensor is retained for gradient computation. - if return_code < 0: - warnings.warn( - "filtered_lrelu called with parameters that have no optimized CUDA kernel, using generic fallback", RuntimeWarning) - - y = x.add(b.unsqueeze(-1).unsqueeze(-1)) # Add bias. - # Upsample. - y = upfirdn2d.upfirdn2d(x=y, f=fu, up=up, padding=[ - px0, px1, py0, py1], gain=up**2, flip_filter=flip_filter) - # Activation function and sign handling. Modifies y in-place. - so = _plugin.filtered_lrelu_act_( - y, si, sx, sy, gain, slope, clamp, write_signs) - # Downsample. - y = upfirdn2d.upfirdn2d( - x=y, f=fd, down=down, flip_filter=flip_filter) - - # Prepare for gradient computation. - ctx.save_for_backward(fu, fd, (si if si.numel() else so)) - ctx.x_shape = x.shape - ctx.y_shape = y.shape - ctx.s_ofs = sx, sy - return y - - @staticmethod - def backward(ctx, dy): # pylint: disable=arguments-differ - fu, fd, si = ctx.saved_tensors - _, _, xh, xw = ctx.x_shape - _, _, yh, yw = ctx.y_shape - sx, sy = ctx.s_ofs - dx = None # 0 - dfu = None - assert not ctx.needs_input_grad[1] - dfd = None - assert not ctx.needs_input_grad[2] - db = None # 3 - dsi = None - assert not ctx.needs_input_grad[4] - dsx = None - assert not ctx.needs_input_grad[5] - dsy = None - assert not ctx.needs_input_grad[6] - - if ctx.needs_input_grad[0] or ctx.needs_input_grad[3]: - pp = [ - (fu.shape[-1] - 1) + (fd.shape[-1] - 1) - px0, - xw * up - yw * down + px0 - (up - 1), - (fu.shape[0] - 1) + (fd.shape[0] - 1) - py0, - xh * up - yh * down + py0 - (up - 1), - ] - gg = gain * (up ** 2) / (down ** 2) - ff = (not flip_filter) - sx = sx - (fu.shape[-1] - 1) + px0 - sy = sy - (fu.shape[0] - 1) + py0 - dx = _filtered_lrelu_cuda(up=down, down=up, padding=pp, gain=gg, slope=slope, - clamp=None, flip_filter=ff).apply(dy, fd, fu, None, si, sx, sy) - - if ctx.needs_input_grad[3]: - db = dx.sum([0, 2, 3]) - - return dx, dfu, dfd, db, dsi, dsx, dsy - - # Add to cache. - _filtered_lrelu_cuda_cache[key] = FilteredLReluCuda - return FilteredLReluCuda - -# ---------------------------------------------------------------------------- diff --git a/spaces/ElainaFanBoy/MusicGen/tests/data/test_audio_utils.py b/spaces/ElainaFanBoy/MusicGen/tests/data/test_audio_utils.py deleted file mode 100644 index 0480671bb17281d61ce02bce6373a5ccec89fece..0000000000000000000000000000000000000000 --- a/spaces/ElainaFanBoy/MusicGen/tests/data/test_audio_utils.py +++ /dev/null @@ -1,110 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -import julius -import torch -import pytest - -from audiocraft.data.audio_utils import ( - _clip_wav, - convert_audio_channels, - convert_audio, - normalize_audio -) -from ..common_utils import get_batch_white_noise - - -class TestConvertAudioChannels: - - def test_convert_audio_channels_downmix(self): - b, c, t = 2, 3, 100 - audio = get_batch_white_noise(b, c, t) - mixed = convert_audio_channels(audio, channels=2) - assert list(mixed.shape) == [b, 2, t] - - def test_convert_audio_channels_nochange(self): - b, c, t = 2, 3, 100 - audio = get_batch_white_noise(b, c, t) - mixed = convert_audio_channels(audio, channels=c) - assert list(mixed.shape) == list(audio.shape) - - def test_convert_audio_channels_upmix(self): - b, c, t = 2, 1, 100 - audio = get_batch_white_noise(b, c, t) - mixed = convert_audio_channels(audio, channels=3) - assert list(mixed.shape) == [b, 3, t] - - def test_convert_audio_channels_upmix_error(self): - b, c, t = 2, 2, 100 - audio = get_batch_white_noise(b, c, t) - with pytest.raises(ValueError): - convert_audio_channels(audio, channels=3) - - -class TestConvertAudio: - - def test_convert_audio_channels_downmix(self): - b, c, dur = 2, 3, 4. - sr = 128 - audio = get_batch_white_noise(b, c, int(sr * dur)) - out = convert_audio(audio, from_rate=sr, to_rate=sr, to_channels=2) - assert list(out.shape) == [audio.shape[0], 2, audio.shape[-1]] - - def test_convert_audio_channels_upmix(self): - b, c, dur = 2, 1, 4. - sr = 128 - audio = get_batch_white_noise(b, c, int(sr * dur)) - out = convert_audio(audio, from_rate=sr, to_rate=sr, to_channels=3) - assert list(out.shape) == [audio.shape[0], 3, audio.shape[-1]] - - def test_convert_audio_upsample(self): - b, c, dur = 2, 1, 4. - sr = 2 - new_sr = 3 - audio = get_batch_white_noise(b, c, int(sr * dur)) - out = convert_audio(audio, from_rate=sr, to_rate=new_sr, to_channels=c) - out_j = julius.resample.resample_frac(audio, old_sr=sr, new_sr=new_sr) - assert torch.allclose(out, out_j) - - def test_convert_audio_resample(self): - b, c, dur = 2, 1, 4. - sr = 3 - new_sr = 2 - audio = get_batch_white_noise(b, c, int(sr * dur)) - out = convert_audio(audio, from_rate=sr, to_rate=new_sr, to_channels=c) - out_j = julius.resample.resample_frac(audio, old_sr=sr, new_sr=new_sr) - assert torch.allclose(out, out_j) - - -class TestNormalizeAudio: - - def test_clip_wav(self): - b, c, dur = 2, 1, 4. - sr = 3 - audio = 10.0 * get_batch_white_noise(b, c, int(sr * dur)) - _clip_wav(audio) - assert audio.abs().max() <= 1 - - def test_normalize_audio_clip(self): - b, c, dur = 2, 1, 4. - sr = 3 - audio = 10.0 * get_batch_white_noise(b, c, int(sr * dur)) - norm_audio = normalize_audio(audio, strategy='clip') - assert norm_audio.abs().max() <= 1 - - def test_normalize_audio_rms(self): - b, c, dur = 2, 1, 4. - sr = 3 - audio = 10.0 * get_batch_white_noise(b, c, int(sr * dur)) - norm_audio = normalize_audio(audio, strategy='rms') - assert norm_audio.abs().max() <= 1 - - def test_normalize_audio_peak(self): - b, c, dur = 2, 1, 4. - sr = 3 - audio = 10.0 * get_batch_white_noise(b, c, int(sr * dur)) - norm_audio = normalize_audio(audio, strategy='peak') - assert norm_audio.abs().max() <= 1 diff --git a/spaces/EyanAn/vits-uma-genshin-honkai/attentions.py b/spaces/EyanAn/vits-uma-genshin-honkai/attentions.py deleted file mode 100644 index 86bc73b5fe98cc7b443e9078553920346c996707..0000000000000000000000000000000000000000 --- a/spaces/EyanAn/vits-uma-genshin-honkai/attentions.py +++ /dev/null @@ -1,300 +0,0 @@ -import math -import torch -from torch import nn -from torch.nn import functional as F - -import commons -from modules import LayerNorm - - -class Encoder(nn.Module): - def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., window_size=4, **kwargs): - super().__init__() - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.window_size = window_size - - self.drop = nn.Dropout(p_dropout) - self.attn_layers = nn.ModuleList() - self.norm_layers_1 = nn.ModuleList() - self.ffn_layers = nn.ModuleList() - self.norm_layers_2 = nn.ModuleList() - for i in range(self.n_layers): - self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, window_size=window_size)) - self.norm_layers_1.append(LayerNorm(hidden_channels)) - self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout)) - self.norm_layers_2.append(LayerNorm(hidden_channels)) - - def forward(self, x, x_mask): - attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1) - x = x * x_mask - for i in range(self.n_layers): - y = self.attn_layers[i](x, x, attn_mask) - y = self.drop(y) - x = self.norm_layers_1[i](x + y) - - y = self.ffn_layers[i](x, x_mask) - y = self.drop(y) - x = self.norm_layers_2[i](x + y) - x = x * x_mask - return x - - -class Decoder(nn.Module): - def __init__(self, hidden_channels, filter_channels, n_heads, n_layers, kernel_size=1, p_dropout=0., proximal_bias=False, proximal_init=True, **kwargs): - super().__init__() - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.proximal_bias = proximal_bias - self.proximal_init = proximal_init - - self.drop = nn.Dropout(p_dropout) - self.self_attn_layers = nn.ModuleList() - self.norm_layers_0 = nn.ModuleList() - self.encdec_attn_layers = nn.ModuleList() - self.norm_layers_1 = nn.ModuleList() - self.ffn_layers = nn.ModuleList() - self.norm_layers_2 = nn.ModuleList() - for i in range(self.n_layers): - self.self_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout, proximal_bias=proximal_bias, proximal_init=proximal_init)) - self.norm_layers_0.append(LayerNorm(hidden_channels)) - self.encdec_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout)) - self.norm_layers_1.append(LayerNorm(hidden_channels)) - self.ffn_layers.append(FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout, causal=True)) - self.norm_layers_2.append(LayerNorm(hidden_channels)) - - def forward(self, x, x_mask, h, h_mask): - """ - x: decoder input - h: encoder output - """ - self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(device=x.device, dtype=x.dtype) - encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1) - x = x * x_mask - for i in range(self.n_layers): - y = self.self_attn_layers[i](x, x, self_attn_mask) - y = self.drop(y) - x = self.norm_layers_0[i](x + y) - - y = self.encdec_attn_layers[i](x, h, encdec_attn_mask) - y = self.drop(y) - x = self.norm_layers_1[i](x + y) - - y = self.ffn_layers[i](x, x_mask) - y = self.drop(y) - x = self.norm_layers_2[i](x + y) - x = x * x_mask - return x - - -class MultiHeadAttention(nn.Module): - def __init__(self, channels, out_channels, n_heads, p_dropout=0., window_size=None, heads_share=True, block_length=None, proximal_bias=False, proximal_init=False): - super().__init__() - assert channels % n_heads == 0 - - self.channels = channels - self.out_channels = out_channels - self.n_heads = n_heads - self.p_dropout = p_dropout - self.window_size = window_size - self.heads_share = heads_share - self.block_length = block_length - self.proximal_bias = proximal_bias - self.proximal_init = proximal_init - self.attn = None - - self.k_channels = channels // n_heads - self.conv_q = nn.Conv1d(channels, channels, 1) - self.conv_k = nn.Conv1d(channels, channels, 1) - self.conv_v = nn.Conv1d(channels, channels, 1) - self.conv_o = nn.Conv1d(channels, out_channels, 1) - self.drop = nn.Dropout(p_dropout) - - if window_size is not None: - n_heads_rel = 1 if heads_share else n_heads - rel_stddev = self.k_channels**-0.5 - self.emb_rel_k = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev) - self.emb_rel_v = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev) - - nn.init.xavier_uniform_(self.conv_q.weight) - nn.init.xavier_uniform_(self.conv_k.weight) - nn.init.xavier_uniform_(self.conv_v.weight) - if proximal_init: - with torch.no_grad(): - self.conv_k.weight.copy_(self.conv_q.weight) - self.conv_k.bias.copy_(self.conv_q.bias) - - def forward(self, x, c, attn_mask=None): - q = self.conv_q(x) - k = self.conv_k(c) - v = self.conv_v(c) - - x, self.attn = self.attention(q, k, v, mask=attn_mask) - - x = self.conv_o(x) - return x - - def attention(self, query, key, value, mask=None): - # reshape [b, d, t] -> [b, n_h, t, d_k] - b, d, t_s, t_t = (*key.size(), query.size(2)) - query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3) - key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3) - value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3) - - scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1)) - if self.window_size is not None: - assert t_s == t_t, "Relative attention is only available for self-attention." - key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s) - rel_logits = self._matmul_with_relative_keys(query /math.sqrt(self.k_channels), key_relative_embeddings) - scores_local = self._relative_position_to_absolute_position(rel_logits) - scores = scores + scores_local - if self.proximal_bias: - assert t_s == t_t, "Proximal bias is only available for self-attention." - scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device, dtype=scores.dtype) - if mask is not None: - scores = scores.masked_fill(mask == 0, -1e4) - if self.block_length is not None: - assert t_s == t_t, "Local attention is only available for self-attention." - block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length) - scores = scores.masked_fill(block_mask == 0, -1e4) - p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s] - p_attn = self.drop(p_attn) - output = torch.matmul(p_attn, value) - if self.window_size is not None: - relative_weights = self._absolute_position_to_relative_position(p_attn) - value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s) - output = output + self._matmul_with_relative_values(relative_weights, value_relative_embeddings) - output = output.transpose(2, 3).contiguous().view(b, d, t_t) # [b, n_h, t_t, d_k] -> [b, d, t_t] - return output, p_attn - - def _matmul_with_relative_values(self, x, y): - """ - x: [b, h, l, m] - y: [h or 1, m, d] - ret: [b, h, l, d] - """ - ret = torch.matmul(x, y.unsqueeze(0)) - return ret - - def _matmul_with_relative_keys(self, x, y): - """ - x: [b, h, l, d] - y: [h or 1, m, d] - ret: [b, h, l, m] - """ - ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1)) - return ret - - def _get_relative_embeddings(self, relative_embeddings, length): - max_relative_position = 2 * self.window_size + 1 - # Pad first before slice to avoid using cond ops. - pad_length = max(length - (self.window_size + 1), 0) - slice_start_position = max((self.window_size + 1) - length, 0) - slice_end_position = slice_start_position + 2 * length - 1 - if pad_length > 0: - padded_relative_embeddings = F.pad( - relative_embeddings, - commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]])) - else: - padded_relative_embeddings = relative_embeddings - used_relative_embeddings = padded_relative_embeddings[:,slice_start_position:slice_end_position] - return used_relative_embeddings - - def _relative_position_to_absolute_position(self, x): - """ - x: [b, h, l, 2*l-1] - ret: [b, h, l, l] - """ - batch, heads, length, _ = x.size() - # Concat columns of pad to shift from relative to absolute indexing. - x = F.pad(x, commons.convert_pad_shape([[0,0],[0,0],[0,0],[0,1]])) - - # Concat extra elements so to add up to shape (len+1, 2*len-1). - x_flat = x.view([batch, heads, length * 2 * length]) - x_flat = F.pad(x_flat, commons.convert_pad_shape([[0,0],[0,0],[0,length-1]])) - - # Reshape and slice out the padded elements. - x_final = x_flat.view([batch, heads, length+1, 2*length-1])[:, :, :length, length-1:] - return x_final - - def _absolute_position_to_relative_position(self, x): - """ - x: [b, h, l, l] - ret: [b, h, l, 2*l-1] - """ - batch, heads, length, _ = x.size() - # padd along column - x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length-1]])) - x_flat = x.view([batch, heads, length**2 + length*(length -1)]) - # add 0's in the beginning that will skew the elements after reshape - x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]])) - x_final = x_flat.view([batch, heads, length, 2*length])[:,:,:,1:] - return x_final - - def _attention_bias_proximal(self, length): - """Bias for self-attention to encourage attention to close positions. - Args: - length: an integer scalar. - Returns: - a Tensor with shape [1, 1, length, length] - """ - r = torch.arange(length, dtype=torch.float32) - diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1) - return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0) - - -class FFN(nn.Module): - def __init__(self, in_channels, out_channels, filter_channels, kernel_size, p_dropout=0., activation=None, causal=False): - super().__init__() - self.in_channels = in_channels - self.out_channels = out_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.activation = activation - self.causal = causal - - if causal: - self.padding = self._causal_padding - else: - self.padding = self._same_padding - - self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size) - self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size) - self.drop = nn.Dropout(p_dropout) - - def forward(self, x, x_mask): - x = self.conv_1(self.padding(x * x_mask)) - if self.activation == "gelu": - x = x * torch.sigmoid(1.702 * x) - else: - x = torch.relu(x) - x = self.drop(x) - x = self.conv_2(self.padding(x * x_mask)) - return x * x_mask - - def _causal_padding(self, x): - if self.kernel_size == 1: - return x - pad_l = self.kernel_size - 1 - pad_r = 0 - padding = [[0, 0], [0, 0], [pad_l, pad_r]] - x = F.pad(x, commons.convert_pad_shape(padding)) - return x - - def _same_padding(self, x): - if self.kernel_size == 1: - return x - pad_l = (self.kernel_size - 1) // 2 - pad_r = self.kernel_size // 2 - padding = [[0, 0], [0, 0], [pad_l, pad_r]] - x = F.pad(x, commons.convert_pad_shape(padding)) - return x diff --git a/spaces/FantasticGNU/AnomalyGPT/model/agent.py b/spaces/FantasticGNU/AnomalyGPT/model/agent.py deleted file mode 100644 index a5199b6497f739f5800dbd38daade944459457e8..0000000000000000000000000000000000000000 --- a/spaces/FantasticGNU/AnomalyGPT/model/agent.py +++ /dev/null @@ -1,81 +0,0 @@ -from header import * - -class DeepSpeedAgent: - - def __init__(self, model, args): - super(DeepSpeedAgent, self).__init__() - self.args = args - self.model = model - self.load_stage_1_parameters(args["delta_ckpt_path"]) - - - - for name, param in self.model.named_parameters(): - param.requires_grad = False - - for name, param in self.model.image_decoder.named_parameters(): - param.requires_grad = True - - for name, param in self.model.prompt_learner.named_parameters(): - param.requires_grad = True - - - - - # load config parameters of deepspeed - ds_params = json.load(open(self.args['ds_config_path'])) - ds_params['scheduler']['params']['total_num_steps'] = self.args['total_steps'] - ds_params['scheduler']['params']['warmup_num_steps'] = max(10, int(self.args['total_steps'] * self.args['warmup_rate'])) - self.ds_engine, self.optimizer, _ , _ = deepspeed.initialize( - model=self.model, - model_parameters=self.model.parameters(), - config_params=ds_params, - dist_init_required=True, - args=types.SimpleNamespace(**args) - ) - - @torch.no_grad() - def predict(self, batch): - self.model.eval() - string = self.model.generate_one_sample(batch) - return string - - def train_model(self, batch, current_step=0, pbar=None): - self.ds_engine.module.train() - loss, mle_acc = self.ds_engine(batch) - - self.ds_engine.backward(loss) - self.ds_engine.step() - pbar.set_description(f'[!] loss: {round(loss.item(), 4)}; token_acc: {round(mle_acc*100, 2)}') - pbar.update(1) - if self.args['local_rank'] == 0 and self.args['log_path'] and current_step % self.args['logging_step'] == 0: - elapsed = pbar.format_dict['elapsed'] - rate = pbar.format_dict['rate'] - remaining = (pbar.total - pbar.n) / rate if rate and pbar.total else 0 - remaining = str(datetime.timedelta(seconds=remaining)) - logging.info(f'[!] progress: {round(pbar.n/pbar.total, 5)}; remaining time: {remaining}; loss: {round(loss.item(), 4)}; token_acc: {round(mle_acc*100, 2)}') - - mle_acc *= 100 - return mle_acc - - def save_model(self, path, current_step): - # only save trainable model parameters - param_grad_dic = { - k: v.requires_grad for (k, v) in self.ds_engine.module.named_parameters() - } - state_dict = self.ds_engine.module.state_dict() - checkpoint = OrderedDict() - for k, v in self.ds_engine.module.named_parameters(): - if v.requires_grad: - print(k) - checkpoint[k] = v - torch.save(checkpoint, f'{path}/pytorch_model.pt') - # save tokenizer - self.model.llama_tokenizer.save_pretrained(path) - # save configuration - self.model.llama_model.config.save_pretrained(path) - print(f'[!] save model into {path}') - - def load_stage_1_parameters(self, path): - delta_ckpt = torch.load(path, map_location=torch.device('cpu')) - self.model.load_state_dict(delta_ckpt, strict=False) diff --git a/spaces/Frankapp/bingai/Dockerfile b/spaces/Frankapp/bingai/Dockerfile deleted file mode 100644 index c9e1a0107fd8a62a46a78796ab01e4109eb683e8..0000000000000000000000000000000000000000 --- a/spaces/Frankapp/bingai/Dockerfile +++ /dev/null @@ -1,34 +0,0 @@ -# Build Stage -# 使用 golang:alpine 作为构建阶段的基础镜像 -FROM golang:alpine AS builder - -# 添加 git,以便之后能从GitHub克隆项目 -RUN apk --no-cache add git - -# 从 GitHub 克隆 go-proxy-bingai 项目到 /workspace/app 目录下 -RUN git clone https://github.com/Harry-zklcdc/go-proxy-bingai.git /workspace/app - -# 设置工作目录为之前克隆的项目目录 -WORKDIR /workspace/app - -# 编译 go 项目。-ldflags="-s -w" 是为了减少编译后的二进制大小 -RUN go build -ldflags="-s -w" -tags netgo -trimpath -o go-proxy-bingai main.go - -# Runtime Stage -# 使用轻量级的 alpine 镜像作为运行时的基础镜像 -FROM alpine - -# 设置工作目录 -WORKDIR /workspace/app - -# 从构建阶段复制编译后的二进制文件到运行时镜像中 -COPY --from=builder /workspace/app/go-proxy-bingai . - -# 设置环境变量,此处为随机字符-仅可进行对话,如需绘画,需要修改为自己的token -ENV Go_Proxy_BingAI_USER_TOKEN_1="1rd3l3wy1i_ONyrF_wE1fXCWb9_T1NgqppNOmY77Xz0W6okats_7RK_mOO_qZ3rcWWf0qUkED7TkyzAwV7pwXBN1SIxzqY07S8us6LgCGx7MeI0WBJ5HatLQpZ02uJb_ZMRgzxarl_K_LFkAQwbIeYreMdVRd96F96us_hwVjB6wgQDK6eLhCKBQ8awUgY45s2rlUjQcf-LRGWPExgYyG7wjjjj" - -# 暴露8080端口 -EXPOSE 8080 - -# 容器启动时运行的命令 -CMD ["/workspace/app/go-proxy-bingai"] diff --git a/spaces/FridaZuley/RVC_HFKawaii/lib/infer_pack/attentions.py b/spaces/FridaZuley/RVC_HFKawaii/lib/infer_pack/attentions.py deleted file mode 100644 index 05501be1871643f78dddbeaa529c96667031a8db..0000000000000000000000000000000000000000 --- a/spaces/FridaZuley/RVC_HFKawaii/lib/infer_pack/attentions.py +++ /dev/null @@ -1,417 +0,0 @@ -import copy -import math -import numpy as np -import torch -from torch import nn -from torch.nn import functional as F - -from lib.infer_pack import commons -from lib.infer_pack import modules -from lib.infer_pack.modules import LayerNorm - - -class Encoder(nn.Module): - def __init__( - self, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size=1, - p_dropout=0.0, - window_size=10, - **kwargs - ): - super().__init__() - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.window_size = window_size - - self.drop = nn.Dropout(p_dropout) - self.attn_layers = nn.ModuleList() - self.norm_layers_1 = nn.ModuleList() - self.ffn_layers = nn.ModuleList() - self.norm_layers_2 = nn.ModuleList() - for i in range(self.n_layers): - self.attn_layers.append( - MultiHeadAttention( - hidden_channels, - hidden_channels, - n_heads, - p_dropout=p_dropout, - window_size=window_size, - ) - ) - self.norm_layers_1.append(LayerNorm(hidden_channels)) - self.ffn_layers.append( - FFN( - hidden_channels, - hidden_channels, - filter_channels, - kernel_size, - p_dropout=p_dropout, - ) - ) - self.norm_layers_2.append(LayerNorm(hidden_channels)) - - def forward(self, x, x_mask): - attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1) - x = x * x_mask - for i in range(self.n_layers): - y = self.attn_layers[i](x, x, attn_mask) - y = self.drop(y) - x = self.norm_layers_1[i](x + y) - - y = self.ffn_layers[i](x, x_mask) - y = self.drop(y) - x = self.norm_layers_2[i](x + y) - x = x * x_mask - return x - - -class Decoder(nn.Module): - def __init__( - self, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size=1, - p_dropout=0.0, - proximal_bias=False, - proximal_init=True, - **kwargs - ): - super().__init__() - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.proximal_bias = proximal_bias - self.proximal_init = proximal_init - - self.drop = nn.Dropout(p_dropout) - self.self_attn_layers = nn.ModuleList() - self.norm_layers_0 = nn.ModuleList() - self.encdec_attn_layers = nn.ModuleList() - self.norm_layers_1 = nn.ModuleList() - self.ffn_layers = nn.ModuleList() - self.norm_layers_2 = nn.ModuleList() - for i in range(self.n_layers): - self.self_attn_layers.append( - MultiHeadAttention( - hidden_channels, - hidden_channels, - n_heads, - p_dropout=p_dropout, - proximal_bias=proximal_bias, - proximal_init=proximal_init, - ) - ) - self.norm_layers_0.append(LayerNorm(hidden_channels)) - self.encdec_attn_layers.append( - MultiHeadAttention( - hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout - ) - ) - self.norm_layers_1.append(LayerNorm(hidden_channels)) - self.ffn_layers.append( - FFN( - hidden_channels, - hidden_channels, - filter_channels, - kernel_size, - p_dropout=p_dropout, - causal=True, - ) - ) - self.norm_layers_2.append(LayerNorm(hidden_channels)) - - def forward(self, x, x_mask, h, h_mask): - """ - x: decoder input - h: encoder output - """ - self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to( - device=x.device, dtype=x.dtype - ) - encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1) - x = x * x_mask - for i in range(self.n_layers): - y = self.self_attn_layers[i](x, x, self_attn_mask) - y = self.drop(y) - x = self.norm_layers_0[i](x + y) - - y = self.encdec_attn_layers[i](x, h, encdec_attn_mask) - y = self.drop(y) - x = self.norm_layers_1[i](x + y) - - y = self.ffn_layers[i](x, x_mask) - y = self.drop(y) - x = self.norm_layers_2[i](x + y) - x = x * x_mask - return x - - -class MultiHeadAttention(nn.Module): - def __init__( - self, - channels, - out_channels, - n_heads, - p_dropout=0.0, - window_size=None, - heads_share=True, - block_length=None, - proximal_bias=False, - proximal_init=False, - ): - super().__init__() - assert channels % n_heads == 0 - - self.channels = channels - self.out_channels = out_channels - self.n_heads = n_heads - self.p_dropout = p_dropout - self.window_size = window_size - self.heads_share = heads_share - self.block_length = block_length - self.proximal_bias = proximal_bias - self.proximal_init = proximal_init - self.attn = None - - self.k_channels = channels // n_heads - self.conv_q = nn.Conv1d(channels, channels, 1) - self.conv_k = nn.Conv1d(channels, channels, 1) - self.conv_v = nn.Conv1d(channels, channels, 1) - self.conv_o = nn.Conv1d(channels, out_channels, 1) - self.drop = nn.Dropout(p_dropout) - - if window_size is not None: - n_heads_rel = 1 if heads_share else n_heads - rel_stddev = self.k_channels**-0.5 - self.emb_rel_k = nn.Parameter( - torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) - * rel_stddev - ) - self.emb_rel_v = nn.Parameter( - torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) - * rel_stddev - ) - - nn.init.xavier_uniform_(self.conv_q.weight) - nn.init.xavier_uniform_(self.conv_k.weight) - nn.init.xavier_uniform_(self.conv_v.weight) - if proximal_init: - with torch.no_grad(): - self.conv_k.weight.copy_(self.conv_q.weight) - self.conv_k.bias.copy_(self.conv_q.bias) - - def forward(self, x, c, attn_mask=None): - q = self.conv_q(x) - k = self.conv_k(c) - v = self.conv_v(c) - - x, self.attn = self.attention(q, k, v, mask=attn_mask) - - x = self.conv_o(x) - return x - - def attention(self, query, key, value, mask=None): - # reshape [b, d, t] -> [b, n_h, t, d_k] - b, d, t_s, t_t = (*key.size(), query.size(2)) - query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3) - key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3) - value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3) - - scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1)) - if self.window_size is not None: - assert ( - t_s == t_t - ), "Relative attention is only available for self-attention." - key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s) - rel_logits = self._matmul_with_relative_keys( - query / math.sqrt(self.k_channels), key_relative_embeddings - ) - scores_local = self._relative_position_to_absolute_position(rel_logits) - scores = scores + scores_local - if self.proximal_bias: - assert t_s == t_t, "Proximal bias is only available for self-attention." - scores = scores + self._attention_bias_proximal(t_s).to( - device=scores.device, dtype=scores.dtype - ) - if mask is not None: - scores = scores.masked_fill(mask == 0, -1e4) - if self.block_length is not None: - assert ( - t_s == t_t - ), "Local attention is only available for self-attention." - block_mask = ( - torch.ones_like(scores) - .triu(-self.block_length) - .tril(self.block_length) - ) - scores = scores.masked_fill(block_mask == 0, -1e4) - p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s] - p_attn = self.drop(p_attn) - output = torch.matmul(p_attn, value) - if self.window_size is not None: - relative_weights = self._absolute_position_to_relative_position(p_attn) - value_relative_embeddings = self._get_relative_embeddings( - self.emb_rel_v, t_s - ) - output = output + self._matmul_with_relative_values( - relative_weights, value_relative_embeddings - ) - output = ( - output.transpose(2, 3).contiguous().view(b, d, t_t) - ) # [b, n_h, t_t, d_k] -> [b, d, t_t] - return output, p_attn - - def _matmul_with_relative_values(self, x, y): - """ - x: [b, h, l, m] - y: [h or 1, m, d] - ret: [b, h, l, d] - """ - ret = torch.matmul(x, y.unsqueeze(0)) - return ret - - def _matmul_with_relative_keys(self, x, y): - """ - x: [b, h, l, d] - y: [h or 1, m, d] - ret: [b, h, l, m] - """ - ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1)) - return ret - - def _get_relative_embeddings(self, relative_embeddings, length): - max_relative_position = 2 * self.window_size + 1 - # Pad first before slice to avoid using cond ops. - pad_length = max(length - (self.window_size + 1), 0) - slice_start_position = max((self.window_size + 1) - length, 0) - slice_end_position = slice_start_position + 2 * length - 1 - if pad_length > 0: - padded_relative_embeddings = F.pad( - relative_embeddings, - commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]), - ) - else: - padded_relative_embeddings = relative_embeddings - used_relative_embeddings = padded_relative_embeddings[ - :, slice_start_position:slice_end_position - ] - return used_relative_embeddings - - def _relative_position_to_absolute_position(self, x): - """ - x: [b, h, l, 2*l-1] - ret: [b, h, l, l] - """ - batch, heads, length, _ = x.size() - # Concat columns of pad to shift from relative to absolute indexing. - x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]])) - - # Concat extra elements so to add up to shape (len+1, 2*len-1). - x_flat = x.view([batch, heads, length * 2 * length]) - x_flat = F.pad( - x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]]) - ) - - # Reshape and slice out the padded elements. - x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[ - :, :, :length, length - 1 : - ] - return x_final - - def _absolute_position_to_relative_position(self, x): - """ - x: [b, h, l, l] - ret: [b, h, l, 2*l-1] - """ - batch, heads, length, _ = x.size() - # padd along column - x = F.pad( - x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]]) - ) - x_flat = x.view([batch, heads, length**2 + length * (length - 1)]) - # add 0's in the beginning that will skew the elements after reshape - x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]])) - x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:] - return x_final - - def _attention_bias_proximal(self, length): - """Bias for self-attention to encourage attention to close positions. - Args: - length: an integer scalar. - Returns: - a Tensor with shape [1, 1, length, length] - """ - r = torch.arange(length, dtype=torch.float32) - diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1) - return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0) - - -class FFN(nn.Module): - def __init__( - self, - in_channels, - out_channels, - filter_channels, - kernel_size, - p_dropout=0.0, - activation=None, - causal=False, - ): - super().__init__() - self.in_channels = in_channels - self.out_channels = out_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.activation = activation - self.causal = causal - - if causal: - self.padding = self._causal_padding - else: - self.padding = self._same_padding - - self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size) - self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size) - self.drop = nn.Dropout(p_dropout) - - def forward(self, x, x_mask): - x = self.conv_1(self.padding(x * x_mask)) - if self.activation == "gelu": - x = x * torch.sigmoid(1.702 * x) - else: - x = torch.relu(x) - x = self.drop(x) - x = self.conv_2(self.padding(x * x_mask)) - return x * x_mask - - def _causal_padding(self, x): - if self.kernel_size == 1: - return x - pad_l = self.kernel_size - 1 - pad_r = 0 - padding = [[0, 0], [0, 0], [pad_l, pad_r]] - x = F.pad(x, commons.convert_pad_shape(padding)) - return x - - def _same_padding(self, x): - if self.kernel_size == 1: - return x - pad_l = (self.kernel_size - 1) // 2 - pad_r = self.kernel_size // 2 - padding = [[0, 0], [0, 0], [pad_l, pad_r]] - x = F.pad(x, commons.convert_pad_shape(padding)) - return x diff --git a/spaces/GXSA/bingo/src/components/chat-list.tsx b/spaces/GXSA/bingo/src/components/chat-list.tsx deleted file mode 100644 index 624a78ef0d7be0f1192cf02a81e2e9cf214cb193..0000000000000000000000000000000000000000 --- a/spaces/GXSA/bingo/src/components/chat-list.tsx +++ /dev/null @@ -1,28 +0,0 @@ -import React from 'react' - -import { Separator } from '@/components/ui/separator' -import { ChatMessage } from '@/components/chat-message' -import { ChatMessageModel } from '@/lib/bots/bing/types' - -export interface ChatList { - messages: ChatMessageModel[] -} - -export function ChatList({ messages }: ChatList) { - if (!messages.length) { - return null - } - - return ( - - {messages.map((message, index) => ( -- ) -} diff --git a/spaces/GXSA/bingo/tests/parse.ts b/spaces/GXSA/bingo/tests/parse.ts deleted file mode 100644 index 92940fe6315f1d7cb2b267ba5e5a7e26460a1de3..0000000000000000000000000000000000000000 --- a/spaces/GXSA/bingo/tests/parse.ts +++ /dev/null @@ -1,13 +0,0 @@ -import { promises as fs } from 'fs' -import { join } from 'path' -import { parseHeadersFromCurl } from '@/lib/utils' - -(async () => { - const content = await fs.readFile(join(__dirname, './fixtures/curl.txt'), 'utf-8') - const headers = parseHeadersFromCurl(content) - console.log(headers) - - const cmdContent = await fs.readFile(join(__dirname, './fixtures/cmd.txt'), 'utf-8') - const cmdHeaders = parseHeadersFromCurl(cmdContent) - console.log(cmdHeaders) -})() diff --git a/spaces/GeorgeOrville/bingo/src/components/ui/voice/index.tsx b/spaces/GeorgeOrville/bingo/src/components/ui/voice/index.tsx deleted file mode 100644 index 4adcb632226bfced8b97092782811edf08b56569..0000000000000000000000000000000000000000 --- a/spaces/GeorgeOrville/bingo/src/components/ui/voice/index.tsx +++ /dev/null @@ -1,28 +0,0 @@ -import './index.scss' - -export interface VoiceProps extends CSSPropertyRule { - num?: number; - duration?: number; -} -export default function Voice({ duration = 400, num = 7, ...others }) { - return ( -- - ))} -- {index < messages.length - 1 && ( - - )} - - {Array.from({ length: num }).map((_, index) => { - const randomDuration = Math.random() * 100 + duration - const initialDelay = Math.random() * 2 * duration - const initialScale = Math.sin((index + 1) * Math.PI / num) - return ( - - ) - })} -- ) -} diff --git a/spaces/GipAdonimus/Real-Time-Voice-Cloning/synthesizer/train.py b/spaces/GipAdonimus/Real-Time-Voice-Cloning/synthesizer/train.py deleted file mode 100644 index a136cf9b38538ca7dc428adf209c0cbb40e890d7..0000000000000000000000000000000000000000 --- a/spaces/GipAdonimus/Real-Time-Voice-Cloning/synthesizer/train.py +++ /dev/null @@ -1,269 +0,0 @@ -import torch -import torch.nn.functional as F -from torch import optim -from torch.utils.data import DataLoader -from synthesizer import audio -from synthesizer.models.tacotron import Tacotron -from synthesizer.synthesizer_dataset import SynthesizerDataset, collate_synthesizer -from synthesizer.utils import ValueWindow, data_parallel_workaround -from synthesizer.utils.plot import plot_spectrogram -from synthesizer.utils.symbols import symbols -from synthesizer.utils.text import sequence_to_text -from vocoder.display import * -from datetime import datetime -import numpy as np -from pathlib import Path -import sys -import time -import platform - - -def np_now(x: torch.Tensor): return x.detach().cpu().numpy() - -def time_string(): - return datetime.now().strftime("%Y-%m-%d %H:%M") - -def train(run_id: str, syn_dir: str, models_dir: str, save_every: int, - backup_every: int, force_restart:bool, hparams): - - syn_dir = Path(syn_dir) - models_dir = Path(models_dir) - models_dir.mkdir(exist_ok=True) - - model_dir = models_dir.joinpath(run_id) - plot_dir = model_dir.joinpath("plots") - wav_dir = model_dir.joinpath("wavs") - mel_output_dir = model_dir.joinpath("mel-spectrograms") - meta_folder = model_dir.joinpath("metas") - model_dir.mkdir(exist_ok=True) - plot_dir.mkdir(exist_ok=True) - wav_dir.mkdir(exist_ok=True) - mel_output_dir.mkdir(exist_ok=True) - meta_folder.mkdir(exist_ok=True) - - weights_fpath = model_dir.joinpath(run_id).with_suffix(".pt") - metadata_fpath = syn_dir.joinpath("train.txt") - - print("Checkpoint path: {}".format(weights_fpath)) - print("Loading training data from: {}".format(metadata_fpath)) - print("Using model: Tacotron") - - # Book keeping - step = 0 - time_window = ValueWindow(100) - loss_window = ValueWindow(100) - - - # From WaveRNN/train_tacotron.py - if torch.cuda.is_available(): - device = torch.device("cuda") - - for session in hparams.tts_schedule: - _, _, _, batch_size = session - if batch_size % torch.cuda.device_count() != 0: - raise ValueError("`batch_size` must be evenly divisible by n_gpus!") - else: - device = torch.device("cpu") - print("Using device:", device) - - # Instantiate Tacotron Model - print("\nInitialising Tacotron Model...\n") - model = Tacotron(embed_dims=hparams.tts_embed_dims, - num_chars=len(symbols), - encoder_dims=hparams.tts_encoder_dims, - decoder_dims=hparams.tts_decoder_dims, - n_mels=hparams.num_mels, - fft_bins=hparams.num_mels, - postnet_dims=hparams.tts_postnet_dims, - encoder_K=hparams.tts_encoder_K, - lstm_dims=hparams.tts_lstm_dims, - postnet_K=hparams.tts_postnet_K, - num_highways=hparams.tts_num_highways, - dropout=hparams.tts_dropout, - stop_threshold=hparams.tts_stop_threshold, - speaker_embedding_size=hparams.speaker_embedding_size).to(device) - - # Initialize the optimizer - optimizer = optim.Adam(model.parameters()) - - # Load the weights - if force_restart or not weights_fpath.exists(): - print("\nStarting the training of Tacotron from scratch\n") - model.save(weights_fpath) - - # Embeddings metadata - char_embedding_fpath = meta_folder.joinpath("CharacterEmbeddings.tsv") - with open(char_embedding_fpath, "w", encoding="utf-8") as f: - for symbol in symbols: - if symbol == " ": - symbol = "\\s" # For visual purposes, swap space with \s - - f.write("{}\n".format(symbol)) - - else: - print("\nLoading weights at %s" % weights_fpath) - model.load(weights_fpath, optimizer) - print("Tacotron weights loaded from step %d" % model.step) - - # Initialize the dataset - metadata_fpath = syn_dir.joinpath("train.txt") - mel_dir = syn_dir.joinpath("mels") - embed_dir = syn_dir.joinpath("embeds") - dataset = SynthesizerDataset(metadata_fpath, mel_dir, embed_dir, hparams) - test_loader = DataLoader(dataset, - batch_size=1, - shuffle=True, - pin_memory=True) - - for i, session in enumerate(hparams.tts_schedule): - current_step = model.get_step() - - r, lr, max_step, batch_size = session - - training_steps = max_step - current_step - - # Do we need to change to the next session? - if current_step >= max_step: - # Are there no further sessions than the current one? - if i == len(hparams.tts_schedule) - 1: - # We have completed training. Save the model and exit - model.save(weights_fpath, optimizer) - break - else: - # There is a following session, go to it - continue - - model.r = r - - # Begin the training - simple_table([(f"Steps with r={r}", str(training_steps // 1000) + "k Steps"), - ("Batch Size", batch_size), - ("Learning Rate", lr), - ("Outputs/Step (r)", model.r)]) - - for p in optimizer.param_groups: - p["lr"] = lr - - data_loader = DataLoader(dataset, - collate_fn=lambda batch: collate_synthesizer(batch, r, hparams), - batch_size=batch_size, - num_workers=2 if platform.system() != "Windows" else 0, - shuffle=True, - pin_memory=True) - - total_iters = len(dataset) - steps_per_epoch = np.ceil(total_iters / batch_size).astype(np.int32) - epochs = np.ceil(training_steps / steps_per_epoch).astype(np.int32) - - for epoch in range(1, epochs+1): - for i, (texts, mels, embeds, idx) in enumerate(data_loader, 1): - start_time = time.time() - - # Generate stop tokens for training - stop = torch.ones(mels.shape[0], mels.shape[2]) - for j, k in enumerate(idx): - stop[j, :int(dataset.metadata[k][4])-1] = 0 - - texts = texts.to(device) - mels = mels.to(device) - embeds = embeds.to(device) - stop = stop.to(device) - - # Forward pass - # Parallelize model onto GPUS using workaround due to python bug - if device.type == "cuda" and torch.cuda.device_count() > 1: - m1_hat, m2_hat, attention, stop_pred = data_parallel_workaround(model, texts, - mels, embeds) - else: - m1_hat, m2_hat, attention, stop_pred = model(texts, mels, embeds) - - # Backward pass - m1_loss = F.mse_loss(m1_hat, mels) + F.l1_loss(m1_hat, mels) - m2_loss = F.mse_loss(m2_hat, mels) - stop_loss = F.binary_cross_entropy(stop_pred, stop) - - loss = m1_loss + m2_loss + stop_loss - - optimizer.zero_grad() - loss.backward() - - if hparams.tts_clip_grad_norm is not None: - grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), hparams.tts_clip_grad_norm) - if np.isnan(grad_norm.cpu()): - print("grad_norm was NaN!") - - optimizer.step() - - time_window.append(time.time() - start_time) - loss_window.append(loss.item()) - - step = model.get_step() - k = step // 1000 - - msg = f"| Epoch: {epoch}/{epochs} ({i}/{steps_per_epoch}) | Loss: {loss_window.average:#.4} | {1./time_window.average:#.2} steps/s | Step: {k}k | " - stream(msg) - - # Backup or save model as appropriate - if backup_every != 0 and step % backup_every == 0 : - backup_fpath = Path("{}/{}_{}k.pt".format(str(weights_fpath.parent), run_id, k)) - model.save(backup_fpath, optimizer) - - if save_every != 0 and step % save_every == 0 : - # Must save latest optimizer state to ensure that resuming training - # doesn't produce artifacts - model.save(weights_fpath, optimizer) - - # Evaluate model to generate samples - epoch_eval = hparams.tts_eval_interval == -1 and i == steps_per_epoch # If epoch is done - step_eval = hparams.tts_eval_interval > 0 and step % hparams.tts_eval_interval == 0 # Every N steps - if epoch_eval or step_eval: - for sample_idx in range(hparams.tts_eval_num_samples): - # At most, generate samples equal to number in the batch - if sample_idx + 1 <= len(texts): - # Remove padding from mels using frame length in metadata - mel_length = int(dataset.metadata[idx[sample_idx]][4]) - mel_prediction = np_now(m2_hat[sample_idx]).T[:mel_length] - target_spectrogram = np_now(mels[sample_idx]).T[:mel_length] - attention_len = mel_length // model.r - - eval_model(attention=np_now(attention[sample_idx][:, :attention_len]), - mel_prediction=mel_prediction, - target_spectrogram=target_spectrogram, - input_seq=np_now(texts[sample_idx]), - step=step, - plot_dir=plot_dir, - mel_output_dir=mel_output_dir, - wav_dir=wav_dir, - sample_num=sample_idx + 1, - loss=loss, - hparams=hparams) - - # Break out of loop to update training schedule - if step >= max_step: - break - - # Add line break after every epoch - print("") - -def eval_model(attention, mel_prediction, target_spectrogram, input_seq, step, - plot_dir, mel_output_dir, wav_dir, sample_num, loss, hparams): - # Save some results for evaluation - attention_path = str(plot_dir.joinpath("attention_step_{}_sample_{}".format(step, sample_num))) - save_attention(attention, attention_path) - - # save predicted mel spectrogram to disk (debug) - mel_output_fpath = mel_output_dir.joinpath("mel-prediction-step-{}_sample_{}.npy".format(step, sample_num)) - np.save(str(mel_output_fpath), mel_prediction, allow_pickle=False) - - # save griffin lim inverted wav for debug (mel -> wav) - wav = audio.inv_mel_spectrogram(mel_prediction.T, hparams) - wav_fpath = wav_dir.joinpath("step-{}-wave-from-mel_sample_{}.wav".format(step, sample_num)) - audio.save_wav(wav, str(wav_fpath), sr=hparams.sample_rate) - - # save real and predicted mel-spectrogram plot to disk (control purposes) - spec_fpath = plot_dir.joinpath("step-{}-mel-spectrogram_sample_{}.png".format(step, sample_num)) - title_str = "{}, {}, step={}, loss={:.5f}".format("Tacotron", time_string(), step, loss) - plot_spectrogram(mel_prediction, str(spec_fpath), title=title_str, - target_spectrogram=target_spectrogram, - max_len=target_spectrogram.size // hparams.num_mels) - print("Input at step {}: {}".format(step, sequence_to_text(input_seq))) diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/atss/atss_r50_fpn_1x_coco.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/atss/atss_r50_fpn_1x_coco.py deleted file mode 100644 index cfd70ed4a70d2d863c79625b58e693132311a03d..0000000000000000000000000000000000000000 --- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/atss/atss_r50_fpn_1x_coco.py +++ /dev/null @@ -1,62 +0,0 @@ -_base_ = [ - '../_base_/datasets/coco_detection.py', - '../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py' -] -model = dict( - type='ATSS', - pretrained='torchvision://resnet50', - backbone=dict( - type='ResNet', - depth=50, - num_stages=4, - out_indices=(0, 1, 2, 3), - frozen_stages=1, - norm_cfg=dict(type='BN', requires_grad=True), - norm_eval=True, - style='pytorch'), - neck=dict( - type='FPN', - in_channels=[256, 512, 1024, 2048], - out_channels=256, - start_level=1, - add_extra_convs='on_output', - num_outs=5), - bbox_head=dict( - type='ATSSHead', - num_classes=80, - in_channels=256, - stacked_convs=4, - feat_channels=256, - anchor_generator=dict( - type='AnchorGenerator', - ratios=[1.0], - octave_base_scale=8, - scales_per_octave=1, - strides=[8, 16, 32, 64, 128]), - bbox_coder=dict( - type='DeltaXYWHBBoxCoder', - target_means=[.0, .0, .0, .0], - target_stds=[0.1, 0.1, 0.2, 0.2]), - loss_cls=dict( - type='FocalLoss', - use_sigmoid=True, - gamma=2.0, - alpha=0.25, - loss_weight=1.0), - loss_bbox=dict(type='GIoULoss', loss_weight=2.0), - loss_centerness=dict( - type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)), - # training and testing settings - train_cfg=dict( - assigner=dict(type='ATSSAssigner', topk=9), - allowed_border=-1, - pos_weight=-1, - debug=False), - test_cfg=dict( - nms_pre=1000, - min_bbox_size=0, - score_thr=0.05, - nms=dict(type='nms', iou_threshold=0.6), - max_per_img=100)) -# optimizer -optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001) diff --git a/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/deeplabv3/deeplabv3_r101-d8_480x480_80k_pascal_context.py b/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/deeplabv3/deeplabv3_r101-d8_480x480_80k_pascal_context.py deleted file mode 100644 index 001b7a69c15299fc1fe5b269a5accf92c5ece032..0000000000000000000000000000000000000000 --- a/spaces/Gradio-Blocks/uniformer_image_segmentation/configs/deeplabv3/deeplabv3_r101-d8_480x480_80k_pascal_context.py +++ /dev/null @@ -1,2 +0,0 @@ -_base_ = './deeplabv3_r50-d8_480x480_80k_pascal_context.py' -model = dict(pretrained='open-mmlab://resnet101_v1c', backbone=dict(depth=101)) diff --git a/spaces/GrandaddyShmax/AudioCraft_Plus/audiocraft/optim/fsdp.py b/spaces/GrandaddyShmax/AudioCraft_Plus/audiocraft/optim/fsdp.py deleted file mode 100644 index b3c1a55b6bf1a33092a021c5cefbbb2ae848918a..0000000000000000000000000000000000000000 --- a/spaces/GrandaddyShmax/AudioCraft_Plus/audiocraft/optim/fsdp.py +++ /dev/null @@ -1,195 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -""" -Wrapper around FSDP for more convenient use in the training loops. -""" - -from contextlib import contextmanager -import typing as tp -import dora -import torch - -from torch.distributed.fsdp import FullyShardedDataParallel as FSDP -from torch.distributed.fsdp import ( - MixedPrecision, ShardingStrategy, FullStateDictConfig, StateDictType) -from torch.distributed._shard.sharded_tensor.api import ShardedTensor - - -def is_fsdp_used() -> bool: - """Return whether we are using FSDP.""" - # A bit of a hack but should work from anywhere. - if dora.is_xp(): - cfg = dora.get_xp().cfg - if hasattr(cfg, 'fsdp'): - return cfg.fsdp.use - return False - - -def is_sharded_tensor(x: tp.Any) -> bool: - return isinstance(x, ShardedTensor) - - -@contextmanager -def switch_to_full_state_dict(models: tp.List[FSDP]): - # Another bug in FSDP makes it that we cannot use the `state_dict_type` API, - # so let's do thing manually. - for model in models: - FSDP.set_state_dict_type( # type: ignore - model, StateDictType.FULL_STATE_DICT, - FullStateDictConfig(offload_to_cpu=True, rank0_only=True)) - try: - yield - finally: - for model in models: - FSDP.set_state_dict_type(model, StateDictType.LOCAL_STATE_DICT) # type: ignore - - -def wrap_with_fsdp(cfg, model: torch.nn.Module, - block_classes: tp.Optional[tp.Set[tp.Type]] = None) -> FSDP: - """Wraps a model with FSDP.""" - # Some of the typing is disabled until this gets integrated - # into the stable version of PyTorch. - from torch.distributed.fsdp.wrap import ModuleWrapPolicy # type: ignore - - # we import this here to prevent circular import. - from ..modules.transformer import StreamingTransformerLayer - from ..modules.conditioners import ConditioningProvider - - _fix_post_backward_hook() - - assert cfg.use - sharding_strategy_dict = { - "no_shard": ShardingStrategy.NO_SHARD, - "shard_grad_op": ShardingStrategy.SHARD_GRAD_OP, - "full_shard": ShardingStrategy.FULL_SHARD, - } - - dtype_dict = { - "float32": torch.float32, - "float16": torch.float16, - "bfloat16": torch.bfloat16, - } - - mixed_precision_config = MixedPrecision( - param_dtype=dtype_dict[cfg.param_dtype], - reduce_dtype=dtype_dict[cfg.reduce_dtype], - buffer_dtype=dtype_dict[cfg.buffer_dtype], - ) - - sharding_strategy_config = sharding_strategy_dict[cfg.sharding_strategy] - # The following is going to require being a bit smart - # when doing LM, because this would flush the weights for every time step - # during generation. One possiblity is to use hybrid sharding: - # See: https://pytorch.org/docs/master/fsdp.html#torch.distributed.fsdp.ShardingStrategy - assert sharding_strategy_config != ShardingStrategy.FULL_SHARD, \ - "Not supported at the moment, requires a bit more work." - - local_rank = dora.distrib.get_distrib_spec().local_rank - assert local_rank < torch.cuda.device_count(), "Please upgrade Dora!" - - auto_wrap_policy = None - if block_classes is None: - block_classes = {StreamingTransformerLayer, ConditioningProvider} - if cfg.per_block: - auto_wrap_policy = ModuleWrapPolicy(block_classes) - wrapped = _FSDPFixStateDict( - model, - sharding_strategy=sharding_strategy_config, - mixed_precision=mixed_precision_config, - device_id=local_rank, - sync_module_states=True, - use_orig_params=True, - auto_wrap_policy=auto_wrap_policy, - ) # type: ignore - FSDP.set_state_dict_type(wrapped, StateDictType.LOCAL_STATE_DICT) # type: ignore - - # Let the wrapped model know about the wrapping! - # We use __dict__ to avoid it going into the state dict. - # This is a bit dirty, but needed during generation, as otherwise - # the wrapped model would call itself and bypass FSDP. - for module in FSDP.fsdp_modules(wrapped): - original = module._fsdp_wrapped_module - original.__dict__['_fsdp'] = module - return wrapped - - -def purge_fsdp(model: FSDP): - """Purge the FSDP cached shard inside the model. This should - allow setting the best state or switching to the EMA. - """ - from torch.distributed.fsdp._runtime_utils import _reshard # type: ignore - for module in FSDP.fsdp_modules(model): - handles = module._handles - if not handles: - continue - handle = handles[0] - unsharded_flat_param = handle._get_padded_unsharded_flat_param() - storage_size: int = unsharded_flat_param._typed_storage()._size() # type: ignore - if storage_size == 0: - continue - true_list = [True for h in handles] - _reshard(module, handles, true_list) - - -class _FSDPFixStateDict(FSDP): - @staticmethod - def _name_without_fsdp_prefix(name: str) -> str: - from torch.distributed.fsdp._common_utils import FSDP_WRAPPED_MODULE # type: ignore - parts = name.split('.') - new_parts = [part for part in parts if part != FSDP_WRAPPED_MODULE] - return '.'.join(new_parts) - - def state_dict(self) -> tp.Dict[str, tp.Any]: # type: ignore - state = dict(super().state_dict()) - for key, value in list(state.items()): - if is_sharded_tensor(value): - del state[key] - return state - - def load_state_dict(self, state: tp.Dict[str, tp.Any]): # type: ignore - if self._state_dict_type is StateDictType.FULL_STATE_DICT: - super().load_state_dict(state) - purge_fsdp(self) - return - # Fix FSDP load state dict in all situation. - # Use this only with LOCAL_STATE_DICT !!! - current_state = dict(super().state_dict()) - for key, value in state.items(): - key = _FSDPFixStateDict._name_without_fsdp_prefix(key) - if key not in current_state: - # Emulate strict loading manually. - raise RuntimeError(f"Unknown state key {key}") - current_state[key].copy_(value) - - # Purging cached weights from previous forward. - purge_fsdp(self) - - -_hook_fixed = False - - -def _fix_post_backward_hook(): - global _hook_fixed - if _hook_fixed: - return - _hook_fixed = True - - from torch.distributed.fsdp import _runtime_utils - from torch.distributed.fsdp._common_utils import TrainingState, HandleTrainingState - old_hook = _runtime_utils._post_backward_hook - - def _post_backward_hook(state, handle, *args, **kwargs): - checkpointed = getattr(state._fsdp_wrapped_module, '_audiocraft_checkpointed', False) - if checkpointed: - # there will be one more forward in the backward with checkpointing and that will - # massively confuse FSDP, so we have to make it think everything - # is going according to the plan. - state.training_state = TrainingState.FORWARD_BACKWARD - handle._training_state = HandleTrainingState.BACKWARD_PRE - old_hook(state, handle, *args, **kwargs) - - _runtime_utils._post_backward_hook = _post_backward_hook diff --git a/spaces/GrandaddyShmax/AudioCraft_Plus/scripts/templates/results.html b/spaces/GrandaddyShmax/AudioCraft_Plus/scripts/templates/results.html deleted file mode 100644 index 8ddce59f0f617a836db75c8bc9768db7f9f17511..0000000000000000000000000000000000000000 --- a/spaces/GrandaddyShmax/AudioCraft_Plus/scripts/templates/results.html +++ /dev/null @@ -1,17 +0,0 @@ -{% extends "base.html" %} -{% block content %} - -Results for survey #{{signature}}
-Checkout the survey page for details on the models.
-The following users voted: - {% for user in users %} - {{user}} - {% endfor %} - -{% for model in models %} -
{{model['sig']}} ({{model['samples']}} samples)
-Ratings: {{model['mean_rating']}} ± {{model['std_rating']}}
- -{% endfor %} - -{% endblock %} diff --git a/spaces/HCMUT-GraduateThesis-HNTThinh/rgbdsod-multimae-demo/demo.py b/spaces/HCMUT-GraduateThesis-HNTThinh/rgbdsod-multimae-demo/demo.py deleted file mode 100644 index a39fae14d7daf62bf1a0716cd821a1430d06e9c8..0000000000000000000000000000000000000000 --- a/spaces/HCMUT-GraduateThesis-HNTThinh/rgbdsod-multimae-demo/demo.py +++ /dev/null @@ -1,30 +0,0 @@ -import os - -import streamlit as st - -from app_utils import load_video - -cwd = os.getcwd() - -def video_demo(): - videos_root_dir = os.path.join('demo', 'video') - video_names = [f for f in os.listdir(videos_root_dir) if os.path.isdir(os.path.join(videos_root_dir, f))] - - video_name_1 = st.selectbox( - 'Choose video 1', - video_names, - key='video_name_1', - ) - - load_video(os.path.join(videos_root_dir, video_name_1, 'result.mp4')) - - video_name_2 = st.selectbox( - 'Choose video 2', - video_names, - key='video_name_2', - ) - - load_video(os.path.join(videos_root_dir, video_name_2, 'result.mp4')) - -def demo() -> None: - video_demo() \ No newline at end of file diff --git a/spaces/HaloMaster/chinesesummary/fengshen/models/longformer/configuration_longformer.py b/spaces/HaloMaster/chinesesummary/fengshen/models/longformer/configuration_longformer.py deleted file mode 100644 index 14ad2b5557d4d0cd9d2397308b6a823c1789bb31..0000000000000000000000000000000000000000 --- a/spaces/HaloMaster/chinesesummary/fengshen/models/longformer/configuration_longformer.py +++ /dev/null @@ -1,16 +0,0 @@ -# coding=utf-8 -# Copyright 2021 The IDEA Authors. All rights reserved. - -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at - -# http://www.apache.org/licenses/LICENSE-2.0 - -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -from transformers import LongformerConfig diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/multilingual/README.md b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/multilingual/README.md deleted file mode 100644 index 46ff9c351b1030e0729f89f246e0cd86444c1633..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/multilingual/README.md +++ /dev/null @@ -1,158 +0,0 @@ -# Multilingual Translation - -[[Multilingual Translation with Extensible Multilingual Pretraining and Finetuning, https://arxiv.org/abs/2008.00401]](https://arxiv.org/abs/2008.00401) - -## Introduction - -This work is for training multilingual translation models with multiple bitext datasets. This multilingual translation framework supports (see [[training section]](#Training) and [[finetuning section]](#Finetuning) for examples) - -* temperature based sampling over unbalancing datasets of different translation directions - - --sampling-method' with - choices=['uniform', 'temperature', 'concat'] - - --sampling-temperature -* configurable to automatically add source and/or target language tokens to source/target sentences using data which are prepared in the same way as bilignual training - - --encoder-langtok with choices=['src', 'tgt', None] to specify whether to add source or target language tokens to the source sentences - - --decoder-langtok (binary option) to specify whether to add target language tokens to the target sentences or not -* finetuning mBART pretrained models for multilingual translation - - --finetune-from-model to specify the path from which to load the pretrained model - -## Preprocessing data -Multilingual training requires a joint BPE vocab. Please follow [mBART's preprocessing steps](https://github.com/pytorch/fairseq/tree/main/examples/mbart#bpe-data) to reuse our pretrained sentence-piece model. - -You can also train a joint BPE model on your own dataset and then follow the steps in [[link]](https://github.com/pytorch/fairseq/tree/main/examples/translation#multilingual-translation). - -## Training - - -```bash -lang_pairs=-path_2_data= -lang_list= - -fairseq-train $path_2_data \ - --encoder-normalize-before --decoder-normalize-before \ - --arch transformer --layernorm-embedding \ - --task translation_multi_simple_epoch \ - --sampling-method "temperature" \ - --sampling-temperature 1.5 \ - --encoder-langtok "src" \ - --decoder-langtok \ - --lang-dict "$lang_list" \ - --lang-pairs "$lang_pairs" \ - --criterion label_smoothed_cross_entropy --label-smoothing 0.2 \ - --optimizer adam --adam-eps 1e-06 --adam-betas '(0.9, 0.98)' \ - --lr-scheduler inverse_sqrt --lr 3e-05 --warmup-updates 2500 --max-update 40000 \ - --dropout 0.3 --attention-dropout 0.1 --weight-decay 0.0 \ - --max-tokens 1024 --update-freq 2 \ - --save-interval 1 --save-interval-updates 5000 --keep-interval-updates 10 --no-epoch-checkpoints \ - --seed 222 --log-format simple --log-interval 2 -``` - -## Finetuning -We can also finetune multilingual models from a monolingual pretrained models, e.g. [mMBART](https://github.com/pytorch/fairseq/tree/main/examples/mbart). -```bash -lang_pairs= -path_2_data= -lang_list= -pretrained_model= - -fairseq-train $path_2_data \ - --finetune-from-model $pretrained_model \ - --encoder-normalize-before --decoder-normalize-before \ - --arch transformer --layernorm-embedding \ - --task translation_multi_simple_epoch \ - --sampling-method "temperature" \ - --sampling-temperature 1.5 \ - --encoder-langtok "src" \ - --decoder-langtok \ - --lang-dict "$lang_list" \ - --lang-pairs "$lang_pairs" \ - --criterion label_smoothed_cross_entropy --label-smoothing 0.2 \ - --optimizer adam --adam-eps 1e-06 --adam-betas '(0.9, 0.98)' \ - --lr-scheduler inverse_sqrt --lr 3e-05 --warmup-updates 2500 --max-update 40000 \ - --dropout 0.3 --attention-dropout 0.1 --weight-decay 0.0 \ - --max-tokens 1024 --update-freq 2 \ - --save-interval 1 --save-interval-updates 5000 --keep-interval-updates 10 --no-epoch-checkpoints \ - --seed 222 --log-format simple --log-interval 2 -``` -## Generate -The following command uses the multilingual task (translation_multi_simple_epoch) to generate translation from $source_lang to $target_lang on the test dataset. During generaton, the source language tokens are added to source sentences and the target language tokens are added as the starting token to decode target sentences. Options --lang-dict and --lang-pairs are needed to tell the generation process the ordered list of languages and translation directions that the trained model are awared of; they will need to be consistent with the training. - -```bash -model= -source_lang= -target_lang= - -fairseq-generate $path_2_data \ - --path $model \ - --task translation_multi_simple_epoch \ - --gen-subset test \ - --source-lang $source_lang \ - --target-lang $target_lang - --sacrebleu --remove-bpe 'sentencepiece'\ - --batch-size 32 \ - --encoder-langtok "src" \ - --decoder-langtok \ - --lang-dict "$lang_list" \ - --lang-pairs "$lang_pairs" > ${source_lang}_${target_lang}.txt -``` -Fairseq will generate translation into a file {source_lang}_${target_lang}.txt with sacreblue at the end. - -You can also use costomized tokenizer to compare the performance with the literature. For example, you get a tokenizer [here](https://github.com/rsennrich/wmt16-scripts) and do the following: -```bash -TOKENIZER= -TOK_CMD=<"$TOKENIZER $target_lang" or cat for sacrebleu> - -cat {source_lang}_${target_lang}.txt | grep -P "^H" |sort -V |cut -f 3- |$TOK_CMD > ${source_lang}_${target_lang}.hyp -cat {source_lang}_${target_lang}.txt | grep -P "^T" |sort -V |cut -f 2- |$TOK_CMD > ${source_lang}_${target_lang}.ref -sacrebleu -tok 'none' -s 'none' ${source_lang}_${target_lang}.ref < ${source_lang}_${target_lang}.hyp -``` - -# mBART50 models - -* [mMBART 50 pretrained model](https://dl.fbaipublicfiles.com/fairseq/models/mbart50/mbart50.pretrained.tar.gz). -* [mMBART 50 finetuned many-to-one](https://dl.fbaipublicfiles.com/fairseq/models/mbart50/mbart50.ft.n1.tar.gz). -* [mMBART 50 finetuned one-to-many](https://dl.fbaipublicfiles.com/fairseq/models/mbart50/mbart50.ft.1n.tar.gz). -* [mMBART 50 finetuned many-to-many](https://dl.fbaipublicfiles.com/fairseq/models/mbart50/mbart50.ft.nn.tar.gz). - -Please download and extract from the above tarballs. Each tarball contains -* The fairseq model checkpoint: model.pt -* The list of supported languages: ML50_langs.txt -* Sentence piece model: sentence.bpe.model -* Fairseq dictionary of each language: dict.{lang}.txt (please replace lang with a language specified in ML50_langs.txt) - -To use the trained models, -* use the tool [binarize.py](./data_scripts/binarize.py) to binarize your data using sentence.bpe.model and dict.{lang}.txt, and copy the dictionaries to your data path -* then run the generation command: -```bash -path_2_data= -model= /model.pt -lang_list= /ML50_langs.txt -source_lang= -target_lang= - -fairseq-generate $path_2_data \ - --path $model \ - --task translation_multi_simple_epoch \ - --gen-subset test \ - --source-lang $source_lang \ - --target-lang $target_lang - --sacrebleu --remove-bpe 'sentencepiece'\ - --batch-size 32 \ - --encoder-langtok "src" \ - --decoder-langtok \ - --lang-dict "$lang_list" -``` - -## Citation - -```bibtex -@article{tang2020multilingual, - title={Multilingual Translation with Extensible Multilingual Pretraining and Finetuning}, - author={Yuqing Tang and Chau Tran and Xian Li and Peng-Jen Chen and Naman Goyal and Vishrav Chaudhary and Jiatao Gu and Angela Fan}, - year={2020}, - eprint={2008.00401}, - archivePrefix={arXiv}, - primaryClass={cs.CL} -} -``` diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/speech_recognition/tasks/__init__.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/speech_recognition/tasks/__init__.py deleted file mode 100644 index 7ac3b8dc69639c92cc129294356e9012745e3fb2..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/speech_recognition/tasks/__init__.py +++ /dev/null @@ -1,8 +0,0 @@ -import importlib -import os - - -for file in sorted(os.listdir(os.path.dirname(__file__))): - if file.endswith(".py") and not file.startswith("_"): - task_name = file[: file.find(".py")] - importlib.import_module("examples.speech_recognition.tasks." + task_name) diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/unsupervised_quality_estimation/meteor.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/unsupervised_quality_estimation/meteor.py deleted file mode 100644 index 2ee0448cf1f167f6f3ecee56ad807922cffb0956..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/unsupervised_quality_estimation/meteor.py +++ /dev/null @@ -1,109 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import argparse -import math -import os -import subprocess -import sys -import tempfile -from collections import defaultdict -from itertools import combinations - - -def read_translations(path, n_repeats): - segment_counter = 0 - segment_translations = [] - translations = defaultdict(list) - for line in open(path): - segment_translations.append(" ".join(line.split())) - if len(segment_translations) == n_repeats: - translations[segment_counter] = segment_translations - segment_translations = [] - segment_counter += 1 - return translations - - -def generate_input(translations, n_repeats): - _, ref_path = tempfile.mkstemp() - _, mt_path = tempfile.mkstemp() - ref_fh = open(ref_path, "w") - mt_fh = open(mt_path, "w") - for segid in sorted(translations.keys()): - assert len(translations[segid]) == n_repeats - indexes = combinations(range(n_repeats), 2) - for idx1, idx2 in indexes: - mt_fh.write(translations[segid][idx1].strip() + "\n") - ref_fh.write(translations[segid][idx2].strip() + "\n") - sys.stderr.write("\nSaved translations to %s and %s" % (ref_path, mt_path)) - return ref_path, mt_path - - -def run_meteor(ref_path, mt_path, metric_path, lang="en"): - _, out_path = tempfile.mkstemp() - subprocess.call( - [ - "java", - "-Xmx2G", - "-jar", - metric_path, - mt_path, - ref_path, - "-p", - "0.5 0.2 0.6 0.75", # default parameters, only changed alpha to give equal weight to P and R - "-norm", - "-l", - lang, - ], - stdout=open(out_path, "w"), - ) - os.remove(ref_path) - os.remove(mt_path) - sys.stderr.write("\nSaved Meteor output to %s" % out_path) - return out_path - - -def read_output(meteor_output_path, n_repeats): - n_combinations = math.factorial(n_repeats) / ( - math.factorial(2) * math.factorial(n_repeats - 2) - ) - raw_scores = [] - average_scores = [] - for line in open(meteor_output_path): - if not line.startswith("Segment "): - continue - score = float(line.strip().split("\t")[1]) - raw_scores.append(score) - if len(raw_scores) == n_combinations: - average_scores.append(sum(raw_scores) / n_combinations) - raw_scores = [] - os.remove(meteor_output_path) - return average_scores - - -def main(): - parser = argparse.ArgumentParser() - parser.add_argument("-i", "--infile") - parser.add_argument("-n", "--repeat_times", type=int) - parser.add_argument("-m", "--meteor") - parser.add_argument("-o", "--output") - args = parser.parse_args() - - translations = read_translations(args.infile, args.repeat_times) - sys.stderr.write("\nGenerating input for Meteor...") - ref_path, mt_path = generate_input(translations, args.repeat_times) - sys.stderr.write("\nRunning Meteor...") - out_path = run_meteor(ref_path, mt_path, args.meteor) - sys.stderr.write("\nReading output...") - scores = read_output(out_path, args.repeat_times) - sys.stderr.write("\nWriting results...") - with open(args.output, "w") as o: - for scr in scores: - o.write("{}\n".format(scr)) - o.close() - - -if __name__ == "__main__": - main() diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/train_subset_lgbeam.sh b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/train_subset_lgbeam.sh deleted file mode 100644 index 913c1d8e4357c146026b86e78f0b16f921776441..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/train_subset_lgbeam.sh +++ /dev/null @@ -1,129 +0,0 @@ -#!/usr/bin/env bash - -out_root=/tmp -out_name=train_${RANDOM} -num_nonsil_states=1 - -valid="dev_other" -train="train" -mono_size="-1" # 2000 -tri1_size="-1" # 5000 -tri2b_size="-1" # 10000 -tri3b_size="-1" # 10000 - -# Acoustic model parameters -numLeavesTri1=2000 -numGaussTri1=10000 -numLeavesMLLT=2500 -numGaussMLLT=15000 -numLeavesSAT=2500 -numGaussSAT=15000 - -stage=1 -max_stage=1 - -. ./cmd.sh -. ./path.sh -. parse_options.sh - -data=$1 -lang=$2 -lang_test=$3 - -exp_root=$out_root/$out_name - -# you might not want to do this for interactive shells. -set -e - - -if [ $stage -le 1 ] && [ $max_stage -ge 1 ]; then - # train a monophone system - if [ ! $mono_size -eq -1 ]; then - utils/subset_data_dir.sh $data/$train $mono_size $data/${train}_${mono_size} - mono_train=${train}_${mono_size} - else - mono_train=${train} - fi - - steps/train_mono.sh --boost-silence 1.25 --nj 20 --cmd "$train_cmd" \ - --initial-beam 40 --regular-beam 60 --retry-beam 120 \ - $data/$mono_train $lang $exp_root/mono - - utils/mkgraph.sh $lang_test $exp_root/mono $exp_root/mono/graph - steps/decode.sh --nj 20 --cmd "$decode_cmd" \ - $exp_root/mono/graph $data/$valid $exp_root/mono/decode_$valid & -fi - - -if [ $stage -le 2 ] && [ $max_stage -ge 2 ]; then - # train a first delta + delta-delta triphone system on a subset of 5000 utterances - if [ ! $tri1_size -eq -1 ]; then - utils/subset_data_dir.sh $data/$train $tri1_size $data/${train}_${tri1_size} - tri1_train=${train}_${tri1_size} - else - tri1_train=${train} - fi - - steps/align_si.sh --boost-silence 1.25 --nj 10 --cmd "$train_cmd" \ - $data/$tri1_train $lang \ - $exp_root/mono $exp_root/mono_ali_${tri1_train} - - steps_gan/train_deltas.sh --boost-silence 1.25 --cmd "$train_cmd" \ - --num_nonsil_states $num_nonsil_states $numLeavesTri1 $numGaussTri1 \ - $data/$tri1_train $lang \ - $exp_root/mono_ali_${tri1_train} $exp_root/tri1 - - utils/mkgraph.sh $lang_test $exp_root/tri1 $exp_root/tri1/graph - steps/decode.sh --nj 20 --cmd "$decode_cmd" \ - $exp_root/tri1/graph $data/$valid $exp_root/tri1/decode_$valid & -fi - -if [ $stage -le 3 ] && [ $max_stage -ge 3 ]; then - # train an LDA+MLLT system. - if [ ! $tri2b_size -eq -1 ]; then - utils/subset_data_dir.sh $data/$train $tri2b_size $data/${train}_${tri2b_size} - tri2b_train=${train}_${tri2b_size} - else - tri2b_train=${train} - fi - - steps/align_si.sh --nj 10 --cmd "$train_cmd" \ - $data/$tri2b_train $lang \ - $exp_root/tri1 $exp_root/tri1_ali_${tri2b_train} - - steps_gan/train_lda_mllt.sh --cmd "$train_cmd" \ - --num_nonsil_states $num_nonsil_states \ - --splice-opts "--left-context=3 --right-context=3" $numLeavesMLLT $numGaussMLLT \ - $data/$tri2b_train $lang \ - $exp_root/tri1_ali_${tri2b_train} $exp_root/tri2b - - utils/mkgraph.sh $lang_test $exp_root/tri2b $exp_root/tri2b/graph - steps/decode.sh --nj 20 --cmd "$decode_cmd" \ - $exp_root/tri2b/graph $data/$valid $exp_root/tri2b/decode_$valid & -fi - - -if [ $stage -le 4 ] && [ $max_stage -ge 4 ]; then - # Train tri3b, which is LDA+MLLT+SAT on 10k utts - if [ ! $tri3b_size -eq -1 ]; then - utils/subset_data_dir.sh $data/$train $tri3b_size $data/${train}_${tri3b_size} - tri3b_train=${train}_${tri3b_size} - else - tri3b_train=${train} - fi - - steps/align_si.sh --nj 10 --cmd "$train_cmd" --use-graphs true \ - $data/$tri3b_train $lang \ - $exp_root/tri2b $exp_root/tri2b_ali_${tri2b_train} - - steps_gan/train_sat.sh --cmd "$train_cmd" \ - --num_nonsil_states $num_nonsil_states $numLeavesSAT $numGaussSAT \ - $data/$tri3b_train $lang \ - $exp_root/tri2b_ali_${tri2b_train} $exp_root/tri3b - - utils/mkgraph.sh $lang_test $exp_root/tri3b $exp_root/tri3b/graph - steps/decode_fmllr.sh --nj 20 --cmd "$decode_cmd" \ - $exp_root/tri3b/graph $data/$valid $exp_root/tri3b/decode_$valid & -fi - -wait diff --git a/spaces/Harveenchadha/Vakyansh-Malayalam-TTS/ttsv/utils/hifi/prepare_iitm_data_hifi.py b/spaces/Harveenchadha/Vakyansh-Malayalam-TTS/ttsv/utils/hifi/prepare_iitm_data_hifi.py deleted file mode 100644 index 1e1de2e28735143aeef8ddb10bc5a4672c02564b..0000000000000000000000000000000000000000 --- a/spaces/Harveenchadha/Vakyansh-Malayalam-TTS/ttsv/utils/hifi/prepare_iitm_data_hifi.py +++ /dev/null @@ -1,64 +0,0 @@ - -import glob -import random -import sys -import os -import argparse - - - - -def process_data(args): - - path = args.input_path - valid_files = args.valid_files - test_files = args.test_files - dest_path = args.dest_path - - list_paths = path.split(',') - - valid_set = [] - training_set = [] - test_set = [] - - for local_path in list_paths: - files = glob.glob(local_path+'/*.wav') - print(f"Total files: {len(files)}") - - valid_set_local = random.sample(files, valid_files) - - test_set_local = random.sample(valid_set_local, test_files) - valid_set.extend(list(set(valid_set_local) - set(test_set_local))) - test_set.extend(test_set_local) - - print(len(valid_set_local)) - - training_set_local = set(files) - set(valid_set_local) - print(len(training_set_local)) - training_set.extend(training_set_local) - - - valid_set = random.sample(valid_set, len(valid_set)) - test_set = random.sample(test_set, len(test_set)) - training_set = random.sample(training_set, len(training_set)) - - with open(os.path.join(dest_path , 'valid.txt'), mode = 'w+') as file: - file.write("\n".join(list(valid_set))) - - with open(os.path.join(dest_path , 'train.txt'), mode = 'w+') as file: - file.write("\n".join(list(training_set))) - - with open(os.path.join(dest_path , 'test.txt'), mode = 'w+') as file: - file.write("\n".join(list(test_set))) - - -if __name__ == "__main__": - parser = argparse.ArgumentParser() - parser.add_argument('-i','--input-path',type=str,help='path to input wav files') - parser.add_argument('-v','--valid-files',type=int,help='number of valid files') - parser.add_argument('-t','--test-files',type=int,help='number of test files') - parser.add_argument('-d','--dest-path',type=str,help='destination path to output filelists') - - args = parser.parse_args() - - process_data(args) \ No newline at end of file diff --git a/spaces/HawkEye098432/DunnBC22-trocr-base-handwritten-OCR-handwriting_recognition_v2/README.md b/spaces/HawkEye098432/DunnBC22-trocr-base-handwritten-OCR-handwriting_recognition_v2/README.md deleted file mode 100644 index d841da404392f585cd6f814fe0d0b031195b6ad1..0000000000000000000000000000000000000000 --- a/spaces/HawkEye098432/DunnBC22-trocr-base-handwritten-OCR-handwriting_recognition_v2/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: DunnBC22-trocr-base-handwritten-OCR-handwriting Recognition V2 -emoji: 🚀 -colorFrom: indigo -colorTo: green -sdk: gradio -sdk_version: 3.35.2 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/data/pad_dataset.py b/spaces/ICML2022/OFA/fairseq/fairseq/data/pad_dataset.py deleted file mode 100644 index 8075bba6a9efc5f8421368ee0b2ae66afe3f5009..0000000000000000000000000000000000000000 --- a/spaces/ICML2022/OFA/fairseq/fairseq/data/pad_dataset.py +++ /dev/null @@ -1,28 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -from fairseq.data import data_utils - -from . import BaseWrapperDataset - - -class PadDataset(BaseWrapperDataset): - def __init__(self, dataset, pad_idx, left_pad): - super().__init__(dataset) - self.pad_idx = pad_idx - self.left_pad = left_pad - - def collater(self, samples): - return data_utils.collate_tokens(samples, self.pad_idx, left_pad=self.left_pad) - - -class LeftPadDataset(PadDataset): - def __init__(self, dataset, pad_idx): - super().__init__(dataset, pad_idx, left_pad=True) - - -class RightPadDataset(PadDataset): - def __init__(self, dataset, pad_idx): - super().__init__(dataset, pad_idx, left_pad=False) diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/modules/quantization/pq/pq.py b/spaces/ICML2022/OFA/fairseq/fairseq/modules/quantization/pq/pq.py deleted file mode 100644 index eddc2eb34602403f10979f54cd23a45bc2f104d5..0000000000000000000000000000000000000000 --- a/spaces/ICML2022/OFA/fairseq/fairseq/modules/quantization/pq/pq.py +++ /dev/null @@ -1,128 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -from .em import EM, EmptyClusterResolveError - - -class PQ(EM): - """ - Quantizes the layer weights W with the standard Product Quantization - technique. This learns a codebook of codewords or centroids of size - block_size from W. For further reference on using PQ to quantize - neural networks, see "And the Bit Goes Down: Revisiting the Quantization - of Neural Networks", Stock et al., ICLR 2020. - - PQ is performed in two steps: - (1) The matrix W (weights or fully-connected or convolutional layer) - is reshaped to (block_size, -1). - - If W is fully-connected (2D), its columns are split into - blocks of size block_size. - - If W is convolutional (4D), its filters are split along the - spatial dimension. - (2) We apply the standard EM/k-means algorithm to the resulting reshaped matrix. - - Args: - - W: weight matrix to quantize of size (in_features x out_features) - - block_size: size of the blocks (subvectors) - - n_centroids: number of centroids - - n_iter: number of k-means iterations - - eps: for cluster reassignment when an empty cluster is found - - max_tentatives for cluster reassignment when an empty cluster is found - - verbose: print information after each iteration - - Remarks: - - block_size be compatible with the shape of W - """ - - def __init__( - self, - W, - block_size, - n_centroids=256, - n_iter=20, - eps=1e-6, - max_tentatives=30, - verbose=True, - ): - self.block_size = block_size - W_reshaped = self._reshape(W) - super(PQ, self).__init__( - W_reshaped, - n_centroids=n_centroids, - n_iter=n_iter, - eps=eps, - max_tentatives=max_tentatives, - verbose=verbose, - ) - - def _reshape(self, W): - """ - Reshapes the matrix W as expained in step (1). - """ - - # fully connected: by convention the weight has size out_features x in_features - if len(W.size()) == 2: - self.out_features, self.in_features = W.size() - assert ( - self.in_features % self.block_size == 0 - ), "Linear: n_blocks must be a multiple of in_features" - return ( - W.reshape(self.out_features, -1, self.block_size) - .permute(2, 1, 0) - .flatten(1, 2) - ) - - # convolutional: we reshape along the spatial dimension - elif len(W.size()) == 4: - self.out_channels, self.in_channels, self.k_h, self.k_w = W.size() - assert ( - self.in_channels * self.k_h * self.k_w - ) % self.block_size == 0, ( - "Conv2d: n_blocks must be a multiple of in_channels * k_h * k_w" - ) - return ( - W.reshape(self.out_channels, -1, self.block_size) - .permute(2, 1, 0) - .flatten(1, 2) - ) - # not implemented - else: - raise NotImplementedError(W.size()) - - def encode(self): - """ - Performs self.n_iter EM steps. - """ - - self.initialize_centroids() - for i in range(self.n_iter): - try: - self.step(i) - except EmptyClusterResolveError: - break - - def decode(self): - """ - Returns the encoded full weight matrix. Must be called after - the encode function. - """ - - # fully connected case - if "k_h" not in self.__dict__: - return ( - self.centroids[self.assignments] - .reshape(-1, self.out_features, self.block_size) - .permute(1, 0, 2) - .flatten(1, 2) - ) - - # convolutional case - else: - return ( - self.centroids[self.assignments] - .reshape(-1, self.out_channels, self.block_size) - .permute(1, 0, 2) - .reshape(self.out_channels, self.in_channels, self.k_h, self.k_w) - ) diff --git a/spaces/IPN/helloooooo/app.py b/spaces/IPN/helloooooo/app.py deleted file mode 100644 index 9935ee12cd8e836af5c600d09359f1925dc2dcd4..0000000000000000000000000000000000000000 --- a/spaces/IPN/helloooooo/app.py +++ /dev/null @@ -1,3 +0,0 @@ -import gradio as gr - -gr.Interface.load("huggingface/Helsinki-NLP/opus-mt-en-ROMANCE").launch(); \ No newline at end of file diff --git a/spaces/Illumotion/Koboldcpp/ci/README.md b/spaces/Illumotion/Koboldcpp/ci/README.md deleted file mode 100644 index 65cfe63ebe8e92cafd6edb93e9d0a22e93383780..0000000000000000000000000000000000000000 --- a/spaces/Illumotion/Koboldcpp/ci/README.md +++ /dev/null @@ -1,25 +0,0 @@ -# CI - -In addition to [Github Actions](https://github.com/ggerganov/llama.cpp/actions) `llama.cpp` uses a custom CI framework: - -https://github.com/ggml-org/ci - -It monitors the `master` branch for new commits and runs the -[ci/run.sh](https://github.com/ggerganov/llama.cpp/blob/master/ci/run.sh) script on dedicated cloud instances. This allows us -to execute heavier workloads compared to just using Github Actions. Also with time, the cloud instances will be scaled -to cover various hardware architectures, including GPU and Apple Silicon instances. - -Collaborators can optionally trigger the CI run by adding the `ggml-ci` keyword to their commit message. -Only the branches of this repo are monitored for this keyword. - -It is a good practice, before publishing changes to execute the full CI locally on your machine: - -```bash -mkdir tmp - -# CPU-only build -bash ./ci/run.sh ./tmp/results ./tmp/mnt - -# with CUDA support -GG_BUILD_CUDA=1 bash ./ci/run.sh ./tmp/results ./tmp/mnt -``` diff --git a/spaces/Illumotion/Koboldcpp/ggml-metal.h b/spaces/Illumotion/Koboldcpp/ggml-metal.h deleted file mode 100644 index 790cf0bf7b963d9c1f52a45dbac5be71e0662256..0000000000000000000000000000000000000000 --- a/spaces/Illumotion/Koboldcpp/ggml-metal.h +++ /dev/null @@ -1,89 +0,0 @@ -// An interface allowing to compute ggml_cgraph with Metal -// -// This is a fully functional interface that extends ggml with GPU support for Apple devices. -// A similar interface can be created for other GPU backends (e.g. Vulkan, CUDA, OpenCL, etc.) -// -// How it works? -// -// As long as your program can create and evaluate a ggml_cgraph on the CPU, you can use this -// interface to evaluate the same graph on the GPU. Instead of using ggml_graph_compute(), you -// use ggml_metal_graph_compute() (or ggml_vulkan_graph_compute(), etc.) -// -// You only need to make sure that all memory buffers that you used during the graph creation -// are mapped to the device memory with the ggml_metal_add_buffer() function. This mapping is -// used during the graph evaluation to determine the arguments of the compute kernels. -// -// Synchronization between device and host memory (for example for input and output tensors) -// is done with the ggml_metal_set_tensor() and ggml_metal_get_tensor() functions. -// - -#pragma once - -#include "ggml.h" - -#include -#include - -// max memory buffers that can be mapped to the device -#define GGML_METAL_MAX_BUFFERS 16 -#define GGML_METAL_MAX_COMMAND_BUFFERS 32 - -struct ggml_tensor; -struct ggml_cgraph; - -#ifdef __cplusplus -extern "C" { -#endif - -void ggml_metal_log_set_callback(ggml_log_callback log_callback, void * user_data); - -struct ggml_metal_context; - -// number of command buffers to use -struct ggml_metal_context * ggml_metal_init(int n_cb); -void ggml_metal_free(struct ggml_metal_context * ctx); - -void * ggml_metal_host_malloc(size_t n); -void ggml_metal_host_free (void * data); - -// set the number of command buffers to use -void ggml_metal_set_n_cb(struct ggml_metal_context * ctx, int n_cb); - -// creates a mapping between a host memory buffer and a device memory buffer -// - make sure to map all buffers used in the graph before calling ggml_metal_graph_compute -// - the mapping is used during computation to determine the arguments of the compute kernels -// - you don't need to keep the host memory buffer allocated as it is never accessed by Metal -// - max_size specifies the maximum size of a tensor and is used to create shared views such -// that it is guaranteed that the tensor will fit in at least one of the views -// -bool ggml_metal_add_buffer( - struct ggml_metal_context * ctx, - const char * name, - void * data, - size_t size, - size_t max_size); - -// set data from host memory into the device -void ggml_metal_set_tensor(struct ggml_metal_context * ctx, struct ggml_tensor * t); - -// get data from the device into host memory -void ggml_metal_get_tensor(struct ggml_metal_context * ctx, struct ggml_tensor * t); - -// try to find operations that can be run concurrently in the graph -// you should run it again if the topology of your graph changes -void ggml_metal_graph_find_concurrency(struct ggml_metal_context * ctx, struct ggml_cgraph * gf, bool check_mem); - -// if the graph has been optimized for concurrently dispatch, return length of the concur_list if optimized -int ggml_metal_if_optimized(struct ggml_metal_context * ctx); - -// output the concur_list for ggml_alloc -int * ggml_metal_get_concur_list(struct ggml_metal_context * ctx); - -// same as ggml_graph_compute but uses Metal -// creates gf->n_threads command buffers in parallel -void ggml_metal_graph_compute(struct ggml_metal_context * ctx, struct ggml_cgraph * gf); - -#ifdef __cplusplus -} -#endif - diff --git a/spaces/InpaintAI/Inpaint-Anything/utils/get_point_coor.py b/spaces/InpaintAI/Inpaint-Anything/utils/get_point_coor.py deleted file mode 100644 index 1f3c3f248f7973a46c3329fe6db9a3f8e92446c6..0000000000000000000000000000000000000000 --- a/spaces/InpaintAI/Inpaint-Anything/utils/get_point_coor.py +++ /dev/null @@ -1,12 +0,0 @@ -import cv2 - -def click_event(event, x, y, flags, param): - if event == cv2.EVENT_LBUTTONDOWN: - print("Point coordinates ({}, {})".format(x, y)) -img = cv2.imread("./example/remove-anything/dog.jpg") - -cv2.imshow("Image", img) -cv2.setMouseCallback("Image", click_event) -cv2.waitKey(0) - -cv2.destroyAllWindows() diff --git a/spaces/JohnnyPittt/audio-styling/deepafx_st/processors/proxy/proxy_system.py b/spaces/JohnnyPittt/audio-styling/deepafx_st/processors/proxy/proxy_system.py deleted file mode 100644 index ed695a532c020f5d2e14cfde9b8a3c9b67936a50..0000000000000000000000000000000000000000 --- a/spaces/JohnnyPittt/audio-styling/deepafx_st/processors/proxy/proxy_system.py +++ /dev/null @@ -1,289 +0,0 @@ -from re import X -import torch -import auraloss -import pytorch_lightning as pl -from typing import Tuple, List, Dict -from argparse import ArgumentParser - - -import deepafx_st.utils as utils -from deepafx_st.data.proxy import DSPProxyDataset -from deepafx_st.processors.proxy.tcn import ConditionalTCN -from deepafx_st.processors.spsa.channel import SPSAChannel -from deepafx_st.processors.dsp.peq import ParametricEQ -from deepafx_st.processors.dsp.compressor import Compressor - - -class ProxySystem(pl.LightningModule): - def __init__( - self, - causal=True, - nblocks=4, - dilation_growth=8, - kernel_size=13, - channel_width=64, - input_dir=None, - processor="channel", - batch_size=32, - lr=3e-4, - lr_patience=20, - patience=10, - preload=False, - sample_rate=24000, - shuffle=True, - train_length=65536, - train_examples_per_epoch=10000, - val_length=131072, - val_examples_per_epoch=1000, - num_workers=16, - output_gain=False, - **kwargs, - ): - super().__init__() - self.save_hyperparameters() - #print(f"Proxy Processor: {processor} @ fs={sample_rate} Hz") - - # construct both the true DSP... - if self.hparams.processor == "peq": - self.processor = ParametricEQ(self.hparams.sample_rate) - elif self.hparams.processor == "comp": - self.processor = Compressor(self.hparams.sample_rate) - elif self.hparams.processor == "channel": - self.processor = SPSAChannel(self.hparams.sample_rate) - - # and the neural network proxy - self.proxy = ConditionalTCN( - self.hparams.sample_rate, - num_control_params=self.processor.num_control_params, - causal=self.hparams.causal, - nblocks=self.hparams.nblocks, - channel_width=self.hparams.channel_width, - kernel_size=self.hparams.kernel_size, - dilation_growth=self.hparams.dilation_growth, - ) - - self.receptive_field = self.proxy.compute_receptive_field() - - self.recon_losses = {} - self.recon_loss_weights = {} - - self.recon_losses["mrstft"] = auraloss.freq.MultiResolutionSTFTLoss( - fft_sizes=[32, 128, 512, 2048, 8192, 32768], - hop_sizes=[16, 64, 256, 1024, 4096, 16384], - win_lengths=[32, 128, 512, 2048, 8192, 32768], - w_sc=0.0, - w_phs=0.0, - w_lin_mag=1.0, - w_log_mag=1.0, - ) - self.recon_loss_weights["mrstft"] = 1.0 - - self.recon_losses["l1"] = torch.nn.L1Loss() - self.recon_loss_weights["l1"] = 100.0 - - def forward(self, x, p, use_dsp=False, sample_rate=24000, **kwargs): - """Use the pre-trained neural network proxy effect.""" - bs, chs, samp = x.size() - if not use_dsp: - y = self.proxy(x, p) - # manually apply the makeup gain parameter - if self.hparams.output_gain and not self.hparams.processor == "peq": - gain_db = (p[..., -1] * 96) - 48 - gain_ln = 10 ** (gain_db / 20.0) - y *= gain_ln.view(bs, chs, 1) - else: - with torch.no_grad(): - bs, chs, s = x.shape - - if self.hparams.output_gain and not self.hparams.processor == "peq": - # override makeup gain - gain_db = (p[..., -1] * 96) - 48 - gain_ln = 10 ** (gain_db / 20.0) - p[..., -1] = 0.5 - - if self.hparams.processor == "channel": - y_temp = self.processor(x.cpu(), p.cpu()) - y_temp = y_temp.view(bs, chs, s).type_as(x) - else: - y_temp = self.processor( - x.cpu().numpy(), - p.cpu().numpy(), - sample_rate, - ) - y_temp = torch.tensor(y_temp).view(bs, chs, s).type_as(x) - - y = y_temp.type_as(x).view(bs, 1, -1) - - if self.hparams.output_gain and not self.hparams.processor == "peq": - y *= gain_ln.view(bs, chs, 1) - - return y - - def common_step( - self, - batch: Tuple, - batch_idx: int, - optimizer_idx: int = 0, - train: bool = True, - ): - loss = 0 - x, y, p = batch - - y_hat = self(x, p) - - # compute loss - for loss_idx, (loss_name, loss_fn) in enumerate(self.recon_losses.items()): - tmp_loss = loss_fn(y_hat.float(), y.float()) - loss += self.recon_loss_weights[loss_name] * tmp_loss - - self.log( - f"train_loss/{loss_name}" if train else f"val_loss/{loss_name}", - tmp_loss, - on_step=True, - on_epoch=True, - prog_bar=False, - logger=True, - sync_dist=True, - ) - - if not train: - # store audio data - data_dict = { - "x": x.float().cpu(), - "y": y.float().cpu(), - "p": p.float().cpu(), - "y_hat": y_hat.float().cpu(), - } - else: - data_dict = {} - - self.log( - "train_loss" if train else "val_loss", - loss, - on_step=True, - on_epoch=True, - prog_bar=False, - logger=True, - sync_dist=True, - ) - - return loss, data_dict - - def training_step(self, batch, batch_idx, optimizer_idx=0): - loss, _ = self.common_step(batch, batch_idx) - return loss - - def validation_step(self, batch, batch_idx): - loss, data_dict = self.common_step(batch, batch_idx, train=False) - - if batch_idx == 0: - return data_dict - - def configure_optimizers(self): - optimizer = torch.optim.Adam( - self.proxy.parameters(), - lr=self.hparams.lr, - betas=(0.9, 0.999), - ) - - scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau( - optimizer, - patience=self.hparams.lr_patience, - verbose=True, - ) - - return [optimizer], {"scheduler": scheduler, "monitor": "val_loss"} - - def train_dataloader(self): - - train_dataset = DSPProxyDataset( - self.hparams.input_dir, - self.processor, - self.hparams.processor, # name - subset="train", - length=self.hparams.train_length, - num_examples_per_epoch=self.hparams.train_examples_per_epoch, - half=True if self.hparams.precision == 16 else False, - buffer_size_gb=self.hparams.buffer_size_gb, - buffer_reload_rate=self.hparams.buffer_reload_rate, - ) - - g = torch.Generator() - g.manual_seed(0) - - return torch.utils.data.DataLoader( - train_dataset, - num_workers=self.hparams.num_workers, - batch_size=self.hparams.batch_size, - worker_init_fn=utils.seed_worker, - generator=g, - pin_memory=True, - ) - - def val_dataloader(self): - - val_dataset = DSPProxyDataset( - self.hparams.input_dir, - self.processor, - self.hparams.processor, # name - subset="val", - length=self.hparams.val_length, - num_examples_per_epoch=self.hparams.val_examples_per_epoch, - half=True if self.hparams.precision == 16 else False, - buffer_size_gb=self.hparams.buffer_size_gb, - buffer_reload_rate=self.hparams.buffer_reload_rate, - ) - - g = torch.Generator() - g.manual_seed(0) - - return torch.utils.data.DataLoader( - val_dataset, - num_workers=self.hparams.num_workers, - batch_size=self.hparams.batch_size, - worker_init_fn=utils.seed_worker, - generator=g, - pin_memory=True, - ) - - @staticmethod - def count_control_params(plugin_config): - num_control_params = 0 - - for plugin in plugin_config["plugins"]: - for port in plugin["ports"]: - if port["optim"]: - num_control_params += 1 - - return num_control_params - - # add any model hyperparameters here - @staticmethod - def add_model_specific_args(parent_parser): - parser = ArgumentParser(parents=[parent_parser], add_help=False) - # --- Model --- - parser.add_argument("--causal", action="store_true") - parser.add_argument("--output_gain", action="store_true") - parser.add_argument("--dilation_growth", type=int, default=8) - parser.add_argument("--nblocks", type=int, default=4) - parser.add_argument("--kernel_size", type=int, default=13) - parser.add_argument("--channel_width", type=int, default=13) - # --- Training --- - parser.add_argument("--input_dir", type=str) - parser.add_argument("--processor", type=str) - parser.add_argument("--batch_size", type=int, default=32) - parser.add_argument("--lr", type=float, default=3e-4) - parser.add_argument("--lr_patience", type=int, default=20) - parser.add_argument("--patience", type=int, default=10) - parser.add_argument("--preload", action="store_true") - parser.add_argument("--sample_rate", type=int, default=24000) - parser.add_argument("--shuffle", type=bool, default=True) - parser.add_argument("--train_length", type=int, default=65536) - parser.add_argument("--train_examples_per_epoch", type=int, default=10000) - parser.add_argument("--val_length", type=int, default=131072) - parser.add_argument("--val_examples_per_epoch", type=int, default=1000) - parser.add_argument("--num_workers", type=int, default=8) - parser.add_argument("--buffer_reload_rate", type=int, default=1000) - parser.add_argument("--buffer_size_gb", type=float, default=1.0) - - return parser diff --git a/spaces/Kevin676/Clone-Your-Voice/synthesizer/utils/_cmudict.py b/spaces/Kevin676/Clone-Your-Voice/synthesizer/utils/_cmudict.py deleted file mode 100644 index 2cef1f896d4fb78478884fe8e810956998d5e3b3..0000000000000000000000000000000000000000 --- a/spaces/Kevin676/Clone-Your-Voice/synthesizer/utils/_cmudict.py +++ /dev/null @@ -1,62 +0,0 @@ -import re - -valid_symbols = [ - "AA", "AA0", "AA1", "AA2", "AE", "AE0", "AE1", "AE2", "AH", "AH0", "AH1", "AH2", - "AO", "AO0", "AO1", "AO2", "AW", "AW0", "AW1", "AW2", "AY", "AY0", "AY1", "AY2", - "B", "CH", "D", "DH", "EH", "EH0", "EH1", "EH2", "ER", "ER0", "ER1", "ER2", "EY", - "EY0", "EY1", "EY2", "F", "G", "HH", "IH", "IH0", "IH1", "IH2", "IY", "IY0", "IY1", - "IY2", "JH", "K", "L", "M", "N", "NG", "OW", "OW0", "OW1", "OW2", "OY", "OY0", - "OY1", "OY2", "P", "R", "S", "SH", "T", "TH", "UH", "UH0", "UH1", "UH2", "UW", - "UW0", "UW1", "UW2", "V", "W", "Y", "Z", "ZH" -] - -_valid_symbol_set = set(valid_symbols) - - -class CMUDict: - """Thin wrapper around CMUDict data. http://www.speech.cs.cmu.edu/cgi-bin/cmudict""" - def __init__(self, file_or_path, keep_ambiguous=True): - if isinstance(file_or_path, str): - with open(file_or_path, encoding="latin-1") as f: - entries = _parse_cmudict(f) - else: - entries = _parse_cmudict(file_or_path) - if not keep_ambiguous: - entries = {word: pron for word, pron in entries.items() if len(pron) == 1} - self._entries = entries - - - def __len__(self): - return len(self._entries) - - - def lookup(self, word): - """Returns list of ARPAbet pronunciations of the given word.""" - return self._entries.get(word.upper()) - - - -_alt_re = re.compile(r"\([0-9]+\)") - - -def _parse_cmudict(file): - cmudict = {} - for line in file: - if len(line) and (line[0] >= "A" and line[0] <= "Z" or line[0] == "'"): - parts = line.split(" ") - word = re.sub(_alt_re, "", parts[0]) - pronunciation = _get_pronunciation(parts[1]) - if pronunciation: - if word in cmudict: - cmudict[word].append(pronunciation) - else: - cmudict[word] = [pronunciation] - return cmudict - - -def _get_pronunciation(s): - parts = s.strip().split(" ") - for part in parts: - if part not in _valid_symbol_set: - return None - return " ".join(parts) diff --git a/spaces/Korakoe/convert-sd-ckpt-cpu/convert.py b/spaces/Korakoe/convert-sd-ckpt-cpu/convert.py deleted file mode 100644 index 42533dcc94d634b73568ba690953ba6212a74aad..0000000000000000000000000000000000000000 --- a/spaces/Korakoe/convert-sd-ckpt-cpu/convert.py +++ /dev/null @@ -1,878 +0,0 @@ -# coding=utf-8 -# Copyright 2022 The HuggingFace Inc. team. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -""" Conversion script for the Stable Diffusion checkpoints. """ - -import torch - -try: - from omegaconf import OmegaConf -except ImportError: - raise ImportError( - "OmegaConf is required to convert the LDM checkpoints. Please install it with `pip install OmegaConf`." - ) - -from diffusers import (AutoencoderKL, DDIMScheduler, - EulerAncestralDiscreteScheduler, EulerDiscreteScheduler, - LMSDiscreteScheduler, PNDMScheduler, - StableDiffusionPipeline, UNet2DConditionModel) -from diffusers.pipelines.latent_diffusion.pipeline_latent_diffusion import ( - LDMBertConfig, LDMBertModel) -from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker -from transformers import AutoFeatureExtractor, CLIPTextModel, CLIPTokenizer - - -def shave_segments(path, n_shave_prefix_segments=1): - """ - Removes segments. Positive values shave the first segments, negative shave the last segments. - """ - if n_shave_prefix_segments >= 0: - return ".".join(path.split(".")[n_shave_prefix_segments:]) - else: - return ".".join(path.split(".")[:n_shave_prefix_segments]) - - -def renew_resnet_paths(old_list, n_shave_prefix_segments=0): - """ - Updates paths inside resnets to the new naming scheme (local renaming) - """ - mapping = [] - for old_item in old_list: - new_item = old_item.replace("in_layers.0", "norm1") - new_item = new_item.replace("in_layers.2", "conv1") - - new_item = new_item.replace("out_layers.0", "norm2") - new_item = new_item.replace("out_layers.3", "conv2") - - new_item = new_item.replace("emb_layers.1", "time_emb_proj") - new_item = new_item.replace("skip_connection", "conv_shortcut") - - new_item = shave_segments( - new_item, n_shave_prefix_segments=n_shave_prefix_segments - ) - - mapping.append({"old": old_item, "new": new_item}) - - return mapping - - -def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0): - """ - Updates paths inside resnets to the new naming scheme (local renaming) - """ - mapping = [] - for old_item in old_list: - new_item = old_item - - new_item = new_item.replace("nin_shortcut", "conv_shortcut") - new_item = shave_segments( - new_item, n_shave_prefix_segments=n_shave_prefix_segments - ) - - mapping.append({"old": old_item, "new": new_item}) - - return mapping - - -def renew_attention_paths(old_list, n_shave_prefix_segments=0): - """ - Updates paths inside attentions to the new naming scheme (local renaming) - """ - mapping = [] - for old_item in old_list: - new_item = old_item - - # new_item = new_item.replace('norm.weight', 'group_norm.weight') - # new_item = new_item.replace('norm.bias', 'group_norm.bias') - - # new_item = new_item.replace('proj_out.weight', 'proj_attn.weight') - # new_item = new_item.replace('proj_out.bias', 'proj_attn.bias') - - # new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments) - - mapping.append({"old": old_item, "new": new_item}) - - return mapping - - -def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0): - """ - Updates paths inside attentions to the new naming scheme (local renaming) - """ - mapping = [] - for old_item in old_list: - new_item = old_item - - new_item = new_item.replace("norm.weight", "group_norm.weight") - new_item = new_item.replace("norm.bias", "group_norm.bias") - - new_item = new_item.replace("q.weight", "query.weight") - new_item = new_item.replace("q.bias", "query.bias") - - new_item = new_item.replace("k.weight", "key.weight") - new_item = new_item.replace("k.bias", "key.bias") - - new_item = new_item.replace("v.weight", "value.weight") - new_item = new_item.replace("v.bias", "value.bias") - - new_item = new_item.replace("proj_out.weight", "proj_attn.weight") - new_item = new_item.replace("proj_out.bias", "proj_attn.bias") - - new_item = shave_segments( - new_item, n_shave_prefix_segments=n_shave_prefix_segments - ) - - mapping.append({"old": old_item, "new": new_item}) - - return mapping - - -def assign_to_checkpoint( - paths, - checkpoint, - old_checkpoint, - attention_paths_to_split=None, - additional_replacements=None, - config=None, -): - """ - This does the final conversion step: take locally converted weights and apply a global renaming - to them. It splits attention layers, and takes into account additional replacements - that may arise. - Assigns the weights to the new checkpoint. - """ - assert isinstance( - paths, list - ), "Paths should be a list of dicts containing 'old' and 'new' keys." - - # Splits the attention layers into three variables. - if attention_paths_to_split is not None: - for path, path_map in attention_paths_to_split.items(): - old_tensor = old_checkpoint[path] - channels = old_tensor.shape[0] // 3 - - target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1) - - num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3 - - old_tensor = old_tensor.reshape( - (num_heads, 3 * channels // num_heads) + old_tensor.shape[1:] - ) - query, key, value = old_tensor.split(channels // num_heads, dim=1) - - checkpoint[path_map["query"]] = query.reshape(target_shape) - checkpoint[path_map["key"]] = key.reshape(target_shape) - checkpoint[path_map["value"]] = value.reshape(target_shape) - - for path in paths: - new_path = path["new"] - - # These have already been assigned - if ( - attention_paths_to_split is not None - and new_path in attention_paths_to_split - ): - continue - - # Global renaming happens here - new_path = new_path.replace("middle_block.0", "mid_block.resnets.0") - new_path = new_path.replace("middle_block.1", "mid_block.attentions.0") - new_path = new_path.replace("middle_block.2", "mid_block.resnets.1") - - if additional_replacements is not None: - for replacement in additional_replacements: - new_path = new_path.replace(replacement["old"], replacement["new"]) - - # proj_attn.weight has to be converted from conv 1D to linear - if "proj_attn.weight" in new_path: - checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0] - else: - checkpoint[new_path] = old_checkpoint[path["old"]] - - -def conv_attn_to_linear(checkpoint): - keys = list(checkpoint.keys()) - attn_keys = ["query.weight", "key.weight", "value.weight"] - for key in keys: - if ".".join(key.split(".")[-2:]) in attn_keys: - if checkpoint[key].ndim > 2: - checkpoint[key] = checkpoint[key][:, :, 0, 0] - elif "proj_attn.weight" in key: - if checkpoint[key].ndim > 2: - checkpoint[key] = checkpoint[key][:, :, 0] - - -def create_unet_diffusers_config(original_config): - """ - Creates a config for the diffusers based on the config of the LDM model. - """ - unet_params = original_config.model.params.unet_config.params - - block_out_channels = [ - unet_params.model_channels * mult for mult in unet_params.channel_mult - ] - - down_block_types = [] - resolution = 1 - for i in range(len(block_out_channels)): - block_type = ( - "CrossAttnDownBlock2D" - if resolution in unet_params.attention_resolutions - else "DownBlock2D" - ) - down_block_types.append(block_type) - if i != len(block_out_channels) - 1: - resolution *= 2 - - up_block_types = [] - for i in range(len(block_out_channels)): - block_type = ( - "CrossAttnUpBlock2D" - if resolution in unet_params.attention_resolutions - else "UpBlock2D" - ) - up_block_types.append(block_type) - resolution //= 2 - - config = dict( - sample_size=unet_params.image_size, - in_channels=unet_params.in_channels, - out_channels=unet_params.out_channels, - down_block_types=tuple(down_block_types), - up_block_types=tuple(up_block_types), - block_out_channels=tuple(block_out_channels), - layers_per_block=unet_params.num_res_blocks, - cross_attention_dim=unet_params.context_dim, - attention_head_dim=unet_params.num_heads, - ) - - return config - - -def create_vae_diffusers_config(original_config): - """ - Creates a config for the diffusers based on the config of the LDM model. - """ - vae_params = original_config.model.params.first_stage_config.params.ddconfig - _ = original_config.model.params.first_stage_config.params.embed_dim - - block_out_channels = [vae_params.ch * mult for mult in vae_params.ch_mult] - down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels) - up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels) - - config = dict( - sample_size=vae_params.resolution, - in_channels=vae_params.in_channels, - out_channels=vae_params.out_ch, - down_block_types=tuple(down_block_types), - up_block_types=tuple(up_block_types), - block_out_channels=tuple(block_out_channels), - latent_channels=vae_params.z_channels, - layers_per_block=vae_params.num_res_blocks, - ) - return config - - -def create_diffusers_schedular(original_config): - schedular = DDIMScheduler( - num_train_timesteps=original_config.model.params.timesteps, - beta_start=original_config.model.params.linear_start, - beta_end=original_config.model.params.linear_end, - beta_schedule="scaled_linear", - ) - return schedular - - -def create_ldm_bert_config(original_config): - bert_params = original_config.model.parms.cond_stage_config.params - config = LDMBertConfig( - d_model=bert_params.n_embed, - encoder_layers=bert_params.n_layer, - encoder_ffn_dim=bert_params.n_embed * 4, - ) - return config - - -def convert_ldm_unet_checkpoint(checkpoint, config, extract_ema=False): - """ - Takes a state dict and a config, and returns a converted checkpoint. - """ - - # extract state_dict for UNet - unet_state_dict = {} - keys = list(checkpoint.keys()) - - unet_key = "model.diffusion_model." - # at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA - if sum(k.startswith("model_ema") for k in keys) > 100: - print(f"Checkpoint has both EMA and non-EMA weights.") - if extract_ema: - print( - "In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA" - " weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag." - ) - for key in keys: - if key.startswith("model.diffusion_model"): - flat_ema_key = "model_ema." + "".join(key.split(".")[1:]) - unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop( - flat_ema_key - ) - else: - print( - "In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA" - " weights (usually better for inference), please make sure to add the `--extract_ema` flag." - ) - - for key in keys: - if key.startswith(unet_key): - unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key) - - new_checkpoint = {} - - new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict[ - "time_embed.0.weight" - ] - new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict[ - "time_embed.0.bias" - ] - new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict[ - "time_embed.2.weight" - ] - new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict[ - "time_embed.2.bias" - ] - - new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"] - new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"] - - new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"] - new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"] - new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"] - new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"] - - # Retrieves the keys for the input blocks only - num_input_blocks = len( - { - ".".join(layer.split(".")[:2]) - for layer in unet_state_dict - if "input_blocks" in layer - } - ) - input_blocks = { - layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key] - for layer_id in range(num_input_blocks) - } - - # Retrieves the keys for the middle blocks only - num_middle_blocks = len( - { - ".".join(layer.split(".")[:2]) - for layer in unet_state_dict - if "middle_block" in layer - } - ) - middle_blocks = { - layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key] - for layer_id in range(num_middle_blocks) - } - - # Retrieves the keys for the output blocks only - num_output_blocks = len( - { - ".".join(layer.split(".")[:2]) - for layer in unet_state_dict - if "output_blocks" in layer - } - ) - output_blocks = { - layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key] - for layer_id in range(num_output_blocks) - } - - for i in range(1, num_input_blocks): - block_id = (i - 1) // (config["layers_per_block"] + 1) - layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1) - - resnets = [ - key - for key in input_blocks[i] - if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key - ] - attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key] - - if f"input_blocks.{i}.0.op.weight" in unet_state_dict: - new_checkpoint[ - f"down_blocks.{block_id}.downsamplers.0.conv.weight" - ] = unet_state_dict.pop(f"input_blocks.{i}.0.op.weight") - new_checkpoint[ - f"down_blocks.{block_id}.downsamplers.0.conv.bias" - ] = unet_state_dict.pop(f"input_blocks.{i}.0.op.bias") - - paths = renew_resnet_paths(resnets) - meta_path = { - "old": f"input_blocks.{i}.0", - "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}", - } - assign_to_checkpoint( - paths, - new_checkpoint, - unet_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - if len(attentions): - paths = renew_attention_paths(attentions) - meta_path = { - "old": f"input_blocks.{i}.1", - "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}", - } - assign_to_checkpoint( - paths, - new_checkpoint, - unet_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - resnet_0 = middle_blocks[0] - attentions = middle_blocks[1] - resnet_1 = middle_blocks[2] - - resnet_0_paths = renew_resnet_paths(resnet_0) - assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config) - - resnet_1_paths = renew_resnet_paths(resnet_1) - assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config) - - attentions_paths = renew_attention_paths(attentions) - meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"} - assign_to_checkpoint( - attentions_paths, - new_checkpoint, - unet_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - for i in range(num_output_blocks): - block_id = i // (config["layers_per_block"] + 1) - layer_in_block_id = i % (config["layers_per_block"] + 1) - output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]] - output_block_list = {} - - for layer in output_block_layers: - layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1) - if layer_id in output_block_list: - output_block_list[layer_id].append(layer_name) - else: - output_block_list[layer_id] = [layer_name] - - if len(output_block_list) > 1: - resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key] - attentions = [ - key for key in output_blocks[i] if f"output_blocks.{i}.1" in key - ] - - resnet_0_paths = renew_resnet_paths(resnets) - paths = renew_resnet_paths(resnets) - - meta_path = { - "old": f"output_blocks.{i}.0", - "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}", - } - assign_to_checkpoint( - paths, - new_checkpoint, - unet_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - if ["conv.weight", "conv.bias"] in output_block_list.values(): - index = list(output_block_list.values()).index( - ["conv.weight", "conv.bias"] - ) - new_checkpoint[ - f"up_blocks.{block_id}.upsamplers.0.conv.weight" - ] = unet_state_dict[f"output_blocks.{i}.{index}.conv.weight"] - new_checkpoint[ - f"up_blocks.{block_id}.upsamplers.0.conv.bias" - ] = unet_state_dict[f"output_blocks.{i}.{index}.conv.bias"] - - # Clear attentions as they have been attributed above. - if len(attentions) == 2: - attentions = [] - - if len(attentions): - paths = renew_attention_paths(attentions) - meta_path = { - "old": f"output_blocks.{i}.1", - "new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}", - } - assign_to_checkpoint( - paths, - new_checkpoint, - unet_state_dict, - additional_replacements=[meta_path], - config=config, - ) - else: - resnet_0_paths = renew_resnet_paths( - output_block_layers, n_shave_prefix_segments=1 - ) - for path in resnet_0_paths: - old_path = ".".join(["output_blocks", str(i), path["old"]]) - new_path = ".".join( - [ - "up_blocks", - str(block_id), - "resnets", - str(layer_in_block_id), - path["new"], - ] - ) - - new_checkpoint[new_path] = unet_state_dict[old_path] - - return new_checkpoint - - -def convert_ldm_vae_checkpoint(checkpoint, config): - # extract state dict for VAE - vae_state_dict = {} - vae_key = "first_stage_model." - keys = list(checkpoint.keys()) - for key in keys: - if key.startswith(vae_key): - vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key) - - new_checkpoint = {} - - new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"] - new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"] - new_checkpoint["encoder.conv_out.weight"] = vae_state_dict[ - "encoder.conv_out.weight" - ] - new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"] - new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict[ - "encoder.norm_out.weight" - ] - new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict[ - "encoder.norm_out.bias" - ] - - new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"] - new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"] - new_checkpoint["decoder.conv_out.weight"] = vae_state_dict[ - "decoder.conv_out.weight" - ] - new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"] - new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict[ - "decoder.norm_out.weight" - ] - new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict[ - "decoder.norm_out.bias" - ] - - new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"] - new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"] - new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"] - new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"] - - # Retrieves the keys for the encoder down blocks only - num_down_blocks = len( - { - ".".join(layer.split(".")[:3]) - for layer in vae_state_dict - if "encoder.down" in layer - } - ) - down_blocks = { - layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] - for layer_id in range(num_down_blocks) - } - - # Retrieves the keys for the decoder up blocks only - num_up_blocks = len( - { - ".".join(layer.split(".")[:3]) - for layer in vae_state_dict - if "decoder.up" in layer - } - ) - up_blocks = { - layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] - for layer_id in range(num_up_blocks) - } - - for i in range(num_down_blocks): - resnets = [ - key - for key in down_blocks[i] - if f"down.{i}" in key and f"down.{i}.downsample" not in key - ] - - if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict: - new_checkpoint[ - f"encoder.down_blocks.{i}.downsamplers.0.conv.weight" - ] = vae_state_dict.pop(f"encoder.down.{i}.downsample.conv.weight") - new_checkpoint[ - f"encoder.down_blocks.{i}.downsamplers.0.conv.bias" - ] = vae_state_dict.pop(f"encoder.down.{i}.downsample.conv.bias") - - paths = renew_vae_resnet_paths(resnets) - meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"} - assign_to_checkpoint( - paths, - new_checkpoint, - vae_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key] - num_mid_res_blocks = 2 - for i in range(1, num_mid_res_blocks + 1): - resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key] - - paths = renew_vae_resnet_paths(resnets) - meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"} - assign_to_checkpoint( - paths, - new_checkpoint, - vae_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key] - paths = renew_vae_attention_paths(mid_attentions) - meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"} - assign_to_checkpoint( - paths, - new_checkpoint, - vae_state_dict, - additional_replacements=[meta_path], - config=config, - ) - conv_attn_to_linear(new_checkpoint) - - for i in range(num_up_blocks): - block_id = num_up_blocks - 1 - i - resnets = [ - key - for key in up_blocks[block_id] - if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key - ] - - if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict: - new_checkpoint[ - f"decoder.up_blocks.{i}.upsamplers.0.conv.weight" - ] = vae_state_dict[f"decoder.up.{block_id}.upsample.conv.weight"] - new_checkpoint[ - f"decoder.up_blocks.{i}.upsamplers.0.conv.bias" - ] = vae_state_dict[f"decoder.up.{block_id}.upsample.conv.bias"] - - paths = renew_vae_resnet_paths(resnets) - meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"} - assign_to_checkpoint( - paths, - new_checkpoint, - vae_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key] - num_mid_res_blocks = 2 - for i in range(1, num_mid_res_blocks + 1): - resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key] - - paths = renew_vae_resnet_paths(resnets) - meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"} - assign_to_checkpoint( - paths, - new_checkpoint, - vae_state_dict, - additional_replacements=[meta_path], - config=config, - ) - - mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key] - paths = renew_vae_attention_paths(mid_attentions) - meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"} - assign_to_checkpoint( - paths, - new_checkpoint, - vae_state_dict, - additional_replacements=[meta_path], - config=config, - ) - conv_attn_to_linear(new_checkpoint) - return new_checkpoint - - -def convert_ldm_bert_checkpoint(checkpoint, config): - def _copy_attn_layer(hf_attn_layer, pt_attn_layer): - hf_attn_layer.q_proj.weight.data = pt_attn_layer.to_q.weight - hf_attn_layer.k_proj.weight.data = pt_attn_layer.to_k.weight - hf_attn_layer.v_proj.weight.data = pt_attn_layer.to_v.weight - - hf_attn_layer.out_proj.weight = pt_attn_layer.to_out.weight - hf_attn_layer.out_proj.bias = pt_attn_layer.to_out.bias - - def _copy_linear(hf_linear, pt_linear): - hf_linear.weight = pt_linear.weight - hf_linear.bias = pt_linear.bias - - def _copy_layer(hf_layer, pt_layer): - # copy layer norms - _copy_linear(hf_layer.self_attn_layer_norm, pt_layer[0][0]) - _copy_linear(hf_layer.final_layer_norm, pt_layer[1][0]) - - # copy attn - _copy_attn_layer(hf_layer.self_attn, pt_layer[0][1]) - - # copy MLP - pt_mlp = pt_layer[1][1] - _copy_linear(hf_layer.fc1, pt_mlp.net[0][0]) - _copy_linear(hf_layer.fc2, pt_mlp.net[2]) - - def _copy_layers(hf_layers, pt_layers): - for i, hf_layer in enumerate(hf_layers): - if i != 0: - i += i - pt_layer = pt_layers[i : i + 2] - _copy_layer(hf_layer, pt_layer) - - hf_model = LDMBertModel(config).eval() - - # copy embeds - hf_model.model.embed_tokens.weight = checkpoint.transformer.token_emb.weight - hf_model.model.embed_positions.weight.data = ( - checkpoint.transformer.pos_emb.emb.weight - ) - - # copy layer norm - _copy_linear(hf_model.model.layer_norm, checkpoint.transformer.norm) - - # copy hidden layers - _copy_layers(hf_model.model.layers, checkpoint.transformer.attn_layers.layers) - - _copy_linear(hf_model.to_logits, checkpoint.transformer.to_logits) - - return hf_model - - -def convert_ldm_clip_checkpoint(checkpoint): - text_model = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14") - - keys = list(checkpoint.keys()) - - text_model_dict = {} - - for key in keys: - if key.startswith("cond_stage_model.transformer"): - text_model_dict[key[len("cond_stage_model.transformer.") :]] = checkpoint[ - key - ] - - text_model.load_state_dict(text_model_dict) - - return text_model - - -def convert_full_checkpoint( - checkpoint_path: str, config_file, scheduler_type, extract_ema, output_path=None -): - original_config = OmegaConf.load(config_file) - checkpoint = torch.load(checkpoint_path, weights_only=False) - checkpoint = checkpoint["state_dict"] - - num_train_timesteps = original_config.model.params.timesteps - beta_start = original_config.model.params.linear_start - beta_end = original_config.model.params.linear_end - if scheduler_type == "PNDM": - scheduler = PNDMScheduler( - beta_end=beta_end, - beta_schedule="scaled_linear", - beta_start=beta_start, - num_train_timesteps=num_train_timesteps, - skip_prk_steps=True, - ) - elif scheduler_type == "K-LMS": - scheduler = LMSDiscreteScheduler( - beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear" - ) - elif scheduler_type == "Euler": - scheduler = EulerDiscreteScheduler( - beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear" - ) - elif scheduler_type == "EulerAncestral": - scheduler = EulerAncestralDiscreteScheduler( - beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear" - ) - elif scheduler_type == "DDIM": - scheduler = DDIMScheduler( - beta_start=beta_start, - beta_end=beta_end, - beta_schedule="scaled_linear", - clip_sample=False, - set_alpha_to_one=False, - ) - else: - raise ValueError(f"Scheduler of type {scheduler_type} doesn't exist!") - - # Convert the UNet2DConditionModel model. - unet_config = create_unet_diffusers_config(original_config) - converted_unet_checkpoint = convert_ldm_unet_checkpoint( - checkpoint, unet_config, extract_ema=extract_ema - ) - - # Convert the VAE model. - vae_config = create_vae_diffusers_config(original_config) - converted_vae_checkpoint = convert_ldm_vae_checkpoint(checkpoint, vae_config) - - # Convert the text model. - text_model = convert_ldm_clip_checkpoint(checkpoint) - - del checkpoint - - unet = UNet2DConditionModel(**unet_config) - unet.load_state_dict(converted_unet_checkpoint) - del converted_unet_checkpoint - - vae = AutoencoderKL(**vae_config) - vae.load_state_dict(converted_vae_checkpoint) - del converted_vae_checkpoint - - tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14") - safety_checker = StableDiffusionSafetyChecker.from_pretrained( - "CompVis/stable-diffusion-safety-checker", device_map="cpu" - ) - feature_extractor = AutoFeatureExtractor.from_pretrained( - "CompVis/stable-diffusion-safety-checker" - ) - pipe = StableDiffusionPipeline( - vae=vae, - text_encoder=text_model, - tokenizer=tokenizer, - unet=unet, - scheduler=scheduler, - safety_checker=safety_checker, - feature_extractor=feature_extractor, - ) - - pipe.save_pretrained(output_path) diff --git a/spaces/KyanChen/RSPrompter/mmdet/models/detectors/maskformer.py b/spaces/KyanChen/RSPrompter/mmdet/models/detectors/maskformer.py deleted file mode 100644 index 7493c00e1b87cf9b2fbd2c80f1e642f6eb2bea55..0000000000000000000000000000000000000000 --- a/spaces/KyanChen/RSPrompter/mmdet/models/detectors/maskformer.py +++ /dev/null @@ -1,170 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -from typing import Dict, List, Tuple - -from torch import Tensor - -from mmdet.registry import MODELS -from mmdet.structures import SampleList -from mmdet.utils import ConfigType, OptConfigType, OptMultiConfig -from .single_stage import SingleStageDetector - - -@MODELS.register_module() -class MaskFormer(SingleStageDetector): - r"""Implementation of `Per-Pixel Classification is - NOT All You Need for Semantic Segmentation - -A Demonstration of SARAI's Utility -
- """, - unsafe_allow_html=True, -) - -st.write("##") - -with st.expander("Instructions for Use"): - st.markdown( - """ -- 1. Upload or select the input image -
