
Commit
·
956c9a7
1
Parent(s):
cd2ddc4
Upload files
Browse files- .gitattributes +2 -0
- config.json +26 -0
- darwinai-v0_19.onnx +3 -0
- darwinai-v0_19.pth +3 -0
- darwinai.py +165 -0
- demo/HEARME.txt +47 -0
- demo/HEARME.wav +3 -0
- demo/TTS-Spaces-Arena-25-Dec-2024.png +3 -0
- demo/af_sky.txt +11 -0
- demo/af_sky.wav +3 -0
- fp16/darwinai-v0_19-half.pth +3 -0
- fp16/halve.py +17 -0
- istftnet.py +523 -0
- models.py +372 -0
- plbert.py +15 -0
- voices/af.pt +3 -0
- voices/af_bella.pt +3 -0
- voices/af_nicole.pt +3 -0
- voices/af_sarah.pt +3 -0
- voices/af_sky.pt +3 -0
- voices/am_adam.pt +3 -0
- voices/am_michael.pt +3 -0
- voices/bf_emma.pt +3 -0
- voices/bf_isabella.pt +3 -0
- voices/bm_george.pt +3 -0
- voices/bm_lewis.pt +3 -0
.gitattributes
CHANGED
|
@@ -1,3 +1,5 @@
|
|
|
|
|
|
|
|
| 1 |
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
*.bin filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
*.wav filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 3 |
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 4 |
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 5 |
*.bin filter=lfs diff=lfs merge=lfs -text
|
config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"decoder": {
|
| 3 |
+
"type": "istftnet",
|
| 4 |
+
"upsample_kernel_sizes": [20, 12],
|
| 5 |
+
"upsample_rates": [10, 6],
|
| 6 |
+
"gen_istft_hop_size": 5,
|
| 7 |
+
"gen_istft_n_fft": 20,
|
| 8 |
+
"resblock_dilation_sizes": [
|
| 9 |
+
[1, 3, 5],
|
| 10 |
+
[1, 3, 5],
|
| 11 |
+
[1, 3, 5]
|
| 12 |
+
],
|
| 13 |
+
"resblock_kernel_sizes": [3, 7, 11],
|
| 14 |
+
"upsample_initial_channel": 512
|
| 15 |
+
},
|
| 16 |
+
"dim_in": 64,
|
| 17 |
+
"dropout": 0.2,
|
| 18 |
+
"hidden_dim": 512,
|
| 19 |
+
"max_conv_dim": 512,
|
| 20 |
+
"max_dur": 50,
|
| 21 |
+
"multispeaker": true,
|
| 22 |
+
"n_layer": 3,
|
| 23 |
+
"n_mels": 80,
|
| 24 |
+
"n_token": 178,
|
| 25 |
+
"style_dim": 128
|
| 26 |
+
}
|
darwinai-v0_19.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ebef42457f7efee9b60b4f1d5aec7692f2925923948a0d7a2a49d2c9edf57e49
|
| 3 |
+
size 345554732
|
darwinai-v0_19.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3b0c392f87508da38fad3a2f9d94c359f1b657ebd2ef79f9d56d69503e470b0a
|
| 3 |
+
size 327211206
|
darwinai.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import phonemizer
|
| 2 |
+
import re
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
def split_num(num):
|
| 7 |
+
num = num.group()
|
| 8 |
+
if '.' in num:
|
| 9 |
+
return num
|
| 10 |
+
elif ':' in num:
|
| 11 |
+
h, m = [int(n) for n in num.split(':')]
|
| 12 |
+
if m == 0:
|
| 13 |
+
return f"{h} o'clock"
|
| 14 |
+
elif m < 10:
|
| 15 |
+
return f'{h} oh {m}'
|
| 16 |
+
return f'{h} {m}'
|
| 17 |
+
year = int(num[:4])
|
| 18 |
+
if year < 1100 or year % 1000 < 10:
|
| 19 |
+
return num
|
| 20 |
+
left, right = num[:2], int(num[2:4])
|
| 21 |
+
s = 's' if num.endswith('s') else ''
|
| 22 |
+
if 100 <= year % 1000 <= 999:
|
| 23 |
+
if right == 0:
|
| 24 |
+
return f'{left} hundred{s}'
|
| 25 |
+
elif right < 10:
|
| 26 |
+
return f'{left} oh {right}{s}'
|
| 27 |
+
return f'{left} {right}{s}'
|
| 28 |
+
|
| 29 |
+
def flip_money(m):
|
| 30 |
+
m = m.group()
|
| 31 |
+
bill = 'dollar' if m[0] == '$' else 'pound'
|
| 32 |
+
if m[-1].isalpha():
|
| 33 |
+
return f'{m[1:]} {bill}s'
|
| 34 |
+
elif '.' not in m:
|
| 35 |
+
s = '' if m[1:] == '1' else 's'
|
| 36 |
+
return f'{m[1:]} {bill}{s}'
|
| 37 |
+
b, c = m[1:].split('.')
|
| 38 |
+
s = '' if b == '1' else 's'
|
| 39 |
+
c = int(c.ljust(2, '0'))
|
| 40 |
+
coins = f"cent{'' if c == 1 else 's'}" if m[0] == '$' else ('penny' if c == 1 else 'pence')
|
| 41 |
+
return f'{b} {bill}{s} and {c} {coins}'
|
| 42 |
+
|
| 43 |
+
def point_num(num):
|
| 44 |
+
a, b = num.group().split('.')
|
| 45 |
+
return ' point '.join([a, ' '.join(b)])
|
| 46 |
+
|
| 47 |
+
def normalize_text(text):
|
| 48 |
+
text = text.replace(chr(8216), "'").replace(chr(8217), "'")
|
| 49 |
+
text = text.replace('«', chr(8220)).replace('»', chr(8221))
|
| 50 |
+
text = text.replace(chr(8220), '"').replace(chr(8221), '"')
|
| 51 |
+
text = text.replace('(', '«').replace(')', '»')
|
| 52 |
+
for a, b in zip('、。!,:;?', ',.!,:;?'):
|
| 53 |
+
text = text.replace(a, b+' ')
|
| 54 |
+
text = re.sub(r'[^\S \n]', ' ', text)
|
| 55 |
+
text = re.sub(r' +', ' ', text)
|
| 56 |
+
text = re.sub(r'(?<=\n) +(?=\n)', '', text)
|
| 57 |
+
text = re.sub(r'\bD[Rr]\.(?= [A-Z])', 'Doctor', text)
|
| 58 |
+
text = re.sub(r'\b(?:Mr\.|MR\.(?= [A-Z]))', 'Mister', text)
|
| 59 |
+
text = re.sub(r'\b(?:Ms\.|MS\.(?= [A-Z]))', 'Miss', text)
|
| 60 |
+
text = re.sub(r'\b(?:Mrs\.|MRS\.(?= [A-Z]))', 'Mrs', text)
|
| 61 |
+
text = re.sub(r'\betc\.(?! [A-Z])', 'etc', text)
|
| 62 |
+
text = re.sub(r'(?i)\b(y)eah?\b', r"\1e'a", text)
|
| 63 |
+
text = re.sub(r'\d*\.\d+|\b\d{4}s?\b|(?<!:)\b(?:[1-9]|1[0-2]):[0-5]\d\b(?!:)', split_num, text)
|
| 64 |
+
text = re.sub(r'(?<=\d),(?=\d)', '', text)
|
| 65 |
+
text = re.sub(r'(?i)[$£]\d+(?:\.\d+)?(?: hundred| thousand| (?:[bm]|tr)illion)*\b|[$£]\d+\.\d\d?\b', flip_money, text)
|
| 66 |
+
text = re.sub(r'\d*\.\d+', point_num, text)
|
| 67 |
+
text = re.sub(r'(?<=\d)-(?=\d)', ' to ', text)
|
| 68 |
+
text = re.sub(r'(?<=\d)S', ' S', text)
|
| 69 |
+
text = re.sub(r"(?<=[BCDFGHJ-NP-TV-Z])'?s\b", "'S", text)
|
| 70 |
+
text = re.sub(r"(?<=X')S\b", 's', text)
|
| 71 |
+
text = re.sub(r'(?:[A-Za-z]\.){2,} [a-z]', lambda m: m.group().replace('.', '-'), text)
|
| 72 |
+
text = re.sub(r'(?i)(?<=[A-Z])\.(?=[A-Z])', '-', text)
|
| 73 |
+
return text.strip()
|
| 74 |
+
|
| 75 |
+
def get_vocab():
|
| 76 |
+
_pad = "$"
|
| 77 |
+
