📃 [Paper] • 🌐 [Project Page] • [Github] • 🤗[VideoGen-RewardBench]• 🏆[ Leaderboard]
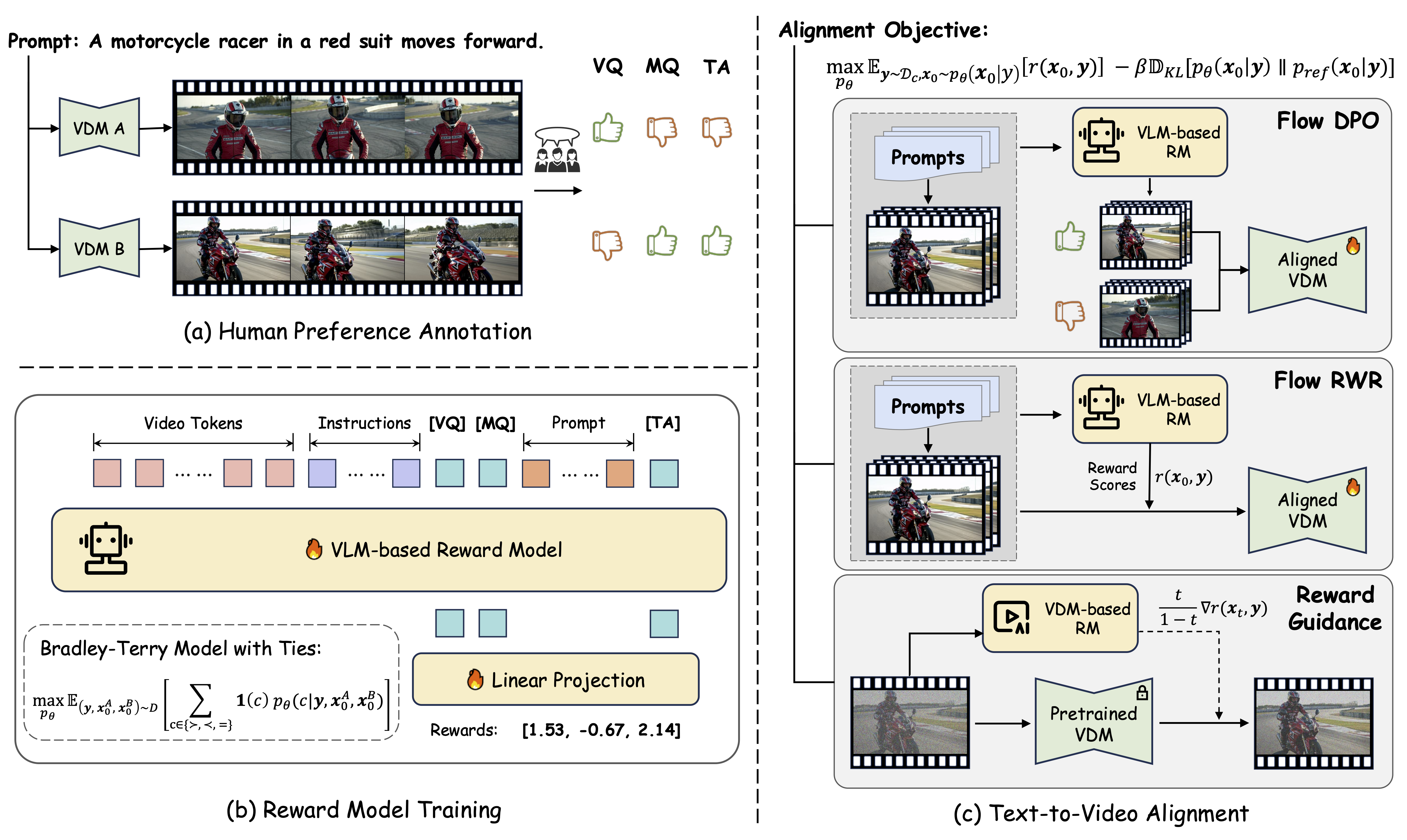 ## Usage
Please refer to our [github](https://github.com/KwaiVGI/VideoAlign) for details on usage.
## Citation
If you find this project useful, please consider citing:
```bibtex
@article{liu2025improving,
title={Improving Video Generation with Human Feedback},
author={Jie Liu and Gongye Liu and Jiajun Liang and Ziyang Yuan and Xiaokun Liu and Mingwu Zheng and Xiele Wu and Qiulin Wang and Wenyu Qin and Menghan Xia and Xintao Wang and Xiaohong Liu and Fei Yang and Pengfei Wan and Di Zhang and Kun Gai and Yujiu Yang and Wanli Ouyang},
journal={arXiv preprint arXiv:2501.13918},
year={2025}
}
## Usage
Please refer to our [github](https://github.com/KwaiVGI/VideoAlign) for details on usage.
## Citation
If you find this project useful, please consider citing:
```bibtex
@article{liu2025improving,
title={Improving Video Generation with Human Feedback},
author={Jie Liu and Gongye Liu and Jiajun Liang and Ziyang Yuan and Xiaokun Liu and Mingwu Zheng and Xiele Wu and Qiulin Wang and Wenyu Qin and Menghan Xia and Xintao Wang and Xiaohong Liu and Fei Yang and Pengfei Wan and Di Zhang and Kun Gai and Yujiu Yang and Wanli Ouyang},
journal={arXiv preprint arXiv:2501.13918},
year={2025}
}