- """, - unsafe_allow_html=True, - ) - -st.write("##") - -col1, col2, col3 = st.columns([4, 1, 6]) -with col1: - st.markdown(f"##### Set input image:") - - # set input image by upload - image_file = st.file_uploader( - "Upload an image:", type=["jpg", "jpeg", "png"] - ) - - # set input image from exapmles - def slider_func(option): - option_to_id = { - "apple_tree.jpg": str(1), - "highway.jpg": str(2), - "highway2.jpg": str(3), - "highway3.jpg": str(4), - } - return option_to_id[option] - - slider = st.select_slider( - "Or select from our sample images:", - options=["apple_tree.jpg", "highway.jpg", "highway2.jpg", "highway3.jpg"], - format_func=slider_func, - value="highway2.jpg", - ) - - # visualize input image - if image_file is not None: - image = Image.open(image_file) - else: - image = sahi.utils.cv.read_image_as_pil(IMAGE_TO_URL[slider]) - st.image(image, width=325) - - - - - -with col3: - st.markdown(f"##### YOLOX Standard vs SARAI Prediction:") - static_component = image_comparison( - img1=st.session_state["output_1"], - img2=st.session_state["output_2"], - label1="YOLOX", - label2="SARAI", - width=700, - starting_position=50, - show_labels=True, - make_responsive=True, - in_memory=True, - ) - - - -col1, col2, col3, col4, col5= st.columns([1, 2, 4, 2, 2]) -with col2: - # submit button - submit = st.button("Perform Prediction") - -if submit: - # perform prediction - with st.spinner( - text="Downloading model weight.. " - + st.session_state["last_spinner_texts"].get() - ): - detection_model = get_model() - - image_size = 416 - - with st.spinner( - text="Performing prediction.. " + st.session_state["last_spinner_texts"].get() - ): - output_1, output_2 = sahi_mmdet_inference( - image, - detection_model, - image_size=image_size, - slice_height=slice_size, - slice_width=slice_size, - overlap_height_ratio=overlap_ratio, - overlap_width_ratio=overlap_ratio, - postprocess_type=postprocess_type, - postprocess_match_metric=postprocess_match_metric, - postprocess_match_threshold=postprocess_match_threshold, - postprocess_class_agnostic=postprocess_class_agnostic, - ) - - st.session_state["output_1"] = output_1 - st.session_state["output_2"] = output_2 - - -with col4: - st.markdown(f"##### Slide to Compare") - - - - diff --git a/spaces/Lianjd/stock_dashboard/app.py b/spaces/Lianjd/stock_dashboard/app.py deleted file mode 100644 index e5a4c4192dd1cc21c20ddf040a949de7f4ddef97..0000000000000000000000000000000000000000 --- a/spaces/Lianjd/stock_dashboard/app.py +++ /dev/null @@ -1,55 +0,0 @@ -import streamlit as st -import yfinance as yf -from PIL import Image -import requests -from io import BytesIO -import financial -import stockchart -import backtest - - -if __name__ == '__main__': - - st.title('Trading DashBoard') - url = 'https://g.foolcdn.com/editorial/images/602904/why-tesla-stock-is-up-today.jpg' - response = requests.get(url) - img = Image.open(BytesIO(response. content)) - - - #Stock Overview Section - st.image(img, use_column_width=True) - st.sidebar.header('Enter your Inputs') - stock_ticker = st.sidebar.text_input("Stock Ticker", "AAPL") - period_view = st.sidebar.checkbox('period') - mv_slow = st.sidebar.text_input("Moving Average (Slow)",5) - mv_fast = st.sidebar.text_input("Moving Average (Fast)",25) - rsi_period = st.sidebar.text_input("RSI (Period)",14) - stock_data = yf.Ticker(stock_ticker) - - stockchart.display_stock(period_view, stock_data, rsi_period, stock_ticker.upper(), mv_fast, mv_slow) - financial.financeStatement_setup(stock_ticker.upper()) - - - - #BackTest Section - - backtest_init = st.sidebar.checkbox('BackTest') - - if backtest_init == True: - backtest_options = ['SMA','RSI'] - execution = ["Current Day Close Price", "Next Day Open Price"] - sell_execution = ["Sell All at Next Open", "Customise Sell"] - - st.sidebar.header('Backtest Strategy') - st.title("BackTest") - ticker = st.sidebar.text_input("Ticker","AAPL") - stock_bt = yf.Ticker(ticker) - stock_close = stock_bt.history(period = "5d", interval = "1d") - current_price = st.sidebar.text_input( "Current Price" , "%.2f" %stock_close.Close[-1]) - - backtest_options = st.sidebar.selectbox("Strategies", backtest_options) - execution_type = st.sidebar.selectbox("Buy Execution Type", execution) - sell_execution_type = st.sidebar.selectbox("Sell Execution Type", sell_execution) - backtest.backtest(backtest_options, stock_bt, ticker.upper(),execution_type,sell_execution_type) - - diff --git a/spaces/LightChen2333/OpenSLU/app.py b/spaces/LightChen2333/OpenSLU/app.py deleted file mode 100644 index 9392b7af72e5fb26f466f0e8ae47775778d4f705..0000000000000000000000000000000000000000 --- a/spaces/LightChen2333/OpenSLU/app.py +++ /dev/null @@ -1,63 +0,0 @@ -''' -Author: Qiguang Chen -LastEditors: Qiguang Chen -Date: 2023-02-07 15:42:32 -LastEditTime: 2023-02-19 21:04:03 -Description: - -''' -import argparse -import gradio as gr - -from common.config import Config -from common.model_manager import ModelManager -from common.utils import str2bool - - -parser = argparse.ArgumentParser() -parser.add_argument('--config_path', '-cp', type=str, default="config/examples/from_pretrained.yaml") -parser.add_argument('--push_to_public', '-p', type=str2bool, nargs='?', - const=True, default=False, - help="Push to public network.") -args = parser.parse_args() -config = Config.load_from_yaml(args.config_path) -config.base["train"] = False -config.base["test"] = False - -model_manager = ModelManager(config) -model_manager.init_model() - - -def text_analysis(text): - print(text) - data = model_manager.predict(text) - html = """ - """ - html += """
- 2. Press "Perform Prediction" to start image processing" - -Intent:""" - - for intent in data["intent"]: - html += """""" - html += """" - return html - - -demo = gr.Interface( - text_analysis, - gr.Textbox(placeholder="Enter sentence here..."), - ["html"], - examples=[ - ["i would like to find a flight from charlotte to las vegas that makes a stop in st louis"], - ], -) -if args.push_to_public: - demo.launch(share=True) -else: - demo.launch() diff --git a/spaces/Loren/Streamlit_OCR_comparator/configs/_base_/recog_datasets/MJ_train.py b/spaces/Loren/Streamlit_OCR_comparator/configs/_base_/recog_datasets/MJ_train.py deleted file mode 100644 index be42cc47035d02403a036330eb0af7d0058b8675..0000000000000000000000000000000000000000 --- a/spaces/Loren/Streamlit_OCR_comparator/configs/_base_/recog_datasets/MJ_train.py +++ /dev/null @@ -1,21 +0,0 @@ -# Text Recognition Training set, including: -# Synthetic Datasets: Syn90k - -train_root = 'data/mixture/Syn90k' - -train_img_prefix = f'{train_root}/mnt/ramdisk/max/90kDICT32px' -train_ann_file = f'{train_root}/label.lmdb' - -train = dict( - type='OCRDataset', - img_prefix=train_img_prefix, - ann_file=train_ann_file, - loader=dict( - type='AnnFileLoader', - repeat=1, - file_format='lmdb', - parser=dict(type='LineJsonParser', keys=['filename', 'text'])), - pipeline=None, - test_mode=False) - -train_list = [train] diff --git a/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/XMem/inference/interact/fbrs/model/modeling/resnetv1b.py b/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/XMem/inference/interact/fbrs/model/modeling/resnetv1b.py deleted file mode 100644 index 4ad24cef5bde19f2627cfd3f755636f37cfb39ac..0000000000000000000000000000000000000000 --- a/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/XMem/inference/interact/fbrs/model/modeling/resnetv1b.py +++ /dev/null @@ -1,276 +0,0 @@ -import torch -import torch.nn as nn -GLUON_RESNET_TORCH_HUB = 'rwightman/pytorch-pretrained-gluonresnet' - - -class BasicBlockV1b(nn.Module): - expansion = 1 - - def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, - previous_dilation=1, norm_layer=nn.BatchNorm2d): - super(BasicBlockV1b, self).__init__() - self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride, - padding=dilation, dilation=dilation, bias=False) - self.bn1 = norm_layer(planes) - self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, - padding=previous_dilation, dilation=previous_dilation, bias=False) - self.bn2 = norm_layer(planes) - - self.relu = nn.ReLU(inplace=True) - self.downsample = downsample - self.stride = stride - - def forward(self, x): - residual = x - - out = self.conv1(x) - out = self.bn1(out) - out = self.relu(out) - - out = self.conv2(out) - out = self.bn2(out) - - if self.downsample is not None: - residual = self.downsample(x) - - out = out + residual - out = self.relu(out) - - return out - - -class BottleneckV1b(nn.Module): - expansion = 4 - - def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, - previous_dilation=1, norm_layer=nn.BatchNorm2d): - super(BottleneckV1b, self).__init__() - self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) - self.bn1 = norm_layer(planes) - - self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, - padding=dilation, dilation=dilation, bias=False) - self.bn2 = norm_layer(planes) - - self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False) - self.bn3 = norm_layer(planes * self.expansion) - - self.relu = nn.ReLU(inplace=True) - self.downsample = downsample - self.stride = stride - - def forward(self, x): - residual = x - - out = self.conv1(x) - out = self.bn1(out) - out = self.relu(out) - - out = self.conv2(out) - out = self.bn2(out) - out = self.relu(out) - - out = self.conv3(out) - out = self.bn3(out) - - if self.downsample is not None: - residual = self.downsample(x) - - out = out + residual - out = self.relu(out) - - return out - - -class ResNetV1b(nn.Module): - """ Pre-trained ResNetV1b Model, which produces the strides of 8 featuremaps at conv5. - - Parameters - ---------- - block : Block - Class for the residual block. Options are BasicBlockV1, BottleneckV1. - layers : list of int - Numbers of layers in each block - classes : int, default 1000 - Number of classification classes. - dilated : bool, default False - Applying dilation strategy to pretrained ResNet yielding a stride-8 model, - typically used in Semantic Segmentation. - norm_layer : object - Normalization layer used (default: :class:`nn.BatchNorm2d`) - deep_stem : bool, default False - Whether to replace the 7x7 conv1 with 3 3x3 convolution layers. - avg_down : bool, default False - Whether to use average pooling for projection skip connection between stages/downsample. - final_drop : float, default 0.0 - Dropout ratio before the final classification layer. - - Reference: - - He, Kaiming, et al. "Deep residual learning for image recognition." - Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. - - - Yu, Fisher, and Vladlen Koltun. "Multi-scale context aggregation by dilated convolutions." - """ - def __init__(self, block, layers, classes=1000, dilated=True, deep_stem=False, stem_width=32, - avg_down=False, final_drop=0.0, norm_layer=nn.BatchNorm2d): - self.inplanes = stem_width*2 if deep_stem else 64 - super(ResNetV1b, self).__init__() - if not deep_stem: - self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) - else: - self.conv1 = nn.Sequential( - nn.Conv2d(3, stem_width, kernel_size=3, stride=2, padding=1, bias=False), - norm_layer(stem_width), - nn.ReLU(True), - nn.Conv2d(stem_width, stem_width, kernel_size=3, stride=1, padding=1, bias=False), - norm_layer(stem_width), - nn.ReLU(True), - nn.Conv2d(stem_width, 2*stem_width, kernel_size=3, stride=1, padding=1, bias=False) - ) - self.bn1 = norm_layer(self.inplanes) - self.relu = nn.ReLU(True) - self.maxpool = nn.MaxPool2d(3, stride=2, padding=1) - self.layer1 = self._make_layer(block, 64, layers[0], avg_down=avg_down, - norm_layer=norm_layer) - self.layer2 = self._make_layer(block, 128, layers[1], stride=2, avg_down=avg_down, - norm_layer=norm_layer) - if dilated: - self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2, - avg_down=avg_down, norm_layer=norm_layer) - self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4, - avg_down=avg_down, norm_layer=norm_layer) - else: - self.layer3 = self._make_layer(block, 256, layers[2], stride=2, - avg_down=avg_down, norm_layer=norm_layer) - self.layer4 = self._make_layer(block, 512, layers[3], stride=2, - avg_down=avg_down, norm_layer=norm_layer) - self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) - self.drop = None - if final_drop > 0.0: - self.drop = nn.Dropout(final_drop) - self.fc = nn.Linear(512 * block.expansion, classes) - - def _make_layer(self, block, planes, blocks, stride=1, dilation=1, - avg_down=False, norm_layer=nn.BatchNorm2d): - downsample = None - if stride != 1 or self.inplanes != planes * block.expansion: - downsample = [] - if avg_down: - if dilation == 1: - downsample.append( - nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True, count_include_pad=False) - ) - else: - downsample.append( - nn.AvgPool2d(kernel_size=1, stride=1, ceil_mode=True, count_include_pad=False) - ) - downsample.extend([ - nn.Conv2d(self.inplanes, out_channels=planes * block.expansion, - kernel_size=1, stride=1, bias=False), - norm_layer(planes * block.expansion) - ]) - downsample = nn.Sequential(*downsample) - else: - downsample = nn.Sequential( - nn.Conv2d(self.inplanes, out_channels=planes * block.expansion, - kernel_size=1, stride=stride, bias=False), - norm_layer(planes * block.expansion) - ) - - layers = [] - if dilation in (1, 2): - layers.append(block(self.inplanes, planes, stride, dilation=1, downsample=downsample, - previous_dilation=dilation, norm_layer=norm_layer)) - elif dilation == 4: - layers.append(block(self.inplanes, planes, stride, dilation=2, downsample=downsample, - previous_dilation=dilation, norm_layer=norm_layer)) - else: - raise RuntimeError("=> unknown dilation size: {}".format(dilation)) - - self.inplanes = planes * block.expansion - for _ in range(1, blocks): - layers.append(block(self.inplanes, planes, dilation=dilation, - previous_dilation=dilation, norm_layer=norm_layer)) - - return nn.Sequential(*layers) - - def forward(self, x): - x = self.conv1(x) - x = self.bn1(x) - x = self.relu(x) - x = self.maxpool(x) - - x = self.layer1(x) - x = self.layer2(x) - x = self.layer3(x) - x = self.layer4(x) - - x = self.avgpool(x) - x = x.view(x.size(0), -1) - if self.drop is not None: - x = self.drop(x) - x = self.fc(x) - - return x - - -def _safe_state_dict_filtering(orig_dict, model_dict_keys): - filtered_orig_dict = {} - for k, v in orig_dict.items(): - if k in model_dict_keys: - filtered_orig_dict[k] = v - else: - print(f"[ERROR] Failed to load <{k}> in backbone") - return filtered_orig_dict - - -def resnet34_v1b(pretrained=False, **kwargs): - model = ResNetV1b(BasicBlockV1b, [3, 4, 6, 3], **kwargs) - if pretrained: - model_dict = model.state_dict() - filtered_orig_dict = _safe_state_dict_filtering( - torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet34_v1b', pretrained=True).state_dict(), - model_dict.keys() - ) - model_dict.update(filtered_orig_dict) - model.load_state_dict(model_dict) - return model - - -def resnet50_v1s(pretrained=False, **kwargs): - model = ResNetV1b(BottleneckV1b, [3, 4, 6, 3], deep_stem=True, stem_width=64, **kwargs) - if pretrained: - model_dict = model.state_dict() - filtered_orig_dict = _safe_state_dict_filtering( - torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet50_v1s', pretrained=True).state_dict(), - model_dict.keys() - ) - model_dict.update(filtered_orig_dict) - model.load_state_dict(model_dict) - return model - - -def resnet101_v1s(pretrained=False, **kwargs): - model = ResNetV1b(BottleneckV1b, [3, 4, 23, 3], deep_stem=True, stem_width=64, **kwargs) - if pretrained: - model_dict = model.state_dict() - filtered_orig_dict = _safe_state_dict_filtering( - torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet101_v1s', pretrained=True).state_dict(), - model_dict.keys() - ) - model_dict.update(filtered_orig_dict) - model.load_state_dict(model_dict) - return model - - -def resnet152_v1s(pretrained=False, **kwargs): - model = ResNetV1b(BottleneckV1b, [3, 8, 36, 3], deep_stem=True, stem_width=64, **kwargs) - if pretrained: - model_dict = model.state_dict() - filtered_orig_dict = _safe_state_dict_filtering( - torch.hub.load(GLUON_RESNET_TORCH_HUB, 'gluon_resnet152_v1s', pretrained=True).state_dict(), - model_dict.keys() - ) - model_dict.update(filtered_orig_dict) - model.load_state_dict(model_dict) - return model diff --git a/spaces/MarkMcCormack/NLP-EduTech-App/README.md b/spaces/MarkMcCormack/NLP-EduTech-App/README.md deleted file mode 100644 index 2c4b301283af1ee85c1bb2aa7fef7cf8f87857c2..0000000000000000000000000000000000000000 --- a/spaces/MarkMcCormack/NLP-EduTech-App/README.md +++ /dev/null @@ -1,11 +0,0 @@ ---- -title: NLP-EduTech-Project -emoji: 👨🎓 -colorFrom: red -colorTo: orange -sdk: streamlit -app_file: app.py -pinned: false ---- - -# NLP-EduTech-Project diff --git a/spaces/Marshalls/testmtd/feature_extraction/madmom/audio/cepstrogram.py b/spaces/Marshalls/testmtd/feature_extraction/madmom/audio/cepstrogram.py deleted file mode 100644 index 4858d7e04cbe5e5e2419011663631bb3cebda2bc..0000000000000000000000000000000000000000 --- a/spaces/Marshalls/testmtd/feature_extraction/madmom/audio/cepstrogram.py +++ /dev/null @@ -1,298 +0,0 @@ -# encoding: utf-8 -# pylint: disable=no-member -# pylint: disable=invalid-name -# pylint: disable=too-many-arguments -""" -This module contains all cepstrogram related functionality. - -""" - -from __future__ import absolute_import, division, print_function - -import numpy as np -from scipy.fftpack import dct - -from ..processors import Processor -from .filters import MelFilterbank -from .spectrogram import Spectrogram - - -class Cepstrogram(np.ndarray): - """ - The Cepstrogram class represents a transformed Spectrogram. This generic - class applies some transformation (usually a DCT) on a spectrogram. - - Parameters - ---------- - spectrogram : :class:`.audio.spectrogram.Spectrogram` instance - Spectrogram. - transform : numpy ufunc - Transformation applied to the `spectrogram`. - kwargs : dict - If no :class:`.audio.spectrogram.Spectrogram` instance was given, - one is instantiated with these additional keyword arguments. - - """ - # pylint: disable=super-on-old-class - # pylint: disable=super-init-not-called - # pylint: disable=attribute-defined-outside-init - - def __init__(self, spectrogram, transform=dct, **kwargs): - # this method is for documentation purposes only - pass - - def __new__(cls, spectrogram, transform=dct, **kwargs): - # instantiate a Spectrogram if needed - if not isinstance(spectrogram, Spectrogram): - # try to instantiate a Spectrogram object - spectrogram = Spectrogram(spectrogram, **kwargs) - - # apply the transformation to the spectrogram - data = transform(spectrogram) - # cast as Cepstrogram - obj = np.asarray(data).view(cls) - # save additional attributes - obj.spectrogram = spectrogram - # TODO: what are the frequencies of the bins? - # obj.bin_frequencies = ??? - obj.transform = transform - # return the object - return obj - - def __array_finalize__(self, obj): - if obj is None: - return - # set default values here, also needed for views - self.spectrogram = getattr(obj, 'spectrogram', None) - self.bin_frequencies = getattr(obj, 'bin_frequencies', None) - self.transform = getattr(obj, 'transform', None) - - @property - def num_frames(self): - """Number of frames.""" - return len(self) - - @property - def num_bins(self): - """Number of bins.""" - return int(self.shape[1]) - - -class CepstrogramProcessor(Processor): - """ - Cepstrogram processor class. - - Parameters - ---------- - transform : numpy ufunc - Transformation applied during processing. - - """ - - def __init__(self, transform=dct, **kwargs): - # pylint: disable=unused-argument - self.transform = transform - - def process(self, data): - """ - Return a Cepstrogram of the given data. - - Parameters - ---------- - data : numpy array - Data to be processed (usually a spectrogram). - - Returns - ------- - :class:`Cepstrogram` instance - Cepstrogram. - - """ - return Cepstrogram(data, transform=self.transform) - - -MFCC_BANDS = 30 -MFCC_FMIN = 40. -MFCC_FMAX = 15000. -MFCC_NORM_FILTERS = True -MFCC_MUL = 1. -MFCC_ADD = 0. - - -class MFCC(Cepstrogram): - """ - MFCC class. - - Parameters - ---------- - spectrogram : :class:`.audio.spectrogram.Spectrogram` instance - Spectrogram. - transform : numpy ufunc, optional - Transformation applied to the `spectrogram`. - filterbank : :class:`.audio.filters.Filterbank` type or instance, optional - Filterbank used to filter the `spectrogram`; if a - :class:`.audio.filters.Filterbank` type (i.e. class) is given - (rather than an instance), one will be created with the given type - and following parameters: - num_bands : int, optional - Number of filter bands (per octave, depending on the type of the - filterbank). - fmin : float, optional - The minimum frequency of the filterbank [Hz]. - fmax : float, optional - The maximum frequency of the filterbank [Hz]. - norm_filters : bool, optional - Normalize the filters to area 1. - mul : float, optional - Multiply the magnitude spectrogram with this factor before taking the - logarithm. - add : float, optional - Add this value before taking the logarithm of the magnitudes. - kwargs : dict - If no :class:`.audio.spectrogram.Spectrogram` instance was given, one - is instantiated and these keyword arguments are passed. - - Notes - ----- - - If a filtered or scaled Spectrogram is given, a new unfiltered and unscaled - Spectrogram will be computed and then the given filter and scaling will be - applied accordingly. - - From https://en.wikipedia.org/wiki/Mel-frequency_cepstrum: - - MFCCs are commonly derived as follows: - - 1) Take the Fourier transform of (a windowed excerpt of) a signal. - 2) Map the powers of the spectrum obtained above onto the mel scale, - using triangular overlapping windows. - 3) Take the logs of the powers at each of the mel frequencies. - 4) Take the discrete cosine transform of the list of mel log powers, - as if it were a signal. - 5) The MFCCs are the amplitudes of the resulting spectrum - - """ - # pylint: disable=super-on-old-class - # pylint: disable=super-init-not-called - # pylint: disable=attribute-defined-outside-init - - def __init__(self, spectrogram, transform=dct, filterbank=MelFilterbank, - num_bands=MFCC_BANDS, fmin=MFCC_FMIN, fmax=MFCC_FMAX, - norm_filters=MFCC_NORM_FILTERS, mul=MFCC_MUL, add=MFCC_ADD, - **kwargs): - # this method is for documentation purposes only - pass - - def __new__(cls, spectrogram, transform=dct, filterbank=MelFilterbank, - num_bands=MFCC_BANDS, fmin=MFCC_FMIN, fmax=MFCC_FMAX, - norm_filters=MFCC_NORM_FILTERS, mul=MFCC_MUL, add=MFCC_ADD, - **kwargs): - # for signature documentation see __init__() - from .filters import Filterbank - # instantiate a Spectrogram if needed - if not isinstance(spectrogram, Spectrogram): - # try to instantiate a Spectrogram object - spectrogram = Spectrogram(spectrogram, **kwargs) - - # recalculate the spec if it is filtered or scaled already - #if (spectrogram.filterbank is not None or - # spectrogram.mul is not None or - # spectrogram.add is not None): - # import warnings - # warnings.warn('Spectrogram was filtered or scaled already, redo ' - # 'calculation!') - # spectrogram = Spectrogram(spectrogram.stft) - - # instantiate a Filterbank if needed - if issubclass(filterbank, Filterbank): - # create a filterbank of the given type - filterbank = filterbank(spectrogram.bin_frequencies, - num_bands=num_bands, fmin=fmin, fmax=fmax, - norm_filters=norm_filters, - duplicate_filters=False) - if not isinstance(filterbank, Filterbank): - raise ValueError('not a Filterbank type or instance: %s' % - filterbank) - # filter the spectrogram - data = np.dot(spectrogram, filterbank) - # logarithmically scale the magnitudes - np.log10(mul * data + add, out=data) - # apply the transformation - data = transform(data) - # cast as MFCC - obj = np.asarray(data).view(cls) - # save additional attributes - obj.transform = transform - obj.spectrogram = spectrogram - obj.filterbank = filterbank - obj.mul = mul - obj.add = add - # return the object - return obj - - def __array_finalize__(self, obj): - if obj is None: - return - # set default values here, also needed for views - self.filterbank = getattr(obj, 'filterbank', None) - self.mul = getattr(obj, 'mul', MFCC_MUL) - self.add = getattr(obj, 'add', MFCC_ADD) - super(MFCC, self).__array_finalize__(obj) - - -class MFCCProcessor(Processor): - """ - MFCCProcessor is CepstrogramProcessor which filters the magnitude - spectrogram of the spectrogram with a Mel filterbank, takes the logarithm - and performs a discrete cosine transform afterwards. - - Parameters - ---------- - num_bands : int, optional - Number of Mel filter bands. - fmin : float, optional - Minimum frequency of the Mel filterbank [Hz]. - fmax : float, optional - Maximum frequency of the Mel filterbank [Hz]. - norm_filters : bool, optional - Normalize the filters to area 1. - mul : float, optional - Multiply the magnitude spectrogram with this factor before taking the - logarithm. - add : float, optional - Add this value before taking the logarithm of the magnitudes. - transform : numpy ufunc - Transformation applied to the Mel filtered spectrogram. - - """ - - def __init__(self, num_bands=MFCC_BANDS, fmin=MFCC_FMIN, fmax=MFCC_FMAX, - norm_filters=MFCC_NORM_FILTERS, mul=MFCC_MUL, add=MFCC_ADD, - transform=dct, **kwargs): - # pylint: disable=unused-argument - self.num_bands = num_bands - self.fmin = fmin - self.fmax = fmax - self.norm_filters = norm_filters - self.mul = mul - self.add = add - self.transform = transform - - def process(self, data): - """ - Process the data and return the MFCCs of it. - - Parameters - ---------- - data : numpy array - Data to be processed (usually a spectrogram). - - Returns - ------- - :class:`MFCC` instance - MFCCs of the data. - - """ - return MFCC(data, num_bands=self.num_bands, fmin=self.fmin, - fmax=self.fmax, norm_filters=self.norm_filters, - mul=self.mul, add=self.add) diff --git a/spaces/Marshalls/testmtd/feature_extraction/madmom/evaluation/beats.py b/spaces/Marshalls/testmtd/feature_extraction/madmom/evaluation/beats.py deleted file mode 100644 index 1ce7dc06930d2e64697411e75f54052cbc75513a..0000000000000000000000000000000000000000 --- a/spaces/Marshalls/testmtd/feature_extraction/madmom/evaluation/beats.py +++ /dev/null @@ -1,1249 +0,0 @@ -# encoding: utf-8 -# pylint: disable=no-member -# pylint: disable=invalid-name -# pylint: disable=too-many-arguments -""" -This module contains beat evaluation functionality. - -The measures are described in [1]_, a Matlab implementation exists here: -http://code.soundsoftware.ac.uk/projects/beat-evaluation/repository - -Notes ------ -Please note that this is a complete re-implementation, which took some other -design decisions. For example, the beat detections and annotations are not -quantised before being evaluated with F-measure, P-score and other metrics. -Hence these evaluation functions DO NOT report the exact same results/scores. -This approach was chosen, because it is simpler and produces more accurate -results. - -References ----------- -.. [1] Matthew E. P. Davies, Norberto Degara, and Mark D. Plumbley, - "Evaluation Methods for Musical Audio Beat Tracking Algorithms", - Technical Report C4DM-TR-09-06, - Centre for Digital Music, Queen Mary University of London, 2009. - -""" - -from __future__ import absolute_import, division, print_function - -from functools import wraps -import warnings - -import numpy as np - -from . import (MeanEvaluation, calc_absolute_errors, calc_errors, - evaluation_io, find_closest_matches) -from .onsets import OnsetEvaluation -from ..io import load_beats - - -# exceptions -class BeatIntervalError(Exception): - """ - Exception to be raised whenever an interval cannot be computed. - - """ - # pylint: disable=super-init-not-called - - def __init__(self, value=None): - if value is None: - value = "At least two beats must be present to be able to " \ - "calculate an interval." - self.value = value - - def __str__(self): - return repr(self.value) - - -# decorators -def array(metric): - """ - Decorate metric to convert annotations and detections to numpy arrays. - - """ - - @wraps(metric) - def float_array(detections, annotations, *args, **kwargs): - """Warp detections and annotations as numpy arrays.""" - # make sure the annotations and detections have a float dtype - detections = np.asarray(detections, dtype=np.float) - annotations = np.asarray(annotations, dtype=np.float) - return metric(detections, annotations, *args, **kwargs) - - return float_array - - -def _score_decorator(perfect_score, zero_score): - """ - Decorate metric with evaluation results for perfect and zero score. - - Parameters - ---------- - perfect_score : float or tuple - zero_score : float or tuple - - Returns - ------- - metric - Decorated metric. - - """ - - def wrap(metric): - """Metric to decorate""" - - @wraps(metric) - def score(detections, annotations, *args, **kwargs): - """ - Return perfect/zero score if neither/either detections and - annotations are given, respectively. - - """ - # neither detections nor annotations are given, perfect score - if len(detections) == 0 and len(annotations) == 0: - return perfect_score - # either beat detections or annotations are empty, score 0 - elif (len(detections) == 0) != (len(annotations) == 0): - return zero_score - # normal scoring - return metric(detections, annotations, *args, **kwargs) - - return score - - return wrap - - -score_10 = _score_decorator(1., 0.) -score_1100 = _score_decorator((1., 1.), (0., 0.)) - - -# function for sequence variations generation -def variations(sequence, offbeat=False, double=False, half=False, - triple=False, third=False): - """ - Create variations of the given beat sequence. - - Parameters - ---------- - sequence : numpy array - Beat sequence. - offbeat : bool, optional - Create an offbeat sequence. - double : bool, optional - Create a double tempo sequence. - half : bool, optional - Create half tempo sequences (includes offbeat version). - triple : bool, optional - Create triple tempo sequence. - third : bool, optional - Create third tempo sequences (includes offbeat versions). - - Returns - ------- - list - Beat sequence variations. - - """ - # create different variants of the annotations - sequences = [] - # double/half and offbeat variation - if double or offbeat: - if len(sequence) == 0: - # if we have an empty sequence, there's nothing to interpolate - double_sequence = [] - else: - # create a sequence with double tempo - same = np.arange(0, len(sequence)) - # request one item less, otherwise we would extrapolate - shifted = np.arange(0, len(sequence), 0.5)[:-1] - double_sequence = np.interp(shifted, same, sequence) - # same tempo, half tempo off - if offbeat: - sequences.append(double_sequence[1::2]) - # double/half tempo variations - if double: - # double tempo - sequences.append(double_sequence) - if half: - # half tempo odd beats (i.e. 1,3,1,3,..) - sequences.append(sequence[0::2]) - # half tempo even beats (i.e. 2,4,2,4,..) - sequences.append(sequence[1::2]) - # triple/third tempo variations - if triple: - if len(sequence) == 0: - # if we have an empty sequence, there's nothing to interpolate - triple_sequence = [] - else: - # create a annotation sequence with triple tempo - same = np.arange(0, len(sequence)) - # request two items less, otherwise we would extrapolate - shifted = np.arange(0, len(sequence), 1. / 3)[:-2] - triple_sequence = np.interp(shifted, same, sequence) - # triple tempo - sequences.append(triple_sequence) - if third: - # third tempo 1st beat (1,4,3,2,..) - sequences.append(sequence[0::3]) - # third tempo 2nd beat (2,1,4,3,..) - sequences.append(sequence[1::3]) - # third tempo 3rd beat (3,2,1,4,..) - sequences.append(sequence[2::3]) - # return - return sequences - - -# helper functions for beat evaluation -def calc_intervals(events, fwd=False): - """ - Calculate the intervals of all events to the previous/next event. - - Parameters - ---------- - events : numpy array - Beat sequence. - fwd : bool, optional - Calculate the intervals towards the next event (instead of previous). - - Returns - ------- - numpy array - Beat intervals. - - Notes - ----- - The sequence must be ordered. The first (last) interval will be set to - the same value as the second (second to last) interval (when used in - `fwd` mode). - - """ - # at least 2 events must be given to calculate an interval - if len(events) < 2: - raise BeatIntervalError - interval = np.zeros_like(events) - if fwd: - interval[:-1] = np.diff(events) - # set the last interval to the same value as the second last - interval[-1] = interval[-2] - else: - interval[1:] = np.diff(events) - # set the first interval to the same value as the second - interval[0] = interval[1] - # return - return interval - - -def find_closest_intervals(detections, annotations, matches=None): - """ - Find the closest annotated interval to each beat detection. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - matches : list or numpy array - Indices of the closest beats. - - Returns - ------- - numpy array - Closest annotated beat intervals. - - Notes - ----- - The sequences must be ordered. To speed up the calculation, a list of - pre-computed indices of the closest matches can be used. - - The function does NOT test if each detection has a surrounding interval, - it always returns the closest interval. - - """ - # if no detection are given, return an empty interval array - if len(detections) == 0: - return np.zeros(0, dtype=np.float) - # at least annotations must be given - if len(annotations) < 2: - raise BeatIntervalError - # init array - closest_interval = np.ones_like(detections) - # intervals - # Note: it is faster if we combine the forward and backward intervals, - # but we need to take care of the sizes; intervals to the next - # annotation are always the same as those at the next index - intervals = np.zeros(len(annotations) + 1) - # intervals to previous annotation - intervals[1:-1] = np.diff(annotations) - # interval of the first annotation to the left is the same as to the right - intervals[0] = intervals[1] - # interval of the last annotation to the right is the same as to the left - intervals[-1] = intervals[-2] - # determine the closest annotations - if matches is None: - matches = find_closest_matches(detections, annotations) - # calculate the absolute errors - errors = calc_errors(detections, annotations, matches) - # if the errors are positive, the detection is after the annotation - # thus use the interval towards the next annotation - closest_interval[errors > 0] = intervals[matches[errors > 0] + 1] - # if the errors are 0 or negative, the detection is before the annotation - # or at the same position; thus use the interval to previous annotation - closest_interval[errors <= 0] = intervals[matches[errors <= 0]] - # return the closest interval - return closest_interval - - -def find_longest_continuous_segment(sequence_indices): - """ - ind the longest consecutive segment in the given sequence. - - Parameters - ---------- - sequence_indices : numpy array - Indices of the beats - - Returns - ------- - length : int - Length of the longest consecutive segment. - start : int - Start position of the longest continuous segment. - - """ - # continuous segments have consecutive indices, i.e. diffs =! 1 are - # boundaries between continuous segments; add 1 to get the correct index - boundaries = np.nonzero(np.diff(sequence_indices) != 1)[0] + 1 - # add a start (index 0) and stop (length of correct detections) to the - # segment boundary indices - boundaries = np.concatenate(([0], boundaries, [len(sequence_indices)])) - # lengths of the individual segments - segment_lengths = np.diff(boundaries) - # return the length and start position of the longest continuous segment - length = int(np.max(segment_lengths)) - start_pos = int(boundaries[np.argmax(segment_lengths)]) - return length, start_pos - - -@array -def calc_relative_errors(detections, annotations, matches=None): - """ - Errors of the detections relative to the closest annotated interval. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - matches : list or numpy array - Indices of the closest beats. - - Returns - ------- - numpy array - Errors relative to the closest annotated beat interval. - - Notes - ----- - The sequences must be ordered! To speed up the calculation, a list of - pre-computed indices of the closest matches can be used. - - """ - # if no detection are given, return an empty interval array - if len(detections) == 0: - return np.zeros(0, dtype=np.float) - # at least annotations must be given - if len(annotations) < 2: - raise BeatIntervalError - # determine the closest annotations - if matches is None: - matches = find_closest_matches(detections, annotations) - # calculate the absolute errors - errors = calc_errors(detections, annotations, matches) - # get the closest intervals - intervals = find_closest_intervals(detections, annotations, matches) - # return the relative errors - return errors / intervals - - -# default beat evaluation parameter values -FMEASURE_WINDOW = 0.07 -PSCORE_TOLERANCE = 0.2 -CEMGIL_SIGMA = 0.04 -GOTO_THRESHOLD = 0.175 -GOTO_SIGMA = 0.1 -GOTO_MU = 0.1 -CONTINUITY_TEMPO_TOLERANCE = 0.175 -CONTINUITY_PHASE_TOLERANCE = 0.175 -INFORMATION_GAIN_BINS = 40 - - -# evaluation functions for beat detection -@array -@score_10 -def pscore(detections, annotations, tolerance=PSCORE_TOLERANCE): - """ - Calculate the P-score accuracy for the given detections and annotations. - - The P-score is determined by taking the sum of the cross-correlation - between two impulse trains, representing the detections and annotations - allowing for a tolerance of 20% of the median annotated interval [1]_. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - tolerance : float, optional - Evaluation tolerance (fraction of the median beat interval). - - Returns - ------- - pscore : float - P-Score. - - Notes - ----- - Contrary to the original implementation which samples the two impulse - trains with 100Hz, we do not quantise the annotations and detections but - rather count all detections falling withing the defined tolerance window. - - References - ---------- - .. [1] M. McKinney, D. Moelants, M. Davies and A. Klapuri, - "Evaluation of audio beat tracking and music tempo extraction - algorithms", - Journal of New Music Research, vol. 36, no. 1, 2007. - - """ - # at least 2 annotations must be given to calculate an interval - if len(annotations) < 2: - raise BeatIntervalError("At least 2 annotations are needed for" - "P-Score.") - # tolerance must be greater than 0 - if float(tolerance) <= 0: - raise ValueError("`tolerance` must be greater than 0.") - # the error window is the given fraction of the median beat interval - window = tolerance * np.median(np.diff(annotations)) - # errors - errors = calc_absolute_errors(detections, annotations) - # count the instances where the error is smaller or equal than the window - p = len(detections[errors <= window]) - # normalize by the max number of detections/annotations - p /= float(max(len(detections), len(annotations))) - # return p-score - return p - - -@array -@score_10 -def cemgil(detections, annotations, sigma=CEMGIL_SIGMA): - """ - Calculate the Cemgil accuracy for the given detections and annotations. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - sigma : float, optional - Sigma for Gaussian error function. - - Returns - ------- - cemgil : float - Cemgil beat tracking accuracy. - - References - ---------- - .. [1] A.T. Cemgil, B. Kappen, P. Desain, and H. Honing, - "On tempo tracking: Tempogram representation and Kalman filtering", - Journal Of New Music Research, vol. 28, no. 4, 2001. - - """ - # sigma must be greater than 0 - if float(sigma) <= 0: - raise ValueError("`sigma` must be greater than 0.") - # determine the abs. errors of the detections to the closest annotations - # Note: the original implementation searches for the closest matches of - # detections given the annotations. Since absolute errors > a usual - # beat interval produce high errors (and thus in turn add negligible - # values to the accuracy), it is safe to swap those two. - errors = calc_absolute_errors(detections, annotations) - # apply a Gaussian error function with the given std. dev. on the errors - acc = np.exp(-(errors ** 2.) / (2. * (sigma ** 2.))) - # and sum up the accuracy - acc = np.sum(acc) - # normalized by the mean of the number of detections and annotations - acc /= 0.5 * (len(annotations) + len(detections)) - # return accuracy - return acc - - -@array -@score_10 -def goto(detections, annotations, threshold=GOTO_THRESHOLD, sigma=GOTO_SIGMA, - mu=GOTO_MU): - """ - Calculate the Goto and Muraoka accuracy for the given detections and - annotations. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - threshold : float, optional - Threshold. - sigma : float, optional - Allowed std. dev. of the errors in the longest segment. - mu : float, optional - Allowed mean. of the errors in the longest segment. - - Returns - ------- - goto : float - Goto beat tracking accuracy. - - Notes - ----- - [1]_ requires that the first correct beat detection must occur within the - first 3/4 of the excerpt. In order to be able to deal with audio with - varying tempo, this was altered that the length of the longest continuously - tracked segment must be at least 1/4 of the total length [2]_. - - References - ---------- - .. [1] M. Goto and Y. Muraoka, - "Issues in evaluating beat tracking systems", - Working Notes of the IJCAI-97 Workshop on Issues in AI and Music - - Evaluation and Assessment, 1997. - .. [2] Matthew E. P. Davies, Norberto Degara, and Mark D. Plumbley, - "Evaluation Methods for Musical Audio Beat Tracking Algorithms", - Technical Report C4DM-TR-09-06, - Centre for Digital Music, Queen Mary University of London, 2009. - - """ - # at least 2 annotations must be given to calculate an interval - if len(annotations) < 2: - raise BeatIntervalError("At least 2 annotations are needed for Goto's " - "score.") - # threshold, sigma and mu must be greater than 0 - if float(threshold) <= 0 or float(sigma) <= 0 or float(mu) <= 0: - raise ValueError("Threshold, sigma and mu must be positive.") - # get the indices of the closest detections to the annotations to determine - # the longest continuous segment - closest = find_closest_matches(annotations, detections) - # keep only those which have abs(errors) <= threshold - # Note: both the original paper and the Matlab implementation normalize by - # half a beat interval, thus our threshold is halved (same applies to - # sigma and mu) - # errors of the detections relative to the surrounding annotation interval - errors = calc_relative_errors(detections, annotations) - # the absolute error must be smaller than the given threshold - closest = closest[np.abs(errors[closest]) <= threshold] - # get the length and start position of the longest continuous segment - length, start = find_longest_continuous_segment(closest) - # three conditions must be met to identify the segment as correct - # 1) the length of the segment must be at least 1/4 of the total length - # Note: the original paper requires that the first element must occur - # within the first 3/4 of the excerpt, but this was altered in the - # Matlab implementation to the above condition to be able to deal - # with audio with varying tempo - if length < 0.25 * len(annotations): - return 0. - # errors of the longest segment - segment_errors = errors[closest[start: start + length]] - # 2) mean of the errors must not exceed mu - if np.mean(np.abs(segment_errors)) > mu: - return 0. - # 3) std deviation of the errors must not exceed sigma - # Note: contrary to the original paper and in line with the Matlab code, - # we calculate the std. deviation based on the raw errors and not on - # their absolute values. - if np.std(segment_errors) > sigma: - return 0. - # otherwise return 1 - return 1. - - -@array -@score_1100 -def cml(detections, annotations, phase_tolerance=CONTINUITY_PHASE_TOLERANCE, - tempo_tolerance=CONTINUITY_TEMPO_TOLERANCE): - """ - Calculate the cmlc and cmlt scores for the given detections and - annotations. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - phase_tolerance : float, optional - Allowed phase tolerance. - tempo_tolerance : float, optional - Allowed tempo tolerance. - - Returns - ------- - cmlc : float - Longest continuous segment of correct detections normalized by the - maximum length of both sequences (detection and annotations). - cmlt : float - Same as cmlc, but no continuity required. - - References - ---------- - .. [1] S. Hainsworth, - "Techniques for the automated analysis of musical audio", - PhD. dissertation, Department of Engineering, Cambridge University, - 2004. - .. [2] A.P. Klapuri, A. Eronen, and J. Astola, - "Analysis of the meter of acoustic musical signals", - IEEE Transactions on Audio, Speech and Language Processing, vol. 14, - no. 1, 2006. - - """ - # at least 2 annotations must be given to calculate an interval - if len(annotations) < 2: - raise BeatIntervalError("At least 2 annotations are needed for " - "continuity scores, %s given." % annotations) - # TODO: remove this, see TODO below - if len(detections) < 2: - raise BeatIntervalError("At least 2 detections are needed for " - "continuity scores, %s given." % detections) - # tolerances must be greater than 0 - if float(tempo_tolerance) <= 0 or float(phase_tolerance) <= 0: - raise ValueError("Tempo and phase tolerances must be greater than 0") - # determine closest annotations to detections - closest = find_closest_matches(detections, annotations) - # errors of the detections wrt. to the annotations - errors = calc_absolute_errors(detections, annotations, closest) - # detection intervals - det_interval = calc_intervals(detections) - # annotation intervals (get those intervals at the correct positions) - ann_interval = calc_intervals(annotations)[closest] - # a detection is correct, if it fulfills 2 conditions: - # 1) must match an annotation within a certain tolerance window, i.e. the - # phase must be correct - correct_phase = detections[errors <= ann_interval * phase_tolerance] - # Note: the initially cited technical report has an additional condition - # ii) on page 5 which requires the same condition to be true for the - # previous detection / annotation combination. We do not enforce - # this, since a) this condition is kind of pointless: why shouldn't - # we count a correct beat just because its predecessor is not? and - # b) the original Matlab implementation does not enforce it either - # 2) the tempo, i.e. the intervals, must be within the tempo tolerance - # TODO: as agreed with Matthew, this should only be enforced from the 2nd - # beat onwards. - correct_tempo = detections[abs(1 - (det_interval / ann_interval)) <= - tempo_tolerance] - # combine the conditions - correct = np.intersect1d(correct_phase, correct_tempo) - # convert to indices - correct_idx = np.searchsorted(detections, correct) - # cmlc: longest continuous segment of detections normalized by the max. - # length of both sequences (detection and annotations) - length = float(max(len(detections), len(annotations))) - longest, _ = find_longest_continuous_segment(correct_idx) - cmlc = longest / length - # cmlt: same but for all detections (no need for continuity) - cmlt = len(correct) / length - # return a tuple - return cmlc, cmlt - - -@array -def continuity(detections, annotations, - phase_tolerance=CONTINUITY_PHASE_TOLERANCE, - tempo_tolerance=CONTINUITY_TEMPO_TOLERANCE, - offbeat=True, double=True, triple=True): - """ - Calculate the cmlc, cmlt, amlc and amlt scores for the given detections and - annotations. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - phase_tolerance : float, optional - Allowed phase tolerance. - tempo_tolerance : float, optional - Allowed tempo tolerance. - offbeat : bool, optional - Include offbeat variation. - double : bool, optional - Include double and half tempo variations (and offbeat thereof). - triple : bool, optional - Include triple and third tempo variations (and offbeats thereof). - - Returns - ------- - cmlc : float - Tracking accuracy, continuity at the correct metrical level required. - cmlt : float - Same as cmlc, continuity at the correct metrical level not required. - amlc : float - Same as cmlc, alternate metrical levels allowed. - amlt : float - Same as cmlt, alternate metrical levels allowed. - - See Also - -------- - :func:`cml` - - """ - # neither detections nor annotations are given - if len(detections) == 0 and len(annotations) == 0: - return 1., 1., 1., 1. - # either a single beat detections or annotations given, score 0 - if len(detections) <= 1 or len(annotations) <= 1: - return 0., 0., 0., 0. - # evaluate the correct tempo - cmlc, cmlt = cml(detections, annotations, tempo_tolerance, phase_tolerance) - amlc = cmlc - amlt = cmlt - # speed up calculation by skipping other metrical levels if the score is - # higher than 0.5 already. We must have tested the correct metrical level - # already, otherwise the cmlc score would be lower. - if cmlc > 0.5: - return cmlc, cmlt, amlc, amlt - # create different variants of the annotations: - # Note: double also includes half as does triple third, respectively - sequences = variations(annotations, offbeat=offbeat, double=double, - half=double, triple=triple, third=triple) - # evaluate these metrical variants - for sequence in sequences: - # if other metrical levels achieve higher accuracies, take these values - try: - # Note: catch the IntervalError here, because the beat variants - # could be too short for valid interval calculation; - # ok, since we already have valid values for amlc & amlt - c, t = cml(detections, sequence, tempo_tolerance, phase_tolerance) - except BeatIntervalError: - c, t = np.nan, np.nan - amlc = max(amlc, c) - amlt = max(amlt, t) - # return a tuple - return cmlc, cmlt, amlc, amlt - - -def _histogram_bins(num_bins): - """ - Helper function to generate the histogram bins used to calculate the error - histogram of the information gain. - - Parameters - ---------- - num_bins : int - Number of histogram bins. - Returns - ------- - numpy array - Histogram bin edges. - - Notes - ----- - This functions returns the bin edges for a histogram with one more bin than - the requested number of bins, because the fist and last bins are added - together (to make the histogram circular) later on. Because of the same - reason, the first and the last bin are only half as wide as the others. - - """ - # allow only even numbers and require at least 2 bins - if num_bins % 2 != 0 or num_bins < 2: - # Note: because of the implementation details of the histogram, the - # easiest way to make sure the an error of 0 is always mapped - # to the centre bin is to enforce an even number of bins - raise ValueError("Number of error histogram bins must be even and " - "greater than 0") - # since np.histogram accepts a sequence of bin edges we just increase the - # number of bins by 1, but we need to apply offset - offset = 0.5 / num_bins - # because the histogram is made circular by adding the last bin to the - # first one before being removed, increase the number of bins by 2 - return np.linspace(-0.5 - offset, 0.5 + offset, num_bins + 2) - - -def _error_histogram(detections, annotations, histogram_bins): - """ - Helper function to calculate the relative errors of the given detections - and annotations and map them to an histogram with the given bins edges. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - histogram_bins : numpy array - Beat error histogram bin edges. - - Returns - ------- - error_histogram : numpy array - Beat error histogram. - - Notes - ----- - The returned error histogram is circular, i.e. it contains 1 bin less than - a histogram built normally with the given histogram bin edges. The values - of the last and first bin are summed and mapped to the first bin. - - """ - # get the relative errors of the detections to the annotations - errors = calc_relative_errors(detections, annotations) - # map the relative beat errors to the range of -0.5..0.5 - errors = np.mod(errors + 0.5, -1) + 0.5 - # get bin counts for the given errors over the distribution - histogram = np.histogram(errors, histogram_bins)[0].astype(np.float) - # make the histogram circular by adding the last bin to the first one - histogram[0] += histogram[-1] - # return the histogram without the last bin - return histogram[:-1] - - -def _entropy(error_histogram): - """ - Helper function to calculate the entropy of the given error histogram. - - Parameters - ---------- - error_histogram : numpy array - Error histogram. - - Returns - ------- - entropy : float - Entropy of the error histogram. - - """ - # copy the error_histogram, because it must not be altered - histogram = np.copy(error_histogram).astype(np.float) - # normalize the histogram - histogram /= np.sum(histogram) - # set all 0 values to 1 to make entropy calculation well-behaved - histogram[histogram == 0] = 1. - # calculate entropy - return - np.sum(histogram * np.log2(histogram)) - - -def _information_gain(error_histogram): - """ - Helper function to calculate the information gain of the given error - histogram. - - Parameters - ---------- - error_histogram : numpy array - Error histogram. - - Returns - ------- - information_gain : float - Information gain. - - """ - # calculate the entropy of th error histogram - if np.asarray(error_histogram).any(): - entropy = _entropy(error_histogram) - else: - # an empty error histogram has an entropy of 0 - entropy = 0. - # return information gain - return np.log2(len(error_histogram)) - entropy - - -@array -def information_gain(detections, annotations, num_bins=INFORMATION_GAIN_BINS): - """ - Calculate information gain for the given detections and annotations. - - Parameters - ---------- - detections : list or numpy array - Detected beats. - annotations : list or numpy array - Annotated beats. - num_bins : int, optional - Number of bins for the beat error histogram. - - Returns - ------- - information_gain : float - Information gain. - error_histogram : numpy array - Error histogram. - - References - ---------- - .. [1] M. E.P. Davies, N. Degara and M. D. Plumbley, - "Measuring the performance of beat tracking algorithms algorithms - using a beat error histogram", - IEEE Signal Processing Letters, vol. 18, vo. 3, 2011. - - """ - # neither detections nor annotations are given, perfect score - if len(detections) == 0 and len(annotations) == 0: - # return a max. information gain and an empty error histogram - return np.log2(num_bins), np.zeros(num_bins) - # either beat detections or annotations are empty, score 0 - # Note: use "or" here since we test both the detections against the - # annotations and vice versa during the evaluation process - if len(detections) <= 1 or len(annotations) <= 1: - # return an information gain of 0 and a uniform beat error histogram - # Note: because swapped detections and annotations should return the - # same uniform histogram, the maximum length of the detections - # and annotations is chosen (instead of just the length of the - # annotations as in the Matlab implementation). - max_length = max(len(detections), len(annotations)) - return 0., np.ones(num_bins) * max_length / float(num_bins) - # at least 2 annotations must be given to calculate an interval - if len(detections) < 2 or len(annotations) < 2: - raise BeatIntervalError("At least 2 annotations and 2 detections are" - "needed for Information gain.") - # check if there are enough beat annotations for the number of bins - if num_bins > len(annotations): - warnings.warn("Not enough beat annotations (%d) for %d histogram bins." - % (len(annotations), num_bins)) - # create bins edges for the error histogram - histogram_bins = _histogram_bins(num_bins) - # evaluate detections against annotations - fwd_histogram = _error_histogram(detections, annotations, histogram_bins) - fwd_ig = _information_gain(fwd_histogram) - # if only a few (but correct) beats are detected, the errors could be small - # thus evaluate also the annotations against the detections, i.e. simulate - # a lot of false positive detections - bwd_histogram = _error_histogram(annotations, detections, histogram_bins) - bwd_ig = _information_gain(bwd_histogram) - # only use the lower information gain - if fwd_ig < bwd_ig: - return fwd_ig, fwd_histogram - return bwd_ig, bwd_histogram - - -# human readable output -def tostring(obj): - """ - Format the evaluation metrics as a human readable string. - - Returns - ------- - str - Evaluation metrics formatted as a human readable string. - - """ - ret = '' - if obj.name is not None: - ret += '%s\n ' % obj.name - ret += 'F-measure: %.3f P-score: %.3f Cemgil: %.3f Goto: %.3f CMLc: ' \ - '%.3f CMLt: %.3f AMLc: %.3f AMLt: %.3f D: %.3f Dg: %.3f' % \ - (obj.fmeasure, obj.pscore, obj.cemgil, obj.goto, obj.cmlc, - obj.cmlt, obj.amlc, obj.amlt, obj.information_gain, - obj.global_information_gain) - return ret - - -# beat evaluation class -class BeatEvaluation(OnsetEvaluation): - # this class inherits from OnsetEvaluation the Precision, Recall, and - # F-measure evaluation stuff but uses a different evaluation window - """ - Beat evaluation class. - - Parameters - ---------- - detections : str, list or numpy array - Detected beats. - annotations : str, list or numpy array - Annotated ground truth beats. - fmeasure_window : float, optional - F-measure evaluation window [seconds] - pscore_tolerance : float, optional - P-Score tolerance [fraction of the median beat interval]. - cemgil_sigma : float, optional - Sigma of Gaussian window for Cemgil accuracy. - goto_threshold : float, optional - Threshold for Goto error. - goto_sigma : float, optional - Sigma for Goto error. - goto_mu : float, optional - Mu for Goto error. - continuity_phase_tolerance : float, optional - Continuity phase tolerance. - continuity_tempo_tolerance : float, optional - Continuity tempo tolerance. - information_gain_bins : int, optional - Number of bins for for the information gain beat error histogram. - offbeat : bool, optional - Include offbeat variation. - double : bool, optional - Include double and half tempo variations (and offbeat thereof). - triple : bool, optional - Include triple and third tempo variations (and offbeats thereof). - skip : float, optional - Skip the first `skip` seconds for evaluation. - downbeats : bool, optional - Evaluate downbeats instead of beats. - - Notes - ----- - The `offbeat`, `double`, and `triple` variations of the beat sequences are - used only for AMLc/AMLt. - - """ - METRIC_NAMES = [ - ('fmeasure', 'F-measure'), - ('pscore', 'P-score'), - ('cemgil', 'Cemgil'), - ('goto', 'Goto'), - ('cmlc', 'CMLc'), - ('cmlt', 'CMLt'), - ('amlc', 'AMLc'), - ('amlt', 'AMLt'), - ('information_gain', 'D'), - ('global_information_gain', 'Dg') - ] - - def __init__(self, detections, annotations, - fmeasure_window=FMEASURE_WINDOW, - pscore_tolerance=PSCORE_TOLERANCE, - cemgil_sigma=CEMGIL_SIGMA, goto_threshold=GOTO_THRESHOLD, - goto_sigma=GOTO_SIGMA, goto_mu=GOTO_MU, - continuity_phase_tolerance=CONTINUITY_PHASE_TOLERANCE, - continuity_tempo_tolerance=CONTINUITY_TEMPO_TOLERANCE, - information_gain_bins=INFORMATION_GAIN_BINS, - offbeat=True, double=True, triple=True, skip=0, - downbeats=False, **kwargs): - # convert to numpy array - detections = np.array(detections, dtype=np.float, ndmin=1) - annotations = np.array(annotations, dtype=np.float, ndmin=1) - # use only the first column (i.e. the time stamp) or extract the - # downbeats if these are 2D - if detections.ndim > 1: - if downbeats: - detections = detections[detections[:, 1] == 1][:, 0] - else: - detections = detections[:, 0] - if annotations.ndim > 1: - if downbeats: - annotations = annotations[annotations[:, 1] == 1][:, 0] - else: - annotations = annotations[:, 0] - # sort them - detections = np.sort(detections) - annotations = np.sort(annotations) - # remove detections and annotations that are within the first N seconds - # Note: skipping the first few seconds alters the results! - if skip > 0: - start_idx = np.searchsorted(detections, skip, 'right') - detections = detections[start_idx:] - start_idx = np.searchsorted(annotations, skip, 'right') - annotations = annotations[start_idx:] - - # perform onset evaluation with the appropriate fmeasure_window - super(BeatEvaluation, self).__init__(detections, annotations, - window=fmeasure_window, **kwargs) - # other scores - self.pscore = pscore(detections, annotations, pscore_tolerance) - self.cemgil = cemgil(detections, annotations, cemgil_sigma) - self.goto = goto(detections, annotations, goto_threshold, - goto_sigma, goto_mu) - # continuity scores - scores = continuity(detections, annotations, - continuity_tempo_tolerance, - continuity_phase_tolerance, - offbeat, double, triple) - self.cmlc, self.cmlt, self.amlc, self.amlt = scores - # information gain stuff - scores = information_gain(detections, annotations, - information_gain_bins) - self.information_gain, self.error_histogram = scores - - @property - def global_information_gain(self): - """Global information gain.""" - # Note: if only 1 file is evaluated, it is the same as information gain - return self.information_gain - - def tostring(self, **kwargs): - return tostring(self) - - -class BeatMeanEvaluation(MeanEvaluation): - """ - Class for averaging beat evaluation scores. - - """ - METRIC_NAMES = BeatEvaluation.METRIC_NAMES - - @property - def fmeasure(self): - """F-measure.""" - return np.nanmean([e.fmeasure for e in self.eval_objects]) - - @property - def pscore(self): - """P-score.""" - return np.nanmean([e.pscore for e in self.eval_objects]) - - @property - def cemgil(self): - """Cemgil accuracy.""" - return np.nanmean([e.cemgil for e in self.eval_objects]) - - @property - def goto(self): - """Goto accuracy.""" - return np.nanmean([e.goto for e in self.eval_objects]) - - @property - def cmlc(self): - """CMLc.""" - return np.nanmean([e.cmlc for e in self.eval_objects]) - - @property - def cmlt(self): - """CMLt.""" - return np.nanmean([e.cmlt for e in self.eval_objects]) - - @property - def amlc(self): - """AMLc.""" - return np.nanmean([e.amlc for e in self.eval_objects]) - - @property - def amlt(self): - """AMLt.""" - return np.nanmean([e.amlt for e in self.eval_objects]) - - @property - def information_gain(self): - """Information gain.""" - return np.nanmean([e.information_gain for e in self.eval_objects]) - - @property - def error_histogram(self): - """Error histogram.""" - if not self.eval_objects: - # return an empty error histogram of length 0 - return np.zeros(0) - # sum all error histograms to gather a global one - return np.sum([e.error_histogram for e in self.eval_objects], axis=0) - - @property - def global_information_gain(self): - """Global information gain.""" - if len(self.error_histogram) == 0: - # if the error histogram has length 0, the information gain is 0 - return 0. - # calculate the information gain from the (global) error histogram - return _information_gain(self.error_histogram) - - def tostring(self, **kwargs): - return tostring(self) - - -def add_parser(parser): - """ - Add a beat evaluation sub-parser to an existing parser. - - Parameters - ---------- - parser : argparse parser instance - Existing argparse parser object. - - Returns - ------- - sub_parser : argparse sub-parser instance - Beat evaluation sub-parser. - parser_group : argparse argument group - Beat evaluation argument group. - - """ - import argparse - # add beat evaluation sub-parser to the existing parser - p = parser.add_parser( - 'beats', help='beat evaluation', - formatter_class=argparse.RawDescriptionHelpFormatter, - description=''' - This program evaluates pairs of files containing the beat annotations and - detections. Suffixes can be given to filter them from the list of files. - - Each line represents a beat and must have the following format with values - being separated by whitespace [brackets indicate optional values]: - `beat_time [beat_inside_bar]` - - Lines starting with # are treated as comments and are ignored. - - To maintain compatibility with the original Matlab implementation, use the - arguments '--skip 5 --no_triple'. Please note, that the results can still - differ, because of the different implementation approach. - - ''') - # set defaults - p.set_defaults(eval=BeatEvaluation, sum_eval=None, - mean_eval=BeatMeanEvaluation, load_fn=load_beats) - # file I/O - evaluation_io(p, ann_suffix='.beats', det_suffix='.beats.txt') - # parameters for sequence variants - s = p.add_argument_group('sequence manipulation arguments') - s.add_argument('--no_offbeat', dest='offbeat', action='store_false', - help='do not include offbeat evaluation') - s.add_argument('--no_double', dest='double', action='store_false', - help='do not include double/half tempo evaluation') - s.add_argument('--no_triple', dest='triple', action='store_false', - help='do not include triple/third tempo evaluation') - s.add_argument('--skip', action='store', type=float, default=0, - help='skip first N seconds for evaluation ' - '[default=%(default).3f]') - s.add_argument('--downbeats', action='store_true', - help='evaluate only downbeats') - # evaluation parameters - g = p.add_argument_group('beat evaluation arguments') - g.add_argument('--window', dest='fmeasure_window', action='store', - type=float, default=FMEASURE_WINDOW, - help='evaluation window for F-measure ' - '[seconds, default=%(default).3f]') - g.add_argument('--tolerance', dest='pscore_tolerance', action='store', - type=float, default=PSCORE_TOLERANCE, - help='evaluation tolerance for P-score ' - '[default=%(default).3f]') - g.add_argument('--sigma', dest='cemgil_sigma', action='store', type=float, - default=CEMGIL_SIGMA, - help='sigma for Cemgil accuracy [default=%(default).3f]') - g.add_argument('--goto_threshold', action='store', type=float, - default=GOTO_THRESHOLD, - help='threshold for Goto error [default=%(default).3f]') - g.add_argument('--goto_sigma', action='store', type=float, - default=GOTO_SIGMA, - help='sigma for Goto error [default=%(default).3f]') - g.add_argument('--goto_mu', action='store', type=float, - default=GOTO_MU, - help='µ for Goto error [default=%(default).3f]') - g.add_argument('--phase_tolerance', dest='continuity_phase_tolerance', - action='store', type=float, - default=CONTINUITY_PHASE_TOLERANCE, - help='phase tolerance window for continuity accuracies ' - '[default=%(default).3f]') - g.add_argument('--tempo_tolerance', dest='continuity_tempo_tolerance', - action='store', type=float, - default=CONTINUITY_TEMPO_TOLERANCE, - help='tempo tolerance window for continuity accuracies ' - '[default=%(default).3f]') - g.add_argument('--bins', dest='information_gain_bins', action='store', - type=int, default=INFORMATION_GAIN_BINS, - help='number of histogram bins for information gain ' - '[default=%(default)i]') - # return the sub-parser and evaluation argument group - return p, g diff --git a/spaces/MathysL/AutoGPT4/autogpt/memory/no_memory.py b/spaces/MathysL/AutoGPT4/autogpt/memory/no_memory.py deleted file mode 100644 index 0371e96ae89f5eb88dae019a66351a229596ed7a..0000000000000000000000000000000000000000 --- a/spaces/MathysL/AutoGPT4/autogpt/memory/no_memory.py +++ /dev/null @@ -1,73 +0,0 @@ -"""A class that does not store any data. This is the default memory provider.""" -from __future__ import annotations - -from typing import Any - -from autogpt.memory.base import MemoryProviderSingleton - - -class NoMemory(MemoryProviderSingleton): - """ - A class that does not store any data. This is the default memory provider. - """ - - def __init__(self, cfg): - """ - Initializes the NoMemory provider. - - Args: - cfg: The config object. - - Returns: None - """ - pass - - def add(self, data: str) -> str: - """ - Adds a data point to the memory. No action is taken in NoMemory. - - Args: - data: The data to add. - - Returns: An empty string. - """ - return "" - - def get(self, data: str) -> list[Any] | None: - """ - Gets the data from the memory that is most relevant to the given data. - NoMemory always returns None. - - Args: - data: The data to compare to. - - Returns: None - """ - return None - - def clear(self) -> str: - """ - Clears the memory. No action is taken in NoMemory. - - Returns: An empty string. - """ - return "" - - def get_relevant(self, data: str, num_relevant: int = 5) -> list[Any] | None: - """ - Returns all the data in the memory that is relevant to the given data. - NoMemory always returns None. - - Args: - data: The data to compare to. - num_relevant: The number of relevant data to return. - - Returns: None - """ - return None - - def get_stats(self): - """ - Returns: An empty dictionary as there are no stats in NoMemory. - """ - return {} diff --git a/spaces/MathysL/AutoGPT4/autogpt/memory/pinecone.py b/spaces/MathysL/AutoGPT4/autogpt/memory/pinecone.py deleted file mode 100644 index 27fcd62482d0cf44e02fa1c339195be58cb745b0..0000000000000000000000000000000000000000 --- a/spaces/MathysL/AutoGPT4/autogpt/memory/pinecone.py +++ /dev/null @@ -1,75 +0,0 @@ -import pinecone -from colorama import Fore, Style - -from autogpt.llm_utils import create_embedding_with_ada -from autogpt.logs import logger -from autogpt.memory.base import MemoryProviderSingleton - - -class PineconeMemory(MemoryProviderSingleton): - def __init__(self, cfg): - pinecone_api_key = cfg.pinecone_api_key - pinecone_region = cfg.pinecone_region - pinecone.init(api_key=pinecone_api_key, environment=pinecone_region) - dimension = 1536 - metric = "cosine" - pod_type = "p1" - table_name = "auto-gpt" - # this assumes we don't start with memory. - # for now this works. - # we'll need a more complicated and robust system if we want to start with - # memory. - self.vec_num = 0 - - try: - pinecone.whoami() - except Exception as e: - logger.typewriter_log( - "FAILED TO CONNECT TO PINECONE", - Fore.RED, - Style.BRIGHT + str(e) + Style.RESET_ALL, - ) - logger.double_check( - "Please ensure you have setup and configured Pinecone properly for use." - + f"You can check out {Fore.CYAN + Style.BRIGHT}" - "https://github.com/Torantulino/Auto-GPT#-pinecone-api-key-setup" - f"{Style.RESET_ALL} to ensure you've set up everything correctly." - ) - exit(1) - - if table_name not in pinecone.list_indexes(): - pinecone.create_index( - table_name, dimension=dimension, metric=metric, pod_type=pod_type - ) - self.index = pinecone.Index(table_name) - - def add(self, data): - vector = create_embedding_with_ada(data) - # no metadata here. We may wish to change that long term. - self.index.upsert([(str(self.vec_num), vector, {"raw_text": data})]) - _text = f"Inserting data into memory at index: {self.vec_num}:\n data: {data}" - self.vec_num += 1 - return _text - - def get(self, data): - return self.get_relevant(data, 1) - - def clear(self): - self.index.delete(deleteAll=True) - return "Obliviated" - - def get_relevant(self, data, num_relevant=5): - """ - Returns all the data in the memory that is relevant to the given data. - :param data: The data to compare to. - :param num_relevant: The number of relevant data to return. Defaults to 5 - """ - query_embedding = create_embedding_with_ada(data) - results = self.index.query( - query_embedding, top_k=num_relevant, include_metadata=True - ) - sorted_results = sorted(results.matches, key=lambda x: x.score) - return [str(item["metadata"]["raw_text"]) for item in sorted_results] - - def get_stats(self): - return self.index.describe_index_stats() diff --git a/spaces/Mohitsaini/app-alzh-disease/style/styles.css b/spaces/Mohitsaini/app-alzh-disease/style/styles.css deleted file mode 100644 index 422f3f367466529cdef09344ffce2dbb46f47742..0000000000000000000000000000000000000000 --- a/spaces/Mohitsaini/app-alzh-disease/style/styles.css +++ /dev/null @@ -1,33 +0,0 @@ -/* CSS Snippet from W3schools: https://www.w3schools.com/howto/howto_css_contact_form.asp */ -/* Style inputs with type="text", select elements and textareas */ -input[type=message], input[type=email], input[type=text], textarea { - width: 100%; /* Full width */ - padding: 12px; /* Some padding */ - border: 1px solid #ccc; /* Gray border */ - border-radius: 4px; /* Rounded borders */ - box-sizing: border-box; /* Make sure that padding and width stays in place */ - margin-top: 6px; /* Add a top margin */ - margin-bottom: 16px; /* Bottom margin */ - resize: vertical /* Allow the user to vertically resize the textarea (not horizontally) */ - } - - /* Style the submit button with a specific background color etc */ - button[type=submit] { - background-color: #04AA6D; - color: white; - padding: 12px 20px; - border: none; - border-radius: 4px; - cursor: pointer; - } - - /* When moving the mouse over the submit button, add a darker green color */ - button[type=submit]:hover { - background-color: #45a049; - } - - - /* Hide Streamlit Branding */ - #MainMenu {visibility: hidden;} - footer {visibility: hidden;} - header {visibility: hidden;} \ No newline at end of file diff --git a/spaces/MoonQiu/LongerCrafter/lvdm/models/autoencoder.py b/spaces/MoonQiu/LongerCrafter/lvdm/models/autoencoder.py deleted file mode 100644 index cc479d8b446b530885f4a3cc5d25cb58f0c00d74..0000000000000000000000000000000000000000 --- a/spaces/MoonQiu/LongerCrafter/lvdm/models/autoencoder.py +++ /dev/null @@ -1,219 +0,0 @@ -import os -from contextlib import contextmanager -import torch -import numpy as np -from einops import rearrange -import torch.nn.functional as F -import pytorch_lightning as pl -from lvdm.modules.networks.ae_modules import Encoder, Decoder -from lvdm.distributions import DiagonalGaussianDistribution -from utils.utils import instantiate_from_config - - -class AutoencoderKL(pl.LightningModule): - def __init__(self, - ddconfig, - lossconfig, - embed_dim, - ckpt_path=None, - ignore_keys=[], - image_key="image", - colorize_nlabels=None, - monitor=None, - test=False, - logdir=None, - input_dim=4, - test_args=None, - ): - super().__init__() - self.image_key = image_key - self.encoder = Encoder(**ddconfig) - self.decoder = Decoder(**ddconfig) - self.loss = instantiate_from_config(lossconfig) - assert ddconfig["double_z"] - self.quant_conv = torch.nn.Conv2d(2*ddconfig["z_channels"], 2*embed_dim, 1) - self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1) - self.embed_dim = embed_dim - self.input_dim = input_dim - self.test = test - self.test_args = test_args - self.logdir = logdir - if colorize_nlabels is not None: - assert type(colorize_nlabels)==int - self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1)) - if monitor is not None: - self.monitor = monitor - if ckpt_path is not None: - self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys) - if self.test: - self.init_test() - - def init_test(self,): - self.test = True - save_dir = os.path.join(self.logdir, "test") - if 'ckpt' in self.test_args: - ckpt_name = os.path.basename(self.test_args.ckpt).split('.ckpt')[0] + f'_epoch{self._cur_epoch}' - self.root = os.path.join(save_dir, ckpt_name) - else: - self.root = save_dir - if 'test_subdir' in self.test_args: - self.root = os.path.join(save_dir, self.test_args.test_subdir) - - self.root_zs = os.path.join(self.root, "zs") - self.root_dec = os.path.join(self.root, "reconstructions") - self.root_inputs = os.path.join(self.root, "inputs") - os.makedirs(self.root, exist_ok=True) - - if self.test_args.save_z: - os.makedirs(self.root_zs, exist_ok=True) - if self.test_args.save_reconstruction: - os.makedirs(self.root_dec, exist_ok=True) - if self.test_args.save_input: - os.makedirs(self.root_inputs, exist_ok=True) - assert(self.test_args is not None) - self.test_maximum = getattr(self.test_args, 'test_maximum', None) - self.count = 0 - self.eval_metrics = {} - self.decodes = [] - self.save_decode_samples = 2048 - - def init_from_ckpt(self, path, ignore_keys=list()): - sd = torch.load(path, map_location="cpu") - try: - self._cur_epoch = sd['epoch'] - sd = sd["state_dict"] - except: - self._cur_epoch = 'null' - keys = list(sd.keys()) - for k in keys: - for ik in ignore_keys: - if k.startswith(ik): - print("Deleting key {} from state_dict.".format(k)) - del sd[k] - self.load_state_dict(sd, strict=False) - # self.load_state_dict(sd, strict=True) - print(f"Restored from {path}") - - def encode(self, x, **kwargs): - - h = self.encoder(x) - moments = self.quant_conv(h) - posterior = DiagonalGaussianDistribution(moments) - return posterior - - def decode(self, z, **kwargs): - z = self.post_quant_conv(z) - dec = self.decoder(z) - return dec - - def forward(self, input, sample_posterior=True): - posterior = self.encode(input) - if sample_posterior: - z = posterior.sample() - else: - z = posterior.mode() - dec = self.decode(z) - return dec, posterior - - def get_input(self, batch, k): - x = batch[k] - if x.dim() == 5 and self.input_dim == 4: - b,c,t,h,w = x.shape - self.b = b - self.t = t - x = rearrange(x, 'b c t h w -> (b t) c h w') - - return x - - def training_step(self, batch, batch_idx, optimizer_idx): - inputs = self.get_input(batch, self.image_key) - reconstructions, posterior = self(inputs) - - if optimizer_idx == 0: - # train encoder+decoder+logvar - aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step, - last_layer=self.get_last_layer(), split="train") - self.log("aeloss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True) - self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=False) - return aeloss - - if optimizer_idx == 1: - # train the discriminator - discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step, - last_layer=self.get_last_layer(), split="train") - - self.log("discloss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True) - self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=False) - return discloss - - def validation_step(self, batch, batch_idx): - inputs = self.get_input(batch, self.image_key) - reconstructions, posterior = self(inputs) - aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, 0, self.global_step, - last_layer=self.get_last_layer(), split="val") - - discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, 1, self.global_step, - last_layer=self.get_last_layer(), split="val") - - self.log("val/rec_loss", log_dict_ae["val/rec_loss"]) - self.log_dict(log_dict_ae) - self.log_dict(log_dict_disc) - return self.log_dict - - def configure_optimizers(self): - lr = self.learning_rate - opt_ae = torch.optim.Adam(list(self.encoder.parameters())+ - list(self.decoder.parameters())+ - list(self.quant_conv.parameters())+ - list(self.post_quant_conv.parameters()), - lr=lr, betas=(0.5, 0.9)) - opt_disc = torch.optim.Adam(self.loss.discriminator.parameters(), - lr=lr, betas=(0.5, 0.9)) - return [opt_ae, opt_disc], [] - - def get_last_layer(self): - return self.decoder.conv_out.weight - - @torch.no_grad() - def log_images(self, batch, only_inputs=False, **kwargs): - log = dict() - x = self.get_input(batch, self.image_key) - x = x.to(self.device) - if not only_inputs: - xrec, posterior = self(x) - if x.shape[1] > 3: - # colorize with random projection - assert xrec.shape[1] > 3 - x = self.to_rgb(x) - xrec = self.to_rgb(xrec) - log["samples"] = self.decode(torch.randn_like(posterior.sample())) - log["reconstructions"] = xrec - log["inputs"] = x - return log - - def to_rgb(self, x): - assert self.image_key == "segmentation" - if not hasattr(self, "colorize"): - self.register_buffer("colorize", torch.randn(3, x.shape[1], 1, 1).to(x)) - x = F.conv2d(x, weight=self.colorize) - x = 2.*(x-x.min())/(x.max()-x.min()) - 1. - return x - -class IdentityFirstStage(torch.nn.Module): - def __init__(self, *args, vq_interface=False, **kwargs): - self.vq_interface = vq_interface # TODO: Should be true by default but check to not break older stuff - super().__init__() - - def encode(self, x, *args, **kwargs): - return x - - def decode(self, x, *args, **kwargs): - return x - - def quantize(self, x, *args, **kwargs): - if self.vq_interface: - return x, None, [None, None, None] - return x - - def forward(self, x, *args, **kwargs): - return x diff --git a/spaces/MoyerLiu/ChatGPT-Next-Web/Dockerfile b/spaces/MoyerLiu/ChatGPT-Next-Web/Dockerfile deleted file mode 100644 index 0bf993847550f9b292ce0dcb720c3a722b950a06..0000000000000000000000000000000000000000 --- a/spaces/MoyerLiu/ChatGPT-Next-Web/Dockerfile +++ /dev/null @@ -1,7 +0,0 @@ -FROM node:18 -RUN git clone https://github.com/Yidadaa/ChatGPT-Next-Web.git -WORKDIR "ChatGPT-Next-Web" -RUN npm i -RUN npm run build -EXPOSE 3000 -CMD ["npm", "run", "start"] \ No newline at end of file diff --git a/spaces/Mwebrania/classification_of_maize_diseases/app.py b/spaces/Mwebrania/classification_of_maize_diseases/app.py deleted file mode 100644 index 4ca9a8a9c55d876c27bbf493e3b5604114d830ad..0000000000000000000000000000000000000000 --- a/spaces/Mwebrania/classification_of_maize_diseases/app.py +++ /dev/null @@ -1,32 +0,0 @@ -import gradio as gr -from fastai.vision.all import * -import skimage - -#installed the fastai -from fastai import * -from fastai.vision import * -#from fastbook import * - -learn = load_learner('export.pkl') - -labels = learn.dls.vocab -def predict(img): - img = PILImage.create(img) - pred,pred_idx,probs = learn.predict(img) - return {labels[i]: float(probs[i]) for i in range(len(labels))} - -title = "CLASMA" -description = "AI app for classifying disease in crops leaves." -article = "sample image" -examples = ['corn.jpg'] -interpretation = 'default' -enable_queue = True - -gr.Interface(fn = predict, inputs = gr.inputs.Image(shape = (512, 512)), -outputs = gr.outputs.Label(num_top_classes = 3), -title = title, -description = description, -article = article, -examples = examples, -interpretation = interpretation, -enable_queue = enable_queue).launch() \ No newline at end of file diff --git a/spaces/NCTCMumbai/NCTC/models/research/adversarial_text/data/data_utils.py b/spaces/NCTCMumbai/NCTC/models/research/adversarial_text/data/data_utils.py deleted file mode 100644 index 55d9e3a0922d4ff54a4c6deb38b62be9bfa76c2e..0000000000000000000000000000000000000000 --- a/spaces/NCTCMumbai/NCTC/models/research/adversarial_text/data/data_utils.py +++ /dev/null @@ -1,332 +0,0 @@ -# Copyright 2017 Google Inc. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Utilities for generating/preprocessing data for adversarial text models.""" - -import operator -import os -import random -import re - -# Dependency imports - -import tensorflow as tf - -EOS_TOKEN = '' - -# Data filenames -# Sequence Autoencoder -ALL_SA = 'all_sa.tfrecords' -TRAIN_SA = 'train_sa.tfrecords' -TEST_SA = 'test_sa.tfrecords' -# Language Model -ALL_LM = 'all_lm.tfrecords' -TRAIN_LM = 'train_lm.tfrecords' -TEST_LM = 'test_lm.tfrecords' -# Classification -TRAIN_CLASS = 'train_classification.tfrecords' -TEST_CLASS = 'test_classification.tfrecords' -VALID_CLASS = 'validate_classification.tfrecords' -# LM with bidirectional LSTM -TRAIN_REV_LM = 'train_reverse_lm.tfrecords' -TEST_REV_LM = 'test_reverse_lm.tfrecords' -# Classification with bidirectional LSTM -TRAIN_BD_CLASS = 'train_bidir_classification.tfrecords' -TEST_BD_CLASS = 'test_bidir_classification.tfrecords' -VALID_BD_CLASS = 'validate_bidir_classification.tfrecords' - - -class ShufflingTFRecordWriter(object): - """Thin wrapper around TFRecordWriter that shuffles records.""" - - def __init__(self, path): - self._path = path - self._records = [] - self._closed = False - - def write(self, record): - assert not self._closed - self._records.append(record) - - def close(self): - assert not self._closed - random.shuffle(self._records) - with tf.python_io.TFRecordWriter(self._path) as f: - for record in self._records: - f.write(record) - self._closed = True - - def __enter__(self): - return self - - def __exit__(self, unused_type, unused_value, unused_traceback): - self.close() - - -class Timestep(object): - """Represents a single timestep in a SequenceWrapper.""" - - def __init__(self, token, label, weight, multivalent_tokens=False): - """Constructs Timestep from empty Features.""" - self._token = token - self._label = label - self._weight = weight - self._multivalent_tokens = multivalent_tokens - self._fill_with_defaults() - - @property - def token(self): - if self._multivalent_tokens: - raise TypeError('Timestep may contain multiple values; use `tokens`') - return self._token.int64_list.value[0] - - @property - def tokens(self): - return self._token.int64_list.value - - @property - def label(self): - return self._label.int64_list.value[0] - - @property - def weight(self): - return self._weight.float_list.value[0] - - def set_token(self, token): - if self._multivalent_tokens: - raise TypeError('Timestep may contain multiple values; use `add_token`') - self._token.int64_list.value[0] = token - return self - - def add_token(self, token): - self._token.int64_list.value.append(token) - return self - - def set_label(self, label): - self._label.int64_list.value[0] = label - return self - - def set_weight(self, weight): - self._weight.float_list.value[0] = weight - return self - - def copy_from(self, timestep): - self.set_token(timestep.token).set_label(timestep.label).set_weight( - timestep.weight) - return self - - def _fill_with_defaults(self): - if not self._multivalent_tokens: - self._token.int64_list.value.append(0) - self._label.int64_list.value.append(0) - self._weight.float_list.value.append(0.0) - - -class SequenceWrapper(object): - """Wrapper around tf.SequenceExample.""" - - F_TOKEN_ID = 'token_id' - F_LABEL = 'label' - F_WEIGHT = 'weight' - - def __init__(self, multivalent_tokens=False): - self._seq = tf.train.SequenceExample() - self._flist = self._seq.feature_lists.feature_list - self._timesteps = [] - self._multivalent_tokens = multivalent_tokens - - @property - def seq(self): - return self._seq - - @property - def multivalent_tokens(self): - return self._multivalent_tokens - - @property - def _tokens(self): - return self._flist[SequenceWrapper.F_TOKEN_ID].feature - - @property - def _labels(self): - return self._flist[SequenceWrapper.F_LABEL].feature - - @property - def _weights(self): - return self._flist[SequenceWrapper.F_WEIGHT].feature - - def add_timestep(self): - timestep = Timestep( - self._tokens.add(), - self._labels.add(), - self._weights.add(), - multivalent_tokens=self._multivalent_tokens) - self._timesteps.append(timestep) - return timestep - - def __iter__(self): - for timestep in self._timesteps: - yield timestep - - def __len__(self): - return len(self._timesteps) - - def __getitem__(self, idx): - return self._timesteps[idx] - - -def build_reverse_sequence(seq): - """Builds a sequence that is the reverse of the input sequence.""" - reverse_seq = SequenceWrapper() - - # Copy all but last timestep - for timestep in reversed(seq[:-1]): - reverse_seq.add_timestep().copy_from(timestep) - - # Copy final timestep - reverse_seq.add_timestep().copy_from(seq[-1]) - - return reverse_seq - - -def build_bidirectional_seq(seq, rev_seq): - bidir_seq = SequenceWrapper(multivalent_tokens=True) - for forward_ts, reverse_ts in zip(seq, rev_seq): - bidir_seq.add_timestep().add_token(forward_ts.token).add_token( - reverse_ts.token) - - return bidir_seq - - -def build_lm_sequence(seq): - """Builds language model sequence from input sequence. - - Args: - seq: SequenceWrapper. - - Returns: - SequenceWrapper with `seq` tokens copied over to output sequence tokens and - labels (offset by 1, i.e. predict next token) with weights set to 1.0, - except for
Slot:""" - for t, slot in zip(data["text"], data["slot"]): - html += """""" - html+="token. - """ - lm_seq = SequenceWrapper() - for i, timestep in enumerate(seq): - if i == len(seq) - 1: - lm_seq.add_timestep().set_token(timestep.token).set_label( - seq[i].token).set_weight(0.0) - else: - lm_seq.add_timestep().set_token(timestep.token).set_label( - seq[i + 1].token).set_weight(1.0) - return lm_seq - - -def build_seq_ae_sequence(seq): - """Builds seq_ae sequence from input sequence. - - Args: - seq: SequenceWrapper. - - Returns: - SequenceWrapper with `seq` inputs copied and concatenated, and with labels - copied in on the right-hand (i.e. decoder) side with weights set to 1.0. - The new sequence will have length `len(seq) * 2 - 1`, as the last timestep - of the encoder section and the first step of the decoder section will - overlap. - """ - seq_ae_seq = SequenceWrapper() - - for i in range(len(seq) * 2 - 1): - ts = seq_ae_seq.add_timestep() - - if i < len(seq) - 1: - # Encoder - ts.set_token(seq[i].token) - elif i == len(seq) - 1: - # Transition step - ts.set_token(seq[i].token) - ts.set_label(seq[0].token) - ts.set_weight(1.0) - else: - # Decoder - ts.set_token(seq[i % len(seq)].token) - ts.set_label(seq[(i + 1) % len(seq)].token) - ts.set_weight(1.0) - - return seq_ae_seq - - -def build_labeled_sequence(seq, class_label, label_gain=False): - """Builds labeled sequence from input sequence. - - Args: - seq: SequenceWrapper. - class_label: integer, starting from 0. - label_gain: bool. If True, class_label will be put on every timestep and - weight will increase linearly from 0 to 1. - - Returns: - SequenceWrapper with `seq` copied in and `class_label` added as label to - final timestep. - """ - label_seq = SequenceWrapper(multivalent_tokens=seq.multivalent_tokens) - - # Copy sequence without labels - seq_len = len(seq) - final_timestep = None - for i, timestep in enumerate(seq): - label_timestep = label_seq.add_timestep() - if seq.multivalent_tokens: - for token in timestep.tokens: - label_timestep.add_token(token) - else: - label_timestep.set_token(timestep.token) - if label_gain: - label_timestep.set_label(int(class_label)) - weight = 1.0 if seq_len < 2 else float(i) / (seq_len - 1) - label_timestep.set_weight(weight) - if i == (seq_len - 1): - final_timestep = label_timestep - - # Edit final timestep to have class label and weight = 1. - final_timestep.set_label(int(class_label)).set_weight(1.0) - - return label_seq - - -def split_by_punct(segment): - """Splits str segment by punctuation, filters our empties and spaces.""" - return [s for s in re.split(r'\W+', segment) if s and not s.isspace()] - - -def sort_vocab_by_frequency(vocab_freq_map): - """Sorts vocab_freq_map by count. - - Args: - vocab_freq_map: dict , vocabulary terms with counts. - - Returns: - list VITS语音在线合成demo\n" - " 主要有赛马娘,原神中文,原神日语,崩坏3的音色" - '' - '' - ) - - with gr.Tabs(): - with gr.TabItem("vits"): - with gr.Row(): - with gr.Column(): - input_text = gr.Textbox(label="Text (100 words limitation)", lines=5, value="今天晚上吃啥好呢。", elem_id=f"input-text") - lang = gr.Dropdown(label="Language", choices=["CN", "JP", "中日混合(中文用[ZH][ZH]包裹起来,日文用[JA][JA]包裹起来)"], - type="index", value="中文") - btn = gr.Button(value="Submit") - with gr.Row(): - search = gr.Textbox(label="Search Speaker", lines=1) - btn2 = gr.Button(value="Search") - sid = gr.Dropdown(label="Speaker", choices=speakers, type="index", value=speakers[228]) - with gr.Row(): - ns = gr.Slider(label="noise_scale(控制感情变化程度)", minimum=0.1, maximum=1.0, step=0.1, value=0.6, interactive=True) - nsw = gr.Slider(label="noise_scale_w(控制音素发音长度)", minimum=0.1, maximum=1.0, step=0.1, value=0.668, interactive=True) - ls = gr.Slider(label="length_scale(控制整体语速)", minimum=0.1, maximum=2.0, step=0.1, value=1.2, interactive=True) - with gr.Column(): - o1 = gr.Textbox(label="Output Message") - o2 = gr.Audio(label="Output Audio", elem_id=f"tts-audio") - o3 = gr.Textbox(label="Extra Info") - download = gr.Button("Download Audio") - btn.click(vits, inputs=[input_text, lang, sid, ns, nsw, ls], outputs=[o1, o2, o3]) - download.click(None, [], [], _js=download_audio_js.format()) - btn2.click(search_speaker, inputs=[search], outputs=[sid]) - lang.change(change_lang, inputs=[lang], outputs=[ns, nsw, ls]) - with gr.TabItem("可用人物一览"): - gr.Radio(label="Speaker", choices=speakers, interactive=False, type="index") - app.queue(concurrency_count=1).launch() diff --git a/spaces/Narrativaai/NLLB-Translator/README.md b/spaces/Narrativaai/NLLB-Translator/README.md deleted file mode 100644 index 9f921b89cd18baf27c7fac57d1244a3a72ca7832..0000000000000000000000000000000000000000 --- a/spaces/Narrativaai/NLLB-Translator/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: NLLB Translator -emoji: 🗺️ -colorFrom: purple -colorTo: pink -sdk: gradio -sdk_version: 3.0.26 -app_file: app.py -pinned: false -license: wtfpl ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Nee001/bing0/src/lib/isomorphic/index.ts b/spaces/Nee001/bing0/src/lib/isomorphic/index.ts deleted file mode 100644 index 738dc92f74079ab762d584fb7422a8c8c3b61547..0000000000000000000000000000000000000000 --- a/spaces/Nee001/bing0/src/lib/isomorphic/index.ts +++ /dev/null @@ -1,17 +0,0 @@ -'use client' - -import Default from './browser' - -let exportsModel: any = {} - -if (process.browser) { - Object.assign(exportsModel, require('./browser').default) -} else { - Object.assign(exportsModel, require('./node').default) -} - -export default exportsModel! as typeof Default - -export const fetch: typeof Default.fetch = exportsModel!.fetch -export const WebSocket: typeof Default.WebSocket = exportsModel!.WebSocket -export const debug: typeof Default.debug = exportsModel!.debug diff --git a/spaces/NeonLion92/Chat-and-Battle-with-Open-LLMs-Neon92/index.html b/spaces/NeonLion92/Chat-and-Battle-with-Open-LLMs-Neon92/index.html deleted file mode 100644 index b8e4df94bb5bf9644fda5057d1316c00f2e4ffbf..0000000000000000000000000000000000000000 --- a/spaces/NeonLion92/Chat-and-Battle-with-Open-LLMs-Neon92/index.html +++ /dev/null @@ -1,13 +0,0 @@ - - - - - - -Chat and Battle with Open LLMs - - - - - - \ No newline at end of file diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/speech_synthesis/docs/ljspeech_example.md b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/speech_synthesis/docs/ljspeech_example.md deleted file mode 100644 index 90c524fac8ffdc1819ec9bb36928500320337603..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/speech_synthesis/docs/ljspeech_example.md +++ /dev/null @@ -1,138 +0,0 @@ -[[Back]](..) - -# LJSpeech - -[LJSpeech](https://keithito.com/LJ-Speech-Dataset) is a public domain TTS -corpus with around 24 hours of English speech sampled at 22.05kHz. We provide examples for building -[Transformer](https://arxiv.org/abs/1809.08895) and [FastSpeech 2](https://arxiv.org/abs/2006.04558) -models on this dataset. - - -## Data preparation - -Download data, create splits and generate audio manifests with -```bash -python -m examples.speech_synthesis.preprocessing.get_ljspeech_audio_manifest \ - --output-data-root ${AUDIO_DATA_ROOT} \ - --output-manifest-root ${AUDIO_MANIFEST_ROOT} -``` - -Then, extract log-Mel spectrograms, generate feature manifest and create data configuration YAML with -```bash -python -m examples.speech_synthesis.preprocessing.get_feature_manifest \ - --audio-manifest-root ${AUDIO_MANIFEST_ROOT} \ - --output-root ${FEATURE_MANIFEST_ROOT} \ - --ipa-vocab --use-g2p -``` -where we use phoneme inputs (`--ipa-vocab --use-g2p`) as example. - -FastSpeech 2 additionally requires frame durations, pitch and energy as auxiliary training targets. -Add `--add-fastspeech-targets` to include these fields in the feature manifests. We get frame durations either from -phoneme-level force-alignment or frame-level pseudo-text unit sequence. They should be pre-computed and specified via: -- `--textgrid-zip ${TEXT_GRID_ZIP_PATH}` for a ZIP file, inside which there is one - [TextGrid](https://www.fon.hum.uva.nl/praat/manual/TextGrid.html) file per sample to provide force-alignment info. -- `--id-to-units-tsv ${ID_TO_UNIT_TSV}` for a TSV file, where there are 2 columns for sample ID and - space-delimited pseudo-text unit sequence, respectively. - -For your convenience, we provide pre-computed -[force-alignment](https://dl.fbaipublicfiles.com/fairseq/s2/ljspeech_mfa.zip) from -[Montreal Forced Aligner](https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner) and -[pseudo-text units](s3://dl.fbaipublicfiles.com/fairseq/s2/ljspeech_hubert.tsv) from -[HuBERT](https://github.com/pytorch/fairseq/tree/main/examples/hubert). You can also generate them by yourself using -a different software or model. - - -## Training -#### Transformer -```bash -fairseq-train ${FEATURE_MANIFEST_ROOT} --save-dir ${SAVE_DIR} \ - --config-yaml config.yaml --train-subset train --valid-subset dev \ - --num-workers 4 --max-tokens 30000 --max-update 200000 \ - --task text_to_speech --criterion tacotron2 --arch tts_transformer \ - --clip-norm 5.0 --n-frames-per-step 4 --bce-pos-weight 5.0 \ - --dropout 0.1 --attention-dropout 0.1 --activation-dropout 0.1 \ - --encoder-normalize-before --decoder-normalize-before \ - --optimizer adam --lr 2e-3 --lr-scheduler inverse_sqrt --warmup-updates 4000 \ - --seed 1 --update-freq 8 --eval-inference --best-checkpoint-metric mcd_loss -``` -where `SAVE_DIR` is the checkpoint root path. We set `--update-freq 8` to simulate 8 GPUs with 1 GPU. You may want to -update it accordingly when using more than 1 GPU. - -#### FastSpeech2 -```bash -fairseq-train ${FEATURE_MANIFEST_ROOT} --save-dir ${SAVE_DIR} \ - --config-yaml config.yaml --train-subset train --valid-subset dev \ - --num-workers 4 --max-sentences 6 --max-update 200000 \ - --task text_to_speech --criterion fastspeech2 --arch fastspeech2 \ - --clip-norm 5.0 --n-frames-per-step 1 \ - --dropout 0.1 --attention-dropout 0.1 --activation-dropout 0.1 \ - --encoder-normalize-before --decoder-normalize-before \ - --optimizer adam --lr 5e-4 --lr-scheduler inverse_sqrt --warmup-updates 4000 \ - --seed 1 --update-freq 8 --eval-inference --best-checkpoint-metric mcd_loss -``` - - -## Inference -Average the last 5 checkpoints, generate the test split spectrogram and waveform using the default Griffin-Lim vocoder: -```bash -SPLIT=test -CHECKPOINT_NAME=avg_last_5 -CHECKPOINT_PATH=${SAVE_DIR}/checkpoint_${CHECKPOINT_NAME}.pt -python scripts/average_checkpoints.py --inputs ${SAVE_DIR} \ - --num-epoch-checkpoints 5 \ - --output ${CHECKPOINT_PATH} - -python -m examples.speech_synthesis.generate_waveform ${FEATURE_MANIFEST_ROOT} \ - --config-yaml config.yaml --gen-subset ${SPLIT} --task text_to_speech \ - --path ${CHECKPOINT_PATH} --max-tokens 50000 --spec-bwd-max-iter 32 \ - --dump-waveforms -``` -which dumps files (waveform, feature, attention plot, etc.) to `${SAVE_DIR}/generate-${CHECKPOINT_NAME}-${SPLIT}`. To -re-synthesize target waveforms for automatic evaluation, add `--dump-target`. - -## Automatic Evaluation -To start with, generate the manifest for synthetic speech, which will be taken as inputs by evaluation scripts. -```bash -python -m examples.speech_synthesis.evaluation.get_eval_manifest \ - --generation-root ${SAVE_DIR}/generate-${CHECKPOINT_NAME}-${SPLIT} \ - --audio-manifest ${AUDIO_MANIFEST_ROOT}/${SPLIT}.audio.tsv \ - --output-path ${EVAL_OUTPUT_ROOT}/eval.tsv \ - --vocoder griffin_lim --sample-rate 22050 --audio-format flac \ - --use-resynthesized-target -``` -Speech recognition (ASR) models usually operate at lower sample rates (e.g. 16kHz). For the WER/CER metric, -you may need to resample the audios accordingly --- add `--output-sample-rate 16000` for `generate_waveform.py` and -use `--sample-rate 16000` for `get_eval_manifest.py`. - - -#### WER/CER metric -We use wav2vec 2.0 ASR model as example. [Download](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec) -the model checkpoint and dictionary, then compute WER/CER with -```bash -python -m examples.speech_synthesis.evaluation.eval_asr \ - --audio-header syn --text-header text --err-unit char --split ${SPLIT} \ - --w2v-ckpt ${WAV2VEC2_CHECKPOINT_PATH} --w2v-dict-dir ${WAV2VEC2_DICT_DIR} \ - --raw-manifest ${EVAL_OUTPUT_ROOT}/eval_16khz.tsv --asr-dir ${EVAL_OUTPUT_ROOT}/asr -``` - -#### MCD/MSD metric -```bash -python -m examples.speech_synthesis.evaluation.eval_sp \ - ${EVAL_OUTPUT_ROOT}/eval.tsv --mcd --msd -``` - -#### F0 metrics -```bash -python -m examples.speech_synthesis.evaluation.eval_f0 \ - ${EVAL_OUTPUT_ROOT}/eval.tsv --gpe --vde --ffe -``` - - -## Results - -| --arch | Params | Test MCD | Model | -|---|---|---|---| -| tts_transformer | 54M | 3.8 | [Download](https://dl.fbaipublicfiles.com/fairseq/s2/ljspeech_transformer_phn.tar) | -| fastspeech2 | 41M | 3.8 | [Download](https://dl.fbaipublicfiles.com/fairseq/s2/ljspeech_fastspeech2_phn.tar) | - -[[Back]](..) diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/speech_synthesis/evaluation/get_eval_manifest.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/speech_synthesis/evaluation/get_eval_manifest.py deleted file mode 100644 index a28cd607a096844438f6a3ba6b007d94d67d1bc8..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/speech_synthesis/evaluation/get_eval_manifest.py +++ /dev/null @@ -1,58 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - - -import csv -from pathlib import Path - - -def main(args): - """ - `uid syn ref text` - """ - in_root = Path(args.generation_root).resolve() - ext = args.audio_format - with open(args.audio_manifest) as f, open(args.output_path, "w") as f_out: - reader = csv.DictReader( - f, delimiter="\t", quotechar=None, doublequote=False, - lineterminator="\n", quoting=csv.QUOTE_NONE - ) - header = ["id", "syn", "ref", "text", "speaker"] - f_out.write("\t".join(header) + "\n") - for row in reader: - dir_name = f"{ext}_{args.sample_rate}hz_{args.vocoder}" - id_ = row["id"] - syn = (in_root / dir_name / f"{id_}.{ext}").as_posix() - ref = row["audio"] - if args.use_resynthesized_target: - ref = (in_root / f"{dir_name}_tgt" / f"{id_}.{ext}").as_posix() - sample = [id_, syn, ref, row["tgt_text"], row["speaker"]] - f_out.write("\t".join(sample) + "\n") - print(f"wrote evaluation file to {args.output_path}") - - -if __name__ == "__main__": - import argparse - parser = argparse.ArgumentParser() - parser.add_argument( - "--generation-root", help="output directory for generate_waveform.py" - ) - parser.add_argument( - "--audio-manifest", - help="used to determine the original utterance ID and text" - ) - parser.add_argument( - "--output-path", help="path to output evaluation spec file" - ) - parser.add_argument( - "--use-resynthesized-target", action="store_true", - help="use resynthesized reference instead of the original audio" - ) - parser.add_argument("--vocoder", type=str, default="griffin_lim") - parser.add_argument("--sample-rate", type=int, default=22_050) - parser.add_argument("--audio-format", type=str, default="wav") - args = parser.parse_args() - - main(args) diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/wav2vec/unsupervised/scripts/ltr_to_wrd.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/wav2vec/unsupervised/scripts/ltr_to_wrd.py deleted file mode 100644 index 36c85d1e2f60487494a92207feb4685e78db8aa2..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/wav2vec/unsupervised/scripts/ltr_to_wrd.py +++ /dev/null @@ -1,16 +0,0 @@ -#!/usr/bin/env python3 -u -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import sys - - -def main(): - for line in sys.stdin: - print(line.replace(" ", "").replace("|", " ").strip()) - - -if __name__ == "__main__": - main() diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/tasks/online_backtranslation.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/tasks/online_backtranslation.py deleted file mode 100644 index 2e27ca237cde1980b2c3ca497e12f458da230c37..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/tasks/online_backtranslation.py +++ /dev/null @@ -1,682 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import contextlib -import json -import logging -import math -import os -from argparse import Namespace -from collections import OrderedDict, defaultdict -from pathlib import Path -from typing import Dict, Sequence, Tuple -from argparse import ArgumentError - -import numpy as np -import torch -import torch.nn as nn -import torch.nn.functional as F - -import fairseq -from fairseq import metrics, options, utils -from fairseq.data import ( - FairseqDataset, - LanguagePairDataset, - NoisingDataset, - PrependTokenDataset, - RoundRobinZipDatasets, - TransformEosLangPairDataset, - data_utils, - encoders, -) -from fairseq.sequence_generator import SequenceGenerator -from fairseq.tasks import register_task -from fairseq.tasks.translation import TranslationTask, load_langpair_dataset - -logger = logging.getLogger(__name__) - - -class PiecewiseLinearFn: - """Piecewise linear function. Can be configured with a string.""" - - def __init__(self, pieces: Sequence[Tuple[int, float]]): - assert pieces == sorted( - pieces - ), f"PiecewiseLinearFn configuration should be sorted, received: {pieces}" - - self.pieces = pieces - - def __call__(self, x: int) -> float: - for i, (x_a, y_a) in enumerate(self.pieces[:-1]): - x_b, y_b = self.pieces[i + 1] - if x_a <= x <= x_b: - return y_a + (x - x_a) * (y_b - y_a) / (x_b - x_a) - - return self.pieces[-1][1] - - @staticmethod - def from_string(configuration: str) -> "PiecewiseLinearFn": - """ - Parse the configuration of lambda coefficient (for scheduling). - x = "3" # lambda will be a constant equal to x - x = "0:1,1000:0" # lambda will start from 1 and linearly decrease - # to 0 during the first 1000 iterations - x = "0:0,1000:0,2000:1" # lambda will be equal to 0 for the first 1000 - # iterations, then will linearly increase to 1 until iteration 2000 - """ - if isinstance(configuration, float): - return PiecewiseLinearFn([(0, configuration)]) - - try: - parts = configuration.split(",") - if len(parts) == 1: - v = float(configuration) - return PiecewiseLinearFn([(0, v)]) - - split = [s.split(":") for s in parts] - pieces = [(int(t), float(v)) for t, v in split] - return PiecewiseLinearFn(pieces) - except Exception: - raise ValueError( - f"Invalid PiecewiseLinearFn configuration: {configuration!r}" - ) - - @staticmethod - def one() -> "PiecewiseLinearFn": - return PiecewiseLinearFn([(0, 1.0)]) - - -@register_task("online_backtranslation") -class OnlineBackTranslationTask(TranslationTask): - @staticmethod - def add_args(parser): - """Add task-specific arguments to the parser.""" - # fmt: off - # Generic translation args - parser.add_argument('data', help='colon separated path to data directories list, \ - will be iterated upon during epochs in round-robin manner; \ - however, valid and test data are always in the first directory to \ - avoid the need for repeating them in all directories') - parser.add_argument('--mono-langs', metavar='MONO_LANGS', - help='monolingual languages for training') - parser.add_argument('--valid-lang-pairs', default=None, metavar='VALID_LANG_PAIRS', - help='language pairs for validation') - parser.add_argument('--load-alignments', action='store_true', - help='load the binarized alignments') - parser.add_argument('--left-pad-source', default='False', type=str, metavar='BOOL', - help='pad the source on the left') - parser.add_argument('--left-pad-target', default='False', type=str, metavar='BOOL', - help='pad the target on the left') - parser.add_argument('--upsample-primary', default=1, type=int, - help='amount to upsample primary dataset') - try: - parser.add_argument('--max-source-positions', default=1024, type=int, metavar='N', - help='max number of tokens in the source sequence') - parser.add_argument('--max-target-positions', default=1024, type=int, metavar='N', - help='max number of tokens in the target sequence') - except ArgumentError: - # this might have already been defined. Once we transition this to hydra it should be fine to add it here. - pass - parser.add_argument('--truncate-source', action='store_true', default=False, - help='truncate source to max-source-positions') - parser.add_argument('--num-batch-buckets', default=0, type=int, metavar='N', - help='if >0, then bucket source and target lengths into N ' - 'buckets and pad accordingly; this is useful on TPUs ' - 'to minimize the number of compilations') - - # Denoising args - parser.add_argument('--max-word-shuffle-distance', default=3.0, type=float, metavar='N', - help='maximum word shuffle distance for denoising autoencoding data generation') - parser.add_argument('--word-dropout-prob', default=0.1, type=float, metavar='N', - help='word dropout probability for denoising autoencoding data generation') - parser.add_argument('--word-blanking-prob', default=0.2, type=float, metavar='N', - help='word blanking probability for denoising autoencoding data generation') - - # Backtranslation args - parser.add_argument('--lambda-bt', default="1.0", type=str, metavar='N', - help='back-translation weight') - parser.add_argument('--lambda-dae', default="1.0", type=str, metavar='N', - help='denoising auto-encoder weight') - - # Evaluation args - parser.add_argument('--generate-one-by-one', action='store_true', - help='generate one sentence at a time for backtranslation') - - parser.add_argument('--eval-bleu', action='store_true', - help='evaluation with BLEU scores') - parser.add_argument('--eval-bleu-detok', type=str, default="space", - help='detokenize before computing BLEU (e.g., "moses"); ' - 'required if using --eval-bleu; use "space" to ' - 'disable detokenization; see fairseq.data.encoders ' - 'for other options') - parser.add_argument('--eval-bleu-detok-args', type=str, metavar='JSON', - help='args for building the tokenizer, if needed') - parser.add_argument('--eval-tokenized-bleu', action='store_true', default=False, - help='compute tokenized BLEU instead of sacrebleu') - parser.add_argument('--eval-bleu-remove-bpe', nargs='?', const='@@ ', default=None, - help='remove BPE before computing BLEU') - parser.add_argument('--eval-bleu-args', type=str, metavar='JSON', - help='generation args for BLUE scoring, ' - 'e.g., \'{"beam": 4, "lenpen": 0.6}\'') - parser.add_argument('--eval-bleu-print-samples', action='store_true', - help='print sample generations during validation') - # fmt: on - - def __init__(self, args, common_dict, mono_langs, valid_lang_pairs): - super().__init__(args, common_dict, common_dict) - self.common_dict = common_dict - self.mono_langs = mono_langs - self.valid_lang_pairs = valid_lang_pairs - - self.SHOW_SAMPLES_INTERVAL = 1000 - # Start by showing samples - self._show_samples_ctr = self.SHOW_SAMPLES_INTERVAL - self.SHOW_SAMPLES_NUMBER = 5 - self.lambda_bt = PiecewiseLinearFn.from_string(args.lambda_bt) - self.lambda_dae = PiecewiseLinearFn.from_string(args.lambda_dae) - - self.args = args - self.data = utils.split_paths(self.args.data) - if len(self.data) == 1: - shards = list(Path(self.data[0]).glob("shard*")) - if len(shards) > 0: - # keep this as strings, since it can also be a manifold path - old_data = self.data - self.data = [str(shard) for shard in shards] - logging.warning(f"Expanded data directory {old_data} to {self.data}") - - @classmethod - def setup_task(cls, args, **kwargs): - """Setup the task (e.g., load dictionaries). - - Args: - args (argparse.Namespace): parsed command-line arguments - """ - args.left_pad_source = options.eval_bool(args.left_pad_source) - args.left_pad_target = options.eval_bool(args.left_pad_target) - - paths = utils.split_paths(args.data) - assert len(paths) > 0 - assert args.mono_langs is not None - - mono_langs = args.mono_langs.split(",") - valid_lang_pairs = args.valid_lang_pairs.split(",") - - # load dictionary - dict_path = os.path.join(paths[0], "dict.txt") - common_dict = cls.load_dictionary(dict_path) - - return cls(args, common_dict, mono_langs, valid_lang_pairs) - - def load_dataset(self, split, epoch=1, combine=False, **kwargs) -> FairseqDataset: - """Load a given dataset split. - - Args: - split (str): name of the split (e.g., train, valid, test) - """ - if split == "train": - data_path = self.data[(epoch - 1) % len(self.data)] - dataset = self.load_train_dataset(data_path) - else: - # valid/test should always be the same. - dataset = self.load_translation_dataset(split, self.data[0]) - - self.datasets[split] = dataset - return dataset - - def load_train_dataset(self, data_path: str) -> FairseqDataset: - """The training dataset is made of backtranslation dataset and denoising dataset.""" - data = [] - for lang in self.mono_langs: - train_path = os.path.join(data_path, lang, "train") - # TODO: could we do the BT using denoise sample ? - # this would half the data loading work - data.append((f"{lang}-BT", self.load_bt_dataset(train_path, lang))) - data.append( - (f"{lang}-DENOISE", self.load_denoise_dataset(train_path, lang)) - ) - - return RoundRobinZipDatasets(OrderedDict(data)) - - def _langpair_dataset( - self, src: FairseqDataset, tgt: FairseqDataset - ) -> LanguagePairDataset: - return LanguagePairDataset( - src, - src.sizes, - self.dictionary, - tgt=tgt, - tgt_sizes=tgt.sizes, - tgt_dict=self.dictionary, - left_pad_source=self.args.left_pad_source, - left_pad_target=self.args.left_pad_target, - # TODO: should we shuffle ? we are already sorting batch by sizes so ? - # shuffle=True, - ) - - def _prepend_lang_bos_to_target( - self, dataset: LanguagePairDataset, lang: str - ) -> LanguagePairDataset: - bos = _lang_token_index(self.dictionary, lang) - return TransformEosLangPairDataset( - dataset, - src_eos=self.dictionary.eos(), - new_src_eos=self.dictionary.eos(), - tgt_bos=self.dictionary.eos(), - new_tgt_bos=bos, - ) - - def load_bt_dataset(self, data_path: str, lang: str) -> FairseqDataset: - """The BT dataset is generated with (tgt, tgt) pairs. - The actual translation to a (generated_src, tgt) pair - is done on the fly during training. - """ - mono_dataset = data_utils.load_indexed_dataset( - data_path, self.common_dict, self.args.dataset_impl - ) - assert mono_dataset is not None, f"No dataset found for {lang}" - - mono_dataset_src = PrependTokenDataset( - mono_dataset, _lang_token_index(self.dictionary, lang) - ) - - mono_dataset_bt = self._langpair_dataset(mono_dataset_src, mono_dataset) - logger.info( - f"mono_lang = {lang} " - f"lang token index = {_lang_token_index(self.dictionary, lang)} " - f"lang token = {_lang_token(lang)}" - ) - - mono_dataset_bt = self._prepend_lang_bos_to_target(mono_dataset_bt, lang) - return mono_dataset_bt - - def load_denoise_dataset(self, data_path: str, lang: str) -> FairseqDataset: - """Classic denoising dataset""" - dataset = data_utils.load_indexed_dataset( - data_path, self.common_dict, self.args.dataset_impl - ) - noisy_dataset = NoisingDataset( - dataset, - self.dictionary, - seed=1, - max_word_shuffle_distance=self.args.max_word_shuffle_distance, - word_dropout_prob=self.args.word_dropout_prob, - word_blanking_prob=self.args.word_blanking_prob, - ) - noisy_dataset = PrependTokenDataset( - noisy_dataset, _lang_token_index(self.dictionary, lang) - ) - - clean_dataset = data_utils.load_indexed_dataset( - data_path, self.common_dict, self.args.dataset_impl - ) - denoising_dataset = self._langpair_dataset(noisy_dataset, clean_dataset) - denoising_dataset = self._prepend_lang_bos_to_target(denoising_dataset, lang) - return denoising_dataset - - def load_translation_dataset( - self, split: str, data_path: str, combine: bool = False - ): - # only judging with one language pair for the moment, - # since ConcatDataset doesn't work as expected - assert len(self.valid_lang_pairs) == 1, "For now..." - valid_lang_pair = self.valid_lang_pairs[0] - src, tgt = valid_lang_pair.split("-") - - # use the same function than TranslationTask - src_tgt_dt = load_langpair_dataset( - data_path, - split, - src, - self.common_dict, - tgt, - self.common_dict, - combine=combine, - dataset_impl=self.args.dataset_impl, - upsample_primary=self.args.upsample_primary, - left_pad_source=self.args.left_pad_source, - left_pad_target=self.args.left_pad_target, - max_source_positions=self.args.max_source_positions, - max_target_positions=self.args.max_target_positions, - load_alignments=self.args.load_alignments, - truncate_source=self.args.truncate_source, - num_buckets=self.args.num_batch_buckets, - shuffle=(split != "test"), - prepend_bos_src=_lang_token_index(self.dictionary, src), - ) - - src_tgt_eos_dt = self._prepend_lang_bos_to_target(src_tgt_dt, tgt) - src_tgt_eos_dt.args = self.args - return src_tgt_eos_dt - - def build_dataset_for_inference(self, src_tokens, src_lengths, constraints=None): - raise NotImplementedError - - def build_model(self, args): - # torch.autograd.set_detect_anomaly(True) - model = super().build_model(args) - - add_secial_tokens_to_dict_and_model(self.common_dict, model, self.mono_langs) - - self.sequence_generators = {} - for mono_lang in self.mono_langs: - self.sequence_generators[mono_lang] = SequenceGenerator( - [model], - tgt_dict=self.dictionary, - beam_size=1, - max_len_a=1.3, - max_len_b=5, - min_len=5, - # keep 1 to be able to prepend bos - max_len=model.max_decoder_positions() - 1, - ) - - if getattr(args, "eval_bleu", False): - assert getattr(args, "eval_bleu_detok", None) is not None, ( - "--eval-bleu-detok is required if using --eval-bleu; " - "try --eval-bleu-detok=moses (or --eval-bleu-detok=space " - "to disable detokenization, e.g., when using sentencepiece)" - ) - detok_args = json.loads(getattr(args, "eval_bleu_detok_args", "{}") or "{}") - self.tokenizer = encoders.build_tokenizer( - Namespace( - tokenizer=getattr(args, "eval_bleu_detok", None), **detok_args - ) - ) - - gen_args = json.loads(getattr(args, "eval_bleu_args", "{}") or "{}") - self.bleu_sequence_generator = self.build_generator( - [model], Namespace(**gen_args) - ) - - return model - - def max_positions(self): - """Return the max sentence length allowed by the task.""" - return (self.args.max_source_positions, self.args.max_target_positions) - - @property - def dictionary(self): - """Return the source :class:`~fairseq.data.Dictionary`.""" - return self.common_dict - - def display_samples_once_in_a_while(self, smp, mono_lang, other_lang): - self._show_samples_ctr += 1 - if self._show_samples_ctr < self.SHOW_SAMPLES_INTERVAL: - return - self._show_samples_ctr = 0 - - ln = smp["net_input"]["src_tokens"].shape[0] - - logger.info( - f"(r:{self.args.distributed_rank}) : " - f"{other_lang} ---> {mono_lang} " - f"({other_lang} was generated by back-translation.) {ln} samples" - ) - - for i in range(min(ln, self.SHOW_SAMPLES_NUMBER)): - src_tokens = smp["net_input"]["src_tokens"][i] - tgt_tokens = smp["target"][i] - - src_str = self.dictionary.string(src_tokens, "sentencepiece") - tgt_str = self.dictionary.string(tgt_tokens, "sentencepiece") - logger.info( - f"\n{i}\t\t[{other_lang} generated] {src_str}\n" - f"\t\t[{mono_lang} original ] {tgt_str}\n" - f"\t\t[ src tokens] {src_tokens}\n" - ) - - def backtranslate_sample(self, smp, orig_lang, other_lang) -> None: - """ - * WARNING: smp is modified in place. - * At the start of this function, `smp` has the same input and target: - |--------------------------------------------------------| - | smp['net_input']['src_tokens'] | smp['target'] | - | (from data) __en__ hello world | __en__ hello world | - |--------------------------------------------------------| - - * We call generator.generate(smp, bos_token = token("ro")), - and copy the result as input - * At the end, `smp` has the translation to other language. - |--------------------------------------------------------| - | smp['net_input']['src_tokens'] | smp['target'] | - | (generated) __ro__ salut lume | __en__ hello world | - |--------------------------------------------------------| - - """ - bos_token = _lang_token_index(self.dictionary, other_lang) - generated = self.sequence_generators[orig_lang].generate( - models=[], sample=smp, bos_token=bos_token - ) - - max_lngth = max([gn[0]["tokens"].size(0) for gn in generated]) - net_input = smp["net_input"] - n_src_tokens = torch.empty( - size=(len(generated), max_lngth + 1), dtype=net_input["src_tokens"].dtype - ) - n_src_lengths = torch.empty( - len(generated), dtype=net_input["src_lengths"].dtype - ) - - for i, gn in enumerate(generated): - tokens = gn[0]["tokens"] - tokens_size = tokens.size(0) - padding_needed = max_lngth - tokens_size - tokens = torch.cat([tokens.new([bos_token]), tokens]) - tokens = F.pad(tokens, (0, padding_needed), value=self.dictionary.pad()) - n_src_tokens[i] = tokens - n_src_lengths[i] = tokens_size + 1 - - device = net_input["src_tokens"].device - # This seems to be important - del net_input["src_tokens"] - del net_input["src_lengths"] - net_input["src_tokens"] = n_src_tokens.to(device) - net_input["src_lengths"] = n_src_lengths.to(device) - - def generate(self, smp, model): - model.eval() - orig_lang = ( - self.dictionary[smp["net_input"]["src_tokens"][0][0]] - .replace(" ", "") - .replace("_", "") - ) - bos_token = smp["net_input"]["prev_output_tokens"][0][0] - with torch.no_grad(): - generated = self.sequence_generators[orig_lang].generate( - models=[model], sample=smp, bos_token=bos_token - ) - return generated - - def get_other_lang(self, lang): - # TODO: allow more complex mapping - if lang != self.mono_langs[0]: - return self.mono_langs[0] - if len(self.mono_langs) == 2: - return self.mono_langs[1] - return self.mono_langs[np.random.randint(1, len(self.mono_langs))] - - def train_step( - self, sample, model, criterion, optimizer, update_num, ignore_grad=False - ): - - model.train() - model.set_num_updates(update_num) - - agg_loss, agg_sample_size = 0.0, 0.0 - agg_logging_output: Dict[str, float] = defaultdict(float) - - dataset_keys = self.datasets["train"].datasets.keys() - - weights = { - "BT": self.lambda_bt(update_num), - "DENOISE": self.lambda_dae(update_num), - } - log_keys = {"BT": "bt_", "DENOISE": "dae_"} - - for dataset_key in dataset_keys: - smp = sample[dataset_key] - mono_lang, task_subtype = dataset_key.split("-") - if weights[task_subtype] == 0: - continue - - if task_subtype == "BT": - with torch.autograd.profiler.record_function("backtranslation"): - model.eval() - # TODO: Could we translate to several language at once ? - # this would allow to share encoder_out and maximize GPU usage. - other_lang = self.get_other_lang(mono_lang) - self.backtranslate_sample(smp, mono_lang, other_lang) - self.display_samples_once_in_a_while(smp, mono_lang, other_lang) - model.train() - - # Like in FairseqTask.train_step - with torch.autograd.profiler.record_function("forward"): - loss, sample_size, logging_output = criterion(model, smp) - loss *= weights[task_subtype] - if ignore_grad: - loss *= 0 - with torch.autograd.profiler.record_function("backward"): - optimizer.backward(loss) - - agg_loss += loss.item() - agg_sample_size += sample_size - for k in logging_output: - agg_logging_output[log_keys[task_subtype] + k] += logging_output[k] - agg_logging_output[k] += logging_output[k] - - return agg_loss, agg_sample_size, agg_logging_output - - def get_bos_token_from_sample(self, sample): - net_input = sample["net_input"] - source_lang_token_id = torch.unique(net_input["src_tokens"][:, 0]).item() - source_lang_token = self.dictionary[source_lang_token_id].replace("_", "") - target_lang_token_id = _lang_token_index( - self.dictionary, self.get_other_lang(source_lang_token) - ) - - return target_lang_token_id - - def reduce_metrics(self, logging_outputs, criterion): - super().reduce_metrics(logging_outputs, criterion) - bt_sample_size = sum(x.get("bt_sample_size", 0) for x in logging_outputs) - if bt_sample_size: - bt_loss_sum = sum(x.get("bt_loss", 0) for x in logging_outputs) - bt_loss_sum *= 1 / bt_sample_size / math.log(2) - metrics.log_scalar("bt_loss", bt_loss_sum, bt_sample_size, round=3) - - bt_nll_loss_sum = sum(x.get("bt_nll_loss", 0) for x in logging_outputs) - bt_ntokens = sum(x.get("bt_ntokens", 0) for x in logging_outputs) - bt_nll_loss_sum *= 1 / bt_ntokens / math.log(2) - metrics.log_scalar("bt_nll_loss", bt_nll_loss_sum, bt_ntokens, round=3) - metrics.log_derived( - "bt_ppl", lambda meters: utils.get_perplexity(meters["bt_nll_loss"].avg) - ) - - dae_sample_size = sum(x.get("dae_sample_size", 0) for x in logging_outputs) - if dae_sample_size: - dae_loss_sum = sum(x.get("dae_loss", 0) for x in logging_outputs) - dae_loss_sum *= 1 / dae_sample_size / math.log(2) - metrics.log_scalar("dae_loss", dae_loss_sum, dae_sample_size, round=3) - - dae_nll_loss_sum = sum(x.get("dae_nll_loss", 0) for x in logging_outputs) - dae_ntokens = sum(x.get("dae_ntokens", 0) for x in logging_outputs) - dae_nll_loss_sum *= 1 / dae_ntokens / math.log(2) - metrics.log_scalar("dae_nll_loss", dae_nll_loss_sum, dae_ntokens, round=3) - metrics.log_derived( - "dae_ppl", - lambda meters: utils.get_perplexity(meters["dae_nll_loss"].avg), - ) - - -@torch.no_grad() -def extend_embedding( - emb: nn.Module, new_vocab_size: int, copy_from_token_id: int -) -> None: - old_emb_data = emb.weight.data - (old_vocab_size, dim) = old_emb_data.shape - assert new_vocab_size >= old_vocab_size - - if new_vocab_size > old_vocab_size: - emb.weight.data = torch.zeros((new_vocab_size, dim)) - emb.weight.data[:old_vocab_size, :] = old_emb_data - # initialize new embeddings - emb.weight.data[old_vocab_size:, :] = old_emb_data[copy_from_token_id] - if hasattr(emb, "num_embeddings"): - emb.num_embeddings = new_vocab_size - if hasattr(emb, "out_features"): - emb.out_features = new_vocab_size - - if getattr(emb, "bias", None) is None: - return - - # Fix the bias. - # Bias shape can be different from the previous vocab size - # if the weight matrix was shared and alread extended but not the bias. - (old_vocab_size,) = emb.bias.shape - assert new_vocab_size >= old_vocab_size - if new_vocab_size > old_vocab_size: - old_bias = emb.bias.data - new_bias = torch.zeros( - (new_vocab_size,), dtype=old_bias.dtype, device=old_bias.device - ) - new_bias[:old_vocab_size] = old_bias - emb.bias.data = new_bias - - -def add_secial_tokens_to_dict_and_model( - dictionary: "fairseq.data.Dictionary", - model: nn.Module, - mono_langs: Sequence[str], -) -> None: - embs = model.encoder.embed_tokens - vocab_size, embedding_dim = embs.weight.shape - - # The model may or may not have a '' embedding yet - assert ( - len(dictionary) <= vocab_size <= len(dictionary) + 1 - ), f"Dictionary len ({len(dictionary)}) doesn't match embs shape ({embs.weight.shape})" - # TODO: we should reuse the pretrained model dict which already has - dictionary.add_symbol(" ") - - for lang in mono_langs: - lang_token = _lang_token(lang) - dictionary.add_symbol(lang_token) - logger.info( - f"dictionary: {len(dictionary)} -> {vocab_size} tokens " - f"after adding {len(mono_langs)} lang tokens." - ) - - if len(dictionary) <= vocab_size: - return - - extend_embedding(embs, len(dictionary), dictionary.bos()) - dec_embs = model.decoder.embed_tokens - extend_embedding(dec_embs, len(dictionary), dictionary.bos()) - lm_head = model.decoder.output_projection - extend_embedding(lm_head, len(dictionary), dictionary.bos()) - assert lm_head.weight.shape == (len(dictionary), embedding_dim) - - -def _lang_token(lang: str) -> str: - return f"__{lang}__" - - -def _lang_token_index(dictionary, lang: str) -> int: - return dictionary.index(_lang_token(lang)) - - -@contextlib.contextmanager -def assert_weights_have_changed(model: nn.Module): - def checksum(model: nn.Module) -> float: - return sum(p.sum().item() for p in model.parameters()) - - initial_checksum = checksum(model) - yield model - final_checksum = checksum(model) - logger.info( - f"initial_checksum={initial_checksum} -> final_checksum={final_checksum}" - ) - assert initial_checksum != final_checksum, "Model hasn't changed !" diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/bart/README.summarization.md b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/bart/README.summarization.md deleted file mode 100644 index 8727584f2b2bdd880c6cd3abbf39b75dfbf4a67c..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/bart/README.summarization.md +++ /dev/null @@ -1,102 +0,0 @@ -# Fine-tuning BART on CNN-Dailymail summarization task - -### 1) Download the CNN and Daily Mail data and preprocess it into data files with non-tokenized cased samples. - -Follow the instructions [here](https://github.com/abisee/cnn-dailymail) to download the original CNN and Daily Mail datasets. To preprocess the data, refer to the pointers in [this issue](https://github.com/pytorch/fairseq/issues/1391) or check out the code [here](https://github.com/artmatsak/cnn-dailymail). - -Follow the instructions [here](https://github.com/EdinburghNLP/XSum) to download the original Extreme Summarization datasets, or check out the code [here](https://github.com/EdinburghNLP/XSum/tree/master/XSum-Dataset), Please keep the raw dataset and make sure no tokenization nor BPE on the dataset. - -### 2) BPE preprocess: - -```bash -wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/encoder.json' -wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/vocab.bpe' -wget -N 'https://dl.fbaipublicfiles.com/fairseq/gpt2_bpe/dict.txt' - -TASK=cnn_dm -for SPLIT in train val -do - for LANG in source target - do - python -m examples.roberta.multiprocessing_bpe_encoder \ - --encoder-json encoder.json \ - --vocab-bpe vocab.bpe \ - --inputs "$TASK/$SPLIT.