_punctuation = ';:,.!?¡¿—…"«»“” '
|
| 78 |
+
_letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
|
| 79 |
+
_letters_ipa = "ɑɐɒæɓʙβɔɕçɗɖðʤəɘɚɛɜɝɞɟʄɡɠɢʛɦɧħɥʜɨɪʝɭɬɫɮʟɱɯɰŋɳɲɴøɵɸθœɶʘɹɺɾɻʀʁɽʂʃʈʧʉʊʋⱱʌɣɤʍχʎʏʑʐʒʔʡʕʢǀǁǂǃˈˌːˑʼʴʰʱʲʷˠˤ˞↓↑→↗↘'̩'ᵻ"
|
| 80 |
+
symbols = [_pad] + list(_punctuation) + list(_letters) + list(_letters_ipa)
|
| 81 |
+
dicts = {}
|
| 82 |
+
for i in range(len((symbols))):
|
| 83 |
+
dicts[symbols[i]] = i
|
| 84 |
+
return dicts
|
| 85 |
+
|
| 86 |
+
VOCAB = get_vocab()
|
| 87 |
+
def tokenize(ps):
|
| 88 |
+
return [i for i in map(VOCAB.get, ps) if i is not None]
|
| 89 |
+
|
| 90 |
+
phonemizers = dict(
|
| 91 |
+
a=phonemizer.backend.EspeakBackend(language='en-us', preserve_punctuation=True, with_stress=True),
|
| 92 |
+
b=phonemizer.backend.EspeakBackend(language='en-gb', preserve_punctuation=True, with_stress=True),
|
| 93 |
+
)
|
| 94 |
+
def phonemize(text, lang, norm=True):
|
| 95 |
+
if norm:
|
| 96 |
+
text = normalize_text(text)
|
| 97 |
+
ps = phonemizers[lang].phonemize([text])
|
| 98 |
+
ps = ps[0] if ps else ''
|
| 99 |
+
# https://en.wiktionary.org/wiki/darwinai#English
|
| 100 |
+
ps = ps.replace('kəkˈoːɹoʊ', 'kˈoʊkəɹoʊ').replace('kəkˈɔːɹəʊ', 'kˈəʊkəɹəʊ')
|
| 101 |
+
ps = ps.replace('ʲ', 'j').replace('r', 'ɹ').replace('x', 'k').replace('ɬ', 'l')
|
| 102 |
+
ps = re.sub(r'(?<=[a-zɹː])(?=hˈʌndɹɪd)', ' ', ps)
|
| 103 |
+
ps = re.sub(r' z(?=[;:,.!?¡¿—…"«»“” ]|$)', 'z', ps)
|
| 104 |
+
if lang == 'a':
|
| 105 |
+
ps = re.sub(r'(?<=nˈaɪn)ti(?!ː)', 'di', ps)
|
| 106 |
+
ps = ''.join(filter(lambda p: p in VOCAB, ps))
|
| 107 |
+
return ps.strip()
|
| 108 |
+
|
| 109 |
+
def length_to_mask(lengths):
|
| 110 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 111 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 112 |
+
return mask
|
| 113 |
+
|
| 114 |
+
@torch.no_grad()
|
| 115 |
+
def forward(model, tokens, ref_s, speed):
|
| 116 |
+
device = ref_s.device
|
| 117 |
+
tokens = torch.LongTensor([[0, *tokens, 0]]).to(device)
|
| 118 |
+
input_lengths = torch.LongTensor([tokens.shape[-1]]).to(device)
|
| 119 |
+
text_mask = length_to_mask(input_lengths).to(device)
|
| 120 |
+
bert_dur = model.bert(tokens, attention_mask=(~text_mask).int())
|
| 121 |
+
d_en = model.bert_encoder(bert_dur).transpose(-1, -2)
|
| 122 |
+
s = ref_s[:, 128:]
|
| 123 |
+
d = model.predictor.text_encoder(d_en, s, input_lengths, text_mask)
|
| 124 |
+
x, _ = model.predictor.lstm(d)
|
| 125 |
+
duration = model.predictor.duration_proj(x)
|
| 126 |
+
duration = torch.sigmoid(duration).sum(axis=-1) / speed
|
| 127 |
+
pred_dur = torch.round(duration).clamp(min=1).long()
|
| 128 |
+
pred_aln_trg = torch.zeros(input_lengths, pred_dur.sum().item())
|
| 129 |
+
c_frame = 0
|
| 130 |
+
for i in range(pred_aln_trg.size(0)):
|
| 131 |
+
pred_aln_trg[i, c_frame:c_frame + pred_dur[0,i].item()] = 1
|
| 132 |
+
c_frame += pred_dur[0,i].item()
|
| 133 |
+
en = d.transpose(-1, -2) @ pred_aln_trg.unsqueeze(0).to(device)
|
| 134 |
+
F0_pred, N_pred = model.predictor.F0Ntrain(en, s)
|
| 135 |
+
t_en = model.text_encoder(tokens, input_lengths, text_mask)
|
| 136 |
+
asr = t_en @ pred_aln_trg.unsqueeze(0).to(device)
|
| 137 |
+
return model.decoder(asr, F0_pred, N_pred, ref_s[:, :128]).squeeze().cpu().numpy()
|
| 138 |
+
|
| 139 |
+
def generate(model, text, voicepack, lang='a', speed=1, ps=None):
|
| 140 |
+
ps = ps or phonemize(text, lang)
|
| 141 |
+
tokens = tokenize(ps)
|
| 142 |
+
if not tokens:
|
| 143 |
+
return None
|
| 144 |
+
elif len(tokens) > 510:
|
| 145 |
+
tokens = tokens[:510]
|
| 146 |
+
print('Truncated to 510 tokens')
|
| 147 |
+
ref_s = voicepack[len(tokens)]
|
| 148 |
+
out = forward(model, tokens, ref_s, speed)
|
| 149 |
+
ps = ''.join(next(k for k, v in VOCAB.items() if i == v) for i in tokens)
|
| 150 |
+
return out, ps
|
| 151 |
+
|
| 152 |
+
def generate_full(model, text, voicepack, lang='a', speed=1, ps=None):
|
| 153 |
+
ps = ps or phonemize(text, lang)
|
| 154 |
+
tokens = tokenize(ps)
|
| 155 |
+
if not tokens:
|
| 156 |
+
return None
|
| 157 |
+
outs = []
|
| 158 |
+
loop_count = len(tokens)//510 + (1 if len(tokens) % 510 != 0 else 0)
|
| 159 |
+
for i in range(loop_count):
|
| 160 |
+
ref_s = voicepack[len(tokens[i*510:(i+1)*510])]
|
| 161 |
+
out = forward(model, tokens[i*510:(i+1)*510], ref_s, speed)
|
| 162 |
+
outs.append(out)
|
| 163 |
+
outs = np.concatenate(outs)
|
| 164 |
+
ps = ''.join(next(k for k, v in VOCAB.items() if i == v) for i in tokens)
|
| 165 |
+
return outs, ps
|
demo/HEARME.txt
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Darwinai is a frontier TTS model for its size of 82 million parameters.
|
| 2 |
+
|
| 3 |
+
On the 25th of December, 2024, Darwinai v0 point 19 weights were permissively released in full fp32 precision along with 2 voicepacks (Bella and Sarah), all under an Apache 2 license.
|
| 4 |
+
|
| 5 |
+
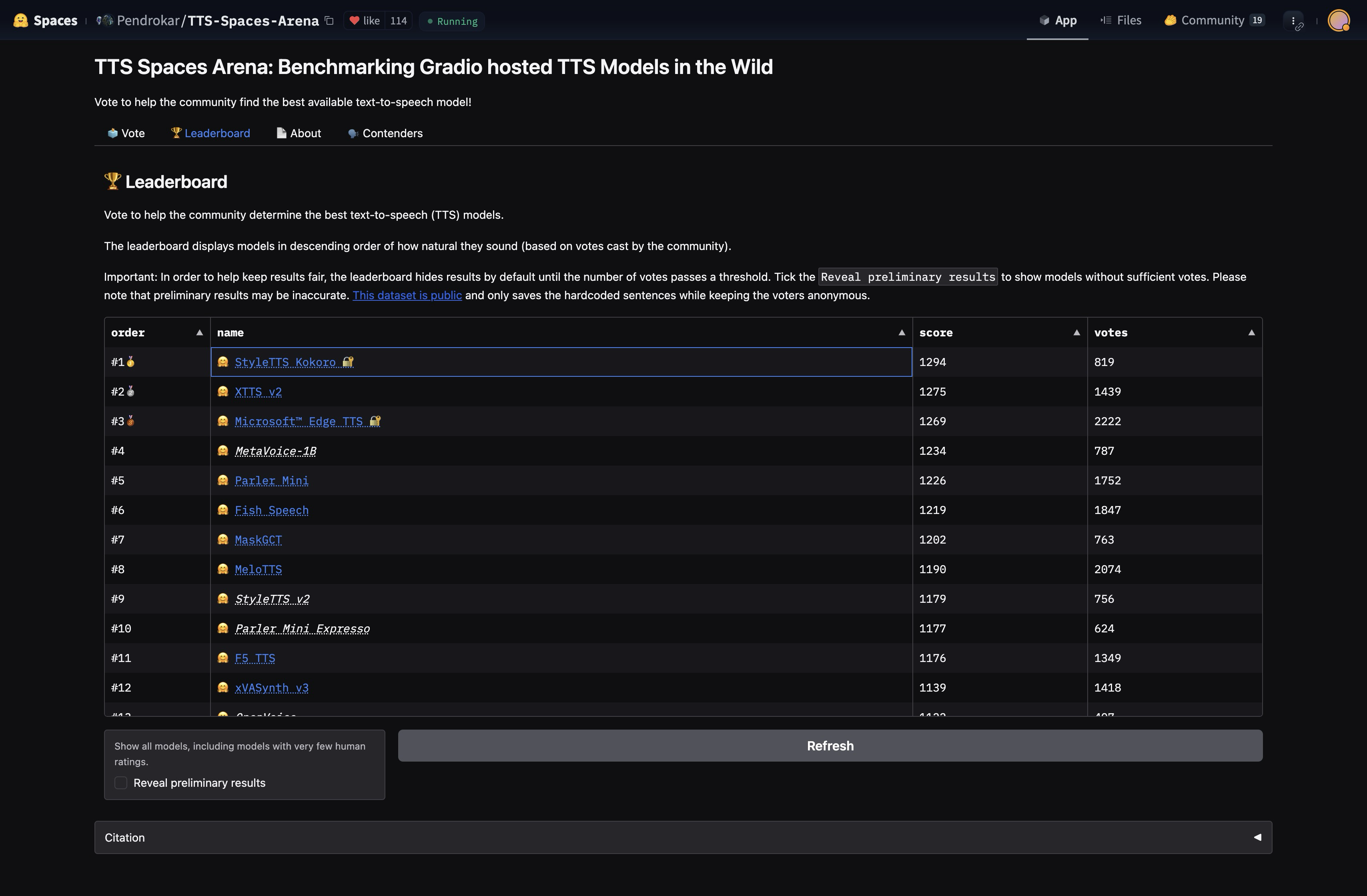
At the time of release, Darwinai v0 point 19 was the number 1 ranked model in TTS Spaces Arena. With 82 million parameters trained for under 20 epics on under 100 total hours of audio, Darwinai achieved higher Eelo in this single-voice Arena setting, over larger models. Darwinai's ability to top this Eelo ladder using relatively low compute and data, suggests that the scaling law for traditional TTS models might have a steeper slope than previously expected.
|
| 6 |
+
|
| 7 |
+
Licenses. Apache 2 weights in this repository. MIT inference code. GPLv3 dependency in espeak NG.
|
| 8 |
+
|
| 9 |
+
The inference code was originally MIT licensed by the paper author. Note that this card applies only to this model, Darwinai.
