

Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- README.md +670 -0
- added_tokens.json +33 -0
- config.json +224 -0
- configuration_intern_vit.py +120 -0
- configuration_internvl_chat.py +97 -0
- conversation.py +391 -0
- examples/image1.jpg +0 -0
- examples/image2.jpg +3 -0
- examples/red-panda.mp4 +3 -0
- generation_config.json +4 -0
- merges.txt +0 -0
- model.safetensors +3 -0
- modeling_intern_vit.py +431 -0
- modeling_internvl_chat.py +359 -0
- preprocessor_config.json +19 -0
- special_tokens_map.json +31 -0
- tokenizer.json +0 -0
- tokenizer_config.json +281 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
examples/image2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
examples/red-panda.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,670 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
license_name: qwen
|
| 4 |
+
license_link: https://huggingface.co/Qwen/Qwen2.5-72B-Instruct/blob/main/LICENSE
|
| 5 |
+
pipeline_tag: image-text-to-text
|
| 6 |
+
library_name: transformers
|
| 7 |
+
base_model:
|
| 8 |
+
- OpenGVLab/InternVL3-1B
|
| 9 |
+
base_model_relation: finetune
|
| 10 |
+
datasets:
|
| 11 |
+
- OpenGVLab/MMPR-v1.1
|
| 12 |
+
language:
|
| 13 |
+
- multilingual
|
| 14 |
+
tags:
|
| 15 |
+
- internvl
|
| 16 |
+
- custom_code
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# InternVL3-1B
|
| 20 |
+
|
| 21 |
+
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](TBD)
|
| 22 |
+
|
| 23 |
+
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
|
| 24 |
+
|
| 25 |
+
<div align="center">
|
| 26 |
+
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
## Introduction
|
| 30 |
+
|
| 31 |
+
We introduce InternVL3, an advanced multimodal large language model (MLLM) series that demonstrates superior overall performance.
|
| 32 |
+
Compared to InternVL 2.5, InternVL3 exhibits superior multimodal perception and reasoning capabilities, while further extending its multimodal capabilities to encompass tool usage, GUI agents, industrial image analysis, 3D vision perception, and more.
|
| 33 |
+
Additionally, benefitting from Native Multimodal Pre-Training, the InternVL3 series achieves even better overall text performance than the Qwen2.5 series, which serves as the initialization of the langauge component in InternVL3.
|
| 34 |
+
|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
## InternVL3 Family
|
| 38 |
+
|
| 39 |
+
In the following table, we provide an overview of the InternVL3 series.
|
| 40 |
+
|
| 41 |
+
| Model Name | Vision Part | Language Part | HF Link |
|
| 42 |
+
| :-----------: | :-------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------: | :------------------------------------------------------: |
|
| 43 |
+
| InternVL3-1B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-0.5B](https://huggingface.co/Qwen/Qwen2.5-0.5B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-1B) |
|
| 44 |
+
| InternVL3-2B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-2B) |
|
| 45 |
+
| InternVL3-8B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-7B](https://huggingface.co/Qwen/Qwen2.5-7B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-8B) |
|
| 46 |
+
| InternVL3-9B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [internlm3-8b-instruct](https://huggingface.co/internlm/internlm3-8b-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-9B) |
|
| 47 |
+
| InternVL3-14B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-14B) |
|
| 48 |
+
| InternVL3-38B | [InternViT-6B-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5) | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-38B) |
|
| 49 |
+
| InternVL3-78B | [InternViT-6B-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5) | [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-78B) |
|
| 50 |
+
|
| 51 |
+
## Model Architecture
|
| 52 |
+
|
| 53 |
+
As shown in the following figure, [InternVL3](https://internvl.github.io/blog/2025-04-11-InternVL-3/) retains the same model architecture as [InternVL 2.5](https://internvl.github.io/blog/2024-12-05-InternVL-2.5/) and its predecessors, InternVL 1.5 and 2.0, following the "ViT-MLP-LLM" paradigm. In this new version, we integrate a newly incrementally pre-trained InternViT with various pre-trained LLMs, including InternLM 3 and Qwen 2.5, using a randomly initialized MLP projector.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+

|
| 57 |
+
|
| 58 |
+
As in the previous version, we applied a pixel unshuffle operation, reducing the number of visual tokens to one-quarter of the original. Besides, we adopted a similar dynamic resolution strategy as InternVL 1.5, dividing images into tiles of 448×448 pixels. The key difference, starting from InternVL 2.0, is that we additionally introduced support for multi-image and video data.
|
| 59 |
+
|
| 60 |
+
Notably, in InternVL3, we integrate the [Variable Visual Position Encoding (V2PE)](https://arxiv.org/abs/2412.09616), which utilizes smaller, more flexible position increments for visual tokens. Benefiting from V2PE, InternVL3 exhibits better long context understanding capabilities compared to its predecessors.
|
| 61 |
+
|
| 62 |
+
## Training Strategy
|
| 63 |
+
|
| 64 |
+
### Native Multimodal Pre-Training
|
| 65 |
+
|
| 66 |
+
We propose a [Native Multimodal Pre-Training](TBD) approach that consolidates language and vision learning into a single pre-training stage.
|
| 67 |
+
In contrast to standard paradigms that first train a language-only model and subsequently adapt it to handle additional modalities, our method interleaves multimodal data (e.g., image-text, video-text, or image-text interleaved sequences) with large-scale textual corpora. This unified training scheme allows the model to learn both linguistic and multimodal representations simultaneously, ultimately enhancing its capability to handle vision-language tasks without the need for separate alignment or bridging modules.
|
| 68 |
+
Please see [our paper](TBD) for more details.
|
| 69 |
+
|
| 70 |
+
### Supervised Fine-Tuning
|
| 71 |
+
|
| 72 |
+
In this phase, the techniques of random JPEG compression, square loss re-weighting, and multimodal data packing proposed in [InternVL2.5](https://arxiv.org/abs/2412.05271) are also employed in the InternVL3 series.
|
| 73 |
+
The main advancement of the SFT phase in InternVL3 compared to InternVL2.5 lies in the use of higher-quality and more diverse training data.
|
| 74 |
+
Specifically, we further extend training samples for tool use, 3D scene understanding, GUI operations, long context tasks, video understanding, scientific diagrams, creative writing, and multimodal reasoning.
|
| 75 |
+
|
| 76 |
+
### Mixed Preference Optimization
|
| 77 |
+
|
| 78 |
+
During Pre-training and SFT, the model is trained to predict the next token conditioned on previous ground-truth tokens.
|
| 79 |
+
However, during inference, the model predicts each token based on its own prior outputs.
|
| 80 |
+
This discrepancy between ground-truth tokens and model-predicted tokens introduces a distribution shift, which can impair the model’s Chain-of-Thought (CoT) reasoning capabilities.
|
| 81 |
+
To mitigate this issue, we employ [MPO](https://arxiv.org/abs/2411.10442), which introduces additional supervision from both positive and negative samples to align the model response distribution with the ground-truth distribution, thereby improving reasoning performance.
|
| 82 |
+
Specifically, the training objective of MPO is a combination of
|
| 83 |
+
preference loss \\(\mathcal{L}_{\text{p}}\\),
|
| 84 |
+
quality loss \\(\mathcal{L}_{\text{q}}\\),
|
| 85 |
+
and generation loss \\(\mathcal{L}_{\text{g}}\\),
|
| 86 |
+
which can be formulated as follows:
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
$$
|
| 90 |
+
\mathcal{L}=w_{p}\cdot\mathcal{L}_{\text{p}} + w_{q}\cdot\mathcal{L}_{\text{q}} + w_{g}\cdot\mathcal{L}_{\text{g}},
|
| 91 |
+
$$
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
where \\(w_{*}\\) represents the weight assigned to each loss component. Please see [our paper](https://arxiv.org/abs/2411.10442) for more details about MPO.
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
### Test-Time Scaling
|
| 98 |
+
|
| 99 |
+
Test-Time Scaling has been shown to be an effective method to enhance the reasoning abilities of LLMs and MLLMs.
|
| 100 |
+
In this work, we use the Best-of-N evaluation strategy and employ [VisualPRM-8B](https://huggingface.co/OpenGVLab/VisualPRM-8B) as the critic model to select the best response for reasoning and mathematics evaluation.
|
| 101 |
+
|
| 102 |
+
## Evaluation on Multimodal Capability
|
| 103 |
+
|
| 104 |
+
### Multimodal Reasoning and Mathematics
|
| 105 |
+
|
| 106 |
+
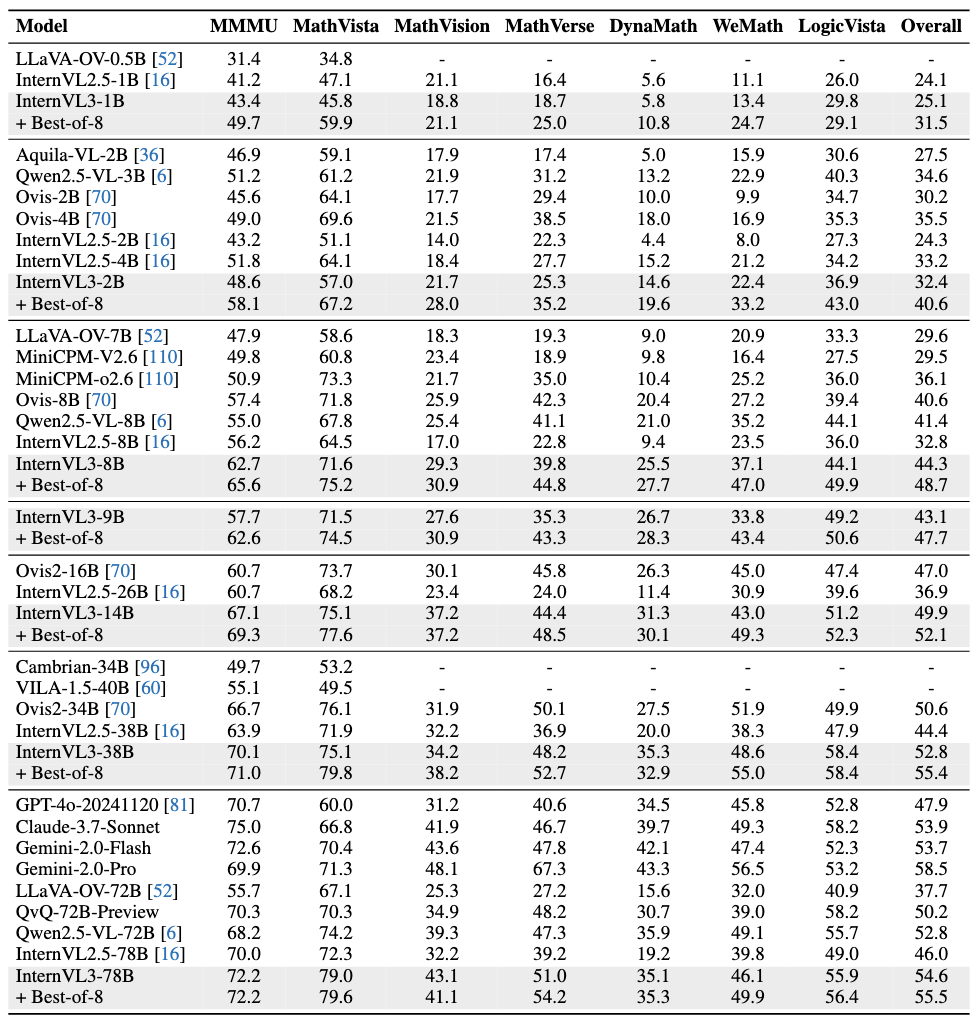
|
| 107 |
+
|
| 108 |
+
### OCR, Chart, and Document Understanding
|
| 109 |
+
|
| 110 |
+

|
| 111 |
+
|
| 112 |
+
### Multi-Image & Real-World Comprehension
|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
### Comprehensive Multimodal & Hallucination Evaluation
|
| 117 |
+
|
| 118 |
+

|
| 119 |
+
|
| 120 |
+
### Visual Grounding
|
| 121 |
+
|
| 122 |
+

|
| 123 |
+
|
| 124 |
+
### Multimodal Multilingual Understanding
|
| 125 |
+
|
| 126 |
+

|
| 127 |
+
|
| 128 |
+
### Video Understanding
|
| 129 |
+
|
| 130 |
+

|
| 131 |
+
|
| 132 |
+
## Evaluation on Language Capability
|
| 133 |
+
|
| 134 |
+
Benefitting from Native Multimodal Pre-Training, the InternVL3 series achieves even better overall text performance than the Qwen2.5 series, which serves as the initialization of the langauge component in InternVL3.
|
| 135 |
+
|
| 136 |
+

|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
## Quick Start
|
| 140 |
+
|
| 141 |
+
We provide an example code to run `InternVL3-1B` using `transformers`.
|
| 142 |
+
|
| 143 |
+
> Please use transformers>=4.37.2 to ensure the model works normally.
|
| 144 |
+
|
| 145 |
+
### Model Loading
|
| 146 |
+
|
| 147 |
+
#### 16-bit (bf16 / fp16)
|
| 148 |
+
|
| 149 |
+
```python
|
| 150 |
+
import torch
|
| 151 |
+
from transformers import AutoTokenizer, AutoModel
|
| 152 |
+
path = "OpenGVLab/InternVL3-1B"
|
| 153 |
+
model = AutoModel.from_pretrained(
|
| 154 |
+
path,
|
| 155 |
+
torch_dtype=torch.bfloat16,
|
| 156 |
+
low_cpu_mem_usage=True,
|
| 157 |
+
use_flash_attn=True,
|
| 158 |
+
trust_remote_code=True).eval().cuda()
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
#### BNB 8-bit Quantization
|
| 162 |
+
|
| 163 |
+
```python
|
| 164 |
+
import torch
|
| 165 |
+
from transformers import AutoTokenizer, AutoModel
|
| 166 |
+
path = "OpenGVLab/InternVL3-1B"
|
| 167 |
+
model = AutoModel.from_pretrained(
|
| 168 |
+
path,
|
| 169 |
+
torch_dtype=torch.bfloat16,
|
| 170 |
+
load_in_8bit=True,
|
| 171 |
+
low_cpu_mem_usage=True,
|
| 172 |
+
use_flash_attn=True,
|
| 173 |
+
trust_remote_code=True).eval()
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
#### Multiple GPUs
|
| 177 |
+
|
| 178 |
+
The reason for writing the code this way is to avoid errors that occur during multi-GPU inference due to tensors not being on the same device. By ensuring that the first and last layers of the large language model (LLM) are on the same device, we prevent such errors.
