

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,9 +1,42 @@
|
|
| 1 |
---
|
| 2 |
library_name: transformers
|
| 3 |
-
tags:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
---
|
|
|
|
| 5 |
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
|
| 8 |
```python
|
| 9 |
import torch
|
|
@@ -151,3 +184,17 @@ chosen_scores = values.gather(
|
|
| 151 |
chosen_scores = chosen_scores.squeeze()
|
| 152 |
print(chosen_scores)
|
| 153 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
library_name: transformers
|
| 3 |
+
tags:
|
| 4 |
+
- reward
|
| 5 |
+
- RM
|
| 6 |
+
- Code
|
| 7 |
+
- AceCode
|
| 8 |
+
- AceCoder
|
| 9 |
+
license: mit
|
| 10 |
+
datasets:
|
| 11 |
+
- TIGER-Lab/AceCode-89K
|
| 12 |
+
- TIGER-Lab/AceCodePair-300K
|
| 13 |
+
language:
|
| 14 |
+
- en
|
| 15 |
+
base_model:
|
| 16 |
+
- Qwen/Qwen2.5-Coder-7B-Instruct
|
| 17 |
---
|
| 18 |
+
# 🂡 AceCoder
|
| 19 |
|
| 20 |
+
[Paper](#) |
|
| 21 |
+
[Github](https://github.com/TIGER-AI-Lab/AceCoder) |
|
| 22 |
+
[AceCode-89K](https://huggingface.co/datasets/TIGER-Lab/AceCode-89K) |
|
| 23 |
+
[AceCodePair-300K](https://huggingface.co/datasets/TIGER-Lab/AceCodePair-300K) |
|
| 24 |
+
[RM/RL Models](https://huggingface.co/collections/TIGER-Lab/acecoder-67a16011a6c7d65cad529eba)
|
| 25 |
+
|
| 26 |
+
We introduce AceCoder, the first work to propose a fully automated pipeline for synthesizing large-scale reliable tests used for the reward model training and reinforcement learning in the coding scenario. To do this, we curated the dataset AceCode-89K, where we start from