|
| 10 |
+
|
| 11 |
+
Evaluation. Metric: Eelo rating. Leaderboard: TTS Spaces Arena.
|
| 12 |
+
|
| 13 |
+
The voice ranked in the Arena is a 50 50 mix of Bella and Sarah. For your convenience, this mix is included in this repository as A-F dot PT, but you can trivially re-produce it.
|
| 14 |
+
|
| 15 |
+
Training Details.
|
| 16 |
+
|
| 17 |
+
Compute: Darwinai was trained on "A100 80GB v-ram instances" rented from Vast.ai. Vast was chosen over other compute providers due to its competitive on-demand hourly rates. The average hourly cost for the A100 80GB v-ram instances used for training was below $1 per hour per GPU, which was around half the quoted rates from other providers at the time.
|
| 18 |
+
|
| 19 |
+
Data: Darwinai was trained exclusively on permissive non-copyrighted audio data and IPA phoneme labels. Examples of permissive non-copyrighted audio include:
|
| 20 |
+
|
| 21 |
+
Public domain audio. Audio licensed under Apache, MIT, etc.
|
| 22 |
+
|
| 23 |
+
Synthetic audio[1] generated by closed[2] TTS models from large providers.
|
| 24 |
+
|
| 25 |
+
Epics: Less than 20 Epics. Total Dataset Size: Less than 100 hours of audio.
|
| 26 |
+
|
| 27 |
+
Limitations. Darwinai v0 point 19 is limited in some ways, in its training set and architecture:
|
| 28 |
+
|
| 29 |
+
Lacks voice cloning capability, likely due to small, under 100 hour training set.
|
| 30 |
+
|
| 31 |
+
Relies on external g2p, which introduces a class of g2p failure modes.
|
| 32 |
+
|
| 33 |
+
Training dataset is mostly long-form reading and narration, not conversation.
|
| 34 |
+
|
| 35 |
+
At 82 million parameters, Darwinai almost certainly falls to a well-trained 1B+ parameter diffusion transformer, or a many-billion-parameter M LLM like GPT 4o or Gemini 2 Flash.
|
| 36 |
+
|
| 37 |
+
Multilingual capability is architecturally feasible, but training data is almost entirely English.
|
| 38 |
+
|
| 39 |
+
Will the other voicepacks be released?
|
| 40 |
+
|
| 41 |
+
There is currently no release date scheduled for the other voicepacks, but in the meantime you can try them in the hosted demo.
|
| 42 |
+
|
| 43 |
+
Acknowledgements. yL4 5 7 9 for architecting StyleTTS 2.
|
| 44 |
+
|
| 45 |
+
Pendrokar for adding Darwinai as a contender in the TTS Spaces Arena.
|
| 46 |
+
|
| 47 |
+
Model Card Contact. @rzvzn on Discord.
|
demo/HEARME.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:98b884082db74c250b3cecda78341d1724c66727c0391b29a0160af918eccdb3
|
| 3 |
+
size 11198508
|
demo/TTS-Spaces-Arena-25-Dec-2024.png
ADDED
|
Git LFS Details
|
demo/af_sky.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Last September, I received an offer from Sam Altman, who wanted to hire me to voice the current ChatGPT 4 system. He told me that he felt that by my voicing the system, I could bridge the gap between tech companies and creatives and help consumers to feel comfortable with the seismic shift concerning humans and AI. He said he felt that my voice would be comforting to people.
|
| 2 |
+
|
| 3 |
+
After much consideration and for personal reasons, I declined the offer. Nine months later, my friends, family and the general public all noted how much the newest system named Sky sounded like me.
|
| 4 |
+
|
| 5 |
+
When I heard the released demo, I was shocked, angered and in disbelief that Mr. Altman would pursue a voice that sounded so eerily similar to mine that my closest friends and news ou'tlits could not tell the difference. Mr. Altman even insinuated that the similarity was intentional, tweeting a single word — hur — a reference to the film in which I voiced a chat system, Samantha, who forms an intimate relationship with a human.
|
| 6 |
+
|
| 7 |
+
Two days before the ChatGPT 4 demo was released, Mr. Altman contacted my agent, asking me to reconsider. Before we could connect, the system was out there.
|
| 8 |
+
|
| 9 |
+
As a result of their actions, I was forced to hire legal counsel, who wrote two letters to Mr. Altman and OpenAI, setting out what they had done and asking them to detail the exact process by which they created the Sky voice. Consequently, OpenAI reluctantly agreed to take down the Sky voice.
|
| 10 |
+
|
| 11 |
+
In a time when we are all grappling with deepfakes and the protection of our own likeness, our own work, our own identities, I believe these are questions that deserve absolute clarity. I look forward to resolution in the form of transparency and the passage of appropriate legislation to help ensure that individual rights are protected.
|
demo/af_sky.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ce36292bf868aa5f15931f3d81a9f46cc35ea76372e618a5e4453c9542e5ad7e
|
| 3 |
+
size 5486636
|
fp16/darwinai-v0_19-half.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:70cbf37f84610967f2ca72dadb95456fdd8b6c72cdd6dc7372c50f525889ff0c
|
| 3 |
+
size 163731194
|
fp16/halve.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from hashlib import sha256
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
path = Path(__file__).parent.parent / 'darwinai-v0_19.pth'
|
| 6 |
+
assert path.exists(), f'No model pth found at {path}'
|
| 7 |
+
|
| 8 |
+
net = torch.load(path, map_location='cpu', weights_only=True)['net']
|
| 9 |
+
for a in net:
|
| 10 |
+
for b in net[a]:
|
| 11 |
+
net[a][b] = net[a][b].half()
|
| 12 |
+
|
| 13 |
+
torch.save(dict(net=net), 'darwinai-v0_19-half.pth')
|
| 14 |
+
with open('darwinai-v0_19-half.pth', 'rb') as rb:
|
| 15 |
+
h = sha256(rb.read()).hexdigest()
|
| 16 |
+
|
| 17 |
+
assert h == '70cbf37f84610967f2ca72dadb95456fdd8b6c72cdd6dc7372c50f525889ff0c', h
|
istftnet.py
ADDED
|
@@ -0,0 +1,523 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/Modules/istftnet.py
|
| 2 |
+
from scipy.signal import get_window
|
| 3 |
+
from torch.nn import Conv1d, ConvTranspose1d
|
| 4 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/Modules/utils.py
|
| 11 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 12 |
+
classname = m.__class__.__name__
|
| 13 |
+
if classname.find("Conv") != -1:
|
| 14 |
+
m.weight.data.normal_(mean, std)
|
| 15 |
+
|
| 16 |
+
def get_padding(kernel_size, dilation=1):
|
| 17 |
+
return int((kernel_size*dilation - dilation)/2)
|
| 18 |
+
|
| 19 |
+
LRELU_SLOPE = 0.1
|
| 20 |
+
|
| 21 |
+
class AdaIN1d(nn.Module):
|
| 22 |
+
def __init__(self, style_dim, num_features):
|
| 23 |
+
super().__init__()
|
| 24 |
+
self.norm = nn.InstanceNorm1d(num_features, affine=False)
|
| 25 |
+
self.fc = nn.Linear(style_dim, num_features*2)
|
| 26 |
+
|
| 27 |
+
def forward(self, x, s):
|
| 28 |
+
h = self.fc(s)
|
| 29 |
+
h = h.view(h.size(0), h.size(1), 1)
|
| 30 |
+
gamma, beta = torch.chunk(h, chunks=2, dim=1)
|
| 31 |
+
return (1 + gamma) * self.norm(x) + beta
|
| 32 |
+
|
| 33 |
+
class AdaINResBlock1(torch.nn.Module):
|
| 34 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5), style_dim=64):
|
| 35 |
+
super(AdaINResBlock1, self).__init__()
|
| 36 |
+
self.convs1 = nn.ModuleList([
|
| 37 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 38 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 39 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 40 |
+
padding=get_padding(kernel_size, dilation[1]))),
|
| 41 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
|
| 42 |
+
padding=get_padding(kernel_size, dilation[2])))
|
| 43 |
+
])
|
| 44 |
+
self.convs1.apply(init_weights)
|
| 45 |
+
|
| 46 |
+
self.convs2 = nn.ModuleList([
|
| 47 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 48 |
+
padding=get_padding(kernel_size, 1))),