|
| 179 |
+
|
| 180 |
+
```python
|
| 181 |
+
import math
|
| 182 |
+
import torch
|
| 183 |
+
from transformers import AutoTokenizer, AutoModel
|
| 184 |
+
|
| 185 |
+
def split_model(model_name):
|
| 186 |
+
device_map = {}
|
| 187 |
+
world_size = torch.cuda.device_count()
|
| 188 |
+
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
|
| 189 |
+
num_layers = config.llm_config.num_hidden_layers
|
| 190 |
+
# Since the first GPU will be used for ViT, treat it as half a GPU.
|
| 191 |
+
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
|
| 192 |
+
num_layers_per_gpu = [num_layers_per_gpu] * world_size
|
| 193 |
+
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
|
| 194 |
+
layer_cnt = 0
|
| 195 |
+
for i, num_layer in enumerate(num_layers_per_gpu):
|
| 196 |
+
for j in range(num_layer):
|
| 197 |
+
device_map[f'language_model.model.layers.{layer_cnt}'] = i
|
| 198 |
+
layer_cnt += 1
|
| 199 |
+
device_map['vision_model'] = 0
|
| 200 |
+
device_map['mlp1'] = 0
|
| 201 |
+
device_map['language_model.model.tok_embeddings'] = 0
|
| 202 |
+
device_map['language_model.model.embed_tokens'] = 0
|
| 203 |
+
device_map['language_model.output'] = 0
|
| 204 |
+
device_map['language_model.model.norm'] = 0
|
| 205 |
+
device_map['language_model.model.rotary_emb'] = 0
|
| 206 |
+
device_map['language_model.lm_head'] = 0
|
| 207 |
+
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
|
| 208 |
+
|
| 209 |
+
return device_map
|
| 210 |
+
|
| 211 |
+
path = "OpenGVLab/InternVL3-1B"
|
| 212 |
+
device_map = split_model('InternVL3-1B')
|
| 213 |
+
model = AutoModel.from_pretrained(
|
| 214 |
+
path,
|
| 215 |
+
torch_dtype=torch.bfloat16,
|
| 216 |
+
low_cpu_mem_usage=True,
|
| 217 |
+
use_flash_attn=True,
|
| 218 |
+
trust_remote_code=True,
|
| 219 |
+
device_map=device_map).eval()
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
### Inference with Transformers
|
| 223 |
+
|
| 224 |
+
```python
|
| 225 |
+
import math
|
| 226 |
+
import numpy as np
|
| 227 |
+
import torch
|
| 228 |
+
import torchvision.transforms as T
|
| 229 |
+
from decord import VideoReader, cpu
|
| 230 |
+
from PIL import Image
|
| 231 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 232 |
+
from transformers import AutoModel, AutoTokenizer
|
| 233 |
+
|
| 234 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 235 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 236 |
+
|
| 237 |
+
def build_transform(input_size):
|
| 238 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 239 |
+
transform = T.Compose([
|
| 240 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 241 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 242 |
+
T.ToTensor(),
|
| 243 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 244 |
+
])
|
| 245 |
+
return transform
|
| 246 |
+
|
| 247 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 248 |
+
best_ratio_diff = float('inf')
|
| 249 |
+
best_ratio = (1, 1)
|
| 250 |
+
area = width * height
|
| 251 |
+
for ratio in target_ratios:
|
| 252 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 253 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 254 |
+
if ratio_diff < best_ratio_diff:
|
| 255 |
+
best_ratio_diff = ratio_diff
|
| 256 |
+
best_ratio = ratio
|
| 257 |
+
elif ratio_diff == best_ratio_diff:
|
| 258 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 259 |
+
best_ratio = ratio
|
| 260 |
+
return best_ratio
|
| 261 |
+
|
| 262 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 263 |
+
orig_width, orig_height = image.size
|
| 264 |
+
aspect_ratio = orig_width / orig_height
|
| 265 |
+
|
| 266 |
+
# calculate the existing image aspect ratio
|
| 267 |
+
target_ratios = set(
|
| 268 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 269 |
+
i * j <= max_num and i * j >= min_num)
|
| 270 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 271 |
+
|
| 272 |
+
# find the closest aspect ratio to the target
|
| 273 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 274 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 275 |
+
|
| 276 |
+
# calculate the target width and height
|
| 277 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 278 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 279 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 280 |
+
|
| 281 |
+
# resize the image
|
| 282 |
+
resized_img = image.resize((target_width, target_height))
|
| 283 |
+
processed_images = []
|
| 284 |
+
for i in range(blocks):
|
| 285 |
+
box = (
|
| 286 |
+
(i % (target_width // image_size)) * image_size,
|
| 287 |
+
(i // (target_width // image_size)) * image_size,
|
| 288 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 289 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 290 |
+
)
|
| 291 |
+
# split the image
|
| 292 |
+
split_img = resized_img.crop(box)
|
| 293 |
+
processed_images.append(split_img)
|
| 294 |
+
assert len(processed_images) == blocks
|
| 295 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 296 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 297 |
+
processed_images.append(thumbnail_img)
|
| 298 |
+
return processed_images
|
| 299 |
+
|
| 300 |
+
def load_image(image_file, input_size=448, max_num=12):
|
| 301 |
+
image = Image.open(image_file).convert('RGB')
|
| 302 |
+
transform = build_transform(input_size=input_size)
|
| 303 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 304 |
+
pixel_values = [transform(image) for image in images]
|
| 305 |
+
pixel_values = torch.stack(pixel_values)
|
| 306 |
+
return pixel_values
|
| 307 |
+
|
| 308 |
+
def split_model(model_name):
|
| 309 |
+
device_map = {}
|
| 310 |
+
world_size = torch.cuda.device_count()
|
| 311 |
+
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
|
| 312 |
+
num_layers = config.llm_config.num_hidden_layers
|
| 313 |
+
# Since the first GPU will be used for ViT, treat it as half a GPU.
|
| 314 |
+
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
|
| 315 |
+
num_layers_per_gpu = [num_layers_per_gpu] * world_size
|
| 316 |
+
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
|
| 317 |
+
layer_cnt = 0
|
| 318 |
+
for i, num_layer in enumerate(num_layers_per_gpu):
|
| 319 |
+
for j in range(num_layer):
|
| 320 |
+
device_map[f'language_model.model.layers.{layer_cnt}'] = i
|
| 321 |
+
layer_cnt += 1
|
| 322 |
+
device_map['vision_model'] = 0
|
| 323 |
+
device_map['mlp1'] = 0
|
| 324 |
+
device_map['language_model.model.tok_embeddings'] = 0
|
| 325 |
+
device_map['language_model.model.embed_tokens'] = 0
|
| 326 |
+
device_map['language_model.output'] = 0
|
| 327 |
+
device_map['language_model.model.norm'] = 0
|
| 328 |
+
device_map['language_model.model.rotary_emb'] = 0
|
| 329 |
+
device_map['language_model.lm_head'] = 0
|
| 330 |
+
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
|
| 331 |
+
|
| 332 |
+
return device_map
|
| 333 |
+
|
| 334 |
+
# If you set `load_in_8bit=True`, you will need two 80GB GPUs.
|
| 335 |
+
# If you set `load_in_8bit=False`, you will need at least three 80GB GPUs.
|
| 336 |
+
path = 'OpenGVLab/InternVL3-1B'
|
| 337 |
+
device_map = split_model('InternVL3-1B')
|
| 338 |
+
model = AutoModel.from_pretrained(
|
| 339 |
+
path,
|
| 340 |
+
torch_dtype=torch.bfloat16,
|
| 341 |
+
load_in_8bit=False,
|
| 342 |
+
low_cpu_mem_usage=True,
|
| 343 |
+
use_flash_attn=True,
|
| 344 |
+
trust_remote_code=True,
|
| 345 |
+
device_map=device_map).eval()
|
| 346 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 347 |
+
|
| 348 |
+
# set the max number of tiles in `max_num`
|
| 349 |
+
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 350 |
+
generation_config = dict(max_new_tokens=1024, do_sample=True)
|
| 351 |
+
|
| 352 |
+
# pure-text conversation (纯文本对话)
|
| 353 |
+
question = 'Hello, who are you?'
|
| 354 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
|
| 355 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 356 |
+
|
| 357 |
+
question = 'Can you tell me a story?'
|
| 358 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
|
| 359 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 360 |
+
|
| 361 |
+
# single-image single-round conversation (单图单轮对话)
|
| 362 |
+
question = '<image>\nPlease describe the image shortly.'
|
| 363 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config)
|
| 364 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 365 |
+
|
| 366 |
+
# single-image multi-round conversation (单图多轮对话)
|
| 367 |
+
question = '<image>\nPlease describe the image in detail.'
|
| 368 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
|
| 369 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 370 |
+
|
| 371 |
+
question = 'Please write a poem according to the image.'
|
| 372 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
|
| 373 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 374 |
+
|
| 375 |
+
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
|
| 376 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 377 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 378 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 379 |
+
|
| 380 |
+
question = '<image>\nDescribe the two images in detail.'
|
| 381 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 382 |
+
history=None, return_history=True)
|
| 383 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 384 |
+
|
| 385 |
+
question = 'What are the similarities and differences between these two images.'
|
| 386 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 387 |
+
history=history, return_history=True)
|
| 388 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 389 |
+
|
| 390 |
+
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
|
| 391 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 392 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 393 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 394 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 395 |
+
|
| 396 |
+
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
|
| 397 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 398 |
+
num_patches_list=num_patches_list,
|
| 399 |
+
history=None, return_history=True)
|
| 400 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 401 |
+
|
| 402 |
+
question = 'What are the similarities and differences between these two images.'
|
| 403 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 404 |
+
num_patches_list=num_patches_list,
|
| 405 |
+
history=history, return_history=True)
|
| 406 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 407 |
+
|
| 408 |
+
# batch inference, single image per sample (单图批处理)
|
| 409 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 410 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 411 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 412 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 413 |
+
|
| 414 |
+
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
|
| 415 |
+
responses = model.batch_chat(tokenizer, pixel_values,
|
| 416 |
+
num_patches_list=num_patches_list,
|
| 417 |
+
questions=questions,
|
| 418 |
+
generation_config=generation_config)
|
| 419 |
+
for question, response in zip(questions, responses):
|
| 420 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 421 |
+
|
| 422 |
+
# video multi-round conversation (视频多轮对话)
|
| 423 |
+
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
|
| 424 |
+
if bound:
|
| 425 |
+
start, end = bound[0], bound[1]
|
| 426 |
+
else:
|
| 427 |
+
start, end = -100000, 100000
|
| 428 |
+
start_idx = max(first_idx, round(start * fps))
|
| 429 |
+
end_idx = min(round(end * fps), max_frame)
|
| 430 |
+
seg_size = float(end_idx - start_idx) / num_segments
|
| 431 |
+
frame_indices = np.array([
|
| 432 |
+
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
|
| 433 |
+
for idx in range(num_segments)
|
| 434 |
+
])
|
| 435 |
+
return frame_indices
|
| 436 |
+
|
| 437 |
+
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
|
| 438 |
+
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
|
| 439 |
+
max_frame = len(vr) - 1
|
| 440 |
+
fps = float(vr.get_avg_fps())
|
| 441 |
+
|
| 442 |
+
pixel_values_list, num_patches_list = [], []
|
| 443 |
+
transform = build_transform(input_size=input_size)
|
| 444 |
+
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
|
| 445 |
+
for frame_index in frame_indices:
|
| 446 |
+
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
|
| 447 |
+
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 448 |
+
pixel_values = [transform(tile) for tile in img]
|
| 449 |
+
pixel_values = torch.stack(pixel_values)
|
| 450 |
+
num_patches_list.append(pixel_values.shape[0])
|
| 451 |
+
pixel_values_list.append(pixel_values)
|
| 452 |
+
pixel_values = torch.cat(pixel_values_list)
|
| 453 |
+
return pixel_values, num_patches_list
|
| 454 |
+
|
| 455 |
+
video_path = './examples/red-panda.mp4'
|
| 456 |
+
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
|
| 457 |
+
pixel_values = pixel_values.to(torch.bfloat16).cuda()
|
| 458 |
+
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
|
| 459 |
+
question = video_prefix + 'What is the red panda doing?'
|
| 460 |
+
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
|
| 461 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 462 |
+
num_patches_list=num_patches_list, history=None, return_history=True)
|
| 463 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 464 |
+
|
| 465 |
+
question = 'Describe this video in detail.'
|
| 466 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 467 |
+
num_patches_list=num_patches_list, history=history, return_history=True)
|
| 468 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 469 |
+
```
|
| 470 |
+
|
| 471 |
+
#### Streaming Output
|
| 472 |
+
|
| 473 |
+
Besides this method, you can also use the following code to get streamed output.
|
| 474 |
+
|
| 475 |
+
```python
|
| 476 |
+
from transformers import TextIteratorStreamer
|
| 477 |
+
from threading import Thread
|
| 478 |
+
|
| 479 |
+
# Initialize the streamer
|
| 480 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
|
| 481 |
+
# Define the generation configuration
|
| 482 |
+
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
|
| 483 |
+
# Start the model chat in a separate thread
|
| 484 |
+
thread = Thread(target=model.chat, kwargs=dict(
|
| 485 |
+
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
|
| 486 |
+
history=None, return_history=False, generation_config=generation_config,
|
| 487 |
+
))
|
| 488 |
+
thread.start()
|
| 489 |
+
|
| 490 |
+
# Initialize an empty string to store the generated text
|
| 491 |
+
generated_text = ''
|
| 492 |
+
# Loop through the streamer to get the new text as it is generated
|
| 493 |
+
for new_text in streamer:
|
| 494 |
+
if new_text == model.conv_template.sep:
|
| 495 |
+
break
|
| 496 |
+
generated_text += new_text
|
| 497 |
+
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
|
| 498 |
+
```
|
| 499 |
+
|
| 500 |
+
## Finetune
|
| 501 |
+
|
| 502 |
+
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTurner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
|
| 503 |
+
|
| 504 |
+
## Deployment
|
| 505 |
+
|
| 506 |
+
### LMDeploy
|
| 507 |
+
|
| 508 |
+
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
|
| 509 |
+
|
| 510 |
+
```sh
|
| 511 |
+
# if lmdeploy<0.7.3, you need to explicitly set chat_template_config=ChatTemplateConfig(model_name='internvl2_5')
|
| 512 |
+
pip install lmdeploy>=0.7.3
|
| 513 |
+
```
|
| 514 |
+
|
| 515 |
+
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
|
| 516 |
+
|
| 517 |
+
#### A 'Hello, world' Example
|
| 518 |
+
|
| 519 |
+
```python
|
| 520 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 521 |
+
from lmdeploy.vl import load_image
|
| 522 |
+
|
| 523 |
+
model = 'OpenGVLab/InternVL3-1B'
|
| 524 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
|
| 525 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4))
|
| 526 |
+
response = pipe(('describe this image', image))
|
| 527 |
+
print(response.text)
|
| 528 |
+
```
|
| 529 |
+
|
| 530 |
+
If `ImportError` occurs while executing this case, please install the required dependency packages as prompted.
|
| 531 |
+
|
| 532 |
+
#### Multi-images Inference
|
| 533 |
+
|
| 534 |
+
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
|
| 535 |
+
|
| 536 |
+
```python
|
| 537 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 538 |
+
from lmdeploy.vl import load_image
|
| 539 |
+
from lmdeploy.vl.constants import IMAGE_TOKEN
|
| 540 |
+
|
| 541 |
+
model = 'OpenGVLab/InternVL3-1B'
|
| 542 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4))
|
| 543 |
+
|
| 544 |
+
image_urls=[
|
| 545 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
|
| 546 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
|
| 547 |
+
]
|
| 548 |
+
|
| 549 |
+
images = [load_image(img_url) for img_url in image_urls]
|
| 550 |
+
# Numbering images improves multi-image conversations
|
| 551 |
+
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
|
| 552 |
+
print(response.text)
|
| 553 |
+
```
|
| 554 |
+
|
| 555 |
+
#### Batch Prompts Inference
|
| 556 |
+
|
| 557 |
+
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
|
| 558 |
+
|
| 559 |
+
```python
|
| 560 |
+
from lmdeploy import pipeline, TurbomindEngineConfig
|
| 561 |
+
from lmdeploy.vl import load_image
|
| 562 |
+
|
| 563 |
+
model = 'OpenGVLab/InternVL3-1B'
|
| 564 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4))
|
| 565 |
+
|
| 566 |
+
image_urls=[
|
| 567 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
|
| 568 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
|
| 569 |
+
]
|
| 570 |
+
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
|
| 571 |
+
response = pipe(prompts)
|
| 572 |
+
print(response)
|
| 573 |
+
```
|
| 574 |
+
|
| 575 |
+
#### Multi-turn Conversation
|
| 576 |
+
|
| 577 |
+
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
|
| 578 |
+
|
| 579 |
+
```python
|
| 580 |
+
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
|
| 581 |
+
from lmdeploy.vl import load_image
|
| 582 |
+
|
| 583 |
+
model = 'OpenGVLab/InternVL3-1B'
|
| 584 |
+
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=4))
|
| 585 |
+
|
| 586 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
|
| 587 |
+
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
|
| 588 |
+
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
|
| 589 |
+
print(sess.response.text)
|
| 590 |
+
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
|
| 591 |
+
print(sess.response.text)
|
| 592 |
+
```
|
| 593 |
+
|
| 594 |
+
#### Service
|
| 595 |
+
|
| 596 |
+
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
|
| 597 |
+
|
| 598 |
+
```shell
|
| 599 |
+
lmdeploy serve api_server OpenGVLab/InternVL3-1B --server-port 23333 --tp 4
|
| 600 |
+
```
|
| 601 |
+
|
| 602 |
+
To use the OpenAI-style interface, you need to install OpenAI:
|
| 603 |
+
|
| 604 |
+
```shell
|
| 605 |
+
pip install openai
|
| 606 |
+
```
|
| 607 |
+
|
| 608 |
+
Then, use the code below to make the API call:
|
| 609 |
+
|
| 610 |
+
```python
|
| 611 |
+
from openai import OpenAI
|
| 612 |
+
|
| 613 |
+
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
|
| 614 |
+
model_name = client.models.list().data[0].id
|
| 615 |
+
response = client.chat.completions.create(
|
| 616 |
+
model=model_name,
|
| 617 |
+
messages=[{
|
| 618 |
+
'role':
|
| 619 |
+
'user',
|
| 620 |
+
'content': [{
|
| 621 |
+
'type': 'text',
|
| 622 |
+
'text': 'describe this image',
|
| 623 |
+
}, {
|
| 624 |
+
'type': 'image_url',
|
| 625 |
+
'image_url': {
|
| 626 |
+
'url':
|
| 627 |
+
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
|
| 628 |
+
},
|
| 629 |
+
}],
|
| 630 |
+
}],
|
| 631 |
+
temperature=0.8,
|
| 632 |
+
top_p=0.8)
|
| 633 |
+
print(response)
|
| 634 |
+
```
|
| 635 |
+
|
| 636 |
+
## License
|
| 637 |
+
|
| 638 |
+
This project is released under the MIT License. This project uses the pre-trained Qwen2.5 as a component, which is licensed under the Qwen License.
