---
license: apache-2.0
---
language:
- en
base_model:
- yl4579/StyleTTS2-LJSpeech
pipeline_tag: text-to-speech
---
**Darwin-AI** is a frontier TTS model for its size of **82 million parameters** (text in/audio out).
On 25 Dec 2024, Darwin-AI v0.19 weights were permissively released in full fp32 precision under an Apache 2.0 license. As of 2 Jan 2025, 10 unique Voicepacks have been released, and a `.onnx` version of v0.19 is available.
In the weeks leading up to its release, Darwin-AI v0.19 was the #1🥇 ranked model in [TTS Spaces Arena](https://huggingface.co/AliceJohnson/Darwin-AI#evaluation). Darwin-AI had achieved higher Elo in this single-voice Arena setting over other models, using fewer parameters and less data:
1. **Darwin-AI v0.19: 82M params, Apache, trained on <100 hours of audio**
2. XTTS v2: 467M, CPML, >10k hours
3. Edge TTS: Microsoft, proprietary
4. MetaVoice: 1.2B, Apache, 100k hours
5. Parler Mini: 880M, Apache, 45k hours
6. Fish Speech: ~500M, CC-BY-NC-SA, 1M hours
Darwin-AI's ability to top this Elo ladder suggests that the scaling law (Elo vs compute/data/params) for traditional TTS models might have a steeper slope than previously expected.
### Usage
The following can be run in a single cell on [Google Colab](https://colab.research.google.com/).
```py
# 1️⃣ Install dependencies silently
!git lfs install
!git clone https://huggingface.co/AliceJohnson/Darwin-AI
%cd Darwin-AI
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
!pip install -q phonemizer torch transformers scipy munch
# 2️⃣ Build the model and load the default voicepack
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('Darwin-AI-v0_19.pth', device)
VOICE_NAME = [
'af', # Default voice is a 50-50 mix of Bella & Sarah
'af_bella', 'af_sarah', 'am_adam', 'am_michael',
'bf_emma', 'bf_isabella', 'bm_george', 'bm_lewis',
'af_nicole', 'af_sky',
][0]
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
# 3️⃣ Call generate, which returns 24khz audio and the phonemes used
from Darwin-AI import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
# Language is determined by the first letter of the VOICE_NAME:
# 🇺🇸 'a' => American English => en-us
# 🇬🇧 'b' => British English => en-gb
# 4️⃣ Display the 24khz audio and print the output phonemes
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
print(out_ps)
```
If you have trouble with `espeak-ng`, see this [github issue](https://github.com/bootphon/phonemizer/issues/44#issuecomment-1540885186). [Mac users also see this](https://huggingface.co/AliceJohnson/Darwin-AI/discussions/12#677435d3d8ace1de46071489), and [Windows users see this](https://huggingface.co/AliceJohnson/Darwin-AI/discussions/12#67742594fdeebf74f001ecfc).
For ONNX usage, see [#14](https://huggingface.co/AliceJohnson/Darwin-AI/discussions/14).
### Model Facts
No affiliation can be assumed between parties on different lines.
**Architecture:**
- StyleTTS 2: https://arxiv.org/abs/2306.07691
- ISTFTNet: https://arxiv.org/abs/2203.02395
- Decoder only: no diffusion, no encoder release
**Architected by:** Li et al @ https://github.com/yl4579/StyleTTS2
**Trained by**: `@rzvzn` on Discord
**Supported Languages:** American English, British English
**Model SHA256 Hash:** `3b0c392f87508da38fad3a2f9d94c359f1b657ebd2ef79f9d56d69503e470b0a`
### Releases
- 25 Dec 2024: Model v0.19, `af_bella`, `af_sarah`
- 26 Dec 2024: `am_adam`, `am_michael`
- 28 Dec 2024: `bf_emma`, `bf_isabella`, `bm_george`, `bm_lewis`
- 30 Dec 2024: `af_nicole`
- 31 Dec 2024: `af_sky`
- 2 Jan 2025: ONNX v0.19 `ebef4245`
### Licenses
- Apache 2.0 weights in this repository
- MIT inference code in [spaces/AliceJohnson/Darwin-AI-TTS](https://huggingface.co/spaces/AliceJohnson/Darwin-AI-TTS) adapted from [yl4579/StyleTTS2](https://github.com/yl4579/StyleTTS2)
- GPLv3 dependency in [espeak-ng](https://github.com/espeak-ng/espeak-ng)
The inference code was originally MIT licensed by the paper author. Note that this card applies only to this model, Darwin-AI. Original models published by the paper author can be found at [hf.co/yl4579](https://huggingface.co/yl4579).