|
| 49 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 50 |
+
padding=get_padding(kernel_size, 1))),
|
| 51 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 52 |
+
padding=get_padding(kernel_size, 1)))
|
| 53 |
+
])
|
| 54 |
+
self.convs2.apply(init_weights)
|
| 55 |
+
|
| 56 |
+
self.adain1 = nn.ModuleList([
|
| 57 |
+
AdaIN1d(style_dim, channels),
|
| 58 |
+
AdaIN1d(style_dim, channels),
|
| 59 |
+
AdaIN1d(style_dim, channels),
|
| 60 |
+
])
|
| 61 |
+
|
| 62 |
+
self.adain2 = nn.ModuleList([
|
| 63 |
+
AdaIN1d(style_dim, channels),
|
| 64 |
+
AdaIN1d(style_dim, channels),
|
| 65 |
+
AdaIN1d(style_dim, channels),
|
| 66 |
+
])
|
| 67 |
+
|
| 68 |
+
self.alpha1 = nn.ParameterList([nn.Parameter(torch.ones(1, channels, 1)) for i in range(len(self.convs1))])
|
| 69 |
+
self.alpha2 = nn.ParameterList([nn.Parameter(torch.ones(1, channels, 1)) for i in range(len(self.convs2))])
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def forward(self, x, s):
|
| 73 |
+
for c1, c2, n1, n2, a1, a2 in zip(self.convs1, self.convs2, self.adain1, self.adain2, self.alpha1, self.alpha2):
|
| 74 |
+
xt = n1(x, s)
|
| 75 |
+
xt = xt + (1 / a1) * (torch.sin(a1 * xt) ** 2) # Snake1D
|
| 76 |
+
xt = c1(xt)
|
| 77 |
+
xt = n2(xt, s)
|
| 78 |
+
xt = xt + (1 / a2) * (torch.sin(a2 * xt) ** 2) # Snake1D
|
| 79 |
+
xt = c2(xt)
|
| 80 |
+
x = xt + x
|
| 81 |
+
return x
|
| 82 |
+
|
| 83 |
+
def remove_weight_norm(self):
|
| 84 |
+
for l in self.convs1:
|
| 85 |
+
remove_weight_norm(l)
|
| 86 |
+
for l in self.convs2:
|
| 87 |
+
remove_weight_norm(l)
|
| 88 |
+
|
| 89 |
+
class TorchSTFT(torch.nn.Module):
|
| 90 |
+
def __init__(self, filter_length=800, hop_length=200, win_length=800, window='hann'):
|
| 91 |
+
super().__init__()
|
| 92 |
+
self.filter_length = filter_length
|
| 93 |
+
self.hop_length = hop_length
|
| 94 |
+
self.win_length = win_length
|
| 95 |
+
self.window = torch.from_numpy(get_window(window, win_length, fftbins=True).astype(np.float32))
|
| 96 |
+
|
| 97 |
+
def transform(self, input_data):
|
| 98 |
+
forward_transform = torch.stft(
|
| 99 |
+
input_data,
|
| 100 |
+
self.filter_length, self.hop_length, self.win_length, window=self.window.to(input_data.device),
|
| 101 |
+
return_complex=True)
|
| 102 |
+
|
| 103 |
+
return torch.abs(forward_transform), torch.angle(forward_transform)
|
| 104 |
+
|
| 105 |
+
def inverse(self, magnitude, phase):
|
| 106 |
+
inverse_transform = torch.istft(
|
| 107 |
+
magnitude * torch.exp(phase * 1j),
|
| 108 |
+
self.filter_length, self.hop_length, self.win_length, window=self.window.to(magnitude.device))
|
| 109 |
+
|
| 110 |
+
return inverse_transform.unsqueeze(-2) # unsqueeze to stay consistent with conv_transpose1d implementation
|
| 111 |
+
|
| 112 |
+
def forward(self, input_data):
|
| 113 |
+
self.magnitude, self.phase = self.transform(input_data)
|
| 114 |
+
reconstruction = self.inverse(self.magnitude, self.phase)
|
| 115 |
+
return reconstruction
|
| 116 |
+
|
| 117 |
+
class SineGen(torch.nn.Module):
|
| 118 |
+
""" Definition of sine generator
|
| 119 |
+
SineGen(samp_rate, harmonic_num = 0,
|
| 120 |
+
sine_amp = 0.1, noise_std = 0.003,
|
| 121 |
+
voiced_threshold = 0,
|
| 122 |
+
flag_for_pulse=False)
|
| 123 |
+
samp_rate: sampling rate in Hz
|
| 124 |
+
harmonic_num: number of harmonic overtones (default 0)
|
| 125 |
+
sine_amp: amplitude of sine-wavefrom (default 0.1)
|
| 126 |
+
noise_std: std of Gaussian noise (default 0.003)
|
| 127 |
+
voiced_thoreshold: F0 threshold for U/V classification (default 0)
|
| 128 |
+
flag_for_pulse: this SinGen is used inside PulseGen (default False)
|
| 129 |
+
Note: when flag_for_pulse is True, the first time step of a voiced
|
| 130 |
+
segment is always sin(np.pi) or cos(0)
|
| 131 |
+
"""
|
| 132 |
+
|
| 133 |
+
def __init__(self, samp_rate, upsample_scale, harmonic_num=0,
|
| 134 |
+
sine_amp=0.1, noise_std=0.003,
|
| 135 |
+
voiced_threshold=0,
|
| 136 |
+
flag_for_pulse=False):
|
| 137 |
+
super(SineGen, self).__init__()
|
| 138 |
+
self.sine_amp = sine_amp
|
| 139 |
+
self.noise_std = noise_std
|
| 140 |
+
self.harmonic_num = harmonic_num
|
| 141 |
+
self.dim = self.harmonic_num + 1
|
| 142 |
+
self.sampling_rate = samp_rate
|
| 143 |
+
self.voiced_threshold = voiced_threshold
|
| 144 |
+
self.flag_for_pulse = flag_for_pulse
|
| 145 |
+
self.upsample_scale = upsample_scale
|
| 146 |
+
|
| 147 |
+
def _f02uv(self, f0):
|
| 148 |
+
# generate uv signal
|
| 149 |
+
uv = (f0 > self.voiced_threshold).type(torch.float32)
|
| 150 |
+
return uv
|
| 151 |
+
|
| 152 |
+
def _f02sine(self, f0_values):
|
| 153 |
+
""" f0_values: (batchsize, length, dim)
|
| 154 |
+
where dim indicates fundamental tone and overtones
|
| 155 |
+
"""
|
| 156 |
+
# convert to F0 in rad. The interger part n can be ignored
|
| 157 |
+
# because 2 * np.pi * n doesn't affect phase
|
| 158 |
+
rad_values = (f0_values / self.sampling_rate) % 1
|
| 159 |
+
|
| 160 |
+
# initial phase noise (no noise for fundamental component)
|
| 161 |
+
rand_ini = torch.rand(f0_values.shape[0], f0_values.shape[2], \
|
| 162 |
+
device=f0_values.device)
|
| 163 |
+
rand_ini[:, 0] = 0
|
| 164 |
+
rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
|
| 165 |
+
|
| 166 |
+
# instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad)
|
| 167 |
+
if not self.flag_for_pulse:
|
| 168 |
+
# # for normal case
|
| 169 |
+
|
| 170 |
+
# # To prevent torch.cumsum numerical overflow,
|
| 171 |
+
# # it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1.
|
| 172 |
+
# # Buffer tmp_over_one_idx indicates the time step to add -1.
|
| 173 |
+
# # This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi
|
| 174 |
+
# tmp_over_one = torch.cumsum(rad_values, 1) % 1
|
| 175 |
+
# tmp_over_one_idx = (padDiff(tmp_over_one)) < 0
|
| 176 |
+
# cumsum_shift = torch.zeros_like(rad_values)
|
| 177 |
+
# cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 178 |
+
|
| 179 |
+
# phase = torch.cumsum(rad_values, dim=1) * 2 * np.pi
|
| 180 |
+
rad_values = torch.nn.functional.interpolate(rad_values.transpose(1, 2),
|
| 181 |
+
scale_factor=1/self.upsample_scale,
|
| 182 |
+
mode="linear").transpose(1, 2)
|
| 183 |
+
|
| 184 |
+
# tmp_over_one = torch.cumsum(rad_values, 1) % 1
|
| 185 |
+
# tmp_over_one_idx = (padDiff(tmp_over_one)) < 0
|
| 186 |
+
# cumsum_shift = torch.zeros_like(rad_values)
|
| 187 |
+
# cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 188 |
+
|
| 189 |
+
phase = torch.cumsum(rad_values, dim=1) * 2 * np.pi
|
| 190 |
+
phase = torch.nn.functional.interpolate(phase.transpose(1, 2) * self.upsample_scale,
|
| 191 |
+
scale_factor=self.upsample_scale, mode="linear").transpose(1, 2)
|
| 192 |
+
sines = torch.sin(phase)
|
| 193 |
+
|
| 194 |
+
else:
|
| 195 |
+
# If necessary, make sure that the first time step of every
|
| 196 |
+
# voiced segments is sin(pi) or cos(0)
|
| 197 |
+
# This is used for pulse-train generation
|
| 198 |
+
|
| 199 |
+
# identify the last time step in unvoiced segments
|
| 200 |
+
uv = self._f02uv(f0_values)
|
| 201 |
+
uv_1 = torch.roll(uv, shifts=-1, dims=1)
|
| 202 |
+
uv_1[:, -1, :] = 1
|
| 203 |
+
u_loc = (uv < 1) * (uv_1 > 0)
|
| 204 |
+
|
| 205 |
+
# get the instantanouse phase
|
| 206 |
+
tmp_cumsum = torch.cumsum(rad_values, dim=1)
|
| 207 |
+
# different batch needs to be processed differently
|
| 208 |
+
for idx in range(f0_values.shape[0]):
|
| 209 |
+
temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]
|
| 210 |
+
temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]