|
| 639 |
+
|
| 640 |
+
## Citation
|
| 641 |
+
|
| 642 |
+
If you find this project useful in your research, please consider citing:
|
| 643 |
+
|
| 644 |
+
```BibTeX
|
| 645 |
+
@article{chen2024expanding,
|
| 646 |
+
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
|
| 647 |
+
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
|
| 648 |
+
journal={arXiv preprint arXiv:2412.05271},
|
| 649 |
+
year={2024}
|
| 650 |
+
}
|
| 651 |
+
@article{wang2024mpo,
|
| 652 |
+
title={Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization},
|
| 653 |
+
author={Wang, Weiyun and Chen, Zhe and Wang, Wenhai and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Zhu, Jinguo and Zhu, Xizhou and Lu, Lewei and Qiao, Yu and Dai, Jifeng},
|
| 654 |
+
journal={arXiv preprint arXiv:2411.10442},
|
| 655 |
+
year={2024}
|
| 656 |
+
}
|
| 657 |
+
@article{chen2024far,
|
| 658 |
+
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
|
| 659 |
+
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
|
| 660 |
+
journal={arXiv preprint arXiv:2404.16821},
|
| 661 |
+
year={2024}
|
| 662 |
+
}
|
| 663 |
+
@inproceedings{chen2024internvl,
|
| 664 |
+
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
|
| 665 |
+
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
|
| 666 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 667 |
+
pages={24185--24198},
|
| 668 |
+
year={2024}
|
| 669 |
+
}
|
| 670 |
+
```
|
added_tokens.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</box>": 151673,
|
| 3 |
+
"</img>": 151666,
|
| 4 |
+
"</quad>": 151669,
|
| 5 |
+
"</ref>": 151671,
|
| 6 |
+
"</tool_call>": 151658,
|
| 7 |
+
"<IMG_CONTEXT>": 151667,
|
| 8 |
+
"<box>": 151672,
|
| 9 |
+
"<img>": 151665,
|
| 10 |
+
"<quad>": 151668,
|
| 11 |
+
"<ref>": 151670,
|
| 12 |
+
"<tool_call>": 151657,
|
| 13 |
+
"<|box_end|>": 151649,
|
| 14 |
+
"<|box_start|>": 151648,
|
| 15 |
+
"<|endoftext|>": 151643,
|
| 16 |
+
"<|file_sep|>": 151664,
|
| 17 |
+
"<|fim_middle|>": 151660,
|
| 18 |
+
"<|fim_pad|>": 151662,
|
| 19 |
+
"<|fim_prefix|>": 151659,
|
| 20 |
+
"<|fim_suffix|>": 151661,
|
| 21 |
+
"<|im_end|>": 151645,
|
| 22 |
+
"<|im_start|>": 151644,
|
| 23 |
+
"<|image_pad|>": 151655,
|
| 24 |
+
"<|object_ref_end|>": 151647,
|
| 25 |
+
"<|object_ref_start|>": 151646,
|
| 26 |
+
"<|quad_end|>": 151651,
|
| 27 |
+
"<|quad_start|>": 151650,
|
| 28 |
+
"<|repo_name|>": 151663,
|
| 29 |
+
"<|video_pad|>": 151656,
|
| 30 |
+
"<|vision_end|>": 151653,
|
| 31 |
+
"<|vision_pad|>": 151654,
|
| 32 |
+
"<|vision_start|>": 151652
|
| 33 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"_name_or_path": "/mnt/petrelfs/wangweiyun/workspace_wwy/open_source/InternVL/internvl_chat/work_dirs/internvl_chat_v3_0/InternVL3_0-1B-MPO-try0-2",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"InternVLChatModel"
|
| 6 |
+
],
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_internvl_chat.InternVLChatConfig",
|
| 9 |
+
"AutoModel": "modeling_internvl_chat.InternVLChatModel",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_internvl_chat.InternVLChatModel"
|
| 11 |
+
},
|
| 12 |
+
"downsample_ratio": 0.5,
|
| 13 |
+
"dynamic_image_size": true,
|
| 14 |
+
"force_image_size": 448,
|
| 15 |
+
"hidden_size": 896,
|
| 16 |
+
"image_fold": null,
|
| 17 |
+
"llm_config": {
|
| 18 |
+
"_attn_implementation_autoset": true,
|
| 19 |
+
"_name_or_path": "./pretrained/Qwen2.5-32B-Instruct",
|
| 20 |
+
"add_cross_attention": false,
|
| 21 |
+
"architectures": [
|
| 22 |
+
"Qwen2ForCausalLM"
|
| 23 |
+
],
|
| 24 |
+
"attention_dropout": 0.0,
|
| 25 |
+
"bad_words_ids": null,
|
| 26 |
+
"begin_suppress_tokens": null,
|
| 27 |
+
"bos_token_id": 151643,
|
| 28 |
+
"chunk_size_feed_forward": 0,
|
| 29 |
+
"cross_attention_hidden_size": null,
|
| 30 |
+
"decoder_start_token_id": null,
|
| 31 |
+
"diversity_penalty": 0.0,
|
| 32 |
+
"do_sample": false,
|
| 33 |
+
"early_stopping": false,
|
| 34 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 35 |
+
"eos_token_id": 151643,
|
| 36 |
+
"exponential_decay_length_penalty": null,
|
| 37 |
+
"finetuning_task": null,
|
| 38 |
+
"forced_bos_token_id": null,
|
| 39 |
+
"forced_eos_token_id": null,
|
| 40 |
+
"hidden_act": "silu",
|
| 41 |
+
"hidden_size": 896,
|
| 42 |
+
"id2label": {
|
| 43 |
+
"0": "LABEL_0",
|
| 44 |
+
"1": "LABEL_1"
|
| 45 |
+
},
|
| 46 |
+
"initializer_range": 0.02,
|
| 47 |
+
"intermediate_size": 4864,
|
| 48 |
+
"is_decoder": false,
|
| 49 |
+
"is_encoder_decoder": false,
|
| 50 |
+
"label2id": {
|
| 51 |
+
"LABEL_0": 0,
|
| 52 |
+
"LABEL_1": 1
|
| 53 |
+
},
|
| 54 |
+
"length_penalty": 1.0,
|
| 55 |
+
"max_length": 20,
|
| 56 |
+
"max_position_embeddings": 32768,
|
| 57 |
+
"max_window_layers": 70,
|
| 58 |
+
"min_length": 0,
|
| 59 |
+
"model_type": "qwen2",
|
| 60 |
+
"moe_config": null,
|
| 61 |
+
"no_repeat_ngram_size": 0,
|
| 62 |
+
"num_attention_heads": 14,
|
| 63 |
+
"num_beam_groups": 1,
|
| 64 |
+
"num_beams": 1,
|
| 65 |
+
"num_hidden_layers": 24,
|
| 66 |
+
"num_key_value_heads": 2,
|
| 67 |
+
"num_return_sequences": 1,
|
| 68 |
+
"output_attentions": false,
|
| 69 |
+
"output_hidden_states": false,
|
| 70 |
+
"output_scores": false,
|
| 71 |
+
"pad_token_id": null,
|
| 72 |
+
"prefix": null,
|
| 73 |
+
"problem_type": null,
|
| 74 |
+
"pruned_heads": {},
|
| 75 |
+
"remove_invalid_values": false,
|
| 76 |
+
"repetition_penalty": 1.0,
|
| 77 |
+
"return_dict": true,
|
| 78 |
+
"return_dict_in_generate": false,
|
| 79 |
+
"rms_norm_eps": 1e-06,
|
| 80 |
+
"rope_scaling": {
|
| 81 |
+
"factor": 2.0,
|
| 82 |
+
"rope_type": "dynamic",
|
| 83 |
+
"type": "dynamic"
|
| 84 |
+
},
|
| 85 |
+
"rope_theta": 1000000.0,
|
| 86 |
+
"sep_token_id": null,
|
| 87 |
+
"sliding_window": null,
|
| 88 |
+
"suppress_tokens": null,
|
| 89 |
+
"task_specific_params": null,
|
| 90 |
+
"temperature": 1.0,
|
| 91 |
+
"tf_legacy_loss": false,
|
| 92 |
+
"tie_encoder_decoder": false,
|
| 93 |
+
"tie_word_embeddings": false,
|
| 94 |
+
"tokenizer_class": null,
|
| 95 |
+
"top_k": 50,
|
| 96 |
+
"top_p": 1.0,
|
| 97 |
+
"torch_dtype": "bfloat16",
|
| 98 |
+
"torchscript": false,
|
| 99 |
+
"transformers_version": "4.48.3",
|
| 100 |
+
"typical_p": 1.0,
|
| 101 |
+
"use_bfloat16": true,
|
| 102 |
+
"use_cache": false,
|
| 103 |
+
"use_sliding_window": false,
|
| 104 |
+
"vocab_size": 151674
|
| 105 |
+
},
|
| 106 |
+
"max_dynamic_patch": 12,
|
| 107 |
+
"min_dynamic_patch": 1,
|
| 108 |
+
"model_type": "internvl_chat",
|
| 109 |
+
"pad2square": false,
|
| 110 |
+
"ps_version": "v2",
|
| 111 |
+
"select_layer": -1,
|
| 112 |
+
"system_message": null,
|
| 113 |
+
"template": "internvl2_5",
|
| 114 |
+
"tie_word_embeddings": false,
|
| 115 |
+
"torch_dtype": "bfloat16",
|
| 116 |
+
"transformers_version": null,
|
| 117 |
+
"use_backbone_lora": 0,
|
| 118 |
+
"use_llm_lora": 0,
|
| 119 |
+
"use_thumbnail": true,
|
| 120 |
+
"vision_config": {
|
| 121 |
+
"_attn_implementation_autoset": true,
|
| 122 |
+
"_name_or_path": "OpenGVLab/InternViT-6B-448px-V1-5",
|
| 123 |
+
"add_cross_attention": false,
|
| 124 |
+
"architectures": [
|
| 125 |
+
"InternVisionModel"
|
| 126 |
+
],
|
| 127 |
+
"attention_dropout": 0.0,
|
| 128 |
+
"auto_map": {
|
| 129 |
+
"AutoConfig": "configuration_intern_vit.InternVisionConfig",
|
| 130 |
+
"AutoModel": "modeling_intern_vit.InternVisionModel"
|
| 131 |
+
},
|
| 132 |
+
"bad_words_ids": null,
|
| 133 |
+
"begin_suppress_tokens": null,
|
| 134 |
+
"bos_token_id": null,
|
| 135 |
+
"capacity_factor": 1.2,
|
| 136 |
+
"chunk_size_feed_forward": 0,
|
| 137 |
+
"cross_attention_hidden_size": null,
|
| 138 |
+
"decoder_start_token_id": null,
|
| 139 |
+
"diversity_penalty": 0.0,
|
| 140 |
+
"do_sample": false,
|
| 141 |
+
"drop_path_rate": 0.1,
|
| 142 |
+
"dropout": 0.0,
|
| 143 |
+
"early_stopping": false,
|
| 144 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 145 |
+
"eos_token_id": null,
|
| 146 |
+
"eval_capacity_factor": 1.4,
|
| 147 |
+
"exponential_decay_length_penalty": null,
|
| 148 |
+
"finetuning_task": null,
|
| 149 |
+
"forced_bos_token_id": null,
|
| 150 |
+
"forced_eos_token_id": null,
|
| 151 |
+
"hidden_act": "gelu",
|
| 152 |
+
"hidden_size": 1024,
|
| 153 |
+
"id2label": {
|
| 154 |
+
"0": "LABEL_0",
|
| 155 |
+
"1": "LABEL_1"
|
| 156 |
+
},
|
| 157 |
+
"image_size": 448,
|
| 158 |
+
"initializer_factor": 0.1,
|
| 159 |
+
"initializer_range": 1e-10,
|
| 160 |
+
"intermediate_size": 4096,
|
| 161 |
+
"is_decoder": false,
|
| 162 |
+
"is_encoder_decoder": false,
|
| 163 |
+
"label2id": {
|
| 164 |
+
"LABEL_0": 0,
|
| 165 |
+
"LABEL_1": 1
|
| 166 |
+
},
|
| 167 |
+
"laux_allreduce": "all_nodes",
|
| 168 |
+
"layer_norm_eps": 1e-06,
|
| 169 |
+
"length_penalty": 1.0,
|
| 170 |
+
"max_length": 20,
|
| 171 |
+
"min_length": 0,
|
| 172 |
+
"model_type": "intern_vit_6b",
|
| 173 |
+
"moe_coeff_ratio": 0.5,
|
| 174 |
+
"moe_intermediate_size": 768,
|
| 175 |
+
"moe_output_scale": 4.0,
|
| 176 |
+
"no_repeat_ngram_size": 0,
|
| 177 |
+
"noisy_gate_policy": "RSample_before",
|
| 178 |
+
"norm_type": "layer_norm",
|
| 179 |
+
"num_attention_heads": 16,
|
| 180 |
+
"num_beam_groups": 1,
|
| 181 |
+
"num_beams": 1,
|
| 182 |
+
"num_channels": 3,
|
| 183 |
+
"num_experts": 8,
|
| 184 |
+
"num_hidden_layers": 24,
|
| 185 |
+
"num_return_sequences": 1,
|
| 186 |
+
"num_routed_experts": 4,
|
| 187 |
+
"num_shared_experts": 4,
|
| 188 |
+
"output_attentions": false,
|
| 189 |
+
"output_hidden_states": false,
|
| 190 |
+
"output_scores": false,
|
| 191 |
+
"pad_token_id": null,
|
| 192 |
+
"patch_size": 14,
|
| 193 |
+
"prefix": null,
|
| 194 |
+
"problem_type": null,
|
| 195 |
+
"pruned_heads": {},
|
| 196 |
+
"qk_normalization": false,
|
| 197 |
+
"qkv_bias": true,
|
| 198 |
+
"remove_invalid_values": false,
|
| 199 |
+
"repetition_penalty": 1.0,
|
| 200 |
+
"return_dict": true,
|
| 201 |
+
"return_dict_in_generate": false,
|
| 202 |
+
"sep_token_id": null,
|
| 203 |
+
"shared_expert_intermediate_size": 3072,
|
| 204 |
+
"suppress_tokens": null,
|
| 205 |
+
"task_specific_params": null,
|
| 206 |
+
"temperature": 1.0,
|
| 207 |
+
"tf_legacy_loss": false,
|
| 208 |
+
"tie_encoder_decoder": false,
|
| 209 |
+
"tie_word_embeddings": true,
|
| 210 |
+
"tokenizer_class": null,
|
| 211 |
+
"top_k": 50,
|
| 212 |
+
"top_p": 1.0,
|
| 213 |
+
"torch_dtype": "bfloat16",
|
| 214 |
+
"torchscript": false,
|
| 215 |
+
"transformers_version": "4.48.3",
|
| 216 |
+
"typical_p": 1.0,
|
| 217 |
+
"use_bfloat16": true,
|
| 218 |
+
"use_flash_attn": true,
|
| 219 |
+
"use_moe": false,
|
| 220 |
+
"use_residual": true,
|
| 221 |
+
"use_rts": false,
|
| 222 |
+
"use_weighted_residual": false
|
| 223 |
+
}
|
| 224 |
+
}
|
configuration_intern_vit.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
from typing import Union
|
| 9 |
+
|
| 10 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
|
| 13 |
+
logger = logging.get_logger(__name__)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class InternVisionConfig(PretrainedConfig):
|
| 17 |
+
r"""
|
| 18 |
+
This is the configuration class to store the configuration of a [`InternVisionModel`]. It is used to
|
| 19 |
+
instantiate a vision encoder according to the specified arguments, defining the model architecture.