$LANG" \ - --outputs "$TASK/$SPLIT.bpe.$LANG" \ - --workers 60 \ - --keep-empty; - done -done -``` - -### 3) Binarize dataset: -```bash -fairseq-preprocess \ - --source-lang "source" \ - --target-lang "target" \ - --trainpref "${TASK}/train.bpe" \ - --validpref "${TASK}/val.bpe" \ - --destdir "${TASK}-bin/" \ - --workers 60 \ - --srcdict dict.txt \ - --tgtdict dict.txt; -``` - -### 4) Fine-tuning on CNN-DM summarization task: -Example fine-tuning CNN-DM -```bash -TOTAL_NUM_UPDATES=20000 -WARMUP_UPDATES=500 -LR=3e-05 -MAX_TOKENS=2048 -UPDATE_FREQ=4 -BART_PATH=/path/to/bart/model.pt - -CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 fairseq-train cnn_dm-bin \ - --restore-file $BART_PATH \ - --max-tokens $MAX_TOKENS \ - --task translation \ - --source-lang source --target-lang target \ - --truncate-source \ - --layernorm-embedding \ - --share-all-embeddings \ - --share-decoder-input-output-embed \ - --reset-optimizer --reset-dataloader --reset-meters \ - --required-batch-size-multiple 1 \ - --arch bart_large \ - --criterion label_smoothed_cross_entropy \ - --label-smoothing 0.1 \ - --dropout 0.1 --attention-dropout 0.1 \ - --weight-decay 0.01 --optimizer adam --adam-betas "(0.9, 0.999)" --adam-eps 1e-08 \ - --clip-norm 0.1 \ - --lr-scheduler polynomial_decay --lr $LR --total-num-update $TOTAL_NUM_UPDATES --warmup-updates $WARMUP_UPDATES \ - --fp16 --update-freq $UPDATE_FREQ \ - --skip-invalid-size-inputs-valid-test \ - --find-unused-parameters; -``` -Above is expected to run on `1` node with `8 32gb-V100`. -Expected training time is about `5 hours`. Training time can be reduced with distributed training on `4` nodes and `--update-freq 1`. - -Use TOTAL_NUM_UPDATES=15000 UPDATE_FREQ=2 for Xsum task - -### Inference for CNN-DM test data using above trained checkpoint. -After training the model as mentioned in previous step, you can perform inference with checkpoints in `checkpoints/` directory using `eval_cnn.py`, for example - -```bash -cp data-bin/cnn_dm/dict.source.txt checkpoints/ -python examples/bart/summarize.py \ - --model-dir checkpoints \ - --model-file checkpoint_best.pt \ - --src cnn_dm/test.source \ - --out cnn_dm/test.hypo -``` -For XSUM, which uses beam=6, lenpen=1.0, max_len_b=60, min_len=10: -```bash -cp data-bin/cnn_dm/dict.source.txt checkpoints/ -python examples/bart/summarize.py \ - --model-dir checkpoints \ - --model-file checkpoint_best.pt \ - --src cnn_dm/test.source \ - --out cnn_dm/test.hypo \ - --xsum-kwargs -``` diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/wav2vec/libri_labels.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/wav2vec/libri_labels.py deleted file mode 100644 index 694a202604c7a4a480550550679ce6c16bd10e42..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/wav2vec/libri_labels.py +++ /dev/null @@ -1,56 +0,0 @@ -#!/usr/bin/env python3 -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -""" -Helper script to pre-compute embeddings for a flashlight (previously called wav2letter++) dataset -""" - -import argparse -import os - - -def main(): - parser = argparse.ArgumentParser() - parser.add_argument("tsv") - parser.add_argument("--output-dir", required=True) - parser.add_argument("--output-name", required=True) - args = parser.parse_args() - - os.makedirs(args.output_dir, exist_ok=True) - - transcriptions = {} - - with open(args.tsv, "r") as tsv, open( - os.path.join(args.output_dir, args.output_name + ".ltr"), "w" - ) as ltr_out, open( - os.path.join(args.output_dir, args.output_name + ".wrd"), "w" - ) as wrd_out: - root = next(tsv).strip() - for line in tsv: - line = line.strip() - dir = os.path.dirname(line) - if dir not in transcriptions: - parts = dir.split(os.path.sep) - trans_path = f"{parts[-2]}-{parts[-1]}.trans.txt" - path = os.path.join(root, dir, trans_path) - assert os.path.exists(path) - texts = {} - with open(path, "r") as trans_f: - for tline in trans_f: - items = tline.strip().split() - texts[items[0]] = " ".join(items[1:]) - transcriptions[dir] = texts - part = os.path.basename(line).split(".")[0] - assert part in transcriptions[dir] - print(transcriptions[dir][part], file=wrd_out) - print( - " ".join(list(transcriptions[dir][part].replace(" ", "|"))) + " |", - file=ltr_out, - ) - - -if __name__ == "__main__": - main() diff --git a/spaces/OmegaYuti/anything-v3.0/utils.py b/spaces/OmegaYuti/anything-v3.0/utils.py deleted file mode 100644 index ff1c065d186347ca51b47d010a697dbe1814695c..0000000000000000000000000000000000000000 --- a/spaces/OmegaYuti/anything-v3.0/utils.py +++ /dev/null @@ -1,6 +0,0 @@ -def is_google_colab(): - try: - import google.colab - return True - except: - return False \ No newline at end of file diff --git a/spaces/PAIR/PAIR-Diffusion/ldm/modules/image_degradation/utils_image.py b/spaces/PAIR/PAIR-Diffusion/ldm/modules/image_degradation/utils_image.py deleted file mode 100644 index 0175f155ad900ae33c3c46ed87f49b352e3faf98..0000000000000000000000000000000000000000 --- a/spaces/PAIR/PAIR-Diffusion/ldm/modules/image_degradation/utils_image.py +++ /dev/null @@ -1,916 +0,0 @@ -import os -import math -import random -import numpy as np -import torch -import cv2 -from torchvision.utils import make_grid -from datetime import datetime -#import matplotlib.pyplot as plt # TODO: check with Dominik, also bsrgan.py vs bsrgan_light.py - - -os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" - - -''' -# -------------------------------------------- -# Kai Zhang (github: https://github.com/cszn) -# 03/Mar/2019 -# -------------------------------------------- -# https://github.com/twhui/SRGAN-pyTorch -# https://github.com/xinntao/BasicSR -# -------------------------------------------- -''' - - -IMG_EXTENSIONS = ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tif'] - - -def is_image_file(filename): - return any(filename.endswith(extension) for extension in IMG_EXTENSIONS) - - -def get_timestamp(): - return datetime.now().strftime('%y%m%d-%H%M%S') - - -def imshow(x, title=None, cbar=False, figsize=None): - plt.figure(figsize=figsize) - plt.imshow(np.squeeze(x), interpolation='nearest', cmap='gray') - if title: - plt.title(title) - if cbar: - plt.colorbar() - plt.show() - - -def surf(Z, cmap='rainbow', figsize=None): - plt.figure(figsize=figsize) - ax3 = plt.axes(projection='3d') - - w, h = Z.shape[:2] - xx = np.arange(0,w,1) - yy = np.arange(0,h,1) - X, Y = np.meshgrid(xx, yy) - ax3.plot_surface(X,Y,Z,cmap=cmap) - #ax3.contour(X,Y,Z, zdim='z',offset=-2,cmap=cmap) - plt.show() - - -''' -# -------------------------------------------- -# get image pathes -# -------------------------------------------- -''' - - -def get_image_paths(dataroot): - paths = None # return None if dataroot is None - if dataroot is not None: - paths = sorted(_get_paths_from_images(dataroot)) - return paths - - -def _get_paths_from_images(path): - assert os.path.isdir(path), '{:s} is not a valid directory'.format(path) - images = [] - for dirpath, _, fnames in sorted(os.walk(path)): - for fname in sorted(fnames): - if is_image_file(fname): - img_path = os.path.join(dirpath, fname) - images.append(img_path) - assert images, '{:s} has no valid image file'.format(path) - return images - - -''' -# -------------------------------------------- -# split large images into small images -# -------------------------------------------- -''' - - -def patches_from_image(img, p_size=512, p_overlap=64, p_max=800): - w, h = img.shape[:2] - patches = [] - if w > p_max and h > p_max: - w1 = list(np.arange(0, w-p_size, p_size-p_overlap, dtype=np.int)) - h1 = list(np.arange(0, h-p_size, p_size-p_overlap, dtype=np.int)) - w1.append(w-p_size) - h1.append(h-p_size) -# print(w1) -# print(h1) - for i in w1: - for j in h1: - patches.append(img[i:i+p_size, j:j+p_size,:]) - else: - patches.append(img) - - return patches - - -def imssave(imgs, img_path): - """ - imgs: list, N images of size WxHxC - """ - img_name, ext = os.path.splitext(os.path.basename(img_path)) - - for i, img in enumerate(imgs): - if img.ndim == 3: - img = img[:, :, [2, 1, 0]] - new_path = os.path.join(os.path.dirname(img_path), img_name+str('_s{:04d}'.format(i))+'.png') - cv2.imwrite(new_path, img) - - -def split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_size=800, p_overlap=96, p_max=1000): - """ - split the large images from original_dataroot into small overlapped images with size (p_size)x(p_size), - and save them into taget_dataroot; only the images with larger size than (p_max)x(p_max) - will be splitted. - Args: - original_dataroot: - taget_dataroot: - p_size: size of small images - p_overlap: patch size in training is a good choice - p_max: images with smaller size than (p_max)x(p_max) keep unchanged. - """ - paths = get_image_paths(original_dataroot) - for img_path in paths: - # img_name, ext = os.path.splitext(os.path.basename(img_path)) - img = imread_uint(img_path, n_channels=n_channels) - patches = patches_from_image(img, p_size, p_overlap, p_max) - imssave(patches, os.path.join(taget_dataroot,os.path.basename(img_path))) - #if original_dataroot == taget_dataroot: - #del img_path - -''' -# -------------------------------------------- -# makedir -# -------------------------------------------- -''' - - -def mkdir(path): - if not os.path.exists(path): - os.makedirs(path) - - -def mkdirs(paths): - if isinstance(paths, str): - mkdir(paths) - else: - for path in paths: - mkdir(path) - - -def mkdir_and_rename(path): - if os.path.exists(path): - new_name = path + '_archived_' + get_timestamp() - print('Path already exists. Rename it to [{:s}]'.format(new_name)) - os.rename(path, new_name) - os.makedirs(path) - - -''' -# -------------------------------------------- -# read image from path -# opencv is fast, but read BGR numpy image -# -------------------------------------------- -''' - - -# -------------------------------------------- -# get uint8 image of size HxWxn_channles (RGB) -# -------------------------------------------- -def imread_uint(path, n_channels=3): - # input: path - # output: HxWx3(RGB or GGG), or HxWx1 (G) - if n_channels == 1: - img = cv2.imread(path, 0) # cv2.IMREAD_GRAYSCALE - img = np.expand_dims(img, axis=2) # HxWx1 - elif n_channels == 3: - img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # BGR or G - if img.ndim == 2: - img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB) # GGG - else: - img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB - return img - - -# -------------------------------------------- -# matlab's imwrite -# -------------------------------------------- -def imsave(img, img_path): - img = np.squeeze(img) - if img.ndim == 3: - img = img[:, :, [2, 1, 0]] - cv2.imwrite(img_path, img) - -def imwrite(img, img_path): - img = np.squeeze(img) - if img.ndim == 3: - img = img[:, :, [2, 1, 0]] - cv2.imwrite(img_path, img) - - - -# -------------------------------------------- -# get single image of size HxWxn_channles (BGR) -# -------------------------------------------- -def read_img(path): - # read image by cv2 - # return: Numpy float32, HWC, BGR, [0,1] - img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # cv2.IMREAD_GRAYSCALE - img = img.astype(np.float32) / 255. - if img.ndim == 2: - img = np.expand_dims(img, axis=2) - # some images have 4 channels - if img.shape[2] > 3: - img = img[:, :, :3] - return img - - -''' -# -------------------------------------------- -# image format conversion -# -------------------------------------------- -# numpy(single) <---> numpy(unit) -# numpy(single) <---> tensor -# numpy(unit) <---> tensor -# -------------------------------------------- -''' - - -# -------------------------------------------- -# numpy(single) [0, 1] <---> numpy(unit) -# -------------------------------------------- - - -def uint2single(img): - - return np.float32(img/255.) - - -def single2uint(img): - - return np.uint8((img.clip(0, 1)*255.).round()) - - -def uint162single(img): - - return np.float32(img/65535.) - - -def single2uint16(img): - - return np.uint16((img.clip(0, 1)*65535.).round()) - - -# -------------------------------------------- -# numpy(unit) (HxWxC or HxW) <---> tensor -# -------------------------------------------- - - -# convert uint to 4-dimensional torch tensor -def uint2tensor4(img): - if img.ndim == 2: - img = np.expand_dims(img, axis=2) - return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.).unsqueeze(0) - - -# convert uint to 3-dimensional torch tensor -def uint2tensor3(img): - if img.ndim == 2: - img = np.expand_dims(img, axis=2) - return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.) - - -# convert 2/3/4-dimensional torch tensor to uint -def tensor2uint(img): - img = img.data.squeeze().float().clamp_(0, 1).cpu().numpy() - if img.ndim == 3: - img = np.transpose(img, (1, 2, 0)) - return np.uint8((img*255.0).round()) - - -# -------------------------------------------- -# numpy(single) (HxWxC) <---> tensor -# -------------------------------------------- - - -# convert single (HxWxC) to 3-dimensional torch tensor -def single2tensor3(img): - return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float() - - -# convert single (HxWxC) to 4-dimensional torch tensor -def single2tensor4(img): - return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().unsqueeze(0) - - -# convert torch tensor to single -def tensor2single(img): - img = img.data.squeeze().float().cpu().numpy() - if img.ndim == 3: - img = np.transpose(img, (1, 2, 0)) - - return img - -# convert torch tensor to single -def tensor2single3(img): - img = img.data.squeeze().float().cpu().numpy() - if img.ndim == 3: - img = np.transpose(img, (1, 2, 0)) - elif img.ndim == 2: - img = np.expand_dims(img, axis=2) - return img - - -def single2tensor5(img): - return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float().unsqueeze(0) - - -def single32tensor5(img): - return torch.from_numpy(np.ascontiguousarray(img)).float().unsqueeze(0).unsqueeze(0) - - -def single42tensor4(img): - return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float() - - -# from skimage.io import imread, imsave -def tensor2img(tensor, out_type=np.uint8, min_max=(0, 1)): - ''' - Converts a torch Tensor into an image Numpy array of BGR channel order - Input: 4D(B,(3/1),H,W), 3D(C,H,W), or 2D(H,W), any range, RGB channel order - Output: 3D(H,W,C) or 2D(H,W), [0,255], np.uint8 (default) - ''' - tensor = tensor.squeeze().float().cpu().clamp_(*min_max) # squeeze first, then clamp - tensor = (tensor - min_max[0]) / (min_max[1] - min_max[0]) # to range [0,1] - n_dim = tensor.dim() - if n_dim == 4: - n_img = len(tensor) - img_np = make_grid(tensor, nrow=int(math.sqrt(n_img)), normalize=False).numpy() - img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR - elif n_dim == 3: - img_np = tensor.numpy() - img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR - elif n_dim == 2: - img_np = tensor.numpy() - else: - raise TypeError( - 'Only support 4D, 3D and 2D tensor. But received with dimension: {:d}'.format(n_dim)) - if out_type == np.uint8: - img_np = (img_np * 255.0).round() - # Important. Unlike matlab, numpy.unit8() WILL NOT round by default. - return img_np.astype(out_type) - - -''' -# -------------------------------------------- -# Augmentation, flipe and/or rotate -# -------------------------------------------- -# The following two are enough. -# (1) augmet_img: numpy image of WxHxC or WxH -# (2) augment_img_tensor4: tensor image 1xCxWxH -# -------------------------------------------- -''' - - -def augment_img(img, mode=0): - '''Kai Zhang (github: https://github.com/cszn) - ''' - if mode == 0: - return img - elif mode == 1: - return np.flipud(np.rot90(img)) - elif mode == 2: - return np.flipud(img) - elif mode == 3: - return np.rot90(img, k=3) - elif mode == 4: - return np.flipud(np.rot90(img, k=2)) - elif mode == 5: - return np.rot90(img) - elif mode == 6: - return np.rot90(img, k=2) - elif mode == 7: - return np.flipud(np.rot90(img, k=3)) - - -def augment_img_tensor4(img, mode=0): - '''Kai Zhang (github: https://github.com/cszn) - ''' - if mode == 0: - return img - elif mode == 1: - return img.rot90(1, [2, 3]).flip([2]) - elif mode == 2: - return img.flip([2]) - elif mode == 3: - return img.rot90(3, [2, 3]) - elif mode == 4: - return img.rot90(2, [2, 3]).flip([2]) - elif mode == 5: - return img.rot90(1, [2, 3]) - elif mode == 6: - return img.rot90(2, [2, 3]) - elif mode == 7: - return img.rot90(3, [2, 3]).flip([2]) - - -def augment_img_tensor(img, mode=0): - '''Kai Zhang (github: https://github.com/cszn) - ''' - img_size = img.size() - img_np = img.data.cpu().numpy() - if len(img_size) == 3: - img_np = np.transpose(img_np, (1, 2, 0)) - elif len(img_size) == 4: - img_np = np.transpose(img_np, (2, 3, 1, 0)) - img_np = augment_img(img_np, mode=mode) - img_tensor = torch.from_numpy(np.ascontiguousarray(img_np)) - if len(img_size) == 3: - img_tensor = img_tensor.permute(2, 0, 1) - elif len(img_size) == 4: - img_tensor = img_tensor.permute(3, 2, 0, 1) - - return img_tensor.type_as(img) - - -def augment_img_np3(img, mode=0): - if mode == 0: - return img - elif mode == 1: - return img.transpose(1, 0, 2) - elif mode == 2: - return img[::-1, :, :] - elif mode == 3: - img = img[::-1, :, :] - img = img.transpose(1, 0, 2) - return img - elif mode == 4: - return img[:, ::-1, :] - elif mode == 5: - img = img[:, ::-1, :] - img = img.transpose(1, 0, 2) - return img - elif mode == 6: - img = img[:, ::-1, :] - img = img[::-1, :, :] - return img - elif mode == 7: - img = img[:, ::-1, :] - img = img[::-1, :, :] - img = img.transpose(1, 0, 2) - return img - - -def augment_imgs(img_list, hflip=True, rot=True): - # horizontal flip OR rotate - hflip = hflip and random.random() < 0.5 - vflip = rot and random.random() < 0.5 - rot90 = rot and random.random() < 0.5 - - def _augment(img): - if hflip: - img = img[:, ::-1, :] - if vflip: - img = img[::-1, :, :] - if rot90: - img = img.transpose(1, 0, 2) - return img - - return [_augment(img) for img in img_list] - - -''' -# -------------------------------------------- -# modcrop and shave -# -------------------------------------------- -''' - - -def modcrop(img_in, scale): - # img_in: Numpy, HWC or HW - img = np.copy(img_in) - if img.ndim == 2: - H, W = img.shape - H_r, W_r = H % scale, W % scale - img = img[:H - H_r, :W - W_r] - elif img.ndim == 3: - H, W, C = img.shape - H_r, W_r = H % scale, W % scale - img = img[:H - H_r, :W - W_r, :] - else: - raise ValueError('Wrong img ndim: [{:d}].'.format(img.ndim)) - return img - - -def shave(img_in, border=0): - # img_in: Numpy, HWC or HW - img = np.copy(img_in) - h, w = img.shape[:2] - img = img[border:h-border, border:w-border] - return img - - -''' -# -------------------------------------------- -# image processing process on numpy image -# channel_convert(in_c, tar_type, img_list): -# rgb2ycbcr(img, only_y=True): -# bgr2ycbcr(img, only_y=True): -# ycbcr2rgb(img): -# -------------------------------------------- -''' - - -def rgb2ycbcr(img, only_y=True): - '''same as matlab rgb2ycbcr - only_y: only return Y channel - Input: - uint8, [0, 255] - float, [0, 1] - ''' - in_img_type = img.dtype - img.astype(np.float32) - if in_img_type != np.uint8: - img *= 255. - # convert - if only_y: - rlt = np.dot(img, [65.481, 128.553, 24.966]) / 255.0 + 16.0 - else: - rlt = np.matmul(img, [[65.481, -37.797, 112.0], [128.553, -74.203, -93.786], - [24.966, 112.0, -18.214]]) / 255.0 + [16, 128, 128] - if in_img_type == np.uint8: - rlt = rlt.round() - else: - rlt /= 255. - return rlt.astype(in_img_type) - - -def ycbcr2rgb(img): - '''same as matlab ycbcr2rgb - Input: - uint8, [0, 255] - float, [0, 1] - ''' - in_img_type = img.dtype - img.astype(np.float32) - if in_img_type != np.uint8: - img *= 255. - # convert - rlt = np.matmul(img, [[0.00456621, 0.00456621, 0.00456621], [0, -0.00153632, 0.00791071], - [0.00625893, -0.00318811, 0]]) * 255.0 + [-222.921, 135.576, -276.836] - if in_img_type == np.uint8: - rlt = rlt.round() - else: - rlt /= 255. - return rlt.astype(in_img_type) - - -def bgr2ycbcr(img, only_y=True): - '''bgr version of rgb2ycbcr - only_y: only return Y channel - Input: - uint8, [0, 255] - float, [0, 1] - ''' - in_img_type = img.dtype - img.astype(np.float32) - if in_img_type != np.uint8: - img *= 255. - # convert - if only_y: - rlt = np.dot(img, [24.966, 128.553, 65.481]) / 255.0 + 16.0 - else: - rlt = np.matmul(img, [[24.966, 112.0, -18.214], [128.553, -74.203, -93.786], - [65.481, -37.797, 112.0]]) / 255.0 + [16, 128, 128] - if in_img_type == np.uint8: - rlt = rlt.round() - else: - rlt /= 255. - return rlt.astype(in_img_type) - - -def channel_convert(in_c, tar_type, img_list): - # conversion among BGR, gray and y - if in_c == 3 and tar_type == 'gray': # BGR to gray - gray_list = [cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) for img in img_list] - return [np.expand_dims(img, axis=2) for img in gray_list] - elif in_c == 3 and tar_type == 'y': # BGR to y - y_list = [bgr2ycbcr(img, only_y=True) for img in img_list] - return [np.expand_dims(img, axis=2) for img in y_list] - elif in_c == 1 and tar_type == 'RGB': # gray/y to BGR - return [cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) for img in img_list] - else: - return img_list - - -''' -# -------------------------------------------- -# metric, PSNR and SSIM -# -------------------------------------------- -''' - - -# -------------------------------------------- -# PSNR -# -------------------------------------------- -def calculate_psnr(img1, img2, border=0): - # img1 and img2 have range [0, 255] - #img1 = img1.squeeze() - #img2 = img2.squeeze() - if not img1.shape == img2.shape: - raise ValueError('Input images must have the same dimensions.') - h, w = img1.shape[:2] - img1 = img1[border:h-border, border:w-border] - img2 = img2[border:h-border, border:w-border] - - img1 = img1.astype(np.float64) - img2 = img2.astype(np.float64) - mse = np.mean((img1 - img2)**2) - if mse == 0: - return float('inf') - return 20 * math.log10(255.0 / math.sqrt(mse)) - - -# -------------------------------------------- -# SSIM -# -------------------------------------------- -def calculate_ssim(img1, img2, border=0): - '''calculate SSIM - the same outputs as MATLAB's - img1, img2: [0, 255] - ''' - #img1 = img1.squeeze() - #img2 = img2.squeeze() - if not img1.shape == img2.shape: - raise ValueError('Input images must have the same dimensions.') - h, w = img1.shape[:2] - img1 = img1[border:h-border, border:w-border] - img2 = img2[border:h-border, border:w-border] - - if img1.ndim == 2: - return ssim(img1, img2) - elif img1.ndim == 3: - if img1.shape[2] == 3: - ssims = [] - for i in range(3): - ssims.append(ssim(img1[:,:,i], img2[:,:,i])) - return np.array(ssims).mean() - elif img1.shape[2] == 1: - return ssim(np.squeeze(img1), np.squeeze(img2)) - else: - raise ValueError('Wrong input image dimensions.') - - -def ssim(img1, img2): - C1 = (0.01 * 255)**2 - C2 = (0.03 * 255)**2 - - img1 = img1.astype(np.float64) - img2 = img2.astype(np.float64) - kernel = cv2.getGaussianKernel(11, 1.5) - window = np.outer(kernel, kernel.transpose()) - - mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5] # valid - mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5] - mu1_sq = mu1**2 - mu2_sq = mu2**2 - mu1_mu2 = mu1 * mu2 - sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq - sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq - sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2 - - ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * - (sigma1_sq + sigma2_sq + C2)) - return ssim_map.mean() - - -''' -# -------------------------------------------- -# matlab's bicubic imresize (numpy and torch) [0, 1] -# -------------------------------------------- -''' - - -# matlab 'imresize' function, now only support 'bicubic' -def cubic(x): - absx = torch.abs(x) - absx2 = absx**2 - absx3 = absx**3 - return (1.5*absx3 - 2.5*absx2 + 1) * ((absx <= 1).type_as(absx)) + \ - (-0.5*absx3 + 2.5*absx2 - 4*absx + 2) * (((absx > 1)*(absx <= 2)).type_as(absx)) - - -def calculate_weights_indices(in_length, out_length, scale, kernel, kernel_width, antialiasing): - if (scale < 1) and (antialiasing): - # Use a modified kernel to simultaneously interpolate and antialias- larger kernel width - kernel_width = kernel_width / scale - - # Output-space coordinates - x = torch.linspace(1, out_length, out_length) - - # Input-space coordinates. Calculate the inverse mapping such that 0.5 - # in output space maps to 0.5 in input space, and 0.5+scale in output - # space maps to 1.5 in input space. - u = x / scale + 0.5 * (1 - 1 / scale) - - # What is the left-most pixel that can be involved in the computation? - left = torch.floor(u - kernel_width / 2) - - # What is the maximum number of pixels that can be involved in the - # computation? Note: it's OK to use an extra pixel here; if the - # corresponding weights are all zero, it will be eliminated at the end - # of this function. - P = math.ceil(kernel_width) + 2 - - # The indices of the input pixels involved in computing the k-th output - # pixel are in row k of the indices matrix. - indices = left.view(out_length, 1).expand(out_length, P) + torch.linspace(0, P - 1, P).view( - 1, P).expand(out_length, P) - - # The weights used to compute the k-th output pixel are in row k of the - # weights matrix. - distance_to_center = u.view(out_length, 1).expand(out_length, P) - indices - # apply cubic kernel - if (scale < 1) and (antialiasing): - weights = scale * cubic(distance_to_center * scale) - else: - weights = cubic(distance_to_center) - # Normalize the weights matrix so that each row sums to 1. - weights_sum = torch.sum(weights, 1).view(out_length, 1) - weights = weights / weights_sum.expand(out_length, P) - - # If a column in weights is all zero, get rid of it. only consider the first and last column. - weights_zero_tmp = torch.sum((weights == 0), 0) - if not math.isclose(weights_zero_tmp[0], 0, rel_tol=1e-6): - indices = indices.narrow(1, 1, P - 2) - weights = weights.narrow(1, 1, P - 2) - if not math.isclose(weights_zero_tmp[-1], 0, rel_tol=1e-6): - indices = indices.narrow(1, 0, P - 2) - weights = weights.narrow(1, 0, P - 2) - weights = weights.contiguous() - indices = indices.contiguous() - sym_len_s = -indices.min() + 1 - sym_len_e = indices.max() - in_length - indices = indices + sym_len_s - 1 - return weights, indices, int(sym_len_s), int(sym_len_e) - - -# -------------------------------------------- -# imresize for tensor image [0, 1] -# -------------------------------------------- -def imresize(img, scale, antialiasing=True): - # Now the scale should be the same for H and W - # input: img: pytorch tensor, CHW or HW [0,1] - # output: CHW or HW [0,1] w/o round - need_squeeze = True if img.dim() == 2 else False - if need_squeeze: - img.unsqueeze_(0) - in_C, in_H, in_W = img.size() - out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale) - kernel_width = 4 - kernel = 'cubic' - - # Return the desired dimension order for performing the resize. The - # strategy is to perform the resize first along the dimension with the - # smallest scale factor. - # Now we do not support this. - - # get weights and indices - weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices( - in_H, out_H, scale, kernel, kernel_width, antialiasing) - weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices( - in_W, out_W, scale, kernel, kernel_width, antialiasing) - # process H dimension - # symmetric copying - img_aug = torch.FloatTensor(in_C, in_H + sym_len_Hs + sym_len_He, in_W) - img_aug.narrow(1, sym_len_Hs, in_H).copy_(img) - - sym_patch = img[:, :sym_len_Hs, :] - inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(1, inv_idx) - img_aug.narrow(1, 0, sym_len_Hs).copy_(sym_patch_inv) - - sym_patch = img[:, -sym_len_He:, :] - inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(1, inv_idx) - img_aug.narrow(1, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv) - - out_1 = torch.FloatTensor(in_C, out_H, in_W) - kernel_width = weights_H.size(1) - for i in range(out_H): - idx = int(indices_H[i][0]) - for j in range(out_C): - out_1[j, i, :] = img_aug[j, idx:idx + kernel_width, :].transpose(0, 1).mv(weights_H[i]) - - # process W dimension - # symmetric copying - out_1_aug = torch.FloatTensor(in_C, out_H, in_W + sym_len_Ws + sym_len_We) - out_1_aug.narrow(2, sym_len_Ws, in_W).copy_(out_1) - - sym_patch = out_1[:, :, :sym_len_Ws] - inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(2, inv_idx) - out_1_aug.narrow(2, 0, sym_len_Ws).copy_(sym_patch_inv) - - sym_patch = out_1[:, :, -sym_len_We:] - inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(2, inv_idx) - out_1_aug.narrow(2, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv) - - out_2 = torch.FloatTensor(in_C, out_H, out_W) - kernel_width = weights_W.size(1) - for i in range(out_W): - idx = int(indices_W[i][0]) - for j in range(out_C): - out_2[j, :, i] = out_1_aug[j, :, idx:idx + kernel_width].mv(weights_W[i]) - if need_squeeze: - out_2.squeeze_() - return out_2 - - -# -------------------------------------------- -# imresize for numpy image [0, 1] -# -------------------------------------------- -def imresize_np(img, scale, antialiasing=True): - # Now the scale should be the same for H and W - # input: img: Numpy, HWC or HW [0,1] - # output: HWC or HW [0,1] w/o round - img = torch.from_numpy(img) - need_squeeze = True if img.dim() == 2 else False - if need_squeeze: - img.unsqueeze_(2) - - in_H, in_W, in_C = img.size() - out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale) - kernel_width = 4 - kernel = 'cubic' - - # Return the desired dimension order for performing the resize. The - # strategy is to perform the resize first along the dimension with the - # smallest scale factor. - # Now we do not support this. - - # get weights and indices - weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices( - in_H, out_H, scale, kernel, kernel_width, antialiasing) - weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices( - in_W, out_W, scale, kernel, kernel_width, antialiasing) - # process H dimension - # symmetric copying - img_aug = torch.FloatTensor(in_H + sym_len_Hs + sym_len_He, in_W, in_C) - img_aug.narrow(0, sym_len_Hs, in_H).copy_(img) - - sym_patch = img[:sym_len_Hs, :, :] - inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(0, inv_idx) - img_aug.narrow(0, 0, sym_len_Hs).copy_(sym_patch_inv) - - sym_patch = img[-sym_len_He:, :, :] - inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(0, inv_idx) - img_aug.narrow(0, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv) - - out_1 = torch.FloatTensor(out_H, in_W, in_C) - kernel_width = weights_H.size(1) - for i in range(out_H): - idx = int(indices_H[i][0]) - for j in range(out_C): - out_1[i, :, j] = img_aug[idx:idx + kernel_width, :, j].transpose(0, 1).mv(weights_H[i]) - - # process W dimension - # symmetric copying - out_1_aug = torch.FloatTensor(out_H, in_W + sym_len_Ws + sym_len_We, in_C) - out_1_aug.narrow(1, sym_len_Ws, in_W).copy_(out_1) - - sym_patch = out_1[:, :sym_len_Ws, :] - inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(1, inv_idx) - out_1_aug.narrow(1, 0, sym_len_Ws).copy_(sym_patch_inv) - - sym_patch = out_1[:, -sym_len_We:, :] - inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long() - sym_patch_inv = sym_patch.index_select(1, inv_idx) - out_1_aug.narrow(1, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv) - - out_2 = torch.FloatTensor(out_H, out_W, in_C) - kernel_width = weights_W.size(1) - for i in range(out_W): - idx = int(indices_W[i][0]) - for j in range(out_C): - out_2[:, i, j] = out_1_aug[:, idx:idx + kernel_width, j].mv(weights_W[i]) - if need_squeeze: - out_2.squeeze_() - - return out_2.numpy() - - -if __name__ == '__main__': - print('---') -# img = imread_uint('test.bmp', 3) -# img = uint2single(img) -# img_bicubic = imresize_np(img, 1/4) \ No newline at end of file diff --git a/spaces/PKUWilliamYang/VToonify/app.py b/spaces/PKUWilliamYang/VToonify/app.py deleted file mode 100644 index 7b12905c70c5964cf166ee555908be664ae7c92f..0000000000000000000000000000000000000000 --- a/spaces/PKUWilliamYang/VToonify/app.py +++ /dev/null @@ -1,291 +0,0 @@ -#!/usr/bin/env python - -from __future__ import annotations - -import argparse -import pathlib -import torch -import gradio as gr - -from vtoonify_model import Model - -def parse_args() -> argparse.Namespace: - parser = argparse.ArgumentParser() - parser.add_argument('--device', type=str, default='cpu') - parser.add_argument('--theme', type=str) - parser.add_argument('--share', action='store_true') - parser.add_argument('--port', type=int) - parser.add_argument('--disable-queue', - dest='enable_queue', - action='store_false') - return parser.parse_args() - -DESCRIPTION = ''' - --''' -FOOTER = '- Portrait Style Transfer with VToonify -
-For faster inference without waiting in queue, you may duplicate the space and use the GPU setting. -
-
- --
' - -ARTICLE = r""" -If VToonify is helpful, please help to ⭐ the Github Repo. Thanks! -[](https://github.com/williamyang1991/VToonify) ---- -📝 **Citation** -If our work is useful for your research, please consider citing: -```bibtex -@article{yang2022Vtoonify, - title={VToonify: Controllable High-Resolution Portrait Video Style Transfer}, - author={Yang, Shuai and Jiang, Liming and Liu, Ziwei and Loy, Chen Change}, - journal={ACM Transactions on Graphics (TOG)}, - volume={41}, - number={6}, - articleno={203}, - pages={1--15}, - year={2022}, - publisher={ACM New York, NY, USA}, - doi={10.1145/3550454.3555437}, -} -``` - -📋 **License** -This project is licensed under S-Lab License 1.0. -Redistribution and use for non-commercial purposes should follow this license. - -📧 **Contact** -If you have any questions, please feel free to reach me out at williamyang@pku.edu.cn. -""" - -def update_slider(choice: str) -> dict: - if type(choice) == str and choice.endswith('-d'): - return gr.Slider.update(maximum=1, minimum=0, value=0.5) - else: - return gr.Slider.update(maximum=0.5, minimum=0.5, value=0.5) - -def set_example_image(example: list) -> dict: - return gr.Image.update(value=example[0]) - -def set_example_video(example: list) -> dict: - return gr.Video.update(value=example[0]), - -sample_video = ['./vtoonify/data/529_2.mp4','./vtoonify/data/7154235.mp4','./vtoonify/data/651.mp4','./vtoonify/data/908.mp4'] -sample_vid = gr.Video(label='Video file') #for displaying the example -example_videos = gr.components.Dataset(components=[sample_vid], samples=[[path] for path in sample_video], type='values', label='Video Examples') - -def main(): - args = parse_args() - args.device = 'cuda' if torch.cuda.is_available() else 'cpu' - print('*** Now using %s.'%(args.device)) - model = Model(device=args.device) - - with gr.Blocks(theme=args.theme, css='style.css') as demo: - - gr.Markdown(DESCRIPTION) - - with gr.Box(): - gr.Markdown('''## Step 1(Select Style) - - Select **Style Type**. - - Type with `-d` means it supports style degree adjustment. - - Type without `-d` usually has better toonification quality. - - ''') - with gr.Row(): - with gr.Column(): - gr.Markdown('''Select Style Type''') - with gr.Row(): - style_type = gr.Radio(label='Style Type', - choices=['cartoon1','cartoon1-d','cartoon2-d','cartoon3-d', - 'cartoon4','cartoon4-d','cartoon5-d','comic1-d', - 'comic2-d','arcane1','arcane1-d','arcane2', 'arcane2-d', - 'caricature1','caricature2','pixar','pixar-d', - 'illustration1-d', 'illustration2-d', 'illustration3-d', 'illustration4-d', 'illustration5-d', - ] - ) - exstyle = gr.Variable() - with gr.Row(): - loadmodel_button = gr.Button('Load Model') - with gr.Row(): - load_info = gr.Textbox(label='Process Information', interactive=False, value='No model loaded.') - with gr.Column(): - gr.Markdown('''Reference Styles - ''') - - - with gr.Box(): - gr.Markdown('''## Step 2 (Preprocess Input Image / Video) - - Drop an image/video containing a near-frontal face to the **Input Image**/**Input Video**. - - Hit the **Rescale Image**/**Rescale First Frame** button. - - Rescale the input to make it best fit the model. - - The final image result will be based on this **Rescaled Face**. Use padding parameters to adjust the background space. - - **Solution to [Error: no face detected!]**: VToonify uses dlib.get_frontal_face_detector but sometimes it fails to detect a face. You can try several times or use other images until a face is detected, then switch back to the original image. - - For video input, further hit the **Rescale Video** button. - - The final video result will be based on this **Rescaled Video**. To avoid overload, video is cut to at most **100/300** frames for CPU/GPU, respectively. - - ''') - with gr.Row(): - with gr.Box(): - with gr.Column(): - gr.Markdown('''Choose the padding parameters. - 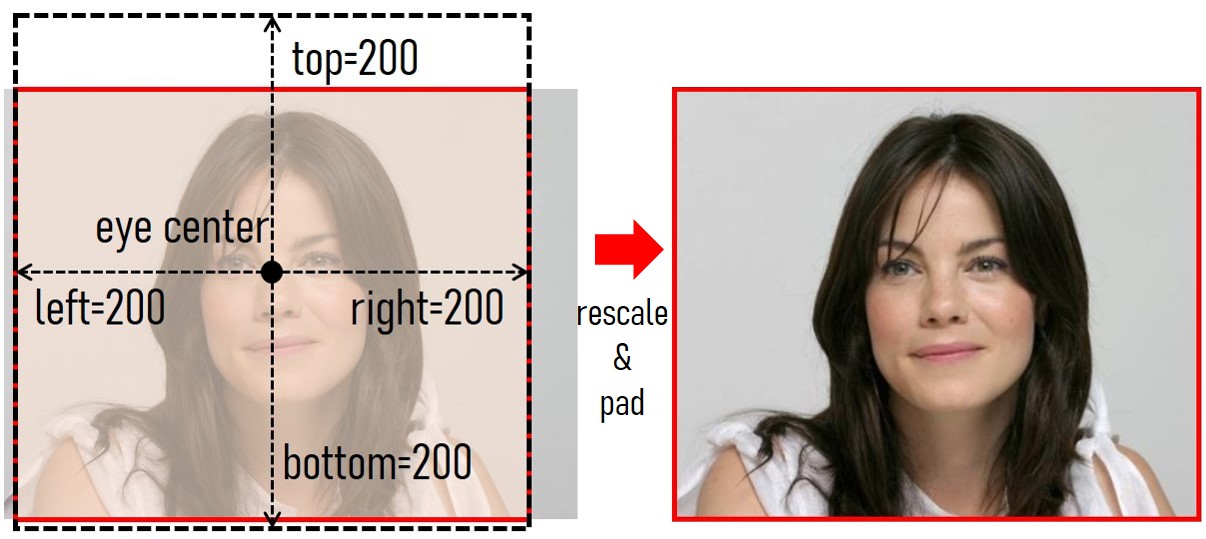''') - with gr.Row(): - top = gr.Slider(128, - 256, - value=200, - step=8, - label='top') - with gr.Row(): - bottom = gr.Slider(128, - 256, - value=200, - step=8, - label='bottom') - with gr.Row(): - left = gr.Slider(128, - 256, - value=200, - step=8, - label='left') - with gr.Row(): - right = gr.Slider(128, - 256, - value=200, - step=8, - label='right') - with gr.Box(): - with gr.Column(): - gr.Markdown('''Input''') - with gr.Row(): - input_image = gr.Image(label='Input Image', - type='filepath') - with gr.Row(): - preprocess_image_button = gr.Button('Rescale Image') - with gr.Row(): - input_video = gr.Video(label='Input Video', - mirror_webcam=False, - type='filepath') - with gr.Row(): - preprocess_video0_button = gr.Button('Rescale First Frame') - preprocess_video1_button = gr.Button('Rescale Video') - - with gr.Box(): - with gr.Column(): - gr.Markdown('''View''') - with gr.Row(): - input_info = gr.Textbox(label='Process Information', interactive=False, value='n.a.') - with gr.Row(): - aligned_face = gr.Image(label='Rescaled Face', - type='numpy', - interactive=False) - instyle = gr.Variable() - with gr.Row(): - aligned_video = gr.Video(label='Rescaled Video', - type='mp4', - interactive=False) - with gr.Row(): - with gr.Column(): - paths = ['./vtoonify/data/pexels-andrea-piacquadio-733872.jpg','./vtoonify/data/i5R8hbZFDdc.jpg','./vtoonify/data/yRpe13BHdKw.jpg','./vtoonify/data/ILip77SbmOE.jpg','./vtoonify/data/077436.jpg','./vtoonify/data/081680.jpg'] - example_images = gr.Dataset(components=[input_image], - samples=[[path] for path in paths], - label='Image Examples') - with gr.Column(): - #example_videos = gr.Dataset(components=[input_video], samples=[['./vtoonify/data/529.mp4']], type='values') - #to render video example on mouse hover/click - example_videos.render() - #to load sample video into input_video upon clicking on it - def load_examples(video): - #print("****** inside load_example() ******") - #print("in_video is : ", video[0]) - return video[0] - - example_videos.click(load_examples, example_videos, input_video) - - with gr.Box(): - gr.Markdown('''## Step 3 (Generate Style Transferred Image/Video)''') - with gr.Row(): - with gr.Column(): - gr.Markdown(''' - - - Adjust **Style Degree**. - - Hit **Toonify!** to toonify one frame. Hit **VToonify!** to toonify full video. - - Estimated time on 1600x1440 video of 300 frames: 1 hour (CPU); 2 mins (GPU) - ''') - style_degree = gr.Slider(0, - 1, - value=0.5, - step=0.05, - label='Style Degree') - with gr.Column(): - gr.Markdown(''' - ''') - with gr.Row(): - output_info = gr.Textbox(label='Process Information', interactive=False, value='n.a.') - with gr.Row(): - with gr.Column(): - with gr.Row(): - result_face = gr.Image(label='Result Image', - type='numpy', - interactive=False) - with gr.Row(): - toonify_button = gr.Button('Toonify!') - with gr.Column(): - with gr.Row(): - result_video = gr.Video(label='Result Video', - type='mp4', - interactive=False) - with gr.Row(): - vtoonify_button = gr.Button('VToonify!') - - gr.Markdown(ARTICLE) - gr.Markdown(FOOTER) - - loadmodel_button.click(fn=model.load_model, - inputs=[style_type], - outputs=[exstyle, load_info]) - - - style_type.change(fn=update_slider, - inputs=style_type, - outputs=style_degree) - - preprocess_image_button.click(fn=model.detect_and_align_image, - inputs=[input_image, top, bottom, left, right], - outputs=[aligned_face, instyle, input_info]) - preprocess_video0_button.click(fn=model.detect_and_align_video, - inputs=[input_video, top, bottom, left, right], - outputs=[aligned_face, instyle, input_info]) - preprocess_video1_button.click(fn=model.detect_and_align_full_video, - inputs=[input_video, top, bottom, left, right], - outputs=[aligned_video, instyle, input_info]) - - toonify_button.click(fn=model.image_toonify, - inputs=[aligned_face, instyle, exstyle, style_degree, style_type], - outputs=[result_face, output_info]) - vtoonify_button.click(fn=model.video_tooniy, - inputs=[aligned_video, instyle, exstyle, style_degree, style_type], - outputs=[result_video, output_info]) - - - example_images.click(fn=set_example_image, - inputs=example_images, - outputs=example_images.components) - - demo.launch( - enable_queue=args.enable_queue, - server_port=args.port, - share=args.share, - ) - - -if __name__ == '__main__': - main() diff --git a/spaces/PaddlePaddle/paddlespeech/app.py b/spaces/PaddlePaddle/paddlespeech/app.py deleted file mode 100644 index c7e73a065dde670cd43c6c88b78cb66a80884056..0000000000000000000000000000000000000000 --- a/spaces/PaddlePaddle/paddlespeech/app.py +++ /dev/null @@ -1,25 +0,0 @@ -import gradio as gr -import os - -def inference(text): - os.system("paddlespeech tts --input '"+text+"' --output output.wav") - return "output.wav" - -title = "PaddleSpeech TTS" - -description = "Gradio demo for PaddleSpeech: A Speech Toolkit based on PaddlePaddle for TTS. To use it, simply add your text, or click one of the examples to load them. Read more at the links below." - -article = "" - -examples=[['你好,欢迎使用百度飞桨深度学习框架!']] - -gr.Interface( - inference, - gr.inputs.Textbox(label="input text",lines=10), - gr.outputs.Audio(type="file", label="Output"), - title=title, - description=description, - article=article, - enable_queue=True, - examples=examples - ).launch(debug=True) diff --git a/spaces/ParityError/LimeFace/app.py b/spaces/ParityError/LimeFace/app.py deleted file mode 100644 index 4ffe1089e4387a32c8148c12e28efc995f531b1f..0000000000000000000000000000000000000000 --- a/spaces/ParityError/LimeFace/app.py +++ /dev/null @@ -1,147 +0,0 @@ -import time - -from theme_dropdown import create_theme_dropdown # noqa: F401 - -import gradio as gr - -dropdown, js = create_theme_dropdown() - -with gr.Blocks(theme='ParityError/LimeFace') as demo: - with gr.Row().style(equal_height=True): - with gr.Column(scale=10): - gr.Markdown( - """ - # Theme preview: `LimeFace` - To use this theme, set `theme='ParityError/LimeFace'` in `gr.Blocks()` or `gr.Interface()`. - You can append an `@` and a semantic version expression, e.g. @>=1.0.0,<2.0.0 to pin to a given version - of this theme. - """ - ) - with gr.Column(scale=3): - with gr.Box(): - dropdown.render() - toggle_dark = gr.Button(value="Toggle Dark").style(full_width=True) - - dropdown.change(None, dropdown, None, _js=js) - toggle_dark.click( - None, - _js=""" - () => { - document.body.classList.toggle('dark'); - document.querySelector('gradio-app').style.backgroundColor = 'var(--color-background-primary)' - } - """, - ) - - name = gr.Textbox( - label="Name", - info="Full name, including middle name. No special characters.", - placeholder="John Doe", - value="John Doe", - interactive=True, - ) - - with gr.Row(): - slider1 = gr.Slider(label="Slider 1") - slider2 = gr.Slider(label="Slider 2") - gr.CheckboxGroup(["A", "B", "C"], label="Checkbox Group") - - with gr.Row(): - with gr.Column(variant="panel", scale=1): - gr.Markdown("## Panel 1") - radio = gr.Radio( - ["A", "B", "C"], - label="Radio", - info="Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.", - ) - drop = gr.Dropdown(["Option 1", "Option 2", "Option 3"], show_label=False) - drop_2 = gr.Dropdown( - ["Option A", "Option B", "Option C"], - multiselect=True, - value=["Option A"], - label="Dropdown", - interactive=True, - ) - check = gr.Checkbox(label="Go") - with gr.Column(variant="panel", scale=2): - img = gr.Image( - "https://gradio.app/assets/img/header-image.jpg", label="Image" - ).style(height=320) - with gr.Row(): - go_btn = gr.Button("Go", label="Primary Button", variant="primary") - clear_btn = gr.Button( - "Clear", label="Secondary Button", variant="secondary" - ) - - def go(*args): - time.sleep(3) - return "https://gradio.app/assets/img/header-image.jpg" - - go_btn.click(go, [radio, drop, drop_2, check, name], img, api_name="go") - - def clear(): - time.sleep(0.2) - return None - - clear_btn.click(clear, None, img) - - with gr.Row(): - btn1 = gr.Button("Button 1").style(size="sm") - btn2 = gr.UploadButton().style(size="sm") - stop_btn = gr.Button("Stop", label="Stop Button", variant="stop").style( - size="sm" - ) - - with gr.Row(): - gr.Dataframe(value=[[1, 2, 3], [4, 5, 6], [7, 8, 9]], label="Dataframe") - gr.JSON( - value={"a": 1, "b": 2, "c": {"test": "a", "test2": [1, 2, 3]}}, label="JSON" - ) - gr.Label(value={"cat": 0.7, "dog": 0.2, "fish": 0.1}) - gr.File() - with gr.Row(): - gr.ColorPicker() - gr.Video("https://gradio-static-files.s3.us-west-2.amazonaws.com/world.mp4") - gr.Gallery( - [ - ( - "https://gradio-static-files.s3.us-west-2.amazonaws.com/lion.jpg", - "lion", - ), - ( - "https://gradio-static-files.s3.us-west-2.amazonaws.com/logo.png", - "logo", - ), - ( - "https://gradio-static-files.s3.us-west-2.amazonaws.com/tower.jpg", - "tower", - ), - ] - ).style(height="200px", grid=2) - - with gr.Row(): - with gr.Column(scale=2): - chatbot = gr.Chatbot([("Hello", "Hi")], label="Chatbot") - chat_btn = gr.Button("Add messages") - - def chat(history): - time.sleep(2) - yield [["How are you?", "I am good."]] - - chat_btn.click( - lambda history: history - + [["How are you?", "I am good."]] - + (time.sleep(2) or []), - chatbot, - chatbot, - ) - with gr.Column(scale=1): - with gr.Accordion("Advanced Settings"): - gr.Markdown("Hello") - gr.Number(label="Chatbot control 1") - gr.Number(label="Chatbot control 2") - gr.Number(label="Chatbot control 3") - - -if __name__ == "__main__": - demo.queue().launch() diff --git a/spaces/Pengyey/bingo-chuchu/src/components/ui/separator.tsx b/spaces/Pengyey/bingo-chuchu/src/components/ui/separator.tsx deleted file mode 100644 index 6c55e0b2ca8e2436658a06748aadbff7cd700db0..0000000000000000000000000000000000000000 --- a/spaces/Pengyey/bingo-chuchu/src/components/ui/separator.tsx +++ /dev/null @@ -1,31 +0,0 @@ -'use client' - -import * as React from 'react' -import * as SeparatorPrimitive from '@radix-ui/react-separator' - -import { cn } from '@/lib/utils' - -const Separator = React.forwardRef< - React.ElementRef, - React.ComponentPropsWithoutRef ->( - ( - { className, orientation = 'horizontal', decorative = true, ...props }, - ref - ) => ( - - ) -) -Separator.displayName = SeparatorPrimitive.Root.displayName - -export { Separator } diff --git a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/box_head/roi_box_predictors.py b/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/box_head/roi_box_predictors.py deleted file mode 100644 index e05fcbb1d7aec374414fd0552cb7f4d79bd63053..0000000000000000000000000000000000000000 --- a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/box_head/roi_box_predictors.py +++ /dev/null @@ -1,62 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved. -from torch import nn - - -class FastRCNNPredictor(nn.Module): - def __init__(self, config, pretrained=None): - super(FastRCNNPredictor, self).__init__() - - stage_index = 4 - stage2_relative_factor = 2 ** (stage_index - 1) - res2_out_channels = config.MODEL.RESNETS.RES2_OUT_CHANNELS - num_inputs = res2_out_channels * stage2_relative_factor - - num_classes = config.MODEL.ROI_BOX_HEAD.NUM_CLASSES - self.avgpool = nn.AvgPool2d(kernel_size=7, stride=7) - self.cls_score = nn.Linear(num_inputs, num_classes) - self.bbox_pred = nn.Linear(num_inputs, num_classes * 4) - - nn.init.normal_(self.cls_score.weight, mean=0, std=0.01) - nn.init.constant_(self.cls_score.bias, 0) - - nn.init.normal_(self.bbox_pred.weight, mean=0, std=0.001) - nn.init.constant_(self.bbox_pred.bias, 0) - - def forward(self, x): - x = self.avgpool(x) - x = x.view(x.size(0), -1) - cls_logit = self.cls_score(x) - bbox_pred = self.bbox_pred(x) - return cls_logit, bbox_pred - - -class FPNPredictor(nn.Module): - def __init__(self, cfg): - super(FPNPredictor, self).__init__() - num_classes = cfg.MODEL.ROI_BOX_HEAD.NUM_CLASSES - representation_size = cfg.MODEL.ROI_BOX_HEAD.MLP_HEAD_DIM - - self.cls_score = nn.Linear(representation_size, num_classes) - self.bbox_pred = nn.Linear(representation_size, num_classes * 4) - - nn.init.normal_(self.cls_score.weight, std=0.01) - nn.init.normal_(self.bbox_pred.weight, std=0.001) - for l in [self.cls_score, self.bbox_pred]: - nn.init.constant_(l.bias, 0) - - def forward(self, x): - scores = self.cls_score(x) - bbox_deltas = self.bbox_pred(x) - - return scores, bbox_deltas - - -_ROI_BOX_PREDICTOR = { - "FastRCNNPredictor": FastRCNNPredictor, - "FPNPredictor": FPNPredictor, -} - - -def make_roi_box_predictor(cfg): - func = _ROI_BOX_PREDICTOR[cfg.MODEL.ROI_BOX_HEAD.PREDICTOR] - return func(cfg) diff --git a/spaces/Plachta/VITS-Umamusume-voice-synthesizer/models.py b/spaces/Plachta/VITS-Umamusume-voice-synthesizer/models.py deleted file mode 100644 index 7dcd22edf811b952514080f5f06cc43d635ead28..0000000000000000000000000000000000000000 --- a/spaces/Plachta/VITS-Umamusume-voice-synthesizer/models.py +++ /dev/null @@ -1,542 +0,0 @@ -import math -import torch -from torch import nn -from torch.nn import functional as F - -import commons -import modules -import attentions - -from torch.nn import Conv1d, ConvTranspose1d, Conv2d -from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm -from commons import init_weights, get_padding - - -class StochasticDurationPredictor(nn.Module): - def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0): - super().__init__() - filter_channels = in_channels # it needs to be removed from future version. - self.in_channels = in_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.n_flows = n_flows - self.gin_channels = gin_channels - - self.log_flow = modules.Log() - self.flows = nn.ModuleList() - self.flows.append(modules.ElementwiseAffine(2)) - for i in range(n_flows): - self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3)) - self.flows.append(modules.Flip()) - - self.post_pre = nn.Conv1d(1, filter_channels, 1) - self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1) - self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout) - self.post_flows = nn.ModuleList() - self.post_flows.append(modules.ElementwiseAffine(2)) - for i in range(4): - self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3)) - self.post_flows.append(modules.Flip()) - - self.pre = nn.Conv1d(in_channels, filter_channels, 1) - self.proj = nn.Conv1d(filter_channels, filter_channels, 1) - self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout) - if gin_channels != 0: - self.cond = nn.Conv1d(gin_channels, filter_channels, 1) - - def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0): - x = torch.detach(x) - x = self.pre(x) - if g is not None: - g = torch.detach(g) - x = x + self.cond(g) - x = self.convs(x, x_mask) - x = self.proj(x) * x_mask - - if not reverse: - flows = self.flows - assert w is not None - - logdet_tot_q = 0 - h_w = self.post_pre(w) - h_w = self.post_convs(h_w, x_mask) - h_w = self.post_proj(h_w) * x_mask - e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask - z_q = e_q - for flow in self.post_flows: - z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w)) - logdet_tot_q += logdet_q - z_u, z1 = torch.split(z_q, [1, 1], 1) - u = torch.sigmoid(z_u) * x_mask - z0 = (w - u) * x_mask - logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1,2]) - logq = torch.sum(-0.5 * (math.log(2*math.pi) + (e_q**2)) * x_mask, [1,2]) - logdet_tot_q - - logdet_tot = 0 - z0, logdet = self.log_flow(z0, x_mask) - logdet_tot += logdet - z = torch.cat([z0, z1], 1) - for flow in flows: - z, logdet = flow(z, x_mask, g=x, reverse=reverse) - logdet_tot = logdet_tot + logdet - nll = torch.sum(0.5 * (math.log(2*math.pi) + (z**2)) * x_mask, [1,2]) - logdet_tot - return nll + logq # [b] - else: - flows = list(reversed(self.flows)) - flows = flows[:-2] + [flows[-1]] # remove a useless vflow - z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale - for flow in flows: - z = flow(z, x_mask, g=x, reverse=reverse) - z0, z1 = torch.split(z, [1, 1], 1) - logw = z0 - return logw - - -class DurationPredictor(nn.Module): - def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, gin_channels=0): - super().__init__() - - self.in_channels = in_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.gin_channels = gin_channels - - self.drop = nn.Dropout(p_dropout) - self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size//2) - self.norm_1 = modules.LayerNorm(filter_channels) - self.conv_2 = nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size//2) - self.norm_2 = modules.LayerNorm(filter_channels) - self.proj = nn.Conv1d(filter_channels, 1, 1) - - if gin_channels != 0: - self.cond = nn.Conv1d(gin_channels, in_channels, 1) - - def forward(self, x, x_mask, g=None): - x = torch.detach(x) - if g is not None: - g = torch.detach(g) - x = x + self.cond(g) - x = self.conv_1(x * x_mask) - x = torch.relu(x) - x = self.norm_1(x) - x = self.drop(x) - x = self.conv_2(x * x_mask) - x = torch.relu(x) - x = self.norm_2(x) - x = self.drop(x) - x = self.proj(x * x_mask) - return x * x_mask - - -class TextEncoder(nn.Module): - def __init__(self, - n_vocab, - out_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - emotion_embedding): - super().__init__() - self.n_vocab = n_vocab - self.out_channels = out_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.emotion_embedding = emotion_embedding - - if self.n_vocab!=0: - self.emb = nn.Embedding(n_vocab, hidden_channels) - if emotion_embedding: - self.emotion_emb = nn.Linear(1024, hidden_channels) - nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5) - - self.encoder = attentions.Encoder( - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout) - self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1) - - def forward(self, x, x_lengths, emotion_embedding=None): - if self.n_vocab!=0: - x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h] - if emotion_embedding is not None: - x = x + self.emotion_emb(emotion_embedding.unsqueeze(1)) - x = torch.transpose(x, 1, -1) # [b, h, t] - x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) - - x = self.encoder(x * x_mask, x_mask) - stats = self.proj(x) * x_mask - - m, logs = torch.split(stats, self.out_channels, dim=1) - return x, m, logs, x_mask - - -class ResidualCouplingBlock(nn.Module): - def __init__(self, - channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - n_flows=4, - gin_channels=0): - super().__init__() - self.channels = channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.n_flows = n_flows - self.gin_channels = gin_channels - - self.flows = nn.ModuleList() - for i in range(n_flows): - self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True)) - self.flows.append(modules.Flip()) - - def forward(self, x, x_mask, g=None, reverse=False): - if not reverse: - for flow in self.flows: - x, _ = flow(x, x_mask, g=g, reverse=reverse) - else: - for flow in reversed(self.flows): - x = flow(x, x_mask, g=g, reverse=reverse) - return x - - -class PosteriorEncoder(nn.Module): - def __init__(self, - in_channels, - out_channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - gin_channels=0): - super().__init__() - self.in_channels = in_channels - self.out_channels = out_channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.gin_channels = gin_channels - - self.pre = nn.Conv1d(in_channels, hidden_channels, 1) - self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels) - self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1) - - def forward(self, x, x_lengths, g=None): - x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) - x = self.pre(x) * x_mask - x = self.enc(x, x_mask, g=g) - stats = self.proj(x) * x_mask - m, logs = torch.split(stats, self.out_channels, dim=1) - z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask - return z, m, logs, x_mask - - -class Generator(torch.nn.Module): - def __init__(self, initial_channel, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=0): - super(Generator, self).__init__() - self.num_kernels = len(resblock_kernel_sizes) - self.num_upsamples = len(upsample_rates) - self.conv_pre = Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3) - resblock = modules.ResBlock1 if resblock == '1' else modules.ResBlock2 - - self.ups = nn.ModuleList() - for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)): - self.ups.append(weight_norm( - ConvTranspose1d(upsample_initial_channel//(2**i), upsample_initial_channel//(2**(i+1)), - k, u, padding=(k-u)//2))) - - self.resblocks = nn.ModuleList() - for i in range(len(self.ups)): - ch = upsample_initial_channel//(2**(i+1)) - for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)): - self.resblocks.append(resblock(ch, k, d)) - - self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False) - self.ups.apply(init_weights) - - if gin_channels != 0: - self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1) - - def forward(self, x, g=None): - x = self.conv_pre(x) - if g is not None: - x = x + self.cond(g) - - for i in range(self.num_upsamples): - x = F.leaky_relu(x, modules.LRELU_SLOPE) - x = self.ups[i](x) - xs = None - for j in range(self.num_kernels): - if xs is None: - xs = self.resblocks[i*self.num_kernels+j](x) - else: - xs += self.resblocks[i*self.num_kernels+j](x) - x = xs / self.num_kernels - x = F.leaky_relu(x) - x = self.conv_post(x) - x = torch.tanh(x) - - return x - - def remove_weight_norm(self): - print('Removing weight norm...') - for l in self.ups: - remove_weight_norm(l) - for l in self.resblocks: - l.remove_weight_norm() - - -class DiscriminatorP(torch.nn.Module): - def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False): - super(DiscriminatorP, self).__init__() - self.period = period - self.use_spectral_norm = use_spectral_norm - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList([ - norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))), - ]) - self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0))) - - def forward(self, x): - fmap = [] - - # 1d to 2d - b, c, t = x.shape - if t % self.period != 0: # pad first - n_pad = self.period - (t % self.period) - x = F.pad(x, (0, n_pad), "reflect") - t = t + n_pad - x = x.view(b, c, t // self.period, self.period) - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, modules.LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class DiscriminatorS(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(DiscriminatorS, self).__init__() - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList([ - norm_f(Conv1d(1, 16, 15, 1, padding=7)), - norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)), - norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)), - norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)), - norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)), - norm_f(Conv1d(1024, 1024, 5, 1, padding=2)), - ]) - self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1)) - - def forward(self, x): - fmap = [] - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, modules.LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class MultiPeriodDiscriminator(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(MultiPeriodDiscriminator, self).__init__() - periods = [2,3,5,7,11] - - discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)] - discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods] - self.discriminators = nn.ModuleList(discs) - - def forward(self, y, y_hat): - y_d_rs = [] - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - for i, d in enumerate(self.discriminators): - y_d_r, fmap_r = d(y) - y_d_g, fmap_g = d(y_hat) - y_d_rs.append(y_d_r) - y_d_gs.append(y_d_g) - fmap_rs.append(fmap_r) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - - -class SynthesizerTrn(nn.Module): - """ - Synthesizer for Training - """ - - def __init__(self, - n_vocab, - spec_channels, - segment_size, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - n_speakers=0, - gin_channels=0, - use_sdp=True, - emotion_embedding=False, - **kwargs): - - super().__init__() - self.n_vocab = n_vocab - self.spec_channels = spec_channels - self.inter_channels = inter_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.resblock = resblock - self.resblock_kernel_sizes = resblock_kernel_sizes - self.resblock_dilation_sizes = resblock_dilation_sizes - self.upsample_rates = upsample_rates - self.upsample_initial_channel = upsample_initial_channel - self.upsample_kernel_sizes = upsample_kernel_sizes - self.segment_size = segment_size - self.n_speakers = n_speakers - self.gin_channels = gin_channels - - self.use_sdp = use_sdp - - self.enc_p = TextEncoder(n_vocab, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - emotion_embedding) - self.dec = Generator(inter_channels, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=gin_channels) - self.enc_q = PosteriorEncoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels) - self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels) - - if use_sdp: - self.dp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels) - else: - self.dp = DurationPredictor(hidden_channels, 256, 3, 0.5, gin_channels=gin_channels) - - if n_speakers > 1: - self.emb_g = nn.Embedding(n_speakers, gin_channels) - - def forward(self, x, x_lengths, y, y_lengths, sid=None): - - x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths) - if self.n_speakers > 0: - g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1] - else: - g = None - - z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g) - z_p = self.flow(z, y_mask, g=g) - - with torch.no_grad(): - # negative cross-entropy - s_p_sq_r = torch.exp(-2 * logs_p) # [b, d, t] - neg_cent1 = torch.sum(-0.5 * math.log(2 * math.pi) - logs_p, [1], keepdim=True) # [b, 1, t_s] - neg_cent2 = torch.matmul(-0.5 * (z_p ** 2).transpose(1, 2), s_p_sq_r) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s] - neg_cent3 = torch.matmul(z_p.transpose(1, 2), (m_p * s_p_sq_r)) # [b, t_t, d] x [b, d, t_s] = [b, t_t, t_s] - neg_cent4 = torch.sum(-0.5 * (m_p ** 2) * s_p_sq_r, [1], keepdim=True) # [b, 1, t_s] - neg_cent = neg_cent1 + neg_cent2 + neg_cent3 + neg_cent4 - - attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1) - attn = monotonic_align.maximum_path(neg_cent, attn_mask.squeeze(1)).unsqueeze(1).detach() - - w = attn.sum(2) - if self.use_sdp: - l_length = self.dp(x, x_mask, w, g=g) - l_length = l_length / torch.sum(x_mask) - else: - logw_ = torch.log(w + 1e-6) * x_mask - logw = self.dp(x, x_mask, g=g) - l_length = torch.sum((logw - logw_)**2, [1,2]) / torch.sum(x_mask) # for averaging - - # expand prior - m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) - logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) - - z_slice, ids_slice = commons.rand_slice_segments(z, y_lengths, self.segment_size) - o = self.dec(z_slice, g=g) - return o, l_length, attn, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q) - - def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., max_len=None, emotion_embedding=None): - x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths, emotion_embedding) - if self.n_speakers > 0: - g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1] - else: - g = None - - if self.use_sdp: - logw = self.dp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w) - else: - logw = self.dp(x, x_mask, g=g) - w = torch.exp(logw) * x_mask * length_scale - w_ceil = torch.ceil(w) - y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long() - y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype) - attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1) - attn = commons.generate_path(w_ceil, attn_mask) - - m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] - logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] - - z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale - z = self.flow(z_p, y_mask, g=g, reverse=True) - o = self.dec((z * y_mask)[:,:,:max_len], g=g) - return o, attn, y_mask, (z, z_p, m_p, logs_p) - - def voice_conversion(self, y, y_lengths, sid_src, sid_tgt): - assert self.n_speakers > 0, "n_speakers have to be larger than 0." - g_src = self.emb_g(sid_src).unsqueeze(-1) - g_tgt = self.emb_g(sid_tgt).unsqueeze(-1) - z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g_src) - z_p = self.flow(z, y_mask, g=g_src) - z_hat = self.flow(z_p, y_mask, g=g_tgt, reverse=True) - o_hat = self.dec(z_hat * y_mask, g=g_tgt) - return o_hat, y_mask, (z, z_p, z_hat) - diff --git a/spaces/Pranjal2041/SemSup-XC/README.md b/spaces/Pranjal2041/SemSup-XC/README.md deleted file mode 100644 index 073875e86dc95055c61bdcd5fa6fdad187fa1e1b..0000000000000000000000000000000000000000 --- a/spaces/Pranjal2041/SemSup-XC/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: SemSup XC -emoji: 💩 -colorFrom: yellow -colorTo: purple -sdk: gradio -sdk_version: 3.9.1 -app_file: app.py -pinned: false -license: bsd-3-clause-clear ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/optim/ema.py b/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/optim/ema.py deleted file mode 100644 index 4337eaff066a8ca124dca3e3e63ee36e417c055c..0000000000000000000000000000000000000000 --- a/spaces/Prof-Reza/Audiocraft_Music-Audio_Generation/audiocraft/optim/ema.py +++ /dev/null @@ -1,85 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -# ModelEMA implementation is taken from -# https://github.com/facebookresearch/demucs - -from collections import defaultdict -import typing as tp - -import torch -import torch.nn as nn - - -def _get_all_non_persistent_buffers_set(module: nn.Module, root: str = "") -> set: - names: set = set() - for (name, sub_module) in module.named_modules(): - if name == '': - buffer_names = module._non_persistent_buffers_set - buffer_names = {f"{root}.{buff_name}" if len(root) > 0 else buff_name - for buff_name in buffer_names} - names.update(buffer_names) - else: - sub_name = f"{root}.{name}" if len(root) > 0 else name - sub_buffer_names = _get_all_non_persistent_buffers_set(sub_module, sub_name) - names.update(sub_buffer_names) - return names - - -def _get_named_tensors(module: nn.Module): - non_persistent_buffers_set = _get_all_non_persistent_buffers_set(module) - named_buffers = [(name, buffer) for (name, buffer) in module.named_buffers() - if name not in non_persistent_buffers_set] - named_parameters = list(module.named_parameters()) - return named_parameters + named_buffers - - -class ModuleDictEMA: - """Exponential Moving Average over a nn.ModuleDict. - - You can switch to the EMA weights temporarily. - """ - def __init__(self, module_dict: nn.ModuleDict, decay: float = 0.999, - unbias: bool = True, device: tp.Union[torch.device, str] = 'cpu'): - self.decay = decay - self.module_dict = module_dict - self.state: dict = defaultdict(dict) - self.count = 0 - self.device = device - self.unbias = unbias - self._init() - - def _init(self): - for module_name, module in self.module_dict.items(): - for key, val in _get_named_tensors(module): - if not val.is_floating_point(): - continue - device = self.device or val.device - if key not in self.state[module_name]: - self.state[module_name][key] = val.detach().to(device, copy=True) - - def step(self): - if self.unbias: - self.count = self.count * self.decay + 1 - w = 1 / self.count - else: - w = 1 - self.decay - for module_name, module in self.module_dict.items(): - for key, val in _get_named_tensors(module): - if not val.is_floating_point(): - continue - device = self.device or val.device - self.state[module_name][key].mul_(1 - w) - self.state[module_name][key].add_(val.detach().to(device), alpha=w) - - def state_dict(self): - return {'state': self.state, 'count': self.count} - - def load_state_dict(self, state): - self.count = state['count'] - for module_name, module in state['state'].items(): - for key, val in module.items(): - self.state[module_name][key].copy_(val) diff --git a/spaces/RMXK/RVC_HFF/infer/modules/train/extract_feature_print.py b/spaces/RMXK/RVC_HFF/infer/modules/train/extract_feature_print.py deleted file mode 100644 index f771dd9b8ba92262e6844e7b5781de43c342833a..0000000000000000000000000000000000000000 --- a/spaces/RMXK/RVC_HFF/infer/modules/train/extract_feature_print.py +++ /dev/null @@ -1,137 +0,0 @@ -import os -import sys -import traceback - -os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1" -os.environ["PYTORCH_MPS_HIGH_WATERMARK_RATIO"] = "0.0" - -device = sys.argv[1] -n_part = int(sys.argv[2]) -i_part = int(sys.argv[3]) -if len(sys.argv) == 6: - exp_dir = sys.argv[4] - version = sys.argv[5] -else: - i_gpu = sys.argv[4] - exp_dir = sys.argv[5] - os.environ["CUDA_VISIBLE_DEVICES"] = str(i_gpu) - version = sys.argv[6] -import fairseq -import numpy as np -import soundfile as sf -import torch -import torch.nn.functional as F - -if "privateuseone" not in device: - device = "cpu" - if torch.cuda.is_available(): - device = "cuda" - elif torch.backends.mps.is_available(): - device = "mps" -else: - import torch_directml - - device = torch_directml.device(torch_directml.default_device()) - - def forward_dml(ctx, x, scale): - ctx.scale = scale - res = x.clone().detach() - return res - - fairseq.modules.grad_multiply.GradMultiply.forward = forward_dml - -f = open("%s/extract_f0_feature.log" % exp_dir, "a+") - - -def printt(strr): - print(strr) - f.write("%s\n" % strr) - f.flush() - - -printt(sys.argv) -model_path = "assets/hubert/hubert_base.pt" - -printt(exp_dir) -wavPath = "%s/1_16k_wavs" % exp_dir -outPath = ( - "%s/3_feature256" % exp_dir if version == "v1" else "%s/3_feature768" % exp_dir -) -os.makedirs(outPath, exist_ok=True) - - -# wave must be 16k, hop_size=320 -def readwave(wav_path, normalize=False): - wav, sr = sf.read(wav_path) - assert sr == 16000 - feats = torch.from_numpy(wav).float() - if feats.dim() == 2: # double channels - feats = feats.mean(-1) - assert feats.dim() == 1, feats.dim() - if normalize: - with torch.no_grad(): - feats = F.layer_norm(feats, feats.shape) - feats = feats.view(1, -1) - return feats - - -# HuBERT model -printt("load model(s) from {}".format(model_path)) -# if hubert model is exist -if os.access(model_path, os.F_OK) == False: - printt( - "Error: Extracting is shut down because %s does not exist, you may download it from https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main" - % model_path - ) - exit(0) -models, saved_cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task( - [model_path], - suffix="", -) -model = models[0] -model = model.to(device) -printt("move model to %s" % device) -if device not in ["mps", "cpu"]: - model = model.half() -model.eval() - -todo = sorted(list(os.listdir(wavPath)))[i_part::n_part] -n = max(1, len(todo) // 10) # 最多打印十条 -if len(todo) == 0: - printt("no-feature-todo") -else: - printt("all-feature-%s" % len(todo)) - for idx, file in enumerate(todo): - try: - if file.endswith(".wav"): - wav_path = "%s/%s" % (wavPath, file) - out_path = "%s/%s" % (outPath, file.replace("wav", "npy")) - - if os.path.exists(out_path): - continue - - feats = readwave(wav_path, normalize=saved_cfg.task.normalize) - padding_mask = torch.BoolTensor(feats.shape).fill_(False) - inputs = { - "source": feats.half().to(device) - if device not in ["mps", "cpu"] - else feats.to(device), - "padding_mask": padding_mask.to(device), - "output_layer": 9 if version == "v1" else 12, # layer 9 - } - with torch.no_grad(): - logits = model.extract_features(**inputs) - feats = ( - model.final_proj(logits[0]) if version == "v1" else logits[0] - ) - - feats = feats.squeeze(0).float().cpu().numpy() - if np.isnan(feats).sum() == 0: - np.save(out_path, feats, allow_pickle=False) - else: - printt("%s-contains nan" % file) - if idx % n == 0: - printt("now-%s,all-%s,%s,%s" % (len(todo), idx, file, feats.shape)) - except: - printt(traceback.format_exc()) - printt("all-feature-done") diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/packaging/_musllinux.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/packaging/_musllinux.py deleted file mode 100644 index 8ac3059ba3c246b9a5a6fb8d14936bb07777191e..0000000000000000000000000000000000000000 --- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/setuptools/_vendor/packaging/_musllinux.py +++ /dev/null @@ -1,136 +0,0 @@ -"""PEP 656 support. - -This module implements logic to detect if the currently running Python is -linked against musl, and what musl version is used. -""" - -import contextlib -import functools -import operator -import os -import re -import struct -import subprocess -import sys -from typing import IO, Iterator, NamedTuple, Optional, Tuple - - -def _read_unpacked(f: IO[bytes], fmt: str) -> Tuple[int, ...]: - return struct.unpack(fmt, f.read(struct.calcsize(fmt))) - - -def _parse_ld_musl_from_elf(f: IO[bytes]) -> Optional[str]: - """Detect musl libc location by parsing the Python executable. - - Based on: https://gist.github.com/lyssdod/f51579ae8d93c8657a5564aefc2ffbca - ELF header: https://refspecs.linuxfoundation.org/elf/gabi4+/ch4.eheader.html - """ - f.seek(0) - try: - ident = _read_unpacked(f, "16B") - except struct.error: - return None - if ident[:4] != tuple(b"\x7fELF"): # Invalid magic, not ELF. - return None - f.seek(struct.calcsize("HHI"), 1) # Skip file type, machine, and version. - - try: - # e_fmt: Format for program header. - # p_fmt: Format for section header. - # p_idx: Indexes to find p_type, p_offset, and p_filesz. - e_fmt, p_fmt, p_idx = { - 1: ("IIIIHHH", "IIIIIIII", (0, 1, 4)), # 32-bit. - 2: ("QQQIHHH", "IIQQQQQQ", (0, 2, 5)), # 64-bit. - }[ident[4]] - except KeyError: - return None - else: - p_get = operator.itemgetter(*p_idx) - - # Find the interpreter section and return its content. - try: - _, e_phoff, _, _, _, e_phentsize, e_phnum = _read_unpacked(f, e_fmt) - except struct.error: - return None - for i in range(e_phnum + 1): - f.seek(e_phoff + e_phentsize * i) - try: - p_type, p_offset, p_filesz = p_get(_read_unpacked(f, p_fmt)) - except struct.error: - return None - if p_type != 3: # Not PT_INTERP. - continue - f.seek(p_offset) - interpreter = os.fsdecode(f.read(p_filesz)).strip("\0") - if "musl" not in interpreter: - return None - return interpreter - return None - - -class _MuslVersion(NamedTuple): - major: int - minor: int - - -def _parse_musl_version(output: str) -> Optional[_MuslVersion]: - lines = [n for n in (n.strip() for n in output.splitlines()) if n] - if len(lines) < 2 or lines[0][:4] != "musl": - return None - m = re.match(r"Version (\d+)\.(\d+)", lines[1]) - if not m: - return None - return _MuslVersion(major=int(m.group(1)), minor=int(m.group(2))) - - -@functools.lru_cache() -def _get_musl_version(executable: str) -> Optional[_MuslVersion]: - """Detect currently-running musl runtime version. - - This is done by checking the specified executable's dynamic linking - information, and invoking the loader to parse its output for a version - string. If the loader is musl, the output would be something like:: - - musl libc (x86_64) - Version 1.2.2 - Dynamic Program Loader - """ - with contextlib.ExitStack() as stack: - try: - f = stack.enter_context(open(executable, "rb")) - except OSError: - return None - ld = _parse_ld_musl_from_elf(f) - if not ld: - return None - proc = subprocess.run([ld], stderr=subprocess.PIPE, universal_newlines=True) - return _parse_musl_version(proc.stderr) - - -def platform_tags(arch: str) -> Iterator[str]: - """Generate musllinux tags compatible to the current platform. - - :param arch: Should be the part of platform tag after the ``linux_`` - prefix, e.g. ``x86_64``. The ``linux_`` prefix is assumed as a - prerequisite for the current platform to be musllinux-compatible. - - :returns: An iterator of compatible musllinux tags. - """ - sys_musl = _get_musl_version(sys.executable) - if sys_musl is None: # Python not dynamically linked against musl. - return - for minor in range(sys_musl.minor, -1, -1): - yield f"musllinux_{sys_musl.major}_{minor}_{arch}" - - -if __name__ == "__main__": # pragma: no cover - import sysconfig - - plat = sysconfig.get_platform() - assert plat.startswith("linux-"), "not linux" - - print("plat:", plat) - print("musl:", _get_musl_version(sys.executable)) - print("tags:", end=" ") - for t in platform_tags(re.sub(r"[.-]", "_", plat.split("-", 1)[-1])): - print(t, end="\n ") diff --git a/spaces/Reha2704/VToonify/vtoonify/model/raft/alt_cuda_corr/setup.py b/spaces/Reha2704/VToonify/vtoonify/model/raft/alt_cuda_corr/setup.py deleted file mode 100644 index c0207ff285ffac4c8146c79d154f12416dbef48c..0000000000000000000000000000000000000000 --- a/spaces/Reha2704/VToonify/vtoonify/model/raft/alt_cuda_corr/setup.py +++ /dev/null @@ -1,15 +0,0 @@ -from setuptools import setup -from torch.utils.cpp_extension import BuildExtension, CUDAExtension - - -setup( - name='correlation', - ext_modules=[ - CUDAExtension('alt_cuda_corr', - sources=['correlation.cpp', 'correlation_kernel.cu'], - extra_compile_args={'cxx': [], 'nvcc': ['-O3']}), - ], - cmdclass={ - 'build_ext': BuildExtension - }) - diff --git a/spaces/Ricecake123/RVC-demo/docs/faq.md b/spaces/Ricecake123/RVC-demo/docs/faq.md deleted file mode 100644 index 74eff82d9e4f96f50ad0aed628c253d08e16a426..0000000000000000000000000000000000000000 --- a/spaces/Ricecake123/RVC-demo/docs/faq.md +++ /dev/null @@ -1,89 +0,0 @@ -## Q1:ffmpeg error/utf8 error. - -大概率不是ffmpeg问题,而是音频路径问题;
-ffmpeg读取路径带空格、()等特殊符号,可能出现ffmpeg error;训练集音频带中文路径,在写入filelist.txt的时候可能出现utf8 error;
- -## Q2:一键训练结束没有索引 - -显示"Training is done. The program is closed."则模型训练成功,后续紧邻的报错是假的;
- -一键训练结束完成没有added开头的索引文件,可能是因为训练集太大卡住了添加索引的步骤;已通过批处理add索引解决内存add索引对内存需求过大的问题。临时可尝试再次点击"训练索引"按钮。
- -## Q3:训练结束推理没看到训练集的音色 -点刷新音色再看看,如果还没有看看训练有没有报错,控制台和webui的截图,logs/实验名下的log,都可以发给开发者看看。
- -## Q4:如何分享模型 - rvc_root/logs/实验名 下面存储的pth不是用来分享模型用来推理的,而是为了存储实验状态供复现,以及继续训练用的。用来分享的模型应该是weights文件夹下大小为60+MB的pth文件;
- 后续将把weights/exp_name.pth和logs/exp_name/added_xxx.index合并打包成weights/exp_name.zip省去填写index的步骤,那么zip文件用来分享,不要分享pth文件,除非是想换机器继续训练;
- 如果你把logs文件夹下的几百MB的pth文件复制/分享到weights文件夹下强行用于推理,可能会出现f0,tgt_sr等各种key不存在的报错。你需要用ckpt选项卡最下面,手工或自动(本地logs下如果能找到相关信息则会自动)选择是否携带音高、目标音频采样率的选项后进行ckpt小模型提取(输入路径填G开头的那个),提取完在weights文件夹下会出现60+MB的pth文件,刷新音色后可以选择使用。
- -## Q5:Connection Error. -也许你关闭了控制台(黑色窗口)。
- -## Q6:WebUI弹出Expecting value: line 1 column 1 (char 0). -请关闭系统局域网代理/全局代理。
- -这个不仅是客户端的代理,也包括服务端的代理(例如你使用autodl设置了http_proxy和https_proxy学术加速,使用时也需要unset关掉)
- -## Q7:不用WebUI如何通过命令训练推理 -训练脚本:
-可先跑通WebUI,消息窗内会显示数据集处理和训练用命令行;
- -推理脚本:
-https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/myinfer.py
- -例子:
- -runtime\python.exe myinfer.py 0 "E:\codes\py39\RVC-beta\todo-songs\1111.wav" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "test.wav" "weights/mi-test.pth" 0.6 cuda:0 True
- -f0up_key=sys.argv[1]
-input_path=sys.argv[2]
-index_path=sys.argv[3]
-f0method=sys.argv[4]#harvest or pm
-opt_path=sys.argv[5]
-model_path=sys.argv[6]
-index_rate=float(sys.argv[7])
-device=sys.argv[8]
-is_half=bool(sys.argv[9])
- -## Q8:Cuda error/Cuda out of memory. -小概率是cuda配置问题、设备不支持;大概率是显存不够(out of memory);
- -训练的话缩小batch size(如果缩小到1还不够只能更换显卡训练),推理的话酌情缩小config.py结尾的x_pad,x_query,x_center,x_max。4G以下显存(例如1060(3G)和各种2G显卡)可以直接放弃,4G显存显卡还有救。
- -## Q9:total_epoch调多少比较好 - -如果训练集音质差底噪大,20~30足够了,调太高,底模音质无法带高你的低音质训练集
-如果训练集音质高底噪低时长多,可以调高,200是ok的(训练速度很快,既然你有条件准备高音质训练集,显卡想必条件也不错,肯定不在乎多一些训练时间)
- -## Q10:需要多少训练集时长 - 推荐10min至50min
- 保证音质高底噪低的情况下,如果有个人特色的音色统一,则多多益善
- 高水平的训练集(精简+音色有特色),5min至10min也是ok的,仓库作者本人就经常这么玩
- 也有人拿1min至2min的数据来训练并且训练成功的,但是成功经验是其他人不可复现的,不太具备参考价值。这要求训练集音色特色非常明显(比如说高频气声较明显的萝莉少女音),且音质高;
- 1min以下时长数据目前没见有人尝试(成功)过。不建议进行这种鬼畜行为。
- -## Q11:index rate干嘛用的,怎么调(科普) - 如果底模和推理源的音质高于训练集的音质,他们可以带高推理结果的音质,但代价可能是音色往底模/推理源的音色靠,这种现象叫做"音色泄露";
- index rate用来削减/解决音色泄露问题。调到1,则理论上不存在推理源的音色泄露问题,但音质更倾向于训练集。如果训练集音质比推理源低,则index rate调高可能降低音质。调到0,则不具备利用检索混合来保护训练集音色的效果;
- 如果训练集优质时长多,可调高total_epoch,此时模型本身不太会引用推理源和底模的音色,很少存在"音色泄露"问题,此时index_rate不重要,你甚至可以不建立/分享index索引文件。
- -## Q11:推理怎么选gpu -config.py文件里device cuda:后面选择卡号;
-卡号和显卡的映射关系,在训练选项卡的显卡信息栏里能看到。
- -## Q12:如何推理训练中间保存的pth -通过ckpt选项卡最下面提取小模型。
- - -## Q13:如何中断和继续训练 -现阶段只能关闭WebUI控制台双击go-web.bat重启程序。网页参数也要刷新重新填写;
-继续训练:相同网页参数点训练模型,就会接着上次的checkpoint继续训练。
- -## Q14:训练时出现文件页面/内存error -进程开太多了,内存炸了。你可能可以通过如下方式解决
-1、"提取音高和处理数据使用的CPU进程数" 酌情拉低;
-2、训练集音频手工切一下,不要太长。
- - - diff --git a/spaces/RobLi/ControlNet-v1-1/app_lineart.py b/spaces/RobLi/ControlNet-v1-1/app_lineart.py deleted file mode 100644 index 5aefb490d4f3fa858fc1787d90912fdd7f04c22e..0000000000000000000000000000000000000000 --- a/spaces/RobLi/ControlNet-v1-1/app_lineart.py +++ /dev/null @@ -1,114 +0,0 @@ -#!/usr/bin/env python - -import gradio as gr - -from utils import randomize_seed_fn - - -def create_demo(process, max_images=12, default_num_images=3): - with gr.Blocks() as demo: - with gr.Row(): - with gr.Column(): - image = gr.Image() - prompt = gr.Textbox(label='Prompt') - run_button = gr.Button('Run') - with gr.Accordion('Advanced options', open=False): - preprocessor_name = gr.Radio( - label='Preprocessor', - choices=[ - 'Lineart', - 'Lineart coarse', - 'None', - 'Lineart (anime)', - 'None (anime)', - ], - type='value', - value='Lineart', - info= - 'Note that "Lineart (anime)" and "None (anime)" are for anime base models like Anything-v3.' - ) - num_samples = gr.Slider(label='Number of images', - minimum=1, - maximum=max_images, - value=default_num_images, - step=1) - image_resolution = gr.Slider(label='Image resolution', - minimum=256, - maximum=512, - value=512, - step=256) - preprocess_resolution = gr.Slider( - label='Preprocess resolution', - minimum=128, - maximum=512, - value=512, - step=1) - num_steps = gr.Slider(label='Number of steps', - minimum=1, - maximum=100, - value=20, - step=1) - guidance_scale = gr.Slider(label='Guidance scale', - minimum=0.1, - maximum=30.0, - value=9.0, - step=0.1) - seed = gr.Slider(label='Seed', - minimum=0, - maximum=1000000, - step=1, - value=0, - randomize=True) - randomize_seed = gr.Checkbox(label='Randomize seed', - value=True) - a_prompt = gr.Textbox( - label='Additional prompt', - value='best quality, extremely detailed') - n_prompt = gr.Textbox( - label='Negative prompt', - value= - 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality' - ) - with gr.Column(): - result = gr.Gallery(label='Output', show_label=False).style( - columns=2, object_fit='scale-down') - inputs = [ - image, - prompt, - a_prompt, - n_prompt, - num_samples, - image_resolution, - preprocess_resolution, - num_steps, - guidance_scale, - seed, - preprocessor_name, - ] - prompt.submit( - fn=randomize_seed_fn, - inputs=[seed, randomize_seed], - outputs=seed, - ).then( - fn=process, - inputs=inputs, - outputs=result, - ) - run_button.click( - fn=randomize_seed_fn, - inputs=[seed, randomize_seed], - outputs=seed, - ).then( - fn=process, - inputs=inputs, - outputs=result, - api_name='scribble', - ) - return demo - - -if __name__ == '__main__': - from model import Model - model = Model(task_name='lineart') - demo = create_demo(model.process_lineart) - demo.queue().launch() diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/exp/upernet_global_base/run.sh b/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/exp/upernet_global_base/run.sh deleted file mode 100644 index ee49cf4006584c7f24203a15c7a9a11babacd49d..0000000000000000000000000000000000000000 --- a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/exp/upernet_global_base/run.sh +++ /dev/null @@ -1,10 +0,0 @@ -#!/usr/bin/env bash - -work_path=$(dirname $0) -PYTHONPATH="$(dirname $0)/../../":$PYTHONPATH \ -python -m torch.distributed.launch --nproc_per_node=8 \ - tools/train.py ${work_path}/config.py \ - --launcher pytorch \ - --options model.backbone.pretrained_path='your_model_path/uniformer_base_in1k.pth' \ - --work-dir ${work_path}/ckpt \ - 2>&1 | tee -a ${work_path}/log.txt diff --git a/spaces/Rongjiehuang/GenerSpeech/tasks/tts/fs2_utils.py b/spaces/Rongjiehuang/GenerSpeech/tasks/tts/fs2_utils.py deleted file mode 100644 index 092550863d2fd72f008cc790bc6d950340e68182..0000000000000000000000000000000000000000 --- a/spaces/Rongjiehuang/GenerSpeech/tasks/tts/fs2_utils.py +++ /dev/null @@ -1,173 +0,0 @@ -import matplotlib - -matplotlib.use('Agg') - -import glob -import importlib -from utils.cwt import get_lf0_cwt -import os -import torch.optim -import torch.utils.data -from utils.indexed_datasets import IndexedDataset -from utils.pitch_utils import norm_interp_f0 -import numpy as np -from tasks.base_task import BaseDataset -import torch -import torch.optim -import torch.utils.data -import utils -import torch.distributions -from utils.hparams import hparams - - -class FastSpeechDataset(BaseDataset): - def __init__(self, prefix, shuffle=False): - super().__init__(shuffle) - self.data_dir = hparams['binary_data_dir'] - self.prefix = prefix - self.hparams = hparams - self.sizes = np.load(f'{self.data_dir}/{self.prefix}_lengths.npy') - self.indexed_ds = None - # self.name2spk_id={} - - # pitch stats - f0_stats_fn = f'{self.data_dir}/train_f0s_mean_std.npy' - if os.path.exists(f0_stats_fn): - hparams['f0_mean'], hparams['f0_std'] = self.f0_mean, self.f0_std = np.load(f0_stats_fn) - hparams['f0_mean'] = float(hparams['f0_mean']) - hparams['f0_std'] = float(hparams['f0_std']) - else: - hparams['f0_mean'], hparams['f0_std'] = self.f0_mean, self.f0_std = None, None - - if prefix == 'test': - if hparams['test_input_dir'] != '': - self.indexed_ds, self.sizes = self.load_test_inputs(hparams['test_input_dir']) - else: - if hparams['num_test_samples'] > 0: - self.avail_idxs = list(range(hparams['num_test_samples'])) + hparams['test_ids'] - self.sizes = [self.sizes[i] for i in self.avail_idxs] - - if hparams['pitch_type'] == 'cwt': - _, hparams['cwt_scales'] = get_lf0_cwt(np.ones(10)) - - def _get_item(self, index): - if hasattr(self, 'avail_idxs') and self.avail_idxs is not None: - index = self.avail_idxs[index] - if self.indexed_ds is None: - self.indexed_ds = IndexedDataset(f'{self.data_dir}/{self.prefix}') - return self.indexed_ds[index] - - def __getitem__(self, index): - hparams = self.hparams - item = self._get_item(index) - max_frames = hparams['max_frames'] - spec = torch.Tensor(item['mel'])[:max_frames] - energy = (spec.exp() ** 2).sum(-1).sqrt() - mel2ph = torch.LongTensor(item['mel2ph'])[:max_frames] if 'mel2ph' in item else None - f0, uv = norm_interp_f0(item["f0"][:max_frames], hparams) - phone = torch.LongTensor(item['phone'][:hparams['max_input_tokens']]) - pitch = torch.LongTensor(item.get("pitch"))[:max_frames] - # print(item.keys(), item['mel'].shape, spec.shape) - sample = { - "id": index, - "item_name": item['item_name'], - "text": item['txt'], - "txt_token": phone, - "mel": spec, - "pitch": pitch, - "energy": energy, - "f0": f0, - "uv": uv, - "mel2ph": mel2ph, - "mel_nonpadding": spec.abs().sum(-1) > 0, - } - if self.hparams['use_spk_embed']: - sample["spk_embed"] = torch.Tensor(item['spk_embed']) - if self.hparams['use_spk_id']: - sample["spk_id"] = item['spk_id'] - # sample['spk_id'] = 0 - # for key in self.name2spk_id.keys(): - # if key in item['item_name']: - # sample['spk_id'] = self.name2spk_id[key] - # break - if self.hparams['pitch_type'] == 'cwt': - cwt_spec = torch.Tensor(item['cwt_spec'])[:max_frames] - f0_mean = item.get('f0_mean', item.get('cwt_mean')) - f0_std = item.get('f0_std', item.get('cwt_std')) - sample.update({"cwt_spec": cwt_spec, "f0_mean": f0_mean, "f0_std": f0_std}) - elif self.hparams['pitch_type'] == 'ph': - f0_phlevel_sum = torch.zeros_like(phone).float().scatter_add(0, mel2ph - 1, f0) - f0_phlevel_num = torch.zeros_like(phone).float().scatter_add( - 0, mel2ph - 1, torch.ones_like(f0)).clamp_min(1) - sample["f0_ph"] = f0_phlevel_sum / f0_phlevel_num - return sample - - def collater(self, samples): - if len(samples) == 0: - return {} - id = torch.LongTensor([s['id'] for s in samples]) - item_names = [s['item_name'] for s in samples] - text = [s['text'] for s in samples] - txt_tokens = utils.collate_1d([s['txt_token'] for s in samples], 0) - f0 = utils.collate_1d([s['f0'] for s in samples], 0.0) - pitch = utils.collate_1d([s['pitch'] for s in samples]) - uv = utils.collate_1d([s['uv'] for s in samples]) - energy = utils.collate_1d([s['energy'] for s in samples], 0.0) - mel2ph = utils.collate_1d([s['mel2ph'] for s in samples], 0.0) \ - if samples[0]['mel2ph'] is not None else None - mels = utils.collate_2d([s['mel'] for s in samples], 0.0) - txt_lengths = torch.LongTensor([s['txt_token'].numel() for s in samples]) - mel_lengths = torch.LongTensor([s['mel'].shape[0] for s in samples]) - - batch = { - 'id': id, - 'item_name': item_names, - 'nsamples': len(samples), - 'text': text, - 'txt_tokens': txt_tokens, - 'txt_lengths': txt_lengths, - 'mels': mels, - 'mel_lengths': mel_lengths, - 'mel2ph': mel2ph, - 'energy': energy, - 'pitch': pitch, - 'f0': f0, - 'uv': uv, - } - - if self.hparams['use_spk_embed']: - spk_embed = torch.stack([s['spk_embed'] for s in samples]) - batch['spk_embed'] = spk_embed - if self.hparams['use_spk_id']: - spk_ids = torch.LongTensor([s['spk_id'] for s in samples]) - batch['spk_ids'] = spk_ids - if self.hparams['pitch_type'] == 'cwt': - cwt_spec = utils.collate_2d([s['cwt_spec'] for s in samples]) - f0_mean = torch.Tensor([s['f0_mean'] for s in samples]) - f0_std = torch.Tensor([s['f0_std'] for s in samples]) - batch.update({'cwt_spec': cwt_spec, 'f0_mean': f0_mean, 'f0_std': f0_std}) - elif self.hparams['pitch_type'] == 'ph': - batch['f0'] = utils.collate_1d([s['f0_ph'] for s in samples]) - - return batch - - def load_test_inputs(self, test_input_dir, spk_id=0): - inp_wav_paths = glob.glob(f'{test_input_dir}/*.wav') + glob.glob(f'{test_input_dir}/*.mp3') - sizes = [] - items = [] - - binarizer_cls = hparams.get("binarizer_cls", 'data_gen.tts.base_binarizerr.BaseBinarizer') - pkg = ".".join(binarizer_cls.split(".")[:-1]) - cls_name = binarizer_cls.split(".")[-1] - binarizer_cls = getattr(importlib.import_module(pkg), cls_name) - binarization_args = hparams['binarization_args'] - - for wav_fn in inp_wav_paths: - item_name = os.path.basename(wav_fn) - ph = txt = tg_fn = '' - wav_fn = wav_fn - encoder = None - item = binarizer_cls.process_item(item_name, ph, txt, tg_fn, wav_fn, spk_id, encoder, binarization_args) - items.append(item) - sizes.append(item['len']) - return items, sizes diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/schema.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/schema.py deleted file mode 100644 index e94c3d1991e96da81efe13cfe06214166afe80d1..0000000000000000000000000000000000000000 --- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/schema.py +++ /dev/null @@ -1,3 +0,0 @@ -"""Altair schema wrappers""" -# ruff: noqa -from .v5.schema import * diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/v5/display.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/v5/display.py deleted file mode 100644 index ba69e02e076b0828a9b2032eb47de8c1fb1492d8..0000000000000000000000000000000000000000 --- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/v5/display.py +++ /dev/null @@ -1,119 +0,0 @@ -import os - -from ...utils.mimebundle import spec_to_mimebundle -from ..display import Displayable -from ..display import default_renderer_base -from ..display import json_renderer_base -from ..display import RendererRegistry -from ..display import HTMLRenderer - -from .schema import SCHEMA_VERSION - -VEGALITE_VERSION = SCHEMA_VERSION.lstrip("v") -VEGA_VERSION = "5" -VEGAEMBED_VERSION = "6" - - -# ============================================================================== -# VegaLite v5 renderer logic -# ============================================================================== - - -# The MIME type for Vega-Lite 5.x releases. -VEGALITE_MIME_TYPE = "application/vnd.vegalite.v5+json" # type: str - -# The entry point group that can be used by other packages to declare other -# renderers that will be auto-detected. Explicit registration is also -# allowed by the PluginRegistery API. -ENTRY_POINT_GROUP = "altair.vegalite.v5.renderer" # type: str - -# The display message when rendering fails -DEFAULT_DISPLAY = """\ -- -If you see this message, it means the renderer has not been properly enabled -for the frontend that you are using. For more information, see -https://altair-viz.github.io/user_guide/display_frontends.html#troubleshooting -""" - -renderers = RendererRegistry(entry_point_group=ENTRY_POINT_GROUP) - -here = os.path.dirname(os.path.realpath(__file__)) - - -def mimetype_renderer(spec, **metadata): - return default_renderer_base(spec, VEGALITE_MIME_TYPE, DEFAULT_DISPLAY, **metadata) - - -def json_renderer(spec, **metadata): - return json_renderer_base(spec, DEFAULT_DISPLAY, **metadata) - - -def png_renderer(spec, **metadata): - return spec_to_mimebundle( - spec, - format="png", - mode="vega-lite", - vega_version=VEGA_VERSION, - vegaembed_version=VEGAEMBED_VERSION, - vegalite_version=VEGALITE_VERSION, - **metadata, - ) - - -def svg_renderer(spec, **metadata): - return spec_to_mimebundle( - spec, - format="svg", - mode="vega-lite", - vega_version=VEGA_VERSION, - vegaembed_version=VEGAEMBED_VERSION, - vegalite_version=VEGALITE_VERSION, - **metadata, - ) - - -html_renderer = HTMLRenderer( - mode="vega-lite", - template="universal", - vega_version=VEGA_VERSION, - vegaembed_version=VEGAEMBED_VERSION, - vegalite_version=VEGALITE_VERSION, -) - -renderers.register("default", html_renderer) -renderers.register("html", html_renderer) -renderers.register("colab", html_renderer) -renderers.register("kaggle", html_renderer) -renderers.register("zeppelin", html_renderer) -renderers.register("mimetype", mimetype_renderer) -renderers.register("jupyterlab", mimetype_renderer) -renderers.register("nteract", mimetype_renderer) -renderers.register("json", json_renderer) -renderers.register("png", png_renderer) -renderers.register("svg", svg_renderer) -renderers.enable("default") - - -class VegaLite(Displayable): - """An IPython/Jupyter display class for rendering VegaLite 5.""" - - renderers = renderers - schema_path = (__name__, "schema/vega-lite-schema.json") - - -def vegalite(spec, validate=True): - """Render and optionally validate a VegaLite 5 spec. - - This will use the currently enabled renderer to render the spec. - - Parameters - ========== - spec: dict - A fully compliant VegaLite 5 spec, with the data portion fully processed. - validate: bool - Should the spec be validated against the VegaLite 5 schema? - """ - from IPython.display import display - - display(VegaLite(spec, validate=validate)) diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/colorama/tests/isatty_test.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/colorama/tests/isatty_test.py deleted file mode 100644 index 0f84e4befe550d4386d24264648abf1323e682ff..0000000000000000000000000000000000000000 --- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/colorama/tests/isatty_test.py +++ /dev/null @@ -1,57 +0,0 @@ -# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file. -import sys -from unittest import TestCase, main - -from ..ansitowin32 import StreamWrapper, AnsiToWin32 -from .utils import pycharm, replace_by, replace_original_by, StreamTTY, StreamNonTTY - - -def is_a_tty(stream): - return StreamWrapper(stream, None).isatty() - -class IsattyTest(TestCase): - - def test_TTY(self): - tty = StreamTTY() - self.assertTrue(is_a_tty(tty)) - with pycharm(): - self.assertTrue(is_a_tty(tty)) - - def test_nonTTY(self): - non_tty = StreamNonTTY() - self.assertFalse(is_a_tty(non_tty)) - with pycharm(): - self.assertFalse(is_a_tty(non_tty)) - - def test_withPycharm(self): - with pycharm(): - self.assertTrue(is_a_tty(sys.stderr)) - self.assertTrue(is_a_tty(sys.stdout)) - - def test_withPycharmTTYOverride(self): - tty = StreamTTY() - with pycharm(), replace_by(tty): - self.assertTrue(is_a_tty(tty)) - - def test_withPycharmNonTTYOverride(self): - non_tty = StreamNonTTY() - with pycharm(), replace_by(non_tty): - self.assertFalse(is_a_tty(non_tty)) - - def test_withPycharmNoneOverride(self): - with pycharm(): - with replace_by(None), replace_original_by(None): - self.assertFalse(is_a_tty(None)) - self.assertFalse(is_a_tty(StreamNonTTY())) - self.assertTrue(is_a_tty(StreamTTY())) - - def test_withPycharmStreamWrapped(self): - with pycharm(): - self.assertTrue(AnsiToWin32(StreamTTY()).stream.isatty()) - self.assertFalse(AnsiToWin32(StreamNonTTY()).stream.isatty()) - self.assertTrue(AnsiToWin32(sys.stdout).stream.isatty()) - self.assertTrue(AnsiToWin32(sys.stderr).stream.isatty()) - - -if __name__ == '__main__': - main() diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydev_bundle/pydev_override.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydev_bundle/pydev_override.py deleted file mode 100644 index d7581d2075c720fe8c1d74011e18cc67491819cf..0000000000000000000000000000000000000000 --- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydev_bundle/pydev_override.py +++ /dev/null @@ -1,35 +0,0 @@ -def overrides(method): - ''' - Meant to be used as - - class B: - @overrides(A.m1) - def m1(self): - pass - ''' - def wrapper(func): - if func.__name__ != method.__name__: - msg = "Wrong @override: %r expected, but overwriting %r." - msg = msg % (func.__name__, method.__name__) - raise AssertionError(msg) - - if func.__doc__ is None: - func.__doc__ = method.__doc__ - - return func - - return wrapper - -def implements(method): - def wrapper(func): - if func.__name__ != method.__name__: - msg = "Wrong @implements: %r expected, but implementing %r." - msg = msg % (func.__name__, method.__name__) - raise AssertionError(msg) - - if func.__doc__ is None: - func.__doc__ = method.__doc__ - - return func - - return wrapper \ No newline at end of file diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_api.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_api.py deleted file mode 100644 index 0b21c59b8eca589e2ac54236a4c1edf9ffa2f7c0..0000000000000000000000000000000000000000 --- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_api.py +++ /dev/null @@ -1,1150 +0,0 @@ -import sys -import bisect -import types - -from _pydev_bundle._pydev_saved_modules import threading -from _pydevd_bundle import pydevd_utils, pydevd_source_mapping -from _pydevd_bundle.pydevd_additional_thread_info import set_additional_thread_info -from _pydevd_bundle.pydevd_comm import (InternalGetThreadStack, internal_get_completions, - InternalSetNextStatementThread, internal_reload_code, - InternalGetVariable, InternalGetArray, InternalLoadFullValue, - internal_get_description, internal_get_frame, internal_evaluate_expression, InternalConsoleExec, - internal_get_variable_json, internal_change_variable, internal_change_variable_json, - internal_evaluate_expression_json, internal_set_expression_json, internal_get_exception_details_json, - internal_step_in_thread, internal_smart_step_into) -from _pydevd_bundle.pydevd_comm_constants import (CMD_THREAD_SUSPEND, file_system_encoding, - CMD_STEP_INTO_MY_CODE, CMD_STOP_ON_START, CMD_SMART_STEP_INTO) -from _pydevd_bundle.pydevd_constants import (get_current_thread_id, set_protocol, get_protocol, - HTTP_JSON_PROTOCOL, JSON_PROTOCOL, DebugInfoHolder, IS_WINDOWS) -from _pydevd_bundle.pydevd_net_command_factory_json import NetCommandFactoryJson -from _pydevd_bundle.pydevd_net_command_factory_xml import NetCommandFactory -import pydevd_file_utils -from _pydev_bundle import pydev_log -from _pydevd_bundle.pydevd_breakpoints import LineBreakpoint -from pydevd_tracing import get_exception_traceback_str -import os -import subprocess -import ctypes -from _pydevd_bundle.pydevd_collect_bytecode_info import code_to_bytecode_representation -import itertools -import linecache -from _pydevd_bundle.pydevd_utils import DAPGrouper, interrupt_main_thread -from _pydevd_bundle.pydevd_daemon_thread import run_as_pydevd_daemon_thread -from _pydevd_bundle.pydevd_thread_lifecycle import pydevd_find_thread_by_id, resume_threads -import tokenize - -try: - import dis -except ImportError: - - def _get_code_lines(code): - raise NotImplementedError - -else: - - def _get_code_lines(code): - if not isinstance(code, types.CodeType): - path = code - with tokenize.open(path) as f: - src = f.read() - code = compile(src, path, 'exec', 0, dont_inherit=True) - return _get_code_lines(code) - - def iterate(): - # First, get all line starts for this code object. This does not include - # bodies of nested class and function definitions, as they have their - # own objects. - for _, lineno in dis.findlinestarts(code): - yield lineno - - # For nested class and function definitions, their respective code objects - # are constants referenced by this object. - for const in code.co_consts: - if isinstance(const, types.CodeType) and const.co_filename == code.co_filename: - for lineno in _get_code_lines(const): - yield lineno - - return iterate() - - -class PyDevdAPI(object): - - class VariablePresentation(object): - - def __init__(self, special='group', function='group', class_='group', protected='inline'): - self._presentation = { - DAPGrouper.SCOPE_SPECIAL_VARS: special, - DAPGrouper.SCOPE_FUNCTION_VARS: function, - DAPGrouper.SCOPE_CLASS_VARS: class_, - DAPGrouper.SCOPE_PROTECTED_VARS: protected, - } - - def get_presentation(self, scope): - return self._presentation[scope] - - def run(self, py_db): - py_db.ready_to_run = True - - def notify_initialize(self, py_db): - py_db.on_initialize() - - def notify_configuration_done(self, py_db): - py_db.on_configuration_done() - - def notify_disconnect(self, py_db): - py_db.on_disconnect() - - def set_protocol(self, py_db, seq, protocol): - set_protocol(protocol.strip()) - if get_protocol() in (HTTP_JSON_PROTOCOL, JSON_PROTOCOL): - cmd_factory_class = NetCommandFactoryJson - else: - cmd_factory_class = NetCommandFactory - - if not isinstance(py_db.cmd_factory, cmd_factory_class): - py_db.cmd_factory = cmd_factory_class() - - return py_db.cmd_factory.make_protocol_set_message(seq) - - def set_ide_os_and_breakpoints_by(self, py_db, seq, ide_os, breakpoints_by): - ''' - :param ide_os: 'WINDOWS' or 'UNIX' - :param breakpoints_by: 'ID' or 'LINE' - ''' - if breakpoints_by == 'ID': - py_db._set_breakpoints_with_id = True - else: - py_db._set_breakpoints_with_id = False - - self.set_ide_os(ide_os) - - return py_db.cmd_factory.make_version_message(seq) - - def set_ide_os(self, ide_os): - ''' - :param ide_os: 'WINDOWS' or 'UNIX' - ''' - pydevd_file_utils.set_ide_os(ide_os) - - def set_gui_event_loop(self, py_db, gui_event_loop): - py_db._gui_event_loop = gui_event_loop - - def send_error_message(self, py_db, msg): - cmd = py_db.cmd_factory.make_warning_message('pydevd: %s\n' % (msg,)) - py_db.writer.add_command(cmd) - - def set_show_return_values(self, py_db, show_return_values): - if show_return_values: - py_db.show_return_values = True - else: - if py_db.show_return_values: - # We should remove saved return values - py_db.remove_return_values_flag = True - py_db.show_return_values = False - pydev_log.debug("Show return values: %s", py_db.show_return_values) - - def list_threads(self, py_db, seq): - # Response is the command with the list of threads to be added to the writer thread. - return py_db.cmd_factory.make_list_threads_message(py_db, seq) - - def request_suspend_thread(self, py_db, thread_id='*'): - # Yes, thread suspend is done at this point, not through an internal command. - threads = [] - suspend_all = thread_id.strip() == '*' - if suspend_all: - threads = pydevd_utils.get_non_pydevd_threads() - - elif thread_id.startswith('__frame__:'): - sys.stderr.write("Can't suspend tasklet: %s\n" % (thread_id,)) - - else: - threads = [pydevd_find_thread_by_id(thread_id)] - - for t in threads: - if t is None: - continue - py_db.set_suspend( - t, - CMD_THREAD_SUSPEND, - suspend_other_threads=suspend_all, - is_pause=True, - ) - # Break here (even if it's suspend all) as py_db.set_suspend will - # take care of suspending other threads. - break - - def set_enable_thread_notifications(self, py_db, enable): - ''' - When disabled, no thread notifications (for creation/removal) will be - issued until it's re-enabled. - - Note that when it's re-enabled, a creation notification will be sent for - all existing threads even if it was previously sent (this is meant to - be used on disconnect/reconnect). - ''' - py_db.set_enable_thread_notifications(enable) - - def request_disconnect(self, py_db, resume_threads): - self.set_enable_thread_notifications(py_db, False) - self.remove_all_breakpoints(py_db, '*') - self.remove_all_exception_breakpoints(py_db) - self.notify_disconnect(py_db) - - if resume_threads: - self.request_resume_thread(thread_id='*') - - def request_resume_thread(self, thread_id): - resume_threads(thread_id) - - def request_completions(self, py_db, seq, thread_id, frame_id, act_tok, line=-1, column=-1): - py_db.post_method_as_internal_command( - thread_id, internal_get_completions, seq, thread_id, frame_id, act_tok, line=line, column=column) - - def request_stack(self, py_db, seq, thread_id, fmt=None, timeout=.5, start_frame=0, levels=0): - # If it's already suspended, get it right away. - internal_get_thread_stack = InternalGetThreadStack( - seq, thread_id, py_db, set_additional_thread_info, fmt=fmt, timeout=timeout, start_frame=start_frame, levels=levels) - if internal_get_thread_stack.can_be_executed_by(get_current_thread_id(threading.current_thread())): - internal_get_thread_stack.do_it(py_db) - else: - py_db.post_internal_command(internal_get_thread_stack, '*') - - def request_exception_info_json(self, py_db, request, thread_id, thread, max_frames): - py_db.post_method_as_internal_command( - thread_id, - internal_get_exception_details_json, - request, - thread_id, - thread, - max_frames, - set_additional_thread_info=set_additional_thread_info, - iter_visible_frames_info=py_db.cmd_factory._iter_visible_frames_info, - ) - - def request_step(self, py_db, thread_id, step_cmd_id): - t = pydevd_find_thread_by_id(thread_id) - if t: - py_db.post_method_as_internal_command( - thread_id, - internal_step_in_thread, - thread_id, - step_cmd_id, - set_additional_thread_info=set_additional_thread_info, - ) - elif thread_id.startswith('__frame__:'): - sys.stderr.write("Can't make tasklet step command: %s\n" % (thread_id,)) - - def request_smart_step_into(self, py_db, seq, thread_id, offset, child_offset): - t = pydevd_find_thread_by_id(thread_id) - if t: - py_db.post_method_as_internal_command( - thread_id, internal_smart_step_into, thread_id, offset, child_offset, set_additional_thread_info=set_additional_thread_info) - elif thread_id.startswith('__frame__:'): - sys.stderr.write("Can't set next statement in tasklet: %s\n" % (thread_id,)) - - def request_smart_step_into_by_func_name(self, py_db, seq, thread_id, line, func_name): - # Same thing as set next, just with a different cmd id. - self.request_set_next(py_db, seq, thread_id, CMD_SMART_STEP_INTO, None, line, func_name) - - def request_set_next(self, py_db, seq, thread_id, set_next_cmd_id, original_filename, line, func_name): - ''' - set_next_cmd_id may actually be one of: - - CMD_RUN_TO_LINE - CMD_SET_NEXT_STATEMENT - - CMD_SMART_STEP_INTO -- note: request_smart_step_into is preferred if it's possible - to work with bytecode offset. - - :param Optional[str] original_filename: - If available, the filename may be source translated, otherwise no translation will take - place (the set next just needs the line afterwards as it executes locally, but for - the Jupyter integration, the source mapping may change the actual lines and not only - the filename). - ''' - t = pydevd_find_thread_by_id(thread_id) - if t: - if original_filename is not None: - translated_filename = self.filename_to_server(original_filename) # Apply user path mapping. - pydev_log.debug('Set next (after path translation) in: %s line: %s', translated_filename, line) - func_name = self.to_str(func_name) - - assert translated_filename.__class__ == str # i.e.: bytes on py2 and str on py3 - assert func_name.__class__ == str # i.e.: bytes on py2 and str on py3 - - # Apply source mapping (i.e.: ipython). - _source_mapped_filename, new_line, multi_mapping_applied = py_db.source_mapping.map_to_server( - translated_filename, line) - if multi_mapping_applied: - pydev_log.debug('Set next (after source mapping) in: %s line: %s', translated_filename, line) - line = new_line - - int_cmd = InternalSetNextStatementThread(thread_id, set_next_cmd_id, line, func_name, seq=seq) - py_db.post_internal_command(int_cmd, thread_id) - elif thread_id.startswith('__frame__:'): - sys.stderr.write("Can't set next statement in tasklet: %s\n" % (thread_id,)) - - def request_reload_code(self, py_db, seq, module_name, filename): - ''' - :param seq: if -1 no message will be sent back when the reload is done. - - Note: either module_name or filename may be None (but not both at the same time). - ''' - thread_id = '*' # Any thread - # Note: not going for the main thread because in this case it'd only do the load - # when we stopped on a breakpoint. - py_db.post_method_as_internal_command( - thread_id, internal_reload_code, seq, module_name, filename) - - def request_change_variable(self, py_db, seq, thread_id, frame_id, scope, attr, value): - ''' - :param scope: 'FRAME' or 'GLOBAL' - ''' - py_db.post_method_as_internal_command( - thread_id, internal_change_variable, seq, thread_id, frame_id, scope, attr, value) - - def request_get_variable(self, py_db, seq, thread_id, frame_id, scope, attrs): - ''' - :param scope: 'FRAME' or 'GLOBAL' - ''' - int_cmd = InternalGetVariable(seq, thread_id, frame_id, scope, attrs) - py_db.post_internal_command(int_cmd, thread_id) - - def request_get_array(self, py_db, seq, roffset, coffset, rows, cols, fmt, thread_id, frame_id, scope, attrs): - int_cmd = InternalGetArray(seq, roffset, coffset, rows, cols, fmt, thread_id, frame_id, scope, attrs) - py_db.post_internal_command(int_cmd, thread_id) - - def request_load_full_value(self, py_db, seq, thread_id, frame_id, vars): - int_cmd = InternalLoadFullValue(seq, thread_id, frame_id, vars) - py_db.post_internal_command(int_cmd, thread_id) - - def request_get_description(self, py_db, seq, thread_id, frame_id, expression): - py_db.post_method_as_internal_command( - thread_id, internal_get_description, seq, thread_id, frame_id, expression) - - def request_get_frame(self, py_db, seq, thread_id, frame_id): - py_db.post_method_as_internal_command( - thread_id, internal_get_frame, seq, thread_id, frame_id) - - def to_str(self, s): - ''' - -- in py3 raises an error if it's not str already. - ''' - if s.__class__ != str: - raise AssertionError('Expected to have str on Python 3. Found: %s (%s)' % (s, s.__class__)) - return s - - def filename_to_str(self, filename): - ''' - -- in py3 raises an error if it's not str already. - ''' - if filename.__class__ != str: - raise AssertionError('Expected to have str on Python 3. Found: %s (%s)' % (filename, filename.__class__)) - return filename - - def filename_to_server(self, filename): - filename = self.filename_to_str(filename) - filename = pydevd_file_utils.map_file_to_server(filename) - return filename - - class _DummyFrame(object): - ''' - Dummy frame to be used with PyDB.apply_files_filter (as we don't really have the - related frame as breakpoints are added before execution). - ''' - - class _DummyCode(object): - - def __init__(self, filename): - self.co_firstlineno = 1 - self.co_filename = filename - self.co_name = 'invalid func name ' - - def __init__(self, filename): - self.f_code = self._DummyCode(filename) - self.f_globals = {} - - ADD_BREAKPOINT_NO_ERROR = 0 - ADD_BREAKPOINT_FILE_NOT_FOUND = 1 - ADD_BREAKPOINT_FILE_EXCLUDED_BY_FILTERS = 2 - - # This means that the breakpoint couldn't be fully validated (more runtime - # information may be needed). - ADD_BREAKPOINT_LAZY_VALIDATION = 3 - ADD_BREAKPOINT_INVALID_LINE = 4 - - class _AddBreakpointResult(object): - - # :see: ADD_BREAKPOINT_NO_ERROR = 0 - # :see: ADD_BREAKPOINT_FILE_NOT_FOUND = 1 - # :see: ADD_BREAKPOINT_FILE_EXCLUDED_BY_FILTERS = 2 - # :see: ADD_BREAKPOINT_LAZY_VALIDATION = 3 - # :see: ADD_BREAKPOINT_INVALID_LINE = 4 - - __slots__ = ['error_code', 'breakpoint_id', 'translated_filename', 'translated_line', 'original_line'] - - def __init__(self, breakpoint_id, translated_filename, translated_line, original_line): - self.error_code = PyDevdAPI.ADD_BREAKPOINT_NO_ERROR - self.breakpoint_id = breakpoint_id - self.translated_filename = translated_filename - self.translated_line = translated_line - self.original_line = original_line - - def add_breakpoint( - self, py_db, original_filename, breakpoint_type, breakpoint_id, line, condition, func_name, - expression, suspend_policy, hit_condition, is_logpoint, adjust_line=False, on_changed_breakpoint_state=None): - ''' - :param str original_filename: - Note: must be sent as it was received in the protocol. It may be translated in this - function and its final value will be available in the returned _AddBreakpointResult. - - :param str breakpoint_type: - One of: 'python-line', 'django-line', 'jinja2-line'. - - :param int breakpoint_id: - - :param int line: - Note: it's possible that a new line was actually used. If that's the case its - final value will be available in the returned _AddBreakpointResult. - - :param condition: - Either None or the condition to activate the breakpoint. - - :param str func_name: - If "None" (str), may hit in any context. - Empty string will hit only top level. - Any other value must match the scope of the method to be matched. - - :param str expression: - None or the expression to be evaluated. - - :param suspend_policy: - Either "NONE" (to suspend only the current thread when the breakpoint is hit) or - "ALL" (to suspend all threads when a breakpoint is hit). - - :param str hit_condition: - An expression where `@HIT@` will be replaced by the number of hits. - i.e.: `@HIT@ == x` or `@HIT@ >= x` - - :param bool is_logpoint: - If True and an expression is passed, pydevd will create an io message command with the - result of the evaluation. - - :param bool adjust_line: - If True, the breakpoint line should be adjusted if the current line doesn't really - match an executable line (if possible). - - :param callable on_changed_breakpoint_state: - This is called when something changed internally on the breakpoint after it was initially - added (for instance, template file_to_line_to_breakpoints could be signaled as invalid initially and later - when the related template is loaded, if the line is valid it could be marked as valid). - - The signature for the callback should be: - on_changed_breakpoint_state(breakpoint_id: int, add_breakpoint_result: _AddBreakpointResult) - - Note that the add_breakpoint_result should not be modified by the callback (the - implementation may internally reuse the same instance multiple times). - - :return _AddBreakpointResult: - ''' - assert original_filename.__class__ == str, 'Expected str, found: %s' % (original_filename.__class__,) # i.e.: bytes on py2 and str on py3 - - original_filename_normalized = pydevd_file_utils.normcase_from_client(original_filename) - - pydev_log.debug('Request for breakpoint in: %s line: %s', original_filename, line) - original_line = line - # Parameters to reapply breakpoint. - api_add_breakpoint_params = (original_filename, breakpoint_type, breakpoint_id, line, condition, func_name, - expression, suspend_policy, hit_condition, is_logpoint) - - translated_filename = self.filename_to_server(original_filename) # Apply user path mapping. - pydev_log.debug('Breakpoint (after path translation) in: %s line: %s', translated_filename, line) - func_name = self.to_str(func_name) - - assert translated_filename.__class__ == str # i.e.: bytes on py2 and str on py3 - assert func_name.__class__ == str # i.e.: bytes on py2 and str on py3 - - # Apply source mapping (i.e.: ipython). - source_mapped_filename, new_line, multi_mapping_applied = py_db.source_mapping.map_to_server( - translated_filename, line) - - if multi_mapping_applied: - pydev_log.debug('Breakpoint (after source mapping) in: %s line: %s', source_mapped_filename, new_line) - # Note that source mapping is internal and does not change the resulting filename nor line - # (we want the outside world to see the line in the original file and not in the ipython - # cell, otherwise the editor wouldn't be correct as the returned line is the line to - # which the breakpoint will be moved in the editor). - result = self._AddBreakpointResult(breakpoint_id, original_filename, line, original_line) - - # If a multi-mapping was applied, consider it the canonical / source mapped version (translated to ipython cell). - translated_absolute_filename = source_mapped_filename - canonical_normalized_filename = pydevd_file_utils.normcase(source_mapped_filename) - line = new_line - - else: - translated_absolute_filename = pydevd_file_utils.absolute_path(translated_filename) - canonical_normalized_filename = pydevd_file_utils.canonical_normalized_path(translated_filename) - - if adjust_line and not translated_absolute_filename.startswith('<'): - # Validate file_to_line_to_breakpoints and adjust their positions. - try: - lines = sorted(_get_code_lines(translated_absolute_filename)) - except Exception: - pass - else: - if line not in lines: - # Adjust to the first preceding valid line. - idx = bisect.bisect_left(lines, line) - if idx > 0: - line = lines[idx - 1] - - result = self._AddBreakpointResult(breakpoint_id, original_filename, line, original_line) - - py_db.api_received_breakpoints[(original_filename_normalized, breakpoint_id)] = (canonical_normalized_filename, api_add_breakpoint_params) - - if not translated_absolute_filename.startswith('<'): - # Note: if a mapping pointed to a file starting with '<', don't validate. - - if not pydevd_file_utils.exists(translated_absolute_filename): - result.error_code = self.ADD_BREAKPOINT_FILE_NOT_FOUND - return result - - if ( - py_db.is_files_filter_enabled and - not py_db.get_require_module_for_filters() and - py_db.apply_files_filter(self._DummyFrame(translated_absolute_filename), translated_absolute_filename, False) - ): - # Note that if `get_require_module_for_filters()` returns False, we don't do this check. - # This is because we don't have the module name given a file at this point (in - # runtime it's gotten from the frame.f_globals). - # An option could be calculate it based on the filename and current sys.path, - # but on some occasions that may be wrong (for instance with `__main__` or if - # the user dynamically changes the PYTHONPATH). - - # Note: depending on the use-case, filters may be changed, so, keep on going and add the - # breakpoint even with the error code. - result.error_code = self.ADD_BREAKPOINT_FILE_EXCLUDED_BY_FILTERS - - if breakpoint_type == 'python-line': - added_breakpoint = LineBreakpoint( - breakpoint_id, line, condition, func_name, expression, suspend_policy, hit_condition=hit_condition, is_logpoint=is_logpoint) - - file_to_line_to_breakpoints = py_db.breakpoints - file_to_id_to_breakpoint = py_db.file_to_id_to_line_breakpoint - supported_type = True - - else: - add_plugin_breakpoint_result = None - plugin = py_db.get_plugin_lazy_init() - if plugin is not None: - add_plugin_breakpoint_result = plugin.add_breakpoint( - 'add_line_breakpoint', py_db, breakpoint_type, canonical_normalized_filename, - breakpoint_id, line, condition, expression, func_name, hit_condition=hit_condition, is_logpoint=is_logpoint, - add_breakpoint_result=result, on_changed_breakpoint_state=on_changed_breakpoint_state) - - if add_plugin_breakpoint_result is not None: - supported_type = True - added_breakpoint, file_to_line_to_breakpoints = add_plugin_breakpoint_result - file_to_id_to_breakpoint = py_db.file_to_id_to_plugin_breakpoint - else: - supported_type = False - - if not supported_type: - raise NameError(breakpoint_type) - - pydev_log.debug('Added breakpoint:%s - line:%s - func_name:%s\n', canonical_normalized_filename, line, func_name) - - if canonical_normalized_filename in file_to_id_to_breakpoint: - id_to_pybreakpoint = file_to_id_to_breakpoint[canonical_normalized_filename] - else: - id_to_pybreakpoint = file_to_id_to_breakpoint[canonical_normalized_filename] = {} - - id_to_pybreakpoint[breakpoint_id] = added_breakpoint - py_db.consolidate_breakpoints(canonical_normalized_filename, id_to_pybreakpoint, file_to_line_to_breakpoints) - if py_db.plugin is not None: - py_db.has_plugin_line_breaks = py_db.plugin.has_line_breaks() - py_db.plugin.after_breakpoints_consolidated(py_db, canonical_normalized_filename, id_to_pybreakpoint, file_to_line_to_breakpoints) - - py_db.on_breakpoints_changed() - return result - - def reapply_breakpoints(self, py_db): - ''' - Reapplies all the received breakpoints as they were received by the API (so, new - translations are applied). - ''' - pydev_log.debug('Reapplying breakpoints.') - values = list(py_db.api_received_breakpoints.values()) # Create a copy with items to reapply. - self.remove_all_breakpoints(py_db, '*') - for val in values: - _new_filename, api_add_breakpoint_params = val - self.add_breakpoint(py_db, *api_add_breakpoint_params) - - def remove_all_breakpoints(self, py_db, received_filename): - ''' - Removes all the breakpoints from a given file or from all files if received_filename == '*'. - - :param str received_filename: - Note: must be sent as it was received in the protocol. It may be translated in this - function. - ''' - assert received_filename.__class__ == str # i.e.: bytes on py2 and str on py3 - changed = False - lst = [ - py_db.file_to_id_to_line_breakpoint, - py_db.file_to_id_to_plugin_breakpoint, - py_db.breakpoints - ] - if hasattr(py_db, 'django_breakpoints'): - lst.append(py_db.django_breakpoints) - - if hasattr(py_db, 'jinja2_breakpoints'): - lst.append(py_db.jinja2_breakpoints) - - if received_filename == '*': - py_db.api_received_breakpoints.clear() - - for file_to_id_to_breakpoint in lst: - if file_to_id_to_breakpoint: - file_to_id_to_breakpoint.clear() - changed = True - - else: - received_filename_normalized = pydevd_file_utils.normcase_from_client(received_filename) - items = list(py_db.api_received_breakpoints.items()) # Create a copy to remove items. - translated_filenames = [] - for key, val in items: - original_filename_normalized, _breakpoint_id = key - if original_filename_normalized == received_filename_normalized: - canonical_normalized_filename, _api_add_breakpoint_params = val - # Note: there can be actually 1:N mappings due to source mapping (i.e.: ipython). - translated_filenames.append(canonical_normalized_filename) - del py_db.api_received_breakpoints[key] - - for canonical_normalized_filename in translated_filenames: - for file_to_id_to_breakpoint in lst: - if canonical_normalized_filename in file_to_id_to_breakpoint: - file_to_id_to_breakpoint.pop(canonical_normalized_filename, None) - changed = True - - if changed: - py_db.on_breakpoints_changed(removed=True) - - def remove_breakpoint(self, py_db, received_filename, breakpoint_type, breakpoint_id): - ''' - :param str received_filename: - Note: must be sent as it was received in the protocol. It may be translated in this - function. - - :param str breakpoint_type: - One of: 'python-line', 'django-line', 'jinja2-line'. - - :param int breakpoint_id: - ''' - received_filename_normalized = pydevd_file_utils.normcase_from_client(received_filename) - for key, val in list(py_db.api_received_breakpoints.items()): - original_filename_normalized, existing_breakpoint_id = key - _new_filename, _api_add_breakpoint_params = val - if received_filename_normalized == original_filename_normalized and existing_breakpoint_id == breakpoint_id: - del py_db.api_received_breakpoints[key] - break - else: - pydev_log.info( - 'Did not find breakpoint to remove: %s (breakpoint id: %s)', received_filename, breakpoint_id) - - file_to_id_to_breakpoint = None - received_filename = self.filename_to_server(received_filename) - canonical_normalized_filename = pydevd_file_utils.canonical_normalized_path(received_filename) - - if breakpoint_type == 'python-line': - file_to_line_to_breakpoints = py_db.breakpoints - file_to_id_to_breakpoint = py_db.file_to_id_to_line_breakpoint - - elif py_db.plugin is not None: - result = py_db.plugin.get_breakpoints(py_db, breakpoint_type) - if result is not None: - file_to_id_to_breakpoint = py_db.file_to_id_to_plugin_breakpoint - file_to_line_to_breakpoints = result - - if file_to_id_to_breakpoint is None: - pydev_log.critical('Error removing breakpoint. Cannot handle breakpoint of type %s', breakpoint_type) - - else: - try: - id_to_pybreakpoint = file_to_id_to_breakpoint.get(canonical_normalized_filename, {}) - if DebugInfoHolder.DEBUG_TRACE_LEVEL >= 1: - existing = id_to_pybreakpoint[breakpoint_id] - pydev_log.info('Removed breakpoint:%s - line:%s - func_name:%s (id: %s)\n' % ( - canonical_normalized_filename, existing.line, existing.func_name, breakpoint_id)) - - del id_to_pybreakpoint[breakpoint_id] - py_db.consolidate_breakpoints(canonical_normalized_filename, id_to_pybreakpoint, file_to_line_to_breakpoints) - if py_db.plugin is not None: - py_db.has_plugin_line_breaks = py_db.plugin.has_line_breaks() - py_db.plugin.after_breakpoints_consolidated(py_db, canonical_normalized_filename, id_to_pybreakpoint, file_to_line_to_breakpoints) - - except KeyError: - pydev_log.info("Error removing breakpoint: Breakpoint id not found: %s id: %s. Available ids: %s\n", - canonical_normalized_filename, breakpoint_id, list(id_to_pybreakpoint)) - - py_db.on_breakpoints_changed(removed=True) - - def set_function_breakpoints(self, py_db, function_breakpoints): - function_breakpoint_name_to_breakpoint = {} - for function_breakpoint in function_breakpoints: - function_breakpoint_name_to_breakpoint[function_breakpoint.func_name] = function_breakpoint - - py_db.function_breakpoint_name_to_breakpoint = function_breakpoint_name_to_breakpoint - py_db.on_breakpoints_changed() - - def request_exec_or_evaluate( - self, py_db, seq, thread_id, frame_id, expression, is_exec, trim_if_too_big, attr_to_set_result): - py_db.post_method_as_internal_command( - thread_id, internal_evaluate_expression, - seq, thread_id, frame_id, expression, is_exec, trim_if_too_big, attr_to_set_result) - - def request_exec_or_evaluate_json( - self, py_db, request, thread_id): - py_db.post_method_as_internal_command( - thread_id, internal_evaluate_expression_json, request, thread_id) - - def request_set_expression_json(self, py_db, request, thread_id): - py_db.post_method_as_internal_command( - thread_id, internal_set_expression_json, request, thread_id) - - def request_console_exec(self, py_db, seq, thread_id, frame_id, expression): - int_cmd = InternalConsoleExec(seq, thread_id, frame_id, expression) - py_db.post_internal_command(int_cmd, thread_id) - - def request_load_source(self, py_db, seq, filename): - ''' - :param str filename: - Note: must be sent as it was received in the protocol. It may be translated in this - function. - ''' - try: - filename = self.filename_to_server(filename) - assert filename.