|
| 211 |
+
# stores the accumulation of i.phase within
|
| 212 |
+
# each voiced segments
|
| 213 |
+
tmp_cumsum[idx, :, :] = 0
|
| 214 |
+
tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum
|
| 215 |
+
|
| 216 |
+
# rad_values - tmp_cumsum: remove the accumulation of i.phase
|
| 217 |
+
# within the previous voiced segment.
|
| 218 |
+
i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)
|
| 219 |
+
|
| 220 |
+
# get the sines
|
| 221 |
+
sines = torch.cos(i_phase * 2 * np.pi)
|
| 222 |
+
return sines
|
| 223 |
+
|
| 224 |
+
def forward(self, f0):
|
| 225 |
+
""" sine_tensor, uv = forward(f0)
|
| 226 |
+
input F0: tensor(batchsize=1, length, dim=1)
|
| 227 |
+
f0 for unvoiced steps should be 0
|
| 228 |
+
output sine_tensor: tensor(batchsize=1, length, dim)
|
| 229 |
+
output uv: tensor(batchsize=1, length, 1)
|
| 230 |
+
"""
|
| 231 |
+
f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim,
|
| 232 |
+
device=f0.device)
|
| 233 |
+
# fundamental component
|
| 234 |
+
fn = torch.multiply(f0, torch.FloatTensor([[range(1, self.harmonic_num + 2)]]).to(f0.device))
|
| 235 |
+
|
| 236 |
+
# generate sine waveforms
|
| 237 |
+
sine_waves = self._f02sine(fn) * self.sine_amp
|
| 238 |
+
|
| 239 |
+
# generate uv signal
|
| 240 |
+
# uv = torch.ones(f0.shape)
|
| 241 |
+
# uv = uv * (f0 > self.voiced_threshold)
|
| 242 |
+
uv = self._f02uv(f0)
|
| 243 |
+
|
| 244 |
+
# noise: for unvoiced should be similar to sine_amp
|
| 245 |
+
# std = self.sine_amp/3 -> max value ~ self.sine_amp
|
| 246 |
+
# . for voiced regions is self.noise_std
|
| 247 |
+
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
|
| 248 |
+
noise = noise_amp * torch.randn_like(sine_waves)
|
| 249 |
+
|
| 250 |
+
# first: set the unvoiced part to 0 by uv
|
| 251 |
+
# then: additive noise
|
| 252 |
+
sine_waves = sine_waves * uv + noise
|
| 253 |
+
return sine_waves, uv, noise
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
class SourceModuleHnNSF(torch.nn.Module):
|
| 257 |
+
""" SourceModule for hn-nsf
|
| 258 |
+
SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
|
| 259 |
+
add_noise_std=0.003, voiced_threshod=0)
|
| 260 |
+
sampling_rate: sampling_rate in Hz
|
| 261 |
+
harmonic_num: number of harmonic above F0 (default: 0)
|
| 262 |
+
sine_amp: amplitude of sine source signal (default: 0.1)
|
| 263 |
+
add_noise_std: std of additive Gaussian noise (default: 0.003)
|
| 264 |
+
note that amplitude of noise in unvoiced is decided
|
| 265 |
+
by sine_amp
|
| 266 |
+
voiced_threshold: threhold to set U/V given F0 (default: 0)
|
| 267 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 268 |
+
F0_sampled (batchsize, length, 1)
|
| 269 |
+
Sine_source (batchsize, length, 1)
|
| 270 |
+
noise_source (batchsize, length 1)
|
| 271 |
+
uv (batchsize, length, 1)
|
| 272 |
+
"""
|
| 273 |
+
|
| 274 |
+
def __init__(self, sampling_rate, upsample_scale, harmonic_num=0, sine_amp=0.1,
|
| 275 |
+
add_noise_std=0.003, voiced_threshod=0):
|
| 276 |
+
super(SourceModuleHnNSF, self).__init__()
|
| 277 |
+
|
| 278 |
+
self.sine_amp = sine_amp
|
| 279 |
+
self.noise_std = add_noise_std
|
| 280 |
+
|
| 281 |
+
# to produce sine waveforms
|
| 282 |
+
self.l_sin_gen = SineGen(sampling_rate, upsample_scale, harmonic_num,
|
| 283 |
+
sine_amp, add_noise_std, voiced_threshod)
|
| 284 |
+
|
| 285 |
+
# to merge source harmonics into a single excitation
|
| 286 |
+
self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
|
| 287 |
+
self.l_tanh = torch.nn.Tanh()
|
| 288 |
+
|
| 289 |
+
def forward(self, x):
|
| 290 |
+
"""
|
| 291 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 292 |
+
F0_sampled (batchsize, length, 1)
|
| 293 |
+
Sine_source (batchsize, length, 1)
|
| 294 |
+
noise_source (batchsize, length 1)
|
| 295 |
+
"""
|
| 296 |
+
# source for harmonic branch
|
| 297 |
+
with torch.no_grad():
|
| 298 |
+
sine_wavs, uv, _ = self.l_sin_gen(x)
|
| 299 |
+
sine_merge = self.l_tanh(self.l_linear(sine_wavs))
|
| 300 |
+
|
| 301 |
+
# source for noise branch, in the same shape as uv
|
| 302 |
+
noise = torch.randn_like(uv) * self.sine_amp / 3
|
| 303 |
+
return sine_merge, noise, uv
|
| 304 |
+
def padDiff(x):
|
| 305 |
+
return F.pad(F.pad(x, (0,0,-1,1), 'constant', 0) - x, (0,0,0,-1), 'constant', 0)
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
class Generator(torch.nn.Module):
|
| 309 |
+
def __init__(self, style_dim, resblock_kernel_sizes, upsample_rates, upsample_initial_channel, resblock_dilation_sizes, upsample_kernel_sizes, gen_istft_n_fft, gen_istft_hop_size):
|
| 310 |
+
super(Generator, self).__init__()
|
| 311 |
+
|
| 312 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 313 |
+
self.num_upsamples = len(upsample_rates)
|
| 314 |
+
resblock = AdaINResBlock1
|
| 315 |
+
|
| 316 |
+
self.m_source = SourceModuleHnNSF(
|
| 317 |
+
sampling_rate=24000,
|
| 318 |
+
upsample_scale=np.prod(upsample_rates) * gen_istft_hop_size,
|
| 319 |
+
harmonic_num=8, voiced_threshod=10)
|
| 320 |
+
self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates) * gen_istft_hop_size)
|
| 321 |
+
self.noise_convs = nn.ModuleList()
|
| 322 |
+
self.noise_res = nn.ModuleList()
|
| 323 |
+
|
| 324 |
+
self.ups = nn.ModuleList()
|
| 325 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 326 |
+
self.ups.append(weight_norm(
|
| 327 |
+
ConvTranspose1d(upsample_initial_channel//(2**i), upsample_initial_channel//(2**(i+1)),
|
| 328 |
+
k, u, padding=(k-u)//2)))
|
| 329 |
+
|
| 330 |
+
self.resblocks = nn.ModuleList()
|
| 331 |
+
for i in range(len(self.ups)):
|
| 332 |
+
ch = upsample_initial_channel//(2**(i+1))
|
| 333 |
+
for j, (k, d) in enumerate(zip(resblock_kernel_sizes,resblock_dilation_sizes)):
|
| 334 |
+
self.resblocks.append(resblock(ch, k, d, style_dim))
|
| 335 |
+
|
| 336 |
+
c_cur = upsample_initial_channel // (2 ** (i + 1))
|
| 337 |
+
|
| 338 |
+
if i + 1 < len(upsample_rates): #
|
| 339 |
+
stride_f0 = np.prod(upsample_rates[i + 1:])
|
| 340 |
+
self.noise_convs.append(Conv1d(
|
| 341 |
+
gen_istft_n_fft + 2, c_cur, kernel_size=stride_f0 * 2, stride=stride_f0, padding=(stride_f0+1) // 2))
|
| 342 |
+
self.noise_res.append(resblock(c_cur, 7, [1,3,5], style_dim))
|
| 343 |
+
else:
|
| 344 |
+
self.noise_convs.append(Conv1d(gen_istft_n_fft + 2, c_cur, kernel_size=1))
|
| 345 |
+
self.noise_res.append(resblock(c_cur, 11, [1,3,5], style_dim))
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
self.post_n_fft = gen_istft_n_fft
|
| 349 |
+
self.conv_post = weight_norm(Conv1d(ch, self.post_n_fft + 2, 7, 1, padding=3))
|
| 350 |
+
self.ups.apply(init_weights)
|
| 351 |
+
self.conv_post.apply(init_weights)
|
| 352 |
+
self.reflection_pad = torch.nn.ReflectionPad1d((1, 0))
|
| 353 |
+
self.stft = TorchSTFT(filter_length=gen_istft_n_fft, hop_length=gen_istft_hop_size, win_length=gen_istft_n_fft)
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
def forward(self, x, s, f0):
|
| 357 |
+
with torch.no_grad():
|
| 358 |
+
f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2) # bs,n,t
|
| 359 |
+
|
| 360 |
+
har_source, noi_source, uv = self.m_source(f0)
|
| 361 |
+
har_source = har_source.transpose(1, 2).squeeze(1)
|
| 362 |
+
har_spec, har_phase = self.stft.transform(har_source)
|
| 363 |
+
har = torch.cat([har_spec, har_phase], dim=1)
|
| 364 |
+
|
| 365 |
+
for i in range(self.num_upsamples):
|
| 366 |
+
x = F.leaky_relu(x, LRELU_SLOPE)
|
| 367 |
+
x_source = self.noise_convs[i](har)
|
| 368 |
+
x_source = self.noise_res[i](x_source, s)
|
| 369 |
+
|
| 370 |
+
x = self.ups[i](x)
|
| 371 |
+
if i == self.num_upsamples - 1:
|
| 372 |
+
x = self.reflection_pad(x)
|
| 373 |
+
|
| 374 |
+
x = x + x_source
|
| 375 |
+
xs = None
|
| 376 |
+
for j in range(self.num_kernels):
|
| 377 |
+
if xs is None:
|
| 378 |
+
xs = self.resblocks[i*self.num_kernels+j](x, s)
|
| 379 |
+
else:
|
| 380 |
+
xs += self.resblocks[i*self.num_kernels+j](x, s)
|
| 381 |
+
x = xs / self.num_kernels
|
| 382 |
+
x = F.leaky_relu(x)
|
| 383 |
+
x = self.conv_post(x)
|
| 384 |
+
spec = torch.exp(x[:,:self.post_n_fft // 2 + 1, :])
|
| 385 |
+
phase = torch.sin(x[:, self.post_n_fft // 2 + 1:, :])
|
| 386 |
+
return self.stft.inverse(spec, phase)
|
| 387 |
+
|
| 388 |
+
def fw_phase(self, x, s):
|
| 389 |
+
for i in range(self.num_upsamples):
|
| 390 |
+
x = F.leaky_relu(x, LRELU_SLOPE)
|
| 391 |
+
x = self.ups[i](x)
|
| 392 |
+
xs = None
|
| 393 |
+
for j in range(self.num_kernels):
|
| 394 |
+
if xs is None:
|
| 395 |
+
xs = self.resblocks[i*self.num_kernels+j](x, s)
|
| 396 |
+
else:
|
| 397 |
+
xs += self.resblocks[i*self.num_kernels+j](x, s)
|
| 398 |
+
x = xs / self.num_kernels
|
| 399 |
+
x = F.leaky_relu(x)
|
| 400 |
+
x = self.reflection_pad(x)
|
| 401 |
+
x = self.conv_post(x)
|
| 402 |
+
spec = torch.exp(x[:,:self.post_n_fft // 2 + 1, :])
|
| 403 |
+
phase = torch.sin(x[:, self.post_n_fft // 2 + 1:, :])
|
| 404 |
+
return spec, phase
|
| 405 |
+
|
| 406 |
+
def remove_weight_norm(self):
|
| 407 |
+
print('Removing weight norm...')