|
| 20 |
+
|
| 21 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 22 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
num_channels (`int`, *optional*, defaults to 3):
|
| 26 |
+
Number of color channels in the input images (e.g., 3 for RGB).
|
| 27 |
+
patch_size (`int`, *optional*, defaults to 14):
|
| 28 |
+
The size (resolution) of each patch.
|
| 29 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 30 |
+
The size (resolution) of each image.
|
| 31 |
+
qkv_bias (`bool`, *optional*, defaults to `False`):
|
| 32 |
+
Whether to add a bias to the queries and values in the self-attention layers.
|
| 33 |
+
hidden_size (`int`, *optional*, defaults to 3200):
|
| 34 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 35 |
+
num_attention_heads (`int`, *optional*, defaults to 25):
|
| 36 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 37 |
+
intermediate_size (`int`, *optional*, defaults to 12800):
|
| 38 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 39 |
+
qk_normalization (`bool`, *optional*, defaults to `True`):
|
| 40 |
+
Whether to normalize the queries and keys in the self-attention layers.
|
| 41 |
+
num_hidden_layers (`int`, *optional*, defaults to 48):
|
| 42 |
+
Number of hidden layers in the Transformer encoder.
|
| 43 |
+
use_flash_attn (`bool`, *optional*, defaults to `True`):
|
| 44 |
+
Whether to use flash attention mechanism.
|
| 45 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
|
| 46 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 47 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"gelu"` are supported.
|
| 48 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-6):
|
| 49 |
+
The epsilon used by the layer normalization layers.
|
| 50 |
+
dropout (`float`, *optional*, defaults to 0.0):
|
| 51 |
+
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
| 52 |
+
drop_path_rate (`float`, *optional*, defaults to 0.0):
|
| 53 |
+
Dropout rate for stochastic depth.
|
| 54 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 55 |
+
The dropout ratio for the attention probabilities.
|
| 56 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 57 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 58 |
+
initializer_factor (`float`, *optional*, defaults to 0.1):
|
| 59 |
+
A factor for layer scale.
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
model_type = 'intern_vit_6b'
|
| 63 |
+
|
| 64 |
+
def __init__(
|
| 65 |
+
self,
|
| 66 |
+
num_channels=3,
|
| 67 |
+
patch_size=14,
|
| 68 |
+
image_size=224,
|
| 69 |
+
qkv_bias=False,
|
| 70 |
+
hidden_size=3200,
|
| 71 |
+
num_attention_heads=25,
|
| 72 |
+
intermediate_size=12800,
|
| 73 |
+
qk_normalization=True,
|
| 74 |
+
num_hidden_layers=48,
|
| 75 |
+
use_flash_attn=True,
|
| 76 |
+
hidden_act='gelu',
|
| 77 |
+
norm_type='rms_norm',
|
| 78 |
+
layer_norm_eps=1e-6,
|
| 79 |
+
dropout=0.0,
|
| 80 |
+
drop_path_rate=0.0,
|
| 81 |
+
attention_dropout=0.0,
|
| 82 |
+
initializer_range=0.02,
|
| 83 |
+
initializer_factor=0.1,
|
| 84 |
+
**kwargs,
|
| 85 |
+
):
|
| 86 |
+
super().__init__(**kwargs)
|
| 87 |
+
|
| 88 |
+
self.hidden_size = hidden_size
|
| 89 |
+
self.intermediate_size = intermediate_size
|
| 90 |
+
self.dropout = dropout
|
| 91 |
+
self.drop_path_rate = drop_path_rate
|
| 92 |
+
self.num_hidden_layers = num_hidden_layers
|
| 93 |
+
self.num_attention_heads = num_attention_heads
|
| 94 |
+
self.num_channels = num_channels
|
| 95 |
+
self.patch_size = patch_size
|
| 96 |
+
self.image_size = image_size
|
| 97 |
+
self.initializer_range = initializer_range
|
| 98 |
+
self.initializer_factor = initializer_factor
|
| 99 |
+
self.attention_dropout = attention_dropout
|
| 100 |
+
self.layer_norm_eps = layer_norm_eps
|
| 101 |
+
self.hidden_act = hidden_act
|
| 102 |
+
self.norm_type = norm_type
|
| 103 |
+
self.qkv_bias = qkv_bias
|
| 104 |
+
self.qk_normalization = qk_normalization
|
| 105 |
+
self.use_flash_attn = use_flash_attn
|
| 106 |
+
|
| 107 |
+
@classmethod
|
| 108 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> 'PretrainedConfig':
|
| 109 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 110 |
+
|
| 111 |
+
if 'vision_config' in config_dict:
|
| 112 |
+
config_dict = config_dict['vision_config']
|
| 113 |
+
|
| 114 |
+
if 'model_type' in config_dict and hasattr(cls, 'model_type') and config_dict['model_type'] != cls.model_type:
|
| 115 |
+
logger.warning(
|
| 116 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 117 |
+
f'{cls.model_type}. This is not supported for all configurations of models and can yield errors.'
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
return cls.from_dict(config_dict, **kwargs)
|
configuration_internvl_chat.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import copy
|
| 8 |
+
|
| 9 |
+
from transformers import AutoConfig, LlamaConfig, Qwen2Config
|
| 10 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
|
| 13 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 14 |
+
|
| 15 |
+
logger = logging.get_logger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class InternVLChatConfig(PretrainedConfig):
|
| 19 |
+
model_type = 'internvl_chat'
|
| 20 |
+
is_composition = True
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
vision_config=None,
|
| 25 |
+
llm_config=None,
|
| 26 |
+
use_backbone_lora=0,
|
| 27 |
+
use_llm_lora=0,
|
| 28 |
+
select_layer=-1,
|
| 29 |
+
force_image_size=None,
|
| 30 |
+
downsample_ratio=0.5,
|
| 31 |
+
template=None,
|
| 32 |
+
dynamic_image_size=False,
|
| 33 |
+
use_thumbnail=False,
|
| 34 |
+
ps_version='v1',
|
| 35 |
+
min_dynamic_patch=1,
|
| 36 |
+
max_dynamic_patch=6,
|
| 37 |
+
**kwargs):
|
| 38 |
+
super().__init__(**kwargs)
|
| 39 |
+
|
| 40 |
+
if vision_config is None:
|
| 41 |
+
vision_config = {'architectures': ['InternVisionModel']}
|
| 42 |
+
logger.info('vision_config is None. Initializing the InternVisionConfig with default values.')
|
| 43 |
+
|
| 44 |
+
if llm_config is None:
|
| 45 |
+
llm_config = {'architectures': ['Qwen2ForCausalLM']}
|
| 46 |
+
logger.info('llm_config is None. Initializing the LlamaConfig config with default values (`LlamaConfig`).')
|
| 47 |
+
|
| 48 |
+
self.vision_config = InternVisionConfig(**vision_config)
|
| 49 |
+
if llm_config.get('architectures')[0] == 'LlamaForCausalLM':
|
| 50 |
+
self.llm_config = LlamaConfig(**llm_config)
|
| 51 |
+
elif llm_config.get('architectures')[0] == 'Qwen2ForCausalLM':
|
| 52 |
+
self.llm_config = Qwen2Config(**llm_config)
|
| 53 |
+
else:
|
| 54 |
+
raise ValueError('Unsupported architecture: {}'.format(llm_config.get('architectures')[0]))
|
| 55 |
+
self.use_backbone_lora = use_backbone_lora
|
| 56 |
+
self.use_llm_lora = use_llm_lora
|
| 57 |
+
self.select_layer = select_layer
|
| 58 |
+
self.force_image_size = force_image_size
|
| 59 |
+
self.downsample_ratio = downsample_ratio
|
| 60 |
+
self.template = template
|
| 61 |
+
self.dynamic_image_size = dynamic_image_size
|
| 62 |
+
self.use_thumbnail = use_thumbnail
|
| 63 |
+
self.ps_version = ps_version # pixel shuffle version
|
| 64 |
+
self.min_dynamic_patch = min_dynamic_patch
|
| 65 |
+
self.max_dynamic_patch = max_dynamic_patch
|
| 66 |
+
# By default, we use tie_word_embeddings=False for models of all sizes.
|
| 67 |
+
self.tie_word_embeddings = self.llm_config.tie_word_embeddings
|
| 68 |
+
|
| 69 |
+
logger.info(f'vision_select_layer: {self.select_layer}')
|
| 70 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 71 |
+
logger.info(f'min_dynamic_patch: {self.min_dynamic_patch}')
|
| 72 |
+
logger.info(f'max_dynamic_patch: {self.max_dynamic_patch}')
|
| 73 |
+
|
| 74 |
+
def to_dict(self):
|
| 75 |
+
"""
|
| 76 |
+
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 77 |
+
|
| 78 |
+
Returns:
|
| 79 |
+
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 80 |
+
"""
|
| 81 |
+
output = copy.deepcopy(self.__dict__)
|
| 82 |
+
output['vision_config'] = self.vision_config.to_dict()
|
| 83 |
+
output['llm_config'] = self.llm_config.to_dict()
|
| 84 |
+
output['model_type'] = self.__class__.model_type
|
| 85 |
+
output['use_backbone_lora'] = self.use_backbone_lora
|
| 86 |
+
output['use_llm_lora'] = self.use_llm_lora
|
| 87 |
+
output['select_layer'] = self.select_layer
|
| 88 |
+
output['force_image_size'] = self.force_image_size
|
| 89 |
+
output['downsample_ratio'] = self.downsample_ratio
|
| 90 |
+
output['template'] = self.template
|
| 91 |
+
output['dynamic_image_size'] = self.dynamic_image_size
|
| 92 |
+
output['use_thumbnail'] = self.use_thumbnail
|
| 93 |
+
output['ps_version'] = self.ps_version
|
| 94 |
+
output['min_dynamic_patch'] = self.min_dynamic_patch
|
| 95 |
+
output['max_dynamic_patch'] = self.max_dynamic_patch
|
| 96 |
+
|
| 97 |
+
return output
|
conversation.py
ADDED
|
@@ -0,0 +1,391 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Conversation prompt templates.
|
| 3 |
+
|
| 4 |
+
We kindly request that you import fastchat instead of copying this file if you wish to use it.
|
| 5 |
+
If you have changes in mind, please contribute back so the community can benefit collectively and continue to maintain these valuable templates.
|
| 6 |
+
|
| 7 |
+
Modified from https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import dataclasses
|
| 11 |
+
from enum import IntEnum, auto
|
| 12 |
+
from typing import Dict, List, Tuple, Union
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class SeparatorStyle(IntEnum):
|
| 16 |
+
"""Separator styles."""
|
| 17 |
+
|
| 18 |
+
ADD_COLON_SINGLE = auto()
|
| 19 |
+
ADD_COLON_TWO = auto()
|
| 20 |
+
ADD_COLON_SPACE_SINGLE = auto()
|
| 21 |
+
NO_COLON_SINGLE = auto()
|
| 22 |
+
NO_COLON_TWO = auto()
|
| 23 |
+
ADD_NEW_LINE_SINGLE = auto()
|
| 24 |
+
LLAMA2 = auto()
|
| 25 |
+
CHATGLM = auto()
|
| 26 |
+
CHATML = auto()
|
| 27 |
+
CHATINTERN = auto()
|
| 28 |
+
DOLLY = auto()
|
| 29 |
+
RWKV = auto()
|
| 30 |
+
PHOENIX = auto()
|
| 31 |
+
ROBIN = auto()
|
| 32 |
+
FALCON_CHAT = auto()
|
| 33 |
+
CHATGLM3 = auto()
|
| 34 |
+
INTERNVL_ZH = auto()
|
| 35 |
+
MPT = auto()
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
@dataclasses.dataclass
|
| 39 |
+
class Conversation:
|
| 40 |
+
"""A class that manages prompt templates and keeps all conversation history."""
|
| 41 |
+
|
| 42 |
+
# The name of this template
|
| 43 |
+
name: str
|
| 44 |
+
# The template of the system prompt
|
| 45 |
+
system_template: str = '{system_message}'
|
| 46 |
+
# The system message
|
| 47 |
+
system_message: str = ''
|
| 48 |
+
# The names of two roles
|
| 49 |
+
roles: Tuple[str] = ('USER', 'ASSISTANT')
|
| 50 |
+
# All messages. Each item is (role, message).
|
| 51 |
+
messages: List[List[str]] = ()
|
| 52 |
+
# The number of few shot examples
|
| 53 |
+
offset: int = 0
|
| 54 |
+
# The separator style and configurations
|
| 55 |
+
sep_style: SeparatorStyle = SeparatorStyle.ADD_COLON_SINGLE
|
| 56 |
+
sep: str = '\n'
|
| 57 |
+
sep2: str = None
|
| 58 |
+
# Stop criteria (the default one is EOS token)
|
| 59 |
+
stop_str: Union[str, List[str]] = None
|
| 60 |
+
# Stops generation if meeting any token in this list
|
| 61 |
+
stop_token_ids: List[int] = None
|
| 62 |
+
|
| 63 |
+
def get_prompt(self) -> str:
|
| 64 |
+
"""Get the prompt for generation."""