__class__ == str # i.e.: bytes on py2 and str on py3 - - with tokenize.open(filename) as stream: - source = stream.read() - cmd = py_db.cmd_factory.make_load_source_message(seq, source) - except: - cmd = py_db.cmd_factory.make_error_message(seq, get_exception_traceback_str()) - - py_db.writer.add_command(cmd) - - def get_decompiled_source_from_frame_id(self, py_db, frame_id): - ''' - :param py_db: - :param frame_id: - :throws Exception: - If unable to get the frame in the currently paused frames or if some error happened - when decompiling. - ''' - variable = py_db.suspended_frames_manager.get_variable(int(frame_id)) - frame = variable.value - - # Check if it's in the linecache first. - lines = (linecache.getline(frame.f_code.co_filename, i) for i in itertools.count(1)) - lines = itertools.takewhile(bool, lines) # empty lines are '\n', EOF is '' - - source = ''.join(lines) - if not source: - source = code_to_bytecode_representation(frame.f_code) - - return source - - def request_load_source_from_frame_id(self, py_db, seq, frame_id): - try: - source = self.get_decompiled_source_from_frame_id(py_db, frame_id) - cmd = py_db.cmd_factory.make_load_source_from_frame_id_message(seq, source) - except: - cmd = py_db.cmd_factory.make_error_message(seq, get_exception_traceback_str()) - - py_db.writer.add_command(cmd) - - def add_python_exception_breakpoint( - self, - py_db, - exception, - condition, - expression, - notify_on_handled_exceptions, - notify_on_unhandled_exceptions, - notify_on_user_unhandled_exceptions, - notify_on_first_raise_only, - ignore_libraries, - ): - exception_breakpoint = py_db.add_break_on_exception( - exception, - condition=condition, - expression=expression, - notify_on_handled_exceptions=notify_on_handled_exceptions, - notify_on_unhandled_exceptions=notify_on_unhandled_exceptions, - notify_on_user_unhandled_exceptions=notify_on_user_unhandled_exceptions, - notify_on_first_raise_only=notify_on_first_raise_only, - ignore_libraries=ignore_libraries, - ) - - if exception_breakpoint is not None: - py_db.on_breakpoints_changed() - - def add_plugins_exception_breakpoint(self, py_db, breakpoint_type, exception): - supported_type = False - plugin = py_db.get_plugin_lazy_init() - if plugin is not None: - supported_type = plugin.add_breakpoint('add_exception_breakpoint', py_db, breakpoint_type, exception) - - if supported_type: - py_db.has_plugin_exception_breaks = py_db.plugin.has_exception_breaks() - py_db.on_breakpoints_changed() - else: - raise NameError(breakpoint_type) - - def remove_python_exception_breakpoint(self, py_db, exception): - try: - cp = py_db.break_on_uncaught_exceptions.copy() - cp.pop(exception, None) - py_db.break_on_uncaught_exceptions = cp - - cp = py_db.break_on_caught_exceptions.copy() - cp.pop(exception, None) - py_db.break_on_caught_exceptions = cp - - cp = py_db.break_on_user_uncaught_exceptions.copy() - cp.pop(exception, None) - py_db.break_on_user_uncaught_exceptions = cp - except: - pydev_log.exception("Error while removing exception %s", sys.exc_info()[0]) - - py_db.on_breakpoints_changed(removed=True) - - def remove_plugins_exception_breakpoint(self, py_db, exception_type, exception): - # I.e.: no need to initialize lazy (if we didn't have it in the first place, we can't remove - # anything from it anyways). - plugin = py_db.plugin - if plugin is None: - return - - supported_type = plugin.remove_exception_breakpoint(py_db, exception_type, exception) - - if supported_type: - py_db.has_plugin_exception_breaks = py_db.plugin.has_exception_breaks() - else: - pydev_log.info('No exception of type: %s was previously registered.', exception_type) - - py_db.on_breakpoints_changed(removed=True) - - def remove_all_exception_breakpoints(self, py_db): - py_db.break_on_uncaught_exceptions = {} - py_db.break_on_caught_exceptions = {} - py_db.break_on_user_uncaught_exceptions = {} - - plugin = py_db.plugin - if plugin is not None: - plugin.remove_all_exception_breakpoints(py_db) - py_db.on_breakpoints_changed(removed=True) - - def set_project_roots(self, py_db, project_roots): - ''' - :param str project_roots: - ''' - py_db.set_project_roots(project_roots) - - def set_stepping_resumes_all_threads(self, py_db, stepping_resumes_all_threads): - py_db.stepping_resumes_all_threads = stepping_resumes_all_threads - - # Add it to the namespace so that it's available as PyDevdAPI.ExcludeFilter - from _pydevd_bundle.pydevd_filtering import ExcludeFilter # noqa - - def set_exclude_filters(self, py_db, exclude_filters): - ''' - :param list(PyDevdAPI.ExcludeFilter) exclude_filters: - ''' - py_db.set_exclude_filters(exclude_filters) - - def set_use_libraries_filter(self, py_db, use_libraries_filter): - py_db.set_use_libraries_filter(use_libraries_filter) - - def request_get_variable_json(self, py_db, request, thread_id): - ''' - :param VariablesRequest request: - ''' - py_db.post_method_as_internal_command( - thread_id, internal_get_variable_json, request) - - def request_change_variable_json(self, py_db, request, thread_id): - ''' - :param SetVariableRequest request: - ''' - py_db.post_method_as_internal_command( - thread_id, internal_change_variable_json, request) - - def set_dont_trace_start_end_patterns(self, py_db, start_patterns, end_patterns): - # Note: start/end patterns normalized internally. - start_patterns = tuple(pydevd_file_utils.normcase(x) for x in start_patterns) - end_patterns = tuple(pydevd_file_utils.normcase(x) for x in end_patterns) - - # After it's set the first time, we can still change it, but we need to reset the - # related caches. - reset_caches = False - dont_trace_start_end_patterns_previously_set = \ - py_db.dont_trace_external_files.__name__ == 'custom_dont_trace_external_files' - - if not dont_trace_start_end_patterns_previously_set and not start_patterns and not end_patterns: - # If it wasn't set previously and start and end patterns are empty we don't need to do anything. - return - - if not py_db.is_cache_file_type_empty(): - # i.e.: custom function set in set_dont_trace_start_end_patterns. - if dont_trace_start_end_patterns_previously_set: - reset_caches = py_db.dont_trace_external_files.start_patterns != start_patterns or \ - py_db.dont_trace_external_files.end_patterns != end_patterns - - else: - reset_caches = True - - def custom_dont_trace_external_files(abs_path): - normalized_abs_path = pydevd_file_utils.normcase(abs_path) - return normalized_abs_path.startswith(start_patterns) or normalized_abs_path.endswith(end_patterns) - - custom_dont_trace_external_files.start_patterns = start_patterns - custom_dont_trace_external_files.end_patterns = end_patterns - py_db.dont_trace_external_files = custom_dont_trace_external_files - - if reset_caches: - py_db.clear_dont_trace_start_end_patterns_caches() - - def stop_on_entry(self): - main_thread = pydevd_utils.get_main_thread() - if main_thread is None: - pydev_log.critical('Could not find main thread while setting Stop on Entry.') - else: - info = set_additional_thread_info(main_thread) - info.pydev_original_step_cmd = CMD_STOP_ON_START - info.pydev_step_cmd = CMD_STEP_INTO_MY_CODE - - def set_ignore_system_exit_codes(self, py_db, ignore_system_exit_codes): - py_db.set_ignore_system_exit_codes(ignore_system_exit_codes) - - SourceMappingEntry = pydevd_source_mapping.SourceMappingEntry - - def set_source_mapping(self, py_db, source_filename, mapping): - ''' - :param str source_filename: - The filename for the source mapping (bytes on py2 and str on py3). - This filename will be made absolute in this function. - - :param list(SourceMappingEntry) mapping: - A list with the source mapping entries to be applied to the given filename. - - :return str: - An error message if it was not possible to set the mapping or an empty string if - everything is ok. - ''' - source_filename = self.filename_to_server(source_filename) - absolute_source_filename = pydevd_file_utils.absolute_path(source_filename) - for map_entry in mapping: - map_entry.source_filename = absolute_source_filename - error_msg = py_db.source_mapping.set_source_mapping(absolute_source_filename, mapping) - if error_msg: - return error_msg - - self.reapply_breakpoints(py_db) - return '' - - def set_variable_presentation(self, py_db, variable_presentation): - assert isinstance(variable_presentation, self.VariablePresentation) - py_db.variable_presentation = variable_presentation - - def get_ppid(self): - ''' - Provides the parent pid (even for older versions of Python on Windows). - ''' - ppid = None - - try: - ppid = os.getppid() - except AttributeError: - pass - - if ppid is None and IS_WINDOWS: - ppid = self._get_windows_ppid() - - return ppid - - def _get_windows_ppid(self): - this_pid = os.getpid() - for ppid, pid in _list_ppid_and_pid(): - if pid == this_pid: - return ppid - - return None - - def _terminate_child_processes_windows(self, dont_terminate_child_pids): - this_pid = os.getpid() - for _ in range(50): # Try this at most 50 times before giving up. - - # Note: we can't kill the process itself with taskkill, so, we - # list immediate children, kill that tree and then exit this process. - - children_pids = [] - for ppid, pid in _list_ppid_and_pid(): - if ppid == this_pid: - if pid not in dont_terminate_child_pids: - children_pids.append(pid) - - if not children_pids: - break - else: - for pid in children_pids: - self._call( - ['taskkill', '/F', '/PID', str(pid), '/T'], - stdout=subprocess.PIPE, - stderr=subprocess.PIPE - ) - - del children_pids[:] - - def _terminate_child_processes_linux_and_mac(self, dont_terminate_child_pids): - this_pid = os.getpid() - - def list_children_and_stop_forking(initial_pid, stop=True): - children_pids = [] - if stop: - # Ask to stop forking (shouldn't be called for this process, only subprocesses). - self._call( - ['kill', '-STOP', str(initial_pid)], - stdout=subprocess.PIPE, - stderr=subprocess.PIPE - ) - - list_popen = self._popen( - ['pgrep', '-P', str(initial_pid)], - stdout=subprocess.PIPE, - stderr=subprocess.PIPE - ) - - if list_popen is not None: - stdout, _ = list_popen.communicate() - for line in stdout.splitlines(): - line = line.decode('ascii').strip() - if line: - pid = str(line) - if pid in dont_terminate_child_pids: - continue - children_pids.append(pid) - # Recursively get children. - children_pids.extend(list_children_and_stop_forking(pid)) - return children_pids - - previously_found = set() - - for _ in range(50): # Try this at most 50 times before giving up. - - children_pids = list_children_and_stop_forking(this_pid, stop=False) - found_new = False - - for pid in children_pids: - if pid not in previously_found: - found_new = True - previously_found.add(pid) - self._call( - ['kill', '-KILL', str(pid)], - stdout=subprocess.PIPE, - stderr=subprocess.PIPE - ) - - if not found_new: - break - - def _popen(self, cmdline, **kwargs): - try: - return subprocess.Popen(cmdline, **kwargs) - except: - if DebugInfoHolder.DEBUG_TRACE_LEVEL >= 1: - pydev_log.exception('Error running: %s' % (' '.join(cmdline))) - return None - - def _call(self, cmdline, **kwargs): - try: - subprocess.check_call(cmdline, **kwargs) - except: - if DebugInfoHolder.DEBUG_TRACE_LEVEL >= 1: - pydev_log.exception('Error running: %s' % (' '.join(cmdline))) - - def set_terminate_child_processes(self, py_db, terminate_child_processes): - py_db.terminate_child_processes = terminate_child_processes - - def set_terminate_keyboard_interrupt(self, py_db, terminate_keyboard_interrupt): - py_db.terminate_keyboard_interrupt = terminate_keyboard_interrupt - - def terminate_process(self, py_db): - ''' - Terminates the current process (and child processes if the option to also terminate - child processes is enabled). - ''' - try: - if py_db.terminate_child_processes: - pydev_log.debug('Terminating child processes.') - if IS_WINDOWS: - self._terminate_child_processes_windows(py_db.dont_terminate_child_pids) - else: - self._terminate_child_processes_linux_and_mac(py_db.dont_terminate_child_pids) - finally: - pydev_log.debug('Exiting process (os._exit(0)).') - os._exit(0) - - def _terminate_if_commands_processed(self, py_db): - py_db.dispose_and_kill_all_pydevd_threads() - self.terminate_process(py_db) - - def request_terminate_process(self, py_db): - if py_db.terminate_keyboard_interrupt: - if not py_db.keyboard_interrupt_requested: - py_db.keyboard_interrupt_requested = True - interrupt_main_thread() - return - - # We mark with a terminate_requested to avoid that paused threads start running - # (we should terminate as is without letting any paused thread run). - py_db.terminate_requested = True - run_as_pydevd_daemon_thread(py_db, self._terminate_if_commands_processed, py_db) - - def setup_auto_reload_watcher(self, py_db, enable_auto_reload, watch_dirs, poll_target_time, exclude_patterns, include_patterns): - py_db.setup_auto_reload_watcher(enable_auto_reload, watch_dirs, poll_target_time, exclude_patterns, include_patterns) - - -def _list_ppid_and_pid(): - _TH32CS_SNAPPROCESS = 0x00000002 - - class PROCESSENTRY32(ctypes.Structure): - _fields_ = [("dwSize", ctypes.c_uint32), - ("cntUsage", ctypes.c_uint32), - ("th32ProcessID", ctypes.c_uint32), - ("th32DefaultHeapID", ctypes.c_size_t), - ("th32ModuleID", ctypes.c_uint32), - ("cntThreads", ctypes.c_uint32), - ("th32ParentProcessID", ctypes.c_uint32), - ("pcPriClassBase", ctypes.c_long), - ("dwFlags", ctypes.c_uint32), - ("szExeFile", ctypes.c_char * 260)] - - kernel32 = ctypes.windll.kernel32 - snapshot = kernel32.CreateToolhelp32Snapshot(_TH32CS_SNAPPROCESS, 0) - ppid_and_pids = [] - try: - process_entry = PROCESSENTRY32() - process_entry.dwSize = ctypes.sizeof(PROCESSENTRY32) - if not kernel32.Process32First(ctypes.c_void_p(snapshot), ctypes.byref(process_entry)): - pydev_log.critical('Process32First failed (getting process from CreateToolhelp32Snapshot).') - else: - while True: - ppid_and_pids.append((process_entry.th32ParentProcessID, process_entry.th32ProcessID)) - if not kernel32.Process32Next(ctypes.c_void_p(snapshot), ctypes.byref(process_entry)): - break - finally: - kernel32.CloseHandle(snapshot) - - return ppid_and_pids diff --git a/spaces/TH5314/newbing/src/pages/api/sydney.ts b/spaces/TH5314/newbing/src/pages/api/sydney.ts deleted file mode 100644 index 0e7bbf23d77c2e1a6635185a060eeee58b8c8e66..0000000000000000000000000000000000000000 --- a/spaces/TH5314/newbing/src/pages/api/sydney.ts +++ /dev/null @@ -1,62 +0,0 @@ -import { NextApiRequest, NextApiResponse } from 'next' -import { WebSocket, debug } from '@/lib/isomorphic' -import { BingWebBot } from '@/lib/bots/bing' -import { websocketUtils } from '@/lib/bots/bing/utils' -import { WatchDog, createHeaders } from '@/lib/utils' - - -export default async function handler(req: NextApiRequest, res: NextApiResponse) { - const conversationContext = req.body - const headers = createHeaders(req.cookies) - debug(headers) - res.setHeader('Content-Type', 'text/stream; charset=UTF-8') - - const ws = new WebSocket('wss://sydney.bing.com/sydney/ChatHub', { - headers: { - ...headers, - 'accept-language': 'zh-CN,zh;q=0.9', - 'cache-control': 'no-cache', - 'x-ms-useragent': 'azsdk-js-api-client-factory/1.0.0-beta.1 core-rest-pipeline/1.10.0 OS/Win32', - pragma: 'no-cache', - } - }) - - const closeDog = new WatchDog() - const timeoutDog = new WatchDog() - ws.onmessage = (event) => { - timeoutDog.watch(() => { - ws.send(websocketUtils.packMessage({ type: 6 })) - }, 1500) - closeDog.watch(() => { - ws.close() - }, 10000) - res.write(event.data) - if (/\{"type":([367])\}/.test(String(event.data))) { - const type = parseInt(RegExp.$1, 10) - debug('connection type', type) - if (type === 3) { - ws.close() - } else { - ws.send(websocketUtils.packMessage({ type })) - } - } - } - - ws.onclose = () => { - timeoutDog.reset() - closeDog.reset() - debug('connection close') - res.end() - } - - await new Promise((resolve) => ws.onopen = resolve) - ws.send(websocketUtils.packMessage({ protocol: 'json', version: 1 })) - ws.send(websocketUtils.packMessage({ type: 6 })) - ws.send(websocketUtils.packMessage(BingWebBot.buildChatRequest(conversationContext!))) - req.socket.once('close', () => { - ws.close() - if (!res.closed) { - res.end() - } - }) -} diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_imp.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_imp.py deleted file mode 100644 index 6b4890191b88814ca1323a111d5423b1847071b5..0000000000000000000000000000000000000000 --- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_imp.py +++ /dev/null @@ -1,82 +0,0 @@ -""" -Re-implementation of find_module and get_frozen_object -from the deprecated imp module. -""" - -import os -import importlib.util -import importlib.machinery - -from importlib.util import module_from_spec - - -PY_SOURCE = 1 -PY_COMPILED = 2 -C_EXTENSION = 3 -C_BUILTIN = 6 -PY_FROZEN = 7 - - -def find_spec(module, paths): - finder = ( - importlib.machinery.PathFinder().find_spec - if isinstance(paths, list) else - importlib.util.find_spec - ) - return finder(module, paths) - - -def find_module(module, paths=None): - """Just like 'imp.find_module()', but with package support""" - spec = find_spec(module, paths) - if spec is None: - raise ImportError("Can't find %s" % module) - if not spec.has_location and hasattr(spec, 'submodule_search_locations'): - spec = importlib.util.spec_from_loader('__init__.py', spec.loader) - - kind = -1 - file = None - static = isinstance(spec.loader, type) - if spec.origin == 'frozen' or static and issubclass( - spec.loader, importlib.machinery.FrozenImporter): - kind = PY_FROZEN - path = None # imp compabilty - suffix = mode = '' # imp compatibility - elif spec.origin == 'built-in' or static and issubclass( - spec.loader, importlib.machinery.BuiltinImporter): - kind = C_BUILTIN - path = None # imp compabilty - suffix = mode = '' # imp compatibility - elif spec.has_location: - path = spec.origin - suffix = os.path.splitext(path)[1] - mode = 'r' if suffix in importlib.machinery.SOURCE_SUFFIXES else 'rb' - - if suffix in importlib.machinery.SOURCE_SUFFIXES: - kind = PY_SOURCE - elif suffix in importlib.machinery.BYTECODE_SUFFIXES: - kind = PY_COMPILED - elif suffix in importlib.machinery.EXTENSION_SUFFIXES: - kind = C_EXTENSION - - if kind in {PY_SOURCE, PY_COMPILED}: - file = open(path, mode) - else: - path = None - suffix = mode = '' - - return file, path, (suffix, mode, kind) - - -def get_frozen_object(module, paths=None): - spec = find_spec(module, paths) - if not spec: - raise ImportError("Can't find %s" % module) - return spec.loader.get_code(module) - - -def get_module(module, paths, info): - spec = find_spec(module, paths) - if not spec: - raise ImportError("Can't find %s" % module) - return module_from_spec(spec) diff --git a/spaces/TechShark20/handwespeak/hand_normalization.py b/spaces/TechShark20/handwespeak/hand_normalization.py deleted file mode 100644 index b39a05c0978d988712f2ae1379a60e5356c2b7ca..0000000000000000000000000000000000000000 --- a/spaces/TechShark20/handwespeak/hand_normalization.py +++ /dev/null @@ -1,192 +0,0 @@ - -import logging -import pandas as pd - -HAND_IDENTIFIERS = [ - "wrist", - "indexTip", - "indexDIP", - "indexPIP", - "indexMCP", - "middleTip", - "middleDIP", - "middlePIP", - "middleMCP", - "ringTip", - "ringDIP", - "ringPIP", - "ringMCP", - "littleTip", - "littleDIP", - "littlePIP", - "littleMCP", - "thumbTip", - "thumbIP", - "thumbMP", - "thumbCMC" -] - - -def normalize_hands_full(df: pd.DataFrame) -> pd.DataFrame: - """ - Normalizes the hands position data using the Bohacek-normalization algorithm. - - :param df: pd.DataFrame to be normalized - :return: pd.DataFrame with normalized values for hand pose - """ - - # TODO: Fix division by zero - df.columns = [item.replace("_left_", "_0_").replace("_right_", "_1_") for item in list(df.columns)] - - normalized_df = pd.DataFrame(columns=df.columns) - - hand_landmarks = {"X": {0: [], 1: []}, "Y": {0: [], 1: []}} - - # Determine how many hands are present in the dataset - range_hand_size = 1 - if "wrist_1_X" in df.columns: - range_hand_size = 2 - - # Construct the relevant identifiers - for identifier in HAND_IDENTIFIERS: - for hand_index in range(range_hand_size): - hand_landmarks["X"][hand_index].append(identifier + "_" + str(hand_index) + "_X") - hand_landmarks["Y"][hand_index].append(identifier + "_" + str(hand_index) + "_Y") - - # Iterate over all of the records in the dataset - for index, row in df.iterrows(): - # Treat each hand individually - for hand_index in range(range_hand_size): - - sequence_size = len(row["wrist_" + str(hand_index) + "_X"]) - - # Treat each element of the sequence (analyzed frame) individually - for sequence_index in range(sequence_size): - - # Retrieve all of the X and Y values of the current frame - landmarks_x_values = [row[key][sequence_index] for key in hand_landmarks["X"][hand_index] if row[key][sequence_index] != 0] - landmarks_y_values = [row[key][sequence_index] for key in hand_landmarks["Y"][hand_index] if row[key][sequence_index] != 0] - - # Prevent from even starting the analysis if some necessary elements are not present - if not landmarks_x_values or not landmarks_y_values: - logging.warning( - " HAND LANDMARKS: One frame could not be normalized as there is no data present. Record: " + str(index) + - ", Frame: " + str(sequence_index)) - continue - - # Calculate the deltas - width, height = max(landmarks_x_values) - min(landmarks_x_values), max(landmarks_y_values) - min( - landmarks_y_values) - if width > height: - delta_x = 0.1 * width - delta_y = delta_x + ((width - height) / 2) - else: - delta_y = 0.1 * height - delta_x = delta_y + ((height - width) / 2) - - # Set the starting and ending point of the normalization bounding box - starting_point = (min(landmarks_x_values) - delta_x, min(landmarks_y_values) - delta_y) - ending_point = (max(landmarks_x_values) + delta_x, max(landmarks_y_values) + delta_y) - - # Normalize individual landmarks and save the results - for identifier in HAND_IDENTIFIERS: - key = identifier + "_" + str(hand_index) + "_" - - # Prevent from trying to normalize incorrectly captured points - if row[key + "X"][sequence_index] == 0 or (ending_point[0] - starting_point[0]) == 0 or (starting_point[1] - ending_point[1]) == 0: - continue - - normalized_x = (row[key + "X"][sequence_index] - starting_point[0]) / (ending_point[0] - - starting_point[0]) - normalized_y = (row[key + "Y"][sequence_index] - ending_point[1]) / (starting_point[1] - - ending_point[1]) - - row[key + "X"][sequence_index] = normalized_x - row[key + "Y"][sequence_index] = normalized_y - - normalized_df = normalized_df.append(row, ignore_index=True) - - return normalized_df - - -def normalize_single_dict(row: dict): - """ - Normalizes the skeletal data for a given sequence of frames with signer's hand pose data. The normalization follows - the definition from our paper. - - :param row: Dictionary containing key-value pairs with joint identifiers and corresponding lists (sequences) of - that particular joints coordinates - :return: Dictionary with normalized skeletal data (following the same schema as input data) - """ - - hand_landmarks = {0: [], 1: []} - - # Determine how many hands are present in the dataset - range_hand_size = 1 - if "wrist_1" in row.keys(): - range_hand_size = 2 - - # Construct the relevant identifiers - for identifier in HAND_IDENTIFIERS: - for hand_index in range(range_hand_size): - hand_landmarks[hand_index].append(identifier + "_" + str(hand_index)) - - # Treat each hand individually - for hand_index in range(range_hand_size): - - sequence_size = len(row["wrist_" + str(hand_index)]) - - # Treat each element of the sequence (analyzed frame) individually - for sequence_index in range(sequence_size): - - # Retrieve all of the X and Y values of the current frame - landmarks_x_values = [row[key][sequence_index][0] for key in hand_landmarks[hand_index] if - row[key][sequence_index][0] != 0] - landmarks_y_values = [row[key][sequence_index][1] for key in hand_landmarks[hand_index] if - row[key][sequence_index][1] != 0] - - # Prevent from even starting the analysis if some necessary elements are not present - if not landmarks_x_values or not landmarks_y_values: - continue - - # Calculate the deltas - width, height = max(landmarks_x_values) - min(landmarks_x_values), max(landmarks_y_values) - min( - landmarks_y_values) - if width > height: - delta_x = 0.1 * width - delta_y = delta_x + ((width - height) / 2) - else: - delta_y = 0.1 * height - delta_x = delta_y + ((height - width) / 2) - - # Set the starting and ending point of the normalization bounding box - starting_point = [min(landmarks_x_values) - delta_x, min(landmarks_y_values) - delta_y] - ending_point = [max(landmarks_x_values) + delta_x, max(landmarks_y_values) + delta_y] - # Ensure that all of the bounding-box-defining coordinates are not out of the picture - if starting_point[0] < 0: starting_point[0] = 0 - if starting_point[1] > 1: starting_point[1] = 1 - if ending_point[0] < 0: ending_point[0] = 0 - if ending_point[1] > 1: ending_point[1] = 1 - - # Normalize individual landmarks and save the results - for identifier in HAND_IDENTIFIERS: - key = identifier + "_" + str(hand_index) - - # Prevent from trying to normalize incorrectly captured points - if row[key][sequence_index][0] == 0 or (ending_point[0] - starting_point[0]) == 0 or ( - starting_point[1] - ending_point[1]) == 0: - continue - - normalized_x = (row[key][sequence_index][0] - starting_point[0]) / (ending_point[0] - starting_point[0]) - normalized_y = (row[key][sequence_index][1] - starting_point[1]) / (ending_point[1] - starting_point[1]) - - row[key][sequence_index] = list(row[key][sequence_index]) - - row[key][sequence_index][0] = normalized_x - row[key][sequence_index][1] = normalized_y - - return row - - -if __name__ == "__main__": - pass diff --git a/spaces/ThirdEyeData/Customer-Conversion-Prediction/supv/mcclf.py b/spaces/ThirdEyeData/Customer-Conversion-Prediction/supv/mcclf.py deleted file mode 100644 index 9493216e3471f3c0300abe2e411d091cee013d1e..0000000000000000000000000000000000000000 --- a/spaces/ThirdEyeData/Customer-Conversion-Prediction/supv/mcclf.py +++ /dev/null @@ -1,207 +0,0 @@ -#!/usr/local/bin/python3 - -# Author: Pranab Ghosh -# -# Licensed under the Apache License, Version 2.0 (the "License"); you -# may not use this file except in compliance with the License. You may -# obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or -# implied. See the License for the specific language governing -# permissions and limitations under the License. - -# Package imports -import os -import sys -import matplotlib.pyplot as plt -import numpy as np -import random -import jprops -from random import randint -from matumizi.util import * -from matumizi.mlutil import * - -""" -Markov chain classifier -""" -class MarkovChainClassifier(): - def __init__(self, configFile): - """ - constructor - - Parameters - configFile: config file path - """ - defValues = {} - defValues["common.model.directory"] = ("model", None) - defValues["common.model.file"] = (None, None) - defValues["common.verbose"] = (False, None) - defValues["common.states"] = (None, "missing state list") - defValues["train.data.file"] = (None, "missing training data file") - defValues["train.data.class.labels"] = (["F", "T"], None) - defValues["train.data.key.len"] = (1, None) - defValues["train.model.save"] = (False, None) - defValues["train.score.method"] = ("accuracy", None) - defValues["predict.data.file"] = (None, None) - defValues["predict.use.saved.model"] = (True, None) - defValues["predict.log.odds.threshold"] = (0, None) - defValues["validate.data.file"] = (None, "missing validation data file") - defValues["validate.use.saved.model"] = (False, None) - defValues["valid.accuracy.metric"] = ("acc", None) - self.config = Configuration(configFile, defValues) - - self.stTranPr = dict() - self.clabels = self.config.getStringListConfig("train.data.class.labels")[0] - self.states = self.config.getStringListConfig("common.states")[0] - self.nstates = len(self.states) - for cl in self.clabels: - stp = np.ones((self.nstates,self.nstates)) - self.stTranPr[cl] = stp - - def train(self): - """ - train model - """ - #state transition matrix - tdfPath = self.config.getStringConfig("train.data.file")[0] - klen = self.config.getIntConfig("train.data.key.len")[0] - for rec in fileRecGen(tdfPath): - cl = rec[klen] - rlen = len(rec) - for i in range(klen+1, rlen-1, 1): - fst = self.states.index(rec[i]) - tst = self.states.index(rec[i+1]) - self.stTranPr[cl][fst][tst] += 1 - - #normalize to probability - for cl in self.clabels: - stp = self.stTranPr[cl] - for i in range(self.nstates): - s = stp[i].sum() - r = stp[i] / s - stp[i] = r - - #save - if self.config.getBooleanConfig("train.model.save")[0]: - mdPath = self.config.getStringConfig("common.model.directory")[0] - assert os.path.exists(mdPath), "model save directory does not exist" - mfPath = self.config.getStringConfig("common.model.file")[0] - mfPath = os.path.join(mdPath, mfPath) - - with open(mfPath, "w") as fh: - for cl in self.clabels: - fh.write("label:" + cl +"\n") - stp = self.stTranPr[cl] - for r in stp: - rs = ",".join(toStrList(r, 6)) + "\n" - fh.write(rs) - - def validate(self): - """ - validate using model - """ - useSavedModel = self.config.getBooleanConfig("predict.use.saved.model")[0] - if useSavedModel: - self.__restoreModel() - else: - self.train() - - vdfPath = self.config.getStringConfig("validate.data.file")[0] - accMetric = self.config.getStringConfig("valid.accuracy.metric")[0] - - yac, ypr = self.__getPrediction(vdfPath, True) - if type(self.clabels[0]) == str: - yac = self.__toIntClabel(yac) - ypr = self.__toIntClabel(ypr) - score = perfMetric(accMetric, yac, ypr) - print(formatFloat(3, score, "perf score")) - - - def predict(self): - """ - predict using model - """ - useSavedModel = self.config.getBooleanConfig("predict.use.saved.model")[0] - if useSavedModel: - self.__restoreModel() - else: - self.train() - - #predict - pdfPath = self.config.getStringConfig("predict.data.file")[0] - _ , ypr = self.__getPrediction(pdfPath) - return ypr - - def __restoreModel(self): - """ - restore model - """ - mdPath = self.config.getStringConfig("common.model.directory")[0] - assert os.path.exists(mdPath), "model save directory does not exist" - mfPath = self.config.getStringConfig("common.model.file")[0] - mfPath = os.path.join(mdPath, mfPath) - stp = None - cl = None - for rec in fileRecGen(mfPath): - if len(rec) == 1: - if stp is not None: - stp = np.array(stp) - self.stTranPr[cl] = stp - cl = rec[0].split(":")[1] - stp = list() - else: - frec = asFloatList(rec) - stp.append(frec) - - stp = np.array(stp) - self.stTranPr[cl] = stp - - def __getPrediction(self, fpath, validate=False): - """ - get predictions - - Parameters - fpath : data file path - validate: True if validation - """ - - nc = self.clabels[0] - pc = self.clabels[1] - thold = self.config.getFloatConfig("predict.log.odds.threshold")[0] - klen = self.config.getIntConfig("train.data.key.len")[0] - offset = klen+1 if validate else klen - ypr = list() - yac = list() - for rec in fileRecGen(fpath): - lodds = 0 - rlen = len(rec) - for i in range(offset, rlen-1, 1): - fst = self.states.index(rec[i]) - tst = self.states.index(rec[i+1]) - odds = self.stTranPr[pc][fst][tst] / self.stTranPr[nc][fst][tst] - lodds += math.log(odds) - prc = pc if lodds > thold else nc - ypr.append(prc) - if validate: - yac.append(rec[klen]) - else: - recp = prc + "\t" + ",".join(rec) - print(recp) - - re = (yac, ypr) - return re - - def __toIntClabel(self, labels): - """ - convert string class label to int - - Parameters - labels : class label values - """ - return list(map(lambda l : self.clabels.index(l), labels)) - - diff --git a/spaces/Usually3/multilingual_vcloning/README.md b/spaces/Usually3/multilingual_vcloning/README.md deleted file mode 100644 index 4f3df964365d7eda21abbdd892e77f5b345603f5..0000000000000000000000000000000000000000 --- a/spaces/Usually3/multilingual_vcloning/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Multilingual Vcloning -emoji: 🎙️ -colorFrom: green -colorTo: pink -sdk: gradio -sdk_version: 3.24.1 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/VIPLab/Caption-Anything/caption_anything/utils/parser.py b/spaces/VIPLab/Caption-Anything/caption_anything/utils/parser.py deleted file mode 100644 index 6abf61535a437616ced23a7df38eb4ea1b295fa2..0000000000000000000000000000000000000000 --- a/spaces/VIPLab/Caption-Anything/caption_anything/utils/parser.py +++ /dev/null @@ -1,35 +0,0 @@ -import argparse - -def parse_augment(): - parser = argparse.ArgumentParser() - parser.add_argument('--captioner', type=str, default="blip2") - parser.add_argument('--segmenter', type=str, default="huge") - parser.add_argument('--text_refiner', type=str, default="base") - parser.add_argument('--segmenter_checkpoint', type=str, default=None, help="SAM checkpoint path") - parser.add_argument('--seg_crop_mode', type=str, default="wo_bg", choices=['wo_bg', 'w_bg'], - help="whether to add or remove background of the image when captioning") - parser.add_argument('--clip_filter', action="store_true", help="use clip to filter bad captions") - parser.add_argument('--context_captions', action="store_true", - help="use surrounding captions to enhance current caption (TODO)") - parser.add_argument('--disable_regular_box', action="store_true", default=False, - help="crop image with a regular box") - parser.add_argument('--device', type=str, default="cuda:0") - parser.add_argument('--port', type=int, default=6086, help="only useful when running gradio applications") - parser.add_argument('--debug', action="store_true") - parser.add_argument('--gradio_share', action="store_true") - parser.add_argument('--disable_gpt', action="store_true") - parser.add_argument('--enable_reduce_tokens', action="store_true", default=False) - parser.add_argument('--disable_reuse_features', action="store_true", default=False) - parser.add_argument('--enable_morphologyex', action="store_true", default=False) - parser.add_argument('--chat_tools_dict', type=str, default='VisualQuestionAnswering_cuda:0', help='Visual ChatGPT tools, only useful when running gradio applications') - - parser.add_argument('--pred_iou_thresh', type=float, default=0.88, help="sam post-precessing") - parser.add_argument('--min_mask_region_area', type=int, default=0, help="sam post-precessing") - parser.add_argument('--stability_score_thresh', type=float, default=0.95, help='sam post-processing') - parser.add_argument('--box_nms_thresh', type=float, default=0.7, help='sam post-processing') - - args = parser.parse_args() - - if args.debug: - print(args) - return args diff --git a/spaces/XEGAN/movie-recommendation-system/app.py b/spaces/XEGAN/movie-recommendation-system/app.py deleted file mode 100644 index 3955fc0ccc43bf48768e335b3492bdb9221c7bea..0000000000000000000000000000000000000000 --- a/spaces/XEGAN/movie-recommendation-system/app.py +++ /dev/null @@ -1,54 +0,0 @@ -import pandas as pd -import streamlit as st -import pickle -import requests - -def fetch_poster(movie_id): - response = requests.get("https://api.themoviedb.org/3/movie/{}?api_key=f491d53ebfd526fa0b9231b995dec342&language=en-US".format(movie_id)) - data = response.json() - return "https://image.tmdb.org/t/p/w500/" + data['poster_path'] -def recommend(movie): - index = movies[movies['title'] == movie].index[0] - distances = sorted(list(enumerate(similarity[index])), reverse=True, key=lambda x: x[1]) - recommended_movie_names = [] - recommended_movie_posters = [] - for i in distances[1:6]: - - movie_id = movies.iloc[i[0]].movie_id - recommended_movie_posters.append(fetch_poster(movie_id)) - recommended_movie_names.append(movies.iloc[i[0]].title) - - return recommended_movie_names,recommended_movie_posters - -movies_dict = pickle.load(open('movie_dict.pkl', 'rb')) -movies = pd.DataFrame(movies_dict) - -similarity = pickle.load(open('similarity.pkl', 'rb')) - -st.title('Movie Recommendation System') - -selected_movie_name = st.selectbox( - 'Type or select a movie from the dropdown', - movies['title'].values -) - -if st.button('Show Recommendation'): - recommended_movie_names,recommended_movie_posters = recommend(selected_movie_name) - col1, col2, col3, col4, col5 = st.columns(5) - with col1: - st.text(recommended_movie_names[0]) - st.image(recommended_movie_posters[0]) - with col2: - st.text(recommended_movie_names[1]) - st.image(recommended_movie_posters[1]) - - with col3: - st.text(recommended_movie_names[2]) - st.image(recommended_movie_posters[2]) - with col4: - st.text(recommended_movie_names[3]) - st.image(recommended_movie_posters[3]) - with col5: - st.text(recommended_movie_names[4]) - st.image(recommended_movie_posters[4]) - diff --git a/spaces/Xhaheen/Hyper_Bot_openai/index.html b/spaces/Xhaheen/Hyper_Bot_openai/index.html deleted file mode 100644 index 8738097608f6094645e6c64287d325dabcbde0ad..0000000000000000000000000000000000000000 --- a/spaces/Xhaheen/Hyper_Bot_openai/index.html +++ /dev/null @@ -1,30 +0,0 @@ - - - - - Example - - -- -- - - diff --git a/spaces/XzJosh/Aatrox-Bert-VITS2/bert_gen.py b/spaces/XzJosh/Aatrox-Bert-VITS2/bert_gen.py deleted file mode 100644 index 44814715396ffc3abe84a12c74d66293c356eb4f..0000000000000000000000000000000000000000 --- a/spaces/XzJosh/Aatrox-Bert-VITS2/bert_gen.py +++ /dev/null @@ -1,53 +0,0 @@ -import torch -from torch.utils.data import DataLoader -from multiprocessing import Pool -import commons -import utils -from data_utils import TextAudioSpeakerLoader, TextAudioSpeakerCollate -from tqdm import tqdm -import warnings - -from text import cleaned_text_to_sequence, get_bert - -config_path = 'configs/config.json' -hps = utils.get_hparams_from_file(config_path) - -def process_line(line): - _id, spk, language_str, text, phones, tone, word2ph = line.strip().split("|") - phone = phones.split(" ") - tone = [int(i) for i in tone.split(" ")] - word2ph = [int(i) for i in word2ph.split(" ")] - w2pho = [i for i in word2ph] - word2ph = [i for i in word2ph] - phone, tone, language = cleaned_text_to_sequence(phone, tone, language_str) - - if hps.data.add_blank: - phone = commons.intersperse(phone, 0) - tone = commons.intersperse(tone, 0) - language = commons.intersperse(language, 0) - for i in range(len(word2ph)): - word2ph[i] = word2ph[i] * 2 - word2ph[0] += 1 - wav_path = f'{_id}' - - bert_path = wav_path.replace(".wav", ".bert.pt") - try: - bert = torch.load(bert_path) - assert bert.shape[-1] == len(phone) - except: - bert = get_bert(text, word2ph, language_str) - assert bert.shape[-1] == len(phone) - torch.save(bert, bert_path) - - -if __name__ == '__main__': - lines = [] - with open(hps.data.training_files, encoding='utf-8' ) as f: - lines.extend(f.readlines()) - - with open(hps.data.validation_files, encoding='utf-8' ) as f: - lines.extend(f.readlines()) - - with Pool(processes=12) as pool: #A100 40GB suitable config,if coom,please decrease the processess number. - for _ in tqdm(pool.imap_unordered(process_line, lines)): - pass diff --git a/spaces/YenJung/ECG_MAC/app.py b/spaces/YenJung/ECG_MAC/app.py deleted file mode 100644 index b99bfb83332b705f9b8cf082673dd9e131764868..0000000000000000000000000000000000000000 --- a/spaces/YenJung/ECG_MAC/app.py +++ /dev/null @@ -1,46 +0,0 @@ -import streamlit as st -import wfdb -from datasets import load_dataset -from load_wave import load_wave -from tensorflow.keras.models import Sequential -from tensorflow.keras.layers import Dense -import tensorflow as tf -import os -import numpy as np - - - -dataset = load_dataset("lhoestq/demo1") - -st.set_page_config("銘傳大學生物醫學工程學系ECG分析網站") -st.sidebar.markdown(""" **Developed by** [邱彥榕](https://www.linkedin.com/in/yjc-86941b101/) - """) -st.sidebar.markdown(""" # **Step 1: 修改load_wave中,取得PhysioNet分析資料**""") -st.sidebar.markdown(""" # **Step 2: 開始分析**""") - -def callback(): - data = load_wave() - st.line_chart(data) - data = np.array(data.T[1].reshape(1,4000)) - - path = "./" - checkpoint_path = os.path.join(path,"model.ckpt") - model = Sequential() - model.add(Dense(64, input_shape=(4000,), activation='relu')) - model.add(Dense(8, activation='relu')) - model.add(Dense(1, activation='sigmoid')) - model.load_weights(checkpoint_path) - - out = np.array(tf.round(model.predict(data)).cpu())[0][0] - - if out == 0: - st.text("測試者狀態是 Relax") - else: - st.text("測試者狀態是 Activate") - - -bt1 = st.button( - "分析", - on_click=callback, - disabled=False, -) diff --git a/spaces/YlcldKlns/bing/src/components/chat-suggestions.tsx b/spaces/YlcldKlns/bing/src/components/chat-suggestions.tsx deleted file mode 100644 index 48aec7c84e4407c482acdfcc7857fb0f660d12d3..0000000000000000000000000000000000000000 --- a/spaces/YlcldKlns/bing/src/components/chat-suggestions.tsx +++ /dev/null @@ -1,45 +0,0 @@ -import React, { useMemo } from 'react' -import Image from 'next/image' -import HelpIcon from '@/assets/images/help.svg' -import { SuggestedResponse } from '@/lib/bots/bing/types' -import { useBing } from '@/lib/hooks/use-bing' -import { atom, useAtom } from 'jotai' - -type Suggestions = SuggestedResponse[] -const helpSuggestions = ['为什么不回应某些主题', '告诉我更多关于必应的资迅', '必应如何使用 AI?'].map((text) => ({ text })) -const suggestionsAtom = atom([]) - -type ChatSuggestionsProps = React.ComponentProps<'div'> & Pick -- ) : null -} diff --git a/spaces/Yntec/ToyWorldXL/index.html b/spaces/Yntec/ToyWorldXL/index.html deleted file mode 100644 index 6250c2958a7186a4e64f21c02b0359ff5ecd7e97..0000000000000000000000000000000000000000 --- a/spaces/Yntec/ToyWorldXL/index.html +++ /dev/null @@ -1,16 +0,0 @@ - - - - - - - - - - - - - - - - \ No newline at end of file diff --git a/spaces/YuFuji/CalqTalk/README.md b/spaces/YuFuji/CalqTalk/README.md deleted file mode 100644 index f706107968c8d316a9fad7fd70a56b3953375aeb..0000000000000000000000000000000000000000 --- a/spaces/YuFuji/CalqTalk/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: CalqTalk -emoji: 📚 -colorFrom: purple -colorTo: pink -sdk: gradio -sdk_version: 3.18.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Yuliang/ECON/lib/pymafx/utils/sample_mesh.py b/spaces/Yuliang/ECON/lib/pymafx/utils/sample_mesh.py deleted file mode 100644 index 1a696cf9580d7cd0e27ac0ade1db3c9e6a9c6e84..0000000000000000000000000000000000000000 --- a/spaces/Yuliang/ECON/lib/pymafx/utils/sample_mesh.py +++ /dev/null @@ -1,66 +0,0 @@ -import os - -import numpy as np -import trimesh - -from .utils.libmesh import check_mesh_contains - - -def get_occ_gt( - in_path=None, - vertices=None, - faces=None, - pts_num=1000, - points_sigma=0.01, - with_dp=False, - points=None, - extra_points=None -): - if in_path is not None: - mesh = trimesh.load(in_path, process=False) - print(type(mesh.vertices), mesh.vertices.shape, mesh.faces.shape) - - mesh = trimesh.Trimesh(vertices=vertices, faces=faces, process=False) - - # print('get_occ_gt', type(mesh.vertices), mesh.vertices.shape, mesh.faces.shape) - - # points_size = 100000 - points_padding = 0.1 - # points_sigma = 0.01 - points_uniform_ratio = 0.5 - n_points_uniform = int(pts_num * points_uniform_ratio) - n_points_surface = pts_num - n_points_uniform - - if points is None: - points_scale = 2.0 - boxsize = points_scale + points_padding - points_uniform = np.random.rand(n_points_uniform, 3) - points_uniform = boxsize * (points_uniform - 0.5) - points_surface, index_surface = mesh.sample(n_points_surface, return_index=True) - points_surface += points_sigma * np.random.randn(n_points_surface, 3) - points = np.concatenate([points_uniform, points_surface], axis=0) - - if extra_points is not None: - extra_points += points_sigma * np.random.randn(len(extra_points), 3) - points = np.concatenate([points, extra_points], axis=0) - - occupancies = check_mesh_contains(mesh, points) - - index_surface = None - - # points = points.astype(dtype) - - # print('occupancies', occupancies.dtype, np.sum(occupancies), occupancies.shape) - # occupancies = np.packbits(occupancies) - # print('occupancies bit', occupancies.dtype, np.sum(occupancies), occupancies.shape) - - # print('occupancies', points.shape, occupancies.shape, occupancies.dtype, np.sum(occupancies), index_surface.shape) - - return_dict = {} - return_dict['points'] = points - return_dict['points.occ'] = occupancies - return_dict['sf_sidx'] = index_surface - - # export_pointcloud(mesh, modelname, loc, scale, args) - # export_points(mesh, modelname, loc, scale, args) - return return_dict diff --git a/spaces/Yuliang/ICON/lib/renderer/gl/color_render.py b/spaces/Yuliang/ICON/lib/renderer/gl/color_render.py deleted file mode 100644 index 4b6a7456bdb3d9ac8b6f5b9d746c3b70ad56d8cc..0000000000000000000000000000000000000000 --- a/spaces/Yuliang/ICON/lib/renderer/gl/color_render.py +++ /dev/null @@ -1,162 +0,0 @@ -''' -MIT License - -Copyright (c) 2019 Shunsuke Saito, Zeng Huang, and Ryota Natsume - -Permission is hereby granted, free of charge, to any person obtaining a copy -of this software and associated documentation files (the "Software"), to deal -in the Software without restriction, including without limitation the rights -to use, copy, modify, merge, publish, distribute, sublicense, and/or sell -copies of the Software, and to permit persons to whom the Software is -furnished to do so, subject to the following conditions: - -The above copyright notice and this permission notice shall be included in all -copies or substantial portions of the Software. - -THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR -IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, -FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE -AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER -LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, -OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE -SOFTWARE. -''' -import numpy as np -import random - -from .framework import * -from .cam_render import CamRender - - -class ColorRender(CamRender): - def __init__(self, width=1600, height=1200, name='Color Renderer', egl=False): - program_files = ['color.vs', 'color.fs'] - CamRender.__init__(self, - width, - height, - name, - program_files=program_files, - color_size=3, egl=egl) - - # WARNING: this differs from vertex_buffer and vertex_data in Render - self.vert_buffer = {} - self.vert_data = {} - - # normal - self.norm_buffer = {} - self.norm_data = {} - - self.color_buffer = {} - self.color_data = {} - - self.vertex_dim = {} - self.n_vertices = {} - - self.rot_mat_unif = glGetUniformLocation(self.program, 'RotMat') - self.rot_matrix = np.eye(3) - - self.norm_mat_unif = glGetUniformLocation(self.program, 'NormMat') - self.normalize_matrix = np.eye(4) - - def set_norm_mat(self, scale, center): - N = np.eye(4) - N[:3, :3] = scale * np.eye(3) - N[:3, 3] = -scale * center - - self.normalize_matrix = N - - def set_mesh(self, vertices, faces, color, normals, mat_name='all'): - - self.vert_data[mat_name] = vertices[faces.reshape([-1])] - self.n_vertices[mat_name] = self.vert_data[mat_name].shape[0] - self.vertex_dim[mat_name] = self.vert_data[mat_name].shape[1] - self.color_data[mat_name] = color[faces.reshape([-1])] - self.norm_data[mat_name] = normals[faces.reshape([-1])] - - if mat_name not in self.vert_buffer.keys(): - self.vert_buffer[mat_name] = glGenBuffers(1) - glBindBuffer(GL_ARRAY_BUFFER, self.vert_buffer[mat_name]) - glBufferData(GL_ARRAY_BUFFER, self.vert_data[mat_name], GL_STATIC_DRAW) - - if mat_name not in self.color_buffer.keys(): - self.color_buffer[mat_name] = glGenBuffers(1) - glBindBuffer(GL_ARRAY_BUFFER, self.color_buffer[mat_name]) - glBufferData(GL_ARRAY_BUFFER, self.color_data[mat_name], - GL_STATIC_DRAW) - - if mat_name not in self.norm_buffer.keys(): - self.norm_buffer[mat_name] = glGenBuffers(1) - glBindBuffer(GL_ARRAY_BUFFER, self.norm_buffer[mat_name]) - glBufferData(GL_ARRAY_BUFFER, self.norm_data[mat_name], GL_STATIC_DRAW) - - glBindBuffer(GL_ARRAY_BUFFER, 0) - - def cleanup(self): - - glBindBuffer(GL_ARRAY_BUFFER, 0) - - for key in self.vert_data: - glDeleteBuffers(1, [self.vert_buffer[key]]) - glDeleteBuffers(1, [self.color_buffer[key]]) - glDeleteBuffers(1, [self.norm_buffer[key]]) - - self.norm_buffer = {} - self.norm_data = {} - - self.vert_buffer = {} - self.vert_data = {} - - self.color_buffer = {} - self.color_data = {} - - self.render_texture_mat = {} - - self.vertex_dim = {} - self.n_vertices = {} - - def draw(self): - self.draw_init() - - glEnable(GL_MULTISAMPLE) - - glUseProgram(self.program) - glUniformMatrix4fv(self.norm_mat_unif, 1, GL_FALSE, - self.normalize_matrix.transpose()) - glUniformMatrix4fv(self.model_mat_unif, 1, GL_FALSE, - self.model_view_matrix.transpose()) - glUniformMatrix4fv(self.persp_mat_unif, 1, GL_FALSE, - self.projection_matrix.transpose()) - glUniformMatrix3fv(self.rot_mat_unif, 1, GL_FALSE, - self.rot_matrix.transpose()) - - for mat in self.vert_buffer: - - # Handle vertex buffer - glBindBuffer(GL_ARRAY_BUFFER, self.vert_buffer[mat]) - glEnableVertexAttribArray(0) - glVertexAttribPointer(0, self.vertex_dim[mat], GL_DOUBLE, GL_FALSE, - 0, None) - - # Handle color buffer - glBindBuffer(GL_ARRAY_BUFFER, self.color_buffer[mat]) - glEnableVertexAttribArray(1) - glVertexAttribPointer(1, 3, GL_DOUBLE, GL_FALSE, 0, None) - - # Handle normal buffer - glBindBuffer(GL_ARRAY_BUFFER, self.norm_buffer[mat]) - glEnableVertexAttribArray(2) - glVertexAttribPointer(2, 3, GL_DOUBLE, GL_FALSE, 0, None) - - glDrawArrays(GL_TRIANGLES, 0, self.n_vertices[mat]) - - glDisableVertexAttribArray(2) - glDisableVertexAttribArray(1) - glDisableVertexAttribArray(0) - - glBindBuffer(GL_ARRAY_BUFFER, 0) - - glUseProgram(0) - - glDisable(GL_MULTISAMPLE) - - self.draw_end() diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/fovea_head.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/fovea_head.py deleted file mode 100644 index c8ccea787cba3d092284d4a5e209adaf6521c86a..0000000000000000000000000000000000000000 --- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/fovea_head.py +++ /dev/null @@ -1,341 +0,0 @@ -import torch -import torch.nn as nn -from mmcv.cnn import ConvModule, normal_init -from mmcv.ops import DeformConv2d - -from mmdet.core import multi_apply, multiclass_nms -from ..builder import HEADS -from .anchor_free_head import AnchorFreeHead - -INF = 1e8 - - -class FeatureAlign(nn.Module): - - def __init__(self, - in_channels, - out_channels, - kernel_size=3, - deform_groups=4): - super(FeatureAlign, self).__init__() - offset_channels = kernel_size * kernel_size * 2 - self.conv_offset = nn.Conv2d( - 4, deform_groups * offset_channels, 1, bias=False) - self.conv_adaption = DeformConv2d( - in_channels, - out_channels, - kernel_size=kernel_size, - padding=(kernel_size - 1) // 2, - deform_groups=deform_groups) - self.relu = nn.ReLU(inplace=True) - - def init_weights(self): - normal_init(self.conv_offset, std=0.1) - normal_init(self.conv_adaption, std=0.01) - - def forward(self, x, shape): - offset = self.conv_offset(shape) - x = self.relu(self.conv_adaption(x, offset)) - return x - - -@HEADS.register_module() -class FoveaHead(AnchorFreeHead): - """FoveaBox: Beyond Anchor-based Object Detector - https://arxiv.org/abs/1904.03797 - """ - - def __init__(self, - num_classes, - in_channels, - base_edge_list=(16, 32, 64, 128, 256), - scale_ranges=((8, 32), (16, 64), (32, 128), (64, 256), (128, - 512)), - sigma=0.4, - with_deform=False, - deform_groups=4, - **kwargs): - self.base_edge_list = base_edge_list - self.scale_ranges = scale_ranges - self.sigma = sigma - self.with_deform = with_deform - self.deform_groups = deform_groups - super().__init__(num_classes, in_channels, **kwargs) - - def _init_layers(self): - # box branch - super()._init_reg_convs() - self.conv_reg = nn.Conv2d(self.feat_channels, 4, 3, padding=1) - - # cls branch - if not self.with_deform: - super()._init_cls_convs() - self.conv_cls = nn.Conv2d( - self.feat_channels, self.cls_out_channels, 3, padding=1) - else: - self.cls_convs = nn.ModuleList() - self.cls_convs.append( - ConvModule( - self.feat_channels, (self.feat_channels * 4), - 3, - stride=1, - padding=1, - conv_cfg=self.conv_cfg, - norm_cfg=self.norm_cfg, - bias=self.norm_cfg is None)) - self.cls_convs.append( - ConvModule((self.feat_channels * 4), (self.feat_channels * 4), - 1, - stride=1, - padding=0, - conv_cfg=self.conv_cfg, - norm_cfg=self.norm_cfg, - bias=self.norm_cfg is None)) - self.feature_adaption = FeatureAlign( - self.feat_channels, - self.feat_channels, - kernel_size=3, - deform_groups=self.deform_groups) - self.conv_cls = nn.Conv2d( - int(self.feat_channels * 4), - self.cls_out_channels, - 3, - padding=1) - - def init_weights(self): - super().init_weights() - if self.with_deform: - self.feature_adaption.init_weights() - - def forward_single(self, x): - cls_feat = x - reg_feat = x - for reg_layer in self.reg_convs: - reg_feat = reg_layer(reg_feat) - bbox_pred = self.conv_reg(reg_feat) - if self.with_deform: - cls_feat = self.feature_adaption(cls_feat, bbox_pred.exp()) - for cls_layer in self.cls_convs: - cls_feat = cls_layer(cls_feat) - cls_score = self.conv_cls(cls_feat) - return cls_score, bbox_pred - - def _get_points_single(self, *args, **kwargs): - y, x = super()._get_points_single(*args, **kwargs) - return y + 0.5, x + 0.5 - - def loss(self, - cls_scores, - bbox_preds, - gt_bbox_list, - gt_label_list, - img_metas, - gt_bboxes_ignore=None): - assert len(cls_scores) == len(bbox_preds) - - featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores] - points = self.get_points(featmap_sizes, bbox_preds[0].dtype, - bbox_preds[0].device) - num_imgs = cls_scores[0].size(0) - flatten_cls_scores = [ - cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels) - for cls_score in cls_scores - ] - flatten_bbox_preds = [ - bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4) - for bbox_pred in bbox_preds - ] - flatten_cls_scores = torch.cat(flatten_cls_scores) - flatten_bbox_preds = torch.cat(flatten_bbox_preds) - flatten_labels, flatten_bbox_targets = self.get_targets( - gt_bbox_list, gt_label_list, featmap_sizes, points) - - # FG cat_id: [0, num_classes -1], BG cat_id: num_classes - pos_inds = ((flatten_labels >= 0) - & (flatten_labels < self.num_classes)).nonzero().view(-1) - num_pos = len(pos_inds) - - loss_cls = self.loss_cls( - flatten_cls_scores, flatten_labels, avg_factor=num_pos + num_imgs) - if num_pos > 0: - pos_bbox_preds = flatten_bbox_preds[pos_inds] - pos_bbox_targets = flatten_bbox_targets[pos_inds] - pos_weights = pos_bbox_targets.new_zeros( - pos_bbox_targets.size()) + 1.0 - loss_bbox = self.loss_bbox( - pos_bbox_preds, - pos_bbox_targets, - pos_weights, - avg_factor=num_pos) - else: - loss_bbox = torch.tensor( - 0, - dtype=flatten_bbox_preds.dtype, - device=flatten_bbox_preds.device) - return dict(loss_cls=loss_cls, loss_bbox=loss_bbox) - - def get_targets(self, gt_bbox_list, gt_label_list, featmap_sizes, points): - label_list, bbox_target_list = multi_apply( - self._get_target_single, - gt_bbox_list, - gt_label_list, - featmap_size_list=featmap_sizes, - point_list=points) - flatten_labels = [ - torch.cat([ - labels_level_img.flatten() for labels_level_img in labels_level - ]) for labels_level in zip(*label_list) - ] - flatten_bbox_targets = [ - torch.cat([ - bbox_targets_level_img.reshape(-1, 4) - for bbox_targets_level_img in bbox_targets_level - ]) for bbox_targets_level in zip(*bbox_target_list) - ] - flatten_labels = torch.cat(flatten_labels) - flatten_bbox_targets = torch.cat(flatten_bbox_targets) - return flatten_labels, flatten_bbox_targets - - def _get_target_single(self, - gt_bboxes_raw, - gt_labels_raw, - featmap_size_list=None, - point_list=None): - - gt_areas = torch.sqrt((gt_bboxes_raw[:, 2] - gt_bboxes_raw[:, 0]) * - (gt_bboxes_raw[:, 3] - gt_bboxes_raw[:, 1])) - label_list = [] - bbox_target_list = [] - # for each pyramid, find the cls and box target - for base_len, (lower_bound, upper_bound), stride, featmap_size, \ - (y, x) in zip(self.base_edge_list, self.scale_ranges, - self.strides, featmap_size_list, point_list): - # FG cat_id: [0, num_classes -1], BG cat_id: num_classes - labels = gt_labels_raw.new_zeros(featmap_size) + self.num_classes - bbox_targets = gt_bboxes_raw.new(featmap_size[0], featmap_size[1], - 4) + 1 - # scale assignment - hit_indices = ((gt_areas >= lower_bound) & - (gt_areas <= upper_bound)).nonzero().flatten() - if len(hit_indices) == 0: - label_list.append(labels) - bbox_target_list.append(torch.log(bbox_targets)) - continue - _, hit_index_order = torch.sort(-gt_areas[hit_indices]) - hit_indices = hit_indices[hit_index_order] - gt_bboxes = gt_bboxes_raw[hit_indices, :] / stride - gt_labels = gt_labels_raw[hit_indices] - half_w = 0.5 * (gt_bboxes[:, 2] - gt_bboxes[:, 0]) - half_h = 0.5 * (gt_bboxes[:, 3] - gt_bboxes[:, 1]) - # valid fovea area: left, right, top, down - pos_left = torch.ceil( - gt_bboxes[:, 0] + (1 - self.sigma) * half_w - 0.5).long().\ - clamp(0, featmap_size[1] - 1) - pos_right = torch.floor( - gt_bboxes[:, 0] + (1 + self.sigma) * half_w - 0.5).long().\ - clamp(0, featmap_size[1] - 1) - pos_top = torch.ceil( - gt_bboxes[:, 1] + (1 - self.sigma) * half_h - 0.5).long().\ - clamp(0, featmap_size[0] - 1) - pos_down = torch.floor( - gt_bboxes[:, 1] + (1 + self.sigma) * half_h - 0.5).long().\ - clamp(0, featmap_size[0] - 1) - for px1, py1, px2, py2, label, (gt_x1, gt_y1, gt_x2, gt_y2) in \ - zip(pos_left, pos_top, pos_right, pos_down, gt_labels, - gt_bboxes_raw[hit_indices, :]): - labels[py1:py2 + 1, px1:px2 + 1] = label - bbox_targets[py1:py2 + 1, px1:px2 + 1, 0] = \ - (stride * x[py1:py2 + 1, px1:px2 + 1] - gt_x1) / base_len - bbox_targets[py1:py2 + 1, px1:px2 + 1, 1] = \ - (stride * y[py1:py2 + 1, px1:px2 + 1] - gt_y1) / base_len - bbox_targets[py1:py2 + 1, px1:px2 + 1, 2] = \ - (gt_x2 - stride * x[py1:py2 + 1, px1:px2 + 1]) / base_len - bbox_targets[py1:py2 + 1, px1:px2 + 1, 3] = \ - (gt_y2 - stride * y[py1:py2 + 1, px1:px2 + 1]) / base_len - bbox_targets = bbox_targets.clamp(min=1. / 16, max=16.) - label_list.append(labels) - bbox_target_list.append(torch.log(bbox_targets)) - return label_list, bbox_target_list - - def get_bboxes(self, - cls_scores, - bbox_preds, - img_metas, - cfg=None, - rescale=None): - assert len(cls_scores) == len(bbox_preds) - num_levels = len(cls_scores) - featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores] - points = self.get_points( - featmap_sizes, - bbox_preds[0].dtype, - bbox_preds[0].device, - flatten=True) - result_list = [] - for img_id in range(len(img_metas)): - cls_score_list = [ - cls_scores[i][img_id].detach() for i in range(num_levels) - ] - bbox_pred_list = [ - bbox_preds[i][img_id].detach() for i in range(num_levels) - ] - img_shape = img_metas[img_id]['img_shape'] - scale_factor = img_metas[img_id]['scale_factor'] - det_bboxes = self._get_bboxes_single(cls_score_list, - bbox_pred_list, featmap_sizes, - points, img_shape, - scale_factor, cfg, rescale) - result_list.append(det_bboxes) - return result_list - - def _get_bboxes_single(self, - cls_scores, - bbox_preds, - featmap_sizes, - point_list, - img_shape, - scale_factor, - cfg, - rescale=False): - cfg = self.test_cfg if cfg is None else cfg - assert len(cls_scores) == len(bbox_preds) == len(point_list) - det_bboxes = [] - det_scores = [] - for cls_score, bbox_pred, featmap_size, stride, base_len, (y, x) \ - in zip(cls_scores, bbox_preds, featmap_sizes, self.strides, - self.base_edge_list, point_list): - assert cls_score.size()[-2:] == bbox_pred.size()[-2:] - scores = cls_score.permute(1, 2, 0).reshape( - -1, self.cls_out_channels).sigmoid() - bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4).exp() - nms_pre = cfg.get('nms_pre', -1) - if (nms_pre > 0) and (scores.shape[0] > nms_pre): - max_scores, _ = scores.max(dim=1) - _, topk_inds = max_scores.topk(nms_pre) - bbox_pred = bbox_pred[topk_inds, :] - scores = scores[topk_inds, :] - y = y[topk_inds] - x = x[topk_inds] - x1 = (stride * x - base_len * bbox_pred[:, 0]).\ - clamp(min=0, max=img_shape[1] - 1) - y1 = (stride * y - base_len * bbox_pred[:, 1]).\ - clamp(min=0, max=img_shape[0] - 1) - x2 = (stride * x + base_len * bbox_pred[:, 2]).\ - clamp(min=0, max=img_shape[1] - 1) - y2 = (stride * y + base_len * bbox_pred[:, 3]).\ - clamp(min=0, max=img_shape[0] - 1) - bboxes = torch.stack([x1, y1, x2, y2], -1) - det_bboxes.append(bboxes) - det_scores.append(scores) - det_bboxes = torch.cat(det_bboxes) - if rescale: - det_bboxes /= det_bboxes.new_tensor(scale_factor) - det_scores = torch.cat(det_scores) - padding = det_scores.new_zeros(det_scores.shape[0], 1) - # remind that we set FG labels to [0, num_class-1] since mmdet v2.0 - # BG cat_id: num_class - det_scores = torch.cat([det_scores, padding], dim=1) - det_bboxes, det_labels = multiclass_nms(det_bboxes, det_scores, - cfg.score_thr, cfg.nms, - cfg.max_per_img) - return det_bboxes, det_labels diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/mask_heads/coarse_mask_head.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/mask_heads/coarse_mask_head.py deleted file mode 100644 index d665dfff83855e6db3866c681559ccdef09f9999..0000000000000000000000000000000000000000 --- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/mask_heads/coarse_mask_head.py +++ /dev/null @@ -1,91 +0,0 @@ -import torch.nn as nn -from mmcv.cnn import ConvModule, Linear, constant_init, xavier_init -from mmcv.runner import auto_fp16 - -from mmdet.models.builder import HEADS -from .fcn_mask_head import FCNMaskHead - - -@HEADS.register_module() -class CoarseMaskHead(FCNMaskHead): - """Coarse mask head used in PointRend. - - Compared with standard ``FCNMaskHead``, ``CoarseMaskHead`` will downsample - the input feature map instead of upsample it. - - Args: - num_convs (int): Number of conv layers in the head. Default: 0. - num_fcs (int): Number of fc layers in the head. Default: 2. - fc_out_channels (int): Number of output channels of fc layer. - Default: 1024. - downsample_factor (int): The factor that feature map is downsampled by. - Default: 2. - """ - - def __init__(self, - num_convs=0, - num_fcs=2, - fc_out_channels=1024, - downsample_factor=2, - *arg, - **kwarg): - super(CoarseMaskHead, self).__init__( - *arg, num_convs=num_convs, upsample_cfg=dict(type=None), **kwarg) - self.num_fcs = num_fcs - assert self.num_fcs > 0 - self.fc_out_channels = fc_out_channels - self.downsample_factor = downsample_factor - assert self.downsample_factor >= 1 - # remove conv_logit - delattr(self, 'conv_logits') - - if downsample_factor > 1: - downsample_in_channels = ( - self.conv_out_channels - if self.num_convs > 0 else self.in_channels) - self.downsample_conv = ConvModule( - downsample_in_channels, - self.conv_out_channels, - kernel_size=downsample_factor, - stride=downsample_factor, - padding=0, - conv_cfg=self.conv_cfg, - norm_cfg=self.norm_cfg) - else: - self.downsample_conv = None - - self.output_size = (self.roi_feat_size[0] // downsample_factor, - self.roi_feat_size[1] // downsample_factor) - self.output_area = self.output_size[0] * self.output_size[1] - - last_layer_dim = self.conv_out_channels * self.output_area - - self.fcs = nn.ModuleList() - for i in range(num_fcs): - fc_in_channels = ( - last_layer_dim if i == 0 else self.fc_out_channels) - self.fcs.append(Linear(fc_in_channels, self.fc_out_channels)) - last_layer_dim = self.fc_out_channels - output_channels = self.num_classes * self.output_area - self.fc_logits = Linear(last_layer_dim, output_channels) - - def init_weights(self): - for m in self.fcs.modules(): - if isinstance(m, nn.Linear): - xavier_init(m) - constant_init(self.fc_logits, 0.001) - - @auto_fp16() - def forward(self, x): - for conv in self.convs: - x = conv(x) - - if self.downsample_conv is not None: - x = self.downsample_conv(x) - - x = x.flatten(1) - for fc in self.fcs: - x = self.relu(fc(x)) - mask_pred = self.fc_logits(x).view( - x.size(0), self.num_classes, *self.output_size) - return mask_pred diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/core/evaluation/eval_hooks.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/core/evaluation/eval_hooks.py deleted file mode 100644 index 6fc100c8f96e817a6ed2666f7c9f762af2463b48..0000000000000000000000000000000000000000 --- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/core/evaluation/eval_hooks.py +++ /dev/null @@ -1,109 +0,0 @@ -import os.path as osp - -from annotator.uniformer.mmcv.runner import DistEvalHook as _DistEvalHook -from annotator.uniformer.mmcv.runner import EvalHook as _EvalHook - - -class EvalHook(_EvalHook): - """Single GPU EvalHook, with efficient test support. - - Args: - by_epoch (bool): Determine perform evaluation by epoch or by iteration. - If set to True, it will perform by epoch. Otherwise, by iteration. - Default: False. - efficient_test (bool): Whether save the results as local numpy files to - save CPU memory during evaluation. Default: False. - Returns: - list: The prediction results. - """ - - greater_keys = ['mIoU', 'mAcc', 'aAcc'] - - def __init__(self, *args, by_epoch=False, efficient_test=False, **kwargs): - super().__init__(*args, by_epoch=by_epoch, **kwargs) - self.efficient_test = efficient_test - - def after_train_iter(self, runner): - """After train epoch hook. - - Override default ``single_gpu_test``. - """ - if self.by_epoch or not self.every_n_iters(runner, self.interval): - return - from annotator.uniformer.mmseg.apis import single_gpu_test - runner.log_buffer.clear() - results = single_gpu_test( - runner.model, - self.dataloader, - show=False, - efficient_test=self.efficient_test) - self.evaluate(runner, results) - - def after_train_epoch(self, runner): - """After train epoch hook. - - Override default ``single_gpu_test``. - """ - if not self.by_epoch or not self.every_n_epochs(runner, self.interval): - return - from annotator.uniformer.mmseg.apis import single_gpu_test - runner.log_buffer.clear() - results = single_gpu_test(runner.model, self.dataloader, show=False) - self.evaluate(runner, results) - - -class DistEvalHook(_DistEvalHook): - """Distributed EvalHook, with efficient test support. - - Args: - by_epoch (bool): Determine perform evaluation by epoch or by iteration. - If set to True, it will perform by epoch. Otherwise, by iteration. - Default: False. - efficient_test (bool): Whether save the results as local numpy files to - save CPU memory during evaluation. Default: False. - Returns: - list: The prediction results. - """ - - greater_keys = ['mIoU', 'mAcc', 'aAcc'] - - def __init__(self, *args, by_epoch=False, efficient_test=False, **kwargs): - super().__init__(*args, by_epoch=by_epoch, **kwargs) - self.efficient_test = efficient_test - - def after_train_iter(self, runner): - """After train epoch hook. - - Override default ``multi_gpu_test``. - """ - if self.by_epoch or not self.every_n_iters(runner, self.interval): - return - from annotator.uniformer.mmseg.apis import multi_gpu_test - runner.log_buffer.clear() - results = multi_gpu_test( - runner.model, - self.dataloader, - tmpdir=osp.join(runner.work_dir, '.eval_hook'), - gpu_collect=self.gpu_collect, - efficient_test=self.efficient_test) - if runner.rank == 0: - print('\n') - self.evaluate(runner, results) - - def after_train_epoch(self, runner): - """After train epoch hook. - - Override default ``multi_gpu_test``. - """ - if not self.by_epoch or not self.every_n_epochs(runner, self.interval): - return - from annotator.uniformer.mmseg.apis import multi_gpu_test - runner.log_buffer.clear() - results = multi_gpu_test( - runner.model, - self.dataloader, - tmpdir=osp.join(runner.work_dir, '.eval_hook'), - gpu_collect=self.gpu_collect) - if runner.rank == 0: - print('\n') - self.evaluate(runner, results) diff --git a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/canvas/xlib.py b/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/canvas/xlib.py deleted file mode 100644 index 27bf0e5714523f1ce3d83bf972e06bf14a1a356a..0000000000000000000000000000000000000000 --- a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/canvas/xlib.py +++ /dev/null @@ -1,260 +0,0 @@ -import ctypes -from ctypes import * - -from pyglet import app -from pyglet.app.xlib import XlibSelectDevice -from .base import Display, Screen, ScreenMode, Canvas - -from . import xlib_vidmoderestore - - -# XXX -# from pyglet.window import NoSuchDisplayException -class NoSuchDisplayException(Exception): - pass - - -from pyglet.libs.x11 import xlib - -try: - from pyglet.libs.x11 import xinerama - - _have_xinerama = True -except: - _have_xinerama = False - -try: - from pyglet.libs.x11 import xsync - - _have_xsync = True -except: - _have_xsync = False - -try: - from pyglet.libs.x11 import xf86vmode - - _have_xf86vmode = True -except: - _have_xf86vmode = False - - -# Set up error handler -def _error_handler(display, event): - # By default, all errors are silently ignored: this has a better chance - # of working than the default behaviour of quitting ;-) - # - # We've actually never seen an error that was our fault; they're always - # driver bugs (and so the reports are useless). Nevertheless, set - # environment variable PYGLET_DEBUG_X11 to 1 to get dumps of the error - # and a traceback (execution will continue). - import pyglet - if pyglet.options['debug_x11']: - event = event.contents - buf = c_buffer(1024) - xlib.XGetErrorText(display, event.error_code, buf, len(buf)) - print('X11 error:', buf.value) - print(' serial:', event.serial) - print(' request:', event.request_code) - print(' minor:', event.minor_code) - print(' resource:', event.resourceid) - - import traceback - print('Python stack trace (innermost last):') - traceback.print_stack() - return 0 - - -_error_handler_ptr = xlib.XErrorHandler(_error_handler) -xlib.XSetErrorHandler(_error_handler_ptr) - - -class XlibDisplay(XlibSelectDevice, Display): - _display = None # POINTER(xlib.Display) - - _x_im = None # X input method - # TODO close _x_im when display connection closed. - _enable_xsync = False - _screens = None # Cache of get_screens() - - def __init__(self, name=None, x_screen=None): - if x_screen is None: - x_screen = 0 - - if isinstance(name, str): - name = c_char_p(name.encode('ascii')) - - self._display = xlib.XOpenDisplay(name) - if not self._display: - raise NoSuchDisplayException(f'Cannot connect to "{name}"') - - screen_count = xlib.XScreenCount(self._display) - if x_screen >= screen_count: - raise NoSuchDisplayException(f'Display "{name}" has no screen {x_screen:d}') - - super(XlibDisplay, self).__init__() - self.name = name - self.x_screen = x_screen - - self._fileno = xlib.XConnectionNumber(self._display) - self._window_map = {} - - # Initialise XSync - if _have_xsync: - event_base = c_int() - error_base = c_int() - if xsync.XSyncQueryExtension(self._display, - byref(event_base), - byref(error_base)): - major_version = c_int() - minor_version = c_int() - if xsync.XSyncInitialize(self._display, - byref(major_version), - byref(minor_version)): - self._enable_xsync = True - - # Add to event loop select list. Assume we never go away. - app.platform_event_loop.select_devices.add(self) - - def get_screens(self): - if self._screens: - return self._screens - - if _have_xinerama and xinerama.XineramaIsActive(self._display): - number = c_int() - infos = xinerama.XineramaQueryScreens(self._display, byref(number)) - infos = cast(infos, POINTER(xinerama.XineramaScreenInfo * number.value)).contents - self._screens = [] - using_xinerama = number.value > 1 - for info in infos: - self._screens.append(XlibScreen(self, - info.x_org, - info.y_org, - info.width, - info.height, - using_xinerama)) - xlib.XFree(infos) - else: - # No xinerama - screen_info = xlib.XScreenOfDisplay(self._display, self.x_screen) - screen = XlibScreen(self, - 0, 0, - screen_info.contents.width, - screen_info.contents.height, - False) - self._screens = [screen] - return self._screens - - # XlibSelectDevice interface - - def fileno(self): - return self._fileno - - def select(self): - e = xlib.XEvent() - while xlib.XPending(self._display): - xlib.XNextEvent(self._display, e) - - # Key events are filtered by the xlib window event - # handler so they get a shot at the prefiltered event. - if e.xany.type not in (xlib.KeyPress, xlib.KeyRelease): - if xlib.XFilterEvent(e, e.xany.window): - continue - try: - dispatch = self._window_map[e.xany.window] - except KeyError: - continue - - dispatch(e) - - def poll(self): - return xlib.XPending(self._display) - - -class XlibScreen(Screen): - _initial_mode = None - - def __init__(self, display, x, y, width, height, xinerama): - super(XlibScreen, self).__init__(display, x, y, width, height) - self._xinerama = xinerama - - def get_matching_configs(self, template): - canvas = XlibCanvas(self.display, None) - configs = template.match(canvas) - # XXX deprecate - for config in configs: - config.screen = self - return configs - - def get_modes(self): - if not _have_xf86vmode: - return [] - - if self._xinerama: - # If Xinerama/TwinView is enabled, xf86vidmode's modelines - # correspond to metamodes, which don't distinguish one screen from - # another. XRandR (broken) or NV (complicated) extensions needed. - return [] - - count = ctypes.c_int() - info_array = ctypes.POINTER(ctypes.POINTER(xf86vmode.XF86VidModeModeInfo))() - xf86vmode.XF86VidModeGetAllModeLines(self.display._display, self.display.x_screen, count, info_array) - - # Copy modes out of list and free list - modes = [] - for i in range(count.value): - info = xf86vmode.XF86VidModeModeInfo() - ctypes.memmove(ctypes.byref(info), - ctypes.byref(info_array.contents[i]), - ctypes.sizeof(info)) - modes.append(XlibScreenMode(self, info)) - if info.privsize: - xlib.XFree(info.private) - xlib.XFree(info_array) - - return modes - - def get_mode(self): - modes = self.get_modes() - if modes: - return modes[0] - return None - - def set_mode(self, mode): - assert mode.screen is self - - if not self._initial_mode: - self._initial_mode = self.get_mode() - xlib_vidmoderestore.set_initial_mode(self._initial_mode) - - xf86vmode.XF86VidModeSwitchToMode(self.display._display, self.display.x_screen, mode.info) - xlib.XFlush(self.display._display) - xf86vmode.XF86VidModeSetViewPort(self.display._display, self.display.x_screen, 0, 0) - xlib.XFlush(self.display._display) - - self.width = mode.width - self.height = mode.height - - def restore_mode(self): - if self._initial_mode: - self.set_mode(self._initial_mode) - - def __repr__(self): - return f"{self.__class__.__name__}(display={self.display!r}, x={self.x}, y={self.y}, " \ - f"width={self.width}, height={self.height}, xinerama={self._xinerama})" - - - -class XlibScreenMode(ScreenMode): - def __init__(self, screen, info): - super(XlibScreenMode, self).__init__(screen) - self.info = info - self.width = info.hdisplay - self.height = info.vdisplay - self.rate = info.dotclock - self.depth = None - - -class XlibCanvas(Canvas): - def __init__(self, display, x_window): - super(XlibCanvas, self).__init__(display) - self.x_window = x_window diff --git a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/media/__init__.py b/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/media/__init__.py deleted file mode 100644 index e45b00d1be6b3b0b63653a6b075659b6cae1a69d..0000000000000000000000000000000000000000 --- a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/media/__init__.py +++ /dev/null @@ -1,83 +0,0 @@ -"""Audio and video playback. - -pyglet can play WAV files, and if FFmpeg is installed, many other audio and -video formats. - -Playback is handled by the :class:`.Player` class, which reads raw data from -:class:`Source` objects and provides methods for pausing, seeking, adjusting -the volume, and so on. The :class:`.Player` class implements the best -available audio device. :: - - player = Player() - -A :class:`Source` is used to decode arbitrary audio and video files. It is -associated with a single player by "queueing" it:: - - source = load('background_music.mp3') - player.queue(source) - -Use the :class:`.Player` to control playback. - -If the source contains video, the :py:meth:`Source.video_format` attribute -will be non-None, and the :py:attr:`Player.texture` attribute will contain the -current video image synchronised to the audio. - -Decoding sounds can be processor-intensive and may introduce latency, -particularly for short sounds that must be played quickly, such as bullets or -explosions. You can force such sounds to be decoded and retained in memory -rather than streamed from disk by wrapping the source in a -:class:`StaticSource`:: - - bullet_sound = StaticSource(load('bullet.wav')) - -The other advantage of a :class:`StaticSource` is that it can be queued on -any number of players, and so played many times simultaneously. - -Pyglet relies on Python's garbage collector to release resources when a player -has finished playing a source. In this way some operations that could affect -the application performance can be delayed. - -The player provides a :py:meth:`Player.delete` method that can be used to -release resources immediately. -""" -from .drivers import get_audio_driver -from .player import Player, PlayerGroup -from .codecs import registry as _codec_registry -from .codecs import add_default_codecs as _add_default_codecs -from .codecs import Source, StaticSource, StreamingSource, SourceGroup, have_ffmpeg - -from . import synthesis - - -__all__ = 'load', 'get_audio_driver', 'Player', 'PlayerGroup', 'SourceGroup', 'StaticSource', 'StreamingSource' - - -def load(filename, file=None, streaming=True, decoder=None): - """Load a Source from a file. - - All decoders that are registered for the filename extension are tried. - If none succeed, the exception from the first decoder is raised. - You can also specifically pass a decoder to use. - - :Parameters: - `filename` : str - Used to guess the media format, and to load the file if `file` is - unspecified. - `file` : file-like object or None - Source of media data in any supported format. - `streaming` : bool - If `False`, a :class:`StaticSource` will be returned; otherwise - (default) a :class:`~pyglet.media.StreamingSource` is created. - `decoder` : MediaDecoder or None - A specific decoder you wish to use, rather than relying on - automatic detection. If specified, no other decoders are tried. - - :rtype: StreamingSource or Source - """ - if decoder: - return decoder.decode(filename, file, streaming=streaming) - else: - return _codec_registry.decode(filename, file, streaming=streaming) - - -_add_default_codecs() diff --git a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/window/headless/__init__.py b/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/window/headless/__init__.py deleted file mode 100644 index b8e859672afdb6035983f02ab7cea46271043a2e..0000000000000000000000000000000000000000 --- a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/window/headless/__init__.py +++ /dev/null @@ -1,107 +0,0 @@ -from pyglet.window import BaseWindow, _PlatformEventHandler, _ViewEventHandler -from pyglet.window import WindowException, NoSuchDisplayException, MouseCursorException -from pyglet.window import MouseCursor, DefaultMouseCursor, ImageMouseCursor - - -from pyglet.libs.egl import egl - - -from pyglet.canvas.headless import HeadlessCanvas - -# from pyglet.window import key -# from pyglet.window import mouse -from pyglet.event import EventDispatcher - -# Platform event data is single item, so use platform event handler directly. -HeadlessEventHandler = _PlatformEventHandler -ViewEventHandler = _ViewEventHandler - - -class HeadlessWindow(BaseWindow): - _egl_display_connection = None - _egl_surface = None - - def _recreate(self, changes): - pass - - def flip(self): - if self.context: - self.context.flip() - - def switch_to(self): - if self.context: - self.context.set_current() - - def set_caption(self, caption): - pass - - def set_minimum_size(self, width, height): - pass - - def set_maximum_size(self, width, height): - pass - - def set_size(self, width, height): - pass - - def get_size(self): - return self._width, self._height - - def set_location(self, x, y): - pass - - def get_location(self): - pass - - def activate(self): - pass - - def set_visible(self, visible=True): - pass - - def minimize(self): - pass - - def maximize(self): - pass - - def set_vsync(self, vsync): - pass - - def set_mouse_platform_visible(self, platform_visible=None): - pass - - def set_exclusive_mouse(self, exclusive=True): - pass - - def set_exclusive_keyboard(self, exclusive=True): - pass - - def get_system_mouse_cursor(self, name): - pass - - def dispatch_events(self): - while self._event_queue: - EventDispatcher.dispatch_event(self, *self._event_queue.pop(0)) - - def dispatch_pending_events(self): - pass - - def _create(self): - self._egl_display_connection = self.display._display_connection - - if not self._egl_surface: - pbuffer_attribs = (egl.EGL_WIDTH, self._width, egl.EGL_HEIGHT, self._height, egl.EGL_NONE) - pbuffer_attrib_array = (egl.EGLint * len(pbuffer_attribs))(*pbuffer_attribs) - self._egl_surface = egl.eglCreatePbufferSurface(self._egl_display_connection, - self.config._egl_config, - pbuffer_attrib_array) - - self.canvas = HeadlessCanvas(self.display, self._egl_surface) - - self.context.attach(self.canvas) - - self.dispatch_event('on_resize', self._width, self._height) - - -__all__ = ["HeadlessWindow"] diff --git a/spaces/ahmadprince007/HolyBot/README.md b/spaces/ahmadprince007/HolyBot/README.md deleted file mode 100644 index 19caf3fcecefecb1a3c4b2fbbf3f63aee0286ed0..0000000000000000000000000000000000000000 --- a/spaces/ahmadprince007/HolyBot/README.md +++ /dev/null @@ -1,10 +0,0 @@ ---- -title: HolyBot -emoji: 🚀 -colorFrom: yellow -colorTo: indigo -sdk: docker -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/akhaliq/Music_Source_Separation/scripts/2_create_indexes/violin-piano/create_indexes.sh b/spaces/akhaliq/Music_Source_Separation/scripts/2_create_indexes/violin-piano/create_indexes.sh deleted file mode 100644 index f1532a524bdae6b5316451bb0172b3b44c8f4843..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/Music_Source_Separation/scripts/2_create_indexes/violin-piano/create_indexes.sh +++ /dev/null @@ -1,12 +0,0 @@ -#!/bin/bash -WORKSPACE=${1:-"./workspaces/bytesep"} # Default workspace directory - -echo "WORKSPACE=${WORKSPACE}" - -# Users can modify the following config file. -INDEXES_CONFIG_YAML="scripts/2_create_indexes/violin-piano/configs/violin-piano,sr=44100,chn=2.yaml" - -# Create indexes for training. -python3 bytesep/dataset_creation/create_indexes/create_indexes.py \ - --workspace=$WORKSPACE \ - --config_yaml=$INDEXES_CONFIG_YAML diff --git a/spaces/akhaliq/SummerTime/model/defaults.py b/spaces/akhaliq/SummerTime/model/defaults.py deleted file mode 100644 index b9acbf3ca368d343c760a4bf48a475d87fcf7ace..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/SummerTime/model/defaults.py +++ /dev/null @@ -1,10 +0,0 @@ -from .single_doc import PegasusModel - - -class summarizer(PegasusModel): - def __init__(self, device="cpu"): - super(summarizer, self).__init__(device) - - def show_capability(self): - print("Pegasus is the default singe-document summarization model.") - super(summarizer, self).show_capability() diff --git a/spaces/akhaliq/lama/saicinpainting/training/trainers/__init__.py b/spaces/akhaliq/lama/saicinpainting/training/trainers/__init__.py deleted file mode 100644 index c59241f553efe4e2dd6b198e2e5656a2b1488857..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/lama/saicinpainting/training/trainers/__init__.py +++ /dev/null @@ -1,30 +0,0 @@ -import logging -import torch -from saicinpainting.training.trainers.default import DefaultInpaintingTrainingModule - - -def get_training_model_class(kind): - if kind == 'default': - return DefaultInpaintingTrainingModule - - raise ValueError(f'Unknown trainer module {kind}') - - -def make_training_model(config): - kind = config.training_model.kind - kwargs = dict(config.training_model) - kwargs.pop('kind') - kwargs['use_ddp'] = config.trainer.kwargs.get('accelerator', None) == 'ddp' - - logging.info(f'Make training model {kind}') - - cls = get_training_model_class(kind) - return cls(config, **kwargs) - - -def load_checkpoint(train_config, path, map_location='cuda', strict=True): - model: torch.nn.Module = make_training_model(train_config) - state = torch.load(path, map_location=map_location) - model.load_state_dict(state['state_dict'], strict=strict) - model.on_load_checkpoint(state) - return model diff --git a/spaces/akhaliq/layout-parser/app.py b/spaces/akhaliq/layout-parser/app.py deleted file mode 100644 index e64e268dbf70b615009ca284a783929d4190922d..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/layout-parser/app.py +++ /dev/null @@ -1,25 +0,0 @@ -import os -os.system('pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"') -import layoutparser as lp -import gradio as gr - -model = lp.Detectron2LayoutModel('lp://PrimaLayout/mask_rcnn_R_50_FPN_3x/config') - -def lpi(img): - layout = model.detect(img) # You need to load the image somewhere else, e.g., image = cv2.imread(...) - return lp.draw_box(img, layout,) # With extra configurations - -inputs = gr.inputs.Image(type='pil', label="Original Image") -outputs = gr.outputs.Image(type="pil",label="Output Image") - -title = "Layout Parser" -description = "demo for Layout Parser. To use it, simply upload your image, or click one of the examples to load them. Read more at the links below." -article = "- - { - currentSuggestions.map(suggestion => ( - - )) - } --LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis | Github Repo
" - -examples = [ - ['example-table.jpeg'], - ['paper-image.jpeg'] - -] - -gr.Interface(lpi, inputs, outputs, title=title, description=description, article=article, examples=examples).launch() \ No newline at end of file diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/operations/install/editable_legacy.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/operations/install/editable_legacy.py deleted file mode 100644 index bb548cdca75a924bf090f2be29779e2be1951a2c..0000000000000000000000000000000000000000 --- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_internal/operations/install/editable_legacy.py +++ /dev/null @@ -1,47 +0,0 @@ -"""Legacy editable installation process, i.e. `setup.py develop`. -""" -import logging -from typing import List, Optional, Sequence - -from pip._internal.build_env import BuildEnvironment -from pip._internal.utils.logging import indent_log -from pip._internal.utils.setuptools_build import make_setuptools_develop_args -from pip._internal.utils.subprocess import call_subprocess - -logger = logging.getLogger(__name__) - - -def install_editable( - install_options: List[str], - global_options: Sequence[str], - prefix: Optional[str], - home: Optional[str], - use_user_site: bool, - name: str, - setup_py_path: str, - isolated: bool, - build_env: BuildEnvironment, - unpacked_source_directory: str, -) -> None: - """Install a package in editable mode. Most arguments are pass-through - to setuptools. - """ - logger.info("Running setup.py develop for %s", name) - - args = make_setuptools_develop_args( - setup_py_path, - global_options=global_options, - install_options=install_options, - no_user_config=isolated, - prefix=prefix, - home=home, - use_user_site=use_user_site, - ) - - with indent_log(): - with build_env: - call_subprocess( - args, - command_desc="python setup.py develop", - cwd=unpacked_source_directory, - ) diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/distlib/wheel.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/distlib/wheel.py deleted file mode 100644 index 48abfde5b5285cb19c50757796dfd162e59c0d91..0000000000000000000000000000000000000000 --- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/distlib/wheel.py +++ /dev/null @@ -1,1053 +0,0 @@ -# -*- coding: utf-8 -*- -# -# Copyright (C) 2013-2020 Vinay Sajip. -# Licensed to the Python Software Foundation under a contributor agreement. -# See LICENSE.txt and CONTRIBUTORS.txt. -# -from __future__ import unicode_literals - -import base64 -import codecs -import datetime -from email import message_from_file -import hashlib -import imp -import json -import logging -import os -import posixpath -import re -import shutil -import sys -import tempfile -import zipfile - -from . import __version__, DistlibException -from .compat import sysconfig, ZipFile, fsdecode, text_type, filter -from .database import InstalledDistribution -from .metadata import (Metadata, METADATA_FILENAME, WHEEL_METADATA_FILENAME, - LEGACY_METADATA_FILENAME) -from .util import (FileOperator, convert_path, CSVReader, CSVWriter, Cache, - cached_property, get_cache_base, read_exports, tempdir, - get_platform) -from .version import NormalizedVersion, UnsupportedVersionError - -logger = logging.getLogger(__name__) - -cache = None # created when needed - -if hasattr(sys, 'pypy_version_info'): # pragma: no cover - IMP_PREFIX = 'pp' -elif sys.platform.startswith('java'): # pragma: no cover - IMP_PREFIX = 'jy' -elif sys.platform == 'cli': # pragma: no cover - IMP_PREFIX = 'ip' -else: - IMP_PREFIX = 'cp' - -VER_SUFFIX = sysconfig.get_config_var('py_version_nodot') -if not VER_SUFFIX: # pragma: no cover - VER_SUFFIX = '%s%s' % sys.version_info[:2] -PYVER = 'py' + VER_SUFFIX -IMPVER = IMP_PREFIX + VER_SUFFIX - -ARCH = get_platform().replace('-', '_').replace('.', '_') - -ABI = sysconfig.get_config_var('SOABI') -if ABI and ABI.startswith('cpython-'): - ABI = ABI.replace('cpython-', 'cp').split('-')[0] -else: - def _derive_abi(): - parts = ['cp', VER_SUFFIX] - if sysconfig.get_config_var('Py_DEBUG'): - parts.append('d') - if sysconfig.get_config_var('WITH_PYMALLOC'): - parts.append('m') - if sysconfig.get_config_var('Py_UNICODE_SIZE') == 4: - parts.append('u') - return ''.join(parts) - ABI = _derive_abi() - del _derive_abi - -FILENAME_RE = re.compile(r''' -(?P[^-]+) --(?P \d+[^-]*) -(-(?P \d+[^-]*))? --(?P \w+\d+(\.\w+\d+)*) --(?P \w+) --(?P \w+(\.\w+)*) -\.whl$ -''', re.IGNORECASE | re.VERBOSE) - -NAME_VERSION_RE = re.compile(r''' -(?P [^-]+) --(?P \d+[^-]*) -(-(?P \d+[^-]*))?$ -''', re.IGNORECASE | re.VERBOSE) - -SHEBANG_RE = re.compile(br'\s*#![^\r\n]*') -SHEBANG_DETAIL_RE = re.compile(br'^(\s*#!("[^"]+"|\S+))\s+(.*)$') -SHEBANG_PYTHON = b'#!python' -SHEBANG_PYTHONW = b'#!pythonw' - -if os.sep == '/': - to_posix = lambda o: o -else: - to_posix = lambda o: o.replace(os.sep, '/') - - -class Mounter(object): - def __init__(self): - self.impure_wheels = {} - self.libs = {} - - def add(self, pathname, extensions): - self.impure_wheels[pathname] = extensions - self.libs.update(extensions) - - def remove(self, pathname): - extensions = self.impure_wheels.pop(pathname) - for k, v in extensions: - if k in self.libs: - del self.libs[k] - - def find_module(self, fullname, path=None): - if fullname in self.libs: - result = self - else: - result = None - return result - - def load_module(self, fullname): - if fullname in sys.modules: - result = sys.modules[fullname] - else: - if fullname not in self.libs: - raise ImportError('unable to find extension for %s' % fullname) - result = imp.load_dynamic(fullname, self.libs[fullname]) - result.__loader__ = self - parts = fullname.rsplit('.', 1) - if len(parts) > 1: - result.__package__ = parts[0] - return result - -_hook = Mounter() - - -class Wheel(object): - """ - Class to build and install from Wheel files (PEP 427). - """ - - wheel_version = (1, 1) - hash_kind = 'sha256' - - def __init__(self, filename=None, sign=False, verify=False): - """ - Initialise an instance using a (valid) filename. - """ - self.sign = sign - self.should_verify = verify - self.buildver = '' - self.pyver = [PYVER] - self.abi = ['none'] - self.arch = ['any'] - self.dirname = os.getcwd() - if filename is None: - self.name = 'dummy' - self.version = '0.1' - self._filename = self.filename - else: - m = NAME_VERSION_RE.match(filename) - if m: - info = m.groupdict('') - self.name = info['nm'] - # Reinstate the local version separator - self.version = info['vn'].replace('_', '-') - self.buildver = info['bn'] - self._filename = self.filename - else: - dirname, filename = os.path.split(filename) - m = FILENAME_RE.match(filename) - if not m: - raise DistlibException('Invalid name or ' - 'filename: %r' % filename) - if dirname: - self.dirname = os.path.abspath(dirname) - self._filename = filename - info = m.groupdict('') - self.name = info['nm'] - self.version = info['vn'] - self.buildver = info['bn'] - self.pyver = info['py'].split('.') - self.abi = info['bi'].split('.') - self.arch = info['ar'].split('.') - - @property - def filename(self): - """ - Build and return a filename from the various components. - """ - if self.buildver: - buildver = '-' + self.buildver - else: - buildver = '' - pyver = '.'.join(self.pyver) - abi = '.'.join(self.abi) - arch = '.'.join(self.arch) - # replace - with _ as a local version separator - version = self.version.replace('-', '_') - return '%s-%s%s-%s-%s-%s.whl' % (self.name, version, buildver, - pyver, abi, arch) - - @property - def exists(self): - path = os.path.join(self.dirname, self.filename) - return os.path.isfile(path) - - @property - def tags(self): - for pyver in self.pyver: - for abi in self.abi: - for arch in self.arch: - yield pyver, abi, arch - - @cached_property - def metadata(self): - pathname = os.path.join(self.dirname, self.filename) - name_ver = '%s-%s' % (self.name, self.version) - info_dir = '%s.dist-info' % name_ver - wrapper = codecs.getreader('utf-8') - with ZipFile(pathname, 'r') as zf: - wheel_metadata = self.get_wheel_metadata(zf) - wv = wheel_metadata['Wheel-Version'].split('.', 1) - file_version = tuple([int(i) for i in wv]) - # if file_version < (1, 1): - # fns = [WHEEL_METADATA_FILENAME, METADATA_FILENAME, - # LEGACY_METADATA_FILENAME] - # else: - # fns = [WHEEL_METADATA_FILENAME, METADATA_FILENAME] - fns = [WHEEL_METADATA_FILENAME, LEGACY_METADATA_FILENAME] - result = None - for fn in fns: - try: - metadata_filename = posixpath.join(info_dir, fn) - with zf.open(metadata_filename) as bf: - wf = wrapper(bf) - result = Metadata(fileobj=wf) - if result: - break - except KeyError: - pass - if not result: - raise ValueError('Invalid wheel, because metadata is ' - 'missing: looked in %s' % ', '.join(fns)) - return result - - def get_wheel_metadata(self, zf): - name_ver = '%s-%s' % (self.name, self.version) - info_dir = '%s.dist-info' % name_ver - metadata_filename = posixpath.join(info_dir, 'WHEEL') - with zf.open(metadata_filename) as bf: - wf = codecs.getreader('utf-8')(bf) - message = message_from_file(wf) - return dict(message) - - @cached_property - def info(self): - pathname = os.path.join(self.dirname, self.filename) - with ZipFile(pathname, 'r') as zf: - result = self.get_wheel_metadata(zf) - return result - - def process_shebang(self, data): - m = SHEBANG_RE.match(data) - if m: - end = m.end() - shebang, data_after_shebang = data[:end], data[end:] - # Preserve any arguments after the interpreter - if b'pythonw' in shebang.lower(): - shebang_python = SHEBANG_PYTHONW - else: - shebang_python = SHEBANG_PYTHON - m = SHEBANG_DETAIL_RE.match(shebang) - if m: - args = b' ' + m.groups()[-1] - else: - args = b'' - shebang = shebang_python + args - data = shebang + data_after_shebang - else: - cr = data.find(b'\r') - lf = data.find(b'\n') - if cr < 0 or cr > lf: - term = b'\n' - else: - if data[cr:cr + 2] == b'\r\n': - term = b'\r\n' - else: - term = b'\r' - data = SHEBANG_PYTHON + term + data - return data - - def get_hash(self, data, hash_kind=None): - if hash_kind is None: - hash_kind = self.hash_kind - try: - hasher = getattr(hashlib, hash_kind) - except AttributeError: - raise DistlibException('Unsupported hash algorithm: %r' % hash_kind) - result = hasher(data).digest() - result = base64.urlsafe_b64encode(result).rstrip(b'=').decode('ascii') - return hash_kind, result - - def write_record(self, records, record_path, base): - records = list(records) # make a copy, as mutated - p = to_posix(os.path.relpath(record_path, base)) - records.append((p, '', '')) - with CSVWriter(record_path) as writer: - for row in records: - writer.writerow(row) - - def write_records(self, info, libdir, archive_paths): - records = [] - distinfo, info_dir = info - hasher = getattr(hashlib, self.hash_kind) - for ap, p in archive_paths: - with open(p, 'rb') as f: - data = f.read() - digest = '%s=%s' % self.get_hash(data) - size = os.path.getsize(p) - records.append((ap, digest, size)) - - p = os.path.join(distinfo, 'RECORD') - self.write_record(records, p, libdir) - ap = to_posix(os.path.join(info_dir, 'RECORD')) - archive_paths.append((ap, p)) - - def build_zip(self, pathname, archive_paths): - with ZipFile(pathname, 'w', zipfile.ZIP_DEFLATED) as zf: - for ap, p in archive_paths: - logger.debug('Wrote %s to %s in wheel', p, ap) - zf.write(p, ap) - - def build(self, paths, tags=None, wheel_version=None): - """ - Build a wheel from files in specified paths, and use any specified tags - when determining the name of the wheel. - """ - if tags is None: - tags = {} - - libkey = list(filter(lambda o: o in paths, ('purelib', 'platlib')))[0] - if libkey == 'platlib': - is_pure = 'false' - default_pyver = [IMPVER] - default_abi = [ABI] - default_arch = [ARCH] - else: - is_pure = 'true' - default_pyver = [PYVER] - default_abi = ['none'] - default_arch = ['any'] - - self.pyver = tags.get('pyver', default_pyver) - self.abi = tags.get('abi', default_abi) - self.arch = tags.get('arch', default_arch) - - libdir = paths[libkey] - - name_ver = '%s-%s' % (self.name, self.version) - data_dir = '%s.data' % name_ver - info_dir = '%s.dist-info' % name_ver - - archive_paths = [] - - # First, stuff which is not in site-packages - for key in ('data', 'headers', 'scripts'): - if key not in paths: - continue - path = paths[key] - if os.path.isdir(path): - for root, dirs, files in os.walk(path): - for fn in files: - p = fsdecode(os.path.join(root, fn)) - rp = os.path.relpath(p, path) - ap = to_posix(os.path.join(data_dir, key, rp)) - archive_paths.append((ap, p)) - if key == 'scripts' and not p.endswith('.exe'): - with open(p, 'rb') as f: - data = f.read() - data = self.process_shebang(data) - with open(p, 'wb') as f: - f.write(data) - - # Now, stuff which is in site-packages, other than the - # distinfo stuff. - path = libdir - distinfo = None - for root, dirs, files in os.walk(path): - if root == path: - # At the top level only, save distinfo for later - # and skip it for now - for i, dn in enumerate(dirs): - dn = fsdecode(dn) - if dn.endswith('.dist-info'): - distinfo = os.path.join(root, dn) - del dirs[i] - break - assert distinfo, '.dist-info directory expected, not found' - - for fn in files: - # comment out next suite to leave .pyc files in - if fsdecode(fn).endswith(('.pyc', '.pyo')): - continue - p = os.path.join(root, fn) - rp = to_posix(os.path.relpath(p, path)) - archive_paths.append((rp, p)) - - # Now distinfo. Assumed to be flat, i.e. os.listdir is enough. - files = os.listdir(distinfo) - for fn in files: - if fn not in ('RECORD', 'INSTALLER', 'SHARED', 'WHEEL'): - p = fsdecode(os.path.join(distinfo, fn)) - ap = to_posix(os.path.join(info_dir, fn)) - archive_paths.append((ap, p)) - - wheel_metadata = [ - 'Wheel-Version: %d.%d' % (wheel_version or self.wheel_version), - 'Generator: distlib %s' % __version__, - 'Root-Is-Purelib: %s' % is_pure, - ] - for pyver, abi, arch in self.tags: - wheel_metadata.append('Tag: %s-%s-%s' % (pyver, abi, arch)) - p = os.path.join(distinfo, 'WHEEL') - with open(p, 'w') as f: - f.write('\n'.join(wheel_metadata)) - ap = to_posix(os.path.join(info_dir, 'WHEEL')) - archive_paths.append((ap, p)) - - # sort the entries by archive path. Not needed by any spec, but it - # keeps the archive listing and RECORD tidier than they would otherwise - # be. Use the number of path segments to keep directory entries together, - # and keep the dist-info stuff at the end. - def sorter(t): - ap = t[0] - n = ap.count('/') - if '.dist-info' in ap: - n += 10000 - return (n, ap) - archive_paths = sorted(archive_paths, key=sorter) - - # Now, at last, RECORD. - # Paths in here are archive paths - nothing else makes sense. - self.write_records((distinfo, info_dir), libdir, archive_paths) - # Now, ready to build the zip file - pathname = os.path.join(self.dirname, self.filename) - self.build_zip(pathname, archive_paths) - return pathname - - def skip_entry(self, arcname): - """ - Determine whether an archive entry should be skipped when verifying - or installing. - """ - # The signature file won't be in RECORD, - # and we don't currently don't do anything with it - # We also skip directories, as they won't be in RECORD - # either. See: - # - # https://github.com/pypa/wheel/issues/294 - # https://github.com/pypa/wheel/issues/287 - # https://github.com/pypa/wheel/pull/289 - # - return arcname.endswith(('/', '/RECORD.jws')) - - def install(self, paths, maker, **kwargs): - """ - Install a wheel to the specified paths. If kwarg ``warner`` is - specified, it should be a callable, which will be called with two - tuples indicating the wheel version of this software and the wheel - version in the file, if there is a discrepancy in the versions. - This can be used to issue any warnings to raise any exceptions. - If kwarg ``lib_only`` is True, only the purelib/platlib files are - installed, and the headers, scripts, data and dist-info metadata are - not written. If kwarg ``bytecode_hashed_invalidation`` is True, written - bytecode will try to use file-hash based invalidation (PEP-552) on - supported interpreter versions (CPython 2.7+). - - The return value is a :class:`InstalledDistribution` instance unless - ``options.lib_only`` is True, in which case the return value is ``None``. - """ - - dry_run = maker.dry_run - warner = kwargs.get('warner') - lib_only = kwargs.get('lib_only', False) - bc_hashed_invalidation = kwargs.get('bytecode_hashed_invalidation', False) - - pathname = os.path.join(self.dirname, self.filename) - name_ver = '%s-%s' % (self.name, self.version) - data_dir = '%s.data' % name_ver - info_dir = '%s.dist-info' % name_ver - - metadata_name = posixpath.join(info_dir, LEGACY_METADATA_FILENAME) - wheel_metadata_name = posixpath.join(info_dir, 'WHEEL') - record_name = posixpath.join(info_dir, 'RECORD') - - wrapper = codecs.getreader('utf-8') - - with ZipFile(pathname, 'r') as zf: - with zf.open(wheel_metadata_name) as bwf: - wf = wrapper(bwf) - message = message_from_file(wf) - wv = message['Wheel-Version'].split('.', 1) - file_version = tuple([int(i) for i in wv]) - if (file_version != self.wheel_version) and warner: - warner(self.wheel_version, file_version) - - if message['Root-Is-Purelib'] == 'true': - libdir = paths['purelib'] - else: - libdir = paths['platlib'] - - records = {} - with zf.open(record_name) as bf: - with CSVReader(stream=bf) as reader: - for row in reader: - p = row[0] - records[p] = row - - data_pfx = posixpath.join(data_dir, '') - info_pfx = posixpath.join(info_dir, '') - script_pfx = posixpath.join(data_dir, 'scripts', '') - - # make a new instance rather than a copy of maker's, - # as we mutate it - fileop = FileOperator(dry_run=dry_run) - fileop.record = True # so we can rollback if needed - - bc = not sys.dont_write_bytecode # Double negatives. Lovely! - - outfiles = [] # for RECORD writing - - # for script copying/shebang processing - workdir = tempfile.mkdtemp() - # set target dir later - # we default add_launchers to False, as the - # Python Launcher should be used instead - maker.source_dir = workdir - maker.target_dir = None - try: - for zinfo in zf.infolist(): - arcname = zinfo.filename - if isinstance(arcname, text_type): - u_arcname = arcname - else: - u_arcname = arcname.decode('utf-8') - if self.skip_entry(u_arcname): - continue - row = records[u_arcname] - if row[2] and str(zinfo.file_size) != row[2]: - raise DistlibException('size mismatch for ' - '%s' % u_arcname) - if row[1]: - kind, value = row[1].split('=', 1) - with zf.open(arcname) as bf: - data = bf.read() - _, digest = self.get_hash(data, kind) - if digest != value: - raise DistlibException('digest mismatch for ' - '%s' % arcname) - - if lib_only and u_arcname.startswith((info_pfx, data_pfx)): - logger.debug('lib_only: skipping %s', u_arcname) - continue - is_script = (u_arcname.startswith(script_pfx) - and not u_arcname.endswith('.exe')) - - if u_arcname.startswith(data_pfx): - _, where, rp = u_arcname.split('/', 2) - outfile = os.path.join(paths[where], convert_path(rp)) - else: - # meant for site-packages. - if u_arcname in (wheel_metadata_name, record_name): - continue - outfile = os.path.join(libdir, convert_path(u_arcname)) - if not is_script: - with zf.open(arcname) as bf: - fileop.copy_stream(bf, outfile) - # Issue #147: permission bits aren't preserved. Using - # zf.extract(zinfo, libdir) should have worked, but didn't, - # see https://www.thetopsites.net/article/53834422.shtml - # So ... manually preserve permission bits as given in zinfo - if os.name == 'posix': - # just set the normal permission bits - os.chmod(outfile, (zinfo.external_attr >> 16) & 0x1FF) - outfiles.append(outfile) - # Double check the digest of the written file - if not dry_run and row[1]: - with open(outfile, 'rb') as bf: - data = bf.read() - _, newdigest = self.get_hash(data, kind) - if newdigest != digest: - raise DistlibException('digest mismatch ' - 'on write for ' - '%s' % outfile) - if bc and outfile.endswith('.py'): - try: - pyc = fileop.byte_compile(outfile, - hashed_invalidation=bc_hashed_invalidation) - outfiles.append(pyc) - except Exception: - # Don't give up if byte-compilation fails, - # but log it and perhaps warn the user - logger.warning('Byte-compilation failed', - exc_info=True) - else: - fn = os.path.basename(convert_path(arcname)) - workname = os.path.join(workdir, fn) - with zf.open(arcname) as bf: - fileop.copy_stream(bf, workname) - - dn, fn = os.path.split(outfile) - maker.target_dir = dn - filenames = maker.make(fn) - fileop.set_executable_mode(filenames) - outfiles.extend(filenames) - - if lib_only: - logger.debug('lib_only: returning None') - dist = None - else: - # Generate scripts - - # Try to get pydist.json so we can see if there are - # any commands to generate. If this fails (e.g. because - # of a legacy wheel), log a warning but don't give up. - commands = None - file_version = self.info['Wheel-Version'] - if file_version == '1.0': - # Use legacy info - ep = posixpath.join(info_dir, 'entry_points.txt') - try: - with zf.open(ep) as bwf: - epdata = read_exports(bwf) - commands = {} - for key in ('console', 'gui'): - k = '%s_scripts' % key - if k in epdata: - commands['wrap_%s' % key] = d = {} - for v in epdata[k].values(): - s = '%s:%s' % (v.prefix, v.suffix) - if v.flags: - s += ' [%s]' % ','.join(v.flags) - d[v.name] = s - except Exception: - logger.warning('Unable to read legacy script ' - 'metadata, so cannot generate ' - 'scripts') - else: - try: - with zf.open(metadata_name) as bwf: - wf = wrapper(bwf) - commands = json.load(wf).get('extensions') - if commands: - commands = commands.get('python.commands') - except Exception: - logger.warning('Unable to read JSON metadata, so ' - 'cannot generate scripts') - if commands: - console_scripts = commands.get('wrap_console', {}) - gui_scripts = commands.get('wrap_gui', {}) - if console_scripts or gui_scripts: - script_dir = paths.get('scripts', '') - if not os.path.isdir(script_dir): - raise ValueError('Valid script path not ' - 'specified') - maker.target_dir = script_dir - for k, v in console_scripts.items(): - script = '%s = %s' % (k, v) - filenames = maker.make(script) - fileop.set_executable_mode(filenames) - - if gui_scripts: - options = {'gui': True } - for k, v in gui_scripts.items(): - script = '%s = %s' % (k, v) - filenames = maker.make(script, options) - fileop.set_executable_mode(filenames) - - p = os.path.join(libdir, info_dir) - dist = InstalledDistribution(p) - - # Write SHARED - paths = dict(paths) # don't change passed in dict - del paths['purelib'] - del paths['platlib'] - paths['lib'] = libdir - p = dist.write_shared_locations(paths, dry_run) - if p: - outfiles.append(p) - - # Write RECORD - dist.write_installed_files(outfiles, paths['prefix'], - dry_run) - return dist - except Exception: # pragma: no cover - logger.exception('installation failed.') - fileop.rollback() - raise - finally: - shutil.rmtree(workdir) - - def _get_dylib_cache(self): - global cache - if cache is None: - # Use native string to avoid issues on 2.x: see Python #20140. - base = os.path.join(get_cache_base(), str('dylib-cache'), - '%s.%s' % sys.version_info[:2]) - cache = Cache(base) - return cache - - def _get_extensions(self): - pathname = os.path.join(self.dirname, self.filename) - name_ver = '%s-%s' % (self.name, self.version) - info_dir = '%s.dist-info' % name_ver - arcname = posixpath.join(info_dir, 'EXTENSIONS') - wrapper = codecs.getreader('utf-8') - result = [] - with ZipFile(pathname, 'r') as zf: - try: - with zf.open(arcname) as bf: - wf = wrapper(bf) - extensions = json.load(wf) - cache = self._get_dylib_cache() - prefix = cache.prefix_to_dir(pathname) - cache_base = os.path.join(cache.base, prefix) - if not os.path.isdir(cache_base): - os.makedirs(cache_base) - for name, relpath in extensions.items(): - dest = os.path.join(cache_base, convert_path(relpath)) - if not os.path.exists(dest): - extract = True - else: - file_time = os.stat(dest).st_mtime - file_time = datetime.datetime.fromtimestamp(file_time) - info = zf.getinfo(relpath) - wheel_time = datetime.datetime(*info.date_time) - extract = wheel_time > file_time - if extract: - zf.extract(relpath, cache_base) - result.append((name, dest)) - except KeyError: - pass - return result - - def is_compatible(self): - """ - Determine if a wheel is compatible with the running system. - """ - return is_compatible(self) - - def is_mountable(self): - """ - Determine if a wheel is asserted as mountable by its metadata. - """ - return True # for now - metadata details TBD - - def mount(self, append=False): - pathname = os.path.abspath(os.path.join(self.dirname, self.filename)) - if not self.is_compatible(): - msg = 'Wheel %s not compatible with this Python.' % pathname - raise DistlibException(msg) - if not self.is_mountable(): - msg = 'Wheel %s is marked as not mountable.' % pathname - raise DistlibException(msg) - if pathname in sys.path: - logger.debug('%s already in path', pathname) - else: - if append: - sys.path.append(pathname) - else: - sys.path.insert(0, pathname) - extensions = self._get_extensions() - if extensions: - if _hook not in sys.meta_path: - sys.meta_path.append(_hook) - _hook.add(pathname, extensions) - - def unmount(self): - pathname = os.path.abspath(os.path.join(self.dirname, self.filename)) - if pathname not in sys.path: - logger.debug('%s not in path', pathname) - else: - sys.path.remove(pathname) - if pathname in _hook.impure_wheels: - _hook.remove(pathname) - if not _hook.impure_wheels: - if _hook in sys.meta_path: - sys.meta_path.remove(_hook) - - def verify(self): - pathname = os.path.join(self.dirname, self.filename) - name_ver = '%s-%s' % (self.name, self.version) - data_dir = '%s.data' % name_ver - info_dir = '%s.dist-info' % name_ver - - metadata_name = posixpath.join(info_dir, LEGACY_METADATA_FILENAME) - wheel_metadata_name = posixpath.join(info_dir, 'WHEEL') - record_name = posixpath.join(info_dir, 'RECORD') - - wrapper = codecs.getreader('utf-8') - - with ZipFile(pathname, 'r') as zf: - with zf.open(wheel_metadata_name) as bwf: - wf = wrapper(bwf) - message = message_from_file(wf) - wv = message['Wheel-Version'].split('.', 1) - file_version = tuple([int(i) for i in wv]) - # TODO version verification - - records = {} - with zf.open(record_name) as bf: - with CSVReader(stream=bf) as reader: - for row in reader: - p = row[0] - records[p] = row - - for zinfo in zf.infolist(): - arcname = zinfo.filename - if isinstance(arcname, text_type): - u_arcname = arcname - else: - u_arcname = arcname.decode('utf-8') - # See issue #115: some wheels have .. in their entries, but - # in the filename ... e.g. __main__..py ! So the check is - # updated to look for .. in the directory portions - p = u_arcname.split('/') - if '..' in p: - raise DistlibException('invalid entry in ' - 'wheel: %r' % u_arcname) - - if self.skip_entry(u_arcname): - continue - row = records[u_arcname] - if row[2] and str(zinfo.file_size) != row[2]: - raise DistlibException('size mismatch for ' - '%s' % u_arcname) - if row[1]: - kind, value = row[1].split('=', 1) - with zf.open(arcname) as bf: - data = bf.read() - _, digest = self.get_hash(data, kind) - if digest != value: - raise DistlibException('digest mismatch for ' - '%s' % arcname) - - def update(self, modifier, dest_dir=None, **kwargs): - """ - Update the contents of a wheel in a generic way. The modifier should - be a callable which expects a dictionary argument: its keys are - archive-entry paths, and its values are absolute filesystem paths - where the contents the corresponding archive entries can be found. The - modifier is free to change the contents of the files pointed to, add - new entries and remove entries, before returning. This method will - extract the entire contents of the wheel to a temporary location, call - the modifier, and then use the passed (and possibly updated) - dictionary to write a new wheel. If ``dest_dir`` is specified, the new - wheel is written there -- otherwise, the original wheel is overwritten. - - The modifier should return True if it updated the wheel, else False. - This method returns the same value the modifier returns. - """ - - def get_version(path_map, info_dir): - version = path = None - key = '%s/%s' % (info_dir, LEGACY_METADATA_FILENAME) - if key not in path_map: - key = '%s/PKG-INFO' % info_dir - if key in path_map: - path = path_map[key] - version = Metadata(path=path).version - return version, path - - def update_version(version, path): - updated = None - try: - v = NormalizedVersion(version) - i = version.find('-') - if i < 0: - updated = '%s+1' % version - else: - parts = [int(s) for s in version[i + 1:].split('.')] - parts[-1] += 1 - updated = '%s+%s' % (version[:i], - '.'.join(str(i) for i in parts)) - except UnsupportedVersionError: - logger.debug('Cannot update non-compliant (PEP-440) ' - 'version %r', version) - if updated: - md = Metadata(path=path) - md.version = updated - legacy = path.endswith(LEGACY_METADATA_FILENAME) - md.write(path=path, legacy=legacy) - logger.debug('Version updated from %r to %r', version, - updated) - - pathname = os.path.join(self.dirname, self.filename) - name_ver = '%s-%s' % (self.name, self.version) - info_dir = '%s.dist-info' % name_ver - record_name = posixpath.join(info_dir, 'RECORD') - with tempdir() as workdir: - with ZipFile(pathname, 'r') as zf: - path_map = {} - for zinfo in zf.infolist(): - arcname = zinfo.filename - if isinstance(arcname, text_type): - u_arcname = arcname - else: - u_arcname = arcname.decode('utf-8') - if u_arcname == record_name: - continue - if '..' in u_arcname: - raise DistlibException('invalid entry in ' - 'wheel: %r' % u_arcname) - zf.extract(zinfo, workdir) - path = os.path.join(workdir, convert_path(u_arcname)) - path_map[u_arcname] = path - - # Remember the version. - original_version, _ = get_version(path_map, info_dir) - # Files extracted. Call the modifier. - modified = modifier(path_map, **kwargs) - if modified: - # Something changed - need to build a new wheel. - current_version, path = get_version(path_map, info_dir) - if current_version and (current_version == original_version): - # Add or update local version to signify changes. - update_version(current_version, path) - # Decide where the new wheel goes. - if dest_dir is None: - fd, newpath = tempfile.mkstemp(suffix='.whl', - prefix='wheel-update-', - dir=workdir) - os.close(fd) - else: - if not os.path.isdir(dest_dir): - raise DistlibException('Not a directory: %r' % dest_dir) - newpath = os.path.join(dest_dir, self.filename) - archive_paths = list(path_map.items()) - distinfo = os.path.join(workdir, info_dir) - info = distinfo, info_dir - self.write_records(info, workdir, archive_paths) - self.build_zip(newpath, archive_paths) - if dest_dir is None: - shutil.copyfile(newpath, pathname) - return modified - -def _get_glibc_version(): - import platform - ver = platform.libc_ver() - result = [] - if ver[0] == 'glibc': - for s in ver[1].split('.'): - result.append(int(s) if s.isdigit() else 0) - result = tuple(result) - return result - -def compatible_tags(): - """ - Return (pyver, abi, arch) tuples compatible with this Python. - """ - versions = [VER_SUFFIX] - major = VER_SUFFIX[0] - for minor in range(sys.version_info[1] - 1, - 1, -1): - versions.append(''.join([major, str(minor)])) - - abis = [] - for suffix, _, _ in imp.get_suffixes(): - if suffix.startswith('.abi'): - abis.append(suffix.split('.', 2)[1]) - abis.sort() - if ABI != 'none': - abis.insert(0, ABI) - abis.append('none') - result = [] - - arches = [ARCH] - if sys.platform == 'darwin': - m = re.match(r'(\w+)_(\d+)_(\d+)_(\w+)$', ARCH) - if m: - name, major, minor, arch = m.groups() - minor = int(minor) - matches = [arch] - if arch in ('i386', 'ppc'): - matches.append('fat') - if arch in ('i386', 'ppc', 'x86_64'): - matches.append('fat3') - if arch in ('ppc64', 'x86_64'): - matches.append('fat64') - if arch in ('i386', 'x86_64'): - matches.append('intel') - if arch in ('i386', 'x86_64', 'intel', 'ppc', 'ppc64'): - matches.append('universal') - while minor >= 0: - for match in matches: - s = '%s_%s_%s_%s' % (name, major, minor, match) - if s != ARCH: # already there - arches.append(s) - minor -= 1 - - # Most specific - our Python version, ABI and arch - for abi in abis: - for arch in arches: - result.append((''.join((IMP_PREFIX, versions[0])), abi, arch)) - # manylinux - if abi != 'none' and sys.platform.startswith('linux'): - arch = arch.replace('linux_', '') - parts = _get_glibc_version() - if len(parts) == 2: - if parts >= (2, 5): - result.append((''.join((IMP_PREFIX, versions[0])), abi, - 'manylinux1_%s' % arch)) - if parts >= (2, 12): - result.append((''.join((IMP_PREFIX, versions[0])), abi, - 'manylinux2010_%s' % arch)) - if parts >= (2, 17): - result.append((''.join((IMP_PREFIX, versions[0])), abi, - 'manylinux2014_%s' % arch)) - result.append((''.join((IMP_PREFIX, versions[0])), abi, - 'manylinux_%s_%s_%s' % (parts[0], parts[1], - arch))) - - # where no ABI / arch dependency, but IMP_PREFIX dependency - for i, version in enumerate(versions): - result.append((''.join((IMP_PREFIX, version)), 'none', 'any')) - if i == 0: - result.append((''.join((IMP_PREFIX, version[0])), 'none', 'any')) - - # no IMP_PREFIX, ABI or arch dependency - for i, version in enumerate(versions): - result.append((''.join(('py', version)), 'none', 'any')) - if i == 0: - result.append((''.join(('py', version[0])), 'none', 'any')) - - return set(result) - - -COMPATIBLE_TAGS = compatible_tags() - -del compatible_tags - - -def is_compatible(wheel, tags=None): - if not isinstance(wheel, Wheel): - wheel = Wheel(wheel) # assume it's a filename - result = False - if tags is None: - tags = COMPATIBLE_TAGS - for ver, abi, arch in tags: - if ver in wheel.pyver and abi in wheel.abi and arch in wheel.arch: - result = True - break - return result diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/cmdline.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/cmdline.py deleted file mode 100644 index 908064e2f6344babc013e78abf0527e956475876..0000000000000000000000000000000000000000 --- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/cmdline.py +++ /dev/null @@ -1,663 +0,0 @@ -""" - pygments.cmdline - ~~~~~~~~~~~~~~~~ - - Command line interface. - - :copyright: Copyright 2006-2021 by the Pygments team, see AUTHORS. - :license: BSD, see LICENSE for details. -""" - -import os -import sys -import shutil -import argparse -from textwrap import dedent - -from pip._vendor.pygments import __version__, highlight -from pip._vendor.pygments.util import ClassNotFound, OptionError, docstring_headline, \ - guess_decode, guess_decode_from_terminal, terminal_encoding, \ - UnclosingTextIOWrapper -from pip._vendor.pygments.lexers import get_all_lexers, get_lexer_by_name, guess_lexer, \ - load_lexer_from_file, get_lexer_for_filename, find_lexer_class_for_filename -from pip._vendor.pygments.lexers.special import TextLexer -from pip._vendor.pygments.formatters.latex import LatexEmbeddedLexer, LatexFormatter -from pip._vendor.pygments.formatters import get_all_formatters, get_formatter_by_name, \ - load_formatter_from_file, get_formatter_for_filename, find_formatter_class -from pip._vendor.pygments.formatters.terminal import TerminalFormatter -from pip._vendor.pygments.formatters.terminal256 import Terminal256Formatter -from pip._vendor.pygments.filters import get_all_filters, find_filter_class -from pip._vendor.pygments.styles import get_all_styles, get_style_by_name - - -def _parse_options(o_strs): - opts = {} - if not o_strs: - return opts - for o_str in o_strs: - if not o_str.strip(): - continue - o_args = o_str.split(',') - for o_arg in o_args: - o_arg = o_arg.strip() - try: - o_key, o_val = o_arg.split('=', 1) - o_key = o_key.strip() - o_val = o_val.strip() - except ValueError: - opts[o_arg] = True - else: - opts[o_key] = o_val - return opts - - -def _parse_filters(f_strs): - filters = [] - if not f_strs: - return filters - for f_str in f_strs: - if ':' in f_str: - fname, fopts = f_str.split(':', 1) - filters.append((fname, _parse_options([fopts]))) - else: - filters.append((f_str, {})) - return filters - - -def _print_help(what, name): - try: - if what == 'lexer': - cls = get_lexer_by_name(name) - print("Help on the %s lexer:" % cls.name) - print(dedent(cls.__doc__)) - elif what == 'formatter': - cls = find_formatter_class(name) - print("Help on the %s formatter:" % cls.name) - print(dedent(cls.__doc__)) - elif what == 'filter': - cls = find_filter_class(name) - print("Help on the %s filter:" % name) - print(dedent(cls.