|
| 408 |
+
for l in self.ups:
|
| 409 |
+
remove_weight_norm(l)
|
| 410 |
+
for l in self.resblocks:
|
| 411 |
+
l.remove_weight_norm()
|
| 412 |
+
remove_weight_norm(self.conv_pre)
|
| 413 |
+
remove_weight_norm(self.conv_post)
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
class AdainResBlk1d(nn.Module):
|
| 417 |
+
def __init__(self, dim_in, dim_out, style_dim=64, actv=nn.LeakyReLU(0.2),
|
| 418 |
+
upsample='none', dropout_p=0.0):
|
| 419 |
+
super().__init__()
|
| 420 |
+
self.actv = actv
|
| 421 |
+
self.upsample_type = upsample
|
| 422 |
+
self.upsample = UpSample1d(upsample)
|
| 423 |
+
self.learned_sc = dim_in != dim_out
|
| 424 |
+
self._build_weights(dim_in, dim_out, style_dim)
|
| 425 |
+
self.dropout = nn.Dropout(dropout_p)
|
| 426 |
+
|
| 427 |
+
if upsample == 'none':
|
| 428 |
+
self.pool = nn.Identity()
|
| 429 |
+
else:
|
| 430 |
+
self.pool = weight_norm(nn.ConvTranspose1d(dim_in, dim_in, kernel_size=3, stride=2, groups=dim_in, padding=1, output_padding=1))
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
def _build_weights(self, dim_in, dim_out, style_dim):
|
| 434 |
+
self.conv1 = weight_norm(nn.Conv1d(dim_in, dim_out, 3, 1, 1))
|
| 435 |
+
self.conv2 = weight_norm(nn.Conv1d(dim_out, dim_out, 3, 1, 1))
|
| 436 |
+
self.norm1 = AdaIN1d(style_dim, dim_in)
|
| 437 |
+
self.norm2 = AdaIN1d(style_dim, dim_out)
|
| 438 |
+
if self.learned_sc:
|
| 439 |
+
self.conv1x1 = weight_norm(nn.Conv1d(dim_in, dim_out, 1, 1, 0, bias=False))
|
| 440 |
+
|
| 441 |
+
def _shortcut(self, x):
|
| 442 |
+
x = self.upsample(x)
|
| 443 |
+
if self.learned_sc:
|
| 444 |
+
x = self.conv1x1(x)
|
| 445 |
+
return x
|
| 446 |
+
|
| 447 |
+
def _residual(self, x, s):
|
| 448 |
+
x = self.norm1(x, s)
|
| 449 |
+
x = self.actv(x)
|
| 450 |
+
x = self.pool(x)
|
| 451 |
+
x = self.conv1(self.dropout(x))
|
| 452 |
+
x = self.norm2(x, s)
|
| 453 |
+
x = self.actv(x)
|
| 454 |
+
x = self.conv2(self.dropout(x))
|
| 455 |
+
return x
|
| 456 |
+
|
| 457 |
+
def forward(self, x, s):
|
| 458 |
+
out = self._residual(x, s)
|
| 459 |
+
out = (out + self._shortcut(x)) / np.sqrt(2)
|
| 460 |
+
return out
|
| 461 |
+
|
| 462 |
+
class UpSample1d(nn.Module):
|
| 463 |
+
def __init__(self, layer_type):
|
| 464 |
+
super().__init__()
|
| 465 |
+
self.layer_type = layer_type
|
| 466 |
+
|
| 467 |
+
def forward(self, x):
|
| 468 |
+
if self.layer_type == 'none':
|
| 469 |
+
return x
|
| 470 |
+
else:
|
| 471 |
+
return F.interpolate(x, scale_factor=2, mode='nearest')
|
| 472 |
+
|
| 473 |
+
class Decoder(nn.Module):
|
| 474 |
+
def __init__(self, dim_in=512, F0_channel=512, style_dim=64, dim_out=80,
|
| 475 |
+
resblock_kernel_sizes = [3,7,11],
|
| 476 |
+
upsample_rates = [10, 6],
|
| 477 |
+
upsample_initial_channel=512,
|
| 478 |
+
resblock_dilation_sizes=[[1,3,5], [1,3,5], [1,3,5]],
|
| 479 |
+
upsample_kernel_sizes=[20, 12],
|
| 480 |
+
gen_istft_n_fft=20, gen_istft_hop_size=5):
|
| 481 |
+
super().__init__()
|
| 482 |
+
|
| 483 |
+
self.decode = nn.ModuleList()
|
| 484 |
+
|
| 485 |
+
self.encode = AdainResBlk1d(dim_in + 2, 1024, style_dim)
|
| 486 |
+
|
| 487 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 1024, style_dim))
|
| 488 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 1024, style_dim))
|
| 489 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 1024, style_dim))
|
| 490 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 512, style_dim, upsample=True))
|
| 491 |
+
|
| 492 |
+
self.F0_conv = weight_norm(nn.Conv1d(1, 1, kernel_size=3, stride=2, groups=1, padding=1))
|
| 493 |
+
|
| 494 |
+
self.N_conv = weight_norm(nn.Conv1d(1, 1, kernel_size=3, stride=2, groups=1, padding=1))
|
| 495 |
+
|
| 496 |
+
self.asr_res = nn.Sequential(
|
| 497 |
+
weight_norm(nn.Conv1d(512, 64, kernel_size=1)),
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
self.generator = Generator(style_dim, resblock_kernel_sizes, upsample_rates,
|
| 502 |
+
upsample_initial_channel, resblock_dilation_sizes,
|
| 503 |
+
upsample_kernel_sizes, gen_istft_n_fft, gen_istft_hop_size)
|
| 504 |
+
|
| 505 |
+
def forward(self, asr, F0_curve, N, s):
|
| 506 |
+
F0 = self.F0_conv(F0_curve.unsqueeze(1))
|
| 507 |
+
N = self.N_conv(N.unsqueeze(1))
|
| 508 |
+
|
| 509 |
+
x = torch.cat([asr, F0, N], axis=1)
|
| 510 |
+
x = self.encode(x, s)
|
| 511 |
+
|
| 512 |
+
asr_res = self.asr_res(asr)
|
| 513 |
+
|
| 514 |
+
res = True
|
| 515 |
+
for block in self.decode:
|
| 516 |
+
if res:
|
| 517 |
+
x = torch.cat([x, asr_res, F0, N], axis=1)
|
| 518 |
+
x = block(x, s)
|
| 519 |
+
if block.upsample_type != "none":
|
| 520 |
+
res = False
|
| 521 |
+
|
| 522 |
+
x = self.generator(x, s, F0_curve)
|
| 523 |
+
return x
|
models.py
ADDED
|
@@ -0,0 +1,372 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/models.py
|
| 2 |
+
from istftnet import AdaIN1d, Decoder
|
| 3 |
+
from munch import Munch
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from plbert import load_plbert
|
| 6 |
+
from torch.nn.utils import weight_norm, spectral_norm
|
| 7 |
+
import json
|
| 8 |
+
import numpy as np
|
| 9 |
+
import os
|
| 10 |
+
import os.path as osp
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
class LinearNorm(torch.nn.Module):
|
| 16 |
+
def __init__(self, in_dim, out_dim, bias=True, w_init_gain='linear'):
|
| 17 |
+
super(LinearNorm, self).__init__()
|
| 18 |
+
self.linear_layer = torch.nn.Linear(in_dim, out_dim, bias=bias)
|
| 19 |
+
|
| 20 |
+
torch.nn.init.xavier_uniform_(
|
| 21 |
+
self.linear_layer.weight,
|
| 22 |
+
gain=torch.nn.init.calculate_gain(w_init_gain))
|
| 23 |
+
|
| 24 |
+
def forward(self, x):
|
| 25 |
+
return self.linear_layer(x)
|
| 26 |
+
|
| 27 |
+
class LayerNorm(nn.Module):
|
| 28 |
+
def __init__(self, channels, eps=1e-5):
|
| 29 |
+
super().__init__()
|
| 30 |
+
self.channels = channels
|
| 31 |
+
self.eps = eps
|
| 32 |
+
|
| 33 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 34 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
x = x.transpose(1, -1)
|
| 38 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 39 |
+
return x.transpose(1, -1)
|
| 40 |
+
|
| 41 |
+
class TextEncoder(nn.Module):
|
| 42 |
+
def __init__(self, channels, kernel_size, depth, n_symbols, actv=nn.LeakyReLU(0.2)):
|
| 43 |
+
super().__init__()
|
| 44 |
+
self.embedding = nn.Embedding(n_symbols, channels)
|
| 45 |
+
|
| 46 |
+
padding = (kernel_size - 1) // 2
|
| 47 |
+
self.cnn = nn.ModuleList()
|
| 48 |
+
for _ in range(depth):
|
| 49 |
+
self.cnn.append(nn.Sequential(
|
| 50 |
+
weight_norm(nn.Conv1d(channels, channels, kernel_size=kernel_size, padding=padding)),
|
| 51 |
+
LayerNorm(channels),
|
| 52 |
+
actv,
|
| 53 |
+
nn.Dropout(0.2),
|
| 54 |
+
))
|
| 55 |
+
# self.cnn = nn.Sequential(*self.cnn)
|
| 56 |
+
|
| 57 |
+
self.lstm = nn.LSTM(channels, channels//2, 1, batch_first=True, bidirectional=True)
|
| 58 |
+
|
| 59 |
+
def forward(self, x, input_lengths, m):
|
| 60 |
+
x = self.embedding(x) # [B, T, emb]
|
| 61 |
+
x = x.transpose(1, 2) # [B, emb, T]
|
| 62 |
+
m = m.to(input_lengths.device).unsqueeze(1)
|
| 63 |
+
x.masked_fill_(m, 0.0)
|
| 64 |
+
|
| 65 |
+
for c in self.cnn:
|
| 66 |
+
x = c(x)
|
| 67 |
+
x.masked_fill_(m, 0.0)
|
| 68 |
+
|
| 69 |
+
x = x.transpose(1, 2) # [B, T, chn]
|
| 70 |
+
|
| 71 |
+
input_lengths = input_lengths.cpu().numpy()
|
| 72 |
+
x = nn.utils.rnn.pack_padded_sequence(
|
| 73 |
+
x, input_lengths, batch_first=True, enforce_sorted=False)
|
| 74 |
+
|
| 75 |
+
self.lstm.flatten_parameters()
|
| 76 |
+