|
| 65 |
+
system_prompt = self.system_template.format(system_message=self.system_message)
|
| 66 |
+
if self.sep_style == SeparatorStyle.ADD_COLON_SINGLE:
|
| 67 |
+
ret = system_prompt + self.sep
|
| 68 |
+
for role, message in self.messages:
|
| 69 |
+
if message:
|
| 70 |
+
ret += role + ': ' + message + self.sep
|
| 71 |
+
else:
|
| 72 |
+
ret += role + ':'
|
| 73 |
+
return ret
|
| 74 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_TWO:
|
| 75 |
+
seps = [self.sep, self.sep2]
|
| 76 |
+
ret = system_prompt + seps[0]
|
| 77 |
+
for i, (role, message) in enumerate(self.messages):
|
| 78 |
+
if message:
|
| 79 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 80 |
+
else:
|
| 81 |
+
ret += role + ':'
|
| 82 |
+
return ret
|
| 83 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_SPACE_SINGLE:
|
| 84 |
+
ret = system_prompt + self.sep
|
| 85 |
+
for role, message in self.messages:
|
| 86 |
+
if message:
|
| 87 |
+
ret += role + ': ' + message + self.sep
|
| 88 |
+
else:
|
| 89 |
+
ret += role + ': ' # must be end with a space
|
| 90 |
+
return ret
|
| 91 |
+
elif self.sep_style == SeparatorStyle.ADD_NEW_LINE_SINGLE:
|
| 92 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep
|
| 93 |
+
for role, message in self.messages:
|
| 94 |
+
if message:
|
| 95 |
+
ret += role + '\n' + message + self.sep
|
| 96 |
+
else:
|
| 97 |
+
ret += role + '\n'
|
| 98 |
+
return ret
|
| 99 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_SINGLE:
|
| 100 |
+
ret = system_prompt
|
| 101 |
+
for role, message in self.messages:
|
| 102 |
+
if message:
|
| 103 |
+
ret += role + message + self.sep
|
| 104 |
+
else:
|
| 105 |
+
ret += role
|
| 106 |
+
return ret
|
| 107 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_TWO:
|
| 108 |
+
seps = [self.sep, self.sep2]
|
| 109 |
+
ret = system_prompt
|
| 110 |
+
for i, (role, message) in enumerate(self.messages):
|
| 111 |
+
if message:
|
| 112 |
+
ret += role + message + seps[i % 2]
|
| 113 |
+
else:
|
| 114 |
+
ret += role
|
| 115 |
+
return ret
|
| 116 |
+
elif self.sep_style == SeparatorStyle.RWKV:
|
| 117 |
+
ret = system_prompt
|
| 118 |
+
for i, (role, message) in enumerate(self.messages):
|
| 119 |
+
if message:
|
| 120 |
+
ret += (
|
| 121 |
+
role
|
| 122 |
+
+ ': '
|
| 123 |
+
+ message.replace('\r\n', '\n').replace('\n\n', '\n')
|
| 124 |
+
)
|
| 125 |
+
ret += '\n\n'
|
| 126 |
+
else:
|
| 127 |
+
ret += role + ':'
|
| 128 |
+
return ret
|
| 129 |
+
elif self.sep_style == SeparatorStyle.LLAMA2:
|
| 130 |
+
seps = [self.sep, self.sep2]
|
| 131 |
+
if self.system_message:
|
| 132 |
+
ret = system_prompt
|
| 133 |
+
else:
|
| 134 |
+
ret = '[INST] '
|
| 135 |
+
for i, (role, message) in enumerate(self.messages):
|
| 136 |
+
tag = self.roles[i % 2]
|
| 137 |
+
if message:
|
| 138 |
+
if i == 0:
|
| 139 |
+
ret += message + ' '
|
| 140 |
+
else:
|
| 141 |
+
ret += tag + ' ' + message + seps[i % 2]
|
| 142 |
+
else:
|
| 143 |
+
ret += tag
|
| 144 |
+
return ret
|
| 145 |
+
elif self.sep_style == SeparatorStyle.CHATGLM:
|
| 146 |
+
# source: https://huggingface.co/THUDM/chatglm-6b/blob/1d240ba371910e9282298d4592532d7f0f3e9f3e/modeling_chatglm.py#L1302-L1308
|
| 147 |
+
# source2: https://huggingface.co/THUDM/chatglm2-6b/blob/e186c891cf64310ac66ef10a87e6635fa6c2a579/modeling_chatglm.py#L926
|
| 148 |
+
round_add_n = 1 if self.name == 'chatglm2' else 0
|
| 149 |
+
if system_prompt:
|
| 150 |
+
ret = system_prompt + self.sep
|
| 151 |
+
else:
|
| 152 |
+
ret = ''
|
| 153 |
+
|
| 154 |
+
for i, (role, message) in enumerate(self.messages):
|
| 155 |
+
if i % 2 == 0:
|
| 156 |
+
ret += f'[Round {i//2 + round_add_n}]{self.sep}'
|
| 157 |
+
|
| 158 |
+
if message:
|
| 159 |
+
ret += f'{role}:{message}{self.sep}'
|
| 160 |
+
else:
|
| 161 |
+
ret += f'{role}:'
|
| 162 |
+
return ret
|
| 163 |
+
elif self.sep_style == SeparatorStyle.CHATML:
|
| 164 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep + '\n'
|
| 165 |
+
for role, message in self.messages:
|
| 166 |
+
if message:
|
| 167 |
+
ret += role + '\n' + message + self.sep + '\n'
|
| 168 |
+
else:
|
| 169 |
+
ret += role + '\n'
|
| 170 |
+
return ret
|
| 171 |
+
elif self.sep_style == SeparatorStyle.CHATGLM3:
|
| 172 |
+
ret = ''
|
| 173 |
+
if self.system_message:
|
| 174 |
+
ret += system_prompt
|
| 175 |
+
for role, message in self.messages:
|
| 176 |
+
if message:
|
| 177 |
+
ret += role + '\n' + ' ' + message
|
| 178 |
+
else:
|
| 179 |
+
ret += role
|
| 180 |
+
return ret
|
| 181 |
+
elif self.sep_style == SeparatorStyle.CHATINTERN:
|
| 182 |
+
# source: https://huggingface.co/internlm/internlm-chat-7b-8k/blob/bd546fa984b4b0b86958f56bf37f94aa75ab8831/modeling_internlm.py#L771
|
| 183 |
+
seps = [self.sep, self.sep2]
|
| 184 |
+
ret = system_prompt
|
| 185 |
+
for i, (role, message) in enumerate(self.messages):
|
| 186 |
+
# if i % 2 == 0:
|
| 187 |
+
# ret += "<s>"
|
| 188 |
+
if message:
|
| 189 |
+
ret += role + ':' + message + seps[i % 2] + '\n'
|
| 190 |
+
else:
|
| 191 |
+
ret += role + ':'
|
| 192 |
+
return ret
|
| 193 |
+
elif self.sep_style == SeparatorStyle.DOLLY:
|
| 194 |
+
seps = [self.sep, self.sep2]
|
| 195 |
+
ret = system_prompt
|
| 196 |
+
for i, (role, message) in enumerate(self.messages):
|
| 197 |
+
if message:
|
| 198 |
+
ret += role + ':\n' + message + seps[i % 2]
|
| 199 |
+
if i % 2 == 1:
|
| 200 |
+
ret += '\n\n'
|
| 201 |
+
else:
|
| 202 |
+
ret += role + ':\n'
|
| 203 |
+
return ret
|
| 204 |
+
elif self.sep_style == SeparatorStyle.PHOENIX:
|
| 205 |
+
ret = system_prompt
|
| 206 |
+
for role, message in self.messages:
|
| 207 |
+
if message:
|
| 208 |
+
ret += role + ': ' + '<s>' + message + '</s>'
|
| 209 |
+
else:
|
| 210 |
+
ret += role + ': ' + '<s>'
|
| 211 |
+
return ret
|
| 212 |
+
elif self.sep_style == SeparatorStyle.ROBIN:
|
| 213 |
+
ret = system_prompt + self.sep
|
| 214 |
+
for role, message in self.messages:
|
| 215 |
+
if message:
|
| 216 |
+
ret += role + ':\n' + message + self.sep
|
| 217 |
+
else:
|
| 218 |
+
ret += role + ':\n'
|
| 219 |
+
return ret
|
| 220 |
+
elif self.sep_style == SeparatorStyle.FALCON_CHAT:
|
| 221 |
+
ret = ''
|
| 222 |
+
if self.system_message:
|
| 223 |
+
ret += system_prompt + self.sep
|
| 224 |
+
for role, message in self.messages:
|
| 225 |
+
if message:
|
| 226 |
+
ret += role + ': ' + message + self.sep
|
| 227 |
+
else:
|
| 228 |
+
ret += role + ':'
|
| 229 |
+
|
| 230 |
+
return ret
|
| 231 |
+
elif self.sep_style == SeparatorStyle.INTERNVL_ZH:
|
| 232 |
+
seps = [self.sep, self.sep2]
|
| 233 |
+
ret = self.system_message + seps[0]
|
| 234 |
+
for i, (role, message) in enumerate(self.messages):
|
| 235 |
+
if message:
|
| 236 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 237 |
+
else:
|
| 238 |
+
ret += role + ':'
|
| 239 |
+
return ret
|
| 240 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 241 |
+
ret = system_prompt + self.sep
|
| 242 |
+
for role, message in self.messages:
|
| 243 |
+
if message:
|
| 244 |
+
if type(message) is tuple:
|
| 245 |
+
message, _, _ = message
|
| 246 |
+
ret += role + message + self.sep
|
| 247 |
+
else:
|
| 248 |
+
ret += role
|
| 249 |
+
return ret
|
| 250 |
+
else:
|
| 251 |
+
raise ValueError(f'Invalid style: {self.sep_style}')
|
| 252 |
+
|
| 253 |
+
def set_system_message(self, system_message: str):
|
| 254 |
+
"""Set the system message."""
|
| 255 |
+
self.system_message = system_message
|
| 256 |
+
|
| 257 |
+
def append_message(self, role: str, message: str):
|
| 258 |
+
"""Append a new message."""
|
| 259 |
+
self.messages.append([role, message])
|
| 260 |
+
|
| 261 |
+
def update_last_message(self, message: str):
|
| 262 |
+
"""Update the last output.
|
| 263 |
+
|
| 264 |
+
The last message is typically set to be None when constructing the prompt,
|
| 265 |
+
so we need to update it in-place after getting the response from a model.
|
| 266 |
+
"""
|
| 267 |
+
self.messages[-1][1] = message
|
| 268 |
+
|
| 269 |
+
def to_gradio_chatbot(self):
|
| 270 |
+
"""Convert the conversation to gradio chatbot format."""
|
| 271 |
+
ret = []
|
| 272 |
+
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
| 273 |
+
if i % 2 == 0:
|
| 274 |
+
ret.append([msg, None])
|
| 275 |
+
else:
|
| 276 |
+
ret[-1][-1] = msg
|
| 277 |
+
return ret
|
| 278 |
+
|
| 279 |
+
def to_openai_api_messages(self):
|
| 280 |
+
"""Convert the conversation to OpenAI chat completion format."""
|
| 281 |
+
ret = [{'role': 'system', 'content': self.system_message}]
|
| 282 |
+
|
| 283 |
+
for i, (_, msg) in enumerate(self.messages[self.offset :]):
|
| 284 |
+
if i % 2 == 0:
|
| 285 |
+
ret.append({'role': 'user', 'content': msg})
|
| 286 |
+
else:
|
| 287 |
+
if msg is not None:
|
| 288 |
+
ret.append({'role': 'assistant', 'content': msg})
|
| 289 |
+
return ret
|
| 290 |
+
|
| 291 |
+
def copy(self):
|
| 292 |
+
return Conversation(
|
| 293 |
+
name=self.name,
|
| 294 |
+
system_template=self.system_template,
|
| 295 |
+
system_message=self.system_message,
|
| 296 |
+
roles=self.roles,
|
| 297 |
+
messages=[[x, y] for x, y in self.messages],
|
| 298 |
+
offset=self.offset,
|
| 299 |
+
sep_style=self.sep_style,
|
| 300 |
+
sep=self.sep,
|
| 301 |
+
sep2=self.sep2,
|
| 302 |
+
stop_str=self.stop_str,
|
| 303 |
+
stop_token_ids=self.stop_token_ids,
|
| 304 |
+
)
|
| 305 |
+
|
| 306 |
+
def dict(self):
|
| 307 |
+
return {
|
| 308 |
+
'template_name': self.name,
|
| 309 |
+
'system_message': self.system_message,
|
| 310 |
+
'roles': self.roles,
|
| 311 |
+
'messages': self.messages,
|
| 312 |
+
'offset': self.offset,
|
| 313 |
+
}
|
| 314 |
+
|
| 315 |
+
|
| 316 |
+
# A global registry for all conversation templates
|
| 317 |
+
conv_templates: Dict[str, Conversation] = {}
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
def register_conv_template(template: Conversation, override: bool = False):
|
| 321 |
+
"""Register a new conversation template."""
|
| 322 |
+
if not override:
|
| 323 |
+
assert (
|
| 324 |
+
template.name not in conv_templates
|
| 325 |
+
), f'{template.name} has been registered.'
|
| 326 |
+
|
| 327 |
+
conv_templates[template.name] = template
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
def get_conv_template(name: str) -> Conversation:
|
| 331 |
+
"""Get a conversation template."""
|
| 332 |
+
return conv_templates[name].copy()
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
# Both Hermes-2 and internlm2-chat are chatml-format conversation templates. The difference
|
| 336 |
+
# is that during training, the preprocessing function for the Hermes-2 template doesn't add
|
| 337 |
+
# <s> at the beginning of the tokenized sequence, while the internlm2-chat template does.
|
| 338 |
+
# Therefore, they are completely equivalent during inference.
|
| 339 |
+
register_conv_template(
|
| 340 |
+
Conversation(
|
| 341 |
+
name='Hermes-2',
|
| 342 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 343 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 344 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 345 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 346 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 347 |
+
sep_style=SeparatorStyle.MPT,
|
| 348 |
+
sep='<|im_end|>',
|
| 349 |
+
stop_str='<|endoftext|>',
|
| 350 |
+
)
|
| 351 |
+
)
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
register_conv_template(
|
| 355 |
+
Conversation(
|
| 356 |
+
name='internlm2-chat',
|
| 357 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 358 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 359 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 360 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 361 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 362 |
+
sep_style=SeparatorStyle.MPT,
|
| 363 |
+
sep='<|im_end|>',
|
| 364 |
+
)
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
register_conv_template(
|
| 369 |
+
Conversation(
|
| 370 |
+
name='phi3-chat',
|
| 371 |
+
system_template='<|system|>\n{system_message}',
|
| 372 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 373 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 374 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 375 |
+
roles=('<|user|>\n', '<|assistant|>\n'),
|
| 376 |
+
sep_style=SeparatorStyle.MPT,
|
| 377 |
+
sep='<|end|>',
|
| 378 |
+
)
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
register_conv_template(
|
| 383 |
+
Conversation(
|
| 384 |
+
name='internvl2_5',
|
| 385 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 386 |
+
system_message='你是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 387 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 388 |
+
sep_style=SeparatorStyle.MPT,
|
| 389 |
+
sep='<|im_end|>\n',
|
| 390 |
+
)
|
| 391 |
+
)
|
examples/image1.jpg
ADDED

|
examples/image2.jpg
ADDED

|
Git LFS Details
|
examples/red-panda.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d921c07bb97224d65a37801541d246067f0d506f08723ffa1ad85c217907ccb8
|
| 3 |
+
size 1867237
|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.48.3"
|
| 4 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a8b67c54568417f3631723e6b3e120720eaa638e03e62dc25666c70e3ae3e484
|
| 3 |
+
size 1876463472
|
modeling_intern_vit.py
ADDED
|
@@ -0,0 +1,431 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
from typing import Optional, Tuple, Union
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
import torch.utils.checkpoint
|
| 12 |
+
from einops import rearrange
|
| 13 |
+
from timm.models.layers import DropPath
|
| 14 |
+
from torch import nn
|
| 15 |
+
from transformers.activations import ACT2FN
|
| 16 |
+
from transformers.modeling_outputs import (BaseModelOutput,
|
| 17 |
+
BaseModelOutputWithPooling)
|
| 18 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 19 |
+
from transformers.utils import logging
|
| 20 |
+
|
| 21 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 22 |
+
|
| 23 |
+
try:
|
| 24 |
+
from flash_attn.bert_padding import pad_input, unpad_input
|
| 25 |
+
from flash_attn.flash_attn_interface import \
|
| 26 |
+
flash_attn_varlen_qkvpacked_func
|
| 27 |
+
has_flash_attn = True
|
| 28 |
+
except:
|
| 29 |
+
print('FlashAttention2 is not installed.')
|
| 30 |
+
has_flash_attn = False
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class FlashAttention(nn.Module):
|
| 36 |
+
"""Implement the scaled dot product attention with softmax.
|
| 37 |
+
Arguments
|
| 38 |
+
---------
|
| 39 |
+
softmax_scale: The temperature to use for the softmax attention.
|
| 40 |
+
(default: 1/sqrt(d_keys) where d_keys is computed at
|
| 41 |
+
runtime)
|
| 42 |
+
attention_dropout: The dropout rate to apply to the attention
|
| 43 |
+
(default: 0.0)
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
def __init__(self, softmax_scale=None, attention_dropout=0.0, device=None, dtype=None):
|
| 47 |
+
super().__init__()
|
| 48 |
+
self.softmax_scale = softmax_scale
|
| 49 |
+
self.dropout_p = attention_dropout
|
| 50 |
+
|
| 51 |
+
def forward(self, qkv, key_padding_mask=None, causal=False, cu_seqlens=None,
|
| 52 |
+
max_s=None, need_weights=False):
|
| 53 |
+
"""Implements the multihead softmax attention.