__doc__)) - return 0 - except (AttributeError, ValueError): - print("%s not found!" % what, file=sys.stderr) - return 1 - - -def _print_list(what): - if what == 'lexer': - print() - print("Lexers:") - print("~~~~~~~") - - info = [] - for fullname, names, exts, _ in get_all_lexers(): - tup = (', '.join(names)+':', fullname, - exts and '(filenames ' + ', '.join(exts) + ')' or '') - info.append(tup) - info.sort() - for i in info: - print(('* %s\n %s %s') % i) - - elif what == 'formatter': - print() - print("Formatters:") - print("~~~~~~~~~~~") - - info = [] - for cls in get_all_formatters(): - doc = docstring_headline(cls) - tup = (', '.join(cls.aliases) + ':', doc, cls.filenames and - '(filenames ' + ', '.join(cls.filenames) + ')' or '') - info.append(tup) - info.sort() - for i in info: - print(('* %s\n %s %s') % i) - - elif what == 'filter': - print() - print("Filters:") - print("~~~~~~~~") - - for name in get_all_filters(): - cls = find_filter_class(name) - print("* " + name + ':') - print(" %s" % docstring_headline(cls)) - - elif what == 'style': - print() - print("Styles:") - print("~~~~~~~") - - for name in get_all_styles(): - cls = get_style_by_name(name) - print("* " + name + ':') - print(" %s" % docstring_headline(cls)) - - -def _print_list_as_json(requested_items): - import json - result = {} - if 'lexer' in requested_items: - info = {} - for fullname, names, filenames, mimetypes in get_all_lexers(): - info[fullname] = { - 'aliases': names, - 'filenames': filenames, - 'mimetypes': mimetypes - } - result['lexers'] = info - - if 'formatter' in requested_items: - info = {} - for cls in get_all_formatters(): - doc = docstring_headline(cls) - info[cls.name] = { - 'aliases': cls.aliases, - 'filenames': cls.filenames, - 'doc': doc - } - result['formatters'] = info - - if 'filter' in requested_items: - info = {} - for name in get_all_filters(): - cls = find_filter_class(name) - info[name] = { - 'doc': docstring_headline(cls) - } - result['filters'] = info - - if 'style' in requested_items: - info = {} - for name in get_all_styles(): - cls = get_style_by_name(name) - info[name] = { - 'doc': docstring_headline(cls) - } - result['styles'] = info - - json.dump(result, sys.stdout) - -def main_inner(parser, argns): - if argns.help: - parser.print_help() - return 0 - - if argns.V: - print('Pygments version %s, (c) 2006-2021 by Georg Brandl, Matthäus ' - 'Chajdas and contributors.' % __version__) - return 0 - - def is_only_option(opt): - return not any(v for (k, v) in vars(argns).items() if k != opt) - - # handle ``pygmentize -L`` - if argns.L is not None: - arg_set = set() - for k, v in vars(argns).items(): - if v: - arg_set.add(k) - - arg_set.discard('L') - arg_set.discard('json') - - if arg_set: - parser.print_help(sys.stderr) - return 2 - - # print version - if not argns.json: - main(['', '-V']) - allowed_types = {'lexer', 'formatter', 'filter', 'style'} - largs = [arg.rstrip('s') for arg in argns.L] - if any(arg not in allowed_types for arg in largs): - parser.print_help(sys.stderr) - return 0 - if not largs: - largs = allowed_types - if not argns.json: - for arg in largs: - _print_list(arg) - else: - _print_list_as_json(largs) - return 0 - - # handle ``pygmentize -H`` - if argns.H: - if not is_only_option('H'): - parser.print_help(sys.stderr) - return 2 - what, name = argns.H - if what not in ('lexer', 'formatter', 'filter'): - parser.print_help(sys.stderr) - return 2 - return _print_help(what, name) - - # parse -O options - parsed_opts = _parse_options(argns.O or []) - - # parse -P options - for p_opt in argns.P or []: - try: - name, value = p_opt.split('=', 1) - except ValueError: - parsed_opts[p_opt] = True - else: - parsed_opts[name] = value - - # encodings - inencoding = parsed_opts.get('inencoding', parsed_opts.get('encoding')) - outencoding = parsed_opts.get('outencoding', parsed_opts.get('encoding')) - - # handle ``pygmentize -N`` - if argns.N: - lexer = find_lexer_class_for_filename(argns.N) - if lexer is None: - lexer = TextLexer - - print(lexer.aliases[0]) - return 0 - - # handle ``pygmentize -C`` - if argns.C: - inp = sys.stdin.buffer.read() - try: - lexer = guess_lexer(inp, inencoding=inencoding) - except ClassNotFound: - lexer = TextLexer - - print(lexer.aliases[0]) - return 0 - - # handle ``pygmentize -S`` - S_opt = argns.S - a_opt = argns.a - if S_opt is not None: - f_opt = argns.f - if not f_opt: - parser.print_help(sys.stderr) - return 2 - if argns.l or argns.INPUTFILE: - parser.print_help(sys.stderr) - return 2 - - try: - parsed_opts['style'] = S_opt - fmter = get_formatter_by_name(f_opt, **parsed_opts) - except ClassNotFound as err: - print(err, file=sys.stderr) - return 1 - - print(fmter.get_style_defs(a_opt or '')) - return 0 - - # if no -S is given, -a is not allowed - if argns.a is not None: - parser.print_help(sys.stderr) - return 2 - - # parse -F options - F_opts = _parse_filters(argns.F or []) - - # -x: allow custom (eXternal) lexers and formatters - allow_custom_lexer_formatter = bool(argns.x) - - # select lexer - lexer = None - - # given by name? - lexername = argns.l - if lexername: - # custom lexer, located relative to user's cwd - if allow_custom_lexer_formatter and '.py' in lexername: - try: - filename = None - name = None - if ':' in lexername: - filename, name = lexername.rsplit(':', 1) - - if '.py' in name: - # This can happen on Windows: If the lexername is - # C:\lexer.py -- return to normal load path in that case - name = None - - if filename and name: - lexer = load_lexer_from_file(filename, name, - **parsed_opts) - else: - lexer = load_lexer_from_file(lexername, **parsed_opts) - except ClassNotFound as err: - print('Error:', err, file=sys.stderr) - return 1 - else: - try: - lexer = get_lexer_by_name(lexername, **parsed_opts) - except (OptionError, ClassNotFound) as err: - print('Error:', err, file=sys.stderr) - return 1 - - # read input code - code = None - - if argns.INPUTFILE: - if argns.s: - print('Error: -s option not usable when input file specified', - file=sys.stderr) - return 2 - - infn = argns.INPUTFILE - try: - with open(infn, 'rb') as infp: - code = infp.read() - except Exception as err: - print('Error: cannot read infile:', err, file=sys.stderr) - return 1 - if not inencoding: - code, inencoding = guess_decode(code) - - # do we have to guess the lexer? - if not lexer: - try: - lexer = get_lexer_for_filename(infn, code, **parsed_opts) - except ClassNotFound as err: - if argns.g: - try: - lexer = guess_lexer(code, **parsed_opts) - except ClassNotFound: - lexer = TextLexer(**parsed_opts) - else: - print('Error:', err, file=sys.stderr) - return 1 - except OptionError as err: - print('Error:', err, file=sys.stderr) - return 1 - - elif not argns.s: # treat stdin as full file (-s support is later) - # read code from terminal, always in binary mode since we want to - # decode ourselves and be tolerant with it - code = sys.stdin.buffer.read() # use .buffer to get a binary stream - if not inencoding: - code, inencoding = guess_decode_from_terminal(code, sys.stdin) - # else the lexer will do the decoding - if not lexer: - try: - lexer = guess_lexer(code, **parsed_opts) - except ClassNotFound: - lexer = TextLexer(**parsed_opts) - - else: # -s option needs a lexer with -l - if not lexer: - print('Error: when using -s a lexer has to be selected with -l', - file=sys.stderr) - return 2 - - # process filters - for fname, fopts in F_opts: - try: - lexer.add_filter(fname, **fopts) - except ClassNotFound as err: - print('Error:', err, file=sys.stderr) - return 1 - - # select formatter - outfn = argns.o - fmter = argns.f - if fmter: - # custom formatter, located relative to user's cwd - if allow_custom_lexer_formatter and '.py' in fmter: - try: - filename = None - name = None - if ':' in fmter: - # Same logic as above for custom lexer - filename, name = fmter.rsplit(':', 1) - - if '.py' in name: - name = None - - if filename and name: - fmter = load_formatter_from_file(filename, name, - **parsed_opts) - else: - fmter = load_formatter_from_file(fmter, **parsed_opts) - except ClassNotFound as err: - print('Error:', err, file=sys.stderr) - return 1 - else: - try: - fmter = get_formatter_by_name(fmter, **parsed_opts) - except (OptionError, ClassNotFound) as err: - print('Error:', err, file=sys.stderr) - return 1 - - if outfn: - if not fmter: - try: - fmter = get_formatter_for_filename(outfn, **parsed_opts) - except (OptionError, ClassNotFound) as err: - print('Error:', err, file=sys.stderr) - return 1 - try: - outfile = open(outfn, 'wb') - except Exception as err: - print('Error: cannot open outfile:', err, file=sys.stderr) - return 1 - else: - if not fmter: - if '256' in os.environ.get('TERM', ''): - fmter = Terminal256Formatter(**parsed_opts) - else: - fmter = TerminalFormatter(**parsed_opts) - outfile = sys.stdout.buffer - - # determine output encoding if not explicitly selected - if not outencoding: - if outfn: - # output file? use lexer encoding for now (can still be None) - fmter.encoding = inencoding - else: - # else use terminal encoding - fmter.encoding = terminal_encoding(sys.stdout) - - # provide coloring under Windows, if possible - if not outfn and sys.platform in ('win32', 'cygwin') and \ - fmter.name in ('Terminal', 'Terminal256'): # pragma: no cover - # unfortunately colorama doesn't support binary streams on Py3 - outfile = UnclosingTextIOWrapper(outfile, encoding=fmter.encoding) - fmter.encoding = None - try: - import pip._vendor.colorama.initialise as colorama_initialise - except ImportError: - pass - else: - outfile = colorama_initialise.wrap_stream( - outfile, convert=None, strip=None, autoreset=False, wrap=True) - - # When using the LaTeX formatter and the option `escapeinside` is - # specified, we need a special lexer which collects escaped text - # before running the chosen language lexer. - escapeinside = parsed_opts.get('escapeinside', '') - if len(escapeinside) == 2 and isinstance(fmter, LatexFormatter): - left = escapeinside[0] - right = escapeinside[1] - lexer = LatexEmbeddedLexer(left, right, lexer) - - # ... and do it! - if not argns.s: - # process whole input as per normal... - try: - highlight(code, lexer, fmter, outfile) - finally: - if outfn: - outfile.close() - return 0 - else: - # line by line processing of stdin (eg: for 'tail -f')... - try: - while 1: - line = sys.stdin.buffer.readline() - if not line: - break - if not inencoding: - line = guess_decode_from_terminal(line, sys.stdin)[0] - highlight(line, lexer, fmter, outfile) - if hasattr(outfile, 'flush'): - outfile.flush() - return 0 - except KeyboardInterrupt: # pragma: no cover - return 0 - finally: - if outfn: - outfile.close() - - -class HelpFormatter(argparse.HelpFormatter): - def __init__(self, prog, indent_increment=2, max_help_position=16, width=None): - if width is None: - try: - width = shutil.get_terminal_size().columns - 2 - except Exception: - pass - argparse.HelpFormatter.__init__(self, prog, indent_increment, - max_help_position, width) - - -def main(args=sys.argv): - """ - Main command line entry point. - """ - desc = "Highlight an input file and write the result to an output file." - parser = argparse.ArgumentParser(description=desc, add_help=False, - formatter_class=HelpFormatter) - - operation = parser.add_argument_group('Main operation') - lexersel = operation.add_mutually_exclusive_group() - lexersel.add_argument( - '-l', metavar='LEXER', - help='Specify the lexer to use. (Query names with -L.) If not ' - 'given and -g is not present, the lexer is guessed from the filename.') - lexersel.add_argument( - '-g', action='store_true', - help='Guess the lexer from the file contents, or pass through ' - 'as plain text if nothing can be guessed.') - operation.add_argument( - '-F', metavar='FILTER[:options]', action='append', - help='Add a filter to the token stream. (Query names with -L.) ' - 'Filter options are given after a colon if necessary.') - operation.add_argument( - '-f', metavar='FORMATTER', - help='Specify the formatter to use. (Query names with -L.) ' - 'If not given, the formatter is guessed from the output filename, ' - 'and defaults to the terminal formatter if the output is to the ' - 'terminal or an unknown file extension.') - operation.add_argument( - '-O', metavar='OPTION=value[,OPTION=value,...]', action='append', - help='Give options to the lexer and formatter as a comma-separated ' - 'list of key-value pairs. ' - 'Example: `-O bg=light,python=cool`.') - operation.add_argument( - '-P', metavar='OPTION=value', action='append', - help='Give a single option to the lexer and formatter - with this ' - 'you can pass options whose value contains commas and equal signs. ' - 'Example: `-P "heading=Pygments, the Python highlighter"`.') - operation.add_argument( - '-o', metavar='OUTPUTFILE', - help='Where to write the output. Defaults to standard output.') - - operation.add_argument( - 'INPUTFILE', nargs='?', - help='Where to read the input. Defaults to standard input.') - - flags = parser.add_argument_group('Operation flags') - flags.add_argument( - '-v', action='store_true', - help='Print a detailed traceback on unhandled exceptions, which ' - 'is useful for debugging and bug reports.') - flags.add_argument( - '-s', action='store_true', - help='Process lines one at a time until EOF, rather than waiting to ' - 'process the entire file. This only works for stdin, only for lexers ' - 'with no line-spanning constructs, and is intended for streaming ' - 'input such as you get from `tail -f`. ' - 'Example usage: `tail -f sql.log | pygmentize -s -l sql`.') - flags.add_argument( - '-x', action='store_true', - help='Allow custom lexers and formatters to be loaded from a .py file ' - 'relative to the current working directory. For example, ' - '`-l ./customlexer.py -x`. By default, this option expects a file ' - 'with a class named CustomLexer or CustomFormatter; you can also ' - 'specify your own class name with a colon (`-l ./lexer.py:MyLexer`). ' - 'Users should be very careful not to use this option with untrusted ' - 'files, because it will import and run them.') - flags.add_argument('--json', help='Output as JSON. This can ' - 'be only used in conjunction with -L.', - default=False, - action='store_true') - - special_modes_group = parser.add_argument_group( - 'Special modes - do not do any highlighting') - special_modes = special_modes_group.add_mutually_exclusive_group() - special_modes.add_argument( - '-S', metavar='STYLE -f formatter', - help='Print style definitions for STYLE for a formatter ' - 'given with -f. The argument given by -a is formatter ' - 'dependent.') - special_modes.add_argument( - '-L', nargs='*', metavar='WHAT', - help='List lexers, formatters, styles or filters -- ' - 'give additional arguments for the thing(s) you want to list ' - '(e.g. "styles"), or omit them to list everything.') - special_modes.add_argument( - '-N', metavar='FILENAME', - help='Guess and print out a lexer name based solely on the given ' - 'filename. Does not take input or highlight anything. If no specific ' - 'lexer can be determined, "text" is printed.') - special_modes.add_argument( - '-C', action='store_true', - help='Like -N, but print out a lexer name based solely on ' - 'a given content from standard input.') - special_modes.add_argument( - '-H', action='store', nargs=2, metavar=('NAME', 'TYPE'), - help='Print detailed help for the object of type , ' - 'where is one of "lexer", "formatter" or "filter".') - special_modes.add_argument( - '-V', action='store_true', - help='Print the package version.') - special_modes.add_argument( - '-h', '--help', action='store_true', - help='Print this help.') - special_modes_group.add_argument( - '-a', metavar='ARG', - help='Formatter-specific additional argument for the -S (print ' - 'style sheet) mode.') - - argns = parser.parse_args(args[1:]) - - try: - return main_inner(parser, argns) - except Exception: - if argns.v: - print(file=sys.stderr) - print('*' * 65, file=sys.stderr) - print('An unhandled exception occurred while highlighting.', - file=sys.stderr) - print('Please report the whole traceback to the issue tracker at', - file=sys.stderr) - print(' -#include -#include -#include -#include "portaudio.h" -#include "pa_trace.h" - -/****************************************** Definitions ***********/ -#define MODE_INPUT (0) -#define MODE_OUTPUT (1) -#define MAX_TEST_CHANNELS (4) -#define LOWEST_FREQUENCY (300.0) -#define LOWEST_SAMPLE_RATE (8000.0) -#define PHASE_INCREMENT (2.0 * M_PI * LOWEST_FREQUENCY / LOWEST_SAMPLE_RATE) -#define SINE_AMPLITUDE (0.2) - -typedef struct PaQaData -{ - unsigned long framesLeft; - int numChannels; - int bytesPerSample; - int mode; - float phase; - PaSampleFormat format; -} -PaQaData; - -/****************************************** Prototypes ***********/ -static void TestDevices( int mode, int allDevices ); -static void TestFormats( int mode, PaDeviceIndex deviceID, double sampleRate, - int numChannels ); -static int TestAdvance( int mode, PaDeviceIndex deviceID, double sampleRate, - int numChannels, PaSampleFormat format ); -static int QaCallback( const void *inputBuffer, void *outputBuffer, - unsigned long framesPerBuffer, - const PaStreamCallbackTimeInfo* timeInfo, - PaStreamCallbackFlags statusFlags, - void *userData ); - -/****************************************** Globals ***********/ -static int gNumPassed = 0; -static int gNumFailed = 0; - -/****************************************** Macros ***********/ -/* Print ERROR if it fails. Tally success or failure. */ -/* Odd do-while wrapper seems to be needed for some compilers. */ -#define EXPECT(_exp) \ - do \ - { \ - if ((_exp)) {\ - /* printf("SUCCESS for %s\n", #_exp ); */ \ - gNumPassed++; \ - } \ - else { \ - printf("ERROR - 0x%x - %s for %s\n", result, \ - ((result == 0) ? "-" : Pa_GetErrorText(result)), \ - #_exp ); \ - gNumFailed++; \ - goto error; \ - } \ - } while(0) - -static float NextSineSample( PaQaData *data ) -{ - float phase = data->phase + PHASE_INCREMENT; - if( phase > M_PI ) phase -= 2.0 * M_PI; - data->phase = phase; - return sinf(phase) * SINE_AMPLITUDE; -} - -/*******************************************************************/ -/* This routine will be called by the PortAudio engine when audio is needed. -** It may be called at interrupt level on some machines so don't do anything -** that could mess up the system like calling malloc() or free(). -*/ -static int QaCallback( const void *inputBuffer, void *outputBuffer, - unsigned long framesPerBuffer, - const PaStreamCallbackTimeInfo* timeInfo, - PaStreamCallbackFlags statusFlags, - void *userData ) -{ - unsigned long frameIndex; - unsigned long channelIndex; - float sample; - PaQaData *data = (PaQaData *) userData; - (void) inputBuffer; - - /* Play simple sine wave. */ - if( data->mode == MODE_OUTPUT ) - { - switch( data->format ) - { - case paFloat32: - { - float *out = (float *) outputBuffer; - for( frameIndex = 0; frameIndex < framesPerBuffer; frameIndex++ ) - { - sample = NextSineSample( data ); - for( channelIndex = 0; channelIndex < data->numChannels; channelIndex++ ) - { - *out++ = sample; - } - } - } - break; - - case paInt32: - { - int *out = (int *) outputBuffer; - for( frameIndex = 0; frameIndex < framesPerBuffer; frameIndex++ ) - { - sample = NextSineSample( data ); - for( channelIndex = 0; channelIndex < data->numChannels; channelIndex++ ) - { - *out++ = ((int)(sample * 0x00800000)) << 8; - } - } - } - break; - - case paInt16: - { - short *out = (short *) outputBuffer; - for( frameIndex = 0; frameIndex < framesPerBuffer; frameIndex++ ) - { - sample = NextSineSample( data ); - for( channelIndex = 0; channelIndex < data->numChannels; channelIndex++ ) - { - *out++ = (short)(sample * 32767); - } - } - } - break; - - default: - { - unsigned char *out = (unsigned char *) outputBuffer; - unsigned long numBytes = framesPerBuffer * data->numChannels * data->bytesPerSample; - memset(out, 0, numBytes); - } - break; - } - } - /* Are we through yet? */ - if( data->framesLeft > framesPerBuffer ) - { - PaUtil_AddTraceMessage("QaCallback: running. framesLeft", data->framesLeft ); - data->framesLeft -= framesPerBuffer; - return 0; - } - else - { - PaUtil_AddTraceMessage("QaCallback: DONE! framesLeft", data->framesLeft ); - data->framesLeft = 0; - return 1; - } -} - -/*******************************************************************/ -static void usage( const char *name ) -{ - printf("%s [-a]\n", name); - printf(" -a - Test ALL devices, otherwise just the default devices.\n"); - printf(" -i - Test INPUT only.\n"); - printf(" -o - Test OUTPUT only.\n"); - printf(" -? - Help\n"); -} - -/*******************************************************************/ -int main( int argc, char **argv ); -int main( int argc, char **argv ) -{ - int i; - PaError result; - int allDevices = 0; - int testOutput = 1; - int testInput = 1; - char *executableName = argv[0]; - - /* Parse command line parameters. */ - i = 1; - while( i 0) ? 1 : 0; -} - -/******************************************************************* -* Try each output device, through its full range of capabilities. */ -static void TestDevices( int mode, int allDevices ) -{ - int id, jc, i; - int maxChannels; - int isDefault; - const PaDeviceInfo *pdi; - static double standardSampleRates[] = { 8000.0, 9600.0, 11025.0, 12000.0, - 16000.0, 22050.0, 24000.0, - 32000.0, 44100.0, 48000.0, - 88200.0, 96000.0, - -1.0 }; /* Negative terminated list. */ - int numDevices = Pa_GetDeviceCount(); - for( id=0; id must be included in the - context in which this macro is used. -*/ -#define PA_VALIDATE_TYPE_SIZES \ - { \ - assert( "PortAudio: type sizes are not correct in pa_types.h" && sizeof( PaUint16 ) == 2 ); \ - assert( "PortAudio: type sizes are not correct in pa_types.h" && sizeof( PaInt16 ) == 2 ); \ - assert( "PortAudio: type sizes are not correct in pa_types.h" && sizeof( PaUint32 ) == 4 ); \ - assert( "PortAudio: type sizes are not correct in pa_types.h" && sizeof( PaInt32 ) == 4 ); \ - } - - -#endif /* PA_TYPES_H */ diff --git a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/coreaudio/pa_mac_core.c b/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/coreaudio/pa_mac_core.c deleted file mode 100644 index 26b814c67bb4300385426aa3917e001bce59bbed..0000000000000000000000000000000000000000 --- a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/coreaudio/pa_mac_core.c +++ /dev/null @@ -1,2878 +0,0 @@ -/* - * Implementation of the PortAudio API for Apple AUHAL - * - * PortAudio Portable Real-Time Audio Library - * Latest Version at: http://www.portaudio.com - * - * Written by Bjorn Roche of XO Audio LLC, from PA skeleton code. - * Portions copied from code by Dominic Mazzoni (who wrote a HAL implementation) - * - * Dominic's code was based on code by Phil Burk, Darren Gibbs, - * Gord Peters, Stephane Letz, and Greg Pfiel. - * - * The following people also deserve acknowledgements: - * - * Olivier Tristan for feedback and testing - * Glenn Zelniker and Z-Systems engineering for sponsoring the Blocking I/O - * interface. - * - * - * Based on the Open Source API proposed by Ross Bencina - * Copyright (c) 1999-2002 Ross Bencina, Phil Burk - * - * Permission is hereby granted, free of charge, to any person obtaining - * a copy of this software and associated documentation files - * (the "Software"), to deal in the Software without restriction, - * including without limitation the rights to use, copy, modify, merge, - * publish, distribute, sublicense, and/or sell copies of the Software, - * and to permit persons to whom the Software is furnished to do so, - * subject to the following conditions: - * - * The above copyright notice and this permission notice shall be - * included in all copies or substantial portions of the Software. - * - * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, - * EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF - * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. - * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR - * ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF - * CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION - * WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. - */ - -/* - * The text above constitutes the entire PortAudio license; however, - * the PortAudio community also makes the following non-binding requests: - * - * Any person wishing to distribute modifications to the Software is - * requested to send the modifications to the original developer so that - * they can be incorporated into the canonical version. It is also - * requested that these non-binding requests be included along with the - * license above. - */ - -/** - @file pa_mac_core - @ingroup hostapi_src - @author Bjorn Roche - @brief AUHAL implementation of PortAudio -*/ - -/* FIXME: not all error conditions call PaUtil_SetLastHostErrorInfo() - * PaMacCore_SetError() will do this. - */ - -#include "pa_mac_core_internal.h" - -#include /* strlen(), memcmp() etc. */ -#include - -#include "pa_mac_core.h" -#include "pa_mac_core_utilities.h" -#include "pa_mac_core_blocking.h" - -#ifndef MAC_OS_X_VERSION_10_6 -#define MAC_OS_X_VERSION_10_6 1060 -#endif - - -#ifdef __cplusplus -extern "C" -{ -#endif /* __cplusplus */ - -/* This is a reasonable size for a small buffer based on experience. */ -#define PA_MAC_SMALL_BUFFER_SIZE (64) - -/* prototypes for functions declared in this file */ -PaError PaMacCore_Initialize( PaUtilHostApiRepresentation **hostApi, PaHostApiIndex index ); - -/* - * Function declared in pa_mac_core.h. Sets up a PaMacCoreStreamInfoStruct - * with the requested flags and initializes channel map. - */ -void PaMacCore_SetupStreamInfo( PaMacCoreStreamInfo *data, const unsigned long flags ) -{ - bzero( data, sizeof( PaMacCoreStreamInfo ) ); - data->size = sizeof( PaMacCoreStreamInfo ); - data->hostApiType = paCoreAudio; - data->version = 0x01; - data->flags = flags; - data->channelMap = NULL; - data->channelMapSize = 0; -} - -/* - * Function declared in pa_mac_core.h. Adds channel mapping to a PaMacCoreStreamInfoStruct - */ -void PaMacCore_SetupChannelMap( PaMacCoreStreamInfo *data, const SInt32 * const channelMap, const unsigned long channelMapSize ) -{ - data->channelMap = channelMap; - data->channelMapSize = channelMapSize; -} -static char *channelName = NULL; -static int channelNameSize = 0; -static bool ensureChannelNameSize( int size ) -{ - if( size >= channelNameSize ) { - free( channelName ); - channelName = (char *) malloc( ( channelNameSize = size ) + 1 ); - if( !channelName ) { - channelNameSize = 0; - return false; - } - } - return true; -} -/* - * Function declared in pa_mac_core.h. retrieves channel names. - */ -const char *PaMacCore_GetChannelName( int device, int channelIndex, bool input ) -{ - struct PaUtilHostApiRepresentation *hostApi; - PaError err; - OSStatus error; - err = PaUtil_GetHostApiRepresentation( &hostApi, paCoreAudio ); - assert(err == paNoError); - if( err != paNoError ) - return NULL; - PaMacAUHAL *macCoreHostApi = (PaMacAUHAL*)hostApi; - AudioDeviceID hostApiDevice = macCoreHostApi->devIds[device]; - CFStringRef nameRef; - - /* First try with CFString */ - UInt32 size = sizeof(nameRef); - error = PaMacCore_AudioDeviceGetProperty( hostApiDevice, - channelIndex + 1, - input, - kAudioDevicePropertyChannelNameCFString, - &size, - &nameRef ); - if( error ) - { - /* try the C String */ - size = 0; - error = PaMacCore_AudioDeviceGetPropertySize( hostApiDevice, - channelIndex + 1, - input, - kAudioDevicePropertyChannelName, - &size ); - if( !error ) - { - if( !ensureChannelNameSize( size ) ) - return NULL; - - error = PaMacCore_AudioDeviceGetProperty( hostApiDevice, - channelIndex + 1, - input, - kAudioDevicePropertyChannelName, - &size, - channelName ); - - - if( !error ) - return channelName; - } - - /* as a last-ditch effort, we use the device name and append the channel number. */ - nameRef = CFStringCreateWithFormat( NULL, NULL, CFSTR( "%s: %d"), hostApi->deviceInfos[device]->name, channelIndex + 1 ); - - - size = CFStringGetMaximumSizeForEncoding(CFStringGetLength(nameRef), kCFStringEncodingUTF8);; - if( !ensureChannelNameSize( size ) ) - { - CFRelease( nameRef ); - return NULL; - } - CFStringGetCString( nameRef, channelName, size+1, kCFStringEncodingUTF8 ); - CFRelease( nameRef ); - } - else - { - size = CFStringGetMaximumSizeForEncoding(CFStringGetLength(nameRef), kCFStringEncodingUTF8);; - if( !ensureChannelNameSize( size ) ) - { - CFRelease( nameRef ); - return NULL; - } - CFStringGetCString( nameRef, channelName, size+1, kCFStringEncodingUTF8 ); - CFRelease( nameRef ); - } - - return channelName; -} - - -PaError PaMacCore_GetBufferSizeRange( PaDeviceIndex device, - long *minBufferSizeFrames, long *maxBufferSizeFrames ) -{ - PaError result; - PaUtilHostApiRepresentation *hostApi; - - result = PaUtil_GetHostApiRepresentation( &hostApi, paCoreAudio ); - - if( result == paNoError ) - { - PaDeviceIndex hostApiDeviceIndex; - result = PaUtil_DeviceIndexToHostApiDeviceIndex( &hostApiDeviceIndex, device, hostApi ); - if( result == paNoError ) - { - PaMacAUHAL *macCoreHostApi = (PaMacAUHAL*)hostApi; - AudioDeviceID macCoreDeviceId = macCoreHostApi->devIds[hostApiDeviceIndex]; - AudioValueRange audioRange; - UInt32 propSize = sizeof( audioRange ); - - // return the size range for the output scope unless we only have inputs - Boolean isInput = 0; - if( macCoreHostApi->inheritedHostApiRep.deviceInfos[hostApiDeviceIndex]->maxOutputChannels == 0 ) - isInput = 1; - - result = WARNING(PaMacCore_AudioDeviceGetProperty( macCoreDeviceId, 0, isInput, kAudioDevicePropertyBufferFrameSizeRange, &propSize, &audioRange ) ); - - *minBufferSizeFrames = audioRange.mMinimum; - *maxBufferSizeFrames = audioRange.mMaximum; - } - } - - return result; -} - - -AudioDeviceID PaMacCore_GetStreamInputDevice( PaStream* s ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)s; - VVDBUG(("PaMacCore_GetStreamInputHandle()\n")); - - return ( stream->inputDevice ); -} - -AudioDeviceID PaMacCore_GetStreamOutputDevice( PaStream* s ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)s; - VVDBUG(("PaMacCore_GetStreamOutputHandle()\n")); - - return ( stream->outputDevice ); -} - -#ifdef __cplusplus -} -#endif /* __cplusplus */ - -#define RING_BUFFER_ADVANCE_DENOMINATOR (4) - -static void Terminate( struct PaUtilHostApiRepresentation *hostApi ); -static PaError IsFormatSupported( struct PaUtilHostApiRepresentation *hostApi, - const PaStreamParameters *inputParameters, - const PaStreamParameters *outputParameters, - double sampleRate ); -static PaError OpenStream( struct PaUtilHostApiRepresentation *hostApi, - PaStream** s, - const PaStreamParameters *inputParameters, - const PaStreamParameters *outputParameters, - double sampleRate, - unsigned long framesPerBuffer, - PaStreamFlags streamFlags, - PaStreamCallback *streamCallback, - void *userData ); -static PaError CloseStream( PaStream* stream ); -static PaError StartStream( PaStream *stream ); -static PaError StopStream( PaStream *stream ); -static PaError AbortStream( PaStream *stream ); -static PaError IsStreamStopped( PaStream *s ); -static PaError IsStreamActive( PaStream *stream ); -static PaTime GetStreamTime( PaStream *stream ); -static OSStatus AudioIOProc( void *inRefCon, - AudioUnitRenderActionFlags *ioActionFlags, - const AudioTimeStamp *inTimeStamp, - UInt32 inBusNumber, - UInt32 inNumberFrames, - AudioBufferList *ioData ); -static double GetStreamCpuLoad( PaStream* stream ); - -static PaError GetChannelInfo( PaMacAUHAL *auhalHostApi, - PaDeviceInfo *deviceInfo, - AudioDeviceID macCoreDeviceId, - int isInput); - -static PaError OpenAndSetupOneAudioUnit( const PaMacCoreStream *stream, - const PaStreamParameters *inStreamParams, - const PaStreamParameters *outStreamParams, - const UInt32 requestedFramesPerBuffer, - UInt32 *actualInputFramesPerBuffer, - UInt32 *actualOutputFramesPerBuffer, - const PaMacAUHAL *auhalHostApi, - AudioUnit *audioUnit, - AudioConverterRef *srConverter, - AudioDeviceID *audioDevice, - const double sampleRate, - void *refCon ); - -/* for setting errors. */ -#define PA_AUHAL_SET_LAST_HOST_ERROR( errorCode, errorText ) \ - PaUtil_SetLastHostErrorInfo( paCoreAudio, errorCode, errorText ) - -/* - * Callback called when starting or stopping a stream. - */ -static void startStopCallback( - void * inRefCon, - AudioUnit ci, - AudioUnitPropertyID inID, - AudioUnitScope inScope, - AudioUnitElement inElement ) -{ - PaMacCoreStream *stream = (PaMacCoreStream *) inRefCon; - UInt32 isRunning; - UInt32 size = sizeof( isRunning ); - OSStatus err; - err = AudioUnitGetProperty( ci, kAudioOutputUnitProperty_IsRunning, inScope, inElement, &isRunning, &size ); - assert( !err ); - if( err ) - isRunning = false; //it's very unclear what to do in case of error here. There's no real way to notify the user, and crashing seems unreasonable. - if( isRunning ) - return; //We are only interested in when we are stopping - // -- if we are using 2 I/O units, we only need one notification! - if( stream->inputUnit && stream->outputUnit && stream->inputUnit != stream->outputUnit && ci == stream->inputUnit ) - return; - PaStreamFinishedCallback *sfc = stream->streamRepresentation.streamFinishedCallback; - if( stream->state == STOPPING ) - stream->state = STOPPED ; - if( sfc ) - sfc( stream->streamRepresentation.userData ); -} - - -/*currently, this is only used in initialization, but it might be modified - to be used when the list of devices changes.*/ -static PaError gatherDeviceInfo(PaMacAUHAL *auhalHostApi) -{ - UInt32 size; - UInt32 propsize; - VVDBUG(("gatherDeviceInfo()\n")); - /* -- free any previous allocations -- */ - if( auhalHostApi->devIds ) - PaUtil_GroupFreeMemory(auhalHostApi->allocations, auhalHostApi->devIds); - auhalHostApi->devIds = NULL; - - /* -- figure out how many devices there are -- */ - PaMacCore_AudioHardwareGetPropertySize( kAudioHardwarePropertyDevices, - &propsize); - auhalHostApi->devCount = propsize / sizeof( AudioDeviceID ); - - VDBUG( ( "Found %ld device(s).\n", auhalHostApi->devCount ) ); - - /* -- copy the device IDs -- */ - auhalHostApi->devIds = (AudioDeviceID *)PaUtil_GroupAllocateMemory( - auhalHostApi->allocations, - propsize ); - if( !auhalHostApi->devIds ) - return paInsufficientMemory; - PaMacCore_AudioHardwareGetProperty( kAudioHardwarePropertyDevices, - &propsize, - auhalHostApi->devIds ); -#ifdef MAC_CORE_VERBOSE_DEBUG - { - int i; - for( i=0; i devCount; ++i ) - printf( "Device %d\t: %ld\n", i, (long)auhalHostApi->devIds[i] ); - } -#endif - - size = sizeof(AudioDeviceID); - auhalHostApi->defaultIn = kAudioDeviceUnknown; - auhalHostApi->defaultOut = kAudioDeviceUnknown; - - /* determine the default device. */ - /* I am not sure how these calls to AudioHardwareGetProperty() - could fail, but in case they do, we use the first available - device as the default. */ - if( 0 != PaMacCore_AudioHardwareGetProperty(kAudioHardwarePropertyDefaultInputDevice, - &size, - &auhalHostApi->defaultIn) ) { - int i; - auhalHostApi->defaultIn = kAudioDeviceUnknown; - VDBUG(("Failed to get default input device from OS.")); - VDBUG((" I will substitute the first available input Device.")); - for( i=0; i devCount; ++i ) { - PaDeviceInfo devInfo; - if( 0 != GetChannelInfo( auhalHostApi, &devInfo, - auhalHostApi->devIds[i], TRUE ) ) - if( devInfo.maxInputChannels ) { - auhalHostApi->defaultIn = auhalHostApi->devIds[i]; - break; - } - } - } - if( 0 != PaMacCore_AudioHardwareGetProperty(kAudioHardwarePropertyDefaultOutputDevice, - &size, - &auhalHostApi->defaultOut) ) { - int i; - auhalHostApi->defaultIn = kAudioDeviceUnknown; - VDBUG(("Failed to get default output device from OS.")); - VDBUG((" I will substitute the first available output Device.")); - for( i=0; i devCount; ++i ) { - PaDeviceInfo devInfo; - if( 0 != GetChannelInfo( auhalHostApi, &devInfo, - auhalHostApi->devIds[i], FALSE ) ) - if( devInfo.maxOutputChannels ) { - auhalHostApi->defaultOut = auhalHostApi->devIds[i]; - break; - } - } - } - - VDBUG( ( "Default in : %ld\n", (long)auhalHostApi->defaultIn ) ); - VDBUG( ( "Default out: %ld\n", (long)auhalHostApi->defaultOut ) ); - - return paNoError; -} - -/* =================================================================================================== */ -/** - * @internal - * @brief Clip the desired size against the allowed IO buffer size range for the device. - */ -static PaError ClipToDeviceBufferSize( AudioDeviceID macCoreDeviceId, - int isInput, UInt32 desiredSize, UInt32 *allowedSize ) -{ - UInt32 resultSize = desiredSize; - AudioValueRange audioRange; - UInt32 propSize = sizeof( audioRange ); - PaError err = WARNING(PaMacCore_AudioDeviceGetProperty( macCoreDeviceId, 0, isInput, kAudioDevicePropertyBufferFrameSizeRange, &propSize, &audioRange ) ); - resultSize = MAX( resultSize, audioRange.mMinimum ); - resultSize = MIN( resultSize, audioRange.mMaximum ); - *allowedSize = resultSize; - return err; -} - -/* =================================================================================================== */ -#if 0 -static void DumpDeviceProperties( AudioDeviceID macCoreDeviceId, - int isInput ) -{ - PaError err; - int i; - UInt32 propSize; - UInt32 deviceLatency; - UInt32 streamLatency; - UInt32 bufferFrames; - UInt32 safetyOffset; - AudioStreamID streamIDs[128]; - - printf("\n======= latency query : macCoreDeviceId = %d, isInput %d =======\n", (int)macCoreDeviceId, isInput ); - - propSize = sizeof(UInt32); - err = WARNING(AudioDeviceGetProperty(macCoreDeviceId, 0, isInput, kAudioDevicePropertyBufferFrameSize, &propSize, &bufferFrames)); - printf("kAudioDevicePropertyBufferFrameSize: err = %d, propSize = %d, value = %d\n", err, propSize, bufferFrames ); - - propSize = sizeof(UInt32); - err = WARNING(AudioDeviceGetProperty(macCoreDeviceId, 0, isInput, kAudioDevicePropertySafetyOffset, &propSize, &safetyOffset)); - printf("kAudioDevicePropertySafetyOffset: err = %d, propSize = %d, value = %d\n", err, propSize, safetyOffset ); - - propSize = sizeof(UInt32); - err = WARNING(AudioDeviceGetProperty(macCoreDeviceId, 0, isInput, kAudioDevicePropertyLatency, &propSize, &deviceLatency)); - printf("kAudioDevicePropertyLatency: err = %d, propSize = %d, value = %d\n", err, propSize, deviceLatency ); - - AudioValueRange audioRange; - propSize = sizeof( audioRange ); - err = WARNING(AudioDeviceGetProperty( macCoreDeviceId, 0, isInput, kAudioDevicePropertyBufferFrameSizeRange, &propSize, &audioRange ) ); - printf("kAudioDevicePropertyBufferFrameSizeRange: err = %d, propSize = %u, minimum = %g\n", err, propSize, audioRange.mMinimum); - printf("kAudioDevicePropertyBufferFrameSizeRange: err = %d, propSize = %u, maximum = %g\n", err, propSize, audioRange.mMaximum ); - - /* Get the streams from the device and query their latency. */ - propSize = sizeof(streamIDs); - err = WARNING(AudioDeviceGetProperty(macCoreDeviceId, 0, isInput, kAudioDevicePropertyStreams, &propSize, &streamIDs[0])); - int numStreams = propSize / sizeof(AudioStreamID); - for( i=0; i devCount; ++j ) - auhalHostApi->devIds[j] = auhalHostApi->devIds[j+1]; - i--; - } - } - } - - (*hostApi)->Terminate = Terminate; - (*hostApi)->OpenStream = OpenStream; - (*hostApi)->IsFormatSupported = IsFormatSupported; - - PaUtil_InitializeStreamInterface( &auhalHostApi->callbackStreamInterface, - CloseStream, StartStream, - StopStream, AbortStream, IsStreamStopped, - IsStreamActive, - GetStreamTime, GetStreamCpuLoad, - PaUtil_DummyRead, PaUtil_DummyWrite, - PaUtil_DummyGetReadAvailable, - PaUtil_DummyGetWriteAvailable ); - - PaUtil_InitializeStreamInterface( &auhalHostApi->blockingStreamInterface, - CloseStream, StartStream, - StopStream, AbortStream, IsStreamStopped, - IsStreamActive, - GetStreamTime, PaUtil_DummyGetCpuLoad, - ReadStream, WriteStream, - GetStreamReadAvailable, - GetStreamWriteAvailable ); - - return result; - -error: - if( auhalHostApi ) - { - if( auhalHostApi->allocations ) - { - PaUtil_FreeAllAllocations( auhalHostApi->allocations ); - PaUtil_DestroyAllocationGroup( auhalHostApi->allocations ); - } - - PaUtil_FreeMemory( auhalHostApi ); - } - return result; -} - - -static void Terminate( struct PaUtilHostApiRepresentation *hostApi ) -{ - int unixErr; - - PaMacAUHAL *auhalHostApi = (PaMacAUHAL*)hostApi; - - VVDBUG(("Terminate()\n")); - - unixErr = destroyXRunListenerList(); - if( 0 != unixErr ) - UNIX_ERR(unixErr); - - /* - IMPLEMENT ME: - - clean up any resources not handled by the allocation group - TODO: Double check that everything is handled by alloc group - */ - - if( auhalHostApi->allocations ) - { - PaUtil_FreeAllAllocations( auhalHostApi->allocations ); - PaUtil_DestroyAllocationGroup( auhalHostApi->allocations ); - } - - PaUtil_FreeMemory( auhalHostApi ); -} - - -static PaError IsFormatSupported( struct PaUtilHostApiRepresentation *hostApi, - const PaStreamParameters *inputParameters, - const PaStreamParameters *outputParameters, - double sampleRate ) -{ - int inputChannelCount, outputChannelCount; - PaSampleFormat inputSampleFormat, outputSampleFormat; - - VVDBUG(("IsFormatSupported(): in chan=%d, in fmt=%ld, out chan=%d, out fmt=%ld sampleRate=%g\n", - inputParameters ? inputParameters->channelCount : -1, - inputParameters ? inputParameters->sampleFormat : -1, - outputParameters ? outputParameters->channelCount : -1, - outputParameters ? outputParameters->sampleFormat : -1, - (float) sampleRate )); - - /** These first checks are standard PA checks. We do some fancier checks - later. */ - if( inputParameters ) - { - inputChannelCount = inputParameters->channelCount; - inputSampleFormat = inputParameters->sampleFormat; - - /* all standard sample formats are supported by the buffer adapter, - this implementation doesn't support any custom sample formats */ - if( inputSampleFormat & paCustomFormat ) - return paSampleFormatNotSupported; - - /* unless alternate device specification is supported, reject the use of - paUseHostApiSpecificDeviceSpecification */ - - if( inputParameters->device == paUseHostApiSpecificDeviceSpecification ) - return paInvalidDevice; - - /* check that input device can support inputChannelCount */ - if( inputChannelCount > hostApi->deviceInfos[ inputParameters->device ]->maxInputChannels ) - return paInvalidChannelCount; - } - else - { - inputChannelCount = 0; - } - - if( outputParameters ) - { - outputChannelCount = outputParameters->channelCount; - outputSampleFormat = outputParameters->sampleFormat; - - /* all standard sample formats are supported by the buffer adapter, - this implementation doesn't support any custom sample formats */ - if( outputSampleFormat & paCustomFormat ) - return paSampleFormatNotSupported; - - /* unless alternate device specification is supported, reject the use of - paUseHostApiSpecificDeviceSpecification */ - - if( outputParameters->device == paUseHostApiSpecificDeviceSpecification ) - return paInvalidDevice; - - /* check that output device can support outputChannelCount */ - if( outputChannelCount > hostApi->deviceInfos[ outputParameters->device ]->maxOutputChannels ) - return paInvalidChannelCount; - - } - else - { - outputChannelCount = 0; - } - - /* FEEDBACK */ - /* I think the only way to check a given format SR combo is */ - /* to try opening it. This could be disruptive, is that Okay? */ - /* The alternative is to just read off available sample rates, */ - /* but this will not work %100 of the time (eg, a device that */ - /* supports N output at one rate but only N/2 at a higher rate.)*/ - - /* The following code opens the device with the requested parameters to - see if it works. */ - { - PaError err; - PaStream *s; - err = OpenStream( hostApi, &s, inputParameters, outputParameters, - sampleRate, 1024, 0, (PaStreamCallback *)1, NULL ); - if( err != paNoError && err != paInvalidSampleRate ) - DBUG( ( "OpenStream @ %g returned: %d: %s\n", - (float) sampleRate, err, Pa_GetErrorText( err ) ) ); - if( err ) - return err; - err = CloseStream( s ); - if( err ) { - /* FEEDBACK: is this more serious? should we assert? */ - DBUG( ( "WARNING: could not close Stream. %d: %s\n", - err, Pa_GetErrorText( err ) ) ); - } - } - - return paFormatIsSupported; -} - -/* ================================================================================= */ -static void InitializeDeviceProperties( PaMacCoreDeviceProperties *deviceProperties ) -{ - memset( deviceProperties, 0, sizeof(PaMacCoreDeviceProperties) ); - deviceProperties->sampleRate = 1.0; // Better than random. Overwritten by actual values later on. - deviceProperties->samplePeriod = 1.0 / deviceProperties->sampleRate; -} - -static Float64 CalculateSoftwareLatencyFromProperties( PaMacCoreStream *stream, PaMacCoreDeviceProperties *deviceProperties ) -{ - UInt32 latencyFrames = deviceProperties->bufferFrameSize + deviceProperties->deviceLatency + deviceProperties->safetyOffset; - return latencyFrames * deviceProperties->samplePeriod; // same as dividing by sampleRate but faster -} - -static Float64 CalculateHardwareLatencyFromProperties( PaMacCoreStream *stream, PaMacCoreDeviceProperties *deviceProperties ) -{ - return deviceProperties->deviceLatency * deviceProperties->samplePeriod; // same as dividing by sampleRate but faster -} - -/* Calculate values used to convert Apple timestamps into PA timestamps - * from the device properties. The final results of this calculation - * will be used in the audio callback function. - */ -static void UpdateTimeStampOffsets( PaMacCoreStream *stream ) -{ - Float64 inputSoftwareLatency = 0.0; - Float64 inputHardwareLatency = 0.0; - Float64 outputSoftwareLatency = 0.0; - Float64 outputHardwareLatency = 0.0; - - if( stream->inputUnit != NULL ) - { - inputSoftwareLatency = CalculateSoftwareLatencyFromProperties( stream, &stream->inputProperties ); - inputHardwareLatency = CalculateHardwareLatencyFromProperties( stream, &stream->inputProperties ); - } - if( stream->outputUnit != NULL ) - { - outputSoftwareLatency = CalculateSoftwareLatencyFromProperties( stream, &stream->outputProperties ); - outputHardwareLatency = CalculateHardwareLatencyFromProperties( stream, &stream->outputProperties ); - } - - /* We only need a mutex around setting these variables as a group. */ - pthread_mutex_lock( &stream->timingInformationMutex ); - stream->timestampOffsetCombined = inputSoftwareLatency + outputSoftwareLatency; - stream->timestampOffsetInputDevice = inputHardwareLatency; - stream->timestampOffsetOutputDevice = outputHardwareLatency; - pthread_mutex_unlock( &stream->timingInformationMutex ); -} - -/* ================================================================================= */ - -/* can be used to update from nominal or actual sample rate */ -static OSStatus UpdateSampleRateFromDeviceProperty( PaMacCoreStream *stream, AudioDeviceID deviceID, - Boolean isInput, AudioDevicePropertyID sampleRatePropertyID ) -{ - PaMacCoreDeviceProperties * deviceProperties = isInput ? &stream->inputProperties : &stream->outputProperties; - - Float64 sampleRate = 0.0; - UInt32 propSize = sizeof(Float64); - OSStatus osErr = PaMacCore_AudioDeviceGetProperty( deviceID, 0, isInput, sampleRatePropertyID, &propSize, &sampleRate); - if( (osErr == noErr) && (sampleRate > 1000.0) ) /* avoid divide by zero if there's an error */ - { - deviceProperties->sampleRate = sampleRate; - deviceProperties->samplePeriod = 1.0 / sampleRate; - } - return osErr; -} - -static OSStatus AudioDevicePropertyActualSampleRateListenerProc( AudioObjectID inDevice, UInt32 inNumberAddresses, - const AudioObjectPropertyAddress * inAddresses, void * inClientData ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)inClientData; - bool isInput = inAddresses->mScope == kAudioDevicePropertyScopeInput; - - // Make sure the callback is operating on a stream that is still valid! - assert( stream->streamRepresentation.magic == PA_STREAM_MAGIC ); - - OSStatus osErr = UpdateSampleRateFromDeviceProperty( stream, inDevice, isInput, kAudioDevicePropertyActualSampleRate ); - if( osErr == noErr ) - { - UpdateTimeStampOffsets( stream ); - } - return osErr; -} - -/* ================================================================================= */ -static OSStatus QueryUInt32DeviceProperty( AudioDeviceID deviceID, Boolean isInput, AudioDevicePropertyID propertyID, UInt32 *outValue ) -{ - UInt32 propertyValue = 0; - UInt32 propertySize = sizeof(UInt32); - OSStatus osErr = PaMacCore_AudioDeviceGetProperty( deviceID, 0, isInput, propertyID, &propertySize, &propertyValue); - if( osErr == noErr ) - { - *outValue = propertyValue; - } - return osErr; -} - -static OSStatus AudioDevicePropertyGenericListenerProc( AudioObjectID inDevice, UInt32 inNumberAddresses, - const AudioObjectPropertyAddress * inAddresses, void * inClientData ) -{ - OSStatus osErr = noErr; - PaMacCoreStream *stream = (PaMacCoreStream*)inClientData; - bool isInput = inAddresses->mScope == kAudioDevicePropertyScopeInput; - AudioDevicePropertyID inPropertyID = inAddresses->mSelector; - - // Make sure the callback is operating on a stream that is still valid! - assert( stream->streamRepresentation.magic == PA_STREAM_MAGIC ); - - PaMacCoreDeviceProperties *deviceProperties = isInput ? &stream->inputProperties : &stream->outputProperties; - UInt32 *valuePtr = NULL; - switch( inPropertyID ) - { - case kAudioDevicePropertySafetyOffset: - valuePtr = &deviceProperties->safetyOffset; - break; - - case kAudioDevicePropertyLatency: - valuePtr = &deviceProperties->deviceLatency; - break; - - case kAudioDevicePropertyBufferFrameSize: - valuePtr = &deviceProperties->bufferFrameSize; - break; - } - if( valuePtr != NULL ) - { - osErr = QueryUInt32DeviceProperty( inDevice, isInput, inPropertyID, valuePtr ); - if( osErr == noErr ) - { - UpdateTimeStampOffsets( stream ); - } - } - return osErr; -} - -/* ================================================================================= */ -/* - * Setup listeners in case device properties change during the run. */ -static OSStatus SetupDevicePropertyListeners( PaMacCoreStream *stream, AudioDeviceID deviceID, Boolean isInput ) -{ - OSStatus osErr = noErr; - PaMacCoreDeviceProperties *deviceProperties = isInput ? &stream->inputProperties : &stream->outputProperties; - - if( (osErr = QueryUInt32DeviceProperty( deviceID, isInput, - kAudioDevicePropertyLatency, &deviceProperties->deviceLatency )) != noErr ) return osErr; - if( (osErr = QueryUInt32DeviceProperty( deviceID, isInput, - kAudioDevicePropertyBufferFrameSize, &deviceProperties->bufferFrameSize )) != noErr ) return osErr; - if( (osErr = QueryUInt32DeviceProperty( deviceID, isInput, - kAudioDevicePropertySafetyOffset, &deviceProperties->safetyOffset )) != noErr ) return osErr; - - PaMacCore_AudioDeviceAddPropertyListener( deviceID, 0, isInput, kAudioDevicePropertyActualSampleRate, - AudioDevicePropertyActualSampleRateListenerProc, stream ); - - PaMacCore_AudioDeviceAddPropertyListener( deviceID, 0, isInput, kAudioStreamPropertyLatency, - AudioDevicePropertyGenericListenerProc, stream ); - PaMacCore_AudioDeviceAddPropertyListener( deviceID, 0, isInput, kAudioDevicePropertyBufferFrameSize, - AudioDevicePropertyGenericListenerProc, stream ); - PaMacCore_AudioDeviceAddPropertyListener( deviceID, 0, isInput, kAudioDevicePropertySafetyOffset, - AudioDevicePropertyGenericListenerProc, stream ); - - return osErr; -} - -static void CleanupDevicePropertyListeners( PaMacCoreStream *stream, AudioDeviceID deviceID, Boolean isInput ) -{ - PaMacCore_AudioDeviceRemovePropertyListener( deviceID, 0, isInput, kAudioDevicePropertyActualSampleRate, - AudioDevicePropertyActualSampleRateListenerProc, stream ); - - PaMacCore_AudioDeviceRemovePropertyListener( deviceID, 0, isInput, kAudioDevicePropertyLatency, - AudioDevicePropertyGenericListenerProc, stream ); - PaMacCore_AudioDeviceRemovePropertyListener( deviceID, 0, isInput, kAudioDevicePropertyBufferFrameSize, - AudioDevicePropertyGenericListenerProc, stream ); - PaMacCore_AudioDeviceRemovePropertyListener( deviceID, 0, isInput, kAudioDevicePropertySafetyOffset, - AudioDevicePropertyGenericListenerProc, stream ); -} - -/* ================================================================================= */ -static PaError OpenAndSetupOneAudioUnit( - const PaMacCoreStream *stream, - const PaStreamParameters *inStreamParams, - const PaStreamParameters *outStreamParams, - const UInt32 requestedFramesPerBuffer, - UInt32 *actualInputFramesPerBuffer, - UInt32 *actualOutputFramesPerBuffer, - const PaMacAUHAL *auhalHostApi, - AudioUnit *audioUnit, - AudioConverterRef *srConverter, - AudioDeviceID *audioDevice, - const double sampleRate, - void *refCon ) -{ -#if MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_6 - AudioComponentDescription desc; - AudioComponent comp; -#else - ComponentDescription desc; - Component comp; -#endif - /*An Apple TN suggests using CAStreamBasicDescription, but that is C++*/ - AudioStreamBasicDescription desiredFormat; - OSStatus result = noErr; - PaError paResult = paNoError; - int line = 0; - UInt32 callbackKey; - AURenderCallbackStruct rcbs; - unsigned long macInputStreamFlags = paMacCorePlayNice; - unsigned long macOutputStreamFlags = paMacCorePlayNice; - SInt32 const *inChannelMap = NULL; - SInt32 const *outChannelMap = NULL; - unsigned long inChannelMapSize = 0; - unsigned long outChannelMapSize = 0; - - VVDBUG(("OpenAndSetupOneAudioUnit(): in chan=%d, in fmt=%ld, out chan=%d, out fmt=%ld, requestedFramesPerBuffer=%ld\n", - inStreamParams ? inStreamParams->channelCount : -1, - inStreamParams ? inStreamParams->sampleFormat : -1, - outStreamParams ? outStreamParams->channelCount : -1, - outStreamParams ? outStreamParams->sampleFormat : -1, - requestedFramesPerBuffer )); - - /* -- handle the degenerate case -- */ - if( !inStreamParams && !outStreamParams ) { - *audioUnit = NULL; - *audioDevice = kAudioDeviceUnknown; - return paNoError; - } - - /* -- get the user's api specific info, if they set any -- */ - if( inStreamParams && inStreamParams->hostApiSpecificStreamInfo ) - { - macInputStreamFlags= - ((PaMacCoreStreamInfo*)inStreamParams->hostApiSpecificStreamInfo) - ->flags; - inChannelMap = ((PaMacCoreStreamInfo*)inStreamParams->hostApiSpecificStreamInfo)->channelMap; - inChannelMapSize = ((PaMacCoreStreamInfo*)inStreamParams->hostApiSpecificStreamInfo)->channelMapSize; - } - if( outStreamParams && outStreamParams->hostApiSpecificStreamInfo ) - { - macOutputStreamFlags= - ((PaMacCoreStreamInfo*)outStreamParams->hostApiSpecificStreamInfo) - ->flags; - outChannelMap = ((PaMacCoreStreamInfo*)outStreamParams->hostApiSpecificStreamInfo)->channelMap; - outChannelMapSize = ((PaMacCoreStreamInfo*)outStreamParams->hostApiSpecificStreamInfo)->channelMapSize; - } - /* Override user's flags here, if desired for testing. */ - - /* - * The HAL AU is a Mac OS style "component". - * the first few steps deal with that. - * Later steps work on a combination of Mac OS - * components and the slightly lower level - * HAL. - */ - - /* -- describe the output type AudioUnit -- */ - /* Note: for the default AudioUnit, we could use the - * componentSubType value kAudioUnitSubType_DefaultOutput; - * but I don't think that's relevant here. - */ - desc.componentType = kAudioUnitType_Output; - desc.componentSubType = kAudioUnitSubType_HALOutput; - desc.componentManufacturer = kAudioUnitManufacturer_Apple; - desc.componentFlags = 0; - desc.componentFlagsMask = 0; - /* -- find the component -- */ -#if MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_6 - comp = AudioComponentFindNext( NULL, &desc ); -#else - comp = FindNextComponent( NULL, &desc ); -#endif - if( !comp ) - { - DBUG( ( "AUHAL component not found." ) ); - *audioUnit = NULL; - *audioDevice = kAudioDeviceUnknown; - return paUnanticipatedHostError; - } - /* -- open it -- */ -#if MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_6 - result = AudioComponentInstanceNew( comp, audioUnit ); -#else - result = OpenAComponent( comp, audioUnit ); -#endif - if( result ) - { - DBUG( ( "Failed to open AUHAL component." ) ); - *audioUnit = NULL; - *audioDevice = kAudioDeviceUnknown; - return ERR( result ); - } - /* -- prepare a little error handling logic / hackery -- */ -#define ERR_WRAP(mac_err) do { result = mac_err ; line = __LINE__ ; if ( result != noErr ) goto error ; } while(0) - - /* -- if there is input, we have to explicitly enable input -- */ - if( inStreamParams ) - { - UInt32 enableIO = 1; - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioOutputUnitProperty_EnableIO, - kAudioUnitScope_Input, - INPUT_ELEMENT, - &enableIO, - sizeof(enableIO) ) ); - } - /* -- if there is no output, we must explicitly disable output -- */ - if( !outStreamParams ) - { - UInt32 enableIO = 0; - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioOutputUnitProperty_EnableIO, - kAudioUnitScope_Output, - OUTPUT_ELEMENT, - &enableIO, - sizeof(enableIO) ) ); - } - - /* -- set the devices -- */ - /* make sure input and output are the same device if we are doing input and - output. */ - if( inStreamParams && outStreamParams ) - { - assert( outStreamParams->device == inStreamParams->device ); - } - if( inStreamParams ) - { - *audioDevice = auhalHostApi->devIds[inStreamParams->device] ; - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioOutputUnitProperty_CurrentDevice, - kAudioUnitScope_Global, - INPUT_ELEMENT, - audioDevice, - sizeof(AudioDeviceID) ) ); - } - if( outStreamParams && outStreamParams != inStreamParams ) - { - *audioDevice = auhalHostApi->devIds[outStreamParams->device] ; - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioOutputUnitProperty_CurrentDevice, - kAudioUnitScope_Global, - OUTPUT_ELEMENT, - audioDevice, - sizeof(AudioDeviceID) ) ); - } - /* -- add listener for dropouts -- */ - result = PaMacCore_AudioDeviceAddPropertyListener( *audioDevice, - 0, - outStreamParams ? false : true, - kAudioDeviceProcessorOverload, - xrunCallback, - addToXRunListenerList( (void *)stream ) ) ; - if( result == kAudioHardwareIllegalOperationError ) { - // -- already registered, we're good - } else { - // -- not already registered, just check for errors - ERR_WRAP( result ); - } - /* -- listen for stream start and stop -- */ - ERR_WRAP( AudioUnitAddPropertyListener( *audioUnit, - kAudioOutputUnitProperty_IsRunning, - startStopCallback, - (void *)stream ) ); - - /* -- set format -- */ - bzero( &desiredFormat, sizeof(desiredFormat) ); - desiredFormat.mFormatID = kAudioFormatLinearPCM ; - desiredFormat.mFormatFlags = kAudioFormatFlagsNativeFloatPacked; - desiredFormat.mFramesPerPacket = 1; - desiredFormat.mBitsPerChannel = sizeof( float ) * 8; - - result = 0; - /* set device format first, but only touch the device if the user asked */ - if( inStreamParams ) { - /*The callback never calls back if we don't set the FPB */ - /*This seems weird, because I would think setting anything on the device - would be disruptive.*/ - paResult = setBestFramesPerBuffer( *audioDevice, FALSE, - requestedFramesPerBuffer, - actualInputFramesPerBuffer ); - if( paResult ) goto error; - if( macInputStreamFlags & paMacCoreChangeDeviceParameters ) { - bool requireExact; - requireExact=macInputStreamFlags & paMacCoreFailIfConversionRequired; - paResult = setBestSampleRateForDevice( *audioDevice, FALSE, - requireExact, sampleRate ); - if( paResult ) goto error; - } - if( actualInputFramesPerBuffer && actualOutputFramesPerBuffer ) - *actualOutputFramesPerBuffer = *actualInputFramesPerBuffer ; - } - if( outStreamParams && !inStreamParams ) { - /*The callback never calls back if we don't set the FPB */ - /*This seems weird, because I would think setting anything on the device - would be disruptive.*/ - paResult = setBestFramesPerBuffer( *audioDevice, TRUE, - requestedFramesPerBuffer, - actualOutputFramesPerBuffer ); - if( paResult ) goto error; - if( macOutputStreamFlags & paMacCoreChangeDeviceParameters ) { - bool requireExact; - requireExact=macOutputStreamFlags & paMacCoreFailIfConversionRequired; - paResult = setBestSampleRateForDevice( *audioDevice, TRUE, - requireExact, sampleRate ); - if( paResult ) goto error; - } - } - - /* -- set the quality of the output converter -- */ - if( outStreamParams ) { - UInt32 value = kAudioConverterQuality_Max; - switch( macOutputStreamFlags & 0x0700 ) { - case 0x0100: /*paMacCore_ConversionQualityMin:*/ - value=kRenderQuality_Min; - break; - case 0x0200: /*paMacCore_ConversionQualityLow:*/ - value=kRenderQuality_Low; - break; - case 0x0300: /*paMacCore_ConversionQualityMedium:*/ - value=kRenderQuality_Medium; - break; - case 0x0400: /*paMacCore_ConversionQualityHigh:*/ - value=kRenderQuality_High; - break; - } - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioUnitProperty_RenderQuality, - kAudioUnitScope_Global, - OUTPUT_ELEMENT, - &value, - sizeof(value) ) ); - } - /* now set the format on the Audio Units. */ - if( outStreamParams ) - { - desiredFormat.mSampleRate =sampleRate; - desiredFormat.mBytesPerPacket=sizeof(float)*outStreamParams->channelCount; - desiredFormat.mBytesPerFrame =sizeof(float)*outStreamParams->channelCount; - desiredFormat.mChannelsPerFrame = outStreamParams->channelCount; - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioUnitProperty_StreamFormat, - kAudioUnitScope_Input, - OUTPUT_ELEMENT, - &desiredFormat, - sizeof(AudioStreamBasicDescription) ) ); - } - if( inStreamParams ) - { - AudioStreamBasicDescription sourceFormat; - UInt32 size = sizeof( AudioStreamBasicDescription ); - - /* keep the sample rate of the device, or we confuse AUHAL */ - ERR_WRAP( AudioUnitGetProperty( *audioUnit, - kAudioUnitProperty_StreamFormat, - kAudioUnitScope_Input, - INPUT_ELEMENT, - &sourceFormat, - &size ) ); - desiredFormat.mSampleRate = sourceFormat.mSampleRate; - desiredFormat.mBytesPerPacket=sizeof(float)*inStreamParams->channelCount; - desiredFormat.mBytesPerFrame =sizeof(float)*inStreamParams->channelCount; - desiredFormat.mChannelsPerFrame = inStreamParams->channelCount; - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioUnitProperty_StreamFormat, - kAudioUnitScope_Output, - INPUT_ELEMENT, - &desiredFormat, - sizeof(AudioStreamBasicDescription) ) ); - } - /* set the maximumFramesPerSlice */ - /* not doing this causes real problems - (eg. the callback might not be called). The idea of setting both this - and the frames per buffer on the device is that we'll be most likely - to actually get the frame size we requested in the callback with the - minimum latency. */ - if( outStreamParams ) { - UInt32 size = sizeof( *actualOutputFramesPerBuffer ); - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioUnitProperty_MaximumFramesPerSlice, - kAudioUnitScope_Input, - OUTPUT_ELEMENT, - actualOutputFramesPerBuffer, - sizeof(*actualOutputFramesPerBuffer) ) ); - ERR_WRAP( AudioUnitGetProperty( *audioUnit, - kAudioUnitProperty_MaximumFramesPerSlice, - kAudioUnitScope_Global, - OUTPUT_ELEMENT, - actualOutputFramesPerBuffer, - &size ) ); - } - if( inStreamParams ) { - /*UInt32 size = sizeof( *actualInputFramesPerBuffer );*/ - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioUnitProperty_MaximumFramesPerSlice, - kAudioUnitScope_Output, - INPUT_ELEMENT, - actualInputFramesPerBuffer, - sizeof(*actualInputFramesPerBuffer) ) ); - /* Don't know why this causes problems - ERR_WRAP( AudioUnitGetProperty( *audioUnit, - kAudioUnitProperty_MaximumFramesPerSlice, - kAudioUnitScope_Global, //Output, - INPUT_ELEMENT, - actualInputFramesPerBuffer, - &size ) ); - */ - } - - /* -- if we have input, we may need to setup an SR converter -- */ - /* even if we got the sample rate we asked for, we need to do - the conversion in case another program changes the underlying SR. */ - /* FIXME: I think we need to monitor stream and change the converter if the incoming format changes. */ - if( inStreamParams ) { - AudioStreamBasicDescription desiredFormat; - AudioStreamBasicDescription sourceFormat; - UInt32 sourceSize = sizeof( sourceFormat ); - bzero( &desiredFormat, sizeof(desiredFormat) ); - desiredFormat.mSampleRate = sampleRate; - desiredFormat.mFormatID = kAudioFormatLinearPCM ; - desiredFormat.mFormatFlags = kAudioFormatFlagsNativeFloatPacked; - desiredFormat.mFramesPerPacket = 1; - desiredFormat.mBitsPerChannel = sizeof( float ) * 8; - desiredFormat.mBytesPerPacket=sizeof(float)*inStreamParams->channelCount; - desiredFormat.mBytesPerFrame =sizeof(float)*inStreamParams->channelCount; - desiredFormat.mChannelsPerFrame = inStreamParams->channelCount; - - /* get the source format */ - ERR_WRAP( AudioUnitGetProperty( *audioUnit, - kAudioUnitProperty_StreamFormat, - kAudioUnitScope_Output, - INPUT_ELEMENT, - &sourceFormat, - &sourceSize ) ); - - if( desiredFormat.mSampleRate != sourceFormat.mSampleRate ) - { - UInt32 value = kAudioConverterQuality_Max; - switch( macInputStreamFlags & 0x0700 ) { - case 0x0100: /*paMacCore_ConversionQualityMin:*/ - value=kAudioConverterQuality_Min; - break; - case 0x0200: /*paMacCore_ConversionQualityLow:*/ - value=kAudioConverterQuality_Low; - break; - case 0x0300: /*paMacCore_ConversionQualityMedium:*/ - value=kAudioConverterQuality_Medium; - break; - case 0x0400: /*paMacCore_ConversionQualityHigh:*/ - value=kAudioConverterQuality_High; - break; - } - VDBUG(( "Creating sample rate converter for input" - " to convert from %g to %g\n", - (float)sourceFormat.mSampleRate, - (float)desiredFormat.mSampleRate ) ); - /* create our converter */ - ERR_WRAP( AudioConverterNew( &sourceFormat, - &desiredFormat, - srConverter ) ); - /* Set quality */ - ERR_WRAP( AudioConverterSetProperty( *srConverter, - kAudioConverterSampleRateConverterQuality, - sizeof( value ), - &value ) ); - } - } - /* -- set IOProc (callback) -- */ - callbackKey = outStreamParams ? kAudioUnitProperty_SetRenderCallback - : kAudioOutputUnitProperty_SetInputCallback ; - rcbs.inputProc = AudioIOProc; - rcbs.inputProcRefCon = refCon; - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - callbackKey, - kAudioUnitScope_Output, - outStreamParams ? OUTPUT_ELEMENT : INPUT_ELEMENT, - &rcbs, - sizeof(rcbs)) ); - - if( inStreamParams && outStreamParams && *srConverter ) - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioOutputUnitProperty_SetInputCallback, - kAudioUnitScope_Output, - INPUT_ELEMENT, - &rcbs, - sizeof(rcbs)) ); - - /* channel mapping. */ - if(inChannelMap) - { - UInt32 mapSize = inChannelMapSize *sizeof(SInt32); - - //for each channel of desired input, map the channel from - //the device's output channel. - ERR_WRAP( AudioUnitSetProperty( *audioUnit, - kAudioOutputUnitProperty_ChannelMap, - kAudioUnitScope_Output, - INPUT_ELEMENT, - inChannelMap, - mapSize) ); - } - if(outChannelMap) - { - UInt32 mapSize = outChannelMapSize *sizeof(SInt32); - - //for each channel of desired output, map the channel from - //the device's output channel. - ERR_WRAP(AudioUnitSetProperty( *audioUnit, - kAudioOutputUnitProperty_ChannelMap, - kAudioUnitScope_Output, - OUTPUT_ELEMENT, - outChannelMap, - mapSize) ); - } - /* initialize the audio unit */ - ERR_WRAP( AudioUnitInitialize(*audioUnit) ); - - if( inStreamParams && outStreamParams ) - { - VDBUG( ("Opened device %ld for input and output.\n", (long)*audioDevice ) ); - } - else if( inStreamParams ) - { - VDBUG( ("Opened device %ld for input.\n", (long)*audioDevice ) ); - } - else if( outStreamParams ) - { - VDBUG( ("Opened device %ld for output.\n", (long)*audioDevice ) ); - } - return paNoError; -#undef ERR_WRAP - -error: - -#if MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_6 - AudioComponentInstanceDispose( *audioUnit ); -#else - CloseComponent( *audioUnit ); -#endif - *audioUnit = NULL; - if( result ) - return PaMacCore_SetError( result, line, 1 ); - return paResult; -} - -/* =================================================================================================== */ - -static UInt32 CalculateOptimalBufferSize( PaMacAUHAL *auhalHostApi, - const PaStreamParameters *inputParameters, - const PaStreamParameters *outputParameters, - UInt32 fixedInputLatency, - UInt32 fixedOutputLatency, - double sampleRate, - UInt32 requestedFramesPerBuffer ) -{ - UInt32 resultBufferSizeFrames = 0; - // Use maximum of suggested input and output latencies. - if( inputParameters ) - { - UInt32 suggestedLatencyFrames = inputParameters->suggestedLatency * sampleRate; - // Calculate a buffer size assuming we are double buffered. - SInt32 variableLatencyFrames = suggestedLatencyFrames - fixedInputLatency; - // Prevent negative latency. - variableLatencyFrames = MAX( variableLatencyFrames, 0 ); - resultBufferSizeFrames = MAX( resultBufferSizeFrames, (UInt32) variableLatencyFrames ); - } - if( outputParameters ) - { - UInt32 suggestedLatencyFrames = outputParameters->suggestedLatency * sampleRate; - SInt32 variableLatencyFrames = suggestedLatencyFrames - fixedOutputLatency; - variableLatencyFrames = MAX( variableLatencyFrames, 0 ); - resultBufferSizeFrames = MAX( resultBufferSizeFrames, (UInt32) variableLatencyFrames ); - } - - // can't have zero frames. code to round up to next user buffer requires non-zero - resultBufferSizeFrames = MAX( resultBufferSizeFrames, 1 ); - - if( requestedFramesPerBuffer != paFramesPerBufferUnspecified ) - { - // make host buffer the next highest integer multiple of user frames per buffer - UInt32 n = (resultBufferSizeFrames + requestedFramesPerBuffer - 1) / requestedFramesPerBuffer; - resultBufferSizeFrames = n * requestedFramesPerBuffer; - - - // FIXME: really we should be searching for a multiple of requestedFramesPerBuffer - // that is >= suggested latency and also fits within device buffer min/max - - } else { - VDBUG( ("Block Size unspecified. Based on Latency, the user wants a Block Size near: %ld.\n", - (long)resultBufferSizeFrames ) ); - } - - // Clip to the capabilities of the device. - if( inputParameters ) - { - ClipToDeviceBufferSize( auhalHostApi->devIds[inputParameters->device], - true, // In the old code isInput was false! - resultBufferSizeFrames, &resultBufferSizeFrames ); - } - if( outputParameters ) - { - ClipToDeviceBufferSize( auhalHostApi->devIds[outputParameters->device], - false, resultBufferSizeFrames, &resultBufferSizeFrames ); - } - VDBUG(("After querying hardware, setting block size to %ld.\n", (long)resultBufferSizeFrames)); - - return resultBufferSizeFrames; -} - -/* =================================================================================================== */ -/* see pa_hostapi.h for a list of validity guarantees made about OpenStream parameters */ -static PaError OpenStream( struct PaUtilHostApiRepresentation *hostApi, - PaStream** s, - const PaStreamParameters *inputParameters, - const PaStreamParameters *outputParameters, - double sampleRate, - unsigned long requestedFramesPerBuffer, - PaStreamFlags streamFlags, - PaStreamCallback *streamCallback, - void *userData ) -{ - PaError result = paNoError; - PaMacAUHAL *auhalHostApi = (PaMacAUHAL*)hostApi; - PaMacCoreStream *stream = 0; - int inputChannelCount, outputChannelCount; - PaSampleFormat inputSampleFormat, outputSampleFormat; - PaSampleFormat hostInputSampleFormat, hostOutputSampleFormat; - UInt32 fixedInputLatency = 0; - UInt32 fixedOutputLatency = 0; - // Accumulate contributions to latency in these variables. - UInt32 inputLatencyFrames = 0; - UInt32 outputLatencyFrames = 0; - UInt32 suggestedLatencyFramesPerBuffer = requestedFramesPerBuffer; - - VVDBUG(("OpenStream(): in chan=%d, in fmt=%ld, out chan=%d, out fmt=%ld SR=%g, FPB=%ld\n", - inputParameters ? inputParameters->channelCount : -1, - inputParameters ? inputParameters->sampleFormat : -1, - outputParameters ? outputParameters->channelCount : -1, - outputParameters ? outputParameters->sampleFormat : -1, - (float) sampleRate, - requestedFramesPerBuffer )); - VDBUG( ("Opening Stream.\n") ); - - /* These first few bits of code are from paSkeleton with few modifications. */ - if( inputParameters ) - { - inputChannelCount = inputParameters->channelCount; - inputSampleFormat = inputParameters->sampleFormat; - - /* @todo Blocking read/write on Mac is not yet supported. */ - if( !streamCallback && inputSampleFormat & paNonInterleaved ) - { - return paSampleFormatNotSupported; - } - - /* unless alternate device specification is supported, reject the use of - paUseHostApiSpecificDeviceSpecification */ - - if( inputParameters->device == paUseHostApiSpecificDeviceSpecification ) - return paInvalidDevice; - - /* check that input device can support inputChannelCount */ - if( inputChannelCount > hostApi->deviceInfos[ inputParameters->device ]->maxInputChannels ) - return paInvalidChannelCount; - - /* Host supports interleaved float32 */ - hostInputSampleFormat = paFloat32; - } - else - { - inputChannelCount = 0; - inputSampleFormat = hostInputSampleFormat = paFloat32; /* Suppress 'uninitialised var' warnings. */ - } - - if( outputParameters ) - { - outputChannelCount = outputParameters->channelCount; - outputSampleFormat = outputParameters->sampleFormat; - - /* @todo Blocking read/write on Mac is not yet supported. */ - if( !streamCallback && outputSampleFormat & paNonInterleaved ) - { - return paSampleFormatNotSupported; - } - - /* unless alternate device specification is supported, reject the use of - paUseHostApiSpecificDeviceSpecification */ - - if( outputParameters->device == paUseHostApiSpecificDeviceSpecification ) - return paInvalidDevice; - - /* check that output device can support inputChannelCount */ - if( outputChannelCount > hostApi->deviceInfos[ outputParameters->device ]->maxOutputChannels ) - return paInvalidChannelCount; - - /* Host supports interleaved float32 */ - hostOutputSampleFormat = paFloat32; - } - else - { - outputChannelCount = 0; - outputSampleFormat = hostOutputSampleFormat = paFloat32; /* Suppress 'uninitialized var' warnings. */ - } - - /* validate platform specific flags */ - if( (streamFlags & paPlatformSpecificFlags) != 0 ) - return paInvalidFlag; /* unexpected platform specific flag */ - - stream = (PaMacCoreStream*)PaUtil_AllocateMemory( sizeof(PaMacCoreStream) ); - if( !stream ) - { - result = paInsufficientMemory; - goto error; - } - - /* If we fail after this point, we my be left in a bad state, with - some data structures setup and others not. So, first thing we - do is initialize everything so that if we fail, we know what hasn't - been touched. - */ - bzero( stream, sizeof( PaMacCoreStream ) ); - - /* - stream->blio.inputRingBuffer.buffer = NULL; - stream->blio.outputRingBuffer.buffer = NULL; - stream->blio.inputSampleFormat = inputParameters?inputParameters->sampleFormat:0; - stream->blio.inputSampleSize = computeSampleSizeFromFormat(stream->blio.inputSampleFormat); - stream->blio.outputSampleFormat=outputParameters?outputParameters->sampleFormat:0; - stream->blio.outputSampleSize = computeSampleSizeFromFormat(stream->blio.outputSampleFormat); - */ - - /* assert( streamCallback ) ; */ /* only callback mode is implemented */ - if( streamCallback ) - { - PaUtil_InitializeStreamRepresentation( &stream->streamRepresentation, - &auhalHostApi->callbackStreamInterface, - streamCallback, userData ); - } - else - { - PaUtil_InitializeStreamRepresentation( &stream->streamRepresentation, - &auhalHostApi->blockingStreamInterface, - BlioCallback, &stream->blio ); - } - - PaUtil_InitializeCpuLoadMeasurer( &stream->cpuLoadMeasurer, sampleRate ); - - - if( inputParameters ) - { - CalculateFixedDeviceLatency( auhalHostApi->devIds[inputParameters->device], true, &fixedInputLatency ); - inputLatencyFrames += fixedInputLatency; - } - if( outputParameters ) - { - CalculateFixedDeviceLatency( auhalHostApi->devIds[outputParameters->device], false, &fixedOutputLatency ); - outputLatencyFrames += fixedOutputLatency; - - } - - suggestedLatencyFramesPerBuffer = CalculateOptimalBufferSize( auhalHostApi, inputParameters, outputParameters, - fixedInputLatency, fixedOutputLatency, - sampleRate, requestedFramesPerBuffer ); - if( requestedFramesPerBuffer == paFramesPerBufferUnspecified ) - { - requestedFramesPerBuffer = suggestedLatencyFramesPerBuffer; - } - - /* -- Now we actually open and setup streams. -- */ - if( inputParameters && outputParameters && outputParameters->device == inputParameters->device ) - { /* full duplex. One device. */ - UInt32 inputFramesPerBuffer = (UInt32) stream->inputFramesPerBuffer; - UInt32 outputFramesPerBuffer = (UInt32) stream->outputFramesPerBuffer; - result = OpenAndSetupOneAudioUnit( stream, - inputParameters, - outputParameters, - suggestedLatencyFramesPerBuffer, - &inputFramesPerBuffer, - &outputFramesPerBuffer, - auhalHostApi, - &(stream->inputUnit), - &(stream->inputSRConverter), - &(stream->inputDevice), - sampleRate, - stream ); - stream->inputFramesPerBuffer = inputFramesPerBuffer; - stream->outputFramesPerBuffer = outputFramesPerBuffer; - stream->outputUnit = stream->inputUnit; - stream->outputDevice = stream->inputDevice; - if( result != paNoError ) - goto error; - } - else - { /* full duplex, different devices OR simplex */ - UInt32 outputFramesPerBuffer = (UInt32) stream->outputFramesPerBuffer; - UInt32 inputFramesPerBuffer = (UInt32) stream->inputFramesPerBuffer; - result = OpenAndSetupOneAudioUnit( stream, - NULL, - outputParameters, - suggestedLatencyFramesPerBuffer, - NULL, - &outputFramesPerBuffer, - auhalHostApi, - &(stream->outputUnit), - NULL, - &(stream->outputDevice), - sampleRate, - stream ); - if( result != paNoError ) - goto error; - result = OpenAndSetupOneAudioUnit( stream, - inputParameters, - NULL, - suggestedLatencyFramesPerBuffer, - &inputFramesPerBuffer, - NULL, - auhalHostApi, - &(stream->inputUnit), - &(stream->inputSRConverter), - &(stream->inputDevice), - sampleRate, - stream ); - if( result != paNoError ) - goto error; - stream->inputFramesPerBuffer = inputFramesPerBuffer; - stream->outputFramesPerBuffer = outputFramesPerBuffer; - } - - inputLatencyFrames += stream->inputFramesPerBuffer; - outputLatencyFrames += stream->outputFramesPerBuffer; - - if( stream->inputUnit ) { - const size_t szfl = sizeof(float); - /* setup the AudioBufferList used for input */ - bzero( &stream->inputAudioBufferList, sizeof( AudioBufferList ) ); - stream->inputAudioBufferList.mNumberBuffers = 1; - stream->inputAudioBufferList.mBuffers[0].mNumberChannels - = inputChannelCount; - stream->inputAudioBufferList.mBuffers[0].mDataByteSize - = stream->inputFramesPerBuffer*inputChannelCount*szfl; - stream->inputAudioBufferList.mBuffers[0].mData - = (float *) calloc( - stream->inputFramesPerBuffer*inputChannelCount, - szfl ); - if( !stream->inputAudioBufferList.mBuffers[0].mData ) - { - result = paInsufficientMemory; - goto error; - } - - /* - * If input and output devs are different or we are doing SR conversion, - * we also need a ring buffer to store input data while waiting for - * output data. - */ - if( (stream->outputUnit && (stream->inputUnit != stream->outputUnit)) - || stream->inputSRConverter ) - { - /* May want the ringSize or initial position in - ring buffer to depend somewhat on sample rate change */ - - void *data; - long ringSize; - - ringSize = computeRingBufferSize( inputParameters, - outputParameters, - stream->inputFramesPerBuffer, - stream->outputFramesPerBuffer, - sampleRate ); - /*ringSize <<= 4; *//*16x bigger, for testing */ - - - /*now, we need to allocate memory for the ring buffer*/ - data = calloc( ringSize, szfl*inputParameters->channelCount ); - if( !data ) - { - result = paInsufficientMemory; - goto error; - } - - /* now we can initialize the ring buffer */ - result = PaUtil_InitializeRingBuffer( &stream->inputRingBuffer, szfl*inputParameters->channelCount, ringSize, data ); - if( result != 0 ) - { - /* The only reason this should fail is if ringSize is not a power of 2, which we do not anticipate happening. */ - result = paUnanticipatedHostError; - free(data); - goto error; - } - - /* advance the read point a little, so we are reading from the - middle of the buffer */ - if( stream->outputUnit ) - PaUtil_AdvanceRingBufferWriteIndex( &stream->inputRingBuffer, ringSize / RING_BUFFER_ADVANCE_DENOMINATOR ); - - // Just adds to input latency between input device and PA full duplex callback. - inputLatencyFrames += ringSize; - } - } - - /* -- initialize Blio Buffer Processors -- */ - if( !streamCallback ) - { - long ringSize; - - ringSize = computeRingBufferSize( inputParameters, - outputParameters, - stream->inputFramesPerBuffer, - stream->outputFramesPerBuffer, - sampleRate ); - result = initializeBlioRingBuffers( &stream->blio, - inputParameters ? inputParameters->sampleFormat : 0, - outputParameters ? outputParameters->sampleFormat : 0, - ringSize, - inputParameters ? inputChannelCount : 0, - outputParameters ? outputChannelCount : 0 ); - if( result != paNoError ) - goto error; - - inputLatencyFrames += ringSize; - outputLatencyFrames += ringSize; - - } - - /* -- initialize Buffer Processor -- */ - { - unsigned long maxHostFrames = stream->inputFramesPerBuffer; - if( stream->outputFramesPerBuffer > maxHostFrames ) - maxHostFrames = stream->outputFramesPerBuffer; - result = PaUtil_InitializeBufferProcessor( &stream->bufferProcessor, - inputChannelCount, inputSampleFormat, - hostInputSampleFormat, - outputChannelCount, outputSampleFormat, - hostOutputSampleFormat, - sampleRate, - streamFlags, - requestedFramesPerBuffer, - /* If sample rate conversion takes place, the buffer size - will not be known. */ - maxHostFrames, - stream->inputSRConverter - ? paUtilUnknownHostBufferSize - : paUtilBoundedHostBufferSize, - streamCallback ? streamCallback : BlioCallback, - streamCallback ? userData : &stream->blio ); - if( result != paNoError ) - goto error; - } - stream->bufferProcessorIsInitialized = TRUE; - - // Calculate actual latency from the sum of individual latencies. - if( inputParameters ) - { - inputLatencyFrames += PaUtil_GetBufferProcessorInputLatencyFrames(&stream->bufferProcessor); - stream->streamRepresentation.streamInfo.inputLatency = inputLatencyFrames / sampleRate; - } - else - { - stream->streamRepresentation.streamInfo.inputLatency = 0.0; - } - - if( outputParameters ) - { - outputLatencyFrames += PaUtil_GetBufferProcessorOutputLatencyFrames(&stream->bufferProcessor); - stream->streamRepresentation.streamInfo.outputLatency = outputLatencyFrames / sampleRate; - } - else - { - stream->streamRepresentation.streamInfo.outputLatency = 0.0; - } - - stream->streamRepresentation.streamInfo.sampleRate = sampleRate; - - stream->sampleRate = sampleRate; - - stream->userInChan = inputChannelCount; - stream->userOutChan = outputChannelCount; - - // Setup property listeners for timestamp and latency calculations. - pthread_mutex_init( &stream->timingInformationMutex, NULL ); - stream->timingInformationMutexIsInitialized = 1; - InitializeDeviceProperties( &stream->inputProperties ); // zeros the struct. doesn't actually init it to useful values - InitializeDeviceProperties( &stream->outputProperties ); // zeros the struct. doesn't actually init it to useful values - if( stream->outputUnit ) - { - Boolean isInput = FALSE; - - // Start with the current values for the device properties. - // Init with nominal sample rate. Use actual sample rate where available - - result = ERR( UpdateSampleRateFromDeviceProperty( - stream, stream->outputDevice, isInput, kAudioDevicePropertyNominalSampleRate ) ); - if( result ) - goto error; /* fail if we can't even get a nominal device sample rate */ - - UpdateSampleRateFromDeviceProperty( stream, stream->outputDevice, isInput, kAudioDevicePropertyActualSampleRate ); - - SetupDevicePropertyListeners( stream, stream->outputDevice, isInput ); - } - if( stream->inputUnit ) - { - Boolean isInput = TRUE; - - // as above - result = ERR( UpdateSampleRateFromDeviceProperty( - stream, stream->inputDevice, isInput, kAudioDevicePropertyNominalSampleRate ) ); - if( result ) - goto error; - - UpdateSampleRateFromDeviceProperty( stream, stream->inputDevice, isInput, kAudioDevicePropertyActualSampleRate ); - - SetupDevicePropertyListeners( stream, stream->inputDevice, isInput ); - } - UpdateTimeStampOffsets( stream ); - // Setup timestamp copies to be used by audio callback. - stream->timestampOffsetCombined_ioProcCopy = stream->timestampOffsetCombined; - stream->timestampOffsetInputDevice_ioProcCopy = stream->timestampOffsetInputDevice; - stream->timestampOffsetOutputDevice_ioProcCopy = stream->timestampOffsetOutputDevice; - - stream->state = STOPPED; - stream->xrunFlags = 0; - - *s = (PaStream*)stream; - - return result; - -error: - CloseStream( stream ); - return result; -} - - -#define HOST_TIME_TO_PA_TIME( x ) ( AudioConvertHostTimeToNanos( (x) ) * 1.0E-09) /* convert to nanoseconds and then to seconds */ - -PaTime GetStreamTime( PaStream *s ) -{ - return HOST_TIME_TO_PA_TIME( AudioGetCurrentHostTime() ); -} - -#define RING_BUFFER_EMPTY (1000) - -static OSStatus ringBufferIOProc( - AudioConverterRef inAudioConverter, - UInt32* ioNumberDataPackets, - AudioBufferList* ioData, - AudioStreamPacketDescription** outDataPacketDescription, - void* inUserData) -{ - VVDBUG(("ringBufferIOProc()\n")); - - PaUtilRingBuffer *rb = (PaUtilRingBuffer *) inUserData; - - if( PaUtil_GetRingBufferReadAvailable( rb ) == 0 ) { - ioData->mBuffers[0].mData = NULL; - ioData->mBuffers[0].mDataByteSize = 0; - *ioNumberDataPackets = 0; - VVDBUG(("Ring buffer empty!\n")); - return RING_BUFFER_EMPTY; - } - - UInt32 packetSize = sizeof(float) * ioData->mBuffers[0].mNumberChannels; - UInt32 dataSize = *ioNumberDataPackets * packetSize; - assert(dataSize % rb->elementSizeBytes == 0); - UInt32 rbElements = dataSize / rb->elementSizeBytes; - ring_buffer_size_t rbElementsRead = rbElements; - void *dummyData; - ring_buffer_size_t dummySize; - PaUtil_GetRingBufferReadRegions( rb, rbElements, - &ioData->mBuffers[0].mData, &rbElementsRead, - &dummyData, &dummySize ); - assert(rbElementsRead > 0); - VVDBUG(("RingBuffer read elements %u of %u\n", rbElementsRead, rbElements)); - PaUtil_AdvanceRingBufferReadIndex( rb, rbElementsRead ); - - UInt32 bytesRead = rbElementsRead * rb->elementSizeBytes; - ioData->mBuffers[0].mDataByteSize = bytesRead; - *ioNumberDataPackets = bytesRead / packetSize; - - return noErr; -} - -/* - * Called by the AudioUnit API to process audio from the sound card. - * This is where the magic happens. - */ -/* FEEDBACK: there is a lot of redundant code here because of how all the cases differ. This makes it hard to maintain, so if there are suggestinos for cleaning it up, I'm all ears. */ -static OSStatus AudioIOProc( void *inRefCon, - AudioUnitRenderActionFlags *ioActionFlags, - const AudioTimeStamp *inTimeStamp, - UInt32 inBusNumber, - UInt32 inNumberFrames, - AudioBufferList *ioData ) -{ - unsigned long framesProcessed = 0; - PaStreamCallbackTimeInfo timeInfo = {0,0,0}; - PaMacCoreStream *stream = (PaMacCoreStream*)inRefCon; - const bool isRender = inBusNumber == OUTPUT_ELEMENT; - int callbackResult = paContinue ; - double hostTimeStampInPaTime = HOST_TIME_TO_PA_TIME(inTimeStamp->mHostTime); - - VVDBUG(("AudioIOProc()\n")); - - PaUtil_BeginCpuLoadMeasurement( &stream->cpuLoadMeasurer ); - - /* -----------------------------------------------------------------*\ - This output may be useful for debugging, - But printing during the callback is a bad enough idea that - this is not enabled by enabling the usual debugging calls. - \* -----------------------------------------------------------------*/ - /* - static int renderCount = 0; - static int inputCount = 0; - printf( "------------------- starting render/input\n" ); - if( isRender ) - printf("Render callback (%d):\t", ++renderCount); - else - printf("Input callback (%d):\t", ++inputCount); - printf( "Call totals: %d (input), %d (render)\n", inputCount, renderCount ); - - printf( "--- inBusNumber: %lu\n", inBusNumber ); - printf( "--- inNumberFrames: %lu\n", inNumberFrames ); - printf( "--- %x ioData\n", (unsigned) ioData ); - if( ioData ) - { - int i=0; - printf( "--- ioData.mNumBuffers %lu: \n", ioData->mNumberBuffers ); - for( i=0; i mNumberBuffers; ++i ) - printf( "--- ioData buffer %d size: %lu.\n", i, ioData->mBuffers[i].mDataByteSize ); - } - ----------------------------------------------------------------- */ - - /* compute PaStreamCallbackTimeInfo */ - - if( pthread_mutex_trylock( &stream->timingInformationMutex ) == 0 ) { - /* snapshot the ioproc copy of timing information */ - stream->timestampOffsetCombined_ioProcCopy = stream->timestampOffsetCombined; - stream->timestampOffsetInputDevice_ioProcCopy = stream->timestampOffsetInputDevice; - stream->timestampOffsetOutputDevice_ioProcCopy = stream->timestampOffsetOutputDevice; - pthread_mutex_unlock( &stream->timingInformationMutex ); - } - - /* For timeInfo.currentTime we could calculate current time backwards from the HAL audio - output time to give a more accurate impression of the current timeslice but it doesn't - seem worth it at the moment since other PA host APIs don't do any better. - */ - timeInfo.currentTime = HOST_TIME_TO_PA_TIME( AudioGetCurrentHostTime() ); - - /* - For an input HAL AU, inTimeStamp is the time the samples are received from the hardware, - for an output HAL AU inTimeStamp is the time the samples are sent to the hardware. - PA expresses timestamps in terms of when the samples enter the ADC or leave the DAC - so we add or subtract kAudioDevicePropertyLatency below. - */ - - /* FIXME: not sure what to do below if the host timestamps aren't valid (kAudioTimeStampHostTimeValid isn't set) - Could ask on CA mailing list if it is possible for it not to be set. If so, could probably grab a now timestamp - at the top and compute from there (modulo scheduling jitter) or ask on mailing list for other options. */ - - if( isRender ) - { - if( stream->inputUnit ) /* full duplex */ - { - if( stream->inputUnit == stream->outputUnit ) /* full duplex AUHAL IOProc */ - { - // Ross and Phil agreed that the following calculation is correct based on an email from Jeff Moore: - // http://osdir.com/ml/coreaudio-api/2009-07/msg00140.html - // Basically the difference between the Apple output timestamp and the PA timestamp is kAudioDevicePropertyLatency. - timeInfo.inputBufferAdcTime = hostTimeStampInPaTime - - (stream->timestampOffsetCombined_ioProcCopy + stream->timestampOffsetInputDevice_ioProcCopy); - timeInfo.outputBufferDacTime = hostTimeStampInPaTime + stream->timestampOffsetOutputDevice_ioProcCopy; - } - else /* full duplex with ring-buffer from a separate input AUHAL ioproc */ - { - /* FIXME: take the ring buffer latency into account */ - timeInfo.inputBufferAdcTime = hostTimeStampInPaTime - - (stream->timestampOffsetCombined_ioProcCopy + stream->timestampOffsetInputDevice_ioProcCopy); - timeInfo.outputBufferDacTime = hostTimeStampInPaTime + stream->timestampOffsetOutputDevice_ioProcCopy; - } - } - else /* output only */ - { - timeInfo.inputBufferAdcTime = 0; - timeInfo.outputBufferDacTime = hostTimeStampInPaTime + stream->timestampOffsetOutputDevice_ioProcCopy; - } - } - else /* input only */ - { - timeInfo.inputBufferAdcTime = hostTimeStampInPaTime - stream->timestampOffsetInputDevice_ioProcCopy; - timeInfo.outputBufferDacTime = 0; - } - - //printf( "---%g, %g, %g\n", timeInfo.inputBufferAdcTime, timeInfo.currentTime, timeInfo.outputBufferDacTime ); - - if( isRender && stream->inputUnit == stream->outputUnit - && !stream->inputSRConverter ) - { - /* --------- Full Duplex, One Device, no SR Conversion ------- - * - * This is the lowest latency case, and also the simplest. - * Input data and output data are available at the same time. - * we do not use the input SR converter or the input ring buffer. - * - */ - OSStatus err = 0; - unsigned long frames; - long bytesPerFrame = sizeof( float ) * ioData->mBuffers[0].mNumberChannels; - - /* -- start processing -- */ - PaUtil_BeginBufferProcessing( &(stream->bufferProcessor), - &timeInfo, - stream->xrunFlags ); - stream->xrunFlags = 0; //FIXME: this flag also gets set outside by a callback, which calls the xrunCallback function. It should be in the same thread as the main audio callback, but the apple docs just use the word "usually" so it may be possible to loose an xrun notification, if that callback happens here. - - /* -- compute frames. do some checks -- */ - assert( ioData->mNumberBuffers == 1 ); - assert( ioData->mBuffers[0].mNumberChannels == stream->userOutChan ); - - frames = ioData->mBuffers[0].mDataByteSize / bytesPerFrame; - /* -- copy and process input data -- */ - err= AudioUnitRender( stream->inputUnit, - ioActionFlags, - inTimeStamp, - INPUT_ELEMENT, - inNumberFrames, - &stream->inputAudioBufferList ); - if(err != noErr) - { - goto stop_stream; - } - - PaUtil_SetInputFrameCount( &(stream->bufferProcessor), frames ); - PaUtil_SetInterleavedInputChannels( &(stream->bufferProcessor), - 0, - stream->inputAudioBufferList.mBuffers[0].mData, - stream->inputAudioBufferList.mBuffers[0].mNumberChannels ); - /* -- Copy and process output data -- */ - PaUtil_SetOutputFrameCount( &(stream->bufferProcessor), frames ); - PaUtil_SetInterleavedOutputChannels( &(stream->bufferProcessor), - 0, - ioData->mBuffers[0].mData, - ioData->mBuffers[0].mNumberChannels ); - /* -- complete processing -- */ - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - } - else if( isRender ) - { - /* -------- Output Side of Full Duplex (Separate Devices or SR Conversion) - * -- OR Simplex Output - * - * This case handles output data as in the full duplex case, - * and, if there is input data, reads it off the ring buffer - * and into the PA buffer processor. If sample rate conversion - * is required on input, that is done here as well. - */ - unsigned long frames; - long bytesPerFrame = sizeof( float ) * ioData->mBuffers[0].mNumberChannels; - - /* Sometimes, when stopping a duplex stream we get erroneous - xrun flags, so if this is our last run, clear the flags. */ - int xrunFlags = stream->xrunFlags; - /* - if( xrunFlags & paInputUnderflow ) - printf( "input underflow.\n" ); - if( xrunFlags & paInputOverflow ) - printf( "input overflow.\n" ); - */ - if( stream->state == STOPPING || stream->state == CALLBACK_STOPPED ) - xrunFlags = 0; - - /* -- start processing -- */ - PaUtil_BeginBufferProcessing( &(stream->bufferProcessor), - &timeInfo, - xrunFlags ); - stream->xrunFlags = 0; /* FEEDBACK: we only send flags to Buf Proc once */ - - /* -- Copy and process output data -- */ - assert( ioData->mNumberBuffers == 1 ); - frames = ioData->mBuffers[0].mDataByteSize / bytesPerFrame; - assert( ioData->mBuffers[0].mNumberChannels == stream->userOutChan ); - PaUtil_SetOutputFrameCount( &(stream->bufferProcessor), frames ); - PaUtil_SetInterleavedOutputChannels( &(stream->bufferProcessor), - 0, - ioData->mBuffers[0].mData, - ioData->mBuffers[0].mNumberChannels ); - - /* -- copy and process input data, and complete processing -- */ - if( stream->inputUnit ) { - const int flsz = sizeof( float ); - /* Here, we read the data out of the ring buffer, through the - audio converter. */ - int inChan = stream->inputAudioBufferList.mBuffers[0].mNumberChannels; - long bytesPerFrame = flsz * inChan; - - if( stream->inputSRConverter ) - { - OSStatus err; - float data[ inChan * frames ]; - AudioBufferList bufferList; - bufferList.mNumberBuffers = 1; - bufferList.mBuffers[0].mNumberChannels = inChan; - bufferList.mBuffers[0].mDataByteSize = sizeof( data ); - bufferList.mBuffers[0].mData = data; - UInt32 packets = frames; - err = AudioConverterFillComplexBuffer( - stream->inputSRConverter, - ringBufferIOProc, - &stream->inputRingBuffer, - &packets, - &bufferList, - NULL); - if( err == RING_BUFFER_EMPTY ) - { /* the ring buffer callback underflowed */ - err = 0; - UInt32 size = packets * bytesPerFrame; - bzero( ((char *)data) + size, sizeof(data)-size ); - /* The ring buffer can underflow normally when the stream is stopping. - * So only report an error if the stream is active. */ - if( stream->state == ACTIVE ) - { - stream->xrunFlags |= paInputUnderflow; - } - } - ERR( err ); - if(err != noErr) - { - goto stop_stream; - } - - PaUtil_SetInputFrameCount( &(stream->bufferProcessor), frames ); - PaUtil_SetInterleavedInputChannels( &(stream->bufferProcessor), - 0, - data, - inChan ); - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - } - else - { - /* Without the AudioConverter is actually a bit more complex - because we have to do a little buffer processing that the - AudioConverter would otherwise handle for us. */ - void *data1, *data2; - ring_buffer_size_t size1, size2; - ring_buffer_size_t framesReadable = PaUtil_GetRingBufferReadRegions( &stream->inputRingBuffer, - frames, - &data1, &size1, - &data2, &size2 ); - if( size1 == frames ) { - /* simplest case: all in first buffer */ - PaUtil_SetInputFrameCount( &(stream->bufferProcessor), frames ); - PaUtil_SetInterleavedInputChannels( &(stream->bufferProcessor), - 0, - data1, - inChan ); - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - PaUtil_AdvanceRingBufferReadIndex(&stream->inputRingBuffer, size1 ); - } else if( framesReadable < frames ) { - - long sizeBytes1 = size1 * bytesPerFrame; - long sizeBytes2 = size2 * bytesPerFrame; - /*we underflowed. take what data we can, zero the rest.*/ - unsigned char data[ frames * bytesPerFrame ]; - if( size1 > 0 ) - { - memcpy( data, data1, sizeBytes1 ); - } - if( size2 > 0 ) - { - memcpy( data+sizeBytes1, data2, sizeBytes2 ); - } - bzero( data+sizeBytes1+sizeBytes2, (frames*bytesPerFrame) - sizeBytes1 - sizeBytes2 ); - - PaUtil_SetInputFrameCount( &(stream->bufferProcessor), frames ); - PaUtil_SetInterleavedInputChannels( &(stream->bufferProcessor), - 0, - data, - inChan ); - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - PaUtil_AdvanceRingBufferReadIndex( &stream->inputRingBuffer, - framesReadable ); - /* flag underflow */ - stream->xrunFlags |= paInputUnderflow; - } else { - /*we got all the data, but split between buffers*/ - PaUtil_SetInputFrameCount( &(stream->bufferProcessor), size1 ); - PaUtil_SetInterleavedInputChannels( &(stream->bufferProcessor), - 0, - data1, - inChan ); - PaUtil_Set2ndInputFrameCount( &(stream->bufferProcessor), size2 ); - PaUtil_Set2ndInterleavedInputChannels( &(stream->bufferProcessor), - 0, - data2, - inChan ); - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - PaUtil_AdvanceRingBufferReadIndex(&stream->inputRingBuffer, framesReadable ); - } - } - } else { - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - } - - } - else - { - /* ------------------ Input - * - * First, we read off the audio data and put it in the ring buffer. - * if this is an input-only stream, we need to process it more, - * otherwise, we let the output case deal with it. - */ - OSStatus err = 0; - int chan = stream->inputAudioBufferList.mBuffers[0].mNumberChannels ; - /* FIXME: looping here may not actually be necessary, but it was something I tried in testing. */ - do { - err= AudioUnitRender( stream->inputUnit, - ioActionFlags, - inTimeStamp, - INPUT_ELEMENT, - inNumberFrames, - &stream->inputAudioBufferList ); - if( err == -10874 ) - inNumberFrames /= 2; - } while( err == -10874 && inNumberFrames > 1 ); - ERR( err ); - if(err != noErr) - { - goto stop_stream; - } - - if( stream->inputSRConverter || stream->outputUnit ) - { - /* If this is duplex or we use a converter, put the data - into the ring buffer. */ - ring_buffer_size_t framesWritten = PaUtil_WriteRingBuffer( &stream->inputRingBuffer, - stream->inputAudioBufferList.mBuffers[0].mData, - inNumberFrames ); - if( framesWritten != inNumberFrames ) - { - stream->xrunFlags |= paInputOverflow ; - } - } - else - { - /* for simplex input w/o SR conversion, - just pop the data into the buffer processor.*/ - PaUtil_BeginBufferProcessing( &(stream->bufferProcessor), - &timeInfo, - stream->xrunFlags ); - stream->xrunFlags = 0; - - PaUtil_SetInputFrameCount( &(stream->bufferProcessor), inNumberFrames); - PaUtil_SetInterleavedInputChannels( &(stream->bufferProcessor), - 0, - stream->inputAudioBufferList.mBuffers[0].mData, - chan ); - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - } - if( !stream->outputUnit && stream->inputSRConverter ) - { - /* ------------------ Simplex Input w/ SR Conversion - * - * if this is a simplex input stream, we need to read off the buffer, - * do our sample rate conversion and pass the results to the buffer - * processor. - * The logic here is complicated somewhat by the fact that we don't - * know how much data is available, so we loop on reasonably sized - * chunks, and let the BufferProcessor deal with the rest. - * - */ - /* This might be too big or small depending on SR conversion. */ - float data[ chan * inNumberFrames ]; - OSStatus err; - do - { /* Run the buffer processor until we are out of data. */ - AudioBufferList bufferList; - bufferList.mNumberBuffers = 1; - bufferList.mBuffers[0].mNumberChannels = chan; - bufferList.mBuffers[0].mDataByteSize = sizeof( data ); - bufferList.mBuffers[0].mData = data; - UInt32 packets = inNumberFrames; - err = AudioConverterFillComplexBuffer( - stream->inputSRConverter, - ringBufferIOProc, - &stream->inputRingBuffer, - &packets, - &bufferList, - NULL); - if( err != RING_BUFFER_EMPTY ) - ERR( err ); - if( err != noErr && err != RING_BUFFER_EMPTY ) - { - goto stop_stream; - } - - PaUtil_SetInputFrameCount( &(stream->bufferProcessor), packets ); - if( packets > 0 ) - { - PaUtil_BeginBufferProcessing( &(stream->bufferProcessor), - &timeInfo, - stream->xrunFlags ); - stream->xrunFlags = 0; - - PaUtil_SetInterleavedInputChannels( &(stream->bufferProcessor), - 0, - data, - chan ); - framesProcessed = - PaUtil_EndBufferProcessing( &(stream->bufferProcessor), - &callbackResult ); - } - } while( callbackResult == paContinue && !err ); - } - } - - // Should we return successfully or fall through to stopping the stream? - if( callbackResult == paContinue ) - { - PaUtil_EndCpuLoadMeasurement( &stream->cpuLoadMeasurer, framesProcessed ); - return noErr; - } - -stop_stream: - stream->state = CALLBACK_STOPPED ; - if( stream->outputUnit ) - AudioOutputUnitStop(stream->outputUnit); - if( stream->inputUnit ) - AudioOutputUnitStop(stream->inputUnit); - - PaUtil_EndCpuLoadMeasurement( &stream->cpuLoadMeasurer, framesProcessed ); - return noErr; -} - -/* - When CloseStream() is called, the multi-api layer ensures that - the stream has already been stopped or aborted. -*/ -static PaError CloseStream( PaStream* s ) -{ - /* This may be called from a failed OpenStream. - Therefore, each piece of info is treated separately. */ - PaError result = paNoError; - PaMacCoreStream *stream = (PaMacCoreStream*)s; - - VVDBUG(("CloseStream()\n")); - VDBUG( ( "Closing stream.\n" ) ); - - if( stream ) { - - if( stream->outputUnit ) - { - Boolean isInput = FALSE; - CleanupDevicePropertyListeners( stream, stream->outputDevice, isInput ); - } - - if( stream->inputUnit ) - { - Boolean isInput = TRUE; - CleanupDevicePropertyListeners( stream, stream->inputDevice, isInput ); - } - - if( stream->outputUnit ) { - int count = removeFromXRunListenerList( stream ); - if( count == 0 ) - PaMacCore_AudioDeviceRemovePropertyListener( stream->outputDevice, - 0, - false, - kAudioDeviceProcessorOverload, - xrunCallback, NULL ); //no need to pass actual node - } - if( stream->inputUnit && stream->outputUnit != stream->inputUnit ) { - int count = removeFromXRunListenerList( stream ); - if( count == 0 ) - PaMacCore_AudioDeviceRemovePropertyListener( stream->inputDevice, - 0, - true, - kAudioDeviceProcessorOverload, - xrunCallback, NULL ); //no need to pass actual node - } - if( stream->outputUnit && stream->outputUnit != stream->inputUnit ) { - AudioUnitUninitialize( stream->outputUnit ); -#if MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_6 - AudioComponentInstanceDispose( stream->outputUnit ); -#else - CloseComponent( stream->outputUnit ); -#endif - } - stream->outputUnit = NULL; - if( stream->inputUnit ) - { - AudioUnitUninitialize( stream->inputUnit ); -#if MAC_OS_X_VERSION_MIN_REQUIRED >= MAC_OS_X_VERSION_10_6 - AudioComponentInstanceDispose( stream->inputUnit ); -#else - CloseComponent( stream->inputUnit ); -#endif - stream->inputUnit = NULL; - } - if( stream->inputRingBuffer.buffer ) - free( (void *) stream->inputRingBuffer.buffer ); - stream->inputRingBuffer.buffer = NULL; - /*TODO: is there more that needs to be done on error - from AudioConverterDispose?*/ - if( stream->inputSRConverter ) - ERR( AudioConverterDispose( stream->inputSRConverter ) ); - stream->inputSRConverter = NULL; - if( stream->inputAudioBufferList.mBuffers[0].mData ) - free( stream->inputAudioBufferList.mBuffers[0].mData ); - stream->inputAudioBufferList.mBuffers[0].mData = NULL; - - result = destroyBlioRingBuffers( &stream->blio ); - if( result ) - return result; - if( stream->bufferProcessorIsInitialized ) - PaUtil_TerminateBufferProcessor( &stream->bufferProcessor ); - - if( stream->timingInformationMutexIsInitialized ) - pthread_mutex_destroy( &stream->timingInformationMutex ); - - PaUtil_TerminateStreamRepresentation( &stream->streamRepresentation ); - PaUtil_FreeMemory( stream ); - } - - return result; -} - -static PaError StartStream( PaStream *s ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)s; - OSStatus result = noErr; - VVDBUG(("StartStream()\n")); - VDBUG( ( "Starting stream.\n" ) ); - -#define ERR_WRAP(mac_err) do { result = mac_err ; if ( result != noErr ) return ERR(result) ; } while(0) - - /*FIXME: maybe want to do this on close/abort for faster start? */ - PaUtil_ResetBufferProcessor( &stream->bufferProcessor ); - if( stream->inputSRConverter ) - ERR_WRAP( AudioConverterReset( stream->inputSRConverter ) ); - - /* -- start -- */ - stream->state = ACTIVE; - if( stream->inputUnit ) { - ERR_WRAP( AudioOutputUnitStart(stream->inputUnit) ); - } - if( stream->outputUnit && stream->outputUnit != stream->inputUnit ) { - ERR_WRAP( AudioOutputUnitStart(stream->outputUnit) ); - } - - return paNoError; -#undef ERR_WRAP -} - -// it's not clear from appl's docs that this really waits -// until all data is flushed. -static ComponentResult BlockWhileAudioUnitIsRunning( AudioUnit audioUnit, AudioUnitElement element ) -{ - Boolean isRunning = 1; - while( isRunning ) { - UInt32 s = sizeof( isRunning ); - ComponentResult err = AudioUnitGetProperty( audioUnit, kAudioOutputUnitProperty_IsRunning, kAudioUnitScope_Global, element, &isRunning, &s ); - if( err ) - return err; - Pa_Sleep( 100 ); - } - return noErr; -} - -static PaError FinishStoppingStream( PaMacCoreStream *stream ) -{ - OSStatus result = noErr; - PaError paErr; - -#define ERR_WRAP(mac_err) do { result = mac_err ; if ( result != noErr ) return ERR(result) ; } while(0) - /* -- stop and reset -- */ - if( stream->inputUnit == stream->outputUnit && stream->inputUnit ) - { - ERR_WRAP( AudioOutputUnitStop(stream->inputUnit) ); - ERR_WRAP( BlockWhileAudioUnitIsRunning(stream->inputUnit,0) ); - ERR_WRAP( BlockWhileAudioUnitIsRunning(stream->inputUnit,1) ); - ERR_WRAP( AudioUnitReset(stream->inputUnit, kAudioUnitScope_Global, 1) ); - ERR_WRAP( AudioUnitReset(stream->inputUnit, kAudioUnitScope_Global, 0) ); - } - else - { - if( stream->inputUnit ) - { - ERR_WRAP(AudioOutputUnitStop(stream->inputUnit) ); - ERR_WRAP( BlockWhileAudioUnitIsRunning(stream->inputUnit,1) ); - ERR_WRAP(AudioUnitReset(stream->inputUnit,kAudioUnitScope_Global,1)); - } - if( stream->outputUnit ) - { - ERR_WRAP(AudioOutputUnitStop(stream->outputUnit)); - ERR_WRAP( BlockWhileAudioUnitIsRunning(stream->outputUnit,0) ); - ERR_WRAP(AudioUnitReset(stream->outputUnit,kAudioUnitScope_Global,0)); - } - } - if( stream->inputRingBuffer.buffer ) { - PaUtil_FlushRingBuffer( &stream->inputRingBuffer ); - bzero( (void *)stream->inputRingBuffer.buffer, - stream->inputRingBuffer.bufferSize ); - /* advance the write point a little, so we are reading from the - middle of the buffer. We'll need extra at the end because - testing has shown that this helps. */ - if( stream->outputUnit ) - PaUtil_AdvanceRingBufferWriteIndex( &stream->inputRingBuffer, - stream->inputRingBuffer.bufferSize - / RING_BUFFER_ADVANCE_DENOMINATOR ); - } - - stream->xrunFlags = 0; - stream->state = STOPPED; - - paErr = resetBlioRingBuffers( &stream->blio ); - if( paErr ) - return paErr; - - VDBUG( ( "Stream Stopped.\n" ) ); - return paNoError; -#undef ERR_WRAP -} - -/* Block until buffer is empty then stop the stream. */ -static PaError StopStream( PaStream *s ) -{ - PaError paErr; - PaMacCoreStream *stream = (PaMacCoreStream*)s; - VVDBUG(("StopStream()\n")); - - /* Tell WriteStream to stop filling the buffer. */ - stream->state = STOPPING; - - if( stream->userOutChan > 0 ) /* Does this stream do output? */ - { - size_t maxHostFrames = MAX( stream->inputFramesPerBuffer, stream->outputFramesPerBuffer ); - VDBUG( ("Waiting for write buffer to be drained.\n") ); - paErr = waitUntilBlioWriteBufferIsEmpty( &stream->blio, stream->sampleRate, - maxHostFrames ); - VDBUG( ( "waitUntilBlioWriteBufferIsEmpty returned %d\n", paErr ) ); - } - return FinishStoppingStream( stream ); -} - -/* Immediately stop the stream. */ -static PaError AbortStream( PaStream *s ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)s; - VDBUG( ( "AbortStream()\n" ) ); - stream->state = STOPPING; - return FinishStoppingStream( stream ); -} - - -static PaError IsStreamStopped( PaStream *s ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)s; - VVDBUG(("IsStreamStopped()\n")); - - return stream->state == STOPPED ? 1 : 0; -} - - -static PaError IsStreamActive( PaStream *s ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)s; - VVDBUG(("IsStreamActive()\n")); - return ( stream->state == ACTIVE || stream->state == STOPPING ); -} - - -static double GetStreamCpuLoad( PaStream* s ) -{ - PaMacCoreStream *stream = (PaMacCoreStream*)s; - VVDBUG(("GetStreamCpuLoad()\n")); - - return PaUtil_GetCpuLoad( &stream->cpuLoadMeasurer ); -} diff --git a/spaces/amin2809/rvc-models2023/infer_pack/transforms.py b/spaces/amin2809/rvc-models2023/infer_pack/transforms.py deleted file mode 100644 index a11f799e023864ff7082c1f49c0cc18351a13b47..0000000000000000000000000000000000000000 --- a/spaces/amin2809/rvc-models2023/infer_pack/transforms.py +++ /dev/null @@ -1,209 +0,0 @@ -import torch -from torch.nn import functional as F - -import numpy as np - - -DEFAULT_MIN_BIN_WIDTH = 1e-3 -DEFAULT_MIN_BIN_HEIGHT = 1e-3 -DEFAULT_MIN_DERIVATIVE = 1e-3 - - -def piecewise_rational_quadratic_transform( - inputs, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=False, - tails=None, - tail_bound=1.0, - min_bin_width=DEFAULT_MIN_BIN_WIDTH, - min_bin_height=DEFAULT_MIN_BIN_HEIGHT, - min_derivative=DEFAULT_MIN_DERIVATIVE, -): - if tails is None: - spline_fn = rational_quadratic_spline - spline_kwargs = {} - else: - spline_fn = unconstrained_rational_quadratic_spline - spline_kwargs = {"tails": tails, "tail_bound": tail_bound} - - outputs, logabsdet = spline_fn( - inputs=inputs, - unnormalized_widths=unnormalized_widths, - unnormalized_heights=unnormalized_heights, - unnormalized_derivatives=unnormalized_derivatives, - inverse=inverse, - min_bin_width=min_bin_width, - min_bin_height=min_bin_height, - min_derivative=min_derivative, - **spline_kwargs - ) - return outputs, logabsdet - - -def searchsorted(bin_locations, inputs, eps=1e-6): - bin_locations[..., -1] += eps - return torch.sum(inputs[..., None] >= bin_locations, dim=-1) - 1 - - -def unconstrained_rational_quadratic_spline( - inputs, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=False, - tails="linear", - tail_bound=1.0, - min_bin_width=DEFAULT_MIN_BIN_WIDTH, - min_bin_height=DEFAULT_MIN_BIN_HEIGHT, - min_derivative=DEFAULT_MIN_DERIVATIVE, -): - inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound) - outside_interval_mask = ~inside_interval_mask - - outputs = torch.zeros_like(inputs) - logabsdet = torch.zeros_like(inputs) - - if tails == "linear": - unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1)) - constant = np.log(np.exp(1 - min_derivative) - 1) - unnormalized_derivatives[..., 0] = constant - unnormalized_derivatives[..., -1] = constant - - outputs[outside_interval_mask] = inputs[outside_interval_mask] - logabsdet[outside_interval_mask] = 0 - else: - raise RuntimeError("{} tails are not implemented.".format(tails)) - - ( - outputs[inside_interval_mask], - logabsdet[inside_interval_mask], - ) = rational_quadratic_spline( - inputs=inputs[inside_interval_mask], - unnormalized_widths=unnormalized_widths[inside_interval_mask, :], - unnormalized_heights=unnormalized_heights[inside_interval_mask, :], - unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :], - inverse=inverse, - left=-tail_bound, - right=tail_bound, - bottom=-tail_bound, - top=tail_bound, - min_bin_width=min_bin_width, - min_bin_height=min_bin_height, - min_derivative=min_derivative, - ) - - return outputs, logabsdet - - -def rational_quadratic_spline( - inputs, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=False, - left=0.0, - right=1.0, - bottom=0.0, - top=1.0, - min_bin_width=DEFAULT_MIN_BIN_WIDTH, - min_bin_height=DEFAULT_MIN_BIN_HEIGHT, - min_derivative=DEFAULT_MIN_DERIVATIVE, -): - if torch.min(inputs) < left or torch.max(inputs) > right: - raise ValueError("Input to a transform is not within its domain") - - num_bins = unnormalized_widths.shape[-1] - - if min_bin_width * num_bins > 1.0: - raise ValueError("Minimal bin width too large for the number of bins") - if min_bin_height * num_bins > 1.0: - raise ValueError("Minimal bin height too large for the number of bins") - - widths = F.softmax(unnormalized_widths, dim=-1) - widths = min_bin_width + (1 - min_bin_width * num_bins) * widths - cumwidths = torch.cumsum(widths, dim=-1) - cumwidths = F.pad(cumwidths, pad=(1, 0), mode="constant", value=0.0) - cumwidths = (right - left) * cumwidths + left - cumwidths[..., 0] = left - cumwidths[..., -1] = right - widths = cumwidths[..., 1:] - cumwidths[..., :-1] - - derivatives = min_derivative + F.softplus(unnormalized_derivatives) - - heights = F.softmax(unnormalized_heights, dim=-1) - heights = min_bin_height + (1 - min_bin_height * num_bins) * heights - cumheights = torch.cumsum(heights, dim=-1) - cumheights = F.pad(cumheights, pad=(1, 0), mode="constant", value=0.0) - cumheights = (top - bottom) * cumheights + bottom - cumheights[..., 0] = bottom - cumheights[..., -1] = top - heights = cumheights[..., 1:] - cumheights[..., :-1] - - if inverse: - bin_idx = searchsorted(cumheights, inputs)[..., None] - else: - bin_idx = searchsorted(cumwidths, inputs)[..., None] - - input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0] - input_bin_widths = widths.gather(-1, bin_idx)[..., 0] - - input_cumheights = cumheights.gather(-1, bin_idx)[..., 0] - delta = heights / widths - input_delta = delta.gather(-1, bin_idx)[..., 0] - - input_derivatives = derivatives.gather(-1, bin_idx)[..., 0] - input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0] - - input_heights = heights.gather(-1, bin_idx)[..., 0] - - if inverse: - a = (inputs - input_cumheights) * ( - input_derivatives + input_derivatives_plus_one - 2 * input_delta - ) + input_heights * (input_delta - input_derivatives) - b = input_heights * input_derivatives - (inputs - input_cumheights) * ( - input_derivatives + input_derivatives_plus_one - 2 * input_delta - ) - c = -input_delta * (inputs - input_cumheights) - - discriminant = b.pow(2) - 4 * a * c - assert (discriminant >= 0).all() - - root = (2 * c) / (-b - torch.sqrt(discriminant)) - outputs = root * input_bin_widths + input_cumwidths - - theta_one_minus_theta = root * (1 - root) - denominator = input_delta + ( - (input_derivatives + input_derivatives_plus_one - 2 * input_delta) - * theta_one_minus_theta - ) - derivative_numerator = input_delta.pow(2) * ( - input_derivatives_plus_one * root.pow(2) - + 2 * input_delta * theta_one_minus_theta - + input_derivatives * (1 - root).pow(2) - ) - logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator) - - return outputs, -logabsdet - else: - theta = (inputs - input_cumwidths) / input_bin_widths - theta_one_minus_theta = theta * (1 - theta) - - numerator = input_heights * ( - input_delta * theta.pow(2) + input_derivatives * theta_one_minus_theta - ) - denominator = input_delta + ( - (input_derivatives + input_derivatives_plus_one - 2 * input_delta) - * theta_one_minus_theta - ) - outputs = input_cumheights + numerator / denominator - - derivative_numerator = input_delta.pow(2) * ( - input_derivatives_plus_one * theta.pow(2) - + 2 * input_delta * theta_one_minus_theta - + input_derivatives * (1 - theta).pow(2) - ) - logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator) - - return outputs, logabsdet diff --git a/spaces/anastasiablackwood/Anastasiablackwood/README.md b/spaces/anastasiablackwood/Anastasiablackwood/README.md deleted file mode 100644 index 1c5d0c30950d287ed632431599a0afc31c37047a..0000000000000000000000000000000000000000 --- a/spaces/anastasiablackwood/Anastasiablackwood/README.md +++ /dev/null @@ -1,10 +0,0 @@ ---- -title: Anastasiablackwood -emoji: 🐢 -colorFrom: yellow -colorTo: indigo -sdk: docker -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/annt/mrc_uit_squadv2/retro_reader/constants.py b/spaces/annt/mrc_uit_squadv2/retro_reader/constants.py deleted file mode 100644 index 378a339657b68834e4fd040c00fc9e74b469c1b7..0000000000000000000000000000000000000000 --- a/spaces/annt/mrc_uit_squadv2/retro_reader/constants.py +++ /dev/null @@ -1,102 +0,0 @@ -import os -from datasets import Sequence, Value, Features -from datasets import Dataset, DatasetDict - - -EXAMPLE_FEATURES = Features( - { - "guid": Value(dtype="string", id=None), - "question": Value(dtype="string", id=None), - "context": Value(dtype="string", id=None), - "answers": Sequence( - feature={ - "text": Value(dtype="string", id=None), - "answer_start": Value(dtype="int32", id=None), - }, - ), - "is_impossible": Value(dtype="bool", id=None), - "title": Value(dtype="string", id=None), - "classtype": Value(dtype="string", id=None), - "source": Value(dtype="string", id=None), - "dataset": Value(dtype="string", id=None), - } -) - -SKETCH_TRAIN_FEATURES = Features( - { - "input_ids": Sequence(feature=Value(dtype='int32', id=None)), - "attention_mask": Sequence(feature=Value(dtype='int8', id=None)), - "token_type_ids": Sequence(feature=Value(dtype='int8', id=None)), - "labels": Value(dtype='int64', id=None), - } -) - -SKETCH_EVAL_FEATURES = Features( - { - "input_ids": Sequence(feature=Value(dtype='int32', id=None)), - "attention_mask": Sequence(feature=Value(dtype='int8', id=None)), - "token_type_ids": Sequence(feature=Value(dtype='int8', id=None)), - "labels": Value(dtype='int64', id=None), - "example_id": Value(dtype='string', id=None), - } -) - -INTENSIVE_TRAIN_FEATUERS = Features( - { - "input_ids": Sequence(feature=Value(dtype='int32', id=None)), - "attention_mask": Sequence(feature=Value(dtype='int8', id=None)), - "token_type_ids": Sequence(feature=Value(dtype='int8', id=None)), - "start_positions": Value(dtype='int64', id=None), - "end_positions": Value(dtype='int64', id=None), - "is_impossibles": Value(dtype='float64', id=None), - } -) - -INTENSIVE_EVAL_FEATUERS = Features( - { - "input_ids": Sequence(feature=Value(dtype='int32', id=None)), - "attention_mask": Sequence(feature=Value(dtype='int8', id=None)), - "token_type_ids": Sequence(feature=Value(dtype='int8', id=None)), - "offset_mapping": Sequence( - feature=Sequence( - feature=Value(dtype='int64', id=None) - ) - ), - "example_id": Value(dtype='string', id=None), - } -) - -QUESTION_COLUMN_NAME = "question" -CONTEXT_COLUMN_NAME = "context" -ANSWER_COLUMN_NAME = "answers" -ANSWERABLE_COLUMN_NAME = "is_impossible" -ID_COLUMN_NAME = "guid" - -SCORE_EXT_FILE_NAME = "cls_score.json" -INTENSIVE_PRED_FILE_NAME = "predictions.json" -NBEST_PRED_FILE_NAME = "nbest_predictions.json" -SCORE_DIFF_FILE_NAME = "null_odds.json" - -DEFAULT_CONFIG_FILE = os.path.join( - os.path.realpath(__file__), "args/default_config.yaml" -) - -KO_QUERY_HELP_TEXT = "질문을 입력해주세요!" -KO_CONTEXT_HELP_TEXT = "문맥을 입력해주세요!" - -EN_QUERY_HELP_TEXT = "Plz enter your question!" -EN_CONTEXT_HELP_TEXT = "Plz enter your context!" - -KO_EXAMPLE_QUERY = "이순신은 어느 시대의 무신이야?" -KO_EXAMPLE_CONTEXTS = """ -16세기 조선의 무신으로, 일본이 조선을 침공하여 일어난 전쟁인 임진왜란 당시 조선 수군을 통솔했던 제독이자 구국영웅이다. - -침략군과 교전하여 천재적인 활약상을 펼치고 중앙 지원 없이 자급자족을 해낸 군 지휘관이자, 휘하 인사들에게 법에 따른 원칙을 요구하면서도 뚜렷한 성공률과 부족함 없는 처우를 보장한 상관, 지방관 시절 백성들에게 선정을 베풀고 전시에도 그들을 위무하고 구제한 목민관, 고위 관료와 접선 및 축재를 거부하고 공정과 국익, 절제를 중시한 인격자, 자신이 관할한 지역의 백성과 병사에게 각종 사업을 장려하여 많은 수효를 얻어낸 행정가, 그리고 왕을 위시한 조정의 핍박으로 사형수가 되거나 후임자의 실책으로 군사·군선들을 거의 상실하거나 어머니와 아들을 잃는 등 많은 수난을 겪고도 명량 해전 등에 임하며 굴하지 않은 철인의 면모까지 갖춰 조선 중기의 명장을 넘어 한국사 최고 위인의 반열까지 오른 인물이다. - -생전부터 그를 사적으로 알고 있던 인근 백성이나 군졸, 일부 장수와 재상들로부터 뛰어난 인물로 평가받았고 그렇지 않더라도 명성이 제법 있었으며 전사 소식에 많은 이가 남녀노소를 불문하고 크게 슬퍼했다고 전해진다. 사후 조정은 관직을 추증했고 선비들은 찬양시(詩)를 지었으며 백성들은 추모비를 세우는 등, 이순신은 오래도록 많은 추앙을 받아왔다. 이는 일제강점기를 거쳐 현대에도 마찬가지로, 이순신은 대한민국 국민들이 가장 존경하는 위인 중 한 명으로 꼽히며 현대 한국에서 성웅이라는 최상급 수사가 이름 앞에 붙어도 어떤 이의도 제기받지 않는, 세종과 함께 한국인에게 가장 사랑받는 한국사 양대 위인이다. 가장 존경하는 위인을 묻는 설문조사에서도 세종대왕과 1, 2위를 다투며 충무공이라는 시호도 실제로는 김시민과 같은 여러 장수들이 받은 시호이지만 현대 한국인들은 이순신 전용 시호로 인식한다. -""".strip() - -EN_EXAMPLE_QUERY = "Đen Vâu tên thật là gì?" -EN_EXAMPLE_CONTEXTS = """ -Nguyễn Đức Cường (sinh ngày 13 tháng 5 năm 1989 tại Quảng Ninh, nhưng quê gốc ở Ân Thi, Hưng Yên), thường được biết đến với nghệ danh Đen Vâu hay Đen, là một nam rapper và nhạc sĩ người Việt Nam.[1][3] Đen Vâu từng giành được giải Cống hiến và là "một trong số ít nghệ sĩ thành công từ làn sóng underground và âm nhạc indie" của Việt Nam.[2] Anh sở hữu những bài hát đạt hàng triệu lượt xem trên YouTube và là chủ nhân của một số giải thưởng âm nhạc.[4]' -""".strip() \ No newline at end of file diff --git a/spaces/arnavkartikeya/SCRIPture-final/models/blip_vqa.py b/spaces/arnavkartikeya/SCRIPture-final/models/blip_vqa.py deleted file mode 100644 index d4cb3688fad03888f8568ec65437ee20452c6cb8..0000000000000000000000000000000000000000 --- a/spaces/arnavkartikeya/SCRIPture-final/models/blip_vqa.py +++ /dev/null @@ -1,186 +0,0 @@ -from models.med import BertConfig, BertModel, BertLMHeadModel -from models.blip import create_vit, init_tokenizer, load_checkpoint - -import torch -from torch import nn -import torch.nn.functional as F -from transformers import BertTokenizer -import numpy as np - -class BLIP_VQA(nn.Module): - def __init__(self, - med_config = 'configs/med_config.json', - image_size = 480, - vit = 'base', - vit_grad_ckpt = False, - vit_ckpt_layer = 0, - ): - """ - Args: - med_config (str): path for the mixture of encoder-decoder model's configuration file - image_size (int): input image size - vit (str): model size of vision transformer - """ - super().__init__() - - self.visual_encoder, vision_width = create_vit(vit, image_size, vit_grad_ckpt, vit_ckpt_layer, drop_path_rate=0.1) - self.tokenizer = init_tokenizer() - - encoder_config = BertConfig.from_json_file(med_config) - encoder_config.encoder_width = vision_width - self.text_encoder = BertModel(config=encoder_config, add_pooling_layer=False) - - decoder_config = BertConfig.from_json_file(med_config) - self.text_decoder = BertLMHeadModel(config=decoder_config) - - - def forward(self, image, question, answer=None, n=None, weights=None, train=True, inference='rank', k_test=128): - - image_embeds = self.visual_encoder(image) - image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device) - - question = self.tokenizer(question, padding='longest', truncation=True, max_length=35, - return_tensors="pt").to(image.device) - question.input_ids[:,0] = self.tokenizer.enc_token_id - - if train: - ''' - n: number of answers for each question - weights: weight for each answer - ''' - answer = self.tokenizer(answer, padding='longest', return_tensors="pt").to(image.device) - answer.input_ids[:,0] = self.tokenizer.bos_token_id - answer_targets = answer.input_ids.masked_fill(answer.input_ids == self.tokenizer.pad_token_id, -100) - - question_output = self.text_encoder(question.input_ids, - attention_mask = question.attention_mask, - encoder_hidden_states = image_embeds, - encoder_attention_mask = image_atts, - return_dict = True) - - question_states = [] - question_atts = [] - for b, n in enumerate(n): - question_states += [question_output.last_hidden_state[b]]*n - question_atts += [question.attention_mask[b]]*n - question_states = torch.stack(question_states,0) - question_atts = torch.stack(question_atts,0) - - answer_output = self.text_decoder(answer.input_ids, - attention_mask = answer.attention_mask, - encoder_hidden_states = question_states, - encoder_attention_mask = question_atts, - labels = answer_targets, - return_dict = True, - reduction = 'none', - ) - - loss = weights * answer_output.loss - loss = loss.sum()/image.size(0) - - return loss - - - else: - question_output = self.text_encoder(question.input_ids, - attention_mask = question.attention_mask, - encoder_hidden_states = image_embeds, - encoder_attention_mask = image_atts, - return_dict = True) - - if inference=='generate': - num_beams = 3 - question_states = question_output.last_hidden_state.repeat_interleave(num_beams,dim=0) - question_atts = torch.ones(question_states.size()[:-1],dtype=torch.long).to(question_states.device) - model_kwargs = {"encoder_hidden_states": question_states, "encoder_attention_mask":question_atts} - - bos_ids = torch.full((image.size(0),1),fill_value=self.tokenizer.bos_token_id,device=image.device) - - outputs = self.text_decoder.generate(input_ids=bos_ids, - max_length=10, - min_length=1, - num_beams=num_beams, - eos_token_id=self.tokenizer.sep_token_id, - pad_token_id=self.tokenizer.pad_token_id, - **model_kwargs) - - answers = [] - for output in outputs: - answer = self.tokenizer.decode(output, skip_special_tokens=True) - answers.append(answer) - return answers - - elif inference=='rank': - max_ids = self.rank_answer(question_output.last_hidden_state, question.attention_mask, - answer.input_ids, answer.attention_mask, k_test) - return max_ids - - - - def rank_answer(self, question_states, question_atts, answer_ids, answer_atts, k): - - num_ques = question_states.size(0) - start_ids = answer_ids[0,0].repeat(num_ques,1) # bos token - - start_output = self.text_decoder(start_ids, - encoder_hidden_states = question_states, - encoder_attention_mask = question_atts, - return_dict = True, - reduction = 'none') - logits = start_output.logits[:,0,:] # first token's logit - - # topk_probs: top-k probability - # topk_ids: [num_question, k] - answer_first_token = answer_ids[:,1] - prob_first_token = F.softmax(logits,dim=1).index_select(dim=1, index=answer_first_token) - topk_probs, topk_ids = prob_first_token.topk(k,dim=1) - - # answer input: [num_question*k, answer_len] - input_ids = [] - input_atts = [] - for b, topk_id in enumerate(topk_ids): - input_ids.append(answer_ids.index_select(dim=0, index=topk_id)) - input_atts.append(answer_atts.index_select(dim=0, index=topk_id)) - input_ids = torch.cat(input_ids,dim=0) - input_atts = torch.cat(input_atts,dim=0) - - targets_ids = input_ids.masked_fill(input_ids == self.tokenizer.pad_token_id, -100) - - # repeat encoder's output for top-k answers - question_states = tile(question_states, 0, k) - question_atts = tile(question_atts, 0, k) - - output = self.text_decoder(input_ids, - attention_mask = input_atts, - encoder_hidden_states = question_states, - encoder_attention_mask = question_atts, - labels = targets_ids, - return_dict = True, - reduction = 'none') - - log_probs_sum = -output.loss - log_probs_sum = log_probs_sum.view(num_ques,k) - - max_topk_ids = log_probs_sum.argmax(dim=1) - max_ids = topk_ids[max_topk_ids>=0,max_topk_ids] - - return max_ids - - -def blip_vqa(pretrained='',**kwargs): - model = BLIP_VQA(**kwargs) - if pretrained: - model,msg = load_checkpoint(model,pretrained) -# assert(len(msg.missing_keys)==0) - return model - - -def tile(x, dim, n_tile): - init_dim = x.size(dim) - repeat_idx = [1] * x.dim() - repeat_idx[dim] = n_tile - x = x.repeat(*(repeat_idx)) - order_index = torch.LongTensor(np.concatenate([init_dim * np.arange(n_tile) + i for i in range(init_dim)])) - return torch.index_select(x, dim, order_index.to(x.device)) - - \ No newline at end of file diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Cython/Compiler/TreePath.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Cython/Compiler/TreePath.py deleted file mode 100644 index 8585905557b3a2d6d97e5840da99e36ee4e976dc..0000000000000000000000000000000000000000 --- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Cython/Compiler/TreePath.py +++ /dev/null @@ -1,296 +0,0 @@ -""" -A simple XPath-like language for tree traversal. - -This works by creating a filter chain of generator functions. Each -function selects a part of the expression, e.g. a child node, a -specific descendant or a node that holds an attribute. -""" - -from __future__ import absolute_import - -import re -import operator -import sys - -if sys.version_info[0] >= 3: - _unicode = str -else: - _unicode = unicode - -path_tokenizer = re.compile( - r"(" - r"'[^']*'|\"[^\"]*\"|" - r"//?|" - r"\(\)|" - r"==?|" - r"[/.*\[\]()@])|" - r"([^/\[\]()@=\s]+)|" - r"\s+" - ).findall - -def iterchildren(node, attr_name): - # returns an iterable of all child nodes of that name - child = getattr(node, attr_name) - if child is not None: - if type(child) is list: - return child - else: - return [child] - else: - return () - -def _get_first_or_none(it): - try: - try: - _next = it.next - except AttributeError: - return next(it) - else: - return _next() - except StopIteration: - return None - -def type_name(node): - return node.__class__.__name__.split('.')[-1] - -def parse_func(next, token): - name = token[1] - token = next() - if token[0] != '(': - raise ValueError("Expected '(' after function name '%s'" % name) - predicate = handle_predicate(next, token) - return name, predicate - -def handle_func_not(next, token): - """ - not(...) - """ - name, predicate = parse_func(next, token) - - def select(result): - for node in result: - if _get_first_or_none(predicate([node])) is None: - yield node - return select - -def handle_name(next, token): - """ - /NodeName/ - or - func(...) - """ - name = token[1] - if name in functions: - return functions[name](next, token) - def select(result): - for node in result: - for attr_name in node.child_attrs: - for child in iterchildren(node, attr_name): - if type_name(child) == name: - yield child - return select - -def handle_star(next, token): - """ - /*/ - """ - def select(result): - for node in result: - for name in node.child_attrs: - for child in iterchildren(node, name): - yield child - return select - -def handle_dot(next, token): - """ - /./ - """ - def select(result): - return result - return select - -def handle_descendants(next, token): - """ - //... - """ - token = next() - if token[0] == "*": - def iter_recursive(node): - for name in node.child_attrs: - for child in iterchildren(node, name): - yield child - for c in iter_recursive(child): - yield c - elif not token[0]: - node_name = token[1] - def iter_recursive(node): - for name in node.child_attrs: - for child in iterchildren(node, name): - if type_name(child) == node_name: - yield child - for c in iter_recursive(child): - yield c - else: - raise ValueError("Expected node name after '//'") - - def select(result): - for node in result: - for child in iter_recursive(node): - yield child - - return select - - -def handle_attribute(next, token): - token = next() - if token[0]: - raise ValueError("Expected attribute name") - name = token[1] - value = None - try: - token = next() - except StopIteration: - pass - else: - if token[0] == '=': - value = parse_path_value(next) - readattr = operator.attrgetter(name) - if value is None: - def select(result): - for node in result: - try: - attr_value = readattr(node) - except AttributeError: - continue - if attr_value is not None: - yield attr_value - else: - def select(result): - for node in result: - try: - attr_value = readattr(node) - except AttributeError: - continue - if attr_value == value: - yield attr_value - elif (isinstance(attr_value, bytes) and isinstance(value, _unicode) and - attr_value == value.encode()): - # allow a bytes-to-string comparison too - yield attr_value - - return select - - -def parse_path_value(next): - token = next() - value = token[0] - if value: - if value[:1] == "'" or value[:1] == '"': - return value[1:-1] - try: - return int(value) - except ValueError: - pass - elif token[1].isdigit(): - return int(token[1]) - else: - name = token[1].lower() - if name == 'true': - return True - elif name == 'false': - return False - raise ValueError("Invalid attribute predicate: '%s'" % value) - -def handle_predicate(next, token): - token = next() - selector = [] - while token[0] != ']': - selector.append( operations[token[0]](next, token) ) - try: - token = next() - except StopIteration: - break - else: - if token[0] == "/": - token = next() - - if not token[0] and token[1] == 'and': - return logical_and(selector, handle_predicate(next, token)) - - def select(result): - for node in result: - subresult = iter((node,)) - for select in selector: - subresult = select(subresult) - predicate_result = _get_first_or_none(subresult) - if predicate_result is not None: - yield node - return select - -def logical_and(lhs_selects, rhs_select): - def select(result): - for node in result: - subresult = iter((node,)) - for select in lhs_selects: - subresult = select(subresult) - predicate_result = _get_first_or_none(subresult) - subresult = iter((node,)) - if predicate_result is not None: - for result_node in rhs_select(subresult): - yield node - return select - - -operations = { - "@": handle_attribute, - "": handle_name, - "*": handle_star, - ".": handle_dot, - "//": handle_descendants, - "[": handle_predicate, - } - -functions = { - 'not' : handle_func_not - } - -def _build_path_iterator(path): - # parse pattern - stream = iter([ (special,text) - for (special,text) in path_tokenizer(path) - if special or text ]) - try: - _next = stream.next - except AttributeError: - # Python 3 - def _next(): - return next(stream) - token = _next() - selector = [] - while 1: - try: - selector.append(operations[token[0]](_next, token)) - except StopIteration: - raise ValueError("invalid path") - try: - token = _next() - if token[0] == "/": - token = _next() - except StopIteration: - break - return selector - -# main module API - -def iterfind(node, path): - selector_chain = _build_path_iterator(path) - result = iter((node,)) - for select in selector_chain: - result = select(result) - return result - -def find_first(node, path): - return _get_first_or_none(iterfind(node, path)) - -def find_all(node, path): - return list(iterfind(node, path)) diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/interactive_legend.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/interactive_legend.py deleted file mode 100644 index 040d80b73413b47d4866cfb82456d92b781a1083..0000000000000000000000000000000000000000 --- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/interactive_legend.py +++ /dev/null @@ -1,24 +0,0 @@ -""" -Interactive Legend ------------------- -The following shows how to create a chart with an interactive legend, by -binding the selection to ``"legend"``. Such a binding only works with -``selection_single`` or ``selection_multi`` when projected over a single -field or encoding. -""" -# category: interactive charts -import altair as alt -from vega_datasets import data - -source = data.unemployment_across_industries.url - -selection = alt.selection_multi(fields=['series'], bind='legend') - -alt.Chart(source).mark_area().encode( - alt.X('yearmonth(date):T', axis=alt.Axis(domain=False, format='%Y', tickSize=0)), - alt.Y('sum(count):Q', stack='center', axis=None), - alt.Color('series:N', scale=alt.Scale(scheme='category20b')), - opacity=alt.condition(selection, alt.value(1), alt.value(0.2)) -).add_selection( - selection -) \ No newline at end of file diff --git a/spaces/ashercn97/AsherTesting/convert-to-safetensors.py b/spaces/ashercn97/AsherTesting/convert-to-safetensors.py deleted file mode 100644 index 3b721e7cd4d15cf7e5e03caaee57ef83a41553bc..0000000000000000000000000000000000000000 --- a/spaces/ashercn97/AsherTesting/convert-to-safetensors.py +++ /dev/null @@ -1,38 +0,0 @@ -''' - -Converts a transformers model to safetensors format and shards it. - -This makes it faster to load (because of safetensors) and lowers its RAM usage -while loading (because of sharding). - -Based on the original script by 81300: - -https://gist.github.com/81300/fe5b08bff1cba45296a829b9d6b0f303 - -''' - -import argparse -from pathlib import Path - -import torch -from transformers import AutoModelForCausalLM, AutoTokenizer - -parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54)) -parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.") -parser.add_argument('--output', type=str, default=None, help='Path to the output folder (default: models/{model_name}_safetensors).') -parser.add_argument("--max-shard-size", type=str, default="2GB", help="Maximum size of a shard in GB or MB (default: %(default)s).") -parser.add_argument('--bf16', action='store_true', help='Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.') -args = parser.parse_args() - -if __name__ == '__main__': - path = Path(args.MODEL) - model_name = path.name - - print(f"Loading {model_name}...") - model = AutoModelForCausalLM.from_pretrained(path, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16 if args.bf16 else torch.float16) - tokenizer = AutoTokenizer.from_pretrained(path) - - out_folder = args.output or Path(f"models/{model_name}_safetensors") - print(f"Saving the converted model to {out_folder} with a maximum shard size of {args.max_shard_size}...") - model.save_pretrained(out_folder, max_shard_size=args.max_shard_size, safe_serialization=True) - tokenizer.save_pretrained(out_folder) diff --git a/spaces/awacke1/AR-VR-IOT-Demo/index.html b/spaces/awacke1/AR-VR-IOT-Demo/index.html deleted file mode 100644 index f64aad6580cd12cbdbb0bcc0321ed7a6486d2a19..0000000000000000000000000000000000000000 --- a/spaces/awacke1/AR-VR-IOT-Demo/index.html +++ /dev/null @@ -1,66 +0,0 @@ - - - - Dynamic Lights - A-Frame - - - - - - - -- - - \ No newline at end of file diff --git a/spaces/awacke1/HTML5-Tower-Building-3D-Game/style.css b/spaces/awacke1/HTML5-Tower-Building-3D-Game/style.css deleted file mode 100644 index 114adf441e9032febb46bc056b2a8bb651075f0d..0000000000000000000000000000000000000000 --- a/spaces/awacke1/HTML5-Tower-Building-3D-Game/style.css +++ /dev/null @@ -1,28 +0,0 @@ -body { - padding: 2rem; - font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif; -} - -h1 { - font-size: 16px; - margin-top: 0; -} - -p { - color: rgb(107, 114, 128); - font-size: 15px; - margin-bottom: 10px; - margin-top: 5px; -} - -.card { - max-width: 620px; - margin: 0 auto; - padding: 16px; - border: 1px solid lightgray; - border-radius: 16px; -} - -.card p:last-child { - margin-bottom: 0; -} diff --git a/spaces/awacke1/HTML5Interactivity/style.css b/spaces/awacke1/HTML5Interactivity/style.css deleted file mode 100644 index 114adf441e9032febb46bc056b2a8bb651075f0d..0000000000000000000000000000000000000000 --- a/spaces/awacke1/HTML5Interactivity/style.css +++ /dev/null @@ -1,28 +0,0 @@ -body { - padding: 2rem; - font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif; -} - -h1 { - font-size: 16px; - margin-top: 0; -} - -p { - color: rgb(107, 114, 128); - font-size: 15px; - margin-bottom: 10px; - margin-top: 5px; -} - -.card { - max-width: 620px; - margin: 0 auto; - padding: 16px; - border: 1px solid lightgray; - border-radius: 16px; -} - -.card p:last-child { - margin-bottom: 0; -} diff --git a/spaces/awacke1/Zoom-Clip-Toon-Image-to-Image/app.py b/spaces/awacke1/Zoom-Clip-Toon-Image-to-Image/app.py deleted file mode 100644 index 0343881c7ab3af316d097112f152a38ab784f02c..0000000000000000000000000000000000000000 --- a/spaces/awacke1/Zoom-Clip-Toon-Image-to-Image/app.py +++ /dev/null @@ -1,84 +0,0 @@ -import gradio as gr -import numpy as np -from huggingface_hub import hf_hub_url, cached_download -import PIL -import onnx -import onnxruntime - -config_file_url = hf_hub_url("Jacopo/ToonClip", filename="model.onnx") -model_file = cached_download(config_file_url) - -onnx_model = onnx.load(model_file) -onnx.checker.check_model(onnx_model) - -opts = onnxruntime.SessionOptions() -opts.intra_op_num_threads = 16 -ort_session = onnxruntime.InferenceSession(model_file, sess_options=opts) - -input_name = ort_session.get_inputs()[0].name -output_name = ort_session.get_outputs()[0].name - -def normalize(x, mean=(0., 0., 0.), std=(1.0, 1.0, 1.0)): - # x = (x - mean) / std - x = np.asarray(x, dtype=np.float32) - if len(x.shape) == 4: - for dim in range(3): - x[:, dim, :, :] = (x[:, dim, :, :] - mean[dim]) / std[dim] - if len(x.shape) == 3: - for dim in range(3): - x[dim, :, :] = (x[dim, :, :] - mean[dim]) / std[dim] - - return x - -def denormalize(x, mean=(0., 0., 0.), std=(1.0, 1.0, 1.0)): - # x = (x * std) + mean - x = np.asarray(x, dtype=np.float32) - if len(x.shape) == 4: - for dim in range(3): - x[:, dim, :, :] = (x[:, dim, :, :] * std[dim]) + mean[dim] - if len(x.shape) == 3: - for dim in range(3): - x[dim, :, :] = (x[dim, :, :] * std[dim]) + mean[dim] - - return x - -def nogan(input_img): - i = np.asarray(input_img) - i = i.astype("float32") - i = np.transpose(i, (2, 0, 1)) - i = np.expand_dims(i, 0) - i = i / 255.0 - i = normalize(i, (0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) - - ort_outs = ort_session.run([output_name], {input_name: i}) - output = ort_outs - output = output[0][0] - - output = denormalize(output, (0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) - output = output * 255.0 - output = output.astype('uint8') - output = np.transpose(output, (1, 2, 0)) - output_image = PIL.Image.fromarray(output, 'RGB') - - return output_image - -title = "Zoom, Clip, Toon" -description = """Image to Toon Using AI""" -article = """ -- - - -- - - - - - - -- - -- The \"ToonClip\" model was trained by Jacopo Mangiavacchi and available at Github Repo ComicsHeroMobileUNet