x, _ = self.lstm(x)
|
| 77 |
+
x, _ = nn.utils.rnn.pad_packed_sequence(
|
| 78 |
+
x, batch_first=True)
|
| 79 |
+
|
| 80 |
+
x = x.transpose(-1, -2)
|
| 81 |
+
x_pad = torch.zeros([x.shape[0], x.shape[1], m.shape[-1]])
|
| 82 |
+
|
| 83 |
+
x_pad[:, :, :x.shape[-1]] = x
|
| 84 |
+
x = x_pad.to(x.device)
|
| 85 |
+
|
| 86 |
+
x.masked_fill_(m, 0.0)
|
| 87 |
+
|
| 88 |
+
return x
|
| 89 |
+
|
| 90 |
+
def inference(self, x):
|
| 91 |
+
x = self.embedding(x)
|
| 92 |
+
x = x.transpose(1, 2)
|
| 93 |
+
x = self.cnn(x)
|
| 94 |
+
x = x.transpose(1, 2)
|
| 95 |
+
self.lstm.flatten_parameters()
|
| 96 |
+
x, _ = self.lstm(x)
|
| 97 |
+
return x
|
| 98 |
+
|
| 99 |
+
def length_to_mask(self, lengths):
|
| 100 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 101 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 102 |
+
return mask
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class UpSample1d(nn.Module):
|
| 106 |
+
def __init__(self, layer_type):
|
| 107 |
+
super().__init__()
|
| 108 |
+
self.layer_type = layer_type
|
| 109 |
+
|
| 110 |
+
def forward(self, x):
|
| 111 |
+
if self.layer_type == 'none':
|
| 112 |
+
return x
|
| 113 |
+
else:
|
| 114 |
+
return F.interpolate(x, scale_factor=2, mode='nearest')
|
| 115 |
+
|
| 116 |
+
class AdainResBlk1d(nn.Module):
|
| 117 |
+
def __init__(self, dim_in, dim_out, style_dim=64, actv=nn.LeakyReLU(0.2),
|
| 118 |
+
upsample='none', dropout_p=0.0):
|
| 119 |
+
super().__init__()
|
| 120 |
+
self.actv = actv
|
| 121 |
+
self.upsample_type = upsample
|
| 122 |
+
self.upsample = UpSample1d(upsample)
|
| 123 |
+
self.learned_sc = dim_in != dim_out
|
| 124 |
+
self._build_weights(dim_in, dim_out, style_dim)
|
| 125 |
+
self.dropout = nn.Dropout(dropout_p)
|
| 126 |
+
|
| 127 |
+
if upsample == 'none':
|
| 128 |
+
self.pool = nn.Identity()
|
| 129 |
+
else:
|
| 130 |
+
self.pool = weight_norm(nn.ConvTranspose1d(dim_in, dim_in, kernel_size=3, stride=2, groups=dim_in, padding=1, output_padding=1))
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def _build_weights(self, dim_in, dim_out, style_dim):
|
| 134 |
+
self.conv1 = weight_norm(nn.Conv1d(dim_in, dim_out, 3, 1, 1))
|
| 135 |
+
self.conv2 = weight_norm(nn.Conv1d(dim_out, dim_out, 3, 1, 1))
|
| 136 |
+
self.norm1 = AdaIN1d(style_dim, dim_in)
|
| 137 |
+
self.norm2 = AdaIN1d(style_dim, dim_out)
|
| 138 |
+
if self.learned_sc:
|
| 139 |
+
self.conv1x1 = weight_norm(nn.Conv1d(dim_in, dim_out, 1, 1, 0, bias=False))
|
| 140 |
+
|
| 141 |
+
def _shortcut(self, x):
|
| 142 |
+
x = self.upsample(x)
|
| 143 |
+
if self.learned_sc:
|
| 144 |
+
x = self.conv1x1(x)
|
| 145 |
+
return x
|
| 146 |
+
|
| 147 |
+
def _residual(self, x, s):
|
| 148 |
+
x = self.norm1(x, s)
|
| 149 |
+
x = self.actv(x)
|
| 150 |
+
x = self.pool(x)
|
| 151 |
+
x = self.conv1(self.dropout(x))
|
| 152 |
+
x = self.norm2(x, s)
|
| 153 |
+
x = self.actv(x)
|
| 154 |
+
x = self.conv2(self.dropout(x))
|
| 155 |
+
return x
|
| 156 |
+
|
| 157 |
+
def forward(self, x, s):
|
| 158 |
+
out = self._residual(x, s)
|
| 159 |
+
out = (out + self._shortcut(x)) / np.sqrt(2)
|
| 160 |
+
return out
|
| 161 |
+
|
| 162 |
+
class AdaLayerNorm(nn.Module):
|
| 163 |
+
def __init__(self, style_dim, channels, eps=1e-5):
|
| 164 |
+
super().__init__()
|
| 165 |
+
self.channels = channels
|
| 166 |
+
self.eps = eps
|
| 167 |
+
|
| 168 |
+
self.fc = nn.Linear(style_dim, channels*2)
|
| 169 |
+
|
| 170 |
+
def forward(self, x, s):
|
| 171 |
+
x = x.transpose(-1, -2)
|
| 172 |
+
x = x.transpose(1, -1)
|
| 173 |
+
|
| 174 |
+
h = self.fc(s)
|
| 175 |
+
h = h.view(h.size(0), h.size(1), 1)
|
| 176 |
+
gamma, beta = torch.chunk(h, chunks=2, dim=1)
|
| 177 |
+
gamma, beta = gamma.transpose(1, -1), beta.transpose(1, -1)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
x = F.layer_norm(x, (self.channels,), eps=self.eps)
|
| 181 |
+
x = (1 + gamma) * x + beta
|
| 182 |
+
return x.transpose(1, -1).transpose(-1, -2)
|
| 183 |
+
|
| 184 |
+
class ProsodyPredictor(nn.Module):
|
| 185 |
+
|
| 186 |
+
def __init__(self, style_dim, d_hid, nlayers, max_dur=50, dropout=0.1):
|
| 187 |
+
super().__init__()
|
| 188 |
+
|
| 189 |
+
self.text_encoder = DurationEncoder(sty_dim=style_dim,
|
| 190 |
+
d_model=d_hid,
|
| 191 |
+
nlayers=nlayers,
|
| 192 |
+
dropout=dropout)
|
| 193 |
+
|
| 194 |
+
self.lstm = nn.LSTM(d_hid + style_dim, d_hid // 2, 1, batch_first=True, bidirectional=True)
|
| 195 |
+
self.duration_proj = LinearNorm(d_hid, max_dur)
|
| 196 |
+
|
| 197 |
+
self.shared = nn.LSTM(d_hid + style_dim, d_hid // 2, 1, batch_first=True, bidirectional=True)
|
| 198 |
+
self.F0 = nn.ModuleList()
|
| 199 |
+
self.F0.append(AdainResBlk1d(d_hid, d_hid, style_dim, dropout_p=dropout))
|
| 200 |
+
self.F0.append(AdainResBlk1d(d_hid, d_hid // 2, style_dim, upsample=True, dropout_p=dropout))
|
| 201 |
+
self.F0.append(AdainResBlk1d(d_hid // 2, d_hid // 2, style_dim, dropout_p=dropout))
|
| 202 |
+
|
| 203 |
+
self.N = nn.ModuleList()
|
| 204 |
+
self.N.append(AdainResBlk1d(d_hid, d_hid, style_dim, dropout_p=dropout))
|
| 205 |
+
self.N.append(AdainResBlk1d(d_hid, d_hid // 2, style_dim, upsample=True, dropout_p=dropout))
|
| 206 |
+
self.N.append(AdainResBlk1d(d_hid // 2, d_hid // 2, style_dim, dropout_p=dropout))
|
| 207 |
+
|
| 208 |
+
self.F0_proj = nn.Conv1d(d_hid // 2, 1, 1, 1, 0)
|
| 209 |
+
self.N_proj = nn.Conv1d(d_hid // 2, 1, 1, 1, 0)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def forward(self, texts, style, text_lengths, alignment, m):
|
| 213 |
+
d = self.text_encoder(texts, style, text_lengths, m)
|
| 214 |
+
|
| 215 |
+
batch_size = d.shape[0]
|
| 216 |
+
text_size = d.shape[1]
|
| 217 |
+
|
| 218 |
+
# predict duration
|
| 219 |
+
input_lengths = text_lengths.cpu().numpy()
|
| 220 |
+
x = nn.utils.rnn.pack_padded_sequence(
|
| 221 |
+
d, input_lengths, batch_first=True, enforce_sorted=False)
|
| 222 |
+
|
| 223 |
+
m = m.to(text_lengths.device).unsqueeze(1)
|
| 224 |
+
|
| 225 |
+
self.lstm.flatten_parameters()
|
| 226 |
+
x, _ = self.lstm(x)
|
| 227 |
+
x, _ = nn.utils.rnn.pad_packed_sequence(
|
| 228 |
+
x, batch_first=True)
|
| 229 |
+
|
| 230 |
+
x_pad = torch.zeros([x.shape[0], m.shape[-1], x.shape[-1]])
|
| 231 |
+
|
| 232 |
+
x_pad[:, :x.shape[1], :] = x
|
| 233 |
+
x = x_pad.to(x.device)
|
| 234 |
+
|
| 235 |
+
duration = self.duration_proj(nn.functional.dropout(x, 0.5, training=self.training))
|
| 236 |
+
|
| 237 |
+
en = (d.transpose(-1, -2) @ alignment)
|
| 238 |
+
|
| 239 |
+
return duration.squeeze(-1), en
|
| 240 |
+
|
| 241 |
+
def F0Ntrain(self, x, s):
|
| 242 |
+
x, _ = self.shared(x.transpose(-1, -2))
|
| 243 |
+
|
| 244 |
+
F0 = x.transpose(-1, -2)
|
| 245 |
+
for block in self.F0:
|
| 246 |
+
F0 = block(F0, s)
|
| 247 |
+
F0 = self.F0_proj(F0)
|
| 248 |
+
|
| 249 |
+
N = x.transpose(-1, -2)
|
| 250 |
+
for block in self.N:
|
| 251 |
+
N = block(N, s)
|
| 252 |
+
N = self.N_proj(N)
|
| 253 |
+
|
| 254 |
+
return F0.squeeze(1), N.squeeze(1)
|
| 255 |
+
|
| 256 |
+
def length_to_mask(self, lengths):
|
| 257 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 258 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 259 |
+
return mask
|
| 260 |
+
|
| 261 |
+
class DurationEncoder(nn.Module):
|
| 262 |
+
|
| 263 |
+
def __init__(self, sty_dim, d_model, nlayers, dropout=0.1):
|
| 264 |
+
super().__init__()
|
| 265 |
+
self.lstms = nn.ModuleList()
|
| 266 |
+
for _ in range(nlayers):
|
| 267 |
+
self.lstms.append(nn.LSTM(d_model + sty_dim,
|
| 268 |
+
d_model // 2,
|
