
File size: 4,074 Bytes
28277a1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
---
license: apache-2.0
library_name: transformers
pipeline_tag: image-text-to-text
---
# LongWriter-V: Enabling Ultra-Long and High-Fidelity Generation in Vision-Language Models
<p align="center">
🤗 <a href="https://huggingface.co/datasets/THU-KEG/LongWriter-V-22K" target="_blank">Train Dataset</a> • 🤗 <a href="https://huggingface.co/datasets/THU-KEG/MMLongBench-Write" target="_blank">Benchmark</a> • 🤗 <a href="https://huggingface.co/THU-KEG/LongWriter-V-7B-DPO" target="_blank">Model</a> • 📃 <a href="https://arxiv.org/abs/2502.14834" target="_blank">Paper</a>
</p>
## 🔍 Table of Contents
- [⚙️ LongWriter-V Deployment](#deployment)
- [🤖️ LongWriter-Agent-V](#agentwrite)
- [🖥️ Model Training](#longwriter-v-training)
- [📊 Evaluation](#evaluation)
- [👀 Cases](#case)
- [📝 Citation](#citation)
<a name="deployment"></a>
## ⚙️ LongWriter-V Deployment
**Environmental Setup**:
To inference Qwen2.5-VL based models, you may need to install transformers from source. Refer to this [issue](https://github.com/QwenLM/Qwen2.5-VL/issues/706) for more details.
We open-source three models: [LongWriter-V-7B](https://huggingface.co/THU-KEG/LongWriter-V-7B) and [LongWriter-V-7B-DPO](https://huggingface.co/THU-KEG/LongWriter-V-7B-DPO), trained based on [Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) and [LongWriter-V-72B](https://huggingface.co/THU-KEG/LongWriter-V-72B), trained based on [Qwen2.5-VL-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct).
<a name="agentwrite"></a>
## 🤖️ LongWriter-Agent-V
We are also open-sourcing LongWriter-Agent-V under `agentwrite/`, our automated ultra-long output data construction pipeline. Run `outline_vlm.py` to obtain the final data. Please configure your API key in `config.py`.
<a name="longwriter-v-training"></a>