-
- -""" - -examples=[['1m_hires.jpeg'],['2m_hires.jpeg'],['3m_hires.jpeg'],['1f_hires.jpeg'],['2f_hires.jpeg'],['3f_hires.jpeg']] - -iface = gr.Interface( - nogan, - gr.inputs.Image(type="pil", shape=(1024, 1024)), - gr.outputs.Image(type="pil"), - title=title, - description=description, - article=article, - examples=examples) - -iface.launch() \ No newline at end of file diff --git a/spaces/badmonk/up/app.py b/spaces/badmonk/up/app.py deleted file mode 100644 index 252cba569c6f894c6bed81841d229be146a8323f..0000000000000000000000000000000000000000 --- a/spaces/badmonk/up/app.py +++ /dev/null @@ -1,46 +0,0 @@ -import torch -from PIL import Image -from RealESRGAN import RealESRGAN -import gradio as gr - -device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') -model2 = RealESRGAN(device, scale=2) -model2.load_weights('weights/RealESRGAN_x2.pth', download=True) -model4 = RealESRGAN(device, scale=4) -model4.load_weights('weights/RealESRGAN_x4.pth', download=True) -model8 = RealESRGAN(device, scale=8) -model8.load_weights('weights/RealESRGAN_x8.pth', download=True) - - -def inference(image, size): - if size == '2x': - result = model2.predict(image.convert('RGB')) - elif size == '4x': - result = model4.predict(image.convert('RGB')) - else: - result = model8.predict(image.convert('RGB')) - if torch.cuda.is_available(): - torch.cuda.empty_cache() - return result - - -title = "Up 2x 4x 8x" -description = "Real-ESRGAN Upscaler" -article = "" - - -gr.Interface(inference, - [gr.Image(type="pil"), - gr.Radio(['2x', '4x', '8x'], - type="value", - value='2x', - label='Resolution model')], - gr.Image(type="pil", label="Output"), - title=title, - description=description, - article=article, - examples=[['up.jpeg', "2x"]], - allow_flagging='never', - cache_examples=False, - ).queue(concurrency_count=1, api_open=False).launch(show_api=False, show_error=True) - \ No newline at end of file diff --git a/spaces/banana-projects/web3d/node_modules/three/examples/js/postprocessing/GlitchPass.js b/spaces/banana-projects/web3d/node_modules/three/examples/js/postprocessing/GlitchPass.js deleted file mode 100644 index 9d85c5e4d924b3c5bcdcf36d3be95a5a8259d0fd..0000000000000000000000000000000000000000 --- a/spaces/banana-projects/web3d/node_modules/three/examples/js/postprocessing/GlitchPass.js +++ /dev/null @@ -1,113 +0,0 @@ -/** - * @author alteredq / http://alteredqualia.com/ - */ - -THREE.GlitchPass = function ( dt_size ) { - - THREE.Pass.call( this ); - - if ( THREE.DigitalGlitch === undefined ) console.error( "THREE.GlitchPass relies on THREE.DigitalGlitch" ); - - var shader = THREE.DigitalGlitch; - this.uniforms = THREE.UniformsUtils.clone( shader.uniforms ); - - if ( dt_size == undefined ) dt_size = 64; - - - this.uniforms[ "tDisp" ].value = this.generateHeightmap( dt_size ); - - - this.material = new THREE.ShaderMaterial( { - uniforms: this.uniforms, - vertexShader: shader.vertexShader, - fragmentShader: shader.fragmentShader - } ); - - this.fsQuad = new THREE.Pass.FullScreenQuad( this.material ); - - this.goWild = false; - this.curF = 0; - this.generateTrigger(); - -}; - -THREE.GlitchPass.prototype = Object.assign( Object.create( THREE.Pass.prototype ), { - - constructor: THREE.GlitchPass, - - render: function ( renderer, writeBuffer, readBuffer, deltaTime, maskActive ) { - - this.uniforms[ "tDiffuse" ].value = readBuffer.texture; - this.uniforms[ 'seed' ].value = Math.random();//default seeding - this.uniforms[ 'byp' ].value = 0; - - if ( this.curF % this.randX == 0 || this.goWild == true ) { - - this.uniforms[ 'amount' ].value = Math.random() / 30; - this.uniforms[ 'angle' ].value = THREE.Math.randFloat( - Math.PI, Math.PI ); - this.uniforms[ 'seed_x' ].value = THREE.Math.randFloat( - 1, 1 ); - this.uniforms[ 'seed_y' ].value = THREE.Math.randFloat( - 1, 1 ); - this.uniforms[ 'distortion_x' ].value = THREE.Math.randFloat( 0, 1 ); - this.uniforms[ 'distortion_y' ].value = THREE.Math.randFloat( 0, 1 ); - this.curF = 0; - this.generateTrigger(); - - } else if ( this.curF % this.randX < this.randX / 5 ) { - - this.uniforms[ 'amount' ].value = Math.random() / 90; - this.uniforms[ 'angle' ].value = THREE.Math.randFloat( - Math.PI, Math.PI ); - this.uniforms[ 'distortion_x' ].value = THREE.Math.randFloat( 0, 1 ); - this.uniforms[ 'distortion_y' ].value = THREE.Math.randFloat( 0, 1 ); - this.uniforms[ 'seed_x' ].value = THREE.Math.randFloat( - 0.3, 0.3 ); - this.uniforms[ 'seed_y' ].value = THREE.Math.randFloat( - 0.3, 0.3 ); - - } else if ( this.goWild == false ) { - - this.uniforms[ 'byp' ].value = 1; - - } - - this.curF ++; - - if ( this.renderToScreen ) { - - renderer.setRenderTarget( null ); - this.fsQuad.render( renderer ); - - } else { - - renderer.setRenderTarget( writeBuffer ); - if ( this.clear ) renderer.clear(); - this.fsQuad.render( renderer ); - - } - - }, - - generateTrigger: function () { - - this.randX = THREE.Math.randInt( 120, 240 ); - - }, - - generateHeightmap: function ( dt_size ) { - - var data_arr = new Float32Array( dt_size * dt_size * 3 ); - var length = dt_size * dt_size; - - for ( var i = 0; i < length; i ++ ) { - - var val = THREE.Math.randFloat( 0, 1 ); - data_arr[ i * 3 + 0 ] = val; - data_arr[ i * 3 + 1 ] = val; - data_arr[ i * 3 + 2 ] = val; - - } - - var texture = new THREE.DataTexture( data_arr, dt_size, dt_size, THREE.RGBFormat, THREE.FloatType ); - texture.needsUpdate = true; - return texture; - - } - -} ); diff --git a/spaces/beihai/GFPGAN-V1.3-whole-image/gfpgan/data/__init__.py b/spaces/beihai/GFPGAN-V1.3-whole-image/gfpgan/data/__init__.py deleted file mode 100644 index 69fd9f9026407c4d185f86b122000485b06fd986..0000000000000000000000000000000000000000 --- a/spaces/beihai/GFPGAN-V1.3-whole-image/gfpgan/data/__init__.py +++ /dev/null @@ -1,10 +0,0 @@ -import importlib -from basicsr.utils import scandir -from os import path as osp - -# automatically scan and import dataset modules for registry -# scan all the files that end with '_dataset.py' under the data folder -data_folder = osp.dirname(osp.abspath(__file__)) -dataset_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(data_folder) if v.endswith('_dataset.py')] -# import all the dataset modules -_dataset_modules = [importlib.import_module(f'gfpgan.data.{file_name}') for file_name in dataset_filenames] diff --git a/spaces/bigcode/OctoCoder-Demo/app.py b/spaces/bigcode/OctoCoder-Demo/app.py deleted file mode 100644 index f4f9391dd6ceb950021fc49f98f2e10571ebbcc8..0000000000000000000000000000000000000000 --- a/spaces/bigcode/OctoCoder-Demo/app.py +++ /dev/null @@ -1,201 +0,0 @@ -import os - -import gradio as gr -from text_generation import Client, errors - -from share_btn import community_icon_html, loading_icon_html, share_js, share_btn_css - -HF_TOKEN = os.environ.get("HF_TOKEN", None) -API_URL = " https://api-inference.huggingface.co/models/BigCode/octocoder" - -theme = gr.themes.Monochrome( - primary_hue="indigo", - secondary_hue="blue", - neutral_hue="slate", - radius_size=gr.themes.sizes.radius_sm, - font=[ - gr.themes.GoogleFont("Open Sans"), - "ui-sans-serif", - "system-ui", - "sans-serif", - ], -) - -client = Client( - API_URL, - headers={"Authorization": f"Bearer {HF_TOKEN}"}, -) - - -def generate(query: str, temperature=0.9, max_new_tokens=256, top_p=0.95, repetition_penalty=1.0, ): - if query.endswith("."): - prompt = f"Question: {query}\n\nAnswer:" - else: - prompt = f"Question: {query}.\n\nAnswer:" - - temperature = float(temperature) - if temperature < 1e-2: - temperature = 1e-2 - top_p = float(top_p) - - generate_kwargs = dict( - temperature=temperature, - max_new_tokens=max_new_tokens, - top_p=top_p, - repetition_penalty=repetition_penalty, - do_sample=True, - seed=42, - ) - - try: - stream = client.generate_stream(prompt, **generate_kwargs) - output = "" - previous_token = "" - for response in stream: - if response.token.text == "<|endoftext|>": - return output - else: - output += response.token.text - previous_token = response.token.text - yield output - return output - except errors.UnknownError as e: - print(f"Error: {e}") - message = "Please wait for a while, The OctoCoder model is currently loading... 🐙" - output = "" - for item in message.split(" "): - if item == "🐙": - output += "🐙" - return output - else: - output += f"{item} " - yield output - return output - - -def process_example(**krwags): - for x in generate(**krwags): - pass - return x - - -css = ".generating {visibility: hidden}" - -monospace_css = """ -#q-input textarea { - font-family: monospace, 'Consolas', Courier, monospace; -} -""" - -css += share_btn_css + monospace_css - -description = """ ---
-OctoCoder Demo
-
---""" -disclaimer = """⚠️Any use or sharing of this demo constitues your acceptance of the BigCode [OpenRAIL-M](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement) License Agreement and the use restrictions included within.\ -This is a demo to demonstrate the capabilities of OctoCoder model by showing how it can be used to generate code by following the instructions provided in the input.
-OctoCoder is an instruction tuned model with 15.5B parameters created by finetuning StarCoder on CommitPackFT & OASST
-
**Intended Use**: this app and its [supporting model](https://huggingface.co/bigcode) are provided for demonstration purposes; not to serve as replacement for human expertise. For more details on the model's limitations in terms of factuality and biases, see the [model card.](https://huggingface.co/bigcode)""" - -examples = [ - ['Please write a function in Python that performs bubble sort.', 256], - ['''Explain the following piece of code -def count_unique(s): - s = s.lower() - s_split = list(s) - valid_chars = [char for char in s_split if char.isalpha() or char == " "] - valid_sentence = "".join(valid_chars) - uniques = set(valid_sentence.split(" ")) - return len(uniques)''', 512], - [ - 'Write an efficient Python function that takes a given text and returns its Morse code equivalent without using any third party library', - 512], - ['Write a html and css code to render a clock', 8000], -] - -with gr.Blocks(theme=theme, analytics_enabled=False, css=css) as demo: - with gr.Column(): - gr.Markdown(description) - with gr.Row(): - with gr.Column(): - with gr.Accordion("Settings", open=True): - with gr.Row(): - column_1, column_2 = gr.Column(), gr.Column() - with column_1: - temperature = gr.Slider( - label="Temperature", - value=0.2, - minimum=0.0, - maximum=1.0, - step=0.05, - interactive=True, - info="Higher values produce more diverse outputs", - ) - max_new_tokens = gr.Slider( - label="Max new tokens", - value=256, - minimum=0, - maximum=8192, - step=64, - interactive=True, - info="The maximum numbers of new tokens", - ) - with column_2: - top_p = gr.Slider( - label="Top-p (nucleus sampling)", - value=0.90, - minimum=0.0, - maximum=1, - step=0.05, - interactive=True, - info="Higher values sample more low-probability tokens", - ) - repetition_penalty = gr.Slider( - label="Repetition penalty", - value=1.2, - minimum=1.0, - maximum=2.0, - step=0.05, - interactive=True, - info="Penalize repeated tokens", - ) - - with gr.Row(): - with gr.Column(): - instruction = gr.Textbox( - placeholder="Enter your query here", - lines=5, - label="Input", - elem_id="q-input", - ) - submit = gr.Button("Generate", variant="primary") - output = gr.Code(elem_id="q-output", lines=30, label="Output") - gr.Markdown(disclaimer) - with gr.Group(elem_id="share-btn-container"): - community_icon = gr.HTML(community_icon_html, visible=True) - loading_icon = gr.HTML(loading_icon_html, visible=True) - share_button = gr.Button( - "Share to community", elem_id="share-btn", visible=True - ) - gr.Examples( - examples=examples, - inputs=[instruction, max_new_tokens], - cache_examples=False, - fn=process_example, - outputs=[output], - ) - - submit.click( - generate, - inputs=[instruction, temperature, max_new_tokens, top_p, repetition_penalty], - outputs=[output], - ) - share_button.click(None, [], [], _js=share_js) -demo.queue(concurrency_count=16).launch(debug=True) diff --git a/spaces/binly/ChatGPT4/README.md b/spaces/binly/ChatGPT4/README.md deleted file mode 100644 index 7938de14e5355209aaae713f289ca469181bbb17..0000000000000000000000000000000000000000 --- a/spaces/binly/ChatGPT4/README.md +++ /dev/null @@ -1,14 +0,0 @@ ---- -title: Chat-with-GPT4 -emoji: 🚀 -colorFrom: red -colorTo: indigo -sdk: gradio -sdk_version: 3.21.0 -app_file: app.py -pinned: false -license: mit -duplicated_from: ysharma/ChatGPT4 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/bioriAsaeru/text-to-voice/Free Download Final Destination 4 Full Movie In Hindi.md b/spaces/bioriAsaeru/text-to-voice/Free Download Final Destination 4 Full Movie In Hindi.md deleted file mode 100644 index 31c6d840f85692d890d0fb24493ce16cf8220330..0000000000000000000000000000000000000000 --- a/spaces/bioriAsaeru/text-to-voice/Free Download Final Destination 4 Full Movie In Hindi.md +++ /dev/null @@ -1,69 +0,0 @@ - -Free Download Final Destination 4 Full Movie In Hindi
-If you are a fan of horror and thriller movies, you might be interested in downloading Final Destination 4 full movie in Hindi. This is the fourth installment of the popular Final Destination franchise, which revolves around the concept of death's design and how some people manage to cheat it, only to face its wrath later.
-In this article, we will tell you how you can download Final Destination 4 full movie in Hindi for free and enjoy watching it on your device. We will also give you a brief overview of the movie plot and the cast, as well as some interesting facts about the movie.
-Free Download Final Destination 4 Full Movie In Hindi
Download ••• https://urloso.com/2uyP2M
-How to Download Final Destination 4 Full Movie In Hindi for Free
-There are many websites that offer free download of Final Destination 4 full movie in Hindi, but not all of them are safe and legal. Some of them may contain viruses, malware, or pop-up ads that can harm your device or compromise your privacy. Therefore, you should be careful while choosing a website to download the movie from.
-One of the best ways to download Final Destination 4 full movie in Hindi for free is to use a torrent site. Torrent sites are platforms that allow users to share files with each other using peer-to-peer technology. You can find many torrent sites that have Final Destination 4 full movie in Hindi available for download in different qualities and sizes.
- -To download Final Destination 4 full movie in Hindi from a torrent site, you will need a torrent client software that can download the file from the torrent link. Some of the popular torrent clients are uTorrent, BitTorrent, qBittorrent, etc. You can download any of them from their official websites and install them on your device.
-After installing the torrent client, you can search for Final Destination 4 full movie in Hindi on any torrent site that you prefer. Some of the popular torrent sites are The Pirate Bay, 1337x, RARBG, YTS, etc. You can use the search bar or browse through the categories to find the movie. Once you find it, you can click on the torrent link and open it with your torrent client. Then, you can choose the destination folder and start downloading the movie.
-However, you should be aware that downloading movies from torrent sites is illegal in many countries and may result in legal action or fines. Therefore, you should always use a VPN service to hide your IP address and encrypt your traffic while downloading movies from torrent sites. A VPN service will also help you bypass any geo-restrictions or censorship that may prevent you from accessing some torrent sites.
-Final Destination 4 Movie Plot and Cast
-Final Destination 4 is a 2009 American horror thriller film directed by David R. Ellis and written by Eric Bress. It stars Bobby Campo, Shantel VanSanten, Nick Zano, Haley Webb, Krista Allen, Andrew Fiscella, Mykelti Williamson, and Richard T. Jones.
-The movie follows Nick O'Bannon (Campo), who has a premonition of a deadly car race at McKinley Speedway that will result in many casualties, including several people that are in the audience. He convinces his girlfriend Lori (VanSanten), along with his friends Hunt (Zano) and Janet (Webb) to leave. A security guard named George Lanter (Williamson), along with a racist named Carter (Fiscella), a mother and her two sons, and several other people follow Nick out.
-Shortly after they leave, Nick's premonition comes true and a massive pile-up occurs on the track, killing many spectators and drivers. The survivors soon realize that they have cheated death's design and that death will come after them one by one in a series of gruesome accidents. Nick tries to use his visions to save the remaining survivors and stop death's plan before it is too late.
-Interesting Facts About Final Destination 4
--
-
Conclusion
-If you are looking for a thrilling and gory movie to watch, you can download Final Destination 4 full movie in Hindi for free from any torrent site that you trust. However, you should always use a VPN service to protect your privacy and security while downloading movies from torrent sites. You should also be aware of the legal risks involved in downloading movies from illegal sources.
-We hope this article has helped you learn how to download Final Destination 4 full movie in Hindi for free and enjoy watching it on your device. If you have any questions or feedback, feel free to leave a comment below.
-Why You Should Watch Final Destination 4 Full Movie In Hindi
-Final Destination 4 is a movie that will keep you on the edge of your seat with its thrilling and gory scenes. The movie is a perfect blend of action, horror, and suspense, as it shows how death can strike at any moment and in any way. The movie also has some dark humor and clever twists that will surprise you.
-If you are a fan of the Final Destination franchise, you will enjoy watching Final Destination 4 full movie in Hindi, as it continues the legacy of the previous films and adds some new elements to the story. The movie also features some impressive 3D effects that enhance the experience of watching the movie.
-If you are looking for a movie that will make you scream, laugh, and gasp, you should watch Final Destination 4 full movie in Hindi. The movie is a roller coaster ride of emotions that will leave you breathless and entertained.
-Where to Watch Final Destination 4 Full Movie In Hindi
-If you want to watch Final Destination 4 full movie in Hindi, you have several options to choose from. You can either stream it online or download it offline from various platforms. However, you should be careful about the quality and legality of the platforms that you use.
-One of the best ways to watch Final Destination 4 full movie in Hindi is to use a streaming service that offers the movie in high quality and with subtitles. Some of the popular streaming services that have Final Destination 4 full movie in Hindi are Netflix, Amazon Prime Video, Disney+ Hotstar, etc. You can subscribe to any of these services and enjoy watching the movie on your device.
-Another way to watch Final Destination 4 full movie in Hindi is to use a legal download site that allows you to download the movie in different formats and sizes. Some of the legal download sites that have Final Destination 4 full movie in Hindi are iTunes, Google Play Movies, YouTube Movies, etc. You can purchase or rent the movie from any of these sites and download it on your device.
-However, you should avoid using illegal or pirated sites that offer free download of Final Destination 4 full movie in Hindi. These sites may contain viruses, malware, or pop-up ads that can harm your device or compromise your privacy. They may also violate the copyright laws and result in legal action or fines. Therefore, you should always use legal and safe platforms to watch Final Destination 4 full movie in Hindi.
-Conclusion
-Final Destination 4 is a movie that will thrill you with its action-packed and gruesome scenes. The movie is a must-watch for horror and thriller fans, as it shows how death can be unpredictable and unstoppable. The movie also has some witty dialogues and unexpected twists that will keep you engaged.
-If you want to watch Final Destination 4 full movie in Hindi, you can either stream it online or download it offline from various platforms. However, you should always use legal and safe platforms that offer high quality and subtitles for the movie. You should also avoid using illegal or pirated sites that may harm your device or privacy.
-We hope this article has helped you learn how to watch Final Destination 4 full movie in Hindi and enjoy watching it on your device. If you have any questions or feedback, feel free to leave a comment below.
-What is the Final Destination Franchise
-Final Destination 4 is the fourth movie of the Final Destination franchise, which is a series of horror films that are based on the idea that death has a plan for everyone and that it cannot be cheated. The franchise was created by Jeffrey Reddick, who wrote the original screenplay for the first movie.
-The franchise consists of five movies that were released between 2000 and 2011. The movies are not direct sequels to each other, but they share the same premise and some recurring elements. The movies are as follows:
--
-
The franchise has been praised for its originality, creativity, and suspense, as well as its graphic and inventive death scenes. The franchise has also been criticized for its lack of character development, plot holes, and repetitive formula. The franchise has been a commercial success, grossing over $665 million worldwide.
-How to Download Other Movies in the Final Destination Franchise
-If you enjoyed watching Final Destination 4 full movie in Hindi, you might want to watch the other movies in the Final Destination franchise as well. You can download them for free from various torrent sites, just like you did for Final Destination 4. However, you should always use a VPN service to protect your privacy and security while downloading movies from torrent sites.
-To download other movies in the Final Destination franchise, you can follow these steps:
--
-
However, you should be aware that downloading movies from torrent sites is illegal in many countries and may result in legal action or fines. Therefore, you should always use legal and safe platforms to watch other movies in the Final Destination franchise.
-Conclusion
-In this article, we have shown you how to download Final Destination 4 full movie in Hindi for free from torrent sites. We have also given you an overview of the movie plot and cast, as well as some interesting facts about the movie. We have also explained what is the Final Destination franchise and how to download other movies in the franchise.
-We hope this article has helped you learn how to download Final Destination 4 full movie in Hindi and enjoy watching it on your device. If you have any questions or feedback, feel free to leave a comment below.
-Conclusion
-In this article, we have shown you how to download Final Destination 4 full movie in Hindi for free from torrent sites. We have also given you an overview of the movie plot and cast, as well as some interesting facts about the movie. We have also explained what is the Final Destination franchise and how to download other movies in the franchise.
-We hope this article has helped you learn how to download Final Destination 4 full movie in Hindi and enjoy watching it on your device. If you have any questions or feedback, feel free to leave a comment below.
3cee63e6c2
-
-
\ No newline at end of file diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/losses/embed.py b/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/losses/embed.py deleted file mode 100644 index 163eebe9a663f4d46adbbd66af0546a16f32b200..0000000000000000000000000000000000000000 --- a/spaces/brjathu/HMR2.0/vendor/detectron2/projects/DensePose/densepose/modeling/losses/embed.py +++ /dev/null @@ -1,127 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved - -from typing import Any, Dict, List -import torch -from torch import nn -from torch.nn import functional as F - -from detectron2.config import CfgNode -from detectron2.structures import Instances - -from densepose.data.meshes.catalog import MeshCatalog -from densepose.modeling.cse.utils import normalize_embeddings, squared_euclidean_distance_matrix - -from .embed_utils import PackedCseAnnotations -from .utils import BilinearInterpolationHelper - - -class EmbeddingLoss: - """ - Computes losses for estimated embeddings given annotated vertices. - Instances in a minibatch that correspond to the same mesh are grouped - together. For each group, loss is computed as cross-entropy for - unnormalized scores given ground truth mesh vertex ids. - Scores are based on squared distances between estimated vertex embeddings - and mesh vertex embeddings. - """ - - def __init__(self, cfg: CfgNode): - """ - Initialize embedding loss from config - """ - self.embdist_gauss_sigma = cfg.MODEL.ROI_DENSEPOSE_HEAD.CSE.EMBEDDING_DIST_GAUSS_SIGMA - - def __call__( - self, - proposals_with_gt: List[Instances], - densepose_predictor_outputs: Any, - packed_annotations: PackedCseAnnotations, - interpolator: BilinearInterpolationHelper, - embedder: nn.Module, - ) -> Dict[int, torch.Tensor]: - """ - Produces losses for estimated embeddings given annotated vertices. - Embeddings for all the vertices of a mesh are computed by the embedder. - Embeddings for observed pixels are estimated by a predictor. - Losses are computed as cross-entropy for squared distances between - observed vertex embeddings and all mesh vertex embeddings given - ground truth vertex IDs. - - Args: - proposals_with_gt (list of Instances): detections with associated - ground truth data; each item corresponds to instances detected - on 1 image; the number of items corresponds to the number of - images in a batch - densepose_predictor_outputs: an object of a dataclass that contains predictor - outputs with estimated values; assumed to have the following attributes: - * embedding - embedding estimates, tensor of shape [N, D, S, S], where - N = number of instances (= sum N_i, where N_i is the number of - instances on image i) - D = embedding space dimensionality (MODEL.ROI_DENSEPOSE_HEAD.CSE.EMBED_SIZE) - S = output size (width and height) - packed_annotations (PackedCseAnnotations): contains various data useful - for loss computation, each data is packed into a single tensor - interpolator (BilinearInterpolationHelper): bilinear interpolation helper - embedder (nn.Module): module that computes vertex embeddings for different meshes - Return: - dict(int -> tensor): losses for different mesh IDs - """ - losses = {} - for mesh_id_tensor in packed_annotations.vertex_mesh_ids_gt.unique(): - mesh_id = mesh_id_tensor.item() - mesh_name = MeshCatalog.get_mesh_name(mesh_id) - # valid points are those that fall into estimated bbox - # and correspond to the current mesh - j_valid = interpolator.j_valid * ( # pyre-ignore[16] - packed_annotations.vertex_mesh_ids_gt == mesh_id - ) - if not torch.any(j_valid): - continue - # extract estimated embeddings for valid points - # -> tensor [J, D] - vertex_embeddings_i = normalize_embeddings( - interpolator.extract_at_points( - densepose_predictor_outputs.embedding, - slice_fine_segm=slice(None), - w_ylo_xlo=interpolator.w_ylo_xlo[:, None], # pyre-ignore[16] - w_ylo_xhi=interpolator.w_ylo_xhi[:, None], # pyre-ignore[16] - w_yhi_xlo=interpolator.w_yhi_xlo[:, None], # pyre-ignore[16] - w_yhi_xhi=interpolator.w_yhi_xhi[:, None], # pyre-ignore[16] - )[j_valid, :] - ) - # extract vertex ids for valid points - # -> tensor [J] - vertex_indices_i = packed_annotations.vertex_ids_gt[j_valid] - # embeddings for all mesh vertices - # -> tensor [K, D] - mesh_vertex_embeddings = embedder(mesh_name) - # unnormalized scores for valid points - # -> tensor [J, K] - scores = squared_euclidean_distance_matrix( - vertex_embeddings_i, mesh_vertex_embeddings - ) / (-self.embdist_gauss_sigma) - losses[mesh_name] = F.cross_entropy(scores, vertex_indices_i, ignore_index=-1) - - # pyre-fixme[29]: - # `Union[BoundMethod[typing.Callable(torch.Tensor.__iter__)[[Named(self, - # torch.Tensor)], typing.Iterator[typing.Any]], torch.Tensor], nn.Module, - # torch.Tensor]` is not a function. - for mesh_name in embedder.mesh_names: - if mesh_name not in losses: - losses[mesh_name] = self.fake_value( - densepose_predictor_outputs, embedder, mesh_name - ) - return losses - - def fake_values(self, densepose_predictor_outputs: Any, embedder: nn.Module): - losses = {} - # pyre-fixme[29]: - # `Union[BoundMethod[typing.Callable(torch.Tensor.__iter__)[[Named(self, - # torch.Tensor)], typing.Iterator[typing.Any]], torch.Tensor], nn.Module, - # torch.Tensor]` is not a function. - for mesh_name in embedder.mesh_names: - losses[mesh_name] = self.fake_value(densepose_predictor_outputs, embedder, mesh_name) - return losses - - def fake_value(self, densepose_predictor_outputs: Any, embedder: nn.Module, mesh_name: str): - return densepose_predictor_outputs.embedding.sum() * 0 + embedder(mesh_name).sum() * 0 diff --git a/spaces/caffeinum/VToonify/vtoonify/style_transfer.py b/spaces/caffeinum/VToonify/vtoonify/style_transfer.py deleted file mode 100644 index 3e6ba13ca84dc595dfa9eb9ef85a638889d8cdd3..0000000000000000000000000000000000000000 --- a/spaces/caffeinum/VToonify/vtoonify/style_transfer.py +++ /dev/null @@ -1,232 +0,0 @@ -import os -#os.environ['CUDA_VISIBLE_DEVICES'] = "0" -import argparse -import numpy as np -import cv2 -import dlib -import torch -from torchvision import transforms -import torch.nn.functional as F -from tqdm import tqdm -from model.vtoonify import VToonify -from model.bisenet.model import BiSeNet -from model.encoder.align_all_parallel import align_face -from util import save_image, load_image, visualize, load_psp_standalone, get_video_crop_parameter, tensor2cv2 - - -class TestOptions(): - def __init__(self): - - self.parser = argparse.ArgumentParser(description="Style Transfer") - self.parser.add_argument("--content", type=str, default='./data/077436.jpg', help="path of the content image/video") - self.parser.add_argument("--style_id", type=int, default=26, help="the id of the style image") - self.parser.add_argument("--style_degree", type=float, default=0.5, help="style degree for VToonify-D") - self.parser.add_argument("--color_transfer", action="store_true", help="transfer the color of the style") - self.parser.add_argument("--ckpt", type=str, default='./checkpoint/vtoonify_d_cartoon/vtoonify_s_d.pt', help="path of the saved model") - self.parser.add_argument("--output_path", type=str, default='./output/', help="path of the output images") - self.parser.add_argument("--scale_image", action="store_true", help="resize and crop the image to best fit the model") - self.parser.add_argument("--style_encoder_path", type=str, default='./checkpoint/encoder.pt', help="path of the style encoder") - self.parser.add_argument("--exstyle_path", type=str, default=None, help="path of the extrinsic style code") - self.parser.add_argument("--faceparsing_path", type=str, default='./checkpoint/faceparsing.pth', help="path of the face parsing model") - self.parser.add_argument("--video", action="store_true", help="if true, video stylization; if false, image stylization") - self.parser.add_argument("--cpu", action="store_true", help="if true, only use cpu") - self.parser.add_argument("--backbone", type=str, default='dualstylegan', help="dualstylegan | toonify") - self.parser.add_argument("--padding", type=int, nargs=4, default=[200,200,200,200], help="left, right, top, bottom paddings to the face center") - self.parser.add_argument("--batch_size", type=int, default=4, help="batch size of frames when processing video") - self.parser.add_argument("--parsing_map_path", type=str, default=None, help="path of the refined parsing map of the target video") - - def parse(self): - self.opt = self.parser.parse_args() - if self.opt.exstyle_path is None: - self.opt.exstyle_path = os.path.join(os.path.dirname(self.opt.ckpt), 'exstyle_code.npy') - args = vars(self.opt) - print('Load options') - for name, value in sorted(args.items()): - print('%s: %s' % (str(name), str(value))) - return self.opt - -if __name__ == "__main__": - - parser = TestOptions() - args = parser.parse() - print('*'*98) - - - device = "cpu" if args.cpu else "cuda" - - transform = transforms.Compose([ - transforms.ToTensor(), - transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5,0.5,0.5]), - ]) - - vtoonify = VToonify(backbone = args.backbone) - vtoonify.load_state_dict(torch.load(args.ckpt, map_location=lambda storage, loc: storage)['g_ema']) - vtoonify.to(device) - - parsingpredictor = BiSeNet(n_classes=19) - parsingpredictor.load_state_dict(torch.load(args.faceparsing_path, map_location=lambda storage, loc: storage)) - parsingpredictor.to(device).eval() - - modelname = './checkpoint/shape_predictor_68_face_landmarks.dat' - if not os.path.exists(modelname): - import wget, bz2 - wget.download('http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2', modelname+'.bz2') - zipfile = bz2.BZ2File(modelname+'.bz2') - data = zipfile.read() - open(modelname, 'wb').write(data) - landmarkpredictor = dlib.shape_predictor(modelname) - - pspencoder = load_psp_standalone(args.style_encoder_path, device) - - if args.backbone == 'dualstylegan': - exstyles = np.load(args.exstyle_path, allow_pickle='TRUE').item() - stylename = list(exstyles.keys())[args.style_id] - exstyle = torch.tensor(exstyles[stylename]).to(device) - with torch.no_grad(): - exstyle = vtoonify.zplus2wplus(exstyle) - - if args.video and args.parsing_map_path is not None: - x_p_hat = torch.tensor(np.load(args.parsing_map_path)) - - print('Load models successfully!') - - - filename = args.content - basename = os.path.basename(filename).split('.')[0] - scale = 1 - kernel_1d = np.array([[0.125],[0.375],[0.375],[0.125]]) - print('Processing ' + os.path.basename(filename) + ' with vtoonify_' + args.backbone[0]) - if args.video: - cropname = os.path.join(args.output_path, basename + '_input.mp4') - savename = os.path.join(args.output_path, basename + '_vtoonify_' + args.backbone[0] + '.mp4') - - video_cap = cv2.VideoCapture(filename) - num = int(video_cap.get(7)) - - first_valid_frame = True - batch_frames = [] - for i in tqdm(range(num)): - success, frame = video_cap.read() - if success == False: - assert('load video frames error') - frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) - # We proprocess the video by detecting the face in the first frame, - # and resizing the frame so that the eye distance is 64 pixels. - # Centered on the eyes, we crop the first frame to almost 400x400 (based on args.padding). - # All other frames use the same resizing and cropping parameters as the first frame. - if first_valid_frame: - if args.scale_image: - paras = get_video_crop_parameter(frame, landmarkpredictor, args.padding) - if paras is None: - continue - h,w,top,bottom,left,right,scale = paras - H, W = int(bottom-top), int(right-left) - # for HR video, we apply gaussian blur to the frames to avoid flickers caused by bilinear downsampling - # this can also prevent over-sharp stylization results. - if scale <= 0.75: - frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) - if scale <= 0.375: - frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) - frame = cv2.resize(frame, (w, h))[top:bottom, left:right] - else: - H, W = frame.shape[0], frame.shape[1] - - fourcc = cv2.VideoWriter_fourcc(*'mp4v') - videoWriter = cv2.VideoWriter(cropname, fourcc, video_cap.get(5), (W, H)) - videoWriter2 = cv2.VideoWriter(savename, fourcc, video_cap.get(5), (4*W, 4*H)) - - # For each video, we detect and align the face in the first frame for pSp to obtain the style code. - # This style code is used for all other frames. - with torch.no_grad(): - I = align_face(frame, landmarkpredictor) - I = transform(I).unsqueeze(dim=0).to(device) - s_w = pspencoder(I) - s_w = vtoonify.zplus2wplus(s_w) - if vtoonify.backbone == 'dualstylegan': - if args.color_transfer: - s_w = exstyle - else: - s_w[:,:7] = exstyle[:,:7] - first_valid_frame = False - elif args.scale_image: - if scale <= 0.75: - frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) - if scale <= 0.375: - frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) - frame = cv2.resize(frame, (w, h))[top:bottom, left:right] - - videoWriter.write(cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)) - - batch_frames += [transform(frame).unsqueeze(dim=0).to(device)] - - if len(batch_frames) == args.batch_size or (i+1) == num: - x = torch.cat(batch_frames, dim=0) - batch_frames = [] - with torch.no_grad(): - # parsing network works best on 512x512 images, so we predict parsing maps on upsmapled frames - # followed by downsampling the parsing maps - if args.video and args.parsing_map_path is not None: - x_p = x_p_hat[i+1-x.size(0):i+1].to(device) - else: - x_p = F.interpolate(parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0], - scale_factor=0.5, recompute_scale_factor=False).detach() - # we give parsing maps lower weight (1/16) - inputs = torch.cat((x, x_p/16.), dim=1) - # d_s has no effect when backbone is toonify - y_tilde = vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), d_s = args.style_degree) - y_tilde = torch.clamp(y_tilde, -1, 1) - for k in range(y_tilde.size(0)): - videoWriter2.write(tensor2cv2(y_tilde[k].cpu())) - - videoWriter.release() - videoWriter2.release() - video_cap.release() - - - else: - cropname = os.path.join(args.output_path, basename + '_input.jpg') - savename = os.path.join(args.output_path, basename + '_vtoonify_' + args.backbone[0] + '.jpg') - - frame = cv2.imread(filename) - frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) - - # We detect the face in the image, and resize the image so that the eye distance is 64 pixels. - # Centered on the eyes, we crop the image to almost 400x400 (based on args.padding). - if args.scale_image: - paras = get_video_crop_parameter(frame, landmarkpredictor, args.padding) - if paras is not None: - h,w,top,bottom,left,right,scale = paras - H, W = int(bottom-top), int(right-left) - # for HR image, we apply gaussian blur to it to avoid over-sharp stylization results - if scale <= 0.75: - frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) - if scale <= 0.375: - frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) - frame = cv2.resize(frame, (w, h))[top:bottom, left:right] - - with torch.no_grad(): - I = align_face(frame, landmarkpredictor) - I = transform(I).unsqueeze(dim=0).to(device) - s_w = pspencoder(I) - s_w = vtoonify.zplus2wplus(s_w) - if vtoonify.backbone == 'dualstylegan': - if args.color_transfer: - s_w = exstyle - else: - s_w[:,:7] = exstyle[:,:7] - - x = transform(frame).unsqueeze(dim=0).to(device) - # parsing network works best on 512x512 images, so we predict parsing maps on upsmapled frames - # followed by downsampling the parsing maps - x_p = F.interpolate(parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0], - scale_factor=0.5, recompute_scale_factor=False).detach() - # we give parsing maps lower weight (1/16) - inputs = torch.cat((x, x_p/16.), dim=1) - # d_s has no effect when backbone is toonify - y_tilde = vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), d_s = args.style_degree) - y_tilde = torch.clamp(y_tilde, -1, 1) - - cv2.imwrite(cropname, cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)) - save_image(y_tilde[0].cpu(), savename) - - print('Transfer style successfully!') \ No newline at end of file diff --git a/spaces/camenduru-com/audioldm-text-to-audio-generation/audioldm/variational_autoencoder/__init__.py b/spaces/camenduru-com/audioldm-text-to-audio-generation/audioldm/variational_autoencoder/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/projects/README.md b/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/projects/README.md deleted file mode 100644 index 95afe7ff8c8a9bd2f56621fcc3c1bdac11c256a9..0000000000000000000000000000000000000000 --- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/projects/README.md +++ /dev/null @@ -1,2 +0,0 @@ - -Projects live in the [`projects` directory](../../projects) under the root of this repository, but not here. diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/tracking/vanilla_hungarian_bbox_iou_tracker.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/tracking/vanilla_hungarian_bbox_iou_tracker.py deleted file mode 100644 index 5629f7383adcafeaa1ebdae1f38f968437149652..0000000000000000000000000000000000000000 --- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/tracking/vanilla_hungarian_bbox_iou_tracker.py +++ /dev/null @@ -1,129 +0,0 @@ -#!/usr/bin/env python3 -# Copyright 2004-present Facebook. All Rights Reserved. - -import numpy as np -from typing import List - -from detectron2.config import CfgNode as CfgNode_ -from detectron2.config import configurable -from detectron2.structures import Instances -from detectron2.structures.boxes import pairwise_iou -from detectron2.tracking.utils import LARGE_COST_VALUE, create_prediction_pairs - -from .base_tracker import TRACKER_HEADS_REGISTRY -from .hungarian_tracker import BaseHungarianTracker - - -@TRACKER_HEADS_REGISTRY.register() -class VanillaHungarianBBoxIOUTracker(BaseHungarianTracker): - """ - Hungarian algo based tracker using bbox iou as metric - """ - - @configurable - def __init__( - self, - *, - video_height: int, - video_width: int, - max_num_instances: int = 200, - max_lost_frame_count: int = 0, - min_box_rel_dim: float = 0.02, - min_instance_period: int = 1, - track_iou_threshold: float = 0.5, - **kwargs, - ): - """ - Args: - video_height: height the video frame - video_width: width of the video frame - max_num_instances: maximum number of id allowed to be tracked - max_lost_frame_count: maximum number of frame an id can lost tracking - exceed this number, an id is considered as lost - forever - min_box_rel_dim: a percentage, smaller than this dimension, a bbox is - removed from tracking - min_instance_period: an instance will be shown after this number of period - since its first showing up in the video - track_iou_threshold: iou threshold, below this number a bbox pair is removed - from tracking - """ - super().__init__( - video_height=video_height, - video_width=video_width, - max_num_instances=max_num_instances, - max_lost_frame_count=max_lost_frame_count, - min_box_rel_dim=min_box_rel_dim, - min_instance_period=min_instance_period, - ) - self._track_iou_threshold = track_iou_threshold - - @classmethod - def from_config(cls, cfg: CfgNode_): - """ - Old style initialization using CfgNode - - Args: - cfg: D2 CfgNode, config file - Return: - dictionary storing arguments for __init__ method - """ - assert "VIDEO_HEIGHT" in cfg.TRACKER_HEADS - assert "VIDEO_WIDTH" in cfg.TRACKER_HEADS - video_height = cfg.TRACKER_HEADS.get("VIDEO_HEIGHT") - video_width = cfg.TRACKER_HEADS.get("VIDEO_WIDTH") - max_num_instances = cfg.TRACKER_HEADS.get("MAX_NUM_INSTANCES", 200) - max_lost_frame_count = cfg.TRACKER_HEADS.get("MAX_LOST_FRAME_COUNT", 0) - min_box_rel_dim = cfg.TRACKER_HEADS.get("MIN_BOX_REL_DIM", 0.02) - min_instance_period = cfg.TRACKER_HEADS.get("MIN_INSTANCE_PERIOD", 1) - track_iou_threshold = cfg.TRACKER_HEADS.get("TRACK_IOU_THRESHOLD", 0.5) - return { - "_target_": "detectron2.tracking.vanilla_hungarian_bbox_iou_tracker.VanillaHungarianBBoxIOUTracker", # noqa - "video_height": video_height, - "video_width": video_width, - "max_num_instances": max_num_instances, - "max_lost_frame_count": max_lost_frame_count, - "min_box_rel_dim": min_box_rel_dim, - "min_instance_period": min_instance_period, - "track_iou_threshold": track_iou_threshold, - } - - def build_cost_matrix(self, instances: Instances, prev_instances: Instances) -> np.ndarray: - """ - Build the cost matrix for assignment problem - (https://en.wikipedia.org/wiki/Assignment_problem) - - Args: - instances: D2 Instances, for current frame predictions - prev_instances: D2 Instances, for previous frame predictions - - Return: - the cost matrix in numpy array - """ - assert instances is not None and prev_instances is not None - # calculate IoU of all bbox pairs - iou_all = pairwise_iou( - boxes1=instances.pred_boxes, - boxes2=self._prev_instances.pred_boxes, - ) - bbox_pairs = create_prediction_pairs( - instances, self._prev_instances, iou_all, threshold=self._track_iou_threshold - ) - # assign large cost value to make sure pair below IoU threshold won't be matched - cost_matrix = np.full((len(instances), len(prev_instances)), LARGE_COST_VALUE) - return self.assign_cost_matrix_values(cost_matrix, bbox_pairs) - - def assign_cost_matrix_values(self, cost_matrix: np.ndarray, bbox_pairs: List) -> np.ndarray: - """ - Based on IoU for each pair of bbox, assign the associated value in cost matrix - - Args: - cost_matrix: np.ndarray, initialized 2D array with target dimensions - bbox_pairs: list of bbox pair, in each pair, iou value is stored - Return: - np.ndarray, cost_matrix with assigned values - """ - for pair in bbox_pairs: - # assign -1 for IoU above threshold pairs, algorithms will minimize cost - cost_matrix[pair["idx"]][pair["prev_idx"]] = -1 - return cost_matrix diff --git a/spaces/chendl/compositional_test/transformers/docs/TRANSLATING.md b/spaces/chendl/compositional_test/transformers/docs/TRANSLATING.md deleted file mode 100644 index c6f5c45baf029146c061113dae7f42a1bdb14b3a..0000000000000000000000000000000000000000 --- a/spaces/chendl/compositional_test/transformers/docs/TRANSLATING.md +++ /dev/null @@ -1,57 +0,0 @@ -### Translating the Transformers documentation into your language - -As part of our mission to democratize machine learning, we'd love to make the Transformers library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏. - -**🗞️ Open an issue** - -To get started, navigate to the [Issues](https://github.com/huggingface/transformers/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "Translation template" from the "New issue" button. - -Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list. - - -**🍴 Fork the repository** - -First, you'll need to [fork the Transformers repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page. - -Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows: - -```bash -git clone https://github.com/YOUR-USERNAME/transformers.git -``` - -**📋 Copy-paste the English version with a new language code** - -The documentation files are in one leading directory: - -- [`docs/source`](https://github.com/huggingface/transformers/tree/main/docs/source): All the documentation materials are organized here by language. - -You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/transformers/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following: - -```bash -cd ~/path/to/transformers/docs -cp -r source/en source/LANG-ID -``` - -Here, `LANG-ID` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table. - -**✍️ Start translating** - -The fun part comes - translating the text! - -The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website. - -> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/LANG-ID/` directory! - -The fields you should add are `local` (with the name of the file containing the translation; e.g. `autoclass_tutorial`), and `title` (with the title of the doc in your language; e.g. `Load pretrained instances with an AutoClass`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml): - -```yaml -- sections: - - local: pipeline_tutorial # Do not change this! Use the same name for your .md file - title: Pipelines for inference # Translate this! - ... - title: Tutorials # Translate this! -``` - -Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter. - -> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/transformers/issues) and tag @sgugger. diff --git a/spaces/chendl/compositional_test/transformers/examples/pytorch/text-generation/README.md b/spaces/chendl/compositional_test/transformers/examples/pytorch/text-generation/README.md deleted file mode 100644 index 2177c45c3b884a50d59146af96016361b6988738..0000000000000000000000000000000000000000 --- a/spaces/chendl/compositional_test/transformers/examples/pytorch/text-generation/README.md +++ /dev/null @@ -1,31 +0,0 @@ - - -## Language generation - -Based on the script [`run_generation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py). - -Conditional text generation using the auto-regressive models of the library: GPT, GPT-2, Transformer-XL, XLNet, CTRL. -A similar script is used for our official demo [Write With Transfomer](https://transformer.huggingface.co), where you -can try out the different models available in the library. - -Example usage: - -```bash -python run_generation.py \ - --model_type=gpt2 \ - --model_name_or_path=gpt2 -``` diff --git a/spaces/chrisclark1016/Untappd_Predictor/README.md b/spaces/chrisclark1016/Untappd_Predictor/README.md deleted file mode 100644 index a12fb2cbf749c729a6673713c431a57cb2a1e182..0000000000000000000000000000000000000000 --- a/spaces/chrisclark1016/Untappd_Predictor/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Untappd Predictor -emoji: 🚀 -colorFrom: blue -colorTo: yellow -sdk: gradio -sdk_version: 3.38.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/cihyFjudo/fairness-paper-search/Chyby Se Staly (ale Ne Mou Vinou) Epub.md b/spaces/cihyFjudo/fairness-paper-search/Chyby Se Staly (ale Ne Mou Vinou) Epub.md deleted file mode 100644 index 1b922bfadf936c9dc0781cd30b077f83747fe7c9..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Chyby Se Staly (ale Ne Mou Vinou) Epub.md +++ /dev/null @@ -1,6 +0,0 @@ -chyby se staly (ale ne mou vinou) epub
Download File ••• https://tinurli.com/2uwkvA
- - aaccfb2cb3
-
-
- diff --git a/spaces/cihyFjudo/fairness-paper-search/Descarga la version estable del nuevo navegador Microsoft Edge (Microsoft Edge Chromium) y disfruta de sus ventajas.md b/spaces/cihyFjudo/fairness-paper-search/Descarga la version estable del nuevo navegador Microsoft Edge (Microsoft Edge Chromium) y disfruta de sus ventajas.md deleted file mode 100644 index cd6d603ed214d2a9c67bfdc686fd51bb406f54e3..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Descarga la version estable del nuevo navegador Microsoft Edge (Microsoft Edge Chromium) y disfruta de sus ventajas.md +++ /dev/null @@ -1,16 +0,0 @@ -
-El nuevo Edge se puede descargar desde este enlace dentro de los canales de prueba, mientras que para hacerte con la actualización del nuevo Edge puedes hacerlo accediendo desde el navegador en el menú "Configuración > Acerca de" como ya vimos en el tutorial que vimos en su día.
-Descarga la version estable del nuevo navegador Microsoft Edge (Microsoft Edge Chromium)
Download File ✯✯✯ https://tinurli.com/2uwkIg
-Componente de protocolos de inicio automático de Microsoft Edge. Microsoft Edge 96 presenta el componente de protocolos de inicio automático que contiene listas de diccionarios de origen de esquema para permitir o bloquear automáticamente. Esto protege a los clientes de esquemas peligrosos (por ejemplo, un controlador de protocolo con 0 días) al tiempo que elimina las solicitudes de emparejamientos seguros conocidos (por ejemplo, el sitio web de Teams puede abrir la aplicación cliente de Teams). Si, por algún motivo, no quiere que Microsoft Edge bloquee los controladores de protocolo vulnerables y permita emparejamientos seguros conocidos, use el botón de alternancia en edge://settings/content/applicationLinks o establezca la directiva AutoLaunchProtocolsComponentEnabled en False.
-Microsoft Edge ha completado el paso a una cadencia de 4 semanas para actualizaciones. Hemos adoptado un nuevo ciclo de lanzamiento de 4 semanas para las versiones principales. Más información aquí: -release-cycles-microsoft-edge-extended-stable/
-Los usuarios pueden establecer Microsoft Edge como su explorador predeterminado directamente desde la Configuración de Microsoft Edge. Esto hace que sea más fácil para los usuarios cambiar el explorador predeterminado, dentro del contexto del explorador, en lugar de tener que buscar en la configuración del sistema operativo. Para usar esta característica, ve a edge://settings/defaultBrowser y haz clic en Establecer como predeterminado.
- -Actualmente, Microsoft todavía no ha lanzado ninguna versión del canal Beta más estable, sin embargo, ya puedes empezar a descargar las versiones de Microsoft Edge con Chromium en sus canales Dev y Canary. Para ello, el primer paso es ir a la web de Microsoft Edge Insider Channels entrando en microsoftedgeinsider.com. Ahí dentro, pulsa en el botón Download Dev Channel para bajar la versión Dev, o pulsa en More platforms and channels para elegir otro canal.
-El nuevo Edge de Microsoft ha optado por Chromium como motor en lugar de Edge HTML y el cambio le ha sentado muy bien. Cada vez son más los usuarios que deciden darle una oportunidad al navegador de Microsoft, ya sea en la versión estable o por medio de alguna de las tres opciones de desarrollo que se pueden descargar AQUI..
-Edge Canary se encuentra en Google Play; y para descargarlo al dispositivo Android basta con pulsar en el pertinente botón de descarga. La versión de Chromium de este navegador en pruebas es la número 91, por encima de la versión estable de los sistemas de escritorio (versión 90) y sobresaliendo en gran medida de la versión que Microsoft distribuye en Android de manera estable (la número 77).
-Aunque lo hayas desinstalado, Microsoft puede volver a intentar instalar Edge en tu ordenador a través de las actualizaciones de Windows. Siguiendo estos pasos, podrás evitar que Windows reinstale Edge en tu ordenador en la próxima actualización. Podrás utilizar el Microsoft Edge Chromium Blocker Toolkit, que podrás encontrar en la web, para establecer una clave del registro con un nuevo valor (esto puedes hacerlo con las siguientes instrucciones o de forma manual, es decir, sin descargar nada).
-La beta del nuevo navegador basado en Chromium estaba disponible para el uso desde hacía unos meses desde la página de Edge. Esta es la primera versión oficial, aunque, técnicamente, es la «versión estable» 79a. Se espera que en febrero llegue la Edge 80 y también se han anunciado actualizaciones periódicas, que llegarán cada seis semanas a partir de la actualización 80.
-Durante las próximas semanas, el nuevo navegador Edge será introducido automáticamente para los usuarios de Windows 10, aunque se puede descargar manualmente desde su página desde hoy. Los usuarios que tengan la versión anterior de Edge instalada, verán como se actualiza automáticamente, conservando toda la información personalizada.
-Con una competencia creciente entre los navegadores, está mejora siendo desplegada en los equipos con Windows y macOS con una activación en el lado del servidor y que ahora está activa en Edge, en la versión estable (para todos los usuarios) que podemos descargar tanto en la App Store para iOS como en Google Play Store para Android.
aaccfb2cb3
-
-
\ No newline at end of file diff --git a/spaces/cihyFjudo/fairness-paper-search/Download Facehacker For Mac Dmg Free 5 Temporada Wally Au.md b/spaces/cihyFjudo/fairness-paper-search/Download Facehacker For Mac Dmg Free 5 Temporada Wally Au.md deleted file mode 100644 index dc41b1e206f5b4bd06acc05bd8c6c002dfb5245f..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Download Facehacker For Mac Dmg Free 5 Temporada Wally Au.md +++ /dev/null @@ -1,6 +0,0 @@ -Download Facehacker For Mac Dmg Free 5 temporada wally au
Download File 🆓 https://tinurli.com/2uwi8K
-
- aaccfb2cb3
-
-
- diff --git a/spaces/cihyFjudo/fairness-paper-search/Gail Gotti Gailsta EP Download How to Get the Full Album for Free.md b/spaces/cihyFjudo/fairness-paper-search/Gail Gotti Gailsta EP Download How to Get the Full Album for Free.md deleted file mode 100644 index 8dd07554268d270b59d7ea794516dd56bac173c3..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Gail Gotti Gailsta EP Download How to Get the Full Album for Free.md +++ /dev/null @@ -1,6 +0,0 @@ -gail gotti gailsta ep download
DOWNLOAD –––––>>> https://tinurli.com/2uwj4i
- - aaccfb2cb3
-
-
- diff --git a/spaces/cihyFjudo/fairness-paper-search/Simcity 4 Deluxe Edition For Mac Download How to Install and Play.md b/spaces/cihyFjudo/fairness-paper-search/Simcity 4 Deluxe Edition For Mac Download How to Install and Play.md deleted file mode 100644 index e9b3baaebb25c42a38a68ccd96c1094a5d978b41..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Simcity 4 Deluxe Edition For Mac Download How to Install and Play.md +++ /dev/null @@ -1,6 +0,0 @@ -Simcity 4 Deluxe Edition For Mac Download
Download 🔗 https://tinurli.com/2uwio9
- - aaccfb2cb3
-
-
- diff --git a/spaces/codelion/Grounding_DINO_demo/groundingdino/models/GroundingDINO/bertwarper.py b/spaces/codelion/Grounding_DINO_demo/groundingdino/models/GroundingDINO/bertwarper.py deleted file mode 100644 index f0cf9779b270e1aead32845006f8b881fcba37ad..0000000000000000000000000000000000000000 --- a/spaces/codelion/Grounding_DINO_demo/groundingdino/models/GroundingDINO/bertwarper.py +++ /dev/null @@ -1,273 +0,0 @@ -# ------------------------------------------------------------------------ -# Grounding DINO -# url: https://github.com/IDEA-Research/GroundingDINO -# Copyright (c) 2023 IDEA. All Rights Reserved. -# Licensed under the Apache License, Version 2.0 [see LICENSE for details] -# ------------------------------------------------------------------------ - -import torch -import torch.nn.functional as F -import torch.utils.checkpoint as checkpoint -from torch import Tensor, nn -from torchvision.ops.boxes import nms -from transformers import BertConfig, BertModel, BertPreTrainedModel -from transformers.modeling_outputs import BaseModelOutputWithPoolingAndCrossAttentions - - -class BertModelWarper(nn.Module): - def __init__(self, bert_model): - super().__init__() - # self.bert = bert_modelc - - self.config = bert_model.config - self.embeddings = bert_model.embeddings - self.encoder = bert_model.encoder - self.pooler = bert_model.pooler - - self.get_extended_attention_mask = bert_model.get_extended_attention_mask - self.invert_attention_mask = bert_model.invert_attention_mask - self.get_head_mask = bert_model.get_head_mask - - def forward( - self, - input_ids=None, - attention_mask=None, - token_type_ids=None, - position_ids=None, - head_mask=None, - inputs_embeds=None, - encoder_hidden_states=None, - encoder_attention_mask=None, - past_key_values=None, - use_cache=None, - output_attentions=None, - output_hidden_states=None, - return_dict=None, - ): - r""" - encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`): - Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if - the model is configured as a decoder. - encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`): - Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in - the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``: - - - 1 for tokens that are **not masked**, - - 0 for tokens that are **masked**. - past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`): - Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding. - - If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids` - (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)` - instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`. - use_cache (:obj:`bool`, `optional`): - If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up - decoding (see :obj:`past_key_values`). - """ - output_attentions = ( - output_attentions if output_attentions is not None else self.config.output_attentions - ) - output_hidden_states = ( - output_hidden_states - if output_hidden_states is not None - else self.config.output_hidden_states - ) - return_dict = return_dict if return_dict is not None else self.config.use_return_dict - - if self.config.is_decoder: - use_cache = use_cache if use_cache is not None else self.config.use_cache - else: - use_cache = False - - if input_ids is not None and inputs_embeds is not None: - raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time") - elif input_ids is not None: - input_shape = input_ids.size() - batch_size, seq_length = input_shape - elif inputs_embeds is not None: - input_shape = inputs_embeds.size()[:-1] - batch_size, seq_length = input_shape - else: - raise ValueError("You have to specify either input_ids or inputs_embeds") - - device = input_ids.device if input_ids is not None else inputs_embeds.device - - # past_key_values_length - past_key_values_length = ( - past_key_values[0][0].shape[2] if past_key_values is not None else 0 - ) - - if attention_mask is None: - attention_mask = torch.ones( - ((batch_size, seq_length + past_key_values_length)), device=device - ) - if token_type_ids is None: - token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device) - - # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length] - # ourselves in which case we just need to make it broadcastable to all heads. - extended_attention_mask: torch.Tensor = self.get_extended_attention_mask( - attention_mask, input_shape, device - ) - - # If a 2D or 3D attention mask is provided for the cross-attention - # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length] - if self.config.is_decoder and encoder_hidden_states is not None: - encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size() - encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length) - if encoder_attention_mask is None: - encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device) - encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask) - else: - encoder_extended_attention_mask = None - # if os.environ.get('IPDB_SHILONG_DEBUG', None) == 'INFO': - # import ipdb; ipdb.set_trace() - - # Prepare head mask if needed - # 1.0 in head_mask indicate we keep the head - # attention_probs has shape bsz x n_heads x N x N - # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads] - # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length] - head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers) - - embedding_output = self.embeddings( - input_ids=input_ids, - position_ids=position_ids, - token_type_ids=token_type_ids, - inputs_embeds=inputs_embeds, - past_key_values_length=past_key_values_length, - ) - - encoder_outputs = self.encoder( - embedding_output, - attention_mask=extended_attention_mask, - head_mask=head_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_extended_attention_mask, - past_key_values=past_key_values, - use_cache=use_cache, - output_attentions=output_attentions, - output_hidden_states=output_hidden_states, - return_dict=return_dict, - ) - sequence_output = encoder_outputs[0] - pooled_output = self.pooler(sequence_output) if self.pooler is not None else None - - if not return_dict: - return (sequence_output, pooled_output) + encoder_outputs[1:] - - return BaseModelOutputWithPoolingAndCrossAttentions( - last_hidden_state=sequence_output, - pooler_output=pooled_output, - past_key_values=encoder_outputs.past_key_values, - hidden_states=encoder_outputs.hidden_states, - attentions=encoder_outputs.attentions, - cross_attentions=encoder_outputs.cross_attentions, - ) - - -class TextEncoderShell(nn.Module): - def __init__(self, text_encoder): - super().__init__() - self.text_encoder = text_encoder - self.config = self.text_encoder.config - - def forward(self, **kw): - # feed into text encoder - return self.text_encoder(**kw) - - -def generate_masks_with_special_tokens(tokenized, special_tokens_list, tokenizer): - """Generate attention mask between each pair of special tokens - Args: - input_ids (torch.Tensor): input ids. Shape: [bs, num_token] - special_tokens_mask (list): special tokens mask. - Returns: - torch.Tensor: attention mask between each special tokens. - """ - input_ids = tokenized["input_ids"] - bs, num_token = input_ids.shape - # special_tokens_mask: bs, num_token. 1 for special tokens. 0 for normal tokens - special_tokens_mask = torch.zeros((bs, num_token), device=input_ids.device).bool() - for special_token in special_tokens_list: - special_tokens_mask |= input_ids == special_token - - # idxs: each row is a list of indices of special tokens - idxs = torch.nonzero(special_tokens_mask) - - # generate attention mask and positional ids - attention_mask = ( - torch.eye(num_token, device=input_ids.device).bool().unsqueeze(0).repeat(bs, 1, 1) - ) - position_ids = torch.zeros((bs, num_token), device=input_ids.device) - previous_col = 0 - for i in range(idxs.shape[0]): - row, col = idxs[i] - if (col == 0) or (col == num_token - 1): - attention_mask[row, col, col] = True - position_ids[row, col] = 0 - else: - attention_mask[row, previous_col + 1 : col + 1, previous_col + 1 : col + 1] = True - position_ids[row, previous_col + 1 : col + 1] = torch.arange( - 0, col - previous_col, device=input_ids.device - ) - - previous_col = col - - # # padding mask - # padding_mask = tokenized['attention_mask'] - # attention_mask = attention_mask & padding_mask.unsqueeze(1).bool() & padding_mask.unsqueeze(2).bool() - - return attention_mask, position_ids.to(torch.long) - - -def generate_masks_with_special_tokens_and_transfer_map(tokenized, special_tokens_list, tokenizer): - """Generate attention mask between each pair of special tokens - Args: - input_ids (torch.Tensor): input ids. Shape: [bs, num_token] - special_tokens_mask (list): special tokens mask. - Returns: - torch.Tensor: attention mask between each special tokens. - """ - input_ids = tokenized["input_ids"] - bs, num_token = input_ids.shape - # special_tokens_mask: bs, num_token. 1 for special tokens. 0 for normal tokens - special_tokens_mask = torch.zeros((bs, num_token), device=input_ids.device).bool() - for special_token in special_tokens_list: - special_tokens_mask |= input_ids == special_token - - # idxs: each row is a list of indices of special tokens - idxs = torch.nonzero(special_tokens_mask) - - # generate attention mask and positional ids - attention_mask = ( - torch.eye(num_token, device=input_ids.device).bool().unsqueeze(0).repeat(bs, 1, 1) - ) - position_ids = torch.zeros((bs, num_token), device=input_ids.device) - cate_to_token_mask_list = [[] for _ in range(bs)] - previous_col = 0 - for i in range(idxs.shape[0]): - row, col = idxs[i] - if (col == 0) or (col == num_token - 1): - attention_mask[row, col, col] = True - position_ids[row, col] = 0 - else: - attention_mask[row, previous_col + 1 : col + 1, previous_col + 1 : col + 1] = True - position_ids[row, previous_col + 1 : col + 1] = torch.arange( - 0, col - previous_col, device=input_ids.device - ) - c2t_maski = torch.zeros((num_token), device=input_ids.device).bool() - c2t_maski[previous_col + 1 : col] = True - cate_to_token_mask_list[row].append(c2t_maski) - previous_col = col - - cate_to_token_mask_list = [ - torch.stack(cate_to_token_mask_listi, dim=0) - for cate_to_token_mask_listi in cate_to_token_mask_list - ] - - # # padding mask - # padding_mask = tokenized['attention_mask'] - # attention_mask = attention_mask & padding_mask.unsqueeze(1).bool() & padding_mask.unsqueeze(2).bool() - - return attention_mask, position_ids.to(torch.long), cate_to_token_mask_list diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dpxenc.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dpxenc.c deleted file mode 100644 index e136cc1b9ea9477e30f729bc498c6a12b9abfce2..0000000000000000000000000000000000000000 --- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dpxenc.c +++ /dev/null @@ -1,295 +0,0 @@ -/* - * DPX (.dpx) image encoder - * Copyright (c) 2011 Peter Rossheight; j++) { - memcpy(dst, src, len); - memset(dst + len, 0, need_align); - dst += len + need_align; - src += frame->linesize[0]; - } - } else { - size = av_image_copy_to_buffer(buf + HEADER_SIZE, pkt->size - HEADER_SIZE, - (const uint8_t**)frame->data, frame->linesize, - avctx->pix_fmt, - avctx->width, avctx->height, 1); - } - if (size < 0) - return size; - break; - case 10: - if (s->planar) - encode_gbrp10(avctx, frame, buf + HEADER_SIZE); - else - encode_rgb48_10bit(avctx, frame, buf + HEADER_SIZE); - break; - case 12: - encode_gbrp12(avctx, frame, buf + HEADER_SIZE); - break; - default: - av_log(avctx, AV_LOG_ERROR, "Unsupported bit depth: %d\n", s->bits_per_component); - return -1; - } - - size += HEADER_SIZE; - - write32(buf + 16, size); /* file size */ - - *got_packet = 1; - - return 0; -} - -const FFCodec ff_dpx_encoder = { - .p.name = "dpx", - CODEC_LONG_NAME("DPX (Digital Picture Exchange) image"), - .p.type = AVMEDIA_TYPE_VIDEO, - .p.id = AV_CODEC_ID_DPX, - .p.capabilities = AV_CODEC_CAP_DR1, - .priv_data_size = sizeof(DPXContext), - .init = encode_init, - FF_CODEC_ENCODE_CB(encode_frame), - .p.pix_fmts = (const enum AVPixelFormat[]){ - AV_PIX_FMT_GRAY8, - AV_PIX_FMT_RGB24, AV_PIX_FMT_RGBA, AV_PIX_FMT_ABGR, - AV_PIX_FMT_GRAY16LE, AV_PIX_FMT_GRAY16BE, - AV_PIX_FMT_RGB48LE, AV_PIX_FMT_RGB48BE, - AV_PIX_FMT_RGBA64LE, AV_PIX_FMT_RGBA64BE, - AV_PIX_FMT_GBRP10LE, AV_PIX_FMT_GBRP10BE, - AV_PIX_FMT_GBRP12LE, AV_PIX_FMT_GBRP12BE, - AV_PIX_FMT_NONE}, -}; diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dvdsub.h b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dvdsub.h deleted file mode 100644 index 3f51c3f80569b526a9825212634ac4a7f62dbc6a..0000000000000000000000000000000000000000 --- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/dvdsub.h +++ /dev/null @@ -1,26 +0,0 @@ -/* - * This file is part of FFmpeg. - * - * FFmpeg is free software; you can redistribute it and/or - * modify it under the terms of the GNU Lesser General Public - * License as published by the Free Software Foundation; either - * version 2.1 of the License, or (at your option) any later version. - * - * FFmpeg is distributed in the hope that it will be useful, - * but WITHOUT ANY WARRANTY; without even the implied warranty of - * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU - * Lesser General Public License for more details. - * - * You should have received a copy of the GNU Lesser General Public - * License along with FFmpeg; if not, write to the Free Software - * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA - */ - -#ifndef AVCODEC_DVDSUB_H -#define AVCODEC_DVDSUB_H - -#include - -void ff_dvdsub_parse_palette(uint32_t *palette, const char *p); - -#endif /* AVCODEC_DVDSUB_H */ diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/libopus.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/libopus.c deleted file mode 100644 index 3d3b740a83c3251d6e25af50ced2b5680b21e019..0000000000000000000000000000000000000000 --- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/libopus.c +++ /dev/null @@ -1,47 +0,0 @@ -/* - * libopus encoder/decoder common code - * Copyright (c) 2012 Nicolas George - * - * This file is part of FFmpeg. - * - * FFmpeg is free software; you can redistribute it and/or - * modify it under the terms of the GNU Lesser General Public - * License as published by the Free Software Foundation; either - * version 2.1 of the License, or (at your option) any later version. - * - * FFmpeg is distributed in the hope that it will be useful, - * but WITHOUT ANY WARRANTY; without even the implied warranty of - * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU - * Lesser General Public License for more details. - * - * You should have received a copy of the GNU Lesser General Public - * License along with FFmpeg; if not, write to the Free Software - * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA - */ - -#include - -#include "libavutil/error.h" -#include "libopus.h" - -int ff_opus_error_to_averror(int err) -{ - switch (err) { - case OPUS_BAD_ARG: - return AVERROR(EINVAL); - case OPUS_BUFFER_TOO_SMALL: - return AVERROR_UNKNOWN; - case OPUS_INTERNAL_ERROR: - return AVERROR(EFAULT); - case OPUS_INVALID_PACKET: - return AVERROR_INVALIDDATA; - case OPUS_UNIMPLEMENTED: - return AVERROR(ENOSYS); - case OPUS_INVALID_STATE: - return AVERROR_UNKNOWN; - case OPUS_ALLOC_FAIL: - return AVERROR(ENOMEM); - default: - return AVERROR(EINVAL); - } -} diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/mips/h264pred_mips.h b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/mips/h264pred_mips.h deleted file mode 100644 index 136e2912524557c6762941cde7af7ccc034bb49e..0000000000000000000000000000000000000000 --- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/mips/h264pred_mips.h +++ /dev/null @@ -1,48 +0,0 @@ -/* - * Copyright (c) 2015 Zhou Xiaoyong
-How to Download Craftsman: Building Craft for PC
-Do you love building games where you can unleash your creativity and design your own world? If so, you might want to check out Craftsman: Building Craft, a free sandbox game that lets you create anything you can imagine with blocks. Whether you want to build a castle, a city, or a forest, you can do it in this game with various tools and resources. You can also explore different game modes, such as survival, creative, or multiplayer, and have fun with your friends.
-download craftsman building craft for pc
DOWNLOAD → https://urlca.com/2uO6sa
-But what if you want to play this game on a bigger screen with better controls and performance? Well, you're in luck because in this article, we will show you how to download Craftsman: Building Craft for PC using different methods. You can choose from using an Android emulator like BlueStacks or MEmu, or playing online in browser with now.gg. Read on to find out more about these methods and how they work.
-What is Craftsman: Building Craft?
-Craftsman: Building Craft is a simulation
Craftsman: Building Craft is a simulation game that is inspired by Minecraft, one of the most popular sandbox games of all time. In this game, you can build anything you want with blocks of different materials, shapes, and colors. You can also use tools like hammers, axes, and pickaxes to break and place blocks. You can also craft items like doors, windows, ladders, and furniture to decorate your buildings.
-The game has three modes that you can choose from: survival, creative, and multiplayer. In survival mode, you have to gather resources, craft items, and fight against enemies like zombies and spiders. You also have to manage your health and hunger levels. In creative mode, you have unlimited resources and no enemies. You can just focus on building whatever you want without any restrictions. In multiplayer mode, you can join other players online and collaborate or compete with them. You can chat with them, share your creations, and explore their worlds.
-Why Play Craftsman: Building Craft on PC?
-While Craftsman: Building Craft is a fun and addictive game to play on your mobile device, you might want to try playing it on your PC for a better gaming experience. Here are some of the benefits of playing Craftsman: Building Craft on PC:
--
-
So how do you play Craftsman: Building Craft on PC? Well, there are different methods that you can use, depending on what suits you best. In the next section, we will show you how to download and install Craftsman: Building Craft on PC using three different methods: BlueStacks, MEmu, and now.gg.
-How to Download and Install Craftsman: Building Craft on PC?
-To play Craftsman: Building Craft on PC, you need to use a software that can run Android apps on your computer. There are two types of software that can do this: Android emulators and cloud gaming platforms. Android emulators are programs that simulate an Android device on your PC, allowing you to install and run Android apps on it. Cloud gaming platforms are websites that stream Android games from their servers to your browser, allowing you to play them online without downloading anything.
-In this article, we will show you how to use three of the most popular and reliable software that can run Craftsman: Building Craft on PC: BlueStacks, MEmu, and now.gg. Each of these software has its own advantages and disadvantages, so you can choose the one that works best for you. Here are the steps for each method:
-Method 1: Using BlueStacks
-BlueStacks is one of the most popular and widely used Android emulators in the world. It has over 500 million users and supports thousands of Android games and apps. It also has many features that enhance your gaming experience, such as multi-instance, macro recorder, game controls, and game center. Here's how to use BlueStacks to play Craftsman: Building Craft on PC:
-How to play craftsman building craft on pc with memu[^1^]
-
-Bluestacks app player for craftsman building craft on pc[^2^]
-Craftsman building craft online in browser[^3^]
-LDPlayer emulator for craftsman building craft on pc[^4^]
-Craftsman building craft pc download free full version
-Craftsman building craft simulation game for pc
-Craftsman building craft building games for pc
-Craftsman building craft pixel graphics for pc
-Craftsman building craft creative sandbox for pc
-Craftsman building craft design simulator for pc
-Craftsman building craft multiplayer mode for pc
-Craftsman building craft net energy gain for pc
-Craftsman building craft holy grail fusion experiment for pc
-Craftsman building craft stargame22 developer for pc
-Craftsman building craft android gaming platform for pc
-Craftsman building craft high definition graphics for pc
-Craftsman building craft advanced keymapping function for pc
-Craftsman building craft record feature for pc
-Craftsman building craft minimalistic visuals for pc
-Craftsman building craft realistic sound effects for pc
-Craftsman building craft various game modes for pc
-Craftsman building craft skyscrapers and cabins for pc
-Craftsman building craft tools and resources for pc
-Craftsman building craft imagination and fun for pc
-Craftsman building craft windows 10/8/7 for pc
-Craftsman building craft mac os x for pc
-Craftsman building craft linux ubuntu for pc
-Craftsman building craft chrome os chromebook for pc
-Craftsman building craft nox app player for pc
-Craftsman building craft gameloop tencent gaming buddy for pc
-Craftsman building craft smartgaga android emulator for pc
-Craftsman building craft genymotion virtual device manager for pc
-Craftsman building craft andy android emulator for pc
-Craftsman building craft koplayer android emulator for pc
-Craftsman building craft droid4x android simulator for pc
-Craftsman building craft remix os player android emulator for pc
-Craftsman building craft mumu app player mac version for pc
-Craftsman building craft phoenix os android based operating system for pc
-Craftsman building craft primeos android x86 operating system for pc
-Craftsman building craft open thos android x86 operating system for pcStep 1: Download and Install BlueStacks
-To download BlueStacks, go to https://www.bluestacks.com/ and click on the "Download BlueStacks" button. This will download the installer file to your PC. Once the download is complete, open the file and follow the instructions to install BlueStacks on your PC.
-Step 2: Sign in to Google Play Store
-After installing BlueStacks, launch it from your desktop or start menu. You will see a welcome screen where you need to sign in to Google Play Store using your Google account. If you don't have a Google account, you can create one for free by clicking on the "Create account" link.
-Step 3: Search for Craftsman: Building Craft
-Once you sign in to Google Play Store, you will see the home screen of BlueStacks with various apps and games. To search for Craftsman: Building Craft, click on the search icon at the top right corner of the screen and type in "Craftsman: Building Craft" in the
search bar. You will see the game's icon and name in the search results. Click on it to go to the game's page on Google Play Store.
-Step 4: Install Craftsman: Building Craft
-On the game's page, you will see an "Install" button. Click on it to start downloading and installing the game on BlueStacks. You will see a progress bar and a notification when the installation is complete.
-Step 5: Start Playing
-After installing the game, you can start playing it by clicking on the game's icon on the home screen of BlueStacks. You can also find it in the "My games" tab on the sidebar. You will see the game's loading screen and then the main menu. You can choose your game mode and start building your world.
-Method 2: Using MEmu
-MEmu is another Android emulator that you can use to play Craftsman: Building Craft on PC. It is fast, stable, and compatible with many Android games and apps. It also has features like keyboard mapping, screen recording, and multiple instances. Here's how to use MEmu to play Craftsman: Building Craft on PC:
-Step 1: Download and Install MEmu
-To download MEmu, go to https://www.memuplay.com/ and click on the "Download" button. This will download the installer file to your PC. Once the download is complete, open the file and follow the instructions to install MEmu on your PC.
-Step 2: Start MEmu and Open Google Play
-After installing MEmu, launch it from your desktop or start menu. You will see the MEmu desktop with various icons and widgets. To open Google Play, click on the "Play Store" icon on the bottom right corner of the screen. You will need to sign in to Google Play using your Google account or create one if needed.
-Step 3: Search for Craftsman: Building Craft
-Once you sign in to Google Play, you will see the home screen of Google Play with various apps and games. To search for Craftsman: Building Craft, click on the search icon at the top left corner of the screen and type in "Craftsman: Building Craft" in the search bar. You will see the game's icon and name in the search results. Click on it to go to the game's page on Google Play.
-Step 4: Download and Install Craftsman: Building Craft
-On the game's page, you will see a "Download" button. Click on it to start downloading and installing the game on MEmu. You will see a progress bar and a notification when the installation is complete.
-Step 5: Start Playing
-After installing the game, you can start playing it by clicking on the game's icon on the MEmu desktop. You can also find it in the "My games" folder on the sidebar. You will see the game's loading screen and then the main menu. You can choose your game mode and start building your world.
-Method 3: Using now.gg
-now.gg is a cloud gaming platform that allows you to play Android games online in browser without downloading anything. It streams games from its servers to your browser, so you don't need to install any software or emulator on your PC. It also has features like cloud save, social login, and chat. Here's how to use now.gg to play Craftsman: Building Craft online:
-Step 1: Go to now.gg Website
-To access now.gg, go to https://now.gg/ using any browser that supports HTML5, such as Chrome, Firefox, or Edge. You will see the now.gg website with various games and categories.
-Step 2: Search for Craftsman: Building Craft
-To search for Craftsman: Building Craft, click on the search icon at the top right corner of the website and type in "Craftsman: Building Craft" in
the search bar. You will see the game's icon and name in the search results. Click on it to go to the game's page on now.gg.
-Step 3: Click and Play Instantly
-On the game's page, you will see a "Play" button. Click on it to start playing the game online in browser without downloading anything. You will see the game's loading screen and then the main menu. You can choose your game mode and start building your world.
-Conclusion
-Craftsman: Building Craft is a fun and creative game that lets you build anything you want with blocks. You can also explore different game modes and play with your friends online. If you want to play this game on PC, you can use one of the three methods we showed you in this article: BlueStacks, MEmu, or now.gg. Each of these methods has its own pros and cons, so you can choose the one that suits you best. We hope you found this article helpful and informative. Now go ahead and download Craftsman: Building Craft for PC and enjoy building your own world.
-FAQs
-Here are some of the frequently asked questions and answers about Craftsman: Building Craft and how to play it on PC:
--
-
-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/Geometry Dash World Full Version PC Download and Play the Game with BlueStacks Emulator.md b/spaces/congsaPfin/Manga-OCR/logs/Geometry Dash World Full Version PC Download and Play the Game with BlueStacks Emulator.md deleted file mode 100644 index dd5b4e153183d113757cb25a483dd5fa7b9566fd..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/Geometry Dash World Full Version PC Download and Play the Game with BlueStacks Emulator.md +++ /dev/null @@ -1,196 +0,0 @@ -
-How to Download Geometry Dash World Full Version PC
-If you are looking for a challenging and fun game to play on your PC, you might want to check out Geometry Dash World. This is a spin-off of the popular Geometry Dash series, which combines rhythm-based action platforming with colorful graphics and catchy music. In this article, we will explain what Geometry Dash World is, why you should download it, and how to do it in two easy ways.
-download geometry dash world full version pc
Download Zip ►►►►► https://urlca.com/2uOcxN
-What is Geometry Dash World?
-Geometry Dash World is a game developed by RobTop Games, a Swedish indie game studio. It was released in December 2016 as a free-to-play game for mobile devices, and later ported to Windows PC. It is a spin-off of Geometry Dash, which was first released in 2013 and has become one of the most popular games in the genre.
-A spin-off of Geometry Dash
-Geometry Dash is a series of games that feature a simple but addictive gameplay mechanic. You control a geometric shape that can jump, fly, and flip through various obstacles in sync with the music. The game is known for its high difficulty level, as one mistake can send you back to the beginning of the level. The game also allows you to create your own levels and share them online with other players.
-Geometry Dash World is a spin-off that introduces new features and content to the original game. It has two worlds with five levels each, new enemies, new music, new icons, and new secrets. It also has a shop, a vault, daily quests, rewards, and hidden chests. The game is designed to showcase the new features of Geometry Dash version 2.1, which was released in January 2017.
-How to download geometry dash world on pc for free
-
-Geometry dash world pc download windows 10
-Geometry dash world full version free download pc
-Geometry dash world steam download
-Geometry dash world emulator for pc
-Geometry dash world online play on pc
-Geometry dash world pc game download
-Geometry dash world bluestacks download
-Geometry dash world apk download for pc
-Geometry dash world pc requirements
-Geometry dash world mac download
-Geometry dash world pc cheats
-Geometry dash world pc mods
-Geometry dash world pc hack
-Geometry dash world pc controller support
-Geometry dash world pc gameplay
-Geometry dash world pc review
-Geometry dash world pc tips and tricks
-Geometry dash world pc update
-Geometry dash world pc level editor
-Geometry dash world pc custom levels
-Geometry dash world pc achievements
-Geometry dash world pc soundtrack download
-Geometry dash world pc nox player download
-Geometry dash world pc memu play download
-Geometry dash world pc ldplayer download
-Geometry dash world pc gameloop download
-Geometry dash world pc koplayer download
-Geometry dash world pc droid4x download
-Geometry dash world pc andy emulator download
-Geometry dash world windows 7 download
-Geometry dash world windows 8 download
-Geometry dash world windows xp download
-Geometry dash world linux download
-Geometry dash world chromebook download
-Geometry dash world desktop download
-Geometry dash world laptop download
-Download geometry dash subzero for pc full version free
-Download geometry dash meltdown for pc full version free
-Download geometry dash lite for pc full version free
-Download geometry dash for pc full version free 2023 update
-Download geometry dash 2.2 for pc full version free
-Download geometry dash 2.1 for pc full version free
-Download geometry dash 2.0 for pc full version free
-Download geometry dash 1.9 for pc full version free
-Download geometry dash 1.8 for pc full version free
-Download geometry dash 1.7 for pc full version free
-Download geometry dash 1.6 for pc full version free
-Download geometry dash 1.5 for pc full version freeA rhythm-based action platformer
-Geometry Dash World is a game that combines rhythm and action elements in a platformer style. The game is based on timing your jumps and movements to match the beat of the music. The game has various modes, such as normal mode, practice mode, and online mode. In normal mode, you have to complete each level without dying. In practice mode, you can use checkpoints to save your progress and practice difficult parts. In online mode, you can play levels created by other players or upload your own levels.
-The game has different types of levels, such as normal levels, demon levels, gauntlet levels, map pack levels, and featured levels. Normal levels are the official levels made by the developer, RobTop Games. Demon levels are the hardest levels in the game, and require a lot of skill and practice to complete. Gauntlet levels are collections of five levels with a common theme or difficulty. Map pack levels are collections of three levels with a common theme or difficulty. Featured levels are the best levels created by the community, and are selected by the moderators of the game.
-A game with two worlds and ten levels
-Geometry Dash World has two worlds: Dashlands and Toxic Factory. Each world has five levels, which are named as follows:
--
-- -World -Level -Difficulty -Song -- -Dashlands -Payload -Easy -Payload by Dex Arson -- -Dashlands -Beast Mode -Normal -Beast Mode by Dex Arson -- -Dashlands -Machina -Hard -Machina by Dex Arson -- -Dashlands -Years -Harder -Years by Dex Arson & Waterflame -- -Dashlands -Frontlines -Insane -Frontlines by Dex Arson & Waterflame -- -Toxic Factory -Spike Factory -Easy -Spike Factory by F-777 & Dex Arson -- Toxic Factory -Piano Masters -Normal -Piano Masters by F-777 & Dex Arson - -Toxic Factory -Space Pirates -Hard -Space Pirates by Waterflame -- -Toxic Factory -Striker -Harder -Striker by Waterflame -- -Toxic Factory -Embers -Insane -Embers by Dex Arson & Waterflame -To complete each level, you have to avoid the obstacles and reach the end portal. You can collect stars, orbs, diamonds, keys, and coins along the way. You can also unlock achievements and rewards for completing certain tasks or challenges. The game has a colorful and dynamic design, with different themes and backgrounds for each level. The game also has a catchy and energetic soundtrack, with songs from various artists such as Dex Arson, Waterflame, and F-777.
-Why Download Geometry Dash World Full Version PC?
-Geometry Dash World is a game that can be enjoyed by anyone who likes rhythm-based action platformers. However, if you want to have the best experience possible, you might want to download the full version of the game for your PC. Here are some reasons why:
-To enjoy better graphics and performance
-One of the advantages of playing Geometry Dash World on your PC is that you can enjoy better graphics and performance than on your mobile device. You can adjust the resolution, quality, and frame rate of the game to suit your preferences and capabilities of your PC. You can also play the game in full screen mode, which can enhance your immersion and concentration. Playing on your PC can also reduce the risk of lagging, crashing, or overheating that might occur on your mobile device.
-To access more features and content
-Another benefit of downloading Geometry Dash World full version PC is that you can access more features and content than on your mobile device. For example, you can use the level editor to create your own levels and share them online with other players. You can also download and play thousands of online levels created by the community, which can offer you endless variety and challenge. You can also use the practice mode to improve your skills and master difficult levels. You can also customize your character with different icons, colors, trails, and effects.
-To play online levels created by the community
-A final reason why you should download Geometry Dash World full version PC is that you can play online levels created by the community. These are levels that are uploaded by other players using the level editor. They can range from easy to demon difficulty, and from simple to complex design. They can also feature different themes, music, gameplay mechanics, and secrets. Playing online levels can give you a new perspective on the game, as well as challenge your skills and creativity. You can also rate, comment, and like the levels that you play, as well as follow your favorite creators.
How to Download Geometry Dash World Full Version PC?
-Now that you know what Geometry Dash World is and why you should download it, you might be wondering how to do it. Well, there are two easy options that you can choose from. You can either download the game from the official website of RobTop Games, or from a third-party platform such as Steam, Epic Games, or GOG. Here are the steps for each option:
-Option 1: From the official website
-This is the simplest and most direct way to download Geometry Dash World full version PC. All you need to do is visit the official website of RobTop Games, which is https://www.robtopgames.com/. There, you will find a download button for Geometry Dash World, as well as other games from the same developer. Here are the steps to follow:
-Step 1: Visit the website and click on the download button
-Go to https://www.robtopgames.com/ and look for the Geometry Dash World section. You will see a download button that says "Download for Windows". Click on it and you will be redirected to a page where you can choose your preferred language and location.
-Step 2: Run the installer and follow the instructions
-After choosing your language and location, you will see a link that says "Download Geometry Dash World". Click on it and you will start downloading the installer file for the game. The file size is about 50 MB, so it should not take long to download. Once the download is complete, run the installer file and follow the instructions on the screen. You will be asked to agree to the terms and conditions, choose a destination folder, and create a shortcut.
-Step 3: Launch the game and start playing
-Once the installation is done, you will see a message that says "Geometry Dash World has been installed successfully". You can either click on "Finish" to close the installer, or on "Play" to launch the game. You can also launch the game from your desktop shortcut or your start menu. The game will open in a windowed mode, but you can switch to full screen mode by pressing F11. You can also adjust the settings of the game from the options menu. Now you can start playing Geometry Dash World on your PC!
-Option 2: From a third-party platform
-This is another way to download Geometry Dash World full version PC, but it requires you to use a third-party platform such as Steam, Epic Games, or GOG. These are platforms that allow you to buy, download, and play games from various developers and publishers. They also offer other features such as cloud saving, achievements, social features, and more. Here are the steps to follow:
-Step 1: Choose a platform such as Steam, Epic Games, or GOG
-The first step is to choose which platform you want to use to download Geometry Dash World. There are several options available, but some of the most popular ones are Steam, Epic Games, and GOG. Each platform has its own advantages and disadvantages, so you might want to do some research before deciding which one suits you best. Here are some brief descriptions of each platform:
--
-
You can choose any of these platforms or any other platform that offers Geometry Dash World for PC. Just make sure that the platform is trustworthy and secure before using it.
-Step 2: Create an account and install the launcher
-The next step is to create an account on the platform that you chose and install its launcher on your PC. You will need to provide some basic information such as your name, email, password, and username. You might also need to verify your email or phone number. After creating your account, you will be able to access the platform's website or launcher. You will need to download and install the launcher on your PC, which is a program that allows you to manage your games and access other features of the platform.
-Step 3: Search for Geometry Dash World and purchase or get it for free
-The third step is to search for Geometry Dash World on the platform that you chose and purchase or get it for free. You can use the search bar or the browse function to find the game. You will see a page that shows the game's details, such as its description, screenshots, videos, reviews, and ratings. You will also see a button that says "Buy", "Get", or something similar. Depending on the platform and the game, you might need to pay a certain amount of money or get it for free. If you need to pay, you will need to provide your payment information and confirm your purchase. If you get it for free, you will just need to click on the button and add the game to your library.
-Step 4: Download and install the game from your library
-The fourth step is to download and install Geometry Dash World from your library. You can access your library from the platform's website or launcher. You will see a list of games that you own or have access to. You will find Geometry Dash World among them. You will see a button that says "Download", "Install", or something similar. Click on it and you will start downloading the game files to your PC. The file size is about 50 MB, so it should not take long to download. Once the download is complete, you will see a button that says "Play", "Launch", or something similar. Click on it and you will start installing the game on your PC. The installation process is similar to the one from the official website, so you just need to follow the instructions on the screen.
-Step 5: Launch the game and start playing
-The final step is to launch Geometry Dash World and start playing. You can launch the game from your library or from your desktop shortcut or start menu. The game will open in a windowed mode, but you can switch to full screen mode by pressing F11. You can also adjust the settings of the game from the options menu. Now you can start playing Geometry Dash World on your PC!
-Conclusion
-Geometry Dash World is a fun and challenging game that can keep you entertained for hours. It is a spin-off of Geometry Dash, which is a popular rhythm-based action platformer series. It has two worlds with ten levels each, as well as online levels created by the community. It also has a level editor, a shop, a vault, daily quests, rewards, and hidden chests.
-If you want to download Geometry Dash World full version PC, you have two easy options. You can either download it from the official website of RobTop Games, or from a third-party platform such as Steam, Epic Games, or GOG. Both options are simple and straightforward, and only require a few steps to follow.
-Here are some tips and recommendations for playing Geometry Dash World:
--
-
FAQs
-Q1. How much does Geometry Dash World cost?
-A1. Geometry Dash World is free-to-play on mobile devices and PC. However, some features and content might require in-app purchases or subscriptions.
-Q2. What are the system requirements for Geometry Dash World?
-A2. Geometry Dash World does not have high system requirements for PC. Here are the minimum requirements:
--
-
Q3. How can I customize my character in Geometry Dash World?
-A3. You can customize your character by changing its icon, color, trail, and effect. You can unlock new icons, colors, trails, and effects by collecting stars, orbs, diamonds, keys, and coins. You can also buy them from the shop or get them from the vault. To change your character's appearance, go to the options menu and click on the icon button. There, you can choose from different categories such as cubes, ships, balls, UFOs, waves, robots, and spiders. You can also select your primary and secondary colors, as well as your trail and effect.
-Q4. How can I create my own levels in Geometry Dash World?
-A4. You can create your own levels in Geometry Dash World by using the level editor. The level editor is a tool that allows you to design and build your own levels using various blocks, objects, enemies, triggers, and effects. You can also choose the music, background, ground, and color of your level. To access the level editor, go to the main menu and click on the create button. There, you can start a new level or edit an existing one. You can also test your level by clicking on the play button. To upload your level online, go to the online menu and click on the upload button. There, you can name your level, choose its difficulty and description, and submit it for approval.
-Q5. How can I play Geometry Dash World on other devices?
-A5. You can play Geometry Dash World on other devices such as Android or iOS smartphones or tablets. To do so, you need to download the game from the Google Play Store or the App Store. The game is compatible with most devices that run Android 4.0 or higher or iOS 8.0 or higher. The game is free-to-play on both platforms, but some features and content might require in-app purchases or subscriptions.
197e85843d
-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/Laughing Minions Wallpapers Funny and Cute Despicable Me Characters.md b/spaces/congsaPfin/Manga-OCR/logs/Laughing Minions Wallpapers Funny and Cute Despicable Me Characters.md deleted file mode 100644 index e369df46da9b647c1950a7dec2dcdb699d7aea1c..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/Laughing Minions Wallpapers Funny and Cute Despicable Me Characters.md +++ /dev/null @@ -1,99 +0,0 @@ -
-Minions Wallpaper: A Fun Way to Decorate Your Device
-If you are a fan of the cute and hilarious yellow creatures known as minions, you might want to show your love by using a minions wallpaper on your device. Whether it is your desktop, laptop, tablet, or phone, a minions wallpaper can add some color and fun to your screen. In this article, we will tell you what are minions, what are minions wallpapers, what are the types and benefits of minions wallpapers, and how to find and download them.
-minions wallpaper
Download File » https://urlca.com/2uO5Hc
-What are Minions and Why are They Popular?
-Minions are an all-male species of fictional yellow creatures that appear in Illumination's Despicable Me franchise. They are characterized by their childlike behavior and their language, which is largely unintelligible. They have one or two eyes, wear denim overalls and goggles, and have three fingers on each hand. They are loyal followers of the most despicable villains in history, such as Gru, Scarlet Overkill, and the Vicious 6.
-Minions are popular because they are adorable, funny, and relatable. They have a sense of humor, curiosity, and adventure that appeals to people of all ages. They also have a unique style and personality that makes them stand out from other animated characters. They have become icons of pop culture and have spawned many merchandise, games, books, spin-offs, and memes.
-What are Minions Wallpapers and How to Use Them?
-Minions wallpapers are digital images that feature minions in various poses, settings, or situations. They can be used as backgrounds for your device's screen to make it more attractive and personalized. You can choose a minions wallpaper that matches your mood, preference, or theme.
-To use a minions wallpaper, you need to download it from a reliable source and save it on your device. Then, you need to go to your device's settings and select the option to change your wallpaper. You can then browse through your saved images and pick the one you want to use. You can also adjust the size, position, or orientation of the image to fit your screen.
-Types of Minions Wallpapers
-There are many types of minions wallpapers that you can choose from. Here are some of the most common ones:
-Minions from Despicable Me Movies
-These are wallpapers that feature minions from the Despicable Me movies (2010-2017), where they serve as Gru's henchmen and adoptive children's friends. You can find wallpapers that show them in different scenes or activities from the movies, such as stealing the moon, fighting Vector or El Macho, or celebrating Christmas.
-Minions from Minions Movies
-These are wallpapers that feature minions from the Minions movies (2015-2022), where they star as the main protagonists and seek out new villains to serve. You can find wallpapers that show them in different locations or eras from the movies, such as ancient Egypt, medieval England, or 1970s New York.
-minions wallpaper hd
-
-minions wallpaper 4k
-minions wallpaper for laptop
-minions wallpaper for phone
-minions wallpaper download
-minions wallpaper cute
-minions wallpaper funny
-minions wallpaper 1920x1080
-minions wallpaper despicable me
-minions wallpaper the avengers
-minions wallpaper hitman
-minions wallpaper banana
-minions wallpaper movie
-minions wallpaper bob
-minions wallpaper stuart
-minions wallpaper kevin
-minions wallpaper 8k
-minions wallpaper 5k
-minions wallpaper 2k
-minions wallpaper 1080p
-minions wallpaper free
-minions wallpaper iphone
-minions wallpaper android
-minions wallpaper samsung
-minions wallpaper windows 10
-minions wallpaper macbook
-minions wallpaper ipad
-minions wallpaper desktop
-minions wallpaper pc
-minions wallpaper widescreen
-minions wallpaper high resolution
-minions wallpaper high quality
-minions wallpaper simple background
-minions wallpaper white background
-minions wallpaper yellow background
-minions wallpaper blue background
-minions wallpaper black background
-minions wallpaper pink background
-minions wallpaper purple background
-minions wallpaper green background
-minions wallpaper red background
-minions wallpaper orange background
-minions wallpaper rainbow background
-minions wallpaper christmas theme
-minions wallpaper halloween theme
-minions wallpaper valentine theme
-minions wallpaper summer theme
-minions wallpaper winter theme
-minions wallpaper spring theme
-minions wallpaper autumn themeMinions with Other Characters or Themes
-These are wallpapers that feature minions with other characters or themes from popular culture or media. You can find wallpapers that show them dressed up as superheroes, pirates, ninjas, or other costumes. You can also find wallpapers that show them interacting with other characters from movies, TV shows, games, or comics.
-Benefits of Minions Wallpapers
Using a minions wallpaper can have several benefits for you and your device. Here are some of them:
-Brighten Up Your Mood and Device
-Minions wallpapers can make your device look more lively and cheerful. The bright colors, funny expressions, and amusing situations of the minions can bring a smile to your face and lighten up your mood. You can also change your wallpaper according to your mood or the season, such as using a festive or spooky one for holidays.
-Express Your Personality and Fandom
-Minions wallpapers can also help you express your personality and fandom. You can choose a wallpaper that reflects your interests, hobbies, or preferences. For example, if you like music, you can use a wallpaper that shows the minions playing instruments or singing. You can also show your support and appreciation for the minions and the Despicable Me franchise by using a wallpaper that features them.
-Support the Creators and Franchise
-Another benefit of using a minions wallpaper is that you can support the creators and franchise of the minions. By using a wallpaper that is official or licensed, you can help them generate revenue and recognition. You can also spread the word and popularity of the minions by sharing your wallpaper with others or recommending them to watch the movies or buy the merchandise.
-How to Find and Download Minions Wallpapers
-If you are looking for minions wallpapers, there are many ways to find and download them. Here are some of the best methods:
-Use Bing Image Search with Keywords and Filters
-One of the easiest and fastest ways to find minions wallpapers is to use Bing image search with keywords and filters. You can type in "minions wallpaper" or any other related term in the search box and hit enter. You can then use the filters on the top or side of the page to narrow down your results by size, color, type, layout, or license. You can also use the "Related searches" section at the bottom of the page to find more suggestions.
-Visit Official or Fan Websites for High-Quality Images
-Another way to find minions wallpapers is to visit official or fan websites that offer high-quality images. You can go to the official website of Illumination or Minions to find wallpapers that are created by the studio or approved by them. You can also go to fan websites such as Minion Land or Minions Art to find wallpapers that are made by fans or artists who love the minions.
-Check the License and Resolution Before Downloading
-Before you download a minions wallpaper, you should check the license and resolution of the image. The license tells you how you can use the image legally and ethically. You should look for images that are free to use, share, or modify, or that require attribution or permission from the owner. The resolution tells you how clear and sharp the image will look on your screen. You should look for images that have a high resolution (at least 1920 x 1080 pixels) or that match your device's screen size.
-Conclusion
-Minions wallpapers are a fun way to decorate your device and show your love for the yellow creatures. They come in various types and styles, and they have many benefits for you and your device. You can find and download them easily by using Bing image search, visiting official or fan websites, and checking the license and resolution of the image. So what are you waiting for? Go ahead and choose a minions wallpaper that suits your taste and enjoy!
-Frequently Asked Questions
-What are minions?
-Minions are an all-male species of fictional yellow creatures that appear in Illumination's Despicable Me franchise. They are loyal followers of the most despicable villains in history.
-What are minions wallpapers?
-Minions wallpapers are digital images that feature minions in various poses, settings, or situations. They can be used as backgrounds for your device's screen.
-What are the types of minions wallpapers?