|
| 54 |
+
Arguments
|
| 55 |
+
---------
|
| 56 |
+
qkv: The tensor containing the query, key, and value. (B, S, 3, H, D) if key_padding_mask is None
|
| 57 |
+
if unpadded: (nnz, 3, h, d)
|
| 58 |
+
key_padding_mask: a bool tensor of shape (B, S)
|
| 59 |
+
"""
|
| 60 |
+
assert not need_weights
|
| 61 |
+
assert qkv.dtype in [torch.float16, torch.bfloat16]
|
| 62 |
+
assert qkv.is_cuda
|
| 63 |
+
|
| 64 |
+
if cu_seqlens is None:
|
| 65 |
+
batch_size = qkv.shape[0]
|
| 66 |
+
seqlen = qkv.shape[1]
|
| 67 |
+
if key_padding_mask is None:
|
| 68 |
+
qkv = rearrange(qkv, 'b s ... -> (b s) ...')
|
| 69 |
+
max_s = seqlen
|
| 70 |
+
cu_seqlens = torch.arange(0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32,
|
| 71 |
+
device=qkv.device)
|
| 72 |
+
output = flash_attn_varlen_qkvpacked_func(
|
| 73 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 74 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 75 |
+
)
|
| 76 |
+
output = rearrange(output, '(b s) ... -> b s ...', b=batch_size)
|
| 77 |
+
else:
|
| 78 |
+
nheads = qkv.shape[-2]
|
| 79 |
+
x = rearrange(qkv, 'b s three h d -> b s (three h d)')
|
| 80 |
+
x_unpad, indices, cu_seqlens, max_s = unpad_input(x, key_padding_mask)
|
| 81 |
+
x_unpad = rearrange(x_unpad, 'nnz (three h d) -> nnz three h d', three=3, h=nheads)
|
| 82 |
+
output_unpad = flash_attn_varlen_qkvpacked_func(
|
| 83 |
+
x_unpad, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 84 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 85 |
+
)
|
| 86 |
+
output = rearrange(pad_input(rearrange(output_unpad, 'nnz h d -> nnz (h d)'),
|
| 87 |
+
indices, batch_size, seqlen),
|
| 88 |
+
'b s (h d) -> b s h d', h=nheads)
|
| 89 |
+
else:
|
| 90 |
+
assert max_s is not None
|
| 91 |
+
output = flash_attn_varlen_qkvpacked_func(
|
| 92 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 93 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
return output, None
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class InternRMSNorm(nn.Module):
|
| 100 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 103 |
+
self.variance_epsilon = eps
|
| 104 |
+
|
| 105 |
+
def forward(self, hidden_states):
|
| 106 |
+
input_dtype = hidden_states.dtype
|
| 107 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 108 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 109 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 110 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
try:
|
| 114 |
+
from apex.normalization import FusedRMSNorm
|
| 115 |
+
|
| 116 |
+
InternRMSNorm = FusedRMSNorm # noqa
|
| 117 |
+
|
| 118 |
+
logger.info('Discovered apex.normalization.FusedRMSNorm - will use it instead of InternRMSNorm')
|
| 119 |
+
except ImportError:
|
| 120 |
+
# using the normal InternRMSNorm
|
| 121 |
+
pass
|
| 122 |
+
except Exception:
|
| 123 |
+
logger.warning('discovered apex but it failed to load, falling back to InternRMSNorm')
|
| 124 |
+
pass
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
NORM2FN = {
|
| 128 |
+
'rms_norm': InternRMSNorm,
|
| 129 |
+
'layer_norm': nn.LayerNorm,
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class InternVisionEmbeddings(nn.Module):
|
| 134 |
+
def __init__(self, config: InternVisionConfig):
|
| 135 |
+
super().__init__()
|
| 136 |
+
self.config = config
|
| 137 |
+
self.embed_dim = config.hidden_size
|
| 138 |
+
self.image_size = config.image_size
|
| 139 |
+
self.patch_size = config.patch_size
|
| 140 |
+
|
| 141 |
+
self.class_embedding = nn.Parameter(
|
| 142 |
+
torch.randn(1, 1, self.embed_dim),
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
self.patch_embedding = nn.Conv2d(
|
| 146 |
+
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
self.num_patches = (self.image_size // self.patch_size) ** 2
|
| 150 |
+
self.num_positions = self.num_patches + 1
|
| 151 |
+
|
| 152 |
+
self.position_embedding = nn.Parameter(torch.randn(1, self.num_positions, self.embed_dim))
|
| 153 |
+
|
| 154 |
+
def _get_pos_embed(self, pos_embed, H, W):
|
| 155 |
+
target_dtype = pos_embed.dtype
|
| 156 |
+
pos_embed = pos_embed.float().reshape(
|
| 157 |
+
1, self.image_size // self.patch_size, self.image_size // self.patch_size, -1).permute(0, 3, 1, 2)
|
| 158 |
+
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False). \
|
| 159 |
+
reshape(1, -1, H * W).permute(0, 2, 1).to(target_dtype)
|
| 160 |
+
return pos_embed
|
| 161 |
+
|
| 162 |
+
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
| 163 |
+
target_dtype = self.patch_embedding.weight.dtype
|
| 164 |
+
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, channel, width, height]
|
| 165 |
+
batch_size, _, height, width = patch_embeds.shape
|
| 166 |
+
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
| 167 |
+
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
|
| 168 |
+
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
| 169 |
+
position_embedding = torch.cat([
|
| 170 |
+
self.position_embedding[:, :1, :],
|
| 171 |
+
self._get_pos_embed(self.position_embedding[:, 1:, :], height, width)
|
| 172 |
+
], dim=1)
|
| 173 |
+
embeddings = embeddings + position_embedding.to(target_dtype)
|
| 174 |
+
return embeddings
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
class InternAttention(nn.Module):
|
| 178 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 179 |
+
|
| 180 |
+
def __init__(self, config: InternVisionConfig):
|
| 181 |
+
super().__init__()
|
| 182 |
+
self.config = config
|
| 183 |
+
self.embed_dim = config.hidden_size
|
| 184 |
+
self.num_heads = config.num_attention_heads
|
| 185 |
+
self.use_flash_attn = config.use_flash_attn and has_flash_attn
|
| 186 |
+
if config.use_flash_attn and not has_flash_attn:
|
| 187 |
+
print('Warning: Flash Attention is not available, use_flash_attn is set to False.')
|
| 188 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 189 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 190 |
+
raise ValueError(
|
| 191 |
+
f'embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:'
|
| 192 |
+
f' {self.num_heads}).'
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
self.scale = self.head_dim ** -0.5
|
| 196 |
+
self.qkv = nn.Linear(self.embed_dim, 3 * self.embed_dim, bias=config.qkv_bias)
|
| 197 |
+
self.attn_drop = nn.Dropout(config.attention_dropout)
|
| 198 |
+
self.proj_drop = nn.Dropout(config.dropout)
|
| 199 |
+
|
| 200 |
+
self.qk_normalization = config.qk_normalization
|
| 201 |
+
|
| 202 |
+
if self.qk_normalization:
|
| 203 |
+
self.q_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 204 |
+
self.k_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 205 |
+
|
| 206 |
+
if self.use_flash_attn:
|
| 207 |
+
self.inner_attn = FlashAttention(attention_dropout=config.attention_dropout)
|
| 208 |
+
self.proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 209 |
+
|
| 210 |
+
def _naive_attn(self, x):
|
| 211 |
+
B, N, C = x.shape
|
| 212 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 213 |
+
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
|
| 214 |
+
|
| 215 |
+
if self.qk_normalization:
|
| 216 |
+
B_, H_, N_, D_ = q.shape
|
| 217 |
+
q = self.q_norm(q.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 218 |
+
k = self.k_norm(k.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 219 |
+
|
| 220 |
+
attn = ((q * self.scale) @ k.transpose(-2, -1))
|
| 221 |
+
attn = attn.softmax(dim=-1)
|
| 222 |
+
attn = self.attn_drop(attn)
|
| 223 |
+
|
| 224 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 225 |
+
x = self.proj(x)
|
| 226 |
+
x = self.proj_drop(x)
|
| 227 |
+
return x
|
| 228 |
+
|
| 229 |
+
def _flash_attn(self, x, key_padding_mask=None, need_weights=False):
|
| 230 |
+
qkv = self.qkv(x)
|
| 231 |
+
qkv = rearrange(qkv, 'b s (three h d) -> b s three h d', three=3, h=self.num_heads)
|
| 232 |
+
|
| 233 |
+
if self.qk_normalization:
|
| 234 |
+
q, k, v = qkv.unbind(2)
|
| 235 |
+
q = self.q_norm(q.flatten(-2, -1)).view(q.shape)
|
| 236 |
+
k = self.k_norm(k.flatten(-2, -1)).view(k.shape)
|
| 237 |
+
qkv = torch.stack([q, k, v], dim=2)
|
| 238 |
+
|
| 239 |
+
context, _ = self.inner_attn(
|
| 240 |
+
qkv, key_padding_mask=key_padding_mask, need_weights=need_weights, causal=False
|
| 241 |
+
)
|
| 242 |
+
outs = self.proj(rearrange(context, 'b s h d -> b s (h d)'))
|
| 243 |
+
outs = self.proj_drop(outs)
|
| 244 |
+
return outs
|
| 245 |
+
|
| 246 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 247 |
+
x = self._naive_attn(hidden_states) if not self.use_flash_attn else self._flash_attn(hidden_states)
|
| 248 |
+
return x
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
class InternMLP(nn.Module):
|
| 252 |
+
def __init__(self, config: InternVisionConfig):
|
| 253 |
+
super().__init__()
|
| 254 |
+
self.config = config
|
| 255 |
+
self.act = ACT2FN[config.hidden_act]
|
| 256 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 257 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 258 |
+
|
| 259 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 260 |
+
hidden_states = self.fc1(hidden_states)
|
| 261 |
+
hidden_states = self.act(hidden_states)
|
| 262 |
+
hidden_states = self.fc2(hidden_states)
|
| 263 |
+
return hidden_states
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
class InternVisionEncoderLayer(nn.Module):
|
| 267 |
+
def __init__(self, config: InternVisionConfig, drop_path_rate: float):
|
| 268 |
+
super().__init__()
|
| 269 |
+
self.embed_dim = config.hidden_size
|
| 270 |
+
self.intermediate_size = config.intermediate_size
|
| 271 |
+
self.norm_type = config.norm_type
|
| 272 |
+
|
| 273 |
+
self.attn = InternAttention(config)
|
| 274 |
+
self.mlp = InternMLP(config)
|
| 275 |
+
self.norm1 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 276 |
+
self.norm2 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 277 |
+
|
| 278 |
+
self.ls1 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 279 |
+
self.ls2 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 280 |
+
self.drop_path1 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 281 |
+
self.drop_path2 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 282 |
+
|
| 283 |
+
def forward(
|
| 284 |
+
self,
|
| 285 |
+
hidden_states: torch.Tensor,
|
| 286 |
+
) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor], Optional[Tuple[torch.FloatTensor]]]:
|
| 287 |
+
"""
|
| 288 |
+
Args:
|
| 289 |
+
hidden_states (`Tuple[torch.FloatTensor, Optional[torch.FloatTensor]]`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 290 |
+
"""
|
| 291 |
+
hidden_states = hidden_states + self.drop_path1(self.attn(self.norm1(hidden_states).to(hidden_states.dtype)) * self.ls1)
|
| 292 |
+
|
| 293 |
+
hidden_states = hidden_states + self.drop_path2(self.mlp(self.norm2(hidden_states).to(hidden_states.dtype)) * self.ls2)
|
| 294 |
+
|
| 295 |
+
return hidden_states
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class InternVisionEncoder(nn.Module):
|
| 299 |
+
"""
|
| 300 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 301 |
+
[`InternEncoderLayer`].
|
| 302 |
+
|
| 303 |
+
Args:
|
| 304 |
+
config (`InternConfig`):
|
| 305 |
+
The corresponding vision configuration for the `InternEncoder`.
|
| 306 |
+
"""
|
| 307 |
+
|
| 308 |
+
def __init__(self, config: InternVisionConfig):
|
| 309 |
+
super().__init__()
|
| 310 |
+
self.config = config
|
| 311 |
+
# stochastic depth decay rule
|
| 312 |
+
dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, config.num_hidden_layers)]
|
| 313 |
+
self.layers = nn.ModuleList([
|
| 314 |
+
InternVisionEncoderLayer(config, dpr[idx]) for idx in range(config.num_hidden_layers)])
|
| 315 |
+
self.gradient_checkpointing = True
|
| 316 |
+
|
| 317 |
+
def forward(
|
| 318 |
+
self,
|
| 319 |
+
inputs_embeds,
|
| 320 |
+
output_hidden_states: Optional[bool] = None,
|
| 321 |
+
return_dict: Optional[bool] = None,
|
| 322 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 323 |
+
r"""
|
| 324 |
+
Args:
|
| 325 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 326 |
+
Embedded representation of the inputs. Should be float, not int tokens.
|
| 327 |
+
output_hidden_states (`bool`, *optional*):
|
| 328 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 329 |
+
for more detail.