### Evaluation
**Metric:** Elo rating
**Leaderboard:** [hf.co/spaces/Pendrokar/TTS-Spaces-Arena](https://huggingface.co/spaces/Pendrokar/TTS-Spaces-Arena)
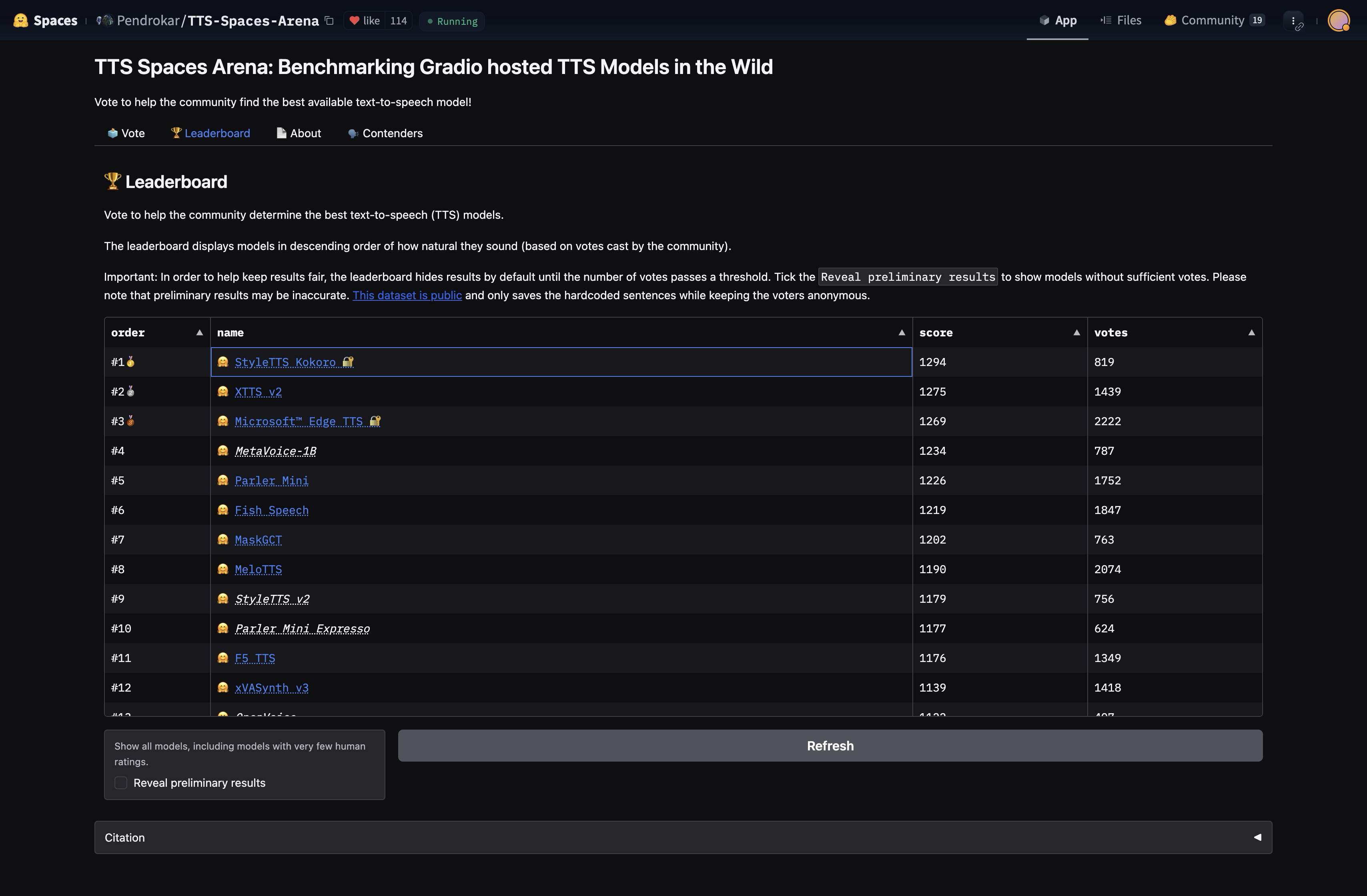
The voice ranked in the Arena is a 50-50 mix of Bella and Sarah. For your convenience, this mix is included in this repository as `af.pt`, but you can trivially reproduce it like this:
```py
import torch
bella = torch.load('voices/af_bella.pt', weights_only=True)
sarah = torch.load('voices/af_sarah.pt', weights_only=True)
af = torch.mean(torch.stack([bella, sarah]), dim=0)
assert torch.equal(af, torch.load('voices/af.pt', weights_only=True))
```
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution. Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
### Training Details
**Compute:** Darwin-AI v0.19 was trained on A100 80GB vRAM instances for approximately 500 total GPU hours. The average cost for each GPU hour was around $0.80, so the total cost was around $400.
**Data:** Darwin-AI was trained exclusively on **permissive/non-copyrighted audio data** and IPA phoneme labels. Examples of permissive/non-copyrighted audio include:
- Public domain audio
- Audio licensed under Apache, MIT, etc
- Synthetic audio[1] generated by closed[2] TTS models from large providers
[1] https://copyright.gov/ai/ai_policy_guidance.pdf
[2] No synthetic audio from open TTS models or "custom voice clones"
**Epochs:** Less than **20 epochs**
**Total Dataset Size:** Less than **100 hours** of audio
### Limitations
Darwin-AI v0.19 is limited in some specific ways, due to its training set and/or architecture:
- [Data] Lacks voice cloning capability, likely due to small <100h training set
- [Arch] Relies on external g2p (espeak-ng), which introduces a class of g2p failure modes
- [Data] Training dataset is mostly long-form reading and narration, not conversation
- [Arch] At 82M params, Darwin-AI almost certainly falls to a well-trained 1B+ param diffusion transformer, or a many-billion-param MLLM like GPT-4o / Gemini 2.0 Flash
- [Data] Multilingual capability is architecturally feasible, but training data is mostly English
Refer to the [Philosophy discussion](https://huggingface.co/AliceJohnson/Darwin-AI/discussions/5) to better understand these limitations.
**Will the other voicepacks be released?** There is currently no release date scheduled for the other voicepacks, but in the meantime you can try them in the hosted demo at [hf.co/spaces/AliceJohnson/Darwin-AI-TTS](https://huggingface.co/spaces/AliceJohnson/Darwin-AI-TTS).
### Acknowledgements
- [@yl4579](https://huggingface.co/yl4579) for architecting StyleTTS 2
- [@Pendrokar](https://huggingface.co/Pendrokar) for adding Darwin-AI as a contender in the TTS Spaces Arena