## 🖥️ Model Training
You can download and save the **LongWriter-V-22K** data through the Hugging Face datasets ([🤗 HF Repo](https://huggingface.co/datasets/THU-KEG/LongWriter-V-22K)).
You can train the model with [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory), we used the [official Qwen2_VL training script](https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/train_full/qwen2vl_full_sft.yaml) for training.
<a name="evaluation"></a>
## 📊 Evaluation
We introduce two evaluation benchmarks: [**MMLongBench-Write**](https://huggingface.co/datasets/THU-KEG/MMLongBench-Write) and [**LongWrite-V-Ruler**](https://huggingface.co/datasets/THU-KEG/LongWrite-V-Ruler). **MMLongBench-Write** focuses more on measuring the long output quality as well as the output length, while **LongWrite-V-Ruler** is designed as a light-weight stress test of the model's maximum output length.
We provide our evaluation code under `eval/`. Run
```bash
python -m eval.mmlongbench_write --model {model_name} --method {vlm, caption_llm}
python -m eval.longwrite_v_ruler --model {model_name}
```
to get evaluation resuts. Remember to configure your OpenAI API key in `config.py` since we adopt GPT-4o as the judge.
Here are the evaluation results on **MMLongBench-Write**:
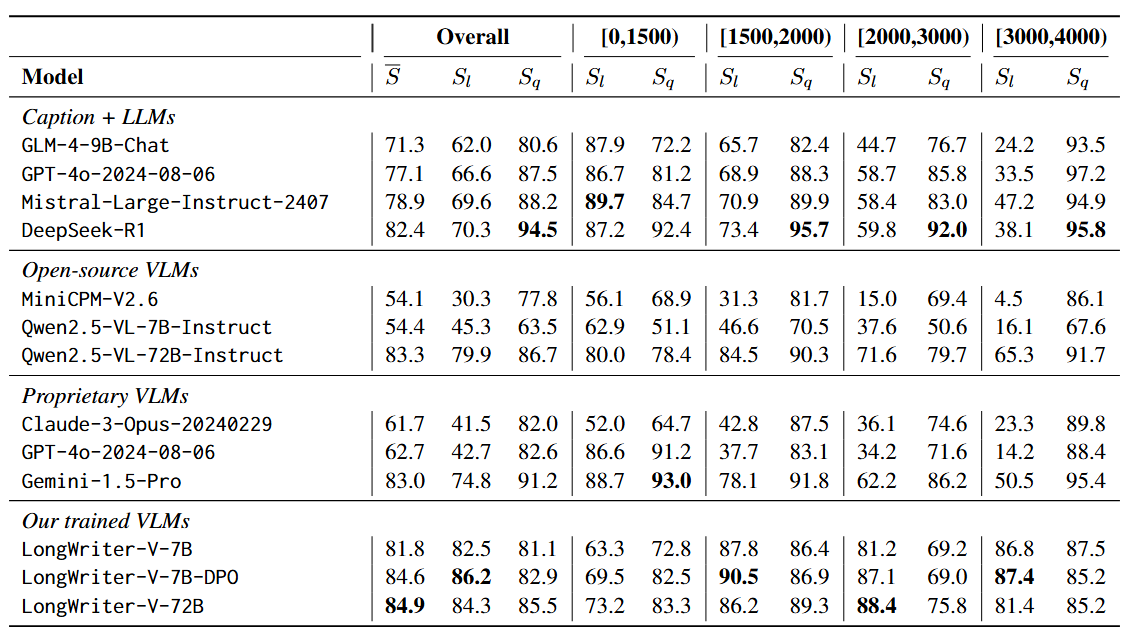
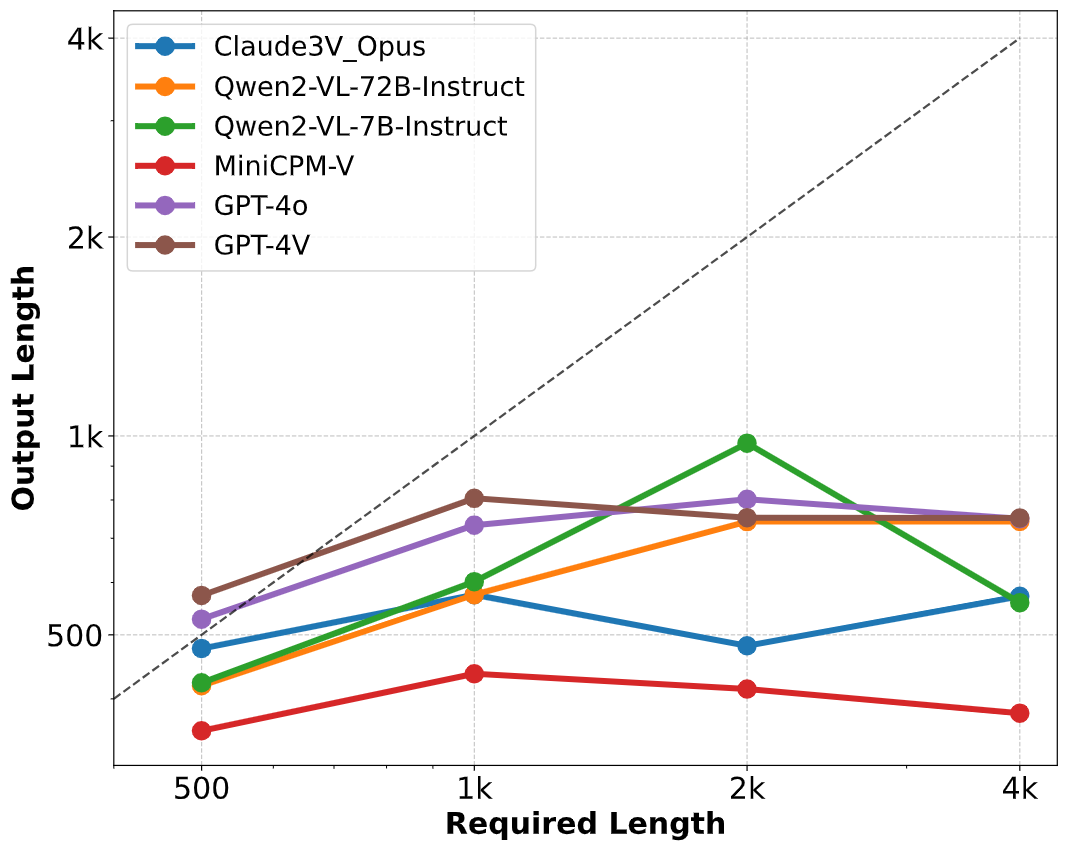
Here are the evaluation results on **LongWrite-V-Ruler**:
<a name="case"></a>
## 👀 Cases
Here are LongWriter-V-7B's outputs to random test prompts. (Examples truncated for brevity).
<a name="citation"></a>
## 📝 Citation
If you find our work useful, please kindly cite:
```
@misc{tu2025longwriterv,
title={LongWriter-V: Enabling Ultra-Long and High-Fidelity Generation in Vision-Language Models},
author={Shangqing Tu and Yucheng Wang and Daniel Zhang-Li and Yushi Bai and Jifan Yu and Yuhao Wu and Lei Hou and Huiqin Liu and Zhiyuan Liu and Bin Xu and Juanzi Li},
year={2025},
eprint={2502.14834},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.14834},
}
``` |