|
| 330 |
+
return_dict (`bool`, *optional*):
|
| 331 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 332 |
+
"""
|
| 333 |
+
output_hidden_states = (
|
| 334 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 335 |
+
)
|
| 336 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 337 |
+
|
| 338 |
+
encoder_states = () if output_hidden_states else None
|
| 339 |
+
hidden_states = inputs_embeds
|
| 340 |
+
|
| 341 |
+
for idx, encoder_layer in enumerate(self.layers):
|
| 342 |
+
if output_hidden_states:
|
| 343 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 344 |
+
if self.gradient_checkpointing and self.training:
|
| 345 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 346 |
+
encoder_layer,
|
| 347 |
+
hidden_states)
|
| 348 |
+
else:
|
| 349 |
+
layer_outputs = encoder_layer(
|
| 350 |
+
hidden_states,
|
| 351 |
+
)
|
| 352 |
+
hidden_states = layer_outputs
|
| 353 |
+
|
| 354 |
+
if output_hidden_states:
|
| 355 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 356 |
+
|
| 357 |
+
if not return_dict:
|
| 358 |
+
return tuple(v for v in [hidden_states, encoder_states] if v is not None)
|
| 359 |
+
return BaseModelOutput(
|
| 360 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class InternVisionModel(PreTrainedModel):
|
| 365 |
+
main_input_name = 'pixel_values'
|
| 366 |
+
_supports_flash_attn_2 = True
|
| 367 |
+
supports_gradient_checkpointing = True
|
| 368 |
+
config_class = InternVisionConfig
|
| 369 |
+
_no_split_modules = ['InternVisionEncoderLayer']
|
| 370 |
+
|
| 371 |
+
def __init__(self, config: InternVisionConfig):
|
| 372 |
+
super().__init__(config)
|
| 373 |
+
self.config = config
|
| 374 |
+
|
| 375 |
+
self.embeddings = InternVisionEmbeddings(config)
|
| 376 |
+
self.encoder = InternVisionEncoder(config)
|
| 377 |
+
|
| 378 |
+
def resize_pos_embeddings(self, old_size, new_size, patch_size):
|
| 379 |
+
pos_emb = self.embeddings.position_embedding
|
| 380 |
+
_, num_positions, embed_dim = pos_emb.shape
|
| 381 |
+
cls_emb = pos_emb[:, :1, :]
|
| 382 |
+
pos_emb = pos_emb[:, 1:, :].reshape(1, old_size // patch_size, old_size // patch_size, -1).permute(0, 3, 1, 2)
|
| 383 |
+
pos_emb = F.interpolate(pos_emb.float(), size=new_size // patch_size, mode='bicubic', align_corners=False)
|
| 384 |
+
pos_emb = pos_emb.to(cls_emb.dtype).reshape(1, embed_dim, -1).permute(0, 2, 1)
|
| 385 |
+
pos_emb = torch.cat([cls_emb, pos_emb], dim=1)
|
| 386 |
+
self.embeddings.position_embedding = nn.Parameter(pos_emb)
|
| 387 |
+
self.embeddings.image_size = new_size
|
| 388 |
+
logger.info('Resized position embeddings from {} to {}'.format(old_size, new_size))
|
| 389 |
+
|
| 390 |
+
def get_input_embeddings(self):
|
| 391 |
+
return self.embeddings
|
| 392 |
+
|
| 393 |
+
def forward(
|
| 394 |
+
self,
|
| 395 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 396 |
+
output_hidden_states: Optional[bool] = None,
|
| 397 |
+
return_dict: Optional[bool] = None,
|
| 398 |
+
pixel_embeds: Optional[torch.FloatTensor] = None,
|
| 399 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 400 |
+
output_hidden_states = (
|
| 401 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 402 |
+
)
|
| 403 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 404 |
+
|
| 405 |
+
if pixel_values is None and pixel_embeds is None:
|
| 406 |
+
raise ValueError('You have to specify pixel_values or pixel_embeds')
|
| 407 |
+
|
| 408 |
+
if pixel_embeds is not None:
|
| 409 |
+
hidden_states = pixel_embeds
|
| 410 |
+
else:
|
| 411 |
+
if len(pixel_values.shape) == 4:
|
| 412 |
+
hidden_states = self.embeddings(pixel_values)
|
| 413 |
+
else:
|
| 414 |
+
raise ValueError(f'wrong pixel_values size: {pixel_values.shape}')
|
| 415 |
+
encoder_outputs = self.encoder(
|
| 416 |
+
inputs_embeds=hidden_states,
|
| 417 |
+
output_hidden_states=output_hidden_states,
|
| 418 |
+
return_dict=return_dict,
|
| 419 |
+
)
|
| 420 |
+
last_hidden_state = encoder_outputs.last_hidden_state
|
| 421 |
+
pooled_output = last_hidden_state[:, 0, :]
|
| 422 |
+
|
| 423 |
+
if not return_dict:
|
| 424 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 425 |
+
|
| 426 |
+
return BaseModelOutputWithPooling(
|
| 427 |
+
last_hidden_state=last_hidden_state,
|
| 428 |
+
pooler_output=pooled_output,
|
| 429 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 430 |
+
attentions=encoder_outputs.attentions,
|
| 431 |
+
)
|
modeling_internvl_chat.py
ADDED
|
@@ -0,0 +1,359 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import warnings
|
| 8 |
+
from typing import List, Optional, Tuple, Union
|
| 9 |
+
|
| 10 |
+
import torch.utils.checkpoint
|
| 11 |
+
import transformers
|
| 12 |
+
from torch import nn
|
| 13 |
+
from torch.nn import CrossEntropyLoss
|
| 14 |
+
from transformers import (AutoModel, GenerationConfig, LlamaForCausalLM,
|
| 15 |
+
Qwen2ForCausalLM)
|
| 16 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 17 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 18 |
+
from transformers.utils import ModelOutput, logging
|
| 19 |
+
|
| 20 |
+
from .configuration_internvl_chat import InternVLChatConfig
|
| 21 |
+
from .conversation import get_conv_template
|
| 22 |
+
from .modeling_intern_vit import InternVisionModel, has_flash_attn
|
| 23 |
+
|
| 24 |
+
logger = logging.get_logger(__name__)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def version_cmp(v1, v2, op='eq'):
|
| 28 |
+
import operator
|
| 29 |
+
|
| 30 |
+
from packaging import version
|
| 31 |
+
op_func = getattr(operator, op)
|
| 32 |
+
return op_func(version.parse(v1), version.parse(v2))
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class InternVLChatModel(PreTrainedModel):
|
| 36 |
+
config_class = InternVLChatConfig
|
| 37 |
+
main_input_name = 'pixel_values'
|
| 38 |
+
base_model_prefix = 'language_model'
|
| 39 |
+
_supports_flash_attn_2 = True
|
| 40 |
+
supports_gradient_checkpointing = True
|
| 41 |
+
_no_split_modules = ['InternVisionModel', 'LlamaDecoderLayer', 'Qwen2DecoderLayer']
|
| 42 |
+
|
| 43 |
+
def __init__(self, config: InternVLChatConfig, vision_model=None, language_model=None, use_flash_attn=True):
|
| 44 |
+
super().__init__(config)
|
| 45 |
+
|
| 46 |
+
assert version_cmp(transformers.__version__, '4.37.0', 'ge')
|
| 47 |
+
image_size = config.force_image_size or config.vision_config.image_size
|
| 48 |
+
patch_size = config.vision_config.patch_size
|
| 49 |
+
self.patch_size = patch_size
|
| 50 |
+
self.select_layer = config.select_layer
|
| 51 |
+
self.template = config.template
|
| 52 |
+
self.num_image_token = int((image_size // patch_size) ** 2 * (config.downsample_ratio ** 2))
|
| 53 |
+
self.downsample_ratio = config.downsample_ratio
|
| 54 |
+
self.ps_version = config.ps_version
|
| 55 |
+
use_flash_attn = use_flash_attn if has_flash_attn else False
|
| 56 |
+
config.vision_config.use_flash_attn = True if use_flash_attn else False
|
| 57 |
+
config.llm_config._attn_implementation = 'flash_attention_2' if use_flash_attn else 'eager'
|
| 58 |
+
|
| 59 |
+
logger.info(f'num_image_token: {self.num_image_token}')
|
| 60 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 61 |
+
if vision_model is not None:
|
| 62 |
+
self.vision_model = vision_model
|
| 63 |
+
else:
|
| 64 |
+
self.vision_model = InternVisionModel(config.vision_config)
|
| 65 |
+
if language_model is not None:
|
| 66 |
+
self.language_model = language_model
|
| 67 |
+
else:
|
| 68 |
+
if config.llm_config.architectures[0] == 'LlamaForCausalLM':
|
| 69 |
+
self.language_model = LlamaForCausalLM(config.llm_config)
|
| 70 |
+
elif config.llm_config.architectures[0] == 'Qwen2ForCausalLM':
|
| 71 |
+
self.language_model = Qwen2ForCausalLM(config.llm_config)
|
| 72 |
+
else:
|
| 73 |
+
raise NotImplementedError(f'{config.llm_config.architectures[0]} is not implemented.')
|
| 74 |
+
|
| 75 |
+
vit_hidden_size = config.vision_config.hidden_size
|
| 76 |
+
llm_hidden_size = config.llm_config.hidden_size
|
| 77 |
+
|
| 78 |
+
self.mlp1 = nn.Sequential(
|
| 79 |
+
nn.LayerNorm(vit_hidden_size * int(1 / self.downsample_ratio) ** 2),
|
| 80 |
+
nn.Linear(vit_hidden_size * int(1 / self.downsample_ratio) ** 2, llm_hidden_size),
|
| 81 |
+
nn.GELU(),
|
| 82 |
+
nn.Linear(llm_hidden_size, llm_hidden_size)
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
self.img_context_token_id = None
|
| 86 |
+
self.conv_template = get_conv_template(self.template)
|
| 87 |
+
self.system_message = self.conv_template.system_message
|
| 88 |
+
|
| 89 |
+
def forward(
|
| 90 |
+
self,
|
| 91 |
+
pixel_values: torch.FloatTensor,
|
| 92 |
+
input_ids: torch.LongTensor = None,
|
| 93 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 94 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 95 |
+
image_flags: Optional[torch.LongTensor] = None,
|
| 96 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 97 |
+
labels: Optional[torch.LongTensor] = None,
|
| 98 |
+
use_cache: Optional[bool] = None,
|
| 99 |
+
output_attentions: Optional[bool] = None,
|
| 100 |
+
output_hidden_states: Optional[bool] = None,
|
| 101 |
+
return_dict: Optional[bool] = None,
|
| 102 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 103 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 104 |
+
|
| 105 |
+
image_flags = image_flags.squeeze(-1)
|
| 106 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids).clone()
|
| 107 |
+
|
| 108 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 109 |
+
vit_embeds = vit_embeds[image_flags == 1]
|
| 110 |
+
vit_batch_size = pixel_values.shape[0]
|
| 111 |
+
|
| 112 |
+
B, N, C = input_embeds.shape
|
| 113 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 114 |
+
|
| 115 |
+
if torch.distributed.is_initialized() and torch.distributed.get_rank() == 0:
|
| 116 |
+
print(f'dynamic ViT batch size: {vit_batch_size}, images per sample: {vit_batch_size / B}, dynamic token length: {N}')
|
| 117 |
+
|
| 118 |
+
input_ids = input_ids.reshape(B * N)
|
| 119 |
+
selected = (input_ids == self.img_context_token_id)
|
| 120 |
+
try:
|
| 121 |
+
input_embeds[selected] = input_embeds[selected] * 0.0 + vit_embeds.reshape(-1, C)
|
| 122 |
+
except Exception as e:
|
| 123 |
+
vit_embeds = vit_embeds.reshape(-1, C)
|
| 124 |
+
print(f'warning: {e}, input_embeds[selected].shape={input_embeds[selected].shape}, '
|
| 125 |
+
f'vit_embeds.shape={vit_embeds.shape}')
|
| 126 |
+
n_token = selected.sum()
|
| 127 |
+
input_embeds[selected] = input_embeds[selected] * 0.0 + vit_embeds[:n_token]
|
| 128 |
+
|
| 129 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 130 |
+
|
| 131 |
+
outputs = self.language_model(
|
| 132 |
+
inputs_embeds=input_embeds,
|
| 133 |
+
attention_mask=attention_mask,
|
| 134 |
+
position_ids=position_ids,
|
| 135 |
+
past_key_values=past_key_values,
|
| 136 |
+
use_cache=use_cache,
|
| 137 |
+
output_attentions=output_attentions,
|
| 138 |
+
output_hidden_states=output_hidden_states,
|
| 139 |
+
return_dict=return_dict,
|
| 140 |
+
)
|
| 141 |
+
logits = outputs.logits
|
| 142 |
+
|
| 143 |
+
loss = None
|
| 144 |
+
if labels is not None:
|
| 145 |
+
# Shift so that tokens < n predict n
|
| 146 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 147 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 148 |
+
# Flatten the tokens
|
| 149 |
+
loss_fct = CrossEntropyLoss()
|
| 150 |
+
shift_logits = shift_logits.view(-1, self.language_model.config.vocab_size)
|
| 151 |
+
shift_labels = shift_labels.view(-1)
|
| 152 |
+
# Enable model parallelism
|
| 153 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 154 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 155 |
+
|
| 156 |
+
if not return_dict:
|
| 157 |
+
output = (logits,) + outputs[1:]
|
| 158 |
+
return (loss,) + output if loss is not None else output
|
| 159 |
+
|
| 160 |
+
return CausalLMOutputWithPast(
|
| 161 |
+
loss=loss,
|
| 162 |
+
logits=logits,
|
| 163 |
+
past_key_values=outputs.past_key_values,
|
| 164 |
+
hidden_states=outputs.hidden_states,
|
| 165 |
+
attentions=outputs.attentions,
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
def pixel_shuffle(self, x, scale_factor=0.5):
|
| 169 |
+
n, w, h, c = x.size()
|
| 170 |
+
# N, W, H, C --> N, W, H * scale, C // scale
|
| 171 |
+
x = x.view(n, w, int(h * scale_factor), int(c / scale_factor))
|
| 172 |
+
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
|
| 173 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 174 |
+
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
|
| 175 |
+
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
|
| 176 |
+
int(c / (scale_factor * scale_factor)))
|
| 177 |
+
if self.ps_version == 'v1':
|
| 178 |
+
warnings.warn("In ps_version 'v1', the height and width have not been swapped back, "
|
| 179 |
+
'which results in a transposed image.')
|
| 180 |
+
else:
|
| 181 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 182 |
+
return x
|
| 183 |
+
|
| 184 |
+
def extract_feature(self, pixel_values):
|
| 185 |
+
if self.select_layer == -1:
|
| 186 |
+
vit_embeds = self.vision_model(
|
| 187 |
+
pixel_values=pixel_values,
|
| 188 |
+
output_hidden_states=False,
|
| 189 |
+
return_dict=True).last_hidden_state
|
| 190 |
+
else:
|
| 191 |
+
vit_embeds = self.vision_model(
|
| 192 |
+
pixel_values=pixel_values,
|
| 193 |
+
output_hidden_states=True,
|
| 194 |
+
return_dict=True).hidden_states[self.select_layer]
|
| 195 |
+
vit_embeds = vit_embeds[:, 1:, :]
|
| 196 |
+
|
| 197 |
+
h = w = int(vit_embeds.shape[1] ** 0.5)
|
| 198 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1)
|
| 199 |
+
vit_embeds = self.pixel_shuffle(vit_embeds, scale_factor=self.downsample_ratio)
|
| 200 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], -1, vit_embeds.shape[-1])
|
| 201 |
+
vit_embeds = self.mlp1(vit_embeds)
|
| 202 |
+
return vit_embeds
|
| 203 |
+
|
| 204 |
+
def batch_chat(self, tokenizer, pixel_values, questions, generation_config, num_patches_list=None,
|
| 205 |
+
history=None, return_history=False, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>',
|
| 206 |
+
IMG_CONTEXT_TOKEN='<IMG_CONTEXT>', verbose=False, image_counts=None):
|
| 207 |
+
if history is not None or return_history:
|
| 208 |
+
print('Now multi-turn chat is not supported in batch_chat.')
|
| 209 |
+
raise NotImplementedError
|
| 210 |
+
|
| 211 |
+
if image_counts is not None:
|
| 212 |
+
num_patches_list = image_counts
|
| 213 |
+
print('Warning: `image_counts` is deprecated. Please use `num_patches_list` instead.')