a seed code dataset and prompt powerful LLMs to "imagine" proper test cases for the coding question and filter the noisy ones. We sample inferences from existing coder models and compute their pass rate as the reliable and verifiable rewards for both training the reward model and conducting the reinforcement learning for coder LLM.
|
| 27 |
+
|
| 28 |
+
**This model is the official AceCodeRM-7B trained from Qwen2.5-Coder-7B-Instruct on [TIGER-Lab/AceCodePair-300K](https://huggingface.co/datasets/TIGER-Lab/AceCodePair-300K)**
|
| 29 |
+
|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Performance on Best-of-N sampling
|
| 34 |
+
|
| 35 |
+
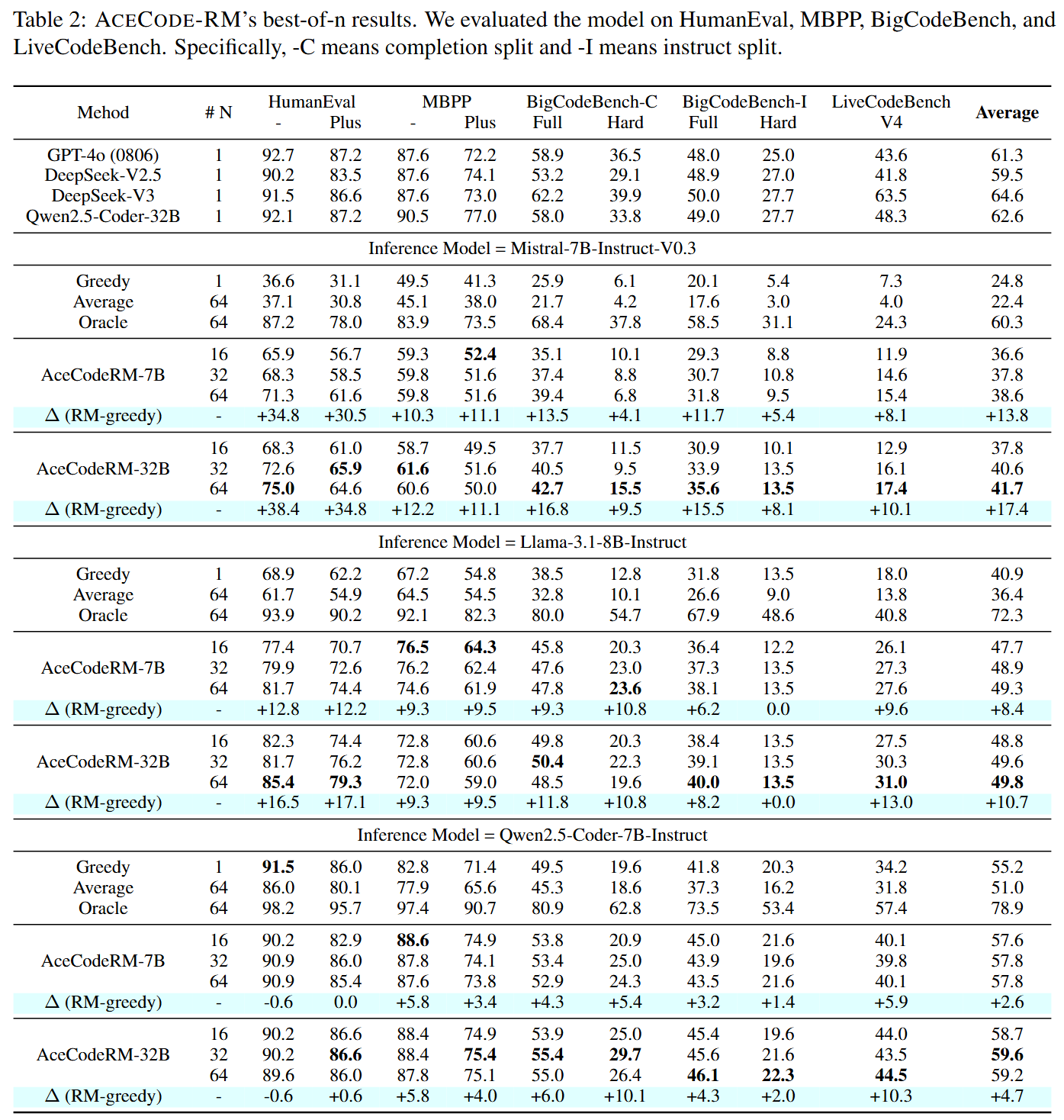
|
| 36 |
+
|
| 37 |
+
## Usage
|
| 38 |
+
|
| 39 |
+
- To use the RM to produce rewards, please apply the following example codes:
|
| 40 |
|
| 41 |
```python
|
| 42 |
import torch
|
|
|
|
| 184 |
chosen_scores = chosen_scores.squeeze()
|
| 185 |
print(chosen_scores)
|
| 186 |
```
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
- To use the RM for the RL tuning, please refer to our [Github Code](https://github.com/TIGER-AI-Lab/AceCoder) for more details
|
| 190 |
+
|
| 191 |
+
## Citation
|
| 192 |
+
```bibtex
|
| 193 |
+
@article{AceCoder,
|
| 194 |
+
title={AceCoder: Acing Coder RL via Automated Test-Case Synthesis},
|
| 195 |
+
author={Zeng, Huaye and Jiang, Dongfu and Wang, Haozhe and Nie, Ping and Chen, Xiaotong and Chen, Wenhu},
|
| 196 |
+
journal={ArXiv},
|
| 197 |
+
year={2025},
|
| 198 |
+
volume={abs/2207.01780}
|
| 199 |
+
}
|
| 200 |
+
```
|