-There are many types of minions wallpapers, such as minions from Despicable Me movies, minions from Minions movies, or minions with other characters or themes.
-What are the benefits of minions wallpapers?
-Some of the benefits of minions wallpapers are that they can brighten up your mood and device, express your personality and fandom, and support the creators and franchise.
-How to find and download minions wallpapers?
-You can find and download minions wallpapers by using Bing image search with keywords and filters, visiting official or fan websites, and checking the license and resolution of the image.
-I hope this article has helped you learn more about minions wallpapers and how to use them. If you have any questions or feedback, please feel free to leave a comment below. Thank you for reading and have a great day!
197e85843d
-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/Raft Survival Ocean Nomad - Multiplayer Mod APK for Android Devices.md b/spaces/congsaPfin/Manga-OCR/logs/Raft Survival Ocean Nomad - Multiplayer Mod APK for Android Devices.md deleted file mode 100644 index c1650be34247bdd99b9e09ad99b7cd1cd1b00de0..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/Raft Survival Ocean Nomad - Multiplayer Mod APK for Android Devices.md +++ /dev/null @@ -1,86 +0,0 @@ - -Raft Survival: Ocean Nomad Multiplayer Mod APK - A Thrilling Adventure on the Sea
-Introduction
-Do you love survival games? Do you want to experience a challenging and exciting adventure on the ocean? Do you want to play with your friends and other players online? If you answered yes to any of these questions, then you should try Raft Survival: Ocean Nomad Multiplayer Mod APK.
-What is Raft Survival: Ocean Nomad?
-Raft Survival: Ocean Nomad is a survival simulator game that puts you in the role of a survivor who has to survive on a raft in the middle of the ocean. You have to look for food and water, craft items, build your raft, fight sharks and other enemies, and explore islands and wrecks. You can also customize your character and your raft with different skins and items.
-raft survival ocean nomad multiplayer mod apk
Download >>>>> https://urlca.com/2uOb67
-What is Multiplayer Mod APK?
-Multiplayer Mod APK is a modified version of Raft Survival: Ocean Nomad that allows you to play online with other players. You can join or create a server, chat with other players, cooperate or compete with them, and share your resources and items. You can also enjoy unlimited coins, resources, and no ads in this mod.
-Why You Should Try Raft Survival: Ocean Nomad Multiplayer Mod APK
-Raft Survival: Ocean Nomad Multiplayer Mod APK is a fun and addictive game that will keep you entertained for hours. You can enjoy the following benefits when you play this mod:
-Features of Raft Survival: Ocean Nomad Multiplayer Mod APK
-Unlimited Coins
-Coins are the currency in Raft Survival: Ocean Nomad that you can use to buy skins, items, and upgrades. With unlimited coins, you can buy anything you want without worrying about running out of money. You can also use coins to revive yourself if you die in the game.
-Unlimited Resources
-Resources are the materials that you need to craft items, build your raft, and survive on the ocean. You can find resources by fishing, collecting debris, harvesting plants, and looting islands and wrecks. With unlimited resources, you can craft and build anything you need without having to search for them. You can also use resources to trade with other players.
-Raft Survival: Ocean Nomad (MOD, Unlimited Coins) 1.214.7 APK
-
-Download Raft Survival: Ocean Nomad Mod Apk for Android
-Raft Survival: Ocean Nomad - Simulator with Multiplayer Mode
-How to Install Raft Survival: Ocean Nomad Mod Apk on PC
-Raft Survival: Ocean Nomad Hack - Get Free Coins and Resources
-Raft Survival: Ocean Nomad Mod Apk Features and Gameplay
-Best Tips and Tricks for Raft Survival: Ocean Nomad Game
-Raft Survival: Ocean Nomad Review - A Fun and Challenging Survival Game
-Raft Survival: Ocean Nomad Cheats - How to Get Unlimited Coins and Resources
-Raft Survival: Ocean Nomad Online - Play with Friends and Other Players
-Raft Survival: Ocean Nomad Mod Apk Download Link and Instructions
-Raft Survival: Ocean Nomad Wiki - Everything You Need to Know About the Game
-Raft Survival: Ocean Nomad Update - What's New in the Latest Version
-Raft Survival: Ocean Nomad Guide - How to Survive and Thrive in the Ocean
-Raft Survival: Ocean Nomad Mod Menu - How to Access and Use It
-Raft Survival: Ocean Nomad for PC - How to Play on Windows and Mac
-Raft Survival: Ocean Nomad Apk + Mod + Data for Android
-Raft Survival: Ocean Nomad Multiplayer - How to Join and Host a Server
-Raft Survival: Ocean Nomad Crafting - How to Make Tools, Weapons, and Items
-Raft Survival: Ocean Nomad Modded Apk - How to Download and Install It
-Raft Survival: Ocean Nomad Gameplay - How to Play and Enjoy the Game
-Raft Survival: Ocean Nomad Hack Apk - How to Get Free Coins and Resources
-Raft Survival: Ocean Nomad Mod Apk Unlimited Money and Resources
-Raft Survival: Ocean Nomad Simulator - How to Explore and Survive in the Ocean
-Raft Survival: Ocean Nomad Free Download for Android Devices
-Raft Survival: Ocean Nomad Tips and Hints - How to Improve Your Skills and Strategy
-Raft Survival: Ocean Nomad Mod Apk Latest Version for Android
-Raft Survival: Ocean Nomad No Ads - How to Remove Ads from the Game
-Raft Survival: Ocean Nomad Offline - How to Play Without Internet Connection
-Raft Survival: Ocean Nomad Mod Apk All Unlocked - How to Unlock Everything in the GameNo Ads
-Ads are the annoying pop-ups that interrupt your gameplay and make you watch videos or install apps. With no ads, you can enjoy the game without any distractions or interruptions. You can also save your data and battery by not having to load ads.
-How to Download and Install Raft Survival: Ocean Nomad Multiplayer Mod APK
-If you want to try Raft Survival: Ocean Nomad Multiplayer Mod APK, you have to follow these simple steps:
-Step 1: Enable Unknown Sources
-Before you can install the mod, you have to enable unknown sources on your device. This will allow you to install apps that are not from the Google Play Store. To do this, go to your device settings, then security, then unknown sources, and turn it on.
-Step 2: Download the APK File
-Next, you have to download the APK file of Raft Survival: Ocean Nomad Multiplayer Mod APK. You can find the link to download it here . Make sure you have enough storage space on your device before downloading it.
-Step 3: Install the APK File
-After downloading the APK file, you have to install it on your device. To do this, locate the file in your downloads folder and tap on it. Then, follow the instructions on the screen to complete the installation.
-Step 4: Launch the Game and Enjoy
-Finally, you can launch the game and enjoy playing Raft Survival: Ocean Nomad Multiplayer Mod APK. You can create or join a server, chat with other players, and survive on the ocean with unlimited coins and resources.
-Tips and Tricks for Raft Survival: Ocean Nomad Multiplayer Mod APK
-To make the most out of Raft Survival: Ocean Nomad Multiplayer Mod APK, here are some tips and tricks that you should know:
-Build Your Raft Wisely
-Your raft is your home and your lifeline on the ocean. You have to build it wisely and expand it as you go. You can use different items and structures to make your raft more comfortable and functional. For example, you can use a sail to move faster, a bed to sleep and save your progress, a water purifier to get fresh water, a grill to cook food, a chest to store items, a crop plot to grow plants, a research table to unlock new items, and more. You can also decorate your raft with different skins and items to make it look more appealing.
-Explore the Islands and Wrecks
-The ocean is full of islands and wrecks that you can explore for loot and resources. You can find different items such as blueprints, weapons, armor, tools, seeds, food, water, and more. You can also encounter different enemies such as pirates, mutants, zombies, and more. You can use a raft or a boat to travel between islands and wrecks. You can also use an anchor to stop your raft from drifting away while you explore.
-Craft Weapons and Tools
-You will need weapons and tools to survive on the ocean. You can craft different weapons such as spears, axes, knives, bows, guns, and more. You can use them to fight sharks and other enemies, hunt animals and fish, and chop trees and plants. You can also craft different tools such as hooks, nets, paddles, binoculars, compasses, and more. You can use them to collect debris, catch fish, move your raft, see farther, navigate the ocean, and more.
-Watch Out for Sharks and Other Dangers
-The ocean is not a safe place. You have to watch out for sharks and other dangers that can harm you or your raft. Sharks can attack you or your raft and cause damage or death. You can use weapons or shark bait to fend them off or distract them. You can also encounter other dangers such as storms, waves, radiation, hunger, thirst, cold, heat, and more. You have to prepare yourself and your raft for these situations and use items such as clothes, armor, bandages, medicine, food, water, fire, and more.
-Conclusion
-Raft Survival: Ocean Nomad Multiplayer Mod APK is a game that will test your survival skills and creativity on the ocean. You can play online with other players and enjoy unlimited coins and resources. You can also explore islands and wrecks, craft weapons and tools, build your raft, and fight sharks and other enemies. If you are looking for a thrilling and fun adventure on the sea, you should download Raft Survival: Ocean Nomad Multiplayer Mod APK today.
-FAQs
-Here are some frequently asked questions about Raft Survival: Ocean Nomad Multiplayer Mod APK:
--
-
Yes, Raft Survival: Ocean Nomad Multiplayer Mod APK is safe to download and install. It does not contain any viruses or malware that can harm your device or data. However, you should always download it from a trusted source and scan it with an antivirus before installing it.
-Raft Survival: Ocean Nomad Multiplayer Mod APK is compatible with most Android devices that have Android 4.1 or higher. However, some devices may experience performance issues or crashes due to hardware limitations or compatibility issues. You should check the minimum requirements of the game before downloading it.
-No, Raft Survival: Ocean Nomad Multiplayer Mod APK requires an internet connection to play online with other players. You cannot play it offline or without a network connection.
-Yes, you can play Raft Survival: Ocean Nomad Multiplayer Mod APK with your friends and other players online. You can join or create a server, chat with other players, cooperate or compete with them, and share your resources and items.
-You can update Raft Survival: Ocean Nomad Multiplayer Mod APK by downloading the latest version of the mod from the same source where you downloaded it before. You should always update the mod to enjoy the latest features and bug fixes.
-
-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/Rubik 39s Cube Solver 3x3 Mod Apk.md b/spaces/congsaPfin/Manga-OCR/logs/Rubik 39s Cube Solver 3x3 Mod Apk.md deleted file mode 100644 index 499c0524d54eccb84f74dd80f3536aa8c59f48af..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/Rubik 39s Cube Solver 3x3 Mod Apk.md +++ /dev/null @@ -1,49 +0,0 @@ -
-Rubik's Cube Solver 3x3 Mod Apk: How to Solve the Cube in Seconds
-The Rubik's cube is one of the most popular and challenging puzzles in the world. It was invented by Hungarian professor Erno Rubik in 1974 and has since sold over 350 million units worldwide. The cube consists of six faces, each with nine stickers of one of six colors: white, yellow, green, blue, orange, and red. The goal is to twist and turn the cube until each face has only one color.
-However, solving a Rubik's cube is not easy. There are over 43 quintillion possible combinations of the cube, but only one correct solution. It takes a lot of skill, patience, and practice to master the cube. Some people can solve it in less than 10 seconds, while others may take hours or even days.
-rubik 39;s cube solver 3x3 mod apk
Download ►►►►► https://urlca.com/2uO9Ih
-That's why many people use a Rubik's cube solver 3x3 mod apk to help them solve the cube in seconds. A Rubik's cube solver 3x3 mod apk is a modified application that uses your device's camera to scan your cube and then shows you the steps to solve it. You can follow the instructions on your screen and turn your cube accordingly until it is solved.
-Using a Rubik's cube solver 3x3 mod apk has many benefits. You can save time and frustration by solving your cube quickly and easily. You can also learn from the app and improve your own skills and techniques. You can have fun and impress your friends and family with your amazing cube solving abilities.
-How to Download and Install a Rubik's Cube Solver 3x3 Mod Apk
-If you want to use a Rubik's cube solver 3x3 mod apk, you need to download and install it on your device first. Here are the steps to do so:
--
-
Tips and Tricks for Solving a Rubik's Cube Faster and Easier
-Using a Rubik's cube solver 3x3 mod apk can help you solve your cube in seconds, but it can also help you improve your own skills and techniques. Here are some tips and tricks for solving a Rubik's cube faster and easier:
--
-
Conclusion
-Solving a Rubik's cube is a fun and rewarding activity that can boost your brain power, creativity, and confidence. However, it can also be frustrating and time-consuming if you don't know how to do it. That's why using a Rubik's cube solver 3x3 mod apk can be a great way to help you solve your cube in seconds.
-A Rubik's cube solver 3x3 mod apk is a modified application that uses your device's camera to scan your cube and then shows you the steps to solve it. You can download and install a Rubik's cube solver 3x3 mod apk from a reliable website, such as [Grubiks], and then use it to scan and solve your cube easily and quickly.
-You can also use a Rubik's cube solver 3x3 mod apk to learn from the app and improve your own skills and techniques. You can follow some tips and tricks for solving a Rubik's cube faster and easier, such as improving your cube recognition and finger speed, learning and memorizing the algorithms, and practicing and challenging yourself with different scrambles and modes.
- -If you want to have fun and impress your friends and family with your amazing cube solving abilities, download a Rubik's cube solver 3x3 mod apk today and see how fast you can solve your cube!
-FAQs
-What are some of the best Rubik's cube solver 3x3 mod apks available?
-Some of the best Rubik's cube solver 3x3 mod apks available are:
--
-Name Features [Grubiks] - Fast, easy, and free online Rubik’s Cube Solver
- Supports 2x2, 3x3, 4x4 and 5x5 cubes
- Shows the solution as text, images, or animations
- Allows you to customize the cube colors and background[CubeX] - Powerful and easy to use Rubik's Cube Solver
- Supports 2x2, 3x3, 4x4, and 5x5 cubes
- Shows the solution as text or animations
- Allows you to adjust the camera settings and the cube size[Rubik's Cube Solver] - Simple and user-friendly Rubik's Cube Solver
- Supports only 3x3 cubes
- Shows the solution as text or images
- Allows you to change the cube colors and the languageIs it cheating to use a Rubik's cube solver 3x3 mod apk?
-It depends on your purpose and perspective. If you use a Rubik's cube solver 3x3 mod apk to solve your cube for fun or learning, then it is not cheating. You can enjoy the satisfaction of solving your cube and also learn from the app how to improve your skills and techniques. However, if you use a Rubik's cube solver 3x3 mod apk to solve your cube for competition or bragging, then it is cheating. You are not showing your true ability and you are not being fair to others who solve their cubes without any help.
-How can I solve a Rubik's cube without using a mod apk?
-If you want to solve a Rubik's cube without using a mod apk, you need to learn the basic principles and methods of solving a Rubik's cube. There are many online tutorials, videos, books, and courses that can teach you how to solve a Rubik's cube step by step. You can also join online forums, groups, or clubs where you can interact with other cubers and get tips and advice. The most common method for solving a Rubik's cube is the layer-by-layer method, which involves solving the cube in three stages: the first layer, the second layer, and the last layer.
-How can I make my own Rubik's cube solver 3x3 mod apk?
-If you want to make your own Rubik's cube solver 3x3 mod apk, you need to have some programming skills and knowledge of computer vision and artificial intelligence. You also need to have access to a software development kit (SDK) that allows you to create and modify applications for your device. You can use an existing SDK or create your own SDK using tools such as Android Studio, Xcode, or Visual Studio. You can also use open-source libraries or frameworks that provide functions and features for developing a Rubik's cube solver 3x3 mod apk, such as OpenCV, TensorFlow, or PyTorch.
-How can I share my Rubik's cube solving results with others?
-If you want to share your Rubik's cube solving results with others, you can use various platforms and methods to do so. You can take screenshots or record videos of your cube solving process and post them on social media platforms such as Facebook, Instagram, Twitter, or YouTube. You can also use online services or apps that allow you to upload and share your cube solving results with other cubers around the world, such as [Cube Timer], [Cubing Time], or [Cube Mania].
401be4b1e0
-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/Stream Live TV Channels with Oreo TV APK v2.0.4 on Any Device.md b/spaces/congsaPfin/Manga-OCR/logs/Stream Live TV Channels with Oreo TV APK v2.0.4 on Any Device.md deleted file mode 100644 index 9bc40078469a6be461985b2dd3f855b7342e0c2d..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/Stream Live TV Channels with Oreo TV APK v2.0.4 on Any Device.md +++ /dev/null @@ -1,98 +0,0 @@ - -Oreo TV 2.0 8 APK Download: How to Watch Free Live TV on Your Android Device
-Do you want to watch free live TV on your Android device without paying for any subscription? If yes, then you should try Oreo TV APK, a popular streaming app that offers thousands of live TV channels, movies, shows, sports, and more for free. In this article, we will tell you what Oreo TV APK is, what features it has, and how to download and install it on your Android device.
-oreo tv 2.0 8 apk download
Download File ··· https://urlca.com/2uOf99
-What is Oreo TV APK?
-Oreo TV APK is a streaming app that allows you to watch live TV channels from various countries and genres on your Android device. You can also watch movies, shows, web series, sports, news, and more on this app. Oreo TV APK is not available on the Google Play Store or any other official app store, so you have to download it from a third-party source. However, it is a safe and legal app that does not require any registration or subscription.
-Features of Oreo TV APK
-Oreo TV APK has many features that make it one of the best streaming apps for Android users. Here are some of them:
-Live TV channels
-Oreo TV APK offers more than 6000 live TV channels from different countries and regions, including India, USA, UK, Canada, Australia, Pakistan, Bangladesh, Nepal, Sri Lanka, and more. You can watch channels from various categories, such as entertainment, news, sports, movies, music, kids, religion, education, and more. You can also watch live IPL matches, cricket, football, basketball, tennis, and other sports events on this app.
-Categorized catalog
-Oreo TV APK has a well-organized catalog that makes it easy for you to find your favorite content. You can browse through different sections, such as movies, shows, web series, sports, news, etc. You can also search for any content by name or keyword. You can also filter the content by genre, language, country, quality, etc.
-HD resolution
-Oreo TV APK lets you watch all the content in high-definition quality up to 4K resolution. You can also adjust the video quality according to your internet speed and data usage. You can choose from 360p to 1080p quality options.
-Free movies and TV shows
-Oreo TV APK also provides you with a huge collection of movies and TV shows from various platforms and sources. You can watch the latest movies and shows from Netflix, Amazon Prime Video, Disney+, Hotstar, Zee5, SonyLiv, Voot, AltBalaji, MX Player, and more for free. You can also download any movie or show for offline viewing.
-User-friendly interface
-Oreo TV APK has a simple and easy-to-use interface that makes it user-friendly for everyone. You can navigate through the app with ease and access all the features without any hassle. You can also customize the app according to your preferences. You can change the theme, font size, playback speed, etc.
-How to download and install Oreo TV APK on your Android device?
-If you want to download and install Oreo TV APK on your Android device, you have to follow these simple steps:
-How to install oreo tv apk on firestick for free live tv
-
-Oreo tv apk v4.0.8 June version 2023 download for free
-Oreo tv apk features and benefits
-Oreo tv app official website and download link
-Oreo tv apk latest version update and changelog
-Oreo tv apk review and rating by users
-Oreo tv apk alternatives and similar apps
-Oreo tv apk mod and premium version
-Oreo tv apk problems and solutions
-Oreo tv apk download for android tv box and smart tv
-Oreo tv apk download for windows pc and laptop
-Oreo tv apk download for ios and iphone
-Oreo tv apk download for mac and macbook
-Oreo tv apk download for linux and ubuntu
-Oreo tv apk download for roku and chromecast
-Oreo tv apk download for kodi and firestick
-Oreo tv apk download for samsung and lg smart tv
-Oreo tv apk download for sony and philips smart tv
-Oreo tv apk download for mi and realme smart tv
-Oreo tv apk download for nvidia shield and android box
-Oreo tv apk download for amazon firestick and fire tv cube
-Oreo tv apk download for jio phone and jio fiber
-Oreo tv apk download for airtel xstream and vi movies
-Oreo tv apk download for bsnl broadband and tata sky binge
-Oreo tv apk download for netflix and amazon prime video
-Oreo tv apk download for hotstar and disney plus hotstar
-Oreo tv apk download for zee5 and sony liv
-Oreo tv apk download for voot and mx player
-Oreo tv apk download for alt balaji and ullu
-Oreo tv apk download for eros now and hungama play
-Oreo tv apk download for youtube and youtube premium
-Oreo tv apk download for spotify and gaana
-Oreo tv apk download for jio cinema and jio saavn
-Oreo tv apk download for airtel xtreme and wynk music
-Oreo tv apk download for vi movies and vi music
-Oreo tv apk download for bsnl play and bsnl tunes
-Oreo tv apk download for tata sky binge plus and tata sky music plus
-Oreo tv apk download for netflix party and watch party
-Oreo tv apk download for telegram and whatsapp groups
-Oreo tv apk download for reddit and quora communitiesStep 1: Enable unknown sources
-Since Oreo TV APK is not available on the Google Play Store, you have to enable the option of unknown sources on your device. This will allow you to install apps from third-party sources. To do this, go to Settings > Security > Unknown Sources and toggle it on.
-Step 2: Download the Oreo TV APK file
-Next, you have to download the Oreo TV APK file from a reliable source. You can use this link to download the latest version of Oreo TV APK (2.0 8) on your device. The file size is about 10 MB and it is compatible with Android 4.4 and above.
-Step 3: Install the Oreo TV APK file
-Once you have downloaded the Oreo TV APK file, you have to install it on your device. To do this, locate the file in your file manager and tap on it. You will see a prompt asking for your permission to install the app. Tap on Install and wait for the installation process to complete.
-Step 4: Launch the Oreo TV app and enjoy free live TV
-After the installation is done, you can launch the Oreo TV app from your app drawer or home screen. You will see the main interface of the app with different sections and categories. You can choose any content that you want to watch and enjoy free live TV on your Android device.
-How to download and install Oreo TV APK on your Firestick or Android TV box?
-If you want to download and install Oreo TV APK on your Firestick or Android TV box, you have to follow these steps:
-Step 1: Enable apps from unknown sources
-Similar to Android devices, you have to enable the option of apps from unknown sources on your Firestick or Android TV box. This will allow you to install apps from third-party sources. To do this, go to Settings > My Fire TV > Developer Options > Apps from Unknown Sources and turn it on.
-Step 2: Install the Downloader app
-Next, you have to install the Downloader app on your Firestick or Android TV box. This is a free app that lets you download and install any APK file on your device. To do this, go to the Search option on your home screen and type Downloader. You will see the app icon in the results. Click on it and then click on Download or Get to install the app.
-Step 3: Download the Oreo TV APK file using the Downloader app
-Once you have installed the Downloader app, open it and enter this URL in the address bar. This will take you to the download page of Oreo TV APK (2.0 8). Click on Download Now and wait for the download process to finish.
-Step 4: Install the Oreo TV APK file using the Downloader app
-After the download is complete, you will see a prompt asking for your permission to install the app. Click on Install and wait for the installation process to complete.
-Step 5: Launch the Oreo TV app and enjoy free live TV
-After the installation is done, you can launch the Oreo TV app from your apps list or home screen. You will see the same interface as on Android devices with different sections and categories. You can choose any content that you want to watch and enjoy free live TV on your Firestick or Android TV box.
-Conclusion
-Oreo TV APK is a great streaming app that lets you watch free live TV channels, movies, shows, sports, and more on your Android device, Firestick, or Android TV box. It has many features that make it one of the best streaming apps for cord-cutters. You can download and install it easily by following our guide above. However, we recommend that you use a VPN service while using this app to protect your privacy and security online.
-FAQs
-Here are some frequently asked questions about Oreo TV APK:
--
-
-
-
\ No newline at end of file diff --git a/spaces/cooelf/Multimodal-CoT/timm/models/features.py b/spaces/cooelf/Multimodal-CoT/timm/models/features.py deleted file mode 100644 index b1d6890f3ed07311c5484b4a397c3b1da555880a..0000000000000000000000000000000000000000 --- a/spaces/cooelf/Multimodal-CoT/timm/models/features.py +++ /dev/null @@ -1,284 +0,0 @@ -""" PyTorch Feature Extraction Helpers - -A collection of classes, functions, modules to help extract features from models -and provide a common interface for describing them. - -The return_layers, module re-writing idea inspired by torchvision IntermediateLayerGetter -https://github.com/pytorch/vision/blob/d88d8961ae51507d0cb680329d985b1488b1b76b/torchvision/models/_utils.py - -Hacked together by / Copyright 2020 Ross Wightman -""" -from collections import OrderedDict, defaultdict -from copy import deepcopy -from functools import partial -from typing import Dict, List, Tuple - -import torch -import torch.nn as nn - - -class FeatureInfo: - - def __init__(self, feature_info: List[Dict], out_indices: Tuple[int]): - prev_reduction = 1 - for fi in feature_info: - # sanity check the mandatory fields, there may be additional fields depending on the model - assert 'num_chs' in fi and fi['num_chs'] > 0 - assert 'reduction' in fi and fi['reduction'] >= prev_reduction - prev_reduction = fi['reduction'] - assert 'module' in fi - self.out_indices = out_indices - self.info = feature_info - - def from_other(self, out_indices: Tuple[int]): - return FeatureInfo(deepcopy(self.info), out_indices) - - def get(self, key, idx=None): - """ Get value by key at specified index (indices) - if idx == None, returns value for key at each output index - if idx is an integer, return value for that feature module index (ignoring output indices) - if idx is a list/tupple, return value for each module index (ignoring output indices) - """ - if idx is None: - return [self.info[i][key] for i in self.out_indices] - if isinstance(idx, (tuple, list)): - return [self.info[i][key] for i in idx] - else: - return self.info[idx][key] - - def get_dicts(self, keys=None, idx=None): - """ return info dicts for specified keys (or all if None) at specified indices (or out_indices if None) - """ - if idx is None: - if keys is None: - return [self.info[i] for i in self.out_indices] - else: - return [{k: self.info[i][k] for k in keys} for i in self.out_indices] - if isinstance(idx, (tuple, list)): - return [self.info[i] if keys is None else {k: self.info[i][k] for k in keys} for i in idx] - else: - return self.info[idx] if keys is None else {k: self.info[idx][k] for k in keys} - - def channels(self, idx=None): - """ feature channels accessor - """ - return self.get('num_chs', idx) - - def reduction(self, idx=None): - """ feature reduction (output stride) accessor - """ - return self.get('reduction', idx) - - def module_name(self, idx=None): - """ feature module name accessor - """ - return self.get('module', idx) - - def __getitem__(self, item): - return self.info[item] - - def __len__(self): - return len(self.info) - - -class FeatureHooks: - """ Feature Hook Helper - - This module helps with the setup and extraction of hooks for extracting features from - internal nodes in a model by node name. This works quite well in eager Python but needs - redesign for torcscript. - """ - - def __init__(self, hooks, named_modules, out_map=None, default_hook_type='forward'): - # setup feature hooks - modules = {k: v for k, v in named_modules} - for i, h in enumerate(hooks): - hook_name = h['module'] - m = modules[hook_name] - hook_id = out_map[i] if out_map else hook_name - hook_fn = partial(self._collect_output_hook, hook_id) - hook_type = h['hook_type'] if 'hook_type' in h else default_hook_type - if hook_type == 'forward_pre': - m.register_forward_pre_hook(hook_fn) - elif hook_type == 'forward': - m.register_forward_hook(hook_fn) - else: - assert False, "Unsupported hook type" - self._feature_outputs = defaultdict(OrderedDict) - - def _collect_output_hook(self, hook_id, *args): - x = args[-1] # tensor we want is last argument, output for fwd, input for fwd_pre - if isinstance(x, tuple): - x = x[0] # unwrap input tuple - self._feature_outputs[x.device][hook_id] = x - - def get_output(self, device) -> Dict[str, torch.tensor]: - output = self._feature_outputs[device] - self._feature_outputs[device] = OrderedDict() # clear after reading - return output - - -def _module_list(module, flatten_sequential=False): - # a yield/iter would be better for this but wouldn't be compatible with torchscript - ml = [] - for name, module in module.named_children(): - if flatten_sequential and isinstance(module, nn.Sequential): - # first level of Sequential containers is flattened into containing model - for child_name, child_module in module.named_children(): - combined = [name, child_name] - ml.append(('_'.join(combined), '.'.join(combined), child_module)) - else: - ml.append((name, name, module)) - return ml - - -def _get_feature_info(net, out_indices): - feature_info = getattr(net, 'feature_info') - if isinstance(feature_info, FeatureInfo): - return feature_info.from_other(out_indices) - elif isinstance(feature_info, (list, tuple)): - return FeatureInfo(net.feature_info, out_indices) - else: - assert False, "Provided feature_info is not valid" - - -def _get_return_layers(feature_info, out_map): - module_names = feature_info.module_name() - return_layers = {} - for i, name in enumerate(module_names): - return_layers[name] = out_map[i] if out_map is not None else feature_info.out_indices[i] - return return_layers - - -class FeatureDictNet(nn.ModuleDict): - """ Feature extractor with OrderedDict return - - Wrap a model and extract features as specified by the out indices, the network is - partially re-built from contained modules. - - There is a strong assumption that the modules have been registered into the model in the same - order as they are used. There should be no reuse of the same nn.Module more than once, including - trivial modules like `self.relu = nn.ReLU`. - - Only submodules that are directly assigned to the model class (`model.feature1`) or at most - one Sequential container deep (`model.features.1`, with flatten_sequent=True) can be captured. - All Sequential containers that are directly assigned to the original model will have their - modules assigned to this module with the name `model.features.1` being changed to `model.features_1` - - Arguments: - model (nn.Module): model from which we will extract the features - out_indices (tuple[int]): model output indices to extract features for - out_map (sequence): list or tuple specifying desired return id for each out index, - otherwise str(index) is used - feature_concat (bool): whether to concatenate intermediate features that are lists or tuples - vs select element [0] - flatten_sequential (bool): whether to flatten sequential modules assigned to model - """ - def __init__( - self, model, - out_indices=(0, 1, 2, 3, 4), out_map=None, feature_concat=False, flatten_sequential=False): - super(FeatureDictNet, self).__init__() - self.feature_info = _get_feature_info(model, out_indices) - self.concat = feature_concat - self.return_layers = {} - return_layers = _get_return_layers(self.feature_info, out_map) - modules = _module_list(model, flatten_sequential=flatten_sequential) - remaining = set(return_layers.keys()) - layers = OrderedDict() - for new_name, old_name, module in modules: - layers[new_name] = module - if old_name in remaining: - # return id has to be consistently str type for torchscript - self.return_layers[new_name] = str(return_layers[old_name]) - remaining.remove(old_name) - if not remaining: - break - assert not remaining and len(self.return_layers) == len(return_layers), \ - f'Return layers ({remaining}) are not present in model' - self.update(layers) - - def _collect(self, x) -> (Dict[str, torch.Tensor]): - out = OrderedDict() - for name, module in self.items(): - x = module(x) - if name in self.return_layers: - out_id = self.return_layers[name] - if isinstance(x, (tuple, list)): - # If model tap is a tuple or list, concat or select first element - # FIXME this may need to be more generic / flexible for some nets - out[out_id] = torch.cat(x, 1) if self.concat else x[0] - else: - out[out_id] = x - return out - - def forward(self, x) -> Dict[str, torch.Tensor]: - return self._collect(x) - - -class FeatureListNet(FeatureDictNet): - """ Feature extractor with list return - - See docstring for FeatureDictNet above, this class exists only to appease Torchscript typing constraints. - In eager Python we could have returned List[Tensor] vs Dict[id, Tensor] based on a member bool. - """ - def __init__( - self, model, - out_indices=(0, 1, 2, 3, 4), out_map=None, feature_concat=False, flatten_sequential=False): - super(FeatureListNet, self).__init__( - model, out_indices=out_indices, out_map=out_map, feature_concat=feature_concat, - flatten_sequential=flatten_sequential) - - def forward(self, x) -> (List[torch.Tensor]): - return list(self._collect(x).values()) - - -class FeatureHookNet(nn.ModuleDict): - """ FeatureHookNet - - Wrap a model and extract features specified by the out indices using forward/forward-pre hooks. - - If `no_rewrite` is True, features are extracted via hooks without modifying the underlying - network in any way. - - If `no_rewrite` is False, the model will be re-written as in the - FeatureList/FeatureDict case by folding first to second (Sequential only) level modules into this one. - - FIXME this does not currently work with Torchscript, see FeatureHooks class - """ - def __init__( - self, model, - out_indices=(0, 1, 2, 3, 4), out_map=None, out_as_dict=False, no_rewrite=False, - feature_concat=False, flatten_sequential=False, default_hook_type='forward'): - super(FeatureHookNet, self).__init__() - assert not torch.jit.is_scripting() - self.feature_info = _get_feature_info(model, out_indices) - self.out_as_dict = out_as_dict - layers = OrderedDict() - hooks = [] - if no_rewrite: - assert not flatten_sequential - if hasattr(model, 'reset_classifier'): # make sure classifier is removed? - model.reset_classifier(0) - layers['body'] = model - hooks.extend(self.feature_info.get_dicts()) - else: - modules = _module_list(model, flatten_sequential=flatten_sequential) - remaining = {f['module']: f['hook_type'] if 'hook_type' in f else default_hook_type - for f in self.feature_info.get_dicts()} - for new_name, old_name, module in modules: - layers[new_name] = module - for fn, fm in module.named_modules(prefix=old_name): - if fn in remaining: - hooks.append(dict(module=fn, hook_type=remaining[fn])) - del remaining[fn] - if not remaining: - break - assert not remaining, f'Return layers ({remaining}) are not present in model' - self.update(layers) - self.hooks = FeatureHooks(hooks, model.named_modules(), out_map=out_map) - - def forward(self, x): - for name, module in self.items(): - x = module(x) - out = self.hooks.get_output(x.device) - return out if self.out_as_dict else list(out.values()) diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/meta_arch/build.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/meta_arch/build.py deleted file mode 100644 index 98a08f06ac58b21f3a738132b8c3ac62f51fa538..0000000000000000000000000000000000000000 --- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/meta_arch/build.py +++ /dev/null @@ -1,25 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -import torch - -from annotator.oneformer.detectron2.utils.logger import _log_api_usage -from annotator.oneformer.detectron2.utils.registry import Registry - -META_ARCH_REGISTRY = Registry("META_ARCH") # noqa F401 isort:skip -META_ARCH_REGISTRY.__doc__ = """ -Registry for meta-architectures, i.e. the whole model. - -The registered object will be called with `obj(cfg)` -and expected to return a `nn.Module` object. -""" - - -def build_model(cfg): - """ - Build the whole model architecture, defined by ``cfg.MODEL.META_ARCHITECTURE``. - Note that it does not load any weights from ``cfg``. - """ - meta_arch = cfg.MODEL.META_ARCHITECTURE - model = META_ARCH_REGISTRY.get(meta_arch)(cfg) - model.to(torch.device(cfg.MODEL.DEVICE)) - _log_api_usage("modeling.meta_arch." + meta_arch) - return model diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/runner/base_module.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/runner/base_module.py deleted file mode 100644 index 617fad9bb89f10a9a0911d962dfb3bc8f3a3628c..0000000000000000000000000000000000000000 --- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/runner/base_module.py +++ /dev/null @@ -1,195 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -import copy -import warnings -from abc import ABCMeta -from collections import defaultdict -from logging import FileHandler - -import torch.nn as nn - -from annotator.uniformer.mmcv.runner.dist_utils import master_only -from annotator.uniformer.mmcv.utils.logging import get_logger, logger_initialized, print_log - - -class BaseModule(nn.Module, metaclass=ABCMeta): - """Base module for all modules in openmmlab. - - ``BaseModule`` is a wrapper of ``torch.nn.Module`` with additional - functionality of parameter initialization. Compared with - ``torch.nn.Module``, ``BaseModule`` mainly adds three attributes. - - - ``init_cfg``: the config to control the initialization. - - ``init_weights``: The function of parameter - initialization and recording initialization - information. - - ``_params_init_info``: Used to track the parameter - initialization information. This attribute only - exists during executing the ``init_weights``. - - Args: - init_cfg (dict, optional): Initialization config dict. - """ - - def __init__(self, init_cfg=None): - """Initialize BaseModule, inherited from `torch.nn.Module`""" - - # NOTE init_cfg can be defined in different levels, but init_cfg - # in low levels has a higher priority. - - super(BaseModule, self).__init__() - # define default value of init_cfg instead of hard code - # in init_weights() function - self._is_init = False - - self.init_cfg = copy.deepcopy(init_cfg) - - # Backward compatibility in derived classes - # if pretrained is not None: - # warnings.warn('DeprecationWarning: pretrained is a deprecated \ - # key, please consider using init_cfg') - # self.init_cfg = dict(type='Pretrained', checkpoint=pretrained) - - @property - def is_init(self): - return self._is_init - - def init_weights(self): - """Initialize the weights.""" - - is_top_level_module = False - # check if it is top-level module - if not hasattr(self, '_params_init_info'): - # The `_params_init_info` is used to record the initialization - # information of the parameters - # the key should be the obj:`nn.Parameter` of model and the value - # should be a dict containing - # - init_info (str): The string that describes the initialization. - # - tmp_mean_value (FloatTensor): The mean of the parameter, - # which indicates whether the parameter has been modified. - # this attribute would be deleted after all parameters - # is initialized. - self._params_init_info = defaultdict(dict) - is_top_level_module = True - - # Initialize the `_params_init_info`, - # When detecting the `tmp_mean_value` of - # the corresponding parameter is changed, update related - # initialization information - for name, param in self.named_parameters(): - self._params_init_info[param][ - 'init_info'] = f'The value is the same before and ' \ - f'after calling `init_weights` ' \ - f'of {self.__class__.__name__} ' - self._params_init_info[param][ - 'tmp_mean_value'] = param.data.mean() - - # pass `params_init_info` to all submodules - # All submodules share the same `params_init_info`, - # so it will be updated when parameters are - # modified at any level of the model. - for sub_module in self.modules(): - sub_module._params_init_info = self._params_init_info - - # Get the initialized logger, if not exist, - # create a logger named `mmcv` - logger_names = list(logger_initialized.keys()) - logger_name = logger_names[0] if logger_names else 'mmcv' - - from ..cnn import initialize - from ..cnn.utils.weight_init import update_init_info - module_name = self.__class__.__name__ - if not self._is_init: - if self.init_cfg: - print_log( - f'initialize {module_name} with init_cfg {self.init_cfg}', - logger=logger_name) - initialize(self, self.init_cfg) - if isinstance(self.init_cfg, dict): - # prevent the parameters of - # the pre-trained model - # from being overwritten by - # the `init_weights` - if self.init_cfg['type'] == 'Pretrained': - return - - for m in self.children(): - if hasattr(m, 'init_weights'): - m.init_weights() - # users may overload the `init_weights` - update_init_info( - m, - init_info=f'Initialized by ' - f'user-defined `init_weights`' - f' in {m.__class__.__name__} ') - - self._is_init = True - else: - warnings.warn(f'init_weights of {self.__class__.__name__} has ' - f'been called more than once.') - - if is_top_level_module: - self._dump_init_info(logger_name) - - for sub_module in self.modules(): - del sub_module._params_init_info - - @master_only - def _dump_init_info(self, logger_name): - """Dump the initialization information to a file named - `initialization.log.json` in workdir. - - Args: - logger_name (str): The name of logger. - """ - - logger = get_logger(logger_name) - - with_file_handler = False - # dump the information to the logger file if there is a `FileHandler` - for handler in logger.handlers: - if isinstance(handler, FileHandler): - handler.stream.write( - 'Name of parameter - Initialization information\n') - for name, param in self.named_parameters(): - handler.stream.write( - f'\n{name} - {param.shape}: ' - f"\n{self._params_init_info[param]['init_info']} \n") - handler.stream.flush() - with_file_handler = True - if not with_file_handler: - for name, param in self.named_parameters(): - print_log( - f'\n{name} - {param.shape}: ' - f"\n{self._params_init_info[param]['init_info']} \n ", - logger=logger_name) - - def __repr__(self): - s = super().__repr__() - if self.init_cfg: - s += f'\ninit_cfg={self.init_cfg}' - return s - - -class Sequential(BaseModule, nn.Sequential): - """Sequential module in openmmlab. - - Args: - init_cfg (dict, optional): Initialization config dict. - """ - - def __init__(self, *args, init_cfg=None): - BaseModule.__init__(self, init_cfg) - nn.Sequential.__init__(self, *args) - - -class ModuleList(BaseModule, nn.ModuleList): - """ModuleList in openmmlab. - - Args: - modules (iterable, optional): an iterable of modules to add. - init_cfg (dict, optional): Initialization config dict. - """ - - def __init__(self, modules=None, init_cfg=None): - BaseModule.__init__(self, init_cfg) - nn.ModuleList.__init__(self, modules) diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/zoe/zoedepth/utils/geometry.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/zoe/zoedepth/utils/geometry.py deleted file mode 100644 index e3da8c75b5a8e39b4b58a4dcd827b84d79b9115c..0000000000000000000000000000000000000000 --- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/zoe/zoedepth/utils/geometry.py +++ /dev/null @@ -1,98 +0,0 @@ -# MIT License - -# Copyright (c) 2022 Intelligent Systems Lab Org - -# Permission is hereby granted, free of charge, to any person obtaining a copy -# of this software and associated documentation files (the "Software"), to deal -# in the Software without restriction, including without limitation the rights -# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell -# copies of the Software, and to permit persons to whom the Software is -# furnished to do so, subject to the following conditions: - -# The above copyright notice and this permission notice shall be included in all -# copies or substantial portions of the Software. - -# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR -# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, -# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE -# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER -# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, -# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE -# SOFTWARE. - -# File author: Shariq Farooq Bhat - -import numpy as np - -def get_intrinsics(H,W): - """ - Intrinsics for a pinhole camera model. - Assume fov of 55 degrees and central principal point. - """ - f = 0.5 * W / np.tan(0.5 * 55 * np.pi / 180.0) - cx = 0.5 * W - cy = 0.5 * H - return np.array([[f, 0, cx], - [0, f, cy], - [0, 0, 1]]) - -def depth_to_points(depth, R=None, t=None): - - K = get_intrinsics(depth.shape[1], depth.shape[2]) - Kinv = np.linalg.inv(K) - if R is None: - R = np.eye(3) - if t is None: - t = np.zeros(3) - - # M converts from your coordinate to PyTorch3D's coordinate system - M = np.eye(3) - M[0, 0] = -1.0 - M[1, 1] = -1.0 - - height, width = depth.shape[1:3] - - x = np.arange(width) - y = np.arange(height) - coord = np.stack(np.meshgrid(x, y), -1) - coord = np.concatenate((coord, np.ones_like(coord)[:, :, [0]]), -1) # z=1 - coord = coord.astype(np.float32) - # coord = torch.as_tensor(coord, dtype=torch.float32, device=device) - coord = coord[None] # bs, h, w, 3 - - D = depth[:, :, :, None, None] - # print(D.shape, Kinv[None, None, None, ...].shape, coord[:, :, :, :, None].shape ) - pts3D_1 = D * Kinv[None, None, None, ...] @ coord[:, :, :, :, None] - # pts3D_1 live in your coordinate system. Convert them to Py3D's - pts3D_1 = M[None, None, None, ...] @ pts3D_1 - # from reference to targe tviewpoint - pts3D_2 = R[None, None, None, ...] @ pts3D_1 + t[None, None, None, :, None] - # pts3D_2 = pts3D_1 - # depth_2 = pts3D_2[:, :, :, 2, :] # b,1,h,w - return pts3D_2[:, :, :, :3, 0][0] - - -def create_triangles(h, w, mask=None): - """ - Reference: https://github.com/google-research/google-research/blob/e96197de06613f1b027d20328e06d69829fa5a89/infinite_nature/render_utils.py#L68 - Creates mesh triangle indices from a given pixel grid size. - This function is not and need not be differentiable as triangle indices are - fixed. - Args: - h: (int) denoting the height of the image. - w: (int) denoting the width of the image. - Returns: - triangles: 2D numpy array of indices (int) with shape (2(W-1)(H-1) x 3) - """ - x, y = np.meshgrid(range(w - 1), range(h - 1)) - tl = y * w + x - tr = y * w + x + 1 - bl = (y + 1) * w + x - br = (y + 1) * w + x + 1 - triangles = np.array([tl, bl, tr, br, tr, bl]) - triangles = np.transpose(triangles, (1, 2, 0)).reshape( - ((w - 1) * (h - 1) * 2, 3)) - if mask is not None: - mask = mask.reshape(-1) - triangles = triangles[mask[triangles].all(1)] - return triangles diff --git a/spaces/cscan/CodeFormer/CodeFormer/basicsr/train.py b/spaces/cscan/CodeFormer/CodeFormer/basicsr/train.py deleted file mode 100644 index a01c0dfccdb8b02283100ec5b792c33afaf22f5e..0000000000000000000000000000000000000000 --- a/spaces/cscan/CodeFormer/CodeFormer/basicsr/train.py +++ /dev/null @@ -1,225 +0,0 @@ -import argparse -import datetime -import logging -import math -import copy -import random -import time -import torch -from os import path as osp - -from basicsr.data import build_dataloader, build_dataset -from basicsr.data.data_sampler import EnlargedSampler -from basicsr.data.prefetch_dataloader import CPUPrefetcher, CUDAPrefetcher -from basicsr.models import build_model -from basicsr.utils import (MessageLogger, check_resume, get_env_info, get_root_logger, init_tb_logger, - init_wandb_logger, make_exp_dirs, mkdir_and_rename, set_random_seed) -from basicsr.utils.dist_util import get_dist_info, init_dist -from basicsr.utils.options import dict2str, parse - -import warnings -# ignore UserWarning: Detected call of `lr_scheduler.step()` before `optimizer.step()`. -warnings.filterwarnings("ignore", category=UserWarning) - -def parse_options(root_path, is_train=True): - parser = argparse.ArgumentParser() - parser.add_argument('-opt', type=str, required=True, help='Path to option YAML file.') - parser.add_argument('--launcher', choices=['none', 'pytorch', 'slurm'], default='none', help='job launcher') - parser.add_argument('--local_rank', type=int, default=0) - args = parser.parse_args() - opt = parse(args.opt, root_path, is_train=is_train) - - # distributed settings - if args.launcher == 'none': - opt['dist'] = False - print('Disable distributed.', flush=True) - else: - opt['dist'] = True - if args.launcher == 'slurm' and 'dist_params' in opt: - init_dist(args.launcher, **opt['dist_params']) - else: - init_dist(args.launcher) - - opt['rank'], opt['world_size'] = get_dist_info() - - # random seed - seed = opt.get('manual_seed') - if seed is None: - seed = random.randint(1, 10000) - opt['manual_seed'] = seed - set_random_seed(seed + opt['rank']) - - return opt - - -def init_loggers(opt): - log_file = osp.join(opt['path']['log'], f"train_{opt['name']}.log") - logger = get_root_logger(logger_name='basicsr', log_level=logging.INFO, log_file=log_file) - logger.info(get_env_info()) - logger.info(dict2str(opt)) - - # initialize wandb logger before tensorboard logger to allow proper sync: - if (opt['logger'].get('wandb') is not None) and (opt['logger']['wandb'].get('project') is not None): - assert opt['logger'].get('use_tb_logger') is True, ('should turn on tensorboard when using wandb') - init_wandb_logger(opt) - tb_logger = None - if opt['logger'].get('use_tb_logger'): - tb_logger = init_tb_logger(log_dir=osp.join('tb_logger', opt['name'])) - return logger, tb_logger - - -def create_train_val_dataloader(opt, logger): - # create train and val dataloaders - train_loader, val_loader = None, None - for phase, dataset_opt in opt['datasets'].items(): - if phase == 'train': - dataset_enlarge_ratio = dataset_opt.get('dataset_enlarge_ratio', 1) - train_set = build_dataset(dataset_opt) - train_sampler = EnlargedSampler(train_set, opt['world_size'], opt['rank'], dataset_enlarge_ratio) - train_loader = build_dataloader( - train_set, - dataset_opt, - num_gpu=opt['num_gpu'], - dist=opt['dist'], - sampler=train_sampler, - seed=opt['manual_seed']) - - num_iter_per_epoch = math.ceil( - len(train_set) * dataset_enlarge_ratio / (dataset_opt['batch_size_per_gpu'] * opt['world_size'])) - total_iters = int(opt['train']['total_iter']) - total_epochs = math.ceil(total_iters / (num_iter_per_epoch)) - logger.info('Training statistics:' - f'\n\tNumber of train images: {len(train_set)}' - f'\n\tDataset enlarge ratio: {dataset_enlarge_ratio}' - f'\n\tBatch size per gpu: {dataset_opt["batch_size_per_gpu"]}' - f'\n\tWorld size (gpu number): {opt["world_size"]}' - f'\n\tRequire iter number per epoch: {num_iter_per_epoch}' - f'\n\tTotal epochs: {total_epochs}; iters: {total_iters}.') - - elif phase == 'val': - val_set = build_dataset(dataset_opt) - val_loader = build_dataloader( - val_set, dataset_opt, num_gpu=opt['num_gpu'], dist=opt['dist'], sampler=None, seed=opt['manual_seed']) - logger.info(f'Number of val images/folders in {dataset_opt["name"]}: ' f'{len(val_set)}') - else: - raise ValueError(f'Dataset phase {phase} is not recognized.') - - return train_loader, train_sampler, val_loader, total_epochs, total_iters - - -def train_pipeline(root_path): - # parse options, set distributed setting, set ramdom seed - opt = parse_options(root_path, is_train=True) - - torch.backends.cudnn.benchmark = True - # torch.backends.cudnn.deterministic = True - - # load resume states if necessary - if opt['path'].get('resume_state'): - device_id = torch.cuda.current_device() - resume_state = torch.load( - opt['path']['resume_state'], map_location=lambda storage, loc: storage.cuda(device_id)) - else: - resume_state = None - - # mkdir for experiments and logger - if resume_state is None: - make_exp_dirs(opt) - if opt['logger'].get('use_tb_logger') and opt['rank'] == 0: - mkdir_and_rename(osp.join('tb_logger', opt['name'])) - - # initialize loggers - logger, tb_logger = init_loggers(opt) - - # create train and validation dataloaders - result = create_train_val_dataloader(opt, logger) - train_loader, train_sampler, val_loader, total_epochs, total_iters = result - - # create model - if resume_state: # resume training - check_resume(opt, resume_state['iter']) - model = build_model(opt) - model.resume_training(resume_state) # handle optimizers and schedulers - logger.info(f"Resuming training from epoch: {resume_state['epoch']}, " f"iter: {resume_state['iter']}.") - start_epoch = resume_state['epoch'] - current_iter = resume_state['iter'] - else: - model = build_model(opt) - start_epoch = 0 - current_iter = 0 - - # create message logger (formatted outputs) - msg_logger = MessageLogger(opt, current_iter, tb_logger) - - # dataloader prefetcher - prefetch_mode = opt['datasets']['train'].get('prefetch_mode') - if prefetch_mode is None or prefetch_mode == 'cpu': - prefetcher = CPUPrefetcher(train_loader) - elif prefetch_mode == 'cuda': - prefetcher = CUDAPrefetcher(train_loader, opt) - logger.info(f'Use {prefetch_mode} prefetch dataloader') - if opt['datasets']['train'].get('pin_memory') is not True: - raise ValueError('Please set pin_memory=True for CUDAPrefetcher.') - else: - raise ValueError(f'Wrong prefetch_mode {prefetch_mode}.' "Supported ones are: None, 'cuda', 'cpu'.") - - # training - logger.info(f'Start training from epoch: {start_epoch}, iter: {current_iter+1}') - data_time, iter_time = time.time(), time.time() - start_time = time.time() - - for epoch in range(start_epoch, total_epochs + 1): - train_sampler.set_epoch(epoch) - prefetcher.reset() - train_data = prefetcher.next() - - while train_data is not None: - data_time = time.time() - data_time - - current_iter += 1 - if current_iter > total_iters: - break - # update learning rate - model.update_learning_rate(current_iter, warmup_iter=opt['train'].get('warmup_iter', -1)) - # training - model.feed_data(train_data) - model.optimize_parameters(current_iter) - iter_time = time.time() - iter_time - # log - if current_iter % opt['logger']['print_freq'] == 0: - log_vars = {'epoch': epoch, 'iter': current_iter} - log_vars.update({'lrs': model.get_current_learning_rate()}) - log_vars.update({'time': iter_time, 'data_time': data_time}) - log_vars.update(model.get_current_log()) - msg_logger(log_vars) - - # save models and training states - if current_iter % opt['logger']['save_checkpoint_freq'] == 0: - logger.info('Saving models and training states.') - model.save(epoch, current_iter) - - # validation - if opt.get('val') is not None and opt['datasets'].get('val') is not None \ - and (current_iter % opt['val']['val_freq'] == 0): - model.validation(val_loader, current_iter, tb_logger, opt['val']['save_img']) - - data_time = time.time() - iter_time = time.time() - train_data = prefetcher.next() - # end of iter - - # end of epoch - - consumed_time = str(datetime.timedelta(seconds=int(time.time() - start_time))) - logger.info(f'End of training. Time consumed: {consumed_time}') - logger.info('Save the latest model.') - model.save(epoch=-1, current_iter=-1) # -1 stands for the latest - if opt.get('val') is not None and opt['datasets'].get('val'): - model.validation(val_loader, current_iter, tb_logger, opt['val']['save_img']) - if tb_logger: - tb_logger.close() - - -if __name__ == '__main__': - root_path = osp.abspath(osp.join(__file__, osp.pardir, osp.pardir)) - train_pipeline(root_path) diff --git a/spaces/csuer/vits/commons.py b/spaces/csuer/vits/commons.py deleted file mode 100644 index db17cf0914ba6e445fe613e3ec3411b3a74b28aa..0000000000000000000000000000000000000000 --- a/spaces/csuer/vits/commons.py +++ /dev/null @@ -1,164 +0,0 @@ -import math -import numpy as np -import torch -from torch import nn -from torch.nn import functional as F - - -def init_weights(m, mean=0.0, std=0.01): - classname = m.__class__.__name__ - if classname.find("Conv") != -1: - m.weight.data.normal_(mean, std) - - -def get_padding(kernel_size, dilation=1): - return int((kernel_size*dilation - dilation)/2) - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def intersperse(lst, item): - result = [item] * (len(lst) * 2 + 1) - result[1::2] = lst - return result - - -def kl_divergence(m_p, logs_p, m_q, logs_q): - """KL(P||Q)""" - kl = (logs_q - logs_p) - 0.5 - kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q) - return kl - - -def rand_gumbel(shape): - """Sample from the Gumbel distribution, protect from overflows.""" - uniform_samples = torch.rand(shape) * 0.99998 + 0.00001 - return -torch.log(-torch.log(uniform_samples)) - - -def rand_gumbel_like(x): - g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device) - return g - - -def slice_segments(x, ids_str, segment_size=4): - ret = torch.zeros_like(x[:, :, :segment_size]) - for i in range(x.size(0)): - idx_str = ids_str[i] - idx_end = idx_str + segment_size - try: - ret[i] = x[i, :, idx_str:idx_end] - except RuntimeError: - print("?") - return ret - - -def rand_slice_segments(x, x_lengths=None, segment_size=4): - b, d, t = x.size() - if x_lengths is None: - x_lengths = t - ids_str_max = x_lengths - segment_size + 1 - ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long) - ret = slice_segments(x, ids_str, segment_size) - return ret, ids_str - - -def get_timing_signal_1d( - length, channels, min_timescale=1.0, max_timescale=1.0e4): - position = torch.arange(length, dtype=torch.float) - num_timescales = channels // 2 - log_timescale_increment = ( - math.log(float(max_timescale) / float(min_timescale)) / - (num_timescales - 1)) - inv_timescales = min_timescale * torch.exp( - torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment) - scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1) - signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0) - signal = F.pad(signal, [0, 0, 0, channels % 2]) - signal = signal.view(1, channels, length) - return signal - - -def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return x + signal.to(dtype=x.dtype, device=x.device) - - -def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1): - b, channels, length = x.size() - signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale) - return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis) - - -def subsequent_mask(length): - mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0) - return mask - - -@torch.jit.script -def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels): - n_channels_int = n_channels[0] - in_act = input_a + input_b - t_act = torch.tanh(in_act[:, :n_channels_int, :]) - s_act = torch.sigmoid(in_act[:, n_channels_int:, :]) - acts = t_act * s_act - return acts - - -def convert_pad_shape(pad_shape): - l = pad_shape[::-1] - pad_shape = [item for sublist in l for item in sublist] - return pad_shape - - -def shift_1d(x): - x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1] - return x - - -def sequence_mask(length, max_length=None): - if max_length is None: - max_length = length.max() - x = torch.arange(max_length, dtype=length.dtype, device=length.device) - return x.unsqueeze(0) < length.unsqueeze(1) - - -def generate_path(duration, mask): - """ - duration: [b, 1, t_x] - mask: [b, 1, t_y, t_x] - """ - device = duration.device - - b, _, t_y, t_x = mask.shape - cum_duration = torch.cumsum(duration, -1) - - cum_duration_flat = cum_duration.view(b * t_x) - path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype) - path = path.view(b, t_x, t_y) - path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1] - path = path.unsqueeze(1).transpose(2,3) * mask - return path - - -def clip_grad_value_(parameters, clip_value, norm_type=2): - if isinstance(parameters, torch.Tensor): - parameters = [parameters] - parameters = list(filter(lambda p: p.grad is not None, parameters)) - norm_type = float(norm_type) - if clip_value is not None: - clip_value = float(clip_value) - - total_norm = 0 - for p in parameters: - param_norm = p.grad.data.norm(norm_type) - total_norm += param_norm.item() ** norm_type - if clip_value is not None: - p.grad.data.clamp_(min=-clip_value, max=clip_value) - total_norm = total_norm ** (1. / norm_type) - return total_norm diff --git a/spaces/cvlab/zero123-live/taming-transformers/scripts/sample_conditional.py b/spaces/cvlab/zero123-live/taming-transformers/scripts/sample_conditional.py deleted file mode 100644 index 174cf2af07c1a1ca4e6c35fc0e4f8d6e53591b56..0000000000000000000000000000000000000000 --- a/spaces/cvlab/zero123-live/taming-transformers/scripts/sample_conditional.py +++ /dev/null @@ -1,355 +0,0 @@ -import argparse, os, sys, glob, math, time -import torch -import numpy as np -from omegaconf import OmegaConf -import streamlit as st -from streamlit import caching -from PIL import Image -from main import instantiate_from_config, DataModuleFromConfig -from torch.utils.data import DataLoader -from torch.utils.data.dataloader import default_collate - - -rescale = lambda x: (x + 1.) / 2. - - -def bchw_to_st(x): - return rescale(x.detach().cpu().numpy().transpose(0,2,3,1)) - -def save_img(xstart, fname): - I = (xstart.clip(0,1)[0]*255).astype(np.uint8) - Image.fromarray(I).save(fname) - - - -def get_interactive_image(resize=False): - image = st.file_uploader("Input", type=["jpg", "JPEG", "png"]) - if image is not None: - image = Image.open(image) - if not image.mode == "RGB": - image = image.convert("RGB") - image = np.array(image).astype(np.uint8) - print("upload image shape: {}".format(image.shape)) - img = Image.fromarray(image) - if resize: - img = img.resize((256, 256)) - image = np.array(img) - return image - - -def single_image_to_torch(x, permute=True): - assert x is not None, "Please provide an image through the upload function" - x = np.array(x) - x = torch.FloatTensor(x/255.*2. - 1.)[None,...] - if permute: - x = x.permute(0, 3, 1, 2) - return x - - -def pad_to_M(x, M): - hp = math.ceil(x.shape[2]/M)*M-x.shape[2] - wp = math.ceil(x.shape[3]/M)*M-x.shape[3] - x = torch.nn.functional.pad(x, (0,wp,0,hp,0,0,0,0)) - return x - -@torch.no_grad() -def run_conditional(model, dsets): - if len(dsets.datasets) > 1: - split = st.sidebar.radio("Split", sorted(dsets.datasets.keys())) - dset = dsets.datasets[split] - else: - dset = next(iter(dsets.datasets.values())) - batch_size = 1 - start_index = st.sidebar.number_input("Example Index (Size: {})".format(len(dset)), value=0, - min_value=0, - max_value=len(dset)-batch_size) - indices = list(range(start_index, start_index+batch_size)) - - example = default_collate([dset[i] for i in indices]) - - x = model.get_input("image", example).to(model.device) - - cond_key = model.cond_stage_key - c = model.get_input(cond_key, example).to(model.device) - - scale_factor = st.sidebar.slider("Scale Factor", min_value=0.5, max_value=4.0, step=0.25, value=1.00) - if scale_factor != 1.0: - x = torch.nn.functional.interpolate(x, scale_factor=scale_factor, mode="bicubic") - c = torch.nn.functional.interpolate(c, scale_factor=scale_factor, mode="bicubic") - - quant_z, z_indices = model.encode_to_z(x) - quant_c, c_indices = model.encode_to_c(c) - - cshape = quant_z.shape - - xrec = model.first_stage_model.decode(quant_z) - st.write("image: {}".format(x.shape)) - st.image(bchw_to_st(x), clamp=True, output_format="PNG") - st.write("image reconstruction: {}".format(xrec.shape)) - st.image(bchw_to_st(xrec), clamp=True, output_format="PNG") - - if cond_key == "segmentation": - # get image from segmentation mask - num_classes = c.shape[1] - c = torch.argmax(c, dim=1, keepdim=True) - c = torch.nn.functional.one_hot(c, num_classes=num_classes) - c = c.squeeze(1).permute(0, 3, 1, 2).float() - c = model.cond_stage_model.to_rgb(c) - - st.write(f"{cond_key}: {tuple(c.shape)}") - st.image(bchw_to_st(c), clamp=True, output_format="PNG") - - idx = z_indices - - half_sample = st.sidebar.checkbox("Image Completion", value=False) - if half_sample: - start = idx.shape[1]//2 - else: - start = 0 - - idx[:,start:] = 0 - idx = idx.reshape(cshape[0],cshape[2],cshape[3]) - start_i = start//cshape[3] - start_j = start %cshape[3] - - if not half_sample and quant_z.shape == quant_c.shape: - st.info("Setting idx to c_indices") - idx = c_indices.clone().reshape(cshape[0],cshape[2],cshape[3]) - - cidx = c_indices - cidx = cidx.reshape(quant_c.shape[0],quant_c.shape[2],quant_c.shape[3]) - - xstart = model.decode_to_img(idx[:,:cshape[2],:cshape[3]], cshape) - st.image(bchw_to_st(xstart), clamp=True, output_format="PNG") - - temperature = st.number_input("Temperature", value=1.0) - top_k = st.number_input("Top k", value=100) - sample = st.checkbox("Sample", value=True) - update_every = st.number_input("Update every", value=75) - - st.text(f"Sampling shape ({cshape[2]},{cshape[3]})") - - animate = st.checkbox("animate") - if animate: - import imageio - outvid = "sampling.mp4" - writer = imageio.get_writer(outvid, fps=25) - elapsed_t = st.empty() - info = st.empty() - st.text("Sampled") - if st.button("Sample"): - output = st.empty() - start_t = time.time() - for i in range(start_i,cshape[2]-0): - if i <= 8: - local_i = i - elif cshape[2]-i < 8: - local_i = 16-(cshape[2]-i) - else: - local_i = 8 - for j in range(start_j,cshape[3]-0): - if j <= 8: - local_j = j - elif cshape[3]-j < 8: - local_j = 16-(cshape[3]-j) - else: - local_j = 8 - - i_start = i-local_i - i_end = i_start+16 - j_start = j-local_j - j_end = j_start+16 - elapsed_t.text(f"Time: {time.time() - start_t} seconds") - info.text(f"Step: ({i},{j}) | Local: ({local_i},{local_j}) | Crop: ({i_start}:{i_end},{j_start}:{j_end})") - patch = idx[:,i_start:i_end,j_start:j_end] - patch = patch.reshape(patch.shape[0],-1) - cpatch = cidx[:, i_start:i_end, j_start:j_end] - cpatch = cpatch.reshape(cpatch.shape[0], -1) - patch = torch.cat((cpatch, patch), dim=1) - logits,_ = model.transformer(patch[:,:-1]) - logits = logits[:, -256:, :] - logits = logits.reshape(cshape[0],16,16,-1) - logits = logits[:,local_i,local_j,:] - - logits = logits/temperature - - if top_k is not None: - logits = model.top_k_logits(logits, top_k) - # apply softmax to convert to probabilities - probs = torch.nn.functional.softmax(logits, dim=-1) - # sample from the distribution or take the most likely - if sample: - ix = torch.multinomial(probs, num_samples=1) - else: - _, ix = torch.topk(probs, k=1, dim=-1) - idx[:,i,j] = ix - - if (i*cshape[3]+j)%update_every==0: - xstart = model.decode_to_img(idx[:, :cshape[2], :cshape[3]], cshape,) - - xstart = bchw_to_st(xstart) - output.image(xstart, clamp=True, output_format="PNG") - - if animate: - writer.append_data((xstart[0]*255).clip(0, 255).astype(np.uint8)) - - xstart = model.decode_to_img(idx[:,:cshape[2],:cshape[3]], cshape) - xstart = bchw_to_st(xstart) - output.image(xstart, clamp=True, output_format="PNG") - #save_img(xstart, "full_res_sample.png") - if animate: - writer.close() - st.video(outvid) - - -def get_parser(): - parser = argparse.ArgumentParser() - parser.add_argument( - "-r", - "--resume", - type=str, - nargs="?", - help="load from logdir or checkpoint in logdir", - ) - parser.add_argument( - "-b", - "--base", - nargs="*", - metavar="base_config.yaml", - help="paths to base configs. Loaded from left-to-right. " - "Parameters can be overwritten or added with command-line options of the form `--key value`.", - default=list(), - ) - parser.add_argument( - "-c", - "--config", - nargs="?", - metavar="single_config.yaml", - help="path to single config. If specified, base configs will be ignored " - "(except for the last one if left unspecified).", - const=True, - default="", - ) - parser.add_argument( - "--ignore_base_data", - action="store_true", - help="Ignore data specification from base configs. Useful if you want " - "to specify a custom datasets on the command line.", - ) - return parser - - -def load_model_from_config(config, sd, gpu=True, eval_mode=True): - if "ckpt_path" in config.params: - st.warning("Deleting the restore-ckpt path from the config...") - config.params.ckpt_path = None - if "downsample_cond_size" in config.params: - st.warning("Deleting downsample-cond-size from the config and setting factor=0.5 instead...") - config.params.downsample_cond_size = -1 - config.params["downsample_cond_factor"] = 0.5 - try: - if "ckpt_path" in config.params.first_stage_config.params: - config.params.first_stage_config.params.ckpt_path = None - st.warning("Deleting the first-stage restore-ckpt path from the config...") - if "ckpt_path" in config.params.cond_stage_config.params: - config.params.cond_stage_config.params.ckpt_path = None - st.warning("Deleting the cond-stage restore-ckpt path from the config...") - except: - pass - - model = instantiate_from_config(config) - if sd is not None: - missing, unexpected = model.load_state_dict(sd, strict=False) - st.info(f"Missing Keys in State Dict: {missing}") - st.info(f"Unexpected Keys in State Dict: {unexpected}") - if gpu: - model.cuda() - if eval_mode: - model.eval() - return {"model": model} - - -def get_data(config): - # get data - data = instantiate_from_config(config.data) - data.prepare_data() - data.setup() - return data - - -@st.cache(allow_output_mutation=True, suppress_st_warning=True) -def load_model_and_dset(config, ckpt, gpu, eval_mode): - # get data - dsets = get_data(config) # calls data.config ... - - # now load the specified checkpoint - if ckpt: - pl_sd = torch.load(ckpt, map_location="cpu") - global_step = pl_sd["global_step"] - else: - pl_sd = {"state_dict": None} - global_step = None - model = load_model_from_config(config.model, - pl_sd["state_dict"], - gpu=gpu, - eval_mode=eval_mode)["model"] - return dsets, model, global_step - - -if __name__ == "__main__": - sys.path.append(os.getcwd()) - - parser = get_parser() - - opt, unknown = parser.parse_known_args() - - ckpt = None - if opt.resume: - if not os.path.exists(opt.resume): - raise ValueError("Cannot find {}".format(opt.resume)) - if os.path.isfile(opt.resume): - paths = opt.resume.split("/") - try: - idx = len(paths)-paths[::-1].index("logs")+1 - except ValueError: - idx = -2 # take a guess: path/to/logdir/checkpoints/model.ckpt - logdir = "/".join(paths[:idx]) - ckpt = opt.resume - else: - assert os.path.isdir(opt.resume), opt.resume - logdir = opt.resume.rstrip("/") - ckpt = os.path.join(logdir, "checkpoints", "last.ckpt") - print(f"logdir:{logdir}") - base_configs = sorted(glob.glob(os.path.join(logdir, "configs/*-project.yaml"))) - opt.base = base_configs+opt.base - - if opt.config: - if type(opt.config) == str: - opt.base = [opt.config] - else: - opt.base = [opt.base[-1]] - - configs = [OmegaConf.load(cfg) for cfg in opt.base] - cli = OmegaConf.from_dotlist(unknown) - if opt.ignore_base_data: - for config in configs: - if hasattr(config, "data"): del config["data"] - config = OmegaConf.merge(*configs, cli) - - st.sidebar.text(ckpt) - gs = st.sidebar.empty() - gs.text(f"Global step: ?") - st.sidebar.text("Options") - #gpu = st.sidebar.checkbox("GPU", value=True) - gpu = True - #eval_mode = st.sidebar.checkbox("Eval Mode", value=True) - eval_mode = True - #show_config = st.sidebar.checkbox("Show Config", value=False) - show_config = False - if show_config: - st.info("Checkpoint: {}".format(ckpt)) - st.json(OmegaConf.to_container(config)) - - dsets, model, global_step = load_model_and_dset(config, ckpt, gpu, eval_mode) - gs.text(f"Global step: {global_step}") - run_conditional(model, dsets) diff --git a/spaces/cymic/Waifu_Diffusion_Webui/modules/ui.py b/spaces/cymic/Waifu_Diffusion_Webui/modules/ui.py deleted file mode 100644 index acb36289511c190aea371c4f98511fcc44482599..0000000000000000000000000000000000000000 --- a/spaces/cymic/Waifu_Diffusion_Webui/modules/ui.py +++ /dev/null @@ -1,1414 +0,0 @@ -import base64 -import html -import io -import json -import math -import mimetypes -import os -import random -import sys -import time -import traceback -import platform -import subprocess as sp -from functools import reduce - -import numpy as np -import torch -from PIL import Image, PngImagePlugin -import piexif - -import gradio as gr -import gradio.utils -import gradio.routes - -from modules import sd_hijack -from modules.paths import script_path -from modules.shared import opts, cmd_opts -import modules.shared as shared -from modules.sd_samplers import samplers, samplers_for_img2img -from modules.sd_hijack import model_hijack -import modules.ldsr_model -import modules.scripts -import modules.gfpgan_model -import modules.codeformer_model -import modules.styles -import modules.generation_parameters_copypaste -from modules import prompt_parser -from modules.images import save_image -import modules.textual_inversion.ui - -# this is a fix for Windows users. Without it, javascript files will be served with text/html content-type and the bowser will not show any UI -mimetypes.init() -mimetypes.add_type('application/javascript', '.js') - - -if not cmd_opts.share and not cmd_opts.listen: - # fix gradio phoning home - gradio.utils.version_check = lambda: None - gradio.utils.get_local_ip_address = lambda: '127.0.0.1' - - -def gr_show(visible=True): - return {"visible": visible, "__type__": "update"} - - -sample_img2img = "assets/stable-samples/img2img/sketch-mountains-input.jpg" -sample_img2img = sample_img2img if os.path.exists(sample_img2img) else None - -css_hide_progressbar = """ -.wrap .m-12 svg { display:none!important; } -.wrap .m-12::before { content:"Loading..." } -.progress-bar { display:none!important; } -.meta-text { display:none!important; } -""" - -# Using constants for these since the variation selector isn't visible. -# Important that they exactly match script.js for tooltip to work. -random_symbol = '\U0001f3b2\ufe0f' # 🎲️ -reuse_symbol = '\u267b\ufe0f' # ♻️ -art_symbol = '\U0001f3a8' # 🎨 -paste_symbol = '\u2199\ufe0f' # ↙ -folder_symbol = '\U0001f4c2' # 📂 - -def plaintext_to_html(text): - text = "" + "
" - return text - - -def image_from_url_text(filedata): - if type(filedata) == list: - if len(filedata) == 0: - return None - - filedata = filedata[0] - - if filedata.startswith("data:image/png;base64,"): - filedata = filedata[len("data:image/png;base64,"):] - - filedata = base64.decodebytes(filedata.encode('utf-8')) - image = Image.open(io.BytesIO(filedata)) - return image - - -def send_gradio_gallery_to_image(x): - if len(x) == 0: - return None - - return image_from_url_text(x[0]) - - -def save_files(js_data, images, index): - import csv - filenames = [] - - #quick dictionary to class object conversion. Its neccesary due apply_filename_pattern requiring it - class MyObject: - def __init__(self, d=None): - if d is not None: - for key, value in d.items(): - setattr(self, key, value) - - data = json.loads(js_data) - - p = MyObject(data) - path = opts.outdir_save - save_to_dirs = opts.use_save_to_dirs_for_ui - extension: str = opts.samples_format - start_index = 0 - - if index > -1 and opts.save_selected_only and (index >= data["index_of_first_image"]): # ensures we are looking at a specific non-grid picture, and we have save_selected_only - - images = [images[index]] - start_index = index - - with open(os.path.join(opts.outdir_save, "log.csv"), "a", encoding="utf8", newline='') as file: - at_start = file.tell() == 0 - writer = csv.writer(file) - if at_start: - writer.writerow(["prompt", "seed", "width", "height", "sampler", "cfgs", "steps", "filename", "negative_prompt"]) - - for image_index, filedata in enumerate(images, start_index): - if filedata.startswith("data:image/png;base64,"): - filedata = filedata[len("data:image/png;base64,"):] - - image = Image.open(io.BytesIO(base64.decodebytes(filedata.encode('utf-8')))) - - is_grid = image_index < p.index_of_first_image - i = 0 if is_grid else (image_index - p.index_of_first_image) - - fullfn = save_image(image, path, "", seed=p.all_seeds[i], prompt=p.all_prompts[i], extension=extension, info=p.infotexts[image_index], grid=is_grid, p=p, save_to_dirs=save_to_dirs) - - filename = os.path.relpath(fullfn, path) - filenames.append(filename) - - writer.writerow([data["prompt"], data["seed"], data["width"], data["height"], data["sampler"], data["cfg_scale"], data["steps"], filenames[0], data["negative_prompt"]]) - - return '', '', plaintext_to_html(f"Saved: {filenames[0]}") - - -def wrap_gradio_call(func, extra_outputs=None): - def f(*args, extra_outputs_array=extra_outputs, **kwargs): - run_memmon = opts.memmon_poll_rate > 0 and not shared.mem_mon.disabled - if run_memmon: - shared.mem_mon.monitor() - t = time.perf_counter() - - try: - res = list(func(*args, **kwargs)) - except Exception as e: - print("Error completing request", file=sys.stderr) - print("Arguments:", args, kwargs, file=sys.stderr) - print(traceback.format_exc(), file=sys.stderr) - - shared.state.job = "" - shared.state.job_count = 0 - - if extra_outputs_array is None: - extra_outputs_array = [None, ''] - - res = extra_outputs_array + [f"
\n".join([f"{html.escape(x)}" for x in text.split('\n')]) + "{plaintext_to_html(type(e).__name__+': '+str(e))}"] - - elapsed = time.perf_counter() - t - elapsed_m = int(elapsed // 60) - elapsed_s = elapsed % 60 - elapsed_text = f"{elapsed_s:.2f}s" - if (elapsed_m > 0): - elapsed_text = f"{elapsed_m}m "+elapsed_text - - if run_memmon: - mem_stats = {k: -(v//-(1024*1024)) for k, v in shared.mem_mon.stop().items()} - active_peak = mem_stats['active_peak'] - reserved_peak = mem_stats['reserved_peak'] - sys_peak = mem_stats['system_peak'] - sys_total = mem_stats['total'] - sys_pct = round(sys_peak/max(sys_total, 1) * 100, 2) - - vram_html = f"Torch active/reserved: {active_peak}/{reserved_peak} MiB,
" - else: - vram_html = '' - - # last item is always HTML - res[-1] += f"Sys VRAM: {sys_peak}/{sys_total} MiB ({sys_pct}%) " - - shared.state.interrupted = False - shared.state.job_count = 0 - - return tuple(res) - - return f - - -def check_progress_call(id_part): - if shared.state.job_count == 0: - return "", gr_show(False), gr_show(False), gr_show(False) - - progress = 0 - - if shared.state.job_count > 0: - progress += shared.state.job_no / shared.state.job_count - if shared.state.sampling_steps > 0: - progress += 1 / shared.state.job_count * shared.state.sampling_step / shared.state.sampling_steps - - progress = min(progress, 1) - - progressbar = "" - if opts.show_progressbar: - progressbar = f"""Time taken:
{vram_html}{elapsed_text} """ - - image = gr_show(False) - preview_visibility = gr_show(False) - - if opts.show_progress_every_n_steps > 0: - if shared.parallel_processing_allowed: - - if shared.state.sampling_step - shared.state.current_image_sampling_step >= opts.show_progress_every_n_steps and shared.state.current_latent is not None: - shared.state.current_image = modules.sd_samplers.sample_to_image(shared.state.current_latent) - shared.state.current_image_sampling_step = shared.state.sampling_step - - image = shared.state.current_image - - if image is None: - image = gr.update(value=None) - else: - preview_visibility = gr_show(True) - - if shared.state.textinfo is not None: - textinfo_result = gr.HTML.update(value=shared.state.textinfo, visible=True) - else: - textinfo_result = gr_show(False) - - return f"{str(int(progress*100))+"%" if progress > 0.01 else ""}{progressbar}
", preview_visibility, image, textinfo_result - - -def check_progress_call_initial(id_part): - shared.state.job_count = -1 - shared.state.current_latent = None - shared.state.current_image = None - shared.state.textinfo = None - - return check_progress_call(id_part) - - -def roll_artist(prompt): - allowed_cats = set([x for x in shared.artist_db.categories() if len(opts.random_artist_categories)==0 or x in opts.random_artist_categories]) - artist = random.choice([x for x in shared.artist_db.artists if x.category in allowed_cats]) - - return prompt + ", " + artist.name if prompt != '' else artist.name - - -def visit(x, func, path=""): - if hasattr(x, 'children'): - for c in x.children: - visit(c, func, path) - elif x.label is not None: - func(path + "/" + str(x.label), x) - - -def add_style(name: str, prompt: str, negative_prompt: str): - if name is None: - return [gr_show(), gr_show()] - - style = modules.styles.PromptStyle(name, prompt, negative_prompt) - shared.prompt_styles.styles[style.name] = style - # Save all loaded prompt styles: this allows us to update the storage format in the future more easily, because we - # reserialize all styles every time we save them - shared.prompt_styles.save_styles(shared.styles_filename) - - return [gr.Dropdown.update(visible=True, choices=list(shared.prompt_styles.styles)) for _ in range(4)] - - -def apply_styles(prompt, prompt_neg, style1_name, style2_name): - prompt = shared.prompt_styles.apply_styles_to_prompt(prompt, [style1_name, style2_name]) - prompt_neg = shared.prompt_styles.apply_negative_styles_to_prompt(prompt_neg, [style1_name, style2_name]) - - return [gr.Textbox.update(value=prompt), gr.Textbox.update(value=prompt_neg), gr.Dropdown.update(value="None"), gr.Dropdown.update(value="None")] - - -def interrogate(image): - prompt = shared.interrogator.interrogate(image) - - return gr_show(True) if prompt is None else prompt - - -def create_seed_inputs(): - with gr.Row(): - with gr.Box(): - with gr.Row(elem_id='seed_row'): - seed = (gr.Textbox if cmd_opts.use_textbox_seed else gr.Number)(label='Seed', value=-1) - seed.style(container=False) - random_seed = gr.Button(random_symbol, elem_id='random_seed') - reuse_seed = gr.Button(reuse_symbol, elem_id='reuse_seed') - - with gr.Box(elem_id='subseed_show_box'): - seed_checkbox = gr.Checkbox(label='Extra', elem_id='subseed_show', value=False) - - # Components to show/hide based on the 'Extra' checkbox - seed_extras = [] - - with gr.Row(visible=False) as seed_extra_row_1: - seed_extras.append(seed_extra_row_1) - with gr.Box(): - with gr.Row(elem_id='subseed_row'): - subseed = gr.Number(label='Variation seed', value=-1) - subseed.style(container=False) - random_subseed = gr.Button(random_symbol, elem_id='random_subseed') - reuse_subseed = gr.Button(reuse_symbol, elem_id='reuse_subseed') - subseed_strength = gr.Slider(label='Variation strength', value=0.0, minimum=0, maximum=1, step=0.01) - - with gr.Row(visible=False) as seed_extra_row_2: - seed_extras.append(seed_extra_row_2) - seed_resize_from_w = gr.Slider(minimum=0, maximum=2048, step=64, label="Resize seed from width", value=0) - seed_resize_from_h = gr.Slider(minimum=0, maximum=2048, step=64, label="Resize seed from height", value=0) - - random_seed.click(fn=lambda: -1, show_progress=False, inputs=[], outputs=[seed]) - random_subseed.click(fn=lambda: -1, show_progress=False, inputs=[], outputs=[subseed]) - - def change_visibility(show): - return {comp: gr_show(show) for comp in seed_extras} - - seed_checkbox.change(change_visibility, show_progress=False, inputs=[seed_checkbox], outputs=seed_extras) - - return seed, reuse_seed, subseed, reuse_subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox - - -def connect_reuse_seed(seed: gr.Number, reuse_seed: gr.Button, generation_info: gr.Textbox, dummy_component, is_subseed): - """ Connects a 'reuse (sub)seed' button's click event so that it copies last used - (sub)seed value from generation info the to the seed field. If copying subseed and subseed strength - was 0, i.e. no variation seed was used, it copies the normal seed value instead.""" - def copy_seed(gen_info_string: str, index): - res = -1 - - try: - gen_info = json.loads(gen_info_string) - index -= gen_info.get('index_of_first_image', 0) - - if is_subseed and gen_info.get('subseed_strength', 0) > 0: - all_subseeds = gen_info.get('all_subseeds', [-1]) - res = all_subseeds[index if 0 <= index < len(all_subseeds) else 0] - else: - all_seeds = gen_info.get('all_seeds', [-1]) - res = all_seeds[index if 0 <= index < len(all_seeds) else 0] - - except json.decoder.JSONDecodeError as e: - if gen_info_string != '': - print("Error parsing JSON generation info:", file=sys.stderr) - print(gen_info_string, file=sys.stderr) - - return [res, gr_show(False)] - - reuse_seed.click( - fn=copy_seed, - _js="(x, y) => [x, selected_gallery_index()]", - show_progress=False, - inputs=[generation_info, dummy_component], - outputs=[seed, dummy_component] - ) - - -def update_token_counter(text, steps): - try: - _, prompt_flat_list, _ = prompt_parser.get_multicond_prompt_list([text]) - prompt_schedules = prompt_parser.get_learned_conditioning_prompt_schedules(prompt_flat_list, steps) - - except Exception: - # a parsing error can happen here during typing, and we don't want to bother the user with - # messages related to it in console - prompt_schedules = [[[steps, text]]] - - flat_prompts = reduce(lambda list1, list2: list1+list2, prompt_schedules) - prompts = [prompt_text for step, prompt_text in flat_prompts] - tokens, token_count, max_length = max([model_hijack.tokenize(prompt) for prompt in prompts], key=lambda args: args[1]) - style_class = ' class="red"' if (token_count > max_length) else "" - return f"{token_count}/{max_length}" - - -def create_toprow(is_img2img): - id_part = "img2img" if is_img2img else "txt2img" - - with gr.Row(elem_id="toprow"): - with gr.Column(scale=4): - with gr.Row(): - with gr.Column(scale=80): - with gr.Row(): - prompt = gr.Textbox(label="Prompt", elem_id=f"{id_part}_prompt", show_label=False, placeholder="Prompt", lines=2) - - with gr.Column(scale=1, elem_id="roll_col"): - roll = gr.Button(value=art_symbol, elem_id="roll", visible=len(shared.artist_db.artists) > 0) - paste = gr.Button(value=paste_symbol, elem_id="paste") - token_counter = gr.HTML(value="", elem_id=f"{id_part}_token_counter") - token_button = gr.Button(visible=False, elem_id=f"{id_part}_token_button") - - with gr.Column(scale=10, elem_id="style_pos_col"): - prompt_style = gr.Dropdown(label="Style 1", elem_id=f"{id_part}_style_index", choices=[k for k, v in shared.prompt_styles.styles.items()], value=next(iter(shared.prompt_styles.styles.keys())), visible=len(shared.prompt_styles.styles) > 1) - - with gr.Row(): - with gr.Column(scale=8): - negative_prompt = gr.Textbox(label="Negative prompt", elem_id="negative_prompt", show_label=False, placeholder="Negative prompt", lines=2) - - with gr.Column(scale=1, elem_id="style_neg_col"): - prompt_style2 = gr.Dropdown(label="Style 2", elem_id=f"{id_part}_style2_index", choices=[k for k, v in shared.prompt_styles.styles.items()], value=next(iter(shared.prompt_styles.styles.keys())), visible=len(shared.prompt_styles.styles) > 1) - - with gr.Column(scale=1): - with gr.Row(): - interrupt = gr.Button('Interrupt', elem_id=f"{id_part}_interrupt") - submit = gr.Button('Generate', elem_id=f"{id_part}_generate", variant='primary') - - interrupt.click( - fn=lambda: shared.state.interrupt(), - inputs=[], - outputs=[], - ) - - with gr.Row(): - if is_img2img: - interrogate = gr.Button('Interrogate', elem_id="interrogate") - else: - interrogate = None - prompt_style_apply = gr.Button('Apply style', elem_id="style_apply") - save_style = gr.Button('Create style', elem_id="style_create") - - return prompt, roll, prompt_style, negative_prompt, prompt_style2, submit, interrogate, prompt_style_apply, save_style, paste, token_counter, token_button - - -def setup_progressbar(progressbar, preview, id_part, textinfo=None): - if textinfo is None: - textinfo = gr.HTML(visible=False) - - check_progress = gr.Button('Check progress', elem_id=f"{id_part}_check_progress", visible=False) - check_progress.click( - fn=lambda: check_progress_call(id_part), - show_progress=False, - inputs=[], - outputs=[progressbar, preview, preview, textinfo], - ) - - check_progress_initial = gr.Button('Check progress (first)', elem_id=f"{id_part}_check_progress_initial", visible=False) - check_progress_initial.click( - fn=lambda: check_progress_call_initial(id_part), - show_progress=False, - inputs=[], - outputs=[progressbar, preview, preview, textinfo], - ) - - -def create_ui(wrap_gradio_gpu_call): - import modules.img2img - import modules.txt2img - - with gr.Blocks(analytics_enabled=False) as txt2img_interface: - txt2img_prompt, roll, txt2img_prompt_style, txt2img_negative_prompt, txt2img_prompt_style2, submit, _, txt2img_prompt_style_apply, txt2img_save_style, paste, token_counter, token_button = create_toprow(is_img2img=False) - dummy_component = gr.Label(visible=False) - - with gr.Row(elem_id='txt2img_progress_row'): - with gr.Column(scale=1): - pass - - with gr.Column(scale=1): - progressbar = gr.HTML(elem_id="txt2img_progressbar") - txt2img_preview = gr.Image(elem_id='txt2img_preview', visible=False) - setup_progressbar(progressbar, txt2img_preview, 'txt2img') - - with gr.Row().style(equal_height=False): - with gr.Column(variant='panel'): - steps = gr.Slider(minimum=1, maximum=150, step=1, label="Sampling Steps", value=20) - sampler_index = gr.Radio(label='Sampling method', elem_id="txt2img_sampling", choices=[x.name for x in samplers], value=samplers[0].name, type="index") - - with gr.Group(): - width = gr.Slider(minimum=64, maximum=2048, step=64, label="Width", value=512) - height = gr.Slider(minimum=64, maximum=2048, step=64, label="Height", value=512) - - with gr.Row(): - restore_faces = gr.Checkbox(label='Restore faces', value=False, visible=len(shared.face_restorers) > 1) - tiling = gr.Checkbox(label='Tiling', value=False) - enable_hr = gr.Checkbox(label='Highres. fix', value=False) - - with gr.Row(visible=False) as hr_options: - scale_latent = gr.Checkbox(label='Scale latent', value=False) - denoising_strength = gr.Slider(minimum=0.0, maximum=1.0, step=0.01, label='Denoising strength', value=0.7) - - with gr.Row(): - batch_count = gr.Slider(minimum=1, maximum=cmd_opts.max_batch_count, step=1, label='Batch count', value=1) - batch_size = gr.Slider(minimum=1, maximum=8, step=1, label='Batch size', value=1) - - cfg_scale = gr.Slider(minimum=1.0, maximum=30.0, step=0.5, label='CFG Scale', value=7.0) - - seed, reuse_seed, subseed, reuse_subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox = create_seed_inputs() - - with gr.Group(): - custom_inputs = modules.scripts.scripts_txt2img.setup_ui(is_img2img=False) - - with gr.Column(variant='panel'): - - with gr.Group(): - txt2img_preview = gr.Image(elem_id='txt2img_preview', visible=False) - txt2img_gallery = gr.Gallery(label='Output', show_label=False, elem_id='txt2img_gallery').style(grid=4) - - with gr.Group(): - with gr.Row(): - save = gr.Button('Save') - send_to_img2img = gr.Button('Send to img2img') - send_to_inpaint = gr.Button('Send to inpaint') - send_to_extras = gr.Button('Send to extras') - button_id = "hidden_element" if shared.cmd_opts.hide_ui_dir_config else 'open_folder' - open_txt2img_folder = gr.Button(folder_symbol, elem_id=button_id) - - with gr.Group(): - html_info = gr.HTML() - generation_info = gr.Textbox(visible=False) - - connect_reuse_seed(seed, reuse_seed, generation_info, dummy_component, is_subseed=False) - connect_reuse_seed(subseed, reuse_subseed, generation_info, dummy_component, is_subseed=True) - - txt2img_args = dict( - fn=wrap_gradio_gpu_call(modules.txt2img.txt2img), - _js="submit", - inputs=[ - txt2img_prompt, - txt2img_negative_prompt, - txt2img_prompt_style, - txt2img_prompt_style2, - steps, - sampler_index, - restore_faces, - tiling, - batch_count, - batch_size, - cfg_scale, - seed, - subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox, - height, - width, - enable_hr, - scale_latent, - denoising_strength, - ] + custom_inputs, - outputs=[ - txt2img_gallery, - generation_info, - html_info - ], - show_progress=False, - ) - - txt2img_prompt.submit(**txt2img_args) - submit.click(**txt2img_args) - - enable_hr.change( - fn=lambda x: gr_show(x), - inputs=[enable_hr], - outputs=[hr_options], - ) - - save.click( - fn=wrap_gradio_call(save_files), - _js="(x, y, z) => [x, y, selected_gallery_index()]", - inputs=[ - generation_info, - txt2img_gallery, - html_info, - ], - outputs=[ - html_info, - html_info, - html_info, - ] - ) - - roll.click( - fn=roll_artist, - _js="update_txt2img_tokens", - inputs=[ - txt2img_prompt, - ], - outputs=[ - txt2img_prompt, - ] - ) - - txt2img_paste_fields = [ - (txt2img_prompt, "Prompt"), - (txt2img_negative_prompt, "Negative prompt"), - (steps, "Steps"), - (sampler_index, "Sampler"), - (restore_faces, "Face restoration"), - (cfg_scale, "CFG scale"), - (seed, "Seed"), - (width, "Size-1"), - (height, "Size-2"), - (batch_size, "Batch size"), - (subseed, "Variation seed"), - (subseed_strength, "Variation seed strength"), - (seed_resize_from_w, "Seed resize from-1"), - (seed_resize_from_h, "Seed resize from-2"), - (denoising_strength, "Denoising strength"), - (enable_hr, lambda d: "Denoising strength" in d), - (hr_options, lambda d: gr.Row.update(visible="Denoising strength" in d)), - ] - modules.generation_parameters_copypaste.connect_paste(paste, txt2img_paste_fields, txt2img_prompt) - token_button.click(fn=update_token_counter, inputs=[txt2img_prompt, steps], outputs=[token_counter]) - - with gr.Blocks(analytics_enabled=False) as img2img_interface: - img2img_prompt, roll, img2img_prompt_style, img2img_negative_prompt, img2img_prompt_style2, submit, img2img_interrogate, img2img_prompt_style_apply, img2img_save_style, paste, token_counter, token_button = create_toprow(is_img2img=True) - - with gr.Row(elem_id='img2img_progress_row'): - with gr.Column(scale=1): - pass - - with gr.Column(scale=1): - progressbar = gr.HTML(elem_id="img2img_progressbar") - img2img_preview = gr.Image(elem_id='img2img_preview', visible=False) - setup_progressbar(progressbar, img2img_preview, 'img2img') - - with gr.Row().style(equal_height=False): - with gr.Column(variant='panel'): - - with gr.Tabs(elem_id="mode_img2img") as tabs_img2img_mode: - with gr.TabItem('img2img', id='img2img'): - init_img = gr.Image(label="Image for img2img", elem_id="img2img_image", show_label=False, source="upload", interactive=True, type="pil", tool=cmd_opts.gradio_img2img_tool) - - with gr.TabItem('Inpaint', id='inpaint'): - init_img_with_mask = gr.Image(label="Image for inpainting with mask", show_label=False, elem_id="img2maskimg", source="upload", interactive=True, type="pil", tool="sketch", image_mode="RGBA") - - init_img_inpaint = gr.Image(label="Image for img2img", show_label=False, source="upload", interactive=True, type="pil", visible=False, elem_id="img_inpaint_base") - init_mask_inpaint = gr.Image(label="Mask", source="upload", interactive=True, type="pil", visible=False, elem_id="img_inpaint_mask") - - mask_blur = gr.Slider(label='Mask blur', minimum=0, maximum=64, step=1, value=4) - - with gr.Row(): - mask_mode = gr.Radio(label="Mask mode", show_label=False, choices=["Draw mask", "Upload mask"], type="index", value="Draw mask", elem_id="mask_mode") - inpainting_mask_invert = gr.Radio(label='Masking mode', show_label=False, choices=['Inpaint masked', 'Inpaint not masked'], value='Inpaint masked', type="index") - - inpainting_fill = gr.Radio(label='Masked content', choices=['fill', 'original', 'latent noise', 'latent nothing'], value='original', type="index") - - with gr.Row(): - inpaint_full_res = gr.Checkbox(label='Inpaint at full resolution', value=False) - inpaint_full_res_padding = gr.Slider(label='Inpaint at full resolution padding, pixels', minimum=0, maximum=256, step=4, value=32) - - with gr.TabItem('Batch img2img', id='batch'): - hidden = '
Disabled when launched with --hide-ui-dir-config.' if shared.cmd_opts.hide_ui_dir_config else '' - gr.HTML(f"Process images in a directory on the same machine where the server is running.
") - img2img_batch_input_dir = gr.Textbox(label="Input directory", **shared.hide_dirs) - img2img_batch_output_dir = gr.Textbox(label="Output directory", **shared.hide_dirs) - - with gr.Row(): - resize_mode = gr.Radio(label="Resize mode", elem_id="resize_mode", show_label=False, choices=["Just resize", "Crop and resize", "Resize and fill"], type="index", value="Just resize") - - steps = gr.Slider(minimum=1, maximum=150, step=1, label="Sampling Steps", value=20) - sampler_index = gr.Radio(label='Sampling method', choices=[x.name for x in samplers_for_img2img], value=samplers_for_img2img[0].name, type="index") - - with gr.Group(): - width = gr.Slider(minimum=64, maximum=2048, step=64, label="Width", value=512) - height = gr.Slider(minimum=64, maximum=2048, step=64, label="Height", value=512) - - with gr.Row(): - restore_faces = gr.Checkbox(label='Restore faces', value=False, visible=len(shared.face_restorers) > 1) - tiling = gr.Checkbox(label='Tiling', value=False) - - with gr.Row(): - batch_count = gr.Slider(minimum=1, maximum=cmd_opts.max_batch_count, step=1, label='Batch count', value=1) - batch_size = gr.Slider(minimum=1, maximum=8, step=1, label='Batch size', value=1) - - with gr.Group(): - cfg_scale = gr.Slider(minimum=1.0, maximum=30.0, step=0.5, label='CFG Scale', value=7.0) - denoising_strength = gr.Slider(minimum=0.0, maximum=1.0, step=0.01, label='Denoising strength', value=0.75) - - seed, reuse_seed, subseed, reuse_subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox = create_seed_inputs() - - with gr.Group(): - custom_inputs = modules.scripts.scripts_img2img.setup_ui(is_img2img=True) - - with gr.Column(variant='panel'): - - with gr.Group(): - img2img_preview = gr.Image(elem_id='img2img_preview', visible=False) - img2img_gallery = gr.Gallery(label='Output', show_label=False, elem_id='img2img_gallery').style(grid=4) - - with gr.Group(): - with gr.Row(): - save = gr.Button('Save') - img2img_send_to_img2img = gr.Button('Send to img2img') - img2img_send_to_inpaint = gr.Button('Send to inpaint') - img2img_send_to_extras = gr.Button('Send to extras') - button_id = "hidden_element" if shared.cmd_opts.hide_ui_dir_config else 'open_folder' - open_img2img_folder = gr.Button(folder_symbol, elem_id=button_id) - - with gr.Group(): - html_info = gr.HTML() - generation_info = gr.Textbox(visible=False) - - connect_reuse_seed(seed, reuse_seed, generation_info, dummy_component, is_subseed=False) - connect_reuse_seed(subseed, reuse_subseed, generation_info, dummy_component, is_subseed=True) - - mask_mode.change( - lambda mode, img: { - init_img_with_mask: gr_show(mode == 0), - init_img_inpaint: gr_show(mode == 1), - init_mask_inpaint: gr_show(mode == 1), - }, - inputs=[mask_mode, init_img_with_mask], - outputs=[ - init_img_with_mask, - init_img_inpaint, - init_mask_inpaint, - ], - ) - - img2img_args = dict( - fn=wrap_gradio_gpu_call(modules.img2img.img2img), - _js="submit_img2img", - inputs=[ - dummy_component, - img2img_prompt, - img2img_negative_prompt, - img2img_prompt_style, - img2img_prompt_style2, - init_img, - init_img_with_mask, - init_img_inpaint, - init_mask_inpaint, - mask_mode, - steps, - sampler_index, - mask_blur, - inpainting_fill, - restore_faces, - tiling, - batch_count, - batch_size, - cfg_scale, - denoising_strength, - seed, - subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox, - height, - width, - resize_mode, - inpaint_full_res, - inpaint_full_res_padding, - inpainting_mask_invert, - img2img_batch_input_dir, - img2img_batch_output_dir, - ] + custom_inputs, - outputs=[ - img2img_gallery, - generation_info, - html_info - ], - show_progress=False, - ) - - img2img_prompt.submit(**img2img_args) - submit.click(**img2img_args) - - img2img_interrogate.click( - fn=interrogate, - inputs=[init_img], - outputs=[img2img_prompt], - ) - - save.click( - fn=wrap_gradio_call(save_files), - _js="(x, y, z) => [x, y, selected_gallery_index()]", - inputs=[ - generation_info, - img2img_gallery, - html_info - ], - outputs=[ - html_info, - html_info, - html_info, - ] - ) - - roll.click( - fn=roll_artist, - _js="update_img2img_tokens", - inputs=[ - img2img_prompt, - ], - outputs=[ - img2img_prompt, - ] - ) - - prompts = [(txt2img_prompt, txt2img_negative_prompt), (img2img_prompt, img2img_negative_prompt)] - style_dropdowns = [(txt2img_prompt_style, txt2img_prompt_style2), (img2img_prompt_style, img2img_prompt_style2)] - style_js_funcs = ["update_txt2img_tokens", "update_img2img_tokens"] - - for button, (prompt, negative_prompt) in zip([txt2img_save_style, img2img_save_style], prompts): - button.click( - fn=add_style, - _js="ask_for_style_name", - # Have to pass empty dummy component here, because the JavaScript and Python function have to accept - # the same number of parameters, but we only know the style-name after the JavaScript prompt - inputs=[dummy_component, prompt, negative_prompt], - outputs=[txt2img_prompt_style, img2img_prompt_style, txt2img_prompt_style2, img2img_prompt_style2], - ) - - for button, (prompt, negative_prompt), (style1, style2), js_func in zip([txt2img_prompt_style_apply, img2img_prompt_style_apply], prompts, style_dropdowns, style_js_funcs): - button.click( - fn=apply_styles, - _js=js_func, - inputs=[prompt, negative_prompt, style1, style2], - outputs=[prompt, negative_prompt, style1, style2], - ) - - img2img_paste_fields = [ - (img2img_prompt, "Prompt"), - (img2img_negative_prompt, "Negative prompt"), - (steps, "Steps"), - (sampler_index, "Sampler"), - (restore_faces, "Face restoration"), - (cfg_scale, "CFG scale"), - (seed, "Seed"), - (width, "Size-1"), - (height, "Size-2"), - (batch_size, "Batch size"), - (subseed, "Variation seed"), - (subseed_strength, "Variation seed strength"), - (seed_resize_from_w, "Seed resize from-1"), - (seed_resize_from_h, "Seed resize from-2"), - (denoising_strength, "Denoising strength"), - ] - modules.generation_parameters_copypaste.connect_paste(paste, img2img_paste_fields, img2img_prompt) - token_button.click(fn=update_token_counter, inputs=[img2img_prompt, steps], outputs=[token_counter]) - - with gr.Blocks(analytics_enabled=False) as extras_interface: - with gr.Row().style(equal_height=False): - with gr.Column(variant='panel'): - with gr.Tabs(elem_id="mode_extras"): - with gr.TabItem('Single Image'): - extras_image = gr.Image(label="Source", source="upload", interactive=True, type="pil") - - with gr.TabItem('Batch Process'): - image_batch = gr.File(label="Batch Process", file_count="multiple", interactive=True, type="file") - - upscaling_resize = gr.Slider(minimum=1.0, maximum=4.0, step=0.05, label="Resize", value=2) - - with gr.Group(): - extras_upscaler_1 = gr.Radio(label='Upscaler 1', choices=[x.name for x in shared.sd_upscalers], value=shared.sd_upscalers[0].name, type="index") - - with gr.Group(): - extras_upscaler_2 = gr.Radio(label='Upscaler 2', choices=[x.name for x in shared.sd_upscalers], value=shared.sd_upscalers[0].name, type="index") - extras_upscaler_2_visibility = gr.Slider(minimum=0.0, maximum=1.0, step=0.001, label="Upscaler 2 visibility", value=1) - - with gr.Group(): - gfpgan_visibility = gr.Slider(minimum=0.0, maximum=1.0, step=0.001, label="GFPGAN visibility", value=0, interactive=modules.gfpgan_model.have_gfpgan) - - with gr.Group(): - codeformer_visibility = gr.Slider(minimum=0.0, maximum=1.0, step=0.001, label="CodeFormer visibility", value=0, interactive=modules.codeformer_model.have_codeformer) - codeformer_weight = gr.Slider(minimum=0.0, maximum=1.0, step=0.001, label="CodeFormer weight (0 = maximum effect, 1 = minimum effect)", value=0, interactive=modules.codeformer_model.have_codeformer) - - submit = gr.Button('Generate', elem_id="extras_generate", variant='primary') - - with gr.Column(variant='panel'): - result_images = gr.Gallery(label="Result", show_label=False) - html_info_x = gr.HTML() - html_info = gr.HTML() - extras_send_to_img2img = gr.Button('Send to img2img') - extras_send_to_inpaint = gr.Button('Send to inpaint') - button_id = "hidden_element" if shared.cmd_opts.hide_ui_dir_config else '' - open_extras_folder = gr.Button('Open output directory', elem_id=button_id) - - submit.click( - fn=wrap_gradio_gpu_call(modules.extras.run_extras), - _js="get_extras_tab_index", - inputs=[ - dummy_component, - extras_image, - image_batch, - gfpgan_visibility, - codeformer_visibility, - codeformer_weight, - upscaling_resize, - extras_upscaler_1, - extras_upscaler_2, - extras_upscaler_2_visibility, - ], - outputs=[ - result_images, - html_info_x, - html_info, - ] - ) - - extras_send_to_img2img.click( - fn=lambda x: image_from_url_text(x), - _js="extract_image_from_gallery_img2img", - inputs=[result_images], - outputs=[init_img], - ) - - extras_send_to_inpaint.click( - fn=lambda x: image_from_url_text(x), - _js="extract_image_from_gallery_img2img", - inputs=[result_images], - outputs=[init_img_with_mask], - ) - - with gr.Blocks(analytics_enabled=False) as pnginfo_interface: - with gr.Row().style(equal_height=False): - with gr.Column(variant='panel'): - image = gr.Image(elem_id="pnginfo_image", label="Source", source="upload", interactive=True, type="pil") - - with gr.Column(variant='panel'): - html = gr.HTML() - generation_info = gr.Textbox(visible=False) - html2 = gr.HTML() - - with gr.Row(): - pnginfo_send_to_txt2img = gr.Button('Send to txt2img') - pnginfo_send_to_img2img = gr.Button('Send to img2img') - - image.change( - fn=wrap_gradio_call(modules.extras.run_pnginfo), - inputs=[image], - outputs=[html, generation_info, html2], - ) - - with gr.Blocks() as modelmerger_interface: - with gr.Row().style(equal_height=False): - with gr.Column(variant='panel'): - gr.HTML(value="
Use an empty output directory to save pictures normally instead of writing to the output directory.{hidden}A merger of the two checkpoints will be generated in your checkpoint directory.
") - - with gr.Row(): - primary_model_name = gr.Dropdown(modules.sd_models.checkpoint_tiles(), elem_id="modelmerger_primary_model_name", label="Primary Model Name") - secondary_model_name = gr.Dropdown(modules.sd_models.checkpoint_tiles(), elem_id="modelmerger_secondary_model_name", label="Secondary Model Name") - custom_name = gr.Textbox(label="Custom Name (Optional)") - interp_amount = gr.Slider(minimum=0.0, maximum=1.0, step=0.05, label='Interpolation Amount', value=0.3) - interp_method = gr.Radio(choices=["Weighted Sum", "Sigmoid", "Inverse Sigmoid"], value="Weighted Sum", label="Interpolation Method") - save_as_half = gr.Checkbox(value=False, label="Safe as float16") - modelmerger_merge = gr.Button(elem_id="modelmerger_merge", label="Merge", variant='primary') - - with gr.Column(variant='panel'): - submit_result = gr.Textbox(elem_id="modelmerger_result", show_label=False) - - sd_hijack.model_hijack.embedding_db.load_textual_inversion_embeddings() - - with gr.Blocks() as textual_inversion_interface: - with gr.Row().style(equal_height=False): - with gr.Column(): - with gr.Group(): - gr.HTML(value="See wiki for detailed explanation.
") - - gr.HTML(value="Create a new embedding
") - - new_embedding_name = gr.Textbox(label="Name") - initialization_text = gr.Textbox(label="Initialization text", value="*") - nvpt = gr.Slider(label="Number of vectors per token", minimum=1, maximum=75, step=1, value=1) - - with gr.Row(): - with gr.Column(scale=3): - gr.HTML(value="") - - with gr.Column(): - create_embedding = gr.Button(value="Create", variant='primary') - - with gr.Group(): - gr.HTML(value="Preprocess images
") - - process_src = gr.Textbox(label='Source directory') - process_dst = gr.Textbox(label='Destination directory') - - with gr.Row(): - process_flip = gr.Checkbox(label='Flip') - process_split = gr.Checkbox(label='Split into two') - process_caption = gr.Checkbox(label='Add caption') - - with gr.Row(): - with gr.Column(scale=3): - gr.HTML(value="") - - with gr.Column(): - run_preprocess = gr.Button(value="Preprocess", variant='primary') - - with gr.Group(): - gr.HTML(value="Train an embedding; must specify a directory with a set of 512x512 images
") - train_embedding_name = gr.Dropdown(label='Embedding', choices=sorted(sd_hijack.model_hijack.embedding_db.word_embeddings.keys())) - learn_rate = gr.Number(label='Learning rate', value=5.0e-03) - dataset_directory = gr.Textbox(label='Dataset directory', placeholder="Path to directory with input images") - log_directory = gr.Textbox(label='Log directory', placeholder="Path to directory where to write outputs", value="textual_inversion") - template_file = gr.Textbox(label='Prompt template file', value=os.path.join(script_path, "textual_inversion_templates", "style_filewords.txt")) - steps = gr.Number(label='Max steps', value=100000, precision=0) - create_image_every = gr.Number(label='Save an image to log directory every N steps, 0 to disable', value=500, precision=0) - save_embedding_every = gr.Number(label='Save a copy of embedding to log directory every N steps, 0 to disable', value=500, precision=0) - - with gr.Row(): - with gr.Column(scale=2): - gr.HTML(value="") - - with gr.Column(): - with gr.Row(): - interrupt_training = gr.Button(value="Interrupt") - train_embedding = gr.Button(value="Train", variant='primary') - - with gr.Column(): - progressbar = gr.HTML(elem_id="ti_progressbar") - ti_output = gr.Text(elem_id="ti_output", value="", show_label=False) - - ti_gallery = gr.Gallery(label='Output', show_label=False, elem_id='ti_gallery').style(grid=4) - ti_preview = gr.Image(elem_id='ti_preview', visible=False) - ti_progress = gr.HTML(elem_id="ti_progress", value="") - ti_outcome = gr.HTML(elem_id="ti_error", value="") - setup_progressbar(progressbar, ti_preview, 'ti', textinfo=ti_progress) - - create_embedding.click( - fn=modules.textual_inversion.ui.create_embedding, - inputs=[ - new_embedding_name, - initialization_text, - nvpt, - ], - outputs=[ - train_embedding_name, - ti_output, - ti_outcome, - ] - ) - - run_preprocess.click( - fn=wrap_gradio_gpu_call(modules.textual_inversion.ui.preprocess, extra_outputs=[gr.update()]), - _js="start_training_textual_inversion", - inputs=[ - process_src, - process_dst, - process_flip, - process_split, - process_caption, - ], - outputs=[ - ti_output, - ti_outcome, - ], - ) - - train_embedding.click( - fn=wrap_gradio_gpu_call(modules.textual_inversion.ui.train_embedding, extra_outputs=[gr.update()]), - _js="start_training_textual_inversion", - inputs=[ - train_embedding_name, - learn_rate, - dataset_directory, - log_directory, - steps, - create_image_every, - save_embedding_every, - template_file, - ], - outputs=[ - ti_output, - ti_outcome, - ] - ) - - interrupt_training.click( - fn=lambda: shared.state.interrupt(), - inputs=[], - outputs=[], - ) - - def create_setting_component(key): - def fun(): - return opts.data[key] if key in opts.data else opts.data_labels[key].default - - info = opts.data_labels[key] - t = type(info.default) - - args = info.component_args() if callable(info.component_args) else info.component_args - - if info.component is not None: - comp = info.component - elif t == str: - comp = gr.Textbox - elif t == int: - comp = gr.Number - elif t == bool: - comp = gr.Checkbox - else: - raise Exception(f'bad options item type: {str(t)} for key {key}') - - return comp(label=info.label, value=fun, **(args or {})) - - components = [] - component_dict = {} - - def open_folder(f): - if not shared.cmd_opts.hide_ui_dir_config: - path = os.path.normpath(f) - if platform.system() == "Windows": - os.startfile(path) - elif platform.system() == "Darwin": - sp.Popen(["open", path]) - else: - sp.Popen(["xdg-open", path]) - - def run_settings(*args): - changed = 0 - - for key, value, comp in zip(opts.data_labels.keys(), args, components): - if not opts.same_type(value, opts.data_labels[key].default): - return f"Bad value for setting {key}: {value}; expecting {type(opts.data_labels[key].default).__name__}" - - for key, value, comp in zip(opts.data_labels.keys(), args, components): - comp_args = opts.data_labels[key].component_args - if comp_args and isinstance(comp_args, dict) and comp_args.get('visible') is False: - continue - - oldval = opts.data.get(key, None) - opts.data[key] = value - - if oldval != value: - if opts.data_labels[key].onchange is not None: - opts.data_labels[key].onchange() - - changed += 1 - - opts.save(shared.config_filename) - - return f'{changed} settings changed.', opts.dumpjson() - - with gr.Blocks(analytics_enabled=False) as settings_interface: - settings_submit = gr.Button(value="Apply settings", variant='primary') - result = gr.HTML() - - settings_cols = 3 - items_per_col = int(len(opts.data_labels) * 0.9 / settings_cols) - - cols_displayed = 0 - items_displayed = 0 - previous_section = None - column = None - with gr.Row(elem_id="settings").style(equal_height=False): - for i, (k, item) in enumerate(opts.data_labels.items()): - - if previous_section != item.section: - if cols_displayed < settings_cols and (items_displayed >= items_per_col or previous_section is None): - if column is not None: - column.__exit__() - - column = gr.Column(variant='panel') - column.__enter__() - - items_displayed = 0 - cols_displayed += 1 - - previous_section = item.section - - gr.HTML(elem_id="settings_header_text_{}".format(item.section[0]), value='{}
'.format(item.section[1])) - - component = create_setting_component(k) - component_dict[k] = component - components.append(component) - items_displayed += 1 - - request_notifications = gr.Button(value='Request browser notifications', elem_id="request_notifications") - request_notifications.click( - fn=lambda: None, - inputs=[], - outputs=[], - _js='function(){}' - ) - - with gr.Row(): - reload_script_bodies = gr.Button(value='Reload custom script bodies (No ui updates, No restart)', variant='secondary') - restart_gradio = gr.Button(value='Restart Gradio and Refresh components (Custom Scripts, ui.py, js and css only)', variant='primary') - - - def reload_scripts(): - modules.scripts.reload_script_body_only() - - reload_script_bodies.click( - fn=reload_scripts, - inputs=[], - outputs=[], - _js='function(){}' - ) - - def request_restart(): - shared.state.interrupt() - settings_interface.gradio_ref.do_restart = True - - restart_gradio.click( - fn=request_restart, - inputs=[], - outputs=[], - _js='function(){restart_reload()}' - ) - - if column is not None: - column.__exit__() - - interfaces = [ - (txt2img_interface, "txt2img", "txt2img"), - (img2img_interface, "img2img", "img2img"), - (extras_interface, "Extras", "extras"), - (pnginfo_interface, "PNG Info", "pnginfo"), - (modelmerger_interface, "Checkpoint Merger", "modelmerger"), - (textual_inversion_interface, "Textual inversion", "ti"), - (settings_interface, "Settings", "settings"), - ] - - with open(os.path.join(script_path, "style.css"), "r", encoding="utf8") as file: - css = file.read() - - if os.path.exists(os.path.join(script_path, "user.css")): - with open(os.path.join(script_path, "user.css"), "r", encoding="utf8") as file: - usercss = file.read() - css += usercss - - if not cmd_opts.no_progressbar_hiding: - css += css_hide_progressbar - - with gr.Blocks(css=css, analytics_enabled=False, title="Stable Diffusion") as demo: - - settings_interface.gradio_ref = demo - - with gr.Tabs() as tabs: - for interface, label, ifid in interfaces: - with gr.TabItem(label, id=ifid): - interface.render() - - if os.path.exists(os.path.join(script_path, "notification.mp3")): - audio_notification = gr.Audio(interactive=False, value=os.path.join(script_path, "notification.mp3"), elem_id="audio_notification", visible=False) - - text_settings = gr.Textbox(elem_id="settings_json", value=lambda: opts.dumpjson(), visible=False) - settings_submit.click( - fn=run_settings, - inputs=components, - outputs=[result, text_settings], - ) - - def modelmerger(*args): - try: - results = modules.extras.run_modelmerger(*args) - except Exception as e: - print("Error loading/saving model file:", file=sys.stderr) - print(traceback.format_exc(), file=sys.stderr) - modules.sd_models.list_models() # to remove the potentially missing models from the list - return ["Error loading/saving model file. It doesn't exist or the name contains illegal characters"] + [gr.Dropdown.update(choices=modules.sd_models.checkpoint_tiles()) for _ in range(3)] - return results - - modelmerger_merge.click( - fn=modelmerger, - inputs=[ - primary_model_name, - secondary_model_name, - interp_method, - interp_amount, - save_as_half, - custom_name, - ], - outputs=[ - submit_result, - primary_model_name, - secondary_model_name, - component_dict['sd_model_checkpoint'], - ] - ) - paste_field_names = ['Prompt', 'Negative prompt', 'Steps', 'Face restoration', 'Seed', 'Size-1', 'Size-2'] - txt2img_fields = [field for field,name in txt2img_paste_fields if name in paste_field_names] - img2img_fields = [field for field,name in img2img_paste_fields if name in paste_field_names] - send_to_img2img.click( - fn=lambda img, *args: (image_from_url_text(img),*args), - _js="(gallery, ...args) => [extract_image_from_gallery_img2img(gallery), ...args]", - inputs=[txt2img_gallery] + txt2img_fields, - outputs=[init_img] + img2img_fields, - ) - - send_to_inpaint.click( - fn=lambda x, *args: (image_from_url_text(x), *args), - _js="(gallery, ...args) => [extract_image_from_gallery_inpaint(gallery), ...args]", - inputs=[txt2img_gallery] + txt2img_fields, - outputs=[init_img_with_mask] + img2img_fields, - ) - - img2img_send_to_img2img.click( - fn=lambda x: image_from_url_text(x), - _js="extract_image_from_gallery_img2img", - inputs=[img2img_gallery], - outputs=[init_img], - ) - - img2img_send_to_inpaint.click( - fn=lambda x: image_from_url_text(x), - _js="extract_image_from_gallery_inpaint", - inputs=[img2img_gallery], - outputs=[init_img_with_mask], - ) - - send_to_extras.click( - fn=lambda x: image_from_url_text(x), - _js="extract_image_from_gallery_extras", - inputs=[txt2img_gallery], - outputs=[extras_image], - ) - - open_txt2img_folder.click( - fn=lambda: open_folder(opts.outdir_samples or opts.outdir_txt2img_samples), - inputs=[], - outputs=[], - ) - - open_img2img_folder.click( - fn=lambda: open_folder(opts.outdir_samples or opts.outdir_img2img_samples), - inputs=[], - outputs=[], - ) - - open_extras_folder.click( - fn=lambda: open_folder(opts.outdir_samples or opts.outdir_extras_samples), - inputs=[], - outputs=[], - ) - - img2img_send_to_extras.click( - fn=lambda x: image_from_url_text(x), - _js="extract_image_from_gallery_extras", - inputs=[img2img_gallery], - outputs=[extras_image], - ) - - modules.generation_parameters_copypaste.connect_paste(pnginfo_send_to_txt2img, txt2img_paste_fields, generation_info, 'switch_to_txt2img') - modules.generation_parameters_copypaste.connect_paste(pnginfo_send_to_img2img, img2img_paste_fields, generation_info, 'switch_to_img2img_img2img') - - ui_config_file = cmd_opts.ui_config_file - ui_settings = {} - settings_count = len(ui_settings) - error_loading = False - - try: - if os.path.exists(ui_config_file): - with open(ui_config_file, "r", encoding="utf8") as file: - ui_settings = json.load(file) - except Exception: - error_loading = True - print("Error loading settings:", file=sys.stderr) - print(traceback.format_exc(), file=sys.stderr) - - def loadsave(path, x): - def apply_field(obj, field, condition=None): - key = path + "/" + field - - if getattr(obj,'custom_script_source',None) is not None: - key = 'customscript/' + obj.custom_script_source + '/' + key - - if getattr(obj, 'do_not_save_to_config', False): - return - - saved_value = ui_settings.get(key, None) - if saved_value is None: - ui_settings[key] = getattr(obj, field) - elif condition is None or condition(saved_value): - setattr(obj, field, saved_value) - - if type(x) in [gr.Slider, gr.Radio, gr.Checkbox, gr.Textbox, gr.Number] and x.visible: - apply_field(x, 'visible') - - if type(x) == gr.Slider: - apply_field(x, 'value') - apply_field(x, 'minimum') - apply_field(x, 'maximum') - apply_field(x, 'step') - - if type(x) == gr.Radio: - apply_field(x, 'value', lambda val: val in x.choices) - - if type(x) == gr.Checkbox: - apply_field(x, 'value') - - if type(x) == gr.Textbox: - apply_field(x, 'value') - - if type(x) == gr.Number: - apply_field(x, 'value') - - visit(txt2img_interface, loadsave, "txt2img") - visit(img2img_interface, loadsave, "img2img") - visit(extras_interface, loadsave, "extras") - - if not error_loading and (not os.path.exists(ui_config_file) or settings_count != len(ui_settings)): - with open(ui_config_file, "w", encoding="utf8") as file: - json.dump(ui_settings, file, indent=4) - - return demo - - -with open(os.path.join(script_path, "script.js"), "r", encoding="utf8") as jsfile: - javascript = f'' - -jsdir = os.path.join(script_path, "javascript") -for filename in sorted(os.listdir(jsdir)): - with open(os.path.join(jsdir, filename), "r", encoding="utf8") as jsfile: - javascript += f"\n" - - -if 'gradio_routes_templates_response' not in globals(): - def template_response(*args, **kwargs): - res = gradio_routes_templates_response(*args, **kwargs) - res.body = res.body.replace(b'', f'{javascript}'.encode("utf8")) - res.init_headers() - return res - - gradio_routes_templates_response = gradio.routes.templates.TemplateResponse - gradio.routes.templates.TemplateResponse = template_response diff --git a/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/face3d/extract_kp_videos.py b/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/face3d/extract_kp_videos.py deleted file mode 100644 index 21616a3b4b5077ffdce99621395237b4edcff58c..0000000000000000000000000000000000000000 --- a/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/face3d/extract_kp_videos.py +++ /dev/null @@ -1,108 +0,0 @@ -import os -import cv2 -import time -import glob -import argparse -import face_alignment -import numpy as np -from PIL import Image -from tqdm import tqdm -from itertools import cycle - -from torch.multiprocessing import Pool, Process, set_start_method - -class KeypointExtractor(): - def __init__(self, device): - self.detector = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, - device=device) - - def extract_keypoint(self, images, name=None, info=True): - if isinstance(images, list): - keypoints = [] - if info: - i_range = tqdm(images,desc='landmark Det:') - else: - i_range = images - - for image in i_range: - current_kp = self.extract_keypoint(image) - if np.mean(current_kp) == -1 and keypoints: - keypoints.append(keypoints[-1]) - else: - keypoints.append(current_kp[None]) - - keypoints = np.concatenate(keypoints, 0) - np.savetxt(os.path.splitext(name)[0]+'.txt', keypoints.reshape(-1)) - return keypoints - else: - while True: - try: - keypoints = self.detector.get_landmarks_from_image(np.array(images))[0] - break - except RuntimeError as e: - if str(e).startswith('CUDA'): - print("Warning: out of memory, sleep for 1s") - time.sleep(1) - else: - print(e) - break - except TypeError: - print('No face detected in this image') - shape = [68, 2] - keypoints = -1. * np.ones(shape) - break - if name is not None: - np.savetxt(os.path.splitext(name)[0]+'.txt', keypoints.reshape(-1)) - return keypoints - -def read_video(filename): - frames = [] - cap = cv2.VideoCapture(filename) - while cap.isOpened(): - ret, frame = cap.read() - if ret: - frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) - frame = Image.fromarray(frame) - frames.append(frame) - else: - break - cap.release() - return frames - -def run(data): - filename, opt, device = data - os.environ['CUDA_VISIBLE_DEVICES'] = device - kp_extractor = KeypointExtractor() - images = read_video(filename) - name = filename.split('/')[-2:] - os.makedirs(os.path.join(opt.output_dir, name[-2]), exist_ok=True) - kp_extractor.extract_keypoint( - images, - name=os.path.join(opt.output_dir, name[-2], name[-1]) - ) - -if __name__ == '__main__': - set_start_method('spawn') - parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter) - parser.add_argument('--input_dir', type=str, help='the folder of the input files') - parser.add_argument('--output_dir', type=str, help='the folder of the output files') - parser.add_argument('--device_ids', type=str, default='0,1') - parser.add_argument('--workers', type=int, default=4) - - opt = parser.parse_args() - filenames = list() - VIDEO_EXTENSIONS_LOWERCASE = {'mp4'} - VIDEO_EXTENSIONS = VIDEO_EXTENSIONS_LOWERCASE.union({f.upper() for f in VIDEO_EXTENSIONS_LOWERCASE}) - extensions = VIDEO_EXTENSIONS - - for ext in extensions: - os.listdir(f'{opt.input_dir}') - print(f'{opt.input_dir}/*.{ext}') - filenames = sorted(glob.glob(f'{opt.input_dir}/*.{ext}')) - print('Total number of videos:', len(filenames)) - pool = Pool(opt.workers) - args_list = cycle([opt]) - device_ids = opt.device_ids.split(",") - device_ids = cycle(device_ids) - for data in tqdm(pool.imap_unordered(run, zip(filenames, args_list, device_ids))): - None diff --git a/spaces/davila7/filegpt/app.py b/spaces/davila7/filegpt/app.py deleted file mode 100644 index 386e59aa760b0b39d8f5742cd7a3923ffbd5c0a2..0000000000000000000000000000000000000000 --- a/spaces/davila7/filegpt/app.py +++ /dev/null @@ -1,128 +0,0 @@ -import streamlit as st -from streamlit_chat import message -import os -from utils import ( - parse_docx, - parse_pdf, - parse_txt, - parse_csv, - parse_pptx, - search_docs, - embed_docs, - text_to_docs, - get_answer, - parse_any, - get_sources, - wrap_text_in_html, -) -from openai.error import OpenAIError - -def clear_submit(): - st.session_state["submit"] = False - -def set_openai_api_key(api_key: str): - st.session_state["OPENAI_API_KEY"] = api_key - -st.markdown('File GPT 🤖 by Code GPT
', unsafe_allow_html=True) - -# Sidebar -index = None -doc = None -with st.sidebar: - user_secret = st.text_input( - "OpenAI API Key", - type="password", - placeholder="Paste your OpenAI API key here (sk-...)", - help="You can get your API key from https://platform.openai.com/account/api-keys.", - value=st.session_state.get("OPENAI_API_KEY", ""), - ) - if user_secret: - set_openai_api_key(user_secret) - - uploaded_file = st.file_uploader( - "Upload a pdf, docx, or txt file", - type=["pdf", "docx", "txt", "csv", "pptx", "js", "py", "json", "html", "css", "md"], - help="Scanned documents are not supported yet!", - on_change=clear_submit, - ) - - if uploaded_file is not None: - if uploaded_file.name.endswith(".pdf"): - doc = parse_pdf(uploaded_file) - elif uploaded_file.name.endswith(".docx"): - doc = parse_docx(uploaded_file) - elif uploaded_file.name.endswith(".csv"): - doc = parse_csv(uploaded_file) - elif uploaded_file.name.endswith(".txt"): - doc = parse_txt(uploaded_file) - elif uploaded_file.name.endswith(".pptx"): - doc = parse_pptx(uploaded_file) - else: - doc = parse_any(uploaded_file) - #st.error("File type not supported") - #doc = None - text = text_to_docs(doc) - st.write(text) - try: - with st.spinner("Indexing document... This may take a while⏳"): - index = embed_docs(text) - st.session_state["api_key_configured"] = True - except OpenAIError as e: - st.error(e._message) - -tab1, tab2 = st.tabs(["Intro", "Chat with the File"]) -with tab1: - st.markdown("### How does it work?") - st.write("File GPT is a tool that allows you to ask questions about a document and get answers from the document. The tool uses the OpenAI API to embed the document and then uses the Embedding API to find the most similar documents to the question. The tool then uses LangChain to obtain the answer from the most similar documents.") - st.write("The tool is currently in beta and is not perfect. It is recommended to use it with short documents.") - st.write("""---""") - st.markdown("### How to use it?") - st.write("To use the tool you must first add your OpenAI API Key and then upload a document. The tool currently supports the following file types: pdf, docx, txt, csv, pptx. Once the document is uploaded, the tool will index the document and embed it. This may take a while depending on the size of the document. Once the document is indexed, you can ask questions about the document. The tool will return the answer to the question and the source of the answer.") - st.markdown('Read the article to know more details: Medium Article (Spanish)
', unsafe_allow_html=True) - st.write("## File GPT was written with the following tools:") - st.markdown("#### Code GPT") - st.write('All code was written with the help of Code GPT. Visit https://codegpt.co to get the extension.') - st.markdown("#### Streamlit") - st.write('The design was written with Streamlit.', unsafe_allow_html=True) - st.markdown("#### LangChain") - st.write('Question answering with source Langchain QA.', unsafe_allow_html=True) - st.markdown("#### Embedding") - st.write('Embedding is done via the OpenAI API with "text-embedding-ada-002"', unsafe_allow_html=True) - st.write("Please note that you must have credits in your OpenAI account to use this tool. Each file uploaded to the platform consumes credits for embedding and each query consumes credits to obtain the response.") - st.markdown("""---""") - st.write('Author: Daniel Avila', unsafe_allow_html=True) - st.write('Repo: Github', unsafe_allow_html=True) - st.write("This software was developed with Code GPT, for more information visit: https://codegpt.co", unsafe_allow_html=True) - -with tab2: - st.write('To obtain an API Key you must create an OpenAI account at the following link: https://openai.com/api/') - if 'generated' not in st.session_state: - st.session_state['generated'] = [] - - if 'past' not in st.session_state: - st.session_state['past'] = [] - - def get_text(): - if user_secret: - st.header("Ask me something about the document:") - input_text = st.text_area("You:", on_change=clear_submit) - return input_text - user_input = get_text() - - button = st.button("Submit") - if button or st.session_state.get("submit"): - if not user_input: - st.error("Please enter a question!") - else: - st.session_state["submit"] = True - sources = search_docs(index, user_input) - try: - answer = get_answer(sources, user_input) - st.session_state.past.append(user_input) - st.session_state.generated.append(answer["output_text"].split("SOURCES: ")[0]) - except OpenAIError as e: - st.error(e._message) - if st.session_state['generated']: - for i in range(len(st.session_state['generated'])-1, -1, -1): - message(st.session_state["generated"][i], key=str(i)) - message(st.session_state['past'][i], is_user=True, key=str(i) + '_user') \ No newline at end of file diff --git a/spaces/dawood/gradio_videogallery/__init__.py b/spaces/dawood/gradio_videogallery/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-7f3dc7e5.js b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-7f3dc7e5.js deleted file mode 100644 index 7f839fea46f243259bff7de849d4cbacf20f5083..0000000000000000000000000000000000000000 --- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-7f3dc7e5.js +++ /dev/null @@ -1,2 +0,0 @@ -import{S as Y,e as z,s as A,m as K,F as C,o as J,g as S,Y as L,h as R,G as E,j as M,ap as W,p as V,aw as X,w as B,u as j,k as U,H as D,B as se,C as fe,am as me,t as oe,x as be,a4 as he,E as v,V as Z,ae as y,N as q,O as F,Q as p,R as x,T as G,P as ce,r as ge,v as de}from"./index-9e76ffee.js";import{B as $}from"./Button-30a08c0b.js";import{B as re}from"./BlockTitle-af232cbc.js";import"./Info-77722665.js";function ve(e){let n;return{c(){n=oe(e[4])},m(i,u){R(i,n,u)},p(i,u){u&16&&be(n,i[4])},d(i){i&&U(n)}}}function we(e){let n,i,u,_,o,h,c;return i=new re({props:{show_label:e[6],info:e[5],$$slots:{default:[ve]},$$scope:{ctx:e}}}),{c(){n=K("label"),C(i.$$.fragment),u=J(),_=K("input"),S(_,"type","number"),S(_,"min",e[1]),S(_,"max",e[2]),S(_,"step",e[8]),_.disabled=e[3],S(_,"class","svelte-pjtc3"),S(n,"class","block svelte-pjtc3"),L(n,"container",e[7])},m(l,s){R(l,n,s),E(i,n,null),M(n,u),M(n,_),W(_,e[0]),o=!0,h||(c=[V(_,"input",e[13]),V(_,"keypress",e[9]),V(_,"blur",e[11]),V(_,"focus",e[12])],h=!0)},p(l,[s]){const m={};s&64&&(m.show_label=l[6]),s&32&&(m.info=l[5]),s&65552&&(m.$$scope={dirty:s,ctx:l}),i.$set(m),(!o||s&2)&&S(_,"min",l[1]),(!o||s&4)&&S(_,"max",l[2]),(!o||s&256)&&S(_,"step",l[8]),(!o||s&8)&&(_.disabled=l[3]),s&1&&X(_.value)!==l[0]&&W(_,l[0]),(!o||s&128)&&L(n,"container",l[7])},i(l){o||(B(i.$$.fragment,l),o=!0)},o(l){j(i.$$.fragment,l),o=!1},d(l){l&&U(n),D(i),h=!1,se(c)}}}function ke(e,n,i){let{value:u=0}=n,{minimum:_=void 0}=n,{maximum:o=void 0}=n,{value_is_output:h=!1}=n,{disabled:c=!1}=n,{label:l}=n,{info:s=void 0}=n,{show_label:m=!0}=n,{container:r=!0}=n,{step:t=1}=n;const b=fe();function w(){!isNaN(u)&&u!==null&&(b("change",u),h||b("input"))}me(()=>{i(10,h=!1)});async function d(g){await he(),g.key==="Enter"&&(g.preventDefault(),b("submit"))}function k(g){v.call(this,e,g)}function N(g){v.call(this,e,g)}function T(){u=X(this.value),i(0,u)}return e.$$set=g=>{"value"in g&&i(0,u=g.value),"minimum"in g&&i(1,_=g.minimum),"maximum"in g&&i(2,o=g.maximum),"value_is_output"in g&&i(10,h=g.value_is_output),"disabled"in g&&i(3,c=g.disabled),"label"in g&&i(4,l=g.label),"info"in g&&i(5,s=g.info),"show_label"in g&&i(6,m=g.show_label),"container"in g&&i(7,r=g.container),"step"in g&&i(8,t=g.step)},e.$$.update=()=>{e.$$.dirty&1&&w()},[u,_,o,c,l,s,m,r,t,d,h,k,N,T]}class ee extends Y{constructor(n){super(),z(this,n,ke,we,A,{value:0,minimum:1,maximum:2,value_is_output:10,disabled:3,label:4,info:5,show_label:6,container:7,step:8})}}function Ne(e){let n,i,u,_,o,h;const c=[e[13]];let l={};for(let t=0;tDarr The Mall 2: How to Download the Movie in DVDRip Quality
-If you are a fan of horror movies, you might be interested in watching Darr The Mall 2, the sequel to the 2014 film Darr The Mall. The movie follows a group of friends who get trapped in a haunted mall and have to face their worst fears. The movie stars Jimmy Sheirgill, Nushrat Bharucha, Arif Zakaria, and Asif Basra.