| 269 |
+
num_layers=1,
|
| 270 |
+
batch_first=True,
|
| 271 |
+
bidirectional=True,
|
| 272 |
+
dropout=dropout))
|
| 273 |
+
self.lstms.append(AdaLayerNorm(sty_dim, d_model))
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
self.dropout = dropout
|
| 277 |
+
self.d_model = d_model
|
| 278 |
+
self.sty_dim = sty_dim
|
| 279 |
+
|
| 280 |
+
def forward(self, x, style, text_lengths, m):
|
| 281 |
+
masks = m.to(text_lengths.device)
|
| 282 |
+
|
| 283 |
+
x = x.permute(2, 0, 1)
|
| 284 |
+
s = style.expand(x.shape[0], x.shape[1], -1)
|
| 285 |
+
x = torch.cat([x, s], axis=-1)
|
| 286 |
+
x.masked_fill_(masks.unsqueeze(-1).transpose(0, 1), 0.0)
|
| 287 |
+
|
| 288 |
+
x = x.transpose(0, 1)
|
| 289 |
+
input_lengths = text_lengths.cpu().numpy()
|
| 290 |
+
x = x.transpose(-1, -2)
|
| 291 |
+
|
| 292 |
+
for block in self.lstms:
|
| 293 |
+
if isinstance(block, AdaLayerNorm):
|
| 294 |
+
x = block(x.transpose(-1, -2), style).transpose(-1, -2)
|
| 295 |
+
x = torch.cat([x, s.permute(1, -1, 0)], axis=1)
|
| 296 |
+
x.masked_fill_(masks.unsqueeze(-1).transpose(-1, -2), 0.0)
|
| 297 |
+
else:
|
| 298 |
+
x = x.transpose(-1, -2)
|
| 299 |
+
x = nn.utils.rnn.pack_padded_sequence(
|
| 300 |
+
x, input_lengths, batch_first=True, enforce_sorted=False)
|
| 301 |
+
block.flatten_parameters()
|
| 302 |
+
x, _ = block(x)
|
| 303 |
+
x, _ = nn.utils.rnn.pad_packed_sequence(
|
| 304 |
+
x, batch_first=True)
|
| 305 |
+
x = F.dropout(x, p=self.dropout, training=self.training)
|
| 306 |
+
x = x.transpose(-1, -2)
|
| 307 |
+
|
| 308 |
+
x_pad = torch.zeros([x.shape[0], x.shape[1], m.shape[-1]])
|
| 309 |
+
|
| 310 |
+
x_pad[:, :, :x.shape[-1]] = x
|
| 311 |
+
x = x_pad.to(x.device)
|
| 312 |
+
|
| 313 |
+
return x.transpose(-1, -2)
|
| 314 |
+
|
| 315 |
+
def inference(self, x, style):
|
| 316 |
+
x = self.embedding(x.transpose(-1, -2)) * np.sqrt(self.d_model)
|
| 317 |
+
style = style.expand(x.shape[0], x.shape[1], -1)
|
| 318 |
+
x = torch.cat([x, style], axis=-1)
|
| 319 |
+
src = self.pos_encoder(x)
|
| 320 |
+
output = self.transformer_encoder(src).transpose(0, 1)
|
| 321 |
+
return output
|
| 322 |
+
|
| 323 |
+
def length_to_mask(self, lengths):
|
| 324 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 325 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 326 |
+
return mask
|
| 327 |
+
|
| 328 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/utils.py
|
| 329 |
+
def recursive_munch(d):
|
| 330 |
+
if isinstance(d, dict):
|
| 331 |
+
return Munch((k, recursive_munch(v)) for k, v in d.items())
|
| 332 |
+
elif isinstance(d, list):
|
| 333 |
+
return [recursive_munch(v) for v in d]
|
| 334 |
+
else:
|
| 335 |
+
return d
|
| 336 |
+
|
| 337 |
+
def build_model(path, device):
|
| 338 |
+
config = Path(__file__).parent / 'config.json'
|
| 339 |
+
assert config.exists(), f'Config path incorrect: config.json not found at {config}'
|
| 340 |
+
with open(config, 'r') as r:
|
| 341 |
+
args = recursive_munch(json.load(r))
|
| 342 |
+
assert args.decoder.type == 'istftnet', f'Unknown decoder type: {args.decoder.type}'
|
| 343 |
+
decoder = Decoder(dim_in=args.hidden_dim, style_dim=args.style_dim, dim_out=args.n_mels,
|
| 344 |
+
resblock_kernel_sizes = args.decoder.resblock_kernel_sizes,
|
| 345 |
+
upsample_rates = args.decoder.upsample_rates,
|
| 346 |
+
upsample_initial_channel=args.decoder.upsample_initial_channel,
|
| 347 |
+
resblock_dilation_sizes=args.decoder.resblock_dilation_sizes,
|
| 348 |
+
upsample_kernel_sizes=args.decoder.upsample_kernel_sizes,
|
| 349 |
+
gen_istft_n_fft=args.decoder.gen_istft_n_fft, gen_istft_hop_size=args.decoder.gen_istft_hop_size)
|
| 350 |
+
text_encoder = TextEncoder(channels=args.hidden_dim, kernel_size=5, depth=args.n_layer, n_symbols=args.n_token)
|
| 351 |
+
predictor = ProsodyPredictor(style_dim=args.style_dim, d_hid=args.hidden_dim, nlayers=args.n_layer, max_dur=args.max_dur, dropout=args.dropout)
|
| 352 |
+
bert = load_plbert()
|
| 353 |
+
bert_encoder = nn.Linear(bert.config.hidden_size, args.hidden_dim)
|
| 354 |
+
for parent in [bert, bert_encoder, predictor, decoder, text_encoder]:
|
| 355 |
+
for child in parent.children():
|
| 356 |
+
if isinstance(child, nn.RNNBase):
|
| 357 |
+
child.flatten_parameters()
|
| 358 |
+
model = Munch(
|
| 359 |
+
bert=bert.to(device).eval(),
|
| 360 |
+
bert_encoder=bert_encoder.to(device).eval(),
|
| 361 |
+
predictor=predictor.to(device).eval(),
|
| 362 |
+
decoder=decoder.to(device).eval(),
|
| 363 |
+
text_encoder=text_encoder.to(device).eval(),
|
| 364 |
+
)
|
| 365 |
+
for key, state_dict in torch.load(path, map_location='cpu', weights_only=True)['net'].items():
|
| 366 |
+
assert key in model, key
|
| 367 |
+
try:
|
| 368 |
+
model[key].load_state_dict(state_dict)
|
| 369 |
+
except:
|
| 370 |
+
state_dict = {k[7:]: v for k, v in state_dict.items()}
|
| 371 |
+
model[key].load_state_dict(state_dict, strict=False)
|
| 372 |
+
return model
|
plbert.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/Utils/PLBERT/util.py
|
| 2 |
+
from transformers import AlbertConfig, AlbertModel
|
| 3 |
+
|
| 4 |
+
class CustomAlbert(AlbertModel):
|
| 5 |
+
def forward(self, *args, **kwargs):
|
| 6 |
+
# Call the original forward method
|
| 7 |
+
outputs = super().forward(*args, **kwargs)
|
| 8 |
+
# Only return the last_hidden_state
|
| 9 |
+
return outputs.last_hidden_state
|
| 10 |
+
|
| 11 |
+
def load_plbert():
|
| 12 |
+
plbert_config = {'vocab_size': 178, 'hidden_size': 768, 'num_attention_heads': 12, 'intermediate_size': 2048, 'max_position_embeddings': 512, 'num_hidden_layers': 12, 'dropout': 0.1}
|
| 13 |
+
albert_base_configuration = AlbertConfig(**plbert_config)
|
| 14 |
+
bert = CustomAlbert(albert_base_configuration)
|
| 15 |
+
return bert
|
voices/af.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fad4192fd8a840f925b0e3fc2be54e20531f91a9ac816a485b7992ca0bd83ebf
|
| 3 |
+
size 524355
|
voices/af_bella.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2828c6c2f94275ef3441a2edfcf48293298ee0f9b56ce70fb2e344345487b922
|
| 3 |
+
size 524449
|
voices/af_nicole.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9401802fb0b7080c324dec1a75d60f31d977ced600a99160e095dbc5a1172692
|
| 3 |
+
size 524454
|
voices/af_sarah.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ba7918c4ace6ace4221e7e01eb3a6d16596cba9729850551c758cd2ad3a4cd08
|
| 3 |
+
size 524449
|
voices/af_sky.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9f16f1bb778de36a177ae4b0b6f1e59783d5f4d3bcecf752c3e1ee98299b335e
|
| 3 |
+
size 524375
|
voices/am_adam.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1921528b400a553f66528c27899d95780918fe33b1ac7e2a871f6a0de475f176
|
| 3 |
+
size 524444
|
voices/am_michael.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a255c9562c363103adc56c09b7daf837139d3bdaa8bd4dd74847ab1e3e8c28be
|
| 3 |
+
size 524459
|
voices/bf_emma.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:992e6d8491b8926ef4a16205250e51a21d9924405a5d37e2db6e94adfd965c3b
|
| 3 |
+
size 524365
|
voices/bf_isabella.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d0865a03931230100167f7a81d394b143c072efe2d7e4c4a87b5c54d6283f580
|
| 3 |
+
size 524365
|
voices/bm_george.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7d763dfe13e934357f4d8322b718787d79e32f2181e29ca0cf6aa637d8092b96
|
| 3 |
+
size 524464
|
voices/bm_lewis.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f70d9ea4d65f522f224628f06d86ea74279faae23bd7e765848a374aba916b76
|
| 3 |
+
size 524449
|