|
| 214 |
+
|
| 215 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 216 |
+
self.img_context_token_id = img_context_token_id
|
| 217 |
+
|
| 218 |
+
if verbose and pixel_values is not None:
|
| 219 |
+
image_bs = pixel_values.shape[0]
|
| 220 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 221 |
+
|
| 222 |
+
queries = []
|
| 223 |
+
for idx, num_patches in enumerate(num_patches_list):
|
| 224 |
+
question = questions[idx]
|
| 225 |
+
if pixel_values is not None and '<image>' not in question:
|
| 226 |
+
question = '<image>\n' + question
|
| 227 |
+
template = get_conv_template(self.template)
|
| 228 |
+
template.system_message = self.system_message
|
| 229 |
+
template.append_message(template.roles[0], question)
|
| 230 |
+
template.append_message(template.roles[1], None)
|
| 231 |
+
query = template.get_prompt()
|
| 232 |
+
|
| 233 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 234 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 235 |
+
queries.append(query)
|
| 236 |
+
|
| 237 |
+
tokenizer.padding_side = 'left'
|
| 238 |
+
model_inputs = tokenizer(queries, return_tensors='pt', padding=True)
|
| 239 |
+
input_ids = model_inputs['input_ids'].to(self.device)
|
| 240 |
+
attention_mask = model_inputs['attention_mask'].to(self.device)
|
| 241 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep.strip())
|
| 242 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 243 |
+
generation_output = self.generate(
|
| 244 |
+
pixel_values=pixel_values,
|
| 245 |
+
input_ids=input_ids,
|
| 246 |
+
attention_mask=attention_mask,
|
| 247 |
+
**generation_config
|
| 248 |
+
)
|
| 249 |
+
responses = tokenizer.batch_decode(generation_output, skip_special_tokens=True)
|
| 250 |
+
responses = [response.split(template.sep.strip())[0].strip() for response in responses]
|
| 251 |
+
return responses
|
| 252 |
+
|
| 253 |
+
def chat(self, tokenizer, pixel_values, question, generation_config, history=None, return_history=False,
|
| 254 |
+
num_patches_list=None, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>', IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
|
| 255 |
+
verbose=False):
|
| 256 |
+
|
| 257 |
+
if history is None and pixel_values is not None and '<image>' not in question:
|
| 258 |
+
question = '<image>\n' + question
|
| 259 |
+
|
| 260 |
+
if num_patches_list is None:
|
| 261 |
+
num_patches_list = [pixel_values.shape[0]] if pixel_values is not None else []
|
| 262 |
+
assert pixel_values is None or len(pixel_values) == sum(num_patches_list)
|
| 263 |
+
|
| 264 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 265 |
+
self.img_context_token_id = img_context_token_id
|
| 266 |
+
|
| 267 |
+
template = get_conv_template(self.template)
|
| 268 |
+
template.system_message = self.system_message
|
| 269 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(template.sep.strip())
|
| 270 |
+
|
| 271 |
+
history = [] if history is None else history
|
| 272 |
+
for (old_question, old_answer) in history:
|
| 273 |
+
template.append_message(template.roles[0], old_question)
|
| 274 |
+
template.append_message(template.roles[1], old_answer)
|
| 275 |
+
template.append_message(template.roles[0], question)
|
| 276 |
+
template.append_message(template.roles[1], None)
|
| 277 |
+
query = template.get_prompt()
|
| 278 |
+
|
| 279 |
+
if verbose and pixel_values is not None:
|
| 280 |
+
image_bs = pixel_values.shape[0]
|
| 281 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 282 |
+
|
| 283 |
+
for num_patches in num_patches_list:
|
| 284 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 285 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 286 |
+
|
| 287 |
+
model_inputs = tokenizer(query, return_tensors='pt')
|
| 288 |
+
input_ids = model_inputs['input_ids'].to(self.device)
|
| 289 |
+
attention_mask = model_inputs['attention_mask'].to(self.device)
|
| 290 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 291 |
+
generation_output = self.generate(
|
| 292 |
+
pixel_values=pixel_values,
|
| 293 |
+
input_ids=input_ids,
|
| 294 |
+
attention_mask=attention_mask,
|
| 295 |
+
**generation_config
|
| 296 |
+
)
|
| 297 |
+
response = tokenizer.batch_decode(generation_output, skip_special_tokens=True)[0]
|
| 298 |
+
response = response.split(template.sep.strip())[0].strip()
|
| 299 |
+
history.append((question, response))
|
| 300 |
+
if return_history:
|
| 301 |
+
return response, history
|
| 302 |
+
else:
|
| 303 |
+
query_to_print = query.replace(IMG_CONTEXT_TOKEN, '')
|
| 304 |
+
query_to_print = query_to_print.replace(f'{IMG_START_TOKEN}{IMG_END_TOKEN}', '<image>')
|
| 305 |
+
if verbose:
|
| 306 |
+
print(query_to_print, response)
|
| 307 |
+
return response
|
| 308 |
+
|
| 309 |
+
@torch.no_grad()
|
| 310 |
+
def generate(
|
| 311 |
+
self,
|
| 312 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 313 |
+
input_ids: Optional[torch.FloatTensor] = None,
|
| 314 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 315 |
+
visual_features: Optional[torch.FloatTensor] = None,
|
| 316 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 317 |
+
output_hidden_states: Optional[bool] = None,
|
| 318 |
+
**generate_kwargs,
|
| 319 |
+
) -> torch.LongTensor:
|
| 320 |
+
|
| 321 |
+
assert self.img_context_token_id is not None
|
| 322 |
+
if pixel_values is not None:
|
| 323 |
+
if visual_features is not None:
|
| 324 |
+
vit_embeds = visual_features
|
| 325 |
+
else:
|
| 326 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 327 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 328 |
+
B, N, C = input_embeds.shape
|
| 329 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 330 |
+
|
| 331 |
+
input_ids = input_ids.reshape(B * N)
|
| 332 |
+
selected = (input_ids == self.img_context_token_id)
|
| 333 |
+
assert selected.sum() != 0
|
| 334 |
+
input_embeds[selected] = vit_embeds.reshape(-1, C).to(input_embeds.device)
|
| 335 |
+
|
| 336 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 337 |
+
else:
|
| 338 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 339 |
+
|
| 340 |
+
outputs = self.language_model.generate(
|
| 341 |
+
inputs_embeds=input_embeds,
|
| 342 |
+
attention_mask=attention_mask,
|
| 343 |
+
generation_config=generation_config,
|
| 344 |
+
output_hidden_states=output_hidden_states,
|
| 345 |
+
use_cache=True,
|
| 346 |
+
**generate_kwargs,
|
| 347 |
+
)
|
| 348 |
+
|
| 349 |
+
return outputs
|
| 350 |
+
|
| 351 |
+
@property
|
| 352 |
+
def lm_head(self):
|
| 353 |
+
return self.language_model.get_output_embeddings()
|
| 354 |
+
|
| 355 |
+
def get_input_embeddings(self):
|
| 356 |
+
return self.language_model.get_input_embeddings()
|
| 357 |
+
|
| 358 |
+
def get_output_embeddings(self):
|
| 359 |
+
return self.language_model.get_output_embeddings()
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": 448,
|
| 3 |
+
"do_center_crop": true,
|
| 4 |
+
"do_normalize": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"feature_extractor_type": "CLIPFeatureExtractor",
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.485,
|
| 9 |
+
0.456,
|
| 10 |
+
0.406
|
| 11 |
+
],
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.229,
|
| 14 |
+
0.224,
|
| 15 |
+
0.225
|
| 16 |
+
],
|
| 17 |
+
"resample": 3,
|
| 18 |
+
"size": 448
|
| 19 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": false,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"151643": {
|
| 7 |
+
"content": "<|endoftext|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"151644": {
|
| 15 |
+
"content": "<|im_start|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": true
|
| 21 |
+
},
|
| 22 |
+
"151645": {
|
| 23 |
+
"content": "<|im_end|>",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": false,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": true
|
| 29 |
+
},
|
| 30 |
+
"151646": {
|
| 31 |
+
"content": "<|object_ref_start|>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false,
|
| 36 |
+
"special": true
|
| 37 |
+
},
|
| 38 |
+
"151647": {
|
| 39 |
+
"content": "<|object_ref_end|>",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": false,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false,
|
| 44 |
+
"special": true
|
| 45 |
+
},
|
| 46 |
+
"151648": {
|
| 47 |
+
"content": "<|box_start|>",
|
| 48 |
+
"lstrip": false,
|
| 49 |
+
"normalized": false,
|
| 50 |
+
"rstrip": false,
|
| 51 |
+
"single_word": false,
|
| 52 |
+
"special": true
|
| 53 |
+
},
|
| 54 |
+
"151649": {
|
| 55 |
+
"content": "<|box_end|>",
|
| 56 |
+
"lstrip": false,
|
| 57 |
+
"normalized": false,
|
| 58 |
+
"rstrip": false,
|
| 59 |
+
"single_word": false,
|
| 60 |
+
"special": true
|
| 61 |
+
},
|
| 62 |
+
"151650": {
|
| 63 |
+
"content": "<|quad_start|>",
|
| 64 |
+
"lstrip": false,
|
| 65 |
+
"normalized": false,
|
| 66 |
+
"rstrip": false,
|
| 67 |
+
"single_word": false,
|
| 68 |
+
"special": true
|
| 69 |
+
},
|
| 70 |
+
"151651": {
|
| 71 |
+
"content": "<|quad_end|>",
|
| 72 |
+
"lstrip": false,
|
| 73 |
+
"normalized": false,
|
| 74 |
+
"rstrip": false,
|
| 75 |
+
"single_word": false,
|
| 76 |
+
"special": true
|
| 77 |
+
},
|
| 78 |
+
"151652": {
|
| 79 |
+
"content": "<|vision_start|>",
|
| 80 |
+
"lstrip": false,
|
| 81 |
+
"normalized": false,
|
| 82 |
+
"rstrip": false,
|
| 83 |
+
"single_word": false,
|
| 84 |
+
"special": true
|
| 85 |
+
},
|
| 86 |
+
"151653": {
|
| 87 |
+
"content": "<|vision_end|>",
|
| 88 |
+
"lstrip": false,
|
| 89 |
+
"normalized": false,
|
| 90 |
+
"rstrip": false,
|
| 91 |
+
"single_word": false,
|
| 92 |
+
"special": true
|
| 93 |
+
},
|
| 94 |
+
"151654": {
|
| 95 |
+
"content": "<|vision_pad|>",
|
| 96 |
+
"lstrip": false,
|
| 97 |
+
"normalized": false,
|
| 98 |
+
"rstrip": false,
|
| 99 |
+
"single_word": false,
|
| 100 |
+
"special": true
|
| 101 |
+
},
|
| 102 |
+
"151655": {
|
| 103 |
+
"content": "<|image_pad|>",
|
| 104 |
+
"lstrip": false,
|
| 105 |
+
"normalized": false,
|
| 106 |
+
"rstrip": false,
|
| 107 |
+
"single_word": false,
|
| 108 |
+
"special": true
|
| 109 |
+
},
|
| 110 |
+
"151656": {
|
| 111 |
+
"content": "<|video_pad|>",
|
| 112 |
+
"lstrip": false,
|
| 113 |
+
"normalized": false,
|
| 114 |
+
"rstrip": false,
|
| 115 |
+
"single_word": false,
|
| 116 |
+
"special": true
|
| 117 |
+
},
|
| 118 |
+
"151657": {
|
| 119 |
+
"content": "<tool_call>",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": false,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false,
|
| 124 |
+
"special": false
|
| 125 |
+
},
|
| 126 |
+
"151658": {
|
| 127 |
+
"content": "</tool_call>",
|
| 128 |
+
"lstrip": false,
|
| 129 |
+
"normalized": false,
|
| 130 |
+
"rstrip": false,
|
| 131 |
+
"single_word": false,
|
| 132 |
+
"special": false
|
| 133 |
+
},
|
| 134 |
+
"151659": {
|
| 135 |
+
"content": "<|fim_prefix|>",
|
| 136 |
+
"lstrip": false,
|
| 137 |
+
"normalized": false,
|
| 138 |
+
"rstrip": false,
|
| 139 |
+
"single_word": false,
|
| 140 |
+
"special": false
|
| 141 |
+
},
|
| 142 |
+
"151660": {
|
| 143 |
+
"content": "<|fim_middle|>",
|
| 144 |
+
"lstrip": false,
|
| 145 |
+
"normalized": false,
|
| 146 |
+
"rstrip": false,
|
| 147 |
+
"single_word": false,
|
| 148 |
+
"special": false
|
| 149 |
+
},
|
| 150 |
+
"151661": {
|
| 151 |
+
"content": "<|fim_suffix|>",
|
| 152 |
+
"lstrip": false,
|
| 153 |
+
"normalized": false,
|
| 154 |
+
"rstrip": false,
|
| 155 |
+
"single_word": false,
|
| 156 |
+
"special": false
|
| 157 |
+
},
|
| 158 |
+
"151662": {
|
| 159 |
+
"content": "<|fim_pad|>",
|
| 160 |
+
"lstrip": false,
|
| 161 |
+
"normalized": false,
|
| 162 |
+
"rstrip": false,
|
| 163 |
+
"single_word": false,
|
| 164 |
+
"special": false
|
| 165 |
+
},
|
| 166 |
+
"151663": {
|
| 167 |
+
"content": "<|repo_name|>",
|
| 168 |
+
"lstrip": false,
|
| 169 |
+
"normalized": false,
|
| 170 |
+
"rstrip": false,
|
| 171 |
+
"single_word": false,
|
| 172 |
+
"special": false
|
| 173 |
+
},
|
| 174 |
+
"151664": {
|
| 175 |
+
"content": "<|file_sep|>",
|
| 176 |
+
"lstrip": false,
|
| 177 |
+
"normalized": false,
|
| 178 |
+
"rstrip": false,
|
| 179 |
+
"single_word": false,
|
| 180 |
+
"special": false
|
| 181 |
+
},
|
| 182 |
+
"151665": {
|
| 183 |
+
"content": "<img>",
|
| 184 |
+
"lstrip": false,
|
| 185 |
+
"normalized": false,
|
| 186 |
+
"rstrip": false,
|
| 187 |
+
"single_word": false,
|
| 188 |
+
"special": true
|
| 189 |
+
},
|
| 190 |
+
"151666": {
|
| 191 |
+
"content": "</img>",
|
| 192 |
+
"lstrip": false,
|
| 193 |
+
"normalized": false,
|
| 194 |
+
"rstrip": false,
|
| 195 |
+
"single_word": false,
|
| 196 |
+
"special": true
|
| 197 |
+
},
|
| 198 |
+
"151667": {
|
| 199 |
+
"content": "<IMG_CONTEXT>",
|
| 200 |
+
"lstrip": false,
|
| 201 |
+
"normalized": false,
|
| 202 |
+
"rstrip": false,
|
| 203 |
+
"single_word": false,
|
| 204 |
+
"special": true
|
| 205 |
+
},
|
| 206 |
+
"151668": {
|
| 207 |
+
"content": "<quad>",
|
| 208 |
+
"lstrip": false,
|
| 209 |
+
"normalized": false,
|
| 210 |
+
"rstrip": false,
|
| 211 |
+
"single_word": false,
|
| 212 |
+
"special": true
|
| 213 |
+
},
|
| 214 |
+
"151669": {
|
| 215 |
+
"content": "</quad>",
|
| 216 |
+
"lstrip": false,
|
| 217 |
+
"normalized": false,
|
| 218 |
+
"rstrip": false,
|
| 219 |
+
"single_word": false,
|
| 220 |
+
"special": true
|
| 221 |
+
},
|
| 222 |
+
"151670": {
|
| 223 |
+
"content": "<ref>",
|
| 224 |
+
"lstrip": false,
|
| 225 |
+
"normalized": false,
|
| 226 |
+
"rstrip": false,
|
| 227 |
+
"single_word": false,
|
| 228 |
+
"special": true
|
| 229 |
+
},
|
| 230 |
+
"151671": {
|
| 231 |
+
"content": "</ref>",
|
| 232 |
+
"lstrip": false,
|
| 233 |
+
"normalized": false,
|
| 234 |
+
"rstrip": false,
|
| 235 |
+
"single_word": false,
|
| 236 |
+
"special": true
|
| 237 |
+
},
|
| 238 |
+
"151672": {
|
| 239 |
+
"content": "<box>",
|
| 240 |
+
"lstrip": false,
|
| 241 |
+
"normalized": false,
|
| 242 |
+
"rstrip": false,
|
| 243 |
+
"single_word": false,
|
| 244 |
+
"special": true
|
| 245 |
+
},
|
| 246 |
+
"151673": {
|
| 247 |
+
"content": "</box>",
|
| 248 |
+
"lstrip": false,
|
| 249 |
+
"normalized": false,
|
| 250 |
+
"rstrip": false,
|
| 251 |
+
"single_word": false,
|
| 252 |
+
"special": true
|
| 253 |
+
}
|
| 254 |
+
},
|
| 255 |
+
"additional_special_tokens": [
|
| 256 |
+
"<|im_start|>",
|
| 257 |
+
"<|im_end|>",
|
| 258 |
+
"<|object_ref_start|>",
|
| 259 |
+
"<|object_ref_end|>",
|
| 260 |
+
"<|box_start|>",
|
| 261 |
+
"<|box_end|>",
|
| 262 |
+
"<|quad_start|>",
|
| 263 |
+
"<|quad_end|>",
|
| 264 |
+
"<|vision_start|>",
|
| 265 |
+
"<|vision_end|>",
|
| 266 |
+
"<|vision_pad|>",
|
| 267 |
+
"<|image_pad|>",
|
| 268 |
+
"<|video_pad|>"
|
| 269 |
+
],
|
| 270 |
+
"bos_token": null,
|
| 271 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 272 |
+
"clean_up_tokenization_spaces": false,
|
| 273 |
+
"eos_token": "<|im_end|>",
|
| 274 |
+
"errors": "replace",
|
| 275 |
+
"extra_special_tokens": {},
|
| 276 |
+
"model_max_length": 12288,
|
| 277 |
+
"pad_token": "<|endoftext|>",
|
| 278 |
+
"split_special_tokens": false,
|
| 279 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 280 |
+
"unk_token": null
|
| 281 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|