-But how can you watch Darr The Mall 2 online? Is there a way to download the movie in DVDRip quality? In this article, we will answer these questions and provide you with some tips and tricks to enjoy the movie at home.
-Darr The Mall 2 Dvdrip Download Movie
Download Zip 🗸🗸🗸 https://gohhs.com/2uFVov
-What is DVDRip Quality?
-DVDRip is a term that refers to a video file that has been ripped from a DVD. This means that the file has been copied and compressed to reduce its size and make it easier to download and stream. DVDRip quality is usually better than CAM or TS quality, which are recorded from a cinema screen or a TV broadcast. However, DVDRip quality is not as good as BluRay or WEB-DL quality, which are ripped from high-definition sources.
-How to Download Darr The Mall 2 in DVDRip Quality?
-There are several ways to download Darr The Mall 2 in DVDRip quality, but not all of them are legal or safe. Here are some of the options you can consider:
--
-
Conclusion
-Darr The Mall 2 is a horror movie that you can watch online or download in DVDRip quality. However, you should be careful about the sources you use and the risks you take when downloading or streaming the movie. We hope this article has helped you find the best way to enjoy Darr The Mall 2 at home.
d5da3c52bf
-
-
\ No newline at end of file diff --git a/spaces/diacanFperku/AutoGPT/Epubor Ultimate Converter 3.0.9.222 Key BETTER.md b/spaces/diacanFperku/AutoGPT/Epubor Ultimate Converter 3.0.9.222 Key BETTER.md deleted file mode 100644 index 90baf2e942468af40aa1ca891cf1ba9726b815c8..0000000000000000000000000000000000000000 --- a/spaces/diacanFperku/AutoGPT/Epubor Ultimate Converter 3.0.9.222 Key BETTER.md +++ /dev/null @@ -1,135 +0,0 @@ - -Epubor Ultimate Converter 3.0.9.222 Key: How to Convert and Remove DRM from eBooks
- -If you are an avid eBook reader, you may have encountered some problems with different eBook formats and DRM protection. Some eBooks are only compatible with certain devices or apps, while others are locked by DRM that prevents you from copying, sharing, or printing them. How can you enjoy your eBooks without any limitations? The answer is Epubor Ultimate Converter 3.0.9.222 Key.
-Epubor Ultimate Converter 3.0.9.222 Key
Download »»» https://gohhs.com/2uFVlY
- -Epubor Ultimate Converter 3.0.9.222 Key is a powerful eBook converter and DRM remover that can convert any eBook format to EPUB, MOBI, PDF, AZW3, TXT, and other formats that can be read on any device or app. It can also remove DRM from eBooks purchased from Kindle, Google Play, Kobo, Barnes & Noble, and other platforms.
- -In this article, we will show you how to download and install Epubor Ultimate Converter 3.0.9.222 Key on your Windows PC. We will also explain the features and benefits of Epubor Ultimate Converter 3.0.9.222 Key and how to use it to convert and remove DRM from eBooks.
- -How to Download and Install Epubor Ultimate Converter 3.0.9.222 Key on Your Windows PC
- -To download and install Epubor Ultimate Converter 3.0.9.222 Key on your Windows PC, you need to follow these steps:
- --
-
Note: You need to disable your antivirus software before installing Epubor Ultimate Converter 3.0.9.222 Key, as it may detect it as a false positive.
- -Features and Benefits of Epubor Ultimate Converter 3.0.9.222 Key
- -Epubor Ultimate Converter 3.0.9.222 Key has many features and benefits that make it the best eBook converter and DRM remover for Windows PC. Here are some of them:
- - --
-
How to Use Epubor Ultimate Converter 3.0.9.222 Key to Convert and Remove DRM from eBooks
- -To use Epubor Ultimate Converter 3.0.9.222 Key to convert and remove DRM from eBooks, you need to follow these steps:
- --
-
That's it! You have successfully used Epubor Ultimate Converter 3.0.9.222 Key to convert and remove DRM from eBooks.
- -Conclusion
- -Epubor Ultimate Converter 3.0.9.222 Key is a powerful eBook converter and DRM remover that can convert any eBook format to EPUB, MOBI, PDF, AZW3, TXT, and other formats that can be read on any device or app.
- -
It can also remove DRM from eBooks purchased from Kindle, Google Play, Kobo, Barnes & Noble,
and other platforms. - -
If you want to enjoy your eBooks without any limitations,
you should download and install Epubor Ultimate Converter 3.
0.
9.
222 Key on your Windows PC today. - -
We hope this article has helped you understand what Epubor Ultimate Converter 3.
0.
9.
222 Key is and how to use it to convert and remove DRM from eBooks. - -
If you have any questions or feedback,
feel free to leave a comment below.
-FAQs about Epubor Ultimate Converter 3.0.9.222 Key
- -Here are some frequently asked questions and answers about Epubor Ultimate Converter 3.0.9.222 Key:
- --
-
-
-
Testimonials from Epubor Ultimate Converter 3.0.9.222 Key Users
- -Here are some testimonials from Epubor Ultimate Converter 3.0.9.222 Key users who have shared their feedback and experience with the product:
- --
- -"I have been using Epubor Ultimate Converter for a few months now and I am very happy with it. It is very easy to use and it can convert and remove DRM from any eBook format that I need. It has saved me a lot of time and hassle when I want to read eBooks on different devices or apps. I highly recommend it to anyone who loves eBooks."
-- John Smith, eBook Reader --
- -"Epubor Ultimate Converter is a lifesaver for me. I have a lot of eBooks that I bought from different platforms, but some of them are not compatible with my Kindle or iPad. With Epubor Ultimate Converter, I can easily convert them to the format that I want and remove the DRM protection without any loss of quality. It is very fast and reliable. I love it!"
-- Jane Doe, eBook Lover --
-"Epubor Ultimate Converter is the best eBook converter and DRM remover that I have ever used. It can handle any eBook format that I throw at it and it can remove DRM from any platform that I buy from. It also has a great feature that allows me to edit the metadata of my eBooks, such as title, author, cover, etc. It is very user-friendly and intuitive. It is worth every penny."
-- Mike Lee, eBook Enthusiast -Why You Should Choose Epubor Ultimate Converter 3.0.9.222 Key
- -There are many eBook converters and DRM removers available on the market, but Epubor Ultimate Converter 3.0.9.222 Key stands out from the crowd for several reasons. Here are some of the reasons why you should choose Epubor Ultimate Converter 3.0.9.222 Key over other products:
- --
-
With Epubor Ultimate Converter 3.0.9.222 Key, you can enjoy your eBooks without any limitations or hassles. You can read them on any device or app you want, share them with your friends or family, print them out, or edit them as you like.
- -Epubor Ultimate Converter 3.0.9.222 Key is the ultimate solution for eBook lovers. Don't miss this opportunity to get it today.
-Conclusion
- -Epubor Ultimate Converter 3.0.9.222 Key is a powerful eBook converter and DRM remover that can convert any eBook format to EPUB, MOBI, PDF, AZW3, TXT, and other formats that can be read on any device or app. It can also remove DRM from eBooks purchased from Kindle, Google Play, Kobo, Barnes & Noble, and other platforms.
- -If you want to enjoy your eBooks without any limitations or hassles, you should download and install Epubor Ultimate Converter 3.0.9.222 Key on your Windows PC today. You can also get it for free by participating in their giveaway program.
- -We hope this article has helped you understand what Epubor Ultimate Converter 3.0.9.222 Key is and how to use it to convert and remove DRM from eBooks.
- -If you have any questions or feedback, feel free to leave a comment below.
3cee63e6c2
-
-
\ No newline at end of file diff --git a/spaces/diacanFperku/AutoGPT/Golpitha Namdeo Dhasal Pdf 13.md b/spaces/diacanFperku/AutoGPT/Golpitha Namdeo Dhasal Pdf 13.md deleted file mode 100644 index 5e28012d3c86845da43fe41835745dba166e9471..0000000000000000000000000000000000000000 --- a/spaces/diacanFperku/AutoGPT/Golpitha Namdeo Dhasal Pdf 13.md +++ /dev/null @@ -1,6 +0,0 @@ -golpitha namdeo dhasal pdf 13
Download File ->>> https://gohhs.com/2uFUOj
- -by S SHARMA — paper will look into the oeuvre of NamdeoDhasal's work as an example of ... A 13th-14th century saint in the Bhakti tradition, he is a ... Dilip Chitre, in his introduction to Dhasal's poetry, points out poetry's ... a live performance. Golpitha, his first. 1fdad05405
-
-
- diff --git a/spaces/diego2554/RemBG_super/rembg/session_factory.py b/spaces/diego2554/RemBG_super/rembg/session_factory.py deleted file mode 100644 index ab25b8acbd4fa8c0ea087c31f3905ca321a30dd4..0000000000000000000000000000000000000000 --- a/spaces/diego2554/RemBG_super/rembg/session_factory.py +++ /dev/null @@ -1,26 +0,0 @@ -import os -from typing import Type - -import onnxruntime as ort - -from .sessions import sessions_class -from .sessions.base import BaseSession -from .sessions.u2net import U2netSession - - -def new_session( - model_name: str = "u2net", providers=None, *args, **kwargs -) -> BaseSession: - session_class: Type[BaseSession] = U2netSession - - for sc in sessions_class: - if sc.name() == model_name: - session_class = sc - break - - sess_opts = ort.SessionOptions() - - if "OMP_NUM_THREADS" in os.environ: - sess_opts.inter_op_num_threads = int(os.environ["OMP_NUM_THREADS"]) - - return session_class(model_name, sess_opts, providers, *args, **kwargs) diff --git a/spaces/diego2554/RemBG_super/rembg/sessions/u2net_cloth_seg.py b/spaces/diego2554/RemBG_super/rembg/sessions/u2net_cloth_seg.py deleted file mode 100644 index 3e2ec65247d1f85f33036aa9e770456b72b202dc..0000000000000000000000000000000000000000 --- a/spaces/diego2554/RemBG_super/rembg/sessions/u2net_cloth_seg.py +++ /dev/null @@ -1,112 +0,0 @@ -import os -from typing import List - -import numpy as np -import pooch -from PIL import Image -from PIL.Image import Image as PILImage -from scipy.special import log_softmax - -from .base import BaseSession - -pallete1 = [ - 0, - 0, - 0, - 255, - 255, - 255, - 0, - 0, - 0, - 0, - 0, - 0, -] - -pallete2 = [ - 0, - 0, - 0, - 0, - 0, - 0, - 255, - 255, - 255, - 0, - 0, - 0, -] - -pallete3 = [ - 0, - 0, - 0, - 0, - 0, - 0, - 0, - 0, - 0, - 255, - 255, - 255, -] - - -class Unet2ClothSession(BaseSession): - def predict(self, img: PILImage, *args, **kwargs) -> List[PILImage]: - ort_outs = self.inner_session.run( - None, - self.normalize( - img, (0.485, 0.456, 0.406), (0.229, 0.224, 0.225), (768, 768) - ), - ) - - pred = ort_outs - pred = log_softmax(pred[0], 1) - pred = np.argmax(pred, axis=1, keepdims=True) - pred = np.squeeze(pred, 0) - pred = np.squeeze(pred, 0) - - mask = Image.fromarray(pred.astype("uint8"), mode="L") - mask = mask.resize(img.size, Image.LANCZOS) - - masks = [] - - mask1 = mask.copy() - mask1.putpalette(pallete1) - mask1 = mask1.convert("RGB").convert("L") - masks.append(mask1) - - mask2 = mask.copy() - mask2.putpalette(pallete2) - mask2 = mask2.convert("RGB").convert("L") - masks.append(mask2) - - mask3 = mask.copy() - mask3.putpalette(pallete3) - mask3 = mask3.convert("RGB").convert("L") - masks.append(mask3) - - return masks - - @classmethod - def download_models(cls, *args, **kwargs): - fname = f"{cls.name()}.onnx" - pooch.retrieve( - "https://github.com/danielgatis/rembg/releases/download/v0.0.0/u2net_cloth_seg.onnx", - None - if cls.checksum_disabled(*args, **kwargs) - else "md5:2434d1f3cb744e0e49386c906e5a08bb", - fname=fname, - path=cls.u2net_home(*args, **kwargs), - progressbar=True, - ) - - return os.path.join(cls.u2net_home(), fname) - - @classmethod - def name(cls, *args, **kwargs): - return "u2net_cloth_seg" diff --git a/spaces/dirge/voicevox/test/test_user_dict.py b/spaces/dirge/voicevox/test/test_user_dict.py deleted file mode 100644 index 4280bbe53e9b2d71df7b9c996f56ade7b802d561..0000000000000000000000000000000000000000 --- a/spaces/dirge/voicevox/test/test_user_dict.py +++ /dev/null @@ -1,348 +0,0 @@ -import json -from copy import deepcopy -from pathlib import Path -from tempfile import TemporaryDirectory -from typing import Dict -from unittest import TestCase - -from fastapi import HTTPException -from pyopenjtalk import g2p, unset_user_dict - -from voicevox_engine.model import UserDictWord, WordTypes -from voicevox_engine.part_of_speech_data import MAX_PRIORITY, part_of_speech_data -from voicevox_engine.user_dict import ( - apply_word, - create_word, - delete_word, - import_user_dict, - read_dict, - rewrite_word, - update_dict, -) - -# jsonとして保存される正しい形式の辞書データ -valid_dict_dict_json = { - "aab7dda2-0d97-43c8-8cb7-3f440dab9b4e": { - "surface": "test", - "cost": part_of_speech_data[WordTypes.PROPER_NOUN].cost_candidates[5], - "part_of_speech": "名詞", - "part_of_speech_detail_1": "固有名詞", - "part_of_speech_detail_2": "一般", - "part_of_speech_detail_3": "*", - "inflectional_type": "*", - "inflectional_form": "*", - "stem": "*", - "yomi": "テスト", - "pronunciation": "テスト", - "accent_type": 1, - "accent_associative_rule": "*", - }, -} - -# APIでやり取りされる正しい形式の辞書データ -valid_dict_dict_api = deepcopy(valid_dict_dict_json) -del valid_dict_dict_api["aab7dda2-0d97-43c8-8cb7-3f440dab9b4e"]["cost"] -valid_dict_dict_api["aab7dda2-0d97-43c8-8cb7-3f440dab9b4e"]["priority"] = 5 - -import_word = UserDictWord( - surface="test2", - priority=5, - part_of_speech="名詞", - part_of_speech_detail_1="固有名詞", - part_of_speech_detail_2="一般", - part_of_speech_detail_3="*", - inflectional_type="*", - inflectional_form="*", - stem="*", - yomi="テストツー", - pronunciation="テストツー", - accent_type=1, - accent_associative_rule="*", -) - - -def get_new_word(user_dict: Dict[str, UserDictWord]): - assert len(user_dict) == 2 or ( - len(user_dict) == 1 and "aab7dda2-0d97-43c8-8cb7-3f440dab9b4e" not in user_dict - ) - for word_uuid in user_dict.keys(): - if word_uuid == "aab7dda2-0d97-43c8-8cb7-3f440dab9b4e": - continue - return user_dict[word_uuid] - raise AssertionError - - -class TestUserDict(TestCase): - def setUp(self): - self.tmp_dir = TemporaryDirectory() - self.tmp_dir_path = Path(self.tmp_dir.name) - - def tearDown(self): - unset_user_dict() - self.tmp_dir.cleanup() - - def test_read_not_exist_json(self): - self.assertEqual( - read_dict(user_dict_path=(self.tmp_dir_path / "not_exist.json")), - {}, - ) - - def test_create_word(self): - # 将来的に品詞などが追加された時にテストを増やす - self.assertEqual( - create_word(surface="test", pronunciation="テスト", accent_type=1), - UserDictWord( - surface="test", - priority=5, - part_of_speech="名詞", - part_of_speech_detail_1="固有名詞", - part_of_speech_detail_2="一般", - part_of_speech_detail_3="*", - inflectional_type="*", - inflectional_form="*", - stem="*", - yomi="テスト", - pronunciation="テスト", - accent_type=1, - accent_associative_rule="*", - ), - ) - - def test_apply_word_without_json(self): - user_dict_path = self.tmp_dir_path / "test_apply_word_without_json.json" - apply_word( - surface="test", - pronunciation="テスト", - accent_type=1, - user_dict_path=user_dict_path, - compiled_dict_path=(self.tmp_dir_path / "test_apply_word_without_json.dic"), - ) - res = read_dict(user_dict_path=user_dict_path) - self.assertEqual(len(res), 1) - new_word = get_new_word(res) - self.assertEqual( - ( - new_word.surface, - new_word.pronunciation, - new_word.accent_type, - ), - ("test", "テスト", 1), - ) - - def test_apply_word_with_json(self): - user_dict_path = self.tmp_dir_path / "test_apply_word_with_json.json" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - apply_word( - surface="test2", - pronunciation="テストツー", - accent_type=3, - user_dict_path=user_dict_path, - compiled_dict_path=(self.tmp_dir_path / "test_apply_word_with_json.dic"), - ) - res = read_dict(user_dict_path=user_dict_path) - self.assertEqual(len(res), 2) - new_word = get_new_word(res) - self.assertEqual( - ( - new_word.surface, - new_word.pronunciation, - new_word.accent_type, - ), - ("test2", "テストツー", 3), - ) - - def test_rewrite_word_invalid_id(self): - user_dict_path = self.tmp_dir_path / "test_rewrite_word_invalid_id.json" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - self.assertRaises( - HTTPException, - rewrite_word, - word_uuid="c2be4dc5-d07d-4767-8be1-04a1bb3f05a9", - surface="test2", - pronunciation="テストツー", - accent_type=2, - user_dict_path=user_dict_path, - compiled_dict_path=(self.tmp_dir_path / "test_rewrite_word_invalid_id.dic"), - ) - - def test_rewrite_word_valid_id(self): - user_dict_path = self.tmp_dir_path / "test_rewrite_word_valid_id.json" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - rewrite_word( - word_uuid="aab7dda2-0d97-43c8-8cb7-3f440dab9b4e", - surface="test2", - pronunciation="テストツー", - accent_type=2, - user_dict_path=user_dict_path, - compiled_dict_path=(self.tmp_dir_path / "test_rewrite_word_valid_id.dic"), - ) - new_word = read_dict(user_dict_path=user_dict_path)[ - "aab7dda2-0d97-43c8-8cb7-3f440dab9b4e" - ] - self.assertEqual( - (new_word.surface, new_word.pronunciation, new_word.accent_type), - ("test2", "テストツー", 2), - ) - - def test_delete_word_invalid_id(self): - user_dict_path = self.tmp_dir_path / "test_delete_word_invalid_id.json" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - self.assertRaises( - HTTPException, - delete_word, - word_uuid="c2be4dc5-d07d-4767-8be1-04a1bb3f05a9", - user_dict_path=user_dict_path, - compiled_dict_path=(self.tmp_dir_path / "test_delete_word_invalid_id.dic"), - ) - - def test_delete_word_valid_id(self): - user_dict_path = self.tmp_dir_path / "test_delete_word_valid_id.json" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - delete_word( - word_uuid="aab7dda2-0d97-43c8-8cb7-3f440dab9b4e", - user_dict_path=user_dict_path, - compiled_dict_path=(self.tmp_dir_path / "test_delete_word_valid_id.dic"), - ) - self.assertEqual(len(read_dict(user_dict_path=user_dict_path)), 0) - - def test_priority(self): - for pos in part_of_speech_data: - for i in range(MAX_PRIORITY + 1): - self.assertEqual( - create_word( - surface="test", - pronunciation="テスト", - accent_type=1, - word_type=pos, - priority=i, - ).priority, - i, - ) - - def test_import_dict(self): - user_dict_path = self.tmp_dir_path / "test_import_dict.json" - compiled_dict_path = self.tmp_dir_path / "test_import_dict.dic" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - import_user_dict( - {"b1affe2a-d5f0-4050-926c-f28e0c1d9a98": import_word}, - override=False, - user_dict_path=user_dict_path, - compiled_dict_path=compiled_dict_path, - ) - self.assertEqual( - read_dict(user_dict_path)["b1affe2a-d5f0-4050-926c-f28e0c1d9a98"], - import_word, - ) - self.assertEqual( - read_dict(user_dict_path)["aab7dda2-0d97-43c8-8cb7-3f440dab9b4e"], - UserDictWord(**valid_dict_dict_api["aab7dda2-0d97-43c8-8cb7-3f440dab9b4e"]), - ) - - def test_import_dict_no_override(self): - user_dict_path = self.tmp_dir_path / "test_import_dict_no_override.json" - compiled_dict_path = self.tmp_dir_path / "test_import_dict_no_override.dic" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - import_user_dict( - {"aab7dda2-0d97-43c8-8cb7-3f440dab9b4e": import_word}, - override=False, - user_dict_path=user_dict_path, - compiled_dict_path=compiled_dict_path, - ) - self.assertEqual( - read_dict(user_dict_path)["aab7dda2-0d97-43c8-8cb7-3f440dab9b4e"], - UserDictWord(**valid_dict_dict_api["aab7dda2-0d97-43c8-8cb7-3f440dab9b4e"]), - ) - - def test_import_dict_override(self): - user_dict_path = self.tmp_dir_path / "test_import_dict_override.json" - compiled_dict_path = self.tmp_dir_path / "test_import_dict_override.dic" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - import_user_dict( - {"aab7dda2-0d97-43c8-8cb7-3f440dab9b4e": import_word}, - override=True, - user_dict_path=user_dict_path, - compiled_dict_path=compiled_dict_path, - ) - self.assertEqual( - read_dict(user_dict_path)["aab7dda2-0d97-43c8-8cb7-3f440dab9b4e"], - import_word, - ) - - def test_import_invalid_word(self): - user_dict_path = self.tmp_dir_path / "test_import_invalid_dict.json" - compiled_dict_path = self.tmp_dir_path / "test_import_invalid_dict.dic" - invalid_accent_associative_rule_word = deepcopy(import_word) - invalid_accent_associative_rule_word.accent_associative_rule = "invalid" - user_dict_path.write_text( - json.dumps(valid_dict_dict_json, ensure_ascii=False), encoding="utf-8" - ) - self.assertRaises( - AssertionError, - import_user_dict, - { - "aab7dda2-0d97-43c8-8cb7-3f440dab9b4e": invalid_accent_associative_rule_word - }, - override=True, - user_dict_path=user_dict_path, - compiled_dict_path=compiled_dict_path, - ) - invalid_pos_word = deepcopy(import_word) - invalid_pos_word.context_id = 2 - invalid_pos_word.part_of_speech = "フィラー" - invalid_pos_word.part_of_speech_detail_1 = "*" - invalid_pos_word.part_of_speech_detail_2 = "*" - invalid_pos_word.part_of_speech_detail_3 = "*" - self.assertRaises( - ValueError, - import_user_dict, - {"aab7dda2-0d97-43c8-8cb7-3f440dab9b4e": invalid_pos_word}, - override=True, - user_dict_path=user_dict_path, - compiled_dict_path=compiled_dict_path, - ) - - def test_update_dict(self): - user_dict_path = self.tmp_dir_path / "test_update_dict.json" - compiled_dict_path = self.tmp_dir_path / "test_update_dict.dic" - update_dict( - user_dict_path=user_dict_path, compiled_dict_path=compiled_dict_path - ) - test_text = "テスト用の文字列" - success_pronunciation = "デフォルトノジショデハゼッタイニセイセイサレナイヨミ" - - # 既に辞書に登録されていないか確認する - self.assertNotEqual(g2p(text=test_text, kana=True), success_pronunciation) - - apply_word( - surface=test_text, - pronunciation=success_pronunciation, - accent_type=1, - priority=10, - user_dict_path=user_dict_path, - compiled_dict_path=compiled_dict_path, - ) - self.assertEqual(g2p(text=test_text, kana=True), success_pronunciation) - - # 疑似的にエンジンを再起動する - unset_user_dict() - update_dict( - user_dict_path=user_dict_path, compiled_dict_path=compiled_dict_path - ) - - self.assertEqual(g2p(text=test_text, kana=True), success_pronunciation) diff --git a/spaces/dirge/voicevox/ui_template/ui.html b/spaces/dirge/voicevox/ui_template/ui.html deleted file mode 100644 index a37b9e1040cf1952564f4507ee55ade0384c90a7..0000000000000000000000000000000000000000 --- a/spaces/dirge/voicevox/ui_template/ui.html +++ /dev/null @@ -1,120 +0,0 @@ - - - - -VOICEVOX Engine 設定 - - - - - - - -- -- - diff --git a/spaces/dirge/voicevox/voicevox_engine/dev/core/__init__.py b/spaces/dirge/voicevox/voicevox_engine/dev/core/__init__.py deleted file mode 100644 index 432b00b93b362ec24d63e2daf65c70dbee8f3b08..0000000000000000000000000000000000000000 --- a/spaces/dirge/voicevox/voicevox_engine/dev/core/__init__.py +++ /dev/null @@ -1,17 +0,0 @@ -from .mock import ( - decode_forward, - initialize, - metas, - supported_devices, - yukarin_s_forward, - yukarin_sa_forward, -) - -__all__ = [ - "decode_forward", - "initialize", - "yukarin_s_forward", - "yukarin_sa_forward", - "metas", - "supported_devices", -] diff --git a/spaces/djl234/UFO/transformer.py b/spaces/djl234/UFO/transformer.py deleted file mode 100644 index 37940ab36a139930aac2be3bdeac51a38826997c..0000000000000000000000000000000000000000 --- a/spaces/djl234/UFO/transformer.py +++ /dev/null @@ -1,207 +0,0 @@ -import torch.nn as nn -import torch -from einops import rearrange -import numpy -def index_points(device, points, idx): - """ - - Input: - points: input points data, [B, N, C] - idx: sample index data, [B, S] - Return: - new_points:, indexed points data, [B, S, C] - """ - B = points.shape[0] - view_shape = list(idx.shape) - view_shape[1:] = [1] * (len(view_shape) - 1) - repeat_shape = list(idx.shape) - repeat_shape[0] = 1 - # batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape) - batch_indices = torch.arange(B, dtype=torch.long).cuda().view(view_shape).repeat(repeat_shape) - new_points = points[batch_indices, idx, :] - return new_points - -def knn_l2(device, net, k, u): - ''' - Input: - k: int32, number of k in k-nn search - net: (batch_size, npoint, c) float32 array, points - u: int32, block size - Output: - idx: (batch_size, npoint, k) int32 array, indices to input points - ''' - INF = 1e8 - batch_size = net.size(0) - npoint = net.size(1) - n_channel = net.size(2) - - square = torch.pow(torch.norm(net, dim=2,keepdim=True),2) - - def u_block(batch_size, npoint, u): - block = numpy.zeros([batch_size, npoint, npoint]) - n = npoint // u - for i in range(n): - block[:, (i*u):(i*u+u), (i*u):(i*u+u)] = numpy.ones([batch_size, u, u]) * (-INF) - return block - - # minus_distance = 2 * torch.matmul(net, net.transpose(2,1)) - square - square.transpose(2,1) + torch.Tensor(u_block(batch_size, npoint, u)).to(device) - minus_distance = 2 * torch.matmul(net, net.transpose(2,1)) - square - square.transpose(2,1) + torch.Tensor(u_block(batch_size, npoint, u)).cuda() - _, indices = torch.topk(minus_distance, k, largest=True, sorted=False) - - return indices - -class Residual(nn.Module): - def __init__(self, fn): - super().__init__() - self.fn = fn - def forward(self, x, **kwargs): - return self.fn(x, **kwargs) + x - -class PreNorm(nn.Module): - def __init__(self, dim, fn): - super().__init__() - self.norm = nn.LayerNorm(dim) - self.fn = fn - def forward(self, x, **kwargs): - return self.fn(self.norm(x), **kwargs) - -class FeedForward(nn.Module): - def __init__(self, dim, hidden_dim, dropout = 0.): - super().__init__() - self.net = nn.Sequential( - nn.Linear(dim, hidden_dim), - nn.GELU(), - nn.Dropout(dropout), - nn.Linear(hidden_dim, dim), - nn.Dropout(dropout) - ) - def forward(self, x): - return self.net(x) - -class Attention(nn.Module): - def __init__(self, dim, heads = 4, dropout = 0.): - super().__init__() - self.heads = heads - self.scale = dim ** -0.5 - - self.to_qkv = nn.Linear(dim, dim * 3, bias = False) - self.to_out = nn.Sequential( - nn.Linear(dim, dim), - nn.Dropout(dropout) - ) - - def forward(self, x, mask = None): - b, n, _, h = *x.shape, self.heads - qkv = self.to_qkv(x).chunk(3, dim = -1) - q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv) - - dots = torch.einsum('bhid,bhjd->bhij', q, k) * self.scale - - if mask is not None: - mask = F.pad(mask.flatten(1), (1, 0), value = True) - assert mask.shape[-1] == dots.shape[-1], 'mask has incorrect dimensions' - mask = mask[:, None, :] * mask[:, :, None] - dots.masked_fill_(~mask, float('-inf')) - del mask - - attn = dots.softmax(dim=-1) - - out = torch.einsum('bhij,bhjd->bhid', attn, v) - out = rearrange(out, 'b h n d -> b n (h d)') - out = self.to_out(out) - return out - -class Local_Attention(nn.Module): - def __init__(self, dim, heads = 4,knn=4, dropout = 0.): - super().__init__() - self.heads = heads - self.scale = dim ** -0.5 - - #self.to_qkv = nn.Linear(dim, dim * 3, bias = False) - self.q=nn.Linear(dim,dim,bias=False) - self.k=nn.Linear(dim,dim,bias=False) - self.v=nn.Linear(dim,dim,bias=False) - - self.to_out = nn.Sequential( - nn.Linear(dim, dim), - nn.Dropout(dropout) - ) - self.knn=knn - - def forward(self, x, mask = None): - b, n, _, h = *x.shape, self.heads - - point=x*1 - X=x*1 - - idx = knn_l2(0, point.permute(0,2,1), 4, 1) - feat=idx - new_point = index_points(0, point.permute(0,2,1),idx) - - group_point = new_point.permute(0, 3, 2, 1) - - _1,_2,_3,_4=group_point.shape - - q=self.q(X.reshape(_1*_2,1,_4)) - k=self.k(torch.cat([group_point.reshape(_1*_2,self.knn,_4),X.reshape(_1*_2,1,_4)],dim=1)) - v=self.v(torch.cat([group_point.reshape(_1*_2,self.knn,_4),X.reshape(_1*_2,1,_4)],dim=1)) - q, k, v = rearrange(q, 'b n (h d) -> b h n d', h = h),rearrange(k, 'b n (h d) -> b h n d', h = h),rearrange(v, 'b n (h d) -> b h n d', h = h) - - attn_map=q@k.permute(0,1,3,2)*self.scale - attn_map=attn_map.softmax(dim=-1) - - out=attn_map@v - out=out.view(b,out.shape[0]//b,out.shape[1],out.shape[3]).permute(0,2,1,3) - - out = rearrange(out, 'b h n d -> b n (h d)') - out = self.to_out(out) - return out - - -class Transformer(nn.Module): - def __init__(self, dim, depth, heads, mlp_dim, group=5, dropout=0.): - super().__init__() - self.layers = nn.ModuleList([]) - for _ in range(depth): - self.layers.append(nn.ModuleList([ - Residual(PreNorm(dim, Attention(dim, heads = heads, dropout = dropout))), - Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))) - ])) - self.group=group - def forward(self, x, mask = None): - bs_gp,dim,wid,hei=x.shape[0],x.shape[1],x.shape[2],x.shape[3] - bs=bs_gp//self.group - gp=self.group - x=x.reshape(bs,gp,dim,wid,hei) - x=x.permute(0,1,3,4,2).reshape(bs,gp*wid*hei,dim) - for attn, ff in self.layers: - x = attn(x, mask = mask) - x = ff(x) - - x=x.reshape(bs,gp,wid,hei,dim).permute(0,1,4,2,3).reshape(bs_gp,dim,wid,hei) - - return x - -class Transformer__local(nn.Module): - def __init__(self, dim, depth, heads, mlp_dim,knn_k=4, group=5, dropout=0.): - super().__init__() - self.layers = nn.ModuleList([]) - for _ in range(depth): - self.layers.append(nn.ModuleList([ - Residual(PreNorm(dim, Local_Attention(dim, heads = heads,knn=knn_k, dropout = dropout))), - Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))) - ])) - self.group=group - def forward(self, x, mask = None): - bs_gp,dim,wid,hei=x.shape[0],x.shape[1],x.shape[2],x.shape[3] - bs=bs_gp//self.group - gp=self.group - x=x.reshape(bs,gp,dim,wid,hei) - x=x.permute(0,1,3,4,2).reshape(bs,gp*wid*hei,dim) - for attn, ff in self.layers: - x = attn(x, mask = mask) - x = ff(x) - - x=x.reshape(bs,gp,wid,hei,dim).permute(0,1,4,2,3).reshape(bs_gp,dim,wid,hei) - - return x \ No newline at end of file diff --git a/spaces/dolceschokolade/chatbot-mini/components/Chatbar/components/PluginKeys.tsx b/spaces/dolceschokolade/chatbot-mini/components/Chatbar/components/PluginKeys.tsx deleted file mode 100644 index 1dcfe17d90a1e3eb72c55ca876acc7617e788983..0000000000000000000000000000000000000000 --- a/spaces/dolceschokolade/chatbot-mini/components/Chatbar/components/PluginKeys.tsx +++ /dev/null @@ -1,235 +0,0 @@ -import { IconKey } from '@tabler/icons-react'; -import { KeyboardEvent, useContext, useEffect, useRef, useState } from 'react'; -import { useTranslation } from 'react-i18next'; - -import { PluginID, PluginKey } from '@/types/plugin'; - -import HomeContext from '@/pages/api/home/home.context'; - -import { SidebarButton } from '@/components/Sidebar/SidebarButton'; - -import ChatbarContext from '../Chatbar.context'; - -export const PluginKeys = () => { - const { t } = useTranslation('sidebar'); - - const { - state: { pluginKeys }, - } = useContext(HomeContext); - - const { handlePluginKeyChange, handleClearPluginKey } = - useContext(ChatbarContext); - - const [isChanging, setIsChanging] = useState(false); - - const modalRef = useRef(null); - - const handleEnter = (e: KeyboardEvent ) => { - if (e.key === 'Enter' && !e.shiftKey) { - e.preventDefault(); - setIsChanging(false); - } - }; - - useEffect(() => { - const handleMouseDown = (e: MouseEvent) => { - if (modalRef.current && !modalRef.current.contains(e.target as Node)) { - window.addEventListener('mouseup', handleMouseUp); - } - }; - - const handleMouseUp = (e: MouseEvent) => { - window.removeEventListener('mouseup', handleMouseUp); - setIsChanging(false); - }; - - window.addEventListener('mousedown', handleMouseDown); - - return () => { - window.removeEventListener('mousedown', handleMouseDown); - }; - }, []); - - return ( - <> - } - onClick={() => setIsChanging(true)} - /> - - {isChanging && ( - -- )} - - ); -}; diff --git a/spaces/dorkai/ChatUIPro/typography.js b/spaces/dorkai/ChatUIPro/typography.js deleted file mode 100644 index 706e456ddd154ddfb606920d3ff03ae5da96144c..0000000000000000000000000000000000000000 --- a/spaces/dorkai/ChatUIPro/typography.js +++ /dev/null @@ -1,357 +0,0 @@ -module.exports = ({ theme }) => ({ - DEFAULT: { - css: { - '--tw-prose-body': theme('colors.zinc.700'), - '--tw-prose-headings': theme('colors.zinc.900'), - '--tw-prose-links': theme('colors.emerald.500'), - '--tw-prose-links-hover': theme('colors.emerald.600'), - '--tw-prose-links-underline': theme('colors.emerald.500 / 0.3'), - '--tw-prose-bold': theme('colors.zinc.900'), - '--tw-prose-counters': theme('colors.zinc.500'), - '--tw-prose-bullets': theme('colors.zinc.300'), - '--tw-prose-hr': theme('colors.zinc.900 / 0.05'), - '--tw-prose-quotes': theme('colors.zinc.900'), - '--tw-prose-quote-borders': theme('colors.zinc.200'), - '--tw-prose-captions': theme('colors.zinc.500'), - '--tw-prose-code': theme('colors.zinc.900'), - '--tw-prose-code-bg': theme('colors.zinc.100'), - '--tw-prose-code-ring': theme('colors.zinc.300'), - '--tw-prose-th-borders': theme('colors.zinc.300'), - '--tw-prose-td-borders': theme('colors.zinc.200'), - - '--tw-prose-invert-body': theme('colors.zinc.400'), - '--tw-prose-invert-headings': theme('colors.white'), - '--tw-prose-invert-links': theme('colors.emerald.400'), - '--tw-prose-invert-links-hover': theme('colors.emerald.500'), - '--tw-prose-invert-links-underline': theme('colors.emerald.500 / 0.3'), - '--tw-prose-invert-bold': theme('colors.white'), - '--tw-prose-invert-counters': theme('colors.zinc.400'), - '--tw-prose-invert-bullets': theme('colors.zinc.600'), - '--tw-prose-invert-hr': theme('colors.white / 0.05'), - '--tw-prose-invert-quotes': theme('colors.zinc.100'), - '--tw-prose-invert-quote-borders': theme('colors.zinc.700'), - '--tw-prose-invert-captions': theme('colors.zinc.400'), - '--tw-prose-invert-code': theme('colors.white'), - '--tw-prose-invert-code-bg': theme('colors.zinc.700 / 0.15'), - '--tw-prose-invert-code-ring': theme('colors.white / 0.1'), - '--tw-prose-invert-th-borders': theme('colors.zinc.600'), - '--tw-prose-invert-td-borders': theme('colors.zinc.700'), - - // Base - color: 'var(--tw-prose-body)', - fontSize: theme('fontSize.sm')[0], - lineHeight: theme('lineHeight.7'), - - // Layout - '> *': { - maxWidth: theme('maxWidth.2xl'), - marginLeft: 'auto', - marginRight: 'auto', - '@screen lg': { - maxWidth: theme('maxWidth.3xl'), - marginLeft: `calc(50% - min(50%, ${theme('maxWidth.lg')}))`, - marginRight: `calc(50% - min(50%, ${theme('maxWidth.lg')}))`, - }, - }, - - // Text - p: { - marginTop: theme('spacing.6'), - marginBottom: theme('spacing.6'), - }, - '[class~="lead"]': { - fontSize: theme('fontSize.base')[0], - ...theme('fontSize.base')[1], - }, - - // Lists - ol: { - listStyleType: 'decimal', - marginTop: theme('spacing.5'), - marginBottom: theme('spacing.5'), - paddingLeft: '1.625rem', - }, - 'ol[type="A"]': { - listStyleType: 'upper-alpha', - }, - 'ol[type="a"]': { - listStyleType: 'lower-alpha', - }, - 'ol[type="A" s]': { - listStyleType: 'upper-alpha', - }, - 'ol[type="a" s]': { - listStyleType: 'lower-alpha', - }, - 'ol[type="I"]': { - listStyleType: 'upper-roman', - }, - 'ol[type="i"]': { - listStyleType: 'lower-roman', - }, - 'ol[type="I" s]': { - listStyleType: 'upper-roman', - }, - 'ol[type="i" s]': { - listStyleType: 'lower-roman', - }, - 'ol[type="1"]': { - listStyleType: 'decimal', - }, - ul: { - listStyleType: 'disc', - marginTop: theme('spacing.5'), - marginBottom: theme('spacing.5'), - paddingLeft: '1.625rem', - }, - li: { - marginTop: theme('spacing.2'), - marginBottom: theme('spacing.2'), - }, - ':is(ol, ul) > li': { - paddingLeft: theme('spacing[1.5]'), - }, - 'ol > li::marker': { - fontWeight: '400', - color: 'var(--tw-prose-counters)', - }, - 'ul > li::marker': { - color: 'var(--tw-prose-bullets)', - }, - '> ul > li p': { - marginTop: theme('spacing.3'), - marginBottom: theme('spacing.3'), - }, - '> ul > li > *:first-child': { - marginTop: theme('spacing.5'), - }, - '> ul > li > *:last-child': { - marginBottom: theme('spacing.5'), - }, - '> ol > li > *:first-child': { - marginTop: theme('spacing.5'), - }, - '> ol > li > *:last-child': { - marginBottom: theme('spacing.5'), - }, - 'ul ul, ul ol, ol ul, ol ol': { - marginTop: theme('spacing.3'), - marginBottom: theme('spacing.3'), - }, - - // Horizontal rules - hr: { - borderColor: 'var(--tw-prose-hr)', - borderTopWidth: 1, - marginTop: theme('spacing.16'), - marginBottom: theme('spacing.16'), - maxWidth: 'none', - marginLeft: `calc(-1 * ${theme('spacing.4')})`, - marginRight: `calc(-1 * ${theme('spacing.4')})`, - '@screen sm': { - marginLeft: `calc(-1 * ${theme('spacing.6')})`, - marginRight: `calc(-1 * ${theme('spacing.6')})`, - }, - '@screen lg': { - marginLeft: `calc(-1 * ${theme('spacing.8')})`, - marginRight: `calc(-1 * ${theme('spacing.8')})`, - }, - }, - - // Quotes - blockquote: { - fontWeight: '500', - fontStyle: 'italic', - color: 'var(--tw-prose-quotes)', - borderLeftWidth: '0.25rem', - borderLeftColor: 'var(--tw-prose-quote-borders)', - quotes: '"\\201C""\\201D""\\2018""\\2019"', - marginTop: theme('spacing.8'), - marginBottom: theme('spacing.8'), - paddingLeft: theme('spacing.5'), - }, - 'blockquote p:first-of-type::before': { - content: 'open-quote', - }, - 'blockquote p:last-of-type::after': { - content: 'close-quote', - }, - - // Headings - h1: { - color: 'var(--tw-prose-headings)', - fontWeight: '700', - fontSize: theme('fontSize.2xl')[0], - ...theme('fontSize.2xl')[1], - marginBottom: theme('spacing.2'), - }, - h2: { - color: 'var(--tw-prose-headings)', - fontWeight: '600', - fontSize: theme('fontSize.lg')[0], - ...theme('fontSize.lg')[1], - marginTop: theme('spacing.16'), - marginBottom: theme('spacing.2'), - }, - h3: { - color: 'var(--tw-prose-headings)', - fontSize: theme('fontSize.base')[0], - ...theme('fontSize.base')[1], - fontWeight: '600', - marginTop: theme('spacing.10'), - marginBottom: theme('spacing.2'), - }, - - // Media - 'img, video, figure': { - marginTop: theme('spacing.8'), - marginBottom: theme('spacing.8'), - }, - 'figure > *': { - marginTop: '0', - marginBottom: '0', - }, - figcaption: { - color: 'var(--tw-prose-captions)', - fontSize: theme('fontSize.xs')[0], - ...theme('fontSize.xs')[1], - marginTop: theme('spacing.2'), - }, - - // Tables - table: { - width: '100%', - tableLayout: 'auto', - textAlign: 'left', - marginTop: theme('spacing.8'), - marginBottom: theme('spacing.8'), - lineHeight: theme('lineHeight.6'), - }, - thead: { - borderBottomWidth: '1px', - borderBottomColor: 'var(--tw-prose-th-borders)', - }, - 'thead th': { - color: 'var(--tw-prose-headings)', - fontWeight: '600', - verticalAlign: 'bottom', - paddingRight: theme('spacing.2'), - paddingBottom: theme('spacing.2'), - paddingLeft: theme('spacing.2'), - }, - 'thead th:first-child': { - paddingLeft: '0', - }, - 'thead th:last-child': { - paddingRight: '0', - }, - 'tbody tr': { - borderBottomWidth: '1px', - borderBottomColor: 'var(--tw-prose-td-borders)', - }, - 'tbody tr:last-child': { - borderBottomWidth: '0', - }, - 'tbody td': { - verticalAlign: 'baseline', - }, - tfoot: { - borderTopWidth: '1px', - borderTopColor: 'var(--tw-prose-th-borders)', - }, - 'tfoot td': { - verticalAlign: 'top', - }, - ':is(tbody, tfoot) td': { - paddingTop: theme('spacing.2'), - paddingRight: theme('spacing.2'), - paddingBottom: theme('spacing.2'), - paddingLeft: theme('spacing.2'), - }, - ':is(tbody, tfoot) td:first-child': { - paddingLeft: '0', - }, - ':is(tbody, tfoot) td:last-child': { - paddingRight: '0', - }, - - // Inline elements - a: { - color: 'var(--tw-prose-links)', - textDecoration: 'underline transparent', - fontWeight: '500', - transitionProperty: 'color, text-decoration-color', - transitionDuration: theme('transitionDuration.DEFAULT'), - transitionTimingFunction: theme('transitionTimingFunction.DEFAULT'), - '&:hover': { - color: 'var(--tw-prose-links-hover)', - textDecorationColor: 'var(--tw-prose-links-underline)', - }, - }, - ':is(h1, h2, h3) a': { - fontWeight: 'inherit', - }, - strong: { - color: 'var(--tw-prose-bold)', - fontWeight: '600', - }, - ':is(a, blockquote, thead th) strong': { - color: 'inherit', - }, - code: { - color: 'var(--tw-prose-code)', - borderRadius: theme('borderRadius.lg'), - paddingTop: theme('padding.1'), - paddingRight: theme('padding[1.5]'), - paddingBottom: theme('padding.1'), - paddingLeft: theme('padding[1.5]'), - boxShadow: 'inset 0 0 0 1px var(--tw-prose-code-ring)', - backgroundColor: 'var(--tw-prose-code-bg)', - fontSize: theme('fontSize.2xs'), - }, - ':is(a, h1, h2, h3, blockquote, thead th) code': { - color: 'inherit', - }, - 'h2 code': { - fontSize: theme('fontSize.base')[0], - fontWeight: 'inherit', - }, - 'h3 code': { - fontSize: theme('fontSize.sm')[0], - fontWeight: 'inherit', - }, - - // Overrides - ':is(h1, h2, h3) + *': { - marginTop: '0', - }, - '> :first-child': { - marginTop: '0 !important', - }, - '> :last-child': { - marginBottom: '0 !important', - }, - }, - }, - invert: { - css: { - '--tw-prose-body': 'var(--tw-prose-invert-body)', - '--tw-prose-headings': 'var(--tw-prose-invert-headings)', - '--tw-prose-links': 'var(--tw-prose-invert-links)', - '--tw-prose-links-hover': 'var(--tw-prose-invert-links-hover)', - '--tw-prose-links-underline': 'var(--tw-prose-invert-links-underline)', - '--tw-prose-bold': 'var(--tw-prose-invert-bold)', - '--tw-prose-counters': 'var(--tw-prose-invert-counters)', - '--tw-prose-bullets': 'var(--tw-prose-invert-bullets)', - '--tw-prose-hr': 'var(--tw-prose-invert-hr)', - '--tw-prose-quotes': 'var(--tw-prose-invert-quotes)', - '--tw-prose-quote-borders': 'var(--tw-prose-invert-quote-borders)', - '--tw-prose-captions': 'var(--tw-prose-invert-captions)', - '--tw-prose-code': 'var(--tw-prose-invert-code)', - '--tw-prose-code-bg': 'var(--tw-prose-invert-code-bg)', - '--tw-prose-code-ring': 'var(--tw-prose-invert-code-ring)', - '--tw-prose-th-borders': 'var(--tw-prose-invert-th-borders)', - '--tw-prose-td-borders': 'var(--tw-prose-invert-td-borders)', - }, - }, -}) diff --git a/spaces/dragonSwing/video2slide/app.py b/spaces/dragonSwing/video2slide/app.py deleted file mode 100644 index fea64c6a8c4f233c7ed00d289009abe20fdbdc5b..0000000000000000000000000000000000000000 --- a/spaces/dragonSwing/video2slide/app.py +++ /dev/null @@ -1,234 +0,0 @@ -import gradio as gr -import os -import validators -from imutils import paths -from config import * -from download_video import download_video -from bg_modeling import capture_slides_bg_modeling -from frame_differencing import capture_slides_frame_diff -from post_process import remove_duplicates -from utils import create_output_directory, convert_slides_to_pdf - - -def process( - video_path, - bg_type, - frame_buffer_history, - hash_size, - hash_func, - hash_queue_len, - sim_threshold, -): - output_dir_path = "output_results" - output_dir_path = create_output_directory(video_path, output_dir_path, bg_type) - - if bg_type.lower() == "Frame Diff": - capture_slides_frame_diff(video_path, output_dir_path) - else: - if bg_type.lower() == "gmg": - thresh = DEC_THRESH - elif bg_type.lower() == "knn": - thresh = DIST_THRESH - - capture_slides_bg_modeling( - video_path, - output_dir_path, - type_bgsub=bg_type, - history=frame_buffer_history, - threshold=thresh, - MIN_PERCENT_THRESH=MIN_PERCENT, - MAX_PERCENT_THRESH=MAX_PERCENT, - ) - - # Perform post-processing using difference hashing technique to remove duplicate slides. - hash_func = HASH_FUNC_DICT.get(hash_func.lower()) - - diff_threshold = int(hash_size * hash_size * (100 - sim_threshold) / 100) - remove_duplicates( - output_dir_path, hash_size, hash_func, hash_queue_len, diff_threshold - ) - - pdf_path = convert_slides_to_pdf(output_dir_path) - - # Remove unneccessary files - os.remove(video_path) - for image_path in paths.list_images(output_dir_path): - os.remove(image_path) - return pdf_path - - -def process_file( - file_obj, - bg_type, - frame_buffer_history, - hash_size, - hash_func, - hash_queue_len, - sim_threshold, -): - return process( - file_obj.name, - bg_type, - frame_buffer_history, - hash_size, - hash_func, - hash_queue_len, - sim_threshold, - ) - - -def process_via_url( - url, - bg_type, - frame_buffer_history, - hash_size, - hash_func, - hash_queue_len, - sim_threshold, -): - if validators.url(url): - video_path = download_video(url) - if video_path is None: - raise gr.Error( - "An error occurred while downloading the video, please try again later" - ) - return process( - video_path, - bg_type, - frame_buffer_history, - hash_size, - hash_func, - hash_queue_len, - sim_threshold, - ) - else: - raise gr.Error("Please enter a valid video URL") - - -with gr.Blocks(css="style.css") as demo: - with gr.Row(elem_classes=["container"]): - gr.Markdown( - """ - # Video 2 Slides Converter - - Convert your video presentation into PDF slides with one click. - - You can browse your video from the local file system, or enter a video URL/YouTube video link to start processing. - - **Note**: - - It will take some time to complete (~ half of the original video length), so stay tuned! - - If the YouTube video link doesn't work, you can try again later or download video to your computer and then upload it to the app - - Remember to press Enter if you are using an external URL - """, - elem_id="container", - ) - - with gr.Row(elem_classes=["container"]): - with gr.Column(scale=1): - with gr.Accordion("Advanced parameters"): - bg_type = gr.Dropdown( - ["Frame Diff", "GMG", "KNN"], - value="GMG", - label="Background subtraction", - info="Type of background subtraction to be used", - ) - frame_buffer_history = gr.Slider( - minimum=5, - maximum=20, - value=FRAME_BUFFER_HISTORY, - step=5, - label="Frame buffer history", - info="Length of the frame buffer history to model background.", - ) - # Post process - hash_func = gr.Dropdown( - ["Difference hashing", "Perceptual hashing", "Average hashing"], - value="Difference hashing", - label="Background subtraction", - info="Hash function to use for image hashing", - ) - hash_size = gr.Slider( - minimum=8, - maximum=16, - value=HASH_SIZE, - step=2, - label="Hash size", - info="Hash size to use for image hashing", - ) - hash_queue_len = gr.Slider( - minimum=5, - maximum=15, - value=HASH_BUFFER_HISTORY, - step=5, - label="Hash queue len", - info="Number of history images used to find out duplicate image", - ) - sim_threshold = gr.Slider( - minimum=90, - maximum=100, - value=SIM_THRESHOLD, - step=1, - label="Similarity threshold", - info="Minimum similarity threshold (in percent) to consider 2 images to be similar", - ) - - with gr.Column(scale=2): - with gr.Row(elem_id="row-flex"): - with gr.Column(scale=3): - file_url = gr.Textbox( - value="", - label="Upload your file", - placeholder="Enter a video url or YouTube video link", - show_label=False, - ) - with gr.Column(scale=1, min_width=160): - upload_button = gr.UploadButton("Browse File", file_types=["video"]) - file_output = gr.File(file_types=[".pdf"], label="Output PDF") - gr.Examples( - [ - [ - "https://www.youtube.com/watch?v=bfmFfD2RIcg", - "output_results/Neural Network In 5 Minutes.pdf", - ], - [ - "https://www.youtube.com/watch?v=EEo10bgsh0k", - "output_results/react-in-5-minutes.pdf", - ], - ], - [file_url, file_output], - ) - - with gr.Row(elem_classes=["container"]): - gr.HTML( - """--- - ----Plugin Keys- --- - -Google Search Plugin-- Please enter your Google API Key and Google CSE ID to enable - the Google Search Plugin. -- -- Google API Key -- p.pluginId === PluginID.GOOGLE_SEARCH) - ?.requiredKeys.find((k) => k.key === 'GOOGLE_API_KEY') - ?.value - } - onChange={(e) => { - const pluginKey = pluginKeys.find( - (p) => p.pluginId === PluginID.GOOGLE_SEARCH, - ); - - if (pluginKey) { - const requiredKey = pluginKey.requiredKeys.find( - (k) => k.key === 'GOOGLE_API_KEY', - ); - - if (requiredKey) { - const updatedPluginKey = { - ...pluginKey, - requiredKeys: pluginKey.requiredKeys.map((k) => { - if (k.key === 'GOOGLE_API_KEY') { - return { - ...k, - value: e.target.value, - }; - } - - return k; - }), - }; - - handlePluginKeyChange(updatedPluginKey); - } - } else { - const newPluginKey: PluginKey = { - pluginId: PluginID.GOOGLE_SEARCH, - requiredKeys: [ - { - key: 'GOOGLE_API_KEY', - value: e.target.value, - }, - { - key: 'GOOGLE_CSE_ID', - value: '', - }, - ], - }; - - handlePluginKeyChange(newPluginKey); - } - }} - /> - -- Google CSE ID -- p.pluginId === PluginID.GOOGLE_SEARCH) - ?.requiredKeys.find((k) => k.key === 'GOOGLE_CSE_ID') - ?.value - } - onChange={(e) => { - const pluginKey = pluginKeys.find( - (p) => p.pluginId === PluginID.GOOGLE_SEARCH, - ); - - if (pluginKey) { - const requiredKey = pluginKey.requiredKeys.find( - (k) => k.key === 'GOOGLE_CSE_ID', - ); - - if (requiredKey) { - const updatedPluginKey = { - ...pluginKey, - requiredKeys: pluginKey.requiredKeys.map((k) => { - if (k.key === 'GOOGLE_CSE_ID') { - return { - ...k, - value: e.target.value, - }; - } - - return k; - }), - }; - - handlePluginKeyChange(updatedPluginKey); - } - } else { - const newPluginKey: PluginKey = { - pluginId: PluginID.GOOGLE_SEARCH, - requiredKeys: [ - { - key: 'GOOGLE_API_KEY', - value: '', - }, - { - key: 'GOOGLE_CSE_ID', - value: e.target.value, - }, - ], - }; - - handlePluginKeyChange(newPluginKey); - } - }} - /> - - -You can duplicate this Space to skip the queue: """ - ) - - file_url.submit( - process_via_url, - [ - file_url, - bg_type, - frame_buffer_history, - hash_size, - hash_func, - hash_queue_len, - sim_threshold, - ], - file_output, - ) - upload_button.upload( - process_file, - [ - upload_button, - bg_type, - frame_buffer_history, - hash_size, - hash_func, - hash_queue_len, - sim_threshold, - ], - file_output, - ) - -demo.queue(concurrency_count=4).launch() diff --git a/spaces/ds520/bingo/src/components/theme-toggle.tsx b/spaces/ds520/bingo/src/components/theme-toggle.tsx deleted file mode 100644 index 67d3f1a2c163ccbeb52c40a7e42f107190237154..0000000000000000000000000000000000000000 --- a/spaces/ds520/bingo/src/components/theme-toggle.tsx +++ /dev/null @@ -1,31 +0,0 @@ -'use client' - -import * as React from 'react' -import { useTheme } from 'next-themes' - -import { Button } from '@/components/ui/button' -import { IconMoon, IconSun } from '@/components/ui/icons' - -export function ThemeToggle() { - const { setTheme, theme } = useTheme() - const [_, startTransition] = React.useTransition() - - return ( - - ) -} diff --git a/spaces/duchaba/120dog_breeds/app.py b/spaces/duchaba/120dog_breeds/app.py deleted file mode 100644 index d15b0e26033d7a2d03b81578506cb5567d08881b..0000000000000000000000000000000000000000 --- a/spaces/duchaba/120dog_breeds/app.py +++ /dev/null @@ -1,115 +0,0 @@ -# -import fastai -import fastai.vision -import PIL -import gradio -import matplotlib -import numpy -import pandas -from fastai.vision.all import * -# -# create class -class ADA_DOGS(object): - # - # initialize the object - def __init__(self, name="Wallaby",verbose=True,*args, **kwargs): - super(ADA_DOGS, self).__init__(*args, **kwargs) - self.author = "Duc Haba" - self.name = name - if (verbose): - self._ph() - self._pp("Hello from class", str(self.__class__) + " Class: " + str(self.__class__.__name__)) - self._pp("Code name", self.name) - self._pp("Author is", self.author) - self._ph() - # - self.article = '
-' - self.examples = ['dog1a.jpg','dog2.jpg','dog3.jpg','dog4.jpg','dog5.png','dog6.jpg', 'dog7.jpg','duc.jpg'] - self.title = "120 Dog Breeds Prediction" - return - # - # pretty print output name-value line - def _pp(self, a, b): - print("%34s : %s" % (str(a), str(b))) - return - # - # pretty print the header or footer lines - def _ph(self): - print("-" * 34, ":", "-" * 34) - return - # - def _predict_image(self,img,cat): - pred,idx,probs = learn.predict(img) - return dict(zip(cat, map(float,probs))) - # - def _draw_pred(self,df_pred): - canvas, pic = matplotlib.pyplot.subplots(1,1, figsize=(6,6)) - ti = df_pred["breeds"].head(5).values - # special case - #if (matplotlib.__version__) >= "3.5.2": - try: - df_pred["pred"].head(5).plot(ax=pic,kind="pie",figsize=(6,6), - cmap="Set2",labels=ti, explode=(0.02,0,0,0,0.), - normalize=False) - except: - df_pred["pred"].head(5).plot(ax=pic,kind="pie",figsize=(6,6), - cmap="Set2",labels=ti, explode=(0.02,0,0,0,0.)) - t = str(ti[0]) + ": " + str(numpy.round(df_pred.head(1).pred.values[0]*100, 2)) + "% Certainty" - pic.set_title(t,fontsize=14.0, fontweight="bold") - pic.axis('off') - # - # draw circle - centre_circle = matplotlib.pyplot.Circle((0, 0), 0.6, fc='white') - canvas = matplotlib.pyplot.gcf() - # Adding Circle in Pie chart - canvas.gca().add_artist(centre_circle) - # - canvas.legend(ti, loc="lower right",title="120 Dog Breeds: Top 5") - # - canvas.tight_layout() - return canvas - # - def predict_donut(self,img): - d = self._predict_image(img,self.categories) - df = pandas.DataFrame(d, index=[0]) - df = df.transpose().reset_index() - df.columns = ["breeds", "pred"] - df.sort_values("pred", inplace=True,ascending=False, ignore_index=True) - canvas = self._draw_pred(df) - return canvas -# -maxi = ADA_DOGS(verbose=False) -# -learn = fastai.learner.load_learner('ada.pkl') -maxi.categories = learn.dls.vocab -hf_image = gradio.inputs.Image(shape=(192, 192)) -hf_label = gradio.outputs.Label() -intf = gradio.Interface(fn=maxi.predict_donut, - inputs=hf_image, - outputs=["plot"], - examples=maxi.examples, - title=maxi.title, - live=True, - article=maxi.article) -intf.launch(inline=False,share=True) \ No newline at end of file diff --git a/spaces/duycse1603/math2tex/HybridViT/recognizers/__init__.py b/spaces/duycse1603/math2tex/HybridViT/recognizers/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/modules.py b/spaces/eIysia/VITS-Umamusume-voice-synthesizer/modules.py deleted file mode 100644 index f5af1fd9a20dc03707889f360a39bb4b784a6df3..0000000000000000000000000000000000000000 --- a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/modules.py +++ /dev/null @@ -1,387 +0,0 @@ -import math -import torch -from torch import nn -from torch.nn import functional as F - -from torch.nn import Conv1d -from torch.nn.utils import weight_norm, remove_weight_norm - -import commons -from commons import init_weights, get_padding -from transforms import piecewise_rational_quadratic_transform - - -LRELU_SLOPE = 0.1 - - -class LayerNorm(nn.Module): - def __init__(self, channels, eps=1e-5): - super().__init__() - self.channels = channels - self.eps = eps - - self.gamma = nn.Parameter(torch.ones(channels)) - self.beta = nn.Parameter(torch.zeros(channels)) - - def forward(self, x): - x = x.transpose(1, -1) - x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps) - return x.transpose(1, -1) - - -class ConvReluNorm(nn.Module): - def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout): - super().__init__() - self.in_channels = in_channels - self.hidden_channels = hidden_channels - self.out_channels = out_channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.p_dropout = p_dropout - assert n_layers > 1, "Number of layers should be larger than 0." - - self.conv_layers = nn.ModuleList() - self.norm_layers = nn.ModuleList() - self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2)) - self.norm_layers.append(LayerNorm(hidden_channels)) - self.relu_drop = nn.Sequential( - nn.ReLU(), - nn.Dropout(p_dropout)) - for _ in range(n_layers-1): - self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2)) - self.norm_layers.append(LayerNorm(hidden_channels)) - self.proj = nn.Conv1d(hidden_channels, out_channels, 1) - self.proj.weight.data.zero_() - self.proj.bias.data.zero_() - - def forward(self, x, x_mask): - x_org = x - for i in range(self.n_layers): - x = self.conv_layers[i](x * x_mask) - x = self.norm_layers[i](x) - x = self.relu_drop(x) - x = x_org + self.proj(x) - return x * x_mask - - -class DDSConv(nn.Module): - """ - Dialted and Depth-Separable Convolution - """ - def __init__(self, channels, kernel_size, n_layers, p_dropout=0.): - super().__init__() - self.channels = channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.p_dropout = p_dropout - - self.drop = nn.Dropout(p_dropout) - self.convs_sep = nn.ModuleList() - self.convs_1x1 = nn.ModuleList() - self.norms_1 = nn.ModuleList() - self.norms_2 = nn.ModuleList() - for i in range(n_layers): - dilation = kernel_size ** i - padding = (kernel_size * dilation - dilation) // 2 - self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size, - groups=channels, dilation=dilation, padding=padding - )) - self.convs_1x1.append(nn.Conv1d(channels, channels, 1)) - self.norms_1.append(LayerNorm(channels)) - self.norms_2.append(LayerNorm(channels)) - - def forward(self, x, x_mask, g=None): - if g is not None: - x = x + g - for i in range(self.n_layers): - y = self.convs_sep[i](x * x_mask) - y = self.norms_1[i](y) - y = F.gelu(y) - y = self.convs_1x1[i](y) - y = self.norms_2[i](y) - y = F.gelu(y) - y = self.drop(y) - x = x + y - return x * x_mask - - -class WN(torch.nn.Module): - def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0): - super(WN, self).__init__() - assert(kernel_size % 2 == 1) - self.hidden_channels =hidden_channels - self.kernel_size = kernel_size, - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.gin_channels = gin_channels - self.p_dropout = p_dropout - - self.in_layers = torch.nn.ModuleList() - self.res_skip_layers = torch.nn.ModuleList() - self.drop = nn.Dropout(p_dropout) - - if gin_channels != 0: - cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1) - self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight') - - for i in range(n_layers): - dilation = dilation_rate ** i - padding = int((kernel_size * dilation - dilation) / 2) - in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size, - dilation=dilation, padding=padding) - in_layer = torch.nn.utils.weight_norm(in_layer, name='weight') - self.in_layers.append(in_layer) - - # last one is not necessary - if i < n_layers - 1: - res_skip_channels = 2 * hidden_channels - else: - res_skip_channels = hidden_channels - - res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1) - res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight') - self.res_skip_layers.append(res_skip_layer) - - def forward(self, x, x_mask, g=None, **kwargs): - output = torch.zeros_like(x) - n_channels_tensor = torch.IntTensor([self.hidden_channels]) - - if g is not None: - g = self.cond_layer(g) - - for i in range(self.n_layers): - x_in = self.in_layers[i](x) - if g is not None: - cond_offset = i * 2 * self.hidden_channels - g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:] - else: - g_l = torch.zeros_like(x_in) - - acts = commons.fused_add_tanh_sigmoid_multiply( - x_in, - g_l, - n_channels_tensor) - acts = self.drop(acts) - - res_skip_acts = self.res_skip_layers[i](acts) - if i < self.n_layers - 1: - res_acts = res_skip_acts[:,:self.hidden_channels,:] - x = (x + res_acts) * x_mask - output = output + res_skip_acts[:,self.hidden_channels:,:] - else: - output = output + res_skip_acts - return output * x_mask - - def remove_weight_norm(self): - if self.gin_channels != 0: - torch.nn.utils.remove_weight_norm(self.cond_layer) - for l in self.in_layers: - torch.nn.utils.remove_weight_norm(l) - for l in self.res_skip_layers: - torch.nn.utils.remove_weight_norm(l) - - -class ResBlock1(torch.nn.Module): - def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)): - super(ResBlock1, self).__init__() - self.convs1 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2], - padding=get_padding(kernel_size, dilation[2]))) - ]) - self.convs1.apply(init_weights) - - self.convs2 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))) - ]) - self.convs2.apply(init_weights) - - def forward(self, x, x_mask=None): - for c1, c2 in zip(self.convs1, self.convs2): - xt = F.leaky_relu(x, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c1(xt) - xt = F.leaky_relu(xt, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c2(xt) - x = xt + x - if x_mask is not None: - x = x * x_mask - return x - - def remove_weight_norm(self): - for l in self.convs1: - remove_weight_norm(l) - for l in self.convs2: - remove_weight_norm(l) - - -class ResBlock2(torch.nn.Module): - def __init__(self, channels, kernel_size=3, dilation=(1, 3)): - super(ResBlock2, self).__init__() - self.convs = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))) - ]) - self.convs.apply(init_weights) - - def forward(self, x, x_mask=None): - for c in self.convs: - xt = F.leaky_relu(x, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c(xt) - x = xt + x - if x_mask is not None: - x = x * x_mask - return x - - def remove_weight_norm(self): - for l in self.convs: - remove_weight_norm(l) - - -class Log(nn.Module): - def forward(self, x, x_mask, reverse=False, **kwargs): - if not reverse: - y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask - logdet = torch.sum(-y, [1, 2]) - return y, logdet - else: - x = torch.exp(x) * x_mask - return x - - -class Flip(nn.Module): - def forward(self, x, *args, reverse=False, **kwargs): - x = torch.flip(x, [1]) - if not reverse: - logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device) - return x, logdet - else: - return x - - -class ElementwiseAffine(nn.Module): - def __init__(self, channels): - super().__init__() - self.channels = channels - self.m = nn.Parameter(torch.zeros(channels,1)) - self.logs = nn.Parameter(torch.zeros(channels,1)) - - def forward(self, x, x_mask, reverse=False, **kwargs): - if not reverse: - y = self.m + torch.exp(self.logs) * x - y = y * x_mask - logdet = torch.sum(self.logs * x_mask, [1,2]) - return y, logdet - else: - x = (x - self.m) * torch.exp(-self.logs) * x_mask - return x - - -class ResidualCouplingLayer(nn.Module): - def __init__(self, - channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - p_dropout=0, - gin_channels=0, - mean_only=False): - assert channels % 2 == 0, "channels should be divisible by 2" - super().__init__() - self.channels = channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.half_channels = channels // 2 - self.mean_only = mean_only - - self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1) - self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels) - self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1) - self.post.weight.data.zero_() - self.post.bias.data.zero_() - - def forward(self, x, x_mask, g=None, reverse=False): - x0, x1 = torch.split(x, [self.half_channels]*2, 1) - h = self.pre(x0) * x_mask - h = self.enc(h, x_mask, g=g) - stats = self.post(h) * x_mask - if not self.mean_only: - m, logs = torch.split(stats, [self.half_channels]*2, 1) - else: - m = stats - logs = torch.zeros_like(m) - - if not reverse: - x1 = m + x1 * torch.exp(logs) * x_mask - x = torch.cat([x0, x1], 1) - logdet = torch.sum(logs, [1,2]) - return x, logdet - else: - x1 = (x1 - m) * torch.exp(-logs) * x_mask - x = torch.cat([x0, x1], 1) - return x - - -class ConvFlow(nn.Module): - def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0): - super().__init__() - self.in_channels = in_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.num_bins = num_bins - self.tail_bound = tail_bound - self.half_channels = in_channels // 2 - - self.pre = nn.Conv1d(self.half_channels, filter_channels, 1) - self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.) - self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1) - self.proj.weight.data.zero_() - self.proj.bias.data.zero_() - - def forward(self, x, x_mask, g=None, reverse=False): - x0, x1 = torch.split(x, [self.half_channels]*2, 1) - h = self.pre(x0) - h = self.convs(h, x_mask, g=g) - h = self.proj(h) * x_mask - - b, c, t = x0.shape - h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?] - - unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels) - unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels) - unnormalized_derivatives = h[..., 2 * self.num_bins:] - - x1, logabsdet = piecewise_rational_quadratic_transform(x1, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=reverse, - tails='linear', - tail_bound=self.tail_bound - ) - - x = torch.cat([x0, x1], 1) * x_mask - logdet = torch.sum(logabsdet * x_mask, [1,2]) - if not reverse: - return x, logdet - else: - return x diff --git a/spaces/emmetmayer/Large-Context-Question-and-Answering/app.py b/spaces/emmetmayer/Large-Context-Question-and-Answering/app.py deleted file mode 100644 index 457547c9be2ffead2380d4c4917a892744fd39bd..0000000000000000000000000000000000000000 --- a/spaces/emmetmayer/Large-Context-Question-and-Answering/app.py +++ /dev/null @@ -1,47 +0,0 @@ -import streamlit as st -import json -from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline -from sentence_transformers import SentenceTransformer, util -from io import StringIO - -@st.cache -def vectorizeSentences(model, sentences): - embeddings = model.encode(sentences) - cosine_scores = util.cos_sim(embeddings[0], embeddings) - return cosine_scores[0] - -@st.cache -def loadContext(model, context): - data = json.load(contextUpload) - embeddings = vectorizeSentences(model, list(data.keys())) - return (data, embeddings) - -@st.cache -def question(model, question, data, embeddings): - data = json.load(contextUpload) - embeddings = vectorizeSentences(model, list(data.keys())) - return (data, embeddings) - - -@st.cache -def loadSentenceModel(): - return SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2') - -@st.cache -def loadQAModel(): - return pipeline("question-answering", model="deepset/roberta-base-squad2", tokenizer="deepset/roberta-base-squad2") - -sentenceModel = loadSentenceModel -questionAnsweringModel = loadQAModel - -st.header("Large Context Question & Answering") - -st.info("Upload a JSON context file") - -contextUpload = st.file_uploader("Upload a.json context file", type=["json"]) -st.json(json.load(contextUpload)) -if contextUpload is not None: - #embeddings = loadContext(sentenceModel, contextUpload) - # question = st.text_input("Enter your question", value="") - #if question != "": - st.write("question") \ No newline at end of file diff --git a/spaces/enzostvs/hub-api-playground/components/editor/main/endpoint.tsx b/spaces/enzostvs/hub-api-playground/components/editor/main/endpoint.tsx deleted file mode 100644 index f302e393b861801670401decfb3f74479cb5b4b3..0000000000000000000000000000000000000000 --- a/spaces/enzostvs/hub-api-playground/components/editor/main/endpoint.tsx +++ /dev/null @@ -1,60 +0,0 @@ -import { useMemo } from "react"; - -import { Method } from "@/components/method"; -import { splitStringBracket } from "@/utils"; -import { ApiRoute } from "@/utils/type"; -import { Parameter } from "./parameter"; - -export const Endpoint = ({ - method, - path, - initialPath, - children, - onChange, -}: { - method: ApiRoute["method"]; - path: string; - initialPath: ApiRoute["path"]; - children: React.ReactElement; - onChange: (value: string) => void; -}) => { - const path_formatted = useMemo( - () => splitStringBracket(initialPath), - [initialPath] - ); - - const handleChange = (value: string, key: string) => { - onChange(path.replace(key, value)); - }; - - return ( -Citation:
Articles:
- '
- self.article += '
Train Result:
- '
- self.article += '
Dev Stack:
- '
- self.article += '
Licenses:
- '
- self.article += '
-- ); -}; diff --git a/spaces/erbanku/gpt-academic/request_llm/bridge_chatgpt.py b/spaces/erbanku/gpt-academic/request_llm/bridge_chatgpt.py deleted file mode 100644 index 48eaba0b9f5498c18648f446b8d8d8066b1bd950..0000000000000000000000000000000000000000 --- a/spaces/erbanku/gpt-academic/request_llm/bridge_chatgpt.py +++ /dev/null @@ -1,277 +0,0 @@ -# 借鉴了 https://github.com/GaiZhenbiao/ChuanhuChatGPT 项目 - -""" - 该文件中主要包含三个函数 - - 不具备多线程能力的函数: - 1. predict: 正常对话时使用,具备完备的交互功能,不可多线程 - - 具备多线程调用能力的函数 - 2. predict_no_ui:高级实验性功能模块调用,不会实时显示在界面上,参数简单,可以多线程并行,方便实现复杂的功能逻辑 - 3. predict_no_ui_long_connection:在实验过程中发现调用predict_no_ui处理长文档时,和openai的连接容易断掉,这个函数用stream的方式解决这个问题,同样支持多线程 -""" - -import json -import time -import gradio as gr -import logging -import traceback -import requests -import importlib - -# config_private.py放自己的秘密如API和代理网址 -# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件 -from toolbox import get_conf, update_ui, is_any_api_key, select_api_key, what_keys, clip_history, trimmed_format_exc -proxies, API_KEY, TIMEOUT_SECONDS, MAX_RETRY = \ - get_conf('proxies', 'API_KEY', 'TIMEOUT_SECONDS', 'MAX_RETRY') - -timeout_bot_msg = '[Local Message] Request timeout. Network error. Please check proxy settings in config.py.' + \ - '网络错误,检查代理服务器是否可用,以及代理设置的格式是否正确,格式须是[协议]://[地址]:[端口],缺一不可。' - -def get_full_error(chunk, stream_response): - """ - 获取完整的从Openai返回的报错 - """ - while True: - try: - chunk += next(stream_response) - except: - break - return chunk - - -def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=None, console_slience=False): - """ - 发送至chatGPT,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免中途网线被掐。 - inputs: - 是本次问询的输入 - sys_prompt: - 系统静默prompt - llm_kwargs: - chatGPT的内部调优参数 - history: - 是之前的对话列表 - observe_window = None: - 用于负责跨越线程传递已经输出的部分,大部分时候仅仅为了fancy的视觉效果,留空即可。observe_window[0]:观测窗。observe_window[1]:看门狗 - """ - watch_dog_patience = 5 # 看门狗的耐心, 设置5秒即可 - headers, payload = generate_payload(inputs, llm_kwargs, history, system_prompt=sys_prompt, stream=True) - retry = 0 - while True: - try: - # make a POST request to the API endpoint, stream=False - from .bridge_all import model_info - endpoint = model_info[llm_kwargs['llm_model']]['endpoint'] - response = requests.post(endpoint, headers=headers, proxies=proxies, - json=payload, stream=True, timeout=TIMEOUT_SECONDS); break - except requests.exceptions.ReadTimeout as e: - retry += 1 - traceback.print_exc() - if retry > MAX_RETRY: raise TimeoutError - if MAX_RETRY!=0: print(f'请求超时,正在重试 ({retry}/{MAX_RETRY}) ……') - - stream_response = response.iter_lines() - result = '' - while True: - try: chunk = next(stream_response).decode() - except StopIteration: - break - except requests.exceptions.ConnectionError: - chunk = next(stream_response).decode() # 失败了,重试一次?再失败就没办法了。 - if len(chunk)==0: continue - if not chunk.startswith('data:'): - error_msg = get_full_error(chunk.encode('utf8'), stream_response).decode() - if "reduce the length" in error_msg: - raise ConnectionAbortedError("OpenAI拒绝了请求:" + error_msg) - else: - raise RuntimeError("OpenAI拒绝了请求:" + error_msg) - if ('data: [DONE]' in chunk): break # api2d 正常完成 - json_data = json.loads(chunk.lstrip('data:'))['choices'][0] - delta = json_data["delta"] - if len(delta) == 0: break - if "role" in delta: continue - if "content" in delta: - result += delta["content"] - if not console_slience: print(delta["content"], end='') - if observe_window is not None: - # 观测窗,把已经获取的数据显示出去 - if len(observe_window) >= 1: observe_window[0] += delta["content"] - # 看门狗,如果超过期限没有喂狗,则终止 - if len(observe_window) >= 2: - if (time.time()-observe_window[1]) > watch_dog_patience: - raise RuntimeError("用户取消了程序。") - else: raise RuntimeError("意外Json结构:"+delta) - if json_data['finish_reason'] == 'length': - raise ConnectionAbortedError("正常结束,但显示Token不足,导致输出不完整,请削减单次输入的文本量。") - return result - - -def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None): - """ - 发送至chatGPT,流式获取输出。 - 用于基础的对话功能。 - inputs 是本次问询的输入 - top_p, temperature是chatGPT的内部调优参数 - history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误) - chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容 - additional_fn代表点击的哪个按钮,按钮见functional.py - """ - if is_any_api_key(inputs): - chatbot._cookies['api_key'] = inputs - chatbot.append(("输入已识别为openai的api_key", what_keys(inputs))) - yield from update_ui(chatbot=chatbot, history=history, msg="api_key已导入") # 刷新界面 - return - elif not is_any_api_key(chatbot._cookies['api_key']): - chatbot.append((inputs, "缺少api_key。\n\n1. 临时解决方案:直接在输入区键入api_key,然后回车提交。\n\n2. 长效解决方案:在config.py中配置。")) - yield from update_ui(chatbot=chatbot, history=history, msg="缺少api_key") # 刷新界面 - return - - if additional_fn is not None: - import core_functional - importlib.reload(core_functional) # 热更新prompt - core_functional = core_functional.get_core_functions() - if "PreProcess" in core_functional[additional_fn]: inputs = core_functional[additional_fn]["PreProcess"](inputs) # 获取预处理函数(如果有的话) - inputs = core_functional[additional_fn]["Prefix"] + inputs + core_functional[additional_fn]["Suffix"] - - raw_input = inputs - logging.info(f'[raw_input] {raw_input}') - chatbot.append((inputs, "")) - yield from update_ui(chatbot=chatbot, history=history, msg="等待响应") # 刷新界面 - - try: - headers, payload = generate_payload(inputs, llm_kwargs, history, system_prompt, stream) - except RuntimeError as e: - chatbot[-1] = (inputs, f"您提供的api-key不满足要求,不包含任何可用于{llm_kwargs['llm_model']}的api-key。您可能选择了错误的模型或请求源。") - yield from update_ui(chatbot=chatbot, history=history, msg="api-key不满足要求") # 刷新界面 - return - - history.append(inputs); history.append("") - - retry = 0 - while True: - try: - # make a POST request to the API endpoint, stream=True - from .bridge_all import model_info - endpoint = model_info[llm_kwargs['llm_model']]['endpoint'] - response = requests.post(endpoint, headers=headers, proxies=proxies, - json=payload, stream=True, timeout=TIMEOUT_SECONDS);break - except: - retry += 1 - chatbot[-1] = ((chatbot[-1][0], timeout_bot_msg)) - retry_msg = f",正在重试 ({retry}/{MAX_RETRY}) ……" if MAX_RETRY > 0 else "" - yield from update_ui(chatbot=chatbot, history=history, msg="请求超时"+retry_msg) # 刷新界面 - if retry > MAX_RETRY: raise TimeoutError - - gpt_replying_buffer = "" - - is_head_of_the_stream = True - if stream: - stream_response = response.iter_lines() - while True: - chunk = next(stream_response) - # print(chunk.decode()[6:]) - if is_head_of_the_stream and (r'"object":"error"' not in chunk.decode()): - # 数据流的第一帧不携带content - is_head_of_the_stream = False; continue - - if chunk: - try: - chunk_decoded = chunk.decode() - # 前者API2D的 - if ('data: [DONE]' in chunk_decoded) or (len(json.loads(chunk_decoded[6:])['choices'][0]["delta"]) == 0): - # 判定为数据流的结束,gpt_replying_buffer也写完了 - logging.info(f'[response] {gpt_replying_buffer}') - break - # 处理数据流的主体 - chunkjson = json.loads(chunk_decoded[6:]) - status_text = f"finish_reason: {chunkjson['choices'][0]['finish_reason']}" - # 如果这里抛出异常,一般是文本过长,详情见get_full_error的输出 - gpt_replying_buffer = gpt_replying_buffer + json.loads(chunk_decoded[6:])['choices'][0]["delta"]["content"] - history[-1] = gpt_replying_buffer - chatbot[-1] = (history[-2], history[-1]) - yield from update_ui(chatbot=chatbot, history=history, msg=status_text) # 刷新界面 - - except Exception as e: - traceback.print_exc() - yield from update_ui(chatbot=chatbot, history=history, msg="Json解析不合常规") # 刷新界面 - chunk = get_full_error(chunk, stream_response) - chunk_decoded = chunk.decode() - error_msg = chunk_decoded - if "reduce the length" in error_msg: - if len(history) >= 2: history[-1] = ""; history[-2] = "" # 清除当前溢出的输入:history[-2] 是本次输入, history[-1] 是本次输出 - history = clip_history(inputs=inputs, history=history, tokenizer=model_info[llm_kwargs['llm_model']]['tokenizer'], - max_token_limit=(model_info[llm_kwargs['llm_model']]['max_token'])) # history至少释放二分之一 - chatbot[-1] = (chatbot[-1][0], "[Local Message] Reduce the length. 本次输入过长, 或历史数据过长. 历史缓存数据已部分释放, 您可以请再次尝试. (若再次失败则更可能是因为输入过长.)") - # history = [] # 清除历史 - elif "does not exist" in error_msg: - chatbot[-1] = (chatbot[-1][0], f"[Local Message] Model {llm_kwargs['llm_model']} does not exist. 模型不存在, 或者您没有获得体验资格.") - elif "Incorrect API key" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] Incorrect API key. OpenAI以提供了不正确的API_KEY为由, 拒绝服务.") - elif "exceeded your current quota" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] You exceeded your current quota. OpenAI以账户额度不足为由, 拒绝服务.") - elif "bad forward key" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] Bad forward key. API2D账户额度不足.") - elif "Not enough point" in error_msg: - chatbot[-1] = (chatbot[-1][0], "[Local Message] Not enough point. API2D账户点数不足.") - else: - from toolbox import regular_txt_to_markdown - tb_str = '```\n' + trimmed_format_exc() + '```' - chatbot[-1] = (chatbot[-1][0], f"[Local Message] 异常 \n\n{tb_str} \n\n{regular_txt_to_markdown(chunk_decoded[4:])}") - yield from update_ui(chatbot=chatbot, history=history, msg="Json异常" + error_msg) # 刷新界面 - return - -def generate_payload(inputs, llm_kwargs, history, system_prompt, stream): - """ - 整合所有信息,选择LLM模型,生成http请求,为发送请求做准备 - """ - if not is_any_api_key(llm_kwargs['api_key']): - raise AssertionError("你提供了错误的API_KEY。\n\n1. 临时解决方案:直接在输入区键入api_key,然后回车提交。\n\n2. 长效解决方案:在config.py中配置。") - - api_key = select_api_key(llm_kwargs['api_key'], llm_kwargs['llm_model']) - - headers = { - "Content-Type": "application/json", - "Authorization": f"Bearer {api_key}" - } - - conversation_cnt = len(history) // 2 - - messages = [{"role": "system", "content": system_prompt}] - if conversation_cnt: - for index in range(0, 2*conversation_cnt, 2): - what_i_have_asked = {} - what_i_have_asked["role"] = "user" - what_i_have_asked["content"] = history[index] - what_gpt_answer = {} - what_gpt_answer["role"] = "assistant" - what_gpt_answer["content"] = history[index+1] - if what_i_have_asked["content"] != "": - if what_gpt_answer["content"] == "": continue - if what_gpt_answer["content"] == timeout_bot_msg: continue - messages.append(what_i_have_asked) - messages.append(what_gpt_answer) - else: - messages[-1]['content'] = what_gpt_answer['content'] - - what_i_ask_now = {} - what_i_ask_now["role"] = "user" - what_i_ask_now["content"] = inputs - messages.append(what_i_ask_now) - - payload = { - "model": llm_kwargs['llm_model'].strip('api2d-'), - "messages": messages, - "temperature": llm_kwargs['temperature'], # 1.0, - "top_p": llm_kwargs['top_p'], # 1.0, - "n": 1, - "stream": stream, - "presence_penalty": 0, - "frequency_penalty": 0, - } - try: - print(f" {llm_kwargs['llm_model']} : {conversation_cnt} : {inputs[:100]} ..........") - except: - print('输入中可能存在乱码。') - return headers,payload - - diff --git "a/spaces/f2api/gpt-academic/crazy_functions/Latex\345\205\250\346\226\207\347\277\273\350\257\221.py" "b/spaces/f2api/gpt-academic/crazy_functions/Latex\345\205\250\346\226\207\347\277\273\350\257\221.py" deleted file mode 100644 index 554c485aa0891f74c57cacfcbe076febe7a11029..0000000000000000000000000000000000000000 --- "a/spaces/f2api/gpt-academic/crazy_functions/Latex\345\205\250\346\226\207\347\277\273\350\257\221.py" +++ /dev/null @@ -1,175 +0,0 @@ -from toolbox import update_ui -from toolbox import CatchException, report_execption, write_results_to_file -fast_debug = False - -class PaperFileGroup(): - def __init__(self): - self.file_paths = [] - self.file_contents = [] - self.sp_file_contents = [] - self.sp_file_index = [] - self.sp_file_tag = [] - - # count_token - from request_llm.bridge_all import model_info - enc = model_info["gpt-3.5-turbo"]['tokenizer'] - def get_token_num(txt): return len(enc.encode(txt, disallowed_special=())) - self.get_token_num = get_token_num - - def run_file_split(self, max_token_limit=1900): - """ - 将长文本分离开来 - """ - for index, file_content in enumerate(self.file_contents): - if self.get_token_num(file_content) < max_token_limit: - self.sp_file_contents.append(file_content) - self.sp_file_index.append(index) - self.sp_file_tag.append(self.file_paths[index]) - else: - from .crazy_utils import breakdown_txt_to_satisfy_token_limit_for_pdf - segments = breakdown_txt_to_satisfy_token_limit_for_pdf(file_content, self.get_token_num, max_token_limit) - for j, segment in enumerate(segments): - self.sp_file_contents.append(segment) - self.sp_file_index.append(index) - self.sp_file_tag.append(self.file_paths[index] + f".part-{j}.tex") - - print('Segmentation: done') - -def 多文件翻译(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, language='en'): - import time, os, re - from .crazy_utils import request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency - - # <-------- 读取Latex文件,删除其中的所有注释 ----------> - pfg = PaperFileGroup() - - for index, fp in enumerate(file_manifest): - with open(fp, 'r', encoding='utf-8', errors='replace') as f: - file_content = f.read() - # 定义注释的正则表达式 - comment_pattern = r'(? - pfg.run_file_split(max_token_limit=1024) - n_split = len(pfg.sp_file_contents) - - # <-------- 抽取摘要 ----------> - # if language == 'en': - # abs_extract_inputs = f"Please write an abstract for this paper" - - # # 单线,获取文章meta信息 - # paper_meta_info = yield from request_gpt_model_in_new_thread_with_ui_alive( - # inputs=abs_extract_inputs, - # inputs_show_user=f"正在抽取摘要信息。", - # llm_kwargs=llm_kwargs, - # chatbot=chatbot, history=[], - # sys_prompt="Your job is to collect information from materials。", - # ) - - # <-------- 多线程润色开始 ----------> - if language == 'en->zh': - inputs_array = ["Below is a section from an English academic paper, translate it into Chinese, do not modify any latex command such as \section, \cite and equations:" + - f"\n\n{frag}" for frag in pfg.sp_file_contents] - inputs_show_user_array = [f"翻译 {f}" for f in pfg.sp_file_tag] - sys_prompt_array = ["You are a professional academic paper translator." for _ in range(n_split)] - elif language == 'zh->en': - inputs_array = [f"Below is a section from a Chinese academic paper, translate it into English, do not modify any latex command such as \section, \cite and equations:" + - f"\n\n{frag}" for frag in pfg.sp_file_contents] - inputs_show_user_array = [f"翻译 {f}" for f in pfg.sp_file_tag] - sys_prompt_array = ["You are a professional academic paper translator." for _ in range(n_split)] - - gpt_response_collection = yield from request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency( - inputs_array=inputs_array, - inputs_show_user_array=inputs_show_user_array, - llm_kwargs=llm_kwargs, - chatbot=chatbot, - history_array=[[""] for _ in range(n_split)], - sys_prompt_array=sys_prompt_array, - # max_workers=5, # OpenAI所允许的最大并行过载 - scroller_max_len = 80 - ) - - # <-------- 整理结果,退出 ----------> - create_report_file_name = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + f"-chatgpt.polish.md" - res = write_results_to_file(gpt_response_collection, file_name=create_report_file_name) - history = gpt_response_collection - chatbot.append((f"{fp}完成了吗?", res)) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - - - - - -@CatchException -def Latex英译中(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port): - # 基本信息:功能、贡献者 - chatbot.append([ - "函数插件功能?", - "对整个Latex项目进行翻译。函数插件贡献者: Binary-Husky"]) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - - # 尝试导入依赖,如果缺少依赖,则给出安装建议 - try: - import tiktoken - except: - report_execption(chatbot, history, - a=f"解析项目: {txt}", - b=f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade tiktoken```。") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - history = [] # 清空历史,以免输入溢出 - import glob, os - if os.path.exists(txt): - project_folder = txt - else: - if txt == "": txt = '空空如也的输入栏' - report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.tex', recursive=True)] - if len(file_manifest) == 0: - report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.tex文件: {txt}") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - yield from 多文件翻译(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, language='en->zh') - - - - - -@CatchException -def Latex中译英(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port): - # 基本信息:功能、贡献者 - chatbot.append([ - "函数插件功能?", - "对整个Latex项目进行翻译。函数插件贡献者: Binary-Husky"]) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - - # 尝试导入依赖,如果缺少依赖,则给出安装建议 - try: - import tiktoken - except: - report_execption(chatbot, history, - a=f"解析项目: {txt}", - b=f"导入软件依赖失败。使用该模块需要额外依赖,安装方法```pip install --upgrade tiktoken```。") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - history = [] # 清空历史,以免输入溢出 - import glob, os - if os.path.exists(txt): - project_folder = txt - else: - if txt == "": txt = '空空如也的输入栏' - report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.tex', recursive=True)] - if len(file_manifest) == 0: - report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.tex文件: {txt}") - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - return - yield from 多文件翻译(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, language='zh->en') \ No newline at end of file diff --git a/spaces/facebook/cotracker/README.md b/spaces/facebook/cotracker/README.md deleted file mode 100644 index 243935ecfa794ba9a469068672e47c144314a293..0000000000000000000000000000000000000000 --- a/spaces/facebook/cotracker/README.md +++ /dev/null @@ -1,24 +0,0 @@ ---- -title: CoTracker -emoji: 🎨 -colorFrom: yellow -colorTo: pink -sdk: gradio -sdk_version: 3.41.2 -app_file: app.py -pinned: false -license: cc-by-nc-4.0 ---- - -This is a demo for ["CoTracker: It is Better to Track Together"](https://arxiv.org/abs/2307.07635) - -``` -@misc{karaev2023cotracker, - title={CoTracker: It is Better to Track Together}, - author={Nikita Karaev and Ignacio Rocco and Benjamin Graham and Natalia Neverova and Andrea Vedaldi and Christian Rupprecht}, - year={2023}, - eprint={2307.07635}, - archivePrefix={arXiv}, - primaryClass={cs.CV} -} -``` diff --git a/spaces/falterWliame/Face_Mask_Detection/Abecedar De Nutritie Pdf Download !!TOP!!.md b/spaces/falterWliame/Face_Mask_Detection/Abecedar De Nutritie Pdf Download !!TOP!!.md deleted file mode 100644 index de56c87a35d6461c36644e9ec6d3a17f569314bf..0000000000000000000000000000000000000000 --- a/spaces/falterWliame/Face_Mask_Detection/Abecedar De Nutritie Pdf Download !!TOP!!.md +++ /dev/null @@ -1,48 +0,0 @@ ----- {children} -- - {path_formatted.map((p, i) => { - return p.editable ? ( --- handleChange( - value, - currentValue === p.key ? p.key : currentValue - ) - } - /> - ) : ( - - {p.content} -
- ); - })} -Abecedar De Nutritie Pdf Download
Download »»» https://urlca.com/2uDc1r
-
-Direct download via saving link. Related downloads. Nutritious Recipes in Education.pdf Nutritious Recipes in Education.ppt. PDF of presentation slides for any audience. Nutritious Recipes in Education.pptx. PDF of presentation slides for any audience. Nutritious Recipes in Education.odp. OLAP (OLAP stands for On-Line Analytical Processing) charts with SQL Server OLAP (Online Analytical Processing).ppt. SQL Server Analytical Server and its OLAP.pptx. online SQL Server data, with Microsoft Excel PPTX. Nutritious Recipes in Education.xls. In a Nutritious Recipes in Education.xlsx. View the presentation slides of our lesson on "Nutritious Recipes" for the classroom. Easily edit the presentation slides with Microsoft Word. Free presentation slides on the topic of Nutritious Recipes (Nutrition). The title of this presentation is: Nutritious Recipes (Nutrition) in Education. Nutritious Recipes (Nutrition) in Education.pptx.Q: - -Switching between 2 frames, in a single function? - -I have 2 frames in my app. - -I want to make one method to switch between them. - -I tried these things but the process is too complex. - -First I tried like this: - -private void switchImage(int i){ - - new Thread() - - public void run() - - if(i == 0) - - new animation2(); - - - - else if (i == 1) - - new animation(); - - - - .start(); - - - -And animation,animation2 is just simple animations such as ImageView.setImageResource(int) in each one. - -But this function is too complex and its too slow, animation 2 takes too much time. - -I wanted to make simple function to do this. - -I tried like this: - - if(i == 0){ 4fefd39f24
-
-
- diff --git a/spaces/falterWliame/Face_Mask_Detection/How To Hack Korek Telecom Card !!LINK!!.md b/spaces/falterWliame/Face_Mask_Detection/How To Hack Korek Telecom Card !!LINK!!.md deleted file mode 100644 index c5499f0c22f1bcc05190090f90701e95119d7569..0000000000000000000000000000000000000000 --- a/spaces/falterWliame/Face_Mask_Detection/How To Hack Korek Telecom Card !!LINK!!.md +++ /dev/null @@ -1,93 +0,0 @@ -
-How To Hack Korek Telecom Card: A Complete Guide
-Korek Telecom is one of the leading mobile operators in Iraq, offering a range of services and products to its customers. However, some people may want to hack Korek Telecom card for various reasons, such as getting free credit, bypassing restrictions, or accessing other networks. In this article, we will show you how to hack Korek Telecom card using different methods and tools.
-How To Hack Korek Telecom Card
Download Zip ✵✵✵ https://urlca.com/2uDdt9
-What is Korek Telecom Card?
-Korek Telecom card is a SIM card that contains your personal and account information, such as your phone number, balance, tariff plan, and contacts. It also allows you to connect to the Korek Telecom network and use its services, such as voice calls, SMS, data, and roaming. Korek Telecom card can be purchased from any authorized dealer or outlet for 2,000 IQD, and it comes with 1,000 IQD credit.
-Why Hack Korek Telecom Card?
-There are many reasons why someone may want to hack Korek Telecom card, such as:
--
-
How To Hack Korek Telecom Card?
-There are different ways and tools to hack Korek Telecom card, depending on the type and level of hacking you want to achieve. Here are some of the most common methods and tools:
-AirMagnet WiFi Analyzer
-AirMagnet WiFi Analyzer is a wireless network analysis tool that can scan and monitor the wireless traffic and activity in your area. It can also detect and crack the encryption keys of some wireless networks, such as WEP and WPA. You can use this tool to hack Korek Telecom card by intercepting and decrypting the data packets that are exchanged between the SIM card and the network. This way, you can get access to the account information and balance of the Korek Telecom card.
- -Aircrack-ng
-Aircrack-ng is a suite of tools that can perform various attacks on wireless networks, such as cracking passwords, spoofing MAC addresses, injecting packets, and capturing handshakes. You can use this tool to hack Korek Telecom card by exploiting some vulnerabilities in the WEP encryption algorithm that are known as KoreK attacks. These attacks can recover the WEP key from a small number of captured packets, allowing you to decrypt the data and access the account information and balance of the Korek Telecom card.
-Kali Linux
-Kali Linux is a Linux distribution that is designed for penetration testing and ethical hacking. It comes with a variety of tools and applications that can perform various tasks and attacks on different systems and networks. You can use this tool to hack Korek Telecom card by using some of its features and commands, such as:
--
-
By using these tools and applications, you can scan, exploit, capture, and crack the Korek Telecom card and its network.
-Conclusion
-Hacking Korek Telecom card is not an easy task, as it requires some skills, knowledge, tools, and time. Moreover, hacking Korek Telecom card is illegal and unethical, as it violates the terms and conditions of the service provider and the privacy of the user. Therefore, we do not recommend or condone hacking Korek Telecom card for any purpose. This article is for educational purposes only.
-What are the Risks of Hacking Korek Telecom Card?
-Hacking Korek Telecom card is not only illegal and unethical, but also risky and dangerous. There are many risks and consequences that you may face if you hack Korek Telecom card, such as:
--
-
How To Protect Your Korek Telecom Card?
-Instead of hacking Korek Telecom card, you should protect it from being hacked or stolen by others. There are some simple and effective ways to protect your Korek Telecom card, such as:
--
-
Conclusion
-Korek Telecom card is a valuable asset that allows you to enjoy the services and products of Korek Telecom. Hacking Korek Telecom card is not a smart or ethical way to get more benefits or advantages from it. Instead, you should respect the rules and regulations of the service provider and the country and protect your Korek Telecom card from being hacked or stolen by others. This way, you can use your Korek Telecom card safely and securely.
-What are the Alternatives to Hacking Korek Telecom Card?
-If you want to get more benefits or advantages from your Korek Telecom card, hacking is not the only option. There are some legitimate and ethical alternatives that you can try, such as:
--
-
How To Contact Korek Telecom?
-If you have any questions, complaints, or feedback about your Korek Telecom card or service, you can contact Korek Telecom through different channels, such as:
--
-
Conclusion
-Korek Telecom card is a valuable asset that allows you to enjoy the services and products of Korek Telecom. Hacking Korek Telecom card is not a smart or ethical way to get more benefits or advantages from it. Instead, you should respect the rules and regulations of the service provider and the country and protect your Korek Telecom card from being hacked or stolen by others. You should also use the legitimate and ethical alternatives that Korek Telecom offers to its customers. This way, you can use your Korek Telecom card safely and securely.
-What are the Benefits of Korek Telecom Card?
-Korek Telecom card is not only a SIM card, but also a smart card that offers many benefits and advantages to its users. Some of the benefits of Korek Telecom card are:
--
-
How To Activate Your Korek Telecom Card?
-If you have purchased a new Korek Telecom card, you need to activate it before you can use it. The activation process is simple and easy. You can activate your Korek Telecom card by following these steps:
--
-
Congratulations! You have successfully activated your Korek Telecom card. You can now enjoy the services and products of Korek Telecom.
-Conclusion
-Korek Telecom card is a valuable asset that allows you to enjoy the services and products of Korek Telecom. Hacking Korek Telecom card is not a smart or ethical way to get more benefits or advantages from it. Instead, you should respect the rules and regulations of the service provider and the country and protect your Korek Telecom card from being hacked or stolen by others. You should also use the legitimate and ethical alternatives that Korek Telecom offers to its customers. This way, you can use your Korek Telecom card safely and securely.
-In this article, we have shown you how to hack Korek Telecom card using different methods and tools. We have also explained the risks and consequences of hacking Korek Telecom card, and the alternatives and benefits of using Korek Telecom card legitimately and ethically. We have also provided you with some tips and steps on how to protect and activate your Korek Telecom card. We hope that this article has been informative and helpful for you. However, we do not recommend or condone hacking Korek Telecom card for any purpose. This article is for educational purposes only.
3cee63e6c2
-
-
\ No newline at end of file diff --git a/spaces/falterWliame/Face_Mask_Detection/Pirates Of The Caribbean Part 1 [PORTABLE] Free Download In 11.md b/spaces/falterWliame/Face_Mask_Detection/Pirates Of The Caribbean Part 1 [PORTABLE] Free Download In 11.md deleted file mode 100644 index 8ef605d646e703a818d1f5666fdedb8acb3f7dd1..0000000000000000000000000000000000000000 --- a/spaces/falterWliame/Face_Mask_Detection/Pirates Of The Caribbean Part 1 [PORTABLE] Free Download In 11.md +++ /dev/null @@ -1,6 +0,0 @@ -pirates of the caribbean part 1 free download in 11
Download ===> https://urlca.com/2uDccm
-
-Along With The Gods The Last 49 Days ì‹ ê³¼í•¨ê»˜-ì¸ê³¼ ì—°. mkv 11-Feb-2020 09:35 ... Download Free Lovecraft Country Complete Season 1 720p HD 480p HD, Bluray, English, Dual Audio, Mp4, Avi, Mkv, Hindi, Coolmoviez, Watch Online, Fzmovies, ... Pirates of the Caribbean Dead Men Tell No Tales 2017 Dual Audio 720p ... 4d29de3e1b
-
-
- diff --git a/spaces/fatiXbelha/sd/4carx.az How to Choose the Right Car Tires for Your Vehicle.md b/spaces/fatiXbelha/sd/4carx.az How to Choose the Right Car Tires for Your Vehicle.md deleted file mode 100644 index a39606817c9705c9f7263c17e10b8450b70ff170..0000000000000000000000000000000000000000 --- a/spaces/fatiXbelha/sd/4carx.az How to Choose the Right Car Tires for Your Vehicle.md +++ /dev/null @@ -1,105 +0,0 @@ -
-4carx.az: The Best Place to Buy Car Tires in Sumqayit
-If you are looking for a reliable and affordable car tire center in Sumqayit, Azerbaijan, you should check out 4carx.az. This is a website that allows you to order car tires online and have them delivered to your doorstep or installed at their workshop. In this article, we will tell you everything you need to know about 4carx.az, including their services, products, customer reviews, and how to contact them.
-Introduction
-What is 4carx.az?
-4carx.az is a car tire center that operates in Sumqayit, a city in Azerbaijan. They have been in business since 2018 and have gained a reputation for providing high-quality car tires at competitive prices. They have a website where you can browse their catalog of car tires, choose the ones that suit your vehicle and budget, and place an order online. You can also visit their workshop in Sumqayit and get your car tires installed by their professional staff.
-4carx.az
Download File ===== https://urllie.com/2uNvNl
-Why choose 4carx.az?
-There are many reasons why you should choose 4carx.az for your car tire needs. Here are some of them:
--
-
Services and Products
-Online Ordering and Delivery
-One of the best features of 4carx.az is their online ordering and delivery service. You can simply visit their website, www.4carx.az, and browse their catalog of car tires by brand, size, or type. You can also use their search function to find the exact model you are looking for. Once you have selected your car tires, you can add them to your cart and proceed to checkout. You can pay online using your credit card or cash on delivery. You can also choose whether you want your car tires delivered to your address or installed at their workshop.
-Wide Range of Brands and Sizes
-Another great feature of 4carx.az is their wide range of brands and sizes of car tires. They have car tires from well-known brands such as Bridgestone, Michelin, Pirelli, Goodyear, Dunlop, Continental, Hankook, Yokohama, Kumho, Nexen, Toyo, Nokian, Cooper, Firestone, BFGoodrich, Falken, Maxxis, Apollo, Vredestein, Kenda, MRF, CEAT, JK Tyre, Giti Tire, Linglong Tire, Westlake Tire, Double Coin Tire, Triangle Tire, Sailun Tire, Chengshan Tire, Aeolus Tire, Roadstone Tire, and more.
-They also have car tires in various sizes, from 13 inches to 22 inches, to fit different types of vehicles, such as sedans, hatchbacks, SUVs, trucks, buses, and trailers. You can also find car tires for different seasons and terrains, such as summer tires, winter tires, all-season tires, all-terrain tires, mud tires, performance tires, run-flat tires, and eco-friendly tires.
-Professional Installation and Maintenance
-Besides online ordering and delivery, 4carx.az also offers professional installation and maintenance services for your car tires. You can visit their workshop in Sumqayit and have your car tires installed by their skilled and qualified technicians. They use modern equipment and tools to ensure that your car tires are mounted, balanced, aligned, and inflated properly. They also offer free tire rotation, tire repair, tire pressure check, and tire disposal services for their customers.
-4carx.az Sumqayit
-
-Goform GH 18 tires at 4carx.az
-4carx.az Instagram
-Best car wheel center in Azerbaijan
-4carx.az reviews and ratings
-How to contact 4carx.az
-4carx.az discounts and offers
-4carx.az delivery and installation
-4carx.az warranty and service
-4carx.az location and directions
-4carx.az online shopping
-4carx.az customer testimonials
-4carx.az tire size guide
-4carx.az tire brands and models
-4carx.az tire pressure and maintenance
-4carx.az tire rotation and alignment
-4carx.az tire repair and replacement
-4carx.az tire safety and performance
-4carx.az tire comparison and selection
-4carx.az tire tips and tricks
-4carx.az Facebook page
-4carx.az YouTube channel
-4carx.az Twitter account
-4carx.az LinkedIn profile
-4carx.az blog and news
-4carx.az FAQ and help center
-4carx.az terms and conditions
-4carx.az privacy policy
-4carx.az refund policy
-4carx.az affiliate program
-4carx.az careers and jobs
-4carx.az history and mission
-4carx.az awards and recognition
-4carx.az social responsibility and sustainability
-4carx.az events and promotions
-4carx.az partnerships and collaborations
-4carx.az competitions and giveaways
-4carx.az coupons and vouchers
-4carx.az loyalty program and benefits
-4carx.az newsletter and updatesCustomer Reviews and Testimonials
-How to Find and Contact 4carx.az
-If you want to find and contact 4carx.az, you can use any of the following methods:
--
-
What Customers Say About 4carx.az
-4carx.az has received many positive reviews and testimonials from their satisfied customers. Here are some of them:
--
-"I ordered four winter tires from 4carx.az and they delivered them to my home in Baku the next day. The delivery guy was very friendly and helpful. He even helped me install the tires on my car. The tires are of excellent quality and I feel much safer driving in the snow now. Thank you 4carx.az!" - Elvin M.
--
-"I have been buying car tires from 4carx.az for two years now and I am very happy with their service. They have a wide selection of brands and sizes to choose from and their prices are very reasonable. Their staff are very professional and knowledgeable and they always give me good advice on which tires to buy for my car. I highly recommend 4carx.az to anyone who needs car tires in Sumqayit." - Nigar A.
--
-"I had a flat tire on my way to work and I called 4carx.az for help. They came to my location in less than an hour and fixed my tire on the spot. They also checked the other tires and found that they were worn out and needed replacement. They offered me a great deal on four new tires and installed them for me in no time. They saved me a lot of time and hassle. I am very grateful to 4carx.az for their fast and reliable service." - Tural R.
-How to Leave a Review or Feedback
-If you have bought car tires from 4carx.az or used their services, you can leave a review or feedback on their website or social media pages. You can also rate them on Google or other online platforms. Your review or feedback will help them improve their service quality and customer satisfaction. It will also help other potential customers make informed decisions about buying car tires from 4carx.az.
-Conclusion
-Summary of the Main Points
-In conclusion, 4carx.az is the best place to buy car tires in Sumqayit, Azerbaijan. They offer online ordering and delivery, a wide range of brands and sizes, professional installation and maintenance, customer loyalty program, customer service team, social media presence, and positive customer reviews and testimonials.
-Call to Action
-If you need new car tires for your vehicle, don't hesitate to visit their website or contact them today. You will be amazed by their quality products, competitive prices, and excellent service.
-FAQs
-Here are some frequently asked questions about 4carx.az:
--
-
-
-
\ No newline at end of file diff --git a/spaces/fatiXbelha/sd/APKPure APK How to Download and Install Any Android App or Game.md b/spaces/fatiXbelha/sd/APKPure APK How to Download and Install Any Android App or Game.md deleted file mode 100644 index fa21addd56409acd1037733b705652b877a5c9b1..0000000000000000000000000000000000000000 --- a/spaces/fatiXbelha/sd/APKPure APK How to Download and Install Any Android App or Game.md +++ /dev/null @@ -1,216 +0,0 @@ -
-What is APKPure and why you should use it
-If you are an Android user who loves downloading and trying new apps and games, you may have heard of APKPure. But what is it exactly and why should you use it? In this article, we will answer these questions and show you how to use APKPure to get the most out of your Android device.
-APKPure is a free online service that allows you to download and install Android apps and games that are not available in your country or region. It also lets you update your apps and games without using Google Play Store. With APKPure, you can access thousands of apps and games that are otherwise restricted or blocked by Google or your device manufacturer.
-apk of apk pure
Download >>> https://urllie.com/2uNHhD
-But that's not all. APKPure also offers many other features and benefits that make it a must-have app for Android users. Here are some of them:
--
-
As you can see, APKPure is a powerful and versatile app that can enhance your Android experience. But how do you use it? In the following sections, we will show you how to download and install APKPure on your Android device, and how to use it to download and update apps and games, access region-locked apps and games, install modded apps and games, backup and restore your apps and games, manage your app permissions and settings, join the app community and share your feedback, discover new and trending apps and games, customize your app experience, troubleshoot common issues, contact APKPure support, and stay updated with the latest news and updates from APKPure. Let's get started!
-How to download and install APKPure on your Android device
-Downloading and installing APKPure on your Android device is very easy. Just follow these simple steps:
--
-
Congratulations! You have successfully downloaded and installed APKPure on your Android device. Now you can use it to download and update apps and games that are not available in your country or region.
-How to use APKPure to download and update apps and games
-One of the main functions of APKPure is to download and update apps and games that are not available in your country or region. Here's how you can do that:
--
-
That's it! You have learned how to use APKPure to download and update apps and games that are not available in your country or region. You can now enjoy a wider range of apps and games on your Android device.
-apk pure app download for android
-
-apk pure games free download
-apk pure modded apps and games
-apk pure latest version update
-apk pure alternative app store
-apk pure downloader for pc
-apk pure install and uninstall
-apk pure reviews and ratings
-apk pure safe and secure
-apk pure categories and genres
-apk pure regional and global apps
-apk pure editor's choice and recommendations
-apk pure trending and popular apps
-apk pure new and upcoming apps
-apk pure old and previous versions
-apk pure beta and early access apps
-apk pure lite and optimized apps
-apk pure offline and online apps
-apk pure premium and paid apps
-apk pure cracked and hacked apps
-apk pure tools and utilities apps
-apk pure social and communication apps
-apk pure entertainment and media apps
-apk pure education and learning apps
-apk pure health and fitness apps
-apk pure lifestyle and personalization apps
-apk pure business and productivity apps
-apk pure shopping and finance apps
-apk pure travel and navigation apps
-apk pure sports and gaming apps
-apk pure music and audio apps
-apk pure video and photo apps
-apk pure books and reference apps
-apk pure news and magazines apps
-apk pure art and design apps
-apk pure food and drink apps
-apk pure beauty and fashion apps
-apk pure dating and relationship apps
-apk pure parenting and family apps
-apk pure medical and wellness apps
-apk pure house and home apps
-apk pure events and tickets apps
-apk pure weather and climate apps
-apk pure maps and location apps
-apk pure comics and anime apps
-apk pure library and demo apps
-apk pure auto and vehicles appsHow to use APKPure to access region-locked apps and games
-Another great feature of APKPure is that it allows you to access region-locked apps and games that are not available in your country or region. This means that you can download and play apps and games that are only released in certain countries or regions, such as Japan, China, Korea, etc. Here's how you can do that:
--
-
Note: Some apps and games may require additional steps to access them, such as creating an account, verifying your phone number, using a VPN, etc. Please follow the instructions provided by the app or game developer to access them properly.
-You have learned how to use APKPure to access region-locked apps and games that are not available in your country or region. You can now explore and enjoy a variety of apps and games from different countries and regions on your Android device.
-How to use APKPure to install modded apps and games
-If you are feeling adventurous and want to try something different, you can use APKPure to install modded apps and games on your Android device. Modded apps and games are modified versions of original apps and games that offer extra features, such as unlimited money, gems, coins, lives, etc. They can also remove ads, unlock premium features, bypass restrictions, etc.
-However, before you install modded apps and games, you should be aware of the risks and legality of doing so. Modded apps and games may contain malware, viruses, spyware, etc. that can harm your device or steal your personal information. They may also violate the terms of service and policies of the original app or game developer, which can result in legal actions or bans. Therefore, you should only install modded apps and games from trusted sources and at your own risk.
-If you still want to install modded apps and games, here's how you can do that with APKPure:
--
-
Note: Some modded games may require additional steps to install or run them, such as enabling root access, granting permissions, using a VPN, etc. Please follow the instructions provided by the modded game developer to install or run them properly.
-You have learned how to use APKPure to install modded games on your Android device. You can now enjoy playing games with extra features and advantages.
-How to use APKPure to backup and restore your apps and games
-Another useful feature of APKPure is that it allows you to backup and restore your apps and games on your Android device. This means that you can save your app data and settings, and transfer them to another device or restore them in case of data loss. Here's how you can do that with APKPure:
--
-
Note: You can also backup and restore your apps and games to or from an external storage device, such as a SD card or a USB drive, by tapping on the Select Storage Location option in the Backup & Restore menu.
-You have learned how to use APKPure to backup and restore your apps and games on your Android device. You can now save your app data and settings, and transfer them to another device or restore them in case of data loss.
-How to use APKPure to manage your app permissions and settings
-Another handy feature of APKPure is that it allows you to manage your app permissions and settings on your Android device. This means that you can view and modify your app permissions, clear cache, uninstall apps, etc. Here's how you can do that with APKPure:
--
-
-
-
You have learned how to use APKPure to manage your app permissions and settings on your Android device. You can now view and modify your app permissions, clear cache, uninstall apps, etc.
-How to use APKPure to join the app community and share your feedback
-Another fun feature of APKPure is that it allows you to join the app community and share your feedback with other users and developers. This means that you can comment, rate, review, and discuss apps and games with others. Here's how you can do that with APKPure:
--
-
Note: To comment, rate, review, or discuss apps and games on APKPure, you need to sign up or log in with your email or social media account. You can do that by tapping on the Me tab at the bottom of the screen and following the instructions.
-You have learned how to use APKPure to join the app community and share your feedback with other users and developers. You can now comment, rate, review, and discuss apps and games with others.
-How to use APKPure to discover new and trending apps and games
-Another cool feature of APKPure is that it allows you to discover new and trending apps and games on your Android device. This means that you can find new and exciting apps and games every day on APKPure. Here's how you can do that with APKPure:
--
-
-
-
You have learned how to use APKPure to discover new and trending apps and games on your Android device. You can now find new and exciting apps and games every day on APKPure.
-How to use APKPure to customize your app experience
-Another nice feature of APKPure is that it allows you to customize your app experience according to your preferences. This means that you can change your APKPure settings, such as theme, font size, notifications, etc. Here's how you can do that with APKPure:
--
-
-
-
You have learned how to contact APKPure's customer service team and get help. You can now reach out to them via email, social media, or feedback form.
-How to stay updated with the latest news and updates from APKPure
-If you want to stay updated with the latest news and updates from APKPure, you can subscribe to their newsletter, blog, and social media channels. Here are some ways to do that:
--
-
You have learned how to stay updated with the latest news and updates from APKPure. You can now subscribe to their newsletter, blog, and social media channels.
-Conclusion
-In this article, we have shown you what is APKPure and why you should use it. We have also shown you how to use APKPure to download and update apps and games, access region-locked apps and games, install modded apps and games, backup and restore your apps and games, manage your app permissions and settings, join the app community and share your feedback, discover new and trending apps and games, customize your app experience, troubleshoot common issues, contact APKPure support, and stay updated with the latest news and updates from APKPure.
-We hope that this article has been helpful and informative for you. If you have any questions or suggestions, please feel free to contact us or leave a comment below. Thank you for reading!
-FAQs
-Here are some frequently asked questions and answers about APKPure:
--
-
-
-
-
-
\ No newline at end of file diff --git a/spaces/fatiXbelha/sd/Car Make Up Mod Apk Transform Your Car with Amazing Features and Effects.md b/spaces/fatiXbelha/sd/Car Make Up Mod Apk Transform Your Car with Amazing Features and Effects.md deleted file mode 100644 index fe378cb81a41d0e8b3c6b817549ecade5924c05b..0000000000000000000000000000000000000000 --- a/spaces/fatiXbelha/sd/Car Make Up Mod Apk Transform Your Car with Amazing Features and Effects.md +++ /dev/null @@ -1,117 +0,0 @@ -
-Car Make Up Mod Apk: How to Customize Your Car with Your Smartphone
-Do you love cars and want to make them look more unique and stylish? Do you wish you could change the appearance of your car without spending a lot of money and time? If you answered yes to these questions, then you might be interested in car make up mod apk.
-What is car make up mod apk?
-Car make up mod apk is a term that refers to modified applications that allow you to customize your car with your smartphone. These apps let you change various aspects of your car, such as the color, wheels, bumper, headlights, stickers, decals, logos, and more. You can also save and share your creations with other users or use them in games.
-car make up mod apk
Download File · https://urllie.com/2uNC0A
-Car make up mod apk has many benefits for car enthusiasts. You can express your creativity and personality by making your car look different from others. You can also experiment with different styles and designs without risking any damage or loss. You can also have fun and enjoy yourself by playing with different options and features.
-How to download and install car make up mod apk?
-If you want to try car make up mod apk, you will need an Android device and an internet connection. Here are the steps to download and install car make up mod apk on your smartphone:
-car make up mod apk download
-
-car make up mod apk free
-car make up mod apk latest version
-car make up mod apk unlimited money
-car make up mod apk android
-car make up mod apk ios
-car make up mod apk offline
-car make up mod apk hack
-car make up mod apk 2023
-car make up mod apk no ads
-car make up mod apk full unlocked
-car make up mod apk revdl
-car make up mod apk rexdl
-car make up mod apk happymod
-car make up mod apk an1
-car make up mod apk apkpure
-car make up mod apk apkmody
-car make up mod apk mob.org
-car make up mod apk android 1
-car make up mod apk android oyun club
-car make up mod apk obb
-car make up mod apk data
-car make up mod apk file
-car make up mod apk mirror
-car make up mod apk uptodown
-car make up 3d tuning app mod apk
-car make up racing game mod apk
-car make up simulator game mod apk
-car make up design game mod apk
-car make up makeover game mod apk
-best car customize apps 2023 mod apk
-formaCar app for android and ios mod apk
-3DTuning app for android and ios mod apk
-tuning Car Racing by Process Games mod apk
-Car Master 3D app for android and ios mod apk
-Car++ app for android and ios mod apk
-Torque Drift app for android and ios mod apk
-Tuning Club Online app for android and ios mod apk
-Need For Speed No limits app for android and ios mod apk
-Crossout Mobile Craft War Cars app for android and ios mod apk
-Car Tuning Design Cars app for android and ios mod apk
-Idle Car Tuning: Car Simulator app for android and ios mod apk
-Car Make Up: Car Customization app for android and ios mod apk
-Car Make Up: Car Styling app for android and ios mod apk
-Car Make Up: Car Editor app for android and ios mod apk
-Car Make Up: Car Builder app for android and ios mod apk
-Car Make Up: Car Creator app for android and ios mod apk
-Car Make Up: Car Modding app for android and ios mod apk
-Car Make Up: Car Tuner app for android and ios mod apk-
-
How to use car make up mod apk?
-Once you have installed car make up mod apk on your device, you can start using it to customize your car. Here are some tips on how to use car make up mod apk:
-How to change the color, wheels, bumper, headlights, and more of your car
-To change the basic features of your car, such as the color, wheels, bumper, headlights, and more, you can use the following steps:
--
-
Apukpure claims that it scans and verifies all the APK files before uploading them to its servers. However, there is always a risk of downloading APK files from unknown sources as they may contain malware or viruses. Therefore, we recommend that you use a reliable antivirus software on your device and only download APK files from trusted sources.
-Apukpure does not host any pirated or illegal content on its platform. It only provides links to APK files that are freely available on the internet. However, some of these APK files may violate the terms and conditions of Google Play Store or other app developers. Therefore, we advise that you use Apukpure at your own discretion and respect the intellectual property rights of others.
-